namedin pereira teles júnior · 2019. 10. 25. · catalogação na fonte bibliotecária jane souto...
TRANSCRIPT

“Backup Markup Language (BKPML): Uma Proposta paraInteroperabilidade e Padronização de Backup de Dados”
Por
Namedin Pereira Teles Júnior
Dissertação de Mestrado
Universidade Federal de Pernambuco
www.cin.ufpe.br/~posgraduacao
RECIFE, Fevereiro/2011

Universidade Federal de Pernambuco
Centro de InformáticaPós-graduação em Ciência da Computação
Namedin Pereira Teles Júnior
“Backup Markup Language (BKPML): Uma Propostapara Interoperabilidade e Padronização de Backup de
Dados”
Trabalho apresentado ao Programa de Pós-graduação em
Ciência da Computação do Centro de Informática da Uni-
versidade Federal de Pernambuco como requisito parcial
para obtenção do grau de Mestre em Ciência da Computa-
ção.
Orientador: Roberto Souto Maior de Barros
RECIFE, Fevereiro/2011

Catalogação na fonte Bibliotecária Jane Souto Maior, CRB4-571 Teles Júnior, Namedin Pereira Backup markup language (BKPML) : uma proposta para interoperabilidade e padronização de backup de dados /
Namedin Pereira Teles Júnior - Recife: O Autor, 2011. xxiv, 107 p. : il., fig., tab. Orientador: Roberto Souto Maior de Barros. Dissertação (mestrado) Universidade Federal de Pernambuco. CIn. Ciência da Computação, 2011. Inclui bibliografia. 1. Sistemas de gerenciamento de banco de dados. 2. Sistemas distribuídos de backup. I. Barros, Roberto Souto Maior de (orientador). II. Título. 005.74 CDD (22. ed.) MEI2011 – 043


Dedico essa dissertação em memória do meu avô
Secundino Rocha.

Agradecimentos
A Deus, por ter me dado saúde e força para proseguir com meus objetivos. E enquantoestive morando em Recife, ajudou-me a suportar toda saudade de minha família emManaus, pondo em meu caminho pessoas maravilhosas e acolhedoras.
A minha mãe, Shirley, pelo grande incentivo e carinho demonstrado durante todaminha vida.
A minha esposa, Nívia, pelo apoio, quando morei em Recife, deixando-a em Ma-naus, pela compreensão ao chegar e dedicar meu tempo exclusivamente ao desenvolvi-mento deste trabalho, e ao grande amor que nos uniu nesta etapa de nossas vidas.
Ao professor e orientador, Roberto, por me orientar sabiamente, me pondo no cami-nho certo quanto ao desenvolvimento deste trabalho. Pela confiança depositada ao meliberar e concordar em me orientar a distância, e por todo tempo a mim dedicado.
A minha irmã, sobrinho e cunhado, Nádia, Cesar e Nailton, pelo incentivo, cuida-dos e ajuda dada em todos os momentos da minha vida, por me apoiarem em decisõesimportantes e estarem ao meu lado sempre que precisei.
Aos integrandes e amigos do CIN, mais especificamente Jair, Emmanuel, Dalasiel,Rebeca, Marco, Jeisa, Felix, Ademir, Rafael e Crescêncio, e todas as pessoas que parti-ciparam de forma direta ou indireta desta conquista.
Aos moradores do condomínio Laranjeiras, por me receberem, não só como umamigo, mas como parte integrante de cada família que lá vive, em especial, Antonieta,Gabriel, Tiazinha, Márcia, Ana, Joel e família, Vitória e família.
À Universidade Federal de Pernambuco, professores e funcionários que ajudam amanter a universidade limpa e organizadas para os alunos e pesquisadores.
A todos que fizeram desta minha luta uma experiência de vida valiosa.
vi

"O sucesso é um professor perverso. Ele seduz as pessoas inteligentes
a as faz pensar que jamais irão cair."
—BILL GATES (Pensamento)

Resumo
O atual modelo de negócios de uma empresa moderna está cada vez mais dependente dastecnologias e dos sistemas de informação. Com isso, é necessário que se mantenha osdados protegidos através de uma cópia segurança, conhecida como backup, que garan-tirá a restauração e migração dos dados quando necessário. Além disso, é comum umaempresa adotar mais de um Sistema de Gerenciamento de Banco de Dados (SGBD) paraarmazenamento dos dados, gerando ambientes heterogêneos e dificultando a interopera-bilidade entre os sistemas quando necessário. Isso porque os SGBD existentes realizambackup, restauração e migração dos dados sob tecnologias específicas e limitadas como(Oracle, Sqlserver, Mysql), não permitindo a restauração dos dados em outros SGBD,somente no seu ambiente de origem.
Nesse contexto, este trabalho propõe o desenvolvimento de uma estrutura padrãopara os arquivos de backup, utilizando a linguagem de marcação eXtensible Markup
Language (XML), denominada como Backup Markup Language (BKPML). A BKPMLtem por objetivo desvincular a dependência dos arquivos de backup de sua fonte de ori-gem, possibilitando manter a interoperabilidade necessária entre SGBD heterogêneosatravés dos arquivos de backup, e a transformação dos dados para arquivos secundá-rios, como TEXTO, EXCEL, JavaScript Object Notation (JSON), YAML Ain’t Markup
Language (YAML), Comma-Separated Values (CSV) e XML. Para isso, foi necessário odesenvolvimento de uma ferramenta responsável por administrar os arquivos BKPMLgerados. Como proposta de armazenamento seguro, além do armazenamento local, estetrabalho utiliza Cloud Computing como alternativa para armazenamento dos arquivosBKPML.
Palavras-chave:Ambientes Heterogêneos, Interoperabilidade, Padronização, XML, Sistemas de Ge-
renciamento de Banco de Dados (SGBD), Backup, Restauração , Migração e Cloud
Computing.
viii

Abstract
The current business model of a modern business is increasingly dependent on techno-logy and information systems. Thus, it is necessary to keep data protected by a securitycopy, known as backup, which will ensure the restoration and migration of data whenneeded. Furthermore, it is common for a company to adopt more than one Database Ma-nagement System (DBMS) for data storage, creating heterogeneous environments andhindering the interoperability between the systems when needed. This happens becausethe existing DBMSs perform backup, restore and data migration under specific and limi-ted platforms such as Oracle, SQLServer, MySQL, not allowing the restoration of datain other database systems, only in its original environment.
In this context, this work proposes to develop a standard framework for the backup fi-les, using the Extensible Markup Language (XML), known as Backup Markup Language(BKPML). The BKPML aims to relieve the dependence of the backup files from theirsources, enabling the interoperability required between heterogeneous database systemsthrough the backup files, and the processing using data for secondary files as text, Excel,JavaScript Object Notation (JSON), YAML Ain’t Markup Language (YAML), comma-separated values (CSV) and XML. This lead us to the development of a tool responsiblefor managing generated BKPML files. As a proposal for the safe storage, in addition tolocal storage, this work uses cloud computing as an alternative to BKPML files storing.
Keywords:Heterogeneous Environments, Interoperability, Standards, XML, DBMS, Backup,
Restore, Migration and Cloud Computing.
ix

Sumário
Lista de Figuras xiii
Lista de Tabelas xv
Lista de Abreviaturas xvi
1 Introdução 11.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Breve Histórico da evolução da TI . . . . . . . . . . . . . . . . . . . . 31.3 Objetivo da dissertação . . . . . . . . . . . . . . . . . . . . . . . . . . 51.4 Objetivos específicos . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.5 Estrutura da dissertação . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Referencial Teórico 82.1 Backup de dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.1 Tipos de mídia para backup de dados . . . . . . . . . . . . . . 92.1.2 Segurança dos dados . . . . . . . . . . . . . . . . . . . . . . . 112.1.3 Criptografia dos dados . . . . . . . . . . . . . . . . . . . . . . 122.1.4 Algoritmo triple des (3DES) . . . . . . . . . . . . . . . . . . . 12
2.2 Migração de dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2.1 Níveis de migração . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Computação nas nuvens . . . . . . . . . . . . . . . . . . . . . . . . . 152.3.1 Backup de dados em nuvens . . . . . . . . . . . . . . . . . . . 162.3.2 Aplicações cloud para backup/recuperação de dados . . . . . . 17
2.4 Padronização da informação . . . . . . . . . . . . . . . . . . . . . . . 182.4.1 eXtensible Markup Language (XML) . . . . . . . . . . . . . . . 192.4.2 XML Schema . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.4.3 YAML Ain’t Markup Language (YAML) . . . . . . . . . . . . . 212.4.4 JavaScript Object Notation (JSON) . . . . . . . . . . . . . . . 22
2.5 Aplicações WEB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.5.1 Tecnologias Web . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.6 Padrões de projeto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.6.1 O padrão estrutural Decorator . . . . . . . . . . . . . . . . . . 262.6.2 O padrão comportamental Strategy . . . . . . . . . . . . . . . . 27
x

2.6.3 O padrão Data Access Object (DAO) . . . . . . . . . . . . . . 282.6.4 O padrão Model View Controller (MVC) . . . . . . . . . . . . . 29
2.7 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3 Backup Markup Language (BKPML) 323.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323.2 Apresentação da estrutura BKPML . . . . . . . . . . . . . . . . . . . . 35
3.2.1 O elemento SchemaDB . . . . . . . . . . . . . . . . . . . . . . 353.2.2 O elemento Objects . . . . . . . . . . . . . . . . . . . . . . . . 38
3.3 Estrutura dos objetos da BKPML . . . . . . . . . . . . . . . . . . . . . 383.3.1 O elemento complexo tableobjecttype . . . . . . . . . . . . . . 393.3.2 O elemento complexo indexobjecttype . . . . . . . . . . . . . . 393.3.3 O elemento complexo viewobjecttype . . . . . . . . . . . . . . 403.3.4 O elemento complexo grantobjecttype . . . . . . . . . . . . . . 403.3.5 O elemento complexo triggerobjecttype . . . . . . . . . . . . . 423.3.6 O elemento complexo methodobjecttype . . . . . . . . . . . . . 42
3.4 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4 A Ferramenta: Backup Markup Language Manager (BKPML Manager) 464.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 464.2 Arquitetura da ferramenta BKPML Manager . . . . . . . . . . . . . . . 50
4.2.1 A camada Cliente . . . . . . . . . . . . . . . . . . . . . . . . . 514.2.2 Lições Aprendidas . . . . . . . . . . . . . . . . . . . . . . . . 524.2.3 A camada Servidor . . . . . . . . . . . . . . . . . . . . . . . . 534.2.4 Lições Aprendidas . . . . . . . . . . . . . . . . . . . . . . . . 544.2.5 A Camada SGBD . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.3 Padrões de projeto utilizados . . . . . . . . . . . . . . . . . . . . . . . 554.3.1 Aplicando o padrão Data Access Object (DAO) . . . . . . . . . 564.3.2 Aplicando o padrão Decorator . . . . . . . . . . . . . . . . . . 584.3.3 Aplicando o Padrão de projetos Strategy . . . . . . . . . . . . . 604.3.4 Aplicando o Padrão de projetos Model View Controller (MVC) . 61
4.4 Funcionalidade da BKPML Manager . . . . . . . . . . . . . . . . . . . 634.5 Considerações finais . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
5 Estudo de caso 685.1 Apresentação da empresa e domínio do problema . . . . . . . . . . . . 68
xi

5.2 Preparando o ambiente para execução do backup . . . . . . . . . . . . 705.3 Cadastrando as ações de backup . . . . . . . . . . . . . . . . . . . . . 735.4 Executando o Backup dos dados . . . . . . . . . . . . . . . . . . . . . 745.5 Preparando o ambiente de restauração e migração . . . . . . . . . . . . 81
5.5.1 Restaurando e transformando os arquivos BKPML . . . . . . . 825.5.2 Migrando os arquivos BKPML de objetos complexos . . . . . . 865.5.3 Testando a eficiência x volume de informação . . . . . . . . . . 90
5.6 Considerações finais . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
6 Conclusões e Trabalhos Futuros 946.1 Conclusões e contribuições . . . . . . . . . . . . . . . . . . . . . . . . 946.2 Limitações e trabalhos futuros . . . . . . . . . . . . . . . . . . . . . . 96
Bibliografia 99
xii

Lista de Figuras
2.1 Principais erros que levam a perda de dados . . . . . . . . . . . . . . . 92.2 Componentes Envolvidos na Criptografia . . . . . . . . . . . . . . . . 122.3 Processo de criptografia . . . . . . . . . . . . . . . . . . . . . . . . . . 132.4 Arquitetura da Computação nas nuvens . . . . . . . . . . . . . . . . . 152.5 Documento XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.6 Documento XMLSchema . . . . . . . . . . . . . . . . . . . . . . . . . 202.7 Documento XML para YAML . . . . . . . . . . . . . . . . . . . . . . 212.8 Documento JSON . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.9 Diagrama de Classes do padrão Decorator . . . . . . . . . . . . . . . . 272.10 Diagrama de Classes do padrão Strategy . . . . . . . . . . . . . . . . . 282.11 Diagrama do Padrão DAO . . . . . . . . . . . . . . . . . . . . . . . . 29
3.1 Representação em árvore da estrutura BKPML . . . . . . . . . . . . . 363.2 Estrutura principal da BKPML . . . . . . . . . . . . . . . . . . . . . . 373.3 Tipo complexo TableObjectType . . . . . . . . . . . . . . . . . . . . . 403.4 Tipo complexo IndexObjectType . . . . . . . . . . . . . . . . . . . . . 413.5 Tipo complexo viewobjecttype . . . . . . . . . . . . . . . . . . . . . . 413.6 Tipo complexo GrantObjectType . . . . . . . . . . . . . . . . . . . . . 423.7 Tipo complexo TriggerObjectType . . . . . . . . . . . . . . . . . . . . 433.8 Tipo complexo MethodObjectType . . . . . . . . . . . . . . . . . . . . 44
4.1 Tela principal da BKPML Manager . . . . . . . . . . . . . . . . . . . 474.2 Ciclo de vida dos processos de Backup/Restore da ferramenta BKPML
Manager . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484.3 Menu da BKPML Manager . . . . . . . . . . . . . . . . . . . . . . . . 504.4 Arquitetura da BKPML Manager . . . . . . . . . . . . . . . . . . . . . 514.5 Padrão DAO da BKPML Manager . . . . . . . . . . . . . . . . . . . . 574.6 Padrão Decorator da BKPML Manager . . . . . . . . . . . . . . . . . . 594.7 Instanciando uma classe backup/Restore . . . . . . . . . . . . . . . . . 594.8 Aplicando o padrão decorator a um objeto backup . . . . . . . . . . . . 604.9 Padrão Strategy da BKPML Manager . . . . . . . . . . . . . . . . . . 614.10 Arquitetura MVC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 624.11 Diagrama de Caso de Uso da BKPML Manager . . . . . . . . . . . . . 64
5.1 Etapa 3 do processo de preparação do ambiente . . . . . . . . . . . . . 72
xiii

5.2 Etapa 4 do processo de preparação do ambiente . . . . . . . . . . . . . 725.3 Tela de cadastro de Ações . . . . . . . . . . . . . . . . . . . . . . . . . 745.4 Tela de execução de backup de dados . . . . . . . . . . . . . . . . . . 755.5 Documento BKPML TBL_CURSO . . . . . . . . . . . . . . . . . . . 755.6 Documento BKPML TBL_EMENTA . . . . . . . . . . . . . . . . . . 765.7 Documento BKPML TBL_SERVICOS . . . . . . . . . . . . . . . . . 775.8 Documento BKPML IDX_BY_DATA_COURSE . . . . . . . . . . . . 785.9 Documento BKPML FNC_INSERIR_CURSO . . . . . . . . . . . . . 785.10 Documento BKPML FNC_DELETAR_CURSO . . . . . . . . . . . . . 795.11 Documento BKPML FNC_ALTERAR_SERVICOS . . . . . . . . . . . 795.12 Documento BKPML PRC_LISTAR_EMENTA . . . . . . . . . . . . . 805.13 Documento BKPML VEW_CURSO_EMENTA . . . . . . . . . . . . . 805.14 Documento BKPML TRG_EXCLUIR_EMENTA . . . . . . . . . . . . 815.15 Tela de Restauração de dados . . . . . . . . . . . . . . . . . . . . . . . 835.16 Restauração dos dados no postgres . . . . . . . . . . . . . . . . . . . . 835.17 Objeto TBL_EMENTA em formato CSV . . . . . . . . . . . . . . . . 845.18 Objeto TBL_CURSO em formato Excel . . . . . . . . . . . . . . . . . 845.19 Objeto TBL_EMENTA em formato JSON . . . . . . . . . . . . . . . . 855.20 Objeto TBL_SERVICOS em formato YAML . . . . . . . . . . . . . . 855.21 Tela de Migração de dados . . . . . . . . . . . . . . . . . . . . . . . . 875.22 Sintaxe padrão para objetos tipo função . . . . . . . . . . . . . . . . . 885.23 Sintaxe padrão para objetos tipo gatilho . . . . . . . . . . . . . . . . . 885.24 Resultado da Migração para o ORACLE Express . . . . . . . . . . . . 89
xiv

Lista de Tabelas
5.1 Objetos do estudo de caso . . . . . . . . . . . . . . . . . . . . . . . . . 695.2 Geração dos arquivos BKPML por volume e tempo . . . . . . . . . . . 91
xv

Lista de Abreviaturas
BKPML Backup Markup Language
CORBA Common Object Request Broker Architecture
CSS Cascading Style Sheets
CSV Comma-Separated Values
DAO Data Access Object
DBMS Database management system
DCOM Distributed Component Object Model
DSAAS Data Storage As A Service
DTD Document Type Definition
GML Generalized Markup Language
HTML Hypertext Markup Language
HTTP Hypertext Transfer Protocol
IAAS Infrastructure As A Service
IBM International Business Machine
JDBC Java DataBase Connection
JSF Java Server Faces
JSON JavaScript Object Notation
JSP JavaServer Pages
JSTL Javaserver page Standard Tag Lib
JVM Java Virtual Machine
MathML Mathematical Markup Language
MVC Model View Controller
xvi

PAAS Platform As A Service
RMI Remote Method Invocation
S3 Simple Storage Service
SAAS Software As A Service
SGBD Sistemas de Gerenciamento de Banco de Dados
SI Sistema de Informação
SQL Structured Query Language
SVG Scalable Vectorial Graphics
TI Tecnologia da Informação
UML Unified Modeling Language
W3C World Wide Web Consortium
XBRL eXtensible Business Reporting Language
XML eXtensible Markup Language
XSIL eXtensible Scientific Interchange Language
YAML YAML Ain’t Markup Language
xvii

1Introdução
As novas demandas e a competitividade do mercado criam uma grande expectativa enecessidade a respeito da aplicação da Tecnologia da Informação (TI). Contudo, hátambém um grande questionamento sobre as reais vantagens da utilização da TI em re-lação aos problemas e limitações encontrados nessa área de conhecimento. Para avaliaros impactos da TI nas operações e estratégias das empresas, faz-se necessário uma préviaapresentação sobre a evolução das tecnologias e sistemas de informação, o impacto damudança de paradigma envolvida, bem como os principais fatores que tendem a aumen-tar o grau de fracasso ou de sucesso na implantação de soluções de TI. Este capítulo tempor objetivo apresentar as principais problemáticas que motivaram o desenvolvimentodeste trabalho, bem como a solução proposta para tais problemas.
1.1 Motivação
Para atender um mercado cada dia mais exigente, empresas e organizações estão tor-nando mais comum, em seus modelos de negócio, a utilização da tecnologia da infor-mação em diversas áreas da empresa, com objetivo estratégico e organizacional.
De acordo com Turban et al. (2002), um modelo de negócios é um método pelo quala empresa consegue agir para gerar lucro e sustentar-se. Esse modelo explica detalha-damente como a empresa agrega valor, quais são os consumidores dispostos a pagar porseus produtos, e qual a melhor forma de gerir seus negócios para atender o mercado.
Nesse novo modelo de negócios, as informações passam a ser o centro de todo pro-cesso empresarial. Martens (2001) comenta que o sucesso empresarial passa a dependerfundamentalmente da capacidade da empresa organizar e administrar sua base de infor-mações, e aproveitar ao máximo as diferenciações competitivas oferecidas pela TI.
É inegável que a TI esteja cada dia mais presente nos ambientes empresariais. Nota-
1

1.1. MOTIVAÇÃO
se que recentes avanços na informática como Internet, novas interfaces gráficas, Business
to Business, e-commerce e Enterprise Resource Planning estão se tornando mais comunse necessárias no cotidiano e diálogos empresariais (Terra, 2005).
Para as empresas, na visão de Quinn et al. (1997) e Terra (2005), a TI, ou mais es-pecificamente o Sistema de Informação (SI), passa a ser considerado o elemento centraldo processo inovador, capaz de diminuir, unir e eliminar várias de suas etapas. O usointensivo de software permite trazer a interação com clientes para um patamar bem maiselevado de qualidade, serviço e personalização, além de permitir a detecção de macrotendências com extrema velocidade.
Nesse novo paradigma, os SI deixam de ser simples aplicativos com objetivo de ar-mazenar e recuperar informação, e passam a se tornar poderosas ferramentas para análisee mineração de dados, tornando as informações o principal fator para que uma empresapossa acompanhar essas mudanças. Esse modelo faz com que a segurança da informa-ção transforme-se na chave para manter a continuidade dos negócios e a integridade dosdados.
Apesar da grande importância da informação para as empresas, ainda existem empre-sas que decidem manter a economia financeira em detrimento da segurança dos dados,e não investem em soluções de hardware, software ou recursos humanos para mantê-losprotegidos. Um estudo, realizado em maio de 2009 com mais de 1600 empresas de 24países, mostrou que no Brasil houve um prejuízo de US 297 mil pela perda de dadoscorporativos (Pernambuco, 2009).
Dentre as soluções para Segurança da Informação estão o backup (cópia de segu-rança) e a restauração dos dados. Chen and Zheng (2008) explicam que aplicaçõesfamosas para backup e recuperação de dados possuem um custo elevado, o que deixaempresas de pequeno e médio porte sem muitas alternativas para segurança dos seusdados. A adoção de ferramentas Open Source é uma opção para tentar baixar o custo,mas, dependendo do modelo de negócios adotado, a utilização total de ferramentas Open
Source pode não atender ao plano de continuidade de negócio adotado.A cópia de segurança em computadores é um instrumento importante para com-
pensar ou tentar sanar problemas oriundos de hardware, software, erros humanos ousegurança dos dados. Em empresas que dependem fortemente dos sistemas e dos com-putadores, a perda dos dados pode representar perda de capital.
Trazendo essa realidade para a vida cotidiana, na qual o computador é usado comoferramenta de trabalho, perder dados significa perder tempo, perdendo tempo, perde-se dinheiro e, por conseguinte, o cliente. Chen and Zheng (2008) comentam que toda
2

1.2. BREVE HISTÓRICO DA EVOLUÇÃO DA TI
empresa deve possuir um plano de backup e restauração de dados, pois suas operaçõesdo dia-a-dia podem gerar uma quantidade considerável de dados, que estão sujeitos adanos lógicos e físicos.
Além de manter os dados seguros e íntegros, os arquivos de backup, quando vistosde forma analítica, contribuem para comunicação e troca de informação recíproca entresistemas legados de uma empresa. Turban et al. (2002) define sistemas legados comosistemas antigos, normalmente desenvolvidos por diferentes fornecedores, utilizando di-ferentes tecnologias, feitos para atender áreas distintas (administrativa, financeira, con-tábil, entre outros), e que hoje se tornaram a principal fonte de importantes informaçõespara muitas empresas.
A grande problemática com sistemas legados é a dispersão da informação entre di-versas tecnologias, o que normalmente compromete a interoperabilidade ou a troca deinformação entre diversos sistemas.
Para possibilitar o backup e restauração de dados, os Sistemas de Gerenciamento deBanco de Dados (SGBD) disponibilizam ferramentas específicas que apresentam limi-tações quanto a impossibilidade de troca de informação entre SGBD distintos, visto quecada SGBD realiza backup e restauração dos dados com suas tecnologias específicas enativas. Como exemplos podem ser citados Oracle (Oracle, 2005), Sqlserver (SQLSer-ver, 2011), Mysql (MYSQL, 2010) e Postgres (Postgres, 2011).
Tal limitação impede a interoperabilidade dos dados e recursos entre SGBD. Paramelhor entendimento sobre a origem dos sistemas legados, bem como as problemáticasgeradas por ele, os tópicos a seguir destinam-se a apresentar um breve histórico sobre aevolução da TI e, por fim, apresentar um breve resumo sobre a solução proposta para oproblema em questão.
1.2 Breve Histórico da evolução da TI
Cronologicamente, a TI teve início da década de 60, contribuindo de forma progressivanas áreas empresariais, transporte, rádio, televisão, entre outras de grande importânciapara a sociedade.
Nessa década, segundo Rezende (2002), conhecida como ERA DO PROCESSA-
MENTO DE DADOS, todos os recursos eram direcionados para processamento centrali-zado, realizado por grandes computadores, denominados MAINFRAMES, responsáveispor processar informações de folhas de pagamento, contabilidade e finanças, de formamecanizada. Esses novos recursos, além de reduzir o tempo de trabalho em dias ou até
3

1.2. BREVE HISTÓRICO DA EVOLUÇÃO DA TI
mesmo meses, tornaram-se a principal fonte de importantes informações para as empre-sas.
A partir da década de 70 a 80, esses sistemas ficariam conhecidos como sistemaslegados, responsáveis pelo início de inúmeras pesquisas sobre comunicação transparenteentre sistemas legados (Turban et al., 2002).
A década de 70, também conhecida como Era dos sistemas de apoio à decisão, apre-senta sistemas que passam a ser um fator vantajoso quanto à concorrência de mercado.Os terminais passam a se tornar flexíveis e com poder de processar diversas tarefas si-multaneamente com diversos usuários.
A maior evolução técnica dessa época foi a transferência dos dados para SGBD e autilização da Generalized Markup Language (GML), criada pela International Business
Machine (IBM) para armazenamento de grandes quantidades de informação de diversostemas. Foi a partir da GML que surgiu a ideia de padronização de documentos.
A partir da década de 80, o termo Processamento de Dados foi perdendo força eabrindo espaço ao termo Tecnologia da Informação. TI tornou-se o termo aceito paraenglobar a rápida expansão de equipamentos (computadores, dispositivos de armazena-mento de dados, redes e dispositivos de comunicação), aplicações e serviços utilizadospelas organizações para fornecer dados, informações e conhecimento (Laurindo, 2000).
Em uma definição mais restrita, TI diz respeito ao aspecto tecnológico de um Sistemade Informação (SI) (Turban et al., 2002). Ela inclui hardware, banco de dados, software,redes e outros dispositivos. A TI evoluiu de uma orientação tradicional de suporte ad-ministrativo para um papel estratégico dentro da organização. Ela não só sustenta asestratégias de negócios existentes, mas também permite viabilizar novas estratégias em-presariais e oportunidades de negócio (Laurindo, 2000).
Foi nesta época que os sistemas legados passaram a tornar-se uma preocupação paraas empresas. Sistemas que antes centralizavam processamento, agora passam a distri-buir e trocar informações com outros sistemas. A questão levantada nessa época foi:Como manter a interoperabilidade entre os novos sistemas e os mais antigos?. A par-tir desse questionamento, foi dado início a inúmeras pesquisas sobre interoperabilidadeentre sistemas legados.
O conceito de gestão dos dados e informação surgiu na década de 90, compreen-dendo atividades como: armazenamento, recuperação e níveis de controle e acesso àinformação. Ele intensifica a criação de um plano de contingência e segurança dos da-dos, além de ver os dados como a principal fonte de apoio a decisões empresarias. Ossistemas estratégicos têm sido vistos como uma melhoria para a competitividade das
4

