nome completo do autor - coordenação de tcc - dsc fernando upe 29-06... · web viewas pessoas do...
TRANSCRIPT

Previsão de Vazões com Máquina de Vetor de Suporte
Trabalho de Conclusão de Curso
Engenharia da Computação
Nome do Aluno: Fernando José Barbosa de Brito FilhoOrientador: Prof. Mêuser Valença

Universidade de PernambucoEscola Politécnica de Pernambuco
Graduação em Engenharia de Computação
Fernando José Barbosa de Brito Filho
Previsão de vazões com Máquina de Vetor de Suporte
Monografia apresentada como requisito parcial para obtenção do diploma de Bacharel em Engenharia de Computação pela Escola Politécnica de Pernambuco –
Universidade de Pernambuco.
Recife, Junho de 2012.
2

De acordo
Recife
____/___________/_____
_____________________________________Orientador da Monografia
3

Dedico este trabalho a todos que,de alguma forma, me ajudaram durante esses muitos anos de curso.
4

AgradecimentosA todos os meus amigos da Escola Politecnica de Pernambuco, pelo apoio e
e motivação, principalmente a Diogo e Cristiano.
As pessoas do Instituto de Tecnologia de Pernambuco, onde cumpri meu
estágio obrigatório, pelo apoio, auxílio e compreensão – principalmente pela
compreensão, não teria terminado a monografia sem isto.
A meu professor orientador Mêuser Valença, não só pela orientação, mas por
ter-me dado bastante estímulo para continuar nesta árdua jornada e com
principalmente bastante paciência.
5

ResumoEste trabalho tem como objetivo apresentar um método para prever vazões
médias diárias a partir de séries temporais de cinco fontes diferentes. Desta forma,
utilizando o algoritmo de Máquina de Vetor-Suporte, que é uma técnica de
classificação e regressão baseada no aprendizado estatístico, será possível
apresentar a utilização de uma ferramenta usada em aprendizagem de máquina e
mineração de dados, na resolução de problemas de previsão, usando para isto,
vários tipos de funções distintas e descobrindo a melhor .
Palavras-chave: previsão de vazões, MLP, SVM, usinas hidrelétricas
.
6

AbstractThis paper aims to present a method for predicting daily average flow time
series from five different sources. Thus, using the algorithm, Support Vector
Machine, which is a classification and regression technique based on statistical
learning, you can make use of a tool used in machine learning and data mining, in
solving problems of prediction , using for this, several different types of functions and
discovering the best.
Keywords: river flow forecasts, MLP, SVM, hydroelectric
7

Sumário
Capítulo 1 Introdução 1
1.1 Formulação do problema 1
1.2 Motivação 2
1.3 Estrutura da monografia 2
Capítulo 2 Revisão Bibliográfica 3
2.1 Introdução à SVM 3
2.2 Fundamentação Teórica 5
2.2.1 Teoria do Aprendizado Estatístico 5
2.2.2 Risco 6
2.2.3 Limites e minimização no Risco Estrutural 7
2.3 Classificação com SVM´s 11
2.3.1 Margens flexíveis 13
2.4 Regressão com SVMs 15
2.5 Kernels 19
2.6 Variações do SV 20
2.6.1 ν - Support Vector Classification 20
2.6.2 ∈- Support Vector Regression 21
Capítulo 3 Ferramentas 19
3.1 Préprocessamento 22
3.2 Weka 24
3.3 Medidas de performance 29
Capítulo 4 Resultados 31
8

4.1 Metodologia 31
4.2 Experimentos e Resultados 34
Capítulo 5 Conclusão
Bibliografia
9

Índice de FigurasFigura 1. Esquema da geração de um classificador.................................................6
Figura 2. Funções lineares de separação dos dados...............................................8
Figura 3. Subconjuntos de F, com ordem crescente deh.........................................9
Figura 4. Separação por hiperplanos de margem máxima.....................................10
Figura 5. Introdução das variáveis ξ.......................................................................13
Figura 6. (a) Função circular (b) Função linear em R3...........................................15
Figura 7. Mudança do espaço original para o de características............................16
Figura 8. Base de dados deslocada........................................................................23
Figura 9. Conjunto de treinamento e teste..............................................................24
Figura 10. Aumentando a memória virtual.............................................................25
Figura 11. Escolha variáveis dependentes e independentes.................................26
Figura 12. Escolha da base de treinamento..........................................................26
Figura 13. Variável independente..........................................................................27
Figura 14. Parâmetros de treinamento..................................................................28
Figura 15. Grupo de teste......................................................................................28
Figura 16. Série original da Usina Itaipu, sem normalização dos dados...............32
Figura 17. Série da Usina Itaipu, após a normalização..........................................32
10

Índice de TabelasTabela 1. Tipos de funções kernel................................................................................19
Tabela 2. Parâmetros das funções kernel....................................................................33
Tabela 3. Resultados Furnas........................................................................................34
Tabela 4. Resultados Itaipu.........................................................................................35
Tabela 5. Resultados Jordão.......................................................................................35
Tabela 6. Resultados Salto Santiago...........................................................................36
Tabela 7. Resultados Sobradinho................................................................................36
Tabela 8a. Usina Furnas- Kernel Linear- 7 dias à frente................................................37
Tabela 8b.Usina Furnas- MLP- 7 dias à frente..............................................................37
Tabela 8c. Intervalos de Confiança- Usina Furnas- 7 dias à frente................................37
Tabela 9a. Usina Jordão- Kernel Linear – 7 dias à frente...............................................38
Tabela 9b.Usina Jordão- MLP – 7 dias à frente.............................................................39
Tabela 9c. Intervalos de Confiança -Usina Jordão- Kernel Linear – 7 dias à frente.......39
Tabela 10a.Usina Salto Santiago- Kernel Linear – 7 dias à frente.................................40
Tabela 10b.Usina Salto Santiago- MLP – 7 dias à frente...............................................40
Tabela 10c. Intervalos de Confiança -Salto Santiago– 7 dias à frente...........................40
Tabela 11a.Usina Itaipú- Kernel Linear – 7 dias à frente...............................................41
Tabela 11b.Usina Itaipú- MLP – 7 dias à frente.............................................................41
Tabela 11c. Intervalos de Confiança -Usina Itaipú- 7 dias à frente................................42
Tabela 12a.Usina Sobradinho- Kernel Linear – 7 dias à frente......................................42
Tabela 12b.Usina Sobradinho- MLP – 7 dias à frente....................................................43
Tabela 12c. Intervalos de Confiança -Usina Sobradinho- 7 dias à frente......................43
11

Tabela de Símbolos e SiglasANEEL- Agência Nacional de Energia Elétrica
CC – Coeficiente de Correlação
CSV - Comma-separated values
libSVM- Library for Support Vector Machine
MAE- Mean Absolute Error
MEP- Mean Error Percentual
MLP- Multi Layer Perceptron
ONS- Operador Nacional do Sistema Elétrico
PMO- Programação Mensal da Operação
RMSE – Root Mean Square Error
SIN- Sistema Interligado Nacional
SRM- Structural Risk Minimization
SVC - Classificação de Vetor de Suporte
SVM - Support Vector Machine
SVR- Support Vector Regression
TAE- Teoria do Aprendizado Estatístico
VC- Vapnik e Chervonenkis
WEKA- Waikato Environment for Knowledge Analysis
12

Capítulo 1 - Introdução
Capítulo 1Introdução
Segundo dados recentes da ANEEL (Agência Nacional de Energia Elétrica)
[2], 66.11% da energia elétrica do país é hidrelétrica, em relação à capacidade
instalada, com quase 82 GW, espalhadas em 950 usinas. Além disso, o Brasil, em
todo mundo, é o país com maior potencial hidrelétrico,com um total de 260 MW,
segundo o plano 2015 da Eletrobrás, do último inventário produzido no país em
1992.
De acordo com o plano Nacional de Energia 2030, o potencial a aproveitar é
cerca de 126 GW.
A capacidade do país em produzir este tipo de energia está relacionada
principalmente às condições naturais intrínsecas da sua bacia hidrográfica [7]: rios
torrenciais com uma grande abundância de água e perenes, variações fluviais
devidas principalmente às chuvas e relevo adequado, onde os rios escoam suas
águas sobre planaltos e depressões.
1.1 Formulação do problema
A responsabilidade da previsão das vazões naturais para os locais de
aproveitamento hidrelétrico que constituem o SIN (Sistema Interligado Nacional) é
da ONS (Operador Nacional do Sistema Elétrico).
Os processos e modelos utilizados para previsão variam de acordo com a
agregação temporal utilizada [19]: diária, semanal ou mensal. Atualmente, as
previsões de vazões diárias têm como objetivo apenas possibilitar o cálculo das
vazões naturais afluentes (vazões para aproveitamento hidrelétrico em determinado
ponto, essenciais na avaliação da energia disponível) médias da semana em curso.
Fernando José Barbosa de Brito Filho Página 1

