inpe-10565-tdi/940 novos algoritmos para rotulaÇÃo cartogrÁfica de...
TRANSCRIPT

INPE-10565-TDI/940
NOVOS ALGORITMOS PARA ROTULAÇÃO CARTOGRÁFICA DE PONTOS
Missae Yamamoto
Tese de Doutorado do Curso de Pós-Graduação em Computação Aplicada, orientada pelo Dr. Luiz Antônio Nogueira Lorena, aprovada em 19 de setembro de 2003.
INPE São José dos Campos
2004

519.863:528.711.7 YAMAMOTO, M.
Novos algoritmos para rotulação cartográfica de pontos / M. Yamamoto. – São José dos Campos: INPE, 2003. 114p. – (INPE-10565-TDI/940). 1.Algoritmo genético. 2.Método heurístico. 3.Sistemas de Informação Geográfica (SIG). 4.Algoritmo. 5.Rotulação cartográfica de pontos. I.Título.



Dedico o presente trabalho
aos meus pais Jusaku Yamamoto
Tereza Yamamoto
aos meus sobrinhos Camila Shinye
Marcelo Shinye
André Hitoshi Yamamoto


AGRADECIMENTOS
Ao orientador Dr. Luiz Antônio Nogueira Lorena, meu professor da graduação e do
mestrado, meu orientador do mestrado e doutorado, uma pessoa muito competente, que
esteve presente nas fases deste trabalho orientando, incentivando, apoiando, revisando a
parte escrita e contribuindo com sugestões úteis, sempre com profissionalismo e
paciência, tornando assim possível a conclusão do trabalho. Espero estar à altura da
atenção que sempre me dedicou.
Ao Dr. Solon Venâncio de Carvalho, presidente da minha banca de proposta de tese,
banca examinadora final do doutorado, banca de exame de qualificação, banca de
dissertação de mestrado preliminar e final. Esteve presente em todas as bancas de exame
feito por mim durante o meu período acadêmico no INPE, incentivando, revisando o
texto e contribuindo com sugestões.
Ao Dr. Luiz Satoru Ochi da UFF, Niterói - RJ, membro da banca examinadora final de
doutorado, que além de revisar o texto, contribuiu com várias idéias e sugestões.
Ao Dr. Reinaldo Morabito Neto da UFSCAR, São Carlos - SP, membro da banca
examinadora final de doutorado, que também contribuiu com várias idéias e sugestões,
além de revisar o texto.
Ao Dr. Luiz Alberto Vieira Dias, Diretor da Faculdade de Ciência da Computação
UNIVAP, SJCampos – SP, membro da banca examinadora final de doutorado, pelo
incentivo e orientações durante o estágio docência estabelecido pela CAPES.
A Mary Minamoto Yamada, Rosa Maria Kato Shimabukuro e Ana Silvia M. Serra
Amaral pela amizade, incentivo e apoio técnico.
A Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES), pela bolsa
concedida.


RESUMO Rotulação de mapas é de importância fundamental em cartografia e sistemas de informações geográficas (SIG) e tem se mostrado pertencer à classe de problemas de difícil solução, conduzindo-nos à necessidade de algoritmos de aproximação, uma vez que não se conhece algoritmo exato capaz de solucioná-lo em um intervalo de tempo aceitável. Uma variedade de métodos tem sido propostas para gerar uma boa rotulação, com resultados dos mais variados. Este trabalho faz uma revisão de alguns algoritmos encontrados na literatura, e depois apresenta métodos ainda não explorados para rotulação de pontos, com o objetivo de alcançar uma rotulação de qualidade na confecção de mapas para impressão, e também um método exato para obter soluções ótimas, com a finalidade de verificar as soluções geradas pelo método heurístico proposto neste trabalho.


NEW ALGORITHMS FOR POINT FEATURES CARTOGRAPHIC LABEL PLACEMENT PROBLEM
ABSTRACT Cartographic label placement is an important task in automated cartography and Geographical Information Systems (GIS). The label placement belongs to a problem area of difficult solution, leading us to the need of approximation algorithms as there is no exact algorithm that is able to solve this problem within an acceptable amount of time. A variety of methods has been proposed to generate quality labelings, with a wide range of results. In this work, we have reviewed some algorithms of the literature, and we presented methods not yet explored for point features label placement with aim to obtain a quality labeling placement for printed map, and an exact method to obtain good solutions with aim to verify heuristic solutions produced in this work.


SUMÁRIO LISTA DE FIGURAS
LISTA DE TABELAS
CAPÍTULO 1 – INTRODUÇÃO .…………...…………………………… 17
CAPÍTULO 2 – REVISÃO BIBLIOGRÁFICA ......………………………. 21
2.1 – Breve Descrição de Alguns Algoritmos da Literatura ........................... 23
2.2 – Busca Tabu (TS)..................................................................................... 24
2.2.1 – Descrição do Processo de Busca do TS .............................................. 25
2.2.2 – Exemplo de Aplicação de TS para 6 Pontos ....................................... 29
2.2.3 – Resultados Obtidos ............................................................................. 33
2.3 – Algoritmo Genético loGA .................…………………………….….... 36
2.4 – Conjunto Independente de Vértices ..........…………………..….…...... 38
2.4.1 – Construção do Grafo de Relacionamento para Rotulação de Pontos .. 38
2.4.2 – Algoritmo ................................................…………………..….…...... 40
2.4.3 – Resultados Obtidos ...............................…………………..….…........ 42
2.5 – Programação matemática ..................................................................... 43
CAPÍTULO 3 – GENÉTICO CONSTRUTIVO PARA ROTULAÇÃO 47
3.1 – Algoritmo Genético (GA) Tradicional .................................................. 47
3.1.1 – Histórico ............................................................................................. 47
3.1.2 – Tecnologia GA.................................................................................... 48
3.1.3 – Operadores Genéticos......................................................................... 49
3.2 – Algoritmo Genético Construtivo (CGA) ............................................... 53
3.3 – Tecnologia CGA .................................................................................... 54
3.3.1 – Representação de Estrutura e Esquema .............................................. 54

3.3.2 – Funções de Avaliação ......................................................................... 54
3.3.3 – Heurística RSF .................................................................................... 55
3.3.4 – Processo de Evolução ......................................................................... 61
3.4 – Operadores do CGA .............................................................................. 63
3.4.1 – População Inicial ................................................................................ 63
3.4.2 – Seleção ............................................................................................... 65
3.4.3 – Recombinação .................................................................................... 66
3.4.4 – Mutação .............................................................................................. 67
3.5 – Algoritmo .............................................................................................. 67
3.6 – Calibragem de Parâmetros .................................................................... 68
3.7 – Resultados obtidos ................................................................................ 69
CAPÍTULO 4 – ANÁLISE COMPARATIVA COM A LITERATURA 73
CAPÍTULO 5 – ALGORITMO EXATO ................................................... 77
5.1 – Algoritmo Exato para Conjunto Independente de Vértices .................. 79
5.2 – Descrição do Algoritmo Exato para Rotulação de Pontos .................... 80
5.3 – Exemplo de Aplicação do Algoritmo Exato para 6 Pontos ................... 84
5.4 – Resultados obtidos ................................................................................. 88
5.5 – Análise Comparativa entre os Algoritmos Exato, CGA e TS ................ 89
CAPÍTULO 6 - CONCLUSÃO . .................................................................. 93
REFERÊNCIAS BIBLIOGRÁFICAS ........................................................ 97
APÊNDICE A ................................................................................................ 103
APÊNDICE B ................................................................................................ 109
APÊNDICE C ................................................................................................ 113

LISTA DE FIGURAS 1.1 – Exemplo de rotulação de mapas .............................................................. 18
1.2 – Exemplo de rotulação de pontos .............................................................. 18
2.1 – Conjunto de 8 posições candidatas para o rótulo de um ponto ................ 21
2.2 – Conjunto de 17 posições candidatas para o rótulo de um ponto com suas
respectivas penalidades ........................................................................... 22
2.3 – calculo de conflitos .................................................................................. 27
2.4 – configuração inicial ................................................................................. 29
2.5 – posições candidatas e preferência cartográfica ....................................... 30
2.6 – após aplicação do TS ao exemplo da Figura 2.4 ..................................... 30
2.7 – Posições candidatas e os conflitos ......................................…………….. 39
2.8 – Grafo de relacionamento das posições candidatas………........………… 39
2.9 – matriz de adjacências do grafo da Figura 2.8 .......................................... 40
2.10 – configuração estável e instável da abordagem do Zoraster .................... 45
2.11 – Uma configuração instável do algoritmo do Zoraster............................. 46
3.1 – Esquema da roleta ......................................……….....................……….. 51
3.2 – Cruzamento de um ponto ...........................……….....................……….. 51
3.3 – Cruzamento de dois pontos ........................……….....................……….. 52
3.4 – Cruzamento uniforme .................................……….....................……….. 52
3.5 – Mutação ......................................................……….....................……….. 53
3.6 – Matriz de adjacência inicial...…………...……………………………….. 57
3.7 – Matriz de adjacência 1ª iteração …………………..........................…….. 58
3.8 – Matriz de adjacência 2ª iteração …..................................……………….. 58
3.9 – Matriz de adjacência 3ª iteração ................…………………......……….. 59
3.10 – Matriz de adjacência 4ª iteração .................…….......................……….. 59

3.11 – Matriz de adjacência 5ª iteração ................................………………….. 60
3.12 – Seleção base-guia ..........................................……..........................….... 66
5.1 – Árvore de configurações possíveis para pontos com 2 posições
candidatas.................................................................................................. 77

LISTA DE TABELAS 2.1 – Resultados obtidos por TS usando o conjunto padrão de dados .......... 35
2.2 – Resultados obtidos por vários algoritmos usando o conjunto padrão
de dados .............................................................................................. 35
2.3 – Resultados obtidos (Dijk et. al., 1998) ................................................. 38
2.4 – Resultados obtidos (Strijk et. al., 2000) ................................................. 42
3.1 – Seleção de parâmetros ............................................................................ 69
3.2 – Resultados obtidos por CGA usando o conjunto padrão de dados
(média) ................................................................................................... 69
3.3 – Resultados obtidos por CGA usando o conjunto padrão de dados
(melhor) .................................................................................................. 70
4.1 – Resultados obtidos por vários algoritmos usando o conjunto padrão
de dados ................................................................................................ 73
4.2 – Tempo de processamento ....................................................................... 74
4.3 – Tempo de processamento total................................................................ 74


17
CAPÍTULO 1
INTRODUÇÃO
Rotulação cartográfica automatizada refere-se ao processo de colocação de texto em
documentos cartográficos utilizando o computador, num ambiente de sistemas de
informações geográficas (SIG), que acessa e manipula dados armazenados em banco de
dados geográficos e gera documentos cartográficos.
Uma área de pesquisa bastante importante em SIG é a rotulação cartográfica pois, um
mapa não deve mostrar apenas a posição geográfica das entidades, mas também
algumas de suas propriedades, de tal forma que a informação seja legível, que respeite
as convenções cartográficas, que fique clara a que entidade ela pertence, preservando
sempre a estética e harmonia na apresentação dessas informações.
Este trabalho está relacionado a rotulação automatizada das entidades ponto (cidades,
pico de montanhas, escolas, hospitais, ...) que tem conquistado uma atenção maior dos
pesquisadores por se tratar de um problema de difícil solução e por conseqüência
recentemente vários algoritmos de rotulação de pontos têm sido descritos na literatura
da cartografia automatizada (Wolff A. and Strijk T., 1996). O problema mais geral
inclui rotulação da entidade linha (rios, estradas, ...) e a rotulação da entidade área
(oceanos, países, estados, ...) que estão descritos no Shawn et al. (1996). A FIGURA
1.1 mostra a rotulação das entidades ponto, linha e área.
Apesar dos esforços dos pesquisadores, a rotulação cartográfica automatizada ainda não
está incorporada à grande maioria dos SIG disponíveis no mercado. Nestes sistemas, os
algoritmos implementados são versões simplificadas e apresentam limitações. Deste
modo, parte da edição e rotulação tem de ser feita manualmente, o que implica num
trabalho tedioso com substancial dispêndio de tempo. Segundo Oliveira (1998) a
rotulação de um mapa constitui cerca de 80% do tempo necessário para a sua confecção.

18
FIGURA 1.1 - Exemplo de rotulação de mapas.
FONTE: Edmondson et. al. (1996, p. 14).
FIGURA 1.2 - Exemplo de rotulação de pontos.
FONTE: Freeman (1991, p. 451).
Uma boa rotulação cartográfica requer que uma associação não ambígua entre o texto e
a entidade correspondente seja alcançada, que não haja sobreposição entre os textos ou

19
entre texto e entidades, que sejam respeitadas as convenções e preferências
cartográficas, que o tempo de processamento seja pequeno e que um alto nível de
harmonia e qualidade seja alcançado. As regras básicas para se conseguir uma rotulação
de alta qualidade se encontram descritas no trabalho de Imhof (1962) citado em
Freeman (1991). A FIGURA 1.2 mostra um exemplo de rotulação de pontos onde a
cidade de “Goodtown” esta rotulada de maneira correta, enquanto que o rótulo
“Poorville” se encontra em posição imprópria pois, a entidade ponto está localizada
próximo ao limite da entidade área, e nestes casos o rótulo deverá ser colocado do
mesmo lado que se encontra a entidade ponto. O rótulo “Constania” encontra-se
rotulado apropriadamente, uma vez que a entidade ponto esta localizada ao longo de um
curso extenso de água, e segundo as regras de Freeman o rótulo deverá ser colocado na
água.
Respeitando as regras básicas, um algoritmo pode tentar rotular tantos pontos do mapa
quantos forem possíveis ou encontrar o tamanho máximo da fonte do caracter que possa
rotular todos os pontos. No geral, os dois problemas são NP-hard (Formann M. and
Wagner F., 1991; Marks J. and Shieber S., 1991).
Dos algoritmos de rotulação de pontos existentes, aqueles que respeitam o número de
posições candidatas (Christensen et. al., 1995; Yamamoto, 1998) para ocupar a posição
do rótulo do ponto em questão, são conhecidos como “fixed-position models” e quando
o rótulo do ponto é colocado em qualquer posição em que a aresta do retângulo coincide
com o ponto, são conhecidos como “slider models” (Hirsch, 1982; Kreveld et. al.,
1999).
Quando queremos produzir um mapa para impressão, que será o objetivo deste trabalho,
devemos nos esforçar para tentar encontrar uma rotulação de ótima qualidade mesmo
que esteja envolvido um tempo de espera. Cumpre ressaltar que para aplicações
modernas tais como sistemas de tempo real para navegação, é essencial a produção
rápida do mapa para visualização no “display”. Esta velocidade de apresentação do
mapa é conseguido diminuindo a densidade das informações a serem mostradas
(Petzold et. al., 1999).

20
O restante do trabalho está organizado da seguinte forma. O Capítulo 2 faz uma revisão
bibliográfica sobre rotulação cartográfica e apresenta o grafo para rotulação de pontos
que visa organizar as informações pertinentes a conflitos de rótulos, gerando assim uma
estrutura de armazenamento destas informações. Para produzir mapas para impressão,
que deverá ser de altíssima qualidade será usado o CGA (“Constructuve Genetic
Algorithm”) que será descrito no Capítulo 3. O Capítulo 4 apresenta uma análise
comparativa dos algoritmos CGA, Busca Tabu e alguns algoritmos descritos na
literatura. No Capítulo 5 é descrito um algoritmo exato e uma análise comparativa com
o CGA e TS. Finalmente o Capítulo 6 apresenta as conclusões e sugere extensões ao
trabalho.

21
CAPÍTULO 2
REVISÃO BIBLIOGRÁFICA
Neste trabalho, a rotulação de pontos é tratada como um problema de otimização
combinatória, portanto serão descritos a seguir conceitos sobre posições candidatas,
preferência cartográfica e função objetivo, que serão necessários para os algoritmos
desenvolvidos.
Entende-se por posições candidatas o conjunto de todas as possíveis posições que o ró-
tulo de um determinado ponto pode ocupar. Estas possíveis posições são escolhidas de
acordo com uma padronização cartográfica (Christensen et al. 1995). A FIGURA 2.1
mostra um conjunto de 8 posições candidatas para o rótulo de um ponto. Os números
mostrados indicam a preferência cartográfica; quanto menor for o número, maior é a
preferência.
FIGURA 2.1 - Conjunto de 8 posições candidatas para o rótulo de um ponto.
FONTE: Christensen et al. (1995, p. 205).
A FIGURA 2.2 mostra um conjunto de 17 posições candidatas para o rótulo de um
ponto com suas respectivas penalidades. Trata-se de uma outra técnica de definição de
posições candidatas, proposta por Shawn et al.(1996).
2 1
43
6
8
57

22
FIGURA 2.2 - Conjunto de 17 posições candidatas para o rótulo de um ponto com suas
respectivas penalidades.
FONTE:Shawn et al(1996, p. 6).
Função objetivo é uma função a ser otimizada que tem por meta medir a qualidade da
rotulação, diferenciando elementos bons dentre as posições candidatas existentes. A
qualidade da rotulação depende principalmente dos conflitos existentes entre os rótulos
e opcionalmente da preferência cartográfica e seleção de pontos.
Seleção de pontos é o ato de excluir os pontos e os respectivos rótulos se os conflitos
persistirem após um determinado número de tentativas. Quando a seleção de pontos é
considerada, geralmente os pontos também recebem um custo ou penalidade para evitar
a deleção de pontos mais importantes tais como uma capital. Neste trabalho não foi
considerada a seleção de pontos.
O restante do capítulo está organizado da seguinte forma. A seção 2.1 faz uma breve
descrição de alguns algoritmos da literatura que se encontram descritos em Yamamoto
(1998). A seção 2.2 faz uma descrição um pouco mais detalhada do algoritmo Busca
Tabu (Yamamoto 1998), que mostrou resultados muito bons comparados aos resultados
dos algoritmos encontrados na literatura. Na seção 2.3 e 2.4 serão descritos outros dois
algoritmos disponíveis na literatura, o algoritmo genético loGA (“local optimiser
0.4000.600
0.575
0.000
0.175
0.150
0.200
City 0.800
0.900
0.470 0.070
0.500 0.100
0.825 0.875
0.950 1.000

