tentativas préviashmo/unidade 1 ti.pdf · como medir a quantidade de informação ... podemos usar...
TRANSCRIPT

tentativas prévias...If you can not measure it, you can not improve it. Lord Kelvin
como medir a quantidade de informação? texto, fala, imagem, video...

Ralph V. Hartley
A quantidade de informação depende do número de escolhas possíveis.
Como na maioria das unidades de engenharia um sistema com base logarítmica é apropriado (ex. dB), para uma situação com N escolhas possíveis, ele propos:
I=log N

Uma tentativa similar foi proposta por Alan Turing (the ban and
the deciban were invented by 1940): I=10 log10N decibans.
Se você tem apenas uma única escolha, N=20, então não há nada a informar (já se sabe).
Se você tem duas escolhas possíveis, N=21, então há uma unidade a informar (qual a escolha).
Se você tem quatro escolhas possíveis, N=22, e há dois códigos para informar a escolha.
Comunicação analógica vs Comunicação Digital*
Eletrônica analógica vs Eletrônica Digital*
Conversão a/d d/a*

Até o meio do Século XX, os sistemas analógicos eram reconhecidos como superiores aos sistemas digital.
Evolução: Telegrafia (digital),
Telefonia, Rádio, TV (analógicos)
* criadas por Shannon, hoje são padrão universal

Medida de informação Definição: [Shannon, 1948] Um evento aleatório E com probabilidade de ocorrência P(E) tem
associado um conteúdo de informação
I(E):=log2 1/P(E)= -log2 P(E).
NB. por sugestão de Tukey, Shannon batizou a unidade por bit (bit
de informação), sendo hoje adotada Shannon como unidade de
medida.

Unidades de medida Bit= binary digit Bit= binary unit (of information)
Unidade de informação
● log tomado em base 2, Shannon ● log tomado em base 10, Hartley ● log neperiano em base e, Nat.
1 bit = 1 Sh ≈ 0.693 nat ≈ 0.301 Hart.iso https://www.iso.org/standard/31898.html

Semântica versus incerteza Não há conotação semântica na interpretação de
Shannon (apenas ligada à incerteza).
Sequencia binária (Bernoulli) Bit 0 ou 1, de igual probabilidade, carrega -log2 (½) =1 Sh
Bit 0 (0.9) carrega 0.952 Sh
Bit 1 (0.1) carrega 3.322 Sh Converter o problema em lançamentos de Bernoulli
equivalentes...

Eventos & Informação Ouvindo Adágio de Albinoni ou Canon de Pachelbel em Ré maior pela primeira
vez… Ou pela trilionésima!
Assistindo a um novo filme: esperado, inesperado, detalhes mínimos…
Jogo de futebol: Flamengo (RJ) versus Ibis (PE). Quais as chances? Se fosse evento certo, nem adiantaria jogar. A zebra é um resultado possível…
– Se é certo que o placar final será de 9 × 0, basta “desligar”: não efetuar o jogo. Para que? (A quoi bom?)
Informação vital (sua vida dependendo dela), por exemplo, pode ter conteúdo muito pequeno de informação de Shannon!
Importância do incerto, inesperado, do improvável na vida.

Lembranças do passado (algo inexistente no presente...)

Qual das imagens possivelmente possui maior conteúdo de informação? [ordem&desordem]
Interpretando e entendendo…
Associe também com o conceito
de complexidade de Kolmogorov

BASES PARA DEFINIÇÃO DE INFORMAÇÃO MARGINAL
modelo: Fonte
“letras" oriundas de um alfabeto discreto, com rótulos inteiros {k}
Considere uma fonte que produz mensagens rotuladas por {k}
mensagem:= vista como uma sequência aleatória de saída da fonte com letras de um “alfabeto fonte”.
Fonte

Proposta: Ik=f(pk)
informação é uma função APENAS da probabilidade da ocorrência do símbolo => f(.) deve ser determinada.
Condições impostas (lembre-se dos axiomas de Kolmogorov):
C1) não negatividade
C2) evento certo não tem informação
C3) monotonicidade f(pk)>f(pl), se pk<pl.
f ( pk )≥0 ,se 0≤ pk ≤1
limpk→ 1
f (pk )= 0

Muitas funções obedecem 1-3, e a ideia final vem da consideração da transmissão de eventos independentes (play the role of mutually exclusive events in Kolmogorov axioms...).
Independência
Se uma mensagem k tem conteúdo de informação Ik e outra mensagem l independente tem conteúdo de informação Il (ex. provindo de fontes independentes),
podemos falar da mensagem conjunta k;l em que pk;l=pk.pl
independentes Ik;l=Ik+Il ou f(pk;l)=f(pk.pl)=f(pk)+f(pl).

Equação funcional de Cauchy
1) f(x)>f(y) se x>y>0.
2) f(x.y)=f(x)+f(y).
Solução única: f(x)=k log x (qualquer base).
para C1, k<0, Cologaritmo, como pH
https://en.wikipedia.org/wiki/Cologarithm

I(k):=-log2 pk =log2 1/pk
Shannon definiu a unidade de medida de informação (sugestão de Tukey) como bit
bit= binary unit of information
bit= binary digit
fonte binária = alfabeto {0,1} um bit pode transportar mais (ou menos) que 1 bit de informação.

bit 0, com p(0)=1/2 bit 0 transporta I0= 1 bit
bit 1, com p(1)=1/2 bit 1 transporta I1= 1 bit.
Mas
bit 0, com p(0)=1/4 bit 0 transporta I0= 2 bit
bit 1, com p(1)=3/4 bit 1 transporta I1= 0.42 bit.

Esquema mais simples de transmissão de informação: símbolos p-ários, cada com duração t seg.
--- --- --- ... --- p-1 --- --- --- ... --- p-2 --- --- --- ... --- ...
. . . . . . . . . . . .
--- --- --- ... --- 1 --- --- --- ... --- 0 t seg t seg ... t seg <------------------------> duração total T seg.

Limitação na quantidade de informação:
tempo para transmissão de um símbolo (aumentar velocidade)
no de níveis diferentes possíveis (potência e ruído)
no de intervalos n=T/t
Teorema da contagem:
p.p.p...p =pT/t sequências distintas possíveis

Se as sequências possíveis tem a mesma probabiliade de ocorrência (equiprováveis), uma sequência S arbitrária tem
p(S)=1/ pT/t => I(S)=- log2 p(S)= .
T maior tempo transmitindo
t símbolos mais rápidos I
p mais opções no alfabeto de símbolos
=Eis a razão por que se fala tanto hoje em redes de alta velocidade
Tt
. log2 p
t ↓

Lidando com probabilidades...
dificuldade em se lidar com valores extremos de probabilidades: p→0 e p →1
são consequências da evolução.
Precisamos “entender/interpretar” apenas a faixa do meio,
para uso eficiente da sobrevivência – seleção natural.
p →1 (evento certo, ignorar a incerteza)
p → 0 (milagre…)
http://www.de.ufpe.br/~hmo/alguns_grandes_numeros.pdf

número estimado de Homo sapiens que já viveram no planeta =100 billion=10^11
(Wolframalpha: World population)

Pensemos em um evento que chamamos de raro:
algo impar, fato que só aconteceu com um único homem na história da humanidade:
P(raríssimo)=10-11.
O que seria um evento de probabilidade 10-60 ?
As pessoas, com hábito de uso de calculadoras, escrevem coisas assim sem ter ideia do significado...

UMA CONVERSA SOBRE O NASCER DO SOL E SUAS IMPLICAÇÕES
Vamos examinar o conteúdo de informação dos eventos:
E ={o sol nascerá amanhã pela manhã} e
EC={o sol não nascerá amanhã}
Sabemos que o evento E é praticamente um evento certo, i.e. P(E) =1.
Mas de fato, não se tem P(E)=1.

Alguns ensaios: usemos este link http://www.de.ufpe.br/~hmo/alguns_grandes_numeros.pdf
a) Digamos que P(E)=1-10-30
b) Digamos que P(E)=1-10-60
c) Digamos que P(E)=1-10-120
Em cada caso, podemos usar a expansão de Taylorcomo uma boa aproximação:
log(1-x) ≈-x e
I(E) ≈-log (1-10-30)/log(2)=1.4427*10-30≈10-30 Sh. De qualquer forma, I(E) ≈ 0 Sh como esperado.

Examinemos agora o evento complementar.
A quantidade de informação associada ao evento EC seria aproximadamente:
a) -log2(10-30) =1.4427*30*ln(10) = 100 Sh
b) -log2(10-60) =1.4427*60*ln(10) = 200 Sh
c) -log2(10-120) =1.4427*120*ln(10) = 400 Sh
A “surpresa" de o sol não nascer amanhã seria praticamente identica aquela de se jogar uma moeda 400 vezes seguidas e observar "Ca" em todos os eventos!!
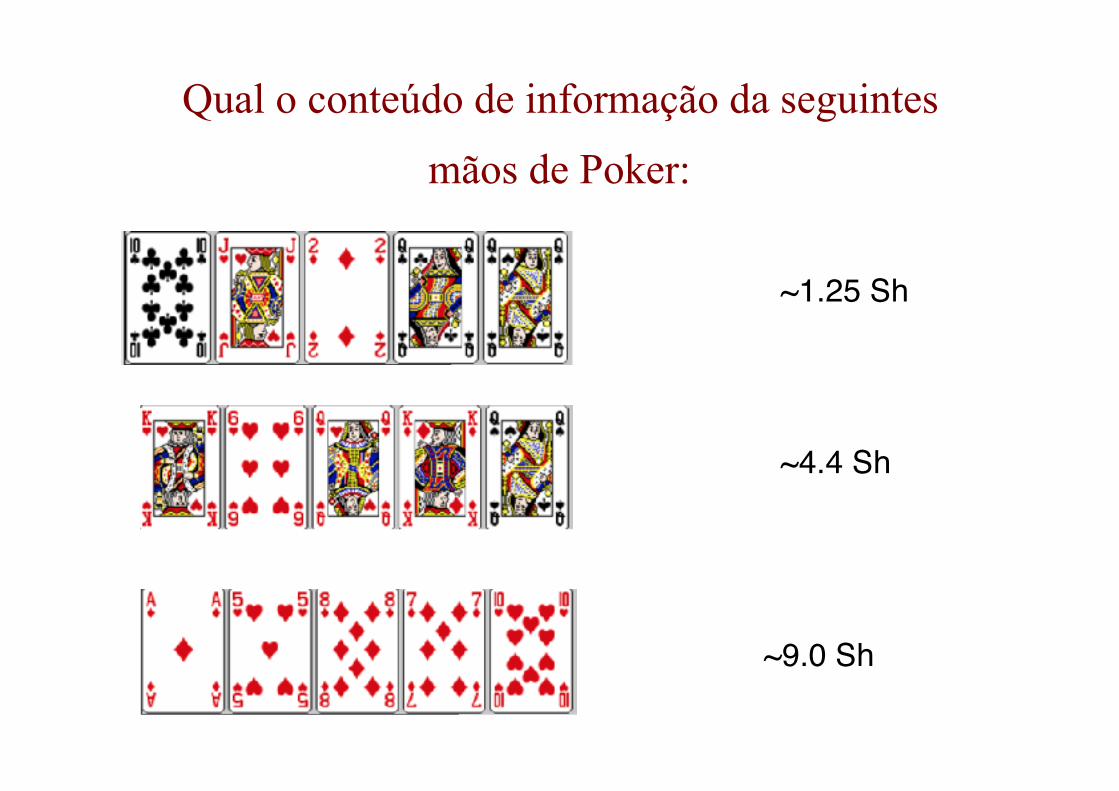
Qual o conteúdo de informação da seguintes
mãos de Poker:
~1.25 Sh
~4.4 Sh
~9.0 Sh
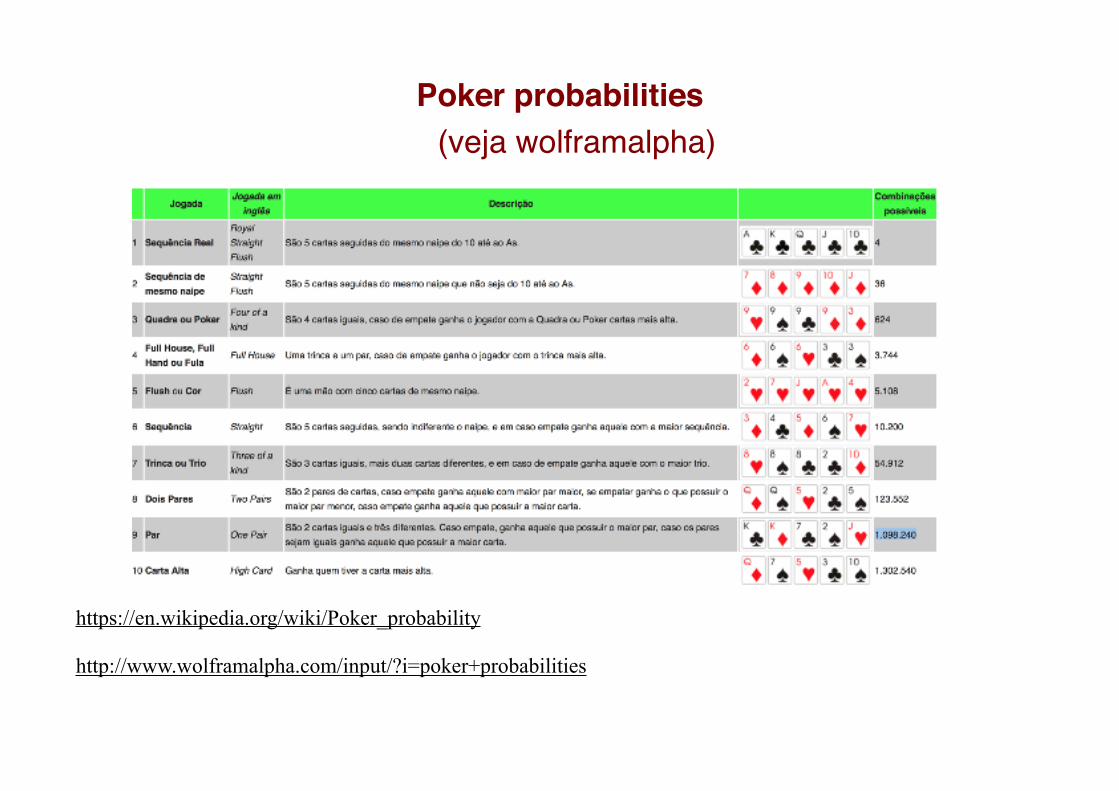
Poker probabilities (veja wolframalpha)
https://en.wikipedia.org/wiki/Poker_probability http://www.wolframalpha.com/input/?i=poker+probabilities

Jogadas raras...
A informação associada à saída de um Royal flush é cerca de
I(royal flush) = -log2(1/649740) ~19.3 Sh
Interpretar Shannons de informação associado a um evento equivalente de sequências de variável de Bernoulli X~Ber(0.5) Next slide...

Mega sena Distribuição hipergeométrica X~Hiper(100,6,6)
A probabilidade de se ganhar na mega sena com um único volante de 6 números é P(X=6)=0,00000008%
O conteúdo de informação associado a ganhar na mega sena com um único volante de 6 números é, portanto, cerca de 30 Sh.
Compare isso com efetuar 30 jogadas sucessivas de uma moeda honesta e obter 30 caras...

