gráfico de pontos gráfico de pontos é a primeira ... · histograma uma forma prática de...
TRANSCRIPT

4. Representação gráfica para variáveis quantitativas
Gráfico de pontos
O gráfico de pontos é a primeira representação da
amostra, fornecendo um aspecto visual da concentração e
distribuição dos pontos na nossa escala de medidas.
No exemplo abaixo, percebemos o conjunto de dados
concentrado na primeira metade da escala, com uma grande
concentração entre os valores 2.5 e 7.5, e uma dispersão
mais acentuada no lado superior (direito) da distribuição,
com valores chegando a 17.5. Esta dispersão indica uma
forte assimetria na cauda superior da distribuição (assimetria
à direita).
Figura 1: Gráfico de pontos.

Histograma
Uma forma prática de representação gráfica para dados
quantitativos (em especial dados contínuos) é dada pelo
histograma, no qual, representamos as frequências de uma
tabela por barras adjacentes para cada intervalo de classe.
Tabela 1: Tabela de frequências com k = 7 classes:
Classe – (Xi) ni fi
0.0 |--- 2.5 34 0.136
2.5 |--- 5.0 74 0.296
5.0 |--- 7.5 86 0.344
7.5 |--- 10.0 30 0.120
10.0 |--- 12.5 16 0.064
12.5 |--- 15.0 5 0.020
15.0 |--- 17.5 5 0.020
Total 250 1,000
Figura 2: Histograma (sobre o gráfico de pontos).

O polígono de frequências
Marcando o ponto médio de cada retângulo do
histograma na sua na parte superior e ligando esses pontos,
teremos uma figura que chamaremos de Polígono de
Frequências (Figura 3).
Figura 3: Polígono de frequências.

Distribuição de frequências
As linhas retas que compõem o polígono de frequências
são uma aproximação rudimentar para uma curva que
representa uma Distribuição de Frequências. Essa
distribuição é descrita por uma função f(x), contínua e
diferenciável, definida num intervalo dos reais, a qual será
denotada por função distribuição de probabilidades ou fdp (Figura 4).
Figura 4: Função de distribuição de probabilidades
sobre o histograma.

4.1. Representação gráfica para dados discretos
Um pesquisador contou o número de ervilhas/vagem em 60
vagens coletadas aleatoriamente num canteiro de sua plantação,
tendo obtido os seguintes dados:
3 3 3 3 3 4 3 1 4 3 5 3 2 5 6 5 4 3 1 4
4 2 6 4 3 4 4 4 5 4 4 3 5 3 5 2 3 4 4 5
2 3 5 4 4 6 3 5 4 3 4 3 5 3 3 4 7 3 6 3
Dados ordenados
1 1 2 2 2 2 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 4 4 4 4 4
4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 6 6 6 6 7
Vamos construir uma tabela com as contagens e frequências
relativas do número de ervilha/vagem
Tabela 2: Distribuição de frequências para o número de ervilha por vagem.
Ervilhas por
vagem
Freq.
absoluta
Freq.
relativa
Freq.
acumulada
ni fi Fac
1 2 0.033 0.033
2 4 0.067 0.100
3 21 0.350 0.450
4 18 0.300 0.750
5 10 0.167 0.917
6 4 0.067 0.084
7 1 0.017 1.001
Totais 60 1.001
Um gráfico para representar as frequências da variável “número
de ervilhas por vagem” é dado a seguir:

Figura 5: Gráfico de frequências para a variável número
de ervilhas por vagem (feito no R).
Também podemos representar a distribuição acima por um
gráfico de barras contínuas (histograma), porém, o mais apropriado
seria a primeira forma uma vez que os dados são discretos.
Figura 6: Histograma para a variável número de ervilhas
por vagem (feito no Excel)

4.2. Representação gráfica para dados contínuos
Seja a variável horas gastas por semana assistindo TV,
referentes aos alunos do primeiro ano do curso de engenharia:
Dados ordenados:
0 2 2 2 2 3 4 5 5 5 5 5 5 5 6 7 7 8
8 8 10 10 10 10 10 10 10 10 10 10 10 12 12 12 12 14
14 14 14 14 15 16 18 20 20 20 25 25 28 30
Estatísticas descritivas no MINITAB
Descriptive Statistics: horasTV
Variable N Mean Median StDev SE Mean
horasTV 50 10.780 10.000 6.891 0.974
Variable Minimum Maximum Q1 Q3
horasTV 0.000 30.000 5.000 14.000
3020100
horas
Gráfico de pontos para horas de TV
Figura 7: Gráfico de pontos (feito no Minitab).

Como construir a tabela de frequências?
Para variáveis contínuas vamos utilizar a regra de Sturges.
a) Número de classes: seja k o número de classes, então, k é
determinado por:
)(log32.31 10 nk ,
em que a função [.] indica o maior inteiro contido que, na
prática, representa o truncamento do valor obtido.
b) Amplitude de classe: denotada por h, é dada por:
Seja )1()(minmax xxA n , a amplitude da amostra, então,
k
Ah
Obs: normalmente o resultado da expressão acima não é inteiro,
por isso, o valor de h deve ser arredondado (convenientemente)
para cima.
Exemplo:
Seja a variável: horas gastas por semana assistindo TV.
Como n = 50, temos
664.6)50(log32.31 10 k classes,
56
030
h h.

