introdução à análise de clusters - técnico lisboa · perguntas que se colocam no decorrer da...
TRANSCRIPT

Introdução à Análise deClusters
JOAO A. BRANCO
Instituto Superior Tecnico
Introducao a Analise de Clusters – p. 0/114

Sumário1. Introdução
2. Medidas de proximidade
3. Métodos gráficos
4. Métodos hierárquicos
5. Métodos não hierárquicos
6. Aplicações
Introducao a Analise de Clusters – p. 1/114

1. Introdução
1.1 Classificação
O que é?Classificação é o verdadeiro ou ideal arranjo em conjuntodaqueles que são iguais, e a separação daqueles que sãodiferentes, sendo que a finalidade deste arranjo é primeira-mente:
(i) formar e conservar o conhecimento,
(ii) analisar a estrutura do fenómeno,
(iii) relacionar entre si os aspectos do fenómeno emquestão.
Introducao a Analise de Clusters – p. 2/114

1. Introdução (cont.)
The science of classification, which dealswith the problems of how classificationsemerge, function and interact, is still un-born. What we have in hand currently isclustering, the discipline aimed at revealingclassifications in observed real-world data.
Introducao a Analise de Clusters – p. 3/114

1. Introdução (cont.)
1.2 Análise de clusters (AC)
O que é?
objectos −→ grupos (clusters)
H H M M M H H M H M• • • • • • • • • •
Introducao a Analise de Clusters – p. 4/114

1. Introdução (cont.)
Exemplos de clusters
(a) (b)
Introducao a Analise de Clusters – p. 5/114

1. Introdução (cont.)
Exemplos de clusters
(c) (d)
Introducao a Analise de Clusters – p. 6/114

1. Introdução (cont.)
Exemplos de clusters
(e) (f)
Introducao a Analise de Clusters – p. 7/114

1. Introdução (cont.)
Objectivos da AC
Exploração dos dados
Redução de dados
Geração de hipóteses
Predição
Introducao a Analise de Clusters – p. 8/114

1. Introdução (cont.)
Outras designações para AC
Aprendizagem não supervisionada
Taxonomia numérica
Classificação automática
Classificação
Introducao a Analise de Clusters – p. 9/114

1. Introdução (cont.)
Aplicações
Áreas tradicionais:
Biologia, Arqueologia, Sismologia,Medicina, Psiquiatria
Novos desafios:
Análise de mercados, Dados demicroarrays, Data mining, Classificação dedocumentos
Introducao a Analise de Clusters – p. 10/114

1. Introdução (cont.)1.3 Dados
Dois tipos de informação (formato das matrizesiniciais)
Matriz de dadosDist. Campo
Planetaao Sol
Diâm. Massa Dens. Grav. Trans. Rot. Satél. Anéis Superf.Magnét.
Mercúrio 0.387 0.383 0.0553 0.984 0.378 0.241 58.8 0 Não Sólida Sim
Vénus 0.723 0.949 0.815 0.951 0.907 0.615 -244 0 Não Sólida Não
Terra 1 1 1 1 1 1 1 1 Não Sólida Sim
Marte 1.52 0.533 0.107 0.713 0.377 1.88 1.03 2 Não Sólida Não
Júpiter 5.20 11.21 317.8 0.240 2.36 11.9 0.415 61 Sim Líquida Sim
Saturno 9.58 9.45 95.2 0.125 0.916 29.4 0.445 31 Sim Líquida Sim
Urano 19.20 4.01 14.5 0.230 0.889 83.7 -0.720 26 Sim Mista Sim
Neptuno 30.05 3.88 17.1 0.297 1.12 163.7 0.673 13 Sim Líquida Sim
Plutão 39.24 0.187 0.0021 0.317 0.059 248.0 6.41 1 Não Sólida -
Introducao a Analise de Clusters – p. 11/114

1. Introdução (cont.)
Matriz de dissemelhanças
obtida a partir da matriz de dadosMercúrio Vénus Terra Marte Júpiter Saturno Urano Neptuno
Vénus 0.950
Terra 1.128 0.210
Marte 0.314 0.846 1.048
Júpiter 317.930 317.152 316.965 317.873
Saturno 95.580 94.770 94.582 95.512 222.607
Urano 14.912 14.040 13.853 14.815 303.385 80.883
Neptuno 17.413 16.558 16.371 17.324 300.789 78.299 2.604
Plutão 0.697 1.265 1.457 0.536 317.989 95.648 14.994 17.492
Introducao a Analise de Clusters – p. 12/114

1. Introdução (cont.)
observada directamente
Cenário
1 Sofrimento pela morte da mãe
2 Saboreando coca-cola
3 Uma surpresa agradável
4 Amor maternal – bebé nos braços
5 Cansaço físico
6 Apercebe-se que há qualquer coisa errada com o avião
7 Acesso de cólera ao ver bater num cão
8 Embaraço – vontade de se esconder
9 Inesperadamente encontra um antigo namorado
10 Mudança súbita de humor
11 Dor intensa
12 Apercebe-se que o avião vai cair
13 Ligeiro descanso
Introducao a Analise de Clusters – p. 13/114

1. Introdução (cont.)
1 2 3 4 5 6 7 8 9 10 11 12
2 4.05
3 8.25 2.54
4 5.57 2.69 2.11
5 1.15 2.67 8.98 3.78
6 2.97 3.88 9.27 6.05 2.34
7 4.34 8.53 11.87 9.78 7.12 1.36
8 4.90 1.31 2.56 4.21 5.90 5.18 8.47
9 6.25 1.88 0.74 0.45 4.77 5.45 10.20 2.63
10 1.55 4.84 9.25 4.92 2.22 4.17 5.44 5.45 7.10
11 1.68 5.81 7.92 5.42 4.34 4.72 4.31 3.79 6.58 1.98
12 6.57 7.43 8.30 8.93 8.16 4.66 1.57 6.49 9.77 4.93 4.83
13 3.93 4.51 8.47 3.48 1.60 4.89 9.18 6.05 6.55 4.12 3.51 12.65
Introducao a Analise de Clusters – p. 14/114

