agentes baseados em lógica
DESCRIPTION
Agentes Baseados em Lógica. Wumpus. Agente caçador de tesouros. Bem-vindos ao “Mundo do Wumpus”. O Mundo do Wumpus: formulação do problema. Ambiente: agente, Wumpus, cavernas, buracos, ouro Estado inicial: agente na caverna (1,1) com apenas uma flecha - PowerPoint PPT PresentationTRANSCRIPT

CIn- UFPE
1
Agentes Baseados em Lógica

CIn- UFPE
2
Bem-vindos ao “Mundo do Wumpus”
Wumpus
Agente caçador de tesouros

CIn- UFPE
4
O Mundo do Wumpus: formulação do problema
Ambiente:– agente, Wumpus, cavernas, buracos, ouro
Estado inicial:– agente na caverna (1,1) com apenas uma flecha– Wumpus e buracos em cavernas quaisquer
Objetivos:– pegar a barra de ouro e voltar à caverna (1,1) com vida
Percepções: – fedor, brisa, luz, choque (contra a parede da caverna) e grito do
Wumpus
Ações:– avançar para próxima caverna– girar 90 graus à direita ou à esquerda– pegar um objeto na mesma caverna que o agente– atirar na direção para onde o agente está olhando (a flecha pára
quando encontra uma parede ou mata o Wumpus)– sair da caverna

CIn- UFPE
5
Raciocinando e Agindo no Mundo do Wumpus
Conhecimento do agente: (a) no início do jogo, depois de receber sua primeira percepção , e (b) depois do 1o movimento, com a seqüência de percepções
[nada,brisa,nada,nada,nada]
1
2
3
41 2 3
4
ok
ok
okA 1
2
3
41 2 3
4
okA
ok
V bok
B?
B?
V - caverna visitada

CIn- UFPE
6
Raciocinando e Agindo no Mundo do Wumpus
Estando em (2,2), o agente move-se para (2,3) e encontra o ouro!!!
1
2
3
41 2 3
4
ok
Afok
V Vbok
B!
W!
ok
1
2
3
41 2 3
4
ok
A
fok
V Vbok
B!
W!
Vok
V
f b lB?
B?

CIn- UFPE
7
Mundo de Wumpus
Tipo de ambiente• Acessível ou Inacessível ?• Determinista ou Não-Determinista? • Episódico ou Não-Episódico? • Estático ou Dinâmico ?• Discreto ou Contínuo ?
Tipo de agente?• Agente tabela• Agente reativo• Agente reativo com estado interno (autômato)• Agente cognitivo (baseado em objetivos)• Agente otimizador• Agente adaptativo

CIn- UFPE
8
Agentes baseado em Lógica
Agentes podem ser formalizados e implementados por Sistemas baseados em conhecimento (aula anterior)
Veremos aqui como formalizar um agente que raciocina com base na Lógica Proposicional• nível do conhecimento
A implementação desse agente pode ser feita com Prolog ou Java+JEOPS, por exemplo