Tabela 3: Distribuição de frequências de horas TV,
com k = 6 classes e h = 5h.
Horas TV
classes
Freq.
absoluta
Freq.
relativa
Freq.
acumulada
ni fi Fac
0 |--- 5 7 0.14 0.14
5 |--- 10 13 0.26 0.40
10 |--- 15 20 0.40 0.80
15 |--- 20 3 0.06 0.86
20 |--- 25 3 0.06 0.92
25 |--- 30 4 0.08 1.00
Totais 50 1.00
Figura 8: Histograma de horas TV, com k = 6 classes
e amplitude h = 5h (feito no R).

Notas:
1) Observe que o valor 30 foi incluído na última classe, para que
não seja criada uma nova classe;
2) Isto se deve pela forma como foi calculada a amplitude de
classes h e pelo fato dos intervalos serem fechados à esquerda e
abertos à direita.
Para contornar esse fato, podemos aumentar ligeiramente o
valor de h (e de forma conveniente) para que os extremos fiquem
contidos na amplitude total das classes.
Para o exemplo o limite inferior deve ser 0 pela natureza da
variável, mas o valor de h pode ser aumentado em 0.5 unidades,
levando o limite superior a 33.0.
Tabela 4: Distribuição de frequências de horas TV,
com k = 6 classes e h = 5.5h.
Horas TV
classes
Freq.
absoluta
Freq.
relativa
Freq.
acumulada
ni fi Fac
0 |--- 5.5 14 0.28 0.28
5.5 |--- 11.0 17 0.34 0.62
11.0 |--- 16.5 12 0.24 0.86
16.5 |--- 22.0 4 0.08 0.94
22.0 |--- 27.5 2 0.04 0.96
27.5 |--- 33.0 2 0.04 1.00
Totais 50 1.00

0.0 5.5 11.0 16.5 22.0 27.5 33.0
0
5
10
15
horas
Fre
qü
ên
cia
Histograma de horas de TV
Figura 9: Histograma de horas TV, com k = 6 classes
e amplitude h = 5.5h (feito no Minitab).
4.2.1. Regras para a escolha do número de classes k
Existem diversas propostas para a determinação do número de
classes k. A regra de Sturges é a mais popular delas, estando
implementada em diversos softwares tal como o R-gui.
A seguir apresentaremos outras maneiras para se definir o
número de classes de um histograma.
a) Sturges: )(log32.31 10 nk
em que [.] indica a função maior inteiro contido.
b) Raiz quadrada: pela regra da raiz quadrada, se:
se n 100 nk
se n > 100 )log(5 nk
c) Velleman (1976): se n 50 nk 2

Outros autores, ainda, criaram procedimentos que primeiro
determina a amplitude das classes h, após o que, o número de
classes é determinado pela relação
h
Ak .
A ideia por trás desses procedimentos consiste em obter uma
melhor visualização para o histograma.
Mais detalhes podem ser obtidos no link: http://www.galileu.esalq.usp.br/vsol.php?posi=3&cod=90&excod=11
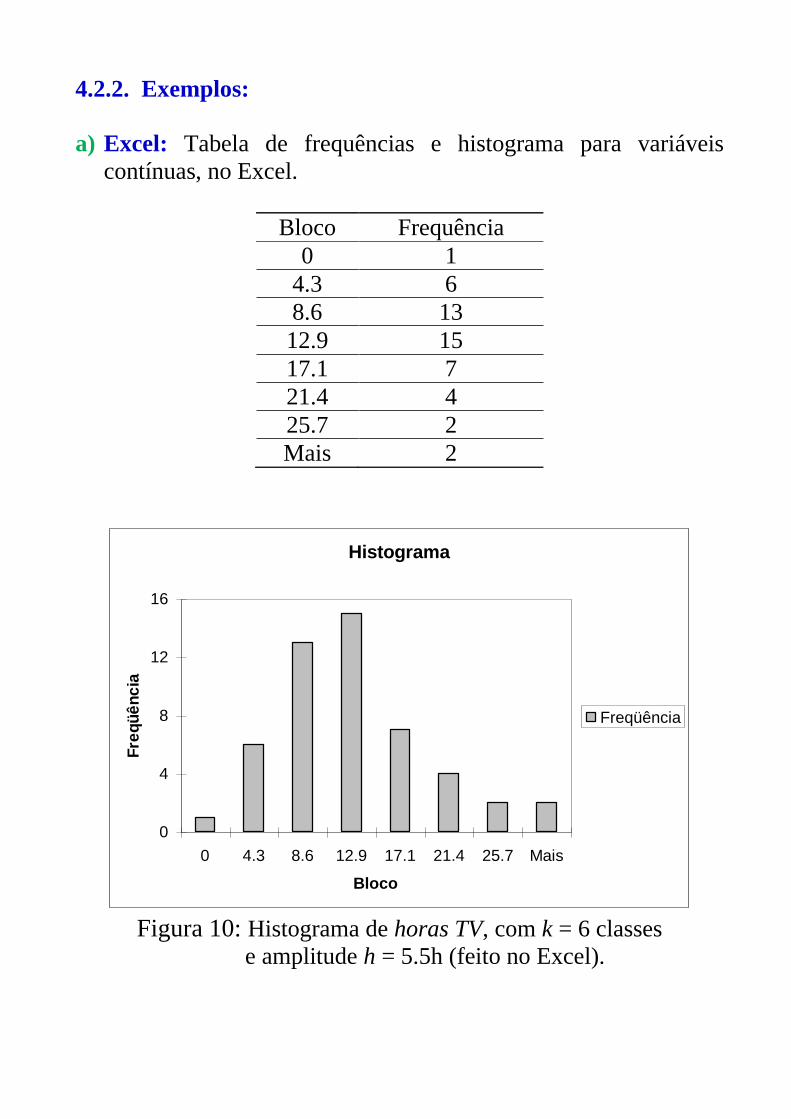
4.2.2. Exemplos:
a) Excel: Tabela de frequências e histograma para variáveis
contínuas, no Excel.
Bloco Frequência
0 1
4.3 6
8.6 13
12.9 15
17.1 7
21.4 4
25.7 2
Mais 2
Histograma
0
4
8
12
16
0 4.3 8.6 12.9 17.1 21.4 25.7 Mais
Bloco
Fre
qü
ên
cia
Freqüência
Figura 10: Histograma de horas TV, com k = 6 classes
e amplitude h = 5.5h (feito no Excel).

