processamento de texto - web.fe.up.pteol/ia/1617/apontamentos/jft_txt_mining... · •text mining...
TRANSCRIPT

IART 2014/2015
Jorge Teixeira
PROCESSAMENTO DE TEXTO(TEXT MINING)


(Enquadramento na UC de Inteligência Artificial - IART)
Parte 1: Introdução à Linguagem Natural Computacional (Secção VI)
• Processamento de texto (Text Mining) e Processamento da Linguagem Natural• Media na Web
Parte 2: Aprendizagem Automática (Secção VII)• Conceitos gerais de Machine Learning• k-Nearest Neighbour e Support Vector Machines• Caso de estudo
AGENDA

PARTE I
INTRODUÇÃO À LINGUAGEM NATURAL COMPUTACIONAL

TEXT MINING
PROCESSAMENTO DA LINGUAGEM NATURAL

• Text mining é uma sub-área do “Data Mining”
• Ciência que trata o processamento de informação (texto)
• Processamento que se espera de elevada qualidade
- relevância, novidade, interesse
TEXT MINING stands for?

• Extracção de padrões
• Extracção de entidades
• Categorização de texto
• Clustering de texto
• Análise de sentimento
• Sumarização de texto
• Visualização de informação
• …
TEXT MINING - Técnicas

• Internet (online media, social media)
• TV (user experience)
• Publicidade
• Saúde
• Segurança
• Smart cities
• E-learning
• …
TEXT MINING - Aplicações

MEDIA NA WEB

ARQUITECTURA
Dados
Extracção Informação
Processamento Informação
Visualização Informação

MEDIA NA WEB
DADOS

NOTÍCIAS

REDES SOCIAIS

MEDIA NA WEB
EXTRAÇÃO DE INFORMAÇÃO

DISPONIBILIDADE DOS DADOS

MEDIA NA WEB
PROCESSAMENTO DE INFORMAÇÃO

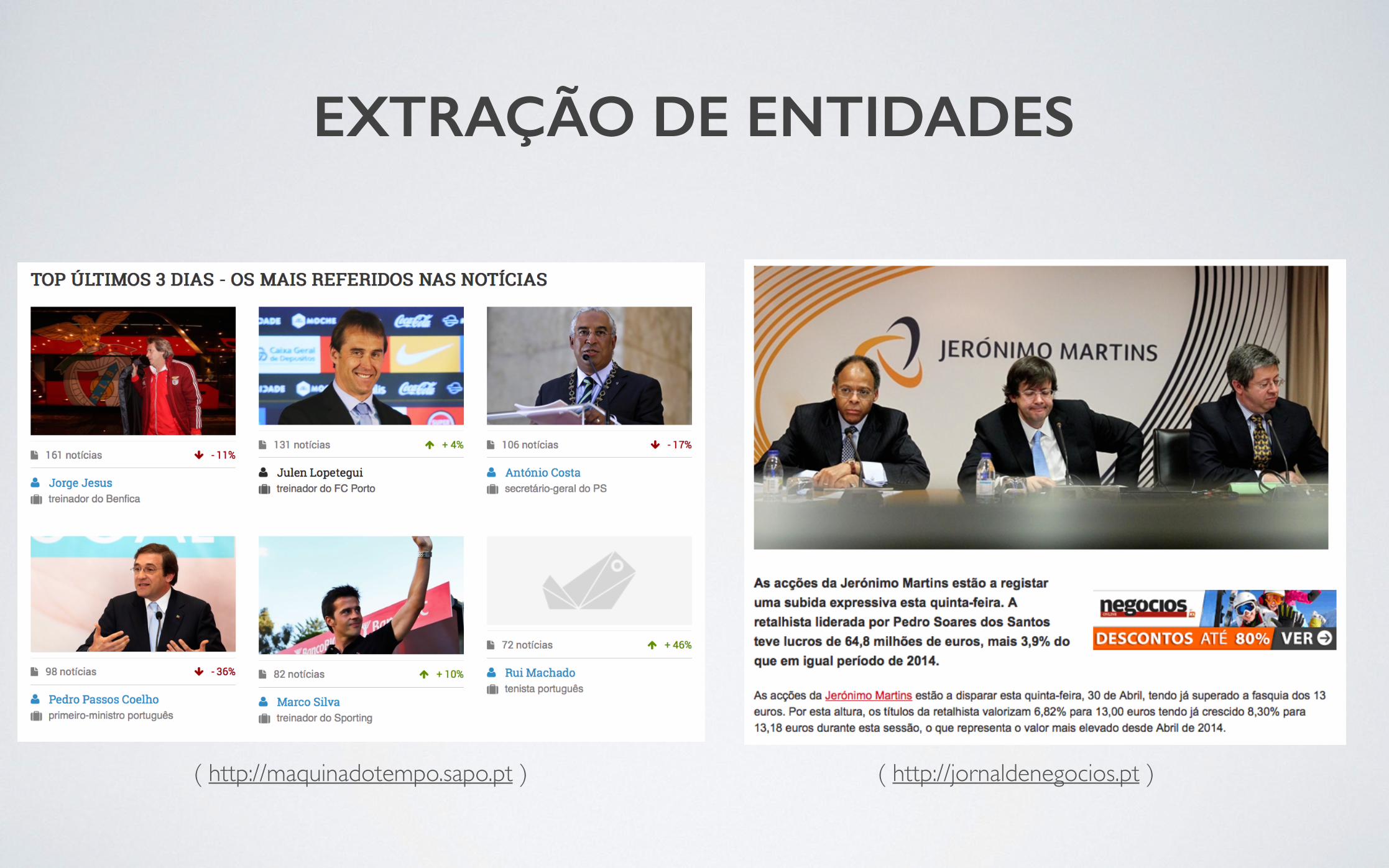
EXTRAÇÃO DE ENTIDADES
( http://maquinadotempo.sapo.pt ) ( http://jornaldenegocios.pt )

