um estudo de diferentes m´etodos aproximados aplicados ao ...adriana/files/binp.pdf · de...
TRANSCRIPT

Um estudo de diferentes metodos aproximados
aplicados ao problema de otimizacao combinatoria
de empacotamento (Bin-Packing Problem)
Adriana Cesario de Faria Alvim
Departamento de InformaticaPontifıcia Universidade Catolica do Rio de Janeiro
Dezembro, 1998
1 Introducao
O problema de Empacotamento em Caixas (Bin Packing Problem - BPP) ba-sicamente consiste em empacotar objetos de diferentes tamanhos em caixas detamanho fixo. Neste problema, deseja-se acomodar n objetos em caixas de igualcapacidade C. O objeto j possui peso wj. O objetivo e determinar o numeromınimo de caixas necessarias para acomodar todos os n objetos. Nenhum objetopode ser acomodado parcialmente em uma caixa e parcialmente em outra.
Exemplo 1 Seja C = 10, n = 6 e W = (5, 6, 3, 7, 5, 4). A Figura 1 mostra umempacotamento dos seis objetos utilizando somente tres caixas. Percebe-se que saonecessarias no mınimo tres caixas.
Figura 1: Empacotamento otimo para o Exemplo 1.
BPP e um problema de otimizacao combinatoria cuja versao de decisao e NP-completa [4]. A resolucao deste tipo de problema tem sido tratada na literaturabasicamente por dois tipos de metodos: exatos e aproximados. Os primeiros garan-tem que a solucao otima para o problema e encontrada, enquanto os metodosaproximados alcancam solucoes sub-otimas, porem possibilitam que instanciasmaiores sejam tratadas em tempo menor.
1

Desta forma, este trabalho tem como objetivo fazer um estudo de algunsmetodos aproximados aplicados ao problema de empacotamento. Na proximasecao apresenta-se a formulacao do problema. Na Secao 3 descreve-se quatrometodos construtivos para a solucao aproximada do problema, na Secao 4 apresenta-se um metodo de busca local, a meta-heurıstica Busca Tabu e utilizada na Secao 5e, para finalizar, os resultados computacionais de todos os metodos utilizados saorelatados e analisados na Secao 6.
2 Formulacao do Problema
BPP, conforme descrito em [9], utiliza a terminologia do problema da mochila daseguinte forma. Sejam n objetos e n caixas, onde:
wj = peso do objeto j,C = capacidade de cada caixa,
Deseja-se colocar cada objeto em uma caixa de forma que o peso total dos objetosem cada caixa nao exceda C e o numero de caixas utilizadas seja mınimo.
Minimizar z =n∑
i=1yi (2.1)
sujeito an∑
j=1wjxij ≤ Cyi, i ∈ N ={1,. . . ,n} (2.2)
n∑
i=1xij = 1, j ∈ N, (2.3)
yi = 0 ou 1, i ∈ N, (2.4)
xij = 0 ou 1, i ∈ N, j ∈ N, (2.5)
onde
yi =
{
1 se caixa i for usada;0 caso contrario,
xij =
{
1 se objeto j for colocado na caixa i;0 caso contrario.
Assume-se, sem perda de generalidade, que os pesos wj sao inteiros positivos,
C e um inteiro positivo, (2.6)wj ≤ C para j ∈ N. (2.7)
Assume-se tambem que em uma solucao viavel as caixas de menores ındicessao utilizadas primeiro, i.e., yi ≥ yi+1 para i = 1, . . . , n− 1.
2

3 Metodos Construtivos
Ha diversas heurısticas gulosas simples para este problema. Em geral, elas naofornecem o empacotamento otimo. Entretanto, elas podem fornecer empacota-mentos que utilizem apenas uma pequena quantidade de caixas a mais do que a
solucao otima. Define-se capacidade residual da caixa i como Ri = C −n∑
j=1wjxij
para i ∈ N .
3.1 First Fit (FF)
Indexe as caixas 1, 2, 3, . . .. Inicialmente todas as caixas estao vazias. Para efetuaro empacotamento, considere os objetos na ordem 1, 2, . . . , n. Para empacotaro objeto j, encontre o ındice mais baixo i tal que o objeto j caiba na caixa i(wj ≤ Ri). Empacote o objeto j na caixa i. Somente quando um objeto nao puderser incluıdo em uma caixa ja usada, uma nova caixa sera considerada.
3.2 Best Fit (BF)
Indexe as caixas 1, 2, 3, . . .. Inicialmente todas as caixas estao vazias. Para efetuaro empacotamento, considere os objetos na ordem 1, 2, . . . , n. Para empacotar oobjeto j, encontre a caixa com menor Ri tal que o objeto j caiba na caixa i(wj ≤ Ri), no caso de empate escolha o menor ındice da caixa i. Empacote oobjeto j na caixa i. O objeto corrente e empacotado na caixa viavel com a menorcapacidade residual.
3.3 First Fit Decrescente (FFD)
Uma modificacao simples pode melhorar a performance do algoritmo FF. Tipica-mente os piores casos ocorrem quando um grande numero de objetos com pesopequeno sao colocados nas primeiras caixas. Ao inves de colocar os objetos naordem em que eles sao apresentados, uma ideia e ordena-los em ordem decrescentede peso, e posteriormente aplicar o algoritmo FF. Assim, ordene os objetos tal quew1 ≥ w2 ≥ . . . ≥ wn, e entao aplique o algoritmo FF.
3.4 Best Fit Decrescente (BFD)
Ordene os objetos tal que w1 ≥ w2 ≥ . . . ≥ wn. Aplique o algoritmo BF paraempacotar os objetos.
Exemplo 2 Considere a instancia do problema do Exemplo 1. Para cada um dosquatro algoritmos apresentados anteriormente, a Figura 2 mostra os empacota-mentos resultantes quando aplicados a esta instancia. Para os algoritmos FFD e
3

BFD os objetos sao considerados na ordem (4, 2, 1, 5, 6, 3). A figura ilustra bemcomo, para esta instancia, os algoritmos FFD e BFD apresentam melhores re-sultados que os algoritmos FF e BF. Apesar de FFD e BFD apresentarem umempacotamento otimo, em geral, este nao e o caso.
Figura 2: Empacotamentos resultantes das quatro heurısticas descritas acima.
3.5 Limites e Complexidade
Teorema 1 Seja I uma instancia do problema de empacotamento e seja z(I)o numero mınimo de caixas necessarias para esta instancia. O empacotamentogerado pelo algoritmo First Fit nunca utiliza mais de 2z caixas.
Prova 1 FF nao pode deixar mais de duas caixas com menos da metade cheias, docontrario os objetos na primeira caixa poderiam ser colocados na segunda. Destaforma, o numero de caixas utilizadas nao pode ser maior do que duas vezes a somados pesos de todos os objetos dividida pela capacidade da caixa (arredondado paracima). O teorema segue do fato de que o numero de caixas da solucao otima naopode ser menor que a soma de todos os pesos de todos os objetos dividida pelacapacidade da caixa.
O limite do teorema 1 e conservativo. A constante 2 pode ser reduzida atravesde uma melhor e mais complexa analise. O proximo teorema, provado em [6],apresenta esses limites.
Teorema 2 Seja I uma instancia do problema de empacotamento e seja z(I)o numero mınimo de caixas necessarias para esta instancia. O empacotamentogerado pelos algoritmos FF ou BF utilizam nao mais de (17/10)z(I) + 2 caixas.O empacotamento gerado pelos algoritmos FFD ou BFD utilizam nao mais de(11/9)z(I)+4 caixas. Estes limites sao os melhores conhecidos para os respectivosalgoritmos [8].
A complexidade das heurısticas FF, BF, FFD e BFD e O(n log n). Isto epossıvel utilizando uma arvore-2-3 cujas folhas guardam a capacidade residual dascaixas inicilizadas. Cada iteracao custa O(log n) e existem n iteracoes. Paradetalhes desta estrutura de dados veja em [1] e [10].
4 Metodo de Busca Local
Nesta secao descreve-se um metodo de busca local para o problema de empacota-mento.
4

