modelos de previsÃo para cheques compensados … · 2013-08-07 · 5 resumo o objetivo deste...
TRANSCRIPT

UNIVERSIDADE FEDERAL DO CEARÁ – UFC CURSO DE PÓS-GRADUAÇÃO EM ECONOMIA – CAEN
MESTRADO PROFISSIONAL EM ECONOMIA – MPE
JOÃO JOSÉ MELO DE CARVALHO
MODELOS DE PREVISÃO PARA CHEQUES COMPENSADOS NO BRASIL
FORTALEZA 2007

1
JOÃO JOSÉ MELO DE CARVALHO
MODELOS DE PREVISÃO PARA CHEQUES COMPENSADOS NO
BRASIL
Dissertação submetida à Coordenação do
Curso de Mestrado Profissional em Economia –
MPE/CAEN, da Universidade Federal do
Ceará, como requisito parcial para a obtenção
do grau de Mestre em Economia.
Orientador: Prof. Dr. Ronaldo de Albuquerque e
Arraes
FORTALEZA
2007

2
JOÃO JOSÉ MELO DE CARVALHO
MODELOS DE PREVISÃO PARA CHEQUES COMPENSADOS NO
BRASIL
Dissertação submetida à Coordenação do
Curso de Mestrado Profissional em Economia –
MPE/CAEN, da Universidade Federal do
Ceará, como requisito parcial para a obtenção
do grau de Mestre em Economia.
Aprovada em _____________________
BANCA EXAMINADORA
_____________________________________ Prof. Dr. Ronaldo de Albuquerque e Arraes
Orientador
__________________________________ Prof. Dr. Pichai Chumvichitra
Membro
__________________________________ Prof. Dr. Roberto Tatiwa Ferreira
Membro

3
Dedico aos meus pais, Miguel Archanjo de
Carvalho (in memoriam) e Joana Melo de
Carvalho, pelo exemplo de vida, e aos
meus irmãos, Antonio, Fernando e Miguel,
pelos estímulos na realização deste
trabalho.

4
AGRADECIMENTOS
A Deus, início de tudo.
Ao meu Orientador Professor Ronaldo Arraes pela paciência, consideração e apoio
que me reservou durante todo o tempo e que sem a sua ajuda, não teria chegando
ao final, bem como aos Professores Pichai Chumvichitra e Roberto Tatiwa Ferreira,
pelas recomendações realizadas durante a defesa.
A todos os professores do mestrado, notadamente os Professores Flávio Ataliba,
Coordenador do Mestrado Profissional em Economia e José Raimundo,
Coordenador do CAEN, que com competência e conhecimento nos conduziram
pelos caminhos da ciência econômica.
Aos colegas mestrandos, especialmente aos amigos Milton Jacques, Antônio
Suerlilton e Nádia Guedes, pelo compartilhamento de vida e conhecimentos
acadêmico e profissional no decorrer deste mestrado.
Especialmente, ao apoio que recebi na Universidade Federal do Pará - UFPA,
através do Professor Edson M. L. S. Ramos e do mestrando Dennison Carvalho, que
mesmo em horários alternativos não mediram esforços na conclusão deste estudo.
A todos os funcionários do CAEN/UFC, principalmente Mônica e Regina da
Biblioteca, Carmem e Márcia na Secretaria e ao Bibi da Coordenação, a colaboração
que sempre recebi mesmo quando distante.
A empresa Agropalma, através do Diretor José Hilário Rodrigues de Freitas, a
FEBRABAN, através do Professor Dr. Roberto Luis Troster e ao Pastor Edmar
Torres Alves, o apoio que recebi durante a execução deste trabalho.
Finalmente, a todas as pessoas que, de alguma maneira, contribuíram para a
realização deste trabalho.
“Prediction is very difficult, especially if it’s about the future”
(Nils Bohr)

5
RESUMO
O objetivo deste estudo foi desenvolver um modelo de previsão para a quantidade de cheques compensados no Brasil visando a sua utilização como ferramenta de política bancária na manutenção de sua regulamentação eficiente, como antecipação de cenários dos meios de pagamentos e para planejamento estratégico das instituições financeiras. Considerando ser o cheque o instrumento fundamental nessa análise, utilizou-se a metodologia estatística de séries temporais, mais especificadamente o alisamento exponencial e a abordagem de Box-Jenkins. Também se buscou analisar a importância do aumento nos depósitos em poupança na redução das transações com cheques no Brasil, bem como a relação entre as transações com cartões e as quantidades de cheques compensados. Os dados utilizados foram obtidos no Banco do Brasil e IPEA e se referem às quantidades mensais compensadas durante o período de 1994 a 2005. As análises foram realizadas utilizando-se os aplicativos computacionais MINITAB/EVIEWS resultando que dos vários modelos de previsões avaliados, o melhor resultado foi com o modelo de alisamento exponencial duplo e Holt-Winters aditivo e multiplicativo.
Palavras-Chave: Séries temporais, Bancos, Cheques, Holt-Winters, Box-Jenkins.

6
ABSTRACT
The main objective of this dissertation was to develop a forecast model for the amount of compensated cheques in Brazil, aiming at its use as tool of bank politics for the maintenance of its efficient regulation, as anticipation of scenes of ways of payments and for strategical planning in financial institutions. Considering the cheque to be the basic instrument in this analysis, the statistic methodology of Time Series was used, specifically the exponential smoothing and the boarding of Box-Jenkins. The importance of the M1 (money supply) was also analyzed to study the reduction of the transactions with cheques in Brazil. The information used has been obtained from Bank of Brazil and IPEA and they relate to the monthly amounts compensated in the period between 1994 the 2005. The analyses have been carried through using MINITAB/EVIEWS (a computer programs) and several evaluated models of forecast, where the best result was using double exponential smoothing model and Holt-Winters models. Key-Words: Time Series, Forecast, Bank, Exponential Method of Winter, ARIMA Models.

7
LISTA DE FIGURAS
FIGURA 1 - Série Não-Estacionária Quanto ao Nível de Inclinação............... 26FIGURA 2 - Número de Cheques Compensados no Brasil (1994-2005)......... 56FIGURA 3 - Número Médio de Cheques Compensados no Brasil (1994-
2005)............................................................................................ 57FIGURA 4 - Histograma da Série Cheques Compensados no Brasil (1994-
2005)............................................................................................ 57FIGURA 5 - Gráficos da Decomposição da Série Cheques Compensados
(Modelo Aditivo)............................................................................ 60FIGURA 6 - Gráfico da Série Ajustada por Decomposição e a Linha de
Tendência (Modelo Aditivo).......................................................... 61FIGURA 7 - Decomposição da Série Cheques Compensados (Modelo
Multiplicativo)................................................................................ 63FIGURA 8 - Série Ajustada por Decomposição e a Linha de Tendência
(Modelo Multiplicativo).................................................................. 63FIGURA 9 - Série Ajustada por Alisamento Exponencial Simples................... 66FIGURA 10 - Série Ajustada por Alisamento Exponencial Duplo-Método de
Brow............................................................................................. 67FIGURA 11 - Modelo Exponencial de Holt-Winters Aditivo................................ 68FIGURA 12 - Modelo Exponencial de Holt-Winters Multiplicativo...................... 70FIGURA 13 - Gráfico da Série com a 1ª Diferença............................................ 72FIGURA 14 - Função de Autocorrelação da Série Quantidade de Cheques
Compensados ............................................................................. 73FIGURA 15 - Função de Autocorrelação Parcial da Série Quantidade de
Cheques Compensados............................................................... 74FIGURA 16 - Função de Autocorrelação dos Resíduos do Modelo ARIMA
(1,1,1)........................................................................................... 75FIGURA 17 - Função de Autocorrelação dos Resíduos do Modelo ARIMA
(0,1,1)........................................................................................... 76FIGURA 18 - Gráfico da Média x o Desvio Padrão da Série............................. 78FIGURA 19 - Função de Autocorrelação dos Resíduos do Modelo SARIMA
(2,1,0)(0,1,1)36..................................................................................................................... 79FIGURA 20 - Função de Autocorrelação dos Resíduos do Modelo SARIMA
(2,1,0)(0,1,1)36 sem o Termo Constante....................................... 81FIGURA 21 - Gráfico de Dispersão para Cheques Compensados e
Transações com Cartões............................................................. 84FIGURA 22 - Teste de Normalidade para os Resíduos da Regressão entre
Cheques Compensados e Transações com Cartões................... 86FIGURA 23 - Teste de Normalidade para os Resíduos da Regressão entre
Cheques Compensados e Depósitos na Poupança..................... 89

8
LISTA DE TABELAS
TABELA 1 - Operações sem uso de papel-moeda.......................................... 22TABELA 2 - Exemplos dos Valores de λ para a Transformação de Box-
Cox............................................................................................... 29TABELA 3 - Estatísticas da Série Cheque Compensado................................. 56TABELA 4 - Valores Observados e Esperados do Modelo de Decomposição
Aditivo........................................................................................... 61TABELA 5 - Modelo de Decomposição Aditivo – Índices de Sazonalidade..... 62TABELA 6 - Valores Observados e Esperados do Modelo de Decomposição
Multiplicativo................................................................................. 64TABELA 7 - Modelo de Decomposição Multiplicativo – Índices de
Sazonalidade................................................................................ 64TABELA 8 - Valores Observados e Esperados do Modelo de Alisamento
Exponencial Simples.................................................................... 66TABELA 9 - Valores Observados e Esperados do Modelo de Alisamento
Exponencial Duplo........................................................................ 67TABELA 10 - Constantes de Alisamento do Modelo de Holt-Winters Aditivo.... 69TABELA 11 - Winters Aditivo – Previsão do Modelo.......................................... 69TABELA 12 - Constantes de Alisamento do Modelo de Holt-Winters
Multiplicativo................................................................................. 70TABELA 13 - Winters Multiplicativo – Previsão do Modelo................................ 71TABELA 14 - Autocorrelações da Série Cheques Compensados...................... 72TABELA 15 - Autocorrelações Parciais da Série Cheques Compensados........ 73TABELA 16 - Estimativas dos Parâmetros para o Modelo ARIMA (1,1,1)......... 75TABELA 17 - Teste de Ljung-Box para a Autocorrelação dos Resíduos do
Modelo ARIMA (1,1,1)............................................................... 76TABELA 18 - Estimativas dos Parâmetros para o Modelo ARIMA (0,1,1)......... 76TABELA 19 - Teste de Ljung-Box para a Autocorrelação dos Resíduos do
Modelo a ARIMA (0,1,1)............................................................... 77TABELA 20 - Estimativas dos Parâmetros para o Modelo SARIMA
(2,1,0)(0,1,1)36.............................................................................. 78TABELA 21 - Teste de Ljung-Box para a Autocorrelação dos Resíduos do
Modelo SARIMA (2,1,0)(0,1,1)36............................................... 79TABELA 22 - Valores Observados e Esperados do Modelo SARIMA
(2,1,0)(0,1,1)36.............................................................................. 80TABELA 23 - Estimativas dos Parâmetros para o Modelo SARIMA
(2,1,0)(0,1,1)36 sem o Termo Constante....................................... 80TABELA 24 - Teste de Ljung-Box para a Autocorrelação dos Resíduos do
Modelo SARIMA (2,1,0)(0,1,1)36 sem o Termo Constante........ 81TABELA 25 - Valores Observados e Esperados do Modelo SARIMA
(2,1,0)(0,1,1)36 sem o Termo Constante....................................... 82

9
TABELA 26 - Medidas de Acurácia dos Modelos Não Paramétricos................. 82TABELA 27 - Medidas de Acurácia dos Modelos Paramétricos........................ 83TABELA 28 - Análise de Regressão para as Variáveis Cheques
Compensados e Transações com Cartões.................................. 85TABELA 29 - Análise da Variância para as Variáveis Cheques Compensados
e Cartões...................................................................................... 85TABELA 30 - Erro Percentual Absoluto Médio (EPAM) para os Valores dos
Cheques Compensados e Quantidade de Transações com Cartões......................................................................................... 86
TABELA 31 - Análise de Regressão para as Variáveis Cheques Compensados e Depósitos na Poupança.................................... 88
TABELA 32 - Análise da Variância para as Variáveis Cheques Compensados e Depósitos na Poupança............................................................ 88
TABELA 33 - Erro Percentual Absoluto Médio (EPAM) para os Valores dos Cheques Compensados e Depósitos em Poupança.................... 89
TABELA 34 - Quantidade de Cheques Compensados no Brasil (1994-2005)... 96TABELA 35 - Quantidade de Cheques Compensados no Brasil, Série
Transformada (1994-2005)........................................................... 97

10
SUMÁRIO
1. INTRODUÇÃO................................................................................................. 121.1 Aspectos Gerais........................................................................................ 121.2 Justificativa e Importância do Trabalho..................................................... 141.3 A Hipótese Básica do Trabalho................................................................. 141.4 Objetivos................................................................................................... 15
1.4.1 Objetivo Geral................................................................................ 151.4.2 Objetivos Específicos..................................................................... 15
1.5 As Limitações do Trabalho........................................................................ 151.6 Estrutura do Trabalho .............................................................................. 16
2. ASPECTOS GERAIS DO MEIO DE PAGAMENTO CHEQUE COMPENSADO.................................................................................................... 17
2.1 Introdução................................................................................................. 172.2 Meios de Pagamento no Brasil e no Mundo............................................. 192.3 O Mundo dos Cheques Compensados..................................................... 202.4 A História dos Cheques............................................................................ 22
3. FUNDAMENTAÇÃO TEÓRICA SOBRE SÉRIES TEMPORAIS..................... 243.1 Introdução................................................................................................. 243.2 Objetivos da Análise de Séries Temporais............................................... 253.3 Estacionariedade...................................................................................... 263.4 Transformações........................................................................................ 27
3.4.1 Transformações de Box-Cox......................................................... 273.4.2 Transformações Matemáticas........................................................ 283.4.3 Teste de Seqüência de Wald-Wolfowitz........................................ 293.4.4 Diferenças Sucessivas................................................................... 30
3.5 Teste de Normalidade de Jarque-Bera(JB).............................................. 303.6 Alguns Modelos para Séries Temporais................................................... 31
3.6.1 Método da Decomposição............................................................. 323.6.2 Alisamento Exponencial Simples................................................... 333.6.3 Alisamento Exponencial Duplo – Método de Brow........................ 353.6.4 Alisamento Exponencial Sazonal Holt-Winters (HW)..................... 353.6.5 Previsões do Modelo de HW.......................................................... 37
3.7 Modelos de Box e Jenkins........................................................................ 383.7.1 Introdução...................................................................................... 383.7.2 Modelos Auto-Regressivos - AR(p)................................................ 413.7.3 Modelo de Médias Móveis - MA(q)................................................ 423.7.4 Modelos Auto-Regressivos e de Médias Móveis-ARMA(p,q)........ 43
3.8 Modelos não Estacionários....................................................................... 44

11
3.8.1 Modelos Auto-Regressivos Integrados de Médias Móveis ARIMA(p,d,q).......................................................................................... 44
3.9 Modelos Sazonais..................................................................................... 453.10 Estimação dos Parâmetros de Modelos ARIMA..................................... 493.11 Diagnóstico de Modelos ARIMA............................................................. 50
3.11.1Teste de Box-Pierce (Ljung e Box)............................................... 503.12 Regressão Linear Simples...................................................................... 52
3.12.1 Estimação de Parâmetros............................................................ 524. APLICAÇÃO.................................................................................................... 55
4.1 Introdução................................................................................................. 554.2 Análise Exploratória.................................................................................. 55
4.2.1 Estatística Descritiva...................................................................... 564.3 Teste Não-Paramétrico de Sequência de Wald-Wolfowitz....................... 574.4 Teste de Normalidade de Jarque-Bera (JB)............................................. 584.5 Modelos e Previsão................................................................................... 59
4.5.1 Modelo de Decomposição.............................................................. 594.5.2 Alisamento Exponencial Simples................................................... 654.5.3 Alisamento Exponencial Duplo-Método de Brow........................... 664.5.4 Alisamento Exponencial de Holt-Winters – HW............................. 684.5.5 Modelos de Box e Jenkins............................................................. 714.5.6 Modelos Ajustados......................................................................... 74
4.6 Comparação e Escolha do Método de Previsão....................................... 825. A IMPORTÂNCIA DAS VARIÁVEIS CARTÕES E DEPÓSITOS NA POUPANÇA NA SÉRIE CHEQUES COMPENSADOS....................................... 846. CONSIDERAÇÕES FINAIS E RECOMENDAÇÕES....................................... 91
6.1 Considerações Finais................................................................................ 916.2 Recomendações....................................................................................... 92
REFERÊNCIAS BIBLIOGRÁFICAS.................................................................... 93APÊNDICES......................................................................................................... 96
Apêndice A – Tabelas e Anexos..................................................................... 96Apêndice B – Medidas de Acurácia dos Métodos de Previsão....................... 98

12
1. INTRODUÇÃO 1.1 Aspectos Gerais
É fator primordial no complexo mundo dos negócios a importância das
organizações empresariais em anteciparem-se a mudanças no ambiente econômico,
sendo a previsão empresarial uma função gerencial crucial, pois sem uma boa
previsão, a empresa e sua administração perderão importantes oportunidades de
negócios. Em todas as áreas e segmentos, nos setores públicos ou privados, da
previsão de receita da Empresa Brasileira de Correios a quantidade de passageiros
desembarcados no aeroporto de Belém, da quantidade de chuvas caídas em Montes
Claros à receita do ICMS no estado do Ceará, a popularização das técnicas de
estimativas formais estão crescendo e cada vez buscando construir modelos, por
exemplo, de séries temporais, que extrapolem para o futuro as tendências passadas.
O dinâmico setor bancário também está integrado dentro desta busca
constante de previsões, sendo comuns as divulgações pela imprensa das projeções
de taxas de juros, PIB, taxa de inflação, cotação do dólar etc, realizadas pelas
instituições financeiras ou entidades de classe como a Federação Brasileira de
Bancos - FEBRABAN. Pode-se afirmar que para quase todas as variáveis que
afetam o negócio bancário, a alta administração dos bancos tenha projeções que
vão desde o resultado operacional para qualquer mês a quantidade de funcionarias
afastadas por licença-maternidade. Buscando agregar estudos a essa área, este
trabalho tem como objetivo desenvolver um modelo econométrico que estime a
quantidade de cheques compensados em determinado agente bancário para o
período que for desejado. Serão abordadas duas linhas de modelos univariados de
séries temporais, os quais têm um perfil voltado para previsões de curto prazo, os
modelos determinísticos de alisamento exponencial e os modelos estocásticos
ARIMA. (Pinheiro,2004). De acordo com Castelar e Arraes (1996), os modelos de
alisamento exponencial e ARIMA são de cunho nitidamente de curto prazo.
O Brasil, mesmo com a atual existência de uma ampla rede bancária para
transações on line, ainda é um dos países com maior emissão de cheques. A partir

13
da implantação do Plano Real em 01/07/1994 aumentou a monetização da
economia brasileira, uma vez que a baixa inflação leva os agentes econômicos a
reterem maiores saldos monetários nominais, o que conseqüentemente os leva a
reduzir as emissões de cheques para pagamentos de contas de pequenos valores
como ocorria anteriormente. Os brasileiros efetuam os pagamentos no varejo
basicamente, através de cinco instrumentos: a moeda manual, o cheque, a
transferência de crédito, o débito e crédito diretos e, finalmente, os cartões de
pagamento (débito, crédito, pré-pago e private-label). Apesar do crescimento
excepcional observado no mercado dos cartões, os cheques no Brasil ainda
respondem por cerca de 27% do volume de negócios no Brasil, sendo utilizados até
como instrumento de crédito a partir dos tradicionais cheques pré-datados.
O Banco Central regula o volume total do meio circulante, retirando parte
do dinheiro em circulação ou restaurando a liquidez quando necessária, sendo que o
volume da oferta de moeda em circulação na economia mais a moeda escritural
constituem os meios de pagamento. É especificadamente numa das séries que
compõe os meios de pagamento, a M-1, ou seja, o papel-moeda em poder do
público e nos depósitos a vista no setor bancário, que o mundo dos cheques
compensados se realiza operacionalmente. Instrumento básico no sistema bancário
o cheque foi um dos responsáveis pela elevada quantidade de funcionários no setor
em meados dos inflacionários anos oitenta. Atualmente, com a existência dos
pagamentos eletrônicos e com a disponibilidade de caixas automáticos em cada
esquina e a facilidade gerada pela Internet, a utilização do cheque foi reduzida, mas
ainda não pode ser desprezada. O volume desses cheques faz com que as
instituições financeiras continuem a manter áreas especificas para compensação de
cheques, e a Centralizadora de Compensação de Cheques e Outros Papeis
(COMPE) do Banco do Brasil a funcionar ininterruptamente. Porém, conforme Bacha
(2004) é importante ressaltar que o cheque não é moeda, mas apenas um
instrumento de transferência de moeda bancária (que são os depósitos a vista nos
bancos) entre os agentes econômicos.
Diante dessa situação, conhecer antecipadamente como se comportará o
mercado de cheques compensados fará com que os bancos possam mensurar os
recursos a serem alocados nessa área, bem como criar alternativas para o cliente

14
visando maior satisfação no atendimento. Com este objetivo, esta dissertação
pretende fornecer uma ferramenta para uma boa política de gerenciamento bancário
na antecipação de cenários do meio de pagamento cheque compensado.
1.2 Justificativa e Importância do Trabalho
Justifica-se inicialmente a realização desta pesquisa pelo próprio desafio
de realizar um trabalho científico que venha trazer novas visões da Microeconomia,
Economia de Empresas e Métodos Quantitativos ao tema proposto, um campo
pouco conhecido e explorado no ambiente acadêmico brasileiro. Percebe-se
atualmente a ausência de trabalhos científicos sobre a história dos cheques
compensados no Brasil, bem como enfocando especificadamente o comportamento
futuro desse mercado, visto que em sua maioria ele é utilizado apenas como
instrumento para outros tipos de abordagens, Em recente pesquisa do Banco
Central sobre pagamentos de varejo, não constou na bibliografia qualquer trabalho
brasileiro sobre o tema.
Em virtude disso, faz-se necessário a criação de um modelo de previsão
para os cheques compensados no Brasil, com o objetivo que essa previsão possa
ser utilizada como ferramenta de política bancária na manutenção de sua
regulamentação eficiente, como antecipação de cenários dos meios de pagamentos
e para planejamento estratégico das instituições financeiras.
1.3 A Hipótese Básica do Trabalho
Trata-se de um trabalho, principalmente, de pesquisa aplicada, cujo
método de raciocínio é o hipotético-dedutivo com adoção da hipótese de que os
modelos univariados propostos, por apresentarem uma formulação estatística
apropriada para otimização de previsões de curto prazo, possa apresentar
estimativas bastante próximas dos valores reais compensados. Logo, o melhor
modelo para a previsão da quantidade mensal de cheques compensados no Brasil
pode ser determinado pelo método apresentado neste trabalho. A nível operacional
foram utilizados os softwares para cálculos econométricos MINITAB e EVIEWS.

