
Capa

Folha de Rosto

Sumário Capa....................................................................................................................................... 1 Folha de Rosto ....................................................................................................................... 2 Resumo .................................................................................................................................. 3 Sumário.................................................................................................................................. 4 1. Introdução........................................................................................................................... 5
1.1. Justificativa................................................................................................................. 7 1.2. Objetivo ....................................................................................................................... 7
1.2.1. Objetivo Geral ...................................................................................................... 7 1.2.2. Objetivos Específicos .......................................................................................... 7
1.3. Metodologia................................................................................................................. 8 2. Conceitos Aplicados sobre grafos ...................................................................................... 9
2.1. Conceitos Gerais.......................................................................................................... 9 2.1.1. Definição Geral de um Grafo ............................................................................... 9 2.1.2. Caminhos.............................................................................................................. 9 2.1.3. Circuitos ............................................................................................................. 10 2.1.4. Homomorfismo................................................................................................... 10 2.1.5. Isomorfismo........................................................................................................ 11 2.1.6. Grafos Bipartidos................................................................................................ 11 2.1.7. Grafos Aleatórios............................................................................................... 12
2.2. Conceitos aplicados ao grafo da web ........................................................................ 13 2.2.1. Características do Grafo da Web........................................................................ 13 2.2.2. Teoria do Mundo Pequeno ................................................................................ 13 2.2.3. Clustering ........................................................................................................... 14 2.2.4. Propriedade de quase todos os grafos................................................................. 15
3. Algoritmos observados..................................................................................................... 16 3.1. Busca em Largura..................................................................................................... 16 3.2. Classificação.............................................................................................................. 17 3.3. Enumeração de Enunciados...................................................................................... 17 3.4. Procura de tópicos .................................................................................................... 20
4. Estudo Realizado .............................................................................................................. 21 4.1. Objetivo ..................................................................................................................... 21 4.2. Algoritmo .................................................................................................................. 22
4.2.1. Estrutura de Dados ............................................................................................. 22 4.2.2. Descarga das páginas ........................................................................................ 24
4.3. Resultados.................................................................................................................. 25 4.4. Conclusões................................................................................................................. 26
5. Conclusão Geral ............................................................................................................... 27 6. Referências ....................................................................................................................... 29
6.1. Bibliográfica .............................................................................................................. 29 6.2. Sitologia..................................................................................................................... 30

1. Introdução
A popularização da internet, e a queda do preço de acesso à rede de computadores
proporcionou e proporciona um crescimento exponencial do número de internautas.
Uma conseqüência lógica estimulado a esse crescimento foi à explosão de páginas na
internet juntamente com seus hiperlinks que servem como uma ponte entre as páginas em
geral.
Esta característica de crescimento, até certo ponto, desenfreado, acrescido ao interesse
mundial pela facilidade que a web pode fornecer em termos de versatilidade e conteúdo
transformou a web em uma estrutura de dados um tanto quanto indefinível. Isso ocorre
devido ao seu gigantesco tamanho e a sua constante mudança. Proporcionados pela
facilidade com que é possível realizar alterações nas características da internet. Por
exemplo: sítios que saem do ar, hiperlinks novos, sítios desconectados, sítios que deixam
de fazer circuitos, indisponibilidade de servidores hospedeiros de sites, etc.
Portanto, a internet chegou a um ponto onde é extremamente difícil generalizar
qualquer tipo de caso.
Sobre esta perspectiva este estudo visa uma forma de verificar uma solução no sentido
de estudo da internet como um todo.
O primeiro passo para isto é a definição de uma estrutura de dados que permita uma
característica semelhante ao grafo da web e a estrutura de dados mais adequada existente na
informática que permite tal simulação é o grafo, o conhecido grafo da web.
Um grafo comum é um conjunto de pontos, chamados vértices (ou nodos ou nós),
conectados por linhas, chamadas de arestas (ou arcos).
Grafo é definido por um par ordenado de conjuntos (V,E) tal que V é um conjunto
finito de vértices do grafo. E é formado por subconjuntos cada qual contendo dois
elementos de E. Este subgrupo conhecido como arestas. [Jair Dornelles]
Dependendo da aplicação, arestas podem ou não ter direção, pode ser permitido ou não
arestas ligarem um vértice a ele próprio e vértices e/ou arestas podem ter um peso

(numérico) associado. Se as arestas têm uma direção associada (indicada por uma seta na
representação gráfica) tem-se um grafo direcionado, ou dígrafo.
Devido às características mencionadas acima é possível realizar uma analogia de grafos
comuns com a web.
Considere a internet um conjunto W contendo dois subconjuntos L e S. O subconjunto
S, onde estão presentes os sítios que compõe a internet. E um outro conjunto L, no qual seja
formado por duplas de elementos de S, chamados de hiperlinks da web. Onde cada
elemento de W seja formado por uma união de elementos de S por meio de elementos de L.
Porém, essa definição, apesar de respeitar as características do grafo, possui uma
infinidade de características particulares.
Considerando esse conjunto W = (S,L); igualmente um grafo comum, o conjunto de
vértices de S é finito, entretanto, pode ser considerado como sendo infinito. Essa
característica se deve a constante mutação que o grafo da web sofre. Ou seja, mesmo que se
extraia uma amostra total da web, com todos os seus sítios e links, no momento exatamente
posterior essa fotografia já pode estar desatualizada, perdendo assim todo o seu significado
para a analise matemática de suas características.[Mark Levene, André Guedes].
Devido à característica mencionada anteriormente é preferível estudar o grafo da web
“em pedaços”, sub-grafos, tornando assim seu estudo mais coerente e com resultados mais
plausíveis para a realidade humana.