23
Genetic Algorithm”) apresentado em Dijk et. al. (1998) e conjunto independente de
vértices de Strijk et. al. (2000).
2.1 Breve Descrição de Alguns Algoritmos da Literatura
Nesta seção será feita uma breve descrição de alguns algoritmos da literatura que se
encontram descritos em Yamamoto (1998).
• BUSCA EXAUSTIVA (Christensen et. al., 1993; 1995): O algoritmo utilizado é o
“backtracking”, onde o rótulo do ponto é colocado em uma das posições não
obstruídas. Se um determinado ponto não pode ser rotulado porque não existem
posições sem conflito, o algoritmo volta para o ponto rotulado anteriormente e muda
a posição do rótulo. E assim o algoritmo continua até que todos os pontos tenham
sido rotulados. Este algoritmo não é recomendado para problemas de tamanho
grande ou moderado pôr causa da sua natureza exponencial.
• ALGORITMO GULOSO (Christensen et. al., 1995): O algoritmo faz
sucessivamente uma otimização local em todos os pontos e então termina. O
resultado final é rápido mas a qualidade não é tão boa.
• “DISCRETE GRADIENTE DESCENT” (Christensen et. al., 1995): Este algoritmo
repete um procedimento até que uma melhora adicional não seja possível. Este
procedimento implica em considerar as posições alternativas do rótulo de cada
ponto, calcular o valor de uma função objetivo que resultará se o rótulo for movido e
implementar o movimento de rótulo que resultar na maior melhora. Um problema
deste algoritmo é a incapacidade de escapar de um mínimo local.
• HIRSCH (Hirsch, 1982): O algoritmo de Hirsch é visto como um sistema dinâmico
de repulsão dos rótulos, ou seja, todos os rótulos que se encontram no estado de
conflito são movidos na tentativa de eliminar o conflito. Em cada iteração todos os
conflitos entre os rótulos são computados, e o movimento de reposicionamento de
cada rótulo em conflito é calculado de acordo com a quantidade de sobreposição

24
existente com os demais rótulos envolvidos. Isto resulta em movimento de repulsão
de todos os rótulos em conflito de uma determinada iteração.
• “SIMULATED ANNEALING” (Christensen et. al., 1993 e 1995): Em cada
iteração move-se um rótulo para uma nova posição e se calcula ∆E, a mudança na
função objetivo causado por reposicionamento do rótulo. Se a nova posição do
rótulo piorou o estado geral, aceitar o reposicionamento com probabilidade P = 1.0 -
exp(-∆E/T). No início a temperatura T é alta e a probabilidade de aceitar soluções
piores também é alta, mas a temperatura é decrementada lentamente com o tempo e
a probabilidade de aceitar soluções piores converge para zero. Este tipo de algoritmo
pode teoricamente assegurar uma otimização global, mas o seu tempo de
processamento pode ser alto.
• ALGORITMO GENÉTICO COM MÁSCARA (Verner et. al., 1997): Neste
algoritmo cada cromossomo representa um candidato a solução do problema ou seja
o cromossomo representa uma configuração de distribuição de rótulos de um dado
conjunto de pontos, onde cada posição no cromossomo corresponde a um ponto e
pode assumir uma das posições candidatas que lhe é permitido. A máscara utilizada
é do mesmo tamanho do cromossomo, e cada componente da máscara possui o valor
0 (com conflito) ou 1 (sem conflito). Desta maneira, aos pontos cujo rótulo se
encontram em conflito será permitido a troca por outra posição candidata através do
cruzamento e talvez corrigir a situação de conflito.
2.2 Busca Tabu (Yamamoto, 1998)
Nesta seção será apresentado o algoritmo Busca Tabu, que mostrou resultados muito
bons comparados aos resultados dos algoritmos encontrados na literatura.
Busca Tabu ou “Tabu Search” (TS) é um procedimento heurístico proposto por Fred
Glover para resolver problemas de otimização combinatória. A idéia básica é evitar que
a busca por soluções ótimas termine ao encontrar um mínimo local ainda distante de um
ótimo global. (Glover. 1989a, 1989b, 1990; Laguna. 1994; Glover et al. 1995; Glover e
Laguna, 1997).

25
Em Yamamoto, 1998 o algoritmo Busca Tabu foi aplicado ao problema de rotulação de
pontos da seguinte forma: Dada uma solução inicial, os pontos que mais degradam a
solução são selecionados. Escolhe-se para cada ponto em questão a posição candidata
com menor custo, gerando assim várias soluções que farão parte da vizinhança. A
melhor solução, ou seja, a solução que apresentar o menor custo, será escolhida para ser
a próxima solução e será aceita mesmo que o custo seja maior que a solução anterior
para escapar de ótimos locais. Para evitar que o procedimento forme um ciclo, os
últimos k pontos visitados são armazenados na lista tabu T e a solução será rejeitada se
o ponto que sofreu a modificação na solução escolhida estiver nesta lista T. A lista T
tem tamanho finito, portanto quando um ponto é introduzido nesta lista, o ponto mais
antigo da lista é removido, podendo então participar novamente da formação das
próximas soluções. Algumas vezes é permitido aceitar que o ponto que faz parte da lista
T participe na formação da próxima solução, se a solução gerada for “suficientemente”
boa. Este procedimento é conhecido como critério de aspiração. No problema de
rotulação foi usado também o conceito de freqüência normalizada para diversificar a
busca e penalizar os pontos que não causam melhora.
2.2.1 Descrição do Processo de Busca do TS
O algoritmo apresentado a seguir descreve em linhas gerais o processo de busca do TS
para resolver o problema de rotulação de pontos.
1) Gerar uma configuração inicial, rotulando cada ponto com o seu rótulo na
posição candidata de menor penalidade;
2) repetir os seguintes passos até alcançar uma solução sem conflitos ou por um
número pré-definido de iterações;
• Criar uma lista de candidatos para iteração corrente;
• Recalcular a lista de candidatos para encontrar posição de rótulo de menor
custo para cada ponto referenciado na lista de candidatos;

26
• Escolher o melhor candidato da lista, baseado no custo, levando em
consideração a lista tabu e o critério de aspiração;
• Realizar a mudança de configuração, designando a solução obtida como
sendo a nova solução corrente. Cada mudança de configuração consiste na
modificação da posição de rótulo de um ponto;
• Atualizar a lista tabu.
O algoritmo TS descrito acima envolve seis componentes: função objetivo, lista tabu,
lista de candidatos, mudança de configuração, critério de aspiração e memória de longo
prazo. Eles serão descritos a seguir.
Função objetivo (F): O algoritmo TS usado aqui é inteiramente determinístico e
seleciona os melhores candidatos. Portanto é necessário examinar e comparar os
candidatos, o que acarreta um grande número de cálculos, especialmente quando o
número de pontos é grande. Então uma boa função objetivo é aquela que o custo pode
ser calculado facilmente, tornando a busca eficiente e obtendo ao mesmo tempo
soluções de qualidade. A função objetivo de minimização usada é
Onde, np = número de pontos; C(i) = custo de cada ponto i, definido onde, overlap(i) =
número de conflitos do rótulo associado ao ponto i (FIGURA 2.3); preference(i) =
preferência cartográfica do rótulo ativo no ponto i e rótulos em conflito com ele; α1
nível de consideração a ser dada aos rótulos em conflito; α2 = nível de consideração a
ser dada a preferência cartográfica.
Para o cálculo de overlap(i), foi utilizado a informação referente ao número de conflitos
do rótulo associado ao ponto i (FIGURA 2.3), pois existe a necessidade de se saber a
informação sobre o número de conflitos do ponto i em questão.
C(i)np
1i∑
=

27
Os parâmetros α1 e α2 são manipulados pelo usuário que pode escolher o que é mais
importante, sem conflitos ou qualidade cartográfica. Se α2 = 0, a preferência
cartográfica não é considerada.
Lista tabu: é um componente essencial do algoritmo, e armazena pontos que
ultimamente sofreram mudança de posição de rótulo.
Em Yamamoto, 1998 foi usada uma lista de tamanho dinâmico, porque o problema de
rotulação de pontos necessita de uma lista tabu grande no início para evitar solucionar
conflitos somente em certas regiões do mapa. Entretanto, quando o número de conflitos
diminui, o tamanho da lista tabu pode ser reduzido, para que a busca seja conduzida em
pequenas regiões do mapa, apenas para se fazer um ajuste final.
O tamanho da lista tabu usado foi 7 + INT(0.25 * número de rótulos em conflito). Após
algumas iterações o número de conflitos diminui e consequentemente o tamanho da lista
tabu. O coeficiente 0.25 assim como o recalculo do tamanho da lista tabu a cada 50
iterações foram estabelecidas depois de testes e experimentos feitos em configurações
com 100, 250, 500, 750 e 1000 pontos (detalhes em Yamamoto, 1998).
P1
P2P3
P4
Número de conflitos = 4 (P1 = 0, P2 = 1, P3 = 2, P4 = 1)Número de rótulos em conflito = 3
FIGURA 2.3 - Calculo de conflitos.
Para o cálculo do tamanho da lista tabu e tamanho da lista de candidatos descrito no
próximo item, foram utilizados a informação referente ao número de rótulos em conflito
(FIGURA 2.3), pois alem de mostrar o número total de rótulos que se encontra em

28
conflito, é o tipo de contagem de conflitos que se é adotado na maioria dos artigos
encontrados na literatura.
Lista de candidatos: Esta lista é composta por um conjunto de triplas (ponto, rótulo,
custo) que apresentam o custo alto na configuração corrente. Os custos associados a
cada ponto são calculados como descrito na memória de longo prazo. Em geral
(dependendo do nível de consideração α1, α2) soluções de custo alto têm um grande
número de conflitos e seus rótulos não estão nas melhores posições cartográficas.
O tamanho da lista é recalculado apos 50 iterações consecutivas usando a expressão:
1 + INT (0.05 * número de rótulos em conflito). O coeficiente 0.05 foi escolhido apos
testes em nove diferentes configurações de 1000 pontos. A média de rótulos sem
sobreposição das nove diferentes configurações para coeficientes 0.03, 0.04, 0.05, 0.06
e 0.07, mostraram que o coeficiente 0.05 produziu resultados melhores (detalhes em
Yamamoto, 1998).
Mudança de configuração: Todas as triplas da lista de candidatos procuram a melhor
posição de rótulo. Apos mudanças nas posições de rótulos, o candidato com o menor
custo é escolhido. Soluções geradas por um ponto que faz parte da lista tabu são
descartados e a próxima melhor alternativa é selecionada.
Critério de aspiração: Em algumas situações, é necessário considerar alternativas que
são parte da lista tabu. Em tais casos, um critério de aspiração é usado para ignorar a
restrição tabu em dois casos:
• A solução é selecionada se o seu custo for menor do que a melhor solução
encontrada.
• Se todas as soluções candidatas são parte da lista tabu e não satisfaz o critério acima,
então o candidato com o maior tempo de permanência na lista tabu é escolhido.
Memória de longo prazo: freqüentemente, o custo de diferentes soluções são iguais,
resultando na entrada dos mesmos pontos na lista de candidatos. Portanto existe a
necessidade de diversificar a busca. Foi usado então a estratégia de memória baseada
em freqüência que conta o número de vezes que o ponto muda a posição do seu rótulo e

29
após 50 iterações consecutivas divide-se o valor acumulado de cada ponto pelo valor
máximo, obtendo a freqüência normalizada. Esta informação é usada para aplicar
penalidades aos pontos que não trazem melhora, fazendo com que perca a sua
atratividade pois, em rotulação a escolha dos pontos que compõe a lista de candidatos é
em função do maior custo. O custo C(i) de cada ponto “i” foi portanto modificado para:
CN(i) = C(i) – freqüência normalizada(i)
Onde a freqüência normalizada(i) é um instrumento de diversificação da busca.
2.2.2 Exemplo de Aplicação de TP para 6 Pontos
FIGURA 2.4 - Configuração Inicial.
Para tornar claro o uso do algoritmo TS, será descrito em detalhes o seu uso. Foi
considerada uma configuração de seis pontos, como ilustrado na FIGURA 2.4. Cada
ponto tem quatro posições potenciais de rótulo (L0, L1, L2 e L3) e cada posição de
rótulo tem um custo associado (0.0, 0.4, 0.6 e 0.9), onde 0.0 indica a melhor posição e
0.9 a pior (FIGURA 2.5).

30
L0L1
L2 L3
0.00.4
0.6 0.9
FIGURA 2.5 - Posições candidatas e preferência cartográfica.
FIGURA 2.6 - Após aplicação do TS ao exemplo da FIGURA 2.4.
Na configuração inicial existem 5 sobreposições de rótulos. Os pontos e seus rótulos
são: P0 = Youngstown (10 caracteres), P1 = Yankton (7 caracteres), P2 = Yakima
(6 caracteres), P3 = Worcester (9 caracteres), P4 = Wisconsin Dells (15 caracteres) e
P5 = Winston-Salem (13 caracteres). Winston-Salem é o único sem sobreposição.
Foi considerado para o exemplo, importâncias iguais para a sobreposição e preferência
cartográfica, portanto foram usados α1 = 1 e α2 = 1 em C(i) = α1 overlap(i) + α2
preference(i), para se calcular o custo do ponto i. A expressão 2 + INT(0.25 * número
de rótulos em conflito) foi usada para calcular o tamanho da lista tabu, mas se o
tamanho da lista for maior que 4, ele é forçado a ficar igual a 4. O tamanho da lista de
candidatos adotado foi 2 + INT(0.05 * número de rótulos em conflito) e eles são

31
recalculados a cada 5 iterações. A seguir o algoritmo para resolver os conflitos entre os
rótulos é apresentado passo a passo.
Estado inicial: tamanho da lista tabu = 4; tamanho da lista de candidatos = 2; solução =
(P0, L0, 1.0), (P1,L0, 3.0), (P2, L0, 3.0), (P3, L0, 2.0), (P4, L0, 3.0), (P5, L0, 0.0);
lista tabu = ; F = 12.0; melhor solução = 12.0 e rótulos em conflito = 5
Iteração 1: lista de candidatos = (P1, L0, 3.0), (P2, L0, 3.0); lista de candidatos
recalculado = (P1, L1, 2.4), (P2, L1, 3.4); candidato escolhido = (P1, L1, 2.4);
solução = (P0, L0, 1.4), (P1, L1, 2.4), (P2, L0, 2.0), (P3, L0, 2.0), (P4, L0, 3.4), (P5,
L0, 0.0); lista tabu = P1; F = 11.2; melhor solução = 11.2 e rótulos em conflito = 5.
A lista de candidatos é composta no início por triplas (P1, L0, 3.0) e (P2, L0, 3.0), os
dois primeiros casos de custo alto. Em seguida, as quatro posições de rótulos potenciais
do ponto P1 são examinados e a posição de rótulo com o menor custo é escolhida. O
mesmo procedimento é repetido para o ponto P2. No exemplo, a posição de rótulo L1
com custo 2.4 é escolhida para o ponto P1 e a posição de rótulo L1 com custo 3.4 é
selecionada para o ponto P2.
O candidato (P1, L1, 2.4) foi escolhido porque seu custo é menor do que o candidato
(P2, L1, 3.4) e P1 não está na lista tabu. Aplicando o mesmos passos iterativamente,
serão obtidos os seguintes resultados:
Iteração 2: lista de candidatos = (P4, L0, 3.4), (P1, L1, 2.4); lista de candidatos
recalculado = (P4, L2, 1.6), (P1, L2, 2.6); candidato escolhido = (P4, L2, 1.6);
solução = (P0, L0, 1.4), (P1, L1, 1.4), (P2, L0, 1.0), (P3, L0, 1.0), (P4, L2, 1.6), (P5,
L0, 1.6); lista tabu = P4, P1; F = 8.0; melhor solução = 8.0 e rótulos em conflito = 6
Iteração 3: lista de candidatos = (P5, L0, 1.6), (P4, L2, 1.6); lista de candidatos
recalculado = (P5, L2, 0.6), (P4, L1, 1.8); candidato escolhido = (P5, L2, 0.6);
solução = (P0, L0, 1.4), (P1, L1, 1.4), (P2, L0, 1.0), (P3, L0, 1.0), (P4, L2, 0.6),
(P5, L2, 0.6); lista tabu = P5, P4, P1; F = 6.0; melhor solução = 6.0 e rótulos em
conflito = 4.

32
Iteração 4: lista de candidatos = (P0, L0, 1.4), (P1, L1, 1.4); lista de candidatos
recalculado = (P0, L1, 1.8), (P1, L0, 2.0); candidato escolhido = (P0, L1, 1.8);
solução = (P0, L1, 1.8), (P1, L1, 1.8), (P2, L0, 1.0), (P3, L0, 1.0), (P4, L2, 0.6),
(P5, L2, 0.6); lista tabu = P0, P5, P4, P1; F = 6.8; melhor solução = 6.0 e rótulos em
conflito = 4.
Iteração 5: lista de candidatos = (P1, L1, 1.8), (P0, L1, 1.8); lista de candidatos
recalculado = (P1, L0, 1.0), (P0, L0, 1.4); candidato escolhido = (P1, L0, 1.0);
solução = (P0, L1, 0.4), (P1, L0, 1.0), (P2, L0, 2.0), (P3, L0, 1.0), (P4, L2, 0.6),
(P5, L2, 0.6); lista tabu = P1, P0, P5, P4; F = 5.6; melhor solução = 5.6 e rótulos em
conflito = 3.
Os pontos P0 e P1 estão na lista tabu, mas o candidato (P1, L0, 1.0) foi escolhido,
porque o valor F= 5.6 da nova configuração é menor do que a melhor solução = 6.0
alcançada.
Iteração 6: lista de candidatos = (P1, L0, 1.0), (P2, L0, 2.0); lista de candidatos
recalculado = (P1, L1, 1.8), (P2, L3, 1.9); candidato escolhido = (P2, L3, 1.9);
solução = (P0, L1, 0.4), (P1, L0, 0.0), (P2, L3, 1.9), (P3, L0, 1.9), (P4, L2, 0.6),
(P5, L2, 0.6); lista tabu = P2, P1, P0, P5; F = 5.4; melhor solução = 5.4 e rótulos em
conflito = 2.
Nesta iteração é recalculado o tamanho da lista tabu, tamanho da lista de candidatos e o
custo da solução para cada ponto usando a freqüência normalizada: tamanho da lista
tabu = 2; tamanho da lista de candidatos = 2; solução = (P0, L1, 0.01), (P1, L0, 0.0),
(P2, L3, 1.44), (P3, L0, 1.9), (P4, L2, 0.14), (P5, L2, 0.14); lista tabu = P2, P1.
O mesmo procedimento é executado até alcançar uma solução sem sobreposição ou até
um pre-especificado limite de iterações. A FIGURA 2.6 mostra o resultado da aplicação
de TS ao exemplo de seis pontos.

