hardware paralelo - nbcgibnbcgib.uesc.br/nbcgib/files/2011_pp/aula03_arq_par.pdf · portabilidade...
TRANSCRIPT

Processamento Paralelo
Hardware Paralelo
Universidade Estadual de Santa CruzBacharelado em Ciência da Computação
Prof. Esbel Tomás Valero Orellana

Portabilidade• O principal problema das primeiras maquinas paralelas foi
a enorme dificuldade para escrever programas portáveis.
• Os programas escritos para uma arquitetura não podiam
ser executados satisfatoriamente em uma arquitetura
diferente.
• Felizmente, essa situação tem mudado drasticamente,
devido ao trabalho de grupos de pessoas em desenvolver
padrões para maquinas paralelas (HPF, MPI, ARB).

Portabilidade
High Performance Fortran (HPF) Forum
•Tem desenvolvido um grupo de extensões do
Fortran 90, que permitem aos programadores
escrever facilmente programas paralelos,
•O mecanismo principal para alcançar o paralelismo
é a divisão dos dados ou paralelismo de dados,
•O domínio de dados é dividido entre vários
processadores e cada um deles realiza as operações
sobre o subdomínio de dados correspondente,

Portabilidade
High Performance Fortran (HPF) Forum
• HPF, fornece um conjunto de funções primitivas que
permitem distribuir vetores e matrizes
convenientemente e operar eles em paralelo,
• A principal deficiência do HPF, é que muitos algoritmos
paralelos não podem ser convertidos em programas
eficientes (linguagem de máquina) pelos compiladores
atuais.

Portabilidade
Message Passing Interface (MPI) Forum
• Um enfoque completamente inovador na criação de
padrões para maquinas paralelas,
• Não é criada uma nova linguagem, e sem uma
biblioteca de funções que podem ser chamadas desde
programas em C ou Fortran*,
• As bases desta biblioteca é um grupo de funções que
permitem alcançar o paralelismo através do intercambio
de mensagens,

Portabilidade
Message Passing Interface (MPI) Forum
• Intercambio de mensagens é um método poderoso e
geral de expressar o paralelismo,
• A principal deficiência do paradigma MPI é que força
ao programador a lidar com muitos detalhes,
dificultando o desenvolvimento, (linguagem de
montagem para computadores paralelos),
• Maiores detalhes sobre MPI serão vistos ao longo do
curso.

Portabilidade
Architecture Review Board - ARB
•Grupo formado pelos principais fabricantes de hardware
(SUN Microsystems, SGI, IBM, Intel);
•Desenvolveram um padrão aberto (domínio público)
para maquinas de memória compartilhada;
•Application Programming Interfase (API) + diretivas de
compilação;
•A maioria dos detalhes da implementação paralela são
deixados ao compilador;
•Padrão OpenMP, será visto no curso.

Taxonomia de Flynn•Existe uma enorme variedade de arquiteturas para
máquinas paralelas, tentar classificá-las seguindo um
padrão lógico é extremamente difícil,
•A classificação original para máquinas paralelas, vem dos
primórdios de teoria da computação e o conhecida como
taxonomia de Flynn,
•Em 1966 Flynn classificou os sistemas de acordo com o
número de fluxos de instruções e o número de fluxos de
dados, que estivessem sendo processados
simultaneamente.

Taxonomia de Flynn
• SISD – Single Instruction Single Data, um fluxo de instruções e um fluxo de dados, Ex: arquitetura convencional de von Neumann,
• SIMD – Single Instruction Multiple Data, um fluxo de instruções vários fluxos de dados,
• MISD – Multiple Instruction Single Data, vários fluxos de instruções um fluxo de dados,
• MIMD – Multiple Instruction Multiple Data, vários fluxos de instruções vários fluxos de dados, uma coleção de processos autônomos com seus próprios dados.

Taxonomia de FlynnSistemas SISD – Arquitetura de Neumann

Taxonomia de Flynn
Sistemas SISD – Arquitetura de Neumann
• O “gargalho” na arquitetura de Neumann é a
transferência de dados entre a memória e a CPU,
• Não importa quanto aumentarmos a velocidade de
execução do processador, a velocidade de execução
do programa é limitada pela velocidade do fluxo de
informações entre a memória e a CPU,
• Na atualidade não existem máquinas estritamente
von Neumann, algumas mudanças tem sido
introduzidas na arquitetura,

Taxonomia de Flynn
Sistemas SISD – Arquitetura de Neumann
• Aprimoramentos á arquitetura de Neumann➢ utilização de uma hierarquia de memórias,➢ utilização de memórias cachê,➢ utilização de vários bancos de memórias,➢ uso de pipeline➢ adicionar instruções vetoriais ao conjunto de
instruções do processador, (realizam operações
com vetores)

Taxonomia de Flynn
Sistemas MISD – Neumann Modificado• Exemplo de Instruções Vetoriais
FORTRAN 77
do 100 i=1,100
z[i] = x[i] + y[i]
100 continue
• a instrução precisa ser carregada e decodificada 100 vezes, o vetor é processado elemento a elemento
FORTRAN 90
z[1:100] = x[1:100] + y[1:100]
• a instrução é carregada e decodificada 1 vez, o vetor é processado como uma entidade

Taxonomia de Flynn
Sistemas MISD – Neumann Modificado
• os processadores vetoriais e com pipeline, foram
muito populares na busca de um maior poder de
computo,
• a arquitetura deste tipo de processadores tem sido
muito estudada e existem compiladores excelentes,
• entretanto, eles apresentam algumas desvantagens,

