dep. matem¶atica fcup -...
TRANSCRIPT

**************************************************************************************************************
Dep. Matematica
FCUP
**************************************************************************************************************
ALGEBRA LINEAR e
GEOMETRIA ANALITICA
Resumo das aulas teoricas e praticas
1.o ano da licenciatura em Matematica, Fısica
Astronomia
Ano lectivo de 2010/2011
Joao Nuno Tavares*******************************************************

INDICE:
1 Um curso rapido de ALGA apenas em R2 1
1.1 Algebra Linear em R2 . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Aplicacoes a geometria . . . . . . . . . . . . . . . . . . . . . . . 23
2 Algebra Linear e Geometria Analıtica em R3 27
2.1 Algebra Linear em R3 . . . . . . . . . . . . . . . . . . . . . . . . 29
3 Espacos vectoriais 57
3.1 Espacos vectoriais . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.2 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.3 Subespacos vectoriais . . . . . . . . . . . . . . . . . . . . . . . . 61
3.4 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
4 ALGA I. Aplicacoes lineares. Isomorfismos lineares 70
4.1 Aplicacoes lineares. Isomorfismos lineares. Operadores lineares.Funcionais lineares. O espaco dual V∗ . . . . . . . . . . . . . . . 70
4.2 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
5 ALGA I. Bases, coordenadas e dimensao 74
5.1 Bases, coordenadas e dimensao . . . . . . . . . . . . . . . . . . . 74
5.2 Calculos com coordenadas. Problemas . . . . . . . . . . . . . . . 82
5.3 Mudancas de base e de coordenadas . . . . . . . . . . . . . . . . 85
5.4 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6 ALGA I. Representacao matricial das aplicacoes lineares 95
6.1 Matriz de uma aplicacao linear . . . . . . . . . . . . . . . . . . . 95
1

2
6.2 Calculo do nucleo e imagem . . . . . . . . . . . . . . . . . . . . . 96
6.3 Matriz da composta . . . . . . . . . . . . . . . . . . . . . . . . . 97
6.4 GL(n). Pontos de vista passivo e activo. . . . . . . . . . . . . . . 98
6.5 Determinantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
6.5.1 Definicao e propriedades . . . . . . . . . . . . . . . . . . . 99
6.5.2 Determinante de um produto . . . . . . . . . . . . . . . . 102
6.5.3 Calculo da matriz inversa. Matriz adjunta . . . . . . . . . 103
6.6 Regra de Cramer . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
6.7 Determinante de um operador linear . . . . . . . . . . . . . . . . 106
6.8 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
7 ALGA I. Espacos vectoriais com produto interno 110
7.1 Espacos Euclideanos reais . . . . . . . . . . . . . . . . . . . . . . 110
7.2 Espacos Hermitianos (ou Unitarios) complexos . . . . . . . . . . 113
7.3 Norma . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
7.4 Ortogonalidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
7.5 Bases ortonormadas num espaco vectorial com produto interno . 119
7.6 Metodo de ortogonalizacao de Gram-Schmidt . . . . . . . . . . . 119
7.7 Decomposicao ortogonal.Teorema da aproximacao optima . . . . . . . . . . . . . . . . . . 122
7.8 Aplicacoes. Mınimos quadrados . . . . . . . . . . . . . . . . . . 129
7.9 Metodo dos mınimos quadrados. Aproximacao de dados por umarecta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
7.10 Transformacoes ortogonais e unitarias. Exemplos . . . . . . . . . 134
7.11 Transformacoes unitarias em C2. Os grupos U(2) e SU(2) . . . . 135
7.12 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
8 ALGA I. Subespacos invariantes. Subespacos proprios. Valoresproprios 142
8.1 Conjugacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
8.2 Subespacos invariantes . . . . . . . . . . . . . . . . . . . . . . . . 145
8.3 Valores e vectores proprios de um operador linear. Operadoresdiagonalizaveis . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
8.4 Calculo de valores e vectores proprios . . . . . . . . . . . . . . . 148
8.5 Sistemas dinamicos lineares discretos . . . . . . . . . . . . . . . . 151

3
8.6 Numeros de Fibonacci. Numero de ouro . . . . . . . . . . . . . . 153
8.7 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
9 ALGA I. Operadores auto-adjuntos (simetricos e hermitianos).Teorema espectral 162
9.1 Operadores auto-adjuntos (simetricos e hermitianos) . . . . . . . 162
9.2 Teorema espectralpara operadores auto-adjuntos . . . . . . . . . . . . . . . . . . . 165
9.3 Diagonalizacao de formas quadraticas reais . . . . . . . . . . . . 167
9.4 Propriedades extremais dos valores proprios . . . . . . . . . . . . 171
9.5 Operadores comutativos . . . . . . . . . . . . . . . . . . . . . . . 173
9.6 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
10 ALGA I. Conicas e quadricas afins 175
10.1 Parabola, Elipse e Hiperbole . . . . . . . . . . . . . . . . . . . . . 175
10.2 Quadricas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
10.3 Conicas e quadricas afins . . . . . . . . . . . . . . . . . . . . . . 183
10.4 Reducao a forma canonica da equacao geral de uma conica . . . 189
11 Quaternioes e Rotacoes 197
11.1 Definicoes e propriedades . . . . . . . . . . . . . . . . . . . . . . 197
11.2 Rotacoes no espaco dos quaternioes puros . . . . . . . . . . . . . 200
12 O homomorfismo SU(2) → SO(3). Parametros de Cayley-Klein 209
12.1 Transformacoes e matrizes hermitianas em C2. . . . . . . . . . . 209
12.2 Matrizes hermitianas de traco nulo. Matrizes de Pauli . . . . . . 210
12.3 O homomorfismo SU(2) → SO(3). Parametros de Cayley-Klein . 213
13 Rotacoes infinitesimais. Algebra do momento angular 217
13.1 so(3) e su(2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 217
13.2 Algebra doo momento angular . . . . . . . . . . . . . . . . . . . 218
13.3 Representacoes de sl(2, C). Spin . . . . . . . . . . . . . . . . . . 219
14 Geometria de Minkowski em R41 224
14.1 Produto escalar de Minkowski . . . . . . . . . . . . . . . . . . . . 224
14.2 Intervalo ou separacao espaco-temporal . . . . . . . . . . . . . . 226

4
14.3 Caracter causal. Cones de Luz . . . . . . . . . . . . . . . . . . . 226
14.4 Cones temporais . . . . . . . . . . . . . . . . . . . . . . . . . . . 227
14.5 Linhas de universo de observadores inerciais . . . . . . . . . . . . 228
14.6 Ortogonalidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229
14.7 O espaco fısico de um observador inercial . . . . . . . . . . . . . 229
14.8 Desigualdade de Cauchy-Shwartz oposta, angulo hiperbolico . . . 229
14.9 Sistemas de coordenadas inerciais. O Factor de Lorentz . . . . . 233
14.10O Factor de Lorentz . . . . . . . . . . . . . . . . . . . . . . . . . 233
15 O grupo de Lorentz O(1, 3). O homomorfismo SL(2, C) → SO(1, 3)↑236
15.1 Transformacoes de Lorentz noespaco de Minkowski R4. O grupo de Lorentz O(1, 3) . . . . . . . 236

ALGEBRA LINEAR e
GEOMETRIA ANALITICA
Referencias bibliograficas
1. T.M. Apostol: “Calculus, vol.1 e vol.2”. Xerox College Publishing Inter-national Textbook series, 1969.
2. Blyth T.S. and Robertson E.F.: “Basic Linear Algebra”. SUMS,Springer-Verlag, New York, 2002.
3. Mansfield L.E.: “Linear Algebra with Geometric Applications”.Marcel Dekker, Inc., 1976.
4. Postnikov M.: “Lecons de Geometrie, vol.1 e 2”. Editions MIR,Moscou,1981.
5. Banchoff T., Wermer J.. “Linear Algebra through Geometry”. UTM,Springer-Verlag, New York, 1983.
6. Smith L.: “Linear Algebra”. UTM, Springer-Verlag, New York, 1978.
7. Curtis C.W.: “Linear Algebra, An Introductory Approach”. UTM,Springer-Verlag, New York, 1974.
8. Lipschutz S.: “Linear Algebra”. Schaum’s Outline Series. McGraw-HillBook Company,1968.
9. Hernandez E.: “Algebra y Geometrıa”(2.a edicion). Addison-Wesley/UniversidadAutonoma de Madrid, 1994.

Modulo 1
Um curso rapido de ALGAapenas em R2
Neste primeiro modulo vamos retomar alguns conceitos ensinados no ensinosecundario, e fazer uma ponte para os assuntos mais sofisticados que precisamosde aprender na disciplina de ALGA. Tentamos por agora usar as notacoes quesao mais familiares ao leitor.
Contents1.1 Algebra Linear em R2 . . . . . . . . . . . . . . . . . 3
1.2 Aplicacoes a geometria . . . . . . . . . . . . . . . . 23
I Palavras chave
Vectores. R2 como espaco vectorial real. Subespacos . Dependencia e in-dependencia linear. Base canonica. Bases, coordenadas e dimensao. AplicacoesLineares. Matriz de uma aplicacao linear. Determinantes. Valores e vectoresproprios.
Geometria Euclideana em R2. Produto interno (euclideano). Norma (eu-clideana). Angulo. Ortogonalidade. Rectas vectoriais e afins. Projeccao or-togonal. Interpretacao geometrica de det e de det A. Reflexoes numa recta.Transformacoes ortogonais em R2. Os grupos O(2) e SO(2).
I Notacoes
x,y,u,v,w... vectores, em vez de ~x, ~y, ~u, ~v, ...
a, b, c, ..., λ, η, µ, ξ, ... escalares, isto e, numeros reais (para ja).
I Numero de aulas
1

2
2 teoricas e 2 teorico-praticas.
I Objectivos
Um forte intuicao geometrica sobre os principais conceitos da ALGA. Re-solver os sistemas que aparecem obrigatoriamente pelo metodo de eliminacaode Gauss.
I Site de apoio a disciplina
http://www.fc.up.pt/cmup/alga
I Site de apoio em temas de Matematica elementar
http://www.fc.up.pt/cmup/apoiomat

1.1. Algebra Linear em R2 3
1.1 Algebra Linear em R2
Vectores
I 1.1 Um vector x em R2 e por definicao um par ordenado de numeros reais,representado, ou na forma x = (x1, x2), ou dispostos segundo uma matriz-coluna de duas linhas:
x =(
x1
x2
)
Os numeros reais xi, i = 1, 2, dizem-se as componentes do vector x ∈ R2.
Geometricamente x =(
x1
x2
)sera representado como na figura seguinte:
R2 como espaco vectorial real
I 1.2 Dados dois vectores x =(
x1
x2
)e y =
(y1
y2
), em R2, define-se a
respectiva soma vectorial, como sendo o vector x + y, dado por:
x + y =(
x1
x2
)+
(y1
y2
)=
(x1 + y1
x2 + y2
)
Geometricamente x+y e obtido atraves da seguinte regra do paralelogramo:
I 1.3 Dado um vector x =(
x1
x2
)em R2, e um escalar (i.e., um numero
real) λ ∈ R, define-se a multiplicacao do escalar λ pelo vector x, comosendo o vector λx dado por:
λx =(
λx1
λx2
)
I 1.4 E facil provar que as duas operacoes definidas anteriormente, satisfazemas propriedades seguintes:
[EV1]. x + y = y + x (1.1.1)[EV2]. (x + y) + z = x + (y + z) (1.1.2)[EV3]. 0 + x = x + 0 = x ∀x ∈ R2 (1.1.3)[EV4]. ∀x,∃(−x) : x + (−x) = 0 (1.1.4)[EV5]. λ(x + y) = λx + λy (1.1.5)[EV6]. (λ + η)x = λx + ηx (1.1.6)[EV7]. λ(ηx) = (λη)x (1.1.7)[EV8]. 1x = x (1.1.8)

1.1. Algebra Linear em R2 4
onde x,y, z ∈ R2, λ, η ∈ R, 0 =(
00
)e o vector nulo de R2, e −x = (−1)x.
Por isso, diz-se que R2 e um espaco vectorial real .
I Exercıcio 1.1 ... Demonstre as 8 propriedades (2.1.1) a (1.1.8).
Subespacos
I 1.5 Um subconjunto nao vazio S ⊆ R2 diz-se um subespaco vectorialde R2, se S e fechado relativamente as operacoes de soma de vectores e demultiplicacao de escalares por vectores, i.e.:
• Sex,y ∈ S tambem x + y ∈ S (1.1.9)• Se λ ∈ R, e x ∈ S tambem λx ∈ S (1.1.10)
Em R2 os subespacos sao de dois tipos:
• triviais: S = {0} e S = R2
• nao triviais: S = {λv : λ ∈ R}, onde v 6= 0, que representa uma rectaque passa na origem, gerada por v 6= 0.
I Exercıcio 1.2 ... Diga quais dos seguintes conjuntos sao subespacos vectoriaisde R2 :
a) A ={(x, y) ∈ R2 : x = y
}; e) E =
{(x, y) ∈ R2 : 3x− y = 1
};
b) B ={(a,−a) ∈ R2 : a ∈ R}
; f) F ={(x, y) ∈ R2 : |x + 2y| = 3
};
c) C ={(x, y) ∈ R2 : x + y 6= 2
}; g) G = {(b, 2a + b) : a, b ∈ R} .
d) D ={(x, y) ∈ R2 : x + 5y = 0
}; g) H = {(b, 2a + 1) : a, b ∈ R} .
Combinacao linear
I 1.6 Um vector x ∈ R2 diz-se uma combinacao linear dos vectores a e bde R2 se existirem escalares λ, η ∈ R tais que:
x = λa + η b (1.1.11)
O conjunto de todas as combinacoes lineares dos vectores a e b, isto e, detodos os vectores da forma λa + η b, onde os escalares λ, η ∈ R sao arbitrarios,chama-se o espaco gerado por a e b e representa-se por span{a,b}:
span{a,b} = {λa + η b : λ, η ∈ R} (1.1.12)

1.1. Algebra Linear em R2 5
I Exercıcio 1.3 ... Em cada uma das alıneas que se seguem, verifique se x ∈span {a,b}:
a) x = (1, 0), a = (1, 1), e b = (0, 1); b) x = (2, 1), a = (1,−1), e b = (1, 1);c) x = (1, 0), a = (1, 1), e b = (2, 2); d) x = (1, 1), a = (2, 1), e b = (−1, 0);e) x = (4, 3), a = (1,−1), e b = (−2, 2). f) x = (0, 0), a = (2,−1), e b = (−4, 2);
I Exercıcio 1.4 ... Em cada um dos casos, calcule o subespaco gerado por a e b,onde
a) a = (1, 1),b = (2, 2), em R2; b) a = ((1, 0),b = (5, 0), em R2;c) a = (2,−1),b = (1, 0), em R2; d) a = (2, 1),b = (0, 0), em R2;
Dependencia e independencia linear
I 1.7 Dois vectores x e y em R2, dizem-se linearmente dependentes, seum deles e multiplo escalar do outro. Se x = 0 (ou y = 0) entao x e y saolinearmente dependentes. Geometricamente x e y sao linearmente dependentes,sse eles sao colineares.
I 1.8 Dois vectores x e y em R2, dizem-se linearmente independentes,se nao sao linearmente dependentes (o que implica que x 6= 0 e y 6= 0).Geometricamente x e y sao linearmente independentes, sse eles sao nao col-ineares.
Simbolicamente:
(x e y sao linearmente independentes) ⇐⇒ (λx + ηy = 0 =⇒ λ = η = 0)
I Exercıcio 1.5 ... Verifique se os vectores que se seguem sao linearmente depen-dentes ou independentes:
a) (1, 0), (2,−1) em R2; b) (1, 1), (2, 2) em R2;c) (π, 0), (0, 1) em R2; d) (1, 2), (2, 3), (1, 1) em R2;
Base canonica
I 1.9 Os vectores de R2:
e1 = i =(
10
)e e2 = j =
(01
)
sao linearmente independentes, e tem a propriedade de que qualquer vector
x =(
x1
x2
), se pode escrever como combinacao linear de e1 e e2. De facto:
x =(
x1
x2
)= x1
(10
)+ x2
(01
)
= x1e1 + x2e2 (1.1.13)

1.1. Algebra Linear em R2 6
Diz-se entao que C = {e1, e2} e uma base (ordenada) - a base canonicade R2.
Bases, coordenadas, dimensao
I 1.10 Qualquer conjunto B = {u1,u2} constituıdo por dois vectores linear-mente independentes, e que tem a propriedade de que qualquer vector x ∈ R,se pode escrever como combinacao linear de u1 e u2:
x = x1u1 + x2u2 (1.1.14)
para certos escalares (unicos) x1, x2 ∈ R, diz-se uma base de R2.
I 1.11 Todas as bases de R2 tem sempre dois elementos, e, por isso, diz-se quea dimensao (real) de R2 e 2:
Os escalares x1, x2 ∈ R, que surgem em (1.1.14), dizem-se as componentes(ou as coordenadas) do vector x, na base B = {u1,u2}. Neste casoescrevemos:
x = (x)B ≡(
x1
x2
)
B
(1.1.15)
I Exercıcio 1.6 ... Verifique se os conjuntos que se seguem, sao ou nao bases decada um dos espacos vectoriais indicados em cada alınea. Calcule as coordenadas dex = (1,−1) relativamente aos que sao bases:
a) {(1, 1), (3, 1)} em R2; b) {(0, 1), (0,−3)} em R2;c) {(2, 1), (1,−1), (0, 2)} em R2; d) {(2, 1), (0, 0), (0, 1)} em R2;
I Exercıcio 1.7 ... Calcule uma base de cada um dos subespacos que se seguem,e depois as coordenadas do vector u em cada uma das bases:
a) S ={(x, y) ∈ R2 : x + y = 0
}, u = (3,−3);
b) S ={(x, y) ∈ R2 : 2x = −y
}, u = (4,−8);
Aplicacoes Lineares
I 1.12 Uma aplicacao A : R2 → R2 diz-se uma aplicacao linear, se Apreserva as operacoes que definem a estrutura vectorial de R2, i.e.:
A(x + y) = A(x) + A(y) (1.1.16)A(λx) = λA(x) (1.1.17)
∀x,y ∈ R2, e ∀λ ∈ R.

1.1. Algebra Linear em R2 7
I 1.13 Dada uma aplicacao linear A : R2 → R2 define-se:
• o nucleo de A:kerA = {x ∈ R2 : A(x) = 0} (1.1.18)
• a imagem de A:
imA = {y : A(x) = y ∈ R2, para algumx ∈ R2} (1.1.19)
I Exercıcio 1.8 ... Mostre que kerA e imA sao subespacos de R2.
I Exercıcio 1.9 ... Das aplicacoes A : R2 −→ R2 que se seguem, indique aquelasque sao lineares. Relativamente a essas, calcule o respectivo nucleo e diga quais as quesao injectivas.
a) A : (x, y) 7−→ (x + y, x− y) b) A : (x, y) 7−→ (|x| , |y|)c) A : (x, y) 7−→ (x + 1, x− y) d) A : (x, y) 7−→ (0, x + y)
I Exercıcio 1.10 ... Mostre que uma aplicacao linear A : R2 −→ R2 fica com-pletamente determinada pelos valores que assume numa base. Mais concretamente,se {e1, e2} e uma base e se A(e1) = f1,A(e2) = f2, onde f1, f2 sao fixos de formaarbitraria, entao estes dados determinam de forma unica a imagem A(x) de um vectorarbitrario.
I Exercıcio 1.11 ... Sabendo que A e uma aplicacao linear, calcule em cada casoa imagem de um vector generico:
a) Sendo A : R2 −→ R2 e A(1, 0) = (1, 1) e A(0, 1) = (1,−2);b) Sendo A : R2 −→ R2 e A(1,−1) = (1, 2) e A(0, 3) = (2,−2);c) Sendo A : R2 −→ R2 e A(2, 1) = (−1, 0) e A(−1, 1) = (3,−2);
Matriz de uma aplicacao linear
I 1.14 Se B = {u1,u2} e uma base fixa de R2, podemos escrever que:
A(u1) = au1 + bu2 (1.1.20)A(u2) = cu1 + du2 (1.1.21)
A matriz:
A =(
a cb d
)(1.1.22)
diz-se a matriz de A na base B, e nota-se por:
A = (A)B

1.1. Algebra Linear em R2 8
Se as coordenadas de um vector x ∈ R2, na base B = {u1,u2}, sao x =(x1
x2
)
B
, i.e., se:
x = x1 u1 + x2 u2
entao as coordenadas de A(x) na base B obtem-se da seguinte forma:
A(x) = A(x1 u1 + x2 u2)= x1 A(u1) + x2 A(u2)= x1 (au1 + bu2) + x2 (cu1 + du2)= (ax1 + cx2)u1 + (bx1 + dx2)u2
(1.1.23)
o que significa que as coordenadas de A(x) na base B:
(A(x))B =(
y1
y2
)
B
obtem-se matricialmente atraves de:(
y1
y2
)
B
=(
a cb d
)(x1
x2
)
B
(1.1.24)
ou mais sucintamente:(A(x))B = (A)B (x)B (1.1.25)
I Exercıcio 1.12 ... Em cada um dos seguintes casos determine a matriz daaplicacao linear A na base indicada e calcule kerA e imA :
a).A : R2 −→ R2
(x, y) 7−→ (3x− y, x + 5y), na base C = {(1, 0), (0, 1)}
b).A : R2 −→ R2
(x, y) 7−→ (3x− y, x + 5y), na base B = {(1, 1), (1,−1)}
c).A : R2 −→ R2
(x, y) 7−→ (3x, x + y), na base B = {(2,−1), (1, 1)}
Composta de aplicacoes lineares. Matriz da composta. Produto dematrizes.
I 1.15 SejamA : IR2 → IR2 e B : IR2 → IR2 (1.1.26)
duas aplicacoes lineares.
A composta A ◦B : IR2 → IR2 (le-se A composta com B, ou A apos B) e aaplicacao definida por:
A ◦B : IR2 −→ IR2
x 7−→ (A ◦B)(x) = A(B(x))(1.1.27)

1.1. Algebra Linear em R2 9
Esquematicamente:
x B7−→ B(x) A7−→ A(B(x))
I Exercıcio 1.13 ... Mostre que A ◦B e linear.
I 1.16 Se B = {u1,u2} e uma base fixa de R2, podemos escrever que:
A(u1) = au1 + bu2 (1.1.28)A(u2) = cu1 + du2 (1.1.29)
construindo assim a matriz de A na base B:
A = (A)B =(
a cb d
)(1.1.30)
Analogamente, podemos escrever que:
B(u1) = eu1 + f u2 (1.1.31)B(u2) = g u1 + hu2 (1.1.32)
construindo assim a matriz de B na base B:
B = (B)B =(
e gf h
)(1.1.33)
Se as coordenadas de um vector x ∈ R2, na base B = {u1,u2}, sao x =(x1
x2
)
B
, i.e., se:
x = x1 u1 + x2 u2
entao B(x) e igual a (verificar):
B(x) = (ex1 + gx2)u1 + (fx1 + hx2)u2
e portanto as coordenadas de A(B(x)) na base B obtem-se da seguinte forma:
A(B(x)) = A((ex1 + gx2)u1 + (fx1 + hx2)u2)= (ex1 + gx2)A(u1) + (fx1 + hx2)A(u2)= (ex1 + gx2) (au1 + bu2) + (fx1 + hx2) (cu1 + du2)= ((ae + cf)x1 + (ag + ch)x2)u1 + ((be + df)x1 + (bg + dh)x2)u2
(1.1.34)
o que significa que as coordenadas de A(B(x)) na base B:
(A(B(x)))B =(
y1
y2
)
B

1.1. Algebra Linear em R2 10
obtem-se matricialmente atraves de:(
y1
y2
)
B
=(
ae + cf ag + chbe + df bg + dh
)(x1
x2
)
B
(1.1.35)
o que e de facto uma formula complicada. Para simplificar os calculos introduz-imos o conceito de produto de matrizes - o produto das matrizes A e B (poresta ordem) define-se atraves de:
AB =(
a cb d
)(e gf h
)=
(ae + cf ag + chbe + df bg + dh
)(1.1.36)
o que nos permite escrever (1.1.35) na forma:
((A ◦B)(x))B = (A)B(B)B(x)B (1.1.37)
I Exercıcio 1.14 ...
1. Mostrar que (A ◦B)B = (A)B(B)B
2. Mostrar que o produto de matrizes nao e, em geral, comutativo, i.e., em geralAB 6= BA.
3. Mostrar que o produto de matrizes e associativo A(BC) = (AB)C.
4. Qual a matriz da aplicacao identidade Id : IR2 → IR2, relativamente a umaqualquer base de IR2?
O conjunto de todas as matrizes quadradas 2×2, de entradas reais, representa-se por M2(IR).
I Exercıcio 1.15 ... Uma matriz A ∈ M2(IR), diz-se inversıvel se existir umamatriz B ∈M2(IR) tal que:
AB = BA = Id
Onde Id =
(1 00 1
)e a matriz identidade. Neste caso escreve-se B = A−1 para
a inversa de A.
1. Calcule explicitamente a inversa da matriz A =
(a cb d
), supondo que ela
existe. Qual a condicao para que exista A−1?
2. Mostre que (A−1)−1 = A
3. Mostre que se A : IR2 → IR2 e um isomorfismo e se B e uma base de IR2, entao:
(A−1)B = ((A)B)−1 (1.1.38)
I Exercıcio 1.16 ... A transposta de uma matriz A =
(a cb d
)e a matriz
At =
(a bc d
)

1.1. Algebra Linear em R2 11
1. Mostrar que (A4)t = A
2. Mostrar que (AB)t = BtAt
I 1.17 Um grupo e um conjunto nao vazio G munido de uma operacaobinaria:
G×G −→ G(g, h) 7−→ g · h
que verifica as propriedades seguintes:
1. associatividade (g · h) · k = g · (h · k), ∀g, h, k ∈ G
2. existe um elemento neutro e ∈ G tal que e · g = g · e = g, ∀g ∈ G
3. cada elemento g tem um inverso , isto e, ∀g ∈ G existe h ∈ G tal queg ·h = h ·g = e. Este inverso nota-se por g−1 (em notacao multiplicativa).
I Exercıcio 1.17 ... Mostre que o conjunto das matrizes inversıveis:
GL(2) = {A ∈M2(IR) : A e inversıvel}munido da operacao de produto de matrizes, e um grupo.
Determinantes
I 1.18 Dada uma matriz A =(
a cb d
), definimos o seu determinante
detA, como sendo o numero real:
det A = det(
a cb d
)= ad− bc (1.1.39)
Representemos por c1 =(
ab
)e c2 =
(cd
)as colunas da matriz A, de
tal forma que:det A = det [c1 c2] = ad− bc (1.1.40)
Um calculo directo mostra que:
det [c1 c2] 6= 0 sse c1, c2 sao linearmente independentes(1.1.41)
det [c1 c2] = −det [c2 c1] (1.1.42)det [c1 + c′1 c2] = det [c1 c2] + det [c′1 c2] (1.1.43)det [c1 c2 + c′2] = det [c1 c2] + det [c1 c′2] (1.1.44)
det [λ c1 c2] = λ det [c1 c2]= det [c1 λ c2] λ ∈ R (1.1.45)

1.1. Algebra Linear em R2 12
e ainda que:
det I = 1 (1.1.46)det (AB) = det A det B (1.1.47)det (A−1) = (det A)−1 ∀A inversıvel (1.1.48)
det (P−1 AP ) = det A ∀P inversıvel (1.1.49)det (A) = det (At) (1.1.50)
onde At e a transposta de A e I =(
1 00 1
)e a matriz identidade.
Alem disso e possıvel provar que para uma matriz A:
A e inversıvel se e so se detA 6= 0 (1.1.51)
I Exercıcio 1.18 ... Demonstre todas as propriedades acima referidas.
I 1.19 Se A : R2 → R2 e uma aplicacao linear, define-se o respectivo deter-minante detA, como sendo o determinante da matriz de A, relativamente auma qualquer base de R2. Por (1.1.49) e (1.1.48), esta definicao nao dependeda base escolhida.
I Exercıcio 1.19 ... Calcule o determinante das aplicacoes lineares descritas noexercıcio 1.13.
Em breve veremos uma interpretacao geometrica da nocao de determinante.
Produto interno (euclideano)
I 1.20 Dados dois vectores x =(
x1
x2
)e y =
(y1
y2
), em R2, define-se o
respectivo produto interno (Euclideano), como sendo o escalar x · y ∈ R,dado por:
x · y = x1y1 + x2y2
= (x1 x2)(
y1
y2
)
= xt y (1.1.52)
I 1.21 O produto interno (euclideano), que acabamos de definir, verifica aspropriedades seguintes:

1.1. Algebra Linear em R2 13
• e bilinear:
(x + y) · z = x · z + y · zx · (y + z) = x · y + x · z
λx · y = x · λy = λ(x · y) (1.1.53)
• e simetrica:x · y = y · x (1.1.54)
• e nao degenerada:
x · y = 0 ∀y ∈ R2 ⇒ x = 0 (1.1.55)
• e definida positiva:
x · x ≥ 0 e x · x = 0 ⇐⇒ x = 0 (1.1.56)
∀x,y, z ∈ R2, ∀λ ∈ R.
I Exercıcio 1.20 ... Verifique que o produto interno (1.1.52) satisfaz as pro-priedades acima referidas.
Norma (euclideana)
I 1.22 Define-se a norma euclideana ‖x‖, de um vector x =(
x1
x2
)∈ R2,
atraves da formula:
‖x‖ ≡ √x · x
=√
xt x
=√
(x1)2 + (x2)2 (1.1.57)
I 1.23 A norma euclideana verifica as propriedades seguintes:
• e positiva e nao degenerada:
‖x‖ ≥ 0 e ‖x‖ = 0 sse x = 0 (1.1.58)
• e homogenea (positiva):
‖λx‖ = |λ| ‖x‖ (1.1.59)
• verifica a desigualdade triangular:
‖x + y‖ ≤ ‖x‖+ ‖y‖ (1.1.60)
∀x,y ∈ R2, ∀λ ∈ R.

1.1. Algebra Linear em R2 14
I 1.24 Todas as propriedades sao de demonstracao imediata com excepcao dadesigualdade triangular, que resulta imediatamente de uma outra importantedesigualdade que passamos a enunciar:
• Desigualdade de Cauchy-Schwarz:
|x · y| ≤ ‖x‖‖y‖ (1.1.61)
∀x,y ∈ R2.
Demonstracao...
Se y = 0 a desigualdade e trivial. Se y 6= 0 consideremos o vector:
u = x− x · y‖y‖2 y
de tal forma que u · y = 0. temos entao que:
0 ≤ ‖u‖2 =(x− x · y
‖y‖2 y)·(x− x · y
‖y‖2 y)
= x · x− (x · y)(y · x)
‖y‖2
= ‖x‖2 − (x · y)2
‖y‖2 (1.1.62)
o que portanto demonstra a desigualdade, CQD.
Demonstremos agora a desigualdade triangular (7.3.4):
‖x + y‖2 = (x + y) · (x + y)= x · x + x · y + y · x + y · y= ‖x‖2 + 2(x · y) + ‖y‖2≤ ‖x‖2 + 2|x · y|+ ‖y‖2≤ ‖x‖2 + 2‖x‖‖y‖+ ‖y‖2, pela desigualdade de Cauchy-Schwarz (2.1.48)= (‖x‖+ ‖y‖)2
e portanto ‖x + y‖ ≤ ‖x‖+ ‖y‖, como se pretendia.
Angulo, ortogonalidade
I 1.25 Dados dois vectores nao nulos x,y ∈ R2, deduzimos da desigualdadede Cauchy-Schwarz que:
−1 ≤ x · y‖x‖‖y‖ ≤ 1 (1.1.63)
o que permite definir o angulo (nao orientado) θ ∈ [0, π], entre os referidosvectores nao nulos x,y ∈ R2, como sendo o unico θ ∈ [0, π], tal que:
cos θ = x·y‖x‖‖y‖ ∈ [−1, 1] (1.1.64)

1.1. Algebra Linear em R2 15
Portanto:x · y = ‖x‖‖y‖ cos θ (1.1.65)
Dois vectores x,y ∈ R2 dizem-se ortogonais se x · y = 0.
Rectas vectoriais e afins
I 1.26 Dado um vector nao nulo a 6= 0, o conjunto dos vectores x que sao daforma:
x = ta, t ∈ R (1.1.66)
diz-se a recta (vectorial) gerada por a. Se a =[
a1
a2
], entao (1.1.66) e
equivalente ao sistema de equacoes:{
x1 = t a1
x2 = t a2, t ∈ R
que se dizem as equacoes parametricas da referida recta. Eliminando t nestasequacoes, obtemos a chamada equacao cartesiana dessa mesma recta:
a2 x1 − a1 x2 = 0 (1.1.67)
o que exibe a recta como o conjunto dos vectores x =(
x1
x2
)que sao ortogonais
ao vector n =[
a2
−a1
], isto e, tais que:
x · n = 0
I 1.27 Dado um ponto A ∈ R2 e um vector nao nulo v 6= 0, o conjunto dospontos P que sao da forma:
P = A + tv, t ∈ R (1.1.68)
diz-se a recta afim que passa em A e e gerada por v 6= 0.
Se P =(
x1
x2
), A =
(a1
a2
), e v =
[v1
v2
], entao (1.1.68) e equivalente
ao sistema de equacoes:{
x1 = a1 + t v1
x2 = a2 + t v2, t ∈ R
que se dizem as equacoes parametricas da referida recta. Eliminando t nestasequacoes, obtemos a chamada equacao cartesiana dessa mesma recta:
v2 (x1 − a1)− v1 (x2 − a2) = 0 (1.1.69)

1.1. Algebra Linear em R2 16
o que exibe a recta como o conjunto dos pontos P =(
x1
x2
)que sao ortogonais
ao vector n =[
v2
−v1
], e que passa em A, i.e., tais que:
(P −A) · n = 0
I Exercıcio 1.21 ... Calcule a imagem do reticulado formado pelas rectas x = ne y = m, m, n ∈ Z, sob:(i). a aplicacao linear A(x, y) = (2x, x + y).(ii). a aplicacao linear B(x, y) = (x− y, x + y).
Valores e vectores proprios
I 1.28 Seja A : R2 → R2 uma aplicacao linear. Um escalar λ ∈ R diz-se umvalor proprio de A se existir um vector nao nulo v ∈ R2 − {0} tal que:
A(v) = λv (1.1.70)
Neste caso, o vector nao nulo v, diz-se um vector proprio associado (ou per-tencente) ao valor proprio λ.
I 1.29 O conjunto constituıdo pelo vector nulo 0 e por todos os vectoresproprios pertencentes a um certo valor proprio λ, de A, e um subespaco deR2, chamado o subespaco proprio de A, pertencente ao valor proprio λ, enota-se por:
E(λ) = EA(λ) = {v : A(v) = λv} (1.1.71)
A restricao de A a EA(λ) e pois uma homotetia de razao λ (eventualmenteλ pode ser 0), i.e.:
A(u) = λu ∀u ∈ EA(λ)
Em particular, a recta gerada pelo vector proprio v 6= 0 fica invariante por A,isto e, a sua imagem por A esta contida nela propria.
I 1.30 Em particular, se λ = 0 e valor proprio de A, isto significa que o nucleode A;
kerA = EA(0)
nao se reduz ao vector nulo 0, e portanto A e nao inversıvel (ou singular), oude forma equivalente, detA = 0.
Quando λ 6= 0, dizer que λ e valor proprio de A, e equivalente a dizer que 0e valor proprio de A−λ Id, o que, pelo paragrafo anterior, e equivalente a dizerque A− λ Id e nao inversıvel (ou singular), ou ainda que:
det (A− λ Id) = 0 (1.1.72)

1.1. Algebra Linear em R2 17
O polinomio p(λ) = det (A − λ Id) diz-se o polinomio caracterıstico deA. Portanto as raızes reais da chamada equacao caracterıstica de A:
p(λ) = det (A− λ Id) = 0 (1.1.73)
(se existirem), sao exactamente os valores proprios (reais) de A.
Exemplo...
Calcule os valores e vectores proprios (reais) da aplicacao linear A : R2 → R2, cujamatriz na base canonica de R2 e:
A =
(3 44 −3
)
A equacao caracterıstica de A e:
p(λ) = det (A− λ Id)
= det
(3− λ 4
4 −3− λ
)
= λ2 − 25 = 0 (1.1.74)
cujas raızes reais (os valores proprios de A) sao λ1 = 5 e λ2 = −5.
Para calcular os vectores poprios v =
(x1
x2
), pertencentes ao valor proprio λ = 5,
devemos resolver o sistema:(3− 5 4
4 −3− 5
) (x1
x2
)=
(00
)
isto e: { −2x1 + 4x2 = 04x1 − 8x2 = 0
cuja solucao geral e: {x1 = 2tx2 = t
t ∈ RPortanto os vectores poprios de A, pertencentes ao valor proprio λ1 = 5, sao da forma:
t
(21
)t ∈ R− {0}
Procedendo da mesma forma relativamente ao outro valor proprio λ2 = −5, pode-mos calcular que os vectores poprios de A, pertencentes ao valor proprio λ2 = −5, saoda forma:
s
(1−2
)s ∈ R− {0}
Note que neste exemplo os vectores proprios u1 =
(21
)e u2 =
(1−2
)formam
uma base B = {u1,u2} de R2 relativamente a qual a matriz de A e diagonal:
(A)B =
(5 00 −5
)

1.1. Algebra Linear em R2 18
I Exercıcio 1.22 ... Em cada um dos seguintes casos, determine, se existirem, osvalores proprios de A, os subespacos proprios associados e as respectivas dimensoese diga se A e diagonalizavel; no caso de o ser, indique uma base do domınio de Acomposta por vectores proprios e indique a matriz de A relativamente a essa base.
a).A : R2 −→ R2
(x, y) 7−→ (2x− y, y)b).
A : R2 −→ R2
(x, y) 7−→ (−x,−y)
c).A : R2 −→ R2
(x, y) 7−→ (3x + y, 12x + 2y)d).
A : R2 −→ R2
(x, y) 7−→ (x− y, x + y)
Projeccao ortogonal
Sejam a 6= 0 e x dois vectores emR2. Entao existe um unico vector u, narecta gerada por a, e um unico vector v,ortogonal a a, tais que x = u+v. O vec-tor u, notado por Pa(x), diz-se a pro-jeccao ortogonal de x sobre a rectagerada por a, e e calculado da seguinteforma.
Uma vez que u = Pa(x) pertence a recta gerada por a, u e da forma u = λapara um certo λ ∈ R, caracterizado pela condicao de que:
(x− λa) · a = 0
Obtemos entao que t =x · a‖a‖2 e portanto:
Pa(x) =x · a‖a‖2 a (1.1.75)
I 1.31 A aplicacao Pa : R2 → R2 definida por (1.1.75), e linear e satisfaz acondicao P2
a = Pa.
E claro que Pa(a) = a. Vemos pois que a e vector proprio de Pa, pertencenteao valor proprio 1. Por outro lado, se considerarmos um qualquer vector b 6= 0ortogonal a a (i.e.: a · b = 0), vemos que Pa(b) = 0 e portanto:
kerPa = {tb : t ∈ R}A matriz de Pa na base {a,b} e pois:
(1 00 0
)

1.1. Algebra Linear em R2 19
Interpretacao geometrica de det e de detA
I 1.32 A distancia d de um ponto B ∈ R2, com vector de posicao b =−−→OP , a
recta vectorial gerada por a 6= 0, e igual a norma do vector b−Pa(b):
Pelo teorema de Pitagoras, e uma vez que Pa(x) = x·a‖a‖2 a, tem-se que:
d2 = ‖b‖2 − (b · a)2
‖a‖2
e atendendo a (1.1.65):d = ‖b‖ sin θ
onde θ ∈ [0, π] e o angulo entre a e b. A area do paralelogramo P(a,b), geradopor a e b e portanto igual a:
area(P(a,b)) = ‖a‖.d = ‖a‖‖b‖ sin θ (1.1.76)
Por outro lado um calculo simples mostra que o quadrado desta area (que esempre ≥ 0, ja que sin θ ≥ 0) e igual ao quadrado do determinante det (a b),donde se deduz que:
|det (a b)| = area(P(a,b)) (1.1.77)
I 1.33 Quando a e b sao linearmente independentes, de tal forma que det [a b] 6=0, dizemos que a base ordenada {a,b} e:
{positiva se det (a b) > 0negativa se det (a b) < 0
I 1.34 Consideremos agora uma aplicacao linear A : R2 → R2. A imagem doquadrado Q, gerado pelos vectores da base canonica (que e positiva) {e1, e2}:
Q = {λ e1 + η e2 : 0 ≤ λ, η ≤ 1}e o paralelogramo A(Q), de lados adjacentes A(e1) e A(e2).
Pondo A(e1) = a e1 + b e2 =[
ab
]e A(e2) = c e1 + d e2 =
[cd
], sabemos
que a area deste paralelogramo e igual a:
area(A(Q)) = |det (A(e1) A(e2)|= |det
(a cb d
)|
= |detA| (1.1.78)
Portanto:

1.1. Algebra Linear em R2 20
area(A(Q)) = |detA| (1.1.79)
Mais geralmente, se R e o paralelogramo gerado pelos vectores linearmenteindependentes u e v, entao a imagem A(R) e o paralelogramo gerado por A(u)e A(v), e e facil provar que a area desta imagem e igual a:
area(A(R)) = |det [A(u) A(v)]|= |detA| area(R) (1.1.80)
isto e:
|detA| = area(A(R))area(R)
(1.1.81)
I 1.35 Diz-se que a aplicacao linear A : R2 → R2:{
preserva a orientacao (ou e positiva) se detA > 0inverte a orientacao (ou e negativa) se detA < 0
I Exercıcio 1.23 ... Calcule o determinante das aplicacoes lineares descritas noexercıcio 1.13, usando a formula (1.1.81).
Reflexao numa recta
Seja a um vector nao nulo em R2. Asimetria relativamente a recta geradapor a, ou reflexao nessa recta, e aaplicacao linear Sa : R2 → R2, definidapela condicao:
12(Sa(x) + x
)= Pa(x) ∀x ∈ R2
(1.1.82)isto e, o ponto medio do segmento queune x a Sa(x) deve ser igual a projeccaode x sobre a recta gerada por a.
I 1.36 Atendendo a (1.1.75), vemos que:
Sa(x) = 2Pa(x)− x = 2x · a‖a‖2 a− x, ∀x ∈ R2
isto e:

1.1. Algebra Linear em R2 21
Sa(x) = 2x · a‖a‖2 a− x, ∀x ∈ R2 (1.1.83)
Note que S2a = Id. Uma vez que Pa(a) = a vemos que Sa = a, e portanto
a e vector proprio de Sa, pertencente ao valor proprio 1. Se considerarmos umqualquer vector b 6= 0 ortogonal a a (i.e.: a · b = 0), vemos que Pa(b) = 0 eportanto Sa(b) = −b.
A matriz de Sa na base {a,b} e portanto:
(1 00 −1
)
o que mostra que detSa = −1 < 0, i.e., Sa inverte orientacao (embora preserveo modulo da area de paralelogramos)
Transformacoes ortogonais em R2
I 1.37 Uma aplicacao linear A : R2 → R2 diz-se uma transformacao ortog-onal ou uma isometria de R2, se A preserva o produto interno (Euclideano)usual de R2, i.e.:
A(x) ·A(y) = x · y ∀x,y ∈ R2 (1.1.84)
Esta condicao e equivalente a:
‖A(x)‖ = ‖x‖ ∀x ∈ R2 (1.1.85)
i.e., A preserva os comprimentos dos vectores. Se A e a matriz de uma tal trans-formacao ortogonal, relativamente a uma qualquer base ortonormada {e1, e2} deR2 (por exemplo, a base canonica), A e uma matriz ortogonal, isto e, AtA = I.Portanto A ∈ O(2). Vejamos como e a forma geral de uma tal matriz.
I 1.38 Se c1 = A(e1), c2 = A(e2) sao as colunas de A, entao:
ci · cj = δij
o que significa que c1 e c2 sao ortonormais. Portanto A transforma basesortonormadas em bases ortonormadas, preservando ou invertendo orientacao,conforme detA = +1 ou detA = −1, respectivamente. Por exemplo, a simetriaSa, descrita em (1.1.83), e uma transformacao ortogonal com det igual a −1.

1.1. Algebra Linear em R2 22
Como c1 = A(e1) ≡(
ab
)e um vec-
tor de norma 1, sabemos que a2+b2 = 1e portanto existe um unico ϕ ∈ [0, 2π[tal que a = cos ϕ e b = sin ϕ (ϕ ∈ [0, 2π[e o angulo polar de c1, i.e., o angulo ori-entado que c1 faz com a parte positivado eixo dos xx):
Portanto c1 =[
cosϕsin ϕ
], e como c2 = A(e2) e tambem um vector unitario e
ortogonal a c1, dois casos podem ocorrer:
(i). c2 =[ − sin ϕ
cosϕ
], ou (ii). c2 =
[sin ϕ
− cos ϕ
]
No primeiro caso, a matriz A tem a forma:
A =[
cos ϕ − sin ϕsin ϕ cos ϕ
](1.1.86)
cujo determinante e 1. Neste caso A diz-se uma rotacao de angulo ϕ (nosentido positivo), em torno da origem, e nota-se por Rϕ:
No segundo caso, a matriz A tem aforma:
A =[
cos ϕ sin ϕsin ϕ − cos ϕ
]
=[
cos ϕ − sin ϕsin ϕ cos ϕ
] [1 00 −1
]
= RϕSe1 (1.1.87)
cujo determinante e −1. Neste casoA pode ser interpretada como uma re-flexao relativamente ao eixo dos xxseguida de uma rotacao Rϕ.
Essa reflexao fixa e1 e transforma e2 em −e2. Se entao rodamos de anguloϕ, temos que:
e1 → e1 → cosϕe1 + sin ϕe2
e2 → −e2 → −(− sin ϕe1 + cos ϕe2) (1.1.88)
De facto, neste caso A representa uma simetria relativamenta a recta que fazum angulo ϕ
2 com a parte positiva do eixo dos xx.

1.2. Aplicacoes a geometria 23
I Exercıcio 1.24 ... Classifique as seguintes isometrias de R2 :
a) A(x, y) = ( 12x +
√3
2y,√
32
x− 12y).
b) A(x, y) = ( 12x +
√3
2y,−
√3
2x + 1
2y).
c) A(x, y) = (− 45x + 3
5y,− 3
5x− 4
5y).
d) A(x, y) = (x, y).e) A(x, y) = (−y, x).
I Exercıcio 1.25 ... Em cada um dos casos que se seguem, determine a simetriaS relativamente a recta indicada, a matriz de S relativamente a base canonica de R2
e uma base B de R2 relativamente a qual a matriz de S seja do tipo
(1 00 −1
).
a) r e a recta de equacao y = 2x;b) r e a recta de equacao 3x− y = 0;c) r e a recta de equacao y = (tg π
5)x;
I Exercıcio 1.26 ... Em cada um dos seguintes casos, mostre que a transformacaolinear A de R2 e uma isometria linear e descreva A geometricamente (isto e, diga seA e uma simetria ou uma rotacao; no caso de ser uma simetria, diga relativamente aque recta, no caso de ser uma rotacao determine o angulo).
a) A(x, y) = (y, x);b) A(x, y) = (y,−x);
c) A(x, y) = (√
2x−√2y2
,√
2x+√
2y2
);d) A(x, y) = ((− cos π
8)x + (sin π
8)y, (sin π
8)x + (cos π
8)y);
Os grupos O(2) e SO(2)
I 1.39 O conjunto de todas as transformacoes ortogonais de R2, constituemum grupo que se diz o grupo ortogonal O(2). Este grupo e isomorfo ao grupodas matrizes ortogonais, tambem notado por O(2).
O subgrupo de O(2) constituıdo por todas as transformacoes ortogonais deR2, que tem determinante 1 (isto e, constituıdo por todas as rotacoes Rθ, θ ∈[0, 2π[, em R2) diz-se o grupo ortogonal especial e nota-se por SO(2). Estegrupo e isomorfo ao grupo das matrizes ortogonais de determinante 1, tambemnotado por SO(2).
I Exercıcio 1.27 ... Demonstre estas afirmacoes, isto e, verifique que O(2) eSO(2) sao grupos (ambos subgrupos de GL(2)).
1.2 Aplicacoes a geometria
I 1.40 Exemplo ... As diagonais de um losango intersectam-se perpendicu-larmente.

1.2. Aplicacoes a geometria 24
Dem.: Como OQRP e um losango, ‖u‖ = ‖v‖. Pretende-se provar que−−→QP ⊥−−→
OR, isto e que, (u− v) · (u + v) = 0. Mas:
(u− v) · (u + v) = ‖u‖2 − ‖v‖2 = 0
I 1.41 Exemplo [Lei dos cossenos] ... Num triangulo plano 4(ABC), ondea = BC, etc. tem-se que:
c2 = a2 + b2 − 2ab cosC
Dem.: Escolhamos um referencial com origem em C, e ponhamos u =−→CA e
v =−−→CB. Entao
−−→AB = v − u, e daı que:
‖−−→AB‖2 = ‖v − u‖2 = ‖v‖2 − 2u · v + ‖u‖2
ou, com as notacoes referidas:
c2 = a2 + b2 − 2ab cosC
I 1.42 Exemplo ... Se R e um ponto sobre um cırculo de diametro POQ,mostre que PR ⊥ QR.

1.2. Aplicacoes a geometria 25
Dem.: Seja u =−−→OQ,v =
−−→OR. Entao
−→PR =
−−→OR−−−→OP = u + v
−−→QR =
−−→OR−−−→OQ = v − u
Sabe-se que ‖u‖ = ‖v‖ e portanto:
−→PR · −−→QR = (u + v) · (v − u) = ‖v‖2 − ‖u‖2 = 0
I 1.43 Exemplo ... As alturas de um triangulo intersectam-se num unicoponto (chamado o ortocentro do triangulo).
Dem.: Pretende-se encontrar um ponto X tal que:
−−→AX · −−→BC = 0,
−−→BX · −→CA = 0,
−−→CX · −−→AB = 0
Identificando um ponto P com o seu vector de posicao−−→OP , relativamente a
uma origem fixa O no plano, e facil verificar a identidade seguinte:
(X −A) · (C −B) + (X −B) · (A− C) + (X − C) · (B −A) = 0 (1.2.1)

1.2. Aplicacoes a geometria 26
Seja X o ponto de interseccao de duas das alturas, digamos, das alturaspartindo de A e de B. Temos entao que, lembrando que
−−→AX = X −A, etc:
(X −A) · (C −B) = 0 (1.2.2)(X −B) · (A− C) = 0 (1.2.3)
Subtraindo (1.2.2) e (1.2.3) de (1.2.1), obtemos:
(X − C) · (B −A) = 0
como se pretendia.
I 1.44 Exemplo ... Dados dois pontos distintos A 6= B no plano, mostrar queo lugar geometrico dos pontos P cuja distancia a A e o dobro da distancia a Be um cırculo.

Modulo 2
Algebra Linear e GeometriaAnalıtica em R3
Neste segundo modulo vamos generalizar os conceitos aprendidos no modulo 1, etambem no ensino secundario, estudando Algebra Linear e Geometria Analıticano espaco R3. Do ponto de vista coceptual a generalizacao e imediata - em vez devectores com duas componentes temos agora vectores com tres componentes. Hano entanto maior diversidade de conceitos e os calculos tornam-se um pouco maistrabalhosos. Mas e apenas isso! No inıcio tentamos usar as notacoes que saomais familiares, analogas as que usamos no modulo 1, mas, quando introduzimoso calculo matricial, vamos comecar a usar notacoes mais apropriadas que serevelarao muito uteis de futuro.
Contents2.1 Algebra Linear em R3 . . . . . . . . . . . . . . . . . 29
Palavras chave
Vectores. R3 como espaco vectorial real. Subespacos . Dependencia e in-dependencia linear. Base canonica. Bases, coordenadas e dimensao. Mudancade base e de coordenadas. Aplicacoes Lineares. Matriz de uma aplicacao linear.GL(2). Pontos de vista passivo e activo. Conjugacao. Determinantes. Valorese vectores proprios.
Geometria Euclideana em R3. Produto interno (euclideano). Norma (eu-clideana). Angulo. Ortogonalidade. Rectas vectoriais e afins. Planos vectoriaise afins. Produto vectorial em R3. Produto misto em R3. Projeccao ortogonal.Interpretacao geometrica de det e de det A. Simetrias relativamente a uma rectae a um plano. Transformacoes ortogonais em R3. Os grupos O(3) e SO(3).
Notacoes
27

28
x,y,u,v,w... vectores, em vez de ~x, ~y, ~u, ~v, ...
a, b, c, ..., λ, η, µ, ξ, ... escalares, isto e, numeros reais (para ja).
I Site de apoio a disciplina
http://www.fc.up.pt/cmup/alga
I Site de apoio em temas de Matematica elementar
http://www.fc.up.pt/cmup/apoiomat

2.1. Algebra Linear em R3 29
2.1 Algebra Linear em R3
Vectores
I 2.1 Um vector em R3 e por definicao um terno ordenado de numeros reais,representado na forma x = (x1, x2, x3), ou dispostos segundo uma matriz-coluna de tres linhas:
x =
x1
x2
x3
Os numeros reais xi, i = 1, 2, 3, dizem-se as componentes do vector x ∈ R3.
R3 como espaco vectorial real
I 2.2 Dados dois vectores x =
x1
x2
x3
e y =
y1
y2
y3
, em R3, define-se a
respectiva soma vectorial, como sendo o vector x + y, dado por:
x + y =
x1
x2
x3
+
y1
y2
y3
=
x1 + y1
x2 + y2
x3 + y3
Geometricamente x+y e novamente obtido atraves da regra do paralelogramo.
I 2.3 Dado um vector x =
x1
x2
x3
em R3, e um escalar (i.e., um numero
real) λ ∈ R, define-se a multiplicacao do escalar λ pelo vector x, comosendo o vector λx dado por:
λx =
λx1
λx2
λx3
I 2.4 E facil provar que as duas operacoes definidas anteriormente, satisfazem

2.1. Algebra Linear em R3 30
mais uma vez as propriedades seguintes:
[EV1]. x + y = y + x (2.1.1)[EV2]. (x + y) + z = x + (y + z) (2.1.2)[EV3]. 0 + x = x + 0 = x ∀x ∈ R3 (2.1.3)[EV4]. ∀x,∃(−x) : x + (−x) = 0 (2.1.4)[EV5]. λ(x + y) = λx + λy (2.1.5)[EV6]. (λ + η)x = λx + ηx (2.1.6)[EV7]. λ(ηx) = (λη)x (2.1.7)[EV8]. 1x = x (2.1.8)
onde x,y, z ∈ R3, λ, η ∈ R, 0 =
000
e o vector nulo de R3, e −x = (−1)x.
Por isso, diz-se que R3 e um espaco vectorial real.
Subespacos
I 2.5 Um subconjunto nao vazio ∅ 6= S ⊆ R3 diz-se um subespaco vectorialde R3, se S e fechado relativamente as operacoes de soma de vectores e demultiplicacao de escalares por vectores, i.e.:
• Se x,y ∈ S tambem x + y ∈ S (2.1.9)• Se λ ∈ R, e x ∈ S tambem λx ∈ S (2.1.10)
I 2.6 Em R3 os subespacos sao de tres tipos:
• triviais: S = {0} e S = R3
• rectas vectoriais: S = {λv : λ ∈ R}, onde v 6= 0, que representa umarecta que passa na origem, gerada por v 6= 0.
• planos vectoriais: S = {λu + η v : λ, η ∈ R}, onde u e v sao doisvectores nao colineares em R3, que representa um plano que passa naorigem, gerado por u e v.
I Exercıcio 2.1 ... Diga quais dos seguintes conjuntos sao subespacos vectoriaisde R3 :
a) A ={(x, y, z) ∈ R3 : x + y + z = 0
}; e) E =
{(a,−a, 5a) ∈ R3 : a ∈ R}
.b) B =
{(x, y, z) ∈ R3 : x + y = 3z
}; f) F =
{(a,−a + 1, 5a) ∈ R3 : a ∈ R}
.c) S =
{(x, y, z) ∈ R3 : x− y = 3z e z = 2y
}; g) G = {(b, 2a + b, 1) : a, b ∈ R} .
d) D ={(x, y, z) ∈ R3 : 0 ≤ x2 + y2 ≤ z
}; h) H =
{(a2, b, 2a + b) : a, b ∈ R}
.

