econometria semestre 2010 - mbarros.com 12... · 125 econometria – semestre 2010.01 125...
TRANSCRIPT

121Econometria – Semestre 2010.01 121
P r o f e s s o r a M ô n i c a B a r r o s ENCE
CAPÍTULO 12 ‐ AUTOCORRELAÇÃO
12.1. A NATUREZA DO PROBLEMA
O objetivo deste capítulo é examinar as conseqüências da violação de uma das hipóteses
fundamentais do modelo linear clássico, a hipótese de que os erros do modelo não são
correlacionados.
Este tipo de problema ocorre na prática quando fazemos regressão de séries temporais, e no
restante do capítulo usaremos o subscrito t (ao invés de i) para explicitar a dependência dos dados
no tempo. Também, por razões que deverão ficar claras ao longo do texto, os erros
(correlacionados) serão denotados por u, enquanto os erros não correlacionados continuarão,
como nos capítulos anteriores, a ser denotados por ε.
Em primeiro lugar, é preciso definir o que entendemos por autocorrelação (ou correlação serial).
A autocorrelação é a correlação que existe entre valores de uma série temporal observados em
diferentes instantes de tempo. A autocorrelação pode também se referir a observações em
diferentes pontos no espaço (correlação espacial), e o tratamento dado ao problema é
basicamente o mesmo apresentado aqui, por isso nosso foco será apresentar o problema no
contexto de séries temporais.
No modelo clássico, uma das premissas é a inexistência de correlação entre os erros em instantes
distintos. Isto é, supõe‐se que: E(ui.uj) = 0 para i ≠ j. Note que esta hipótese implica em Cov(ui, uj) =
0 para i ≠ j pois a média do erro é zero por hipótese.
Em que situação esta premissa costuma ser violada? Considere, por exemplo, um modelo para a
venda mensal de TVs no varejo. No passado recente, houve a redução de imposto sobre produtos
industrializados para combater a recessão, e isso incrementou as vendas. Também, em 2009, as

122Econometria – Semestre 2010.01 122
P r o f e s s o r a M ô n i c a B a r r o s ENCE
taxas de juros ao consumidor caíram. Agora, em 2010, estamos a um passo da Copa do Mundo
que, sabidamente, tem um impacto positivo sobre as vendas de TVs. E os erros de um modelo,
como ficam? Muito provavelmente, o erro do modelo num mês terá uma expressiva correlação
com o erro do modelo em meses adjacentes. Ou seja, a hipótese de que erros em instantes
diferentes são descorrelatados é falsa, ou seja, existe autocorrelação entre os erros. Isso quer
dizer que as perturbações que ocorrem num instante de tempo afetam as que ocorrem em outro
instante.
Antes de descobrir por que existe autocorrelação, é essencial esclarecer algumas questões sobre
nomenclatura. É prática comum tratar a autocorrelação e a correlação serial como sinônimos, mas
alguns autores preferem distinguir os dois termos. Nós não faremos isso aqui – para nós,
autocorrelação e correlação serial significam a mesma coisa.
A Figura 12.1. a seguir exibe alguns padrões plausíveis para a presença e ausência de
autocorrelação. Nela são plotados os erros (ou, na prática, os resíduos) contra o eixo dos tempos.
A Figura 12.1a mostra um padrão cíclico. A Figura 12.1b sugere uma tendência ascendente nos
erros, enquanto a Figura 12.1.c mostra um padrão linear descendente linear nos distúrbios. 12.1d
mostra termos de tendência linear e quadrática nos distúrbios. Apenas a Figura 12.1.e não exibe
um padrão sistemático, apoiando a hipótese de autocorrelação nula dos erros, que é a premissa
do modelo clássico de regressão.
FIGURA 12.1

123Econometria – Semestre 2010.01 123
P r o f e s s o r a M ô n i c a B a r r o s ENCE
A pergunta natural é: Por que a correlação serial ocorre? Há diversas razões, algumas mostradas a
seguir.
Inércia
Séries temporais econômicas apresentam inércia ou lentidão. O PIB, índices de preços, produção,
emprego e desemprego apresentam ciclos. A partir do fundo da recessão, começa a recuperação
econômica e a maioria destas séries começar a se mover para cima. Neste movimento, o valor de
uma série num ponto no tempo é maior do que seu valor anterior. Assim, há uma dinâmica que
continua até que algo aconteça (por exemplo, o aumento na taxa de juros ou os impostos, ou
ambos) para atrasá‐los. Por isso, nas regressões envolvendo séries temporais, observações
sucessivas tendem a ser interdependentes.
Viés de Especificação – variáveis excluídas
Na prática o pesquisador muitas vezes começa com um modelo de regressão plausível que não
podem ser o mais "perfeito''. Após a análise de regressão, o pesquisador examina os resultados

