qconsp16 - apache cassandra evoluindo sistemas distribuídos
TRANSCRIPT

EVOLUINDO SISTEMAS DISTRIBUÍDOS6 ANOS DE NoSQL DAS TRINCHEIRAS
Eiti KimuraFernando GonçalvesMAR 2016

QUEM SOMOS NÓS?

• Arquiteto de software e Coordenador de TI na Movile• Apache Cassandra Developer 1.1 Certified (2013)• Apache Cassandra MVP (2014 e 2015)• Apache Cassandra Contributor (2015)• Cassandra Summit Speaker (2014 e 2015)
Eiti Kimura
eitikimura

• Desenvolvedor na Movile• Estudante de Ciência da Computação na Unicamp
Fernando Gonçalves
fhsgoncalves

Sumário● INTRODUÇÃO
● CASOS DE USO
○ Plataforma de Tarifação e controle de assinaturas
○ Registro de dados de apps e envio de notificações push
● CONCLUSÃO
○ Problemas encontrados, lições aprendidas.

LÍDER EM DESENVOLVIMENTO DE PLATAFORMAS DE COMÉRCIO E CONTEÚDO MÓVEL NA AMÉRICA LATINA

A Movile é a empresa por trás das apps que fazem sua vida mais fácil!

O Melhor conteúdo para Crianças

Líder em delivery de comida no Brasil

A empresa registrou um crescimento anual de 80% nos últimos 6 anos.
80%

INTRODUÇÃO


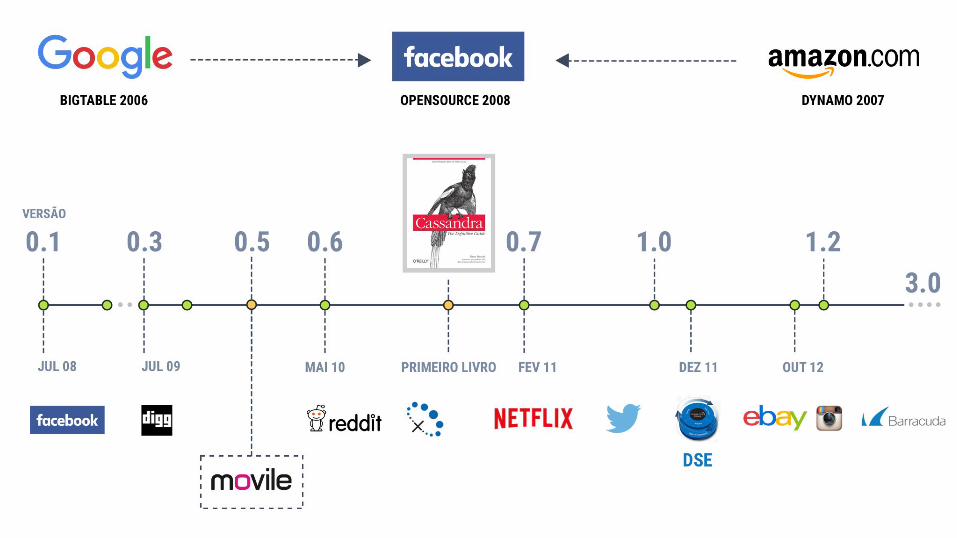
Apache Cassandra é um banco de dados não relacional (NoSQL) orientado a colunas, distribuído,
escalável, de alta disponibilidade, tolerante a falhas.
[The Definitive Guide, Eben Hewitt, 2010]