2.1. Algebra Linear em R3 31
Combinacao linear
I 2.7 Dados n vectores em R3, digamos {a1,a2, · · · ,ak}, um vector x ∈ R3 diz-se uma combinacao linear dos vectores {a1,a2, · · · ,ak} se existirem escalaresλ1, λ2, · · · , λn ∈ R tais que:
x = λ1 a1 + λ2 a2 + · · ·+ λk ak (2.1.11)
I 2.8 O conjunto de todas as combinacoes lineares dos vectores a1,a2, · · · ,ak,isto e, de todos os vectores da forma λ1 a1 + λ2 a2 + · · · + λk ak, onde os es-calares λi ∈ R sao arbitrarios, chama-se o espaco gerado pelos vectoresa1,a2, · · · ,ak e representa-se por span{a1,a2, · · · ,ak}:
span{a1,a2, · · · ,ak} = {λ1 a1 + λ2 a2 + · · ·+ λk ak : λ1, · · · , λn ∈ R}(2.1.12)
I Exercıcio 2.2 ... Mostre que S = span{a1,a2, · · · ,ak} e um subespaco de R3.
I Exercıcio 2.3 ... Em cada uma das alıneas que se seguem, verifique se x ∈span {a,b, c}:
a) x = (1, 0, 0), a = (1, 1, 1), b = (−1, 1, 0) e c = (1, 0,−1);b) x = (1, 0, 0), a = (1, 1, 2), b = (−1, 1, 0) e c = (1, 0, 1);c) x = (1, 1, 1), a = (0, 1,−1), b = (1, 1, 0) e c = (1, 0, 2);d) x = (0, 0, 1), a = (1, 1, 1), b = (−1, 1, 0) e c = (1, 0,−1);e) x = (1, 2, 3), a = (1, 1, 1), b = (−2,−2, 0) e c = (0, 0,−1).f) x = (1, 0, 0), a = (1, 1, 1), b = (2, 2, 0) e c = (1, 0,−1).
I Exercıcio 2.4 ... Em cada um dos casos, calcule o subespaco gerado por a, be c, onde
a) a = (1, 1,−1),b = (2, 2,−2), c = (0, 0, 0), em R3;b) a = ((1, 0, 1),b = (5, 0,−1), c = (0, 1, 0), em R3;c) a = (2,−1, 1),b = (1, 0, 1)c = (1, 0, 1), em R3;d) a = (2, 1, 2),b = (0, 0, 0), em R3;
Dependencia e independencia linear
I 2.9 Dois vectores x e y em R3, dizem-se linearmente dependentes, seum deles e multiplo escalar do outro. Se x = 0 (ou y = 0) entao x e y saolinearmente dependentes. Geometricamente x e y sao linearmente dependentes,sse eles sao colineares.
I 2.10 Tres vectores x,y e z em R3, dizem-se linearmente dependentes, seum deles e multiplo escalar dos restantes. Se x = 0 (ou y = 0, ou z = 0) entaox,y e z sao linearmente dependentes. Geometricamente x,y e z sao linearmentedependentes, sse eles sao coplanares.

2.1. Algebra Linear em R3 32
I 2.11 Dois vectores x e y em R2, dizem-se linearmente independentes,sse nao sao linearmente dependentes (o que implica que x 6= 0 e y 6= 0).Geometricamente x e y sao linearmente independentes, sse eles sao nao col-ineares. Simbolicamente:
(x e y sao lin. indep.) ⇐⇒ (λx + ηy = 0 =⇒ λ = η = 0)
I 2.12 Tres vectores x,y e z em R3,, dizem-se linearmente independentes,sse nao sao linearmente dependentes (o que implica que x 6= 0, y 6= 0 e z 6=0). Geometricamente x,y e z sao linearmente independentes, sse eles sao naocoplanares. Simbolicamente:
(x, y e z sao lin. indep.) ⇐⇒ (λx + η y + µ z = 0 =⇒ λ = η = µ = 0)
I Exercıcio 2.5 ... Verifique se os vectores que se seguem sao linearmente depen-dentes ou independentes:
a) (1, 0, 1), (2,−1, 1) em R3; b) (1, 0, 1), (2, 2, 0) em R3;c) (0, 0, 0), (0, 1, 1), (0,−1, 2) em R3; d) (1, 1, 2), (2, 3, 0), (1, 1,−1) em R3;
Base canonica
I 2.13 Os vectores de R3:
e1 = i =
100
e2 = =
010
e e3 = k =
001
sao linearmente independentes, e tem a propriedade de que qualquer vector
x =
x1
x2
x3
, se pode escrever como combinacao linear de e1, e2 e e3. De
facto:
x =
x1
x2
x3
= x1
100
+ x2
010
+ x3
001
= x1 e1 + x2 e2 + x3 e3 (2.1.13)
Diz-se entao que C = {e1, e2, e3} e uma base (ordenada): a base canonicade R3.
Bases, coordenadas, dimensao

2.1. Algebra Linear em R3 33
I 2.14 Qualquer conjunto B = {u1,u2,u3} constituıdo por tres vectores lin-earmente independentes, e que tem a propriedade de que qualquer vector x ∈ R3,se pode escrever como combinacao linear de u1, u2 e u3:
x = a1 u1 + a2 u2 + a3 u3 (2.1.14)
para certos escalares (unicos) a1, a2, a3 ∈ R, diz-se uma base de R3. Os escalaresa1, a2, a3 dizem-se as coordenadas do vector x na base B escreve-se:
x =
a1
a2
a3
B
(2.1.15)
Todas as bases de R3 tem sempre tres elementos, e por isso, diz-se que adimensao (real) de R3 e 3.
I Exercıcio 2.6 ... Verifique se os conjuntos que se seguem, sao ou nao bases decada um dos espacos vectoriais indicados em cada alınea. Calcule as coordenadas dex = (1,−1) relativamente aos que sao bases:
a) {(1, 1, 1), (1,−1, 5)} em R3;b) {(1, 1, 1), (1, 2, 3), (2,−1, 1)} em R3;c) {(1, 2, 3), (1, 0,−1), (3,−1, 0), (2, 1,−2)} em R3;d) {(1, 1, 2), (1, 2, 5), (5, 3, 4)} em R3;
I Exercıcio 2.7 ... Calcule uma base de cada um dos subespacos que se seguem,e depois as coordenadas do vector u em cada uma das bases:
a) S ={(x, y, z) ∈ R3 : x + y + z = 0
}, u = (1, 1,−2);
b) S ={(x, y, z) ∈ R3 : 2x− y = z
}, u = (3, 2, 4);
b) S ={(x, y, z) ∈ R3 : 2x− y = 0 = x + y − z
}, u = (−1, 2, 3);
Aplicacoes Lineares
I 2.15 Uma aplicacao A : R3 → R3 diz-se uma transformacao linear, se Apreserva as operacoes que definem a estrutura vectorial de R3, i.e.,:
A(x + y) = A(x) + A(y) (2.1.16)A(λx) = λA(x) (2.1.17)
∀x,y ∈ R3, e ∀λ ∈ R.
I 2.16 Dada uma aplicacao linear A : R3 → R3 define-se:
• o nucleo de A:kerA = {x ∈ R3 : A(x) = 0} (2.1.18)

2.1. Algebra Linear em R3 34
• a imagem de A:
imA = {y : A(x) = y ∈ R3, para algumx ∈ R3} (2.1.19)
I Exercıcio 2.8 ... (i). Mostrar que kerA e ImA sao subespacos de R3.(ii). Mostrar que A e injectiva se e so se kerA = {0}.
I Exercıcio 2.9 ... Das aplicacoes que se seguem, indique aquelas que sao lin-eares. Relativamente a essas, calcule o respectivo nucleo e diga quais as que saoinjectivas.
a) A : R3 −→ R3 ; (x, y, z) 7−→ (x + y, x− y, x + z)b) A : R3 −→ R3; (x, y) 7−→ (|x| , |y| , x− z2)c) A : R3 −→ R3 ; (x, y, z) 7−→ (x + 1, x− y, 3)d) A : R3 −→ R3; (x, y, z) 7−→ (0, x + y, 0)
I Exercıcio 2.10 ... Sabendo que A : R3 −→ R3 e uma aplicacao linear, calculeem cada caso a imagem de um vector generico:
a) sendo que A(1, 0, 0) = (1, 1,−1), A(0, 1, 0) = (1,−2, 0); e A(0, 0, 1) = (1, 1, 1)b) sendo A(1,−1, 1) = (1, 2, 0) e A(0, 3,−1) = (2,−2, 0); e A(1, 0, 0) = (1, 1, 1)
Matriz de uma aplicacao linear
I 2.17 Vamos nesta seccao introduzir pela primeira vez as notacoes que seraousadas na parte mais avancada do curso. A primeira vista, estas notacoes pare-cem muito complicadas mas, apos algum treino, veremos que elas facilitamsubstancialmente os calculos e as deducoes teoricas que vamos estudar. E naofossem elas usadas intensivamente por Einstein ... As principais diferencas sao:
• para as coordenadas dos vectores usamos ındices superiores x1, x2, x3, ...em vez de ındices inferiores x1, x2, x3, .... O risco aqui e a possıvel confusaoentre ındices superiores x1, x2, x3, ... e expoentes. Neste contexto, por ex-emplo, x2 nao representa “x ao quadrado”mas sim a segunda componentedo vector x. Nao faca pois essa confusao e esteja atento ao contexto.
• o uso de ındices superiores e inferiores A11, A
32, A
33, ... para as entradas de
uma matriz, de tal forma que na matriz A = (Aij), o ındice superior i e o
ındice-linha - o que numera as linhas - enquanto que o ındice inferior j
e o ındice-coluna - o que numera as colunas:
Ai→ ındice linha: numera as linhas de Aj→ ındice coluna: numera as colunas de A

2.1. Algebra Linear em R3 35
I 2.18 Se B = {u1,u2 u3} e uma base fixa de R3, podemos escrever que:
A(u1) = A11 u1 + A2
1 u2 + A31 u3 (2.1.20)
A(u2) = A12 u1 + A2
2 u2 + A32 u3 (2.1.21)
A(u3) = A13 u1 + A2
3 u2 + A33 u3 (2.1.22)
A matriz:
A =
A11 A1
2 A13
A21 A2
2 A23
A31 A3
2 A33
(2.1.23)
diz-se a matriz de A na base B, e nota-se por:
A = (A)B
I 2.19 Se as coordenadas de um vector x ∈ R2, na base B, sao x =
x1
x2
x3
B
,
i.e., se:x = x1u1 + x2u2 + x3u3
entao as coordenadas de A(x) na base B obtem-se da seguinte forma:
A(x) = A(x1u1 + x2u2 + x3u3)= x1A(u1) + x2A(u2) + x3A(u3)= x1 (A1
1u1 + A21u2 + A3
1u3) + x2 (A12u1 + A2
2u2 + A32u3)
+x3 (A13u1 + A2
3u2 + A33u3)
= (A11x
1 + A12x
2 + A13x
3)u1 + (A21x
1 + A22x
2 + A23x
3)u2
+(A31x
1 + A32x
2 + A33x
3)u3 (2.1.24)
o que significa que as coordenadas de A(x) na base B:
(A(x))B =
y1
y2
y3
B
se obtem matricialmente atraves de:
y1
y2
y3
B
=
A11 A1
2 A13
A21 A2
2 A23
A31 A3
2 A33
x1
x2
x3
B
(2.1.25)
ou mais sucintamente:
(A(x))B = (A)B (x)B (2.1.26)

2.1. Algebra Linear em R3 36
ou ainda, em “notacao tensorial” , pondo (A)B = (Aij) e yi = (Ax)i:
yi =∑3
i=1 Aij xj = Ai
j xj (2.1.27)
onde, na segunda igualdade adoptamos a chamada “convencao de Einstein”que consiste em omitir o sinal de somatorio, ficando subentendido que o factode surgir o ındice j repetido, uma vez em cima e outra em baixo, implica quese faca esse somatorio no ındice j.
Determinantes
I 2.20 Dada uma matriz A =
A11 A1
2 A13
A21 A2
2 A23
A31 A3
2 A33
, definimos o seu determi-
nante detA, como sendo o numero real:
det A =
∣∣∣∣∣∣
A11 A1
2 A13
A21 A2
2 A23
A31 A3
2 A33
∣∣∣∣∣∣
= A11
∣∣∣∣A2
2 A23
A32 A3
3
∣∣∣∣−A12
∣∣∣∣A2
1 A23
A31 A3
3
∣∣∣∣ + A13 det
∣∣∣∣A2
1 A22
A31 A3
2
∣∣∣∣(2.1.28)
Veremos en breve uma interpretacao geometrica para det A.
I 2.21 Representemos por:
c1 =
A11
A21
A31
, c2 =
A12
A22
A32
e c3 =
A13
A23
A33
as colunas da matriz A, de tal forma que:
detA = det (c1 c2 c3) (2.1.29)
E possıvel mostrar as seguintes propriedades do det :
(i). det (c1 c2 c3) 6= 0 sse c1, c2, c3 sao linearmente independentes.
(ii). det [c1 c2 c3] muda de sinal, sempre que se permuta um par de colunas.
(iii).
det (c1 + c′1 c2 c3) = det (c1 c2 c3) + det (c′1 c2 c3) (2.1.30)det (c1 c2 + c′2 c3) = det (c1 c2 c3) + det (c1 c′2 c3) (2.1.31)det (c1 c2 c3 + c′3) = det (c1 c2 c3) + det (c1 c2 c′3) (2.1.32)
det (λ c1 c2 c3) = λ det (c1 c2 c3)= det (c1 λ c2 c3)= det (c1 c2 λ c3) λ ∈ R (2.1.33)

2.1. Algebra Linear em R3 37
e ainda que:
(iv).
det I = 1 (2.1.34)det (AB) = det A detB (2.1.35)det (A−1) = (det A)−1 ∀A ∈ GL(3) (2.1.36)
det (P−1 AP ) = det A ∀P ∈ GL(3) (2.1.37)det (A) = det (At) (2.1.38)
onde At e a transposta de A.
(v). Alem disso e possıvel provar que para uma matriz A:
A e inversıvel se e so se det A 6= 0
.
I 2.22 Finalmente, se A : R3 → R3 e uma aplicacao linear, define-se o re-spectivo determinante detA, como sendo o determinante da matriz de A,relativamente a uma qualquer base de R3. Veremos, num proximo capıtulo, queesta definicao nao depende da base escolhida.
Veremos en breve uma interpretacao geometrica para detA.
I Exercıcio 2.11 ... Calcule o determinante das aplicacoes lineares descritas noexercıcio ??.
Produto interno (euclideano)
I 2.23 Dados dois vectores x =
x1
x2
x3
e y =
y1
y2
y3
, em R3, define-se o
respectivo produto interno (euclideano), como sendo o escalar x · y ∈ R,dado por:
x · y = x1y1 + x2y2 + x3y3
= (x1 x2 x3)
y1
y2
y3
= xt y (2.1.39)
I 2.24 O produto interno (euclideano), que acabamos de definir, verifica aspropriedades seguintes:

2.1. Algebra Linear em R3 38
• e bilinear:
(x + y) · z = x · z + y · zx · (y + z) = x · y + x · z
λx · y = x · λy = λ(x · y) (2.1.40)
• e simetrica:x · y = y · x (2.1.41)
• e nao degenerada:
x · y = 0 ∀y ∈ R2 ⇒ x = 0 (2.1.42)
• e definida positiva:
x · x ≥ 0 e x · x = 0 ⇐⇒ x = 0 (2.1.43)
∀x,y, z ∈ R3, ∀λ ∈ R.
I Exercıcio 2.12 ... Verifique que o produto interno (2.1.39) satisfaz as pro-priedades acima referidas.
Norma (euclideana)
I 2.25 Define-se a norma euclideana ‖x‖, de um vector x =
x1
x2
x3
∈ R3,
atraves da formula:
‖x‖ ≡ √x · x
=√
xt x
=√
(x1)2 + (x2)2 + (x3)2 (2.1.44)
I 2.26 A norma euclideana verifica as propriedades seguintes:
• e positiva e nao degenerada:
‖x‖ ≥ 0 e ‖x‖ = 0 sse x = 0 (2.1.45)
• e homogenea (positiva):
‖λx‖ = |λ| ‖x‖ (2.1.46)

2.1. Algebra Linear em R3 39
• verifica a desigualdade triangular:
‖x + y‖ ≤ ‖x‖+ ‖y‖ (2.1.47)
∀x,y ∈ R2, ∀λ ∈ R.
Todas as propriedades sao de demonstracao imediata com excepcao da de-sigualdade triangular, que resulta imediatamente de uma outra importante de-sigualdade que passamos a enunciar, e cuja prova e em tudo analoga a que foifeita no capıtulo anterior:
• Desigualdade de Cauchy-Schwarz:
|x · y| ≤ ‖x‖‖y‖ (2.1.48)∀x,y ∈ R2.
Angulo, ortogonalidade
I 2.27 Dados dois vectores nao nulos x,y ∈ R3, deduzimos da desigualdadede Cauchy-Schwarz que:
−1 ≤ x · y‖x‖‖y‖ ≤ 1 (2.1.49)
o que permite definir o angulo (nao orientado) θ ∈ [0, π], entre os referidosvectores nao nulos x,y ∈ R3, como sendo o unico θ ∈ [0, π], tal que:
cos θ =x · y‖x‖‖y‖ ∈ [−1, 1] (2.1.50)
Portanto:x · y = ‖x‖‖y‖ cos θ (2.1.51)
Dois vectores x,y ∈ R3 dizem-se ortogonais se x · y = 0.
Rectas vectoriais e afins
I 2.28 Dado um vector nao nulo v 6= 0, o conjunto dos vectores x que sao daforma:
x = tv t ∈ R (2.1.52)
diz-se a recta (vectorial) gerada por v. Se v =
v1
v2
v3
, entao (3.3.4) e
equivalente ao sistema de equacoes:
x1 = t v1
x2 = t v2
x3 = t v3
t ∈ R
que se dizem as equacoes parametricas da referida recta.

2.1. Algebra Linear em R3 40
I 2.29 Dado um ponto A ∈ R3 e um vector nao nulo v 6= 0, o conjunto dospontos P que sao da forma:
P = A + tv t ∈ R (2.1.53)
isto e, tais que−→AP = tv, diz-se a recta (afim) que passa em A e e gerada
por v.
Se P =
x1
x2
x3
, A =
a1
a2
a3
, e v =
v1
v2
v3
, entao (2.1.53) e equivalente
ao sistema de equacoes:
x1 = a1 + t v1
x2 = a2 + t v2
x3 = a3 + t v3
t ∈ R
que se dizem as equacoes parametricas da referida recta.
Resolvendo em ordem a t podemos escrever as chamadas equacoes ho-mogeneas da referida recta, na forma:
x1 − a1
v1=
x2 − a2
v2=
x3 − a3
v3, se v1v2v3 6= 0 (2.1.54)
Planos vectoriais e afins
I 2.30 Dados dois vectores u,v ∈ R3 − {0}, linearmente independentes, aosubespaco gerado por esses dois vectores, i.e., ao conjunto constituıdo portodas as combinacoes lineares de u e v:
span{u,v} ≡ {x ∈ R3 : x = λu + η v λ, η ∈ R} (2.1.55)
chama-se o plano (vectorial) gerado por u e v. Se P e um ponto generico
desse plano, com vector de posicao−−→OP = x =
x1
x2
x3
, e se u =
u1
u2
u3
,
v =
v1
v2
v3
, a equacao vectorial:
x = λu + η v λ, η ∈ Rque define o referido plano, e equivalente as seguintes equacoes parametricas:
x1 = λu1 + η v1
x2 = λu2 + η v2
x3 = λu3 + η v3
λ, η ∈ R (2.1.56)

2.1. Algebra Linear em R3 41
I 2.31 Dado um ponto A ∈ R3 e dois vectores u,v ∈ R3 − {0}, linearmenteindependentes, ao conjunto dos pontos P que sao da forma:
P = A + λu + η v λ, η ∈ R (2.1.57)
chama-se o plano (afim) que passa em p e e gerada por u e v.
As equacoes parametricas de um tal plano, sao do tipo:
x1 = a1 + λu1 + η v1
x2 = a2 + λu2 + η v2
x3 = a3 + λu3 + η v3
λ, η ∈ R (2.1.58)
I 2.32 Dado um vector nao nulo n ∈ R3−{0}, o conjunto dos pontos P cujosvectores de posicao
−−→OP = x ∈ R3 sao ortogonais a n:
{x ∈ R3 : x · n = 0} (2.1.59)
formam um subespaco de dimensao 2 em R3, que se diz o plano (vectorial)
ortogonal a n. Se x =
x1
x2
x3
e se n =
n1
n2
n3
, a equacao x · n = 0, e
equivalente a seguinte equacao cartesiana:
n1 x1 + n2 x2 + n3 x3 = 0 (2.1.60)
I 2.33 Dado um ponto arbitrario A ∈ R3 e um vector nao nulo n ∈ R3 − {0},o conjunto dos pontos P que verificam a equacao:
−→AP · n = 0 (2.1.61)
diz-se o plano afim que passa em A e e ortogonal a n. Se−−→OP = x =
x1
x2
x3
, A =
a1
a2
a3
e n =
n1
n2
n3
, a equacao cartesiana de um tal plano
e do tipo:
n1 (x1 − a1) + n2 (x2 − a2) + n3 (x3 − a3) = 0 (2.1.62)
I 2.34 Exemplo ... Calcular a distancia entre um ponto P e um hiperplanoafim em IEn.

2.1. Algebra Linear em R3 42
Res... Suponhamos que esse hiperplano e perpendicular ao vector u 6= 0 epassa num ponto a e, portanto, tem equacao:
(x− a) · u = 0
oux · u + c = 0, c = −a · u
A recta que passa em P ' −−→OP = p e tem a direccao do vector u, tem
equacao:x(t) = p + tu
O ponto desta recta que pertence ao plano referido, corresponde ao valor doparametro t que verifica:
0 = x(t) · u + c = (p + tu) · u + c = p · u + t‖u‖2 + c ⇒ t = −p · u + c
‖u‖2
A distancia entre um ponto P ' p e o hiperplano afim e pois dada por:
d = ‖p− x(t)‖ =∥∥∥∥p− p +
p · u + c
‖u‖2 u∥∥∥∥ =
|p · u + c|‖u‖
Assim por exemplo:
• No plano, a distancia entre um ponto P = (α, β) e a recta afim ax+by+c =0 e:
d =|p · u + c|‖u‖ =
|(α, β) · (a, b) + c|‖(a, b)‖ =
|aα + bβ + c|(a2 + b2)1/2
• No espaco, a distancia entre um ponto P = (α, β, γ) e o plano afim ex +fy + gz + h = 0 e:
d =|p · u + c|‖u‖ =
|(α, β, γ) · (e, f, g) + h|‖(e, f, g)‖ =
|eα + fβ + gγ + h|(e2 + f2 + g2)1/2

2.1. Algebra Linear em R3 43
I 2.35 Exemplo ... Calcular a distancia entre um ponto P e uma recta afimem IE3, quando:
1. essa recta e definida parametricamente.
2. essa recta e definida como interseccao de dois planos afins.
Produto vectorial em E3
I 2.36 Definamos agora o chamado produto vectorial de dois vectores noespaco Euclideano E3:
Dados dois vectores x =
x1
x2
x3
,y =
y1
y2
y3
, em E3, define-se o produto
vectorial, x× y, de x por y, como sendo o seguinte vector de R3:
x× y ≡ (x2y3 − x3y2)i + (x3y1 − x1y3)j + (x1y2 − x2y1)k (2.1.63)
O produto vectorial x × y, pode ser obtido desenvolvendo segundo a primeiralinha, o determinante formal:
x× y =
∣∣∣∣∣∣
i j kx1 x2 x3
y1 y2 y3
∣∣∣∣∣∣
I 2.37 O produto vectorial verifica as propriedades seguintes:
• e bilinear:
(x + y)× z = x× z + y × z
x× (y + z) = x× y + x× z
λx× y = x× λy = λ (x× y) (2.1.64)
• e antissimetrico:x× y = −y × x (2.1.65)
• verifica a identidade de Jacobi:
(x× y)× z + (y × z)× x + (z× x)× y = 0 (2.1.66)
Alem disso, se x ∈ R3 e y ∈ R3, sao ambos nao nulos, entao:

2.1. Algebra Linear em R3 44
• x× y e perpendicular a x e a y, i.e.:
(x× y) · x = 0 = (x× y) · y (2.1.67)
Se x e y sao linearmente independentes, x × y e perpendicular ao planogerado por x e y.
•‖x× y‖ = ‖x‖‖y‖ sin θ (2.1.68)
onde θ e o angulo entre x e y. Portanto, ‖x × y‖ e igual a area doparalelogramo cujos lados adjacentes sao x e y.
• x× y = 0 ⇔ x e y sao linearmente dependentes.
• O produto vectorial nao e associativo. De facto, sao validas as seguintesidentidades de Lagrange:
(x× y)× z = (x · z)y − (y · z)x (2.1.69)
enquanto que:x× (y × z) = (x · z)y − (x · y)z (2.1.70)
I 2.38 Em particular, se consideramos o paralelogramo de lados adjacentes
x =
x1
x2
0
e y =
y1
y2
0
, contido no plano x3 = 0, vemos que a respectiva
area e dada por:
‖x× y‖ =
∣∣∣∣∣∣det
i j kx1 x2 0y1 y2 0
∣∣∣∣∣∣
=∣∣∣∣det
(x1 x2
y1 y2
)∣∣∣∣ (2.1.71)
I 2.39 Uma equacao (cartesiana) para o plano vectorial span{u,v}, geradopor dois vectores u,v ∈ R3 − {0}, linearmente independentes, e:
x · (u× v) = 0 (2.1.72)
Produto misto (ou triplo) em R3. Interpretacao geometrica do det
I 2.40 Definamos agora, ainda em E3, o chamado produto misto (ou triplo).
Dados tres vectores x,y, z em R3, define-se o produto misto (ou triplo)[x,y, z], de x,y e z (por esta ordem), atraves de:
[x,y, z] ≡ x · (y × z) (2.1.73)

2.1. Algebra Linear em R3 45
E facil ver que [x,y, z] e dado por:
[x,y, z] = det [x y z]
= det
x1 y1 z1
x2 y2 z2
x3 y3 z3
(2.1.74)
I 2.41 O produto misto verifica as propriedades seguintes:
•[x,y, z] = [y, z,x] = [z,x,y] = −[y,x, z]
= −[x, z,y] = −[z,y,x] (2.1.75)
• O volume vol (x,y, z), do paralelipıpedo de lados adjacentes x,y, z ∈ R3,e igual ao modulo do produto misto:
vol (x,y, z) = |[x,y, z]| (2.1.76)
De facto, o volume de um paralelipıpedo e igual ao produto da area dabase pela sua altura. A base e o paralelogramo de lados adjacentes x e y,e por isso, a sua area e ‖x × y‖. A altura e igual a norma da projeccaode z sobre um vector perpendicular a base. Mas x× y e perpendicular abase, e atendendo a (2.1.87), a projeccao de z sobre x× y, e igual a:
z · (x× y)‖x× y‖2 (x× y) (2.1.77)
donde se deduz facilmente o resultado .
Quando x1,x2 e x3 sao linearmente independentes, de tal forma que:
det [x1 x2 x3] 6= 0
dizemos que a base ordenada {x1,x2,x3} e
• positiva se det [x1 x2 x3] > 0, e
• negativa se det [x1 x2 x3] < 0.
Interpretacao geometrica de detA
I 2.42 Consideremos agora uma aplicacao linear A : R3 → R3. A imagemdo cubo Q ⊂ R3, gerado pelos vectores da base canonica (que e positiva){e1, e2, e3}:
Q = {ae1 + be2 + ce3 : 0 ≤ a, b, c ≤ 1}

2.1. Algebra Linear em R3 46
e o paralelipıpedo A(Q), de lados adjacentes A(e1),A(e2) e A(e3).
Pondo A(e1) = a11e1 + a2
1e2 + a3e3 =
a11
a21
a31
, A(e2) = a1
2e1 + a22e2 + a3
2 =
a12
a22
a32
, e A(e3) = a1
3e1 + a23e2 + a3
3 =
a13
a23
a33
sabemos que o volume deste
paralelipıpedo e igual a:
volA(Q) = |[A(e1),A(e2),A(e3)]|= |det [A(e1) A(e2) A(e3)]|
= |det
a11 a1
2 a13
a21 a2
2 a23
a31 a3
2 a33
|
= |detA| (2.1.78)
Portanto:volA(Q) = |detA| (2.1.79)
I 2.43 Mais geralmente, se P e um paralelipıpedo gerado pelos vectores x,y ez, entao a imagem A(P) e o paralelipıpedo gerado por A(x),A(y) e A(z), e efacil provar que o volume dessa imagem e igual a:
volA(P) = |[A(x),A(y),A(z)]|= |det [A(x) A(y) A(z)]|= |detA| vol (P)) (2.1.80)
Em particular, se os vectores x,y e z sao linearmente independentes, de talforma que volP 6= 0, entao:
|detA| = volA(P)volP (2.1.81)
I 2.44 Diz-se que uma aplicacao linear inversıvel A : R3 → R3
• preserva a orientacao (ou e positiva) se detA > 0, e que
• inverte a orientacao (ou e negativa) se detA < 0
Valores e vectores proprios
I 2.45 Seja A : R3 → R3 uma aplicacao linear. Um escalar λ ∈ R diz-se umvalor proprio de A se existir um vector nao nulo v ∈ R3 − {0} tal que:
A(v) = λv (2.1.82)

2.1. Algebra Linear em R3 47
Neste caso, o vector nao nulo v, diz-se um vector proprio pertencente ao valorproprio λ.
I 2.46 O conjunto constituıdo pelo vector nulo 0 e por todos os vectoresproprios pertencentes a um certo valor proprio λ, de A, e um subespaco deR3, chamado o subespaco proprio de A, pertencente ao valor proprio λ, enota-se por:
EA(λ) = E(λ) = {x : A(x) = λx} (2.1.83)
A restricao de A a E(λ) e pois uma homotetia de razao λ (eventualmente λpode ser 0), i.e.:
A(x) = λx ∀x ∈ E(λ)
I 2.47 Em particular, se λ = 0 e valor proprio de A, isto significa que o nucleode A;
kerA = EA(0)
nao se reduz ao vector nulo 0, e portanto A e nao inversıvel (ou singular), oude forma equivalente, detA = 0.
Quando λ 6= 0, dizer que λ e valor proprio de A, e equivalente a dizer que 0e valor proprio de A−λ Id, o que, pelo paragrafo anterior, e equivalente a dizerque A− λ Id e nao inversıvel (ou singular), ou ainda que:
det (A− λ Id) = 0 (2.1.84)
I 2.48 O polinomio p(λ) = det (A− λ Id) diz-se o polinomio caracterısticode A. Portanto as raızes reais da chamada equacao caracterıstica de A:
p(λ) = det (A− λ Id) = 0 (2.1.85)
(se existirem), sao exactamente os valores proprios (reais) de A.
Num capıtulo posterior demonstrar-se-a que o polinomio caracterıstico deuma aplicacao linear A : R3 → R3, nao depende da representacao matricial deA.
I 2.49 Note ainda que o polinomio caracterıstico p(λ) = det (A − λ Id), deuma aplicacao linear A : R3 → R3, e sempre um polinomio do 3.o grau, do tipo:
p(λ) = −λ3 + bλ2 + cλ + d b, c, d ∈ R
e por isso admite sempre uma raiz real λ ∈ R (eventualmente nula). Se λ 6=0, concluımos portanto que, neste caso, existe sempre um subespaco proprioinvariante E(λ) ⊆ R3, de dimensao superior ou igual a 1, tal que:
A(E(λ)) ⊆ E(λ)A(x) = λx x ∈ E(λ)

2.1. Algebra Linear em R3 48
Exemplo...
Calcule os valores e vectores proprios (reais) da aplicacao linear A : R3 → R3, cujamatriz na base canonica de R3 e:
A =
1 0 0−5 2 0
2 3 7
A equacao caracterıstica de A e:
p(λ) = det (A− λ Id)
=
∣∣∣∣∣∣
1− t 0 0−5 2− t 02 3 7− t
∣∣∣∣∣∣= (1−)(2− t)(7− t) = 0 (2.1.86)
cujas raızes reais (os valores proprios de A) sao λ1 = 1, λ2 = 2 e λ3 = 7.
Para calcular os vectores poprios x =
x1
x2
x3
, pertencentes ao valor proprio
λ2 = 2, devemos resolver o sistema:
1− 2 0 0−5 2− 2 02 3 7− 2
x1
x2
x3
=
000
isto e:
−x1 = 0−5x1 = 02x1 + 3x2 + 5x3 = 0
cuja solucao geral e:
x1 = 0x2 = − 5
3s
x3 = ss ∈ R
Portanto os vectores poprios de A, pertencentes ao valor proprio λ2 = 2, sao da forma:
s
0− 5
3
1
s ∈ R− {0}
Procedendo da mesma forma relativamente aos outros valores proprios λ1 = 1 e
λ3 = 7, podemos calcular os correspondentes vectores poprios.
Projeccao ortogonal sobre uma recta gerada por a 6= 0

2.1. Algebra Linear em R3 49
Sejam a 6= 0 e x dois vectores em R3,com a nao nulo. Entao existe um unicovector u, na recta gerada por a, e umunico vector v, ortogonal a a, tais quex = u + v. O vector u, notado porPa(x), diz-se a projeccao ortogonalde x sobre a recta gerada por a, e edado por:
Pa(x) =x · a‖a‖2 a (2.1.87)
I 2.50 A aplicacao Pa : R3 → R3 definida por (7.7.7), e linear. Note queP2
a = Pa. Uma vez que Pa(a) = a vemos que a e vector proprio de Pa,pertencente ao valor proprio 1. Por outro lado, se considerarmos um qualquervector b 6= 0 ortogonal a a (i.e.: a · b = 0), vemos que Pa(b) = 0 e portanto:
kerPa = span{b} = {b ∈ R3 : b · a = 0} = a⊥
e o plano vectorial ortogonal a a.
A matriz de Pa numa base {a,b1,b2}, onde b1,b2 geram o kerPa, e por-tanto:
1 0 00 0 00 0 0
Projeccao ortogonal sobre um plano vectorial, em IE3
Consideremos um plano vectorial ortog-onal a um vector n ∈ R3 − {0} (seesse plano e gerado por dois vectoresu,v linearmente independentes, pode-mos tomar n = u × v). Notemos esseplano por π = n⊥. Dado um vectorx ∈ R3, ao vector:
Pπ(x) ≡ x−Pn(x)
chamamos a projeccao ortogonal dex sobre o plano vectorial π = n⊥, or-togonal a n.
I 2.51 De acordo com (2.1.87), temos que:
Pπ(x) ≡ x−Pn(x) = x− x · n‖n‖2 n

2.1. Algebra Linear em R3 50
isto e:Pπ(x) = x− x · n
‖n‖2 n (2.1.88)
A aplicacao Pπ : R3 → R3 definida por (7.7.8), e linear. Note que P2π = Pπ.
Se x · n = 0, i.e., se x e ortogonal a n, entao Pπ(x) = x, enquanto que, poroutro lado, Pπ(n) = 0. Portanto vemos que:
kerPπ = span{n}
e:Pπ(x) = x ∀x ∈ π = n⊥
Portanto a matriz de Pπ numa base {n,b1,b2}, onde b1,b2 geram o plano π,e:
0 0 00 1 00 0 1
Reflexao num plano vectorial
Consideremos novamente um plano vec-torial n⊥, ortogonal a um vector n ∈R3 − {0} (se esse plano e gerado pordois vectores u,v linearmente indepen-dentes, podemos tomar n = u× v).A simetria relativamente ao plano vec-torial π = n⊥, ou reflexao em π, e aaplicacao linear Sπ : R3 → R3, definidapela condicao:
12(Sπ(x) + x
)= Pπ(x) ∀x ∈ R3
(2.1.89)isto e, o ponto medio do segmento queune x a Sπ(x) deve ser igual a projeccaode x sobre o plano vectorial π = n⊥.
I 2.52 Atendendo a (2.1.88), vemos que:
Sπ(x) = 2Pπ(x)− x = 2(x− x · n
‖n‖2 n)− x = x− 2
x · n‖n‖2 n
isto e:
Sπ(x) = x− 2x · n‖n‖2 n, ∀x ∈ R3 (2.1.90)

2.1. Algebra Linear em R3 51
Note que S2π = Id. Alem disso, e facil ver que :
Sπ(n) = −n
o que significa que n e vector proprio de Sπ, pertencente ao valor proprio −1, eainda que:
Sπ(x) = x ∀x ∈ π
Portanto a matriz de Sπ numa base {n,b1,b2}, onde b1,b2 geram o plano π,e:
−1 0 00 1 00 0 1
o que mostra que detSπ = −1 < 0, i.e., Sπ inverte orientacao.
Isometrias em R3. Rotacoes. Os grupos O(3) e SO(3)
I 2.53 Uma aplicacao linear A : R3 → R3 diz-se uma transformacao ortog-onal ou uma isometria de R3, se A preserva o produto interno (Euclideano)usual de R3, i.e.:
A(x) ·A(y) = x · y ∀x,y ∈ R3 (2.1.91)
Esta condicao e equivalente a:
‖A(x)‖ = ‖x‖ ∀x ∈ R3 (2.1.92)
i.e., A preserva os comprimentos dos vectores. Se A e a matriz de uma tal trans-formacao ortogonal, relativamente a uma qualquer base ortonormada {e1, e2, e3}de R2 (por exemplo, a base canonica), A e uma matriz ortogonal, isto e, AtA = I.Portanto A ∈ O(3). Vejamos como e a forma geral de uma tal matriz.
I 2.54 Se c1 = A(e1), c2 = A(e2), c3 = A(e3) sao as colunas de A, entao:
ci · cj = δij
o que significa que c1, c2 e c3 sao ortonormais. Portanto A transforma basesortonormadas em bases ortonormadas, preservando ou invertendo orientacao,conforme detA = +1 ou detA = −1, respectivamente. Por exemplo, a reflexaoSπ, descrita em (2.1.89), e uma transformacao ortogonal com det igual a −1.
I 2.55 Como ja vimos A admite sempre um valor proprio real. De facto, seA : R3 → R3 e uma isometria entao esse valor proprio (real) ou e 1 ou −1. Comefeito, se λ ∈ R e valor proprio de A, e v e um vector proprio pertencente a λ,temos que:
‖v‖ = ‖A(v)‖ = ‖λv‖ = |λ| ‖v‖

2.1. Algebra Linear em R3 52
o que implica que |λ| = 1 (uma vez que v 6= 0), i.e., λ = ±1.
Analisemos agora a estrutura das isometrias de R3 com determinante iguala 1, isto e, a estrutura das matrizes A ∈ SO(3). Seja A : R3 → R3 uma talisometria, com:
detA = 1
Pelo paragrafo anterior, A admite o valor proprio 1 ou −1. Vamos analisar cadaum destes casos:
(i). λ = 1 e valor proprio de A (e detA = 1) ... Seja u 6= 0 um vectorproprio de A, pertencente ao valor proprio 1:
A(u) = u
Podemos supor tambem que ‖u‖ = 1. Se Π = u⊥ e o plano ortogonal a u, efacil ver que A deixa Π invariante:
A(Π) ⊆ Π
e que a restricao de A a Π e uma isometria de Π. Portanto existe uma baseortonormada {e, f} de Π, relativamente a qual a matriz da restricao de A a Π,e de um dos seguintes dois tipos:
(i 1).[
cosϕ − sinϕsin ϕ cosϕ
](2.1.93)
ou:
(i 2).[
cosϕ sin ϕsin ϕ − cos ϕ
](2.1.94)
A matriz de A, relativamente a baseortonormada {u, e, f} de R3 e portantono caso (i 1):
A =
1 0 00 cos ϕ − sin ϕ0 sin ϕ cosϕ
(2.1.95)
que tem de facto determinante 1, e rep-resenta uma rotacao em torno da rectagerada por u ∈ Π (que se diz o eixo darotacao), de angulo ϕ.
Por outro lado, no caso (i 2), a matriz de A, relativamente a base ortonor-mada {u, e, f} de R3, e:
A =
1 0 00 cos ϕ sin ϕ0 sin ϕ − cosϕ
(2.1.96)

2.1. Algebra Linear em R3 53
que tem determinante −1 e por isso nao pode ser a matriz de A.
(i). λ = −1 e valor proprio de A (e detA = 1) ... Seja u 6= 0 um vec-tor proprio de A, pertencente ao valor proprio −1:
A(u) = −u
Podemos supor tambem que ‖u‖ = 1.
Mais uma vez, se Π = u⊥ e o plano ortogonal a u, A deixa Π invariante:
A(Π) ⊆ Π
e a restricao de A a Π e uma isometria de Π. Portanto existe uma base ortonor-mada {e, f} de Π, relativamente a qual a matriz da restricao de A a Π, e de umdos seguintes dois tipos:
(ii 1).[
cos ϕ − sin ϕsin ϕ cos ϕ
](2.1.97)
ou:
(ii 2).[
cosϕ sin ϕsin ϕ − cos ϕ
](2.1.98)
Como vimos anteriormente, esta e uma matriz de uma simetria relativamentea uma recta no plano Π, e portanto podemos escolher uma base ortonormada{e′, f ′} para Π, relativamente a qual a matriz dessa simetria e:
[1 00 −1
]
A matriz de A, relativamente a base ortonormada {u, e, f} de R3 e portanto nocaso (ii 1):
A =
−1 0 0
0 cos ϕ − sin ϕ0 sin ϕ cosϕ
(2.1.99)
que tem determinante −1, e por isso nao pode ser a matriz de A.
Finalmente no caso (ii 2), a matriz de A, relativamente a base ortonormada{u, e′, f ′} de R3, e:
A =
−1 0 0
0 1 00 0 −1
(2.1.100)
que tem determinante 1, e representa uma rotacao em torna da recta geradapor e′ ∈ Π, de angulo π.
I 2.56 Resumindo ... Uma isometria A em R3, com detA = 1, e sempreuma rotacao em torno de uma certa recta R{u} (o eixo de rotacao), e de angulo

2.1. Algebra Linear em R3 54
ϕ no sentido directo. Representamos uma tal rotacao por R(u;ϕ). As matrizesdas rotacoes em torno dos eixos coordenados de R3, e de angulo ϕ no sentidodirecto, sao respectivamente:
R1(ϕ) = R(e1;ϕ) =
1 0 00 cos ϕ − sin ϕ0 sin ϕ cos ϕ
(2.1.101)
R2(ϕ) = R(e2;ϕ) =
cos ϕ 0 sin ϕ0 1 0
− sin ϕ 0 cos ϕ
(2.1.102)
R3(ϕ) = R(e3;ϕ) =
cos ϕ − sin ϕ 0sin ϕ cos ϕ 0
0 0 1
(2.1.103)
Os grupos O(3) e SO(3)
O conjunto de todas as transformacoes ortogonais de R3, constituem umgrupo que se diz o grupo ortogonal O(3). Este grupo e isomorfo ao grupo dasmatrizes ortogonais, tambem notado por O(3).
O subgrupo de O(3) constituıdo por todas as transformacoes ortogonais deR3, que tem determinante 1 (isto e, constituıdo por todas as rotacoes em R3)diz-se o grupo ortogonal especial e nota-se por SO(3). Este grupo e isomorfoao grupo das matrizes ortogonais de determinante 1, tambem notado por SO(3).
I Exercıcio 2.13 ... Demonstre as afirmacoes anteriores.
~ Angulos de Euler
I 2.57 Angulos de Euler ... Qualquer rotacao pode ser escrita como umproduto de rotacoes dos tipos acima indicados.
Com efeito consideremos uma qualquer rotacao R ∈ SO(3) e duas basesortonormadas de R3:
B = {e1, e2, e3}B = B R = {e1, e2, e3} (2.1.104)
com a mesma orientacao. A base B = B R pode ser obtida atraves das seguintestres fases sucessivas:

2.1. Algebra Linear em R3 55
1. Obter uma base ortonormada B′ = {e′1, e′2, e′3 = e3}, atraves de uma rotacaoR3(φ), em torno de e3 e de angulo φ, onde φ e o angulo entre e1 e a chamadalinha dos nodos (a recta de interseccao dos planos gerados respectivamentepor {e1, e2} e {e1, e2}):
B′ = B R3(φ) (2.1.105)
2. Obter uma base ortonormada B′′ = {e′1, e′′2 , e3}, atraves de uma rotacaoR2(θ), em torno da linha dos nodos, gerada por e′1, e de angulo θ, onde θ e oangulo entre e3 e e3:
B′′ = B′R2(θ) (2.1.106)

2.1. Algebra Linear em R3 56
3. Finalmente, obter a base ortonormada B = B R = {e1, e2, e3}, atraves deuma rotacao R2(ϕ), em torno de e3, e de angulo ψ, onde ψ e o angulo entre alinha dos nodos e e1:
B = B′′R3(ψ) (2.1.107)
I 2.58 Portanto:
B = B R
= BR3(φ)R2(θ)R3(ψ) (2.1.108)
e:
R = R3(φ)R2(θ)R3(ϕ)
=
cos φ − sin φ 0sin φ cos φ 0
0 0 1
cos θ 0 sin θ0 1 0
− sin θ 0 cos θ
cos ψ − sin ψ 0sin ψ cos ψ 0
0 0 1
(2.1.109)
Os angulos φ, θ, ψ chamam-se angulos de Euler.

Modulo 3
Espacos vectoriais
Contents3.1 Espacos vectoriais . . . . . . . . . . . . . . . . . . . 57
3.2 Exemplos . . . . . . . . . . . . . . . . . . . . . . . . 58
3.3 Subespacos vectoriais . . . . . . . . . . . . . . . . 61
3.4 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . 66
3.1 Espacos vectoriais
Em tudo o que se segue Ik designa o corpo R dos numeros reais ou o corpo Cdos numeros complexos. Aos elementos de Ik chamam-se escalares.
I Definicao 3.1 ... Um conjunto V, cujos elementos se chamam vectores,diz-se um espaco vectorial, ou um espaco linear, sobre o corpo Ik, se estaodefinidas duas operacoes:
V × V −→ V(v,w) 7−→ v + w (3.1.1)
chamada soma de vectores e:
Ik× V −→ V(λ,v) 7−→ λv (3.1.2)
57

3.2. Exemplos 58
chamada multiplicacao por escalares, que satisfazem as propriedades seguintes:
[EV 1]. v + w = w + v
[EV 2]. (u + v) + w = u + (v + w)[EV 3]. ∃0 ∈ V : 0 + v = v + 0 = v
[EV 4]. ∀v,∃(−v) : v + (−v) = 0
[EV 5]. λ(v + w) = λv + λw (3.1.3)[EV 6]. (λ + µ)v = λv + µv
[EV 7]. λ(µv) = (λµ)v[EV 8]. 1v = v
para todos os vectores u,v,w ∈ V, e escalares λ, µ ∈ Ik. 0 diz-se o vector nulode V, e −v = (−1)v o simetrico de v. Quando Ik = R, V diz-se um espacovectorial real e quando Ik = C, V diz-se um espaco vectorial complexo.
3.2 Exemplos
Vamos de imediato apresentar diversos exemplos desta importante definicao.Para fixar ideias, nos exemplos que se seguem, vamos supor que Ik = R (seIk = C, a discussao e completamente analoga). A verificacao detalhada de que,em cada exemplo, se verificam as oito propriedades (3.1.3) fica a cargo do leitor.E um exercıcio facil mas instrutivo.
I Exemplo 3.1 [Os espacos coordenados Rn] ... Para cada inteiron ≥ 0, definamos V = Rn como o conjunto de todas as sequencias ordenadasde n numeros reais. Estas sequencias ordenadas podem ser apresentadas sob aforma:
x = (x1, x2, · · · , xn) = (xi) (3.2.1)
ou sob a forma de vectores-coluna:
xdef=
x1
x2
...xn
def= [xi] (3.2.2)
As operacoes de soma de vectores e multiplicacao por escalares definem-se re-spectivamente por:
Rn × Rn −→ Rn
(x = [xi],y = [yi]) 7−→ x + ydef= [xi + yi]
(3.2.3)
e:R× Rn −→ Rn
(λ,x = [xi]) 7−→ λxdef= [λxi]
(3.2.4)

3.2. Exemplos 59
Quando n = 0, poe-se R0 = {0} e quando n = 1, R1 = R. O espaco Rn
chama-se o espaco coordenado real de dimensao1 n.
¥.
I Exemplo 3.2 [Espacos de funcoes] ... Seja S um conjunto qualquernao vazio e definamos V = F(S;R) como o conjunto de todas as funcoes reaisf : S −→ R, definidas em S:
V = F(S;R)def= {f : S −→ R} (3.2.5)
As operacoes de soma de vectores e multiplicacao por escalares definem-se re-spectivamente por:
(f + g)(s)def= f(s) + g(s)
(λf)(s)def= λf(s), ∀s ∈ S (3.2.6)
onde f, g ∈ F(S;R).
¥.
I Exemplo 3.3 [Espacos de polinomios numa indeterminada X] ...Seja V = R[X] o conjunto de todos os polinomios (de qualquer grau) numaindeterminada X, com coeficientes reais:
V = R[X]def= {p(X) = a0 + a1X + a2X
2 + · · ·+ anXn; ai ∈ R, n ∈ IN0}
= {p(X) =n∑
k=0
akXk; ai ∈ R, n ∈ IN0} (3.2.7)
O inteiro n ≥ 0 diz-se o grau do polinomio p(X) (depende de p) e os escalaresai dizem-se os coeficientes de p. As operacoes de soma de vectores e multi-plicacao por escalares definem-se respectivamente por:
p(X) + q(X) =∑
akXk +∑
bkXk def=
∑(ak + bk)Xk
λp(X) = λ∑
akXk def=
∑(λak)Xk (3.2.8)
onde p, q ∈ R[X].
¥.
1A definicao formal de “dimensao”sera em breve tratada.