Taxonomia de Flynn
Sistemas MISD – Neumann Modificado
• Desvantagens:✔ os princípios de vetorização e pipeline não
funcionam adequadamente para algoritmos com
estruturas de dados irregulares ou programas com
grandes quantidades de desvios,✔ na atualidade é impossível escalar estes
processadores para aumentar o desempenho,➔ aumentar o tamanho do pipeline ???➔ incrementar as operações vetoriais ???,

Taxonomia de Flynn
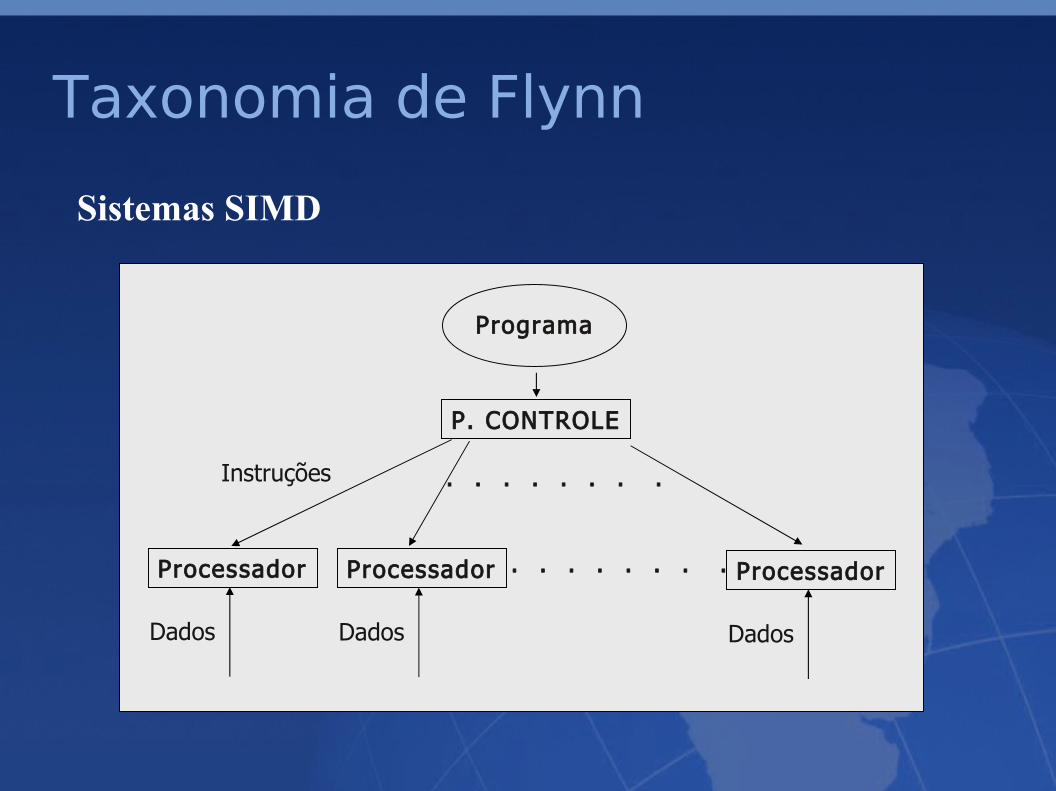
Sistemas SIMD
• um sistema SIMD puro é composto por:➢ um processador de alto padrão dedicado
exclusivamente a funções de controle,➢ uma coleção de processadores mais simples (ULA
+ memória) subordinados ao processador principal• durante um ciclo de instrução, o processador principal envia uma instrução a cada um dos processadores subordinados (broadcast), cada um dos processadores executa a instrução ou permanece inativo,
Taxonomia de Flynn
Sistemas SIMD
Processador
Programa
Instruções
Dados
P. CONTROLE
Processador
Dados
Processador
Dados
. . . . . . . .
. . . . . . . .

Taxonomia de Flynn
Sistemas SIMD
• Exemplo• x, y, z arrays distribuídos em i processadores, de forma que o processador i contem o i-esimo elemento de cada array,• a máquina paralela vai a executar o seguinte código:
for (i=0; i<N; i++)
if (y[i]!=0)
z[i] = x[i]/y[i];
else
z[i] = x[i]

Taxonomia de Flynn
Sistemas SIMD
• Exemplo• os processos subordinados executam a seguinte seqüência de operações:
CICLO 1
CICLO 2
CICLO 3
testar se local_y !=0
se local_y diferente de zero local_z = local_x/local_y
se local_y igual a zero INACTIVO
se local_y diferente de zero INACTIVO
se local_y igual a zero local_z = local_x

Taxonomia de Flynn
Sistemas SIMD
• O processo de execução das instruções é síncrono;
• Em um ciclo de instrução determinado, um
processador estará ativo e executando a mesma
instrução que os outros processadores ativos, ou ele
estará inativo;
• A principal deficiência de sistemas SIMD, é que
para programas com muitos desvios, muitos
processadores subordinados podem ficar inativos por
longos períodos de tempo;

Taxonomia de Flynn
Sistemas SIMD
• Entretanto, máquinas SIMD são muito fácies de
serem programadas para algoritmos simples que
utilizem estruturas de dados regulares;
• Outra vantagem, é que elas podem ser escaladas
facilmente;
• Os exemplos mais bem sucedidos de máquinas
SIMD são:
• CM1 e CM2 produzidas por Thinking Machines
• MP2 produzida pela MASPAR

