construindo soluÇÕes de business intelligence com pentaho …
TRANSCRIPT

UNIVERSIDADE DO SUL DE SANTA CATARINA
MICHEL ANGELO DA SILVA DARABAS
CONSTRUINDO SOLUÇÕES DE BUSINESS INTELLIGENCE COM PENTAHO BI
SUITE COMMUNITY EDITION (CE)
Palhoça
2012

MICHEL ANGELO DA SILVA DARABAS
CONSTRUINDO SOLUÇÕES DE BUSINESS INTELLIGENCE COM PENTAHO BI
SUITE COMMUNITY EDITION (CE)
Este Trabalho de Conclusão de Curso foi julgado
adequado à obtenção do título de Bacharel em
Sistemas de Informação e aprovado em sua forma
final pelo Curso de Graduação em Sistemas de
Informação da Universidade do Sul de Santa
Catarina.
Orientador: Prof. Aran Morales, Dr.
Palhoça
2012

MICHEL ANGELO DA SILVA DARABAS
CONSTRUINDO SOLUÇÕES DE BUSINESS INTELLIGENCE COM PENTAHO BI
SUITE COMMUNITY EDITION (CE)
Este Trabalho de Conclusão de Curso foi julgado
adequado à obtenção do título de Bacharel em
Sistemas de Informação e aprovado em sua forma
final pelo Curso de Graduação em Sistemas de
Informação da Universidade do Sul de Santa
Catarina.
Palhoça, 21 de novembro de 2012.

Dedico este trabalho a minha esposa e a minha
família, principalmente aos mais próximos, que
me ajudaram a alcançar mais um objetivo.

AGRADECIMENTOS
A Deus por tudo que me proporciona na vida.
A minha esposa, Jacqueline F. R. Darabas, pelo seu apoio, paciência e incentivo
no decorrer deste projeto.
A minha mãe, Terezinha da Silva, pelo seu suporte e apoio.
Ao amigo, João A. Bertotti, por seu apoio, incentivo e aconselhamento.
Ao professor e orientador Aran Morales, por ter dado a ideia e orientação para
este trabalho e, também, pelo incentivo na trajetória de conclusão do mesmo.
Aos professores do curso de Sistemas de Informação, que foram tão importantes
na minha vida acadêmica e no desenvolvimento desta monografia.
A todos que de alguma forma contribuíram para este trabalho, com dicas,
sugestões e opiniões.

RESUMO
Os recursos de business intelligence (BI) são muito utilizados na indústria. Porém a utilização
de ferramentas open source ainda é um tanto limitada. Essas ferramentas têm como vantagem
o fato de não terem custo de licenciamento de software e de possuírem código fonte aberto.
Este trabalho mostra a criação de uma solução de BI, através da construção de um repositório
de dados do tipo data warehouse, utilizando as ferramentas open source da suite Pentaho
para, no fim, se ter um uma interface gráfica ou front end para o usuário final. Para a criação
da solução, foram escolhidos dados públicos do Portal da Transparência e do IBGE, ambos
subordinados ao governo federal, com o objetivo de cruzar informações sobre a transferência
de recursos federais para os estados e municípios com a estimativa da população dos mesmos,
entre os anos de 2005 e 2011, subdivididos por projeto em que o recurso foi aplicado. Esta
solução de BI, que utiliza ferramentas da suite Pentaho, começa com a criação do data
warehouse, seguindo pela criação de um repositório de metadados com a ferramenta
Metadata Editor. Na sequência, mostra o processo ETL criado com ferramenta Kettle, e a
conclusão da carga dos dados. A ferramenta utilizada para criação de relatórios é a Report
Designer e, para a criação de gráficos, a Design Studio. Por fim, são criados cubos de dados
OLAP com a ferramenta Schema Workbench, e tanto os cubos como os relatórios e gráficos
são publicados no BI Server. Este último possui o motor para o fornecimento de uma série de
funções essenciais para suite Pentaho e também contém um servidor web com uma ferramenta
chamada de Console do Usuário, sendo este um front end para interagir com o usuário final.
Palavras-chave: Business Intelligence. Data Warehouse. ETL. OLAP. Pentaho. Kettle.
Mondrian. Metadata Editor. Report Designer. Schema Workbench. Design Studio.

LISTA DE ILUSTRAÇÕES
Figura 1 – Uma arquitetura de alto nível do BI ........................................................................ 18
Figura 2 – Ilustração data mart ................................................................................................. 20
Figura 3 – Importância da definição da granularidade no projeto de data warehouse ........... 21
Figura 4 – Elementos participantes da ocorrência de uma compra .......................................... 23
Figura 5 – Modelo multidimensional ....................................................................................... 24
Figura 6 – Modelo estrela ......................................................................................................... 25
Figura 7 – Modelo floco de neve .............................................................................................. 26
Figura 8 – O processo de ETL .................................................................................................. 27
Figura 9 – Pilha BI Pentaho ..................................................................................................... 29
Figura 10 – Console do Usuário .............................................................................................. 31
Figura 11 – Interface de Pentaho Metadata Editor .................................................................. 32
Figura 12 – Pentaho Data Integration, ferramentas e componentes ........................................ 35
Figura 13 – Arquitetura do processo de geração de relatórios ................................................. 36
Figura 14 – Data warehouse com Mondrian ........................................................................... 38
Figura 15 – Visão geral dos componentes Pentaho OLAP ...................................................... 39
Figura 16 – Etapas Metodológicas ........................................................................................... 44
Figura 17 – Modelo no formato estrela para o banco de dados multidimensional .................. 50
Figura 18 – Administration Console – Conexão com o banco de dados .................................. 52
Figura 19 – Console do Usuário – Solução transferência de recursos ..................................... 53
Figura 20 – Console do Usuário - Relatório aberto na parte central ........................................ 54
Figura 21 – Publisher config .................................................................................................... 54
Figura 22 – Modelo de metadados Transferência de Recursos ................................................ 55
Figura 23 – Modelo lógico de tabelas de negócio .................................................................... 57
Figura 24 – Propriedades da tabela de negócio Fato População .............................................. 57
Figura 25 – Configuração de um relacionamento com PME ................................................... 58
Figura 26 – Visão de negócios com PME ................................................................................ 59
Figura 27 – Publicação de PME para o BI Server .................................................................... 60
Figura 28 – Exemplo de interface do PDI Spoon – Transformação Dimensão Tempo ........... 61
Figura 29 – Job principal do processo ETL ............................................................................. 62
Figura 30 – Job Carrega Dimensão Geográfica ....................................................................... 62

Figura 31 – Transformação Carrega Dimensão Geográfica 1 .................................................. 63
Figura 32 – Transformação Carrega Dimensão Geográfica 2 .................................................. 64
Figura 33 – Transformação Código Portal da Transparência 1 ................................................ 65
Figura 34 – Transformação – Configuração Modifield Java Script Value ............................... 67
Figura 35 – Transformação Dimensão Tempo ......................................................................... 68
Figura 36 – Job Carrega Fato População.................................................................................. 69
Figura 37 – Transformação Carrega Fato População 2005 ...................................................... 69
Figura 38 – Carga Fato População 2005, Merge Join .............................................................. 70
Figura 39 – População dos municípios em PDF para o ano de 2008 ....................................... 71
Figura 40 – Transformação Carga Fato População 2008 ......................................................... 72
Figura 41 – Job Carrega Dimensão Projeto.............................................................................. 73
Figura 42 – Transformação Dimensão Projeto 2011 ................................................................ 73
Figura 43 – Configuração do Componente Insert / Update ..................................................... 74
Figura 44 – Job Carrega Fato Recurso Transferido ................................................................. 75
Figura 45 - Transformação Carrega Fato Recurso Transferido 2011 ....................................... 76
Figura 46 – Transformação Fato Recurso Transferido por Habitante ...................................... 77
Figura 47 – Métricas da transformação da dimensão tempo .................................................... 78
Figura 48 – Relatório Transferência de Recursos por Função e Estado ................................... 80
Figura 49 – PRD – Metadados como fonte dos dados ............................................................. 81
Figura 50 – PRD – Query Editor .............................................................................................. 82
Figura 51 – PRD Wizard, Definição do Layout do Relatório .................................................. 83
Figura 52 – Interface de relatório de Pentaho Report Designer............................................... 84
Figura 53 – Configuração de parâmetros ................................................................................. 85
Figura 54 – Publicação no BI Server ........................................................................................ 86
Figura 55 – Relatório Transferência de Recursos aos Municípios por Estado e Ano .............. 87
Figura 56 – Gráfico Bolha Transferência de Recursos por Localidade ................................... 88
Figura 57 – Interface de Pentaho Design Studio ...................................................................... 90
Figura 58 – Design Studio código fonte XML ......................................................................... 91
Figura 59 – Gráfico Linha Transferência de Recursos por Localidade e Ano ......................... 92
Figura 60 – Configuração do gráfico com XML ...................................................................... 93
Figura 61 – Gráfico Linha Transferência de Recursos por Regiões do Brasil e Ano .............. 94
Figura 62 – Interface de Pentaho Schema Workbench ............................................................. 95

Figura 63 – Cubo Transferência de Recursos com JPivot no Console do Usuário ................. 96
Figura 64 – Árvore do cubo Transferência de Recursos .......................................................... 97
Figura 65 – Atributos da medida valor transferido................................................................... 99
Figura 66 – Cubo Transferência de Recursos por Habitante – JPivot...................................... 99
Figura 67 – Publicação no BI Server por Schema Workbench ............................................... 101

LISTA DE SIGLAS
BI - Business Intelligence
BPM - Business Performance Management
CDF - Community Dashboard Framework
CE - Community Edition
CFO - Chief Financial Officer
CGU - Controladoria Geral da União
DB - Data Base
DM - Data Mart
DML - Data Manipulation Language
DS - Data Source
DW - Data Warehouse
ETL - Extract, Transform and Load
IBGE - Instituto Brasileiro de Geografia e Estatística
IDE - Integrated Development Environment
JDBC - Java Database Connectivity
MDX - Multidimensional Expressions
OLAP - On-Line Analytical Processing
OLTP - Online Transaction Processing
PDI - Pentaho Data Integration
PDS - Pentaho Design Studio
PL/pgSQL - Procedural Language/Postgre SQL
PME - Pentaho Metadata Editor
PRD - Pentaho Report Designer
PSW - Pentaho Schema Workbench
RDBMS - Relational Database Management System
ROLAP - Relacional OLAP
SQL - Structured Query Language
TCU - Tribunal de Contas da União
XML - Extensible Markup Language
XML/A - XML for Analysis

SUMÁRIO
1 INTRODUÇÃO................................................................................................................. 14
1.1 PROBLEMÁTICA .......................................................................................................... 14
1.2 OBJETIVOS .................................................................................................................... 15
1.2.1 Objetivo Geral ............................................................................................................. 15
1.2.2 Objetivos Específicos................................................................................................... 15
1.3 JUSTIFICATIVA ............................................................................................................ 15
1.4 ESTRUTURA DA MONOGRAFIA ............................................................................... 16
2 REFERENCIAL BIBLIOGRÁFICO ............................................................................. 17
2.1 DEFINIÇÕES E CONCEITOS DE BI ............................................................................ 17
2.2 ARQUITETURAS DE BI ................................................................................................ 17
2.2.1 Data Warehouse (DW) ................................................................................................ 18
2.2.1.1 Data Mart (DM) .......................................................................................................... 19
2.2.1.2 Granularidade ............................................................................................................. 20
2.2.1.2 Metadados................................................................................................................... 21
2.2.2 Modelagem Multidimensional .................................................................................... 22
2.2.2.1 Modelo Estrela............................................................................................................ 24
2.2.2.2 Modelo Floco de Neve ............................................................................................... 25
2.2.3 Extract, transform and load (ETL) ........................................................................... 26
2.2.4 On-Line Analytical Processing (OLAP) .................................................................... 27
2.3 SUITE PENTAHO ........................................................................................................... 28
2.3.1 Arquitetura Pentaho ................................................................................................... 28
2.3.2 BI Server ...................................................................................................................... 30
2.3.3 Pentaho Metadata Editor (PME) ............................................................................... 31
2.3.4 Pentaho Data Integration (Kettle) ............................................................................. 33
2.3.5 Pentaho Reporting....................................................................................................... 35
2.3.5.1 Pentaho Report Designer ............................................................................................ 36
2.3.6 Pentaho Design Studio ................................................................................................ 37
2.3.7 Pentaho Analysis Services (Mondrian) ..................................................................... 37
2.3.7.1 Pentaho Schema Workbench ...................................................................................... 40
2.4 CONSIDERAÇÕES FINAIS .............................................................................................. 40

3 MÉTODO .......................................................................................................................... 42
3.1 CARACTERIZAÇÃO DO TIPO DE PESQUISA .......................................................... 42
3.2 ETAPAS METODOLÓGICAS ....................................................................................... 43
3.3 DELIMITAÇÕES ............................................................................................................ 43
4 SOLUÇÃO DE BI TRANSFERÊNCIA DE RECURSOS ............................................ 45
4.1 ESCOLHA DA FONTE DOS DADOS ........................................................................... 45
4.1.1 Portal da Transparência ............................................................................................. 45
4.1.1.1 Dados do Portal da Transparência .............................................................................. 46
4.1.2 Portal do IBGE ............................................................................................................ 46
4.1.2.1 Pesquisa Demográfica ................................................................................................ 47
4.1.2.2 Dados do Portal da IBGE ........................................................................................... 47
4.2 MODELAGEM MULTIDIMENSIONAL ...................................................................... 48
4.2.1 Tabelas de Fatos .......................................................................................................... 48
4.2.2 Tabelas de Dimensões ................................................................................................. 48
4.2.3 Modelo .......................................................................................................................... 49
4.3 PLATAFORMA DE BI PENTAHO (SERVER) ............................................................ 50
4.3.1 Administration Console .............................................................................................. 51
4.3.2 Console do Usuário ..................................................................................................... 52
4.3.3 Publicações Externas................................................................................................... 54
4.4 REPOSITÓRIO DE METADADOS (PME) ................................................................... 55
4.4.1 Conexão ........................................................................................................................ 56
4.4.2 Modelo de Negócios ..................................................................................................... 56
4.4.2.1 Tabelas de Negócios ................................................................................................... 56
4.4.2.2 Relacionamentos......................................................................................................... 57
4.4.2.3 Visão de Negócios ...................................................................................................... 58
4.4.3 Publicação no BI Server ............................................................................................. 59
4.5 PROCESSO ETL (KETTLE) .......................................................................................... 60
4.5.1 Job Carrega Dimensão Geográfica ............................................................................ 62
4.5.1.1 Transformação Dimensão Geográfica 1 ..................................................................... 63
4.5.1.2 Transformação Dimensão Geográfica 2 ..................................................................... 64
4.5.1.3 Transformação Dimensão Geográfica 3 – Nomes dos Estados.................................. 64

4.5.1.4 Transformação Dimensão Geográfica – Código Portal da Transparência ................. 65
4.5.1.5 Transformação Dimensão Geográfica – Registro de Estados .................................... 67
4.5.2 Transformação Dimensão Tempo.............................................................................. 67
4.5.3 Job Carrega Fato População ...................................................................................... 68
4.5.3.1 Transformação - Carga Fato População 2005, 2006, 2007 e 2011 ............................ 69
4.5.3.2 Transformação - Carga Fato População 2008 e 2009 ................................................ 70
4.5.3.3 Transformação - Carga Fato População 2010 ............................................................ 72
4.5.4 Job Carrega Dimensão Projeto .................................................................................. 72
4.5.4.1 Transformação Dimensão Projetos de 2005 a 2011 ................................................... 73
4.5.5 Job Carrega Fato Recurso Transferido .................................................................... 74
4.5.5.1 Transformações - Carga Fato Recurso Transferido de 2005 a 2011 .......................... 75
4.5.6 Transformação Fato População Recurso Transferido por Habitante ................... 76
4.5.7 Execução do Job Principal do Processo ETL ........................................................... 77
4.6 PENTAHO REPORTING ............................................................................................... 78
4.6.1 Pentaho Report Designer ............................................................................................ 78
4.6.1.1 Relatório Transferência de Recursos por Função e Estado ........................................ 79
4.6.1.2 Relatório Transferência de Recursos aos Municípios por Estado e Ano ................... 86
4.7 PENTAHO DESIGN STUDIO ........................................................................................ 87
4.7.1 Gráfico Bolha Transferência de Recursos por Localidade ..................................... 88
4.7.2 Gráfico Linha Transferência de Recursos por Localidade e Ano .......................... 91
4.8 PENTAHO MONDRIAN COM SCHEMA WORKBENCH ......................................... 94
4.8.1 Cubo de Dados Transferência de Recursos .............................................................. 95
4.8.1.1 Elementos do Cubo de Dados ..................................................................................... 96
4.8.2 Cubo de Dados Transferência de Recursos por Habitante ..................................... 99
4.8.3 Publicação no BI Server ........................................................................................... 100
5 CONCLUSÕES E TRABALHOS FUTUROS ............................................................. 102
REFERÊNCIAS ................................................................................................................... 104
APÊNDICES ......................................................................................................................... 108
APÊNDICE A – Script SQL para Criação do Data Warehouse ...................................... 109
APÊNDICE B – Script PL/pgSQL Auxiliar para Execução dos Gráficos ...................... 111
ANEXO .................................................................................................................................. 118
ANEXO A – Exemplo de Origem dos Dados ..................................................................... 119

14
1 INTRODUÇÃO
Segundo Scheps (2008), Business Intelligence (BI) é um conjunto de ferramentas
com o propósito principal de entregar as informações adequadas para os corretos tomadores
de decisões em momentos oportunos. Contudo, isso só funciona se os últimos forem não
somente capazes de usar as ferramentas de BI, mas também devem ser capazes de formular as
questões certas. Com soluções de BI, empresas podem descobrir informações valiosas dentro
de uma massa de dados complexa.
As soluções de BI tratadas, nesta proposta, são as da Pentaho BI Suite
Community Edition (CE), que representam um conjunto de ferramentas Pentaho
mantidas pela comunidade, open source1 e com processos de extração de dados e
organização dos mesmos para que se tornem informações. Isto através de ferramentas de
análise e de apresentação de relatórios e gráficos.
1.1 PROBLEMÁTICA
A utilização de soluções de BI vem crescendo gradativamente ao longo dos anos,
cada vez mais organizações procuram por esse tipo de tecnologia para terem parâmetros
precisos na tomada de decisão.
Os sistemas transacionais, Online Transaction Processing (OLTP2) geram um
grande número de dados, tornando-se difícil, com o tempo, a obtenção de informações
históricas precisas, sendo assim, necessária uma solução de BI para utilizar as informações
temporais de forma compacta e objetiva, tornando-se possível a obtenção de informações
valiosas para a tomada de decisão.
Soluções de BI podem exigir adequação às necessidades específicas de uma
organização, em muitos casos, sendo necessário realizar customizações no código fonte, ou
até mesmo, de novas implementações de software e, ainda, essa organização pode necessitar
distribuir esta solução customizada para suas filiais. As soluções de BI proprietárias têm
condições mais rígidas de licenciamento e distribuição, neste caso, uma solução open source
pode ser inevitável, pois o custo de se desenvolver uma solução de BI do zero pode ser
inviável. Em contra partida, as soluções open source não possuem custo com licenciamento e
1 Open source é uma modalidade de licenciamento de software no qual não há custos com licenças. É baseado
em padrões abertos e o código fonte está disponível para qualquer um. (BOUMAN; DANGEN, 2009). 2 Processamento de Transações online (OLTP) são ambientes de software que lidam com os negócios rotineiros
no andamento de uma empresa, sendo eficientes no processamento de transações, porém ineficientes na geração
de consultas e relatórios. (TURBAN et al., 2008).

15
também possuem código fonte aberto, podendo ser modificadas e depois distribuídas à
vontade.
Neste sentido, a pesquisa deste trabalho procura responder a seguinte pergunta:
Como construir soluções de BI com ferramentas open source para auxílio ao
processo de tomada de decisão?
1.2 OBJETIVOS
Os objetivos podem ser divididos em objetivo geral e objetivos específicos.
1.2.1 Objetivo Geral
Construir uma solução de BI, para auxílio ao processo decisório, utilizando
ferramentas open source e disponibilizadas pela Pentaho em sua suite3 de aplicativos.
1.2.2 Objetivos Específicos
Construir um repositório de dados tipo data warehouse4 de uma base de dados
pública específica.
Realizar o processo de extração, transformação e carga de dados com uma
ferramenta gráfica e open source.
Construir soluções de análises de dados com ferramentas open source e
disponibiliza-las através de uma ferramenta de front end5.
1.3 JUSTIFICATIVA
Como objetivos principais do BI estão relacionados, o acesso interativo aos dados,
a manipulação dos mesmos e a análise adequada dos dados por parte dos gerentes e analistas
3 Suite são um conjunto de programas de computador, com um design uniforme e com a capacidade de
compartilhar dados. (OXFORD, 2012). 4 Data warehouse é grande base de dados capaz de reunir as informações de interesse de uma empresa,
provenientes de fontes de dados diversas. (MACHADO, 2004). 5 Front end são programas que fornecem uma interface amigável com o usuário, permitindo que os mesmos
interajam com o software. (BOUMAN; DANGEN, 2009).

16
de negócios. O processo do BI baseia-se em transformar os dados em informações, as
mesmas em decisões, para, no final, tomar as ações adequadas. (TURBAN et al., 2008).
O uso de ferramentas de business intelligence é muito popular na indústria.
Entretanto, o uso de ferramentas open source é ainda um tanto limitada se comparada com
outros tipos de software. As ferramentas dominantes são as de código fechado e comercial.
(THOMSEN; PEDERSEN, 2009).
Para apresentar este trabalho, os softwares escolhidos foram os da suite de
ferramentas Pentaho, por ser um ferramental de BI bem completo, bastante difundido,
multiplataforma, baseado em padrões abertos e open source.
Segundo Weber (2003), ferramentas open source permitem o acesso ao código
fonte das mesmas sem limites, não possuem custos com licenciamento e ainda podem ter seu
código fonte customizado, conforme a necessidade, para que depois se possam distribuir as
aplicações modificadas.
1.4 ESTRUTURA DA MONOGRAFIA
O capítulo 1 apresentou a problemática e justificativas sobre a construção de
soluções de BI com Pentaho BI Suite Community Edition (CE).
No capítulo 2 é apresentado o referencial teórico que dará embasamento científico
para o desenvolvimento deste trabalho, nessa seção, serão apresentados conceitos sobre BI,
incluindo ELT, data warehouse, OLAP e sobre a suite de Ferramentas Pentaho.
O capítulo 3 apresenta o método proposto juntamente com a metodologia adotada
e delimitação do trabalho.
No capítulo 4, é apresentada a solução do projeto.
No quinto e último capítulo, serão apresentadas as conclusões e trabalhos futuros.

17
2 REFERENCIAL BIBLIOGRÁFICO
Neste capítulo, são apresentados os conceitos essenciais para a construção de um
repositório de dados do tipo data warehouse, assim como conceitos de business intelligence.
Também, são apresentadas as ferramentas open source da suite Pentaho que serão
utilizadas para apresentar a solução de BI aqui proposta.
2.1 DEFINIÇÕES E CONCEITOS DE BI
Business Intelligence (BI) não é um simples produto, aplicação, programa,
usuário, área ou sistema, mas, sim, uma arquitetura abrangente de sistemas integrados e
métodos que oferecem informações para tomada de decisão e aprendizado. As pressões
competitivas fazem com que as organizações tenham que continuamente se adaptarem e
melhorarem para obterem sucesso em ambientes de negócio que estão em constante mudança.
As informações podem ser requeridas em todos os níveis da organização para contínua
tomada de decisão. (WOODSIDE, 2010).
O benefício principal do BI para uma organização é a capacidade do mesmo
fornecer informações precisas de acordo com a necessidade, incluindo uma visão do
desempenho da empresa em tempo real e, também, de suas partes. (TURBAN et al., 2008).
De acordo com Chaudhuri, Dayal e Narasayya (2011), software de BI são um
conjunto de tecnologias de apoio à decisão direcionadas a trabalhadores do conhecimento
como: executivos, gerentes e analistas, permitindo com que tomem decisões mais rápidas e
confiáveis.
2.2 ARQUITETURAS DE BI
De acordo com Turban e outros (2008), o BI tem quatro grandes componentes:
a) data warehouse com seus dados fonte, ver seção 2.2.1;
b) ferramentas para monitoramento e análise dos dados (OLAP), ver seção 2.2.4, do data
warehouse, inclusive data mining. Segundo Turban e outros (2008), data mining é
uma classe de análise de informações, que procura padrões ocultos num conjunto de
dados com o objetivo de prever comportamentos futuros;
c) business performance management (BPM), que serve para monitorar e analisar o
desempenho. Segundo Turban e outros (2008, p. 31), “é uma forma de conectar

18
métricas de nível superior, como as informações financeiras criadas pelo diretor
financeiro (CFO), a desempenhos reais de todos os níveis hierárquicos da
corporação”;
d) interface com o usuário, como dashboards, sendo que, segundo Turban e outros
(2008), eles fornecem uma visão abrangente e visual das medidas através de
indicadores-chaves de desempenho.
Cada um desses componentes é demonstrado na figura 1.
Figura 1 – Uma arquitetura de alto nível do BI
Fonte: Turban e outros, 2008, p. 30.
2.2.1 Data Warehouse (DW)
Segundo Turban e outros (2008), DW é uma infra-estrutura reorganizada de banco
de dados, de modo a estar sempre on-line, contendo todas as informações de sistemas OLTP,
incluindo dados históricos, porém que ofereça eficiência e rapidez nas consultas, análises e
suporte à decisão. É uma coleção de dados projetada para oferecer suporte à tomada de
decisões gerenciais.
Data warehouse representa uma grande base de dados capaz de integrar as
informações de interesse para a empresa, de forma confiável e concisa, sendo que estão
espalhadas pelos sistemas operacionais e fontes externas a empresa para, posteriormente,
serem utilizados nos sistemas de apoio à decisão. (MACHADO, 2004).