15
1.4 Objetivos
1.4.1 Objetivo Geral
O objetivo desta dissertação é propor um modelo de previsão para a
quantidade de cheques compensados a partir da utilização de modelos estatísticos e
econométricos na análise das séries temporais de 1994 a 2005, a partir das técnicas
de Decomposição, Alisamento Exponencial e da abordagem de Box-Jenkins. Essas
previsões devem caracterizar-se pela precisão ou acurácia nos resultados obtidos,
pela simplicidade dos diversos métodos utilizados e pelo grau de confiança dos
modelos empregados para gerar as previsões.
1.4.2 Objetivos Específicos
Como objetivos específicos podem-se relacionar:
• Mostrar a Econometria como ferramenta fundamental na previsão da
quantidade de cheques compensados;
• Analisar o comportamento histórico da série;
• Pesquisar e avaliar diversos modelos de previsão;
• Demonstrar a aplicabilidade e resultados do trabalho.
1.5 As Limitações do Trabalho
Entre as principais limitações nesta dissertação, verificou-se a ausência
de trabalhos na Área relacionados especificadamente ao setor bancário bem como
bibliografia especifica sobre o assunto. Em uma pesquisa localizada, o Relatório do
Banco Central realizado em maio/2005 sobre o ”Diagnóstico do Sistema de
Pagamentos de Varejo do Brasil”, não constam referências brasileiras. Entretanto, a
existência de diversas outras pesquisas que tratam da análise de séries temporais
para previsão da arrecadação de tributos foram instrumentos importantes de estudo
para análise dos modelos desenvolvidos e dos softwares utilizados na modelagem
econométrica.

16
Estrutura do Trabalho
Este estudo está dividido em 6 capítulos, a saber:
• Capítulo 1: Refere-se a uma breve apresentação do cheque
compensado no contexto dos meios de pagamento no Brasil e no
mundo, bem como a apresentação dos objetivos, as justificativas e as
limitações deste trabalho;
• Capítulo 2: Descreve-se uma breve história do cheque, além de uma
visão geral dos meios de pagamento;
• Capítulo 3: Mostra as definições dos métodos para análise de séries
temporais e os testes para verificações dos resultados;
• Capítulo 4: São apresentados os resultados das análises realizadas,
comparando se os modelos obtidos com os resultados reais em
análise;
• Capítulo 5: Verifica a importância da variável depósito na conta de
poupança interna na série cheques compensados, bem como a relação
existente entre as quantidades de cheques compensados com os
cartões transacionados;
• Capítulo 6: Apresenta o modelo ideal de previsão conseguido e
recomendações para aprofundamento do assunto.

17
2. ASPECTOS GERAIS DO MEIO DE PAGAMENTO CHEQUE COMPENSADO 2.1 Introdução
Na historiografia do dinheiro existiu o escambo, a mercadoria como
moeda, o metal como moeda, a moeda em forma de objeto, as moedas antigas,
ouro, prata e cobre como moeda, a moeda de papel, o formato do dinheiro em
moedas e cédulas e a formação do sistema monetário. Posteriormente ocorreu o
surgimento da moeda escritural: o cheque, o documento de crédito. Fato é que nas
sociedades as transações comerciais passaram por diversas mudanças, sendo que
atualmente o dinheiro é transacionado por diversas formas. Uma delas é a partir do
cheque, que apesar de não ser um instrumento de crédito, mas um meio rápido de
pagamento, facilita bastante às operações comerciais e se enquadra na categoria de
moeda escritural. Com base em dados de 2004, o cheque em termos de quantidade
de transações, era o instrumento de pagamento não em espécie mais utilizado no
Brasil. Uma das razões para que isso ocorra decorre da própria cultura do brasileiro
e das variadas utilizações que o comércio faz com os cheques recebidos de seus
clientes.
Porém, observa-se já a partir de 1994 que os indicadores de cheques
compensados apresentam uma redução desses números. Entre as causas
microeconômicas dessa redução está o interesse muito grande dos bancos para que
os clientes utilizem cada vez menos seus talões de cheques, pois dados das
próprias instituições informam que uma transação com cheque custa 455% a mais
que a transação eletrônica, o que representa uma redução de custo substancial no
resultado operacional dos bancos. Outros estudos concluíram que o custo de um
pagamento eletrônico representa entre 1/3 a 1/2 do custo de um pagamento em
papel. Em média, em 2006, o custo de uma operação realizada com cheque é R$
1,07 enquanto uma transação via internet banking tem o custo de R$ 0,01. Isso pode
resultar numa redução anual de custos na ordem de 1% a 3% do Produto Interno
Bruno (PIB).

18
No entanto, fundamentalmente a redução na quantidade de cheques
compensados está ligada ao controle da inflação, iniciado quando do lançamento do
Plano Real em 01/07/1994. Outra explicação para essa queda foi a implantação, em
22/04/2002, do Sistema de Pagamentos Brasileiro (SPB), que entre um de seus
vários resultados foi que os correntistas tiveram que se preparar para pagarem
tarifas mais elevadas na utilização dos cheques.
Conforme Sandroni (2005), o cheque é uma ordem escrita, emitida por
uma pessoa em talão especial, para que uma instituição financeira pague certa
quantia à outra pessoa, não sendo instrumento de crédito, mas um meio de
pagamento rápido que facilita muito as operações comerciais e se enquadra na
categoria de moeda escritural. Trata-se de um documento que pode ser recebido
diretamente na agência bancária que o emitente mantém a conta corrente ou
depositado em outra agência para ser compensado e creditado na conta do
correntista.
Segundo o Banco Central, os agentes envolvidos em um pagamento com
cheque, desde a emissão até a liquidação financeira interbancária, são os seguintes:
a) Emitente: pessoa física ou jurídica, detentora da conta corrente, que
emite o cheque;
b) Beneficiário: pessoa física ou jurídica favorecida pelo pagamento que
apresenta o cheque diretamente ao banco sacado ou o deposita no
banco em que tem conta corrente;
c) Banco acolhedor: banco no qual o beneficiário tem conta corrente e
deposita o cheque;
d) Banco sacado: banco no qual o emitente possui a conta corrente;
e) Sistema de compensação: efetua a compensação das transações
com cheques;

19
f) Sistema de liquidação: efetua a liquidação financeira das transações
com cheques.
2.2 Meios de Pagamento no Brasil e no Mundo
Meios de pagamento são o “volume da oferta de moeda em circulação na
economia, excluídos os montantes mantidos em caixa pelas autoridades monetárias
e pelos bancos comerciais, mais a moeda escritural que são os depósitos a vista do
público nos bancos” (SANDRONI, 2005). Desde 2001, o Banco Central adotou as
seguintes séries distintas de meios de pagamento que são: a M-1 constituída pela
soma das moedas manual (papel-moeda e moedas metálicas em poder do público)
e escritural (depósitos a vista do público nos bancos comerciais, bancos múltiplos e
caixas econômicas); a M-2 que inclui a M-1 mais os depósitos especiais
remunerados, mais os de poupança e os títulos privados emitidos por instituições
depositárias; a M-3 que engloba a M-2 mais as quotas de fundo de renda fixa e as
operações compromissadas com títulos federais e a M-4, que adiciona a M-3 o saldo
dos títulos públicos federais, estaduais e municipais de alta liquidez. O elemento
principal deste trabalho está localizado na série M-1 e representa ainda em plena
era da internet um dos meios de pagamento mais utilizados pela população
brasileira, o tradicional cheque bancário. Apesar da baixa interoperabilidade da infra-
estrutura dos canais de distribuição dos instrumentos de pagamentos como os
terminais ATM e POS, aliado as restrições dos bancos ao fornecimento de talões e o
custo cobrado, os cheques continuam sendo transacionados em todo o território
nacional como instrumento de pagamento e operador de crédito na modalidade
cheque pré-datado.
As conclusões das cinco teorias sobre a demanda de moeda que são o
modelo clássico de demanda de moeda, o modelo de expectativas regressivas, o
modelo da composição ótima dos ativos, o modelo de Tobin e Baumol que considera
a demanda de moeda para fins de transações e o modelo de Friedman que analisa a
moeda como sendo uma mercadoria comum, sintetizam que o aumento do produto
real aumenta a demanda de moeda, enquanto os aumentos da taxa de juros e da
taxa de inflação reduzem a demanda de moeda. Na analise da serie cheques

20
compensados, no capitulo 5 será demonstrada a relação das variáveis cartões e
depósitos em contas de poupança com a serie.
O cheque, que detinha a maior parcela na utilização agora vem sendo
substituído por instrumentos eletrônicos como o cartão e até mesmo pelo
pagamento em espécie. Em 1995, do total de pagamentos no Brasil, 7% eram com
cartões, 26% com cheque e 55% com dinheiro. Dez anos depois, a participação dos
cartões subiu para 20%, a dos cheques caiu para 14% e a do dinheiro ficou
praticamente estável, em 53%, o que se configura que pelos menos nos próximos
anos, os cartões irão continuar mantendo taxas de crescimento superiores a 10%,
resultado do potencial do mercado brasileiro, aliado ao baixo índice de ativação e o
pequeno alcance nas classes de menor poder aquisitivo. Registros da Associação
Brasileira das Empresas de Cartões e Serviços - ABECS indicam que ao final de
2006 definitivamente os cartões de crédito, débito e de lojas se consolidam como o
segundo meio de pagamento mais utilizado no mercado brasileiro. As transações
realizadas com dinheiro continuam em primeiro e os cheques em terceiro lugar.
Segundo a ABECS o uso dos cheques vem caindo em média 7% ao ano, enquanto
as transações com cartões aumentam 22%. Dados do próprio Banco Central
informam que em 2005 as transações com cartões de pagamento cresceram cerca
de 40% em relação a 2004, enquanto as com cheques tiveram uma redução de
6,5%.
O dinheiro em espécie é utilizado principalmente para pagamentos de
baixo valor, relacionados com as compras básicas do consumo doméstico. Como
outras formas de pagamento que não envolvam a utilização do papel-moeda ou do
cheque, existem os cartões de crédito e de débito, os caixas eletrônicos - ATMS, os
cheques eletrônicos, os smart cards, a moeda eletrônica, as transferências de
crédito e a compensação automatizada.
2.3 O Mundo dos Cheques Compensados
A grande utilidade prática do cheque é a de servir como instrumento de
pagamento, sendo o cheque verdadeiramente uma ordem de pagamento a vista. As
próprias condições econômicas e o aspecto cultural existente fizeram do brasileiro

21
um dos maiores usuários mundiais de cheques. Dados do Banco Central registram
que em 1994, a média mensal de cheques compensados através da Centralizadora
de Compensação de Cheques e Outros Papéis - COMPE foi de 344 milhões, sendo
que em setembro de 2006 essa média reduziu para 132 milhões de cheques. No
período de 1994 a 2005 a compensação diária teve uma queda da média de 17
milhões para 7 milhões, ou seja, a cada dia útil os bancos deixaram de compensar,
em média, 10 milhões de cheques. Também quando se compara o volume dos
cheques compensados nesse período, a queda mantém-se, pois, se em 2001 o
volume mensal médio de cheques compensados totalizava 159 bilhões de reais, em
setembro de 2006 esse volume caiu para 78 bilhões.
As dificuldades que o comércio tinha ao tentar resgatar um cheque
devolvido, bem como o aumento dos caixas automáticos e a utilização maciça que
os bancos fazem com a internet, de certa maneira foram fatores que levaram cada
vez mais o emitente de cheque a fazer menor uso do seu talonário. Mesmo com o
potencial de crescimento calculado pela relação entre o crédito total e o PIB de
cerca de 27% que o mercado bancário brasileiro apresenta em comparação a países
como o Chile com 53%, a Coréia do Sul com 74%, 120% com a Alemanha, cada vez
mais os cheques são menos emitidos pelos brasileiros. Isso resultou que após
muitos anos na composição dos instrumentos de pagamento o uso dos cartões de
pagamento superasse o do cheque, resultando que a quantidade de pagamentos
por meio de instrumentos eletrônicos já seja responsável por aproximadamente 85%
dos pagamentos não em espécie. Entretanto a importância do cheque continua forte
no mercado brasileiro, pois somente em 2005 foram emitidos cerca de 2,6 bilhões de
cheques, no valor total de R$ 2,3 trilhões e com o valor médio por cheque de R$
893,00.
Em outros países a utilização de cheque já vem sendo substituída por
meios eletrônicos de pagamento e o cheque se torna peça de museu. A criação de
novas tecnologias, principalmente as ligadas às comunicações sem fio, como o
telefone celular, faz com que os cartões cheguem aos mais distantes lugares,
resultando que as empresas preferem vender através de cartão a receber cheques.
Conforme estatística divulgada pelo Banco Central a utilização de cheques na

22
Europa já está caindo para zero em alguns países e em outros está muito baixa,
conforme pode ser visualizado na Tabela 1:
TABELA – 1 – Operações sem uso de papel-moeda
País 1999 2002
Holanda 1 0 Alemanha 3,1 1,1 Suíça 0,8 0,5 Espanha 10,7 6 Itália 25,2 17,2 Reino Unido 28,8 21 Portugal 34,1 24,1 França 40,1 34,2 Estados Unidos 61,9 49,9 Brasil 62,9 46
Fonte: Banco Central do Brasil
2.4 A História dos Cheques
A substituição do dinheiro em metal por papel-moeda foi difícil. Em junho
de 1716, o aventureiro inglês, jogador apaixonado e banqueiro audacioso, John Low,
no prédio de um velho hotel, fundou o primeiro banco emissor da Franca, chamado
Banque General. Foi o milagre da criação da moeda por um banco o que John Low
demonstrou e que pode estimular a indústria e o comércio e fornecer a todos um
sentido de bem estar.
Enquanto os franceses atribuem ao vocabulário inglês to check a origem
da palavra cheque, os ingleses afirmam que palavra tem origem no francês ichequier
que significa retirar, dar baixa no jogo de xadrez ou como vocábulo que também
significa o tabuleiro de xadrez usado pelos cambistas e tesoureiros reais, o que
recorda o formato das mesas utilizadas pelos banqueiros. Segundo o Banco Central,
baseado no clássico ”Dinheiro no Brasil” de Santos Trigueiro, data de 1762, os
primeiros cheques impressos na Inglaterra, mas antes disso, no mesmo país o uso
do cheque já tinha começado a desenvolver-se. Alguns cheques recebidos de
diferentes clientes pelos banqueiros, sacados contra diversificados bancos traziam o
inconveniente de obrigá-los a visitar os estabelecimentos sacadores para obtenção
do pagamento. Visando melhorar esse inconveniente os banqueiros depositavam os

23
cheques nos seus próprios bancos e depois realizavam a coleta com seus
mensageiros em diversas viagens aos bancos sacados. Para reduzir o número
dessas viagens os banqueiros resolveram se encontrar em uma taverna, onde
trocavam seus maços de cheques. Apesar da resistência dos banqueiros a esse
sistema, foi percebida a sua utilidade e criada as caixas de Compensação a que são
levadas todos os cheques entregues a um banco sacado contra os outros,
atualmente conhecidas como Câmaras de Compensação.
Ainda conforme o Banco Central, em 1865, na Franca foi criada a primeira
legislação específica sobre cheques, apesar de ter sido na Inglaterra o país que ele
mais se expandiu, porém somente em 1882 foi aprovada a legislação competente.
Já no Brasil a primeira referência sobre cheque surgiu em 1845, quando da
fundação do banco Comercial da Bahia, mas mesmo assim sob a denominação de
cautela. Somente em 1893, pela Lei 149- B, surgiu a primeira referência ao cheque,
no seu artigo 16 letra A, vindo a posterior regulamentação pelo decreto 2.591 de
1912.
O manuseio dos cheques para realização de pagamentos é mais fácil,
principalmente quando se trata de transações de grande valor monetário. Os
pagamentos por intermédio de cheques permitem o melhor controle e a melhor
contabilização de despesas, ao mesmo tempo em que podem servir de
comprovação de determinadas finalidades legais, especialmente quando nominais e
cruzados.