b) Dados discretizados:
Uma grande companhia está preocupada com o tempo que seus
equipamentos ficam em manutenção na assistência técnica. Sendo
assim, fez um levantamento do tempo de manutenção (dias) de 50
equipamentos para um estudo mais detalhado.
X = dias em manutenção de equipamentos.
15 13 21 9 5 5 10 6 2 2
9 10 3 4 2 13 12 16 7 6
4 11 8 6 6 10 17 13 9 5
2 5 9 14 15 3 6 18 3 4
5 7 8 3 10 5 5 4 5 2
Dados Ordenados:
2 2 2 2 2 3 3 3 3 4
4 4 4 5 5 5 5 5 5 5
5 6 6 6 6 6 7 7 8 8
9 9 9 9 10 10 10 10 11 12
13 13 13 14 15 15 16 17 18 21
Tabela de frequências:
k = [1 + 3.32·log1050] = [ 6.64 ] = 6 a 7 classes
A = 21 – 2 = 19 h = 19/6 = 3.16 3.2

Com k = 7 classes:
Xi (dias) ni fi Fac
2 a 4 13 0.26 0.26
5 a 7 15 0.30 0.56
8 a 10 10 0.20 0.76
11 a 13 5 0.10 0.86
14 a 16 4 0.08 0.94
17 a 19 2 0.04 0.98
20 a 22 1 0.02 1.00
Total 50 1.00 -
Figura 11: Histograma de dias de manutenção,
dados discretizados (feito no Excel).

Figura 12: Gráfico frequências acumuladas de dias de
manutenção (feito no Excel).
Medidas Descritivas de Posição:
i) Média: xi = 392 84.750
392x dias
ii) Mediana: Md(x) = 62
66
2
)26()25(
xx dias
iii) Moda: Mo(x) = 5 dias aparece 8 vezes na amostra.

Com k = 6 classes:
Xi (dias) ni fi Fac
0 a 3 9 0.18 0.18
4 a 7 19 0.38 0.56
8 a 11 11 0.22 0.78
12 a 15 7 0.14 0.92
16 a 19 3 0.06 0.98
20 a 23 1 0.02 1.00
Total 50 1.00 -
Figura 13: Histograma de dias de manutenção, (k = 6)
dados discretizados (feito no Excel).

Comandos do R-gui para o histograma:
x <-c(15, 13, 21, 9, 5, 5, 10, 6, 2, 2, 9,
10, 3, 4, 2, 13, 12, 16, 7, 6, 4, 11,
8, 6, 6, 10, 17, 13, 9, 5, 2, 5, 9,
14, 15, 3, 6, 18, 3, 4, 5, 7, 8, 3,
10, 5, 5, 4, 5, 2)
# pela regra de Sturges
#######################
nclass.Sturges(x)
hist(x, col="bisque")
hist(x, breaks="Sturges", col="bisque")
# pela regra de Scott
#####################
nclass.scott(x)
hist(x, breaks="Scott", col="bisque")
# pela regra de Fridman-Diacomis
################################
nclass.FD(x)
hist(x, breaks="FD", col="bisque")
hist(x, breaks=7, col="bisque")
hist(x, breaks=8, col="bisque")
# definindo os intervalos
#########################
h1 <- c(0.5,4.5,8.5,12.5,16.5,20.5,24.5)
hist(x, breaks=h1, col="bisque")
h2 <- c(1.5,4.5,7.5,10.5,13.5,16.5,18.5,22.5)
hist(x, breaks=h2, col="bisque")