19
De acordo com Turban e outros (2008), um data warehouse possui as seguintes
características fundamentais:
a) orientados por assunto: O DW se baseia nos principais assuntos de interesse da
empresa, como vendas, produtos ou clientes. A ideia é não só permitir determinar
como está o desempenho da empresa, mas, também, determinar o porquê deste
desempenho. (TURBAN et al., 2008). Esses assuntos devem estar representados no
modelo de dados da empresa em uma série de tabelas relacionadas inseridas no DW.
(INMON, 1997);
b) integrado: Dados de diferentes fontes devem ser alocados no DW de forma
consistente. Sendo assim, conflitos de nomenclatura e unidades de medida de
diferentes fontes devem ser resolvidos para que ocorra integração. (TURBAN et al.,
2008);
c) variável no tempo (série temporal): De acordo com Turban e outros (2008, p. 58), “O
tempo é uma dimensão importante à qual todo data warehouse deve oferecer suporte”.
Um DW mantém os dados históricos para ser possível detectar tendências, variações,
relações de longo prazo para revisão e variações, levando à tomada de decisão.
(TURBAN et al., 2008);
d) não-volátil: Após a inserção dos dados no data warehouse, os mesmos não podem
mais serem alterados. Porém dados obsoletos podem ser descartados. (TURBAN et al.,
2008). A não volatilidade do DW se dá pois os dados têm alta durabilidade no tempo,
diferente dos sistemas operacionais. (INMON, 1997).
2.2.1.1 Data Mart (DM)
Segundo Machado (2004), um DM é um subconjunto de dados em um data
warehouse e é direcionado a uma área ou departamento específico de processos do negócio,
conforme figura 2.

20
Figura 2 – Ilustração data mart
Fonte: Machado. 2004, p. 44.
Um data mart é um mecanismo de armazenamento de dados semelhante a um
data warehouse, contudo menor e especializado. Um DW armazena dados para toda a
organização, enquanto um DM armazena dados para uma determinada unidade funcional,
divisão, ou departamento dentro da organização. (WITHEE, 2010).
2.2.1.2 Granularidade
De acordo com Inmon (1997), o aspecto mais importante de um projeto de DW é
a questão da granularidade. Ela diz respeito ao nível de detalhamento dos dados contidos no
data warehouse. Quanto menor o nível de detalhe, maior será o nível de granularidade.
A razão para a granularidade ser a principal questão de um projeto de data
warehouse é que ela afeta o volume de dados que será contido no DW, ao mesmo tempo
afetando o tipo de consulta que poderá ser efetuada. Sendo que o volume de dados de um DW
é balanceado conforme o nível de detalhe que se deseja em uma consulta. (INMON, 1997).
Como mostra a figura 3, a tabela chamada de regatividade, no lado esquerdo, tem
mais detalhes (informações) do que a tabela com o mesmo nome do lado direito,
consequentemente, precisa ser projetada para um volume de dados maior, resultando num
menor grau de granularidade do que a tabela do lado direito. Assim, quando menor o nível de
detalhe, maior o nível de granularidade. (INMON, 1997).

21
Figura 3 – Importância da definição da granularidade no projeto de data warehouse
Fonte: Machado, 2004, p. 47.
2.2.1.3 Metadados
Metadados são dados de alto nível que contêm informações sobre os dados que
estão armazenados no sistema, os dados de mais baixo nível. Um data warehouse possui um
dicionário de metadados que fornece ao usuário informações que permitem ao mesmo julgar a
qualidade do conteúdo. (MACHADO, 2004).
Conforme Turban e outros (2008), os metadados descrevem a estrutura e o
significado dos dados, contribuindo para o seu uso, que pode ser eficiente ou ineficiente.
De acordo com Machado (2004), para um data warehouse, o processo de
metadados deve realizar a geração e o gerenciamento de uma documentação sobre:
a) o levantamento dos dados;
b) banco de dados;
c) relatórios que serão gerados;
d) origem dos dados que alimentarão o data warehouse;
e) processos de extração e carga dos dados;
f) regras de negócio da empresa e suas mudanças.

22
Os metadados permitirão a transformação dos dados crus em informações que
gerem conhecimento, sendo um processo de vital importância para qualquer projeto de data
warehouse. (MACHADO, 2004).
2.2.2 Modelagem Multidimensional
Segundo Kimball e Ross (2002), o método dimensional representa uma força dos
projetos de banco de dados, no qual o projetista tem como principais objetivos a capacidade
de compreensão da base de dados e melhor desempenho nas consultas em cima dessa base.
Quando se desenha um modelo de dados, cria-se uma visualização que representa
tabelas no banco de dados. Os dados geralmente analisados tomam a forma de dados
numéricos, como: número de vendas, quantidade em estoque, valores ou qualquer coisa que
possa ser quantificada. Esses valores numéricos, também conhecidos como medidas ou fatos
são geralmente colocados em uma tabela no centro do modelo projetado. Essa tabela leva o
nome de tabela de fato. Também há tabelas que representam as dimensões, que são meios de
dividir os dados, que, geralmente, ficam situadas ao redor da tabela de fato. (WITHEE, 2010).
De acordo com Machado (2004, p. 79, grifo nosso), “A modelagem
multidimensional é uma técnica de concepção e visualização de um modelo de dados de um
conjunto de medidas que descrevem aspectos comuns de negócios. [..] Um modelo
multidimensional é formado por três elementos básicos: Fatos, Dimensões e Medidas”.
a) fatos:
- fato é um assunto que pode ser medido com valores numéricos para descrevê-
lo, tendo os seus valores mutáveis no decorrer do tempo. Ex: “O índice de
aprovação escolar da cadeira de Cálculo vem aumentando nos últimos dois
anos”. (MACHADO, 2004, p. 100);
- segundo Kimball e Ross (2002), a lista de dimensões define qual vai ser a
granularidade da tabela de fatos, definindo qual é o escopo da medição, sendo
que uma medição é uma linha na tabela de fatos.
b) dimensões:
- de acordo com Machado (2004), dimensões são elementos que participam de
algum fato, ou seja o: ‘Onde?’, ‘Quando?’, ‘Quem?’ ou ‘O Que?’ relativos
aos dados. A única dimensão que deve estar presente em todo data warehouse
é a de tempo, por isso tem uma importância acentuada;
- ex: Considerando o fato compra: (MACHADO, 2004, p. 115). Ver figura 4;

23
- “Quando foi realizada a compra”;
- “Onde foi realizada a compra”;
- “Quem realizou a compra”;
- “O que foi comprado”;
Figura 4 – Elementos participantes da ocorrência de uma compra
Fonte: Machado, 2004, p. 115.
- “As tabelas de dimensões contêm informações de classificação e agregação
sobre as linhas de fatos centrais. Elas incluem atributos que descrevem dados
contidos na tabela de fatos e tratam de como os dados serão analisados.”.
(TURBAN et al, 2008, p. 80).
c) medidas:
- Conforme Machado (2004), medidas são atributos numéricos que representam
um fato, são atributos do mesmo, como, por exemplo, o fato venda: valor de
vendas, quantidade de determinado produto vendido, total em estoque do
produto, o custo de venda, etc.
Um exemplo de modelagem multidimensional pode ser visto na Figura 5, no qual
a tabela de fatos está no centro, sendo que inclui as medidas: quantidade vendida, valor total
de venda e valor total de custo, com as dimensões: tempo, geográfica, cliente e produto ao
redor da tabela de fato.

24
Figura 5 – Modelo multidimensional
Fonte: Adaptado de Machado, 2004 e Withee, 2010.
2.2.2.1 Modelo Estrela
Modelo Estrela (Star schema) é um termo comum utilizado para designar modelos
multidimensionais em geral. (MACHADO, 2004).
Segundo Turban e outros (2008, p. 80), “O esquema estrela oferece tempo
extremamente rápido de resposta a consultas, simplicidade e facilidade de manutenção para
estruturas de banco de dados somente leitura“.
Como é ilustrado na Figura 6, a tabela de fatos está associada a um conjunto de
tabelas de dimensões com características semelhantes a uma estrela. Essa característica é
normalmente denominada: “esquema de junção em estrela”. (KIMBALL; ROSS, 2002, p. 27).
Um conjunto de entidades menores, denominadas dimensões, ao redor de uma
entidade principal, tabela de fato, forma uma estrela. (MACHADO, 2004).
Conforme figura a seguir:

25
Figura 6 – Modelo estrela
Fonte: Machado, 2004, p. 93.
2.2.2.2 Modelo Floco de Neve
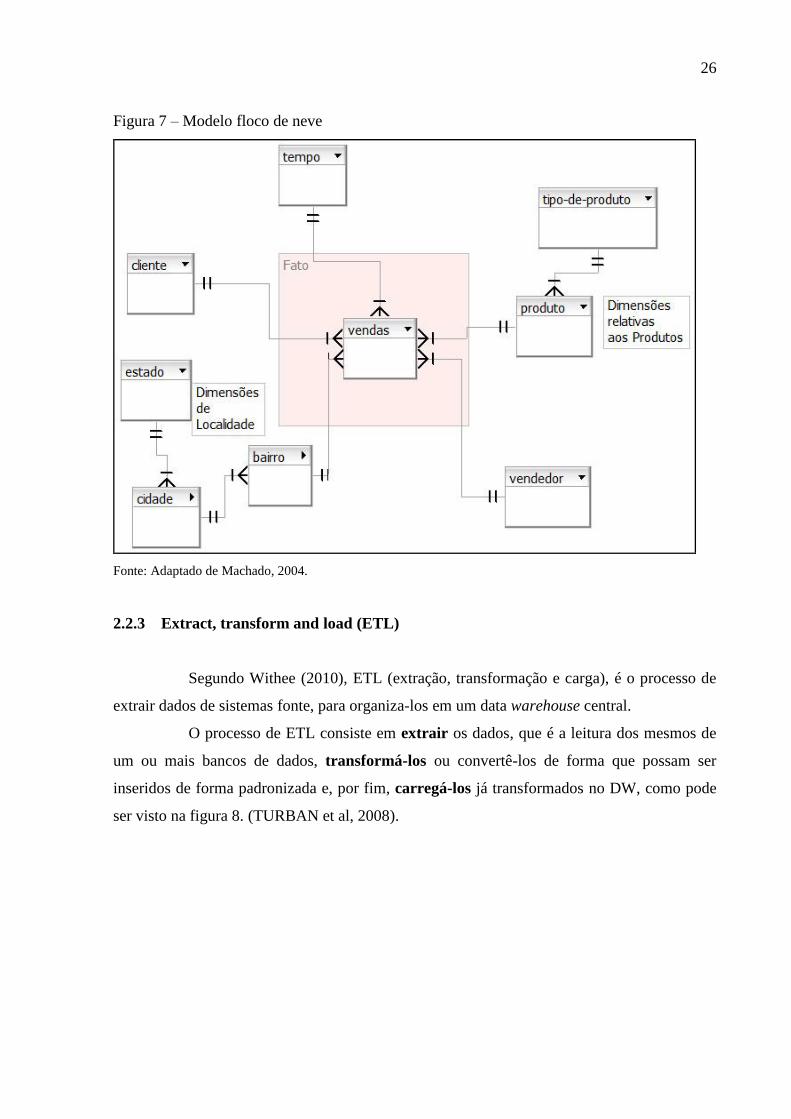
O modelo Floco de Neve (Snowflake) ocorre quando há divisão de uma ou mais
dimensões, do modelo estrela, de forma hierárquica. Desse modo, ocorre a normalização
dessa dimensão, evitando a redundância de valores textuais em uma tabela. (MACHADO,
2004).
É importante resaltar que os dados de um data warehouse não possuem valores
incluídos diretamente por um digitador, não sendo necessário controles para garantir
unicidade dos dados. O importante é garantir a informação de forma rápida e não economizar
espaço para armazenamento de dados. (MACHADO, 2004).
Segundo Machado (2004), o modelo de dados tem esse nome devido a sua
semelhança visual com um floco de neve. As tabelas de dimensões no modelo de banco de
dados floco de neve tem tabelas adicionais em relação ao modelo em estrela. Essas são
anexadas para reduzir a quantidade de dados armazenados em uma única tabela de dimensão,
como pode ser visto na figura 7.
26
Figura 7 – Modelo floco de neve
Fonte: Adaptado de Machado, 2004.
2.2.3 Extract, transform and load (ETL)
Segundo Withee (2010), ETL (extração, transformação e carga), é o processo de
extrair dados de sistemas fonte, para organiza-los em um data warehouse central.
O processo de ETL consiste em extrair os dados, que é a leitura dos mesmos de
um ou mais bancos de dados, transformá-los ou convertê-los de forma que possam ser
inseridos de forma padronizada e, por fim, carregá-los já transformados no DW, como pode
ser visto na figura 8. (TURBAN et al, 2008).

27
Figura 8 – O processo de ETL
Fonte: Turban e outros, 2008, p. 72.
Para migrar os dados para um data warehouse, varias fontes relevantes podem
estar envolvidas, como: bancos de dados OLTP, planilhas, banco de dados pessoais, etc. Um
DW contém várias regras de negócio, e qualquer problema, na qualidade dos dados, precisa
ser corrigido antes que os mesmos sejam inseridos no data warehouse. Essas regras podem
ser armazenadas em um repositório de metadados. (TURBAN et al, 2008).
De acordo com Brown (2004, apud Turban et al, 2008, p. 73), ferramentas ETL já
existentes podem ser utilizadas, poupando-se do trabalho de se criar softwares ETL novos,
sendo que, para selecionar qual ferramental utilizar, devem-se ser observados importantes
critérios como:
a) ter a capacidade de ler e gravar dados, em uma ilimitada quantidade de formatos de
fontes de dados;
b) ter a capacidade de captura e entrega imediata de metadados;
c) estar em conformidade com padrões abertos em seu histórico;
d) ter uma interface de fácil utilização tanto para o desenvolvedor quanto para o usuário
final.
2.2.4 On-Line Analytical Processing (OLAP)
De acordo com Machado (2004), OLAP, ou processamento analítico on-line, é um
conjunto de ferramentas que possibilita a análise dos dados em um data warehouse.
A análise multidimensional OLAP, ao longo do tempo, possibilita a descoberta de
tendências e cenários através de operações como: os dez maiores, comparações entre valores,

28
médias, percentuais de variação, somas, valores cumulativos e outras diversas operações
estatísticas e financeiras, possibilitando, assim, a transformação dos dados de um data
warehouse em informação estratégica. (MACHADO, 2004).
Conforme Turban e outros (2008, p. 109), “produtos OLAP oferecem recursos de
modelagem, análise de visualização de grandes volumes de dados [..] mais frequentemente
para sistemas de data warehouse. Os produtos oferecem também uma visão conceitual
multidimensional dos dados”.
Segundo Withee (2010), banco de dados OLAP são otimizados para análise ao
invés de recebimento e armazenamento de dados. OLAP pode dividir os dados para observá-
los por diferentes ângulos. Desde que o objetivo de bancos de dados OLAP é aumentar o
desempenho da análise dos dados, muito dos dados são armazenados redundantemente.
2.3 SUITE PENTAHO
Segundo Bouman e Dangen (2009), Pentaho é uma suite de ferramentas de
business intelligence ao invés de um simples produto. É construído sobre um conjunto de
programas de computadores que trabalham juntos para criar e oferecer soluções de BI.
Algumas dessas ferramentas fornecem funcionalidades desde as básicas, como, autenticação
de usuário ou gerenciamento de conexão com banco de dados, até funcionalidades de alto
nível, como a visualização de dados utilizando tabelas e gráficos.
De acordo com Bouman e Dangen (2009), praticamente todos os programas da
suite Pentaho são programados na linguagem de programação Java. A plataforma Java é
extremamente portável entre arquiteturas de hardware e sistemas operacionais.
Consequentemente, Pentaho está disponível para diferentes arquiteturas e sistemas
operacionais.
2.3.1 Arquitetura Pentaho
O conjunto de programas que compõem a suite Pentaho pode ser visualizado
como uma pilha de componentes, como pode ser visto na figura 9, no qual todos os
componentes que constituem a solução completa são apresentados. (BOUMAN; DANGEN,
2009).

29
Figura 9 – Pilha BI Pentaho
Fonte: Bouman e Dangen, 2009, p. 64.
Como apresentado na figura 9, a camada principal da pilha é a de apresentação no
topo e a camada de dados junto com integração de aplicação na parte baixa. A maioria dos
usuários finais interagem com a camada de aplicação. Através da suite Pentaho, essa camada
pode ser acessada de um simples navegador web, pode estar embutida em portais de terceiros
ou até mesmo enviar relatórios no formato PDF por e-mail. (BOUMAN; DANGEN, 2009).
As principais áreas funcionais da pilha de BI são: reporting (relatórios), analysis
(análise), dashboards (painéis) e gerenciamento de processos, que constituem a camada do
meio da pilha, enquanto a plataforma de BI em si oferece recursos básicos de administração e
segurança. A integração dos dados completa a pilha e é necessária para se obter dados de
diferentes fontes, unindo-os em um ambiente compartilhado de data warehouse. (BOUMAN;
DANGEN, 2009).
Uma arquitetura define a estrutura e o esboço de uma solução, mas não diz
exatamente como uma solução deve ser construída. No caso da Pentaho, a arquitetura define

30
as camadas e blocos de construção, mas não obriga ninguém a utilizar tudo da pilha ou das
ferramentas da suite Pentaho. Embora haja várias vantagens em usar software Pentaho para
construir a pilha, os projetistas estão livres para misturar outros componentes também.
(BOUMAN; DANGEN, 2009).
Segundo Bouman e Dangen (2009, p.65, tradução nossa), "A pilha de BI Pentaho
é portanto, uma entidade em evolução, como uma cidade onde os novos edifícios são criados
e os mais velhos são restaurados, expandidos, ou substituídos em uma base contínua".
2.3.2 BI Server
Pentaho BI Server é um conjunto de programas que trabalham juntos para
fornecer uma série de funções essenciais da suite BI Pentaho. Esses programas são
implementados como servlets Java. Os servlets são executados dentro de um contêiner de um
servidor web (ou Servidor HTTP). (BOUMAN; DANGEN, 2009).
Segundo Bouman e Dangen (2009), em um nível funcional, Pentaho Server pode
ser dividido em três camadas:
a) a plataforma: As funcionalidades desta camada são, relativamente, de baixo nível e
constituem uma infraestrutura básica da plataforma de BI. Essa camada fornece uma
coleção de componentes que oferecem os seguintes serviços:
- repositório de soluções e motor de soluções;
- gerenciamento do pool de conexão com o banco de dados;
- autenticação de usuários e autorização de serviços;
- logging e serviços de auditoria;
- agendamento de tarefas;
- serviços de e-mail.
b) componentes de BI: Os seguintes componentes são encontrados nessa camada:
- camada de metadados;
- ad hoc serviço de relatório;
- motor ETL;
- motor Reporting;
- motor OLAP;
- motor de mineração de dados.
c) a camada de apresentação: Pentaho vem com uma interface web embutida, chamada
de Console do Usuário. Esse forma um front end que permite ao usuário humano

31
interagir com o servidor. A camada de apresentação pode ser usada para navegação e,
para abrir conteúdo existente como: relatórios, dashboards (painéis) e análises, porém
em certa medida pode ser utilizado para criar novo conteúdo de BI.
A figura 10 apresenta o Console do Usuário em uma interface web, tendo na
esquerda superior, uma árvore de diretórios utilizada para organizar arquivos, na esquerda
inferior, o conteúdo da pasta selecionada, e no centro direito, abas do conteúdo aberto como:
dashboards, análises e relatórios. (PENTAHO, 2012a).
Figura 10 – Console do Usuário
Fonte: Pentaho, 2012a.
2.3.3 Pentaho Metadata Editor (PME)
PME, ou Pentaho Editor de Metadados, é uma aplicação desktop multiplataforma,
que pode editar e criar metadados para a suite de ferramentas Pentaho. Um exemplo da
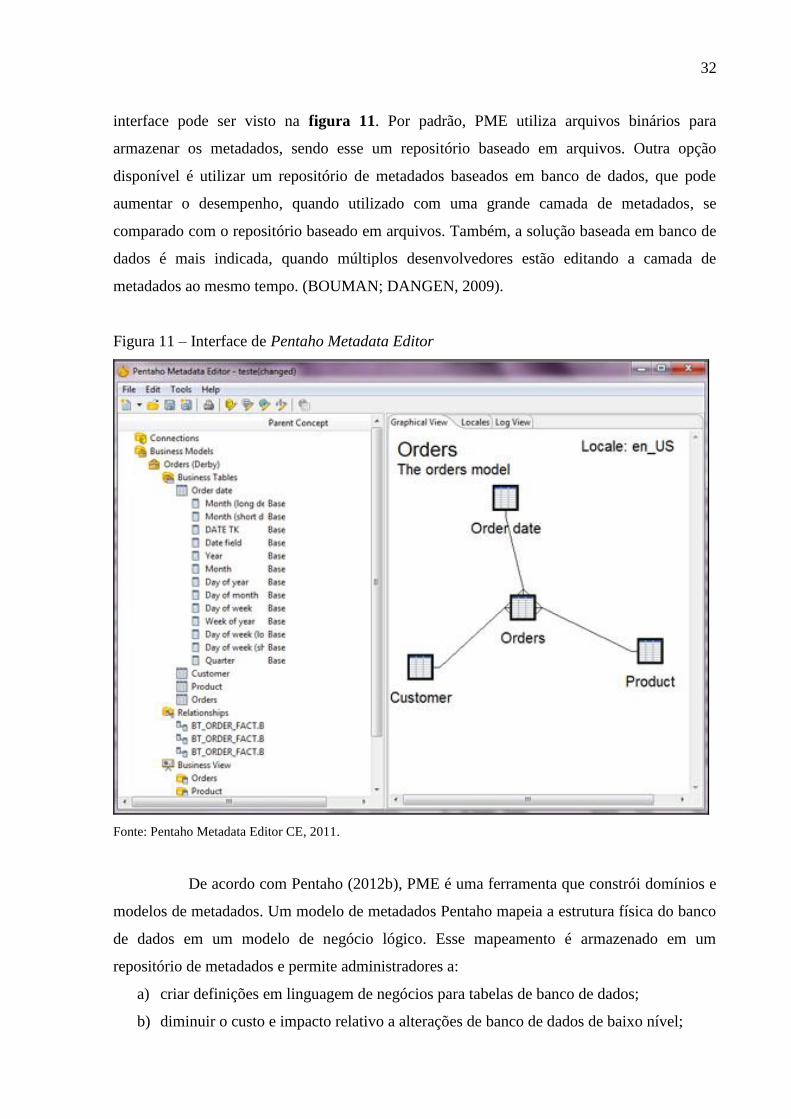
32
interface pode ser visto na figura 11. Por padrão, PME utiliza arquivos binários para
armazenar os metadados, sendo esse um repositório baseado em arquivos. Outra opção
disponível é utilizar um repositório de metadados baseados em banco de dados, que pode
aumentar o desempenho, quando utilizado com uma grande camada de metadados, se
comparado com o repositório baseado em arquivos. Também, a solução baseada em banco de
dados é mais indicada, quando múltiplos desenvolvedores estão editando a camada de
metadados ao mesmo tempo. (BOUMAN; DANGEN, 2009).
Figura 11 – Interface de Pentaho Metadata Editor
Fonte: Pentaho Metadata Editor CE, 2011.
De acordo com Pentaho (2012b), PME é uma ferramenta que constrói domínios e
modelos de metadados. Um modelo de metadados Pentaho mapeia a estrutura física do banco
de dados em um modelo de negócio lógico. Esse mapeamento é armazenado em um
repositório de metadados e permite administradores a:
a) criar definições em linguagem de negócios para tabelas de banco de dados;
b) diminuir o custo e impacto relativo a alterações de banco de dados de baixo nível;

33
c) definir parâmetros de segurança relativo ao acesso de usuários aos dados;
d) conduzir a formatação de dados textuais, datas e valores numéricos, melhorando a
manutenção de relatórios;
e) localizar a informação com base nas configurações regionais do usuário.
Com PME, designers podem criar camadas de metadados que servem como uma
camada de abstração entre um banco de dados relacional e um usuário final. A camada de
metadados pode levar objetos de usuários, como Nome do Cliente e País e traduzir essa
seleção na correta instrução SQL necessária para recuperar essas informações do banco de
dados. (BOUMAN; DANGEN, 2009).
Segundo Bouman e Dangen (2009), uma camada de metadados é organizada em
um ou mais domínios, que são contêineres de conjunto de objetos de metadados que podem
ser usados como fonte de metadados para alguma solução Pentaho. A camada de metadados
pode ser dividida em três subcamadas: a física, a lógica e a de entrega:
a) a camada Física: Mais ou menos, os elementos dessa camada correspondem aos
elementos do banco de dados como: conectores, tabelas e colunas;
b) a camada Lógica: O propósito dessa camada é descrever como os objetos da camada
física se relacionam com o negócio;
c) a camada de entrega contém objetos de metadados que são visíveis ao usuário final,
como Visões de Negócio e Categorias de Negócio.
2.3.4 Pentaho Data Integration (Kettle)
Pentaho Data Integration (PDI), também conhecido como Kettle, oferece
capacidades de ETL, usando uma abordagem orientada por metadados. Tem uma interface
gráfica intuitiva, com ferramentas de arrastar e soltar e é baseado em padrões abertos.
(PENTAHO, 2012e).
Soluções de Pentaho Data Integration são construídas a partir de dois tipos de
objetos: transformações e jobs (Tarefas). O core do produto PDI é formado pelo motor PDI.
Esse motor é um componente de software que é capaz de interpretar e executar os jobs e
transformações. Além do motor PDI, a solução fornece uma série de ferramentas e utilitários
para criar, gerenciar e iniciar transformações e jobs. Uma visão de alto nível pode ser vista na
figura 12. (BOUMAN; DANGEN, 2009).

