implementaÇÃo de data warehouse para pequenas empresas: estudo de caso para o setor de...
DESCRIPTION
O Data Warehouse surgiu nos anos 90 como uma maneira prática e eficiente para o tratamento de grandes volumes de informações, proporcionando consultas que auxiliam no processo decisório dentro da organização, e a cada dia vem sendo mais utilizado em grandes corporações. O objetivo deste trabalho é iniciar um processo de implantação do ambiente de Data Warehouse dentro de uma pequena empresa, demonstrando não só a sua viabilidade como também o excelente retorno que pode ser alcançado pela organização. Neste trabalho foi feito um estudo em um grupo de pequenas empresas do setor de distribuição de medicamentos, que foi usado como modelo para o projeto e implementação do Data Warehouse apresentado. O grande problema está em como implantar um Data Warehouse com custo reduzido, visto que a sua implementação não é simples e demanda de grandes recursos financeiros. Para tanto foi utilizado o máximo possível de ferramentas livres visando a redução dos custos.TRANSCRIPT

CENTRO UNIVERSITÁRIO DE MARINGÁ
CURSO DE PÓS-GRADUAÇÃO EM BANCO DE DADOS ORACLE E DB2
ÉDSON MUNDIN FERREIRA
IMPLEMENTAÇÃO DE DATA WAREHOUSE PARA PEQUENAS EMPRESAS:
ESTUDO DE CASO PARA O SETOR DE DISTRIBUIÇÃO DE MEDICAMENTOS
MARINGÁ
2009

ÉDSON MUNDIN FERREIRA
IMPLEMENTAÇÃO DE DATA WAREHOUSE PARA PEQUENAS EMPRESAS:
ESTUDO DE CASO PARA O SETOR DE DISTRIBUIÇÃO DE MEDICAMENTOS
MARINGÁ 2009
Monografia apresentada ao Centro Universitário de Maringá como requisito para obtenção do título de especialista em Banco de Dados Oracle e DB2, sob orientação da professora Aline Maria Malachini Miotto Amaral.

Dedico este trabalho à todos aqueles que
ousaram sair da linha de conforto, para após
muito sacrifício, abandonar a ignorância.

AGRADECIMENTOS
Um trabalho como este não se realiza sozinho. Sem a colaboração de
diversas pessoas sua realização não seria possível, assim quero compartilhar a
alegria de ter terminado este trabalho agradecendo a todos que de forma direta ou
indireta me ajudaram.
Agradeço aos meus pais que sempre me orientaram de forma ética e
moral direcionando meu caminho nesta jornada terrena.
Aos professores deste curso que não mediram esforços em apresentar as
disciplinas e compartilhar conosco seus conhecimentos.
Ao Cesumar pela excelente estrutura fornecida, sem a qual este curso
não seria possível.
À minha orientadora que pacientemente tolerou meus atrasos, e me
incentivou para o término deste.
À empresa e aos amigos de trabalho, pela compreensão tida em relação
aos dias faltados.
À empresa que cedeu informações e permitiu a realização do estudo de
caso.
À minha esposa e filhos que permitiram que eu sacrificasse dias de
convívio familiar para concluir esse curso.
Ao meu bom anjo que me inspirou desde o inicio até a conclusão desde
sempre me incentivando ao término.
À Deus criador de tudo e de todos, que com sua permissão e auxílio
chegamos até aqui.

Alegria é o cântico das horas com que Deus te afaga a passagem no mundo.
Em toda parte, desabrocham flores por sorrisos da natureza e o vento penteia a
cabeleira do campo com música de ninar.
A água da fonte é carinho liquefeito no coração da terra e o próprio grão de areia,
inundado de sol, é mensagem de alegria a falar-te do chão.
Não permitas, assim, que a tua dificuldade se faça tristeza entorpecente nos outros.
Ainda mesmo que tudo pareça conspirar contra a felicidade que esperas, ergue os
olhos para a face risonha da vida que te rodeia e alimenta a alegria por onde
passes.
Abençoa e auxilia sempre, mesmo por entre lágrimas.
A rosa oferece perfume sobre a garra do espinho e a alvorada aguarda, generosa,
que a noite cesse para renovar-se diariamente, em festa de amor e luz.
Meimei

FERREIRA, Édson Mundin. Implementação de Data Warehouse para pequenas empresas: estudo de caso para o setor de distribuição de medicamentos. 2009. Monografia (Especialização em Banco de Dados Oracle e DB2) – Centro Universitário de Maringá.
RESUMO
O Data Warehouse surgiu nos anos 90 como uma maneira prática e eficiente para o
tratamento de grandes volumes de informações, proporcionando consultas que
auxiliam no processo decisório dentro da organização, e a cada dia vem sendo mais
utilizado em grandes corporações. O objetivo deste trabalho é iniciar um processo de
implantação do ambiente de Data Warehouse dentro de uma pequena empresa,
demonstrando não só a sua viabilidade como também o excelente retorno que pode
ser alcançado pela organização. Neste trabalho foi feito um estudo em um grupo de
pequenas empresas do setor de distribuição de medicamentos, que foi usado como
modelo para o projeto e implementação do Data Warehouse apresentado. O grande
problema está em como implantar um Data Warehouse com custo reduzido, visto
que a sua implementação não é simples e demanda de grandes recursos
financeiros. Para tanto foi utilizado o máximo possível de ferramentas livres visando
a redução dos custos.
Palavras-chave: Data Warehouse, Data Warehousing, Banco de Dados, Data Mart,
Pequenas Empresas, Distribuição de Medicamentos.

FERREIRA, Édson Mundin. Implementation of a Data Warehouse for small businesses: a case study for the sector of medicines distribution. 2009. Monografia (Especialização em Banco de Dados Oracle e DB2) – Centro Universitário de Maringá.
ABSTRACT
The Data Warehouse has emerged in the 90s as a practical and efficient way to treat
large volumes of information, providing consults to assist in decision process within
the organization, and each day is being frequently used in large corporations. The
objective of this work is to initiate a process for implementing the Data Warehouse
environment, within a small business, demonstrating not only its feasibility but also
the excellent feedback that can be obtained by the organization. In this work a study
was done in a group of small companies in the sector of distribution of medications,
which was used as a model for the design and implementation of Data Warehouse
presented. The major problem is how to implement a Data Warehouse with reduced
cost, since its implementation is not simple and demands a large financial resources.
For this, we used the most possible free tools to reduce costs.
Keywords: Data Warehouse, Data Warehousing, Database, Data Mart, Small
Businesses, Distribution of Medications.

LISTA DE FIGURAS
Figura 1 - Estrutura interna do Data Warehouse ......................................................... 6
Figura 2 - Definição do Data Warehouse .................................................................... 6
Figura 3 - Orientado a assuntos .................................................................................. 7
Figura 4 - A questão da integração ............................................................................. 8
Figura 5 - A questão da variação em relação ao tempo .............................................. 9
Figura 6 - A questão da não-volatilidade ..................................................................... 9
Figura 7 - Estrutura de dados do Data Warehouse ................................................... 12
Figura 8 - Arquitetura conceitual de um Data Warehouse ......................................... 13
Figura 9 - Exemplo de esquema estrela .................................................................... 21
Figura 10 - Balanceamento da granularidade ........................................................... 22
Figura 11 - Particionamento de dados ...................................................................... 23
Figura 12 - Evolução do hard disk - preço por gbyte ................................................. 29
Figura 13 - Modelagem do sistema atual .................................................................. 30
Figura 14 - Modelagem proposta para o ambiente do Data Warehouse ................... 31
Figura 15 - Planilha - Resumo de vendas por grupo de clientes ............................... 34
Figura 16 - Planilha - Resumo de vendas por unidade ............................................. 34
Figura 17 - Planilha - Resumo anual de vendas por cidade ...................................... 35
Figura 18 - Planilha - Os dez produtos mais vendidos .............................................. 36
Figura 19 - Planilha - Maiores vendas ....................................................................... 36

LISTA DE TABELAS
Tabela 1 - Sistema Operacional x Sistema Informacional ......................................... 10
Tabela 2 - Componetes do Data Warehouse e suas características ......................... 12
Tabela 3 - Classificação das empresas segundo o porte .......................................... 26
Tabela 4 – DB2 Express C versus Oracle Express Edition ....................................... 33

LISTA DE ABREVIATURAS E SIGLAS
DM – Data Mart
DW – Data Warehouse
EIS – Executive information systems (Sistemas de informações executivas)
ERP – Enterprise Resource Planning (Sistemas integrados de gestão empresarial)
ETL – Extraction, Transformation and Load (Extração, Transformação e Carga)
MQT – Materialized Query Tables (Tabelas materializadas para consultas)
OLAP - On-Line Analytical Processing (Processamento analítico On-Line)
OLTP – On-Line Transaction Processing (Processamento de transações on-line)
SAD – Sistema de Apoio a Decisão
SDLC – System Development Life Cycle (Ciclo de vida do desenvolvimento de
sistemas)
SGBD – Sistema de gerenciamento de banco de dados
TI – Tecnologia da Informação

SUMÁRIO
1 INTRODUÇÃO ......................................................................................................... 1
2 O AMBIENTE DE DATA WAREHOUSE ................................................................. 4
2.1 Considerações iniciais ...................................................................................... 4
2.2 Definição de Data Warehouse .......................................................................... 4
2.3 Características do Data Warehouse ................................................................. 6
2.3.1 Orientado a assuntos........................................................................................ 6
2.3.2 Integrado .......................................................................................................... 8
2.3.3 Variável no tempo ............................................................................................. 8
2.3.4 Não volátil ......................................................................................................... 9
2.4 Processamento Operacional x Processamento Informacional ....................... 10
2.5 A estrutura do Data Warehouse ..................................................................... 10
2.6 O projeto do Data Warehouse ........................................................................ 13
2.7 Data Mart e Data Warehouse ......................................................................... 16
2.8 Metodologia de desenvolvimento ................................................................... 18
2.9 Modelagem dos dados ................................................................................... 20
2.9.1 Granularidade ................................................................................................. 22
2.9.2 Particionamento .............................................................................................. 22
3 PROJETO E IMPLEMENTAÇÃO DE UM DATA WAREHOUSE: Estudo de
caso no setor de Distribuição de Medicamentos ....................................................... 24
3.1 Considerações iniciais .................................................................................... 24
3.2 O setor de Distribuição de Medicamentos ...................................................... 24
3.3 Classificando como Pequena Empresa .......................................................... 26
3.4 A empresa foco do estudo .............................................................................. 26
3.5 A Proposta de Implementação ....................................................................... 27
3.6 Estratégia ....................................................................................................... 28
3.7 Metodologia .................................................................................................... 28
3.8 Granularidade e Particionamento ................................................................... 28
3.9 Modelagem do ambiente operacional atual .................................................... 29
3.10 Modelagem proposta para o ambiente do data warehouse ............................ 30
3.11 Extração, transformação e carga (ETL) .......................................................... 31