Controle de Assinaturas e Tarifações
• Composto de uma API de serviço;
• Responsável pelo gerenciamento de assinaturas de usuários;
• Cobrança dos usuários nas operadoras;
O serviço não pode parar de forma alguma e deve ser muito rápido.
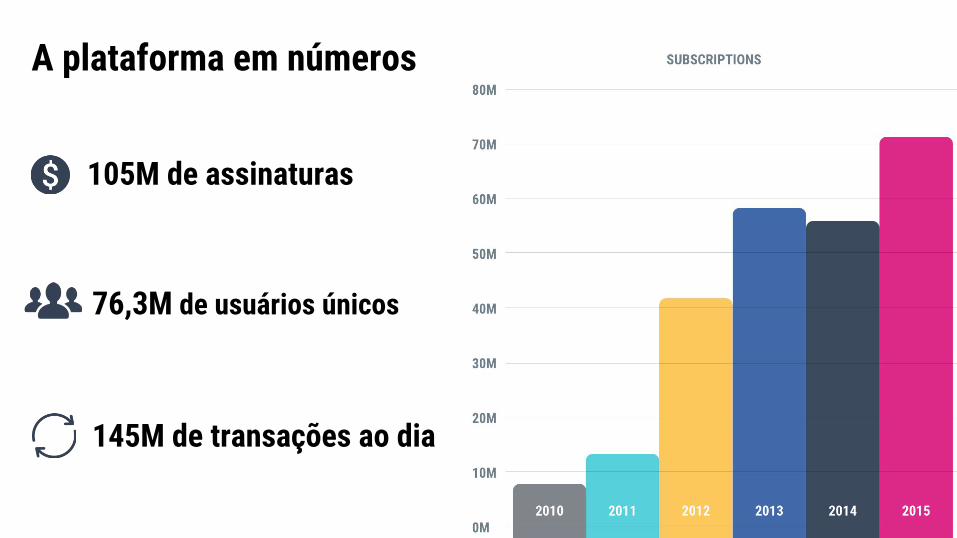
A plataforma em números
105M de assinaturas
76,3M de usuários únicos
145M de transações ao dia
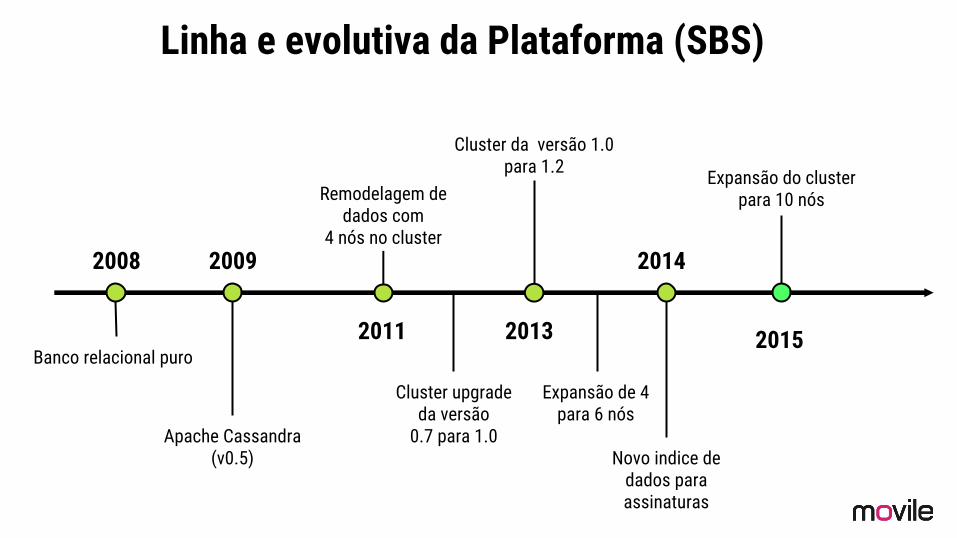
Linha e evolutiva da Plataforma (SBS)
2008
Banco relacional puro
2009
Apache Cassandra (v0.5)
2011
Remodelagem de dados com
4 nós no cluster
Cluster da versão 1.0 para 1.2
2013
Cluster upgrade da versão
0.7 para 1.0
Expansão de 4 para 6 nós
2014
Novo indice de dados para assinaturas
2015
Expansão do cluster para 10 nós

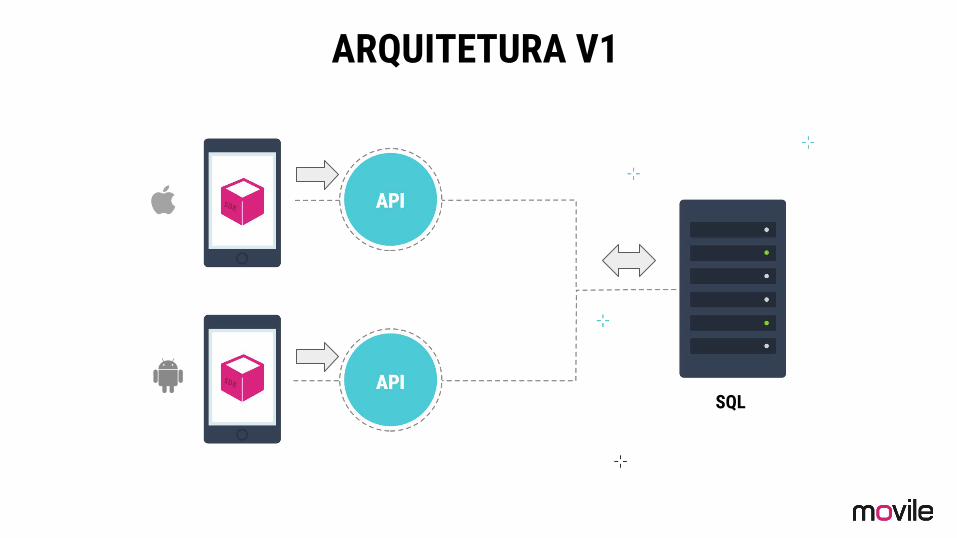
ARQUITETURA V1
API
DB
API APIAPI API
Engine
Engine Engine

Desvantagens da Arquitetura
• Ponto único de falha
• Tempos de resposta lentos
• Downtimes frequentes
• Caro e difícil para escalar
Escalar uma plataforma sem escalar as dependências externas resulta em falha.
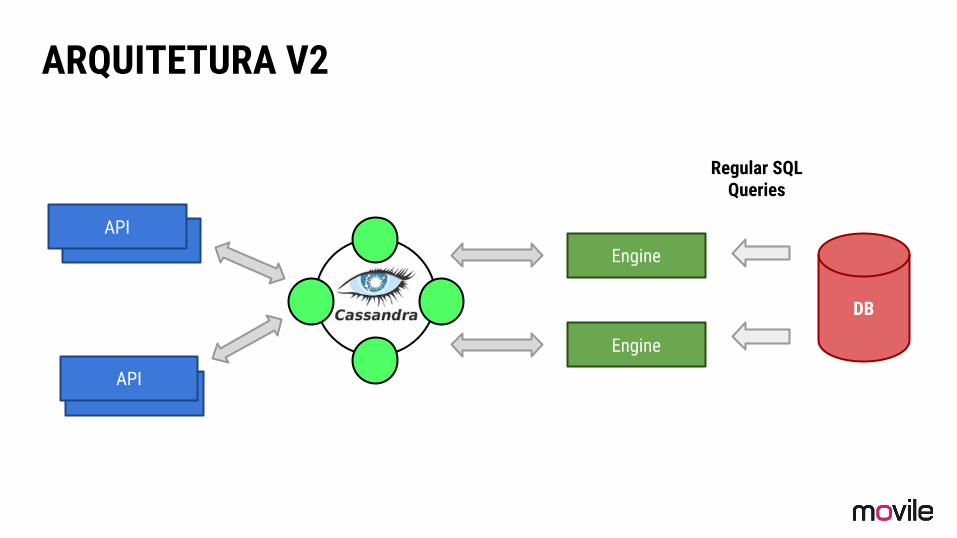
ARQUITETURA V2
APIAPI
Engine
Engine
DB
Regular SQLQueries
APIAPI