1.3. OBJETIVO DA DISSERTAÇÃO
empresas, através do aumento de produtividade, melhorias no trabalho em equipe e co-municação entre empresas, fornecedores e clientes.
Segundo REINHARD (1996); Brito et al. (1997); Voas and Zhang (2009), as cons-tantes mudanças ocorridas na TI, aconteceram de acordo com as necessidades, sejamelas voltadas ao aspecto empresarial, ou sob qualquer outra necessidade, ou até mesmopela realização de grandes e significativos investimentos em novos produtos, serviços eprocessos fundamentados e apoiados por tecnologias. Além disso, pode-se vincular esseimpulso de mudanças às problemáticas oriundas das décadas supracitadas.
1.3 Objetivo da dissertação
Em virtude dos problemas relacionados à interoperabilidade entre SGBD no que tangeo backup e restauração de dados, este trabalho propõe a padronização de uma estrutura,utilizando a linguagem de marcação XML (Ray, 2006), denominada Backup Markup
Language (BKPML), cujo objetivo é desvincular a dependência dos arquivos de bac-kup de sua fonte de origem, possibilitando manter a interoperabilidade necessária entreSGBD heterogêneos através dos arquivos de backup.
A possibilidade de migrar os dados para bases heterogêneas a partir de arquivos debackup é algo que vem influenciar de forma positiva os processos de migração, pois,desta forma, os backups de dados originados em um SGBD A poderiam facilmente serrestaurados em um SGBD B.
A solução proposta almeja que o backup e restauração dos dados possam ser rea-lizados de forma transparente, e até mesmo a possibilidade de migrar os arquivos debackup (BKPML) para arquivos secundários em formato Texto, eXtensible Markup Lan-
guage (XML), YAML Ain’t Markup Language (YAML) (YAML, 2010), Comma-Separated
Values (CSV) (Creativyst, 2011) e Excel (Microsoft, 2010).Existem três fatores que justificam o desenvolvimento tecnológico deste projeto:
• Problemas relacionados com dados mantidos em ambientes heterogêneos que tor-nam difícil a troca de informação e a migração dos dados para outros sistemas.Existem inúmeros motivos pelos quais as empresas precisam migrar os dados:redução dos altos custos com armazenamento de dados em tecnologias proprietá-rias, obter padronização dos dados em uma tecnologia específica, atualização detecnologias ou incompatibilidade entre sistemas de banco de dados; e
• Migrar dados para bases heterogêneas a partir de arquivos de backup é algo que
5

1.4. OBJETIVOS ESPECÍFICOS
pode influenciar de forma positiva em um processo de migração, pois desta formaos dados não precisariam ser restaurados em sua base de origem para então seremtransferidos para a base de destino.
O foco da pesquisa proposta está na solução de interoperabilidade entre diferentesplataformas de SGBD. Hoje, os arquivos de backup de dados são gerados baseados emformatos proprietários (Oracle, Sqlserver, Mysql, Postgres, entre outros), e seu principalobjetivo está no armazenamento, segurança e restauração das informações apenas emseus ambientes de origem, não podendo ser restaurados em outros ambientes. Atual-mente, a interoperabilidade está em estágio pouco avançado. Poucas são as ferramentasque conseguem interagir com outras para a realização de transações.
A padronização da estrutura de arquivos de backup não é algo relativamente novo.Oumtanaga et al. (2007) propõe a utilização de um formato XML como modelo parabackup de dados. A estrutura proposta foi desenvolvida utilizando Document Type De-
finition (DTD) (Ray, 2006), que é uma tecnologia mais antiga e limitada para definiçãode estruturas em XML.
No artigo supracitado, podem-se citar desvantagens quanto ao desenvolvimento euso de certas tecnologias: sintaxe não XML, poucos tipos de dados, limitação na defini-ção de cardinalidade e baixo poder de expressão. Além disso, a proposta foca a migraçãoapenas de objetos tabela, não garantindo a migração de objetos como: visões, gatilhos,permissões e funções.
A BKPML propõe a migração dos principais objetos existentes em um esquema debanco de dados. Por se tratar de uma nova linguagem de marcação, a BKPML neces-sitará de uma aplicação para gerar, restaurar, validar e migrar os dados a partir dessesarquivos.
1.4 Objetivos específicos
• Apresentar os principais conceitos sobre padronização da informação, interope-rabilidade de dados, ambientes heterogêneos, backup, migração e segurança dainformação;
• Definir e apresentar uma linguagem para criação e validação das regras sintáticaspara os documentos XML como XML Schema;
• Definir as regras para criação e validação da estrutura do arquivo BKPML;
6

1.5. ESTRUTURA DA DISSERTAÇÃO
• Desenvolver a aplicação responsável por criar, validar e gerenciar os arquivosBKPML;
• Definir um ambiente de testes;
• Realizar os testes da aplicação e ajustes da mesma para atingir os objetivos pro-postos.
1.5 Estrutura da dissertação
Como ponto de partida, o Capítulo 2 apresenta a fundamentação teórica desta disser-tação, que consiste em uma rápida apresentação sobre os principais conceitos a seremtratados nesta dissertação como: backup e restauração de dados, segurança dos dados,padronização da informação e cloud computing, conceito esse que será abordado nestadissertação como meio de armazenamento dos backups de dados.
O Capítulo 3 consiste em apresentar a estrutura BKPML, que tem por objetivo man-ter os dados em um formato padrão, dando assim mobilidade aos arquivos de backup,e possibilitando que os mesmos sejam migrados para qualquer SGBD independente dequal SGBD foram originados.
No Capítulo 4 é apresentada a arquitetura e são descritas as tecnologias utilizadaspara o desenvolvimento da aplicação denominada BKPML Manager, aplicação respon-sável por gerar, validar, armazenar, restaurar e migrar os dados contidos nos arquivosBKPML para SGBD distintos.
O Capítulo 5 apresenta um estudo de caso de uma empresa de pequeno porte deManaus, utilizando a ferramenta BKPML Manager para gerar e restaurar dados de umSGBD para outro, apresentando os resultados obtidos nos testes realizados para esteestudo de caso.
Por fim, no Capítulo 6, apresentam-se as conclusões do trabalho, discutindo suaaplicabilidade, abrangência, as condições em que se pode ser usado, suas vantagens,limitações e também discussão sobre possíveis futuras melhorias a respeito da estruturaBKPML e da aplicação BKPML Manager.
7

2Referencial Teórico
Este capítulo tem por objetivo abordar os principais conceitos fundamentais para o de-senvolvimento deste trabalho. O capítulo se inicia abordando os conceitos básicos debackup de dados, abrangendo aspectos importantes como, segurança de dados e cripto-grafia de arquivos. Em seguida, este capítulo tratará conceitos sobre, migração de dados,computação nas nuvens, padronização da informação, entre outros conceitos de grandeimportância para o entendimento deste trabalho como um todo.
2.1 Backup de dados
Backup é uma palavra em inglês que significa cópia de segurança de um dispositivo dearmazenamento (sistema operacional, banco de dados, sistemas administrativos, entreoutros.) a outro para que possam ser restaurados em caso de perda dos dados originais.
É cada vez maior o número de empresas, organizações e usuários que perdem anosde vida através da perda de dados importantes, sejam estes causado por desastres lógicos,físicos ou fatores humanos. AGUIRRE et al. (2006) relata que cerca de 90 porcento dasempresas de pequeno porte não realizam regularmente o backup de segurança dos dados,o que resulta na perda de renda, produtividade e clientes.
As causas mais comuns em relação à perda dos dados, segundo AGUIRRE et al.
(2006); Packard (2010), é o mau funcionamento ou falhas nos equipamentos de hard-
ware e as falhas humanas, como, exclusão ou alteração acidental de dados ou arquivos,instalação de softwares, roubo de informação, além de incêndio ou desastres naturais,entre outros.
A Figura 2.1 mostra os resultados de uma pesquisa realizada em 2002 sobre os prin-cipais problemas relacionados à perda de dados corporativos.
8

2.1. BACKUP DE DADOS
Figura 2.1 Principais erros que levam a perda de dados (Packard, 2010)
2.1.1 Tipos de mídia para backup de dados
Fazer cópia de segurança dos dados não necessariamente significa que seus dados estãototalmente protegidos contra danos ou catástrofes. Além da realização do backup dosdados, é necessário definir o melhor tipo de dispositivo de armazenamento a ser utilizadopara manter essas cópias de segurança. A escolha da mídia correta varia de acordo comlocal a ser armazenado tais mídias, no mais é aconselhado que além da escolha da mídiacorreta, é preciso manter essas mídias em locais seguros, de acesso restrito e com menorprobabilidade de danos e fatores de risco.
As mídias mais utilizadas para cópias de segurança de dados são as seguintes (Fialho,2007):
• Fitas - Também conhecidas como fitas streaming ou DAT. São pequenas e suasunidades podem ser instaladas tão fácil quanto as de disquete, CD, DVD, entreoutros;
• Discos - É o meio mais comum utilizado nos dias de hoje; sua capacidade dearmazenamento é de 750 MB ou superior a terabytes.
• Pen Driver - São dispositivos bastante seguros, rápidos e práticos. Usados comu-mente para armazenar temporariamente os dados; e
9

2.1. BACKUP DE DADOS
• Em nuvens - O armazenamento em nuvens é um novo meio para armazenamentode dados de forma remota. Para acesso a esse serviço, o cliente deverá contratar omesmo mediante empresa prestadora, como por exemplo: Amazon Web Services
(Amazon, 2011) e Locaweb (Locaweb, 2011).
Independente do dispositivo de armazenamento utilizado, é importante considerar aimportância da cópia de segurança dos dados para continuidade dos negócios de umaempresa. No Brasil está se tornando comum a utilização da Internet como um meio paracompra, pagamento e solicitação de serviços.
Além das inúmeras formas de armazenamento de dados, os backups de dados sãodivididos em diferentes tipos, para atender a diferentes necessidades.
Após determinar qual o tipo de dispositivo de armazenamento utilizar, deve-se de-terminar que tipo de backup será utilizado. As ferramentas de backup mais utilizadas,disponibilizam opções para definir os seguintes tipos de backup: Normal, Incremental,Diferencial, Cópia e Diário. O controle sobre o tipo de backup realizado é feito pelaferramenta utilizada (Cardia, 2010; Petkovic, 2008).
• Backup Normal - Todos os dados do SGBD são copiados, todo backup se ini-cia com um backup normal, que também é conhecido como backup total. Backups
normais são demorados e exigem mais capacidade de armazenamento do que qual-quer outro;
• Backup Incremental - Backups incrementais são os tipos mais rápidos e de menortamanho. Entretanto, eles são eficientes como conjuntos de recuperação, porquepara restauração deve-se primeiro recuperar o normal e em seguida o incremental;e
• Backup Diferencial - tendem a ser maiores e mais demorados do que os backups
incrementais. Quanto à restauração, deve-se restaurar primeiro o normal e emseguida o diferencial mais recente.
Os tipos de backup supracitados são normalmente aplicados a backups de sistemasoperacionais, no qual se envolve um grande número de arquivos e informações sobretal. Além desses tipos, pode-se citas os tipos utilizados por ferramentas para backup dedados armazenados em SGBD. Eles são (Oracle, 2005; MYSQL, 2010).
• Backup Lógico e Físico - É uma cópia dos arquivos de armazenamento de umSGBD para outro local, seja em disco ou armazenamento off-line, como fita. Bac-
10

2.1. BACKUP DE DADOS
kup lógico contém os dados lógicos de um SGBD, como: tabelas, visões, índices,procedimentos, entre outros;
• Backup Online e Offline - a diferença entre backup online e off-line está no mo-mento de sua execução. Backup online é realizado enquanto o SGBD está sendoexecutado. Backup off-line é executado enquanto o servidor do SGBD está parado.Tais backups também são conhecidos como quente e frio; e
• Backup Local e Remoto - Uma cópia de segurança local é feita na mesma má-quina onde o SGBD é executado. Já um backup remoto é feito em um servidornão local. Para alguns tipos de backups, o backup pode ser iniciado a partir de umservidor remoto e gravado em um servidor local.
Além dessas características, um arquivo de backup deve possuir uma característicafundamental para segurança e integridade dos dados: a utilização de criptografia dosdados mantidos pelo backup. Existem inúmeros algoritmos para criptografia de dados,tanto de 64 quanto de 128 bits, o que garante ainda mais a segurança e integridade dosdados (Packard, 2010).
2.1.2 Segurança dos dados
A segurança dos dados é um conjunto de técnicas, processos e componentes que visagarantir certo nível de confiabilidade às transações digitais. A ferramenta que proporci-ona e garante o nível de confiabilidade requerida é a proteção. O que se visa é protegero valor da informação. Esse valor depende de três princípios básicos: confidenciali-dade, integridade e disponibilidade dos dados (CARUSO and STEFFEN, 1999; van Bon,2006).
• Confidencialidade - Proteção das informações contra o acesso e uso não autori-zados;
• Integridade - precisão, inteireza e pontualidade das informações; e
• Disponibilidade - as informações devem ser acessíveis em qualquer ocasião acor-dada. Essa acessibilidade depende da continuidade proporcionada pelos sistemasde processamento das informações.
11

2.1. BACKUP DE DADOS
2.1.3 Criptografia dos dados
Uma solução adotada para proteção dos dados é a utilização de criptografia. De acordocom CARUSO and STEFFEN (1999), criptografia é um processo matemático usado paraembaralhar os dados, ou a ciência e a arte da transformação de mensagens tornando-as seguras e imunes a ataques. A Figura 2.2 mostra os componentes envolvidos nacriptografia (FOROUZAN, 2004).
Figura 2.2 Componentes envolvidos na criptografia (FOROUZAN, 2004)
Antes de ser criptografada, uma mensagem é denominada como texto limpo. Apósser criptografada, passa a ser conhecida como texto cifrado. Um algoritmo de cifragem éresponsável por tal transformação. O processo reverso é feito através de um algoritmo dedecifragem, responsável por transformar o texto cifrado em um texto claro. O transmis-sor utiliza um algoritmo de cifragem, enquanto o receptor um algoritmo de decifragem(FOROUZAN, 2004).
Processos de criptografia e descriptografia utilizam a técnica de cifras públicas, queutiliza chaves secretas para criptografar ou descriptografar mensagens. Para criptografaruma mensagem, faz-se necessário o uso de um algoritmo de criptografia, uma chave euma mensagem limpa. Desse conjunto origina-se o texto criptografado.
Para descriptografar essa mensagem, precisa-se de um algoritmo de descriptogra-fia, a chave utilizada na criptografia e a mensagem. Esse conjunto revela a mensagemoriginal. A Figura 2.3 ilustra a idéia (FOROUZAN, 2004).
Os algoritmos de cifragem e decifragem são públicos, podem ser usados por qualquerum. As chaves são secretas, precisam ser protegidas.
2.1.4 Algoritmo triple des (3DES)
É o principal algoritmo de criptografia utilizado comercialmente por aplicações na In-ternet. O algoritmo triple DES usa chaves de 168 bits. Esse algoritmo é uma extensão
12

2.2. MIGRAÇÃO DE DADOS
Figura 2.3 Processo de criptografia (FOROUZAN, 2004)
do algoritmo DES. Triple ou três significa que esse algoritmo é três vezes mais pesadoe mais seguro que o DES, porque criptografa as mensagens três vezes seguidas, usandoo DES. Então, em suma, ele usa três chaves diferentes de 56 bits, que combinadas, re-sultam em uma chave de 168bits. O Triple DES é utilizado em diversos aplicativos daMicrosoft (CARUSO and STEFFEN, 1999; Carmona, 2005).
2.2 Migração de dados
Migração de dados é o processo de transferência de informação de uma base de dadospara outra, com finalidade de economizar recursos e melhoria de controle e desempre-nho.
Existem muitos motivos que levam uma empresa a decidir sobre a migração de dadospara tecnologias de gerenciamento de dados mais atuais. Antes de migrar, uma empresadeve escolher cuidadosamente a tecnologia que atenda às necessidades atuais e futurasda empresa. Todos os projetos de migração embutem certo nível de risco. Entretanto,um projeto de migração bem planejado e corretamente executado pode fazer com que aempresa proporcione acesso aos dados sem problemas (STERN, 2010).
Existem inúmeras razões que levam uma empresa a optar pela migração de dados(IBM, 2010). Dentre elas:
• Simplificação da infra-estrutura - Ao simplificar a arquitetura de TI e integrartodos os componentes em uma só solução, pode-se economizar recursos e melho-rar o controle;
• Redução de Custos - Hoje, a maioria das companhias que se expõem à possibili-dade de migrar, escolhe estratégica e proativamente aumentar o valor do negócio,vinculando os objetivos da empresa com a infra-estrutura de TI. Migrar para outrastecnologias pode proporcionar soluções de impacto que oferecem grande flexibi-lidade e liberdade de escolha;
13

2.2. MIGRAÇÃO DE DADOS
• Melhorar rendimento das aplicações - Permite que os clientes desfrutem de ummelhor serviço e que a equipe de TI administre melhor os sistemas e responda aosobjetivos do negócio com maior eficácia;
• Gestão dos dados - migração de dados para melhores servidores com melhorcapacidade de gerir dados sem comprometer a confiabilidade dos mesmos; e
• Reduzir complexidade e melhoria de gestão - A dificuldade em gerir e adaptar-se a certas tecnologias obriga muitas empresas a abandonar e migrar para outrasde melhor gestão.
Ao migrar dados, existem diversos fatores a serem considerados. Em primeiro lugar,a empresa deve decidir o tipo de migração. Gateway ou migração completa.
Na migração com gateway, os dados continuam no banco de dados antigo e sãoacessados através de um software especial denominado gateway. O gateway lê e gravaos dados no SGBD antigo. Mas, do ponto de vista do aplicativo, é como se os dadosestivessem no SGBD atual. Por esse motivo os gateways são normalmente lentos.
Na migração completa, os dados, objetos e o código fonte do aplicativo são conver-tidos para acessar os dados do novo SGBD. Uma vez que este tipo de migração sejafeito, todas as referências ao SGBD antigo são perdidas. Esse é o tipo de migração maiscomum, mas cabe ressaltar que existem outras alternativas além da migração completa.
2.2.1 Níveis de migração
A migração de dados é classificada em três níveis. Esses níveis determinam a quantidadede trabalho e os elementos envolvidos na migração. Por simplicidade, neste trabalho nosreferimos aos três níveis simplesmente como nível um, dois e três (STERN, 2010).
• Nível 1 - Uma migração de nível 1 inclui apenas o esquema, ou definições dedados, e os dados em si. O cenário mais comum para uma migração de nível 1 équando o aplicativo está usando uma interface que existe tanto no sistema de bancode dados antigo quanto no novo. É necessário migrar somente as definições dedados e os dados em si. São também necessários trabalhos de configuração, mas,uma vez que os dados tenham sido migrados, o aplicativo estará funcionando;
• Nível 2 - Uma migração de nível 2 inclui o esquema, os dados e alterações no có-digo fonte. Este nível pode ser visto como uma extensão do nível 1. Por exemplo,
14

2.3. COMPUTAÇÃO NAS NUVENS
em uma migração de nível 1 onde são usadas diferentes versões da mesma inter-face no banco de dados antigo e no novo. Neste caso, migrar apenas o esquemae os dados não faz com que o aplicativo funcione completamente; é necessárioanalisar as diferenças entre as versões. Uma vez que essas diferenças tenhamsido identificadas, pode-se alterar o código para que o aplicativo funcione com osistema de banco de dados novo; e
• Nível 3 - Uma migração de nível 3 é bastante diferente dos dois níveis anteriores.Nos níveis anteriores, o único objetivo da migração é alterar o sistema de armaze-namento de dados, isto é, fazer com que o aplicativo funcione com o novo bancode dados, ao invés de apenas os recursos específicos oferecidos pelo novo bancode dados. Em uma migração de nível 3, a maioria dos aplicativos são reescritos.
Normalmente, o nível de migração estará em um ou qualquer ponto intermediárionessa escala de três níveis.
2.3 Computação nas nuvens
A utilização de software em máquinas locais é um fator que leva à insatisfação de usuá-rios finais em virtude do baixo desempenho da incompatibilidade de software com hard-
ware. Esse e outros motivos estão fazendo com que, de acordo com Voas and Zhang(2009), computação nas nuvens receba um número cada vez maior de seguidores, ape-sar desta não possuir uma definição concreta. Abaixo a Figura 2.4 apresenta a arquiteturade computação em nuven.
Figura 2.4 Arquitetura da Computação nas nuvens
15

2.3. COMPUTAÇÃO NAS NUVENS
Uma característica de computação nas nuvens é a simplicidade e acessibilidade, pois,a partir de qualquer dispositivo com acesso à Internet, pode-se manipular uma aplicaçãonas nuvens. Por sua vez, Grossman (2009) define que computação nas nuvens, alémde oferecer todos os recursos disponíveis na Internet, tem por objetivo oferecer serviçossob demanda, tais como:
• Infrastructure As A Service (IAAS) - Toda infra-estrutura está concentrada emum centro de dados e oferece serviços para seus clientes;
• Platform As A Service (PAAS) - É um serviço oferecido nas nuvens para dar totalsuporte a desenvolvedores corporativos na criação e teste de aplicações web;
• Software As A Service (SAAS) - O software é executado em um servidor sem anecessidade de ser instalado localmente; e
• Data Storage As A Service (DSAAS) - Permite o armazenamento de dados nas nu-vens em data centers com capacidade de armazenamento escalável e praticamenteilimitado.
Segundo Maggiani (2009), os serviços SAAS e DSAAS são os mais vantajosos dis-poníveis nas nuvens, pois permitem a disponibilização de aplicações e armazenamentode dados, que podem ser acessados de qualquer computador através de um navegador.
2.3.1 Backup de dados em nuvens
De acordo com Whitehouse (2009), a utilização do serviço DSAAS é possível porquea capacidade de armazenamento disponível através da nuvem é enorme, aparentementeinterminável. A proposta é a seguinte: ao invés de se possuir e manter sua própria infra-estrutura, computação nas nuvens oferece ao usuário o armazenamento de informaçõesem seus servidores, acessíveis sempre que necessário.
A habilidade de se fazer backup de banco de dados e armazená-los em nuvens éfundamental para a sua segurança, uma vez que esses estarão guardados em unidadesexternas seguras. Backups armazenados em nuvens são mais acessíveis e na maioria dascircunstâncias são mais rápidos para restaurar e muito mais confiáveis (Oracle3, 2008).
De acordo com Staimer (2008), métodos primitivos para proteção dos dados têm setornado cada vez mais frustrantes para organizações que são obrigadas a adotar solu-ções mistas para assegurar a proteção dos dados. Armazenamento em nuvens está se
16

2.3. COMPUTAÇÃO NAS NUVENS
tornando uma atraente opção para proteção dos dados, além de oferecer benefícios in-contáveis, como o consumo baseado em preços e a capacidade operacional, que fazemdessa abordagem uma alternativa atraente diante dos métodos tradicionais.
2.3.2 Aplicações cloud para backup/recuperação de dados
Segundo Oracle2 (2008), apesar da difusão dos conceitos de computação nas nuvens ali-ados à idéia de utilizar as nuvens como nova alternativa para armazenamento de dadosserem algo relativamente novo, algumas empresas já estão trabalhando em soluções paraatender a esse novo conceito de backup de dados. Dentre estas empresas, pode-se citar aOracle, com o módulo Oracle Secure Backup Cloud integrado ao módulo Oracle Reco-
very Manager (RMAN) e ao serviço Amazon Simple Storage Service (S3), a Microsoft,com integração do seu módulo SQL Data Service ao Zmanda Internet Backup (ZIB), e aAsigra, com o desenvolvimento de uma aplicação para backup de dados em nuvens:
• Oracle Secure Backup Cloud - Oracle Secure Backup Cloud é um módulo in-tegrado ao Oracle Recovery Manager e que oferece a possibilidade de se fazerbackup de banco de dados nas nuvens. Segundo Oracle3 (2008), quando com-parado aos métodos tradicionais, o armazenamento nas nuvens é mais acessível,mais rápido para restaurar e, na maioria das circunstâncias, mais confiável. Aindade acordo com Oracle3 (2008) o novo módulo Oracle Secure Backup Cloud possuiinúmeras vantagens sobre os métodos tradicionais de backup como: acessibilidadecontínua, confiabilidade e redução de custos;
• Zmanda Cloud Backup - Segundo Zmanda (2008), Zmanda Cloud Backup é umsoftware desenvolvido para realização de backups online. Seu objetivo é a desa-fiadora tarefa de backups de arquivos, aplicações, SGBD, dispositivos de e-mail
e de rede. Todos esses dados devem ser protegidos para garantir a continuidade econformidade do negócio. Possui um baixo custo, é fácil de utilizar e configurar,e apresenta soluções para empresas de pequeno e médio portes que necessitam debackup e recuperação contra desastres; e
• Asigra Hybrid Cloud Backup - De acordo com Staimer (2008), Asigra é uma em-presa que tem sido líder em soluções de backups distribuídos por 23 anos. O pri-meiro backup com base em armazenamento remoto foi lançado por ela em 1986.O módulo Asigra Hybrid Cloud Backup and Restore da Asigra supera aplicaçõescomo Oracle Secure Backup Cloud e Zmanda Cloud Backup, pois seu objetivo é
17

2.4. PADRONIZAÇÃO DA INFORMAÇÃO
a realização de backups de ambientes híbridos. Com ele é possível verificar se umbackup está corrompido ou não antes que seu armazenamento seja efetivado. Emtermos de vantagem em nuvens, o Asigra Hybrid Cloud Backup possui as mesmasvantagens oferecidas pelas aplicações supracitadas.
2.4 Padronização da informação
De acordo com dicionário popular, padronizar é manter algo em estado concreto, é or-ganizar a informação de forma regular, padronizando o comportamento das informaçõesde forma estruturada, tornando seu entendimento geral e eficiente. Adotar padroniza-ção da informação proporciona melhores resultados quanto há necessidade de troca eentendimento da informação entre as partes envolvidas. Existem casos que há tambémredução de custo, tanto financeiro, quanto temporal.
Hoje, com a complexidade dos processos produtivos e gerenciais, torna-se cada vezmais necessário registrar de forma padronizada a maneira de se produzir e trocar infor-mações. Portanto, a padronização deve ser vista dentro de empresas, indústrias e orga-nizações como algo benéfico a todos, desde o nível operacional ao estratégico (Crem,2010).
A necessidade de se padronizar não se restringe apenas às áreas da computação.Segundo Jacoski and Lamberts (2002) houve um crescimento acentuado nos últimosanos de uso de ferramentas eletrônicas, o que conseqüentemente gera um grande vo-lume informações, que apesar da importância, são incapazes de se relacionar. A falta depadronização da informação dificulta na criação de relatórios gerenciais entre os váriosdepartamentos de uma empresa (TOLEDO et al., 2010).
No dia 16 de novembro de 2006 a Agência Nacional de Saúde (ANS) apresentouao mercado o projeto TISS (Troca de Informação da Saúde Suplementar), que visa ofornecimento de informações por parte dos prestadores de serviços médicos. Dadosque antes eram trocados via FAX, passam a ser trocados via padrão TISS, tornando ainformação clara, padrão e manipulável, permitindo a ANS ter total controle dos dadosenviados (Saúde, 2008).
Em resumo, padronizar uma informação é torná-la legível a todos os sistemas que amanipulam, independente de plataforma, linguagem ou fabricante. Assim como Inglêse Espanhol foram definidas como linguagens padrão de comunicação entre pessoas, eminformática a ideia é a mesma, mas para isso são utilizadas linguagens como XML,YAML, JSON (JSON, 2010), Comma-Separated Values (CSV), entre outras. Sendo
18

2.4. PADRONIZAÇÃO DA INFORMAÇÃO
assim, as seções a seguir abordam os principais padrões utilizados para padronização dainformação.
2.4.1 eXtensible Markup Language (XML)
XML é uma linguagem de marcação utilizada para definição e padronização de estrutu-ras. Sua definição segundo Ray (2006) não é tão fácil de definir, uma vez que, em umnível, XML é um protocolo para conter e gerenciar informações. Em outro, é uma famí-lia de tecnologias que pode fazer tudo, desde formatar documentos até filtrar dados. Emum nível mais alto, é uma filosofia para tratamento de informações, que busca o máximode utilidade e flexibilidade para os dados.
XML representa os dados através de marcações intercaladas para descrever os dadose suas propriedades. As marcações são predominantemente representadas em formade tags que se distinguem dos textos não marcados. Toda Marcação aberta deverá serfechada para indicar o início e fim do escopo.Abaixo a Figura 2.5 apresenta um exemplosimples de documento XML.
Figura 2.5 Documento XML
Os documentos XML podem ser validados a partir de estruturas pré-definidas, deforma que se possam ter vários documentos que sigam a mesma estruturação (W3C,2010). Estas estruturas podem ser definidas através do XML Schema. Normalmente umdocumento XML bem formatado possui uma estrutura equivalente que o defina.
2.4.2 XML Schema
É um padrão utilizado para definição de estruturas e representação de dados em XML,recomendada pela World Wide Web Consortium (W3C) em maio de 2001. XML Schema
19