3.12 SGBDs envolvidos .......................................................................................... 32
3.13 Exemplos práticos de dados consultados ....................................................... 33
4 CONCLUSÕES ...................................................................................................... 37
4.1 Resultados alcançados ................................................................................... 37
4.2 Trabalhos futuros ............................................................................................ 38
REFERÊNCIAS ......................................................................................................... 39
APÊNDICES .............................................................................................................. 42
APÊNDICE - A – Script para Criação das Tabelas e Índices .................................... 43
APÊNDICE - B – Script para Carga de uma Unidade ............................................... 45
APÊNDICE - C – Script para Criação da Dimesão Tempo ....................................... 48
APÊNDICE - D – Script para Carga das Tabelas Resumo e Execução de Estatísticas
50

1
1 INTRODUÇÃO
A área de tecnologia da informação (TI) é algo relativamente novo quando
comparado com outras áreas, os primeiros profissionais da área de processamento
de informações surgiram no início da década de 1960, enquanto áreas como
edificações, medicina, artes, entre muitas outras, são milenares. Ainda hoje é
comum encontrarmos pequenas empresas que não fazem o uso devido da
tecnologia da informação, algumas nem ao menos têm um computador.
Inevitavelmente muitas já aderiram a informatização de seus processos, buscando
soluções diversas, algumas empresas motivadas pelo ambiente competitivo, outras
pelas imposições fiscais e governamentais. Porém, uma grande maioria tem se
restringido aos controles operacionais, uma vez que poucas têm utilizado a
tecnologia da informação como suporte a decisão estratégica. Quando se fala em
Data Warehouse em um ambiente destes é como falar de física quântica para alunos
do ensino primário. Ao questionar se haveria alguma utilidade a implementação de
um Data Warehouse para pequenas empresas, surgiu uma dúvida, e também ao
mesmo tempo descortinou-se um horizonte antes não divisado, um filão
pouquíssimo explorado.
O Data Warehouse, como um grande repositório de informações,
históricas e/ou atuais, resumidas ou não, o qual fornece ferramentas especializadas
no apoio a decisão, pode trazer grandes resultados a serem usados
estrategicamente nos negócios.
Gurovitz (1999) busca demonstrar a importância estratégica de um Data
Warehouse apresentando alguns exemplos de utilização:

2
No setor bancário temos o banco Itaú (pioneiro no uso de Data
Warehouse no Brasil) que costumava enviar mais de 1 milhão de
malas diretas para os correntistas mas cujo retorno não passava de
2%. Partindo-se da análise dos dados armazenados, as cartas
passaram a ser enviadas apenas para aqueles com maior chance de
responder. Com isso a taxa de retorno subiu para 30% e a conta do
correio foi reduzida para um quinto;
Uma das maiores redes de varejo americana, o Wall-Mart, descobriu
uma interessante relação entre a venda de fraldas e cervejas (um caso
clássico no mundo do Data Warehouse). Com base nessas
informações os produtos foram colocados lado a lado e as vendas
aumentaram;
A Sprint, um dos grandes do setor de telecomunicações americano,
desenvolveu um método capaz de prever com 61% de certeza se um
cliente trocaria de empresa no prazo de dois meses. Através de um
marketing agressivo, conseguiu evitar a deserção de 120.000 clientes e
uma redução de 35 milhões de dólares em faturamento.
Esses são apenas alguns exemplos de ótimos resultados obtidos pela
boa utilização de um Data Warehouse.
Dentro deste contexto, o objetivo desta pesquisa é apresentar quais os
passos para implementar, de forma eficiente e a baixo custo, um Data Warehouse
em pequenas empresas.
O desenvolvimento deste trabalho foi iniciado com o levantamento
bibliográfico sobre o tema, com a intenção de compor uma base teórica. Foi usado o
estudo de caso de uma empresa do setor de distribuição de medicamentos, por

3
possuir um ambiente favorável aos propósitos elencados, e também pelo
pesquisador já possuir conhecimento anterior neste setor, conhecendo assim as
necessidades de informações gerenciais do mesmo.
Após diversas entrevistas para conhecimento mais aprofundado do setor
e das necessidades de informação adaptou-se um modelo de construção de um
Data Warehouse com as necessidades do ambiente pesquisado. Foi criada uma
ferramenta para extração, transformação e carga dos dados a qual será descrita
posteriormente com mais detalhes. Também foi modelado o sistema transacional
atual e criado o novo modelo para o Data Warehouse.
Deve-se ressaltar que não foi encontrada literatura específica que trate de
Data Warehouse para pequenas empresas. Por fim, foram criadas algumas planilhas
EXCEL, para demonstrar alguns exemplos de possíveis informações a serem
extraídas do Data Warehouse.
Organização do trabalho
Além da introdução, este trabalho contém mais três capítulos, no capítulo
2 é apresentada a definição de Data Warehouse, suas características, sua estrutura,
as diferenças entre Data Mart e Data Warehouse e como projetar, desenvolver e
modelar um Data Warehouse. O capítulo 3 é voltado ao estudo de caso no setor de
distribuição de medicamentos, onde se tem uma rápida visão do setor, um descritivo
da empresa estudada, e a proposta de implementação de um ambiente de Data
Warehouse voltado às necessidades da empresa. Finalmente, no capítulo 4 são
apresentadas as principais contribuições desta pesquisa.

4
2 O AMBIENTE DE DATA WAREHOUSE
2.1 Considerações iniciais
Segundo Inmon (1999b), quando um CEO (Chief Executive Officer) diz:
“somos uma empresa de tecnologia que faz um bilhão de dólares por ano e estou
cansado de reuniões em que três pessoas diferentes apresentam números
diferentes que de alguma forma estão corretos. Eu quero apenas um número”, Data
Warehouses acabam sendo criados.
A multiplicidade de sistemas transacionais que coletam informações
reunindo-as de forma a satisfazer necessidades originalmente operacionais, acabou
por dificultar o gerenciamento das informações. Desta forma surge o Data
Warehouse com o propósito de fornecer um ambiente que pode ser usado como
fonte de dados para sistemas de apoio a decisão dando ao usuário final a
possibilidade de tomar decisões rápidas e mais corretas.
O Data Warehouse fica com o encargo de buscar e carregar informações
deixando os sistemas de apoio a decisão livres para se preocuparem apenas com as
consultas.
2.2 Definição de Data Warehouse
Inmon (1997) define Data Warehouse como “um conjunto de dados
baseado em assuntos, integrado, não-volátil, e variável em relação ao tempo, de
apoio às decisões gerenciais”.
Data Warehouse é uma Base de dados que coleta informações de negócios de diversas áreas da corporação, cobrindo todos os aspectos da empresa no que diz respeito a processos, produtos e clientes. O repositório dá aos usuários uma visão multidimensional dos dados, permitindo que todas as condições do negócio sejam analisadas (BARROS, 2002).

5
O conceito de Data Warehouse surgiu da necessidade de integrar dados
corporativos espalhados em diferentes máquinas e sistemas operacionais, para
tornarmos acessíveis a todos os usuários dos níveis decisórios. Outro fator que
contribuiu para o estabelecimento desse conceito foi a evolução da Tecnologia da
Informação, particularmente os Sistemas de Apoio à Decisão (SAD).
O Data Warehouse surge como uma solução para suprir as necessidades
de informações do usuário de nível decisório (NAVARRO, 1996).
A figura a seguir ilustra a estrutura interna que o ambiente de Data
Warehouse representa, onde clientes operacionais geram informações do dia a dia,
que são armazenadas em bancos de dados operacionais, o Data Warehouse
através de sua estrutura constrói um banco de dados a partir de informações obtidas
dos bancos de dados operacionais e também de bancos de dados externos, um
exemplo de banco de dados externo seria uma planilha eletrônica do IBGE1
contendo o número de habitantes por município, por fim clientes informacionais
podem obter dados resumidos em um determinado nível de detalhe, atuais ou
históricos, a partir do Data Warehouse.
1 IBGE: Instituto Brasileiro de Geografia e Pesquisa

6
Figura 1 - Estrutura interna do Data Warehouse (LOPES & OLIVEIRA, 2006)
2.3 Características do Data Warehouse
Conforme a definição de Inmon (1997) pode-se destacar quatro
importantes características do Data Warehouse: orientado a assuntos, integrado,
variável no tempo e não-volátil.
Figura 2 - Definição do Data Warehouse (INMON, 1997)
2.3.1 Orientado a assuntos
No Data Warehouse os dados são organizados de acordo com os
assuntos de interesse da empresa, enquanto no ambiente operacional estão
organizados de acordo com a funcionalidade da empresa.

7
Os dados voltados para aplicações do ambiente operacional possuem
detalhes que satisfazem o momento, esses detalhes podem ser irrelevantes ao
analista de Sistemas de Apoio a Decisão (SAD), o Data Warehouse baseia-se nos
principais assuntos e negócios da organização, não incluindo dados que não serão
usados para processamento de Sistemas de Apoio a Decisão (SAD) (INMON, 1997).
Inmon (1997) exemplifica o caso de uma companhia de seguros, onde
dados são organizados em torno de aplicações que podem ser automóvel, saúde,
vida e perdas. O Data Warehouse da companhia é baseado em assuntos e negócios
da empresa que podem ser cliente, apólice, prêmio e indenização.
Figura 3 - Orientado a assuntos (INMON, 1997)
Outro exemplo interessante é o caso onde temos um sistema de vendas
no varejo, um sistema de vendas no atacado e um sistema de vendas por catálogo,
cada um desses sistemas oferece suporte para consultas a respeito das informações
que ele captura, quando desejamos alguma informação de vendas no atacado
buscamos as informações no sistema de vendas no atacado, mas quando queremos
informações das vendas em geral (atacado, varejo e por catálogo) entra o Data
Warehouse orientado ao assunto vendas, independente do tipo de venda.

