universidade f g i ricardo belloti dos santos modelo · 1.1 exemplos de formas presentes em...
TRANSCRIPT

Mod
eloUNIVERSIDADE FEDERAL DE GOIÁS
INSTITUTO DE INFORMÁTICA
RICARDO BELLOTI DOS SANTOS
Reconhecimento de Esboços de FormasGeométricas Contidas em Fluxogramas
Goiânia2010

UNIVERSIDADE FEDERAL DE GOIÁS
INSTITUTO DE INFORMÁTICA
AUTORIZAÇÃO PARA PUBLICAÇÃO DE DISSERTAÇÃO
EM FORMATO ELETRÔNICO
Na qualidade de titular dos direitos de autor, AUTORIZO o Instituto de Infor-mática da Universidade Federal de Goiás – UFG a reproduzir, inclusive em outro formatoou mídia e através de armazenamento permanente ou temporário, bem como a publicar narede mundial de computadores (Internet) e na biblioteca virtual da UFG, entendendo-seos termos “reproduzir” e “publicar” conforme definições dos incisos VI e I, respectiva-mente, do artigo 5o da Lei no 9610/98 de 10/02/1998, a obra abaixo especificada, sem queme seja devido pagamento a título de direitos autorais, desde que a reprodução e/ou publi-cação tenham a finalidade exclusiva de uso por quem a consulta, e a título de divulgaçãoda produção acadêmica gerada pela Universidade, a partir desta data.
Título: Reconhecimento de Esboços de Formas Geométricas Contidas em Fluxogramas
Autor(a): Ricardo Belloti dos Santos
Goiânia, 22 de Julho de 2010.
Ricardo Belloti dos Santos – Autor
– Orientador

RICARDO BELLOTI DOS SANTOS
Reconhecimento de Esboços de FormasGeométricas Contidas em Fluxogramas
Dissertação apresentada ao Programa de Pós–Graduação doInstituto de Informática da Universidade Federal de Goiás,como requisito parcial para obtenção do título de Mestre emComputação.
Área de concentração: Recuperação de Informação.
Orientadora: Profa. Dra. Ana Paula Laboissière Ambrósio
Goiânia2010

RICARDO BELLOTI DOS SANTOS
Reconhecimento de Esboços de FormasGeométricas Contidas em Fluxogramas
Dissertação defendida no Programa de Pós–Graduação do Instituto deInformática da Universidade Federal de Goiás como requisito parcialpara obtenção do título de Mestre em Computação, aprovada em 22 deJulho de 2010, pela Banca Examinadora constituída pelos professores:
Profa. Dra. Ana Paula Laboissière AmbrósioInstituto de Informática – UFG
Presidente da Banca
Prof. Dr. Díbio Leandro BorgesCIC–UnB
Prof. Dr. Ronaldo Martins da CostaINF–UFG

Todos os direitos reservados. É proibida a reprodução total ou parcial dotrabalho sem autorização da universidade, do autor e do orientador(a).
Ricardo Belloti dos Santos
Graduado em Ciêncida da Computação pelo Instituto de Informática (INF)da Universidade Federal de Goiás (UFG). Atualmente é Gestor de Tecnologiada Informação na Secretaria da Fazenda do Estado de Goiás (SEFAZ-GO),atuando no Centro de Documentação, Informação e Memória (CDIM), umprojeto de parceria entre o Estado de Goiás e a UFG para a integração dedados e disponibilização de conjuntos documentais digitais.

Dedico a DEUS, que me deu condições de seguir com firmeza e sabedoriadurante toda a execução deste trabalho.
Dedico também a meus pais que sempre colocaram a educação dos filhos acimade qualquer coisa. Obrigado pelo amor, carinho e pelos ensinamentos recebidos durantetoda a minha vida.

Agradecimentos
À minha família, especialmante a meu pai Jorge e a minha mãe Maria, pelocarinho, dedicação e apoio em todos os momentos da minha vida.
À minha orientadora Dra. Ana Paula L. Ambrósio, por sua sabedoria, compe-tência e por ter confiado em meu trabalho. Pela grande ajuda e paciência ao longo desteperíodo, e pela orientação que contribui para o meu desenvolvimento pessoal e profissio-nal.
À minha namorada Talita, pelo companheirismo, pela cumplicidade, por estarcomigo em horas difíceis e pelo constante incentivo e estímulo para a conclusão destetrabalho.
Ao Instituto de Informática da UFG, a cada um dos meus professores e funcio-nários, sempre dispostos a cooperar e cujo contato foi indispensável para minha formaçãoacadêmica.
Aos meus colegas de mestrado, que tantas vezes me ajudaram a resolver proble-mas que pareciam impossíveis. Fico grato pela amizade, companherismo e solidariedadeem todos os momentos. Em especial aos amigos Luciana Oliveira e Halley Wesley, vocêsme ajudaram muito nesta caminhada.
Meus agradecimentos especiais a meus colegas de trabalho Lívia Leite, MarcelLuiz e Mário Mendes Barbosa Júnior, pelo apoio na materialização deste trabalho, pelosquais tenho grande estima e gratidão.
Finalmente, agradeço a todos aqueles que, de forma direta ou indireta, contribuí-ram para a elaboração deste trabalho.
Muito obrigado a todos!E a DEUS, por tudo!

“A melhor maneira de predizer o futuro é inventá-lo.”
Alan Kay,Encontro em 1971, na PARC (Palo Alto Research Center).

Resumo
dos Santos, Ricardo Belloti. Reconhecimento de Esboços de Formas Geomé-tricas Contidas em Fluxogramas. Goiânia, 2010. 96p. Dissertação de Mes-trado. Instituto de Informática, Universidade Federal de Goiás.
Grandes mudanças na sociedade e na educação vêm surgindo com o contínuo desen-volvimento tecnológico e sua disseminação em todas as áreas. É preciso considerar queo momento proporciona uma oportunidade de aproximar novas tecnologias ao processoeducativo como possibilidade de melhorar os tradicionais sistemas de ensino. Celularese computadores com tinta digital, tela touchscreen e cameras vêm revolucionando a ma-neira como as pessoas interagem com tais dispositivos. Neste sentido, sistemas vêm sendodesenvolvidos para permitir a recuperação, seleção, extração de características, indexaçãoe reconhecimento de imagens através de seu conteúdo. Enquanto aplicações para o reco-nhecimento de imagens vêm sendo criadas para vários domínios, até hoje os sistemas parao reconhecimento de esboços ainda não são acessíveis para educadores que necessitam desistemas específicos para atingir os objetivos de suas aulas. Este trabalho apresenta ummétodo para reconhecimento de imagens baseado em conteúdo, utilizando esboços dese-nhados pelo usuário com tinta digital, para reconhecer formas geométricas presentes emfluxogramas. O método é baseado na técnica Chain Code e as informações são extraídasa partir do contorno da imagem. Para a avaliação, um conjunto de mais de quatro mile setecentos esboços, das diferentes formas contidas em fluxogramas, foi utilizado. Osresultados obtidos mostraram um índice de reconhecimento próximo de 90%.
Palavras–chave
Ensino da Computação, Recuperação da informação, CBIR, Fluxogramas, ChainCode, Código de Freeman.

Abstract
dos Santos, Ricardo Belloti. Reconition of geometric shapes sketched inflowcharts. Goiânia, 2010. 96p. MSc. Dissertation. Instituto de Informática,Universidade Federal de Goiás.
The continued technological development has brought many changes to society andeducation. The moment provides a good opportunity to bring new technologies to theeducational process as a possibility to improve the traditional education systems. Phonesand computers with digital ink, touchscreen and cameras are revolutionizing the waypeople interact with and use such devices. In this sense, systems have been developed toallow retrieval, selection, feature extraction, indexing and image recognition based on itscontents. While image retrieval applications have been created for many domains, sketchretrieval and recognition systems are not yet available for educators, who need specificsystems to achieve the objectives in their classes. This work presents a method for imagerecognition based on its content using user-drawn sketches with digital ink, to recognizegeometric shapes found in flowcharts. The method is based on the Chain Code technique,and the information is extracted from the image contour. For evaluation, a set of morethan four thousand and seven hundred sketches, containing the various shapes containedin flowcharts, was used. The results obtained showed recognition rates near of 90%.
Keywords
Information Retrieval, CBIR, Flowcharts, Chain Code, Freeman Code.

Sumário
Lista de Figuras 11
Lista de Tabelas 13
1 Introdução 141.1 Fluxogramas 171.2 Objetivo 191.3 Justificativa 201.4 Metodologia 201.5 Estrutura da Dissertação 21
2 Processamento de Imagens Digitais 222.1 Descritores de Conteúdo da Imagem 22
2.1.1 Cor 232.1.2 Textura 232.1.3 Forma 24
2.2 Pixel 252.3 Transformadas e Filtros 272.4 Histograma 282.5 Região de Interesse 292.6 Passos Fundamentais no Processamento de Imagens Digitais 292.7 Conclusão 30
3 Trabalhos Relacionados 313.1 Reconhecimento de Formas 323.2 Sistemas 34
3.2.1 QBIC 343.2.2 Virage 353.2.3 PhotoBook 363.2.4 VisualSEEk 36
3.3 Conclusão 37
4 Técnicas de Representação de Formas 384.1 Baseada no contorno 39
4.1.1 Métodos globais 39Descritores de forma simples 39Assinatura da forma 39Boundary Moments 40Elastic matching 40

Stochastic Method 40Scale Space Method 40Trasformações espectrais 41
4.1.2 Métodos Estruturais 41Representação Chain-Code 41Polygon Decomposition 43Smooth curve decomposition 43Curvature-tuned Smoothing 43Syntatic Analysis 44Shape invariants 44
4.2 Baseada na região 454.2.1 Métodos Globais 45
Geometric Moment Invariants 45Grid Based Method 45Shape Matrix 46
4.2.2 Métodos Estruturais 46Convex Hull 46Medial Axis 47
4.3 Conclusão 47
5 O Projeto 485.1 O Sketch 485.2 Escopo do projeto 505.3 Tinta Digital 515.4 O Reconhecimento das Formas 53
5.4.1 Formulação da consulta 535.4.2 Processamento da consulta 535.4.3 Resposta ao usuário 54
5.5 O Modelo do Sistema 545.6 O Sistema Desenvolvido 545.7 O Método de Extração de Características 56
5.7.1 Pré-processamento da Imagem 575.7.2 Análise da Imagem 605.7.3 Aprimoramento da Cadeia de Contorno 615.7.4 Extração de Características 64
5.8 Conclusão 69
6 Avaliação 706.1 O Reconhecimento 706.2 Base de dados para o teste 716.3 Resultados 72
7 Conclusão e Trabalhos Futuros 817.1 Trabalhos Futuros 82
Referências Bibliográficas 84
A Exemplos de formas desenhadas pelos usuários 92

Lista de Figuras
1.1 Exemplos de formas presentes em fluxogramas 19
2.1 Exemplos de texturas visuais 242.2 Exemplos de formas 242.3 Representação dos pixels de uma imagem digital [31] 262.4 Representação matricial de uma imagem digital 262.5 Aplicação de um filtro sobre uma matriz de pixels [31] 282.6 Passos fundamentais no processamento de imagens digitais [31] 29
3.1 Demonstrações da utilização do QBIC 35
4.1 Métodos para representação de forma 384.2 Conectividade 424.3 Syntatic Analysis 444.4 Convex Hull - (adaptado de [41]) 47
5.1 Exemplos de esboços 495.2 Formas 505.3 Exemplos de imagens 515.4 Utilização da tinta 525.5 Transformação da tinta para imagem binária 535.6 Etapas do Sistema 535.7 Processos em cada uma das etapas 545.8 Interface do Sistema 555.9 Exemplos da utilização do sistema 555.10 Sketch desenhado pelo usuário 575.11 Esboço binarizado 585.12 Grade - Matriz de pixels 595.13 Identificação dos pixels de borda 605.14 Exemplo da utilização do Chain Code 615.15 Agrupamento de transições 625.16 Remoção de transições isoladas - 1 625.17 Remoção de transições isoladas - 2 625.18 Remoção de transições isoladas - 3 635.19 Re-agrupamento 635.20 Simplificações para cadeias de tamanho 2 645.21 Exemplos de formas 665.22 Exemplos de aplicação da equação 5-3 665.23 Ângulos entre cada uma das transições 66

5.24 Formas e suas propriedades 685.25 Aproximações para círculos e elipses 69
6.1 Exemplos de formas removidas 746.2 Exemplos de formas movidas para outros grupos 756.3 Simplificações para elipses com segmentos de 3 e 5 transições 776.4 Formas com escala diferente mas com mesma cadeia de contorno 796.5 Losango 80
A.1 Exemplos de Círculos 92A.2 Exemplos de Elipses 93A.3 Exemplos de Hexágonos 93A.4 Exemplos de Quadrados 94A.5 Exemplos de Retângulos 94A.6 Exemplos de Linhas 95A.7 Exemplos de Losangos 95A.8 Exemplos de Triângulos 96A.9 Exemplos de Trapézios 96

Lista de Tabelas
6.1 Teste 1 - Resultados 736.2 Teste 2 - Resultados 756.3 Teste 3 - Resultados para segmentos de tamanho 4 e 5 766.4 Teste 4 - Resultados - Segmentos de tamanho 4,3 786.5 Teste 5 - Avaliando a invariância 79

CAPÍTULO 1Introdução
Com a explosão do número de usuários de computadores e usuários da internet,tem ocorrido um crescimento vertiginoso na quantidade de informação digital disponívelno mundo. Equipamentos eletrônicos como celulares, Personal digital assistants (PDA’s),computadores, cada vez mais baratos e ao alcance da população, permitem que pratica-mente qualquer pessoa no mundo possa gerar conteúdo digital na forma de texto, som,imagem e vídeo. Com isso modelos para recuperação precisa de informações passaram ater ainda mais importância. Na sociedade do conhecimento e da informação, as pessoasprecisam ser capazes de obter, rapidamente, o maior número possível de informações re-levantes [83]. O grande volume de dados produzido diariamente requer o uso de novastecnologias para a organização, classificação, recuperação e processamento dessa infor-mação.
O cérebro humano apresenta uma grande capacidade de reconhecer informaçõesgraficamente e possui mecanismos bastante eficientes para reconhecer e interpretar ima-gens. Se comparada à capacidade humana, a tecnologia atualmente disponível é muitoincipiente para a construção de sistemas computacionais que analisem imagens digitali-zadas e recuperem informações a partir delas. Isso causa uma grande distinção entre oque um indivíduo pode reconhecer de uma imagem e o que pode ser esperado de umsistema computacional que tente fazer este reconhecimento. Esta distinção é comumenteconhecida como descontinuidade semântica (semantic gap) no reconhecimento de ima-gens [82].
Neste sentido, processar uma imagem como é feito pelo sistema visual humanoé extremamente complexo. Para um sistema computacional realizar as mesmas tarefasrealizadas por um ser humano, exige-se , por antecedência, uma compreensão “filosófica”do mundo ou dos conhecimentos humanos. Por isso, os métodos para o processamentode imagens possuem extrema dependência do sistema ao qual ele está associado, nãoexistindo uma solução única e abrangente para todos os problemas [1].
Recuperação da Informação (RI) é uma área da computação que lida com oarmazenamento de objetos e a sua recuperação automática. Esses objetos podem estardisponíveis sob a forma de textos, sons, imagens, vídeo, entre outros. Entre as atividades

15
desenvolvidas pode-se citar a busca por informações nesses objetos, a busca pelos objetospropriamente ditos, busca por metadados que descrevam os objetos e busca em banco dedados.
As aplicações para imagens digitais vêm se destacando nas linhas de pesquisa. Oformato digital fornece grande facilidade para armazenamento e manipulação de imagens.Com este crescimento, surge naturalmente a necessidade de se estabelecer técnicas quepermitam uma melhor manipulação destes conteúdos. As primeiras técnicas propostasbaseavam-se na busca mediante uma descrição textual das imagens. Esta proposta logose deparou com duas grandes dificuldades: a necessidade de muito trabalho manual pararepresentar imagens na forma de texto e a subjetividade da percepção humana [30].
Tradicionalmente, recuperar desenhos (ou imagens) é uma tarefa lenta, complexae sujeita a erros, exigindo um exame visual exaustivo, uma boa memória ou ambos [27].Uma implicação direta desses problemas é a busca de novas técnicas ou extensões paraas técnicas tradicionais de recuperação da informação, de forma a atender essa novanecessidade incluindo informação visual contida nas imagens. Essa linha de pesquisa éconhecida como Recuperação de Imagens Baseado em Conteúdo - Content-Based Image
Retrieval (CBIR) [26]: imagens passam as ser indexadas pelo seu próprio conteúdo visual,utilizando-se de algoritmos capazes de extrair das mesmas características, como: cor,estrutura, textura, forma, entre outras, que serão utilizadas para o reconhecimento do seuconteúdo.
Um Sistema CBIR necessita extrair informações, a partir de uma imagem, quepossa ser processada e comparada com a consulta feita pelo usuário. A idéia central étentar “descobrir” o conteúdo da imagem através da extração de informações que venhama caracterizar seu conteúdo. Para isso utilizam-se principalmente dados primitivos comocor, textura, forma ou uma combinação das mesmas [63], [8].
A área de recuperação de imagens por conteúdo tem proporcionado um avançoconsiderável no campo de visão computacional. Esse avanço é atribuído à necessidade dese administrar grande quantidades de dados e imagens. À medida que cresce o volumede imagens armazenadas, cresce também o interesse por sistemas capazes de recuperarinformações visuais de maneira eficiente e com grau de automação maior [82]. Em [59] oautor classifica as pesquisas em CBIR em três tipos:
• recuperação por desenho (esboço): o usuário esboça uma imagem aproximadadaquilo que ele deseja recuperar;• recuperação por exemplos (QBE - Query By Example): o usuário fornece uma
imagem de exemplo, similar àquela que ele deseja recuperar;• busca parametrizada: o usuário fornece parâmetros de busca que descrevam a
imagem, como: "buscar imagens com 50% de azul, 20% de amarelo e 30% deverde".