4.1 Partida
A solucao inicial sera obtida atraves do metodo construtivo FFD descrito na Secao3.3.
4.2 Vizinhanca
Define-se uma solucao S para o problema de empacotamento como um par (x, y)que satisfaz as restricoes 2.3 a 2.5 da Secao 2, onde z(S) igual ao numero de caixasdo empacotamento. Diz-se que S e viavel se S tambem satisfaz a restricao decapacidade da equacao 2.2.
Seja a solucao viavel S = (x, y), define-se vizinhanca de S, N(S), como oconjunto das solucoes S ′ = (x′, y′), S ′ ∈ N(S), onde:
z(S ′) = z(S)− 1; (4.1)y′
i ≤ yi, ∀i ∈ N ={1,. . . ,n}; (4.2)xij = 1 e y′
i = 0⇒ ∃ k 6= i, x′kj = 1 e xkj = 0, i ∈ N, j ∈ N. (4.3)
A restricao 4.1 diz que o numero de caixas de um vizinho de uma solucao viavele exatamente igual ao numero de caixas da solucao viavel menos uma. A restricao4.2 diz que todas as caixas utilizadas na solucao vizinha S ′ tambem sao utilizadasna solucao viavel S. E a ultima restricao, 4.3, diz que se existe uma caixa queera utilizada na solucao S e esta mesma caixa nao e utilizada na solucao S ′, entaoos objetos que estavam nesta caixa na solucao S estao em alguma outra caixa dasolucao S ′.
Desta forma, a vizinhanca N(S) e definida em termos da (i) quantidade decaixas retiradas (uma), (ii) caixa retirada (z(S) opcoes) e (iii) das possibilidades dedistribuicao dos objetos da caixa retirada nas demais caixas. De forma especıfica, avizinhanca para o algoritmo de busca local proposto ira considerar, para cada caixaretirada, apenas uma possibilidade de distribuicao, especificada pelo algoritmoEmpacotamento descrito adiante. Assim, uma solucao viavel S possui z(S)vizinhos.
4.3 Criterio de parada
Para uma solucao viavel a busca local termina quando o limite inferior de caixasfor atingido ou quando todos os seus vizinhos tiverem sido analisados.
4.4 Algoritmo
O algoritmo apresentado a seguir define a estrategia de busca na vizinhanca pro-posta.
5

Procedimento BuscaLocal (S, limite inferior)Inıcio
Construa uma solucao viavel S usando um metodo construtivo;melhorou← VERDADEIRO;enquanto ( ( z(S) 6= limite inferior ) e ( melhorou ) ) faca
b← 1;melhorou← FALSO;enquanto ( b ≤ z(S) ) e ( NAO melhorou ) faca
S ′ ← Empacotamento(S, {b});se ( NAO viavel(S ′) ) entao
S ′ ← OperadorDeViabilidade(S ′);fim-se;se ( viavel(S ′) ) entao
melhorou← VERDADEIRO;S ← S ′;
fim-se;fim-enquanto;
fim-enquanto;Retorne S;
Fim.
Criterio de empacotamento dos objetos da(s) caixa(s) retirada(s): considera-secada objeto na ordem em que ele foi colocado na caixa a ser retirada, coloca-seo objeto considerado na caixa com a maior capacidade residual da solucao viavelcorrente. A cada passo, tenta-se manter a maior violacao de capacidade das caixas,a menor possıvel.
Procedimento Empacotamento(S, {b})Inıcio
S ′ ← S − b;para i = 1 a i = n faca
se xib = 1 entao
b′ ← Min{k : minn∑
j=1w′
jx′kj, k ∈ N};
x′ib′ ← 1;
fim-se;fim-para;Retorne S ′;
Fim.
A solucao gerada pela rotina Empacotamento nao e necessariamente umasolucao viavel. Quer dizer, muito provavelmente existirao caixas cujo peso e maiorque a capacidade da mesma. Neste caso, aplica-se o procedimento OperadorDe-
6

Viabilidade com o objetivo tentar viabilizar a solucao, o que e possıvel mexendo-se na composicao das caixas. Considerando-se apenas duas caixas, o “Metodo deDiferenciacao” de Karmarkar-Karp, implementado pela rotina MetodoDeDiferenciacao,e um excelente metodo para diminuir a diferenca de peso entre elas. A estrategia doprocedimento OperadorDeViabilidade e aplicar este metodo, sucessivamente,ate nao existirem mais caixas com a capacidade violada ou ter atingido o numeromaximo de verificacoes. O criterio de selecao dos pares de caixas e do numeromaximo de verificacoes determina o numero de iteracoes do procedimento. Nestaversao, a cada iteracao, considera-se apenas uma caixa de maior peso. Alem disso,um par de caixas e analisado, no maximo, uma vez, mesmo se a composicao deuma das caixas tenha sido alterada em alguma iteracao anterior. Seja Peso(i) o
peso da caixa i,n∑
j=1wjxi,j.
Procedimento OperadorDeViabilidade(S)Inıcio
Faca Tabu(i1, i2)← 0 para i1 6= i2 , yi1 = yi2 = 1, i1, i2 ∈ N ;Faca Tabu(i1, i2)← 1 para i1 = i2 , yi1 = 1, i1 ∈ N ;B ← {i1, i2, . . . , iz(S)} onde Peso(i1) ≤ Peso(i2) ≤ Peso(iz(S)) e yi1 = yi2 =
yiz(S)= 1∀ i1, i2 ∈ N ;
maior ← iz(S);
enquanto ( (NAO viavel(S)) e ∃ Tabu(maior, i) = 0, i ∈ N ) facamenor ← ik, ik ∈ B e k = Min{k : ik ∈ B e Tabu(maior, k) = 0};S ← MetodoDeDiferenciacao(S,menor,maior);Tabu(maior,menor)← 1; Tabu(menor,maior)← 1;B = {i1, i2, . . . , iz(S)} onde Peso(i1) ≤ Peso(i2) ≤ Peso(iz(S)) e yi1 = yi2 =
yiz(S)= 1, ∀ i1, i2 ∈ N ;maior ← iz(S);
fim-enquanto;Retorne S;
Fim.
Procedimento MetodoDeDiferenciacao(S,menor,maior)Inıcio
Aplique o metodo de Diferenciacao [7] para tentar igualar o peso das caixasmaior e menor de S gerando S ′;
Retorne S ′;Fim.
7