1. Introdução (cont.)
1.4 Fases de uma AC1. Selecção de objectos2. Selecção de variáveis3. Transformação de
variáveis
4. Construção da medidade dissemelhança/semelhança
5. Escolha do método aaplicar aos dados
6. Discussão e apresentaçãodos resultados
Número de clustersValidação/descrição/interpretação
?
Gráfico Hierárquico Partição Outro
? ?
Matriz dedados
Matriz dedissemelhanças
-
��
��
���
@@
@@
@@@R
Objectos
Introducao a Analise de Clusters – p. 15/114

1. Introdução (cont.)
Perguntas que se colocam no decorrer da análise
(i) Como seleccionar os objectos?
(ii) Que variáveis devem ser incluídas?
(iii) Que medida de dissemelhança deve ser usa-da?
(iv) Qual a forma mais clara de apresentar os re-sultados e como proceder de forma convin-cente à sua validação?
Introducao a Analise de Clusters – p. 16/114

2. Medidas deproximidade
2.1 Introdução
Proximidade
Semelhança
Dissemelhança
Dissemelhança:
1. dij ≥ 0, ∀i,j2. dii = 0, ∀i3. dij = dji, ∀i,j (simétrica)
Introducao a Analise de Clusters – p. 17/114

2. Medidas deproximidade (cont.)
4. dij ≤ dik + dkj, ∀i,j,k (triangular)5. dij = 0 sse i = j
6. dij ≤ max (dik, djk) , ∀i,j,k (ultramétrica)
Semelhança:
1. sij ≥ 0, ∀i,j2. sij = sji, ∀i,j3. sij é tanto maior quanto maior for a
semelhança entre os objectos.
Introducao a Analise de Clusters – p. 18/114

2. Medidas deproximidade (cont.)
Exemplo – Matriz de semelhanças (observação directa)
Frequências absolutas do número de estudantes que escolheu
cada par de universidades:
U1 U2 U3 U4 U5 U6
U1
U2 13
U3 22 0
U4 10 61 18
U5 150 25 120 7
U6 15 12 5 19 23
Introducao a Analise de Clusters – p. 19/114

2. Medidas deproximidade (cont.)
Relação entre sij e dij:
sij -função decrescente dij = k − sij
sij =k
k+dij�função decrescente dij
Introducao a Analise de Clusters – p. 20/114

2. Medidas deproximidade (cont.)
2.1 Medidas de proximidade entre objectos
Variáveis quantitativas
Dissemelhanças derivadas da distância euclidiana
Dados: X = [xij], i = 1, . . . , n e j = 1, . . . , p
dij =
[
p∑
k=1
(xik − xjk)2
]1
2
=[
(xi − xj)′ (xi − xj)
]1
2
Introducao a Analise de Clusters – p. 21/114

2. Medidas deproximidade (cont.)
Exemplo (idade e altura de três pessoas):
Nome Idade Altura (cm)
Pedro 18 165
António 19 198
José 20 181
d12 = [(18 − 19)2 + (165 − 198)2]1/2 (cm)d12 = [(18 − 19)2 + (1.65 − 1.98)2]1/2 (m)
Altura (cm) Altura (m)
d12 33.015 1.053
d13 16.125 2.006
d23 17.029 1.014
Introducao a Analise de Clusters – p. 22/114

2. Medidas deproximidade (cont.)
Distância euclidiana ponderada
dij =[
(xi − xj)′A (xi − xj)
]1
2
A = I, distância euclidiana
A = 1pI, distância euclidiana média
A = D−1 =[
diag(s21, s22, . . . , s
2p)]
−1, distância euclidiana
estandardizada
A = S−1, distância de Mahalanobis
A = R−1 =[
diag(r21, r22, . . . , r
2p)]
−1,
com rk = maxi,j |xik − xjk|Introducao a Analise de Clusters – p. 23/114

2. Medidas deproximidade (cont.)
Exemplo (Densidade e gravidade dos planetas):
Planeta Dens. Grav.
Mercúrio 0.984 0.378
Vénus 0.951 0.907
Terra 1 1
Marte 0.713 0.377
Júpiter 0.240 2.36
Saturno 0.125 0.916
Urano 0.230 0.889
Neptuno 0.297 1.12
Plutão 0.317 0.059
Distância da Terra a Marte
A = I: 0.686
A = 12I: 0.485
A = D−1: 1.231
A = S−1: 1.470
A = R−1: 0.425
Introducao a Analise de Clusters – p. 24/114

2. Medidas deproximidade (cont.)
Dissemelhanças usando métricas de Minkowski
dij =
[
p∑
k=1
|xik − xjk|r]
1
r
, r ≥ 1
r = 1−→ L1 (city-block/taxicab/Manhattan)
r = 2−→ L2 (distância euclidiana)
r → ∞−→ L∞ = limr→∞ dij = supk=1,...,p |xik − xjk| (supremo)
Introducao a Analise de Clusters – p. 25/114

2. Medidas deproximidade (cont.)
Posição relativa de pontos à distância unitária de um outroponto O, segundo as métricas L1, L2 e L∞:
-
6
O1 1
1
1�
��
L∞
L1
L2
Introducao a Analise de Clusters – p. 26/114

2. Medidas deproximidade (cont.)
Interpretação geométrica das métricas L1, L2 e L∞:
-
6
O
y
x
q
q
P2
P1
-
6
O
y
x
q
q
P2
P1���
-
6
O
y
x
q
q
P2
P1
Métrica L1 Métrica L2 Métrica L∞
Introducao a Analise de Clusters – p. 27/114

2. Medidas deproximidade (cont.)
Outras dissemelhanças
Métrica de Camberra: dij =p
∑
k=1
|xik − xjk|xik + xjk
com dij = 0 se xik = xjk = 0
Métrica de Gower: dij =p
∑
k=1
|xik − xjk|rk
Coeficiente de correlação:
rij =
∑p
k=1 (xik − xi·) (xjk − xj·)[∑p
k=1 (xik − xi·)2 ∑p
k=1 (xjk − xj·)2]
1
2
Introducao a Analise de Clusters – p. 28/114

