relatório de atividade terceiro trimestre: …...2implantação de nuvem openstack o fiware se...
TRANSCRIPT

Universidade Federal do Rio Grande do NorteInstituto Metrópole Digital
SmartMetropolis – Plataforma e Aplicações para Cidades Inteligentes
WP4 – Infraestrutura
Relatório de Atividade Terceiro Trimestre:Desenvolvimento, implantação e operação de infraestrutura
computacional
Natal-RN, BrasilOutubro 2016

Equipe TécnicaDocentes
Prof. Dr. Carlos Eduardo da Silva (Coordenador) – IMD/UFRN
DiscentesGabriela Cavalcante da SilvaRafael VarelaWelkson Renny de Medeiros
Pesquisadores vinculadosThomas Filipe da Silva Diniz - Anolis TIHiago Miguel da Silva Rodrigues - Anolis TI

Sumário1 Introdução 7
2 Implantação de Nuvem OpenStack 82.1 Recursos Disponíveis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2 Preparação de Ambiente OpenStack . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Papéis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2.2 Arquitetura de Rede . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Implantação com Fuel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.3.1 Criação de um Ambiente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.3.2 Adicionando Nós . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.3.3 Configurando a Rede . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.3.4 Configurações do OpenStack . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.4 Discussão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3 Estudos sobre Ambientes de Gerenciamento de Containers 313.1 Containers Docker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.1.1 Arquitetura do Docker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323.1.2 Instalação e Uso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.2 Gerenciando Aplicações multi-containers . . . . . . . . . . . . . . . . . . . . . . . . . 333.2.1 Arquitetura e Funcionamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.2.2 Instalação e Uso do Docker-Compose . . . . . . . . . . . . . . . . . . . . . . . 34
3.3 Discussão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4 Estudos sobre Implantação de GEs em Ambiente de Produção 364.1 Keyrock . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.1.1 Arquitetura de Implantação do Keyrock . . . . . . . . . . . . . . . . . . . . . . 374.1.2 Opções de Implantação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.1.3 Experiência com a implantação do Keyrock . . . . . . . . . . . . . . . . . . . . 394.1.4 Discussão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.2 AuthZForce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404.2.1 Arquitetura de Implantação do AuthZForce . . . . . . . . . . . . . . . . . . . . 414.2.2 Opções de Implantação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 424.2.3 Experiência com implantação do AuthZForce . . . . . . . . . . . . . . . . . . . 424.2.4 Discussão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.3 Orion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 444.3.1 Arquitetura de Implantação do Orion . . . . . . . . . . . . . . . . . . . . . . . 454.3.2 Opções para Implantação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.3.3 Experiência com implantação do Orion . . . . . . . . . . . . . . . . . . . . . . 464.3.4 Discussão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5 Implantação de Ambiente de Desenvolvimento para SGeoL 505.1 Arquitetura do SGeOL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 515.2 Arquitetura de Implantação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 525.3 Discussão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54

4
6 Considerações Finais 54

Lista de Figuras1 Arquitetura utilizada na nuvem de produção. . . . . . . . . . . . . . . . . . . . . . . . . 112 Arquitetura de Rede da Instância FIWARE de Produção . . . . . . . . . . . . . . . . . . 153 Criando um ambiente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164 Definindo o nome e a release . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175 Definindo o hypervisor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176 Definindo aspectos da rede . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187 Definindo o backend de armazenamento . . . . . . . . . . . . . . . . . . . . . . . . . . 198 Selecionando serviços adicionais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209 Finalizando a criação do ambiente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2010 Adicionando um nó ao ambiente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2111 Definindo um papel de um nó . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2112 Visualizando um nó adicionado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2113 Configurando um nó . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2214 Exemplo de particionamento de disco de um nó . . . . . . . . . . . . . . . . . . . . . . 2215 Exemplo de configuração de interfaces de rede de um nó . . . . . . . . . . . . . . . . . 2316 Configurando a rede pública . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2417 Configurando a rede de armazenamento . . . . . . . . . . . . . . . . . . . . . . . . . . 2418 Configurando a rede de gerenciamento . . . . . . . . . . . . . . . . . . . . . . . . . . . 2419 Configurando a rede privada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2520 Configurando a rede flutuante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2521 Configurando a rede interna administrativa . . . . . . . . . . . . . . . . . . . . . . . . . 2522 Configurando os servidores DNS das instâncias . . . . . . . . . . . . . . . . . . . . . . 2623 Atribuição da rede pública . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2624 Configuração avançada do Neutron . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2625 Configuração de DNS e NTP dos nós do ambiente . . . . . . . . . . . . . . . . . . . . . 2726 Configuração de Acesso ao OpenStack . . . . . . . . . . . . . . . . . . . . . . . . . . . 2727 Configuração de Acesso ao Sistema Operacional . . . . . . . . . . . . . . . . . . . . . . 2828 Repositórios padrão utilizado pelo OpenStack Mirantis . . . . . . . . . . . . . . . . . . 2829 Pacotes a serem instalados nos nós durante o provisionamento . . . . . . . . . . . . . . 2830 Configuração de TLS para os endpoints do ambiente . . . . . . . . . . . . . . . . . . . 2931 Configuração do papel compute . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2932 Configuração dos backends de armazenamento . . . . . . . . . . . . . . . . . . . . . . 3033 Arquitetura do Docker . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3234 Arquitetura do Docker-Compose . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3435 Arquitetura do Keyrock . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3736 Arquitetura de Segurança do Fiware . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4137 Arquitetura do AuthZForce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4138 Arquitetura do Orion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4539 Diagrama de implantação do Orion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4540 Context Broker Plugin v0.15 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4941 Arquitetura do SGEoL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5142 Arquitetura dos containers do SGeOL . . . . . . . . . . . . . . . . . . . . . . . . . . . 52

Lista de Tabelas1 Recursos disponíveis para o provisionamento da Instância Fiware de produção. . . . . . 92 Tipos de partições utilizadas pelo Fuel. . . . . . . . . . . . . . . . . . . . . . . . . . . . 123 Particionamento do nó Controller . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134 Particionamento do nó Compute R730 . . . . . . . . . . . . . . . . . . . . . . . . . . . 135 Particionamento do nó Compute Bl460c . . . . . . . . . . . . . . . . . . . . . . . . . . 136 Particionamento do nó Storage VM_IMD . . . . . . . . . . . . . . . . . . . . . . . . . 147 Particionamento do nó Storage R530-2 . . . . . . . . . . . . . . . . . . . . . . . . . . . 14

7
1 Introdução
O projeto Smart Metropolis, conduzido pelo Instituto Metrópole Digital (IMD) da Universidade Federaldo Rio Grande do Norte (UFRN), tem como objetivo o desenvolvimento de soluções de tecnologia dainformação e comunicação para Cidades Inteligentes e Humanas. O projeto é organizado em seis Pacotesde Trabalho (Work Packages - WP) temáticos, liderados cada por um coordenador. Cada WP possuium conjunto de objetivos a serem alcançados ao longo dos cinco anos de execução do projeto. Esterelatório está inserido no contexto do WP 4 - Infraestrutura Computacional, e visa relatar as atividadesdesenvolvidas no âmbito da tarefa de Desenvolvimento, implantação e operação de infraestruturacomputacional.
Esta tarefa tem como objetivo aspectos relacionados a formação de mão de obra capacitada para operara infraestrutura computacional do projeto, assim como todos os aspectos relacionados à implantaçãode uma instância da plataforma Fiware a nível de produção no ambiente computacional do IMD. Aequipe atuante nesta tarefa é formada por: Prof. Dr. Carlos Eduardo da Silva (Coordenador da tarefa),Welkson de Medeiros (Bolsista Mestrado), Gabriela Cavalcante da Silva (Bolsista Graduação) RafaelVarela (Bolsista Graduação). Além disso, a equipe recebe o apoio da empresa incubada Anolis TI atravésde Thomas Filipe da Silva Diniz, e Hiago Miguel.
Após considerações sobre os resultados alcançados no segundo trimestre do projeto, e de reuniões commembros dos WPs de aplicações e middleware, foram elencadas as seguintes atividades para o terceirotrimestre:
• Estudo sobre ambientes de gerenciamento de containers.
Esta atividade visa a realização de um estudo experimental sobre ambientes de gerenciamento decontainers usando a plataforma Docker. Tal estudo visa fornecer subsídios para a implantação deGEs Fiware além de continuar uma das tarefas iniciadas no trimestre anterior, que visava experi-mentos com esse tipo de ambiente.
• Implantação de instância Fiware de produção.
A implantação da instância Fiware de produção para ser utilizada pelos membros do projeto foidividida em duas etapas: implantação de nuvem OpenStack, e implantação de GEs. Desse modo,esta atividade engloba a primeira etapa deste processo, com o objetivo de oferecer o conjunto deserviços descritos pelo capítulo técnico de Cloud hosting do Fiware (serviços de IaaS da plataformaOpenStack).
• Estudos sobre implantação de GEs em ambiente de produção.
Esta atividade contempla a segunda etapa do processo de implantação, e tem como objetivo a im-plantação de algumas GEs em um ambiente de produção. As GEs escolhidas para tal estudo foramaquelas oferecidas pelo capítulo técnico de segurança da plataforma Fiware (Keyrock, AuthZForcee Wilma), uma vez que essas GEs são utilizadas por quaisquer aplicações que desejem empregarmecanismos de autenticação e controle de acesso. Além disso, o estudo englobou também a GEOrion Context Broker, uma das GEs que serão utilizada por outros membros do projeto.
Além das atividades elencadas acima, o WP de Infraestrutura recebeu uma demanda do WP de Apli-cações para a implantação de um conjunto de GEs integradas e configuradas em um ambiente de desen-volvimento. Tal demanda foi recebida no terceiro mês do trimestre corrente, de forma que algumas dasatividades acima tiveram que ser interrompidas.

8
Os WPs de Aplicações e Middleware iniciaram o desenvolvimento de uma aplicação que visa de-monstrar a utilização de diversas GEs Fiware, e atenda a demandas da prefeitura municipal do Natal. Talaplicação é denominada Smart Geo Layers (SGeoL), teve seu inicio durante o terceiro trimestre de exe-cução do projeto. Deste modo, o WP de infraestrutura teve que readequar seu cronograma de atividadespara incluir uma atividade extra que contempla a definição da infraestrutura de suporte para a aplicaçãoSGeoL. Esta infraestrutura será composta por um conjunto de GEs Fiware, implantadas e configuradasde forma integrada, utilizando-se de um ambiente de gerenciamento de containers para tal.
O restante deste documento está organizado da seguinte forma: Seção 2 descreve o processo de im-plantação da nuvem OpenStack que servirá de base para a instância Fiware a ser utilizada pelos membrosdo projeto. Seção 3 descreve o estudo sobre a tecnologia de containers Docker. Seção 4 apresenta umestudo sobre a implantação de algumas GEs. Seção 5 apresenta a arquitetura da infraestrutura de suporteda aplicação SGeoL. As considerações finais são apresentadas na Seção 6.
2 Implantação de Nuvem OpenStack
O Fiware se baseia na plataforma de nuvem OpenStack como infraestrutura básica para a provisão de umconjunto de serviços. Desse modo, a implantação de uma instância Fiware apresenta um elevado graude complexidade devido aos requisitos para a operação de uma nuvem OpenStack. Nesse contexto, aimplantação de uma instância Fiware para ser utilizada pelos membros do projeto foi dividida em duasetapas: implantação de nuvem OpenStack, e implantação de GEs. A implantação da nuvem OpenStacké descrita nesta seção, e envolve o conjunto de serviços (GEs) descritos pelo capítulo técnico de Cloudhosting do Fiware (serviços de IaaS da plataforma OpenStack). A segunda etapa será descrita na Seção 4,e envolve o conjunto de GEs específicas que serão utilizadas pelos membros do projeto Smart Metropolis.
A definição do projeto de implantação da instância Fiware de produção seguiu as recomendações nodocumento de análise de requisitos produzido no primeiro trimestre de execução do projeto [1], assimcomo a proposta de projeto de implantação produzida no segundo trimestre do projeto [2]. Dessa forma,o projeto de implantação descrito neste documento propõe o planejamento de uma nuvem OpenStack quepossa ser utilizada como uma instância Fiware de produção, levando em conta um ambiente escalável,e que possa atingir futuramente (de acordo com a disponibilidade de recursos) uma arquitetura de altadisponibilidade.
Conforme decidido e relatado [2] no segundo trimestre do projeto, a implantação da plataforma seráfeita utilizando a ferramenta Fuel [3] em sua versão 9.0, provisionando assim um ambiente com o OpenS-tack versão Mitaka. A utilização do Fuel para a implantação de uma nuvem OpenStack pode ser resumidaem quatro passos:
1. Preparação do Ambiente: envolve a configuração básica de servidores, definição de papéis quecada servidor vai adotar na infraestrutura e arquitetura de redes.
2. Instalação e configuração do servidor Fuel master: envolve a instalação de sistema operacionalbaseado em imagem ISO Fuel, contendo os diversos serviços necessários para seu funcionamentto,assim como uma interface de acesso Web.
3. Configuração do ambiente OpenStack via interface Web Fuel: uma vez instalado e operacional,o servidor Fuel master é capaz de detectar os servidores disponíveis no ambiente, que precisamentão serem configurados em termos dos serviços OpenStack que cada uma vai executar.

9
4. Implantação e testes: o último passo consiste na implantação do ambiente, conduzida de formaautomática pela ferramental Fuel, e na realização de um conjunto de testes para verificar a corretaimplantação do ambiente OpenStack.
Na sequencia apresentamos os recursos disponíveis para o ambiente, seguido de uma descrição doambiente a ser provisionado, onde identificamos os diferentes papéis que cada um dos servidores assu-mirá, suas configurações, e a arquitetura de rede adotada para o ambiente. Na sequencia, descrevemos oprocesso de implantação utilizando Fuel, seguido de uma beve discussão sobre esta atividade.
2.1 Recursos Disponíveis
Essa seção apresenta uma descrição dos recursos disponíveis para a implantação do ambiente. Estesrecursos incluem servidores que estavam alocados inicialmente para a criação de uma instância Fiwarede treinamento para a equipe do projeto, e servidores disponibilizados pelo Datacenter do IMD para oprojeto. Estão disponíveis para uso imediato um total de seis servidores: três servidores Dell PowerEdgeR530, um servidor Dell PowerEdge R730, uma Lâmina do Datacenter do IMD e uma máquina virtual queroda no ambiente de virtualização do Datacenter do IMD. A configuração desses servidores é apresentadana Tabela 1.
Tabela 1: Recursos disponíveis para o provisionamento da Instância Fiware de produção.
SERVIDOR CPU RAM DISCO REDE3 x Dell PowerEdge
R530Intel R© Xeon R© E5-2620 v3
2.4GHz16GB 2 x 1 TB
4 x Placas1 Gigabit Ethernet
1 x Dell PowerEdgeR730
Intel R© Xeon R© E5-2630 v32.4 GHz
128GB8 x SAS
de 600 GB4 x Placas
1 Gigabit Ethernet1 x BladeHP ProLiant
BL460c G72 x Intel Xeon X56506 160GB
2 x 1 TB e1 x 136.7 GB
4 x Placas10 Gigabit Ethernet
Máquina VirtualIntel R© Xeon(R) CPU X5650
2.67GHz(4 núcleos virtuais)
6GB2 x 1 TB e1 x 60 GB
5 x Placas1 Gigabit Ethernet
O três servidores Dell PowerEdge R530 serão identificados ao longo do texto como R530-1, R530-2 eR530-3. O servidor Dell PowerEdge R730 será identificado como R730. O servidor Blade HP ProLiantBL460c G7 será identificado como BL460c. A máquina virtual será identificada como VM_IMD.
Na próxima seção será exposto como esses servidores serão utilizados e qual será o papel de cada umdeles no ambiente OpenStack a ser provisionado.
2.2 Preparação de Ambiente OpenStack
Conforme mencionado, o primeiro passo para a implantação de uma nuvem OpenStack consiste na pre-paração do ambiente. Tal preparação inclui a configuração básica dos servidores que farão parte dainfraestrutura, a definição dos papéis que esses servidores irão adotar, e a arquitetura de redes que seráutilizada. Apesar da quantidade de recursos limitada, o ambiente proposto foi planejado visando fácilescalabilidade a alta-disponibilidade com a adição de mais recursos (servidores).