16
Nos sistemas CBIR, as imagens são representadas, normalmente, através de umvetor de características que é uma representação numérica e compacta de uma dada ima-gem, ou de parte dela. Este vetor caracteriza as medidas dos aspectos que representam aimagem. Idealmente, o vetor de características deve ser capaz de representar, unicamente,o conteúdo da imagem a partir da qual foi gerado. O ponto-chave é encontrar um vetor decaracterísticas, ou um conjunto de atributos, que: reduza a dimensão dos dados, ressalteos aspectos mais significativos da imagem, e seja invariante a alguns tipos de transforma-ção na imagem. Durante o processo de busca, o sistema deve trabalhar diretamente como vetor de características e não com a imagem.
As técnicas de recuperação utilizadas em CBIR consideram a informação visualda imagem e não apenas uma simples descrição textual da mesma. De fato, existe certonível de subjetividade em se caracterizar uma imagem pelo seu conteúdo, visto quediferentes especialistas podem estar interessados em diferentes aspectos de uma mesmaimagem [8].
Com a expansão do uso de dispositivos com tinta digital na educação, a Recu-peração por Esboços (ou Sketch Retrieval) apresenta um vasto campo de pesquisa para odesenvolvimento de sistemas para uso didático.
O cenário abaixo foi adaptado de [34] e, embora ainda futurista, ilustra umasituação não tão distante de nossa realidade com as tecnologias disponíveis atualmente:
"Alunos entram na sala de aula para uma aula de Computação. O instrutor desenha, em
um SmartBoard na frente da turma, um fluxograma e explica seu funcionamento. Ele
desenha este fluxograma de forma natural, insere algumas informações como entrada e
clica no botão “executar”. Passo-a-passo esta entrada é processada dentro do
fluxograma e o caminho correto é acionado. A cada etapa da execução o estado corrente
é destacado para facilitar o acompanhamento do processo. Os alunos fazem anotações
em seus “tablet pcs”. Os alunos então utilizam e testam o fluxograma criado pelo
professor em seus próprios “laptops”; alteram as entradas e também alteram o
fluxograma; eles assistem a simulação dos seus próprios fluxogramas, ajudando no
entendimento e aprendizado desses novos conceitos. O teste e a manipulação destes
fluxogramas possibilita que os alunos forneçam um “feedback” imediato ao professor.
Este, por sua vez, avalia o aprendizado de seus alunos pedindo para que os alunos
alterem o fluxo de execução, alterem as entradas do fluxograma ou até mesmo criem
novos fluxogramas. Assim que cada aluno estiver satisfeito com sua solução, o mesmo
envia seu trabalho pela rede para seu professor. Cada solução recebida é
automaticamente testada e classificada como certa ou errada. Os grupos são exibidos
ao instrutor no seu próprio “tablet pc”. O professor, então, pode selecionar uma
submissão errada e exibí-la no “SmartBoard”. Ele testa o fluxograma fornecendo uma
certa entrada e acompanha a simulação de seu funcionamento. O erro é então detectado

1.1 Fluxogramas 17
e o professor questiona seus alunos sobre possíveis correções a serem feitas. Quando a
aula termina os alunos deixam a sala com um entendimento completo do que são
fluxogramas e seu funcionamento, enquanto o professor recebe um “feedback” sobre o
grau de aprendizado de seus alunos sobre fluxogramas ."
Desenhar um fluxograma e simular o seu funcionamento mantém os alunosmotivados e aplicados durante o processo de aprendizagem dentro da sala de aula. Oreconhecimento de esboços pode ser utilizado para interpretar os desenhos feitos e fazercom que o fluxograma “ganhe vida”. De acordo com [34], sistemas para reconhecimentode sketches têm grande efeito pedagógico, pois:
• permitem interação de forma natural, oferecendo liberdade de desenho• fornecem capacidades de edição avançada• explicam o conteúdo gráfico desenhado pelo usuário de uma forma interativa• permitem que os alunos realizem exercícios práticos em sala de aula• auxiliam os alunos a realizarem exercícios práticos em casa• corrigem automaticamente os exercícios de casa realizados• corrigem automaticamente os exercícios realizados em sala de aula e fornecem ao
professor um feedback imediato
Embora aplicações para o reconhecimento de imagens vêm sendo desenvolvidaspara vários domínios, poucos sistemas com fins didatico-pedagógicos, como [34] e[38], estão disponíveis para educadores. Tais sistemas, por sua vez, possuem foco bemespecífico, como auxiliar no processo de ensino e aprendizagem de algoritmos
1.1 Fluxogramas
A aprendizagem de algoritmos é considerada fundamental em cursos da áreacomputacional. Seu principal objetivo é iniciar o desenvolvimento da lógica de progra-mação, que será amplamente utilizada durante o restante do curso. Porém, a disciplina dealgoritmos é considerada desafiadora em virtude de possuir um alto índice de problemasde aprendizagem, desistências e reprovações [71].
Fluxograma é um tipo de diagrama ou uma representação gráfica de um deter-minado processo ou fluxo de trabalho, e pode ser entendido como uma representaçãoesquemática de um processo, muitas vezes feito através de gráficos que ilustram de formadescomplicada a transição de informações entre os elementos que o compõem [40]. Naprática, pode ser visto como a documentação dos passos necessários para a execução deuma determinada atividade. Através desta representação gráfica é possível compreender,de maneira rápida e fácil, a transição de informações entre os elementos que participam do

1.1 Fluxogramas 18
processo em questão. Ele é composto, geralmente, de figuras geométricas normalizadas elinhas unindo essas figuras geométricas.
Como exposto em [3], o uso de fluxogramas para o ensino de programação sedeve a três razões principais:
• fluxogramas possuem uma sintaxe mínima e, quando se reduz o foco na sintaxe,pode-se aumentar o esforço em análise;• fluxograma é uma representação universal;• fluxogramas são mais fáceis e mais compreensíveis para estudantes iniciantes em
computação do que o próprio código.
É sabido que o ser humano tem mais habilidade para interpretar um algoritmousando formas visuais do que código fonte. Isso se deve ao fato que o hemisfério esquerdodo cérebro processa informação oral e lógica, enquanto o hemisfério direito processainformação visual e espacial. Assim, a chave para tornar o ensino de algoritmos maisacessível está em utilizar aspectos visuais e textuais estimulando ambos os hemisfériosdo cérebro [3].
Existem estudos que comprovam que o ser humano consegue gravar melhor umamensagem, quando esta é acompanhada de imagens:
• em [19], o autor verificou que estudantes iniciantes em algoritmos cometem menoserros, têm maior confiança e resolvem problemas representados por algoritmossimples e médios mais rapidamente, quando utilizam fluxogramas,• em [79], o autor verificou que o uso de fluxogramas leva a uma diminuição dos
erros em algoritmos complexos.
Vale ressaltar que fluxograma é uma forma de representação bastante adequada àescrita humana. No entanto, para torná-los estéticamente mais agradáveis e poder incluí-los em documentos, são usados diversos aplicativos de edição de texto e desenho (ex:Word). Muitos deles oferecem, inclusive, uma palheta contendo as formas de fluxogra-mas, que podem variar, assim como seu significado dentro do fluxograma.
A Figura 1.1 exibe alguns exemplos de formas utlizadas para a construção defluxogramas.

1.2 Objetivo 19
Figura 1.1: Exemplos de formas presentes em fluxogramas
1.2 Objetivo
Reconhecimento de esboços é uma área emergente no campo da computaçãoque utiliza interfaces baseadas em canetas digitais e busca tornar a interação homem-computador mais natural [64]. Nessas interfaces o usuário pode desenhar livremente,direto na tela, sem utilizar o mouse ou teclado. A principal vantagem desta tecnologiaé a sua intuitividade e facilidade de uso. O usuário pode desenhar e até mesmo escrevertextos manuscritos diretamente sobre a tela.
Sistemas para o reconhecimento de sketches podem ter um efeito pedagógicoprofundo e facilitar o processo de ensino [36]. Diagramas gráficos são importantes emvárias áreas do conhecimento e podem ser utilizados em todo o processo de aprendizagem.
Este trabalho tem como objetivo apresentar um método para reconhecimento deimagens baseado na sua forma. As imagens são esboços de formas geométricas contidasem fluxogramas, criadas naturalmente pelo usuários com a utilização de tinta digital. Elefaz parte de um projeto maior e servirá como “ponto de partida” para o desenvolvimentode um sistema de geração de código automático a partir de fluxogramas expressadospelo usuário. Neste sistema maior, um fluxograma esboçado pelo usuário poderá ser

1.3 Justificativa 20
interpretado, executado e convertido em código fonte específico.
1.3 Justificativa
A tecnologia de tinta digital está cada vez mais presente nos equipamentoseletrônicos: celulares, notebooks, computadores pessoais, tablet PC’s, entre outros. Suagrande vantagem é permitir uma forma de comunicação mais natural entre homeme máquina. Os fluxogramas constituem uma boa ferramenta para que alunos possamrepresentar e visualizar algoritmos durante o processo de aprendizagem. Uma ferramentaque permita a utilização de tinta digital durante a elaboração de fluxogramas é muitointeressante para disciplinas de Introdução à Computação.
Para a criação de uma ferramenta que permita o reconhecimento e a interpretaçãode fluxogramas, primeiro é necessário o desenvolvimento de um método que reconheçaas diferentes estruturas (ou formas geométricas) presentes nos fluxogramas.
Durante os estudos iniciais deste trabalho, não foram encontrados sistemas queabordavam o reconhecimento de formas geométricas presentes em fluxogramas. Entre ossistemas estudados, o Sistema LADDER [35] mostrou-se o mais promissor por trabalhardiretamente com tinta digital, mas sua utilização não foi possível dada a indisponibilidadedo mesmo. Este sistema permite a definição e o reconhecimento de formas a partir deuma linguagem própria que, por sua vez, permite a especificação de formas em umdomínio. Esta especificação é feita com a definição de como cada forma é desenhada:sua geometria, restrições e a informação contextual associada a cada forma.
Os outros sistemas encontrados utilizam descritores como: histograma de inten-sidade da cor, cor, distribuição de texturas, disposição de cor e forma, saliências dos ob-jetos, localização de “cantos”, entre outros, que infelizmente, como apresentado em [25],não fornecem bons resultados quando a entrada são segmentos lineares desenhados pelousuário. Nesses casos, informações como cor e textura não estão disponíveis.
Sendo assim, como não foram encontrados outros sistemas direcionados aoreconhecimento de formas geométricas contidas em fluxogramas, desenhadas usandotinta digital, optou-se por desenvolver um método específico para este domínio. Foidesenvolvido um método para o reconhecimento e especificação das formas geométricas,justificando, portanto, o projeto descrito neste trabalho
1.4 Metodologia
O estudo em questão foi dividido em diversas etapas, que juntas, integramo trabalho desenvolvido. O primeiro passo foi realizar um levantamento bibliográfico(livros, artigos e Internet) acerca dos conceitos, dos desenvolvimentos e das aplicações em

1.5 Estrutura da Dissertação 21
reconhecimento de padrões, indexação e recuperação de imagens, mais especificamentesobre o problema de reconhecimento de esboços.
Uma vez levantadas as técnicas mais utilizadas, partiu-se para o desenvolvimentode um método que permitisse o reconhececimento de formas. São formas geométricascontida em fluxogramas, e o reconhecimento é feito sobre formas isoladas, ou seja, ofluxograma deve estar segmentado.
Tendo desenvolvido o método, o próximo passo era a sua validação. Para testá-louma massa de dados foi criada. Alguns usuários desenharam em um tablet pc, utilizandotinta digital, várias formas geométricas similares aquelas presentes nos fluxogramas. Estasimagens foram, então, analisadas por um sistema em que o método foi implementado.
O método proposto, a elaboração do conjunto de amostras para o teste, aavaliação do método e os resultados estão descritos nos capítulos seguintes.
O trabalho é encerrado com a apresentação das conclusões, obtidas durante osexperimentos realizados, e com a apresentação de possíveis trabalhos futuros.
1.5 Estrutura da Dissertação
Este trabalho é dividido em sete capítulos. Neste primeiro capítulo encontram-seas considerações iniciais e os objetivos do trabalho.
No segundo capítulo é feita uma breve introdução sobre o que é o Processamentode Imagens. Alguns conceitos elementares e algumas das técnicas utilizadas neste traba-lho são abordadas.
No terceiro capítulo apresentam-se alguns Trabalhos Relacionados que, diretaou indiretamente, serviram como fonte de inspiração para esta dissertação. Exemplos desistemas e trabalhos sobre o reconhecimento de formas são alguns dos temas abordados.
No quarto capítulo é apresentado um resumo das principais técnicas de represen-tação de formas.
No quinto capítulo apresenta-se o projeto desenvolvido. Temas como: o escopodo trabalho, a utilização da tinta digital, o sistema desenvolvido, o método utilizado, e aextração das características da imagem, são alguns dos assuntos tratados.
O sexto capíutlo trata da avaliação do método. Como foi criada a base de imagenspara o teste, como a avaliação do método proposto foi feita e, por fim, os resultadosobtidos.
Para finalizar, no sétimo capítulo, as conclusões e sugestões de trabalhos futurossão apresentados.

CAPÍTULO 2Processamento de Imagens Digitais
Processamento de imagem é qualquer forma de processamento de dados no quala entrada são imagens tais como fotografias, quadros de um vídeo ou desenhos feitopor um usuário [1]. Ao contrário do tratamento de imagens, que preocupa-se somentena manipulação de figuras para sua representação final, o processamento de imagens éum estágio para novos processamentos de dados tais como aprendizagem de máquina oureconhecimento de padrões.
A visão é o nosso sentido mais aguçado, logo imagens têm um papel muitoimportante na nossa percepção do mundo. Uma imagem pode ser definida como umafunção bi-dimensional, f(x,y), onde x e y são coordenadas espaciais e a amplitude de fnos pontos (x,y) é chamada de nível de intensidade neste dado ponto [31].
Nas seções seguintes serão descritos alguns conceitos comumente utilizados naÁrea de Processamento de Imagens Digitais e que serão utilizados ao longo deste trabalho.
2.1 Descritores de Conteúdo da Imagem
Os conteúdos visuais extraídos de uma imagem são também chamados dedescritores das imagens, e são utilizados para representá-las e indexá-las. Dependendodo domínio da aplicação, pode ser suficiente apenas descrever as imagens parcialmente,ou seja, descrever alguma característica particular que represente o seu conteúdo dentrodo contexto da aplicação. A recuperação da imagem está baseada na similaridade dascaracterísticas extraídas a partir destes atributos.
O objetivo principal é aumentar/destacar os aspectos da imagem que sejamrelevantes para a pesquisa sendo feita e minimizar/descartar os aspectos restantes. Dentrodesta filosofia, pode-se descrever o conteúdo de uma imagem através de sua cor, forma ouestrutura visual (layout).

2.1 Descritores de Conteúdo da Imagem 23
2.1.1 Cor
Também referida como descritor de conteúdo cromático, a cor é a característicavisual mais utilizada para a indexação e recuperação de imagens em CBIR´s [74]. Existemdiferentes representações de cores que incluem desde o RGB (red, green, blue) até o HSI(hue, saturation, intensity).
O conteúdo cromático de uma imagem digital pode ser descrito através de umhistograma de cores. De acordo com [17] grande parte dos trabalhos de extração decaracterísticas baseadas em distribuição de cores estão concentrados no histograma decor. Computacionalmente, este histograma é uma estrutura unidimensional, que armazenao número de ocorrências de cada possível valor cromático em uma imagem. O tamanhodesta estrutura deve ser igual ao número de cores possíveis no espaço cromático utilizadopara representar a imagem.
Em um histograma associamos a cada intensidade de cor presente na imagem,sua frequência de ocorrência, ou seja, o número de pixels da imagem que utilizam cadacor. Os histogramas de cor são invariantes à translação e rotação da imagem, sendo quecom a normalização dos histogramas, obtém-se também a invariância à escala.
Uma desvantagem evidente é que o vetor de características poderá ser muitogrande se a imagem contém um número muito alto de cores.
2.1.2 Textura
A análise de texturas é um dos aspectos fundamentais da visão humana, na qual épossível discriminar entre superfícies e objetos. Textura pode ser definida como mudançasna intensidade da imagem que formam determinados padrões repetitivos, já que paraos autores de [88] não existe uma deifinição clara do que seja textura. De uma formagenérica, pode-se considerar que texturas são padrões visuais complexos compostos porpadrões que possuem propriedades peculiares (como densidade, brilho, granulação, etc),ou de acordo com [86], são os padrões visuais homogêneos não resultantes da presença deuma única cor ou intensidade de cores. É uma propriedade visual de praticamente todasas superfícies, como nuvens, cabelo, pele, árvores, rochas, etc
De acordo com [30], as texturas de uma imagem também podem ser descritasatravés de histogramas. Para a criação destes histogramas, a imagem é inicialmenteconvertida para representação em escala de cinza. Depois desta conversão é aplicado umalgoritmo de detecção de bordas, como o Algoritmo de Canny, um método amplamenteutilizado na detecção de bordas de imagens digitais. Depois da detecção das bordas daimagem descrita em tons de cinza obtem-se uma imagem binária. Nesta imagem ospixels pretos correspondem aos pontos da imagem onde foi caracterizada a presença de

2.1 Descritores de Conteúdo da Imagem 24
uma borda, provavelmente resultante de um contraste com o plano de fundo descrito naimagem, ou seja, onde houve mudança de textura.
Segundo [52], modelos computacionais que utilizam textura podem ser agrupa-dos em três categorias: estrutural, estatístico e espectral. Modelos estruturais caracterizamtexturas de acordo com o relacionamento local entre pixels da imagem, ou seja, lidam como arranjo espacial de primitivas estruturais. Modelos estatísticos organizam as texturas deacordo com medidas estatísticas de características visuais, tais como grossura, granulari-dade, regularidade, entre outros. E, por fim, modelos espectrais caracterizam textura comopropriedades da transformada de Fourier ou nos resultados de filtragem das texturas porfiltros apropriados. A Figura 2.1 apresenta alguns exemplos de textura.
Figura 2.1: Exemplos de texturas visuais
Sua principal vantagem no processo de reconhecimento é de definir os limites deum objeto, bem como identificar o relacionamento entre os objetos e o ambiente em queestão inseridos. Assim como no caso das cores, um grande problema enfrentado é o dadimensionalidade do vetor de características [77] que pode acabar ficando muito elevadotornando a recuperação mais lenta.
2.1.3 Forma
Assim como a cor e a textura, a forma também é muito importante no processode identificação e reconhecimento de um objeto. É possível identificar diferentes objetosem uma imagem analisando apenas as formas dos mesmos. Em muitos problemas reais,tais como reconhecimento de caracteres e reconhecimentos de digitais, as formas são oobjeto de busca [78]. A Figura 2.2 exibe alguns exemplos de formas de imagens.
Figura 2.2: Exemplos de formas