34
Uma transformação Pentaho representa uma tarefa ETL em sentido restrito.
Transformações são orientadas aos dados e seu propósito é extrair, transformar e carregar os
dados. (BOUMAN; DANGEN, 2009).
Jobs são compostos por uma ou mais transformações, como, por exemplo,
carregar um esquema estrela, normalmente se construiria uma transformação para fazer a
extração em si, e uma transformação para tabela de dimensão e outra, para a tabela de fatos.
(BOUMAN; DANGEN, 2009).
Segundo Bouman e Dangen (2009), o PDI inclui o seguinte conjunto de
ferramentas e utilitários:
a) Spoon: Uma IDE de integração de dados para criar transformações e jobs;
b) Kitchen: Uma ferramenta de linha de comando para rodar jobs;
c) Pan: Uma ferramenta de linha de comando para rodar transformações;
d) Carte: Um servidor leve para executar transformações e jobs de em um host remoto.
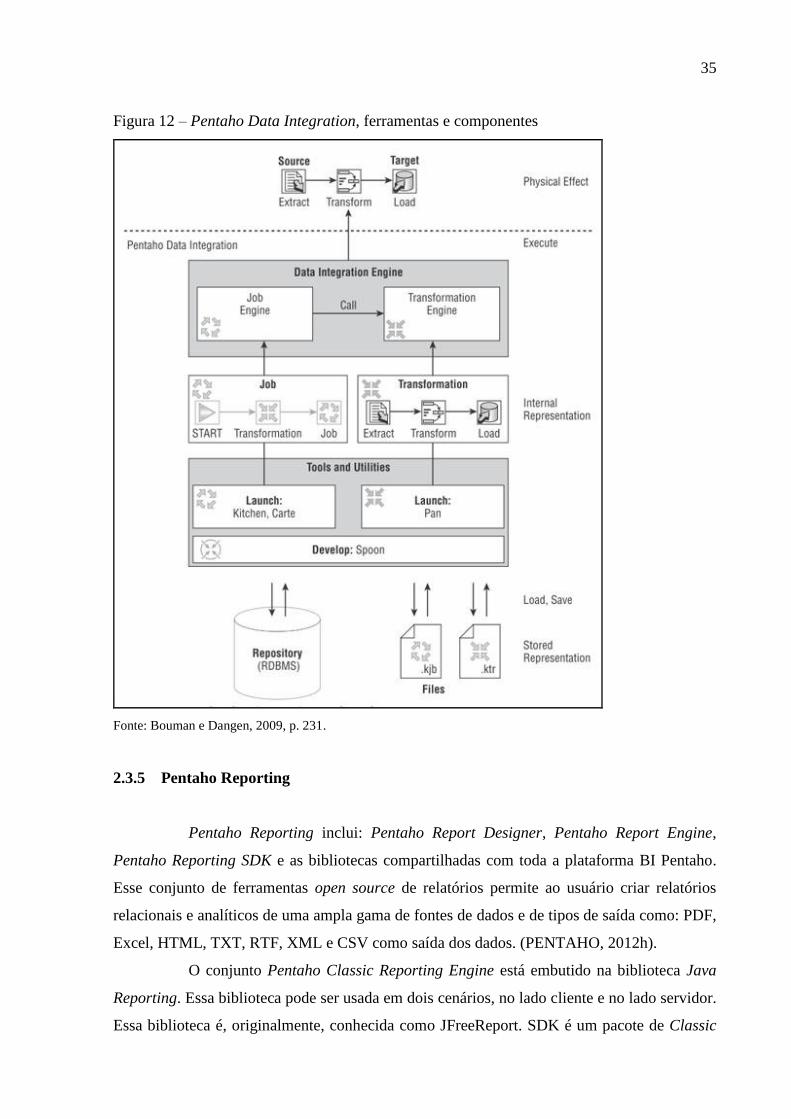
35
Figura 12 – Pentaho Data Integration, ferramentas e componentes
Fonte: Bouman e Dangen, 2009, p. 231.
2.3.5 Pentaho Reporting
Pentaho Reporting inclui: Pentaho Report Designer, Pentaho Report Engine,
Pentaho Reporting SDK e as bibliotecas compartilhadas com toda a plataforma BI Pentaho.
Esse conjunto de ferramentas open source de relatórios permite ao usuário criar relatórios
relacionais e analíticos de uma ampla gama de fontes de dados e de tipos de saída como: PDF,
Excel, HTML, TXT, RTF, XML e CSV como saída dos dados. (PENTAHO, 2012h).
O conjunto Pentaho Classic Reporting Engine está embutido na biblioteca Java
Reporting. Essa biblioteca pode ser usada em dois cenários, no lado cliente e no lado servidor.
Essa biblioteca é, originalmente, conhecida como JFreeReport. SDK é um pacote de Classic

36
Engine, documentação e todas as bibliotecas de apoio necessárias para inserir o Pentaho
Reporting Engine em aplicações de terceiros. (PENTAHO, 2012c).
De acordo com Bouman e Dangen (2009), todas modernas soluções de relatórios
têm uma arquitetura similar com a da figura 13. A figura mostra os diferentes componentes de
um arquitetura de relatórios, como:
a) um report designer para definir a especificação do relatório;
b) a especificação do relatório em um formato aberto XML;
c) um motor de relatório para executar o mesmo de acordo com as especificações e gerar
a saída em diferentes formatos;
d) definição da conexão com o banco de dados que pode usar uma middleware padrão,
como JDBC para se conectar a diferentes fontes de dados.
Figura 13 – Arquitetura do processo de geração de relatórios
Fonte: Bouman e Dangen, 2009, p. 372.
2.3.5.1 Pentaho Report Designer
Pentaho Report Designer (PRD) é um front end gráfico para criar, editar e
publicar relatórios para a plataforma BI Pentaho. PRD tem como vantagem, frente a outros

37
criadores de relatórios, o fato de usar modelos de metadados Pentaho como fontes dos dados.
(BOUMAN; DANGEN, 2009).
Segundo Pentaho (2012g), PRD é uma aplicação desktop que fornece um
ambiente de design visual para criar definições de relatórios. Os relatórios podem ser salvos
localmente ou publicados para um sistema BI Server.
2.3.6 Pentaho Design Studio
Pentaho Design Studio (PDS) é baseado na IDE Eclipse e pode ser baixado como
uma solução pronta que contém o Eclipse, mas também pode ser adicionado, a IDE Eclipse já
pré-instalada, como um plugin. (BOUMAN; DANGEN, 2009).
PDS tem como propósito a criação e manutenção de sequências de ações, que são
conjuntos de ações que podem ser executadas no BI Server. Uma execução de uma ação pode
ser desencadeada através da ação de um usuário, de um agendamento, ou qualquer outro
evento, incluindo outra sequência de ação. As ações podem ser simples como: executar um
gráfico ou um relatório. Também pode disparar mensagens na tela, algumas até complexas
como, por exemplo: localizar todos os clientes com itens atrasados e enviar-lhes um lembrete
no formato PDF, contendo uma descrição dos itens. (BOUMAN; DANGEN, 2009).
2.3.7 Pentaho Analysis Services (Mondrian)
Pentaho Analysis Services (Mondrian) é um servidor OLAP que permite aos
usuários de negócios analisarem grandes quantidades de dados em tempo real. Usuários
exploram dados de negócios através do detalhamento e cruzamento de informações com alta
velocidade a consultas analíticas complexas. (PENTAHO, 2012f).
Conforme Bouman e Dangen (2009), Mondrian é o motor OLAP da Pentaho que
traduz MDX queries (Expressões Multidimensionais) ou XML/A (XML Analítico) em SQL
para um modelo multidimensional, sendo que fornece uma sintaxe especializada para consulta
de dados armazenados em cubos OLAP. Mondrian faz muito mais do que apenas traduzir de
uma linguagem para outra, também trabalha com cache e buffering para otimizar o
desempenho, guardando resultados e cálculos prévios em memória para tornar consultas
posteriores mais rápidas.

38
De acordo com Bouman e Dangen (2009), Mondrian, também, tem um módulo de
segurança que permite o controle de papéis a serem atribuídos aos usuários, restringindo
acesso a determinados relatórios e dados.
Mondrian também é conhecido com uma ferramenta ROLAP (Relacional OLAP)
pelo fato dos dados e suas agregações estarem armazenados um banco de dados relacional
padrão. (BOUMAN; DANGEN, 2009).
Pentaho Mondrian não é nem um banco de dados nem uma ferramenta de análise,
sendo necessário um banco de dados relacional para armazenamento dos dados do data
warehouse e uma ferramenta de front end para analisar os dados, como pode ser visto na
figura 14 abaixo. (BOUMAN; DANGEN, 2009).
Figura 14 – Data warehouse com Mondrian
Fonte: Bouman e Dangen, 2009, p. 123.
A figura 15 abaixo mostra uma visão esquemática dos componentes de serviço de
análise da Pentaho e seus relacionamentos com uma típica solução Pentaho. (BOUMAN;
DANGEN, 2009).
a) o usuário de um navegador web faz uma requisição HTTP para visualizar, detalhar ou
procurar em uma tabela dinâmica OLAP;
b) JPivot Servlet recebe a requisição e a transforma em uma consulta MDX;
c) Mondrian interpreta a consulta MDX e a transforma em uma ou mais consultas SQL;
d) o sistema de gerenciamento do banco de dados relacional (RDBMS) executa as
consultas SQL enviadas pelo Mondrian e na sequência este recebe os dados tabulados;
e) Mondrian processa os resultados recebidos e os transforma em uma conjunto de
resultados multidimensional e envia-os como resposta da consulta MDX no passo b;
f) JPivot recebe e usa o resultado da consulta, a transformando em uma página HTML
que é enviada para o navegador e apresentado para o usuário.
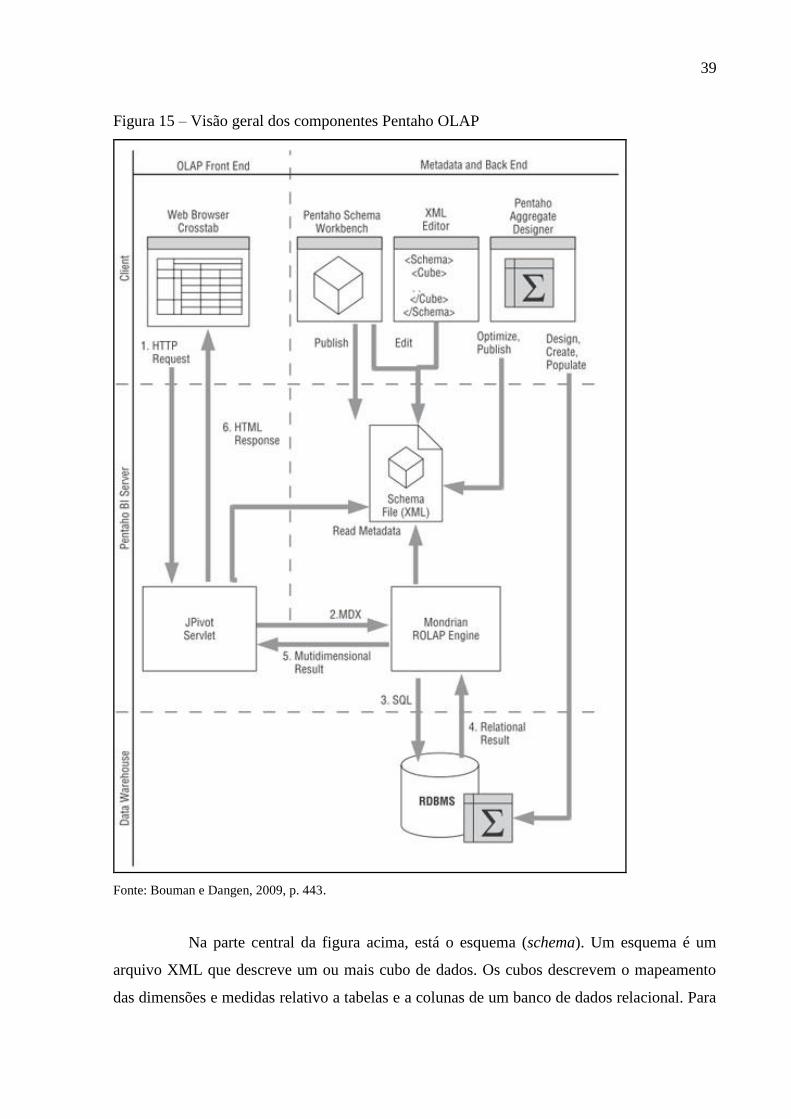
39
Figura 15 – Visão geral dos componentes Pentaho OLAP
Fonte: Bouman e Dangen, 2009, p. 443.
Na parte central da figura acima, está o esquema (schema). Um esquema é um
arquivo XML que descreve um ou mais cubo de dados. Os cubos descrevem o mapeamento
das dimensões e medidas relativo a tabelas e a colunas de um banco de dados relacional. Para

40
o Mondrian, o esquema é a chave para traduzir uma query MDX em uma query SQL.
(BOUMAN; DANGEN, 2009).
Na parte superior central direita da figura acima, são mostradas ferramentas
utilizadas para design e construção de esquemas XML, incluindo a ferramenta Pentaho
Schema Workbench. Porém qualquer editor XML poderia realizar a configuração do esquema.
(BOUMAN; DANGEN, 2009).
O motor Mondrian já está incluso no Pentaho BI Server e não precisa ser baixado
separadamente, caso já se esteja utilizando o último. Mas, caso se queira fazer alguma
atualização do motor Mondrian no BI Server ou utiliza-lo separadamente, também é possível
baixá-lo isoladamente. (BOUMAN; DANGEN, 2009).
O Console com o Usuário do BI Server permite a criação de visões de análise com
JPivot, permitindo, assim, analisar cubos Mondrian de forma facilitada. JPivot front end é
uma ferramenta baseada em Java incluída no BI Server, para trabalhar com cubos OLAP.
(BOUMAN; DANGEN, 2009).
2.3.7.1 Pentaho Schema Workbench
Pentaho Schema Workbench (PSW), oferece uma interface gráfica ao usuário para
criar esquemas de cubos de dados multidimensionais Mondrian. Essa ferramenta, também,
pode publicar os esquemas diretamente no Servidor Pentaho, dentro de um repositório de
solução. (BOUMAN; DANGEN, 2009).
2.4 CONSIDERAÇÕES FINAIS
A suite de ferramentas Pentaho aqui apresentada é open source e chamada
Community Edition CE (Edição da Comunidade), pois é mantida pela comunidade através de
um grupo de pessoas de talentos variados que estão dedicados a entregar um completo, bem
integrado e de alta qualidade conjunto de software de Business Intelligence. (PENTAHO,
2012d).
Pentaho também tem uma versão comercial denominada Enterprise Edition (EE),
que oferece além de suporte, alguns componentes que não estão disponíveis na edição da
comunidade. Apesar da distinção entre as duas distribuições estar mais ligada ao suporte do
que aos componentes na verdade. (BOUMAN; DANGEN, 2009).

41
Como apresentado, a suite Pentaho se mostra um conjunto de ferramentas de BI
bastante completa, além de ser quase em toda sua totalidade open source.

42
3 MÉTODO
Neste capítulo, serão apresentadas a caracterização do tipo de pesquisa, as etapas
metodológicas e as delimitações do projeto.
Através do estudo da suite de ferramentas Pentaho e da criação de uma solução
para dar subsidio a análise dos dados, espera-se, aqui, mostrar que é possível construir uma
solução open source de qualidade levando em conta as etapas necessárias para se construir
uma solução de BI de qualidade.
3.1 CARACTERIZAÇÃO DO TIPO DE PESQUISA
Segundo Silva e Menezes (2005, p. 20), “Pesquisa Aplicada: objetiva gerar
conhecimentos para aplicação prática e dirigidos à solução de problemas específicos”. Esta
pesquisa do ponto de vista da natureza é aplicada, pois o que será desenvolvido é uma
solução de BI com o uso da suite de ferramentas Pentaho, sendo uma aplicação prática com o
objetivo de auxiliar no processo decisório.
De acordo com Silva e Menezes (2005 p. 21), “Pesquisa Exploratória: visa
proporcionar maior familiaridade com o problema com vistas a torná-lo explícito ou a
construir hipóteses. Envolve levantamento bibliográfico”. Esta pesquisa do ponto de vista dos
objetivos é exploratória, pois envolve levantamento bibliográfico, tornando a questão do
custo benefício do uso de ferramentas open source explícita.
Uma pesquisa é bibliográfica do ponto de vista de procedimentos técnicos,
quando a mesma envolve pesquisa em materiais publicados, como em livros ou periódicos.
(SILVA; MENEZES, 2005). Assim, esta pesquisa é bibliográfica, pois é baseada em material
já publicado como: livros, artigos de periódicos e material obtido através da Internet.
Porém, a pesquisa também pode ser considerada um estudo de caso no ponto de
vista de procedimentos técnicos, pois, segundo Silva e Menezes (2005, p. 21), “Estudo de
caso: quando envolve o estudo profundo e exaustivo de um ou poucos objetos de maneira que
se permita o seu amplo e detalhado conhecimento”, assim, no caso desta pesquisa, o foco está
em algumas das Ferramentas da suite Pentaho para a construção de uma solução de BI.
Também, permitindo o conhecimento dessas com bom nível de detalhamento.
Conforme Silva e Menezes (2005, p. 20), “Pesquisa Qualitativa: [..] um vínculo
indissociável entre o mundo objetivo e a subjetividade do sujeito que não pode ser traduzido
em números. [..] Não requer o uso de métodos e técnicas estatísticas”. Com relação à

43
abordagem, está pesquisa é qualitativa, pois a relação de custo benefício com o uso de
Ferramentas open source é algo subjetivo, assim como a análise da qualidade de uma solução
de BI, não requerendo o uso de métodos estatísticos.
3.2 ETAPAS METODOLÓGICAS
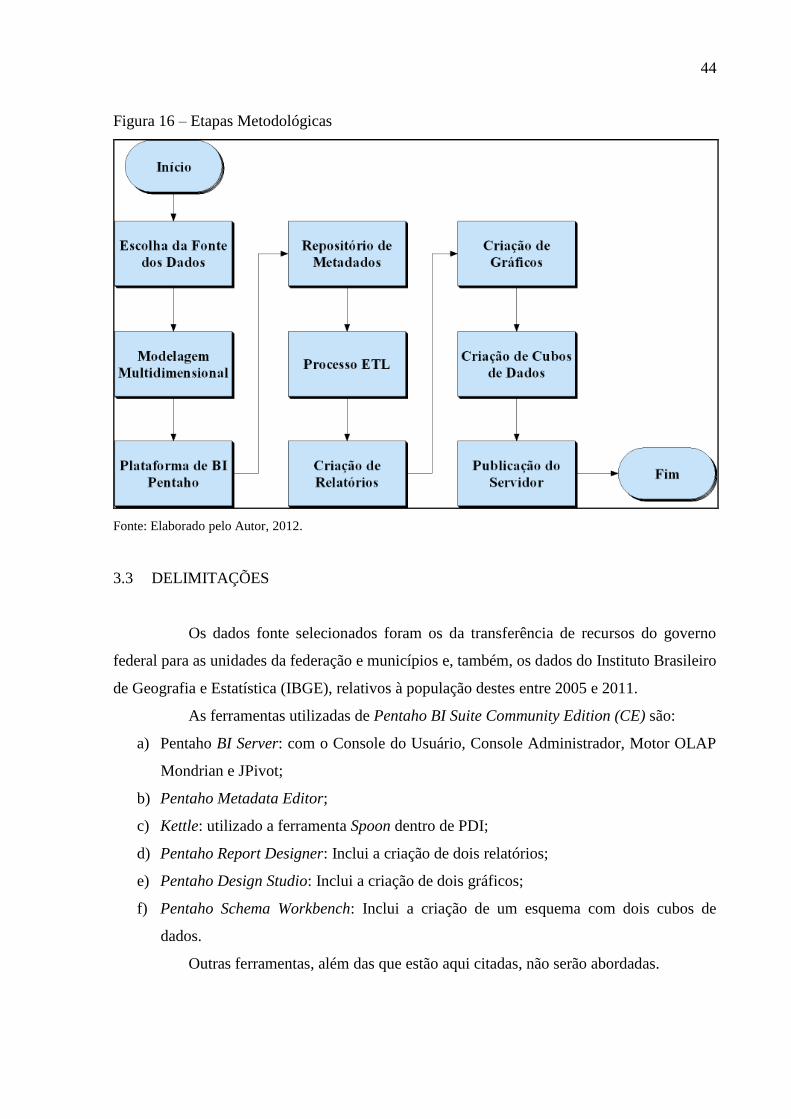
Utilizando-se da suite Pentaho, a solução segue aos seguintes passos:
a) escolha de uma fonte de dados como base para a construção da solução;
b) modelagem de uma base de dados multidimensional, incluindo a escolha das
dimensões e fatos abordados;
instalação da ferramenta Pentaho BI Server e configuração da mesma, realizando conexão
com o data warehouse;
c) construção de um modelo de metadados com a ferramenta Pentaho Metadata Editor;
d) realização do processo ETL com a utilização da ferramenta Kettle, e a criação de jobs
e tranformações para a concretização do data warehouse;
e) utilização de Pentaho Report Designer para criação de relatórios, utilizando-se do
modelo de metadados criado por PME, para serem publicados no BI Server e serem
acessados no front end Console do Usuário;
f) utilização de Pentaho Design Studio para criação de gráficos, para serem publicados
no BI Server e, também, serem acessados no front end Console do Usuário;
g) construção de um esquema com cubos de dados com Pentaho Schema Workbench,
para que o esquema seja publicado no BI Server, permitindo acesso pelo front end
Console do Usuário com JPivot.
Os passos das etapas acima podem ser visualizados na figura 16 a seguir.
44
Figura 16 – Etapas Metodológicas
Fonte: Elaborado pelo Autor, 2012.
3.3 DELIMITAÇÕES
Os dados fonte selecionados foram os da transferência de recursos do governo
federal para as unidades da federação e municípios e, também, os dados do Instituto Brasileiro
de Geografia e Estatística (IBGE), relativos à população destes entre 2005 e 2011.
As ferramentas utilizadas de Pentaho BI Suite Community Edition (CE) são:
a) Pentaho BI Server: com o Console do Usuário, Console Administrador, Motor OLAP
Mondrian e JPivot;
b) Pentaho Metadata Editor;
c) Kettle: utilizado a ferramenta Spoon dentro de PDI;
d) Pentaho Report Designer: Inclui a criação de dois relatórios;
e) Pentaho Design Studio: Inclui a criação de dois gráficos;
f) Pentaho Schema Workbench: Inclui a criação de um esquema com dois cubos de
dados.
Outras ferramentas, além das que estão aqui citadas, não serão abordadas.

45
4 SOLUÇÃO DE BI TRANSFERÊNCIA DE RECURSOS
Este capítulo apresenta a solução do projeto proposto, desde a obtenção dos dados
fonte até a apresentação de resultados através de relatórios, gráficos e ferramentas de análise
no Console do Usuário no BI Server.
Para que as ferramentas Pentaho conseguissem acesso ao banco de dados Postgre
Sql, foi necessário a obtenção do driver JDBC versão 9.1-902. Este driver pode ser obtido em
PostgreSql (2012) .
4.1 ESCOLHA DA FONTE DOS DADOS
Visando apresentar a suite Pentaho e seu potencial, foram consideradas algumas
fontes públicas e privadas para criação do data warehouse, sendo desejado obter informações
reais durante um determinado período de tempo.
Após a pesquisa, foram escolhidos dados públicos que podem ser encontrados no
Portal da Transparência, no endereço: http://www.portaltransparencia.gov.br/ e no
Portal do IBGE, no endereço http://www.ibge.gov.br/, com o objetivo de cruzar
informações sobre a transferência de recursos federais para os estados e municípios, com a
estimativa da população dos mesmos, entre os anos de 2005 e 2011, subdivididos por área em
que o recurso foi aplicado.
4.1.1 Portal da Transparência
Através de uma iniciativa da Controladoria Geral da União (CGU), em novembro
de 2004, foi lançado o Portal da Transparência. Com o objetivo de aumentar a transparência
relativo aos gastos públicos, visando garantir a correta aplicação de recursos, permite a
população ajudar a fiscalizar de que forma o dinheiro público está sendo gasto. (BRASIL,
2012d).
Nesse portal, podem ser encontradas informações sobre transferências de recursos
para os estados, municípios, pessoas jurídicas, feitas no exterior ou diretamente para pessoas
físicas. Também, podem ser encontradas informações sobre gastos diretos do governo como a
contratação de obras e serviços, gastos feitos diariamente com cartões de pagamento pelo
governo federal, informações sobre receitas previstas organizadas por órgão e por categoria

46
das receitas e, também, informações sobre agentes e servidores públicos do Poder Executivo
federal, entre outras. (BRASIL, 2012e).
Também, podem ser encontradas informações sobre a lista de Empresas
Sancionadas pelos órgãos e entidades da administração pública, desde que da esfera federal e
informações sobre projetos e ações do governo federal, que são divulgados pelos órgãos em
suas respectivas páginas eletrônicas, formando assim uma rede de transparência. (BRASIL,
2012e).
Segundo Brasil (2012a), a responsabilidade sobre os dados contidos no portal são
dos ministérios e outros órgãos do Poder Executivo Federal, devido serem eles os
responsáveis pela execução dos programas e pela administração de ações do governo. A CGU
é a responsável por disponibilizar essas informações no portal.
4.1.1.1 Dados do Portal da Transparência
As despesas do Governo Federal escolhidas foram a de transferência de recursos,
que segundo Brasil (2012c), "Transferência de Recursos - No Portal representam os recursos
federais transferidos da União para estados, municípios, Distrito Federal ou diretamente
repassados a cidadãos".
O formato original em que os dados foram coletados foi em CSV, encontrados no
seguinte link http://www.portaldatransparencia.gov.br/planilhas/, Item DESPESAS –
TRANSFERÊNCIAS, entre os anos de 2005 e 2011. (BRASIL, 2012b).
4.1.2 Portal do IBGE
Segundo o Instituto Brasileiro de Geografia e Estatística (2012l), "IBGE se
constitui no principal provedor de dados e informações do país, que atendem às necessidades
dos mais diversos segmentos da sociedade civil, bem como dos órgãos das esferas
governamentais federal, estadual e municipal".
Como uma instituição de administração pública federal, o IBGE está subordinado
ao Ministério do Planejamento, possuí 27 unidades nas capitais dos estados e no distrito
federal e 539 agências de coleta nos principais estados e municípios. (INSTITUTO
BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA, 2012l).

