introdução à inferência teorema do limite central ... · ach2138 modelagem e simulação de...
TRANSCRIPT

ACH2138 Modelagem e Simulação de Sistemas Complexos
Introdução à Inferência
Teorema do Limite Central Intervalos de Confiança
Prof. Marcelo S. Lauretto [email protected] www.each.usp.br/lauretto
Referência:
W.O.Bussab, P.A.Morettin. Estatística Básica, 6ª Edição. São Paulo: Saraiva, 2010 – Capítulo 10
Seções mais relevantes para nossa disciplina: 7, 8, 9
1

1. Inferência Estatística: Introdução
• Definição de Inferência Estatística:
– Processo de aprender (inferir/generalizar) as características
de uma população a partir de uma amostra
– As características da população são denominadas parâmetros
• Usualmente, não são observáveis diretamente
– As características da amostra são denominadas estatísticas
• São observadas / computadas a partir dos dados
• Contraste com a Estatística Descritiva:
– Estatística descritiva foca exclusivamente nas propriedades
dos dados observados
– Não se assume que os dados vieram de uma população maior
– Não há preocupação com a generalização para a população
2

1. Inferência Estatística: Introdução
• Principais problemas da inferência estatística:
– Estimação
• Derivação de estimativas pontuais e intervalos estatísticos para os
parâmetros
– Testes de hipóteses
– Previsão
3

2. População e Amostra
• Definição:
– População é o conjunto de todos os elementos ou resultados
sob investigação.
– Amostra é qualquer subconjunto da população.
• Exemplo 10.1 (adaptado): Salários dos moradores de um bairro
– Consideremos uma pesquisa para estudar as remunerações
dos moradores de um bairro em São Paulo (população)
– Seleciona-se uma amostra de 2000 moradores daquele bairro
– Esperamos que a distribuição observada dos salários na
amostra reflita a distribuição de todos os salários – desde que
a amostra tenha sido escolhida com cuidado.
4

2. População e Amostra
• Exemplo 10.3: Duração de lâmpadas
– Suponha que o interesse seja investigar a duração de um
novo tipo de lâmpada
– Uma amostra de 100 lâmpadas do novo tipo são deixadas
acesas até queimarem, e a duração (h) de cada lâmpada é
registrada
– População: universo de todas as lâmpadas fabricadas ou a
serem fabricadas por essa empresa sob o mesmo processo
• Impossível observar toda a população:
– Ensaio destrutivo
– Não é possível conhecer todas as lâmpadas que ainda serão
produzidas
5

2. População e Amostra
• Exemplo 10.5: Moeda
– Suponha que, no lançamento de uma moeda específica,
consideramos a variável aleatória X definida como:
• X = 1 se a moeda der cara; X = 0 se der coroa
– A probabilidade da moeda dar cara, denotada por p, é
desconhecida. Ou seja, Pr 𝑋 = 1 = 𝑝, Pr 𝑋 = 0 = 1 − 𝑝
– Para poder conhecer melhor a moeda e podermos fazer
algumas inferências sobre 𝑝, lançamos a moeda 50 vezes e
contamos o número de caras observadas.
– A população pode ser considerada como tendo distribuição de
Bernoulli com parâmetro 𝑝.
– A amostra será uma sequência de 50 números 0’s e 1’s.
6

3. Problemas de Inferência
• Exemplos de formulações e problemas de inferência:
• Retornando ao Exemplo 10.5 – moeda
– Indicando por Y o número de caras obtidas depois de lançar a
moeda 50 vezes, se pudermos assumir que os lançamentos
são independentes e realizados aproximadamente sob as
mesmas condições, sabemos que Y segue uma distribuição
binomial, 𝑌 ∼ 𝐵𝑖𝑛 50, 𝑝
– Suponha que, após os lançamentos da moeda, tenham
ocorrido 36 caras.
• Podemos concluir que a moeda é “honesta”?
– Problema de teste de hipótese
• Supondo que tenhamos concluído que a moeda não é honesta (ou seja,
concluímos que 𝑝 ≠ 1/2), qual é a melhor estimativa para 𝑝?
– Problema de estimação 7

5. Amostragem aleatória simples
• A amostragem aleatória simples (AAS) é a maneira mais fácil para seleção de uma amostra probabilística de uma população
• Para populações finitas, onde se tem uma listagem de todas as N unidades elementares, pode-se atribuir um número sequencial para cada elemento, e em seguida sortear-se n desses números (por métodos manuais ou por rotinas computacionais)
• Todos os elementos têm a mesma probabilidade de ser selecionados
8

5. Amostragem aleatória simples
• Amostragem pode ser feita com reposição ou sem reposição
– Amostragem sem reposição: fornece maior quantidade de
informação (pois mais elementos distintos são observados)
– Amostragem com reposição: tratamento teórico mais simples
• Implica em independência entre as unidades selecionadas
• Facilita o desenvolvimento das propriedades dos estimadores
– Para efeitos práticos, quando a população é grande e a
amostra é relativamente pequena, a diferença entre as duas
formas se torna baixa
• Por exemplo, em uma amostra de tamanho 200 de uma população de
1.000.000, a probabilidade de repetição de pelo menos um elemento é
de aproximadamente 2%
– Neste curso, o plano amostral considerado será o de
amostragem aleatória simples com reposição 9

5. Amostragem aleatória simples
• Exemplo 10.7 (adaptado):
– Uma urna (população) contém cinco tiras de papel,
numeradas 1,3,5,5,7
– Defina a variável X como sendo o valor assumido por um
elemento retirado ao acaso da população. A distribuição de X
é dada pela Tabela 10.1 abaixo
– Suponha que duas tiras sejam retiradas ao acaso da urna,
com reposição.
– Denote por 𝑋1 e 𝑋2 os números sorteados na 1ª e na 2ª
extração 10