2. Medidas deproximidade (cont.)
Variáveis qualitativas
nominais (com 2 e mais níveis)
ordinais
• Variáveis binárias (Exemplo – Duas universidades observadas em
10 características):
Variáveis
Univ. X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12 X13
i 1 0 1 1 1 0 1 1 1 1 0 1 0
j 1 1 0 0 1 0 1 1 0 1 1 0 0
Introducao a Analise de Clusters – p. 29/114

2. Medidas deproximidade (cont.)
No. de pares (1, 1), (1, 0), (0, 1) e (0, 0) para v. binárias:
objecto j1 0
1 a b a+ bobjecto i
0 c d c+ d
a+ c b+ d p = a+ b+ c+ d
a distância euclidiana média (para o exemplo) é
dij =
[
1
13
13∑
i=1
(xik − xjk)2
]
1
2
=
(
b+ c
a+ b+ c+ d
)1
2
= 0.680.
dij - dissemelhança; sij = (a+ d)/p - semelhança
Introducao a Analise de Clusters – p. 30/114

2. Medidas deproximidade (cont.)
Três coeficientes de semelhança (de uma longa lista)Jacard:
sij =a
a+ b+ c(= 0.45)
Sorenson:
sij =2a
2a+ b+ c(= 0.62)
Concordância simples:
sij =a+ d
a+ b+ c+ d(= 0.54)
Introducao a Analise de Clusters – p. 31/114

2. Medidas deproximidade (cont.)
• Variáveis nominais com mais de 2 níveis (Exemplo):
Variáveis nominais
cor do cabelo altura aparência
Níveis P C L R B M A C R M
Variáveis
binárias
sim
não
1
0
1
0
1
0
1
0
1
0
1
0
1
0
1
0
1
0
1
0
Homens
A
B
1
0
0
0
0
1
0
0
0
0
1
0
0
1
0
0
1
1
0
0
Homem A: cabelo preto, altura média, aparência razoávelHomem B: cabelo louro, alto, aparência razoável
Introducao a Analise de Clusters – p. 32/114

2. Medidas deproximidade (cont.)
homem B1 0
1 1 2homem A
0 2 5
Jacard: sAB =1
1 + 2 + 2= 0.2
Sorenson: sAB =2
2 + 3 + 2= 0.33
Concordancia simples: sAB =1 + 5
10= 0.6
Introducao a Analise de Clusters – p. 33/114

2. Medidas deproximidade (cont.)
Outros métodos:
sAB =c
p
sAB =
p∑
k=1
lk I (yk(A), yk(B))
p∑
k=1
lk
Introducao a Analise de Clusters – p. 34/114

2. Medidas deproximidade (cont.)
Variáveis ordinais
Bassab et al. (1990): ordenam-se os níveis davariável (1, 2, . . . , l)
dAB =|r − s|
l
sAB = 1− |r − s|l
Introducao a Analise de Clusters – p. 35/114

2. Medidas deproximidade (cont.)
Variáveis de tipos diferentesEstratégia de RomesburgRealizar análises separadasReduzir todas as variáveis a variáveis bináriasConstruir um coeficiente de semelhança combinado
sij = ω1sqij + ω2s
nij + ω3s
oij
sij =
p∑
k=1
ωijksijk
p∑
k=1
ωijk
(Gower)
Introducao a Analise de Clusters – p. 36/114

2. Medidas deproximidade (cont.)
2.3 Medidas de proximidade entre variáveis
Variáveis quantitativas
sij =
∑n
k=1 xkixkj
(∑n
k=1 x2ki
∑n
k=1 x2kj
)1
2
= cosα
rij =
∑n
k=1 (xki − x·i) (xkj − x·j)[∑n
k=1 (xki − x·i)2 ∑n
k=1 (xkj − x·j)2]
1
2
Introducao a Analise de Clusters – p. 37/114

2. Medidas deproximidade (cont.)
Variáveis qualitativasVariáveis binárias
j1 0
1 a b a+ bi
0 c d c+ d
a+ c b+ d a+ b+ c+ d
sij =a
√
(a+ b)(a+ c)= cosα rij =
ad− bc
[(a+ b)(c+ d)(a+ c)(b+ d)]1
2
Introducao a Analise de Clusters – p. 38/114

2. Medidas deproximidade (cont.)
Variáveis nominais (mais de 2 níveis)
h1 2 · · · s
12
g... nij (fij) ni· (fi·)r
n·j (f·j) n (1)
χ2 = nr
∑
i=1
s∑
j=1
(fij − fi·f·j)2
fi·f·jφ2 =
χ2
n
Introducao a Analise de Clusters – p. 39/114

2. Medidas deproximidade (cont.)
Variáveis ordinais
rs = 1−6
n∑
k=1
d2k
n(n2 − 1)
dk é a diferença entre as ordens (ranks) dos valores que oobjecto k assume nas duas variáveis i e j.
Introducao a Analise de Clusters – p. 40/114

2. Medidas deproximidade (cont.)
2.3 Considerações de ordem prática
Selecção de objectos
Selecção de variáveis
Estandardização
Escolha da medida de proximidade
Dados omissos
Introducao a Analise de Clusters – p. 41/114

2. Medidas deproximidade (cont.)
Estandardização: sim ou não?
Dados não estandardizados Dados estandardizados
5 10 15 20 25 30
510
1520
2530
x1
x2
−2 −1 0 1 2
−2
−1
01
2
x1 (estand.)
x2 (
esta
nd.)
Introducao a Analise de Clusters – p. 42/114

3. Métodos gráficos
3.1 IntroduçãoObjectivo: vizualizar os clusters a partir da representação
gráfica dos objectos ou das variáveis.
Sete objectos e três clusters
A1
A2
A3
A4
A5A6
A7
Sem estrutura aparente de grupos
Introducao a Analise de Clusters – p. 43/114