1.1. Justificativa
O presente estudo pretende identificar as características do grafo da web, determinando
assim um processo pelo qual seja possível extrair estatísticas, que possa servir para
inúmeros objetivos.
Este processo será feito tendo sempre em vista as limitações que o próprio estudo impõe
a uma definição mais específica, ou seja, devido ao tamanho que a internet tem e suas
peculiaridades esse estudo se faz ao mesmo tempo necessário e difícil.
Portanto, este estudo tem como motivação uma necessidade crescente, a dificuldade de
conseguir medir e construir uma estrutura para a internet sem levar em conta a sua
versatilidade, dinâmica e a abstração de dados que esse estudo determina.
1.2. Objetivo
1.2.1. Objetivo Geral
Estudar as características gerais do grafo da web e desenvolver um algoritmo que possa
ser aplicado na internet.
1.2.2. Objetivos Específicos
� Estudar teoremas aplicados a grafos comuns;
� Estudar teoremas de matemática discreta que possam ser aplicadas a grafos de web;
� Pesquisar algoritmos já desenvolvidos para a internet;
� Desenvolver a própria solução que possibilite a determinação de estatísticas no
grafo da web.

1.3. Metodologia
Para cumprir os objetivos propostos para este estudo, foi definido um processo
metodológico, que tem por objetivo provar a necessidade das informações geradas e sua
utilidade de uma forma geral, essa metodologia consiste em:
� Pesquisar conceitos relacionados a grafos;
� Pesquisar características da internet;
� Pesquisar a respeito de algoritmos existentes para a web;
� Desenvolver um web crowler que possa extrair características de um sub grafo da
web.

2. Conceitos Aplicados sobre grafos
2.1. Conceitos Gerais
Os conceitos apresentados nessa seção servem de base para o estudo do grafo da web de
uma maneira geral em seu conjunto total e ao mesmo tempo específica com relação aos
seus sub-grafos.
2.1.1. Definição Geral de um Grafo
Esta seção tem como objetivo formalizar uma definição de grafo, o qual será utilizado
em várias outras partes da monografia como um todo.
Um grafo é formado por um par ordenado de dois conjuntos, conjunto S dos vértices e o
conjunto L das arestas. O qual é definido como uma estrutura de dados a partir da
interligação dos vértices através das arestas.
Por definição geral do trabalho, considera-se um Grafo W = (S,L); W é um conjunto
que possui um par de conjuntos S e L já definidos anteriormente.
2.1.2. Caminhos
Um caminho é uma seqüência de vértices tal que de cada um dos vértices existe uma
aresta para o vértice seguinte. Um caminho é chamado simples se nenhum dos vértices no
caminho se repete. Ou seja, um caminho de comprimento k de um vértice x até um vértice
y, onde x e y pertencem a E. Esse caminho corresponde a uma seqüência de vértices (v0,
v1, v2, ..., vk) onde v0 = x e vk = y. O comprimento do caminho é o número de arestas
nele, o caminho contem os vértices v0, v1, v2, ...., vk e as arestas (v0,v1); (v1,v2); ....;(vk-
1,vk).
Existem dois tipos básicos de grafos, os grafos direcionados e os não direcionados,
ambos serão abordados no decorrer do estudo.

Grafos não direcionados, não existem um caminho determinado a seguir, ou seja, a
ordem da seqüência dos vértices com arestas não importa para a determinação do caminho.
Enquanto isso, grafos direcionados possuem direcionamento em suas arestas, ou seja, a
ordem de aparecimento da seqüência de vértices e arestas faz diferença na determinação do
caminho.
Figura1. Exemplo caminho em grafo.
Fonte: http://www.inf.ufpr.br/andre/Disciplinas/BSc/CI065/michel/Intro/grafo_dir_iso.gif (30/07/2007)
É notável a diferença entre o grafo direcionado (a) e o grafo não direcionado (b) com
relação aos seus caminhos, por exemplo no grafo (b) um caminho possível entre os vértices
A e D seria (A1C2D) ou (A3B4D). Enquanto, por sua vez o grafo (a) teria uma única opção
de caminho entre A e D (A3B4D), devido ao direcionamento de suas arestas.
2.1.3. Circuitos
Um ciclo (ou circuito) é um caminho que começa e acaba com o mesmo vértice. Ciclos
de comprimento um são laços. No grafo de exemplo, (a, c, e, f, d, b, a) é um ciclo de
comprimento seis. Um ciclo simples é um ciclo que tem um comprimento pelo menos de 3
e no qual o vértice inicial só aparece mais uma vez, como vértice final, e os outros vértices
aparecem só uma vez. No grafo acima, (a, c, d, b, a) é um ciclo simples. Um grafo chama-
se acíclico se não contém ciclos simples.