124Econometria – Semestre 2010.01 124
P r o f e s s o r a M ô n i c a B a r r o s ENCE
para descobrir se eles estão de acordo com as expectativas a priori e as premissas básicas dos
modelos de mínimos quadrados. Por exemplo, o pesquisador pode plotar os resíduos obtidos a
partir da regressão ajustada e observar padrões como os mostrados na Figura 12.1a a d. Esses
resíduos podem sugerir que algumas variáveis que foram originalmente candidatas, mas não
foram incluídas no modelo, devem ser incluídas. Este é o caso do viés de especificação da variável
excluída. Muitas vezes, a inclusão dessas variáveis remove o padrão de correlação observado nos
resíduos. Por exemplo, suponha que temos o modelo de demanda:
Onde Y = quantidade demandada de carne de boi, X2 = preço da carne de boi, X3 = renda do
consumidor, X4 = preço da carne de porco e t = tempo. No entanto, por alguma razão, ajustamos a
regressão que se segue:
Agora, se (12.1.2) é o modelo verdadeiro, mas ajustamos (12.1.3), isso equivale a fazer vt = β4.X4t +
ut. E na medida que o preço da carne suína afeta o consumo de carne, o termo de erro ou
distúrbio v irá refletir um padrão sistemático, criando assim uma (falsa) autocorrelação. Um teste
simples disso seria executar os dois modelos (12.1.2) e (12.1.3) e ver se autocorrelação, observada
no modelo (12.1.3) desaparece quando (12.1.2) é ajustado. A mecânica de detecção de
autocorrelação será discutida na seção 12.6.
Viés de Especificação – Forma Funcional Incorreta Suponha que o modelo verdadeiro é:
Mas em vez deste, ajustamos o seguinte modelo:
Ou seja, ajustamos uma forma funcional errada para a função custo marginal, que é a variável
dependente no modelo. As curvas de custo marginal correspondentes ao modelo "verdadeiro'' e “
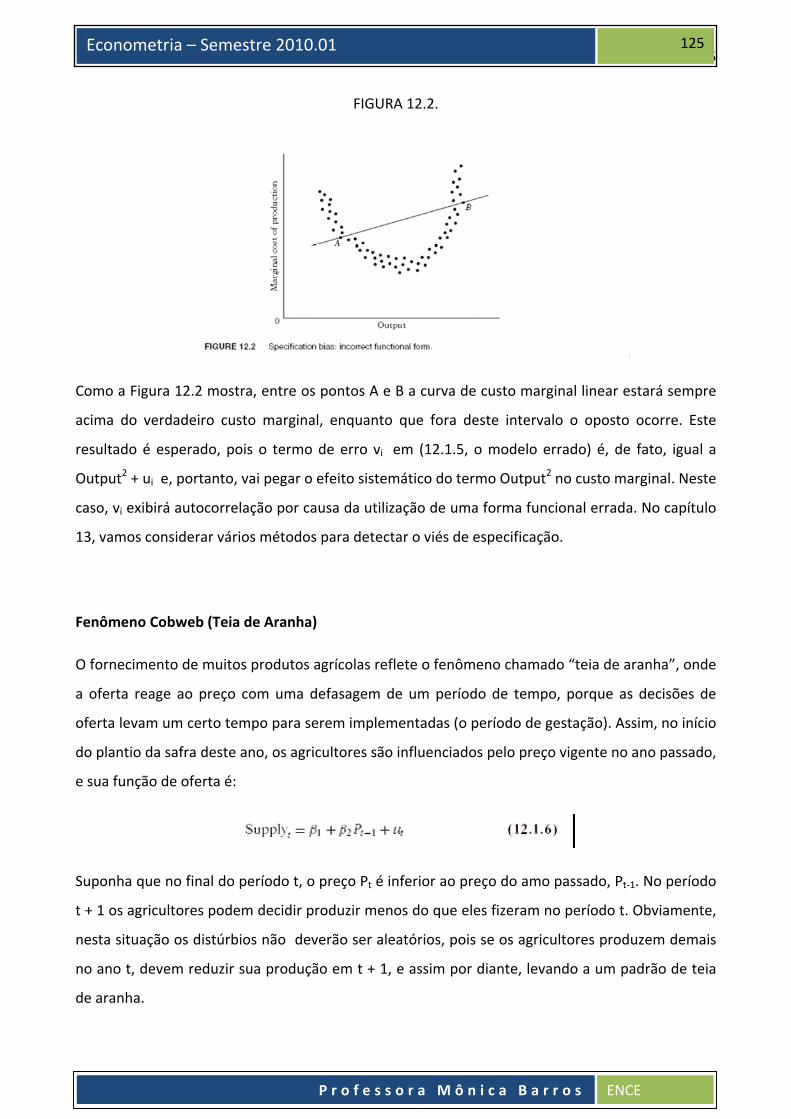
incorreto” são mostradas na Figura 12.2.
125Econometria – Semestre 2010.01 125
P r o f e s s o r a M ô n i c a B a r r o s ENCE
FIGURA 12.2.
Como a Figura 12.2 mostra, entre os pontos A e B a curva de custo marginal linear estará sempre
acima do verdadeiro custo marginal, enquanto que fora deste intervalo o oposto ocorre. Este
resultado é esperado, pois o termo de erro vi em (12.1.5, o modelo errado) é, de fato, igual a
Output2 + ui e, portanto, vai pegar o efeito sistemático do termo Output2 no custo marginal. Neste
caso, vi exibirá autocorrelação por causa da utilização de uma forma funcional errada. No capítulo
13, vamos considerar vários métodos para detectar o viés de especificação.
Fenômeno Cobweb (Teia de Aranha)
O fornecimento de muitos produtos agrícolas reflete o fenômeno chamado “teia de aranha”, onde
a oferta reage ao preço com uma defasagem de um período de tempo, porque as decisões de
oferta levam um certo tempo para serem implementadas (o período de gestação). Assim, no início
do plantio da safra deste ano, os agricultores são influenciados pelo preço vigente no ano passado,
e sua função de oferta é:
Suponha que no final do período t, o preço Pt é inferior ao preço do amo passado, Pt‐1. No período
t + 1 os agricultores podem decidir produzir menos do que eles fizeram no período t. Obviamente,
nesta situação os distúrbios não deverão ser aleatórios, pois se os agricultores produzem demais
no ano t, devem reduzir sua produção em t + 1, e assim por diante, levando a um padrão de teia
de aranha.

126Econometria – Semestre 2010.01 126
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Defasagens
Em uma regressão de séries temporais das despesas de consumo sobre a renda, é comum
observar que a despesa de consumo do período atual período depende, entre outras coisas, das
despesas de consumo dos períodos anteriores. Por exemplo:
Um modelo de regressão como (12.1.7) é conhecido como auto‐regressivo porque uma das
variáveis explicativas é o valor defasado da variável dependente. (Estes modelos serão novamente
estudados no capítulo 17.) A justificativa para um modelo como (12.1.7) é simples. Os
consumidores não mudam seus hábitos de consumo facilmente por motivos psicológicos,
tecnológicos ou institucionais. Agora, se nós negligenciarmos o termo defasado em (12.1.7), o
termo de erro resultante refletirá um padrão sistemático devido à influência do consumo
defasado sobre o consumo atual.
Manipulação de dados
Na análise empírica, os dados brutos são frequentemente "Manipulados''. Por exemplo, em
regressões envolvendo séries trimestrais, os dados são às vezes obtidos a partir dos dados mensais
simplesmente adicionando três observações mensais e dividindo a soma por 3. Esta média suaviza
as flutuações do dados mensais, e o gráfico dos dados trimestrais parece muito mais suave do que
o dos dados mensais, e essa mesma regularidade pode gerar um padrão sistemático nos termos
de erro, introduzindo assim autocorrelação.
Outra fonte de manipulação é interpolação ou extrapolação de dados. Por exemplo, o Censo de
População é realizado a cada 10 anos. Se existe uma necessidade de obter dados para alguns anos
no período intercensitários 1990‐2000 ou 2000‐2010, a prática comum é a interpolação com base
em algum pressuposto “ad‐hoc”. Estas técnicas de “massagem” dos dados podem impor aos
dados um padrão sistemático que pode não existir nos dados originais.