Benefícios da nova solução
❏ Problemas de desempenho: OK;
❏ Problemas de disponibilidade: OK;
❏ Ponto único de falha: Parcialmente Resolvido;
❏ Aumento significante no throughput de leitura e escrita;
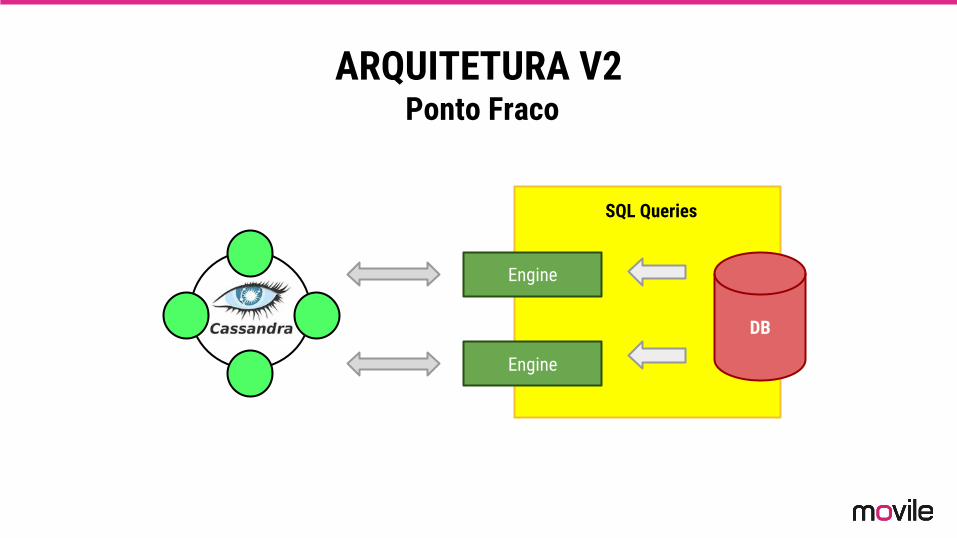
ARQUITETURA V2 Ponto Fraco
Engine
Engine
DB
SQL Queries

QUAIS SÃO OS PROBLEMAS?

Problemas na Arquitetura
Com o aumento da concorrência ocorre degradação de desempenho nas operações com o banco de dados relacional.
Consultas ao banco relacional podem consumir tempo
Continua com impacto na escalabilidade

Proposta de Evolução
➔ Extrair dados do Apache Cassandra ao invés do banco relacional;
➔ Sem ponto único de falha;
➔ Melhoria de desempenho, porém mais trabalho filtrando a informação;


BACKEND SERVICE

KIWI - BACKEND SERVICE
Foco em smartphones
Alta performance Alta disponibilidade
Analytics
Engajamento de usuário
Notificações por Push

40MTotal de instalações de apps
450MTotal de notificações push enviadas
Análise de dadosAlguns dados do Kiwi em 2015
20MTotal de configurações de usuários