Figura2. Exemplo de grafo com circuito. Fonte:
http://www.professeurs.polymtl.ca/michel.gagnon/Disciplinas/Bac/Grafos/EulerHam/euler_ham.html (30/07/2007)
2.1.4. Isomorfismo
Dizemos que um grafo é isomorfo a outro se é possível escrever uma função bijetora
que consiga traduzir um grafo em outro, ou seja, isso ocorre quando um sub grafo induzido
possui a mesma quantidade de vértices e esses vértices por suas vezes possuem o mesmo
número de graus em ambos os grafos, então pode se dizer que o isomorfismo, indica dois
grafos que possuem características muito semelhantes em termos de conexidade e
disposição “física” ou lógica no caso da internet.
2.1.5. Grafos Bipartidos
Grafos bipartidos são grafos que possuem dois grupos de arestas, as quais não possuem
interligações entre elementos pertencentes ao mesmo grupo, sobrando somente ligações
entre os grupos de uma forma geral.
Considera-se uma variação do Grafo G, na qual o seu subconjunto de vértices V, seja a
união de outros dois subconjuntos P e Q, ou seja, P U Q = V, sendo que |P| + |Q| = |V|. E
não possuam arestas dentro destes subconjuntos, então temos que E(P) = E(Q) = 0. Embora
E(G) >= 0.
Figura 3. Exemplo de grafo bipartido. Fonte: http://www.lmc.fc.ul.pt/~pduarte/tmf/Grafos/Bipartidos.html (12/06/2007)

2.1.6. Grafos Aleatórios
Grafos aleatórios são grafos gerados a partir de um número qualquer de vértices, sobre
as quais são adicionadas arestas através de algum método aleatório, diferentes modelos de
grafos aleatórios produzem diferentes distribuições nos grafos [4].
O processo mais comum para a geração de um grafo aleatório é conhecido por G(n,p); o
qual insere cada aresta de maneira independente com uma probabilidade p que é individual
para cara uma das arestas em questão.
Um segundo processo é conhecido como G(n,M); onde cada aresta possui a mesma
probabilidade de ser inclusa no grafo.
Ambos os processos utilizam processos estocásticos (randômicos), e começam com n
vértices e nenhuma aresta e a cada loop inserem uma aresta de acordo com as arestas
disponíveis e que ainda não pertençam ao grafo.
Modelo de Erdös-Rényi O modelo de Erdös-Rényi é baseado no seguinte grafo aleatório: um grafo com n
vértices fixos e m arestas selecionadas aleatoriamente das M = (n2) das arestas possíveis.
Sendo assim no total existem (Mm) grafos com n vértices e m arestas, o que se pode definir
como um espaço de probabilidade que todo grafo com m vértices tem a possibilidade de
aparecer.
O objetivo deste modelo é responder a uma pergunta normalmente não feita a estruturar
de dados definidos por meio da aleatoriedade, ou seja, definir propriedades em cima de suas
características, e isso se torna possível graças à possibilidade de construir espaços de
probabilidade de uma mesma estrutura aparecer.
O modelo funciona da seguinte maneira: para cada par de vértices pertencente ao grafo
em questão, defini-se um experimento aleatório (por exemplo, jogar um dado),
considerando o resultado desse experimento preponderante para a inserção de uma aresta

no grafo, ou seja, se o experimento atingir algum valor previamente definido para a sua
função aleatória, a aresta é inclusa, caso contrário não.
Portanto, um grafo genérico que atende a esse modelo é definido por Gn,p e é chamado
grafo aleatório com n vértices e probabilidade p. [14]

2.2. Conceitos aplicados ao grafo da web
2.2.1. Características do Grafo da Web
Considere uma variação do Grafo W, pôr nessa definição considere que os vértices são
as páginas que podem ser acessadas pela internet e as arestas sendo os hiperlinks que as
unem.
De acordo com essa analogia podem se aplicar os conceitos mais diversos sobre a
internet, baseados nos conceitos de grafos.
Por outro lado a internet é uma ferramenta global que permite acessos múltiplos e
possibilita alterações de seu meio sem uma metodologia previamente declarada.
Portanto, a internet pode ser considerada um grafo gigantesco, a qual devido a sua
característica principal de acessibilidade com uma mutabilidade instantânea. Promove os
grafos aleatórios como seus representantes mais aproximados, inclusive podendo afirmar
que o método de formação de um grafo aleatório que mais se aproxima à internet é o
W(n,p), pois a probabilidade de cada Hyperlink, existir é individual.
2.2.2. Teoria do Mundo Pequeno
O teorema do mundo pequeno tem como principal objetivo demonstrar que qualquer
duas pessoas espalhadas aleatoriamente possuem uma distância média entre si, a qual pode
ser calculada.
Um estudo realizado em 1967, o sociólogo Stanley Milgram apresentou um resultado:
foi preciso, em geral, entre duas a dez pessoas para alcançar o objetivo, uma média de seis
pessoas, aos tais Seis Graus de separação.
Apesar deste comportamento apresentado, essa teoria não apresenta uma organização
propriamente dita. Posteriormente Erdös e Rényi demonstraram que a distância típica entre
qualquer dois vértices de um grafo qualquer é o logaritmo do tamanho do grafo.
Portanto, aproveitando a definição do grafo da web apresentada à cima, é possível
constatar que a internet adquiriu esta característica por simples indução, ou seja, a distância