Capítulo 1 - Introdução
São utilizadas as previsões diárias elaboradas a partir dos modelos vazão x vazão
e/ou chuva-vazão do ONS.
Especificamente o objetivo do trabalho é prever vazões médias diárias, utilizando
SVM (Support Vector Machine) [13], com o horizonte de 7 dias à frente, um dos
padrões de previsão utilizado pelo setor elétrico no PMO (Programação Mensal da
Operação), levando em consideração 14 valores passados.
1.2 MotivaçãoPara um planejamento consistente na geração de energia, almejando sempre
seu patamar máximo, é preciso saber antecipadamente os níveis dos reservatórios.
Com este objetivo o setor elétrico nacional é coordenado pelo ONS, que é
responsável pela operação coordenada de todas as usinas hidrelétricas que fazem
parte do sistema interligado nacional. Para que esta coordenação ótima seja
executada faz-se necessário que para cada mês seja realizada uma programação
chamada de PMO onde se define o que será gerado por cada usina. Uma das
entradas fundamentais para esta tomada de decisão são os valores semanais de
vazões afluentes a cada usina.
Desta forma, neste trabalho vamos avaliar o desempenho destas previsões
para cinco usinas: Furnas, Itaipú, Sobradinho, Salto Santiago e Jordão, por meio da
técnica de máquinas de vetores de suporte e comparar seus resultados com outros
modelos utilizados.
1.3 Estrutura da monografiaNo capítulo 2, é apresentada uma revisão bibliográfica que abrange os
principais conceitos matemáticos necessários para a compreensão deste trabalho.
No capítulo 3, é apresentada a ferramenta usada para a previsão.
No capítulo 4, são descritas as metodologias utilizadas durante o
desenvolvimento e os resultados da aplicação dos algoritmos de SVM.
Fernando José Barbosa de Brito Filho Página 2

Capítulo 1 - Introdução
O capítulo 5 contém as conclusões e as sugestões para trabalhos futuros.
Capítulo 2Revisão Bibliográfica
Neste capítulo são apresentados conceitos e definições matemáticas e
estatísticas necessárias à compreensão deste trabalho. Na seção 2.1, são
apresentadas a noção básica da SVM e suas aplicações. Na seção 2.2 são
apresentados os conceitos da Teoria do Aprendizado Estatísitico e seu
embasamento matemático.
2
2.1 Introdução à SVM
Quando lê-se o termo relacionado à Máquina de Vetor de Suporte (SVM), os
primeiros questionamentos a aparecerem são: é um dispositivo mecânico ou
orgânico que executa ou ajuda no desempenho das tarefas1? O que está sendo
suportado? Como vetores podem suportar algo?
SVM é um algoritmo de classificação que provê o estado da arte para um
amplo domínio de aplicações, como reconhecimento de escrita, reconhecimento de
objetos, identificação de fala, detecção de face, categorização de texto; previsão de
iterações proteínas-proteínas2 em biologia, na previsão de séries temporais
1 Definição de Máquina: http://pt.wikipedia.org/wiki/M%C3%A1quina
2 Support vector machine applications in computational biology- William Sta®ord Noble -Department of Genome Sciences -University of Washington
Fernando José Barbosa de Brito Filho Página 3

Capítulo 1 - Introdução
financeiras3; análise de crédito4; em química, no projeto de
medicamentos5.Problemas de generalização de modelos matemáticos, como
classificadores, são relevantes em um projeto. Primeiramente, todo modelo tem que
ser treinado, usando exemplos para o mesmo. Portanto, o número e a qualidade dos
exemplos está intrisicamente relacionada ao seu desempenho. Paralelamente, a
finalidade de um modelo é relacionar entradas às saídas, tendo como resposta
deduções ainda não informadas, como previsões ou classificações, sua habilidade
de generalização.
O impulso para proposição das SVM´s foi justamente esse panorama, em que
modelos matemáticos de aproximação universal, como as redes neurais artificiais
[10], não tem capacidade sistemática de generalização, o que pode levar a um
overfiting do modelo, em relação aos dados.
Os algoritmos de vetor de suporte foram desenvolvidos na Rússia na década
de 60 [Vapnik and Lerner, 1963, Vapnik and Chervonenkis, 1964], tendo uma
abordagem similar nos EUA [Mangasarian,1965,1968,1969]. É baseado na teoria do
aprendizado estatístico ou teoria VC [21], que vem sendo desenvolvida por Vapnik e
Chervonenkis ao longo das últimas décadas. Em suma, a teoria VC caracteriza
propriedades das máquinas de aprendizagem que lhes permitam generalizar bem os
dados não conhecidos.
Nas SVM´s há uma minimização do Risco Empírico, como nas Redes Neurais
Artificiais, e uma minimização dos erros sobre a base de dados, juntamente com a
minimização do Risco Estrutural. Foi apresentado que o princípio SRM (Structural
Risck Minimization) é superior ao ERM (Empirical Risk Minimization) Vapnik et al
3 TAY, Francis E. H. and Lijuan CAO, 2001. Application of support vector machines in financial time series forecasting, Omega: The International Journal of Management Science, Volume 29, Issue 4, August 2001, Pages 309-317.
4 MARTENS, David, et al., 2006. Comprehensible Credit Scoring Models using Rule Extraction from Support Vector Machines, European Journal of Operational Research, Accepted for publication.
5 Applications of Support Vector Machines in Chemistry- Ovidiu Ivanciuc- Sealy Center for Structural Biology,Department of Biochemistry and Molecular Biology, University of Texas Medical Branch, Galveston, Texas
Fernando José Barbosa de Brito Filho Página 4

Capítulo 1 - Introdução
(1997), por envolver a imposição de um limite superior para a possilidade de
classificações erradas, diminuindo ao máximo o erro de generalização.
Neste trabalho, o termo SVM irá se referir tanto a classificação quanto
aos métodos de regressão, e os termos de classificação de Vetor de
Suporte (SVC) e Support Vector Regression (SVR) serão utilizados para a
especificação.
2.2 Fundamentação Teórica
A partir das subseções abaixo serão desenvolvidos os principais conceitos
necessários ao suporte teórico desse trabalho.
2.2.1 Teoria do Aprendizado Estatístico
Também conhecida como Teoria VC (Vapnik-Chervonenkis), abrange quatro
partes importantes para sua implementção: a Teoria da Consistência dos Processos
de Aprendizagem [26], Teoria da Taxa de Convergência dos Processos de
Aprendizagem [26], Teoria da Minimização do Risco Estrutural [26], e Teoria da
Otimização [26], que são sintetizadas e introduzidas a seguir.
Tendo dados de treinamento {(x1, y1),...,(xn,yn)}, conforme a figura 1, ∈ Rn x
Y , assume-se inicialmente que eles são gerados de forma independente e
identicamente distribuído (i.i.d.), de acordo com a probabilidade P(x , y), que
descreve a relação entre seus dados x e rótulos y. Sendo f um modelo e F um
conjunto de todos os modelos que um algoritmo pode gerar. Este, durante o
processo de aprendizagem, utiliza um processo de treinamento T , composto de n
Fernando José Barbosa de Brito Filho Página 5

Capítulo 1 - Introdução
Figura 1. Esquema da geração de um classificador
pares (x i , y i), para gerar um modelo particular j ∈F.
O objetivo de um processo de aprendizagem é encontrar um modelo, por
exemplo, que separara os dados de treinamento “-” e “+” . Através de funções de
separação (limites de decisão) as classes são separadas.
2.2.2 Risco
O risco R(g), também denominado erro, foi definido por Vapnik (1995) como a
probabilidade de classificação incorreta, tendo como argumento uma função g(.). O
risco esperado mede então a capacidade de generalização de g, para os dados de
teste, segundo a Eq.1, sendo c (g(x ) , y ) uma função custo relacionada a previsão
g(x ) quando a saida desejada é y e P(x , y) uma medida de probabilidade:
Eq.1 R (g )=∫ c(g (x) , y)dP(x , y)
Exemplificando, uma função custo utilizada em problemas de classificação,
12|y−g ( x )|, retorna 0 caso a classificação seja correta e 1 caso contrário. Uma
função comumente utilizada em problemas de regressão é ( y−g (x)) ².
O função de risco empírico g, dada pela Eq. 2, retorna a taxa de erro médio
do treinamento em T , medindo seu desempenho.
Eq.2 Remp (g )= 1N ∑
i=1
N
c (f (x i ) , y i)
Fernando José Barbosa de Brito Filho Página 6