5. Amostragem aleatória simples
• Exemplo 10.7 (cont):
– A distribuição conjunta do par 𝑋1, 𝑋2 pode ser calculada
diretamente por Pr 𝑋1, 𝑋2 = Pr 𝑋1 Pr 𝑋2 , já que 𝑋1 e 𝑋2 são
independentes. Exemplos:
• Pr 1,1 = Pr 1 Pr 1 =1
5
1
5=
1
25
• Pr 1,5 = Pr 1 Pr 5 =1
5
2
5=
2
25
• Tabela 10.2 apresenta as probabilidades de todos os pares
– Além disso, as distribuições marginais de 𝑋1 e 𝑋2 (somas das
linhas e das colunas na tabela anterior) são independentes e
iguais às distribuições de X.
11

5. Amostragem aleatória simples
• Exemplo 10.7 (cont):
– Desse modo, cada uma das 25 possíveis amostras de
tamanho 2 que podemos extrair dessa população corresponde
a observar uma realização particular da variável aleatória
conjunta (𝑋1, 𝑋2), com 𝑋1 e 𝑋2 independentes e Pr 𝑋1 = 𝑥 = Pr 𝑋2 = 𝑥 = Pr(𝑋 = 𝑥), para todo 𝑥.
– Essa é a caracterização de amostra casual simples que
usaremos nesta disciplina.
12

5. Amostragem aleatória simples
13
• Exemplo 10.7 (cont):

5. Amostragem aleatória simples
• Exemplo 10.7 (cont):
– As distribuições marginais de 𝑋1 e 𝑋2 (somas das linhas e das
colunas na tabela anterior) são independentes e iguais às
distribuições de X.
– Desse modo, cada uma das 25 possíveis amostras de
tamanho 2 que podemos extrair dessa população corresponde
a observar uma realização particular da variável aleatória
conjunta (𝑋1, 𝑋2), com 𝑋1 e 𝑋2 independentes e Pr 𝑋1 = 𝑥 =Pr 𝑋2 = 𝑥 = Pr(𝑋 = 𝑥), para todo 𝑥.
– Essa é a caracterização de amostra casual simples que
usaremos nesta disciplina.
14

5. Amostragem aleatória simples
• Definição:
– Uma amostra aleatória simples de tamanho 𝑛 de uma variável
aleatória 𝑋, com dada distribuição, é o conjunto de 𝑛 variáveis
aleatórias independentes 𝑋1, 𝑋2, … , 𝑋𝑛, cada uma com a
mesma distribuição de 𝑋.
– A amostra será a 𝑛-upla ordenada (𝑋1, 𝑋2, … , 𝑋𝑛), onde 𝑋𝑖
indica a observação do 𝑖-ésimo elemento sorteado.
15

5. Amostragem aleatória simples
• Note que amostras aleatórias obtidas sem reposição não satisfazem à definição acima.
– Tomando o Exemplo 10.7 (urna com cinco tiras), suponha que
𝑋1 e 𝑋2 sejam retirados sem reposição
– Note que 𝑋1 e 𝑋2 não são independentes, e a distribuição de
probabilidades de 𝑋2 após a retirada de 𝑋1 não é igual à
distribuição original. P.ex.
• Pr 𝑋2 = 1|𝑋1 = 1 = 0 ≠ Pr 𝑋2 = 1 =1
5
• Pr 𝑋2 = 3|𝑋1 = 1 =1
4≠ Pr 𝑋2 = 3 =
1
5
• Pr 𝑋2 = 5|𝑋1 = 1 =1
2≠ Pr 𝑋2 = 5 =
2
5
16

5. Amostragem aleatória simples
• Problemas:
17
(d) Responder ao item (b) por meio de simulação (gerando 10.000 pares de famílias e calculando suas probabilidades através das respectivas frequências); comparar os resultados com os do item (b)

6. Estatísticas e parâmetros
• Obtida uma amostra, quase sempre desejamos usá-la para produzir alguma característica específica
• Por exemplo, se quisermos calcular a média da amostra (𝑋1, 𝑋2, … , 𝑋𝑛), esta será dada por
– Note que 𝑋 também uma variável aleatória!
(Pois só é conhecida após a observação da amostra)
• Outras características da amostra também serão funções do vetor (𝑋1, 𝑋2, … , 𝑋𝑛).
18

6. Estatísticas e parâmetros
• Definição:
– Uma estatística é uma característica da amostra, ou seja, uma
estatística 𝑇 é uma função de 𝑋1, 𝑋2, … , 𝑋𝑛.
Notação: 𝑟(𝑋1, 𝑋2, … , 𝑋𝑛)
• Algumas estatísticas comuns são:
19

6. Estatísticas e parâmetros
• Algumas estatísticas comuns são (cont):
• Em inferência estatística, usamos nomenclaturas distintas para as características da amostra e da população.
20

6. Estatísticas e parâmetros
• Definição:
– Um parâmetro é uma medida usada para descrever uma
característica da população.
• Assim, se estivermos colhendo amostras de uma população, identificada pela variável aleatória X, seriam parâmetros a média 𝐸(𝑋) e a variância Var(𝑋).
21

6. Estatísticas e parâmetros
• Símbolos mais comuns para parâmetros e estatísticas:
22

6. Estatísticas e parâmetros
• Símbolos mais comuns para parâmetros e estatísticas:
23

7. Distribuições amostrais
• O problema da inferência é fazer uma afirmação sobre os parâmetros da população através da amostra
• Digamos que nossa afirmação deva ser feita sobre um parâmetro 𝜃 da população (p.ex. média, variância ou qualquer outra medida)
• Suponha que foi adotada uma AAS de n elementos sorteados dessa população.
• Nossa decisão será baseada na estatística T, que será uma função da amostra (𝑋1, 𝑋2, … , 𝑋𝑛), isto é, 𝑇 = 𝑟(𝑋1, 𝑋2, … , 𝑋𝑛)
• Colhida a amostra, teremos observado um particular valor de T, digamos 𝑡0, e baseados nesse valor é que faremos a afirmação sobre 𝜃, o parâmetro populacional
24