3. Métodos gráficos(cont.)
Limitações
Usa espaços de dimensão ≤ 3
Difícil para muitos objectos
Método subjectivo
Interessam métodos analíticos e automáticospara qualquer número de objectos e dimen-sões.
Introducao a Analise de Clusters – p. 44/114

3. Métodos gráficos(cont.)
3.2 Representação gráfica directa
1 vari avel
Histograma
Outros gráficos (barras, caule e folhas, circulares,etc.)
2 vari aveis
Diagrama de dispersão
3 ou mais vari aveis
Introducao a Analise de Clusters – p. 45/114

Energia Proteínas Lípidos Cálcio Ferro(kcal) (g) (g) (mg) (mg)
Azeite 900 0 100 0.1 0.05Manteiga 770 0 85 13 0.2Pescada 85 19 1 25 0.9Vaca 208 18 15 12 1.5Frango 158 20 8.5 18 1.8Leite 57 3 3 126 0.1Iogurte 59 3.2 3.2 125 0.2Q. flamengo 316 26 23.2 800 0.8Q. serra 392 26 32 800 1.2Arroz 350 7.5 0.5 10 0.5Pão 258 7 0.6 24 1.6Feijão 290 20 1.2 170 6.5Açúcar 400 0 0 15 1Massas 365 10 0.5 20 1Alface 22 1.8 0.2 70 1.5Cebola 22 0.9 0.2 31 0.5Espinafres 22 2.6 0.9 104 3.6Cenoura 22 0.6 0 104 3.6Batata 90 2.5 0 9 0.2Couve 30 2.9 0.5 234 1.8
Introducao a Analise de Clusters – p. 46/114

3. Métodos gráficos(cont.)
Análise gráfica:
5 histogramas
10 diagramas de dispersão
Introducao a Analise de Clusters – p. 47/114

Energia
0 5 10 15 20 25 0 200 400 600 800
020
060
0
05
1015
2025
Proteinas
Lipidos
020
4060
80
020
040
060
080
0
Calcio
0 200 400 600 800 0 20 40 60 80 100 0 1 2 3 4 5 6
01
23
45
6
Ferro
Introducao a Analise de Clusters – p. 48/114

3 maneiras engenhosasCaras de Chernoff: objecto — cara
azeite manteiga pescada vaca frango
leite iogurte q.flamengo q.serra arroz
pao feijao acucar massas alface
cebola espinafres cenoura batata couve
Introducao a Analise de Clusters – p. 49/114

Estrelas: objecto — círculo (estrela)
azeite manteiga pescada vaca frango
leite iogurte q.flamengo q.serra arroz
pao feijao acucar massas alface
cebola espinafres cenoura batata couve
Introducao a Analise de Clusters – p. 50/114

Curvas de Andrews: objecto — função harmónica
fr(t) =xr1√2+xr2 sen t+xr3 cos t+xr4 sen (2t)+xr5 cos(2t)+· · ·
−π < t < π
−3 −2 −1 0 1 2 3
−3−2
−10
12
3
1
2
8
912
Introducao a Analise de Clusters – p. 51/114

3. Métodos gráficos(cont.)
Outras ideias
grifos, caixas, bolhas, perfis, contornos
Introducao a Analise de Clusters – p. 52/114

3. Métodos gráficos(cont.)
3.3 Representação gráfica indirecta
Métodos da AM−→ redução do número de dimensõesdo espaço de trabalho inicial
Interessam espaços de baixa dimensão (em geral 2) onde osobjectos podem ser visualizados
Componentes principaisMatriz de correlações dos alimentos:
CP1 – contraste: Energia + Lípidos versus restantes
CP2 – média (ponderada) das 5 variáveis observadas
Introducao a Analise de Clusters – p. 53/114
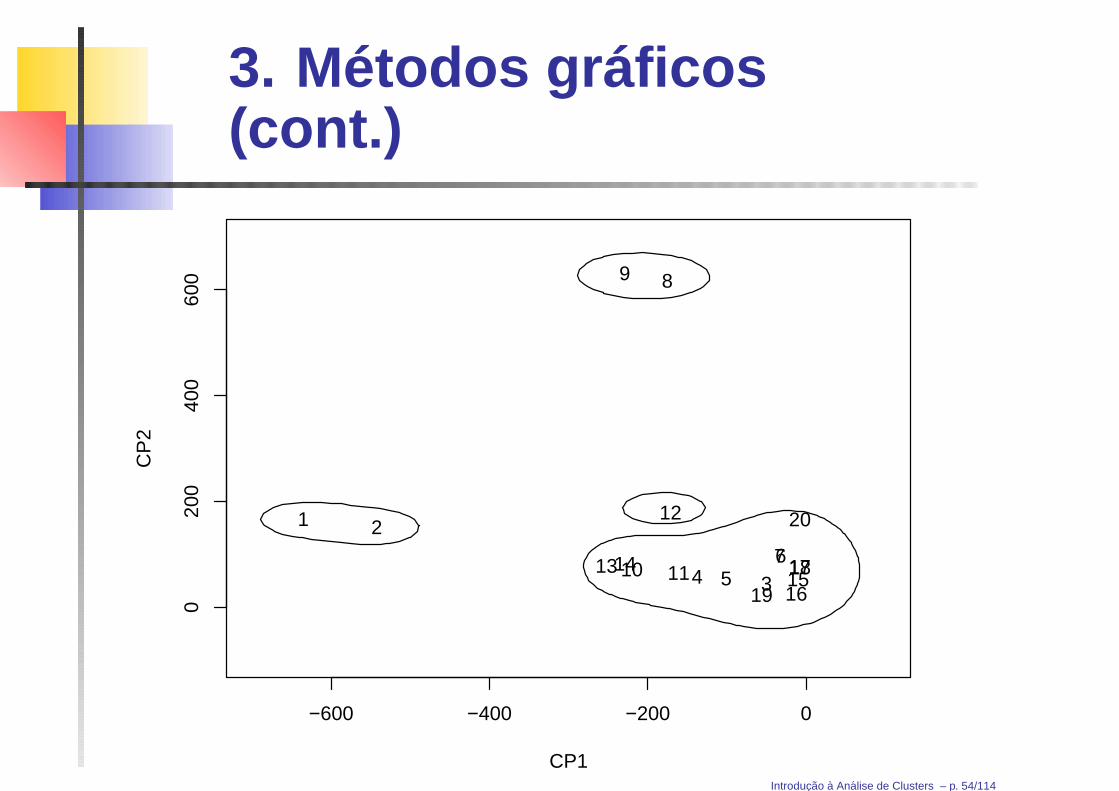
3. Métodos gráficos(cont.)
−600 −400 −200 0
020
040
060
0
CP1
CP
2
1 2
34 567
89
10 11
12
131415161718
19
20
Introducao a Analise de Clusters – p. 54/114