10
Na sequencia, descrevemos os papéis definidos para a infraestrutura sendo implantada com suas res-pectivas configurações, seguido do projeto da arquitetura de redes para a instância Fiware sendo implan-tada.
2.2.1 Papéis
A implantação de um ambiente OpenStack, baseado na ferramenta Fuel, define alguns papéis que sãoadotados pelos servidores físicos da infraestrutura. Cada papel define um conjunto de serviços OpenStackque serão executados nos respectivos servidores, além de um conjunto de configurações que são aplicadasnesses servidores. Os papéis definidos pelo Fuel são:
• Fuel Master: Responsável pela implantação do ambiente OpenStack nos outros servidores dainfraestrutura. Esse nó é encarregado por controlar os nós slaves que formam a arquitetura OpenS-tack, definindo quais serviços serão instalados em cada servidor, de acordo com seu papel.
• Controller: Responsável pelo gerenciamento e operação da nuvem, além dos mecanismos degestão de identidades e controle de acesso. Esse nó executa os seguintes serviços do OpenS-tack: nova-scheduler, nova-api, nova-conductor, nova-consoleauth, nova-novncproxy, cinder-api,cinder-scheduler, glance, neutron-server, neutron-l3-agent, neutron-dhcp-agent, neutron-metadata-agent, heat-api, heat-engine, swift-proxy, ceilometer-api, ceilometer-collector, ceilometer-agent-central, ceilometer-agent-notification, keystone, murano, e horizon.
• Compute: Responsável pelas máquinas virtuais instanciadas através da plataforma OpenStack.Esse nó executa o serviço OpenStack nova-compute diretamente sobre o sistema operacional damáquina física, utilizando o KVM [4] como hypervisor para as máquinas virtuais.
• Storage: Responsável pelo armazenamento, tanto de bloco (OpenStack Cinder) quanto de obje-tos (OpenStack Swift). Esse nó executa os seguintes serviços OpenStack: cinder-volume, swift-container-server, swift-account-server e swift-object-server, além gerenciar o banco de dados detais serviços. É importante notar que o Fuel disponibiliza dois tipos de backends para esse papel,o Ceph ou a configuração padrão.
• Telemetry - MongoDB: Responsável pelo armazenamento de métricas e estatísticas de dadoscoletados do ambiente OpenStack. Esse nós executa o banco de dados NoSQL MongoDB comoparte do serviço Ceilometer da plataforma OpenStack.
É importante salientar que, através desses papéis, esse ambiente segue os requisitos definidos pelaplataforma Fiware, que define um conjunto mínimo de serviços que precisam ser oferecidos por umanuvem OpenStack para que a mesma possa ser identificada como uma instância Fiware.
Baseado nos papéis identificados acima, descrevemos em seguida o papel definido para cada um dosservidores disponíveis, apresentados na Figura 1. Os servidores com fundo em azul correspondem amáquinas virtuais, enquanto que os outros são máquinas físicas, todos no ambiente de Datacenter doIMD. O servidor R530-1, que recebeu o hostname de srv-sm-mgmt, tem como sistema operacional adistribuição GNU/Linux CentOS e contém duas máquinas virtuais gerenciadas pela equipe do projetoque servirão como infraestrutura de base para a implantação da nuvem OpenStack. A primeira máquinavirtual, com o hostname de fuel, adotará o papel de Fuel Master, enquanto que a segunda máquina vir-tual, chamada de sm-ctrl01, terá os papéis de Controller e Telemetry - MongoDB. Os servidores R730,chamado de sm-comp01, e Bl460c, chamado de sm-comp02, irão desempenhar o papel de Compute do

11
ambiente. Isso se deve ao fato de ambos possuírem melhores aspectos de configuração para a execução demáquinas virtuais, isto é, possuem um melhor processamento e têm uma quantidade significativa de me-mória RAM, permitindo um maior número de instâncias do que os demais nós. Os servidores VM_IMD,chamado de sm-str01, e R530-2, chamado de sm-str02, adotarão o papel de Storage, executando osserviços relacionados ao serviço de armazenamento de objetos Swift, e serviço de armazenamento deblocos Cinder.
Figura 1: Arquitetura utilizada na nuvem de produção.
O OpenStack possui dois componentes básicos que lidam com armazenamento. O OpenStack Swift,que fornece o serviço de armazenamento de objetos acessíveis através de uma API REST, e o OpenStackCinder, que fornece o serviço de armazenamento de blocos utilizado pelas máquinas virtuais gerenciadaspelo OpenStack. Além disso, existe também o OpenStack Ceph, que fornece um serviço de armazena-mento unificado para objetos, blocos e arquivos. Dentre as opções de configurações disponíveis, o Cephpode ser utilizado como backend para o Cinder, além de poder substituir o Swift com um API similarprovida pelo Ceph Object Gateway, porém com algumas limitações, uma vez que a API disponibilizadaé apenas um sub-conjunto da API do Swift [5]. Nesse contexto, é importante definir qual a configuraçãoadotada para a instância Fiware sendo implantada.
O Swift é melhor empregado no armazenamento de dados não estruturados, como documentos, ima-gens, arquivos de áudio e vídeo, além de imagens de máquinas virtuais. Os objetos e arquivos são arma-zenados em múltiplos discos, e são replicados através de um cluster. O Swift é um dos serviços básicosoferecidos por uma instância Fiware, de forma que o mesmo será configurado seguindo as definições deconfiguração padrão do Fuel, isto é, utilizando-se armazenamento local como mecanismos de backend.Além disso, utilizaremos o Swift como mecanismo de armazenamento para as imagens de máquinasvirtuais que são gerenciadas pelo OpenStack Glance.
Por outro lado, o Cinder oferece serviços de armazenamento de blocos que possibilita a persistênciados dados em máquinas virtuais de uma nuvem. O Cinder tem como padrão a utilização de LVM [6]como backend de armazenamento, onde cada volume é armazenado como um volume lógico em um

12
grupo de volume em um dos nós que executam o Cinder. Entretanto, tal solução não considera aspectosde alta-disponibilidade. Além disso, a documentação oficial da plataforma Fiware [7] afirma que outrassoluções de backend podem ser adotadas para o componente Cinder. Desse modo, decidimos por adotaro OpenStack Ceph como backend de armazenamento para o Cinder. A principal vantagem de se utilizaro Cinder com o Ceph ao invés de se utilizar com LVM, é que o Ceph tem uma arquitetura distribuída,além de oferecer redundância através da replicação dos dados armazenados. Assim, o uso do Ceph comobackend permite que um ambiente possua um armazenamento com alta disponibilidade e redundância, oque demonstra ser bem mais robusto do que o LVM.
Outra configuração referente ao papel que cada servidor vai adotar na infraestrutura diz respeito aoesquema de particionamento dos discos de cada servidor. Porém, antes de se detalhar o particionamentodos nós que constituem o ambiente de produção, é importante abordar como os discos de armazenamentoestão sendo utilizados nos servidores.
Com a finalidade de se obter uma certa redundância, o servidor Dell R530-1, que virtualiza o nóFuel Master e o nó Controller, utilizará os seus dois discos de 1TB em RAID1. Dessa forma, o servidorutilizará um disco para armazenar os seus dados, e o outro disco para replicar os mesmos. Assim, emcaso de falha de um dos discos, o ambiente não será comprometido. Já os servidores que desempenhamo papel de Storage irão utilizar os discos em JBOD1. A redundância e replicação ficará por conta doOpenStack Ceph. Quanto aos nós que desempenham o papel de Compute, eles irão utilizar os discos emRAID02 O motivo disso é que esses nós irão armazenar apenas dados não persistentes do ambiente, noque se refere às instâncias criadas. Além de precisarem ter um ótima performance na leitura e escrita dedisco.
A ferramenta Fuel define um conjunto de tipos de partição que são alocadas aos servidores no mo-mento da definição de seus papéis. A Tabela 2 apresenta um sumário dos diferentes tipos.
Tabela 2: Tipos de partições utilizadas pelo Fuel.
Tipo de Partição Descrição
Base SystemCompreende o espaço do swap, do sistema operacional,além das opções básicas de softwares
Virtual StorageArmazenamento não persistente para as instâncias demáquina virtual a serem criadas na nuvem
Image StoragePartição utilizada pelo Glance para armazenar asimages das instâncias virtuais
Cinder Armazenamento persistente. Alocado para o CinderCeph e Ceph Journal Armazenamento alocado para o Ceph
MongoDBArmazenamento utilizado pelo Ceilometer para armazenaras informações do ambiente no MongoDB
MySQLArmazenamento utilizado pelo Keystone e outrosserviços opcionais
Logs Armazenamento destinado aos logs do ambiente
Agora, pode-se detalhar o particionamento adotado por cada servidor que compõe o nosso ambiente.
1just a bunch of disks - Arranjo onde cada disco é exposto de maneira individual2Arranjo onde os dados são espalhados em vários discos.

13
Controller O nó Controller possui um total de 3 discos, o seu esquema de particionamento pode servisto na Tabela 3.
Tabela 3: Particionamento do nó Controller
Discos Partições
Disco I (300GB)
Base System (80GB)Image Storage (40GB)Logs (40GB)MySQL (120GB)Horizon Temp (20GB)
Disco II (300GB) MongoDB (300GB)
Disco III (100GB) Image Storage (100GB)
Compute (Dell R730) O nó R730 possui um total de seis discos físicos de 600GB (Tabela 4). Taisdiscos são agrupados em quatro discos virtuais. Dois discos são agrupados em RAID1, onde o discovirtual I e II se encontram. Os discos restantes, por sua vez, são agrupados em dois discos virtuais, o IIIe o IV, cada um com três discos físicos em RAID0.
Tabela 4: Particionamento do nó Compute R730
Discos PartiçõesDisco Virtual I (80GB) Base System (80GB)
Disco Virtual II (475GB) Virtual Storage (475GB)
Disco Virtual III (1.65TB) Virtual Storage (1.65TB)
Disco Virtual IV (1.65TB) Virtual Storage (1.65TB)
Compute (Proliant Bl460c G7) O nó Compute, representado pela lâmina Bl460c, possui um totalde 4 discos (Tabela 5). Sendo dois deles discos locais de 136.1GB, e dois deles LUNs de 1TB (espaçode armazenamento disponibilizado no sistema de armazenamento de alto-desempenho do Datacenter doIMD). Os discos de 136.1GB são agrupados em RAID1, para criação de um único volume virtual.
Tabela 5: Particionamento do nó Compute Bl460c
Discos PartiçõesDisco Virtual I (136.1GB) Base System (136.1GB)
LUN I (1TB) Virtual Storage (1TB)
LUN II (1TB) Virtual Storage (1TB)
Storage (VM_IMD) O nó Storage representado pela VM_IMD, utiliza um total de três discos, e sãodispostos conforme apresentado na Tabela 6.

14
Tabela 6: Particionamento do nó Storage VM_IMD
Discos PartiçõesDisco I (60GB) Base System (60GB)
Disco II (1TB)Ceph Journal (84GB)Ceph OSD (846.5GB)
Disco III (1TB)Ceph Journal (84GB)Ceph OSD (846.5GB)
Storage (Dell R530-2) O nó R530-2 possui um total de dois discos de 1TB. Tais discos foram agru-pados em três volumes em RAID0, e particionados conforme Tabela 7.
Tabela 7: Particionamento do nó Storage R530-2
Discos PartiçõesDisco Virtual I (60GB) Base System (60GB)
Disco Virtual II (870GB)Ceph Journal (79GB)Ceph OSD (791GB)
Disco Virtual III (1TB)Ceph Journal (84GB)Ceph OSD (846GB)
2.2.2 Arquitetura de Rede
Antes de entender a atual arquitetura de rede da nuvem de produção, é necessário compreender algunsconceitos definidos pelo Fuel. Primeiramente, tem-se que essa ferramenta implementa cinco redes lógi-cas, descritas abaixo:
• Rede Pública: Permite que as máquinas virtualizadas do ambiente tenham acesso à rede externa.
• Rede Administrativa PXE: rede administrativa Utilizada pelo nó Fuel Master para o provisiona-mento e orquestração do ambiente OpenStack.
• Rede de Gerenciamento: Contém o tráfego de requisições de banco de dados, de mensagensAMQP e serviços de alta disponibilidade, além do tráfego iSCSI entre os nós compute e storage.
• Rede Privada: É utilizada para o tunelamento do tráfego de projetos OpenStack.
• Rede de Armazenamento: Lida com o tráfego de replicação do Swift, além do tráfego geradopelo Cinder
Cada rede lógica ou vlan, com exceção da rede administrativa PXE, pode ser identificada por uma tagde acordo com as características do ambiente. No contexto do ambiente de produção, tem-se que as redespública e administrativa não são identificadas por nenhuma tag, enquanto que as redes de gerenciamento,privada e de armazenamento são identificadas, respectivamente, pelas tags 1101, 1102 e 1103. Noteque, segundo a documentação do Fuel3, a rede PXE nunca deve utilizar uma tag.
3https://docs.mirantis.com/openstack/fuel/fuel-9.1/mos-planning-guide/network/
logical_networks.html

15
A Figura 2 ilustra a arquitetura de rede definida para a nuvem. Com exceção do nó Fuel Master, queutiliza apenas as redes pública e administrativa, todos os demais nós que compõe a nuvem utilizam todasas cinco redes definidas pelo Fuel.
Figura 2: Arquitetura de Rede da Instância FIWARE de Produção
A implementação de tais redes ocorre durante o provisionamento da nuvem OpenStack, onde cincobridges são definidas em cada nó do ambiente que será utilizado pelo Fuel Master para a nuvem, cadauma delas com a sua respectiva rede. Tais bridges podem ser vistas na Figura 2 e são descritas logoabaixo:
• Bridge br-fw-admin. Essa bridge é utilizada para o tráfego dos dados da rede administrativa PXE;
• Bridge br-ex. Tal bridge é utilizada pela rede pública, sendo assim, nela ocorre o tráfego dos dadosdas redes pública e flutuante;
• Bridge br-mgmt. Essa bridge é utilizada pela rede de gerenciamento;
• Bridge br-mesh. Tal bridge é utilizada para o tráfego dos dados da rede Privada;
• Bridge br-storage. Essa bridge é utilizada pela rede de armazenamento.
Além disso, para que o nós da nuvem se comunicassem propriamente, foi preciso alterar a configuraçãode alguns switches do Datacenter do IMD alocados ao projeto. De acordo com a documentação4 daMirantis, a seguinte configuração foi adotada:
4https://docs.mirantis.com/openstack/fuel/fuel-9.1/reference-architecture/
network-concepts/6034-switch.html

16
1 i n t e r f a c e G i g a b i t E t h e r n e t 0 / 02 s w i t c h p o r t t r u n k e n c a p s u l a t i o n do t1q3 s w i t c h p o r t t r u n k n a t i v e v l a n 324 s w i t c h p o r t t r u n k a l l o w e d v l a n 1101 ,1102 ,11035 s w i t c h p o r t mode t r u n k6 spann ing−t r e e p o r t f a s t t r u n k7 v l a n 32 ,1101 ,1102 ,1103
Procedimento 1: Configurando as portas de um Switch do projeto
A configuração vista no Procedimento 1, basicamente define as rede lógicas liberadas em um dasinterfaces de um switch, no caso a vlan do projeto, 32, e as vlans das redes de gerenciamento, 1101,privada, 1102 e de armazenamento, 1103. Tais configuração foram realizadas em conjunto com a equipede redes do IMD.
2.3 Implantação com Fuel
Após a instalação do nó Fuel Master, uma interface web se torna disponível para a configuração e imple-mentação de uma nuvem OpenStack. O Fuel Web UI permite a adição de servidores ao ambiente, comotambém a designação de papéis, configuração de particionamento e rede, além de aspectos gerais do am-biente e adição de outros componentes do OpenStack à nuvem. Nas demais subseções serão detalhadosos passos tomados para a implantação de uma nuvem através do Fuel Web UI.
2.3.1 Criação de um Ambiente
O Fuel permite a criação e gerenciamento de múltiplos ambientes OpenStack, cada um com os seusrespectivos nós e configurações. Assim, o primeiro passo a ser tomado é a criação de um ambiente. Paraisso, basta o usuário clicar em New OpenStack Environment.
Figura 3: Criando um ambiente
Logo após deverá ser definido o nome do ambiente a ser criado e a versão a ser utilizada (Figura 4)Como estamos utilizando o Fuel 9, a versão Mitaka será implementada. Quanto a seleção da versão, háduas opções por padrão, Mitaka no Ubuntu 14.04 e Mitaka no Ubuntu+UCA 14.04. A diferença entreas opções é que a última utiliza o Ubuntu Cloud Archive, que basicamente é um repositório que ofereceacesso aos últimos pacotes do OpenStack. Porém, não há nenhum impacto no ambiente coma a escolhade uma dessas opções.

17
Figura 4: Definindo o nome e a release
A próxima tela, representada pela Figura 5, permite a escolha do Hypervisor a ser utilizado no ambi-ente. Por padrão o Fuel dispões de duas opções, QEMU-KVM ou vCenter. Como a nuvem de produçãonão será executada no VMware vCenter, a primeira opção foi selecionada. Vale salientar que o Fueloferece outras opções de virtualização através de plugins.
Figura 5: Definindo o hypervisor
O próximo aspecto a ser definido é a utilização do Neutron, componente OpenStack que oferece "redecomo serviço". Há duas opções, a utilização do Neutron com segmentação de VLAN, suportando até4095 redes, e a utilização do Neutron com segmentação de tunelamento (VXLAN), suportando milhõesde redes. Devido a sua melhor escalabilidade, a última opção foi selecionada, como visto na Figura 6.

18
Figura 6: Definindo aspectos da rede
A tela seguinte, Figura 7, permite a escolha dos backends a serem utilizados pelos componentes doOpenStack Cinder, Swift, Glance, e Nova. Na nuvem de produção será utilizado o Cinder juntamente como Ceph. O Glance utilizará o seu backend padrão, o Swift. Isso se deve ao fato do Ceph não suportar oformato de imagem qcow2, apenas RAW, o que impediria aos usuários da nuvem de realizarem snapshotsde suas instâncias. Um outro fator, é que ao se habilitar essa opção, o Swift não seria instalado na nuvem.O que não é uma escolha para o ambiente final, já que o FIWARE aponta o Swift como um componentenecessário. O mesmo vale para a escolha do backend do Swift, isto é, ele deve utilizar o seu backendpadrão, disco local. Por fim, como o Glance não utilizará o Ceph como backend, não é ideal armazenaros volumes efêmeros do Nova juntamente com o Ceph. Sendo assim, o Nova também utilizará o seubackend padrão.

19
Figura 7: Definindo o backend de armazenamento
O Fuel ainda permite a instalação e configuração de componentes adicionais do OpenStack. Durantea criação do ambiente, ele disponibiliza 4 opções:
• Sahara. Permite habilitar, sob demanda, o provisionamento de clusters Hadoop no OpenStack.
• Murano. É uma aplicação de catálogo que permite com que desenvolvedores publiquem aplica-ções voltadas para nuvem em um catálogo bastante intuitivo. Dessa forma, usuários finais podemexecutar aplicações com um simples clique.
• Ceilometer e Aodh. O Ceilometer prover a coleta de métricas e monitoramento de uma nuvemOpenStack. Já o Aodh é um serviço de alarme que utiliza os dados coletados pelo Ceilometer.
• Ironic. Habilita o provisionamento de baremetal, isto é, máquinas virtuais podem ser instaladasdiretamente no hardware.
Dessas opções, a nuvem irá utilizar duas, o Murano e o Ceilometer, ambos recomendados pela docu-mentação do FIWARE, como visto na Figura 8

20
Figura 8: Selecionando serviços adicionais
Por fim, basta o usuário clicar no botão create, Figura 9, e o ambiente será criado com as opçõesescolhidas. É interessante notar que a maiorias dos aspectos do ambiente podem ser alterados após a suacriação.
Figura 9: Finalizando a criação do ambiente
2.3.2 Adicionando Nós
Com o ambiente criado, novos servidores podem ser adicionados ao se configurar os mesmos para bootvia PXE. Desse modo, o Fuel Master é capaz de detectar os servidores, sendo capaz de carregar umaimagem de bootstrap. Uma vez detectados, os servidores são exibidos como nós disponíveis para uso nainterface Fuel (como membros do grupo de nós desalocados), e podem então ter seu papel designado.