RECOMENDAÇÃO DE CONTEÚDO
( http://expresso.sapo.pt )
( http://lifestyle.sapo.pt )


MEDIA NA WEB
VISUALIZAÇÃO DE INFORMAÇÃO







PARTE II
APRENDIZAGEM AUTOMÁTICA

Conceitos Gerais
Sistemas de aprendizagem automática (ML) aprendem automaticamente a partir de características dos dados.
A B C ?

Conceitos Gerais
• ML é usada na classificação de conteúdos, filtros de spam, sistemas de recomendação, posicionamento de anúncios, fraude em transações electrónicas, etc.
• Vamo-nos focar na classificação, um dos principais tipos de ML
• Um classificador é um sistema que recebe (tipicamente) vectores discretos e/ou contínuos de características (features) e retorna um ou várias classe.
• Exemplo: sistema de filtro de spam
• Principais tipos de algoritmos: supervisionados, não-supervisionados e semi-supervisionados
• A capacidade de generalização do classificador é um dos principais fatores associados à qualidade de um classificador
• A quantidade de dados nem sempre corresponde a uma melhoria da classificação

Conceitos Gerais
• Learning = Representation + Evaluation + Optimization
( Pedro Domingos. 2012. A few useful things to know about machine learning. Communications of the ACM, Volume 55, Issue 10, Pages 78-87. October 2012. )

Conceitos Gerais
http://peekaboo-vision.blogspot.pt/2013/01/machine-learning-cheat-sheet-for-scikit.html

k-Nearest Neighbour
• K-NN classifica um exemplo de teste a partir da pesquisa dos k exemplos de treino (vizinhos) mais semelhantes e atribui (prevê) a classe maioritária.
• Os exemplos de treino são vectores de features num espaço multi-dimensionais, cada um deles com uma classe atribuída.
•Métricas típicas: distância Euclidiana e distância de Hamming
http://www.byclb.com/TR/Tutorials/neural_networks/ch11_1_dosyalar/image087.jpg