CIn- UFPE
9
Um Agente-BC para o Mundo do Wumpus
A Base de Conhecimento consiste em:• sentenças representando as percepções do agente• sentenças válidas implicadas a partir das sentenças das
percepções• regras utilizadas para implicar novas sentenças a partir das
sentenças existentes
Símbolos:• Ax-y significa que “o agente está na caverna (x,y)”• Bx-y significa que “existe um buraco na caverna (x,y)”• Wx-y significa que “o Wumpus está na caverna (x,y)”• Ox-y significa que “o ouro está na caverna (x,y)”• bx-y significa que “existe brisa na caverna (x,y)”• fx-y significa que “existe fedor na caverna (x,y)”• lx-y significa que “existe luz na caverna (x,y)”
CIn- UFPE
10
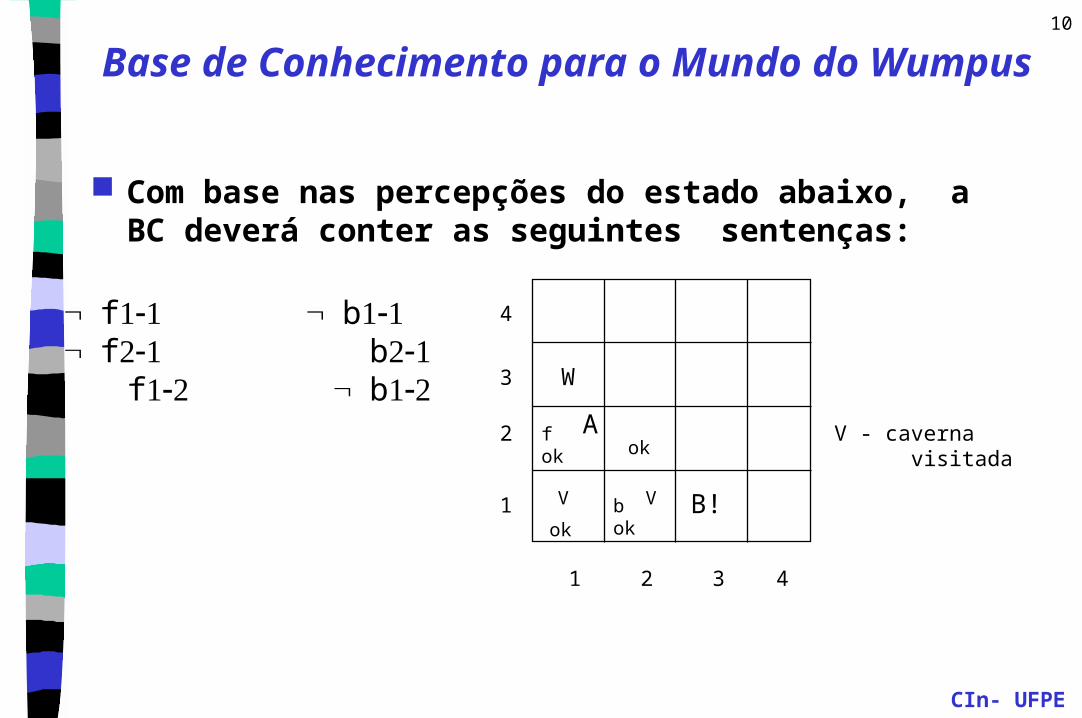
Base de Conhecimento para o Mundo do Wumpus
Com base nas percepções do estado abaixo, a BC deverá conter as seguintes sentenças:
V - caverna visitada
1
2
3
41 2 3
4
ok
okAf
ok
V Vbok
B!
W
fbfbfb

CIn- UFPE
11
Base de Conhecimento para o Mundo do Wumpus
O agente também tem algum conhecimento prévio sobre o ambiente, e.g.:• se uma caverna não tem fedor, então o Wumpus não está nessa
caverna, nem está em nenhuma caverna adjacente a ela.
O agente terá uma regra para cada caverna no seu ambienteR1: fWWWR2: fWWWWR3: fWWWW
O agente também deve saber que, se existe fedor em (1,2), então deve haver um Wumpus em (1,2) ou em alguma caverna adjacente a ela:R4: fWWWW

CIn- UFPE
12
Como Encontrar o Wumpus - Inferência!
O Wumpus está em (1,3). Como provar isto?
(1) construindo a Tabela-Verdade para a sentença
– existem 12 símbolos proposicionais na BC, então a Tabela-Verdade terá 12 colunas.
(2) usando regras de inferência!
2 409612

CIn- UFPE
13
Lógica Proposicional: Regras de Inferência
Modus Ponens:
E-eliminação:
E-introdução:
Ou-introdução:
Eliminação de dupla negação:
Resolução unidade:
Resolução:
,
i
n
...21
n
n
...
,...,,
21
21
n
i
...21
,,
,
diz que a sentença pode ser derivada de por inferência.

CIn- UFPE
14
Como Encontrar o Wumpus - Inferência!
Inicialmente, vamos mostrar que o Wumpus não está em nenhuma outra caverna, e então concluir, por eliminação, que ele está em (1,3).
1. Aplicando Modus Ponens a feR1obtemosWWW
2. Aplicando E-eliminação a (1), obtemos três sentenças isoladas:WWW
3. Aplicando Modus Ponens a feR2e em seguida aplicando E-eliminaçãoobtemosWWWW
4. Aplicando Modus Ponens a feR4obtemosWWW2-W

CIn- UFPE
15
Como Encontrar o Wumpus - Inferência!
5. Aplicando Resolução Unidade, onde é WWWe é Wobtemos (do passo 2, temos WWWW
6. Aplicando Resolução Unidade, onde é WWe é WobtemosWW
7. Aplicando Resolução Unidade, onde é We é WobtemosW