127Econometria – Semestre 2010.01 127
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Transformação de dados
Considere o seguinte modelo:
Onde, por exemplo, Y = despesa de consumo e X = renda. Como (12.1.8) é válido em todos os
períodos de tempo, ele é válido também no período anterior (t ‐ 1). Assim, podemos escrever
(12.1.8) como:
Yt‐1, Xt‐1, e ut‐1 são conhecidos como os valores defasados de Y, X, e U respectivamente. Neste caso
a defasagem é de um período. Subtraindo (12.1.9) de (12.1.8), obtemos:
Onde Δ é conhecido como o operador de primeira diferença.
Assim, ΔYt = (Yt ‐ Yt‐1), ΔXt = (Xt ‐ Xt‐1) e ΔUt = (Ut ‐ Ut‐1). Podemos escrever (12.1.10) como:
A equação (12.1.9) é conhecida como forma de nível e a equação (12.1.10) é conhecida como a
forma de primeira diferença. Ambas as formas são frequentemente utilizadas em pesquisas
empíricas. Por exemplo, se em (12.1.9) Y e X representam os logaritmos das despesas de consumo
e renda, então em (12.1.10) ΔY e ΔX representam variações nos logaritmos das despesas de
consumo e renda. Mas, uma variação no logaritmo é uma mudança relativa (percentual), se ela for
multiplicada por 100. Assim, em vez de estudar relações entre as variáveis na forma de nível,
podemos estar interessados em suas relações na forma de crescimento.
Se o termo de erro em (12.1.8) satisfaz as hipóteses‐padrão MQO, especialmente a hipótese de
não autocorrelação, pode‐se mostrar que o erro vt em (12.1.11) é autocorrelacionado. (A prova é
dada no apêndice 12A, Seção 12A.1.)

128Econometria – Semestre 2010.01 128
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Modelos como (12.1.11) são conhecidos como modelos de regressão dinâmica, ou seja, modelos
que envolvem regressandos defasados. Eles serão estudados em profundidade no Capítulo 17. O
que interessa no exemplo anterior é que às vezes a autocorrelação pode ser induzida como
resultado da transformação do modelo original.
Não‐estacionariedade
Lembre‐se que uma série temporal é estacionária se suas características (por exemplo, média,
variância e covariância) são invariantes no tempo, ou seja, eles não mudam ao longo do tempo. Se
isso não acontecer, a série temporal é dita não estacionária. Como veremos na Parte V, em um
modelo de regressão na forma do nível como (12.1.8) é possível que tanto Y e X sejam não‐
estacionárias e, portanto, o erro u também seja não‐estacionário, e irá exibir autocorrelação.
Em resumo, existem diversas razões pelas quais o termo de erro em um modelo de regressão
pode ser autocorrelacionado. No restante do capítulo, investigamos os problemas decorrentes da
autocorrelação e que pode ser feito sobre isso.
A autocorrelação pode ser positiva (Figura 12.3a) ou negativa, embora a maioria das séries
temporais econômica geralmente apresente autocorrelação positiva. Isso acontece porque a
maioria delas move‐se para cima ou para baixo durante longos períodos de tempo e não
apresenta um movimento constante para cima e para baixo como o mostrado na Figura 12.3b.
FIGURA 12.3. – AUTOCORRELAÇÃO POSITIVA (a) E NEGATIVA (b)

129Econometria – Semestre 2010.01 129
P r o f e s s o r a M ô n i c a B a r r o s ENCE
12.2. ESTIMATIVA MQO NA PRESENÇA DE AUTOCORRELAÇÃO
O que acontece com os estimadores de MQO e suas variâncias se os erros do modelo apresentam
autocorrelação?
Suponha agora que E (ut.ut + s) ≠ 0 para s ≠ 0 e que todas as outras hipóteses do modelo clássico
são mantidas.
Considere o modelo de regressão com duas variáveis: Yt = β1 + β2.Xt + ut.
Suponha que os ruídos deste modelo têm agora a seguinte estrutura:
Onde ρ (a letra grega rô) é o coeficiente de autocorrelação e εt é o erro estocástico que satisfaz as
hipóteses usuais do modelo de mínimos quadrados, a saber:

130Econometria – Semestre 2010.01 130
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Na literatura de engenharia, um termo de erro com as propriedades (12.2.2) é chamado de “ruído
branco”. O que (12.2.1) postula é que a valor do termo de erro no período t é igual a ρ vezes o seu
valor no período anterior, acrescido de um termo de erro puramente aleatório.
O esquema (12.2.1) é conhecido como esquema autoregressivo de primeira ordem de Markov, ou
simplesmente regime auto‐regressivo de primeira ordem, geralmente denotado como AR (1). O
nome autoregressivo é apropriado porque (12.2.1) pode ser interpretado como a regressão de ut
em sim mesmo defasado em um período. Diz‐se que é de primeira ordem porque ut e seu valor
imediatamente anterior estão envolvidos, ou seja, o máximo atraso é 1. Se o modelo for ut = ρ1ut‐1
+ ρ2 ut‐2 + εt, seria um AR (2), um modelo autoregressivo de segunda ordem.
Pode‐se provar que, na situação de ruídos AR(1):
Onde cov(ut,ut + s) indica a covariância entre os termos de erro separados por s instantes e
cor(ut,ut + s) a correlação entre estes mesmos termos de erro. Note que cor(ut,ut) = 1 sempre, pois
a correlação de uma variável com si mesma é sempre um. Por causa da propriedade de simetria de
covariâncias e correlações, cov(ut,ut + s) = cov(ut,ut ‐ s) e o mesmo ocorre com as correlações.
O coeficiente ρ é uma constante entre ‐1 e +1 e então (12.2.3) mostra que, sob o esquema AR (1),
a variância de ut é ainda constante (ut é homocedástico), mas ut está correlacionado não só com
o seu valor imediatamente anterior, mas também com seus valores em outros instantes do
passado.
É fundamental observar que |ρ|< 1, ou seja, o valor absoluto de ρ é menor que um. Se ρ = 1, as
variâncias e covariâncias acima não estão definidas. Se |ρ| <1, dizemos que o processo AR (1)
dado em (12.2.1) é estacionário, ou seja, sua média, variância e covariância não mudam ao longo
do tempo. Se |ρ| é menor que um, então a covariância diminuirá à medida que avançamos no
passado distante, ou seja, à medida que a diferença entre as defasagens (“lags”) aumenta. Se |ρ|