8
2.3.2 Integrado
Uma das características marcante do Data Warehouse é o fato dele ser
integrado. De todos os aspectos do data warehouse, esse é o mais importante.
A integração de dados ocorre quando os dados são passados do
ambiente operacional baseado em aplicações para o ambiente de Data Warehouse.
Por exemplo, o atributo sexo pode ser codificado como m/f, 1/0 ou
masculino/feminino. Conforme os dados são carregados no Data Warehouse eles
serão convertidos para uma única codificação (INMON, 1997).
Figura 4 - A questão da integração (INMON, 1997)
2.3.3 Variável no tempo
O Data Warehouse deve ser variante ao tempo, sempre contém algum
elemento de tempo, deve manter registros históricos dos fatos por um período muito
superior dos ambientes operacionais em que um tempo de 60 a 90 dias é
considerado suficiente, no ambiente do Data Warehouse o período é de 5 a 10 anos
(INMON, 1997).

9
Figura 5 - A questão da variação em relação ao tempo (INMON, 1997)
2.3.4 Não volátil
Não volátil significa que após o Data Warehouse ser carregado não
haverá mudanças, ou seja, alterações ou exclusões dos dados. No ambiente
operacional os dados são geralmente atualizados registro a registro, isto requer
muito trabalho para que a integridade e a consistência dos dados sejam mantidas.
Já no ambiente do Data Warehouse esse trabalho é reduzido visto que os dados são
carregados em blocos de registros (INMON, 1997).
Figura 6 - A questão da não-volatilidade (INMON, 1997)

10
2.4 Processamento Operacional x Processamento Informacional
Para melhor entender a diferença entre Processamento Operacional e
Processamento Informacional, é apresentada a seguir, tabela com as características
de ambos:
Característica Sistema Operacional Sistema Informacional
Tipo de dados Detalhados Detalhados e sumariados
Organização dos dados Por aplicação Por assunto
Estabilidade dos dados Dinâmico Estático
Qualidade dos dados Na entrada No processo (ETL2)
Estrutura dos dados Otimizados para transações Otimizados para pesquisas complexas
Dados por transação Poucos (dezenas) Muitos (milhares)
Frequência de acesso Alta Média para baixa
Volume de dados Megabytes – Gigabytes Gigabytes – Terabytes
Tipo de Informação Atual e volátil Histórica e não volátil
Operação Atualização Leitura e análise
Processamento Dirigido à transação (OLTP3) Dirigido à análise (OLAP
4)
Uso Operacional, repetitivo e estruturado Informativo, analítico e não estruturado
Comunidade atendida Funcional, com necessidades cotidianas. Decisões do dia-a-dia
Gerencial, com necessidades gerenciais. Decisões estratégicas. Longo-prazo.
Redundância Não ocorre (normalizado) Ocorre (desnormalizado)
Objetivo Manutenção do negócio Análise do negócio
Interação Pré-definida Pré-definida e ad hoc
Histórico Baixo (até 3 meses) Alto (até 10 anos)
Tempo de resposta Até 2-3 segundos De segundos a minutos
Atualização Atualizado em tempo real Atualizado periodicamente (Batch)
Disponibilidade Alta Atenuada Tabela 1 - Sistema Operacional x Sistema Informacional (COME, 2001)
2.5 A estrutura do Data Warehouse
A estrutura de Data Warehouse deve ser custo-eficiente, adaptável e de
fácil implementação (BOMFIM, 2001).
2 ETL – Extraction, Transformation and Load (Extração, Transformação e Carga)
3 OLTP – On-Line Transaction Processing (Processamento de Transações On-Line)
4 OLAP – On-Line Analytical Processing (Processamento Analítico On-Line)

11
O Data Warehouse tem uma estrutura distinta com diferentes níveis de
sintetização e detalhe que definem o Data Warehouse, e ainda diferentes níveis de
idade dos dados (INMON, 1997).
Veja a seguir, tabela dos componentes do Data Warehouse com suas
características:
Componente Característica Dados detalhados atuais Refletem acontecimentos recentes, sempre de grande
interesse; Volumosos, de baixa granularidade; Geralmente armazenados em disco, meio de acesso
rápido mas de gerenciamento difícil e caro.
Dados detalhados antigos Armazenados em meios de armazenamento de massa, normalmente não é em disco;
Nível de detalhe consistente com os dados detalhados atuais;
Acessados com pouca freqüência.
Dados levemente resumidos Resumidos dos detalhes dos dados atuais; Geralmente armazenados em disco; Na sua arquitetura gera problemas do tipo:
o Qual o espaço de tempo que o resumo será feito?
o Qual o conteúdo e atributos dos dados ligeiramente resumidos?
Dados altamente resumidos Compactos; De fácil acesso; Às vezes armazenados dentro do ambiente do Data
Warehouse e as vezes fora, mesmo assim são parte do Data Warehouse independente da localização física.
Metadados São dados sobre os dados do Data Warehouse; Não contém dados retirados diretamente do ambiente
operacional; Constituem papel importante e especial na estrutura
do Data Warehouse, muito mais do que nos ambientes operacionais clássicos;
Situam-se em uma dimensão diferente dos outros dados do Data Warehouse;
Podem conter as seguintes informações: o A estrutura dos dados; o Os algoritmos usados para sintetização; o A fonte de dados que alimenta o Data
Warehouse; o O modelo de dados; o O relacionamento entre o modelo de dados e o
Data Warehouse; o O histórico de extrações; o Estatística de uso de dados;

12
o Medições de desempenho; o Diferentes elementos por atributo;
Formas de uso dos metadados: o No auxílio de analistas de SAD para localizar
dados no Data Warehouse; o Como guia para mapear os dados em sua
transformação do ambiente operacional até o Data Warehouse;
o Como um guia para os algorítimos utilizados para sintetização entre dados detalhados atuais e dados levemente resumidos, e entre estes e os dados altamente resumidos.
Tabela 2 - Componetes do Data Warehouse e suas características (INMON, 1997), (BOMFIM, 2001)
A figura abaixo demonstra o relacionamento entre os diversos níveis de
detalhes e de tempo, dentro da estrutura do Data Warehouse.
Figura 7 - Estrutura de dados do Data Warehouse (INMON, 1997)
Na figura a seguir é demonstrado um modelo conceitual do Data
Warehouse, observe que os dados que vão para o Data Warehouse passam por um

13
processo de ETL5, a extração dos dados é feita a partir de fontes internas e/ou
externas, depois é feita a transformação/limpeza dos dados e a carga/atualização do
Data Warehouse, por fim ferramentas OLAP6 permitem a análise dos dados. Ainda
pode-se contar com ferramentas de monitoramento e administração, que são
responsáveis pela segurança e acompanhamento do uso do Data Warehouse. Data
Marts podem ser criados a partir dos dados organizados no Data Warehouse,
podendo-se também ocorrer o inverso, como veremos mais a frente.
Figura 8 - Arquitetura conceitual de um Data Warehouse (SOUZA, 2003a)
2.6 O projeto do Data Warehouse
A elaboração de um projeto de Data Warehouse não é uma tarefa fácil,
pois envolve diversos conceitos e diversas tecnologias que deverão ser integradas
para que trabalhem em harmonia e gerem bons resultados (BISPO-1998).
A equipe deve ser composta por pessoal da área de negócios e da área
de tecnologia. A área de negócios monitora para que as necessidades do negócio
sejam atendidas, e a área de tecnologia dá o suporte necessário para a
implementação do sistema (BISPO, 1998).
5 ETL: Extraction, Transformation and Load (Extração, Transformação e Carga)
6 OLAP: On-Line Analytical Processing (Processamento analítico On-Line)

14
Para Inmon (1997) não se constroem data warehouse de uma só vez, em
vez disso, eles são projetados e povoados passo a passo, sendo, portanto,
evolucionários e não revolucionários. Os custos de construir um data warehouse de
uma vez, os recursos necessários e o transtorno causado ao ambiente, tornam
imperativo que o data warehouse seja construído de maneira ordenadamente
iterativa, passo a passo.
Ainda segundo Inmon (1997) a palavra “projeto” não é uma descrição
exata do que acontece durante a construção do data warehouse, visto que ele é
construído de modo heurístico. Num primeiro momento o Data Warehouse é
povoado com alguns dados, depois esses dados são usados e minuciosamente
examinados pelo analista de SAD, na sequência dados do Data Warehouse são
modificados ou adicionados com base no feedback dos usuários finais. Esse ciclo
segue por toda a vida do Data Warehouse. Os requisitos para a criação do data
warehouse não serão conhecidos até que ele esteja parcialmente povoado e sendo
usado pelo analista de SAD. Portanto, o Data Warehouse não pode ser projetado do
mesmo modo pelo qual são construídos os sistemas clássicos baseados em
requisitos, porém não se deve pensar que não há necessidade de se prever
requisitos. A realidade se encontra em algum ponto intermediário.
Em Bispo (1998) encontra-se uma lista de questões para definir se um
projeto de Data Warehouse será útil:
A empresa baseia-se em informações para a tomada de decisões?
O segmento de negócios da empresa é caracterizado por uma forte
concorrência e mudanças rápidas?
A base de clientes é grande e diversificada?
Os dados estão armazenados em diversos locais?

15
Os dados estão duplicados e espalhados por diversos sistemas?
Os dados estão em formatos e especificações diferentes?
A sua empresa está distribuindo o processo decisório, buscando maior
agilidade e rapidez?
Ainda em BISPO (1998) é encontrada uma lista de etapas, organizadas a
partir de diversas fontes, para um projeto lógico de Data Warehouse, não
necessariamente na ordem abaixo, e podem ser realizadas concomitantemente:
Identificar os objetivos da organização;
Identificar os processos de negócio diretamente a esses objetivos;
Definir as informações necessárias para dar suporte aos processos
decisórios e onde serão obtidas;
Modelar os dados;
Determinar a granularidade e as agregações dos dados;
Definir e detalhar as tabelas de fatos;
Definir e detalhar as dimensões;
Criar os metadados;
Definir a freqüência de atualização do Data Warehouse com os dados
do ambiente operacional;
Definir o tempo em que os dados se manterão armazenados;
Definir as especificações técnicas e as alternativas tecnológicas para a
implementação física;
Escolher cuidadosamente os fornecedores dos produtos;
Criar o banco de dados físico do Data Warehouse;
Povoar o Data Warehouse;
Fornecer as ferramentas de consulta necessárias para os usuários;