24
3. FUNDAMENTAÇÃO TEÓRICA SOBRE SÉRIES TEMPORAIS
3.1 Introdução
Uma série temporal é um conjunto de informações feitas sequencialmente
ao longo do tempo. A característica mais importante deste tipo de dados é que as
observações vizinhas são dependentes e estamos interessados em analisar e
modelar esta dependência. Enquanto em modelos de regressão, por exemplo, a
ordem das observações é irrelevante para a análise, em séries temporais a ordem
dos dados é crucial.
Considerando o parâmetro t como sendo o tempo, a série Z(t) poderá ser
função de algum outro parâmetro físico, como espaço ou volume. Morettin e Toloi
(2006) afirmam de um modo bastante geral que, uma série temporal poderá ser um
vetor Z(t), de ordem r x 1 onde, por sua vez, t é um vetor p x 1. Por exemplo,
Z(t) = [ Z1(t), Z2(t), Z3(t) ]
onde as 3 (três) componentes denotam, respectivamente, a altura, a temperatura e a
pressão de um ponto do oceano e t = (tempo, latitude, longitude). Diz-se que a série
é multivariada (r=3) e multidimensional (p=3).
Uma série de tempo é uma série de observações de alguma quantidade
de interesse em relação ao tempo. Para Kazmier (2007), uma série temporal é um
conjunto de valores observados, tais como dados de venda ou produção, para uma
série sequencialmente ordenada de períodos de tempo. De um modo geral, pode-se
considerar que uma série temporal é qualquer conjunto de observações ordenadas
no tempo, ainda segundo Morettin e Toloi (2006), que cita abaixo como exemplos de
séries temporais:
a) valores diários de poluição na cidade de São Paulo (i);
b) valores mensais de temperatura na cidade de Cananéia-SP (ii);
c) índices diários da Bolsa de Valores de São Paulo (iii);

25
d) precipitação atmosférica anual na cidade de Fortaleza (iv);
e) número médio anual de manchas solares (v);
f) registro de marés no porto de Santos (vi).
Nas séries (i) - (v) tem-se séries temporais discretas, enquanto (vi) é um
exemplo de uma série contínua.
Objetivos da Análise de Séries Temporais
Segundo Morettin e Toloi (2006), obtida uma série temporal Z(t),..., Z(tn)
observada nos instantes t1,..., tn, podemos estar interessados em:
• Investigar o mecanismo gerador da série temporal;
• Fazer previsões de valores futuros da série; estas podem ser a curto
prazo, como por exemplo, para séries de vendas, produção ou
estoque, ou a longo prazo, como por exemplo, para séries
populacionais, de produtividade, etc;
• Descrever apenas o comportamento da série; neste caso, a construção
do gráfico, a verificação da existência de tendências, ciclos e variações
sazonais, a construção de histogramas e diagramas de dispersão etc,
podem ser ferramentas úteis;
• Procurar periodicidades relevantes nos dados; neste caso, a análise
espectral pode ser de grande utilidade.
Na revisão bibliográfica realizada, resumidamente registra-se a seguir
diversos trabalhos sobre séries temporais, nos quais foram desenvolvidos modelos
de alisamento exponencial e ARIMA. Para a previsão mensal da arrecadação do
ICMS no estado do Ceará, Castelar e Arraes (1996) e Ferreira (1996), usaram
modelos de alisamento exponencial, ARIMA e função de transferência, junto com
uma técnica de combinação das previsões desses modelos. Arraes e Chumvichitra
(1997) formularam modelos ARIMA para previsão trimestral da arrecadação de

26
ICMS no estado do Ceará. Rocha (2003) realizou a previsão do ISS da cidade do
Rio de Janeiro analisando três modelos de séries temporais: Decomposição
Clássica, o de Holt-Winters e o SARIMA. Liebel (2003), buscou a aplicação das
principais técnicas quantitativas de previsão a uma série temporal de arrecadação
de ICMS no estado do Paraná, enquanto Passos (2004), apresentou detalhes sobre
o comportamento da série ICMS do estado do Pará e sua modelagem através dos
modelos automáticos de Decomposição e Exponencial Linear de Winter.
3.3 Estacionariedade Uma das suposições mais freqüentes que se faz a respeito de uma série
temporal é a de que ela é estacionária. Segundo Morettin e Toloi (2006) dizer que
uma série é estacionária, é dizer que ela se desenvolve no tempo aleatoriamente ao
redor de uma média constante, refletindo alguma forma de equilíbrio estável.
Todavia, a maior parte das séries que encontramos na prática apresentam alguma
forma de não-estacionariedade. A Figura 1 ilustra uma forma de série não-
estacionária com comportamento explosivo. Segundo Morettin e Toloi (2006) este
tipo de não-estacionariedade é chamado homogêneo. A série pode ser estacionária,
flutuando ao redor de um nível, por certo tempo, depois mudar de nível e flutuar ao
redor de um novo nível e assim por diante, ou então mudar de inclinação, ou ambas
as coisas.
FIGURA – 1 – Série Não-Estacionária quanto ao nível e inclinação

27
Na prática, não é muito comum encontrar-se séries estacionárias. Nestes
casos é necessário fazer uma transformação nos dados originais, conforme será
abordado na próxima seção.
3.4 Transformações
Para Morettin e Toloi (2006), existem duas razões básicas para se
transformar os dados originais: estabilizar a variância e tornar o efeito sazonal
aditivo. É comum em séries econômicas e financeiras a existência de tendência e
pode ocorrer um acréscimo da variância da série à medida que o tempo passa.
Neste caso uma transformação logarítimica pode ser adequada.
Entretanto, Nelson (1976) conclui que transformações não melhoram a
qualidade da previsão. Makridakis e Hibon (1979) verificaram que os dados
transformados têm pouco efeito na melhoria da previsão e, sob bases mais teóricas,
Granger e Newbold (1976) mostram que as previsões dos antilogaritimos dos dados
transformados são estimadores viesados e deveriam, portanto, serem ajustados,
mas isto não é feito em alguns programas de computador, o que significa que,
depois que os dados são transformados, um viés é introduzido nas previsões,
decorrente de tal transformação. Além disso, Granger e Newbold observam que a
heterocedasticidade não afeta a adequação da previsão, pois ela não implica em
estimadores viesados, como no caso de regressão múltipla.
3.4.1 Transformações de Box-Cox
Na prática é muito comum em séries temporais, em particular séries
econômicas, que os dados sejam não estacionários e por conseguinte, estes dados
apresentam padrões de aumento na variância a medida que o tempo passa.
Portanto, os principais motivos para se fazer transformações em uma série, são:
1. Tornar os dados mais simétricos;
2. Estabilizar a variância.

28
λtt ZW =
Em muitos casos, uma série temporal torna-se extremamente difícil de ser
modelada por apresentar o seu desvio padrão proporcional a média. Quando este
padrão é detectado é necessário fazer uma transformação na série.
Segundo Morettin e Toloi (2006), em geral é necessário aplicar à série
original, uma transformação não-linear, como a transformação logarítima. De um
modo geral utiliza-se uma transformação da forma:
⎪⎩
⎪⎨⎧
=
≠−
=0,log
,0,)(
λ
λλ
λ
λ
seZ
secZ
Zt
t
t
Esta transformação é denominada transformação de Box-Cox. Onde λ e
c são os parâmetros a serem estimados. Para verificar se o desvio padrão é
proporcional a média de uma série temporal qualquer, bastar dividi-la em grupos e,
posteriormente, calcular a média e o desvio padrão destes. Utiliza-se de um gráfico
que traz nos seus eixos os valores da média e do desvio padrão. Vale ressaltar que,
pode-se utilizar uma outra medida de variabilidade além do desvio padrão, assim
como, pode-se também utilizar uma outra medida de tendência central além da
média, porém, o desvio padrão e a média são utilizados com maior freqüência.
3.4.2 Transformações Matemáticas A transformação de Box-Cox automaticamente identifica uma
transformação a partir de uma família de transformações de potência de Zt. A família
de transformações de potência é dada por: (MAKRIDAKIS e WHEELWRIGHT,
1998).
onde pode-se observar que Wt é o novo valor da série transformada.
A Tabela 2 mostra os valores de λ e o respectivo valor da série
transformada.

29
1.2 21 +=N
nnµ
)1().2(.2
22121
−−
=NN
Nnnnnσ
TABELA – 2 - Exemplos dos Valores de λ para a transformação de Box-Cox.
λ Wt = Ztλ
2 Wt = Zt2
0.5 Wt = tZ
-0.5 Wt = tZ1
0 Wt = Zt
3.4.3 Teste de Seqüência de Wald-Wolfowitz Outra forma de análise da estacionariedade é obtida através do teste não-
paramétrico de Wald-Wolfowitz. Neste teste supõe-se inicialmente que m = mediana
da série e atribui-se a cada valor Zt os símbolos: A se Zt ≥ m e B se Zt < m.
Tem-se então N = (n1 pontos A) + (n2 pontos B).
A estatística do teste ´e: T1 = número total de sequências (isto é, grupos
de símbolos iguais).
Portanto, rejeita-se H0 se há poucas sequências, ou seja, se T1 é
pequeno. Para dado nível de significância α , rejeita-se H0 se αω<1T , onde w é o α
- quantil da distribuição T1, que é tabelado.
Para n1 ou n2 maior que 20 pode-se usar a aproximação para a
distribuição normal, isto é, ),(~ 21 σµNT onde:
(3.4)
e
(3.5)
Maiores detalhes ver Siegel (1975).

30
),1()()( −−=∆ tZtZtZ
[ ] [ ],)1()()()(2 −−∆=∆∆=∆ tZtZtZtZ
),2()1(2)()(2 −+−−=∆ tZtZtZtZ
[ ],)()( 1 tZtZ nn −∆∆=∆
3.4.4 Diferenças Sucessivas
Uma das razões para transformar os dados originais é a presença de não-
estacionariedade. Em Morettin e Toloi (2006), a transformação mais comum consiste
em tomar diferenças sucessivas da série original, até se obter uma série
estacionária. A primeira diferença de Z(t) é definida por:
(3.6)
a segunda diferença é:
(3.7)
ou seja,
(3.8)
de modo geral, a n-ésima diferença de Z(t) é:
(3.9)
Em situações normais, será suficiente tomar uma ou duas diferenças para
que a série se torne estacionária.
3.5 Teste de Normalidade de Jarque-Bera (JB) Uma outra suposição a respeito das séries temporais é a de normalidade
(evento puramente aleatório), sendo que um teste para que se verifique esta
suposição é o teste de Jarque-Bera (JB), utilizado desde 1981.
O teste de JB de normalidade é um teste assintótico, ou seja para
grandes amostras e se baseia nos resíduos de Mínimos Quadrados Ordinários
(MQO). Este teste primeiro calcula a assimetria e a curtose dos resíduos de (MQO)
e utiliza a seguinte estatística:

31
,24
)3(6
22
⎥⎦
⎤⎢⎣
⎡ −+=
CAnBJ
,,...,1,)( NtatfZ tt =+=
(3.10)
em que A representa assimetria e C representa a curtose.
Uma vez que, em uma distribuição normal (simética e mesocúrtica), o
valor de assimetria é zero e o valor de curtose é 3, (C - 3) representa em (3.10), o
excesso de curtose. Sob a hipótese nula de que os resíduos se distribuem
normalmente, Jarque e Bera (1987) mostraram que, assintoticamente (isto é, em
grandes amostras), a estatística BJ dada em (3.10), segue a distribuição qui-
quadrado com 2 graus de liberdade. Se o valor p da estatística qui-quadrado
calculada em uma aplicação for suficientemente baixo, pode-se rejeitar a hipótese
de que os resíduos têm distribuição normal. Mas se o valor p for razoavelmente alto,
não rejeita-se a hipótese de normalidade.
3.6 Alguns Modelos para Séries Temporais
Morettin e Toloi (2006) afirmam que os modelos utilizados para descrever
séries temporais são processos estocásticos, isto é, processos controlados por leis
probabilísticas.
Definição 3.6.1. Seja T um conjunto arbitrário. Um processo estocástico é uma
família { }TttZZ ∈= ),( ; tal que, para cada Tt ∈ , Z(t) é uma variável aleatória.
Sendo uma possibilidade de escrever uma série temporal observada na
forma:
(3.11)
onde f(t) é chamado sinal e ta o ruído (MORETTIN e TOLOI, 2006).

32
tj
jtj
m
j
jjt aDtZ ++= ∑∑
==
12
10
αβ
∑=
=12
1jjtjt DS α
∑=
=m
j
jjt tT
0
β
tttt aSTZ ++=
3.6.1 Método da Decomposição
Para Morettin e Toloi (2006), dada uma série temporal {Zt; t =1,...,N}, um
modelo de decomposição consiste em escrever Zt como uma soma de três
componentes não observáveis,
(3.12)
onde St, corresponde à componente sazonal para o período t ; Tt é a componente de
tendência no período t; at é a componente aleatória, de média zero e variância
constante 2aσ .
sendo que:
(3.13)
onde j é o grau do polinômio e:
(3.14)
sendo que jα são as constantes sazonais (médias mensais) e Djt são variáveis
periódicas, neste caso dados por:
1, se o período t corresponde ao mês j, j=1,2, ... 12 -1 se o período t corresponde ao mês 12; (3.15)
0 caso contrário.
Assim o modelo de decomposição aditivo pode ser escrito da seguinte
forma:
(3.16)
=ijD

33
tttt aSTZ ××=
O modelo de decomposição multiplicativo é escrito da seguinte forma:
(3.17)
Segundo Makridakis e Wheelwrigth (1998), um modelo aditivo é
apropriado se a amplitude das variações sazonais não variam com o nível da série.
Porém, se as flutuações sazonais aumentam ou diminuem proporcionalmente com o
aumento ou decréscimo do nível da série, então o modelo multiplicativo é mais
adequado. O modelo de decomposição multiplicativo é mais prevalecente com
séries econômicas, pois séries econômicas mais sazonais têm variação sazonal que
aumenta com o nível das séries.
Segundo Morettin e Toloi (2006), a componente sazonal representa as
flutuações da série de acordo com algum fator de sazonalidade, e que ocorrem
dentro de um curto período de tempo. O ciclo apresenta um comportamento similar à
componente sazonal, embora tenha normalmente comprimento maior que aquela. A
tendência representa o aumento ou declínio gradual nos valores das observações de
uma série temporal.
Com a remoção das componentes de sazonalidade, ciclo e tendência, a
componente aleatória fica determinada. Vários procedimentos para a decomposição
de séries temporais foram desenvolvidos, cada qual tentando isolar as componentes
não observáveis da série o mais acuradamente possível. O objetivo desses
procedimentos consiste em remover cada uma das componentes, permitindo que o
comportamento da série temporal seja melhor compreendido e, consequentemente,
prognosticar valores futuros mais apropriados (MAKRIDAKIS e WHEELWRIGTH,
1985).
3.6.2 Alisamento Exponencial Simples
A princípio, este método se assemelha ao da média móvel, por extrair das
observações da série temporal o comportamento aleatório pelo alisamento dos
dados históricos. Entretanto, a inovação introduzida pelo alisamento exponencial

34
( ) ttt FxF αα −+=+ 11
simples advém do fato de este método atribuir pesos diferentes a cada observação
da série. Enquanto que na média móvel as observações usadas para encontrar a
previsão do valor futuro contribuem em igual proporção para o cálculo dessa
previsão, (MORETTIN e TOLOI, 2006), no alisamento exponencial simples as
informações mais recentes são evidenciadas pela aplicação de um fator que
determina essa importância.
Para Pindyck e Rubinfeld (1991), a técnica de alisamento providencia um
meio de se remover ou, pelo menos, reduzir as flutuações de curto prazo presentes
em séries temporais. O método de alisamento exponencial baseia-se em um sistema
de médias ponderadas móveis que atribuem um peso maior aos dados mais
recentes da série temporal (KRAJEWSKI & RITZMAN, 1998). Os pesos atribuídos
aos elementos da série temporal decaem exponencialmente (razão do nome
alisamento ou suavização exponencial), do mais recente para o mais antigo.
Conforme Makridakis e Wheelwrigth (1985), o argumento para o tratamento
diferenciado das observações da série temporal é fundamentado na suposição de
que as últimas observações contém mais informações sobre o futuro, e, portanto,
são mais relevantes para a previsão. Wheelwrigth (1985), especifica o método
através da equação:
(3.18)
onde Ft+1 representa a previsão no tempo t + 1 e α é o peso atribuído à observação
xt, 0 < α < 1.
O valor assumido por α determina o ajuste aplicado aos dados. Quanto
menor o valor da constante, mais estáveis serão as previsões, visto que a utilização
de baixo valor implica na atribuição de peso maior às observações passadas e,
consequentemente, qualquer flutuação aleatória no presente contribui com menor
importância para a obtenção da previsão. Contudo, não há metodologia que oriente
quanto à seleção de um valor apropriado para α , sendo normalmente encontrado
por tentativa e erro. Um procedimento mais objetivo seria a seleção do valor que
forneça a melhor previsão das observações contidas na série temporal.

35
( ) 1~1~
−−+= ttt YYY αα
( ) ∗−
∗ −+= 1~1~
ttt YYY αα
kY ttkt βσ ˆˆˆ +=+
∗−= ttt YY ~~2σ̂
( )∗−−
= ttt YY ~~1
ˆα
αβ
O alisamento exponencial simples é apropriado para séries localmente
constantes, isto é, séries temporais sem tendência ou sazonalidade.
3.6.3 Alisamento Exponencial Duplo - Método de Brow
Holt apub Makridakis (1998) realizou estudos que permitiram a aplicação
de um modelo de alisamento exponencial a uma série temporal com padrão de
tendência acrescentado a série estacionária. Morettin e Toloi (2006) comentam que
o alisamento exponencial duplo processa-se em duas fases: primeiro, realiza-se o
alisamento exponencial simples, obtendo-se a série alisada tY~ ,
(3.19)
Em seguida, alisa-se esta série novamente através do operador de
alisamento exponencial, obtendo-se a série de segunda ordem:
(3.20)
Assim, a previsão de valores futuros é feita através do modelo:
(3.21)
onde:
(3.22)
e
(3.23)
É apropriado utilizarmos o alisamento exponencial duplo, em séries
temporais com tendência, mas sem o fator de sazonalidade. De acordo com
Bowerman e OConell (1987), este método serve como ferramenta de previsão para
séries que exibem tendência linear.
3.6.4 Alisamento Exponencial Sazonal Holt-Winters (HW)

36
As séries não estacionárias além de exibir tendência crescente ou
decrescente, também podem apresentar sazonalidade. O modelo de Holt-Winters
pode ser entendido como uma técnica a ser aplicada quando a série temporal Z (t)
mostra esses dois componentes, sendo que a incorporação do efeito sazonal pode
ser feita de forma aditiva ou multiplicativa, o que permite presumir serem modelos
mais completos que os citados anteriormente. Para Morettin e Toloi (2006) existem
dois tipos de procedimentos cuja utilização depende das características da série
considerada. Tais procedimentos são baseados em três equações com constantes
de suavização diferentes, que são associadas a cada uma das componentes do
padrão da série: nível, tendência e sazonalidade.
I. Série Sazonal Multiplicativa
De acordo com Morettin e Toloi (2006), dada uma série temporal qualquer
com período s, o método de HW considera o fator sazonal como sendo multiplicativo
e as outras componentes do modelo permanecem aditiva, isto é,
NtaTFZ ttttt ...,,2,1, =++= µ (3.24)
onde as três equações de suavização são dadas por:
( ) NstDFDZZDF st
t
tt ...,,1,10,ˆ1ˆ +=<<−+⎟⎟
⎠
⎞⎜⎜⎝
⎛= − (3.25)
NstATZAFZAZ tt
st
tt ...,,1,10),ˆˆ)(1(ˆ 11 +=<<+−+⎟⎟
⎠
⎞⎜⎜⎝
⎛= −−
−
(3.26)
NstCTCZZCT tttt ...,,1,10ˆ)1()(ˆ,11 +=<<−+−= −− (3.27)
Estas equações representam estimativas do fator sazonal, do nível e da
tendência, respectivamente; A, C e D são as constantes de suavização.
II. Série Sazonal Aditiva

37
( ) ( ) ,10,ˆ1ˆ <<−+−= − DFDZZDF stttt
( ) ,10),ˆ)(1(ˆ11 <<+−+−= −−− ATZAFZAZ ttsttt
,10ˆ)1()(ˆ,11 <<−+−= −− CTCZZCT tttt
( ) ,,2,1,ˆ)(ˆ shFThZhZ shthtt K=+= −+
( ) ,2,1,ˆ)(ˆ2 sshFThZhZ shthtt K+=+= −+
( ) stt
tt FD
ZZDF −+
+
++ −+⎟⎟
⎠
⎞⎜⎜⎝
⎛= 1
1
11
ˆ1ˆ
( )( )ttst
tt TZA
FZAZ ˆ1ˆ
1
11 +−+⎟⎟
⎠
⎞⎜⎜⎝
⎛=
−+
++
O procedimento anterior pode ser modificado para tratar com situações
onde o fator sazonal é aditivo,
ttttt aFTZ +++= µ (3.28)
as estimativas do fator sazonal, nível e tendência da série aditiva (3.26) são dadas
por:
(3.29)
(3.30)
(3.31)
onde A, C e D são as constantes de suavização, respectivamente.
3.6.5 Previsões do Modelo de Holt-Winters (HW) I. Modelo Multiplicativo
(3.32)
(3.33)
Para fazer novas previsões quando tem-se uma nova observação Zt+1,
utiliza-se as seguintes equações:
(3.34)
(3.35)
( ) ( ) ,11ˆ1ˆtttt TCZZCT −+−= ++ (3.36)
e a nova previsão para a observação Zt+h será:

38
( )( ) ,1...,,2,1ˆˆ1)1(ˆ,1111 +=−+=− −+++++ shFThZhZ shtttt
( )( ) .12...,,2ˆˆ1)1(ˆ,21111 ++=−+=− −+++++ sshFThZhZ shtttt
;...,,2,1,1
ˆ
1
sjZ
s
ZF s
kk
jj =
⎟⎠⎞
⎜⎝⎛
=
∑=
∑=
==s
ksks TZ
sZ
1.0ˆ;1
,...,,2,1ˆˆ)(ˆ, shFThZhZ shtttt =++= −+
sshFThZhZ shtttt 2...,,1ˆˆ)(ˆ,2 +=++= −+
( ) ( ) ,ˆ1ˆ1111 stttt FDZZDF −++++ −+−=
( ) ),ˆ)(1(ˆ111 ttsttt TZAFZAZ +−+−= −+++
,11ˆ)1()(ˆtttt TCZZCT −+−= ++
( ) ,1...,,2,1ˆˆ1)1(ˆ,1111 +=+−+=− −+++++ shFThZhZ shtttt
( ) .12...,,2ˆˆ1)1(ˆ,21111 ++=+−+=− −+++++ sshFThZhZ shtttt
(3.37)
(3.38)
Os valores iniciais das equações de recorrência são calculados por meio
das seguintes fórmulas:
(3.39)
(3.40)
II. Modelo Aditivo
(3.41)
(3.42)
Para fazer novas previsões quando tem-se uma nova observação Zt+1,
utiliza-se as seguintes equações:
(3.43)
(3.44)
(3.45)
e a nova previsão para o valor Zt+h será:
(3.46)
(3.47)
3.7 Modelos de Box e Jenkins

39
3.7.1 Introdução
Os modelos de Box e Jenkins são modelos paramétricos conhecidos
genericamente como modelos ARIMA. De acordo com Maddala (2003), a
abordagem Box-Jenkins é uma das metodologias mais usadas para a análise de
dados em séries temporais. Ela é popular em conseqüência de sua generalidade;
ela pode lidar com qualquer série, estacionária ou não, com ou sem elementos
sazonais e tem programas de computador bem documentados. Tratam-se de
modelos matemáticos que objetivam captar o comportamento da correlação seriada
ou da autocorrelação entre os valores da série temporal e, com base nesse
comportamento, realizar previsões. Os modelos ARIMA resultam da combinação de
três componentes denominados ”filtros”: o componente auto-regressivo (AR), o filtro
de integração (I) e o componente de médias móveis (MA). Uma série de tempo pode
conter os três filtros ou apenas um subconjunto desses, resultando daí várias
alternativas de modelos passíveis de análise pela metodologia de Box e Jenkins
(VASCONCELLOS, 2000). Esta metodologia consiste em ajustar modelos
autoregressivos e integrados de médias móveis, ARIMA (p,d,q), a uma série
qualquer. Onde p, d e q são os parâmetros a serem estimados, sendo que:
p= número de parâmetros autoregressivos;
d= número de diferenças aplicadas na série;
q= número parâmetros de médias móveis.
Segundo Makridakis e Wheelwright(1998), a estratégia para a construção
destes modelos consiste em três fases: identificação, estimação e teste, e aplicação.
Onde na verdade, antes da aplicação é feito o diagnóstico do modelo ajustado a
partir, principalmente, da análise das autocorrelações e autocorrelações parciais.
Para Morettin e Toloi (2006), a estratégia para a construção do modelo é
baseada em um ciclo iterativo, no qual a escolha da estrutura do modelo é baseada
nos próprios dados. Os estágios do ciclo iterativo são:

40
a) Especificação: uma classe geral de modelos é considerada para
análise;
b) Identificação: É com base na análise de autocorrelações,
autocorrelações parciais e outros critérios. Esta etapa consiste em
identificar quais dos filtros AR, I, MA fazem parte do processo
estocástico que gerou a série temporal Z (t), bem como identificar as
suas respectivas ordens (VASCONCELLOS e ALVES, 2000).
Conforme Gujarati (2005), as principais ferramentas dessa etapa são a
função de autocorrelação (FAC), a função de autocorrelação parcial
(FACP) e os correlogramas resultantes, que são simplesmente as
representações gráficas das FACs e FACPs contra o tamanho da
defasagem;
c) Estimação: É a fase na qual os parâmetros do modelo identificado são
estimados. Caso a condição de estacionariedade esteja presente, e
verificadas as possíveis configurações de modelos na fase anterior da
identificação, a etapa de estimação leva em consideração três
aspectos a parcimômia do modelo, as condições de estacionariedade e
de invertibilidade e a quantidade do ajuste (ENDERS, 1995);
d) Verificação ou Diagnóstico: é feita através da análise de resíduos, para
saber se o modelo é adequado para os objetivos, por exemplo, de
realizar previsões. Na verificação da correta especificação do modelo
ARIMA (p,d,q) ou SARIMA (p,d,q) (P,D,Q), analisa-se o termo aleatório
tε , que deve apresentar as características de um ruído branco.
Caso o modelo não seja adequado o ciclo é repetido, voltando-se à fase
de identificação. Um procedimento muitas vezes utilizado é identificar vários
modelos que são estimados e verificados. A fase crítica é a identificação, sendo
possível que vários pesquisadores identifiquem modelos diferentes para a mesma
série temporal.

41
A notação de operadores, alguns já comentados na sub-seção (3.4.2),
será muito usada neste capítulo, sendo que para Morettin e Toloi (2006) estes
operadores são:
a) operador translação para o passado, definido por:
;;1 mttm
tt ZZBZBZ −− ==
b) operador translação para o futuro, definido por:
;;1 mttm
tt ZZFZFZ ++ ==
c) operador diferença já definido antes,
( ) ;11 tttt ZBZZZ −=−=∆ −
Segue-se que:
B−=∆ 1 ; e
d) operador soma, denotado por S e definido por:
( )∑∞
=−− +++=++==
0
21 ;...1...
jtttjtt ZBBZZZSZ
do que segue:
( ) ;1 11ttt ZZBSZ −− ∆=−=
ou seja, 1−∆=S ;
3.7.2 Modelos Auto-Regressivos - AR(p)
São modelos cuja característica principal é que em lugar das variáveis
independentes o processo utilizar-se-á dos valores prévios da serie temporal para
estimação do modelo. Neste caso, a serie temporal Z (t) é descrita somente pelos

42
tptpttt aZZZZ ++++= −−−~...~~~
2211 φφφ
( ) tt aZB =~φ
ttt aZZ += −1~~ φ
0;...2211 >+++= −−− jpjpjjj ρφρφρφρ
qtqttt aaaZ −− −−−+= θθµ ...11
seus valores realizados e pelos termos aleatórios. No modelo Auto-Regressivo (AR),
o comportamento de uma variável é explicado pelo seu próprio passado. Seja at um
processo puramente aleatório com média µ e variância 2aσ . Um processo Zt é
chamado de processo autoregressivo de ordem p, ou AR(p), se
(3.48)
Reescrevendo-se o modelo em termos de operador atraso, temos o
operador autoregressivo de ordem p:
p
p BBBB φφφφ −−−−= ...1 221 (3.49)
Então pode-se escrever:
(3.50)
O caso mais simples de um modelo auto-regressivo é o de ordem p = 1,
ou seja, um AR(1) dado por:
(3.51)
A função de autocorrelação de um modelo AR(p) é dada por:
(3.52)
3.7.3 Modelo de Médias Móveis - MA(q)
Nestes modelos, a serie temporal Z (t) é resultado da combinação linear
dos choques aleatórios (ruídos brancos) ocorridos no período corrente t e em
períodos anteriores. Seja at um processo puramente aleatório com média µ e
variância 2aσ . Um processo Zt é chamado de média móveis de ordem q, ou MA(q),
se:
(3.53)

43
ttq
qt aBaBBBZ )()...1(~ 221 θθθθ =−−−=
( ) )...1( 221
qq BBBB θθθθ −−−=
ouaaZ ttt ;~1−−= θ
.)1(~tt aBZ θ−=
⎪⎪⎪⎪
⎩
⎪⎪⎪⎪
⎨
⎧
=
=⎟⎟⎠
⎞⎜⎜⎝
⎛+−
>
=
∑
∑
=
−
=+
01
;,...1
,0
0
2
0
kse
qkse
qkse
q
jj
kq
jjkjk
k
θ
θθθρ
O processo MA(q) pode ser expresso usando-se o operador atraso da
seguinte maneira:
(3.54)
onde:
(3.55)
É o operador de médias móveis de ordem q.
O caso mais simples de um modelo de médias móveis é o de ordem q =
1, ou seja, um MA(1) dado por:
(3.56)
(3.57)
A função de autocorrelação de um modelo MA(q) é dada por:
(3.58)
3.7.4 Modelos Auto-Regressivos e de Médias Móveis - ARMA (p,q)
Para este modelo, a serie temporal Z(t) é função de seus valores
históricos e pelos choques aleatórios corrente e passados. Os modelos auto-
regressivos são bastante populares em algumas áreas, como em Economia, onde é
natural pensar o valor de alguma variável no instante t como função de valores
defasados da mesma variável.

44
qtqttptpttt aaaZZZZ −−−−− −−−++++= θθφφφ ...~...~~~112211
( ) ( ) tt aBZB θφ =~
11 −= jj ρφρ
ttttt ZZBZZW ∆=−=−= − )1(1
( ) ( ) tt aBWB θφ =
Segundo Morettin e Toloi (2006) para muitas séries na encontradas na
prática, se quisermos um modelo com um número não muito grande de parâmetros,
a inclusão de termos auto-regressivos e de médias móveis é a solução adequada.
A forma da combinação de modelos auto-regressivos e de média móveis
é a seguinte:
(3.59)
Da forma compacta:
(3.60)
Para o caso mais simples de um ARMA(1,1) temos que:
(3.61)
3.8 Modelos não Estacionários
Os modelos estudados na seção 3.7 são apropriados para descrever
séries estacionárias, isto é, que se desenvolvem no tempo ao redor de uma média
comum (MORETTIN e TOLOI, 2006). É comum se encontrar séries econômicas e
financeiras não estacionárias, mas quando diferenciadas tornam-se estacionárias
(não estacionariedade homogênea). Por exemplo, se a série Zt é não estacionária,
mas sua primeira diferença é estacionária, então podemos representá-la como,
(3.62)
3.8.1 Modelos Auto-Regressivos Integrados de Médias Móveis - ARIMA(p,d,q)
Conforme Morettin e Toloi (2006), se a série td
t ZW ∆= for estacionária,
pode-se representar Wt por um modelo ARMA (p,q), ou seja,
(3.63)

45
( ) ( ) td aBZB θφ =∆
( ) ( ) tt aBZB θϕ =
( ) ( ) ( ) dd BBBB )1( −=∆= φφϕ
11 −− −+= tttt aaZZ θ
qtqttdptdpttt aaaZZZZ −−−−+−− −−−++++= θθϕϕϕ ...... 112211
Se Wt for uma diferença de Zt, então Zt é uma integral de Wt, daí dizermos
que Zt segue um modelo auto-regressivo integrado de médias móveis, ou modelo
ARIMA,
(3.64)
de ordem (p,d,q) e escreve-se ARIMA(p,d,q), se p e q são as ordens de ( )Bφ e ( )Bθ ,
respectivamente.
No modelo (3.63) todas as raízes estão fora do círculo unitário. Escrever
(3.64) é equivalente a escrever:
(3.65)
onde ( )Bϕ é um operador auto-regressivo não-estacionário, de ordem p+d, com d
raízes iguais a um (sobre o círculo unitário) e as restantes p fora do círculo unitário,
ou seja,
(3.66)
Alguns casos particulares do modelo (3.64) são:
1. ARIMA(0,1,1): ( ) tt aBZ θ−=∆ 1
2. ARIMA(1,1,1): ( ) ( ) tt aBZB θφ −=∆− 11
3. ARIMA(p,0,0) = AR(p);
4. ARIMA(0,0,q) = MA(q);
5. ARIMA(p,0,q) = ARMA(p,q).
Observe que o caso 1, é muito importante e conhecido como modelo
integrado de média móveis, IMA(1,1),
(3.67)
A forma usual do modelo (3.63), útil para fazer previsões é dado por:
(3.68)

46
onde ( ) dpdp BBBB =
+−−−−= ϕϕϕϕ ...1 221
3.9 Modelos Sazonais
Os modelos que contemplam séries que apresentam autocorrelação
sazonal são popularmente conhecimentos como modelos SARIMA. Esses modelos
contem uma parte não sazonal com parâmetros (p,d,q), e uma outra sazonal com
parâmetros (P,D,Q). Quando se está modelando uma série que apresenta
sazonalidade, o objetivo será estimar a componente sazonal St e,
consequentemente, subtrair a mesma do seguinte modelo:
Zt = Tt + St + at; t = 1,2,…,N (3.69)
Muitas séries temporais contém uma componente periódica sazonal que
se repete a cada s observações (s > 1). Por exemplo, com dados mensais e s = 12
tipicamente espera-se que Zt dependa de Zt-12 e talvez de Zt-24 e assim
sucessivamente. Detalha-se abaixo conforme Morettin e Toloi (2006) as
sazonalidades determinísticas e estocásticas.
I. Sazonalidade Determinística
Para uma dada série Zt, com um comportamento sazonal determinístico
com período s=12, o modelo que pode ser aplicado é:
Zt = tµ + Nt; (3.70)
onde tµ é uma função determinística periódica com 12−− tt µµ = 0 , ou
(1 + B12) = tµ = 0 (3.71)
e Nt é um processo estacionário que pode ser modelado por um ARMA(p,q).
Portanto, Nt satisfaz a equação:

47
( )Bφ Nt = ( )Bθ at (3.72)
Sendo assim, para um modelo sazonal determinístico tem-se:
(1 - B12)Zt = (1 - B12) tµ + (1 - B12)Nt (3.73)
e de acordo com (3.71), tem-se:
(1 - B12)Zt = (1 - B12)Nt (3.74)
Substituindo (3.72) em (3.74), obtem-se:
( )Bφ (1 - B12)Zt = ( )Bθ (1 - B12)at ou (3.75)
( )Bφ Wt = ( )Bθ (1 - B12)at (3.76)
onde Wt = (1 - B12)Zt
II. Sazonalidade Estocástica
No modelo (3.70), considerando tµ como um processo estocástico, tem-
se:
(1 - B12) tµ = Yt; (3.77)
onde Yt é um processo estacionário.
Aplicando o operador (1 - B12) à equação (3.77), obtêm-se:
(1 - B12)Zt = (1 - B12) tµ + (1 - B12) Nt (3.78)
então:
Yt e Nt são processos estacionários que podem ser modelados por um ARMA(p, q),
com:
( )BYφ Yt = ( )BYθ at e (3.79)

48
( ) ( ) ,tt aBaB θϕ =
( ) ,1 1212
DD B−=∆
( ),1 1212 B−=∆
( ) ttD aBZB 1212
12 Θ=∆Φ
( ) ,1 12121
12 Pp BBB Φ−−Φ−=Φ K
( ) ,1 12121
12 QQ BBB Θ−−Θ−=Θ K
( )BNφ Nt = ( )BNθ tε (3.80)
onde at e tε são ruídos brancos independentes.
Pode-se demonstrar que a equação (3.78) é equivalente a:
( )( ) ( ) tQ
QtDP
F aBBZBBB 12121
1212121 ...11...1 Θ−−Θ−=−Φ−−Φ− (3.81)
(3.82)
que é denominado modelo sazonal puro, onde:
(3.83)
é o operador auto-regressivo sazonal de ordem P, estacionário;
(3.84)
é o operador de médias móveis sazonal de ordem Q, invertível;
(3.85)
é o operador diferença sazonal:
(3.86)
e D indica o n´umero de “diferenças sazonais”.
Se o processo at da equação (3.82) satisfaz um modelo ARIMA(p,d,q),
(3.87)

49
12−Θ−= ttt aaZ
,12 ttt aZZ +Φ= −
,1 ttt aZZ += −φ
( ) ,1 1q
q BBB θθθ −−−= K
( ) ,1 1p
p BBB φφφ K−−=
( ) ( )( ) ( ) ( ) ( ) ,11 121212tt
dD aBBZBBBB Θ=−−Φ θφ
onde ' ( ) ( ) ( )BBB dφϕ −= 1 e at é um processo de ruído branco. Então demonstra-se
que Zt satisfaz o modelo:
(3.88)
onde:
(3.89)
é o operador AR(p) não sazonal e:
(3.90)
é o operador MA(q) não sazonal.
O modelo (3.88) é um SARIMA(p,d,q)x(P,D,Q)12, isto é, um modelo
ARIMA sazonal multiplicativo.
Existe uma maneira mais simples de se “construir” modelos sazonais. Do
mesmo modo que podemos modelar uma série Zt, observada mês a mês, por um
modelo ARIMA, por exemplo,
(3.91)
pode-se modelar uma associação ano a ano na série Zt a partir de um modelo
ARIMA sazonal, da seguinte forma:
(3.92)
que corresponde a equação (3.91).
Do mesmo modo, pode-se considerar um modelo de médias móveis
sazonais, como:
(3.93)

50
3.10 Estimação dos Parâmetros de Modelos ARIMA
Após identificar a ordem dos parâmetros de um modelo é necessário
verificar se estes são significativos. A hipótese a ser testada para um modelo MA(q),
por exemplo, é a seguinte:
H0: θ = 0, o parâmetro não é significativo;
H1: θ ≠ 0, o parâmetro é significativo.
Considere um modelo MA(1)
11 −−= ttt aaZ θ
se θ = 0, este parâmetro não terá significância nenhuma para o modelo, pois o
mesmo se reduziria ao erro. Rejeita-se a hipótese de nulidade quando o p-valor for
menor que o nível de significância α , geralmente adota-se α =0,05. Quando isto
ocorre, pode-se passar a próxima fase que é a análise dos resíduos, fase
fundamental na modelagem de Box e Jenkins.
3.11 Diagnóstico de Modelos ARIMA
Após identificar a ordem e estimar eficientemente os parâmetros de um
modelo é necessário verificar sua adequação antes de utilizá-lo, por exemplo, para
fazer previsões. Por isso é necessário verificar se os resíduos são ruído branco, isto
é, observa-se se os resíduos do modelo apresentam média 0 (zero) e variância
constante.
3.11.1 Teste de Box-Pierce (Ljung e Box)
Esta estatística é utilizada para testar todas as autocorrelações dos erros
do modelo e não apenas o seu primeiro lag. Quanto maior o seu valor, maior será a
autocorrelação.
Considere o seguinte teste de hipóteses:

51
ttt aZZ += −1φ
( ) ( ) ( )∑=
−+=
1 2ˆ2
jmj
jnr
nnKQ
H0: 0=ρ os resíduos do modelo não são auto-correlacionados;
H1: 0≠ρ os resíduos do modelo são auto-correlacionados.
Sob a hipótese nula (H0), a auto-correlação amostral é aproximadamente,
normalmente distribuída com média zero e variância 1/n. O teste de Ljung-Box-
Pierce pode ser usado para testar a significância de auto-correlações em lags acima
de ordem m.
Sob a hipótese H0: 021 ==== mρρρ K , Q tem distribuição qui-quadrado
com m graus de liberdade. Rejeita-se a hipótese de nulidade ao nível de
significância α se Q 2,αχm≥ ou se o p-valor do teste for menor que o nível de
significância ®. Se o modelo for apropriado a estatística:
(3.94)
onde jr̂ é a auto-correlação amostral dos resíduos, terá aproximadamente
distribuição 2χ com K-p-q graus de liberdade. Em geral basta utilizar as 10 ou 15
primeiras jr̂ .Morettin e Toloi (2006).
Se a hipótese de nulidade não for rejeitada, isto implica que os resíduos
do modelo que está sendo testado não são auto-correlacionados, ou seja, eles
apresentam características de ruído branco. Isto é, os resíduos do modelo se
distribuem aproximadamente segundo uma normal com média 0 (zero) e variância
constante (µ = 0 e var = 2aσ ).
Esta é a principal fase da modelagem de Box e Jenkins. Suponha o
modelo AR(1):
e seja 6.0=φ sendo altamente significativo, ou seja, p-valor=0,000. Suponha que,
apesar de que o modelo tenha se ajustado bem aos dados e apresente seu