7. Distribuições amostrais
• Esquema de inferência sobre 𝜃
25
Figura 10.1 (a): Esquema de inferência sobre

7. Distribuições amostrais
• A validade da afirmação (inferência) sobre 𝜃 depende de conhecermos o que ocorreria com a estatística T, se pudéssemos retirar todas as amostras da população (usando o mesmo plano amostral).
• Ou seja, deveríamos conhecer qual seria a distribuição de T se pudéssemos calcular T para todos os valores possíveis de (𝑋1, 𝑋2, … , 𝑋𝑛).
• Essa distribuição é chamada distribuição amostral da estatística T e desempenha papel fundamental na teoria da inferência estatística frequentista.
– Obs: Na inferência Bayesiana, busca-se conhecer a
distribuição do próprio parâmetro populacional 𝜃 sem
necessidade do conceito de distribuição amostral; todavia,
essa abordagem não será estudada nesta disciplina. 26

7. Distribuições amostrais
• A distribuição amostral pode ser compreendida esquematicamente conforme figura 10.1 (b), onde se tem:
– Uma variável aleatória X na população segue uma distribuição
de probabilidade 𝑋 ∼ 𝑓(𝑥|𝜃), onde 𝜃 é o parâmetro de
interesse
– Todas as amostras retiradas da população, de acordo com um
procedimento de amostragem pré-definido
– Para cada amostra, calcula-se o valor 𝑡 da estatística 𝑇
– Os valores 𝑡 formam uma nova população, cuja distribuição
recebe o nome de distribuição amostral de 𝑇
27

7. Distribuições amostrais
28
Figura 10.1 (b): Distribuição amostral da estatística T

7. Distribuições amostrais
• Exemplo 10.9:
– Voltemos ao exemplo 10.7, no qual consideramos a seleção
de amostras de tamanho 2, com reposição, da população
{1, 3, 5, 5, 7}
– Consideremos a distribuição da estatística
𝑋 =𝑋1 + 𝑋2
2
– Essa distribuição é obtida com o auxílio da Tabela 10.2
• Por exemplo, 𝑋 = 1 somente ocorre o par (1,1) e portanto
Pr 𝑋 = 1 = 1/25.
• 𝑋 = 3 ocorre para os pares {(1,5), (3,3), (5,1)} e portanto
Pr 𝑋 = 3 =2
25+
1
25+
2
25=
5
25=
1
5.
29

7. Distribuições amostrais
30
• Exemplo 10.9 (cont):

7. Distribuições amostrais
• Exemplo 10.9 (cont):
– Procedendo de maneira análoga para os demais valores que
𝑋 pode assumir, obtemos a Tabela 10.3
31

7. Distribuições amostrais
• Exemplo 10.9 (cont):
– Distribuições amostrais de outras estatísticas de interesse
podem ser obtidas:
– P.ex:
32

7. Distribuições amostrais • Exemplo 10.5 (cont):
– No caso do lançamento de uma moeda 50 vezes, usando
como estatística
Y = número de caras obtidas,
a obtenção da distribuição amostral, que já foi vista, é feita por
meio do modelo binomial 𝐵𝑖𝑛 50, 𝑝 , onde p denota a
probabilidade de ocorrência de cara em um lançamento,
0 < 𝑝 < 1.
– Suponha que, na realização do experimento, obtivemos
Y = 36 caras
– Se a moeda fosse honesta, a probabilidade de se obterem 36
ou mais caras em 50 lançamentos seria da ordem de 1/1000
– Ou seja, se a moeda fosse honesta, o resultado observado
(36 caras) seria muito pouco provável, o que indica que a
probabilidade de cara é maior do que meio, ou seja, 𝑝 > 0,5.
33

7. Distribuições amostrais
• Exemplo 10.5 (cont):
34

7. Distribuições amostrais • Exemplo 10.5 (cont):
– Outra forma de calcular Pr 𝑌 ≥ 36 𝑝 = 0.5 : Simulação
1. Sorteie M valores 𝑌1, 𝑌2, … , 𝑌𝑀, cada qual com distribuição 𝐵𝑖𝑛 50, 𝑝 .
M deve ser um número moderado (p.ex. M=10000)
2. A probabilidade Pr 𝑌 ≥ 36 𝑝 = 0.5 será estimada por
Pr 𝑌 ≥ 36 𝑝 = 0.5 =|𝐴|
𝑀, emque 𝐴 = quant.valores𝑌𝑖 ≥ 36
– Exemplo de script em R:
M = 10000
Y = rbinom(n=M, size=50, prob=0.5)
hist(Y, breaks=100)
prY = length(which(Y>=36)) / M
print(prY)
35

7. Distribuições amostrais
• Exemplo 10.8:
– Considere a retirada de uma AAS de 5 alturas (em cm) de
uma população de mulheres cujas alturas X seguem a
distribuição normal N 167; 25 (𝜇 = 167, 𝜎2 = 25, 𝜎 = 5)
– Qual seria a distribuição amostral da mediana das 5 alturas
retiradas da população?
– Como não podemos gerar todas as possíveis amostras de
tamanho 5 da população, é possível simular, via Excel ou R,
um conjunto grande de amostras de tamanho 5, calcular a
mediana de cada amostra e em seguida calcular algumas
estatísticas de interesse sobre as medianas calculadas
36

