unioeste - universidade estadual do oeste do paraná centro ...tcc/2008/tcc - leonardo garcia...
TRANSCRIPT

Unioeste - Universidade Estadual do Oeste do ParanáCENTRO DE CIÊNCIAS EXATAS E TECNOLÓGICASColegiado de InformáticaCurso de Bacharelado em Informática
Uma Aplicação das Redes Neurais Artificiais de Elman e Time Delay NeuralNetwork na Predição de Séries Temporais
Leonardo Garcia Tampelini
CASCAVEL2008

Leonardo Garcia Tampelini
Uma Aplicação das Redes Neurais Artificiais de Elman e Time Delay NeuralNetwork na Predição de Séries Temporais
Monografia apresentada como requisito parcialpara obtenção do grau de Bacharel em Informática,do Centro de Ciências Exatas e Tecnológicas daUniversidade Estadual do Oeste do Paraná - Cam-pus de Cascavel.
Orientador: Prof. Dr. Clodis Boscarioli
CASCAVEL2008

Leonardo Garcia Tampelini
Uma Aplicação das Redes Neurais Artificiais de Elman e Time Delay NeuralNetwork na Predição de Séries Temporais
Monografia apresentada como requisito parcial para obtenção do Título de Bacharel emInformática, pela Universidade Estadual do Oeste do Paraná, Campus de Cascavel, aprovada
pela Comissão formada pelos professores:
Prof. Dr. Clodis Boscarioli (Orientador)Colegiado de Informática, UNIOESTE
Prof. Dr. Silvio César Sampaio (Co-Orientador)Colegiado de Engenharia Agrícola, UNIOESTE
Prof. Dr. Jorge BidarraColegiado de Informática, UNIOESTE
Cascavel, 8 de junho de 2009.

DEDICATÓRIA
Dedico este trabalho a todos os espíritosde luz que me acompanham, os quais de-ram a mim o maior título que terei emtoda minha vida, Filho da Casa.

AGRADECIMENTOS
Ao meu pai Fernando Celso Tampelini, por me mostrar o que é ser um homem de caráter,
tomando as decisões certas mesmo nos momentos mais difíceis.
A minha mãe Valentina Aparecida Garcia Tampelini, por ser esta pessoa maravilhosa, cora-
josa sendo sempre uma “LEOA”, protegendo e amando seus filhos.
A minha irmã Fernanda Garcia Tampelini, por sempre demonstrar seu amor por mim, mos-
trando o quanto eu sou querido. Irmã eu te amo tanto que não da nem pra descrever, só posso
lhe dizer que te amo mais que todos os planetas, de todos os mundos, de todos os universos.
Obrigado minha família por ser sempre meu porto seguro.
A Isméria, pelas longas e objetivas conversas, que me ajudaram a compreender minhas
falhas e meus acertos, sempre me guiando para um caminho de luz.
A minha grande amiga Mariazinha, que em muitos momentos falou comigo, mesmo sem
eu escutar, me guiando, incentivando, protegendo e guardando com tanto amor meus bens mais
preciosos.
A minha namorada e companheira Keila Okuda Tavares pela compreensão, alegria, amor,
carinho, encorajamento e apoio de todos os momentos. Sem você eu não sei se teria conseguido.
Ao Prof. Dr. Clodis Boscarioli, meu orientador, pelo apoio e paciência durante elaboração
deste trabalho. Clodis obrigado por ter sido exigente comigo, pois você fez com que eu eu
percebesse o meu potencial.
Ao Prof. Dr. Silvio Cezar Sampaio, pela minha iniciação científica que tanto contribuiu
para escolha do tema desse trabalho e por aceitar participar desta banca, contribuindo em grande
parte no desenvolvimento desse trabalho.
Ao Prof. Dr. Jorge Bidarra, por aceitar participar desta banca e pelo incentivo no desenvol-
vimento desse trabalho.
Aos meus amigos, colegas e conhecidos, tesouros de minha vida, que me ajudam, me acon-
selham e me ensinam muitas coisas que vão além da universidade.
A SUDERHSA, por ter fornecido os dados necessários para a elaboração desse estudo.

Lista de Figuras
2.1 Diagrama de dispersão (representado pelos pontos em vermelho) e um possível
ajuste exponencial (representado pela curva em azul). . . . . . . . . . . . . . . 9
3.1 Modelo de um neurônio artificial. . . . . . . . . . . . . . . . . . . . . . . . . 15
3.2 Rede alimentada adiante ou acíclica com uma única camada de neurônios. . . . 19
3.3 Exemplo de uma rede Multi-Layer Perceptron com uma camada oculta. . . . . 20
3.4 Janela temporal inserida em uma RNA do tipo MLP. . . . . . . . . . . . . . . 21
3.5 TDNN com uma linha de atraso. . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.6 RNA de Elman. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.1 Ciclo hidrológico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.2 Representação gráfica do tempo de retardo de uma bacia hidrogáfica hipotética. 29
5.1 Diagrama de sequência do processo de Descoberta de Conhecimento efetuada
neste estudo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.2 Bacia hidrográfica do rio Piquiri. . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.3 Distribuição espacial das 102 estações pluviométricas na bacia do rio Piquiri. . 36
5.4 Precipitação média diária dos 22 postos pluviométricos selecionados para o es-
tudo de caso. Série de vazão diária referentes ao mês de janeiro de 1981. . . . . 42
5.5 Precipitação média diária dos 22 postos selecionados para o estudo de caso.
Série de vazão diária referentes ao mês de maio de 2002. . . . . . . . . . . . . 43
5.6 Precipitação média diária dos 22 postos selecionados para o estudo de caso.
Série de vazão diária referentes ao mês de dezembro de 2002. . . . . . . . . . . 43
5.7 Representação da interpolação feita para as falhas do mês de janeiro de 1982. . 45
5.8 Representação da interpolação feita para as falhas do mês de maio de 2002. . . 46
vi

5.9 Representação da interpolação feita para as falhas do mês de dezembro de 2002. 47
5.10 Série de vazão coletada na ponte do rio Piquiri, após a imputação dos dados
ausentes. As linhas pontilhadas verticais representam a divisão dos dados se-
guindo os critérios da Seção 5.2. . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.11 Ilustração dos dados coletados (eixo das abcissas) versus os resultados preditos
pela melhor rede de Elman (eixo das ordenadas), para os conjuntos de treina-
mento (a) e de teste (b). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.12 Melhor resultado das redes de Elman para a predição de 5 anos de vazões. . . . 51
5.13 Ilustração dos dados coletados (eixo das abcissas) versus os resultados preditos
pela melhor rede TDNN (eixo das ordenadas), para os conjuntos de treinamento
(a) e de teste (b). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.14 Melhor resultado das redes TDNN para a predição de 5 anos de vazões. . . . . 52
5.15 Limiar inferior imposto pela rede TDNN. . . . . . . . . . . . . . . . . . . . . . 53
vii

Lista de Tabelas
5.1 Características das estações pluviométricas utilizadas. . . . . . . . . . . . . . . 39
5.2 Relação das estações usadas como referência na imputação dos dados. . . . . . 41
5.3 Desempenho das redes de Elman. . . . . . . . . . . . . . . . . . . . . . . . . 50
5.4 Desempenho das redes de TDNN. . . . . . . . . . . . . . . . . . . . . . . . . 50
viii

Lista de Abreviaturas e Siglas
AR Auto RegressiveARMA Auto Regressive Moving AverageARIMA Auto Regressive Integrated Moving AverageKDD Knowledge Discovery DatabaseMA Moving AverageMAE Mean Absolute ErrorMLP Multi-Layer PerceptronMSE Mean Squared ErrorRBF Radial Basis FunctionRHESA Recursos Hídricos e Saneamento AmbientalRNAs Redes Neurais ArtificiaisRNN Rede Neural NebulosaRNR Rede Neural RecorrenteRMSE Root Mean Squared ErrorSUDERHSA Superintendência de Desenvolvimento de Recursos Hídricos
e Saneamento AmbientalTDNN Time Delay Neural Network
ix

Lista de Símbolos
a Saída resultante de um neurônio artificial.b Bias associado a um neurônio artificial.d Equivale ao número de diferenciações necessárias para transformar uma
série temporal não-estacionária em estacionaria.e Representa o erro aleatório em um modelo de série temporal.i Representa a i-ésima entrada de um neurônio artificial.j Índice inteiro qualquer.k Tamanho da linha de atraso de uma TDNN.n Resultante do somatório ponderado da entradas de um neurônio artificial.p Ordem do operador Auto Regressivo.q Ordem do operador de Médias Moveis.t Unidade de tempo discreto.x Elemento discreto de uma série temporal.xmin Valor mínimo de uma série temporal;xmax Valor máximo de uma série temporal;x Médio de uma série temporal;L Linha de atraso de uma TDNN.N Número de valores de um conjunto.Pj Valor previsto por um RNA;R Componente aleatório de uma série temporal (Ruído).S Sazonalidade de uma série temporal.T Tendência de uma série temporal.W Peso sináptico de um neurônio artificial.Z Série temporal discreta.Zj Valor original de uma série temporal;W Vetor de pesos associados a cada entrada.α Denota um elemento discreto de um período.4 Polinómio resultante da diferenciação entre duas séries temporais.Φ Corresponde ao parâmetro do modelo AR de ordem p.υ Limite de superior estabelecido em um processo de normalização;% Limite de inferior estabelecido em um processo de normalização;ω Desvio padrão.Θ Corresponde ao parâmetro do modelo MA de ordem q.ϕ Função de ativação de um neurônio artificial.
x

Sumário
Lista de Figuras vi
Lista de Tabelas viii
Lista de Abreviaturas e Siglas ix
Lista de Símbolos x
Sumário xi
Resumo xiii
1 Introdução 1
1.1 Justificativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Organização do Documento . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Predição de Séries Temporais 6
2.1 Séries Temporais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.1 Principais Componentes . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Modelos de Regressão Polinomial . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Modelos Auto Regressivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 Modelagem por Redes Neurais Artificiais . . . . . . . . . . . . . . . . . . . . 12
2.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Redes Neurais Artificiais para Tratamento de Séries Temporais 14
3.1 Fundamentos de Redes Neurais Artificiais . . . . . . . . . . . . . . . . . . . . 14
3.2 Estruturas de Redes Neurais Artificiais . . . . . . . . . . . . . . . . . . . . . . 18
3.2.1 Redes Diretas de Única Camada . . . . . . . . . . . . . . . . . . . . . 18
3.2.2 Redes Diretas de Múltiplas Camadas . . . . . . . . . . . . . . . . . . 19
3.2.3 Redes Recorrentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
xi

3.3 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4 Modelagem Chuva-Vazão 26
4.1 Transformação de Chuva em Vazão . . . . . . . . . . . . . . . . . . . . . . . 26
4.2 Modelos Empíricos e Conceituais de Chuva-Vazão . . . . . . . . . . . . . . . 30
4.3 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5 Estudo de Caso 33
5.1 Caracterização do Problema . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.1.1 Área de Estudo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.2 Definição do Modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.3 Pré-Processamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.3.1 Imputação de Dados de Precipitação . . . . . . . . . . . . . . . . . . . 39
5.3.2 Imputação de Dados de Vazão . . . . . . . . . . . . . . . . . . . . . . 42
5.4 Mineração de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
6 Conclusões 54
Referências Bibliográficas 57
xii

Resumo
Redes Neurais Artificiais (RNAs) podem ser vistas como técnicas computacionais que bus-
cam imprimir os sistemas de computador um processamento distribuído e paralelo simulando
o que seria o funcionamento do sistema nervoso humano. Esses modelos artificiais têm-se
revelado bem sucedidos em lidar com problemas complexos e dinâmicos, como aproximação
de funções e reconhecimento de padrões, a exemplo da previsão de dados hidrológicos, que
possui alta complexidade dos processos físicos envolvidos e alta variabilidade de fatores
como a precipitação de chuva. A modelagem de séries hidrológicas por métodos conceituais
é considerada um processo custoso, exigindo em muitos momentos a intervenção de um
especialista. Uma alternativa viável tem sido aplicar RNAs na captura automática dos padrões
existentes na série temporal, diminuindo a intervenção do especialista e reduzindo o tempo de
construção do modelo. O objetivo geral desse trabalho foi investigar a capacidade das RNAs
na modelagem temporal de séries hidrológicas. Com intuito de avaliar a capacidade das RNAs
em predizer valores de médio e longo prazo, redes dinâmicas (Time Delay Neural Network e
Elman) foram utilizadas na construção de modelos Chuva-Vazão. Estas RNAs foram treinadas
com séries de dados pluviométricos e fluviométricos referentes à bacia do rio Piquiri de forma
a constatar que as RNAs podem ser aplicadas na modelagem de séries temporais generalizando
seu comportamento e promovendo previsões confiáveis.
Palavras-chave: Mineração de Dados, Modelagem Chuva-Vazão, Predição, Redes Neurais
Artificiais, Séries Temporais.
xiii

Capítulo 1
Introdução
A constante e crescente evolução das tecnologias possibilita a criação, a coleta e o armazena-
mento de grandes volumes de dados nas mais diversas áreas. Com esse gigantesco acúmulo de
informações armazenadas em meio digital, surge a necessidade de ferramentas computacionais
apropriadas para sua gerência e análise.
O estudo de técnicas e ferramentas que auxiliem a capacidade humana de analisar, sintetizar
e extrair conhecimento a partir dos dados, é temática de uma área conhecida como Descoberta de
Conhecimento em Banco de Dados (KDD - Knowledge Discovery Database) [7], que pode ser
definida como um processo, de várias etapas, não trivial, interativo e iterativo, para identificação
de padrões compreensíveis, válidos, novos e potencialmente úteis a partir de bases de dados
[47].
O processo de busca por conhecimento pode ser dividido em três etapas distintas: Pré-
Processamento, Mineração de Dados e Pós-Processamento [26].
Dentre as etapas de KDD, a Mineração de Dados é considerada uma das mais importan-
tes do processo, pois é nela que, por meio de algoritmos, a busca por padrões (identificação
de relacionamentos implícitos existentes nos dados) é efetivada [6]. Existem diversas tarefas
atribuídas à Mineração de Dados, como Classificação, Regras de Associação, Agrupamento e
Predição [47].
Dentre essas tarefas, a Predição se destaca pelo amplo número de aplicações que exigem
algum tipo de previsão [26]. A busca por informações futuras ou desconhecidas, em certo
instante do tempo, é baseada em observações históricas, denominadas séries temporais, e, a
partir do estudo destas séries, os modelos comportamentais são inferidos [12].
Formalmente, séries temporais são definidas como um conjunto de observações de uma

variável aleatória x, indexada no tempo t, denotada por xt, t ∈ <+; onde <+ (conjunto dos
números reais positivos) representa um espaço contínuo do tempo [2]. A aplicabilidade das
séries temporais se dá principalmente na construção de modelos físicos-matemáticos que pro-
curam, com alto grau de veracidade, descrever seu comportamento. Estes modelos, por sua vez,
são utilizados no planejamento e na adequação de projetos que necessitam de certos valores
previamente desconhecidos.
O conjunto de hipóteses, sobre a estrutura ou comportamento de certo fenômeno físico
da natureza, pode ser descrito por meio de modelos matemáticos. Porém, segundo Gahegan
[18] & Bogorny [7], nem todas as variáveis necessárias para uma descrição formal ideal são
mapeáveis1; pois, certos domínios, como o geográfico, apresentam fatores de dependência rela-
cionados a inúmeras outras variáveis, que podem pertencer a escalas distintas como freqüência,
espaço e tempo. Outro problema está na complexidade associada ao domínio de origem, a qual
possibilita que padrões de interesse permaneçam ocultos diante de fenômenos mais expressivos,
encontrados em séries temporais, como tendências e sazonalidade [7], [18].
Nas décadas de 70 e 80, as técnicas de predição de séries temporais consistiam em procurar,
em um universo limitado de modelos, aqueles que melhor representassem os processos gera-
dores das séries. A discretização destes modelos restringia a aplicação da predição a modelos
mais simples, uma vez que modelos reais compostos por muitas variáveis, exigiriam muitos
cálculos, inviabilizando sua execução em um tempo hábil [12]. Novas técnicas, ditas não con-
ceituais, passaram a permitir a análise de séries mais longas e complexas. Dentre o conjunto de
metodologias não conceituais estão as Redes Neurais Artificiais (RNAs) [45].
Uma RNA é um mecanismo inspirado nos princípios básicos de manipulação de informação
do cérebro humano, capaz de capturar e aplicar conhecimento experimental na resolução de
problemas [36].
Diferentes trabalhos na área de previsões de séries temporais implementam RNAs como o
principal mecanismo de predição, tendo por objetivo encontrar a rede que melhor se adeqúe a
representação temporal dos dados em estudo. Dentre as diferentes RNAs aplicadas na área de
previsão de séries temporais destacam-se: MLP (Multlayer Perceptron) [32]; RNR (Redes Neu-
rais Recorrentes) [44]; RNN (Rede Neural Nebulosa) [2] e [33]; RBF (Radial Basis Function)1Mapeável que refere à localização e identificação das características da variável (domínio de atuação), bem
como a identificação dos atributos correlacionados à mesma.
2