52
parâmetro auto-regressivo significativo, se este apresenta os resíduos auto-
correlacionados, deve-se voltar a fase de identificação do modelo, pois ele não será
adequado para fazer previsões, por exemplo.
3.12 Regressão Linear Simples
O termo regressão é usado para designar a expressão de um variável
dependente (Y) em função de outra (X), considerada independente. Diz-se
regressão de Y sobre X. Se a relação funcional entre elas é expressa por uma
equação de 1o grau, cuja representação geométrica é uma linha reta, a regressão é
dita linear.
Postulada a existência de uma relação linear entre duas variáveis, pode-
se representar aquele conjunto de pontos pela equação da reta: iiY βα += que
expressa o valor de Y em função de X, onde:
X: é a variável dependente ou regredida, ou resposta;
Y: é a variável independente, ou regressora ou explanatória;
α e β são constantes, α é o intercepto e expressa o valor de Y quando X é zero e
β é o coeficiente de regressão, coeficiente angular ou inclinação da reta.
O problema consiste em estimar os parâmetros α e β para que se
conheça a equação da reta. Se a é uma estimativa de α e b uma estimativa de β ,
a equação é estimada por ii bXaY +=ˆ Dizemos então que o problema consiste em
ajustar uma regressão linear simples, isto é, a equação de uma reta ajustada aos
dados.
3.12.1 Estimação de Parâmetros
Suponha que para cada uma das variáveis (X e Y), temos N valores.
Cada valor Xi de X corresponde a um valor Yi de Y segundo a equação:

53
∑ ∑= ==+
n
i
n
i ii YXn1 1 ,
2ˆˆ βα
∑∑ ∑ == ==+
n
i iin
i
n
i ii YXXX1 ,1 1
2ˆˆ βα
,ˆˆ XY βα −=
.,,2,1, niXY iii K=−−= βαε
iii XY εβα ++= (3.95)
iε é chamado de desvio ou erro aleatório com média zero (µ = 0) e desvio padrão
igual a um (σ = 1).
A teoria mostra que a melhor maneira de estimar α e β é por meio do
Método dos Mínimos Quadrados (MQ), o qual consiste em minimizar a soma de
quadrados dos desvios ii YY ˆ− . Sendo ii YY ˆ− a diferença entre o valor observado e o
estimado pela equação de regressão para cada observação, procura-se, então,
estimar α e β , de tal modo que ( )2iˆY∑ − iY seja mínima. O MQ consiste em
encontrar os valores de α e β , que minimizam a soma dos erros, dados por:
(3.96)
Obtem-se, então, a quantidade de informação perdida pelo modelo ou
soma dos quadrados dos erros (ou desvios ou resíduos).
( ) ( ){ }2
1
2, ii
n
ii XYSQ βαεβα +−==∑
=
(3.97)
Para cada valor de α e β teremos um resultado para essa soma de
quadrados, e a solução de mínimos quadrados é aquela que torna essa soma
mínima. Tem-se, então, o problema de encontrar o mínimo de uma função de duas
variáveis, α e β no caso. Derivando em relação a α e β e igualando a zero,
observa-se que as soluções α̂ e β̂ devem satisfazer:
(3.98)
(3.99)
estas equações produzem:
(3.100)

54
( )XXYXXYY iii −+=+−= βββ ˆˆˆˆ
21
21ˆ
XnX
YXnYXn
i i
n
i ii
−
−=∑∑
=
=β
,,,1,ˆˆˆ niXY ii K=+= βα
( ) ,,,2,1,ˆˆ niXX ii K=+= βαµ
(3.101)
Substituindo nas equações (3.98) e (3.99), teremos o estimador para a
média µ (X), dados por:
(3.102)
que será indicado por:
(3.103)
ou, ainda, por:
(3.104)

55
4. APLICAÇÃO 4.1 Introdução
A série em estudo refere-se a quantidade de cheques compensados
emitidos no Brasil no período de janeiro de 1994 a dezembro de 2005, totalizando
144 observações. Porém, para o estudo desta série foram utilizadas apenas 138
observações, ou seja, no período de janeiro de 1994 a junho de 2005, com o
objetivo de fazer previsões com os seis meses restantes. Os dados a respeito desta
série podem ser encontrados no site do Banco Central (www.bcb.gov.br).
Neste capítulo será apresentada uma análise da série cheques
compensados, tendo como principais enfoques:
1. O comportamento da série;
2. Construção de modelos para a série;
3. Comparação e escolha do melhor modelo.
4.2 Análise Exploratória
Verifica-se a partir da Figura 2 o comportamento da série cheques
compensados, onde se pode observar graficamente que existe uma tendência
negativa na série, isto é, no decorrer do tempo (no período estudado) a quantidade
de cheques compensados no Brasil reduziu. Mais adiante será apresentado um
teste estatístico para confirmar se a série apresenta realmente alguma tendência ou
não.

56
FIGURA – 2 - Número de Cheques Compensados no Brasil (1994-2005)
4.2.1 Estatística Descritiva
A Tabela 3 mostra as estatísticas descritivas da série cheques
compensados no período de janeiro de 1994 a junho de 2005. Neste período,
verifica-se que a média de cheques compensados foi de 230610127 ± 49445990.
Onde no mínimo foram compensados 153792702 e no máximo 414049721 cheques.
TABELA – 3 - Estatísticas da Série Cheque Compensado
Estatísticas Quantidades
Média 230610127 Mínimo 153792702 Maximo 414049721
Desvio Padrão 49445990
A Figura 3 mostra a média de cheques compensados para o período de
janeiro de 1994 a dezembro de 2005. Pode-se verificar que existe um decaimento na
média dos cheques compensados à medida que o tempo passa, este
comportamento reforça ainda mais a idéia de que a série apresenta tendência, ou
seja, ela é não estacionária. Para ratificar esta hipótese, será feito o teste da
seqüência de Wald-Wolfowitz.

57
FIGURA – 3 - Número Médio de Cheques Compensados no Brasil (1994-2005)
A Figura 4 apresenta o histograma da série em estudo, sendo que o
objetivo desta figura é verificar o comportamento da distribuição da série cheques
compensados. Na próxima seção será apresentado o teste de Jarque-Bera para
verificar se a série se distribui normalmente ou não.
FIGURA – 4 - Histograma da Série Cheques Compensados no Brasil (1994-2005)
4.3 Teste Não-Paramétrico de Seqüência de Wald-Wolfowitz
Para verificar a estacionariedade da série, utilizou-se o teste não-
paramétrico de seqüência de Wald-Wolfowitz mostrado a seguir:

58
1o passo: Encontra-se a mediana = 221407447 1
2o passo: Encontra-se A = valores maiores que a mediana: n1 = 69;
3o passo: Encontra-se B = valores menores que a mediana: n2 = 69;
4o passo: Encontra-se r = número total de seqüências: 34;
5o passo: Faz-se o seguinte Teste de Hipótese
H0 = a série não apresenta tendência;
H1 = a série apresenta tendência.
Como a estatística teste é T1 = número total de seqüências e n1 e n2 são
maiores que 20 observações, pode-se utilizar a aproximação normal, onde
T1 ( )2,σµN≅ . Assim, calcula-se o valor de Z conforme mostrado a seguir:
67113895221
.2 21 =+=+=N
nnµ
85,52609028
89354448)1(
).2(.22
2121 ==−
−=
NNNnnnn
σ
15,685,5
7034=
−=
−=
σµr
Z
Observa-se que o valor de Z=6,15 apresenta probabilidade altamente
significativa ( valorp − < 0,0001) na tabela normal padrão (Bussab e Morettin, 2004),
portanto, rejeita-se a hipótese de nulidade ao nível de 5%. Isto é, a série cheques
compensados apresenta tendência.
4.4 Teste de Normalidade de Jarque-Bera (JB)
O teste de JB, a normalidade ou não dos dados, a partir do coeficiente de
curtose e assimetria, assim tem-se que:
1 Usa-se a mediana como referência para o teste, pois ela divide o conjunto de dados em duas partes iguais e por sua robustez em relação aos efeitos dos valores extremos (outliers).

59
( ) 86,4224
3868,16
242,113824
)3(6
2222
=⎥⎦
⎤⎢⎣
⎡ −+×=⎥
⎦
⎤⎢⎣
⎡ −+=
CAnBJ
Verifica-se na tabela da estatística qui-quadrado (BUSSAB e MORETTIN,
2004) com 2 graus de liberdade o valor de 9,210 para o nível de significância de α =
0; 01. Portanto, como o valor da estatística JB é superior ao valor crítico encontrado,
não rejeita-se a hipótese de normalidade.
4.5 Modelos e Previsão
Nesta seção é realizada a modelagem da série cheques compensados.
Inicialmente será feita a decomposição da série para se verificar o comportamento
da mesma, sem a tendência e sem a sazonalidade. Em seguida, mostrar-se-á a
modelagem da série através de alguns modelos exponenciais e consequentemente
é escolhido o modelo que melhor se aproprie a série estudada.
Os métodos automáticos são provavelmente os mais utilizados para
suavizar séries temporais discretas e prever valores futuros. A razão deste fato é a
simplicidade dos métodos e a eficiência computacionais, além de boa precisão.
Essas técnicas tornaram-se muito populares como métodos de previsão para uma
grande variedade de séries temporais.
4.5.1 Modelo de Decomposição
O objetivo principal de decompor a série é observar o comportamento da
mesma sem as componentes tendência e sazonalidade. Como foi visto
anteriormente a série em estudo apresenta sazonalidade e uma breve tendência. Na
decomposição, a série será modelada sem estes componentes, com o objetivo de se
observar o comportamento da mesma sem estes fatores.
I. Modelo Aditivo
A Figura 5 apresenta o resultado gráfico da série após a aplicação do
método de decomposição aditivo, mostrando o comportamento da série cheques

60
compensados e seus dados sem as componentes, tendência e sazonalidade. Nela
pode-se observar que a série em estudo sem a componente tendência fica
praticamente estacionária. A mesma série sem as componentes tendências e
sazonalidade mostram que a série fica estacionária e sem picos sazonais. O que
implica, teoricamente, que o modelo de decomposição aditivo pode se ajustar bem
aos dados desta série.
FIGURA – 5 - Gráficos da Decomposição da Série Cheques Compensados (Modelo Aditivo).
A Figura 6 mostra o comportamento da série com base no modelo
estimado de Decomposição Aditivo e dos valores de tendência da série. A linha de
cor preta com os pontos no formato de bola corresponde aos dados originais da
série. A linha vermelha com os pontos na forma de um quadrado são os valores
ajustados segundo o modelo de Decomposição Aditivo. Na linha azul com pontos
em forma de triângulo, estão os valores de previsão obtidos a partir do modelo em
teste e a linha verde, corresponde a linha de tendência do modelo. Graficamente
pode-se verificar que os dados foram bem ajustados a partir deste modelo.

61
FIGURA – 6 - Gráfico da Série Ajustada por Decomposição e a Linha de Tendência (Modelo Aditivo)
A Tabela 4 mostra os valores de previsão da série Cheques
Compensados, a partir do modelo de decomposição aditivo para 6 meses. Observa-
se que o Erro Percentual Médio de Previsão (EPM) para este modelo foi de 1,61%.
A equação de decomposição modelo aditivo é dada por:
Zt = Tt + St + at (4.2)
A partir das estimativas destas componentes encontrou-se a seguinte
equação:
Zt = 306101847 - 1083340t + ∑ =
12
1j jα Djt + at: (4.3)
A partir da equação 4.3 encontrou-se os valores de previsão para os
meses de julho de 2005 à dezembro de 2005, mostrados na Tabela 4.
TABELA – 4 - Valores Observados e Esperados do Modelo de Decomposição Aditivo
Período (t) Mês/Ano Observados Previsão Erro Percentual
139 Jul/05 154405910 156708342 -1,49 140 Ago/05 170711332 158300388 7,27 141 Set/05 157741350 148999714 5,54 142 Out/05 157799414 157515119 0,18

62
Período (t) Mês/Ano Observados Previsão Erro Percentual
143 Nov/05 157440578 151379340 3,85 144 Dez/05 162271068 171491216 -5,68
Erro Percentual Médio 1,61
A Tabela 5 mostra os valores dos índices de sazonalidade da série
cheques compensados, onde pode-se observar que o maior índice encontra-se no
12º. período, ou seja, no mês de dezembro, onde existe um aumento na quantidade
de cheques compensados no Brasil devido as compras de final de ano.
TABELA – 5 - Modelo de Decomposição Aditivo
Índices de Sazonalidade
Período Índices ( jα )
1 6692685 2 -22672375 3 633334 4 -7562891 5 -233724 6 -4396111 7 1190818 8 3866204 9 -4351129
10 5247617 11 195177 12 21390394
II. Modelo Multiplicativo
A Figura 7 apresenta o resultado gráfico da série após a aplicação do
método de Decomposição Multiplicativo, mostrando o comportamento da série
cheques compensados e seus dados sem as componentes tendências e
sazonalidade. Nela pode-se observar que a série em estudo sem a componente
tendência fica praticamente estacionária. A mesma série sem as componentes
tendências e sazonalidade mostra que a mesma fica estacionária e sem picos
sazonais. O que implica, teoricamente, que o modelo de Decomposição
Multiplicativo, também pode se ajustar bem aos dados desta série.

63
FIGURA – 7 - Decomposição da Série Cheques Compensados (Modelo Multiplicativo)
A Figura 8 mostra o comportamento da série com base no modelo
estimado de decomposição multiplicativo e dos valores de tendência da série. A
linha vermelha com os pontos na forma de um quadrado são os valores ajustados
segundo o modelo de Decomposição Multiplicativo. Na linha azul com pontos em
forma de triângulo, estão os valores de previsão obtidos a partir do modelo em teste.
E a linha verde, corresponde a linha de tendência do modelo. Graficamente pode-se
verificar que os dados foram bem ajustados a partir deste modelo.
FIGURA – 8 - Série Ajustada por Decomposição e a Linha de Tendência (Modelo Multiplicativo)

64
A Tabela 6 mostra os valores de previsão da série Cheques
Compensados, a partir do modelo de decomposição multiplicativo para 6 meses.
Observa-se que o Erro Percentual Médio de Previsão (EPM) para este modelo é de
2,69%. A equação de decomposição modelo multiplicativo é dada por:
Zt = Tt * St * at; (4.4)
A partir das estimativas destas componentes encontrou-se a seguinte
equação:
Zt = (306471161 - 1087391 * t) * (∑=
12
1jijj Dα ) * at (4.5)
A partir da Equação 4.5 encontrou-se os valores de previsão para os
meses de julho de 2005 a dezembro de 2005.
TABELA – 6 - Valores Observados e Esperados do Modelo de Decomposição Multiplicativo
Período (t) Mês/Ano Observados Previsão Erro Percentual
139 Jul/05 154405910 156378764 -1,28 140 Ago/05 170711332 156590797 8,27 141 Set/05 157741350 150375919 4,67 142 Out/05 157799414 156298644 0,95 143 Nov/05 157440578 151318048 3,89 144 Dez/05 162271068 162830967 -0,35
Erro Percentual Médio 2,69
A Tabela 7 mostra os valores dos índices de sazonalidade da série
cheques compensados, onde pode-se observar que o maior índice encontra-se no
12º período, ou seja, no mês de dezembro, onde efetivamente existe um aumento
na quantidade de cheques compensados no Brasil, resultado das compras de Natal .
TABELA – 7 - Modelo de Decomposição Multiplicativo
Índices de Sazonalidade
Período Índice( jα )
1 1,03033 2 0,89613 3 1,00435

65
Período Índice( jα )
4 0,96572 5 1,00025 6 0,98277 7 1,00679 8 1,01527 9 0,98189
10 1,02786 11 1,00228 12 1,08636
4.5.2 Alisamento Exponencial Simples
Conforme o Capítulo 3 deste trabalho, o Alisamento Exponencial Simples
é apropriado para séries com tendência ou sazonalidade. A série em estudo
apresenta estas componentes, portanto este método também será mostrado.
A Figura 9 apresenta os dados originais da série Cheques Compensados
com os dados ajustados ao método de Alisamento Exponencial Simples. A linha com
pontos pretos se refere aos dados originais e a linha com pontos vermelhos são os
dados ajustados ao método de Alisamento Exponencial Simples. Na linha verde,
observa-se os valores das previsões do modelo e as linhas azuis, são os intervalos
de confiança para a previsão. Verifica-se neste gráfico, que os dados ajustados por
este método não se adequaram muito bem a série.
A Tabela 8 mostra os valores observados e esperados da série Cheques
Compensados a partir do modelo de alisamento exponencial simples. Nela pode-se
observar que, a partir da constante de alisamento α = 0,322294 foi encontrado um
Erro Percentual Médio De Previsão para este modelo de 3,20%. Verifica-se que este
erro foi tão alto quanto o erro do modelo de Decomposição Multiplicativo. Logo, em
relação ao Erro Percentual Médio de Previsão, este modelo não é adequado.

66
FIGURA – 9 - Série Ajustada por Alisamento Exponencial Simples
TABELA – 8 - Valores Observados e Esperados do Modelo de Alisamento Exponencial Simples
Período (t) Mês/Ano Observados Previsão Erro Percentual
139 Jul/05 154405910 165010611 -6,87 140 Ago/05 170711332 165010611 3,34 141 Set/05 157741350 165010611 -4,61 142 Out/05 157799414 165010611 -4,57 143 Nov/05 157440578 165010611 -4,81 144 Dez/05 162271068 165010611 -1,69
Erro Percentual Médio -3,20
4.5.3 Alisamento Exponencial Duplo-Método de Brow
Este método se utiliza de uma constante de alisamento para os
componentes de nível e tendência da série. Para este método utilizou-se α =
0,777989 e γ = 0,021886, para o nível e a tendência da série em estudo,
respectivamente.
A Figura 10 apresenta os dados originais da série Cheques
Compensados com os dados ajustados ao método de Alisamento Exponencial
Duplo. A linha com pontos pretos se refere aos dados originais e a linha com pontos
vermelhos são os dados ajustados ao método de Alisamento Exponencial Duplo. Na

67
linha verde, observa-se os valores das previsões do modelo e as linhas azuis, são
os intervalos de confiança para a previsão. Verifica-se neste gráfico, que os dados
ajustados por este método aparentemente se ajustam melhor a série que os
modelos anteriores.
FIGURA – 10 - Série Ajustada por Alisamento Exponencial Duplo-Método de Brow.
A Tabela 9 mostra os valores observados e esperados da série Cheques
Compensados a partir do modelo de alisamento exponencial simples. Nela pode-se
observar que, a partir das constantes de alisamento α = 0,777989 e γ = 0,021886
foi encontrado um Erro Percentual Médio de Previsão para este modelo de apenas
0,52%. Em comparação ao Erro Percentual Médio de Previsão dos outros modelos
já mencionados, o método de Brow apresenta-se como o melhor modelo.
TABELA – 9 - Valores Observados e Esperados do Modelo de Alisamento Exponencial Duplo
Período (t) Mês/Ano Observados Previsão Erro Percentual
139 Jul/05 154405910 161837375 -4,81 140 Ago/05 170711332 160724908 5,85 141 Set/05 157741350 159612441 -1,19 142 Out/05 157799414 158499974 -0,44 143 Nov/05 157440578 157387507 0,03 144 Dez/05 162271068 156275040 3,70
Erro Percentual Médio 0,52

68
4.5.4 Alisamento Exponencial de Holt-Winters – HW
Como o método de alisamento exponencial é considerado um
procedimento automático de previsão, não se faz necessário a aplicação de
nenhuma estratégia de modelagem, a menos que se deseje verificar a existência de
tendências ou sazonalidades. Sendo característico do modelo, a grande dificuldade
em se determinar os valores apropriados das constantes de alisamento.
I. Modelo Aditivo
No modelo aditivo, considera-se o fator sazonal aditivo, onde: alfa, gama
e delta são as constantes de alisamento. A Figura 11 mostra a modelagem da série
cheques compensados através da suavização exponencial sazonal de Holt-Winters
modelo aditivo. Observa-se a partir da Figura 11 que o método de HW ajustou-se
bem aos dados da série em estudo.
FIGURA – 11 - Modelo Exponencial de Holt-Winters Aditivo
Mostra-se na Tabela 10 os valores das constantes de alisamento do
modelo de HW aditivo. Foram testadas várias constantes até chegar a estes valores
que se apresentaram com os menores Erros Percentuais Médios De Previsão
(EPM).