33
2.2.3 Resultados Obtidos
Christensen et al. (1995) e Verner et al. (1997) compararam vários algoritmos usando
um conjunto padrão de dados gerados randomicamente:
• Região de tamanho 792 x 612 unidades
• Rótulo de tamanho fixo 30 x 7 unidades
• Folha de papel de tamanho 11 x 8.5 polegada
• Número de pontos: n = 100, 250, 500, 750, 1000
• Para cada n, gerar 25 configurações diferentes de distribuição aleatória de pontos
através do uso de diferentes sementes.
• Para cada n calcular a média percentual do número de rótulos sem conflito das
25 configurações.
• Não foi determinada nenhuma penalidade para os rótulos que se situam além do
limite da região.
• Foram consideradas 4 posições candidatas.
• Não foi considerada a preferência cartográfica ( todas as posições candidatas são
igualmente desejáveis).
• Não houve seleção de pontos ( não deleta ponto ou rótulo que estiver em conflito
na configuração final).
O algoritmo TS, implementado em linguagem C++, foi aplicado a 25 configurações
diferentes de distribuição de pontos para 100, 250, 500, 750 e 1000 pontos
(Apêndice A3), usando o mesmo conjunto padrão de dados gerados aleatoriamente e as
mesmas condições impostas pelos autores da literatura Christensen et al.(1995) e Verner
et al.(1997).

34
Os parâmetros utilizados pela Busca Tabu foram:
• Tamanho da lista tabu: 7 + INT(0.25 * num. de rótulos em conflito)
• Tamanho da vizinhança: 1 + INT (0.05 * num. de rótulos em conflito)
• Número de iterações para recalculo: 50
As médias obtidas da aplicação de TS nas 25 configurações estão mostradas na Tabela
2.1, onde as linhas se referem a:
• Tempo: tempo médio de processamento do algoritmo TS em segundos para
alcançar o estado de não conflito, ou de menor número de conflitos dentre as
30000 iterações, em um processador Pentium II 350 Mhz. O tempo mostrado se
refere apenas ao tempo de processamento do algoritmo TS, ou seja, as
informações de conflitos são dados de entrada.
• Tempo total: tempo médio de processamento do algoritmo TS em segundos para
processar 30000 iterações em um processador Pentium II 350 Mhz.
• Com conflito: número médio de rótulos em estado de conflito.
• Desvio padrão: desvio padrão dos rótulos colocados sem conflito.
• Sem conflito: número médio de rótulos em estado de não conflito.
• Sem conflito (%): trata-se da média percentual do número de rótulos sem
conflito das 25 configurações.

35
TABELA 2.1 – Resultados obtidos por TS usando o conjunto padrão de dados.
Num. de pontos 100 pontos
250 pontos
500 pontos
750 pontos
1000 pontos
Tempo 0 0 1.36 76 352.9
Tempo total 0 0 9 202 507
Com conflito 0 0 4 24 100
Desvio padrão 0.0 0.0 2.2 6.1 12.8
Sem conflito 100 250 496 726 900
Sem conflito (%) 100.00 100.00 99.3 96.8 90.0
TABELA 2.2 – Resultados obtidos por vários algoritmos usando o conjunto padrão
de dados.
Algoritmo 100 pontos
250 pontos
500 pontos
750 pontos
1000 pontos
**Busca Tabu 100.00 100.00 99.28 96.76 90.00
GA com máscara 100.00 99.98 98.79 95.99 88.96
*GA sem máscara 100.00 98.40 92.59 82.38 65.70
“Simulated Annealing” 100.00 99.90 98.30 92.30 82.09
Zoraster 100.00 99.79 96.21 79.78 53.06
Hirsch 100.00 99.58 95.70 82.04 60.24
*“3-OptGradient Descent” 100.00 99.76 97.34 89.44 77.83
*“2-Opt Gradient Descent” 100.00 99.36 95.62 85.60 73.37
“Gradient Descent” 98.64 95.47 86.46 72.40 58.29
Algoritmo guloso 95.12 88.82 75.15 58.57 43.41
Busca exaustiva 84.56 65.63 44.06 29.06 19.53
FONTE: Adaptada de Verner et al. (1997, p.273).
* Algoritmos não estudados neste trabalho. Verner et al. (1997); Christensen et al.
(1995);

36
** A Tabela 2.2 é uma cópia fiel da tabela encontrada em Verner et al. (1997) com
exceção do algoritmo Busca Tabu que foi inserido por nós.
A Tabela 2.2 mostra os resultados obtidos por vários algoritmos da literatura. As
colunas se referem ao percentual médio de rótulos sem conflitos para 100, 250, 500, 750
e 1000 pontos, por diferentes algoritmos da literatura e as linhas mostram o percentual
médio de rótulos sem conflito alcançados pelos algoritmos de otimização testados na
literatura por Christensen et al. (1995) (Busca Exaustiva, Algoritmo Guloso, “Gradient
Descent”, “2-Opt Gradient Descent’, “3-Opt Gradient Descent”, Algoritmo de Hirsch,
Zoraster (seção 2.5) e “Simulated Annealing”), por Verner et al. (1997) (GA sem
máscara e GA com máscara) e por Yamamoto et. al. (1999) (Busca Tabu).
Não foi possível fazer as comparações dos tempos computacionais entre os algoritmos,
pois o processamento do Busca Tabu foi feito usando um processador pentium II
350 Mhz, o Christensen utilizou uma estação de trabalho DEC 3000/400 AXP e
Verner usou uma estação de trabalho Sun-Sparc 10.
2.3 Algoritmo Genético Loga (Dijk Et. Al. , 1998)
Nesta seção, será descrito o algoritmo genético loGA (“local optimiser Genetic
Algorithm”) de Dijk et. al., que se encontra disponível na literatura. De acordo com a
sua formulação, cada cromossomo representa uma configuração de distribuição de
rótulos de um dado conjunto de pontos, onde cada posição de cromossomo corresponde
a um ponto e pode assumir uma das posições candidatas que lhe é permitido.
O algoritmo apresentado a seguir, descreve em linhas gerais o processo de busca do
loGA para resolver o problema de rotulação de pontos.
Algoritmo loGA:
1.Gerar população inicial aleatoriamente ou usar qualquer método de inicialização.
2.Repetir até alcançar a condição de término
• Selecionar 2 cromossomos aleatórios da população para reprodução

37
• Fazer o cruzamento
• Aplicar otimizador local nos filhos
• Selecionar os 2 melhores cromossomos para substituir os pais, dentre
os 4 cromossomos (2 filhos e 2 pais), levando em consideração o número de
rótulos sem conflito.
Para o cruzamento são usados as máscaras dos cromossomos que são pre-computados.
Cada máscara é do mesmo tamanho do cromossomo e é formada pôr 0 (conflito) e 1
(não conflito).
As máscaras dos pais selecionados são usadas para formar uma única máscara através
da operação “OR”. Esta máscara conhecida por multi-máscara será usada para realizar o
cruzamento.
Na operação de cruzamento o filho C1 receberá os genes do pai P1 se a multi-máscara
possuir valor 1 na posição equivalente ao gen, caso contrário receberá os gens do pai
P2. O filho C2 receberá por sua vez os gens do pai P1, quando a multi-máscara
apresentar valor 0 e gens do pai P2 quando a multi-máscara apresentar o valor 1.
Após o cruzamento usa-se um otimizador local nos cromossomos filhos, que verifica as
posições candidatas dos gens que apresentam conflito e troca, se possível, com uma
posição candidata que não apresenta conflito.
Os autores implementaram os algoritmos SA de Christensen et.al. (1995) e GA de
Verner et al. (1997) e compararam os resultados usando o conjunto padrão de dados
gerados aleatoriamente. A Tabela 2.3 mostra os resultados obtidos pelos algoritmos. As
colunas se referem ao percentual médio de rótulos sem conflitos para 100, 250, 500,
750, 1000 e 1500 pontos, por diferentes algoritmos e as linhas mostram o percentual
médio de rótulos sem conflito alcançados pelos algoritmos LoGA, SA e GA.
Infelizmente, não é possível incluir o loGA, na Tabela 2.2 dos resultados obtidos por
vários algoritmos, pois SA e GA alcançaram resultados diferentes dos trabalhos
originais de Christensen et.al. (1995) e Verner et al. (1997).

38
TABELA 2.3 – Resultados obtidos.
Algoritmo 100 pontos
250 pontos
500 pontos
750 pontos
1000 pontos
1500 pontos
LoGA 100.00 99.36 98.00 93.333 84.94 63.346
SA 100.00 99.36 97.92 92.933 84.70 63.466
GA 99.40 99.20 96.80 87.146 69.76 17.466
FONTE: Dijk et. al. (1998, p. 54, 56, 58, 59, 60).
2.4 Conjunto Independente de Vértices (Strijk et. al., 2000)
A versão do problema de rotulação de pontos com seleção de pontos pode ser vista
como o de encontrar o maior conjunto independente de vértices em um grafo.
2.4.1 Construção do Grafo de Relacionamento para Rotulação De Pontos
O objetivo aqui é organizar as informações referentes a conflitos de rótulos de pontos,
usando uma representação em grafo. Cada vértice representa um rótulo e vértices
adjacentes são compostos por posições candidatas que não podem estar ativas
simultaneamente sem que ocorra conflito e estão interligados por uma aresta. O
conjunto independente de vértices diz respeito a par de vértices não adjacentes, ou seja,
é composto por rótulos que podem estar ativos simultaneamente sem causar conflitos.
Rótulos ativos neste contexto diz respeito a posições candidatas do ponto que são
mostrados no mapa.
A FIGURA 2.7 mostra 2 pontos com 4 posições candidatas e os conflitos existentes
entre os rótulos, e a FIGURA 2.8 mostra o grafo associado.
L1L2
L3
L8
L6
L7
L5
L4
FIGURA 2.7 posições candidatas e os conflitos

39
FIGURA 2.8 grafo de relacionamento das posições candidatas.
Portanto dado uma instância do problema de n pontos, onde cada ponto possui 4
posições candidatas, podemos representar o relacionamento das posições candidatas em
um grafo G (V,E), onde V = L1, L2, ....., Ln representa o conjunto de rótulos, ou seja,
cada rótulo está representado pôr um vértice e E = A1, A2, ....., Am representa o
conjunto de arestas formados por 2 rótulos que não podem estar ativos simultaneamente
pôr causar conflito ou porque os 2 rótulos pertencem ao mesmo ponto.
Se usarmos a matriz de adjacências para representarmos o grafo de relacionamento das
posições candidatas, teremos uma matriz simétrica onde a soma por linha ou coluna
fornece o grau de cada vértice, que representa o número de posições candidatas que não
podem estar ativas se o vértice em questão estiver ativo. Assim sendo, quanto maior o
número de conflitos com outras posições candidatas, maior é o grau do vértice como
pode ser visto na matriz de adjacências da FIGURA 2.9, onde as linhas e as colunas são
as posições candidatas e o “1” da matriz representa que as posições candidatas i e j não
podem estar ativas ao mesmo tempo.
L 8L 7
L 6 L 5
L 4L 3
L 2 L 1

40
FIGURA 2.9 matriz de adjacências do grafo da FIGURA 2.8.
Grau dos vértces: L1 = 3; L2 = 3; L3 = 4; L4 = 5; L5 = 4; L6 = 5; L7 = 3; L8 = 3.
2.4.2 ALGORITMO
Nesta seção será apresentado em linhas gerais o algoritmo de busca local que usa Busca
Tabu. O algoritmo apresentado em Strijk et. al. (2000) está composto de algoritmo
principal e algoritmo Busca Tabu.
Algoritmo principal
Início:
S := ∅ conjunto independente (solução)
L := V lista de vértices ativos
Enquanto L ≠ ∅
• Extrair vértice v de L
• Tentar encontrar S’ de tamanho |S| + 1, usando algoritmo Busca
Tabu com S0 = S ∪ v
• Se não encontrar S’
• Tornar vértice v inativo
• Senão
• S’ = (S – U) ∪ W, onde U é o vetor com vértices removidos de S e W é
o vetor com vértices adicionados ao S
01110000L810110000L711011100L611101000L500110111L400101011L300001101L200001110L1
L8L7L6L5L4L3L2L1

41
• Acrescentar em L todo vértice u∉L que seja adjacente ao W ativo
FIM_Enquanto
Algoritmo Busca Tabu descrito em Strijk et. al. (2000)
Início:
S = S0 solução inicial
T = ∅ lista tabu
Tmin = 2 tamanho mínimo de T
Tmax = 7 tamanho máximo de T
C1 = 100 número de iterações para se conseguir escapar do mínimo local
C2 = 10 número de tentativas para sair do mínimo local
C3 = 3 número de iterações realizados com a função objetivo perturbada
Iteração:
• S’ = (S – u) ∪ w
u ∈ S e w ∈ (V – S) são escolhidos visando minimizar a f(S). Os vértices u
e w não devem pertencer a lista tabu
• S ← S’
• Se f(S) não diminuir, os vértices envolvidos vão para lista tabu T
• Quando f(S) = 0, S é o conjunto independente e a busca termina.
Dado uma solução inicial S0 com |S0| = α0, tenta-se encontrar uma solução S que
satisfaz |S| = α0 e minimize a função objetivo f(S) = |E(S)| onde E(S) = u,v ∈ E | u,v
∈ S que denota o conjunto de arestas com pontos terminais em S. Para tanto
mantêm-se 2 partições, uma com vértices S e outra com vértices V-S.
O algoritmo encontra mínimo local se em C1 iterações não encontrar uma solução
melhor do que a melhor solução até então encontrada S*. Neste caso, faz-se (C2 – 1)
tentativas para escapar do mínimo local, onde cada tentativa consiste de C1 iterações
com as C3 primeiras iterações realizados com a função objetivo perturbada:

42
onde cada elemento do vetor X recebe valor 1(um) se v∈S e recebe valor 0(zero) se
v∉S. P é um vetor que possui a informação de quantas vezes cada vértice v ∈ V esteve
envolvido em conflito. Neste caso o tamanho da lista tabu é modificado para T(i) =
Tmin + i (Tmax – Tmin) / C2 onde i é o número da tentativa.
Se encontrar a solução S, onde | E(S) | < | E(S*) |, volta-se a usar a função objetivo
normal, o tamanho da lista tabu é Tmin e o processamento continua. Caso as tentativas
não tenham sucesso a busca termina.
2.4.3 Resultados Obtidos
TABELA 2.4 – Resultados obtidos.
Algoritmo 100 pontos
250 pontos
500 pontos
750 pontos
950 pontos
TS (Strijk et. al., 2000) 100 249.5 490.9 704.6 844.7
SA (Christensen et.al., 1995)
100 249.6 491.7 703.1 834.4
FONTE: Strijk et. al. (2000, p. 34).
Os autores compararam com o algoritmo SA de Christensen et.al. (1995) usando o
conjunto padrão de dados gerados aleatoriamente. A Tabela 2.4 mostra os resultados
obtidos, onde as linhas referem-se a número médio de rótulos em estado de não conflito,
alcançados por TS (Strijk et. al., 2000) e SA (Christensen et. al., 1995). As colunas
referem-se a número médio de rótulos em estado de não conflito das 25 configurações,
para 100, 250, 500, 750 e 1000 pontos. É possível verificar que, quando o número
de pontos é maior, o algoritmo TS (Strijk et. al., 2000) traz resultados melhores
do que SA (Christensen et. al., 1995).
Estes resultados não são comparáveis com os da Tabela 2.2, pois estes últimos foram
obtidos para um problema que não admite seleção de pontos.
XP 21 | E(S)| ff(S) ST∑
∈
+=Vv

43
2.5 Programação Matemática
Trata-se de uma programação inteira 0-1, introduzido pôr Zoraster (1986, 1990, 1991)
para resolver o problema de sobreposição de rótulos. Dado:
O autor combina relaxação lagrangeana, “subgradient optimization” e várias heurísticas
específicos ao problema em questão para alcançar a solução. Primeiramente, ele fez
uma relaxação com relação a sobreposição de dois rótulos, incluindo um termo
adicional de penalidade na função objetivo.
Temos então:
0,1
Q q 1 1
k j 1 1 :a Suj.
in M
:então Temos
s' ponto do r' candidata posição Q q 1
s ponto dor candidata posição Q q 1 .candidatos
rótulos dois de ãosobreposiç nãoa expressa Q q 1 1 1. sendo como adocontabiliz
é ãosobreposiç depar Cada .candidatos rótulos entre ãosobreposiç de número Q
cacartográfia preferência representak j 1 N i 1
ativo rótulo um somentea ter pontocada obriga k j 1 1
rótulo dopresença 1
rótulo doausência 0
j ponto do icandidata posiçãok j 1 N i 1 j ponto do candidatas posições de númerok j 1 N
pontos denúmerok
xxx
x
xw
xx
xx
wx
xx
x
ij
qs' q,r'sq rq,
N
1iij
ij
k
1j
N
1iij
qs' q,r'
sq rq,
qs' q,r'sq rq,
jij
N
1iij
ij
ij
jij
j
j
j
j
∈
≤≤≤+
≤≤=
≤≤
≤≤
≤≤≤+
≤≤≤≤
≤≤=
=
=
≤≤≤≤
≤≤
∑
∑∑
∑
=
= =
=

44
Algoritmo:
• Rotular cada ponto na melhor posição candidata e gerar rotulação corrente (CL)
• Inicializar ACS (conjunto de conflitos ativo) como vazio
• Repetir pôr 40 iterações ou até alcançar uma configuração sem conflito
• Identificar os conflitos entre os rótulos e adicionar em ACS se não existir
• Fazer uma copia CL’ de CL
• Chamar heurística lagrangeano
• Retornar CL
Com o objetivo de produzir novas soluções, a heurística lagrangeano usa “subgradient
optimization”. O multiplicador lagrangiano é incrementado, decrementado ou não e
levado em consideração no calculo da função objetivo dos rótulos em conflito.
Algoritmo: heurística lagrangeano para rotulação
Repetir até 400 iterações ou até alcançar uma solução aceitável.
• Atualizar CL’ , escolhendo posições candidatas com menor função objetivo
para cada ponto
• Se CL’ é melhor que CL, copiar CL’ para CL
( )
olagrangeandor multiplica Q q 1 0 dq
1 0,
k j 1 1 :a Suj.
dq 1 - Min
xx
xxxw
ij
N
1iij
Q
1qqs' q,r'sq rq,ij
k
1j
N
1iij
j
j
≤≤≥
∈
≤≤=
++
∑
∑∑∑
=
== =
( )
o)lagrangeandor multiplica oa (increment dq 1 1- 1 1 o)lagrangeandor multiplica o ãoconsideraç emleva (não dq 0 1- 0 1 o)lagrangeandor multiplica o ãoconsideraç emleva (não dq 0 1- 1 0
o)lagrangeandor multiplica oa (decrement dq 1- 1- 0 0
dq 1 -
:são possíveis õesconfiguraç as logo ,1 0, que se-Sabe
xxxqs' q,r'sq rq,
ij
====
+
∈

45
• Se os dois rótulos em conflito estiverem ativos, incrementar o multiplicador
lagrangeano a função objetivo dos dois rótulos em questão
• Se os dois rótulos em conflito não estiverem ativos, decrementar o
multiplicador lagrangeano da função objetivo dos dois rótulos em questão
O algoritmo possui duas fraquezas:
• Mínimo local
• Comportamento cíclico inútil
FIGURA 2.10 – configuração estável e instável da abordagem do Zoraster.
A FIGURA 2.10 mostra a convergência do algoritmo para o mínimo local, como pode
ser visto na FIGURA 2.10(a), a função objetivo dos rótulos ativos em conflito são
incrementados com multiplicador lagrangeano tornando-se menos atraente, enquanto
que a função objetivo dos rótulos inativos em conflito são decrementados de
multiplicador lagrangeano tornando-se assim mais atraente. Isto conduz a configuração
modificada da FIGURA 2.10(b) que pôr sua vez volta a configuração da FIGURA
2.10(a) pôr mesmos motivos descritos acima e nunca consegue alcançar a configuração
da FIGURA 2.10(c).
O autor tenta resolver o problema aplicando o multiplicador lagrangeano a função
objetivo de apenas um dos rótulos em conflito. Mas a qual das duas funções objetivos o
multiplicador lagrangeano será então aplicado? Será de acordo com a iteração corrente,
ou seja se a iteração corrente for impar, o multiplicador lagrangeano será aplicado a
função objetivo da primeira variável e quando a iteração corrente for par, o
multiplicador lagrangeano será aplicado a função objetivo da segunda variável.