2.4. PADRONIZAÇÃO DA INFORMAÇÃO
representa uma importante alternativa ao uso de DTD (W3C, 2010). Esse padrão permitea definição de tipos de dados usando XML. Os tipos de dados ajudam na restrição dosdados a serem validados. Tais tipos são divididos em, tipos especificados pelo usuário etipos internos.
Os internos fornecem tipagem permitida para os valores de entrada das marcações,tipos como, string, número inteiro, decimal, lógico, data, tempo, binários, entre outros.Os tipos definidos pelo usuário são especificados como parte do esquema e podem pos-suir restrições adicionais para os tipos internos, como um intervalo de números ou umalista explicitamente enumerada de valores (GRAVES, 2003). A Figura 2.6 apresenta adefinição do esquema do documento XML da Figura 2.5
Figura 2.6 Documento XMLSchema
Um documento XMLSchema é constituído de elementos, atributos e regras que odefinem. Os elementos são definidos pela palavra reservada ELEMENT, que por suavez utiliza os atributos NAME e TYPE para definir o nome do elemento e o tipo deinformação aceita. Além disso, podem-se definir restrições através do uso dos elementosSIMPLETYPE e RESTRICTION.
Os atributos são definidos de forma semelhante aos elementos, porém, utilizandoa palavra reservada ATTRIBUTE, juntamente com os atributos NAME e TYPE. Além
20

2.4. PADRONIZAÇÃO DA INFORMAÇÃO
disso é possível utilizar outros atributos no XML Schema para funções específicas, porexemplo, se uma marcação possui valor fixo ou padrão, definidos respectivamente pelosatributos FIXED e DEFAULT (W3C, 2010).
2.4.3 YAML Ain’t Markup Language (YAML)
É uma linguagem aberta para serialização de dados projetada para ser amigável e maispróxima possível da linguagem humana. Projetada para trabalhar nas linguagens deprogramação mais modernas em tarefas comuns. YAML foi concebida para ser útil eamigável para as pessoas que trabalham com dados e os manipulam (YAML, 2010).Inspirada em conceitos de linguagens como XML (Fonseca and Simões, 2007).
Para melhor representação dos dados, a YAML é dividida em três partes: classe,sintaxe e processador. A classe representa um documento YAML. A sintaxe é a re-presentação da YAML através de uma série de caracteres e palavras reservadas. Porfim, o processador YAML é uma ferramenta usada para processamento e conversão dasinformações.
Em YAML todos os dados podem ser representados adequadamente, como combina-ção de listas e dados escalares. A sintaxe é relativamente simples e de fácil mapeamento,aceita os tipos mais comuns de dados assim como a maioria das linguagens de alto ní-vel. Além disso, YAML utiliza uma notação baseada em identação e um conjunto decaracteres distintos dos utilizados por XML, fazendo com que as duas linguagens se-jam facilmente combinadas. A Figura 2.7 apresenta o exemplo de um documento XMLconvertido para YAML.
Figura 2.7 Documento XML para YAML
21

2.5. APLICAÇÕES WEB
2.4.4 JavaScript Object Notation (JSON)
É um formato leve utilizado para troca de dados e objetos Javascript. Baseada em umsubconjunto da linguagem de programação. JSON é em formato texto e completamenteindependente de linguagem de programação e possui implementação para maioria daslinguagens disponíveis no mercado (JSON, 2010).
JSON utiliza como limitador de escopo a chave aberta que indica o início de umobjeto, e a chave fechada indicando o fim. Os pares de nome e valor são separadosutilizando virgula e ":".Esta estrutura pode ser combinada aos caracteres [ e ] para repre-sentar uma coleção de objetos. A Figura 2.8 apresenta dois tipos de informação, dadossimples, representados pelos pares, nome e valor, e uma lista de objetos, representadospelo [ seguidos dos pares, nome e valor, e o ]. Conforme abaixo.
Figura 2.8 Documento JSON
2.5 Aplicações WEB
Uma aplicação Web é um sistema que permite a seus usuários executar a regra de ne-gócio (ou lógica do negócio, business logic) com um navegador (Conallen, 2003); umaaplicação Web pode ser desde um simples site, até uma aplicação Web completa. Exis-tem destinções entre uma aplicação Web e um site. Uma aplicação Web é um site emque a entrada do usuário, navegação e entrada dos dados afeta diretamente o estado donegócio, além dos contadores e logs de acesso. Já um site é essencialmente uma pá-gina constituída de texto, objetos, links, entre outros, usada como front end para umaaplicação de negócio (Conallen, 2003).
As aplicações WEB podem ser classificadas em duas categorias: aplicações hiper-mídia e aplicações de software. As aplicações hipermídia são aplicações não convenci-onais caracterizadas pela publicação de informação utilizando links, âncoras e estruturade acesso disponibilizado através da WEB. Já a aplicação de software depende da infra-estrutura Web para sua execução. O termo aplicação WEB representa uma aplicação quepossui características de ambas as aplicações, hipermídia e software.
22

2.5. APLICAÇÕES WEB
2.5.1 Tecnologias Web
Dependendo da linguagem de programação escolhida, inúmeras tecnologias poderão seraplicadas para se chegar a um resultado final esperado, como tais tecnologias pode-secitar:
• Hypertext Markup Language (HTML) (Markup, 2010) - É uma linguagem clarapara publicação de hipertexto na Internet. É um formato não proprietário mantidopela W3C. A HTML pode ser desenvolvida usando simples editores de texto atésofisticados editores. HTML utiliza tags para estruturar o texto em cabeçalhos,parágrafos, listas, links, entre outros;
• Cascading Style Sheets (CSS) (CSS, 2010) - É um mecanismo simples utilizadopara adicionar estilo a documentos Web como, fontes, cores, espaçamentos, entreoutros. Um documento CSS pode ser escrito no próprio documento HTML, ouem um documento separado que para ser aplicado ao documento HTML;
• JavaServer Pages (JSP) (JSP, 2010) - É uma tecnologia criada para desenvolvi-mento de páginas Web, permitindo que desenvolvedores possam criar de formarápida e fácil páginas Web dinâmicas, além de potencializar os sistemas existen-tes. Como parte da família da tecnologia Java, a tecnologia JSP permite o de-senvolvimento rápido de aplicativos baseados na Web que são independentes deplataforma. Tecnologia JSP separa a interface de usuário de geração de conteúdo,permitindo aos designers alterar o layout geral da página sem alterar o seu con-teúdo dinâmico;
• Javaserver page Standard Tag Lib (JSTL) (JSTL, 2010) - É uma coleção de bi-bliotecas encapsuladas com o objetivo de oferecer as principais funcionalidadesutilizadas pelas páginas web em JSP. Assim como HTML e JSP, JSTL define umconjunto de tags para acesso às funcionalidades encapsuladas. Como tais funcio-nalidades citam-se: formatação de data e hora, acesso a banco de dados e comandopara processamento dos dados; e
• JavaScript (Flanagan, 2002) - É uma linguagem de programação leve, interpretadae com recursos de orientação a objetos. Adicionada aos principais navegadores deInternet, aprimora a programação Web com a adição de objetos que representemjanelas, botões, caixas de texto, entre outros. O JavaScript do lado cliente permiteque o conteúdo executável seja incluído na página Web. Isso significa que uma
23

2.5. APLICAÇÕES WEB
página não precisa mais de HTML estático, mas pode incluir programas que inte-ragem com o usuário, controlam o navegador e criam conteúdo HTML dinâmico.
Para desenvolvimento da camada de aplicação/processamento, pode-se utilizar asseguintes tecnologias:
• Java (Deitel and Deitel, 2009) - Linguagem de programação mantida pela SUN
Microsystems idealizada por James Gosling. Java inicialmente foi projetada paraprogramar dispositivos eletrônicos, mas gerou interesse na comunidade comercialpor causa do grande interesse pela Internet. Java agora é utilizada para criar pá-ginas Web com conteúdo interativo e dinâmico, além de aplicativos para desktop,celulares, pagers, entre outros;
• STRUTS2 (Struts2, 2010) - É uma estrutura elegante e extensível para a criaçãode aplicações Web em Java. A estrutura foi projetada para otimizar o ciclo dedesenvolvimento de aplicativos Web, desde a construção, a implantação, a ma-nutenção das aplicações ao longo do tempo. Struts2 era originalmente conhecidacomo WebWork2. Depois de trabalhar de forma independente durante vários anos,o WebWork Struts e comunidades se uniram para criar Struts2;
• XERCES (Xerces, 2010) - É um projeto de desenvolvimento de software colabora-tivo dedicado a fornecer recursos, qualidade comercial parsers XML e tecnologiasrelacionadas a uma ampla variedade de plataformas de linguagem de programa-ção. Este projeto é gerido em colaboração com várias pessoas de todo o mundo,que utilizam a Internet para se comunicar, planejar e desenvolver software XML.Foi criado para geração, manipulação, validação e melhoria em documento XML;
• DOM4J (Beat, 2010) - É um framework de código aberto de fácil utilização paratrabalhar com XML, XPATH e XSLT na plataforma Java utilizando uma coleçãode métodos para manipulação de arquivos XML. Esse framework possui suportecompleto às API, DOM, SAX e JAXP; e
• TOMCAT (Tomcat, 2010) - É um container de servlet desenvolvido pela APACHE
FOUNDATION com intuito de manter e executar aplicações Web JAVA utilizandoservlets. TOMCAT é uma implementação open source destinada para ser umacolaboração para os programadores de todo o mundo, dando poder em grandeescala às aplicações Web. Atualmente, TOMCAT encontra-se na versão 7.0, im-plementando servlet 3.0 e Javaserver Page 2.2, além de incluir recursos adicionais
24

2.6. PADRÕES DE PROJETO
que a torna uma plataforma útil para desenvolvimento de aplicações Web e Web
Services.
Para camada de acesso aos dados, pode-se UTILIZAR as seguintes tecnologias:
• Hibernate (Gonçalves, 2007) - É um projeto que procura soluções completas parao problema de gerenciamento de dados persistentes em JAVA. O hibernate é umframework que se relaciona com o banco de dados, onde esse relacionamento éconhecido como mapeamento objeto/relacional para JAVA, deixando o desenvol-vedor livre para se concentrar em problemas da lógica de negócios. O hibernate
se integra ao sistema se comunicando com o banco de dados como se fosse direta-mente feito por sua aplicação. Uma mudança de banco de dados, nesse caso, nãose torna traumática, alterando apenas um ou outro detalhe nas configurações; e
• Java DataBase Connection (JDBC) (Reese, 2001) - Percebendo o aumento no nú-mero de API proprietárias para acesso a banco de dados, a SUN desenvolveu umaAPI única para acesso a banco de dados, a JDBC. JDBC é uma API que permiteacessar banco de dados e construir instruções Structured Query Language (SQL)
e incorporá-las dentro de chamadas de API Java, usando basicamente a lingua-gem SQL. JDBC permite-se traduzir harmoniosamente entre o mundo de bancode dados e o mundo das aplicações Java. Seus resultados do banco de dados sãoretornados como objetos Java e os problemas de acesso são considerados exce-ções.
2.6 Padrões de projeto
A ideia de padrões foi inicialmente idealizada por Christopher Alexander ao se fazera seguinte pergunta: O que está presente em um projeto de boa qualidade que não
está presente em um projeto de baixa qualidade? Observando as estruturas, Alexanderpercebeu que ele poderia discernir similaridades entre fatores que resultaram em projetosde alta qualidade, e a esses fatores ele deu o nome de padrões. Cada padrão descreveum problema que ocorre repetidamente em nosso ambiente e, portanto, descreve o cerneda solução desse problema, de tal forma que se pode utilizar essa solução várias vezesrepetidas, sem nunca fazê-la duas vezes do mesmo modo (SHALLOWAY and TROTT,2002; GAMMA et al., 1995).
Foi com base nas pesquisas de Alexander que Erich Gamma, Richard Helm, Ralph
Johnson e John Vlissides, aplicaram os conceitos de padrões arquiteturais para padrões
25

2.6. PADRÕES DE PROJETO
estruturais de software, formalizando vinte e três padrões de projeto classificados em trêspropósitos, criação, estrutural e comportamental. Os padrões de criação se preocupamcom o processo de criação dos objetos. Os padrões estruturais lidam com a composiçãode classes ou de objetos. Os padrões comportamentais caracterizam as maneiras pelasquais classes ou objetos integram e distribuem responsabilidades. Esses padrões ficaramconhecidos como padrões GOF (Gang Of Four) ou gangue dos quatro (Lasater, 2006;GAMMA et al., 1995).
Mas o que são exatamente padrões de projeto? Segundo Braude (2004), padrõessão combinações de classes e algoritmos associados que cumprem com propósitos co-muns de projeto. Um padrão de projeto, segundo GAMMA et al. (1995), nomeia, abs-trai e identifica os aspectos-chave de uma estrutura de projeto comum para torná-la útilpara criação de um projeto de software orientado a objetos reutilizável. Ainda segundoGAMMA et al. (1995), projetar software orientado a objetos é difícil, mas projetar
software reutilizável orientado a objeto é ainda mais complicado. Por esse motivo queprojetistas experientes preferem reutilizar estruturas ao invés de desenvolver uma dozero.
2.6.1 O padrão estrutural Decorator
Sua intenção é agregar responsabilidades adicionais a um objeto de forma dinâmica.Os decorators fornecem uma alternativa flexível ao uso de subclasses para extensão defuncionalidades. Uma forma de adicionar responsabilidade é através do uso de herança.Decorator utiliza herança para adicionar funcionalidades dinamicamente a um objeto.Por exemplo, um toolkit para construção de interfaces gráficas deve permitir a adiçãode propriedades, como bordas, ou comportamentos, como rolamento de tela (GAMMAet al., 1995).
O padrão decorator trabalha permitindo criar uma cadeia de objetos que inicia comos Decorators, os quais são responsáveis pelas novas funções. O diagrama de classe dopadrão decorator, mostrado na Figura 2.9, contém uma cadeia de objetos, Scrolldecora-
tor e Borderdecorator, cada cadeia inicia com uma classe componente (seja componenteconcreto ou decorator). Cada decorator é seguido de outro decorator ou o componenteconcreto original. Uma classe componente concreta sempre encerra a cadeia (SHAL-LOWAY and TROTT, 2002).
26

2.6. PADRÕES DE PROJETO
Figura 2.9 Diagrama de Classes do padrão Decorator (SHALLOWAY and TROTT, 2002)
Segundo GAMMA et al. (1995), deve-se usar decorator para:
• Acrescentar responsabilidade a objetos individuais de forma dinâmica e transpa-rente, ou seja, sem afetar outros objetos;
• Responsabilidades que podem ser removidas;
• Quando a extensão através do uso de subclasse não é prática. Às vezes, um grandenúmero de extensões independentes é possível e isso poderia produzir uma explo-são de subclasses para dar suporte a cada combinação. Ou a definição de umaclasse pode estar oculta ou não estar disponível para utilização da classe.
2.6.2 O padrão comportamental Strategy
Um padrão de estratégia é um conjunto de algoritmos encapsulados dentro de classeintercambiáveis que possibilitam que o algoritmo possa variar dependendo da classeutilizada. As estratégias são utilizadas quando se deseja decidir em tempo de execução autilização de cada algoritmo. Essa variação entre os algoritmos fica sob responsabilidadeda classe contexto (Lasater, 2006).
O padrão Strategy tem três componentes principais: the Strategy, the Concrete Stra-
tegy e Context. O componente Strategy é uma interface comum que une todos os algo-ritmos implementados no padrão. Normalmente essa classe é abstrata. O componenteConcrete Strategy é a classe de implementação, é nela que se encontra toda a lógica dosalgoritmos implementados. Esta classe é dividida em grupo de algoritmos, dependende
27

2.6. PADRÕES DE PROJETO
de quantas estratégias concretas se deseja usar. O componente Context é o objeto que as-socia uma estratégia concreta a um fluxo de código específico (Lasater, 2006). A Figura2.10 mostra o diagrama de classes do padrão Strategy.
Figura 2.10 Diagrama de Classes do padrão Strategy (Lasater, 2006)
Vantagens de se utilizar o padrão Strategy (SHALLOWAY and TROTT, 2002).
• Define uma família de algoritmos;
• Os comandos switch e/ou condicionais podem ser eliminados; e
• Deve-se invocar todos os algoritmos da mesma maneira. A interação entre asclasses concretas e de contexto pode requerer a adição de novos métodos, o quepode ser facilmente adicionada sem muitas alterações.
O padrão Strategy representa uma escolha melhor em situações onde a classe Com-
ponent é intrinsecamente pesada, dessa forma tornando a aplicação do padrão Decorator
muito onerosa. No padrão Strategy, o componente repassa parte do seu comportamentopara um objeto strategy separado, além de permitir alterar ou estender a funcionalidadedo componente pela substituição do objeto strategy.
2.6.3 O padrão Data Access Object (DAO)
Aplicativos usam a API JDBC para acesso a dados persistentes, permitindo acesso pa-drão para manipulação dos dados através do uso de instruções SQL. No entanto, a sin-taxe dos comandos SQL pode variar, dependendo do fabricante. Essa dependência tornadifícil e tediosa a migração de uma fonte de dados para outra. Quanto às alterações nasfontes de dados, os componentes precisam ser mudados para lidar com a nova fonte de
28

2.6. PADRÕES DE PROJETO
dados. Uma forma de contornar esse tipo de problema é utilizar o padrão DAO paraabstrair e encapsular todo o acesso à fonte de dados (DAO, 2010).
DAO implementa um mecanismo para acesso as diversas fontes de dados. O compo-nente de negócio que se baseia no DAO usa uma interface simples que oculta completa-mente os detalhes da fonte de dados em execução. Como a interface exposta pelo DAOpara os clientes não se altera quando há mudanças na implementação do código, essepadrão permite que o DAO possa se adaptar a diferentes esquemas de armazenamentosem afetar seus clientes ou os componentes do negócio. Essencialmente, o DAO agecomo um adaptador entre o componente e a fonte de dados.
O padrão DAO fornece uma interface independente, na qual pode-se usar para per-sistir objetos de dados. A ideia é colocar todas as funcionalidades de acesso e trabalhocom os dados em um só local, tornando simples sua manutenção. Tipicamente um DAOinclui métodos para inserir, selecionar, atualizar e excluir objetos de um banco de dados.Dependendo de como se implementa o padrão DAO, pode-se ter um DAO para cadaclasse de objetos na aplicação, ou podera-se ter um único DAO responsável por todos osobjetos (Gonçalves, 2007). A Figura 2.11 mostra o diagrama de classe que representa asrelações para o padrão DAO (DAO, 2010).
Figura 2.11 Diagrama do Padrão DAO (DAO, 2010)
2.6.4 O padrão Model View Controller (MVC)
MVC é um conceito de desenvolvimento e design que tenta separar uma aplicação emtrês partes distintas. A primeira, o modelo, está relacionada ao trabalho atual que aaplicação administra, outra parte, a visão, está relacionada com a exibição dos dados ou
29

2.7. CONSIDERAÇÕES FINAIS
informações de uma aplicação, a terceira parte, controle, é responsável por coordenaras camadas Modelo e Visão, exibindo a interface correta ou executando algum trabalhoque a aplicação precisa completar (Gonçalves, 2007).
• Modelo - O modelo é o objeto que representa os dados do programa. Maneja essesdados e controla todas as transformações. Esse modelo não tem conhecimentoespecífico dos controladores e das apresentações, nem contém referência para eles.Portanto, o modelo é composto pelas classes que trabalham no armazenamento ebusca de dados;
• Visão - é o que maneja a apresentação visual dos dados representados pelo Mo-delo. Em resumo, é responsável por apresentar os dados resultantes do modelodo usuário. Por exemplo, uma apresentação poderá ser um local administrativoonde os administradores se logam em uma aplicação. Cada administrador poderávisualizar uma parte do sistema que outro não vê; e
• Controle - é o objeto que responde as ordens executadas pelo usuário, atuandosobre os dados apresentados pelo modelo, decidindo como o modelo deverá seralterado ou ser revisto, e qual apresentação deverá ser exibida. Por exemplo, ocontrolador recebe um pedido para exibir uma lista de clientes interagindo com omodelo e entregando uma apresentação onde essa lista poderá ser exibida.
O modelo MVC é uma forma de desenvolvimento que ajuda na manutenção do sis-tema, um padrão muito aceito no desenvolvimento de aplicações Java, principalmenteno de aplicações escritas para Web.
A separação lógica da aplicação assegura que a camada Modelo não conheça o queserá exibido; limitando-se a representar as partes do problema a ser resolvido pela apli-cação. Igualmente, a camada de apresentação está condicionada apenas na exibiçãp dosdados, e não com a implementação da lógica de negócios que é controlada pelo modelo.O controlador, como um gerenciador de tráfego, dirige as apresentações a serem exi-bidas e com as devidas mudanças de dados e recuperações vindas da camada modelo(Gonçalves, 2007).
2.7 Considerações Finais
Este capítulo abordou os conceitos básicos necessários para o entendimento deste traba-lho. Assim, o capítulo tratou os conceitos relacionados a backup, segurança, criptografia
30

2.7. CONSIDERAÇÕES FINAIS
e migração de dados, uma vez que, o foco principal do protótipo proposto neste trabalho,possui essas finalidades. Por conseguinte, foram apresentados os conceitos relacionadosà computação nas nuvens, tendo como foco principal as principais ferramentas respon-sável pela realização de backup em nuvens, bem como também o armazenamento dedados.
A padronização da informação também é foco principal deste trabalho, uma vez queo mesmo propõe a padronização dos arquivos de backup de dados com objetivo de des-vincular sua dependência entre ambientes ou aplicações, dando liberdade aos mesmospara serem usados por qualquer aplicação que conheça sua estrutura. Para isso forampesquisadas as principal linguagem utilizadas para padronização e intercâmbio de dadosentre sistemas heterogêneos.
Neste contexto as sequintes linguagens foram encontradas, e seus conceitos descritosneste capítulo: XML, cujo foco principal foi à tecnologia XML Schema, utilizada paradesenvolvimento da estrutura proposta por esse trabalho, a BKPML a ser vista no pró-ximo capítulo,YAML e JSON foram utilizadas para compor o processo de trasformaçãodos dados de um arquivo de backup para esse tipo de formato, além de outras, que porsua simplicidade e popularidade, não se fez necessário abordar.
Aplicações e tecnologias Web também foram discutidas neste capítulo. É impor-tante ressaltar que tais tecnologias apresentadas são voltadas unicamente para o ambi-ente JAVA, embiente esse utilizado para desenvolvimento do protótipo. Além das tec-nologias, foram abordados os principais conceitos de padrões de projeto, bem como osprincipais padrões utilizados para desenvolvimento deste trabalho.
31

3Backup Markup Language (BKPML)
A modernização dos sistemas de informação, a cada dia, tem fortalecido a dependênciados dados em relação às aplicações proprietárias que, em sua maioria, buscam a restriçãodos dados a uma única ferramenta, fortalecendo o vínculo obrigatório entre clientes efornecedores de software. Para resolver tal problema, inúmeros estudos e soluções têmsurgido nas áreas de pesquisa de engenharia de software. eXtensible Markup Language
(XML) é um exemplo que se pode citar como resultado de tais pesquisas. Este capítulotem por objetivo propor uma nova estrutura, não proprietária, baseada em XML, cujoobjetivo é a padronização de arquivos de backup de dados, denominada BKPML. Alémdisso, serão apresentados todos os elementos e tipos que a constituem.
3.1 Introdução
Após a evolução dos Sistemas de Informação (SI) na década de 80, com o surgimento daarquitetura cliente/servidor e o conceito de sistemas integrados, a informação deixa deser centralizada e passa a ser compartilhada entre sistemas através de uma rede de com-putadores, deixando os sistemas centralizados/legados isolados, mas com uma grandequantidade de dados de suma importância para tomada de decisões de empresas e orga-nizações (Turban et al., 2002; Laurindo, 2000).
Para manter a interoperabilidade entre os sistemas novos e legados, foram desenvol-vidos diversos frameworks como, Common Object Request Broker Architecture (CORBA)
(OMG, 2010), Remote Method Invocation (RMI) (RMI, 2010) e Distributed Component
Object Model (DCOM) (DCOM, 2010). Apesar de cumprirem seu propósito, tais fra-
meworks apresentavam limitações entre linguagens de programação, nível de dificuldadeelevada, alguns por serem frameworks proprietários e o custo elevado, que na maioriadas vezes não compensava manter a interoperabilidade entre as aplicações, levando al-
32

3.1. INTRODUÇÃO
gumas empresas a utilizar os sistemas em paralelo, atualizando-os de forma manual.Com o surgimento das linguagens para definição e padronização de estruturas de
dados como XML, notou-se a grande vantagem de se utilizar tal linguagem para padro-nização de dados e interoperabilidade dos mesmos entre aplicações heterogêneas. OsWeb Services são exemplos que podem ser citados, pois possuem em sua especificaçãoa linguagem XML para troca de informações entre aplicações.
Além dos Web Services, existem inúmeras linguagens derivadas de XML com ob-jetivo de interoperabilidade como a eXtensible Business Reporting Language (XBRL)
(XBRL, 2010), eXtensible Scientific Interchange Language (XSIL) (CACR, 2010), Sca-
lable Vectorial Graphics (SVG) (SVG, 2010), Mathematical Markup Language (Math-ML) (MathML, 2010), entre outras.
A BKPML é uma nova linguagem eletrônica, baseada em XML, desenvolvida comoparte integrante deste trabalho, com intuito de padronizar os arquivos de backups debanco de dados. Seu objetivo é desvincular a dependência dos backups do seu SGBD deorigem, facilitando assim a recuperação do mesmo em qualquer outro SGBD.
Esta linguagem, com o apoio de uma aplicação, permite que um arquivo de backup
possa ser restaurado em qualquer SGBD, independente da origem dos dados. Outra van-tagem é a possibilidade de transformar os arquivos BKPML para arquivos secundários(Texto, Excel, CSV, XML, JSON e YAML). A BKPML facilita a manipulação das infor-mações de acordo com as necessidades dos usuários, uma vez que a mesma defende aliberdade das informações e a flexibilidade dos dados.
SGBD proprietários possuem como objetivo principal o armazenamento, segurança,backup e restauração dos dados em suas plataformas proprietárias, quando copiados paraarquivos de backup, os dados oriundos de tais SGBD só poderão ser restaurados no seuambiente de origem, não podendo ser restaurados em outros ambientes. Com arquivosem formato BKPML, esses dados tornam-se independentes de aplicação, facilitando amanipulação dos dados por parte dos usuários.
Para facilitar a persistência e recuperação dos dados, foram selecionados dois for-matos de arquivos para armazenamento de grandes volumes de dados, CSV (Creativyst,2011) e JSON (JSON, 2010).
CSV é um formato de arquivo que armazena dados tabelados e que utiliza delimita-dores (vírgula e quebra de linha) para separar os valores. O formato também usa aspasem campos no qual são usados os caracteres reservados (vírgula e quebra de linha).
JSON é um formato adequado para intercâmbio de dados computacionais, e utilizadoprincipalmente para tráfego de informações em ambientes heterogêneos via Hypertext
33

3.1. INTRODUÇÃO
Transfer Protocol (HTTP) (Tanenbaum, 2003), assim como XML. JSON e do CSV pos-suem implementações em várias linguagens de programação, o que viabiliza a utilizaçãodos mesmos junto a XML (JSON, 2010).
Os principais fatores que levaram a utilização do JSON e CSV como as principaistecnologias para persistência dos dados na estrutura BKPML, foram:
• Recuperação da Informação - JSON e CSV possuem uma estrutura padroni-zada para manter os dados e facilitar a recuperação dos mesmos. Suas interfacespossuem implementações em diversas linguagens de programação, o que facilitaainda mais o processo de recuperação das informações, além de visualmente se-rem mais organizados que outras estruturas;
• Representação da Informação - em XML existem certas dificuldades em se re-presentar alguns tipos de dados, lista é um exemplo. JSON, nesses casos, tem semostrado uma linguagem promissora para representação de dados de tipos maiscomplexos, pois, através da sua forma de marcação, é possível representar listas deobjetos. CSV, por sua vez, apesar de não ser tão claro e organizado quanto JSON,possui uma estrutura conhecida o que facilita muito a recuperação da informaçãoatravés de outras ferramentas; e
• Suporte em várias linguagens - JSON e CSV possuem suporte em várias lingua-gens de programação, facilitando assim o uso da estrutura e reduzindo o trabalhopor parte dos programadores no desenvolvimento de algoritmos para retorno dosdados em uma estrutura com marcação não padronizada.
Além do CSV e JSON foram pesquisadas outras alternativas para uso e persistên-cia dos dados. Hoje existem alternativas para geração de estrutura e marcação de texto,YAML Ain’t Markup Language (YAML) é uma dessas alternativas. YAML é um for-mato para serialização de dados legível por humanos, assim como XML, mas com umanotação muito mais leve e legível (YAML, 2010).
Apesar da YAML também possuir implementações em diversas linguagens de pro-gramação, seu uso ainda se torna restrito por se tratar de uma nova linguagem pararepresentação de informação, o que torna difícil seu uso e implementação em outras fer-ramentas, além da baixa aceitabilidade das mesmas por parte de usuários leigos em taltecnologia. Apesar da YAML não ser utilizada para persistir as informações na estru-tura BKPML, a mesma será utilizada como uma das linguagens para transformação dosarquivos BKPML.
34