[12].
Devido à grande aplicabilidade de séries temporais em várias áreas de estudo, pesquisa-
dores buscam, cada vez mais, aprimorar e ajustar as técnicas de predição. A especialização
dessa tarefa evolui juntamente com o desenvolvimento computacional, pois através de recursos
computacionais, técnicas mais complexas e dinâmicas, como as RNAs, podem ser utilizadas,
permitindo a criação de modelos mais realísticos.
As RNAs podem ser construídas de inúmeros modos, alterando a organização, arquitetura,
função de ativação e parâmetros de treinamento [21]. A escolha de qual RNA deve ser aplicada
na análise e predição de séries temporais pode ser um obstáculo, exigindo um estudo detalhado
de diferentes RNAs, a fim de encontrar a mais apropriada para a tarefa de Predição.
A solução de problemas dinâmicos por meio de RNAs exige dessas redes a capacidade de
representação temporal (memória) [21]. As RNAs são usualmente aplicadas na modelagem
de problemas físicos que envolvem a representação de séries temporais, produzindo resultados
promissores em diversas áreas de estudo [48].
Em recursos hídricos, RNAs que apresentam a capacidade de representação temporal, vêm
sendo utilizadas na solução de vários problemas. Jain et al [24] utilizam RNAs na previsão
de vazão afluente e operação de reservatórios. Neelakantan e Pundarikanthan [37] aplicaram
RNAs para simulação e otimização de reservatórios. Machado [32] aplicou RNAs na modela-
gem de Chuva-Vazão. Estes trabalhos demonstram bons resultados, incentivando a utilização
de RNAs na análise de séries temporais.
O dimensionamento de projetos de infra-estrutura hídricos é efetivado mediante o uso de
um bom estimador, como as RNAs, de modo a satisfazer níveis de segurança pré-estabelecidos,
promovendo um projeto economicamente racional [6].
1.1 Justificativa
A construção de modelos de predição de vazão surge como uma forma de diminuir o im-
pacto das incertezas na tomada de decisão. Porém, a modelagem conceitual impõe dificuldades
(como o prévio conhecimento dos principais processos envolvidos no ciclo hidrológico e como
eles são representados matematicamente) deixando a qualidade dos resultados obtidos, muito
dependente da experiência do especialista. Deste modo, técnicas capazes de estabelecer relações
3

estáveis entre as variáveis de entrada e saída, sem considerar os processos físicos envolvidos, se
mostram úteis.
Sendo o Brasil um país com uma hidrográfia propícia às construções de grandes hidrelétri-
cas, sistemas de controle de vazão cada vez mais sofisticados são necessários. Estes sistemas
trabalham tipicamente com dados incertos, sendo algumas informações hidrológicas coletadas
por meio de processos manuais, que necessitam da intervenção humana. O uso de abordagens
capazes de capturar incertezas, não-lineariedades e padrões existentes ao longo da série de va-
zões, como as RNAs, aparecem como alternativas promissoras.
Este trabalho se justifica na tentativa de criar um modelo de predição de vazão fluvial, uti-
lizando RNAs, com o intuito de facilitar a modelagem Chuva-Vazão, diminuindo a quantidade
de variáveis necessárias, minimizando o tempo de construção desses modelos e reduzindo a
necessidade de um especialista para a calibração desses modelos.
1.2 Objetivos
O objetivo geral do trabalho é analisar a aplicação de RNAs na predição de séries temporais.
Este objetivo ramifica-se:
1. Identificação das principais arquiteturas e organizações de RNAs são voltadas à tarefa de
Predição de séries temporais, enfatizando séries hidrológicas.
2. Construção de um modelo Chuva-Vazão baseado em RNAs e avalição de sua capacidade
em prover prognósticos confiáveis de valores futuros de vazões fluviais, baseando-se ape-
nas em dados de precipitação de chuva.
1.3 Organização do Documento
Este trabalho é dividido em 6 capítulos, sendo o primeiro esta introdução, que apresenta os
conceitos gerais e os objetivos deste trabalho.
O Capítulo 2 é dedicado ao estudo de séries temporais e sua aplicabilidade na predição de
valores futuros. Também são apresentados as características básicas das principais técnicas de
modelagem, com enfoque nos modelos conceituais e em RNAs.
4

No Capítulo 3 são descritos os conceitos básicos de RNAs, enfatizando a representação de
sinais dependentes do tempo (séries temporais) por meio destas.
O Capítulo 4 traz uma descrição do processo Chuva-Vazão e os principais conceitos envol-
vidos em sua modelagem.
O Capítulo 5 é dedicado à apresentação do modelo Chuva-Vazão construído. O principal
objetivo deste capítulo é analisar, por meio do modelo, a aplicação de RNAs na predição de
séries temporais hidrológicas. Para alcançar este objetivo duas RNAs (TDNN e Elman) foram
utilizadas na construção de um modelo Chuva-Vazão da bacia hidrográfica do rio Piquiri.
Por fim Capítulo 6 traz as conclusões e sugestões de trabalhos futuros desse estudo.
5

Capítulo 2
Predição de Séries Temporais
É importante o estudo de métodos de previsão de séries temporais, tanto para fins de iden-
tificação de características relevantes, quanto para predição de valores futuros. Por meio de
análises, das variáveis que descrevem o presente e descreveram o passado, é possível compre-
ender e inferir algumas informações futuras.
O conhecimento das equações que modelam os mecanismos responsáveis pela geração das
séries temporais, cria a situação ideal para a realização de predições. No entanto, os mode-
los atuais de séries temporais, nem sempre conseguem descrever séries reais com a precisão
desejada.
Neste capítulo serão apresentados a definição de séries temporais, seus principais compo-
nentes e uma breve revisão relacionada a alguns modelos de séries temporais.
2.1 Séries Temporais
Uma série temporal consiste em um conjunto de observações efetuadas em determinada
ordem cronológica1. Em geral, as observações vizinhas são dependentes entre si, característica
de suma importância à análise e à modelagem de séries temporais [51].
Modelar séries temporais, além de tornar possível a predição de valores futuros, também
permite a geração de seqüências sintéticas equiprováveis (simulações de séries), úteis quando a
coleta de dados em campo é difícil de ser realizada ou quando se deseja imputar dados em séries
temporais descontinuadas. A construção de modelos aplicáveis, resulta da correta identificação
1Vale ressaltar que o fator cronológico pode ser substituído por outras variáveis como espaço, freqüência eprofundidade.

dos parâmetros geradores da série, os quais devem ser suficientes para descrevê-la da forma
mais realística possível [35].
A relação intrínseca dos dados de uma série temporal, permite a construção de modelos
que representem seu comportamento, tornando possível previsões de valores futuros. O grau de
previsibilidade de uma série (veracidade em inferir valores futuros) está diretamente relacionado
a dois fatores principais, sua origem e o horizonte de previsão [51].
Entende-se por origem o fenômeno gerador da série temporal, que caracteriza o compor-
tamento da série e a forma como os dados da série estão relacionados. Horizonte de previsão
compreende a distância entre o último valor coletado da série e o valor a ser previsto no futuro.
Este intervalo está diretamente relacionado à incerteza da predição: quanto maior o horizonte
maior a incerteza associada à predição [19].
De acordo com o horizonte de previsão, pode-se obter vários tipos de previsões [51]: de
curtíssimo prazo ou tempo real (de poucos minutos a uma hora à frente); de curto prazo (período
de até uma semana à frente); de médio prazo (vários meses); e de longo prazo (superiores a um
ano).
A maior parte dos estudos em séries temporais baseia-se na análise das observações da série
de interesse. No entanto, alguns procedimentos de previsão tentam explicar o comportamento
de uma série temporal pela evolução dos fenômenos observacionais de outras séries. Neste
trabalho são construídos modelos preditivos de vazão fluvial de longo prazo, através de um
conjunto de séries temporais pluviais.
2.1.1 Principais Componentes
Séries temporais podem ser descritas e modeladas com base em três fatores: tendência,
sazonalidade e um componente aleatório (ruído) [52].
A tendência (T ) indica a “direção” da série temporal, ou seja, determina o incremento ou
o decréscimo de seus valores, no decorrer do tempo. Uma série temporal que não apresenta
qualquer tipo de tendência, nem ascendente, nem descendente, é chamada de série tendência-
estacionária.
Sazonalidade (S) é um movimento de longa duração, de aparência quase-periódica, com
fases alternadas de picos e vales, geralmente expressa em períodos de um ano. Ela pode ser in-
7

terpretada como a representação de movimentos sistemáticos, causados por fenômenos externos
ao fator gerador da série.
O componente aleatório (R) é considerado um movimento oscilatório de curta duração e
de grande instabilidade, que exprime a influência de fatores casuais como secas, enchentes e
variações climáticas.
A soma desses três componentes indexados no tempo (t) dá origem a um modelo aditivo
(Zt = St + Tt + Rt), representando a série temporal (Zt) [30]. Modificando o modelo aditivo
pode-se construir, um modelo multiplicativo (Zt = St ∗Tt ∗Rt), o qual pode ser modificado por
transformações do tipo log-linear [35].
Para analisar a tendência, os métodos mais utilizados são [35]: o ajuste de uma função
polinomial do tempo (regressão polinomial); e análise do comportamento da série ao redor de
um ponto, estimando a tendência naquele ponto (utilizando-se de modelos Auto Regressivos).
A sazonalidade é um componente da série difícil de ser estimado, estando relacionada a
uma grande quantidade de variáveis estatísticas. Incorporando funções do tipo seno e coseno
nos modelos multiplicativos é possível identificar a periodicidade de uma série [11]. Outra
forma mapear a sazonalidade é por meio de modelos empíricos (RNAs), os quais, baseados nas
relações de entrada e saída dos dados, ajustam a periodicidade da série [48].
2.2 Modelos de Regressão Polinomial
Modelos de regressão polinomial representam os valores da séries temporal por uma variável
x e os períodos por uma variável independente α. Neste modelo, primeiramente deve-se fazer
o diagrama de dispersão de Zt(α) em relação ao tempo. Este diagrama representa graficamente
a distribuição dos valores da série (Figura 2.1). Desse modo, é possível visualizar qual função
mais se ajusta à trajetória dos pontos, distribuídos em função do tempo [40].
Para evitar a correlação serial entre os termos da equação de regressão, recomenda-se fazer
a transformação da variável período, na variável período-centralizada (período menos o ponto
médio da série histórica), estimando-se então, o modelo de regressão correspondente2.
A segunda opção para a análise de séries históricas, é pelo ajuste da tendência. Para isto,
pode-se analisar o comportamento da série ao redor de um ponto ajustando a função de regressão
2Latorre em [40] detalha o processo de centralização da variável tempo.
8
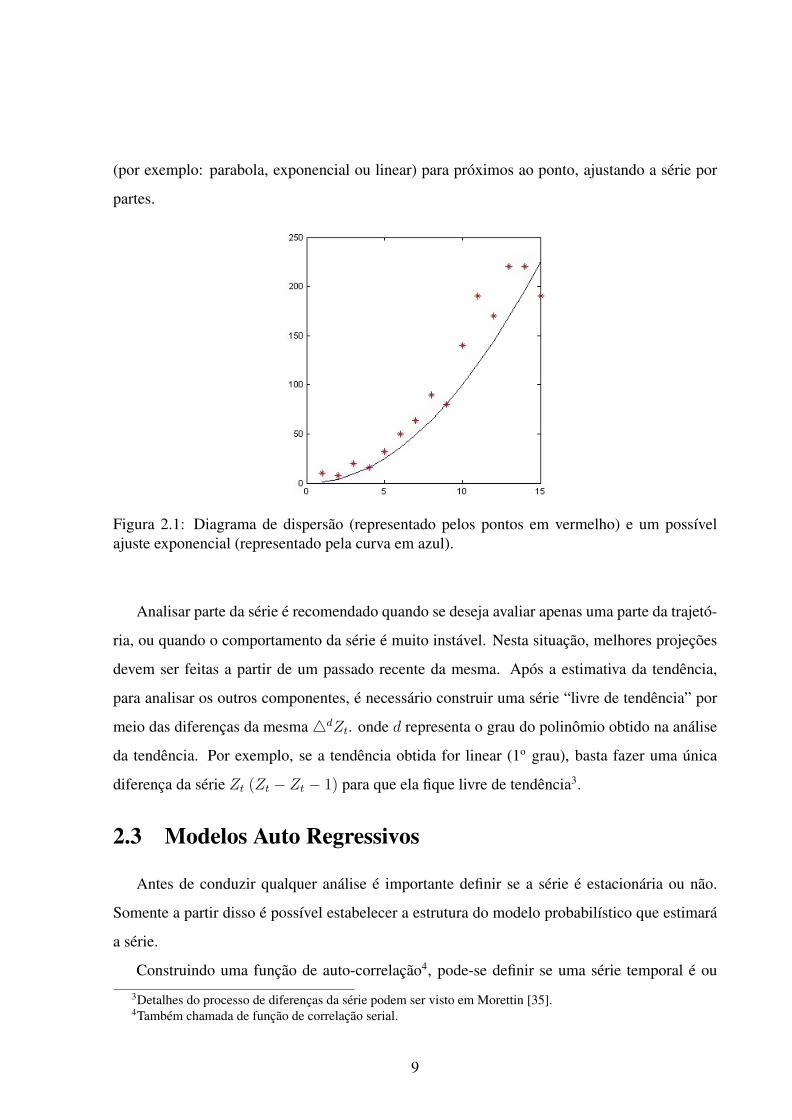
(por exemplo: parabola, exponencial ou linear) para próximos ao ponto, ajustando a série por
partes.
Figura 2.1: Diagrama de dispersão (representado pelos pontos em vermelho) e um possívelajuste exponencial (representado pela curva em azul).
Analisar parte da série é recomendado quando se deseja avaliar apenas uma parte da trajetó-
ria, ou quando o comportamento da série é muito instável. Nesta situação, melhores projeções
devem ser feitas a partir de um passado recente da mesma. Após a estimativa da tendência,
para analisar os outros componentes, é necessário construir uma série “livre de tendência” por
meio das diferenças da mesma4dZt. onde d representa o grau do polinômio obtido na análise
da tendência. Por exemplo, se a tendência obtida for linear (1o grau), basta fazer uma única
diferença da série Zt (Zt − Zt − 1) para que ela fique livre de tendência3.
2.3 Modelos Auto Regressivos
Antes de conduzir qualquer análise é importante definir se a série é estacionária ou não.
Somente a partir disso é possível estabelecer a estrutura do modelo probabilístico que estimará
a série.
Construindo uma função de auto-correlação4, pode-se definir se uma série temporal é ou
3Detalhes do processo de diferenças da série podem ser visto em Morettin [35].4Também chamada de função de correlação serial.
9

não estacionária [35], [15]. Esta função representa o quanto certa variável é influenciada por
outra (e por implicação quanta interdependência existe entre elas) entre observações efetuadas
em uma série.
A função de correlação calcula em cada período de observação j da série, o coeficiente de
correlação entre as observações no tempo t e t + j. Desse modo, um período j de certa série é
dita independente ou estacionária, caso a correlação entre t e t+ j seja igual a zero.
Os modelos mais simples são aqueles que consideram uma série estacionária. Essa classe de
modelos é conhecida como modelos Auto Regressivos (AR - Auto Regressive). Nesses modelos
uma série pode ser escrita como a combinação aleatória dos seus valores anteriores (Equação
2.1), pois o único fator de influência é dado pelo ruído [35], [51].
xt = Φ1xt−1 + Φ2xt−2 + . . .+ Φpxt−p + et (2.1)
onde:
xt corresponde à observação da série temporal no tempo t;
Φ corresponde ao parâmetro do modelo AR de ordem p; e
et representa o erro aleatório que não podem ser explicados pelo modelo.
Para a construção de modelos AR é necessário identificar a ordem p da função modeladora.
A identificação da ordem pode ser considerada como um possível complicador, pois modelos
diferentes, com ordem de função distintas, podem ser construídos para uma mesma série tem-
poral. Para muitas séries, a melhor solução encontra-se em combinar o modelo AR com o de
Médias Móveis (MA - Moving Average) [51].
Modelos de MA são combinações lineares dos valores próximos da série, explorando a es-
trutura de auto-correlação dos erros de previsão, isto é, a correlação entre os erros sucessivos
[35]. Nestes modelos quanto maior for o número de observações incluídas na média móvel,
maior o efeito de alisamento na previsão [51].
O termo Médias Móveis é utilizado porque à medida que a próxima observação se torna
disponível, a média das observações é recalculada, incluindo esse novo valor ao conjunto de
observações, desprezando a observação mais antiga [35]. Formalmente este modelo é definido
pela Equação 2.2.
10