47
4.1.2.1 Pesquisa Demográfica
De acordo com Instituto Brasileiro de Geografia e Estatística (2012k), realizado
de dez em dez anos, “o Censo Demográfico se constitui como núcleo das estatísticas
sociodemográficas”. No intervalo entre um Censo e outro, é realizada a contagem da
população, “operação censitária fundamental para aprimorar as estimativas anuais de
população”.
4.1.2.2 Dados do Portal do IBGE
Os dados utilizados são os do Censo 2010, os da contagem da população de 2007
e estimativas da população nos anos de 2005, 2006, 2008, 2009 e 2011.
Em 2010, foi realizado levantamento cessionário em todos os municípios do país
através do Censo realizado neste ano. Foram visitados 67,6 milhões de domicílios nos 5.656
municípios brasileiros. (INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA,
2012b).
Para o ano de 2007, foi realizada a contagem da população com referência a 1° de
abril de 2007, incluindo 5435 municípios com levantamento censitário e o restante com base
em estimativas. (INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA, 2012c).
Com relação aos anos de 2011, 2009, 2008, 2006 e 2005, foram consideradas
estimativas populacionais com referencia a 1° de julho do respectivo ano, no qual são
publicadas anualmente desde 1991, para os Municípios, Unidades da Federação e Brasil.
(INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA, 2012j).
Para os anos de 2011, 2009, 2008 e 2006, foram utilizados dados enviados para o
Tribunal de Contas da União (TCU), e para o ano de 2005, foram utilizados dados publicados
no Diário Oficial da União.
Os dados estão organizados por unidade da federação e por município, sendo uma
planilha ou tabela para cada ano, exceto em 2010, que tem uma planilha para cada unidade da
federação. Esses dados se encontram nos formatos XLS e PDF, sendo que foram obtidos, nas
seguintes referências para os respectivos anos:
a) 2011: Foi feito download de uma planilha no formato XLS em Instituto Brasileiro de
Geografia e Estatística (2012i);

48
b) 2010: Foi realizado download de múltiplas planilhas, por unidade da federação, no
formato XLS, totalizando 27 planilhas, em Instituto Brasileiro de Geografia e
Estatística (2012m);
c) 2009: O download ocorreu no formato PDF em Instituto Brasileiro de Geografia e
Estatística (2012h);
d) 2008: O download também no formato PDF ocorreu em Instituto Brasileiro de
Geografia e Estatística (2012g);
e) 2007: Download no formato XLS em Instituto Brasileiro de Geografia e Estatística
(2012d);
f) 2006: Download no formato XLS em Instituto Brasileiro de Geografia e Estatística
(2012f);
g) 2005: Download no formato XLS em Instituto Brasileiro de Geografia e Estatística
(2012e).
4.2 MODELAGEM MULTIDIMENSIONAL
A ferramenta escolhida para a modelagem multidimensional foi o DB Designer
Fork verão 1.5, pois é uma ferramenta simples que gera scripts para posterior criação do data
warehouse que será criado como uma base relacional do Postgre Sql versão 9.1.4-1.
4.2.1 Tabela de Fatos
A primeira tabela de fatos contém, como medidas, a quantidade de população e o
valor transferido por habitante em reais de determinado município em determinada UF em
determinado ano, sendo que o nome dessa tabela é de ft_populacao.
A segunda tabela de fatos contém como medida o valor transferido em reais que
foi repassado ao município de determinado unidade da federação em determinado ano,
subdivididos em: função, subfunção, programa e ação. O nome dessa tabela é de
ft_recurso_transferido.
4.2.2 Tabelas de Dimensões
As dimensões utilizadas são as seguintes:
a) tempo: Com o atributo ano, esta tabela se chama de di_tempo;

49
b) geográfica: Com os atributos na sequência conforme modelo abaixo, figura 16: código
do município segundo o IBGE, código do município segundo o Portal da
Transparência, nome do município, código, sigla e nome da unidade da federação
(UF), código e nome da região, código e nome da meso região, código e nome da
micro região. O nome desta tabela é di_geo;
c) projeto: Com os atributos, código e nome da função, código e nome da sub função,
código e nome do programa, código e nome da ação e nome da linguagem cidadã.
Esta tabela tem o nome de di_projeto.
4.2.3 Modelo
O modelo escolhido para a criação do data warehouse foi o Modelo Estrela, pois
apesar do mesmo apresentar algumas redundâncias, tem um melhor desempenho em relação
ao modelo floco de neve. Segue o modelo na figura a seguir, com as tabelas de fatos (prefixo
ft) e dimensões (prefixo di).
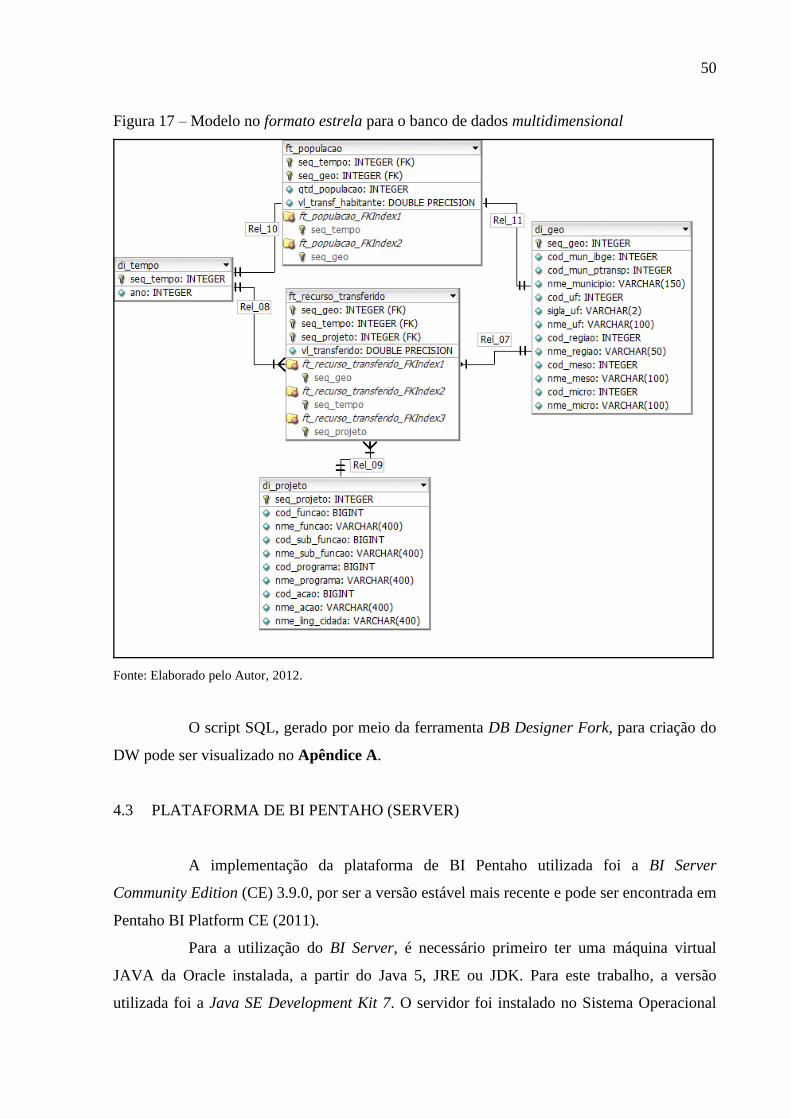
50
Figura 17 – Modelo no formato estrela para o banco de dados multidimensional
Fonte: Elaborado pelo Autor, 2012.
O script SQL, gerado por meio da ferramenta DB Designer Fork, para criação do
DW pode ser visualizado no Apêndice A.
4.3 PLATAFORMA DE BI PENTAHO (SERVER)
A implementação da plataforma de BI Pentaho utilizada foi a BI Server
Community Edition (CE) 3.9.0, por ser a versão estável mais recente e pode ser encontrada em
Pentaho BI Platform CE (2011).
Para a utilização do BI Server, é necessário primeiro ter uma máquina virtual
JAVA da Oracle instalada, a partir do Java 5, JRE ou JDK. Para este trabalho, a versão
utilizada foi a Java SE Development Kit 7. O servidor foi instalado no Sistema Operacional

51
Windows 7 profissional, suficiente para os fins deste trabalho, contudo vale a pena ressaltar
que tanto o Java, quanto a suite de ferramentas da Pentaho são multiplataforma.
Esta implementação de solução de BI da Pentaho, que inclui por padrão o servidor
Java Web Apache Tomcat, permite acesso ao usuário final através do protocolo HTTP,
chamado de Console do Usuário. Por padrão, o acesso à interface do usuário final se dá por
http://localhost:8080/.
Também, é incluída nesta implementação, a ferramenta Administration Console,
que pode ser acessada por padrão em http://localhost:8099/.
Antes de iniciar os servidores, é necessário configurar algumas variáveis de
ambiente no Sistema Operacional. Basta clicar na pasta-do-servidor/biserver-ce/et-
pentaho-env.bat para tudo seja feito automaticamente.
Para iniciar ou parar os servidores, BI Server e Administration Console, basta
clicar em pasta-do-servidor/biserver-ce/start-pentaho.bat ou stop-pentaho.bat para o BI
Server, e pasta-do-servidor/administration-console/start-pac.bat ou stop-pac.bat, para o
Administration Console.
4.3.1 Administration Console
Este console de administração, acessado por http://localhost:8099/ em um
navegador web, pode ser utilizado para criação de usuários e papéis, porém para o fins deste
trabalho, os usuários utilizados são os que vêm cadastrado por padrão, como joe e admin,
ambos com papel (role) de administrador.
Esta ferramenta também permite a criação de conexões com o banco de dados,
permitindo que outras ferramentas como o Design Studio e o Console do Usuário tenham
acesso a esta conexão.
A figura 17 abaixo mostra a configuração de uma conexão chamada dwtransf-
recursos¸ que é necessária para a construção e reprodução de gráficos do Design Studio, por
exemplo.
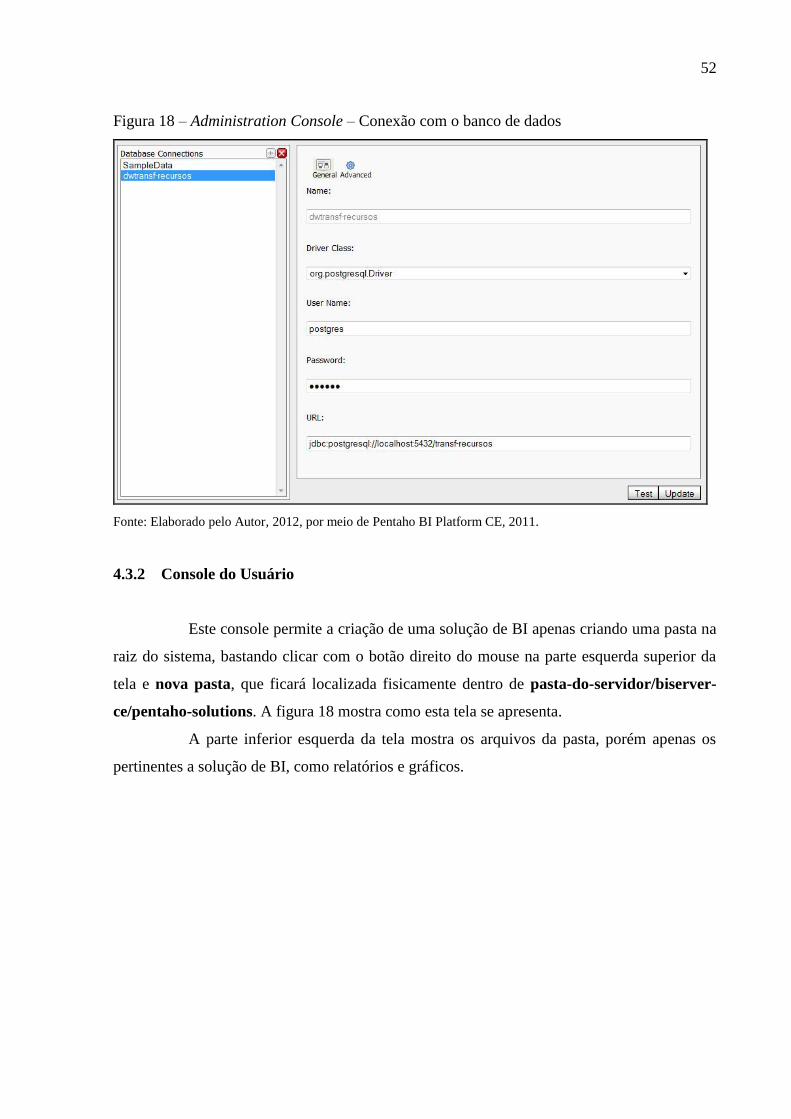
52
Figura 18 – Administration Console – Conexão com o banco de dados
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho BI Platform CE, 2011.
4.3.2 Console do Usuário
Este console permite a criação de uma solução de BI apenas criando uma pasta na
raiz do sistema, bastando clicar com o botão direito do mouse na parte esquerda superior da
tela e nova pasta, que ficará localizada fisicamente dentro de pasta-do-servidor/biserver-
ce/pentaho-solutions. A figura 18 mostra como esta tela se apresenta.
A parte inferior esquerda da tela mostra os arquivos da pasta, porém apenas os
pertinentes a solução de BI, como relatórios e gráficos.
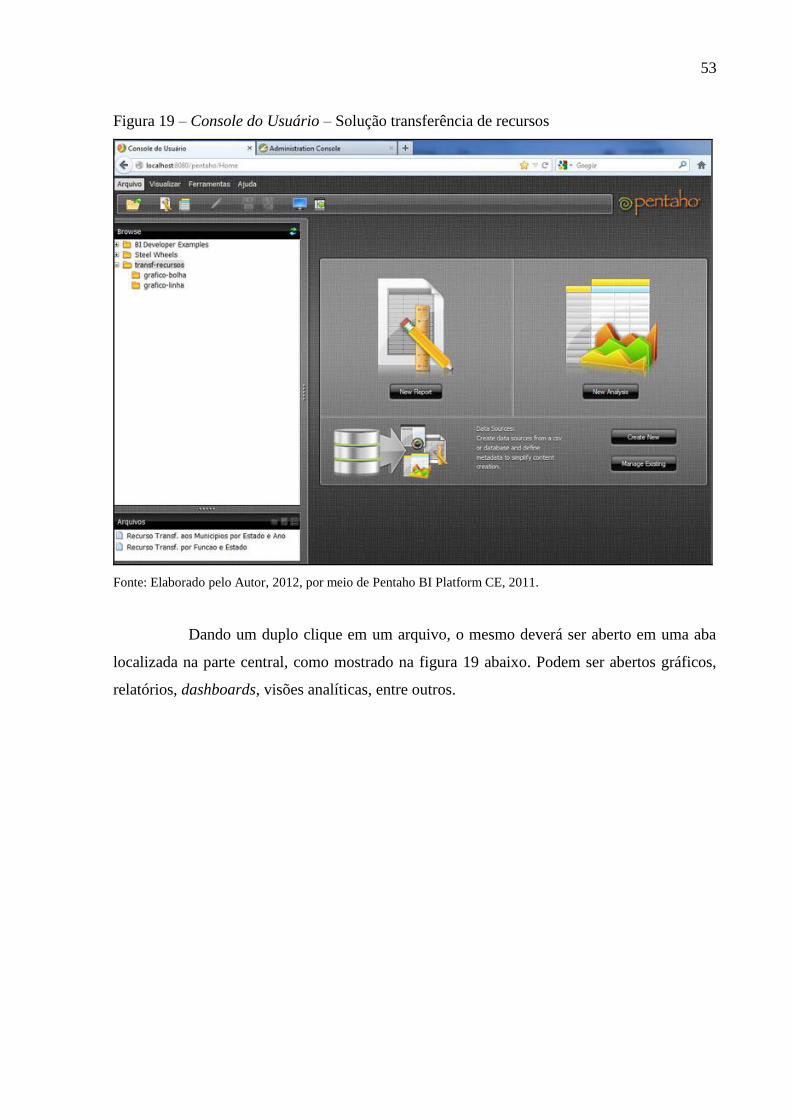
53
Figura 19 – Console do Usuário – Solução transferência de recursos
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho BI Platform CE, 2011.
Dando um duplo clique em um arquivo, o mesmo deverá ser aberto em uma aba
localizada na parte central, como mostrado na figura 19 abaixo. Podem ser abertos gráficos,
relatórios, dashboards, visões analíticas, entre outros.
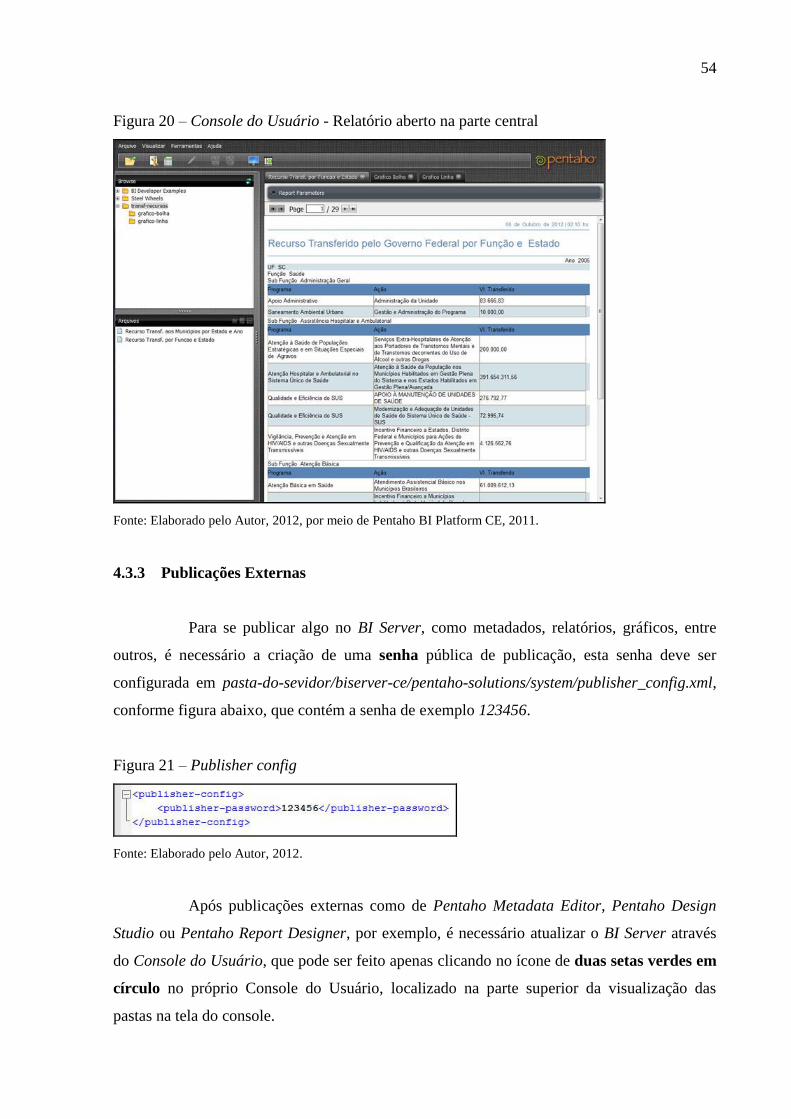
54
Figura 20 – Console do Usuário - Relatório aberto na parte central
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho BI Platform CE, 2011.
4.3.3 Publicações Externas
Para se publicar algo no BI Server, como metadados, relatórios, gráficos, entre
outros, é necessário a criação de uma senha pública de publicação, esta senha deve ser
configurada em pasta-do-sevidor/biserver-ce/pentaho-solutions/system/publisher_config.xml,
conforme figura abaixo, que contém a senha de exemplo 123456.
Figura 21 – Publisher config
Fonte: Elaborado pelo Autor, 2012.
Após publicações externas como de Pentaho Metadata Editor, Pentaho Design
Studio ou Pentaho Report Designer, por exemplo, é necessário atualizar o BI Server através
do Console do Usuário, que pode ser feito apenas clicando no ícone de duas setas verdes em
círculo no próprio Console do Usuário, localizado na parte superior da visualização das
pastas na tela do console.
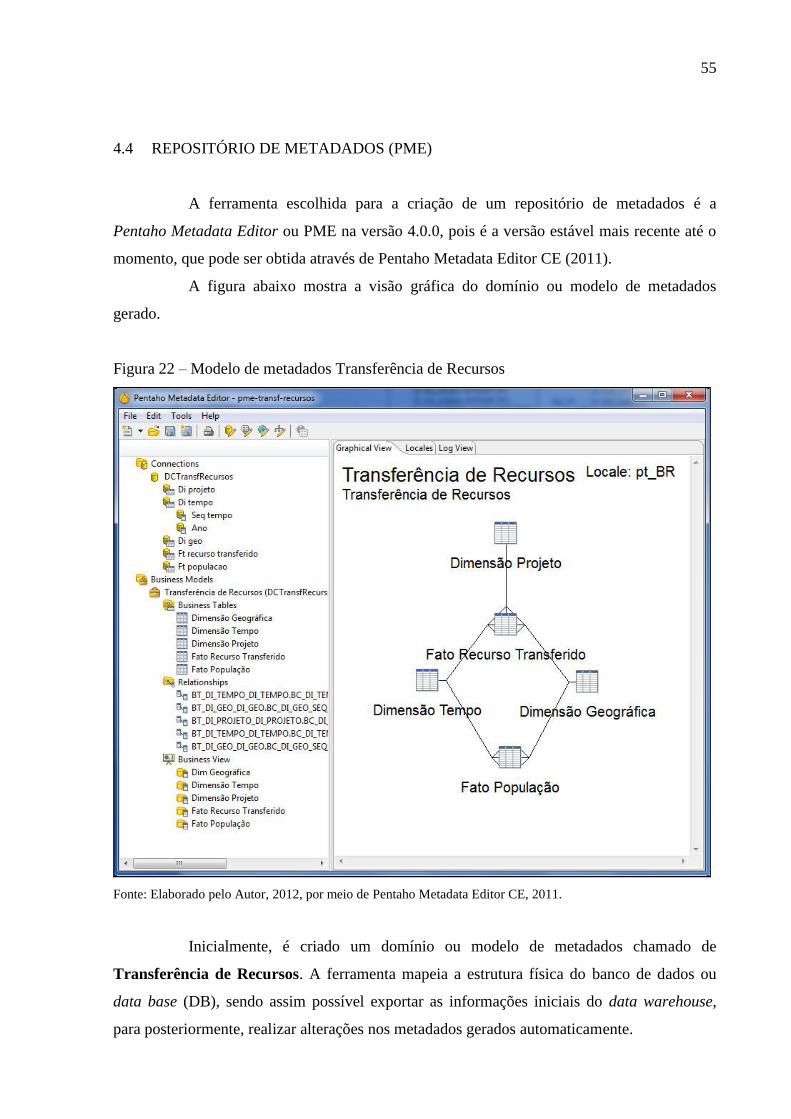
55
4.4 REPOSITÓRIO DE METADADOS (PME)
A ferramenta escolhida para a criação de um repositório de metadados é a
Pentaho Metadata Editor ou PME na versão 4.0.0, pois é a versão estável mais recente até o
momento, que pode ser obtida através de Pentaho Metadata Editor CE (2011).
A figura abaixo mostra a visão gráfica do domínio ou modelo de metadados
gerado.
Figura 22 – Modelo de metadados Transferência de Recursos
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Metadata Editor CE, 2011.
Inicialmente, é criado um domínio ou modelo de metadados chamado de
Transferência de Recursos. A ferramenta mapeia a estrutura física do banco de dados ou
data base (DB), sendo assim possível exportar as informações iniciais do data warehouse,
para posteriormente, realizar alterações nos metadados gerados automaticamente.

56
4.4.1 Conexão
Foi criada uma nova conexão com o DB Postgre Sql, e na sequência, escolhida as
tabelas a serem exportadas, que foram di_projeto, di_tempo, di_geo, ft_recurso_transferido e
ft_populacao. Essa estrutura física mapeada pode ser vista na parte superior esquerda da
figura 21, logo abaixo de Connerctions em DCTransfRecursos.
4.4.2 Modelo de Negócios
Na sequência, construiu-se um Modelo de Negócios (Business Model), nomeado
de Transferência de Recursos, logo abaixo de Connections. Esse modelo é responsável pelo
mapeamento lógico do data warehouse e possui três camadas: Tabelas de Negócios (Business
Tables), Relacionamentos (Relationships) e Visões de Negócios (Business View).
4.4.2.1 Tabelas de Negócios
As Tabelas de Negócios são criadas quando seguramos com o mouse e
arrastarmos as mesmas da camada física para Business Tables.
Ao expandir o fato população, por exemplo, temos a visão dos campos da tabela
como pode ser visto na figura 22. Ao dar um duplo clique ou na tabela ou em algum campo,
algumas propriedades podem e devem ser alteradas, como, por exemplo, para o componente
tabela: nome, descrição, informações de segurança com permissões de acesso, entre outras.
Para os campos, há opções como: nome, descrição, tipo de dado, tipo de função de agregação
permitida (Máximo, Mínimo, Soma, Contagem, Média, e mais), entre outras. Para o campo
físico vl_transf_habitante, por exemplo, temos o nome lógico de Vl. Transf. Por
Habitante, que é o nome que será visto pelo usuário final de um relatório, por exemplo, como
pode ser visto na figura 23.
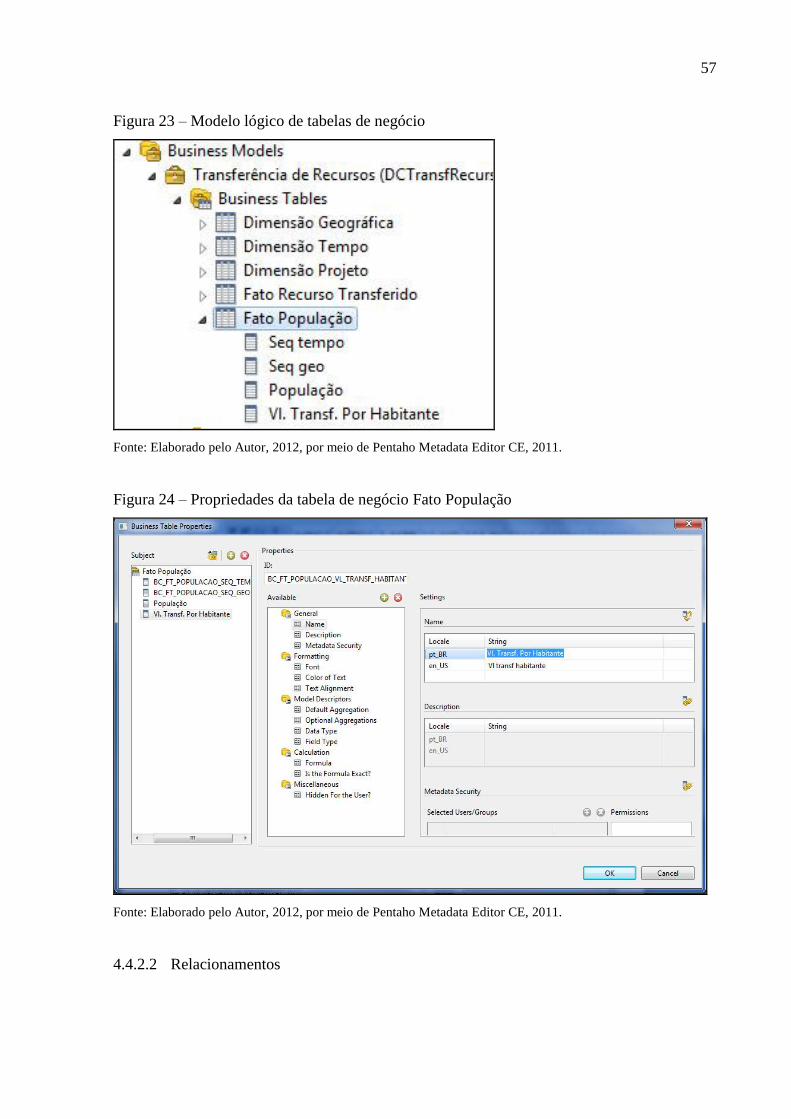
57
Figura 23 – Modelo lógico de tabelas de negócio
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Metadata Editor CE, 2011.
Figura 24 – Propriedades da tabela de negócio Fato População
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Metadata Editor CE, 2011.
4.4.2.2 Relacionamentos

58
Os relacionamentos (Relationships) criados são configurações de como as tabelas
lógicas ou de negócio devem se relacionar, como por exemplo, o relacionamento entre a
dimensão geográfica e o fato população, que pode ser visto na figura 24, na qual se escolhe a
tabela origem e o campo origem (From Table/Field) e a tabela destino com o campo destino
(To Table/Field). Em seguida, é escolhida a cardinalidade (1:N) e o tipo de relacionamento
(Inner).
Figura 25 – Configuração de um relacionamento com PME
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Metadata Editor CE, 2011.
4.4.2.3 Visão de Negócios
A visão de negócios criada (Business View), que são os meta dados visíveis ao
usuário final, foram criadas arrastando com o mouse das Tabelas de Negócios e soltando em
Visão de Negócios, cada tabela dessa arrastada cria uma categoria. Alguns campos das
categorias foram excluídos, pois são indiferentes ao usuário final, como: Seq geo da
Dimensão Geográfica, Seq tempo da Dimensão Tempo e Seq tempo, Seq geo e Seq projeto
da Tabela de Fato Recurso Transferido, como pode ser visto na figura abaixo que não
contém mais estes campos.