3.2. APRESENTAÇÃO DA ESTRUTURA BKPML
BKPML utilizará JSON e CSV para armazenamento dos dados, pois, além de seremformatos de fácil utilização, foi levada em consideração sua afinidade em relação aosframeworks encontrados, bem como, o desempenho dos mesmos para transferência degrandes volumes de dados. A Figura 3.1 apresenta a estrutura em árvore da BKPML.
3.2 Apresentação da estrutura BKPML
Para se obter embasamento necessário para desenvolvimento da estrutura da BKPML,bem como de todos os objetos dos SGBD aceitos pela estrutura, foi necessário adqui-rir profundos conhecimentos sobre a estrutura das tabelas de metadados dos principaisSGBD utilizados pelo mercado (Oracle, Sqlserver, MYSQL e Postgres).
Todo enbasamento para desenvolvimento da estrutura dos objetos (Table, Index,
View, Grant, Trigger e Method) foram retirados através de suas sintaxes de criação, uti-lizando o padrão SQL em sua forma mais pura, evitando assim incompatibilidade entreobjetos de um SGBD para o outro. Em caso de diferença entre objetos, a mesma deveráser adicionada de forma manual após a restauração/migração dos dados. A Figura 3.2apresenta de forma descritiva a estrutura da BKPML bem como de seus objetos.
A estrutura principal do documento é constituída de três elementos complexos: oelemento <BKPML>, <SchemaDB> e <Objects>. O elemento <BKPML> é a estru-tura raiz do documento, é nele que se encontram as principais informações do arquivoBKPML.
O elemento BKPML é constituído de um elemento, denominado <SchemaDB>, cujoobjetivo é manter as informações do esquema a ser copiado, bem como os atributosFile_Name (nome do arquivo gerado) e Date_Created (data de geração do arquivo).A seguir serão apresentados de forma detalhada todos os elementos que constituem aestrutura BKPML e seus respectivos atributos.
3.2.1 O elemento SchemaDB
O elemento <SchemaDB> possui como tipo, o elemento complexo SchemaDBType, queé responsável por guardar as informações referentes ao esquema. Esta estrutura é cons-tituída dos atributos, Schema_Name, que como o próprio nome já diz, refere-se ao nomedo esquema, o atributo DataBase_Source que refere-se ao SGBD que originou os dados.
O atributo DataBase_Source é de grande importância para migração dos dados, poisé a partir dele que a arquitetura responsável pela geração dos arquivos BKPML se baseia
35
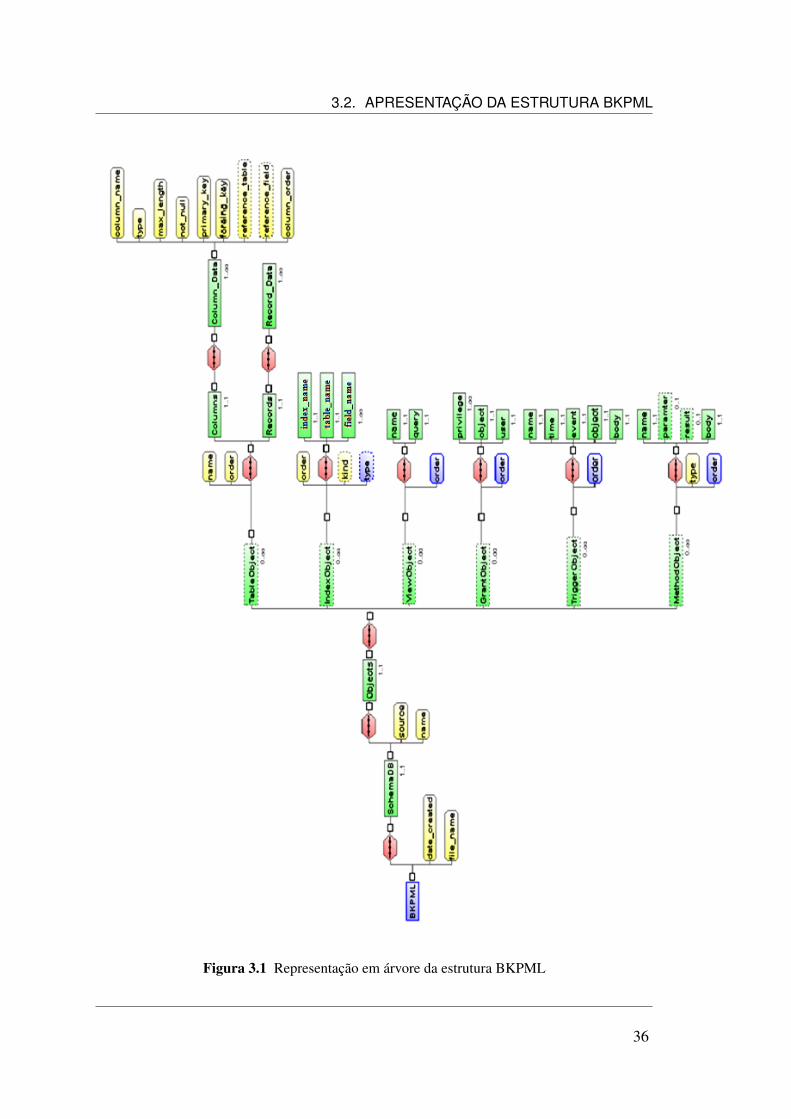
3.2. APRESENTAÇÃO DA ESTRUTURA BKPML
Figura 3.1 Representação em árvore da estrutura BKPML
36

3.2. APRESENTAÇÃO DA ESTRUTURA BKPML
Figura 3.2 Estrutura principal da BKPML
para fazer o mapeamento DE-PARA dos tipos e sintaxes de um sistema de banco dedados para outro.
A cardinalidade do elemento <SchemaDB> foi definida como 1..1 para que a estru-tura BKPML possa dar suporte a apenas a cópia de um único esquema em um mesmoarquivo.
Ao migrar um banco de dados, o esquema pode ser um desafio, pois é necessário ma-pear os tipos de dados do banco antigo para os tipos de dados do banco novo. Eles nãoprecisam ter o mesmo nome, mas devem ter as mesmas funções. Por exemplo, se nãoforem mapeados os tipos de dados corretamente na migração dos dados, podem ocor-rer resultados imprevisíveis ou, pior ainda, os dados podem ser danificados e perdidos(STERN, 2010).
37

3.3. ESTRUTURA DOS OBJETOS DA BKPML
3.2.2 O elemento Objects
Assim como o elemento <SchemaDB>, o elemento <Objects> possui como tipo umelemento complexo ObjectType, que é a estrutura mais importante do documento, poisé nela que serão mantidos todos os objetos pertencentes a um esquema a ser copiado. Acardinalidade desta estrutura foi definida como 1..1 para não permitir que um esquemapossa possuir mais de uma coleção de objetos.
A primeira versão da BKPML é projetada para atender aos principais objetos exis-tentes em um banco de dados, tais como: tabelas, índices, visões, permissões, gatilho,procedimentos e funções, seqüencialmente representadas pelos tipos complexos: Table-
ObjectType, IndexObjectType, ViewObjectType, GrantObjectType, TriggerObjectType e
MethodObjectType apresentados a seguir.
3.3 Estrutura dos objetos da BKPML
Conforme mencionado, a estrutura da BKPML dá suporte aos principais objetos utili-zados em um SGBD. As seções a seguir destinam-se a apresentar apenas as estruturasXML Schema dos objetos aceitos pela BKPML. É importante ressaltar que a estruturaXML Schema desenvolvida foi totalmente baseada na sintaxe SQL padrão dos objetosde SGBD, aceitos pela BKPML.
Para melhor aproveitar as vantagens oferecidas pelo XML Schema, a estrutura daBKPML foi dividida em elementos complexos. Essa estratégia possibilita reuso nasestruturas e facilita a manutenção dos objetos. Os elementos complexos serão seqüenci-almente apresentados conforme abaixo:
• TableObjectType
• IndexObjectType
• ViewObjectType
• GrantObjectType
• TriggerObjectType
• MethodObjectType
38

3.3. ESTRUTURA DOS OBJETOS DA BKPML
3.3.1 O elemento complexo tableobjecttype
O elemento complexo TableObjectType foi preparado para atender apenas a objetos dotipo tabela. Sua cardinalidade foi definida 0..* pois, em um esquema, pode-se possuirzero ou nenhum objeto do tipo tabela dentro de seu domínio. As informações perten-centes a essa estrutura são: o atributo name, que se refere ao nome da tabela copiada,os elementos <Columns> que mantém todas as informações das colunas de uma tabelae <Records> que são os dados existentes na tabela. O atributo order servirá como oidentificador das ocorrências das tabelas.
O elemento <Columns>, conforme mencionado, contém uma coleção de elemen-tos <Column_Data> cujo objetivo é manter as informações referentes às colunas databela, representado pelos atributos, column_name (nome da coluna), type (tipo de da-dos) , not_null (se aceita ou não campos nulos), max_length (tamanho do campo), pri-
mary_key (atributo booleano que indica se é chave primária ou não), foreing_key (chaveestrangeira, assim com o campo chave primária este campo também é booleano), refe-
rence_table (nome da tabela de referência em caso de chave estrangeira), reference_field
(campo de referência da tabela).Quanto ao atributo foreing_key, se o mesmo estiver indicando uma relação de chave
estrangeira para um campo, torna-se obrigatória a inserção das informações para os atri-butos reference_table e reference_field para que a ferramenta possa montar de formacorreta essa relação. O atributo column_order é utilizado como identificador para con-trole das várias ocorrências do elemento <Column_Data>.
O elemento <Records> é o elemento no qual persistirão os dados da tabela. Essaestrutura terá como dados uma coleção de elementos <Record_Data>, responsável porrepresentar os registros oriundos da tabela copiada em formato JSON ou CSV. A Figura3.3 apresenta a estrutura do elemento complexo TableObjectType.
3.3.2 O elemento complexo indexobjecttype
A próxima estrutura a ser apresentada é a do elemento complexo IndexObjectType. Essaestrutura possui um total de seis objetos, três elementos e três atributos em seu es-copo. São eles: <index_name> (nome do índice), <index_table> (nome da tabela),<index_field> (campos da tabela) e os atributos: order que é um atributo obrigatóriopara controle interno de ocorrências, kind e type que são atributos opcionais que repre-sentam que tipo de índice se deseja criar (Index, Primary, Unique, fulltext ou Spatial), equal o tipo do índice (Btree, Hash e Rtree). A Figura 3.4 apresenta essa estrutura.
39

3.3. ESTRUTURA DOS OBJETOS DA BKPML
Figura 3.3 Tipo complexo TableObjectType
3.3.3 O elemento complexo viewobjecttype
O elemento complexo ViewObjectType é destinado à persistência de objetos de visão, suaestrutura é constituída por dois elementos, <name> e <query>, e o atributo order, queé responsável pelo controle das visões adicionadas no documento. O elemento <name>
é o nome da visão a ser copiada. Já o elemento <query> guarda a consulta responsávelpor gerar os dados da visão. A Figura 3.5 apresenta a estrutura completa do elementocomplexo ViewObjectType.
3.3.4 O elemento complexo grantobjecttype
O próximo elemento complexo a ser apresentado é o tipo GrantObjectType, essa estru-tura é responsável por aplicar as regras de segurança e acessibilidade dos usuários do
40

3.3. ESTRUTURA DOS OBJETOS DA BKPML
Figura 3.4 Tipo complexo IndexObjectType
Figura 3.5 Tipo complexo viewobjecttype
SGBD. Ela é composta por três elementos e um atributo, são eles: <privilege>, <ob-
ject>, <user> e order.O elemento <privilege> receberá um ou uma lista de privilégios a serem cedidos a
um usuário, esses privilégios podem ser (select, insert, delete, entre outros).O elemento <Object> receberá o nome do objeto (tables, views, triggers, functions,
entre outros) a ser concedido o privilégio. Já o elemento <user> indica para que usuáriodo SGBD os privilégios estão sendo concedidos. A Figura 3.6 apresenta o tipo complexoGrantObjectType.
41

3.3. ESTRUTURA DOS OBJETOS DA BKPML
Figura 3.6 Tipo complexo GrantObjectType
3.3.5 O elemento complexo triggerobjecttype
O elemento complexo TriggerObjectType destina-se a representar a estrutura de co-mando para criação de um objeto trigger ou gatilho. A definição da estrutura Trig-
gerObjectType é composta por cinco elementos: <name>, <time>, <event>, <object>,<body> e o atributo order.
Os elementos <name> e <time> destinam-se a manter o nome do gatilho e o tempoem que o comando será executado, antes ou depois de um determinado evento. Já oselementos <event> e <object> destinam-se a guardar em que evento o gatilho será exe-cutado (insert, update ou delete) e em que objeto.
O último e mais importante elemento desta estrutura é o elemento <body> quedestina-se a guardar a lógica ou o algoritmo executado pelo gatilho. A Figura 3.7 apre-senta de forma detalhada a estrutura definida para o elemento complexo TriggerOb-
jectType.
3.3.6 O elemento complexo methodobjecttype
O elemento complexo MethodObjectType unifica dois objetos de sintaxes comuns, exis-tentes na maioria dos SGBD comerciais, os objetos procedure e function. Esses objetospossuem o mesmo objetivo (execução de blocos de comandos).
O desenvolvimento dessa estrutura foi unificado devido às poucas diferenças entresuas sintaxes. A principal diferença refere-se ao retorno ou não de valor. Em algunsSGBD, é implementado apenas o conceito de procedimentos, cujo retorno se dá atravésde seus parâmetros. Em funções, esse retorno é realizado através do nome da função.
A estrutura MethodObjectType é composta por 3 elementos e 2 atributos, são eles:<name>, <parameter>, <result> e os atributos type e order. O elemento <name> é onome do procedimento ou função a ser copiada.
O elemento <parameter> representa os nomes e tipos de parâmetros associados ao
42

3.4. CONSIDERAÇÕES FINAIS
Figura 3.7 Tipo complexo TriggerObjectType
corpo do método. Esse elemento possui cardinalidade 0..1 para evitar a obrigatoriedadedo mesmo, uma vez que um método pode ou não possuir parâmetros.
O elemento <result> representa o tipo de valor que a função retornará. Esse campopossui cardinalidade 0..1 pois em caso de procedimento, este campo não será levado emconsideração.
O elemento <body> representa o bloco de comandos executados pelo método.O atributo type identifica que tipo de método está sendo mantido na estrutura: proce-
dimento ou função, controlados pela tag restriction na estrutura. A Figura 3.8 apresentaa estrutura MethodObjectType.
3.4 Considerações Finais
Tendo em vista as dificuldades encontradas nos processos de restauração e migração dedados, este capítulo apresentou a estrutura BKPML, elaborada como proposta para pro-blemas voltados a restauração e migração de dados. BKPML foi projetada com intuito
43

3.4. CONSIDERAÇÕES FINAIS
Figura 3.8 Tipo complexo MethodObjectType
de desvincular a dependência dos arquivos de backup de dados de seus SGBD de origem,uma vez que essa dependência gera um grande esforço quanto à restauração/migraçãode dados em SGBD Heterogêneos.
A idéia principal da BKPML é dar liberdade aos arquivos de backup para que osmesmos possam ser restaurados ou migrados para qualquer SGBD, independente daorigem dos mesmos.
Migrar e/ou restaurar dados para SGBD heterogêneos a partir dos arquivos de bac-
kup, é uma idéia que pode ajudar a reduzir o tempo e custo envolvidos em tais processos,pois com a padronização dos arquivos de backup, não mais será necessário a restauraçãodos dados no SGBD de origem, eles poderão ser restaurados diretamenta para o SGBDde destino.
A seguir são descritas as principais vantagens apresentadas pela BKPML:
• Independência dos dados - com BKPML os dados já não mais pertencerão atecnologias específicas e proprietárias. Esses dados poderão ser restaurados paraqualquer SGBD, sem que haja necessidade de grandes esforços para que isso acon-teça;
• Redução do tempo para migração - a utilização da BKPML para migração erestauração de dados em sistemas heterogêneos, propõe a redução de tempo ecusto envolvidos nos processos de migração e restauração de dados em ambientes
44

3.4. CONSIDERAÇÕES FINAIS
heterogêneos, através da redução de uma das fases do processo, que é a restauraçãodos dados em seu ambiente de origem;
• Estrutura padronizada - quando se deseja chegar à independência dos dados, éimportante que se tenha uma estrutura padrão para que outros aplicativos possamsaber como utilizar essa estrutura para persistir ou recuperar dados a partir dediferentes programas; e
• Independência de Tecnologia ou Ambiente - Como BKPML é uma linguagemderivada de XML, não se tem atrelado a essa tecnologia outras tecnologias quevenham a manter certo grau de dependência entre a estrutura e uma tecnologia.Isso também se aplica à dependência entre ambientes operacionais.
Por se tratar de uma nova linguagem de marcação, a BKPML necessitará de umaaplicação para gerar, restaurar, validar e migrar os dados a partir dos arquivos BKPML.O capítulo a seguir destina-se a apresentar o desenvolvimento da aplicação gerenciadorade arquivos BKPML, bem como abordar as tecnologias que facilitaram o desenvolvi-mento dessa aplicação e as principais características propostas para a mesma.
45

4A Ferramenta: Backup Markup Language
Manager (BKPML Manager)
Backup de dados tem se tornado o principal alicerce para proteção e continuidade dosnegócios de muitas empresas. Atualmente, o mercado disponibiliza inúmeras ferramen-tas que pressagiam a continuidade dos negócios através de backup de dados, mas comarquivos em formatos proprietários. O grande problema com esse tipo de formato étornar os dados dependentes da ferramenta que os originou, dificultando ou até mesmoimpossibilitando que outras ferramentas, da mesma área de atuação, possam manipularesses arquivos.
Este capítulo tem por objetivo apresentar a BKPML Manager, uma ferramenta de-senvolvida para gerar, manipular e gerenciar os arquivos em formato BKPML. Alémdisso, são apresentados de forma detalhada o desenvolvimento de sua arquitetura, astecnologias utilizadas e os padrões de projeto da arquitetura, além da apresentação dosprincipais diagramas e funcionalidades implementadas na ferramenta.
4.1 Introdução
Pelo fato da BKPML se tratar de uma nova linguagem de marcação, foi necessário odesenvolvimento de uma ferramenta, responsável por gerenciar as principais funciona-lidades da criação de backups em formato BKPML. BKPML Manager é o nome dadoà ferramenta desenvolvida para gerenciar e manter todos os artefatos obrigatórios para ageração da estrutura desse formato. Além disso, a ferramenta objetiva facilitar o uso dosprocessos de Backup, Restauração e Migração através de uma interface amigável.
Como a BKPML Manager é uma ferramenta específica para uma determinada área,é evidente que, para utilização desta ferramenta, faz-se necessário ter ou obter profundos
46

4.1. INTRODUÇÃO
conhecimentos sobre SGBD e a organização de suas tabelas internas, responsáveis pormanter os dados e metadados de todos os objetos mantidos pelo sistema.
A ferramenta BKPML Manager é baseada em uma arquitetura cliente-servidor (Ta-nenbaum, 2003), composta por um cliente Web gráfico, responsável por enviar requisi-ções para o servidor de aplicações (Servlet Container) Tomcat6.0 (Tomcat, 2010), e secomunicar com um sistema de banco de dados MYSQL5.0 (MYSQL, 2010), através dodriver JDBC disponível em http://dev.mysql.com/downloads/connector.
Java foi a linguagem de programação utilizada para desenvolvimento da BKPML
Manager, com isso, a BKPML Manager pode ser executada em qualquer servidor queutilize um sistema operacional compatível com a Java Virtual Machine (JVM) (JVM,2010). Além disso, a BKPML Manager pode ser executada em qualquer computadorcom acesso à Internet, através de um navegador (Browser) como o Mozilla Firefox (Fi-refox, 2010) e o Internet Explorer (Internet Explorer, 2010).
Além de sua portabilidade, garantida pela JVM, a BKPML Manager possibilita, deforma simples, o uso dos processos de Backup, Restauração e Migração de dados emqualquer plataforma gerenciadora de banco de dados. Para isso, os mesmos devem serpreviamente cadastrados nas tabelas internas da ferramenta. Esse cadastro possibilitaque um arquivo BKPML possa ser facilmente restaurado em qualquer SGBD, indepen-dente de qual SGBD essas informações foram oriundas. A Figura 4.1 apresenta a telaprincipal da BKPML Manager.
Figura 4.1 Tela principal da BKPML Manager
Para possibilitar uma visão macro dos principais processos executados pela ferra-menta, bem como obter informações sobre as principais funcionalidades existentes, aFigura 4.2 apresenta o ciclo de vida dos processos de backup e restauração dos arquivos
47

4.1. INTRODUÇÃO
BKPML em suas respectivas ordens de execução. Esses processos são apresentados pelafigura em forma de camadas, possibilitando melhor visão da troca de mensagens entreas camadas que representam os principais serviços oferecidos pela BKPML Manager.
Figura 4.2 Ciclo de vida dos processos de Backup/Restore da ferramenta BKPML Manager
Dependendo do tipo de processo executado pelo ciclo, a leitura do mesmo poderá seriniciada na camada Conectar Banco de dados e finalizada na camada Salvar/Recuperar
arquivos, no caso do processo de backup. Já o processo de restauração, inicia-se na ca-mada Salvar/Recuperar arquivos e finaliza na camada Conectar Banco de dados, caso osdados sejam restaurados em um SGBD, ou na camada Transformação, se a transferênciados dados for direcionada para arquivos secundários. O ciclo de vida dos processos debackup e restore só poderá ser iniciado se e somente se todos os cadastros obrigatóriosforem realizados. As camadas de processos são apresentadas abaixo, de acordo com suaordem de execução:
• Camada Conectar banco de dados - É a primeira camada a ser executada, poisé esta a responsável por extrair os dados desejados de um banco de dados e re-passar os mesmos para a camada backup. Esta camada também é responsável porrepassar os dados a serem restaurados para o seu SGBD de origem;
• Camada backup - A camada backup é responsável por transformar os dados re-passados pela camada Conectar Banco de Dados em um arquivo de backup em
48

4.1. INTRODUÇÃO
formato BKPML válido. Para isso, essa camada realiza as seguintes operações:Gerar BKPML, Compactar e Gerar Hash. A operação Gerar BKPML é responsá-vel pela geração da estrutura BKPML a partir dos dados oriundos da camada Co-
nectar Banco de dados. A operação Criptografar criptografa o arquivo BKPMLgerado usando o algoritmo triple DES e encaminha o novo arquivo para a ope-ração Compactar, que por sua vez comprime o arquivo facilitando o envio domesmo para armazenamento em nuvens se necessário. Após isso, a operação Ge-
rar Hash extrai o código hash do arquivo, para que a integridade do mesmo possaser validada após sua restauração;
• Camada Salvar/Restaurar arquivo - essa camada é responsável pelo armazena-mento e restauração dos arquivos em formato BKPML. Em um processamento derestauração de dados, essa camada é a primeira a ser executada, pois busca um ar-quivo solicitado e repassa para camada Restore iniciar seu ciclo de processamento;
• Camada Restore - Ao receber o arquivo solicitado da camada Salvar/Restaurar
arquivo, a camada Restore executa a primeira de suas quatro operações existentesem seu ciclo. A operação Validar Hash recupera o hash do arquivo restauradoe compara com o hash do processamento de backup para verificar a integridadedo arquivo. A operação Descompactar descompacta o arquivo e disponibiliza oarquivo criptografado para a operação Descriptografar, que após descriptografarenvia o arquivo para a operação Restaurar BKPML fazer suas validações de estru-tura e repassar os dados para a camada Transformação ou para camada Conectar
banco de dados; e
• Camada Transformação - A camada transformação é responsável por aplicartransformações nos dados e transferi-los para os formatos desejados. Os formatoscom suporte na ferramenta BKPML Manager são: Texto, Excel, XML, CSV, JSON
e YAML. A camada transformação é executada quando solicitada, caso contrário,a camada Conectar banco de dados será executada para realizar a transferênciados dados para um SGBD de destino.
Além de responsável pela execução do ciclo de processamento de backup e Restau-ração dos dados, a ferramenta BKPML Manager é também responsável pelas operaçõesbásicas e funcionalidades de cadastros necessários para início dos processos de backup,restauração e migração de dados.
Essas funcionalidades estão disponíveis para acesso através de um menu, disponívelna tela principal da ferramenta. Vale ressaltar que a ordem disposta no menu é a ordem
49

4.2. ARQUITETURA DA FERRAMENTA BKPML MANAGER
de cadastros a ser seguida pelos usuários para se iniciar qualquer processo, tanto debackup quando de restauração de dados.
A ferramenta BKPML Manager, por padrão, possui em sua base de dados internao cadastro dos principais tipos, sintaxes e objetos e propriedades dos principais SGBDutilizados no mercado. A Figura 4.3 apresenta o menu com as opções de cadastrosbásicos a serem realizados antes de se iniciar os processos de backup, restauração emigração de dados e objetos.
Figura 4.3 Menu da BKPML Manager
Além de todas as funcionalidades e processos supracitados, a ferramenta BKPML
Manager possui em sua arquitetura, o controle e registro de log (históricos) para todosos processamentos, backup, restore e migração dos dados, para facilitar a resolução deerros oriundos dos processamentos dos dados na ferramenta. Após o término de cadaprocessamento, uma linha de log deverá constar na tela principal da BKPML Manager,conforme apresentado pela Figura 4.1, informando se o processamento foi realizado comsucesso ou com erro.
4.2 Arquitetura da ferramenta BKPML Manager
Conforme mencionado, para o desenvolvimento da ferramenta, foram unidas todas ascaracterísticas conglomeradas em uma aplicação WEB, tendo em vista a crescente de-manda de clientes que estão migrando suas preferências e utilizando aplicativos WEBpara realização de suas atividades cotidianas.
50

4.2. ARQUITETURA DA FERRAMENTA BKPML MANAGER
A estrutura da ferramenta BKPML Manager está baseada em um modelo cliente ser-vidor, ou seja, há a separação dos modelos computacionais em modelo cliente e modeloservidor, bem como a integração de tais modelos utilizando uma rede de computadorespara se comunicar através da troca de mensagens.
A maioria das aplicações Web modernas realiza processamento e armazenamentode pequenos, médios e grandes volumes de dados. Para isso, é imprescindível mantera comunicação direta com um banco de dados que atenda essas necessidades. Nessecenário, a arquitetura cliente servidor possibilita a melhor forma para organização dosdados e para troca de informações entre as camadas. A Figura 4.4 apresenta a arquiteturautilizada.
Figura 4.4 Arquitetura da BKPML Manager
A arquitetura desenvolvida foi dividida em três camadas, com o objetivo de facilitaro entendimento e demonstrar de forma clara como as requisições são realizadas entrecada camada. As seções a seguir destinam-se à explicação de cada uma das camadas,bem como às tecnologias utilizadas para o desenvolvimento das mesmas.
4.2.1 A camada Cliente
A camada cliente é a parte gráfica da aplicação que é apresentada por um navegador(browser) pelo qual o cliente tem acesso direto à aplicação. É nessa camada que ocliente irá manipular suas requisições para realização de cadastros, execução de proces-samentos, geração de relatórios, entre outras funcionalidades disponíveis na ferramenta.Para o desenvolvimento dessa camada foram utilizadas as seguintes tecnologias:
51