xt = et −Θ1et−1 −Θ2et−2 − . . .−Θqet−1 (2.2)
onde:
et representa o erro aleatório que não podem ser explicados pelo modelo; e
Θq corresponde ao parâmetro do modelo MA de ordem q.
A Equação 2.2 é similar à Equação 2.1, exceto pelo fato de que o valor previsto para a
observação depende dos valores dos erros observados em cada período passado, ao invés das
observações propriamente ditas [51].
Modelos que exploram simultaneamente a estrutura de auto-correlação do processo gerador
da série (modelos AR) e os erros de previsão (modelos MA) são denominados Auto Regressivo e
de Média Móvel, também conhecido como misto ou ARMA (Auto Regressive Moving Average).
Apesar dos modelos ARMA serem capazes de descrever muitas séries, estes são considerados
limitados, pois assim como no modelo AR, assume-se a existência de uma relação linear entre
os elementos da seqüência e baseia-se na hipótese de que a série é estacionária. Este modelo
pode ser expresso pela Equação 2.3.
xt = Θ1xt−1 + Θ2xt−2 + . . .+ Θpxt−p + et − Φ1et−1 − Φ2et−2 − . . .− Φqet−q (2.3)
Analisando a Equação 2.3 é possível verificar que os modelos ARMA relacionam os valores
futuros com as observações passadas, assim como também com os erros passados apurados
entre os valores reais e os previstos.
Outro fator limitante na utilização destes modelos é discretização. Conforme cresce o fator
de discretização temporal, a dificuldade para representar cada componente da série (sazonali-
dade, tendência e ruído) por meio de técnicas como AR e/ou MA aumenta, devido ao acréscimo
de detalhes na representação da série. Em séries hidrológicas, foco deste trabalho, a discretiza-
ção é feita intervalos em mensais, semanais ou até mesmo diários, muitas vezes inviabilizando
a utilização desses métodos [31].
Uma alternativa para modelagem de séries temporais não estacionárias e discretizadas são
os modelos Auto Regressivos Integrados com Médias Móveis (ARIMA - Auto Regressive In-
tegrated Moving Average). Estes modelos, propostos por Box & Jenkins [8] na década de 70,
11

baseiam-se nos princípios da parcimônia e em filtros lineares, ou seja, procuram representar
uma série temporal selecionando um número mínimo de parâmetros.
Uma característica importante dos modelos ARIMA é sua capacidade de transformar, por
meio de processos de diferenciação e integração, séries temporais não estacionárias em estaci-
onárias, capacitando-os a trabalhar com séries não estacionárias. Uma variável diferenciada é,
normalmente, representada nestes modelos pelo acompanhamento do símbolo4, dessa forma,
a variável y com a primeira diferença será representada pela seguinte equação4dtx = xt−xt−1,
ou seja, x diferenciado é igual aos valores de x no período t menos os valores de x no período
anterior (t− 1). Sua ordem pode, ainda, ser representada pela letra d. No caso, para a primeira
diferença, temos d = 1; para a segunda diferença temos d = 2 e a equação42tx = xt−1 − xt−2.
A fórmula geral do modelo ARIMA pode ser expressa pela Equação 2.4:
wdt = Φ1wt−1 + . . .+ Φpwt−p + et −Θ1et−1 − . . .−Θqet−q (2.4)
onde:
wdt = xt − xt−d;
Φp e Θq são parâmetros de ordem p e q do modelo ARMA (ARMA(p, q));
et corresponde ao erro de eventos aleatórios que não podem ser explicados pelo modelo; e
d equivale ao número de diferenciações necessárias para transformar a série em estacionaria.
2.4 Modelagem por Redes Neurais Artificiais
O propósito dos métodos de previsão consiste em distinguir o padrão de qualquer ruído que
possa estar contido nas observações e então usar esse padrão para prever os valores futuros da
série temporal [51].
RNAs funcionam conceitualmente de forma similar ao cérebro humano, sendo capazes de
aprender a partir de exemplos e abstrair características essenciais em um conjunto de dados
irrelevantes [21]. Talvez a maior vantagem do uso de RNAs seja a possibilidade de modelar um
fenômeno físico sem conhecer a teoria intrínseca ao problema.
Apesar das RNAs serem consideradas como aproximadores universais, capazes de capturar
qualquer tipo de comportamento, não importando o quão complexo ele seja [9], elas possuem
12

deficiências. As maiores deficiências estão na falta de procedimentos estabelecidos para definir
testes e na dificuldade em encontrar parâmetros de significância estatística para validação desses
modelos [39].
Mesmo diante algumas deficiências, RNAs vêm desempenhando um papel crescente nos
últimos anos, sendo amplamente aplicadas em soluções de problemas estatísticos importantes,
contribuindo para solução de problemas de modelagem que envolvem predição de séries tem-
porais [48].
Esses modelos não tem por objetivo substituir os modelos conceituais baseados em equa-
ções físicas, mas eles podem ser vistos como uma alternativa viável para substituir alguns dos
modelos teóricos de Box & Jenkins quando o objetivo é previsão [48].
Porém modelos baseados em RNAs devem ser aplicados de forma coerente, estudando o
problema e avaliando como e onde RNAs podem ser utilizadas em sua solução, sendo essencial
a compreensão dos princípios envolvidos na sua construção e em seu treinamento.
2.5 Considerações Finais
O entendimento dos principais componentes que caracterizaram um série temporal é de
suma importância na escolha do modelo estatístico, cada um mais adequado a uma trajetória
específica no tempo. Considerando os modelos de análise de séries temporais mais difundidos
na literatura, introduzidos neste capítulo, percebe-se que algumas limitações impostas pela de-
pendência linear dos mesmos têm tornado difícil a modelagem realística de séries temporais
reais.
As RNAs são considerados como modelos alternativos à tarefa de predição, geralmente apli-
cadas na modelagem de séries complexas. Porém, para que obtenha resultados válidos é preciso
compreender as diferentes formas de se construir e aplicar uma RNA na modelagem de séries,
analisando as especificidades de cada rede e avaliando qual melhor se adequa a modelagem
temporal.
13

Capítulo 3
Redes Neurais Artificiais para Tratamentode Séries Temporais
RNAs são poderosas ferramentas para tratar uma grande diversidade de problemas, tais
como reconhecimento de padrões, processamento de sinais, aproximação de funções e previsão
de séries temporais.
Uma das mais importantes vantagens das RNAs é sua capacidade em resolver problemas
complexos do mundo real, cuja solução por métodos matemáticos seja dispendiosa e difícil de
ser encontrada.
Neste capítulo, uma revisão sobre as RNAs é realizada, descrevendo os conceitos envolvidos
no processamento temporal por meio das mesmas.
3.1 Fundamentos de Redes Neurais Artificiais
RNAs são modelos matemáticos, biologicamente inspirados, que por meio de abstrações a
respeito da estrutura neural de organismos inteligentes visam a resolução de problemas. Haykin
[21] descreve uma RNA como:
“Um processador maciçamente paralelamente distribuído constituído de unidades
de processamento simples, que têm a propensão natural para armazenar conheci-
mento experimental e torná-lo disponível para o uso. Ela se assemelha ao cére-
bro em dois aspectos: 1. O conhecimento é adquirido pela rede a partir de seu
ambiente através de um processo de aprendizagem. 2. Forças de conexão entre
neurônios, conhecidas como pesos sinápticos, são utilizadas para armazenar o co-
nhecimento adquirido.”

O processamento dessa maciça rede é efetivado por unidades denominadas de neurônios
artificiais. Uma ilustração esquemática desta unidade de processamento é exibida na Figura
3.1.
Figura 3.1: Modelo de um neurônio artificial.Fonte: Adaptado de Haykin [21].
Um neurônio artificial pode ter um número i de entradas e uma saída a. A saída de um
neurônio é determinada por uma função linear ou não-linear ϕ, conhecida como função de
ativação, que possui como entrada a soma ponderada dos pesos das entradas W somada ao
valor de um bias1. Deste modo, a saída resultante de um neurônio artificial pode ser facilmente
calculada pela Equação 3.1.
a = ϕ(Wi + b) (3.1)
onde:
i representa a i-ésima entrada;
W o vetor de pesos associados a cada entrada;
a a saída resultante do neurônio;
ϕ a função de ativação; e
b o bias associado ao neurônio;
1Neurônio artificial que possui valor constante.
15

Semelhante a um neurônio biológico, um neurônio artificial produz um sinal de saída quando
a soma dos impulsos de entrada multiplicados por seus respectivos pesos sinápticos ultrapassa o
seu limiar de excitação, definido por uma função denominada função de ativação. A função de
ativação pode ser representada de diferentes formas, entre as mais usuais estão: função do tipo
degrau, função sigmoidal, função tangente hiperbólica, função linear e função logística [21].
Os pesos sinápticos são parâmetros adaptáveis ajustados via processo de treinamento [21].
Esse processo é efetivado por um conjunto de regras bem-definidas para a solução de um pro-
blema, denominadas de algoritmos de aprendizagem.
Os algoritmos de aprendizagem podem ser classificados em dois tipos: supervisionados e
não-supervisionados. Aprendizagem supervisionada é utilizada quando há um valor alvo (de-
sejável) associado com cada entrada do conjunto de treinamento (amostra utilizada para ajuste
dos pesos). Neste a saída da rede é comparada com o valor alvo e sua diferença é utilizada
para alterar os pesos. Aprendizagem não-supervisionada ocorre quando não há valores alvo
para a saída da rede. Nesse caso, a rede aprende através de correlações entre os padrões das
variáveis de entrada [21]. Devido a disponibilidade dos dados de treinamento, neste estudo, a
aprendizagem supervisionada foi utilizada.
Existem várias formas de decidir se uma rede já esta treinada, entre elas [21]: especificar
um erro mínimo a ser atingido; definir um número fixo de épocas de treinamento; e utilizar da
técnica de validação cruzada.
Um grande número de medidas de desempenho pode ser encontrado na literatura, e cada
uma possui suas vantagens e limitações [52]. Entre as mais usuais, utilizadas na avaliação
de RNAs, estão: MAE - Erro Médio Absoluto (Equação 3.2); MSE - Erro Médio Quadrático
(Equação 3.3); e RMSE - Raiz do Erro Médio Quadrático (Equação 3.4). Neste estudo optou-se
em utilizar MSE com um dos critérios de avaliação de desempenho.
MAE =1
N
N∑j=1
|Pj − Zj| (3.2)
MSE =1
N
N∑j=1
(Pj − Zj)2 (3.3)
16

RMSE = 2
√√√√ 1
N
N∑j=1
(Pj − Zj)2 (3.4)
onde:
Pj é o valor previsto;
Zj é o valor original; e
N é o número de valores do conjunto de verificação.
Cada ciclo de um algoritmo de treinamento consiste em uma época. Geralmente muitas
épocas de treinamento são necessárias até que o erro propagado seja tão pequeno quanto o
desejado. Porém, nem sempre o erro mínimo desejado é atingido, desse modo um número fixo
de épocas deve ser determinado a fim que o o processo de treinamento seja interrompido.
A validação cruzada tem por objetivo evitar que uma rede perca sua capacidade de gene-
ralização. Uma RNA perde sua capacidade de generalização quando ocorre o fenômeno de
superajuste (overfiting) dos parâmetros, devido, em geral, a um treinamento excessivo, situação
em que a rede memoriza os exemplos de treinamento [21]. O maior segredo, portanto, para
construir RNAs bem sucedidas é saber quando parar o treinamento.
O superajuste é evitado na validação cruzada pelo uso de um conjunto de dados, geralmente
referido como conjunto de validação, contendo exemplos não presentes no conjunto de treina-
mento. Neste caso, o desempenho da rede no conjunto de validação é avaliado periodicamente
durante o treinamento. Sendo o treinamento interrompido, quando o erro do conjunto validação
começar a crescer durante um número pré-determinado de épocas [50].
Outro parâmetro de fundamental importância no processo de treinamento é o a taxa de
aprendizagem, a qual determina o valor do incremento e decremento dos pesos sinápticos no
processo de treinamento. Quanto maior for essa taxa, maior será a mudança nos pesos, aumen-
tando a velocidade do aprendizado, o que pode levar à uma oscilação do modelo na superfície
de erro. O ideal seria utilizar a maior taxa de aprendizado possível que não levasse à uma
oscilação, resultando em um aprendizado mais rápido [21], [50].
O treinamento das RNAs pode demandar muito tempo e durante este processo um mínimo
local pode ser encontrado, estacionando o processo de otimização da rede. Uma maneira de
tentar evitar esse mínimos locais é incluir o termo momentum, uma constante que determina
17

quanto do efeito das mudanças passadas dos pesos sinápticos, deve influenciar no próximo
ajuste [50].
Desta forma, o termo momentum leva em consideração o efeito de mudanças anteriores de
pesos na direção do movimento atual no espaço de pesos. O termo momentum torna-se útil em
espaços de busca que contenham muitos mínimos locais, com curvas acentuadas ou vales com
descidas suaves [50].
3.2 Estruturas de Redes Neurais Artificiais
A arquitetura de uma rede é especificada em termos do números de entradas, números de
camadas intermediárias, números de neurônios em cada camada, número de saídas e no modo
como os neurônios são conectados [50].
Um dos principais objetivos de pesquisa sobre RNAs é a definição de arquiteturas que per-
mitam à rede realizar o processamento de dados de forma desejada. Isto ocorre, principalmente,
pela restrição que a arquitetura impõe ao tipo de problema que pode ser tratado pela rede.
A construção de uma arquitetura ideal, de forma que a mesma seja tão grande quanto o
necessário para alcançar a representação desejada, e ao mesmo tempo pequena o suficiente para
obter um treinamento eficiente, não é facilmente alcançável. Este fato ocorre principalmente
por não existir regras claras que definem a quantia de neurônios nas camadas intermediárias, o
número de camadas, ou como devem ser as conexões entre essas unidades. Deixando a cargo
de um especialista - o qual, muitas vezes, utiliza-se de testes empíricos - a definição de uma
arquitetura eficiente.
Haykin [21], baseado na arquitetura, classifica as RNAs em três tipos fundamentais: Redes
Diretamente Propagadas de Única Camada; Redes Diretamente Propagadas de Múltipla Cama-
das e Redes Recorrentes.
3.2.1 Redes Diretas de Única Camada
As primeiras e mais simples RNAs, são as que possuem uma única camada de neurônios
que realizam processamento. Este modelo é composto por duas camadas de neurônios: uma
de entrada e uma de saída. Os neurônios de entrada são considerados propagadores puros, ou
seja, eles simplesmente repetem o sinal de entrada em sua saída distribuída. Desse modo, a
18

responsabilidade de processar os dados, são das unidades da camada de saída.
As Redes Neurais Diretas (Única ou Múltiplas Camadas) possuem como principal caracte-
rística a inexistência de ciclos no seu grafo neural, em outras palavras, esta rede é estritamente
alimentada adiante (sentido entrada-saída) como na Figura 3.2.
Figura 3.2: Rede alimentada adiante ou acíclica com uma única camada de neurônios.Fonte: Adaptado de Haykin [21].
3.2.2 Redes Diretas de Múltiplas Camadas
A disposição de mais de uma camada com alimentação acíclica forma uma Rede de Múlti-
plas Camadas propagada diretamente, como na Figura 3.3. Este tipo de rede foi concebido para
resolver problemas mais complexos, os quais não poderiam ser resolvidos pelo modelo de única
camada [21].
Redes de uma única camada podem realizar determinadas operações, como classificação
de itens linearmente separáveis. Porém, a resolução de problemas não linearmente separáveis,
exige mais níveis ou camadas de conexões [21].
Nesta arquitetura, os neurônios pertencentes a camada de entrada, assim como nas Redes
Diretas de Única Camada, não possuem capacidade de processamento, apenas difundindo as
entradas para as camadas seguintes. Já as camadas intermediárias são responsáveis pelas tarefas
mais complexas, extraindo progressivamente as características mais significativas dos padrões
(vetores) de entrada [21]. Finalmente, na camada de saída, cujos neurônios são nomeados de
unidades de saída, refina-se e transmite a resposta referente ao vetor de entrada aplicado à rede.
As Redes Diretas de Múltiplas Camadas, são treinadas pelo algoritmo de retropropagação
do erro (backpropagation). Este algoritmo requer a propagação direta do sinal de entrada atra-
19