4.5 Complexidade
Seja S a solucao gerada pelo metodo construtivo e k a diferenca entre o numerode caixas da solucao otima e o numero de caixas de S (limite inferior− z(S)). Oprimeiro laco do procedimento BuscaLocal sera executado no maximo k vezes.O segundo laco deste procedimento sera executado um numero de vezes igualao numero de caixas da solucao viavel S, z(S). Como, no pior caso, o numeromaximo de caixas igual ao numero de objetos n, este laco sera executado, nomaximo n vezes. O procedimento Empacotamento considera cada objeto deuma determinada caixa e coloca em outra caixa. O numero maximo de obje-tos a serem considerados e igual a n. Para escolher a caixa onde o objeto seracolocado, o procedimento utiliza uma rotina para ordenar as caixas pelo peso,cuja complexidade e O(n log n). Assim a complexidade do procedimento Em-
pacotamento e O(n2log n). A matriz Tabu do procedimento Operador de
Viabilidade possui (n2 − n)/2 posicoes validas o que corresponde a quantidademaxima de iteracoes do laco deste procedimento. Cada iteracao executa o proced-imento MetodoDeDiferenciacao, cuja complexidade e O(n log n). Portanto,a complexidade do procedimento MetodoDeDiferenciacao e da ordem deO(n3 log n). Inicializar ou atualizar uma solucao tem custo igual a O(n). Alemdisso, tem-se que se somar ao custo total do procedimento BuscaLocal o custodo metodo construtivo = O(n log n) + (k ∗ (n ∗ (O(n2log n) + O(n3log n)))) =O(kn4log n).
5 Busca Tabu
Busca Tabu e um procedimento adaptativo que guia um algoritmo de busca localna exploracao contınua do espaco de busca. Caracteriza-se pela utilizacao deestruturas flexıveis de memoria para armazenar conhecimento sobre o espaco debusca. A ideia basica e: parte de uma solucao inicial e, a cada iteracao, move paraa melhor solucao na vizinhanca.
Para o problema de empacotamento a abordagem de busca tabu sera empre-gada pelo procedimento Operador de Viabilidade Tabu. A definicao demovimento (transicao entre solucoes na vizinhanca) consiste em mexer na com-posicao de um par de caixas da solucao nao viavel (realizada pelo procedimentoMetodoDeDiferenciacao). Desta forma, a cada iteracao um conjunto demovimentos candidatos e dado pelas combinacoes de pares de caixas (de difer-entes pesos) da solucao nao viavel inicial. Um movimento que leva a uma solucaoja visitada (quando o peso das duas caixas selecionadas nao e alterado) e dito tabu,e e proibido. Utiliza-se uma estrutura de memoria basica (lista tabu) para guardarinformacoes historicas dos movimentos de busca e proibir movimentos tabu.
Operador de Viabilidade Tabu: Seja It(i) a iteracao mais recente queo peso da caixa i foi alterado e seja Tabu(i1, i2) a iteracao mais recente que o
8

metodo de diferenciacao foi aplicado ao par de caixas i1 e i2, independente dopeso das caixas terem sido alterados ou nao. Inicialmente Tabu(i1, i2) = −1 paratodo i1 e i2 onde Peso(i1) 6= Peso(i2), Tabu(i1, i2) = 1 para todo i1 e i2 ondePeso(i1) = Peso(i2), e It(i) = 0 para todo i ∈ N . Entao, quando o par (i1, i2) eexaminado pelo metodo de diferenciacao, faz-se Tabu(i1, i2) = iteracao corrente, ese, como resultado deste exame, o peso das caixas i1 e i2 e alterado tambem faz-seIt(i1) = It(i2) = iteracao corrente. Desta forma, aplica-se o metodo de diferen-ciacao ao par de caixas (i1, i2) somente quando Maior(It(i1), It(i2)) > Tabu(i1, i2),pois, do contrario, o metodo nao mudaria o peso das caixas.
Procedimento BuscaTabu (S, limite inferior)Inıcio
Construa uma solucao viavel S usando um metodo construtivo;It(i)← 0, yi = 1, ∀ i ∈ N ;Tabu(i1, i2)← 1 se Peso(i1) = Peso(i1), yi1 = yi2 = 1, ∀ i1, i2 ∈ N ;Tabu(i1, i2)← −1 se Peso(i1) 6= Peso(i2), yi1 = yi2 = 1, ∀ i1, i2 ∈ N ;it← 0;melhorou← VERDADEIRO;enquanto ( ( z(S) 6= limite inferior ) e ( melhorou ) ) faca
b← 1;melhorou← FALSO;enquanto ( b ≤ z(S) ) e ( NAO melhorou ) faca
S ′ ← Empacotamento(S, {b});se ( NAO viavel(S ′) ) entao
it← it + 1;S ′ ← OperadorDeViabilidadeTabu(S ′, it, It, Tabu)
fim-se;se ( viavel(S ′) ) entao
melhorou← VERDADEIRO;S ← S ′;
fim-se;fim-enquanto;
fim-enquanto;Retorne S;
Fim.
Procedimento OperadorDeViabilidadeTabu(S, it, It, Tabu)Inıcio
viavel ← FALSO;existe par ← FALSO;B ← {i1, i2, . . . , iz(S)} onde Peso(i1) ≤ Peso(i2) ≤ Peso(iz(S)) e yi1 = yi2 =
yiz(S)= 1∀ i1, i2 ∈ N ;
9

maior ← iz(S); /*ındice da caixa de maior peso*/menor ← i1; /*ındice da caixa de menor peso*/enquanto ( (NAO viavel(S)) e existe par ) faca
alterou← MetodoDeDiferenciacaoTabu(S,menor,maior);Tabu(maior,menor)← Tabu(menor,maior)← it;se ( alterou ) entao
It(maior)← It(menor)← it;se (NAO viavel(S)) faca
existe par ← ExistePar(S, It, Tabu,maior,menor);fim-enquanto;Retorne S;
Fim.
Existe Par: Como a matriz Tabu(i, j) e simetrica, para verificar se existe parque possa ser analisado pela rotina MetodoDeDiferenciacaoTabu, percorre-se apenas a diagonal inferior da matriz.
Procedimento ExistePar(S, It, Tabu,maior,menor)Inıcio
B ← {i1, i2, . . . , iz(S)} onde Peso(i1) ≤ Peso(i2) ≤ Peso(iz(S)) e yi1 = yi2 =yiz(S)
= 1∀ i1, i2 ∈ N ;k maior ← z(S); maior ← ik maior; /* ındice da caixa de maior peso */achou par ← FALSO;enquanto ( (k maior > 1) e ( Peso(maior) > C ) e ( NAO achou par ) faca
k menor ← 1; menor ← ik menor;enquanto ( (k menor < k maior) e ( NAO achou par ) faca
se Max(It(maior), It(menor)) > Tabu(maior,menor) entaoachou par ← VERDADEIRO;
senaok menor ← k menor + 1; menor ← ik menor;
fim-se;fim-enquanto;se ( NAO achou par ) entao
k maior ← k maior − 1; maior ← ik maior;fim-se;
fim-enquanto;Retorne achou par,maior,menor;
Fim.
MetodoDeDiferenciacaoTabu: A versao I deste procedimento consid-era que houve alteracao na composicao das caixas quando consegue diminuir adiferenca de peso do par de caixas analisado. Ja a versao II tambem considera
10

alteracao quando, apesar da diferenca de peso continuar a mesma, a composicaodos objetos nas caixas for alterada. A versao III considera que houve alteracaona composicao das caixas quando a diferenca de peso do par de caixas analisadofor diferente (nao importa se para mais ou para menos), alem disso esta versaosempre retorna a composicao das caixas modificadas, mesmo que a diferenca depeso seja a mesma. E importante dizer que esta ultima versao corresponde a umaimplementacao “errada” da ideia da versao I.
Procedimento MetodoDeDiferenciacaoTabuI(S,menor,maior)Inıcio
S ′ ← S;alterou← FALSO;Aplique o metodo de Diferenciacao [7] para tentar igualar o peso das caixas
maior e menor de S ′;se ( ( valorabsoluto(Peso(maior) − Peso(menor)), maior,menor ∈ S ′) <
(valorabsoluto(Peso(maior)− Peso(menor)), maior,menor ∈ S)) entaoalterou← VERDADEIRO;S ← S ′;
fim-se;Retorne alterou, S;
Fim.
Procedimento MetodoDeDiferenciacaoTabuII(S,menor,maior)Inıcio
S ′ ← S;alterou← FALSO;Aplique o metodo de Diferenciacao [7] para tentar igualar o peso das caixas
maior e menor de S ′;se ( ( valorabsoluto(Peso(maior) − Peso(menor)), maior,menor ∈ S ′) <
(valorabsoluto(Peso(maior)− Peso(menor)), maior,menor ∈ S)) entaoalterou← VERDADEIRO;
senao se ( ( valorabsoluto(Peso(maior) − Peso(menor)), maior,menor ∈S ′) = (valorabsoluto(Peso(maior)− Peso(menor)), maior,menor ∈ S)) entao
se A composicao das caixas foi alterada entaoalterou← VERDADEIRO;
fim-se;fim-se;se (alterou) entao
S ← S ′;fim-se;Retorne alterou, S;
Fim.
11