NOSSO DESAFIONotificação por push
iOS ANDROID
ARQUITETURA V1
SQL
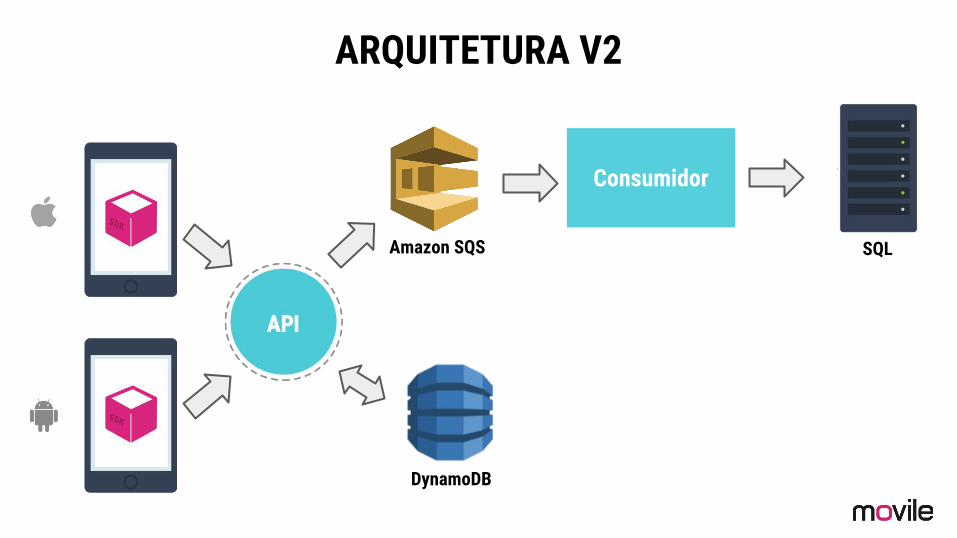
ARQUITETURA V2
Amazon SQS
DynamoDB
Consumidor
SQL
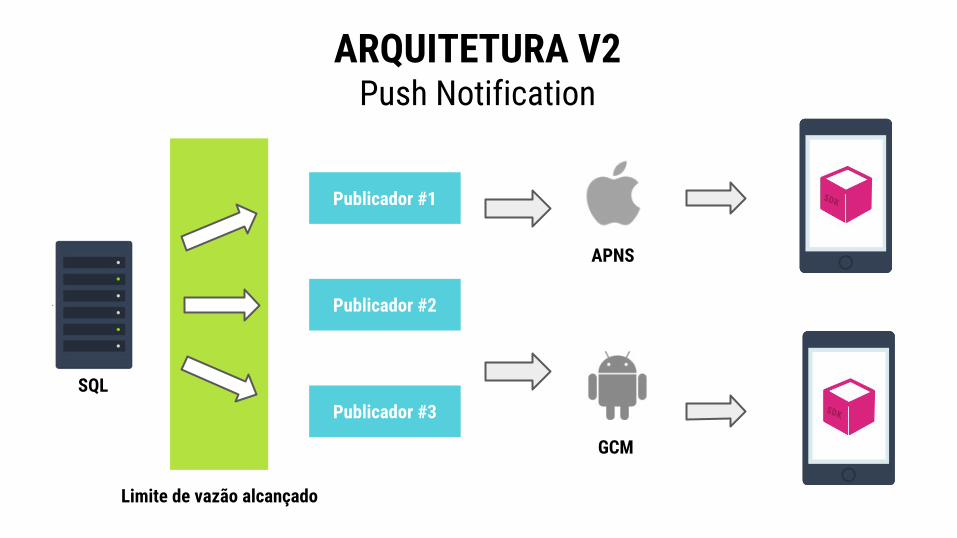
Publicador #1
Publicador #2
Publicador #3
Limite de vazão alcançado
APNS
GCM
SQL
ARQUITETURA V2 Push Notification

Problemas na Arquitetura
$$ Custos altos
Vazão de leitura muito baixaDynamoDB
Vazão de leitura atingidaSQL

Lentidão no envio de Notificações por Push
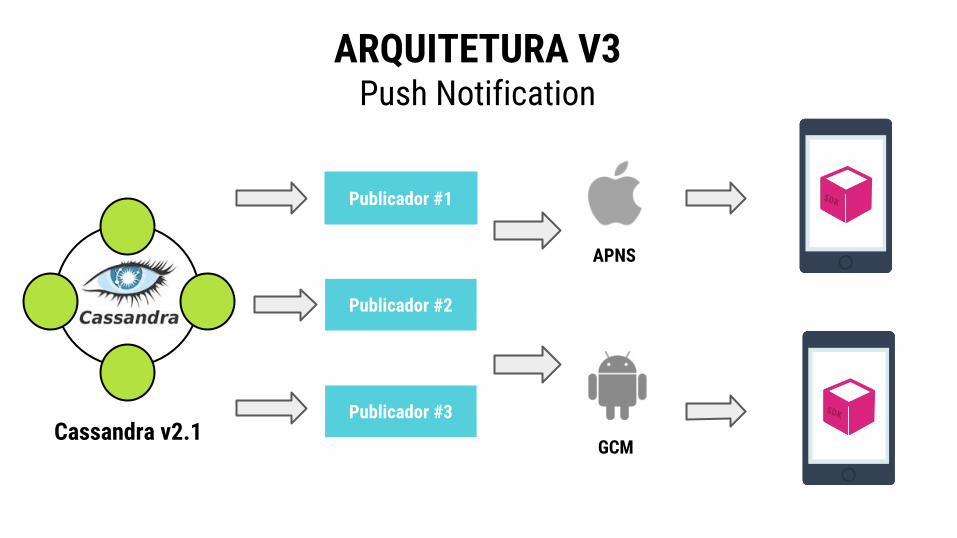
ARQUITETURA V3 Push Notification
Publicador #1
Publicador #2
Publicador #3
APNS
GCMCassandra v2.1

Mudanças no modelo
➔ Amazon DynamoDB◆ Objeto serializado com Avro◆ Poucas colunas
➔ Apache Cassandra ◆ Objeto explodido◆ Mais de 80 colunas sem serialização

US$ 10.825,00/mês
Vazão de leitura = ~ 12.000/s
PRÉ MIGRAÇÃO
Custo total da solução
Resultados
DynamoDB
+SQL

Resultados
US$ 2.580,00/mês
Vazão de leitura = ~ 200.000/s
PÓS MIGRAÇÃO
(8 nós c3.2xlarge)
77% DE ECONOMIA
17x VazãoCusto total da nova solução

Lições Aprendidas
O que deu errado

COLLECTIONS

Introdução a collections
map<type1, type2>
set<type1>
list<type1>Problema com
tombstones
http://bit.ly/cassandra-tombstones