21
Assim, para adicionar um nó qualquer, basta com que um usuário, na aba Nodes, clique no botão AddNodes (Figura 10).
Figura 10: Adicionando um nó ao ambiente
Logo após, a tela de designação de papéis (Figura 11) estará disponível. Resta apenas selecionar onó e o papel desejado, e então clicar no botão Apply Changes para aplicar as mudanças feitas. O Fuelpermite que um nó tenha mais de um papel, ou seja, é possível mesclar papéis. Porém, nem todas ascombinações são possíveis.
Figura 11: Definindo um papel de um nó
Com o papel definido, o nó agora se encontrará visível na aba Nodes. Clicando na engrenagem (Fi-gura 12) é possível definir o nome do nó adicionado, além de partir para a configuração de discos e deinterfaces de rede, como visto na Figura 13.
Figura 12: Visualizando um nó adicionado
O Fuel ainda exibe as definições de hardware de um nó, isto é, o processador utilizado, a disposiçãodos discos, as características das interfaces de rede, a quantidade de memória RAM disponível, além dopapel, do ambiente a qual o nó pertence, o seu nome e entre outros detalhes que podem ser visualizadosna Figura 13. Através dessas informações é possível se identificar qual servidor cada nó representa.

22
Figura 13: Configurando um nó
Configurando Discos Como visto na Figura 13, é possível configurar os discos de um nó do ambi-ente. O Fuel permite com que um usuário defina o particionamento de um nó e o disco, caso haja maisde um, no qual o sistema deverá realizar o processo de inicialização, boot. Todas as partições possuemum tamanho mínimo, sendo algumas delas optativas e outras obrigatórias.
Figura 14: Exemplo de particionamento de disco de um nó

23
A Figura 14 exemplifica o processo de particionamento, que foi realizado de acordo com as partiçõesdefinidas na Subseção 2.2.
Configurando Intefaces de Rede A tela retratada pela Figura 13, permite ainda com que o usuárioconfigure as interfaces de rede de um determinado nó. É possível adicionar mais de uma rede a umamesma interface, desde que as vlans designadas utilizem tags para identificá-las, como também é possíveldesignar cada rede a uma única interface. O Fuel também permite com que seja feito uma agragaçãonas interfaces, de forma que duas interfaces sejam tratadas como uma, permitindo assim uma maiorredundância e melhor vazão.
Figura 15: Exemplo de configuração de interfaces de rede de um nó
2.3.3 Configurando a Rede
Na aba de redes do Fuel Web UI é possível configurar vários detalhes da rede da nuvem OpenStack. Ini-cialmente é necessário definir aspectos da rede pública, de gerenciamento, privada e de armazenamento.Várias outras opções de configuração da rede se encontram presentes nesta aba e serão detalhadas nasseções abaixo.
Configuração da rede pública, de gerenciamento, privada e de armazenamento É essen-cial definir as redes a serem utilizadas pelo ambiente OpenStack. Para todas elas define-se um CIDR5, aextensão dos endereços IP, o gateway e se a rede utilizará tag ou não. Também é importante notar que aextensão de IP determinada para essas redes serão utilizadas apenas pelos nós que compõe o ambiente.
No caso da rede pública, como pode ser visto na Figura 16, o CIDR utilizado é o 10.7.49.0/24, com osendereços IPs variando de 10.7.49.200 a 10.7.49.254, com gateway 10.7.49.1 e sem tag.
5Classless Inter-Domain Routing

24
Figura 16: Configurando a rede pública
Já a rede de armazenamento, de acordo com a Figura 17, utiliza o CIDR 192.168.103.0/24, com osendereços IPs variando de 192.168.103.2 a 192.168.103.254, com gateway 192.168.103.1 e com tag1103.
Figura 17: Configurando a rede de armazenamento
A rede de gerenciamento, por sua vez, como pode ser visto na Figura 18, tem como CIDR o bloco192.168.101.0/24, com os endereços IP variando de 192.168.101.2 a 192.168.101.254, com gateway192.168.101.1 e com tag 1101.
Figura 18: Configurando a rede de gerenciamento
Por fim, a rede privada utiliza o CIDR 192.168.102.0/24, com os endereços IP variando de 192.168.102.2a 192.168.102.254, com gateway 192.168.102.1 e com tag 1102, como retratado na Figura 19.

25
Figura 19: Configurando a rede privada
Configurando aspectos do Neutron Após a rede pública ser definida, é necessário configurardetalhes da camada de rede do Neutron, através da opção Neutron L3 no menu lateral6. Primeiramente,é preciso definir os parâmetros da rede flutuante, que são a extensão do IP flutuante e o nome da redeflutuante. É importante perceber que tal extensão deve estar contida no CIDR definido da rede pública, eque as instâncias a serem criadas na nuvem irão utilizar os endereços IP aqui definidos.
No caso da nuvem de produção, a extensão utilizada tem o seu início no IP 10.7.49.11 e o seu términono IP 10.7.49.138, como visto na Figura 20.
Figura 20: Configurando a rede flutuante
Além da rede flutuante, também é necessário configurar a rede interna administrativa. Essa rede proveracesso à rede interna para as instâncias da nuvem, sendo apenas utilizada por tenants administrativos.Basta definir um bloco CIDR que não intercepte nenhuma rede já definida no ambiente.
Figura 21: Configurando a rede interna administrativa
Por fim, ainda é possível determinar os servidores DNS a serem utilizados pelas instâncias criadasna nuvem. Por padrão o Fuel utiliza o DNS do Google, mas no caso da nuvem de produção, também éinteressante adicionar os servidores DNS do Instituto Metrópole Digital, como visto na Figura 22.
6Ver Figura 16

26
Figura 22: Configurando os servidores DNS das instâncias
Outras Opções de Rede Há ainda outros parâmetros de configuração de rede que podem ser aces-sadas por meio do menu lateral, através da opção Other. Nela é possível determinar aspectos da redepública, opções avançadas de configuração do Neutron, além da definição dos servidores DNS e NTP aserem utilizados pelos nós da nuvem.
Quanto aos aspectos da rede pública, temos que o Fuel permite com que todos os nós do ambientetenham um IP público, Figura 23. Perceba que o IP a ser utilizado por um nó se encontra dentro daextensão determinada na configuração da rede pública7. No contexto da nuvem de produção, foi optadopor cada nó do ambiente ter um um IP público.
Figura 23: Atribuição da rede pública
Quanto as opções de configuração avançada do Neutron, há dois parâmetros, Figura 24 que valem apena serem habilitados:
• Neutron L2 population. Permite a diminuição do tráfego de broadcast na rede.
• Neutron QoS. Permite definir regras de qualidade de serviço por tenant na nuvem.
Figura 24: Configuração avançada do Neutron
Por fim, como já dito, é possível determinar os servidores DNS e NTP a serem utilizados pelos nós danuvem, como visto na figura 25. No contexto da nuvem de produção, são utilizados os servidores DNS
7Ver tópico Configuração da rede pública, de gerenciamento, privada e de armazenamento na Subsubseção 2.3.3

27
do IMD, representados pelos IPs 10.7.5.2 e 10.7.5.3. Além dos servidores NTP utilizados pelo IMD epela SINFO.
Figura 25: Configuração de DNS e NTP dos nós do ambiente
2.3.4 Configurações do OpenStack
O Fuel permite configurar vários parâmetros do ambiente OpenStack. Isso é possível através da aba deconfigurações, no Fuel Web UI. Nas seções abaixo serão abordados praticamente todos os aspectos deconfiguração oferecidos pelo Fuel.
Configurações Gerais A primeira série de configurações possíveis pode ser acessada por meio daopção "Geral"no menu lateral. Nela são definidas questões de acesso
A figura 26 retrata a configuração de acesso ao OpenStack, isto é, ao Horizon, dashboard de gerenci-amento da nuvem. Basicamente é definido o nome do usuário, senha, tenant e email. O usuário e senhapadrão de um ambiente a ser provisionado é admin e admin, respectivamente. É altamente recomendadonão utilizar o usuário e senha padrão, obviamente por questões de segurança.
Figura 26: Configuração de Acesso ao OpenStack
Também é possível configurar um usuário para acessar os nós que compõe o ambiente. É possíveldefinir o nome de usuário, senha, diretório home, chave SSH de acesso e configurações do sudoers,como visto na figura 27. Por motivos de segurança, não será retratado no relatório o usuário de acesso danuvem de produção.

28
Figura 27: Configuração de Acesso ao Sistema Operacional
Além disso, o Fuel permite adição, remoção e alteração de repositórios. Isso pode ser feito atravésdo botão Add Extra repo, figura 28, restando inserir o nome do repositório, a sua url e uma proridade(opcional).
Figura 28: Repositórios padrão utilizado pelo OpenStack Mirantis
Por fim, também é possível adicionar ou alterar os pacotes a serem instalados durante o provisiona-mento do ambiente. No caso da nuvem de produção, foi alterada a versão do kernel a ser instalada, parauma melhor compatibilidade com um dos servidores da nuvem.
Figura 29: Pacotes a serem instalados nos nós durante o provisionamento

29
Configurações de Segurança Através da opção Security, no menu lateral, é possível definir certosaspectos de segurança da nuvem. O Fuel permite habilitar uma terminação TLS8 no HAProxy9 paraserviços do OpenStack. Pode-se utilizar um certificado autoassinado ou um próprio, como também pode-se definir um nome para os certificados, como visto na figura 30.
Figura 30: Configuração de TLS para os endpoints do ambiente
Configurações do Papel Compute Na opção Compute é possível definir o hypervisor do ambi-ente, por padrão QEMU ou KVM, como também algumas opção de comportamento do Nova. No quediz respeito a nuvem de produção, a mesma utilizará, como já visto, o KVM como hypervisor. Alémdisso, será utilizado quotas para o Nova, permitindo assim a limitação de CPU e memória por tenant,como também será habilitada a opção de restaurar o estado de um instância quando um nó compute forreiniciado no ambiente. As configuração adotadas podem ser vistas na figura 30.
Figura 31: Configuração do papel compute
Configurações do Papel de Armazenamento Através da opção Storage, na aba de configura-ções, pode-se definir os backends dos componentes de Block Storage, Object Storage, Image Storage e
8Transport Layer Security, é um protocolo de segurança que garante a integridade e privacidade dos dados. Com por exemplo,em navegações HTTPS.
9Balanceador de carga open source e proxy reverso que suporta diversas funcionalidades.

30
Compute. Note que essas opções são também determinadas durante a criação do ambiente, mas podemser alteradas após a criação.
Para a nuvem de produção, foi optado utilizar o Ceph como backend do Cinder, e para os demaiscomponentes foi optado o backend padrão. Além disso, por falta de recursos, o fator de replicação doCeph foi alterado para 2, sendo o padrão 3. Esse fator indica a quantidade de vezes que um dado seráreplicado na nuvem, no caso será replicado duas vezes pelo fato do projeto possuir apenas dois nós como papel de Storage. A figura 32 retrata a configuração adotada.
Figura 32: Configuração dos backends de armazenamento
2.4 Discussão
Com os atuais recursos alocados para o estudo da plataforma Fiware, não foi possível, a priori, arqui-tetar um ambiente com alta disponibilidade (High Availability — HA), já que um ambiente desse tipodemanda mais recursos. Porém, o ambiente proposto é escalável, o que significa que com a adição demais dispositivos, o ambiente pode ser moldado em uma arquitetura que ofereça alta disponibilidade,confiabilidade e redundância.
Durante o decorrer do trimestre, uma série de problemas foram encontrados para a implementaçãoda nuvem FIWARE de produção. Tais problemas, em sua maioria, se relacionaram com aspectos deconfiguração dos nós que constituem o ambiente proposto. Primeiramente, tem-se que a configuraçãoda lâmina e da máquina virtual presente no datacenter do IMD demandou um certo período de tempo,principalmente no que diz respeito a configuração da rede, isto é, configuração de vlans, switchs e testesde verificação de rede.
Além disso, o servidor Dell R730 apresentou um problema de "congelamento", sendo necessário atua-lizar a BIOS do sistema, e problemas com os drivers de rede disponíveis no kernel linux 3.13, padrão doUbuntu 14.04. A solução adotada foi a configuração de uma nova imagem bootstrap no Fuel, utilizandouma versão mais recente do kernel, a 4.4, padrão do Ubuntu 16.04.
Houveram também problemas durante o processo de implementação da nuvem. O primeiro deles ocor-reu com o servidor Bl460c. O mesmo apresentava uma instalação corrompida do Grub (boot loader),implicando na não inicialização do Ubuntu. Isso ocorria pela fato do Fuel selecionar o primeiro discoda lâmina como disco bootável, sendo que o SO estava sendo instalado no terceiro disco. Assim, foi

31
necessário selecionar o terceiro disco como bootável, seguindo a documentação10 do Fuel. As novas atu-alizações do Fuel, posteriores ao problema citado, passaram a permitir a seleção de um disco bootávelatravés da própria interface web.
O datacenter do IMD também se apresentou com problemas durante alguns dias do trimestre, devido àfalta de combustível, afetando o processo de implementação da nuvem diretamente. Isso causou tambémo corrompimento dos dados LVM do servidor srv-sm-mgmt. Os dados foram restaurados, porém asmáquinas virtualizadas, Fuel Master e o Controller, foram perdidas. Dessa forma, foi necessário reinstalaro Fuel. Porém, o mesmo apresentou, durante alguns dias, problemas com os repositórios utilizados, nãosendo possível a conclusão da instalação do mesmo.
No tocante à implantação da nuvem OpenStack, e baseado na experiência deste terceiro trimestre,temos como sugestão principal de próximas atividades o estudo sobre aspectos de recuperação da in-fraestrutura em caso de disastre (disaster recovery), incluindo diversos testes simulando situações dedisastre. Além disso, sugerimos também a utilização da nuvem por um conjunto reduzido de usuários deforma a conduzir alguns testes operacionais com a mesma.
3 Estudos sobre Ambientes de Gerenciamento de Containers
Nesta seção serão apresentados os resultados obtidos durante a fase de pesquisa relacionada ao gerenci-amento de ambientes com containers utilizando Docker. No contexto do projeto SmartMetropolis, esta-mos considerando o uso de containers Docker para implantação de GE’s Fiware em produção, e este éprincipal motivador desse estudo.
No trimestre anterior, a equipe deu início aos experimentos envolvendo containers, inclusive efetuandocorreções no código do plugin nova-docker 11 para Fuel 9, no entanto não foi possível efetuar testesrelacionados ao gerenciamento dos containers, e principalmente, o uso dos mesmos em ambientes deprodução. Desse modo, este estudo visa oferecer subsídios para que estes testes possam ser realizados.
Na sequencia, apresentamos o funcionamento básico de Containers Docker, seguido de uma descriçãode mecanismos que permitem sua utilização para aplicações distribuídas.
3.1 Containers Docker
O Docker [8] é uma plataforma que automatiza a implantação de aplicações dentro de ambientes iso-lados denominados containers. O principal objetivo dessa tecnologia é proporcionar o empacotamentode aplicações com todas as suas dependências (bibliotecas do sistema operacional, ferramentas, etc.) emuma unidade padronizada para desenvolvimento de software. O ambiente Docker é bem semelhante àsestruturas de ambiente virtualizados tradicionais como hypervisor. Entretanto, difere no que diz respeitoà necessidade de uma camada intermediária de sistema operacional entre o hospedeiro e as aplicaçõeshospedadas. Tal camada intermediária é dispensável pela plataforma Docker, uma vez que as soluçõesbaseadas nesta tecnologia utilizam o mesmo kernel para todas as aplicações, criando ambientes isola-dos a nível de disco, memória e processamento. Portanto, o Docker é mais “leve” que um virtualizador(hypervisor).
10http://docs.openstack.org/developer/fuel-docs/userdocs/fuel-user-guide/
configure-environment/select-bootable-device.html11https://github.com/SmartInfrastructures/fuel-plugin-novadocker
32
3.1.1 Arquitetura do Docker
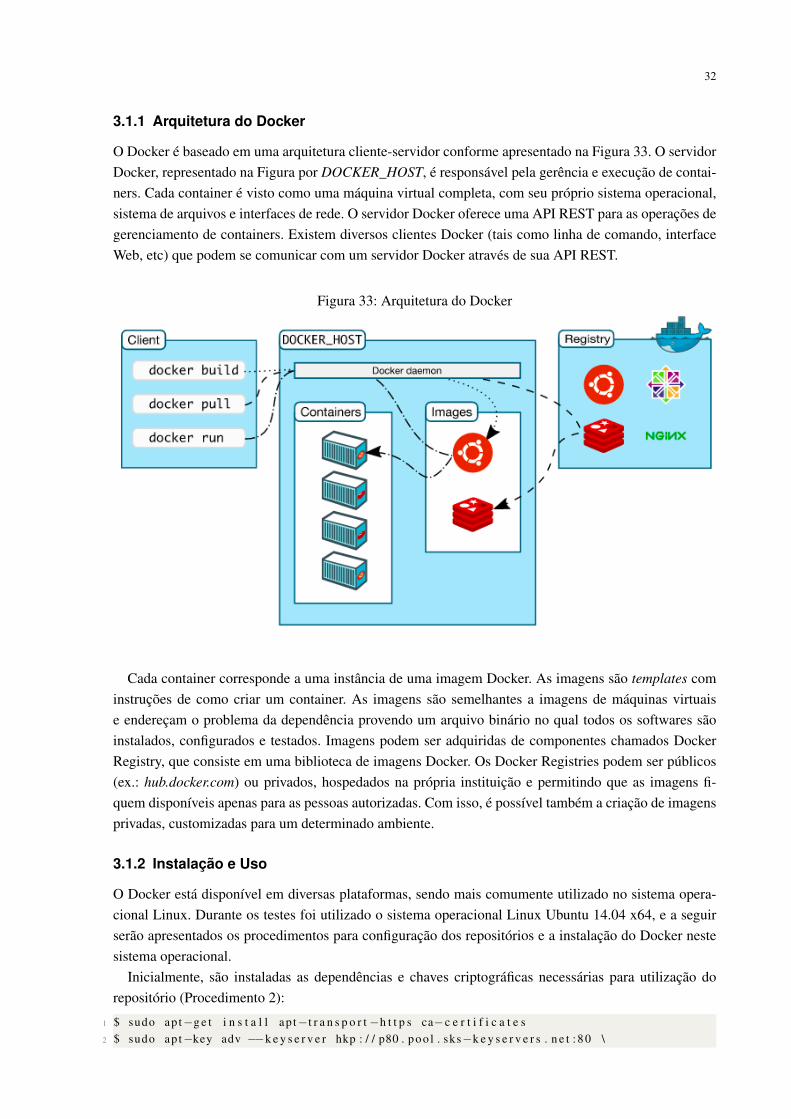
O Docker é baseado em uma arquitetura cliente-servidor conforme apresentado na Figura 33. O servidorDocker, representado na Figura por DOCKER_HOST, é responsável pela gerência e execução de contai-ners. Cada container é visto como uma máquina virtual completa, com seu próprio sistema operacional,sistema de arquivos e interfaces de rede. O servidor Docker oferece uma API REST para as operações degerenciamento de containers. Existem diversos clientes Docker (tais como linha de comando, interfaceWeb, etc) que podem se comunicar com um servidor Docker através de sua API REST.
Figura 33: Arquitetura do Docker
Cada container corresponde a uma instância de uma imagem Docker. As imagens são templates cominstruções de como criar um container. As imagens são semelhantes a imagens de máquinas virtuaise endereçam o problema da dependência provendo um arquivo binário no qual todos os softwares sãoinstalados, configurados e testados. Imagens podem ser adquiridas de componentes chamados DockerRegistry, que consiste em uma biblioteca de imagens Docker. Os Docker Registries podem ser públicos(ex.: hub.docker.com) ou privados, hospedados na própria instituição e permitindo que as imagens fi-quem disponíveis apenas para as pessoas autorizadas. Com isso, é possível também a criação de imagensprivadas, customizadas para um determinado ambiente.
3.1.2 Instalação e Uso
O Docker está disponível em diversas plataformas, sendo mais comumente utilizado no sistema opera-cional Linux. Durante os testes foi utilizado o sistema operacional Linux Ubuntu 14.04 x64, e a seguirserão apresentados os procedimentos para configuração dos repositórios e a instalação do Docker nestesistema operacional.
Inicialmente, são instaladas as dependências e chaves criptográficas necessárias para utilização dorepositório (Procedimento 2):
1 $ sudo ap t−g e t i n s t a l l ap t−t r a n s p o r t −h t t p s ca−c e r t i f i c a t e s2 $ sudo ap t−key adv −−k e y s e r v e r hkp : / / p80 . poo l . sks−k e y s e r v e r s . n e t : 8 0 \