Capítulo 1 - Introdução
Em geral, a distribuição de probabilidade P(x i , y i) não é conhecida, não sendo
possível minimizar a Eq. 1. O que é conhecido são as informações dos dados de
treinamento, também amostrados de P(x i , y i) . Então recorre-se à minimização do
risco empírico (Eq.2) e espera-se que esse procedimento também diminua o erro
sobre os dados de teste. Com um conjunto grande de dados, fazendo-se n→∞ é
possível fazer o R(emp) convergir para o R(g), mas com conjuntos de dados pequenos
não é possível. Como os dados de treinamento têm densidade amostral fixa, pois
correspondem a uma amostra da população, a relação entre os funcionais R(g) e
Remp (g) será determinada pela função g.
Tendo um conjunto F, sempre é possível encontrar uma função f , com risco
empírico pequeno, pois a tarefa de calcular este risco reduz-se a um simples média,
por exemplo, o erro médio quadrático. A TAE (Teoria do Aprendizado Estatístico)
provê diversos limites no risco esperado de uma função f , pois os exemplos de
treinamento podem se tornar pouco informativos para a tarefa de aprendizado,
podendo ser empregados na escolha do melhor classificador.
2.2.3 Limites e minimização no Risco Estrutural
Um índice importante intrínseco a classes de funções é introduzido abaixo,
antes da continuação da subseção.
A dimensão VC (Vapnik–Chervonenkis) do conjunto de funções de
classificação F, é o número máximo de exemplos de treinamento que podem ser
aprendidos pela máquina sem erro, para todas as rotulações possíveis das funções
de classificação [10] .
Fernando José Barbosa de Brito Filho Página 7

Capítulo 1 - Introdução
No exemplo da Figura 2, considera-se uma função linear no R2 como modelo
de
classificação. A função deve separar os dados dos pontos positivos dos pontos
negativos. Existem conjuntos de 3 pontos que podem realmente ser quebrados
usando este modelo (quaisquer 3 pontos que não sejam colineares, na mesma linha,
podem ser quebrados). No entanto, nenhum conjunto de quatro pontos pode ser
quebrado. Assim, a dimensão VC do classificador específicado é de 3. De forma
geral, em R2, com n≥2, a dimensão VC é n + 1 (Vapnik, 1995).
É primordial restringir a classe de funções f , para que se tenha capacidade de
adequar a quantidade de dados de treinamento disponíveis. A Teoria VC fornece
limites sobre o erro de teste. A minimização desses limites, que dependem tanto do
Remp quanto da capacidade da classe função, a dimensão VC, definido este como h,
leva ao princípio da minimização do risco estrutural R( f ) Eq.3. Esse limite é
garantido com probabilidade 1−∅ , em que ∅ pertence ao limite [0,1].
Eq.3 R ( f )≤ Remp (f )=√ h (ln( 2nh )+1)−ln (∅4 )
n
O termo n representa a quantidade de exemplos no conjunto de treinamento T
. Do limitante 1−∅ , deduz-se que a minimização do risco esperado está
relacionado tanto ao risco empírico Remp , a razão da dimensão VC como do número
de exemplos de treinamento. Há um valor ótimo para h, pois o risco empírico é uma
função decrescente do mesmo. O bom desempenho do modelo está relacionado
então a um bom valor para h, sendo controlado muitas vezes pelos seus parâmetros
livres.
Fernando José Barbosa de Brito Filho Página 8
Figura 1.

Capítulo 1 - Introdução
Mesmo um risco empírico Remp pequeno, não significa um risco estrutural R(f )
pequeno. O risco é chamado “estrutural” porque o termo h referencia-se a classe de
funções F e o risco empírico Remp ao classificador particular f e para minimizar
ambas as parcelas divide-se inicialmente F em subconjuntos de funções com
dimensão VC crescente [14], chamados estruturas. Então minimiza-se o limite de
cada estrutura dessas. Pondo as estruturas em ordem crescente de h (Figura 3),
tendo um classificador particular f k, a medida que k cresce, a complexidade dos
classificadores aumentam e o risco empírico Remp diminui.
Na
prática, no princípio SRM (Structural Risk Minimization), surgem alguns problemas,
dificuldades em sua implementação. Calcular o h não é uma tarefa trivial, já que ele
pode ser infinito ou desconhecido, além disso poucas são as classes de funções
para as quais se sabe como efetuar esse cálculo. V
O conceito de margem [23] pode ser aplicado, ao risco estrutural R(f ), como
forma alternativa, em funções lineares do tipo f ( x )= (W .x )+b (Eq.4). A margem de
um exemplo será uma medida de confiança de previsão do classificador. É definida
como a distância mínima de uma amostra (Figura 4) à superfície de decisão V [17], e
pode ser medida pelo comprimento do peso vetor V na Eq. 4. Assumindo que as
amostras de treinamento são linearmente separáveis, redimensiona-se w e b, tal que
os pontos mais próximos do hiplerplano satisfaçam |(w .x i )+b|=1 (Eq.5).
Fernando José Barbosa de Brito Filho Página 9
Figura 3. Subconjuntos de F, com ordem
crescente deh

Capítulo 1 - Introdução
Aplicando-se dois exemplos do treinamento, de classes diferentes, a Eq. 5,
tem-se |(w .x1 )+b|=1 e |(w .x2 )+b|=−1 . Em seguida, a margem é dada pela
distância destes dois pontos, medida perpendicular ao hiperplano: W¿¿ (Eq.6).
2.3 Classificação com SVM´s
O problema de classificação pode ser restrito ao problema de duas classes,
sem perda de generalidade [9].
Uma SVC acha o melhor hiperplano de separação entre as duas classes de
amostras de treinamento, no espaço de características, com margem máxima [15] .
O objetivo é produzir um classificador que funcionar bem com exemplos não
conhecidos, ou seja, um classificador que generaliza bem.
Uma função do tipo linear (Eq.4), correspondente ao hiperplano, separa o
espaço de características. Denotando-se y i∈{+1,−1} como o valor numérico das
saídas, x i os vetores de entrada, i=1 ,…N , w o vetor de pesos e m a margem
Fernando José Barbosa de Brito Filho Página 10
Figura 4. Separação por hiperplanos de margem máxima

Capítulo 1 - Introdução
máxima, o problema de classificação é equivalente a achar o funcional f , que
satisfaça y i ( (w ,xi )+b )≥m que maximize m.
Em termos geométricos, achar o hiperplano que maximize a margem m
¿∨m∨¿
, sendo H (w ,b ) : (w ,x )+b=0, é satisfazer y i ¿ para todos os exemplos de treinamento,
onde ||m|| é a norma Euclidiana da distânica máxima. A margem geométrica (Figura 4) representa a distância mínima dos exemplos de treinamento para as duas
classes, separadas pelo hiperplano H . Assumindo m = 1, chamado hiperplano
canônico, o problema de classificação torna-se equivalente a forma
H (w ,b ) : (w ,x )+b=0, maximizando a margem total (Eq.6), ou 12(¿∨w∨¿2) e
satisfazendo y i ( (w ,xi )+b )≥1.
O problema relacionado acima é de otimização quadrática6 (adotando-se a
norma euclidiana), com restrições de desigualdade linear e abordagem algébrica, e
por padrão, a solução é uso do método dos multiplicadores de Lagrange [16]:
Eq.7 L=12¿W∨¿2−∑
i=1
N
∝i {[ (w .x i )+b ] y i−1}¿
onde ∝i (i = 1,..,N) são os multiplicadores de Lagrange. O lagrangeano [13] da Eq.7
tem que ser minimizado com respeito a w e b e maximizado com respeito a ∝i . O
problema de otimização dual é equivalente a maximizar:
Lmax=∑i∝i−
12∑i
∑jy i y j∝i∝ j(x i , x j)
tendo como restrições ∝i ≥0 e ∑i yi∝i=0 ;então a solução[13] produzida é:
6 An Iterative Approach to Quadratic Optimization -H. K. XU - JOURNAL OF OPTIMIZATION THEORY AND APPLICATIONS: Vol. 116, No. 3, pp. 659–678, March 2003
Fernando José Barbosa de Brito Filho Página 11