Dennis Gabor Gabor provou seu princípio de incerteza aplicando para sinais
arbitrários a mesma técnica matemática usada na dedução de Heisenberg-Weyl do princípio da incerteza na mecânica quântica.
O PRINCÍPIO DA INCERTEZA DE SINAIS Vale citar também uma formulação para o Princípio da Incerteza de
Heisenberg (tempo × freqüência), desenvolvida por Gabor [1946].
Trata-se de uma relação entre a duração efetiva de um sinal e sua banda passante efetiva, obtida no contexto de sinais determinísticos.

Seja f(t) um sinal de energia finita, não necessariamente real, possuindo transformada F(w).
Definem-se os momentos temporais e freqüenciais pelas seguintes relações:
Werner Heisenberg (1901-1976) Dennis Gabor (1900-1978)

Considere a seguinte analogia com a teoria das Probabilidades:
O integrando |f(t)|2/E denotando uma densidade de energia no tempo, em
que a energia E é um fator de normalização para que a integral da
densidade seja unitária.
É usual se trabalhar com a densidade espectral de energia ψ(w)=|F(w)|2,
cuja integral definida em dado intervalo de freqüências fornece a energia
do sinal nesta faixa do espectro.

A duração (banda passante) efetiva de um sinal f(t) (F(w)) pode ser definida via:
Duração rms
Banda rms

Δt e Δf correspondem aos desvios padrões
(raiz quadrada da variância), medidas clássicas de espalhamento.
Aplicando argumentos típicos da mecânica quântica, Gabor provou uma relação de incerteza do tipo:
estabelecendo que t e f não podem ser simultaneamente definidos de forma exata. Os valores de Δt e Δf são freqüentemente referidos como largura de pulso equivalente e banda passante equivalente, respectivamente.
Δt . Δf ≥ 1/2,

Claramente, α≤1 e β ≤1. Sem perda de generalidade, pode-se considerar
sinais de energia normalizada E=1. Então:
O princípio da incerteza estabelece que, fixada uma das duas
quantidades α ou β, a outra deve ser mantida abaixo de certo valor
máximo, dependendo do produto TΩ.

Fixado α, há um sinal para o qual um máximo β é obtido.
Alternativamente, fixado β, a um sinal para o qual um máximo valor de
α é atingido. Se o sinal é banda limitada em Ω, então β=1 e α<1.
Qual o maior valor de α, e para que função ele é atingido?
Em termos de otimização (f(t)↔F(w)), o problema é colocado sob a forma:
⇔
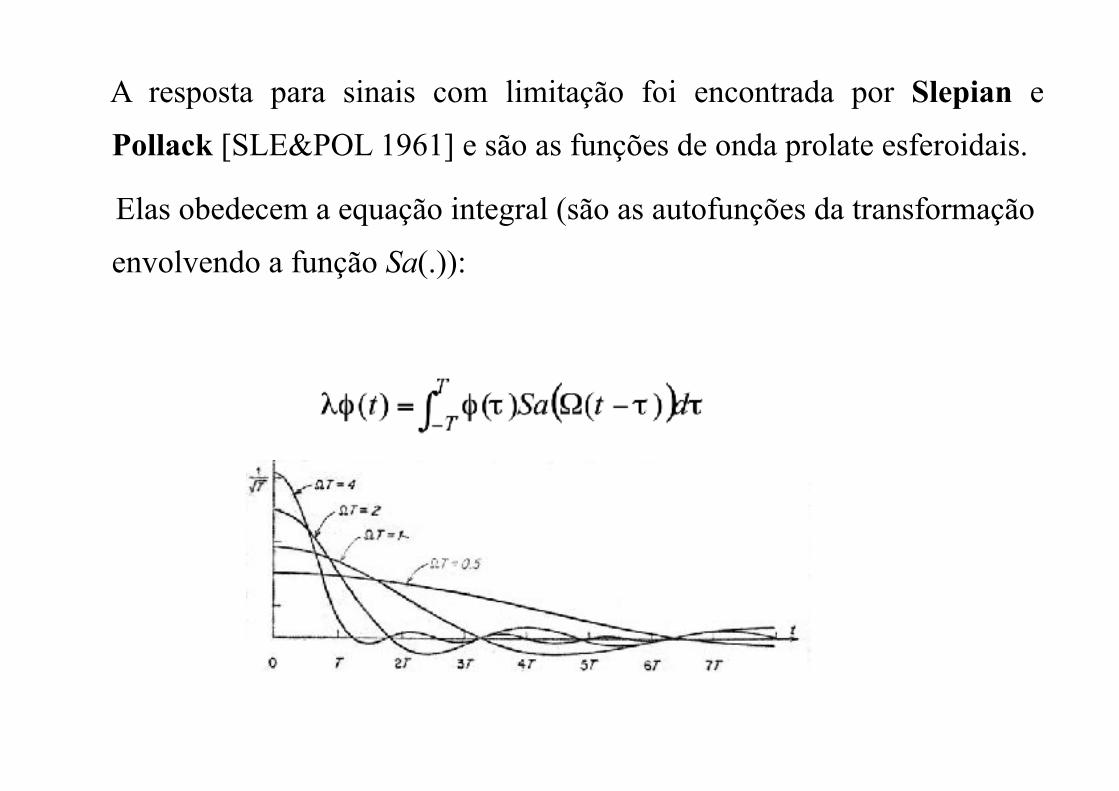
A resposta para sinais com limitação foi encontrada por Slepian e
Pollack [SLE&POL 1961] e são as funções de onda prolate esferoidais.
Elas obedecem a equação integral (são as autofunções da transformação
envolvendo a função Sa(.)):

Essas funções são relacionadas com soluções da equação diferencial:
t∈ [-1,1].
Considerando a possibilidade de atingir a cota inferior da desigualdade, a
menor área de um retangulo (quantum de sinal de informação seria
Δt . Δf = 1/2
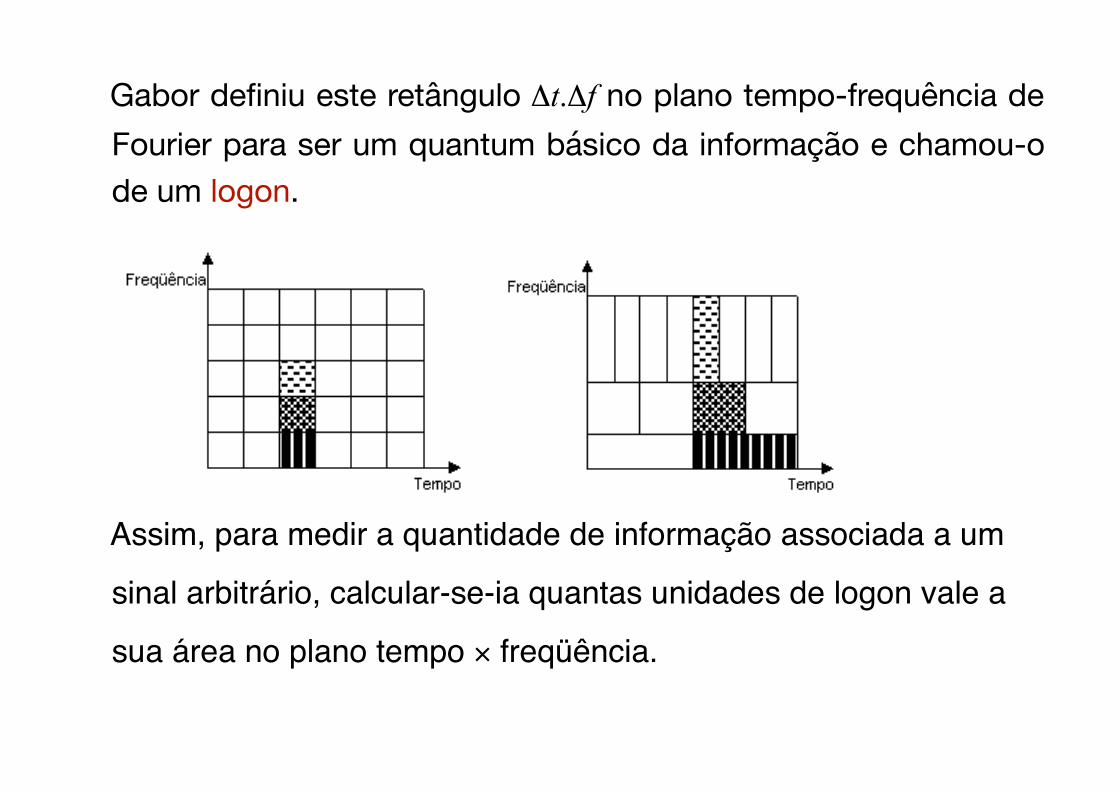
Gabor definiu este retângulo Δt.Δf no plano tempo-frequência de Fourier para ser um quantum básico da informação e chamou-o de um logon.
Assim, para medir a quantidade de informação associada a um
sinal arbitrário, calcular-se-ia quantas unidades de logon vale a
sua área no plano tempo × freqüência.

Viva a Gaussiana!
O sinal contínuo que atinge esta cota (melhor preenchimento do plano t-f, mais compacto) é um pulso de formato gaussiano.
Está em todas!
● Vide teorema central do limite…● Vide autofunções da transformada Fourier● Vide capacidade de canal com ruído branco

Teoria da Informação é um ramo da matemática que trata de três conceitos básicos:
a) a medida de informação
b) a capacidade de um canal de informação em transferir informação
(de um ponto ao outro)
c) codificação como uma maneira de utilizar canais (e memórias) com
capacidade plena
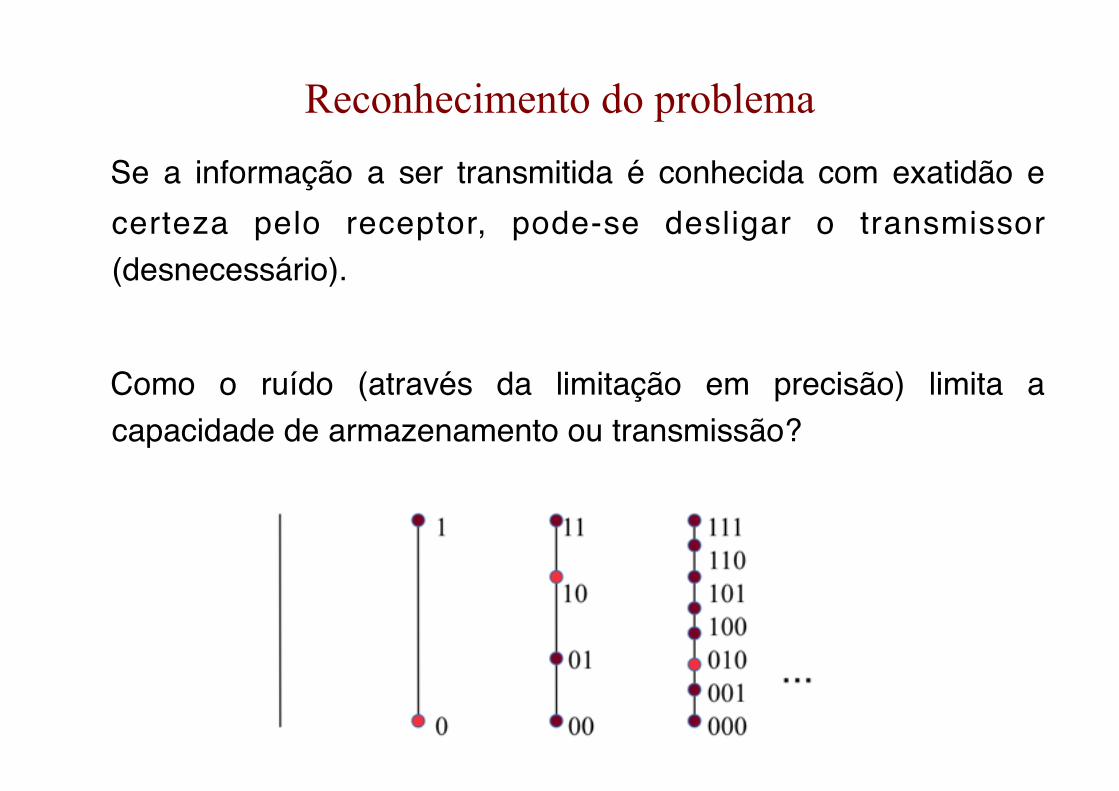
Reconhecimento do problema
Se a informação a ser transmitida é conhecida com exatidão e certeza pelo receptor, pode-se desligar o transmissor (desnecessário).
Como o ruído (através da limitação em precisão) limita a capacidade de armazenamento ou transmissão?

Teoria Estatística da Comunicações
Anterior a 1940, poucos passos foram dados no sentido de construir uma Teoria das comunicações. (investigações telegráficas, Nyquist, Hartley). Após a II Guerra, Claude Shannon & Norbert Wiener estabeleceram os novos conceitos os quais continuam a ter impacto. “Juntas”, estas ideias estabeleceram a TEORIA MODERNA DAS COMUNICAÇÕES

ENTROPIA
Fonte discreta de alfabeto
j=0 p0 I0=-log2 p0
j=1 p1 I1=-log2 p1
... ... ...
j=J-1 pJ-1 IJ-1=-log2 pJ-1
qual a informação média fornecida? (quanto?)

X é v.a. discreta, X=j com probabilidade pj
Esta é a quantidade de informação necessitada, em média, para
remover totalmente a incerteza associada a X.
O nome entropia e o símbolo H(.) foram emprestados da mecânica estatística

Quando Shannon derivou sua famosa fórmula para definir informação, ele perguntou a von Neumann como deveria ser chamada e von Neumann respondeu:
"Você deve chamá-la de entropia por dois motivos: primeiro porque
isso é a fórmula aparece em mecanização estatística, mas segundo e mais importante, como ninguém sabe o que é
entropia, sempre que você usar o termo, você estará em vantagem!”

A VIDA E A MORTE --- LIGAÇÃO COM A TERMODINÂMICA1a lei da termodinâmica
a energia não pode ser criada nem destruída e a energia total em um sistema fechado permanece a mesma (o universo é fechado ou aberto?)
2a lei da termodinâmica
qualquer processo real só pode prosseguir na direção de um aumento da ENTROPIA.