33
3 −−recv−keys 58118 E89F3A912897C070ADBF76221572C52609D4 $ sudo echo " deb h t t p s : / / a p t . d o c k e r p r o j e c t . o rg / r epo ubuntu− t r u s t y main " > / e t c / a p t /
s o u r c e s . l i s t . d / do ck e r . l i s t
Procedimento 2: Instalando dependências do Docker, e inserindo repositórios
Em seguida, será instalado alguns drivers extras requeridos pelo Docker (Procedimento 3):
1 $ sudo ap t−g e t u p d a t e2 $ sudo ap t−g e t i n s t a l l l i n u x−image−e x t r a−$ ( uname −r ) \3 l i n u x−image−e x t r a−v i r t u a l
Procedimento 3: Instalando drivers extras do Docker
Por fim, o Docker é instalado e seu serviço iniciado (Procedimento 4):
1 $ sudo ap t−g e t i n s t a l l docker−e n g i n e2 $ sudo s e r v i c e do ck e r s t a r t
Procedimento 4: Instalando e iniciando o Docker
Para testar o ambiente será criado um container baseado na imagem padrão do Apache como exemplo(Procedimento 5):
1 FROM h t t p d : 2 . 42 COPY . / p u b l i c−html / / u s r / l o c a l / apache2 / h t d o c s /
Procedimento 5: Exemplo de Dockerfile para Apache
O comando FROM especifica qual será a imagem e tag (versão) utilizada como base para criaçãodo container, e o COPY é utilizado para copiar o conteúdo do diretório public-html que se encontra namáquina hospedeira para o diretório /usr/local/apache2/htdocs que se encontra no container.
Após salvar o arquivo com o nome Dockerfile, via shell efetue o build do container (o build baixa aimagem apartir do hub do Docker) (Procedimento 6):
1 d oc ke r b u i l d − t apache_img .
Procedimento 6: Efetuando build no container do Apache
O parâmetro -t define qual nome será utilizado para a imagem, e para esse exemplo utilizaremos"apache_img". Por fim é informado o diretório onde se encontra o Dockerfile, ou pode ser utilizado "."para considerar o diretório atual.
O próximo passo é criar um container apartir da imagem (apacheimg) gerada no passo anterior. Paracriar o container execute o seguinte comando: (Procedimento 7)
1 d oc ke r run −d −−name apache_app apache_img
Procedimento 7: Executando o container do Apache
O parâmetro -d é utilizado para que o container rode em segundo plano (background), em seguidafoi utilizado o parâmetro –name para especificar o nome do container (nesse exemplo foi utilizado apa-che_app), e por fim o nome da imagem gerada no Procedimento 6, ou seja, apache_img.
3.2 Gerenciando Aplicações multi-containers
Dependendo da arquitetura da aplicação, a mesma pode ser desenvolvida em um único container. Emoutros casos, pode ser necessário o desenvolvimento de vários containers, que poderão se comunicarentre si, por exemplo, um container com a aplicação web, e outro com o banco de dados.

34
No contexto de aplicações baseadas na plataforma Fiware, cada GE roda em seu próprio container.Por exemplo, se uma aplicação desenvolvida necessita utilizar o gerenciamento de identidades, proxy desegurança e controle de acesso baseados em atributos do Fiware, então teremos containers baseados nasimagens do Fiware IDM, PEP Proxy Wilma e AuthZForce respectivamente.
Gerenciar o ciclo de vida de um elevado número de containers manualmente se torna inviável, poisvários fatores terão que ser considerados, tais como ordem em que os mesmos serão iniciados (ex.: aaplicação não pode ser iniciada antes do banco), integração entre containers (ex.: o container do IDMdeve ter acesso via IP ao AuthZForce, PEP, etc.), recriar os containers quando estes forem alterados, etc.
Em seguida apresentamos uma ferramenta que facilita o gerenciamento de múltiplos containers Doc-ker.
3.2.1 Arquitetura e Funcionamento
O projeto Docker disponibiliza uma ferramenta open-source denominada Docker-Compose, que permitegerenciar múltiplos containers. Os containers e seus respectivos serviços, portas, links e demais particula-ridades são definidos no arquivo de configurações declarativas docker-compose.yml, e usando o comandodocker-compose é possível gerenciar de forma integrada o processo de build e execução dos containers.
Conforme apresentado na figura 34, a ferramenta Docker-Compose processa o arquivo de configuraçãodocker-compose.yml (sombreado em verde), e apartir dessas informações utiliza o Docker para construiros containers (sombreados em cinza), etc.
Figura 34: Arquitetura do Docker-Compose
O docker-compose.yml utiliza YAML (YAML Ain’t Markup Language) para definir os serviços, networkse volumes que serão aplicados para cada container. O arquivo suporta 2 formatos: version 1 (legado, nãosuporta volumes ou networks) e version 2, que suporta volumes e networks.
Os procedimentos e comandos utilizados para instalação do Docker-Compose serão apresentados napróxima seção.
3.2.2 Instalação e Uso do Docker-Compose
A instalação do Docker-Compose foi realizada na mesma máquina virtual utilizada durante os testescom o Docker (Ubuntu 14.04 LTS x64). A documentação oficial do Docker-Compose foi utilizada comoreferência 12 durante o processo de instalação.
12https://docs.docker.com/compose/install/

35
O primeiro passo a ser realizado é fazer o download do script de instalação do Docker-compose viacURL e executá-lo: (Procedimento 8):
1 sudo c u r l −L \2 " h t t p s : / / g i t h u b . com / do ck e r / compose / r e l e a s e s / download / 1 . 8 . 1 / \3 docker−compose−$ ( uname −s )−$ ( uname −m) " > / u s r / l o c a l / b i n / docker−compose
Procedimento 8: Baixando e instalando o Docker-Compose
Caso o comando cURL não seja encontrado, efetue a instalação do mesmo utilizando apt-get installcurl.
Por fim, as permissões de execução deverão ser aplicadas no binário do Docker-Compose (Procedi-mento 9):
1 sudo chmod +x / u s r / l o c a l / b i n / docker−compose
Procedimento 9: Aplicando permissão de execução no Docker-Compose
A seguir temos um exemplo de um docker-compose.yml para uma aplicação web desenvolvida emDjango que utiliza banco de dados PostgreSQL. (Procedimento 10
1 v e r s i o n : ’2 ’2 s e r v i c e s :3 db :4 image : p o s t g r e s5 web :6 b u i l d : .7 command : py thon manage . py r u n s e r v e r 0 . 0 . 0 . 0 : 8 0 0 08 volumes :9 − . : / code
10 p o r t s :11 − " 8000:8000 "12 depends_on :13 − db
Procedimento 10: Exemplo de docker-compose para aplicação web
No exemplo apresentado em Procedimento 10 o docker-compose foi dividido em 2 serviços (services):db (baseado na imagem do postgres) e web, baseado em um Dockerfile que se encontra no diretório doDocker-compose (build: .). Em command é informado o comando que deve ser executado quando ocontainer for inicializado, e volumes define qual diretório da máquina hospedeira será mapeado dentrodo container em /code.
A configuração ports é utilizada para definir as portas TCP que aguardarão conexões na máquinahospedeira e no container, ou seja, ao tentar conectar na porta 8080 da máquina hospedeira o Dockerencaminhará o tráfego para a porta 8080 do container web, e por fim a configuração depends_on, quedefine a ordem de inicialização dos containers (o container web depende de db, e devido isso a aplicaçãoserá iniciada após o banco).
Para iniciar os containers o seguinte comando deve ser executado: (Procedimento 11
1 docker−compose up
Procedimento 11: Exemplo de docker-compose para aplicação web
Demais comandos e exemplos estão disponíveis na documentação do Docker-compose13.
13https://docs.docker.com/compose/compose-file/

36
3.3 Discussão
O Docker-Compose se mostra como uma ferramenta bastante útil para gerenciar o ciclo de vida deum grande número de containers. Considerando que ambientes de desenvolvimento baseado em Fiwarepodem utilizar diversos GEs, a utilização de Docker para tal se mostra bastante promissora, além de serrecomendada pela equipe de desenvolvimento do Fiware (quase todos os GEs oferecem imagens Dockerpara serem utilzadas em ambiente de desenvolvimento).
Nesse sentido, em um ambiente de produção o Docker-Compose pode ser utilizado para gerenciaras GEs implantadas no ambiente. Além disso, existem também outras ferramentas que se integramao Docker-Compose para permitir que o ambiente se torne escalável e considere aspectos de alta-disponibilidade.
Com intuito de prover um ambiente de alta-disponibilidade, recomendamos para as próximas ações aavaliação das seguintes soluções em conjunto com a nuvem OpenStack:
• Kubernetes: Plataforma open-source para automação de implantação e gerenciamento escalávelde containers através de cluster.
• Docker-Swarm: Solução nativa de cluster para Docker que possibilita que os containers escalemde forma transparente por múltiplos hosts.
4 Estudos sobre Implantação de GEs em Ambiente de Produção
Conforme mencionado anteriormente, a implantação da instância Fiware de produção foi dividida emduas etapas. Enquanto que a primeira etapa foi descrita na Seção 2, esta seção descreve as atividadesrealizadas no contexto da segunda etapa da implantação, que consiste no estudo sobre implantação deGEs em ambiente de produção.
Nesse contexto, se faz necessário elencar um conjunto de GEs que serão alvo do estudo a ser reali-zado. Desse modo, o estudo sobre implantação de GEs em ambiente de produção iniciou-se com as GEsrelacionadas a segurança (Keyrock e AuthZForce), uma vez que essas GEs são utilizadas por quaisqueraplicações que deseje empregar mecanismos de autenticação e controle de acesso. Além disso, o estudoenglobou também a GE Orion Context Broker, que oferece serviços de registro, publicação e notificaçãode informações de contexto.
Ao final do terceiro trimestre do projeto, foi apresentada a demanda de um ambiente de produção parasuporte a aplicação SGeoL. Entretanto, como não havia tempo hábil para a definição e implantação de talambiente, foi decidido que o mesmo não seria considerado neste momento como ambiente de produção.Além disso, algumas atividades relacionadas ao estudo sobre a implantação de GEs em ambiente deprodução tiveram que ser interrompidas.
Na sequencia, descrevemos o estudo realizado com os componentes Keyrock, AuthZForce e Orion.
4.1 Keyrock
O Keyrock é a implementação de referência do Identity Management GE (IdM), sendo responsável pelogerenciamento de identidades de usuários, organizações e aplicações, assim como de suas respectivascredenciais, e da autenticação dessas entidades. Desenvolvedores interagem com este componente pararegistrarem suas aplicações no IdM, e para gerenciar a segurança de suas aplicações (credenciais, papéis epolíticas de autorização). Usuário finais usam o IdM GE para se registrarem, e gerenciar seus respectivos

37
perfis e suas organizações, enquanto que todas as entidades clientes de aplicações utilizam o IdM parafins de autenticação.
Esta seção descreve o estudo realizado acerca da implantação deste componente na instância Fiwaredo projeto. Iniciamos descrevendo a arquitetura de implantação do Keyrock em termos dos serviços ne-cessários para seu funcionamento, seguido das opções de implantação de acordo com sua documentaçãooficial.
4.1.1 Arquitetura de Implantação do Keyrock
O Keyrock é baseado em dois componentes OpenStack, o gerenciador de identidades Keystone comoback-end, e o Dashboard Horizon como front-end, que foram modificados para atender aos requisitosda plataforma Fiware. O Keyrock exporta toda a API do Keystone, além de oferecer um conjunto deAPIs customizadas, possuindo assim as suas próprias APIs REST. O principal objetivo do Keyrock éde permitir aos desenvolvedores o uso do gerenciamento de identidades em suas aplicações baseadas noFiware Identity, sendo isso possível graças aos protocolos SAML e OAuth2, disponibilizados por APIsdesenvolvidas para a extensão ao Horizon.
Figura 35: Arquitetura do Keyrock
A Figura 35 apresenta uma visão de implantação do Keyrock em termos de serviços Linux necessá-rios, identificando quais portas TCP são necessárias para seu funcionamento. Tais serviços podem serinstalados tanto em uma mesma máquina, quanto em máquinas diferentes, desde que haja conectividadeentre elas. Como extensão ao Keystone, o Keyrock oferece seus serviços na porta 5000 (a mesma portautilizada pelo Keystone), além de necessitar de um servidor de banco de dados MySQL (que utiliza aporta 3306). De maneira similar, como extensão ao Horizon, é necessário um servidor Web (utilizando aporta 8000 e 443), além de um servidor de e-mail (no caso, Postfix que escuta na porta 25).
4.1.2 Opções de Implantação
De acordo com sua documentação oficial, o IDM Keyrock pode ser instalado por meio das seguintesopções:

38
• Container Docker: É possível construir uma imagem do Keyrock através de seu Dockerfile, dis-ponível em seu repositório, ou simplesmente utilizar a imagem pública disponibilizada no DockerHub.
• Imagem de uma VM. São disponibilizados scripts que podem ser executados através de uma má-quina virtual contendo o Ubuntu como sistema operacional.
• Chef. É disponibilizado um script que automatiza o processo de instalação baseado na ferramentaChef.
Entretanto, a implantação do Keyrock em um ambiente de produção requer alguns cuidados e confi-gurações extras que não atendidas por nenhuma das opções apresentadas, conforme indicado pela docu-mentação oficial do mesmo.
Por padrão, as ferramentas de automação utilizadas na instalação do Keyrock utilizam o SQLite comobanco de dados, o que não é recomendado para produção. Assim, é preferencial utilizar um SGBD SQL,como o MySQL. Além disso, as ferramentas de automação implementam um servidor web que tam-bém não é adequado para produção. Dessa forma, é recomendado a utilização do servidor web Apachejuntamente com o módulo mod_wsgi. Por fim, para que o serviço de email do IdM funcione propria-mente, é preciso que um servidor SMTP, como o POSTFIX, seja configurado ou utilizado para o envio erecebimento de emails.
Baseado na documentação oficial para implantação em ambiente de produção, e considerando a forteintegração do Keyrock com componentes essenciais da plataforma OpenStack, analisamos as opções deimplantação existente.
A imagem pública disponibilizada para o uso de contêineres Docker, assim como o script de cons-trução de imagens (Dockerfile), não atendem aos critérios de um ambiente de produção. De forma que,a utilização de contêineres Docker exige uma reformulação no processo de construção da imagem demodo que a mesma seja personalizada para nosso ambiente.
A opção de se utilizar máquinas virtuais são indicadas para um ambiente de teste e desenvolvimentoisolado, não atendendo aos critérios de um ambiente de produção, principalmente no que diz respeito àescalabilidade do ambiente.
Os scripts disponibilizados para a ferramenta Chef podem servir de base para a implantação de um am-biente que seja gerenciado por esta ferramenta. Entretanto, nosso ambiente é gerenciado pela ferramentaFuel, baseado nas orientações do capítulo técnico de operações da plataforma Fiware.
Após essas considerações, realizamos uma análise considerando alguns aspectos do Keyrock e donosso ambiente, o que nos levou à possibilidade de se utilizar a ferramenta Fuel como mecanismo paraimplantação do Keyrock. Tal análise considerou os seguintes aspectos: (i) A arquitetura do Keyrockapresenta uma forte integração com componentes essenciais da plataforma OpenStack, uma vez que oKeystone é o componente responsável pelos aspectos de gerenciamento de identidades e controle deacesso para todos os serviços OpenStack. (ii) Os serviços Linux utilizados pelo Keyrock (por exemplo,servidor de banco de dados SQL, e servidor Web) também são utilizados pelos outros componentesda plataforma OpenStack. (iii) Como mencionado anteriormente, o capítulo técnico de operações daplataforma Fiware é baseado na ferramenta Fuel, que foi adotada como ferramenta de gerenciamento denosso ambiente.
Baseado nisso, consideramos inicialmente duas possibilidades para implantação do Keyrock: Contêi-neres Docker e ferramenta Fuel.