7. Distribuições amostrais
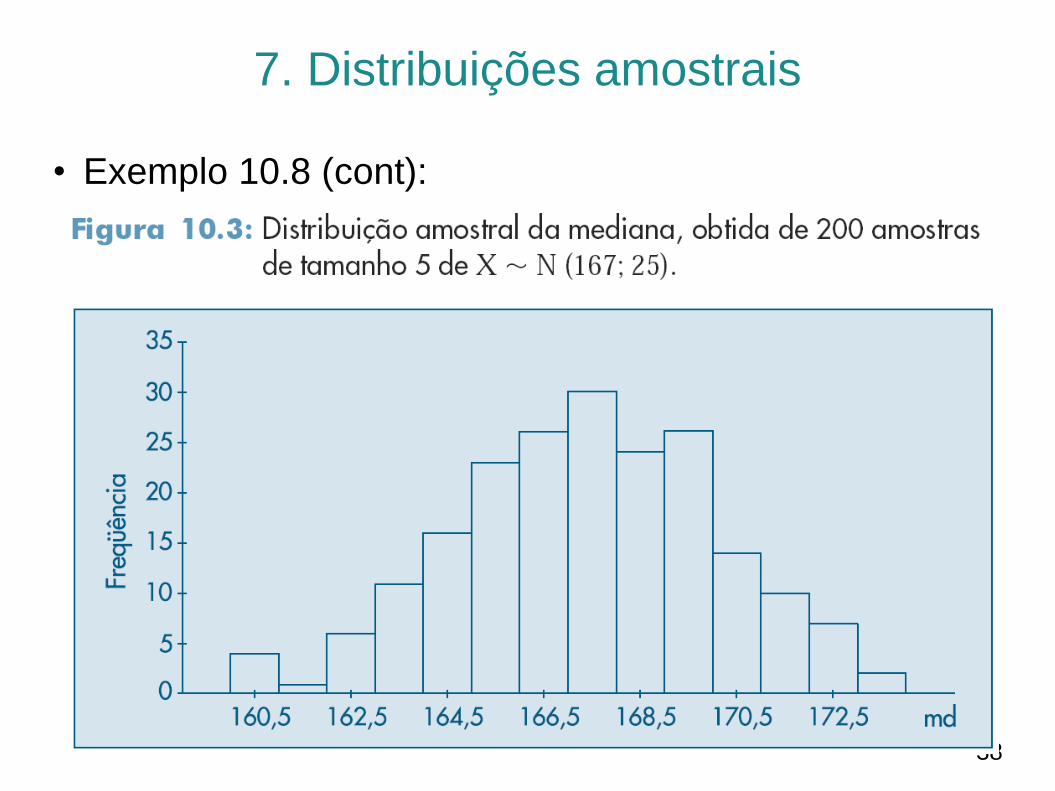
• Exemplo 10.8 (cont):
– No exemplo do livro, os autores geraram 200 amostras de
tamanho 5 (denotadas por 𝑋1, 𝑋2, … , 𝑋200) e obtiveram os
seguintes resultados:
– Os resultados indicam que a distribuição amostral de md deve
ser próxima de uma normal, com média próxima de 𝜇 = 167 e
desvio padrão menor do que 𝜎 = 5.
– Figura 10.3 apresenta o histograma dos valores das medianas
obtidos nas 200 amostras
37
7. Distribuições amostrais
• Exemplo 10.8 (cont):
38

7. Distribuições amostrais
• Exemplo 10.8 (cont):
– Simulação em Excel de amostras deste exemplo para estimar
as distribuições da média e da mediana:
1. Cada amostra 𝑋𝑖 = (𝑋𝑖1, 𝑋𝑖2, 𝑋𝑖3, 𝑋𝑖4, 𝑋𝑖5) é gerada pelo método da
transformação inversa1: Para cada elemento 𝑋𝑖:
a) Gerar um número 𝑈 com distribuição uniforme no intervalo [0,1]
» Excel: função ALEATÓRIO
b) O número 𝑋𝑖 é dado pela equação𝑋𝑖 = 𝐹−1(𝑈), onde 𝐹−1(𝑝) denota aqui o inverso da função de distribuição acumulada normal
com média 167 e desvio padrão 5
» Com esse procedimento, 𝑋𝑖~𝑁(167,25)
» Excel: função INV.NORM.N
– Fórmula em Excel: =INV.NORM.N(ALEATÓRIO(), 167, 5)
• (continua no próximo slide)
39
1Referência:Sheldon Ross. A First Course in Probability. 8th Ed. – Seção 10.2.1

7. Distribuições amostrais
• Exemplo 10.8 (cont):
– Simulação em Excel de amostras deste exemplo para estimar
as distribuições da média e da mediana (cont):
2. Repetir o procedimento 1 para gerar um número grande de amostras
p.ex. 10.000 amostras
3. Calcular a média/mediana para cada amostra
4. Organizar k blocos para o histograma (p.ex. k=20):
– maxmed: máximo das médias (ou das medianas) calculadas sobre as
amostras
– minmed: mínimo das médias (ou das medianas) calculadas sobre as
amostras
– Para i=0 até k:
limite(i) = i * (maxmed-minmed)/k + minmed
5. Gerar o histograma através do suplemento “Análise de Dados”
– Planilha Excel disponível na página da disciplina 40