4.2. ARQUITETURA DA FERRAMENTA BKPML MANAGER
• Hypertext Markup Language (HTML) (Markup, 2010) - HTML foi utilizada paraformatar o layout das páginas e se beneficiar dos principais objetos utilizados pelaferramenta, tais objetos são: textos, botões, tabelas, links, entre outros. A forma-tação do estilo do layout ficou a cargo do CSS;
• Cascading Style Sheets (CSS) (CSS, 2010) - foi utilizado CSS para criação deestilo e formatação do layout da página e dos objetos, botões, textos, tabelas, cores,entre outros, e para a criação e formatação do menu de opções da ferramenta;
• JavaServer Pages (JSP) (JSP, 2010) - JSP foi utilizado como ambiente media-dos (páginas) para uso e integração das tecnologias JSTL, JAVA e HTML. Alémdisso foram utilizadas algumas bibliotecas e marcações da JSP para formatação eentrada dos dados.
• Javaserver page Standard Tag Lib (JSTL) (JSTL, 2010) - JSTL é usada parafazer a comunicação entre a camada de negócios e a camada de visão, além damanipulação de estruturas de dados como lista, variáveis, objetos, entre outros; e
• Java Script (Flanagan, 2002) - JavaScript foi utilizado para desenvolvimento demétodos e funções para a validação de campos, criação de objetos dinâmicos,ações dinâmicas existentes nas páginas e submeter as páginas através do métodopost, que consiste em transmitir os dados de uma página WEB para o servidor deaplicação (Servlet Container).
4.2.2 Lições Aprendidas
O desenvolvimento da camada cliente foi desafiador, uma vez que tecnologias comoCSS, JSTL, tags do struts2, entre outras, foram novidades no momento do desenvolvi-mento da aplicação, sem contar com a falta de experiência para configuração e uso dastecnologias utilizadas. Para isso, foi necessária a realização de uma extensa pesquisapara entendimento, avaliação e conhecimento das formas como essas tecnologias pode-riam ser utilizadas para compor a camada cliente de forma a satisfazer as necessidadespara desenvolvimento da ferramenta.
No início do desenvolvimento, foram utilizadas as tags do struts2 para realizar acomunicação entre a camada de visão (cliente) e a camada de negócios (servidor). Masno decorrer do projeto, foi notado que alguns objetos pertencentes a essas tags como,buttons, textbox, listbox, entre outros objetos, não mantinham o alinhamento correto naspáginas, o que deixava o layout das páginas ilegível.
52

4.2. ARQUITETURA DA FERRAMENTA BKPML MANAGER
O problema com a formatação das páginas que utilizavam as tags do struts2 poderiater sido revertido através da utilização de CSS, para reformular a posição de cada objeto.O principal problema nessa técnica é o tempo levado para formatar a posição de cadaobjeto da página, sem contar que essa posição muda de acordo com a funcionalidadeutilizada. A alternativa tomada para resolução desse problema foi a utilização dos obje-tos HTML, vinculada ao poder da JSTL para manter a comunicação entre a camada denegócios e a camada de visão, deixando o CSS apenas na formatação do layout principaldas páginas.
4.2.3 A camada Servidor
A camada servidor é responsável por processar e responder às requisições enviadas pelacamada cliente. Todo processamento é realizado através da aplicação disponibilizadana camada servidora, que com a ajuda de um servidor de aplicação ou um container deservlet como o Tomcat (neste caso), a aplicação torna-se disponível para acesso atravésde um navegador.
Observa-se que na camada servidor tem-se três artefatos disponibilizados. O pri-meiro é o artefato container de servlet, que utiliza o Tomcat como servidor WEB paracarregar as aplicações nele disponibilizadas. A seguir, tem-se o artefato Aplicação, querepresenta a aplicação BKPML Manager disponível no servidor e pronta para ser execu-tada pelo mesmo.
O último artefato disponibilizado na arquitetura da BKPML Manager é o artefatoDrivers. O termo foi utilizado no plural porque para cada SGBD cadastrado, deve-seter um driver vinculado que possibilite a ferramenta realizar a conexão com o SGBDcorrespondente. Esses drivers, de um modo geral, são utilizados para fazer que com aferramenta BKPML Manager possa se comunicar com os SGBD registrados na aplicaçãopara realização de transações.
Abaixo são descritas todas as tecnologias utilizadas nas camadas e artefatos supraci-tados:
• Tomcat (Tomcat, 2010) - A tecnologia de servidor de aplicação Tomcat é repre-sentada pelo artefato Container de servlet. Conforme já comentado, Tomcat estásendo utilizado para disponibilização e execução da BKPML Manager através daWEB;
• Struts2 (Struts2, 2010) - Esse framework é utilizado no artefato Aplicação e faz ocontrole das requisições entre as camadas modelo, visão e controle existentes na
53

4.2. ARQUITETURA DA FERRAMENTA BKPML MANAGER
estrutura da ferramenta BKPML Manager. Feito o controle dessa camada atravésdo struts2, foi utilizado o framework Hibernate3 (Gonçalves, 2007) para controlee gerenciamento de persistências entre as camadas Servidor e SGBD;
• Hibernate3 (Gonçalves, 2007) - O Hibernate é utilizado para facilitar o mapea-mento dos atributos entre a base de dados tradicional e o modelo de objetos daaplicação. Esse framework utiliza o artefato Drivers para manter a comunicaçãoentre a camada SGBD;
• DOM4J (Beat, 2010) - é um framework para leitura e criação de arquivos XMLem aplicações Java. Como a ferramenta BKPML Manager trabalha criando ar-quivos em formato BKPML, a utilização do framework DOM4J é crucial para osprocessos de Backup, Restauração e Migração de dados nesse formato;
• Xerces (Xerces, 2010) - Na ferramenta BKPML Manager o framework Xerces
é responsável pela validação dos arquivos BKPML gerados através de seu XML
schema; e
• Database Drivers for Java - A ferramenta BKPML Manager mantém toda suabase de dados no SGBD MYSQL5.0, além de realizar transações com diversosSGBD como POSTGRES, ORACLE e SQL SERVER. Para isso, a BKPML Ma-
nager necessita manter em sua estrutura um driver para cada SGBD cadastrado,pois é a partir deles que a aplicação iniciará a conexão para realizar transações deconsulta, inserção ou alteração dos dados. Esses drivers são representados peloartefato Drivers localizado na camada Servidor.
4.2.4 Lições Aprendidas
No processo inicial do desenvolvimento da arquitetura, foram pesquisados diversos plug-
ins e frameworks para gerenciamento das mensagens entre as camadas modelo, visão econtrole. Dentre eles, apenas dois frameworks foram classificados para testes iniciais daarquitetura: JSF (JSF, 2010) e STRUTS2.
Como a BKPML Manager se trata de uma ferramenta Open Source, os critériosescolhidos para classificação dos plug-ins e frameworks foram, facilidade para uso emanutenção, utilização e aceitação dos mesmos no mercado. Após a escolha e realizaçãode testes, o framework STRUTS2 foi escolhido para compor a arquitetura. Os motivosque levaram a essa escolha foram simplicidade de manipulação, fácil utilização semmuitas configurações, facilidade de manutenção e integração com outras tecnologias.
54

4.3. PADRÕES DE PROJETO UTILIZADOS
Outro fator importante quanto ao desenvolvimento da arquitetura é a utilização depadrões de projeto (design pattern) para compor a arquitetura e facilitar o desenvolvi-mento, reuso e manutenção da aplicação, além de deixar o código padronizado e legível.A aplicação de padrões em uma arquitetura não é algo trivial, pois, para isso, é necessá-rio conhecer bem o padrão a ser aplicado, bem como, onde aplicar, para que o projetopossa usufruir das vantagens propostas. Para isso, antes de se escolher um padrão, énecessário que se tenha conhecimento de quais objetos irão compor a arquitetura doprojeto e qual grau de relação entre eles.
De acordo com FOWLER (2003); Kerievsky (2005) os padrões, apesar de vanta-josos, devem ser utilizados com moderação, devem ser usados de forma cautelosa noprojeto que venha a se beneficiar de sua utilização. Em outras palavras, segundo Am-bler (2002), se suspeita-se que um padrão seja aplicável, deve-se modelá-lo de modo aimplementar a mínima funcionalidade de que se precisa hoje, mas que se torne fácil derefazer mais tarde, caso necessário, ou seja, não modele em excesso.
4.2.5 A Camada SGBD
Essa camada representa todos os drivers responsáveis por manter a conexão entre osSGBD cadastrados. Inicialmente, a ferramenta mantém em sua biblioteca de componen-tes os principais drivers para conexão com os SGBD mais utilizados no mercado, comoOracle, MySql5.0, Postgre8.4 e SQL Server, conforme mencionado, qualquer SGBDdiferente dos apresentados, os drivers devem ser adicionados de forma manual e a fer-ramenta recompilada.
Além dos componentes supracitados, a arquitetura da BKPML Manager se beneficiacom a utilização de três padrões de projeto que facilitam a comunicação entre as classesinternas e reduzem o alto acoplamento entre as mesmas. Os tópicos a seguir abordam ospadrões de projeto utilizados na arquitetura, bem como apresentar os benefícios encon-trados pelo uso dos mesmos no projeto.
4.3 Padrões de projeto utilizados
A definição de padrões de projeto pode ser resumida em: personalização de classes eobjetos comunicantes para resolver um problema geral de objetos num contexto particu-lar (GAMMA et al., 1995). Para que se possa usufruir dos benefícios oferecidos pelospadrões de projeto, faz-se necessário obter profundos conhecimentos sobre os mesmos,saber a devida aplicabilidade na arquitetura, além da seleção de padrões de projeto simi-
55

4.3. PADRÕES DE PROJETO UTILIZADOS
lares, e compará-los para então verificar o que melhor proporciona flexibilidade e reusona arquitetura.
Considerando que todo projeto tende a ser alterado a cada novo requisito solicitado,a arquitetura da BKPML Manager foi definida com base em padrões de projeto, que ofe-recem diversas vantagens para facilitar a implementação de novas funcionalidades oumanutenções das já existentes. A evolução do paradigma orientado a objetos faz comque a arquitetura de software torne-se flexível em relação a aspectos como manutenibili-dade e reuso, e o uso de padrões de projeto vem apresentar modelos que viabilizam taisaspectos.
As funcionalidades da BKPML Manager beneficiadas pelos padrões de projeto sãoprocesso de backup, restauração de dados, cadastros básicos, transformação dos dados
e a troca de mensagem entre as camadas apresentadas.O primeiro padrão implantado na arquitetura foi o padrão DAO (DAO, 2010), res-
ponsável por gerenciar todas as requisições referentes à camada de persistência. Coma utilização desse padrão, todas as requisições aos dados passam a ser encaminhadasdiretamente às classes do padrão DAO. Esse padrão de projeto pode ser desenvolvido deacordo com as necessidades de cada projeto. A seção abaixo apresenta a aplicabilidadedo padrão DAO na arquitetura, bem como aborda os outros padrões utilizados.
4.3.1 Aplicando o padrão Data Access Object (DAO)
Gonçalves (2007) comenta que, quanto ao desenvolvimento de aplicações utilizandoJDBC, colocar instruções de consulta em meio aos códigos torna o código fonte ilegívele de difícil manutenção. O padrão DAO fornece uma interface independente, que é usadapara persistir objetos de dados. A ideia é centralizar as funcionalidades de acesso aosdados em um só local, ou seja, sempre que houver a necessidade de acesso aos dados deuma aplicação, a utilização deste padrão é a melhor a ser empregada.
Dependendo da maneira que se utiliza o padrão DAO, pode ser necessário imple-mentar um DAO para cada classe de objetos em sua aplicação, ou pode-se usar umúnico DAO, responsável por todos os seus objetos. A arquitetura da BKPML Manager
implementa um DAO para cada classe de entidade, bem como a utilização das caracte-rísticas genéricas de Java5.0, permitindo que uma classe Java possa ser parametrizadacom diferentes tipos, conforme apresentado pela Figura 4.5.
A principal motivação para o desenvolvimento de uma classe DAO para cada classede persistência foi que, além das classes possuírem todas as características herdadas declasse mãe Genericdao, cada classe de persistência possui também suas próprias caracte-
56

4.3. PADRÕES DE PROJETO UTILIZADOS
Figura 4.5 Padrão DAO da BKPML Manager
57

4.3. PADRÕES DE PROJETO UTILIZADOS
rísticas, o que impossibilita o desenvolvimento de uma única classe para gerenciamentode todas as classes de persistência existentes na arquitetura. Um exemplo disso é a classeDatabasedao, que além de herdar os métodos padrãos da classe mãe, a mesma imple-menta métodos extras para conexão com outros bancos de dados via JDBC ao invés dehibernate.
Como a ferramenta BKPML Manager possibilita a conexão com vários SGBD, essasconexões extras são realizadas via JDBC, deixando o hibernate gerenciar apenas osdados da ferramenta. Outros métodos que motivaram a criação de uma classe DAO paracada entidade foram os métodos copydata que informa a cada classe como e quais dadostransferir para um objeto, o método validate que diz a cada classe como validar seusdados, e a sobrecarga do método getbyid que para algumas classes é realizado de formadiferente do método herdado da classe mãe.
Com a implantação do padrão de projeto DAO na arquitetura, nota-se inúmeras van-tagens quanto à reutilização de código, uma vez que não houve a necessidade de escreverem cada classe os métodos salvar, alterar, excluir e buscar, deixando apenas o desenvol-vimento de características incomuns de cada classe.
4.3.2 Aplicando o padrão Decorator
O padrão Decorator tem por finalidade fornecer uma maneira de anexar novos estados,comportamentos e características a um objeto de forma dinâmica (GAMMA et al., 1995;SHALLOWAY and TROTT, 2002). As operações de backup e restauração de dados daferramenta BKPML Manager são beneficiadas por este padrão estrutural de projetos.
A Figura 4.6 apresenta o diagrama de classes do padrão de projeto Decorator im-plementado na arquitetura. Suponha-se que seja necessário que o objeto Operations,responsável pela execução das operações de backup e restore precise iniciar um pro-cesso para realização de backup de dados; para isso, faz necessário a declaração de umavariável do tipo Operations que instancie a classe Backup e dentro do parâmetro doconstrutor da classe Backup, deve-se instanciar as classes decorators BKPML, Cripto,Compression e Hash. Após isso, o método execute deve ser chamado, conforme apre-sentado pela Figura 4.8 linha 11.
Quando executado, o decorator repassa a solicitação de execução para os compo-nentes de ações adicionais (backup ou Restore). Após isso, os decorators adicionamnovas características à classe que utilizará o padrão Decorator de forma recursiva. Essetipo de execução permite que um número ilimitado de características ou funcionalidadesseja adicionado ao objeto aplicando o padrão decorator a classe desejada.
58

4.3. PADRÕES DE PROJETO UTILIZADOS
Figura 4.6 Padrão Decorator da BKPML Manager
A classe mãe Operations possui todos os métodos comuns entre as classes, nestecaso, os métodos execute() e addloghistoric(). As classes Backup e Restore são classesresponsáveis por adicionar, de forma dinâmica, novos comportamentos a um objeto.Essas classes estendem a classe Operations, que é responsável por iniciar os métodos aela repassados, conforme exemplo abaixo apresentado pela figura 4.7.
Figura 4.7 Instanciando uma classe backup/Restore
A classe Decorator estende a classe Operations e para cada decorator instanciadotem-se um componente de operations, neste caso o método execute é esse componente.Isso significa que o decorator tem uma variável de instância que contém a referênciapara acesso a esse componente. Por fim, têm-se as classes decorators: BKPML, Cripto,Compression e Hash, nas quais os decorators adicionam novos comportamentos aos
59

4.3. PADRÕES DE PROJETO UTILIZADOS
objetos. É importante observar que os docorators precisam implementar o método exe-
cute(). Abaixo é apresentado um exemplo do uso do padrão decorator na arquitetura daBKPML Manager, na Figura 4.8.
Figura 4.8 Aplicando o padrão decorator a um objeto backup
No exemplo, é executado o backup para ação com código 1. Este backup utilizaas classes decorators: gerar arquivo BKPML, Comprimir arquivo e extrair o códigohash. Nesse processo não foi necessário criptografar o arquivo gerado, mas se preciso,bastaria apenas adicionar o decorator Cripto e o resultado final será um arquivo debackup criptografado. O processo de restore utiliza as mesmas classes, mas que realizamoperações inversas do processo de backup de dados.
4.3.3 Aplicando o Padrão de projetos Strategy
Outro padrão utilizado na arquitetura da ferramenta é o padrão Strategy, que como visto,é uma família de algoritmos encapsulados e intercambiáveis, permitindo que os algo-ritmos variem independente do cliente que o utilize. A ferramenta BKPML Manager
utiliza esse padrão de projetos para gerenciar o processo de transformação dos dados,uma vez que nesse processo utiliza-se uma família de algoritmos responsáveis por trans-formar os dados para arquivos externos. A Figura 4.9 apresenta o diagrama de classe dopadrão Strategy implementado na arquitetura.
O diagrama de classes do padrão de projetos Strategy, implementado na arquiteturada BKPML Manager, é constituído de uma classe mãe abstrata e seis subclasses. Aclasse abstrata Transformation representa o supertipo abstrato, que poderia ser repre-sentado por uma interface ou uma classe abstrata. Na BKPML Manager, foi utilizada asegunda alternativa, contendo todos os métodos comuns entre as subclasses, que devemse responsabilizar apenas pela implementação concreta dos métodos herdados.
60

4.3. PADRÕES DE PROJETO UTILIZADOS
Figura 4.9 Padrão Strategy da BKPML Manager
Todas as novas classes herdadas de transformação precisam apenas implementar ométodo execute(). As subclasses de transformação devem possuir diferentes algorit-mos executados pelo seu método execute (). Nesse contexto, caso seja considerada umasolicitação para uma nova transformação, HTML, por exemplo, o procedimento a sertomado nessa situação seria apenas criar uma subclasse que estenda Transformation eimplemente no método execute() o algoritmo necessário para essa transformação. Apartir desse exemplo, é possível perceber que há uma grande vantagem da utilização dopadrão de projetos Strategy em uma arquitetura que tende a estar em constantes mudan-ças.
4.3.4 Aplicando o Padrão de projetos Model View Controller (MVC)
Como a BKPML Manager é baseada em uma arquitetura Web, o padrão de projetosMVC foi utilizado para dividir a arquitetura do projeto em camadas, facilitando o uso emanutenção do mesmo. Inúmeros são os frameworks encontrados para implementaçãodesse padrão, sendo que: Java Server Faces (JSF) (JSF, 2010), Spring MVC (HEM-RAJANI, 2005) e Struts são os mais conhecidos, utilizados e discutidos pelos usuáriosdas comunidades Java. Após análise e teste dos mesmos, o framework escolhido parautilização no projeto da BKPML Manager foi o Struts2.
A implantação do MVC em uma arquitetura é organizada através da divisão das
61
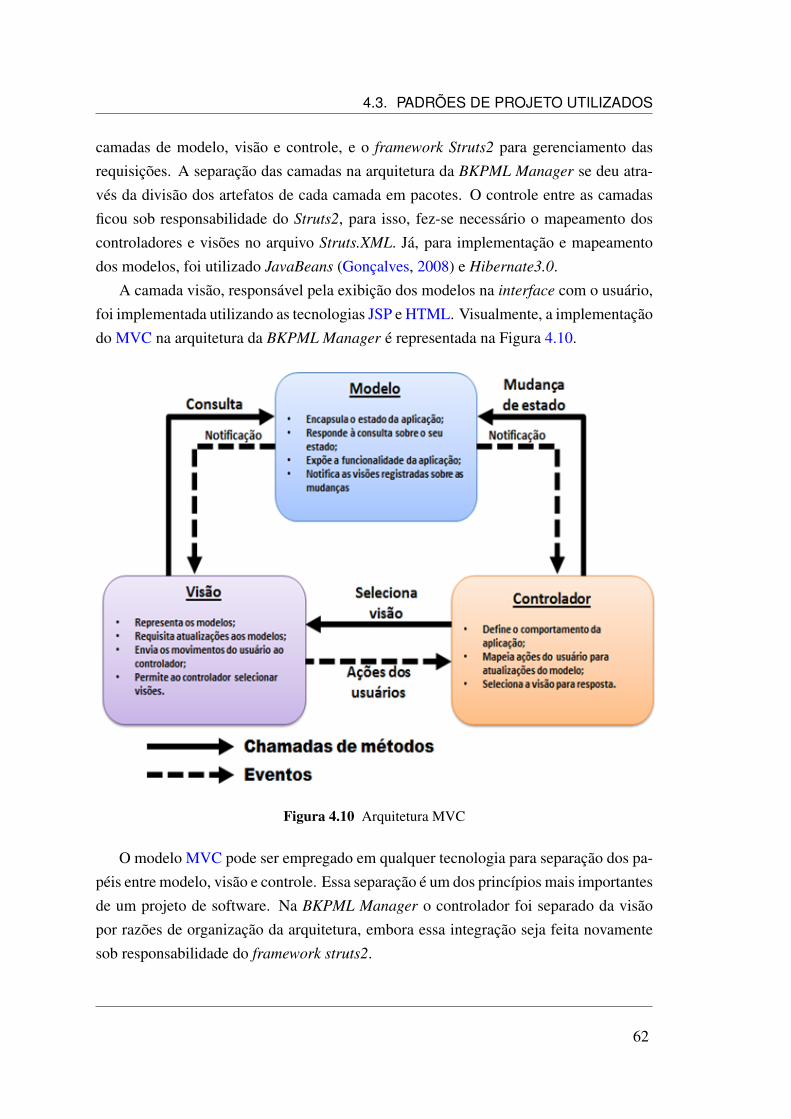
4.3. PADRÕES DE PROJETO UTILIZADOS
camadas de modelo, visão e controle, e o framework Struts2 para gerenciamento dasrequisições. A separação das camadas na arquitetura da BKPML Manager se deu atra-vés da divisão dos artefatos de cada camada em pacotes. O controle entre as camadasficou sob responsabilidade do Struts2, para isso, fez-se necessário o mapeamento doscontroladores e visões no arquivo Struts.XML. Já, para implementação e mapeamentodos modelos, foi utilizado JavaBeans (Gonçalves, 2008) e Hibernate3.0.
A camada visão, responsável pela exibição dos modelos na interface com o usuário,foi implementada utilizando as tecnologias JSP e HTML. Visualmente, a implementaçãodo MVC na arquitetura da BKPML Manager é representada na Figura 4.10.
Figura 4.10 Arquitetura MVC
O modelo MVC pode ser empregado em qualquer tecnologia para separação dos pa-péis entre modelo, visão e controle. Essa separação é um dos princípios mais importantesde um projeto de software. Na BKPML Manager o controlador foi separado da visãopor razões de organização da arquitetura, embora essa integração seja feita novamentesob responsabilidade do framework struts2.
62

4.4. FUNCIONALIDADE DA BKPML MANAGER
4.4 Funcionalidade da BKPML Manager
A ferramenta BKPML Manager é constituída de dezessete funcionalidades, das quaisonze são destinadas à configuração dos processos básicos, obrigatórios para uso dasfuncionalidades de backup, restauração e migração de dados. O restante das funcionali-dades é usado para controle interno da ferramenta.
Para melhor entendimento das funcionalidades, a Figura 4.11 apresenta o diagramade casos de uso com todas as funcionalidades presentes no escopo da ferramenta. Éimportate ressaltar que as funcionalidades descritas por esta seção limitam-se apenas aoscadastros obrigatórios para configuração e uso das funcionalidades backup, restauraçãoe migração de dados, bem como a descrição sucinta das mesmas.
As funcionalidades da BKPML Manager foram divididas em quatro módulos, aces-sados através do menu principal da ferramenta.
No primeiro, foram unificadas todas as funcionalidades para cadastros e configu-rações obrigatórias para uso da ferramenta. Tais funcionalidades podem ser acessadasatravés da opção Cadastros básicos, disponível na tela principal da ferramenta.
No segundo, encontram-se todas as funcionalidades utilizadas para geração, restau-ração e migração de arquivos de backup BKPML. Essas funcionalidades podem seracessadas através da opção Funcionalidades.
Nos últimos, encontram-se o gerador de relatórios, utilizado para análise dos dadoscopiados e o monitoramento dos dados, que como o próprio nome diz, é utilizado paramonitorar os processos em andamento, parados, com erros, entre outros. Esses módulosestão disponíveis através das opções Relatórios e Monitoramento localizados no menuprincipal da ferramenta.
Para facilitar o uso e localização das funcionalidades na ferramenta, as mesmas se-rão apresentadas de acordo com as divisões supracitadas. Sendo assim, as divisões serãorestritas aos módulos cadastros básicos e funcionalidades, uma vez que nesses se en-contram todas as funcionalidades obrigatórias para uso adequado da ferramenta.
As funcionalidades encontradas no módulo de cadastros básicos são:
• Manter tipos, sintaxes e objetos - Utilizada para registar os tipos, sintaxes e ob-jetos não encontrados nas tabelas internas da ferramenta, uma vez que por padrão,a BKPML Manager possui o cadastro de tipos básicos (inteiro, real, lógico, nu-
mérico, entre outros), das sintaxes básicas (se, senão, então, enquanto, para, entreoutros), e dos objetos aceitos pela estrutura BKPML (table, view, trigger, entreoutros). É importante frisar que esses cadastros são de grande importância para o
63
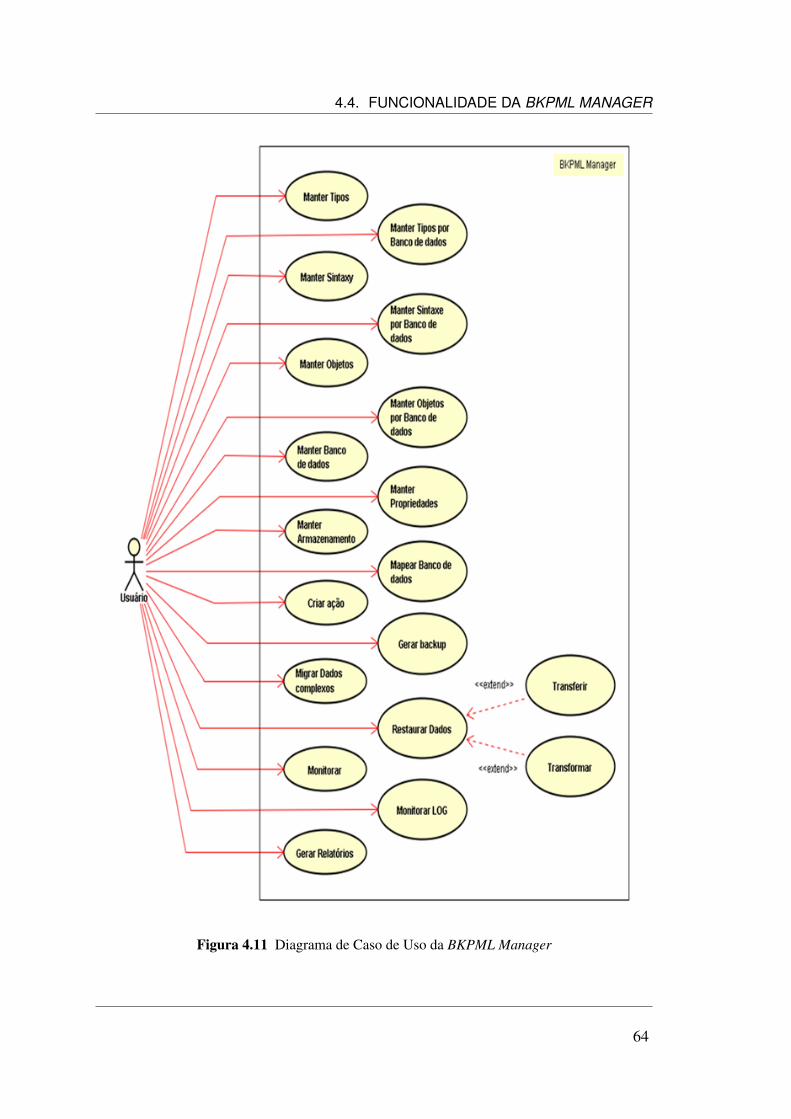
4.4. FUNCIONALIDADE DA BKPML MANAGER
Figura 4.11 Diagrama de Caso de Uso da BKPML Manager
64