Taxonomia de Flynn
Sistemas MIMD
• A diferença fundamental entre um sistema SIMD e
um sistema MIMD, é que nos sistemas MIMD os
processadores são autônomos,
• Cada processador conta com a unidade de controle,
ULA e registros, porém cada processador executa seu
próprio programa,
• Sistemas MIMD são máquinas assíncronas não
existe um ciclo de instruções global,
• Os processadores devem ser instruídos pelo
programa para fazerem as tarefas de sincronização,

Taxonomia de Flynn
Sistemas MIMD
• Para um instante de tempo dado os processadores
podem estar executando instruções diferentes mesmo
que eles estivessem executando o mesmo programa,
• Sistemas multiprocessados de propósito geral;
• Cada processo tem um programa próprio que geram
fluxos de instruções diferentes;
• Cada processador trabalha com dados diferentes;

Taxonomia de Flynn
Sistemas MIMD
Programa
Processador
Instruções
Dados
Programa
Processador
Instruções
Dados
Programa
Instruções
Dados
. . . . . . . .
. . . . . . . .

Taxonomia de Flynn
Sistemas MIMD
• As máquinas MIMD podem ser classificadas como:
1. sistemas de memória compartilhada, multiprocessadores, ou ambientes fortemente acoplados;
2. sistemas de memória distribuída, multi-computadores, ou ambientes fracamente acoplados.

Taxonomia de Flynn
SIMPLES MULTIPLOS
SIMPLES SISDVon Neuman
SIMDarray
MULTIPLAS MISDPipeline
MIMDMáquinas paralelas

MIMD – Memória Compartilhada
• Uma coleção de processadores e módulos de memória interconectados por uma rede
• A velocidade de acesso de um processador a um módulo de memória independe do módulo de memória a ser acessado,
CPU CPU CPU. . .
REDE DE INTERCONEXÃO
MEMÓRIA MEMÓRIA MEMÓRIA. . .

MIMD – Memória Compartilhada
• A arquitetura mais simples para implementar uma máquina de memória compartilhada é utilizar como rede de interconexão um BUS de dados,
• Se vários processadores tentarem acessar a memória simultaneamente, o BUS pode ficar saturado, provocando atrasos na transferência de dados,
CPU CPU CPU
CACHE CACHE CACHE
. . .
BUS

MIMD – Memória Compartilhada
BUS de dados
• Para minimizar a saturação do BUS a cada processador se acopla uma memória cache de grande capacidade,
• Devido ao limite de amplitude de banda do BUS, esta arquitetura não pode ser utilizada para um número de processadores muito grande,
• Ex: SGI Challenge XL 36 processadores. (http://en.wikipedia.org/wiki/SGI_Challenge)

MIMD – Memória Compartilhada
Interruptores• A maioria das máquinas de memória compartilhada utilizam uma rede de interconexão baseada em interruptores,
• A rede de interconexão pode ser interpretada como uma grade retangular de cabos, com interruptores em seus pontos de interseção,
• Os interruptores permitem transmitir sinais na direção vertical e horizontal simultaneamente ademais um sinal pode ser redirecionado da vertical a horizontal ou vice-versa,

MIMD – Memória Compartilhada
Interruptores
Building Linux Clusters, David H. M. Spector, O'Reilly Media

MIMD – Memória Compartilhada
Interruptores
• A comunicação entre dois unidades (CPU-memória) não interfere na comunicação entre outras dois unidades,
• A rede de interconexão usando interruptores tende a ser muito cara e não pode ser utilizada para um número alto de processadores.
HP/Convex SPP 1200

MIMD – Memória Compartilhada
Multicore• Porque surgiram os processadores multicore?• Diminuir o consumo de energia,• Aumentar a capacidade de processamento sem aumentar a liberação de calor no chip.
● Colocam em um único chip vários cores de
processamento,
● Cada um destes cores funciona como um processador
independente;
● Fornecem alto poder de processamento a baixo custo.

MIMD – Memória Compartilhada
Multicore• Primeira geração

MIMD – Memória Compartilhada
Multicore• Segunda geração
• Aparece a cache L2 compartilhada;• Executam eficientemente processos independentes;• Novos desafios em processamento paralelo.

MIMD – Memória Compartilhada
Memoria Cache
• Um problema que encontramos em qualquer arquitetura de memória compartilhada que utilize memórias cache, é a coerência da cache.
• Se o processador acessar a uma variável que esta na memória cache como sabemos que o valor da variável é valido?
• Existem vários protocolos de coerência da cache, eles variam consideravelmente em complexidade.

MIMD – Memória Compartilhada
Memoria Cache• Protocolo Snoopy: é o protocolo de coerência de cache mais simples, apropriado para máquinas que usam BUS como rede de interconexão.
• Protocolo Snoopy:• a cada CPU é adicionado um controlador de cache,• o controlador monitora o trafego de dados no BUS,• quando um processador atualiza uma variável na cache, o controlador atualiza seu valor na memória principal,• os outros controladores atualizam o valor na cache dos outros processadores.

MIMD – Memória Compartilhada
Memoria Cache• Resolver a coerência da cachê implica uma sobrecarga ao sistema.
• Existem protocolos mais avançados para resolver a coherencia da memória cachê:• MSI: Modified Shared Invalid;• MESI: Modified Exclusive Shared Invalid;• MOESI: Modified Owned Exclusive Shared Invalid; • Firefly: DEC Workstations; • Dragon: Xerox Workstations.