39
4.1.3 Experiência com a implantação do Keyrock
Nesta seção descrevemos a experiência de implantação do Keyrock utilizando ambos Docker e Fuel. Aexperiência com Docker visa auxiliar os outros membros do projeto que necessitem de um ambiente dedesenvolvimento com Keyrock. A utilização do Docker foi concluída com sucesso, e serviu de base parao ambiente de desenvolvimento implantado para a aplicação SGeoL, que será detalhado na seção 5. Já aexperiência com o Fuel tem como objetivo a implantação do Keyrock em um ambiente de produção, eteve que ser interrompida devido aos problemas encontrados durante a implantação da nuvem (relatadosna Seção 2).
Visando a utilização do Keyrock em um ambiente de desenvolvimento, fizemos a instalação do mesmoutilizando container Docker. Para simplificar o processo, usamos o docker compose, uma ferramenta paraa definição e execução de aplicativos Docker multi-containers. Dessa forma, pudemos usar um arquivocompose para configurar os serviços da aplicação e com um único comando, foi possível criar e iniciartodos os serviços a partir dessa configuração.
Usando o docker compose foi necessário definir os serviços que compõem a aplicação no arquivodocker-compose.yml para que eles possam ser executados em conjunto em um ambiente isolado. Abaixo mostramos nosso arquivo docker-compose.yml para
1 idm :2 r e s t a r t : a lways3 image : f i w a r e / idm4 p o r t s :5 − 8000:80006 − 5000:5000
Por último, executamos docker-comporse up e o compose irá iniciar e executar o aplicativo inteiro.
1 $ docker−comporse up
Procedimento 12: Comando para executar e iniciar o Keyrock.
Entretanto, devido ao alto grau de acoplamento entre o Keyrock e os outros componentes da plataformaOpenStack, e no fato que nosso ambiente é gerenciado pela ferramenta Fuel, foi decidido explorar o Fuelcomo ambiente de implantação para o Keyrock. O motivo principal dessa escolha se deve ao fato que umambiente de produção requer aspectos de redundância, disponibilidade, e escalabilidade. Tais aspectospodem ser facilmente alcançados utilizando o Fuel.
O Fuel adota uma arquitetura baseada em plugins, permitindo a personalização do ambiente atravésdos mesmos. Desse modo existem uma gama de plugins Fuel disponibilizados pela comunidade, taiscomo plugins para Zabbix, OpenLDAP, VPN, etc., e com isso automatizar o deploy desses serviçosdurante a configuração da instância OpenStack. Nesse contexto, o objetivo deste estudo é a criação deum plugin Fuel para a implantação do Keyrock em conjunto com um ambiente OpenStack.
Considerando que estamos focando em um ambiente de produção, é necessário atentar para aspectosde alta disponibilidade e escalabilidade. Estes aspectos são geridos pelo próprio Fuel para um ambienteOpenStack, e portanto serão aplicados também ao Keyrock. O backend do Keyrock utiliza o MySQLcomo banco de dados em conjunto com a ferramenta Galera cluster14 para a replicação de dados. Quantoao acesso ao Horizon, o mesmo será gerenciado pelo o HAProxy15, um balanceador de carga utilizadopelo Fuel. Assim, se um nó Controller perde acesso a rede, é desligado ou se encontra inoperável, o
14http://galeracluster.com/15http://www.haproxy.org/

40
HAProxy garantirá o acesso ao Horizon por meio de outro nó Controller. A redundância e disponibilidadeparte do pressuposto que haja pelo menos 3 nós com o papel de Controller.
Com isso, após entrar em contato com desenvolvedores do OpenStack Keystone e da ferramenta Fuel,foi iniciado o processo de desenvolvimento de um plugin Fuel para o Keyrock. Seguindo sugestões dosdesenvolvedores oficiais, utilizamos como base os plugins Fuel disponibilizados para implantação doOpenStack Keystone16, e nos scripts de implantação disponibilizados pelo Keyrock17.
Porém, esta tarefa teve que ser interrompida devido aos problemas encontrados com a implantação danuvem OpenStack, que exigiram a atenção da equipe inicialmente alocada para o estudo do Keyrock.Embora tenhamos criado uma versão inicial do plugin, não tivemos condições de testar o mesmo pois aequipe teve que ser realocada.
4.1.4 Discussão
A experiência de implantar o Keyrock utilizando containers Docker foi concluída com sucesso, e for-neceu subsídios que já estão sendo utilizados por diversos membros do projeto que necessitem da GEKeyrock em um ambiente de desenvolvimento. Dentre os casos mais interessantes, temos a utilizaçãodo Keyrock para o desenvolvimento de aplicações de estudo de caso, demonstrando como incorporarautenticação em aplicações Fiware através do protocolo OAuth. Tal aplicação é descrita no relatório doWP-Middleware. Outro caso foi a utilização do Keyrock no ambiente de desenvolvimento da aplicaçãoSGeoL. A experiência com Docker explorando o Keyrock facilitou bastante o trabalho na definição dainfraestrutura de suporte para a SGeoL, que será apresentada na Seção 5.
Entretanto, devido aos problemas encontrados com nuvem OpenStack, não tivemos condições de con-cluir todos os testes com um plugin Fuel para implantação do Keyrock em um ambiente de produção.Desse modo, os próximos passos consistem em continuar esta tarefa.
4.2 AuthZForce
O AuthZForce é a implementação de referência do Authorization PDP GE (PDP - Policy Decision Point),sendo responsável por gerenciar políticas de autorização na plataforma Fiware. As políticas definidaspelos desenvolvedores por meio do IdM são gerenciadas pelo PDP, que é responsável também por avaliarrequisições de acesso baseado em políticas de autorização, garantindo que somente usuários com asdevidas permissões tenham acesso aos recursos protegidos.
O AuthZForce trabalha em conjunto com outros dois GEs para contemplar os mecanismos de con-trole de acesso da plataforma Fiware: o Identify Management GE (KeyRock), e o PEP Proxy (Wilma)conforme apresentado na figura 36.
O IDM KeyRock provê o gerenciamento de usuários, gerenciamento de identidade de organizações eaplicações, e autenticação. Os desenvolvedores interagem com o IDM KeyRock para registrar suas apli-cações, gerenciar papéis e permissões de acesso. O processo de implantação deste GE foi apresentadona seção anterior (seção 4.1). O PEP Proxy Wilma funciona como um proxy transparente que fica nafrente dos serviços REST para garantir a proteção, interceptando as requisições e autenticando as ses-sões junto ao IDM KeyRock. Por fim, o PEP envia os dados da requisição para o PDP (AuthZForce) paraque este efetue o processo de autorização, onde é verificado se a requisição será permitida ou negada.Se a decisão do PDP for permitir, o PEP encaminha a requisição para o serviço protegido, e por fim
16https://github.com/openstack/fuel-plugin-detach-keystone17https://github.com/ging/fiware-idm

41
Figura 36: Arquitetura de Segurança do Fiware
encaminha a resposta para o requisitante. Conforme apresentado na figura, outros PEP’s podem ser utili-zados para aplicações que não sejam REST ou para serviços não baseados em HTTP. Por fim temos o GEAuthZForce, que avalia requisições de acesso baseado em políticas definidas através do IDM keyrock.
Nas próximas seções apresentaremos detalhes sobre a arquitetura de implantação do AuthZForce,descrevendo os procedimentos de instalação e configuração do mesmo. A instalação foi dividida em 2etapas, na primeira efetuamos a instalação do AuthZForce em uma máquina virtual, permitindo assimconhecer melhor a solução, e utilizando essa experiência como base para a etapa seguintes, que foi ainstalação via containers Docker.
4.2.1 Arquitetura de Implantação do AuthZForce
O AuthZForce consiste em uma aplicação Web desenvolvida em Java, e portanto necessita de um con-tainer de aplicações Java Web para sua execução. A Figura 37 apresenta a arquitetura de implantação doAuthZForce, que é composta por um sistema operacional Linux Ubuntu 14.04 LTS x64, onde é instaladoo container de aplicações Java Tomcat
Figura 37: Arquitetura do AuthZForce
De acordo com sua documentação oficial, para instalação do AuthZForce é necessário um servidor oumáquina virtual com os seguintes pré-requisitos:
• CPU: 2.6 GHz (mínimo recomendado)
• Arquitetura da CPU: i686/x86_64
• RAM: 4GB (mínimo recomendado)

42
• Espaço em disco: 10 GB (mínimo recomendado)
• Ambiente Java: JDK 7 (Oracle ou OpenJDK) e Tomcat 7.x
Os requisitos e o procedimento para instalação do AuthZForce serão detalhados na próxima seção.
4.2.2 Opções de Implantação
A documentação oficial do AuthZForce 18 fornece os procedimentos e recomendações a serem adotadospara deploy do AuthZForce em ambientes de produção. Para o ambiente alcançar alta-disponibilidadepodem ser instaladas múltiplas instâncias do AuthZForce em cluster. O AuthZForce não utiliza bancode dados, no entanto, os domínios e demais arquivos de configurações são armazenados em alguns dire-tórios, e esses devem está sincronizados entre todos os nós do cluster. Para manter os diretórios sincro-nizados é recomendado o uso de NFS (Network File System) ou csync2 19. Os diretórios que devem sersincronizados são:
• /opt/authzforce-ce-server/conf: Diretório onde são armazenadas as configurações do AuthZForce.
• /opt/authzforce-ce-server/data: Diretório onde são armazenados os dados dos domínios e políti-cas de controle de acesso.
Após um estudo sobre as melhores práticas para instalação e configuração do AuthZForce em ambi-ente de produção, foram iniciados alguns experimentos para detectar a forma mais eficiente de implantareste serviço na nuvem do projeto SmartMetropolis. O primeiro teste realizado foi a instalação manual doAuthZForce em uma máquina virtual com sistema operacional Ubuntu 14.04 LTS para validar o processode instalação, documentar as dificuldades, possíveis erros, etc. Superado essa primeira etapa, foram ini-ciados os testes de deploy do AuthZForce utilizando containers Docker, com intuito de proporcionar umamaneira simplificada de instalação e utilização deste GE pelos desenvolvedores dos projetos de nuvemdo SmartMetropolis.
Na próxima seção serão apresentados os resultados obtidos em cada uma dessas etapas citadas, comotambém as dificuldades encontradas e as soluções propostas durante a execução das mesmas.
4.2.3 Experiência com implantação do AuthZForce
Em um ambiente de produção a documentação e os procedimentos a serem realizados para instalaçãoe configuração de um serviço devem está sempre atualizados, para que durante a recuperação de umdesastre tais serviços possam ser restabelecidos de forma mais ágil, diminuindo assim os danos causados.
Baseado na documentação oficial do projeto AuthZForce, foi realizado a instalação deste serviço deforma manual em uma máquina virtual, e por fim a instalação utilizando containers Docker. Os procedi-mentos e dificuldades encontradas serão apresentadas serão apresentados a seguir.
Implantação manual Para validar os procedimentos descritos a seguir foi realizado o downloaddo Ubuntu 14.04 LTS x64 a partir do site do Ubuntu 20. Em seguida foi realizado a instalação dessa
18http://authzforce-ce-fiware.readthedocs.io19http://oss.linbit.com/csync2/20http://releases.ubuntu.com/14.04/ubuntu-14.04.5-server-amd64.iso/

43
imagem usando uma máquina virtual criada com VirtualBox. A documentação do projeto AuthZForcefoi utilizada como referência21.
O primeiro passo é a instalação do Java 7 e Tomcat 7 (Procedimento 13).
1 $ sudo a p t i t u d e i n s t a l l openjdk−7−j d k2 $ sudo a p t i t u d e i n s t a l l t omca t7
Procedimento 13: Instalação do Java JDK 7 e Tomcat 7.
Em seguida, é necessário baixar a última versão do AuthZForce e instalar usando gdebi (Procedi-mento 14).
1 $ wget h t t p : / / r epo1 . maven . o rg / maven2 / o rg / ow2 / a u t h z f o r c e \2 / a u t h z f o r c e −ce−s e r v e r −d i s t / 5 . 4 . 1 / a u t h z f o r c e −ce−s e r v e r −d i s t −5 . 4 . 1 . deb3 $ sudo a p t i t u d e i n s t a l l g d e b i c u r l4 $ sudo g d e b i a u t h z f o r c e −ce−s e r v e r −d i s t −5 . 4 . 1 . deb
Procedimento 14: Baixando e instalando AuthZForce
É necessário também ajustar o pool de alocação de memória para o Java no Tomcat 7 (Procedi-mento 15).
1 $ sudo sed − i ’ s /−Xmx128m/−Xmx1024m / ’ / e t c / d e f a u l t / t omca t7
Procedimento 15: Ajustando configuração XMX do Java no Tomcat 7.
Após o ajuste na configuração do Tomcat, basta iniciar o mesmo (Procedimento 16).
1 $ sudo s e r v i c e tomca t7 r e s t a r t
Procedimento 16: Iniciando o Tomcat.
Uma vez que o Tomcat tenha sido iniciado, pode-se testar se o AuthZForce está respondendo a requi-sição utilizando o comando cUrl ou wget (Procedimento 17).
1 $ c u r l −−v e r b o s e −−show−e r r o r −−w r i t e−o u t ’ \ n ’ −−r e q u e s t GET \2 h t t p : / / l o c a l h o s t : 8 0 8 0 / a u t h z f o r c e −ce / domains3 $ wget −v −O a u t h z f o r c e . wadl h t t p : / / l o c a l h o s t : 8 0 8 0 / a u t h z f o r c e −ce / ? _wadl
Procedimento 17: Testando a instância AuthZForce
Implantação usando containers Docker O projeto AuthZForce desenvolveu uma imagem Doc-ker e disponibilizou no seu repositório público que se encontra no GitHub 22, como também no DockerHub 23. Desse modo, para se iniciar uma instância do AuthZForce em um container Docker, basta utilizaruma de suas imagens públicas (Procedimento 18). O procedimento a seguir considera que o Docker já seencontra instalado no Linux.
1 $ do ck e r run −d −p 8080:8080 −−name a z f \2 f i w a r e / a u t h z f o r c e −ce−s e r v e r : r e l e a s e −5 .4 .1
Procedimento 18: Baixando imagem Docker do AuthZForce
21http://authzforce-ce-fiware.readthedocs.io/en/latest/InstallationAndAdministrationGuide.
html22https://github.com/authzforce/fiware/tree/master/docker23https://hub.docker.com/r/fiware/authzforce-ce-server/

44
Onde o parâmetro “-d” indica que o container vai ser executado em modo daemon (sem interfacetextual), enquanto que o parâmetro “-p” indica o mapeamento de portas entre a máquina hospedeira e ocontainer. O parâmetro “–name azf” indica o nome do container no sistema (azf de "AuthZForce"). Oúltimo parâmetro representa o caminho da imagem padrão no Docker Hub.
Uma vez em execução, é possível verificar o log do Tomcat através do comando apresentado no Pro-cedimento 19.
1 $ do ck e r l o g s −f a z f
Procedimento 19: Verificando os logs do container
Após a inicialização do container o serviço será disponibilizado na porta 8080/tcp conforme especifi-cado no parâmetro -p". Os mesmos testes realizados usando cURL na seção anterior podem utilizados.
4.2.4 Discussão
Em ambientes de produção é essencial que os GEs utilizados pelos projetos estejam disponíveis sempreque forem requisitados, e para tal, é necessário avaliar ferramentas e técnicas que resultem em um am-biente de alta-disponibilidade. Nessa fase do projeto, testes foram realizados com intuito de avaliar ospossíveis formatos para disponibilização do serviço AuthZForce em um ambiente de produção.
Durante esta experiência, conseguimos automatizar a implantação do AuthZForce. Embora não tenha-mos concluído todos os testes desejados para a implantação do AuthZForce em um ambiente de produçãono tocante a aspectos de alta-disponibilidade, os experimentos conduzidos nos forneceu subsídios para aimplantação do AuthZForce em um ambiente de desenvolvimento integrado com outras GEs, permitindoassim que se atenda a demanda de infraestrutura para a aplicação SGeoL. Além disso, o entendimentodo funcionamento básico do AuthZForce, e dos serviços necessários para o mesmo, é requisito impres-cindível para o correto planejamento de sua implantação em produção.
Neste sentido, indicamos como próximos passos a implantação em um ambiente replicado, conformeas instruções da documentação oficial do AuthZForce. É importante mencionar que esta tarefa dependedo mecanismos de alta-disponibilidade em ambientes em Containers a ser adotado pela equipe (conformemencionado na Seção 3).
4.3 Orion
O Orion Context Broker é uma implementação C++ da NGSI 9/10 API REST desenvolvido como parteda plataforma Fiware. Este componente permite gerenciar todo o ciclo de vida de informações de con-texto, incluindo atualizações, consultas, registros e assinaturas.
A Figura 38 mostra de modo geral, como o Orion interage com as aplicações produtoras e consumido-ras de contexto. Além disso, pode-se observar como estão distribuídos outros componentes no ContextBroker, como: as operações de subscrições, porta utilizada pelo Orion para se comunicar com as aplica-ções e a base de dados. O Orion se utiliza de três funções para se comunicar com as aplicações, são elas:update, query e notify. A primeira é utilizada pelas aplicações produtoras para enviarem informações decontexto para o Orion, a segunda e a terceira são funções utilizadas pelas aplicações consumidoras como intuito de fazer consultas de informações contextuais (query) ou podem fazer subscrições para seremnotificadas sobre mudanças no contexto.

45
Figura 38: Arquitetura do Orion
4.3.1 Arquitetura de Implantação do Orion
Conforme mencionado anteriormente, o Orion é uma aplicação C++ que utiliza a porta tcp 1026 paracomunicação com produtores e consumidores de informações de contexto. Para sua implantação, o Orionnecessita de um banco de dados NoSQL, trazendo como padrão o Mongodb. A Figura 39 apresenta comoesse GE pode ser implantado em um ambiente Linux.
Figura 39: Diagrama de implantação do Orion
4.3.2 Opções para Implantação
De acordo com a documentação oficial, existem 3 opções de instalação para o Orion Context Broker:manual através de yum, manual através de rpm, e através de container Docker. Além disso, versõesanteriores da ferramenta OPS-Deploy, baseada na ferramenta Fuel, traziam um plugin que permite aimplantação do Orion em um ambiente gerenciado pelo Fuel.
A implantação de forma manual exige a instalação de um conjunto de dependências, além da instalaçãoe configuração do banco de dados Mongodb. Já a implantação através de container Docker pode serrealizada através da imagem pública do Orion no Docker Hub. A implantação através do Fuel traz umaversão bastante antiga (0.15), e foi considerada aqui como base para o possível desenvolvimento de umnovo plugin para versão corrente do Orion.