2.2 Pixel 25
Apesar da sua importância, a recuperação baseada em forma não é simples. Naverdade, em sistemas CBIR, o atributo forma é o que apresenta maior dificuldade quandousado na recuperação de imagens [77].
Existe uma variedade de técnicas propostas na literatura para representação deformas. Segundo [91] e [18], existem basicamente dois tipos de descritores de forma:os baseados em contorno (contour-based) e os baseados em região (region-based).Dependendo da abordagem utilizada os resultados são diferentes. Dentro de cada umadessas abordagens uma nova divisão pode ser feita: se primitivas tais como segmentose figuras geométricas são utilizadas, considera-se uma abordagem estrutural; no casoda forma ser tratada como um todo, a abordagem é considerada global. Dentro dessasabordagens vários descritores podem ser enumerados. A seção 4 aprofunda, um poucomais nesta divisão.
Deve-se levar em conta a necessidade de métodos que possuam invariância amudanças de orientação (rotação e translação) bem como a variações de escala, poisobjetos semelhantes, mas com tamanhos diferentes devem ser considerados similaresindependente de seu tamanho.
2.2 Pixel
Uma imagem digital é composta de um número finito de elementos, cada umcontendo uma localização particular e um valor. Esses elementos que compõem a imagemdigital são chamados de "Picture elements" ou pixels.
Um pixel é o elemento básico de uma imagem. A representação mais conhecidapara imagens digitais e seu conjunto de ”pixels” é a adotada em [31]. Uma imagem érepresentada por uma matriz MxN onde cada elemento da matriz representa um pixel daimagem digital. A Figura 2.3 ilustra esta notação.
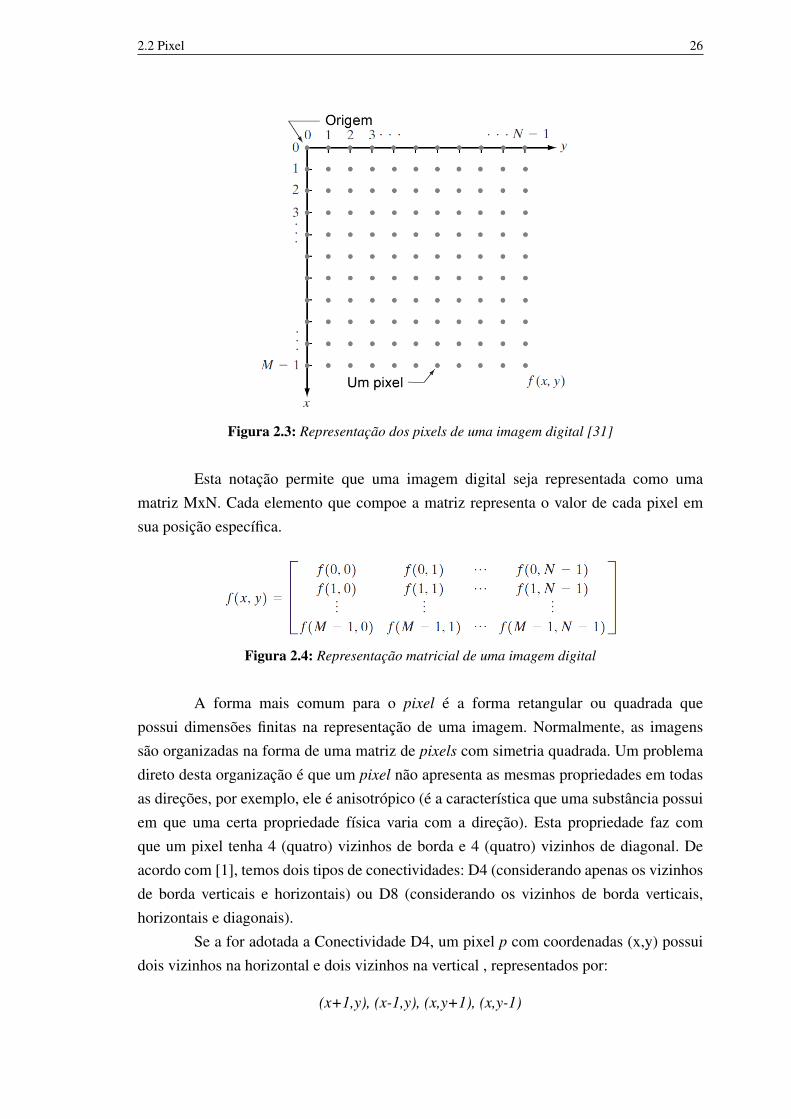
2.2 Pixel 26
Figura 2.3: Representação dos pixels de uma imagem digital [31]
Esta notação permite que uma imagem digital seja representada como umamatriz MxN. Cada elemento que compoe a matriz representa o valor de cada pixel emsua posição específica.
Figura 2.4: Representação matricial de uma imagem digital
A forma mais comum para o pixel é a forma retangular ou quadrada quepossui dimensões finitas na representação de uma imagem. Normalmente, as imagenssão organizadas na forma de uma matriz de pixels com simetria quadrada. Um problemadireto desta organização é que um pixel não apresenta as mesmas propriedades em todasas direções, por exemplo, ele é anisotrópico (é a característica que uma substância possuiem que uma certa propriedade física varia com a direção). Esta propriedade faz comque um pixel tenha 4 (quatro) vizinhos de borda e 4 (quatro) vizinhos de diagonal. Deacordo com [1], temos dois tipos de conectividades: D4 (considerando apenas os vizinhosde borda verticais e horizontais) ou D8 (considerando os vizinhos de borda verticais,horizontais e diagonais).
Se a for adotada a Conectividade D4, um pixel p com coordenadas (x,y) possuidois vizinhos na horizontal e dois vizinhos na vertical , representados por:
(x+1,y), (x-1,y), (x,y+1), (x,y-1)

2.3 Transformadas e Filtros 27
Caso seja adotada a conectividade D8, além dos vizinhos horizontais e verticais tem-semais quatro vizinhos nas diagonais, representados por:
(x+1, y+1), (x+1, y-1), (x-1, y+1), (x-1, y-1)
Dois pixels são conectados se, e somente se, forem vizinhos. A distância entre umpixel e seus vizinhos é igual a 1 (um), se for um vizinho de borda, ou
√2 (raiz quadrada
de dois), se for um vizinho de diagonal.
2.3 Transformadas e Filtros
Transformadas são operações realizadas sobre uma imagem para obtenção deuma nova representação de seu conteúdo que seja mais adequada, ou mais apropriada,para a aplicação. Como exemplos de algumas transformadas podemos citar:
- Conversão para tons de cinza: converte uma imagem do padrão RGB ouCMKY para o padrão de tons de cinza.
- Convolve: é uma operação espacial onde se aplica uma máscara sobre aimagem. Ela é composta de uma série de iterações e em cada passo a máscara é sobrepostaa um grupo de pixels da imagem. Cada pixel da imagem é multiplicado pelo pixel que osobrepõe, estes produtos são somados para obter o pixel resultante [47]. Esse processo éaplicado a todos os pixels da imagem, gerando o efeito de suavização (smoothing). Estaoperação não afeta os pixels da borda da imagem, pois ela utiliza pixels vizinhos paracalcular o pixel resultante.
Os filtros são modos de se manipular as matrizes de pixels para se obter informa-ções desejadas ou eliminar aquelas informações que prejudicam o correto funcionamentoda aplicação. Basicamente, uma máscara é uma pequena matriz em que seus coeficientesdeterminam a natureza do processo a que se aplicam. Eles se baseiam em uma matrizde convolução, que é uma matriz responsável por definir, para cada elemento, como estese relaciona com os seus vizinhos. O valor de cada pixel da imagem obtida após a fil-tragem será determinado, então, como resultado das operações definidas pela matriz deconvolução para os elementos correspondentes da matriz original [9]. A convolução éuma operação bastante comum entre as aplicações para processamento de imagens.
A máscara, ou filtro, aplicado a uma imagem irá determinar o efeito resultante.Algoritmo: Para cada pixel da imagem
• Posicionar centro do filtro sobre o pixel sendo analisado• Calcular média ponderada dos pixels vizinhos segundo os valores do filtro• O pixel correspondente na imagem final ganhará essa média
A figura 2.5 ilustra o processo de aplicação de um filtro sobre uma imagem.

2.4 Histograma 28
Figura 2.5: Aplicação de um filtro sobre uma matriz de pixels [31]
2.4 Histograma
Um histograma é uma função h(rk) = nk, onde r é o valor do pixel e nk é onúmero de pixels na imagem que possuem o valor igual a rk. Uma prática bem comum énormalizar o histograma dividindo-se cada um de seus valores pelo número total de pixels
na imagem, denotado por n [31]. Desta forma, um histograma normalizado é dado pelaEquação 2-1 e a soma de todos os seus componentes é igual a 1 (um).
p(rk) =nkn
(2-1)

2.5 Região de Interesse 29
2.5 Região de Interesse
Outro conceito importante é o de Região de Interesse (ROI - “Region OfInterest”). A ROI é a região definida a partir de parâmetros da imagem (ou por um usuário)onde o processamento está mais concentrado. Desta forma é possível isolar/destacar umadeterminada região da imagem e desconsiderar todo o restante.
2.6 Passos Fundamentais no Processamento de ImagensDigitais
A figura 2.6 é uma simplificação feita a partir de [31] e ilustra os passosfundamentais presentes em um Sistema de Processamento de Imagens Digitais:
Figura 2.6: Passos fundamentais no processamento de imagensdigitais [31]
O primeiro passo no processo é a aquisição da imagem, isto é, adquirir umaimagem digital. Após a obtenção de uma imagem digital, o próximo passo trata de pré-processar aquela imagem. A função chave no pré-processamento é realçar as característi-cas de interesse e ocultar ou minimizar as características contidas na imagem que não sãorelevantes ao sistema, ou seja, melhorar a imagem de forma a aumentar as chances para osucesso dos processos seguintes. Um exemplo típico de pré-processamento envolve téc-nicas para o realce de contrastes, remoção de ruído e isolamento de regiões de interesse,entre outros.
O próximo estágio trata da segmentação que divide uma imagem de entradaem partes ou objetos constituintes. Em geral, a segmentação automática é uma dastarefas mais difíceis no processamento de imagens digitais. Um processo de segmentação

2.7 Conclusão 30
robusto é essencial para o bom desempenho do sistema, favorecendo uma solução bemsucedida. Algoritmos de segmentação fracos ou erráticos quase sempre prejudicam ofuncionamento do sistema. No caso de reconhecimento de objetos pelo seu contorno,o papel básico da segmentação é extrair objetos individuais do fundo da imagem e buscardistinguir objetos distintos.
A saída do estágio de segmentação é constituída tipicamente por dados em formade pixels, correspondendo tanto à fronteira de uma região como a todos os pontos dentroda mesma. Em ambos os casos é necessário converter os dados para uma forma adequadaao processamento computacional. A representação por fronteira é adequada quando ointeresse se concentra nas características da forma externa, tais como cantos ou pontosde inflexão. A representação por região é adequada quando o interesse se concentraem propriedades internas, tais como textura ou a forma do objeto. A escolha de umarepresentação é apenas parte da solução para transformar os dados iniciais numa formaadequada para o subseqüente processamento computacional.
Um método para descrever os dados também deve ser especificado, de forma queas características de interesse sejam enfatizadas. O processo de descrição, também cha-mado seleção de características, procura extrair caracteristicas que resultem em algumainformação de interesse ou que sejam básicas para discriminação entre classes de objetos.
O último estágio envolve o reconhecimento e a interpretação. Reconhecimentoé o processo que atribui um rótulo a um objeto, baseado na informação fornecida pelo seudescritor. A interpretação envolve a atribuição de significado a um conjunto de objetosreconhecidos.
2.7 Conclusão
Neste capítulo foram apresentadas algumas técnicas comumente utilizadas noprocessamento de imagens digitais. O objetivo não foi fazer uma revisão completa sobreo assunto, mas apenas elucidar alguns conceitos importantes sobre este tema que foramfundamentais para o desenvolvimento deste trabalho e para compreensão do mesmo.

CAPÍTULO 3Trabalhos Relacionados
Diariamente, equipamentos civis e militares geram gigabytes de imagens [74].Com esse crescimento das bases de imagens, devido às inovações tecnológicas, tornou-senecessário manter algum tipo de mecanismo de indexação e recuperação desse conteúdovisual.
Enquanto buscas baseadas em texto têm conseguido recuperar textos com rela-tivo “sucesso”, sem compreender o seu conteúdo, as mesmas técnicas utilizadas na recu-peração textual, quando aplicadas no reconhecimento de imagens, não têm obtido bonsresultados. Por isso, pesquisadores de várias partes do mundo vêm trabalhando em no-vos métodos de busca para serem aplicados nas imagens. Ao longo das últimas décadas,tentativas ambiciosas foram feitas no desenvolvimento de sistemas que permitissem àsmáquinas “reconhecer” e recuperar imagens das mais variadas fontes. Em [22] foram dis-cutidas as principais contribuições relacionadas à recuperação de imagens feitas na últimadécada.
As características, ou feições, que compõem uma imagem formam a base dosSistemas CBIR. Dentro do escopo de características visuais, pode-se classificá-las comocaracterísticas gerais (cor, textura e forma) ou específicas de um domínio (rostos humanos,impressões digitais, exames de ressonância magnética, etc.). Em [84] o autor apresenta umuma distinção entre os domínios das aplicações de CBIR:
• domínios restritos (narrow domains): é um domínio limitado em que a variabilidadedas imagens é previsível em todos os aspectos. Ou seja, o conjunto das imagensé conhecido. Normalmente possuem pequeno gap semântico1, o que favorece autilização de modelos específicos ao domínio em questão.• domínios abertos (broad domains): é um domínio em que a variabilidade das
imagens é ilimitado e imprevisível. Em alguns casos a imagem é composta de vários
1É a diferença entre características de baixo nível, extraídas da imagem, e o alto nível da informaçãonecessária para o usuário. Ou seja, é a diferença entre o que o usuário necessita e as características extraídasda imagem [28].

3.1 Reconhecimento de Formas 32
objetos distintos e complica a interpretação do seu conteúdo. Em outros, o conteúdoda imagem pode ter várias interpretações.
As características da imagem e os métodos utilizados para recuperar, reconhecere indexar essas imagens, dependem diretamente do domínio da aplicação desenvolvida.Para o reconhecimento de esboços feitos pelo usuário, o foco do reconhecimento é dadona forma do esboço desenhado. Informações como cor e textura não são relevantes duranteo processo de reconhecimento.
3.1 Reconhecimento de Formas
A forma é um atributo chave nas regiões segmentadas de imagens, e sua re-presentação possui um papel muito importante em todo o processo de reconhecimento.Em geral, as representações utilizadas para forma de uma imagem podem ser divididasem dois grupos: baseadas nas bordas (boundary-based) ou baseadas em região (region-
based). O primeiro tipo utiliza a informação visual contida na borda externa do objeto,enquanto o segundo tipo utiliza toda a região ocupada pelo objeto [73]. No capítulo 4 éapresentado um estudo mais aprofundado sobre as técnicas utilizadas em cada um dosgrupos.
Dependendo da natureza da aplicação, deve-se utilizar representações da formaque sejam invariantes a translação, rotação, escala e espelhamento. Durante o levanta-mento bibliográfico foram encontrados vários trabalhos relacionados ao reconhecimentode formas e reconhecimento de esboços, evidenciando a importância deste tema.
Em [84] é apresentado um estudo comparativo da performance das representa-ções baseadas na borda (Chain Code, Fourier Descriptor, UNL Fourier Descriptor), repre-sentações baseadas em regiões (Moments Invariants, Zernike Moments, Pseudo-Zernike
Moments) e representações combinadas.Para a identificação de formas dentro de imagens, a segmentação é um processo
muito importante. Embora um processo de segmentação como o feito pelo cérebrohumano esteja longe de ser alcançado, algumas ténicas de segmentação podem serencontradas em [22]. A segmentação é um processo de suma importância no que dizrespeito ao “entendimento” de uma imagem.
Após a detecção das bordas, a forma de um objeto pode ser identificada. Medidascomo área, excentricidade (ex: o raio do maior e menor eixo), circularidade (ex: proximi-dade do círculo de área igual), assinatura da forma (shape signature - uma seqüência dedistâncias dos pontos das bordas ao centro), curvatura (a velocidade em que os contornosdas bordas são alterados), entre outros, são frequentemente utilizadas [5].
Com a disseminação de equipamentos que utilizam tinta digital, uma nova linhade pesquisa para o reconhecimento de formas tem atraído a atenção de pesquisadores. A

3.1 Reconhecimento de Formas 33
possiblidade de integrar o reconhecimento de esboços e as interfaces de usuário vem setornando uma tendência nos sistemas modernos. Nesse sentido, o LADDER [35] ganhougrande destaque porque foi a primeira linguagem para descrição de formas. Ele podeser utilizado para descrever como formas e grupos de formas são desenhados, editados eexibidos, e também é o primeiro protótipo implementado que permite a criação automáticade uma interface, baseada em esboços, a partir da descrição deste domínio [37].
Em [34] os criadores do LADDER, apresentam o GUILD, um sistema para gerarautomaticamente as interfaces de usuário a partir de descrições LADDER. Seu objetivoé permitir que professores criem sistemas de reconhecimento de esboços para seremutilizados em sala de aula.
Outro sistema que trata do reconhecimento de esboços é o PaleoSketch [65].Neste sistema praticamente não existem restrições sobre a maneira como o usuário fazseu esboço. Cada traço (conjunto de pontos entre os eventos pendown-penup) feito pelousuário é classficado em uma das primitivas: linha, múltiplas-linhas, círculo, elipse, arco,curva, espiral e hélice.
Em [76], o autor apresenta o método chamado Vertex Representation, que ébaseado na ténica do Chain Code. É um método que analisa a borda do objeto, porémarmazena apenas as alterações de direção.
Em [8], os autores apresentam um método que utiliza a forma e a textura para oreconhecimento de imagens médicas. Ele realiza segmentação baseada na textura, ondecada textura distinta é representada por uma classe e os pixels da mesma classe constituemuma região de textura homogênea. As características que definem uma imagem sãoobtidas extraindo-se, de cada uma das regiões homogêneas, as seguintes medidas: o centroda massa da região, a massa da região, dispersão e a média e variância da região. Adesvantagem desse método é o custo elevado para a segmentação.
O Biram [59], é um sistema que permite a recuperação de imagens por conteúdo.Suporta diversos algoritmos de extração de características e é focado em imagens médi-cas. A busca por imagens semelhantes é feita da seguinte forma: uma imagem fornecidacomo exemplo é processada por um dos algoritmos armazenados, gerando um descritor;em seguinda o descritor é comparado com outros descritores armazenados pelo sistema;durante essa compraração, é calculada a distância entre os descritores; os resultados são,então, ordenados pelo cálculo da distância de seus descritores.
Em [67] é apresentada uma técnica para recuperar imagens por região, utilizandoinformações de cor, forma e localização. A imagem é dividida em regiões e, cada região,é indexada a partir das características extraídas da sua cor, forma e disposição dascaracterísticas.
No trabalho apresentado em [12], saliências em um objeto são utilizadas parao reconhecimento e recuperação de imagens. A forma de um objeto é particionada em