MIMD – Memória Compartilhada
UMA vs NUMA
• Frequentemente as máquinas de MC são classificadas segundo a velocidade de acesso dos processadores à memória;
• UMA (Uniform Memory Access)
• O tempo de acesso aos dados localizados em qualquer posição de memória é o mesmo em todos os processadores;
• Um único barramento de memória;
• Máquinas de pequeno e médio porte .

MIMD – Memória Compartilhada
UMA vs NUMA
• NUMA (Non-Uniform Memory Access)• O tempo de acesso aos dados da memória depende da posição relativa entre o bloco de memória e o processador;• O acesso do processador aos blocos mais próximos é maior que aos blocos mais distantes;• Vários barramentos de memória;• Máquinas de grande porte.
• Recentemente as máquinas de memória compartilhada estão sendo chamadas de SMPs (Symetric Multi Processors).

MIMD – Memória Distribuída
• Em um sistema de memória distribuída cada processador tem seu próprio módulo de memória,
• Um módulo de memória somente pode ser acessado pelo processador associado a ele,
CPU CPU CPU. . .
REDE DE INTERCONEXÃO
MEMÓRIA MEMÓRIA MEMÓRIA

MIMD – Memória Distribuída
• Podemos interpretar um sistema de memória
distribuída como um grafo (arestas e vértices),
• Arestas se correspondem com os cabos de conexão,
• Nodos se correspondem com um conjunto de
processador e módulo de memória,
• Podemos ter então dois tipos de sistemas de
interconexão: sistemas estáticos e sistemas dinâmicos.

MIMD – Memória Distribuída
......
...
. . .
. . .
. . .
• Cada vértice corresponde a um nodo,
• Não são necessários dispositivos adicionais,
• Podem ocorrer problemas na comunicação.
MD – Sistema Estático

MIMD – Memória Distribuída
• Cada vértice corresponde a um nodo,
• Não são necessários dispositivos adicionais,
• Podem ocorrer problemas na comunicação.
MD – Sistema Dinâmico
...
. . .
. . .
. . .
......
...

MIMD – Memória Distribuída
MD – Sistemas Completamente Conectados
• Considerando o desempenho e a facilidade de
programação, o sistema de interconexão ideal, é
uma rede completamente conectada, i.e., cada nodo
esta diretamente ligado a todos os outros nodos,

MIMD – Memória Distribuída
MD – Sistemas Completamente Conectados
• cada nodo pode comunicar-se diretamente com qualquer outro nodo,
• a comunicação não envolve nenhum atraso (delay),
• a comunicação entre dois nodos não interfere na comunicação entre outros dois nodos,
• o alto custo deste tipo de rede de interconexão, impossibilita sua construção para máquinas paralelas com muitos nodos.
MIMD – Memória Distribuída
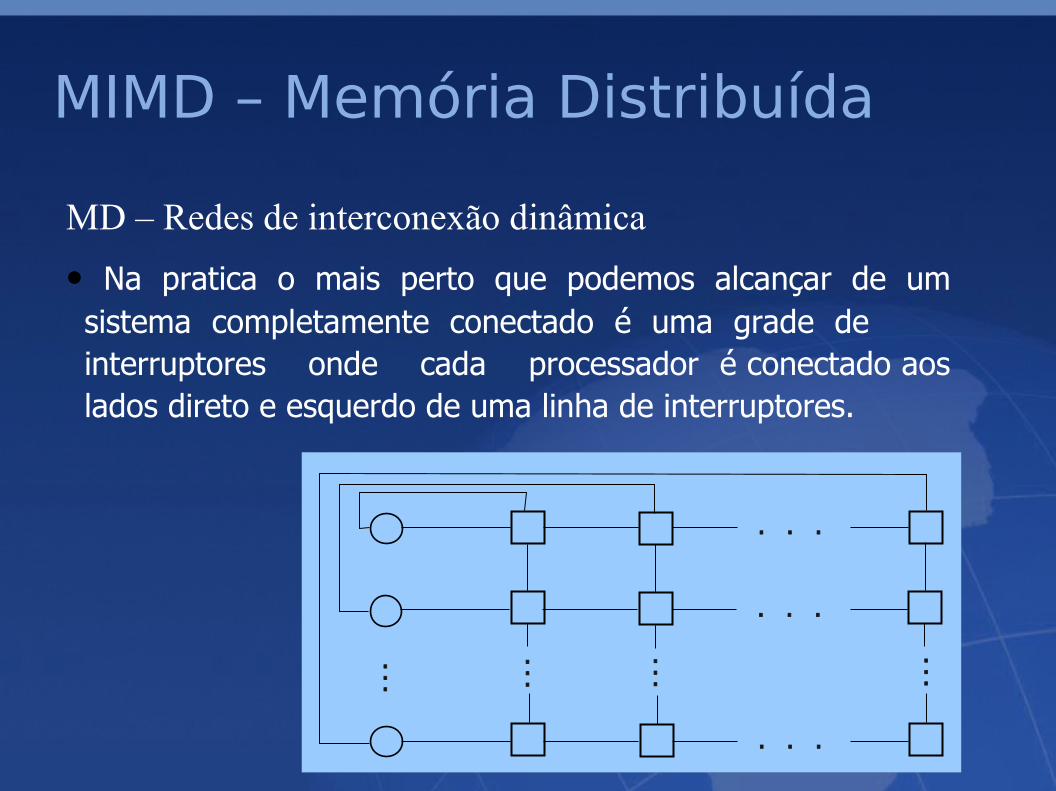
MD – Redes de interconexão dinâmica
• Na pratica o mais perto que podemos alcançar de um sistema completamente conectado é uma grade de interruptores onde cada processador é conectado aos lados direto e esquerdo de uma linha de interruptores.
...
. . .
. . .
. . .
......
...