69
( ) ( ) ,10,ˆ86,0140,0ˆ <<+−= − DFZZF stttt
( ) ,10),ˆ)(68,0(ˆ320,0 11 <<++−= −−− ATZFZZ ttsttt
,10ˆ)61,0()(390,0ˆ,11 <<+−= −− CTZZT tttt
TABELA – 10 - Constantes de Alisamento do Modelo de Holt-Winters Aditivo
A (Nível) 0,320 B (Tendência) 0,390 D (Sazonal) 0,140
O modelo de Holt-Winters Aditivo é dado por:
Zt = tµ + Tt + Ft + at (4.6)
onde tµ é o nível, Tt a tendência, Ft a sazonalidade e at o erro. Sendo que
as estimativas destes fatores são dadas por:
(4.7)
(4.8)
(4.9)
A Tabela 11 mostra os valores das previsões obtidos a partir da Equação
4.6 para a série cheques compensados para os próximos seis meses. Observe que
este modelo apresentou melhores previsões que os anteriores, sendo que o erro
percentual médio das previsões (EPM) foi bem menor (0,11%).
TABELA – 11 - Winters Aditivo - Previsão do Modelo
Período (t) Mês/Ano Observados Previsão Erro Percentual
139 Jul/05 154405910 164963767 -6,84 140 Ago/05 170711332 163063717 4,48 141 Set/05 157741350 154376065 2,13 142 Out/05 157799414 158736979 -0,59 143 Nov/05 157440578 151666550 3,67 144 Dez/05 162271068 167967101 -3,51
Erro Percentual Médio -0,11
II. Modelo Multiplicativo
O modelo multiplicativo de Holt-Winters considera o fator sazonal como
sendo multiplicativo, enquanto que a tendência permanece aditiva.
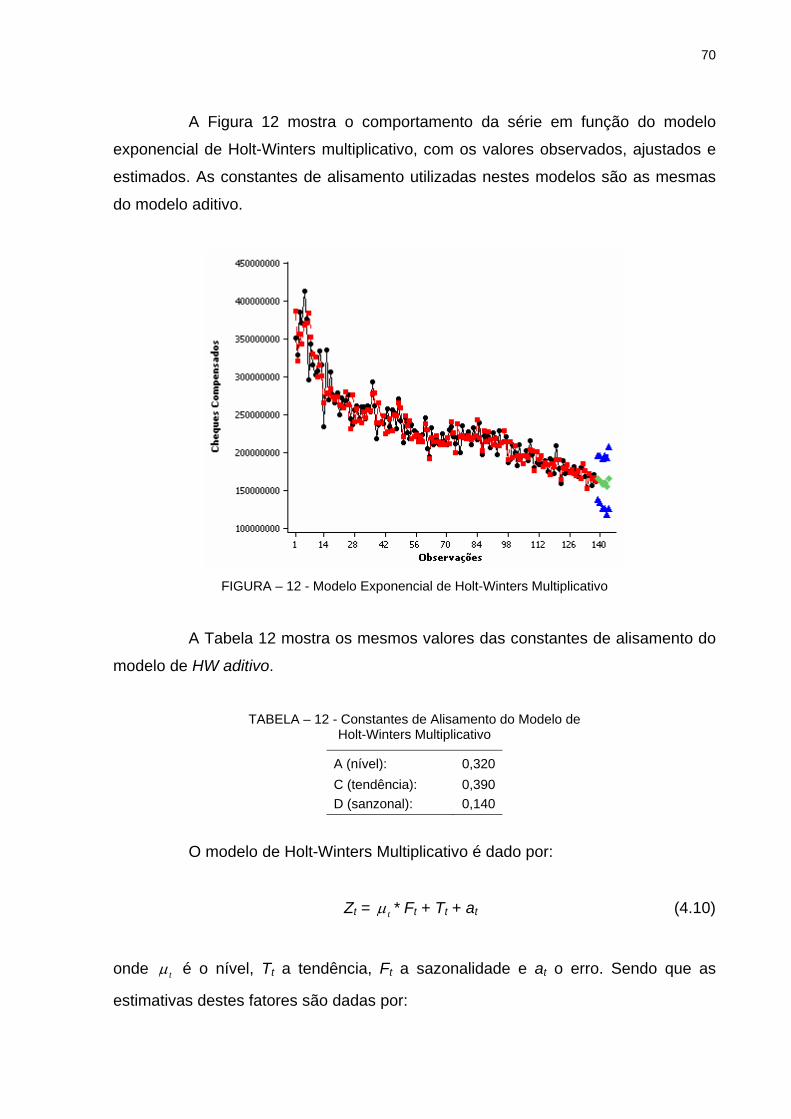
70
A Figura 12 mostra o comportamento da série em função do modelo
exponencial de Holt-Winters multiplicativo, com os valores observados, ajustados e
estimados. As constantes de alisamento utilizadas nestes modelos são as mesmas
do modelo aditivo.
FIGURA – 12 - Modelo Exponencial de Holt-Winters Multiplicativo
A Tabela 12 mostra os mesmos valores das constantes de alisamento do
modelo de HW aditivo.
TABELA – 12 - Constantes de Alisamento do Modelo de
Holt-Winters Multiplicativo
A (nível): 0,320 C (tendência): 0,390 D (sanzonal): 0,140
O modelo de Holt-Winters Multiplicativo é dado por:
Zt = tµ * Ft + Tt + at (4.10)
onde tµ é o nível, Tt a tendência, Ft a sazonalidade e at o erro. Sendo que as
estimativas destes fatores são dadas por:

71
( ) NstFZZF st
t
tt ,,1,ˆ86,0140,0ˆ K+=+⎟⎟
⎠
⎞⎜⎜⎝
⎛= −
( )( ) NstTZFZZ tt
st
tt ,,1,ˆˆ68,0ˆ320,0 11 K+=++⎟⎟
⎠
⎞⎜⎜⎝
⎛= −−
−
( ) ( ) NstFZZT tttt ,,1,ˆ61,0390,0ˆ1 K+=+−= −
(4.11)
(4.12)
(4.13)
A Tabela 13 mostra os valores previstos a partir da Equação 4.10 da série
cheques compensados, segundo o alisamento exponencial de HW multiplicativo,
onde o EPM de previsão para os seis meses foi de 0,52%. Por coincidência o EPM
deste modelo foi o mesmo do modelo de Alisamento Exponencial Duplo.
TABELA – 13 - Winters Multiplicativo - Previsão do Modelo
Período (t) Mês/Ano Observados Previsão Erro Percentual
139 Jul/05 154405910 165294144 -7,05 140 Ago/05 170711332 163032110 4,50 141 Set/05 157741350 157015087 0,46 142 Out/05 157799414 159722290 -1,22 143 Nov/05 157440578 154342054 1,97 144 Dez/05 162271068 165201617 -1,81
Erro Percentual Médio -0,52 4.5.5 Modelos de Box e Jenkins
Como foi salientado no Capítulo 3 deste trabalho, os modelos de Box e
Jenkins são muito utilizados em séries econômicas não estacionárias. Portanto,
nesta seção mostrar-se-á as fases para a escolha do melhor modelo de Box e
Jenkins para a série em estudo.
Como foi verificada anteriormente, a série em estudo apresenta
tendência, ou seja, ela não é estacionária. Portanto, será necessário torná-la,
tomando diferenças na série. A Figura 13 apresenta o gráfico da série com uma
diferença. Pode-se observar a partir da mesma que a série tornou-se estacionária
com apenas uma diferença.
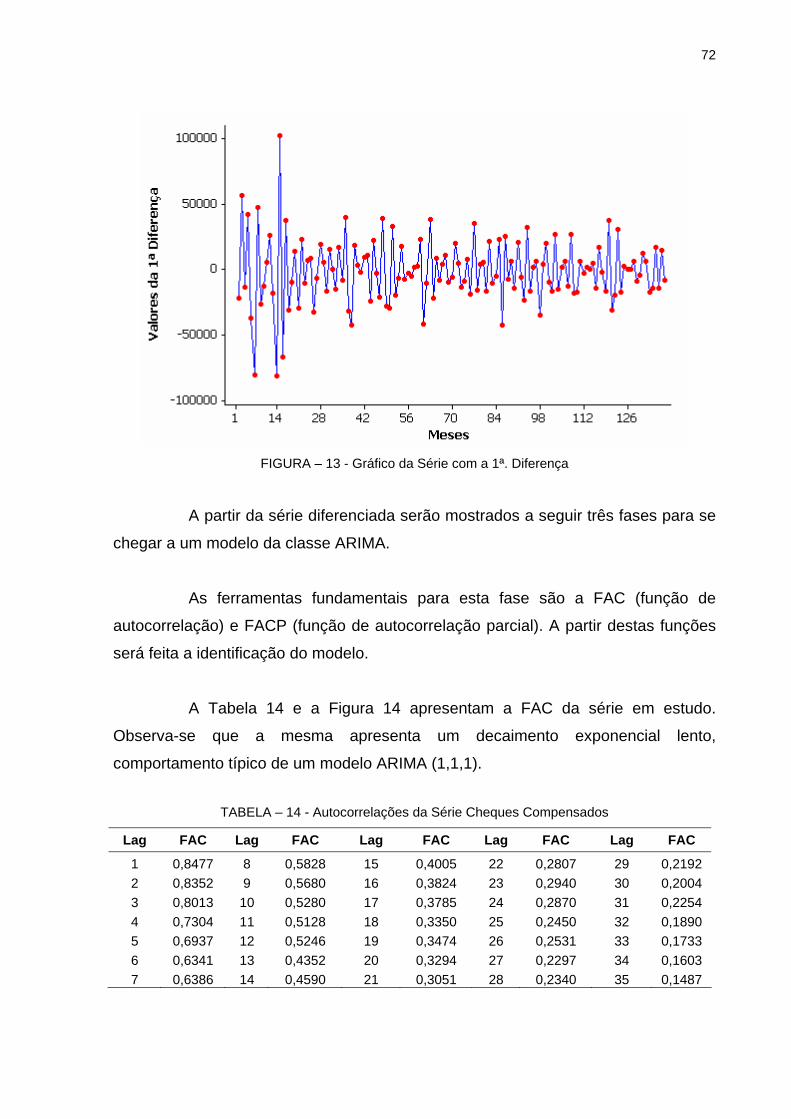
72
FIGURA – 13 - Gráfico da Série com a 1ª. Diferença
A partir da série diferenciada serão mostrados a seguir três fases para se
chegar a um modelo da classe ARIMA.
As ferramentas fundamentais para esta fase são a FAC (função de
autocorrelação) e FACP (função de autocorrelação parcial). A partir destas funções
será feita a identificação do modelo.
A Tabela 14 e a Figura 14 apresentam a FAC da série em estudo.
Observa-se que a mesma apresenta um decaimento exponencial lento,
comportamento típico de um modelo ARIMA (1,1,1).
TABELA – 14 - Autocorrelações da Série Cheques Compensados
Lag FAC Lag FAC Lag FAC Lag FAC Lag FAC
1 0,8477 8 0,5828 15 0,4005 22 0,2807 29 0,2192 2 0,8352 9 0,5680 16 0,3824 23 0,2940 30 0,2004 3 0,8013 10 0,5280 17 0,3785 24 0,2870 31 0,2254 4 0,7304 11 0,5128 18 0,3350 25 0,2450 32 0,1890 5 0,6937 12 0,5246 19 0,3474 26 0,2531 33 0,1733 6 0,6341 13 0,4352 20 0,3294 27 0,2297 34 0,1603 7 0,6386 14 0,4590 21 0,3051 28 0,2340 35 0,1487

73
FIGURA – 14 - Função de Autocorrelação da Série Quantidade de Cheques Compensados
A partir da Tabela 15 e da Figura 15 verifica-se que a FACP da série
apresenta senóides amortecidos após o “lag”1, comportamento típico de um modelo
ARIMA(1,1,1). Portanto, depois da análise da FAC e da FACP da série, na próxima
fase serão apresentadas as estimativas para os modelos ajustados a série cheques
compensados.
TABELA – 15 - Autocorrelações Parciais da Série Cheques Compensados.
Lag FACP Lag FACP Lag FACP Lag FACP Lag FACP
1 0,8477 8 -0,0337 15 -0,1249 22 0,0150 29 0,0176 2 0,4142 9 0,0296 16 0,0908 23 0,0851 30 -0,0753 3 0,1520 10 -0,1149 17 0,1202 24 0,0421 31 -0,0013 4 -0,1265 11 0,0726 18 -0,0633 25 -0,0622 32 -0,0661 5 -0,0376 12 0,1790 19 -0,0191 26 -0,1149 33 0,0382 6 -0,0676 13 -0,2477 20 0,0870 27 0,0766 34 -0,0460 7 0,2186 14 0,0556 21 -0,1211 28 0,0893 35 -0,0184

74
FIGURA – 15 - Função de Autocorrelação Parcial da Série Quantidade de Cheques Compensados
O procedimento ARIMA ajusta um modelo com um certo número de
parâmetros e testes para a significação destes parâmetros. Isto significa que testa
se os parâmetros são zero (hipótese nula, H0) ou diferente de zero (hipótese
alternativa, H1). Se o p-valor (p-value), que é a probabilidade de se obter amostras
com valores tão extremos quanto o observado dado H0 verdadeira, for maior que o
nível de significância (geralmente adota-se α = 0; 05), não rejeita-se H0.
A seguir serão mostrados os resultados de alguns modelos de Box e
Jenkis ajustados a série cheques compensados.
4.5.6 Modelos Ajustados
I. ARIMA (1,1,1)
• Estimação
A Tabela 16 apresenta os valores dos parâmetros estimados para o
modelo ARIMA (1,1,1), onde pode-se observar que o parâmetro auto-regressivo
AR(1), não foi significativo (p-valor=0,169), portanto deverá ser excluído do modelo.
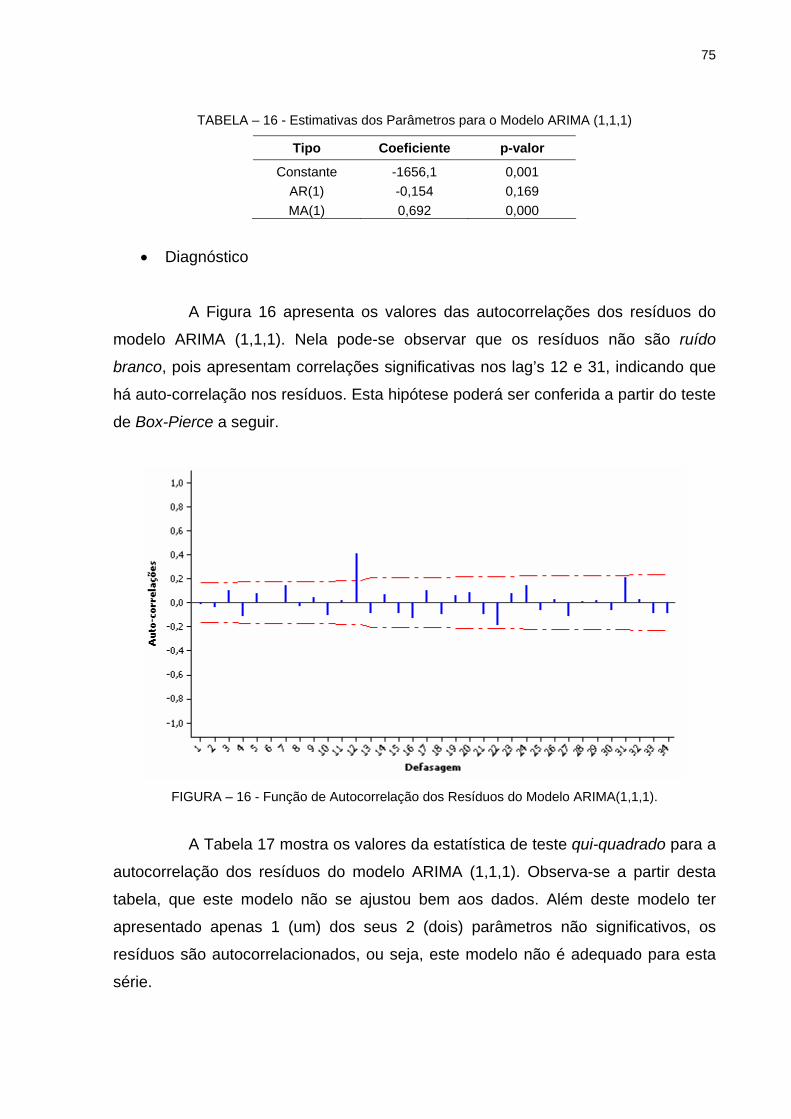
75
TABELA – 16 - Estimativas dos Parâmetros para o Modelo ARIMA (1,1,1)
Tipo Coeficiente p-valor
Constante -1656,1 0,001 AR(1) -0,154 0,169 MA(1) 0,692 0,000
• Diagnóstico
A Figura 16 apresenta os valores das autocorrelações dos resíduos do
modelo ARIMA (1,1,1). Nela pode-se observar que os resíduos não são ruído
branco, pois apresentam correlações significativas nos lag’s 12 e 31, indicando que
há auto-correlação nos resíduos. Esta hipótese poderá ser conferida a partir do teste
de Box-Pierce a seguir.
FIGURA – 16 - Função de Autocorrelação dos Resíduos do Modelo ARIMA(1,1,1).
A Tabela 17 mostra os valores da estatística de teste qui-quadrado para a
autocorrelação dos resíduos do modelo ARIMA (1,1,1). Observa-se a partir desta
tabela, que este modelo não se ajustou bem aos dados. Além deste modelo ter
apresentado apenas 1 (um) dos seus 2 (dois) parâmetros não significativos, os
resíduos são autocorrelacionados, ou seja, este modelo não é adequado para esta
série.

76
TABELA – 17 - Teste de Ljung-Box para a Autocorrelação dos Resíduos do Modelo a ARIMA (1,1,1)
Lag 12 24 36 48
χ2 (Estatística do Teste) 34,3 57,2 75,2 97,1 Graus de Liberdade 9 21 33 45 P-Valor <0,001 <0,001 <0,001 <0,001
II. ARIMA (0,1,1)
• Estimação
A Tabela 18 apresenta os valores dos parâmetros estimados para o
modelo ARIMA (0,1,1), onde observar-se que o parâmetro de médias móveis MA(1),
foi altamente significativo (p-valor=0,000).
TABELA – 18 - Estimativas dos Parâmetros para o Modelo ARIMA (0,1,1)
Tipo Coeficiente p-valor
Constante -1428 0,001 MA(1) 0,749 <0,001
• Diagnóstico
A Figura 17 apresenta os valores das autocorrelações dos resíduos do
modelo ARIMA (0,1,1). Nela pode-se observar que os resíduos não são ruído
branco, pois apresentam correlações significativas também nos lag’s 12 e 31,
indicando que há auto-correlação nos resíduos. Esta hipótese poderá ser conferida a
partir do teste de Box-Pierce a seguir.
FIGURA – 17 - Função de Autocorrelação dos Resíduos do Modelo ARIMA (0,1,1)

77
A Tabela 19 mostra os valores da estatística de teste qui-quadrado para a
autocorrelação dos resíduos do modelo ARIMA (0,1,1). Este modelo, também
chamado de IMA, integrado de médias móveis, apresenta um parâmetro de média
móvel significativo, porém,como pode-se observar a partir da tabela, os resíduos
deste modelo também são autocorrelacionados, o que compromete a adequação
deste modelo para a série em estudo. Todos os lag’s foram altamente significativos,
portanto rejeita-se a hipótese de nulidade de que os resíduos são ruído branco.
TABELA – 19 - Teste de Ljung-Box para a Autocorrelação dos
Resíduos do Modelo a ARIMA (0,1,1)
Lag 12 24 36 48
χ2 (Estatística do Teste) 38,9 63,0 81,0 105,9 Graus de Liberdade 10 22 34 46 P-Valor <0,001 <0,001 <0,001 <0,001
III SARIMA (2,1,0)x(0,1,1)36
Antes da aplicação do modelo sazonal, foi necessário fazer uma
transformação de Box-Cox na série. Como foi visto anteriormente, todos os modelos
de Box e Jenkins testados, não apresentaram característica de ruído branco, ou
seja, os resíduos destes modelos são alto-correlacionados. Portanto, para obter uma
distribuição dos dados mais simétricas e próxima de uma normal, efetuou-se a
transformação de Box-Cox.
Para confirmar que a série precisaria passar por uma transformação,
dividiu-se a série em doze grupos e em seguida, calculou-se a média e o desvio
padrão de cada grupo. Feito isto, plotou-se um gráfico com essas medidas.
A Figura 18 mostra os valores da média e do desvio padrão dos 12
grupos da série em estudo. Nela pode-se observar que o desvio padrão é
proporcional a média, indicando que uma transformação de Box-Cox pode ser muito
adequada.