c) Dados contínuos:
X = notas de avaliação de teste verbal aplicado em 87 alunos.
2.5 2.8 2.8 3.2 3.5 3.6 3.7 3.8 3.9 4.0
4.1 4.1 4.1 4.1 4.2 4.5 4.6 4.7 4.7 4.7
4.7 4.8 4.8 4.9 4.9 5.0 5.0 5.1 5.1 5.1
5.2 5.2 5.2 5.2 5.2 5.3 5.3 5.3 5.3 5.4
5.4 5.4 5.4 5.5 5.5 5.5 5.6 5.7 5.7 5.8
5.9 5.9 5.9 5.9 6.0 6.1 6.1 6.1 6.1 6.2
6.2 6.2 6.3 6.4 6.4 6.4 6.4 6.5 6.5 6.5
6.5 6.5 6.6 6.6 6.7 6.7 6.7 6.7 6.8 6.9
6.9 7.0 7.0 7.1 7.2 7.3 7.5
k = [1 + 3.32·log10(87)] = [ 7.44 ] = 7 a 8 classes
A = 7.5 – 2.5 = 5 h = 5/7 = 0.714 0.72
Com k = 7 classes:
Xi (nota) ni fi Fac
2.50 |--- 3.22 4 0.046 0.046
3.22 |--- 3.94 5 0.057 0.103
3.94 |--- 4.66 8 0.092 0.195
4.66 |--- 5.38 22 0.253 0.448
5.38 |--- 6.10 16 0.184 0.632
6.10 |--- 6.82 24 0.276 0.908
6.82 |--- 7.54 8 0.092 1.000
Total 87 1.000 -

Figura 11: Histograma de nota de avaliação
verbal, (feito no Excel).
Medidas descritivas de posição:
i) Média: xi = 475.8 47.587
8.475x
ii) Mediana: 50.5)( )44( xxMd
iii) Moda: )(xMo 5.2 e 6.5 (bimodal)

Comandos do R para o histograma: v <- c(2.5, 2.8, 2.8, 3.2, 3.5, 3.6, 3.7, 3.8,
3.9, 4.0, 4.1, 4.1, 4.1, 4.1, 4.2, 4.5, 4.6,
4.7, 4.7, 4.7, 4.7, 4.8, 4.8, 4.9, 4.9, 5.0,
5.0, 5.1, 5.1, 5.1, 5.2, 5.2, 5.2, 5.2, 5.2,
5.3, 5.3, 5.3, 5.3, 5.4, 5.4, 5.4, 5.4, 5.5,
5.5, 5.5, 5.6, 5.7, 5.7, 5.8, 5.9, 5.9, 5.9,
5.9, 6.0, 6.1, 6.1, 6.1, 6.1, 6.2, 6.2, 6.2,
6.3, 6.4, 6.4, 6.4, 6.4, 6.5, 6.5, 6.5, 6.5,
6.5, 6.6, 6.6, 6.7, 6.7, 6.7, 6.7, 6.8, 6.9,
6.9, 7.0, 7.0, 7.1, 7.2, 7.3, 7.5)
hist(v, col="bisque")
# pela regra de Sturges
#######################
Nclass.Sturges(v)
hist(v, breaks="Sturges", col="bisque")
# pela regra de Scott
#####################
nclass.scott(v)
hist(v, breaks="Scott", col="bisque")
# pela regra de Fridman-Diaconis
################################
nclass.FD(v)
hist(v, breaks="FD", col="bisque")
hist(v, breaks=7, col="bisque")
hist(v, breaks=8, col="bisque")
# definindo os intervalos
#########################
h <- c(2.50,3.22,3.94,4.66,5.38,6.10,6.82,7.54)
hist(v, breaks=h, col="bisque")
boxplot(v, col="yellow2", horizontal=FALSE)
boxplot(v, col="yellow2")
boxplot(v, plot=F)

4.3. Média. moda, mediana e a simetria dos dados
Figura 12: Função de distribuição de probabilidades
sobre o histograma.
O que podemos dizer acerca desta distribuição de frequências
em relação a sua simetria?
Quando uma distribuição de frequências é simétrica, teremos
que a média, a moda e a mediana serão iguais, ou seja:
x = Mo(x) = Md(x)

E quanto ao exemplo acima, como podemos classificá-lo em
função da sua falta de simetria?
Quando a distribuição não é simétrica, podemos distinguir
duas situações possíveis
a) Quando a cauda superior da distribuição for mais alongada,
puxando a distribuição para a direita. Neste caso, a média é
maior do que a moda e a assimetria é dita à direita ou
positiva.
b) Quando a cauda inferior da distribuição for mais alongada.
puxando a distribuição para a esquerda. Neste caso, a média é
menor do que a moda e a assimetria é dita à esquerda ou
negativa.
Figura 13: Assimetrias à direita e à esquerda, respectivamente.

4.3.1. Relação entre média, moda e mediana
i) A Média é sempre influenciada por valores extremos, sendo
puxada na direção da cauda mais alongada;
ii) A Moda é o elemento de maior frequência, sendo o ponto
de máximo de f(x); iii) A Mediana está sempre no meio do conjunto, dividindo-o
em duas partes iguais, ficando entre as duas medidas
anteriores.
Assim, para cada situação, teremos:
a) Quando a simetria é perfeita as três medidas são iguais.

b) Na situação em que ocorre a assimetria à direita, teremos a
moda menor do que a mediana que é menor do que a média.
c)E, para a assimetria à esquerda, devemos ter a média menor
do que a mediana que é menor do que a moda.