MIMD – Memória Distribuída
MD – Redes de interconexão dinâmica
• Nesta configuração o único atraso que pode existir na comunicação, e o tempo necessário para selecionar o interruptor correspondente,
• Todos os processadores podem comunicar-se simultaneamente,
• Esta configuração é custosa (p2 interruptores),
• Incomum para mais de 16 processadores,
• Uma alternativa menos custosa é a utilização de redes de interconexão com interruptores de múltiplos estados,
MIMD – Memória Distribuída
MD – Redes de interconexão dinâmica
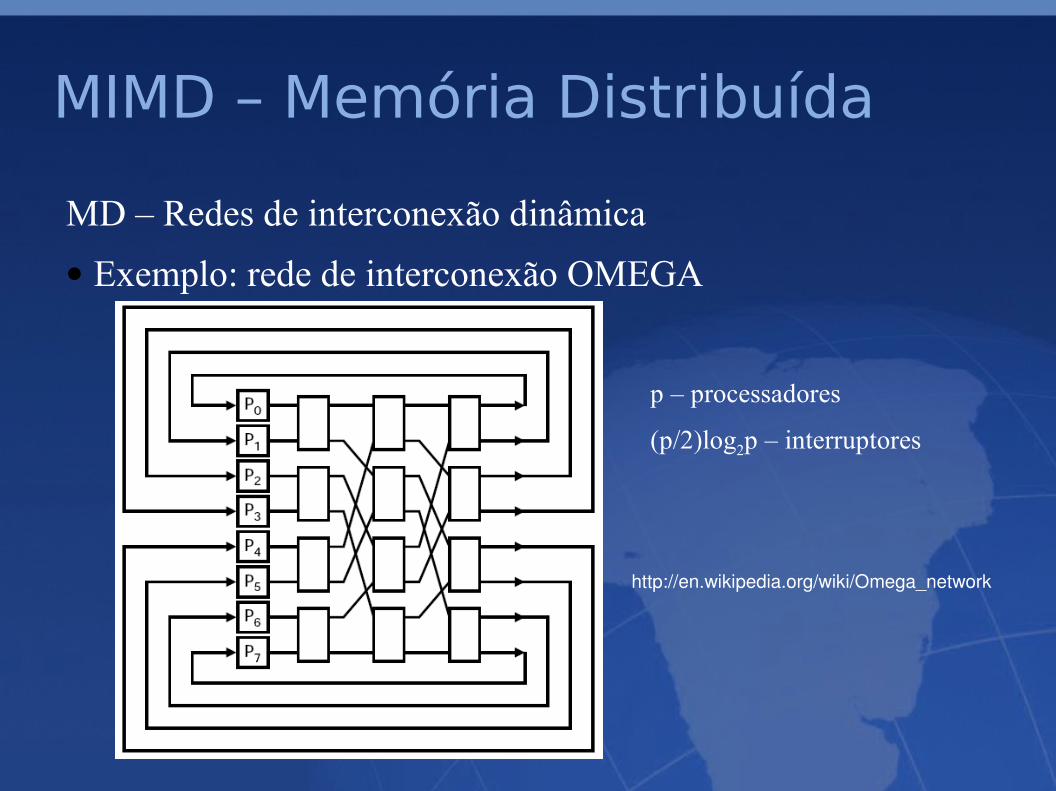
• Exemplo: rede de interconexão OMEGA
p – processadores
(p/2)log2p – interruptores
http://en.wikipedia.org/wiki/Omega_network

MIMD – Memória Distribuída
MD – Redes de interconexão dinâmica
• Redes de interconexão OMEGA ...
• cada processador pode comunicar-se diretamente com outro processador,
• podem existir interferências na comunicação e conseqüentemente atrasos,
• existem máquinas com esta rede de interconexão de até 512 processadores.

MIMD – Memória Distribuída
MD – Redes de interconexão estática
• O extremo oposto a um sistema completamente conectado é um arranjo linear,
• Podemos melhorar esta configuração conectando os nodos dos extremos e teremos um anel,
. . .
...

MIMD – Memória Distribuída
MD – Redes de interconexão estática• Vantagens:• Configuração muito barata (apenas p-1 cabos)• Facilmente escalável,
• Desvantagens:• O número de canais de comunicação é extremamente limitado,• Apenas podem comunicar-se dois nodos ao mesmo tempo,
• A rede de interconexão estática que mais se aproxima de um sistema completamente conectado é o hipercubo.

MIMD – Memória Distribuída
MD – Redes de interconexão estática• O hipercubo:• O hipercubo de dimensão zero consiste de um único nodo,• Para construir um hipercubo de dimensão d>0, tomamos dois hipercubos de dimensão d-1 e unimos seus nodos correspondentes,
d = 1
d = 2
d = 3

MIMD – Memória Distribuída•O hipercubo:
d = 4

MIMD – Memória Distribuída
MD – Redes de interconexão estática
• O hipercubo:
• cada vez que incrementarmos uma dimensão,
duplicamos o numero de nodos,
• um hipercubo de dimensão d contem p=2d
processadores
• cada nodo é diretamente conectado a d nodos,
• na configuração hipercubo é possível organizar as
comunicações entre os nodos para minimizar os
atrasos.