131Econometria – Semestre 2010.01 131
P r o f e s s o r a M ô n i c a B a r r o s ENCE
é MAIOR que um, o processo é não estacionário e tem um comportamento claramente
“explosivo”. Gere uma sequência de erros iid {et} no Excel e ajuste o modelo ut = 1,2ut‐1 + et para
verificar que isso acontece. Utilize qualquer valor inicial para u0. Se ρ = 1, o processo é descrito por
ut = ut‐1 + et, e é um processo NÃO ESTACIONÁRIO bastante importante na prática, chamado de
“random walk”, ou passeio aleatório. O fato interessante é que a primeira diferença de um passeio
aleatório é um processo estacionário, pois ut ‐ ut‐1 = et, ou seja, Δut = et onde Δ é o operador 1a.
diferença.
Uma razão para usar o modelo AR (1) não é apenas por sua simplicidade em relação aos modelos
AR de ordem superior, mas também porque, mostrou ser útil em aplicações práticas.
Considere novamente o modelo de regressão de duas variáveis: Yt = β1 + β2.Xt + ut. No capítulo 3
vimos que o estimador MQO do coeficiente angular é:
Cuja variância é dada por:
Onde a letra minúscula indica que a variável é calculada como um desvio em relação à média.
Sob a hipótese AR(1), pode‐se mostrar que a variância deste estimador é:
Onde Var(β^2)AR1 indica a variância do estimador sob a hipótese de erros AR(1).
A comparação de (12.2.8) e (12.2.7) mostra que a variância sob o esquema AR(1) tem uma coleção
de termos adicionais (em relação à variância sob a hipótese de erros não correlacionados). Estes
termos adicionais dependem de ρ e também das autocorrelações amostrais da variável explicativa
X em vários períodos anteriores.

132Econometria – Semestre 2010.01 132
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Além disso, em geral não podemos prever se a variância dada por (12.2.7) será maior ou menor
que a dada por (12.2.8). É claro que se ρ = 0, as duas fórmulas coincidirão. Mas, como princípio
geral, as duas variâncias não serão iguais.
Para dar uma idéia da diferença entre as variâncias (12.2.7) e (12.2.8), suponha que o regressor X
também siga um processo AR(1) com um coeficiente de autocorrelação r. Pode‐se mostrar que
(12.2.8) se reduz a:
Se, por exemplo, r = 0,6 e ρ = 0,8, utilizando (12.2.9) segue que Var(β^2)AR1 = 2,8461 Var(β^2)MQO.
Dito de outra forma, Var(β^2)MQO = (1/ 2,8461) Var(β^2)AR1 = 0,3513 Var(β^2)AR1. Ou seja, a fórmula
usual de MQO [(12.2.7)] subestimará a variância de β2 sob o esquema AR(1) por cerca de 65%.
Em resumo: uma aplicação cega das fórmulas MQO usuais para calcular os desvios e os erros
padrão dos estimadores MQO estimadores pode levar a resultados totalmente enganosos.
Suponha que a gente insista em continuar usando o estimador MQO de β2 e que corrigimos a
variância levando em conta a estrutura AR(1) para o erro. Quais as propriedades de β^2 ? Ele é
ainda linear e não tendencioso, mas não é BLUE (ou seja, não é eficiente). Já tínhamos chegado a
conclusões semelhantes quanto estudamos o problema da heterocedasticidade, e vimos que
naquelas condições era possível encontrar um estimador eficiente através de mínimos quadrados
generalizados. Na próxima seção veremos quais os passos necessários para encontrar estimadores
BLUE sob a hipótese de erros AR(1).
12.3. O ESTIMADOR BLUE NA PRESENÇA DE AUTOCORRELAÇÃO
Considere ainda o modelo de regressão com duas variáveis e suponha a existência de erros AR(1)
como na seção anterior. Pode‐se mostrar que o estimador BLUE do coeficiente angular é dado por:

133Econometria – Semestre 2010.01 133
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Onde C é um fator de correção que pode ser ignorado na prática. Note que em (12.3.1) o subscrito
t vai de 2 até n (pois o estimador depende de y e x defasados em um instante). A variância deste
estimador é dada por:
Onde D é um outro fator de correção, que também pode ser ignorado na prática.
O estimador β^2GLS , como o expoente sugere, é obtido pelo método de mínimos quadrados
generalizados. Como observado no Capítulo 11, o método de mínimos quadrados generalizados
quer incorporar quaisquer informações adicionais disponíveis (por exemplo, a natureza da
heterocedasticidade ou a autocorrelação) diretamente no processo de estimação através da
transformação das variáveis, enquanto que os mínimos quadrados ordinários esta informação não
é diretamente levada em consideração.
A fórmula do estimador de mínimos quadrados generalizados dado em (12.3.1) depende
explicitamente do parâmetro de autocorrelação ρ enquanto o estimador MQO dado por (12.2.6)
ignora esta informação.
Intuitivamente, essa é a razão pela qual o estimador de mínimos quadrados generalizados é BLUE
e não o estimador MQO. O estimador de mínimos quadrados generalizados usa toda a informação
disponível, o que não ocorre com o estimador MQO. Se ρ = 0, não existem informações adicionais
a serem consideradas, e, portanto, os estimadores por mínimos quadrados generalizados e
mínimos quadrados ordinários são idênticos.

134Econometria – Semestre 2010.01 134
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Em resumo, sob autocorrelação, é o estimador de mínimos quadrados generalizados dado em
(12.3.1) que é BLUE e a variância mínima é agora dada por (12.3.2) e não por (12.2.8) ou (12.2.7).
Você pode reescrever o estimador de mínimos quadrados generalizados de uma forma mais
parecida com o estimador usual MQO. Sejam:
1*
1*
.
.
−
−
−=
−=
ttt
ttt
yyy
xxx
ρ
ρ
Então, a equação (12.3.1) torna‐se:
Cx
yx
t
ttGLS +=∑∑
2*
**
2β̂ , que tem praticamente a mesma forma que a do estimador MQO, mas agora
aplicado às variáveis ** e tt yx . Também é importante notar que em (12.3.1) e em (12.2.6) os
estimadores estão expressos como funções das variáveis centradas em torno das suas médias
(expressas por letras minúsculas).
Nota técnica
O Teorema de Markov fornece apenas uma condição suficiente para o estimador MQO ser BLUE.
As condições necessárias e suficientes para que este estimador seja BLUE são dadas pelo teorema
de Krushkal, mencionado no capítulo anterior. Logo, em alguns casos o estimador MQO pode se
BLUE apesar da autocorrelação. Mas, estes casos não são comuns na prática.
12.4 O QUE ACONTECE SE USAMOS MQO E EXISTE AUTOCORRELAÇÃO?
Lembre‐se: mesmo quando existe autocorrelação, os estimadores MQO são ainda não
tendenciosos e lineares, além de consistentes e assintoticamente Normais. Mas, eles não são mais
estimadores de variância mínima (ou seja, não são BLUE)!
Suponha que continuamos a usar os estimadores MQO. Levaremos em conta duas situações.
1) Estimação MQO levando em conta a autocorrelação
Suponha que usamos o estimador usual MQO, dado por:

135Econometria – Semestre 2010.01 135
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Mas, agora decidimos empregar sua variância corrigida para a autocorrelação, isto é:
Se empregarmos esta variância (12.2.8) na construção de intervalos de confiança, os IC tendem a
ser mais largos que os obtidos a partir dos estimadores de mínimos quadrados generalizados, e
isto ocorre mesmo se aumentarmos indefinidamente o tamanho da amostra. Ou seja, na
situação de autocorrelação dos erros, o estimador MQO não é assintoticamente eficiente.
Em resumo: não use estimadores MQO na presença de autocorrelação, pois você estará tirando
conclusões erradas, e aumentar o tamanho da amostra não melhorará a situação.
2) Estimação MQO sem levar em conta a autocorrelação
A situação torna‐se ainda pior se, além de usarmos o estimador MQO na presença de
autocorrelação, deixarmos de corrigir sua variância, isto é, continuamos a usar:
Quais os problemas decorrentes desta decisão?
A variância dos resíduos, dada por: 22
ˆˆ
22
−=
−= ∑
nRSS
nutσ será provavelmente menor que a
variância real σ2. Isso nos leva a superestimar R2 e as estatísticas t.
Mesmo que σ2 não seja subestimado, Var(β^2) poderá subestimar Var(β^2)AR1 dada pela
equação (12.2.8), a variância do estimador MQO sob a premissa de autocorrelação dos
resíduos de lag 1. Assim, os testes t e F construídos a partir de Var(β^2) levarão a
conclusões erradas sobre a significância dos parâmetros na regressão.

136Econometria – Semestre 2010.01 136
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Sob a premissa do modelo clássico (inexistência de autocorrelação dos resíduos), o
estimador da variância 22
ˆˆ
22
−=
−= ∑
nRSS
nutσ é não tendencioso para σ2, isto é: ( ) 22ˆ σσ =E .
Se a hipótese de inexistência de autocorrelação for violada e supormos que os erros
seguem uma estrutura AR(1) então pode‐se mostrar que:
Onde r é o coeficiente de correlação amostral entre valores sucessivos da variável
explicativa X, dado por:
Suponha que ambos ρ e r são positivos, o que é usual no caso de séries econômicas. Então,
de (12.4.1) segue que ( ) 22ˆ σσ <E , ou seja, o estimador usual da variância subestimará a
variância verdadeira.
Além disso, Var(β^2) é um estimador tendencioso de Var(β^2)AR1, o que pode ser observado
comparando‐se (12.2.7) e (12.2.8). Se ambos ρ e r são positivos segue que Var(β^2) <
Var(β^2)AR1 e então a variância do estimador MQO subestima sua variância sob a premissa
de erros AR(1). Então, ao usar o estimador MQO β^2 estamos supondo que ele tem uma
precisão maior que a real (isto é, estamos subestimando seu erro padrão). Assim, ao
calcular a estatística t para β2 estaremos “inflando” o valor desta estatística, que parecerá
maior do que é, na verdade. Isso nos leva a acreditar que o parâmetro β2 é significante,
quando, não verdade, não o é.
Exemplo – simulação de Monte Carlo
O objetivo deste exemplo é mostrar como o uso do estimador MQO na situação de erros AR(1)
tende a subestimar σ2 e Var(β^2). Suponha que o modelo real é conhecido e dado por:
ttt
ttt
uuuXY
ε+=++=
−17,08,01
(12.4.3 e 12.4.5)
Onde os εt são um ruído branco com média zero e variância 1.