46
Outra modificação sugerido pôr ele é a de reduzir o valor do multiplicador lagrangeano
se um especificado número de iterações tem passado sem apresentar uma melhora, pois
neste caso o algoritmo se encontra na região próximo ao mínimo local e redução do
valor do multiplicador lagrangeano de tempos em tempos, torna o algoritmo capaz de
identificar o melhor mínimo.
A FIGURA 2.11 ilustra o caso de sobreposição de 3 rótulos, onde os rótulos dos dois
pontos abaixo são encorajados a mover para a área em conflito. O autor tenta sanar esta
deficiência fixando os Xij dos rótulos com mais de 3 conflitos para 0 (zero), quando
após 400 iterações ainda não conseguiu alcançar uma solução aceitável.
FIGURA 2.11 – Uma configuração instável do algoritmo do Zoraster.
A outra modificação sugerida pôr ele foi com relação a escolha do valor inicial do
multiplicador lagrangeano. Ele sugere 1/8 para rótulos ativos em conflito e -1/16 para
rótulos inativos em conflito. O autor forneceu estes valores baseados em seus
experimentos com uma variedade de diferentes mapas, mas valores ótimos são
provavelmente dependentes da densidade de rótulos.

47
CAPÍTULO 3
GENÉTICO CONSTRUTIVO PARA ROTULAÇÃO
O foco deste trabalho está relacionado à rotulação de pontos usando a proposta do
“Constructive Genetic Algorithm” ( Furtado, 1998; Lorena e Ribeiro Filho, 1997;
Lorena e Furtado, 2001; Ribeiro Filho, 2000; Ribeiro Filho e Lorena, 2001; Oliveira e
Lorena, 2002; Lorena, Narciso e Beasley, 2002) para a solução do problema, portanto
vamos inicialmente revisar o GA (“Genetic Algorithm”) tradicional.
3.1 Algoritmo Genético Tradicional
Nesta seção será feito: uma breve descrição histórica de quando e como surgiu o GA,
um breve relato sobre as suas características, apresentação do pseudocódigo e descrição
dos operadores genéticos de seleção, cruzamento e mutação. As informações descritas
nesta seção foram adaptadas dos links que se encontram no final da seção.
3.1.1 Histórico
Dos tempos de Aristóteles até a metade do século XIX, os naturalistas acreditavam na
hipótese da geração espontânea e na criação das espécies de maneira separada por um
ser supremo. Mas através de trabalhos como o do naturalista Carolus Linnaeus, que
levou a acreditar numa certa relação entre as espécies, influenciaram muitos outros
naturalistas a direcionarem-se para a teoria da seleção natural.
Charles Darwin, em 1838, teve a oportunidade de ler o livro do reverendo sociólogo
Thomas Robert Malthus intitulado Teoria das populações. Esta obra refere-se a
limitações naturais que retringiam o crescimento de uma população devido a fatores
ambientais tais como doenças e a fome. Segundo Darwin, foi este livro que despertou
nele a inspiração que o levaria à teoria da seleção natural. Após 20 anos de observações
e experimentos, em 1858, apresentou a teoria de evolução através da seleção natural,
simultaneamente com o naturalista inglês Alfred Russel Wallace.

48
No início do século XX, os cientistas resgataram o trabalho de Gregor Mendel sobre os
princípios básicos da herança genética desenvolvida em 1865, o qual teve enorme
influência nos trabalhos futuros relacionados à evolução.
Desenvolvida entre os anos 30 e 40 por biólogos e matemáticos de grandes centros de
pesquisa, a teoria moderna da evolução combina a genética com as idéias de Darwin e
Wallace sobre a seleção natural, criando um princípio básico de genética populacional:
“a variabilidade entre indivíduos numa população de organismos é produzida pela
recombinação genética e mutação”.
O desenvolvimento dos algoritmos genéticos teve início nos anos 50 e 60 através de
muitos biólogos, mas foi John Holland quem começou a desenvolver as primeiras
pesquisas no tema. Em 1975, Holland publicou “Adaptation in Natural and Artificial
Systems” ponto inicial dos GA’s. David E. Goldberg, aluno de Holland, nos anos 80
obteve seu primeiro sucesso em aplicação industrial com GA. Desde então, os GA’s são
utilizados para solucionar problemas de otimização combinatória e de outras áreas.
3.1.2 Tecnologia GA
GA é um procedimento computacional capaz de emular o processo Darwiniano de
seleção natural e mostrou ser bastante interessante em aplicações da otimização
combinatória. (Holland. 1975; Goldberg. 1989; Colin. 1995)
Em analogia com o sistema biológico, cada candidato à solução do problema representa
o cromossomo ou indivíduo da população e o conjunto de todos os candidatos deno-
mina-se uma geração.
Cada indivíduo da população pode ser representado no GA por um conjunto binário 0 e
1, pôr números inteiros, pôr números de ponto flutuante ou pôr caracteres; e tem um
custo associado que determina sua habilidade para sobreviver e produzir descendentes
no processo de seleção natural.

49
O processo de reprodução nos GA’s pode ser de simples cópia ou de cruzamento dos
cromossomos pais, fazendo com que descendentes de cada geração – ou seja, as novas
soluções – sejam semelhantes, possuindo muitas de suas características. Vale ressaltar
ainda que os descendentes podem sofrer mutação, ou seja, o resultado dos cromossomos
pode ser modificado por perturbações aleatórias.
A forma básica de um GA tradicional é mostrado no algoritmo a seguir:
GA tradicional
t := 0;
Gerar população inicial
Repetir (até alcançar a condição de término)
Avaliar os indivíduos da população
Selecionar os melhores indivíduos para reprodução
Recombinar usando os operadores: cópia, cruzamento ou mutação
t := t + 1;
Fim_Repetir
3.1.3 Operadores Genéticos
A população inicial do GA tradicional é composta por indivíduos criados aleatoriamente
ou através dos métodos de inicialização. Cada indivíduo é um cromossomo de tamanho
fixo que contém informações codificadas representando normalmente uma solução do
problema. Para melhorar o custo ou a aptidão dos indivíduos das populações sucessivas
são necessários os operadores genéticos. Esses operadores permitem selecionar
indivíduos mais aptos à sobrevivência para reprodução, além de manter as
características de adaptação adquiridas pelas gerações passadas, criando indivíduos
cada vez mais aptos à sobrevivência. Os operadores genéticos de seleção, cruzamento e
mutação estão descritos a seguir.
Seleção: responsável pelo processo de seleção dos indivíduos mais adaptados ao
ambiente. O método de seleção muito utilizado é o da roleta, onde cada indivíduo da

50
população é representado na roleta conforme seu valor de aptidão ou custo. Dessa
forma, os indivíduos com elevada aptidão receberão um intervalo maior na roleta,
enquanto aqueles que têm baixa aptidão receberão menor intervalo na roleta. Após a
distribuição, são gerados aleatoriamente números no intervalo entre 0 e o valor da
somatória de aptidão de todos os indivíduos da população. O indivíduo que possuir em
seu intervalo o número gerado, será selecionado para o cruzamento. A FIGURA 3.1
mostra o esquema da roleta. A primeira coluna mostra os indivíduos da população, a
segunda coluna o valor de aptidão dos indivíduos, a terceira coluna o intervalo de cada
indivíduo e a quarta coluna a percentagem correspondente a cada indivíduo. Como
exemplo, foram gerados de maneira aleatória, 10 números pertencentes ao intervalo de 0
a 81 (51-1-22-74-46-60-42-65-41-34). Os indivíduos selecionados para o cruzamento
foram (I3, I1, I1, I5, I2, I3, I2, I4, I2, I2), levando em consideração que um indivíduo
pode ser selecionado mais de uma vez para o cruzamento.
Cruzamento: responsável por geração de novos descendentes. O objetivo do
cruzamento é a propagação das características dos indivíduos mais aptos a
sobrevivência, por meio de troca de segmentos entre pares de indivíduos, dando assim
origem a novos indivíduos. A seguir será descrito algumas formas de reprodução em
GA: cruzamento de um ponto, cruzamento de dois pontos e cruzamento uniforme.
Cruzamento de um ponto: o ponto de quebra dos cromossomos pai são escolhidos de
forma aleatória, e depois faz-se a troca do conjunto de genes entre os cromossomos para
gerar os filhos, como mostrado na FIGURA 3.2.
Cruzamento de dois pontos: similar ao cruzamento de um ponto, mas a troca de
segmentos de genes ocorre como mostrado na FIGURA 3.3.
Cruzamento uniforme: Cada gene do filho é criado, copiando o gene de um dos pais,
que é escolhido de acordo com uma máscara de cruzamento gerada aleatoriamente. Se a
máscara de cruzamento apresentar 1, o filho recebe gen do primeiro pai, caso contrário
recebe gen do segundo pai, como mostrado na FIGURA 3.4.

51
I3
I4
I5
12% 27%
9%
21% 31%
FIGURA 3.1 – Esquema da roleta
Pontos de cruzamento
Pais 1011 0110 0100 1001
Filhos 1011 1001 0100 0110
FIGURA 3.2 – Cruzamento de um ponto
Mutação: responsável por manutenção e introdução da diversidade genética na
população. Altera aleatoriamente um ou mais genes do cromossomo escolhido, com a
finalidade de introduzir novos elementos na população e melhorar a chance de chegar a
Indivíduos Índice de Aptidão Roleta Percentagem I1 10110 22 0 - 22 27% I2 11001 25 23 - 47 31% I3 10001 17 48 - 64 21% I4 00111 7 65 - 71 9% I5 01010 10 72 - 81 12%
I1
I2

52
qualquer ponto do espaço de busca. A FIGURA 3.5 ilustra o processo de mutação do
filho.
Para informações atualizadas sobre aplicações de GA’s veja os links:
(http://www.faqs.org/faqs/ai-faq/genetic/), Projeto Isis – Sistemas Inteligentes: Uma Incursão
aos Algoritmos Genéticos (http://www.geocities.com/igoryepes/visualizar2.htm), JEICG Home
Page – Algorítmos Genéticos (http://www.orbita.starmedia.com/~jeicg/), Algoritmos
Genéticos: Fundamentos e Aplicações (http://www.gta.ufrj.br/~marcio/genetic.html),
Algoritmo Genético (http://www.sites.uol.com.br/jamwer/GA.HTM) e Mimura e Oliveira,
2002.
Pontos de cruzamento
Pais 10 1101 10 01 0010 01
Filhos 01 1101 01 10 0010 10
FIGURA 3.3 – Cruzamento de dois pontos.
Máscara 1 0 0 1 0 1 0 1 1 0 0 1 0 1 0 1
Pai1 1 0 1 0 0 1 0 0 0 1 1 0 1 0 1 1
Filhos 1 1 1 0 1 1 1 0 0 0 1 0 0 0 0 1
Pai2 0 1 1 0 1 0 1 1 1 0 1 0 0 1 0 0
FIGURA 3.4 – Cruzamento uniforme.

53
Ponto de mutação
Filho 1 0 1 0 0 1 0 0
Filho com 1 0 1 1 0 1 0 0 mutação
FIGURA 3.5 – Mutação.
3.2 Algoritmo Genético Construtivo
Atualmente os GA’s são muito conhecidos e muito utilizados para solucionar problemas
de otimização combinatória por fornecer mecanismos de busca adaptativos, poderosos e
robustos, que conduzem a soluções de alta qualidade. Existem muitas variações do GA
clássico tradicional, aplicados a diversos problemas combinatórios (Dijk et. al., 1998;
Verner et.al.,1997; Lorena e Furtado, 2001; Oliveira A.C.M. e Lorena L.A.N., 2002).
Este Capítulo apresenta a aplicação do CGA (“Constructive Genetic Algorithm” ) ao
problema de rotulação de pontos.
O CGA (Furtado, 1998; Lorena e Ribeiro Filho, 1997; Lorena e Furtado, 2001; Ribeiro
Filho, 2000; Ribeiro Filho e Lorena, 2001; Oliveira e Lorena, 2002; Lorena, Narciso e
Beasley, 2002) difere do GA tradicional descrito na seção 3.1, por avaliar esquemas
diretamente e também por apresentar algumas características novas tais como o
tamanho dinâmico da população que é composto por esquemas e estruturas, e a
possibilidade de usar heurísticas na definição da função objetivo.
Como o objetivo deste trabalho foi a de resolver o problema de rotulação de pontos para
gerar mapas de impressão, que devem ser de boa qualidade, foi usado o CGA, que é um
algoritmo da família dos GA’s e como tal, apesar do tempo de processamento ser
grande, costuma trazer resultados robustos de altíssima qualidade.

54
3.3 Tecnologia CGA
Serão descritos a seguir aspectos de modelagem das representações esquema e estrutura,
considerações sobre o problema de rotulação de pontos como um problema de
otimização bi_objetivo e o processo de evolução do CGA.
3.3.1 Representação de Estrutura e Esquema
Em rotulação de pontos, cada esquema representa uma configuração de distribuição de
rótulos de um dado conjunto de pontos, onde cada posição do esquema corresponde a
um ponto e pode assumir uma das posições candidatas que lhe é permitido ou o símbolo
# que informa que o ponto não está temporariamente sendo considerado.
Pôr exemplo para um problema com 10 pontos a serem rotulados: S = (L1, L4, #, #, L1,
L3, L2, L1, #, L2) é um possível esquema, onde L1, L2, L3, L4 refere-se a posições
candidatas e o símbolo # implica que o ponto em questão não está sendo considerado
temporariamente, assim o esquema S não apresenta soluções candidatas para 3 dos 10
pontos do problema.
As estruturas por representarem soluções completas de um problema, não apresentam o
símbolo # na sua composição. Por exemplo: S = (L1, L4, L2, L1, L1, L3, L2, L1, L4,
L2) é uma possível estrutura, onde L1, L2, L3, L4 refere-se a posições candidatas.
O CGA tem pôr objetivo avaliar tanto estruturas, quanto partes dessas estruturas,
chamadas esquemas.
3.3.2 Funções de Avaliação
O CGA utiliza duas funções, f(S) e g(S) para avaliar a qualidade da rotulação. O f(S)
refere-se ao número de rótulos colocados sem sobreposição considerando o esquema S e
o g(S) corresponde ao número de rótulos colocados sem sobreposição considerando o
esquema S após a aplicação de uma heurística. Para a contagem de conflitos foi
utilizado a informação referente ao número de rótulos em conflito (FIGURA 2.3), pois

55
alem de mostrar o número total de rótulos que se encontra em conflito, é o tipo de
contagem de conflitos que se é adotado na maioria dos artigos encontrados na literatura.
Assim sendo, seja X o conjunto de todas as estruturas e esquemas formadas pelos
símbolos L1, L2, L3, L4, # para pontos com 4 posições candidatas, temos
segundo (Lorena e Furtado, 2001) que, g : X → R+, f : X → R+, g(S) ≥ f(S) e os
objetivos são minimizar g(S) – f(S) e alcançar o estado em que g(S) aproxime o
número total de pontos. Assim sendo o CGA é modelado como segue:
Min g(S) – f(S)
Max g(S) (3.1)
Sujeito a: g(S) ≥ f(S), S ε X
3.3.3 heurística RSF
A heurística usada para calcular g(S), para o problema de rotulação de pontos, foi
denominada RSF (“Recursive Smallest First”). Este algoritmo tenta rotular tantos
pontos do mapa quantos forem possíveis, deixando então alguns pontos sem o rótulo
para evitar conflitos. O número de pontos sem o rótulo cresce de acordo com o número
de pontos sendo mostrado na área do mapa, mas consegue alcançar o estado próximo ao
número total de pontos com um tempo mínimo de processamento. A heurística RSF
aproxima, portanto a solução ótima do problema de encontrar o maior conjunto
independente de vértices no grafo de relacionamentos (ver seção 2.4). A seguir será
apresentado o algoritmo RSF adaptado de Strijk et. al. (2000).
Dado uma instância do problema de n pontos, podemos representar o relacionamento
das posições candidatas em um grafo G (V,E), onde V = L1, L2, ....., Ln representa o
conjunto de rótulos, ou seja, cada rótulo está representado pôr um vértice e E = A1,
A2, ....., Am representa o conjunto de arestas formados pôr 2 rótulos que não podem
estar ativos simultaneamente pôr causar conflito ou porque os 2 rótulos pertencem ao
mesmo ponto.

56
Algoritmo RSF
Início:
S := ∅ conjunto independente (solução)
L := V lista de vértices ativos
Enquanto L ≠ ∅
• Calcular grau dos vértices de L
• Escolher de L, vértice v de menor grau e acrescentar em S
• Tornar vértice v e vértices adjacentes a v inativos em L
FIM_Enquanto
O algoritmo RSF sempre escolhe do conjunto de vértices ativos, o vértice de menor
grau e no caso de haver empate a escolha será pelo vértice (posição candidata) cujo
ponto se encontra com menos posições candidatas, uma vez que cada posição candidata
pertence a um determinado ponto e o ponto que possui mais posições candidatas tem
mais chance de receber um rótulo do que o ponto que possui menos posições
candidatas. O algoritmo termina quando a lista de vértices ativos ficar vazia. A seguir
um exemplo de funcionamento do algoritmo RSF.
Dados: ponto posições candidatas
P1 L01, L02, L03, L04
P2 L05, L06, L07, L08
P3 L09, L10, L11, L12
P4 L13, L14, L15, L16
P5 L17, L18, L19, L20
P6 L21, L22, L23, L24
E a matriz de adjacências descrita na FIGURA 3.6, e o grau dos vértices.