Procedimento MetodoDeDiferenciacaoTabuIII(S,menor,maior)Inıcio
S ′ ← S;alterou← FALSO;Aplique o metodo de Diferenciacao [7] para tentar igualar o peso das caixas
maior e menor de S ′;se ( ( valorabsoluto(Peso(maior) − Peso(menor)), maior,menor ∈ S ′) <
(valorabsoluto(Peso(maior)− Peso(menor)), maior,menor ∈ S)) entaoalterou← VERDADEIRO;
fim-se;S ← S ′;Retorne alterou, S;
Fim.
5.1 Complexidade
A diferenca da complexidade da Busca Tabu em relacao a Busca Local (Secao4) esta na complexidade do procedimento OperadorDeViabilidadeTabu. Onumero de iteracoes deste procedimento nao e dado somente pelo numero deposicoes validas da matriz Tabu, uma vez que quando um par de caixas e alter-ado aproximadamente n posicoes da matriz (relativas as duas caixas analisadas)sao alteradas aumentando o numero de iteracoes do procedimento. Por isso acomplexidade da Busca Tabu e = O(kn5log n).
6 Resultados Computacionais
Falkenauer (1996) apresenta em [3] um algoritmo genetico de agrupamento hıbrido(HGGA) para resolver o problema de empacotamento. Para testar a tecnicaHGGA e o metodo de busca exaustiva proposto por Martello (MTP), Falkenauergerou duas classes de problemas. O autor observa que entre varias classes deproblemas (entenda-se por classe de problemas diferentes capacidades das caixase diferentes tamanhos dos objetos) consideradas em [9] a seguinte configuracaomostrou-se a mais difıcil: capacidade da caixa igual a 150 e tamanho dos objetosdistribuıdos uniformemente de forma aleatoria entre 20 e 100. Para esta classede problemas, chamada uniforme, o autor gerou 20 instancias para cada uma dasquantidade de objetos iguais a 120, 250, 500 e 1000 ∗. Entre todas estas instanciasem apenas cinco casos o algoritmo HGGA nao obteve resultado igual ao limite infe-rior teorico (a soma dos pesos de todos os objetos divida pela capacidade da caixa,
∗Estes dados estao disponıveis atraves da OR Library, http://mscmga.ms.ic.ac.uk/info.html.
12

arredondado para cima). Falkenauer supoe que para estes problemas nao e possıvelencontrar solucao igual a este limite. Recentemente (1998), Gent prova em [5] queutilizando uma heurıstica simples juntamente com muito trabalho manual, esteslimites podem ser alcancados para quatro dos cinco casos. A maior contribuicaodo trabalho de Gent e mostrar que deve-se ter muito cuidado ao se escolher umconjunto de problemas testes supostamente difıceis. Apesar da importancia detal constatacao, esta mesma classe de problemas uniformes foram utilizadas nosexperimentos computacionais deste trabalho. Ate o momento, apenas o valor dasolucao otima do problema u250 13 continua em aberto.
O codigo do algoritmo BT-III foi escrito em C e o compilador utilizado foi occ versao ?. Os testes computacionais deste algoritmo foram conduzidos em umamaquina Origin 200 com dois processadores MIPS R10000 de 180 MHz, 128 Mb dememoria RAM, utilizando o sistema operacional IRIX64 Release 6.4. Os demaistestes computacionais foram conduzidos em uma Workstation SUN Ultra Sparc1, 167 MHz, 256 Mb de memoria RAM, utilizando o sistema operacional SunOS5.5.1. Os codigos dos algoritmos FF, BF, FFD, BFD, BLS, BL, BT-I e BT-IIforam escritos em C e o compilador utilizado foi o gcc versao 2.7.
6.1 Estudo da Complexidade da Implementacao da HeurısticaBest-Fit
O objetivo desta secao e fazer um estudo que compare a complexidade teoricade um metodo construtivo com a complexidade verificada, na pratica, da suaimplementacao. Para tal, tomou-se duas implementacoes da heurıstica Best-Fit.
Um metodo simples de implementar o algoritmo BF e fazer, para cada objetoconsiderado, uma varredura em todas as caixas ja utilizadas a fim de encontrar ade menor capacidade residual que caiba o objeto sendo considerado. Esta primeiraimplementacao, aqui denominada BF-2, tem complexidade O(n2).
Outra implementacao, denominada BF-Tree, utilizou uma arvore binaria debusca para armazenar a capacidade residual das caixas ja utilizadas. Todas asoperacoes basicas em uma arvore binaria custam O(h), onde h e a altura da arvore.Desta forma, a complexidade do algoritmo BF com esta estrutura de dados e iguala O(nh). Sabe-se que, no pior caso, a altura de uma arvore e n e portanto acomplexidade desta implementacao, no pior caso, e igual a O(n2). Tambem prova-se em [2] que a altura de uma arvore construıda de forma aleatoria e O(log n),neste caso a complexidade do algoritmo seria de O(n log n).
Para realizar os testes computacionais utilizou-se 20 instancias de cada uma dasquantidades de objetos iguais a 250, 500, 750, 1000, 1250 e 1500. As instanciascom 250, 500 e 1000 objetos sao as mesmas descritas no inıcio desta secao, asdemais foram geradas segundo a mesma configuracao: capacidade da caixa iguala 150 e tamanho dos objetos distribuıdos uniformemente de forma aleatoria entre20 e 100.
13