46
É importante mencionar que após diversas buscas em sua documentação oficial, e em diversos fóruns,não encontramos nenhuma referência explicita ao processo de implantação do Orion Context Broker emum ambiente de produção.
4.3.3 Experiência com implantação do Orion
Iniciamos os testes com uma instalação manual do Orion. O Orion tem como referência o uso da versãodo CentOS/RedHat 6.3. Sendo assim, foi necessário fazer uma instalação seguindo a documentação doContext Broker para o CentOS 6.
Na documentação do Orion sugeriu-se duas formas para instalação manual, usando o yum ou rpm.Inicialmente foi utilizado o yum para fazer a instalação, porém por padrão, o CentOS 6 não possui aversão mais estável do context Broker, e mesmo tentando atualizar o repositório para usar o yum, oupgrade não ocorria, por isso foi escolhido fazer a instalação por meio do rpm.
Nosso primeiro passo foi realizar a instalação da versão 1.40 do Orion de forma manual. Quando foiexecutado o comando de instalação (rpm -i), o Context Broker exigiu um conjunto de dependências,em alguns casos, com versões específicas. De acordo com sua documentação, o Orion Context Brokernecessita das dependências abaixo para ser instalado:
• Ferramentas de compilação
• boost: 1.41
• libmicrohttpd: 0.9.48
• libcurl: 7.19.7
• libuuid: 2.17.2
• Mongo Driver: legacy-1.0.7
• rapidjson: 1.0.2
Em seguida, descrevemos os passos para instalar as dependências do Orion, começando pelas ferra-mentas de compilação (Procedimento 20).
1 $ sudo yum i n s t a l l make cmake gcc−c++ s c o n s
Procedimento 20: Ferramentas de compilação
Em seguida, instalamos o conjunto de bibliotecas que se encontram no repositório padrão do CentOS(Procedimento 21).
1 $ sudo yum i n s t a l l boos t−d e v e l l i b c u r l −d e v e l g n u t l s −d e v e l l i b g c r y p t −d e v e l l i b u u i d −d e v e l l i b m i c r o h t t p d
Procedimento 21: Instalação de bibliotecas Boost, Libcurl, Libuuid
Em seguida, instalamos aqueles componentes para os quais não existem pacotes disponíveis (Procedi-mento 22 e Procedimento 23).
1 $ wget h t t p s : / / g i t h u b . com / mongodb / mongo−cxx−d r i v e r / a r c h i v e / l egacy −1 . 0 . 7 . t a r . gz2 $ t a r x fvz l egacy −1 . 0 . 7 . t a r . gz3 $ cd mongo−cxx−d r i v e r −l egacy −1 .0 .74 $ s c o n s5 $ sudo s c o n s i n s t a l l −−p r e f i x = / u s r / l o c a l
Procedimento 22: Instalção do Mongo Driver

47
1 $ wget h t t p s : / / g i t h u b . com / m i l o y i p / r a p i d j s o n / a r c h i v e / v1 . 0 . 2 . t a r . gz2 $ t a r x fvz v1 . 0 . 2 . t a r . gz3 $ sudo mv r a p i d j s o n −1 . 0 . 2 / i n c l u d e / r a p i d j s o n / / u s r / l o c a l / i n c l u d e
Procedimento 23: Instalação do Rapidjson
Finalmente o Orion pode ser instalado utilizando o comando rpm
1 $ sudo rpm − i o r i o n
Procedimento 24: Instalação do Orion através de RPM
Após a instalação notou-se que alguns serviços como o mongo e o contextBroker não estavam execu-tando, por meio dos comandos (/etc/init.d/mongod status) e (/etc/init.d/contextBroker status) foi possívelverificar a inatividade dos processos. Para inicializá-los foi preciso executar o comando service mongodstart para o mongo e o /etc/init.d/contextBroker start para o Orion, porém existem outras formas testadaspara iniciar o serviço do Orion, exemplo: contextBroker ou contextBroker -port porta (com esse comandovocê pode especificar a porta em que o contextBroker pode escutar, por padrão é a 1026).
Após a instalação manual do Orion, decidimos experimentar sua implantação através de containerDocker. De acordo com a documentação oficial, é recomendado a utilização de duas imagens Docker:mongo:3.2 e fiware/orion. Desse modo, optamos por utilizar o Docker Compose para gerenciar a ins-talação. O compose é importante, pois permite ligar um container ContextBroker com um containerMongoDB em pouco tempo. Abaixo será feito um passo a passo de como instalar o Context Brokerusando Docker:
1o Passo : Criar um diretório fiware no seu ambiente de trabalho (Exemplo: /fiware).
2o Passo : Dentro do diretório do fiware, crie um novo documento chamado docker-compose.yml(touch docker-compose.yml), com o editor de sua preferência edite seu docker-compose de acordo como Procedimento 25. A opção –nojournal não é recomendado em um ambiente de produção, mas elepermite que o container mongo seja inicializado mais rapidamente.
1 mongo :2 image : mongo : 3 . 23 command : −−n o j o u r n a l4 o r i o n :5 image : f i w a r e / o r i o n6 l i n k s :7 − mongo8 p o r t s :9 − " 1026:1026 "
10 command : −d b h o s t mongo
Procedimento 25: docker-compose.yml
3o Passo : Usando linha de comando execute o comando inicializar os containers (Procedimento 26).
1 $ sudo docker−compose up
Procedimento 26: Inicializando os containers Docker de acordo com docker-compose.
Após alguns segundos, você deve ter o seu Context Broker rodando e escutando na porta 1026.

48
4o Passo : Verifique se tudo está funcionando com o comando cUrl (Procedimento 27).
1 $ c u r l l o c a l h o s t : 1 0 2 6 / v e r s i o n
Procedimento 27: Verificação de funcionamento
O Docker possibilita ao administrador de redes manipular containers da maneira que ele se sentir maisa vontade, dito isto, existem várias maneiras de configurar os containers para o Orion.
A primeira forma considera que tanto o Orion quanto o MongoDB rodam em um mesmo container(Procedimento 28).
1 $ sudo do ck e r run −d −−name o r i o n 1 −p 1026:1026 f i w a r e / o r i o n
Procedimento 28: Orion e Mongodb em um mesmo container.
Já a segunda abordagem considera que cada componente, Orion e Mongodb, rodam em um containerdiferente (Procedimento 29). Esta foi a abordagem automatizada com o uso do Docker Compose.
1 $ sudo do ck e r run −−name mongodb −d mongo : 3 . 22 $ sudo do ck e r run −d −−name o r i o n 1 −− l i n k mongodb : mongodb −p 1026:1026 f i w a r e /
o r i o n −d b h o s t mongodb
Procedimento 29: Orion e Mongodb executando em containers diferentes.
Entretanto, nas duas opções apresentadas acima, container do Mongodb não possui persistência dedados. Sendo assim, caso ocorra problemas no container, ou o mesmo seja reinicializado, os dados serãoperdidos. Isso é um problema grave para um ambiente de produção. Todavia existe uma forma de contor-nar o problema da falta de persistência de dados da instalação padrão do Orion com o Docker, para issobasta iniciar o Orion deixando a base de dados em um host diferente (Procedimento 30). Esta abordagemassume a existência de um banco de dados Mongodb acessível via rede.
1 $ sudo do ck e r run −d −−name o r i o n 1 −p 1026:1026 f i w a r e / o r i o n −d b h o s t <MongoDB Host >
Procedimento 30: Orion em container e Mongodb em um host diferente.
Além das opções disponibilizadas pela documentação oficial, existe também um plugin do Fuel quepermite fazer a instalação do Context Broker. Nesse sentido, foi feito um levantamento do cenário atualdo plugin. O plugin está bastante desatualizado, instalando a versão 0.15 do Orion (a versão atual éa 1.40), sendo compatível com a versão 6.1 do Fuel. De forma a investigar seu funcionamento, e embusca de melhores práticas que pudessem ser aproveitadas em um ambiente de produção, foi iniciada ainstalação do Orion de acordo com o plugin disponível.
Para fazer testes com fuel-plugin-context-broker, foi necessário instalar o virtualbox na versão 5.1,pois na documentação do fuel indica usar a versão 5.1. A instação foi baseada na wiki do virtual-box https://www.virtualbox.org/wiki/Linux_Downloads, mesmo assim alguns problemas com depen-dências foram encontrados, por isso foi necessário instalar as seguintes dependências: libqt5x11extras5,libsdl1.2debian e libvpx3.
Para a realização de testes com o plugin, o Fuel foi instalado através de um conjunto de scripts queautomatiza sua implantação em um ambiente baseado em Virtualbox. Foi escolhido esse modo de insta-lação, pois além de não precisar fazer configurações manuais de rede e de hardware a própria documen-tação recomenda usar o Mirantis VirtualBox scripts.
Inicialmente foi feita a preparação do ambiente para instalação do plugin no fuel 7, instalando asferramentas necessárias para tal (Procedimento 31).
1 $ sudo ap t−g e t i n s t a l l c r e a t e r e p o rpm dpkg−dev
Procedimento 31: Instalação das ferramentas padrão de desenvolvimento para Ubuntu 14.04 LTS

49
Os próximos passos serão responsáveis pela instalação do fuel plugin builder (Procedimento 32).
1 $ easy \ _ i n s t a l l p i p2 $ p i p i n s t a l l f u e l−p l u g i n−b u i l d e r
Procedimento 32: Instalação do fuel plugin builder
No procedimento acima foi encontrado um problema na preparação do ambiente para instalação doplugin ocorreu um problema depedência pbr>=1.8, sendo assim foi instalada a depedência como sugeridopela documentação que está na wiki do python (https://pypi.python.org/pypi/pbr/1.8.1#downloads)
Depois de preparado o ambiente para instalação, foram executados alguns procedimentos para instalaro plugin no Fuel 7.
1 $ g i t c l o n e h t t p s : / / g i t h u b . com / S m a r t I n f r a s t r u c t u r e s / f u e l−p l u g i n−c o n t e x t−b r o k e r . g i t2 $ fpb −−b u i l d f u e l−p l u g i n−c o n t e x t−b r o k e r3 $ scp f u e l−p l u g i n−c o n t e x t−b r o k e r / f u e l−p l u g i n−c o n t e x t−broke r −∗. no a r c h . rpm root@10
. 2 0 . 0 . 2 :4 $ f u e l p l u g i n s −− i n s t a l l f u e l−p l u g i n−c o n t e x t−broke r −∗. no a r c h . rpm
Procedimento 33: Procedimentos para instalação do plugin
Na dashboard do fuel na guia plugins será possível visualizar o Context Broker v0.15. Sem precisarfazer nenhuma alteração no código, o plugin mostrou-se compatível com a versão 7 do fuel. A figura 40mostra o plugin depois de instalado.
Figura 40: Context Broker Plugin v0.15
Embora o plugin tenha sido instalado com sucesso na ferramenta Fuel, não conseguimos realizar aimplantação do mesmo nesta instância da ferramenta.
4.3.4 Discussão
De modo a se identificar uma abordagem para a implantação do Orion em um ambiente de produção,decidimos estudar todas as formas de instalação indicadas em sua documentação oficial.
A instalação do Orion foi concluída com sucesso tanto de forma manual como a partir de containersDocker. Ambas as maneiras permitiram adquirir experiência na implantação do ambiente. Também rea-lizamos uma tentativa de implantação através de um plugin Fuel de forma a investigar o funcionamentodo mesmo em busca de práticas que pudessem ser adotadas em nosso ambiente.
No tocante à instalação manual, foi seguido a documentação oficial, utilizando-se das duas opçõesapresentadas: instalação usando a ferramenta yum e instalação usando a ferramente rpm. Na instalaçãocom yum foi visto que seria inviável, visto que mesmo adicionando o repositório do contextBroker da

50
versão mais estável, a instalação não foi possível. Para a instalação manual notou-se que foi mais viávelinstalar por meio do rpm, foram instaladas várias dependências, no qual foram destacadas no tópico dainstalação manual. Somente depois de instalar todas as dependências escolheu-se a versão mais estáveldo Orion (recomendada pela documentação a versão 1.30).
O grande desafio da instalação manual foi executar a instalação de cada dependência, de modo quepara instalar uma dependência do Orion existiam outras por trás dela e isso dificultava mais ainda otrabalho manual. Era sabido que instalar de forma manual o context broker seria a forma mais trabalhosaque as demais opções, mas as vezes ter um trabalho manual muitas vezes implica num conforto naadministração e operação do serviço, contudo o Orion não se mostrou um serviço estável por meio dessainstalação, pois existiram constantes quedas do serviço sem motivo aparente.
A implantação por meio de containers Docker se mostrou o meio mais eficiente para subir um ambientecom Orion na versão mais estável, bastando para isso editar o arquivo docker-compose.yml de acordocom a documentação do Orion. Para subir os container foram abordadas três formas, sendo que umadelas apresentou problemas com a persistência de dados como foi visto na seção de implantação com odocker, porém nesta mesma seção, foi mostrada uma solução para resolver o problema da persistênciade dados, para isso bastaria executar o Mongodb em um host diferente.
Por fim, foi tentado utilizar uma opção para implatação do Orion via fuel, contudo, foi observado queo plugin foi desenvolvido para versão 6.1 do fuel e com a versão do Context Broker 0.15 (versão muitoantiga).
Antes de instalar o ambiente com fuel e context broker foi necessário instalar o virtualbox na versão5.1, que aparentemente seria uma tarefa pouco trabalhosa. Contudo o virtualbox exigia ter instalado nosistema algumas dependências que tornou o trabalho de instalação mais trabalhoso do que aparentava.Instalar o plugin foi uma tarefa simples, porém trabalhosa, pois antes de fazer qualquer instalação foinecessário entender como funciona o plugin e do que era preciso para poder usá-lo. Foi instalado o fuel7 para ver se o plugin, mesmo sendo feito para versão 6.1, apresentaria compatibilidade para o fuel 7, epara no uso futuro ser testado no fuel 9.
Os próximos passos consistem na implantação do Orion através de um plugin para o Fuel 9. Para tal,pretendemos utilizar o pluging disponível, que foi estudado ao longo desse trimestre, como base para odesenvolvimento de um novo plugin compatível com a versão utilizada do Fuel, e que considere a versãoatual do Orion e suas dependências. Além disso, sugerimos também um estudo acerca da implantaçãodo Orion com containers Docker usando ferramentas que dão suporte a alta-disponibilidade.
5 Implantação de Ambiente de Desenvolvimento para SGeoL
Conforme mencionado anteriomente, como parte do projeto Smart Metropolis, está sendo desenvolvidauma aplicação que visa atender demanda da Prefeitura Municipal do Natal. Tal aplicação é denominadaSmart Geo Layers (SGeoL), e foi utilizada como base para definição sobre quais GEs Fiware seriamexplorados durante nosso estudo com ambiente baseado em containers Docker.
Inicialmente a equipe fez um levantamento de todos os GE’s (Generic Enablers do Fiware) que serãoutilizados para o ambiente de desenvolvimento do projeto SGeOL, e em seguida iniciou a implemen-tação dos scripts Docker para que fosse possível efetuar a implantação do referido ambiente de formaautomatizada.
Nas seções seguintes serão apresentados a arquitetura da aplicação SGeoL, identificando os GEs utili-zados, e seguido de uma breve descrição de como esses GEs foram implantados usando Docker.

51
5.1 Arquitetura do SGeOL
A Smart Geo Layers é uma plataforma para visualização, edição e análise de informações multicamadasrepresentadas por dados geoespaciais. Através da Smart Geo Layers os usuários interessados podemefetuar o confrontamento de dados e criar suas próprias camadas.
Figura 41: Arquitetura do SGEoL
A Figura 41 apresenta a arquitetura do SGEoL, destacando a integração entre os diversos componentesdo Fiware, disponibilizados no formato de GE’s. Os componentes sombreados em cinza correspondemaos GEs que serão implantados. Para atender aos requisitos de segurança a aplicação utiliza os GEsFiware KeyRock, PEP_Proxy, e o AuthZForce. Os demais GEs são relacionados a captura de dados desensores IoT (IOT GEs), informações de contexto (Orion Context Broker), armazenamento e visualiza-ção de dados (CKan), e desenvolvimento de front-ends Web (WireCloud).
Após realizado o levantamento de todos os GE’s requeridos para o funcionamento do SGeOL, a equipepassou para a fase de buscar imagens Docker já existentes dos GE’s em questão. O projeto Fiware dispo-nibiliza imagens Docker oficiais para os principais GE’s. Para alguns outros utilizamos GE’s desenvol-vidas pela comunidade.
A seguir serão listados os repositórios com os códigos utilizados durante o desenvolvimento das ima-gens dos GE’s:
• AuthZForce: https://github.com/authzforce/fiware/tree/master/docker
• CKAN: https://github.com/okfn/docker-fiware-ckan
• KeyRock:: https://github.com/ging/fiware-idm
• PEPProxy: https://github.com/ging/fiware-pep-proxy
• Orion: https://github.com/telefonicaid/fiware-orion
• IoT-Broker: https://github.com/Aeronbroker/Aeron/tree/master/docker
• IoT-Discovery: https://github.com/UniSurreyIoT/fiware-iot-discovery-ngsi9/
• WireCloud: https://github.com/Wirecloud/docker-wirecloud
Estas imagens serão utilizadas como base para o desenvolvimento de imagens personalizadas, quandonecessário, que atendam às configurações e requisitos de nosso ambiente.