As ideias de Boltzmann foram exploradas por Schrödinger, o qual notou que alguns sistemas, como a vida, parecem desafiar a 2a lei da termodinâmica.
Um organismo permanece vivo no seu estado de organização ao “importar” energia de fora de si e ao degradá-la para sustentar sua estrutura organizacional.
Ou como disse Schrödinger, a única maneira de um sistema vivo permanecer vivo, longe da entropia máxima ou da morte é“retirando continuamente entropia negativa do seu ambiente… portanto, o estrategema que o roganismo usa para se manter estacionário (baixa entropia) consiste em continuamente “sugar” ordenação do seu ambiente (Schödinger, 1949)”
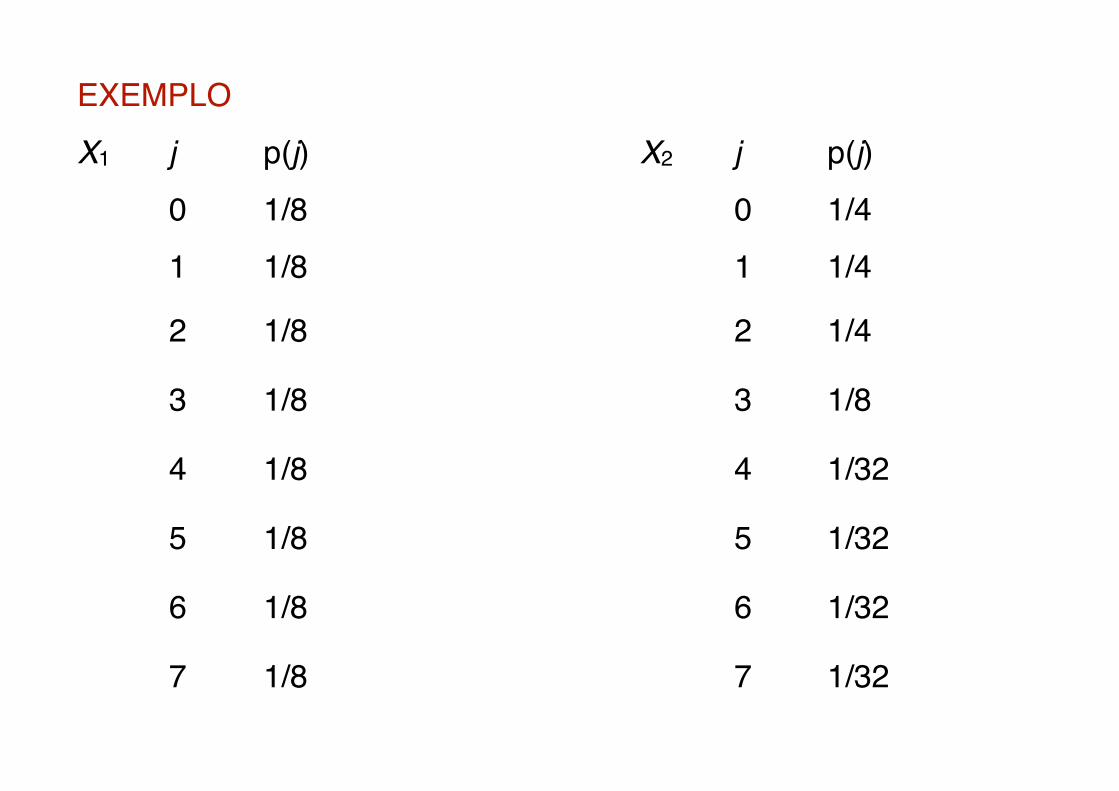
EXEMPLOX1 j p(j) X2 j p(j)
0 1/8 0 1/41 1/8 1 1/4
2 1/8 2 1/4
3 1/8 3 1/8
4 1/8 4 1/32
5 1/8 5 1/32
6 1/8 6 1/32
7 1/8 7 1/32

Adiante veremos que H(X) nos fornece um limite inferior para o número médio de digitos binários necessários para codificar X (1o Teorema de Shannon).
A entropia é máxima para eventos equiprováveis.

Teorema. Dado um conjunto X de possíveis ocorrências, em que X assume valores no alfabeto com distribuição de probabilidade ,tem-se :
em que a desigualdade à direita é satisfeita sss as ocorrências são equiprováveis e à esquerda sss prova.

a) como Se existe j0 tal que p(j0)=1, então p(j)=0 (Kolmogorov)
Logo
Avaliando-se:
Então H(X)=0 se j0 tal que p(j0)=1.
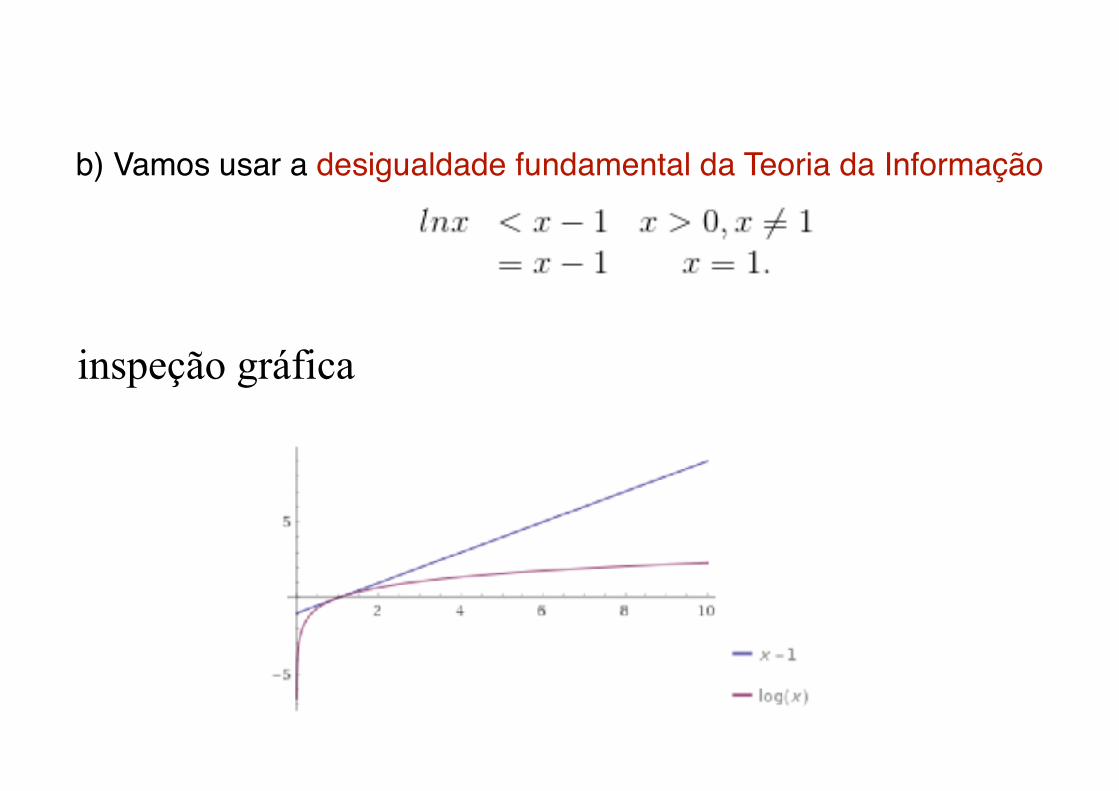
b) Vamos usar a desigualdade fundamental da Teoria da Informação
inspeção gráfica

inspeção analítica
seja � .
y’=0 em x=1 (ponto crítico). Além disso, máximo.
vamos considerar apenas os valores de j estritamente positivos.
y := ln(x) − x + 1

De
segue-se Verificando que a igualdade é verdadeira somente quando os
eventos são equiprováveis:
para eventos equiprováveis, p(j)=1/J para todo j, donde H(X)-log2J=0 Q.E.D.

ENTROPIA DE VARIÁVEIS ALEATÓRIAS
Denotemos por E o valor esperado. Assim, se X ∼ p(x), o valor esperado da variável aleatória g(X) é
no caso particular em que g(X)=log 1/p(x), tem-se a entropia H(X).
Lema 1. prova. Como
logo

Lema 2.prova. mudança de base.
Entropia binária. Bernoulli.
a entropia de X vale:

Exemplo.

Entropia conjunta e Entropia condicional
Definição. (entropia conjunta de duas v.a’s)
então

Definição. (entropia condicional entre v.a’s).Se
Teorema (regra da cadeia)

prova.
logo�
e a prova segue.
corolário.
H(X, Y ) = − ∑x∈χ
∑y∈Υ
p(x, y) . log p(x) − ∑x∈χ
∑y∈Υ
p(x, y) . log p(y |x)

Nota (assimetria). �
�
Entropia relativa
A entropia relativa é uma medida de distância entre duas distribuições de probabilidade.
(em estatística, aparece como o valor esperado do log da razão de verossimilhança)
H(X |Y ) ≠ H(Y |X )
H(X ) − H(X |Y ) = H(Y ) − H(Y |X ) .

Se sabemos que a “verdadeira" distribuição de probabilidade é p, mas usamos uma outra distribuição q (por exemplo, distribuição aproximada), será necessário, em média, H(p)+D(p||q) Sh para descrever a variável aleatória.
Definição. A entropia relativa (ou distância de Kullback-Leibler, denotada por D(p||q) ou H(p||q)) entre duas distribuições discretas de probabilidade p(x) e q(x) é definida por
nota: por convenção, aqui 0.log(0/0)=0.

Definição (informação mútua entre v.a.’s). I(X;Y)
A informação mútua é a entropia relativa entre a distribuição conjunta p(X,Y) e a distribuição produto p(X).p(Y) (caso de independência)
Observação: em geral

Relações entre entropia e informação mútua:
mostre que
Finalmente, mostremos que
Analise também o caso de informação mútua de X com X (autoinformação I(X,X)). Temos o seguinte resumo:
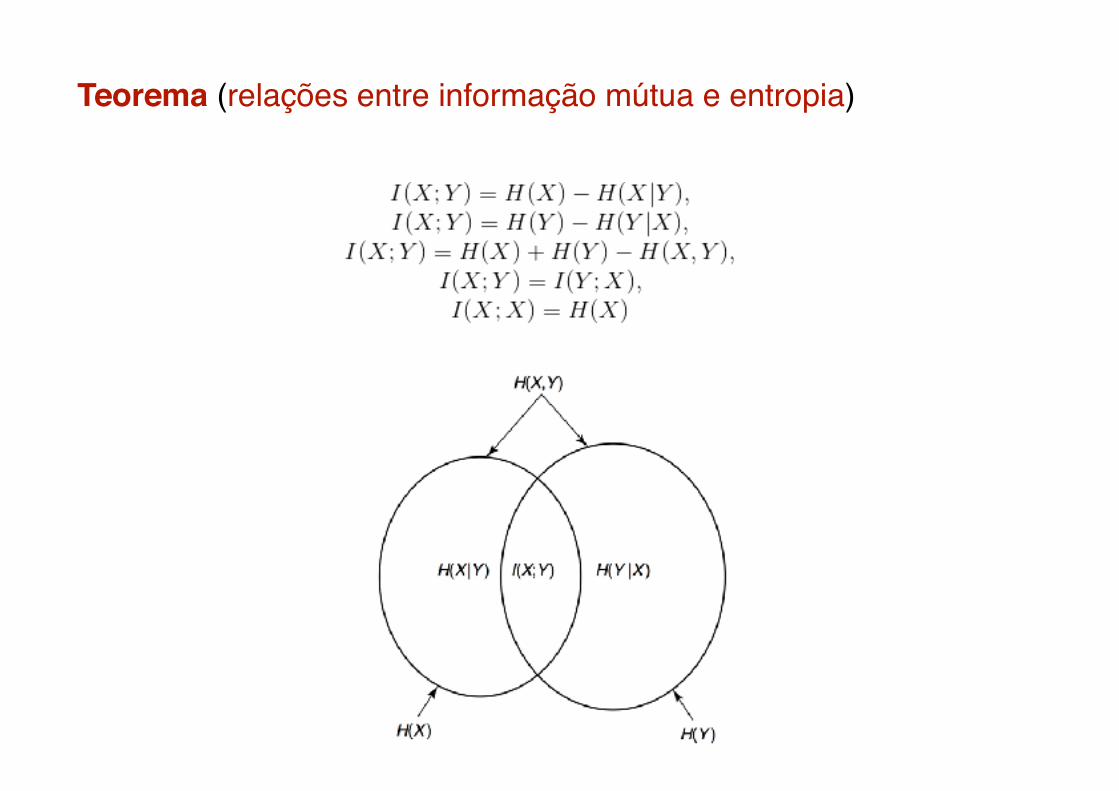
Teorema (relações entre informação mútua e entropia)

Regras da cadeia
• Regra da cadeia para entropia
• Regra da cadeia para entropia relativa
• Regra da cadeia para informação mútua

Teorema (regra da cadeia para a entropia)
Sejam X1,X2,...Xn variáveis com distribuição conjunta p(X1,X2,...Xn).
prova.
i) para duas variáveis:

ii) para três variáveis:
então:
passando ao caso n variáveis:
Q.E.D.

Definição (informação mútua condicional).A informação mútua entre duas variáveis X e Y condicionada a Z é
então
Teorema (regra da cadeia para a informação)

prova.
e, portanto,
Q.E.D.

convexidade �
seja uma énupla no espaço vetorial euclidiano # : � .
�
�
�
Definição. Uma região convexa � é dita ser convexa, se dados dois pontos quaisquer � e dado um número real � , então
�
∪ & ∩
ℝn
(x1, x2, . . . , xn)∀ x, y ∈ ℝn, ∀c ∈ ℝ
x + y := (x1 + y1, x2 + y2, . . . , xn + yn)
c . x := (cx1, cx2, . . . , cxn) .
S ⊂ ℝn
α, β ∈ S0 ≤ θ ≤ 1
θα + (1 − θ)β ∈ S .

interpretaçãoS é convexa se a reta que une quaisquer pontos interiores de S, tem todos os seus pontos também pertencentes a S.
exemploo conjunto � de vetores de probabilidade no � é uma região convexa.
ℙ ℝn

� e � com
� �
verificação.veremos se � é também um vetor de probabilidades para todo e qualquer � , �
Ora, � , logo � e
� .
α = (α1, α2, . . . , αn) β = (β1, β2, . . . , βn)n
∑i=1
αi = 1, αi ≥ 0 ∀i = 1,n .n
∑i=1
βi = 1, βi ≥ 0 ∀i = 1,n .
γ := θα + (1 − θ)βθ 0 ≤ θ ≤ 1.
γk = θαk + (1 − θ)βk γk ≥ 0 ∀k = 1,nn
∑k=1
γk = θn
∑k=1
αk + (1 − θ)n
∑k=1
βk = 1

Desigualdade de Jensen & suas consequências
seja f uma fução de valores reais definida em uma região convexa do espaço euclidiano.
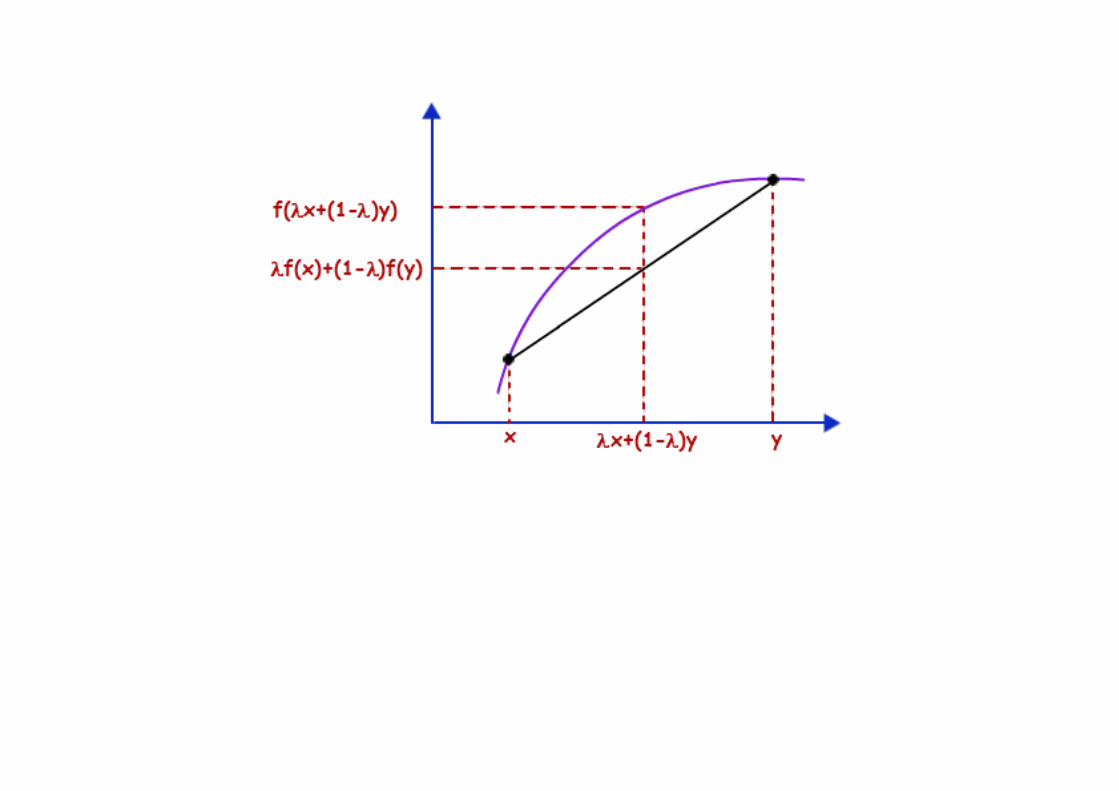
Definição. Uma função f(x) é dita ser convexa � no intervalo (a,b) se para cada tem-se
ela é dita estritamente convexa se a igualdade só é atingida nos valores extremos de � .
∩
λ

Propriedades da funções convexas �
P1- sejam � funções convexas definidas numa região S.
Sejam � constantes reais positivas. Então a
combinação linear de funções � também é uma função
convexa em S.prova.
�
�
∩
f1, f2, . . . , flc1, c2, . . . , cl
l
∑i=1
ci fi
α, β ∈ S, com f convexa .
θf(α) + (1 − θ)f(β) ≤ f(θα + (1 − θ)β) .