entre duas páginas aleatórias na internet é aproximadamente em média o logaritmo do
tamanho da própria internet.
2.2.3. Clustering
O Clustering é um processo que tem por objetivo demonstrar de maneira matemática a
tendência natural das pessoas de uma maneira mais geral tem de se agruparem entre seus
semelhantes.
Clustering é uma técnica de mineração de dados, que visa realizar agrupamentos
automáticos de dados segundo seu grau de semelhança. O critério de semelhança faz parte
da definição do problema e, dependendo, do algoritmo.
Em 1998 Watts e Strogatz, proporam um coeficiente de agrupamento, na qual pode
quantificar essa tendência. O qual pode ser determinado da seguinte maneira:
A relação entre o número Ei de arestas que existem entre os d(i) vértices e o número
total de pares de vértices d(i) · (d(i) − 1)/2 dá o valor do coeficiente de agrupamento do
vértice i:
Figura 4. Fórmula da determinação do coeficiente de agrupamento de um vértice i.
Fonte: Ricardo Fabiano Samila Modelos de Grafos Aleatórios e Aplicações, 2005
O coeficiente de agrupamento da rede inteira é a média dos Ci’s de cada vértice.
Ou seja, um cluster em um grafo é um conjunto de nós interligados, nos quais existe
sempre um caminho entre quaisquer dois vértices dentro de um mesmo cluster.
Uma propriedade interessante destes grafos aparece quando medimos a evolução do
tamanho do maior cluster: à medida que se vão fazendo ligações, de inicio o tamanho do

maior cluster vai crescendo muito lentamente, mas a certa altura há uma "transição de fase"
em que o tamanho do maior cluster cresce drasticamente e passa a cobrir quase todo o
grafo. Dai em diante o crescimento volta a ser lento.
2.2.4. Propriedade de quase todos os grafos
A teoria dos grafos aleatórios se utiliza o espaço de probabilidade associado ao grafo
quando o número de seus vértices tende ao infinito.
Uma propriedade de um grafo é uma classe fechada sob isomorfismo, de acordo com o
proposto por Erdös e Rényi, tem-se que uma propriedade P qualquer, onde G Є P,
considerando G como um grafo aleatório do tipo G(n,p), quando a probabilidade p tende a
um então P pertence a quase todos os grafos. De maneira análoga, quando a probabilidade p
tende a zero a propriedade P pertence à quase nenhum grafo.
Este teorema gera dois corolários igualmente interessantes:[14]
Corolário um: Para qualquer número p no intervalo (0,1) e qualquer número natural k,
quase todo grafo em G(n,p) é k-conexo. [15]
Corolário dois: Para qualquer grafo número p no intervalo (0,1) e qualquer grafo H,
quase todo grafo em G(n,p) tem um subgrafo induzido isomorfo a H. [15]

3. Algoritmos Motivadores do estudo
Esta seção tem como objetivo apresentar quatro algoritmos que serviram como
motivação para este estudo.
Os algoritmos apresentados posteriormente se adequar ao modelo do grafo da web e
utilizam os conceitos mencionados anteriormente, e o que os torna interessantes é a maneira
como abordam o grafo da web.
3.1. Busca em Largura
O Algoritmo de Busca em Largura é o algoritmo base nos estudos em grafos, ele está
presente em todos os algoritmos que serão apresentas posteriormente.
O Algoritmo é chamado busca em largura, pois, ele expande a fronteira entre os vértices
descobertos uniformemente por meio da largura da fronteira.
O seu funcionamento pode ser exemplificado da seguinte forma:
Considerando uma variação do grafo W (S,L) e um vértice de origem u, onde u
pertence a S, a busca em largura explora sistematicamente todos os vértices vizinhos de u,
enfileirando eles de acordo com a ordem de aparecimento na busca, isto ocorre até que a
busca abrange todos os vértices vizinhos de u. Posteriormente, se pega o próximo vértice da
fila e repete o processo desconsiderando os vértices já visitados. E isto é feito até que todos
os vértices do grafo tenham sido visitados pela busca.
Por exemplo, considerando o grafo representado pela figura abaixo, a ordem de acesso
dos vértices numerados de acordo com o algoritmo citado seria: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
11, 12.[5]

Figura 5. Ilustração da busca em largura.
Fonte: http://pt.wikipedia.org/wiki/Busca_em_largura (15/06/2007)

3.2. Classificação
O Algoritmo da Classificação, foi originalmente pensado para resolver um problema
muito freqüente na internet: a falta de conteúdo presente nas páginas da internet como um
todo.
Uma prática comum verificada na internet é a fraca quantidade de conteúdo presente
nas páginas da web, isso quando tem. Por outro lado percebe-se a existência de uma
quantidade extremamente grande de hiperlinks, os quais comutados poderiam gerar uma
quantidade bastante razoável do conteúdo pré-determinado, e é exatamente neste ponto que
se encontra a verdadeira riqueza de conteúdo na internet, na quantidade de páginas sobre o
assunto.
Este algoritmo de Classificação visa utilizar conceitos da inteligência artificial,
classificação e clustering, para conseguir produzir conteúdo apropriado.
O algoritmo, chamado Hyperclass funciona da seguinte maneira:
Ao invés de aplicar o conceito de classificação apenas sobre a página p, o algoritmo
considerara toda a vizinhança de p, o método é aplicado a q, onde q pertence à vizinhança
de p, se e somente se q -> p ou p -> q. Sendo assim a cada nova página que o algoritmo
acessa ele pega o conteúdo da página em questão e vai juntando com o conteúdo das
demais. Inclusive se os links estiverem categorizados, o resultado acaba sendo muito mais
preciso.[6]
Portanto, a partir deste algoritmo é possível gerar muito conteúdo sobre um
determinado tema, mesmo que para isso seja necessário visitar inúmeras páginas para que o
objetivo seja alcançado, e no final do processo, a quantidade de páginas acessadas ficaria
inerente ao processo e totalmente oculto ao usuário.[9][10][11][12][13]
3.3. Enumeração de Enunciados
O problema vislumbrado por este algoritmo é a dificuldade presente na web de
determinar comunidades, ou seja, conseguir dividir as páginas semelhantes em
comunidades.