As Tabelas 1 e 2 relatam os resultados computacionais das implementacoesBF-2 e BF-Tree, respectivamente. Para cada instancia (Prob.), a coluna (seg.)mostra o tempo em segundos para 100.000 execucoes. A ultima linha mostra asmedias de cada grupo de 20 instancias (mesma quantidade de objetos).
Prob seg. Prob. seg. Prob. seg. Prob. seg. Prob. seg. Prob. seg.u250 00 3 u500 00 14 u750 00 30 u1000 00 54 u1250 00 83 u1500 00 122u250 01 3 u500 01 14 u750 01 31 u1000 01 54 u1250 01 82 u1500 01 118u250 02 3 u500 02 14 u750 02 31 u1000 02 56 u1250 02 84 u1500 02 116u250 03 3 u500 03 14 u750 03 31 u1000 03 55 u1250 03 83 u1500 03 120u250 04 3 u500 04 15 u750 04 31 u1000 04 53 u1250 04 81 u1500 04 118u250 05 4 u500 05 14 u750 05 31 u1000 05 54 u1250 05 82 u1500 05 120u250 06 3 u500 06 15 u750 06 31 u1000 06 53 u1250 06 84 u1500 06 121u250 07 4 u500 07 14 u750 07 31 u1000 07 55 u1250 07 83 u1500 07 117u250 08 4 u500 08 13 u750 08 31 u1000 08 54 u1250 08 85 u1500 08 122u250 09 3 u500 09 14 u750 09 31 u1000 09 54 u1250 09 84 u1500 09 120u250 10 4 u500 10 14 u750 10 31 u1000 10 54 u1250 10 85 u1500 10 117u250 11 4 u500 11 14 u750 11 31 u1000 11 54 u1250 11 82 u1500 11 119u250 12 4 u500 12 14 u750 12 30 u1000 12 53 u1250 12 84 u1500 12 120u250 13 4 u500 13 14 u750 13 31 u1000 13 53 u1250 13 83 u1500 13 119u250 14 4 u500 14 14 u750 14 31 u1000 14 53 u1250 14 84 u1500 14 120u250 15 4 u500 15 14 u750 15 30 u1000 15 54 u1250 15 83 u1500 15 120u250 16 3 u500 16 14 u750 16 31 u1000 16 55 u1250 16 85 u1500 16 117u250 17 3 u500 17 14 u750 17 31 u1000 17 55 u1250 17 87 u1500 17 120u250 18 3 u500 18 14 u750 18 31 u1000 18 54 u1250 18 85 u1500 18 121u250 19 3 u500 19 14 u750 19 31 u1000 19 53 u1250 19 84 u1500 19 119media 3,45 media 14,05 media 30,85 media 54 media 83,70 media 119,30
Tabela 1: Tempos obetidos pela implementacao BF-2.
A partir do tempo medio de execucao da menor instancia considerada (250 ob-jetos) calculou-se os tempos das demais instancias segundo a complexidade decada implementacao. Por exemplo, se o tempo medio de execucao da imple-mentacao BF-2 para 250 objetos e 3,45 segundos, e como esta implementacaopossui complexidade O(n2), entao o tempo medio de execucao da implementacaoBF-2 para 500 objetos deveria ser x = 5002 ∗ 3, 45/2502 = 13, 8. Da mesmaforma, se o tempo medio de execucao da implementacao BF-Tree para 250 ob-jetos e 30,35 segundos, considerando a complexidade de O(n log n), o tempomedio de execucao da implementacao BF-Tree para 500 objetos deveria ser x =((500 log 500) ∗ 30, 35)/(250 log 250) = 68, 32. Para esta ultima implementacaotambem pode-se calcular o tempo considerando a complexidade de pior caso O(n2).A Tabela 3 mostra estes dados. A coluna (n) mostra a quantidade de objetos con-siderada, para cada uma das implementacoes (BF-2 e BF-Tree) a coluna (media)mostra as medias dos tempos de execucao de 20 instancias (mesma das Tabelas 1e 2) e as demais colunas mostram o tempo que cada implementacao deveria levarpara rodar segundo sua complexidade.
Os graficos das Figuras 3 e 4 permitem visualizar melhor os dados da Tabela3. Percebe-se que, para a implementacao BF-2 a curva da media e ligeiramenteinferior a curva da complexidade O(n2), o que e bastante coerente. Como a com-plexidade e para o pior caso, a pequena diferenca dos tempos significa que nem
14

Prob seg. Prob. seg. Prob. seg. Prob. seg. Prob. seg. Prob. seg.u250 00 19 u500 00 81 u750 00 160 u1000 00 233 u1250 00 284 u1500 00 598u250 01 44 u500 01 94 u750 01 110 u1000 01 292 u1250 01 387 u1500 01 389u250 02 35 u500 02 90 u750 02 192 u1000 02 209 u1250 02 287 u1500 02 402u250 03 42 u500 03 65 u750 03 182 u1000 03 237 u1250 03 493 u1500 03 531u250 04 29 u500 04 91 u750 04 235 u1000 04 240 u1250 04 308 u1500 04 410u250 05 36 u500 05 83 u750 05 110 u1000 05 282 u1250 05 386 u1500 05 322u250 06 24 u500 06 76 u750 06 125 u1000 06 275 u1250 06 411 u1500 06 429u250 07 33 u500 07 78 u750 07 174 u1000 07 249 u1250 07 344 u1500 07 431u250 08 29 u500 08 62 u750 08 131 u1000 08 215 u1250 08 413 u1500 08 518u250 09 34 u500 09 121 u750 09 156 u1000 09 238 u1250 09 304 u1500 09 460u250 10 23 u500 10 89 u750 10 167 u1000 10 218 u1250 10 374 u1500 10 415u250 11 32 u500 11 89 u750 11 169 u1000 11 224 u1250 11 247 u1500 11 581u250 12 28 u500 12 80 u750 12 133 u1000 12 271 u1250 12 398 u1500 12 438u250 13 26 u500 13 76 u750 13 111 u1000 13 212 u1250 13 221 u1500 13 501u250 14 24 u500 14 84 u750 14 147 u1000 14 244 u1250 14 292 u1500 14 437u250 15 22 u500 15 79 u750 15 112 u1000 15 213 u1250 15 295 u1500 15 489u250 16 25 u500 16 83 u750 16 138 u1000 16 226 u1250 16 279 u1500 16 550u250 17 27 u500 17 81 u750 17 149 u1000 17 258 u1250 17 396 u1500 17 347u250 18 46 u500 18 87 u750 18 163 u1000 18 323 u1250 18 302 u1500 18 527u250 19 29 u500 19 84 u750 19 156 u1000 19 200 u1250 19 315 u1500 19 522media 30,35 media 83,65 media 151 media 242,95 media 336,8 media 464,85
Tabela 2: Tempos obtidos pela implementacao BF-Tree.
BF-2 BF-Treen media O(n2) media O(n log n) O(n2)
250 3,45 3,25 30,35 30,35 30,35500 14,05 13,80 83,65 68,32 121,40750 30,85 31,05 151,00 109,00 273,151000 54,00 55,20 242,95 151,88 485,601250 83,70 86,25 336,80 195,98 758,751500 119,30 124,20 464,85 241,19 1092,60
Tabela 3: Complexidades das implementacoes BF-2 e BF-Tree.
sempre o pior caso e atingido, o que fica mais evidente quando o tamanho dasinstancias aumenta. Pode-se dizer assim, que a implementacao esta de acordocom a complexidade do algoritmo. Tambem vale notar que os tempos das Tabelas1 e 2, para uma mesma quantidade de objetos, variam muito pouco entre as 20instancias. Em relacao a implementacao BF-Tree todos os pontos da curva damedia estao acima dos pontos da curva de complexidade O(n log n) (caso medio)e abaixo dos pontos da curva de complexidade O(n2) (pior caso). Alem disso, ostempos foram bem superiores aos observados na implementacao BF-2, que, teori-camente, possui complexidade maior. Tal incoerencia pode ser interpretada deduas formas: (i) a arvore binaria de busca nao e a estrutura de dados adequada,como mencionado na Secao 3.5 deve-se utilizar uma arvore balanceda; (ii) como,para o tamanho das instancias testadas, os tempos observados na implementacaoBF-2 eram pouco significativos (inferiores a um centesimo de segundos, e por isso o
15