• Para um dado conjunto de dados de input, prevêem qual das duas classes possíveis caracteriza melhor cada exemplo de teste. É tipicamente um problema de classificação binário.
• Um modelo SVM é uma representação de pontos no espaço multi-dimensional, mapeados de tal forma que seja possível criar uma área de separação (margem) entre dois conjuntos de pontos.
• Cada uma destas áreas representa uma classe.
Support Vector Machines

Support Vector Machines
• A margem entre as classes deve ser a maior possível
• Os vectores de suporte são vectores perpendiculares ao hiper-plano de separação (margem) que partem do ponto mais próximo de cada uma das classes.
• SVMs suportam classificação não-linear através de kernels também não lineares.

CASO DE ESTUDO

VERBETESEXTRACÇÃO AUTOMÁTICA DE MICRO-BIOGRAFIAS

• Serviço para pesquisa biográfica de entidades (pessoas, organizações)
• Este serviço responde a perguntas como:
- Quem é Alberto João Jardim?
- Qual a profissão/cargo de Paulo Portas em Julho 2011? e hoje?
- Quem é o ministro da defesa de Israel?
O que é o Verbetes?

Abordagem:
• Identificar nomes de personalidades de notícias• Extraír tuplos das notícias com base em padrões
• [ Pedro Passos Coelho; Primeiro ministro; 2011-06-21; “hoje”]• Identificar nomes alternativos (Passos Coelho, Passos)• Classificar os tuplos como pessoa, organizacão ou outro
Abordagem usada

Desafios:
• Desambiguação:- Paulo Bento: seleccionador nacional- Rui Bento: treinador do Beira-Mar- Vítor Bento: economista
• Inclusão de outras entidades (organizações):- Alfredo da Costa- Jerónimo Martins
Desafios