57
FIGURA 3.6 - Matriz de adjacência inicial.
Grau dos vértices: L01 = 5, L02 = 4, L03 = 9, L04 = 12, L05 = 8, L06 = 7, L07 = 13,
L08 = 11, L09 = 8, L10 = 13, L11 = 14, L12 = 9, L13 = 12, L14 = 12, L15 = 8, L16 = 7,
L17 = 14, L18 = 9, L19 = 9, L20 = 12, L21 = 9, L22 = 5, L23 = 3, L24 = 3.
Algoritmo RSF
Iteração 1: L = L01, L02, L03, ... , L24
S = L24 (vértice de menor grau de L)
L23 e L24 são posições candidatas do ponto P6, portanto a escolha entre L23 e L24 é
indiferente uma vez que a preferência cartográfica não esta sendo considerada.
011100000000000000000000101100000000000000000000110101000100000000000000111011001100110000000000000101111111110011000000001110110110010001000000000011010010011001100100000011100011111111110100000110000111110000000000001111001011010000000000000011111101011001001100000010011110111111001000000110011001011110000000000111111111101111000000000000110011110111111100000000010001111010011000000010010001111101111000000011110011011010111100000000000000001011011011000000010000001111101001000000010011001111110111000000110010001001101011000000000000000000101101000000000000000000111110
L24L23L22L21L20L19L18L17L16L15L14L13L12L11L10L09L08L07L06L05L04L03L02L01
L24L23L22L21L20L19L18L17L16L15L14L13L12L11L10L09L08L07L06L05L04L03L02L01

58
L01 L02 L03 L04 L05 L06 L07 L08 L09 L10 L11 L12 L13 L14 L15 L16 L17 L18 L19 L20
L01 0 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0L02 1 0 1 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 L03 1 1 0 1 0 1 1 0 0 1 0 0 0 1 0 0 1 1 0 0 L04 1 1 1 0 1 1 1 1 1 1 0 0 1 1 0 0 1 0 0 0 L05 1 0 0 1 0 1 1 1 1 1 0 0 0 0 0 0 1 0 0 0 L06 1 1 0 1 1 0 1 1 0 1 0 0 0 0 0 0 0 0 0 0 L07 0 0 1 1 1 1 0 1 0 1 1 0 1 1 0 0 1 1 1 1 L08 0 0 0 1 1 1 1 0 1 1 1 1 1 0 0 0 1 0 0 1 L09 0 0 0 1 1 0 0 1 0 1 1 1 1 0 0 0 1 0 0 0 L10 0 0 1 1 1 1 1 1 1 0 1 1 1 1 0 0 1 1 0 0 L11 0 0 0 0 0 0 1 1 1 1 0 1 1 1 1 1 1 1 1 1 L12 0 0 0 0 0 0 0 1 1 1 1 0 1 0 0 1 1 0 0 1 L13 0 0 0 1 0 0 1 1 1 1 1 1 0 1 1 1 1 0 0 1 L14 0 0 1 1 0 0 1 0 0 1 1 0 1 0 1 1 1 1 1 1 L15 0 0 0 0 0 0 0 0 0 0 1 0 1 1 0 1 0 0 1 1 L16 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 0 0 0 0 1 L17 0 0 1 0 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 L18 0 0 1 0 0 1 1 0 0 1 1 0 0 1 0 0 1 0 1 1 L19 0 0 0 0 0 0 1 0 0 0 1 0 0 1 1 0 1 1 0 1 L20 0 0 0 0 0 0 1 1 0 0 1 1 1 1 1 1 1 1 1 0
FIGURA 3.7 - Matriz de adjacência 1ª iteração.
Grau dos vértices: L01 = 5, L02 = 4, L03 = 9, L04 = 12, L05 = 8, L06 = 7, L07 = 13,
L08 = 11, L09 = 8, L10 = 13, L11 = 13, L12 = 8, L13 = 12, L14 = 12, L15 = 6, L16 = 6,
L17 = 14, L18 = 9, L19 = 7, L20 = 11.
Iteração 2: L = L01, L02, L03, ... , L20
S = L24, L02 (vértices de menor grau de L)
L05 L07 L08 L09 L10 L11 L12 L13 L14 L15 L16 L17 L18 L19 L20
L05 0 1 1 1 1 0 0 0 0 0 0 1 0 0 0L07 1 0 1 0 1 1 0 1 1 0 0 1 1 1 1 L08 1 1 0 1 1 1 1 1 0 0 0 1 0 0 1 L09 1 0 1 0 1 1 1 1 0 0 0 1 0 0 0 L10 1 1 1 1 0 1 1 1 1 0 0 1 1 0 0 L11 0 1 1 1 1 0 1 1 1 1 1 1 1 1 1 L12 0 0 1 1 1 1 0 1 0 0 1 1 0 0 1 L13 0 1 1 1 1 1 1 0 1 1 1 1 0 0 1 L14 0 1 0 0 1 1 0 1 0 1 1 1 1 1 1 L15 0 0 0 0 0 1 0 1 1 0 1 0 0 1 1 L16 0 0 0 0 0 1 1 1 1 1 0 0 0 0 1 L17 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 L18 0 1 0 0 1 1 0 0 1 0 0 1 0 1 1 L19 0 1 0 0 0 1 0 0 1 1 0 1 1 0 1 L20 0 1 1 0 0 1 1 1 1 1 1 1 1 1 0
FIGURA 3.8 - Matriz de adjacência 2ª iteração.

59
Grau dos vértices: L05 = 5, L07 = 10, L08 = 9, L09 = 7, L10 = 10, L11 = 13, L12 = 8,
L13 = 11, L14 = 10, L15 = 6, L16 = 6, L17 = 12, L18 = 7, L19 = 7, L20 = 11.
Iteração 3: L = L05, L07, L08, ... , L20
S = L24, L02, L05 (vértices de menor grau de L)
L11 L12 L13 L14 L15 L16 L18 L19 L20
L11 0 1 1 1 1 1 1 1 1L12 1 0 1 0 0 1 0 0 1 L13 1 1 0 1 1 1 0 0 1 L14 1 0 1 0 1 1 1 1 1 L15 1 0 1 1 0 1 0 1 1 L16 1 1 1 1 1 0 0 0 1 L18 1 0 0 1 0 0 0 1 1 L19 1 0 0 1 1 0 1 0 1 L20 1 1 1 1 1 1 1 1 0
FIGURA 3.9 - Matriz de adjacência 3ª iteração.
Grau dos vértices: L11 = 8, L12 = 4, L13 = 6, L14 = 7, L15 = 6, L16 = 6, L18 = 4,
L19 = 5, L20 = 8.
Iteração 4: L = L11, L12, L13, L14, L15, L16, L18, L19, L20
S = L24, L02, L05, L12 (vértices de menor grau de L)
P3 possui as posições candidatas L11, L12 e P5 possui as posições candidatas L18,
L19, L20, portanto L12 foi escolhido ao invés de L18.
L14 L15 L18 L19
L14 0 1 1 1L15 1 0 0 1 L18 1 0 0 1 L19 1 1 1 0
FIGURA 3.10 - Matriz de adjacência 4ª iteração.
Grau dos vértices: L14 = 3, L15 = 2, L18 = 2, L19 = 3.
Iteração 5: L = L11, L15, L18, L19
S = L24, L02, L05, L12, L15 (vértices de menor grau de L)

60
P4 possui a posição candidata L15 e P5 possui as posições candidatas L18, L19,
portanto L15 foi escolhido ao invés de L18.
L18
L18 0
FIGURA 3.11 - Matriz de adjacência 5ª iteração.
Iteração 6: L = L18
S = L24, L02, L05, L12, L15, L18
Iteração 7: L =
Na iteração 1 o conjunto L é composto por todos os vértices e o vértice L24 é escolhido
de L, por ser o vértice de menor grau. O vértice escolhido é adjacente a vértices L21,
L22 e L23 como pode ser visto na matriz de adjacência da FIGURA 3.6 acima, portanto
o conjunto L agora é composto por todos os vértices menos L21, L22 e L23. Na iteração
2, o L2 é o vértice de menor grau, portanto será escolhido e novamente o conjunto L
será construído por vértices não adjacentes a L24 e L2. E assim o processamento
continua até L ser ∅.
Como pode ser visto no exemplo acima, o conjunto independente máximo foi
S = L24, L02, L05, L12, L15, L18, ou seja, os 6 pontos foram rotulados sem
conflitos: P1/L02, P2/L05, P3/L12, P4/L15, P5/L18 e P6/L24.
Será mostrado a seguir, através de um exemplo de 8 pontos, o calculo
das funções f e g para o esquema ( L2, L5, L11, L15, L17, L23, #, # ).
f(L02, L05, L11, L15, L17, L23, #, #) = 3 pontos rotulados sem conflitos, pois L05
conflita com L17, L11 conflita com L15, L11 conflita com L17, L17 conflita com L05 e
L17 conflita com L11, como pode ser visto na matriz de adjacência da FIGURA 3.6.
Como pode ser visto no exemplo anterior de 6 pontos, o g( L02, L05, L11, L15,
L17, L23, #, # ) = L02, L05, L12, L15, L18, L24 = 6 pontos rotulados sem
conflitos. O RSF deste trabalho escolhe o melhor rótulo para cada ponto do esquema

61
que não apresenta # pois, este símbolo implica que o ponto em questão não está sendo
considerado temporariamente. Assim sendo, as posições candidatas L02, L05 e L15
foram mantidas ativas, enquanto que as posições candidatas L11, L17 e L23 foram
trocadas por posições candidatas L12, L18 e L24 respectivamente, e o melhor
esquema ficou sendo L02, L05, L12, L15, L18, L24, #, #, que não apresenta
nenhum conflito.
3.3.4 Processo de Evolução
Outra característica do algoritmo é o tamanho variável da população que é controlado
pelo uso de um parâmetro para eliminação de indivíduos ao longo das gerações. Neste
contexto, indivíduo refere-se a um esquema ou a cada estrutura candidata a solução do
problema e o conjunto de todos os indivíduos denomina-se uma geração.Assim sendo, o
indivíduo Si criado recebe um valor de rank δ(Si) e ele é removido da população
quando α ≥ δ(Si). O α refere-se ao tempo de evolução e o valor de rank do indivíduo Si,
δ(Si) é definido como:
δ(Si) = [dgmax – [g(Si) – f(Si)]] / d [gmax – g(Si)] (3.2)
onde gmax é o número total de pontos a serem rotulados.
Quanto maior for o valor de δ(Si), mais adaptado é considerado o indivíduo Si em
relação aos objetivos de minimização [g(Si) – f(Si)] e maximização de g(Si), e mais
tempo de sobrevivência para cruzamento ele tem. O parâmetro d é um número real pré-
definido 0<d≤1, o número real não negativo gmax é o limite superior para g(Si), tal
que gmax ≥ MAXSi∈X g(Si) e α está relacionado ao tempo de evolução, começando
com o valor zero na primeira geração e sendo acrescido lentamente de ∆α durante o
processo. Assim a população Pα tem seu tamanho influenciado dinamicamente por α e
pode eventualmente ficar vazia durante o processo.

62
Os melhores indivíduos apresentam alto valor de rank, refletindo em pequenas variações
de [g(Si) – f(Si)] e/ou grande valor de g(Si), ou seja, os melhores indivíduos são aqueles
que são treinados pela heurística RSF e os que apresentam maior número de rótulos sem
conflitos.
Analisando o δ(Si) da equação 3.2, é possível notar o efeito de d e gmax no tamanho da
população. Quando o valor de d é pequeno, a população apresenta um crescimento lento
e se mantém pequena, enquanto que um valor grande de d apresenta uma população
grande trazendo problemas de armazenamento da população, mas eventualmente com
boas estruturas. O efeito indesejável de gmax, é quando gmax >> g(Si) para um grande
número de indivíduos da população. Isto pode conduzir a eliminação de indivíduos de
uma geração para outra e naturalmente, o efeito pode ser uma enorme redução no
tamanho da população em apenas algumas gerações. Logo a definição dos parâmetros d
e gmax precisa ser o resultado de um estudo cuidadoso.
Considerando que os indivíduos bem adaptados precisam ser preservados para o
cruzamento e que o tamanho da população Pα no tempo α varia de acordo com o ∆α, o
incremento ∆α tem grande importância no funcionamento do CGA pois, um incremento
acelerado demais pode rapidamente eliminar todos os indivíduos da população sem que
esses tenham tempo de se reproduzir. Oliveira e Lorena (2002) sugerem variar ∆α de
acordo com o tamanho da população corrente, levando em consideração a iteração em
que se encontra e o δ máximo (δtop) e o δ mínimo (δbot) alcançado. Assim sendo, o
incremento adotado neste trabalho foi:
∆α = k * |P| * ((δtop - δbot) / Gr) + ι (3.3)
Onde k é uma constante de proporção, ι é o incremento mínimo permitido, Gr é o
número restante de gerações e (δtop - δbot) é o intervalo corrente dos valores de δ.

63
3.4 Operadores do CGA
Nesta seção serão descritos os operadores de seleção, recombinação e mutação que
trabalham no processo de evolução do CGA. A população inicial é composta
exclusivamente de esquemas e a recombinação cria novos esquemas ou estruturas. A
melhor estrutura gerada durante o processo de evolução é mantida para representar a
melhor solução encontrada e a mutação é usada para diversificar a busca para encontrar
melhores soluções.
3.4.1 População Inicial
A população inicial é composta exclusivamente de indivíduos do tipo esquema, e a
população das próximas gerações pode aumentar por adição de novos indivíduos
gerados através do cruzamento de dois indivíduos.
Cada indivíduo da população inicial é criado com um número de # pré-estabelecido. Os
gens que recebem # são escolhidos aleatoriamente. O restante dos gens do indivíduo
recebem as posições candidatas geradas aleatoriamente.
A proporção de rótulos do tipo # tem influência direta no processo de evolução.
Esquemas que apresentam um número pequeno de #, podem chegar a gerar estruturas
durante o cruzamento, mas como os esquemas gerados aleatoriamente não são de boa
qualidade, as estruturas encontradas também não o são, com o seu tempo de
sobrevivência bastante pequeno. Isto conduz, a diminuição considerável da população
em apenas algumas gerações, contribuindo até mesmo para a sua extinção. Por outro
lado, se o número de # for grande, a probabilidade de gerar filhos do tipo estrutura é
pequena e a probabilidade de serem removidos da população se torna grande, uma vez
que a diferença (gmax – g(Si)) da equação 3.2 é maior e novamente as populações
futuras podem sofrer enorme redução no seu tamanho em apenas algumas gerações,
chegando até mesmo a se extinguir. Logo a escolha do número de # em um esquema,
precisa ser feito com cuidado, como descrito na seção 3.6.

64
A população inicial criada aleatoriamente é composta por esquemas, que na maioria não
são de boa qualidade e apresentam f(Si) pequeno. Para garantir uma população
razoavelmente grande no início, a diferença [g(Si) – f(Si)] da equação 3.2 deve ser
pequena, conduzindo-nos ao uso do algoritmo busca local descrito abaixo para obter o
g(Si), pois este tipo de algoritmo conduz a resultados inferiores ao do algoritmo RSF
usado para se obter g(Si) dos filhos gerados do cruzamento
O processo de busca local visa trocar, para cada ponto com informação, a posição dos
rótulos ( por exemplo se o rótulo L4 está ativo no ponto 2 e existe conflito, tenta-se
ativar a posição candidata que traz menor número de conflitos) até percorrer o último
ponto. Este processo foi repetido 5 vezes para cada esquema, com a finalidade de
melhorar um pouco mais o valor de g(si).
Algoritmo busca local
Início:
S := ∅ solução
Repetir (para todos os pontos(pi)/gens do indivíduo)
Se # colocar # no ponto pi em S
senão Escolher a posição candidata com menor número de conflitos Colocar a posição candidata escolhida no ponto pi em S FIM_ Repetir
Os indivíduos gerados por busca local só serão usados para calcular o valor de g,
portanto não fará parte da população em questão. Porém, o melhor esquema será
mantido.
Para o exemplo de uma população inicial de 6 pontos, mostrado abaixo, foi estabelecido
2 # para cada indivíduo do tipo esquema gerado. Os 6 pontos e as suas 4 posições
candidatas são: P1(L01, L02, L03, L04), P2(L05, L06, L07, L08), P3(L09, L10, L11,
L12), P4(L13, L14, L15, L16), P5(L17, L18, L19, L20), P6(L21, L22, L23, L24). A

65
matriz de adjacência da FIGURA 3.6 foi usada para verificar os conflitos e o custo
refere-se a número de rótulos sem conflitos.
Esquema gerado aleatoriamente custo Depois de aplicar a busca local custo
S1 = (#, L06, L10, L16, #, L22) 2 S1 = (#, L05, L11, L16, #, L22) 4
S2 = (L02, L07, #, L15, #, L21) 2 S2 = (L02, L05, #, L13, #, L21) 4
S3 = (L01, L08, L09, L14, #, #) 2 S3 = (L01, L06, L09, L13, #, #) 2
S4 = (L02, #, L12, #, L20, L24) 2 S4 = (L01, #, L09, #, L18, L21) 4
S5 = (#, #, L12, L16, L19, L22) 4 S5 = (#, #, L09, L13, L18, L21) 4
S6 = (#, L06, L12, #, L20, L23) 2 S6 = (#, L05, L12, #, L18, L21) 4
3.4.2 Seleção
A cada geração do CGA os indivíduos da população são ordenados em ordem crescente,
de acordo com uma chave ϕ(Si), onde:
ϕ(Si) = [1 + d(Si)] / η(Si) (3.4)
e d(Si) = [g(Si) – f(Si)] / g(Si)
O parâmetro η(Si) é o número de gens com símbolos diferentes de # do esquema Si em
questão. A equação 3.4 acima privilegia os esquemas melhor adaptados que possuem
[g(Si) – f(Si)] pequeno e η(Si) grande, ou seja, esquemas que apresentam menor
número de conflitos e próximos de estruturas.
Uma parte do início da população fará parte da sub-população base (Sbase) e a população
guia (Sguia) é composta por toda população. O método de seleção para recombinação é
do tipo base-guia, onde um indivíduo da sub-população base e um indivíduo da
população guia são escolhidos aleatoriamente e então o algoritmo de cruzamento
descrito abaixo é aplicado, gerando assim um novo esquema, ou até mesmo uma nova
estrutura. O objetivo do Sguia é o de conduzir uma modificação dirigida no Sbase. O