3.2. Exemplos 60
I Exemplo 3.4 [Espacos de polinomios numa indeterminada X, degrau ≤ N ]. Fixemos um inteiro N ≥ 0 e seja V = RN [X] o conjunto de todosos polinomios com coeficientes reais, numa indeterminada X, mas agora de grauinferior ou igual a N :
V = RN [X]def= {p(X) = a0 + a1X + a2X
2 + · · ·+ aNXN ; ai ∈ R}
= {p(X) =N∑
k=0
akXk; ai ∈ R} (3.2.9)
As operacoes de soma de vectores e multiplicacao por escalares definem-se comono exemplo anterior, respectivamente por:
N∑
k=0
akXk +N∑
k=0
bkXk def=
N∑
k=0
(ak + bk)Xk
λ
N∑
k=0
akXk def=
N∑
k=0
(λak)Xk (3.2.10)
onde p, q ∈ RN [X].
¥.
I Exemplo 3.5 [Espacos de matrizes m×n] ... Fixemos dois inteirosm ≥ 1 e n ≥ 1 e seja V = Mm,n(R) o conjunto de todas as matrizes comentradas reais com m linhas e n colunas:
V = Mm,n(R)def=
A =
A11 A1
2 A13 · · · A1
n
A21 A2
2 A23 · · · A2
n
A31 A3
2 A33 · · · A3
n...
...... · · · ...
Am1 Am
2 Am3 · · · Am
n
= [Aij ]; Ai
j ∈ R
(3.2.11)
Portanto na matriz A = [Aij ], o ındice superior i, com i = 1, 2, · · · ,m, e o
ındice-linha - o que numera as linhas - enquanto que o ındice inferior j, com
j = 1, 2, · · · , n, e o ındice-coluna - o que numera as colunas:
Ai→ındice linha: numera as linhas de A
j→ındice coluna: numera as colunas de A

3.3. Subespacos vectoriais 61
As operacoes de soma de vectores e multiplicacao por escalares definem-serespectivamente por:
[Aij ] + [Bi
j ]def= [Ai
j + Bij ]
λ [Aij ]
def= [λAi
j ] (3.2.12)
Em particular Mm,1(R) = Rm e o espaco dos vectores-coluna com m com-ponentes.
¥.
I Exemplo 3.6 [Espaco de sucessoes] ... Consideremos agora o con-junto de todas as sucessoes reais:
V = RIN def= {s = (s1, s2, · · · , si, · · · ) = (si)i≥1; si ∈ R, ∀i ≥ 1} (3.2.13)
As operacoes de soma de vectores e multiplicacao por escalares definem-se re-spectivamente por:
(si) + (ti)def= (si + ti)
λ (si)def= (λsi) (3.2.14)
E claro que RIN coincide com o espaco de todas as funcoes reais s : IN → R,isto e, RIN ≡ F(IN,R).
¥.
Os exemplos apresentados sao de espacos vectoriais reais. Se em cada umdesses exemplos substituirmos o corpo de escalares R pelo corpo C dos numeroscomplexos, obtemos os espacos vectoriais analogos complexos. Nomeadamente,Cn - o espaco coordenado complexo de dimensao n; F(S; C) - o espaco dasfuncoes complexas f : S → C; C[X] - o espaco dos polinomios numa indeter-minada e com coeficientes complexos; CN [X] - o espaco dos polinomios numaindeterminada, com coeficientes complexos e de grau ≤ N ; Mm,n(C) - o espacodas matrizes m × n de entradas complexas; e finalmente, CIN = F(IN;C) - oespaco das sucessoes complexas.
3.3 Subespacos vectoriais
I Definicao 3.2 ... Seja V um espaco vectorial sobre um corpo Ik. Umsubconjunto nao vazio S ⊆ V diz-se um subespaco vectorial de V, se S e

3.3. Subespacos vectoriais 62
fechado relativamente as operacoes de soma de vectores e de multiplicacao porescalares, i.e.:
[S1]. v,w ∈ S ⇒ v + w ∈ S[S2]. λ ∈ Ik, v ∈ S ⇒ λv ∈ S (3.3.1)
∀v,w ∈ V e ∀λ ∈ Ik. Portanto, com as operacoes induzidas, S e ele proprio umespaco vectorial sobre Ik. Os subespacos S = {0} e S = V dizem-se triviais.
¥.
Como S 6= ∅ existe um vector v 6= 0 em S. Portanto, por (3.3.1) [S1] e [S2],v+(−1)v = 0 ∈ S, isto e, se S e um subespaco o vector nulo tem que pertencera S.
I Definicao 3.3 ... Seja V um espaco vectorial sobre um corpo Ik.Se {v1,v2, · · · ,vm} e um conjunto de m vectores em V, a uma soma (finita)do tipo:
m∑
i=1
λivi = λ1v1 + λ2v2 + · · ·+ λmvm (3.3.2)
onde λi ∈ Ik, chama-se uma combinacao linear dos vectores v1,v2, · · · ,vm
(com coeficientes em Ik).
¥.
I Definicao 3.4 ... Seja S ⊆ V um conjunto qualquer (nao vazio) em V.O subespaco gerado por S e, por definicao, o conjunto spanIk{S} constituıdopor todas as combinacoes lineares de vectores de S:
spanIk{S}def=
{m∑
i=1
λivi; λi ∈ Ik, vi ∈ S, m ∈ IN
}(3.3.3)
¥.
E imediato verificar que spanIk{S} e de facto um subespaco vectorial de V.Quando nao ha risco de confusao escreve-se simplesmente span{S}.
I Exemplo 3.7 ... Os subespacos vectoriais em R2 sao de dois tipos:
(i). triviais: S = {0} e S = R2.
(ii). nao triviais: S = spanR{a} = {λa : λ ∈ R}, onde a 6= 0, querepresenta uma recta que passa na origem, gerada por a 6= 0. Se x representaum vector generico dessa recta, entao:
x = λa, λ ∈ R (3.3.4)

3.3. Subespacos vectoriais 63
Esta equacao diz-se a equacao vectorial da recta span{a} = Ra. Se a =(a1
a2
), entao (3.3.4) e equivalente ao sistema de equacoes:
{x1 = λa1
x2 = λa2 (3.3.5)
que se dizem as equacoes parametricas da referida recta. Eliminando λnestas equacoes, obtemos a chamada equacao cartesiana dessa mesma recta:
a2x1 − a1x2 = 0 (3.3.6)
¥.
I Exemplo 3.8 ... Os subespacos vectoriais em R3 sao de tres tipos:
(i). triviais: S = {0} e S = R3
(ii). nao triviais de dimensao 1: S = spanR{a} = {λa : λ ∈ R}, ondea 6= 0, que representa uma recta que passa na origem, gerada por a 6= 0. Se xrepresenta um vector generico dessa recta, entao:
x = λa, λ ∈ R (3.3.7)
Esta equacao diz-se a equacao vectorial da recta span{a} = Ra. Se a =
a1
a2
a3
, entao (3.3.7) e equivalente ao sistema de equacoes:
x1 = λa1
x2 = λa2
x3 = λa3(3.3.8)
que se dizem as equacoes parametricas da referida recta.
(iii). nao triviais de dimensao 2: S = spanR{a,b} = {λa + ηb : λ, η ∈ R},onde a e b sao dois vectores nao colineares em R3, que representa um plano
que passa na origem, gerado por a e b. Se x =
x1
x2
x3
e um ponto generico
do plano span{a,b}, e se a =
a1
a2
a3
, b =
b1
b2
b3
, a equacao vectorial:
x = λa + η b λ, η ∈ R (3.3.9)

3.3. Subespacos vectoriais 64
que define o referido plano, e equivalente as seguintes equacoes parametricas:
x1 = λa1 + η b1
x2 = λa2 + η b2
x3 = λa3 + η b3λ, η ∈ R (3.3.10)
Eliminando λ e η nestas equacoes obtemos a equacao cartesiana do plano:
(a2b3 − a3b2)x1 + (a3b1 − a1b3)x2 + (a1b2 − a2b1)x3 = 0 (3.3.11)
¥.
I Exemplo 3.9 ... Para cada inteiro fixo N ≥ 0, RN [X] e um subespacode R[X] (ver os exemplos 3.3 e 3.4).
¥.
I Exemplo 3.10 ... Consideremos um intervalo I ⊆ R. O conjuntoC0(I;R), constituıdo por todas as funcoes contınuas f : I → R, e um subespacode F(I;R) (ver o exemplo 3.2). Mais geralmente, se k = 0, 1, · · · ,∞ e uminteiro fixo ou ∞, o conjunto Ck(I;R), constituıdo por todas as funcoes f : I →R que admitem derivadas contınuas de ordem ≤ k, e um subespaco de F(I;R)
¥.
E facil ver que a interseccao de uma famılia qualquer de subespacos, numespaco vectorial V, e ainda um subespaco de V.
I Definicao 3.5 ... Seja V um espaco vectorial sobre um corpo Ik, e S eT dois subespacos de V. Diz-se que V e soma directa de S e T , e nota-se por:
V = S ⊕ Tse cada vector v ∈ V se escreve como combinacao linear unica de um vector deS com um vector de T :
v = s + t, para vectores unicos s ∈ S e t ∈ T¥.
I Proposicao 3.1 ... Seja V um espaco vectorial sobre um corpo Ik, e S eT dois subespacos de V. Entao V = S ⊕ T sse se verificam as duas condicoesseguintes:
[SD1]. V = S + T def= spanIk{S ∪ T }
[SD2]. S ∩ T = {0}(3.3.12)

3.3. Subespacos vectoriais 65
Dem.: Suponhamos que se verificam as duas condicoes (3.3.12). Entao,dado um qualquer vector v ∈ V, por [SD1] podemos escrever v = s+t, com s ∈ Se t ∈ T (nao necessariamente unicos). Mas se houvesse outra representacao dotipo v = s′ + t′, com s′ ∈ S e t′ ∈ T , entao s− s′ = t− t′ ∈ S ∩ T . Como, por[SD2], S ∩ T = {0}, concluımos que s = s′ e t = t′ e a representacao e unica,isto e, V e soma directa de S e T .
Recıprocamente, se V e soma directa de S e T , entao [SD1] e imediato. Poroutro lado, 0 = s + (−s), onde s ∈ S e −s ∈ T . Mas como esta representacao eunica, devemos ter s = 0 e portanto S ∩ T = {0}.
¥.
Generalizando, temos a seguinte definicao:
I Definicao 3.6 ... Seja V um espaco vectorial sobre um corpo Ik, e S1, · · · ,Sk
subespacos de V. Diz-se que V e soma directa de S1, · · · ,Sk, e nota-se por:
V = S1 ⊕ · · · ⊕ Sk = ⊕kj=1 Sj
se cada vector v ∈ V se escreve como combinacao linear unica:
v = s1 + · · ·+ sk, para vectores unicos s1 ∈ S1, · · · sk ∈ Sk
¥.
I Proposicao 3.2 ... Seja V um espaco vectorial sobre um corpo Ik, eS1, · · · ,Sk subespacos de V. Entao V = ⊕k
j=1 Sj sse se verificam as duascondicoes seguintes:
[SD1′]. V = S1 + · · ·+ Sk =∑k
j=1 Sidef= spanIk{∪k
j=1Sj}[SD2′]. Sj ∩
(∑i 6=j Si
)= {0} j = 1, . . . , k
(3.3.13)¥.
I Exemplo 3.11 ... (i). O plano R2 e soma directa de duas quaisquerrectas vectoriais distintas.
(ii). O espaco R3 e soma directa de tres quaisquer rectas vectoriais distintasnao coplanares. E tambem soma directa de um plano vectorial e de uma rectanao pertencente a esse plano.
¥.

3.4. Exercıcios 66
I Exemplo 3.12 ... No espaco vectorial F(R; C) das funcoes complexasdefinidas em R, consideremos os subespacos:
P = {funcoes pares} = {f : R→ C : f(t) = f(−t)}I = {funcoes ımpares} = {f : R→ C : f(t) = −f(−t)}
E facil ver que, de facto, P e I sao ambos subespacos de F(R; C) e que, alemdisso:
F(R; C) = P ⊕ IDe facto, se f ∈ F(R; C), entao ∀t ∈ R:
f(t) =12[f(t) + f(−t)]
︸ ︷︷ ︸P
+12[f(t)− f(−t)]
︸ ︷︷ ︸I
e, se f ∈ P ∩ I, entao:
f(t) = f(−t) = −f(t) ⇒ 2f(t) = 0, ∀t ∈ R ⇒ f = 0
¥.
3.4 Exercıcios
I Exercıcio 3.1 ... Diga quais dos seguintes conjuntos sao subespacosvectoriais de R2 :
a) A ={(x, y) ∈ R2 : x = y
};
b) B ={(a,−a) ∈ R2 : a ∈ R}
;
c) C ={(x, y) ∈ R2 : x + y 6= 2
};
d) D ={(x, y) ∈ R2 : x + 5y = 0
};
e) E ={(x, y) ∈ R2 : 3x− y = 1
};
f) F ={(x, y) ∈ R2 : |x + 2y| = 3
};
g) G = {(b, 2a + b) : a, b ∈ R} .
I Exercıcio 3.2 ... Diga quais dos seguintes conjuntos sao subespacosvectoriais de R3 :
a) A ={(x, y, z) ∈ R3 : x + y + z = 0
};
b) B ={(x, y, z) ∈ R3 : x + y = 3z
};
c) C ={(x, y, z) ∈ R3 : x− y = 3z e z = 2y
};
d) D ={(x, y, z) ∈ R3 : 0 ≤ x2 + y2 ≤ z
};
e) E ={(a,−a, 5a) ∈ R3 : a ∈ R}
.

3.4. Exercıcios 67
I Exercıcio 3.3 ... Diga quais dos seguintes conjuntos sao subespacos vec-toriais de C2 ou C3 , espacos vectoriais munidos da estrutura usual de espacosvectoriais complexos:
a) A ={(z, w) ∈ C2 : z − w = 1
};
b) B ={(z, w) ∈ C2 : z + 2w = 0
};
c) C ={(u, z, w) ∈ C3 : z − w = 2u
};
d) D ={(u, z, w) ∈ C3 : u + z + w > 0
};
e) E = {(a + b, a− b, a + 1) : a, b ∈ C} .
I Exercıcio 3.4 ... Diga quais dos seguintes conjuntos, sao subespacosvectoriais de M2,2(R):
a){(
a bc d
)∈ M2,2(R) : a + 2b = 0
};
b){(
a bc d
)∈ M2,2(R) : c ≤ 0
};
c){(
a 0c a
)∈ M2,2(R) : a, c ∈ R
}.
I Exercıcio 3.5 ... Diga quais dos seguintes conjuntos sao subespacosvectoriais de R (X) :
a) {P ∈ R2 (X) : P (3) = 0} ;
b) {P ∈ R2 (X) : P (0) = 1} ;
c) {P ∈ R3 (X) : P ′(X) = 0} ;
d) {P ∈ R3 (X) : P (1) = 0 e P (2) = 0} ;
e){P (X) = aX + bX2 : a, b ∈ R}
.
I Exercıcio 3.6 ... Sendo V = Co(R,R) o espaco vectorial das funcoesreais de variavel real contınuas, indique dos conjuntos que se seguem, quais osque sao subespacos vectoriais de V:
a) {f ∈ V : f e par} ; b) {f ∈ V : f (2) = f(3)} ;c) {f ∈ V : f (2) = f(3) = 0} ;d) {f ∈ V : f (2) = f(3) = 1} ;e) {f ∈ V : f (x) ≥ 0, ∀x ∈ R} ; f) {f ∈ V : f e injectiva} .
I Exercıcio 3.7 ... Considere os seguintes subespacos vectoriais de R3:
S = {(x, y, z) : x + y + z = 0} , T = {(x, y, 0) : x, y ∈ R} ,U = {(λ, λ, λ) : λ ∈ R} .
a) Mostre que R3 = S + U = S + T .
b) Calcule S ∩ U e S ∩ T .

3.4. Exercıcios 68
I Exercıcio 3.8 ... a) De exemplos de subespacos E1 e E2 de R2 tais queE1 ∪ E2 nao seja um subespaco de R2.
b) De exemplos de E1, E2 ⊂ R2 tais que E1 6= R2 e subespaco de R2, E1 6⊆ E2,E2 nao e subespaco de R2 e E1 ∪ E2 e subespaco de R2.
c) De exemplos de E1, E2 ⊂ R2 tais que E1 nao e subespaco de R2, E2 nao esubespaco de R2 e E1 ∪ E2 e subespaco de R2.
I Exercıcio 3.9 ... Em cada uma das alıneas que se seguem, verifique sex ∈ span {a,b}:
a) x = (1, 0), a = (1, 1), e b = (0, 1);
b) x = (2, 1), a = (1,−1), e b = (1, 1);
c) x = (1, 0), a = (1, 1), e b = (2, 2);
d) x = (1, 1), a = (2, 1), e b = (−1, 0);
e) x = (4, 3), a = (1,−1), e b = (−2, 2).
f) x = (4i, 3), a = (1, 0), e b = (1, 1), em C2 como espaco vectorialcomplexo;
g) x = (4i, 3), a = (1, 0), e b = (1, 1), em C2 como espaco vectorial real.
I Exercıcio 3.10 ... Em cada uma das alıneas que se seguem, verifique severifique se x ∈ span {a,b, c}:
a) x = (1, 0, 0), a = (1, 1, 1), b = (−1, 1, 0) e c = (1, 0,−1);
b) x = (1, 0, 0), a = (1, 1, 2), b = (−1, 1, 0) e c = (1, 0, 1);
c) x = (1, 1, 1), a = (0, 1,−1), b = (1, 1, 0) e c = (1, 0, 2);
d) x = (0, 0, 1), a = (1, 1, 1), b = (−1, 1, 0) e c = (1, 0,−1);
e) x = (1, 2, 3), a = (1, 1, 1), b = (−2,−2, 0) e c = (0, 0,−1).
I Exercıcio 3.11 ... Diga quais dos elementos de R (X) sao combinacaolinear de X,X + X2 e 2X −X2 :
a) 1 + X + X2 + X3;
b) X2;
c) 3X + X2;
d) 0.
I Exercıcio 3.12 ... Diga quais dos seguintes elementos de M3,2(R) per-tencem a:
span
1 10 10 0
,
0 10 01 0
:

3.4. Exercıcios 69
a)
1 30 12 0
, b)
−1 21 13 −2
.

Modulo 4
ALGA I. Aplicacoeslineares. Isomorfismoslineares
Contents4.1 Aplicacoes lineares. Isomorfismos lineares. Op-
eradores lineares. Funcionais lineares. O espacodual V∗ . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4.2 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . 73
4.1 Aplicacoes lineares. Isomorfismos lineares.Operadores lineares. Funcionais lineares. Oespaco dual V∗
I Definicao 4.1 ... 1. Sejam V e W dois espacos vectoriais sobre umcorpo Ik. Uma aplicacao L : V → W diz-se uma aplicacao linear ou umhomomorfismo linear de V em W, se L satisfaz as seguintes propriedades:
[L1]. L(v + w) = L(v) + L(w)[L2]. L(λv) = λL(v) (4.1.1)
∀v,w ∈ V e ∀λ ∈ Ik. O conjunto constituıdo por todas as aplicacoes linearesde V em W representa-se por HomIk(V,W) ou simplesmente por Hom(V,W),quando nao ha risco de confusao.
2. Uma aplicacao linear Φ : V → W diz-se um isomorfismo linear, seexiste uma aplicacao Ψ : W → V tal que Φ ◦ Ψ = IdW e Ψ ◦ Φ = IdV . Nestecaso Ψ = Φ−1 e necessariamente linear (prova ?).
70

4.1. Aplicacoes lineares. Isomorfismos lineares. Operadoreslineares. Funcionais lineares. O espaco dual V∗ 71
O conjunto constituıdo por todos os isomorfismos lineares entre os espacosvectoriais V e W representa-se por IsomIk(V,W).
3. Uma aplicacao linear L : V → V chama-se um operador linear em V.O conjunto de todos os operadores lineares em V representa-se por OpIk(V) ouapenas por Op(V).
4. Um isomorfismo linear Φ : V → V diz-se um automorfismo linearde V. O conjunto de todos os automorfismos lineares de V representa-se porAutIk(V) ou simplesmente por Aut(V).
5. Uma aplicacao linear ϕ : V → Ik, diz-se um funcional linear ou umaforma linear em V. O conjunto constituıdo por todos os funcionais linearesem V diz-se o espaco dual de V e nota-se por V∗.
¥.
HomIk(V,W) tem uma estrutura natural de espaco vectorial sobre Ik, definindoa soma de aplicacoes lineares e a multiplicacao por escalares, respectivamentepor:
(L + M)(v) def= L(v) + M(v)
(λL)(v) def= λL(v) (4.1.2)
Em particular o espaco dual V∗ tem uma estrutura natural de espaco vectorialsobre Ik. Alias V∗ e um subespaco de F(V; Ik) (ver o exemplo 3.2).
Op(V) tem uma estrutura natural de Ik-algebra, que se diz a algebra deoperadores (lineares) de V.
Aut(V) tem uma estrutura natural de grupo que se diz o grupo lineargeral de V, e que se nota por G`(V).
I Definicao 4.2 ... Dado uma aplicacao linear L : V → W define-se orespectivo nucleo, kerL ⊆ V, atraves de:
kerLdef= {v ∈ V; L(v) = 0} (4.1.3)
e a imagem, imL ⊆ W, atraves de:
imLdef= {w ∈ W; w = L(v), v ∈ V} (4.1.4)
¥.
I Proposicao 4.1 ... O nucleo kerL e um subespaco de V. A imagemimL e um subespaco de W.

4.1. Aplicacoes lineares. Isomorfismos lineares. Operadoreslineares. Funcionais lineares. O espaco dual V∗ 72
Dem.: [S1]. se v,w ∈ kerL, entao L(v + w) = L(v) + L(w) = 0 + 0 = 0e portanto v + w ∈ kerL. [S2]. Se v ∈ kerL e λ ∈ Ik, entao L(λv) = λL(v) =λ0 = 0 e portanto λv ∈ kerL.
Demostracao analoga para imL.
¥.
Uma aplicacao linear L : V → W envia sempre o vector nulo de V no vectornulo de W. Por outro lado, L : V → W e injectiva se e so se kerL = {0}. Comefeito, se kerL = {0} entao L(u) = L(v) ⇒ 0 = L(u) − L(v) = L(u − v) ⇒u − v ∈ kerL = {0} ⇒ u = v. Se L e injectiva, entao, se v ∈ kerL tem-seL(v) = 0 = L(0) ⇒ v = 0.
I Exemplo 4.1 ... Seja V = C0(R;R) = {f : R→ R; f contınua}.Entao:
δ0 : C0(R;R) −→ R
f 7−→ δ0[f ]def= f(0)
(4.1.5)
e um funcional linear que se diz o funcional de Dirac. O seu nucleo ker δ0 econstituıdo por todas as funcoes f : R→ R que se anulam no ponto 0.
¥.
I Exemplo 4.2 ... Seja V = C0([a, b];R) = {f : [a, b] → R; f contınua}.Entao:
ϕ : C0([a, b];R) −→ R
f 7−→ ϕ[f ]def=
∫ b
af(t)dt
(4.1.6)
e um funcional linear. O nucleo kerϕ e trivial, isto e, e constituıdo pelas funcoescontınuas de area (algebrica) nula, i.e., tais que ϕ[f ] =
∫ b
af(t)dt = 0.
¥.
I Exemplo 4.3 ... Seja V = Rn o espaco coordenado real de dimensaon do exemplo 3.1. Fixemos uma sequencia ordenada de n numeros reais a =(a1, a2, · · · , an), representada por um vector-linha [a1 a2 · · · an] = [ai], istoe, por uma matriz com uma so linha e n colunas. Definimos entao um funcionallinear ϕa em Rn, associado a a, atraves de:
ϕa(x) = [a1 a2 · · · an]
x1
x2
...xn
def=
n∑
i=1
aixi (4.1.7)

4.2. Exercıcios 73
Num capıtulo futuro demonstrar-se-a que todo o funcional linear em Rn edo tipo ϕa, para algum a = [ai]. Portanto o espaco dual (Rn)∗ identifica-se como espaco dos vectores-linha a = [ai]. Quando a 6= 0 o nucleo kerϕa define umhiperplano em Rn.
Consideracoes completamente analogas permitem concluir que (Cn)∗ se iden-tifica com o espaco dos vectores-linha a = [ai], mas agora com ai ∈ C.
¥.
4.2 Exercıcios
I Exercıcio 4.1 ... Das aplicacoes que se seguem, indique aquelas que saolineares. Relativamente a essas, calcule o respectivo nucleo e diga quais as quesao injectivas.
a) f : R2 −→ R2 ; (x, y) 7−→ (x + y, x− y)
b) f : R3 −→ R2; (x, y, z) 7−→ (2x + y, z − 3y)
c) f : R2 −→ R2; (x, y) 7−→ (|x| , |y|)d) f : R2 −→ R3; (x, y) 7−→ (x2, y2, 0)
e) f : R4 −→ R2; (x, y, z, t) 7−→ (x + y + 1, z + t + 2)
f) f : R2 −→ R1 (X) ; (a, b) 7−→ a + bX
g) f : R3 (X) −→ R1 (X) ; a + bX + cX2 + dX3 7→ (a + b) + (c− 2d)X
h) f : R2 (X) −→ R2 (X) ; a + bX + cX2 7→ (a + 1) + (b + c)X + 2cX2
i) f : R3 (X) −→ R; P 7→ P (1)
j) f : R (X) −→ R (X) ; P 7→ P ′
l) f : C2 −→ C2; (z, w) 7→ (iz + w, z + iw) considere K = R
m) f : C2 −→ C2; (z, w) 7→ (iz, w) considere K = R
n) f : C2 −→ C2; (z, w) 7→ (iz, w) considere K = C

Modulo 5
ALGA I. Bases,coordenadas e dimensao
Contents5.1 Bases, coordenadas e dimensao . . . . . . . . . . . 74
5.2 Calculos com coordenadas. Problemas . . . . . . . 82
5.3 Mudancas de base e de coordenadas . . . . . . . . 85
5.4 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . 88
5.1 Bases, coordenadas e dimensao
I Definicao 5.1 ... Seja V um espaco vectorial sobre um corpo Ik. Diz-se que os vectores v1,v2, · · · ,vm ∈ V sao linearmente independentes severificam a condicao seguinte:
[LI]. λ1v1 + λ2v2 + · · ·+ λmvm = 0 ⇒ λ1 = λ2 = · · · = λm = 0(5.1.1)
Caso contrario esses mesmos vectores dizem-se linearmente dependentes.Portanto v1,v2, · · · ,vm ∈ V sao linearmente dependentes quando existem es-calares λ1, · · · , λm ∈ Ik nao todos nulos tais que:
λ1v1 + λ2v2 + · · ·+ λmvm = 0
I Definicao 5.2 [Base finita] ... Seja V um espaco vectorial sobre umcorpo Ik. Um conjunto ordenado de vectores B = {e1, e2, · · · , en} em V diz-seuma base finita (ordenada) de V se:
[B1]. e1, e2, · · · , en sao linearmente independentes[B2]. spanIk{e1, e2, · · · , en} = V (5.1.2)
74

5.1. Bases, coordenadas e dimensao 75
O espaco vectorial V diz-se de dimensao finita se admite uma base finita.Caso contrario diz-se de dimensao infinita.
¥.
Suponhamos que B = {e1, e2, · · · , en} e uma base (finita) de V. Entao por(5.1.2) [B2]., todo o vector v ∈ V pode escrever-se como combinacao linear dosvectores de B, isto e, existem escalares vi ∈ Ik, i = 1, · · · , n, tais que:
v =n∑
i=1
viei = v1e1 + · · ·+ vnen (5.1.3)
Alem disso, por (5.1.2) [B1]. esses escalares sao unicos (dependem apenas dev). De facto, se existissem outros escalares λi ∈ Ik, i = 1, · · · , n, tais quev =
∑ni=1 λiei entao viria que:
0 =n∑
i=1
(vi − λi)ei ⇒ λi = vi, ∀i = 1, · · · , n
uma vez que por [B1]. os vectores de B sao linearmente independentes.
I Proposicao 5.1 ... Sejam V eW dois espacos vectoriais sobre um mesmocorpo Ik, em que V tem dimensao finita. Seja {e1, . . . , en} uma base de V ew1, . . . ,wn, n vectores quaisquer de W. Entao existe uma e uma so aplicacaolinear L : V → W tal que:
L(ei) = wi, i = 1, . . . , n
Dem.: Todo o vector v ∈ V exprime-se na forma unica v =∑
i viei.Se se pretende que L seja linear, devemos ter que L(v) = L
(∑i viei
)=∑
i viL(ei) =∑
i viwi. Basta entao definir:
L(v) =∑
i
viwi
que e linear. Se existisse outra aplicacao M tal que M(ei) = wi = L(ei), entao(L−M)(ei) = 0 e, como {ei} e uma base, L = M.
¥.
Desta forma, se V tem dimensao finita, cada base finita B estabelece umisomorfismo ΦB : V ∼= Ikn, entre V e Ikn, definido por:
ΦB : v 7−→
v1
v2
...vn
, onde v =
n∑
i=1
viei ∈ V (5.1.4)

5.1. Bases, coordenadas e dimensao 76
Os escalares vi, i = 1, · · · , n dizem-se as coordenadas de v, relativas a baseB. Escrevemos, neste caso, v = [vi]B, ou apenas v = [vi] (ou ate v = vi), senao houver risco de confusao.
I Lema 5.1 ... Seja {v1, · · · ,vn} uma sucessao de n vectores num espacovectorial V. Seja w1, · · · ,wn+1 uma sucessao de n + 1 combinacoes linearesdos vectores v1, · · · ,vn. Entao os vectores w1, · · · ,wn+1 sao linearmente de-pendentes.
Portanto, dois vectores w1 e w2, que sejam colineares com um vector v1,sao linearmente dependentes; tres vectores w1,w2 e w3, que sejam coplanarescom dois vectores v1 e v2, sao linearmente dependentes; etc...
Dem.: (facultativa) (prova por inducao sobre n).
• Se n = 1, entao w1 = λ1v1 e w2 = λ2v1 sao linearmente dependentes.
• Suponhamos agora que o teorema e verdadeiro para n e demonstremosque continua verdadeiro para n + 1. Sejam w1, · · · ,wn+2 combinacoeslineares dos vectores v1, · · · ,vn+1. Podemos entao escrever:
w1 = λ1v1 + u1
w2 = λ2v1 + u2
...wn+1 = λn+1v1 + un+1
wn+2 = λn+2v1 + un+2
onde u1, · · · ,un+2 sao combinacoes lineares dos vectores v2, · · · ,vn+1.
Se λ1 = · · · = λn+1 = 0 entao terıamos que w1, · · · ,wn+1 sao com-binacoes lineares dos vectores v2, · · · ,vn+1. Pela hipotese de inducao, osw1, · · · ,wn+1 sao linearmente dependentes e portanto os w1, · · · ,wn+2
sao tambem linearmente dependentes.
Suponhamos agora que algum dos λj 6= 0, para j = 1, · · · , n+1. Mudandose necessario a ordem dos vectores, podemos supor que j = 1, isto e, queλ1 6= 0. Temos entao que:
v1 =1λ1
w1 − 1λ1
u1
w2 = λ2v1 + u2
=λ2
λ1w1 − λ2
λ1u1 + u2
⇒ w2 − λ2
λ1w1 = u′2, onde u′2 e combinacao linear de u1 e u2

5.1. Bases, coordenadas e dimensao 77
Analogamente se obtem que:
w3 − λ3
λ1w1 = u′3
...
wn+2 − λn+2
λ1w1 = u′n+2
onde os u′2, · · · ,u′n+2 sao n + 1 combinacoes lineares de u1, · · · ,un+2 eportanto tambem dos vectores v2, · · · ,vn+1. Pela hipotese de inducao, osu′2, · · · ,u′n+2 sao linearmente dependentes:
α′2u′2 + · · ·+ α′n+2u′n+2 = 0
donde:
α′2(w2 − λ2
λ1w1
)+ · · ·+ α′n+2
(wn+2 − λn+2
λ1w1
)= 0
isto e:α′1w1 + α′2w2 + · · ·+ α′n+2wn+2 = 0
onde pelo menos um dos α′2, · · · , α′n+2 e nao nulo, o que significa quew1, · · · ,wn+2 sao linearmente dependentes.
¥.
I Teorema 5.1 (Dimensao) ... Seja V um espaco vectorial de dimensaofinita sobre Ik. Entao:
[1.] todas as bases tem o mesmo numero de vectores linearmente indepen-dentes.
A este numero, comum a todas as bases, chama-se a dimensao de V (sobreIk), e nota-se por dim IkV, ou simplesmente por dimV, quando nao ha risco deconfusao.
[2.] Se dim IkV = n, n vectores linearmente independentes formam uma base.
Dem.: [1.] Sejam {e1, · · · , en} e {f1, · · · , fp} duas bases de V. Se p > n,entao, uma vez que os f1, · · · , fp sao combinacoes lineares dos ei, pelo lema 5.1,concluımos que os f1, · · · , fp sao linearmente dependentes, o que e absurdo pordefinicao de base. Analogamente, nao podemos ter n > p.
[2.] Seja {e1, · · · , en} uma base de V e v1, · · · ,vn uma sucessao de vectoreslinearmente independentes em V. Para mostrar que formam uma base bastamostrar que geram V. Seja v ∈ V. Pelo lema 5.1, a sucessao {v1, · · · ,vn,v}

5.1. Bases, coordenadas e dimensao 78
e uma sucessao de vectores linearmente dependentes, uma vez que esses n + 1vectores sao combinacoes lineares dos {e1, · · · , en}. Portanto:
λ1v1 + · · ·+ λnvn + λv = 0
onde os λ1, · · · , λn, λ nao sao todos nulos. Mas λ 6= 0, caso contrario osv1, · · · ,vn seriam linearmente dependentes. Logo:
v = −λ1
λv1 − · · · − λn
λvn
o que mostra que os v1, · · · ,vn geram V.
¥.
I Teorema 5.2 (da base incompleta) ... Seja V um espaco vectorialde dimensao finita sobre um corpo Ik: dim IkV = n. Entao, dada uma qualquersucessao {f1, · · · , fp}, com p ≤ n, de vectores linearmente independentes, pode-mos encontrar q = n− p vectores fp+1, · · · , fn tais que {f1, · · · , fp, fp+1, · · · , fn}formam uma base para V.
Dem.: (facultativa) (inducao sobre q = 0, 1, · · · , n). Se q = 0 nada ha aprovar. Seja
Aq: para todo o V, todo o n = dimV, e todo o p tal que n = p+q,toda a sucessao {f1, · · · , fp}, de vectores linearmente indepen-dentes, pode ser completada a uma base de V.
Demonstremos que Aq ⇒ Aq+1, se 0 ≤ q < q + 1 ≤ n. Seja {f1, · · · , fp−1}uma sucessao de vectores linearmente independentes. Como p ≤ n, temos quep − 1 ≤ n − 1 e o subespaco gerado por f1, · · · , fp−1 e distinto de V. Se fp eum vector de V, que nao pertence a esse subespaco, entao {f1, · · · , fp−1, fp} eainda uma sucessao de vectores linearmente independentes, que, de acordo comAq, podemos completar numa base de V Resulta entao que {f1, · · · , fp−1} podeigualmente ser completada numa base de V, o que demonstra Aq+1.
¥.
I Teorema 5.3 ... SejaV um espaco vectorial de dimensao finita,W um espaco vectorial qualquerL : V → W uma aplicacao linear
Entao kerL e imL sao ambos de dimensao finita e:
dim kerL + dim imL = dimV (5.1.5)

5.1. Bases, coordenadas e dimensao 79
Dem.: kerL tem dimensao finita por ser subespaco de um espaco vectorialde dimensao finita. Seja {e1, . . . , em} uma base de kerL e completemos esta basea uma base {e1, . . . , em, em+1, . . . , en} de V, onde n = dimV. Vamos mostrarque {L(em+1), . . . ,L(en)} formam uma base para imL, o que demonstrara oteorema.
Qualquer vector em imL tem a forma:
L
(n∑
i=1
viei
)=
n∑
i=m+1
vi L(ei)
o que mostra que L(em+1), . . . ,L(en) geram imL.
Suponhamos agora que∑n
i=m+1 vi L(ei) = 0. Entao L(∑n
i=m+1 vi ei
)= 0,
o que significa que∑n
i=m+1 vi ei ∈ kerL, isto e:
n∑
i=m+1
vi ei =m∑
j=1
λj ej
Mas isto so e possıvel se todos os coeficientes vi e λj se anularem, ja que{e1, . . . , en} e uma base de V. Portanto os vectores L(em+1), . . . ,L(en) saolinearmente independentes.
¥.
I Corolario 5.1 ... SejaV um espaco vectorial de dimensao finitaW um espaco vectorial qualquerL : V → W uma aplicacao linear
Entao as propriedades seguintes sao equivalentes:
(i). L e injectiva(ii). dimV = dim (imL)(iii). kerL = {0}
(5.1.6)
¥.
I Teorema 5.4 ... SejaV um espaco vectorial qualquerS, T dois subespacos de dimensao finita de V
Entao S ∩ T e S + T tem dimensao finita e, alem disso:
dim (S + T ) = dim S + dim T − dim (S ∩ T ) (5.1.7)
Dem.: (facultativa) Recorde que S + T = spanIk{S ∪ T }. Como S + Te gerado pela reuniao de bases para S e T , respectivamente, entao S + T tem

5.1. Bases, coordenadas e dimensao 80
dimensao finita. Por outro lado, S ∩ T tem dimensao finita por estar contidoem subespacos de dimensao finita.
Suponhamos agora m = dimS∩T , s = dimS e t = dim T . Escolhamos umabase {e1, . . . , em} para S ∩T . Pelo teorema da base incompleta, esta base podeser completada a bases de S e T , digamos {e1, . . . , em, e′m+1, . . . , e
′s}, para S, e
{e1, . . . , em, e′′m+1, . . . , e′′t } para T , respectivamente.
Vamos mostrar que {e1, . . . , em, e′m+1, . . . , e′s, e
′′m+1, . . . , e
′′t } e uma base para
S + T , o que provara (5.1.7).
Como qualquer vector em S + T e uma soma de vectores em S e T , isto e,uma soma de combinacoes lineares de
{e1, . . . , em, e′m+1, . . . , e′s} e {e1, . . . , em, e′′m+1, . . . , e
′′t }
a reuniao destes conjuntos de vectores geram S + T . Resta portanto provar aindependencia linear. Suponhamos entao que:
n∑
i=1
xiei +s∑
j=m+1
yje′j +t∑
k=m+1
zke′′k
e uma combinacao linear nao trivial.
Entao deverao existir ındices j e k, tais que yj 6= 0 e zk 6= 0 pois, casocontrario, obterıamos uma dependencia linear nao trivial entre os elementos dasbases de S e T , acima escolhidas.
Portanto, o vector nao nulo∑t
k=m+1 zke′′k ∈ T deve pertencer tambem a
S porque e igual a −(∑n
i=1 xiei +∑s
j=m+1 yje′j). Mas entao esse vector tem
que estar em S ∩T e pode pois ser representado por uma combinacao linear dosvectores {e1, . . . , em}. Mas esta representacao da uma dependencia linear naotrivial entre os {e1, . . . , em, e′′m+1, . . . , e
′′t } o que e absurdo, ja que eles formam
uma base de T .
¥.
I Exemplo 5.1 ... Os vectores de R3:
e1 = ı =
100
e2 = =
010
e e3 = k =
001
sao linearmente independentes, e tem a propriedade de que qualquer vector x =

5.1. Bases, coordenadas e dimensao 81
x1
x2
x3
, se pode escrever como combinacao linear de e1, e2 e e3. De facto:
x =
x1
x2
x3
= x1
100
+ x2
010
+ x3
001
= x1e1 + x2e2 + x3e3
= x1ı + x2 + x3k (5.1.8)
Diz-se entao que {ı, , k} = {e1, e2, e3} e uma base (ordenada): a basecanonica de R3. Portanto dim RR3 = 3.
I Exemplo 5.2 ... Mais geralmente os n vectores {ei}i=1,··· ,n definidospor:
ei =
0...1...0
, com 1 na linha i e zeros nas outras entradas (5.1.9)
constituem a base canonica de Ikn. Portanto dim IkIkn = n.
I Exemplo 5.3 ... Os monomios {1, X, X2, · · · , XN} constituem umabase para o espaco IkN [X] dos polinomios em X, com coeficientes em Ik, degrau ≤ N . Portanto dim IkIkN [X] = N + 1.
I Exemplo 5.4 ... No exemplo 3.3, onde V = F(S;R) suponhamos que Se um conjunto finito, com n elementos, digamos S = {1, 2, · · · , n}. Definamosas funcoes de Dirac δi ∈ F(S;R), para i = 1, · · · , n, atraves de:
δi(j) ={
1 se i = j0 se i 6= j
(5.1.10)
Entao B = {δi}i=1,··· ,n constituem uma base para F({1, 2, · · · , n};R). De facto:
[B1]. Se λ1δ1+· · ·+λnδn = 0 ⇒ λ1δ1(j)+· · ·+λnδn(j) = 0(j) = 0, ∀j ∈S. Fazendo sucessivamente j = 1, 2, · · · , n obtemos que λ1 = λ2 = · · · = λn = 0,isto e os δi
′s sao linearmente independentes.
[B2]. Seja f uma funcao em F({1, 2, · · · , n};R). E obvio que:
f =n∑
i=1
f(i)δi

5.2. Calculos com coordenadas. Problemas 82
e portanto spanR{δi} = F(S;R), quando S = {1, 2, · · · , n}. As coordenadas def relativas a base B = {δi} sao os escalares f(i) ∈ R, 1, · · · , n.
Portanto dim RF(S;R) = n, quando S tem n elementos.
I Exemplo 5.5 ... No espaco Mm,n(Ik) das matrizes m×n com entradasem Ik, o conjunto das mn matrizes elementares Eij que tem um 1 na entrada(i, j), isto e, na interseccao da linha i com a coluna j, e 0’s em todas as outrasentradas, formam uma base de Mm,n(Ik). Portanto dim IkMm,n(Ik) = mn.
¥.
5.2 Calculos com coordenadas. Problemas
Nesta seccao
V representa um espaco vectorial sobre um corpo Ik, dedimensao finita, dim IkV = n, e B = {e1, · · · , en} uma base fixapara V.
Usamos frequentemente a convencao de Einstein.
I Problema 5.1 ... Dados m vectores v1, · · · ,vm, em V, verificar seeles sao ou nao linearmente independentes.
Resolucao ... Por definicao de independencia linear, a questao e saber se:∑
j
λjvj = λ1v1 + · · ·+ λmvm = 0 ⇒ λ1 = · · · = λm = 0 (5.2.1)
Representemos cada vector dado, na base B:
vj = vij ei j = 1, · · · ,m (5.2.2)
Entao (5.2.1) escreve-se na forma:
λjvj = (λjvij) ei = 0 ⇔
∑
j
vijλ
j = 0, i = 1, · · · , n
As equacoes∑
j vijλ
j = 0, i = 1, · · · , n, constituem um sistema homogeneode n equacoes lineares a m incognitas λ1, · · · , λm.
• Se este sistema admite uma unica solucao - a trivial, em que todos os λj
sao nulos - os vectores v1, · · · ,vm, sao linearmente independentes

5.2. Calculos com coordenadas. Problemas 83
• Se este sistema admite outras solucoes nao triviais, os vectores v1, · · · ,vm
sao linearmente dependentes.
¥.
I Problema 5.2 ... Dados m vectores v1, · · · ,vm, em V, e um vectorv ∈ V, verificar se:
v ∈ spanIk{v1, · · · ,vm}
Resolucao ... Por definicao de spanIk{v1, · · · ,vm}, a questao e saber seexistem escalares λ1, · · · , λm ∈ Ik, tais que:
v = λ1v1 + · · ·+ λmvm =∑
j
λjvj (5.2.3)
Representemos cada vector dado, na base B:
v = vi ei
vj = vij ei, j = 1, · · · , m (5.2.4)
Entao (5.2.3) escreve-se na forma:
vi ei = λjvj = (λjvij) ei = 0 ⇔ vi =
∑
j
vijλ
j , i = 1, · · · , n
As equacoes∑
j vijλ
j = vi, i = 1, · · · , n, constituem um sistema nao ho-mogeneo de n equacoes lineares a m incognitas λ1, · · · , λm. A questao resume-seagora em saber se este sistema admite solucao.
¥.
I Problema 5.3 ... Sabendo que dimV = n, e dados n vectoresf1, · · · , fn, em V, verificar se eles formam uma base para V.
Resolucao ... Basta mostrar que f1, · · · , fn sao linearmente independentes,o que se reduz ao problema 5.1.
¥.
I Problema 5.4 ... Dados m vectores a1, · · · ,am, em V, calcularuma base para:
S = spanIk{a1, · · · ,am}e calcular a dimensao dim IkS.

5.2. Calculos com coordenadas. Problemas 84
Resolucao ... Por definicao, spanIk{a1, · · · ,am} consiste de todos os vec-tores v que sao combinacao linear dos vectores a1, · · · ,am:
S = spanIk{a1, · · · ,am}= {v =
∑
j
λjaj : λj ∈ Ik, j = 1, · · · , m} (5.2.5)
O problema consiste em encontrar vectores em S que sejam linearmente inde-pendentes e que gerem S. A resolucao baseia-se no lema seguinte, cuja demon-stracao e simples (exercıcio):
I Lema 5.2 ... Com as notacoes anteriores, tem-se que, ∀λ 6= 0 e j 6= k:
[OpEl1]. spanIk{a1, · · · ,aj , · · · ,ak, · · · ,am}= spanIk{a1, · · · ,ak, · · · ,aj , · · · ,am}
[OpEl2]. spanIk{a1, · · · ,aj , · · · ,am} = spanIk{a1, · · · , λaj , · · · ,am}[OpEl3]. spanIk{a1, · · · ,aj , · · · ,ak, · · · ,am}
= spanIk{a1, · · · ,aj , · · · ,aj + λak, · · · ,am}(5.2.6)
¥.
Representemos agora cada vector dado aj , j = 1, · · · , m, na base B:
aj =∑
i
aij ei j = 1, · · · ,m (5.2.7)
e consideremos a matriz A = [aij ], que e uma matriz n×m, cujas colunas sao as
componentes de cada aj na base B. E mais tradicional (e natural, como veremosadiante) tomar a matriz transposta At = [aj
i ], que e agora uma matriz m × n,cujas linhas sao as componentes de cada aj na base B:
At =
a11 a2
1 · · · an1
a12 a2
2 · · · an2
......
...a1
m a2m · · · an
m
As operacoes referidas no lema 5.2, traduzem-se nas seguintes operacoes ele-mentares sobre as linhas de At:
[OpEl1]. −→ permutar as linhas j e k[OpEl2]. −→ substituir a linha j pela linha que se obtem multiplicando-a
por um escalar nao nulo λ[OpEl3]. −→ substituir a linha k pela linha que se obtem adicionando-lhe
a linha j multiplicada por um escalar nao nulo λ(5.2.8)

5.3. Mudancas de base e de coordenadas 85
O lema afirma que spanIk{a1, · · · ,am} se mantem inalterado por estas operacoeselementares. Resta entao reduzir a matriz At a forma escalonada, usando asoperacoes elementares referidas, para daı deduzir uma base para spanIk{a1, · · · ,am}.Vejamos um exemplo concreto:
I Exemplo 5.6 ... Em R3[X] calcular uma base para:
spanR{1 + X −X3, X −X2, 1 + X2 −X3}
Os calculos vao efectuar-se usando a base B = {1, X, X2, X3} para R3[X].A matriz At e portanto:
At =
1 1 0 −10 1 −1 01 0 1 −1
que se reduz a forma escalonada, atraves das operacoes elementares seguintes:
1 1 0 −10 1 −1 01 0 1 −1
−→[OpEl1]
1 1 0 −11 0 1 −10 1 −1 0
−→[OpEl2]
1 1 0 −1−1 0 −1 10 1 −1 0
−→[OpEl3]
1 1 0 −10 1 −1 00 1 −1 0
−→[OpEl3]
1 1 0 −10 1 −1 00 0 0 0
Portanto {1 + X −X3, X −X2} e uma base para S que tem por isso dimensao2.
¥.
5.3 Mudancas de base e de coordenadas
Suponhamos que V e um espaco vectorial e que:
C =(
e1 e2 · · · en
)

5.3. Mudancas de base e de coordenadas 86
e uma base qualquer, escrita como um vector-linha com entradas vectoriais ei.Se v ∈ V e um vector qualquer em V, designemos por vi as suas componentesna base C , isto e:
v =∑
i
viei
=(
e1 e2 · · · en
)
v1
v2
...vn
= C [v]C (5.3.1)
Suponhamos agora que mudamos para uma outra base:
C −→ C =(
e1 e2 · · · en
)(5.3.2)
Dado um vector arbitrario v ∈ V, como se relacionam ascoordenadas de v na base C com as coordenadas de v nabase C ?
Mais detalhadamente, dado v ∈ V , podemos escrever v como combinacaolinear dos elementos da base C e tambem como combinacao linear dos elementosda base C :
v =n∑
i=1
viei
=n∑
j=1
vj ej (5.3.3)
Isto significa que o vector-coluna das coordenadas de v, relativamente a baseC , e:
v1
v2
...vn
C
= (vi)C
enquanto que o vector-coluna das coordenadas de v, relativamente a base C , e:
v1
v2
...vn
C
= (vi)C

5.3. Mudancas de base e de coordenadas 87
A questao e pois: como se relacionam as coordenadas vi com as co-ordenadas vi?
Para responder a esta questao, comecemos por escrever cada elemento dabase C , como combinacao linear dos vectores da base C , isto e, paracada j = 1, 2, · · · , n fixo pomos:
ej =n∑
i=1
P ij ei = eiP
ij (5.3.4)
que escrevemos na forma matricial seguinte:
(e1 e2 · · · en
)=
(e1 e2 · · · en
)
P 11 P 1
2 · · · P 1n
P 21 P 2
2 · · · P 2n
...... · · · ...
Pn1 Pn
2 · · · Pnn
(5.3.5)ou muito simplesmente:
C = C P
Recordando que vi sao as componentes do vector v na base C , e que vj saoas componentes do mesmo vector v na base C isto e:
v =∑
i
viei
= C [v]C (5.3.6)
vem entao que:C [v]C = v = C [v]C = C P [v]CP
o que implica que, uma vez que v e arbitrario:
[v]C = P [v]CP
Multiplicando a esquerda por P−1, conclui-se entao que:
C −→ C P ⇒ [v]CP = P−1[v]C (5.3.7)
Podemos tambem fazer os calculos com a notacao de Einstein:
v = vj ej
= vj(P ij ei) por (5.3.4)
= (P ijv
j) ei (5.3.8)
Como, por outro lado:v = vi ei

5.4. Exercıcios 88
comparando com (5.3.8), concluımos que:
vi = (P−1)ijv
j (5.3.9)
o que confirma o que tınhamos obtido.
A matriz P = [P ij ], calculada atraves de (5.3.4), diz-se a matriz de pas-
sagem da base C para a base C . Esta mesma matriz permite passar dascoordenadas vi para as coordenadas vi:
Nota... A afirmacao (5.3.7) diz-nos que um vector v e um objecto contravariante.Por outras palavras, um vector v ∈ V, pode ser definido como sendo uma classe deequivalencia de pares
(C , (vi)
), onde dois desses pares sao considerados equivalentes:
(C , (vi)
) ∼ (C , (vi)
)
se e so se existe uma matriz P = (P ij ) inversıvel tal que:
C = C P e vi =(P−1)i
kvk
¥.
5.4 Exercıcios
I Exercıcio 5.1 ... Verifique se os vectores que se seguem sao linearmentedependentes ou independentes:
a) (1, 1, 1), (0, 1,−2) em R3;
b) (1, 1, 0), (0, 1,−1) e (1, 3,−2) em R3;
c) (1, 0), (2,−1) em R2;
d) (1, 1), (2, 2) em R2;
e) (−1, 1, 0), (0, 1, 2) em R3;
f) (π, 0), (0, 1) em R2;
g) (1, 2), (2, 3), (1, 1) em R2;
h) (0, 1, 1), (0, 2, 1), (1, 5, 3) em R3;
i) {(1, i), (i,−1)} em C2;
j) {(1, i, 0), (i + 1,−1 + i, 0), (0, 0, 1)} em C3;
I Exercıcio 5.2 ... Considere o espaco vectorial real E das funcoes de Rem R representadas por f(x).
Verifique se as seguintes funcoes sao linearmente independentes em E :

5.4. Exercıcios 89
a) f(x) = 1, f(x) = x b) f(x) = x, f(x) = x2 c) f(x) = 2, f(x) = x,f(x) = 1 + 3x d) f(x) = xex, f(x) = e2x e) f(x) = sin x, f(x) = cosxj) f(x) = sin2 x, f(x) = cos2 x, f(x) = 3 l) f(x) = sin2 x, f(x) = cos2 x,f(x) = cos 2x.
I Exercıcio 5.3 ... Diga se os seguintes subconjuntos de R (X) sao livresou ligados:
a){1 + X + X2, 1 + X, 2−X
};
b){1−X −X2, 1 + 2X + X2, 4
};
c){1 + X + X2, 1 + X, 2 + 2X + X2
}.
I Exercıcio 5.4 ... No espaco dos polinomios V = R2[X], considere B ={1, X, X2} e B = {1−X2, 1−X, 1 + X + 3X2}.
(i). Mostre que B e B sao ambas bases de V.
(ii). Calcule a matriz de passagem da base B para a base B.
(iii). Calcule as coordenadas de p(X) = 2 − X relativamente a cada umadas bases referidas.
I Exercıcio 5.5 ... Sejam u,v,w tres vectores linearmente independentesde um espaco vectorial V. Mostre que u + v,u − v e u − 2v + w tambem saolinearmente independentes.
I Exercıcio 5.6 ... Seja E um espaco vectorial real.
a) Mostre que se u,v,w sao tais que w = 2u + v entao, u,v e w saolinearmente dependentes.
b) Mostre que se u1,u2, . . . ,un−1,un ∈E sao tais que un e combinacao linearde u1,u2, . . . ,un−1, entao u1,u2, . . . ,un−1,un sao linearmente dependentes.
c) De um exemplo para E=R2 de dois vectores u,v linearmente dependentes,tais que v nao seja multiplo de u.
I Exercıcio 5.7 ... Em cada um dos casos, calcule o subespaco gerado porA :
a) A = {(1, 1), (2, 2)} em R2;
b) A = {(1, 0), (5, 0)} em R2;
c) A = {(2,−1), (1, 0)} em R2;
d) A = {(1, 0, 1), (0, 1, 0)} em R3;
e) A = {(1, 0, 1), (0, 1, 0), (0, 0, 1)} em R3;
f) A = {(3, 0, 0), (0, 2, 0)} em R3;

5.4. Exercıcios 90
g) A ={1 + X,X2
}em R (X) ;
h) A ={1−X, X2, 1−X + X2
}em R (X) ;
i) A ={1, 1 + X, 2X + X2
}em R (X) ;
j) A ={(
1 00 1
),
(0 20 0
)}em M2,2(R);
l) A = {(1, 0, i), (0, i, i)} em C2.
I Exercıcio 5.8 ... Verifique se os conjuntos que se seguem, sao ou naobases de cada um dos espacos vectoriais indicados em cada alınea:
a) {(1, 1), (3, 1)} em R2;
b) {(0, 1), (0,−3)} em R2;
c) {(2, 1), (1,−1), (0, 2)} em R2;
d) {(1, 1, 1), (1,−1, 5)} em R3;
e) {(1, 1, 1), (1, 2, 3), (2,−1, 1)} em R3;
f) {(1, 2, 3), (1, 0,−1), (3,−1, 0), (2, 1,−2)} em R3;
g) {(1, 1, 2), (1, 2, 5), (5, 3, 4)} em R3;
h){1 + X, X2, 2 + 2X + 3X2
}em R2 (X) ;
i){1 + X, X2, 3
}em R2 (X) ;
j){1 + X, X2, 2 + 2X + 3X2, X3
}em R2 (X) ;
l){(
1 11 1
),
(1 00 0
),
(1 2−1 3
)}em M2,2 (R) .
I Exercıcio 5.9 ... Seja W o subespaco de R (X) gerado por X3 − 2X2 +4X + 1, 2X3 − 3X2 + 9X − 1, X3 + 6X − 5, 2X3 − 5X2 + 7X + 5. Determineuma base e a dimensao de W.
I Exercıcio 5.10 ... Determine a dimensao do subespaco gerado por:
a) (1,−2, 3,−1), (1, 1,−2, 3);
b) (3,−6, 3,−9), (−2, 4,−2, 6);
c) X3 + 2X2 + 3X + 1, 2X3 + 4X2 + 6X + 2;
d) X3 − 2X2 + 5, X2 + 3X − 4;
e)(
1 21 2
),
(1 12 2
);
f)(
1 1−1 −1
),
( −3 −33 3
).