Capítulo 1 - Introdução
Eq.8 ∝=argmin [ 12∑i=1
N
∑j=1
N
∝i∝ j y i y j (x i x j )−∑i−1
N
∝i]
Considerando as restrições impostas a Eq.8, a solução resultante:
w=∑i=1
N
∝i x i y i e b=−12
((w . xr )+(w . x s))
Onde xr e xs são os vetores de suporte da classe dada.
As condições de Karush-Kuhn-Tucker [12], que são condições necessárias e
suficientes, estabelecem que as soluções ótimas ∝¿ ,w¿ eb¿ devem satisfazer a
seguinte igualdade:
Eq.9 ∝¿ [ y j ( (w ¿ . x j)+b¿ )−1 ]=0, para j = 1,2...N.
Com base na equação acima (Eq.9), observam-se que os pontos y i((w .x j )+b)
=1 devem ter necessarimente ∝ = 0. Só os pontos com margem 1 podem ter os
correspondentes ∝=0 , chamados vetores-suporte (SVs).
2.3.1 Margens flexíveis
Nas seções anteriores foram levados em consideração apenas problemas em
que as amostras de treinamento eram linearmente separáveis. Agora analisa-se o
caso em que os exemplos de treinamento são não linearmente separáveis, onde não
é possível construir um hiperplano de separação que classifique corretamente todos
os exemplos.
A abordagem ainda continua sendo um hiperplano para a classificação, no
espaço orginal das amostras de treinamento. O conceito de espaço de
características será incorporado nas seções posteriores.
Fernando José Barbosa de Brito Filho Página 12

Capítulo 1 - Introdução
A formulação da SVM nesta seção permite erros de classificação, como na
Figura 5, introduzindo-se variáveis de erro não negativa ξ ≥0 [6] e uma função de
penalidade (Eq.10):
Eq.10 [ y j¿((w¿ . x j)+b
¿)+ξ j−1] para j = 1,2...N,
onde w é o vetor de pesos em Rn, o escalar b é o bias, e o ε j é a variável não
negativa associada a cada vetor de treinamento x j. Se ξ j encontra-se no intervalo
[0,1] , então o exemplo x encontra-se no lado certo do hiperplano, portanto,
classificado corretamente. Então os pontos x j em que o ξ j é maior que 1, são pontos
classificados incorretamente.
Quando sabe-se a priori, ou existe a possibilidade do hiperplano não separar
adequadamente os dados de treinamento, é introduzido um parâmetro C , chamado
também de constante de regularização, além da variável ξ j , associado também ao
erro de classificação. A equação contém abaixo com os dois parâmetros:
Eq.11 Φ (w ,ξ )=12
¿w∨¿2+C∑i=1
N
ξ i ¿
Fernando José Barbosa de Brito Filho Página 13
Figura 5. Introdução das variáveis ξ

Capítulo 1 - Introdução
A Eq.11 também está sujeita as mesmas restrições da Eq.10. A constate C,
controla o peso do número de erros [1], que é limitado pelo somatório das variáveis
ξ i e pelo tamanho da margem, que é inversamente proporcional a norma w.
Para resolver o problema primal (Eq.11), utiliza-se também o método dos
multiplicadores de Lagrange [16] e suas restrições, tendo como resultado um
problema dual, onde não aparecem as variáveis ξ i:
Eq.12W (∝ )=∑i=1
N
∝i−12 ∑
i , j=1
N
∝i∝ j y i y j(x i . x j),
que, para que seja máxima, satisfaça ∑i=1
N
∝i y i=0 e 0≤∝i≤C.
De acordo com as condições Karush-Kuhn-Tucker, parecido com o caso dos
exemplos linearmente separáveis, os vetores-suporte (SVs) são apenas os pontos
em que y j ((w . x j )+b)=1 tem os correspondentes ∝=0.
Segundo [6], o procedimento sistemático de determinação de C não é claro.
Há momentos em que C pode ser diretamente relacionado com um parâmetro de
regularização [24], sendo mais aceitável que seu valor seja compatível com a
variação do ruído dos exemplos de treinamento [13].
2.4 Regressão com SVMs
Existem casos que não é possível utilizar as SVMs com separação linear ou
mesmo as com margens flexíveis, pois teriam resultados insatisfatórios na divisão
Fernando José Barbosa de Brito Filho Página 14

Capítulo 1 - Introdução
dos exemplos de treinamento, como por exemplo na Figura 6a, em que o emprego
de uma função circular seria mais apropriado ou na Figura 6b, em que uma função
linear, no espaço de características seria mais apropriada.
As SVRs tratam de problemas não lineares mapeando seu conjunto de
treinamento de seu espaço original, associoado às entradas, para um novo espaço
dimensional, mais complexo, denominado espaço de características [11], como na
Figura 7.
O mapeamento não linear funciona da seguinte forma [17]:
Definição:
Φ :RN❑→I
x→Φ( x)
Fernando José Barbosa de Brito Filho Página 15
Figura 7. Mudança do espaço original para o de características

Capítulo 1 - Introdução
Sendo x1,…, xn ∈ Rn são mapeados em um espaço de características
potencialmente muito maior de dimensões I. Para um determinado problema de
aprendizado, passou-se a considerar o mesmo algoritmo I em vez de Rn , ou seja,
trabalha-se com a amostra:
(Φ (x1 ) , y1 ) ,…,(ϕ (xn ) , yn )∈ I xY
Em I pode ser encontrado tanto dados mapeados de uma simples
classificação quanto de uma regressão. Implicitamente, tem a mesma função que
uma camada escondida de uma rede neural MLP (Multi Layer Perceptron) [10], uma
rede RBF (Radial Basic Funtion) ou algoritmos de boosting [8], onde os dados de
entrada são mapeados para alguma representação dada pela camada escondida.
A adversidade conhecida como dimensionalidade das estatísticas, diz
essencialmente que a dificuldade de um problema de estimação aumenta
drasticamente com a dimensão N do espaço. Em princípio, são necessários
exemplos de ordem exponencial para provar que o espaço é adequado. Esta
afirmação, bem conhecida, induz a algumas dúvidas, como se é uma boa idéia
usar um espaço dimensional maior dimensionado como recurso de aprendizagem.
Porém, a teoria de aprendizagem estatística nos afirma que o oposto
pode ser verdade: a aprendizagem em I pode ser mais simples usando-se uma
baixa complexidade, ou seja, classificadores lineares, por exemplo. Toda a
variabilidade e riqueza é introduzida então pelo mapeamento Φ.
Fernando José Barbosa de Brito Filho Página 16

Capítulo 1 - Introdução
Demonstrando os conceitos introduzidos, tomando os dados do exemplo da
Figura 6a e modificando seu espaço dimensional, de R2 para R3, tendo como
função de mapeamento (Eq.13):
Eq.13 Φ ( x )=( x , y )=x2+√2 x . y+ y2,
é possível encontrar um hiperplano no espaço tridimensional, Figura 6b, separando
os dados convenientemente (Eq.14):
Eq.14 f ( x )=w .Φ ( x )+b=w1x2+w2√2 x . y+w3 y2+b=0
No espaço em R3 , a função de separação é linear (Figura 6b), embora em R2 também poderia ser.
Após encontrar o hiperplano ótimo, com maior margem de separação, em Φ ,
utiliza-se a abordagem das SVMs com margens flexíveis, com as variáveis ξ, que
permite lidar melhor com dados ruidosos. Aplica-se Φ aos exemplos de problema de
otimização da Eq.12,com as mesmas restrições, conforme a Eq.15 abaixo:
Eq.15max (∝ )=∑i=1
N
∝i−12 ∑
i , j=1
N
∝i∝ j y i y j ¿,
A partir do problema Eq.15 produz-se a Eq.16:
Eq.16∝=argmin∝
¿¿,
Fernando José Barbosa de Brito Filho Página 17

Capítulo 1 - Introdução
onde ϕ (x¿¿ i , x j)¿ é uma função kernel, que representa o mapeamento não-linear
que leva ao espaço de características. Assim, é extraído o classificador que
implementa o hiperplano ótimo (Eq.17):
Eq.17 g ( x )=sgn ( f ( x ) )=sgn¿,
onde:
(w¿ . x)=∑i=1
N
∝i y iΦ (x¿¿ i , x¿)¿¿,
b¿=−12 ∑
SVs∝i
¿ y i[Φ (xr , x i )+Φ (xs , xi)]
2.5 Kernels
Tendo-se que:
Eq.18 K (x i , x j )=Φ(x i , x j),
define-se um kernel K como sendo uma função que recebe dois argumentos x i e x j
do espaço de entradas de dados e calcula o produto escalar desses argumentos no
espaço de características [10].
A construção do mapeamento Φ é implícita, pois se utiliza o Kernel sem
conhecê-la, tornando seu uso mais simplificado.
Fernando José Barbosa de Brito Filho Página 18