Introdução a atualização de dados no Cassandra
sstables tombstones repair
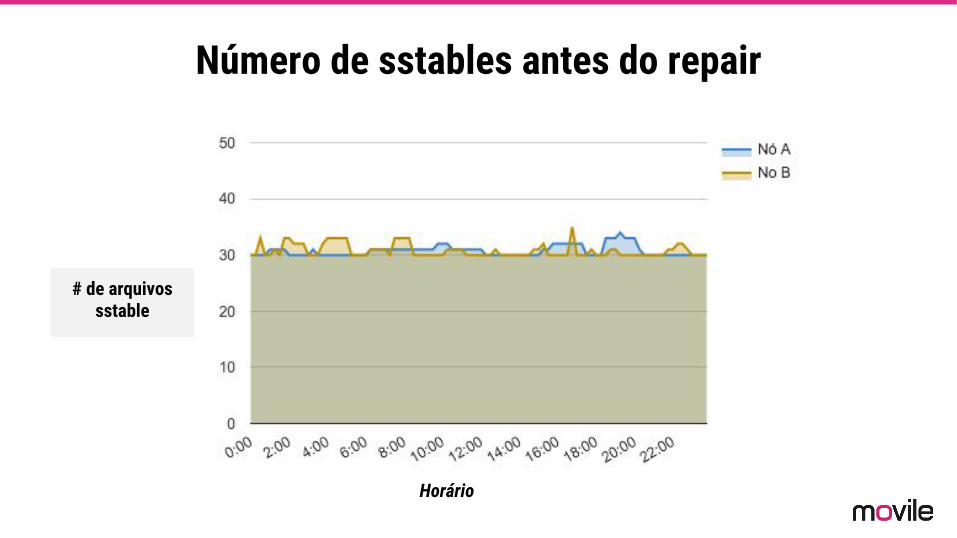
Número de sstables antes do repair
# de arquivos sstable
Horário
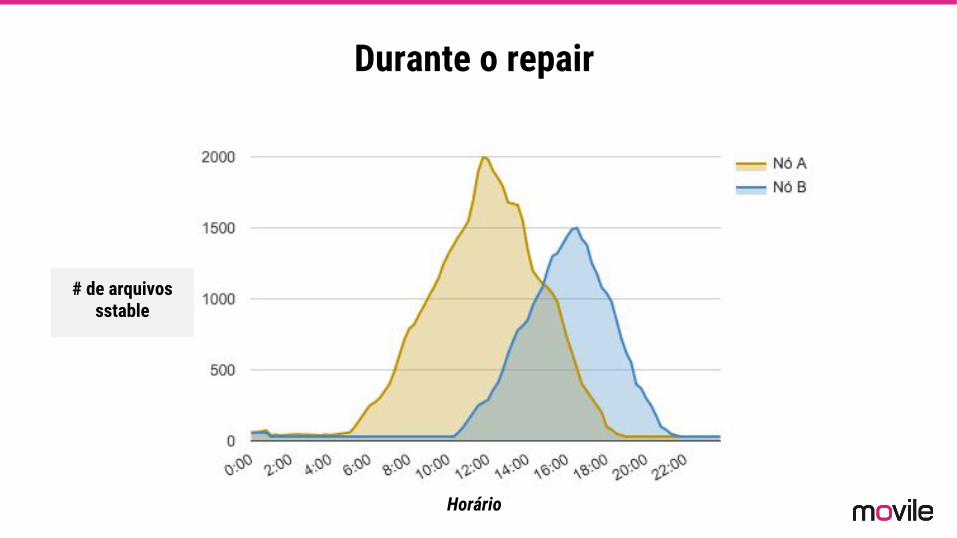
Durante o repair
Horário
# de arquivos sstable

Alteração do tipo de dados
Usando Collections Usando blob
cqlsh:test> CREATE TABLE teste_com_mapa( ... id int, ... mapa map<text, text> , ... PRIMARY KEY (id) );
cqlsh:test> CREATE TABLE teste_sem_mapa( ... id int, ... mapa blob, ... PRIMARY KEY (id) );
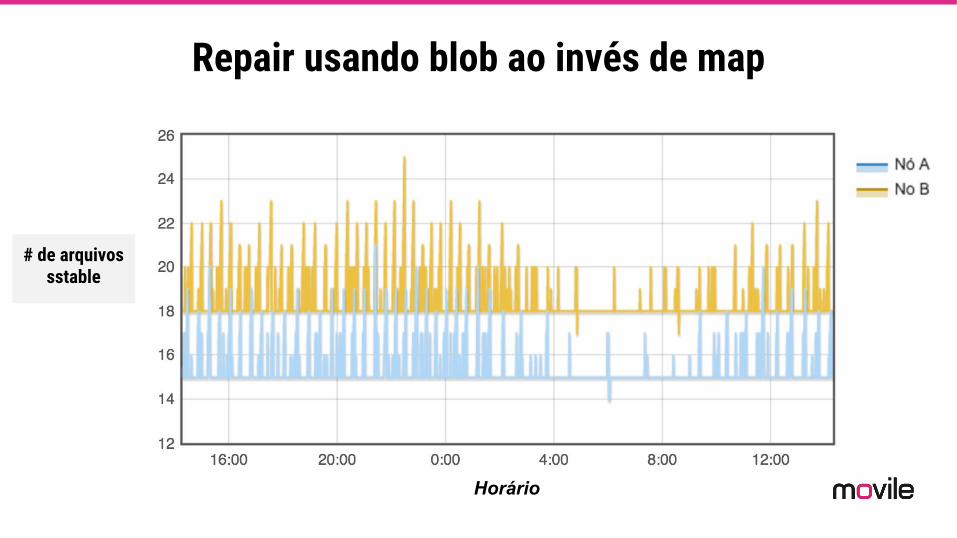
Repair usando blob ao invés de map
Horário
# de arquivos sstable