O algoritmo de Enumeração de Enunciados tem como base de seu funcionamento os
conceitos de clustering e da propriedade de quase todos os grafos. O seu funcionamento é
da seguinte forma:
A determinação direta de uma comunidade em um subgrafo na internet, é um processo
extremamente custoso, por exemplo, em um subgrafo o qual contenha páginas com três
links cada, existiriam cerca de 1040 possibilidade de grafos diferentes, para um grafo
original de 108 nodos.
Para evitar esse gasto monstruoso de recurso, o algoritmo, começa raciocinando como
um grafo bipartido, embora isto não seja um requisito, ajuda muito na maneira de pensar do
algoritmo.
A partir disto faz uma busca em largura das páginas deste pedaço da web, alterando a
cada interação a sua disposição espacial. Ao mesmo tempo o algoritmo descobre as páginas
que mais acessam as mesmas outras páginas. Esse processo pode ser visualizado melhor na
figura abaixo:
Figura 6. Figura ilustrativa do algoritmo de Enumeração de Enunciados
Fonte: Artigo: Ravi Kumar, Prabhakar Raghavan, Sridhar Rajagopalan, D. Sivakumar, Andrew Tomkins
e Eli Upfaly: The Web as a graph
Na figura temos a determinação de uma comunidade das maiores empresas de aviação
do mundo, isto ocorreu devido ao número de acessos que o conjunto de páginas que estão à
esquerda realizou sobre o conjunto de páginas à direita.

Portanto, Dado um pedaço da internet, é possível determinar quantos grupos de páginas
semelhantes existem através da utilização do algoritmo de Enumeração de Tópicos. [7][8].

3.4. Procura de tópicos
A enormidade do tamanho da internet se deve ao fato da existência de um número
extremamente grande de páginas, o que por sua vez ocorre devido à facilidade da inclusão
de novas páginas na web. Porem analisando esses aspectos de uma forma mais ampla pode-
se chegar a duas conclusões. Primeira é que dificilmente algum assunto não será encontrado
na internet, e a segunda é a igual dificuldade de conseguir determinar se o dado encontrado
é válido ou não.
Tendo em mente este problema, que talvez seja o maior de todos no que se diz a
respeito da internet, o algoritmo de Procura de tópicos, o qual utiliza os conceitos de
mundos pequenos e clustering, tenta responder.
A idéia do algoritmo é colocar pesos nas arestas do grafo da web, isso é feito devido ao
número de acessos que uma determinada página possui, ou seja, quanto mais referências
uma determinada página possui mais peso a mesma igualmente possui.
Entretanto, esta estratégia não se mostrou muito competente, visto que não existe
nenhuma relação lógica sobre a relação das páginas entre si, ou seja, o que se verificou foi à
existência de páginas com baixa qualidade de conteúdos mais extremamente apontadas por
outras páginas contendo um peso exageradamente alto, e ficando a frente de páginas com
conteúdo comprovadamente correto.
Para solucionar este problema a idéia foi atribuir a órgãos competentes pesos próximos
ao infinito, por exemplo sites de universidades e autoridades possuiriam pesos muito
elevados, o que garantiria um ganho na concorrência com outros sites sem tal denominação.
Esta estratégia possibilitava inclusive que outras páginas que fossem apontadas por estas
páginas confiáveis, também, por sua vez, conseguissem pesos altos, o que certamente seria
viável visto que por ética, nenhuma página confiável apontaria para uma página sem
nenhum valor.
Portanto, a cada referência de uma nova página é executada um algoritmo destes que
por sua vez determina o peso de confiança que determinada página possui, isto é
extremamente útil visto que através deste algoritmo é possível chegar a conteúdos cada vez
mais confiáveis dentro da internet.

4. Estudo Realizado
4.1. Objetivo Baseado no estudo até então feito, padrões e características apresentadas por um Grafo
da Web. Podemos citar como principais características as seguintes: grafo direcionado e
dinâmico, tamanho real desconhecido e extremamente grande, crescimento exponencial do
número de vértices e arestas de acordo com a profundidade, estrutura baseada em strings,
alta localidade espacial determinada por conteúdo, etc. Características que estão presentes
no grafo global, e que portanto devem se manifestam total ou parcialmente, qualquer que
seja o subgrafo do mesmo.
A partir das características antes citadas, projetaremos um robô de busca(web
crawler[4]), para extração de dados relevantes à obtenção de informações referentes ao
Grafo da Web. Dentre os dados foco de nosso estudo podemos citar, taxa de crescimento do
número de vértices de um Grafo da Web em cada nível percorrido dentro do mesmo, esse
representa a taxa de crescimento da web e que utilizaremos para estimar o tamanho
aproximado da cintura do grafo. Contagem do número de domínios encontrados dentre
cada simulação, segundo sua classificação oficial [1], que serve se verificar a existência de
comunidades, subgrafos conexos, informação que é de grande relevância para o
desenvolvimento de mecanismos de busca, para estudos sociológicos,etc.
O robô efetuará uma busca em largura, devido ao enorme tamanho do grafo com
número estimado de páginas superior a 24 bilhões e de hiperlinks de 360 bilhões, a
ferramenta fará a varredura até o 2000º sítio. Esse tamanho foi definido baseado na
capacidade de processamento, estruturas de dados e largura de banda e restrições impostas
pela política interna da rede do Departamento de Informática, para compartilhamento de
recursos. Os sítios iniciais de busca que serão empregados em cada simulação, foram
obtidos de listas públicas da internet.