Se � , dados � ,
provar que h(.) é convexa, i.e.�
Ora �
multiplicando por � constante positiva
�
escrevendo as desigualdades para i=1,l e somando-se membro a membro...
h(α) :=l
∑i=1
ci fi(α) ∀α ∈ S α, β, e 0 ≤ θ ≤ 1
θh(α) + (1 − θ)h(β) ≤ h(θα + (1 − θ)β) .
θfi(α) + (1 − θ)fi(β) ≤ fi(θα + (1 − θ)β)∀i = 1,l
ci
θci fi(α) + (1 − θ)ci fi(β) ≤ ci fi(θα + (1 − θ)β)

�
Q.E.D.
P2- Se f for uma função convexa � definida em um intervalo da reta real, então
� (f admite um máximo).
θl
∑i=1
ci fi(α) + (1 − θ)l
∑i=1
ci fi(β) ≤l
∑i=1
ci fi(θα + (1 − θ)β)
∩
∂2f∂x2
≤ 0 ∀x ∈ I

Aplicação.
Seja X uma v.a. discreta com entropia �
Note que H(.) é uma combinação linear de funções � com coeficientes reais positivos 1.
Examinando: � �
�
H(X) = −K−1
∑k=0
pk log2 pk .
h(pk) := − pk log2 pk
h(pk) := − pk log2 pk ⇒
∂h(pk)∂pk
= −∂
∂pk
pk . ln pk
ln 2
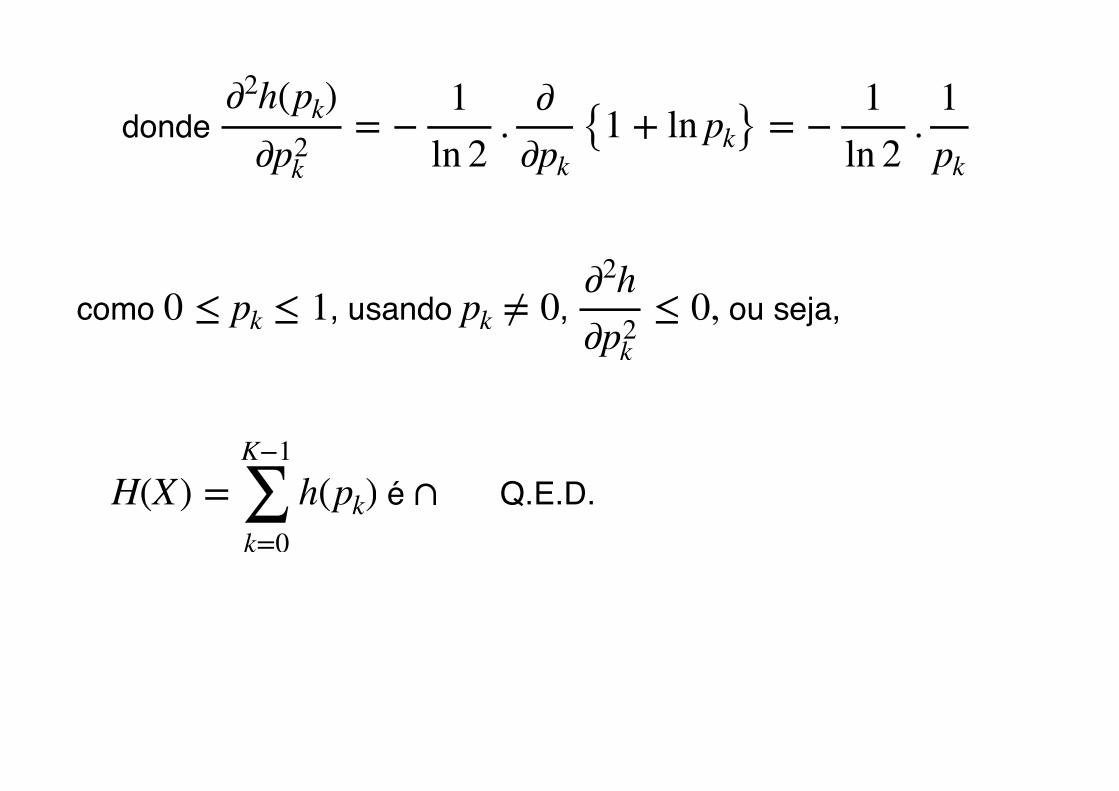
donde �
como � , usando � , � ou seja,
� é � Q.E.D.
∂2h(pk)∂p2
k= −
1ln 2
.∂
∂pk{1 + ln pk} = −
1ln 2
.1pk
0 ≤ pk ≤ 1 pk ≠ 0∂2h∂p2
k≤ 0,
H(X) =K−1
∑k=0
h(pk) ∩

Teorema. se uma função tem segunda derivada que é não-negativa (positiva) no intervalo, então a função é convexa (estritamente convexa).
prova. Usando a expansão de Taylor em torno de um ponto interno do intervalo
sendo x* entre x0 e x.
Por hipótese, f’’(x0)>0 e assim o último termo é não negativo para qualquer valor de x no intervalo.

Seja
e avaliando a expressão no ponto x=x1, e em x=x2
combinando as duas expressões (eq1� e eq2 � ), o
resultado segue. Q.E.D. * λ * (1 − λ)

Teorema (Desiguladade de Jensen). Se f é uma função convexa e X é uma variável aleatória, então
OBS. se a função for estritamente convexa, então X=E(X) com probabilidade 1.prova.por indução. Para distribuição com valores não nulos em apenas 2 pontos, Suponha que o teorema é verdadeiro para k-1 pontos de massa na distribuição. Vamos mostrar que também será para k pontos.
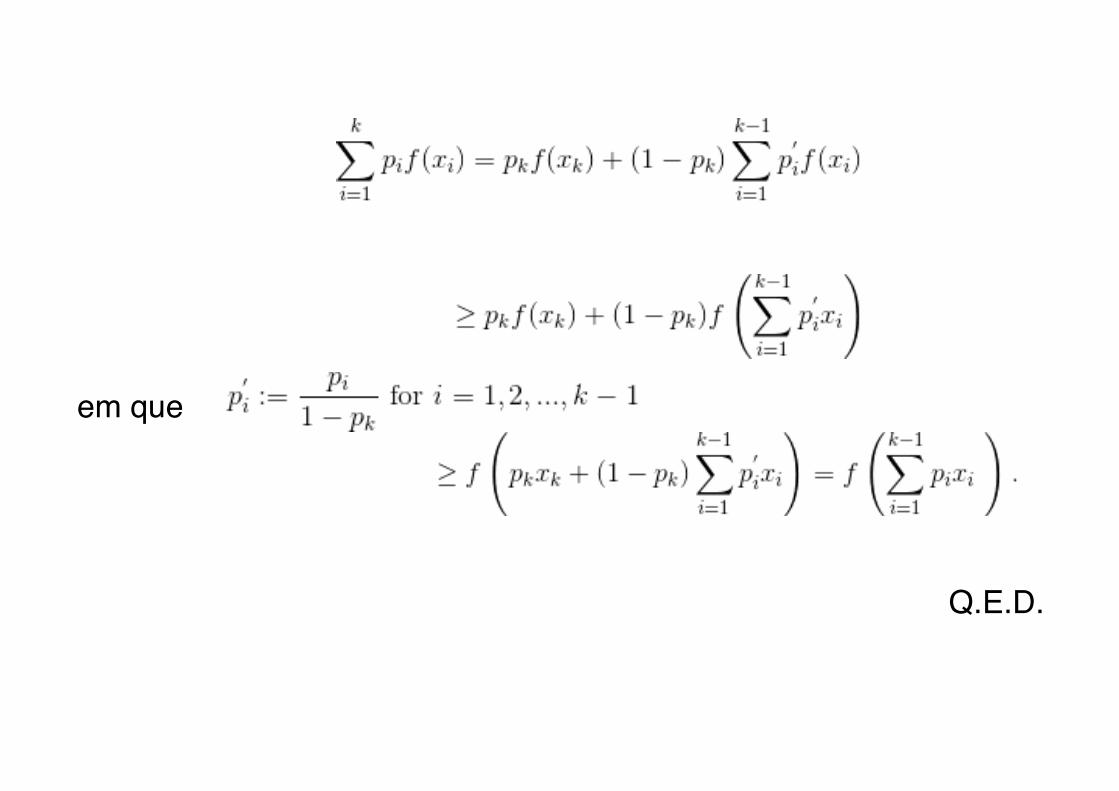
em que
Q.E.D.

Teorema (desigualdade de informação). Sejam p(x), q(x) duas distribuições discretas de probabilidade.
Então: com igualdade prova.
Seja o suporte de p(x). Então:
e portanto, via desigualdade de Jensen:
(a condição sss deve ser verificada...) Q.E.D.

Corolário (não-negatividade da informação mútua).Para quaisquer duas variáveis aleatórias X e Y,
com igualdade sss X e Y são independentes.prova.
� , com igualdade apenas quando p(x,y)=p(x).p(y).
corolário.com igualdade sss as v.a.’s X e Y são condicionalmente independentes de Z.
I(X; Y ) = D(p(x, y) | |p(x) . p(y)) ≥ 0

Teorema (já provado; uma prova alternativa). A entropia de uma v.a. X é máxima para variável uniformemente distribuída,
prova.seja a distribuição uniforme e p(x) outra arbitrária.
�
Claro que D é não-negativa, donde o resultado.Q.E.D.
D(u | |p) = ∑ p(x)logp(x)u(x)
= log | χ | − H(X ) .

Teorema (informação não machuca ninguém). , com igualdade sss X e Y são independentes.
prova.Decorre de
Q.E.D.
Teorema (cota da entropia por independência).
com igualdade sss todos os Xi's são mutuamente independentes.

prova.
com igualdade atingida na independência. Q.E.D.
DESIGUALDADE DE PROCESSAMENTO DE DADOS
X, Y e Z formam um cadeia markoviana nesta ordem
( � ) se a distribuição condicional de Z depende apenas
de Y e é independente condicionalmente em X.
X → Y → Z

Definição. Cascata markoviana
Conjunto de v.a.’s X,Y,Z com H(Z|X,Y)=H(Z|Y).A incerteza sobre Z conhecida apenas Y em nada altera pelo conhecimento suplementar de X, pois que Z só depende de (X,Y) por intermédio de Y.
Proposição.
A igualdade (cascata markoviana) ocorre sss

Prova. �
= �
isto pode ser escrito como:
=�
o somatório em z é uma entropia relativa D(.), logo não negativa.
Então � Q.E.D.
H(Z |X, Y ) − H(Z |Y ) = E {−log P(Z |X, Y ) + log P(Z |Y )}
∑x
∑y
∑z
P(x, y, z) logP(Z |Y )
P(Z |X, Y ).
∑x
∑y
P(x, y)∑z
P(Z |X, Y ) . logP(Z |Y )
P(Z |X, Y ).
H(Z |X, Y ) − H(Z |Y ) ≥ 0

Corolário. Uma condição necessária e suficiente para que X,Y,Z
forme uma cadeia markoviana é que I(X,Z |Y)=0.
O seguinte teorema (des igualdade fundamenta l de processamento de dados) prova que nenhum procedimento sobre Y, de natureza determinística ou aleatória, pode aumentar a informação que Y contém sobre X.
Teorema. Se � , então � .X → Y → Z I(X; Y ) ≥ I(X; Z)

prova:Pela regra da cadeia, �
e também �
Como X e Z são condicionalmente independentes dado Y, �
Lembrando a não-negatividade � temos:
�
Igualdade sss � Q.E.D.
Corolário. Se Z=g(Y), tem-se �
I(X; Y, Z) = I(X; Z) + I(X; Y |Z)I(X; Y, Z) = I(X; Y ) + I(X; Z |Y ) .
I(X; Z |Y ) = 0.
I(X; Y |Z) ≥ 0,I(X; Y ) ≥ I(X; Z)
I(X; Y |Z) = 0.
I(X; Y ) ≥ I(X; g(Y ))

Algumas outras definições de entropia em TI
entropia de Rényi
Alfréd Rényi, matemático húngaro
"Um matemático é um dispositivo que transforma café em teoremas.",
A entropia de Rényi de ordem , é definida como
com ≥0 e ≠1
α
Hα(X ) :=1
1 − αlog (
n
∑i=1
pαi ) α α

entropia binária de Rényi (compare com a entropia H2)

casos limites
.
(entropia de Shannon)
(min-entropy)
limα→0
Hα(X ) = H0(X ) = max-entropy(X ) = log2 ∥ X ∥
limα→1
Hα(X ) = H(X )
limα→∞
Hα(X ) = H∞(X ) = mini
(−log2 pi)

Examinemos a aproximação para a entropia de Shannon.
.
Seja .
Logo . Mas e
podemos usar o desenvolvimento em série de Taylor:
Hα(X) :=1
1 − αlog (
n
∑i=1
pαi )
α = 1 − ϵ
Hα(X) :=1ϵ
log2 (n
∑i=1
p1−ϵi ) p1−ϵ
i = pip−ϵi
p−ϵi = exp[−ϵ ln(pi)] = 1 − ϵ ln(pi) + O(ϵ2) .