3.2 Sistemas 34
segmentos, de acordo com as saliências desse objeto. Cada segmento é analisado eindexado de acordo com sua curvatura e sua orientação. Uma vantagem do método épermitir a identificação de objetos parcialmente oclusos.
Existem sistemas, como o apresentado em [46], que aceitam um esboço feitopelo usuário para a recuperação de imagens similares (QVE - Query by Visual Example).As bordas das imagens armazenadas são extraídas para serem comparadas ao esboço,utilizando como métrica a correlação entre blocos vizinhos. Cada imagem é dividida empequenos blocos e cada um desses blocos é comparado aqueles blocos calculados a partirdo esboço.
Em [44] é apresentado um reconhecedor de símbolos, desenhados pelo usuário,para ser utilizado em interfaces baseadas em esboço. É um método que utiliza treinamento(trainable system), ou seja, os símbolos são ajustados aos esboços dos usuários. Cadaum dos símbolos desenhados é armazenado internamente como modelos binários. Parasuperar o problema da invariância à rotação, os modelos binários armazenados comocoordenadas cartesianas são transformados para uma representação em coordenadaspolares.
Outros trabalhos também merecem ser mencionados, entre eles pode-se citar astécnicas para recuperação de imagens por conteúdo apresentadas em [27] e [69], o sistemaSOUSA [43] e os métodos para reconhecimentos de esboços apresentados em [38], [25],[64] e [50].
3.2 Sistemas
Entre os sistemas comercias, para recuperação de imagens através de seu con-teúdo, de acordo com [74] os mais importantes são:
3.2.1 QBIC
O QBIC (Query By Image Content) é o primeiro sistema comercial para recupe-ração de imagens baseado em conteúdo [74]. Foi desenvolvido pela IBM 2(International
Business Machines) e trata-se de um sistema que permite a criação e consultas em gran-des Bancos de Dados de Imagens baseadas no conteúndo visual das imagens, utilizandocaracterísticas como porcentagem de cor, layout das cores e texturas que ocorrem dentroda imagem. Estas consultas utilizam as propriedades visuais das imagens, de maneira queo usuário pode combinar cores, texturas e suas posições, sem ter que descrevê-las textual-
2http://www.ibm.com/us/en/
3.2 Sistemas 35
mente. As consultas baseadas em conteúdo ainda podem ser combinadas com predicadostextuais e palavras-chaves para se obter métodos de recuperação mais completos.
No sistema QBIC, uma cena é a imagem inteira (ou um frame simples de vídeo)e um objeto é uma parte da cena. Após a identificação dos objetos, o QBIC calcula ascaracterísticas de cada objeto da imagem. Ele utiliza conjuntos de características quecapturam a cor, textura e forma das imagens. Suporta duas classes do conteúdo de cor:local e global. No QBIC a extração de regiões locais (objetos) é feita manualmente, poisrequer uma pessoa para desenhar os limites da região usando um mouse. As informaçõesda cor local e global são representadas pela média das cores e o histograma de cor.
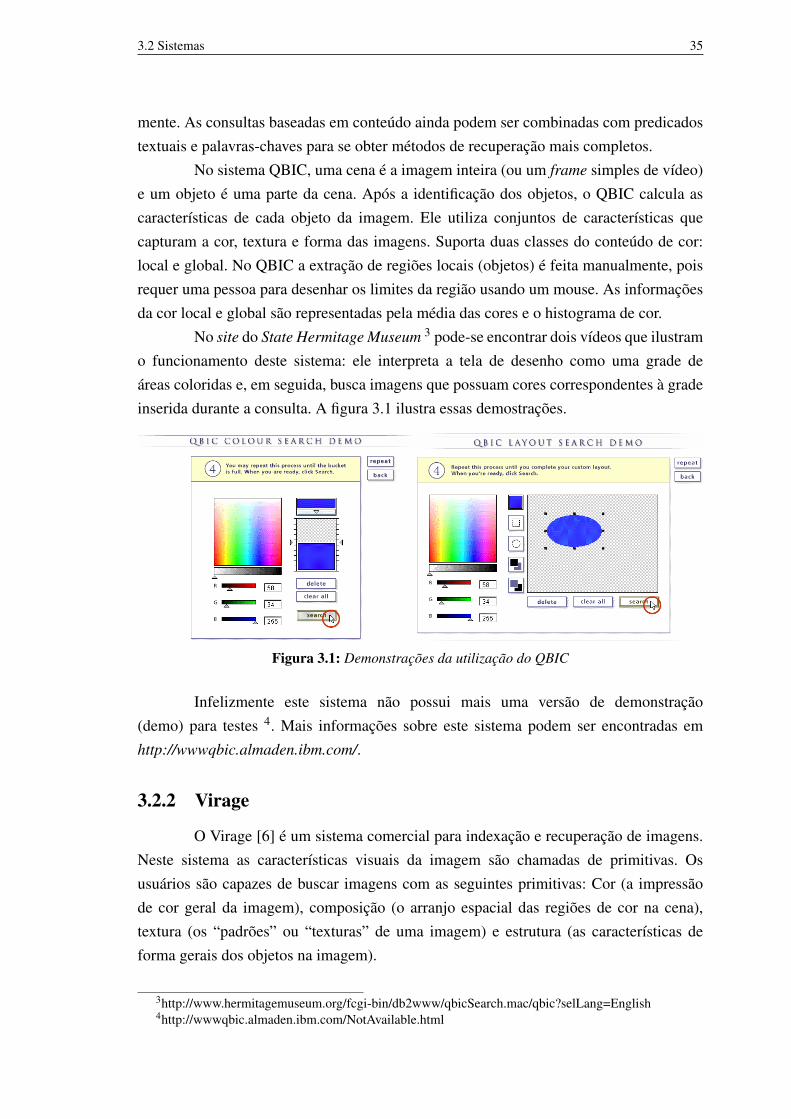
No site do State Hermitage Museum 3 pode-se encontrar dois vídeos que ilustramo funcionamento deste sistema: ele interpreta a tela de desenho como uma grade deáreas coloridas e, em seguida, busca imagens que possuam cores correspondentes à gradeinserida durante a consulta. A figura 3.1 ilustra essas demostrações.
Figura 3.1: Demonstrações da utilização do QBIC
Infelizmente este sistema não possui mais uma versão de demonstração(demo) para testes 4. Mais informações sobre este sistema podem ser encontradas emhttp://wwwqbic.almaden.ibm.com/.
3.2.2 Virage
O Virage [6] é um sistema comercial para indexação e recuperação de imagens.Neste sistema as características visuais da imagem são chamadas de primitivas. Osusuários são capazes de buscar imagens com as seguintes primitivas: Cor (a impressãode cor geral da imagem), composição (o arranjo espacial das regiões de cor na cena),textura (os “padrões” ou “texturas” de uma imagem) e estrutura (as características deforma gerais dos objetos na imagem).
3http://www.hermitagemuseum.org/fcgi-bin/db2www/qbicSearch.mac/qbic?selLang=English4http://wwwqbic.almaden.ibm.com/NotAvailable.html

3.2 Sistemas 36
A indexação é realizada após diversas operações de pré-processamento, taiscomo, suavizar e enfatizar contrastes. Cada rotina de extração primitiva toma umaimagem pré-processada e, dependendo das propriedades da imagem, calcula um conjuntoespecífico de dados para aquela primitiva. Um vetor com os dados primitivos computadosé armazenado em uma estrutura de dados própria para futuras consultas.
3.2.3 PhotoBook
Em [66], os autores descrevem o Sistema PhotoBook como um conjunto deferramentas interativas de navegação e pesquisa de imagens e seqüências de imagens,desenvolvido pelo MIT Media Lab5. Essas ferramentas extraem diretamente o conteúdoda imagem ao invés de depender de anotações textuais.
As imagens podem ser pesquisadas de três maneiras: pela aparência (distribuiçãode cores), pela estrutura (disposiçao das cores) e pelas propriedades texturais (texturas).Estas descrições do conteúdo da imagem podem ser combinadas entre si, e com asdescrições textuais, para proporcionar uma navegação sofisticada e aumentar o poder depesquisa. Em [5] o autor cita algumas aplicações desenvolvidas com esta ferramenta,entre elas: sistema para reconhecimento facial, recuperação de imagem por similaridadeda textura e anotação semi-automática baseada em rótulos fornecidos pelo usuário.
3.2.4 VisualSEEk
O VisualSEEk [85] é um sistema híbrido que integra indexação de imagem base-ada em conteúdo (cor e textura) e em propriedades espaciais (como tamanho, localizaçãoe relações com outras regiões). A integração confia na representação de regiões através deum conjunto de cores. Inicialmente o usuário fornece um conjunto de cores para o sistemade extração de regiões. Em seguida, os conjuntos de cores são facilmente indexados paraa recuperação de imagens com um conjunto de cores semelhantes. Desta forma, as ima-gens são comparadas através de suas regiões. Além disto, o sistema permite que o usuáriocontrole a seleção das regiões e defina quais parâmetros são mais importantes durante aconsulta por similaridade.
O projeto do VisualSEEk enfatiza diversos objetivos únicos a fim de melhorar arecuperação de imagens, como:
1. extração automática de características e regiões localizadas,2. examina informações e as características espaciais,3. extração de características de dados compactados,
5http://www.media.mit.edu/

3.3 Conclusão 37
4. desenvolvimento de técnicas para indexação e recuperação rápida e5. desenvolvimento de ferramentas altamente funcionais para o usuário.
Este sistema foi desenvolvido pela Universidade de Columbia6.
3.3 Conclusão
Analisando estes sistemas de recuperação de imagens, pode-se notar que existeuma preocupação crescente quanto ao aumento descontrolado do volume de imagensdigitais, devido ao desenvolvimento tecnológico e maior acessibilidade dos meios. Istotem criado uma necessidade de ferramentas eficientes e efetivas para catalogar, indexar,gerenciar, comprimir e buscar informações visuais de maneira automática.
O maior problema de um sistema de indexação e recuperação de imagem é adeterminação de um conjunto de características que possa fornecer uma boa performancena classificação das imagens para uma recuperação adequada. A este conjunto de carac-terísticas devem-se os diferentes tipos de sistemas encontrados na literatura.
Não foi encontrado, no decorrer do desenvolvimento deste trabalho, nenhum sis-tema direcionado para o reconhecimento de formas geométricas contidas em fluxogramas.Grande parte das técnicas encontradas utilizam descritores como: histograma de intensi-dade da cor, cor, distribuição de texturas, disposição de cor e forma, saliências dos obje-tos, localização de “cantos”, etc. Infelizmente, como apresentado em [25], tais descritoresnão fornecem bons resultados quando a entrada são segmentos lineares desenhados pelousuário. Nesses casos, informações como cor e textura não estão disponíveis.
Apenas o trabalho desenvolvido em [34] tinha como foco auxiliar professorese alunos em sala de aula, mas não pode ser utilizado por não estar disponível. Destaforma, surge a necessidade de se desenvolver um método simples para o reconhecimentode formas geométricas contidas em fluxogramas desenhados pelo usuário. O métodoproposto está descrito no Capítulo 5.
6http://www.ee.columbia.edu/ln/dvmm/researchProjects/MultimediaIndexing/VisualSEEk/VisualSEEk.htm

CAPÍTULO 4Técnicas de Representação de Formas
A forma é uma característica visual muito importante para a descrição e reconhe-cimento de uma imagem. Porém, descrever o conteúdo de uma forma não é uma tarefasimples [41]. Durante o desenvolvimento do MPEG-7, seis requisitos foram definidospara descrição de uma forma: recuperação precisa, características compactas, ampla apli-cabilidade, baixa complexidade computacional, boa performance de recuperação e repre-sentação hierárquica.
Em [41] o autor apresenta uma classificação das técnicas de recuperação deformas. A Figura 4.1 ilustra esta divisão.
Figura 4.1: Métodos para representação de forma
Resumidamente existem dois grandes grupos de abordagens: baseada em con-torno versus a baseada em região. Os métodos baseados em contorno são os mais popu-lares. Isto porque acredita-se que a capacidade humana para discriminar formas seja feitaa partir de suas características de borda. Além disso, os métodos baseados em contornogeralmente envolvem menos processamento que os baseados em região. Entretanto, tam-

4.1 Baseada no contorno 39
bém são mais facilmente afetados por ruídos e variações na forma, pois se utilizam demenos informação.
Os descritores baseados em região são, geralmente, mais robustos e independen-tes da aplicação. Porém, envolvem um maior processamento dos descritores e necessitamde mais espaço para armazenamento.
4.1 Baseada no contorno
Existem duas abordagens diferentes para as técnicas baseadas em contorno:global e estrutural. Na abordagem global a forma não é dividida em partes e para descrevera forma um vetor de característica derivado de toda a borda da forma é utilizado. Naabordagem estrutural a borda da forma é quebrada em segmentos, chamados de primitivas,utilizando um critério próprio para cada tipo de aplicação. O resultado desta técnica é umastring ou um grafo descrevendo a forma.
4.1.1 Métodos globais
Métodos globais para representação do contorno de uma forma geralmente com-putam um vetor de características multidimensional a partir das informações extraídas daborda. A comparação é feita utilizando distâncias métricas, como a distância Euclidiana.Estes métodos utilizam todo o contorno do objeto para representação e descrição de suaforma. Para cada abordagem há sempre uma troca entre eficiência e precisão. Por um lado,a forma deve ser descrita da maneira mais precisa possível; por outro lado, a descriçãodeve ser a mais compacta possível para facilitar a busca e a comparação. Descritores glo-bais são compactos, porém, são menos precisos. Eles podem ser combinados com outrosdescritores de forma para criar descritores úteis dentro de um cenário prático.
Descritores de forma simples
Os descritores globais mais simples para representar uma forma são: área,circularidade (perímetro/área), ecentricidade (eixo maior/eixo menor), orientação do eixomaior e ”bending energy”. Devido a simplicidade desses descritores eles servem apenaspara diferenciar formas com grandes dissimilaridades, por isso eles são normalmenteutilizados para filtragem ou combinados com outros descritores para diferenciar entreas formas. Se utilizados sozinhos, não oferecem bons resultados.
Assinatura da forma
Este método representa uma forma como uma função uni-dimensional derivadaa partir dos pontos de sua borda. Existem vários tipos de assinaturas: coordenadas com-

4.1 Baseada no contorno 40
plexas (complex coodinates), coordenadas polares (polar coordinates), distância central(central distance), ângulo tangente (tangent angle), ângulo cumulativo (cumulative an-
gle), curvatura (curvature), área e “chord-length”. Em [62] é apresentado um estudo sobreo assunto.
A grande vantagem desta técnica é que são, geralmente, invariantes à translaçãoe à escala. E a grande desvantagem é que são muito sensíveis aos ruídos, pequenasalterações na borda podem causar grandes diferenças durante a comparação.
Boundary Moments
São utilizados para reduzir a dimensão da representação das bordas. Em [87],esta técnica é descrita em mais detalhes.
Elastic matching
Em [13] é proposta o elastic matching para a recuperação de imagens baseadana forma. Nesta técnica um modelo deformável é gerado a partir da soma do modelooriginal e do coeficiente de deformação. Esta técnica não é adequada para processamentoe recuperação online, devido ao seu custo computacional e a complexidade no processode comparação.
Stochastic Method
Modelos de séries temporais e, especialmente, modelagem auto-regressiva (AR)também foram utilizadas para o cálculo dos descritores de uma forma [45], [21] , [39] e[80]. Métodos AR envolvem operações com matrizes com um custo alto.
Scale Space Method
A representação scale space de uma forma é criada a partir dos pontos de infle-xão1 da borda da forma filtrados por um Filtro Gaussiano passa-baixa de largura variável.Os pontos de inflexão remanescentes são considerados como pontos "significantes"paradescrição da forma. O resultado normalmente é uma árvore, também conhecida como“fingerprint”, contendo apenas os pontos de inflexão. A maior dificuldade dessa técnicaé a interpretação do resultado final.
Em [58] é apresentado o CSS, um método que tenta encontrar a melhor compara-ção entre dois ramos das árvores de comparação dos contornos. Para cada comparação, o
1Os pontos de inflexão de uma curva são os pontos em que a curva passa de côncava a convexa, ou deconvexa a côncava.

4.1 Baseada no contorno 41
contorno é redimensionado e rotacionado para ser comparado. O método descreve e com-para objetos ou imagens utilizando o seu contorno fechado. Em [2], o autor afirma que oCSS é confiável e bastante robusto em relação a ruído, escala e mudanças de orientação.
Trasformações espectrais
Descritores espectrais superam o problema de sensibilidade ao ruído e variaçõesna borda através da análise espectral do domínio da forma. Descritores espectrais incluemFourier Descriptors (FD) e Wavelet Descriptor (WD), que são geralmente derivados detransformações espectrais das assinaturas uni-dimensionais da assinatura da forma. FD éuma das técnicas mais utilizadas até hoje. Referências podem ser encontradas em [54],[72] e [56]. Esta técnica se baseia na Teoria de Fourier. Suas principais vantagens são:facilidade para calcular, cada descritor tem um significado específico, facilidade de nor-malizar facilitando a tarefa de comparação entre as formas, captura tanto característicasglobais quanto locais. FD também minimiza o efeito dos ruídos. É uma técnica simplesde implementar e o descritor resultante é compacto.
4.1.2 Métodos Estruturais
Nesta abordagem, a borda da forma e dividida em vários segmentos chamadosde primitivas. Os diversos métodos existentes diferem entre si pela seleção e organizaçãodas primitivas para a representação da forma.
A maior vantagem desta abordagem é a capacidade de lidar com problemas deoclusão e permitir comparação parcial. Porém possuem uma série de desvantagens [41]:
• a geração de primitivas e características. Não existe uma definição formal do queseria a ”forma” de um objeto, logo a quantidade de primitivas necessárias paradefinir cada forma é desconhecida• não captura características globais da forma que, frequentemente, são importantes
para representação e reconhecimento da forma• falta de robustez. Isto porque os métodos estruturais não preservam a estrutura do
objeto, logo variações nas extremidades do objeto causam mudanças significativasna sua estrutura.
Representação Chain-Code
Também conhecida com Freeman Code, esta técnica foi apresentada inicialmentepor [29] e consiste em segmentos de linhas sobrepostos em uma grade de tamanhofixo e um conjunto de possíveis orientações. Apenas o ponto incial é representado

4.1 Baseada no contorno 42
pela sua localização; todos os demais pontos na curva são representados por sucessivosdeslocamentos ponto a ponto na grade através da curva.
Esta técnica descreve um objeto como um sequência de segmentos lineares comuma orientação específica. Nesta abordagem, uma curva arbitrária é representada poruma sequência de pequenos vetores de tamanhos unitários e um conjunto limitado depossíveis direções. Para sua implementação, um grid (ou grade) é sobreposto à imagem eos pontos da borda são aproximados para os pontos da grade mais próximos para formarsua representação.
Chain Code é uma técnica utilizada para representar formas e contornos, poispermite considerável redução na descrição das formas [51]. Este código (code) se moveatravés de uma curva digital ou uma sequência de pixels de borda baseado na suaconectividade, que pode ser de 4 (quatro) ou 8 (oito) conectividades.
Utilizando a conectividade 4, temos 4 possíveis direções identificadas de {i|i =0,1,2,3}, denotando um ângulo de 90o entre cada uma das direções. Caso seja utilizada aconectividade 8, temos 8 possíveis direções numeradas {i|i = 0,1,2,3,4,5,6,7}, denotandoum ângulo de 45o entre cada uma das direções. A Figura 4.2 ilustra estas duas opções:
Figura 4.2: Conectividade
Existem diversas variações e aperfeiçoamentos desta técnica. Entre elas pode-secitar os trabalhos desenvolvidos por [14], [76], [20] e [51].
As principais vantagens desse método são: preserva a informação, permiteconsiderável redução de dados e é invariante a translação. Por outro lado, suas principaisdesvantagens são: a codificação é dependente do ponto incial, não é invariante a rotaçãoe não é invariante a transformação do tipo espelhamento.

4.1 Baseada no contorno 43
Polygon Decomposition
Em [33], a borda da forma é quebrada em segmentos lineares através da aproxi-mação poligonal. Os vértices do polígono são utilizados como primitivas. As caracterís-ticas para cada primitiva são expressas como uma string de quatro elementos: o ângulointerno, distância para o próximo vértice, e as coordenadas x e y. Desta forma esta ca-racterística não é invariante quanto a translação, escala e rotação. As características sãoentão organizadas em uma estrutura de árvore.
O matching entre as formas é feito em duas etapas: característica-a-característicana primeira etapa e modelo-a-modelo (forma-a-forma) na segunda etapa. No primeiropasso, dado um conjunto de características de uma forma, cada característica é procuradadentro da árvore de índice. Se um modelo similar for encontrado, uma lista com as formasassociadas a esse modelo é recuperada. No segundo passo, a comparação é feita entrea forma de consulta e a lista recuperada através da comparação entre suas strings deprimitivas.
Smooth curve decomposition
Em [12], os pontos de curvatura obtidos através das bordas suavizadas pelosfiltros Gaussianos são utilizados para obtenção das primitivas chamadas tokens. A carac-terística para cada token é a curvatura máxima e a orientação, e a similaridade entre doistokens é medida através da distância Euclidiana. Como a característica inclui a orientaçãoda curva, esta técnica não é invariante quanto à rotação.
Dada uma forma para consulta, a recuperação ocorre em duas etapas. O primeiropasso é a recuperação do token: para cada um dos N tokens presentes na forma deconsulta, os tokens similares são encontrados percorrendo a árvore de índices N vezes. Oconjunto de tokens recuperados possuindo os mesmos identificadores formam o conjuntode candidatas. O segundo passo é comparar a forma de consulta e as formas candidatasatravés de um algoritmo que compara todos os tokens das duas formas.
A eficiência do processo de comparação depende do número de tokens utilizadospor cada forma.
Curvature-tuned Smoothing
Nesta abordagem, as primitivas são obtidas a partir da técnica de "curvature-
tuned smoothing", obtendo um conjunto de segmentos. Cada descritor de segmento possuiseu comprimento, posição ordinal e ajuste de curvatura, obtidos a partir de cada umadas primitivas. Então uma string de descritores de segmentos é formada para descrevera forma. A comparação é feita através da utilização de um algoritmo de programaçãodinâmica.