16
Dar treinamento para os usuários e técnicos para utilização e
manutenção do ambiente;
Prever nos orçamentos os gastos que se farão necessários com a
evolução tecnológica, devido ao aumento gradativo do volume de
dados.
2.7 Data Mart e Data Warehouse
O Data Mart é uma espécie de Data Warehouse departamental, criado
com o propósito de atender departamentos ou organizações específicas.
Um dos pontos mais importantes a ser decidido é se é melhor construir
primeiro um Data Warehouse ou Data Mart (INMON, 1999a).
“... o Data Warehouse não é nada mais que a união de todos os Data
Marts ...” Kimball (1997) apud (INMON, 1999a).
“Você pode pegar todos pequenos peixes do oceano e juntá-los mais
ainda assim não terá uma baleia” (INMON, 1999a).
Data warehouse implementa uma arquitetura centralizada que embora
forneça uniformidade, controle e maior segurança, não é uma tarefa fácil a sua
implementação. Requer metodologia rigorosa e uma completa compreensão dos
negócios da empresa. Esta abordagem pode ser longa e dispendiosa e por isto sua
implementação exige um planejamento bem detalhado.
Com o aparecimento de data mart ou warehouse departamental, a
abordagem descentralizada passou a ser uma das opções de arquitetura data
warehouse. As vantangens em relação a um data warehouse centralizado são custo
mais baixo e implementação mais rápida. As desvantagens estão no maior número
de extração/transformação dos dados das bases operacionais para os data marts e

17
também quando data marts se proliferam sem controle, gerando problemas de
integração.
Estratégia Top-down
Quando os dados fluem das bases operacionais para o data warehouse e
deste para os data marts. A vantagem desta abordagem é a redução no número de
extrações da produção para o warehouse. A desvantagem é que pode ser uma
implementação longa.
Estratégia Bottom-up
Quando os data marts são carregados diretamente das bases
operacionais e o data warehouse é carregado a partir dos data marts. Conforme
INMON (1997) esta abordagem não é a ideal, mas é a utilizada quando data marts
são construídos antes do data warehouse.
A longo prazo, a implementação de uma estratégia top-down é a solução
ideal para o projeto data warehouse de uma empresa. Esta solução provê uma
simples fonte de dados integrados e consistentes assim como data marts elaborados
para as necessidades de determinado grupo. Entretanto é um projeto mais difícil e
oneroso de ser implementado e gerenciado, tornando possível o surgimento na
empresa de data warehouses e data marts isolados.
Algumas organizações são atraídas aos Data Marts não apenas por
causa do custo mais baixo e tempo menor de implementação, mas também por
causa dos correntes avanços tecnológicos. São eles que fornecem um SAD
customizado para grupos pequenos de tal modo que um sistema centralizado pode
não estar apto a fornecer. Data marts podem servir como veículo de teste para
companhias que desejam explorar os benefícios do data warehouse. (SOUZA,
2003b).

18
2.8 Metodologia de desenvolvimento
Uma das melhores ferramentas para tratar dos riscos do armazenamento
é a metodologia. Uma metodologia pode ser vista como um “livro de receitas” para
desenvolver data warehouses. Ela deve esboçar as etapas que você precisa
executar e fornecer informações para ajudá-lo a planejar e fazer o orçamento dessas
etapas. Uma metodologia pode ser personalizada conforme necessidades
específicas (COREY, 2001).
O Data Warehouse é conceituado pela utilização de estruturas
multidimensionais, segundo Bonfim (2001) sua modelagem deve seguir os seguintes
propósitos:
Deixar que o usuário final avalie uma determinada situação sobre
diversas formas, de acordo com a sua necessidade;
Permitir análises complexas e uma melhor visualização da informação;
Disponibilizar a informação em uma estrutura que facilite o trabalho das
ferramentas que a manipularão.
Deve ser selecionado um processo de negócio para modelar. Esse
processo deve ser uma operação importante na empresa e deve ser
suportado por algum tipo de sistema de onde seja possível coletar
dados;
Deve ser selecionado a granularidade do negócio. O item mais
detalhado (grão) é o nível atômico que representará esse processo na
tabela de fatos. Transações individuais, instantâneos individuais diários
e instantâneos individuais mensais são considerados grãos típicos;
Deve ser selecionado as dimensões que serão aplicadas a cada
registro da tabela de fato. Para cada dimensão escolhida, deve se

19
descrever todos os atributos de dimensão que preencham cada tabela
dimensional;
Deve ser selecionado os atos importantes que irão popular cada
registro da tabela de fatos.
Conforme Bonfim (2001) para se detalhar um processo de
desenvolvimento pode-se utilizar, de acordo com a visão de Ralph Kimball, os nove
pontos de decisão a seguir:
1. Deve-se identificar a tabela de fatos. Neste ponto são identificados os
principais processos da empresa onde os dados serão coletados;
2. É estabelecido o detalhamento (granularidade) de cada tabela de fatos.
Neste ponto é determinado o nível de detalhe de interesse para a
análise;
3. Deve-se descobrir as dimensões de cada tabela de fatos. A partir da
granularidade desejada são obtidas as dimensões primárias. Outras
dimensões adicionais poderão surgir ao longo do desenvolvimento.
Estas dimensões não são necessárias para a definição da
granularidade da tabela de fatos;
4. Obter os fatos, incluindo fatos pré-calculados. Neste ponto serão
estabelecidos os fatos mensuráveis;
5. Obter os atributos da dimensão com descrições completas e
terminologia apropriada;
6. Rastear dimensões de modificação lenta. Representa o rastreamento
de dimensões que sofram mudanças graduais ao longo dos eixos
temporais;

20
7. Analisar agregados, dimensões heterogêneas, minidimensões, modos
de consultas e outras decisões de armazenamento físico;
8. Selecionar a amplitude de tempo do histórico do banco de dados;
9. Estabelecer os intervalos com que os dados serão extraídos e
carregados no Data Warehouse.
2.9 Modelagem dos dados
A compreensão dos dados é um dos maiores problemas no
desenvolvimento do Data Warehouse. A construção do modelo de dados é
fundamental para o desenvolvimento, ajudando a compreender as regras de negócio
e a organização dos dados para melhor tempo de resposta (BONFIM, 2001).
Esquema Estrela (Star Schema)
O esquema Star é a uma das maneiras mais popular de construir
estruturas de dados para Data Warehouse, é uma modelagem dimensional, e o fato
de se ver os dados de uma forma dimensional não diz que os mesmos precisam ser
arquivados da mesma forma. Uma visão dimensional da organização é muito mais
relevante para a tomada de decisão que uma visão tradicional fornecida pelos
sistemas transacionais. Essa combinação (relacional e dimensional) fornece o
benefício da funcionalidade analítica enquanto mantém as vantagens dos bancos de
dados relacionais, como arquivamento de dados ao nível de detalhes, performance e
compatibilidade com várias plataformas de hardware. Em outras palavras, a opção
pela modelagem dimensional está associada à performance desejada durante o
acesso aos dados bem como na possibilidade de se analisar o negócio por diversas
perspectivas e níveis de detalhes.

21
O modelo estrela é composto de uma entidade fato que possui as chaves
de relacionamento com todas as entidades de dimensão, usando cardinalidade
“muitos para um”, contém também medidas, por exemplo, preços, quantidades de
vendas. A entidade fato fica no centro da estrela, conforme demonstrado na figura
abaixo.
Venda (Fato)
Tempo (Dimensão)
Cliente (Dimensão)Produto (Dimensão)
Vendedor (Dimensão)
Filial (Dimensão)
Figura 9 - Exemplo de esquema estrela
As entidades dimensão armazenam informações descritivas, são
equivalentes às dimensões de um cubo, normalmente não são normalizadas,
apresentando redundância nos dados.
Uma das vantagens do esquema estrela é a redução de operações de
junção entre tabelas durante as consultas, o que resulta na otimização do tempo de
acesso KANASHIRO (2007).

22
2.9.1 Granularidade
A granularidade é um aspecto importante do Data Warehouse a ser
considerado, visto que afeta demasiadamente o volume de dados a ser armazenado
e também as consultas que a serem feitas.
Inmon (1997) questiona: “De que quantidade de dados detalhados você
precisa para que seu ambiente de EIS/SAD funcione?” e responde dizendo “Há uma
linha de pensamento que afirma que você precisa de tanto detalhe quanto possível”
No processo de decisão da granularidade observaremos que o nível de
detalhe está diretamente relacionado com a capacidade de hardware disponível.
Inmon (1997) apresenta na figura a seguir um balanceamento da granularidade,
demonstrando que um alto nível de detalhe gera grandes volumes de dados,
enquanto um baixo nível de detalhe gera pequenos volumes.
Figura 10 - Balanceamento da granularidade (INMON, 1997)
2.9.2 Particionamento
Conforme Inmon (1997), além da granularidade outra questão importante
no projeto é o particionamento de dados. O particionamento de dados é a separação

23
dos dados de detalhe corrente em unidades físicas separadas que podem ser
tratadas de forma independente, por serem menores permitem maior flexibilidade no
gerenciamento dos dados (INMON, 1997).
Quando os dados são armazenados em unidades físicas maiores, fica
complexo o processo de reestruturação, indexação ou pesquisa sequencial, o que
não ocorre com o particionamento. Pode-se observar na figura a seguir a
importância do particionamento dos dados no projeto de dados do Data Warehouse.
Figura 11 - Particionamento de dados (INMON, 1997)

24
3 PROJETO E IMPLEMENTAÇÃO DE UM DATA WAREHOUSE: ESTUDO DE
CASO NO SETOR DE DISTRIBUIÇÃO DE MEDICAMENTOS
3.1 Considerações iniciais
Para que seja possível entender a implementação de um data warehouse
voltado para o setor de Distribuição de Medicamentos é necessário conhecer um
pouco sobre o setor, neste capítulo será apresentado conhecimentos sobre o setor
de Distribuição de Medicamentos e em seguida a solução de data warehouse objeto
do estudo de caso.
3.2 O setor de Distribuição de Medicamentos
Nos anos 60 e 70, quando as indústrias de bens de consumo expandiram
as suas vendas no país, o mercado brasileiro era dominado por grandes atacadistas
que compravam os produtos das indústrias e os revendiam diretamente aos milhares
de pequenos varejistas que serviam os consumidores. Estes varejistas, donos de
pequenas vendas, lojas e mercearias, foram sendo aos poucos substituídos por
supermercados. Estes, por sua vez, deram origem a redes que negociavam
diretamente com as indústrias, tornando desnecessária a ação dos distribuidores, ou
atacadistas.
Nos anos 80, estes atacadistas conseguiram sobreviver graças à inflação.
Eles formavam grandes estoques, compravam a prazo e vendiam à vista, aplicando
o seu capital de giro no mercado financeiro e auferindo altos juros. Quando a
inflação acabou, as firmas atacadistas passaram por grandes mudanças e poucas
conseguiram adaptar-se à nova realidade.
De qualquer forma, os distribuidores conseguiam manter o seu domínio
no mercado de medicamentos, por duas razões principais:

25
1. Este mercado é pulverizado, isto é, os maiores laboratórios têm
participações entre 3 e 4% no total de medicamentos vendidos. Assim, manter forças
de vendas próprias torna-se muito oneroso.
2. As farmácias são muito numerosas (há cerca de 50.000) e as grandes
redes varejistas só agora começam a crescer no mercado.
Grandes redes varejistas têm maior presença nos grandes centros,
enquanto os distribuidores atuam mais nas cidades menores e na periferia dos
grandes centros. Tais distribuidores servem milhares de clientes e o seu sucesso
depende de sua capacidade de realizar essas vendas (e fazer as entregas) a custos
muito baixos. De certa forma, uma distribuidora é uma organização logística, mais do
que uma organização de marketing.
Em meados dos anos 90 faliram muitas distribuidoras que não se
prepararam para o fim da inflação (o setor tinha cerca de 600 empresas. Metade
desapareceu). Adicionalmente, várias distribuidoras, que atuavam também com
redes de farmácias próprias, ressentiram-se da falta de foco. A distribuidora precisa
ser rápida no atendimento (FURTADO & GRACIOSO, 2001).
A distribuição de medicamentos é um serviço altamente especializado,
requerendo cuidados especiais no manuseio da carga. A maior dificuldade para o
transporte de medicamentos no País são as precárias condições da vasta malha
rodoviária brasileira.
Muitas redes de farmácias optam pela compra de mercadorias do
distribuidor em vez de fazê-lo diretamente da indústria, tendo em vista o elevado giro
do estoque de suas farmácias e a maior agilidade na entrega dos medicamentos.
Além disso, o distribuidor atacadista oferece condições de fracionamento de
embalagens, o que atende aos pequenos comerciantes (CARNEIRO, 2005).