algoritmo foi executado 100.000 vezes), o custo de manter uma estrutura de dadosmais complexa nao foi vantajoso.
0
20
40
60
80
100
120
140
200 400 600 800 1000 1200 1400 1600
tem
po e
m s
egun
dos
n
mediao(n**2)
Figura 3: Complexidade da implementacao BF-2.
0
200
400
600
800
1000
1200
200 400 600 800 1000 1200 1400 1600
tem
po e
m s
egun
dos
n
mediaO(n log n)
O(n**2)
Figura 4: Complexidade da implementacao BF-Tree.
6.2 Metodos Construtivos
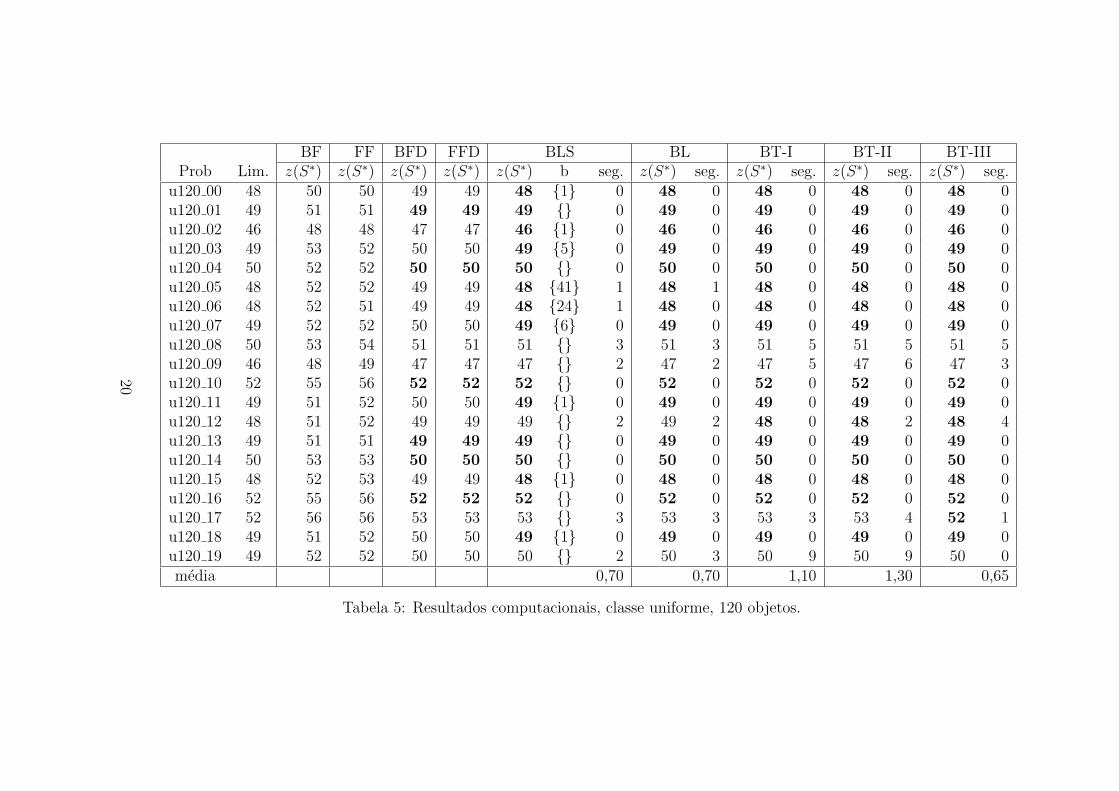
As Tabelas 5-8 relatam os resultados computacionais. Cada tabela mostra, paracada uma das 20 instancias, a identificacao da instancia (Prob), o limite inferior decaixas (Lim.) e as respectivas solucoes z(S∗) (quantidades de caixas) encontradaspelos procedimentos BF, FF, BFD, FFD. As solucoes otimas encontram-se emnegrito.
Comparando-se as heurısticas BF e FF observa-se que de 80 casos as duasheurısticas nao obtiveram as mesmas solucoes para 51 casos, dos quais FF obteve
16

melhor resultado para seis deles (problemas u120 03, u120 06, u250 00, u250 01,u500 02 e u500 18). E possıvel dizer, que para esta classe de problemas a heurısticaBF superou a FF. Em todos os casos as heurısticas BFD e FFD superaram asheurısticas BF e FF. As heurısticas BFD e FFD obtiveram os mesmos resultadospara todos os casos e em apenas cinco casos (problemas u120 01, u120 04, u120 10,u120 13 e u120 14) alcancaram a solucao otima. No entanto, e importante ressaltarque, na maioria dos casos, o empacotamento encontrado pelas heurısticas BFD eFFD utilizaram poucas caixas a mais (muitas vezes apenas uma) do que o em-pacotamento otimo. O problema de empacotamento e um bom exemplo de comoheurısticas gulosas simples podem fornecer bons resultados.
6.3 Busca Local
As Tabelas 5-8, mencionadas na secao anterior, mostram os resultados de duasversoes do procedimento Busca Local: (i) Busca Local Simples (BLS), naodetalhada neste trabalho, considera uma vizinhanca menor que a descrita na Secao4 (tenta-se retirar cada caixa da solucao inicial gerada na fase de construcao nomaximo uma vez) e tambem utiliza uma rotina de Empacotamento diferente dadetalhada na mesma secao; (ii) Busca Local (BL), conforme descrito na Secao 4.Para cada versao, a coluna z(S∗) mostra a solucao encontrada e a coluna (seg.)o tempo de processamento em segundos. Para a versao BLS a coluna coluna (b)mostra o conjunto dos ındices das caixas que foram retiradas. As solucoes otimasencontram-se em negrito.
Em relacao a versao BLS e possıvel fazer as seguintes observacoes. A solucaoviavel inicial (obtida pelo metodo FFD) pode ser melhorada para 74 dos 80 prob-lemas, uma vez que a solucao otima ja tinha sido encontrada para seis deles. Con-siderando estes 74 problemas a versao BLS so nao foi capaz de melhorar a solucaode cinco problemas (u120 08, u120 09, u120 12, u120 17, u120 19), todos com 120objetos. Destes 69 problemas, o metodo BLS alcancou a solucao otima para 9problemas com 120 objetos, 11 problemas com 250 objetos, 12 problemas com 500objetos e 12 problemas com 1000 objetos. O metodo BL melhorou a solucao de69/74 = 93% dos problemas e encontrou a solucao otima para 44/74 = 59% dosproblemas.
Observa-se que, para os problemas com 1000 objetos por exemplo, em todos oscasos no mınimo duas caixas foram retiradas, e em todos os casos as duas primeirascaixas consideradas (caixas de ındices um e dois) foram retiradas. Para os prob-lemas com 500 objetos, apenas em um caso somente uma caixa saiu, em todosos casos a primeira caixa considerada (caixa de ındice um) foi retirada e em 14casos a segunda caixa considerada (caixa de ındice dois) foi retirada. Na maioriados casos o ındice da ultima caixa a ser retirada e diferente do ındice da caixaretirada anteriormente mais um. Uma possıvel interpretacao e que, nao importaa ordem considerada, as primeiras caixas a serem retiradas tem mais chances de
17

obter sucesso, por outro lado, quando o numero de caixas da solucao viavel cor-rente e igual ao limite inferior mais uma caixa, muitas tentativas precisam serfeitas para conseguir tirar esta ultima caixa. Esta hipotese sugere uma estrategiamais agressiva de busca local a ser explorada. Faz-se b igual a metade da diferencaentre o limite inferior e a solucao encontrada na fase de construcao. Na primeiraiteracao da BL tenta-se tirar b caixas. Se a retirada obteve sucesso tenta-se re-tirar uma caixa nas proximas iteracoes, caso contrario volta a solucao inicial dafase de construcao e tenta-se tirar de uma em uma caixa. Ja uma estretegia deparalelizacao poderia usar este metodo mais agressivo ate faltar apenas uma caixapara atingir o limite inferior, e a partir desta solucao viavel paralelizar as caixasrestantes. O primero processo a conseguir retirar a ultima caixa faz os demaisprocessos pararem suas buscas. Uma outra estrategia de paralelizacao: seja n onumero de caixas da solucao S encontrada na fase de construcao, seja b a diferencaentre o limite inferior e n e seja C o conjunto das combinacoes C(n, b). Cada pro-cessador disponıvel recebe S e um elemento de C, que e o conjunto dos ındices dascaixas que ele devera retirar de S. Se retirando as caixas de S o processador encon-trar uma solucao viavel entao ele encontrou uma solucao otima para o problemade empacotamento.
Comparando-se as versoes BLS e BL, observa-se que a versao BL melhorou asolucao de 6 problemas (u250 18, u500 11, u1000 00, u1000 11, u1000 15, u1000 17)conseguindo encontrar a solucao otima para cinco deles. A versao BLS so encon-trou uma solucao melhor que a versao BL, para o problema u500 19. Alem daversao BL ter encontrado um numero maior de melhores solucoes, na media, seutempo medio de processamento foi menor (so foi maior para instancias de 250 ob-jetos). A rotina Empacotamento utilizada pela versao BLS distribui os objetosdas caixas retiradas sem levar em consideracao o peso das caixas (o que e feitona versao BL). Provavelmente esta diferenca, juntamente com uma vizinhanca umpouco maior, possibilitou a versao BL encontrar melhores solucoes. A diferenca detempo se explica, talvez, por ter encontrado melhores solucoes mais rapidamente.
6.4 Busca Tabu
As Tabelas 5-8 mostram os resultados de tres versoes do procedimento Busca
Tabu: BT-I utiliza a rotina Procedimento MetodoDeDiferenciacaoTabuI,BT-II utiliza a rotina Procedimento MetodoDeDiferenciacaoTabuII eBT-II utiliza a rotina Procedimento MetodoDeDiferenciacaoTabuIII.Para cada versao, a coluna z(S∗) mostra a solucao encontrada e a coluna (seg.)o tempo de processamento em segundos. As solucoes otimas encontram-se emnegrito. A Tabela 4 mostra, para cada classe de problemas, o numero de solucoesotimas encontrada por cada heurıstica. Como os resultados para a classe de prob-lemas com 1000 objetos nao estao completos mostra-se a linha de sub-total, naoconsiderando esta classe.
18