4.1 Baseada no contorno 44
Syntatic Analysis
Este método é inspirado no fato de que a composição natural de um cenárioé análogo à composição de uma linguagem, isto é, sentenças são formadas por frases,frases são formadas por palavras e palavras são formadas por alfabetos [16]. Nessesmétodos, a forma é representada por um conjunto de primitivas pré-definidas. Esteconjunto de primitivas pré-definidas é chamado de codebook e as primitivas são chamadasde codewords. Por exemplo, as codewords no lado direito da Figura 4.3 , forma presenteno lado esquerdo da Figura 4.3 poderia ser representada da seguinte maneira: S =”dbabcbabdbabcbab”.
Figura 4.3: Syntatic Analysis
A comparação entre as formas é feita a partir da comparação de strings, encon-trando o menor número de alterações para converter uma string na outra.
Estas técnicas são baseadas na teoria da Linguagem Formal desenvolvida porChomsky 2.
Shape invariants
Shape Invariants representam uma forma como um conjunto de primitivasbaseadas nas informações extraídas a partir de sua borda. As invariantes são nomeadasde acordo com o número de características utilizadas para sua definição. Uma invariantede ordem um é definida com uma única característica: invariante unária; uma invariantede ordem dois é definida com duas características: invariante binária; e assim por diante.[87]
Invariantes podem ser: geométricas (cross-ratio, length-ratio, distance ratio, ân-gulo, área, triângulo, pontos coplanares), algébricas (determinante, eigenvalues, trace) e
2http://www.chomsky.info/

4.2 Baseada na região 45
diferenciais (curvatura, torção e Curvatura Gaussiana). Invariantes geométricas e algébri-cas são úteis em contextos onde as bordas podem ser representadas por linhas retas oucurvas algébricas. Caso contrário, invariantes diferenciais devem ser utilizadas.
4.2 Baseada na região
Nos métodos baseados em região, todos os pixels dentro da região ocupada pelaimagem são considerados durante o processo de representação da forma.
4.2.1 Métodos Globais
Métodos globais consideram a forma integralmente e sua representação é feitacom um vetor de características numérico que pode ser utilizado para descrever a forma.
Estes métodos medem a distribuição dos pixels dentro da região ocupada pelaforma, diminuindo assim o efeito do ruído e suas variações.
Geometric Moment Invariants
Em [42] foi publicado o primeiro trabalho sobre a utilização de Geométric Mo-
ments Invariants (Momentos Geométricos Invariantes) para o reconhecimento de padrõesbidimensionais. Utilizando combinações não-lineares de momentos de baixa ordem, umconjunto de momentos invariantes também chamados de momentos geométricos, os quaispossuem as propriedades de serem invariantes a translação, rotação e escala, podem serrecuperados.
O maior problema deste método é que invariantes de ordem mais alta são difíceisde derivar e existem poucas invariantes derivadas a partir de momentos de baixa ordem,não sendo suficientemente precisos para descrever uma forma.
Grid Based Method
Descritores de forma baseados em grade foram propostos em [53]. Basicamente,um grid com um número determinado de células é sobreposto à imagem e percorrido daesquerda para direita e de cima para baixo. O resultado é um bitmap. As células cobertaspela forma recebem valor 1 (um) e as demais valor 0 (zero). A forma pode, então, serrepresentada com um vetor de características binário. Para medir a similaridade entreduas formas podemos utilizar as técnicas de Binary Hamming distance ou block distance.Para tratar a translação, rotação e a escala, a forma primeiro é normalizada antes de serlida. A forma é redimensionada dentro de um retângulo de tamanho fixo, deslocada para ocanto superior esquerdo deste retângulo e rotacionada de forma que o eixo maior da formafique na horizontal. Figuras espelhadas e invertidas devem ser tratadas separadamente.

4.2 Baseada na região 46
As principais vantagens desta abordagem são sua simplicidade de representação,conformidade com a intuição humana, e a concordância com a codificação da forma uti-lizada no MPEG-4. No entanto, sua principal desvantagem é o alto custo computacional.
Shape Matrix
Os métodos tradicionais para tratamento de formas utilizam um grid para obteras informações necessárias. Isso gera representações que normalmente não são invariantesquanto a escala, rotação e translação. Logo um processo extra de normalização se tornanecessário. Em [32] o autor propôs uma matriz de forma circular (cicurlar shape matrix).
A ideia é a mesma do grid tradicional, porém ao invés de sobrepor uma matrizquadrada sobre a imagem, é utilizado um raster polar de círculos concêntricos comlinhas radiais partindo do centro de massa da imagem. O valor binário representando aforma é extraído das interseções entre os círculos e as linhas radiais. A shape matrix éformada de maneira que os círculos correspondam às colunas da matriz e as linhas radiaiscorrespondam às linhas da matriz. A matriz da forma resultante é invariante a translação,rotação e escala.
Infelizmente este método é bastante sensível ao ruídos pois a matriz resultante daforma é muito esparsa. Além da comparação entre duas formas ser computacionalmentecara.
4.2.2 Métodos Estruturais
Os métodos estruturais baseados em região decompõem a forma em partes , sub-regiões, que são utilizadas para representar e descrever a forma.
Convex Hull
Uma região R é convexa se, e somente se, para dois pontos x1,x2 ∈ R, toda linhaligando x1 e x2 estiver contida dentro de R. O convex hull de uma região é a menor regiãoconvexa H que satisfaça a condição R ⊂ H. Em outras palavras, objetivo é determinar omenor polígono que englobe um determinado conjunto de pontos. A Figura 4.4 ilustra oprocesso de segmentação utilizado neste método:

4.3 Conclusão 47
Figura 4.4: Convex Hull - (adaptado de [41])
As bordas da forma tendem a ser irregulares devido ao processo de digitalização,ruído e variações na sua segmentação, o que normalmente resulta em uma deficiênciaconvexa que tem um pequeno componente influenciando as bordas.
Medial Axis
Assim como o método Convex Hull, um esqueleto da região pode ser utilizadopara representar e descrever a forma. O esqueleto pode ser definido como um conjuntode linhas ao longo de todos os elementos da imagem [23]. A idéia básica do esqueleto éeliminar informações redundantes e preservar apenas as informações topológicas sobrea estrutura do objeto que favoreçam o processo de reconhecimento. Os métodos desqueleton são representados pelos métodos de medial axis transformation.
4.3 Conclusão
Neste capítulo foram apresentadas algumas técnicas utlizadas para a represen-tação de formas. Dentro do escopo deste projeto, o esboço desenhado pelo usuário nadamais é do que um contorno da forma geométrica contida dentro de um fluxograma. Parao reconhecimento desta forma geométrica, a informação extraída a partir de sua borda éde vital importância.
Para a extração de características de um esboço feito pelo usuário, utilizandotinta digital, as técnicas mais adequadas são aquelas baseadas no contorno da imagem.Isto ocorre porque o desenho contém apenas o controno no objeto.
Dentro deste conjunto de técnicas baseadas no contorno, foi escolhida a técnicade Chain Code como base para o método proposto. Sua escolha se justifica por causa desuas vantagens previamente apresentadas, tais como: redução e preservação dos dados,e por ser uma técnica com baixa complexidade de implementação. Suas desvantagens elimitações, para o reconhecimento de formas, serão superadas com a utilização de outrascaracterísticas extraídas a partir do esboço desenhado (ver Seção 5.7.4).

CAPÍTULO 5O Projeto
Processar uma imagem consiste em transformá-la, sucessivamente, com o ob-jetivo de extrair a informação nela presente que seja relevante à aplicação. Há tempossabe-se que uma imagem pode representar ideias, ações, sentimentos até melhor do quepalavras [77]. A informação tida como relevante depende diretamente da aplicação que aestá manipulando.
Reconhecer um esboço feito, manualmente, pelo usuário é equivalente a buscarformas que sejam, em algum critério, similares ao esboço feito.
Trabalhar diretamente com uma imagem para indexação e recuperação é muitocaro computacionalmente, logo a extração de características que definam a imagem e arepresentem em uma forma mais compacta se torna necessário. Elaborar sistemas CBIR,que sejam rápidos e eficientes, é uma tarefa desafiadora, e pesquisadores frequentementedevem escolher entre performance ou precisão [48].
De acordo com [18], uma das características mais importantes para a representa-ção do conteúdo visual de uma imagem é a forma do objeto. Infelizmente, como expostoem [89], não existe uma definição universal sobre o que é uma forma. Desta maneira,neste trabalho vamos considerar a forma como algo geométrico, contendo um conjuntode pontos, linhas e curvas. Logo, como apresentado na Seção 1.2, a proposta deste traba-lho é tratar o reconhecimento de imagens pelo seu conteúdo utilizando a forma do objeto.Informações como cores e textura não foram utilizadas pois, no contexto desta aplicação,não trariam ganhos durante o processo de reconhecimento.
5.1 O Sketch
Também conhecido como esboço, ou rascunho, é um desenho feito pelo própriousuário do sistema. São imagens informais criadas manualmente com o intuito de resolverum determinado problema ou ilustrar alguma situação. Pode ser feito de várias maneirasdiferentes, variando de pessoa para pessoa. Isto é, assim como na escrita, cada pessoa temcaracterísticas particulares que se refletem no esboço. Além disso, o esboço está sujeito

5.1 O Sketch 49
a ruídos, que surgem da inabilidade da pessoa em desenhar com precisão linhas retas ecurvas.
A principal vantagem na utilização de esboços é permitir uma comunicaçãomais natural entre o homem e os sistemas computacionais [65] e, por isso, tem ganhadopopularidade como meio de interação nas interfaces com o usuário.
A Figura 5.1 exemplifica alguns exemplos de esboços. Nela estão repesentadostrês exemplos de três possíveis formas de esboços: quadrado, triângulo e círculo, respec-tivamente.
Figura 5.1: Exemplos de esboços
Como o esboço é feito manualmente, e cada pessoa tem uma forma de desenhar,o reconhecimento de esboços não é uma tarefa fácil. Uma maneira de amenizar esteproblema é restringir a liberdade no esboço exigindo que restrições sejam aplicadas aodesenho, tornando sua interpretação menos complexa [3].
De acordo com [38], o reconhecimento de esboços é o entendimento automáticode uma entrada fornecida manualmente através de tinta eletrônica. As técnicas para oreconhecimento de esboços se dividem em duas categorias:
• baseada em gestos (gesture-based): permitem alta-precisão, mas exigem que ousuário aprenda um estilo particular de desenho para que as formas sejam reco-nhecidas.• desenho livre (free-sketch): permitem que o usuário desenhe formas como desenha-
ria naturalmente, mas infelizmente a maioria dessas técnicas possui baixa precisãoou exigem muitas restrições para serem úteis.
No reconhecimento baseado em gestos, os usuários devem aprender a desenharcada símbolo, pois a ordem, a direção e o número de traços (strokes) são determinantes

5.2 Escopo do projeto 50
para o processo de reconhecimento. A velocidade, as direções inicial e final, e a rotaçãodos traços também são utilizados para o reconhecimento. A grande vantagem é que nocaso do usuário desenhar as formas como foram definidas, a taxa de reconhecimento podeser alta. A desvantagem é que o usúário tem que aprender como desenhar cada forma.
Quando o reconhecimento de desenho livre é utilizado, os usuários podemdesenhar como desenhariam naturalmente. A vantagem desta abordagem é permitirque o usuário desenhe livremente, sem restrições. A desvantagem é que a taxa dereconhecimento é modesta. Devido a esta limitação, os sistemas de desenho livre buscamuma abordagem intermediária, liberando algums restrições e mantendo outras.
Considere as duas formas presentes na Figura 5.2. Se o reconhecimento porgestos é utilizado, elas são consideradas como formas distintas. Por outro lado, quandoreconhecimento de estilo livre é utilizado elas são consideradas como formas similares.
Figura 5.2: Formas
O método proposto utiliza uma abordagem mista, ou seja, permite que o usuáriodesenhe naturalmente, porém algumas restrições são impostas. Nas seções seguintes, esteassunto será abordado com mais detalhes.
5.2 Escopo do projeto
O ambiente proposto permite o reconhecimento de esboços de formas contidasem fluxogramas utilizando tinta digital. Dentro do cenário proposto na introdução destetrabalho, o sistema aqui desenvolvido deve ser capaz de identificar e reconhecer formasgeométricas presentes em fluxogramas. Este trabalho é parte de um trabalho maior quepretende reconhecer e gerar código fonte automaticamente a partir de um fluxogramadesenhado pelo usuário. Como exemplos temos as imagens presentes na Figura 5.3.

5.3 Tinta Digital 51
Figura 5.3: Exemplos de imagens
O método utilizado para o reconhecimento deve ser capaz de identificar imagenscontendo apenas objetos simples/singulares, ou seja, apenas um único objeto em seuinterior e que possuam forma fechada. Esta restrião é feita porque a segmentação dofluxograma esta fora do escopo deste projeto, e será tratada em um Trabalho Futuro.
Caso se queira utilizar imagens mais complexas, com mais de um objeto em seucontexto, torna-se necessário aplicar um método de segmentação que seja mais adequadopara o domínio da aplicação.
5.3 Tinta Digital
A utilização de tinta digital amplia as possibilidades de interação homem-máquina. Ter a liberdade de escrever e desenhar diretamente na tela torna algumas apli-cações muito mais atrativas para seus usuários. Aplicações que utilizam esta tecnologiasão, geralmente, mais intuitivas.
De acordo com [68], duas abordagens podem ser utilizadas para extrair informa-ções do esboço feito pelo usuário: uma baseada nos traços (stroke-based), e outra baseadana imagem (image-based). Na primeira abordagem, as informações são extraídas de cadastroke individualmente, enquanto na segunda abordagem o conjunto de strokes é agrupadoem uma única imagem, a partir da qual as informações são extraídas.
Inicialmente, a adordagem stroke-based foi adotada, buscando-se extrair o má-ximo de informação a partir dos dados capturados diretamente dos strokes: a extração dasinformações é feita no nível dos strokes e as características extraídas são agrupadas du-rante o processo de recohecimento. Infelizmente a utilização desta abordagem não trouxeganhos significativos para o método de reconhecimento. Os principais problemas encon-trados foram:
• a utilização de strokes é muito local, ou seja, prejudica a interpretação de caracte-rísticas globais da forma,• imprevisibilidade da forma como um usuário pode desenhar,• maior complexidade para interpretação e reconhecimento da forma.

5.3 Tinta Digital 52
Na Figura 5.4 temos 3 exemplos que ilustram esses problemas. Na Figura 5.4-(A) temos um possível desenho de um quadrado feito pelo usuário. Na Figura 5.4-(B)foram utilizado dois strokes para fazer a base do quadrado e na Figura 5.4-(C) foramutilizados dois segmentos de strokes para representar um único segmento lógico. Paraextrair informações diretamente dos strokes, seria necessário um pré-processamento sobreestes strokes. A ideia do método é permitir que o usuário desenhe livremente. Mas comoprever como o desenho será feito? Um lado do quadrado pode ser feito com um únicostroke (Figura 5.4-(A)), com vários strokes sobrepostos (Figura 5.4-(B)), ou como umasequência de strokes (Figura 5.4-(C)).
Figura 5.4: Utilização da tinta
Algumas vezes dois ou mais segmentos lógicos/semânticos podem ser represen-tados por um único ”stroke”, ou seja, o sistema deve fazer um pré-processamento nessesstrokes para interpretar este tipo de comportamento. Em outros casos, como na Figura 5.4-(C) mais de um stroke é utilizado para representar um mesmo segmento lógico, neste casoum dos lados de um quadrado. Diferenciar estes dois strokes representando um único ob-jeto e dois strokes representando dois objetos distintos é uma tarefa complexa. Por último,temos o caso presente na Figura 5.4-(B) em que vários strokes deveriam ser combinadosem um para a correta interpretação. Nesses casos técnicas mais complexas seriam neces-sárias.
Sendo assim, a abordagem stroke-based tornou o processo de extração de carac-terísticas mais complexo, inviabilizando sua utilização no sistema proposto. Este restul-tado também foi confirmado no trabalho apresentado em [68].
Devido a dificuldade de trabalhar diretamente no nível dos strokes, foi adotadaa abordagem image-based. Tratar os vários strokes como uma imagem única, e não umconjunto de traços individuais, mostrou-se mais viável.
Nesta nova abordagem, o primeiro passo é converter a informação, obtida datinta, em uma imagem binária. Uma maneira de realizar esta conversão é sobrepor umagrade de pixels sobre a imagem, marcar os pixels que forem cobertos pela tinta digital enão marcar os que não se sobrepõem a tinta. Este processo pode ser visto na Figura 5.5:

5.4 O Reconhecimento das Formas 53
Figura 5.5: Transformação da tinta para imagem binária
Após esta conversão, o método pode ser aplicado diretamente sobre a imagem eas informações necessários para o reconhecimento da forma podem ser extraídas.
5.4 O Reconhecimento das Formas
O reconhecimento é o processo no qual o usuário pode especificar sua necessi-dade de informação, ou seja, desenhar um esboço livremente, e o sistema deve processaresta entrada e exibir o resultado do reconhecimento. Ele é composto das seguintes eta-pas: formulação da consulta (desenho do esboço), processamento da consulta (tentativade reconhecimento) e resposta ao usuário. A Figura 5.6 ilustra essas etapas.
Figura 5.6: Etapas do Sistema
5.4.1 Formulação da consulta
Durante a formulação da consulta, é exibida ao usuário uma tela onde o mesmopode desenhar, livremente, uma forma que representa um elemento do fluxograma. Odesenho feito pelo usuário deve conter apenas o contorno dos objetos que ele estáprocurando. A informação visual contida no esboço é extraída e passada ao módulo deprocessamento da consulta.
5.4.2 Processamento da consulta
O esboço feito pelo usuário é processado e o vetor de característica extraído. Suascaracterísticas são comparadas às características das várias formas geométricas tratadaspelo sistema.