26
3.3 Classificando como Pequena Empresa
Para classificar uma empresa como pequena, considerou-se o critério do
BNDES (2002), veja a seguir tabela das empresas segundo o porte.
PORTE
Microempresa Pequena Empresa Média Empresa Grande Empresa
Receita operacional bruta anual ou anualizada de até R$ 1,2 milhão.
Receita operacional bruta anual ou anualizada superior a R$ 1,2 milhão e inferior ou igual a R$ 10,5 milhões.
Receita operacional bruta anual ou anualizada superior a R$ 10,5 milhões e inferior ou igual a R$ 60 milhões.
Receita operacional bruta anual ou anualizada superior a R$ 60 milhões.
Tabela 3 - Classificação das empresas segundo o porte (BNDES, 2002)
3.4 A empresa foco do estudo
Como foco de estudo foi escolhido um grupo de pequenas empresas do
setor de distribuição de medicamentos, composto de 5 empresas, distribuídas
fisicamente em localidades geográficas diferentes, que vendem medicamentos para
o comércio varejista, sendo a maior clientela as farmácias.
Tais empresas aceitam pedidos de compra com valores mínimos de R$
200,00. As entregas são feitas em no máximo 48 horas, sendo a maioria destas
realizadas num prazo máximo de 24 horas. Deve-se ressaltar que o transporte
utilizado para as entregas é terceirizado.
O grupo trabalha de forma descentralizada, cada empresa do grupo
possui seu ambiente operacional e tecnológico separado.
Todas as empresas do grupo possuem, instalado, o mesmo ERP7 para os
controles operacionais e gerenciais.
O grupo de empresas trabalha com um catálogo de aproximadamente
4.000 produtos ativos.
7 ERP – Enterprise Resource Planning – Sistema Integrado de Gestão Empresarial

27
Com relação ao expediente executado por estas empresas é de segunda
a sexta-feira das 08 h às 21 h.
3.5 A Proposta de Implementação
O setor de distribuição de medicamentos como uma organização logística
precisa ser rápido no atendimento, precisa ter controle preciso do seu estoque,
acompanhamento dos vencimentos dos produtos, pois lida com produtos perecíveis
e controlados pelo ministério da saúde. Para não perder os produtos em estoque e
também não ficar sem produtos para vender, as empresas deste setor precisam
acompanhar estoques mínimos e máximos, verificar a sazonalidade dos produtos e
tendências de mercado. Tais empresas trabalham com uma grande variedade de
produtos. A regra de negócio é complexa, pois existem muitas condições de
pagamento, descontos, preços, bonificações, brindes, etc.
Dentro deste cenário, que sugere-se a implementação de um Data
Warehouse visando-se o seguinte:
Centralização das informações em um único local;
Obter informações sobre giro dos produtos, o que permite a
implantação de uma central de compras;
Obter informações sobre produtos mais vendidos, maiores clientes,
grupos de produtos mais vendidos, total de vendas por laboratório
classificando os maiores;
Estatística de clientes por região;
Determinação de períodos de picos de vendas;
Traçar relação entre produtos versus região;
Estas são apenas algumas, dentro de uma infinidade de possíveis
utilidades para o Data Warehouse.

28
3.6 Estratégia
Foi escolhida a área de vendas como foco da implementação do Data
Warehouse, visto ser a área que mais rapidamente pode trazer informações
estratégicas para a organização, satisfazendo os itens acima citados com elevado
nível de confiança.
Desta forma usou-se a estratégia “Botom-up”, permitindo que após criado
o Data Mart da área de vendas, possibilite a implementação de novos Data Marts
voltados para outras áreas e que futuramente poderão vir a formar um Data
Warehouse corporativo.
3.7 Metodologia
Como metodologia usou-se a o esquema dimensional estrela, seguindo-
se os pontos de decisão citados por Bonfim (2001).
3.8 Granularidade e Particionamento
Para se obter informações de picos de vendas, desvios de
comportamento de clientes e sazonalidade tornou-se necessário definir como
granularidade a informação diária. Como se trata de pequenas empresas, o volume
de dados não é tão preocupante, pois encontram-se dispositivos de
armazenamento, a custo relativamente acessível. Atualmente hard disks com 1
terabyte já se encontram a disposição para uso pessoal.
A seguir é apresentado gráfico que representa a evolução do hard disk,
com preços em dólares por gigabyte.

29
Figura 12 - Evolução do hard disk - preço por gbyte (http://www.willus.com/archive/cpu/2006/hard_drive_price_history.png. Acesso em: 14/01/2009).
Acreditando-se que o volume de dados produzido por pequenas
empresas não seja demasiadamente grande, os quais devem se adequar bem a
uma única unidade de armazenamento, não se vê a necessidade de
particionamento.
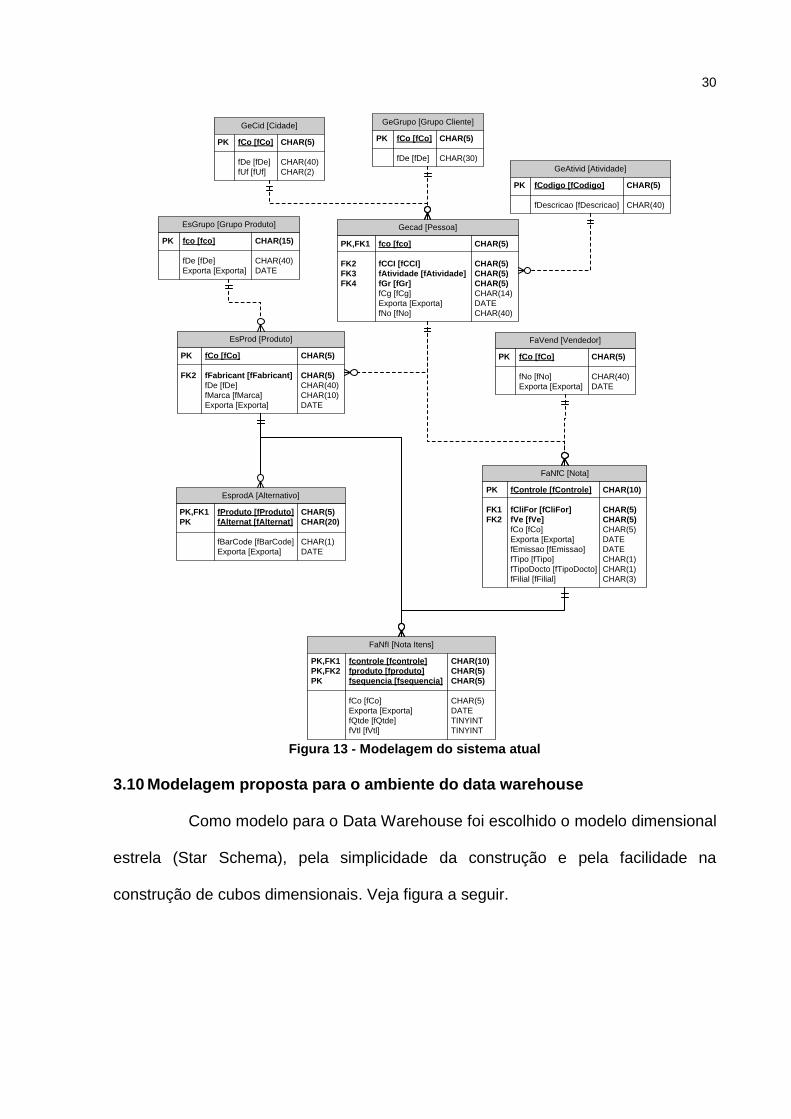
3.9 Modelagem do ambiente operacional atual
A compreensão dos dados é um dos maiores problemas no
desenvolvimento do Data Warehouse. A construção do modelo de dados é
fundamental para o desenvolvimento, ajudando a compreender as regras de negócio
e a organização dos dados para melhor tempo de resposta (BOMFIM, 2001). A
seguir é apresentada a figura do modelo atual.
30
FaNfC [Nota]
PK fControle [fControle] CHAR(10)
FK1 fCliFor [fCliFor] CHAR(5)
FK2 fVe [fVe] CHAR(5)
fCo [fCo] CHAR(5)
Exporta [Exporta] DATE
fEmissao [fEmissao] DATE
fTipo [fTipo] CHAR(1)
fTipoDocto [fTipoDocto] CHAR(1)
fFilial [fFilial] CHAR(3)
FaNfI [Nota Itens]
PK,FK1 fcontrole [fcontrole] CHAR(10)
PK,FK2 fproduto [fproduto] CHAR(5)
PK fsequencia [fsequencia] CHAR(5)
fCo [fCo] CHAR(5)
Exporta [Exporta] DATE
fQtde [fQtde] TINYINT
fVtl [fVtl] TINYINT
FaVend [Vendedor]
PK fCo [fCo] CHAR(5)
fNo [fNo] CHAR(40)
Exporta [Exporta] DATE
EsProd [Produto]
PK fCo [fCo] CHAR(5)
FK2 fFabricant [fFabricant] CHAR(5)
fDe [fDe] CHAR(40)
fMarca [fMarca] CHAR(10)
Exporta [Exporta] DATE
EsGrupo [Grupo Produto]
PK fco [fco] CHAR(15)
fDe [fDe] CHAR(40)
Exporta [Exporta] DATE
Gecad [Pessoa]
PK,FK1 fco [fco] CHAR(5)
FK2 fCCI [fCCI] CHAR(5)
FK3 fAtividade [fAtividade] CHAR(5)
FK4 fGr [fGr] CHAR(5)
fCg [fCg] CHAR(14)
Exporta [Exporta] DATE
fNo [fNo] CHAR(40)
EsprodA [Alternativo]
PK,FK1 fProduto [fProduto] CHAR(5)
PK fAlternat [fAlternat] CHAR(20)
fBarCode [fBarCode] CHAR(1)
Exporta [Exporta] DATE
GeCid [Cidade]
PK fCo [fCo] CHAR(5)
fDe [fDe] CHAR(40)
fUf [fUf] CHAR(2) GeAtivid [Atividade]
PK fCodigo [fCodigo] CHAR(5)
fDescricao [fDescricao] CHAR(40)
GeGrupo [Grupo Cliente]
PK fCo [fCo] CHAR(5)
fDe [fDe] CHAR(30)
Figura 13 - Modelagem do sistema atual
3.10 Modelagem proposta para o ambiente do data warehouse
Como modelo para o Data Warehouse foi escolhido o modelo dimensional
estrela (Star Schema), pela simplicidade da construção e pela facilidade na
construção de cubos dimensionais. Veja figura a seguir.