4.4. FUNCIONALIDADE DA BKPML MANAGER
correto funcionamento da ferramenta;
• Manter SGBD - Funcionalidade responsável pelo cadastro e teste de conectivi-dade dos SGBD utilizados pela ferramenta para backup, restauração e migraçãode dados. Tanto SGBD de origem (fonte de dados para backup), quanto SGBD dedestino (repositórios de dados) devem ser devidamente cadastrados;
• Manter Armazenamento - A BKPML Manager exige que, para iniciar um pro-cessamento de backup de dados, o mesmo deverá estar associado a um local dearmazenamento. Além disso, a ferramenta permite cadastrar inúmeros armaze-nadores, tanto local quando em nuvens, que servirão como repositórios de dadosa um ou mais processos de backup de dados. Essa funcionalidade destina-se aocadastro desses repositórios;
• Manter Propriedades - Essa funcionalidade é responsável por cadastrar todos osmetadados dos objetos aceitos pela estrutura BKPML. Esse cadastro é de grandeimportância para realização do mapeamento entre os metadados da BKPML e dosobjetos do SGBD. Por padrão a BKPML Manager possui em sua base de dados ocadastro de todas as propriedades (metadados) para todos os objetos aceitos pelaestrutura BKPML;
• Mapear SGBD - Essa funcionalidade mapeia todas as propriedades dos obje-tos cadastradas na funcionalidade manter propriedades, com as propriedades dosobjetos dos SGBD, informando à ferramenta onde e como buscar a propriedademapeada nas tabelas de metadados dos SGBD. Em resumo, esse mapeamento éum relacionamento DE-PARA entre as propriedades da BKPML e as dos SGBD;
• Manter Tipos, Sintaxe e Objetos por SGBD - Esses cadastros também são re-lacionamentos do tipo DE-PARA. É a partir deles que são feitas as relaçãos DE-
PARA entre os tipos e sintaxes da ferramenta, com os tipos e sintaxes dos SGBD.Para isso, o usuário deverá informar o SGBD desejado, o tipo ou sintaxe, e infor-mar sua equivalência. Já o cadastro de Objetos por SGBD destina-se à geração deconsultas (queries) para obtenção dos metadados informados na funcionalidadeMaper SGBD; e
• Criar ação de backup - Ação é o cadastro das configurações para execução deum backup de dados. No cadastro de ações defini-se o objeto a ser copiado, a datade início para execução, a hora , o repositório de armazenamento de dados, entre
65

4.5. CONSIDERAÇÕES FINAIS
outras informações referentes à configuração de um backup de dados. Após essecadastro o processo de backup pode ser iniciado.
As funcionalidades encontradas no módulo Funcionalidades são:
• Gerar backup - Essa funcionalidade tem por objeto a geração de arquivos em for-mato BKPML de acordo com as configurações previamente informadas na tela deCriar ação de backup. Tal funcionalidade dá início à execução dos processamen-tos responsáveis pela geração do backup dos dados. A execução desses processosinicia-se através do clique com o mouse no botão de execução da ação desejada;
• Restaurar dados - Essa funcionalidade restaura os arquivos BKPML nos ban-cos de dados cadastrados. Conforme se pode observar na Figura 4.11, esse casode uso estende duas funcionalidades, transferir e transformar. A funcionalidadetransferir faz a transferência dos dados do arquivo BKPML para um SGBD dedestino. Já a funcionalidade transformar converte os dados para arquivos externosde diversos formatos (CSV, XLS, JSON, YAML e XML). É importante ressaltarque essa funcionalidade utiliza apenas arquivos BKPML de objetos não comple-xos, ou seja, apenas objetos do tipo tabela. Os demais objetos são utilizados pelafuncionalidade Migrar dados complexos; e
• Migrar dados complexos - É a funcionalidade utilizada para migração de dadoscomplexos. São considerados complexos todos os objetos que necessitam de aná-lise visual ou alteração manual em sua estrutura. A ferramenta BKPML Manager
considera como complexo todos os objetos, com excessão do objeto tabela. Agrande diferença dessa funcionalidade para a funcionalidade de migração de da-dos é que nessa os dados sofrem análise visual e alterações manuais, enquanto quena de restauração os dados são migrados de forma direta, sem que haja intervençãodo usuário para isso.
4.5 Considerações finais
Este capítulo apresentou o protótipo da ferramenta BKPML Manager, cuja proposta éa criação de backups de dados em formato BKPML e sua restauração e migração emdiversos SGBD, bastando para isso que os mesmos estejam devidamente cadastradosna base de dados da BKPML Manager. Este Capítulo foi dividido em quatro partes:a primeira destina-se a apresentar a ferramenta BKPML Manager, o ciclo de vida dos
66

4.5. CONSIDERAÇÕES FINAIS
principais processos (backup e restauração) e a apresentação em ordem de prioridadedas funcionalidades com suporte na ferramenta.
A segunda parte destinou-se a apresentar a arquitetura cliente/servidor da ferramenta.Tal arquitetura foi dividida em três camadas: a camada cliente, a camada servidora e acamada SGBD. Na apresentação de cada camada são abordadas todas as tecnologiasque a compõem. Em alguns casos foram descritos tópicos de lições aprendidas no de-correr da fase de elaboração e desenvolvimento da arquitetura. A terceira parte foca ospadrões de projeto utilizados na arquitetura, com objetivo de facilitar a manutenção damesma, bem como torná-la reutilizável. Para facilitar o entendimento dos mesmos, sãoapresentados os diagramas de classe referentes a cada padrão apresentado.
Por fim são apresentadas de forma detalhada as principais funcionalidades disponí-veis na ferramenta BKPML Manager, desde o módulo de cadastro, apresentado em suasrespectivas ordens de cadastro, até o módulo de funcionalidades, as quais são constituí-das por backup, Restauração e Migração de dados complexos.
67

5Estudo de caso
Após a conclusão do desenvolvimento da ferramenta, foram iniciados os testes paraavaliação dos cadastros básicos, das funcionalidades de backup, restauração e migraçãode dados, e do desempenho da ferramenta quanto a pequeno, médio e grande volume dedados. Para início dos testes, foi necessário a realização dos mesmos em ambiente real,para análise de aceitação da ferramenta em empresas de pequeno porte e desempenho damesma em diferentes ambientes. Este capítulo destina-se a apresentar o estudo de casorealizado em uma empresa de consultoria e treinamento em tecnologia da informação egerenciamento de projetos, localizada na cidade de Manaus.
5.1 Apresentação da empresa e domínio do problema
Primeiramente foi realizada uma pesquisa com um conjunto de empresas de pequenoporte da cidade de Manaus. Empresas essas que em sua grande maioria destinam-se aserviços de consultoria e treinamento nas áreas de tecnologia da informação, gerencia-mento de projetos e gestão empresarial. As buscas foram feitas através da Internet, e ocontato via e-mail.
Apenas uma das empresas procuradas concordou em participar dos testes, a empresaKnowhow consultoria. Essa empresa não permitiu a divulgação e acesso a todos osdados, mas autorizou o uso restrito do sistema para testes com a ferramenta BKPML
Manager. Mediante a oportunidade cedida, com ajuda de profissionais da empresa, foiconfigurado o ambiente para início dos testes.
A Knowhow consultoria cedeu acesso a uma área restrita do seu sistema de acompa-nhamento de serviços e avaliação de cursos. Para resguardar informações confidenciaisde clientes e da própria empresa, a Knowhow consultoria elaborou uma lista de objetospúblicos cujas informações poderiam ser divulgadas e testadas, conforme apresentado
68

5.1. APRESENTAÇÃO DA EMPRESA E DOMÍNIO DO PROBLEMA
pela Tabela 5.1.
Tabela 5.1 Objetos do estudo de casoOrdem Objeto Tipo
1 TBL_CURSO TABELA2 TBL_EMENTA TABELA3 TBL_SERVICOS TABELA4 FNC_INSERIR_CURSO FUNCTION5 FNC_DELETAR_CURSO FUNCTION6 PRC_LISTAR_EMENTA PROCEDURE7 FNC_ALTERAR_SERVICOS FUNCTION8 VEW_CURSO_EMENTA VIEW9 TRG_EXCLUIR_EMENTA TRIGGER10 IDX_BY_DATA_COURSE INDEX
O estudo de caso se iniciou com o entendimento de cada objeto cedido pela empresa.O primeiro objeto refere-se à tabela TBL_CURSO. Esse objeto contém informações re-ferentes aos cursos ministrados pela empresa. A tabela TBL_EMENTA é responsávelpor manter os dados da ementa dos cursos oferecidos pela empresa. Nesse cenário umcurso pode conter um ou mais itens de ementa. A tabela TBL_SERVICOS armazena asinformações dos serviços prestados pela empresa.
Os objetos FNC_INSERIR_CURSO e FNC_DELETAR_CURSO são objetos do tipométodo, responsáveis pelo controle de inserção e exclusão de registros da TBL_CURSO.O método FNC_LISTAR_EMENTA lista o curso e sua respectiva ementa, a partir do IDdo curso passado como parâmetro para o método. O método FNC_ALTERAR_SERVI -
COS altera os registros dos serviços prestados pela empresa.O objeto visão VEW_CURSO_EMENTA é a visão responsável por exibir o curso e
sua respectiva ementa, essa visão é utilizada pelo método FNC_LISTAR_EMENTA.O gatilho TRG_EXCLUIR_EMENTA é responsável por excluir a ementa de um curso,
esse é executado de forma automática toda vez que um curso é excluído.O objeto IDX_BY_DATA_COURSE é o índice criado para agilizar a busca de cursos
pelo campo data.O estudo de caso propõe a geração de backup, restauração e migração dos objetos
listados na Tabela 5.1. Esses objetos estão localizados em um dos servidores da empresa,armazenados no SGBD MYSQL5.0.
A restauração e migração dos objetos após o backup serão realizadas para os SGBDPOSTGRES 8.4 e ORACLE EXPRESS.
69

5.2. PREPARANDO O AMBIENTE PARA EXECUÇÃO DO BACKUP
O primeiro passo para iniciar o processo de backup dos dados é iniciar a prepara-ção do ambiente. Para isso, as seções a seguir apresentam de forma didática os passosnecessários para a criação do backup dos dados.
5.2 Preparando o ambiente para execução do backup
Antes de dar início ao processo de backup de dados, é necessário conhecer e realizartodas as etapas obrigatórias envolvidas na preparação do ambiente de execução desseprocesso. Essas etapas foram divididas em quatro funcionalidades básicas de cadas-tro: cadastro de SGBD, cadastro de armazenadores, mapeamento de propriedades de
objetos por SGBD, e cadastro de objetos por SGBD.Todos os quatro cadastros básicos são de grande importância para a realização do
processo de backup de dados, uma vez que esse processo é composto por todas as infor-mações cadastradas por essas funcionalidades. A não realização de uma dessas etapaspode comprometer um ou mais processos envolvidos na geração de backup dos dados.
Todas as funcionalidades de cadastros básicos são disponíveis para acesso atravésdo menu, localizado na tela principal da ferramenta. As funcionalidades de cadastrosbásicos serão apresentadas de forma simplificada, uma vez que não há dificuldades narealização dessas etapas, ou seja não serão abordados detalhes sobre preenchimento deinformações, apenas as telas consideradas importantes serão apresentadas para se obtermelhor ideia desses processos.
A primeira etapa refere-se à funcionalidade de cadastro de SGBD. Essa atapa éresponsável pelo cadastro e testes de todos os SGBD envolvidos em um processo debackup, restauração e migração de dados. Para realizar tal tarefa, deve-se clicar com omouse na opção SGBD no menu principal, opção cadastros básicos, e iniciar o cadastrodos SGBD. Nesse caso, foram cadastrados os SGBD MYSQL5.0, POSTGRES8.4 e o
ORACLE XE.Para realização dos testes de conexão, a BKPML Manager dispõe, em sua biblio-
teca, dos principais drivers JDBC utilizados para conexão com os SGBD supracitados,incluindo o Sql Server. Para uso de qualquer outro SGBD, faz-se necessária a inserçãodo respectivo driver JDBC na biblioteca da ferramenta e a recompilação da mesma, paraque as modificações possam ser efetivadas.
A segunda etapa é a funcionalidade de cadastro de armazenadores, a qual tem porobjetivo realizar o cadastro de todos os repositórios de dados que serão utilizados paraarmazenamento dos arquivos de backup gerados. Os locais de armazenamento são clas-
70

5.2. PREPARANDO O AMBIENTE PARA EXECUÇÃO DO BACKUP
sificados em dois tipos: local e em nuvens.No armazenamento local, deve-se informar o endereço onde se deseja armazenar os
dados. Esse endereço pode ser um diretório local ou remoto. Para o armazenamento dedados em nuvens, a ferramenta BKPML Manager utiliza o serviço Simple Storage Ser-
vice (S3) da Amazon Web Services. Para isso, o usuário deverá possuir uma conta no sitehttp://aws.amazon.com e adquirir as chaves de acesso e secreta. Além disso, ousuário deverá solicitar acesso ao serviço S3, de acordo com os pacotes disponibilizadospela Amazon Web Services.
No momento dos testes, essa funcionalidade foi questionada pela equipe técnica daKnowhow nos seguintes aspectos: o que aconteceria se o diretório informado não exis-
tisse? E se o nome do diretório informado for inválido? Em resposta aos questionamen-tos, quando o processamento de backup verifica a inexistência do diretório cadastrado, amesma se responsabiliza por gerar o diretório de acordo com os níveis informados. Nocaso de ser um nome inválido, um erro é retornado ao usuário, e o processo de backup écancelado.
A terceira etapa é a funcionalidade de mapeamento de propriedades de objetos porSGBD. Por definição, uma propriedade é um atributo ou característica que define umobjeto ou parte dele. Por exemplo, as propriedades que definem um objeto tabela sãonome da tabela, campos da tabela, tipo de dados dos campos, entre outros. Todo SGBDtem salvo em suas tabelas internas essas informações (metadados) e são essas tabelasque precisam ser mapeadas para que a ferramenta possa saber onde e como montar aestrutura de metadados dos objetos em BKPML.
A BLPML Manager possui em suas tabelas internas o cadastro de todas as propri-edades dos objetos aceitos pela BKPML, bastando o usuário fazer um cadastro do tipoDE-PARA entre as propriedades dos objetos da BKPML e as dos SGBD. A Figura 5.1apresenta a tela referente a essa etapa.
A quarta e última etapa é a funcionalidade de cadastro de objetos por SGBD, a qualtem por objetivo vincular cada objeto cadastrado na ferramenta ao seu SGBD de destino.Isso se faz necessário, pois, após esse vínculo, deve-se executar a funcionalidade Gerar
Consultas para que a consulta de metadados para o objeto selecionado seja gerada deacordo com o SGBD. A geração da estrutura de metadados na BKPML funciona daseguinte maneira: a ferramenta verifica para que tipo de objeto o backup será gerado,localiza a consulta de metadados desse objeto, executa a consulta, e os dados retornadossão repassados para o método responsável por gerar a estrutura BKPML. Essas etapassão comuns a todos os objetos da BKPML. Todos os dados utilizados para geração da
71
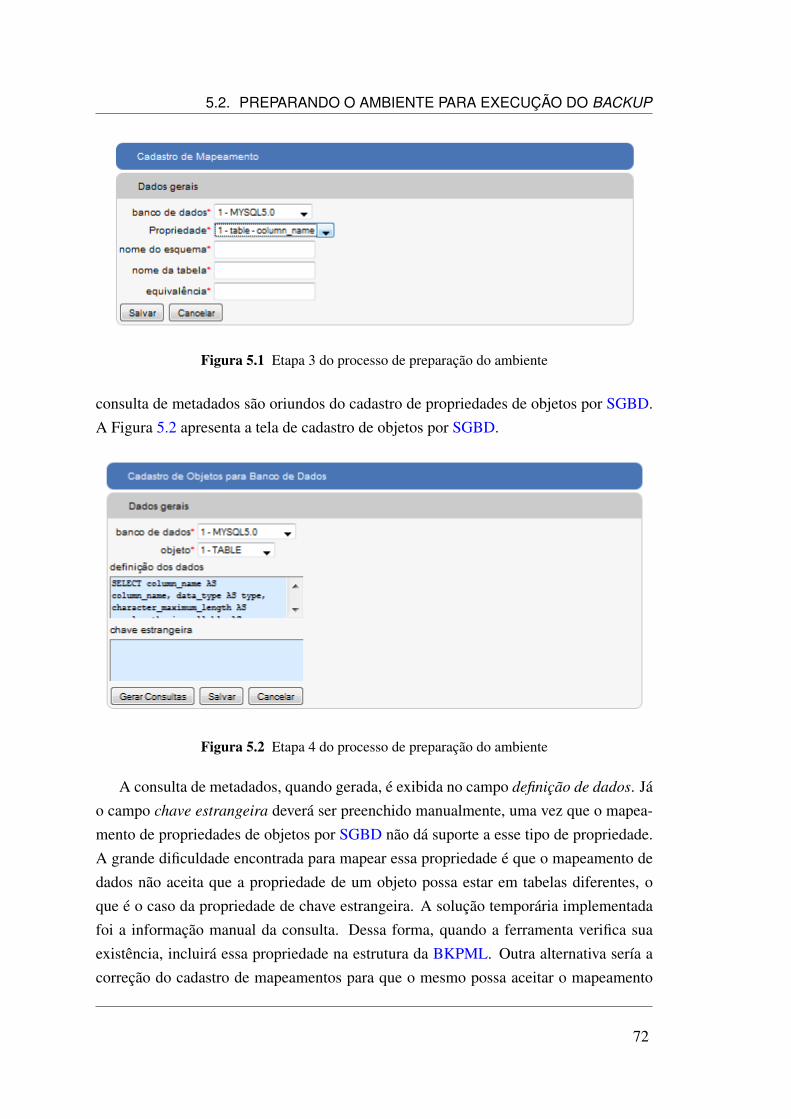
5.2. PREPARANDO O AMBIENTE PARA EXECUÇÃO DO BACKUP
Figura 5.1 Etapa 3 do processo de preparação do ambiente
consulta de metadados são oriundos do cadastro de propriedades de objetos por SGBD.A Figura 5.2 apresenta a tela de cadastro de objetos por SGBD.
Figura 5.2 Etapa 4 do processo de preparação do ambiente
A consulta de metadados, quando gerada, é exibida no campo definição de dados. Jáo campo chave estrangeira deverá ser preenchido manualmente, uma vez que o mapea-mento de propriedades de objetos por SGBD não dá suporte a esse tipo de propriedade.A grande dificuldade encontrada para mapear essa propriedade é que o mapeamento dedados não aceita que a propriedade de um objeto possa estar em tabelas diferentes, oque é o caso da propriedade de chave estrangeira. A solução temporária implementadafoi a informação manual da consulta. Dessa forma, quando a ferramenta verifica suaexistência, incluirá essa propriedade na estrutura da BKPML. Outra alternativa sería acorreção do cadastro de mapeamentos para que o mesmo possa aceitar o mapeamento
72

5.3. CADASTRANDO AS AÇÕES DE BACKUP
de propriedades de um objeto existentes em outras tabelas. É importante ressaltar queessa propriedade se aplica apenas a objetos do tipo tabela. Para os demais objetos, essecampo deverá permanecer em branco.
5.3 Cadastrando as ações de backup
É a partir deste cadastro que o processo de backup de dados será configurado. Até omomento, todos os cadastros realizados referem-se ao SGBD e a seus objetos. Nessatela, apresentada pela Figura 5.3, são utilizadas as informações de todos os cadastrosrealizados nas seções anteriores. É nessa etapa que serão cadastradas as ações de backup
para cada objeto, apresentado pelo Tabela 5.1.Na tela de cadastro de ações, o usuário deverá selecionar o SGBD com relação ao
objeto a ser cadastrado, caso o objeto selecionado seja diferente ao do cadastrado, aferramenta retornará um erro e o backup dos dados falhará. A segunda informaçãoa ser preenchida é o local para armazenamento dos arquivos de backup. A terceirainformação é o nome do objeto cadastrado, esse nome deve ser idêntico ao apresentadono Tabela 5.1, caso contrário o backup falhará. As demais informações por motivo desimplicicação não serão apresentadas.
Além disso, é importante ressaltar que o campo Consulta de extração refere-se àconsulta responsável por retornar os dados de um objeto tabela, e por esse motivo estainformação é obrigatória para esse tipo de objeto. Para os demais, esse campo não deveráser preenchido.
Em resumo, uma ação é um processo de backup não executado, uma vez que estecadastro possui todas as configurações necessárias para isso. A Figura 5.3 apresenta atela de cadastro de ações para maiores detalhes.
O campo frequência é responsável por controlar o número de execuções semanaisdos processos de backup. Esse campo pode receber valores no intervalo de [1..7], queé o intervalo equivalente aos dias da semana. O controle de execução dos processos debackup é independente do dia da semana. Para tando, a ferramenta BKPML Manager
gerencia um contador interno de execuções, que é zerado toda semana, tendo como basea data da última execução.
73

5.4. EXECUTANDO O BACKUP DOS DADOS
Figura 5.3 Tela de cadastro de Ações
5.4 Executando o Backup dos dados
Após a conclusão do cadastro de ações de backup, o próximo passo a ser tomado é aexecução das ações (backup) cadastradas. Para isso, deve-se acessar o menu Funciona-
lidades opção Backup.Na tela de backup de dados, são encontrados todos os backups cadastrados pela
funcionalidade cadastro de ações. Além disso, são apresentadas informações referentesà configuração de cada backup. Na coluna AÇÕES são encontrados dois métodos. Oprimeiro método representado pelo botão com a imagem de proibição, é responsávelpela desativação de um backup de dados. A desativação de um backup de dados consisteem remover esse backup de lista de backups, impossibilitando assim a sua execução.Uma vez desativado, um backup de dados só poderá ser ativado novamente através datela de cadastro de ações.
O segundo método disponível, representado pelo botão com a imagem de continui-
dade, é responsável por dar início à execução do backup desejado. Quando executado,esse objeto será submetido ao ciclo de vida do processo de backup, apresentado no ca-pítulo 4 Figura 4.2. No final desse processo o arquivo será armazenado no seu devidolocal de armazenamento. A Figura 5.4 apresenta a tela de execução de backup de dados.
No final do ciclo de vida do processo de backup, os resultados obtidos podem servistos conforme apresentado. Vale ressaltar que os resultados apresentados pertencemaos objetos disponibilizados no Tabela 5.1. Além disso, os resultados apresentados nãoseguem a ordem apresentada pela Figura 5.4, uma vez que os mesmos foram agrupados
74

5.4. EXECUTANDO O BACKUP DOS DADOS
Figura 5.4 Tela de execução de backup de dados
por tipo de objeto. Os primeiros resultados apresentados referem-se aos arquivos debackup de objetos do tipo tabela. O primeiro resultado refere-se ao objeto TBL_CURSO,apresentado pela Figura 5.5.
Figura 5.5 Documento BKPML TBL_CURSO
O objeto TBL_CURSO é um objeto de tipo tabela, constituído de sete campos edois registros, representados respectivamente pelas marcações <COLUMNS> e <RE-
CORDS>. Essas marcações representam o conjunto de dados e metadados pertencentes
75

5.4. EXECUTANDO O BACKUP DOS DADOS
ao objeto copiado.Na marcação <COLUMNS>, encontram-se os metadados do objeto copiado, que
são representados pela marcação <COLUMN_DATA>. Já na marcação <RECORDS>,encontram-se todos os dados pertencentes a um objeto do tipo tabela. Esses dados sãorepresentados pela marcação <RECORD>. Essa marcação se repetirá a quantidade deregistros existentes na tabela TBL_CURSO. A Figura 5.6 apresenta a estrutura BKPMLdo arquivo TBL_EMENTA.
Os próximos resultados obtidos do processamento de backup de dados são referentesàs tabelas TBL_EMENTA e TBL_SERVICOS representadas pelas Figuras 5.6 e 5.7
Figura 5.6 Documento BKPML TBL_EMENTA
A estrutura BKPML do objeto tabela TBL_EMENTA é constituída de quatro campos.Os campos ID e ID_CURSO são as chaves primárias dessa tabela. O campo ID_CURSO
funciona como chave estrangeira da tabela TBL_CURSO, como o mesmo não foi ma-peado na tabela TBL_EMENTA, a estrutura BKPML contém apenas o mapeamento dechave primária nas tabelas de metadados.
Quando um objeto é transposto para a estrutura da BKPML, a análise dos dados podeser feita de forma rápida e fácil. Com essa análise é possível identificar facilmente erros
76

5.4. EXECUTANDO O BACKUP DOS DADOS
relacionados à modelagem dos objetos e informações inválidas como caracteres especi-ais oriundos do SGBD de origem. Erros desse tipo muitas vezes podem comprometer oobjeto quando restaurado. O próximo arquivo de backup a ser apresentado refere-se aoobjeto TBL_SERVICOS representado na Figura 5.7.
Figura 5.7 Documento BKPML TBL_SERVICOS
A estrutura BKPML do objeto tabela TBL_SERVICOS é composta por três camposID, NOME e DESCRICAO, mantidos pela marcação <Columns> que representa os me-tadados de um objeto do tipo tabela. Como se pode observar, essa tabela não possui umcampo chave primária. Com o uso da BKPML, basta apenas realizar a edição do arquivoBKPML e adicionar de forma manual o atributo primary_key no campo desejado.
Outro fator que influencia de forma positiva na representatividade dos dados naBKPML, é que a mesma se beneficia do poder de XML representar essas informações.Além disso, o uso da tecnologia JSON para representar os dados de objetos do tipotabela também ajuda na detecção visual de erros.
Por se tratar de erros na entrada dos dados, esse tipo de problema pode comprometero processamento dos dados como os processos de restauração ou migração, uma vez queum SGBD de destino pode interpretar essas entradas como um erro grave, impedindo arestauração dos mesmos em seu ambiente. Com a estrutura BKPML, esse tipo de erro éfacilmente identificado e corrigido, sem comprometer a integridade dos dados. A Figura5.8 apresenta a arquivo de backup de um objeto do tipo índice.
A estrutura BKPML para um objeto do tipo índice é composta de três importan-tes informações que possibilitam a restauração do mesmo em qualquer SGBD: <in-
77

5.4. EXECUTANDO O BACKUP DOS DADOS
Figura 5.8 Documento BKPML IDX_BY_DATA_COURSE
dex_name>, que representa ao nome do índice, o campo <index_table>, que representao nome da tabela indexada, e o campo <index_field>, que é o campo indexado, alémdos atributos type e kind, mantidos pela marcação <IndexObject>.
A partir dessas informações é possível gerar a sintaxe SQL padrão para esse tipo deobjeto, aceita por qualquer SGBD. Quaisquer outros detalhes para esse tipo de objeto,particular do SGBD de destino, deverá ser feita de forma manual. Caso contrário, omesmo poderá ser migrado sem qualquer problema. Os próximos documentos apresen-tados referem-se a estruturas do tipo método, apresentado pela Figura 5.9.
Figura 5.9 Documento FNC_INSERIR_CURSO
A estrutura BKPML de um objeto do tipo method é composta pelas principais infor-mações necessárias para geração de sua sintaxe padrão, definida pela própria ferramenta,tendo em vista que esse tipo de objeto não possui uma estrutura padrão comum a todosos SGBD. A estrutura deste tipo de objeto muda de SGBD para SGBD. Para resolver
78

5.4. EXECUTANDO O BACKUP DOS DADOS
esse tipo de problema, foram definidas as principais informações que compõem os ob-jetos do tipo função e procedimento, e essas foram acopladas em uma só estrutura, umavez que esses objetos possuem poucas características que os distinguem.
Uma estrutura BKPML do tipo métodos é composta pelas seguintes informações:<name>, parameter>, <result> e <body>. Qualquer dúvida a respeito dessas infor-mações, o Capítulo 3 deste trabalho deverá ser consultado. Os próximos documentos aserem apresentados referem-se a objetos do tipo função, apresentados pelas Figuras 5.10e 5.11
Figura 5.10 Documento FNC_DELETAR_CURSO
Figura 5.11 Documento FNC_ALTERAR_SERVICOS
Esses métodos são responsáveis por deletar e alterar os dados da tabela TBL_CURSO
79

5.4. EXECUTANDO O BACKUP DOS DADOS
e da tabela TBL_SERVICOS, conforme pode-se observar pela marcação <body> de am-bos os arquivos. O próximo arquivo a ser apresentado é o PRC_LISTAR_EMENTA, queé um objeto do tipo método que representa a estrutura de uma procedure, conformeapresentado pela Figura 5.12.
Figura 5.12 Documento PRC_LISTAR_EMENTA
O atributo type da marcação <MethodObject> informa à ferramenta qual o tipo daestrutura que está sendo representada pela BKPML: procedure ou function. Além disso,pode-se observar essa diferença pela falta da marcação <return> uma vez que um pro-cedimento não possui um valor de retorno. Os últimos resultados a serem apresentadossão referentes a objetos do tipo Visão e Gatilho. Representados pelas Figuras 5.13 e5.14.
Figura 5.13 Documento BKPML VEW_CURSO_EMENTA
80