137Econometria – Semestre 2010.01 137
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Os εt ´s serão gerados aleatoriamente da distribuição N(0,1) (usando o Excel), e usamos como
valor inicial ε0 = 0. Note que, a partir da geração dos εt ´s e de um valor inicial para u, por exemplo
u0 =5, podemos usar a equação (12.4.5) para gerar uma sequência de ut que apresentam
correlação serial de lag 1.
Na tabela abaixo estão os εt ´s gerados aleatoriamente da distribuição N(0,1).
instante (t) e(t) instante (t) e(t) instante (t) e(t) instante (t) e(t) instante (t) e(t)0 0 11 -0,690 22 -0,370 33 0,539 44 -0,3631 -0,300 12 -1,690 23 1,343 34 0,902 45 -0,0322 -1,278 13 -1,847 24 -0,085 35 1,919 46 0,0283 0,244 14 -0,978 25 -0,186 36 -0,085 47 -0,3234 1,276 15 -0,774 26 -0,513 37 -0,524 48 2,1955 1,198 16 -2,118 27 1,972 38 0,675 49 -1,7426 1,733 17 -0,568 28 0,866 39 -0,381 50 -0,7367 -2,184 18 -0,404 29 2,376 40 0,7588 -0,234 19 0,135 30 -0,655 41 -1,4449 1,095 20 -0,365 31 1,661 42 -0,847
10 -1,087 21 -0,327 32 -1,612 43 -1,522
A partir desta tabela podemos gerar os ut de acordo com a equação (12.4.5) e a condição inicial u0
= 5. Por exemplo:
u1 = 0,7.u0 +ε1 = 0,7(5) + (‐0,300) = 3,200
u2 = 0,7.u1 +ε2 = 0,7(3,200) + (‐1,278) = 0,962 etc...
A próxima figura mostra a evolução dos ut´s ao longo do tempo.
u(t) = 0,7*u(t-1)+e(t)
-6
-4
-2
0
2
4
6
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
138Econometria – Semestre 2010.01 138
P r o f e s s o r a M ô n i c a B a r r o s ENCE
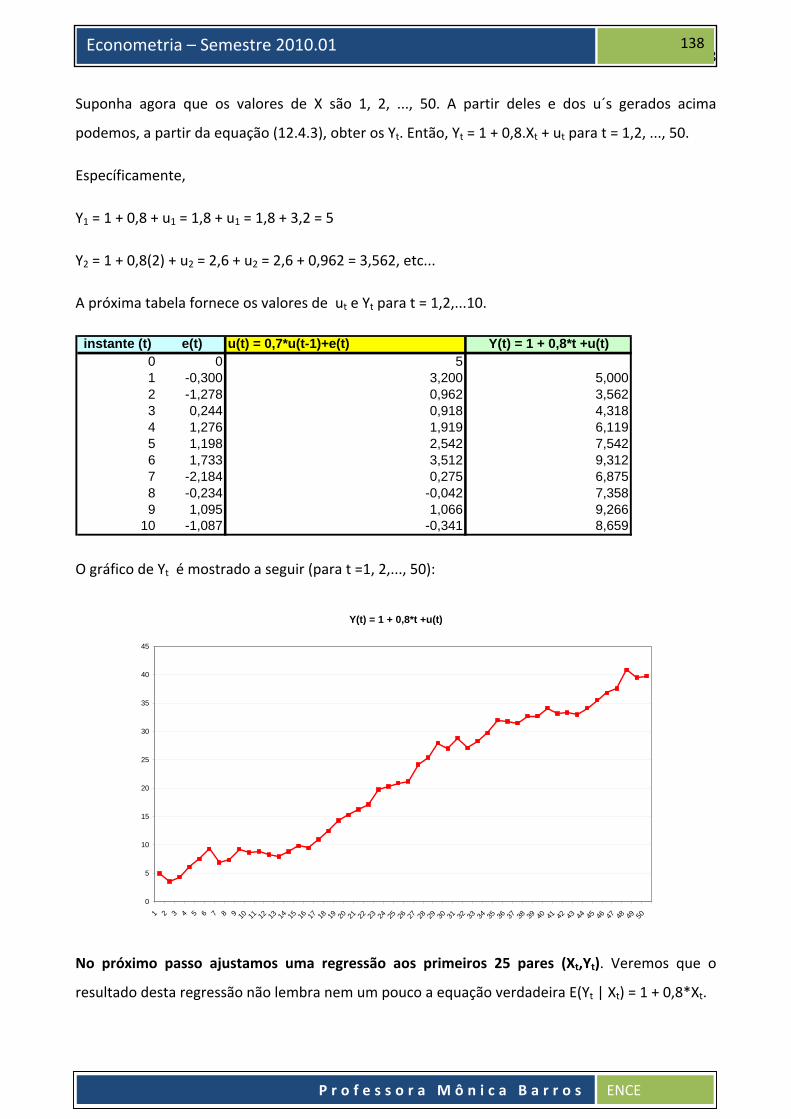
Suponha agora que os valores de X são 1, 2, ..., 50. A partir deles e dos u´s gerados acima
podemos, a partir da equação (12.4.3), obter os Yt. Então, Yt = 1 + 0,8.Xt + ut para t = 1,2, ..., 50.
Específicamente,
Y1 = 1 + 0,8 + u1 = 1,8 + u1 = 1,8 + 3,2 = 5
Y2 = 1 + 0,8(2) + u2 = 2,6 + u2 = 2,6 + 0,962 = 3,562, etc...
A próxima tabela fornece os valores de ut e Yt para t = 1,2,...10.
instante (t) e(t) u(t) = 0,7*u(t-1)+e(t) Y(t) = 1 + 0,8*t +u(t)0 0 51 -0,300 3,200 5,0002 -1,278 0,962 3,5623 0,244 0,918 4,3184 1,276 1,919 6,1195 1,198 2,542 7,5426 1,733 3,512 9,3127 -2,184 0,275 6,8758 -0,234 -0,042 7,3589 1,095 1,066 9,266
10 -1,087 -0,341 8,659
O gráfico de Yt é mostrado a seguir (para t =1, 2,..., 50):
Y(t) = 1 + 0,8*t +u(t)
0
5
10
15
20
25
30
35
40
45
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
No próximo passo ajustamos uma regressão aos primeiros 25 pares (Xt,Yt). Veremos que o
resultado desta regressão não lembra nem um pouco a equação verdadeira E(Yt | Xt) = 1 + 0,8*Xt.

139Econometria – Semestre 2010.01 139
P r o f e s s o r a M ô n i c a B a r r o s ENCE
O resultado da regressão linear no Excel é:
ANOVAgl SQ MQ F F de significação
Regressão 1 521,03 521,03 148,91 0,00Resíduo 23 80,48 3,50Total 24 601,50
Coeficientes Erro padrão Stat t valor-P 95% inferiores 95% superioresInterseção 2,5160 0,7712 3,2623 0,0034 0,9206 4,1115X 0,6331 0,0519 12,2029 0,0000 0,5258 0,7404
O R2 desta regressão é 86,6%. Note que a variância estimada 2σ̂ é 3,50 (igual à RSS/(n‐2) =
80,48/23 =3,50), um valor MUITO diferente do real.
Da tabela acima nota‐se que a equação estimada usando os primeiros 25 pares é:
tt XY *633,0516,2ˆ += e ambos os coeficientes angular e linear são significantes, de acordo com
as estatísticas t correspondentes.
A próxima figura mostra os valores de Yt e as retas real (1 + 0,8Xt) e ajustada pelo modelo de
regressão nos 25 primeiros pontos (2,516 + 0,633Xt).
Valor Real de Y, reta estimada por MQO e reta verdadeira
0
4
8
12
16
20
24
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Y real Reta verdadeira (1 +0,8*X) Y Previsto MQO
A figura anterior justifica porque o procedimento de MQO tende a subestimar a variância se existe
autocorrelação dos resíduos. Note que os resíduos computados em relação à reta vermelha (reta
MQO) tendem a ser menores que os resíduos calculados em relação à reta real (reta azul). Para
verificar isso, basta selecionar um ponto Y qualquer e traçar a linha vertical entre Y e a reta