Capítulo 1 - Introdução
São utilizadas funções Kernel que seguem os princípios do Teorema de
Mercer [20], garantindo o cálculo do produto escalar na Eq.18. e a convexidade na
Eq.15. Na Tabela 1 encontram-se alguns tipos de funções kernel:
Tabela1. Tipos de funções kernel
Tipo de Kernel Função K (x i x j)
Polinomial ((x¿¿ i , x j)+1)p¿
RBF exp(−¿∨x i−x j∨¿
2σ22
)
Sigmoidal ta hn (β0 (x i . x j )+ β0)
Série de Fourier ∏k=1
n
K (xk , x ik)
Splines Lineares ∑i=1
N
∝i K (x , x i)
2.6 Variações do SV
Ainda existe uma grande variedade de algoritmos de Vetor de Suporte (SV),
que são adequados a configurações peculiares, tanto em SVC (classificação) quanto
em SVR (regressão). Há diferentes maneiras de medir a capacidade e as reduções
de programação linear, além de diferentes formas de controle de capacidade. São
mencionados alguns nas duas subseções seguintes.
2.6.1 ν - Support Vector Classification
Fernando José Barbosa de Brito Filho Página 19

Capítulo 1 - Introdução
O ν- Support Vector Classification [22] introduz um novo parâmetroν ϵ [0,1]. É
provado que ν é um limite superior em uma fração de erros de treinamento e um
limite inferior de uma fração de vetores de suporte [22].
O problema de otimização primal será descrita como:
min Fw ,b , ξ, ρ=12W T .W−νρ+1
l ∑i=1l
ξ i,
onde l é a quantidade de vetores-suporte, y i ϵ Rl , y i ϵ {−1,1 }, tendo como restrições:
y i (wT ϕ (xi )+b )≥ ρ−ξi ,
ξ i≥0 , i=1 ,…,l , ρ ≥0.
O problema dual é:
min F∝=12∝TQ∝ ,
tendo como restrições:
0≥∝i≤1l, l=1 ,…, l ,
eT∝i≥ν , yT∝=0
Onde Qij= y i y jϕ (x i x j). A função de decisão é dada como:
sgn(∑i=1
l
y i∝iϕ (x i x j )+b).
2.6.2 ∈- Support Vector Regression
Sendo os parâmetros C>0 e ∈>0 , a forma padrão da SVR é:
min Fw ,b , ξ , ξ¿=12wTw+C∑
i=1
l
ξ i+C∑i=1
l
ξ i¿,
tendo como restrições:
Fernando José Barbosa de Brito Filho Página 20

Capítulo 1 - Introdução
wT ϕ (xi )+b−z i≤∈+ξ i¿,
ξ i ξi¿≥0 , i=1 ,…,l .
O problema dual fica na forma:
min F∝ ,∝¿=12
(∝−∝¿)TQ (∝−∝¿)+∈∑i=1
l
(∝+∝¿ )+∑i=1
l
zi (∝−∝¿) ,
tendo as restrições:
eT (∝−∝¿)=0 ,
0≤∝i ,∝i¿≤C ,i=1 , .. ,l .
onde:
Qij=ϕ (x i , x j )=ϕ (xi )T ϕ (x j ) .
Capítulo 3
Fernando José Barbosa de Brito Filho Página 21

Capítulo 1 - Introdução
FerramentasNeste capítulo, é apresentado a principal característica da ferramenta
utilizada neste trabalho, para treinamento e previsão de vazões, o Weka. Na seção
3.1 é apresentado o processo de préprocessamento que ocorre na base de dados.
Na seção 3.2 são descritos as características pricipais da ferramenta. Na seção 3.3
são apresentadas as medidas de performance.
3
3.1 Preprocessamento As bases de dados utilizadas como entrada na SVM nesse trabalho são
obtidas a partir de modelos diários vazão x vazão e/ou chuva-vazão fornecidos pela
ONS, correspondendo as Usinas: Furnas, em Minas Gerais, Itaipu, localizada entre
o Brasil e o Paraguai, Sobradinho, na Bahia, Salto Santiago, no Paraná e do rio
Jordão. Os dados correspondem a séries temporais armazenadas em m3/s de
Janeiro/1931 à Dezembro/2007, e estão em formato CSV (Comma Separated
Value).
Antes de serem utilizados pela ferramenta de apoio, a base de dados deve
ser padronizada ou normalizada, com o objetivo de fazer com que os valores da
base tenham uma determinadana propriedade [25]. A regra de normalização
aplicada é mostrada a seguir:
B=( A−minValue(A)maxValue(A)−minValue (A ))∗(D−C )+C,
onde A é o valor a ser normalizado, D é o limite máximo estipulado entre todos os
valores, determinado como 0.85, C o valor mínimo estipulado dentre todos os
Fernando José Barbosa de Brito Filho Página 22

Capítulo 1 - Introdução
valores, determinado como 0,15, e minValue e maxvalue, o valor mínimo e máximo,
respectivamente e B o valor normalizado.
O passo seguinte ao procedimento de préprocessamento é transformar a
base de dados, composta por uma única coluna já normalizada, em várias colunas,
deslocando-as quantas vezes forem necessárias. Nesse trabalho, para prever 7 dias
à frente, é necessário ter conhecimento de até 14 dias anteriores. Então, desloca-se
a coluna 14 vezes à esquerda, representando os 14 dias anteriores e desloca-se a
coluna primordial também 6 vezes à frente, representando os 7 dias de previsão,
como na Figura 8.
Por fim, os exemplos foram separados em dois conjuntos (Figura 9):
treinamento, 75% da base (train) e teste 25% da base (test) .
Fernando José Barbosa de Brito Filho Página 23
Figura 8. Base de dados deslocada

Capítulo 1 - Introdução
3.2 Weka
O Weka é uma coleção de algoritmos de aprendizado de máquina para
tarefas de mineração de dados. Os algoritmos podem ser aplicados diretamente a
um conjunto de dados ou chamado a partir do seu próprio código
Java. Weka contém ferramentas para dados de préprocessamento,
classificação, regressão, clustering, regras de associação e visualização. É também
ideal para o desenvolvimento de novos sistemas de aprendizagem de máquina [27].
Até versões anteriores ao Weka 3.7.2, o pacote contendo a libSVM7 (Library
for Support Vector Machine) vêm associada a ferramenta. Essa biblioteca permite
que os usuários utilizem vários métodos de classificação e regressão, como: One-
Class SVM, Regression SMV e Nu-SVM apoiada na ferramenta LibSVM. Neste
trabalho foi utilizada a versão 3.7.5 do Weka, sendo a libSVM e o Multiplayer
Perceptron instalados utilizando o Package Manager da própria ferramenta.
7 http://www.csie.ntu.edu.tw/~cjlin/libsvm/
Fernando José Barbosa de Brito Filho Página 24
Figura 9. Conjunto de treinamento e teste

Capítulo 1 - Introdução
Depois de selecionado o caminho onde o Weka foi instalado, o comando descrito na
Figura 10 é executado, aumentando a memória da MV (Machine Virtual), necessário
em razão do grande volume de dados e cálculos. O software é inicializado.
Após a opção Explorer ter sido selecionada, a base de treinamento desejada
é carregada (Open File) (Figura 12) e os atributos contínuos que não são utilizados
na produção do modelo de previsão são excluídos (Figura 11).
Atributos são ditos contínuos quando são números do tipo real, normalmente
representados por variáveis de tipo ponto-flutuante, como temperatura e altura [25].
Fernando José Barbosa de Brito Filho Página 25
Figura 10. Aumentando a memória virtual

Capítulo 1 - Introdução
Em contrapartida, atributos discretos são aqueles que possuem um conjunto
finito ou contavelmente infinitos [25].
Fernando José Barbosa de Brito Filho Página 26
Escolha variáveis dependentes e independentes