31
Produto [Produto]
PK idProduto [idProduto] CHAR(20)
Descricao [Descricao] CHAR(40)
Marca [Marca] CHAR(10)
Fabricante [Fabricante] CHAR(40)
Grupo [Grupo] CHAR(40)
Cliente [Cliente]
PK idCliente [idCliente] CHAR(20)
Nome [Nome] CHAR(40)
Cidade [Cidade] CHAR(40)
UF [UF] CHAR(2)
Atividade [Atividade] CHAR(40)
Grupo [Grupo] CHAR(40)
Vendedor [Vendedor]
PK idVendedor [idVendedor] CHAR(20)
Nome [Nome] CHAR(40)
Cidade [Cidade] CHAR(40)
UF [UF] CHAR(2)
Tempo [Tempo]
PK idTempo [idTempo] DATE
Data [Data] DATE
DiaSemana [DiaSemana] CHAR(7)
DiaMes [DiaMes] SMALLINT
SemanaAno [SemanaAno] SMALLINT
Mes [Mes] CHAR(9)
MesNumero [MesNumero] SMALLINT
Ano [Ano] SMALLINT
UltimoDiaMes [UltimoDiaMes] SMALLINT
DiaAno [DiaAno] SMALLINT
Bimestre [Bimestre] SMALLINT
Trimestre [Trimestre] SMALLINT
Quadrimestre [Quadrimestre] SMALLINT
Semestre [Semestre] SMALLINT
Feriado [Feriado] CHAR(3)
DiaUtil [DiaUtil] CHAR(3)
FimSemana [FimSemana] CHAR(3)
Venda [Venda]
PK Unidade [Unidade] CHAR(10)
PK,FK3 IdCliente [IdCliente] CHAR(20)
PK,FK2 IdProduto [IdProduto] CHAR(20)
PK,FK1 idVendedor [idVendedor] CHAR(40)
PK,FK4 idTempo [idTempo] DATE
Quantidade [Quantidade] DECIMAL(20;6)
Valor [Valor] DECIMAL(14;2)
Figura 14 - Modelagem proposta para o ambiente do Data Warehouse
No apêndice A é apresentado o script para criação das tabelas, índices,
views e tabelas resumo.
3.11 Extração, transformação e carga (ETL)
Inmon (1997) diz que 80% do tempo gasto na construção de um Data
Warehouse é gasto com ETL8. Daí observa-se a importância desse processo. Foi
desenvolvida uma aplicação para facilitar o processo de ETL.
Como o horário de expediente da empresa encerra-se às 21h tem-se uma
janela de tempo suficiente para fazer o processo de ETL, aproximadamente 10 horas
disponíveis, já contando com diferença de uma hora de fuso horário de duas
empresas do grupo que estão sediadas no Mato Grosso do Sul.
8 ETL – Extraction, Transformation and Load (Extração, Transformação e Carga)

32
A ferramenta trabalha a partir de um arquivo contendo um script das
operações a serem realizadas, veja exemplo de carga, de uma unidade, no apêndice
B.
Os processos foram agendados para serem executados através do
serviço de agendamento de tarefas do Windows.
Exemplo de execução do aplicativo ETL:
ETL script_unidade1.ini
É possível informar o período a ser considerado:
ETL script_unidade1.ini 01/01/2009 05/01/2009
Se o período não for informado a aplicação irá automaticamente definir o
período considerando como data inicial a última data que foi executada a aplicação
mais um dia, e como data final a data atual menos um dia.
Veja também o script para carga da dimensão tempo no apêndice C e
script para carga das tabelas resumo e execução das estatísticas das tabelas no
apêndice D.
3.12 SGBDs9 envolvidos
A empresa usa um ERP que trabalha com SGBD Postgresql 8.1.11, para
hospedar a base de dados do Data Warehouse optamos como SGBD o DB2
EXPRESS C 9.5 da IBM, por ser uma solução de uso gratuito, com poucas
limitações, o qual permitiu a implementação do Data Warehouse sem grandes
problemas. Poderia ser usada a SGBD Oracle Database 10g Express Edition, porém
a base de dados é limitada a 4GB o que não é atrativo para ambiente de Data
Warehouse, veja tabela comparativa abaixo.
9 SGBD – Sistema de gerenciamento de banco de dados

33
Características DB2 Express C Oracle Express Edition
Processadores 2 1
Memória 4GB 1GB
Base de dados Ilimitado 4GB
Arquiteturas 32 e 64 bits 32 e 64 bits
Linux Sim Sim
Windows Sim Sim
Suporte a XML Sim Sim Tabela 4 – DB2 Express C versus Oracle Express Edition
ORACLE. Disponível em: http://www.oracle.com/lang/pt/technology/products/database/xe/index.html. Acesso em: 15/01/2009 IBM. Disponível em: http://www.ibm.com/expressadvantage/br/catalogo/db2_express-c.phtml. Acesso em: 15/01/2009)
O DB2 EXPRESS C 9.5 não tem disponível o recurso para criar tabelas
materializadas para consulta (MQT10), para resolver esta situação, utilizamos uma
alternativa que consiste no uso de views e tabelas. Os comandos usados para criar
as tabelas materializadas podem ser vistos no apêndice A.
3.13 Exemplos práticos de dados consultados
Para que se possa ter uma idéia das possibilidades de consultas que
podem ser obtidas a partir do Data Warehouse construído, foram elaboradas
algumas planilhas. Utilizou-se como ferramenta para criação das planilhas o
Microsoft Office Excel 2007. Na sequência são apresentados alguns exemplos das
planilhas criadas.
10
MQT – Materialized Query Tables

34
Figura 15 - Planilha - Resumo de vendas por grupo de clientes
Figura 16 - Planilha - Resumo de vendas por unidade
35
Figura 17 - Planilha - Resumo anual de vendas por cidade

36
Figura 18 - Planilha - Os dez produtos mais vendidos
Figura 19 - Planilha - Maiores vendas

37
4 CONCLUSÕES
O Data Warehouse como grande repositório de informações históricas
e/ou atuais, permite analisar a evolução da organização através das diversas
ferramentas de que disponibiliza, é necessário para tanto que os dados sejam
processados, selecionados e disponibilizados para o ambiente corporativo, esse não
é um trabalho rápido, tão pouco simples, exige conhecimento do negócio, habilidade
técnica e consciência da necessidade de retrabalho, pois conforme afirmação de
Inmon (1997), um Data Warehouse não se constrói de uma só vez, são projetados
passo a passo, ordenadamente de forma iterativa, portanto são evolucionários e não
revolucionários.
Como o foco do estudo se dirige a pequenas empresas, um dos
problemas encontrados foi a falta de material bibliográfico específico, esta
dificuldade foi contornada através de experiências próprias e da consulta a
bibliografias não específicas buscando fazer correlação.
4.1 Resultados alcançados
Ao término deste trabalho pode-se afirmar a excelente aplicabilidade do
ambiente de Data Warehouse dentro de pequenas empresas, como o estudo de
caso foi todo elaborado utilizando ferramentas livres, não pagas, o custo do projeto
resumiu-se à mão de obra aplicada para o seu projeto e criação, que no caso não
excedeu 200 (duzentas) horas de 1 (um) profissional. Isto demonstra ser um custo
acessível às pequenas organizações.
Uma dificuldade que se pode prever é a seleção do profissional certo para
este trabalho, visto que para se manter um custo baixo é necessário que o mesmo

38
seja multidisciplinar, dominando mais que um assunto, como regras de negócio,
banco de dados, desenvolvimento de aplicações, etc.
O estudo de Data Warehouse é, sem dúvida, de uma abrangência
enorme, o que merece muita pesquisa e estudo a respeito. Este trabalho certamente
vem contribuir e de certo modo abrir caminho dentro das pequenas empresas
visando a inserção do ambiente de Data Warehouse no seu meio.
4.2 Trabalhos futuros
Fica claro que o assunto não foi esgotado, e que este é apenas o ponto
de partida. Há outros estudos a serem realizados que podem complementar, como
um estudo acerca das ferramentas OLAP existentes, tanto livres como proprietárias,
e também acerca de ferramentas ETL.

39
REFERÊNCIAS
BARROS, Fábio. Guia para implementação prática de um Data Warehouse. São
Paulo: Revista ComputerWorld, 2002, n.367. Disponível em: <
http://computerworld.uol.com.br/tecnologia/2002/07/29/idgnoticia.2006-05-
15.6255650158/ >. Acesso em: 11 jan. 2009.
BISPO, Carlos Alberto Ferreira. Uma análise da nova geração de sistemas de apoio
à decisão. 1998. 160 p. Dissertação. (Mestrado em Engenharia da Produção).
Escola de Engenharia de São Carlos, Universidade de São Paulo. São Carlos, São
Paulo.
BNDES. Carta-Circular nº 64/2002 – Porte das empresas. Rio de Janeiro: 2002.
Disponível em: http://www.bndes.gov.br/produtos/download/02cc64.pdf. Acesso em:
14 jan. 2009.
BOMFIM, Marcus Mosquéra. A implementação e utilização de data warehouse em
instituições públicas no Brasil: um estudo descritivo das implicações envolvidas.
2001. 119 p. Dissertação. (Mestrado em Engenharia da Produção). Universidade
Federal de Santa Catarina. Florianópolis, Santa Catarina.
CARNEIRO, Teresa Cristina Janes. Integração organizacional e tecnologia da
informação: um estudo na indústria farmacêutica. 2005. 184 p. Tese. (Doutorado em
Administração. Universidade Federal do Rio de Janeiro, Instituto COPPEAD de
Administração - Rio de Janeiro.