78
FIGURA – 18 - Gráfico da Média x o Desvio Padrão da Série.
Os dados da série foram transformados usando λ =-0.5, ou seja, foi feita
a transformação do inverso da raiz quadrada da série original. Isto é, utilizou-se a
transformação
tt Z15,0 =⇒−= ωλ
Os valores da série transformada estão na Tabela A.2. Depois dos dados
transformados, a nova série foi multiplicado por 1000 (mil) para facilitar a
modelagem e análise dos dados.
• Estimação
A Tabela 20 mostra os parâmetros estimados para o modelo SARIMA
(2,1,0)(0,1,1)36. Nela pode-se observar que todos os parâmetros, exceto a constante,
foram altamente significativos para o modelo. Como somente a constante não foi
significativa, será estimado um novo modelo retirando a constante do mesmo.
TABELA – 20 - Estimativas dos Parâmetros para o
Modelo SARIMA (2; 1; 0)(0; 1; 1)36
Tipo Coeficiente p-valor
Constante -0,000162 0,441 AR(1) -0,9577 0,000 AR(2) -0,6718 0,000
SMA(1) 0,3782 0,000

79
• Diagnóstico
A Figura 19 apresenta os valores das autocorrelações dos resíduos do
modelo SARIMA (2,1,0)(0,1,1)36. Nela pode-se observar que os resíduos são ruído
branco, pois não apresentam correlações significativas em nenhum lag, indicando
que não há auto-correlação nos resíduos. Esta hipótese poderá ser conferida a partir
do teste de Box-Pierce a seguir.
FIGURA – 19 - Função de Autocorrelação dos Resíduos do Modelo SARIMA(2; 1; 0)(0; 1; 1)36
A Tabela 21 mostra os valores da estatística de teste qui-quadrado para a
autocorrelação dos resíduos do modelo SARIMA (2,1,0)(0,1,1)36. Nela verifica-se que
os resíduos deste são Ruído Branco, pois o “p-valor” foi bem maior que o nível de
significância (α = 0,05) em todos os lag’s. Logo, este modelo ´e apropriado para a
série em estudo.
TABELA – 21 - Teste de Ljung-Box para a Autocorrelação dos
Resíduos do Modelo a SARIMA (2,1,0)(0, 1,1)36
Lag 12 24 36 48
χ2 (Estatística do Teste) 7,3 19,2 26,1 36,2 Graus de Liberdade 8 20 32 44 P-Valor 0,501 0,507 0,759 0,791

80
A Tabela 22 mostra os valores das previsões com o modelo SARIMA
(2,1,0)(0,1,1)36. Nela pode-se observar que em média este modelo apresenta um
erro de aproximadamente 5,0% em cada previsão. Comparado com os modelos
anteriores, este foi o maior Erro Percentual Médio de Previsão, apesar de ter
passado em todos os requisitos necessários para se fazer previsões.
TABELA – 22 - Valores Observados e Esperados do Modelo SARIMA (2,1,0)(0,1,1)36
Período (t) Mês/Ano Observados Previsão Erro Percentual
139 Jul/05 154405910 162709646 -5,38 140 Ago/05 170711332 169466185 0.73 141 Set/05 157741350 165919837 -5,18 142 Out/05 157799414 163279823 -3,47 143 Nov/05 157440578 166828878 -5,96 144 Dez/05 162271068 181457275 -11,82
Erro Percentual Médio -5,18
IV SARIMA (2,1,0)(0,1,1)36 sem o termo constante do modelo
No modelo anterior, verificou-se que a constante não foi significativa.
Portanto, optou-se por refazer o modelo com uma única diferença e excluir a
constante. Ao retirar a constante, o novo modelo será mais parcimonioso, logo será
melhor, pelo menos teoricamente.
• Estimação
A Tabela 23 mostra os parâmetros estimados para o modelo SARIMA
(2,1,0)(0,1,1)36 sem o termo constante. Nela pode-se observar que todos os
parâmetros foram altamente significativos para o modelo.
TABELA – 23 - Estimativas dos Parãmetros para o Modelo
SARIMA (2,1,0)(0,1,1)36 sem o termo constante
Tipo Coeficiente p-valor
AR(1) -0,9573 0,000 AR(2) -0,6719 0,000
SMA(36) 0,3715 0,000

81
• Diagnóstico
A Figura 20 apresenta os valores das autocorrelações dos resíduos do
modelo SARIMA (2,1,0)(0,1,1)36 sem o termo constante. Nela pode-se observar que
os resíduos são ruído branco, pois não apresentam correlações significativas em
nenhum lag, indicando que não há auto-correlação nos resíduos. Esta hipótese
poderá ser conferida a partir do teste de Box-Pierce a seguir.
FIGURA – 20 - Função de Autocorrelação dos Resíduos do Modelo SARIMA(2,1,0)(0,1,1)36
sem o termo constante
A Tabela 24 mostra os valores da estatística de teste qui-quadrado para a
autocorrelação dos resíduos do modelo SARIMA (2,1,0)(0,1,1)36 sem o termo
constante. Nela verifica-se que os resíduos deste são ruído branco, pois o “p-valor”
foi bem maior que o nível de significância (α = 0,05) em todos os lag’s. Logo, este
modelo é apropriado para a série em estudo.
TABELA – 24 - Teste de Ljung-Box para a Autocorrelação dos Resíduos do Modelo
a SARIMA (2,1,0)(0,1,1)36 sem o termo constante
Lag 12 24 36 48
χ2 (Estatística do Teste) 7,3 19,7 26,5 36,7 Graus de Liberdade 9 21 33 45 P-Valor 0,602 0,543 0,780 0,807

82
A Tabela 25 mostra os valores das previsões com o modelo SARIMA
(2,1,0)(0,1,1)36 sem o termo constante. Nela pode-se observar que em média este
modelo apresenta um erro de aproximadamente 4,29% em cada previsão.
Comparado com os modelos anteriores, este foi o segundo maior Erro Percentual
Médio de Previsão, sendo que este modelo apresentou todos os requisitos
necessários para fazer previsões.
TABELA – 25 - Valores Observados e Esperados do Modelo
SARIMA (2,1, 0)(0,1, 1)36 sem o termo Constante
Período (t) Mês/Ano Observados Previsão Erro Percentual
139 Jul/05 154405910 161930000 -4,87 140 Ago/05 170711332 168563105 1,26 141 Set/05 157741350 164888549 -4,53 142 Out/05 157799414 161668623 -2,45 143 Nov/05 157440578 165017781 -4,81 144 Dez/05 162271068 179073350 -10,35
Erro Percentual Médio -4,29
4.6 Comparação e Escolha do Método de Previsão
A comparação e escolha do melhor método de previsão, discutidos nesta
seção, será feita a partir das medidas de acurácia, que são o erro percentual médio
(EPM), erro percentual absoluto médio (EPAM) e o erro quadrático médio (EQM).
Mais detalhes a respeito dessas medidas de acurácia podem ser vistos no Apêndice
B.
A Tabela 26 mostra os valores das medidas de acurácia dos modelos não
paramétricos. Nela pode-se observar que o modelo que apresentou o menor EPM foi
o modelo de Holt Winter Aditivo, com apenas 0,11%. Em relação ao EPAM, o
modelo de Alisamento duplo foi o menor, com 2,67%. O modelo de Alisamento
Duplo também apresentou o EQM com 3,25E+13. De um modo geral, observa-se
que o modelo de Alisamento Duplo apresentou as menores medidas de acurácia
entre os modelos não paramétricos.
TABELA – 26 - Medidas de Acurácia dos Modelos não Paramétricos
Modelos EPM EPAM EQM
Decomposição Aditivo 1,61 4,00 5.96e+13

83
Modelos EPM EPAM EQM
Decomposição Multiplicativo 2,69 3,23 4,96e+13 Alisamento Simples 3,20 4,31 5,24e+13 Alisamento Duplo 0,52 2,67 3,25e+13 Holt Winter Aditivo 0,11 3,64 4,13e+13 Holt Winter multiplicativo 0,52 2,83 3,33e+13
A Tabela 27 mostra os valores das medidas de acurácia dos modelos
paramétricos. Verifica-se a partir desta tabela que o modelo SARIMA com o termo
constante só foi melhor que o modelo sem a constante em relação ao EQM. Nas
demais medidas, o modelo sem a constante apresenta valores menores que o
modelo com o termo constante.
TABELA – 27 - Medidas de Acurácia dos Modelos Paramétricos
Modelos EPM EPAM EQM
SARIMA(2,1,0)(0,1,1)36* 5,18 5,43 1,03946e+14
SARIMA(2,1,0)(0,1,1)36** 4,29 4,71 7,78351e+13
NOTA: * Modelo com a constante **Modelo sem a constante

84
5. A IMPORTÂNCIA DAS VARIÁVEIS CARTÕES E DEPÓSITOS NA POUPANÇA NA SÉRIE CHEQUES COMPENSADOS
Neste capítulo será analisada a existência de relação independente das
variáveis quantidades de transações com cartões no mercado brasileiro e do total de
“depósitos mensais na poupança” com as quantidades e valores de cheques
compensados no período de janeiro/2004 a dezembro/2006 e setembro/1994 a
dezembro/2006, respectivamente. As análises foram realizadas em períodos
mensais, a fim de que a hipótese alternativa proposta pelo modelo pudesse ser
testada, sendo a análise estatística realizada através do modelo de regressão linear
simples pelo método dos mínimos quadrados ordinários. Os resultados das duas
regressões não foram capazes de rejeitar a hipótese nula do modelo, isto é, de que
não existe relação estatisticamente significante entre as duas variáveis e os cheques
compensados.
Primeiramente verificou-se o comportamento destas variáveis
graficamente a partir de um gráfico de dispersão. Pode-se observar na Figura 21
que a quantidade de cheques compensados é inversamente proporcional a
quantidade de cartões, ou seja, a medida que o uso cartões está aumentando, a
quantidade de cheques compensados está diminuindo.
FIGURA – 21 - Gráfico de Dispersão Para Cheques Compensados e Transações com Cartões

85
CartõesTransaçõesEsCompensadoCheques 172,00812,2 −+=
A Tabela 28 apresenta os resultados da regressão entre as variáveis em
estudo. Nela pode-se observar que os parâmetros foram altamente significativos
para o modelo (p-valor= 0,000). Verifica-se ainda que 40,4% das variações de
cheques compensados são explicadas pela variação dos cartões.
TABELA – 28 - Análise de Regressão Para as Variáveis Cheques Compensados
e Transações com Cartões
Preditores Coeficientes Desvio Padrão T P
Constante(α) 211960037 11046649 19,19 0,000 Transações com Cartões(β) -0,17218 0,03589 -4,80 0,000
A Tabela 29 apresenta os valores da análise da variância (ANOVA) para o
modelo proposto, onde pode-se observar que a estatística F=23,02 foi
extremamente significativa (p-valor=0,000), o que implica que realmente existem
fortes evidências de que existe uma relação entre estas variáveis.
TABELA – 29 - Análise da Variância Para as Variáveis Cheques Compensados e Cartões
Fonte de Variação
Graus de Liberdade
Soma de Quadrados
Quadrado Médio F P-valor
Regressão 1 3,73969E+15 3,73969E+15 23,02 <0,001 Resíduo 34 5,52352E+15 1,62457E+14 - - Total 35 9,26321E+15 - - -
A partir destes resultados estimou-se o seguinte modelo de regressão
para as variáveis Cheques Compensados e Transações com cartões
(5.1)
Pode-se verificar a partir da Figura 22 a estatística do teste de
normalidade para os resíduos da regressão entre Cheques Compensados e
Transações com Cartões Ad=0; 407 apresentou um p-valor maior que 0,333, isto é,
os resíduos apresentam normalidade.

86
FIGURA – 22 - Teste de Normalidade Para os Resíduos da Regressão
Entre Cheques Compensados e Transações com Cartões
A regressão “quantidade de Cheques Compensados = 211.960.037 -
(0,17218 x Quantidade de Transações com Cartões)” foi utilizada para os três
últimos meses de 2006 e apresentou um Erro Percentual Absoluto Médio - EPAM de
1,60%, conforme Tabela 30. Esse resultado está de acordo com a situação real,
uma vez que a um aumento na quantidade de transações com cartões, a quantidade
de cheques compensados reduz. Foram analisados os resíduos da regressão
através do Teste de Dickey-Fuller aumentado (teste ADF) e ao nível de 5% foi
rejeitada a hipótese nula de que os resíduos das séries tenham uma raiz unitária e
aceita a alternativa de que são estacionários.
TABELA – 30 - Erro Percentual Absoluto Médio (EPAM) para os Valores dos
Cheques Compensados e Quantidade de Transações com Cartões
Mês Cartões Cheques Previsão EPAM
Out/06 371.870.657 145.011.909 147.931.347 -2,01 Nov/06 376.897.670 137.789.099 147.065.796 -6,73 Dez/06 462.630.045 137.734.980 132.304.396 3,94
-1,60
O mercado brasileiro de cartões, neste caso incluindo os cartões de
crédito, débito e os de loja, vem apresentando um crescimento bastante superior ao
índices do PIB. O ano de 2006 encerrou com mais de 390 milhões de cartões, um
aumento de 15% em comparação a 2005, movimentando aproximadamente R$

87
261,8 milhões), um crescimento de 24% segundo dados da Associação Brasileira
das Empresas de Cartões de Crédito e Serviços - ABECS, mas que distribuídos
entre toda a população brasileira chega à média de apenas dois cartões por
habitante no Brasil. Segundo o Sr. Antonio Luiz Rios, diretor da ABECS, “esses
números indicam que os brasileiros já se acostumaram a usar meios eletrônicos de
pagamento”. No aspecto macroeconômico os cartões contribuem para a
modernização do sistema de pagamentos no varejo, uma vez que apresentam maior
eficiência com relação aos instrumentos em papel, como é o caso dos cheques.
Em 1995, do total de pagamentos no Brasil, 7% eram com cartões, 26%
com cheques e 55% com dinheiro. Em 2005, a participação dos cartões subiu para
20%, a dos cheques caiu para 14% e a de pagamentos em dinheiro manteve-se
estabilizada em 53%. Dados preliminares da ABECS informam que ao final de 2005
as transações com cartões foram responsáveis por 21,5% do consumo privado
brasileiro, com o Brasil se consolidando como o terceiro emissor mundial, atrás
apenas dos Estados Unidos e da China. Entre as causas para esse desempenho a
ABECS considera o ainda baixo índice de ativação dos cartões, aliado ao pequeno
alcance na baixa renda. A tendência é um aumento ainda consistente dos cartões,
considerando o potencial do crescimento do Brasil. As empresas de cartões
reconhecem que por questões de segurança, facilidades na organização do
orçamento doméstico e benefícios como milhagens, a cada dia o consumidor prefere
mais o cartão, em detrimento ao cheque. Somente entre 1994 e 2004 as transações
com cheque caíram 49%, enquanto as transações com cartões (neste exemplo, de
crédito) cresceram 536%. A consolidação dos cartões como o segundo meio de
pagamento mais utilizado no Brasil, abaixo apenas das transações com dinheiro,
indica ser resultado da boa aceitação entre os usuários portadores de cartões e
lojistas. Atualmente, a quantidade de negócios realizados com cartões é quase o
triplo dos realizados com cheques. No geral, o uso dos cheques vem caindo cerca
de 7% ano, enquanto as transações com cartões aumentam 22%, sendo que o
Banco Central busca continuamente incentivar o uso de meios eletrônicos de
pagamento em substituição aos cheques e outros papéis.

88
PoupançanaDepósitosCompesadosCheques 67,11175.1 −+=
A Tabela 31 apresenta os resultados da regressão entre as variáveis em
estudo. Nela pode-se observar que os parâmetros foram altamente significativos
para o modelo (p-valor= 0,000). Verifica-se ainda que 88,1% das variações de
Cheques Compensados são explicadas pela variação de Depósitos na Poupança.
TABELA – 31 - Análise de Regressão Para as Varáveis Cheques Compensados
e Depósitos na Poupança
Preditores Coeficientes Desvio Padrão T P-Valor
Constante(α) 339484848 4020226 84,44 0,000 Depósitos na Poupança(β) 1109,56 33,74 -32,88 0,000
A Tabela 32 apresenta os valores da análise da variância (ANOVA) para o
modelo proposto, onde pode-se observar que a estatística F=60,24 foi
extremamente significativa (p-valor=0,000), o que implica que realmente existem
fortes evidências de que existe uma relação entre estas variáveis.
TABELA – 32 - Análise da Variância Para as Variáveis Cheques Compensados
e Depósitos na Poupança
Fonte de Variação
Graus de Liberdade
Soma de Quadrados
Quadrado Médio F P-valor
Regressão 1 2,44488e+17 2,44488e+17 1081,20 <0,001 Resíduo 146 3,30144e+16 2,26126e+14 - - Total 147 2,77503e+17 - - -
A partir destes resultados estimou-se o seguinte modelo de regressão
para os variáveis Cheques Compensados e Depósitos na Poupança
(5.2)
Pode-se verificar a partir da Figura 23 a estatística do teste de
normalidade para os resíduos da regressão entre Cheques Compensados e
Depósitos na Poupança Ad=0,627 apresentou um p-valor maior que 0,101, isto é, os
resíduos apresentam normalidade.

89
FIGURA – 23 - Teste de Normalidade Para os Resíduos da Regressão Entre
Cheques Compensados e Depósitos na Poupança
Quanto à regressão “valores dos Cheques Compensados = 339.484.848 -
(1.109,56 x Depósitos em Poupança)” também foi utilizada para os três últimos
meses de 2006 e apresentou um Erro Percentual Absoluto Médio - EPAM de 0,44%,
conforme Tabela 33. A esse resultado se observa que ao crescimento dos depósitos
mensais na conta de poupança, os valores totais dos cheques compensados
continuam em queda, situação que corresponde à realidade atual. Foram analisados
os resíduos da regressão através do Teste de Dickey-Fuller aumentado (teste ADF)
e ao nível de 5% foi rejeitada a hipótese nula de que os resíduos das séries tenham
uma raiz unitária e aceita a alternativa de que são estacionários.
TABELA – 33 - Erro Percentual Absoluto Médio(EPAM) para os valores dos
Cheques Compensados e Depósitos em Poupança
Mês Cartões Cheques Previsão EPAM
Out/06 145.006.288 174.963 145.352.901 -0,23 Nov/06 136.996.174 177.738 142.273.872 -3,85 Dez/06 137.714.289 185.296 133.887.818 2,77
-0,44
O que se observa a partir de setembro/94 é um crescimento constante
dos depósitos em contas de poupança, sendo que nesse mês seu valor
correspondia a apenas 0,01% da quantidade total de cheques compensados, porém

90
atingindo em dezembro/06 o percentual de 0,13%. Com a queda da inflação a partir
de meados de 1994, que era um dos maiores desestímulos a poupança no Brasil
considerando outros investimentos mais atrativos, porém com a manutenção de
taxas elevadas de juros o investidor foi aos poucos retornando a poupança, tendo
em junho/06 essa aplicação conseguido atingir R$ 125,683 bilhões em depósitos.
Historicamente o Brasil registra taxas baixas de poupança. Mesmo entre os anos 60
e 70 de elevados crescimentos a taxa de poupança doméstica foi baixa, tendo
somente na década de 1980 ocorrido um aumento na poupança resultado da
elevação da taxa inflacionária no período. Dados do Banco Central informam que em
2004, foram emitidos cerca de 2,5 bilhões de cheques, no valor global de R$ 2,0
trilhões, uns valores médios de R$ 781 reais por cheque. Para o período 2000/2004,
os cheques emitidos apresentaram redução de 12,4% no que diz respeito à
quantidade, uma média de menos 3% ao ano.