Capítulo 1 - Introdução
Os atributos escolhidos no passo anterior (Figura 11) são as variáveis
independentes, aquelas manipuladas pelo experimento, suas entradas, e as
variáveis dependentes, nas quais, com a manipulação das primeiras, são
Figura 13. Variável independente
observadas as mudanças, a que se quer prever, como na Figura 13, onde por
exemplo, variável independente é “1 dia à frente”.
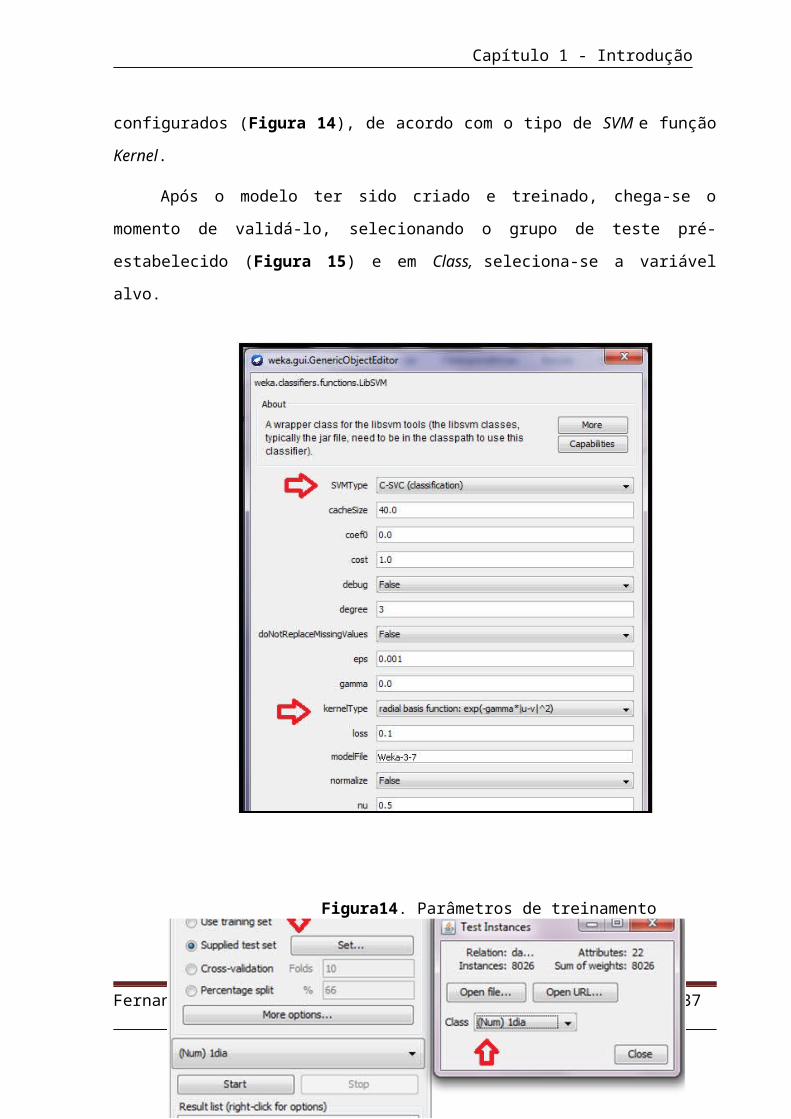
A função LibSVM, na aba Classify, é selecionada. A partir daí, os parâmetros
para o treinamento do modelo são configurados (Figura 14), de acordo com o tipo
Fernando José Barbosa de Brito Filho Página 27
Figura 12. Escolha da base de treinamento

Capítulo 1 - Introdução
de SVM e função Kernel.
Após o modelo ter sido criado e treinado, chega-se o momento de validá-lo,
selecionando o grupo de teste pré-estabelecido (Figura 15) e em Class, seleciona-
se a variável alvo.
Fernando José Barbosa de Brito Filho Página 28
Figura14. Parâmetros de treinamento

Capítulo 1 - Introdução
Procedimento
semelhante ao anterior é utilizado para formação de um modelo de previsão com o
MLP, empregando a função Multilayer Perceptron da aba Classify e selecionando os
parâmetros adequados.
Na próxima seção serão abordados os coeficientes de erros utilizados como
referência na escolha do melhor modelo.
3.3 Medidas de performance
Uma das medidas de performace usadas pela biblioteca LibSVM [4] e
incorporadas pela ferramenta Weka, medindo a precisão em classificações é
mostrada abaixo:
Accuracy=¿dados previstos corretamente¿ totalde dadosde teste
∗100
Já no campo das regressões, a libSVM prove vários coeficientes de medidas,
como:
O RMSE ( Root Mean-Square Error) ou Raiz Quadrada Média do Erro, que
diz:
RMSE=√ 1l̂ ∑i=1n (f (x i )− yi),
onde n é a quantidade de vetores de treinamento, f (x i ) é o valor desejado e y i
é o valor encontrado.
Fernando José Barbosa de Brito Filho Página 29
Figura 15. Grupo de teste

Capítulo 1 - Introdução
Outro coeficiente utilizado na regressão é o r2 , chamado de coeficiente de
correlação quadrático ou coeficiente de determinação:
r2=¿¿ ,
que indica quanto da variância da variável resposta f (x i), é explicada pela variância
das variáveis explicativas y i, em outras palavras, um valor que mede o grau de
relacionamentos entre as duas variáveis. Seu valor está no intervalo [0,1]. Quanto
maior, mais explicativo é o modelo.
O Mean Absolute Error (MAE) ou Erro Absoluto Médio:
MAE=1n∑i=1
n
|f ( xi )− y i| ,
onde f (x i) é a previsão e y i é o valor.
E finalmente o teste t , onde primeiro é achado o R:
R=√( 1n+ 1m )( (m−1 )S1
2+(n−1)S22
n+m−2),
onde n e m são as quantidades de amostras das bases, S12 e S2
2 são os desvios-
padrão de cada amostra. Tendo o valor do R, calcula-se o intervalo mínimo e
máximo da confiança:
( ( X – Y )−bR ) , ( X – Y )+bR ¿¿ ,
onde X e Y são as médias das amostras eb é escolhido de acordo com grau de
liberdade, na tabela t de student. Em outras palavras, o teste t analisa pequenas
amostras, testa se a média entre dois grupos é significantemente diferente8. Usa o
intervalo de confiança, uma distribuição amostral de média X e desvio-padrão S. É
uma distribuição aproximadamente normal, em forma de sino, sendo de se esperar,
por exemplo, que 95% das medidas das amostras estejam no intervalo de confiança
mostrado na última fórmula acima, compreendido nestes limites.
8 http://www.slideshare.net/celiamdsales/teste-t-student
Fernando José Barbosa de Brito Filho Página 30

Capítulo
Capítulo 4ResultadosNeste capítulo é apresentado como os experimentos foram realizados na tarefa de
escolha da função kernel na previsão das vazões. Na seção 4.1 é descrita a
metodologia utilizada na tarefa de previsão, e na seção 4.2 são apresentados os
experimentos realizados e os resultados.
4
4.1 Metodologia
Este trabalho tem como objetivo apresentar um método de previsão de
vazões médias diárias tendo como entrada vazões de quatorze dias anteriores,
utilizando Máquina de Vetor de Suporte, com horizonte máximo de sete dias, para
efeito de avaliação de desempenho.
A estratégia é comparar os resultados obtidos, os valores de erro médio
absoluto para sete dias à frente, entre as várias funções kernel.
A primeira etapa do processo está relacionada ao preprocessamento das
bases de dados, onde houve um tratamento das séries. As bases foram separadas
em dois grupos, treinamento e teste, aplicando-se a regra de normalização descrita
na seção 3 e mostrada graficamente na Figura 16, antes da normalização, e depois,
na Figura 17. De acordo com a Figura 17, ainda existem problemas de outliers, que
são pontos da série situados significativamente fora da média, que são tratados pela
SVM.
Fernando José Barbosa de Brito Filho Página 31

Capítulo
28/jan/1931 3/fev/1943 9/fev/1955 15/fev/196721/fev/197927/fev/1991 5/mar/20030
5000
10000
15000
20000
25000
30000
35000
40000
45000
Series1
Figura 2.
Figura 3.
Figura 4.
Figura 5.
Figura 6.
Figura 7.
Figura 8.
Figura 9.
Figura 10.
Figura 11.
Figura 12.
Figura 13.
Figura 14.
Figura 15.
Figura 16. Série original da Usina Itaipu, sem normalização dos dados.
Fernando José Barbosa de Brito Filho Página 32

Capítulo
28/jan/1931 8/dez/1942 18/out/195428/ago/1966 8/jul/1978 18/mai/199028/mar/20020
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Series1
Figura 17. Série da Usina Itaipu, após a normalização.
A segunda etapa consiste em escolher uma função kernel apropriada, usando
a opção Epsílon- SVR, no Weka, para no espaço de características, separar os
vetores-suporte adequadamente. Um bom desempenho de uma SVR, em relação a
seu grau de generalização, depende de uma boa escolha dos parâmetros C, εou γ,
dependendo da função kernel, descritas na seção 2. O problema de seleção dos
parâmetros ótimos é bastante complexo pelo fato de que a complexidade do modelo
SVR depende de vários parâmetros simultaneamente.
Foram testados 4 tipos de funções kernel, as mais utilizadas, para previsão de
7 dias à frente, segundo a Tabela 2:
Tabela2. Parâmetros das funções kernels
Kernel Epsílon(ε) Custo(C) Gamma(γ) Coef0 Degree
Fernando José Barbosa de Brito Filho Página 33