CIn- UFPE
16Problemas com o Agente Proposicional Problema: existem proposições demais a considerar
• ex.: a regra: “não avance se o Wumpus estiver em frente a você“ só pode ser representada com um conjunto de 64 regras.
– serão necessárias milhares de regras para definir um agente eficiente, e o processo de inferência ficará muito lento.
Outro problema: domínios dinâmicos!• Quando o agente faz seu primeiro movimento, a proposição A1-1
torna-se falsa, e A2-1 torna-se verdadeira.• Soluções:
– “apagar” A(1,1) - não! => o agente precisa saber onde esteve antes.– usar símbolos diferentes para a localização do agente a cada tempo t
=> a BC teria que ser “reescrita” a cada tempo t.
Se o agente executar 100 passos, a BC terá 6400 regras apenas para dizer que ele não deve avançar quando o Wumpus estiver em frente a ele.

CIn- UFPE
17
Agentes que raciocinam com base na lógica de primeira ordem (LPO)
Engajamentos, sintaxe e semântica da LPO
Uso da LPO em agentes baseados em conhecimento
Aplicação ao mundo do Wumpus
Representando mudanças no mundo
Deduzindo propriedades escondidas do mundo

CIn- UFPE
18
Motivação
LPO: o formalismo de referência para representação de conhecimento, o mais estudado e o melhor formalizado
LPO satisfaz em grande parte os seguintes critérios• adequação representacional ( > L Proposicional)
– para representar o mundo (expressividade)
• adequação inferencial ( = L Proposicional)– para fazer inferência
• eficiência aquisicional ( = L Proposicional)– facilidade de adicionar conhecimento
• modularidade ( > L Proposicional)
Embora tenha problemas com • legibilidade e eficiência inferencial

CIn- UFPE
19
Engajamento ontológico
Engajamento ontológico:• Trata da realidade, uma descrição do mundo
Na Lógica Proposicional, o mundo consiste em fatos.
Na Lógica de Primeira Ordem, o mundo consiste em:
• objetos: coisas” com identidade própria– ex. pessoas, casas, Wumpus, caverna, etc.
• relações entre esses objetos– ex. irmão-de, tem-cor, parte-de, adjacente, etc.
• propriedades, que distinguem esses objetos– ex. vermelho, redondo, fundo, fedorento, etc.
• funções: um ou mais objetos se relacionam com um único objeto
– ex. dobro, distância, pai_de, etc.

CIn- UFPE
20
Engajamento ontológico
Além disso, a LPO exprime: • fatos sobre todos objetos do universo ()• fatos sobre objetos particulares ()
Exemplos:• 1 + 1 = 2
– objetos: 1, 2; relação: =; função: +.• Todas as Cavernas adjacentes ao Wumpus são fedorentas.
– objetos: cavernas, Wumpus; propriedade: fedorentas; relação: adjacente.
A LPO não faz engajamentos ontológicos para coisas como tempo, categorias, e eventos.• neutralidade favorece flexibilidade

CIn- UFPE
21
Engajamento epistemológico
Engajamento epistemológico:• estados do conhecimento (crenças)
A LPO tem o mesmo engajamento epistemológico que a
lógica proposicional• tudo é verdadeiro ou falso
Para tratar incerteza• Outras lógicas (de n-valoradas, fuzzy, para-consistente, etc.) • Probabilidade

CIn- UFPE
22
Resumo
Linguagem Eng. Ontolog. Eng. Epistem.
L. Proposicional Fatos V, F, ?
LPO Fatos, objetos,relações
V, F, ?
L. Temporal Fatos, objetos,relações, tempo
V, F, ?
Probabilidade Fatos Grau de crença:0-1
L. Difusa Grau de verdadesobre fatos,
objetos, relações
Grau de crença:0-1

CIn- UFPE
23Agentes Baseados em Conhecimento Dedutivo:
Arquitetura
sensoresAgente
efetuadores
a m
b i
e n
t e Base de Conhecimento
Máquina de Inferência (Raciocínio)Mecanismo de Aprendizagem - opcional
Tell
TellAsk
Tell - - adiciona novas sentenças à BCAsk - consulta a BC

CIn- UFPE
24
Agente baseados em LPO
função Agente-BC(percepção) retorna uma açãoTellTell(BC, Percepções-SentençaPercepções-Sentença(percepção,t))
ação AskAsk(BC Pergunta-AçãoPergunta-Ação(t))
TellTell(BC, Ação-SentençaAção-Sentença(ação,t))
t t + 1
retorna ação
Onde...• função Pergunta-Ação Pergunta-Ação cria uma query tal como: a Ação(a,6)
• função ASKASK devolve uma lista de instanciações:{a / Pegar} - Pegar é atribuída à variável ação.
• TELLTELL gravar a ação escolhida na BC.