Tem-se então
.
Separando os termos
, donde
n
∑i=1
p1−ϵi = ∑
i
pi [1 − ϵ ln(pi) + O(ϵ2)]
n
∑i=1
p1−ϵi = 1 − ϵ∑
i
pi [ln(pi) + O(ϵ)]
log2 (n
∑i=1
p1−ϵi ) =
1ln 2
ln{1 − ϵ∑i
pi[ln(pi) − O(ϵ)]}

ou, finalmente,
.
Dividindo por e passando ao limite,
.
Q.E.D.
log2 (n
∑i=1
p1−ϵi ) = − ϵ
1ln 2 ∑
i
pi ln(pi) + O(ϵ2)
ϵ
limα→1
Hα(X) = −1
ln 2 ∑i
pi ln(pi) = ∑i
pi log(pi) = H(X)

entropia de von Neumann
János Neumann, gênio Húngaro-Americano
� ,
definida em mecânica quântica!
� é a matriz de densidade e tr(.) denota o traço da matriz
S := − tr (ρ ln ρ)
ρ

entropia de Tsallis (1988)
Constantino Tsallis, matemático grego
� .
q real, chamado de índice entrópico.No limite � , transforma-se na entropia de Boltzmann.
Sq(pi) :=k
q − 1 (1 − ∑i
pqi )
q → 1

A Entropia diferencial de Shannon
Shannon também lidou com o caso contínuo, propondo a definição de entropia diferencial
abordagem heurística: X, com densidade de probabilidade �
Separação com uma partição.
�
fX(x)
H([X]π) = −+∞
∑j=−∞
fX(xj)Δxj . log2[ fX(xj)Δxj]

�
no limite de refinamento da partição:
� .
o 2o termo diverge e não tem sentido físico.
= −+∞
∑j=−∞
fX(xj) . log2[ fX(xj)] ++∞
∑j=−∞
fX(xj) . log2[1
Δxj] . Δxj
H(X) = − ∫+∞
−∞fX(x) log2 fX(x)dx + ∫
+∞
−∞fX(x) log2{
1dx
}dx

Definição. A entropia diferencial de Shannon de uma variável aleatória X contínua com densidade de probabilidade � é
� .
Notas:a) não é invariante a uma transformação afimb) pode resultar em quantidade negativas (valores negativos)
fX(x)
H(X) := − ∫+∞
−∞fX(x) log2 fX(x)dx = E − log fX(x)

Generalizando: Definir uma informação mútua no caso contínuo:
� .
Modernamente, esta definição é estabelecida através da derivada de Radon-Nikodym:
� .
****************************************************************************
I(X; Y ) := − ∫+∞
−∞ ∫+∞
−∞fX,Y(x, y) log2
fX,Y(x, y)fX(x) . fY(y)
dxdy
H(X) := E − log ( dμX
dμ )

uma tentativa de redefinição da entropia no caso contínuoA proposta de entropia de "de oliveira"
�
a ideia não é particionar o intervalo � da abscissas, como na integral de Riemann, mas sim as ordenadas, como ocorre na integral de Lebesgue. O que interessa são os pontos em que � assume valores maiores que a unidade, sendo associados a um conteúdo de informação “negativo”.
Note que há um isomorfismo (one-to-one) entre os intervalos:
� via o mapeamento � .
HdeO(X) := − ∫{x|fX(x)≤1}fX(x) log2 fX(x)dx − ∫{x|fX(x)>1}
1fX(?)
log21
fX(?)d ( 1
x )(−∞, + ∞)
fX(x)
[0,1], (1, + ∞) ⊂ ℝ+ 1x
← x

Estatística Suficiente
a desigualdade de processamento de dados em TI está ligada ao conceito de estatística suficiente.
Seja � uma família de distribuições discretas indexada por um parâmetro � . Seja X uma amostra desta família.
Seja T(X) uma estatística. Então: � donde
� .
Se a igualdade é atingida, nenhuma informação é perdida.
{fθ(x)}θ
θ → X → T(X),I(θ; T(X)) ≤ I(θ; X)

Definição. Uma estatística T(X) é dita ser uma estatística suficiente relativa à família � se X é independente de � dado T(X) para qualquer distribuição sobre � .
� forma uma cascata markoviana.
Estatística suficiente preserva a informação mútua...
Aqui segue também o conceito de estatística suficience mínima ... (não apresentado, vide texto)
{fθ(x)} θθ
θ → T(X) → X

Aproximação de coeficientes binomiais.
Para � , tomando a fração � ,
� em que
�
Pode ser usada a cota
�
0 < k < n q := k /n
2nH2(q)
n + 1≤ (n
k) ≤ 2nH2(q)
H2(q) := − q log2 q − (1 − q)log2(1 − q)
( nλn) ≈ 2nH2(λ)[1−ϵ(n)]

Modelos para Fontes de Texto1. Alfabetos
conjunto de letras maiúsculas A,B,C,D,E,...,X,Y,Z conjunto de letras e numeraisA,B,C,D,...,Y,Z,0,1,2,...9
conjunto de maiúsculas, minúsculas, espaço, pontuação
conjunto A,T,C,G
conjunto de palavras do Grande dicionário Houaiss 270.000 verbetes
...

n-gramas
� �
� �
�
digramas �
trigramas� ...
A = {a1, a2, a3, . . . , am−1} ∥ A ∥= m
ℤm := {0,1,2,...,m − 1} ∥ ℤm ∥= m
A ↔ ℤm
A2 = A × A = {a0a0, a0a1, . . . , a0am−1, . . . , am−1am−1}
A3 = A × A × A = {a0a0a0, a0a0a1, . . . , a0a0am−1, . . . , am−1am−1am−1}

mensagens (textos) são n-gramas sobre � �
A saída da fonte é modelada via um processo estocástico discreto, uma sequência de v.a’s contendo elementos de
� ou �
Sobre os n-gramas:
1) normalização �
2) consistência de Kolmogorov, �
�
ℤm ⇔ ℤnm
s ∈ {A, A2, A3, A4, . . . } s ∈ ⋃k=1
Ak
∑xn∈ℤm
P (x0, x1, . . . , xn−1) = 1
s > n
∑xn∈ℤm
P (x0, x1, . . . , xn−1) = ∑xn,xn+1,...,xs−1
P (x0, x1, . . . , xn−1, xn, xn+1, . . . , xs−1)

exemplo.
3-grama BIO sobre �
5-grama BIO** sobre � �
MODELO 1: texto de ordem-0 (unigramas)
uniforme em � , � .
Em � , A={A,B,C,...,Z,_} �
ℤ3m
ℤ5m
262
∑k = 1
* *
P(BIO * * ) = P(BIO)
ℤm P(ai) =1m
ai ∈ ℤm
ℤ27 P(ai) =127
ai ∈ ℤ27

MODELO 2: texto de ordem-1 (unigramas independentes)
Em � , A={A,B,C,...,Z,_} �
�
ℤ27P(ai) = freq. relativa ocorrência de ai, ai ∈ ℤ27
P (x0, x1, . . . , xn−1) =n−1
∏k=0
P(xk)

Digramas P(QU)=P(Q).P(U)=0.007 x 0.030 =2.1 10-4 P(QR)=P(Q).P(R)=0.007 x 0.053 =3.7 10-4
MODELO 3: texto de ordem-2 (digramas independentes)
�
�
�
P (x0, x1, . . . , x2n−1) = P(x0, x1) . P(x2, x3) . . . . . P(x2n−2, x2n−1)
P(s, t) ≥ 0 0 ≤ s, t ≤ m
∑s
∑t
P(s, t) = 1

Digramas P(QU)= 0.0072 P(QR)= 0.0000
MODELO 4: fonte markoviana (modelo com memória)
cadeia de Markov com matriz de probabilidades de transição
�
Para cadeia ergódica, a distribuição estacionária de equilíbrio:
�
{P(s | t)} 0 ≤ t, s < m
π = {π0, π1, . . . , πm−1}

Distribuição de equilíbrio segue da matriz de transição
�
� ...�
ou � .
π0 = π0P(0 |0) + π1P(0 |1) + π2P(0 |2) + . . . + πm−1P(0 |m − 1)
π1 = π0P(1 |0) + π1P(1 |1) + π2P(1 |2) + . . . + πm−1P(1 |m − 1)
πm−1 = π0P(m − 1 |0) + π1P(m − 1 |1) + π2P(m − 1 |2) + . . . + πm−1P(m − 1 |m − 1)
π = π[P]

�
Simulando: 1) abra texto de referência em página aleatória 1o caractere é x1
2) abra texto de referência em página aleatória procure x1; o próximo caractere é x2
3) abra texto de referência em página aleatória procure x2; o próximo caractere é x3 ...
P =
P(A |A) P(B |A) . . . P(Z |A) P(_ |A)P(A |B) P(B |B) . . . P(Z |B) P(_ |B)
. . . . . . . . .P(A |Z) P(B |Z) . . . P(Z |Z) P(_ |Z)P(A |_) P(B |_) . . . P(Z |_) P(_ |_)

Considere um modelo markoviano de ordem-n mais elevada � n=1 monograma-a-monograma � n=2 digrama-a-diagrama � n=3 trigrama-a-trigrama � ... com alfabeto maiúsculas, minúsculas e números, � :
Para tetragramas,
a matriz P de probabilidades de transição tem dimensão:
�
ℤ27m × m → 27 × 27m2 × m2 → 272 × 272
m3 × m3 → 273 × 273
ℤ63
15.752.961 × 15.752.961

Entropia da língua inglesa (Claude Shannon)Zero-order approximation. (The symbols are independent and equiprobable.)
XFOML RXKHRJFFJUJ ZLPWCFWKCYJFFJEYVKCQSGXYD QPAAMKBZAACIBZLHJQD
The entropy of zeroth-order model = log 27 = 4.76 Sh per letter.

First-order approximation. (The symbols are independent. The frequency of letters matches English text.)
OCRO HLI RGWR NMIELWIS EU LL NBNESEBYA TH EEIALHENHTTPA OOBTTVA NAH BRL
The first order model gives an estimate of the entropy of 4.03 Sh per letter

Second-order approximation. (The frequency of pairs of letters matches English text.)
ON IE ANTSOUTINYS ARE T INCTORE ST BE S DEAMYACHIN D ILONASIVE TUCOOWE AT TEASONARE FUSOTIZIN ANDY TOBE SEACE CTISBE
EXT OR SYMAD RES FUN PLUDEFOLY FOR ORY THER CURSOR STEME TO OU ANNINPUT

Third-order approximation. (The frequency of triplets of letters matches English text.)
IN NO IST LAT WHEY CRATICT FROURE BERS GROCIDPONDENOME OF DEMONSTURES OF THE REPTAGIN ISREGOACTIONA OF CRE
MAJORIZONTAL IS ZEROUS COMPUT COPY OF AND THE LIMILABLESPOT LEVE AVE MODE IS DEALINE OF PERMINORMATION

Fourth-order approximation.
(The frequency of quadruplets of letters matches English text.)
THE GENERATED JOB PROVIDUAL BETTER TRAND THE DISPLAYED CODE, ABOVERY UPONDULTS WELL THE CODERST IN THESTICAL IT DO HOCK BOTHE MERG. (INSTATES CONS ERATION. NEVER ANY OF PUBLE AND TO THEORY. EVENTIAL CALLEGAND TO ELAST BENERATED IN WITH PIES AS IS WITH THE )fourth-order model gives an estimate of 2.8 Sh per letter.

Entropy of English using Shannon guessing game.
Shannon 1950: entropy rate for English using a human gambler to estimate probabilities. 1.34 Sh per letter.
entropia modelo4.60 Sh fonte simétrica sem memória com 27 símbolos4.13 Sh fonte de 1a ordem, frequência de letras estimada3.34 Sh fonte de 2a ordem2.80 Sh fonte de 4a ordem1.30 Sh Shannon guessing game

First-order word model. (The words are chosen independently but with frequencies as in English.)
REPRESENTING AND SPEEDILY IS AN GOOD APT OR COME CANDIFFERENT NATURAL HERE HE THE A IN CAME THE TO OF TOEXPERT GRAY COME TO FURNISHES THE LINE MESSAGE HAD BE THESE.
(The word transition probabilities match English text.)
THE HEAD AND IN FRONTAL ATTACK ON AN ENGLISH WRITERTHAT THE CHARACTER OF THIS POINT IS THEREFORE ANOTHERMETHOD FOR THE LETTERS THAT THE TIME OF WHO EVER TOLDTHE PROBLEM FOR AN UNEXPECTED

Fontes de Markov
caracterizada por estados 1,2,...,. J
letras do alfabeto �
sequencia da fonte: �
sequencia de estados: �
Denota-se por Qji a probabilidade condicional de ir ao estado i quando o estado anterior é j
� PROB. TRANSIÇÃO DE ESTADOS
Fonte Markov: Propriedade: � .
a1, a2, . . . , aK
u = (u1, u2, . . . )s = (s1, s2, . . . )
Qji = Pr(sl = i |sl−1 = j)
Pr(sl |sl−1, sl−2, sl−2, . . . ) = Pr(sl |sl−1)

Cadeia de Markov discretaSeja �
a probabilidade da letra ak ser emitida quando a fonte está no estado j.
Exemplo.
ramos rotulados pelos símbolos de saída � ; probabilidade � .
Pj(ak) = Pr[ul = ak |sl = j]
ak Pj(ak)

Cadeias de Markov homogêneas
um estado s é transitório se há outro estado que pode ser alcançado a partir dele, mas que do mesmo é impossível retornar a s.
vide ESTADO 1
um conjunto de estados é irredutível se, de cada dos estados, nenhum estado fora do conjunto pode ser atingido e cada estado do conjunto pode ser atingido em uma ou mais transições.
vide ESTADOS {2,3} e ESTADOS {4,5}
transitórios + irredutíveis
com probabilidade 1 a cadeia vai para um dos conjuntos irredutíveis e estaciona lá

período de estados irredutíveis:
maior inteiro m tal que todas as recorrências para os estados são múltiplos de m.
ESTADOS {2,3} período m=1
ESTADOS {4,5} período m=2.
Se uma cadeia é homogenea com estados irredutíveis de período m=1, ela é chamada ergódica.

Probabilidade limite de estados ergódicos E.
Há probabilidades estacionárias � para cada estado, soluções de:
�
� .
Além disso, as probabilidades assintóticas de estados � verificam:
�
se a fonte iniciou em um estado ergódico há infinitamente muito tempo atrás
�
q( j)
∑j∈E
q( j)Qji = q(i)
∑j∈E
q( j) = 1
i ∈ E
liml→∞
Pr(sl = i |s1 = j) = q(i) .
Pr(sl = i) = q(i) ∀l .
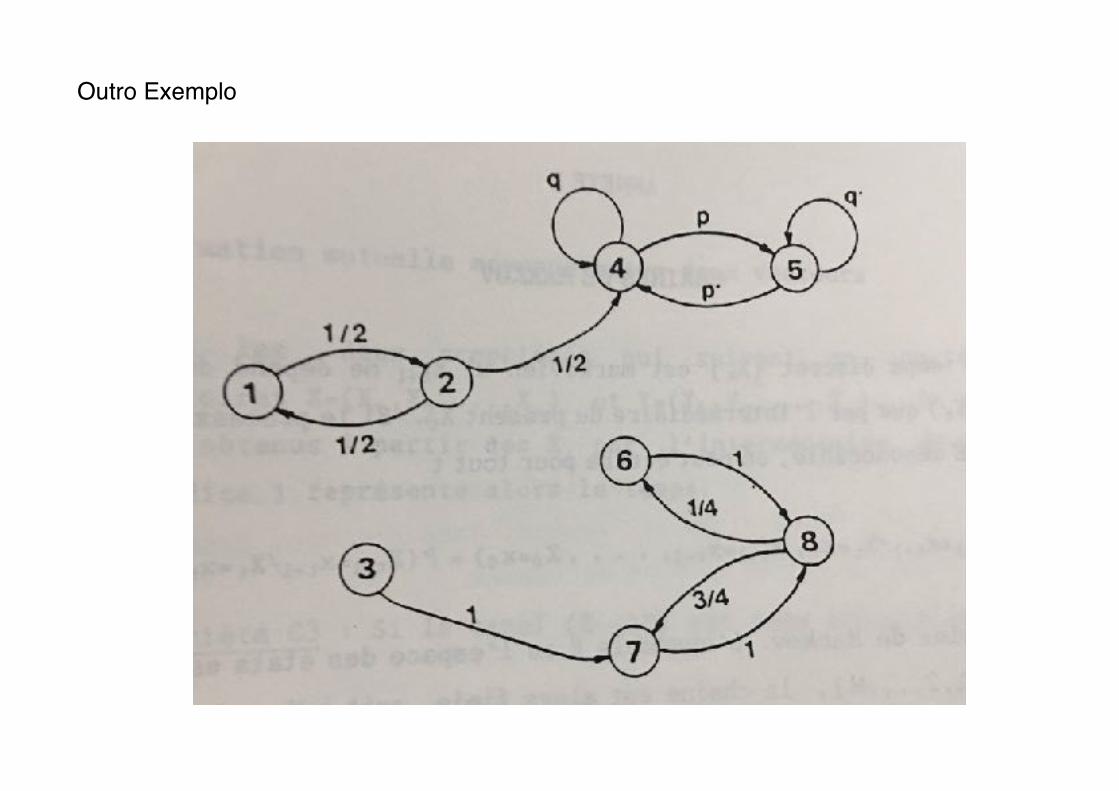
Outro Exemplo