5.5 O Modelo do Sistema 54
5.4.3 Resposta ao usuário
Como resposta ao usuário, o sistema exibe o resultado do reconhecimento. Nestetrabalho, apenas uma mensagem de texto é exibida informando a forma reconhecida.Após o reconhecimento, várias ações poderiam ser tomadas: beautification (desenharuma versão “melhorada” da forma reconhecida), gerar código automático, executar algumaplicativo, entre outras.
5.5 O Modelo do Sistema
Na Seção 2.6, foi apresentado um modelo genérico para Sistemas de Processa-mento de Imagens Digitais. Dependendo da aplicação, algumas etapas podem ser adicio-nadas ou removidas. Neste sentido, a figura 5.7 ilustra as etapas presentes no sistema aquiproposto:
Figura 5.7: Processos em cada uma das etapas
5.6 O Sistema Desenvolvido
Para testar o método proposto neste trabalho, um sistema computacional foiimplementado. Ele apresenta uma interface de entrada onde o usuário pode desenhar umaforma para ser analisada ou especificar um repositório local (diretório) contendo formaspara serem analisadas. A Figura 5.8 exibe a interface do sistema:

5.6 O Sistema Desenvolvido 55
Figura 5.8: Interface do Sistema
A Figura 5.9 exibe as duas formas de interação com o sistema. Na primeira, ousuário esboça o desenho de uma forma e o sistema retorna o resultado do reconheci-mento. Na segunda, o usuário indica um dirétorio contendo as formas que gostaria dereconhecer e o sistema retorna a lista de imagens e o reconhecimento para cada uma dasformas.
Figura 5.9: Exemplos da utilização do sistema

5.7 O Método de Extração de Características 56
O sistema foi implementado utilizando-se a arquitetura .NET1, com a linguagemCSharp [7] por possuir suporte nativo à utilização de tinta digital2. Já as imagens foramarmazenadas em formato GIF3 - Graphics Interchange Format (“.gif”) por ser umpadrão usado largamente na Internet e possui uma boa qualidade combinado com umtamanho relativamente baixo de armazenamento. Outros formatos, como JPEG4 (Joint
Photographic Experts Group) ou PNG5 (Portable Network Graphics), também podemser utilizados.
O formato GIF é um tipo de arquivo para imagens que trabalha com umapaleta de 256 cores e foi criado pela empresa CompuServe, em 1987. Devido a essacaracterística, o uso do formato GIF é voltado para ícones ou imagens que não precisam demuitas cores. Ele utiliza um formato de compressão que não altera a qualidade da imagema cada salvamento, como ocorre com o JPEG. Considerando esta forma de compressãojuntamente com a capacidade de trabalhar apenas com 256 cores, o GIF consegue criarimagens com tamanho bastante reduzido.
5.7 O Método de Extração de Características
Construir um sistema para o reconhecimento de sketchs não é uma tarefa simples.De acordo com [34], algumas questões podem ser utilizadas como guia nesta tarefa:
• Quais as formas existentes neste domínio?• Como cada forma é reconhecida?• O que deve acontecer quando a forma é reconhecida?• Como a forma pode ser editada?
Muitos eventos específicos ao domínio podem ocorrer após o reconhecimento daforma, sendo que o mais comum deles é a alteração visual da forma, pois transmite aousuário uma confirmação de que seu esboço foi reconhecido corretamente.
De uma maneira geral, o sistema para o reconhecimento de formas geométri-cas presentes em fluxogramas, através de esboços feitos pelo usuário, é composto dosseguintes elementos:
• interface de entrada que possibilite ao usuário desenhar o seu esboço, ou indicar um“repositório” contendo as imagens que gostaria de avaliar,
1http://www.microsoft.com/net/2http://msdn.microsoft.com/pt-br/library/ms749012.aspx3Mais informações em: http://www.w3.org/Graphics/GIF/spec-gif89a.txt4Mais informações em: http://www.w3.org/Graphics/JPEG/5Mais informações em: http://www.w3.org/Graphics/PNG/

5.7 O Método de Extração de Características 57
• módulo de extração das características,• módulo de reconhecimento,• interface de saída que possibilite a exibição dos resultados do reconhecimento.
O método utilizado para extrair as informações a partir do esboço desenhadopelo usuário é dividido em quatro passos: Pré-processamento da imagem (extração,identificação e marcação dos pixels), Análise da imagem (registro do caminho seguidopelo contorno do objeto), Aprimoramento da Cadeia de Contorno e a Extração dasCaracterísticas.
Considere a Figura 5.10 como exemplo deste processo:
Figura 5.10: Sketch desenhado pelo usuário
5.7.1 Pré-processamento da Imagem
Nesta etapa o esboço desenhado pelo usuário passa por uma série de transforma-ções para facilitar a extração das suas características e facilitar o seu processamento.
Inicialmente o esboço é convertido para uma imagem binária distinguindo-seentre os pixels que compõem a imagem e os pixels de fundo: os pixels desenhados pelousuário são da cor preta e os demais são brancos. Esta imagem binária é sobreposta poruma grade com células de tamanho fixo (um pixels de largura por um pixels de altura),como na Figura 5.11.

5.7 O Método de Extração de Características 58
Figura 5.11: Esboço binarizado
Essa grade então é convertida em uma matriz de pixels da seguinte forma: cadacélula da grade corresponde a uma posição da matriz, cada célula na cor preta é marcadana matriz com o caractere ’x’, as demais posições são marcadas como vazias e preenchidascom o caractere ’-’. A Figura 5.12 ilustra este processo:

5.7 O Método de Extração de Características 59
Figura 5.12: Grade - Matriz de pixels
Dentro dessa matriz identificam-se os pixels que compõem o contorno do objetodesenhado. Eles são identificados e são marcados como o caractere ’o’. Em seguidaaplica-se o processo conhecido como Projeção de Contorno (”Contour Projection”) [70]para preencher a forma do objeto. Este processo é utilizado para preencher a forma doesboço e minimizar algumas lacunas entre os strokes desenhados pelo usuário. Destamaneira, temos: pixels de borda representados pelo caractere ’o’, pixels do interior daimagem representados pelo caractere ’x’ e os pixels que não fazem parte da imagemrepresentados pelo caractere ’-’, como visto na Figura 5.13.

5.7 O Método de Extração de Características 60
Figura 5.13: Identificação dos pixels de borda
O resultado final desta etapa é uma matriz contendo uma representação fiel doobjeto esboçado pelo usuário. Fiel, pois o que o usuário desenhou está representado dentrodesta matriz. A imagem "bruta"contém todas as imperfeições provenientes do desenhofeito, bem como aquelas originadas durante o processo de binarização.
5.7.2 Análise da Imagem
Nesta etapa a matriz de pixels, contento o objeto completo, é inicialmente percor-rida para identificar os pixels de borda, ou seja, os pixels que ficam nas extremidades doobjeto. Essa identificação dos pixels de borda é feita porque a forma do objeto é extraídaa partir do seu contorno.
O primeiro passo é a identificação do traçado da borda. Este é um processoessencial para a identificação e reconhecimento da forma do objeto [20]. O métodoutilizado consiste em visitar o contorno externo do objeto (borda) no sentido horário eidentificar cada uma das transições feitas. Todos os pixels de borda serão visitados eidentificados uma única vez. Uma janela 3x3 é utilizada para acompanhar a forma decada objeto, verificando a cada passo a direção do contorno.

5.7 O Método de Extração de Características 61
A partir da matriz da forma é aplicado o seguinte algoritmo:
1. Percorra a matriz até encontrar o primeiro pixel (o pixel mais à esquerda e naposição mais alta da matriz) e definir este pixel como sendo a posição inicial dacadeia de contorno,
2. A partir deste pixel visite cada um dos seus vizinhos no sentido horário e armazeneo código da direção ( ver Figura 5.14),
3. repita o passo 2 até que o pixel atual seja igual ao primeiro pixel.
Durante este processo percorre-se todo o contorno da imagem armazenando otrajeto percorrido. Ou seja, percorrem-se os pixels que compõem a borda do esboçoregistrando todas as transições deste trajeto. Esta sequência de passos forma uma cadeiade caracteres conhecida como Chain Code (ver Seção 4.1.2). A forma é percorrida nosentido horário, inciando-se do pixel mais à esquerda e mais alto da matriz. A cadatransição identifica-se o caminho a partir da posição anterior. A Figura 5.14 exemplificaesse processo: na parte (A) temos as identificações para cada direção, na parte (B) temosum exemplo que como é aplicada o método e código gerado a partir deste contorno.
Figura 5.14: Exemplo da utilização do Chain Code
O resultado final desta etapa é uma sequência de caracteres, também chamadode código do contorno (ou chain code), que identifica o caminho percorrido através docontorno do objeto. A partir desta sequência de caracteres/transições é que será feito oreconhecimento do objeto desenhado pelo usuário.
5.7.3 Aprimoramento da Cadeia de Contorno
Antes de iniciar o reconhecimento da forma desenhada, algumas simplificaçõespodem ser feitas sobre o código do contorno extraído. Essas simplificações tem como

5.7 O Método de Extração de Características 62
objetivo reduzir a quantidade de informações a ser processada, reduzir ruídos presentesno esboço, eliminar transições com baixo ou nenhum valor semântico e agilizar o processode comparação e identificação.
A primeira etapa deste processo é o agrupamento de transições iguais. Cadasequência de dois ou mais caracteres idênticos é agrupada em uma única sequência. AFigura 5.15 exibe alguns exemplos:
Figura 5.15: Agrupamento de transições
Na segunda etapa removem-se transições isoladas entre cadeias de transições domesmo tipo. A Figura 5.16 exibe alguns exemplos:
Figura 5.16: Remoção de transições isoladas - 1
Na terceira etapa removem-se transições isoladas entre uma cadeia e uma transi-ção do mesmo tipo da cadeia. A Figura 5.17 exemplifica este processo:
Figura 5.17: Remoção de transições isoladas - 2
Na quarta etapa removem-se transições isoladas entre cadeias de transiçõesdistintas. A Figura 5.18 exibe alguns exemplos deste processo:

5.7 O Método de Extração de Características 63
Figura 5.18: Remoção de transições isoladas - 3
No final de cada uma dessas estapas realiza-se um novo agrupamento de tran-sições. Transições singulares, ou cadeias de transições, que são vizinhas a cadeias detransições de mesmo tipo devem ser agupadas. A Figura 5.19 apresenta alguns exemplos:
Figura 5.19: Re-agrupamento
Na quinta etapa realizam-se simplificações entre transições. Algumas combina-ções de transições podem ser simplificadas para reduzir as imprecisões nos esboços feitospelo usuário oriundas de erros de desenho ou erros introduzidos durante a binarização daimagem. A Figura 5.20 exemplifica todas as simplificações diretas feitas entre cadeias detamanho 2 (dois), ou seja, que envolvem apenas duas transições.

5.7 O Método de Extração de Características 64
Figura 5.20: Simplificações para cadeias de tamanho 2
Este processo é repetido enquanto houver transições a serem agrupadas, simpli-ficadas ou removidas da cadeia.
5.7.4 Extração de Características
Com a cadeia simplificada e reduzida, o passo seguinte é a extração das carac-terísticas presentes no contorno do sketch que permitam reconhecer a forma desenhadapelo usuário. As características utilizadas são:
• a altura do objeto,• a largura do objeto,• o número de “retas” (transições) que compõe o contorno do objeto, e• os ângulos internos entre cada uma das transições.
As variáveis, altura e largura, fornecem uma relação importante para análise daimagem. Vamos chamar de resultado (R) a relação entre a altura e a largura do objetodesenhado, ou seja:

5.7 O Método de Extração de Características 65
Se altura for menor que a largura:
R =altura
largura(5-1)
E se altura for maior que a largura:
R =larguraaltura
(5-2)
A partir desta relação entre altura e largura do objeto, pode-se dividir as imagensem três grupos, baseados na forma de sua estrutura:
• forma de linha• forma quadrada• forma retangular
Cada um desses grupos é limitado pelo valor R. Desta maneira pode-se iniciara distinção entre os objetos subdividindo-os em cada um destes três grupos utilizando aseguinte relação entre as formas:
• Se R tende a 0, então a forma é de linha• Se R tende a 1, então a forma é quadrada• Se R esta entre 0 e 1, então a forma é retangular
Um esboço, feito manualmente pelo usuário, não possui dimensões perfeitas enem proporções ideais. Um usuário interessado em desenhar um quadrado não precisadesenhá-lo com a altura e a largura exatamente iguais. Por isso, deve haver uma certatolerância, ou um certo “limite” de imprecisão para seu desenho. Pensando nisso, umvalor para este Limite (L) deve ser considerado durante a divisão dos objetos entre essestrês grupos. Sendo assim, os valores que definem cada um dos três grupos são calculadosde acordo com a seguinte equação:
LINHA≤ L2< RETANGULO≤ (1−L)< QUADRADO≤ 1 (5-3)
O valor de L é a margem de tolerância para a imprecisão do desenho feito pelousuário e seu valor deve estar entre 0 (zero) e 1 (um). Por exemplo, se a tolerância forde 30% o limite será igual a 0,3. Para exemplificar este processo considere a Figura 5.21.Nesta figura tem-se quatro formas distintas (A, B, C e D) e suas propriedades (dimensõese os respectivos valores de R).
5.7 O Método de Extração de Características 66
Figura 5.21: Exemplos de formas
Na Figura 5.22, classificam-se essas formas de acordo com a equação 5-3. Trêsvalores distintos de L são adotados para ilustrar os possíveis resultados desta classificação.
Figura 5.22: Exemplos de aplicação da equação 5-3
Os ângulos entre cada uma das transições são dados de acordo com a Figura5.23:
Figura 5.23: Ângulos entre cada uma das transições

5.7 O Método de Extração de Características 67
A última característica necessária para o reconhecimento das formas é o númerode transições, ou seja, o número de “segmentos de retas” que compõe o objeto. Nesteponto algumas questões devem ser respondidas:
• Mas o que vem a ser uma reta?• Qual o número ideal de transições para formar uma reta?
A resposta da primeira pergunta é simples, um segmento de reta é uma sequênciade transições iguais, de tamanho variável. Já a segunda pergunta exige um pouco mais deatenção. Este número deve ser grande o suficiente para eliminar segmentos irrelevantes,como pequenas imprecisões no desenho, e pequeno o suficiente para não perder segmen-tos relevantes à interpretação da forma. Após alguns testes iniciais, foi adotado o valortrês (3), ou seja, apenas segmentos com 3 ou mais transições iguais seriam consideradoscomo uma “reta”.
Após os cáculos deste conjunto de características, o sistema deve ser capaz deidentificar e reconhecer o esboço do usuário. Este reconhecimento é possível pois cadaforma existente possui uma combinação única deste conjunto de características. A Figura5.24 apresenta as formas encontradas em fluxogramas e as características que definemcada uma destas formas unicamente.

5.7 O Método de Extração de Características 68
Figura 5.24: Formas e suas propriedades

5.8 Conclusão 69
Algumas considerações importantes devem ser ressaltadas:
• losangos e trapézios têm, praticamente, as mesmas características e diferem entresi pela sequência de seus ângulos. Ambos tem dois ângulos de 45◦ e dois ângulosde 135o. A diferença é que nos losangos os ângulos são intercalados, ou seja, umângulo 45◦ é vizinho dos ângulos de 135◦. Já no trapézio os ângulos iguais sãovizinhos.• circulos e elipses são aproximados para heptágonos (7 retas) ou octógonos (8 retas),
pois o método de aprimoramento da cadeia de contorno (Seção - 5.7.3) transformasegmentos curvelíneos em segmentos retos (ver Figura 5.25).• o intervalo entre os ângulos é múltiplo de 45◦ pois o Método Chain Code divide um
intervalo de 360◦ em oito intervalos de igual valor.
Figura 5.25: Aproximações para círculos e elipses
5.8 Conclusão
Neste capítulo foi introduzido um método de representação e reconhecimentode formas geométricas, que é baseado na Representação do tipo Chain Code. Ele utilizacomo características: o número de retas, os ângulos entre cada uma das retas e a relaçãoentre as dimensões do esboço. O método é invariante a transformações de escala, rotação,espelhamento e translação, assim como é independente do ponto inicial.
Uma questão que merece destaque é a possibilidade do sistema admitir novasformas. Se uma dada forma puder ser definida, unicamente, com o conjunto de caracte-ríticas apresentadas na seção 5.7.4, então ela pode ser adicionada à base de formas dosistema. Aumentando, assim, o número de formas reconhecíveis.

CAPÍTULO 6Avaliação
A área de reconhecimentos de sketchs carece de um conjunto único de dadosque possa ser utilizado para comparar os algoritmos existentes com os novos algoritmos[43]. Desta forma, sem esse conjunto único de dados, os resultados exibidos por cadaalgoritmo não podem ser comparados de maneira a avaliar se um novo algoritmo é melhorque os anteriores, ou até mesmo qual o melhor algoritmo para este fim. Métodos parateste e avaliação de Sistemas de Recuperação de Imagens ainda são muito difíceis deserem aplicados. Sendo assim, para avaliar o método proposto neste trabalho, uma basede esboços foi criada.
A utilização do gráfico de Recall x Precision constitui uma abordagem simplese bem conhecida para avaliação de sistemas computacionais. A precisão (precision) re-presenta a porção de imagens recuperadas que são relevantes à consulta. Já a revocação(recall) corresponde à porção de imagens relevantes que foram recuperadas [8]. Infeliz-mente, de acordo com [84], essa abordagem não é suficiente para sistemas de recuperaçãode imagens pois selecionar as imagens que são relevantes não é tão simples devido às di-ficuldades de se definir, precisamente, o conteúdo de uma imagem.
Devido a essa ausência de métodos próprios para avaliação de sistemas CBIR,adotou-se como medida o Nível de Reconhecimento: dado um conjunto de formas dese-nhadas pelo usuário, dentro deste conjunto calcula-se a porcentagem de reconhecimentosfeitos de maneira correta. Por exemplo, se temos 200 quadrados desenhados pelos usuá-rios e, durante o reconhecimento, o sistema foi capaz de reconhecer corretamente 180 dos200 quadrados, então o Nível de Reconhecimento (% de Reconhecimento) foi de 90%.
6.1 O Reconhecimento
Dados dois objetos, a similaridade é uma medida de quão parecidos esses doisobjetos são. No caso de imagens, a similaridade pode ser medida de várias formas: na cor,forma, no tamanho, entre outros. Após a extração dos descritores de conteúdo da ima-gem, pode-se compará-los aos descritores extraídos de outras imagens [30]. Inicialmente

6.2 Base de dados para o teste 71
as imagens são submetidas a um processo de extração de características. Essas caracterís-ticas, por sua vez, são utilizadas para identificação da forma desenhada.
Como o usuário pode desenhar livremente, torna-se necessário a utilização detécnicas capazes de recuperar imagens similares [26]. A similaridade buscada neste tipode sistema é a similaridade humana. Infelizmente, ainda não se encontrou um métodode reconhecimento ideal, aplicável a vários domínios diferentes. Para domínios restritos,diversas simplificações e restrições podem ser aplicadas com o objetivo de minimizar avariabilidade das características a serem analisadas diminuindo, assim, a complexidadedurante o processo de reconhecimento. Se dois objetos são equivalentes em algumacaracterística sobre um grupo de transformações, então o reconhecimento pode ser feito.
Neste trabalho, após a extração das características do esboço desenhado pelousuário (ver Seção 5.7.4), as mesmas são comparadas com as características pré-definidaspara as formas reconhecidas pelo sistema (ver Figura 5.24) nas sua base de imagens.Isto nada mais é do que um problema de decisão, ou seja, o esboço do usuário temcaracterísticas iguais às caracteristicas das formas reconhecidas pelo sistema? Se sim, aforma é reconhecida e a ação correta pode ser tomada; se não, a forma não é reconhecidapelo sistema e o usuário deve ser informado.
6.2 Base de dados para o teste
Para testar o método proposto neste trabalho, uma massa de dados precisou sergerada contendo vários exemplos de cada uma das formas geométricas. Desta maneira,foi solicitado a dez (10) pessoas que criassem manualmente alguns esboços para cadagrupo de formas. A cada um dos participantes foi entregue uma lista contendo as mesmasformas presentes na Figura 5.24 e um tablet PC contendo o sistema referido na seção 5.6.Os esboços foram feitos com a utilização de uma caneta, mas também poderiam ter sidofeitos com a utilização de um mouse. Cada usuário realizou este processo individualmentee após a conclusão dos desenhos, as imagens foram organizadas de acordo com seu tipo.
Antes de iniciarem os desenhos, algumas exigências foram feitas aos usuários:
1. desenhe o mais preciso possível2. as formas desenhadas, com exceção do Grupo das Linhas, devem ser formas
fechadas3. desenhar as formas no mesmo sentido e na mesma orientação presentes na lista de
formas
Foram desenhados um total de 845 (oitocentas e quarenta e cinco) imagens. Apósa geração deste conjunto incial de formas, elas foram testadas no sistema para verificar oseu funcionamento. Os resultados obtidos estão expressos na Tabela 6.1. Em um segundo

6.3 Resultados 72
momento, esses esboços desenhados pelos usuários também sofreram transformações derotação e espelhamento para se verificar a invariância do método quanto a transformaçãode rotação.
É importante ressaltar que o sistema implementado, para avaliar o métodoproposto, possui uma área para o desenho de esboços com uma dimensão de 256x256pixels. Este tamanho permite que o usuário crie formas com até 65.536 pixels. Durantea fase de Pré-processamento (ver seção 5.7.1), o método converte este esboço em umamatriz de pixels que é diretamente proporcional ao tamanho do desenho. Logo quantomaior o desenho, maior é a matriz gerada. Quanto maior for a matriz, mais dados o sistemadeverá processar.
Caso seja necessário trabalhar com desenhos maiores, por questões de perfor-mace, pode-se utilizar a normalização do tamanho do esboço antes de gerar a matriz.Isto é, independente do tabamnho do desenho feito, o mesmo seria redimensionado paraum tamanho previamente definido e, só então, a matriz de pixels seria gerada. Com isso,evita-se que matrizes muito grandes sejam geradas, o que prejudicaria o desempenho dométodo.
Desenhos muito pequenos também podem afetar o método. Como o sistematrabalha com agrupamentos de transições iguais (ver seção 5.7.4), se as sequências detransições forém pequenas o método não conseguirá formar segmentos de reta válidos.Neste caso existem duas soluções: utilizar a normalização do desenho, ou pode-se ajustaro método para que sequências menores sejam consideradas para a formação de segmentosválidos.
Atualmente, o sistema não implementa o redimensionamento (normalização)pois não se fez necessário para avaliação do método proposto. Durante a fase de testes,foram utilizados diferentes tamanhos de segmento para avaliar a sensibilidade do métodoem um conjunto de amostras. Os resulstados desta avaliação estão descritos na seçãoseguinte.
6.3 Resultados
A Tabela 6.1 exibe os resultados por cada tipo de forma obtidos durante oprimeiro teste do método sobre as formas criadas pelos usuários.