4.2. Algoritmo
O algoritmo empregado no robô de busca, consiste no seguinte pseudo-código de
busca em largura, seus pontos mais críticos serão discutidos de forma independente, note
que o seguinte pseudo-código é apenas uma pequena variação do algoritmo de busca em
largura, apenas adaptado para o processamento de strings, e não números como
convencionalmente aparece na literatura:
Enfila(string_sítio);
enquanto Tamanho_Grafo < 2000 faça
string_sítio = desenfila();
sítio = Resolve_Nome(string_sítio);
pagina = Download(sítio);
links = Parser(sítio);
para_cada link em links faça
Adiciona_Aresta_Direcionada(sítio,link);
se sítio_Nao_Conhecido(link) então
enfila(link);
fim_se
fim_para
fim_enquanto
4.2.1. Estrutura de Dados
Um dos pontos mais importante a serem abordados, dentro do funcionamento do
algoritmo. A estrutura de armazenamento do grafo, será um primeiro ponto a ser analisado.
O tamanho total estimado para o grafo da web é de 24 bilhões de vértices(páginas) e 360
bilhões de arestas(links). Para se armazenar apenas as url de todos esses sítios, levando-se
em conta um tamanho médio de 20 caracteres seriam de 48 gigabytes. Vez que limitaremos
nosso grafo a 2000, o espaço ocupado não deverá ultrapassar 40 kilobytes. Para o
armazenamento do grafo será utilizado uma matriz, por apresentar um tempo de resposta a
consultas muito pequeno, e também servir de recipiente para o armazenamento do dados
coletados durante a simulação.

Para melhorar o desempenho da estrutura de dados para consulta, não seria possível a
utilização do nome de cada sítio, como chave da estrutura de dados que armazena o grafo.
Como substitutas foram utilizadas chaves MD5[2], provenientes de cada nome. Uma chave
MD5 consiste em um número de 128 bits, ou 16 bytes utilizado para verificar integridade
de arquivos.
Matriz indexada pelos nomes dos sítios
Tabela Hash indexada pela chave MD5, Matriz indexada com a posição indexada armazena o índice da na matriz índices.
Com essa mudança na forma como é feita a indexação da estrutura de dados, o grau
de complexidade do algoritmo passou a ser o mesmo para uma consulta, a uma tabela hash,
o que representa uma complexidade de O(1).
ufp
r.b
r
inf.
ufp
r.b
r
go
vern
o.o
rg.b
r
fun
def.
org
.br
caix
a.b
r
am
eri
can
as.c
om
ufpr.br 0 1 1 0 0 0
inf.ufpr.br 1 0 0 1 0 0
governo.org.br 0 1 0 1 1 0
fundef.org.br 1 1 0 0 0 0
caixa.br 0 0 0 0 0 1
ufpr.br 9613e58dd8fbb035f7ee8a300ba0114e 0
inf.ufpr.br 7d487b49ad464e2d4bdab6ed3f3894f9 1
governo.org.br 89c7fe684299554f6492ef7dd1ccac7b 2
fundef.org.br 55e53c6b05a358dd690022047ac1de88 3
caixa.br C837b66ae31ef4a13d8ed0b7d42a4452 4
americanas.com D45244104b9de8741de4af4d42a44a1 5
0 1 2 3 4 5
0 0 1 1 0 0 0
1 1 0 0 1 0 0
2 0 1 0 1 1 0
3 1 1 0 0 0 0
4 0 0 0 0 0 1
5 0 0 1 1 0 0