5.4. Exercıcios 91
I Exercıcio 5.11 ... Calcule uma base de cada um dos subespacos que seseguem, e depois as coordenadas do vector u em cada uma das bases:
a) S ={(x, y) ∈ R2 : x + y = 0
}, u = (3,−3);
b) S ={(x, y) ∈ R2 : 2x = −y
}, u = (4,−8);
c) S ={(x, y, z) ∈ R3 : x + y + z = 0
}, u = (1, 1,−2);
d) S ={(x, y, z) ∈ R3 : 2x− y = z
}, u = (3, 2, 4);
e) S ={(x, y, z, t) ∈ R4 : x− y = 0, z + t = 0
}, u = (1, 1,−2, 2);
f) S ={a + bX + cX2 + dX3 ∈ R3 (X) : a + 2c = 0
}, u = 2 + 2X −X2 +
3X3;
g) S ={a + bX + cX2 + dX3 ∈ R3 (X) : a + 2c = 0, a + c + d = 0
}, u =
2 + 2X −X2 −X3;
h) S ={(
a b cd e f
)∈ M2,3 (R) : a + b + c = 0, a + d = e, f = e = c
}, u =
(1 1 −2−3 −2 −2
);
i) S ={(z, w, t) ∈ C3 : z = w = t
}, u = (1 + i, 1 + i, 1 + i).
I Exercıcio 5.12 ... Sejam V e W os seguintes subespacos de R4 :
V ={(x, y, z, t) ∈ R4 : y − 2z + t = 0
}e W =
{(x, y, z, t) ∈ R4 : x = t, y = 2z
}
Determine uma base e a dimensao de: a) V b) W c) V ∩W.
I Exercıcio 5.13 ... Sabendo que f e uma aplicacao linear, calcule emcada caso a imagem de um vector generico:
a) Sendo f : R2 −→ R2 e f(1, 0) = (1, 1) e f(0, 1) = (1,−2);
b) Sendo f : R2 −→ R2 e f(1,−1) = (1, 2) e f(0, 3) = (2,−2);
c) Sendo f : R2 −→ R2 e f(2, 1) = (−1, 0) e f(−1, 1) = (3,−2);
d) Sendo f : R3 −→ R2 e f(1, 0, 1) = (1, 1) e f(0, 1, 0) = (1,−2) e f(0, 0, 2) =(4, 5);
e) Sendo f : R3 −→ R3 e f(1, 0, 1) = (1, 1, 0) e f(0, 1, 0) = (0,−2, 3) ef(0, 0, 2) = (1, 4, 5);
f) Sendo f : R3 −→ R1 (X) e f(1, 0, 1) = 1 e f(0, 1, 0) = 1+X e f(0, 0, 2) =X;
g) Sendo f : R2 (X) −→ R2 (X) e f(1 + 2X) = X2 e f(2) = 1 + X ef(3X2) = X;
h) Sendo f : R2 (X) −→ M2,2(R) e f(2 + X) =(
1 1−1 2
)e f(1 −X) =
(1 0−1 0
)e f(3X2) =
(0 3−1 4
);

5.4. Exercıcios 92
I Exercıcio 5.14 ... Mostre que nao e possivel definir nenhuma dasseguintes aplicacoes lineares:
a) f : R2 −→ R2 tal que, ker(f) ={(x, y) ∈ R2 : x = 3y
}e f e sobrejectiva;
b) f : R3 −→ R3 sendo f injectiva e na o sobrejectiva;
c) f : R4 (X) −→ R3 tal que ker(f) = span{2 + X, 3 + X4
}e im (f) =
span {(1, 1, 1), (1,−1, 0)} ;
d) f : C2 −→ C3 tal que f e injectiva e sobrejectiva.
I Exercıcio 5.15 ... Calcule as seguintes matrizes de passagem:
a) De B = {(1, 2), (0,−1)} para B = {(2, 1), (1, 1)};b) De B = {(1, 1), (0, 1)} para B = {(2, 1), (1, 1)};d) De B = {(1 + X, 1 + X2, 1 + X + X2} para B = {1, X,X2};e) De B = {(1, 1 + X2, 1 + X + X2} para B = {1, 1−X, 3X2};f) De B = {(1, 0, 0), (0,−i, 1), (0, 0, i)} para B = {(i, 0, 0), (1, 1, 1), (0, 0, 1)};
I Exercıcio 5.16 ... Em cada um dos casos, determine uma base ortonor-mada do subespaco de R3 gerado pelos seguintes vectores:
a) x1 = (1, 1, 1), x2 = (1, 0, 1), x3 = (3, 2, 3).
b) x1 = (1, 1, 1), x2 = (−1, 1,−1), x3 = (1, 0, 1).
I Exercıcio 5.17 ... Em cada um dos casos, determine uma base ortonor-mada do subespaco de R4 gerado pelos seguintes vectores:
a) x1 = (1, 1, 0, 0), x2 = (0, 1, 1, 0), x3 = (0, 0, 1, 1), x4 =(1, 0, 0, 1).
b) x1 = (1, 1, 0, 1), x2 = (1, 0, 2, 1), x3 = (1, 2,−2, 1) .
I Exercıcio 5.18 ... No espaco vectorial real R (t), com o produto interno〈x, y〉 =
∫ 1
0x(t)y(t) dt, mostre que as funcoes que se seguem formam uma base
ortonormada do subespaco por elas gerado:
y1(t) = 1, y2(t) =√
3(2t− 1), y3(t) =√
5(6t2 − 6t + 1).
I Exercıcio 5.19 ... Seja S um subespaco de um espaco vectorial V.Mostre que o S⊥ e o conjunto dos vectores ortogonais a todos os vectores deuma base de S.

5.4. Exercıcios 93
I Exercıcio 5.20 ... Seja W o subespaco de R5 gerado pelos vectoresu = (1, 2, 3,−1, 2) e v = (2, 4, 7, 2,−1). Determine uma base do complementoortogonal W⊥ de W .
I Exercıcio 5.21 ... Determine uma base do subespaco W de R4 ortogonala u1 = (1,−2, 3, 4) e u2 = (3,−5, 7, 8).
I Exercıcio 5.22 ... Considere o espaco vectorial real R2 (t) no qual estadefinido o produto interno 〈f, g〉 =
∫ 1
0f(t)g(t) dt.
a) Determine uma base do subespaco W ortogonal a h(t) = 2t + 1.
b) Aplique o metodo de ortogonalizacao de Gram-Schmidt a base (1, t, t2)para obter uma base ortonormada (u1(t), u2(t), u3(t)) de R2 (X) .
I Exercıcio 5.23 ... Seja V o espaco linear das matrizes 2 × 2 de com-ponentes reais, com as operacoes usuais. Prove que fica definido um produtointerno em V por:
〈A,B〉 = a11b11 +a12b12 +a21b21 +a22b22 onde A = (aij) e B = (bij) .
Calcule a matriz da forma(
a b−b a
), com a, b ∈ R, mais proxima da
matriz A =(
1 2−1 3
).
I Exercıcio 5.24 ... Considere o subespaco S de R3 gerado pelos vectores(1, 0, 0) e (0, 1, 0).
a) Verifique que fica definido em R3 um produto interno por:
〈x, y〉 = 2x1y1 + x1y2 + x2y1 + x2y2 + x3y3, onde x = (x1, x2, x3) ey = (y1, y2, y3).
b) Determine uma base ortonormal para o subespaco S, com este produtointerno.
c) Determine o elemento de S mais proximo do ponto (0, 0, 1),usando oproduto interno de a).
d) Calcule um vector diferente de zero e ortogonal a S usando o produtointerno de a).
I Exercıcio 5.25 ... No espaco vectorial real das funcoes contınuas definidasem (0, 2) , com o produto interno 〈f, g〉 =
∫ 2
0f(x)g(x) dx, seja f(x) = exp(x).
Mostre que, o polinomio constante g, mais proximo de f e g = 12 (exp(2) − 1).
Calcule ‖g − f‖2.

5.4. Exercıcios 94
I Exercıcio 5.26 ... Usando os produtos internos usuais em R2 e R3 ,calcule em cada caso a projeccao ortogonal Pu(v), de v sobre a recta gerada pru:
a) u=(1,1), v=(2,3);
b) u=(4,3), v=(0,1);
c) u=(1,1,1) , v=(1,-1,0);
d) u=(1,0,0), v=(0,1,2).
I Exercıcio 5.27 ... Determine as projeccoes ortogonais seguintes:
b) v = 2t− 1, w = t2 sobre R1 (t) usando o produto interno L2.

Modulo 6
ALGA I. Representacaomatricial das aplicacoeslineares
Contents6.1 Matriz de uma aplicacao linear . . . . . . . . . . . 95
6.2 Calculo do nucleo e imagem . . . . . . . . . . . . . 96
6.3 Matriz da composta . . . . . . . . . . . . . . . . . . 97
6.4 GL(n). Pontos de vista passivo e activo. . . . . . 98
6.5 Determinantes . . . . . . . . . . . . . . . . . . . . . 99
6.5.1 Definicao e propriedades . . . . . . . . . . . . . . . . 99
6.5.2 Determinante de um produto . . . . . . . . . . . . . 102
6.5.3 Calculo da matriz inversa. Matriz adjunta . . . . . . 103
6.6 Regra de Cramer . . . . . . . . . . . . . . . . . . . 105
6.7 Determinante de um operador linear . . . . . . . . 106
6.8 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . 107
6.1 Matriz de uma aplicacao linear
Sejam V e W dois espacos vectoriais sobre o mesmo corpo Ik (= R ou C, comohabitualmente), e de dimensoes finitas, respectivamente iguais a n = dim IkV em = dim IkW.
Consideremos uma aplicacao linear L : V −→ W. Vamos aprender nestaseccao a representar L atraves de uma matriz m× n com entradas em Ik.
95

6.2. Calculo do nucleo e imagem 96
Para isso comecemos por fixar bases B = {e1, · · · , en} para V, e C ={f1, · · · , fm} para W. Temos entao isomorfismos ΦB : V → Ikn e ΦC : W → Ikm,definidos respectivamente por:
ΦB : v =∑n
i=1 viei 7−→ [vi] ∈ Ikn
ΦC : w =∑m
j=1 wjfj 7−→ [wj ] ∈ Ikm(6.1.1)
Consideremos agora o diagrama seguinte:
V L //
ΦB²²
WΦC
²²Ikn // Ikm
ou mais detalhadamente, usando a convencao de Einstein:
viei//
²²
L(viei)a= viL(ei)
b= viLji fj
c= (Ljiv
i)fj
²²[vi] // [wj ] = [Lj
ivi]
A igualdade (a) resulta do facto de L ser linear. A igualdade (b) obtem-se exprimindo, para cada i = 1, · · · , n, a imagem L(ei), de ei por L, comocombinacao linear dos elementos da base fj para W:
L(ei) =m∑
j=1
Lji fj , i = 1, · · · , n
Este e o passo essencial do calculo. Os elementos Lji , que assim se obtem,
formam uma matriz L = [Lji ], que e uma matriz m× n, e que se diz a matriz
da aplicacao linear L, relativamente as bases {ei} e {fj}, respectivamentepara V e W. Esta matriz L nota-se as vezes por M(L)BC ou por BM(L)C .
6.2 Calculo do nucleo e imagem
Sejam V e W dois espacos vectoriais sobre o mesmo corpo Ik, e de dimensoesfinitas, respectivamente iguais a n = dim IkV e m = dim IkW, e consideremosuma aplicacao linear L : V −→ W. Seja L = [Lj
i ] a matriz da aplicacao linearL, relativamente as bases {ei} e {fj}, obtida atraves de (6.1).

6.3. Matriz da composta 97
• Como calcular kerL ? ...
Por definicao, kerL e o subespaco de V constituıdo por todos os vectoresv ∈ V que sao enviados por L no vector nulo de W.
Se v = viei, entao L(v) = (Ljiv
i) fj = 0 sse:
n∑
i=1
Lji vi = 0, j = 1, · · · ,m
Este e um sistema homogeneo de m equacoes lineares com n incognitasvi, cuja resolucao permite calcular os vi tais que v = viei ∈ kerL.
• Como calcular imL ? ...
Por definicao, imL e o subespaco de W gerado por L(ei), i = 1, · · · , n =dimV:
imL = spanIk{L(e1), · · · ,L(en)}Podemos pois aplicar o metodo explicado no problema 5.4 para calcularuma base para imL.
A caracterıstica ou rank da aplicacao linear L, nota-se por rankL edefine-se por:
rankL = dim (imL) (6.2.1)
6.3 Matriz da composta
Suponhamos que temos aplicacoes lineares M : U −→ V e L : V −→ W, ondeU ,V e W sao espacos vectoriais de dimensao finita, com bases B = {ei}i=1,...,n,C = {fj}j=1,...,m e D = {gk}k=1,...,p, respectivamente para U ,V e W.
Suponhamos que M(M)BC = M e que M(L)CD = L. O nosso objectivo ecalcular a matriz da composta L ◦M : U −→ W, relativamente as bases B e D,respectivamnte para U e W, em termos das matrizes M e L.
O diagrama seguinte esclarece a situacao:
U M //
ΦB²²
V L //
ΦC²²
WΦD
²²Ikn
M//
∼=²²
IkmL
// Ikp
∼=²²
IknLM
// Ikp
Calculos...

6.4. GL(n). Pontos de vista passivo e activo. 98
(L ◦M)(ei) = Aki gk (6.3.1)
por outro lado:
(L ◦M)(ei) = L(M(ei))= L(M j
i fj)
= M ji L(fj)
= M ji Lk
j gk
= (Lkj M j
i )gk
= (LM)ki gk (6.3.2)
donde se deduz que A = LM , isto e, a representacao matricial de L ◦M e dadapelo produto LM das matrizes L por M , que se define da seguinte forma -a entrada (k, i) da matriz LM (linha k e coluna i), e dada por:
(LM)ki =
m∑
j=1
Lkj M j
i (6.3.3)
Esquematicamente:
(LM)ki = Lk
1 Lk2 · · · Lk
m︸ ︷︷ ︸linha k
M1i
M2i
...Mm
i
coluna i
= Lk1M1
i + Lk2M2
i + · · ·+ LkmMm
i
=m∑
j=1
Lkj M j
i (6.3.4)
6.4 GL(n). Pontos de vista passivo e activo.
Seja V um espaco vectorial de dimensao n = dimV. O conjunto de todas asaplicacoes lineares L : V → V que sao inversıveis, isto e, o conjunto de todos osautomorfismos de V, constitui um grupo que se diz o grupo linear geral deV. Este grupo e isomorfo ao grupo de todas as matrizes (n × n) inversıveis, enota-se por:
GL(n)
Em Fısica, e usual encarar um automorfismo linear L : V → V sob doispontos de vista diferentes: o ponto de vista passivo e o ponto de vista activo.

6.5. Determinantes 99
• No ponto de vista passivo, um mesmo “estado de um sistema”, isto e,um vector v ∈ V, e descrito por dois “observadores” diferentes, i.e., rela-tivamente a duas bases (ou referencais) C e C . Neste caso, P ∈ GL(n) ea matriz de passagem da base C para a base C :
C P = C
e, como vimos atras, P−1 permite passar das coordenadas vi para ascoordenadas vi:
[v]C = [v]CP = P−1 [v]C
como vimos atras.
• Por outro lado, no ponto de vista activo, existe um unico “observador”C , enquanto que o “estado do sistema”, v ∈ V, e submetido a uma trans-formacao, como por exemplo uma “simetria” do “espaco de estados” dosistema. Neste caso P ∈ GL(n), e a matriz dessa transformacao relativa-mente a base C .
6.5 Determinantes
Comece por recordar a definicao e as propriedades do determinante de matrizes2× 2 e matrizes 3× 3 que vimos nos modulos 1 e 2, respectivamente.
6.5.1 Definicao e propriedades
I Teorema 6.1 Existe uma unica aplicacao:
det : Mn(Ik) −→ IkA 7−→ detA = det(A1, · · · ,An) (6.5.1)
onde A1, · · · ,An representam as colunas de A, com as seguintes propriedades:
1. e linear como funcao de cada uma das colunas Ai da matriz A.
2. se A′ se obtem a partir de A permutando duas colunas, entao detA′ =−detA
3. det In = 1
¥
Antes de demonstrar este teorema, vejamos um corolario que tem uma im-portancia pratica muito grande no calculo de determinantes:

6.5. Determinantes 100
I Corolario 6.1 Seja det : Mn(Ik) −→ Ik uma aplicacao que verifica aspropriedades 1. e 2. do teorema anterior. Entao:
4. se A tem duas colunas linearmente dependentes, detA = 0
5. se A′ se obtem a partir de A multiplicando uma coluna por λ ∈ Ik, detA′ =λ detA
6. se A′ se obtem a partir de A substituindo uma coluna pela que se obtemsomando-lhe um multiplo escalar de uma outra, entao detA′ = detA
I Exercıcio 6.1 demonstre este corolario.
Demonstracao do teorema ...
Unicidade:
Suponhamos que tınhamos duas funcoes, det : Mn(Ik) → Ik e det ′ : Mn(Ik) →Ik, ambas verificando as tres propriedades referidas no teorema, e seja
∆ = det − det ′
Entao ∆(In) = 0 e ∆ verifica as duas primeiras propriedades - linearidadeem cada coluna e alternancia de sinal quando se permutam duas colunas.
Consideremos agora uma matriz arbitraria A = (A1, · · · ,An). Se e1, · · · , en
e a base canonica de Ikn, podemos escrever cada Ai como combinacao linear:
Ai = Ajiej , i = 1, · · · , n
usando como sempre a convencao de Einstein. Usando a linearidade em cadacoluna e o facto de que ∆(In) = ∆(e1, · · · , en) = 0, e agora facil ver que:
∆(A1, · · · ,An) = 0
e portanto det = det ′.
Existencia:
Inducao sobre n:
• para n = 1 poe-se det (a) = a
• supondo que existe um det definido para matrizes A ∈ Mn−1(Ik), e queverifica as tres propriedades referidas no teorema, vamos mostrar como sedefine para matrizes A ∈ Mn(Ik) mantendo, e claro, ainda as referidastres propriedades.
Dada uma matriz A ∈ Mn(Ik), representemos por Aij ∈ Mn−1(Ik) amatriz que se obtem de A eliminando a linha i e a coluna j.

6.5. Determinantes 101
Definamos entao:
detA =n∑
i=1
(−1)i+1A1i · det A1i (6.5.2)
o que corresponde ao chamado “desenvolvimento do determinante segundoa primeira linha”.
Pretende-se mostrar agora que esta funcao satisfaz as tres propriedades referidasno teorema.
[1]. Vejamos um exemplo que esclarece o que esta a acontecer:
det
a + a′ d gb + b′ e hc + c′ f k
= (a + a′) · det(
e hf k
)− d · det
(b + b′ hc + c′ k
)+ g ·
(b + b′ ec + c′ f
)
A primeira parcela e obviamente linear, enquanto que as duas ultimas o sao,por hipotese de inducao.
Em geral, o argumento e o mesmo - a linearidade em cada coluna de Aresulta do facto de que cada parcela da soma em (6.5.2), (−1)i+1A1
i · det A1i,tem essa propriedade. De facto, a linearidade na coluna k, resulta do facto deque as parcelas (−1)i+1A1
i · det A1i, com i 6= k, sao lineares por hipotese deinducao, enquanto que a parcela (−1)k+1A1
k · det A1k o e obviamente.
[2]. Basta mostrar que o det de uma matriz que tenha duas colunas iguais seanula (porque?). Mais uma vez os exemplos seguintes esclarecem o argumentogeral:
det
a a gb b hc c k
= a · det(
b hc k
)− a · det
(b hc k
)+ g ·
(b bc c
)= 0
det
a d ab e bc f c
= a · det(
e bf c
)− d · det
(b bc c
)+ a ·
(b ec f
)= 0
Suponhamos entao que as colunas r e s de A sao iguais. Entao, pela hipotesede inducao:
n∑
i=1
(−1)i+1A1i · det A1i = (−1)r+1A1
r · det A1r + (−1)s+1A1s · det A1s

6.5. Determinantes 102
uma vez que todas as outras parcelas se anulam, atendendo a que as matrizesenvolvidas tem duas colunas iguais (hipotese de inducao).
Como podem diferir A1r e A1s?
Se r e s sao adjacentes, entao A1r = A1s ja que quando duas colunas saoadjacentes e indiferente qual delas se omite.
Se existe apenas uma coluna a separar as linhas r e s, podemos mudarA1r em A1s por uma simples permutacao de duas linhas. Mais geralmente ser = s + t (podemos sempre supor que r > s), podemos mudar A1r em A1s port− 1 dessas permutacoes de duas colunas. Como pela hipotese de inducao paramatrizes (n−1)× (n−1) permutacao de 2 colunas muda o sinal de det , e comoA1
r = A1s pela igualdade das colunas r e s, vem que
detA = (−1)r+1A1r · det A1r + (−1)s+1A1
s · det A1s
= (−1)r+1A1r · det A1r + (−1)s+1A1
r · (−1)t+1 · det A1r
= (−1)r+1A1r · det A1r + (−1)s+1A1
r · (−1)r−s+1 · det A1r
= [(−1)r+1 + (−1)r+1+1] A1r · det A1r
= 0
[3.] det In = 0 facil.
¥.
6.5.2 Determinante de um produto
I Lema 6.1 Seja f : Mn(Ik) → Ik uma funcao que satisfaz as duasprimeiras propriedades referidas no teorema 6.1, isto e, e linear em cada colunae muda o sinal se se permutam duas colunas. Entao:
f(A1, · · · ,An) = f(e1, · · · , en) · det (A1, · · · ,An) (6.5.3)
Dem.: Se f(e1, · · · , en) = 1 entao f = det , pela unicidade do teorema 6.1,e o lema esta demonstrado. Se f(e1, · · · , en) 6= 1, considere-se:
∆(A1, · · · ,An) =det (A1, · · · ,An)− f(A1, · · · ,An)
1− f(e1, · · · , en)(6.5.4)
E facil ver que ∆ satisfaz as 3 propriedades referidas no teorema 6.1 e portanto,por unicidade, ∆(A1, · · · ,An) = det (A1, · · · ,An). Resolvendo a igualdade(6.5.4) em ordem a f(A1, · · · ,An), obtem-se o que se pretende.
¥

6.5. Determinantes 103
I Teorema 6.2 ∀A, B ∈Mn(Ik):
det (AB) = det A · det B (6.5.5)
Dem.: Defina-se f : Mn(Ik) → Ik por:
f(A1, · · · ,An) = det (BA1, · · · , BAn) (6.5.6)
f satisfaz as condicoes do lema anterior, pelo que:
f(A1, · · · ,An) = f(e1, · · · , en)︸ ︷︷ ︸det (Be1,··· ,Ben)
· det (A1, · · · ,An)︸ ︷︷ ︸detA
isto e:det (BA1, · · · , BAn) = det (Be1, · · · , Ben) · det A
Mas e facil ver que (verifique):
det (BA1, · · · , BAn) = det (BA)
e que:det (Be1, · · · , Ben) = det B
o que demonstra o teorema.
¥
I Corolario 6.2 Se A ∈Mn(Ik) e inversıvel entao det A 6= 0 e det A−1 =(det A)−1.
Dem.: 1 = det In = det (AA−1) = det (A) · det (A−1). ¥
6.5.3 Calculo da matriz inversa. Matriz adjunta
Se A e uma matriz quadrada n × n, o seu determinante pode ser calculadodesenvolvendo segundo a linha i, de acordo com a formula:
det A =n∑
j=1
(−1)i+j Aij · detAij i fixo (6.5.7)
onde, como vimos, Aij e a matriz que se obtem de A retirando-lhe a linha i e acoluna j.
A formula anterior sugere a formula da multiplicacao de duas matrizes. Defacto:

6.5. Determinantes 104
det A =n∑
j=1
(−1)i+j Aij · detAij
=∑
j
Aij (−1)i+j detAij︸ ︷︷ ︸
def= Aji
=∑
j
Aij Aj
i
= elemento i da diagonal do produto AA (6.5.8)
Isto conduz portanto a uma nova matriz A definida por:
Aji = (−1)i+j det Aij
Porque ha aqui uma troca de indıces incomoda, consideramos a transposta deA e formulamos a seguinte definicao:
I Definicao 6.1 ... se A e uma matriz quadrada n×n, define-se uma novamatriz quadrada n× n, A, chamada a adjunta de A, atraves de:
Aij
def= (−1)i+jdet (At)ij (6.5.9)
Nao esqueca que (At)ij e a matriz que se obtem de At retirando-lhe a linha i ea coluna j. Portanto:
A =
det (At)11 −det (At)12 det (At)13 · · ·det (At)21 −det (At)22 det (At)23 · · ·det (At)31 −det (At)32 det (At)33 · · ·
......
... · · · ...
O calculo (6.5.8) mostra pois que todos os elementos da diagonal do produtoAA sao iguais a det A, donde se deduz o seguinte teorema:
I Teorema 6.3 Se A e a matriz deduzida de A atraves de (6.5.9), entao:
AA =
det A. . .
det A
= detA In
Portanto, se detA 6= 0, A e inversıvel e:
A−1 =1
det AA (6.5.10)

6.6. Regra de Cramer 105
¥
Dem.: Falta mostrar que os elementos fora da diagonal do produto AA saotodos nulos. Para isso, consideremos a matriz B que se obtem de A substituindoa linha k pela linha h, com h 6= h. Atencao que isto nao e uma operacaoelementar! B fica entao com duas linhas iguais (ambas iguais a linha h deA) e por isso o seu determinante e nulo. Por outro lado, calculando det Bdesenvolvendo segundo a linha k, obtemos:
0 = det B
=∑
j
(−1)k+j Bkj · detBkj , k fixo
=∑
j
(−1)k+j Bkj · detAkj , porque B e A coincidem fora da linha k
=∑
j
(−1)k+j Ahj · detAkj , porque B e A coincidem na linha h
=∑
j
Ahj · (−1)k+j detAkj
=∑
j
Ahj · Aj
k (6.5.11)
¥
6.6 Regra de Cramer
Dado um sistema do tipo:Ax = b
podemos escreve-lo na forma:
x1A1 + x2A2 + · · ·+ xnAn = b
onde, como antes, A1,A2, · · · ,An representam as colunas da matriz A. Paracada i fixo, substitua-se a coluna Ai pelo vector-coluna b, e calcule-se o deter-minante dos n vectores assim obtidos. Vem entao que (justificar):
det (A1,A2, · · · , b︸︷︷︸posicao i
, · · · ,An) = det (A1,A2, · · · , xkAk︸ ︷︷ ︸posicao i
, · · · ,An)
= xi det (A1,A2, · · · ,Ai, · · · ,An)= xi detA (6.6.1)

6.7. Determinante de um operador linear 106
Portanto, se det A 6== 0, deduzimos a chamada regra de Cramer para assolucoes do sistema Ax = b:
xi =1
detA· det (A1, · · · , b︸︷︷︸
posicao i
, · · · ,An) (6.6.2)
6.7 Determinante de um operador linear
Suponhamos que V e um espaco vectorial de dimensao finita n, e que:
C =(
e1 e2 · · · en
)
e uma base qualquer, escrita como um vector-linha com entradas vectoriais ei.
Mudemos para uma outra base:
C −→ C P = C =(
e1 e2 · · · en
)(6.7.1)
que escrevemos na forma matricial seguinte:
(e1 e2 · · · en
)=
(e1 e2 · · · en
)
P 11 P 1
2 · · · P 1n
P 21 P 2
2 · · · P 2n
...... · · · ...
Pn1 Pn
2 · · · Pnn
(6.7.2)ou muito simplesmente:
C = C P
Suponhamos agora que L : V → V e um operador linear, cuja matriz relati-vamente a base C = {e1, e2, · · · , en}, para V, e:
[L]C = [Lij ] (6.7.3)
Recorde que isto significa que:
L(ej) =∑
j
Lij ei
Como muda a representacao matricial de L? Isto e, se amatriz de L nesta nova base e Li
j, como e que esta matriz serelaciona com a matriz Li
j?
Os calculos sao faceis de fazer (serao feitos em detalhe no modulo 8) e oresultado e o seguinte:

6.8. Exercıcios 107
Se L : V → V e um operador linear num espaco vectorial dedimensao finita, entao a representacao matricial de L varia,com a escolha da base, da seguinte forma:
C → C P ⇒ [L]CP = P−1[L]C P (6.7.4)
Isto permite dar um sentido invariante ao conceito de determinante deum operador L - e, por definicao, o determinante de uma qualquer matriz queo representa, relativamente a uma qualquer base C de V:
detL = det ([L]C ) (6.7.5)
A formula (6.7.4) mostra que:
det ([L]CP ) = det(P−1[L]C P
)= det
(P−1
)det ([L]C ) det P = det ([L]C )
e portanto a definicao (6.7.5) nao depende da base escolhida.
6.8 Exercıcios
I Exercıcio 6.2 ... Seja V o espaco vectorial das funcoes polinomiaisp : R→ R de grau ≤ 4:
V = {p(x) = ao + a1x + a2x2 + a3x
3 + a4x4 : ai ∈ R}
e W o espaco vectorial das funcoes polinomiais q : R → R de grau ≤ 3.Considere a aplicacao L : V → W definida por:
L[p(x)] =(
d2
dx2− d
dx
)[p(x)] = p′′(x)− p′(x)
Mostrar que L e linear. Calcular a matriz de L relativamente as bases {1, x, x2, x3, x4}para V e {1, x, x2, x3} para W. Calcular kerL e imL.
I Exercıcio 6.3 ... Em cada um dos seguintes casos determine MBB(f),calcule ker(f) e im (f) :
a) f : R2 −→ R2 ,B = B = ((1, 0), (0, 1)
(x, y) 7−→ (3x− y, x + 5y)
(x, y) 7−→ (−x + y, 5x + 2y)
c) f : R3 −→ R1 (X) ,B = ((1, 0, 0), (0, 1, 0), (0, 0, 1)), B =(1, X)

6.8. Exercıcios 108
(a, b, c) 7−→ a + b + c + (a + 2b)X
d) f : R2 (X) −→ R2 ,B = (1 + X, 1 + 2X,X2), B =((3, 1), (5, 2));
a0 + a1X + a2X2 7→ (a0 + a1 + a2, a0 + 2a1)
e) f :{(x, y, z) ∈ R3 : x = 2y
} −→ {(x, y, z) ∈ R3 : x = y = −z
}
(x, y, z) 7→ (2y + z, x + z,−x− z)
,
B = ((2, 1, 0), (0, 0, 1)), B = ((−1,−1, 1));
f) D : R4 (X) −→ R4 (X) ,B = B = (1, X, X2, X3, X4);
P 7−→ P ′
g) f : R4 (X) −→ R4 (X) ,B = (1, X,X2, X3, X4), B = (1, X, X2, X3, X4);
P 7−→ X2 P ′
(x, y, z) 7−→ (x + y, y + 2z)
i) f : C3 −→ C2 ,B = ((i, 0, 0), (1, 1, 0), (0, 0, 1)), B =((1, i), (0, 1)).
(z, v, w) 7→ (z + v + w, z − w)
I Exercıcio 6.4 ... Em cada um dos seguintes casos, determine MBB(g ◦f).
a) MBB(f) =(
1 20 −1
), MBB(g) =
0 212 −3−2 1
5
;
b) MBB(f) =
1 0−2 13 50 0
, MBB(g) =
1 0 0 2−2 −1 −1 35 1 −2 1
;
c) MBB(f) =(
1 −10 2
), MBB(g) =
(2 2−1 −1
);
d) MBB(f) =(
1 −10 2
), MBB(g) =
(2 2−1 −1
);
e) MBB(f) =(
3 5),MBB(g) =
246
;
f) MBB(f) =(
1 −i0 2 + i
), MBB(g) =
(2 2i −1 + i
).

6.8. Exercıcios 109
I Exercıcio 6.5 ... Calcule os seguintes determinantes usando diferentesmetodos em cada uma das alıneas:
a)∣∣∣∣
2 54 1
∣∣∣∣ ; b)∣∣∣∣
6 13 −2
∣∣∣∣ ; c)
∣∣∣∣∣∣
1 0 21 0 30 2 4
∣∣∣∣∣∣; d)
∣∣∣∣∣∣
1 1 12 0 20 1 −1
∣∣∣∣∣∣; e)
∣∣∣∣∣∣
2 1 33 2 70 1 2
∣∣∣∣∣∣;
f)
∣∣∣∣∣∣∣∣
3 1 0 −15 3 7 10−1 0 1 21 3 0 2
∣∣∣∣∣∣∣∣; g)
∣∣∣∣∣∣∣∣
2 −1 3 10 3 1 00 0 1 20 0 0 2
∣∣∣∣∣∣∣∣; h)
∣∣∣∣∣∣∣∣
0 0 0 20 0 1 20 3 1 02 −1 3 1
∣∣∣∣∣∣∣∣;
i)
∣∣∣∣∣∣∣∣
1 −1 1 11 −1 −1 −11 1 −1 −11 1 1 −1
∣∣∣∣∣∣∣∣.
I Exercıcio 6.6 ... De exemplos de matrizes A, B ∈ M2,2(R), nao nulas,tais que :
a) det (A + B) 6= det (A) + det (B);
b) det (A + B) = det (A) + det (B).;
c) det (3A) 6= 3 det (A);
d) det (3A) = 3 det (A)
I Exercıcio 6.7 ... Usando determinantes, calcule o volume do par-alelipıpedo gerado pelos vectores u, v, w :
a) u = (1, 1, 2), v = (−1− 2, 3) e w = (0,−1, 1);
b) u = (1, 1, 0), v = (−1, 0, 3) e w = (0,−1, 1);
c) u = (1, 0, 0), v = (−1− 2, 3) e w = (0,−2, 3);
I Exercıcio 6.8 ... Calcule o volume do paralelipıpedo P em R3 geradopor S. Considere depois a aplicacao linear L : R3 −→ R3 e calcule vol (L(P)).Verifique que:
|detL| = vol (L(P))volP
a) S = {(1, 0, 0), (0, 0, 1), (0, 1, 0)} , L(x, y, z) = (x, x + y, x + y + z);
b) S = {(1, 1, 0), (0, 1, 1), (0, 0, 2)} , L(x, y, z) = (x− y, x + y, 2x− y + 3z);
c) S = {(1, 2, 0), (0, 0, 1), (0, 3, 0)} , L(x, y, z) = (2x− y, x + y, y + 5z).

Modulo 7
ALGA I. Espacos vectoriaiscom produto interno
Contents7.1 Espacos Euclideanos reais . . . . . . . . . . . . . . 110
7.2 Espacos Hermitianos (ou Unitarios) complexos . 113
7.3 Norma . . . . . . . . . . . . . . . . . . . . . . . . . . 115
7.4 Ortogonalidade . . . . . . . . . . . . . . . . . . . . . 117
7.5 Bases ortonormadas num espaco vectorial com pro-duto interno . . . . . . . . . . . . . . . . . . . . . . . 119
7.6 Metodo de ortogonalizacao de Gram-Schmidt . . 119
7.7 Decomposicao ortogonal.Teorema da aproximacao optima . . . . . . . . 122
7.8 Aplicacoes. Mınimos quadrados . . . . . . . . . . 129
7.9 Metodo dos mınimos quadrados. Aproximacao dedados por uma recta . . . . . . . . . . . . . . . . . 132
7.10 Transformacoes ortogonais e unitarias. Exemplos 134
7.11 Transformacoes unitarias em C2. Os grupos U(2)e SU(2) . . . . . . . . . . . . . . . . . . . . . . . . . . 135
7.12 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . 136
7.1 Espacos Euclideanos reais
I 7.1 Definicao ... Seja V um espaco vectorial real. Um produto internoem V e, por definicao, uma aplicacao:
〈 | 〉 : V × V −→ R(u,v) 7−→ 〈u|v〉 (7.1.1)
110

7.1. Espacos Euclideanos reais 111
que satisfaz as tres propriedades seguintes:
[PI1]. e uma forma bilinear:
〈(u + v)|w〉 = 〈u|w〉+ 〈v|w〉〈u|(v + w)〉 = 〈u|w〉+ 〈u|w〉
〈λu|v〉 = 〈u|λv〉 = λ〈u|v〉 (7.1.2)
[PI2]. e uma forma simetrica:
〈u|v〉 = 〈v|u〉 (7.1.3)
[PI3]. e nao degenerada:
〈u|v〉 = 0 ∀v ∈ V ⇒ u = 0 (7.1.4)
∀u,v,w ∈ V ,∀λ ∈ R. Um produto interno diz-se um produto interno Eu-clideano, se satisfaz alem disso a seguinte propriedade:
[PI4]. e uma forma definida positiva:
〈u|u〉 ≥ 0, ∀u ∈ V (7.1.5)
Um espaco vectorial real, munido de um produto interno Euclideano chama-seum espaco Euclideano. Outras notacoes muito comuns para 〈u|v〉 sao porexemplo 〈u,v〉, β(u,v), g(u, v), u · v ou ainda u|v.
I 7.2 Exemplo [Produto interno Euclideano usual em Rn] ... Dados doisvectores x = [xi] e y = [yi], em Rn, define-se o respectivo produto interno(Euclideano), como sendo o escalar x · y ∈ R, dado por:
x · y def=n∑
i=1
xiyi = x1y1 + x2y2 + · · ·+ xnyn
= xt y em notacao matricial (7.1.6)
O espaco vectorial Rn, munido deste produto interno Euclideano, diz-se o espacoEuclideano usual e nota-se por IEn.
I 7.3 Exemplo [Produto interno L2 em Co([a, b],R)] ... Consideremos oespaco vectorial real constituıdo pelas funcoes contınuas reais, definidas no in-tervalo [a, b] ⊂ R. Dadas duas funcoes f, g ∈ Co([a, b],R), define-se o respectivoproduto interno L2, como sendo o escalar 〈f |g〉 ∈ R, dado por:
〈f |g〉 def=∫ b
a
f(t)g(t) dt (7.1.7)

7.1. Espacos Euclideanos reais 112
I 7.4 Exemplo [Produto interno de Minkowski em R4] ... Dados dois
vectores x =
x0
x1
x2
x3
e y =
y0
y1
y2
y3
, em R4, define-se o respectivo produto
interno de Minkowski, como sendo o escalar x · y ∈ R, dado por:
x · y = −x0y0 + x1y1 + x2y2 + x3y3
= [−x0 x1 x2 x3]
y0
y1
y2
y3
= xt η y (7.1.8)
onde η representa a matriz simetrica:
−1 0 0 00 1 0 00 0 1 00 0 0 1
(7.1.9)
O produto interno de Minkowski nao e definido positivo, isto e, nao e verdade
que x · x ≥ 0, ∀x ∈ R4. Com efeito, por exemplo o vector e0 = (1, 0, 0, 0),satisfaz e0 · e0 = −1. Note no entanto que a restricao do produto escalar deMinkowski ao hiperplano {0} × R3 = {x = (xα) ∈ R4 : x0 = 0} ∼= R3, e umproduto interno euclideano, portanto em particular definido positivo.
I 7.5 Expressoes matriciais ... Seja (V, 〈 | 〉) um espaco vectorial real, dedimensao n, com um produto interno Euclideano.
Seja C =(
e1 e2 · · · en
)uma base qualquer para V, escrita como um
vector-linha com entradas vectoriais ei. Se u,v ∈ V podemos escrever:
v =∑
i
viei
=(
e1 e2 · · · en
)
v1
v2
...vn
= C [v]C (7.1.10)
onde [v]C =
v1
...vn
e o vector-coluna das componentes do vector v na base
C . Analogamente:u =
∑
i
uiei = C [u]C

7.2. Espacos Hermitianos (ou Unitarios) complexos 113
Calculemos agora o produto interno 〈u|v〉:
〈u|v〉 =⟨ ∑
i
uiei|∑
j
vjej
⟩
=∑
i,j
uivj〈ei|ej〉
=∑
i,j
gijuivj
= [u]tC GC [v]C (7.1.11)
onde definimos a chamada matriz de Gram, GC = [gij ], do produto interno〈 | 〉, na base C atraves de:
gijdef= 〈ei|ej〉 (7.1.12)
Como 〈u|v〉 = 〈v|u〉, deduzimos que a matriz de Gram GC e simetrica, istoe:
GTC = GC
Como 〈v|v〉 > 0, ∀v 6= 0 ∈ V deduzimos que a matriz de Gram GC e definidapositiva, isto e:
[v]TC GC [v]C =∑
i,j
gijvivj > 0, ∀vi nao simultaneamente nulos
E possıvel provar os criterios seguintes (necessarios e suficientes) para decidirquando uma matriz simetrica G = [gij ] e definida positiva:
n = 2
gij > 0,
∣∣∣∣g11 g12
g21 g22
∣∣∣∣ > 0
n = 3
gij > 0,
∣∣∣∣g11 g12
g21 g22
∣∣∣∣ > 0,
∣∣∣∣∣∣
g11 g12 g13
g21 g22 g23
g31 g32 g33
∣∣∣∣∣∣> 0
7.2 Espacos Hermitianos (ou Unitarios) complexos
I 7.6 Definicao ... Seja V um espaco vectorial complexo. Um produtointerno Hermitiano em V e, por definicao, uma aplicacao:
〈 | 〉 : V × V −→ C(u,v) 7−→ 〈u|v〉 (7.2.1)
que satisfaz as propriedades seguintes:

7.2. Espacos Hermitianos (ou Unitarios) complexos 114
[PH1]. e uma forma sesquilinear, isto e, e linear na primeira variavele semi-linear na segunda variavel 1:
〈(u + v)|w〉 = 〈u|w〉+ 〈v|w〉〈u|(v + w)〉 = 〈u|w〉+ 〈u|w〉 (7.2.2)
〈λu|v〉 = λ〈u|v〉〈u|λv〉 = λ〈u|v〉 (7.2.3)
[PH2]. e uma forma Hermitiana:
〈u|v〉 = 〈v|u〉 (7.2.4)
[PH3]. e nao degenerada:
〈u|v〉 = 0 ∀v ∈ V ⇒ u = 0 (7.2.5)
[PH4]. e definida positiva:
〈u|u〉 ≥ 0 (7.2.6)
∀u,v,w ∈ V, ∀λ ∈ C.
Um espaco vectorial complexo, munido de um produto interno Hermitianochama-se um espaco Hermitiano ou um espaco unitario.
I 7.7 Exemplo [Produto interno Hermitiano usual em Cn] ... Dadosdois vectores z = [zi] e w = [wi], em Cn, define-se o respectivo produtointerno (Hermitiano), como sendo o escalar 〈x|y〉 ∈ C, dado por:
〈z|w〉 def=n∑
i=1
ziwi = z1w1 + z2w2 + · · ·+ znwn
= [z1 z2 · · · zn]
w1
w2
...wn
= zt w em notacao matricial (7.2.7)
O espaco vectorial Cn, munido deste produto interno Euclideano, diz-se o espacounitario usual e nota-se por Un.
I 7.8 Exemplo [Produto interno L2 em Co([a, b],C)] ... Consideremos oespaco vectorial real constituıdo pelas funcoes contınuas complexas, definidasno intervalo [a, b] ⊂ R. Dadas duas funcoes f, g ∈ Co([a, b], C), define-se orespectivo produto interno L2, como sendo o escalar 〈f |g〉 ∈ C, dado por:
〈f |g〉 def=∫ b
a
f(t)g(t) dt (7.2.8)
1em Fısica, nomeadamente em Mecanica Quantica, e usual considerar outra convencao -linearidade na segunda variavel e semi-linearidade na primeira variavel!

7.3. Norma 115
7.3 Norma
I 7.9 Definicao [Norma] ... Seja (V, 〈 | 〉) um espaco com um produto interno(Euclideano se V e real ou Hermitiano se V e complexo). Define-se a norma‖v‖, de um vector v ∈ V, atraves da formula:
‖v‖ def=√〈v|v〉 (7.3.1)
I 7.10 A norma verifica as propriedades seguintes:
[N1]. e positiva e nao degenerada:
‖v‖ ≥ 0 e ‖v‖ = 0 sse v = 0 (7.3.2)
[N2]. e homogenea (positiva):
‖λv‖ = |λ| ‖v‖ (7.3.3)
[N3]. satisfaz a “desigualdade triangular” seguinte:
‖v + w‖ ≤ ‖v‖+ ‖w‖ (7.3.4)
∀v,w ∈ V, ∀λ ∈ Ik = R ou C.
Todas as propriedades sao de demonstracao imediata com excepcao da de-sigualdade triangular, que resulta da seguinte proposicao:
I 7.11 Proposicao [Desigualdade de Cauchy-Schwarz] ...
|〈v|w〉| ≤ ‖v‖‖w‖, ∀v,w ∈ V (7.3.5)
Dem.: Se w = 0 a desigualdade e trivial. Se w 6= 0 consideremos o vector:
u = v − 〈v|w〉‖w‖2 w
de tal forma que 〈u|w〉 = 0. Temos entao que:
0 ≤ ‖u‖2 =⟨(
v − 〈v|w〉‖w‖2 w
)|(v − 〈v|w〉
‖w‖2 w)⟩
= 〈v|v〉 − 〈v|w〉〈w|v〉‖w‖2
= ‖v‖2 − |〈v|w〉|2‖w‖2 (7.3.6)
o que demonstra a desigualdade.

7.3. Norma 116
I 7.12 Demonstremos agora a desigualdade triangular (7.3.4):
‖u + v‖2 = 〈u + v|u + v〉= 〈u|u〉+ 〈u|v〉+ 〈v|u〉+ 〈v|v〉= ‖u‖2 + 〈u|v〉+ 〈u|v〉+ ‖v‖2= ‖u‖2 + 2Re 〈u|v〉+ ‖v‖2≤ ‖u‖2 + 2|〈u|v〉|+ ‖v‖2≤ ‖u‖2 + 2‖u‖‖v‖+ ‖v‖2, por Cauchy-Schwarz (7.3.5)= (‖u‖+ ‖v‖)2
e portanto ‖u + v‖ ≤ ‖u‖+ ‖v‖, como se pretendia.
I 7.13 Exemplos ... (i) . No espaco Euclideano IEn, a norma de um vectorx = (xi) ∈ Rn e dada pelo teorema de Pitagoras:
‖x‖ =√
xtx =
(n∑
i=1
(xi)2)1/2
(7.3.7)
(ii). No espaco Unitario Un, a norma de um vector z = (zi) ∈ Cn e dadapor:
‖z‖ =√
ztz =
(n∑
i=1
|zi|2)1/2
(7.3.8)
(iii). No espaco Unitario Co([a, b], C), munido do produto interno L2, dado
por (7.2.8): 〈f |g〉 def=∫ b
af(t)g(t) dt, a norma de uma funcao f ∈ Co([a, b], C)
e dada por:
‖f‖ =√〈f |f〉 =
(∫ b
a
|f(t)|2 dt
)1/2
(7.3.9)
Neste exemplo, a desigualdade de Cauchy-Schwarz toma o aspecto:
∣∣∣∣∣∫ b
a
f(t)g(t) dt
∣∣∣∣∣ ≤(∫ b
a
|f(t)|2 dt
)1/2 (∫ b
a
|g(t)|2 dt
)1/2
(7.3.10)
enquanto que a desigualdade triangular tem o aspecto seguinte:
(∫ b
a
|f(t) + g(t)|2 dt
)1/2
≤(∫ b
a
|f(t)|2 dt
)1/2
+
(∫ b
a
|g(t)|2 dt
)1/2
(7.3.11)

7.4. Ortogonalidade 117
7.4 Ortogonalidade
I 7.14 Definicao ... Seja (V, 〈 | 〉) um espaco com um produto interno (Eu-clideano se V e real ou Hermitiano se V e complexo). Dois vectores u,v ∈ Vdizem-se ortogonais se:
〈u|v〉 = 0 (7.4.1)
I 7.15 Angulo nao orientado ... Suponhamos agora que (V, 〈 | 〉) e um espacoreal Euclideano. Dados dois vectores nao nulos u,v ∈ V , deduzimos da de-sigualdade de Cauchy-Schwarz que:
−1 ≤ 〈u|v〉‖u‖‖v‖ ≤ 1 (7.4.2)
o que permite definir o angulo (nao orientado) θ = θ(u,v) ∈ [0, π], entre osreferidos vectores nao nulos u,v ∈ V, como sendo o unico θ ∈ [0, π], tal que:
cos θ =〈u|v〉‖u‖‖v‖ ∈ [−1, 1] (7.4.3)
Portanto:〈u|v〉 = ‖u‖‖v‖ cos θ(u,v) (7.4.4)
Como vimos antes, dois vectores u,v ∈ V dizem-se ortogonais se 〈u|v〉 = 0.Se ambos sao nao nulos isto significa que o angulo θ(u,v) e igual a π/2.
I 7.16 Definicao [Ortogonal de um subconjunto] ... Seja (V, 〈 | 〉) umespaco com um produto interno (Euclideano se V e real ou Hermitiano se V ecomplexo). Se S e um subconjunto nao vazio de V, define-se o ortogonal de Scomo sendo o subconjunto S⊥ de V constituıdo por todos os vectores que saoortogonais a todos os vectores de S:
S⊥ def= {u ∈ V : 〈u|s〉 = 0, ∀s ∈ S} (7.4.5)
Vamos verificar que S⊥ e um subespaco de V. De facto, se u,v ∈ S⊥, entao〈u|s〉 = 0 e 〈v|s〉 = 0, ∀s ∈ S e portanto 〈u + v|s〉 = 〈u|s〉+ 〈v|s〉 = 0, ∀s ∈ S,i.e., u + v ∈ S⊥. Analogamente λu ∈ S⊥, ∀λ ∈ Ik, se u ∈ S⊥.
I 7.17 Hiperplanos vectoriais ... No espaco Euclideano IEn, dado um vectornao nulo u ∈ Rn−{0}, o conjunto dos vectores x ∈ IEn que sao ortogonais a u:
{x ∈ IEn : x · u = 0} (7.4.6)
formam um subespaco em IEn, que se diz o hiperplano (vectorial) ortogonala u. Se x = (xi) e um ponto generico desse hiperplano, e se u = (ui), a equacaox · u = 0, e equivalente a seguinte equacao cartesiana:
∑
i
uixi = u1x1 + u2x2 + · · ·+ unxn = 0 (7.4.7)

7.4. Ortogonalidade 118
I 7.18 Hiperplanos afins em IEn ...
No espaco Euclideano IEn, com a estrutura afim canonica, dado um ponto Ae um vector nao nulo u ∈ Rn − {0}, o conjunto dos pontos P ∈ IEn tais que−→AP = P −A e ortogonal a u:
{P ∈ IEn :−→AP · u = 0} (7.4.8)
diz o hiperplano (afim) ortogonal a u, que passa em A. Se−→OA = (ai),
u = (ui) e se−−→OP = (xi) e um ponto generico desse hiperplano, a equacao−→
AP · u = 0, e equivalente a:
0 = (−−→OP −−→OA) · u =
−−→OP · u−−→OA · u =
∑
i
uixi −∑
i
aiui
e portanto a seguinte equacao cartesiana:∑
i
uixi = u1x1 + u2x2 + · · ·+ unxn = c (7.4.9)
onde c =−→OA) · u =
∑i aiui.
I 7.19 Teorema [Pitagoras] ... Seja (V, 〈 | 〉) um espaco com um produtointerno (Euclideano se V e real ou Hermitiano se V e complexo), e u,v ∈ V doisvectores ortogonais. Entao:
‖u + v‖2 = ‖u‖2 + ‖v‖2 (7.4.10)
Dem.:
‖u + v‖2 = 〈u + v|u + v〉= ‖u‖2 + ‖v‖2 + 〈u|v〉+ 〈v|u〉= ‖u‖2 + ‖v‖2 (7.4.11)

7.5. Bases ortonormadas num espaco vectorial com produto interno119
7.5 Bases ortonormadas num espaco vectorialcom produto interno
I 7.20 Definicao [Base ortonormada] ... Seja (V, 〈 | 〉) um espaco vectorialde dimensao n com um produto interno (Euclideano se V e real ou Hermitianose V e complexo).
Uma base {e1, · · · , en} diz-se uma base ortonormada para V se:
〈ei|ej〉 = δijdef=
{1 se i = j0 se i 6= j
(7.5.1)
I 7.21 Proposicao ... Seja (V, 〈 | 〉) um espaco vectorial de dimensao n comum produto interno (Euclideano se V e real ou Hermitiano se V e complexo) e{e1, · · · , en} uma base ortonormada para V. Entao v ∈ V:
v =n∑
i=1
〈v|ei〉 ei (7.5.2)
e:
‖v‖2 =n∑
i=1
|〈v|ei〉|2 (7.5.3)
Dem.: Calculo directo.
7.6 Metodo de ortogonalizacao de Gram-Schmidt
I 7.22 Ortogonalizacao de Gram-Schmidt ...
Dada uma base qualquer {f1, · · · , fn}, para V, e possıvel construir, a partirdela, uma base ortogonal {e1, · · · , en}, para V:
〈ei|ej〉 = 0, i 6= j
atraves do chamado processo de ortogonalizacao de Gram-Schmidt, quepassamos a descrever:
[1.] Em primeiro lugar pomos:
e1 = f1 (7.6.1)
[2.]