6.3 Resultados 73
Tabela 6.1: Teste 1 - Resultados
Formas Quantidade Acertos Erros % de ReconhecimentoCírculo 96 84 12 87,50 %Elipse 92 70 22 76,08 %
Hexágono 97 61 36 62,88 %Linha 66 59 07 89,39 %
Losango 73 36 37 49,31 %Quadrado 115 89 26 77,39 %Retângulo 88 67 21 76,13 %Trapézio 74 62 12 83,78 %Triângulo 144 96 48 66,66 %
Os resultados apresentados no primeiro teste não foram satisfatórios. Este con-junto de 845 imagens foi então analisado criticamente e revisado por um olhar humano.Após análise do resultados obtidos, foi constatado que uma parecela significativa dosreconhecimentos mal sucedidos ocorreu porque algumas das formas desenhadas não cor-respondiam a formas válidas.
Esta análise é necessária para avaliar se o reconhecimento foi feito de maneiracorreta e se o índice de reconhecimento pode ser melhorado. Após esta primeira revisão,alguns problemas foram detectados e, após uma análise detalhada das suas causas, foiverificado que parte dos erros de reconhecimento não foram ocasionados por falha dométodo. A lista abaixo exibe alguns dos erros mais comuns detectados:
• desenhar retângulos ao invés de quadrados e vice-versa,• desenhar círculos no lugar de elipses e vice-versa,• desenhar quadrados ou retângulos aos invés de losângos,• não atender as regras apresentadas na Seção 6.2,• desenhar formas irreconhecíveis até por um humano.
As formas irreconhecíveis são esboços desenhados pelos usuários que não pu-deram ser identificados nem por um olhar humano. O conjunto de formas que não foireconhecido pelo sistema foi então analisado por uma pessoa. As formas que nem o indi-víduo conseguiu identificar foram removidas da base de amostragem. Isso foi feito poisse mesmo um humano conseguiu identificar a forma desenhada, o sistema também nãoteria esta capacidade.
Esses erros prejudicaram a eficiência do método de reconhecimento e, após estaanálise crítica da formas desenhadas, algumas ações foram tomadas:
• imagens irreconhecíveis foram removidas do conjunto de amostras ,

6.3 Resultados 74
• imagens que não atendiam à Regra 2 da Seção 6.2 foram removidas (a Figura 6.1exibe alguns exemplos),• algumas imagens foram movidas para grupos mais adequados (a Figura 6.2 exibe
alguns exemplos).
Figura 6.1: Exemplos de formas removidas

6.3 Resultados 75
Figura 6.2: Exemplos de formas movidas para outros grupos
Este “novo” conjunto de amostras, contendo 787 imagens, foi então testadonovamente no sistema. Os resultados deste novo teste são exibidos na Tabela 6.2.
Tabela 6.2: Teste 2 - Resultados
Formas Quantidade Acertos Erros % de ReconhecimentoCírculo 92 84 08 91,30 %Elipse 83 70 13 84,33 %
Hexágono 83 61 22 73,49 %Linha 61 59 02 96,72 %
Losango 65 36 29 55,38 %Quadrado 108 97 11 89,81 %Retângulo 86 72 14 83,72 %Trapézio 72 62 10 86,11 %Triângulo 137 99 38 72,26 %
Os resultados apresentados no segundo teste tiveram uma melhora considerável.Porém as formas com traçados diagonais (triângulo, losango e hexágono) ainda apresenta-ram um índice de reconhecimento inferior. Durante análise destas formas, foi constatado

6.3 Resultados 76
que o método não reconhecia segmentos diagonais de maneira apropriada. Então altera-ções no método foram efetuadas para a execução de novos testes. A principal alteraçãofeita foi aumentar o número de transições iguais para formar um segmento de “reta” vá-lido (ver Seção 5.7.4). Este valor foi alterado de 3 para 4 e 5 com o objetivo de removerpequenas falhas de desenho e eliminar pequenos segmentos inexpressivos para a identifi-cação da forma.
Um novo teste foi executado para segmentos de tamanho 4 e para segmentos detamanho 5, e os resultados são exibidos na Tabela 6.3 abaixo:
Tabela 6.3: Teste 3 - Resultados para segmentos de tamanho 4 e 5
Formas Quantidade % de Reconhecimentosegmentos de tamanho 4
% de Reconhecimentosegmentos de tamanho 5
Círculo 92 92,39 % 92,39 %Elipse 83 67,46 % 50,60 %
Hexágono 83 87,95 % 83,13 %Linha 61 98,36 % 98,36 %
Losango 65 67,69 % 66,15 %Quadrado 108 93,51 % 93,51 %Retângulo 86 86,04 % 86,04 %Trapézio 72 94,44 % 88,88 %Triângulo 137 85,40 % 88,32 %
Os resultados obtidos no terceiro teste foram melhores para todas as formas,exceto para as elipses. De uma forma geral, todas as formas tiveram uma melhora noreconhecimento, principalmente as formas com traçados diagonais (triângulo, losango ehexágono).
No caso das elipses, uma análise mais criteriosa foi feita. Alterando o tamanhodo segmento de 3 para 5 transições fez com que o índice de reconhecimento desta formacaísse de 84,33% para 50,60%. Por quê? Se todas as formas tiveram uma melhora,por que o grupo das elipses teve esta queda tão acentuada? Este queda no índice dereconhecimento ocorreu porque ao aumentar o tamanho do segmento fez com queas elipses fossem “confundidas” com hexágonos e pentágonos. A consideração feitaanteriormente, de que as elipses eram reduzidas para octógonos e heptágonos (ver Figura5.25), não estava mais sendo verificada. Com segmentos maiores, algumas das elipsesdesenhadas estavam sendo transformadas em pentágonos e hexágonos. A Figura 6.3 exibeesta situação.

6.3 Resultados 77
Figura 6.3: Simplificações para elipses com segmentos de 3 e 5transições
Isto ocorreu porque nos segmentos com curvatura mais acentuada (as laterais daelipse), houve uma dimunição no número de segmentos considerados válidos. Ou seja,para um mesmo intervalo, quando se aumenta o tamanho dos segmentos, naturalmenteo número de segmentos diminui. Por isso as elipses se transformaram em hexágonos epentágonos ao invés de octógonos e heptágonos, como previsto anteriormente.
Para melhorar o índice de reconhecimento, os resultados obtidos para segmentosde tamanho 3, 4 e 5 foram avaliados. Pode-se verificar que, com exceção das elipses, todasas formas tiveram uma melhora, ou mantiveram, seus índices de reconhecimento a medidaque aumentamos o tamanho do segmento. Algumas formas (hexágono, losango e trapézio)tiveram resultados melhores com segmentos de tamanho 4, outras (triângulo) tiveramresultados melhores com segmentos de tamanho 5 e as demais formas (círculo, linha,quadrado e retângulo) apresentaram os mesmos resultados para segmentos de tamanho 4ou 5. Então, qual seria o valor ideal para o tamanho do segmento?
• Elipses tem índice de reconhecimento melhor com segmentos de tamanho 3,• Hexágonos, losangos e trapézio tem índices de reconhecimento melhor com seg-
mentos de tamanho 4, e• Triângulos tem índice de reconhecimento menor com segmentos de tamanho 5.
O método, outra vez, teve que ser revisado em busca de novas melhorias. Ide-almente, deve-se adotar um tamanho de segmento que maximize o índice de reconheci-mento para todas as formas. Este valor deveria ser um valor entre 3 e 5. Como este valordeve ser único para todas as formas, decidiu-se adotar uma abordagem diferente: ao invésde ter um único valor para definir o tamanho de um segmento válido, serão utilizadosdois valores. Para o primeiro agrupamento, foram adotados segmentos de tamanho maior

6.3 Resultados 78
e para os agrupamentos subsequentes adotam-se segmentos com menor tamanho. A novaabordagem é explicada abaixo:
• Durante o primeiro agrupamento, ou seja, feito diretamente no esboço do usuário,foi adotado um tamanho de segmento igual a 4,• Nos agrupamentos seguintes, feitos a partir da cadeia de contorno já agupada e
simplificada, foi adotado um tamanho de segmento igual a 3.
Um novo teste foi executado e os resultados são exibidos na Tabela 6.4.
Tabela 6.4: Teste 4 - Resultados - Segmentos de tamanho 4,3
Formas Quantidade Acertos Erros % de ReconhecimentoCírculo 92 84 08 91,30 %Elipse 83 69 13 72,28 %
Hexágono 83 70 13 84,33 %Linha 61 60 01 98,36 %
Losango 65 44 21 67,69 %Quadrado 108 98 10 90,74 %Retângulo 86 74 12 86,04 %Trapézio 72 67 05 93,05 %Triângulo 137 116 21 84,67 %
O teste 4 obteve, na média, resultados melhores que os testes anteriores. Depen-dendo da aplicação e das formas adotadas, pode-se optar por valores diferenciados parao tamanho dos segmentos válidos. Pode-se utilizar um único valor, ou até mesmo criarnovas combinações de valores, como a combinação feita para o teste 4.
Para finalizar a avaliação do método, deve-se testar sua invariância quanto a ro-tação e ao espelhamento da formas. Para isto, cada um dos sketchs foi, então, rotacionado3 vezes consecutivas com intervalos de 90◦ (90◦, 180◦ e 270◦ respectivamente) e tam-bém rotacionados em torno dos eixos X e Y (espelhamento), totalizando 4.712 (quatromil setecentos e doze) imagens. Este processo de rotação e espelhamento dos esboços énecessário para testar a invariância do método quanto a rotação. Os resultados para esteteste final são exibidos na Tabela 6.5:

6.3 Resultados 79
Tabela 6.5: Teste 5 - Avaliando a invariância
Formas Quantidade Acertos Erros % de ReconhecimentoCírculo 551 504 47 91,47 %Elipse 498 409 89 82,12 %
Hexágono 498 418 80 83,93 %Linha 364 358 06 98,35 %
Losango 390 261 129 66,92 %Quadrado 648 584 64 90,12 %Retângulo 514 448 66 87,15 %Trapézio 427 392 35 91,80 %Triângulo 822 696 126 84,67 %
Como esperado, os índices de reconhecimento foram, praticamente, os mesmos.Isto prova que o método é invariante à transformação de rotação. Ele é invariante àtranslação porque sua posição dentro da área de desenho não influência na formaçãoda cadeia de contorno, que sempre tem início no pixel mais a esquerda e na posiçãomais elevada (ver 5.7.2). E também é invariante às alterações de escala porque duranteo processo de aprimoramento da cadeia de contorno, o tamanho da cadeia é reduzido asegmentos elementares. A Figura 6.4 exibe dois exemplos de quadrados, e ambos gerama mesma cadeia de contorno: 2n4n6n0n, ou seja: uma sequência de transições tipo Dois,uma sequência de transições tipo Quatro, uma sequência de transições tipo Seis e umasequência de transições tipo Zero.
Figura 6.4: Formas com escala diferente mas com mesma cadeiade contorno
Uma consideração importante deve ser feita quanto a forma dos losangos. Umlosango é um polígono formado por quatro lados (quadrilátero) de igual comprimentoe cuja soma dos ângulos internos é igual a 360◦. Por definição todo retângulo e todoquadrado são casos particulares de losangos: um quadrilátero com 4 ângulos de 90◦.Logo, todo retângulo e todo quadrado também são losangos. Conforme mencionado

6.3 Resultados 80
anteriormente (ver Seção 4.1.2), o método divide o intervalo de ângulos em 8 partes de45o. Um losango perfeito, com intervalos de 45o, teria a seguinte configuração: 2 ângulosde 45o e 2 ângulos de 135◦, conforme a Figura 6.5-(A). De acordo com a Tabela 5.23esta combinação de ângulos é gerada a partir da forma presente na Figura 6.5-(B). Oprocesso de simplificação da cadeia de contorno apresentado na Seção 5.7.3, transforma aFigura 6.5-(A) em um quadrado rotacionado 45◦ (ver Figura 6.5-(C)). Isto ocorre porqueo tamanho da cadeia é sempre reduzido a segmentos elementares. Neste caso temos aseguinte cadeia: 3n5n7n1n, ou seja, quatro segmentos diagonais.
Figura 6.5: Losango
Por definição, todo losango é também um paralelogramo. A Figura 6.5-(B) éum parelelogramo e, neste trabalho, está sendo adotado como uma forma “equivalente” aforma do losango. Dependendo da aplicação pode-se substituir os losangos, sem prejuízoalgum, por retângulos ou quadrados rotacionados 45◦ ou por paralelogramos, como estespresentes na Figura 6.5-(C) e 6.5-(B), respectivamente.
Para a formação do conjunto de amostras, os usuários poderiam desenhar as 3formas presentes na Figura 6.5, sendo que as figuras (A) e (B) representariam losangos ea figura (C) representaria retângulos (ou quadrados dependendo da relação altura
largura ). Umnovo teste foi executado mas desta vez o conjunto dos losangos foi dividido em 2 grupos:
1. grupo losango-paralelogramo, sketchs similares à Figura 6.5-(B), e2. grupo losango-losango, sketchs similares à Figura 6.5-(A).
Os resultados obtidos nestes 2 grupos apresentam valores bem distintos. Parao grupo losango-paralelogramo o índice de reconhecimento foi de 92,39%. Já para ogrupo 2, losango-losango, o índice de reconhecimento é de apenas 5,26% das formasreconhecidas como losangos e 68,42% desse conjunto de formas reconhecidos comoretângulos. Como afirmado anteriormente, as formas similares à forma 6.5-(A) acabaramsendo transformadas para quadrados ou retângulos rotacionados 45◦.
Esta “limitação” não prejudica a aplicabilidade do método pois, dependendo dasformas utilizadas no fluxograma, basta que o usuário utilize um paralelogramo ou umquadrado (rotacionados 45◦) para que o sistema reconheça como losango e o códigoapropriado possa ser gerado.

CAPÍTULO 7Conclusão e Trabalhos Futuros
Para que o computador possa tratar semanticamente imagens, é necessário queele possa reconhecer o seu conteúdo. Reconhecer uma imagem, para os seres humanos,é um processo trivial e bastante intuitivo. Para uma máquina, reconhecer uma imagem éum processo complexo e, muitas vezes, ambíguo. Apesar dos avanços alcançados, muitoainda resta ser feito.
Como ocorre em outras áreas, a educação também pode se beneficiar dosavanços no reconhecimento de imagens. Em particular o reconhecimento de esboços podecontribuir, já que o desenho é uma forma natural de representação, bastante usado para acomunicação de ideias e discussão de soluções.
No ensino de programação de computadores, o uso de fluxogramas, por ser umarepresentação gráfica, torna o entendimento mais fácil e mais compreensível para estudan-tes iniciantes em computação do que a utilização código em linguagem de programação.Além disto, auxiliam no aprendizado, já que possuem uma sintaxe mínima que reduz ofoco na sintaxe, aumentando o esforço em análise.
Para permitir o tratamento semântico dos fluxogramas em aplicações, é neces-sária a “compreensão” das representações utilizadas. Isto passa pelo “reconhecimento”automático das formas esboçadas pelo usuário.
Este trabalho apresenta uma abordagem para o reconhecimento de esboços, uti-lizando informações extraídas a partir da forma do objeto. Para a extração de característi-cas, um método, baseado na técnica de Chain Code, foi proposto para analisar a borda daimagem. Foi implementada uma ferramenta, fundamentada na abordagem proposta, parateste e validação do método proposto.
A aplicação foi desenvolvida utilizando a plataforma Microsoft .Net Framework,já que esta possui suporte nativo para a utilização de tinta digital. A ferramenta desenvol-vida extrai, dos esboços, um conjunto de características necessárias para a identificação eo reconhecimento das formas. As características utilizadas foram: as dimensões (altura elargura), o número de segmentos que compõe o contorno da imagem e os ângulos internosentre cada um segmentos.

7.1 Trabalhos Futuros 82
Para avaliação do método uma base de imagens, contendo formas geométricasesboçadas por usuários, foi criada. O reconhecimento foi feito inicialmente pelos usuários,depois por um revisor humano e, então, pelo sistema desenvolvido. Os resultados obtidosdurante os testes mostraram a viabilidade do método proposto.
O trabalho proposto é parte de um trabalho maior, que busca construir umaferramenta, com fins educacionais e didático-pedagógicos, para ser utilizada em cursosiniciais de Algoritmos e Programação de Computadores. Nela o aluno poderá esboçar umfluxograma utilizando tinta digital, que será convertido para código fonte, que poderá sertestado e avaliado, validando o raciocínio e o aprendizado dos alunos.
É preciso considerar que o momento proporciona uma oportunidade de aproxi-mar novas tecnologias ao processo educativo como possibilidade de melhorar os tradici-onais sistemas de ensino. Assim que as demais partes do sistema forem sendo desenvol-vidas, testes mais próximos da realidade poderão ser executados.
O método, aqui apresentado, pode ser utilizado em qualquer área onde haja anecessidade de reconhecimento de formas geométricas. Novas formas ainda podem seradicionadas a base de imagens, aumentando a capacidade de reconhecimento do método.A utilização de técnicas de Processamento de Imagens, CBIR e a análise das formaspresentes em fluxogramas foram essenciais para o desenvolvimento desta dissertação.
7.1 Trabalhos Futuros
Primeiramente, deve-se desenvolver o processo de segmentação dos fluxogramaspara permitir uma caracterização completa dos fluxogramas. Este é um processo com-plexo, mas que pode ser implementado levando em consideração o domínio da aplicação.
Além disto, novas idéias surgiram para a continuação futura do mesmo.Propõem-se:
• aceitar imagens não fechadas utilizando uma técnica que complete sua borda,• estender o reconhecimento para outros tipos de formas como letra e formas mais
complexas,• verificar a existência de novas características que possam ser utilizadas para o
reconhecimento das formas,• verificar a viabilidade de realizar treinamentos, por parte dos usuários e por parte
do sistema.
O método apresentado neste trabalho se mostrou promissor. Com o desenvolvi-mento de outros trabalhos como:
• animação do fluxograma, e

7.1 Trabalhos Futuros 83
• a geração de código fonte a partir das formas reconhecidas.
Um sistema para reconhecimento e geração de código de máquina a partir defluxogramas esboçados pelo usuário poderá ser criado. Desta forma, o método propostoneste trabalho poderá, novamente, ser testado em um ambiente real para avaliar suaaplicabilidade dentro do sistema.
O processo de beautification também deve ser avaliado. Um estudo deve ser feitocom o intuito de escolher a melhor maneira de utilizá-lo dentro do sistema: qual técnicaescolher, qual o momento de executar o beautification de cada forma e do fluxograma.
Com a criação de um sistema que reconheça e execute fluxogramas, outrastarefas também podem ser executadas de maneira automatizada: correção automática,agrupamento de esboços similares e recuperação de fluxogramas que gerem o mesmorestultado.
Utilizar outras características, como a cor, podem expandir as possibilidade dereconhecimento. Por exemplo, em um fluxograma retângulos podem ser utilizados pararepresentar entrada/saída de dados. Com a utilização de duas cores distintas, pode-seutilizar a mesma forma para representar funções diferentes: um retângulo azul poderiarepresentar Entrada de Dados e um retângulo vermelho poderia representar Saída dedados.