4.2.2. Descarga das páginas
O grafo da web se trata de um grafo dinâmico, portanto, o ideal para seu estudo é
que seus dados sejam extraídos o mais rápido possível, para se tentar atenuar os efeitos das
mudanças em sua morfologia. Tal necessidade é equivalente a se tentar tirar uma foto da
web, quão maior for o tempo em que à lente esteja aberta para a captura da imagem, maior
será a probabilidade de ocorram distorções na imagem.
Para que seja efetuada a “montagem” do grafo da web, necessitamos que seja feito à
descarga de cada sítio. Por mais que se tenha uma largura de banda grande, esse processo
deve ocorrer como se os sítios já estivessem na máquina host da simulação.
Esse é o maior limitante para uma simulação desse tipo. Pois há a necessidade de se
resolver o nome do sítio, efetuar conexão com seu respectivo servidor e por fim efetuar o
download. Sempre levando em conta como limitante a velocidade menor dos pontos de
comunicação entre cliente e servidor.
Levando-se em conta um tempo médio de download de cada sítio de 5 segundos,
teríamos em média, um tempo de simulação para 2000 sítios de 10.000 segundos ou 2 horas
e 47 minutos. Para que se extraiam estatísticas é necessário que sejam feitos um número
significativo de simulações. A partir dos resultados obtidos se analisarem padrões dos
grafos e então obter informações significativas ao nosso estudo. Portanto, torna-se
necessário que os passos descritos pelo pseudo-código sejam executados em paralelo,
aumentando assim o número de sítios descarregados por segundo, melhorando
significativamente o desempenho do robô.
Para isso, a estrutura que armazenava até então, apenas os nomes de sítios, passará a
comportar tarefas concorrentes, que efetuam com ilustrado a seguir:
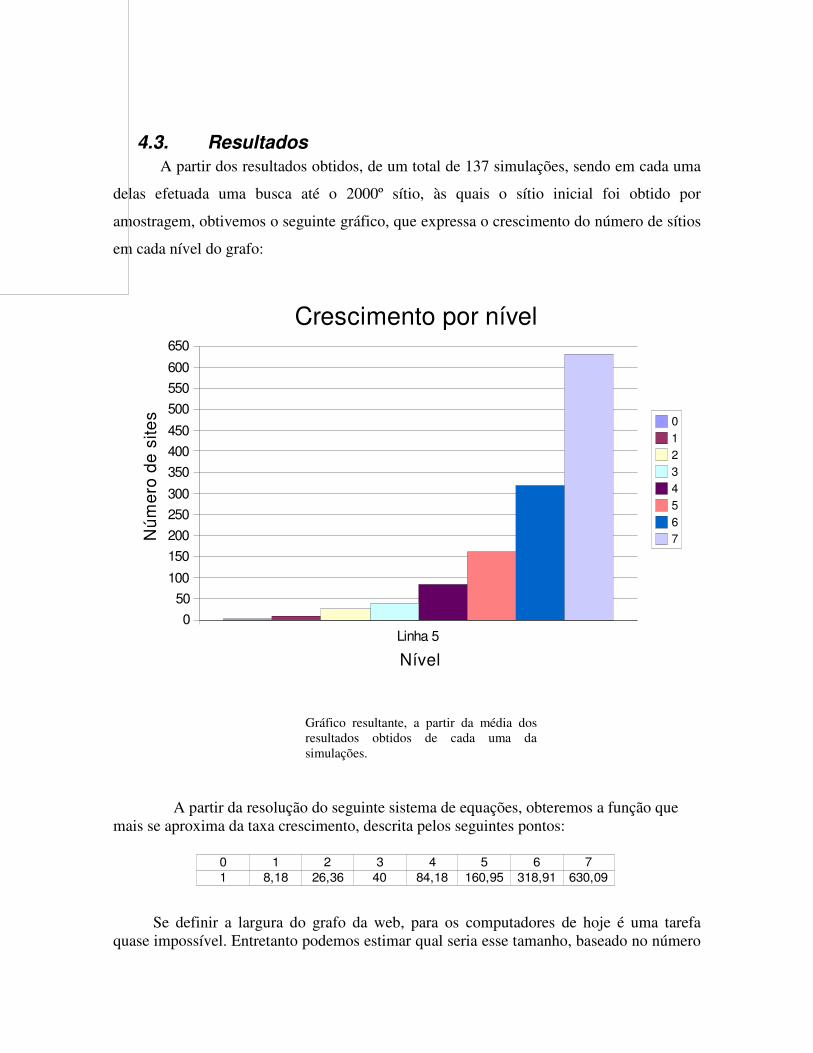
4.3. Resultados A partir dos resultados obtidos, de um total de 137 simulações, sendo em cada uma
delas efetuada uma busca até o 2000º sítio, às quais o sítio inicial foi obtido por
amostragem, obtivemos o seguinte gráfico, que expressa o crescimento do número de sítios
em cada nível do grafo:
Gráfico resultante, a partir da média dos resultados obtidos de cada uma da simulações.
A partir da resolução do seguinte sistema de equações, obteremos a função que mais se aproxima da taxa crescimento, descrita pelos seguintes pontos:
Se definir a largura do grafo da web, para os computadores de hoje é uma tarefa quase impossível. Entretanto podemos estimar qual seria esse tamanho, baseado no número
Linha 5
0
50
100
150
200
250
300
350
400
450
500
550
600
650
Crescimento por nível
0
1
2
3
4
5
6
7
Nível
Nú
me
ro d
e s
ite
s
0 1 2 3 4 5 6 7
1 8,18 26,36 40 84,18 160,95 318,91 630,09

vértices e em uma função baseada nesses pontos, utilizando-se a leis de potência(power
law) de uso muito comum na física.
(X+1)^2.87 X é o nível do grafo
Baseado nessa equação, que descreve o número de páginas em um grafo da web de profundidade X. Podemos estimar a largura do grafo da internet, para um grafo com 24.000.000.000 de páginas.
(X+1)^2.87 = 24.000.000.000
(X+1) = (24.000.000.000)^(1/2.87)
(X+1) = 4138,07
X = 4137
O domínio “http://www.w3.org”, foi o que apresentou um grande número de
refringências dentre todas as simulações. Fato explicado pela grande aceitação da
tecnologia XML, para representação de dados na internet.
Tamanho médio de cada página, sem imagens: 20 Kb Tamanho médio de cada URL: 16 caracteres Grau médio: 5,23 Cintura média: 7,95
Domínios %
.com.br 91,12%
.org.br 2,30%
.gov.br 0,75%
.com 5,83%