7.6. Metodo de ortogonalizacao de Gram-Schmidt 120
Em segundo lugar, comecamos por calcular a chamada projeccao ortogonalde f2 sobre a recta gerada por f1 = e1. Esta projeccao ortogonal, por estar narecta gerada por f1 = e1, vai ser um vector do tipo λe1, onde λ ∈ Ik e calculadopela condicao de que 〈f2 − λe1|e1〉 = 0. Obtemos entao:
λ =〈f2|e1〉‖e1‖2
Pomos agora e2 igual a:
e2 = f2 − 〈f2|e1〉‖e1‖2 e1 (7.6.2)
[3.]
Em terceiro lugar, comecamos por calcular a chamada projeccao ortogonalde f3 sobre o plano gerado por {f1, f2}, que e tambem o plano gerado por{e1, e2}. Esta projeccao ortogonal, por estar no plano gerado por {e1, e2}, vaiser um vector do tipo λe1 + ηe2, onde λ, η ∈ Ik sao calculados pela condicao deque 〈f3 − (λe1 + ηe2)|e1〉 = 0 e 〈f3 − (λe1 + ηe2)|e2〉 = 0. Fazendo os calculos,atendendo a que e1 ⊥ e2, obtemos:
λ =〈f3|e1〉‖e1‖2 , η =
〈f3|e2〉‖e2‖2

7.6. Metodo de ortogonalizacao de Gram-Schmidt 121
Portanto a projeccao ortogonal de f3 sobre o plano gerado por {e1, e2} e dadapor:
〈f3|e1〉‖e1‖2 e1 +
〈f3|e2〉‖e2‖2 e2
Pomos agora e3 igual a:
e3 = f3 − 〈f3|e1〉‖e1‖2 e1 − 〈f3|e2〉
‖e2‖2 e2 (7.6.3)
[k.] o processo decorre agora indutivamente: se supomos ja construıdos osvectores ortogonais {e1, . . . , ek}, de tal forma que:
span{e1, . . . , ek} = span{f1, . . . , fk}o vector ek+1 sera construıdo da seguinte forma - comecamos por calcular achamada projeccao ortogonal de fk+1 sobre o subespaco gerado por {e1, . . . , ek}.Esta projeccao ortogonal e dada por:
k∑
i=1
〈fk+1|ei〉‖ei‖2 ei
Pomos agora ek+1 igual a:
ek+1 = fk+1 −k∑
i=1
〈fk+1|ei〉‖ei‖2 ei (7.6.4)
E claro que a base ortogonal assim obtida, pode ser transformada numa baseortonormada, normalizando os vectores ei, isto e, dividindo cada um deles pelarespectiva norma.
I 7.23 Polinomios de Legendre ... Consideremos o espaco vectorial V con-stituıdo por todas as funcoes polinomiais de grau ≤ n, definidas no intervalo[−1, 1], munido do produto interno L2:
〈p|q〉 =∫ 1
−1
p(t)q(t) dt
Uma base para V e {1, t, t2, · · · , tn}. Quando aplicamos o processo de ortogo-nalizacao de Gram-Schmidt a esta base obtemos os chamados polinomios deLegendre {ψ0, ψ1, ψ2, · · · , ψn}. Vejamos como. Em primeiro lugar pomos:
ψ0(t) = 1
Depois pomos:
ψ1 = t− 〈t|1〉‖1‖2
= t−∫ 1
−1t dt
‖ ∫ 1
−112 dt‖2
1
= t (7.6.5)

7.7. Decomposicao ortogonal.Teorema da aproximacao optima 122
Em seguida:
ψ2 = t2 − 〈t2|1〉‖1‖2 1− 〈t2|t〉
‖t‖2 t
= t−∫ 1
−1t2 dt
‖ ∫ 1
−112 dt‖2
1−∫ 1
−1t3 dt
‖ ∫ 1
−1t2 dt‖2
t
= t2 − 13
(7.6.6)
e procedendo da mesma forma:
ψ3 = t3 − 35t
ψ4 = t4 − 67t2 +
335
... (7.6.7)
Quando normalizamos estes polinomios obtemos os chamados polinomios deLegendre normalizados {ϕ0, ϕ1, ϕ2, · · · , ϕn}:
ϕ0 =
√12
ϕ1 =
√32t
ϕ2 =12
√52(3t2 − 1)
ϕ3 =12
√72(5t3 − 3t)
... (7.6.8)
7.7 Decomposicao ortogonal.Teorema da aproximacao optima
I 7.24 Teorema [Decomposicao ortogonal] ... Consideremos um espacovectorial com um produto interno (V, 〈 | 〉) (Euclideano se V e real ou Hermitianose V e complexo), e seja S um subespaco de dimensao finita. Entao:
V = S ⊕ S⊥ (7.7.1)
isto e, qualquer vector v ∈ V pode ser representado de maneira unica como umasoma de dois vectores:
v = s + (v − s), onde s ∈ S e v − s ∈ S⊥ (7.7.2)

7.7. Decomposicao ortogonal.Teorema da aproximacao optima 123
Alem disso:‖v‖2 = ‖s‖2 + ‖v − s‖2 (7.7.3)
Dem.: Como S tem dimensao finita, existe uma base ortonormada {e1, . . . , em}para S, onde m = dimS. Dado um vector qualquer v ∈ V, definamos:
s def=m∑
i=1
〈v|ei〉 ei (7.7.4)
E claro que s ∈ S. Por outro lado, como:
〈v − s|ej〉 = 〈v|ej〉 − 〈s|ej〉 = 〈v|ej〉 − 〈v|ej〉 = 0, j = 1, . . . ,m
o que significa que v−s esta em S⊥. Obtemos portanto a decomposicao (7.7.2).
Mostremos agora que esta decomposicao e unica. Isto e equivalente a provar,como ja sabemos, que S ∩ S⊥ = {0}. Suponhamos entao que 0 6= u ∈ S ∩ S⊥.Entao, por definicao de S⊥, e como u ∈ S⊥, u e ortogonal a todo o vector de S.Em particular e ortogonal a si proprio, isto e, 0 = 〈u|u〉 = ‖u‖2, o que implicaque u = 0.
Finalmente (7.7.3) deduz-se do Teorema de Pitagoras (ver o teorema 7.19).
I 7.25 Projectores ... Consideremos de novo um espaco vectorial com umproduto interno (V, 〈 | 〉) (Euclideano se V e real ou Hermitiano se V e complexo),e suponhamos que S e um subespaco de dimensao finita em V. Entao, comoV = S ⊕ S⊥, podemos ainda definir uma aplicacao linear:
PS : V −→ V (7.7.5)
chamada a projeccao ortogonal sobre S da seguinte forma. Por definicao desoma directa, todo o vector v ∈ V admite uma decomposicao unica da forma:v = s + (v − s), onde s ∈ S e v − s ∈ S⊥. Pomos entao PS(v) = s. E facil verque PS verifica as propriedades seguintes:
• imPS = S• kerPS = S⊥
• P2S = PS
• ‖PS(v)‖ ≤ ‖v‖, ∀v ∈ V• Se {e1, · · · , em} e uma base ortonormada para S, entao:
PS(v) =m∑
i=1
〈v|ei〉 ei (7.7.6)

7.7. Decomposicao ortogonal.Teorema da aproximacao optima 124
I 7.26 Exemplo [Projeccao ortogonal sobre uma recta, em IE3] ...
Sejam a 6= 0 e x dois vectores em R3, com a nao nulo. Entao existe um unicovector u, na recta gerada por a, e um unico vector v, ortogonal a a, tais quex = u + v. O vector u, notado por Pa(x), diz-se a projeccao ortogonal de xsobre a recta gerada por a, e e dado por:
Pa(x) =x · a‖a‖2 a (7.7.7)
A aplicacao Pa : R3 → R3 definida por (7.7.7), e linear. Note que P2a = Pa.
Por outro lado, se considerarmos um qualquer vector b 6= 0 ortogonal a a (i.e.:a · b = 0), vemos que Pa(b) = 0 e portanto:
kerPa = span{b} = {b ∈ R3 : b · a = 0} = a⊥
e o plano vectorial ortogonal a a.
I 7.27 Exemplo [Projeccao ortogonal sobre um plano vectorial, emIE3]

7.7. Decomposicao ortogonal.Teorema da aproximacao optima 125
Consideremos um plano vectorial ortogonal a um vector n ∈ R3 − {0} (se esseplano e gerado por dois vectores u,v linearmente independentes, podemos tomarn = u×v). Notemos esse plano por π = n⊥. Dado um vector x ∈ R3, ao vector:
Pn⊥ ≡ x−Pn(x)
chamamos a projeccao ortogonal de x sobre o plano vectorial ortogonal a n.
De acordo com (7.7.7), temos que:
Pn⊥def= x−Pn(x) = x− x · n
‖n‖2 n (7.7.8)
A aplicacao Pn⊥ : R3 → R3 definida por (7.7.8), e linear. Note que P2n⊥ =
Pn⊥ . Se x · n = 0, i.e., se x e ortogonal a n, entao Pn⊥(x) = x, enquanto que,por outro lado, Pn⊥(n) = 0. Portanto vemos que:
kerPn⊥ = span{n}
e:Pn⊥(x) = x ∀x ∈ n⊥
I 7.28 Teorema [da aproximacao optima] ... Consideremos um espacovectorial com um produto interno (V, 〈 | 〉) (Euclideano se V e real ou Hermitianose V e complexo), e seja S um subespaco de dimensao finita. Dado um vectorv ∈ V, a projeccao ortogonal de v sobre S:
s = PS(v) ∈ S
e o vector de S que esta mais perto de v, isto e:
‖v −PS(v)‖ ≤ ‖v − u‖, ∀u ∈ S (7.7.9)
e ‖v −PS(v)‖ = ‖v − u‖, com u ∈ S se e so se u = PS(v).

7.7. Decomposicao ortogonal.Teorema da aproximacao optima 126
Dem.: Por (7.7.2), temos que v = s+(v−s), onde s = PS(v) ∈ S e v−s ∈ S⊥.Como ∀u ∈ S se tem:
v − u = (s− u)︸ ︷︷ ︸∈S
+(v − s)︸ ︷︷ ︸∈S⊥
esta e a decomposicao ortogonal de v − u. Pelo teorema de Pitagoras:
‖v − u‖2 = ‖s− u‖2 + ‖v − s‖2 ≥ ‖v − s‖2
sendo a igualdade valida sse ‖s− u‖2 = 0, isto e, sse s = u.
I 7.29 Exemplo (Aproximacao de funcoes contınuas em [0, 2π] por po-linomios trigonometricos) ... Seja V = Co([0, 2π];R) o espaco das funcoesreais contınuas definidas em [0, 2π], munido do produto L2:
〈f |g〉 =∫ 2π
0
f(t)g(t) dt
e Sn o subespaco de dimensao 2n + 1 seguinte:
Sn = spanR
{ϕ0(t) =
1√2, ϕ2k−1(t) =
cos kt√π
, ϕ2k(t) =sin kt√
π: k = 1, · · · , n
}
(7.7.10)
As 2n + 1 funcoes {ϕ0, ϕ1, · · · , ϕ2n−1, ϕ2n}, chamadas polinomios trigo-nometricos, formam uma base ortonormada para S (mostrar isto2).
Se f ∈ Co([0, 2π];R), representemos por Fn(f) a projeccao ortogonal de fsobre Sn. De acordo com a formula da projeccao ortogonal (7.7.6), temos que:
Fn(f) =2n∑
k=0
〈f |ϕk〉ϕk (7.7.11)
onde:
〈f |ϕk〉 =∫ 2π
0
f(t)ϕk(t) dt (7.7.12)
sao os chamados coeficientes de Fourier de f . Usando a definicao das funcoesϕk, podemos escrever as formulas anteriores na forma:
Fn(f) =12a0 +
n∑
k=1
(ak cos kt + bk sin kt) (7.7.13)
2Usar as relacoes trigonometricas seguintes:
cos A cos B =1
2{cos(A−B) + cos(A + B)}
sin A sin B =1
2{cos(A−B)− cos(A + B)}
sin A cos B =1
2{sin(A−B) + sin(A + B)}

7.7. Decomposicao ortogonal.Teorema da aproximacao optima 127
onde os coeficientes de Fourier sao dados por:
ak =1π
∫ 2π
0
f(t) cos kt dt
bk =1π
∫ 2π
0
f(t) sin kt dt (7.7.14)
para k = 0, 1, 2, . . . , n. O teorema da aproximacao optima diz-nos que o polinomiotrigonometrico Fn(f) ∈ Sn, dado por (7.7.13), aproxima f melhor que qualqueroutro polinomio trigonometrico em Sn, no sentido em que ‖f−Fn(f)‖ e o menorpossıvel.
I 7.30 Exemplo Seja V = Co([−1, 1];R) o espaco das funcoes reais contınuasdefinidas em [−1, 1], munido do produto L2:
〈f |g〉 =∫ 1
−1
f(t)g(t) dt
e Sn o subespaco de dimensao n + 1 gerado pelos polinomios de Legendre nor-malizados, introduzidos no exemplo 7.23:
Sn = spanR {ϕo, ϕ1, · · · , ϕn} (7.7.15)
E claro que S e o subespaco constituıdo por todas as funcoes polinomiais de grau≤ n, definidas no intervalo [−1, 1]. f ∈ Co([−1, 1];R), representemos por Pn(f)a projeccao ortogonal de f sobre Sn. De acordo com a formula da projeccaoortogonal (7.7.6), temos que:
Pn(f) =n∑
k=0
〈f |ϕk〉ϕk, onde 〈f |ϕk〉 =∫ 1
−1
f(t)ϕk(t) dt (7.7.16)
que e o polinomio de grau ≤ n, para o qual ‖f − Pn(f)‖ e o menor possıvel.Por exemplo, se f(t) = sin πt, os coeficientes 〈f |ϕk〉 sao dados por:
〈f |ϕk〉 =∫ 1
−1
sin πtϕk(t) dt
Em particular, 〈f |ϕ0〉 = 0 E.
〈f |ϕ1〉 =∫ 1
−1
√32t sin πt dt =
√32
2π
I 7.31 Exemplo ... Considere o espaco vectorial R3[t] das funcoes polinomiaisp(t), de grau ≤ 3, de coeficientes reais, munido do produto interno:
〈p(t)|q(t)〉 =∫ +1
0
p(t)q(t) dt

7.7. Decomposicao ortogonal.Teorema da aproximacao optima 128
a.) Mostre que:
S = {p(t) ∈ R3[t] : p(t) = p(−t) }
e um subespaco vectorial. Calcule dim S e determine uma base ortonormadapara S.
b.) Calcule o polinomio de S que esta mais proximo do polinomio p(t) = t.
c.) Calcule o ortogonal de T = span{1} em R3[t].
d.) Calcule o nucleo e a imagem da aplicacao linear:
T : R3[t] −→ R3[t]p(t) 7−→ T[p(t)] = p′′(t)− 2tp′(t)
Resolucao ...
a.) Se p, q ∈ S entao (p+ q)(t) = p(t)+ q(t) = p(−t)+ q(−t) = (p+ q)(−t) eportanto p + q ∈ S. Se p ∈ S e λ ∈ R entao (λp)(t) = λp(t) = λp(−t) = λp(−t)e portanto λp ∈ S.
Se p(t) = a + bt + ct2 + dt3 ∈ S entao a + bt + ct2 + dt3 = p(t) = p(−t) =a− bt + ct2 − dt3, isto e, 2bt + 2dt3 = 0 e portanto b = d = 0. Logo:
S = {p(t) = a + bt + ct2 + dt3 ∈ R3[t] : b = d = 0 }= {p(t) = a + ct2 ∈ R3[t] : a, c ∈ R }= span{1, t2}
e dim S = 2. Os polinomios p(t) ≡ 1 e q(t) = t2 constituem uma base para S.
Uma base ortonormada obtem-se pelo processo de Gram-Schmidt. ‖1‖2 =∫ 1
01 dt = 1 e t2 − 〈t2|1〉
‖1‖2 1 = t2 − ∫ 1
0t2 dt = t2 − 1/3. Alem disso
∥∥t2 − 1/3∥∥2 =∫ 1
0(t2 − 1/3)2 dt = 4/45. Logo os polinomios 1 e (3
√5/2)(t2 − 1/3) constituem
uma base ortonormada para S.
b.) Pelo teorema da aproximacao optima esse polinomio e dado pela pro-jeccao ortogonal de t sobre S:
PS(t) = 〈t|1〉 1 + 〈t|(3√
5/2)(t2 − 1/3)〉 (3√
5/2)(t2 − 1/3)
=∫ 1
0
t dt + (45/4)(∫ 1
0
t(t2 − 1/3) dt
)(t2 − 1/3)
= 1/2 + (45/48)(t2 − 1/3)
c.) Um polinomio p(t) = a + bt + ct2 + dt3 ∈ R3[t] estara em T ⊥ sse〈(a + bt + ct2 + dt3)|1〉 = 0 isto e, sse a + b/2 + c/3 + d/4 = 0. Portanto:
T ⊥ = {p(t) = a + bt + ct2 + dt3 ∈ R3[t] : a + b/2 + c/3 + d/4 = 0 }

7.8. Aplicacoes. Mınimos quadrados 129
que e um hiperplano em R3[t].
d.) Um polinomio p(t) = a + bt + ct2 + dt3 ∈ R3[t] estara em kerT sse:
0 = T[p(t)] = p′′(t)− 2tp′(t)= (a + bt + ct2 + dt3)′′ − 2t(a + bt + ct2 + dt3)′
= (2c + 6dt)− 2t(b + 2ct + 3dt2)= 2c + (6d− 2b)t− 4ct2 − 6dt3
donde 2c = 0, 6d − 2b = 0, 4c = 0, 6d = 0, isto e, b = c = d = 0. Portanto okerT e constituıdio pelos polinomios p(t) = a + bt + ct2 + dt3 ∈ R3[t] tais queb = c = d = 0, isto e, kerT = {a : a ∈ R} = span{1}.
imT e constituıdia pelos polinomios P (t) = A+Bt +Ct2 +Dt3 ∈ R3[t] taisque:
T(a + bt + ct2 + dt3) = A + Bt + Ct2 + Dt23
para algum polinomio p(t) = a + bt + ct2 + dt3 ∈ R3[t]. Como T[p(t)] =2c + (6d− 2b)t− 4ct2 − 6dt3, vem que:
2c + (6d− 2b)t− 4ct2 − 6dt3 = A + Bt + Ct2 + Dt3
isto e:
2c = A− 2b + 6d = B
− 4c = C− 6d = D
⇒
− 2b + 6d = B2c = A
− 6d = D0 = 2A + C
⇒
e portanto imT = {P (t) = A + Bt + Ct2 + Dt3 ∈ R3[t] : 2A + C = 0}.
7.8 Aplicacoes. Mınimos quadrados
I 7.32 Solucao dos mınimos quadrados ... Seja:
Ax = b (7.8.1)
um sistema de equacoes lineares, nao homogeneo, escrito em forma matricial.A e uma matriz m× n, x ∈ Rn e b ∈ Rm e um vector fixo.

7.8. Aplicacoes. Mınimos quadrados 130
Uma “solucao” dos mınimos quadrados do sistema (7.8.1) e, por definicao,um vector x, que satisfaz:
‖Ax− b‖ e mınimo (7.8.2)
Interpretando A como a matriz de uma aplicacao linear A : Rn → Rm, relati-vamente as bases canonicas de cada um destes espacos, vemos que o significadode uma “solucao” dos mınimos quadrados e o seguinte:
e um vector x ∈ Rn cuja imagem Ax esta mais proxima de b.
I 7.33 Quando kerA = {0} a “solucao” x e unica. Quando b ∈ im A, x euma solucao exacta do sistema. Quando b /∈ imA, e kerA = {0} a “solucao”x e dada por:
x = A−1PimA(b) (7.8.3)
Isto e, para calcular a “solucao”dos mınimos quadrados do sistema (7.8.1)procede-se da seguinte forma:
1. Calcula-se a projeccao ortogonal y = PimA(b) ∈ imA, de b sobre aimagem de A. Pelo teorema da aproximacao optima, este sera o vectorda imagem de A, que melhor aproxima b.
2. Calcula-se x tal que:Ax = y = PimA(b) (7.8.4)
I 7.34 Exemplo ... Considere a aplicacao linear A : R2 → R3 definida por:
A(x, y) = (x + y, x− y, x)
a.) Calcule o ortogonal da imagem de A em R3, com a estrutura Euclideanausual.

7.8. Aplicacoes. Mınimos quadrados 131
b.) Calcule a “solucao”dos mınimos quadrados do sistema:
x + y = 1x− y = 1x = 0
Calcule o erro associado a essa solucao e explique qual o seu significado geometrico(da solucao e do seu erro).
Resolucao ...
a.) A imagem de A e constituıda por todos os vectores (X,Y, Z) ∈ R3 taisque:
(X, Y, Z) = A(x, y) = (x + y, x− y, x)
para algum vector (x, y) ∈ R2. A questao e pois: quais os vectores (X, Y, Z) ∈R3 para os quais existe (x, y) tal que:
x + y = Xx− y = Yx = Z
?
Resolvendo o sistema em ordem a x, y (com X, Y, Z como parametros), vemque:
x = Zy = X − Z0 = X + Y − 2Z
Portanto a imagem de A e o plano X + Y − 2Z = 0 em R3. O seu ortogonal ea recta gerada pelo vector n = (1, 1,−2).
b.) Por definicao (e pelo teorema da aproximacao optima), a “solucao”dosmınimos quadrados e a solucao do sistema:
Ax = PimA(b)
onde PimA(b) e a projeccao ortogonal do vector b = (1, 1, 0) sobre o planoimagem de A: X + Y − 2Z = 0.
Essa projeccao pode ser calculada pela seguinte formula:
PimA(1, 1, 0) = (1, 1, 0)− (1, 1, 0) · (1, 1,−2)‖(1, 1,−2)‖2 (1, 1,−2) =
23(1, 1, 1)
Logo a solucao procurada e a solucao do sistema:
x + y = 2/3x− y = 2/3x = 2/3

7.9. Metodo dos mınimos quadrados. Aproximacao de dados poruma recta 132
que e:x = 2/3, y = 0
O erro associado e, por definicao, igual a distancia entre o ponto (1, 1, 0) ea PimA(b):
e = ‖(1, 1, 0)− 23(1, 1, 1)‖ =
√6/3
I 7.35 Exemplo ... Calcular a “solucao” dos mınimos quadrados do sistema:
x + 2y = 13x − y + z = 0−x + 2y + z = −1
x − y − 2z = 22x + y − z = 2
(7.8.5)
e o erro correspondente.
7.9 Metodo dos mınimos quadrados. Aproximacao dedados por uma recta
I 7.36 Aproximacao de dados por uma recta pelo metodo dos mınimosquadrados
Suponhamos que se fazem n medicoes de uma certa grandeza y, em n instantesti, i = 1, ..., n, obtendo os resultados:
t1 t2 t3 · · · tny1 y2 y3 · · · yn
(7.9.1)

7.9. Metodo dos mınimos quadrados. Aproximacao de dados poruma recta 133
Representemos os n pontos (ti, yi) no plano em R2t,y,e suponhamos que se
pretende calcular uma recta do tipo:
y = αt + β (7.9.2)
que melhor ajuste esses dados.
Em que sentido deve ser entendido este “melhor”ajustamento?
Para cada ti, o erro ei entre o valor medido yi e o valor estimado a partir darecta referida (supondo que ela esta ja calculada) e igual a:
εi = yi − (αti + β), i = 1, 2, · · · , n
Podemos reunir estas equacoes numa unica em forma matricial:
ε = y − Ax (7.9.3)
onde:
ε =
ε1
ε2
...εn
, y =
y1
y2
...yn
, A =
t1 1t2 1...tn 1
, x =
(αβ
)
ε e o chamado vector de erro e y o vector de dados. Os coeficientes α e β,as incognitas do problema, sao as componentes do vector x.
Se os dados se ajustassem exactamente, yi = αti + β, os erros seriam todosnulos εi = 0, e poderıamos resolver o sistema Ax = y. Por outras palavras, osdados estarao todos numa linha recta sse y ∈ imA. Se eles nao forem colinearesentao devemos procurar a recta para a qual o erro total:
‖ε‖ =(ε21 + · · ·+ ε2
n
)1/2
seja mınimo.
Em linguagem vectorial, procuramos pois o vector x =(
αβ
)que minimiza
a norma Euclideana do vector erro:
‖ε‖ = ‖Ax− y‖que e exactamente a situacao que caracteriza a procura da solucao dos mınimosquadrados para o sistema Ax = y, que foi explicada no ponto anterior.
I 7.37 Exemplo ... Calcular a recta de aproximacao dos mınimos quadradospara os dados seguintes:
ti 0 1 3 6yi 2 3 7 12
(7.9.4)
Solucao: y = 12/7(1 + t).

7.10. Transformacoes ortogonais e unitarias. Exemplos 134
7.10 Transformacoes ortogonais e unitarias. Ex-emplos
I 7.38 Definicao ... [Transformacoes ortogonais] ... Seja (V, 〈 | 〉) umespaco Euclideano de dimensao n, isto e, um espaco vectorial real com umproduto interno Euclideano. Um operador linear A : V → V diz-se uma trans-formacao ortogonal de V, se A preserva o produto interno 〈 | 〉, i.e.:
〈A(v)|A(w)〉 = 〈v|w〉 ∀v,w ∈ V (7.10.1)
Se A e a matriz de uma tal transformacao ortogonal, relativamente a umabase ortonormada de V, entao (7.10.1) escreve-se na seguinte forma matricial:
(Av)t Aw = vt w ∀v,w ∈ V
ou ainda:vtAtAw = vtw = vtIw ∀v,w ∈ V
o que significa que a matriz A e uma matriz ortogonal, isto e:
AtA = I (7.10.2)
Note ainda que se A e uma matriz ortogonal entao, uma vez que:
1 = det I = det (AAt) = det A det (At) = (det A)2, e detA ∈ R
concluımos que det A = ±1 e, em particular A e inversıvel com:
A−1 = At
O conjunto de todas as matrizes ortogonais n × n reais formam um sub-grupo de G`(n) = G`(n;R), que se diz o grupo ortogonal em dimensao n enota-se por O(n). O conjunto de todas as matrizes ortogonais n × n reais, dedeterminante 1, formam um subgrupo de O(n), que se diz o grupo ortogonalespecial em dimensao n e nota-se por SO(n):
O(n) ={A ∈Mn(R) : AtA = I
}
SO(n) ={A ∈Mn(R) : AtA = I, e det A = 1
}(7.10.3)
I 7.39 Definicao ... [Transformacoes unitarias] ... Seja (V, 〈 | 〉) um espacounitario de dimensao n, isto e, um espaco vectorial complexo com um produtointerno Hermitiano. Um operador linear A : V → V diz-se uma transformacaounitaria de V, se A preserva o produto interno hermitiano 〈 | 〉, i.e.:
〈A(v)|A(w)〉 = 〈v|w〉 ∀v,w ∈ V (7.10.4)

7.11. Transformacoes unitarias em C2. Os grupos U(2) e SU(2)135
Se A e a matriz de uma tal transformacao unitaria, relativamente a umabase ortonormada de V, entao (7.11.1) escreve-se na seguinte forma matricial:
(Av)t Aw = vt w ∀v,w ∈ V
ou ainda:vtAtAw = vtw = vtIw ∀v,w ∈ V
o que significa que a matriz A e uma matriz unitaria, isto e:
AtA = I (7.10.5)
Dada uma matriz A, define-se a respectiva matriz adjunta A†, como sendoa conjugada transposta de A:
A† = At
(7.10.6)
Portanto A e unitaria sse:AA† = I (7.10.7)
Note ainda que, uma vez que:
det (AA†) = det (AAt) = det A det (A
t) = det A detA = |detA|
concluımos que, se A e unitaria, entao |detA| = 1 e, em particular A e inversıvelcom:
A−1 = A†
Note que agora det A ∈ C.
O conjunto de todas as matrizes unitarias n × n complexas formam umsubgrupo de G`(n; C), que se diz o grupo unitario em dimensao n e nota-se por U(n). O conjunto de todas as matrizes unitarias n × n complexas, dedeterminante 1, formam um subgrupo de U(n), que se diz o grupo unitarioespecial em dimensao n e nota-se por SU(n):
U(n) ={A ∈Mn(C) : A†A = I
}
SU(n) ={A ∈Mn(C) : A†A = I, e det A = 1
}(7.10.8)
7.11 Transformacoes unitarias em C2. Os gru-pos U(2) e SU(2)
I 7.40 Uma aplicacao linear A : C2 → C2 diz-se uma transformacaounitaria de C2, se A preserva o produto interno hermitiano usual de C2, i.e.:
〈A(z)|A(w)〉 = 〈z|w〉 ∀z,w ∈ C2 (7.11.1)

7.12. Exercıcios 136
Se A e a matriz de uma tal transformacao unitaria, relativamente a base canonicade C2, entao (7.11.1) escreve-se na seguinte forma matricial:
(Az)t Aw = ztw ∀z,w ∈ C2
ou ainda:ztAtAw = ztw = ztIw ∀z,w ∈ C2
o que significa que a matriz A e uma matriz unitaria, i.e.:
AtA = I (7.11.2)
Recordemos que, dada uma matriz A, define-se a respectiva matriz adjuntaA†, como sendo a conjugada transposta de A:
A† = At
Portanto A e unitaria sse:AA† = I (7.11.3)
Note ainda que, uma vez que det (AA†) = det (AAt) = det A det (A
t) = det A detA =
|detA|, concluımos que, se A e unitaria, entao |det A| = 1 e, em particular A einversıvel com A−1 = A†.
I 7.41 O subgrupo de U(2) constituıdo por todas as transformacoes unitariasde C2, que tem determinante 1 diz-se o grupo unitario especial e nota-se porSU(2). Este grupo e isomorfo ao grupo das matrizes unitarias de determinante1, tambem notado por SU(2).
Suponhamos que A =(
α βγ δ
)e uma matriz em SU(2), de tal forma que
A−1 = A† e det A = αδ − βγ = 1. Temos entao que:
A−1 =(
δ −β−γ α
)= A† =
(α γ
β δ
)
isto e: δ = α e γ = −β. Portanto SU(2) e o grupo das matrizes que sao daforma:
A =(
α β
−β α
)e detA = |α|2 + |β|2 = 1 (7.11.4)
7.12 Exercıcios
I Exercıcio 7.1 ... Verifique quais das seguintes funcoes sao produtos in-ternos Euclidianos em R2 ou R3 :
a) 〈u,v〉 = x1y1 − x1y2 − x2y1 + 3x2y2, sabendo que u = (x1, x2), e v =(y1, y2).

7.12. Exercıcios 137
b) 〈u,v〉 = x1y1 + x1y2 − 2x2y1 + 3x2y2, sabendo que u = (x1, x2), e v =(y1, y2).
c) 〈u,v〉 = 6x1y1 + 2x2y2, sabendo que u = (x1, x2), e v = (y1, y2).
d) 〈u,v〉 = x1y1 + 3x2y2 + 4x3y3, sabendo que u = (x1, x2, x3), e v =(y1, y2, y3).
e) 〈u,v〉 = x1y1 +3x2y2 +4x3y3−x1y2−y1x2, sabendo que u = (x1, x2, x3),e v = (y1, y2, y3).
I Exercıcio 7.2 ... Calcule em cada caso 〈u,v〉 usando o produto internoEuclidiano usual e o produto interno definido em 7.1-a). Depois, calcule ‖u‖ e‖v‖ recorrendo tambem a cada um desses dois produtos internos.
a) u = (1, 1), v = (−1, 1);
b) u = (1, 0), v = (1, 2);
c) u = (2, 1), v = (4,−1);
I Exercıcio 7.3 ... Calcule em cada caso 〈u,v〉 usando o produto internoeuclidiano usual e o produto interno definido em 7.1-d). Depois, calcule ‖u‖ e‖v‖ recorrendo tambem a cada um destes dois produtos internos.
a) u = (1, 1, 1), v = (−1, 1, 2);
b) u = (1, 0,−1), v = (3,−1, 2);
c) u = (0, 0, 1), v = (−1, 4, 6);
I Exercıcio 7.4 ... Determine todos os valores reais de k para os quais〈u,v〉 e um produto interno Euclidiano em R2 :
〈u,v〉 = x1y1 − 3x1y2 − 3x2y1 + kx2y2
I Exercıcio 7.5 ... Determine todos os valores reais de a, b, c, d para osquais 〈u,v〉 e um produto interno Euclidiano em R2 :
〈u,v〉 = ax1y1 + bx1y2 + cx2y1 + dx2y2
I Exercıcio 7.6 ... Sejam, u = (z1, z2) e v = (w1, w2) elementos de C2.Verifique que a funcao que se segue e um produto interno Hermitiano em C2 :
f(u,v) = z1w1 + (1 + i)z1w2 + (1− i)z2w1 + 3z2w2
Calcule a norma de v = (1 − 2i, 2 + 3i) usando o produto interno Hermitianousual e depois o produto interno definido neste exercıcio.

7.12. Exercıcios 138
I Exercıcio 7.7 ... Em cada caso, determine o cos do angulo θ entre osvectores u e v :
a) u = (1,−3, 2), v = (2, 1, 5) em R3, usando o produto interno euclidianousual e o produto interno definido em 7.1-d).
b) u = 2t−1, v = t2 em R (t), usando o produto interno Euclidiano definidono exercıcio 7.14.
I Exercıcio 7.8 ... No espaco linear R (t) verifique se 〈f, g〉 e um produtointerno.
a) 〈f, g〉 = f(1)g(1)
b) 〈f, g〉 =∣∣∣∫ 1
0f(t)g(t) dt
∣∣∣
c) 〈f, g〉 =∫ 1
0f ′(t)g′(t) dt
d) 〈f, g〉 =(∫ 1
0f(t) dt
)(∫ 1
0g(t) dt
)
I Exercıcio 7.9 ... No espaco vectorial real das funcoes contınuas em(−1, 1), seja 〈f, g〉 =
∫ 1
−1f(t)g(t) dt. Considere as tres funcoes u1, u2, u3 dadas
por:
u1(t) = 1, u2(t) = t, u3(t) = 1 + t.
Mostre que duas delas sao ortogonais, duas fazem um angulo de π3 entre si
e as outras duas fazem um angulo de π6 entre si.
I Exercıcio 7.10 ... Prove cada uma das afirmacoes das alıneas seguintese interprete-as geometricamente no caso do produto interno usual em R2 ou R3.
a) 〈x,y〉 = 0 ⇔ ‖x + y‖2 = ‖x‖2 + ‖y‖2 .
b) 〈x,y〉 = 0 ⇔ ‖x + y‖2 = ‖x− y‖2 .
c) 〈x,y〉 = 0 ⇔ ‖x + cy‖ ≥ ‖x‖ para todo o real c.
d) 〈x + y,x− y〉 = 0 ⇐⇒ ‖x‖ = ‖y‖ .
I Exercıcio 7.11 ... Calcule o angulo que o vector (1, 1, · · · , 1) de Rn fazcom os vectores coordenados unitarios de Rn.
I Exercıcio 7.12 ... Como se sabe, num espaco Euclidiano real com pro-duto interno 〈x,y〉 fica definida ume norma por ‖x‖ = 〈x,x〉 1
2 . De uma formulapara obter o produto interno 〈x,y〉 a partir de normas de vectores apropriados.
I Exercıcio 7.13 ... Seja V um espaco linear real normado e designe-se anorma de x ∈ V por ‖x‖ . Prove que se a norma se pode obter de um produtointerno na forma ‖x‖ = 〈x,y〉 1
2 entao:

7.12. Exercıcios 139
‖x− y‖2 + ‖x + y‖2 = 2 ‖x‖2 + 2 ‖y‖2
Esta identidade e conhecida por lei do paralelogramo. Verifique que corre-sponde a afirmar que para um paralelogramo a soma dos quadrados dos compri-mentos dos lados e igual a soma dos quadrados dos comprimentos das diagonais.
I Exercıcio 7.14 ... Considere o espaco vectorial real R (t) no qual estadefinido o seguinte produto interno: 〈f, g〉 =
∫ 1
0f(t)g(t) dt. Seja f(t) = t + 2 e
g(t) = t2 − 2t− 3. Determine :
a) 〈f, g〉 b) ‖f‖ c) Um vector unitario com a direccao de g.
I Exercıcio 7.15 ... Seja E um espaco vectorial no qual esta definido umproduto escalar. Mostre que :
a) ‖u + v‖2 + ‖u− v‖2 = 2 ‖u‖2 + 2 ‖v‖2 b) 〈u,v〉 = 14 ‖u + v‖2 −
14 ‖u− v‖2
I Exercıcio 7.16 ... Em cada um dos casos, determine uma base ortonor-mada do subespaco de R3 gerado pelos seguintes vectores:
a) x1 = (1, 1, 1), x2 = (1, 0, 1), x3 = (3, 2, 3).
b) x1 = (1, 1, 1), x2 = (−1, 1,−1), x3 = (1, 0, 1).
I Exercıcio 7.17 ... Em cada um dos casos, determine uma base ortonor-mada do subespaco de R4 gerado pelos seguintes vectores:
a) x1 = (1, 1, 0, 0), x2 = (0, 1, 1, 0), x3 = (0, 0, 1, 1), x4 =(1, 0, 0, 1).
b) x1 = (1, 1, 0, 1), x2 = (1, 0, 2, 1), x3 = (1, 2,−2, 1) .
I Exercıcio 7.18 ... No espaco vectorial real R (t), com o produto interno〈x, y〉 =
∫ 1
0x(t)y(t) dt, mostre que as funcoes que se seguem formam uma base
ortonormada do subespaco por elas gerado:
y1(t) = 1, y2(t) =√
3(2t− 1), y3(t) =√
5(6t2 − 6t + 1).
I Exercıcio 7.19 ... Seja S um subespaco de um espaco vectorial V. Mostreque o S⊥ e o conjunto dos vectores ortogonais a todos os vectores de uma basede S.

7.12. Exercıcios 140
I Exercıcio 7.20 ... Seja W o subespaco de R5 gerado pelos vectoresu = (1, 2, 3,−1, 2) e v = (2, 4, 7, 2,−1). Determine uma base do complementoortogonal W⊥ de W .
I Exercıcio 7.21 ...
I Exercıcio 7.22 ... Considere o espaco vectorial real R2 (t) no qual estadefinido o produto interno 〈f, g〉 =
∫ 1
0f(t)g(t) dt.
a) Determine uma base do subespaco W ortogonal a h(t) = 2t + 1.
b) Aplique o metodo de ortogonalizacao de Gram-Schmidt a base (1, t, t2)para obter uma base ortonormada (u1(t), u2(t), u3(t)) de R2 (X) .
I Exercıcio 7.23 ... Seja V o espaco linear das matrizes 2 × 2 de com-ponentes reais, com as operacoes usuais. Prove que fica definido um produtointerno em V por:
〈A,B〉 = a11b11 +a12b12 +a21b21 +a22b22 onde A = (aij) e B = (bij) .
Calcule a matriz da forma(
a b−b a
), com a, b ∈ R, mais proxima da
matriz A =(
1 2−1 3
).
I Exercıcio 7.24 ... Considere o subespaco S de R3 gerado pelos vectores(1, 0, 0) e (0, 1, 0).
a) Verifique que fica definido em R3 um produto interno por:
〈x, y〉 = 2x1y1 + x1y2 + x2y1 + x2y2 + x3y3, onde x = (x1, x2, x3) ey = (y1, y2, y3).
b) Determine uma base ortonormal para o subespaco S, com este produtointerno.
c) Determine o elemento de S mais proximo do ponto (0, 0, 1),usando oproduto interno de a).
d) Calcule um vector diferente de zero e ortogonal a S usando o produtointerno de a).
I Exercıcio 7.25 ... No espaco vectorial real das funcoes contınuas definidasem (0, 2) , com o produto interno 〈f, g〉 =
∫ 2
0f(x)g(x) dx, seja f(x) = exp(x).
Mostre que, o polinomio constante g, mais proximo de f e g = 12 (exp(2) − 1).
Calcule ‖g − f‖2.

7.12. Exercıcios 141
I Exercıcio 7.26 ... Usando os produtos internos usuais em R2 e R3 ,calcule em cada caso a projeccao ortogonal Pu(v), de v sobre a recta gerada pru:
a) u=(1,1), v=(2,3);
b) u=(4,3), v=(0,1);
c) u=(1,1,1) , v=(1,-1,0);
d) u=(1,0,0), v=(0,1,2).
I Exercıcio 7.27 ... Determine as projeccoes ortogonais seguintes:
b) v = 2t− 1, w = t2 sobre R1 (t) usando o produto interno L2.

Modulo 8
ALGA I. Subespacosinvariantes. Subespacosproprios. Valores proprios
Contents8.1 Conjugacao . . . . . . . . . . . . . . . . . . . . . . . 142
8.2 Subespacos invariantes . . . . . . . . . . . . . . . . 145
8.3 Valores e vectores proprios de um operador linear.Operadores diagonalizaveis . . . . . . . . . . . . . . 147
8.4 Calculo de valores e vectores proprios . . . . . . . 148
8.5 Sistemas dinamicos lineares discretos . . . . . . . 151
8.6 Numeros de Fibonacci. Numero de ouro . . . . . 153
8.7 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . 158
8.1 Conjugacao
I 8.1 Mudanca de base ... Suponhamos que V e um espaco vectorial e que:
C =(
e1 e2 · · · en
)
e uma base qualquer, escrita como um vector-linha com entradas vectoriais ei.Se v ∈ V e um vector qualquer em V, designemos por vi as suas componentes
142

8.1. Conjugacao 143
na base C , isto e:
v =∑
i
viei
=(
e1 e2 · · · en
)
v1
v2
...vn
= C [v]C (8.1.1)
Suponhamos agora que mudamos de base:
C −→ C P = C =(
e1 e2 · · · en
)(8.1.2)
que escrevemos na forma matricial seguinte:
(e1 e2 · · · en
)=
(e1 e2 · · · en
)
P 11 P 1
2 · · · P 1n
P 21 P 2
2 · · · P 2n
...... · · · ...
Pn1 Pn
2 · · · Pnn
(8.1.3)ou muito simplesmente:
C = C P
Se vi sao as componentes do mesmo vector v na base C , isto e, se:
v =∑
i
viei
= C [v]C (8.1.4)
entao vem que:C [v]C = v = C [v]C = C P [v]CP
donde se conclui que:
C −→ C P ⇒ [v]CP = P−1[v]C (8.1.5)
I 8.2 Suponhamos agora que L : V → V e um operador linear, cuja matrizrelativamente a base C = {e1, e2, · · · , en}, para V, e:
[L]C = [Lij ] (8.1.6)
Recorde que isto significa que:
L(ej) =∑
j
Lij ei

8.1. Conjugacao 144
Portanto, se v = C [v]C ∈ V, isto e, se o vector das coordenadas de v,relativamente a base C e:
[v]C =
v1
v2
...vn
entao:L(v) = L(vjej) = vjL(ej) = vj(Li
jei) = (Lijv
j)ei
isto e, o vector das coordenadas de L(v), relativamente a base C , e obtidomultiplicando a matriz [L]C pelo vector-coluna [v]C :
[Lv]C = [L]C [v]C (8.1.7)
I 8.3 Conjugacao ... Suponhamos agora que escolhemos uma nova base paraV:
C = C P
Como muda a representacao matricial de L? Isto e, se amatriz de L nesta nova base e Li
j, como e que esta matriz serelaciona com a matriz Li
j?
Para responder a esta questao, consideremos um vector arbitrario v ∈ V.Podemos entao escrever:
v = C [v]C = (C P )[v]CP ⇒ [v]CP = P−1[v]C
Portanto:
• por um lado:L(v) = C [L(v)]C = C [L]C [v]C (8.1.8)
• e, por outro lado:
L(v) = (C P )[L(v)]CP
= (C P )[L]CP [v]CP
= (C P )[L]CP P−1[v]C (8.1.9)
Comparando (8.1.8) com (8.1.9), vem que:
C [L]C [v]C = (C P )[L]CP P−1[v]C ⇒ [L]C [v]C = P [L]CP P−1[v]C
e como esta igualdade e valida ∀v, temos que:
[L]CP = P−1[L]C P (8.1.10)
Concluindo:

8.2. Subespacos invariantes 145
Se L : V → V e um operador linear num espaco vectori-al de dimensao finita, entao a representacao matricial de Lvaria, com a escolha da base, numa classe de conjugacao dematrizes:
C → C P ⇒ [L]CP = P−1[L]C P (8.1.11)
I 8.4 Esta possibilidade de variar a representacao matricial de L, variando abase, conduz-nos naturalmente ao seguinte problema:
Como escolher a base de V de tal forma que a representacaomatricial de L seja o mais “simples” possıvel? Mais formal-mente - se L = [L]C e a representacao matricial de L numacerta base C, como seleccionar na classe de conjugacao de L:
{P−1 LP : P ∈ G`(n)}
o representante mais “simples” possıvel?
I 8.5 Uma solucao intuitiva para este problema consiste, grosso modo, emdecompor o espaco vectorial V em “blocos simples” onde a accao de L sejafacil de descrever. Os conceitos que intervem nesta discussao sao os seguintes:
• subespacos invariantes, em particular, subespacos proprios (e valores propriosassociados)
• decomposicao de V como soma directa de subespacos invariantes
• estrutura da restricao de L a cada subespaco invariante
Vamos de seguida discutir estes conceitos e posteriormente, no capıtulo 8,vamos dar uma solucao do problema anterior para uma classe muito importantede operadores - a classe de operadores hermıticos em espacos unitarios (emparticular, os operadores simetricos em espacos Euclideanos).
8.2 Subespacos invariantes
I 8.6 Definicao ... Seja V um espaco vectorial e L : V → V um operadorlinear. Um subespaco S ⊆ V diz-se um subespaco invariante do operadorL se:
L(S) ⊆ S (8.2.1)
Um subespaco invariante de dimensao um diz-se um subespaco proprio dooperador L.

8.2. Subespacos invariantes 146
I 8.7 Teorema ... Seja V um espaco vectorial e L : V → V um operadorlinear. Entao V, {0}, kerL e imL sao subespacos invariantes do operador L.
Dem.: Basta aplicar directamente as definicoes.
I 8.8 Teorema ... Seja V um espaco vectorial de dimensao finita n, e L : V →V um operador linear.
1. Suponhamos que S e um subespaco invariante de dimensao k ≤ n. Entaoexiste uma representacao matricial de L da forma:
L =(
A B0 D
)(8.2.2)
onde A e uma matriz k × k, B uma matriz k × (n − k) e D uma matriz(n− k)× (n− k).
2. Suponhamos que S e T sao subespacos invariantes de dimensao k e n−k,respectivamente, tais que:
V = S ⊕ TEntao existe uma representacao matricial de L da forma:
L =(
A 00 D
)(8.2.3)
onde A e uma matriz k × k e D uma matriz (n− k)× (n− k).
Dem.: 1. Seja {e1, . . . , ek} uma base para S, e completemos essa base auma base {e1, . . . , ek, ek+1, . . . , en} de V (isto e possıvel, pelo teorema da baseincompleta). E claro que o subespaco T = span{ek+1, . . . , en} nao e, em geral,um subespaco invariante de L, embora V = S⊕T . De qualquer forma, podemossempre por:
L(ei) =∑k
j=1 Aji ej +
∑nβ=k+1 Cβ
i eβ , i = 1, . . . , k
L(eα) =∑k
j=1 Bjα ej +
∑nβ=k+1 Dβ
α eβ , α = k + 1, . . . , n
Mas como, por hipotese, L(S) ⊆ S, temos que Cβi = 0, ∀i, β, e portanto a
representacao matricial de L, na base indicada, e:
L =(
Aji Bj
α
0 Dβα
)
2. Analogo.
¥.

8.3. Valores e vectores proprios de um operador linear. Operadoresdiagonalizaveis 147
8.3 Valores e vectores proprios de um operadorlinear. Operadores diagonalizaveis
I 8.9 Suponhamos que S ⊆ V e um subespaco proprio do operador L, isto e,S e um subespaco invariante de dimensao um. Como dimS = 1, S e geradopor um qualquer dos seus vectores nao nulos. Suponhamos que v ∈ S − {0}.Entao, como dimS = 1, tem-se que:
L(v) = λv (8.3.1)
para algum escalar λ ∈ Ik.
I 8.10 Definicoes ... λ ∈ Ik diz-se um valor proprio de L se existir umvector nao nulo v 6= 0, em V, tal que:
L(v) = λv (8.3.2)
Neste caso, v diz-se um vector proprio pertencente ao valor proprio λ.Ao subespaco gerado por todos os vectores proprios, associados ao valor proprioλ, chama-se o espaco proprio de L, associado ao valor proprio λ e nota-seusualmente por EL(λ), ou simplesmente por E(λ). Portanto:
E(λ) = EL(λ) def= {v ∈ V : L(v) = λv} (8.3.3)
A dimensao dim E(λ) chama-se a multiplicidade geometrica do valor proprioλ. O valor proprio λ diz-se degenerado quando dim E(λ) ≥ 2.
I 8.11 Teorema ... Suponhamos que u,v ∈ V − {0} sao vectores propriospertencentes respectivamente aos valores proprios distintos λ, η ∈ Ik, de umoperador linear L : V → V. Entao u e v sao linearmente independentes.
Dem.: De facto, se por exemplo v = ru, para algum r ∈ Ik − {0}, entaoviria que:
η ru = η v = L(v) = L(ru) = r L(u) = r λu
e portanto:r (λ− η)u = 0
o que implica, uma vez que λ 6= η e r 6= 0, que u = 0, o que e absurdo.
¥
I 8.12 Definicao [Operador diagonalizavel] ... Um operador linear L :V → V diz-se diagonalizavel se qualquer das seguintes condicoes equivalentesse verifica:
• Existe uma base de V, relativamente a qual a matriz de L e uma matrizdiagonal.
• V decompoe-se numa soma directa de subespacos proprios (subespacosinvariantes de dimensao um) de L.

8.4. Calculo de valores e vectores proprios 148
8.4 Calculo de valores e vectores proprios
I 8.13 Suponhamos que λ ∈ Ik e um valor proprio do operador L : V → V eque E(λ) e espaco proprio associado. Como ja vimos, a restricao de L a E(λ) euma homotetia de razao λ (eventualmente λ pode ser 0), isto e:
L(v) = λv ∀v ∈ E(λ)
Em particular, se λ = 0 e valor proprio de L, isto significa que o nucleo deL:
kerL = E(0)
nao se reduz ao vector nulo 0, e portanto L e nao inversıvel (por outras palavras,L e singular), ou de forma equivalente, detL = 0.
Quando λ 6= 0, dizer que λ e valor proprio de L, e equivalente a dizer que 0e valor proprio de L− λ Id, o que, pelo paragrafo anterior, e equivalente a dizerque L− λ Id e singular, ou ainda que:
det (L− λ Id) = 0 (8.4.1)
I 8.14 Definicao ... O polinomio:
p(t) = det (L− t Id) (8.4.2)
diz-se o polinomio caracterıstico de L.
Portanto as raızes em Ik da chamada equacao caracterıstica de L:
p(t) = det (L− t Id) = 0 (8.4.3)
(se existirem), sao exactamente os valores proprios de L em Ik.
I 8.15 Para calcular o polinomio caracterıstico de L, usamos uma repre-sentacao matricial qualquer L do operador L, e pomos p(t) = det (L − t Id).Note que o polinomio caracterıstico nao depende da representacao matricial deL. De facto, qualquer outra representacao matricial de L, e do tipo PLP−1,onde P e uma matriz inversıvel, e tem-se que:
det (PLP−1 − t Id) = det (PLP−1 − tPP−1) = det(P (L− t Id)P−1
)
= det (L− t Id) = p(t)
I 8.16 Exemplo [Calculo de valores proprios] ... Calcule os valores evectores proprios (reais) do operador linear A : R2 → R2, cuja matriz na basecanonica de R2 :
A =(
3 44 −3
)

8.4. Calculo de valores e vectores proprios 149
A equacao caracterıstica de A e:
p(t) = det (A− t Id)
= det(
3− t 44 −3− t
)
= t2 − 25 = 0 (8.4.4)
cujas raızes reais (os valores proprios reais de A) sao λ1 = 5 e λ2 = −5.
Para calcular os vectores poprios x =(
x1
x2
), pertencentes ao valor proprio
λ = 5, devemos resolver o sistema:(
3− 5 44 −3− 5
)(x1
x2
)=
(00
)
isto e: { −2x1 + 4x2 = 04x1 − 8x2 = 0
cuja solucao geral e:{
x1 = 2sx2 = s
s ∈ R
Portanto os vectores poprios de A, pertencentes ao valor proprio λ1 = 5, sao daforma:
s
(21
)s ∈ R− {0}
Por outras palavras, o espaco proprio E(5) e:
E(5) = span{(
21
)}
Procedendo da mesma forma relativamente ao outro valor proprio λ2 = −5,podemos calcular que os vectores poprios de A, pertencentes ao valor proprioλ2 = −5, sao da forma:
s
(1−2
)s ∈ R− {0}
Note que neste exemplo os vectores proprios u1 =(
21
)e u2 =
(1−2
)
formam uma base B = {u1,u2} de R2 relativamente a qual a matriz de A ediagonal:
[A]B =(
5 00 −5
)
portanto A e um operador diagonalizavel.