52
5.2 Arquitetura de Implantação
O projeto SGeOL utiliza diversos GE’s conforme apresentado nas seções anteriores. De forma a integraresses GEs, utilizamos o Docker-Compose, onde os containers e seus respectivos serviços, portas, links edemais particularidades são definidos em um arquivo de configurações declarativas docker-compose.yml.O repositório do projeto SGeOL-Docker está disponível no GitLab do IMD. 24
Para validar o trabalho realizado com containers junto com a equipe de desenvolvimento do SGEoLutilizamos três máquinas virtuais (VM’s) sediadas no Datacenter do IMD. As VM têm as seguintesespecificações:
• CPU: 2.6 GHz (2 cores)
• RAM: 4GB
• Disco: 20 GB (o disco dispõe de mais 50GB reservados para expansão via LVM)
• Sistema Operacional: Ubuntu 14.04.3 LTS (x64)
• Endereços IPv4 (por VM): 10.7.31.28 / 10.7.31.29 / 10.7.31.32
A 42 apresenta a distribuição dos diversos GEs entre esses três servidores.
Figura 42: Arquitetura dos containers do SGeOL
Na VM Containers Server (10.7.31.28) foi efetuado a instalação do Docker-compose seguindo osprocedimentos já apresentados em seções anteriores deste documento. Em seguida foi realizado o clonedo projeto SGEoL-Docker, e por fim o build e inicialização dos containers utilizando o comando docker-compose up -d.
A configuração padrão do Docker cria uma sub-rede específica para os containers (172.17.0.0/16).Cada container tem seu próprio IP pertencente a esse sub-rede, que por padrão é acessível apenas para oservidor (host) onde se encontra o Docker, portanto os serviços fornecidos pelos containers só poderãoser acessados externamente se durante sua especificação (arquivo Dockerfile ou no docker-compose.yml)as portas forem definidas como EXPOSE.
Na VM SGeOL Server (10.7.31.29) foi instalado o Tomcat implantado o SGeOL.Para integrar os GE’s envolvidos no projeto SGeOL foi criado um docker-compose.yml especificando
detalhes sobre cada serviço, tais como nome do serviço, local da imagem no Docker Hub, portas TCPutilizadas, link’s entre outras GE’s, etc. Tirando os GEs Keyrockk, AuthZForce e PEP Wilma, todos os
24http://projetos.imd.ufrn.br/SmartMetropolis-InfraestruturaGroup/SGeoL-Docker

53
GEs foram utilizados a partir de sua imagem padrão, sem necessitarem de qualquer alteração para seufuncionamento.
Entretanto, no momento de integrar o PEP_Proxy com o IdM KeyRock e o PDP AuthZForce nosdeparamos com o primeiro problema: como alterar dinamicamente os parâmetros de configuração doPEP para que o mesmo pudesse comunicar via IP/porta com os GE’s do KeyRock e AuthZForce? Apósdiversas pesquisas e testes observamos que ao integrar um container com outro usando o parâmetro"link"o Docker passa a resolver o IP dos containers apartir do nome dos mesmos.
Para facilitar a compreensão serão destacados trechos do docker-compose.yml do projeto SGeOLenvolvendo os containers do PEP_Proxy, KeyRock e AuthZForce.
6 a u t h z f o r c e :7 image : f i w a r e / a u t h z f o r c e −ce−s e r v e r : r e l e a s e −5 .4 .18 hostname : a u t h z f o r c e9 c o n t a i n e r _ n a m e : a u t h z f o r c e
10 expose :11 − "8080"12
13 keyrock :14 image : f i w a r e / idm : v5 . 3 . 015 hostname : key rock16 c o n t a i n e r _ n a m e : key rock17 expose :18 − "5000"19 − "8000"20 p o r t s :21 − "5 00 0 : 50 00 "22 − "8 00 0 : 80 00 "23
24 pepproxy :25 b u i l d : Docker / f i w a r e−pep−proxy26 hostname : pepproxy27 c o n t a i n e r _ n a m e : pepproxy28 expose :29 − "80"30 l i n k s :31 − a u t h z f o r c e32 − keyrock
Procedimento 34: Trecho do Docker-Compose.yml envolvendo PEP, PDP e IDM
Ao acessar o shell do PEP_Proxy (docker exec -it pepproxy /bin/bash) e efetuar um ping para osnomes "authzforce"e "keyrock"percebemos que o Docker resolve o IP dos mesmos (o Docker atualizao /etc/hosts dinamicamente a cada inicialização do container). Caso os containers sejam reiniciados épossível que esses IP’s mudem, e consequentemente a resolução de nomes apontará para os novos IP’s.
Superados os problemas envolvendo a comunicação entre os containers dos GE’s, nos deparamos comum outro problema, a imagem do PEP traz um config.js de exemplo, mas esse precisa ser atualizadodurante a inicialização do container para que possa apontar para os GE’s do IdM e PDP.
Para sanar esse problema decidimos criar uma imagem personalizada do PEP_Proxy, que utiliza aimagem ging/fiware-pep-proxy como referência, e estende novas funcionalidades, tais como inserção deum config.js personalizado, e facilitando futuras modificações para adequar os GE’s para atender aosrequisitos do projeto. No docker-compose.yml essa alteração é refletida no uso da instrução build em vezde image. A instrução image informa ao Docker que o mesmo deve procurar essa imagem no Docker

54
Hub, já no caso da instrução build o Docker vai procurar em um diretório dentro do próprio projeto, quenesse caso é o diretório Docker/fiware-pep-proxy. Neste diretório há um arquivo Dockerfile, que utilizaa imagem do PEP do DockerHub como base (instrução FROM, no entanto as demais instruções inseremnovos comportamentos (ADD é utilizado para copiar o config.js já previamente configurado no diretóriodo PEP-Proxy).
Durante a evolução do projeto outras imagens podem necessitar de customizações. Para facilitar essegerenciamento optamos por criar um sub-diretório no repositório SGeOL-Docker denominado Docker, edentro dele outros sub-diretórios para cada imagem a ser personalizada. Esses sub-diretórios das imagenscontém um arquivo Dockerfile com a especificação da imagem.
5.3 Discussão
No contexto do projeto SGeOL, os testes realizados com containers até o momento foram focados emfacilitar o deploy dos GE’s utilizados pela aplicação. O Docker-Compose se mostrou uma ferramentabastante útil para gerenciar o ciclo de vida de um grande número de containers. Conforme apresentado,com apenas um comando todos os containers dos GE’s do Fiware utilizados nesse teste efetuaram as eta-pas de download da imagem, construção dos containers, links entre os mesmos, portas a serem expostas,e por fim as instâncias foram iniciadas na ordem correta.
Entretanto, para uso em ambientes de produção se faz necessário a utilização de ferramentas e técnicas,tais como cluster computacional, que permitam que a carga seja distribuída entre diversos nós, resultandoem uma maior disponibilidade para o ambiente.
Como sugestão para as próximas ações, recomendamos que sejam avaliadas soluções de cluster paracontainers (ex.: Kubernetes, Docker-Swarm, etc.), como também os ajustes necessários para adequar osGE’s para executar nesses ambientes.
6 Considerações Finais
Este documento apresentou um relato das atividades realizadas durante o terceiro trimestre de execucaodo projeto Smart Metropolis por parte do WP4 - Infraestrutura, no âmbito da tarefa de Desenvolvimento,implantação e operação de infraestrutura computacional.
Ao longo do terceiro trimestre a equipe do WP focou principalmente em atender aos seguintes objeti-vos:
• Implantação de instância Fiware de produção.
• Estudos sobre implantação de GEs em ambiente de produção.
• Estudo sobre ambientes de gerenciamento de containers.
• Implantação de um ambiente de desenvolvimento para a aplicação SGeoL
Devido a alta complexidade apresentada pelo processo de implantação do Fiware, tal processo foidividido em duas etapas: (I) Implantação da nuvem OpenStack e (II) a implantação de GEs.
A implantação da nuvem OpenStack foi de responsabilidade de Hiago Miguel, e foi concluída comsucesso. A nuvem se encontra atualmente em funcionamento, oferecendo o conjunto de serviços descritospelo capítulo técnico de Cloud hosting do Fiware (serviços de IaaS da plataforma OpenStack), porém,por estar sendo utilizada para outros testes de implantação, teve que ser reinstalada algumas vezes, o quefez com que ela não tenha sido disponibilizada para uso.

55
Dentre as dificuldades encontradas, podemos salientar problemas apresentados por um dos servidoresfísicos disponíveis para a nuvem (o referido problema foi sanado ao atualizar a BIOS do servidor), eproblemas em utilizar uma das lâminas disponibilizadas ao projeto pelo Datacenter do IMD. Esses doiscasos foram resolvidos, mas tomaram um tempo considerável da equipe. Outro problema enfrentado sedeve a uma falha no fornecimento de energia do Datacenter do IMD, que acarretou o corrompimento dosdados de um dos servidores.
Neste sentido, os próximos passos consideram aspectos relacionados a planejamento de recuperaçãoem caso de disastre (disaster recovery) na infraestrutura.
No tocante ao Estudo sobre implantação de GEs em ambiente de produção, Foram realizados estudose testes com a implantação das seguintes GEs: Keyrock (conduzida por Hiago Miguel), AuthZForce(conduzida por Welkson de Medeiros )e Orion (conduzida por Rafael Varela). Em busca de melhorespráticas a serem adotadas em um ambiente de produção, foram feitos testes com as diversas formasde instalação sugeridas na documentação oficial de cada GE. A GE Orion apresentou problemas em seufuncionamento quando da instalação manual, enquanto que todas as GEs foram implantadas com sucessoutilizando-se do ambiente de containers Docker. Entretanto, testes envolvendo a implantação destas GEsusando a ferramenta Fuel não puderam ser concluídos.
As dificuldades encontradas nesta atividade envolvem problemas de resolução de dependencias na ins-talação de GEs (Orion), bugs encontrados em algumas GEs (Keyrock e AuthZForce), e a prioridade paraoutras tarefas (resolução de problemas com a infraestrutura de nuvem, e implantação de infraestruturapara o SGeoL) que acabaram por afetar o andamento desta atividade.
Os próximos passos envolvem a finalização de testes com a ferramenta Fuel na infraestrutura do pro-jeto com o Keyrock, além de estudos mais aprofundados em outras GEs que serão utilizadas por membrosdo projeto.
A Implantação de Infraestrutura de suporte para a Aplicação SGeoL visa atender a uma demanda dosWPs de Aplicação e Middleware, que iniciaram o desenvolvimento de uma aplicação que visa atenderdemandas da prefeitura municipal do Natal (Smart Geo Layers - SGeoL). Essa infraestrutura envolvedivesos GEs que precisaram ser configurados e integrados em um ambiente de fácil implantação, e re-cuperação em caso de problemas. Para atender a esta demanda, inicialmente foram deslocados HiagoMiguel e Welkson de Medeiros, que ficaram responsáveis pelo planejamento da arquitetura de implan-tação. Em seguida, Welkson de Medeiros tomou a frente desta tarefa, tendo concluído com sucesso aimplantação de tal ambiente.
As dificuldades referente a esta tarefa dizem respeito ao uso de diversos GEs Fiware em containersDocker, com os quais a equipe ainda não tinha tido contato. Esses problemas foram solucionados graçasao estudo sobre ambiente de containers Docker. Como próximos passos, indicamos o acompanhamentoda equipe de desenvolvimente do SGeoL no uso do ambiente, na expectativa de fornecer subsídios quepossam ser incorporados à implantação e operação do ambiente de produção.
As atividades relacionadas a ambientes de gerenciamento de containers foram conduzida por Welksonde Medeiros, com o apoio de Gabriela da Silva. Esta tarefa foi concluída com sucesso, resultando emum conjunto de instruções que permitiram o avanço com outras tarefas do grupo. As dificuldades encon-tradas dizem respeito a questões relacionadas a instalação do ambiente, e seu uso para a implantação deaplicações baseada em múltiplos componentes distribuídos.
Os próximos passos em relação a esta tarefa consistem em estudos em ferramentas que dêem suportea alta-disponibilidade em ambientes baseado em containers, tal como Kubernetes e docker-swarm, e suaintegração com uma nuvem OpenStack.

56
Referências
[1] da Silva, C. E.; da Silva Solino, A. L.; de Freitas Junior, A. A. & da Penha Lourenço, R.S. Projeto SmartMetropolis: Requisitos de Infraestrutura para Suporte ao FIWARE, Dispo-nível em http://smartmetropolis.imd.ufrn.br/wp-content/uploads/2016/
05/RT1-WP4_Requisitos.pdf, IMD/UFRN, 2016
[2] da Silva, C. E.; de Souza, W. S.; da Rocha Neto, A. F.; da Silva, I. M. D.; Silva, L. W. P.; Clemente,R. P.; Varela, R.; da Penha Lourenço, R. S.; de Freitas, T. A.; da Silva Diniz, T. F. & da SilvaRodrigues, H. M. Projeto SmartMetropolis: Relatório de Atividades do Segundo Trimestre, Dispo-nível em http://smartmetropolis.imd.ufrn.br/wp-content/uploads/2016/
08/RT2-WP4-infra.pdf, IMD/UFRN, 2016.
[3] Ferramenta Fuel, Disponível em https://wiki.openstack.org/wiki/Fuel, acessadoem 31/10/2016.
[4] Kernel-based Virtual Machine, Disponível em http://www.linux-kvm.org/, acessado em31/10/2016.
[5] Ceph Object Gateway, Disponível em http://docs.ceph.com/docs/jewel/radosgw/,acessado em 31/10/2016.
[6] Logical Volume Management, Disponível em https://wiki.ubuntu.com/Lvm, acessadoem 31/10/2016.
[7] FIWARE Lab Nodes Handbook, Disponível em http://wiki.fiware.org/FIWARE_Lab_
Nodes_Handbook, acessado em 31/10/2016.
[8] Documentação Docker, Disponível em http://docs.docker.com/, acessado em31/10/2016.

Universidade Federal do Rio Grande do Norte Instituto Metrópole Digital
Projeto SmartMetropolis WP4 – Infraestrutura
Smart HotSpot
Relatório de Atividades T3
NatalRN, Brasil Outubro/2016

1
Equipe Técnica Docentes Prof. MSc. Aluizio Ferreira da Rocha Neto IMD/UFRN Discentes Rafael Pereira Clemente Ramon Santos Malaquias Thais Alves de Freitas

2
SUMÁRIO
1 Introdução 4
2 Sensoriamento 4 2.1 Sistema de monitoramento interno 4 2.2 Equipamentos utilizados 4
2.2.1 Sensor de Gás MQ2 Inflamável e Fumaça 4 2.2.2 Sensor de luminosidade 5 2.2.3 Sensor de temperatura e umidade DHT22 6 2.2.4 Plataforma computacional BeagleBone Black 7
3 Monitoramento 8 3.1 Plataformas Guardião Cloud e ThingSpeak.com 8 3.2 Sistema de Gerenciamento PoleManager 9
4 Estrutura 14 4.1 Dimensionamento de cabos e conexões 14 4.2 Instalação do protótipo 16
5 Redes 16 5.1 Descrição 16 5.2 Topologia de Rede 17
5.2.1 Protocolos de Roteamento 18
6 Conclusões 19
7 Referências 19

3
1 Introdução
Este é o terceiro relatório do projeto do Smart Hotspot, solução de poste autonômico como plataforma de conectividade, sensoriamento e monitoramento por câmeras para cidades inteligentes.
Nesta etapa do projeto, tevese como objetivo o aperfeiçoamento do poste, no que diz
respeito a sua estrutura, bem como o seu funcionamento. Foi feito um sistema de monitoramento interno do poste, baseado em sensores, bem como estudos sobre plataformas de gerenciamento com a criação de um software próprio capaz de realizar a administração da solução e coleta dos dados. Além disso, realizaramse estudos a fim de determinar a topologia de rede a ser aplicada.
2 Sensoriamento
2.1 Sistema de monitoramento interno
Nesta parte do projeto, desenvolvemos um sistema de sensoriamento para a parte interna da caixa de acomodação dos equipamentos indoor, a fim de garantir segurança e confiabilidade na sua utilização. Continuando o que tinha sido iniciado na etapa anterior, foi acrescentado a este sistema o sensor de gás e fumaça MQ2, sensor de umidade e temperatura DHT22 e um sensor de luminosidade, os quais serão detalhados na seção seguinte.
O sistema de sensoriamento será acoplado em uma caixa impressa em 3d, que suporta diversas condições de temperatura e ambiente. O objetivo desta montagem foi usar os sensores de gás e fumaça e o de umidade e temperatura para evitar danos espontâneos, devido a clima e ambiente com altas temperaturas, e o sensor de luminosidade controlará os momento de abertura da caixa, sendo enviada uma notificação ao sistema toda vez que a caixa for verificada.
2.2 Equipamentos utilizados
2.2.1 Sensor de Gás MQ2 Inflamável e Fumaça
O sensor de gás inflamável e fumaça MQ2, visto na Figura 1, é capaz de detectar concentrações de gases combustíveis como GLP, metano, propano, butano, hidrogênio, álcool e gás natural e fumaça no ar de forma confiável e simples.