40
COME, Gilberto. Contribuição ao estudo da implementação de data warehousing:
Um caso no setor de telecomunicações. 2001. 133 p. Dissertação. (Mestrado em
Administração de Empresas) – Universidade de São Paulo - São Paulo.
COREY, Michael; ABBEY, Michael; ABRAMSON, Ian; TAUB, Ben. Oracle 8i Data
Warehouse. 1 ed. Rio de Janeiro: Campus, 2001. 817 p.
COREY, Michael; et al. Oracle 8i data warehouse. Rio de Janeiro: Editora Campus,
2001. 817 p.
FURTADO, José Maria; GRACIOSO, Francisco. Estruturas Estratégicas da
Panarello, uma das maiores distribuidoras de remédios do Brasil. Central de Cases
ESPM/EXAME: 2001. Disponível em: http://www.alexandria.unama.br. Acesso em:
14 jan. 2009.
GIL, Antonio Carlos. Como elaborar projetos de pesquisa. 4. ed. São Paulo: Atlas,
2006. 175 p.
GUROVITZ, Helio. O que cerveja tem a ver com fraldas? Revista Info. São Paulo:
v30, n.08, p88-90, abr., 1997.
INMON, William H. Como construir o data warehouse (tradução da 2ª edição). 1. ed.
Rio de Janeiro: Campus. 1997. 388 p.
INMON, William H. Data Mart Does Not Equal Data Warehouse – DM Review,
November 1999a. Disponível em:
http://www.dmreview.com/dmdirect/19991120/1675-1.html. Acesso em: 15 jan. 2009.

41
INMON, Willian H.; et al. Gerenciando Data Warehouse. 1. ed. São Paulo: Makron
Books, 1999b. 375 p.
KANASHIRO, Augusto. Um data warehouse de publicações científicas: indexação
automática da dimensão tópicos de pesquisa dos data marts. 2007. 93 p.
Dissertação. (Mestrado em Ciência da Computação é Matemática Computacional) –
Instituto de Ciências Matemáticas de Computação – ICMC/USP – São Paulo, São
Carlos.
LOPES, Maurício Capobianco; OLIVEIRA, Percio Alexandre. Ferramenta de
construção de Data Warehouse. Blumenau: 2006. Disponível em:
<http://www.datawarehouse.inf.br/Academicos/CONSTRUCAO_DW.pdf>. Acesso
em: 11 jan. 2009.
NAVARRO, Maria Cristina de Araújo. O que é Data Warehouse? Brasilia: 1996.
Disponível em:
<http://www.serpro.gov.br/imprensa/publicacoes/tematec/1996/ttec27>. Acesso em:
11 jan. 2009.
SOUZA, Carla Oran Fonseca de. Desenvolvimento de aplicações ETL como uma
proposta para redução de custos em projetos de data warehouse. 2003a. 62 p.
Dissertação. (Mestrado em Engenharia Elétrica) – Universidade Federal de
Pernambuco – Recife, Pernambuco.
SOUZA, Michel. BI: data marts. Imaster: 2003b. Disponível em:
http://imasters.uol.com.br/artigo/1612/bi/bi_data_marts/. Acesso em: 21/01/2009.

42
APÊNDICES

43
APÊNDICE - A – Script para Criação das Tabelas e Índices
-- Dimensão produto DROP TABLE dw.produto;
CREATE TABLE dw.produto
(
idProduto CHAR(20),
descricao VARCHAR(40),
marca CHAR(10),
fabricante CHAR(40),
grupo CHAR(15),
grupoDescricao VARCHAR(40)
);
-- Dimensão vendedor DROP TABLE dw.vendedor;
CREATE TABLE dw.vendedor
(
idVendedor CHAR(20),
Nome VARCHAR(40),
Cidade VARCHAR(40),
UF VARCHAR(2)
);
-- Dimensão cliente DROP TABLE dw.cliente;
CREATE TABLE dw.cliente
(
idCliente CHAR(20),
Nome VARCHAR(40),
Cidade VARCHAR(40),
UF VARCHAR(2),
Atividade VARCHAR(40),
Grupo VARCHAR(40)
);
-- Dimensão tempo DROP TABLE dw.tempo;
CREATE TABLE dw.tempo
(
idTempo DATE,
Data DATE,
DiaSemana VARCHAR(7),
DiaMes SmallInt,
SemanaAno Integer,
Mes Char(9),
MesNumero SmallInt,
Ano SmallInt,
UltimoDiaMes SmallInt,
DiaAno SmallInt,
Bimestre SmallInt,
Trimestre SmallInt,
Quadrimestre SmallInt,
Semestre SmallInt,
Feriado Char(3),
DiaUtil Char(3),
FimSemana Char(3)
);
-- Fato venda DROP TABLE dw.venda;
CREATE TABLE dw.venda
(
Unidade CHAR(10),
idCliente VARCHAR(20),
idProduto VARCHAR(20),
idVendedor VARCHAR(20),
idTempo DATE,
Quantidade NUMERIC(20,6),
Valor NUMERIC(14,2)

44
);
-- Criação dos indices CREATE UNIQUE INDEX ik_tempo_idtempo ON tempo (idtempo ASC);
CREATE UNIQUE INDEX ik_vendedor_idvendedor ON vendedor (idvendedor ASC);
CREATE UNIQUE INDEX ik_produto_idproduto ON produto (idproduto ASC);
CREATE UNIQUE INDEX ik_cliente_idcliente ON cliente (idcliente ASC);
CREATE INDEX ik_venda_idCliente ON venda (idcliente ASC);
CREATE INDEX ik_venda_idProduto ON venda (idProduto ASC);
CREATE INDEX ik_venda_idTempo ON venda (idTempo ASC);
-- Criação de VIEWS CREATE VIEW DW.VRESUMOVENDEDOR AS
SELECT v.unidade,
r.nome AS vendedor,
c.cidade,
c.uf,
c.grupo AS grupocliente,
t.mes,
t.ano,
SUM(v.valor) AS valorvenda
FROM dw.venda AS V
JOIN dw.tempo AS T ON t.idtempo = v.idtempo
JOIN dw.vendedor AS R ON r.idvendedor = v.idvendedor
JOIN dw.cliente AS C ON c.idcliente = v.idcliente
GROUP BY v.unidade,r.nome,c.cidade,c.uf,c.grupo,t.mes,t.ano;
CREATE VIEW DW.VRESUMOCLIENTE AS
SELECT v.unidade,
c.nome AS cliente,
c.cidade,
c.uf,
c.grupo AS grupocliente,
t.mes,
t.ano,
SUM(v.valor) AS valorvenda
FROM dw.venda AS V
JOIN dw.tempo AS T ON t.idtempo = v.idtempo
JOIN dw.cliente AS C ON c.idcliente = v.idcliente
GROUP BY v.unidade,c.nome,c.cidade,c.uf,c.grupo,t.mes,t.ano;
CREATE VIEW DW.VRESUMOUNIDADE AS
SELECT v.unidade,
t.data, t.mes, t.ano, t.DiaSemana, t.DiaMes, t.SemanaAno, t.Bimestre,
t.Trimestre, t.Quadrimestre, t.Semestre,
SUM(v.valor) AS valorvenda
FROM dw.venda AS V
JOIN dw.tempo AS T ON t.idtempo = v.idtempo
GROUP BY v.unidade, t.data, t.mes, t.ano, t.DiaSemana, t.DiaMes, t.SemanaAno, t.Bimestre,
t.Trimestre, t.Quadrimestre,t.Semestre;
-- Criação de tabelas resumo CREATE TABLE DW.RESUMOVENDEDOR AS (
SELECT * FROM DW.VRESUMOVENDEDOR
)
DEFINITION ONLY
NOT LOGGED INITIALLY;
CREATE TABLE DW.RESUMOCLIENTE AS (
SELECT * FROM DW.VRESUMOCLIENTE
)
DEFINITION ONLY
NOT LOGGED INITIALLY;
CREATE TABLE DW.RESUMOUNIDADE AS (
SELECT * FROM DW.VRESUMOUNIDADE
)
DEFINITION ONLY
NOT LOGGED INITIALLY;

45
APÊNDICE - B – Script para Carga de uma Unidade
[PARAMETROS]
Unidade = UNIDADE1
DSN Origem = pgs=localhost;uid=supervisor;dtb=unidade1;pwd=1234
DSN Destino = DRIVER={IBM DB2 ODBC DRIVER};DATABASE=dw;SERVER=localhost;PORT=50000;
UID=db2admin; PWD=1234
Debug = NAO
[TABELAS]
produto
vendedor
cliente
venda
[PRODUTO_EXTRACAO]
SET SEARCH_PATH=XEMP_0002;
SELECT DISTINCT ON (TRIM(EsProdA.fAlternat))
TRIM(EsProdA.fAlternat)::CHAR(20) AS fId,
TO_ASCII(EsProd.fde) AS fDe,
EsProd.fGr,
EsGrupo.fDe AS fDescGrupo,
EsProd.fMr,
GeCad.fNo AS fFabricant
FROM EsProd
JOIN EsGrupo ON EsGrupo.fCo = EsProd.fGR
JOIN GeCad ON GeCad.fCo = EsProd.fFabricant
JOIN (
SELECT
DISTINCT ON (fProduto) -- não repetir produtos, pegar somente o que tiver o maior
código de barras
fProduto,
fAlternat,
Exporta
FROM EsProdA
WHERE EsProdA.fBarCode = 'S'
ORDER BY 1,2 DESC
) AS EsProdA ON EsProdA.fProduto = EsProd.fCo
WHERE GeCad.fCg > '00000000000000'
AND ( EsProd.Exporta BETWEEN {mDataI} AND {mDataF}
OR EsProdA.Exporta BETWEEN {mDataI} AND {mDataF}
OR GeCad.Exporta BETWEEN {mDataI} AND {mDataF}
OR EsGrupo.Exporta BETWEEN {mDataI} AND {mDataF} )
[PRODUTO_CARGA]
DELETE FROM dw.produto
WHERE idProduto IN (
SELECT fId FROM tmpArq
);
COMMIT;
INSERT INTO dw.produto
( idProduto, Descricao, marca, Fabricante, grupo, grupoDescricao)
(SELECT fId, fde, fmr, fFabricant, fGr, fDescGrupo
FROM tmpArq);
[VENDEDOR_EXTRACAO]
SET SEARCH_PATH=XEMP_0002;
SELECT DISTINCT
('2' || FaVend.fCo)::VARCHAR(20) AS fId,
TO_ASCII(FaVend.fNo)::VARCHAR(40) AS fNome,
fCi AS fCidade,
fUf AS fUf
FROM FaVend
WHERE FaVend.Exporta BETWEEN {mDataI} AND {mDataF}
ORDER BY 2
[VENDEDOR_CARGA]
DELETE FROM dw.vendedor
WHERE idVendedor IN (