CIn- UFPE
25
LPO em agentes baseados em conhecimento
No mundo :A. Pedro possui um cachorro.B. Todo dono de cachorro é um protetor dos animais.C. Nenhum protetor dos animais mata um animal.
Na Lógica:A. x cachorro(x) possui(Pedro,x)B. x y cachorro(y) possui(x,y)) protetorAnimais(x)C. x protetorAnimais(x) y animal(y) mata(x,y)
Representação
do mundoRepresentação
lógica inicial
Representação
lógica atualizada
Mecanismo Mecanismo
de inferênciade inferênciaConhecimento de Conhecimento de
LógicaLógica

Sistema Formal em LPO
Cálculo = Cálculo de Predicados
Teoria
Linguagem= LPO
Regras de derivação= regras de inferência
sintaxe + semântica
Teoremas = fatos derivados(axiomas + regras de derivação)
Axiomas= fatos + regras
DiacrônicasSíncronas
causais de diagnóstico
BC = fatos e regras básicos (só axiomas!)MT = fatos particulares à instância do problema e fatos derivadosMáquina de Inferência = regras de inferência

CIn- UFPE
27
LPO em agentes baseados em conhecimento
Axiomas = fatos e regras básicos e fatos do problema• exs. Pai(Caetano,Zeca), Mãe(Canô, Caetano)• (x,z) Avó(x,z) (y) Mãe(x,y) (Mãe(y,z) Pai(y,z))
Teoremas = fatos derivados• ex. Avó(Canô, Zeca)
Pesquisa = ASK • Quantificador : a resposta é booleana
– ASK(BC, Irmã(Betânia,Caetano)) -> true– ASK(BC, x (Irmã(x,Caetano) Cantora(x))) -> false
• Quantificador : a resposta é uma lista de instanciações/substituições de variáveis - binding
– ASK (BC, x Irmã(x,Caetano)) -> {x/Betânia,x/Irene}– ASK (BC, x (Irmã(x,Caetano) Cantora(x))) -> {x/Betânia}

CIn- UFPE
28
Um Agente LPO para o Mundo do Wumpus
Interface entre o agente e o ambiente:• sentença de percepções, que inclui as percepções e o tempo
(passo) em que elas ocorreram, e.g.:– Percepção ([Fedor, Brisa, Luz, nada, nada], 6)
Ações do agente:• Girar(Direita), Girar(Esquerda), Avançar, Atirar, Pegar, Soltar e
Sair das cavernas
Três arquiteturas de Agentes baseados em LPO:• Agente reativo• Agente com Modelo do Mundo • Agente baseado em Objetivo

CIn- UFPE
29
Agente reativo baseado em LPO
Possui regras ligando conjuntos de percepções às ações• Essas regras assemelham-se a reações, f,b,c,g,t Percepção([f,b,Luz,c,g], t) Ação(Pegar, t)
Essas regras dividem-se entre • Regras de (interpretação) da percepçãob,l,c,g,t Percepção([Fedor,b,l,c,g], t) Fedor (t)f,l,c,g,t Percepção([f,Brisa,l,c,g], t) Brisa (t)f,b,c,g,t Percepção([f,b,Luz,c,g], t) Junto-do-Ouro (t)
. . .
• Regras de ação:t Junto-do-Ouro (t) Ação(Pegar, t)

CIn- UFPE
30
Limitações do agente reativo
um agente ótimo deveria:• recuperar o ouro ou• determinar que é muito perigoso pegar o ouro e• em qualquer dos casos acima, voltar para (1,1) e sair da
caverna.
Um agente reativo nunca sabe quando sair,• estar com o ouro e estar na caverna (1,1) não fazem parte da
sua percepção (se pegou, esqueceu).• esses agentes podem entrar em laços infinitos.
Para ter essas informações, o agente precisa guardar uma representação do mundo.

CIn- UFPE
31
Agentes LPO com Modelo do Mundo
Modelo interno do mundo • sentenças sobre o mundo atual, em vez de percepções
passadas– “às 4h30 pegou o ouro” ===> “está com o ouro”
• as sentenças serão atualizadas quando o agente receber novas percepções e realizar ações
– ex. chaves no bolso, pegou o ouro,..