Figura 3.3: Exemplo de uma rede Multi-Layer Perceptron com uma camada oculta.Fonte: Adaptado de Haykin [21].
vés da rede, e a retropropagação (propagação reversa, ou backpropagation) do sinal de erro.
Sucintamente, pode-se definir este algoritmo em dois passos [20]:
1. Propagação progressiva do sinal funcional: durante este processo, todos os pesos da rede
são mantidos fixos;
2. Retropropagação do erro: durante este processo os pesos da rede são ajustados basea-
dos no erro. O sinal de erro é propagado em sentido oposto ao de propagação do sinal
funcional, por isso o nome de retropropagação do erro.
Uma rede Direta de Múltiplas Camadas amplamente difundida é a rede Muli-Layer Per-
ceptron (MLP). Redes MLP são estruturas capazes de processar de forma eficiente sinais inde-
pendentes do tempo. Porém, estas estruturas não incorporam o tempo em seu processamento,
tornando-as ineficientes em mapear processos não estacionários, como predição de séries tem-
porais. Para a solução deste problema surgem estruturas neurais capazes de processar sinais
temporais.
Uma solução para capacitar a MLP a processar padrões dinâmico é modificar seu processo
de treinamento. Um artifício utilizado para esta adequação envolve o uso de janelas de tempo,
em que a entrada da rede utiliza trechos dos dados temporais, fixando um padrão estático, per-
mitindo a estas redes o processamento temporal (Figura 3.4).
O hiper-dimensionamento de uma RNA pode inviabilizar seu uso, devido ao extensivo
tempo necessário para seu treinamento. Utilizar uma janela temporal no seccionamento do
conjunto de dados de entrada, possibilita a construção de Redes Diretas de Múltiplas Camadas
20

menores e viáveis (menos neurônios na camada de entrada). Porém, dividir sequências contí-
nuas de dados pode impedir que a rede identifique padrões temporais distantes, contidos em um
intervalo maior que a janela temporal [44]. Por exemplo, na Figura 3.4 a tendência da série não
seria reconhecida pela RNA, pois a janela de apenas cinco elementos restringe a "visão"da rede
com relação ao crescimento macro da série temporal.
Figura 3.4: Janela temporal inserida em uma RNA do tipo MLP.
Deste modo, esta solução não é a mais indicada para o processamento temporal [9]. A
principal questão, portanto, é como estender a estrutura das redes MLP para que assumam um
comportamento que varie com o tempo, sendo capaz de tratar sinais temporais.
Para solucionar o problema do tamanho limitado da janela, uma modificação na estrutura da
MLP, conhecida como Time Delay Neural Network (TDNN), pode ser realizada. Esta modifica-
ção consiste em introduzir uma segunda camada escondida (linha de atraso), que recebe como
entrada uma janela da primeira, assim como a camada de saída recebe os valores de uma janela
da segunda camada escondida [49].
Esta rede, diferentemente de redes com “janelamento”, proporciona memória a todos os
neurônios das camadas escondidas e da camada de saída. Deste modo, níveis de memória
21

podem ser inseridos, onde memória de ordem 1 corresponde a atrasos na primeira camada, de
ordem 2 à segunda, e assim sucessivamente, até a camada de saída.
Esta memória é efetivada por neurônios especializados em replicar os sinais de entrada,
semelhante a uma fila, representada na Figura 3.5 como linha de atraso. Inserir linhas de atraso
acarreta na inserção de mais neurônios, tornando a rede mais complexa. [42].
Figura 3.5: TDNN com uma linha de atraso.Fonte: Adaptado de Haykin [21].
Em resumo, as TDNNs não passam de redes estáticas que aprendem não com uma entrada,
mas com uma seqüência de entrada que representa os dados do presente e do passado [21].
Um dos modelos mais utilizados tanto comercialmente quanto para a realização de bench-
marks é o das MLP, sendo as TDNN modificações dessas redes, a TDNN foi escolhida como
uma das RNAs a serem implementadas neste estudo.
3.2.3 Redes Recorrentes
Redes recorrentes são as redes mais apropriadas para resolver problemas que envolvem pro-
cessamento temporal [21]. As RNAs recorrentes recebem este nome pois possuem pelo menos
um laço realimentando a saída de neurônios para outros neurônios da rede. Estas realimentações
podem ser feitas de diferentes modos, caracterizando as subclasses de redes neurais recorrentes
[43], [21].
22

Redes Localmente Recorrentes
O tempo pode ser representado pelo efeito que acarreta no processamento de sinais, que
significa oferecer características dinâmicas ao mapeamento realizado pela rede, tornando-a sen-
sível a sinais que variem com o tempo [1].
Para uma RNA ser considerada dinâmica, é preciso que ela possua memória [16]. Nas redes
localmente recorrentes esta memória é representada explicitamente através de uma modificação
do neurônio, onde uma realimentação dentro da estrutura é efetuada, armazenando o estado
anterior do neurônio e utilizando-o para o próximo processamento de sinal.
Redes Globalmente Recorrentes
Redes globalmente recorrentes são caracterizadas pela alta diversidade de ligações recorren-
tes. Nestas redes cada neurônio pode ser ligado a qualquer outro neurônios, exceto a ele mesmo
[9]. Em outras palavras, a saída de cada neurônio é realimentada, através de um elemento de
atraso unitário, formando um sistema de realimentação de múltiplos laços.
O paradigma das redes globalmente recorrentes teve inicio com Tank Hopfield [22], que in-
centivou outros estudos nesta área, como em Kosko [27] e Williams & Zipser [54]. Estes estudos
ressaltam que a aplicação de recorrência global pode ser considerado como uma faca de dois
gumes, pois quando aplicada indevidamente pode produzir efeitos prejudiciais. Em particular, a
aplicação de realimentação pode tornar instável (oscilatória) um sistema que originalmente era
estável [1].
A estabilidade de um sistema dinâmico não-linear é uma questão difícil de se tratar, devido
a diversas interpretações que se pode dar ao termo estabilidade não-linear [21]. No contexto de
redes neurais, estabilidade significa que a saída de um sistema não deve crescer como resultado
de uma entrada, condição inicial, ou distúrbio indesejável, limitados [10]
Elman [16] propôs a representação temporal através de unidades de ocultas, denominadas de
unidades de contexto, as quais realimentam a camada oculta. Na Figura 3.6 esta realimentação é
demonstrada pelas linhas em azuis e vermelhas, sendo as linhas azuis responsáveis por propagar
os sinais de saída dos neurônios da camada oculta para camada de contexto (memória da rede) e
as linhas vermelhas responsáveis por ponderar os valores passados no processamento temporal
da rede.
23

Figura 3.6: RNA de Elman.Fonte: Adaptado de Haykin [21].
Nas redes de Elman, as unidades de contexto são usadas apenas para memorizar as ativa-
ções anteriores das unidades intermediárias e podem ser consideradas como atraso no tempo
em um passo [16]. O aprendizado ou ajuste dos pesos é efetuado com o algoritmo backpropa-
gation. Isto é possível pois em um intervalo de tempo específico t as ativações das unidades
intermediárias (em t − 1) e as entradas correntes (em t) são utilizadas como simples entradas.
Resumidamente pode-se definir o treinamento dessa rede da seguinte forma [9]:
1. Ligações recorrentes são ignoradas ou retiradas.
2. As entradas são propagadas para frente a fim de produzir as saídas.
3. O treinamento da rede é realizado com o algoritmo backpropagation
4. As unidades intermediárias no tempo t são reintroduzidas através das ligações recorrentes
nas unidades de contexto.
A utilização de realimentação na camada escondida permite que todas as amostras anteriores
apresentadas a rede influenciem em sua resposta, sendo maior o grau de influência às entradas
mais recentes apresentadas à rede [9].
Apesar de existir inúmeros RNAs recorrentes como rede de Jordan [16], rede de Elman
[16], rede de Hopfield [22], rede Echo State Network [56], a rede de Elman foi escolhida como
24

a rede recorrente a ser utilizada na elaboração do estudo de caso (modelagem Chuva-Vazão),
devido sua capacidade de representação temporal e da facilidade em construir algoritmos para
seu treinamento.
3.3 Considerações Finais
Quando se pretende trabalhar com problemas físicos linearmente descritos, boas soluções
podem ser obtidas por meio de teorias estatísticas e modelos matemáticos robustos [35]. Porém,
quando o sistema ou mecanismo físico for não-linear, ou ainda, não bem compreendido modelos
estatísticos lineares podem não ser suficientes. Neste ponto as RNAs podem vir a fornecer uma
solução viável.
Diante das diferentes RNAs, cabe ao projetista identificar qual melhor se enquadra na reso-
lução de um problema. No caso especifico deste trabalho, que trabalha com séries temporais
hidrológicas, redes neurais recorrentes são mais recomendadas, haja vista a capacidade que
estes modelos de RNAs possuem em representar relações históricas complexas e dinâmicas.
25

Capítulo 4
Modelagem Chuva-Vazão
A modelagem do processo de transformação de chuva em vazão em uma determinada bacia
hidrográfica é um grande desafio aos hidrólogos, dada à complexidade envolvida nos processos
físicos da natureza. Estes modelos operacionais se destinam a apoiar atividades que dependem,
com regularidade, de previsões de dados hidrológicos, exigindo acurácia em suas respostas.
Conhecer a dinâmica de funcionamento do ciclo hidrológico, mais precisamente de dados
de vazão e precipitação, permite a avaliação do potencial hídrico de uma região. Para a mo-
delagem dessa dinâmica, há que compreender as características desse problema, provendo o
embasamento teórico necessário à construção de modelos robustos e coerentes.
Este capítulo traz uma descrição do processo Chuva-Vazão e os principais conceitos envol-
vidos em sua modelagem.
4.1 Transformação de Chuva em Vazão
A representação do processo Chuva-Vazão por meio de modelos matemáticos, denominados
modelos de simulação Chuva-Vazão ou simplesmente modelos Chuva-Vazão, tem como obje-
tivo principal avaliar respostas em termos de vazão de uma bacia hidrográfica em função de uma
precipitação qualquer [41].
Estes modelos devem ser capazes de descrever, em função da precipitação de chuva, as
perdas por evaporação, interceptação, infiltração e percolação da água subterrânea e, calcular o
escoamento superficial e o escoamento de base [31].
Por meio desses modelos também é possível simular situações que ainda não ocorreram na
natureza (predição), o que é muito útil para aplicações nas Engenharias e no gerenciamento de

recursos hídricos. Dentre as aplicações práticas destacam-se [38]:
• Construção de sistemas de drenagem baseados em avaliações de máxima vazão;
• Prevenção de vazões, para dimensionar e subsidiar construção de reservatórios;
• Reconstrução de séries históricas de vazões (útil em bacias hidrográficas com poucos
postos de coleta de vazão);
• Avaliação de vazões mínimas em períodos de estiagem, utilizadas para um melhor geren-
ciamento dos recursos hídricos disponíveis;
• Análise de consistências e preenchimento de falhas em séries de vazões.
Devido a sua alta relevância em projetos de engenharia e no gerenciamento de recursos hí-
dricos, modelos Chuva-Vazão vêm sendo há muito tempo considerados como objeto de pesquisa
(os primeiros modelos surgiram logo após a 2a Guerra Mundial), sendo até hoje desenvolvidos
inúmeros modelos [17].
O desafio na construção de modelos Chuva-Vazão é representar o ciclo hidrológico e os
diversos fatores que influenciam na transformação de chuva em vazão [31].
Ciclo hidrológico é o conjunto dos diversos caminhos percorridos pela água entre a super-
fície e a atmosfera, impulsionado fundamentalmente pela energia solar, gravidade e rotação
terrestre. Dentre os diversos fatores que compõem este ciclo destacam-se [38]: evaporação;
transpiração das plantas; precipitação de chuva; infiltração no solo e escoamentos superficiais
(Figura 4.1).
27

Figura 4.1: Ciclo hidrológico.Fonte: Adaptado de Tucci [31].
Os fatores que constituem o ciclo hidrológico influenciam diretamente como e quanto da
agua de chuva irá ser transformada em vazão. Após a ocorrência de um período de chuva sobre
uma bacia hidrográfica, o excesso da água de chuva que não é infiltrado no solo, nem evaporado,
acumula-se inicialmente nas pequenas depressões do terreno para, em seguida, formar uma
lâmina d’água e, consequentemente, o escoamento de superfície ou deflúvio superficial.
O deflúvio superficial é composto de escoamentos de superfície, distribuídos espacialmente
em pequenas áreas. Esses escoamentos representam contribuições laterais aos microcanais exis-
tentes na bacia, os quais alimentam os pequenos canais da bacia e estes, por sua vez, transportam
as águas pluviais da bacia para os córegos e cursos d’água do sistema fluvial [41].
Nas aplicações da hidrologia à engenharia, a quantificação das vazões resultantes das preci-
pitações pode ser obtida por técnicas diversas, dependendo do objetivo da análise do processo
de transformações de chuva em vazões. Para modelagem de sistemas de drenagem urbana, em
geral, modelos físicos, os quais quantificam os escoamentos superficiais, produzem resultados
satisfatórios [41].
Embora se reconheça que o deflúvio superficial ocorre por meio de escoamentos sobre o
terreno com a formação de uma fina lâmina d’água, é irreal admitir que esse escoamento se dá
28

por meio de um deslocamento uniforme, principalmente quando se trata de um bacia de grande
porte. Construir modelos não-lineares de bacias de grande porte é um processo complexo, tanto
pela falta de dados quanto pelas dificuldades matemáticas envolvidas em sua elaboração [41].
A distribuição da vazão em função do tempo numa dada seção de um curso d’água é usu-
almente chamada de hidrograma e é interpretada como sendo a resposta da bacia ou área de
drenagem quando estimulada pelas chuvas que caem sobre essa área [41]. Essa resposta, ge-
ralmente, ocorre com uma defasagem no tempo, referida como tempo de retardo da bacia, ou
seja, após a ocorrência de chuva Qa seu correspondente efeito sobre a vazão Qb na seção de
controle (bacia hidrográfica), ocorrerá após certo intervalo de tempo4t. Este tempo de retardo
não depende apenas da intensidade e distribuição espacial da precipitação, mas também de ca-
racterísticas físicas da bacia, como área, conformação topográfica e geográfica, tipos de solo e
usos empreendidos em sua superfície [31].
Figura 4.2: Representação gráfica do tempo de retardo de uma bacia hidrogáfica hipotética.Fonte: Adaptado de Tucci [31]
A Figura 4.2 demonstra o tempo de retardo de uma bacia hipotética, utilizando duas curvas:
Qa representando precipitação média acumulada; Qb representando a vazão resultante. Anali-
sando esta figura, percebe-se que após a ocorrência de um montante de chuva (ponto máximo de
Qa), sua resultante em vazão (ponto máximo da curva Qb), só ocorre após um atraso temporal,
neste caso pouco mais de um dia (4 = 1, 3). Deste modo, a vazão na seção de controle está
relacionada ao conjunto das precipitações antecedentes ao tempo de retardo da bacia.
29

Modelos Chuva-Vazão devem englobar o maior número possível de variáveis que represen-
tem as características da bacia, possibilitando uma melhor representação do tempo de retardo.
Porém, algumas dessas características estão espacialmente distribuídas pela bacia hidrográfica
(relevo), possuindo grande variação temporal (provocadas principalmente pela variação na uti-
lização do solo), dificultando sua mensuração e adequação desses modelos [4].
Historicamente, diferentes abordagens têm sido utilizadas na representação do processo
Chuva-Vazão, sendo essas classificadas em dois grupos [45]: abordagens que descrevem os as-
pectos físicos envolvidos na transformação, chamados de modelos determinísticos conceituais e
abordagens que buscam representar as relações implícitas entre os dados de entrada (chuva) e de
saída (vazão) sem considerar os processos físicos subjacentes, denominados modelos teóricos
empíricos.
4.2 Modelos Empíricos e Conceituais de Chuva-Vazão
Modelos conceituais Chuva-Vazão têm sido desenvolvidos para representar, de maneira re-
alista, os subprocessos e relações envolvidas no processo Chuva-Vazão [5]. Esses modelos
geralmente são constituídos por combinações de funções de transferências e de reservatórios
fictícios, que procuram representar em suas formulações, simplificações das leis da física [23].
Franchini & Pacciani em [17], realizaram um estudo comparativo de vários modelos con-
ceituais Chuva-Vazão, definindo algumas características comuns a todos os modelos. Nesse es-
tudo, duas fases distintas foram identificadas nos modelos levantados; a primeira caracterizada
pela realização de um balanço hídrico, calculando a vazão para os cursos d’água; e a segunda,
pelo cálculo da translação e acumulo das vazões locais até a seção de controle, considerando o
tempo de retardo da bacia.
Um modelo empírico é definido basicamente por uma equação matemática. Este modelo
consiste em estabelecer uma relação estável entre as variáveis de entrada e saída, ignorando o
processo físico natural de transformação da chuva em vazão. [32].
Modelos que usam RNAs são classificados como modelos teóricos empíricos. Esses mo-
delos, auxiliados por ferramentas computacionais, podem ser construídos rapidamente se com-
parados aos modelos conceituais, mostrando-se eficiente em muitos trabalhos [13], [25], [34].
Por esse motivo, nos últimos anos, as RNAs vem se tornado cada vez mais popular em estudos
30

hidrológicos, especialmente na modelagem Chuva-Vazão.
Após a definição do modelo Chuva-Vazão, seja ele empírico ou conceitual, este deve ser
ajustado, visando determinar os valores para os parâmetros do modelo, de tal forma que o
mesmo possa reproduzir satisfatoriamente as vazões observadas. Os vários ciclos necessários
para o ajuste adequado do modelo, caracteriza o processo de calibração [55].
A calibração é considerado como uma das etapas mais críticas no processo de desenvolvi-
mento de modelos Chuva-Vazão, demandando muito tempo, esforço e experiência do especi-
alista. Modelos teóricos empíricos baseados em RNAs, são capazes de expressar as relações
implícitas dos dados sem necessidade de muitos ajustes manuais, trazendo grande economia
tempo [23].
O processo de calibração pode ser efetivado de duas formas [55]: processo manual, também
conhecido como tentativa e erro, ou de forma automática.
Pelo método manual, vários conjuntos de parâmetros são avaliados, prosseguindo nesta ope-
ração até alcançar um vetor de parâmetros que, quando utilizado no modelo, responda satisfa-
toriamente segundo critérios pré-estabelecidos. Nesta metodologia a experiência do modelador
é de fundamental importância, exigindo precisão e rapidez no ajuste dos parâmetros, para que o
modelo esteja pronto no prazo esperado.
O ajuste por métodos automáticos por sua vez, consiste em otimizar uma função objetivo.
Esta otimização é efetuada por algoritmos que buscam no espaço de representação o conjunto
de valores que produza o mínimo erro possível (mínimo global). Apesar de muitas dificuldades
encontradas na utilização de calibragem automática, resumidas por Franchini & Pacciani [17],
estes algoritmos são focos de muitos estudos. A motivação para estes estudos vai além economia
de tempo, acarretando maior confiabilidade dos resultados, uma vez que evitam a subjetividade
do especialista [28].
4.3 Considerações Finais
Modelos de simulação Chuva-Vazão são ferramentas de importância fundamental para qual-
quer projeto ou planejamento na área de recursos hídricos. Modelos conceituais utilizam muitos
parâmetros e requerem muito esforço em sua construção e calibração. Alguns dos parâmetros
requeridos, neste tipo de modelagem, estão relacionados com características físicas da bacia
31

hidrográfica, exigindo coletas de dados em capo. Este tipo de coleta além de exigir mais tempo,
resulta em grandes despesas económicas.
Modelos baseados em RNAs assumem que as relações físicas da bacia hidrográfica estão
implicitamente inseridas nos dados, não exigindo do modelador conhecimento dos processos
envolvidos no ciclo hidrológico. Estes modelos vêm sendo considerados como alternativas
viáveis e promissoras, aplicados de forma eficiente em diversos estudos.
A compreensão da dimensão e da dinâmica envolvida no processo de transformação de
chuva em vazão é essencial no processo de modelagem, permitindo uma melhor compreensão
dos resultados obtidos por estes modelos e possibilitando melhores avaliações dos modelos
propostos.
32