7. Distribuições amostrais
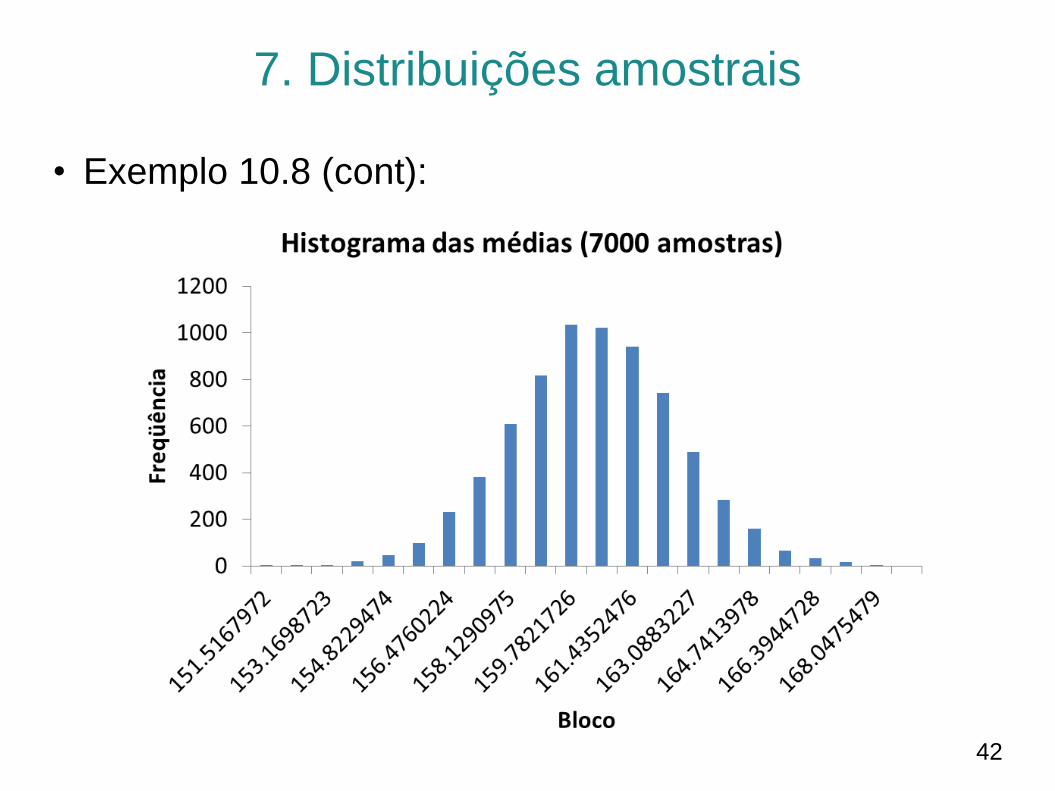
• Exemplo 10.8 (cont):
– Resultados:
• Média:
𝐸 𝑋 = 160.03; 𝑉𝑎𝑟 𝑋 = 4.9; 𝑑𝑝 𝑋 = 2.21; min 𝑋 = 152.51;max 𝑋 = 168.76
• Mediana:
𝐸 𝑚𝑑 = 160.06; 𝑉𝑎𝑟 𝑚𝑑 = 7.11; 𝑑𝑝 𝑚𝑑 = 2.67; min 𝑚𝑑 = 149.62;max 𝑚𝑑 = 169.64
41
7. Distribuições amostrais
• Exemplo 10.8 (cont):
42

7. Distribuições amostrais
• Exemplo 10.8 (cont):
43

7. Distribuições amostrais
• Exemplo 10.8 (cont):
– Script em R para simulação:
mu = 167
sigma = 5
alturas = rnorm(n=5*M, mean=mu, sd=sigma)
X = matrix(alturas, ncol=5)
medias = apply(X, 1, mean)
print(c(mean(medias), var(medias), sd(medias),
min(medias), max(medias)))
hist(medias, breaks=100)
medianas = apply(X, 1, median)
print(c(mean(medianas), var(medianas), sd(medianas),
min(medianas), max(medianas)))
hist(medianas, breaks=100)
44

7. Distribuições amostrais
• Problemas
45

7. Distribuições amostrais
• Problemas
46

8. Distribuição amostral da média
• Estudaremos a distribuição amostral da estatística 𝑋 , a média da amostra
• Consideremos uma população identificada pela variável 𝑋, cujos parâmetros média populacional 𝜇 = 𝐸(𝑋) e variância populacional 𝜎2 = 𝑉𝑎𝑟(𝑋) são supostamente conhecidos
• Vamos retirar todas as possíveis AAS de tamanho n dessa população, e para cada uma calcular a média 𝑋
• Em seguida, consideremos a distribuição amostral e estudemos suas propriedades
47

8. Distribuição amostral da média
• Exemplo 10.10:
– Voltemos ao Exemplo 10.7
– A população {1,3,5,5,7} tem média 𝜇 = 4,2 e variância
𝜎2 = 4,16. A distribuição amostral de 𝑋 está na Tabela 10.3,
da qual obtemos
– Analogamente, encontramos
𝑉𝑎𝑟 𝑋 = 𝑝𝑖𝑖 (𝑥𝑖 − 𝐸 𝑋 )2= 𝑝𝑖𝑖 𝑥𝑖 2 − 𝐸 𝑋 2, resultando em
48

8. Distribuição amostral da média
• Exemplo 10.10:
– Verificamos dois fatos:
• A média das médias amostrais coincide com a média populacional
• A variância de 𝑋 é igual à variância de X, dividida por 𝑛 = 2
– Esses fatos não são casos isolados.
– O resultado a seguir mostra que isso vale no caso geral
49

8. Distribuição amostral da média
50
Obs: As propriedades mencionadas na prova acima são que, se 𝑋1, … , 𝑋𝑛 são variáveis aleatórias independentes, então a média de suas somas é igual à soma de suas médias, e a variância de suas variâncias é igual à soma de suas variâncias

8. Distribuição amostral da média
• O desvio padrão da distribuição amostral de uma estatística 𝑇 = 𝑟(𝑋1, 𝑋2, … , 𝑋𝑛)é usualmente denominado erro padrão
– Termo adotado para evitar confusão entre o desvio padrão de
𝑋e o desvio padrão de 𝑇
– Por essa razão, é usual nos referirmos a 𝜎/ 𝑛 (o desvio
padrão de 𝑋 ) como o erro padrão de 𝑋
51