Multidimensional scaling (MDS)matriz de dissemelhanças das expressões da face
−6 −4 −2 0 2 4 6
−4
−2
02
4
Dim 1
Dim
2
1
2
3
4
5
6
7
8
9
10
11
12
13
Introducao a Analise de Clusters – p. 55/114

3. Métodos gráficos(cont.)
Análise factorialmatriz de correlações de oito características físicas
Variável 1 2 3 4 5 6 7 8
1. Altura 1.000
2. Envergadura 0.846 1.000
3. Antebraço 0.805 0.881 1.000
4. Tíbia 0.859 0.826 0.801 1.000
5. Peso 0.473 0.376 0.380 0.436 1.000
6. Anca 0.398 0.326 0.319 0.329 0.762 1.000
7. Peito-c 0.301 0.277 0.237 0.327 0.730 0.583 1.000
8. Peito-d 0.382 0.415 0.345 0.365 0.629 0.577 0.539 1.000
Introducao a Analise de Clusters – p. 56/114

3. Métodos gráficos(cont.)
Estimativas dos loadings correspondentes à análise facto-rial de oito características físicas:
FactoresVariáveis 1 2
1 0.856 −0.324
2 0.848 −0.410
3 0.809 −0.409
4 0.831 −0.342
5 0.746 0.563
6 0.632 0.496
7 0.570 0.513
8 0.608 0.353Introducao a Analise de Clusters – p. 57/114

3. Métodos gráficos(cont.)
6
-
F2
F1
.2 .4 .6 .8 1.0
.2
.4
.6
.8
1.0
-.2
-.4
r
rr
r
r
rr
r
1
23
4
567
8
Introducao a Analise de Clusters – p. 58/114

4. Métodos hierárquicos(MH)
4.1 IntroduçãoMH – dois grupos ou são disjuntos ou um deles está contidono outroDois procedimentos para MH:
aglomerativosn objectos (grupos singulares) −→ 1 grupo final
divisivos1 grupo (c/ n objectos) −→ grupos singulares
Resultado: estrutura hierárquica representada por um grá-fico em 2 dimensões (dendrograma)
Introducao a Analise de Clusters – p. 59/114

4. Métodos hierárquicos(cont.)
dis
tância
sentre
grupos
Raiz
RamosObjectosGrupos
s
r
1 2 3 4 5 6 7 8 9A A A B B C C C C
0.5
1.0
2.0
3.0
4.5
6.0
8.0
12.0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
d∗ - nível mínimo a que
os objectos se ligam
para formar novo cluster
d∗67 = d67 = 1,
d∗68 = 2, d∗65 = 8
d∗ satisfaz a desigual-
dade ultramétrica,
d∗ij ≤ max(d∗ik, d∗
kj), ∀i,j,k
Introducao a Analise de Clusters – p. 60/114

4. Métodos hierárquicos(cont.)
4.2 Procedimentos aglomerativos(são os mais populares)
Algoritmo:
Passo 1: n objectos (grupos singulares). Distância entregrupos ≡ D = [dij ].
Passo 2: Identificar menor elemento de D, o par correspon-dente, A e B, e a distância dAB.
Passo 3: Unir A e B à distância dAB. Actualizar D. (Qual adistância de (AB) aos restantes grupos?)
Passo 4: Repetir 2 e 3 n−1 vezes até obter um único grupo.Introducao a Analise de Clusters – p. 61/114

4. Métodos hierárquicos(cont.)
Três métodos muito comuns:
1
2
3 4
5
6
7
(1) Ligação simplesdAB
A B
Introducao a Analise de Clusters – p. 62/114

4. Métodos hierárquicos(cont.)
Três métodos muito comuns:
1
2
3 4
5
6
7
(2) Ligação completadAB
A B
Introducao a Analise de Clusters – p. 63/114

4. Métodos hierárquicos(cont.)
Três métodos muito comuns:
1
2
3 4
5
6
7
(3) Ligação média
dAB = 112[(d15 + d16 + d17) + (d25 + d26 + d27)+
+(d35 + d36 + d37) + (d45 + d46 + d47)]
A B
Introducao a Analise de Clusters – p. 64/114

4. Métodos hierárquicos(cont.)
Ligação simples
dAB = min {dij : i ∈ A, j ∈ B}
Ligação completa
dAB = max {dij : i ∈ A, j ∈ B}
Ligação média
dAB =
nA∑
i=1
nB∑
j=1
dij
nAnB
Introducao a Analise de Clusters – p. 65/114

4. Métodos hierárquicos(cont.)
Ligação simples (ilustração):
Dados artificiais (5 objectos hipotéticos)
D = [dij ] =
1 2 3 4 5
1
2
3
4
5
0
7 0
4 2 0
8 5 8 0
3 10 9 1© 0
Novo cluster: (45)
Introducao a Analise de Clusters – p. 66/114

4. Métodos hierárquicos(cont.)
d(45)1 = min (d41, d51) = min (8, 3) = 3
d(45)2 = min (d42, d52) = min (5, 10) = 5
d(45)3 = min (d43, d53) = min (8, 9) = 8
D1 =
1 2 3 (45)
1
2
3
(45)
0
7 0
4 2© 0
3 5 8 0
Novo cluster: (23)
Introducao a Analise de Clusters – p. 67/114