MIMD – Memória Distribuída
MD – Redes de interconexão estática
• O hipercubo:
• a principal desvantagem desta configuração é a
dificuldade de escalar o sistema (sempre devemos
duplicar o número de nodos),
• Ex: nCube 10 (1024 nodos),
• Os hipercubos foram muito populares nos anos 80.
• Entre os hipercubos e os conjuntos lineares (array
ou anel) podemos encontrar a configuração de
grade e a configuração de toróide

MIMD – Memória Distribuída
MD – Redes de interconexão estática
• Configuração de grade:
• É obtida aumentando a dimensão do array linear
• 2D e 3D
. . .
. . .
. . .
. . .

MIMD – Memória Distribuída
MD – Redes de interconexão estática
• Configuração de toróide:
• É obtida aumentando a dimensão do anel

MIMD – Memória Distribuída
MD – Redes de interconexão estática
• Nas configurações de grade e toróide na medida que
aumentamos a dimensão, aumenta o número de rotas
entre nodos e conseqüentemente diminuem as
interferências,
• Ambas configurações são muito populares e tem sido
escaladas a miles de nodos.

MIMD – Memória DistribuídaMD – Redes de interconexão estática
• Sistemas de interconexão baseados em Ethernet:
• é o sistema de interconexão mais simples e de menor
custo,
• um CLUSTER é o exemplo clássico deste tipo de
sistemas,
• a rede de interconexão é “extremamente lenta” e
freqüentemente fica saturada pela comunicação de uns
poucos nodos,• entretanto, por sua simplicidade, baixos custos e
aprimoramentos na tecnologia tem-se popularizados nos
últimos anos,

MIMD – Memória DistribuídaMD – Cluster Beowulf
• É uma denominação para Cluster de baixo custo;
• Baseados em hardware de computadores pessoais;
• A tecnologia de conexão é Ethernet, TCP-IP, LAN;
• Elementos de software livres e de código aberto (Sistema
Operacional: Linux, MPI, FORTRAN, C)
• Este tipo de hardware têm-se convertido no carro chefe das
máquinas paralelas nos últimos anos.
http://www.beowulf.org/

MIMD – Memória DistribuídaMD – Cluster Beowulf
• Vantagens:
• Podem ser construídas maquinas de alto desempenho a
baixo custo;
• Processadores mais potentes podem ser incorporados a
estas maquinas assim estejam disponíveis;
• Os softwares deste tipo de maquinas são continuamente
atualizados e melhorados;• Rede de interconexão aprimoradas: Ethernet para
Gigabit Ethernet.

MIMD – Memória DistribuídaMD – Cluster Beowulf

MIMD – Memória DistribuídaMD – Comunicação e Roteamento
• Uma questão que deve ser estudada ao analisar as
comunicações em sistemas de memória distribuída é o
roteamento,
• Se dois nodos estiverem diretamente conectados, como os
dados serão transmitidos entre eles?
• O problema do roteamento pode ser dividido em:
• Se existirem múltiplas rotas para unir dois nodos qual
rota será escolhida?• Como os nodos intermédios encaminharam as
mensagens?

MIMD – Memória DistribuídaMD – Seleção da rota
• O processo de seleção de rotas utiliza algoritmos de
otimização visando escolher a rota mais curta,
• A maioria dos sistemas utilizam algoritmos determinísticos
de seleção de rotas, i. e.,
• se o nodo A se comunica com o nodo B então a rota de
comunicação será sempre a mesma, e será aquela que
utiliza menos linhas de conexão.

MIMD – Memória DistribuídaMD – Encaminhamento de mensagens
• O nodo A envia uma mensagem ao nodo C, e o nodo B se
encontra entre eles dois,
• Existem dois enfoques básicos:
• store and forward (sf): o nodo B recebe a mensagem
inteira e então encaminha ao nodo C.
• cut through (ct): cada vez que o nodo B recebe uma
peça da mensagem (pacote) a encaminha ao nodo C.
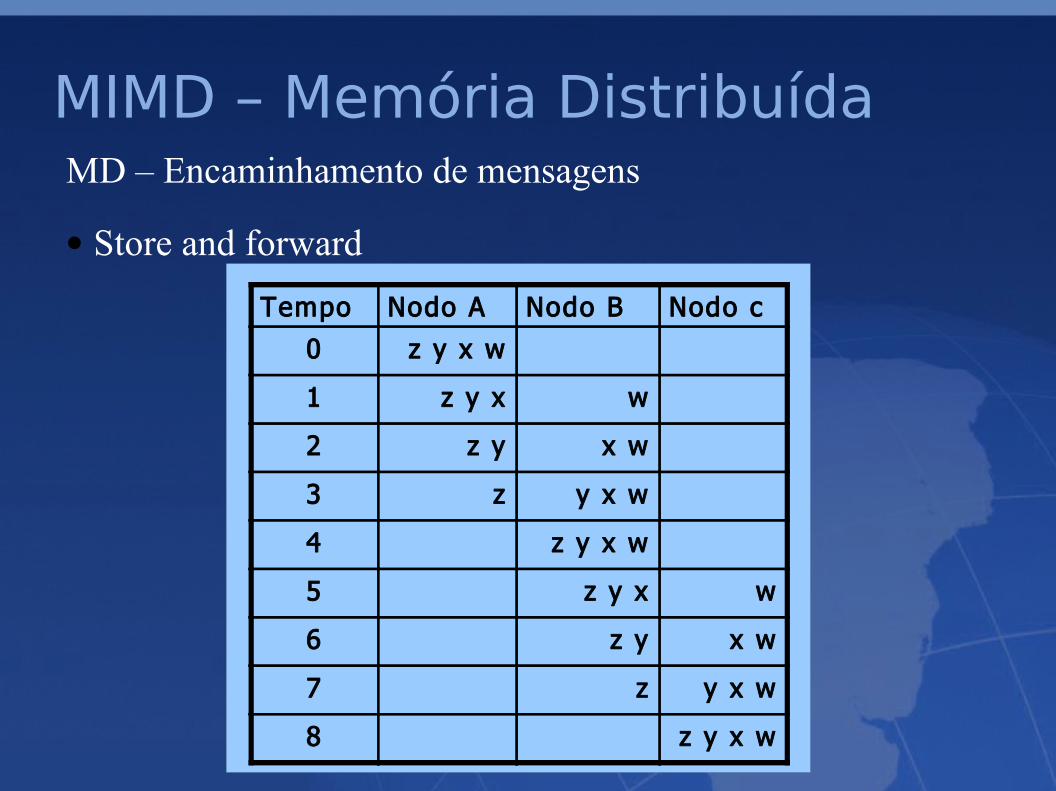
MIMD – Memória DistribuídaMD – Encaminhamento de mensagens
• Store and forward
Tempo Nodo A Nodo B Nodo c
0 z y x w
1 z y x w
2 z y x w
3 z y x w
4 z y x w
5 z y x w
6 z y x w
7 z y x w
8 z y x w