• Tecnologias usadas:
• Sistema baseado em padrões existentes nas notícias:- O primeiro ministro, Pedro Passos Coelho, ....- … o ex-primeiro ministro José Sócrates, …
• Baseado essencialmente em técnicas de processamento de linguagem natural e aprendizagem automática.
• Utilização de CRFs (Conditional Random Fields):- Para a identificação de entidades no texto
Tecnologias usadas
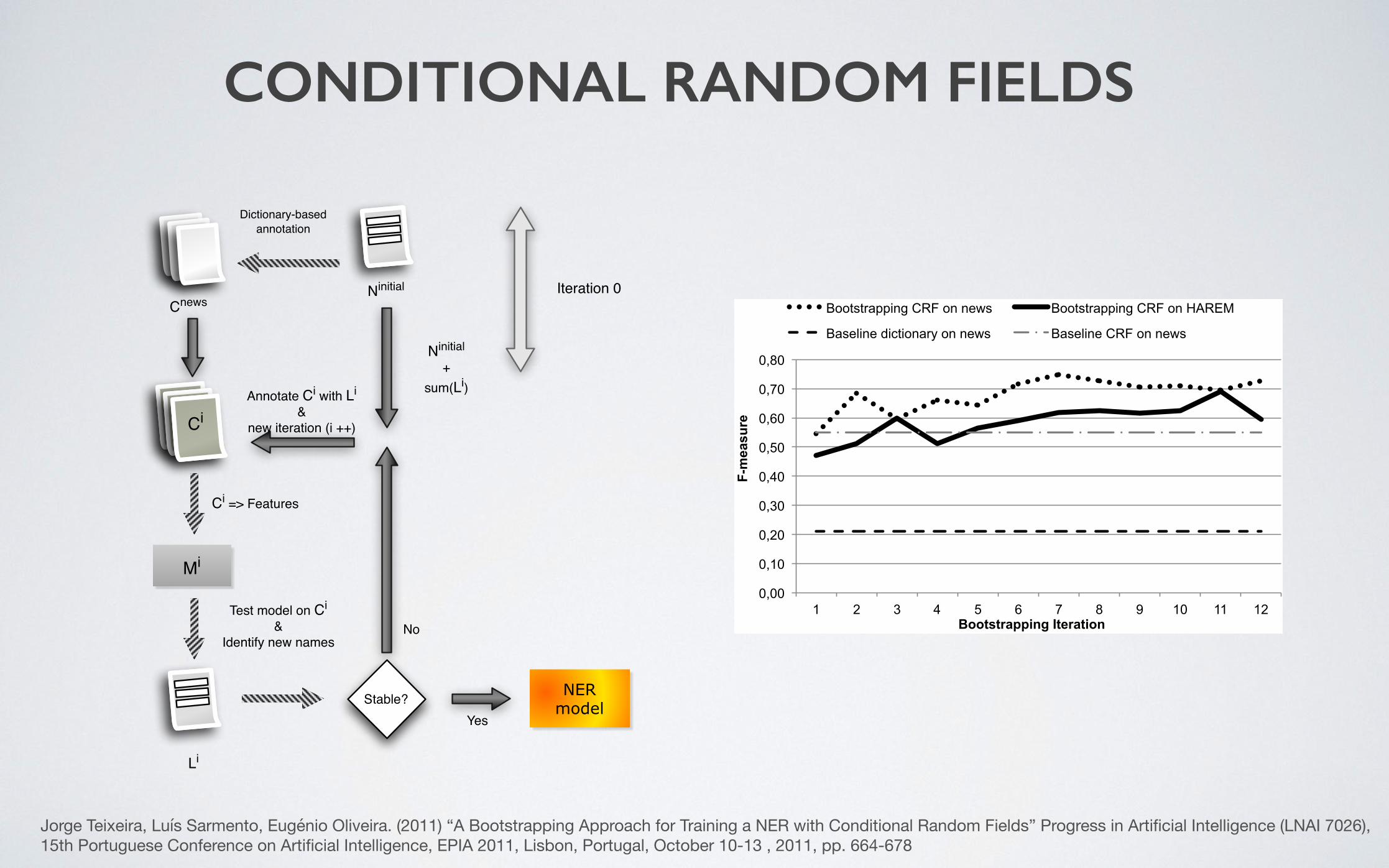
CONDITIONAL RANDOM FIELDS
Bootstrapping CRF on newsBootstrapping CRF on HAREM
0,00
0,10
0,20
0,30
0,40
0,50
0,60
0,70
0,80
1 2 3 4 5 6 7 8 9 10 11 12
F-m
easu
re
Bootstrapping Iteration
Bootstrapping CRF on news Bootstrapping CRF on HAREM
Baseline dictionary on news Baseline CRF on news
Cnews
Dictionary-basedannotation
Ci
Iteration 0
Ci => Features
Mi
Test model on Ci
&Identify new names
Li
Stable? NER model
Yes
No
Annotate Ci with Li&
new iteration (i ++)
Ninitial +
sum(Li)
Ninitial
Jorge Teixeira, Luís Sarmento, Eugénio Oliveira. (2011) “A Bootstrapping Approach for Training a NER with Conditional Random Fields” Progress in Artificial Intelligence (LNAI 7026), 15th Portuguese Conference on Artificial Intelligence, EPIA 2011, Lisbon, Portugal, October 10-13 , 2011, pp. 664-678

RECURSOS DISPONÍVEIS
• Notícias publicadas em sites de notícias portugueses• Citações de personalidades públicas• Comentários de notícias• Tweets (mensagens de utilizadores portugueses e perfis)• Listas de personalidades, co-menções, etc (Verbetes)• Listas de profissões, nacionalidades, palavrões, etc (SemanticLists)• Listas de palavras polarizadas (sentiment analysis)

• Extracção de informação
• Extracção de outros descritores (projecto Verbetes)• Normalização de tópicos (“OE2014” vs “Orçamento de Estado 2014”)• Criação de perfis opinativos a partir dos tweets e comentários
• Aprendizagem Automática (Machine Learinig)
• Hierarquização de tópicos (“Desporto”, “Futebol” e “Liga Sagres”)• Identificação de citações com CRFs
PROJETOS IART 14/15