140Econometria – Semestre 2010.01 140
P r o f e s s o r a M ô n i c a B a r r o s ENCE
ajustada MQO (ou entre Y e a linha verdadeira – linha azul). Assim, os resíduos MQO não
fornecem uma boa estimativa dos erros ui.
Considere um outro experimento de Monte Carlo, usando os mesmos dados que antes, mas
suponha que ρ = 0 na equação (12.4.5), e não mais 0,7 como suposto na experiência anterior.
Então os ut são agora descorrelatados, u1 = ε1 = ‐0,300, u2 = ε2 = ‐1,278, etc...
Daí:
Y1 = 1 + 0,8 + u1 = 1,8 + u1 = 1,8 – 0,3 = 1,5
Y2 = 1 + 0,8(2) + u2 = 2,6 + u2 = 2,6 – 1,278 = 1,322 etc...
A seguir ajustamos a reta por MQO para os primeiros 25 pares (Xt,Yt). Note que agora a hipótese
de erros descorrelatados é válida e assim a reta ajustada deve se aproximar da reta verdadeira 1 +
0,8Xt. Os 25 valores de X e Y são mostrados na próxima tabela:
X Y X Y1 1,50 14 11,222 1,32 15 12,233 3,64 16 11,684 5,48 17 14,035 6,20 18 15,006 7,53 19 16,337 4,42 20 16,638 7,17 21 17,479 9,30 22 18,23
10 7,91 23 20,7411 9,11 24 20,1112 8,91 25 20,8113 9,55
A equação estimada usando os primeiros 25 pares é: tt XY *790,0785,0ˆ +=
Note que o coeficiente linear da regressão não é significante (a 5%). O R2 desta regressão é 96,7%
(no caso anterior era 86,6%). A variância estimada 2σ̂ é 1,20 (vide tabela ANOVA), bem mais
próxima do valor verdadeiro (1).

141Econometria – Semestre 2010.01 141
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Modelo Simulado SEM Autocorrelação dos Resíduos - valores reais, reta teórica e reta ajustada por MQO
0
5
10
15
20
25
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Y Reta verdadeira (1 +0,8*X) Y Previsto MQO
RESUMO DOS RESULTADOS
Estatística de regressãoR múltiplo 0,9834R-Quadrado 0,9672R-quadrado ajustad 0,9657Erro padrão 1,0951Observações 25
ANOVAgl SQ MQ F F de significação
Regressão 1 812,31 812,31 677,31 0,00Resíduo 23 27,58 1,20Total 24 839,89
Coeficientes Erro padrão Stat t valor-P 95% inferiores 95% superioresInterseção 0,785 0,452 1,739 0,095 -0,149 1,719X 0,790 0,030 26,025 0,000 0,728 0,853
O gráfico a seguir apresenta os pares (X, Y) e as retas real e ajustada por MQO.
12.5. EXEMPLO ‐ RELAÇÃO ENTRE SALÁRIOS E PRODUTIVIDADE NOS EUA
Os dados da tabela 12.4 apresentam índices de remuneração real por hora (Y) e produção por hora (X) em empresas dos EUA no período entre 1959 e 1998.
A figura a seguir mostra estes dados.

142Econometria – Semestre 2010.01 142
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Gujarati ajusta dois modelos, um linear e outro log‐linear, com os resultados mostrados a seguir.
1) Modelo linear
Ode d é a estatística de Durbin‐Watson, que será discutida a seguir e se(.) indica o erro padrão do
estimador.
2) Modelo log‐linear
As questões que se colocam na prática são:
Os modelos exibem resultados parecidos.
Os coeficientes estimados, avaliados pelas estatísticas t, parecem altamente significantes.
Mas, até que ponto os resultados das regressões (12.5.1) e (12.5.2) são confiáveis?
A autocorrelação deve ser um problema aqui, pois ambas as séries evoluem no tempo, e
nesta situação não podemos confiar nos erros padrão (e assim as estatísticas t produzidas
também não são confiáveis).

143Econometria – Semestre 2010.01 143
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Então a questão principal é: COMO DETECTAR A AUTOCORRELAÇÃO?
12.6. DETECTANDO A AUTOCORRELAÇÃO
Lembre‐se que a ausência de autocorrelação é uma premissa feita sobre os erros do modelo, que
não são observáveis – o melhor que temos para “inferir” sobre os erros são os resíduos do
modelo, que podem ser calculados. Então o melhor que podemos fazer é usar os resíduos para
verificar se a premissa de correlação zero dos erros está sendo violada (usamos este mesmo
raciocínio para inferir sobre a heterocedasticidade, lembra‐se?).
1) Método Gráfico
O gráfico dos resíduos (ou do quadrado dos resíduos) pode revelar a existência de autocorrelação.
SE NÃO EXISTE AUTOCORRELAÇÃO, o gráfico dos resíduos ao longo do tempo deve ser puramente
aleatório, com o seguinte aspecto:
Volte ao exemplo da seção 12.5. e considere o modelo linear (12.5.1). O gráfico dos resíduos (e
dos resíduos padronizados, i.e., divididos pelo erro padrão da regressão σ̂ ) é mostrado a seguir:
144Econometria – Semestre 2010.01 144
P r o f e s s o r a M ô n i c a B a r r o s ENCE
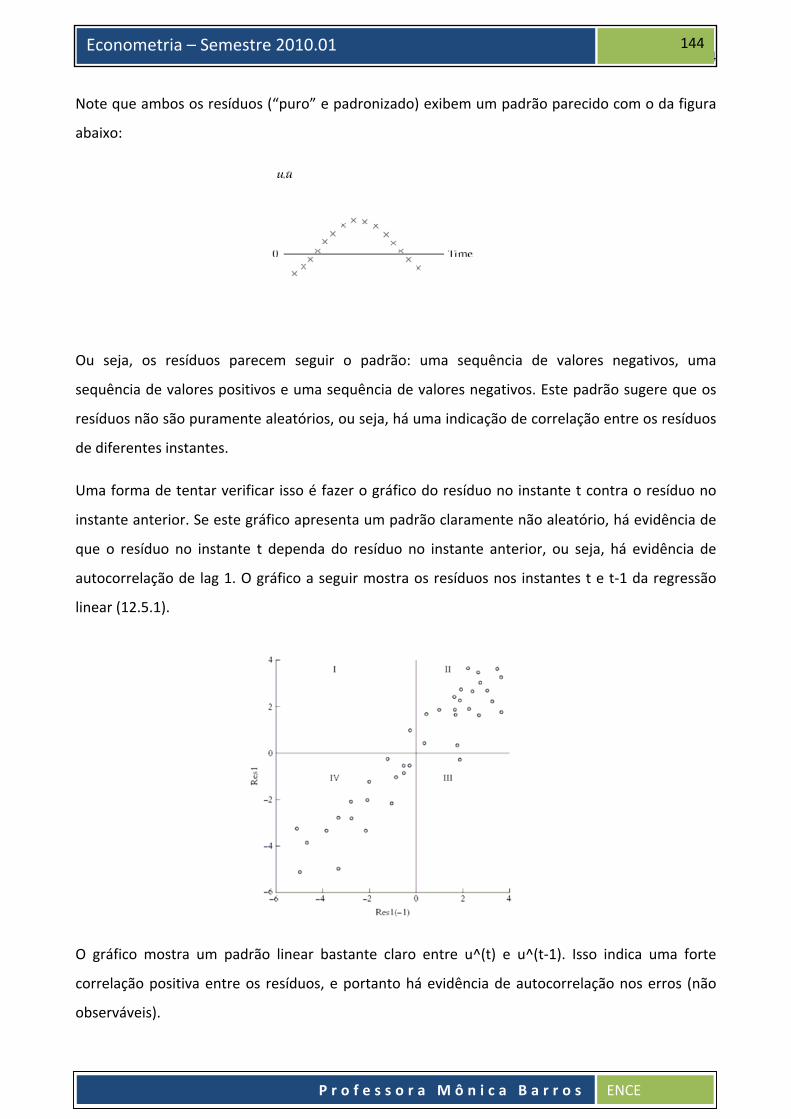
Note que ambos os resíduos (“puro” e padronizado) exibem um padrão parecido com o da figura
abaixo:
Ou seja, os resíduos parecem seguir o padrão: uma sequência de valores negativos, uma
sequência de valores positivos e uma sequência de valores negativos. Este padrão sugere que os
resíduos não são puramente aleatórios, ou seja, há uma indicação de correlação entre os resíduos
de diferentes instantes.
Uma forma de tentar verificar isso é fazer o gráfico do resíduo no instante t contra o resíduo no
instante anterior. Se este gráfico apresenta um padrão claramente não aleatório, há evidência de
que o resíduo no instante t dependa do resíduo no instante anterior, ou seja, há evidência de
autocorrelação de lag 1. O gráfico a seguir mostra os resíduos nos instantes t e t‐1 da regressão
linear (12.5.1).
O gráfico mostra um padrão linear bastante claro entre u^(t) e u^(t‐1). Isso indica uma forte
correlação positiva entre os resíduos, e portanto há evidência de autocorrelação nos erros (não
observáveis).