8. Distribuição amostral da média
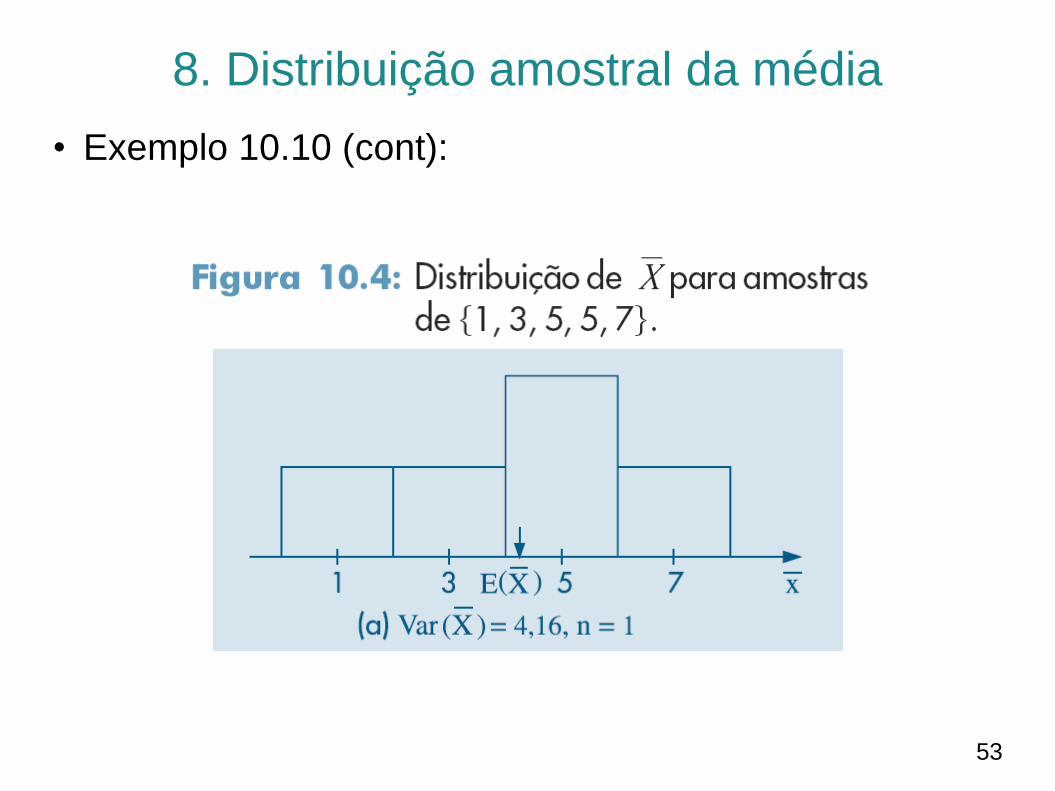
• Exemplo 10.10 (cont):
– Para a população {1,3,5,5,7}, vamos construir os histogramas
das distribuições de 𝑋 para 𝑛 = 1,2 e 3
52
8. Distribuição amostral da média
• Exemplo 10.10 (cont):
53

8. Distribuição amostral da média
• Exemplo 10.10 (cont):
54

8. Distribuição amostral da média
• Exemplo 10.10 (cont):
55

8. Distribuição amostral da média
• Exemplo 10.10 (cont):
– Observe nos histogramas que, conforme o tamanho da
amostra (n) vai aumentando, o histograma tende a se
concentrar cada vez mais em torno de E 𝑋 = 𝐸 𝑋 = 4.2, já
que a variância vai diminuindo.
– Quando n for suficientemente grande, o histograma alisado
aproxima-se de uma distribuição normal.
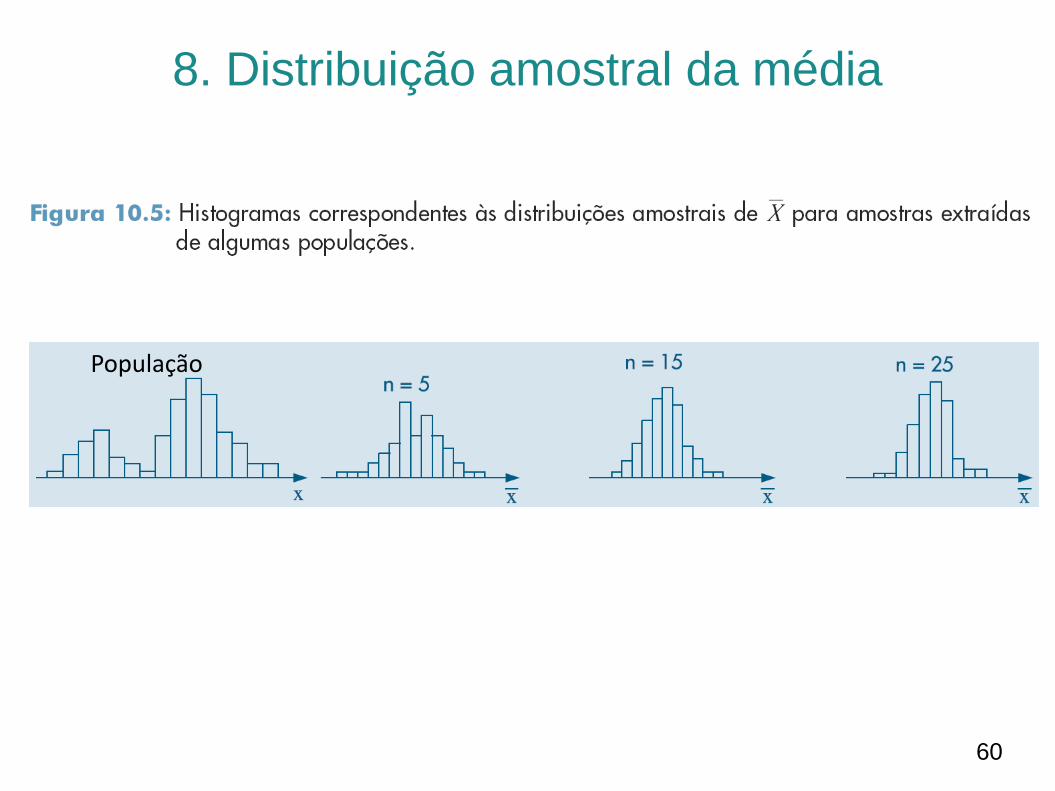
– Essa aproximação pode ser verificada analisando-se os
gráficos da Figura 10.5 (próximos slides), que mostram o
comportamento do histograma de 𝑋 para várias formas da
distribuição da população e vários valores do tamanho da
amostra n.
56