Referências Bibliográficas
[1] ALBUQUERQUE, M. P.; ALBUQUERQUE, M. P. Processamento de imagens:
métodos e análises. Editora da FACET, Rio de Janeiro, 2001.
[2] ALMEIDA, C. W. D.; POEL, J. V. D.; BATISTA, L. V.; AMORIM, H. L. E. Análise de
formas baseada no método da curvature scale space para tumores de câncer
de mama. In: IV SBQS - V Workshop de Informática Médica, 2005.
[3] AMBRÓSIO, A. P.; GONDIM, H. W. A. S. Esboço de fluxogramas no ensino de
algoritmos. In: WEI - Workshop sobre Educação em Computação 2008, Belém do
Pará - PA. Anais do WEI 2008, 2008.
[4] AMORIN, S. R. L.; CHERIAF, M. Sistema de indexação e recuperação de infor-
mação em construção baseado em ontologia. III Encontro de Tecnologia de Infor-
mação e Comunicação na Construção Civil, p. 1–8, 2007.
[5] ASLANDOGAN, Y. A.; YU, C. T. Techniques and systems for image and video
retrieval, 1999.
[6] BACH, J. R.; FULLER, C.; GUPTA, A.; HAMPAPUR, A.; HOROWITZ, B.; HUMPHREY,
R.; JAIN, R.; SHU, C.-F. Virage image search engine: An open framework for
image management. In: Storage and Retrieval for Image and Video Databases
(SPIE), p. 76–87, 1996.
[7] BAGNALL, B.; OUTROS. C# Para Programadores Java. Alta Books, 2005.
[8] BALAN, A. G. R.; TRAINA, A. J. M.; TRAINA JR, C.; AZEVEDO-MARQUES, P. M.
Integrando textura e forma para a recuperação de imagens por conteúdo. Anais
do IX Congresso Brasileiro de Informática em Saúde (CBIS 2004), 1(1):1–6, 2004.
[9] BARROS, R. A. B.; RIBEIRO, C. H. C. Implementação de métodos e classes
de processamento de imagens para sistema de navegação robótica. Technical
report, Instituto Tecnológico de Aeronáutica, Conselho Nacional de Desenvolvimento
Científico e Tecnológico, São José dos Campos, SP, 2005.

Referências Bibliográficas 85
[10] BARTOLINI, I.; CIACCIA, P.; PATELLA, M. Warp: Accurate retrieval of shapes using
phase of fourier descriptions and time warping distance. IEEE Trans. Pattern
Analysis and Machine Intelligence, 27(1):142–147, 2005.
[11] BELONGIE, S.; MALIK, J.; PUZICHA, J. Shape maching and object recognitions
using shape context. IEEE Trans. Pattern Analysis and Machine Intelligence,
24(4):509–522, 2002.
[12] BERRETTI, S.; BIMBO, A. D.; PALA, P. Retrieval by shape similarity with percep-
tual distance and effective indexing. IEEE Transactions on Multimedia, 2(4):225–
239, 2000.
[13] BIMBO, A. D.; PALA, P. Visual image retrieval by elastic matching of user
sketches. IEEE Transactions on Multimedia, 19(2):121–132, 1997.
[14] BRIBIESCA, E. A new chain code. The Journal of the Pattern Recognition Society,
32:235–251, 1999.
[15] BRUNELLI, R.; MICH, O. On the use of histograms for image retrieval. Multimedia
Computing and Systems, International Conference on, 2:143, 1999.
[16] BUCHANAN, J. Review of syntactic methods in pattern recognition by k. s. fu.
SIGART Bull., p. 11–11, 1974.
[17] CASTANON, C. A. B. Recuperação de imagens por conteúdo através de análise
multiresolução por wavelets. Master’s thesis, Instituto de Ciências Matemáticas e
de Computação (ICMC), 2003.
[18] CHAKRABARTI, K.; ORTEGA-BINDERBERGER, M.; PORKAEW, K.; MEHROTRA, S.
Similar shape retrieval in mars. In: Multimedia and Expo, 2000. ICME 2000. 2000
IEEE International Conference on, volume 2, p. 709–712 vol.2, 2000.
[19] CREWS, T.; ZIEGLER, U. The flowchart interpreter for introductory programming
courses. In: FIE ’98: Proceedings of the 28th Annual Frontiers in Education, p. 307–
312, Washington, DC, USA, 1998. IEEE Computer Society.
[20] CRUZ, H. S.; BRIBIESCA, E.; DAGNINO, R. M. R. Effiency of chain codes to
represent binary objects. Pattern Recognition, 1(40):1600–1674, 2007.
[21] DAS, M.; PAULIK, M.; LOH, N. A bivariate autoregressive technique for analysis
and classification of planar shapes. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 12(1):97–103, 1990.

Referências Bibliográficas 86
[22] DATTA, R.; LI, J.; WANG, J. Z. Content-based image retrieval - approaches and
trends of the new age. Intl. Workshop on Multimedia Information Retrieval - ACM
Multimedia, 2005.
[23] DAVIES, E. R. Machine Vision: Theory, Algorithms, Practicalities. Academic
Press, Amsterdam, 1997.
[24] DUDEK, G.; TSOTSOS, J. K. Shape representation and recognition from multis-
cale curvature. Comput. Vis. Image Underst., 68(2):170–189, 1997.
[25] EITZ, M.; HILDEBRAND, K.; BOUBEKEUR, T.; ALEXA, M. A descriptor for large
scale image retrieval based on sketched feature lines. In: Eurographics Sympo-
sium on Sketch-Based Interfaces and Modeling, p. 29–38, 2009.
[26] ERPEN, L. R. C. Recuperação de informação visual. In: II Jornada do Conheci-
mento e da Tecnologia, Porto Alegre - RS - Brasil, 2000.
[27] FONSECA, M. J. C. M. Sketch-Based Retrieval in Large Sets of Drawings. PhD
thesis, Universidade Técnica de Lisboa - Instituto Superior Técnico, Lisboa - Portugal,
2004.
[28] FRANCISCANI, J. D. F. Redução do gap semântico em cbir utilizando ontologia
de objeto, 2008.
[29] FREEMAN, H. Computer processing of line drawing images. ACM Computing
Surveys, 6(1):57–97, 1974.
[30] GONCALVES, D. B.; COSTA, Y. M. G.; BRUSCAGIM, M.; SILVA, G. C. Re-
cuperação de imagens por combinação dos aspectos cromático e estrutural,
2005.
[31] GONZALEZ, R. C.; WOODS, R. E. Digital Image Processing - Second Edition.
Prentice Hall, 2002.
[32] GOSHTASBY, A. Description and discrimination of planar shapes using shape
matrices. IEEE Transactions, 7(6):738–743, 2009.
[33] GROSKEY, W. I.; MEHROTRA, R. Index-based object recognition in pictorial data
management. Computer Vision, Graphics, and Image Processing, 52(3):416–436,
1990.
[34] HAMMOND, T. Enabling instructors to develp sketch recognition applications
for the classroom. 37th ASEE/IEEE Frontiers in Education Conference, 1(1):11–16,
2007.

Referências Bibliográficas 87
[35] HAMMOND, T. LADDER: A Perceptually-based Languge to Simplify Sketch
Recognition User Interface Development. PhD thesis, MIT - PhD Thesis, 2007.
[36] HAMMOND, T. Sketch recognition at texas a&m university. Brown Workshop on
Pen-Centric Computing March 25, p. 1–6, 2007.
[37] HAMMOND, T.; DAVIS, R. Ladder, a sketching language for user interface
developers. Comput. Graph., 29(4):518–532, 2005.
[38] HAMMOND, T.; EOFF, B.; PAULSON, B.; WOLIN, A.; DAHMEN, K.; JOHNSTON, J.;
RAJAN, P. Free-sketch recognition: Putting the chi in sketching. In: CHI ’08: CHI
’08 extended abstracts on Human factors in computing systems, p. 3027–3032, New
York, NY, USA, 2008. ACM.
[39] HE, Y.; KUNDU, A. 2-d shape classification using hidden markov model. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 13(11):1172–1184, 1991.
[40] HOSTINS, H.; RAABE, A. Auxiliando a aprendizagem de algoritmos com a
ferramenta webportugol. Anais do XXVII Congresso da SBC, p. 96–105, 2007.
[41] ZHANG, D. Image Retrieval Based on Shape. PhD thesis, Monash University, 2002.
[42] HU, M. K. Visual pattern recognition by moment invariants. IRE Transactions on
Information Theory, 8(2):179–187, 1962.
[43] JACOBSON, R. E.; KASTER, B. L.; HAMMOND, D. T. Sousa: The sketch-based
online user stydy application. Eurographics 5th Annual Workshop on Sketch-
Based Interfaces and Modeling, p. 81–88, 2008.
[44] KARA, L. B. An image-based trainable symbol recognizer for sketch-based
interfaces. In: in AAAI Fall Symposium Series 2004: Making Pen-Based Interaction
Intelligent and Natural, p. 99–105. AAAI Press, 2004.
[45] KASHYAP, K. L.; CHELLAPPA, R. Stochastic models for closed boundary analysis:
Representation and reconstruction. IEEE Transaction on Information Theory,
27(5):627–637, 1981.
[46] KATA, T.; KURITA, T.; OTSU, N.; HIRATA, K. Sketch retrieval method for full color
image database - query by visual example. 11th IAPR International Conference on
Pattern Recognition ,Conference A: Computer Vision and Applications, 1(1):530–533,
1992.
[47] KISHI, A. K.; FANG, C. Ferramenta para análise de informções do olhar. Trabalho
de Formatrua Supervisionado - Universidade de São Paulo - Instituto de Matemática
e Estatística - Departamento de Ciência da Computação, 2007.

Referências Bibliográficas 88
[48] LANDRÉ, J.; TRUCHETET, F. Image regrieval with binary hamming distance.
VISAPP (2), p. 237–240, 2007.
[49] LATECKI, L. J.; LAKAMPER, R. Shape similarity measure based on correspon-
dence of visual parts. IEEE trans. Pattern Analysis and Machine Intelligence,
22(10):1185–1190, 2000.
[50] LEUNG, W. H.; CHEN, T. User-independent retrieval of free-form hand-drawn
sketches, 2002.
[51] LIU, Y. K.; ZALIK, B. An efficient chain code with huffman coding. The Jounal of
the Pattern Recognition Society, 38:553–557, 2004.
[52] LONG, H. Z.; LEOW, W. K.; CHUA, F. K. Perceptual texture space for content-
based image retrieval. In: In Proc. Int. Conf. on Multimedia Modeling (MMM 2000),
p. 167–180, 2000.
[53] LU, G. J.; SAJJANHAR, A. Region-based shape representation and similarity me-
asure suitable for content-based image retrieval. Multimedia Systems, 7(2):165–
174, 2000.
[54] MARINE, F. J. S. Automatic recognition of biological shapes with and without
representation of shape. Artificial Intelligence in Medicine, 18(2):173–186, 2000.
[55] MEER, P.; GEORGESCU, B. Edge detection with embedded confidence. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 23(12):1351–1365, 2001.
[56] MEHTRE, B. M.; KANKANHALLI, M. S.; LEE, W. F. Shape measures for content
based image retrieval: A comparison. Information Processing & Management,
33(3):319–337, May 1997.
[57] MENDES, A. J. N.; GOMES, A. J. Sicas: Interactive system for algorithm deve-
lopment and simulation, 2001.
[58] MOKHTARIAN, F.; ABBASI, S.; KITTLER, J. Robust and efficient shape indexing
through curvature scale space. In: In Proceedings of British Machine Vision
Conference, p. 53–62, 1996.
[59] MORENO, R. A.; FURUIE, S. S. Biram: Sistema para recuperação de imagens
por conteudo. Anais do X Congresso Brasileiro de Informática em Saúde, 1(1):554–
559, 2006.
[60] MURUGAPPAN, S.; SELLAMANI, S.; RAMANI, K. Towards beautification of freehand
sketches using suggestions. In: SBIM ’09: Proceedings of the 6th Eurographics

Referências Bibliográficas 89
Symposium on Sketch-Based Interfaces and Modeling, p. 69–76, New York, NY, USA,
2009. ACM.
[61] NUNES, A. M.; FILETO, R. Uma arquitetura para recuperação de informação
baseada em semântica e sua aplicação no apoio a jurisprudência. Anais da III
Escola Regional de Banco de Dados (ERBD) - Caxias do Sul - RS, 2007.
[62] OTTERLOO, P. J. V. A contour-oriented approach to shape analysis. Prentice Hall
International, 1(1):90–108, 1991.
[63] PAULA, L. B. D.; PINHEIRO, M. G.; ROSA, N. A.; FIGUEIREDO, L. R. D.; AZEVEDO-
MARQUE.; MAZZONCINI, P. Sistema para recuperação de mamografias com base
em conteúdo: Extração do vetor de características. Revista Iluminart, 1(1):124–
137, 2009.
[64] PAULSON, B.; HAMMOND, T.; WOLIN, A. Sort, merge, repeat: An algorithm for
effectively finding corners in hand-sketched strokes, 2000.
[65] PAULSON, B.; HAMMOND, T. Paleosketch: accurate primitive sketch recognition
and beautification. In: IUI ’08: Proceedings of the 13th international conference on
Intelligent user interfaces, p. 1–10, New York, NY, USA, 2008. ACM.
[66] PENTLAND, A.; PICARD, R. W.; SCLAROFF, S. Photobook: Content-based mani-
pulation of image databases, 1995.
[67] PRASAD, B. G.; BISWAS, K. K.; GUPTA, S. K. Region-based image retrieval
using integrated color, shape and location index. In: Computer Vision & Image
Understanding, Vol.94, No.1-3 (April 2004) pp 193-233, ISSN, p. 193–233, 2003.
[68] PRINCE, C. Using clustering to assist understanding of digital ink in low
attention environments, 2005. Acessado em 20/05/2010.
[69] RAFIEI, D.; MENDELZON, A. O. Efficient retrieval of similar shapes. The VLDB
Journal, 11(1):17–27, 2002.
[70] RODRIGUES, R. J.; SILVA, E.; THOMÉ, A. C. G. Feature extraction using contour
projection. 5th World Multi-Conference on Systemics, Cybernetics and Informatics -
SCI 2001, Orlando, Florida, 13(1):561–566, 2001.
[71] RODRIGUES JR., M. C. Experiências positivas para o ensino de algoritmos,
2004.
[72] RUI, Y. A modified fourier descriptor for shape matching in mars. In: Chang,
S. K., editor, Image Databases and Multimedia Search, Series of Software Engn.

Referências Bibliográficas 90
and Knowledge Engn., volume 8, p. 165–180. World Scientific Publishing, Singapore,
1998.
[73] RUI, Y.; SHE, A.; HUANG, T. Modified fourier descriptors for shape represen-
tation – a practical approach. In: Proc of First International Workshop on Image
Databases and Multi Media Search., 1996.
[74] RUI, Y.; HUANG, T. S.; CHANG, S.-F. Image retrieval: Current techniques,
promising directions, and open issues. Journal of Visual Communication and
Image Representation, 1(39):39–62, 1999.
[75] SAJJANHAR, A. A technique for similarity retrieval of shapes. Master’s thesis,
Monash University , Australia, 1997.
[76] SALEM, A.-B. M.; SEWISY, A. A.; ELYAN, U. A. A vertex chain code approach for
image recognition. GVIP, 05(V3), 2005.
[77] SANTANA, R. C. D. Uma aplicação de cbir à análise de imagens médicas de
imuno-histoquímica utilizando morfologia matemática e espectro de padrões,
2008.
[78] SANTOS, C. D. F. D. Uso de saliências do contorno via esqueletização para
recuperação de imagens. Master’s thesis, Universidade Federal de Uberlândia,
2007.
[79] SCANLAN, D. A. Structured flowcharts outperform pseudocode: An experimen-
tal comparison. IEEE Softw., 6(5):28–36, 1989.
[80] SEKITA, I.; KURITA, T.; OTSU, N. Complex autoregressive model for shape
recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence,
14(4):489–496, 1992.
[81] SHI, J.; MALIK, J. Normalized cuts and image segmentation. IEEE Transactions
on Pattern Analysis and Machine Intelligence, 22(12):888–905, 2000.
[82] SILVA, L. S. P.; GONZAGA, A. Recuperação de sub-imagem baseada em
conteúdo utilizando algoritmo bic e realimentação de relevância. Anais do WVC
2006 - II WORKSHOP DE VISÃO COMPUTACIONAL, 1(1):190–193, 2006.
[83] SILVA, L. O. Bookish - uma ferramenta para contextualização de documentos
utilizando mineração de textos e expansão de consulta, 2009.
[84] SMEULDERS, A. W. M.; WORRING, M.; SANTINI, S.; GUPTA, A.; JAIN, R. Content-
based image retrieval at the end of the early years. IEEE Transactions on Pattern
Analysis and Machine Intelligence, 22(12):1349–1380, 2000.

Referências Bibliográficas 91
[85] SMITH, J. R.; CHANG, S.-F. Visualseek: a fully automated content-based image
query system. In: MULTIMEDIA ’96: Proceedings of the fourth ACM international
conference on Multimedia, p. 87–98, New York, NY, USA, 1996. ACM.
[86] SMITH, J.; CHANG, S.-F. Automated binary texture feature sets for image retri-
eval. In: Acoustics, Speech, and Signal Processing, 1996. ICASSP-96. Conference
Proceedings., 1996 IEEE International Conference on, volume 4, p. 2239–2242, May
1996.
[87] SONKA, M.; HLAVAC, V.; BOYLE, R. Image Processing, Analysis and Machine
Vision. Chapman and Hall Computing, 1993.
[88] TUCERYAN, M.; JAIN, A. K. Texture Analysis, chapter 2, p. 207–248. World
Scientific Publishing Co., second edition, 1998.
[89] VELTKAMP, R. C. Shape matching - similarity measures and algorithms. In: IEEE
Press - Proceedings Shape Modelling International, p. 188–197, 2001.
[90] WANG, B.; SUN, J.; PLIMMER, B. Exploring sketch beautification techniques. In:
CHINZ ’05: Proceedings of the 6th ACM SIGCHI New Zealand chapter’s international
conference on Computer-human interaction, p. 15–16, New York, NY, USA, 2005.
ACM.
[91] ZHANG, D.; LU, G. A comparative study of three region shape descriptors. In:
Digital Image Computing Techniques and Applications, p. 21–22, 2002.
[92] ZHOU, X. S.; HUANG, T. S. Relevance feedback in image retrieval: A compeen-
sive review. Multimedia Systems, 1(8):536–544, 2003.

APÊNDICE AExemplos de formas desenhadas pelos usuários
Figura A.1: Exemplos de Círculos

Apêndice A 93
Figura A.2: Exemplos de Elipses
Figura A.3: Exemplos de Hexágonos

Apêndice A 94
Figura A.4: Exemplos de Quadrados
Figura A.5: Exemplos de Retângulos

Apêndice A 95
Figura A.6: Exemplos de Linhas
Figura A.7: Exemplos de Losangos

Apêndice A 96
Figura A.8: Exemplos de Triângulos
Figura A.9: Exemplos de Trapézios