145Econometria – Semestre 2010.01 145
P r o f e s s o r a M ô n i c a B a r r o s ENCE
2) O teste das carreiras (“runs test”)
Nas páginas anteriores mostramos algumas maneiras de tentar detectar a autocorrelação nos
erros a partir de gráficos dos resíduos. O problema é que estas análises, embora muito
importantes, são bastante empíricas e subjetivas, não há uma “receita” infalível para dizer
inequivocamente que a autocorrelação existe ou não.
O teste das carreiras (também conhecido com teste de Geary ou teste de Wald‐Wolfowitz) é um
teste de aleatoriedade, e será aplicado aos resíduos do modelo. Ele se baseia no sinal dos resíduos
da regressão. Lembre‐se que os resíduos têm média zero, e assim o que o teste verifica é se os
padrões de resíduos acima e abaixo da média (zero) são aleatórios. O teste pode ser estendido a
séries com médias diferentes de zero, basta aplicar o teste à série com a média subtraída.
No caso da regressão (12.5.1) existem 40 resíduos, que apresentam o seguinte padrão:
9 resíduos negativos
21 resíduos positivos
10 resíduos negativos
Definição (“carreira”)
Uma carreira (“run”) é uma sequência ininterrupta de resultados com o mesmo sinal. A extensão
da carreira é o número de elementos que a compõem. No caso dos resíduos da regressão (12.5.1)
existem 3 carreiras, a primeira de extensão (comprimento) 9, a segunda de comprimento 21 e a
terceira de comprimento 10. Será que estas 3 carreiras se comportam mais ou menos da mesma
forma que uma sequência de 3 carreiras de 40 observações aleatórias?
Sejam:
N = número total de observações = N1 + N2
N1 = número de sinais positivos
N2 = número de sinais negativos
R = número de carreiras

146Econometria – Semestre 2010.01 146
P r o f e s s o r a M ô n i c a B a r r o s ENCE
Considere a hipótese nula de que os resultados sucessivos são independentes. Suponha que
AMBOS N1 e N2 > 10. Nestas condições, o número de carreiras ® é assintoticamente Normal com
média e variância:
Sob a hipótese nula de aleatoriedade e usando um intervalo de confiança 95% então:
{ } 95,0.96,1)(.96,1)(Pr =+≤≤− RR RERRE σσ (12.6.3)
Ou seja, R está no intervalo descrito acima com 95% de probabilidade. Logo, REJEITA‐SE A
HIPÓTESE DE ALEATORIEDADE DAS CARREIRAS (COM NÍVEL 5%) SE O INTERVALO DESCRITO EM
(12.6.3) NÃO CONTÉM R.
No s resíduos da regressão (12.5.1), N1 = 21, N2 = 19, N = 21 19 = 40 e R = 3. Então:
95,20140
)19)(21(2)( =+== REμ (ATENÇÃO – CORRIGIR O VALOR NO GUJARATI)
( )( )( )( ) ( )
( )22
2 3,11349,693662400604884
394040)19)(21(219212
===−
=rσ
Logo, o IC 95% para R é:
(20,95 – 1,96*3,11, 20,95 + 1,96*3,11) = (14,85, 27,05) que obviamente não inclui R = 3.
Logo, rejeitamos a hipótese de que os resíduos da regressão (12.5.1) são aleatórios, ou sejam, eles
apresentam algum tipo de comportamento sistemático.
Nota
O teste apresentado é válido quando ambos N1 e N2 > 10. Swed e Eisenhart elaboraram tabelas
para valores menores que estes. As tabelas estão no apêndice D.6 de Gujarati e são reproduzidas a
seguir. As tabelas D.6A e D.6B fornecem o número crítico n de carreiras. Se n é menor que o valor

147Econometria – Semestre 2010.01 147
P r o f e s s o r a M ô n i c a B a r r o s ENCE
em D.6A ou maior que o valor em D.6B, rejeita‐se a hipótese de aleatoriedade ao nível
5%.
Por exemplo, suponha que existem N = 30 observações, das quais N1=20 são positivas e N2=10
são negativas. Então, se olharmos para as tabelas anteriores, rejeita‐se a hipótese de
aleatoriedade se R <= 9 (tabela D.6A) ou R => 20 (tabela D.6B).