Capítulo 5
Estudo de Caso
Existindo informações suficientes sobre o sistema em estudo, uma abordagem estatística
matemática pode ser utilizada para representar uma série temporal. No entanto, em muitos pro-
blemas reais não se tem informações e/ou condições ideais suficientes para construir equações
que caracterizem o comportamento das variáveis de uma série temporal. Na ausência ou na
dificuldade em encontrar essas equações, é mais atrativo usar abordagens alternativas como as
RNAs.
A modelagem de séries temporais baseadas em RNAs é um exemplo de modelagem teórica
empírica. Portanto, ao invés de explicitamente deduzir equações que descrevem o comporta-
mento subjacente do sistema em estudo, um capturador automático de um modelo não linear
usando um algoritmo de aprendizagem neural é construído para aproximar as equações ideais.
Neste capítulo são apresentados os materias e métodos utilizados no desenvolvimento do
modelo preditivo baseado em RNAs, que procura representar de forma realística o processo de
transformação de chuva em vazão fluvial.
5.1 Caracterização do Problema
Considerando o que foi exposto nos capítulos anteriores, o problema de modelagem de uma
série temporal voltada à predição, pode ser apresentado da seguinte maneira: “Dado um con-
junto discreto de valores indexados no tempo, como capturar e modelar as correlações existentes
nos dados, de modo que, a partir dessa representação, seja possível inferir valores futuros?”
O principal objetivo deste trabalho é analisar a viabilidade do uso de RNAs na modelagem
e predição de séries temporais, mais especificamente, em séries hidrológicas. Para alcançar este

objetivo, duas RNAs foram utilizadas na modelagem Chuva-Vazão: a primeira uma TDNN; e a
segunda uma rede recorrente conhecida como rede de Elman.
Estas redes foram construídas a partir de dados de precipitação e de vazão fluvial, referentes
a bacia hidrográfica do rio Piquiri. Desse modo, o modelo resultante tenta representar de forma
realística o processo Chuva-Vazão desta bacia.
A construção de todas RNAs foi feita com auxílio do ambiente computacional MatLabr e
da ferramenta NeuralNetworkToolboxr.
Definido o problema e de posse de um conjunto de dados referente ao mesmo, o processo
de Descoberta de Conhecimento pode ser iniciado. Para uma melhor organização, neste traba-
lho, a Descoberta de Conhecimeno foi dividida nas seguintes etapas (Figura 5.1): Análise da
área de estudo; Pré-Processamento; Mineração de Dados; e Pós-Processamento. A análise dos
resultados referente ao Pós-Processamento foi efetuada paralelamente em cada uma das etapas
citadas.
Figura 5.1: Diagrama de sequência do processo de Descoberta de Conhecimento efetuada nesteestudo.
5.1.1 Área de Estudo
A bacia hidrogáfica do rio Piquiri (Figura 5.2), localizada no Estado do Paraná, foi utilizada
para aplicação do estudo de caso. Com uma área de drenagem de 24.731 Km2, esta bacia se
classifica como bacia de grande porte, sendo a terceira maior em área física do Estado do Paraná.
Seu índice pluviométrico médio anual e sua vazão média anual correspondem, respectivamente,
a 1.600 mm e 524 m3/s.
34
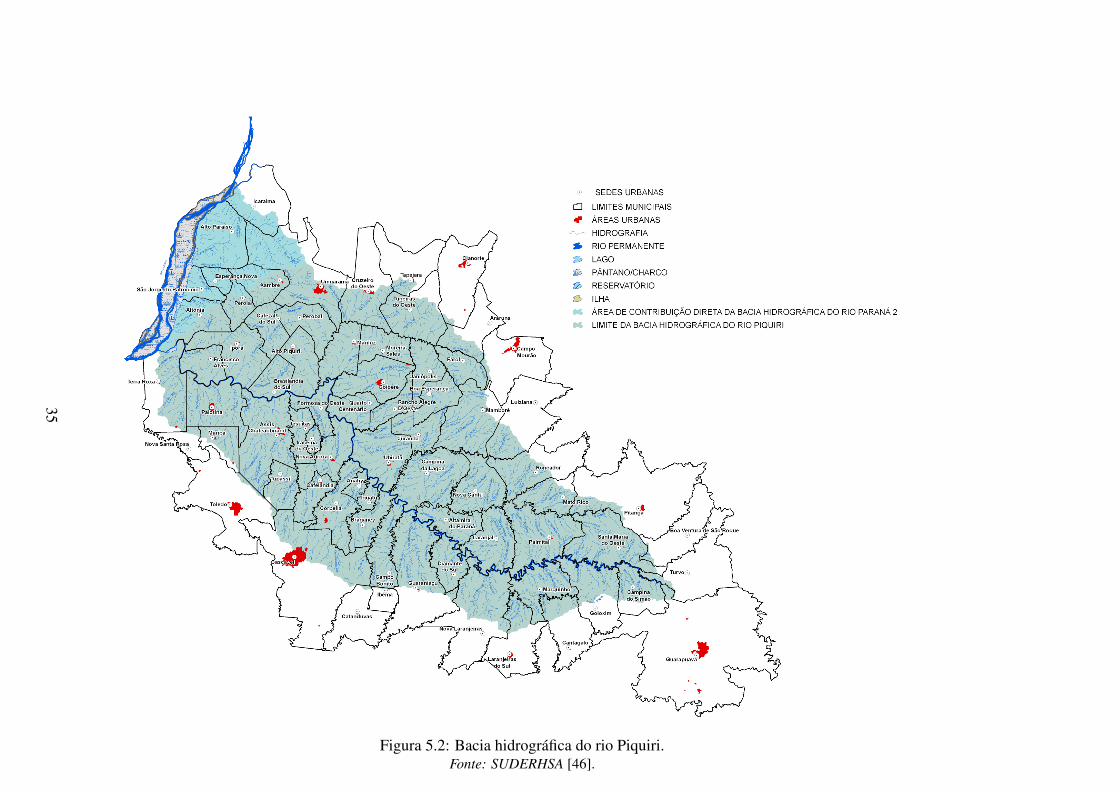
Figura 5.2: Bacia hidrográfica do rio Piquiri.Fonte: SUDERHSA [46].
35

Os solos predominantes são Latossolo, Argilossolo e Nitossolo vermelhos, e a leste, porções
mais significativas de Neossolos. Ao norte as texturas variam pouco entre arenosa e média
arenosa, prevalecendo texturas mais argilosas nas demais regiões. Seu relevo em toda bacia
varia pouco entre suave ondulado e ondulado com altitudes que vão de 410 a 994 metros.
Um dos principais fatores que determinou a escolha dessa bacia foi a disponibilidade de
uma razoável quantidade de postos pluviométricos, bem distribuídos pela área da bacia (Figura
5.3). As séries históricas disponíveis para a bacia compreendem dados diários de precipitação
e vazão, coletados em 102 estações pluviométricas e uma estação fluviométrica (localizada na
ponte do rio Piquiri).
Figura 5.3: Distribuição espacial das 102 estações pluviométricas na bacia do rio Piquiri.Fonte: SUDERHSA [46]
Todos os dados utilizados neste estudo foram cedidos pela Superintendência de Desenvol-
vimento de Recursos Hídricos e Saneamento Ambiental [46]. Entre os dados fornecidos estão:
102 séries históricas de precipitação de chuva (contidas no período de 1956 a 2008); uma série
36

de vazão (1971 a 2003); descrições dos postos de coleta; e mapas hidrológicos.
5.2 Definição do Modelo
Para possibilitar comparações entre as duas RNAs, critérios foram adotados na definição de
seus parâmetros. Apesar de algumas características individuais pertencentes às duas RNAs apli-
cadas neste estudo, alguns parâmetros, comuns a ambas as redes, foram definidos da seguinte
forma:
• Validação cruzada: Caso o erro do conjunto de validação cresça durante 10 épocas con-
secutivas, o treinamento é interrompido para evitar a perca da generalização.
• Avaliação do desempenho: A acuidade dos modelos foram medidas através do Erro Mé-
dio Quadrático (Equação 3.3).
• Número de épocas de treinamento: Caso o procedimento de validação cruzada não in-
terrompa o treinamento e nem se chegue a uma taxa de erro igual a zero, o treinamento
supervisionado é interrompido quando o número de épocas atingir 600 ciclos.
• Inicialização dos pesos iniciais: Os valores iniciais dos pesos são gerados aleatoriamente.
Para tentar evitar mínimos locais causados pela inicialização, cada rede foi inicializada e
treinada três vezes.
• Momentum: Este parâmetro foi ajustado dinamicamente com uma taxa de 0.1 no intervalo
de [0.001, 1E10].
• Taxa de aprendizagem: A atualização dos pesos foi feita de acordo com o algoritmo de
aprendizado Levenberg-Marquardt [1].
Para capturar o comportamento de uma série hidrológica, é recomendo utilizar períodos
iguais ou maiores a 20 anos [41]. Dessa forma, o conjunto de dados, séries de precipitação e a
série de vazão, utilizados no treinamento, na validação e nos testes, foram divididos seguindo
os seguintes critérios:
• Conjunto de Validação: Dado o inicio da série, os primeiros 15% dos dados foram dedi-
cados a este fim.
37

• Conjunto de Treinamento: Após o conjunto de validação, os seguintes 70% dos dados
foram destinados a esta etapa.
• Conjunto de Teste: Com intuito de avaliar os modelos, os 15% restantes, foram dedicados
a este conjunto.
Os modelos propostos têm como premissa básica que as variáveis de saída tem influência
dos valores atuais e passados de todas as variáveis de entrada. As duas RNAs utilizadas diferem
em suas representações temporal, exigindo diferentes modos para determinar esse parâmetro.
Para rede TDNN, o processo de busca pelo atraso de tempo (tamanho da linha de atraso) foi
efetuado de forma empírica, variando sua memória entre 1 e 5, sendo os melhores resultados
obtidos com 3 valores passados. Para esta rede uma única camada escondida de 20 neurônios
foi utilizada.
A memória de uma rede de Elman está inserida em sua camada de contexto, dessa forma
definindo o número de neurônios em sua camada escondida, conseqüentemente em sua camada
de contexto, seu atraso temporal é estabelecido. A escolha do número de neurônios na camada
escondida foi realizada empiricamente, variando o número de neurônios entre 20, 25, 30 e 35,
sendo os melhores resultados obtidos com 35 neurônios1.
5.3 Pré-Processamento
A preparação dos dados foi iniciada com a definição das estações a serem utilizadas no
estudo de caso. Um requisito essencial para a modelagem Chuva-Vazão com suporte das RNAs,
é que todas séries temporais utilizadas (precipitação e vazão) contenham o mesmo período de
coleta de dados. Dada a disponibilidade de uma única série de vazão, esta foi considerada como
referência de corte para as demais séries hidrológicas.
A série temporal de vazão utilizada, coletada no posto fluviométrico da ponte do rio Piquiri,
possui um período 32 anos, iniciando em 1971 e terminando em 2003. Sendo assim, séries
pluviométricas que não contenham este período, foram descartadas. Esta seleção restringiu as
102 séries pluvimétricas a 24.
1Redes com mais números de camadas e com mais neurônios não foram construídas devido ao custo computa-cional: alto tempo de treinamento; e grande quantidade memória exigida.
38
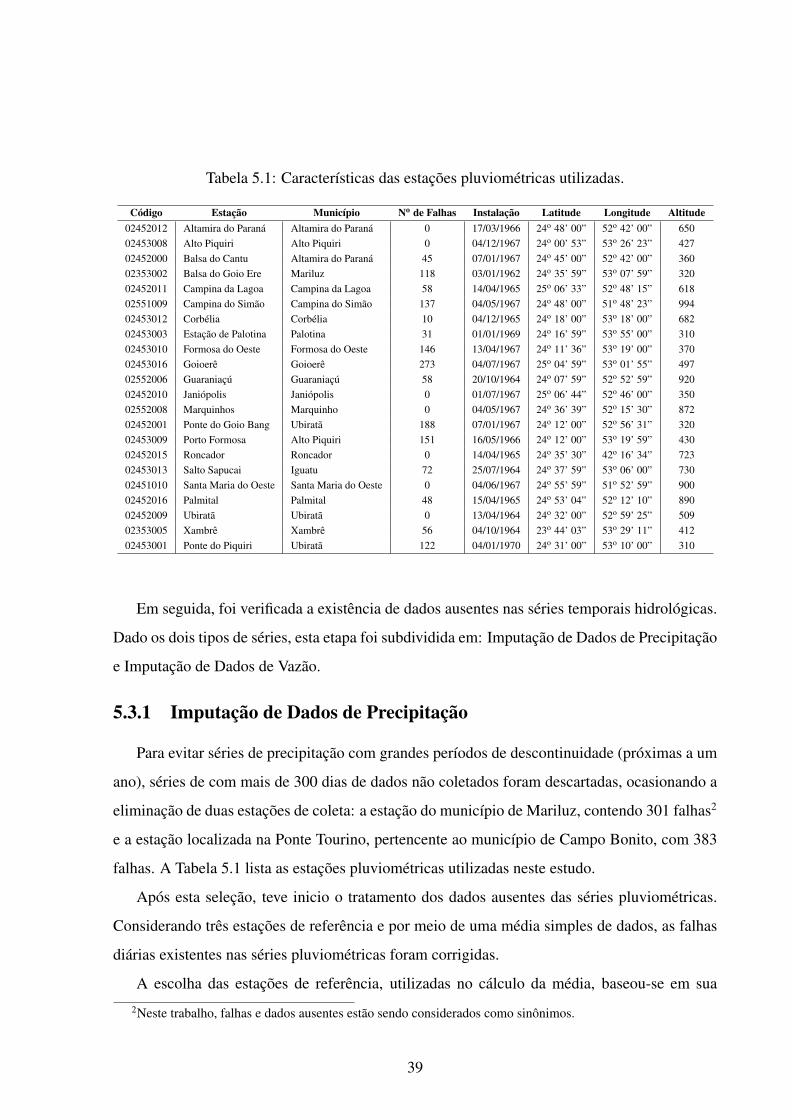
Tabela 5.1: Características das estações pluviométricas utilizadas.
Código Estação Município No de Falhas Instalação Latitude Longitude Altitude02452012 Altamira do Paraná Altamira do Paraná 0 17/03/1966 24o 48’ 00” 52o 42’ 00” 65002453008 Alto Piquiri Alto Piquiri 0 04/12/1967 24o 00’ 53” 53o 26’ 23” 42702452000 Balsa do Cantu Altamira do Paraná 45 07/01/1967 24o 45’ 00” 52o 42’ 00” 36002353002 Balsa do Goio Ere Mariluz 118 03/01/1962 24o 35’ 59” 53o 07’ 59” 32002452011 Campina da Lagoa Campina da Lagoa 58 14/04/1965 25o 06’ 33” 52o 48’ 15” 61802551009 Campina do Simão Campina do Simão 137 04/05/1967 24o 48’ 00” 51o 48’ 23” 99402453012 Corbélia Corbélia 10 04/12/1965 24o 18’ 00” 53o 18’ 00” 68202453003 Estação de Palotina Palotina 31 01/01/1969 24o 16’ 59” 53o 55’ 00” 31002453010 Formosa do Oeste Formosa do Oeste 146 13/04/1967 24o 11’ 36” 53o 19’ 00” 37002453016 Goioerê Goioerê 273 04/07/1967 25o 04’ 59” 53o 01’ 55” 49702552006 Guaraniaçú Guaraniaçú 58 20/10/1964 24o 07’ 59” 52o 52’ 59” 92002452010 Janiópolis Janiópolis 0 01/07/1967 25o 06’ 44” 52o 46’ 00” 35002552008 Marquinhos Marquinho 0 04/05/1967 24o 36’ 39” 52o 15’ 30” 87202452001 Ponte do Goio Bang Ubiratã 188 07/01/1967 24o 12’ 00” 52o 56’ 31” 32002453009 Porto Formosa Alto Piquiri 151 16/05/1966 24o 12’ 00” 53o 19’ 59” 43002452015 Roncador Roncador 0 14/04/1965 24o 35’ 30” 42o 16’ 34” 72302453013 Salto Sapucai Iguatu 72 25/07/1964 24o 37’ 59” 53o 06’ 00” 73002451010 Santa Maria do Oeste Santa Maria do Oeste 0 04/06/1967 24o 55’ 59” 51o 52’ 59” 90002452016 Palmital Palmital 48 15/04/1965 24o 53’ 04” 52o 12’ 10” 89002452009 Ubiratã Ubiratã 0 13/04/1964 24o 32’ 00” 52o 59’ 25” 50902353005 Xambrê Xambrê 56 04/10/1964 23o 44’ 03” 53o 29’ 11” 41202453001 Ponte do Piquiri Ubiratã 122 04/01/1970 24o 31’ 00” 53o 10’ 00” 310
Em seguida, foi verificada a existência de dados ausentes nas séries temporais hidrológicas.
Dado os dois tipos de séries, esta etapa foi subdividida em: Imputação de Dados de Precipitação
e Imputação de Dados de Vazão.
5.3.1 Imputação de Dados de Precipitação
Para evitar séries de precipitação com grandes períodos de descontinuidade (próximas a um
ano), séries de com mais de 300 dias de dados não coletados foram descartadas, ocasionando a
eliminação de duas estações de coleta: a estação do município de Mariluz, contendo 301 falhas2
e a estação localizada na Ponte Tourino, pertencente ao município de Campo Bonito, com 383
falhas. A Tabela 5.1 lista as estações pluviométricas utilizadas neste estudo.
Após esta seleção, teve inicio o tratamento dos dados ausentes das séries pluviométricas.
Considerando três estações de referência e por meio de uma média simples de dados, as falhas
diárias existentes nas séries pluviométricas foram corrigidas.
A escolha das estações de referência, utilizadas no cálculo da média, baseou-se em sua
2Neste trabalho, falhas e dados ausentes estão sendo considerados como sinônimos.
39