66
tamanho da sub-população base é um parâmetro do CGA e pode variar de acordo com o
tamanho do problema. A FIGURA 3.12 representa seleção do tipo base-guia.
Sguia Sbase
Toda população
FIGURA 3.12 – seleção base-guia
3.4.3 RECOMBINAÇÃO
A recombinação foi feita, usando o algoritmo de cruzamento com máscara, baseado em
Verner et al. (1997):
Sbase um indivíduo da sub-população base
Sguia um indivíduo da população guia
Snovo um novo indivíduo
Mbase máscara de Sbase (0 = conflito, 1 = sem conflito, 2 = #)
Mguia máscara de Sguia (0 = conflito, 1 = sem conflito, 2 = #)
U 0 ou 1 (gerado aleatoriamente)
Repetir para todos os gens do cromossomo
• Se Mbase (j) = 1 então Snovo (j) ← Sbase (j)
• Se Mbase (j) ≠ 1 e Mguia (j) = 1 então Snovo (j) ← Sguia (j)
• Se Mbase (j) ≠ 1 e Mguia (j) ≠ 1 e U = 0 então Snovo (j) ← Sguia (j)
• Se Mbase (j) ≠ 1 e Mguia (j) ≠ 1 e U = 1 então Snovo (j) ← Sbase (j)
Após a recombinação, o esquema gerado Snovo sofre um processo de busca local descrito
na seção 3.4.1 e fará parte da próxima geração se for um sobrevivente, ou seja, se

67
α < δ( Snovo) na equação 3.2 for satisfeito. O número de novos indivíduos sendo criados
a cada geração é outro parâmetro do CGA e pode variar de acordo com o problema.
3.4.4 MUTAÇÃO
Após a geração dos filhos, o melhor esquema obtido até o momento e todos esquemas
da sub-população base sofrem um processo de mutação. Todos os símbolos # são
substituídos pôr uma melhor posição candidata e depois o algoritmo de busca local
descrito na seção 3.4.1 é executado 5 vezes, com o objetivo de melhorar a qualidade
destes indivíduos. A melhor estrutura encontrada até o momento é mantida como a
melhor solução até então encontrada e se não apresentar conflitos será a solução final.
Os mutantes não farão parte da próxima geração. A mutação foi aplicada aos melhores
indivíduos da população na tentativa de encontrar uma solução de qualidade.
3.5 ALGORITMO
CGAConstructive Genetic Algorithm
Iniciar α = 0
Criar Pα
Calcular f(Si), g*(Si) e δ(Si) para todo Si ε Pα
Repetir (até alcançar a condição de término)
Se α < δ(Si), acrescentar Si em Pα+1, para todo Si ε Pα
Estabelecer Sbase e Sguia
Repetir (número de recombinação)
Selecionar Sbase e Sguia de Pα
Recombinar Sbase e Sguia → Snovo
Aplicar busca local em Snovo
Calcular f(Snovo), g(Snovo) e δ( Snovo)
Se α < δ( Snovo), acrescentar Snovo em Pα+1
Fim_repetir
Mutação de Sbase e salvar a melhor solução

68
Atualizar α
Fim_repetir
O g*() refere-se ao cálculo do g, usando o algoritmo busca local descrito na seção 3.4.1
e o g() refere-se ao cálculo do g usando o RSF descrito na seção 3.3.3. O melhor g() ou
a melhor Sbase é mantida durante o processo como a melhor solução até então
encontrada, como descrito em 3.4.4.
O valor de α é incrementado de ∆α e o processo é repetido para uma nova geração. O
processo pode parar quando atingir um certo número de gerações, quando uma solução
satisfatória for obtida, ou quando a população ficar vazia por causa do processo de
eliminação de indivíduos.
3.6 CALIBRAÇÃO DE PARÂMETROS
Existem alguns parâmetros que influenciam no funcionamento do CGA e que devem ser
especificados a priori. São eles:
• população: Número de indivíduos na população inicial;
• k: constante de proporção;
• ι: incremento mínimo permitido;
• nova solução: quantidade de indivíduos novos criados em uma determinada geração;
• gerações: número de gerações para parada do processo;
• d: um número real 0<d≤1;
• símbolo #: número de símbolos #, nas estruturas que compõe a população inicial.
• sub-população base: tamanho da sub-população base;
Os valores ideais destes parâmetros variam de acordo com o problema sendo tratado, e
seu valor é determinado de modo empírico, isto é, o algoritmo é executado algumas
vezes até se encontrar valores para os parâmetros que proporcionem resultados

69
satisfatórios. Para o CGA implementado neste trabalho, os valores dos parâmetros são
mostrados na Tabela 3.1 abaixo.
TABELA 3.1 – Seleção de parâmetros
num. de pontos 100 pontos
250 pontos
500 pontos
750 pontos
1000 pontos
população 30 75 150 200 300
k 0.01 0.01 0.01 0.01 0.01
ι 0.00001 0.00001 0.00001 0.00001 0.00001
nova solução 30 30 30 30 30
gerações 25 25 25 25 25
d 0.2 0.2 0.2 0.2 0.2
símbolo # 1 2 10 30 70
sub-população base (% da população)
15% 15% 15% 15% 15%
3.7 RESULTADOS OBTIDOS
TABELA 3.2 – Resultados obtidos por CGA usando o conjunto padrão de dados
(média).
Num. de pontos 100 pontos
250 pontos
500 pontos
750 pontos
1000 pontos
Tempo 0 0.6 21.5 195.9 981.8
Tempo total 0 0.6 620.8 2178.7 4261.1
Com conflito 0 0 2 24 96
Desvio padrão 0.0 0.0 1.9 6.1 19.8
Sem conflito 100 250 498 726 904
Sem conflito (%) 100.00 100.00 99.6 96.8 90.4

70
TABELA 3.3 – Resultados obtidos por CGA usando o conjunto padrão de dados
(melhor).
Num. de pontos 100 pontos
250 pontos
500 pontos
750 pontos
1000 pontos
Tempo 0 0.6 21.5 228.9 1227.2
Tempo total 0 0.6 620.8 2195.8 4243.5
Com conflito 0 0 2 22 93
Desvio padrão 0.0 0.0 1.9 7.1 12.4
Sem conflito 100 250 498 728 907
Sem conflito (%) 100.00 100.00 99.6 97.1 90.7
Os leiautes com configuração de rótulos após aplicação do CGA para 100, 250, 500,
750 e 1000 pontos encontram-se no Apêndice A1.
Testes foram feitos usando o mesmo conjunto padrão de dados descritos na seção 2.2.3.
O algoritmo CGA, implementado em linguagem C++, foi aplicado a 25 configurações
diferentes de distribuição de pontos para 100, 250, 500, 750 e 1000 pontos
(Apêndice A3). Para cada distribuição de pontos o CGA foi aplicado 6 vezes gerando
assim seis amostras para cada configuração. A média obtida da aplicação do CGA nas
25 configurações, onde cada configuração é a média das seis amostras estão mostradas
na Tabela 3.2. A média obtida da aplicação do CGA nas 25 configurações, onde cada
configuração é a melhor das seis amostras estão mostradas na Tabela 3.3. As linhas das
tabelas se referem a:
• Tempo: tempo médio de processamento do algoritmo CGA em segundos para
alcançar o estado de não conflito ou de mínimo conflito em um processador Pentium
II 350 Mhz. O tempo mostrado se refere apenas ao tempo de processamento do
algoritmo CGA, ou seja, as informações de conflitos são dados de entrada.

71
• Tempo total: tempo médio de processamento do algoritmo CGA em segundos para
processar 25 gerações ou iterações em um processador Pentium II 350 Mhz.
• Com conflito: número médio de rótulos em estado de conflito nas 25 diferentes
configurações de distribuição de pontos.
• Desvio padrão: desvio padrão dos rótulos colocados sem conflito.
• Sem conflito: número médio de rótulos em estado de não conflito nas 25 diferentes
configurações de distribuição de pontos.
• Sem conflito (%): trata-se da média percentual do número de rótulos sem conflito
das 25 diferentes configurações de distribuição de pontos.

72

73
CAPÍTULO 4
ANÁLISE COMPARATIVA COM A LITERATURA
Os resultados de alguns algoritmos de otimização citados na literatura e os algoritmos
testados por nós se encontram na Tabela 4.1, onde as colunas se referem ao percentual
médio de rótulos sem conflitos para 100, 250, 500, 750 e 1000 pontos, por diferentes
algoritmos e a linhas mostram o percentual médio de rótulos sem conflito alcançados
por algoritmos de otimização testados por Christensen et. al., 1995 (Busca Exaustiva,
Algoritmo Guloso, “Gradient Descent”, “2-Opt Gradient Descent’, “3-Opt Gradient
Descent”, Algoritmo de Hirsch, Zoraster e “Simulated Annealing”), por Verner et al.,
1997 (GA sem máscara e GA com máscara) e por nós (CGA e TS).
TABELA 4.1 – Resultados obtidos por vários algoritmos usando o conjunto padrão de
dados.
Algoritmo 100 pontos
250 pontos
500 pontos
750 pontos
1000 pontos
**CGA-Melhor 100.00 100.00 99.6 97.1 90.7
**CGA-Média 100.00 100.00 99.6 96.8 90.4
**Busca Tabu 100.00 100.00 99.3 96.8 90.00
GA com máscara 100.00 99.98 98.79 95.99 88.96
*GA sem máscara 100.00 98.40 92.59 82.38 65.70
“Simulated Annealing” 100.00 99.90 98.30 92.30 82.09
Zoraster 100.00 99.79 96.21 79.78 53.06
Hirsch 100.00 99.58 95.70 82.04 60.24
* “3-Opt Gradient Descent” 100.00 99.76 97.34 89.44 77.83
* “2-Opt Gradient Descent” 100.00 99.36 95.62 85.60 73.37
“Gradient Descent” 98.64 95.47 86.46 72.40 58.29
Algoritmo guloso 95.12 88.82 75.15 58.57 43.41
Busca exaustiva 84.56 65.63 44.06 29.06 19.53
FONTE: Adaptada de Verner et al. (1997, p.273).

74
* Algoritmos não estudados neste trabalho. Verner et al. (1997); Christensen et al. (1995).
** A Tabela 4.1 é uma cópia fiel da tabela encontrada em Verner et al. (1997) com exceção dos algoritmos Busca Tabu, apresentado em Yamamoto (1998), e dos algoritmos CGA-Melhor e CGA-Média que foram inseridos neste trabalho.
Como pode ser visto o CGA mostrou resultados muito bons, chegando a superar o
Busca Tabu que mostrou resultados superiores aos demais algoritmos citados na
literatura.
TABELA 4.2 – Tempo de processamento.
Algoritmo 100 pontos
250 pontos
500 pontos
750 pontos
1000 pontos
CGA-Melhor 0 0.6 21.5 228.9 1227.2
CGA-Média 0 0.6 21.5 195.9 981.8
Busca Tabu 0 0 1.36 76.0 352.9
TABELA 4.3 – Tempo de processamento total
Algoritmo 100 pontos
250 pontos
500 pontos
750 pontos
1000 pontos
CGA-Melhor 0 0.6 620.8 2195.8 4243.5
CGA-Média 0 0.6 620.8 2178.7 4261.1
Busca Tabu 0 0 9.0 202.0 507.0
O tempo de processamento usado pelos algoritmos testados neste trabalho se encontram
na Tabela 4.2 e Tabela 4.3, onde as colunas se referem ao tempo médio em segundos
para processar 100, 250, 500, 750 e 1000 pontos, pelos diferentes algoritmos e as linhas
mostram o tempo médio em segundos usado pelos algoritmos de otimização
(CGA-Melhor, CGA_Média, TS). A Tabela 4.2 mostra o tempo médio de
processamento gasto em segundos para alcançar o estado de não conflito ou de mínimo

75
conflito e a Tabela 4.3 mostra o tempo médio gasto em segundos para processar número
de iterações pre-estabelecidas (30000 para TS e 25 para CGA).
O tempo médio de processamento gasto por GA com máscara implementado por Verner
et. al.(1997), para resolver o problema de rotulação para 100, 250, 500, 750 e 1000
pontos foi 6, 49, 414, 1637 e 7256 segundos respectivamente, usando um Sun-Sparc 10
workstation. As implementações dos algoritmos (CGA e TS) foram feitas no
microcomputador PC com processador Pentium II 350 Mhz, 120MB RAM de memória,
Microsoft Windows 98 e Microsoft Visual Studio versão 6.0. O Christensen utilizou no
seu trabalho uma estação de trabalho DEC 3000/400 AXP. As comparações do tempo
de processamento entre CGA e TS estão mostrados na Tabela 4.2 , mas não foi possível
fazer as comparações do tempo de processamento entre CGA, TS e demais algoritmos,
pois os processadores utilizados são diferentes.

76

77
CAPÍTULO 5
ALGORITMO EXATO
Um problema de otimização combinatória pode ser definido matematicamente a partir
do par (Ω,C), onde Ω é o conjunto (finito) de soluções possíveis e C é uma função
C : Ω→ℜ, sendo ℜ o conjunto dos reais. O objetivo, no problema de otimização de
minimização, é encontrar uma solução ótima S ∈ Ω, tal que C(S) ≤ C(S’), ∀S’ ∈ Ω; ou
seja, tal que a função C, conhecida como função custo do problema, seja minimizada.
Como Ω é finito, intuitivamente poderíamos, selecionar a solução ótima por
enumeração. Essa proposta de enumeração exaustiva funciona teoricamente, mas torna-
se inviável para os problemas de interesse, devido ao tamanho extremamente grande –
apesar de finito – do conjunto de soluções. Cada pequeno incremento na dimensão do
problema introduz uma gama muito grande de possibilidades, configurando uma
explosão combinatória de soluções possíveis, e uma conseqüente explosão no tempo
necessário para encontrar a solução ótima (Bjorndal et al. 1995).
1 ponto 2¹ configurações 2 pontos 2² configurações 3 pontos 2³ configurações
• • • • • • • • • • • •
1000 pontos 2¹ººº configurações • FIGURA 5.1 - Árvore de configurações possíveis para pontos
• com 2 posições candidatas.
P1/L0 P1/L1
P2/L0 P2/L1 P2/L0 P2/L1
P3/L0 P3/L1 P3/L0 P3/L1 P3/L0 P3/L1 P3/L0 P3/L1

78
Em rotulação cartográfica se considerarmos 2 posições candidatas – L0 e L1 – para cada
ponto pi, onde i varia entre 1 e o número de pontos, e desenvolvermos uma árvore de
configurações veremos que o número de configurações possíveis aumenta exponen-
cialmente dependendo do número de pontos do leiaute (FIGURA 5.1) .
Esta explosão combinatória mostra que se trata de um problema de otimização combi-
natória e neste caso a enumeração completa de todas as soluções viáveis de um
problema conduzirá a solução ótima em um número finito de passos. Infelizmente
mostra-se que, mesmo para problemas de porte pequeno, o número de passos será tão
grande que o computador mais avançado levaria séculos no processo de cálculo.
Campello R. E. e Maculan N., 1994 apresentam um exemplo de um problema cujo
número de soluções viáveis é (n!). A Tabela 5.1 mostra a explosão exponencial, ou seja,
a grande variação observada no tempo de execução, quando o valor de n aumenta de
apenas uma unidade, levando em consideração que cada solução possa ser examinada
em 10**(-9) segundos (1 nanosegundo).
TABELA 5.1 – Explosão exponencial.
n Tempo de Execução
20 80 anos
21 1680 anos
Neste caso muitos pesquisadores não acreditam na existência de um algoritmo exato
eficiente e, mesmo que esse algoritmo fosse encontrado, ele seria bastante lento para
problemas grandes, assim sendo existe a necessidade de introduzir heurísticas tais como
o CGA e TS, que não buscam a solução exata, mas uma solução suficientemente boa em
termos de custo.
Neste Capítulo está sendo proposto um algoritmo exato, com o objetivo de obtermos
soluções ótimas para verificar a qualidade das soluções geradas pelo CGA e TS.
Basicamente o algoritmo exato trabalha com busca em profundidade em uma árvore,

79
mas com possibilidades de corte de ramificações da árvore em algumas situações, pois
como foi visto anteriormente a enumeração total causa uma explosão no tempo de
execução, uma vez que o número de passos necessários, para garantir a obtenção da
solução ótima cresce exponencialmente com o número de variáveis, digamos 2ⁿ , onde
no caso da rotulação de pontos, n é o número de variáveis ou pontos e 2 é o número de
posições candidatas do ponto. Na seção 5.2 será descrito com mais detalhes o algoritmo
exato proposto neste trabalho. A próxima seção faz uma breve descrição do algoritmo
exato para conjunto independente de vértices.
5.1 Algoritmo Exato para Conjunto Independente de Vértices
Dowsland (1987) aplica o algoritmo exato, para o máximo conjunto estável de Loukakis
e Tsouros (1982), ao problema de empacotamento bi-dimensional. O objetivo é
encontrar um leiaute ótimo, para retângulos menores do mesmo tamanho, dispostos em
um retângulo maior. O problema possui o grafo G(V, E), onde V = v1, v2, ..., vn
representa o conjunto de posições possíveis dos retângulos menores, dentro do retângulo
maior, e E = e1, e2, ..., em é o conjunto de arestas formadas pôr dois retângulos que se
sobrepõem.
Trata-se de um algoritmo de busca em árvore, onde os nós pertencem a um dos três
conjuntos: S — lista de vértices da solução, S+ — lista de vértices disponíveis que
podem fazer parte de S, e S- — lista de vértices descartados que não podem fazer parte
de S. Com o objetivo de diminuir o tamanho da busca, as seguintes restrições são
impostas:
Se | S | + | S+ | < Nub então “backtracking”
Se | S | = Nub então parar
Onde Nub é o limite superior, ou seja, é o maior número de retângulos menores que
podem ser colocados no retângulo maior, sem causar sobreposição. Este valor foi

80
estimado pelo autor. O “backtracking” refere-se a voltar um nível da árvore e escolher
outras opções.
5.2 Descrição do Algoritmo Exato para Rotulação de Pontos
O algoritmo exato descrito a seguir, aproveitou a idéia principal de Dowsland (1987),
que aplica cortes nas ramificações da árvore, em um algoritmo de busca em árvore.
O algoritmo exato proposto coloca então, o rótulo do ponto selecionado na primeira
posição candidata, até alcançar o número permitido de rótulos em conflito. Um corte de
ramificação da árvore é executado, quando alcançar o limite permitido de rótulos em
conflito. Neste caso, as sucessivas posições candidatas do ponto em questão são testadas
para se executar um novo corte ou a continuação da busca em profundidade. Se um
determinado ponto não puder ser rotulado porque não existem posições sem conflito, o
algoritmo volta para o ponto rotulado anteriormente e muda a posição do rótulo. E
assim o algoritmo continua até que todos os pontos tenham sido rotulados ou até que
todas as soluções tenham sido verificadas, retendo neste caso a melhor solução.
A seguir será descrito o algoritmo exato para um problema de n pontos que possui o
grafo G(V,E), onde V = L1, L2, ..., Ln representa o conjunto de rótulos e E = A1,
A2, ..., Am representa o conjunto de arestas formados por 2 rótulos que não podem
estar ativos simultaneamente por causar conflito ou porque os 2 rótulos pertencem ao
mesmo ponto. O grafo G(V,E), o número de pontos, a previsão do número de rótulos
sem conflitos (M) e grau dos vértices são dados de entrada. O valor de M usado por nós
para o corte das ramificações da árvore é dado levando em consideração o valor obtido
da aplicação do CGA ou TS ao problema em questão, mas este valor pode ser obtido
usando um algoritmo simples de busca exaustiva, algoritmo guloso ou qualquer outro
algoritmo que consiga resolver o problema de rotulação de pontos, ou ainda estabelecer
um valor inicial pequeno de acordo com a sua intuição como um limitante inferior, pois
o valor M é atualizado toda vez que um valor maior de número de rótulos sem conflitos
for encontrado.