91
6. CONSIDERAÇÕES FINAIS E RECOMENDAÇÕES
6.1 Considerações Finais
Este trabalho teve como objetivo, desenvolver um modelo de previsão
para a série cheques compensados, através da análise de séries temporais. A série
cheques compensados mostra de modo simplificado, a quantidade de cheques
compensados, no período de janeiro de 1994 à dezembro de 2005. Entretanto, o
período da série utilizado neste trabalho, se limita de janeiro de 1994 à junho de
2005, pois os outros seis meses restantes ficaram para comparação com os valores
estimados da série.
No Capítulo 4 deste trabalho, mostrou-se de modo resumido as etapas
para se chegar a um modelo que melhor se ajustasse aos dados em estudo, através
da análise das medidas de acurácia. A partir destas medidas verificou-se que, em
relação aos modelos não paramétricos, o modelo de Alisamento Duplo apresentou o
menor EPAM e também o menor EQM e ainda apresentou um erro percentual médio
de previsão de apenas 0,52%. Portanto, com base nestas medidas, pode-se concluir
que, de um modo geral, o melhor modelo não paramétrico para a série cheques
compensados é o modelo de Alisamento Duplo.
Quanto as medidas de acurácia dos modelos paramétricos, observou-se
que o modelo SARIMA sem o termo constante apresentou o menor EPM, EPAM e
EQM. Portanto, este modelo é o mais adequado para a série cheques compensados
em relação aos modelos paramétricos.
Contudo, pode-se concluir ao final deste trabalho que após tomados todos
os cuidados para se modelar uma série temporal, verifica-se que existem dois
modelos para ajustar os dados da série cheques compensados: o modelo de
Alisamento Duplo, no caso dos modelos não paramétricos.
As previsões obtidas através das regressões entre as quantidades
mensais dos cheques compensados e os valores de depósitos mensais na conta de

92
poupança interna, bem como entre as quantidades de cheques compensados e a de
cartões resultaram nos EPAMs de 0,52% e 1,60% respectivamente, mesmo
considerando um horizonte previsto de apenas três meses.
6.2 Recomendações
Recomenda-se para trabalhos futuros:
• Elaborar um modelo de séries temporais para séries cheques
compensados, com base em observações mais atuais;
• Investigar o mecanismo da série m função de diversas variáveis
relacionadas ao cheque compensado;
• Analisar a distribuição geográfica dos usuários de cartões e a relação
entre o cheque sem fundo e o nível de renda do emitente.
• Identificar o potencial das pessoas de baixa renda na utilização dos
cartões, bem como o crédito desse meio qualifica seu ambiente sócio-
econômico.
• Verificar outros métodos que podem ser testados para a realização de
previsões, como é o caso dos modelos de função de transferência, os
quais consideram além das observações passadas da variável a ser
predita, outra informação correlacionada a mesma.
• Analisar a participação dos meios eletrônicos de pagamento no
consumo privado por estado ou região geográfica, buscando identificar
o grau de utilização desses meios entre as regiões com menor renda.
• Aplicar modelos vetoriais de correção de erro.

93
REFERÊNCIAS BIBLIOGRAFICAS
ARRAES, Ronaldo de Albuquerque e CHUMVICHITRA, Pichai. Modelos Autoregressivos e Poder de Previsão: uma aplicação com ICMS, Fortaleza: UFC/CAEN - Texto para discussão, 1996.
BACHA, Carlos José Caetano. Macroeconomia Aplicada a Análise da Economia Brasileira, São Paulo: Editora da Universidade de São Paulo, 2004.
BANCO CENTRAL DO BRASIL. Diagnóstico do Sistema de Pagamentos de Varejo do Brasil, Brasília: 2005.
BERA, A. K; JARQUE, C. M. An efficient Large Sample Test for Normality of Observations and Regression Residual. Working Papers in Econometrics, 40, Autralian National University, Camberra, 1981.
BUSSAB, Wilton de O; MORETTIN, P.A. Estatística básica. 5. ed. São Paulo: Editora Saraiva, 2004.
CASTELAR, Luiz Ivan de Melo; ARRAES, Ronaldo de Albuquerque. Modelos de previsão das finanças publicas do Estado do Ceará - Receitas - Volume I. Fortaleza: UFC/CAEN Texto para discussão, 1996.
CRUZ, Martins M. Séries Temporais de Pesquisas Amostrais, 15o SINAPE, 2002.
FERREIRA, Roberto Tatiwa. Modelos de análise de séries temporais para previsão do ICMS mensal do estado do Ceará., Fortaleza: Dissertação UFC/CAEN, 1996.
GRANGER E NEWBOLD, Forecasting Transformed Series, Journal of The Royal Statistical Society, Series B, 38, 189-203, 1976.
GUJARATI, Damodar N. Econometria Básica. 3. ed. Pearson Makron Books, 2005.
HILL, R.Carter, GRIFFITHS, William E., JUDGE, George G. Econometria. 2. ed. São Paulo: Editora Saraiva, 2006.

94
KAZMIER, Leonard J. Estatística aplicada a administração e economia. 4. ed. Porto Alegre: Bookman Editora, 2007.
LIEBEL, Marlon Jorge. Previsão de Receitas Tributárias - O caso do ICMS no estado do Paraná. Porto Alegre: Dissertação Escola de Engenharia, 2004.
MADDALA, G.S. Introdução a Econometria. 3. ed. Rio de Janeiro: LTC, 2003.
MAKRIDAKIS, S. and Hibon, M. Accuracy of Forecasting an Empirical Investigation, Journal of the Royal Statistical Society, Series A, 142, 97.145, 1979
MAKRIDAKIS, Spyros. e WHEELWRIGHT, Steven C. Forecasting Methods for Management, 4. ed. New York, John Wiley e Sons Inc, 1985.
MAKRIDAKIS, Spyros G. Forecasting: Methods and Applications. 3. ed., Editora John Wiley e Sons, Inc., 1998.
MORETTIN, Pedro A. Séries Temporais em Finanças, Texto para um Curso na Universidade Católica de Lima, Peru, 2002.
MORETTIN, Pedro A. e TOLOI, Clélia M. Análise de Séries Temporais,2. ed. São Paulo: Editora Edgard Blucher, 2006.
NELSON, H. L. The Use the Box-Cox Transformations in Economic Time Series Analysis: An Empirical Study. Doctoral Dissertation, Univ. of California, San Diego, 1976. PASSOS, Jairo J. Um modelo de Previsão para a Arrecadação do ICMS no Estado do Pará, Trabalho de Conclusão de Curso (TCC): Estatística. Belém: UFPA, 2003.
PINDYCK, Robert S., RUBINFELD, Daniel L. Econometria Modelos e Previsão, São Paulo: Elsevier Editora, 2004.
PINHEIRO, Aurélio Ferreira. Modelos Univariados de Séries Temporais para previsões de curto prazo da arrecadação nacional do FGTS. Fortaleza: UFC, Dissertação, 2004.

95
ROCHA, Fábio Guimaraes. Contribuição de Modelos de Series Temporais para a Previsão da Arrecadação de ISS, Campinas: UNICAMP, Dissertação Instituto de Economia, 2003. SANDRONI, Paulo. Dicionário de Economia do Século XXI, Rio de Janeiro: Editora Record, 2005.
SIEGEL, Sidney. Estatistica Não-Paramétrica: para as Ciências do Comportamento, Editora Mc-Graw Hill, 1975.
SOARES, Ilton G. e CASTELAR, Ivan. Econometria aplicada com o uso do Eviews, Fortaleza: Edições Livro Técnico, 2003.
VASCONCELLOS, M.A.S. et all. Manual de Econometria: nível intermediário. São Paulo: Editora Atlas, 2000.

96
APÊNDICES
Apêndice A
TABELAS E ANEXOS
TABELA – 34 - Quantidade de Cheques Compensados no Brasil (1994 - 2005)
Mês Quantidade de
Cheques Compensados
Mês Quantidade de
Cheques Compensados
Mês Quantidade de
Cheques Compensados
Jan/94 351211884 Jan/98 242541814 Jan/02 221109849 Fev/94 328912304 Fev/98 213043069 Fev/02 185871205 Mar/94 385415709 Mar/98 245648771 Mar/02 190105726 Abr/94 371728594 Abr/98 225800164 Abr/02 210190889 Mai/94 414049721 Mai/98 218768355 Mai/02 199986942 Jun/94 376461529 Jun/98 236264090 Jun02 183068522 Jul/94 296021365 Jul/98 228728105 Jul/02 209855994 Ago/94 343021760 Ago/98 225870102 Ago/02 194534152 Set/94 316116339 Set/98 220264511 Set/02 195783566 Out/94 302963735 Out/98 221705045 Out/02 202073816 Nov/94 308379943 Nov/98 223826253 Nov/02 188843438 Dez/94 334062968 Dez/98 246445796 Dez/02 215871180 Jan/95 315936099 Jan/99 204726011 Jan/03 197544004 Fev/95 234426048 Fev/99 194411334 Fev/03 180309162 Mar/95 336339721 Mar/99 232872995 Mar/03 186408375 Abr/95 269583031 Abr/99 210620437 Abr/03 183730310 Mai/95 307061565 Mai/99 219422178 Mai/03 185317429 Jun/95 275790916 Jun/99 211015183 Jun/03 185293419 Jul/95 265926676 Jul/99 214546236 Jul/03 189538837 Ago/95 279365628 Ago/99 25435492 Ago/03 175212446 Set/95 249652462 Set/99 215585109 Set/03 191740791 Out/95 272898628 Out/99 209904453 Out/03 189425889 Nov/95 261932557 Nov/99 230010644 Nov/03 172324766 Dez/95 268734688 Dez/99 23431368 Dez/03 209582874 Jan/96 276949027 Jan/00 220885767 Jan/04 178378668 Fev/96 244090256 Fev/00 211485606 Fev/04 158397439 Mar/96 237127065 Mar/00 21902918 Mar/04 189256864 Abr/96 256348247 Abr/00 19985168 Abr/04 171497219 Mai/96 262000401 Mai/00 234904052 Mai/04 174104969 Jun/96 244905642 Jun/00 219002593 Jun/04 174374552 Jul/96 260105241 Jul/00 222548441 Jul/04 174681109 Ago/96 260183258 Ago/00 227783111 Ago/04 180827402 Set/96 244657717 Set/00 210822526 Set/04 171972790 Out/96 261420283 Out/00 232551689 Out/04 67641573 Nov/96 253385093 Nov/00 222082064 Nov/04 179697111
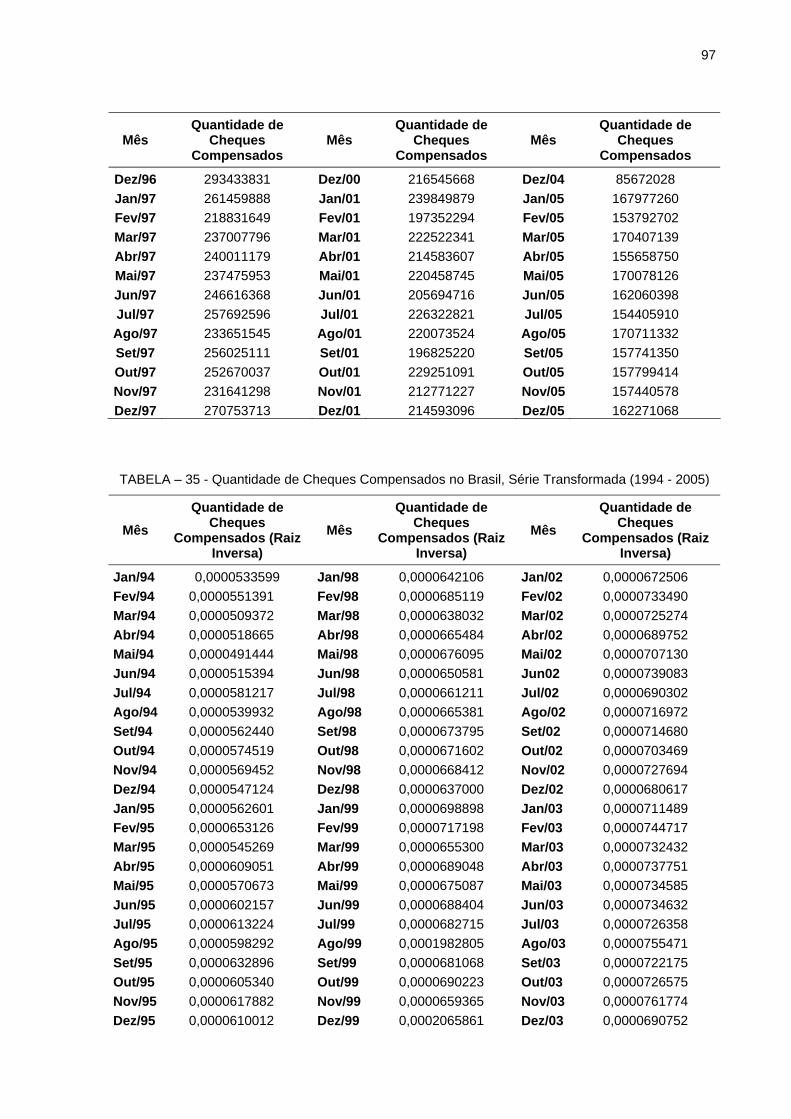
97
Mês Quantidade de
Cheques Compensados
Mês Quantidade de
Cheques Compensados
Mês Quantidade de
Cheques Compensados
Dez/96 293433831 Dez/00 216545668 Dez/04 85672028 Jan/97 261459888 Jan/01 239849879 Jan/05 167977260 Fev/97 218831649 Fev/01 197352294 Fev/05 153792702 Mar/97 237007796 Mar/01 222522341 Mar/05 170407139 Abr/97 240011179 Abr/01 214583607 Abr/05 155658750 Mai/97 237475953 Mai/01 220458745 Mai/05 170078126 Jun/97 246616368 Jun/01 205694716 Jun/05 162060398 Jul/97 257692596 Jul/01 226322821 Jul/05 154405910 Ago/97 233651545 Ago/01 220073524 Ago/05 170711332 Set/97 256025111 Set/01 196825220 Set/05 157741350 Out/97 252670037 Out/01 229251091 Out/05 157799414 Nov/97 231641298 Nov/01 212771227 Nov/05 157440578 Dez/97 270753713 Dez/01 214593096 Dez/05 162271068
TABELA – 35 - Quantidade de Cheques Compensados no Brasil, Série Transformada (1994 - 2005)
Mês Quantidade de
Cheques Compensados (Raiz
Inversa) Mês
Quantidade de Cheques
Compensados (Raiz Inversa)
Mês Quantidade de
Cheques Compensados (Raiz
Inversa)
Jan/94 0,0000533599 Jan/98 0,0000642106 Jan/02 0,0000672506 Fev/94 0,0000551391 Fev/98 0,0000685119 Fev/02 0,0000733490 Mar/94 0,0000509372 Mar/98 0,0000638032 Mar/02 0,0000725274 Abr/94 0,0000518665 Abr/98 0,0000665484 Abr/02 0,0000689752 Mai/94 0,0000491444 Mai/98 0,0000676095 Mai/02 0,0000707130 Jun/94 0,0000515394 Jun/98 0,0000650581 Jun02 0,0000739083 Jul/94 0,0000581217 Jul/98 0,0000661211 Jul/02 0,0000690302 Ago/94 0,0000539932 Ago/98 0,0000665381 Ago/02 0,0000716972 Set/94 0,0000562440 Set/98 0,0000673795 Set/02 0,0000714680 Out/94 0,0000574519 Out/98 0,0000671602 Out/02 0,0000703469 Nov/94 0,0000569452 Nov/98 0,0000668412 Nov/02 0,0000727694 Dez/94 0,0000547124 Dez/98 0,0000637000 Dez/02 0,0000680617 Jan/95 0,0000562601 Jan/99 0,0000698898 Jan/03 0,0000711489 Fev/95 0,0000653126 Fev/99 0,0000717198 Fev/03 0,0000744717 Mar/95 0,0000545269 Mar/99 0,0000655300 Mar/03 0,0000732432 Abr/95 0,0000609051 Abr/99 0,0000689048 Abr/03 0,0000737751 Mai/95 0,0000570673 Mai/99 0,0000675087 Mai/03 0,0000734585 Jun/95 0,0000602157 Jun/99 0,0000688404 Jun/03 0,0000734632 Jul/95 0,0000613224 Jul/99 0,0000682715 Jul/03 0,0000726358 Ago/95 0,0000598292 Ago/99 0,0001982805 Ago/03 0,0000755471 Set/95 0,0000632896 Set/99 0,0000681068 Set/03 0,0000722175 Out/95 0,0000605340 Out/99 0,0000690223 Out/03 0,0000726575 Nov/95 0,0000617882 Nov/99 0,0000659365 Nov/03 0,0000761774 Dez/95 0,0000610012 Dez/99 0,0002065861 Dez/03 0,0000690752

98
Mês Quantidade de
Cheques Compensados (Raiz
Inversa) Mês
Quantidade de Cheques
Compensados (Raiz Inversa)
Mês Quantidade de
Cheques Compensados (Raiz
Inversa)
Jan/96 0,0000600897 Jan/00 0,0000672847 Jan/04 0,0000748736 Fev/96 0,0000640066 Fev/00 0,0000687638 Fev/04 0,0000794559 Mar/96 0,0000649396 Mar/00 0,0002136727 Mar/04 0,0000726899 Abr/96 0,0000624575 Abr/00 0,0002236898 Abr/04 0,0000763610 Mai/96 0,0000617802 Mai/00 0,0000652461 Mai/04 0,0000757869 Jun/96 0,0000639000 Jun/00 0,0000675733 Jun/04 0,0000757283 Jul/96 0,0000620048 Jul/00 0,0000670329 Jul/04 0,0000756619 Ago/96 0,0000619955 Ago/00 0,0000662581 Ago/04 0,0000743649 Set/96 0,0000639323 Set/00 0,0000688718 Set/04 0,0000762553 Out/96 0,0000618487 Out/00 0,0000655753 Out/04 0,0001215887 Nov/96 0,0000628217 Nov/00 0,0000671032 Nov/04 0,0000745984 Dez/96 0,0000583774 Dez/00 0,0000679556 Dez/04 0,0001080390 Jan/97 0,0000618440 Jan/01 0,0000645699 Jan/05 0,0000771569 Fev/97 0,0000675997 Fev/01 0,0000711834 Fev/05 0,0000806366 Mar/97 0,0000649559 Mar/01 0,0000670368 Mar/05 0,0000766048 Abr/97 0,0000645482 Abr/01 0,0000682656 Abr/05 0,0000801518 Mai/97 0,0000648919 Mai/01 0,0000673498 Mai/05 0,0000766789 Jun/97 0,0000636779 Jun/01 0,0000697250 Jun/05 0,0000785528 Jul/97 0,0000622944 Jul/01 0,0000664716 Jul/05 0,0000804763 Ago/97 0,0000654208 Ago/01 0,0000674087 Ago/05 0,0000765365 Set/97 0,0000624969 Set/01 0,0000712787 Set/05 0,0000796209 Out/97 0,0000629105 Out/01 0,0000660457 Out/05 0,0000796063 Nov/97 0,0000657040 Nov/01 0,0000685557 Nov/05 0,0000796969 Dez/97 0,0000607733 Dez/01 0,0000682641 Dez/05 0,0000785018
Apêndice B
MEDIDAS DE ACURÁCIA DOS MÉTODOS DE PREVISÃO
De acordo com Makridakis (1998), a suposição básica de qualquer
técnica de previsão de séries temporais é que o valor observado na série fica
determinado por um padrão que se repete no tempo e por alguma influência
aleatória. Isto significa dizer que mesmo quando o padrão exato que caracteriza o
comportamento da série temporal tenha sido isolado, algum desvio ainda existirá
entre os valores de previsão e os valores realmente observados. Essa aleatoriedade
não pode ser prevista; entretanto, se isolada, sua magnitude pode ser estimada e
usada para determinar a variação ou erro entre as observações e previsões
realizadas. Portanto, a precisão de um método de previsão pode ser mensurada a

99
( )n
xxEM
n
i ii∑ =−
= 1ˆ
nxx
EMAn
i ii∑ =−
= 1ˆ
( )n
xxEQM
n
i ii∑ =−
= 12ˆ
100ˆ×
−=
i
ii
xxx
EPA
( )
nx
xx
EPM
n
ii
ii 100ˆ
1×
−
=∑ =
( )
nx
xx
EPMA
n
ii
ii 100ˆ
1×
−
=∑ =
partir de muitas medidas de erro, entre as quais pode-se citar [Makridakis e
Wheelwright (1985)]
a) Erro Médio
(B.1)
onde xi é o valor observado no instante i, ix̂ é o valor previsto no instante i e n
corresponde ao número de previsões efetuadas.
b) Erro Médio Absoluto
(B.2)
c) Erro Quadrado Médio
(B.3)
d) Erro Percentual Absoluto
(B.4)
e) Erro Percentual Médio
(B.5)
f) Erro Percentual Absoluto Médio
(B.6)
Dessa forma, a verificação da adequação de um determinado modelo
supostamente representativo da série histórica de dados é dependente da medida
de erro adotada para efetuar essa validação.