proximidade com a estação que possui dados ausentes. A Tabela 5.2 lista, para cada estação
que contém dados ausentes, as estações de referencia utilizadas para o cálculo da média e suas
distâncias com relação a estação a ser corrigida. Para calcular a distância entre as estações,
foram utilizadas coordenadas geodésicas: latitude e longitude.
Concluindo a etapa de imputação, os dados foram ajustados e organizados de modo que
servissem como entrada para as RNAs. Apesar do conjunto de entrada ser formado apenas por
séries pluviométricas, essas, geralmente, possuem intervalos distintos de variação. Portanto,
para assegurar que as variáveis de entrada recebam igual atenção durante o processo de treina-
mentoas, elas devem ser normalizadas [48].
A escolha do processo de normalização depende do tipo de função de ativação que se pre-
tende usar. Por exemplo, uma função de ativação logística limita a representação dos dados
entre [0, 1], já uma função tangente hiperbólica restringe a representação em [−1, 1] e uma fun-
ção linear não limita a representação. Os tipos de normalização mais frequentemente utilizados
são [48]:
• transformação linear: N = (υ − %)(xi − xmin)/(Xmax − xmax − xmin) + %
• normalização estatística: N = (xi − x)/ω
• normalização simples: N = xi/xmax
onde;
N é o valor normalizado;
xi é um valor original discreto de uma série temporal;
xmin é o valor mínimo da variável;
xmax é o valor máximo da variável;
x é o valor médio da variável;
υ e % são os limites; e
ω é o desvio padrão.
Neste estudo, o processo de normalização escolhido para ser executado nos dados de entrada
foi a transformação linear. Esta normalização reescala os dados para uma amplitude que varia
entre [−1, 1]. Desse modo, para melhor representação interna nas RNAs, optou-se em utilizar
na camada de entrada e nas camadas ocultas, uma função de ativação tangente hiperbólica.
40
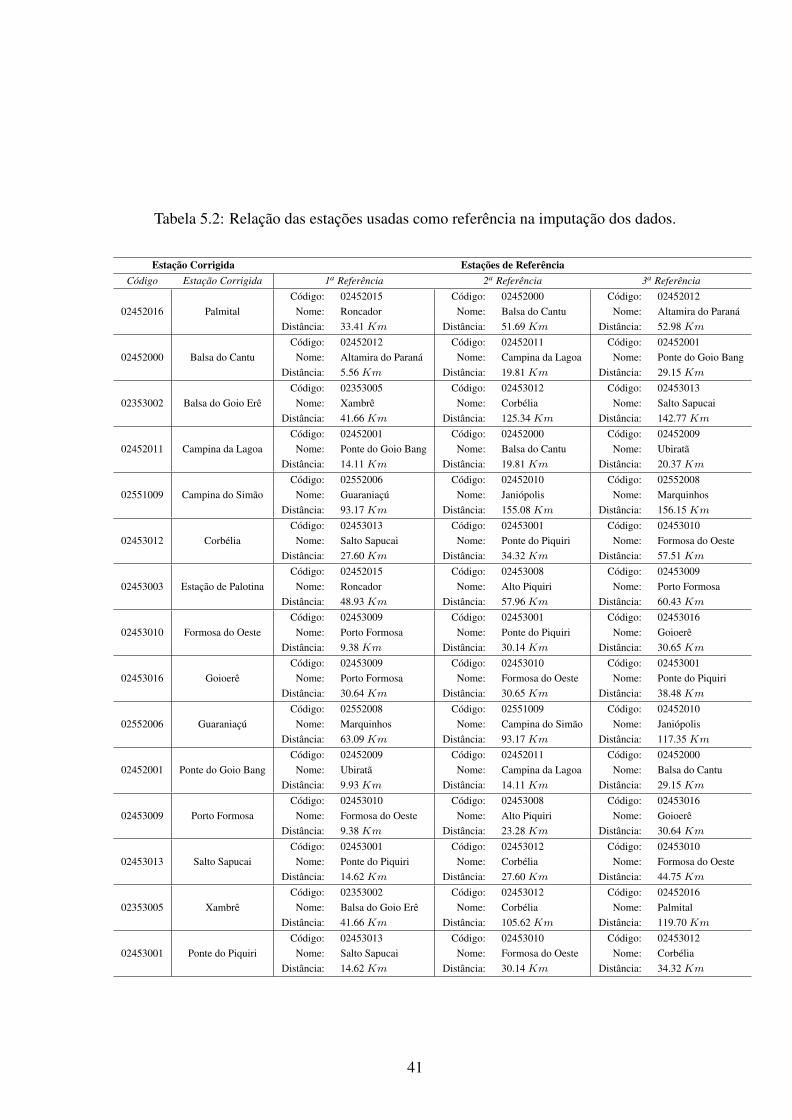
Tabela 5.2: Relação das estações usadas como referência na imputação dos dados.
Estação Corrigida Estações de ReferênciaCódigo Estação Corrigida 1a Referência 2a Referência 3a Referência
Código: 02452015 Código: 02452000 Código: 0245201202452016 Palmital Nome: Roncador Nome: Balsa do Cantu Nome: Altamira do Paraná
Distância: 33.41 Km Distância: 51.69 Km Distância: 52.98 Km
Código: 02452012 Código: 02452011 Código: 0245200102452000 Balsa do Cantu Nome: Altamira do Paraná Nome: Campina da Lagoa Nome: Ponte do Goio Bang
Distância: 5.56 Km Distância: 19.81 Km Distância: 29.15 Km
Código: 02353005 Código: 02453012 Código: 0245301302353002 Balsa do Goio Erê Nome: Xambrê Nome: Corbélia Nome: Salto Sapucai
Distância: 41.66 Km Distância: 125.34 Km Distância: 142.77 Km
Código: 02452001 Código: 02452000 Código: 0245200902452011 Campina da Lagoa Nome: Ponte do Goio Bang Nome: Balsa do Cantu Nome: Ubiratã
Distância: 14.11 Km Distância: 19.81 Km Distância: 20.37 Km
Código: 02552006 Código: 02452010 Código: 0255200802551009 Campina do Simão Nome: Guaraniaçú Nome: Janiópolis Nome: Marquinhos
Distância: 93.17 Km Distância: 155.08 Km Distância: 156.15 Km
Código: 02453013 Código: 02453001 Código: 0245301002453012 Corbélia Nome: Salto Sapucai Nome: Ponte do Piquiri Nome: Formosa do Oeste
Distância: 27.60 Km Distância: 34.32 Km Distância: 57.51 Km
Código: 02452015 Código: 02453008 Código: 0245300902453003 Estação de Palotina Nome: Roncador Nome: Alto Piquiri Nome: Porto Formosa
Distância: 48.93 Km Distância: 57.96 Km Distância: 60.43 Km
Código: 02453009 Código: 02453001 Código: 0245301602453010 Formosa do Oeste Nome: Porto Formosa Nome: Ponte do Piquiri Nome: Goioerê
Distância: 9.38 Km Distância: 30.14 Km Distância: 30.65 Km
Código: 02453009 Código: 02453010 Código: 0245300102453016 Goioerê Nome: Porto Formosa Nome: Formosa do Oeste Nome: Ponte do Piquiri
Distância: 30.64 Km Distância: 30.65 Km Distância: 38.48 Km
Código: 02552008 Código: 02551009 Código: 0245201002552006 Guaraniaçú Nome: Marquinhos Nome: Campina do Simão Nome: Janiópolis
Distância: 63.09 Km Distância: 93.17 Km Distância: 117.35 Km
Código: 02452009 Código: 02452011 Código: 0245200002452001 Ponte do Goio Bang Nome: Ubiratã Nome: Campina da Lagoa Nome: Balsa do Cantu
Distância: 9.93 Km Distância: 14.11 Km Distância: 29.15 Km
Código: 02453010 Código: 02453008 Código: 0245301602453009 Porto Formosa Nome: Formosa do Oeste Nome: Alto Piquiri Nome: Goioerê
Distância: 9.38 Km Distância: 23.28 Km Distância: 30.64 Km
Código: 02453001 Código: 02453012 Código: 0245301002453013 Salto Sapucai Nome: Ponte do Piquiri Nome: Corbélia Nome: Formosa do Oeste
Distância: 14.62 Km Distância: 27.60 Km Distância: 44.75 Km
Código: 02353002 Código: 02453012 Código: 0245201602353005 Xambrê Nome: Balsa do Goio Erê Nome: Corbélia Nome: Palmital
Distância: 41.66 Km Distância: 105.62 Km Distância: 119.70 Km
Código: 02453013 Código: 02453010 Código: 0245301202453001 Ponte do Piquiri Nome: Salto Sapucai Nome: Formosa do Oeste Nome: Corbélia
Distância: 14.62 Km Distância: 30.14 Km Distância: 34.32 Km
41

5.3.2 Imputação de Dados de Vazão
A série de vazão disponível, referente ao posto fluviométrico da ponte do rio Piquiri, pos-
sui três períodos de dados ausentes: 04/01/1982 a 31/01/1982 (Figura 5.4); 01/05/2002 a
31/05/2002 (Figura 5.5); e 1/12/2002 a 31/12/2002 (Figura 5.6). Considerado apenas o período
da série sem falhas, esta se restringe a um período de 18 anos (1983 a 2001).
Figura 5.4: Precipitação média diária dos 22 postos pluviométricos selecionados para o estudode caso. Série de vazão diária referentes ao mês de janeiro de 1981.
Com intuito de aumentar a extensão dessa série, utilizada como referência de corte para
todas as outras séries hidrológicas, as falhas encontradas nesta série foram preenchidas.
Dados ausentes em séries fluviométricas geralmente são imputados pelo método de regio-
nalização de vazões máximas, baseado no princípio da semelhança de séries hidrológicas [3].
A partir de informações de vazão das estações fluviométricas com a regionalização dos dados,
busca-se transferir informações hidrológicas entre bacias hidrográficas [29].
Considerando os pequenos períodos com falhas e diante da ausência de outras séries de
vazões, optou-se em utilizar um método indireto, baseado em RNAs, para imputar os dados
ausentes. Apesar dessas falhas estarem localizadas em pequenos períodos, as do ano de 2002
estão em um ponto crítico, momentos de alta incidência chuva.
42

Figura 5.5: Precipitação média diária dos 22 postos selecionados para o estudo de caso. Sériede vazão diária referentes ao mês de maio de 2002.
Figura 5.6: Precipitação média diária dos 22 postos selecionados para o estudo de caso. Sériede vazão diária referentes ao mês de dezembro de 2002.
Na tentativa de obter boas aproximações do comportamento da série de vazão, dois modelos
foram construídos: o primeiro com uma rede TDNN e o seguindo com uma rede de Elman.
Esses modelos foram treinados utilizando o período da série de vazão que não contém dados
ausentes, ou seja, o período de 1983 a 2001 (18 anos de dados diários).
Dados de vazões fluviais geralmente são utilizados no dimensionamento de obras hidráuli-
43

cas, sendo essencial que as vazões de pico não sejam sub-dimensionandos [6]. Neste trabalho,
um dos critérios utilizados para avaliar da confiabilidade das predições foi o ajuste de vazões
máximas.
Devido a existência de vários picos na série de vazão e para evitar que futuros valores de
vazões extrapolem um limite imposto por uma normalização, esta série não foi normalizada.
Por esse motivo, uma função do tipo linear positiva foi adotada como função de ativação dos
neurônios de saída, representando os dados entre [0,+ inf].
Após o ajuste dos parâmetros (Seção 5.2) e a execução do treinamento, os melhores re-
sultados foram obtidos pela rede de Elman (Figura 5.7-a, Figura 5.8-a e Figura 5.9-a). Estas
redes produziram resultados iguais ou superiores ao comportamento da curva de vazões, sendo
avaliados como boas aproximações.
Um problema encontrado nas rede TDNN foi uma instabilidade nos resultados (Figura 5.7-
b, Figura 5.8-b e Figura 5.9-b ). Para tentar diminuir a instabilidade (oscilações), os parâmetros
momentum e a taxa de aprendizagem foram diminuídos, esperando que estas oscilações ficas-
sem mais suaves. Porém estes ajustes não contribuíram de maneira significativa na diminuição
das oscilações dos resultados.
Outra possibilidade é que esta instabilidade seja causada pela representação temporal da
RNA, sendo difícil seu ajuste, pois acrescentando poucos níveis em sua linha de atraso, a rede
pode ficar instável por não capturar corretamente o comportamento temporal da série e, inse-
rindo muitos níveis de memória, ela pode se tornar muito extensa e instável em alguns momen-
tos (imprevisível), exigindo muito tempo no seu treinamento, inviabilizando seu uso [1]. Apesar
de várias modificações neste quesito, as oscilações não foram corrigidas, sendo descartados os
dados obtidos por estas redes.
Diante dos resultados estáveis obtidos pelas redes de Elman, coerentes com o comporta-
mento hidrológico da bacia, essa foi utilizada para interpolar os dados ausentes. Concluído a
imputação dos dados de vazões, o período da série temporal foi ampliado de 18 anos para 32
anos de dados (Figura 5.10).
44
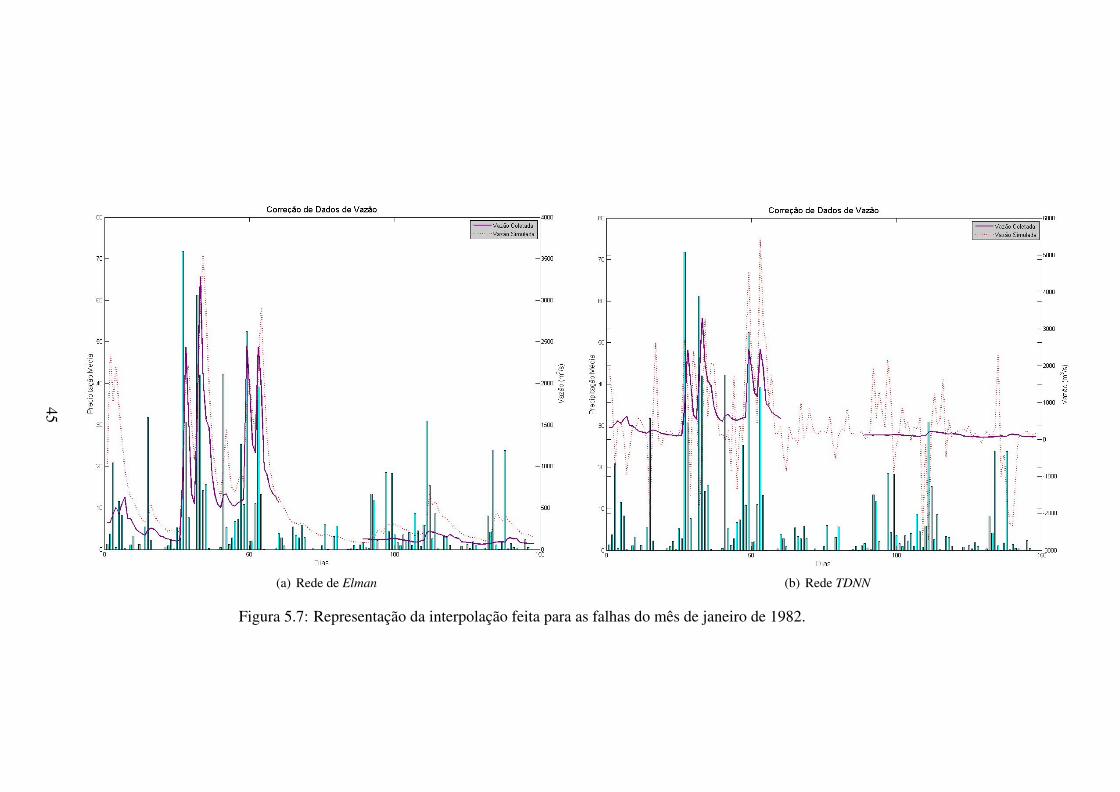
(a) Rede de Elman (b) Rede TDNN
Figura 5.7: Representação da interpolação feita para as falhas do mês de janeiro de 1982.
45
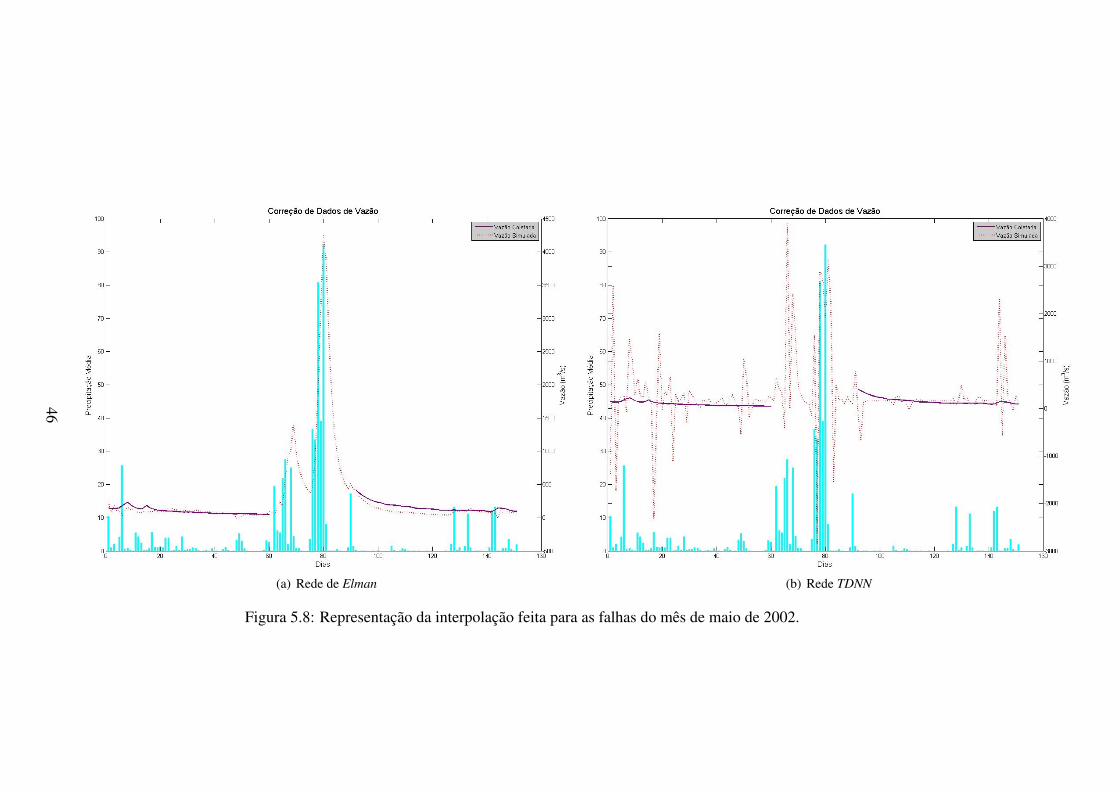
(a) Rede de Elman (b) Rede TDNN
Figura 5.8: Representação da interpolação feita para as falhas do mês de maio de 2002.
46