Capítulo
Polinomia
l0,1 1 0 0 3
Linear 0,1 1 ---- ---- ----
RBF 0,1 1 0 ---- ----
Sigmoid ----- 1 0 0 ----
Esses valores são os defaults da ferramenta Weka. As células da Tabela 2 que foram preenchidas com linhas tracejadas, representam parâmetros que não
fazem parte da função determinada9. A partir dos resultados desses primeiros testes,
as funçãos que obtiverem, segundo as medidas R2 (CC ¿, MAE e RMSE (seção 3.3),
os melhores resultados, serão as escolhidas para a próxima etapa.
A terceira etapa consiste em comparar os resultados do modelo de previsão
ótimo criado a partir de um Multilayer Perceptron (MLP) com o melhor modelo
produzido pela SVM , agora levando-se em consideração o intervalo de confiança o
critério de escolha do melhor modelo de previsão. Em razão dos pesos primordiais
da MLP serem inicializados aleatoriamente, foi calculada uma média dos valores em
30 configurações de seeds distintas. Essa variação da semente (seed) dos números
aleatórios só foi realizada para a arquitetura de rede com menor MAE, dentre as 7
propostas de variação da quantidade de neurônios da camada escondida, na MLP,
descritas mais a frente.
4.2 Experimentos e Resultados
9 http://www.csie.ntu.edu.tw/~cjlin/libsvm/
Fernando José Barbosa de Brito Filho Página 34

Capítulo
A ordem e os resultados dos experimentos que foram realizados, nesta etapa,
estão mostrados, respectivamente: Furnas (Tabela 3), Itaipu (Tabela 4), Jordão
(Tabela 5), Salto Santiago (Tabela 6) e Sobradinho (Tabela 7), tendo-se
inicialmente, 14 dias anteriores para a previsão de 7 dias à frente e levando-se em
consideração três medidas de erro: coeficiente correlação (CC), erro médio absoluto
(MAE), raiz do erro médio quadrático (RMSE), para esta etapa.
Tabela3. Resultados Furnas
Usina Furnas CC MAE RMSE
Linear 0,7834 0,068 0,0739
Polinomial0,6359
0,0692
0,076
RBF 0,7793 0,071 0,0759
Sigmoid0,7744
0,0707
0,0757
Seguindo o critério, a função kernel escolhida foi a linear, pois obteve os
melhores coeficientes de erro: CC , que quanto maior, melhor a correlação entre as
variáveis; MAE e RMSE, que quanto menores, menores são os erros relacionados.
Os melhores resultados na Tabela 3 e também nas posteriores, até a Tabela 7,
estão destacados em vermelho.
Tabela4. Resultados Usina Itaipu
Fernando José Barbosa de Brito Filho Página 35

Capítulo
Usina Itaipu CC MAE RMSE
Linear0,8553
0,045
20,0534
Polinomial0,7395
0,046
80,0603
RBF0,8441
0,048
50,0567
Sigmoid -
0,3875
0,221
20,0553
Tabela5. Resultados Jordão
Usina Furnas CC MAE RMSE
Linear 0,7834 0,068 0,0739
Polinomial0,4412
0,0771
0,0796
RBF0,5534
0,0838
0,0858
Sigmoid0,5518
0,0823
0,0844
Tabela6. Resultados Salto Santiago
Santo Santiago CC MAE RMSE
Fernando José Barbosa de Brito Filho Página 36

Capítulo
Linear 0,69640,0759
0,0714
Polinomial 0,5320,0685
0,0738
RBF 0,6828 0,076 0,0767
Sigmoid 0,67920,0759
0,0795
Tabela7. Resultados Usina Sobradinho
Usina
SobradinhoCC MAE RMSE
Linear 0,9473
0,0196 0,0257
Polinomial 0,7468
0,0683 0,075
RBF 0,9356
0,0378 0,0418
Sigmoid 0,9336
0,0342 0,0385
Nesta próxima etapa, os parâmetros do kernel linear são variados, para cada
série e para sete dias de previsão. C (Custo) e ε (Epíslon) variam segundo o
Fernando José Barbosa de Brito Filho Página 37

Capítulo
intervalo fechado I=[10−4 ,10]. Valores diferentes aos de I , sendo maiores ou
menores não provocam diferenças substanciais nos valores das medidas de erro. Os resultados das Tabelas 8 à Tabela 12 são os ótimos dentro do intervalo I :
Tabela8a. Usina Furnas- Kernel Linear- 7dias à frente
C=1
ε=10−3 CC MAE RMSE
0.7862 0.0203 0.0388
Tabela8b. Usina Furnas- MLP- 7 dias à frente
CC
Médio
MAE
MédioRMSE
Médio
0.819
40.02639 0.0416
Tabela8c. Intervalos de Confiança -Usina Furnas- 7 dias à frente
Fernando José Barbosa de Brito Filho Página 38
Métricas Intervalos de Confiança
CC -0.098138071 < (µ1 - µ2) < 0.111725168
MEP -6.831691474< (µ1 - µ2) <7.879433409
RMSE -0.038176244 < (µ1 - µ2) < 0.041111728

Capítulo
Na Tabela 8a, os parâmetros ótimos para a série temporal da Usina Furnas,
para os intervalos informados e 7 dias à frente são C= 1 e ε = 10−3, achados
experimentalmente. O intervalo de variação dos neurônios da camadas escondida
na MPL, para a geração do melhor modelo é Imlp= [0,6], também para 7 dias à
frente. Foi utilizada taxa de aprendizagem ∝=0,1 , 500 ciclos para o treinamento. Na Tabela 8b, são mostrados os melhores coeficientes atingidos nesse intervalo,
resultante de 1 neurônio na camada escondida. Valores acima de 6 neurônios na
camada escondida não revelaram resultados melhores, em todos os testes. Na
Tabela 8c, revela-se os intervalos de confiança para cada coeficiente de erro CC ,
MEP (Mean Erro Percentual) e RMSE, calculados a partir do teste t de Student,
entre os modelos produzidos pela MLP e SVM. Foi usado grau de liberdade 29, 95%
de confiança e coeficiente de confiança igual a 2.045, para este e todos os testes
seguintes. Segundo a tabela dos limites dos IC´s, existe a possibilidade dos modelos
produzidos pela MLP e SVM serem iguais, para todas as métricas, pois o intervalo
de confiança (µ1 - µ2) pode incluir também o valor zero.
Tabela9a. Jordão- Kernel Linear – 7 dias à frente
C=1
ε=10−3 CC MAE RMSE
0.5613 0.0115 0.0247
Fernando José Barbosa de Brito Filho Página 39

Capítulo
Tabela9b. Jordão- MLP- 7dias à frente
Tabela9c. Intervalos de Confiança- Jordão- 7 dias à frente
Na Tabela 9a, os parâmetros ótimos, para o rio Jordão, achados
experimentalmente são: ε=10−3 e C = 1. Na MLP, Tabela 9b, os resultados foram
obtidos com 3 neurônios na camada escondida. Em relação aos intervalos de
confiança (µ1 - µ2) , calculados a partir do teste t de Student , entre o modelo SVM e
Fernando José Barbosa de Brito Filho Página 40
CC
Médio
MAE
Médio
RMSE
Médio
0.59320.0139
70.0247
Métricas Limites de Confiança
CC -0.068329325 < (µ1 - µ2) < 0.093877712
MEP -2.254686396 < (µ1 - µ2) < 2.658557364
RMSE -0.021901154 < (µ1 - µ2) < 0.020417283

Capítulo
MLP, em todos existe a possilibildade do valor ser zero, para todas as 3 métricas
utilizadas (Tabela 9c).
Tabela10a. Salto Santiago- Kernel Linear – 7 dias à frente
C=10
ε=10−3 CC MAE RMSE
0.7094 0.0162 0.0332
Tabela10b. Salto Santiago – MLP- 7dias à frente
CC
Médio
MAE
Médio
RMSE
Médio
0.7292 0.0191 0.0340
Tabela10c. Intevalos de Confiança- Salto Santiago- 7 dias à frente
Fernando José Barbosa de Brito Filho Página 41
Métricas Limites de Confiança
CC -0.024461395 < (µ1 - µ2) < 0.017042041
MEP-3.319806506 < (µ1 - µ2) < 3.777871022
RMSE-0.013113283 < (µ1 - µ2) < 0.012377799