Classe BF FF BFD FFD BLS BL BT-I BT-II BT-III
120 0 0 6 6 15 15 16 16 17250 0 0 0 0 11 12 11 12 12500 0 0 0 0 12 12 11 10 13
Sub-total 0 0 6 6 38 39 38 38 42
1000 0 0 0 0 12 15 9 11 13
Total 0 0 6 6 50 54 47 49 55
Tabela 4: Quantidade de solucoes otimas de cada heurıstica, para cada classe deproblemas.
Comparando-se as tres versoes da Busca Tabu e curioso observar que a versaoque obteve melhores resultados foi a versao III, supostamente uma implementacao“menos inteligente”. Nesta versao, sempre quando o metodo de diferenciacao eempregado altera-se a composicao do par de caixas analisado sem levar-se em con-sideracao se a mudanca foi para melhor ou para pior. Contrariamente, as versoes Ie II alteraram a composicao do par de caixas somente quando o metodo nao piora adiferenca de peso das duas caixas. Nas tres versoes o conhecimento adquirido pelaBusca Tabu foi util para evitar-se solucoes ja visitadas. No entanto, a utilizacaodo conhecimento sobre a diferenca de peso do par de caixas nao ajudou a melhoraros resultados. Para um dado par de caixas, uma composicao dos objetos nas duascaixas cuja diferenca de peso resultante seja menor que outra composicao, poderiaser considerada uma boa solucao (solucao de elite). No entanto, observou-se naoser vantajoso conservar a estrutura destas solucoes. Do ponto de vista de umaabordagem Tabu, a utilizacao da diversificacao da composicao das caixas (empre-gada na versao III) apresentou melhores resultados que a utilizacao de solucoes deelite (versoes I e II).
A diferenca da implementacao dos metodos Busca Local e Busca Tabu esta nosprocedimentos MetodoDeDiferenciacao e MetodoDeDiferenciacaoTabu.O segundo metodo utiliza uma estrutura de memoria que permite conhecer todosos pares de caixas ainda nao analisados da solucao corrente. Espera-se por isso,que os algoritmos que utilizam a abordagem Tabu sejam superiores aos que uti-lizam simplesmente a Busca Local. Apesar disso, a abordagem Tabu nao melhorousensivelmente os resultados. Observando os resultados da Tabela 4, a versao IIIda abordagem Tabu foi superior a abordagem de Busca Local, no entanto a abor-dagem de Busca Local foi superior as versoes I e II da Busca Tabu, com a vantagemda Busca Local ser mais rapida e menos complexa.
19
BF FF BFD FFD BLS BL BT-I BT-II BT-IIIProb Lim. z(S∗) z(S∗) z(S∗) z(S∗) z(S∗) b seg. z(S∗) seg. z(S∗) seg. z(S∗) seg. z(S∗) seg.
u120 00 48 50 50 49 49 48 {1} 0 48 0 48 0 48 0 48 0u120 01 49 51 51 49 49 49 {} 0 49 0 49 0 49 0 49 0u120 02 46 48 48 47 47 46 {1} 0 46 0 46 0 46 0 46 0u120 03 49 53 52 50 50 49 {5} 0 49 0 49 0 49 0 49 0u120 04 50 52 52 50 50 50 {} 0 50 0 50 0 50 0 50 0u120 05 48 52 52 49 49 48 {41} 1 48 1 48 0 48 0 48 0u120 06 48 52 51 49 49 48 {24} 1 48 0 48 0 48 0 48 0u120 07 49 52 52 50 50 49 {6} 0 49 0 49 0 49 0 49 0u120 08 50 53 54 51 51 51 {} 3 51 3 51 5 51 5 51 5u120 09 46 48 49 47 47 47 {} 2 47 2 47 5 47 6 47 3u120 10 52 55 56 52 52 52 {} 0 52 0 52 0 52 0 52 0u120 11 49 51 52 50 50 49 {1} 0 49 0 49 0 49 0 49 0u120 12 48 51 52 49 49 49 {} 2 49 2 48 0 48 2 48 4u120 13 49 51 51 49 49 49 {} 0 49 0 49 0 49 0 49 0u120 14 50 53 53 50 50 50 {} 0 50 0 50 0 50 0 50 0u120 15 48 52 53 49 49 48 {1} 0 48 0 48 0 48 0 48 0u120 16 52 55 56 52 52 52 {} 0 52 0 52 0 52 0 52 0u120 17 52 56 56 53 53 53 {} 3 53 3 53 3 53 4 52 1u120 18 49 51 52 50 50 49 {1} 0 49 0 49 0 49 0 49 0u120 19 49 52 52 50 50 50 {} 2 50 3 50 9 50 9 50 0media 0,70 0,70 1,10 1,30 0,65
Tabela 5: Resultados computacionais, classe uniforme, 120 objetos.
20

BF FF BFD FFD BLS BL BT-I BT-II BT-IIIProb Lim. z(S∗) z(S∗) z(S∗) z(S∗) z(S∗) b seg. z(S∗) seg. z(S∗) seg. z(S∗) seg. z(S∗) seg.
u250 00 99 105 104 100 100 99 {87} 30 99 8 99 1 99 0 99 15u250 01 100 108 107 101 101 100 {3} 1 100 0 100 0 100 0 100 0u250 02 102 109 109 104 104 103 {1} 43 103 42 102 6 102 2 103 37u250 03 100 106 106 101 101 100 {1} 0 100 1 100 0 100 0 100 0u250 04 101 107 107 102 102 101 {1} 0 101 7 101 3 101 0 101 10u250 05 101 107 107 104 104 102 {1, 8} 38 102 41 102 205 102 175 102 94u250 06 102 107 107 103 103 102 {1} 0 102 0 102 0 102 0 102 0u250 07 103 109 110 105 105 104 {1} 82 104 79 104 275 104 257 104 280u250 08 105 111 112 107 107 106 {1} 49 106 46 106 170 106 152 106 229u250 09 101 108 108 102 102 101 {41} 20 101 6 102 66 101 12 101 6u250 10 105 111 112 106 106 105 {61} 24 105 5 105 2 105 2 105 2u250 11 101 108 109 103 103 102 {1} 42 102 34 102 61 102 69 102 145u250 12 105 111 112 107 107 106 {1} 73 106 93 106 528 106 553 106 347u250 13 102 108 110 104 104 103 {1} 71 103 75 103 574 103 511 103 270u250 14 100 105 105 101 101 100 {1} 0 100 0 100 0 100 0 100 0u250 15 105 113 114 107 107 106 {1} 60 106 60 106 566 106 572 106 163u250 16 97 103 103 99 99 97 {1, 61} 16 97 9 98 214 98 163 97 4u250 17 100 106 106 101 101 100 {1} 0 100 0 100 1 100 1 100 0u250 18 100 105 106 102 102 101 {1} 47 100 40 100 0 100 1 100 2u250 19 102 107 108 103 103 102 {17} 5 102 3 102 0 102 1 102 1media 30,05 54,90 267,7 123,55 80,25
Tabela 6: Resultados computacionais, classe uniforme, 250 objetos.
21

