Download - Conteúdo Mendel DepartamentodeGenética 4
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
LGN5830 - Biometria de Marcadores GenéticosTópico 3: Mapas Genéticos ISegregação Mendeliana
Antonio Augusto Franco Garciahttp://[email protected]
Departamento de GenéticaESALQ/USP
2019
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Conteúdo
1 Introdução ao MapeamentoHistóriaMapas modernos
2 Teste de SegregaçãoTestes de Hipótesesp-valoresTeste de Aderência
3 Múltiplos TestesPrincípiosCorreção de BonferroniFalse Discovery Rate (FDR)
4 Referências
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
História
Mendel
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
História
Sturtevant, 1913Primeiro mapa genético
0 1.0 30.7 33.7 57.6
B C P R M
O

Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Mapas modernos
Populações baseadas em linhagens
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Mapas modernos
F1’s de genitores não-endogâmicos
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Mapas modernos
MarcadoresSNPs, indels, SSR, ...
Marcadores tradicionais (RFLP, RAPD, AFLP, SSR, ...)
SNPs (chips, Sequenom, GBS, ...)
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Testes de Hipóteses
EtapasCartoon Guide to Statistics
Hipóteses

Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Testes de Hipóteses
EtapasCartoon Guide to Statistics
Estatística do Teste
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Testes de Hipóteses
EtapasCartoon Guide to Statistics
Obtenha o p-valor
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Testes de Hipóteses
EtapasCartoon Guide to Statistics
Tome a decisão
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Testes de Hipóteses
Teste t
Exemplo: Diferença entre duas médias
Uma população homogênea foi genotipada com ummarcadordominante
Deseja-se saber se o peso dos indivíduos é diferente em função dogenótipo do marcador (presença/ausência)
Dados:
µ1 = 17.5 n1 = 20 σ21 = 7.4
µ2 = 15.0 n2 = 18 σ22 = 6.9
H0: µ1 = µ2 vsHa: µ1 ̸= µ2
Estatística:t =
µ1 − µ2√σ21
n1+
σ22
n2

Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Testes de Hipóteses
Teste t
Exemplo: Diferença entre duas médias
µ1 = 17.5 n1 = 20 σ21 = 7.4
µ2 = 15.0 n2 = 18 σ22 = 6.9
tobs = 2.88, t0.05; 36 = 2.028
Conclusão?
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Testes de Hipóteses
Simulação
População com µ = 16 e σ2 = 7.15 (distribuição normal)10000 pares de amostras (com reposição) com n1 = 20 e n2 = 18Estatística t para cada par de amostras
2.5% 97.5%−2.040624 2.023649
Simulações
−4 −2 0 2 4
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
p-valores
Decisão
Neyman-Pearson: significativo ou não-significativo (comparaçãocom o nível de significância)
Fisher: uso dos p-valores
p-valor
Muito usado em Genética (e várias outras áreas), mas possuiinterpretação e significado pouco intuitivos.
Fisher nunca disse explicitamente como os cientistas deveminterpretar o p-valor
Fisher: “. . . below p of 0.01 one can declare an effect (that is –significance), above 0.2 not (that is – insignificant), and in-betweenit might be smart to do another experiment.”
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
p-valores
Testes de Hipóteses
Abordagem frequentista: uso do p-valor e do α como evidênciaspara se testar uma dada hipótese
Para se testar hipóteses científicas, geralmente dois modelos sãocomparados: H0: θ = 0 eH1: θ ̸= 0
Testes estatísticos são realizados para medir desvios da hipótese denulidade
Há muita confusão na literatura sobre p e α
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
p-valores
Testes de Hipóteses
VERDADEIRO OU FALSO?
(1) O p-valor é a probabilidade de estar errado casoH0 sejaverdadeiroFALSO! Esta é a definição de α
(2) O p-valor é a probabilidade observar falsos positivosFALSO!
(3) Se LOD = 3, o p-valor é igual a 10−3
FALSO!
FIQUE ATENTO! Um erro muito comum é assumir que α é o p-valorobservado
SÃO EQUIVALENTES: falsa descoberta (false discovery), erro tipo I, falsopositivo
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
p-valores
Testes de Hipóteses
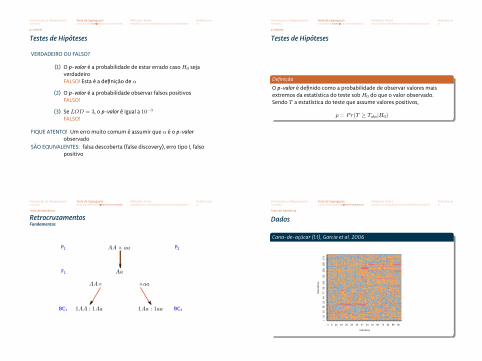
Definição
O p-valor é definido como a probabilidade de observar valores maisextremos da estatística do teste sobH0 do que o valor observado.Sendo T a estatística do teste que assume valores positivos,
p = Pr(T ≥ Tobs|H0)
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Teste de Aderência
RetrocruzamentosFundamentos
P1 P2
F1
BC1 BC2
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Teste de Aderência
Dados
Cana-de-açúcar (1:1), Garcia et al. 2006
1 6 12 19 26 33 40 47 54 61 68 75 82 89 961
1225
3851
6477
9010
512
213
915
617
3
Indivíduos
Mar
cado
res
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Teste de Aderência
Retrocruzamentos
AA Aa
Freq. esperada 1/2 1/2n. esp. n/2 n/2n. obs. n1 n2
χ2 =∑ (n.obs− n.esp)2
n.esp=
(n1 − n/2)2
n/2+
(n2 − n/2)2
n/2=
=(n1 − n2)
2
n∼ χ2
1
Quantos GLs?
1 (para θ = 1/2)
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Teste de Aderência
Retrocruzamento
Faça o teste da segregação mendeliana para um dos marcadores
Exercício - Mouse data (RC)1 1 1 1 1 1 1 1 1 1 1 1 1 1 12 1 1 1 1 1 1 1 1 1 1 1 1 1 03 0 1 1 1 1 1 1 1 1 1 1 1 1 14 0 0 0 0 0 0 0 0 0 0 0 0 0 0
...100 1 1 1 1 0 0 0 0 0 0 0 0 0 0101 1 1 1 0 0 0 0 0 0 0 0 0 0 0102 0 0 0 0 0 0 0 0 0 0 0 0 0 1103 1 0 0 0 0 0 0 0 0 0 0 0 0 0
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Teste de Aderência
Distribuição de frequências
0 1
Marcador M1
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Teste de Aderência
Resultados usando o R
chi.square p.valor[1,] 4.281553398 0.03852812[2,] 3.504854369 0.06118923[3,] 2.805825243 0.09392250[4,] 3.504854369 0.06118923[5,] 2.805825243 0.09392250[6,] 2.184466019 0.13940941[7,] 1.640776699 0.20021894[8,] 0.242718447 0.62224957[9,] 0.087378641 0.76753650[10,] 0.087378641 0.76753650[11,] 0.087378641 0.76753650[12,] 0.009708738 0.92150913[13,] 0.786407767 0.37518855[14,] 0.242718447 0.62224957

Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Teste de Aderência
Populações F2Fundamentos
P1 P2
F1
F2
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Teste de Aderência
Dados
Milho (1:2:1), Sibov et al. 2003
1 22 47 72 97 125 157 189 221 253 285 317 349 381
17
1423
3241
5059
6877
8695
105
116
Indivíduos
Mar
cado
res
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Teste de Aderência
F2
AA Aa aa
Freq. esperada 1/4 1/2 1/4n. esp. n/4 n/2 n/4n. obs. n1 n2 n3
χ2 =∑ (n.obs− n.esp)2
n.esp=
(n1 − n/4)2
n/4+
(n2 − n/2)2
n/2+
+(n3 − n/4)2
n/4∼ χ2
2
Quantos GL?
Dois: θ1 e θ2 (multinomial)
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Teste de Aderência
RILsCampos et al., 2011
0 100 200 300
Individual
Mark
er
Genotype
-
AA
BB

Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Teste de Aderência
RILs
AA aa
Freq. esperada 1/2 1/2n. esp. n/2 n/2n. obs. n1 n2
χ2 =∑ (n.obs− n.esp)2
n.esp=
(n1 − n2)2
n∼ χ2
1
1 GL
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Princípios
Polvo Paul
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Princípios
Acaso?
Qual a probabilidade de observar este evento (excluindo empates)?(12
)81 em 256
A fama do polvo começou após acertar o resultado de Alemanha vsInglaterraPorém, com 178 indivíduos, há grande chance de alguém acertar oresultado de uma série de 8 jogos
Qual a probabilidade de encontrar duas pessoas que fazem aniversáriona mesma data, numa sala com pessoas tomadas ao acaso?Com 57 pessoas, a probabilidade é 99%! (http://goo.gl/5irBA)
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Princípios
Copa de 2018https://bit.ly/2FWaStZ

Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Princípios
Copa de 2018
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Princípios
Copa de 2018
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Princípios
Copa de 2018
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Princípios
Copa de 2018

Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Princípios
Copa de 2018
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Princípios
Múltiplos Testes
Mapeamento Genético: normalmente, os testes são realizadosrepetidas vezes
1− α: probab. de não cometer erro tipo I em um teste
(1− α)m: prob. de não cometer erro tipo I nosm testes
Note que estamos assumindo que osm testes são independentes
α∗: erro conjunto tipo I
Logo, 1− α∗ = (1− α)m e α∗ = 1− (1− α)m
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Princípios
Múltiplos Testes
Exemplo - Mouse Datam = 14
α = 0.05
Qual a probabilidade de ocorrer pelo menos um falso positivo nos 14testes?
Resp.: α∗ = 0.51
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Princípios
Múltiplos Testes
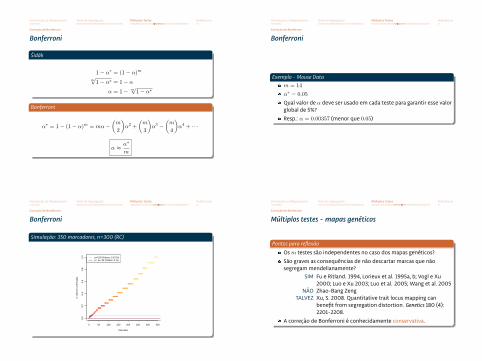
Simulação: 350 marcadores, n=300 (RC)
ooooooooooooo
ooooooooooooooooo
ooooooooooooooo
ooooooooooooooooooooooooooooooooooo
oooooooooooooooooooo
oooooooooooooooooooooo
oooooooooooooooooooooooo
ooooooooooooooooooooooooo
ooooooooooooooooooooooooooo
oooooooooooooooooooooooooooo
oooooooooooooooooooooooo
oooooooooooooooooooooooo
ooooooooooooooooooooooooo
ooooooooooooooooooooooooooooooooo
oooooooooooooooooo
0 50 100 150 200 250 300 3500.
00.
20.
40.
60.
81.
0
Marcador
p−va
lore
s or
dena
dos
p=0.05 (Falsos: 5.43 %)
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Correção de Bonferroni
Bonferroni
Šidák
1− α∗ = (1− α)m
m√1− α∗ = 1− α
α = 1− m√1− α∗
Bonferroni
α∗ = 1− (1− α)m = mα−(m
2
)α2 +
(m
3
)α3 −
(m
4
)α4 + · · ·
α ≈ α∗
m
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Correção de Bonferroni
Bonferroni
Exemplo - Mouse Datam = 14
α∗ = 0.05
Qual valor de α deve ser usado em cada teste para garantir esse valorglobal de 5%?
Resp.: α = 0.00357 (menor que 0.05)
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Correção de Bonferroni
Bonferroni
Simulação: 350 marcadores, n=300 (RC)
ooooooooooooo
ooooooooooooooooo
ooooooooooooooo
ooooooooooooooooooooooooooooooooooo
oooooooooooooooooooo
oooooooooooooooooooooo
oooooooooooooooooooooooo
ooooooooooooooooooooooooo
ooooooooooooooooooooooooooo
oooooooooooooooooooooooooooo
oooooooooooooooooooooooo
oooooooooooooooooooooooo
ooooooooooooooooooooooooo
ooooooooooooooooooooooooooooooooo
oooooooooooooooooo
0 50 100 150 200 250 300 350
0.0
0.2
0.4
0.6
0.8
1.0
Marcador
p−va
lore
s or
dena
dos
p=0.05 (Falsos: 5.43 %)p= 1e−04 (Falsos: 0 %)
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Correção de Bonferroni
Múltiplos testes - mapas genéticos
Pontos para reflexão
Osm testes são independentes no caso dos mapas genéticos?
São graves as consequências de não descartar marcas que nãosegregammendelianamente?
SIM Fu e Ritland. 1994, Lorieux et al. 1995a, b; Vogl e Xu2000; Luo e Xu 2003; Luo et al. 2005; Wang et al. 2005
NÃO Zhao-Bang ZengTALVEZ Xu, S. 2008. Quantitative trait locus mapping can
benefit from segregation distortion. Genetics 180 (4):2201-2208.
A correção de Bonferroni é conhecidamente conservativa.

Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Correção de Bonferroni
“Naive approach” para mapas genéticos
Assumindo independência condicional (propriedade markoviana)
M1,M2, . . . ,Mi︸ ︷︷ ︸37.5 cM
,Mi+1,Mi+2, . . . ,Mm︸ ︷︷ ︸37.5 cM
M1,M2, . . . ,Mi︸ ︷︷ ︸(1− α) · 1 . . . · 1
,Mi+1,Mi+2, . . . ,Mm︸ ︷︷ ︸(1− α) · 1 . . . · 1
1− α∗ = (1− α)2 = (1− α)m∗
Número de Testes
m∗ =L
37.5
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
Razão de Falsas Descobertas (FDR)
False Discovery Rate: alternativa para controle do erro tipo I
Seu uso é frequente em experimentos de expressão gênica, SNPs(genômica), etc (e várias outras áreas)
Motivação: usar α = 0.05 (ou α = 0.01) fornece muitos falsopositivos; usar α∗ elimina muitos positivos verdadeiros
Princípio: dados os resultados significativos, determina-se quantosdeles (proporção) são verdadeiramente significativos (1− FDR)
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
Resultados possíveis
m p-valores
Signif. Não signif. Total
H0 verdadeiro F m0 − F m0
Ha verdadeiro T m1 − T m1
Total S m− S m
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
Signif. Não signif. Total
H0 verdadeiro F m0 − F m0Ha verdadeiro T m1 − T m1Total S m − S m
Definição
FDR: É a proporção esperada de falsas descobertas dentre as hipótesesH0
rejeitadas
n. falsos positivosn. testes significativos
=F
F + T=
F
S
FDR = E
[F
F + T
]= E
[F
S
]

Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
FDR
Signif. Não signif. Total
H0 verdadeiro F m0 − F m0Ha verdadeiro T m1 − T m1Total S m − S m
Seja t o threshold (limiar) usado para considerar os p-valores comosignificativos (0 < t ≤ 1)Parammuito grande (p. ex., milhares):
FDR(t) = E
[F (t)
S(t)
]≈ E[F (t)]
E[S(t)]
Uma estimativa de E[S(t)] é o número S(t) observado (isto é, onúmero observado de p-valoresmenores ou iguais a t)E[F (t)] = m0.t
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
FDR
Signif. Não signif. Total
H0 verdadeiro F m0 − F m0Ha verdadeiro T m1 − T m1Total S m − S m
Note quem0 não é conhecido!
É usual considerar π0 = m0/m, e nãom0 (fácil interpretação)
Estimativa do FDR
F̂DR(t) =m0.t
S(t)=
π̂0m.t
S(t)
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
FDR
π0 =m0m : pode ser estimado com base na distribuição dos p-valores
sobH0
Simulação - 350 locos (1:1) sobH0
ooooooooooooo
ooooooooooooooooo
ooooooooooooooo
ooooooooooooooooooooooooooooooooooo
oooooooooooooooooooo
oooooooooooooooooooooo
oooooooooooooooooooooooo
ooooooooooooooooooooooooo
ooooooooooooooooooooooooooo
oooooooooooooooooooooooooooo
oooooooooooooooooooooooo
oooooooooooooooooooooooo
ooooooooooooooooooooooooo
ooooooooooooooooooooooooooooooooo
oooooooooooooooooo
0 50 100 150 200 250 300 350
0.0
0.2
0.4
0.6
0.8
1.0
Marcador
p−va
lore
s or
dena
dos
p=0.05 (Falsos: 5.43 %)p= 1e−04 (Falsos: 0 %)
p−valor
Fre
quên
cia
0.0 0.2 0.4 0.6 0.8 1.0
020
4060
80
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
FDR
Cálculo
F̂DR(t) =π̂0m.t
S(t)
t =F̂DR(t).S(t)
π̂0m

Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
Simulação
100 ind., 5000 marc. (3500 1:1 e 1500 3:1), teste para 1:1
ooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
ooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
ooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
oooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
oooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
ooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
oooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
oooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
oooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
oooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
0 1000 2000 3000 4000 5000
0.0
0.2
0.4
0.6
0.8
1.0
Marcador
p−va
lore
s or
dena
dos
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●
●●●●●●●●●
●
p=0.05 (1:1) rej.: 5.63 %Bonf. (1:1) rej.: 0 %FDR (1:1) rej.: 1.57 %
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
π0
p-valores
p−valor
Fre
quênci
a
0.0 0.2 0.4 0.6 0.8 1.0
0500
1000
1500
2000
Estimativas de π0Análise visualπ̂0 =
0.8×7500.2×2200+0.8×750 = 0.59
Software Q-VALUEhttp://genomine.org/qvalue/library(qvalue)q. <- qvalue(X[,1])q.$pi0[1] 0.5648856$qvalues
[1] 1.756017e-11 9.618898e-11 ......
Valor Real
π0 =m0m = 3500
3500+1500 = 0.70
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
FDR vs Erro Tipo I
Signif. Não signif. Total
H0 verdadeiro F m0 − F m0Ha verdadeiro T m1 − T m1Total S m − S m
Erro Tipo I:II
II+III
FDR: III+II
Comparação
t =FDR(t).i
π0m
α =α∗
m
Atenção
FDR é conservativo
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
Dados reais
Hedenfalk et al. 2001
Expressão diferencial de 3226 genes (câncer)
Usando p-valor 0.001 para determinar significância, encontraram 51genes diferencialmente expressos (sugestivos), sendo apenas 9-11deles tomados como diferencialmente expressos
Com base nos q-valores (limiar 0.05), Storey e Tibshirani (2003)encontraram evidências de que 160 genes são diferencialmenteexpressos (sendo que cerca de 8 desses 160 possivelmente sejamfalsos positivos)

Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
False Discovery Rate (FDR)
Considerações Finais
Alguns pontos
FDR: balanço entre o número de falsos positivos e o número depositivos verdadeiros
Interessante para estudos exploratórios (ex: expressão gênica), emque não faz sentido preocupar-se em demasia com os genes sobH0
Não é recomendado para mapas genéticos ou QTLs (!)
Pode ser interessante para Mapeamento Associativo
Trabalhos recentes consideram o problema da dependência dostestes (discutiremos oportunamente)
Introdução ao Mapeamento Teste de Segregação Múltiplos Testes Referências
Principais Referências
Storey, John D.; Tibshirani, RobertStatistical significance for genomewide studiesProc. Nat. Acad. Sci. 100: 9440-9445, 2003
Storey, John D.False Discovery RatesInternational Encyclopedia of Statistical Science 1: 504-508, 2011
Käll, L.; Storey, J. D.; MacCoss, M. J.; Noble, W. S.Posterior error probabilities and false discovery rates: two sides ofthe same coinJournal of Proteome Research 7: 40-44, 2008