MIMD – Memória DistribuídaMD – Encaminhamento de mensagens
• Store and forward
• A mensagem demora o dobro do tempo que demoraria se
os nodos fossem adjacentes,
• Maior consumo de memória nos nodos intermédios,
• Pacotes mais pequenos, os pacotes intermédios não
contem informação de endereçamento.

MIMD – Memória DistribuídaMD – Encaminhamento de mensagens
• Cut through
Tempo Nodo A Nodo B Nodo c
0 z y x w
1 z y x w
2 z y x w
3 z y x w
4 z y x w
5 z y x w

MIMD – Memória DistribuídaMD – Encaminhamento de mensagens
• Cut through
• a mensagem demora praticamente o mesmo tempo que
se os nodos fossem adjacentes (mais o tempo de enviar
um pacote),
• não precisa de memória nos nodos intermédios,
• pacotes mais grandes, todos os pacotes devem carregar
informação de endereçamento.
• A maioria dos sistemas utiliza alguma variante ct para o encaminhamento de mensagens.

Distribuída vs Compartilhada
Memória Compartilhada
Memória Distribuída
Escabalabilidade Difícil Fácil
Coerência de Memória
Problema -
Comunicação e Roteamento
- Problema
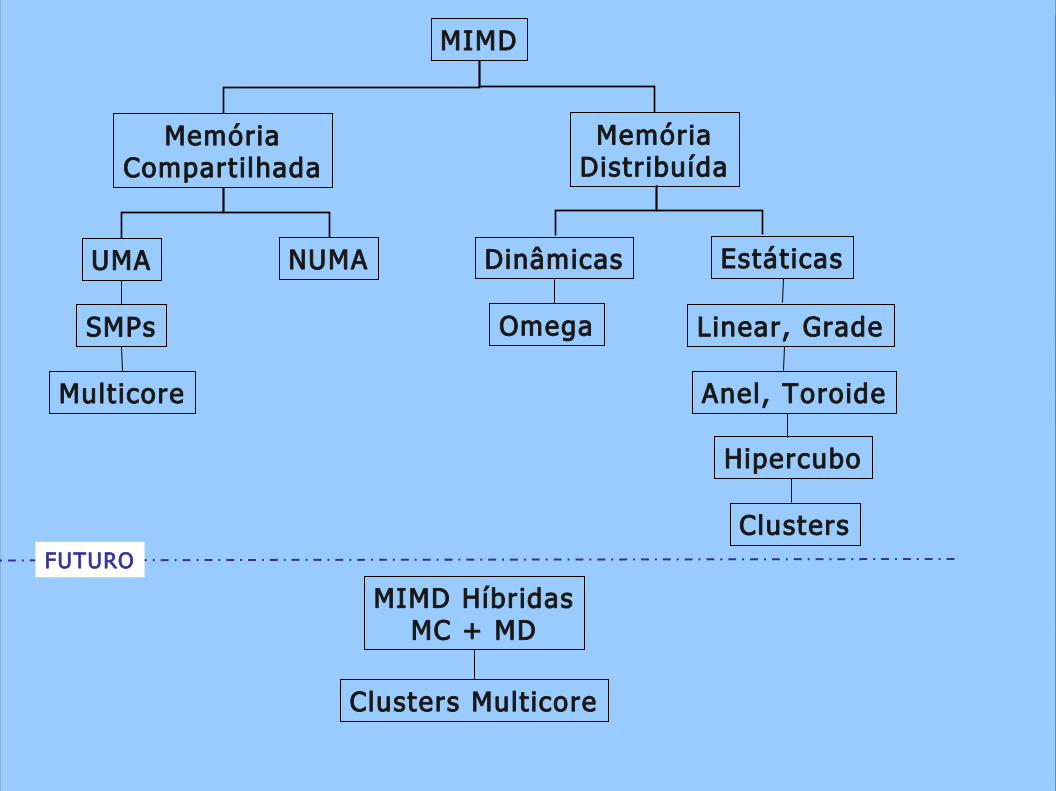
MIMD
MemóriaCompartilhada
MemóriaDistribuída
UMA NUMA
SMPs
Multicore
Dinâmicas Estáticas
Omega Linear, Grade
Anel, Toroide
Hipercubo
Clusters
MIMD HíbridasMC + MD
Clusters Mult icore
FUTURO