81
Algoritmo exato
Início:
S := ∅ conjunto de rótulos ativos (solução)
V lista de todos os rótulos
M número de rótulos sem conflito (resultado CGA ou TS)
P pontos em ordem crescente por grau dos vértices
Enquanto |S| ≠ n
• Escolher de V, rótulo vi do ponto Pi e acrescentar em S
• Calcular nc (número de rótulos com conflito de S)
• Calcular nsc (número de rótulos sem conflito de S)
• Se nsc > M então M := nsc
• Verificar futuro (número de pontos ainda não rotulados, que
possuem posições candidatas que não conflitam com S)
• Se (nsc + futuro ≤ M) ou (nc > n - M) executar corte
FIM_Enquanto
O algoritmo exato descrito acima envolve alguns conceitos: ordenação dos pontos,
escolha de rótulos, verifica futuro e corte de ramificações da árvore. Eles serão descritos
a seguir.
Ordenação de pontos: os pontos são ordenados de acordo com o grau dos vértices que
o compõe, ou seja, a seqüência de escolha dos pontos depende do número de conflitos
que as posições candidatas do ponto apresentam. Assim sendo, o ponto escolhido será
aquele que possui a posição candidata, que apresenta o menor número de conflitos,
entre todas as posições candidatas, de todos os pontos do cenário.
Usando o exemplo de 6 pontos, temos que a ordem dos pontos é P6, P1, P4, P3, P5 e P2
como mostrado na tabela 5.2. Como pode ser visto, uma vez escolhido o ponto, o
restante das posições candidatas do ponto em questão, não são consideradas, mesmo

82
apresentando o segundo menor número de conflitos entre todos os rótulos do cenário,
como por exemplo o L24 do ponto P6 e L01 do ponto P1.
TABELA 5.2 – Ordenação de pontos.
Pontos vértices (rótulos)
Grau dos vértices
Ordem crescente
P1 L01 5 P1 L02 4 2 P1 L03 8 P1 L04 10 P2 L05 8 6 P2 L06 10 P2 L07 13 P2 L08 11 P3 L09 7 4 P3 L10 11 P3 L11 11 P3 L12 7 P4 L13 9 P4 L14 9 P4 L15 7 P4 L16 5 3 P5 L17 15 P5 L18 9 P5 L19 7 5 P5 L20 11 P6 L21 5 P6 L22 4 P6 L23 3 1 P6 L24 3
Outro detalhe a ser considerado é o fato de ficar com o primeiro rótulo que apresenta o
menor número de conflitos, quando existir mais de um, como pode ser visto com L09
do ponto P3 e L19 do ponto P5, ambos rótulos apresentam 7 conflitos, mas o ponto P3
teve a preferência.

83
O objetivo de se escolher vértices de menor grau ou posições candidatas que apresentam
menor número de conflitos, vem do fato de que quanto menos conflitos apresentarem, a
probabilidade de conflitos com os rótulos ativos de outros pontos é menor.
Optou-se por ordenar a seqüência dos pontos a serem rotulados, com o objetivo de se
encontrar a solução boa ou a solução ótima logo no início, pois isto aumenta o valor de
M (no início é um valor obtido via leitura, que representa um limitante inferior do
número de rótulos sem conflito) e o corte das ramificações da árvore acontecem em um
nível não muito profundo, diminuindo assim o tempo de processamento, que em
algoritmos exatos é bastante grande.
Escolha de rótulos: os pontos são rotulados na seqüência em que foram ordenados, e
o rótulo de cada ponto, é escolhido seqüencialmente pôr ordem crescente de custo,
dentre as posições candidatas de cada ponto. Se considerarmos o exemplo de 4 posições
candidatas da FIGURA 2.5, a posição candidata a se tornar ativa será na seguinte
ordem: L0, L1, L2 e L3.
O algoritmo faz primeiro a busca em profundidade e depois a busca por largura.
Tenta-se sempre rotular cada ponto na ordem estabelecida com a posição candidata L0,
mas quando o número de conflitos ultrapassa o limite estabelecido, ou o número de
rótulos sem conflito atual, somado ao número de rótulos sem conflito que pode existir
no futuro, ultrapassa o limite estabelecido, a próxima posição candidata, no caso L1 é
escolhida. Novamente o teste é aplicado e caso seja verdadeiro em um dos casos a
próxima posição candidata L2 é escolhida, mas se as duas questões forem falsas, o
próximo ponto é rotulado na posição L0. O algoritmo continua neste processo, até que
um determinado ponto não pode ser rotulado porque não existem posições sem conflito.
Neste caso ele executa o “backtracking”, ou seja, o algoritmo volta para o ponto
rotulado anteriormente e muda para a próxima posição candidata. E assim o algoritmo
continua até que todas as soluções possíveis tenham sido verificadas.

84
Verifica futuro: Para verificar se o número de rótulos sem conflito atual, somado ao
número de rótulos sem conflito que pode existir no futuro, ultrapassa o limite
estabelecido, é necessário fazer uma previsão do futuro quanto ao número de rótulos
sem conflito que teremos, levando em consideração os pontos que ainda não foram
rotulados. Esta previsão é feita, verificando se pelo menos uma posição candidata dos
pontos que ainda não foram rotulados, não tem conflito com os rótulos ativos dos
pontos já rotulados.
Corte de ramificações da árvore: este termo diz respeito ao corte das ramificações de
um determinado nível de uma árvore, ou seja, todas as ramificações que vierem abaixo
do nível que sofreu o corte, não precisarão ser analisados. O problema de rotulação de
pontos pode ser visualizado em forma de uma árvore através da FIGURA 5.1, que
mostra uma árvore de configurações possíveis para pontos com duas posições
candidatas. Se a árvore do exemplo sofrer corte em uma das ramificações do nível dos
2**900 ramificações, estamos deixando de analisar 2**100 configurações, o que
equivale a ganho em tempo de processamento. Este tipo de técnica se torna bastante
atraente nos algoritmos exatos, se conseguir fazer corte em níveis bem acima dos níveis
terminais, pois reduz bastante o número de configurações que precisa ser analisado, e
por conseguinte diminui o tempo de processamento.
No algoritmo exato implementado por nós, o corte acontece quando existe a
necessidade de troca da posição do rótulo por causa dos conflitos. Neste caso, todas as
configurações possíveis de posições de rótulo, que possam ter os demais pontos que o
sucedem, perdem a atratividade de análise.
5.3 Exemplo de Aplicação do Algoritmo Exato para 6 Pontos
Será descrito em detalhes a aplicação do algoritmo exato implementado por nós,
utilizando um exemplo de 6 pontos com 4 posições candidatas, cuja matriz de
adjacência inicial e o grau dos vértices se encontram descritos na FIGURA 3.6. Para o
exemplo, a estimativa inicial do número de rótulos sem conflito foi estabelecido como

85
(continua)
sendo M = 5 e a seqüência em que os pontos foram rotulados foi: P6, P1, P4, P3, P5 e
P2.
O exemplo do algoritmo exato para 6 pontos está mostrado na Tabela 5.3, onde as
linhas se referem à seqüência de passos seguidos para alcançar a solução, e as colunas
se referem a:
• Ponto: pontos sendo rotulados
• Solução: rótulo que está sendo atribuído ao ponto
• nc: número de rótulos com conflito de S
• nsc: número de rótulos sem conflito de S
• futuro: número de pontos ainda não rotulados, que possuem posições candidatas
que não conflitam com S
• previsão: nsc + futuro (mostra a tendência, de quanto será o número de rótulos
sem conflito que pode se obter, se continuarmos analisando todas as
ramificações da posição corrente da árvore até o fim)
TABELA 5.3 – Exemplo do algoritmo exato para 6 pontos.
ponto solução nc nsc futuro previsão P6 L21 0 1 5 6 P1 L01 0 2 4 6 P4 L13 0 3 2 5 P4 L14 0 3 2 5 P4 L15 2 1 3 4 P4 L16 2 1 3 4 P1 L02 0 2 4 6 P4 L13 0 3 3 6 P3 L09 0 4 1 5 P3 L10 0 4 1 5 P3 L11 2 2 1 3 P3 L12 2 2 2 4

86
TABELA 5.3 – (continuação)
(continua)
P4 L14 0 3 2 5 P4 L15 2 1 3 4 P4 L16 2 1 3 4 P1 L03 0 2 4 6 P4 L13 0 3 3 6 P3 L09 0 4 1 5 P3 L10 2 2 1 3 P3 L11 2 2 1 3 P3 L12 2 2 2 4 P4 L14 0 3 2 5 P4 L15 2 1 2 3 P4 L16 2 1 3 4 P1 L04 0 2 3 5 P6 L22 0 1 5 6 P1 L01 0 2 4 6 P4 L13 0 3 2 5 P4 L14 0 3 2 5 P4 L15 2 1 3 4 P4 L16 0 3 3 6 P3 L09 0 4 2 6 P5 L17 2 3 0 3 P5 L18 0 5 0 5 P5 L19 0 5 0 5 P5 L20 2 3 0 3 P3 L10 0 4 1 5 P3 L11 0 4 0 4 P3 L12 0 4 2 6 P5 L17 2 3 0 3 P5 L18 0 5 0 5 P5 L19 0 5 0 5 P5 L20 3 2 0 2 P1 L02 0 2 4 6 P4 L13 0 3 3 6 P3 L09 0 4 1 5 P3 L10 0 4 1 5 P3 L11 2 2 1 3 P3 L12 2 2 2 4 P4 L14 0 3 2 5 P4 L15 2 1 3 4 P4 L16 0 3 3 6

87
TABELA 5.3 – ( conclusão )
P3 L09 0 4 2 6 P5 L17 2 3 0 3 P5 L18 0 5 0 5 P5 L19 0 5 0 5 P5 L20 2 3 0 3 P3 L10 0 4 1 5 P3 L11 0 4 1 5 P3 L12 0 4 2 6 P5 L17 2 3 0 3 P5 L18 0 5 1 6 P2 L05 0 6 0 6
A solução ótima: P1 = L02, P2 = L05, P3 = L12, P4 = L16, P5 = L18 e P6 = L22 foi
encontrada, analisando apenas 63 configurações até um determinado nível da árvore, de
um total de 4096 configurações. A maioria dos cortes aconteceu no nível 3 e 4 da árvore
de configurações do exemplo dado, como pode ser visto na Tabela 5.4, onde as linhas
estão mostrando os pontos na ordem em que foram rotulados, ou seja, cada ponto esta
representando um determinado nível da árvore, e as colunas referem se a:
• ponto: pontos rotulados
• nv: número de vezes que sofreu o corte
• %: valor percentual do número de vezes que sofreu o corte
TABELA 5.4 – Localização dos cortes.
ponto nv % P6 1 2 P1 5 9 P4 19 33 P3 19 33 P5 13 23 P2 0 0

88
No exemplo acima a estimativa inicial do número de rótulos sem conflito foi
estabelecida como sendo M = 5 e conseguimos chegar à solução ótima examinando 63
configurações até um determinado nível da árvore, que é aproximadamente 1.6% de
todas as 4096 configurações possíveis do exemplo. Para verificar a influência do valor
inicial de M, foi processado novamente o mesmo exemplo de 6 pontos nas mesmas
condições, mas com o valor de M = 4. Neste caso a solução ótima foi encontrada
analisando-se 241 configurações até um determinado nível da árvore que é
aproximadamente 6% de 4096, ou seja, a quantidade de análises feitas é pequena se
considerarmos todas as configurações, mas é importante notar que quanto mais próximo
o valor de M, mais rápido o algoritmo encontra a solução ótima. Não foi testado com o
valor de M = 6, pois o M deve ser o limitante inferior do número de rótulos sem
conflito.
5.4 Resultados Obtidos
O algoritmo exato, implementado em linguagem C++, foi aplicado a 8 configurações
diferentes de distribuição de pontos, onde cada configuração é composta de 25 pontos
gerados randomicamente (Apêndice A3). Tentou-se criar as mesmas dificuldades
impostas pelos autores da literatura Christensen et al. (1995) e Verner et. al. (1997)
quando geraram o conjunto padrão de dados randomicamente para 1000 pontos. Para
tanto manteve-se o tamanho da região, tamanho da folha de papel e aumentou-se o
tamanho do rótulo de 8.5%. As demais condições foram mantidas: os rótulos podem
ultrapassar o limite da região, foram consideradas 4 posições candidatas, não foi
considerada a preferência cartográfica e não houve seleção de pontos. Os resultados da
aplicação do algoritmo exato a 8 configurações estão mostrados na Tabela 5.5, onde a
ultima linha refere-se a média das 8 configurações e as colunas se referem a:
• : número da configuração;
• Tempo: tempo de processamento do algoritmo exato em segundos para
encontrar a solução ótima em uma estação de trabalho SUN – SPARC20;

89
• Com conflito: número de rótulos em estado de conflito;
• Sem conflito: número de rótulos em estado de não conflito;
• Sem conflito (%): valor percentual do número de rótulos sem conflito;
TABELA 5.5 – Resultados obtidos por algoritmo exato.
Tempo Com conflito
Sem conflito
Sem conflito (%)
1 681 2 23 92 2 876 3 22 88 3 864 3 22 88 4 1495 7 18 72 5 749 3 22 88 6 572 4 21 84 7 1726 7 18 72 8 2061 4 21 84
média 1128 4.125 20.875 83.5
5.5 Análise Comparativa entre os Algoritmos Exato, CGA e TS
Usando o mesmo conjunto de dados, das 8 configurações geradas na seção 5.4, foram
feitos testes usando o TS e CGA, para tornar possível a análise comparativa dos
resultados obtidos pelas duas heurísticas, com a solução ótima gerada pelo método
exato proposto neste trabalho.
Apesar do exemplo, ser de apenas 25 pontos, o grau de dificuldade do problema é igual
ou até um pouco maior do que de 1000 pontos, pois os rótulos são maiores, apesar da
área ser o mesmo. Assim sendo os parâmetros da TS continuaram os mesmos e
precisou-se calibrar novamente os parâmetros do CGA.
Os parâmetros utilizados pela Busca Tabu foram:
• Tamanho da lista tabu: 7 + INT(0.25 * num. de rótulos em conflito);

90
• tamanho da vizinhança: 1 + INT (0.05 * num. de rótulos em conflito);
• número de iterações para recálculo: 50;
Os parâmetros utilizados pelo CGA foram:
• Número de indivíduos na população inicial: 500;
• constante de proporção: 0.00005;
• incremento mínimo permitido: 0.0001;
• quantidade de indivíduos novos criados em uma determinada geração: 500;
• número de gerações para parada do processo: 100;
• um número real 0<d≤1: 0.9;
• número de símbolos #, nas estruturas que compõe a população inicial: 13;
• tamanho da sub-população base (% da população): 15%;
Os resultados da aplicação do algoritmo exato, TS e CGA, a 8 configurações estão
mostrados na Tabela 5.6, onde a ultima linha refere-se a média das 8 configurações e as
colunas se referem a:
• : número da configuração;
• Sem conflito (exato): número de rótulos em estado de não conflito;
• % (exato): valor percentual do número de rótulos sem conflito;
• Sem conflito (TS): número de rótulos em estado de não conflito;
• % (TS): valor percentual do número de rótulos sem conflito;
• * Sem conflito (CGA-média): número de rótulos em estado de não conflito.
Refere-se a média das 6 amostras;
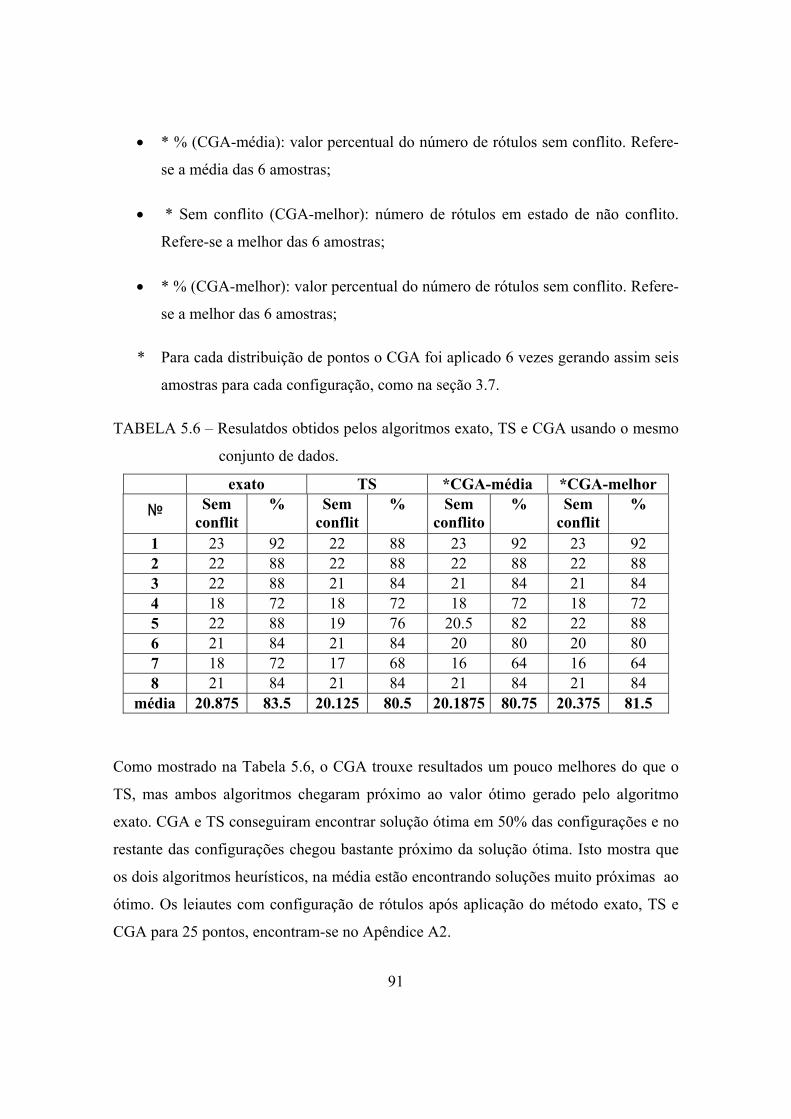
91
• * % (CGA-média): valor percentual do número de rótulos sem conflito. Refere-
se a média das 6 amostras;
• * Sem conflito (CGA-melhor): número de rótulos em estado de não conflito.
Refere-se a melhor das 6 amostras;
• * % (CGA-melhor): valor percentual do número de rótulos sem conflito. Refere-
se a melhor das 6 amostras;
* Para cada distribuição de pontos o CGA foi aplicado 6 vezes gerando assim seis
amostras para cada configuração, como na seção 3.7.
TABELA 5.6 – Resulatdos obtidos pelos algoritmos exato, TS e CGA usando o mesmo
conjunto de dados.
exato TS *CGA-média *CGA-melhor
Sem conflit
% Sem conflit
% Sem conflito
% Sem conflit
%
1 23 92 22 88 23 92 23 92 2 22 88 22 88 22 88 22 88 3 22 88 21 84 21 84 21 84 4 18 72 18 72 18 72 18 72 5 22 88 19 76 20.5 82 22 88 6 21 84 21 84 20 80 20 80 7 18 72 17 68 16 64 16 64 8 21 84 21 84 21 84 21 84
média 20.875 83.5 20.125 80.5 20.1875 80.75 20.375 81.5
Como mostrado na Tabela 5.6, o CGA trouxe resultados um pouco melhores do que o
TS, mas ambos algoritmos chegaram próximo ao valor ótimo gerado pelo algoritmo
exato. CGA e TS conseguiram encontrar solução ótima em 50% das configurações e no
restante das configurações chegou bastante próximo da solução ótima. Isto mostra que
os dois algoritmos heurísticos, na média estão encontrando soluções muito próximas ao
ótimo. Os leiautes com configuração de rótulos após aplicação do método exato, TS e
CGA para 25 pontos, encontram-se no Apêndice A2.