4.4. Conclusões
A tarefa de se mensurar a internet, constitui um desafio computacional muito grande
para os computadores atuais. Devido a isso, para se efetuar um estudo, em geral escolhe-se
uma fração do problema para estudo.
O estudo das características do grafo da web, dentre essas: sua taxa de crescimento,
morfologia de comunidades, tecnologias mais utilizadas. Associadas a um processamento
de imagens ou strings, abre-se uma gama de possibilidades para os usuários da rede, dentre
essas podemos citar: mecanismos de busca, mineração de dados(data mining[3]), pesquisas
de opinião, pesquisas de tendências de mercado, etc.
Por se tratar de uma estrutura gigantesca e dinâmica, um grafo da web também sofre
influência em sua morfologia, derivadas da região que se está analisando, de possíveis
indisponibilidades de servidores hospedeiros, indisponibilidade de roteadores, etc. Sendo
assim, torna-se necessário que se façam inúmeras simulações sobre o mesmo espaço
amostra, para se obter um aspecto mais próximo possível da realidade.

5. Conclusão Geral
Ao final do estudo proposto por essa monografia é possível realizar algumas conclusões
a respeito do concerto do grafo da web.
Verificou-se com esse trabalho que qualquer estudo realizado na internet é
extremamente complicado, visto que o seu tamanho gigantesco somado à sua constante
mutação, versatilidade e dinâmica, torna proibitiva uma generalização sobre suas
características.
Vislumbrando este problema a fundo percebe-se que existem apenas duas maneiras de
trabalhar com essa perspectiva, ou se tira um modelo total da web, a qual ficaria
desatualizada muito rapidamente, ou se trabalha com pequenas parcelas deste grafo maior,
a qual foi abordada como solução para o problema proposto para este trabalho. Após o
estudo verificou-se que esta é a escolha mais acertada, pois, através do conceito de
combinatória que normalmente é empregado em algoritmos destinados a este processo
pode-se chegar a uma conclusão aproximada que vale para boa parte do grafo.
Outro aspecto importante a ser vislumbrado pelo estudo em cima do grafo da web é o
descompromisso e a facilidade que se pode incluir novos dados na internet.
E este é o principal fator que implica no problema anterior, e conseqüentemente o maior
empecilho de qualquer estudo vinculado à rede de computadores.
Através do estudo do grafo da web é possível entender melhor o funcionamento da
internet e uma maneira geral e tirar proveito a partir disto.
Portanto, este estudo se refere principalmente em criar um método para que seja
possível olhar a internet não como aglomerado de dados dispostos de forma aleatória e sim
uma estrutura semelhante a um grafo que possua suas características e estatísticas e a partir
destes dados tomar decisões mais pontuais que anteriormente seria inviável.
Sobre esse aspecto é possível afirmar que o estudo atingiu o seu objetivo, pois, com
base nos conceitos colocados e observados para o estudo do grafo da web, e com base na
ferramenta construída, a extração de dados é feita satisfatoriamente e com aplicação dos
teoremas aqui dispostos sobre a estruturação de dados pode-se definir padrões e fazer
analises complexas e precisas sobre a internet.

6. Referências
6.1. Bibliográfica
[4] Béla Bollobás, Random Graphs, 2nd Edition, 2001, Cambridge University Press
[5] Nivio Ziviani, Projeto de Algoritmos, 2ª edição, Editora Thompson
[6] S. Chakrabarti, B. Dom, and P. Indyk. Enhanced hypertext classication using
hyperlinks. Proc. ACM SIGMOD, 1998.
[7] R. Downey and M. Fellows. Parametrized computational feasibility. In Feasible
Mathematics II, P. Clote and J. Remmel, eds., Birkhauser, 1994.
[8] S. R. Kumar, P. Raghavan, S. Rajagopalan, and A. Tomkins. Trawling emerging
cyber-communities automatically. Proc. 8th WWW Conf., 1999.
[9] G. Golub and C. F. Van Loan. Matrix Computations. Johns Hopkins University
Press, 1989.
[10] J. Kleinberg. Authoritative sources in a hyperlinked environment. J. of the ACM,
1999, to appear. Also appears as IBM Research Report RJ 10076(91892) May 1997.
[11] K. Bharat and M. R. Henzinger. Improved algorithms for topic distillation in a
hyperlinked environment. Proc. ACM SIGIR, 1998.
[12] S. Chakrabarti, B. Dom, D. Gibson, J. Kleinberg, P. Raghavan, and S. Rajagopalan.
Automatic resource compilation by analyzing hyperlink structure and associated text. Proc.
7th WWW Conf., 1998.
[13] S. Chakrabarti, B. Dom, S. R. Kumar, P. Raghavan, S. Rajagopalan, and A.
Tomkins. Experiments in topic distillation. SIGIR workshop on Hypertext IR, 1998.
[14] Ricardo Fabiano Samila, Modelos de Grafos Aleatórios e Aplicações, 2005.
6.2. Sitologia
[1] http://pt.wikipedia.org/wiki/Lista_de_TLDs
[2] http://pt.wikipedia.org/wiki/MD5
[3] http://pt.wikipedia.org/wiki/Minera%C3%A7%C3%A3o_de_dados

[15] http://www.ime.usp.br/~pf/mac5827/aulas/random.html