59
Figura 26 – Visão de negócios com PME
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Metadata Editor CE, 2011.
4.4.3 Publicação no BI Server
O modelo de metadados pode ser exportado como arquivo XMI ou publicado
diretamente no BI Server, sendo que, também, ira gerar um arquivo de mesmo formato. Para
efeito deste trabalho, foi escolhida a importação para o BI Server, para que este modelo seja
utilizado para a criação de relatórios com Pentaho Report Designer.
Com o simples procedimento de clicar em File / Publish To Server, a tela de
publicação é apresentada, como mostrado na figura 26. Filename deve ser metadata.xmi, isso
para que o BI Server entenda o modelo, sendo que o arquivo será colocado dentro da pasta da
solução criada no Console do Usuário (transf-recursos). O nome desta solução deve ser
colocado em Publish Location. Web Publish URL deve ser preenchido com o host onde se
encontra o servidor Web seguido de RepositoryFilePublisher, como demonstrado na figura
26. A senha de publicação, configurada previamente no BI Server, deve ser informada em
Publish Password. Por fim, deve ser informado o usuário e senha do BI Server, com um
usuário com perfil de administrador, para realizar a publicação.
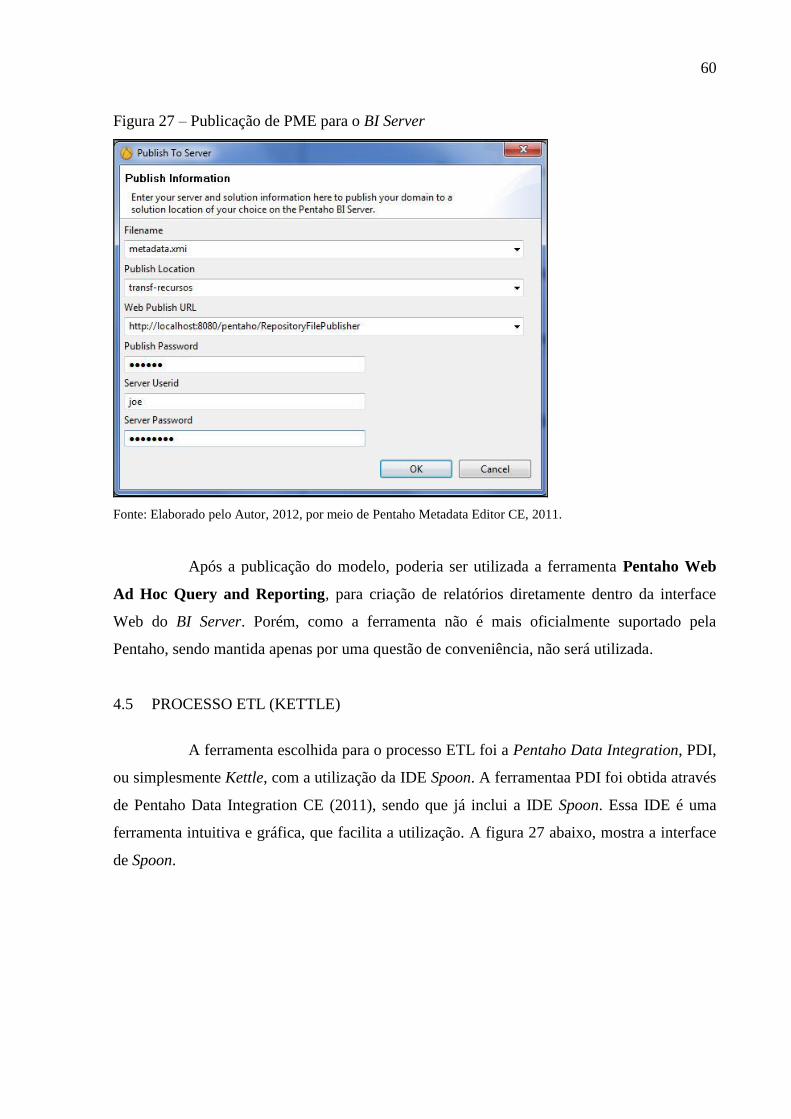
60
Figura 27 – Publicação de PME para o BI Server
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Metadata Editor CE, 2011.
Após a publicação do modelo, poderia ser utilizada a ferramenta Pentaho Web
Ad Hoc Query and Reporting, para criação de relatórios diretamente dentro da interface
Web do BI Server. Porém, como a ferramenta não é mais oficialmente suportado pela
Pentaho, sendo mantida apenas por uma questão de conveniência, não será utilizada.
4.5 PROCESSO ETL (KETTLE)
A ferramenta escolhida para o processo ETL foi a Pentaho Data Integration, PDI,
ou simplesmente Kettle, com a utilização da IDE Spoon. A ferramentaa PDI foi obtida através
de Pentaho Data Integration CE (2011), sendo que já inclui a IDE Spoon. Essa IDE é uma
ferramenta intuitiva e gráfica, que facilita a utilização. A figura 27 abaixo, mostra a interface
de Spoon.
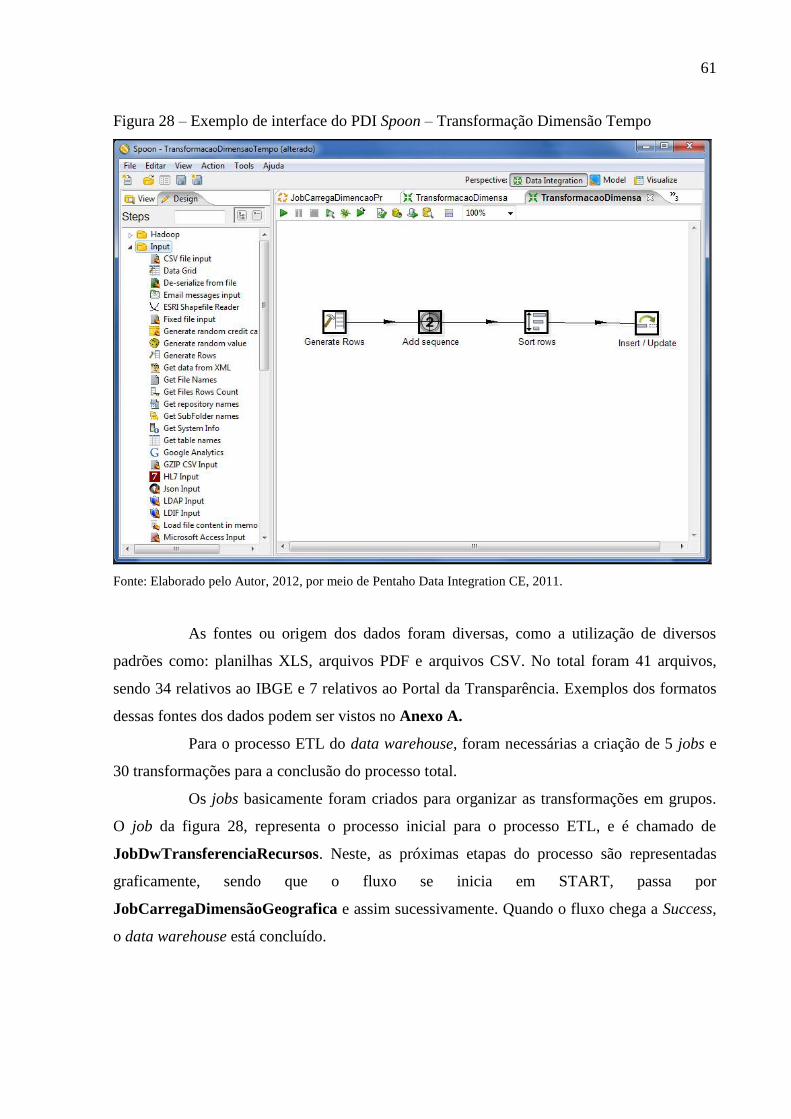
61
Figura 28 – Exemplo de interface do PDI Spoon – Transformação Dimensão Tempo
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
As fontes ou origem dos dados foram diversas, como a utilização de diversos
padrões como: planilhas XLS, arquivos PDF e arquivos CSV. No total foram 41 arquivos,
sendo 34 relativos ao IBGE e 7 relativos ao Portal da Transparência. Exemplos dos formatos
dessas fontes dos dados podem ser vistos no Anexo A.
Para o processo ETL do data warehouse, foram necessárias a criação de 5 jobs e
30 transformações para a conclusão do processo total.
Os jobs basicamente foram criados para organizar as transformações em grupos.
O job da figura 28, representa o processo inicial para o processo ETL, e é chamado de
JobDwTransferenciaRecursos. Neste, as próximas etapas do processo são representadas
graficamente, sendo que o fluxo se inicia em START, passa por
JobCarregaDimensãoGeografica e assim sucessivamente. Quando o fluxo chega a Success,
o data warehouse está concluído.
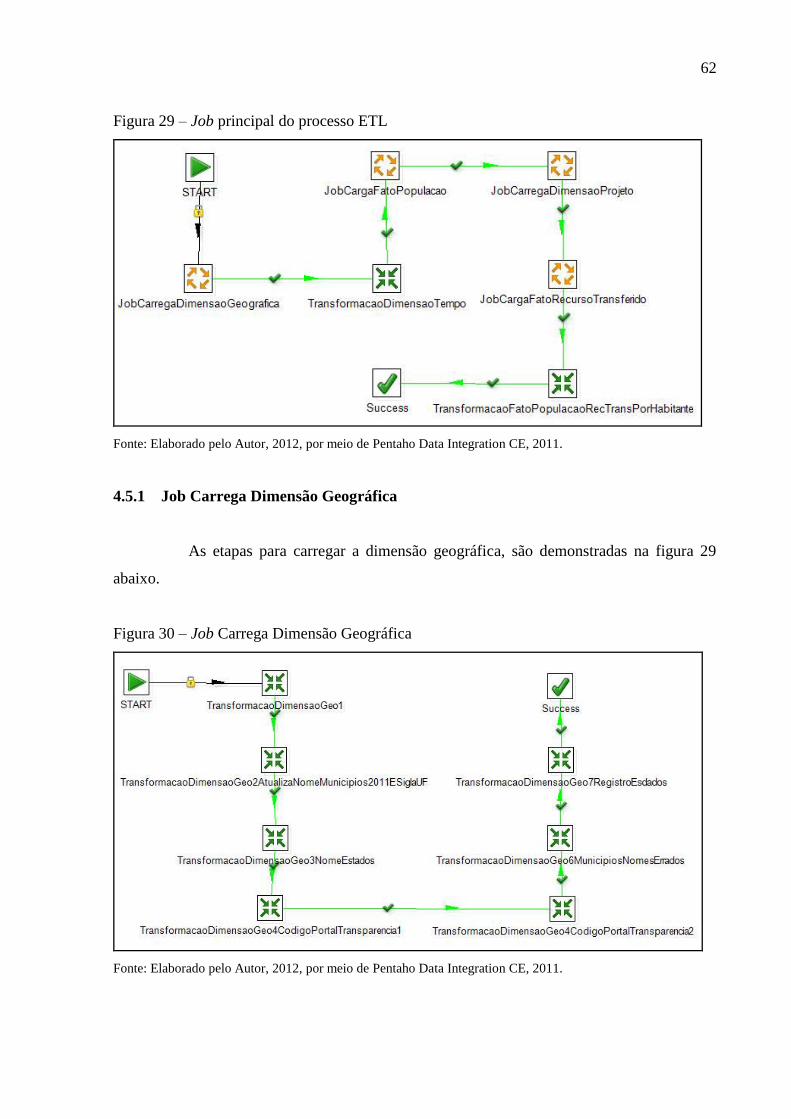
62
Figura 29 – Job principal do processo ETL
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
4.5.1 Job Carrega Dimensão Geográfica
As etapas para carregar a dimensão geográfica, são demonstradas na figura 29
abaixo.
Figura 30 – Job Carrega Dimensão Geográfica
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.

63
4.5.1.1 Transformação Dimensão Geográfica 1
Responsável pelos dados iniciais da tabela di_geo do banco, como:
cod_mun_ibge, nme_municipio, cod_uf, cod_regiao, nme_regiao, cod_meso, nme_meso,
cod_micro, nme_micro. A transformação é representada no diagrama abaixo:
Figura 31 – Transformação Carrega Dimensão Geográfica 1
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
Inicialmente, são carregados os mesmos arquivos CSV por quatro vezes, porém
com objetivos diferentes, como pode ser visto na figura acima com o componente CSV file
input. O mesmo arquivo CSV carrega as informações de região, UF, meso região, micro
região e município de forma hierárquica, sendo que as localidades estão em linhas diferentes e
relacionados por códigos.
Em seguida, são aplicados filtros para cada objetivo: municípios, micro região,
meso região e regiões do Brasil. Os dados passados como positivo nos filtros, são ordenados
com os componentes Sort Rows. Na sequência, os componentes Merge Join atuam, fazendo
relacionamento através de códigos entre os municípios e as micro regiões, depois a mesma
lógica com as meso regiões e, ao final, com a regiões.

64
Por fim, são inseridos os registros organizados pelo componente Insert/Update,
que se conecta com o banco Postgre Sql.
O arquivo CSV utilizado não tem as siglas das unidades da federação, e por isso
tanto os nomes quanto as siglas foram deixados para depois, e também com o objetivo de
simplificar a estrutura.
4.5.1.2 Transformação Dimensão Geográfica 2
Essa transformação tem como objetivo atualizar os nomes dos municípios de
di_geo, através da planilha mais recente do IBGE de 2011, que teoricamente teria os nomes
mais atualizados e já aproveitando também, atualiza as siglas das unidades da federação.
Figura 32 – Transformação Carrega Dimensão Geográfica 2
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
O processo acima relaciona os dados já inseridos no data warehouse, Table input,
relativo aos municípios e os relaciona com a planilha de dados populacionais XLS de 2011.
Os componentes Modified Java Script Value atuam para que possa existir um relacionamento
entre a tabela di_geo e a planilha com os dados, pois as mesmas não seguem o mesmo
padrão de código, porém seguem uma lógica parecida, sendo que os códigos puderam ser
corelacionados.
4.5.1.3 Transformação Dimensão Geográfica 3 – Nomes dos Estados

65
Esta transformação é simples e utiliza a mesma planilha da Transformação
Geográfica 1, simplesmente para atualizar o nome dos estados.
4.5.1.4 Transformação Dimensão Geográfica – Código Portal da Transparência
As próximas três transformações foram criadas para atualizar os códigos dos
municípios do Portal da Transparência, campo cod_mun_ptransp de di_geo, este necessário
para, depois se ter, a relação entre os valores transferidos por município com os dados
populacionais do IBGE.
O problema foi que não existe relação entre os códigos dos municípios do IBGE e
dos municípios do Portal da Transparência, sendo assim, a correlação teve que se dar
comparando os nomes dos municípios e dos estados.
A primeira transformação a tratar do assunto retira os acentos dos nomes dos
municípios, ignora caracteres como aspas simples (‘) e traço (-) e, em seguida, coloca tudo em
caixa alta, tanto para os dados obtidos da tabela di_geo, quanto para os dados do arquivo
CSV do Portal da Transparência de 2011, o mais recente. Estas transformações são realizadas
através dos componentes Modifield Java Script Value. O diagrama do processo pode ser visto
na figura abaixo.
Figura 33 – Transformação Código Portal da Transparência 1
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.

66
A segunda transformação a tratar do código do Portal da Transparência resolve
problemas de comparação entre nomes de municípios, que ainda não foram correlacionados,
com problemas básicos de grafia, como excesso de espaços entre palavras compostas, ou de
preposições diferentes em palavras compostas como: do, da, de, dos, das, como, por exemplo,
comparando BRACO DE NORTE (SC) e BRACO DO NORTE (SC), que na verdade, são os
mesmos municípios com problema de grafia. A solução foi ignorar as proposições de ambos
os lados.
A terceira transformação a tratar da atualização do código do Portal da
Transparência da tabela de dimensão geográfica di_geo, foi realizada para corrigir
problemas de grafia ou de trocas de nomes de 38 municípios que ficaram sem código do
Portal da Transparência. Após pesquisa no site do IBGE relativo a história dos municípios, foi
possível obter uma correlação entre nome atual e antigo de um mesmo município. O
componente utilizado para realizar a troca dos nomes, para assim ser possível comparar os
municípios para se obter o código do Portal da Transparência, foi Modifield Java Script
Value. Entre os municípios que deram problema podem ser citados alguns exemplos:
a) para o estado do Amapá, Pedra Branca do Amapari se considerou o mesmo que
Ampari;
b) para o estado da Bahia, Lajedo do Tabocal com ‘j’ se considerou o mesmo que
Lagedo do Tabocal com ‘g’;
c) para o estado da Paraíba, Joca Claudino considerou-se o mesmo que Santarem para
efeito de obtenção do código do Portal da Transparência, pois Santarem é o nome
antigo.
Parte da configuração do componente Modifield Java Script Value pode ser visto
na figura 33, onde a variável nme_municipio recebe o nome do Portal da Transparência, isso
se dá somente para a obtenção do código do Portal da Transparência, que é o único campo
atualizado nesta transformação.
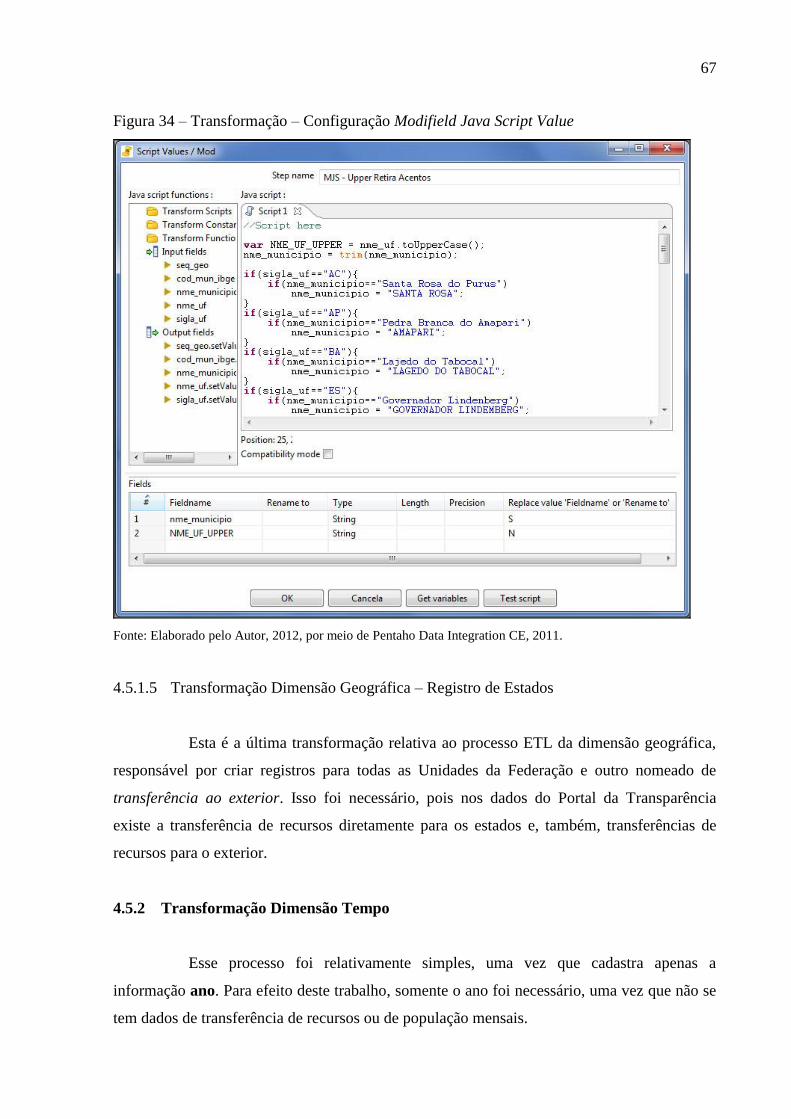
67
Figura 34 – Transformação – Configuração Modifield Java Script Value
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
4.5.1.5 Transformação Dimensão Geográfica – Registro de Estados
Esta é a última transformação relativa ao processo ETL da dimensão geográfica,
responsável por criar registros para todas as Unidades da Federação e outro nomeado de
transferência ao exterior. Isso foi necessário, pois nos dados do Portal da Transparência
existe a transferência de recursos diretamente para os estados e, também, transferências de
recursos para o exterior.
4.5.2 Transformação Dimensão Tempo
Esse processo foi relativamente simples, uma vez que cadastra apenas a
informação ano. Para efeito deste trabalho, somente o ano foi necessário, uma vez que não se
tem dados de transferência de recursos ou de população mensais.
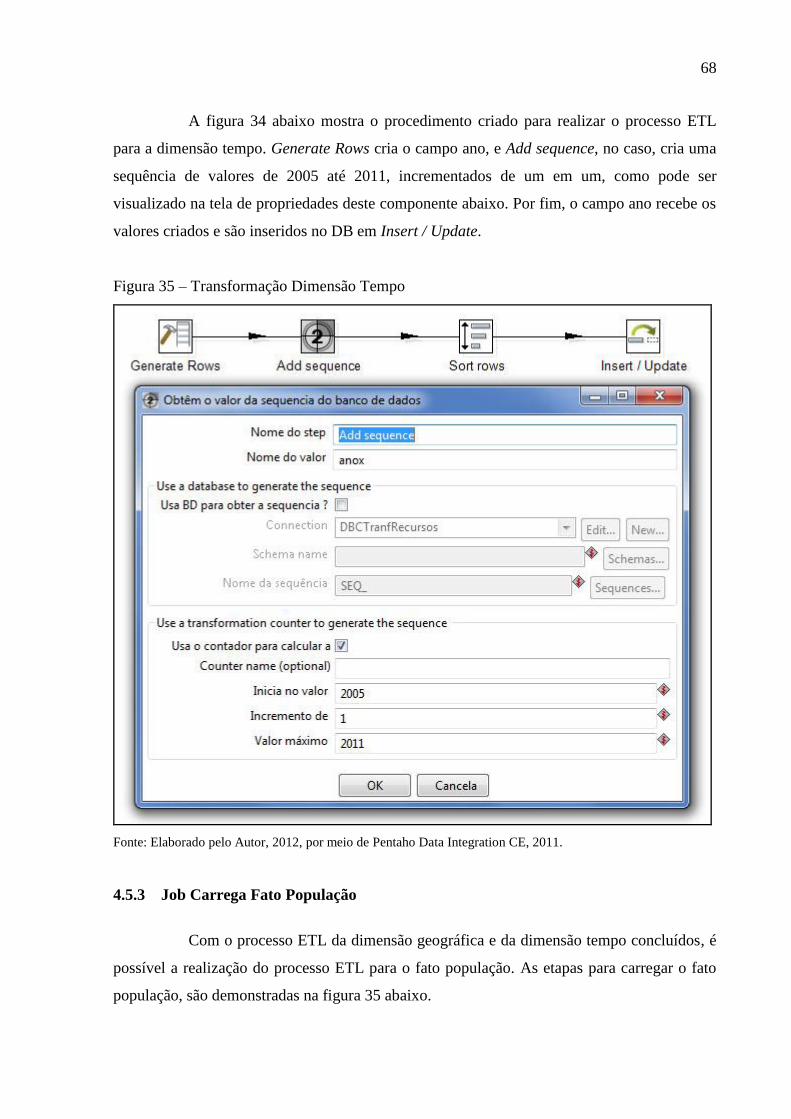
68
A figura 34 abaixo mostra o procedimento criado para realizar o processo ETL
para a dimensão tempo. Generate Rows cria o campo ano, e Add sequence, no caso, cria uma
sequência de valores de 2005 até 2011, incrementados de um em um, como pode ser
visualizado na tela de propriedades deste componente abaixo. Por fim, o campo ano recebe os
valores criados e são inseridos no DB em Insert / Update.
Figura 35 – Transformação Dimensão Tempo
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
4.5.3 Job Carrega Fato População
Com o processo ETL da dimensão geográfica e da dimensão tempo concluídos, é
possível a realização do processo ETL para o fato população. As etapas para carregar o fato
população, são demonstradas na figura 35 abaixo.
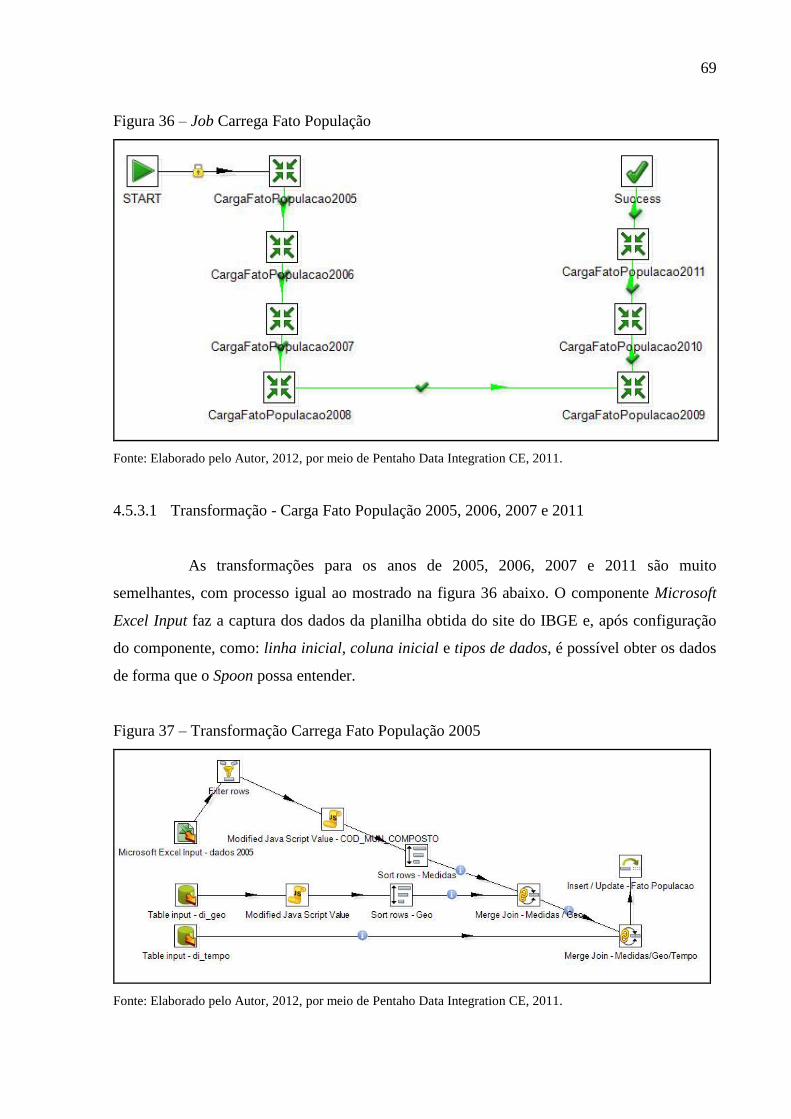
69
Figura 36 – Job Carrega Fato População
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
4.5.3.1 Transformação - Carga Fato População 2005, 2006, 2007 e 2011
As transformações para os anos de 2005, 2006, 2007 e 2011 são muito
semelhantes, com processo igual ao mostrado na figura 36 abaixo. O componente Microsoft
Excel Input faz a captura dos dados da planilha obtida do site do IBGE e, após configuração
do componente, como: linha inicial, coluna inicial e tipos de dados, é possível obter os dados
de forma que o Spoon possa entender.
Figura 37 – Transformação Carrega Fato População 2005
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
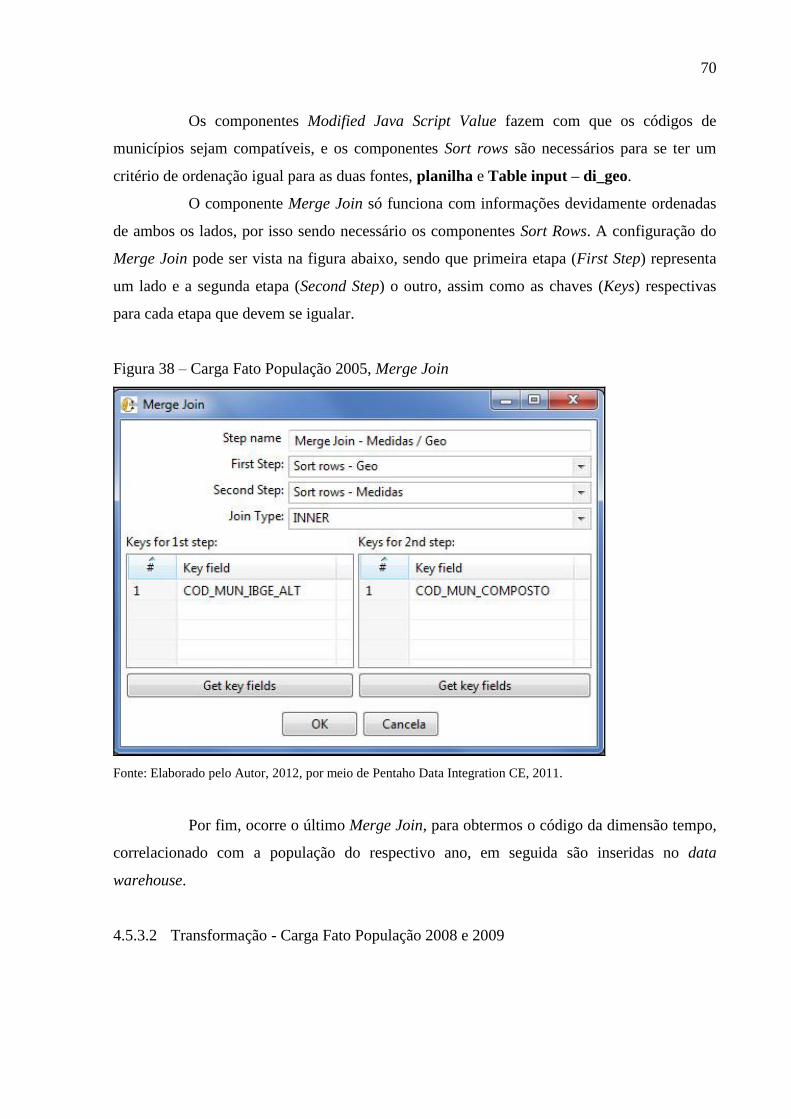
70
Os componentes Modified Java Script Value fazem com que os códigos de
municípios sejam compatíveis, e os componentes Sort rows são necessários para se ter um
critério de ordenação igual para as duas fontes, planilha e Table input – di_geo.
O componente Merge Join só funciona com informações devidamente ordenadas
de ambos os lados, por isso sendo necessário os componentes Sort Rows. A configuração do
Merge Join pode ser vista na figura abaixo, sendo que primeira etapa (First Step) representa
um lado e a segunda etapa (Second Step) o outro, assim como as chaves (Keys) respectivas
para cada etapa que devem se igualar.
Figura 38 – Carga Fato População 2005, Merge Join
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
Por fim, ocorre o último Merge Join, para obtermos o código da dimensão tempo,
correlacionado com a população do respectivo ano, em seguida são inseridas no data
warehouse.
4.5.3.2 Transformação - Carga Fato População 2008 e 2009
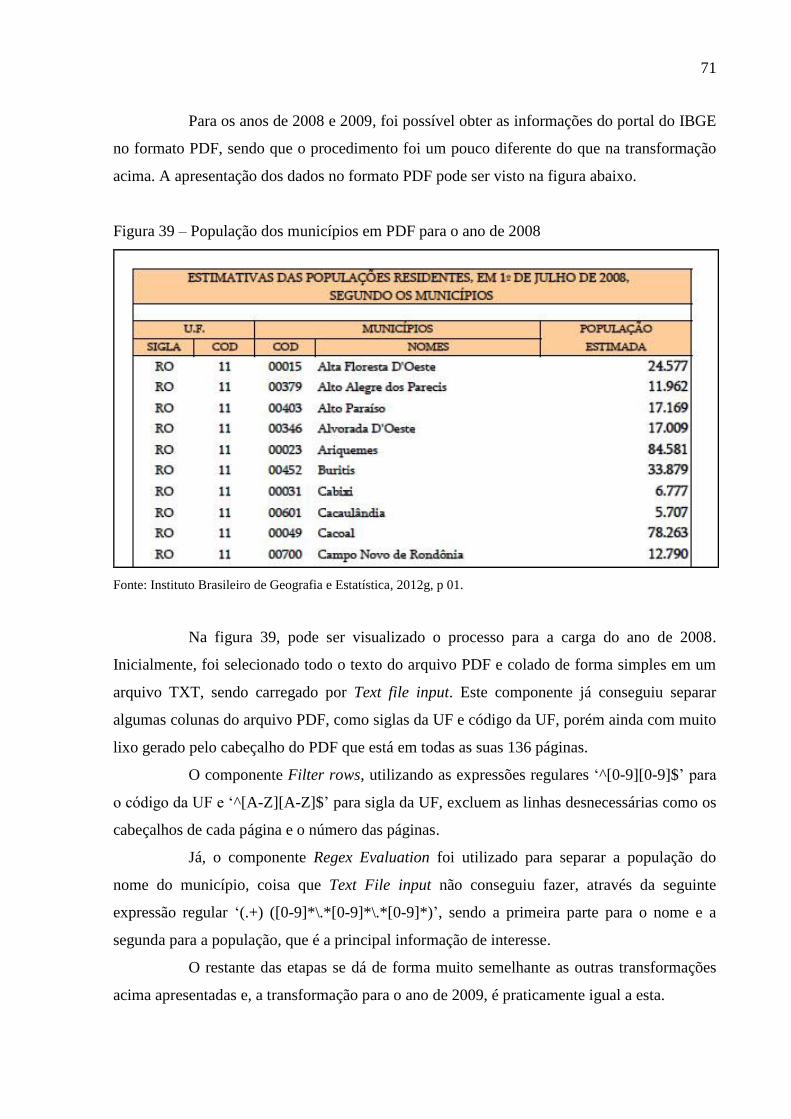
71
Para os anos de 2008 e 2009, foi possível obter as informações do portal do IBGE
no formato PDF, sendo que o procedimento foi um pouco diferente do que na transformação
acima. A apresentação dos dados no formato PDF pode ser visto na figura abaixo.
Figura 39 – População dos municípios em PDF para o ano de 2008
Fonte: Instituto Brasileiro de Geografia e Estatística, 2012g, p 01.
Na figura 39, pode ser visualizado o processo para a carga do ano de 2008.
Inicialmente, foi selecionado todo o texto do arquivo PDF e colado de forma simples em um
arquivo TXT, sendo carregado por Text file input. Este componente já conseguiu separar
algumas colunas do arquivo PDF, como siglas da UF e código da UF, porém ainda com muito
lixo gerado pelo cabeçalho do PDF que está em todas as suas 136 páginas.
O componente Filter rows, utilizando as expressões regulares ‘^[0-9][0-9]$’ para
o código da UF e ‘^[A-Z][A-Z]$’ para sigla da UF, excluem as linhas desnecessárias como os
cabeçalhos de cada página e o número das páginas.
Já, o componente Regex Evaluation foi utilizado para separar a população do
nome do município, coisa que Text File input não conseguiu fazer, através da seguinte
expressão regular ‘(.+) ([0-9]*\.*[0-9]*\.*[0-9]*)’, sendo a primeira parte para o nome e a
segunda para a população, que é a principal informação de interesse.
O restante das etapas se dá de forma muito semelhante as outras transformações
acima apresentadas e, a transformação para o ano de 2009, é praticamente igual a esta.