4.3.2. Relação empírica entre média, moda e mediana
Karl Pearson, metemático famoso, no final do século XIX e início
do XX, observou empiricamente, a seguinte relação entre as três
medidas de posição média mediana e moda.
)(3)( xmedxxmox
Observações:
i) A relação só se aplica à distribuições com boa simetria;
ii) Só é valida para casos unimodais;
iii) Depende de um tamanho de amostra n elevado.
4.3.3. Moda de Czuber
Figura 14: Cálculo da moda de Czuber

Distribuição de frequências de horas TV,
Horas TV
classes
Freq.
absoluta
Freq.
relativa
Freq.
acumulada
ni fi Fac
0 |--- 5.5 14 0.28 0.28
5.5 |--- 11.0 17 0.34 0.62
11.0 |--- 16.5 12 0.24 0.86
16.5 |--- 22.0 4 0.08 0.94
22.0 |--- 27.5 2 0.04 0.96
27.5 |--- 33.0 2 0.04 1.00
Totais 50 1.00
56.78
5.60
)53(
35.55.5)(
xmo
CZ
4.4. O gráfico box-plot
Representação gráfica da dispersão dos dados em torno da
mediana
Valores discrepantes Valores discrepantes
Q1–1.5AQ Q1 x~ Q3 Q3+1.5AQ

Procedimento para a construção do box-plot
i) Construir a “caixa” ou “box” com os quartis Q1 e Q3;
ii) Com uma linha, demarcar a mediana, dividindo a caixa em
duas partes;
iii) Calcular os limites inferior (LI) e superior (Ls):
- LI = Q1 – 1.5AQ
- LS = Q3 + 1.5AQ
Os valores da amostra menores do que LI ou maiores do que LS
são identificados como “valores discrepantes” e destacados no
box-plot com pontos além desses limites.
iv) Para os “braços” do box-plot, traçar linhas a partir dos centros
das laterais inferior e superior da caixa até os valores mais
afastados que não sejam discrepantes, ou seja:
- traçar uma linha da lateral inferior da caixa até o menor valor
que não seja discrepante e marcar os pontos discrepantes
(menores do que LI );
- traçar uma linha da lateral superior da caixa até o maior valor
que não seja discrepante e marcar os pontos discrepantes
(menores do que LS );
Exemplo:
Seja a variável: horas gastas por semana assistindo TV.
10
Q 5 14
E 0 30

Figura 15: Box-plot para a variável horas de TV
Comandos do R para o box-plot:
x <- c( 0, 2, 2, 2, 2, 3, 4, 5, 5, 5, 5,
5, 5, 5, 6, 7, 7, 8, 8, 8, 10, 10,
10, 10, 10, 10, 10, 10, 10, 10, 10, 12, 12,
12, 12, 14, 14, 14, 14, 14, 15, 16, 18, 20,
20, 20, 25, 25, 28, 30)
boxplot(x, col="bisque", main="Horas assistindo
TV", ylab="Horas", pch=19)

Exemplo:
Dados do estudo sobre exposição à violência familiar de
crianças em idade escolar
(2 grupos Expostos à violência e Não Expostos)
Variável: Renda PC grupo (Exposto e Não Exposto)
Grupo:
EXP 68 96 100 100 112 112 117 120 120 135
150 160 160 200 260
- Mediana: 120)( )8( xxMd reais
- 1o Quartil: Q1 = x(4) = 100 reais
- 3o Quartil: Q3 = x(12) = 160 reais
- Média: 13415
2010
n
xx reais
- Variância: 3009422x
14
269340300942
)115(
)134(15300942
)1(
2222
n
xnxs
286.225714
316022 s
- Desvio-padrão: 51.47286.22572 ss reais

50 150 250
Box-plot renda per capita
Grupo Exposto
Figura 16: Box-plot renda, grupo exposto
35 85 135 185 235 285
0
1
2
3
4
5
6
7
8
Grupo Exposto
Fre
qü
ên
cia
Figura 17: Histograma renda, grupo exposto

Grupo
NEXP 36 50 70 84 108 109 120 120 150 150
180 220 250 260 300
- Mediana: 120)( )8( xxMd reais
- 1o Quartil: Q1 = x(4) = 184 reais
- 3o Quartil: Q3 = x(12) = 220 reais
- Média: 13.14715
2207
n
xx reais
- Variância: 4139972x
14
27.324723413997
)115(
)13.147(15413997
)1(
2222
n
xnxs
695.637614
73.892732 s
- Desvio-padrão: 85.79695.63762 ss reais

0 100 200 300
Grupo Não Exposto
Box-plot renda per capita
Figura 18: Box-plot renda, grupo não exposto
0 66 132 198 264 330
0
1
2
3
4
5
6
Grupo não Exposto
Fre
qü
ên
cia
Figura 19: Histograma renda, grupo não exposto

Figura 20: Box-plot renda, comparativo entre
os grupos exposto e não exposto
Comandos do R-gui para o box-plot comparativo
ex <- c( 68, 96,100,100,112,112,117,120,120,135,150,
160,160,200,260)
nex <- c( 36, 50, 70, 84,108,109,120,120,150,150,180,
220,250,260,300)
renda <- c(ex,nex)
gr <- c(rep("ex",length(ex)),rep("nex",length(nex)))
boxplot(renda~gr, col=c("red3","green3"))