MANUTENÇÃO DO CLUSTER

Sobre adição de nós (Cassandra v2.1)
PARA NÃO PERDER DADOS:
1. Não adicionar em paralelo (ESPERAR BALANCEAR)
2. Rodar repair a cada adição
3. Consulte o procedimento no manual.
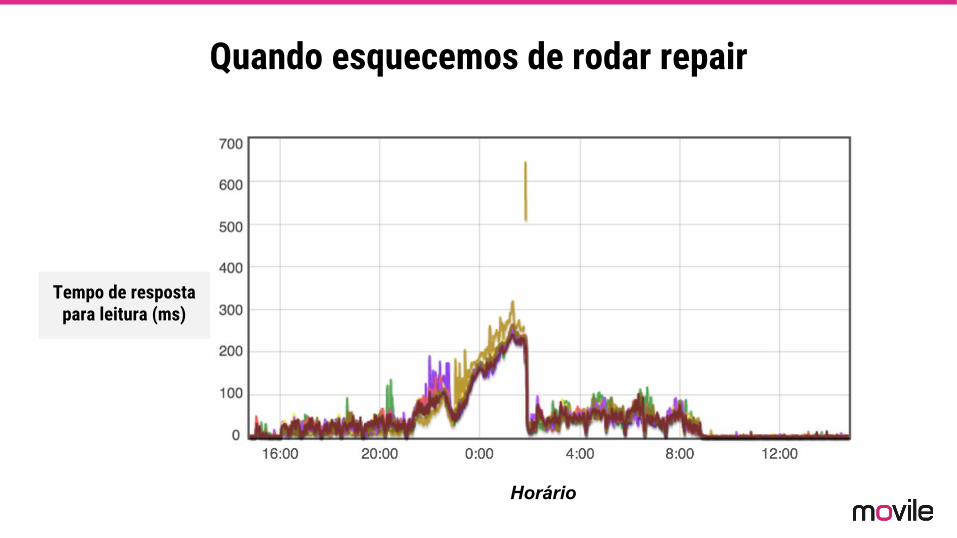
Quando esquecemos de rodar repair
Horário
Tempo de respostapara leitura (ms)

Lembre-se sempre...
AUTOMATIZAR
MONITORAR

HINTED HANDOFF
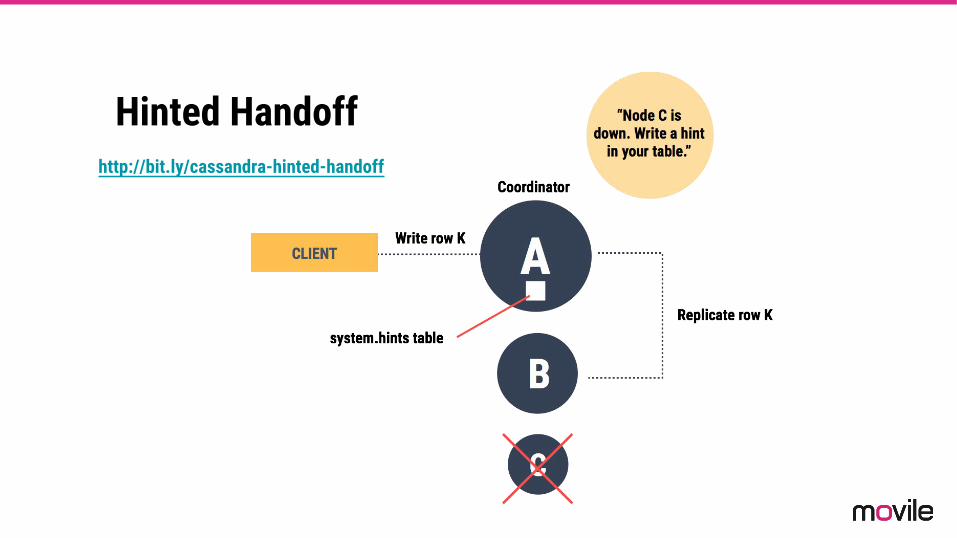
Hinted Handoffhttp://bit.ly/cassandra-hinted-handoff