Capítulo
Na Tabela 10a, os respectivos resultados de Salto Santiago, os parâmetros
ótimos, achados experimentalmente são: ε=10−3 e C=10. Dois neurônios na camada
escondida, para os resultados da Tabela 10b. Em relação aos intervalos de
confiança, calculados a partir do teste t de Student, entre os modelos SVM e MLP,
em todos existe a possibilidade do valor ser zero, para todas as 3 métricas utilizadas
(Tabela 10c).
Tabela11a. Usina Itaipu- Kernel Linear – 7 dias à frente
C=10
ε=10−2 CC MAE RMSE
0.8606 0.0307 0.0459
Tabela11b. Usina Itaipu –MLP-7 dias à frente
CC
Médio
MAE
Médio
RMSE
Médio
0.9211 0.0342 0.0475
Fernando José Barbosa de Brito Filho Página 42

Capítulo
Tabela11c. Intervalos de Confiança - Usina Itaipu - 7 dias à frente
Na Tabela 11a, série temporal das vazões da Usina de Itaipu, os parâmetros
ótimos, achados experimentalmente são: ε=10−2 e C =10. Foram utilizados 5
neurônios na camada escondida da MLP (Tabela 11b). Segundo os intervalos de
confiança, calculados a partir do teste t de Student, entre os modelos SVM e MLP,
em todos existe a possibilidade do valor ser zero, para todas as 3 métricas utilizadas
(Tabela 11c).
Tabela12a. Usina Sobradinho- Kernel Linear – 7 dias à frente
C=10
ε=10−3
CC MAE RMSE
0.9619 0.0113 0.0201
Fernando José Barbosa de Brito Filho Página 43
Métricas Limites de Confiança
CC -0.008376409< (µ1 - µ2) < 0.014318345
MEP -2.629639724< (µ1 - µ2) < 2.93738166
RMSE -0.026690418< (µ1 - µ2) < 0.027000096
Capítulo
Tabela12b. Usina Sobradinho – MLP- 7 dias à frente
CC
Médio
MAE
Médio
RMSE
Médio
0.9608 0.0147 0.0216
Tabela12c. Intervalos de Confiança- Usina Sobradinho - 7 dias à frente
E finalmente, na Tabela 12a, os parâmetros ótimos para a série temporal da
Usina de Sobradinho, achados experimentalmente foram: ε=10−2 e C=10. Os
resultados da MLP (Tabela 12b) foram achados com dois neurônios na camada
escondida. Para (µ1 - µ2), que é o intervalo de confiança, para os três coeficientes:
Fernando José Barbosa de Brito Filho Página 44
Métricas Limites de Confiança
CC -0.008839521< (µ1 - µ2) < 0.006710489
MEP -3.61473984 < (µ1 - µ2) < 4.301191453
RMSE -0.026870194 < (µ1 - µ2) < 0.030063742

Capítulo
CC, MEP e RMSE, existe a possibilidade do valor ser zero, tornando os modelos
estatisticamente equivalentes.
Fernando José Barbosa de Brito Filho Página 45

Capítulo
Capítulo 5Conclusão
Neste trabalho de conclusão de curso, foi apresentado o problema de
previsão de vazões. Na tentativa de melhorar o desempenho em relação aos atuais
modelos utilizados, foi proposta uma metodologia com o uso de máquinas de vetor
de suporte para a previsão das vazões. Sendo assim, foi necessária para a
implantação da metodologia, a utilização de uma ferramenta que contivesse os
vários tipos de algoritmos de regressão de vetor-suporte (SVR) e uma ferramenta de
planilha eletrônica, para realizar o preprocessamento e testes estatísticos finais, das
várias bases de dados usadas.
Com os resultados alcançados foi possível comprovar que essa metodologia
pode ser empregada na previsão de vazões equivalentemente aos modelos de
previsão que utlizam MLP, para todas as cinco séries utilizadas, pois conforme o
teste t de Student, levando-se em consideração os limites de confiança, existe a
possibilidade do valor ser zero, tornando os dois modelos, SVM e MLP,
estatisticamente iguais, para cada uma das três métricas utilizadas.
Como trabalhos futuros, podem-se fazer comparações de desempenho da
SVM com outros tipos de modelos de previsão, não somente a MLP, testando-se
uma gama maior de funções kernel e intervalos de variação.
Bibliografia
Fernando José Barbosa de Brito Filho Página 46

Capítulo
[1]
Almeida, F. F. (2007). Support Vector Machine. Universidade Federal de
Campina Grande Centro de Ciências e Tecnologia .
[2] ANEEL. (2011). Acesso em 28 de Setembro de 2011, disponível em
Agência Nacional de Energia Elétrica: http://www.aneel.gov.br/
[3] Cabral, G. (2005). Ferramenta para auxílio na previsão de séries
temporais com intervalos de confiança usando Máquinas de Vetor de Suporte.
[4] Chang, C., & Lin, C. (2001). A Library for Support Vector Machines.
Taipei, Taiwan: National Taiwan University.
[5] Cherkassky, V., & Mulier, F. (1998). Learning from data: Concepts,
Theory and Methods. New York: Wiley.
[6] Cortes, C., & Vapnik, V. (1995). Support Vector networks. Machine
Learning , pp. 273-297.
[7] Eletronorte. (2011). Parte II - Fontes Renováveis. Energia Hidráulica .
[8] Freund, Y., & Schapire, R. E. (August de 1997). A decision-theoretic
generalization of on-line learning and an application to boosting. J. Comput.
Syst. Sci. , pp. vol. 55, no. 1,119–139.
[9] Gunn, S. R. (10 de Maio de 1998). Support Vector Machines
forClassification and Regression.
[10] HAYKIN, S. S. (1999). Redes Neurais, Principios e Pratica. Bookman.
[11] Hearst, M. A., Schölkopf, B., Dumais, S., Osuna, E., & Platt, J. (1998).
Trends and controversies- Support Vector Machine. IEEE Intelligent Systems ,
pp. 13(4):18–28.
[12] Kuhn, M. (Novembro de 2006). The Karush-Kuhn-Tucker Theorem.
CDSEM Uni Mannheim .
[13] Lima, C. A. (10 de Dezembro de 2004). Comitê de Máquinas: Uma
Abordagem Unificada Empregando Máquinas de Vetores-Suporte. pp. 111-
118.
Fernando José Barbosa de Brito Filho Página 47

Capítulo
[14] Lorena, A. C., & Carvalho, A. C. (2007). Uma Introdução às SVM´s.
[15] Mavroforakis, M. E. (Maio de 2006). A Geometric Approach to Support
Vector Machine(SVM) Classification. IEEE TRANSACTIONS ON NEURAL
NETWORKS , p. 672.
[16] Minoux, M. (1986 ). Mathematical programming: Theory and algorithms.
Chichester W. Sussex and New York: Wiley.
[17] Müller, K.-R., Mika, S., Rätsch, G., Tsuda, K., & Schölkopf, B. (Março
de 2001). An Introduction to Kernel- Based Learning. IEEE TRANSACTIONS
ON NEURAL NETWORKS , p. 183.
[18] Noble, W. S. (s.d.). Support vector machine applications in Biology.
University of Washington.
[19] ONS. (Outubro de 2011). Acesso em 28 de Setembro de 2011,
disponível em PROGRAMA MENSAL DA OPERAÇÃO (PMO) RELATÓRIO
MENSAL DE PREVISÃO DE VAZÕES E GERAÇÃO DE CENÁRIOS DE
AFLUÊNCIAS: http://www.ons.gov.br/
[20] Passerini, A. (2004). Kernel Methods, multiclass classification and
applications to computational molecular biology. Università Degli Studi di
Firenze.
[21] Scholkopf, A. J. (2003). A Tutorial on Support Vector Regression.
[22] Schölkopf, A. S., Williamson, R. C., & Bartlett, P. L. (2000). New
support vector algorithms. Neural Computation , pp. 2:1207-1245.
[23] Smola, A. J. (1999). Introduction to large margin classifiers. pp. 1–28.
[24] Smola, A., & Schölkopf, B. (1998). A Tutorial os support vector
regression. NeuroColt2 TR 1998-03 .
[25] Tan, P., Steinbach, M., & Kumar, V. (2009). Introdução ao Data Mining.
Rio de Janeiro: Ciência Moderna.
[26] Vapnik, V. N. (1998). Statistical Learnig Theory. Canadá.
Fernando José Barbosa de Brito Filho Página 48

Capítulo
[27] Weka - The University of Waikato. Machine Learning Group [citado em
24 de Junho de 2012 - 21:12]. Disponível em URL:
http://www.cs.waikato.ac.nz/ml/weka/
Fernando José Barbosa de Brito Filho Página 49