(a) Rede de Elman (b) Rede TDNN
Figura 5.9: Representação da interpolação feita para as falhas do mês de dezembro de 2002.
47
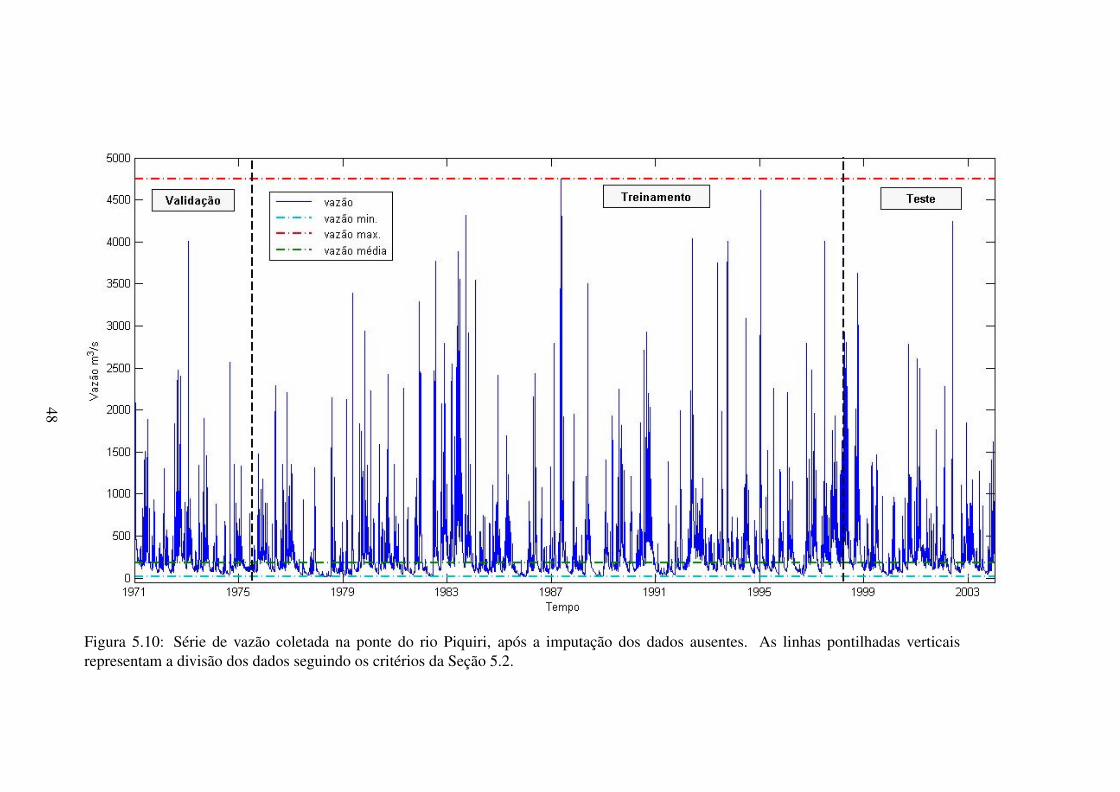
Figura 5.10: Série de vazão coletada na ponte do rio Piquiri, após a imputação dos dados ausentes. As linhas pontilhadas verticaisrepresentam a divisão dos dados seguindo os critérios da Seção 5.2.
48

5.4 Mineração de Dados
Face à disponibilidade de dados de precipitação distribuídos pela bacia (Figura 5.3) e de
dados de vazões de uma seção transversal do canal principal de escoamento da bacia, foi deci-
dido desenvolver um modelo Chuva-Vazão do tipo distribuído, ou seja, um modelo que utiliza
informações de precipitação diária dos 22 postos pluviométricos para estimar a vazão diária na
seção de controle, localizada na ponte do rio Piquiri.
Estes modelos foram construídos a partir de dois modelos de RNAs: rede TDNN, e rede
de Elman. Após a configuração dos parâmetros e a definição dos conjuntos de treinamento e
validação (Seção 5.2), teve início a etapa de treinamento das RNAs.
O tempo de treinamento das redes foram aproximadamente de 180 horas para as redes de
Elman e 100 horas para as TDNN3. Esta demora se deu ao tamanho de cada época de treina-
mento, sendo necessário apresentar a RNA 22 séries temporais, cada uma com um período de
27 anos de dados diários, dos quais 5 anos pertencem ao conjunto de validação e 22 anos ao
conjunto de treinamento.
Concluído esta etapa, o conjunto de teste foi apresentado as redes e suas respostas (previ-
sões) foram armazenadas. Essas respostas demonstram a capacidade das RNAs utilizadas em
predizer valores com um horizonte máximo de 5 anos, horizonte pré-determinado pelo tamanho
do conjunto de testes (5 anos). Um resumo do desempenho das redes é apresentado nas Tabelas
5.4 e Tabela 5.4, onde os melhores resultados estão destacados em negrito.
No geral, as redes de Elman obtiveram melhores resultados, tendo suas melhores represen-
tações nos fluxos máximos de vazões, contudo a maior frequência de erros ocorreu nas vazões
médias. A ocorrência desses erros pode ter sido causada pelo alto número de combinações pos-
síveis das entradas que culminam em um valor médio, dificultando o processo de generalização
temporal da rede.
Contudo, considerando o fluxo médio anual da bacia (524 m3/s), o erro médio foi pequeno,
tendo uma variação de 24,141 m3/s. Uma possível alternativa para tentar melhorar os resulta-
dos seria aumentar a representação temporal. Vale lembrar que essa modificação exigiria mais
recursos computacionais, aumentando o tempo de treinamento e a memória necessária para
3Os testes foram executados utilizando o sistema operacional Windows XP, um processador Pentium IV3000MHz e 1024MB de memória RAM
49
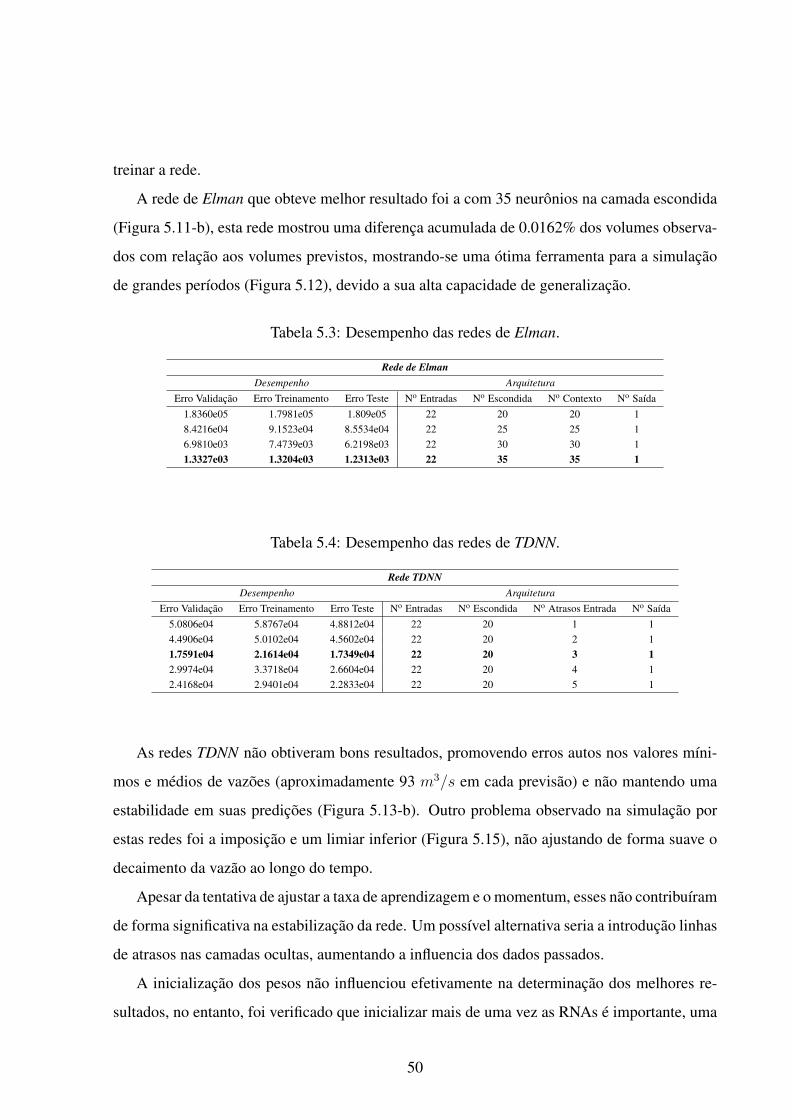
treinar a rede.
A rede de Elman que obteve melhor resultado foi a com 35 neurônios na camada escondida
(Figura 5.11-b), esta rede mostrou uma diferença acumulada de 0.0162% dos volumes observa-
dos com relação aos volumes previstos, mostrando-se uma ótima ferramenta para a simulação
de grandes períodos (Figura 5.12), devido a sua alta capacidade de generalização.
Tabela 5.3: Desempenho das redes de Elman.
Rede de ElmanDesempenho Arquitetura
Erro Validação Erro Treinamento Erro Teste No Entradas No Escondida No Contexto No Saída1.8360e05 1.7981e05 1.809e05 22 20 20 18.4216e04 9.1523e04 8.5534e04 22 25 25 16.9810e03 7.4739e03 6.2198e03 22 30 30 11.3327e03 1.3204e03 1.2313e03 22 35 35 1
Tabela 5.4: Desempenho das redes de TDNN.
Rede TDNNDesempenho Arquitetura
Erro Validação Erro Treinamento Erro Teste No Entradas No Escondida No Atrasos Entrada No Saída5.0806e04 5.8767e04 4.8812e04 22 20 1 14.4906e04 5.0102e04 4.5602e04 22 20 2 11.7591e04 2.1614e04 1.7349e04 22 20 3 12.9974e04 3.3718e04 2.6604e04 22 20 4 12.4168e04 2.9401e04 2.2833e04 22 20 5 1
As redes TDNN não obtiveram bons resultados, promovendo erros autos nos valores míni-
mos e médios de vazões (aproximadamente 93 m3/s em cada previsão) e não mantendo uma
estabilidade em suas predições (Figura 5.13-b). Outro problema observado na simulação por
estas redes foi a imposição e um limiar inferior (Figura 5.15), não ajustando de forma suave o
decaimento da vazão ao longo do tempo.
Apesar da tentativa de ajustar a taxa de aprendizagem e o momentum, esses não contribuíram
de forma significativa na estabilização da rede. Um possível alternativa seria a introdução linhas
de atrasos nas camadas ocultas, aumentando a influencia dos dados passados.
A inicialização dos pesos não influenciou efetivamente na determinação dos melhores re-
sultados, no entanto, foi verificado que inicializar mais de uma vez as RNAs é importante, uma
50

vez que em alguns casos, ainda que poucos, as RNAs direcionaram a solução do problema para
um mínimo local.
(a) Dados de treinamento (b) Dados de testes
Figura 5.11: Ilustração dos dados coletados (eixo das abcissas) versus os resultados preditospela melhor rede de Elman (eixo das ordenadas), para os conjuntos de treinamento (a) e de teste(b).
Figura 5.12: Melhor resultado das redes de Elman para a predição de 5 anos de vazões.
51

(a) Dados de treinamento (b) Dados de testes
Figura 5.13: Ilustração dos dados coletados (eixo das abcissas) versus os resultados preditospela melhor rede TDNN (eixo das ordenadas), para os conjuntos de treinamento (a) e de teste(b).
Figura 5.14: Melhor resultado das redes TDNN para a predição de 5 anos de vazões.
52
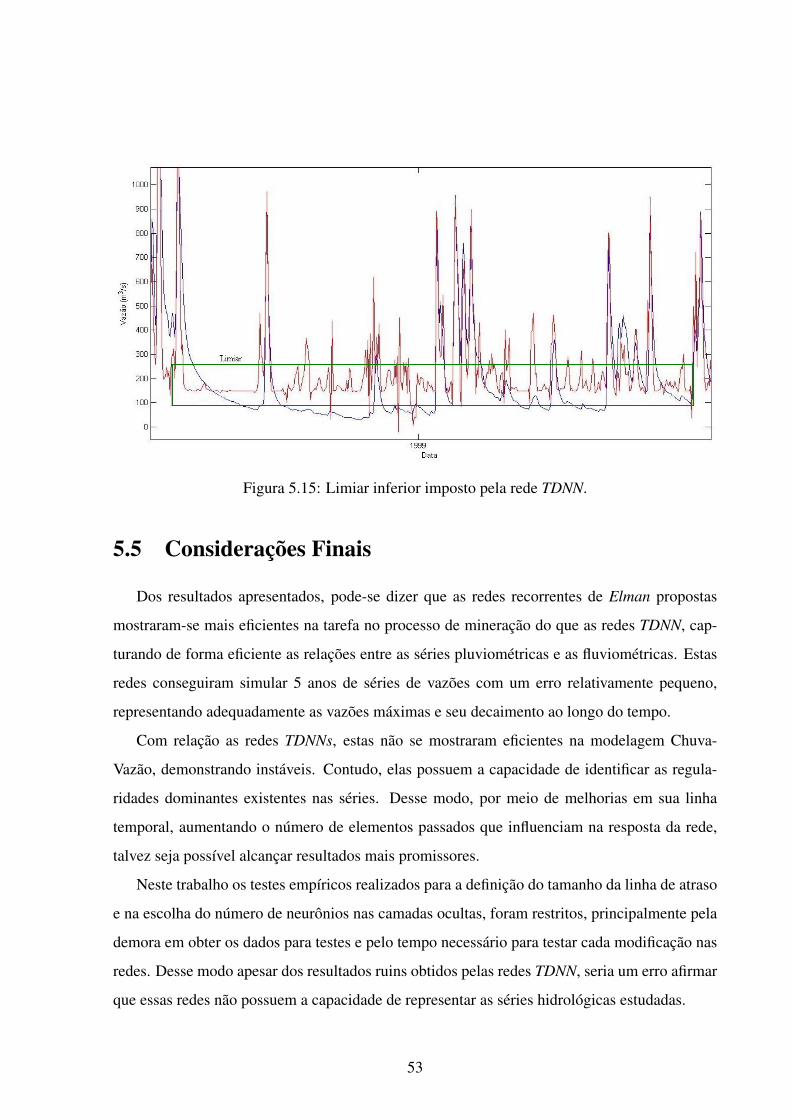
Figura 5.15: Limiar inferior imposto pela rede TDNN.
5.5 Considerações Finais
Dos resultados apresentados, pode-se dizer que as redes recorrentes de Elman propostas
mostraram-se mais eficientes na tarefa no processo de mineração do que as redes TDNN, cap-
turando de forma eficiente as relações entre as séries pluviométricas e as fluviométricas. Estas
redes conseguiram simular 5 anos de séries de vazões com um erro relativamente pequeno,
representando adequadamente as vazões máximas e seu decaimento ao longo do tempo.
Com relação as redes TDNNs, estas não se mostraram eficientes na modelagem Chuva-
Vazão, demonstrando instáveis. Contudo, elas possuem a capacidade de identificar as regula-
ridades dominantes existentes nas séries. Desse modo, por meio de melhorias em sua linha
temporal, aumentando o número de elementos passados que influenciam na resposta da rede,
talvez seja possível alcançar resultados mais promissores.
Neste trabalho os testes empíricos realizados para a definição do tamanho da linha de atraso
e na escolha do número de neurônios nas camadas ocultas, foram restritos, principalmente pela
demora em obter os dados para testes e pelo tempo necessário para testar cada modificação nas
redes. Desse modo apesar dos resultados ruins obtidos pelas redes TDNN, seria um erro afirmar
que essas redes não possuem a capacidade de representar as séries hidrológicas estudadas.
53