Hinted Handoff
ERROR [HintedHandoff:1] 2015-08-31 18:31:55,600 CassandraDaemon.java:182 - Exception in thread Thread
[HintedHandoff:1,1,main]
java.lang.IndexOutOfBoundsException: null
at java.nio.Buffer.checkIndex(Buffer.java:538) ~[na:1.7.0_79]
at java.nio.HeapByteBuffer.getLong(HeapByteBuffer.java:410) ~[na:1.7.0_79]
at org.apache.cassandra.utils.UUIDGen.getUUID(UUIDGen.java:106) ~[apache-cassandra-2.2.0.jar:2.2.0]
at org.apache.cassandra.db.HintedHandOffManager.scheduleAllDeliveries(HintedHandOffManager.java:515)
~[apache-cassandra-2.2.0.jar:2.2.0]
at org.apache.cassandra.db.HintedHandOffManager.access$000(HintedHandOffManager.java:88) ~[apache-
cassandra-2.2.0.jar:2.2.0]
at org.apache.cassandra.db.HintedHandOffManager$1.run(HintedHandOffManager.java:168) ~[apache-
cassandra-2.2.0.jar:2.2.0]
at org.apache.cassandra.concurrent.DebuggableScheduledThreadPoolExecutor$UncomplainingRunnable.run
(DebuggableScheduledThreadPoolExecutor.java:118) ~[apache-cassandra-2.2.0.jar:2.2.0]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) [na:1.7.0_79]
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:304) [na:1.7.0_79]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThread)
CASSANDRA-10233 - IndexOutOfBoundsException in HintedHandOffManagerCASSANDRA-10485 - Missing host ID on hinted handoff write
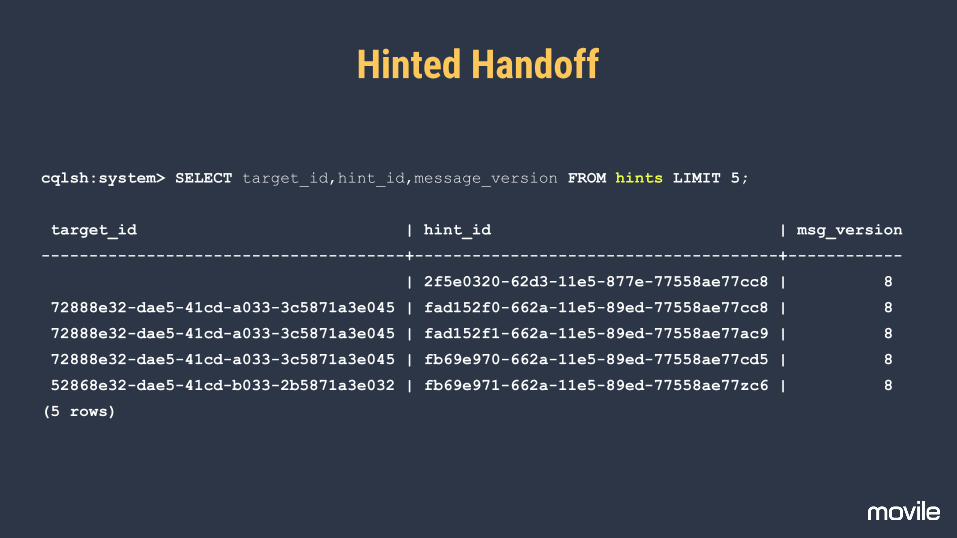
Hinted Handoff
cqlsh:system> SELECT target_id,hint_id,message_version FROM hints LIMIT 5;
target_id | hint_id | msg_version
--------------------------------------+--------------------------------------+------------
| 2f5e0320-62d3-11e5-877e-77558ae77cc8 | 8
72888e32-dae5-41cd-a033-3c5871a3e045 | fad152f0-662a-11e5-89ed-77558ae77cc8 | 8
72888e32-dae5-41cd-a033-3c5871a3e045 | fad152f1-662a-11e5-89ed-77558ae77ac9 | 8
72888e32-dae5-41cd-a033-3c5871a3e045 | fb69e970-662a-11e5-89ed-77558ae77cd5 | 8
52868e32-dae5-41cd-b033-2b5871a3e032 | fb69e971-662a-11e5-89ed-77558ae77zc6 | 8
(5 rows)

Hinted Handoff
- POSSÍVEIS CAUSAS -
# enable assertions. disabling this in production will give a modest performance benefit (around 5%).
JVM_OPTS="$JVM_OPTS -ea"
Problemas de bootstrap na adição de novos nós ao cluster

Hinted Handoff
Correção de Emergência
Executar operação de 'truncate' na tabela de hintsAtualizar para versão >= 2.1.11
A versão 3.x não foi afetada pelo problema, pois a nova StorageEngine armazena os hints em arquivos e não mais na estrutura de
uma tabela do Cassandra.

ULTRA WIDE ROW(ANTI-PATTERN)
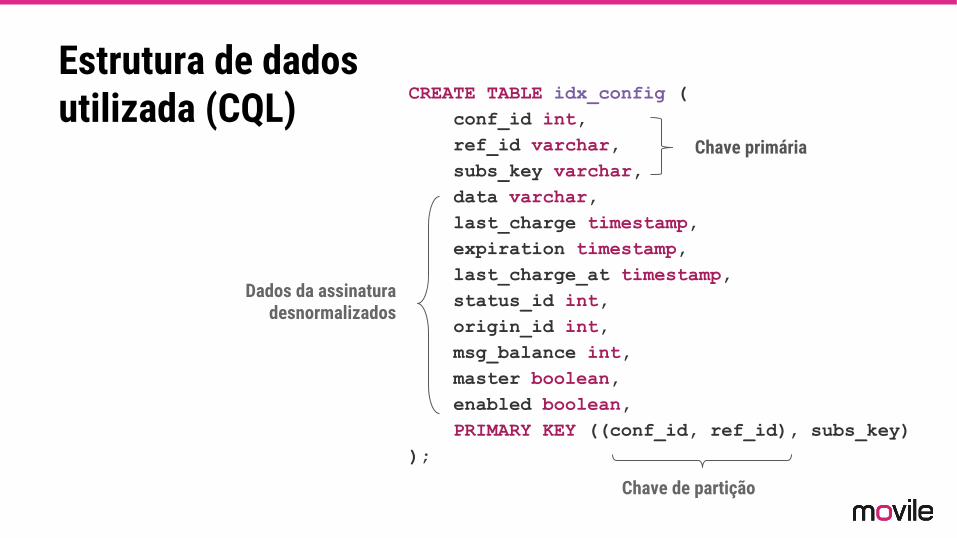
CREATE TABLE idx_config ( conf_id int, ref_id varchar, subs_key varchar, data varchar, last_charge timestamp, expiration timestamp, last_charge_at timestamp, status_id int, origin_id int, msg_balance int, master boolean, enabled boolean, PRIMARY KEY ((conf_id, ref_id), subs_key));
Estrutura de dados utilizada (CQL)
Chave primária
Dados da assinatura desnormalizados
Chave de partição