Exemplo:
Dados simulados do tempo de uma reação química em função do
tipo do catalisador.
Comandos do R para o exemplo
# Entrada dos dados
################### Cat.A <- c(77.9,72.6,74.2,76.1,77.8,81.9,83.2,76.3,79.3,77.2,90.8,
79.7,79.7,80.4,84.4,81.7,80.0,71.5,73.4,81.7,71.5,70.9,
85.1,84.0,63.4)
Cat.B <- c(87.4,89.3,99.4,100.2,99.4,85.6,102.2,94.7,92.4,89.4,
91.9,88.9,98.0,99.8,91.9,99.1,95.9,89.4,90.5,91.4,87.6,
89.7,92.5,77.4,90.8)
Cat.C <- c(89.4,84.2,86.2,82.2,83.4,87.0,82.3,81.9,86.4,80.7,83.2,
87.6,88.9,84.2,85.1,83.8,85.2,88.1,84.2,87.1,87.6,87.3,
85.1,85.6,96.7)
Cat.D <- c(84.6,92.3,85.7,88.1,85.5,98.0,98.1,86.5,89.3,93.4,91.2,
93.7,97.3,79.5,94.6,87.9,87.4,88.2,97.3,92.2,98.5,94.5,
93.3,92.8,94.4)
# Estatísticas descritivas
########################## medias <- round(c(mean(Cat.A), mean(Cat.B), mean(Cat.C),
mean(Cat.D)),3)
desvios <- round(c(sd(Cat.A),sd(Cat.B),sd(Cat.C),sd(Cat.D)),4)
quantis <- rbind(quantile(Cat.A), quantile(Cat.B),
quantile(Cat.C), quantile(Cat.D))
descr <- cbind(medias, desvios, quantis)
dimnames(descr)[1] <- list(c("Catalisador A","Catalisador
B","Catalisador C","Catalisador D"))
dimnames(descr)[2] <- list(c("Média","D.Padrão","Min.", "Q1",
"Mediana", "Q3","Max."))
dimnames(descr)[1] <- list(c("Catalisador A","Catalisador B",
"Catalisador C","Catalisador D"))
descr
Média D.Padrão Min. Q1 Mediana Q3 Max.
Catalisador A 78.188 5.7634 63.4 74.2 79.3 81.7 90.8
Catalisador B 92.592 5.6885 77.4 89.4 91.9 98.0 102.2
Catalisador C 85.736 3.2337 80.7 83.8 85.2 87.3 96.7
Catalisador D 91.372 4.9439 79.5 87.9 92.3 94.5 98.5

# box-plot comparativo
###################### tempo <- c(Cat.A, Cat.B, Cat.C, Cat.D)
ni <- length(Cat.A)
cat <- c(rep("Catalisador A",ni), rep("Catalisador B",ni),
rep("Catalisador C",ni), rep("Catalisador D",ni))
boxplot(tempo ~ cat, col=c("green4","blue3","red3","yellow3",
main="Tempo de reação x catalisador"),
ylab="Tempo de reação", cex=0.8)

4.5. Estatísticas descritivas para dados agrupados
Exemplo 1: dados coletados em entrevistas com 500 pessoas
a) – variável número de divórcios por indivíduo
b) – variável tempo (em anos) até o primeiro divórcio
a) Variável discreta: tabela do número de divórcios por indivíduo.
Divórcios = xi ni fi xi fi Fac ni xi2
1 240 0.480 0.480 0.480 240
2 125 0.250 0.500 0.730 500
3 81 0.162 0.486 0.892 729
4 48 0.096 0.384 0.988 768
5 6 0.012 0.060 1.000 150
Total 500 1.000 1.910 - 2387
Média amostral: ii fxx = 1.91 divórcios
Variância e desvio-padrão amostrais:
13.1499
95.562
)1500(
)910.1(5002387
)1(
2222
n
xnxs i
06.1s divórcios
Outra forma de representação: Divórcios = xi ni fi xi fi Fac (xi – x ) ni (xi – x )
2
1 240 0.480 0.480 0.480 –0.910 198.744
2 125 0.250 0.500 0.730 0.090 1.013
3 81 0.162 0.486 0.892 1.090 96.236
4 48 0.096 0.384 0.988 2.090 209.669
5 6 0.012 0.060 1.000 3.090 57.289
Total 500 1.000 1.910 – – 562.951
Média amostral: ii fxx = 1.91 divórcios
Variância amostral:
13.1499
951.562
)1(
22
n
xxs i

b) Variável contínua: tabela do tempo até o primeiro divórcio.
Anos
Casados
ponto médio
xi ni fi xi fi Fac ni xi
2
0 |----- 6 3 280 0.56 1.68 0.56 2520
6 |----- 12 9 140 0.28 2.52 0.84 11340
12 |----- 18 15 60 0.12 1.80 0.96 13500
18 |----- 24 21 15 0.03 0.63 0.99 6615
24 |----- 30 27 5 0.01 0.27 1.00 3645
Total
500 1.00 6.90 – 37620
Média amostral: ii fxx = 6.90 anos
Variância e desvio-padrão amostrais:
685.27499
13815
)1500(
)90.6(50037620
)1(
2222
n
xnxs i
26.5s anos
Outra forma de representação: Anos = xi
ptos. médios ni fi xi fi Fac (xi – x ) ni (xi – x )
2
3 280 0.56 1.68 0.56 -3.9 4258.80
9 140 0.28 2.52 0.84 2.1 617.40
15 60 0.12 1.80 0.96 8.1 3936.60
21 15 0.03 0.63 0.99 14.1 2982.15
27 5 0.01 0.27 1.00 20.1 2020.05
Total 500 1.00 6.90 - - 13815.00
Média amostral: ii fxx = 6.90 anos
Variância amostral:
685.27499
00.13815
)1(
22
n
xxs i