72
Figura 40 – Transformação Carga Fato População 2008
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
4.5.3.3 Transformação - Carga Fato População 2010
Para o ano de 2010, a carga da população foi muito semelhante às de 2005, 2006,
2007 e 2011, com a diferença de que, em vez de selecionar uma planilha no componente
Microsoft Excel Input, foi selecionada uma pasta que continha 27 arquivos, sendo um para
cada UF, porém todos seguindo o mesmo padrão.
4.5.4 Job Carrega Dimensão Projeto
A carga da dimensão projeto, mostrada na figura abaixo, se dá de modo
semelhante para todos os anos, pois todos os arquivos do Portal da Transparência utilizados
seguem o mesmo padrão, sendo que estão no formato CSV.

73
Figura 41 – Job Carrega Dimensão Projeto
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
4.5.4.1 Transformação Dimensão Projetos de 2005 a 2011
A estrutura para as transformações de 2005 a 2011 são iguais, mudando apenas o
arquivo CSV. A figura 41 abaixo mostra o exemplo para 2011, sendo que esse processo
carrega o arquivo com CSV file input e o separa em colunas, na sequência Sort rows ordena os
campos e Unique rows os torna únicos.
Figura 42 – Transformação Dimensão Projeto 2011
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
Por fim, Insert / Update insere os registros únicos (Keys) por códigos de: função,
subfunção, programa e ação como pode ser visualizado na figura 42 abaixo. Em campos a
serem atualizados (Update fields), estão os campos e os respectivos valores que serão
inseridos no DW.
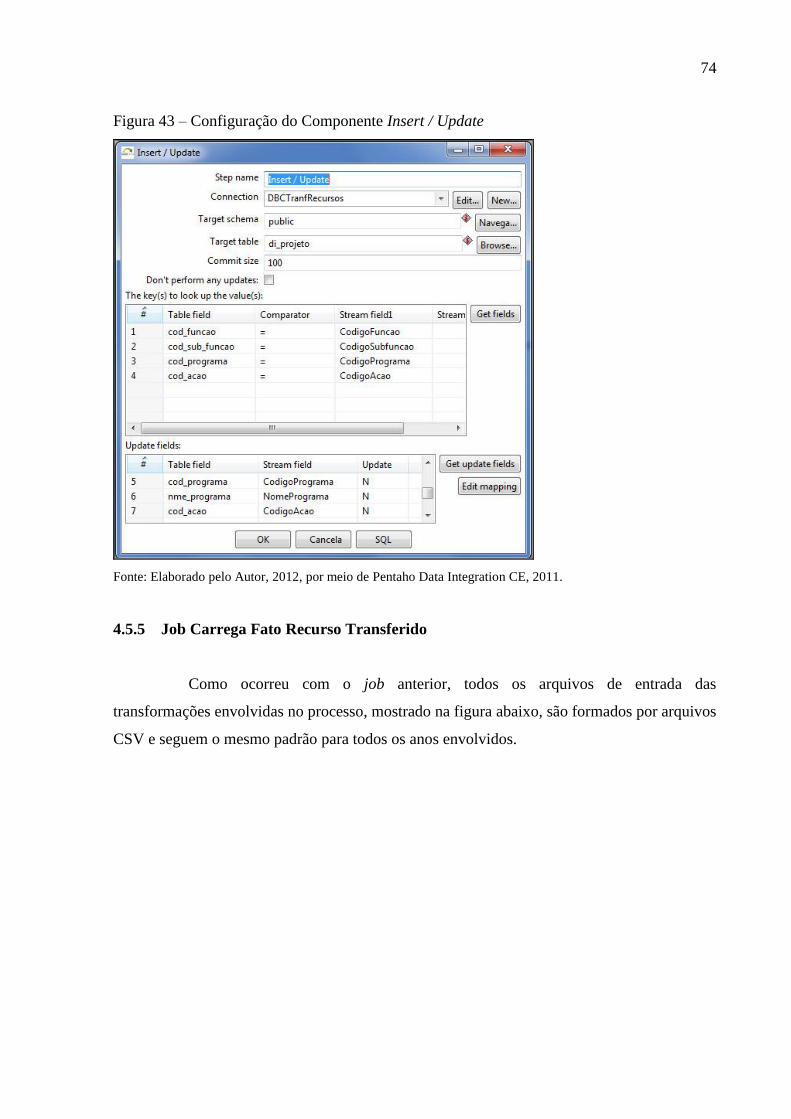
74
Figura 43 – Configuração do Componente Insert / Update
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
4.5.5 Job Carrega Fato Recurso Transferido
Como ocorreu com o job anterior, todos os arquivos de entrada das
transformações envolvidas no processo, mostrado na figura abaixo, são formados por arquivos
CSV e seguem o mesmo padrão para todos os anos envolvidos.

75
Figura 44 – Job Carrega Fato Recurso Transferido
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
4.5.5.1 Transformações - Carga Fato Recurso Transferido de 2005 a 2011
Com as dimensões geográfica, tempo e projeto prontas, o próximo passo a fazer
a carga dos recursos transferidos obtidos pelo Portal da Transparência, já devidamente
organizados por ano, local e projetos, conforme as dimensões apresentadas. A figura próxima
mostra o processo necessário para a carga dos recursos para o ano de 2011, que também serve
de referência para os outros anos.

76
Figura 45 - Transformação Carrega Fato Recurso Transferido 2011
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
Primeiro é carregado o arquivo CSV file input com o arquivo CSV do Portal da
Transparência que contém 151.896 registros de transferência de recursos para o ano de 2011.
Em seguida, o componente Modified Java Script Value modifica o código do município de
transferência para o exterior para -1, sendo que o mesmo vem nulo e, também, o município de
Pinto Bandeira/RS que é colocado como sendo o mesmo que Bento Gonçalves/RS, pois Pinto
Bandeira não existe nos registros de IBGE utilizados. Segundo o Instituto Brasileiro de
Geografia e Estatística (2012a), o município de Pinto Bandeira teve sua área agregado a Bento
Gonçalves por decisão da Justiça.
O componente Group by soma e agrupa os recursos transferidos para um mesmo
projeto, com função, sub função, programa e ação iguais.
Na sequência, as informações vão sendo mescladas com os componentes Merge
Join. Primeiramente o arquivo CSV é mesclado com di_geo, depois com di_tempo e no fim
di_projeto. Por fim, as informações são inseridas no DW.
4.5.6 Transformação Fato População Recurso Transferido por Habitante
Esta transformação apenas executa uma atualização no campo
vl_transf_habitante, na tabela de fato ft_populacao. Esses valores são obtidos através de
uma consulta aos dados já existentes no data warehouse e, em seguida, são inseridos

77
conforme localização geográfica e tempo. A figura abaixo mostra o componente que executa
instruções de data manipulation language (DML) ou linguagem de manipulação de dados no
banco, com o componente Execute SQL script.
Figura 46 – Transformação Fato Recurso Transferido por Habitante
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
4.5.7 Execução do Job Principal do Processo ETL
Por fim, ao executar o job principal, todos os outros jobs e transformações são
executados na sequência das flechas, e o processo corre até terminar.
Por medida de precaução, durante a construção das transformações as mesmas
foram sendo testadas. E, após as inserções ou atualizações do DW, foram realizadas consultas
que contavam quantos registros foram inseridos ou alterados e, também, foram observadas as
métricas mostradas pelo Kettle, como pode ser observado na figura 46 abaixo, que apresenta
métricas da transformação da dimensão tempo. Na figura, pode ser vista a coluna Saída para o
componente Insert / Update. O número 7 de saída, neste caso, indica que foram inseridos sete
registros, no caso os anos de 2005 a 2011.
Após a execução de cada transformação, a quantidade de inserções ou alterações
tinha que bater com a quantidade de linhas alvo dos arquivos fontes dos dados. Foi dessa
forma que foi descoberto que alguns municípios estavam com nomes diferentes ao do Portal
da Transparência, ou a descoberta de que não existia Pinto Bandeira nos dados populacionais
obtidos do IBGE.
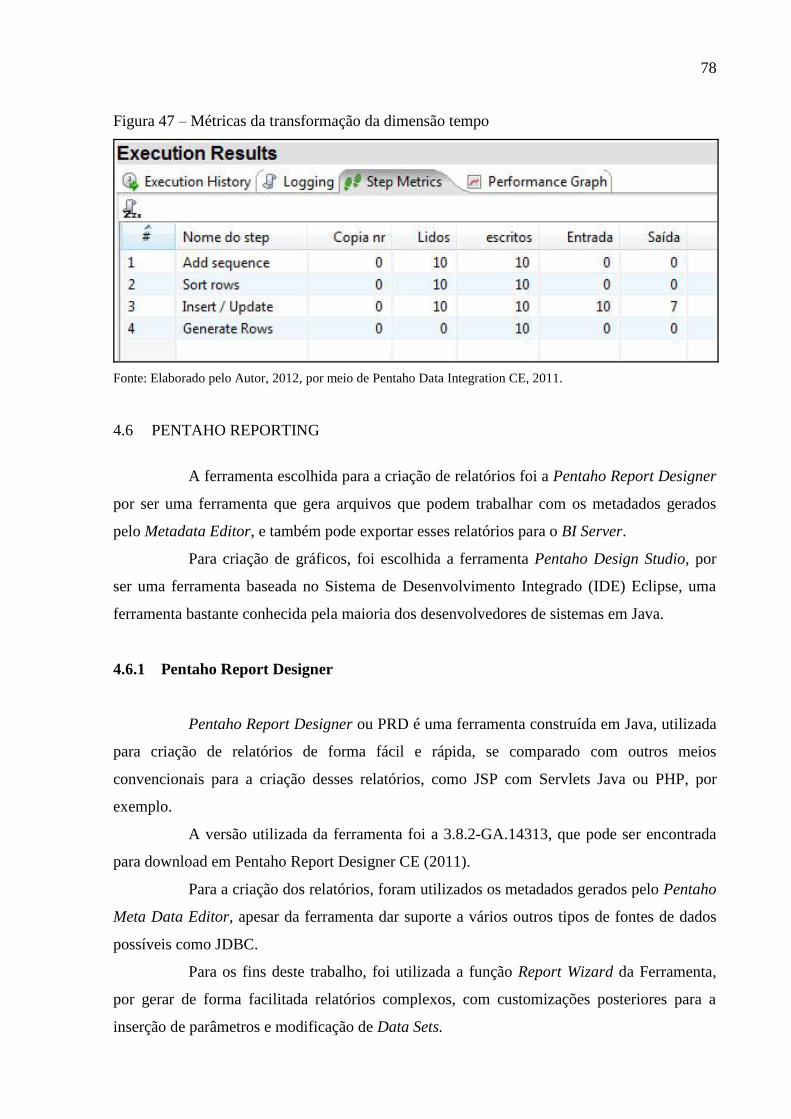
78
Figura 47 – Métricas da transformação da dimensão tempo
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Data Integration CE, 2011.
4.6 PENTAHO REPORTING
A ferramenta escolhida para a criação de relatórios foi a Pentaho Report Designer
por ser uma ferramenta que gera arquivos que podem trabalhar com os metadados gerados
pelo Metadata Editor, e também pode exportar esses relatórios para o BI Server.
Para criação de gráficos, foi escolhida a ferramenta Pentaho Design Studio, por
ser uma ferramenta baseada no Sistema de Desenvolvimento Integrado (IDE) Eclipse, uma
ferramenta bastante conhecida pela maioria dos desenvolvedores de sistemas em Java.
4.6.1 Pentaho Report Designer
Pentaho Report Designer ou PRD é uma ferramenta construída em Java, utilizada
para criação de relatórios de forma fácil e rápida, se comparado com outros meios
convencionais para a criação desses relatórios, como JSP com Servlets Java ou PHP, por
exemplo.
A versão utilizada da ferramenta foi a 3.8.2-GA.14313, que pode ser encontrada
para download em Pentaho Report Designer CE (2011).
Para a criação dos relatórios, foram utilizados os metadados gerados pelo Pentaho
Meta Data Editor, apesar da ferramenta dar suporte a vários outros tipos de fontes de dados
possíveis como JDBC.
Para os fins deste trabalho, foi utilizada a função Report Wizard da Ferramenta,
por gerar de forma facilitada relatórios complexos, com customizações posteriores para a
inserção de parâmetros e modificação de Data Sets.

79
Com a utilização do modelo de metadados do PME, fica mais fácil para se criar
relatórios, pois somente a visão de negócios do mesmo fica visível para ao criador de
relatórios, não sendo necessário ter conhecimento de SQL. Sendo assim, um usuário de
negócios poderia utilizar a ferramenta PRD de forma mais facilitada.
Para os fins deste trabalho, foram criados dois relatórios, um trata da transferência
de recursos por função e estado, com foco nos projetos do governo federal, e o outro trata dos
recursos transferidos aos municípios por ano e estado.
4.6.1.1 Relatório Transferência de Recursos por Função e Estado
Este relatório, que pode ser visto na figura 47, mostra os recursos transferidos
para um determinado estado e função selecionados pelos filtros, e apresenta as seguintes
informações:
a) Dimensão Tempo: Com o atributo Ano, mostrado no canto superior direito, apresenta
informações de 2005 a 2012;
b) Dimensão Geográfica: Com o atributo UF, que pode ser visualizado na parte superior
esquerda, apresenta o estado selecionado pelo filtro;
c) Dimensão Projeto: Com os atributos Função, Sub Função, Programa e Ação, que
podem ser visualizados nas legendas da figura, mostra os dados relativos à função
selecionada por filtro;
d) Fato Recurso Transferido: Com o atributo Valor Transferido, está agregado por
soma através dos atributos das dimensões citadas acima.