92
Como o objetivo aqui foi a de verificar a qualidade da solução alcançada por CGA e TS
com relação à solução ótima, não foi mostrado o tempo de processamento dos mesmos,
uma vez que o processamento foi feito usando um processador pentium II 350 Mhz. O
processamento do algoritmo exato foi feito, usando uma estação de trabalho
SUN – SPARC20, pois o tempo de processamento foi demasiadamente grande, quando
foi utilizado um processador pentium II 350 Mhz.

93
CAPÍTULO 6
CONCLUSÃO
A rotulação de pontos é um problema de grande importância prática em geoproces-
samento e cartografia automatizada. Este trabalho teve por objetivo fazer uma revisão
de alguns algoritmos de rotulação de pontos descritos na literatura e apresentar soluções
ou outros algoritmos ainda não explorados para resolver o problema de rotulação de
pontos.
Para atender os usuários que querem produzir um mapa para impressão, um grafo de
relacionamentos foi usado para organizar os dados referentes a conflitos entre os rótulos
e o algoritmo CGA em conjunto com o algoritmo RSF para resolver o problema de
rotulação de pontos. O CGA é um algoritmo da família dos algoritmos genéticos e como
tal foi preciso um tempo extra para calibração dos parâmetros e também um tempo de
processamento maior como descrito nos artigos, mas ao mesmo tempo o algoritmo
mostrou ser bastante robusto para resolver problemas com instâncias maiores. O CGA
implementado e testado mostrou resultados de alta qualidade, sendo portanto
recomendado para confecção de mapas de impressão.
A heurística RSF usada no cálculo da função de avaliação do CGA, mostrou ser um
algoritmo extremamente rápido para encontrar o maior conjunto independente de
vértices no grafo de relacionamento, aproximando-se da solução ótima dos problemas
desta classe. A sua influência no CGA foi considerável, conduzindo os a alcançar
soluções de qualidade superior a todos os algoritmos de rotulação de pontos encontrados
na literatura até o presente momento.
Comparando os algoritmos CGA e TS, verificou-se que ambos algoritmos apresentaram
resultados de excelente qualidade ao resolver problemas de instâncias pequenas ou
grandes. O tempo de processamento varia entre o médio (TS) e o mais demorado
(CGA), assim como existe a sutil variação na qualidade dos resultados gerados por eles.
Mas de uma forma geral, os dois algoritmos são os melhores existentes até o momento

94
para resolver os problemas de rotulação de pontos, que considera todos os pontos, ou
seja, todos os pontos devem ser rotulados.
O CGA alcançou resultados muito próximos à solução ótima, como pode ser
comprovado pelos testes feitos no Capítulo 5, onde comparamos com os resultados
obtidos pelo método exato. Apesar de o número de pontos do teste ser pequeno, por
causa do tempo de processamento gasto pelo método exato, o grau de dificuldade foi
mantido.
Para resolver problemas de instâncias consideradas grandes, costuma-se usar heurísticas
que não buscam a solução exata, mas uma solução suficientemente boa em termos de
custo, pois algoritmos exatos costumam ser bastante lentos nestes casos. Mas muitas
vezes queremos ter a certeza de que a heurística em uso está alcançando soluções
próxima do ótimo, e foi com este intuito que desenvolvemos o algoritmo exato deste
trabalho.
Outros algoritmos exatos que rotulam todos os pontos da configuração, não foram
encontrados na literatura até a presente data. O algoritmo exato proposto neste trabalho,
rotula todos os pontos independente de apresentar alguns conflitos ou não, e visa
alcançar uma solução ótima em um tempo razoável, aplicando cortes nas ramificações
das árvores que se sabe de antemão que não trará resultados superiores à solução
corrente, que é inicializado, no nosso caso, com o resultado obtido do CGA ou TS, e
que com o decorrer do tempo, ele é atualizado por soluções melhores, quando
encontradas.
Os resultados obtidos do algoritmo exato proposto foram bons, pois o tempo de
processamento para se obter a solução ótima foi razoavelmente pequeno, se levar em
consideração o número total de configurações existentes, que graças à técnica de corte
aplicado pelo algoritmo, diminuiu o número de configurações a serem analisadas.
Como extensões desta pesquisa, sugerimos encontrar outras técnicas mais sofisticadas,
que consigam diminuir ainda mais o tempo de processamento de um algoritmo exato,

95
que rotula todos os pontos da configuração. Este trabalho teve como foco, a rotulação de
pontos, mas pode-se estender a pesquisa, estudando de forma análoga a rotulação
cartográfica de linhas e áreas.

96

97
REFERÊNCIAS BIBLIOGRÁFICAS
Bentley, J. L. Multidimensional binary search trees used for associative searching.
Communications of the ACM, v. 18, n. 9, p. 509-526, 1975.
Bjorndal, M. H.;Caprara, A.;Cowling, P. I.; Croce, F. D.; Lourenço, H.; Malucelli, F.;
Orman, A. J.; Pisinger, D.; Rego, C.; Salazar, J. J. Some thoughts on combinatorial
optimisation. European Journal of Operational Research, v. 83, p. 253-270, June
1995.
Campello R. E. ; Maculan N. Algoritmos e heurísticas. Niteroí: Editora da
Universidade Federal Fluminense; 1994.
Chistensen, J.; Marks, J.; Shieber, S. An empirical study of algorithms for point-feature
label placement. ACM Transactions on Graphics, v. 14, n. 3, p. 203-232, 1995.
Christensen, J.; Marks, J.; Shieber, S. Placing text labels on maps and diagrams.
London: Academic, 1993. 10p.
Colin, R. R. Genetic algorithm. In: Colin, R. R. eds. Modern heuristic techniques for
combinatorial problems. Local: McGraw-Hill book company, 1995. p. 151-196.
Dijk, S. V.; Thierens, D.; Berg, M. Robust genetic algorithms for high quality map
labeling. Dec, 1998. 60p. Disponível em: <ftp://ftp.cs.uu.nl/pub/RUU/CS/techreps/CS-
1998/1998-41.ps.gz> . Acesso em: 2003.
Dowsland, K. A.; An exact algorithm for the pallet loading problem. European
Journal of Operational Research, v. 31, p. 78-84, 1987.

98
Freeman, H. Computer name placement. In: Maguire, D. J.; Goodchild, M. F.; Rhind,
D. W. eds. Geographic information systems: principles and applications. New
York: Longman Scientific, 1991. v.1, cap. 29, p. 445-456.
Forman, M.; Wagner, F. A packing problem with applications to lettering of maps. In:
Annual ACM Symposium on Computational Geometry, 7., 1991, North Conway, N.
H. Proceedings… North Conway: ACM, 1991. p. 281-288.
Furtado, J. C. Algoritmo genético construtivo na otimização de problemas
combinatoriais de agrupamentos. Tese (Doutorado em Computação Aplicada) –
Instituto Nacional de Pesquisas Espaciais, São José dos Campos, 1998.
Glover, F. Tabu search – part I. ORSA Journal on Computing, v. 1, n. 3, p. 190-206,
Summer 1989a.
______ Tabu Search – part II. ORSA Journal on Computing, v. 2, n. 1, p.4-32,
Winter 1989b.
______ Tabu Search – a tutorial. Interfaces, v. 20, n. 4, p. 74-94, July-Aug. 1990.
Glover, F.; Laguna, M. Tabu search. In: Colin, R. R. Modern heuristic techniques
for combinatorial problems. New York: McGraw-Hill, 1995. p. 70-150.
Glover, F.; Laguna, M. Tabu search. Boston: Kluwer Academic Publishers, 1997.
408p.
Goldberg, D. E. Genetic algorithms in search, optimization and machine learning.
New York: Addison-Wesley, 1989. 412p.

99
Hirsch, S. A. An algorithm for automatic name placement around point data.
American Cartographer, v. 9, n. 1, p. 5-17, 1982.
Holland, J. H. Adaptation in natural and artificial systems. Ann Arbor: University
of Michigan Press, 1975. 211p.
Imhof, E. Die anordnung der namen in der karte. In: Annuaire International de
Cartographie II. Zurich: Orell Fuessli Verlag, 1962. p. 93-129.
Johnson, D. S.; Aragon, C. R.; Mcgeoch, L. A.; Schevon, C. Optimization by simulated
annealing: an experimental evaluation. Part II, graph coloring and number
partitioning. Operations Research, v. 39, n. 3, p. 378-406, 1991.
Kreveld, M. V.; Strijk, T. W.; Wolff, A. point labeling with sliding labels.
Computational geometry: theory and applications, n.13, p. 21-47, 1999.
Laguna, M. A guide to implementing tabu search. Investigación Operativa, v. 4,
p.5-25, 1994.
Leighton, F. T. A graph coloring algorithm for large scheduling problems. Journal of
Research, v. 84, n. 6, p. 489-506, 1979.
Lorena, L. A. N. and Furtado, J. C Constructive genetic algorithm for clustering
problems. Evolutionary Computation. v.9, n.3, p. 309-327, 2001. Disponível em:
<http://www.lac.inpe.br/~lorena/cga/cga_clus.PDF>. Acesso em: 2002.
Lorena, L. A. N.; Narciso, M. G.; Beasley, J. E. A Constructive Genetic Algorithm for
the generalized assignment problem. Aceito para publicar no Evolutionary
Optmization. 2002.

100
Lorena, L. A. N. ; Ribeiro Filho, G. A constructive genetic algorithm for graph coloring.
In: Congresso APORS'97 , 1997, Melbourne Australia. Proceedings... Melbourne
Australia: APORS, 1997. Disponível em:
< http://www.lac.inpe.br/~geraldo.cgacolor.ps>. Acesso em: 2002.
Loukakis, E. and Tsouros, C. Determining the number of internal stability of a graph.
International Journal of Computer Mathematics. v. 11, p. 207 – 220, 1982.
Marks, J.; Shieber, S. The computational complexity of cartographic label
placement. local: Center for Research in Computing Technology, Harvard
University, TR-05-91, 1991.
Mimura, P. H. ; Oliveira P. Uma aplicação do algoritmo genético com máscara ao
problema de rotulação de pontos. TG (graduação em ciência da computação) –
Universidade do Vale do Paraiba, São José dos Campos, 2002.
Oliveira A.C.M. and Lorena, L. A. N. A constructive genetic algorithm for gate matrix
layout problems. IEEE Transactions on Computer-Aided Design of Integrated
Circuits and Systems, v. 21, n. 8, p. 969-974, 2002.
Oliveira, C. Curso de cartografia moderna. Rio de Janeiro: IBGE, 1988. 152p.
Oosterom, P. V. Reactive data structures for geographic information systems. New
York: Oxford University Press, 1993. 198p.
Petzold, I.; Plümer, L.; Heber, M. Label placement dor dynamically generated
screen maps. Ottawa: ICA/ACI, 1999, p. 893-903.

101
Ribeiro Filho, G. Melhoramentos no algoritmo genetico construtivo e novas
aplicacoes em problemas de agrupamento. 2000 (INPE – 8432 – TDI/774). Tese
(Doutorado em Computação Aplicada) – Instituto Nacional de Pesquisas Espaciais,
São José dos Campos, 2000.
Ribeiro Filho, G. and Lorena, L. A. N. Constructive genetic algorithm and Column
Generation: an application to graph coloring. IEEE Transactions on Evolutionary
Computation. 2001. (Submetido ).
Shawn, E.; Christensen, J.; Marks, J.; Shieber, S. A general cartographic labeling
algorithm. December, 1996. 19p. Disponível em:
http://www.eecs.harvard.edu/~shieber/papers/gen-label.os.gz . Acesso em: 2002.
Strijk, T.; Verweij, B.; Aardal, K. Algorithms for maximum independent set applied
to map labeling. Sept, 2000. 42p. Disponível em:
ftp://ftp.cs.uu.nl/pub/RUU/CS/techreps/CS-2000/2000-22.ps.gz . Acesso em 2002.
Verner, O. V.; Wainwright, R. L.; Schoenefeld, D. A. Placing text labels on maps and
diagrams using genetic algorithms with masking. INFORMS Journal on
Computing, v. 9, p. 266-275, 1997.
Wolff, A.; Strijk, T. A map labeling bibliography. 1996. Disponível em:
http://www.math-inf.uni-greifswald.de/map-labeling/bibliography/. Acesso em: 2001.
Yamamoto, M. Uma aplicação da busca tabu ao problema de rotulação
cartográfica de pontos. 1998 (INPE – 7250 – TDI/694). Dissertação (Mestrado em
Computação Aplicada) – Instituto Nacional de Pesquisas Espaciais, São José dos
Campos, 1998.

102
Yamamoto, M., Camara, G. and Lorena, L. A. N. Tabu search heuristic for point-feature
cartographic label placement. GeoInformatica An International Journal on
Advances of Computer Science for Geographic Information Systems, v. 6, n.1, p.
77-90, 2002.
Zoraster, S. Expert systems and the map label placement problem. Cartographica, v.
28, n. 1, p. 1-9, 1991.
______. Integer programming applied to the map label placement problem.
Cartographica, v. 23, n. 3, p . 16-27, 1986.
______. The solution of large 0-1 integer programming problems encountered in
automated cartography. Operations Research, v. 38, n. 5, p. 752-759, Sept.-Oct.
1990.

103
APÊNDICE A
ROTULAÇÃO DE 100 PONTOS CONFIGURAÇÃO APÓS APLICAÇÃO DO CGA
CONFLITOS = 0

104
ROTULAÇÃO DE 250 PONTOS CONFIGURAÇÃO APÓS APLICAÇÃO DO CGA
CONFLITOS = 0

105
ROTULAÇÃO DE 500 PONTOS CONFIGURAÇÃO APÓS APLICAÇÃO DO CGA
CONFLITOS = 0

106
ROTULAÇÃO DE 750 PONTOS CONFIGURAÇÃO APÓS APLICAÇÃO DO CGA
CONFLITOS = 10

107
ROTULAÇÃO DE 1000 PONTOS CONFIGURAÇÃO APÓS APLICAÇÃO DO CGA
CONFLITOS = 88

108

109
APÊNDICE B
ROTULAÇÃO DE 25 PONTOS CONFIGURAÇÃO APÓS APLICAÇÃO DO MÉTODO EXATO
CONFLITOS = 2

110
ROTULAÇÃO DE 25 PONTOS CONFIGURAÇÃO APÓS APLICAÇÃO DO BUSCA TABU
CONFLITOS = 3

111
ROTULAÇÃO DE 25 PONTOS CONFIGURAÇÃO APÓS APLICAÇÃO DO CGA
CONFLITOS = 2

112

113
APÊNDICE C
O conjunto padrão de dados gerados randomicamente neste trabalho, encontra-se
disponível em http://www.lac.inpe.br/~lorena/instancias.html. É composto por 25
configurações diferentes de distribuições de pontos para 100, 250, 500, 750 e 1000
pontos. Estes dados foram usados para os testes do CGA e TS.
As 8 configurações diferentes de distribuição de 25 pontos, usadas nos testes do método
exato, TS e CGA, também encontram-se no endereço acima.
A estrutura de armazenamento dos dados é como segue:
• Linha 1: número de pontos;
• Linha 2: número de posições candidatas;
• Linha 3: número de rótulos que não podem estar ativos simultaneamente com o
rótulo 1 (grau do vértice 1);
• Linha 4: rótulos que não podem estar ativos simultaneamente com o rótulo 1;
• Linha 5: número de rótulos que não podem estar ativos simultaneamente com o
rótulo 2 (grau do vértice 2);
• Linha 6: rótulos que não podem estar ativos simultaneamente com o rótulo 2;
• Linha 7: número de rótulos que não podem estar ativos simultaneamente com o
rótulo 3 (grau do vértice 3); .
.
.
.
.

114
Como exemplo, se considerarmos 2 pontos da Figura 2.7, cujo grafo de relacionamento
das posições candidatas esta mostrado na Figura 2.8 e a matriz de adjacências do grafo
na Figura 2.9, teremos o seguinte arquivo:
2 4 3 2 3 4 3 1 3 4 4 1 2 4 6 5 1 2 3 5 6 4 4 6 7 8 5 3 4 5 7 8 3 5 6 8 3 5 6 7
O exemplo mostra que é composto por 2 pontos de 4 posições candidatas. A linha 3
mostra que a posição candidata 1, possui 3 rótulos que não podem estar ativos
simultaneamente com ela, e a linha 4 mostra quais são eles: posições candidatas 2, 3 e 4.
E assim por diante, as linhas impares indicam o número de rótulos que não podem estar
ativas simultaneamente com a posição candidata em questão, e as linhas pares mostram
quais são elas.