Os estados 1,2 e 3 são transitórios (não essenciais)
Duas cadeias irredutíveis: {estados 4 e 5, aperiódica} e {estados 6,7 e 8, de período m=2)
Teorema. Para uma cadeia de Markov finita, irredutível e aperiódica, existem os limites
� e são independentes de i.limn→∞
pnij = πj

Entropia de uma fonte de Markov
� .
Teorema. A entropia por letra de uma fonte ergódica markoviana é dada por
� , em que � .
(o limite sempre existe). Se a cadeia só possui um conjunto de estados irredutíveis, então
� , as probabilidades estacionárias dos estados.
prova. vide Robert Gallager Book.
H(U |s = j) = −K
∑k=1
Pj(ak)log Pj(ak)
H∞(U ) :=J
∑i=1
q(1,∞)H(U |s = i) q(1,∞) = limL→∞
1L
L
∑l=1
P(sl = i)
q(1,∞)(i) = q(i)
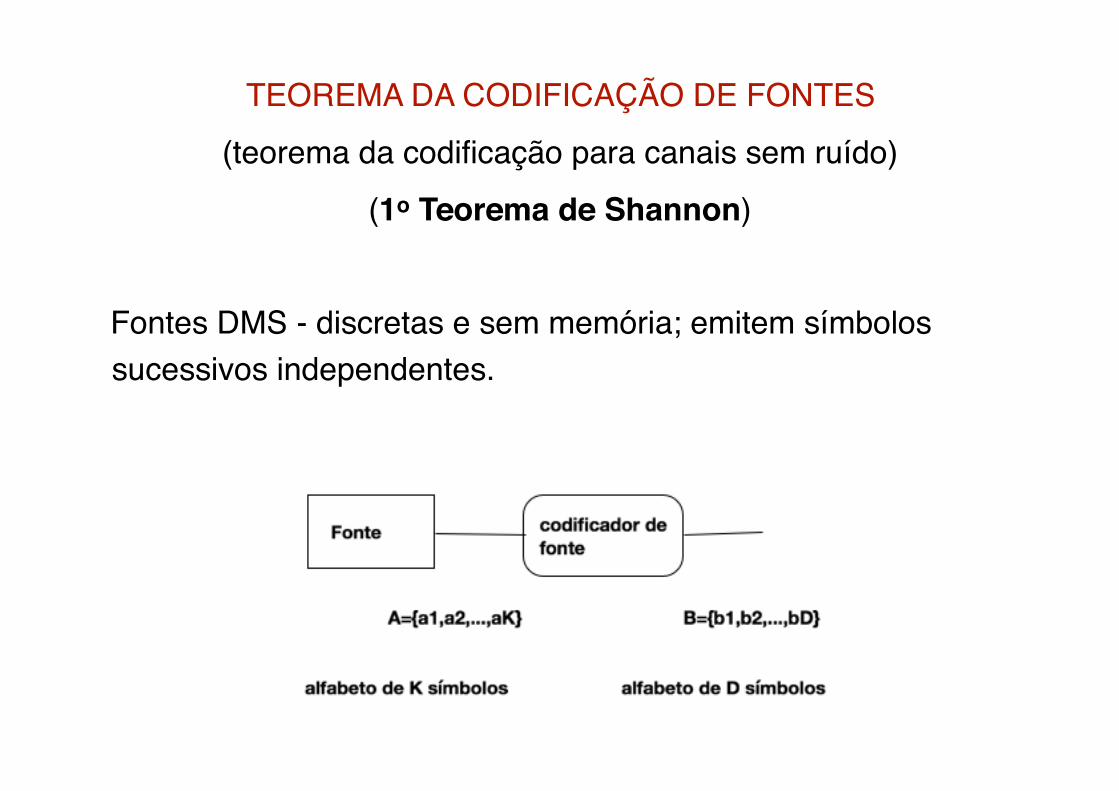
TEOREMA DA CODIFICAÇÃO DE FONTES(teorema da codificação para canais sem ruído)
(1o Teorema de Shannon)
Fontes DMS - discretas e sem memória; emitem símbolos sucessivos independentes.

Estamos interessados em codificar a saída da fonte usando um novo alfabeto de “D" letras. A codificação deve ser tal que:
1) Dada um sequencia emitida pela fonte, queremos que a sequencia código transmitida seja tal que de posse da mesma, possamos recuperar a sequencia da fonte com um probabilidade tão alta como se queira.
2) o número de letras código “gasto" por letras fonte deve ser o mínimo possível (compressão de dados).

Entender compactação como “retirada” da informação redundante
POXM LIT ST ISNVE N IT
A PROXM LITA EST ISPNIVE N SIT
A PROXMA LITA EST ISPNIVE NO SIT
A PROXIMA LISTA ESTÁ DISPONIVEL NO SITE
Como achar a sequencia mais curta tal que possamos recuperar toda a mensagem??

Seja � uma sequência de tamanho L, com letras de um alfabeto de cardinalidade K. O número de possíveis sequencias distintas é � .
Suponha que desejamos codificá-la em uma sequencia de tamanho N com letras oriundas de um alfabeto de cardinalidade D. Há, naturalmente, � delas.
uL := (u1, u2, . . . , uL)
KL
DN

Devemos impor, vista a condição 1, que � ou seja
� .
N/L é o número de letras do alfabeto código/número de letras do alfabeto fonte
podemos fazer melhor?
É possível se escolher � e ainda assim satisfazer 1.
Mas há um limite em quanto reduzir N/L.
DN ≥ KL
NL
≥log2 Klog2 D
NL
<log2 Klog2 D

1o Teorema de Shannon codificação de fontes com comprimento fixo.
Teorema. Seja uma fonte DMS de entropia H(U), com alfabeto de cardinalidade K e C um código de comprimento N sobre um alfabeto de cardinalidade D. Se Pe denota a probabilidade de uma sequência de comprimento L da fonte não coberta pela código, então para qualquer � :
mensagem direta.
Se , então Pe pode ser feita
arbitrariamente pequena fazendo-se L suficientemente grande.
δ > 0
NL
≥H(U) + δ
log2 D

mensagem inversa.
Se , então Pe se tornará arbitrariamente
próxima de 1 a medida que L cresce.
prova.Vejamos
� .
NL
≤H(U) − δ
log2 D
I(uL) = − log2 P(uL) = − log2
L
∏i=1
p(ui) = −L
∑i=1
log2 p(ui)

Assim,
� para fonte sem memória.
Portanto, � é uma soma de v.a.’s iid.
Versão fraca da lei dos grandes números
Se � são v.a.’s i.i.d. com média comum � , então
� .
(média amostral converge para a média estatística).
I(uL) =L
∑i=1
I(ui)
I(uL)
{Xi}Li=1 X̄
limL→∞
1L
L
∑i=1
Xi → X̄ em probabilidade

------A média de � é igual à entropia da fonte, denotada por H(U).
� .
Então
� .
I(ui) ∀i
H(U) := −K
∑k=1
P(ak)I(ak)
limL→∞
1L
L
∑i=1
I(ui) → H(U) em probabilidade

significado grosseiro.
� , ou seja, �
� .
A probabilidade de uma sequência típica de comprimento L emitida pela fonte é � e o número de sequencias-típicas será grosseiramente igual a:
� .
Pela condição 1, impõe-se � .
1L
L
∑i=1
I(ui) →?
H(U) I(uL) →?
LH(U) .
−log2 P(uL) →?
LH(U) ∴ P(uL) →?
2−LH(U)
2−LH(U)
ML ≈ 2LH(U)
DN ≥ ML ≈ 2LH(U)

Esta condição conduz a � . Caso binário, D=2 e
� .
Procedendo agora de modo rigoroso. [prova].
� significa:
NL
≥H(U)log2 D
NL
≥ H(U)
limL→+∞
1L
L
∑i=1
I(ui) → H(U) em probabilidade

Dado �
� ,
em que �
Denominemos por T o conjunto de todas as sequências � da
fonte tais que
� (*TIPICAS)
(chamaremos esta sequências de típicas).
δ > 0 ∃ϵ(δ, L) |
P[ |1L
L
∑i=1
I(ui) − H(U) | > δ] ≤ ϵ(δ, L)
limL→+∞
ϵ(δ, L) = 0.
uL
|I(uL)
L− H(U) | < δ

Logo � .
De (*), � , donde
�
e usando a definição de I(.),
�
P(T ) = 1 − P[ |I(uL)
L− H(U) | ≥ δ] ≥ 1 − ϵ(δ, L)
−δ ≤I(uL)
L− H(U) ≤ δ
L [H(U) − δ] ≤ I(uL) ≤ L [H(U) + δ]
2−L [H(U)−δ] > P(uL) > 2−L [H(U)+δ]

Para L suficientente grande � .
a) podemos afirmar que � ou seja,
�
de modo que o número de sequências típicas é limitado por
�
b) Por outro lado,
�
P(uL) ≈ 2−L [H(U)]
P(T ) = ∑u∈T
P(u)
1 ≥ P(T ) ≥ ML.2L[H(U)+δ]
ML ≤ 2L[H(U)+δ]
1 − ϵ(δ, L) ≤ P(T ) ≤ ML.2L[H(U)−δ]

de modo que o número de seq. típicas é limitado por
�
COMBINANDO-SE a) e b)
� .
i) Mensagem direta do teorema.Suponha que as sequências típicas sejam codificadas de tal modo que
ML ≥ [1 − ϵ(δ, L)].2L[H(U)−δ]
[1 − ϵ(δ, L)].2L[H(U)−δ] ≤ ML ≤ 2L[H(U)+δ]

� �
Logo, a cada sequência típica poderá corresponder uma sequência código e
�
Mas a probabilidade de sequências atípicas vai a zero:
� ,
DN ≥ 2L[H(U)+δ] ≥ MLNL
≥H(U) + δ
log2 D
Pe ≤ P(T̄, não ser codificada) ≤ P(T̄ )
P(T̄ ) = 1 − P(T ) ≤ 1 − {1 − ϵ(δ, L)} ≤ ϵ(δ, L)

assim
� .
ii) Mensagem inversa do teorema.
Codificando a sequência fonte de modo que �
� .
�
com
limL→+∞
P(T̄ ) = 0
DN < 2L[H(U)−2δ]
NL
<H(U) − 2δ
log2 D
1 − Pe = P(T, ser codificada) + P(T̄, ser codificada)

�
�
Finalmente,
� ,
ou seja,
�
P(T, ser codificada) = ∑uL∈T
P(uL) ≤ DN maxuL
P(uL)
P(T̄, ser codificada) ≤ P(T̄ ) ≤ ϵ(δ, L)
1 − Pe ≤ 2L[H(U)−2δ].2−L[H(U)−δ] + ϵ(δ, L)
Pe ≥ 1 − 2−Lδ + ϵ(δ, L) → 1.

Códigos: comprimento fixo vs comprimento variávelK=4 D=2
alfabeto � probabilidades �a1, a2, a3, a4 P(a1), P(a2), P(a3), P(a4)
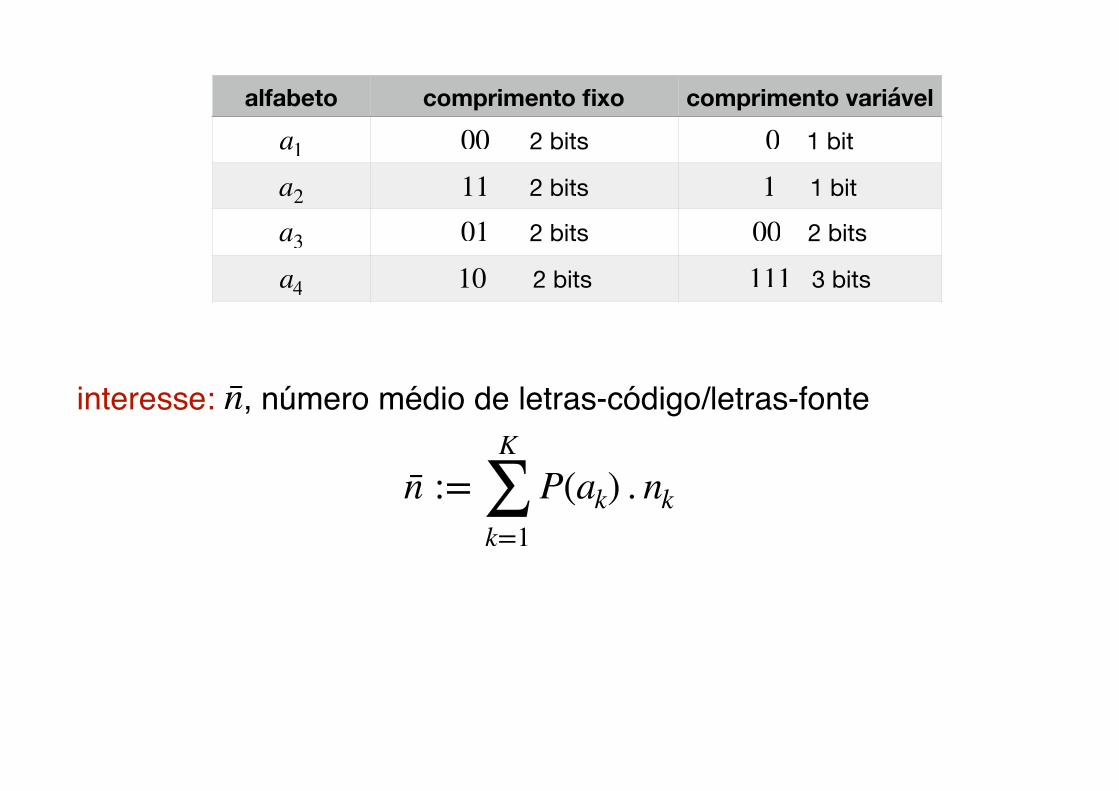
interesse: � , número médio de letras-código/letras-fonte
�
alfabeto comprimento fixo comprimento variável
� 2 bits11
� 3 bits111�a4
� 1 bit0�a1
� 2 bits01� 1 bit1�a2
� 2 bits10
� 2 bits00
� 2 bits00�a3
n̄
n̄ :=K
∑k=1
P(ak) . nk

Uma fonte DMS emite 5 símbolos � com
probabilidade � .
Considere dois códigos binários diferentes para os símbolos da fonte:
� 0 � 00
� 10 � 01
� 110 � 10
� 1110 � 110
� 1111 � 111
{a1, a2, a3, a4, a5}
{ 12
,18
,18
,18
,18 }
a1 → a1 →a2 → a2 →a3 → a3 →a4 → a4 →a5 → a5 →