5.5. PREPARANDO O AMBIENTE DE RESTAURAÇÃO E MIGRAÇÃO
Figura 5.14 Documento BKPML TRG_EXCLUIR_EMENTA
Assim como o objeto do tipo índice, a estrutura do objeto tipo visão é compostapelas informações básicas necessárias para geração de sua sintaxe SQL padrão aceitapor todos os SGBD relacionais. Sua estrutura possui apenas dois elementos <name> e<query>.
Já a estrutura do objeto de tipo gatilho, assim como a estrutura do objeto de tipo mé-todo, é composta pelas informações comuns desse objeto para qualquer SGBD. A partirdessas informações a ferramenta transpõe esses dados para uma sintaxe comum, que re-ceberá as adaptações necessárias de acordo com o SGBD de destino. Essas informaçõessão: <name>, <time>, <event>, <object> e <body>.
Todos os objetos aqui apresentados são compostos apenas por suas característicascomuns para todos os SGBD. Características particulares de SGBD para SGBD, con-forme mencionado, devem ser adicionadas manualmente. A seção a seguir destina-se aapresentar as etapas e resultados obtidos nos testes de restauração e migração de dados.
5.5 Preparando o ambiente de restauração e migração
Para dar início aos processos de restauração e migração de dados, é necessária a reali-zação das configurações básicas para execução desses processos. Essas configuraçõessão divididas em duas etapas: o cadastro de tipos por SGBD e o cadastro de sintaxe por
SGBD. Esses cadastros são de grande importância para esses processos pois, antes darestauração dos dados, todos os tipos devem ser validados. O processo de migração de
81

5.5. PREPARANDO O AMBIENTE DE RESTAURAÇÃO E MIGRAÇÃO
dados complexos utiliza essas informações para auxiliar o processo de substituição detipos e sintaxes de um objeto complexo.
A primeira etapa a ser realizada é o cadastro de tipos por SGBD. Essa etapa consisteem vincular os tipos básicos mantidos pela ferramenta BKPML Manager aos tipos equi-valentes dos SGBD receptores. A não realização dessa etapa impossibilitará o processode transferência dos dados. Uma transferência consiste em passar as informações de umarquivo BKPML para um SGBD. O processo de transformação dos dados, ou seja, aconversão de um arquivo BKPML para um arquivo em formato CSV, EXCEL, YAML,XML ou JSON, não é afetado, uma vez que para isso não se faz necessária validação detipos.
A segunda etapa é o cadastro de sintaxes por SGBD. Esse cadastro possui os mesmosobjetivos da primeira etapa: vincular as sintaxes básicas mantidas pela BKPML Manager
às sintaxes equivalentes dos SGBD receptores. Ao contrário da primeira etapa, a nãorealização dessa não impossibilita a realização de nenhum dos processos supracitados,uma vez que esse cadastro é utilizado apenas para auxiliar a funcionalidade de migraçãodos dados.
5.5.1 Restaurando e transformando os arquivos BKPML
O processo de restauração de dados está disponível para acesso através do menu princi-pal, opção funcionalidades. Na tela de restauração de dados complexos são encontradastodas as informações necessárias sobre arquivos BKPML pertencentes a objetos de tipotabela, uma vez que essa funcionalidade só trabalha com esse tipo de objeto. Essa telaé composta por dois processos: o processo de transferência e o de transformação. Paraisso, o usuário deverá informar na própria tela o tipo de ação desejada: transferênciaou transformação. A ferramenta não exibe explicitamente a palavra transformação, massim os tipos de transformação permitidos pela ferramenta CSV, JSON, YAML, XML eEXCEL.
Para execução do processo de transferência dos dados, o usuário deverá selecionar oSGBD de destino e a opção transferência. Após isso, o botão localizado na coluna açãodeverá ser clicado com o mouse para dar início à transferência dos dados no arquivoBKPML para o SGBD selecionado. No processo de transformação dos dados, não sedeve informar um SGBD, somente o tipo de transformação desejada. Após isso, o botãode execução deverá ser pressionado com o mouse para dar início ao processo. A Figura5.15 apresenta a tela para restauração de transformação de dados.
Assim como a tela de execução dos backups de dados, a tela de restauração segue
82

5.5. PREPARANDO O AMBIENTE DE RESTAURAÇÃO E MIGRAÇÃO
Figura 5.15 Tela de Restauração de dados
o mesmo padrão, com a diferença nos dados de entrada. O primeiro destina-se a infor-mar o SGBD para destino. Quando clicado com o mouse, esse objeto apresenta todosos SGBD cadastrados na ferramenta. O segundo destina-se às funcionalidades de trans-ferência e transformação. É importante ressaltar que a palavra transformação não éexibida nesse componente, subentende-se que transformação é qualquer opção diferenteà transferência. Esse componente quando clicado com o mouse, exibirá todos os tiposde transformação permitidos pela ferramenta.
Após a execução e finalização dos processos de restauração e transformação dosdados, alguns resultados serão apresentados a seguir. O primeiro resultado a ser vistorefere-se à restauração dos dados dos objetos tabela TBL_CURSO, TBL_EMENTA eTBL_SERVICOS no SGBD Postgres8.4, conforme apresentado pela Figura 5.16.
Figura 5.16 Restauração dos dados no postgres
Esses resultados foram obtidos a partir da seleção do SGBD POSTGRES8.4 e daseleção do formato tipo transferência. A seleção desse formato informa à aplicação que
83

5.5. PREPARANDO O AMBIENTE DE RESTAURAÇÃO E MIGRAÇÃO
a restauração dos dados será realizada diretamente para o SGBD selecionado. Qualqueroutra opção indica que os dados serão transferidos para arquivos secundários.
As figuras 5.17 a 5.20 apresentam os resultados obtidos com as funcionalidades detransformação dos dados. Vale ressaltar que os resultados apresentados seguem a mesmaordem disposta no menu de opções dessa tela. O formato XML não será apresentado,uma vez que para esse formato a ferramenta retornará o arquivo BKPML, já apresentadoanteriormente.
O primeiro resultado é a transformação do arquivo de backup da tabela TBL_EMENTA
para o formato CSV. Este formato foi escolhido pois a maioria dos SGBD comerciaisutiliza esse formato para transferência e restauração de grandes volumes de dados. AFigura 5.17 apresenta os resultados obtidos dessa transformação.
Figura 5.17 Objeto TBL_EMENTA em formato CSV
No formato EXCEL os dados são transpostos para uma planilha de forma simples,qualquer formatação fica a cargo do usuário. Esse formato foi escolhido para facilitar,quando necessário, a geração de relatórios para dados específicos e que necessitem servisualizados em formato popular para empresas e organizações. A Figura 5.18 apresentaa transformação dos dados da tabela TBL_CURSO para o formato EXCEL.
Figura 5.18 Objeto TBL_CURSO em formato Excel
A próxima transformação a ser apresentada é referente ao formato JSON. Esse for-
84

5.5. PREPARANDO O AMBIENTE DE RESTAURAÇÃO E MIGRAÇÃO
mato inicialmente foi desenvolvido com objetivo de fazer intercâmbio de objetos JavaS-
cript através da Internet, e hoje em dia é utilizado tanto para intercâmbio quanto pararepresentação de informações na Internet. A ferramenta utiliza esse formato por ser umfacilitador para transferência de dados entre diferentes plataformas e representar os da-dos de forma clara. Quando os dados são transformados para esse formato, os mesmossão armazenados em um vetor JSON, o que facilita a restauração dos mesmos utilizandoa função eval() no javaScript ou utilizando um framework JSON para realização dessatarefa. A Figura 5.19 apresenta a transformação dos dados da tabela TBL_EMENTA parao formato JSON.
Figura 5.19 Objeto TBL_EMENTA em formato JSON
O formato YAML foi escolhido como formato para transformação pois, além de serum formato novo e em expansão no mercado, esse formato propõe a disponibilizaçãodos dados de forma mais legível a humanos, o que facilitaria a análise visual dos dadosquando necessário. O último resultado dessa fase de testes é apresentado a seguir pelaFigura 5.20.
Figura 5.20 Objeto TBL_SERVICOS em formato YAML
A BKPML Manager implementou as funcionalidades de migração de dados parapermitir que as informações mantidas nos arquivos BKPML pudessem ser compartilha-das com outras aplicações, sem o intermédio da ferramenta BKPML Manager. Além
85

5.5. PREPARANDO O AMBIENTE DE RESTAURAÇÃO E MIGRAÇÃO
disso, formatos como XML e JSON, foram utilizados para facilitar o intercâmbio dasinformações para outros sistemas através da Web. Por fim, pode-se concluir que os tes-tes apresentados alcançaram os objetivos esperados. Todos os arquivos de backup foramrestaurados e transformados corretamente. A seção a seguir destina-se a apresentar ostestes e resultados obtidos com a funcionalidade de migração de dados complexos.
5.5.2 Migrando os arquivos BKPML de objetos complexos
A funcionalidade de migração de dados complexos é utilizada quando o objeto a sermigrado refere-se a um objeto complexo. Um objeto complexo é aquele que necessitade análise visual e alteração manual em sua estrutura para que a restauração possa serefetivada. A ferramenta considera como objeto complexo os objetos: visão, índice,
permissão, gatilho e método. O único tipo de objeto que não é considerado complexo éo objeto tabela, testado na seção anterior.
Os objetos visão, índice e permissão, apesar de possuírem uma estrutura simples, sãoclassificados como objetos complexos pois, na sua migração de um SGBD para outro, ousuário poderá realizar as alterações necessárias antes de sua restauração. Caso contrá-rio, os mesmos poderão ser carregados e submetidos sem intervenção do usuário, umavez que a ferramenta carrega cada objeto em sua estrutura padrão SQL, com exceçãodos objetos dos tipos método e gatilho.
O processo de migração de dados funciona da seguinte maneira. Para início desseprocesso, o usuário deverá selecionar o arquivo BKPML desejado e pressionar o bo-tão carregar objetos. Após isso, o método carregarObjeto envia uma mensagem como nome do arquivo para o método SalvarRestaurarArquivos, que por sua vez resgata oarquivo solicitado e devolve para o método que o solicitou. Caso o arquivo não sejaencontrado, uma mensagem de erro "arquivo não encontrado" será retornada e o pro-cesso será cancelado. Ao receber o arquivo solicitado, o método carregarObjeto executaquatro processos de forma recursiva utilizando o padrão decorator: validarHash, Des-
compactar, Descriptografar e RestaurarBKPML.O método validarHash é responsável por validar o hash do arquivo solicitado com o
do arquivo quando gerado. Para isso, o primeiro hash é solicitado do sistema de bancode dados, em seguida o código hash do arquivo enviado é extraído e comparado como do banco. Caso os códigos não sejam compatíveis, uma mensagem de erro "Arquivo
Corrompido" será retornada e o processo será cancelado. Caso contrário, esse métodoé finalizado e enviado para o próximo método da pilha de recursão, o método Descom-pactar.
86
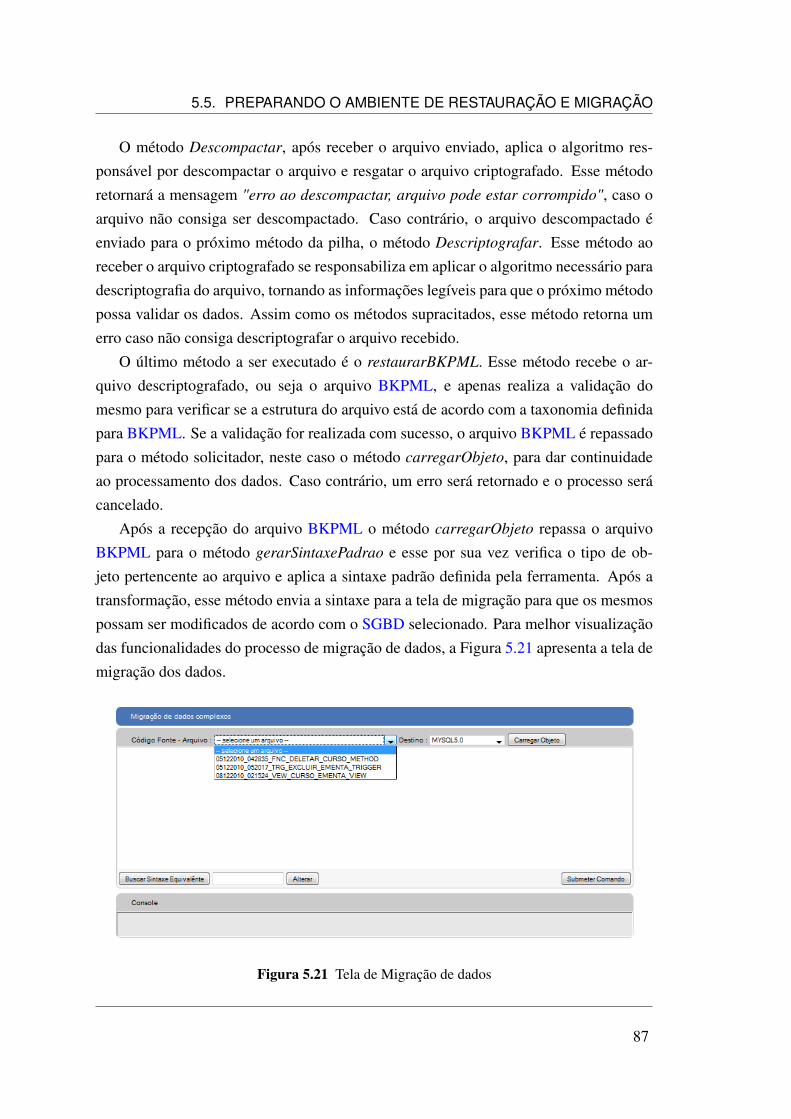
5.5. PREPARANDO O AMBIENTE DE RESTAURAÇÃO E MIGRAÇÃO
O método Descompactar, após receber o arquivo enviado, aplica o algoritmo res-ponsável por descompactar o arquivo e resgatar o arquivo criptografado. Esse métodoretornará a mensagem "erro ao descompactar, arquivo pode estar corrompido", caso oarquivo não consiga ser descompactado. Caso contrário, o arquivo descompactado éenviado para o próximo método da pilha, o método Descriptografar. Esse método aoreceber o arquivo criptografado se responsabiliza em aplicar o algoritmo necessário paradescriptografia do arquivo, tornando as informações legíveis para que o próximo métodopossa validar os dados. Assim como os métodos supracitados, esse método retorna umerro caso não consiga descriptografar o arquivo recebido.
O último método a ser executado é o restaurarBKPML. Esse método recebe o ar-quivo descriptografado, ou seja o arquivo BKPML, e apenas realiza a validação domesmo para verificar se a estrutura do arquivo está de acordo com a taxonomia definidapara BKPML. Se a validação for realizada com sucesso, o arquivo BKPML é repassadopara o método solicitador, neste caso o método carregarObjeto, para dar continuidadeao processamento dos dados. Caso contrário, um erro será retornado e o processo serácancelado.
Após a recepção do arquivo BKPML o método carregarObjeto repassa o arquivoBKPML para o método gerarSintaxePadrao e esse por sua vez verifica o tipo de ob-jeto pertencente ao arquivo e aplica a sintaxe padrão definida pela ferramenta. Após atransformação, esse método envia a sintaxe para a tela de migração para que os mesmospossam ser modificados de acordo com o SGBD selecionado. Para melhor visualizaçãodas funcionalidades do processo de migração de dados, a Figura 5.21 apresenta a tela demigração dos dados.
Figura 5.21 Tela de Migração de dados
87

5.5. PREPARANDO O AMBIENTE DE RESTAURAÇÃO E MIGRAÇÃO
A tela de migração de dados funciona como um editor para adaptação da estruturados objetos complexos. Essa tela é composta pelas funcionalidades carregar objeto
que, conforme apresentada, é responsável pela transformação dos objetos mantidos noarquivo BKPML para sua sintaxe padrão SQL, com exceção dos objetos do tipo métodoe gatilho. Para esses objetos, seus metadados são transferidos para uma sintaxe não SQLdefinida pela própria ferramenta. Para melhor entendimento da sintaxe utilizada pelaferramenta para esses objetos, as Figuras 5.22 e 5.23 apresentam essas sintaxes.
Figura 5.22 Sintaxe padrão para objetos tipo função
Nesse caso, a estrutura modificada pertence a um objeto do tipo função. A sintaxe deum objeto tipo procedimento segue a mesma ideia, bastando para isso substituir o nomeFUNCTION por PROCEDURE e remover o retorno dos dados. O restante é idêntico aambos os objetos. A Figura 5.23 apresenta a sintaxe para um objeto do tipo gatilho.
Figura 5.23 Sintaxe padrão para objetos tipo gatilho
Após a sintaxe de um objeto ser carregada para tela de edição, o usuário deverá adap-tar a mesma para a sintaxe correspondente do SGBD selecionado. Após isso, o botãoSubmeter Comando deverá ser pressionado para que o objeto possa ser transferido. Atransferência dos objetos complexos ficam sob responsabilidade do método submeter-
Comando, que envia os dados para que o sistema de banco de dados possa validar egerar o mesmo em seu ambiente. Toda validação de sintaxe, tipos e estrutura ficam sobresponsabilidade do SGBD, que retornará um erro caso a sintaxe não esteja de acordocom seus padrões.
A alteração da sintaxe dos objetos pode ser realizada de duas formas: manual, ouutilizando os métodos Buscar sintaxe Equivalente e Alterar, disponíveis na parte inferior
88
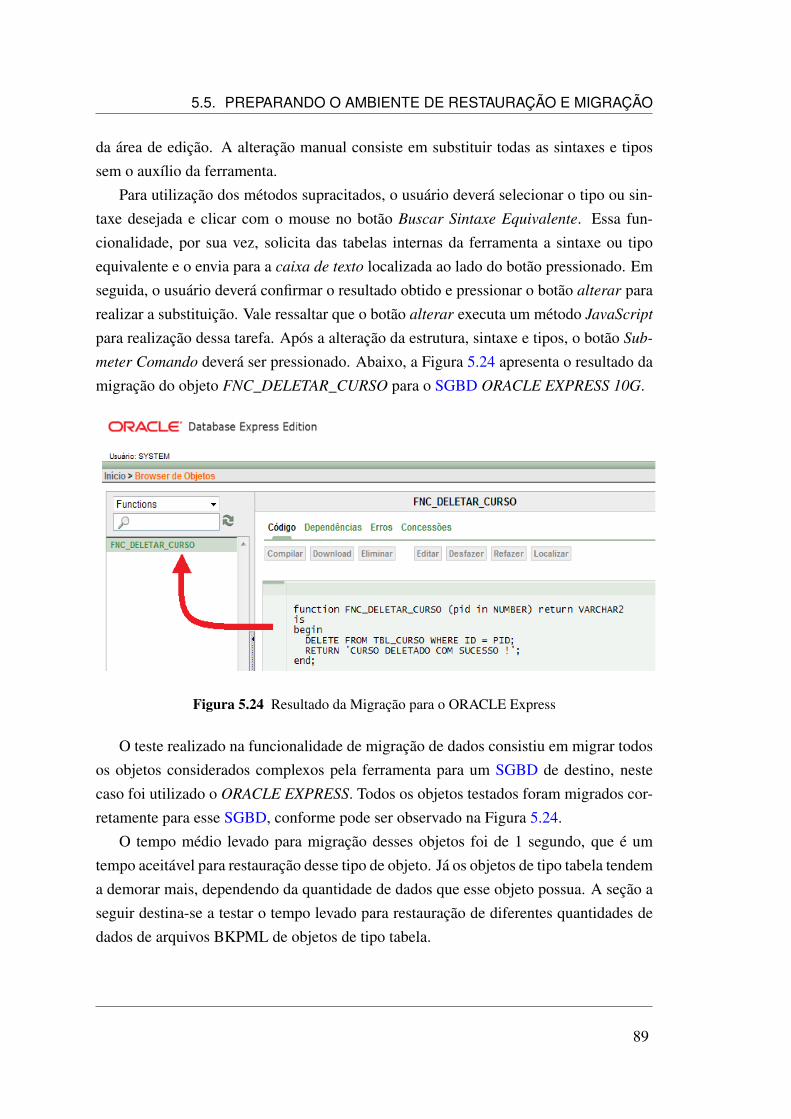
5.5. PREPARANDO O AMBIENTE DE RESTAURAÇÃO E MIGRAÇÃO
da área de edição. A alteração manual consiste em substituir todas as sintaxes e tipossem o auxílio da ferramenta.
Para utilização dos métodos supracitados, o usuário deverá selecionar o tipo ou sin-taxe desejada e clicar com o mouse no botão Buscar Sintaxe Equivalente. Essa fun-cionalidade, por sua vez, solicita das tabelas internas da ferramenta a sintaxe ou tipoequivalente e o envia para a caixa de texto localizada ao lado do botão pressionado. Emseguida, o usuário deverá confirmar o resultado obtido e pressionar o botão alterar pararealizar a substituição. Vale ressaltar que o botão alterar executa um método JavaScript
para realização dessa tarefa. Após a alteração da estrutura, sintaxe e tipos, o botão Sub-
meter Comando deverá ser pressionado. Abaixo, a Figura 5.24 apresenta o resultado damigração do objeto FNC_DELETAR_CURSO para o SGBD ORACLE EXPRESS 10G.
Figura 5.24 Resultado da Migração para o ORACLE Express
O teste realizado na funcionalidade de migração de dados consistiu em migrar todosos objetos considerados complexos pela ferramenta para um SGBD de destino, nestecaso foi utilizado o ORACLE EXPRESS. Todos os objetos testados foram migrados cor-retamente para esse SGBD, conforme pode ser observado na Figura 5.24.
O tempo médio levado para migração desses objetos foi de 1 segundo, que é umtempo aceitável para restauração desse tipo de objeto. Já os objetos de tipo tabela tendema demorar mais, dependendo da quantidade de dados que esse objeto possua. A seção aseguir destina-se a testar o tempo levado para restauração de diferentes quantidades dedados de arquivos BKPML de objetos de tipo tabela.
89

5.5. PREPARANDO O AMBIENTE DE RESTAURAÇÃO E MIGRAÇÃO
5.5.3 Testando a eficiência x volume de informação
Como o teste de restauração foi realizado com uma baixa quantidade de dados, a equipetécnica da knowhow consultoria levantou a seguinte questão: Como a ferramenta se
comportaria quanto a geração de arquivos BKPML com diferentes volumes de dados?
E quanto tempo esses dados levariam para ser restaurados? A partir desses questiona-mentos, sentiu-se a necessidade de realizar esse tipo de teste e, para isso, foi solicitadoum computador para que o ambiente de testes pudesse ser configurado. A knowhow con-sultoria cedeu um computador com as seguintes configurações: processador intel DUAL
CORE 2.1GHZ com 2GB de RAM e HD de 200GB.A configuração do ambiente de testes foi iniciada com a instalação do SGBD POST-
GRES8.4, as configurações necessárias para execução da ferramenta BKPML Manager,a criação de uma tabela no SGBD instalado, o desenvolvimento de uma aplicação res-ponsável pela inserção de dados aleatórios na tabela de testes, a execução da BKPML
Manager, a realização de todos os cadastros para o objeto de tipo tabela, e o cadastrodo SGBD envolvido. É importante ressaltar que a restauração dos dados foi realizadano próprio POSTGRES8.4, ou seja, o mesmo foi utilizado como SGBD de origem e dedestino.
Para se obter melhores conclusões sobre os testes, é importante conhecer a estruturacriada para a tabela de testes. A tabela de testes é composta por três campos não indexa-dos. O campo nome, do tipo texto, com tamanho máximo para 100 caracteres; o campofone, do tipo inteiro; e o campo endereço, do tipo texto, com tamanho máximo de 255caracteres. Essas informações se fazem necessárias uma vez que o tempo e tamanho dosarquivos tendem a variar para tabelas com estrutura de tamanhos diversificados.
Após a finalização da configuração do ambiente de testes e dos cadastros obrigató-rios na ferramenta, o próximo passo tomado foi a definição de quantos arquivos seriamgerados e qual seria o volume de dados para cada um. Com isso, foram definidos osseguintes volumes em quantidade de registros: [500, 1.000, 2.000, 4.000, 8.000, 16.000,32.000, 64.000, 128.000, 256.000, 512.000 e 1.024,000]. Concluiu-se que a partir des-ses volumes seria possível verificar o desempenho da ferramenta em relação a diferentesvolumes de dados, tanto para geração dos arquivos BKPML quanto para restauração dosmesmos.
Após isso, o sistema responsável por gerar os dados aleatórios foi executado deacordo com os volumes definidos, e a BKPML Manager foi usada para gerar os ar-quivos BKPML para cada volume inserido na tabela de testes. Após o termino da cargados dados e a execução da BKPML Manager, oito arquivos de teste em formato BKPML
90
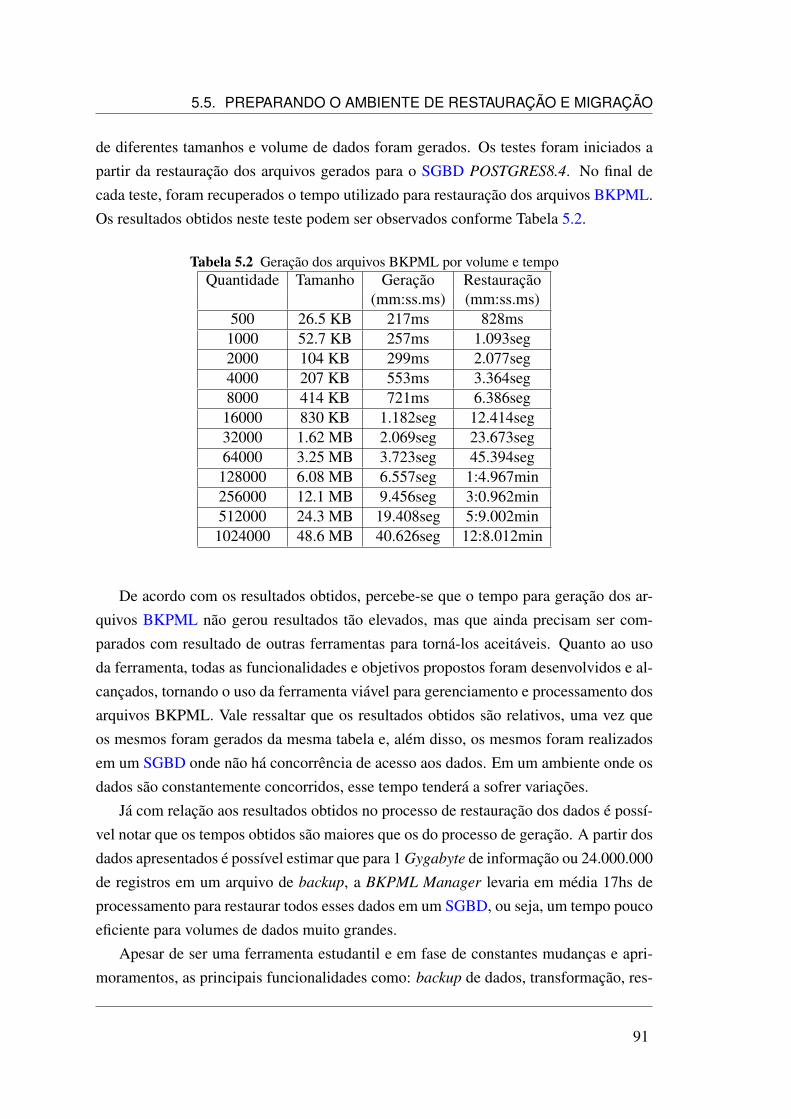
5.5. PREPARANDO O AMBIENTE DE RESTAURAÇÃO E MIGRAÇÃO
de diferentes tamanhos e volume de dados foram gerados. Os testes foram iniciados apartir da restauração dos arquivos gerados para o SGBD POSTGRES8.4. No final decada teste, foram recuperados o tempo utilizado para restauração dos arquivos BKPML.Os resultados obtidos neste teste podem ser observados conforme Tabela 5.2.
Tabela 5.2 Geração dos arquivos BKPML por volume e tempoQuantidade Tamanho Geração Restauração
(mm:ss.ms) (mm:ss.ms)500 26.5 KB 217ms 828ms
1000 52.7 KB 257ms 1.093seg2000 104 KB 299ms 2.077seg4000 207 KB 553ms 3.364seg8000 414 KB 721ms 6.386seg
16000 830 KB 1.182seg 12.414seg32000 1.62 MB 2.069seg 23.673seg64000 3.25 MB 3.723seg 45.394seg
128000 6.08 MB 6.557seg 1:4.967min256000 12.1 MB 9.456seg 3:0.962min512000 24.3 MB 19.408seg 5:9.002min
1024000 48.6 MB 40.626seg 12:8.012min
De acordo com os resultados obtidos, percebe-se que o tempo para geração dos ar-quivos BKPML não gerou resultados tão elevados, mas que ainda precisam ser com-parados com resultado de outras ferramentas para torná-los aceitáveis. Quanto ao usoda ferramenta, todas as funcionalidades e objetivos propostos foram desenvolvidos e al-cançados, tornando o uso da ferramenta viável para gerenciamento e processamento dosarquivos BKPML. Vale ressaltar que os resultados obtidos são relativos, uma vez queos mesmos foram gerados da mesma tabela e, além disso, os mesmos foram realizadosem um SGBD onde não há concorrência de acesso aos dados. Em um ambiente onde osdados são constantemente concorridos, esse tempo tenderá a sofrer variações.
Já com relação aos resultados obtidos no processo de restauração dos dados é possí-vel notar que os tempos obtidos são maiores que os do processo de geração. A partir dosdados apresentados é possível estimar que para 1 Gygabyte de informação ou 24.000.000de registros em um arquivo de backup, a BKPML Manager levaria em média 17hs deprocessamento para restaurar todos esses dados em um SGBD, ou seja, um tempo poucoeficiente para volumes de dados muito grandes.
Apesar de ser uma ferramenta estudantil e em fase de constantes mudanças e apri-moramentos, as principais funcionalidades como: backup de dados, transformação, res-
91