Capítulo 6
Conclusões
Esse trabalho propôs a modelagem de Chuva-Vazão por meio de RNAs, a partir de dados
de séries hidrológicas, objetivando a avaliação dessa abordagem na representação do comporta-
mento temporal do processo de transformação de chuva em vazão.
A escolha da modelagem Chuva-Vazão se deu devido à complexidade envolvida na repre-
sentação de séries temporais hidrológicas. Uma das principais dificuldades encontradas nestas
séries é a presença da sazonalidade devido aos períodos seco e úmido do ano.
Modelos conceituais foram por um longo período de tempo a alternativa mais comum para
gerar modelos hidrológicos na análise de predição de vazões. Contudo, pesquisas por aborda-
gens mais ágeis e práticas, capazes de capturar automaticamente os padrões temporais existen-
tes nos dados, representando o comportamento das séries, têm sido intensas. Uma das atuais
tendências é a aplicação de RNAs para a modelagem e previsão de séries vazões fluviais.
A construção do modelo Chuva-Vazão foi baseado em duas RNAs, a rede TDNN e a rede
recorrente de Elman. A primeira, pelos experimentos realizados, se mostrou ineficiente na
tarefa de Predição, apresentando instabilidade em suas predições. O número restrito de séries
temporais utilizadas (22 séries de precipitação e uma de vazão) ou as inconsistências existentes
nas séries hidrológicas podem ter sido os causadores desta instabilidade; no entanto, essa é
apenas uma hipótese e deve ser melhor avaliada em pesquisas futuras, para uma afirmação mais
categórica.
Outro motivo que pode ter influenciado nos resultados (ruins) obtidos pelas redes TDNN é
o tamanho da linha temporal, sendo necessários muitos experimentos para chegar a uma repre-
sentação adequada. O limite de 5 níveis de memória, imposto pelo longo tempo de treinamento
dessa rede, pode não ter sido suficiente para capturar as componentes das séries. Para confirmar

esta hipótese, testes com linhas temporais maiores devem ser realizados.
Com relação à rede recorrente de Elman, os resultados foram promissores, promovendo
prognósticos confiáveis para períodos longos (5 anos). As previsões efetuadas pela rede apre-
sentaram erros relativamente pequenos, aproximadamente 24 m3/s por previsão, mostrando
alta capacidade de generalização temporal.
Com base nos resultados obtidos pela rede de Elman, esta foi considerada uma ferramenta
útil e eficiente na para resolução de problemas de pesquisas e de gestão dos recursos hídricos
da bacia do rio Piquiri.
Para o ambiente computacional em que os testes foram realizados, o tempo de treinamento
de aproximadamente de 180 horas por rede, embora considerado alto computacionalmente, é
pequeno se comparado à construção de modelos conceituais, que podem levar anos para ser
construídos e calibrados. Ademais, após a preparação dos dados, o treinamento das RNAs se dá
de forma automática, diminuindo o esforço e a influência do especialista na construção desses
modelos.
Os resultados obtidos nessa pesquisa estimulam a investigação da aplicação de RNA na
modelagem de séries temporais hidrológicas, mas é um assunto extenso. Para trabalhos futuros
recomenda-se:
• Construir redes TDNN com mais níveis de atraso para melhor avaliar sua a capacidade
em modelar séries hidrológicas. Considerando que a inserção de grandes linhas de atraso
culmina em um aumento dos custos computacionais (alta quantidade de memória), uma
opção seria trabalhar com séries de precipitação acumuladas, reduzindo a quantidade de
neurônios na camada de entrada (no caso desse trabalho, foram 22 neurônios, um para
cada série), de forma que expandir a linha de atraso ainda manteria o custo computacional
em um patamar considerado viável.
• Testar outras RNAs para o problema em questão, em especial as recorrentes, investigando
diferentes algoritmos de treinamento e analisando diferentes formas de representação e
normalização dos dados de entrada e de saída.
• Selecionar séries de precipitação utilizando verificações de consistência, evitando séries
que contribuam desfavoravelmente ao processo de generalização das RNAs. Essa avalia-
55

ção pode ser efetivada pela análise de correlação entre as séries de entrada e sua contri-
buição na vazão resultante.
• Na etapa de pré-processamento, utilizar outros modelos de imputação de dados ausentes,
testando a consistência, de forma comparativa, dos seus resultados.
• Empregar índices estatísticos para validar os resultados estimados, a exemplo d o coefici-
ente de Camargo [14], que avalia a precisão e a exatidão das predições, promovendo uma
métrica hidrológica para validação dos modelos Chuva-Vazão. Neste método, a precisão
é considerada como sendo o grau de dispersão dos dados com relação à média (esta avali-
ação é obtida por cálculos de correlação) e a exatidão como sendo o grau de afastamento
dos valores estimados em relação aos observados (coeficiente de Willmontt [53]).
56

Referências Bibliográficas
[1] ARDRIB, M. A. The Handbook of Brain Theory and Neural Networks, chapter:
Articles, p.81–1239. A Brandford Book, Cambridge, MA, USA, 2. ed., 2003.
[2] BALLINI, R. Análise e Previsões de Vasões Utilizando Modelos de Séries Tem-
porais, Redes Neurais e Redes Neurais Nebulosas. Campinas, SP: Universidade
Estadual de Campinas, Setembro, 2000. Tese.
[3] BARTH, F. T. et al. Modelos para Gerenciamento de Recursos Hídricos. 1. ed.
São Paulo: NOBEL/ABRH, 1987.
[4] BARP, A. R. B. Modelagem Chuva-vazão em Bacias Hidrográficas com Su-
porte em Redes Neurais Artificiais. Campinas - SP: Universidade Estadual de
Campinas, Outubro, 1999. Tese.
[5] BARBALHO, V. M. S. Sistemas Baseados em Conhecimento e Lógica Difusa
para Simulação do Processo Chuva-Vazão. Rio de Janeiro, RJ: Universidade
Federal do Rio de Janeiro, Novembro, 2001. Tese.
[6] BARBOSA, F. A. R. Medidas de proteção e controle de inundações urbanas na
bacia do rio Mamanguape/PB. João Pessoa - PB: UFPB – Universidade Federal
da Paraíba, Março, 2006. Dissertação.
[7] BOGORNY, V. Algoritmos e Ferramentas de Descoberta de Conhecimento em
Banco de Dados Geográficos. Porto Alegre - RS: UFRGS – Universidade Federal
do Rio Grande do Sul, Março, 2003. Monografia.
[8] BOX, G.; JENKINS, G. M.; REINSEL, G. C. Time Series Analysis: forecasting
and control. 3. ed. New Jersey: Prentice Hall, 1994.

[9] BRAGA, A. P.; CARVALHO, A. P. L.; LUDERMIR, T. B. Redes Neurais Artifi-
ciais: teoria e aplicações. 2. ed. Rio de Janeiro: LTC, 2007.
[10] BROGAN, W. L. Modern Control Theory. 2. ed. Englewood Cliffs - NJ: Prentice
Hall, 1985.
[11] CAMPOS, J. A brief look on the literature on deseasonalization. Revista de
Econometria, Rio de Janeiro, v.11, n.2, p.217–236, Novembro, 1991.
[12] CASTRO, M. C. F. Predição Não-Linear de Séries Temporais Usando Redes
Neurais RBF por Decomposição em Componentes Principais. Campinas, SP:
Universidade Estadual de Campinas, Março, 2001. Tese.
[13] DAWSON, D. W.; WILBY, R. An artificial neural network approach to rainfall
runoff modeling. Journal Hydrological Sciences, Canada, v.43, p.47–65, 1998.
[14] DE CAMARGO, N. P. Determination of The Water Balance Components and
Drought Sensitivity Indices for a Sorghum Crop. UN, Estados Unido: University
of Nebraska, Janeiro, 1993. Tese.
[15] DIGGLE, P. Time series: A Biostatistical Introduction. 2. ed. New York: Oxford
Science Publications, 1990.
[16] ELMAN, J. L. Finding structure in time. Cognitive Science, San Francisco, CA,
USA, v.14, n.2, p.179–211, 1990.
[17] FRANCHINI, F.; PACCIANI, M. Comparative analysis of several conceptual
rainfall-runoff models. Journal of Hydrology, Toscana, v.122, n.1-4, p.161–219,
Janeiro, 1991.
[18] GAHEGAN, M. Data mining and knowledge discovery in the geographical domain.
National Academies Computer Science and Telecommunications Board, [S.l.],
v.1, n.14, p.113–139, Setembro, 2001.
[19] GRANGER, C. W. J.; NEWBOLD, P. Forecasting Economic Time Series. 2. ed.
New York: Academic Press, 1977.
58

[20] GROUP, C. P. R. Parallel distributed processing: explorations in the micros-
tructure of cognition, vol. 1: foundations. Cambridge, MA, USA: MIT Press,
1986.
[21] HAYKIN, S. Redes Neurais: Princípios e Prática. 2. ed. São Paulo - SP: BOOK-
MAN, 2000.
[22] HOPFIELD, J.; TANK, D. Computing with neural circuits: A model. Science,
Cambridge, Massachusetts, v.233, n.1, p.625–833, Agosto, 1986.
[23] HSU, K.; GUPTA, H.; SOROOSHIAN, S. Artifical neural network modelling of the
rainfall-runoff process. Water Resource Research, USA, v.31, n.10, p.2517–2530,
Outubro, 1995.
[24] JAIN, S. K.; DAS, A.; SRIVASTAVA, D. K. Appication of ann for reservoir inflow
prediciton and operation. Jounal of Water Resources Planning and Manange-
mente, USA, v.25, n.5, p.263–271, Setembro/Outubro, 1999.
[25] JAIN, A.; INDURTHY, S. K. V. P. Comparative analysis of event based rainfall
runoff modeling techniques deterministic, statistical, and artificial neural networks.
Journal Hydrology, Canada, v.8, p.93–98, Março/Abril, 2003.
[26] KORTH, H.; SILBERSCHATZ, A. Sistemas de Banco de Dados. 1. ed. São Paulo
- SP: Campus Ltda, 2006.
[27] KOSKO, B. Bidirectional associative memories. IEEE Trans. Systems, Man, and
Cybernetics, Piscataway, NJ, USA, v.18, n.1, p.49–60, Janeiro/Fevereiro, 1988.
[28] KRAUSKOPF, R. Atualização de Modelos Chuva-Vazão-Propagação com Es-
timadores de Estado. Curtiba - PR: UFPR – Universidade Federal do Paraná,
outubro, 2005. Dissertação.
[29] LATTENMAIER, D. P.; POTTER, K. W. Testing flood frequency estimation
methods using a regional flood generation model. Water Resources Research,
USA, v.21, n.12, p.1903–1914, 1985.
59

[30] LATORRE, M. R. O.; CARDOSO, M. R. A. Análise de séries temporais em epide-
miologia: uma introdução sobre os aspectos metodológicos. Revista Brasileira de
Epidemiologia, São Paulo - SP, v.4, n.3, p.145–152, Novembro, 2001.
[31] M., T. C. E. Modelos hidrológicos. 1. ed. Porto Alegre - RS: UFRGS & ABRH,
1998.
[32] MACHADO, F. W. Modelagem Chuva-Vazão Mensal Utilizando Redes Neu-
rais Artificiais. Curitiba - PR: UFPR – Universidade Federal de Campina Grande,
Agosto, 2005. Dissertação.
[33] MAGALHÃES, M. H. Redes Neurais, Metodologias de Agrupamento e Com-
binação de Previsores Aplicados à Previsão de Vazões Naturais. Campinas - SP:
UNICAMP – Universidade Estadual de Campinas, Novembro, 2004. Dissertação.
[34] MINNS, A. W.; HALL, M. J. Artificial neural networks as rainfall runoff models.
Journal Hydrological Sciences, Canada, v.41, n.3, p.399–417, 1996.
[35] MORETTIN, P. A.; TOLOI, C. M. C. Previsão de Séries Temporais. 2. ed. São
Paulo - SP: Atual Editora, 1985.
[36] MUELLER, A. Uma Aplicação de Redes Neurais Artificiais na Previsão do
Mercado Acionário. Florianópolis - SC: UFSC – Universidade Federal de Santa
Catarina, Julho, 2006. Dissertação.
[37] NEELANKANTAN, T. R. Neural network-based simulation-optimization model
for reservoir operation. Journal of Water Resources Planning and Mangement,
Índia, v.126, n.2, p.57–64, Março/Abril, 2000.
[38] R., L.; FRANZINI, J. Engenharia de Recursos Hídricos. 3. ed. Recife, PE:
USP/McGraw Hill do Brasil, 1978.
[39] REFENES, A. N.; BURGESS, A.; BENTZ, Y. Neural networks in financial engi-
neering: a study in metodology. Neural Networks, IEEE Transactions, Canada,
v.8, n.6, p.1222–1267, Novembro, 1997.
60

[40] RICHARD, D. N. Applied regression analysis. 3. ed. New York: JOHN WILEY
AND SONS LTDA, 1981.
[41] RIGHETTO, A. M. Hidrologia e Recursos Hídricos. 1. ed. São Carlos, SP:
EESC-USP, 1998.
[42] SAWAI, H. TDNN-LR continuous speech recognition system using adaptive incre-
mental TDNN training. In: ICASSP ’91: ACOUSTICS, SPEECH, AND SIGNAL
PROCESSING, 1991. Proceedings... Washington, DC, USA: IEEE Computer So-
ciety, 1991. p.53–56.
[43] SCHREIBER, D. S.; CLEEREMANS, A.; MCCLELLAND, J. L. Learning subse-
quential structure in simple recurrent networks. Canada, p.643–652, 1988.
[44] SCHNELL, E.; SCHÜHLI. Reconhecimento de Gestos de Maestro Utilizando
Redes Neurais Artificiais Parcialmente Recorrentes. Curitiba - PR: UFPR –
Universidade Federal do Paraná, 2005. Dissertação.
[45] SRINIVASULU, S.; JAIN, A. A comparative analysis of training methods for arti-
ficial neural network rainfall runoff models. Applied Soft Computing, USA, v.6,
n.3, p.295–306, Março, 2006.
[46] SUDERHSA. Superintendência de Desenvolvimento de Recursos Hídricos e
Saneamento Ambiental. Disponível em <http://www.suderhsa.pr.gov.br>. Ultimo
acesso: 08 de novembro de 2008.
[47] U., F.; PIATETSKY-SHAPIRO, G.; SMYTH, P. The kdd process for extracting
useful knowledge from volumes of data. Commun. ACM, New York, NY, USA,
v.39, n.11, p.27–34, 1996.
[48] VALENÇA, M. Aplicando Redes Neurais: Um Guia Completo. 1. ed. Olinda -
PE: Livro Rápido - Elógica, 2005.
[49] WAIBEL, A. et al. Phoneme recognition using time-delay neural networks. San
Francisco, CA, USA, p.393–404, 1990.
61

[50] WASSERMAN; PHILIP, D. Neural Computing : Theory and Practice. 1. ed.
New York: Van Nostrand Reinhold, 1989.
[51] WHEELWRIGHT, S.; MAKRIDAKIS, S. Forecasting Methods for Manage-
ment. 4. ed. New York: John Wiley & Sons Inc, 1985.
[52] WHEELWRIGHT, S.; MAKRIDAKIS, S. Forecasting Methods for Manage-
ment. 1. ed. John Wiley and Sons LTDA, 1989.
[53] WILLMOTT, C. J.; CKLESON, S. G.; DAVIS, R. E. Statistics for evaluation and
comparation of models. Journal of Geophysical Research, Ottawa, v.90, n.5,
p.8995–9005, Setembro, 1985.
[54] WILLIAMS, R. J.; ZIPSER, D. A Learning Algorithm for Continually Running
Fully Recurrent Neural Networks.
[55] XAVIER, A. E. Calibração automática de modelos chuva-vazão por meio de técni-
cas de suavização. Lisboa, Portugal, p.237–253, Agosto, 1989.
[56] XIAOWEI, L.; ZEHONG, Y.; YIXU, S. The Application of Echo State Network
in Stock Data Mining, v.5012 of Lecture Notes in Computer Science, p.932–
937. Springer, Osaka, Japão, Maio, 2008.
62