8. Distribuição amostral da média
57

8. Distribuição amostral da média
58
População

8. Distribuição amostral da média
59
População
8. Distribuição amostral da média
60
População

8. Distribuição amostral da média
• As observações empíricas nos gráficos anteriores de que 𝑋 se aproxima de uma distribuição normal para valores grandes de n são consequência do Teorema do Limite Central (TLC), apresentado abaixo:
• Embora não seja apresentada a demonstração desse teorema, o importante é saber como esse resultado pode ser usado
61

8. Distribuição amostral da média
• Exemplo 10.11 (Teorema do Limite Central):
– Suponha que uma máquina empacotadora de café está
regulada para encher pacotes cujos pesos X (em gramas)
devem seguir uma 𝑋 ∼ 𝑁(500,100) – média de 500g e desvio
padrão de 10g
– Denotamos por X o peso de um pacote enchido pela máquina
– Suponha que nosso interesse seja avaliar se essa máquina
está regulada
– Para isso, colhemos uma amostra de 𝑛 = 100 pacotes e
pesando-os
– Pelo Teorema do Limite Central, 𝑋 deverá ter uma distribuição
normal com média 500g e variância 100/100=1, e portanto seu
desvio padrão será de 1g.
62

8. Distribuição amostral da média
• Exemplo 10.11:
– Logo, se a máquina estiver regulada, a probabilidade de
obtermos uma amostra de 100 pacotes com média diferindo
de 500g por uma diferença menor que dois gramas será
onde Z é a transformação de padronização de 𝑋 :
𝑍 =𝑋 − 𝜇
𝜎/ 𝑛
– Ou seja, dificilmente 100 pacotes terão uma média fora do
intervalo (498, 502).
– Se observarmos uma média fora desse intervalo, podemos
considerar como um evento raro, e será razoável supor que a
máquina esteja desregulada.
63

8. Distribuição amostral da média
– No corolário acima, basta notar que se usou a transformação
de padronização de 𝑋
• A variável aleatória 𝑒 = 𝑋 − 𝜇 é chamada erro amostral da média; o resultado abaixo é imediato.
𝑒
𝜎/ 𝑛=
𝑋 − 𝜇
𝜎/ 𝑛∼ 𝑁(0,1)
64

8. Distribuição amostral da média
• O parâmetro 𝜎𝑋 = 𝜎/ 𝑛 é usualmente denominado erro padrão da média amostral 𝑋
– Tecnicamente, esse parâmetro é na realidade o desvio padrão de 𝑋 , mas
usa-se o termo erro padrão para não confundir com o desvio-padrão da
variável original X.
• O Teorema do Limite Central afirma que a distribuição de 𝑋 aproxima-se da distribuição normal quando n tende a infinito
• A rapidez dessa convergência depende da distribuição original da população da qual a amostra é retirada (ver Figura 10;5)
– Se a população original tem uma distribuição próxima da normal, a
convergência é rápida
– Se a população original se afasta muito de uma distribuição normal, a
convergência é mais lenta
• precisamos de amostras maiores
65

8. Distribuição amostral da média
• Problemas:
66
Dicas: Para o item (a), calcule 𝐹−1 0.1 𝜇, 𝜎 = 10), para valores de 𝜇 = 500, 501, 502,… onde 𝐹−1 denota a função quantil (inversa) da distribuição normal; escolha o menor valor de 𝜇 para o qual 𝐹−1 0.1 𝜇, 𝜎 = 10) ≥ 500; para o item (b), calcule Pr(𝑋 < 500)

9. Intervalos de confiança
• Intervalos de confiança são intervalos estatísticos baseados na distribuição amostral de um estimador pontual
• Exemplo 11.12:
– Suponha que queiramos estimar a média 𝜇 de uma população
qualquer, e para tanto usamos a média 𝑋 de uma amostra de
tamanho n. Do TLC,
com 𝑉𝑎𝑟 𝑋 = 𝜎𝑋 2 = 𝜎2/𝑛.
– Desse resultado podemos determinar a probabilidade de
cometermos erros de determinadas magnitudes
67