5.6. CONSIDERAÇÕES FINAIS
tauração e migração de objetos complexos obtiveram bons resultados, mas que aindaassim precisam ser aprimorados.
5.6 Considerações finais
Esse Capítulo apresentou o estudo de caso realizado na empresa Knowhow consultoria,empresa localizada na cidade de Manaus e que presta serviços de consultoria e treina-mento para empresas e profissionais interessados. Essa empresa aceitou a realizaçãodos testes da ferramenta em um ambiente real. Isso se fez necessário uma vez que ostestes iniciais foram realizados no mesmo computador utilizado para desenvolvimentoda ferramenta, espelhando resultados viciosos e não conclusivos quanto à eficiência daferramenta em outros ambientes.
Os primeiros testes realizados foram referentes às funcionalidades de cadastros bá-sicos, que demonstraram bom desempenho quanto a inserção, alteração e exclusão dedados neste ambiente. Além disso, esses cadastros foram necessários uma vez que osmesmos são requisitos importantes para o funcionamento das próximas funcionalidadesa serem testadas.
O segundo teste consistiu na execução dos backups dos objetos cedidos pela em-presa, e no final todos os arquivos gerados foram analisados para verificar se as estrutu-ras dos mesmos haviam sido geradas de acordo com as regras impostas pela taxonomiada BKPML. Os resultados obtidos nesses testes se mostraram satisfatórios quanto aoresultado do processamento dos dados e geração dos arquivos BKPML.
A partir da geração desses arquivos de backup, o próximo teste a ser realizado foio de restauração e transformação dos dados dos arquivos BKPML gerados nos testesanteriores. Primeiramente foi testado o processo de restauração dos objetos do tipotabela disponibilizados pela empresa. Esse teste mostrou bons resultados em relação àrestauração dos dados, mais nada conclusivo, uma vez que a quantidade de dados eramínima. O teste de transformação foi realizado gerando os arquivos secundários deforma correta. Em seguida, os testes de migração de dados complexos foram realizadosgerando bons resultados quanto a migração de objetos complexos para SGBD distintos.O mais demorado nesse processo é a adaptação do objeto para a sintaxe exigida peloSGBD de destino.
Por fim, para analisar o comportamento da ferramenta quanto a testes de grandes vo-lumes de dados foi necessária a solicitação de um novo computador para configurar umnovo ambiente de testes. Após isso, os testes foram iniciados. A partir dos resultados
92

5.6. CONSIDERAÇÕES FINAIS
obtidos pode-se concluir que a funcionalidade de backup de dados gerou resultados con-forme esperado quanto a grande volume de dados. Já a funcionalidade de restauração, apartir dos testes, foi possível estimar um desempenho fraco para volumes de dados muitograndes. É importante ressaltar que apesar do resultado obtido, os testes de uma formageral foram eficientes quanto a seus objetivos, mas que necessitam de ajustes quanto apontos específicos.
93

6Conclusões e Trabalhos Futuros
Este capítulo apresenta as considerações finais do trabalho desenvolvido, as dificulda-des enfrentadas na fase de pesquisa e desenvolvimento da estrutura BKPML, bem comodo protótipo da ferramenta proposta. Além das dificuldades, serão apresentadas as li-mitações da ferramenta quanto aos processos de cadastros básicos e funcionalidades debackup, restauração e migração de dados. Por fim, serão apresentadas as propostas depossíveis trabalhos futuros a serem desenvolvidos para aperfeiçoamento e continuidadedeste projeto.
6.1 Conclusões e contribuições
O desenvolvimento deste trabalho foi motivado principalmente pelos problemas enfren-tados por projetos de migração de dados para diferentes plataformas de SGBD, e dasdificuldades enfrentadas para manipulação e integração de dados mantidos em arquivosde backup em formato proprietário. Esses problemas foram observados através de ex-periências e estudos de caso que relatam as principais dificuldades enfrentadas como:não cumprimento dos prazos, aumento do tempo e custos envolvidos em tais projetose problemas relacionados às ferramentas existentes que limitam-se a atender níveis es-pecíficos de migração. Níveis importantes como a migração de objetos índices, visão,
permissão, gatilhos, entre outros, em muitos casos não são atendidos.Outro fator que tende a levar projetos de migração a tempos mais elevados são pro-
blemas relacionados aos arquivos de backup proprietários que, na maioria das vezes,detêm uma quantidade grande de informações e que só podem ser manipulados por ou-tros SGBD perante a restauração dos mesmos em seu ambiente de origem, elevando otempo do projeto e por consequência os custos envolvidos.
Assim, este trabalho apresentou uma estrutura padrão em formato aberto desenvol-
94

6.1. CONCLUSÕES E CONTRIBUIÇÕES
vida com objetivo de desvincular a dependência dos dados dos arquivos de formatoproprietários, facilitando a sua manipulação entre diversos ambientes de SGBD. Maisespecificamente, esse formato visa auxiliar os projetos de migração de dados em rela-ção às dificuldades enfrentadas. Esse formato foi desenvolvido baseado na linguagemde marcação XML, denominado BKPML. Além disso, foi utilizada a tecnologia XML
Schema para definição da taxonomia da BKPML e dos objetos aceitos por ela, proporci-onando assim maior segurança quanto à validação dessa estrutura.
Após o desenvolvimento da estrutura proposta, foi necessário o desenvolvimento deum protótipo para validação da BKPML denominado BKPML Manager. A BKPML Ma-
nager foi desenvolvida em uma plataforma cliente/servidor e utilizando a linguagem deprogramação Java para Web, disponibilizando assim acesso a BKPML Manager e suasfuncionalidades através da Internet. A BKPML Manager foi desenvolvida para gerar evalidar arquivos de backup em formato BKPML, bem como para auxiliar a restauraçãoe migração dos dados para diversas plataformas de SGBD como: Oracle, SQLServer,
MYSQL e Postgres.Além de auxiliar os processos supracitados, essa ferramenta possui duas implemen-
tações de grande importância para portabilidade das informações e segurança dos dados.A portabilidade das informações é garantida através do processo de transformação dosdados. Esse processo consiste em restaurar os dados de um arquivo BKPML para arqui-vos secundário nos formatos: CSV, JSON, YAML, EXCEL, XML e TEXTO. Esses sãomuito utilizados por SGBD para migração de grandes volumes de dados como o CSV, oupara intercâmbio de informações através da Web como o JSON e o XML. Além disso,a ferramenta implementa dois métodos para armazenamento dos dados, armazenamentolocal ou em nuvens. O armazenamento local consiste em salvar os dados em servidoreslocais ou remotos. Já o armazenamento em nuvens utiliza os servidores da Amazon Web
Service para armazenamento dos dados utilizando o serviço S3. Para implementação deoutros serviços, faz-se necessário a implementação dos mesmos conforme especificaçãodo provedor desejado.
Após o desenvolvimento da BKPML Manager, foi necessária a realização de testespara verificar o desempenho da ferramenta e das funcionalidades desenvolvidas. Paraisso, foi apresentado um estudo de caso, mostrando todo o processo de cadastro e con-figuração do ambiente de backup, restauração e migração de dados, desde os cadastrosbásicos até às funcionalidades de backup, restauração e migração. Após isso, foi dadoinício aos testes de desempenho da ferramenta quando a grandes volumes de dados. Nofinal dos testes, foram apresentadas as conclusões sobre os resultados obtidos.
95

6.2. LIMITAÇÕES E TRABALHOS FUTUROS
As principais contribuições deste trabalho foram:
• O desenvolvimento de um formato aberto para padronização de backup de dados;
• O desenvolvimento de uma ferramenta para auxiliar o formato BKPML e propor-cionar aos projetos de backup e migração de dados maior flexibilidade quanto àmanipulação dos dados em qualquer plataforma de SGBD;
• Facilitar a portabilidade e manipulação dos dados através da transformação dosmesmos para arquivos secundários;
• Desenvolvimento de uma estrtuura em XML para backup de dados que não selimita apenas a objetos de tipo tabela;
• Integração entre SGBD distintos e interoperabilidade dos dados através dos arqui-vos de backup; e
• Permitir o armazenamento dos arquivos de BKPML em núvens utilizando os ser-viços da Amazon Webservices.
6.2 Limitações e trabalhos futuros
Analisando o trabalho desenvolvido, é possível observar limitações que não afetam oresultado final esperado, mas seriam de grande importância que fossem corrigidas. Essaslimitações foram impostas pela complexidade no desenvolvimento, outras por limitaçõesimpostas ao escopo do projeto, tornando seu desenvolvimento inviável devido à restriçãode tempo. Dentre essas limitações, são complexas o suficiente para serem apontadascomo possíveis trabalhos futuros.
Apesar do objetivo inicial deste trabalho ter sido alcançado, é possível ver que aindahá o que fazer. Com isso, pode-se ressaltar pontos que podem ser estendidos e melhora-dos.
A estrutura BKPML está limitada aos objetos comuns entre os SGBD mais utiliza-dos no mercado, como: TABLES, INDEX, VIEWS, GRANTS, TRIGGERS e METHODS.Seria importante para expansão do poder de representação de objetos da BKPML, ainclusão de mais objetos como: Roles e Packages, uma vez que grandes SGBD comoOracle e SQL Server utilizam com grande frequência esse tipo de objetos. Além disso,percebe-se uma limitação quanto ao uso da ferramenta em relação à quantidade de ca-dastros exigidos para geração da BKPML. Assim, sugere-se o desenvolvimento de uma
96

6.2. LIMITAÇÕES E TRABALHOS FUTUROS
linguagem também derivada da XML para manter o mapeamento dos SGBD a serem uti-lizados no processo, deixando a ferramenta responsável apenas pelas funções de backup,restauração e migração dos dados.
Outra limitação encontrada nas funcionalidades de cadastro da ferramenta é a limita-ção no cadastro de ações de backup, uma vez que nesse cadastro as ações são cadastradaspor objeto e não por esquema, o que torna o cadastro de ações cansativo e demorado casoo SGBD configurado tenha uma grande quantidade de objetos. A solução proposta paraessa limitação é a mudança desse cadastro de OBJETOS para ESQUEMA. Essa soluçãoalém de reduzir significativamente o número de cadastros a serem realizados, reduziriao número de arquivos gerados. Outra proposta seria a adaptação deste cadastro paraaceitar as duas opções, OBJETOS ou ESQUEMA.
É importante ressaltar que as limitações existentes não afetam o resultado final es-perado, apenas limitam ou dificultam a utilização da ferramenta e da estrutura BKPML.Entretanto, seria de grande importância a implementação dos mesmos para tornar a fer-ramenta mais viável na prática. Com isso em mente, pode-se ressaltar pontos a seremestendidos e melhorados:
• O editor de migração de objetos complexos necessita de melhorias quanto a suautilização. Uma melhoria seria implementar sintaxes coloridas, bem como méto-dos mais eficazes para busca e substituição das sintaxes. Além disso, seria inte-ressante a implementação de um mecanismo para converter os arquivos BKPMLpara a sintaxe de acordo com o SGBD, evitando que o usuário fique responsávelpela maioria das alterações;
• A implementação de um framework para ser acoplado a sistemas de backup dedados que desejam utilizar o formato BKPML. Esse framework ficaria responsá-vel por todas as funcionalidades implementadas pela ferramenta como: Backup,Restauração, Transformação e Migração de dados complexos;
• A BKPML Manager relaciona o armazenamento do arquivo ao associado no mo-mento do seu cadastro. Caso esses arquivos necessitem ser movimentados paraoutros diretórios, as funcionalidades de restauração e migração apresentar erro dearquivo não encontrado. Quanto a isso, seria de grande importância a implemen-tação de uma tela para localizar o arquivo BKPML em outras pastas caso o mesmonão tenha sido encontrado em sua pasta de destino;
• Como a linguagem XML tende a se tornar lenta de acordo com a quantidade dedados, seria importante o desenvolvimento de um mecanismo para quebrar um ar-
97

6.2. LIMITAÇÕES E TRABALHOS FUTUROS
quivo muito grande em vários arquivos menores, melhorando o processo de leiturados arquivos, evitando que JVM apresente erro de estouro de memória, e por con-seqüência dessa mudança, acelerar o processo de restauração dos dados. XLinknesse processo poderia ser utilizado para ligar de forma correta a ordem dos ar-quivos, evitando problemas quanto a restauração e perda de arquivos e dados; e
• Por fim, a implementação da BKPML em um SGBD Open Source, fazendo comque esse SGBD torne-se apto a gerar e restaurar arquivos BKPML sem a interven-ção da ferramenta BKPML Manager. Um exemplo de SGBD propício a esse tipode alteração é o SGBD Postgres.
98

Referências Bibliográficas
AGUIRRE, J. V., ÁLVAREZ, R., NOGUERA, J., and ZAMORA, A. (2006). A secureremote database backup system. In Int. Conf. on Artificial Intelligence, Knowledge
Engineering and Data Bases, pages 43–46. ACM.
Amazon (2011). Amazon webservices. http://aws.amazon.com/. ÚltimoAcesso em Fev/2011.
Ambler, S. W. (2002). Modelagem ágil, práticas eficazes para a programação extrema
e o processo unificado. ARTMED EDITORA S.A, Santana, Porto Alegre - RS.
Beat, J. (2010). Introduction to dom4j. http://www.javabeat.net/
articles/44-introduction-to-dom4j-1.html. Último Acesso emFev/2011.
Braude, E. (2004). PROJETO DE SOFTWARE. ARMED EDITORA S.A, Santana -Porto Alegre - RS.
Brito, M., Antonialli, L. M., and Santos, A. C. d. (1997). Tecnologia da informação eprocesso produtivo de gestão em uma organização coorporativa: Um enfoque estraté-gico. Revista de Administração Contemporânia, 3, 77–95. http://www.scielo.br/pdf/rac/v1n3/v1n3a05.pdf. Último Acesso em Fev/2011.
CACR (2010). Extensible scientific interchange language. http://www.xml.com/pub/r/287. Último Acesso em Fev/2011.
Cardia, A. (2010). Recuperação de desastres: Backup. http://www.
andrecardia.pro.br. Último Acesso em Nov/2010.
Carmona, T. (2005). Segredos da Espionagem Digital. Digerate Books, São Paulo - SP.
CARUSO, C. A. A. and STEFFEN, F. D. (1999). SEGURANÇA EM INFORMATICA E
DE INFORMAÇOES: EDIÇÃO REVISTA E AMPLIADA. Editora SENAC São Paulo,São Paulo - SP.
Chen, H. and Zheng, Z. (2008). Design and implementation of xml-based gui for crossplatform backup system. Computer Science and Computational Technology, Interna-
tional Symposium on, 2, 380–382.
Conallen, J. (2003). Building Web Application with UML. Pearson Education, Canada.
99

REFERÊNCIAS BIBLIOGRÁFICAS
Creativyst (2011). The comma separated value (csv) file format. http://
creativyst.com/Doc/Articles/CSV/CSV01.htm. Último Acesso emFev/2011.
Crem, A. B. (2010). Importância da padronização de dados e informações geográficasna cvrd. http://www.mundogeo.com.br/revistas-interna.php?id_noticia=10095. Último Acesso em Fev/2011.
CSS, W. (2010). Cascading style sheets. http://www.w3.org/Style/CSS/.Último Acesso em Fev/2011.
DAO, S. (2010). Dao reference. http://java.sun.com/blueprints/
corej2eepatterns/Patterns/DataAccessObject.html. ÚltimoAcesso em Fev/2011.
DCOM, M. (2010). Dcom especification. http://www.microsoft.com/com/
default.mspx. Último Acesso em Fev/2011.
Deitel, P. and Deitel, H. (2009). Java How to Program: Late Objects Version. PERSON,Upper Saddle River - New Jersey.
Fialho, M. (2007). GUIA ESSENCIAL DO BACKUP. Digerate Books, São Paulo - SP.
Firefox, M. (2010). Firefox reference and download. http://br.mozdev.org.Último Acesso em Fev/2011.
Flanagan, D. (2002). JAVASCRIPT - O GUIA DEFINITIVO. ARTMED EDITORA S.A,Santana - Porto Alegre - RS.
Fonseca, R. and Simões, A. (2007). Alternativas ao xml : Yaml e json. In XATA2007
: XML : aplicações e tecnologias associadas : actas da Conferência Nacional.XATA2007.
FOROUZAN, B. A. (2004). COMUNICAÇAO DE DADOS E REDES DE COMPUTA-
DORES. Laser House, New York - NY.
FOWLER, M. (2003). Padrões de Arquitetura de Aplicações Corporativas. ARTMEDEDITORA S.A, Santana, Porto Alegre - RS.
GAMMA, E., JOHNSON, R., VLISSIDES, J., and HELM, R. (1995). PADRÕES DE
PROJETO. ARTMED EDITORA S.A, Santana - Porto Alegre - RS.
100

REFERÊNCIAS BIBLIOGRÁFICAS
Gonçalves, E. (2007). Desenvolvendo Aplicações WEB com JSP, Servlets, JSF, Hiber-
nate, EJB e AJAX. Editora Moderna, Rio de Janeiro - RJ.
Gonçalves, E. (2008). Dominando JavaServer Faces e Facelets utilizando Spring 2 5,
Hibernate e JPA. CIÊNCIA MODERNA, Rio de Janeiro - RJ.
GRAVES, M. (2003). Projeto de Banco de Dados com XML. Makron Books, São Paulo- SP.
Grossman, R. L. (2009). The case for cloud computing. IT Professional, 11, 23–27.
HEMRAJANI, A. (2005). desenvolvendo ágil em JAVA com Spring, hibernate e eclipse.Pearson, São Paulo - SP.
IBM (2010). Razões para migrar. http://www.ibm.com/br/systems/
migratetoibm/whymigrate/index.phtml. Último Acesso em Fev/2011.
Internet Explorer, M. (2010). Site oficial do internet explorer. http://
www.microsoft.com/brasil/windows/internet-explorer/. ÚltimoAcesso em Fev/2011.
Jacoski, C. A. and Lamberts, R. (2002). Vetores de virtualização da indústria da constru-ção, a integração da informação como elemento fundamental ao uso de ti. In Encontro
Nacional de Tecnologia do Ambiente Construido. ENTAC2002.
JSF, O. (2010). Java server faces. http://www.oracle.com/technetwork/
java/javaee/javaserverfaces-139869.html. Último Acesso emFev/2011.
JSON (2010). Json specification. http://www.json.org/json-pt.html. Úl-timo Acesso em Fev/2011.
JSP, S. (2010). Java server pages. http://java.sun.com/products/jsp/.Último Acesso em Fev/2011.
JSTL, S. (2010). Java server pages standard tag lib. http://java.sun.com/
products/jsp/jstl/reference/docs/index.html. Último Acesso emFev/2011.
JVM, S. (2010). Java virtual machine. www.java.com/pt_BR/download. ÚltimoAcesso em Fev/2011.
101

REFERÊNCIAS BIBLIOGRÁFICAS
Kerievsky, J. (2005). Refactoring to patterns. ARTMED EDITORA S.A, München -Germany.
Lasater, C. G. (2006). Design Patterns. Library of Congress Cataloging-in-PublicationData, Texas.
Laurindo, F. J. B. (2000). Um estudo sobre a avaliação da eficácia da tecnologia da
informação nas empresas. Ph.D. thesis, Escola Politécnica da Universidade de SãoPaulo.
Locaweb (2011). Cloud server pro. http://www.locaweb.com.br/
produtos/cloud-server/precos.html. Último Acesso em Fev/2011.
Maggiani, R. (2009). Cloud computing is changing how we communicate. International
Professional Communication Conference, 0, 1–4.
Markup, W. (2010). Hipertext markup language. http://www.w3.org/MarkUp/.Último Acesso em Fev/2011.
Martens, C. D. P. (2001). A Tecnologia de Informação (TI) em Pquenas Empresas In-
dustriais do Vale do Taquari/RS. Master’s thesis, Universidade Federal do Rio Grandedo Sul, Porto Alegre, Rio grande do Sul, Brazil.
MathML, W. (2010). W3c math home. http://www.w3.org/Math/. ÚltimoAcesso em Fev/2011.
Microsoft (2010). Excel 2010 site oficial. http://office.microsoft.com/
pt-br/excel/microsoft-excel-2010-FX010048762.aspx. ÚltimoAcesso em Fev/2011.
MYSQL (2010). Mysql backup and recovery. http://dev.mysql.com/
doc/mysql-backup-excerpt/5.1/en/index.html. Último Acesso emFev/2011.
OMG, C. (2010). Corba especification. http://www.corba.org/. Último Acessoem Fev/2011.
Oracle (2005). Backup and recovery basics 10g release 2 (10.2). http://download.oracle.com/docs/cd/B19306_01/backup.102/b14192/toc.htm.Último Acesso em Fev/2011.
102

REFERÊNCIAS BIBLIOGRÁFICAS
Oracle2 (2008). Oracle in the cloud. http://www.emodus.pl/cms/
zalaczone_pliki/oracle-in-the-cloud-datasheet.pdf. ÚltimoAcesso em Fev/2011.
Oracle3 (2008). Oracle database backup in the cloud. http://www.oracle.com/technology/tech/cloud/pdf/cloud-backup-whitepaper.pdf. Úl-timo Acesso em Nov/2010.
Oumtanaga, S., Lambert, K. T., Tiémoman, K., Pierre, T., and Florent, D. N. (2007).Use xml format like a model of data backup. International Journal of Computer and
Information Engineering, 1, 398–403.
Packard, H. (2010). Why back up? the importance of protecting your data. http:
//static.compusa.com/pdf/hp_why_backup.pdf. Último Acesso emFev/2011.
Pernambuco, d. F. (2009). Folha de pernambuco, edição de 18 de agosto de2009. feche a porta antes de perder seus dados. http://www.folhape.
com.br/edicoes-anteriores/index.php/component/content/
article/58-informatica/525835-%E2%80%9Cfeche-a-porta%E2%
80%9D-antes-de-perder-seus-dados. Último Acesso em Fev/2011.
Petkovic, D. (2008). Microsoft SQL Server 2008: A Beginner’s Guide. Microsoft Books,USA.
Postgres (2011). Postgresql br. http://www.postgresql.org.br/. ÚltimoAcesso em Fev/2011.
Quinn, J. B., Baruch, J. J., and Zien, K. A. (1997). Innovation explosion: using intellect
and software to revolutionize growth strategies. Free Press, New York.
Ray, E. J. (2006). Aprendendo XML. Campus, São Paulo - SP.
Reese, G. (2001). Programação para banco de dados with JDBC e Java. editora Ber-keley, São Paulo - SP.
REINHARD, N. (1996). Evolução das ênfases gerenciais e de pesquisa na área de tec-nologia de informática e de telecomunicações aplicadas nas empresas. Revista de
Administração, 31, 5–6.
103

REFERÊNCIAS BIBLIOGRÁFICAS
Rezende, D. A. (2002). Evolução da tecnolodia da informação nos últimos 45 anos.http://www.fae.edu/publicacoes/pdf/revista_fae_business/
n4_dezembro_2002/tecnologia2_evolucao_da_informacao_nos_
ultimos.pdf. Revista FAE BUSINESS N.4 - Último Acesso em Fev/2011.
RMI, O. (2010). Rmi especification. http://www.oracle.com/technetwork/java/javase/tech/index-jsp-136424.html. Último Acesso emFev/2011.
Saúde, M. d. (2008). Padrão troca de informações em saúde suplementar(tiss). http://www.ans.gov.br/portal/site/_hotsite_tiss/pdf/
texto_completo.pdf. Último Acesso em Fev/2011.
SHALLOWAY, A. and TROTT, J. (2002). Explicando Padrões de Projeto. BookManEditora, Santana - Porto Alegre - RS.
SQLServer, M. (2011). Microsoft sqlserver 2008 r2. http://www.microsoft.
com/sqlserver/2008/pt/br/default.aspx. Último Acesso emFev/2011.
Staimer, M. (2008). Why cloud backup/recovery will be your data protection. http://asigra.com/pdf/cloudbackup.pdf. Último Acesso em Nov/2010.
STERN (2010). Migração de banco de dados. http://www.stern.com.br/
suporte/documentos/MigracaodeBancosdeDados.pdf. Último Acessoem Fev/2011.
Struts2, A. (2010). Struts2 reference. http://struts.apache.org/. ÚltimoAcesso em Fev/2011.
SVG, W. (2010). Scalable vector graphics. http://www.w3.org/Graphics/
SVG/. Último Acesso em Fev/2011.
Tanenbaum, A. S. (2003). Computer Networks. Person, Upper Saddle River - NewJersey.
Terra, J. C. C. (2005). Gestão do Conhecimento: O Grande Desafio Empresarial. Art-med Editora S.A, Rio de Janeiro - RJ.
TOLEDO, L. A., TOLEDO, L. A. D., CAMPOMAR, M. C., MORAES, C. A. D.,and SHIRAISHI, G. D. F. (2010). Estilos gerenciais da tecnologia de informação
104

REFERÊNCIAS BIBLIOGRÁFICAS
sob o prisma do setor de telecomunicação. http://www.ead.fea.usp.br/
semead/11semead/resultado/trabalhosPDF/2.pdf. Último Acessoem Fev/2011.
Tomcat, A. (2010). Tomcat. http://tomcat.apache.org/. Último Acesso emFev/2011.
Turban, E., McLean, E., and Wetherbe, J. (2002). Tecnologia da Informação para Ges-
tão. Artmed Editora S.A, Santana, Porto Alegre - RS.
van Bon, J. (2006). Fundamentos do gerenciamento de serviços em TI: baseado no ITIL.Van Haren Publishing, Holanda.
Voas, J. and Zhang, J. (2009). Cloud computing: New wine or just a new bottle? IT
Professional, 11, 15–17.
W3C (2010). Namespaces in xml. http://www.w3.org/TR/xml-names11. Úl-timo Acesso em Fev/2011.
Whitehouse, L. (2009). The pros and cons of cloud backup technolo-gies. http://searchdatabackup.techtarget.com/tip/0,289483,
sid187_gci1351211_mem1,00.html. Último Acesso em Fev/2011.
XBRL, O. (2010). Xbrl official site. http://www.xbrl.org/Home/. ÚltimoAcesso em Fev/2011.
Xerces, A. (2010). Xerces reference. http://xerces.apache.org/. ÚltimoAcesso em Fev/2011.
YAML (2010). Yaml specification. http://www.yaml.org/spec/1.2/spec.html. Último Acesso em Fev/2011.
Zmanda (2008). Zmanda cloud backup datasheet. http://www.zmanda.com/
zmanda-cloud-backup-for-windows-server.html. Último Acesso emFev/2011.
105