4. Métodos hierárquicos(cont.)
d(23)1 = min (d21, d31) = min (7, 4) = 4
d(23)(45) = min(
d2(45), d3(45))
= min (5, 8) = 5
D2 =
1 (23) (45)
1
(23)
(45)
0
4 0
3© 5 0
Novo cluster: (145)
Introducao a Analise de Clusters – p. 68/114

4. Métodos hierárquicos(cont.)
d(145)(23) = min(
d1(23), d(45)(23))
= min(4, 5) = 4
D3 =
(23) (145)
(23)
(145)
0
4© 0
Novo e último cluster: (12345)
Introducao a Analise de Clusters – p. 69/114

4. Métodos hierárquicos(cont.)
Resultado – Dendrograma (mostra a sequência de passose os níveis de fusão):
12 3 4 5
01
23
4
D
Introducao a Analise de Clusters – p. 70/114

4. Métodos hierárquicos(cont.)
Propriedades da ligação simples:
Simples e geral (detecta grupos de forma muitovariada)
Dois objectos chegam para determinar a distânciaentre grupos
Detecta outliers
Não é capaz de isolar grupos cuja separação não sejanítida (efeito de cadeia)
Introducao a Analise de Clusters – p. 71/114

4. Métodos hierárquicos(cont.)
Propriedades da ligação simples (cont.):
Não robusto (adição de dados pode alterarcompletamente o resultado)
É capaz de isolar grupos de forma não elíptica
Indiferente a empates (comportamento robusto)
Invariante em relação a transformações monótonas dasdistâncias
Introducao a Analise de Clusters – p. 72/114

4. Métodos hierárquicos(cont.)
A função agnes (package cluster do R) produz aindaGráfico em bandeira (fornece a mesma informação do
dendrograma)
D
Coeficiente aglomerativo = 0.55
0.0 0.4 0.8 1.2 1.6 2.0 2.4 2.8 3.2 3.6 4.0
3
2
5
4
1
Para os 5 objectos
(método da ligação
simples)
Introducao a Analise de Clusters – p. 73/114

4. Métodos hierárquicos(cont.)
Coeficiente aglomerativo, AC (medida da magnitude daestrutura existente)
AC = 1, máximo da estrutura
AC = 0, não há estrutura
AC aumenta com a presença de outliers (mas ográfico mostra os outliers)
Introducao a Analise de Clusters – p. 74/114

4. Métodos hierárquicos(cont.)
Outros métodos hierárquicos:
Centróide (distância entre 2 grupos = distância entreos seus centróides)
dAB = d(xA, xB)
com
xA =
∑
i∈A xi
nA
e xB =
∑
i∈B xi
nB
Mediana (semelhante ao centróide mas x = (xA+xB)/2
para evitar que o grupo maior engula o menor, ficandoeste sem identidade)
Introducao a Analise de Clusters – p. 75/114

4. Métodos hierárquicos(cont.)
WardCritério: incremento da soma dos quadrados queocorre quando se unem dois clusters,SSWC − (SSWA + SSWB), com C = A ∪ B e
SSWH =∑
i∈H
p∑
j=1
(xijH − xjH)2 , H = A,B,C
Em cada passo formar todos os pares de clustersJuntar os dois clusters a que corresponde o menorincremento
Introducao a Analise de Clusters – p. 76/114

4. Métodos hierárquicos(cont.)
Resultado dos 6 métodos sobre os 5 objectos hipotéticos
Ligação simples Ligação completa
2 3 1 4 5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
D
4 5 1 2 3
02
46
810
D
Introducao a Analise de Clusters – p. 77/114

4. Métodos hierárquicos(cont.)
Resultado dos 6 métodos sobre os 5 objectos hipotéticos
Ligação média Centróide
4 5 1 2 3
12
34
56
7
D
4 5 1 2 3
12
34
5
D
Introducao a Analise de Clusters – p. 78/114

4. Métodos hierárquicos(cont.)
Resultado dos 6 métodos sobre os 5 objectos hipotéticos
Mediana Ward
4 5 1 2 3
12
34
5
D
4 5 1 2 3
02
46
810
12
D
Todos os métodos revelam três grupos
Introducao a Analise de Clusters – p. 79/114

O processo manual é geralmente impraticável epor isso não há AC sem computador
vaca porco carneiro aves outra
Áustria 18 56 1 18 1
Bélg.+Lux. 20 46 2 18 4
Dinamarca 22 63 1 21 1
Finlândia 12 32 0 15 3
França 25 37 4 26 6
Alemanha 10 54 1 19 2
Grécia 19 32 13 20 1
Holanda 19 43 1 22 0
Irlanda 17 39 5 31 2
Itália 23 38 2 18 5
Portugal 15 44 3 32 3
Espanha 13 66 6 27 3
Suécia 21 35 1 13 3
Reino Unido 19 25 6 29 0
Introducao a Analise de Clusters – p. 80/114

Dendrogram
apara
paísesda
UE
(método
daligação
simples)
Austria
Bel+Lux
Dinamarca
Finlandia
Franca
Alemanha
Grecia
Holanda
Irlanda
Italia
Portugal
Espanha
Suecia
Reino Unido
0 2 4 6 8 10 12 14
D
Introducaoa
Analise
deC
lusters–
p.81/114

4. Métodos hierárquicos(cont.)
Fórmula de recorrência de Lance-Williams:
dC(AB) = αAdCA + αBdCB + βdAB + γ |dCA − dCB|
Vantagem computacional (a matriz de dissemelhançasé actualizada em cada passo sem ser necessário man-ter a informação inicial)
Dá acesso a muitos métodos e soluções o que é umadesvantagem em termos de decisão e escolha
Introducao a Analise de Clusters – p. 82/114

4. Métodos hierárquicos(cont.)
Particularizando os valores dos parâmetros obtêm-se osmétodos anteriores:Método αA αB β γ
Ligação simples 12
12 0 −1
2
Ligação completa 12
12 0 1
2
Ligação média nA
nA+nB
nB
nA+nB0 0
Centróide nA
nA+nB
nB
nA+nB− nAnB
(nA+nB)20
Mediana 12
12 −1
4 0
Ward nC+nA
nC+nA+nB
nC+nB
nC+nA+nB− nC
nC+nA+nB0
Lance-Williams 1−β2
1−β2 < 1 0
Introducao a Analise de Clusters – p. 83/114