8.4. Calculo de valores e vectores proprios 150
I 8.17 Exemplo [Calculo de valores proprios] ... Calcule os valores evectores proprios (reais) do operador linear A : R3 → R3, cuja matriz na basecanonica de R3 e:
A =
1 0 0−5 2 02 3 7
A equacao caracterıstica de A e:
p(t) = det (A− t Id)
= det
1− t 0 0−5 2− t 02 3 7− t
= (1−)(2− t)(7− t) = 0 (8.4.5)
cujas raızes reais (os valores proprios reais de A) sao λ1 = 1, λ2 = 2 e λ3 = 7.
Para calcular os vectores poprios x =
x1
x2
x3
, pertencentes ao valor proprio
λ2 = 2, devemos resolver o sistema:
1− 2 0 0−5 2− 2 02 3 7− 2
x1
x2
x3
=
000
isto e: −x1 = 0−5x1 = 02x1 + 3x2 + 5x3 = 0
cuja solucao geral e:
x1 = 0x2 = − 5
3sx3 = s
s ∈ R
Portanto os vectores poprios de A, pertencentes ao valor proprio λ2 = 2, sao daforma:
s
0− 5
31
s ∈ R− {0}
Procedendo da mesma forma relativamente aos outros valores proprios a1 = 1e a3 = 7, podemos calcular os correspondentes vectores poprios.
Notas ...

8.5. Sistemas dinamicos lineares discretos 151
1. Note que o polinomio caracterıstico p(t) = det (L− t Id), de um operadorlinear L : R3 → R3, e sempre um polinomio do 3.o grau, do tipo:
p(t) = −t3 + bt2 + ct + d b, c, d ∈ Re por isso admite sempre uma raiz real λ ∈ R (eventualmente nula). Seλ 6= 0, concluımos portanto que, neste caso, existe sempre um subespacoproprio invariante E(λ) ⊆ R3, de dimensao superior ou igual a 1.
2. Todo o operador linear L : R3 → R3 tem quando muito 3 valores propriosdistintos. Se L tem exactamente 3 valores proprios distintos, entao oscorrespondentes vectores proprios formam uma base de R3, e a matriz deL nessa base, e uma matriz diagonal cujas entradas da diagonal principal,sao esses valores proprios.
8.5 Sistemas dinamicos lineares discretos
I 8.18 Um sistema dinamico linear discreto e um sistema recursivo dotipo:
x(k + 1) = Ax(k) (8.5.1)
onde A e uma matriz n× n, e
x : INo → Rn
e uma funcao que a cada ”instante de tempo” discreto k = 0, 1, 2, ..., associaum vector (ou um ponto) x(k) em Rn.
A equacao (8.5.1) indica pois a lei de evolucao do sistema: conhecido o valorinicial do sistema:
x(0) = xo (8.5.2)
os valores nos instantes seguintes sao calculados sucessivamente atraves de:
x(1) = Axo
x(2) = Ax(1) = A2xo
x(3) = Ax(2) = A3xo
...x(k) = Ax(k − 1) = Akxo
... (8.5.3)
I 8.19 Quando a matriz A de evolucao e diagonalizavel, o calculo explıcitoda evolucao atraves da equacao (8.5.3):
x(k) = Akx(0) (8.5.4)

8.5. Sistemas dinamicos lineares discretos 152
torna-se particularmente simples.
De facto, suponhamos que B = [v1 v2 · · · vn] e uma base de Rn con-stituıda por vectores proprios (nao necessariamente distintos) da matriz A:
Avj = λjvj , j = 1, 2, ..., n (8.5.5)
Se C = [e1 e2 · · · en] e a base canonica de Rn, pomos, como habitualmente:
B = C P ⇒ xB = xCP = P−1xC (8.5.6)
Portanto, pondo xC (k) = x(k) em (8.5.4), vem que:
xB(k) = P−1xC (k)= P−1AkxC (0)= P−1AkP xB(0)= (P−1AP )k xB(0)= (diag(λ1, λ2, ..., λn))kxB(0)= diag(λk
1 , λk2 , ..., λk
n)xB(0) (8.5.7)
Isto e, a i-componente de x(k) na base B, que diagonaliza A, e obtida muitosimplesmente multiplicando a potencia de expoente k, do valor proprio λi, pelai -componente do vector inicial x(0) na base B:
xiB(k) = (λi)kxi
B(0) (8.5.8)
Note que no membro direito da equacao anterior nao ha soma no ındice i!
Na pratica procedemos como segue:
[1]. Escrevemos o vector inicial x(0) na base B, calculando assim as compo-nentes ci = xi
B(0):
x(0) = BxB(0) =∑
i
civi
[2]. Pomos:
x(k) = CxC (k) = BxB(k) =∑
i
(ciλki )vi
Concluindo :
x(k) =∑
i
(ciλki )vi, onde x(0) =
∑
i
civi (8.5.9)

8.6. Numeros de Fibonacci. Numero de ouro 153
8.6 Numeros de Fibonacci. Numero de ouro
I 8.20 Numeros de Fibonacci ... sao definidos pela lei recursiva (de se-gunda ordem) seguinte:
x(k + 2) = x(k + 1) + x(k) (8.6.1)
isto e, cada numero de Fibonacci e obtido somando os dois anteriores. Ascondicoes iniciais sao:
x(0) = a, x(1) = b (8.6.2)
Por exemplo, para:
x(0) = a = 0, x(1) = b = 1 (8.6.3)
obtem-se:0 1 1 2 3 5 8 13 21 34 · · · (8.6.4)
Foram criados pelo matematico italiano Fibonacci como um modelo simplificadodo crescimento de uma populacao de coelhos. Neste modelo:
x(n) = numero total de pares de coelhos no ano n (8.6.5)
O processo inicia-se no ano n = 0 com um unico par de coelhos jovens. Ao fimde cada ano, cada par da origem a um novo par de descendentes. No entanto,cada par necessita de um ano para procriar o seu par de descendentes.
I 8.21 Numeros de Fibonacci. Escrita matricial ... Definamos, para cadak ∈ IN, um vector x(k) ∈ R2 atraves de:
x(k) =(
x(k)x(k + 1)
)∈ R2 (8.6.6)

8.6. Numeros de Fibonacci. Numero de ouro 154
Entao (8.6.1) pode ser escrita na forma matricial:(
x(k + 1)x(k + 2)
)=
(0 11 1
)(x(k)
x(k + 1)
)(8.6.7)
isto e:
x(k + 1) = Ax(k), onde A =(
0 11 1
)(8.6.8)
I 8.22 Calculo explıcito dos numeros de Fibonacci ... Para calcular aforma explıcita dos numeros de Fibonacci, usamos o metodo descrito no numero8.19.
Para isso, determinamos os valores e vectores proprios da matriz A =(0 11 1
). Um calculo simples mostra que eles sao:
λ1 =1 +
√5
2= 1.618034..., v1 =
( −1+√
521
)
λ2 =1−√5
2= −0.618034..., v2 =
( −1−√521
)(8.6.9)
Escrevemos agora o vector inicial na base B:
xB(0) = P−1xC (0)
=( −1+
√5
2−1−√5
21 1
)−1 (ab
)
=
2a+(1+√
5)b
2√
5
− 2a+(1−√5)b
2√
5
B
(8.6.10)
isto e:
x(0) =2a + (1 +
√5)b
2√
5v1 − 2a + (1−√5)b
2√
5v2 (8.6.11)
Usando a formula (8.5.9) vem entao que:
x(k) =2a + (1 +
√5)b
2√
5λk
1v1 − 2a + (1−√5)b2√
5λk
2v2
=2a + (1 +
√5)b
2√
5
(1 +
√5
2
)k ( −1+√
521
)−
2a + (1−√5)b2√
5
(1−√5
2
)k ( −1−√521
)

8.6. Numeros de Fibonacci. Numero de ouro 155
donde se deduz que:
x(k) =(−1 +
√5)a + 2b
2√
5
(1 +
√5
2
)k
+(1 +
√5)a− 2b
2√
5
(1−√5
2
)k
(8.6.12)
I 8.23 Formula de Binet ... Para os valores iniciais a = 0 e b = 1, obtemosa chamada formula de Binet:
x(k) =1√5
(1 +
√5
2
)k
−(
1−√52
)k (8.6.13)
I 8.24 Numero de ouro ... Os valores proprios da matriz A, verificam asdesigualdades seguintes:
0 < |λ2| =√
5− 12
< 1 < λ1 =1 +
√5
2(8.6.14)
Portanto os termos que envolvem λk1 divergem para ∞, enquanto que os que
envolvem λk2 convergem para 0.
O valor proprio dominante λ1 = 1+√
52 = 1.618034... e o chamado numero
de ouro (ou razao de ouro). Desempenha um papel muito importante emcrescimento em espiral em varios fenomenos naturais bem como em certascriacoes artısticas em arquitectura e pintura.
I 8.25 Exercıcio ... Considere a aplicacao linear:
T : R3 −→ R3
(x, y, z) 7−→ T(x, y, z) = (4z, x + 2y + z, 2x + 4y − 2z)
a.) Calcular a matriz de T relativamente a base canonica de R3. Calcularo nucleo e a imagem de T.
b.) Calcular os valores proprios de T e, se possıvel, uma base de R3 con-stituıda por vectores proprios de T. Calcule a matriz de T relativamente a estanova base.
c.) Usando os resultados das alıneas anteriores, calcule T3(0, 0,−4), ondeT3 = T ◦T ◦T.
Resolucao ...
a.) A matriz e T =
0 0 41 2 12 4 −2
. kerT = {(x, y, z) ∈ R3 : T(x, y, z) =

8.6. Numeros de Fibonacci. Numero de ouro 156
(4z, x + 2y + z, 2x + 4y − 2z) = (0, 0, 0)} o que implica que:
4z = 0x + 2y + z = 0
2x + 4y − 2z = 0⇒
z = 0x + 2y = 0
2x + 4y = 0⇒
{z = 0
x + 2y = 0 ⇒
x = −2ty = tz = 0
t ∈ R
isto e kerT = {t(−2, 1, 0) : t ∈ R3} = span{(−2, 1, 0)} que e a recta de R3
gerada por (−2, 1, 0) e de equacoes cartesianas x + 2y = 0 e z = 0.
A imagem de T e gerada por T(e1) = (0, 1, 2),T(e2) = (0, 2, 4) e T(e3) =(4, 1,−2), isto e:
imT = span{(0, 1, 2), (0, 2, 4), (4, 1,−2)}= {(x, y, z) ∈ R3 : (x, y, z) = a(0, 1, 2) + b(0, 2, 4) + c(4, 1,−2), a, b, c ∈ R}
Portanto:
4c = xa + 2b + c = y
2a + 4b− 2c = z⇒ ........ ⇒
a + 2b + c = y4c = 2y − z0 = x− 2y + z
isto e, imT e o plano x− 2y + z = 0 em R3.
E(T;−4) = span{(1, 0,−1)}E(T; 0) = span{(−2, 1, 0)}
E(T;−4) = span{(1, 1, 1)}
e os vectores {e1 = (1, 0,−1), e2 = (−2, 1, 0), e3 = (1, 1, 1)} constituem umabase de vectores proprios de T que e, por isso, diagonalizavel. Nesta base amatriz de T e diag(−4, 0, 4).
c.) Calculando as componentes do vector (0, 0,−4) na base de vectoresproprios de T, calculada anteriormente, vem que:
(0, 0,−4) = a(1, 0,−1) + b(−2, 1, 0) + c(1, 1, 1) = (a− 2b + c, b + c,−a + c)
donde se deduz que a = −1, b = 1, c = −1. Portanto:
T3(0, 0,−4) = −T3(1, 0,−1) + T3(−2, 1, 0)−T3(1, 1, 1)= −(−4)3(1, 0,−1) + 03(−2, 1, 0)− 43(1, 1, 1)= (0,−64,−128)

8.6. Numeros de Fibonacci. Numero de ouro 157
I 8.26 Exercıcio ... Considere a aplicacao linear A : R2 → R2 definida por:
A(x, y) = (6x− 2y,−2x + 9y)
a.) Mostrar que A e diagonalizavel e calcular uma base ortonormada paraR2 (com a estrutura Euclideana usual) constituıda por vectores proprios de A.
b.) Considere as sucessoes (xn) e (yn), definidas pelas formulas de recorrenciaseguintes:
{xn+1 = 6xn − 2yn
yn+1 = −2xn + 9yn, n ≥ 0 e
{x0 = 1y0 = 1
Calcule xn e yn como funcoes de n.
Resolucao ...
a.) A matriz de A relativamente a base canonica de R3 e a matriz simetrica:
A =(
6 −2−2 9
)
Os valores proprios calculam-se por:
det (A− λId) = det(
6− λ −2−2 9− λ
)= (6− λ)(9− λ)− 4 = 0 ⇒
Como existem dois (= dimR2) valores proprios distintos, A e diagonalizavel.Os espacos proprios calculam-se da forma habitual e sao:
E (5) = R(
21
)e E (10) = R
(1
−2
)
Estes espacos sao ortogonais (tinham que o ser, pelo teorema espectral!). Umbase ortonormada para R2 constituıda por vectores proprios de A e:
B ={u1 =
(2, 1)√5
, u2 =(1,−2)√
5
}
a.) Pondo xn =(
xn
yn
), as formulas de recorrencia dadas escrevem-se na
forma vectorial:xn+1 = Axn, x0 = (1, 1)

8.7. Exercıcios 158
onde A =(
6 −2−2 9
). Os calculos devem ser feitos na base B que diagonaliza
o operador A. Escrevendo o vector xn na base B, vem que:
xn = (xn · u1)u1 + (xn · u2)u2
=1√5
(2xn + yn)u1 +1√5
(xn − 2yn)u2 (8.6.15)
isto e, as componentes de xn na base B sao xn = 2xn+yn√5
, yn = xn−2yn√5
.
Na base B as formulas de recorrencia escrevem-se na forma:(
xn+1
yn+1
)=
(5 00 10
)(xn
yn
)=
(5xn
10yn
)
Portanto:(
x1
y1
)=
(5x0
10y0
),
(x2
y2
)=
(5x1
10y1
)=
(52x0
102y0
)
· · ·(
xn
yn
)=
(5nx0
10ny0
)
Mas x0 = 2x0+y0√5
= 3√5, y0 = x0−2y0√
5= −1√
5. Portanto:
{xn = 2xn+yn√
5= 5n 3√
5
yn = xn−2yn√5
= 10n−1√5
e resolvendo em ordem a xn e yn obtemos:
xn = 2× 5n−1(3− 2n−1), yn = 5n−1(3 + 4× 2n−1)
8.7 Exercıcios
I Exercıcio 8.1 ... Seja f um endomorfismo de R2 (X) tal que X + X2 eum vector proprio associado ao valor proprio 2, −1 + X e um vector proprioassociado ao valor propprio 5 e X2 e um vector proprio associado ao valorproprio -3. Determine f(a0 + a1X + a2X
2).
I Exercıcio 8.2 ... Seja f um endomorfismo de C2 (X) munido da estru-tura usual de espaco vectorial complexo. Suponha que :
1 + iX e um vector proprio de valor proprio i,
1−X e um vector proprio de valor proprio 1 e
X2 e um vector proprio de valor proprio −1.
Calcule f(a + bX + cX2).

8.7. Exercıcios 159
I Exercıcio 8.3 ... Seja f um automorfismo de um espaco vectorial E.Qual a relacao entre os valores proprios de f e os valores proprios de f−1?
I Exercıcio 8.4 ... Sejam f e g endomorfismos de E.
a) Mostre que, se u e um vector proprio de f , com valor proprio as-sociado λ entao u e um vector proprio de f ◦ f com valor proprio associadoλ2.
b) Mostre que, se u e um vector proprio de f e de g, entao u e umvector proprio de g ◦ f e de qualquer combinacao linear de f e de g, af + bg.
c) Mostre que, se todos os elementos nao nulos de E sao vectoresproprios de f , entao f tem um unico valor proprio (e, portanto, existe α ∈ Rtal que, para qualquer u ∈ E, f(u) = αu).
I Exercıcio 8.5 ... Seja f : R3 −→ R3 um endomorfismo tal que:{(x, y, z) ∈ R3 : x = y = z
}e
{(x, y, z) ∈ R3 : x− y + z = 0
}
sao subespacos proprios associados respectivamente aos valores proprios 1 e 2.Determine f((x, y, z)).
I Exercıcio 8.6 ... Em cada um dos seguintes casos, determine, se exis-tirem, os valores proprios de f , os subespacos proprios associados e as respec-tivas dimensoes e diga se f e diagonalizavel; no caso de f ser diagonalizavel,indique uma base do domınio de f composta por vectores proprios de f e indiquea matriz de f relativamente a essa base.
a) f : R2 −→ R2, f(x, y) = (2x− y, y); b) f : R2 −→ R2, f(x, y) =(−x,−y);
c) f : R2 −→ R2, f(x, y) = (3x + y, 12x + 2y);
d) f : R3 −→ R3, f(x, y, z) = (3x + y + z, 3y + z, 3z);
e) f : R3 −→ R3, f(x, y, z) = (3x + y + z, 3y, 3z);
f) f : R2 (X) −→ R2 (X) , f(P ) = P (0) + XP (1) + X2P (−1);
g) f : R3 (X) −→ R3 (X), f(P ) = P + (X + 1)P ′;h) f : M2,2(R) −→ M2,2(R),
f
(a bc d
)=
(3a + 2b + c + d 2a + 3b + c− d
2c −c
).
i) f : C2 → C2, f(u, v) = (iu, u + v);
I Exercıcio 8.7 ... Calcular formulas explıcitas para as solucoes das seguintesformulas recursivas:

8.7. Exercıcios 160
a).{
x(k + 1) = x(k)− 2y(k)y(k + 1) = −2x(k) + y(k) ,
{x(0) = 1y(0) = 0
b).
x(k + 1) = 12x(k) + y(k)
y(k + 1) = y(k)− 2z(k)z(k + 1) = 1
3z(k),
x(0) = 1y(0) = −1z(0) = 1
c). x(k + 2) = −x(k + 1) + 2x(k), x(0) = 1, x(1) = 2
d). x(k+3) = 2x(k+2)+x(k+1)−2x(k), x(0) = 0, x(1) = 2, x(2) = 3
I Exercıcio 8.8 ... Classifique as seguintes isometrias em R2 :
a) f(x, y) = ( 12x +
√3
2 y,√
32 x− 1
2y).
b) f(x, y) = ( 12x +
√3
2 y,−√
32 x + 1
2y).
c) f(x, y) = (− 45x + 3
5y,− 35x− 4
5y).
d) f(x, y) = (x, y).
e) f(x, y) = (−y, x).
I Exercıcio 8.9 ... Em cada um dos casos que se seguem, determine Sr(x, y),
bcMbc(Sr) e uma base b de R2 tal que bMb(Sr) =(
1 00 −1
).
a) r e a recta de equacao y = 2x;
b) r e a recta de equacao 3x− y = 0;
c) r e a recta de equacao y = (tg π5 )x;
I Exercıcio 8.10 ... Em cada um dos seguintes casos, mostre que o endo-morfismo f de R2 ou R3 e uma isometria linear e descreva f geometricamente(isto e, diga se f e uma simetria ou uma rotacao; no caso de ser uma simetria,diga relativamente a que recta, no caso de ser uma rotacao determine o angulo).
a) f(x, y) = (y, x);
b) f(x, y) = (y,−x);
c) f(x, y) = (√
2x−√2y2 ,
√2x+
√2y
2 );
d) f(x, y) = ((− cos π8 )x + (sin π
8 )y, (sin π8 )x + (cos π
8 )y);
I Exercıcio 8.11 ... Dado:
a) a = (1, 4,−3), calcule Pa(x) sendo x = (x, y, z) ∈ R3. Calcule kerPa.Defina Sa(x).
b) a = (0, 1, 2), calcule Pa(x) sendo x = (x, y, z) ∈ R3. Calcule kerPa.Defina Sa(x).

8.7. Exercıcios 161
c) a = (1, 1, 1), calcule Pa(x) sendo x = (x, y, z) ∈ R3. Calcule kerPa.Defina Sa(x).
d) a = (1, 1), calcule Pa(x) sendo x = (x, y) ∈ R2. Calcule kerPa. DefinaSa(x).
e) a = (1, 0), calcule Pa(x) sendo x = (x, y) ∈ R2. Calcule kerPa. DefinaSa(x).
I Exercıcio 8.12 ... Defina a simetria relativamente a recta 2x− y = 0 emR2.
I Exercıcio 8.13 ... Em cada uma das alıneas que se seguem, calcule Pπ(x)e kerPπ, em R3 sendo π cada um dos planos que se seguem. Calcule tambemem cada caso, os valores proprios e os vectores proprios de Pπ. Finalmente,defina Defina Sπ(x).
a) 2x− y + 3z = 0;
b) x + y + z = 0;
c) 3x + y + 2z = 0.
I Exercıcio 8.14 ... As matrizes que se seguem, representam rotacoes emR3 relativamente a base canonica. Mostre que sao matrizes ortogonais de de-terminante igual a 1. Calcule o eixo e o angulo de rotacao:
a) A =
0 1 0√2
2 0√
22√
22 0 −
√2
2
; b) A =
0√
22
√2
21 0 00
√2
2 −√
22
; c) A =
0 1 00 0 11 0 0
.

Modulo 9
ALGA I. Operadoresauto-adjuntos (simetricos ehermitianos). Teoremaespectral
Contents9.1 Operadores auto-adjuntos (simetricos e hermitianos)162
9.2 Teorema espectralpara operadores auto-adjuntos . . . . . . . . . 165
9.3 Diagonalizacao de formas quadraticas reais . . . . 167
9.4 Propriedades extremais dos valores proprios . . . 171
9.5 Operadores comutativos . . . . . . . . . . . . . . . 173
9.6 Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . 173
9.1 Operadores auto-adjuntos (simetricos e her-mitianos)
I 9.1 Como ja vimos numa seccao anterior, se L : V → V e um operador linearnum espaco vectorial de dimensao finita, entao a representacao matricial de Lvaria com a escolha da base numa classe de conjugacao de matrizes:
C → C P ⇒ [L]C → [L]CP = P−1 [L]C P (9.1.1)
Esta possibilidade de variar a representacao matricial de L, variando a base,conduz-nos naturalmente ao seguinte problema:
162

9.1. Operadores auto-adjuntos (simetricos e hermitianos) 163
Como escolher a base de V de tal forma que a representacaomatricial de L seja o mais “simples” possıvel? Mais formal-mente - se [L]C e a representacao matricial de L numa certabase C , como seleccionar na classe de conjugacao de L:
{[L]CP = P−1 [L]C P : P ∈ G`(n)}
o representante mais “simples” possıvel ?
I 9.2 Suponhamos agora que V e um espaco vectorial com um produto interno〈 | 〉 (como sempre, Euclideano se V e real, ou Hermitiano, se V for complexo). Eclaro que nestes espacos, a classe de todas as bases ortonormadas desempenhaum papel central.
I 9.3 Suponhamos que C e C = C P sao duas bases ortonormadas em V.Entao a matriz P e:
• uma matriz ortogonal, P ∈ O(n), se V e Euclideano.
• uma matriz unitaria, P ∈ U(n), se V e Hermitiano.
De facto, se C = {ei} e C = {ej}, com 〈ei|ej〉 = δij e analogamente〈e`|ek〉 = δ`k, entao, como:
ei = e` P `i
vem que (supondo que V e Hermitiano):
δij = 〈ei|ej〉= 〈e` P `
i |ek P kj 〉
= P `i P k
j 〈e`|ek〉= P `
i P kj δ`k
=∑
k
P ki P k
j
= (P t)ikP k
j ⇒ P tP = Id (9.1.2)
o que mostra que P e unitaria: P †P = Id. No caso Euclideano, a demonstracaoe analoga e, neste caso, P e ortogonal: P tP = Id.
I 9.4 Portanto, quando V e um espaco vectorial com um produto interno, apergunta anterior deve ser reformulada da seguinte forma:

9.1. Operadores auto-adjuntos (simetricos e hermitianos) 164
Como escolher a base ortonormada de V de tal forma que arepresentacao matricial de L seja o mais “simples” possıvel?Mais formalmente - se [L]C e a representacao matricial de Lnuma certa base ortonormada C , como seleccionar na classede conjugacao de [L]C :
{[L]CP = P−1 [L]C P : P ∈ U(n)}
o representante mais “simples” possıvel? (no caso Eu-clideano, U(n) sera substituıdo por O(n), e claro!)
I 9.5 Definicao ... Seja (V, 〈 | 〉) um espaco com um produto interno (Eu-clideano se V e real, ou Hermitiano, se V for complexo). Um operador linearS : V → V, diz-se auto-adjunto se S satisfaz a condicao:
〈S(v)|w〉 = 〈v|S(w)〉 ∀v,w ∈ V (9.1.3)
No caso Euclideano S diz-se um operador simetrico, enquanto que no casoHermitiano, S diz-se um operador Hermitiano.
I 9.6 Teorema ... A matriz S = [Sij ] de um operador auto-adjunto S : V → V,
num espaco com um produto interno (V, 〈 | 〉), relativamente a uma baseortonormada B = {e1, e2, · · · , en} de V, e:
• uma matriz simetrica, S = St, no caso Euclideano.
• uma matriz Hermitiana, S = S†, no caso Hermitiano1.
Dem.: De facto (no caso Hermitiano), se S(ej) = Skj ek, entao:
〈ei|S(ej)〉 = 〈ei|Skj ek〉 = Sk
j 〈ei|ek〉 = Skj δik = Si
j
enquanto que, por outro lado, atendendo a (9.1.3):
〈ei|S(ej)〉 = 〈S(ei)|ej〉 = Ski 〈ek|ej〉 = Sk
i δkj = Sji = (St)i
j
Portanto St = S, ou ainda S† = S. O caso Euclideano e analogo.
¥
1Se U(ε) e uma curva de matrizes unitarias, tais que:
U(0) = Id, e U ′(0) = iH
entao:
U(ε)tU(ε) = Id ⇒ U ′(0)t + U ′(0) = 0 ⇒ iHt − iH = 0 ⇒ Ht = H
isto e, H e Hermitiana

9.2. Teorema espectralpara operadores auto-adjuntos 165
I 9.7 Teorema ... Seja S : V → V, um operador auto-adjunto num espacocom um produto interno (V, 〈 | 〉). Entao:
• Se S tem um valor proprio, esse valor proprio e real.
• Suponhamos que v e w sao vectores proprios, pertencentes respectivamenteaos valores proprios distintos λ e η, de S. Entao v e w sao ortogonais:〈v|w〉 = 0.
Dem.:
1. Seja v ∈ V − {0}, um vector proprio pertencente ao valor proprio λ:
S(v) = λv (9.1.4)
Usando o produto interno 〈 | 〉, podemos exprimir o valor proprio λ, na forma:
λ =〈Sv|v〉‖v‖2 (9.1.5)
onde v e um vector proprio pertencente ao valor proprio λ. De facto:
S(v) = λv ⇒ 〈Sv|v〉 = 〈λv|v〉 = λ ‖v‖2
o que implica (9.1.5), ja que v 6= 0. Portanto se S e auto-adjunto temos que:
λ =〈S(v)|v〉‖v‖2 =
〈v|S(v)〉‖v‖2 = λ
isto e λ ∈ R.
2. Por hipotese, S(v) = λv e S(w) = ηw. Por 1. sabemos ja que λ, η ∈ R.Temos entao sucessivamente que (no caso Hermitiano):
λ 〈v|w〉 = 〈λv|w〉 = 〈Sv|w〉 = 〈v|Sw〉 = 〈v|η w〉 = η 〈v|w〉 = η 〈v|w〉o que implica que (λ − η) 〈v|w〉 = 0, e portanto 〈v|w〉 = 0, ja que λ 6= η. Ocaso Euclideano e analogo.
¥
9.2 Teorema espectralpara operadores auto-adjuntos
I 9.8 Notemos que um operador linear real pode nao ter valores proprios reais(por exemplo, uma rotacao em R2). No entanto, e possıvel provar que todo ooperador auto-adjunto tem pelo menos um valor proprio que, pela proposicaoanterior, e real.

9.2. Teorema espectralpara operadores auto-adjuntos 166
O facto de maior interesse sobre operadores auto-adjuntos em espacos comproduto interno de dimensao finita, e que eles podem ser diagonalizados porconjugacao pelo grupo ortogonal O(n) (no caso Euclideano, isto e, quando Se operador simetrico) ou pelo grupo unitario U(n) (no caso Hermitiano, istoe, quando S e operador Hermitiano). Mais precisamente, e valido o seguinteteorema fundamental.
I 9.9 Teorema ... [Teorema espectral para operadores auto-adjuntosem espacos com produto interno de dimensao finita] ...
Seja S : V → V, um operador auto-adjunto num espaco com produto interno(V, 〈 | 〉), de dimensao finita n.
Entao existe uma base ortonormada {u1,u2, · · · ,un}, para V, cons-tituıda por vectores proprios de S.
A matriz de S nessa base e portanto a matriz diagonal diag(λ1, λ2, · · · , λn),onde λk e o valor proprio correspondente ao vector proprio uk, para (k =1, · · · , n).
Dem.: A demonstracao far-se-a por inducao sobre a dimensao n. Se n = 1,o resultado e trivial. Suponhamos que ele e valido, para todo o espaco vectorialcom produto interno, com dim ≤ n− 1.
Como se referiu acima, S admite sempre um valor proprio (real) λ1. Sejau1 6= 0 um vector proprio pertencente ao valor proprio λ1: S(u1) = λ1 u1.Podemos supor que ‖u1‖ = 1. Seja S o subespaco ortogonal a u1, de tal formaque:
V = Ru1 ⊕ S (9.2.1)
Entao S deixa S invariante: S(S) ⊆ S (porque?). Alem disso, S e um espacovectorial com um produto interno, de dimensao n − 1, e S|S e auto-adjunto.Resta aplicar a hipotese de inducao para concluir a prova.
¥
I 9.10 Exemplo ... Seja S o operador simetrico em R3, cuja matriz na basecanonica de R3 e (a matriz simetrica):
S =
1 0 00 1 20 2 1
A equacao caracterıstica e:
p(t) = det (S − t Id) =
1− t 0 00 1− t 20 2 1− t
= 0

9.3. Diagonalizacao de formas quadraticas reais 167
isto e:(1− t)[(1− t)2 − 4] = 0
Os valores proprios de S, sao portanto t = 1,−1, 3. Calculemos uma baseortonormada de vectores proprios. Para isso substituımos sucessivamente t por1,−1 e 3, na equacao matricial seguinte:
1− t 0 00 1− t 20 2 1− t
x1
x2
x3
=
000
Resolvendo os correspondentes sistemas de equacoes, e tendo o cuidado de nor-malizar os vectores proprios para que eles tenham norma 1, obtemos a baseseguinte:
u1 =
100
pertencente ao valor proprio λ = 1
u2 =1√2
01−1
pertencente ao valor proprio λ = −1
u3 =1√2
011
pertencente ao valor proprio λ = 3
Designando por C = [i k] a base canonica de R3 e por B = [u1 u2 u3],a base constituıda pelos vectores proprios de S, atras calculados, e pondo:
B = C P
vemos que a matriz P (que e ortogonal - (P−1 = P tr - como vimos), e dadapor:
P =
1 0 00 1√
21√2
0 − 1√2
1√2
Podemos verificar directamente que:
P tSP =
1 0 00 −1 00 0 3
9.3 Diagonalizacao de formas quadraticas reais
I 9.11 Suponhamos agora que V e um espaco vectorial real de dimensao n,com um produto interno Euclideano 〈 | 〉, e que:
β : V × V −→ R (9.3.1)

9.3. Diagonalizacao de formas quadraticas reais 168
e uma forma bilinear simetrica em V. A forma quadratica associada a β e,por definicao, a funcao Q = Qβ : V → R dada por:
Q(v) = β(v,v), v ∈ V (9.3.2)
I 9.12 Seja C = {e1, · · · , en} uma base para V. Por definicao, a matriz deGram de β na base C , e a matriz simetrica [β]C = [βij ], dada por:
βijdef= β(ei, ej), i, j = 1, . . . , n (9.3.3)
Se v = xiei, entao:
Q(v) = Q(xiei)def= Q(x1, · · · , xn)= β(xiei, x
jej)
=∑
ij
βij xixj
= [v]tC [β]C [v]C , em notacao matricial (9.3.4)
I 9.13 Se mudarmos a base C , para uma nova base C P :
C −→ C P
sabemos ja que as coordenadas de um vector v mudam de acordo com a formula:
C −→ C P =⇒ [v]CP = P−1[v]C
Qual e a matriz de Gram de β na base C P?
Por um lado:
Q(v) = [v]tC [β]C [v]C= (P [v]CP )t [β]C P [v]CP
= [v]tCP P t[β]C P [v]CP (9.3.5)
e, por outro lado:Q(v) = [v]tCP [β]CP [v]CP
Comparando as duas expressoes, concluımos que:
C −→ C P =⇒ [β]CP = P t[β]C P (9.3.6)
I 9.14 A forma bilinear simetrica β, podemos associar um operador simetricoS = Sβ : V → V, tal que:
β(u,v) = 〈S(u)|v〉, ∀u,v ∈ V (9.3.7)

9.3. Diagonalizacao de formas quadraticas reais 169
De facto, se u ∈ V, a formula (9.3.7) define S(u) como sendo o unico vectorde V tal que 〈S(u)|v〉 = β(u,v), ∀v ∈ V. Nao ha ambiguidade nesta definicaouma vez que o produto interno 〈 | 〉 e nao degenerado. Alem disso:
〈S(u)|v〉 = β(u,v) = β(v,u) = 〈S(v)|u〉 = 〈u|S(v)〉e portanto S e um operador simetrico.
E facil ver que a matriz de S, relativamente a base C , e a matriz de Gram[β]C . Pelo teorema espectral da seccao anterior, podemos encontrar uma baseortonormada B = C P = {u1, · · · ,un}, de V, constituıda por vectores propriosde S, e relativamente a qual a matriz de S e a matriz diagonal:
[β]CP = D = diag[λ1 λ2 · · · λn]
onde λk e o valor proprio correspondente ao vector proprio uk, para (k =1, . . . , n).
I 9.15 Atendendo a (9.3.6), vemos que:
Q(v) = [v]tCP [β]CP [v]CP
= [v]tCP diag[λ1 λ2 · · · λn][v]CP (9.3.8)
Pondo v = xiei = yjuj , isto e:
[v]C = [xi], [v]CP = [yj ]
concluımos que:
Q(v) = Q(xiei)def= Q(x1, . . . , xn)= [v]tC [β]C [v]C= Q(yjuj)def= Q(y1, . . . , yn)= [v]tCP [β]CP [v]CP
= [v]tCP diag[λ1 λ2 · · · λn][v]CP
=∑
i
λi(yi)2 (9.3.9)
Portanto, a forma quadratica associada a β, que nas x-coordenadas (relati-vamente a base C ) foi escrita na forma (ver (9.3.4)):
Q(x1, . . . , xn) =∑
ij
bij xixj
escreve-se agora, nas y-coordenadas (relativamente a base B = C P , que diago-naliza S), na forma:
Q(y1, . . . , yn) =∑
i
λi (yi)2

9.3. Diagonalizacao de formas quadraticas reais 170
I 9.16 Exemplo ... Continuando o exemplo da seccao anterior, consideremosa forma quadratica associada ao endomorfismo simetrico aı referido:
q(x1, x2, x3) = [x1 x2 x3]
1 0 00 1 20 2 1
x1
x2
x3
= (x1)2 + (x2)2 + (x3)2 + 4x2x3
Se designamos por
y1
y2
y3
as coordenadas de um vector v, na base B, entao,
se as coordenadas desse mesmo vector, na base C , sao
x1
x2
x3
, vem que:
x1
x2
x3
= P
y1
y2
y3
, onde P =
1 0 00 1√
21√2
0 − 1√2
1√2
isto e:
x1 = y1
x2 =1√2y2 +
1√2y3
x3 = − 1√2y2 +
1√2y3
e nas novas coordenadas (yi), q escreve-se na forma:
q(y1, y2, y3) = (y1)2 − (y2)2 + 3(y3)2
como alias pode ser verificado directamente.
I 9.17 Definicao ... Uma forma quadratica em R3, Q(x) = Sx · x, diz-se:
• definida positiva, se Q(x) > 0, ∀x 6= 0.
• definida negativa, se Q(x) < 0, ∀x 6= 0.
• indefinida, se Q toma valores positivos e negativos.
A proposicao seguinte e consequencia imediata da possibilidade de reduziruma forma quadratica a forma diagonal.
I 9.18 Teorema ... Uma forma quadratica em R3, Q(x) = Sx · x, e:
• definida positiva, se todos os valores proprios de S sao estritamentepositivos.

9.4. Propriedades extremais dos valores proprios 171
• definida negativa, se todos os valores proprios de S sao estritamentenegativos.
• indefinida, se os valores proprios de S sao alguns positivos e alguns neg-ativos (eventualmente nulos).
9.4 Propriedades extremais dos valores proprios
Vamos ver que os valores proprios de um operador simetrico em IRn, podem serobtidos considerando um certo problema de mınimo acerca da forma quadraticaassociada.
Para ja um lema preparatorio:
I 9.19 Lema ... Seja S : Rn → Rn um operador simetrico em Rn, para o quala forma quadratica associada Q(x) = Sx · x e nao negativa:
Q(x) = Sx · x ≥ 0, ∀xSe para um certo vector u:
Q(u) = Su · u = 0
entao Su = 0.
Dem.: Seja x = u + th, onde t ∈ IR e h ∈ IRn sao arbitrarios. Entao:
Q(u + th) = S(u + th) · (u + th)= Su · u + t(Su · h + Sh · u) + t2Sh · h= t(Su · h + h · Su) + t2Sh · h (porque?)= t(Su · h + h · Su) + t2Sh · h (porque?)= 2tSu · h + t2Sh · h (porque?)
Portanto:2tSu · h + t2Sh · h ≥ 0, ∀t
o que implica que Su · h, ∀h e portanto Su = 0. ¥
No teorema que se segue, representamos por S a esfera unitaria em IRn:
S def= {x ∈ IRn : , ‖x‖ = 1}
I 9.20 Teorema ... Seja S : Rn → Rn um operador simetrico em Rn, eQ : Rn → R a forma quadratica associada a S, definida por Q(x) = Sx · x.
Entao a restricao de Q a esfera unitaria S, assume o seu valor mınimo λ1
num certo ponto u1 dessa esfera. Alem disso:

9.4. Propriedades extremais dos valores proprios 172
λ1 e valor proprio de S e u1 e um vector proprio associado.
Dem.: Como a esfera unitaria S e limitada e fechada, existe um pontou1 ∈ S onde a restricao de Q a S assume o seu valor mınimo, digamos λ1:
Q(u1) = λ1, e Q(x) ≥ λ1, ∀x ∈ S
Como x · x = 1 podemos escrever a desigualdade na forma:
Sx · x ≥ λ1 x · x, onde x · x = 1
Mas esta desigualdade e valida qualquer que seja x (porque?). Portanto:
(Sx− λ1 x) · x ≥ 0, ∀x ∈ IRn (9.4.1)
e, em particular, para x = u1:
(Su1 − λ1u1) · u1 = 0 (9.4.2)
Isto significa que o operador S− λ1 Id satisfaz as condicoes do lema anterior e,por isso:
Su1 − λ1u1 = 0
isto e:Su1 = λ1u1
¥
Para calcular o proximo vector proprio λ2 consideramos a restricao de Sao hiperplano ortogonal a u1. Esta restricao e um operador simetrico ao qualpodemos aplicar o mesmo argumento - o valor proprio λ2 e o valor mınimo deS|u⊥1 restrito a esfera unitaria de u⊥1 . Um vector proprio associado e um ponto
desta esfera onde S toma o valor mınimo λ2. E claro que λ2 ≤ λ1 e que u2 ⊥ u1.Procedendo sucessivamente desta forma obtemos o seguinte teorema.
I 9.21 Teorema ... A base ortonormada {u1 u2 ...un}, de Rn, constituıda porvectores proprios de S (S(uk) = λk uk, k = 1, ..., n), e relativamente a qual amatriz de S e a matriz diagonal:
D = diag(λ1, λ2, ..., λn)
pode ser escolhida de tal forma que, para cada k = 1, ..., n, λk = Q(uk) e o valormınimo de Q, restrita a esfera unitaria no subespaco de Rn, perpendicular aosvectores u1,u2, ...,uk−1.

9.5. Operadores comutativos 173
9.5 Operadores comutativos
I 9.22 Lema ... Suponhamos que S e T sao dois operadores num ev V dedimensao finita, que comutam, isto e:
ST = TS
Seja λ um valor proprio de S e E(λ) o correspondente espaco proprio. Entao ooperador T deixa invariante E(λ), isto e:
T(E(λ)) ⊆ E(λ) (9.5.1)
Dem.:
Seja v ∈ E(λ), de tal forma que Sv = λv. Pretende-se mostrar que Tv ∈E(λ). De facto:
STv = TSv = T(λv) = λTv =⇒ Tv ∈ E(λ)
¥
I 9.23 Corolario ... Se S e T sao dois operadores comutativos (ST = TS)num ev complexo de dimensao finita, entao S e T tem um vector proprio co-mum.
I 9.24 Teorema ... Suponhamos que S e T sao dois operadores auto-adjuntosnum ev Hermitiano V de dimensao finita.Entao existe uma base ortogonal que diagonaliza simultaneamente os dois oper-adores S e T se e so se eles sao comutativos, isto e, ST = TS.
Dem.: Se ST = TS entao, pelo corolario anterior, S e T tem um vectorproprio u1 comum:
Su1 = λu1 e Tu1 = ηu1
Considere agora o ortogonal u⊥1 , as restricoes de S e T a esse ortogonal erepita o argumento.
O recıproco e obvio.
¥.
9.6 Exercıcios
I Exercıcio 9.1 ... Em cada uma das alıneas que se seguem, determine:

9.6. Exercıcios 174
I) Uma matriz simetrica A que represente a forma quadratica que se segue;
II) Os valores proprios de A;
III) Uma base ortonormal de vectores proprios;
IV) Uma matriz ortogonal diagonalizante C;
V) Diagonalize a forma quadratica.
a) q(x1, x2) = 4x21 + 4x1x2 + x2
2;
b) q(x1, x2) = x1x2;
c) q(x1, x2) = x21 + 2x1x2 − x2
2;
d) q(x1, x2) = 34x21 − 24x1x2 + 41x2
2;
e) q(x1, x2, x3) = x21 + x1x2 + x2x3 + x1x3;
f) q(x1, x2, x3) = 2x21 + x2
2 − x23 + 4x1x3;
g) q(x1, x2, x3) = 3x21 + 4x1x2 + 4x2x3 + 8x1x3 + 3x2
3.

Modulo 10
ALGA I. Conicas equadricas afins
Contents10.1 Parabola, Elipse e Hiperbole . . . . . . . . . . . . . 175
10.2 Quadricas . . . . . . . . . . . . . . . . . . . . . . . . 179
10.3 Conicas e quadricas afins . . . . . . . . . . . . . . . 183
10.4 Reducao a forma canonica da equacao geral deuma conica . . . . . . . . . . . . . . . . . . . . . . . 189
10.1 Parabola, Elipse e Hiperbole
175

10.1. Parabola, Elipse e Hiperbole 176
I 10.1 Parabola
Uma parabola e uma curva em IE2 cuja equacao, em coordenadas cartesianas(x, y) usuais, e:
y2 = 2px, p > 0 (10.1.1)
Os seus elementos principais sao:
• O parametro p > 0
• A distancia focal p/2
• O foco F = (p/2, 0)
• A directriz - a recta de equacao:
x = −p/2
I 10.2 Propriedade focal ... A parabola e o lugar geometrico dos pontosP (x, y) equidistantes do foco F (p/2, 0) e da directrix x = −p/2:
d(P, F ) = d(P, d)
Com efeito:
d(P, F )2 = ‖(x, y)− (p/2, 0)‖2= (x− p/2)2 + y2
= (x− p/2)2 + 2px = (x + p/2)2
= d(P, d)2

10.1. Parabola, Elipse e Hiperbole 177
I 10.3 Elipse ... Uma elipse e uma curva em IE2 cuja equacao, em coorde-nadas cartesianas (x, y) usuais, e:
x2
a2+
x2
b2= 1, a ≥ b > 0 (10.1.2)
Os seus elementos principais sao:
• O semi-eixo maior a > 0
• O semi-eixo menor b > 0
• A distancia focal 2c = 2√
a2 − b2
• A excentricidade e = c/a =√
1− (b/a)2
• O parametro p = b2/a
• Os focos (±c, 0)
• Os vertices (±a, 0) e (0,±b)
• As directrizes - as rectas de equacao:
x = ±a/e
I 10.4 Propriedade focal I ... A elipse e o lugar geometrico dos pontosP (x, y) cuja soma das distancias aos focos e constante e igual a 2a:
d(P, F1) + d(P, F2) ≡ 2a
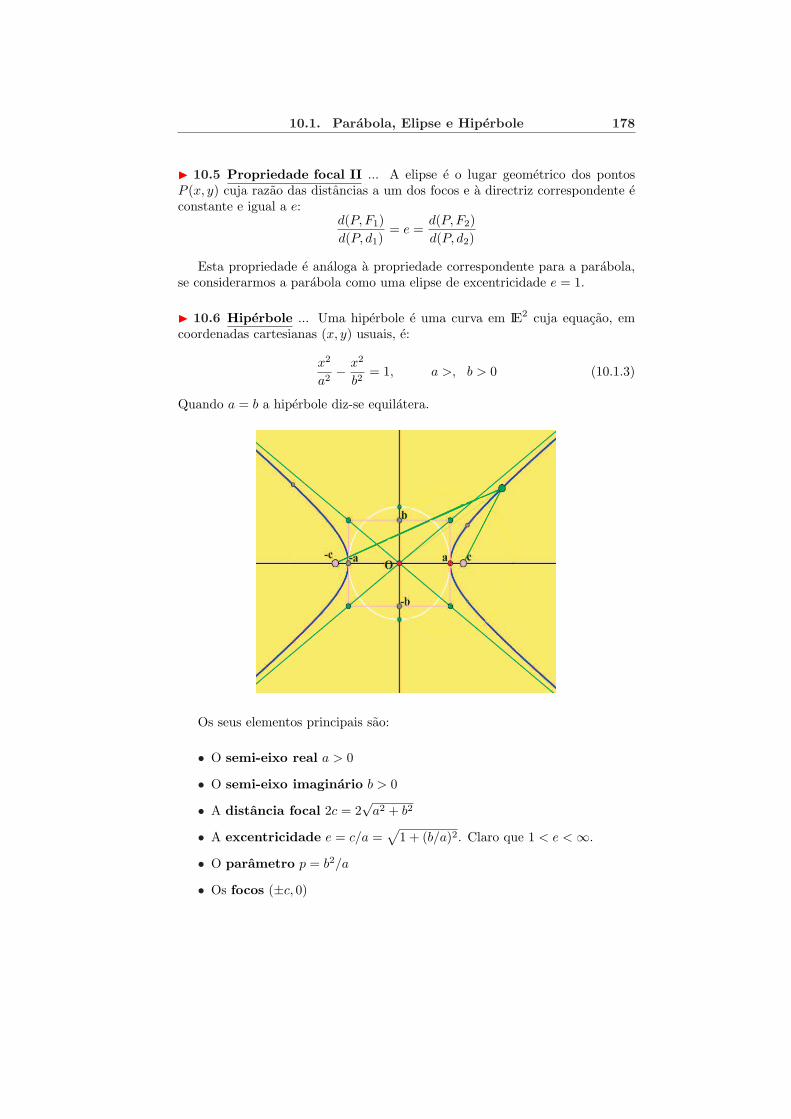
10.1. Parabola, Elipse e Hiperbole 178
I 10.5 Propriedade focal II ... A elipse e o lugar geometrico dos pontosP (x, y) cuja razao das distancias a um dos focos e a directriz correspondente econstante e igual a e:
d(P, F1)d(P, d1)
= e =d(P, F2)d(P, d2)
Esta propriedade e analoga a propriedade correspondente para a parabola,se considerarmos a parabola como uma elipse de excentricidade e = 1.
I 10.6 Hiperbole ... Uma hiperbole e uma curva em IE2 cuja equacao, emcoordenadas cartesianas (x, y) usuais, e:
x2
a2− x2
b2= 1, a >, b > 0 (10.1.3)
Quando a = b a hiperbole diz-se equilatera.
Os seus elementos principais sao:
• O semi-eixo real a > 0
• O semi-eixo imaginario b > 0
• A distancia focal 2c = 2√
a2 + b2
• A excentricidade e = c/a =√
1 + (b/a)2. Claro que 1 < e < ∞.
• O parametro p = b2/a
• Os focos (±c, 0)

10.2. Quadricas 179
• Os vertices (±a, 0)
• As directrizes - as rectas de equacao:
x = ±a/e
• As assımptotas - as rectas de equacao:
x = ±b/a
I 10.7 Propriedade focal I ... A hiperbole e o lugar geometrico dos pontosP (x, y) cuja diferenca das distancias aos focos e, em valor absoluto, constante eigual a 2a:
|d(P, F1)− d(P, F2)| ≡ 2a
I 10.8 Propriedade focal II ... A hiperbole e o lugar geometrico dos pontosP (x, y) cuja razao das distancias a um dos focos e a directriz correspondente econstante e igual a e:
d(P, F1)d(P, d1)
= e =d(P, F2)d(P, d2)
10.2 Quadricas
I 10.9 Elipsoides ...
Sao superfıcies em IE3 definidas por uma equacao do tipo:
x2
a2+
y2
b2+
z2
c2= 1, a ≥ b ≥ c > 0 (10.2.1)

10.2. Quadricas 180
I 10.10 Hiperboloides de duas folhas ...
Sao superfıcies em IE3 definidas por uma equacao do tipo:
x2
a2+
y2
b2− z2
c2= −1, a ≥ b > 0, c > 0 (10.2.2)
I 10.11 Hiperboloides de uma folha ...
Sao superfıcies em IE3 definidas por uma equacao do tipo:
x2
a2+
y2
b2− z2
c2= 1, a ≥ b > 0, c > 0 (10.2.3)

10.2. Quadricas 181
I 10.12 Cones ...
Sao superfıcies em IE3 definidas por uma equacao do tipo:
x2
a2+
y2
b2− z2
c2= 0, a ≥ b > 0, c > 0 (10.2.4)
com 1/a2 + 1/b2 + 1/c2 = 1.
I 10.13 Paraboloide elıptico ...
Sao superfıcies em IE3 definidas por uma equacao do tipo:
x2
a2+
y2
b2= 2z, a ≥ b > 0 (10.2.5)

10.2. Quadricas 182
I 10.14 Paraboloide hiperbolico ...
Sao superfıcies em IE3 definidas por uma equacao do tipo:
x2
a2− y2
b2= 2z, a > 0, b > 0 (10.2.6)
I 10.15 Cilindro elıptico ...
Sao superfıcies em IE3 definidas por uma equacao do tipo:
x2
a2+
y2
b2= 1, a ≥ b > 0 (10.2.7)
I 10.16 Cilindro hiperbolico ...

10.3. Conicas e quadricas afins 183
Sao superfıcies em IE3 definidas por uma equacao do tipo:
x2
a2− y2
b2= 1, a > 0, b > 0 (10.2.8)
I 10.17 Cilindro parabolico ...
Sao superfıcies em IE3 definidas por uma equacao do tipo:
y2 = 2px, p > 0 (10.2.9)
10.3 Conicas e quadricas afins
I 10.18 Conica afim ... Consideremos o plano IE2 com a sua estrutura afime Euclideana usuais. Fixemos um referencial afim ortonormado R = {O; e1, e2}.