46
SELECT fId FROM tmpArq
);
COMMIT;
INSERT INTO dw.vendedor
( idVendedor, Nome, Cidade, Uf)
(SELECT fId, fNome, fCidade, fUf
FROM tmpArq);
[CLIENTE_EXTRACAO]
SET SEARCH_PATH=XEMP_0002, XGERAL;
SELECT DISTINCT ON (GeCad.fCg)
GeCad.fCg AS fID,
TO_ASCII(GeCad.fNo) AS fNome,
TO_ASCII(COALESCE(GeCid.fDe, GeCad.fCi)) AS fCidade,
TO_ASCII(COALESCE(GeCid.fUf, GeCad.fUf)) AS fUf,
TO_ASCII(GeAtivid.fDescricao) AS fAtividade,
TO_ASCII(GeGrupo.fDe) AS fGrupo
FROM GeCad
LEFT JOIN GeCid ON GeCid.fCo = GeCad.fCCI
LEFT JOIN GeAtivid ON GeAtivid.fCodigo = GeCad.fAtividade
LEFT JOIN GeGrupo ON GeGrupo.fCo = GeCad.fGr
WHERE GeCad.fCg > '00000000000000'
AND ( GeCad.Exporta BETWEEN {mDataI} AND {mDataF}
OR GeGrupo.Exporta BETWEEN {mDataI} AND {mDataF}
OR GeAtivid.Exporta BETWEEN {mDataI} AND {mDataF} )
order by 1
[CLIENTE_CARGA]
DELETE FROM dw.Cliente
WHERE idCliente IN (
SELECT fId FROM tmpArq
);
COMMIT;
INSERT INTO dw.Cliente
( idcliente, Nome, Cidade, UF, Atividade, Grupo)
(SELECT fId, fNome, fCidade, fUf, fAtividade, fGrupo
FROM tmpArq);
[VENDA_EXTRACAO]
SET SEARCH_PATH=XEMP_0002;
SELECT FaNfC.fEmissao AS fIdTempo,
GeCad.fCg AS fIdCliente,
TRIM(EsProdA.fAlternat)::CHAR(20) AS fIdProduto,
('2' || FaVend.fCo)::VARCHAR(20) AS fIdVend,
SUM(FaNfI.fQtde)::DECIMAL(20,6) AS fQtde,
SUM(FaNfI.fVtl)::DECIMAL(14,2) AS fValor
FROM FaNfC
JOIN FaNfI USING (fControle)
JOIN GeCad ON GeCad.fCo = FaNfC.fCliFor
JOIN FaVend ON FaVend.fCo = FaNfC.fVe
JOIN (
SELECT
DISTINCT ON (fProduto) -- não repetir produtos, pegar somente o que tiver o maior
código de barras
fProduto,
fAlternat
FROM EsProdA
WHERE EsProdA.fBarCode = 'S'
ORDER BY 1,2 DESC
) AS EsProdA ON EsProdA.fProduto = FaNfI.fProduto
WHERE FaNfC.fEmissao BETWEEN {mDataI} AND {mDataF}
AND FaNfC.fTipo = 'S'
AND FaNfC.fTipoDocto = 'N'
AND FaNfC.fFilial = '001'
AND GeCad.fCg > '00000000000000'
GROUP BY 1,2,3,4
ORDER BY 1,2,3,4
[VENDA_CARGA]
DELETE FROM dw.Venda

47
WHERE idTempo BETWEEN {mDataI} AND {mDataF}
AND Unidade = {mUnidade};
COMMIT;
INSERT INTO dw.venda
( Unidade, idTempo, idCliente, idProduto, idVendedor, Quantidade,
Valor)
(SELECT {mUnidade}, fIdTempo, fIdCliente, fIdProduto, fidVend, fQtde,
fValor
FROM tmpArq);
[FIM]

48
APÊNDICE - C – Script para Criação da Dimesão Tempo
[PARAMETROS]
Unidade = foco
DSN Origem = pgs=localhost;uid=supervisor;dtb=unidade1;pwd=1234
DSN Destino = DRIVER={IBM DB2 ODBC DRIVER}; DATABASE=dw; SERVER=localhost; PORT=50000;
UID=db2admin; PWD=1234
Debug = NAO
[TABELAS]
tempo
[TEMPO_EXTRACAO]
SELECT fId,
fId AS fData,
CASE EXTRACT(DOW FROM FID)
WHEN 0 THEN 'DOMINGO'
WHEN 1 THEN 'SEGUNDA'
WHEN 2 THEN 'TERCA'
WHEN 3 THEN 'QUARTA'
WHEN 4 THEN 'QUINTA'
WHEN 5 THEN 'SEXTA'
WHEN 6 THEN 'SABADO'
END AS fDiaSemana,
Extract(day from fID) AS fDiaMes,
EXTRACT(WEEK FROM FID+1) AS fSemanaAno,
CASE EXTRACT(MONTH FROM FID)
WHEN 1 THEN 'JANEIRO'
WHEN 2 THEN 'FEVEREIRO'
WHEN 3 THEN 'MARÇO'
WHEN 4 THEN 'ABRIL'
WHEN 5 THEN 'MAIO'
WHEN 6 THEN 'JUNHO'
WHEN 7 THEN 'JULHO'
WHEN 8 THEN 'AGOSTO'
WHEN 9 THEN 'SETEMBRO'
WHEN 10 THEN 'OUTUBRO'
WHEN 11 THEN 'NOVEMBRO'
WHEN 12 THEN 'DEZEMBRO'
END AS fMes,
EXTRACT(MONTH FROM fID) AS fMesNumero,
EXTRACT(YEAR FROM fID) AS fAno,
EXTRACT(DAY FROM (DATE_TRUNC('MONTH', fId + interval '1 month')::DATE -
1)) AS fUltDiaMes,
EXTRACT(DOY FROM fID) AS fDiaAno,
CASE WHEN Extract(month from fID) BETWEEN 1 AND 2 THEN 1
WHEN Extract(month from fID) BETWEEN 3 AND 4 THEN 2
WHEN Extract(month from fID) BETWEEN 5 AND 6 THEN 3
WHEN Extract(month from fID) BETWEEN 7 AND 8 THEN 4
WHEN Extract(month from fID) BETWEEN 9 AND 10 THEN 5 ELSE 6 END AS fBimestre,
CASE WHEN Extract(month from fID) BETWEEN 1 AND 3 THEN 1
WHEN Extract(month from fID) BETWEEN 4 AND 6 THEN 2
WHEN Extract(month from fID) BETWEEN 7 AND 9 THEN 3 ELSE 4 END AS fTrimestre,
CASE WHEN Extract(month from fID) BETWEEN 1 AND 4 THEN 1
WHEN Extract(month from fID) BETWEEN 5 AND 8 THEN 2 ELSE 3 END
AS fQuadrim,
CASE WHEN Extract(month from fID) BETWEEN 1 AND 6 THEN 1 ELSE 2 END
AS fSemestre,
CASE WHEN TO_CHAR(fId,'DD/MM') IN
('01/01','21/04','01/05','07/09','12/10','02/11','15/11','25/12')
THEN 'SIM'
ELSE 'NAO'
END AS fFeriado,
CASE WHEN TO_CHAR(fId, 'D') IN (1,7) OR TO_CHAR(fId,'DD/MM') IN
('01/01','21/04','01/05','07/09','12/10','02/11','15/11','25/12') THEN 'NAO' ELSE 'SIM' END AS
fDiaUtil,
CASE WHEN TO_CHAR(fId, 'D') IN (1,7) THEN 'SIM' ELSE 'NAO' END AS fFimSemana
FROM (
SELECT {mDataI}::DATE + GENERATE_SERIES AS fId
FROM GENERATE_SERIES(0, {mDataF - mDataI})
) AS tmp

49
[TEMPO_CARGA]
DELETE FROM dw.tempo
WHERE idTempo IN (
SELECT fId FROM tmpArq
);
COMMIT;
INSERT INTO dw.tempo
( idTempo, Data, DiaSemana, DiaMes, SemanaAno, Mes, MesNumero, Ano,
UltimoDiaMes, DiaAno, Bimestre, Trimestre, Quadrimestre, Semestre, Feriado, DiaUtil,
FimSemana
)
(SELECT fId, fData, fDiaSemana, fDiaMes, fSemanaAno, fMes, fMesNumero, fAno,
fUltDiaMes, fDiaAno, fBimestre, fTrimestre, fQuadrim, fSemestre, fFeriado, fDiaUtil,
fFimSemana
FROM tmpArq);
[FIM]

50
APÊNDICE - D – Script para Carga das Tabelas Resumo e Execução de
Estatísticas
-- Carga das tabelas resumo DELETE FROM DW.RESUMOVENDEDOR;
INSERT INTO DW.RESUMOVENDEDOR (SELECT * FROM DW.VRESUMOVENDEDOR);
DELETE FROM DW.RESUMOCLIENTE;
INSERT INTO DW.RESUMOCLIENTE (SELECT * FROM DW.VRESUMOCLIENTE);
DELETE FROM DW.RESUMOUNIDADE;
INSERT INTO DW.RESUMOUNIDADE (SELECT * FROM DW.VRESUMOUNIDADE);
-- Executar estatísticas RUNSTATS ON TABLE dw.vendedor AND INDEXES ALL;
RUNSTATS ON TABLE dw.cliente AND INDEXES ALL;
RUNSTATS ON TABLE dw.tempo AND INDEXES ALL;
RUNSTATS ON TABLE dw.produto AND INDEXES ALL;
RUNSTATS ON TABLE dw.venda AND INDEXES ALL;
RUNSTATS ON TABLE dw.resumovendedor AND INDEXES ALL;
RUNSTATS ON TABLE dw.resumocliente AND INDEXES ALL;
RUNSTATS ON TABLE dw.resumounidade AND INDEXES ALL;