80
Figura 48 – Relatório Transferência de Recursos por Função e Estado
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Report Designer CE, 2011.
Este relatório foi iniciado com um wizard, menu File / Report Wizard, onde pode
ser escolhido um template, ou esquema de cores. Neste caso, foi escolhido o template de
nome Cobalt.
Na sequência, são escolhidos os Data Sources (DS) ou fontes dos dados, sendo
que a opção metadata foi selecionada. A figura 48, mostra como deve ser configurado o DS
metadata. Primeiro deve ser indicado onde está o arquivo XML correspondente ao modelo de
metadados. Segundo, deve ser preenchido o nome da solução do BI Server, no qual o relatório
deverá ser publicado. Em seguida, clica-se no sinal de mais para adicionar uma query e se
escolhe um nome para a mesma em Query Name.
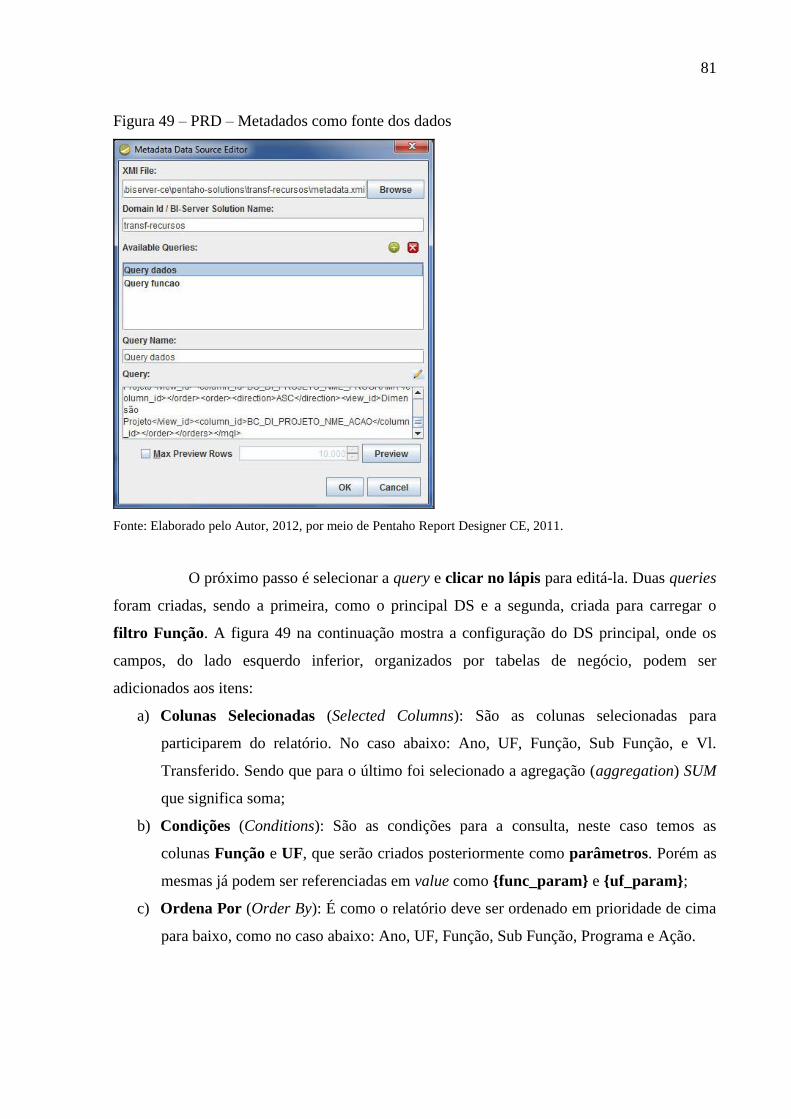
81
Figura 49 – PRD – Metadados como fonte dos dados
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Report Designer CE, 2011.
O próximo passo é selecionar a query e clicar no lápis para editá-la. Duas queries
foram criadas, sendo a primeira, como o principal DS e a segunda, criada para carregar o
filtro Função. A figura 49 na continuação mostra a configuração do DS principal, onde os
campos, do lado esquerdo inferior, organizados por tabelas de negócio, podem ser
adicionados aos itens:
a) Colunas Selecionadas (Selected Columns): São as colunas selecionadas para
participarem do relatório. No caso abaixo: Ano, UF, Função, Sub Função, e Vl.
Transferido. Sendo que para o último foi selecionado a agregação (aggregation) SUM
que significa soma;
b) Condições (Conditions): São as condições para a consulta, neste caso temos as
colunas Função e UF, que serão criados posteriormente como parâmetros. Porém as
mesmas já podem ser referenciadas em value como {func_param} e {uf_param};
c) Ordena Por (Order By): É como o relatório deve ser ordenado em prioridade de cima
para baixo, como no caso abaixo: Ano, UF, Função, Sub Função, Programa e Ação.
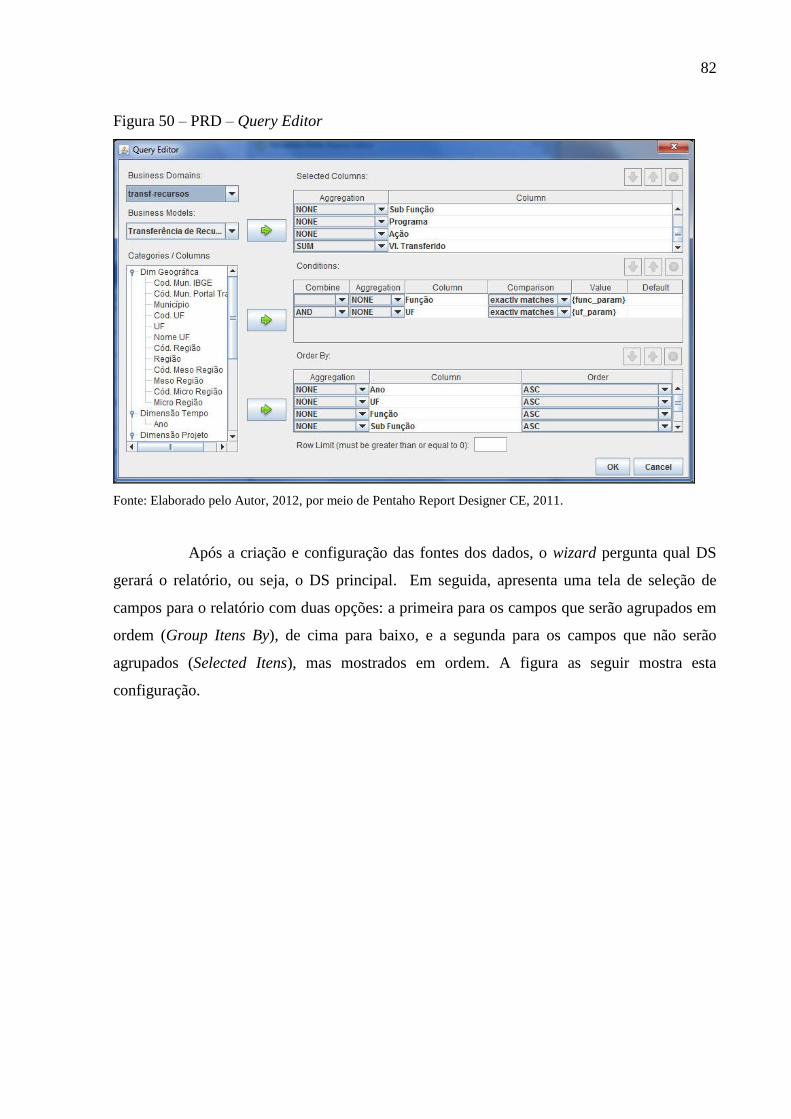
82
Figura 50 – PRD – Query Editor
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Report Designer CE, 2011.
Após a criação e configuração das fontes dos dados, o wizard pergunta qual DS
gerará o relatório, ou seja, o DS principal. Em seguida, apresenta uma tela de seleção de
campos para o relatório com duas opções: a primeira para os campos que serão agrupados em
ordem (Group Itens By), de cima para baixo, e a segunda para os campos que não serão
agrupados (Selected Itens), mas mostrados em ordem. A figura as seguir mostra esta
configuração.

83
Figura 51 – PRD Wizard, Definição do Layout do Relatório
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Report Designer CE, 2011.
Ao se clicar em next, aparece uma tela com opções como: alterar legendas dos
campos e modificar o formato dos dados. Para o campo Vl. Transferido foi selecionado o
formato sugerido ‘#,###.00;(#,###.00)’, que mostra o valor com duas casas após a vírgula e
com pontos a cada milhar. O botão Preview é muito útil, pois pode mostrar como o relatório
está ficando antes de encerrar o Wizard. Por fim, é só clicar em Finish e a interface do
relatório é apresentada, como mostrado na figura a seguir.
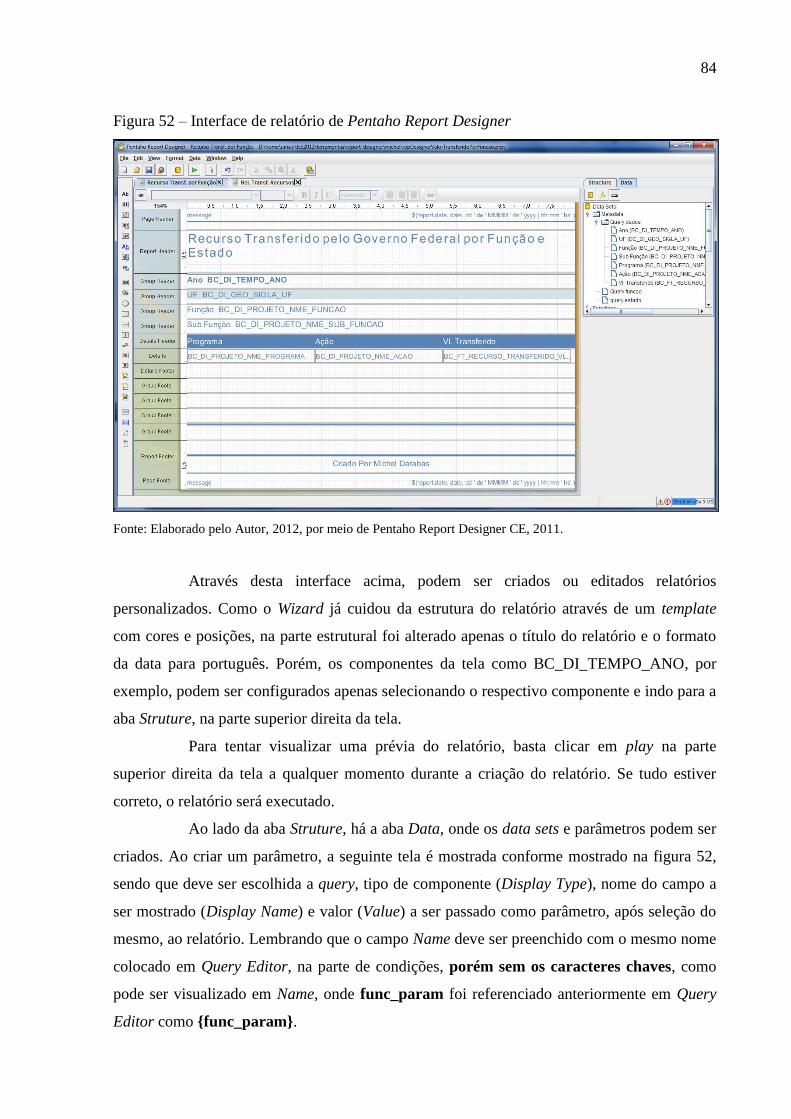
84
Figura 52 – Interface de relatório de Pentaho Report Designer
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Report Designer CE, 2011.
Através desta interface acima, podem ser criados ou editados relatórios
personalizados. Como o Wizard já cuidou da estrutura do relatório através de um template
com cores e posições, na parte estrutural foi alterado apenas o título do relatório e o formato
da data para português. Porém, os componentes da tela como BC_DI_TEMPO_ANO, por
exemplo, podem ser configurados apenas selecionando o respectivo componente e indo para a
aba Struture, na parte superior direita da tela.
Para tentar visualizar uma prévia do relatório, basta clicar em play na parte
superior direita da tela a qualquer momento durante a criação do relatório. Se tudo estiver
correto, o relatório será executado.
Ao lado da aba Struture, há a aba Data, onde os data sets e parâmetros podem ser
criados. Ao criar um parâmetro, a seguinte tela é mostrada conforme mostrado na figura 52,
sendo que deve ser escolhida a query, tipo de componente (Display Type), nome do campo a
ser mostrado (Display Name) e valor (Value) a ser passado como parâmetro, após seleção do
mesmo, ao relatório. Lembrando que o campo Name deve ser preenchido com o mesmo nome
colocado em Query Editor, na parte de condições, porém sem os caracteres chaves, como
pode ser visualizado em Name, onde func_param foi referenciado anteriormente em Query
Editor como {func_param}.
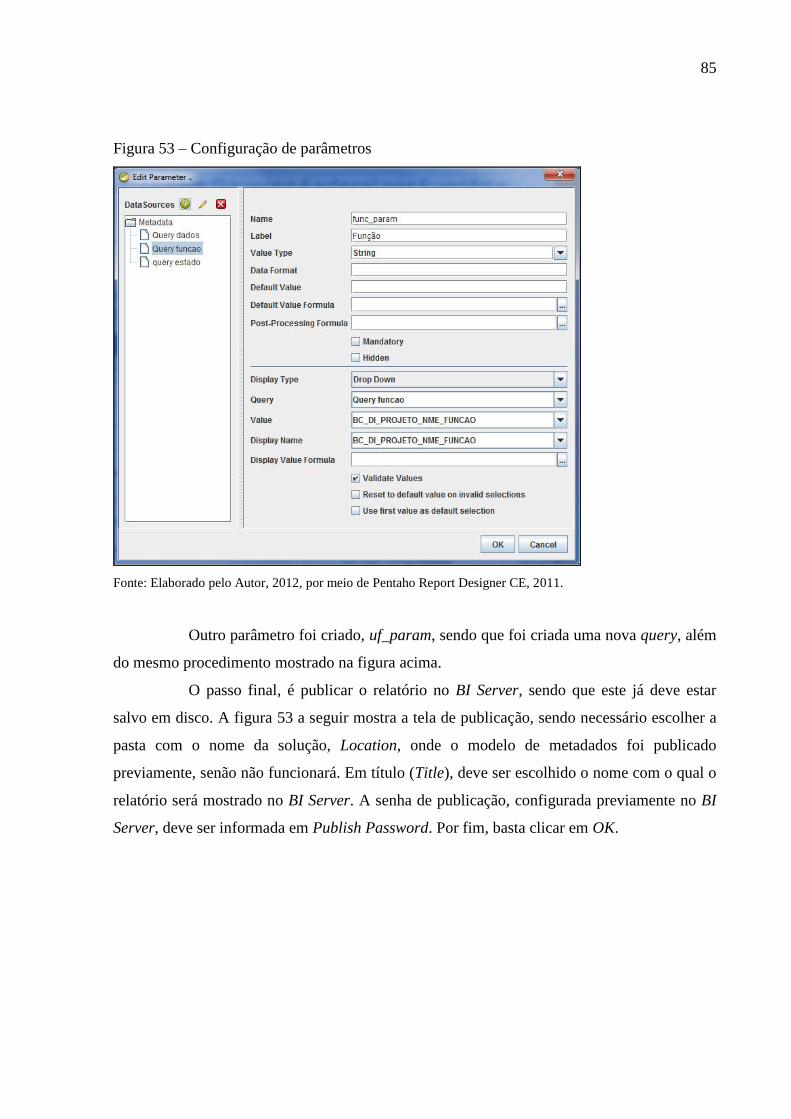
85
Figura 53 – Configuração de parâmetros
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Report Designer CE, 2011.
Outro parâmetro foi criado, uf_param, sendo que foi criada uma nova query, além
do mesmo procedimento mostrado na figura acima.
O passo final, é publicar o relatório no BI Server, sendo que este já deve estar
salvo em disco. A figura 53 a seguir mostra a tela de publicação, sendo necessário escolher a
pasta com o nome da solução, Location, onde o modelo de metadados foi publicado
previamente, senão não funcionará. Em título (Title), deve ser escolhido o nome com o qual o
relatório será mostrado no BI Server. A senha de publicação, configurada previamente no BI
Server, deve ser informada em Publish Password. Por fim, basta clicar em OK.
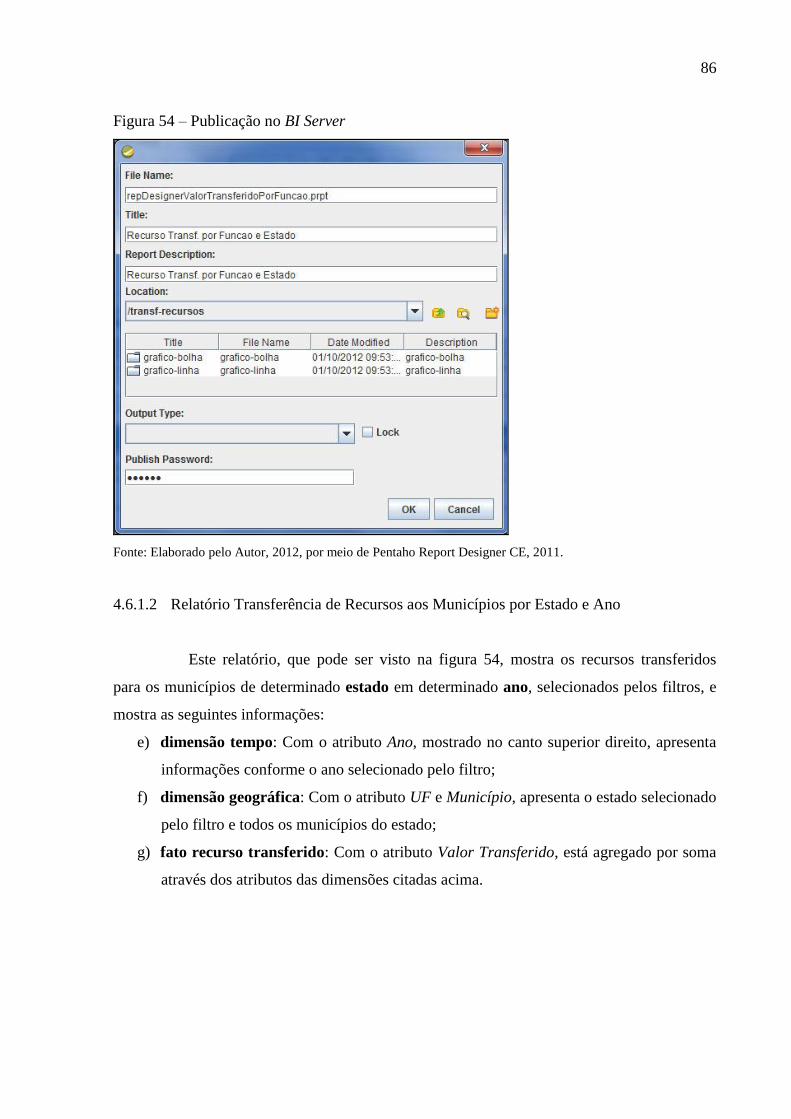
86
Figura 54 – Publicação no BI Server
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Report Designer CE, 2011.
4.6.1.2 Relatório Transferência de Recursos aos Municípios por Estado e Ano
Este relatório, que pode ser visto na figura 54, mostra os recursos transferidos
para os municípios de determinado estado em determinado ano, selecionados pelos filtros, e
mostra as seguintes informações:
e) dimensão tempo: Com o atributo Ano, mostrado no canto superior direito, apresenta
informações conforme o ano selecionado pelo filtro;
f) dimensão geográfica: Com o atributo UF e Município, apresenta o estado selecionado
pelo filtro e todos os municípios do estado;
g) fato recurso transferido: Com o atributo Valor Transferido, está agregado por soma
através dos atributos das dimensões citadas acima.
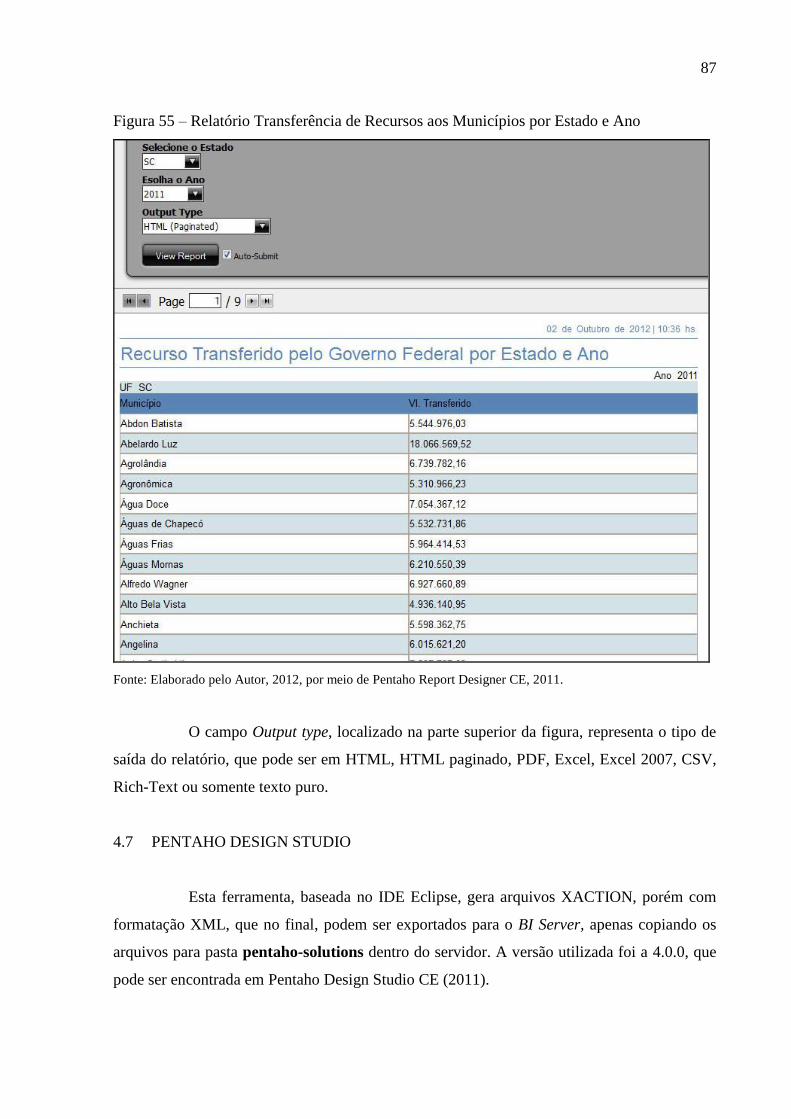
87
Figura 55 – Relatório Transferência de Recursos aos Municípios por Estado e Ano
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Report Designer CE, 2011.
O campo Output type, localizado na parte superior da figura, representa o tipo de
saída do relatório, que pode ser em HTML, HTML paginado, PDF, Excel, Excel 2007, CSV,
Rich-Text ou somente texto puro.
4.7 PENTAHO DESIGN STUDIO
Esta ferramenta, baseada no IDE Eclipse, gera arquivos XACTION, porém com
formatação XML, que no final, podem ser exportados para o BI Server, apenas copiando os
arquivos para pasta pentaho-solutions dentro do servidor. A versão utilizada foi a 4.0.0, que
pode ser encontrada em Pentaho Design Studio CE (2011).

88
Com está ferramenta, é possível criar relatórios e gráficos, porém para este
trabalho, esta foi utilizada somente para a criação do último.
Esta ferramenta trabalha com uma conexão com o banco de dados chamada
dwtransf-recursos, sendo que esta foi criada e configurada com a ferramenta web
Administration Console, como foi mostrado na seção 4.3 Pentaho BI Server.
4.7.1 Gráfico Bolha Transferência de Recursos por Localidade
O gráfico no formato de bolha pode ser visto na figura abaixo, sendo que possui
filtros por Ano, Região, Estado, Micro Região e Meso Região, sendo o único obrigatório o
ano. Os arquivos do gráfico foram salvos dentro da pasta pentaho-solutions/transf-
recursos/grafico-bolha no BI Server.
Figura 56 – Gráfico Bolha Transferência de Recursos por Localidade
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Design Studio CE, 2011.

89
O gráfico mostra a transferência de recursos para as regiões do Brasil para o ano
selecionado de 2011. O eixo Y mostra a população, enquanto o eixo X o valor transferido
para a região em milhares de reais. Quanto menor o círculo, menor a quantidade de
transferência de recurso por habitante no ano. Fica claro no gráfico, por exemplo, que o
Nordeste além de ter recebido uma fatia maior dos recursos em 2011, também teve uma
grande transferência de recursos por habitante. Contudo, o circulo do Nordeste deu uma
pequena crescida pelo fato do mouse estar em cima dele, porém a região com maior
transferência de recursos per capta em 2011 na verdade, foi a Norte. Também, fica visível que
o Sul e o Sudeste, os dois círculos menores, tiveram a menor transferência por habitante para
o ano de 2011.
Para a criação do gráfico, foi necessário a criação dos seguintes arquivos:
a) graficoBubble.xaction: Arquivo principal, responsável por chamar os outros
arquivos. Formatado com XML, possui as principais funções SQL e filtra os
resultados conforme os filtros aplicados;
b) localizacaoParameterTemplate.html: Arquivo HTML responsável pelo layout da
página que contém o gráfico, porém não o layout do gráfico;
c) graficoBubble.xml: Arquivo responsável pela configuração do gráfico em si, como:
tipo de gráfico, legendas, tipo de fonte, cores e muito mais. Sendo que o gráfico é
processado digitalmente por um componente em Flash disponibilizado pelo BI Server;
d) estadosPorRegiao.xaction: Arquivo chamado via Javascript, para fazer a alteração
dinâmica do componente de seleção HTML Estado, ao se alterar uma região;
e) mesoPorEstado.xaction: Arquivo chamado via Javascript, para fazer a alteração
dinâmica do componente de seleção HTML Meso Região, ao se alterar um estado;
f) microPorEstadoMeso.xaction: Arquivo chamado via Javascript, para fazer a
alteração dinâmica do componente de seleção HTML Micro Região, ao se alterar uma
meso região.
Com o Design Studio, não é necessária a criação dos arquivos XACTION
digitando todo o arquivo. A IDE têm características que ajudam a criar e manipular esses
arquivos de forma organizada.
A interface de Pentaho Design Studio pode ser vista na figura 56, sendo que, na
parte esquerda, temos os arquivos físicos do projeto. Na parte direita central, temos o arquivo
principal graficoBubble.xaction aberto com abas na sua parte inferior, sendo as principais,
Geral (General), Definição do Processo (Define Process) e Fonte do Arquivo em XML (XML
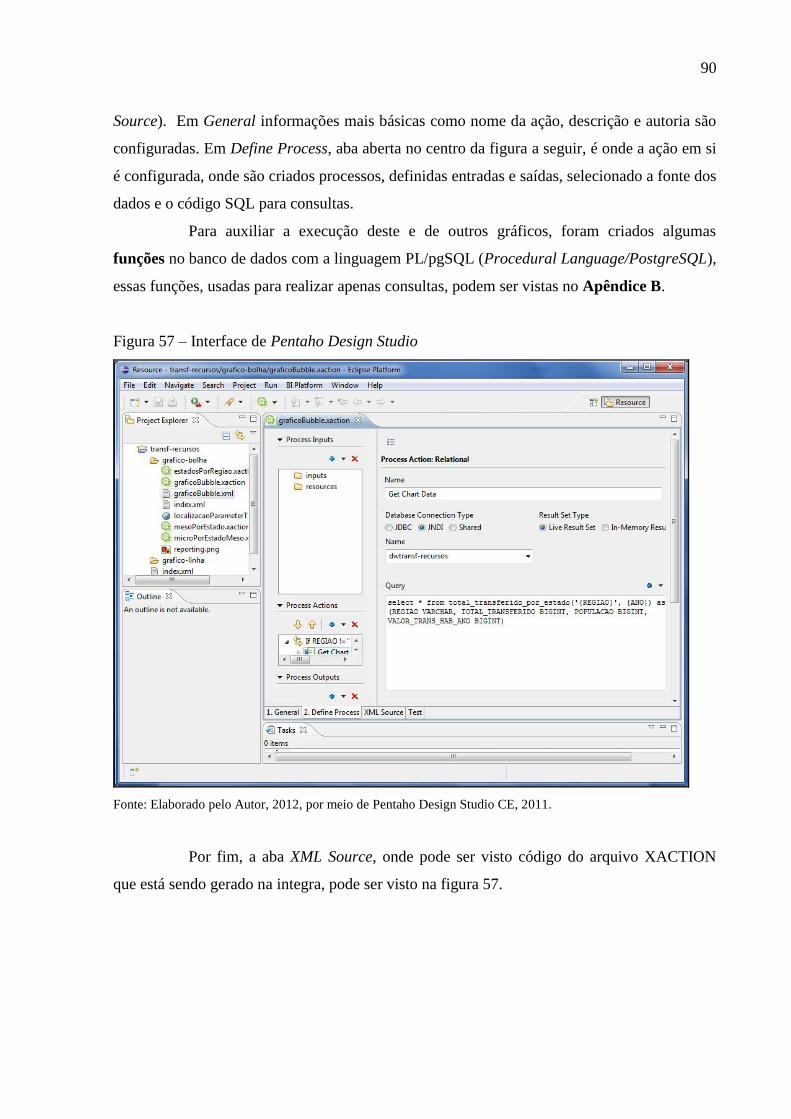
90
Source). Em General informações mais básicas como nome da ação, descrição e autoria são
configuradas. Em Define Process, aba aberta no centro da figura a seguir, é onde a ação em si
é configurada, onde são criados processos, definidas entradas e saídas, selecionado a fonte dos
dados e o código SQL para consultas.
Para auxiliar a execução deste e de outros gráficos, foram criados algumas
funções no banco de dados com a linguagem PL/pgSQL (Procedural Language/PostgreSQL),
essas funções, usadas para realizar apenas consultas, podem ser vistas no Apêndice B.
Figura 57 – Interface de Pentaho Design Studio
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Design Studio CE, 2011.
Por fim, a aba XML Source, onde pode ser visto código do arquivo XACTION
que está sendo gerado na integra, pode ser visto na figura 57.