10.3. Conicas e quadricas afins 184
Um ponto P em IE2 sera identificado com o seu vector de posicao x =−−→OP ∈
R2. Uma conica afim em IE2 e o conjunto dos pontos P cujas coordenadas, x ey, relativas ao referencial R:
−−→OP = xe1 + ye2
satisfazem a equacao:
Q(x, y) = ax2 + by2 + 2cxy + 2dx + 2ey + f = 0 (10.3.1)
onde a, b, c, d, e, f ∈ R com a, b, c nao simultaneamente nulos.
I 10.19 Quadrica afim ... Consideremos o espaco IE3 com a sua estru-tura afim e Euclideana usuais. Fixemos um referencial afim ortonormado R ={O; e1, e2, e3}.
Um ponto P em IE3 sera identificado com o seu vector de posicao x =−−→OP ∈
R3. Uma quadrica afim em IE3 e o conjunto dos pontos P cujas coordenadas,x, y e z, relativas ao referencial R:
x =−−→OP = xe1 + ye2 + ze3
satisfazem a equacao:
Q(x, y, z) = ax2+by2+cz2+2dxy+2exz+2fyz+2gx+2hy+2kz+l = 0 (10.3.2)
onde a, b, c, d, ... ∈ R com a, b, c, d, e, f nao simultaneamente nulos.
I 10.20 Expressoes matriciais. Conicas afins ... Podemos escrever a formula(10.3.1) em forma matricial:
Q(x, y) =(
x y) (
a cc b
)(xy
)+ 2
(d e
)(xy
)+ f
= xtAx + 2xtb + f (10.3.3)
ou ainda na forma:
Q(x, y) =(
x y 1)
a c dc b ed e f
xy1
=(
x 1)t
(A bbt f
)(x1
)
=(
x 1)t
B(
x1
)(10.3.4)

10.3. Conicas e quadricas afins 185
I 10.21 Expressoes matriciais. Quadricas ... Analogamente podemos es-crever a formula (10.3.2) em forma matricial:
Q(x, y, z) =(
x y z)
a d ed b fe f c
xyz
+ 2
(g h k
)
xyz
+ l
= xtAx + 2xtb + f (10.3.5)
ou ainda na forma:
Q(x, y, z) =(
x y z 1)
a d e gd b f he f c kg h k l
xyz1
=(
x 1)t
(A bbt f
) (x1
)
=(
x 1)t
B(
x1
)(10.3.6)
I 10.22 Efeito de uma translaccao ... Estudemos como muda a expressao(10.3.1) quando optamos por um outro referencial R′ = {O′; e1, e2}, com umanova origem O′. Como: −−→
OP =−−→OO′ +
−−→O′P (10.3.7)
Pondo:−−→OP = xe1 + ye2−−→OO′ = xoe1 + yoe2−−→O′P = x′e1 + y′e2 (10.3.8)
vem que: {x = xo + x′
y = yo + y′ (10.3.9)
e substituindo em (10.3.1), obtemos:
Q(x′, y′) = Q(x = xo + x′, y = yo + y′)= a(xo + x′)2 + b(yo + y′)2 + 2c(xo + x′)(yo + y′) + 2d(xo + x′) + 2e(yo + y′) + f
= a(x′)2 + b(y′)2 + 2cx′y′ + 2(axo + cyo + d)x′ + 2(byo + cxo + e)y′ + Q(xo, yo)(10.3.10)
Quando escrevemos Q na forma (10.3.1), mas agora nas coordenadas x′, y′:
Q(x′, y′) = a′x′2 + b′y′2 + 2c′x′y′ + 2d′x′ + 2e′y′ + f ′ = 0 (10.3.11)

10.3. Conicas e quadricas afins 186
e comparamos com a expressao (10.3.10), obtemos:
a′ = a
b′ = b
c′ = c
d′ = d + axo + cyo
e′ = e + byo + cxo
f = Q(xo, yo) (10.3.12)
isto e, os termos quadraticos mantem-se inalterados, mas os lineares alteram-secomo e natural. Em particular, o determinante:
δ =∣∣∣∣
a cc b
∣∣∣∣ = ab− c2 (10.3.13)
mantem-se inalterado.
I 10.23 Efeito de uma translaccao. Escrita matricial ... Os calculos donumero anterior podem ser feitos em forma matricial o que permite uma gen-eralizacao imediata para o caso das quadricas afins. De facto, pondo:
x = xo + x′
onde x =−−→OP,xo =
−−→OO′ e x =
−−→O′P , e substituindo em (10.3.3) ou (10.3.5), vem
que:
Q(x′) = Q(xo + x′) = (xo + x′)tA(xo + x′) + 2(xo + x′)tb + C
= x′tAx′ + xtoAx′ + x′tAxo + xt
oAxo + 2xtob + 2x′tb + C
= x′tAx′ + (xtoAx′)t + x′tAxo + xt
oAxo + 2xtob + 2x′tb + C
= x′tAx + 2x′t(Axo + b) + xtoAxo + 2xt
ob + C (10.3.14)
Escrevendo Q(x′) def= Q(x) = Q(xo + x′) na forma (10.3.5):
Q(x′) = x′tA′x′ + 2x′tb′ + C ′ (10.3.15)
e comparando com (10.3.14), vem que:
A′ = A
b′ = Axo + b
C ′ = Q(xo) (10.3.16)
I 10.24 Mas podemos ainda escrever a translaccao x = xo + x′ na seguinteforma matricial:
(x1
)=
(Id xo
0 1
)(x′
1
)
= P(
x′
1
)(10.3.17)

10.3. Conicas e quadricas afins 187
Substituindo directamente em (10.3.4) ou (10.3.6) vem que:
Q(x′) =(
x′ 1)PtBP
(x′
1
)(10.3.18)
onde P =(
Id xo
0 1
). De facto:
B′ =(
A′ b′
b′t C ′
)= PtBP =
(Id 0xt
o 1
)(A bbt C
)(Id xo
0 1
)=
(A Axo + b
xtoA + bt Q(xo)
)
donde se deduz mais uma vez que:
A′ = A
b′ = Axo + b
C ′ = Q(xo) (10.3.19)
Note que detP = 1. Estas formulas permitem pois concluir que:
I 10.25 Teorema ... A matriz A dos termos quadraticos, o determinante eo rank da matriz B permanecem invariantes quando transladamos a origem dascoordenadas:
A′ = A, detB′ = detB, rankB′ = rankB (10.3.20)
I 10.26 Centro ... Uma conica (ou uma quadrica) diz-se central se detA 6=0. Neste caso, existe um unico ponto xo, chamado o centro da quadrica, talque:
b′ = Axo + b = 0
De facto, basta por xo = −A−1b e, com esta escolha para a origem do novoreferencial acima referido, a equacao (10.3.15) fica na forma:
Q(x) = x′tA′x′ + C (10.3.21)
I 10.27 Centro de uma conica ... Um ponto O′ = (xo, yo) diz-se um centroda conica (10.3.1), se:
b′ = Axo + b = 0 (10.3.22)
isto e: {axo + cyo + d = 0byo + cxo + e = 0 (10.3.23)
Um centro e pois uma interseccao das rectas dadas pelas equacoes:{
ax + cy + d = 0by + cx + e = 0 (10.3.24)
e portanto podem ocorrer 3 hipoteses:

10.3. Conicas e quadricas afins 188
• As rectas intersectam-se num unico ponto. A conica tem pois um unico centro e diz-seentao uma conica central. Isto acontece quando:
δ =∣∣∣∣
a cc b
∣∣∣∣ 6= 0 (10.3.25)
• As rectas sao paralelas e nao se intersectam. Neste caso a conica nao tem centro. Istoacontece quando:
δ =∣∣∣∣
a cc b
∣∣∣∣ = 0 e ∆ =
∣∣∣∣∣∣
a c dc b ed e f
∣∣∣∣∣∣6= 0 (10.3.26)
• As rectas coincidem. Neste caso a conica tem uma recta de centros. Isto acontecequando:
δ =∣∣∣∣
a cc b
∣∣∣∣ = 0 e ∆ =
∣∣∣∣∣∣
a c dc b ed e f
∣∣∣∣∣∣= 0 (10.3.27)
I 10.28 Quando a conica e central, devemos escolher a nova origem O′ do refe-rencial R′, coincidente com esse centro. Neste caso os termos lineares anulam-see a equacao da conica, nas novas coordenadas x′, y′ e:
Q(x′, y′) = ax′2 + by′2 + 2cx′y′ + Q(xo, yo) = 0 (10.3.28)
I 10.29 Efeito da mudanca de base ortonormada ... Escolhamos agorauma nova base ortonormada B = {ui}. Nesta nova base, a matriz de GramA, que representa a parte quadratica xtAx, transforma-se, como sabemos, daseguinte forma:
C → C P = B ⇒ A → P tAP
enquanto que b transforma-se como um vector:
C → C P = B ⇒ b → P tb
(recorde que P e uma matriz ortogonal: P−1 = P t).
Portanto a funcao quadratica, que nas x-coordenadas (relativamente a base{O; ei}) foi escrita na forma:
Q(x) = xtAx + 2xtb + C
escreve-se agora, nas x′-coordenadas, relativamente a base {O;ui}, na forma:
Q(x′) = x′t(P tAP )x′ + 2x′t(P tb) + C (10.3.29)

10.4. Reducao a forma canonica da equacao geral de uma conica189
isto e:
A′ = P tAP
b′ = P tb
C ′ = C (10.3.30)
I 10.30 Mas mais uma vez podemos usar a escrita matricial. Vem entao que:(
x1
)=
(P 00 1
) (x′
1
)(10.3.31)
Substituindo directamente em (10.3.4) ou (10.3.6) vem que:
Q(x) =(
x 1)B
(x1
)
=(
x′ 1) (
P t 00 1
)(A bbt C
)(P 00 1
)(x′
1
)
=(
x′ 1) (
P tAP P tbbtP C
)(x′
1
)(10.3.32)
Destas formulas deduzimos o seguinte:
I 10.31 Teorema ... O determinante e o rank das matrizes A e B sao in-variantes sob mudancas de origem e de base ortonormada.
10.4 Reducao a forma canonica da equacao geralde uma conica
I 10.32 Consideremos de novo um referencial afim ortonormado R = {O; e1, e2}e uma conica afim em IE2 de equacao:
Q(x, y) = ax2 + by2 + 2cxy + 2dx + 2ey + f = 0 (10.4.1)
Designemos por C = {e1, e2}. Sem mudar a origem, escolhamos agorauma nova base ortonormada B = {u1,u2}, constituıda por vectores propriosasociados aos valores proprios λ, η da matriz simetrica:
A =(
a cc b
)(10.4.2)
Nesta nova base, a parte quadratica ax2 + by2 + 2cxy reduz-se a formadiagonal. Mais detalhadamente, se:
−−→OP = xe1 + ye2 = x′u1 + y′u2
entao:Q(x′, y′) = λ(x′)2 + η(y′)2 + 2d′x′ + 2e′y′ + f = 0 (10.4.3)

10.4. Reducao a forma canonica da equacao geral de uma conica190
I 10.33 Distinguimos agora varias situacoes possıveis:
1. Ambos os valores proprios sao nao nulos: λ 6= 0 e η 6= 0. Neste caso,completamos quadrados em (10.4.3):
Q(x′, y′) = λ(x′)2 + η(y′)2 + 2d′x′ + 2e′y′ + f
= λ
(x′ +
d
λ
)2
− d2
λ+ η
(y′ +
e
η
)2
− e2
η+ f
= λ
(x′ +
d
λ
)2
+ η
(y′ +
e
η
)2
+(
f − d2
λ− e2
η
)(10.4.4)
Transladamos entao a origem para a nova origem atraves das formulas:
x′ = x− d
λ
y′ = y − e
η(10.4.5)
e a nova equacao, nas coordenadas x, y fica na seguinte forma canonica:
λx2 + ηy2 = C (10.4.6)
2. Um dos valores proprios e nulo. Por exemplo, λ 6= 0 e η = 0.
Neste caso decompomos o vector b =(
de
)segundo a base ortonormada
de vectores u1,u2 associados aos valores proprios λ e η, respectivamente:
b = βu1 − µu2 (10.4.7)
A parte linear muda entao como segue:
2dx + 2ey = 2b · x= 2(βu1 − µu2) · x= 2βx′ − 2µy′ (10.4.8)
Nas coordenadas x′, y′ a equacao da conica fica entao na forma:
Q(x′, y′) = λx′2 + 2βx′ − 2µy′ + f
= λ
(x′ +
β
λ
)2
− β2
λ− 2µy′ + f
= λ
(x′ +
β
λ
)2
− 2µy′ +(
f − β2
λ
)(10.4.9)

10.4. Reducao a forma canonica da equacao geral de uma conica191
• 2(i). Se µ = 0, a equacao fica:
λ
(x′ +
β
λ
)2
︸ ︷︷ ︸x2
+(
f − β2
λ
)
︸ ︷︷ ︸C
= 0
isto e:λx2 = C (10.4.10)
• 2(ii). Se µ 6= 0, a equacao fica:
λ
(x′ +
β
λ
)2
︸ ︷︷ ︸x2
−2µy′ +(
f − β2
λ
)
︸ ︷︷ ︸C
= λx2 − 2µ
(y′ − C
µ
)
︸ ︷︷ ︸y
= 0
isto e:λx2 − 2µy = 0 (10.4.11)
I 10.34 Resumindo ... temos as 3 formas canonicas seguintes (omitindo ostildes):
(I). λx2 + ηy2 = C, λ, η 6= 0(II). λx2 − 2µy = 0, λ, µ 6= 0
(III). λx2 = C, λ 6= 0
Conforme os valores de λ, η, µ e C temos as seguintes possibilidades (nocampo real):
x2
a2 + y2
b2 = 1 a ≥ b > 0 elipse x2
a2 + y2
b2 = 0 a ≥ b > 0 pontox2
a2 − y2
b2 = 1 a > 0, b > 0 hiperbole x2
a2 − y2
b2 = 0 a > 0, b > 0 duas rectasy2 = 2px p > 0 parabola y2 − b2 = 0 b > 0 duas rectas paralelas distintas
y2 = 0 duas rectas paralelas iguais
I 10.35 Exemplo ... Reduzir a forma canonica a conica:
q(x, y) = x2 + xy + y2 − 3x + 4y − 5 = 0
Escrevendo na forma matricial, vem que:
q(x) = xtAx + 2xtb + c = 0
=(
x y) (
1 1/21/2 1
)(xy
)+ 2
(x y
) ( −3/2 2)t − 5(10.4.12)
Como δ = detA = det(
1 1/21/2 1
)= 3/4 6= 0, a conica e central de centro:
xo = −A−1b = −(
4/3 −2/3−2/3 4/3
)( −3/22
)=
(10/3
−11/3
)

10.4. Reducao a forma canonica da equacao geral de uma conica192
Escolhendo o centro para nova origem, e relativamente ascoordenadas x′ = x− 10/3, y′ = y +11/3, a conica tem porequacao:
Q(x′, y′) = xtAx′ + Q(x0)
=(
x′ y′) (
1 1/21/2 1
)(x′
y′
)− 52/3
Como det(
1− λ 1/21/2 1− λ
)= (1 − λ)2 − 1/4 = 0, con-
cluımos que os valores proprios de A sao λ = 1/2, e λ = 3/2.
A base u1 =( √
2/2−√2/2
),u2 =
( √2/2√2/2
)e uma base de vectores proprios
de A. Como P =( √
2/2√
2/2−√2/2
√2/2
), se representarmos as coordenadas rela-
tivas a base u1,u2, por x, y, entao:(
xy
)=
( √2/2 −√2/2√2/2
√2/2
) (x′
y′
)
isto e:
x =√
2/2x′ −√
2/2y′ =√
2/2(x− 10/3)−√
2/2(y + 11/3)
y =√
2/2x′ +√
2/2y′ =√
2/2(x− 10/3) +√
2/2(y + 11/3)
e nas coordenadas x, y a conica tem por equacao canonica:
12x2 +
32y2 − 52/3 = 0
ou ainda:x2
(√
104/3)2+
y2
(√
104/9)2= 1 (10.4.13)
que e uma elipse de centro (−10/3, 11/3) e semi-eixos√
104/3 e√
104/9.
I 10.36 Exemplo ... Reduzir a forma canonica a conica:
q(x, y) = 4x2 − 4xy + y2 − 2x− 14y + 7 = 0
A matriz de Gram da parte quadratica 4x2 − 4xy + y2 e:
A =(
4 −2−2 1
)

10.4. Reducao a forma canonica da equacao geral de uma conica193
cujos valores proprios sao λ = 5, η = 0. Note que esta conica nao e central umavez que detA = 0. O vector u1 =
√5
5 (1, 2) e um vector proprio associado aovalor proprio η = 0, enquanto que o vector u2 =
√5
5 (2,−1) e um vector proprioassociado ao valor proprio λ = 5. B = {u1,u2} e uma base ortonormada naqual a parte quadratica se reduz a forma diagonal 5(y′)2.
Decompomos agora o vector b = (−2,−14) segundo a base B:
b = (b · u1)u1 + (b · u2)u2
=
((−2,−14) ·
√5
5(1, 2)
)u1 +
((−2,−14) ·
√5
5(2,−1)
)u2
= −6√
5u1 + 2√
5u2 (10.4.14)
A parte linear −2x− 14y muda entao de acordo com:
−2x− 14y = (−2,−14) · x, ondex = (x, y)
= (−6√
5u1 + 2√
5u2) · x= −6
√5x′ + 2
√5y′ (10.4.15)
onde pusemos x = (x · u1)u1 + (x · u2)u2 = x′u1 + y′u2.
Resumindo - relativamente as coordenadas (x′, y′) relativas a base ortonor-mada B = {u1,u2}, q escreve-se na forma:
q(x′, y′) = 5(y′)2 − 6√
5x′ + 2√
5y′ + 7 = 0
ou ainda:
q(x′, y′) = (y′)2 − 6√
55
x′ + 2√
55
y′ +75
= 0 (10.4.16)
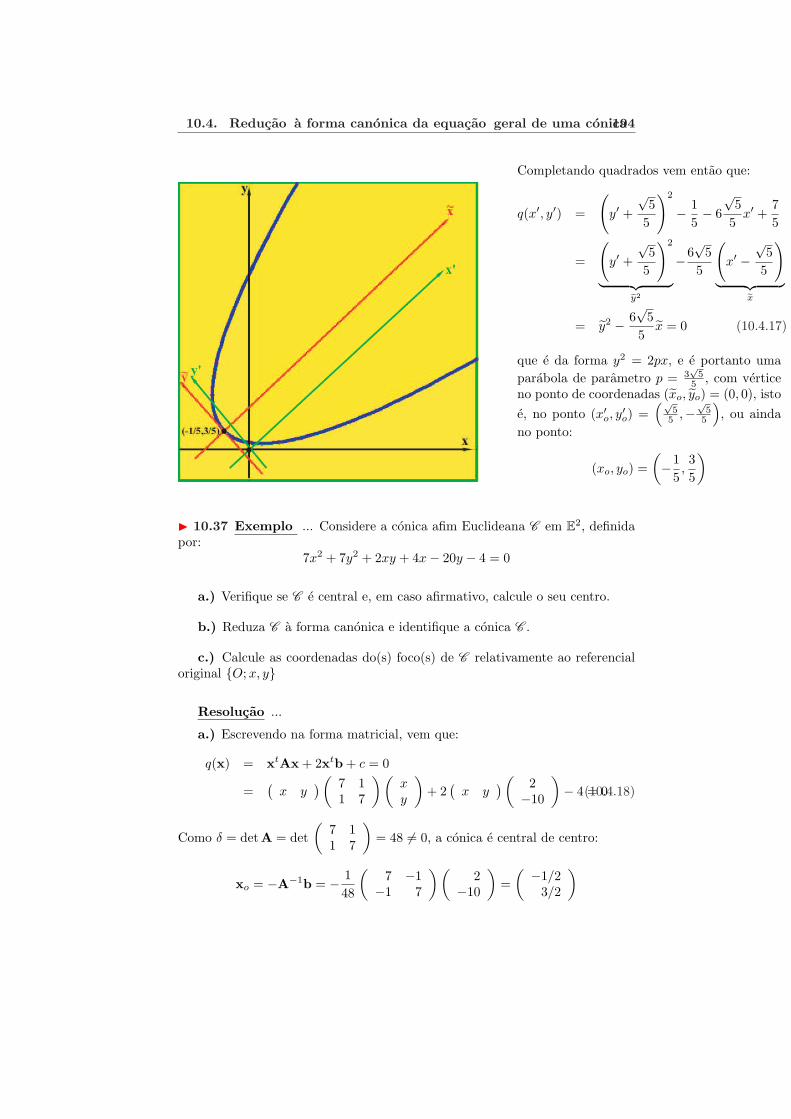
10.4. Reducao a forma canonica da equacao geral de uma conica194
Completando quadrados vem entao que:
q(x′, y′) =
(y′ +
√5
5
)2
− 15− 6
√5
5x′ +
75
=
(y′ +
√5
5
)2
︸ ︷︷ ︸y2
−6√
55
(x′ −
√5
5
)
︸ ︷︷ ︸x
= y2 − 6√
55
x = 0 (10.4.17)
que e da forma y2 = 2px, e e portanto umaparabola de parametro p = 3
√5
5 , com verticeno ponto de coordenadas (xo, yo) = (0, 0), istoe, no ponto (x′o, y′o) =
(√5
5 ,−√
55
), ou ainda
no ponto:
(xo, yo) =(−1
5,35
)
I 10.37 Exemplo ... Considere a conica afim Euclideana C em E2, definidapor:
7x2 + 7y2 + 2xy + 4x− 20y − 4 = 0
a.) Verifique se C e central e, em caso afirmativo, calcule o seu centro.
b.) Reduza C a forma canonica e identifique a conica C .
c.) Calcule as coordenadas do(s) foco(s) de C relativamente ao referencialoriginal {O; x, y}
Resolucao ...
a.) Escrevendo na forma matricial, vem que:
q(x) = xtAx + 2xtb + c = 0
=(
x y)(
7 11 7
) (xy
)+ 2
(x y
) (2−10
)− 4 = 0(10.4.18)
Como δ = detA = det(
7 11 7
)= 48 6= 0, a conica e central de centro:
xo = −A−1b = − 148
(7 −1
−1 7
)(2
−10
)=
( −1/23/2
)

10.4. Reducao a forma canonica da equacao geral de uma conica195
b.) Valores proprios da matriz A =(
7 11 7
): λ = 6, 8.
Base ortonormada de vectores proprios: B ={u1 = (1,−1)√
2,u2 = (1,1)√
2
}
A matriz de passagem da base canonica C para a base B e matriz ortogonal
P = 1√2
(1 1
−1 1
).
O vector x muda de acordo com:
C → B = C P ⇒ xB = x =(
xy
)= P txC =
1√2
(1 −11 1
)(xy
)
e analogamente para o vector b:
C → B = C P ⇒ bB = b = P tbC =1√2
(1 −11 1
) (2−10
)=
(12/
√2
−8/√
2
)
Na nova base B a equacao da conica e:
q(x) = xtdiag(6, 8)x + 2xtb + c = 0
=(
x y)(
6 00 8
) (xy
)+ 2
(x y
) (12/
√2
−8/√
2
)− 4
= 6x2 + 8y2 + 12√
2x− 8√
2y − 4 = 0 (10.4.19)
Completando quadrados vem que:
6(x +√
2)2 + 8(y −√
2/2)2 = 20
ou:X2
(√206
)2 +Y 2
(√208
)2 = 1
onde pusemos X = x +√
2, Y = y − √2/2. A conica e pois uma elipse com
semieixos iguais a a =√
206 e b =
√208 . Como:
{x = x−y√
2
y = x+y√2
, e{
X = x +√
2Y = y −√2/2
vem que: {X = x−y√
2+√
2Y = x+y√
2−√2/2
A nova origem do referencial {O; X, Y } esta situada no ponto cujas coorde-nadas x, y obtem-se atraves de:
{x−y√
2+√
2 = 0x+y√
2−√2/2 = 0

10.4. Reducao a forma canonica da equacao geral de uma conica196
Resolvendo vem:x = −1/2, y = 3/2
que sao exactamente as coordenadas x, y do centro da conica.
Os focos da elipse estao situados nos pontos de coordenadas X,Y iguais,respectivamente, (±
√5/6, 0), uma vez que a distancia semi-focal e dada por c =√
a2 − b2 =√
5/6. As correspondentes coordenadas x, y obtem-se resolvendo,em ordem a x e y, o sistema:
{x−y√
2+√
2 = ±√
5/6x+y√
2−√2/2 = 0

Modulo 11
Quaternioes e Rotacoes
11.1 Definicoes e propriedades
I 11.1 Quaternioes ... Um quaterniao e uma matriz 2× 2 da forma:
q =(
a + ib c + id−c + id a− ib
), a, b, c, d ∈ R (11.1.1)
Podemos ainda escreve-lo na forma:
q = a1 + b i + c j + dk (11.1.2)
usando as matrizes:
1 =(
1 00 1
), i =
(i 00 −i
), j =
(0 1
−1 0
), k =
(0 ii 0
)
(11.1.3)
Um quaterniao da forma:
p = b i + c j + dk
diz-se puro.
I 11.2 Matrizes de Pauli ... Note que as matrizes i, j e k relacionam-secom as chamadas matrizes de Pauli, σ1, σ2, σ3, definidas por:
σ1 =(
1 00 −1
), σ2 =
(0 −ii 0
), σ3 =
(0 11 0
)(11.1.4)
atraves das formulas:
i = iσ1, j = iσ2, k = iσ3 (11.1.5)
197

11.1. Definicoes e propriedades 198
I 11.3 Corpo H dos quaternioes ... E facil mostrar que as matrizes i, j ek, definidas em (11.1.3), satisfazem as relacoes seguintes:
ij = k, jk = i, ki = j
ij = −ji, jk = −kj, ik = −ki
i2 = j2 = k2 = −1 (11.1.6)
com as quais e extremamente simples multiplicar dois quaternioes escritos naforma (11.1.2).
Com esta multiplicacao o conjunto dos quaternioes fica munidode estrutura de corpo nao comutativo, notado por H, designadopor corpo dos quaternioes de Hamilton.
E claro que, como espaco vectorial real, H e isomorfo a R4.
I 11.4 Conjugacao. Norma ... O conjugado de um quaterniao q = a1 +bi + cj + dk define-se por:
q = a1− bi− cj− dk (11.1.7)
A norma de um quaterniao q ∈ H, escrito na forma (11.1.1) ou (11.1.2),nota-se por |q| e coincide, por definicao, com a norma de q visto como um vectorde R4 com a sua estrutura Euclideana usual:
|q|2 = a2 + b2 + c2 + d2
= det q
= det(
a + ib c + id−c + id a− ib
)(11.1.8)
A distancia entre dois quaternioes q1, q2 ∈ H define-se como habitualmentea custa da norma, atraves de:
d(q1, q2) = |q1 − q2| (11.1.9)
I 11.5 Propriedades ... As propriedades seguintes sao faceis de verificar:
(1). pq = q p
(2). qq = qq = |q|2
(3). q−1 =q
|q|2 , se q 6= 0

11.1. Definicoes e propriedades 199
(4). |pq| = (det (pq))1/2 = (det p)1/2(det q)1/2 = |p| |q|
(5). |q−1| = |q|−1
(6). Um quaterniao p e puro sse p = −p. Designaremos por P o subespaco dosquaternioes puros:
P = {p = xi + yj + zk : x,y, z ∈ R3} ∼= R3
que e pois isomorfo a R3. Um quaterniao puro p sera sempre identificadocom o vector correspondente de R3.
(7). O produto de dois quaternioes puros nao e, em geral, puro. De facto, evalida a seguinte formula:
pq = −(p · q)1 + p ∧ q (11.1.10)
onde p · q e p ∧ q representam, respectivamente, o produto interno e oproduto vectorial usuais em P ∼= R3.
(8). Se p,q ∈ P sao dois quaternioes puros, entao o seu anti-comutador {p,q},e dado por:
{p,q} def= pq + qp = −2(p · q) (11.1.11)
(9). Se p,q ∈ P sao dois quaternioes puros, entao o seu comutador [p,q], edado por:
[p,q] def= pq− qp = 2(p ∧ q) (11.1.12)
Em particular o comutador de dois quaternioes puros e um quaterniaopuro.
(10). Para cada q ∈ H, a aplicacao:
Lq : H→ H, r 7→ Lq(r) = qr
multiplica todas as distancias por |q|. De facto:
d(Lq(r1), Lq(r2)) = |qr1 − qr2|= |q(r1 − r2)|= |q||r1 − r2|= |q| d(r1, r2) (11.1.13)
Em particular, se |q| = 1, a aplicacao Lq e uma isometria de H ∼= R4.
I Exercıcio 11.1 ... Provar todas as propriedades anteriores (note a analo-gia com propriedades analogas familiares para numeros complexos).

11.2. Rotacoes no espaco dos quaternioes puros 200
11.2 Rotacoes no espaco dos quaternioes puros
I 11.6 Rotacoes no espaco dos quaternioes puros ... Como ja vimos, osubespaco P de H constituıdo pelos quaternioes puros, e isomorfo a R3:
P = {p = xi + yj + zk : x,y, z ∈ R3} ∼= R3
O quaterniao puro p = xi + yj + zk sera pois identicado ao vector p =(x, y, z) ∈ R3. Em particular, os quaternioes puros i, j e k sao identificados aosvectores da base canonica de R3, designados pelas mesmas letras.
Se q ∈ H e um quaterniao arbitrario, tem-se que:
qpq−1 ∈ P sempre que p ∈ P (11.2.1)
De facto:qpq−1 =
1|q|2 qpq =
1|q|2 q p q = −qpq−1
(recorde que um quaterniao p e puro sse p = −p).
I 11.7 Teorema ... Se q ∈ H a aplicacao:
Rq : P ∼= R3 −→ P ∼= R3
p 7−→ qpq−1 (11.2.2)
e uma isometria de P ∼= R3.
Dem.: Como ja vimos em (11.2.1), Rq(P) ⊆ P. E facil ver que Rq e linear.Por ultimo, tem-se que:
‖Rq(p)‖ = |qpq−1| = |q||p||q|−1 = ‖p‖, ∀p ∈ P ∼= R3
e portanto Rq e uma isometria de R3.
I 11.8 Representacao quaternionica de uma simetria Sπ ... Consider-emos agora uma simetria Sπ : R3 → R3, relativamente ao plano π = n⊥, onden e um vector nao nulo em R3 ∼= P. Como sabemos:
Sπ(p) = p− 2p · n‖n‖2 n, p ∈ R3 ∼= P (11.2.3)
Mas, em H, esta formula escreve-se na forma:
Sπ(p) = p− 2p · n|n|2 n
= p + (pn + np)n|n|2
= p− (pn + np)n−1
= −npn−1 (11.2.4)

11.2. Rotacoes no espaco dos quaternioes puros 201
onde usamos os factos seguintes: pn+np = −2(p ·n), p,n ∈ P (ver (11.1.11)),n−1 = n/|n|2 e n = −n para um quaterniao puro.
Concluindo: a simetria Sπ : R3 → R3 relativamente ao plano π = n⊥,pode ser escrita na forma:
Sπ(p) = −npn−1 (11.2.5)
I 11.9 Teorema ...
(1). Qualquer rotacao de R3 ∼= P pode ser representada na forma:
Rq : p 7−→ Rq(p) = qpq−1, p ∈ P ∼= R3 (11.2.6)
onde q ∈ H e um quaterniao nao nulo.
(2).Rq = Rq′ se e so se q = λq′, λ ∈ R− {0} (11.2.7)
(3).Rq ◦Rq′ = Rqq′ (11.2.8)
Dem.: Comecemos com (11.2.8):
Rq ◦Rq′(p) = q(q′pq′−1)q−1 = (qq′)p(qq′)−1 = Rqq′(p), ∀p ∈ P
Quanto a (11.2.7):
Rq(p) = Rq′(p), ∀p ∈ P ⇔ qpq−1 = q′pq′−1 ⇔ (q′−1q)p = p(q′−1q)
o que significa que q′−1q comuta com todo o quaterniao puro. Como q′−1qtambem comuta com R1, tem-se que q′−1q = λ, para algum escalar λ 6= 0.Portanto q = λq′.
Finalmente, para demonstrar a parte (1.), basta atender ao facto de queuma rotacao de R3 e um produto de duas simetrias relativamente a planos deR3. De facto, por (11.2.5), tem-se que:
Sπ ◦ Sπ′ = Sπ(−npn′−1)= −n(−npn′−1)n−1
= nn′p(nn′)−1
= Rq(p), onde q = nn′ (11.2.9)
I Exercıcio 11.2 ... Calcular, usando quaternioes, o simetrico do vectorp = (−1, 0, 2) relativamente ao plano π : x− y − 3z = 0 de R3.
I 11.10 Teorema ... Seja q = qo + q um quaterniao nao nulo, onde qo ∈ Re q ∈ P. Entao:

11.2. Rotacoes no espaco dos quaternioes puros 202
(1). o eixo da rotacao Rq, definida por (11.2.6), e a recta gerada por q.
(2). o angulo de rotacao e π/2 se qo = 0 e, quando qo 6= 0, e o angulo θ > 0tal que:
tanθ
2=|q|qo
(11.2.10)
Dem.: Para demostrar (1.), basta verificar que q fica invariante sob Rq.De facto:
Rq(q) = qqq−1 = (qo1 + q)q(qo1 + q)−1 = · · · = q
(verificar como exercıcio).
Vejamos agora a parte (2.). Dados dois quaternioes puros p,p′ ∈ P, com amesma norma, existe sempre um quaterniao u tal que p′ = upu−1 (porque?).Aplicando esta observacao aos quaternioes puros q e ρi, onde escolhemos ρ > 0de tal forma a que |q| = |ρi|, calculamos um quaterniao u tal que uqu−1 = ρi.Como Ruqu−1 = RuRqR−1
u , podemos limitarmo-nos ao caso em que q = ρi,isto e, a uma rotacao em torno do eixo gerado por i (o eixo dos x′s).
Suponhamos entao que q = qo + ρi. Como q−1 =qo − ρiq2o + ρ2
, vem que:
Rq(j) =1
q2o + ρ2
(qo + ρi) j (qo − ρi) =q2o − ρ2
q2o + ρ2
j +2qoρ
q2o + ρ2
k
donde se deduz que o angulo de rotacao θ satisfaz:
cos θ =q2o − ρ2
q2o + ρ2
, sin θ =2qoρ
q2o + ρ2
Para obter (11.2.10) basta atender a identidade trigonometrica:
tanθ
2=
sin θ
1 + cos θ=
2qoρq2
o+ρ2
1 + q2o−ρ2
q2o+ρ2
= ... =|q|qo
I 11.11 Nota ... Podemos representar qualquer quaterniao q ∈ H na formapolar seguinte:
q = cosθ
2+ sin
θ
2n (11.2.11)
onde n e um quaterniao puro de norma 1: |n| = 1.
Note que n satisfaz n2 = −1 (porque?). O quaterniao q = cos θ2 + sin θ
2nrepresenta a rotacao R(n;θ) de eixo gerado por n e angulo θ (no sentido directo).
I 11.12 Exemplos ... Por exemplo, temos que:

11.2. Rotacoes no espaco dos quaternioes puros 203
q = cosθ
21 + sin
θ
2i −→ Rq =
1 0 00 cos θ − sin θ0 sin θ cos θ
(11.2.12)
q = cosθ
21 + sin
θ
2j −→ Rq =
cos θ 0 sin θ0 1 0
− sin θ 0 cos θ
(11.2.13)
q = cosθ
21 + sin
θ
2k −→ Rq =
cos θ − sin θ 0sin θ cos θ 0
0 0 1
(11.2.14)
I 11.13 Exemplo ... Considere as duas rotacoes seguintes:
- rotacao R1 de angulo π/3 em torno do eixo (orientado) gerado por u =(−1, 1, 0), no sentido directo.
- rotacao R2 de angulo π/2 em torno do eixo (orientado) gerado por v =(1, 0,−1), no sentido directo.
Calcular R1 ◦R2 e R2 ◦R2.
Res... A rotacao R1 pode ser representada pelo quaterniao q = qo + qcom parte pura q = u = (−1, 1, 0) = −i + j e parte real:
qo = |q| tanθ
2= | − i + j| tan
π
6=√
2
√3
3=√
63
Portanto:
R1 = Rq, com q =√
63− i + j
Analogamente a segunda rotacao R2 pode ser representada pelo quaterniaoq′ = q′o + q′ com parte pura q′ = v = (1, 0,−1) = i− k e parte real:
q′o = |q′| tanθ′
2= |i− k| tan
π
4=√
2
√2
2= 1
Portanto:R2 = Rq′ , com q′ = 1 + i− k
Calculemos agora os produtos qq′ e q′q:
qq′ =
(√6
3− i + j
)(1 + i− k)
=
(√6
3+ 1
)+
(√6
3− 2
)i−
(√6
3+ 1
)k
q′q = (1 + i− k)
(√6
3− i + j
)
= ..... (11.2.15)

11.2. Rotacoes no espaco dos quaternioes puros 204
Como:R1 ◦R2 = Rq ◦Rq′ = Rqq′
vemos que a rotacaoR1 ◦R2 e representada pelo quaterniao:
qq′ =
(√6
3+ 1
)+
(√6
3− 2
)i−
(√6
3+ 1
)k
Logo trata-se de uma rotacao em torno do eixo gerado por:(√
63− 2, 0,−
√6
3− 1
)
e de angulo θ que satisfaz:
tanθ
2=
((√6
3 + 1)2
+(√
63 − 2
)2
+(√
63 + 1
)2)1/2
√6
3 + 1
I 11.14 O teorema 11.9 diz-nos que podemos sempre escrever uma rotacaode R3, na forma Rs : p 7→ sps−1, onde s e um quaterniao de norma 1, multi-plicando por um escalar se necessario.
Representemos por:
S3 = {s ∈ H : |s| = 1} ⊂ R4 (11.2.16)
o conjunto dos quaternioes de norma 1. Como o produto de dois quaternioesde norma 1 e ainda um quaterniao de norma 1, vemos que S3 e um grupo (naocomutativo).
Os teoremas anteriores mostram que temos um homorfismo sobrejectivodeste grupo sobre o grupo SO(3) das rotacoes de R3:
S3 ³ SO(3)
cujo nucleo e o subgrupo de ordem 2 em S3: Z2 = {±1}. Isto significa que acada rotacao φ ∈ SO(3) correspondem dois quaternioes opostos ±s ∈ S3, denorma 1, tais que:
R±s = φ
¥
I Exercıcio 11.3 ... Considere o grupo de Lie Sp(1) constituıdo pelosquaternioes de norma unitaria:
Sp(1) = {x = x01+x1i+x2j+x3k ∈ IH : N(x) = xx = (x0)2+(x1)2+(x2)2+(x3)2 = 1}

11.2. Rotacoes no espaco dos quaternioes puros 205
(i). Mostre que a algebra de Lie de Sp(1) e:
sp(1) = Im IH = IR3
e que com a identificacao Im IH = IR3, dada por ξ = ξ1i+ξ2j+ξ3k ∈ Im IH 7→ξ = (ξ1, ξ2, ξ3) ∈ IR3, o patentisis de Lie e dado por [ξ, η] = 2ξ × η.
(ii). Considere o grupo de Lie SU(2) = SU(2,C) = {A ∈ G`(2, C) : AA† =1 e det A = 1} e a respectiva algebra de Lie su(2) = {ξ ∈ gl(2,C) : ξ =−ξ† e tr ξ = 0}.
Mostre que a aplicacao γ : IH →M2(C), dada por:
x ∈ IH 7→ γ(x) =(
x0 + ix3 x2 + ix1
−x2 + ix1 x0 − ix3
). (11.2.17)
onde x = x01 + x1i + x2j + x3k ∈ IH, e um homomorfismo real de algebras: γe IR-linear, γ(1) = 1 e γ(xy) = γ(x)γ(y). Mostre ainda que:
γ(x) = (γ(x))†
(iii). Considere as matrizes de Pauli seguintes:
σ1 =[
0 11 0
]σ2 =
[0 −ii 0
]σ3 =
[1 00 −1
]
Mostre que [σ1, σ2] = 2iσ3 (+ permutacoes cıclicas). Mostre que γ(i) = iσ1,γ(j) = iσ2, γ(k) = iσ3, onde γ e a aplicacao (11.2.17), e que portanto {iσ1, iσ2, iσ3}formam uma base para su(2).
(iv). Mostre que (11.2.17) pode ser escrita na forma:
γ(x) = x01 + i∑
k
xkσk
def= x0 + ix · ~σ
onde x = x01 + x1i + x2j + x3k = x0 + x ∈ IH, com x ∈ Im IH = IR3, e~σ = (σ1, σ2, σ3).
(v). Considere o conjunto Ho das matrizes hermitianas que tem traco nulo:
Ho ={ [
c a− iba + ib −c
]: a, b, c ∈ IR
}
Mostre que a aplicacao ˜ : IR3 → Ho, definida por:
˜ : x = (xk) ∈ IR3 7→ x =3∑
k=1
xkσk =[
x3 x1 − ix2
x1 + ix2 −x3
]

11.2. Rotacoes no espaco dos quaternioes puros 206
e um isomorfismo linear (que permite identificar Ho com IR3). Mostre aindaque:
det x = −‖x‖2, (x · y)1 =12(xy + yx)
‖x‖21 = x2 x× y =i
2(xy − yx) =
i
2[x, y]
e ainda:xy = (x · y)1 + i x× y
Esta ultima igualdade escreve-se habitualmente na forma:
(~x · ~σ)(~y · ~σ) = (~x · ~y)σo + i (~x× ~y) · ~σ
onde se pos σo = 1 e ~σ = (σ1, σ2, σ3). Isto e, o produto de dois elementosx, y ∈ Ho, e um elemento de IR1 + iHo, cuja parte real e o produto interno, ea parte imaginaria e o produto vectorial.
(vi). Mostre que os valores proprios de x ∈ Ho sao ±‖x‖, e deduza que cadax ∈ IR3 − {0} induz uma decomposicao de C2 em soma directa:
C2 = S+x ⊕ S−x
Calcule essa decomposicao quando x = (1, 1, 0). Mostre ainda que essa decom-posicao fica inalterada quando substituimos x por ax, onde a > 0 e um numeroreal positivo arbitrario, isto e, cada direccao IR+{x} = {ax : a > 0} em IR3
(onde x 6= 0), determina (unıvocamente) uma decomposicao de C2 da formareferida (1).
(vii). Considere agora, para cada A ∈ SU(2), a aplicacao:
ψA : Ho∼= IR3 −→ IR3 ∼= Ho
definida por:ψA(x) = AxA† x ∈ Ho
Mostre que ψA esta bem definida, e que ψA e uma transformacao ortogonal emIR3.
(viii). Deduza a formula de Euler seguinte:
ψA(x) =((a0)2 − ‖a‖2)x + 2(x · a)a− 2a0 ˜(a× x)
1A interpretacao fısica deste facto, e a seguinte: C2 representa o espaco de estados inter-nos de um sistema quantico, uma partıcula de spin 1
2, localizada perto da origem 0 ∈ IR3
(por exemplo, um electrao). A existencia de um campo magnetico, determina uma direccaoIR+{x} = {ax : a > 0} em IR3. Neste campo o sistema tera dois estados estacionarios, quesao precisamente S+
x e S−x . Se por exemplo, a direccao IR+{x} corresponde a parte positivado eixo dos zz, entao o estado S+
x diz-se o estado com projeccao de spin + 12, ao longo do eixo
dos zz (ou spin up ), enquanto que S−x se diz o estado com projeccao de spin − 12, ao longo
do eixo dos zz (ou spin down ).

11.2. Rotacoes no espaco dos quaternioes puros 207
ou em termos do isomorfismo IR3 ∼= H0:
y = ψA(x) =((a0)2 − ‖a‖2)x + 2(x · a)a− 2a0 (a× x) (11.2.18)
onde A = γ(a) = a01 + i∑
k akσk = a0 + ia · ~σ ∈ SU(2), e x ∈ Ho = IR3.Deduzir que ψA e uma rotacao de IR3 de eixo gerado por a.
Nota... Como detA = (a0)2 + ‖a‖2 = 1, podemos escolher θ tal que: a0 =cos θ
2 e ‖a‖ = sin θ2 . Temos entao duas possıveis escolhas para a orientacao
do eixo da rotacao, dadas respectivamente pelos vectores unitarios u = ± asin θ
2.
Uma vez escolhido o angulo θ e o vector u, a formula de Euler toma a forma:
y = ψA(x) = (cos θ)x + (1− cos θ) (u · x)u + (sin θ) (u× x) (11.2.19)
que representa uma rotacao de eixo gerado por u, e angulo θ no sentido directo.
(ix). Mostrar que ψ : SU(2) → SO(3), definida por A 7→ ψA, e um ho-momorfismo de grupos. Mostrar que se R(u;ϕ) e a rotacao de eixo gerado pelovector unitario u ∈ IR3, e de angulo ϕ, entao A = cos θ 1− i sin θ u ∈ SU(2) etal que Ψ(±A) = R(u;ϕ), e em particular ψ e sobrejectivo.
Nota... Por exemplo, temos que:
cosθ
21− i sin
θ
2σ1 =
[cos θ
2 −i sin θ2
−i sin θ2 cos θ
2
]ψ−→
1 0 00 cos θ − sin θ0 sin θ cos θ
(11.2.20)
cosθ
21− i sin
θ
2σ2 =
[cos θ
2 − sin θ2
sin θ2 cos θ
2
]ψ−→
cos θ 0 sin θ0 1 0
− sin θ 0 cos θ
(11.2.21)
cosθ
21− i sin
θ
2σ3 =
[cos θ
2 − i sin θ2 0
0 cos θ2 + i sin θ
2
]ψ−→
cos θ − sin θ 0sin θ cos θ 0
0 0 1
(11.2.22)
(x). Mostrar que kerψ = {±1} = IZ2 e que SO(3) e isomorfo a SU(2)/IZ2.
(xi). Para cada A = γ(a) = a01 + i∑
k akσk = a0 + ia · ~σ ∈ SU(2),definem-se os chamados parametros de Cayley-Klein (tambem chamadosparametros de Euler, ou ainda de Euler-Rodrigues), atraves das notacoes maisusuais seguintes:
a0 = ρ a = (a1, a2, a3) = (α, β, γ)

11.2. Rotacoes no espaco dos quaternioes puros 208
Mostre utilizando a formula de Euler (12.3.7), que a matriz de ψA (notadapor R(ρ, α, β, γ)), na base canonica de IR3, e a matriz:
R(ρ, α, β, γ) =
ρ2 + α2 − β2 − γ2 2(αβ − γρ) 2(αγ + βρ)2(αβ + γρ) ρ2 + β2 − α2 − γ2 2(βγ − αρ)2(αγ − βρ) 2(βγ − αρ) ρ2 + γ2 − α2 − β2
.
Nota... Desta forma obtemos uma parametrizacao das rotacoes de SO(3)atraves dos 4 parametros de Cayley-Klein ρ, α, β, γ, que satisfazem a condicaoρ2 + α2 + β2 + γ2 = 1.
¥

Modulo 12
O homomorfismoSU(2) → SO(3). Parametrosde Cayley-Klein
12.1 Transformacoes e matrizes hermitianas emC2.
Uma aplicacao linear A : C2 → C2 diz-se uma transformacao hermitiana(ou auto-adjunta) de C2, se A verifica a condicao:
〈A(z)|w〉 = 〈z|A(w)〉 ∀z,w ∈ R2 (12.1.1)
Se A e a matriz de uma tal transformacao hermitiana, relativamente a basecanonica de C2, entao (12.1.1) escreve-se na seguinte forma matricial:
(Az)t w = ztAw ∀z,w ∈ R2
ou ainda:ztAtw = ztAw ∀z,w ∈ C2
o que significa que a matriz A e uma matriz hermitiana (ou auto-adjunta),i.e.:
A† = At= A (12.1.2)
Suponhamos que A =(
α βγ δ
)e uma matriz hermitiana, de tal forma que
A = A†. Temos entao que:(
α βγ δ
)= A = A† =
(α γ
β δ
)
209

12.2. Matrizes hermitianas de traco nulo. Matrizes de Pauli 210
isto e: α = α, δ = δ e γ = β. Portanto α e δ sao reais: digamos α = r ∈ R,δ = s ∈ R, enquanto que γ = β. Uma tal matriz hermitiana A, tem portanto aforma geral:
A =(
r a− iba + ib s
)a, b, r, s ∈ R (12.1.3)
I Proposicao 12.1 ... Seja A : C2 → C2, um endomorfismo hermitiano(ou auto-adjunto) em C2.
(i). Os valores proprios de A sao reais.
(ii). Suponhamos que z e w sao vectores proprios, pertencentes respecti-vamente aos valores proprios (reais) distintos a e b, de A. Entao z e w saoortogonais: 〈z|w〉 = 0.
Dem.:
(i). Seja z ∈ C2 − {0}, um vector proprio pertencente ao valor proprio α:
A(z) = α z (12.1.4)
Temos entao que:
α〈z|z〉 = 〈αz|z〉 = 〈A(z)|z〉 = 〈z|A(z)〉 = 〈z|αz〉 = α〈z|z〉o que implica que α = α, i.e., α ∈ R.
(ii). Temos sucessivamente que:
a〈z|w〉 = 〈az|w〉 = 〈A(z)|w〉 = 〈z|A(w)〉 = 〈z|bw〉 = b〈z|w〉o que implica que (a− b)〈z|w〉 = 0, e portanto 〈z|w〉 = 0, ja que a 6= b,
¥.
12.2 Matrizes hermitianas de traco nulo. Ma-trizes de Pauli
Designemos por H = H(2) o conjunto das matrizes hermitianas (12.1.3), e porHo o subconjunto das que tem traco nulo. Portanto:
Ho ={ (
c a− iba + ib −c
): a, b, c ∈ R
}(12.2.1)
Em particular, em Ho estao as chamadas matrizes de Pauli σ1, σ2, σ3,definidas por:
σ1 =(
0 11 0
), σ2 =
(0 −ii 0
), σ3 =
(1 00 −1
)(12.2.2)

12.2. Matrizes hermitianas de traco nulo. Matrizes de Pauli 211
Qualquer outra matriz X =(
c a− iba + ib −c
)∈ Ho, com a, b, c ∈ R, pode ser
escrita como combinacao linear unica, com coeficientes reais, das matrizes dePauli. Com efeito:
X =(
c a− iba + ib −c
)
= a
(0 11 0
)+ b
(0 −ii 0
)+ c
(1 00 −1
)
= a σ1 + b σ2 + c σ3 (12.2.3)
Concluımos portanto que a aplicacao Φ : R3 → Ho, definida por:
Φ : x = (xi) 7→ X =3∑
i=1
xiσi =(
x3 x1 − ix2
x1 + ix2 −x3
)(12.2.4)
e um isomorfismo linear, o que permite identificar Ho com R3.
Um calculo imediato mostra que:
• os valores proprios de uma matriz X = Φ(x) ∈ Ho sao ±‖x‖Aos valores proprios ±‖x‖ de uma matriz X = Φ(x) ∈ Ho, correspondem
duas rectas complexas ortogonais em C2:
C2 = S(X; +‖x‖)⊕ S(X;−‖x‖)≡ S+
X ⊕ S−X (12.2.5)
Se X =∑3
i=1 xiσi =(
x3 x1 − ix2
x1 + ix2 −x3
), a recta S+
X e dada pelas
equacoes: {(x3 − ‖x‖) z1 + (x1 − ix2) z2 = 0(x1 + ix2) z1 − (x3 + ‖x‖) z2 = 0 (12.2.6)
Por exemplo, se x = (xi) = (0, 0, ‖x‖), a recta S+X e a recta z2 = 0, em C2,
enquanto que se x = (xi) = (0, 0,−‖x‖), a recta S+X e a recta z1 = 0, em C2.
E evidente que a decomposicao (12.2.5), fica inalterada se substituirmos Xpor aX, onde a > 0 e um numero real positivo arbitrario.
Reformulando isto, em termos do isomorfismo R3 ∼= Ho dado por (12.2.4),vemos que cada direccao:
R+{x} = {ax : a > 0} (12.2.7)
em R3 (onde x 6= 0), determina (unıvocamente) uma decomposicao de C2 daforma (12.2.5):

12.2. Matrizes hermitianas de traco nulo. Matrizes de Pauli 212
Nota... A interpretacao fısica deste facto, e a seguinte: C2 representa o espaco deestados internos de um sistema quantico, uma partıcula de spin 1
2, localizada perto
da origem 0 ∈ R3 (por exemplo, um electrao). A existencia de um campo magnetico,determina uma direccao R+{x} = {ax : a > 0} em R3. Neste campo o sistema teradois estados estacionarios, que sao precisamente S+
X e S−X.
Se por exemplo, a direccao R+{x} corresponde a parte positiva do eixo dos zz,entao o estado S+
X diz-se o estado com “projeccao de spin + 12, ao longo do eixo dos
zz”(ou “spin up”), enquanto que S−X se diz o estado com “projeccao de spin − 12, ao
longo do eixo dos zz”(ou “spin down”).
¥
Sao ainda validas as seguintes igualdades:
detX = −‖x‖2 (12.2.8)
(x · y)1 =12(XY + YX) (12.2.9)
‖x‖2 1 = X2 (12.2.10)
Φ(x× y) =i
2(XY −YX) (12.2.11)
onde X = Φ(x),Y = Φ(y) ∈ Ho, x,y ∈ R3, x ·y e o produto interno euclideano
em R3, ‖x‖ a norma euclideana de x ∈ R3, e 1 =(
1 00 1
).
Em particular, (12.2.9) implica que x e y sao ortogonais sse os correspon-dentes elementos X,Y ∈ Ho anticomutam: XY = −YX, enquanto que (12.2.10)implica que x e um vector de norma 1, sse X2 = 1.
Note que o produto de dois elementos X,Y ∈ Ho nao e em geral um elementode Ho. De facto, as igualdades anteriores mostram que:
XY = (x · y)1 + i Φ(x× y) (12.2.12)
igualdade que em livros de Fısica se escreve habitualmente na forma:
(~x · ~σ)(~y · ~σ) = (~x · ~y)σo + i (~x× ~y) · ~σ (12.2.13)
onde se pos σo = 1 e ~σ = (σ1, σ2, σ3). Isto e, o produto de dois elementosX,Y ∈ Ho, e um elemento de R1 + iHo, cuja “parte real”e o produto interno,e a “parte imaginaria”e o produto vectorial.