4. Métodos hierárquicos(cont.)
4.3 Procedimentos divisivos ou de desagregação
Movem-se da raiz para os ramos do dendrograma(contrário ao procedimento aglomerativo).
Exigentes em termos computacionais (2k−1 − 1
dissemelhanças em cada passo).
Podem ter vantagens sobre os aglomerativos (secomputacionalmente viáveis). Podem fornecergrandes grupos logo nos primeiros passos.
Função diana do package cluster do R.
Introducao a Analise de Clusters – p. 84/114

5. Métodos nãohierárquicos
Hierárquicos
Usam matriz de dados ou dissemelhanças
Se um objecto entra num cluster não mais o abandona
Desconhece-se o número de clusters à partida
serve para objectos e variáveis
Os métodos não hierárquicos seguem outros princípios
Introducao a Analise de Clusters – p. 85/114

5. Métodos nãohierárquicos (cont.)
5.1 Métodos de partição
Operam sobre matriz de dados
Aplicam-se apenas a objectos
Os grupos devem satisfazer os critérios de coesãointerna e isolamento externo
O número de grupos é fixado à partida
Um objecto pode viajar por vários clusters
Introducao a Analise de Clusters – p. 86/114

5. Métodos nãohierárquicos (cont.)
Não convém analisar todas as partições.Número de partições de n objectos em k grupos
P (n, k) =
[
kn −k−1∑
i=1
k!
(k − i)!P (n, i)
]/
k!
Muito elevado!!!
Modo de proceder:Examinar algumas partições e seleccionar a melhor, opti-mizando algum critério de formação de clusters.
Introducao a Analise de Clusters – p. 87/114

5. Métodos nãohierárquicos (cont.)
Procedimento geral
1. Seleccionar uma partição inicial
2. Considerar todas as deslocações de objectos dosseus grupos para os outros grupos e registar aalteração no valor do critério
3. Decidir pela deslocação que deu o maior valor damelhoria
4. Repetir 2 e 3 até verificar que a deslocação de qualquerobjecto não produz melhoria.
Introducao a Analise de Clusters – p. 88/114

5. Métodos nãohierárquicos (cont.)
Partição inicial, Como escolher?
Com base em conhecimentos anteriores
Usar o resultado da aplicação de outro método
Escolher os centróides dos potenciais grupos
Deslocação dos objectosHá várias possibilidades (um de cada vez é o mais cor-rente)
Introducao a Analise de Clusters – p. 89/114

5. Métodos nãohierárquicos (cont.)
Critério de formação de clustersA equação T = W +B fornece várias possibilidades
(i) Minimizar traço de W. É equivalente a minimizar
trW =k
∑
i=1
ni∑
j=1
(xij − xi)′ (xij − xi) =
k∑
i=1
ni∑
j=1
d2ij,i
(ii) Maximizar determinante de W
(iii) Maximizar traço de BW−1
Introducao a Analise de Clusters – p. 90/114

5. Métodos nãohierárquicos (cont.)
Algoritmo das k-médias
1. Seleccionar a partição inicial
2. Deslocar cada objecto para o grupo que tem ocentróide mais próximo
3. Recalcular os centróides dos novos grupos
4. Repetir 2 e 3 até não haver mais deslocações.
Introducao a Analise de Clusters – p. 91/114

5. Métodos nãohierárquicos (cont.)
Aplicação a dados artificiais
Variáveis
Objectos x1 x2
A 2 8
B 5 1
C 4 12
D 15 4
E 16 5
Introducao a Analise de Clusters – p. 92/114

5. Métodos nãohierárquicos (cont.)
1. Partição inicial (arbitrária) AB e CDE
2. Centróides d2
Clusters x1 x2 A B C D E
AB 3.5 4.5 14.5 14.5 56.5 132.75 156.5
CDE 11.67 7 94.51 80.49 83.83 20.09 22.75
3. Centróides d2
Clusters x1 x2 A B C D E
ABC 3.67 7 3.79 37.77 25.11 137.77 156.03
DE 15.5 4.5 194.5 122.5 188.75 0.5 0.5
Introducao a Analise de Clusters – p. 93/114

5. Métodos nãohierárquicos (cont.)
k-médias é não robusto!
Algoritmo dos k-medóidesO representante do grupo é um objecto do próprio grupo(o objecto mais central – medóide)
O passo 2 é agora: deslocar cada objecto para ogrupo que tem o medóide mais próximo
Função pam (package cluster do R)
Introducao a Analise de Clusters – p. 94/114

5. Métodos nãohierárquicos (cont.)
Representantes dos dois clusters para k-médias ek-medóides (dados artificais anteriores):
Centróides Medóides
Clusters x1 x2 x1 x2
ABC 3.67 7 2 8
DE 15.5 4.5 15 4
Introducao a Analise de Clusters – p. 95/114

5. Métodos nãohierárquicos (cont.)
5.1 Outros métodosMétodos baseados em modelos (Banfield and Raftery,
1993)Hipótese:x tem f.d.p. fi(x;θθθi) se provém do grupo i, i = 1, . . . , k e
f(x;p, θθθ) =k
∑
i=1
pifi(x;θθθi) ,k
∑
i=1
pi = 1
Estimar os parâmetros em cada modelo equivale a identi-ficar o respectivo grupo.
Introducao a Analise de Clusters – p. 96/114

5. Métodos nãohierárquicos (cont.)
Pesquisa de densidades
objectos −→ pontos no espaço euclidiano
Procurar regiões de alta densidade de pontos separadospor regiões de baixa densidade.
Métodos difusos (fuzzy)Generalização da ideia de partiçãoNa partição cada objecto pertence a um e um sócluster. Mas isto nem sempre é claro.
Na prática há por vezes dúvidas em decidir qual o grupoa que um objecto pertence
Introducao a Analise de Clusters – p. 97/114