CIn- UFPE
32Representando Mudanças no Mundo: abordagens
“Como representar as mudanças realmente?• O agente foi de (1,1) para (1,2)
“Apagar” da BC sentenças que já não são verdade• ruim: perdemos o conhecimento sobre o passado, o que
impossibilita previsões de diferentes futuros.
Cada estado é representado por uma BC diferente:• ruim: pode explorar situações hipotéticas, porém não pode
raciocinar sobre mais de uma situação ao mesmo tempo.– ex. “existiam buracos em (1,2) e (3,2)?”
Solução: Cálculo situacional• uma maneira de escrever mudanças no tempo em LPO.• representação de diferentes situações na mesma BC

CIn- UFPE
33
Cálculo Situacional
O mundo consiste em uma seqüência de situações• situação N ===ação===> situação N+1
Predicados que mudam com o tempo têm um argumento de situação adicional
– Ao invés de Em(Agente,local) teremos (Em(Agente,[1,1],S0) Em(Agente,[1,2],S1))
Predicados que denotam propriedades que não mudam com o tempo • não necessitam de argumentos de situação• ex. no mundo do Wumpus:Parede(0,1) e Parede(1,0)
Para representar as mudanças no mundo: função Resultado • Resultado (ação,situação N) = situação N+1

CIn- UFPE
34
Exemplo de cálculo situacional
Result(Forward,S0) = S1
Result(Turn(Right),S1) = S2
Result(Forward,S2) = S3

CIn- UFPE
35
Descrição completa de como o mundo evolui uma coisa é verdade depois [uma ação acabou de torná-la verdade
ela já era verdade e nenhuma ação a tornou falsa ]
• Ex. a,x,s Segurando(x, Resultado(a,s)) (a = Pegar Presente (x, s) Portável(x)) (Segurando (x,s) (a Soltar)]
É necessário escrever uma axioma estado-sucessor para cada predicado que pode mudar seu valor no tempo.
Axiomas estado-sucessor

CIn- UFPE
36
O agente precisa lembrar por onde andou e o que viu• para poder deduzir onde estão os buracos e o Wumpus, • para garantir uma exploração completa das cavernas
O agente precisa saber:• localização inicial = onde o agente está
Em (Agente,[1,1],S0 )• orientação: a direção do agente (em graus)
Orientação (Agente,S0 ) = 0• localização um passo à frente: função de locais e orientações
x,y PróximaLocalização ([x,y ],0) = [x+1,y ] x,y PróximaLocalização ([x,y ],90) = [x,y+1 ]x,y PróximaLocalização ([x,y ],180) = [x-1,y ]x,y PróximaLocalização ([x,y ],270) = [x,y-1 ]
Guardando localizações

CIn- UFPE
37
A partir desses axiomas, pode-se deduzir que quadrado está em frente ao agente “ag” que está na localização “l”:ag,l,s Em (ag,l,s )
localizaçãoEmFrente (ag,s) = PróximaLocalização (l,Orientação (ag,s))
Podemos também definir adjacência:l1,l2 Adjacente (l1,l2 ) d l1 = PróximaLocalização (l2,d )
E detalhes geográficos do mapa:x,y Parede([x,y]) (x =0 x =5 y =0 y =5)
Guardando localizações

CIn- UFPE
38
Resultado das ações sobre a localização do agente:• Axioma Estado-Sucessor: avançar é a única ação que muda a
localização do agente (a menos que haja uma parede)a,l,ag,s Em(ag,l,Resultado(a,s)) [(a = Avançar l = localizaçãoEmFrente(ag,s) Parede(l))
(Em(ag,l,s) a Avançar)]
Efeito das ações sobre a orientação do agente:• Axioma ES: girar é a única ação que muda a direção do agentea,d,ag,s Orientação(ag,Resultado(a,s)) = d
[(a = Girar(Direita) d = Mod(Orientação(ag,s) - 90, 360) (a = Girar(Esquerda) d = Mod(Orientação(ag,s) + 90,
360) (Orientação(ag,s) = d (a = Girar(Direita) a =
Girar(Esquerda))]
Guardando localizações

CIn- UFPE
39
Agora que o agente sabe onde está, ele pode associar propriedades aos locais: l,s Em (Agente,l,s) Brisa(s) Ventilado(l) l,s Em (Agente,l,s) Fedor(s) Fedorento(l)
Sabendo isto o agente pode deduzir:• onde estão os buracos e o Wumpus, e• quais são as cavernas seguras (predicado OK).
Os predicados Ventilado e Fedorento não necessitam do argumento de situação
Deduzindo Propriedades do Mundo