Exemplo 2: Escores GMAT (Graduate Management Apititude
Test) aplicado num processo seletivo para a escolha de alunos num
programa de graduação.
Escores Pto. Médio
xi ni fi Fac xi fi ni xi
2
300 |-- 350 325 3 0.035 0.035 11.5 316875
350 |-- 400 375 7 0.082 0.117 30.9 984375
400 |-- 450 425 18 0.212 0.329 90.0 3251250
450 |-- 500 475 24 0.282 0.611 134.1 5415000
500 |-- 550 525 15 0.177 0.788 92.6 4134375
550 |-- 600 575 10 0.118 0.906 67.6 3306250
600 |-- 650 625 4 0.047 0.953 29.4 1562500
650 |-- 700 675 4 0.047 1.000 31.8 1822500
Totais 85 1.000 488 20793125
Histograma:

Pela interpolação linear (ou semelhança de triângulos), temos:
a) 212.0
117.025.0
400450
4001
Q 4.431
212.0
)133.0(504001 Q
b) 282.0
329.050.0
50
450~
x 3.480
282.0
)171.0(50450~ x
c) 177.0
611.075.0
50
5003
Q 3.539
177.0
)139.0(505003 Q

4.6. Representação gráfica para variáveis qualitativas
Exemplo 1: Pesquisa PNAD 2004 – Moradores por domicílio
Brasil.
a) Tabela de uma entrada: número de domicílios por região
Região Domicílios %
SE 23157114 44.8
NE 13090124 25.3
S 8198266 15.8
CO 3745500 7.2
N 3561524 6.9
51752528 100.0
b) Tabela de dupla entrada: moradores/dom, por região (dados brutos)
Moradores
por
domicílio
Região
N NE SE S CO
1 292910 1190705 2612431 890834 424563
2 506597 2141312 4816793 1857904 739632
3 747866 2793052 5630782 2103424 843770
4 791985 2936946 5532907 1888026 948878
5 532447 1858876 2682387 917583 457745
6 308311 991114 1094518 322794 189354
7 161696 532787 410151 131936 75022
8 ou + 219712 645332 377145 85765 66536
Total 3561524 13090124 23157114 8198266 3745500

Tabela de dupla entrada: moradores/dom, por região (porcentagens)
Moradores
por domicílio
Região
N NE SE S CO
1 8.2 9.1 11.3 10.9 11.3
2 14.2 16.4 20.8 22.7 19.7
3 21.0 21.3 24.3 25.7 22.5
4 22.2 22.4 23.9 23.0 25.3
5 14.9 14.2 11.6 11.2 12.2
6 8.7 7.6 4.7 3.9 5.1
7 4.5 4.1 1.8 1.6 2.0
8 OU + 6.2 4.9 1.6 1.0 1.8
Total 100.0 100.0 100.0 100.0 100.0
c) Gráfico de setores (pizza): número de domicílios por região
Região Domicílios proporção ângulo
SE 23157114 0.447 161
NE 13090124 0.253 91
S 8198266 0.158 57
CO 3745500 0.072 26
N 3561524 0.069 25
51752528 1 360
- Para achar o ângulo, deve-se usar a relação: 100% = 360o.
- Portanto, se uma categoria tem proporção de 0.447, basta
multiplicar 0.447 por 360o para encontrar o ângulo
correspondente (regra de três).
Logo: 0.447 • 360o = 161o 0.072 • 360o = 26o
0.253 • 360o = 91o 0.069 • 360o = 25o
0.158 • 360o = 57o

