visão geral sobre text mining
DESCRIPTION
Uma abordagem introdutória sobre text mining em uma apresentação no ITV (Instituto Tecnológico Vale). Ministrado por Ehilton Kazuo e Fernando Gama da Mata.TRANSCRIPT

Visão geral sobreText Mining
Instituto tecnológico Vale (ITV)
Ehilton Kazuo Chiba Yoshidome - CBCC/UFPA
Fernando Fábio D. Gama da Mata - CBSI/UFPA

Agenda● Introdução (O que é text mining e qual sua importância?) (Fernando)● KDT: ● - Introdução (Kazuo)● - Etapas do processo (Fernando)● - Categorização (Kazuo)● - Classificação (Fernando)● - Tarefa de mineração (Kazuo)● - Estudo de caso (Ambos)

Introdução● Crescimento no volume de informações.● ~80% dos dados de uma empresa são não estruturados.
● Problemas:● “Lixo de dados”● Sobrecarga de informações.

KDT: introdução
Tipos de Descoberta de Conhecimento (Morais & Ambrósio ,2007)
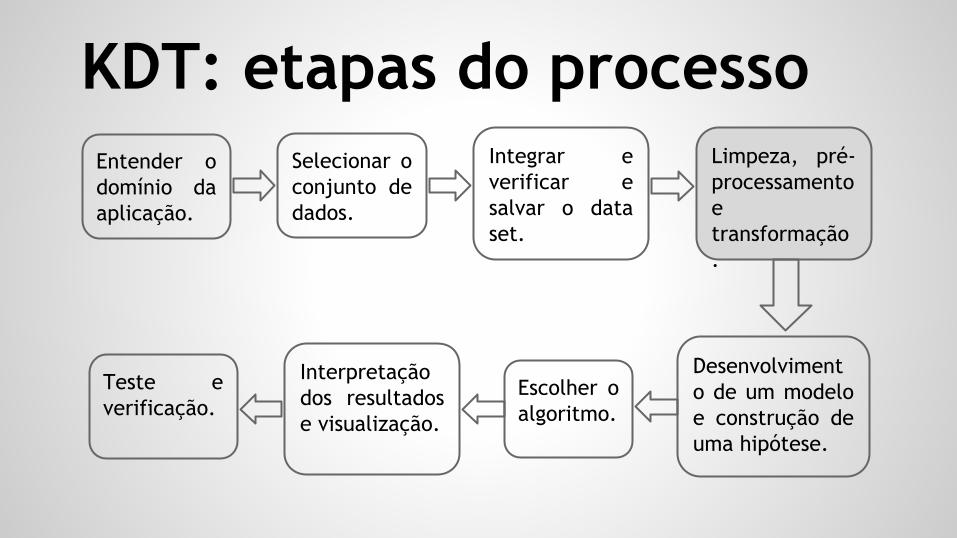
KDT: etapas do processoEntender o domínio da aplicação.
Selecionar o conjunto de dados.
Integrar e verificar e salvar o data set.
Limpeza, pré-processamento e transformação.
Desenvolvimento de um modelo e construção de uma hipótese.
Escolher o algoritmo.
Interpretação dos resultados e visualização.
Teste e verificação.

KDT: etapas do processo
Limpeza, pré-processamento e transformação.
DADOS
Remover espaços em branco
Remover pontuações
Remover números
Converter maiúsculas em minúsculas
Remover stopwords
Remover words
Remover stemmings

CATEGORIZAÇÃO
● Rocchio (centroid);○ Desvantagem: contexto
de palavras (palavras próximas)
● Métodos:○ palavras-chave ou frases;○ grau de relevância.

CLASSIFICAÇÃO● Gerar definição de conceitos.
- Termos e grau de associação e relevância.
● Pode-se utilizar um dicionário.● É possível gerar automaticamente umvocabulário próprio.

TAREFA DE MINERAÇÃO● Lista de conceitos-chave:
○ Permite a constatação de que existem temas dominantes em uma coleção ou em um único texto
● Associação ou correlação:
○ Confiança: proporção nos textos que tem em X e Y. Relação ao número de textos que têm apenas no X;
○ Suporte: é a proporção nos textos que têm X e Y. Relação a todos os textos da coleção.
Confiança = 82.1%, Suporte = 23 documentos
Confiança = 93.3%, Suporte = 14 documentos
X Y

ESTUDO DE CASO
Ehilton Kazuo Fernando Gama
● Trabalho com foco no delineamento de padrões associativos relativos ao índice de risco de atropelamento nas ferrovias operadas pela Vale.
● A base para o desenvolvimento consiste em dados textuais descritos pelos funcionários da Vale.
● Trabalho com foco na extração de artigos científicos na área da Metagenômica;
● Buscar frameworks similares no ramo.
● Criar um dicionário com os jargões da área analisada.

REFERÊNCIASLOH, S.; WIVES, L.K.; OLIVEIRA, J.P.M. Concept-Based Knowledge Discovery in Texts Extracted from the Web.
MORAIS, E. A. M.; AMBRÓSIO, A. P. L. Mineração de Textos (2007).
WIVES, L.K. Agrupamento de Informações Textuais. <http://www.leandro.wives.nom.br/pt-br/publicacoes/semacad.pdf>. Acesso em 24/04/2014.