5. Métodos nãohierárquicos (cont.)
Métodos difusos (cont.)
objecto −→ vector (componentes = grau depertença do objecto a cada grupo)
grupo −→ vector (componentes = grau depertença de cada objecto ao grupo)
Ajustamento de mistura de densidades é caso fuzzy,com componentes = pi
Informa melhor sobre os dados (do que hierarquias epartições)
É exigente em termos de algoritmo e cálculo e dá re-sultados de difícil interpretação
Introducao a Analise de Clusters – p. 98/114

5. Métodos nãohierárquicos (cont.)
Métodos de sobreposição
Há situações em que um objecto pertence amais do que um grupo. Exemplo: um professor podeensinar em várias universidades.
Duas abordagens: ADCLUS (additive clustering) ePirâmides (Diday, 1986).
Introducao a Analise de Clusters – p. 99/114

5. Métodos nãohierárquicos (cont.)
SOM (self organizing maps)
Devido a Kohonen (1982, 1990). Usado no contexto daaprendizagem automática
A dados multidimensionais associa nós de uma redede baixa densidade
Nós e observações associadas formam clusters.
Introducao a Analise de Clusters – p. 100/114

5. Métodos nãohierárquicos (cont.)
AC com restrições
Usada em dados espaciais/temporais: geografia, pro-cessamento de imagens, marketing, arqueologia, geologia,análise de documentos multimédia, etc.
São impostas restrições no conjunto de soluções pos-síveis
Introducao a Analise de Clusters – p. 101/114

5. Métodos nãohierárquicos (cont.)
5.3 Considerações de ordem prática
Que método? Que algoritmo?
A escolha depende dos objectivos da investigação.
Sugestões:Operar com vários métodos– Comparar resultados– Escolher a solução mais consistente e de
interpretação mais simples
Produzir uma solução hierárquica para ser usada comopartição inicial dos métodos de partição.
Introducao a Analise de Clusters – p. 102/114

5. Métodos nãohierárquicos (cont.)
Quantos clusters?
Hierárquicos – decisão finalPartição – decisão inicial
Análise gráfica ajuda a decidir
Hierárquicos: nível de fusão contra número de clustersNão hierárquicos: valor do critério contra número declusters, ou usar o índice
R2k =
trBk
trT= 1− trWk
trT
Introducao a Analise de Clusters – p. 103/114

5. Métodos nãohierárquicos (cont.)
Validação
AC conduz sempre a uma solução.A solução corresponde a uma estrutura real ou é impostanos dados?
1. Existe de facto uma estrutura?
2. A solução é válida?
Critérios →
Introducao a Analise de Clusters – p. 104/114

5. Métodos nãohierárquicos (cont.)
Critérios externosA estrutura é útil, consistente com diferentes amostras,tem boa capacidade preditiva?
Critérios internosA estrutura é consistente com os dados? (Há muitostestes) Nos métodos hierárquicos usa-se o coeficientede correlação cofenético.
Critérios relativosConfronta diferentes soluções para os mesmos objec-tos, procurando associações entre elas.
Introducao a Analise de Clusters – p. 105/114

5. Métodos nãohierárquicos (cont.)
Apresentação dos resultados de uma AC
Não basta um diagrama final. É importante indicar:
que teoria está subjacente ao estudo
qual o enquadramento
como foram seleccionados os objectos e as variáveis
quais as medidas de proximidade usadas
que métodos e algoritmos foram utilizados
que software foi usado
como foi decidido o número de clusters
os argumentos usados para suportar a validade da es-trutura produzida
Introducao a Analise de Clusters – p. 106/114

6. Aplicações
Revisitar dados anteriores
Comparar resultados de vários métodos
Introducao a Analise de Clusters – p. 107/114

Dendrograma para os planetas do sistema solar com base nas
variáveis diâmetro, massa, densidade e gravidade (dados es-
tandardizados, método da ligação média)
Mer
curio
Ven
us
Ter
ra
Mar
te
Jupi
ter
Sat
urno
Ura
no
Nep
tuno
Plu
tao
01
23
4
D
Introducao a Analise de Clusters – p. 108/114

Dendrograma para os dados dos cenários faciais (método da li-
gação média) Confirma a análise gráfica
12 3 4 56 78 9 101112 13
02
46
D
Introducao a Analise de Clusters – p. 109/114

Dendrograma para os dados dos alimentos (método da ligação
média) Sol. estand. mais próxima da sol. gráfica
azei
te
man
teig
a
pesc
ada
vaca
fran
go
leite
iogu
rte
q.fla
men
go
q.se
rra
arro
z
pao
feija
o
acuc
ar
mas
sas
alfa
ce
cebo
la
espi
nafr
es
ceno
ura
bata
ta
couv
e
020
040
060
080
0
D
(dados não estandardizados)Introducao a Analise de Clusters – p. 110/114

Dendrogram
apara
osdados
dosalim
entos(m
étododa
ligação
média)
azeite
manteiga
pescada
vaca
frango
leite
iogurte
q.flamengo
q.serra
arroz
pao
feijao
acucar
massas
alface
cebola
espinafres
cenoura
batata
couve
0 1 2 3 4
D
(dadosestandardizados)
Introducaoa
Analise
deC
lusters–
p.111/114

Dendrograma para os 7 objectos artificiais (método da ligação
completa) Problema da estandardização
1 2 3 456 7
05
1015
D
(dados não estandardizados)Introducao a Analise de Clusters – p. 112/114

Dendrograma para os 7 objectos artificiais (método da ligação
completa)
1 23 4 56 7
01
23
D
(dados estandardizados)Introducao a Analise de Clusters – p. 113/114

Dendrograma para as variáveis correspondentes às característi-
cas físicas de raparigas (método da ligação média)
Confirma a análise gráfica
altu
ra
enve
rgad
ura
ante
brac
o
tibia
peso
anca
peito
-c
peito
-d
0.0
0.1
0.2
0.3
0.4
0.5
0.6
D
Introducao a Analise de Clusters – p. 114/114