Estimando o comprimento médio das palavras-código:
código 1
� = 2.125 bits/letra
código 2
� = 2.250 bits/letra
Há um melhor código? (de menor comprimento, i.e. de representação mais compacta da fonte). Como encontrá-lo?
n̄1 = 1.12
+18
[2 + 3 + 2 × 4]
n̄2 = 2.12
+18
[2 × 2 + 2 × 3]
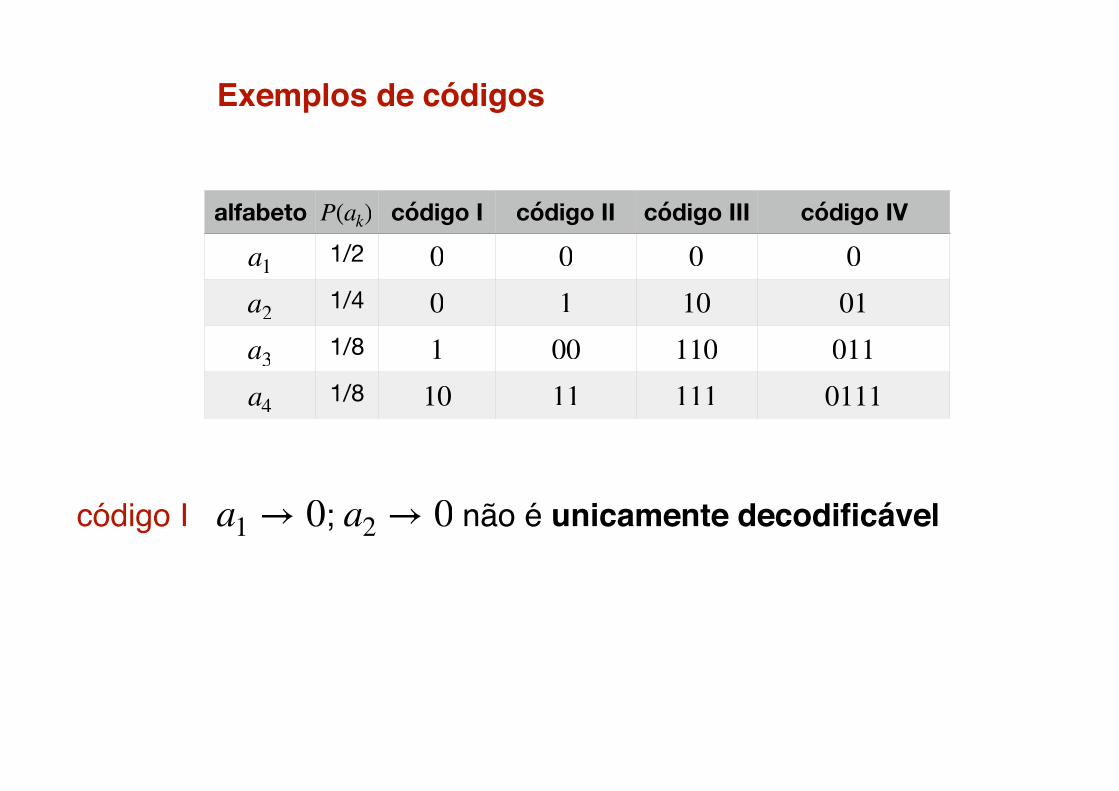
Exemplos de códigos
código I � ; � não é unicamente decodificável
alfabeto código I código II código III código IV1/2
1/4
1/8
1/8
�01�0�00
�111�a3
�0�10
�011
�a1
�1�11
�0�P(ak)
�a4
�0�1
�110�a2
�0111�10
�0
a1 → 0 a2 → 0

código II
�
unicamente decodificável [univocamente decodificável]Se qualquer sequência fonte distinta de comprimento finito tem sequência de letras-código diferentes a ela associadas.
0 0 1 1 1...
→ a1 a1 a2 a2 a2 . . .→ a3 a2 a2 a2 . . .→ a3 a4 a4 . . . . . .→ a1 a1 a4 a3 a3 . . .

código com condição de prefixo [códigos instantâneos]Um código com condição de prefixo é aquele no qual nenhuma palavra-código é prefixo de outra palavra-código.
códigos I & II & IV não são.
códigos prefixo � unicamente decodificável
código III 1 1 1 1 0 0 ... � 111 | 10 | 0 ... = �
código sem pontuação (comma free code)
código IV 0 0 0 1 0 1 1 1 0 � 0 | 0 | 01 | 0111 | 0 |...
código com pontuação (comma code)
⇒⇒ a4 a2 a1 . . .
⇒
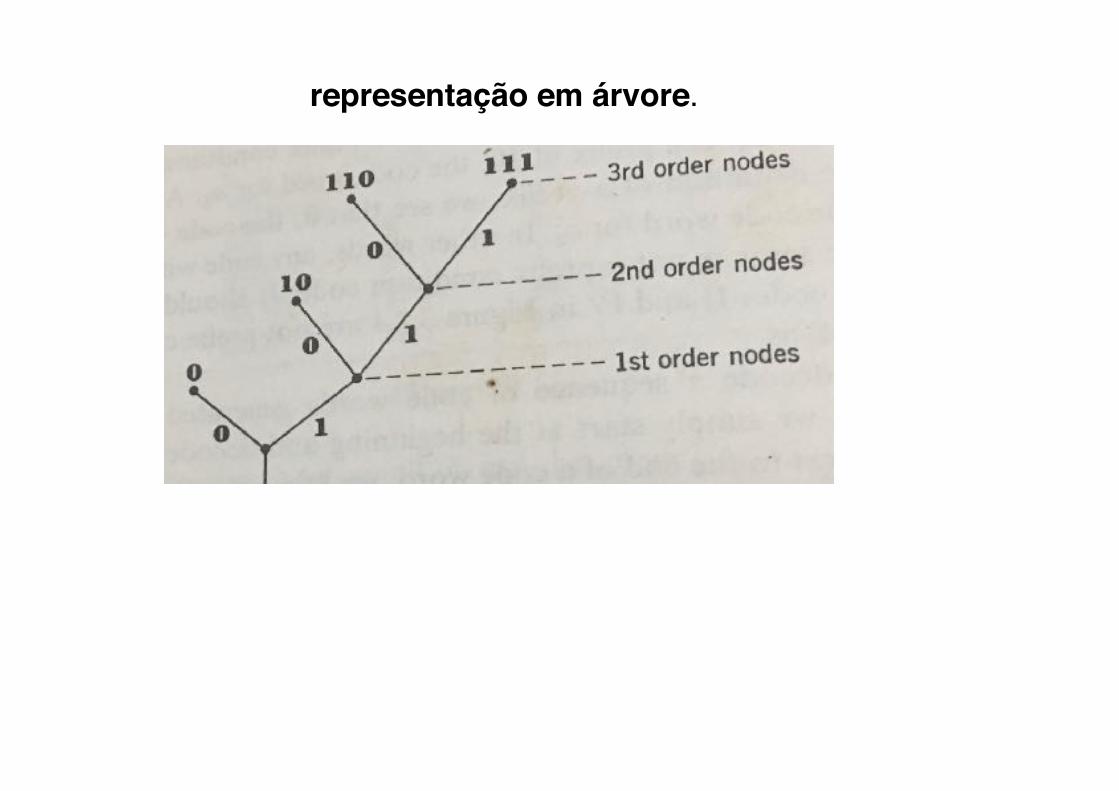
representação em árvore.

Desigualdade de KraftSe os inteiros � satisfazem a desigualdade
�
� então existe um código com alfabeto de cardinalidade D que satisfaz a condição de prefixo e tem estes inteiros como comprimento das palavras-código.
� Os comprimentos de todos os códigos com condição de prefixo satisfazem a desigualdade de Kraft.
necessidade & suficiência
n1, n2, . . . , nKK
∑k=1
D−nk ≤ 1
⇒
⇐

prova [esboço]árvore completa árvore completa de ordem n, no alfabeto D � � nós terminais
exemplo: D=2 árvore binária
⇒ Dn
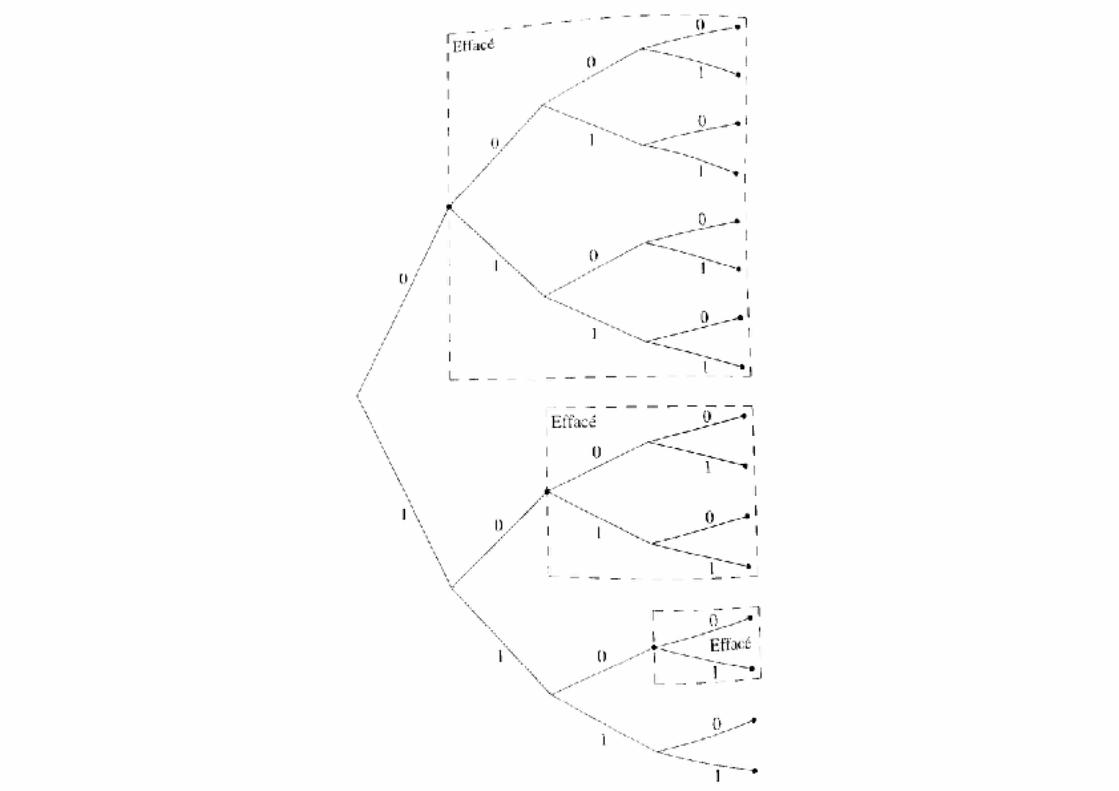

exemplo: D=3 árvore ternária
(esboço de prova � )
A fração de nós partindo de um nó terminal na ordem i é �
ao se selecionar um nó como "nó terminal" para alocar uma palavra-código, elimina-se esta fração de nós candidatos.
⇒D−i

Como nó terminal, não haverá nenhuma palavra-código mapeada em nós acima dele (garantindo a condição de prefixo).
aloca-se um nó terminal na ordem � � � fração descartada
aloca-se um nó terminal na ordem � � � fração descartada
... aloca-se um nó terminal na ordem � � � fração descartada
como � , ainda há nó disponível na alocação do nó
terminal para a última letra do alfabeto [cabe alocar terminais]
n1 ⇒ D−n1
n2 ⇒ D−n2
nK ⇒ D−nK
K
∑k=1
D−nk ≤ 1
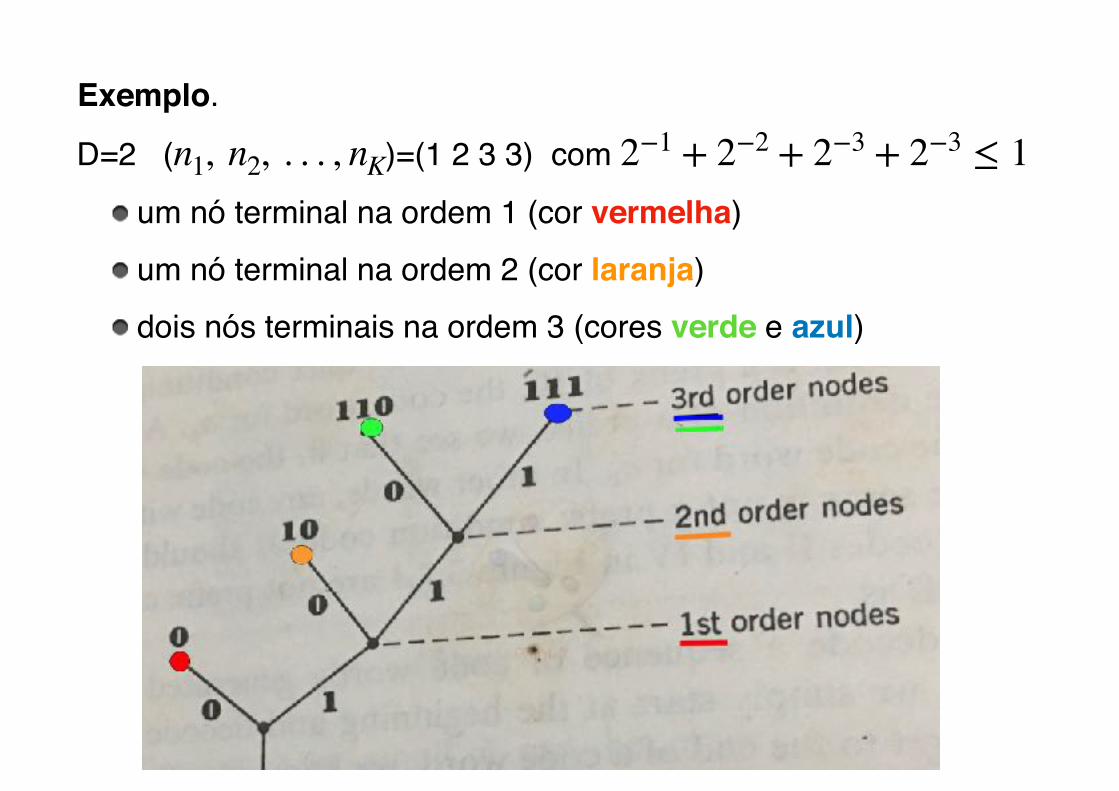
Exemplo.
D=2 ( � )=(1 2 3 3) com �
um nó terminal na ordem 1 (cor vermelha)um nó terminal na ordem 2 (cor laranja)dois nós terminais na ordem 3 (cores verde e azul)
n1, n2, . . . , nK 2−1 + 2−2 + 2−3 + 2−3 ≤ 1

(esboço de prova � )
qualquer código com condição de prefixo está incluso na árvore completa [vide detalhes da prova]
Teorema.Considere um código cujos comprimentos das palavras-código valem � sobre símbolos de um alfabeto de cardinalidade D.Se o código é unicamente decifrável, então a desigualdade de Kraft deve ser satisfeita.
prova. [vide livro texto TI]. unicamente decodificável � Kraft � código com condição de prefixo.
⇐
n1, n2, . . . , nK
⇒ ⇔