Limites Lógicos

Cassandra 1.2
ERROR [CompactionExecutor:6523] 2015-10-09 12:33:23,551CassandraDaemon.java (line 191) Exception in threadThread[CompactionExecutor:6523,1,main]java.lang.AssertionError: incorrect row data size 3758096384 written to/movile/cassandra-data/SBSPlatform/idx_config/SBSPlatform-idx_config-tmp-ic-715-Data.db; at org.apache.cassandra.io.sstable.SSTableWriter.append(SSTableWriter.java:162) at org.apache.cassandra.db.compaction.CompactionTask.runWith(CompactionTask.java:162) at org.apache.cassandra.io.util.DiskAwareRunnable.runMayThrow(DiskAwareRunnable.java:48) at org.apache.cassandra.utils.WrappedRunnable.run(WrappedRunnable.java:28)
+3GB em 1 linha

Limites Físicos de Partição
Cassandra 2.0 ou Anterior
● ~ 100MB ou menos / partição;● ~ 100k valores (colunas na linha).
Cassandra 2.1+
● Algumas centenas de MB por partição;● Milhões de valores (colunas por partição).

DS220 Data Modeling
Datastax Academy
GRATUITO
http://bit.ly/cassandra-ds220

CLIENT SIDE JOINS(ANTI-PATTERN)

Modelo v1 Cópia do modelo relacional

Modelo v1 Client Side Joins
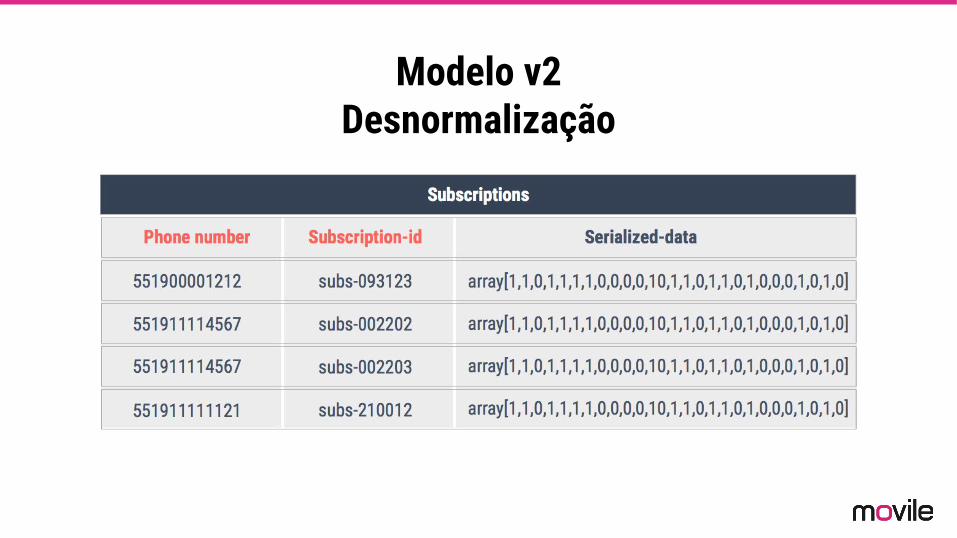
Modelo v2 Desnormalização


NÃO COMETA OS MESMOS ERROS

❏ Evitar Collections do Cassandra;
❏ Adição de nós em paralelo;
❏ Problemas no HintedHandOff;
❏ Client Side Joins (anti-pattern) - Copiar banco relacional;
❏ Ultra wide row (anti-pattern);
❏ Não verificar limites da ferramenta (lógicos e físicos).
O que não fazer

E isso é tudo, pessoal!

MUITO OBRIGADO!
eitikimura eiti-kimura-movile [email protected]
fhsgoncalves fhsgoncalves [email protected]
Design by Tiago Cardoso, thanks

Links de Referência:
Al Tobey Cassandra 2.1 Tuning Guide https://tobert.github.io/pages/als-cassandra-21-tuning-guide.html
Academia Datastax: Modelagem de dadoshttps://academy.datastax.com/courses/ds220-data-modeling
Cassandra, lists, and tombstoneshttp://bit.ly/1MwGuGT
How to drop and recreate a table in Cassandra versions older than 2.1http://bit.ly/1R481LO