4
Quando a concentração de gases fica acima do nível ajustado pelo potenciômetro, a saída digital D0, fica em estado alto, e se abaixo do nível, fica em estado baixo e para ter uma noção melhor da concentração, foi usada sua saída analógica A0 e conectada a um conversor AD no microcontrolador.
Figura 1 : Sensor de Gás MQ2.
Especificações:
Tensão de operação: 5v Sensibilidade ajustável por potenciômetro Comparador LM393 LED indicador para tensão LED indicador para saída digital Dimensões 32 x 20 x 15mm
Pinagem
Saída analógica(A0) Saída digital(D0) GND: GND VCC: 5V
2.2.2 Sensor de luminosidade
O sensor LDR ( Light Dependent Resistor ) é um componente cuja resistência varia de acordo com a intensidade da luz. Quanto mais luz incidir sobre o componente, menor a resistência. A Figura 2 exibe uma foto deste sensor.
Figura 2 : Sensor LDR GL5528.
Especificações:
Modelo: GL5528

5
Diâmetro: 5mm Tensão máxima: 150VDC Potência máxima: 100mW Tensão de operação: 30ªC a 70ªC Espectro: 540mm Comprimento com terminais: 32mm Resistência no Escuro: 1 Mohm Resistência na luz: 1020komh
2.2.3 Sensor de temperatura e umidade DHT22
O sensor DHT22 é um sensor de temperatura e umidade que permite fazer leituras entre 40 a 80 graus e umidade de 0 a 100%. A Figura 3 mostra uma foto deste sensor.
Figura 3 : Sensor DHT22.
O modelo AM2302 deste sensor é compatível com os modelos DHT22AM2303 e é
formado por um sensor de umidade capacitivo e um termistor para medir as condições do ar ao redor, enviando no pino de dados um sinal digital, não sendo necessários pinos analógicos.
Especificações:
Modelo: AM2302 Tensão de operação: 35VDC [5,5VDC máximo] Faixa de medição de umidade:0 a 100% UR Faixa de medição de temperatura: 40º a +80ºC Corrente: 2,5mA max. durante uso, em stand by de 100uA A 150uA Precisão de umidade de medição: +\ 2,0% UR Precisão de medição de temperatura:: +\ 0,5ºC Resolução: 0,1 Tempo de resposta: 2s Dimensões: 25x 15x 7 mm(sem terminais)

6
2.2.4 Plataforma computacional BeagleBone Black A BeagleBoard é um computador de placa única desenvolvido pela Texas Instruments
e classificada como hardware livre sob a licença Creative Commons SharedAlike. O modelo BeagleBone Black é considerada uma plataforma de desenvolvimento Linux de baixo custo, acessível a qualquer pessoa mesmo com baixo nível de conhecimento em openhardware. A Figura 4 mostra uma foto da placa utilizada.
Figura 4 : Computador BeagleBone Black.
Especificações:
Processador AM335x 1GHz ARM® CortexA8 512MB DDR3 RAM 4GB 8bit eMMC onboard flash storage 3D graphics accelerator NEON floatingpoint accelerator 2x PRU 32bit microcontrollers Connectivity: USB client for power & communications, USB host, Ethernet, HDMI e 92
pinos de E/S. Softwares compatíveis:Debian, Android, Ubuntu, IDE Cloud9 em Node.js com a
biblioteca BoneScript.
A interação entre os sensores e o Linux foi feita aproveitando o máximo de praticidade oferecida pela plataforma de desenvolvimento Cloud9, já préinstalada e disponível nesta placa. Foi utilizada a linguagem Python para esta interação com os sensores.
A alimentação da BeagleBone, que por sua vez alimenta todos os sensores, foi feita
através das baterias do poste, usando o conversor de 12V 5A para 5V em porta USB, mostrado na Figura 5. Esta saída de 5V em porta USB facilitou a ligação da BeagleBone, pois foi utilizado o próprio cabo USB para a sua alimentação.

7
Figura 5 : Conversor 12V para 5V em portas USB.
3 Monitoramento
3.1 Plataformas Guardião Cloud e ThingSpeak.com
Com o intuito de realizar os primeiros testes de coleta e tratamento dos dados, foi analisada algumas plataformas de nuvem para IoT ( Internet of Things ) que fornecessem tais serviços, enquanto a plataforma de middleware de IoT do projeto ainda não estivesse disponível. As plataformas analisadas foram a Guardião Cloud System ( http://www.guardiaocloud.com.br/ ) da Web One System e a Thing Speak ( https://thingspeak.com ) da MathWorks, fabricante do software MATLAB.
Ambas as plataformas permitem a rápida geração de gráficos sobre os dados coletados e possuem conectividade com os dispositivos via Internet usando o protocolo HTTP REST. A plataforma testada com o sistema de sensoriamento foi a ThingSpeak (Figura 6). O uso da ThingSpeak serviu para as primeiras visualizações dos dados coletados através de gráficos estatísticos e testes de conectividade da BeagleBone. Contudo, os testes serão em breve substituídos pela plataforma de IoT do projeto.
Figura 6: Canal criado na plataforma ThingSpeak para o Smart HotSpot.

8
3.2 Sistema de Gerenciamento PoleManager O gerenciamento e controle dos postes deverá ser realizado através de um sistema
web de fácil utilização. Tal sistema deve fornecer meios para que o usuário possa monitorar o estado dos postes, ter acesso às informações e dados coletados por ele através dos sensores e mostrar o estado da bateria de cada poste, assim como acessar a Câmera IP e monitorar o estado de todos os equipamentos nele instalados.
A ideia de implementação de um sistema de gerenciamento surgiu da necessidade de
se ter acesso fácil aos dados coletados pelos postes, a fim de transformálos em informações que possam ser úteis à seus usuários. Dessa forma, concluise que seria mais interessante implementar uma ferramenta que pudesse reunir em apenas um lugar todas as funcionalidades do produto, facilitando o acesso e controle dos aparelhos presentes no poste, por parte do usuário final.
O desenvolvimento da aplicação está sendo baseado na linguagem Java, através do
Java EE (Java Enterprise Edition), que tem a sua interface de usuário baseada no Java Server Faces (JSF), uma especificação Java para construção de interfaces de usuário com base em componentes para aplicações Web. Além disso, é utilizado também o Primefaces, um Framework opensource para projetos JSF.
Com o objetivo de simplificar a programação com Java, está sendo utilizado o Spring
Framework, que traz consigo a possibilidade de injeção de dependências (CDI) através do módulo core, e um melhor controle transacional, integrado com o framework para realizar o mapeamento objeto relacional (ORM), que, neste caso, está sendo utilizado o Hibernate. Como Sistema Gerenciador de Banco de Dados Objeto Relacional (SGBDOR) está sendo utilizado o PostgreSQL.
Outro módulo do Spring Framework que também está sendo utilizado no
desenvolvimento do sistema é o Spring Security, que trata da segurança da aplicação, que é responsável pela autenticação do usuário e pelo controle de acesso ao sistema, cuidando dos papéis de cada usuário na utilização deste.
Toda a aplicação descrita acima é executada no Servidor de Aplicação Apache
Tomcat, um container de código aberto baseado em Java que foi desenvolvido para executar aplicações Web que utilizam tecnologias JavaServlet e JavaServer Pages (JSP).
Para o versionamento e repositório dos códigos do sistema está sendo utilizado um
repositório no Gitlab, que pode ser acessado através do link: https://gitlab.com/rsanttos/PoleManager .
Atualmente, o sistema conta com os CRUDs (Create, Read, Update e Delete) de Poste e de Usuário devidamente implementados. Além disso, a navegação após a realização do login se dá de acordo com o papel do usuário logado, administrador (ADMIN) ou usuário

9
(USER). Esse controle de acesso acontece em virtude das regras de negócio do sistema, que seguem abaixo:
Apenas o usuário administrador pode cadastrar ou desativar um usuário; Apenas o usuário administrador pode cadastrar ou deletar um poste; O usuário administrador tem acesso à listagem de todos os usuários cadastrados no
sistema, porém não pode alterar a senha destes; O usuário administrador tem acesso à listagem de todos os postes cadastrados no
sistema; O usuário administrador tem acesso à uma página de dashboard que mostra a
posição real em um mapa e a listagem de todos os postes cadastrados no sistema; O usuário "user" tem acesso à listagem de todos os postes cadastrados no sistema
que lhe pertencem; O usuário "user" tem acesso aos detalhes (situação da bateria, imagem da câmera,
dados do sensoriamento e do sinal de internet) de cada um dos postes cadastrados no sistema que lhe pertencem;
O usuário "user" tem acesso à uma página de dashboard que mostra a posição real em um mapa e a listagem de todos os postes cadastrados no sistema que lhe pertencem; Foram completamente implementadas as páginas de login (Figura 7), dashboard para
administrador (Figuras 8 e 9), dashboard para usuário (Figura 10 e 11), cadastro de usuário (Figura 12), listagem de usuários (figura 13), cadastro de postes (figura 14), listagem de todos os postes do sistema (figura 15), listagem dos postes de um usuário (figura 16) e página de detalhes de um poste (figura 17). Essa última se trata de uma página que irá expôr os dados coletados e referentes ao poste, tais como: estado da bateria, imagem da câmera IP, dados coletados pelo sensoriamento e informações sobre o sinal de internet que está sendo recebido e enviado pelas antenas do poste.
Figura 7: Tela de Login do PoleManager.

10
Figura 8: Tela de Dashboard para ADMIN do PoleManager (parte 1).
Figura 9: Tela de Dashboard para ADMIN do PoleManager (parte 2).
Figura 10: Tela de Dashboard para USER do PoleManager (parte 1).

11
Figura 11: Tela de Dashboard para USER do PoleManager (parte 2).
Figura 12: Tela de cadastro de usuário do PoleManager.
Figura 13: Tela de listagem de usuários do PoleManager.

12
Figura 14: Tela de cadastro de usuário do PoleManager.
Figura 15: Tela de listagem de todos os Postes do PoleManager.
Figura 16: Tela de listagem dos Postes de um usuário do PoleManager.

13
Figura 17: Tela do Poste de um usuário do PoleManager.
Para implementação do mapa, presente na página de dashboard apresentando a
localização real dos postes, foi utilizada a API (Application Programming Interface) do próprio Google Maps, baseada em Javascript, através do Plano Padrão (gratuito).
A página de detalhes de um poste está apenas estruturada e não mostra os dados
reais referentes a cada poste. A transmissão das imagens da Câmera IP não foi realizada pois de acordo com as pesquisas feitas, o modelo de Câmera IP utilizado não possui endereço público das imagens, impossibilitando, dessa forma, a transmissão do vídeo através de uma aplicação externa à câmera. No entanto, serão realizadas mais pesquisas a fim de encontrar uma forma de acessar as imagens utilizando a atual câmera. Os dados do sensoriamento e informações sobre o sinal de internet após ser coletados, deverão ser disponibilizados em uma plataforma de IoT (Internet of Things) e serão acessados através de um webservice que disponibilizará esses dados para serem acessados pela aplicação web.
Portanto, os próximos passos do desenvolvimento desta aplicação serão: 1. Transmitir o vídeo da câmera na página de detalhes de poste; 2. Desenvolver webservice para acessar e disponibilizar os dados do
sensoriamento e as informações sobre o sinal de internet;
4 Estrutura
4.1 Dimensionamento de cabos e conexões
O cabeamento presente na estrutura do poste foi feito de modo emergencial para os primeiros testes com a solução. A instalação foi realizada de forma simplificada mas, mesmo assim, foram obtidos resultados satisfatórios. Contudo, a forma com a qual a instalação se

14
dispõe, dificulta o manuseio e acompanhamento de toda a estrutura, como mostrado na figura 18.
Figura 18 : Dimensionamento dos cabos e conexões com as baterias do poste.
Tendo em vista as limitações trazidas pela instalação destes cabos, foi feita uma
análise com base na norma ABNT NBR 5410 aplicada a estas soluções para que fossem trocados os cabos que captam a alimentação da bateria. Esta Norma aplicase também às instalações elétricas:
em áreas descobertas das propriedades, externas às edificações; de reboques de acampamento (trailers), locais de acampamento (campings), marinas
e instalações análogas; de canteiros de obra, feiras, exposições e outras instalações temporárias; aos circuitos elétricos alimentados sob tensão nominal igual ou inferior a 1 000 V em
corrente alternada, com freqüências inferiores a 400 Hz, ou a 1 500 V em corrente contínua;
aos circuitos elétricos, que não os internos aos equipamentos, funcionando sob uma tensão superior a 1 000 V e alimentados através de uma instalação de tensão igual ou inferior a 1 000 V em corrente alternada (por exemplo, circuitos de lâmpadas a descarga, precipitadores eletrostáticos etc.);
a toda fiação e a toda linha elétrica que não sejam cobertas pelas normas relativas aos equipamentos de utilização; e
às linhas elétricas fixas de sinal (com exceção dos circuitos internos dos equipamentos).
Na próxima etapa do projeto é tido como objetivo realizar a instalação no poste em
tamanho real e realizar a montagem e especificação do dimensionamento, já para testes em campo a nível mais real possível.

15
4.2 Instalação do protótipo
Nesta etapa do projeto, o conjunto de peças que compõem o poste está sendo instalado no estacionamento do Instituto Metrópole Digital. Já foram escolhidas a base para as antenas, a base para o poste e o local de instalação para melhor aproveitamento das informações a fim de chegar a resultados mais realistas.
5 Redes
5.1 Descrição
Como o meio de transmissão em redes wireless se dá pelo ar, características como, alcance e velocidade variam bastantes, dependendo não apenas do tipo de antenas utilizadas e potência dos transmissores, como também dos obstáculos e interferências presentes no ambiente. Munidos destes conceitos iniciais, exploraremos alguns aspectos fundamentais, a serem aplicados em nosso contexto, para que obtenhase confiabilidade à rede Smart Hotspot .
A escolha da antena, seu tipo e qualidade, são importantes quando desejase criar
redes longas e de alto desempenho. As antenas têm como função primordial, propagar sinal pelo ambiente, irradiandoo em certa direção. As antenas escolhidas para conectar a torre principal ao nosso Smart Hotspot é do tipo dipole com chapa refletora, popularmente chamada de antena ou painel setorial.
Estas antenas setoriais concentram a transmissão em um ângulo menor, sendo 43° na
polaridade horizontal e 41° na polaridade vertical e, com grau de elevação na horizontal e vertical de 15°. Ou seja, o grau de abertura da antena permite determinar que outros equipamentos de rádio, instalados dentro do raio de alcance da antena, levandose em conta o ângulo de irradiação nas polarizações horizontal e vertical, possam estabelecer comunicação entre si. Enquanto o grau de elevação define, em altura, o posicionamento de ambos os equipamentos para que estabeleçase o enlace entre ambos os rádios.
Tomouse como base os equipamentos que compõem o protótipo e que estavam a
disposição para realização de testes e análises. Tais análises poderiam ter sido aplicadas a quaisquer equipamentos, desde que contemplem ajustes em suas configurações que permitam as condições descritas.
Quando um grande número de hosts estão interconectados, podem ocorrer
problemas, como por exemplo, congestionamento no tráfego e sobrecarga de recursos. Analisar os aspectos destas redes, a fim de otimizálas, são muito importantes, pois possibilita que mesmo às redes com alto número de transmissões, para que a infraestrutura que propomos, funcione bem, com desempenho satisfatório.

16
A partir disso e, tomando como base estudos feitos em nosso modelo, simulando um contexto de situação real, propõemse os seguintes aspectos para a rede Smart Hotspot .
5.2 Topologia de Rede
A topologia inicial pensada para a rede de postes, seria a mostrada como exemplo na Figura 19, a qual é chamada de pointtomultpoint . Nesta topologia, todo o acesso à Internet é fornecido por algum equipamento sem fio multiponto, usando antenas omnidirecionais, a todos os outros pontos, no caso os postes, com antenas setoriais ou direcionais apontando para o multiponto.
Figura 19 : Topologia pointtomultipoint da rede Smart Hotspot .
Utilizando esta topologia, ao propormos a construção de uma infraestrutura de
conectividade capaz de cobrir todo um espaço físico, seja pequeno ou grande, como por exemplo um campus universitário ou toda uma cidade, surgiram alguns problemas desafiadores: como capacidade de expansão da rede, custo de implantação e, principalmente, perda de conectividade com o ponto de provimento do acesso à toda a rede, já que ele é a queda do mesmo faz cair toda a rede.
Analisando estes e outros aspectos, foi proposta a adoção da topologia e protocolos de redes Mesh , na qual, os nós (dispositivos que encaminham pacotes entre as redes), criam uma malha sem fio para comunicação entre si através do padrão IEEE 802.11s. Em tais redes em malha, os pacotes são encaminhados até o destino através de múltiplos saltos por qualquer nó que compõe a rede. O conjunto de protocolos das redes mesh determinam, de forma automática, o melhor caminho pelo qual os pacotes devem passar antes de chegar ao destino final. A figura 20 mostra um exemplo genérico da topologia de uma rede mesh na qual, qualquer poste que tivesse à Internet poderá compartilhar este acesso com os outros postes.

17
Figura 20: Exemplo de topologia de rede wireless mesh metropolitana.
5.2.1 Protocolos de Roteamento
As questões de protocolos de roteamento, estão em pesquisas e em desenvolvimentos constantes para que atendam aos requisitos desta nova topologia. Por isso, os protocolos já existentes estão sendo estudados, a fim de encontrar o que melhor se adapte à nossa infraestrutura, com um direcionamento maior ao protocolo multicast , onde os pacotes provenientes do nó de origem são repassados a um grupo de nós destino. Os protocolos Multicast têm duas classificações: Tree Based e Mesh Based .
Tree Based: Existe um único caminho entre o nó de origem e o nó de destino, esses
protocolos são eficientes no fluxo de dados. A árvore de Multicast é uma característica principal desse protocolo (SANTOS et al., 2010).
Mesh Based: Ao contrário da Tree Based, Mesh Based possui múltiplos caminhos entre o nó de origem e nó de destino, portanto é mais robusta (SANTOS et al., 2010).
Os protocolos utilizados também podem ser PróAtivos, Reativos ou Híbridos. Os
Protocolos PróAtivos mantêm a constante atualização da rede, através do envio e recebimento de mensagens de controle, que são utilizadas para determinar os caminhos entre destino e origem. Um nó envia mensagens de controle, informando seu status de ativo na rede. Com essas informações, os nós calculam a sua tabela interna de roteamento utilizando métricas prédeterminadas pelo protocolo.
Os Protocolos Reativos criam caminhos apenas quando há necessidade que um nó origem inicie a comunicação com um nó destino. O nó origem descobre uma ou mais rotas da rede. Esse grupo de caminhos é avaliado para que se encontre a melhor entre elas.

18
Os Protocolos Híbridos contêm características de ambos os protocolos, PróAtivos e Reativos. Em uma rede em que os nós estão ativos, a tabela de roteamento precisa estar sempre atualizada. Porém os nós podem com o tempo ficarem menos ativos, passando a ser Reativo.
6 Conclusões
Os resultados alcançados até o momento para a solução do poste inteligente são bastante animadores, pois é possível observar que a proposta tem grande potencial de aplicabilidade e aceitação.
Como atividades para o próximo entregável, temos: Testes de uso da solução com a plataforma de IoT escolhida para o SmartMetropolis; Desenvolvimento de um protótipo de produto final para o sistema de sensoriamento
com BeagleBone; e Finalização do desenvolvimento do sistema de monitoramento e controle da solução.
7 Referências [1] BEAGLEBONE BLACK. Disponível em: <https://www.beagleboard.org/black/>. Acesso em: 18 de Outubro de 2016; [2] TANENBAUM, Andrew S; DAVID, Wetherall. Redes de Computadores. 5. ed. São Paulo: Pearson Prentice Hall, 2011. [3] MORIMOTO, Carlos Eduardo. Redes, guia prático: ampliada e atualizada . 2. ed. Porto Alegre: Sul Editores, 2011. [4] THINGSPEAK. Disponível em: <https:/www.thingspeak.com//>. Acesso em: 18 de Outubro de 2016.