MD- Grids ComputacionaisO que são Grids Computacionais
• Um modelo computacional emergente, baseado em
criar uma máquina paralela virtual com alta taxa de
processamento, a partir de várias máquinas
interconectadas numa rede local ou de longa
distância;
• Surgiram em meados da década de 90 com a
promessa de viabilizar a execução de aplicações
paralelas em recursos geograficamente dispersos e
pertencentes a múltiplas organizações;

MD- Grids ComputacionaisO que são Grids Computacionais
• De forma geral os Grids potencializam a utilização dos recursos inativos, ou seja ciclos de CPU e/ou armazenamento em disco, de um grande número de computadores, como por exemplo computadores de escritório,
• Os Grids computacionais objetivam transformar estes computadores num cluster virtual embebido em uma infra-estrutura de comunicações.

MD- Grids ComputacionaisObjetivos dos Grids Computacionais1. Fornecer uma plataforma muito mais barata para
execução de aplicações distribuídas, (mais barata que os supercomputadores paralelos por exemplo)
2. Possibilitar (através da aglomeração de recursos dispersos) a execução de aplicações paralelas em uma escala simplesmente impossível em um único supercomputador
3. Aproveitar a grande quantidade de recursos computacionais disponíveis.

MD- Grids Computacionais• os Grids são mais distribuídos, diversos e
complexos que outras plataformas.• Características de Grids:
● Heterogeneidade: Os componentes que formam a infraestrutura tendem ser extremamente heterogêneos (hardaware e software)
● Alta dispersão geográfica: Essa característica se refere a escala que um Grid pode atingir (escala global)

MD- Grids Computacionais• Características de Grids ...
● Compartilhamento: informação, aplicações, armazenamento, processador, ...
● Múltiplos domínios administrativos: Grids congregam recursos de várias instituições (diferentes políticas de acesso e uso de serviços)
● Controle distribuído: Tipicamente não há uma única entidade que tenha poder sobre todo o Grid.

MD- Grids Computacionais• A utilização de Grids introduz os seguintes
problemas:
• recursos computacionais não são administrados centralmente,
• dificuldade no gerenciamento de usuários,
• necessidade de acesso remoto aos recursos,
• diversidade de arquiteturas e sistemas operacionais,
• dificuldades em proporcionar serviços de qualidade.

MD- Grids ComputacionaisPrincipais middlewares de computação em grid:• Globus (http://www.globus.org/): • conjunto de serviços que permitem a submissão e controle de aplicações, descoberta de recursos, movimentação de dados e segurança no ambiente do grid.• Tendo sido a solução de maior impacto na comunidade da computação de alto desempenho, o Globus e os protocolos definidos em sua arquitetura tornaram-se um padrão como infra-estrutura para computação em grid (escopo amplio).

MD- Grids ComputacionaisPrincipais middlewares de computação em grid:
• MyGrid (http://www.mygrid.org.uk/):
• uma plataforma simples, completa e segura;
• um intento de popularizar o uso de grids para executar aplicações paralelas leves, chamadas bag-of-tasks (aplicações cujas tarefas são independentes, podendo ser executadas em qualquer ordem) ;
• aplicações bag-of-task se adéquam melhor a ampla distribuição, heterogeneidade e dinamicidade do Grid, e resolvem vários problemas importantes, tais como mineração de dados, processamento genômico, pesquisa massiva (como quebra de chaves criptográficas), simulações Monte Carlo, e manipulação de imagem (como tomografia).

MD- Grids ComputacionaisPrincipais middlewares de computação em grid:• Condor(http://www.cs.wisc.edu/condor/):• é um middleware de aproveitamento dos ciclos ociosos de um conjunto de estações de trabalho em uma rede institucional (Condor pool),• Com a utilização desses pools em diversas instituições, surgiram diversos mecanismos para o compartilhamento de recursos disponíveis em diferentes instituições e domínios, antes mesmo do surgimento do conceito de computação em grid;• Tendo sido um esforço pioneiro (1984) e se adaptado à evolução das perspectivas da computação de alta performance para a computação em grid, o projeto Condor tem, em sua história, uma série de lições sobre os problemas gerenciais e operacionais da criação e utilização de grids computacionais.

MD- Grids ComputacionaisPrincipais middlewares de computação em grid:
● SETI@home, Entropia e distributed.net
• São exemplos de soluções que utilizam middlewares próprios para formar um grid proprietário,
• Através da instalação voluntária do middleware em máquinas ao redor do globo, o sistema ganha acesso ao seu poder computacional ocioso,

MD- Grids ComputacionaisPrincipais middlewares de computação em grid:
● SETI@home, Entropia e distributed.net
• o controle do acesso ao grid é centralizado na figura de uma instituição que possui o grid. Apenas aplicações submetidas pelos proprietários do grid têm acesso aos recursos,
• Principalmente dedicados a aplicações científicas,
• O projeto SETI@home reune 6 milhões de computadores em tarefas de analise de dados para busca de vida extraterrestre.

MD- Grids ComputacionaisPrincipais middlewares de computação em grid:
● http://setiathome.berkeley.edu/
● http://www.distributed.net/