CIn- UFPE
40
Regras diacrônicas (do grego “através do tempo”)• descrevem como o mundo evolui (muda ou não) com o tempo
x,s Presente(x,s) Portável(x) Segurando(x,Resultado(Pegar,s))
Regras Síncronas:• relacionam propriedades na mesma situação (tempo). o,s Em(Agente,l,s) Brisa(s) Ventilado(l)• axiomas que possibilitam deduzir propriedades escondidas no
mundo
Existem dois tipos principais de regras síncronas:• Regras Causais• Regras de Diagnóstico
Tipos de regras

CIn- UFPE
41
As regras que definimos até agora não são modulares:• mudanças nas crenças do agente sobre algum aspecto do mundo
requerem mudanças nas regras que lidam com outros aspectos que não mudaram.
• Para tornar essas regras mais modulares, separamos fatos sobre ações de fatos sobre objetivos:
• assim, o agente pode ser “reprogramado” mudando-se o seu objetivo.
• Ações descrevem como alcançar resultados.• Objetivos descrevem a adequação (desirability) de estados
resultado, não importando como foram alcançados.
Descrevemos a adequação das regras e deixamos que a máquina de inferência escolha a ação mais adequada.
Modularidade das Regras

CIn- UFPE
42
Escala, em ordem decrescente de adequação: • ações podem ser: ótimas, boas, médias, arriscadas e mortais.• O agente escolhe a mais adequada a,s Ótima(a,s) Ação(a,s) a,s Boa(a,s) ( b Ótima(b,s)) Ação(a,s) a,s Média(a,s) ( b (Ótima(b,s) Boa(b,s) )) Ação(a,s) a,s Arriscada(a,s) ( b (Ótima(b,s) Boa(b,s)
Média(a,s) )) Ação(a,s)
Essas regras são gerais, podem ser usadas em situações diferentes:• uma ação arriscada na situação S0 (onde o Wumpus está vivo)
pode ser ótima na situação S2, quando o Wumpus já está morto.
Modularidade: Adequação das Regras

CIn- UFPE
43
sistema de ação-valor: Um sistema baseados em regras de adequação• Não se refere ao que a ação faz, mas a quão desejável ela é.
Prioridades do agente até encontrar o ouro:• ações ótimas: pegar o ouro quando ele é encontrado, e sair
das cavernas.• ações boas: mover-se para uma caverna que está OK e ainda
não foi visitada.• ações médias: mover-se para uma caverna que está OK e já
foi visitada.• ações arriscadas:mover-se para uma caverna que não se sabe
com certeza que não é mortal, mas também não é OK• ações mortais: mover-se para cavernas que sabidamente
contêm buracos ou o Wumpus vivo.
Sistema de Ação-Valor

CIn- UFPE
44
O conjunto de ações-valores é suficiente para prescrever uma boa estratégia de exploração inteligente das cavernas. • quando houver uma seqüência segura de ações , ele acha o
ouro• Porém... isso é tudo o que um agente baseado em LPO pode
fazer.
Depois de encontrar o ouro, a estratégia deve mudar...• novo objetivo: estar na caverna (1,1) e sair.
s Segurando(Ouro,s) LocalObjetivo ([1,1],s)
A presença de um objetivo explícito permite que o agente encontre uma seqüência de ações que alcançam esse objetivo.
Agentes Baseados em Objetivos

CIn- UFPE
45
(1) Busca:• Usar Busca pela Melhor Escolha para encontrar um caminho até
o objetivo.• Nem sempre é fácil traduzir conhecimento em um conjunto de
operadores, e representar o problema (ambiente) em estados para poder aplicar o algoritmo.
(2) Inferência:• idéia: escrever axiomas que perguntam à BC uma seqüência de
ações que com certeza alcança o objetivo.• Porém: para um mundo mais complexo isto se torna muito caro.• como distinguir entre boas soluções e soluções mais
dispendiosas (onde o agente anda “à toa” pelas cavernas)?
Como encontrar seqüências de ações

CIn- UFPE
46
(3) Planejamento:• envolve o uso de um sistema de raciocínio dedicado, projetado
para raciocinar sobre ações e conseqüências para objetivos diferentes.
ficar rico e feliz
pegar o ouro
ações e conseqüênciasações e conseqüências ações e conseqüênciasações e conseqüências
sair das cavernas
Agentes Baseados em Objetivos