9. Intervalos de confiança
• Exemplo 11.12 (cont):
– Por exemplo,
ou
que é equivalente a
e, finalmente,
68

9. Intervalos de confiança
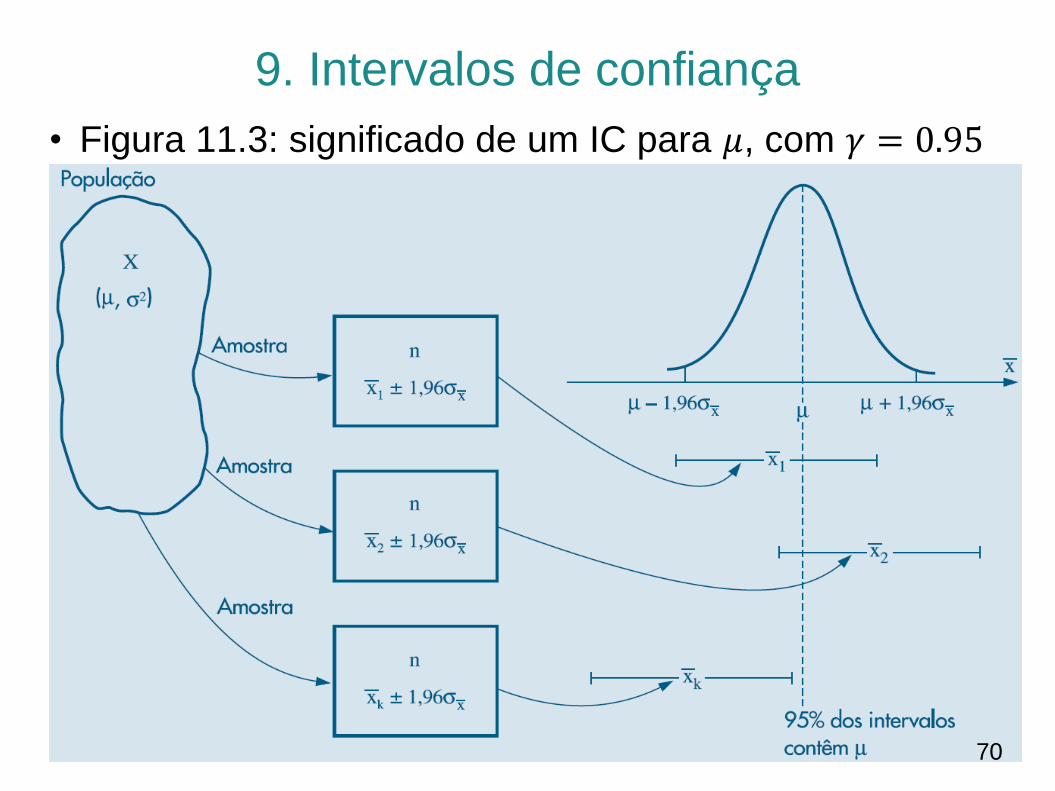
• É importante lembrar que, sob o ponto de vista frequentista, 𝜇 não é uma variável aleatória e sim um parâmetro, e a expressão (11.33) deve ser interpretada da seguinte maneira:
• Se pudéssemos construir uma quantidade grande de intervalos (aleatórios) da forma 𝑋 − 1.96𝜎𝑋 , 𝑋 + 1.96𝜎𝑋 , todos baseados em amostras de tamanho n, 95% deles conteriam o parâmetro 𝜇.
– Figura 11.13 mostra o funcionamento e o significado de um
intervalo de confiança (IC) para 𝜇, com 𝛾 = 0.95 e 𝜎2
conhecido
• Dizemos que 𝛾 é o coeficiente de confiança
• Escolhida uma amostra e encontrada sua média 𝑥 0, e admitindo-se 𝜎2 conhecido, podemos construir o intervalo
𝑥 0 − 1.96𝜎𝑋 , 𝑥 0 + 1.96𝜎𝑋 (11.34)
• Esse intervalo pode ou não conter o parâmetro 𝜇, mas pelo exposto acima temos 95% de confiança de que contenha.
69
9. Intervalos de confiança
• Figura 11.3: significado de um IC para 𝜇, com 𝛾 = 0.95
70

9. Intervalos de confiança
• Para ilustrar, consideremos o seguinte experimento de simulação:
– Foram geradas 20 amostras de tamanho 𝑛 = 25 de uma distribuição
normal com média 𝜇 = 5 e desvio padrão 𝜎 = 3
– Para cada amostra foi construído o intervalo de confiança para 𝜇, com
coeficiente de confiança 𝛾 = 0.95:
𝜎𝑋 =3
25=
3
5= 0.6 ⟹ 1.96𝜎𝑋 = 1.176
ou seja, cada intervalo é da forma 𝑋 ± 1.176
– Figura 11.4 apresenta os intervalos obtidos, dentre os quais 3 intervalos
(amostras 5, 14 e 15) não contêm a média 𝜇 = 5
• Exercício:
– Repetir a simulação descrita acima, com 1000 amostras de tamanho
𝑛 = 25 e demais parâmetros similares ao exemplo
– Calcular a proporção de intervalos contendo a média 𝜇 = 5
71

9. Intervalos de confiança
• Figura 11.4: Intervalos de confiança para a média de uma 𝑁(5,9), para 20 amostras de tamanho 𝑛 = 25
72

9. Intervalos de confiança
• Usando a aproximação pela distribuição normal (Eq. 11.34), para um coeficiente de confiança qualquer 𝛾, teremos que usar
o valor 𝑧𝛾 tal que P −𝑧𝛾 ≤ 𝑍 ≤ 𝑧𝛾 = 𝛾, com 𝑍~𝑁(0,1). O valor
de 𝑧𝛾 é calculado por
𝑧𝛾 = −Φ−11 − 𝛾
2
– Outra forma de calcular 𝑧𝛾: 𝛼 = (1 − 𝛾); 𝑧𝛾 = Φ−1 1 −𝛼
2
• O intervalo fica então:
𝑋 − 𝑧𝛾𝜎𝑋 , 𝑋 + 𝑧𝛾𝜎𝑋 (11.37)
• Observe que a amplitude do intervalo (11.37) é 𝐿 = 2𝑧𝛾𝜎/ 𝑛,
que é uma constante, independente de 𝑋
– Se construirmos vários intervalos de confiança para o mesmo valor de 𝑛, 𝜎
e 𝛾, estes terão extremos aleatórios, mas todos terão a mesma amplitude 𝐿
73

9. Intervalos de confiança
• Se o desvio padrão populacional 𝜎 não for conhecido, podemos substituir em (11.37) 𝜎𝑋 pelo desvio padrão amostral 𝑠, dado por:
𝑠2 =1
𝑛 − 1 (𝑋𝑖 − 𝑋 )2
𝑛
𝑖=1, 𝑠 = 𝑠2
Assim, podemos estimar 𝜎𝑋 por:
𝜎 𝑋 = 𝑠𝑛
– Para n grande, da ordem de 100 ou superior, o intervalo
(11.37) pode ser usado com 𝜎 𝑋 no lugar de 𝜎𝑋
• Em simulação, utiliza-se normalmente 𝑛 ≫ 100, e portanto essa
aproximação pode ser usada sem problemas.
• Quando n é pequeno, é mais adequado construir o intervalo de confiança
usando a distribuição t de Student ao invés da distribuição normal padrão
(assunto não abordado nesta disciplina, pela razão exposta no item
acima). 74