12.3. O homomorfismo SU(2) → SO(3). Parametros de Cayley-Klein213
12.3 O homomorfismo SU(2) → SO(3). Parametrosde Cayley-Klein
Continuemos a identificar R3 com Ho, atraves do isomorfismo (12.2.4):
x = (xi) ↔ X =3∑
i=1
xiσi
Recordemos que SU(2) e o grupo das matrizes A unitarias (i.e.: A−1 = A†)de determinante 1:
SU(2) ={ (
α β
−β α
): |α|2 + |β|2 = 1
}(12.3.1)
Consideremos agora, para cada A ∈ SU(2), uma aplicacao:
ψA : Ho∼= R3 −→ R3 ∼= Ho
definida por:ψA(X) = AXA† X ∈ Ho (12.3.2)
Note que ψA esta bem definida, isto e, AXA† = (AXA†)† e Traco (AXA†) =0. Mais ainda, atendendo a (12.2.8) e como det (AXA†) = det (AXA−1) =detX, concluımos que ψA e uma transformacao ortogonal em R3. De facto ψA
e uma rotacao: ψA ∈ SO(3), como vamos demonstrar de seguida.
Vamos calcular o eixo e o angulo desta rotacao ψA, de R3, a partir dasentradas da matriz A ∈ SU(2).
Em primeiro lugar notemos que qualquer A ∈ SU(2) pode ser escrita demaneira unica, na forma:
A =(
α β
−β α
)
=(
a0 − ia3 −a2 − ia1
a2 − ia1 a0 + ia3
)
= a0
(1 00 1
)− i
(a3 a1 − ia2
a1 + ia2 −a3
)
= a0 1− i
3∑
k=1
akσk (12.3.3)
com det A = (a0)2 + (a1)2 + (a2)2 + (a3)2 = 1, ou mais sucintamente:
A = a0 1− iA (12.3.4)

12.3. O homomorfismo SU(2) → SO(3). Parametros de Cayley-Klein214
onde A =∑3
k=1 akσk ∈ Ho. Alem disso:
A† = A−1 = a0 1 + iA (12.3.5)
Portanto tem-se que:
Y ≡ ψA(X) = AXA†
= (a0 1− iA)X (a0 1 + iA)= (a0)2 X− ia0AX + ia0XA + AXA
= (a0)2 X− ia0AX + ia0XA + AXA + AAX−AAX
=((a0)2 −A2
)X− ia0 (AX−XA) + A (XA + AX)
=((a0)2 − ‖a‖2)X− ia0 2iΦ(a× x) + A 2(x · a)1
=((a0)2 − ‖a‖2)X + 2(x · a)A + 2a0 Φ(a× x) (12.3.6)
ou em termos do isomorfismo R3 ∼= H0:
y = ψA(x) =((a0)2 − ‖a‖2)x + 2(x · a)a + 2a0 (a× x) (12.3.7)
que e a chamada formula de Euler.
Da formula de Euler, deduzimos que:
(i). Se A = O (⇔ a = (ai) = 0), entao (a0)2 = 1, e portanto a0 = ±1,donde se deduz que A = ±1 e ainda:
ψ±1 = Id (12.3.8)
(ii). Se A 6= O (⇔ a = (ai) 6= 0), entao:
ψA(a) =((a0)2 − ‖a‖2)a + 2(a · a)a
=((a0)2 + ‖a‖2)a
= a
(12.3.9)
ja que (a0)2 + ‖a‖2 = 1, e portanto a gera o eixo da rotacao.
Como det A = (a0)2 + (a1)2 + (a2)2 + (a3)2 = (a0)2 + ‖a‖2 = 1, escolhamosθ tal que: a0 = cos θ
2 e ‖a‖ = sin θ2 . Temos entao duas possıveis escolhas para
a orientacao do eixo da rotacao, dadas respectivamente pelos vectores unitariosu = ± a
sin θ2.
Uma vez escolhido o angulo θ e o vector u, a formula de Euler toma a forma:
y = ψA(x) = (cos θ)x + (1− cos θ) (u · x)u + (sin θ) (u× x) (12.3.10)
Suponhamos agora que v e um vector unitario ortogonal a u, de tal formaque {u,v,u× v} formam uma base positiva de R3:

12.3. O homomorfismo SU(2) → SO(3). Parametros de Cayley-Klein215
Temos entao que, por (12.3.10):
ψA(v) = (cos θ)v + (sin θ) (u× v)ψA(u× v) = (cos θ)u× v − (sin θ)v (12.3.11)
e a matriz de ψA na base {u,v,u× v} e:
1 0 00 cos θ − sin θ0 sin θ cos θ
que representa uma rotacao de eixo gerado por u, e angulo θ no sentido directo.
Demonstremos agora que a aplicacao:
Ψ : A ∈ SU(2) −→ ψA ∈ SO(3) (12.3.12)
e um homomorfismo de grupos.
De facto ∀X ∈ Ho∼= R3, tem-se que:
Ψ(AB)(X) = ψAB(X) = (AB)X(AB)† = ABXB†A† = ψA
(ψB(X)
)= Ψ(A)Ψ(B)(X)
Finalmente demonstremos que o homomorfismo (12.3.12), e sobrejectivo.
Consideremos uma rotacao R(u;ϕ), de eixo gerado pelo vector unitario u ∈R3, e de angulo ϕ. E facil ver que, se U = Φ(u) ∈ H0 e θ = ϕ
2 , entao A =cos θ 1− i sin θ U ∈ SU(2) e tal que Ψ(±A) = R(u;ϕ).
Por exemplo, temos que:
cosθ
21− i sin
θ
2σ1 =
(cos θ
2−i sin θ
2
−i sin θ2
cos θ2
)Ψ−→
1 0 00 cos θ − sin θ0 sin θ cos θ
(12.3.13)
cosθ
21− i sin
θ
2σ2 =
(cos θ
2− sin θ
2
sin θ2
cos θ2
)Ψ−→
cos θ 0 sin θ0 1 0
− sin θ 0 cos θ
(12.3.14)
cosθ
21− i sin
θ
2σ3 =
(cos θ
2− i sin θ
20
0 cos θ2
+ i sin θ2
)Ψ−→
cos θ − sin θ 0sin θ cos θ 0
0 0 1
(12.3.15)
De facto kerΨ = {±1} e resumindo toda a discussao anterior, temos aseguinte:
I Proposicao 12.2 ... O grupo das rotacoes SO(3), em R3, e isomorfo aSU(2)/{±1}. ¥

12.3. O homomorfismo SU(2) → SO(3). Parametros de Cayley-Klein216
Vamos terminar esta seccao, definindo uma parametrizacao das rotacoes deSO(3) atraves dos chamados parametros de Cayley-Klein (tambem chama-dos parametros de Euler, ou ainda de Euler-Rodrigues).
Para isso, utilizemos as notacoes mais usuais seguintes:
a0 = ρ a = (a1, a2, a3) = (α, β, γ)
e calculemos a matriz de ψA, na base canonica de R3, a partir da formula deEuler (12.3.7). Apos um calculo simples, concluımos que essa matriz, notadapor R(ρ, α, β, γ) e igual a:
R(ρ, α, β, γ) =
ρ2 + α2 − β2 − γ2 2(αβ − γρ) 2(αγ + βρ)2(αβ + γρ) ρ2 + β2 − α2 − γ2 2(βγ − αρ)2(αγ − βρ) 2(βγ − αρ) ρ2 + γ2 − α2 − β2
(12.3.16)
Desta forma obtemos uma parametrizacao das rotacoes de SO(3) atravesdos 4 parametros de Cayley-Klein ρ, α, β, γ, que satisfazem a condicao:
ρ2 + α2 + β2 + γ2 = 1 (12.3.17)
¥

Modulo 13
Rotacoes infinitesimais.Algebra do momentoangular
13.1 so(3) e su(2)
Calculando as derivadas em ordem a θ, par θ = 0, dos elementos de SU(2) e deSO(3), respectivamente, que figuram no tema de estudo no3:
cosθ
21− i sin
θ
2σ1 =
(cos θ
2−i sin θ
2
−i sin θ2
cos θ2
)Ψ−→
1 0 00 cos θ − sin θ0 sin θ cos θ
(13.1.1)
cosθ
21− i sin
θ
2σ2 =
(cos θ
2− sin θ
2
sin θ2
cos θ2
)Ψ−→
cos θ 0 sin θ0 1 0
− sin θ 0 cos θ
(13.1.2)
cosθ
21− i sin
θ
2σ3 =
(cos θ
2− i sin θ
20
0 cos θ2
+ i sin θ2
)Ψ−→
cos θ − sin θ 0sin θ cos θ 0
0 0 1
(13.1.3)
obtemos as matrizes:
r1 = − i
2σ1 r2 = − i
2σ2 r3 = − i
2σ3
R1 =
0 0 00 0 −10 1 0
R2 =
0 0 10 0 0−1 0 0
R3 =
0 −1 01 0 00 0 0
(13.1.4)
217

13.2. Algebra doo momento angular 218
E facil verificar que as matrizes r1, r2, r3 verificam as seguintes relacoes decomutacao:
[r1, r2] = r3 [r2, r3] = r1 [r3, r1] = r2 (13.1.5)
e que analogamente as matrizes R1, R2, R3 (as chamadas rotacoes infinitesi-mais), verificam tambem:
[R1, R2] = R3 [R2, R3] = R1 [R3, R1] = R2 (13.1.6)
Ao espaco vectorial real de dimensao 3, gerado por {r1, r2, r3}, e munido daoperacao de comutacao definida por (13.1.5), chama-se a algebra de Lie dogrupo SU(2), e nota-se por su(2).
Analogamente, ao espaco vectorial real de dimensao 3, gerado por {R1, R2, R3},e munido da operacao de comutacao definida por (13.1.6), chama-se a algebrade Lie do grupo SO(3), e nota-se por so(3).
E claro que estas algebras sao isomorfas atraves da aplicacao definida porrk 7→ Rk, k = 1, 2, 3. Por isso vamos apenas fixarmo-nos no estudo de umadelas, por exemplo su(2).
13.2 Algebra doo momento angular
Em Fısica e habitual definir su(2) atraves das matizes que se obtem multipli-cando r1, r2, r3 por i, uma vez que desta forma obtemos operadores hermitianos.Definamos pois:
J1 = ir1 =12σ1 J2 = ir2 =
12σ2 J3 = ir3 =
12σ3
de tal forma que sao validas as seguintes relacoes de comutacao:
[J1, J2] = i J3 [J2, J3] = i J1 [J3, J1] = i J2 (13.2.1)
Como por definicao qualquer elemento X na algebra real su(2) se pode es-crever na forma:
X =∑
k
xkrk =∑
k
xk(− i
2σk
)=
∑
k
(−i xk)(12σk
)=
∑
k
(−i xk)Jk
vemos que su(2) se pode definir alternativamente como o espaco vectorial realde dimensao 3, gerado por {J1, J2, J3} (combinacoes lineares com coeficientesimaginarios puros!!), e munido da operacao de comutacao definida por (13.2.1).A esta algebra tambem se chama a algebra do momento angular.

13.3. Representacoes de sl(2, C). Spin 219
13.3 Representacoes de sl(2, C). Spin
Vamos agora calcular todos os espacos unitarios de dimensao finita, nos quaisos operadores {J1, J2, J3} actuam como operadores hermitianos.
Para isso, e conveniente considerar a algebra complexa sl(2,C) = su(2)C,definida como sendo o espaco vectorial complexo de dimensao 3, gerado por{J1, J2, J3} (combinacoes lineares com coeficientes complexos), e munido daoperacao de comutacao definida por (13.2.1).
Em sl(2,C) vamos considerar uma nova base, constituıda pelos operadores:
H3 ≡ J3
H+ ≡ J1 + i J2
H− ≡ J1 − i J2 (13.3.1)
que verificam agora as seguintes relacoes de comutacao:
[H3,H+] = H+ [H3,H−] = −H− [H+,H−] = 2 H3 (13.3.2)
A condicao de que {J1, J2, J3} devem ser operadores hermitianos (J†k = Jk),traduz-se nas condicoes:
H†3 = H3 H†
+ = H− H†− = H+ (13.3.3)
Definamos ainda um operador H2 atraves de:
H2 = J21 + J2
2 + J23
= H+H− + H23 −H3
= H−H+ + H23 + H3 (13.3.4)
que, como e facil verificar, comuta com os operadores H3,H±:
[H2,H3] = 0 [H2,H±] = 0 (13.3.5)
Uma vez que H2 e H3 comutam, e possıvel encontrar um vector x 6= 0 (quepodemos supor de norma 1), que seja simultaneamente vector proprio de H2 eH3, associado respectivamente aos valores proprios c ∈ R e m ∈ R: H2x = cxe H3x = mx.
Utilizemos a notacao de Dirac, pondo x = |c,m〉, de tal forma que:
H2|c,m〉 = c|c,m〉 (13.3.6)H3|c,m〉 = m|c,m〉 (13.3.7)
e ainda ‖x‖2 = 1. Os vectores |c,m〉 dizem-se vectores peso e m o correspon-dente peso.
Vejamos de imediato algumas propriedades dos vectores peso |c,m〉, con-sequencia do facto de que os Jk sao hermitianos e das relacoes de comutacao(13.3.5).

13.3. Representacoes de sl(2, C). Spin 220
(i). c ≥ 0Com efeito:
c = 〈c, m|H2|c, m〉 = 〈c, m|(J21 + J2
2 + J23 )|c, m〉
= ‖J1|c, m〉‖2 + ‖J2|c, m〉‖2 + ‖J3|c, m〉‖2 ≥ 0 (13.3.8)
(ii). m2 ≤ c, qualquer que seja o valor proprio m de H3.Com efeito:
0 ≤ ‖J1|c, m〉‖2 + ‖J2|c, m〉‖2= 〈c, m|(J2
1 + J22 + J2
3 )|c, m〉 − 〈c, m|J23 |c, m〉
= 〈c, m|H2|c, m〉 − 〈c, m|H23 |c, m〉
= c−m2 (13.3.9)
uma vez que |c, m〉 tem norma 1. Portanto m2 ≤ c.
(iii). H+|c,m〉 e H−|c,m〉 sao vectores proprios de H2, associados ao mesmovalor c.
(iv). Se H+|c,m〉 for nao nulo, entao e vector proprio de H3 associado ao valorproprio m + 1.Com efeito, usando as relacoes de comutacao (13.3.2) e ainda (13.3.7), vem que:
H3 H+|c, m〉 = (H+H3 + H+)|c, m〉= H+H3|c, m〉+ H+|c, m〉= m H+|c, m〉+ H+|c, m〉= (m + 1)H+|c, m〉 (13.3.10)
o que significa que H+|c, m〉 (se for diferente de 0) e vector proprio de H3,
associado ao valor proprio m + 1.
Analogamente se demonstra que:
(v). Se H−|c, m〉 for nao nulo, entao e vector proprio de H3 associado ao valorproprio m− 1.
Por este motivo, e habitual chamar a H+ um operador de criacao e aH− um operador de destruicao. Podemos escrever portanto:
H+|c,m〉 = αm |c,m + 1〉H−|c,m〉 = βm |c, m− 1〉 (13.3.11)
onde αm, βm sao constantes de normalizacao a calcular posteriormente.
Portanto se comecarmos com um qualquer |c,m0〉 nao nulo e aplicarmossucessivamente H+, obtemos, de acordo com (13.3.10), novos vectores peso|c,m〉, com peso m cada vez maior. No entanto, atendendo a que m2 ≤ c,apos um numero finito de etapas deveremos atingir o vector peso |c, l〉,

13.3. Representacoes de sl(2, C). Spin 221
com peso maximo l. Para este vector peso maximo, H+|c, l〉 deveraportanto ser nulo:
H+|c, l〉 = 0 (13.3.12)
Utilizando a definicao (13.3.4) de H2 e atendendo a (13.3.12), deduzimosentao que:
c|c, l〉 = H2|c, l〉 = H−H+ + H23 + H3|c, l〉 = H2
3 + H3|c, l〉 = l(l + 1)|c, l〉(13.3.13)
e portanto o valor poprio c de H2, e o peso maximo l estao relacionadospela igualdade:
c = l(l + 1) (13.3.14)
Podemos por isso caracterizar os vectores peso por l e m, em vez de c em, escrevendo |l,m〉 em vez de |c,m〉 e de tal forma que (13.3.6) e (13.3.7)tem agora a forma seguinte:
H2|l, m〉 = l(l + 1)|l, m〉 (13.3.15)H3|l, m〉 = m|l, m〉 (13.3.16)
e o vector peso maximo a forma |l, l〉.Aplicando agora sucessivamente H−, ao vector peso maximo |l, l〉, obtemosde acordo com (13.3.11), novos vectores peso |l, m〉, com peso m cada vezmenor. Mais uma vez, atendendo a que m2 ≤ c = l(l+1), apos um numerofinito de etapas, deveremos atingir o vector peso |l, µ〉, com peso mınimoµ. Para este vector peso mınimo, H−|l, µ〉 devera ser nulo:
H−|l, µ〉 = 0 (13.3.17)
Utilizando (13.3.15), (13.3.4) e (13.3.17), deduzimos entao que:
l(l+1)|l, µ〉 = H2|l, µ〉 = H+H−+H23−H3|l, µ〉 = H2
3−H3|l, µ〉 = µ(µ−1)|l, µ〉e portanto:
l(l + 1) = µ(µ− 1) ⇒ µ = −l (13.3.18)
atendendo a propriedade (ii). acima.
Comecando portanto com o vector peso maximo |l, l〉, aplicando suces-sivamente H− a |l, l〉, e normalizando, obtemos a sequencia seguinte devectores peso:
|l, l〉|l, l − 1〉 = (βl)−1 H−|l, l〉|l, l − 2〉 = (βl−1)−1 H−|l, l − 1〉
...|l,m− 1〉 = (βm)−1 H−|l,m〉
...|l,−l〉 = (β−l+1)−1 H−|l,−l + 1〉 (13.3.19)

13.3. Representacoes de sl(2, C). Spin 222
em numero de 2l + 1, e que sao ortogonais:
〈l, m′|l, m〉 = δmm′ m 6= m′
Como 2l + 1 deve ser um inteiro, devemos ter para os valores possıveis dopeso maximo:
l = 0,12, 1,
32, 2, · · ·
Determinemos finalmente os valores das constantes de normalizacao βm eαm:
βmβm = 〈H−|l,m〉,H−|l,m〉〉 = 〈|l, m〉,H+H−|l, m〉〉= 〈|l,m〉, (H2 −H2
3 + H3)|l, m〉〉 = l(l + 1)−m2 + m
isto e, a menos de um factor de fase (que permanece indeterminado):
βm =√
l(l + 1)−m2 + m =√
(l + m)(l −m + 1)
e portanto:
H−|l, m〉 =√
(l + m)(l −m + 1) |l, m− 1〉 (13.3.20)
Resta calcular os αm, em H+|l, m〉 = αm |l,m + 1〉. Calculando:
αm〈|l, m + 1〉, |l, m + 1〉〉 = 〈H+|l,m〉, |l, m + 1〉〉 = 〈|l, m〉,H−|l,m + 1〉〉= βm+1〈|l, m〉, |l, m〉〉
e portanto:αm = βm+1 =
√(l + m + 1)(l −m) = αm
e:H+|l, m〉 =
√(l −m)(l + m + 1) |l,m + 1〉 (13.3.21)
Concluindo:
• Para cada valor do peso maximo:
l = 0,12, 1,
32, 2, · · ·
(tambem chamado valor de spin), existem 2l + 1 vectores ortogonais:
{ |l, m〉 : m = l, l − 1, l − 2, · · · ,−l + 1,−l}que geram um espaco vectorial complexo unitario de dimensao 2l + 1, Dl:
Dl = {z =l∑
m=−l
αm |l, m〉 }

13.3. Representacoes de sl(2, C). Spin 223
no qual os operadores H2,H3,H± operam da seguinte forma:
H2|l, m〉 = l(l + 1)|l, m〉H3|l, m〉 = m|l, m〉H+|l, m〉 =
√(l −m)(l + m + 1) |l, m + 1〉
H−|l, m〉 =√
(l + m)(l −m + 1) |l, m− 1〉 (13.3.22)
¥

Modulo 14
Geometria de Minkowskiem R4
1
14.1 Produto escalar de Minkowski
I 14.1 Seja η a matriz simetrica:
η = ηµν =
−1 0 0 00 1 0 00 0 1 00 0 0 1
(14.1.1)
Dado um vector x = xµ =
x0
x1
x2
x3
∈ IR4, define-se o covector associado xµ
atraves de xµ = ηµνxν , isto e:
xµ =( −x0 x1 x3 x4
)
Dados dois vectores x = xµ =
x0
x1
x2
x3
e y = yν =
y0
y1
y2
y3
, em R4
1,
define-se o respectivo produto escalar de Minkowski, como sendo o escalar
224

14.1. Produto escalar de Minkowski 225
x · y ∈ R, dado por uma das igualdades seguintes:
x · y = xµyµ
= −x0y0 + x1y1 + x2y2 + x3y3
= (−x0 x1 x2 x3)
y0
y1
y2
y3
= xt η y (14.1.2)
I 14.2 O produto escalar de Minkowski, que acabamos de definir, verifica aspropriedades seguintes:
• e uma forma bilinear:
(x + y) · z = x · z + y · zx · (y + z) = x · y + x · z
ax · y = x · λy = λ(x · y) (14.1.3)
• e uma forma simetrica:x · y = y · x (14.1.4)
• e nao degenerada:
x · y = 0 ∀y ∈ R41 ⇒ x = 0 (14.1.5)
∀x, y, z ∈ R41, ∀λ ∈ R.
No entanto:
• nao e definida positiva, isto e, nao e verdade que:
x · x ≥ 0 (14.1.6)
∀x ∈ R41. Assim, por exemplo o vector e0 = (1, 0, 0, 0), satisfaz e0 · e0 = −1.
Note no entanto que a restricao do produto escalar de Minkowski ao hiper-plano {0} × R3 = {x = xµ ∈ R4
1 : x0 = 0} ∼= R3, e um produto internoeuclideano, e portanto e, em particular, definido positivo.
I 14.3 Define-se ainda a norma ‖x‖, de um vector x ∈ R41, atraves da formula:
‖x‖ ≡√|x · x|
=√|xt η x|
=√|xµxµ| (14.1.7)

14.2. Intervalo ou separacao espaco-temporal 226
14.2 Intervalo ou separacao espaco-temporal
I 14.4 Dados dois pontos (acontecimentos) A,B ∈ R41, ao numero:
s(A,B) = ‖−−→AB‖=
√|(B −A) · (B −A)| (14.2.1)
chama-se o intervalo ou separacao espaco-temporal entre A e B. Em breveveremos qual o significado fısico de s(A,B).
14.3 Caracter causal. Cones de Luz
I 14.5 Em geometria de Minkowski, distinguimos os vectores segundo o re-spectivo caracter causal, de acordo com a seguinte definicao:
Um vector x ∈ R41 diz-se:
espacial: se x · x > 0 ou x = 0de luz: se x · x = 0 e x 6= 0.temporal: se x · x < 0.
I 14.6 O conjunto CL(o) dos vectores de luz:
CL(o) = {x ∈ R41 − {o} : x · x = 0} (14.3.1)
diz-se o cone de luz com origem em o, e e constituıdo pelos vectores x = xµ,tais que:
x · x = xµxµ
= −x0x0 + x1x1 + x2x2 + x3x3
= −(x0)2 + (x1)2 + (x2)2 + (x3)2
= 0 (14.3.2)
Note que a interseccao do cone de luz CL(o) com cada um dos hiperplanosx0 ≡ c (onde c e uma constante nao nula), e um esfera de raio
√|c|, situada
nesse hiperplano:

14.4. Cones temporais 227
I 14.7 Dado um ponto A ∈ R41, define-se o cone de luz com origem em A,
CL(A), como sendo o conjunto dos pontos P ∈ R41 tais que
−→AP ∈ CL(o), i.e.:
(P −A) · (P −A) = −(p0 − a0)2 + (p1 − a1)2 + (p2 − a2)2 + (p3 − a3)2
= 0 (14.3.3)
Quando P pertence ao cone de luz com origem em A: P ∈ CL(A), a rectade equacao:
F (τ) = A + τ−→AP τ ∈ R− {0} (14.3.4)
diz-se o raio de luz que parte de A, e passa em P (em Fısica, corresponde alinha de universo de uma partıcula que se move a velocidade da luz, comopor exemplo, um fotao ou um neutrino).
14.4 Cones temporais
I 14.8 Consideremos o conjunto T de todos os vectores temporais em R41:
T = {x ∈ R41 − {o} : x · x < 0}
= {x ∈ R41 − {0} : (x1)2 + (x2)2 + (x3)2 < (x0)2} (14.4.1)
T e reuniao disjunta de dois subconjuntos: o subconjunto T + de todos osvectores temporais tais que x0 > 0, e o subconjunto T − de todos os vectorestemporais tais que x0 < 0. T + (resp., T −) e constituıdo por todos os vectorestemporais que tem a mesma orientacao temporal positiva (resp., negativa),e por isso T + (resp., T −) diz-se o conjunto dos vectores temporais dirigidospara o futuro (resp., dirigidos para o passado).
I 14.9 Mais geralmente, dado um ponto (acontecimento) A ∈ R41, define-se o
cone temporal do futuro com origem em A, C+T (A), como sendo o conjunto
dos pontos P ∈ R41 − {A}, tais que
−→AP ∈ T +:
C+T (A) = {P ∈ R4
1 − {A} :−→AP ∈ T +} (14.4.2)
e analogamente, o cone temporal do passado com origem em A, C−T (A),como sendo o conjunto:
C−T (A) = {P ∈ R41 − {A} :
−→AP ∈ T −} (14.4.3)

14.5. Linhas de universo de observadores inerciais 228
14.5 Linhas de universo de observadores inerci-ais
I 14.10 Dado um vector temporal unitario u ∈ R41 − {o}, tal que u · u = −1,
dirigido para o futuro:
u ∈ C+T = C+
T (o) e u · u = −1
e um ponto A ∈ R41, a recta gerada por u e que passa em A:
O(τ) = A + τ u τ ∈ R (14.5.1)
chama-se a linha de universo de um observador inercial que passa em A.
O parametro τ chama-se o tempo proprio do observador O.
I 14.11 Se O(τ1) e O(τ2) sao dois pontos na linha de universo (14.5.1), arespectiva separacao s
(O(τ1), O(τ2)
), definida por (14.2.1), e igual a:
s(O(τ1), O(τ2)
)= ‖O(τ2)−O(τ1)‖=
√|(O(τ2)−O(τ1)) · (O(τ2)−O(τ1))|
=√|(A + τ2 u−A− τ1 u) · (A + τ2 u−A− τ1 u)|
= |τ2 − τ1|√|u · u|
= |τ2 − τ1| (14.5.2)
uma vez que u · u = −1.
A separacao s(O(τ1), O(τ2)
)= |τ2−τ1| e pois igual ao intervalo de tempo que
separa os dois acontecimentos O(τ1), O(τ2) , medido por um relogio transportadopelo obervador O.
Nota... Em todas as interpretacoes fısicas deste capıtulo, supomos que estamos
sempre a trabalhar num sistema de unidades no qual a velocidade da luz e constante
e igual 1.

14.6. Ortogonalidade 229
14.6 Ortogonalidade
I 14.12 Dois vectores x, y ∈ R41 dizem-se ortogonais se x · y = 0.
Note que agora, uma vez que o produto escalar de Minkowski nao e definidopositivo, dois vectores ortogonais nao formam necessariamente um angulo de90o entre si.
Por exemplo, x = (b, 1, 0, 0) e y = (1, b, 0, 0) sao ortogonais segundo Minkowski,e o vector de luz u = (1, 1, 0, 0) e ortogonal a si proprio!
14.7 O espaco fısico de um observador inercial
I 14.13 O teorema seguinte, cuja demonstracao omitimos, vai ser utilizadofrequentemente:
I Teorema 14.1 Se u e um vector temporal, entao o subespaco ortogonala u, u⊥:
u⊥ = {x ∈ R41 : x · u = 0} (14.7.1)
e um hiperplano, no qual a restricao do produto escalar de Minkowski, e umproduto interno euclideano. Alem disso, R4
1 e soma directa de Ru e u⊥:
R41 = Ru⊕ u⊥ (14.7.2)
Quando:u ∈ C+
T = C+T (o) e u · u = −1
e:O(τ) = A + τ u τ ∈ R (14.7.3)
e a linha de universo de um observador inercial que passa em A, ao hiperplanoafim:
A + u⊥ (14.7.4)
chama-se o espaco fısico (instantaneo) em A, do observador inercial cujalinha de universo e (14.7.3). Todos os pontos (acontecimentos) em A + u⊥
sao interpretados pelo observador (14.7.3) como ocorrendo “agora”. Para umobservador diferente O′(τ ′) = A+τ ′ v, com v ·v = −1 e v 6= u, os acontecimentosno espaco fısico de O, A + u⊥, nao sao interpretados como simultaneos, umavez que v⊥ 6= u⊥.
14.8 Desigualdade de Cauchy-Shwartz oposta,angulo hiperbolico
I 14.14 Recorde que dados dois vectores nao nulos x,y ∈ R3 com a estruturaEuclideana usual (ou mais geralmente num espaco com um produto interno

14.8. Desigualdade de Cauchy-Shwartz oposta, angulo hiperbolico230
euclideano), a desigualdade de Cauchy-Schwarz |x ·y| ≤ ‖x‖‖y‖ permite definiro angulo convexo ou nao orientado θ ∈ [0, π], entre os referidos vectores naonulos x,y ∈ R3, como sendo o unico θ ∈ [0, π], tal que:
cos θ =x · y‖x‖‖y‖
I 14.15 O facto de que em geometria de Minkowski, o produto escalar e in-definido, conduz no entanto a diferencas surpreendentes que sao muito impor-tantes do ponto de vista fısico.
Assim, por exemplo, a desigualdade de Cauchy-Schwartz para vectores tem-porais, tem agora a seguinte forma (recorde que a norma de um vector x ∈ R4
1
foi definida pela formula ‖x‖ =√|x · x| = √|xµxµ|):
I Proposicao 14.1 (Desigualdade de Cauchy-Schwartz oposta) Se u
e v sao vectores temporais em R41, entao:
|u · v| ≥ ‖u‖‖v‖ (14.8.1)
e o sinal de igualdade ocorre se e so se u e v sao colineares.
Dem.: Pomos:v = λ u + ~v ~v ∈ u⊥
Como v e temporal, vem que:
v · v = (λ u + ~v) · (λ u + ~v) = λ2(u · u) + (~v · ~v) < 0 (14.8.2)
Vem entao que:
(u · v)2 =(u · (λ u + ~v)
)2
= λ2(u · u)2
=((v · v)− (~v · ~v)
)(u · u), por (14.8.2)
≥ (v · v)(u · u)
= ‖u‖2‖v‖2
uma vez que ~v · ~v ≥ 0 e u · u < 0. E claro que a igualdade se verifica sse ~v · ~v = 0, oque e equivalente a ~v = 0, isto e v = λ u.
¥
I Proposicao 14.2 (Angulo hiperbolico) Suponhamos que u e v per-tencem ao mesmo cone temporal C+
T (o) (ou C−T (o)). Entao:
u · v < 0
e alem disso, existe um unico numero ϕ ≥ 0, chamado o angulo hiperbolicoentre u e v, tal que:
u · v = −‖u‖‖v‖ cosh ϕ (14.8.3)

14.8. Desigualdade de Cauchy-Shwartz oposta, angulo hiperbolico231
Dem.: Suponhamos por exemplo que u e v pertencem ambos ao cone temporalC+
T (o). Pomos:
u = λ e0 + ~u ~u ∈ e⊥0 ∼= R3
v = η e0 + ~v ~v ∈ e⊥0 ∼= R3
Note que λ < 0 e η < 0. Alem disso, como u e v sao temporais e u, v ∈ C+T (o),
deduzimos que |λ| > ‖~u‖ e |η| > ‖~v‖. Portanto:
u · v = (λ e0 + ~u) · (η e0 + ~v)
= −λη + ~u · ~v< 0
uma vez que |~u ·~v| ≤ ‖~u‖‖~v‖ < λη (recorde que em e⊥0 ∼= R3 a geometria e euclideana,e por isso e valida a desigualdade usual de Cauchy-Schwartz).
Como u · v < 0, atendendo a desigualdade de Cauchy-Schwartz oposta (14.8.1),vem que:
|u · v| = −u · v ≥ ‖u‖‖v‖isto e:
− u · v‖u‖‖v‖ ≥ 1
e portanto existe um unico numero ϕ ≥ 0, tal que:
cosh ϕ = − u · v‖u‖‖v‖ (14.8.4)
¥
I Corolario 14.1 (Desigualdade triangular oposta) Suponhamos queos vectores temporais u e v pertencem ao mesmo cone temporal C+
T (o) (ouC−T (o)). Entao u + v pertence a esse mesmo cone temporal, e:
‖u + v‖ ≥ ‖u‖+ ‖v‖ (14.8.5)
e o sinal de igualdade ocorre se e so se u e v sao colineares.
Dem.: Como u · v < 0, a desigualdade de Cauchy-Schwartz oposta (14.8.1),implica que:
|u · v| = −u · v ≥ ‖u‖‖v‖e portanto:
(‖u‖+ ‖v‖)2 = ‖u‖2 + 2‖u‖‖v‖+ ‖v‖2 ≤ −(u + v) · (u + v) = ‖u + v‖2
A igualdade verifica-se sse ‖u‖‖v‖ = −u ·v. Mas −u ·v = |u ·v| e a colinearidade segue
da proposicao anterior. ¥

14.8. Desigualdade de Cauchy-Shwartz oposta, angulo hiperbolico232
I Proposicao 14.3 Suponhamos que u e v pertencem ao mesmo cone tem-poral C+
T (o), e que u e ortogonal a v − u. Entao:
(i).‖v‖2 = ‖u‖2 − ‖v − u‖2 (14.8.6)
(ii).
‖u‖ = ‖v‖ cosh ϕ (14.8.7)‖v − u‖ = ‖v‖ sinhϕ (14.8.8)
Dem.: (i). Como u e v sao temporais, ‖u‖2 = −u · u e ‖v‖2 = −v · v. Alemdisso, como u e ortogonal a v − u, vem que:
−‖v‖2 = v ·v = (u+(v−u)) · (u+(v−u)) = u ·u+(v−u) · (v−u) = −‖u‖2 +‖v−u‖2
uma vez que v − u e espacial e portanto ‖v − u‖2 = (v − u) · (v − u).
(ii). Por (14.8.4):
u · v = −‖u‖‖v‖ cosh ϕ
Mas por outro lado:
u · v = u · (u + (v − u)) = u · u = −‖u‖2
e portanto ‖u‖ = ‖v‖ cosh ϕ.
Aplicando agora (14.8.6) a esta ultima igualdade, vem que:
‖v − u‖2 = ‖v‖2(cosh2 ϕ− 1) = ‖v‖2 sinh2 ϕ
e como ϕ ≥ 0, sinh ϕ ≥ 0 e portanto ‖v − u‖ = ‖v‖ sinh ϕ. ¥
I 14.16 Vemos portanto que o Teorema de Pitagoras e substituıdo por (14.8.6),enquanto que as projeccoes ortogonais sao dadas por cossenos e senos hiperbolicos,em vez de circulares! Note ainda que a projeccao temporal ‖u‖ e sempre ≥ ‖v‖,ja que cosh ϕ ≥ 1 (ver a figura), o que tem aplicacoes fısicas importantes queem breve analisaremos.

14.9. Sistemas de coordenadas inerciais. O Factor de Lorentz233
14.9 Sistemas de coordenadas inerciais. O Fac-tor de Lorentz
I 14.17 Consideremos a linha de universo de um observador inercial:
O(τ) = τ u0 τ ∈ Ronde u0 e um vector temporal unitario (‖u0‖ = 1) dirigido para o futuro:
u0 ∈ C+T (o) e u0 · u0 = −1
e seja {u1, u2, u3} uma base ortonormada (ui · uj = δij) positiva ([u1, u2, u3] ≡u1 · (u2 × u3) > 0) do respectivo espaco fısico u⊥0 ∼= R3.
Entao {u0, u1, u2, u3} formam uma base de R41, e o sistema de coordenadas
associado a esta base diz-se um sistema de coordenadas inerciais.
Num tal sistema de coordenadas inerciais, tem-se que:
x · y = (xµuµ) · (yνuν) = −x0y0 + xiyi
= −x0y0 + ~x · ~y (14.9.1)
onde x = x0u0 + ~x com ~x ∈ u⊥0 , e analogamente par y.
14.10 O Factor de Lorentz
I 14.18 Consideremos dois observadores inerciais distintos O1 e O2, cujas lin-has de universo sao respectivamente:
O1(τ1) = τ1 u1 τ1 ∈ RO2(τ2) = τ2 u2 τ2 ∈ R
onde u1, u2 sao vectores temporais unitarios distintos dirigidos para o futuro:
u1, u2 ∈ C+T (o) e u1 · u1 = −1 = u2 · u2
O primeiro observador O1, partindo inicialmente da origem, atinge o pontoA1 = O(1) = u1 no tempo proprio τ1 = 1. Nesse ponto A1, o respectivo espaco

14.10. O Factor de Lorentz 234
fısico e por definicao:A1 + u⊥1
O segundo observador O2, partindo inicialmente da origem, atinge este espacofısico A1 + u⊥1 , num certo ponto O2(τ2), onde τ2 ∈ R fica determinado pelacondicao de que O2(τ2) ∈ (A1 + u⊥1 ), i.e.:
(O2(τ2)−A1) · u1 = 0 (14.10.1)
Como O2(τ2) = τ2u2 e A1 = u1, fazendo so calculos, obtemos:
τ2 =−1
u1 · u2(14.10.2)
I 14.19 A distancia entre o ponto A1 e O2(τ2) (onde τ2 e dado por (14.10.2)), emedida relativamente a metrica euclideana no espaco fısico u1 +u⊥1 , do primeiroobservador O1. E portanto igual a distancia percorrida por O2 no seu afasta-mento de O1, durante o tempo proprio τ1 = 1.
Por outras palavras, essa distancia e igual a velocidade relativa υ21 de O2,relativamente a O1. Calculemos υ21, atendendo a (14.10.1) e a (14.10.2):
(υ21)2 = ‖τ2u2 − u1‖2= (τ2u2 − u1) · (τ2u2 − u1)= (τ2u2 − u1) · (τ2u2)= −(τ2)2 − τ2(u1 · u2)
= −( −1
u1 · u2
)2
− −1u1 · u2
(u1 · u2)
= − 1(u1 · u2)2
) + 1 (14.10.3)
e portanto:
Λ def= u1 · u2 =−1√
1− (υ21)2(14.10.4)
que e o chamado factor de Lorentz.
Nota... Recorde que u1 · u2 < 0 e que estamos a supor a velocidade da luz igual a
1. Portanto 0 < υ21 < 1.
I 14.20 Em particular:
τ2 =−1
u1 · u2=
√1− υ2
21 (14.10.5)
isto e, no instante em que o tempo proprio do primeiro observador O1 e τ1 = 1,o segundo observador esta situado no espaco fısico de O1, no seu tempo proprio
τ2 =√
1− υ221 < 1

14.10. O Factor de Lorentz 235
Isto reflecte o fenomeno relativista da chamada “contraccao temporal” paraum observador em movimento:
Quanto mais depressa O2 se move relativamente a O1, isto e,quanto maior for υ21, mais devagar passa o tempo proprio τ2 =√
1− υ221 de O2, relativamente ao tempo proprio τ1 de O1!
Se ϕ > 0 e o angulo hiperbolico entre u1 e u2, podemos ainda escrever:
cosh ϕ =1√
1− υ221
sinhϕ =υ21√
1− υ221
(14.10.6)

Modulo 15
O grupo de Lorentz O(1, 3).O homomorfismoSL(2, C) → SO(1, 3)↑
15.1 Transformacoes de Lorentz noespaco de Minkowski R4. O grupo de LorentzO(1, 3)
Uma aplicacao linear A : R4 → R4 diz-se uma transformacao de Lorentz, doespaco de Minkowski R4, se A preserva o produto escalar de Minkowski, i.e.::
A(x) ·A(y) = x · y ∀x,y ∈ R4 (15.1.1)
Se A e a matriz de uma tal transformacao de Lorentz, relativamente a basecanonica de R4, entao (15.1.1) escreve-se na seguinte forma matricial:
(Ax)t η (Ay) = xt η y ∀x,y ∈ R4
ou ainda:xtAt η Ay = xt η y ∀x,y ∈ R4
o que significa que a matriz A e uma matriz de Lorentz, i.e.:
At η A = η (15.1.2)
Note que, se A e uma matriz de Lorentz deduzimos de (15.1.2) que det (At η A) =(det A)2det η = det η = −1, i.e.:
det A = ±1
236

15.1. Transformacoes de Lorentz noespaco de Minkowski R4. O grupo de Lorentz O(1, 3) 237
Em particular A e inversıvel e:
A−1 = η At η
O conjunto de todas as transformacoes de Lorentz em R4, constituem umgrupo que se diz o grupo de Lorentz O(1, 3). Este grupo e isomorfo ao grupodas matrizes de Lorentz, tambem notado por O(1, 3).
O subconjunto de O(1, 3) constituıdo por todas as transformacoes de Lorentzque tem determinante 1, e um subgrupo de O(1, 3), chamado o grupo deLorentz especial (ou proprio) e notado por SO(1, 3). Este grupo e iso-morfo ao grupo das matrizes de Lorentz de determinante 1, tambem notado porSO(1, 3).
O grupo de Lorentz especial ortocrono SO(1, 3)↑. Boosts.
Vamos ainda destacar um subconjunto de SO(1, 3) constituıdo por todasas matrizes de Lorentz A = (Aβ
α) tais que A00 ≥ 1. Este subconjunto e ainda
um subgrupo de SO(1, 3). E chamado o grupo de Lorentz especial (ouproprio) ortocrono e e notado por Λ↑+, ou SO(1, 3)↑.
Por exemplo, em Λ↑+ = SO(1, 3)↑, estao as matrizes da forma:
R(θ) =
1 0 0 000 R(~u, θ)0
(15.1.3)
onde R(~u, θ) representa uma rotacao de {0} × R3 ∼= R3 em torno de um eixo~u ∈ R3 e de angulo θ no sentido directo. Portanto SO(3) e um subgrupo deΛ↑+ = SO(1, 3)↑.
Em particular temos as seguintes matrizes do tipo (15.1.3):
R1(θ) =
1 0 0 00 1 0 00 0 cos θ − sin θ0 0 sin θ cos θ
(15.1.4)
R2(θ) =
1 0 0 00 cos θ 0 sin θ0 0 1 00 − sin θ 0 cos θ
(15.1.5)
R3(θ) =
1 0 0 00 cos θ − sin θ 00 sin θ cos θ 00 0 0 1
(15.1.6)

15.1. Transformacoes de Lorentz noespaco de Minkowski R4. O grupo de Lorentz O(1, 3) 238
Consideremos dois vectores temporais unitarios dirigidos para o futuro u0
e u0, e os espacos fısicos F0 = u⊥0 e F0 = u⊥0 , associados aos observadoresinerciais Ru0 e Ru0.
Vamos provar que nessas condicoes existe uma transformacao de Lorentz Bem Λ↑+ = SO(1, 3)↑, que transforma u0 em u0. A esta transformacao de Lorentzchama-se um boost.
Quando u0 = u0, B = Id. Quando u0 6= u0, B pode ser calculada daseguinte forma: consideremos o plano (F0∩ F0)⊥, que contem evidentemente u0
e u0. A restricao do produto escalar de Minkowski a esse plano e nao degenerada,e podemos encontrar dois vectores u1 e u1, nesse plano, de norma 1 e ortogonaisrespectivamente a u0 e a u0:
Na base {uo,u1} do plano (F0 ∩ F0)⊥, a restricao do produto escalar deMinkowski, escreve-se na forma:
x · y = −x0y0 + x1y1
onde x = x0u0 + x1u1 e y = y0u0 + y1u1.
O boost B ∈ Λ↑+ transforma u0 em u0 e u1 em u1, deixando inalterado oplano F0 ∩ F0. Para calcular os elementos da matriz:
[u0 u1] = [u0 u1](
a bc d
)
notemos em primeiro lugar que, atendendo a definicao (14.10.4) do factor deLorentz:
a = u0 · u0 =−1√1− v2
onde v e a velocidade relativa dos observadores inerciais gerados por u0 e u0.
Por outro lado, como B ∈ Λ↑+, temos que (uma vez que u0 ·u0 = −1, u0 ·u1 =0, u1 · u1 = 1):
−a2 + b2 = −1 − ac + bd = 0 − c2 + d2 = 1
e ainda det(
a bc d
)= ad− bc = 1.

15.1. Transformacoes de Lorentz noespaco de Minkowski R4. O grupo de Lorentz O(1, 3) 239
Deduzimos portanto da primeira equacao e atendendo ao valor ja calculadode a, que:
b =v√
1− v2
Atendendo a que detB = 1, deduzimos que d = a e c = b, e portanto a matrizde B, na base {u0,u1,u2,u3}, onde {u2,u3} e uma base ortonormada para oplano (F0 ∩ F0)⊥, tem a forma:
B =
−1√1−v2
v√1−v2 0 0
v√1−v2
−1√1−v2 0 0
0 0 1 00 0 0 1
(15.1.7)
ou em termos de coordenadas espaco-temporais:
x0 =−x0 + vx1√
1− v2, x1 =
vx0 − x1√1− v2
, x2 = x2, x3 = x3
Se ϕ > 0 e o angulo hiperbolico entre u0 e u0, podemos ainda escrever:
coshϕ =1√
1− v2
sinhϕ =v√
1− v2(15.1.8)
e:
B =
cosh ϕ sinhϕ 0 0cosh ϕ coshϕ 0 0
0 0 1 00 0 0 1
(15.1.9)
Partindo de duas bases ortonormadas identicamente orientadas {u0,u1,u2,u3}e {u0, u1, u2, u3}, a transformacao de Lorentz em Λ↑+ que transforma uma naoutra, pode ser representada como produto de um boost, transformando uo emu0, seguida de uma rotacao euclideana em u⊥0 , que transforma a imagem dabase {u1,u2,u3} apos o boost, na base {u1, u2, u3} deixando fixo u⊥o .
Em particular temos as seguintes matrizes de boosts:
B1(ϕ) =
cosh ϕ sinh ϕ 0 0sinhϕ cosh ϕ 0 0
0 0 1 00 0 0 1
(15.1.10)
B2(ϕ) =
cosh ϕ 0 sinh ϕ 00 1 0 0
sinhϕ 0 cosh ϕ 00 0 0 1
(15.1.11)

15.1. Transformacoes de Lorentz noespaco de Minkowski R4. O grupo de Lorentz O(1, 3) 240
B3(ϕ) =
cosh ϕ 0 0 sinh ϕ0 1 0 00 0 1 0
sinhϕ 0 0 cosh ϕ
(15.1.12)
Recorde que uma matriz hermitiana A em C2, tem a forma geral:
A =(
r a− iba + ib s
)a, b, r, s ∈ R (15.1.13)
Designemos por H = H(2) o conjunto das matrizes hermitianas em C2.
Em particular, em H estao as matrizes de Pauli σ1, σ2, σ3, definidas por:
σ1 =(
0 11 0
), σ2 =
(0 −ii 0
), σ3 =
(1 00 −1
)(15.1.14)
Qualquer outra matriz X =(
r a− iba + ib s
)∈ H, com a, b, r, s ∈ R, pode ser
escrita como combinacao linear unica, com coeficientes reais, de σ0 =(
1 00 1
)
e das matrizes de Pauli. Com efeito:
X =(
r a− iba + ib s
)
= x0
(1 00 1
)+ x1
(0 11 0
)+ x2
(0 −ii 0
)+ x3
(1 00 −1
)
= x0 σ0 + x1 σ1 + x2 σ2 + x3 σ3
= xα σα (15.1.15)
onde x0 = r+s2 , x1 = a, x2 = b e x3 = r−s
2 . Concluımos portanto que a aplicacao
Φ : R4 → H, definida por:
Φ : x = (xα) 7→ X = xασα =(
x0 + x3 x1 − ix2
x1 + ix2 x0 − x3
)(15.1.16)
e um isomorfismo linear, o que permite identificar H com R4.
Um calculo imediato mostra ainda que:
det X = det(
x0 + x3 x1 − ix2
x1 + ix2 x0 − x3
)
= (x0)2 − (x1)2 − (x2)2 − (x3)2
= −x · x (15.1.17)

15.1. Transformacoes de Lorentz noespaco de Minkowski R4. O grupo de Lorentz O(1, 3) 241
onde · representa o produto escalar de Minkowski em R4. Portanto:
x · x = −detΦ(x) ∀x ∈ R4 (15.1.18)
Recorde agora que SL(2, C) e o grupo das matrizes A, complexas (2× 2) dedeterminante 1:
SL(2,C) ={ (
α βγ δ
): αδ − βγ = 1
}(15.1.19)
Consideremos agora, para cada A ∈ SL(2,C), uma aplicacao:
ψA : H ∼= R4 −→ R4 ∼= H
definida por:
ψA(X) = AX A∗ X ∈ H (15.1.20)
Note que ψA esta bem definida, isto e, det (AXA∗) = det X, o que mostraainda que ψA : R4 → R4 preserva o produto escalar de Minkowski (uma vez queψA(x) · ψA(x) = −det (AXA∗) = −detX = x · x), isto e, ψA ∈ O(1, 3), paracada A ∈ SL(2,C).
De facto e possıvel demonstrar a seguinte:
I Proposicao 15.1 ... A aplicacao:
Ψ : A ∈ SL(2, C) −→ ψA ∈ Λ↑+ = SO(1, 3)↑ (15.1.21)
onde ψA se define por (15.1.20), e um homomorfismo sobrejectivo de SL(2, C)sobre o grupo de Lorentz proprio ortocrono Λ↑+ = SO(1, 3)↑, cujo nucleo e{±Id}. Portanto:
Λ↑+ = SO(1, 3)↑ ∼= SL(2,C)/{±Id}
Por exemplo, temos que:

15.1. Transformacoes de Lorentz noespaco de Minkowski R4. O grupo de Lorentz O(1, 3) 242
cosθ
21− i sin
θ
2σ1 =
(cos θ
2 −i sin θ2
−i sin θ2 cos θ
2
)Ψ−→
1 0 0 00 1 0 00 0 cos θ − sin θ0 0 sin θ cos θ
(15.1.22)
cosθ
21− i sin
θ
2σ2 =
(cos θ
2 − sin θ2
sin θ2 cos θ
2
)Ψ−→
1 0 0 00 cos θ 0 sin θ0 0 1 00 − sin θ 0 cos θ
(15.1.23)
cosθ
21− i sin
θ
2σ3 =
(cos θ
2 − i sin θ2 0
0 cos θ2 + i sin θ
2
)Ψ−→
1 0 0 00 cos θ − sin θ 00 sin θ cos θ 00 0 0 1
(15.1.24)
e:
coshϕ
21 + sinh
ϕ
2σ1 =
(cosh ϕ
2 sinh ϕ2
sinh ϕ2 cosh ϕ
2
)Ψ−→
cosh ϕ sinhϕ 0 0sinh ϕ cosh ϕ 0 0
0 0 1 00 0 0 1
(15.1.25)
coshϕ
21 + sinh
ϕ
2σ2 =
(cosh ϕ
2 −i sinh ϕ2
i sinh ϕ2 cosh ϕ
2
)Ψ−→
cosh ϕ 0 sinh ϕ 00 1 0 0
sinhϕ 0 cosh ϕ 00 0 0 1
(15.1.26)
coshϕ
21 + sinh
ϕ
2σ3 =
(cosh ϕ
2 + sinh ϕ2 0
0 cosh ϕ2 − sinh ϕ
2
)Ψ−→
cosh ϕ 0 0 sinh ϕ0 1 0 00 0 1 0
sinhϕ 0 0 cosh ϕ
(15.1.27)
Transformacoes de Lorentz infinitesimais
Calculando as derivadas em ordem a θ, par θ = 0, dos elementos de SL(2, C)e de SO(1, 3)↑, respectivamente, que figuram em (15.1.22), (15.1.23) e (15.1.24),

15.1. Transformacoes de Lorentz noespaco de Minkowski R4. O grupo de Lorentz O(1, 3) 243
obtemos as matrizes:
r1 = − i
2σ1 r2 = − i
2σ2 r3 = − i
2σ3
R1 =
0 0 0 00 0 0 00 0 0 −10 0 1 0
R2 =
0 0 0 00 0 0 10 0 0 00 −1 0 0
R3 =
0 0 0 00 0 −1 00 1 0 00 0 0 0
(15.1.28)
e analogamente, calculando as derivadas em ordem a ϕ, par ϕ = 0, dos elementosde SL(2, C) e de SO(1, 3)↑, respectivamente, que figuram em (15.1.25), (15.1.26)e (15.1.27), obtemos as matrizes:
b1 =12σ1 b2 =
12σ2 b3 =
12σ3
B1 =
0 1 0 01 0 0 00 0 0 00 0 0 0
B2 =
0 0 1 00 0 0 01 0 0 00 0 0 0
B3 =
0 0 0 10 0 0 00 0 0 01 0 0 0
(15.1.29)
E facil verificar que as matrizes r1, r2, r3, b1, b2, b3 verificam as seguintesrelacoes de comutacao:
[r1, r2] = r3 [r2, r3] = r1 [r3, r1] = r2
[b1, r2] = b3 [b2, r3] = b1 [b3, r1] = b2
[b1, b2] = −r3 [b2, b3] = −r1 [b3, b1] = −r2 (15.1.30)
e que analogamente as matrizes R1, R2, R3, B1, B2, B3 verificam tambem:
[R1, R2] = R3 [R2, R3] = R1 [R3, R1] = R2
[B1, R2] = B3 [B2, R3] = B1 [B3, R1] = B2
[B1, B2] = −R3 [B2, B3] = −R1 [B3, B1] = −R2 (15.1.31)
Ao espaco vectorial real de dimensao 6, gerado por {r1, r2, r3, b1, b2, b3}, emunido da operacao de comutacao definida por (15.1.30), chama-se a algebrade Lie do grupo SL(2, C), e nota-se por sl(2, C).

15.1. Transformacoes de Lorentz noespaco de Minkowski R4. O grupo de Lorentz O(1, 3) 244
Analogamente, ao espaco vectorial real de dimensao 6, gerado por {R1, R2, R3, B1, B2, B3},e munido da operacao de comutacao definida por (15.1.31), chama-se a algebrade Lie do grupo SO(1, 3), e nota-se por so(1, 3).
E claro que estas algebras sao isomorfas atraves da aplicacao definida porrk 7→ Rk, bk 7→ Bk k = 1, 2, 3. Por isso vamos apenas fixarmo-nos no estudode uma delas, por exemplo sl(2,C).
Para estudar as representacoes de sl(2,C), e conveniente considerar o com-plexificado de sl(2, C), notado por sl(2, C)C, isto e, o espaco vectorial complexode dimensao complexa 6, gerado por {r1, r2, r3, b1, b2, b3}, e munido da operacaode comutacao definida por (15.1.30).
Em sl(2,C)C existe uma base (complexa) constituıda pelos seguintes ele-mentos:
ck =12(rk + ibk) k = 1, 2, 3
dk =12(rk − ibk) k = 1, 2, 3 (15.1.32)
que satisfazem as relacoes de comutacao seguintes:
[c1, c2] = c3 [c2, c3] = c1 [c3, c1] = c2
[d1, d2] = d3 [d2, d3] = d1 [d3, d1] = d2
[ck, dm] = 0 ∀k, m = 1, 2, 3 (15.1.33)
o que mostra que:sl(2,C)C ∼= sl(2, C)⊕ sl(2, C)
facto que desempenha papel essencial na teoria de representacoes do grupo deLorentz.