45%
25%
16%
7%7%
Domicílios por região
SE
NE
S
CO
N
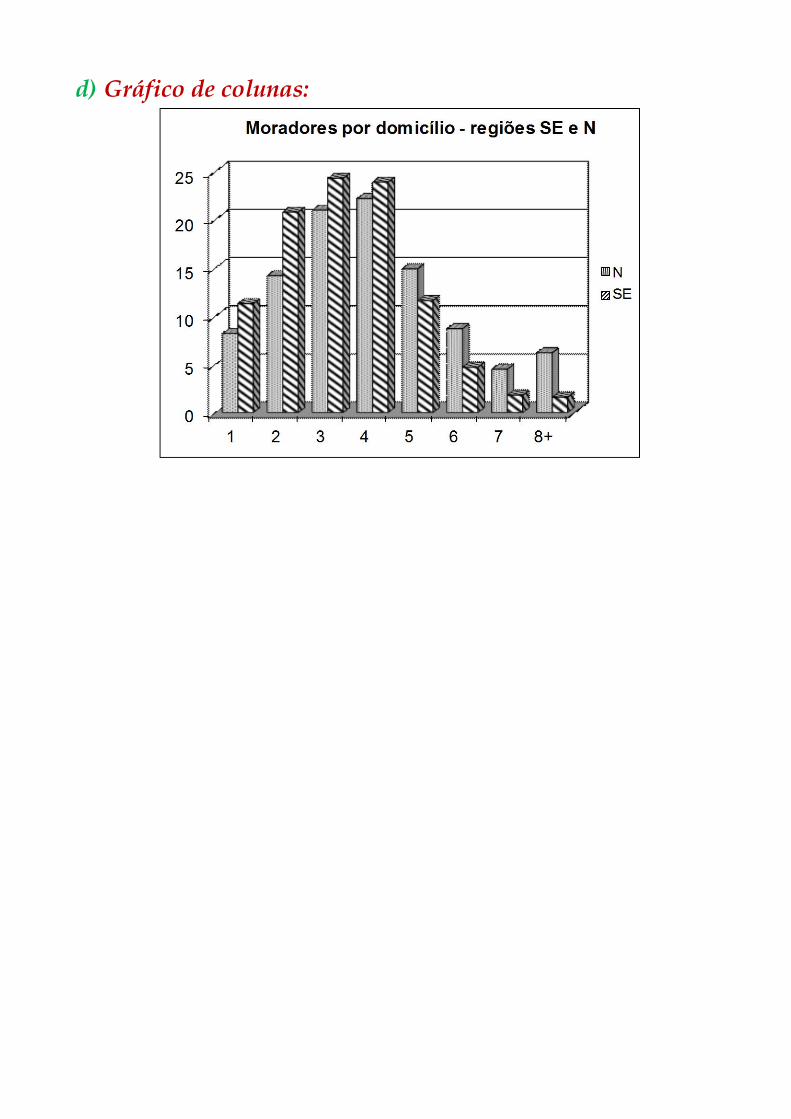
d) Gráfico de colunas:
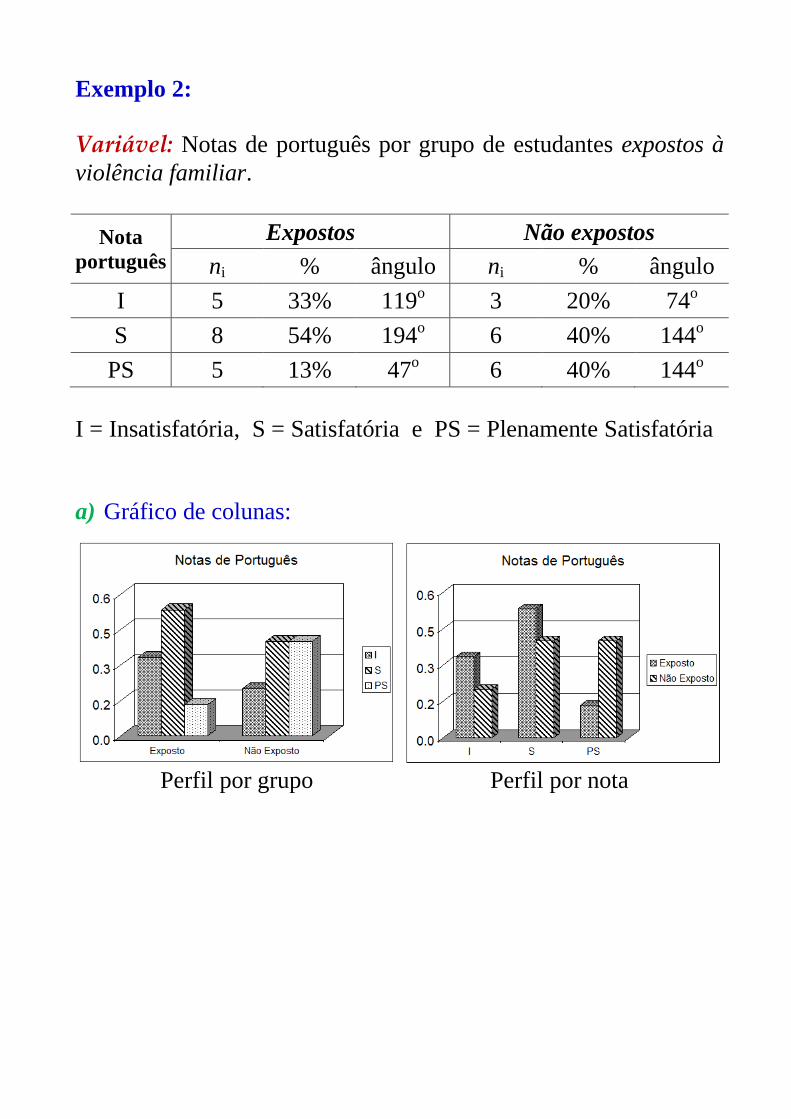
Exemplo 2:
Variável: Notas de português por grupo de estudantes expostos à
violência familiar.
Nota
português
Expostos Não expostos
ni % ângulo ni % ângulo
I 5 33% 119o 3 20% 74o
S 8 54% 194o 6 40% 144o
PS 5 13% 47o 6 40% 144o
I = Insatisfatória, S = Satisfatória e PS = Plenamente Satisfatória
a) Gráfico de colunas:
Perfil por grupo Perfil por nota

b) Gráfico de setores (pizza):