BF FF BFD FFD BLS BL BT-I BT-II BT-IIIProb Lim. z(S∗) z(S∗) z(S∗) z(S∗) z(S∗) b seg. z(S∗) seg. z(S∗) seg. z(S∗) seg. z(S∗) seg.
u500 00 198 211 211 201 201 199 {1, 2} 1043 199 867 199 1921 199 2063 199 3114u500 01 201 212 213 204 204 202 {1, 2} 876 202 688 202 2441 202 2018 202 3191u500 02 202 213 212 205 205 202 {1, 2, 20} 50 202 18 202 38 202 0 202 31u500 03 204 215 216 207 207 205 {1, 27} 736 205 923 205 3468 205 2501 205 4792u500 04 206 218 219 209 209 206 {1, 2, 21} 32 206 2 206 1 206 18 206 20u500 05 206 218 219 207 207 206 {1} 1 206 12 206 0 206 0 206 26u500 06 207 217 220 210 210 208 {1, 2} 1593 208 1362 208 12890 208 11376 208 210u500 07 204 216 219 207 207 205 {1, 2} 1476 205 1123 205 8498 205 9289 205 4202u500 08 196 207 207 199 199 197 {1, 10} 678 197 646 197 963 197 943 196 394u500 09 202 212 213 204 204 202 {1, 2} 0 202 0 202 1 202 1 202 0u500 10 200 209 210 202 202 200 {1, 2} 2 200 15 200 112 200 14 200 3u500 11 200 212 212 203 203 201 {1, 5} 956 200 26 201 3488 201 2296 201 3789u500 12 199 210 210 202 202 199 {1, 2, 62} 250 199 791 200 3409 200 3868 200 2581u500 13 196 207 208 198 198 196 {1, 11} 31 196 6 196 2 196 0 196 1u500 14 204 215 215 206 206 204 {1, 2} 1 204 29 204 0 204 0 204 21u500 15 201 211 212 204 204 202 {1, 2} 895 202 837 201 349 201 866 201 108u500 16 202 211 212 205 205 202 {1, 2, 3} 1 202 1 202 1 202 0 202 0u500 17 198 207 207 201 201 198 {1, 2, 41} 112 198 213 198 94 199 995 198 87u500 18 202 213 212 205 205 202 {1, 2, 32} 84 202 30 202 1 202 2 202 43u500 19 196 206 208 199 199 196 {1, 28, 194} 854 197 708 197 6200 197 3408 196 1026media 967,10 414,85 4387,70 1982,90 1181,95
Tabela 7: Resultados computacionais, classe uniforme, 500 objetos.
22

BF FF BFD FFD BLS BL BT-I BT-II BT-IIIProb Lim. z(S∗) z(S∗) z(S∗) z(S∗) z(S∗) b seg. z(S∗) seg. z(S∗) seg. z(S∗) seg. z(S∗) seg.
u1000 00 399 419 420 403 403 400 {1, 2, 3} 26636 399 3422 399 59 399 241 399 13923u1000 01 406 426 427 411 411 406 {1, 2, 3, 15, 46} 964 406 663 407 9125 406 21 406 14u1000 02 411 433 433 416 416 411 {1, 2, 3, 4, 100} 1892 411 363 412 15449 412 18841 411 1598u1000 03 411 434 435 416 416 412 {1, 2, 14, 351} 22816 412 40464 413 16882* 412 262188 412 190152u1000 04 397 417 419 402 402 398 {1, 2, 3, 4} 34196 398 19881 398 75351u1000 05 399 420 421 404 404 399 {1, 2, 3, 4, 9} 234 399 532 401 15640 400 41971 399 30u1000 06 395 415 416 399 399 395 {1, 2, 3, 4} 8 395 200 395 1195 395 20 395 7u1000 07 404 425 426 408 408 404 {1, 2, 20, 49} 1615 404 99 404 291 404 9 404 485u1000 08 399 418 419 404 404 399 {1, 2, 3, 4, 9} 144 399 33 400 1670 399 12 399 10u1000 09 397 417 418 404 404 398 {1, 2, 3, 4, 14, 27} 29749 398 25157 398 115798 399 22857 398 62200u1000 10 400 418 420 404 404 400 {1, 2, 3, 4} 6 400 17 400 14 400 7 400 2u1000 11 401 422 423 405 405 402 {1, 2, 3} 22948 401 1812 402 38179 402 32108 401 10u1000 12 393 412 414 398 398 393 {1, 2, 3, 4, 5} 5 393 14 393 6 393 6 393 1u1000 13 396 414 415 401 401 396 {1, 2, 3, 4, 20} 272 396 54 396 96 396 187 396 195u1000 14 394 414 415 400 400 395 {1, 2, 3, 4, 5} 27369 395 32042 396 40301 395 129255u1000 15 402 422 422 408 408 404 {1, 2, 3, 29} 17151 403 33683 403 85155u1000 16 404 423 425 407 407 404 {1, 2, 3} 9 404 24 404 304 404 162 404 22u1000 17 404 422 422 409 409 405 {1, 2, 3, 4} 30304 404 22836 405 19449 405 23222 405 93696u1000 18 399 419 419 403 403 399 {1, 2, 3, 4} 14 399 3 399 6 399 58 399 644u1000 19 400 417 421 406 406 400 {1, 2, 3, 4, 5, 108} 5862 400 694 400 6 400 18 400 23media 11109,7 9099,65
Tabela 8: Resultados computacionais, classe uniforme, 1000 objetos.
23

Referencias
[1] A.V. Aho, J.E. Hopcroft e J.D. Ullman, Data Structures and Algorithms, Addison-Wesley, 1983, Reading.
[2] T.H. Cormem, C.E. Leiserson e R.L. Rivest, Introduction to Algorithms, McGraw-Hill, 1990, New York.
[3] E. Falkenauer, “A Hybrid Grouping Genetic Algorithm for Bin Packing”, Journal
of Heuristics 2 (1996), 5-30.
[4] M.R. Garey e D.S.Johnson, Computers and Intractability: A Guide to the Theory
of NP-Completeness, W.H. Freeman and Company, 1979, Sao Francisco.
[5] I. Gent, “Heuristic Solution of Open Bin Packing Problems”, Journal of Heuristics
3 (1998), 299-304.
[6] D.S. Johnson, A. Demers, J.D. Ullman, M.R. Garey e R.L. Graham, “Worst-CasePerformance Bounds For Simple One-Dimensional Packing Algorithms”, SIAM J.
On Computing 3 (1974), 299-325.
[7] N. Karmarkar e R.M. Karp, The Differencing Method of Set Partioning, Universityof California, Berkeley, 1982.
[8] U. Manber, Introduction to Algorithms: Theory and Practice, Prentice-Hall, 1988,Englewood Cliffs.
[9] S. Martello e P. Toth, “Bin-Packing Problem”, In Knapsack Problems, Algorithmsand Computer Implementations, Wiley, 221-245, 1990.
[10] N. Wirth, Algorithms + Data Structures = Programs, Prentice-Hall, 1976, Engle-wood Cliffs.
24