1o Teorema de Shannon codificação de fontes com comprimento variável.
Teorema. Seja uma fonte DMS de entropia H(U), com alfabeto de cardinalidade K e C um código sobre um alfabeto de cardinalidade D. É possível atribuir palavras-código para as letras fonte satisfazendo a condição de prefixo e cujo comprimento médio das palavras-código � verifica:
� .
Além disso, para qualquer conjunto de palavras-código unicamente decodificáveis, tem-se
� .
n̄
n̄ ≤H(U)log D
+ 1
n̄ ≥H(U)log D

prova.Sejam � as probabilidades das letras-fonte e sejam � os comprimentos das palavras-código correspondentes.
�
pondo -nk no logaritmo e combinando termos
� .
P(a1), . . . , P(aK)n1, . . . , nK
H(U) − n̄D =K
∑k=1
P(ak) . log21
P(ak)−
K
∑k=1
P(ak)nk . log D
H(U) − n̄D =K
∑k=1
P(ak) . log2D−nk
P(ak)

Da desigualdade fundamental da TI,
�
A última desigualdade segue da desigualdade de Kraft que é válida para qualquer código univocamente decifrável.
A igualdade se verifica sss � . (**)parte ii provada.
H(U) − n̄D ≤ (log e)[K
∑k=1
D−nk − ∑k
P(ak)] ≤ 0.
P(ak) = D−nk, 1 ≤ k ≤ K

Para satisfazer a equação (**), podem ser escolhidos nk tais que
�
Escrevendo cada equação e somando todas membro a membro, o lado esquerdo se torna a desigualdade de Kraft (existe código com condição de prefixo).O lado direito, via log, resulta �
Finalmente,
�
Multiplicando por � e somando, chega-se ao resultado Q.E.D.
D−nk ≤ P(ak) ≤ D−nk+1, 1 ≤ k ≤ K
log P(ak) < (−nk + 1) . log D
nk <−log P(ak)
log D+ 1
P(ak)

Teorema. Seja uma fonte DMS de entropia H(U) e C um código sobre um alfabeto de cardinalidade D. É possível atribuir palavras-código para sequencia de L letras-fonte satisfazendo a condição de prefixo e cujo comprimento médio das palavras-código � verifica:
� .
Além disso, a desigualdade a esquerda é satisfeita por qualquer código unicamente decodificável.
n̄
H(U)log2 D
≤ n̄ <H(U)
log2 D+
1L

prova.Para codificar sequências de L letras, a entropia é LH(U) e o comprimento médio das palavras-código � de modo que aplicando o teorema anterior,
� ,
o resultado segue dividindo-se por L todos os membros.
Ln̄
LH(U)log2 D
≤ Ln̄ <LH(U)log2 D
+ 1

Uma discussão do teorema da codificação para códigos de comprimento variável também se aplica para fontes de Markov, mostrando o seguinte resultado:
Teorema (codificação de fontes de Markov estacionárias).o número médio � de letras código por letra fonte, codificando L letras fonte (L grande) verifica
� .
n̄
H∞(U)log D
≤ n̄ ≤H∞(U)log D
+1L

propagação de erros em arquivos comprimidos
Considere um código instântaneo para uma fonte DMS de 3 símbolos
� 0
� 10
� 11
Verifique o problema da propagação de erros (arquivos zip são facilmente corrompidos)
a1 →a2 →a3 →

Seja uma sequência � codificada em:
0 11 11 11 11 10...
Suponha que há, durante a transmissão, um erro no 2o bit do arquivo.
0 01 11 11 11 10 ... � 0 0 11 11 11 11 0
A decodificação seria:� ao invés de
�
s1 s3 s3 s3 s3 s2 . . .
→
s1 s1 s3 s3 s3 s1 . . .s1 s3 s3 s3 s3 s2 . . .

Esquema simples de codificação: RLE
códigos de comprimento de carreiraRun Lenght Encoder
https://en.wikipedia.org/wiki/Run-length_encoding
Uma sequência binária, e.g., produzida por uma fonte binária, corresponde a realizações de uma v.a. X ~Ber(p).
0000100010000011001000000000000000000100...
definimos uma “carreira de zeros” como a sequencia de zeros até que o próximo 1 seja encontrado.

Os comprimento das carreiras são distribuídos de acordo com uma do tipo distribuição geométrica, l~Geo [ligeiramente modificada]
mapeando a sequencia binária:
0000100010000011001000000000000000000100... l=4 | l=3 | l=5 |l=0| l=2| l=18 | l=...
como o mapeamento é biunívoco (one-to-one), as entropias das sequencias são idênticas...
E s t e e s q u e m a é e fi c i e n t e q u a n d o h á u m g r a n d e “desbalanceamento” entre 0 (branco) e 1 (pretos). É isto que acontece na codificação para fax - facsimile: textos binarizados. O número de zeros é muito, muito maior que o número de uns.

Veja o exemplo com X~Ber(0.1)
�
l~"Geo"(0.9) e � , com k=0,1,2,...
O tamanho médio esperado das carreiras de brancos é:
�
X = {1 com probabilidade q = 0.10 com probabilidade p = 0.9
P(l = k) = pkq = 0.9k0.1
l̄ = E(l) =∞
∑k=0
kP(l = k) = 0.1∞
∑k=0
k0.9k = 0.1.1
0.12= 10

REGRA DE CODIFICAÇÃO PARA �
(pacotes de tamanho 4 bits)
Observe l, tamanho da carreira de zeros e codifique:
1) � codificar com 4 bits, l escrito em binário2) � codificar 1111 seguido de � em binário3) � codificar 1111 1111 seguido de � 4) ...
retomando: para codificar
0000100010000011001000000000000000000100... l=4 | l=3 | l=5 |l=0| l=2| l=18 | l=30...
κ = 4
0 ≤ l ≤ 1415 ≤ l ≤ 29 l mod (15)30 ≤ l ≤ 44 l mod (15)

tem-se: 4 3 5 0 2 18 mod 15 30 mod 15 ...0100 0010 0101 0000 0010 1111 0011 1111 1111 0000 ...
No caso geral, separando pacotes de � bits na decodificação:
κ
comprimento da carreira de zeros número de digitos enviados
... ...� bits3κ
� bitsκ
�2(2κ − 1) ≤ l ≤ 2(2κ − 1) − 1
�0 ≤ l ≤ (2κ − 1) − 1� bits2κ�(2κ − 1) ≤ l ≤ 2(2κ − 1) − 1

Para simplificar (for the sake of simplicity) denotaremos
� .
Estimando o comprimento médio das palavras-código:
�
�
m := 2κ − 1
n̄ = [m−1
∑l=0
P(l)] κ + [2m−1
∑l=m
P(l)] 2κ + [3m−1
∑l=2m
P(l)] 3κ + . . .
n̄ = q [m−1
∑l=0
pl] κ + q . pm [2m−1
∑l=m
pl] 2κ + qp2m [3m−1
∑l=2m
pl] 3κ + . . .
�
ou seja
� .
Assim
� � .
n̄ = q [ 1 − pm
q ] [1 + 2pm + 3p2m + . . . ] κ
n̄ = (1 − pm) [ 1(1 − pm)2 ] κ =
κ1 − pm
n̄ =κ
1 − p2κ−1p ≥ 1/2

O comprimento médio das carreiras de zeros, no caso geral, vale:
�
� � .
l̄ = E(l) =+∞
∑l=1
l . plq = q .1
(1 − p)2=
11 − p
l̄ =1
1 − pp ≥ 1/2
SUMARIZANDO RLE
� � .
� � .
n̄ =κ
1 − p2κ−1p ≥ 1/2
l̄ =1
1 − pp ≥ 1/2

Otimizando os códigos:
suponha um dado p para DMS binária, e.g., p=0.9. Vamos achar a melhor escolha de � .
� Wolframalpha:
κ
n̄ =κ
1 − 0.92κ−1

Comparando � com a entropia da fonte
A entropia para a fonte X ~Ber(0.1)
X=0, p=0.9 e X=1, q=0.1
Vale �
�
� bits
� praticamente o mais compacto possível...
n̄
H(X) = − 0.9 log2 0.9 − 0.1 log2 0.1 = H2(0.9) ≈ 0.469
H(X) ≈ 0.469 Sh
n̄ ≈ 0.504
n̄ ≈ H(X)

Fazendo a otimização para diversos valores de p, obtém-se:
Tabela de eficiência de RLE (Run Lenght encoders)
� é a taxa de compressão= �
N.B. p=0.5 qualquer codificador tem taxa de compressão 0% p=1 codificador pode ter taxa de compressão 100%
p0.6 1 2.5 2.5 00.7 2 3.04 3.33 9%0.8 3 3.80 5 24%0.9 4 5.04 10 50%0.95 6 6.25 20 69%0.99 8 8.67 100 91%
�l̄�n̄� ótimoκ �η
η 1 −n̄l̄

Codificação universal
Uma desvantagem do código de Huffman é que ele requer o conhecimento do modelo probabilistico da fonte (o que seria de se esperar). Entretanto...
Uma solução prática foi através de uma codificação adaptativa e simples de implementar
NÃO DEPENDE DA FONTE = universal
Ziv J. and Lempel A. Compression of individual sequences via variable-rate coding, IEEE trans. on Inf. Theory, IT-24, No.5, pp530-536, Sept., 1978

Algoritmo de Lempel-Ziv
analisando o fluxo de dados da fonte em segmentos que sejam as subsequencias mais breves não encontradas anteriormente.
supõe-se que as sequências previamente armazenadas (inicialização são 0 e 1)
0 0 0 1 0 1 1 1 0 0 1 0 1 0 0 1 0 ...
Transformou-se em algoritmo padrão para compressão de arquivos: .zip
texto em ingles: um resultado típico ~55% de compactação

subsequencias armazenadas 0, 1Dados a serem analisados 0 0 0 1 0 1 1 1 0 0 1 0 1 0 0 1 0 ...
A subsequencia nova mais breve encontrada (primeira vez) é 00
subsequencias armazenadas 0, 1, 00Dados a serem analisados 0 1 0 1 1 1 0 0 1 0 1 0 0 1 0 ...
A nova subsequencia mais breve não vista é 01
subsequencias armazenadas 0, 1, 00, 01Dados a serem analisados 0 1 1 1 0 0 1 0 1 0 0 1 0 ...
A nova subsequencia mais breve não vista é 011
subsequencias armazenadas 0, 1, 00, 01, 011

Dados a serem analisados 1 0 0 1 0 1 0 0 1 0 ...o dicionário-adaptativo obtido para esta sequencia é mostrado na 2a linha da tabela.
Lempel-Ziv para a sequencia 0 0 0 1 0 1 1 1 0 0 1 0 1 0 0 1 0 ...
00 = 0+0 � 1 1 10 =1+0 � 21 01 = 0+1 � 1 2 010=01+0 � 41011= 01+1� 4 2 100=10+0 � 61 101=10+1� 62...
posições numéricas
1 2 3 4 5 6 7 8 9
sequencias dicionário
0 1 00 01 011 10 010 100 101
repres. numéricas
11 12 42 21 41 61 62
blocos codificados
0010 0011 1001 0100 1000 1100 1101
→ →→ →→ → →

decodificação Lempel-Ziv
Sequencias de tamanho fixo (aqui em 4 bits) dos blocos codificados são separadas em:
raiz (escrito em binário) | bit de inovação (único bit: sublinhado)
(raiz)2 | inovação (raiz)10 | inovação (raiz)10 =endereço dic.001 | 0 --- raiz 1 | 0 = 00001 | 1 --- raiz 1 | 1 = 01100 | 1 --- raiz 4 | 1 = 011010 | 0 --- raiz 2 | 0 = 10100 | 0 --- raiz 4 | 0 = 010110 | 0 --- raiz 6 | 0 = 100110 | 1 --- raiz 6 | 1 = 101

Na prática são usados blocos fixos com um tamanho de 12 bits, o que implica em um dicionário com 4096 palavras-código.

Esquemas típicos de compressão de imagens
Além da compressão sem perdas, usa-se frequentemente a compressão com perdas: Uma saída muito adotada na compressão de imagens é permitir que a imagem recuperada a partir do arquivo original comprimido não seja “exatamente" idêntica" àquela do original. Ao adotar um critério de discrepancia entre as imagens (perda de informação), pode-se realizar um interessante compromisso:
Ao se impor uma maior taxa de compressão, aceita-se uma maior degradação na imagem...

O princípio: eliminar a informação menos relevante. O sinal é levado a algum domínio e os coeficientes que se situam abaixo de um limiar crítico (função da taxa de compressão) são assassinados.
A imagem é recuperada através da transformada inversa, após eliminar conteúdo que não é crítico na "recontrução" do sinal.
Os domínios mais usados são:
Transformada de Hotelling (PCA) - componentes principaisTransformada discreta do cosseno (DCT) - padrão jpegTransformada discreta de wavelets ( DWT) - padrão jpeg 2000
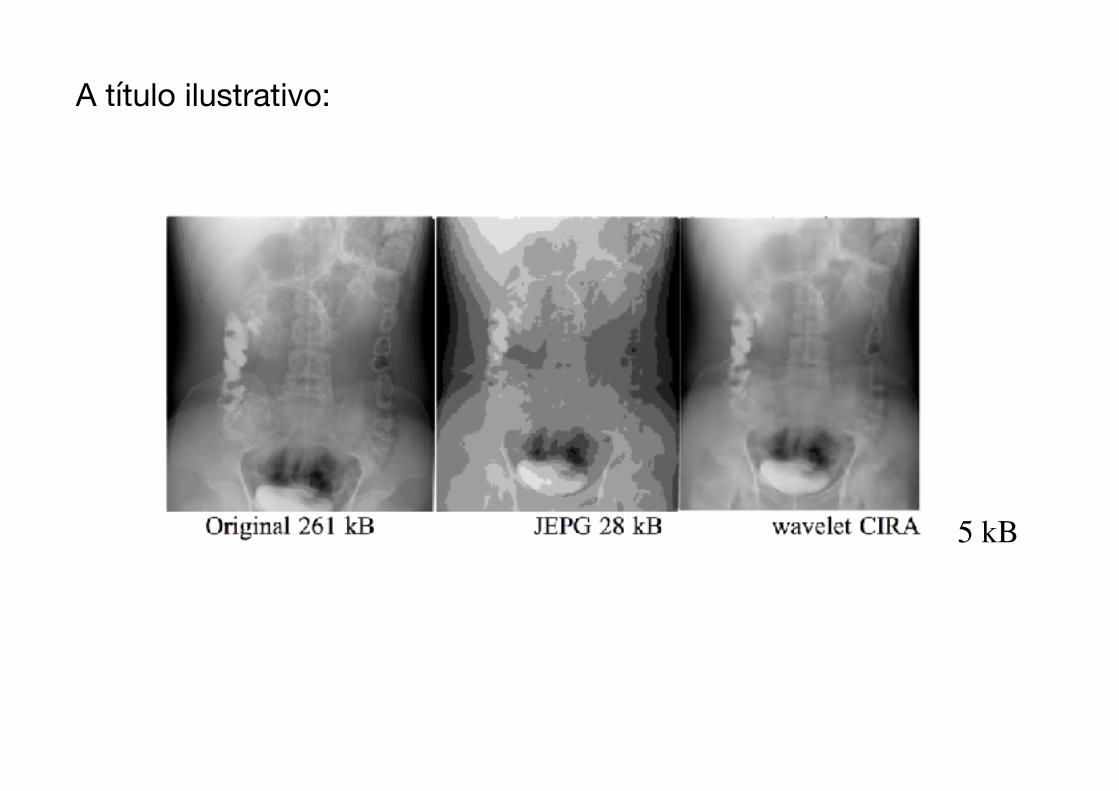
A título ilustrativo:
5 kB