91
Figura 58 – Design Studio código fonte XML
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Design Studio CE, 2011.
4.7.2 Gráfico Linha Transferência de Recursos por Localidade e Ano
O gráfico, no formato de linha, pode ser visto na figura 58 a seguir, este possui
filtros por Ano, Região, Estado, Micro Região e Meso Região, não tendo nenhum campo
obrigatório. Os arquivos do gráfico foram salvos dentro da pasta pentaho-solutions/transf-
recursos/grafico-linha no BI Server.
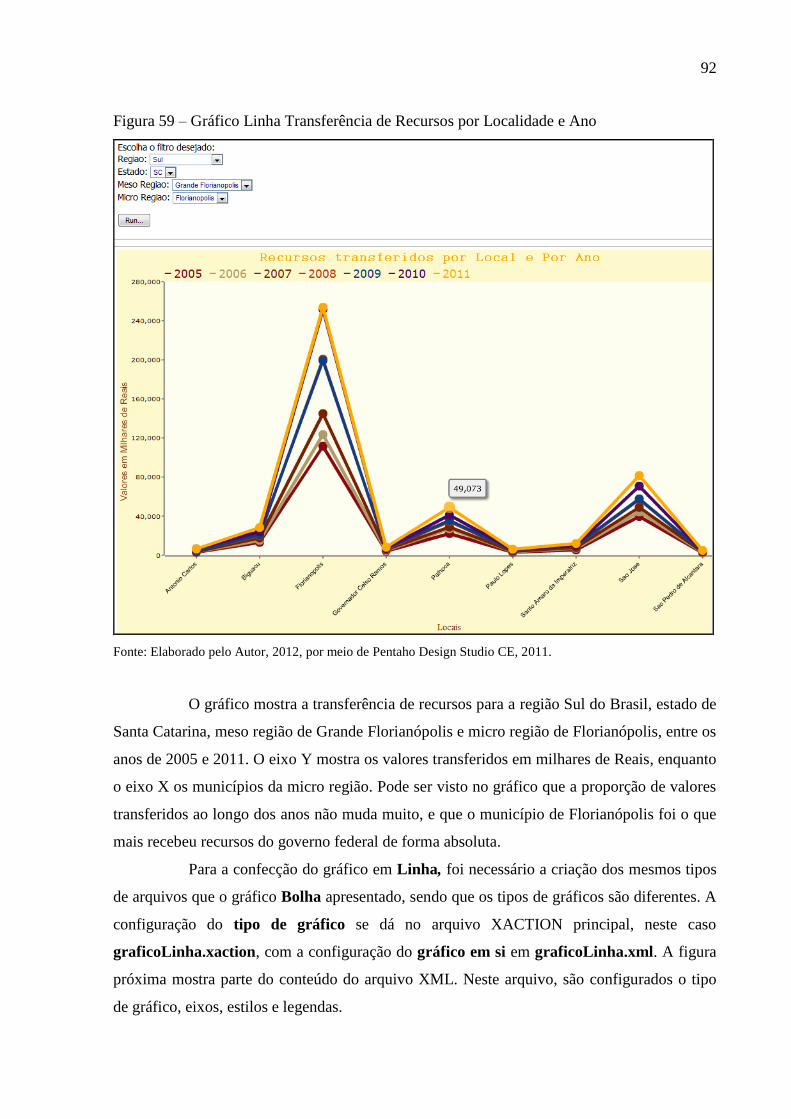
92
Figura 59 – Gráfico Linha Transferência de Recursos por Localidade e Ano
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Design Studio CE, 2011.
O gráfico mostra a transferência de recursos para a região Sul do Brasil, estado de
Santa Catarina, meso região de Grande Florianópolis e micro região de Florianópolis, entre os
anos de 2005 e 2011. O eixo Y mostra os valores transferidos em milhares de Reais, enquanto
o eixo X os municípios da micro região. Pode ser visto no gráfico que a proporção de valores
transferidos ao longo dos anos não muda muito, e que o município de Florianópolis foi o que
mais recebeu recursos do governo federal de forma absoluta.
Para a confecção do gráfico em Linha, foi necessário a criação dos mesmos tipos
de arquivos que o gráfico Bolha apresentado, sendo que os tipos de gráficos são diferentes. A
configuração do tipo de gráfico se dá no arquivo XACTION principal, neste caso
graficoLinha.xaction, com a configuração do gráfico em si em graficoLinha.xml. A figura
próxima mostra parte do conteúdo do arquivo XML. Neste arquivo, são configurados o tipo
de gráfico, eixos, estilos e legendas.

93
Figura 60 – Configuração do gráfico com XML
Fonte: Elaborado pelo Autor, 2012, adaptado de Pentaho Design Studio CE, 2011.
Um exemplo interessante pode se visto na figura 60, a qual mostra o gráfico em
nível de regiões do Brasil entre os anos de 2005 e 2011. Pode ser visto que houve um
crescimento mais acentuado na transferência de recursos ao longo dos anos para o Nordeste e
Sudeste, se comparado com as outras regiões.
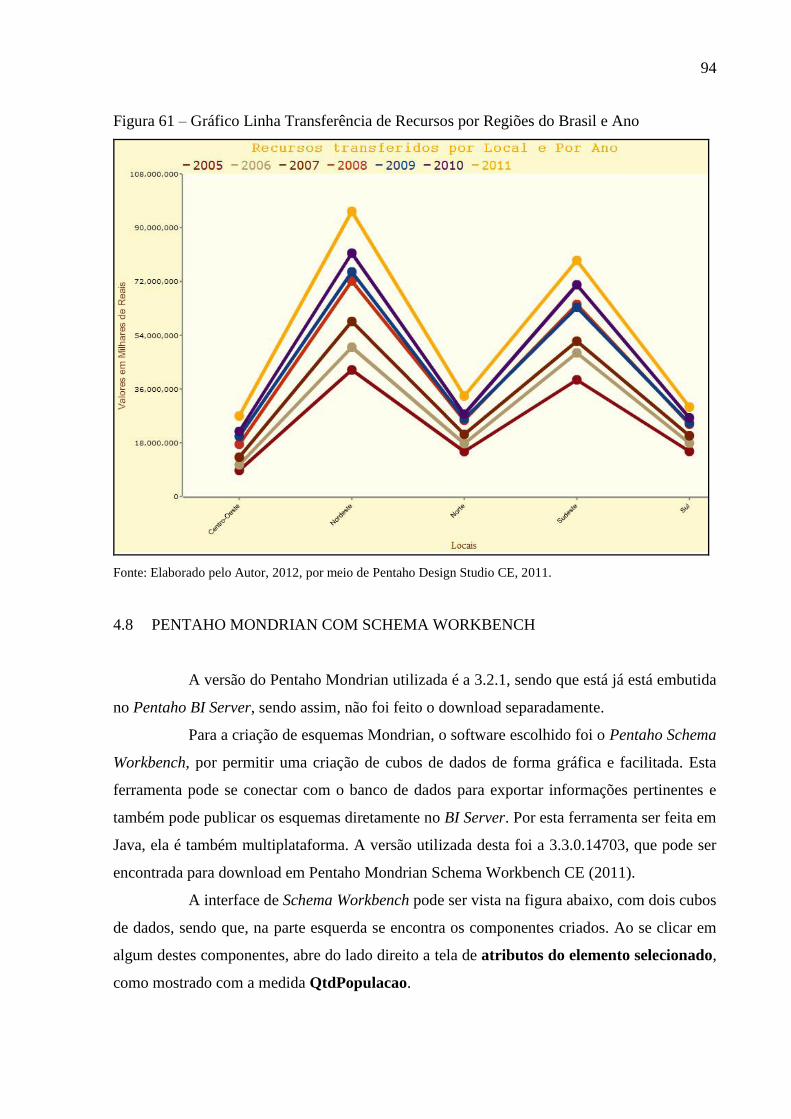
94
Figura 61 – Gráfico Linha Transferência de Recursos por Regiões do Brasil e Ano
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Design Studio CE, 2011.
4.8 PENTAHO MONDRIAN COM SCHEMA WORKBENCH
A versão do Pentaho Mondrian utilizada é a 3.2.1, sendo que está já está embutida
no Pentaho BI Server, sendo assim, não foi feito o download separadamente.
Para a criação de esquemas Mondrian, o software escolhido foi o Pentaho Schema
Workbench, por permitir uma criação de cubos de dados de forma gráfica e facilitada. Esta
ferramenta pode se conectar com o banco de dados para exportar informações pertinentes e
também pode publicar os esquemas diretamente no BI Server. Por esta ferramenta ser feita em
Java, ela é também multiplataforma. A versão utilizada desta foi a 3.3.0.14703, que pode ser
encontrada para download em Pentaho Mondrian Schema Workbench CE (2011).
A interface de Schema Workbench pode ser vista na figura abaixo, com dois cubos
de dados, sendo que, na parte esquerda se encontra os componentes criados. Ao se clicar em
algum destes componentes, abre do lado direito a tela de atributos do elemento selecionado,
como mostrado com a medida QtdPopulacao.
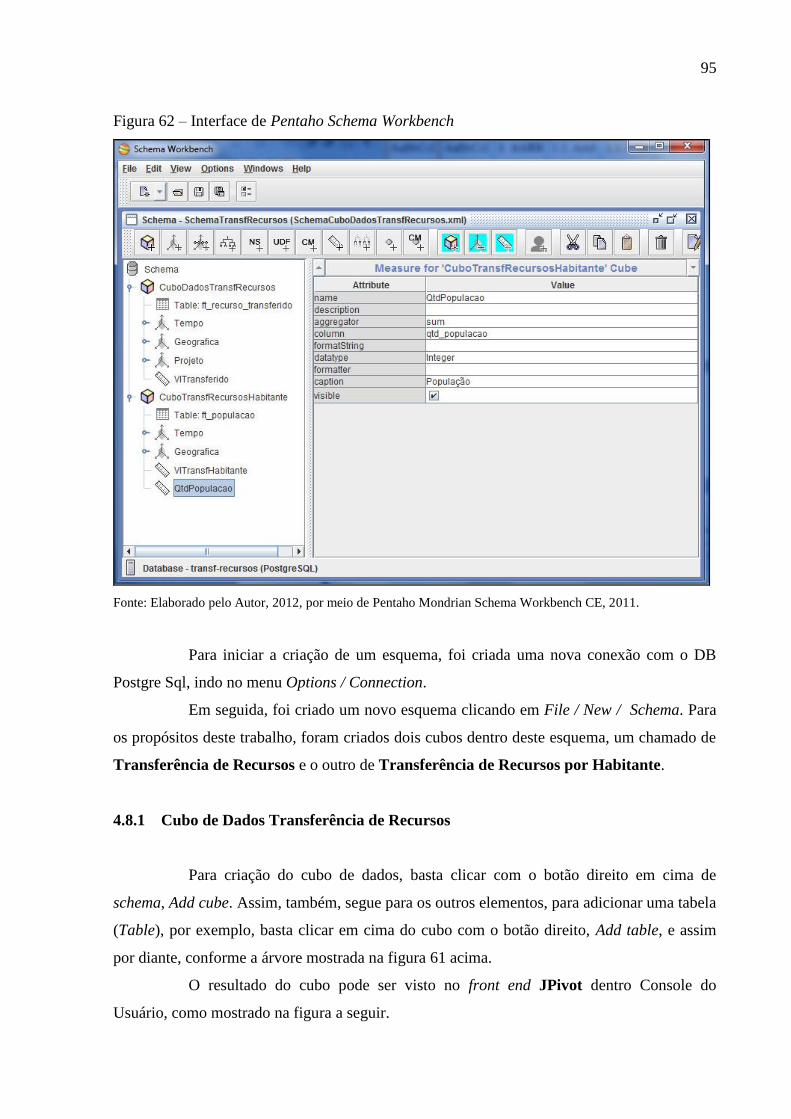
95
Figura 62 – Interface de Pentaho Schema Workbench
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Mondrian Schema Workbench CE, 2011.
Para iniciar a criação de um esquema, foi criada uma nova conexão com o DB
Postgre Sql, indo no menu Options / Connection.
Em seguida, foi criado um novo esquema clicando em File / New / Schema. Para
os propósitos deste trabalho, foram criados dois cubos dentro deste esquema, um chamado de
Transferência de Recursos e o outro de Transferência de Recursos por Habitante.
4.8.1 Cubo de Dados Transferência de Recursos
Para criação do cubo de dados, basta clicar com o botão direito em cima de
schema, Add cube. Assim, também, segue para os outros elementos, para adicionar uma tabela
(Table), por exemplo, basta clicar em cima do cubo com o botão direito, Add table, e assim
por diante, conforme a árvore mostrada na figura 61 acima.
O resultado do cubo pode ser visto no front end JPivot dentro Console do
Usuário, como mostrado na figura a seguir.
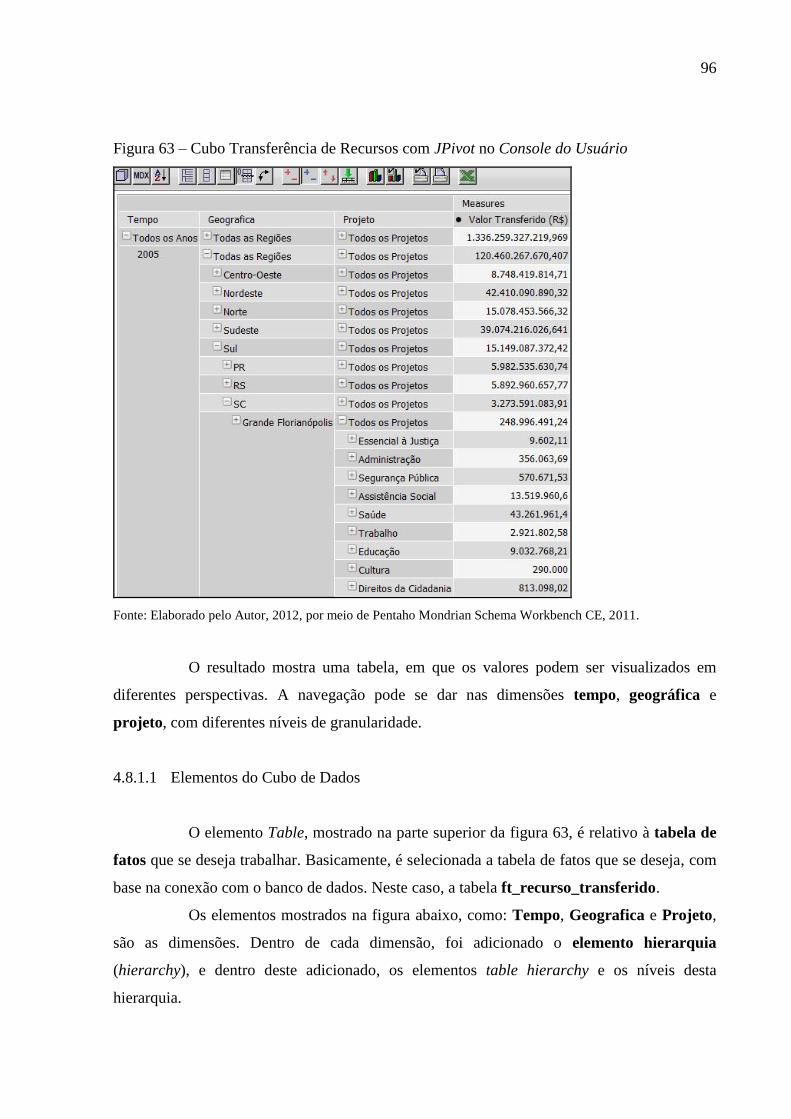
96
Figura 63 – Cubo Transferência de Recursos com JPivot no Console do Usuário
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Mondrian Schema Workbench CE, 2011.
O resultado mostra uma tabela, em que os valores podem ser visualizados em
diferentes perspectivas. A navegação pode se dar nas dimensões tempo, geográfica e
projeto, com diferentes níveis de granularidade.
4.8.1.1 Elementos do Cubo de Dados
O elemento Table, mostrado na parte superior da figura 63, é relativo à tabela de
fatos que se deseja trabalhar. Basicamente, é selecionada a tabela de fatos que se deseja, com
base na conexão com o banco de dados. Neste caso, a tabela ft_recurso_transferido.
Os elementos mostrados na figura abaixo, como: Tempo, Geografica e Projeto,
são as dimensões. Dentro de cada dimensão, foi adicionado o elemento hierarquia
(hierarchy), e dentro deste adicionado, os elementos table hierarchy e os níveis desta
hierarquia.

97
A figura abaixo mostra a árvore para o cubo Transferência de Recursos, contendo
todos os elementos utilizados.
Figura 64 – Árvore do cubo Transferência de Recursos
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Mondrian Schema Workbench CE, 2011.
Pegando como exemplo a dimensão Geografica, ela possui uma hierarquia com o
mesmo nome. Dentro desta, existem os elementos Table e outros cinco representando os
níveis da dimensão no cubo. Ao selecionar um elemento qualquer, o Schema Workbench abre
do lado direito uma tela onde os atributos desse elemento podem ser modificados.
Configuração dos atributos dos elementos:
a) Table: di_geo: Basicamente, é informada qual a tabela física no data warehouse;
b) NivelMunicipio: Os seguintes atributos (em negrito) foram configurados com os
valores (em itálico), seguido pela explicação de cada atributo abaixo:
- name: NivelMunicipio;
- Nome do elemento.
- columm: cod_mun_ibge;
- Selecionado a coluna física na tabela do data warehouse.

98
- ordinalColumn: nme_municipio;
- A coluna física responsável pela ordenação.
- type: String;
- O tipo de dados, neste caso com caracteres literais (String).
- hideMemberif: Never;
- Nunca esconderá um membro, mesmo que este seja nulo.
- captionColumn: nme_municipio;
- Coluna física cujos valores serão apresentados no cubo de dados no
lugar do atributo column acima.
a) Outros níveis: Seguem a mesma lógica de NivelMunicipio.
b) Hierarchi: Geografica: Os seguintes atributos (em negrito) foram configurados com
os valores (em itálico), seguido pela explicação de cada atributo abaixo:
- name: Geografica;
- Nome do elemento.
- allMemberName: Todas as Regiões;
- Nome que representa os registros iniciais da dimensão Geográfica
mostrados no cubo.
- primary key: seq_geo;
- Chave primária física da tabela di_geo.
c) Dimension: Geografica: Neste elemento foram configurados os seguintes atributos:
- name: Geografica;
- Nome do elemento;
- foreignKey: seq_geo;
- A chave estrangeira relativa a tabela de fato.
- type: StandardDimension;
- O tipo de dimensão, que no caso é a padrão.
d) As dimensões Tempo e Projeto seguem a mesma lógica da dimensão Geografica.
O elemento VlTransferido, diretamente abaixo do nível do cubo, representa uma
medida (Measure), que no caso é valor transferido. Este elemento foi configurado, conforme
imagem 64. O atributo name recebe o nome do componente, o atributo aggregator
(agregador) recebe o valor sum (soma), agregador responsável por mudar o valor transferido,
conforme o nível de granularidade. O tipo de dado (datatype) é configurado com o valor
numérico (numeric).

99
Figura 65 – Atributos da medida valor transferido
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Mondrian Schema Workbench CE, 2011.
4.8.2 Cubo de Dados Transferência de Recursos por Habitante
O resultado do cubo pode ser visto no front end JPivot dentro Console do
Usuário, como mostrado na figura abaixo.
Figura 66 – Cubo Transferência de Recursos por Habitante - JPivot
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Mondrian Schema Workbench CE, 2011.

100
O resultado mostra uma tabela, em que os valores transferidos por habitante
podem ser visualizados em diferentes perspectivas, ao lodo da respectiva população.
A configuração deste cubo é bastante semelhante ao cubo anterior, com a
diferença de que a tabela de fato considerada é a ft_populacao, e a dimensão Projeto não é
utilizada. Também aqui são utilizadas duas medidas ao invés de uma. Uma das medidas
chamada de VlTransfHabitante recebe o agregador AGV (average) ou média aritmética, ao
invés de soma, ou seja, na medida em que o menor nível de granularidade é alcançado, sendo
o menor possível o de valor transferido por habitante por município e no ano, este último é
absoluto e a média não precisa ser aplicada. Contudo, para grãos maiores como UF, por
exemplo, o valor apresentado será uma média entre os municípios, isto no caso deste cubo. Já
a outra medida, chamada de QtdPopulacao, utiliza o agregador soma.
4.8.3 Publicação no BI Server
Após o esquema pronto, o mesmo pode ser publicado no BI Server, clicando no
menu File / Publish. A tela de autenticação é apresentada, solicitando informações como:
URL do servidor, usuário e senha. Após a autenticação, a seguinte tela é apresentada,
conforme figura abaixo. A pasta com a solução do BI Server deve ser indicada, neste caso a
pasta transf-recursos. Uma informação muito importante é a Pentaho or JDNI Data Source,
que representa o nome da conexão com o banco criada com a ferramenta Administration
Console do BI Server, neste caso: dwtransf-recursos. Esta informação é necessária para que o
Mondrian ligue o esquema criado com o data warehouse.
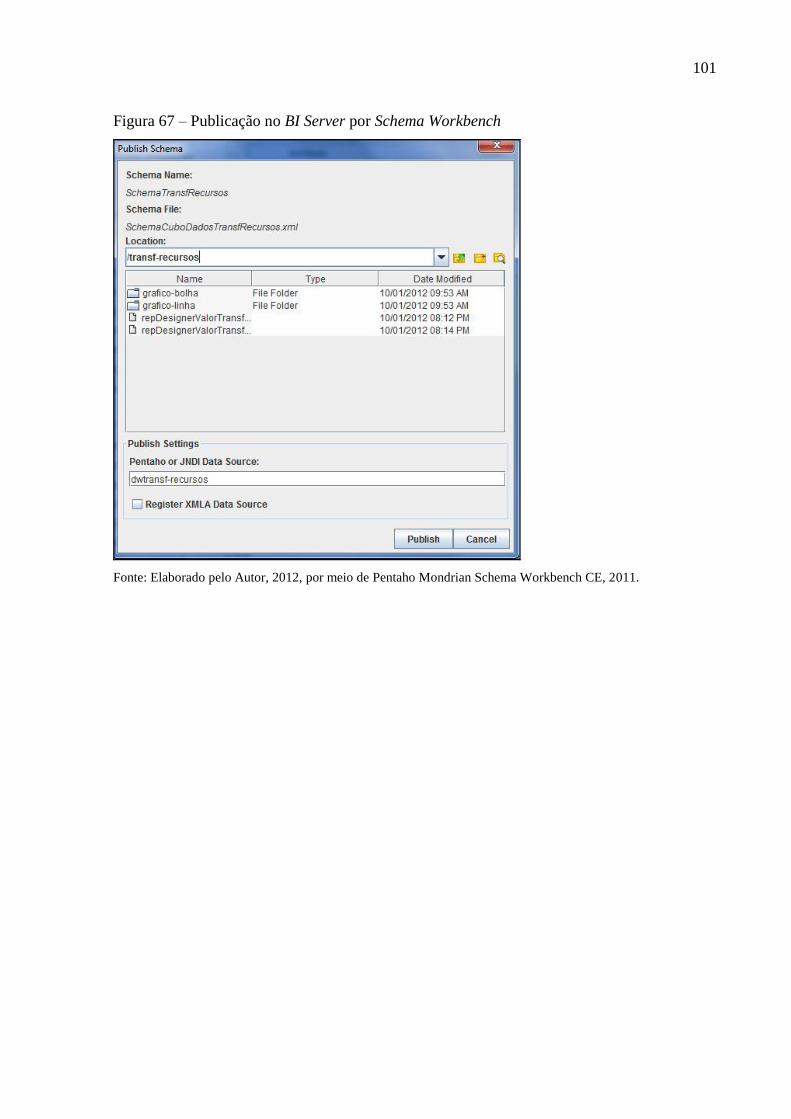
101
Figura 67 – Publicação no BI Server por Schema Workbench
Fonte: Elaborado pelo Autor, 2012, por meio de Pentaho Mondrian Schema Workbench CE, 2011.

102
5 CONCLUSÕES E TRABALHOS FUTUROS
A construção de uma solução de BI com ferramentas open source se tornou
viável, devido a forte cobertura da comunidade internacional em volta das ferramentas
Pentaho. Esses permitem o download e instalação das ferramentas de forma facilitada e
também fornecem documentação e fóruns de discussões relativo a cada programa da suite
Pentaho. Estes materiais podem ser encontrados no portal web Pentaho de forma gratuita em
Pentaho (2012d), com o objetivo de auxiliar as organizações que desejarem utilizar as
ferramentas da Pentaho BI Suite CE.
A solução, aqui criada, atingiu os objetivos propostos relativo à criação de uma
solução de BI, pois iniciou-se com a criação do data warehouse e permitiu a efetivação do
processo ETL com suporte a vários formatos de fonte de dados, de forma gráfica e facilitada.
Seguido pela criação de um repositório de metadados, que foram utilizados para criação de
relatórios. Estes últimos, juntamente com os gráficos e cubos de dados criados, podem
auxiliar na obtenção de informações e no processo decisório de interesse. Também, foi
instalado o servidor BI com motor OLAP que possui uma ferramenta web de front end para
interagir com o usuário final.
A forma de que a solução foi criada foi facilitada, sem a necessidade de utilização
de linguagens de programação mais complexas como, por exemplo, C++, JAVA ou PHP.
Estas necessitariam de muito mais tempo, trabalho e especialização para se desenvolver do
zero a solução apresentada. Contudo, as ferramentas Pentaho são de código fonte aberto,
permitindo assim, que customizações possam ser feitas por programadores especializados,
caso seja necessário.
Vale apena ressaltar que, apesar de não ter sido necessário a utilização de
linguagens de programação mais complexas para a criação da solução, um bom nível de
conhecimento em banco de dados e SQL foi necessário. Exceto para a forma em que a
ferramenta Report Designer foi empregada, pois a mesma foi utilizada com um modelo de
metadados gerado por PME, permitindo a um usuário de negócios criar relatórios de forma
facilitada, sem utilizar SQL diretamente.
Para as ferramentas open source utilizadas, ou outras da Pentaho não exploradas
no escopo deste trabalho, não há custo com licenciamento de software, sendo assim, as
organizações interessadas podem utilizar, customizar e distribuir as soluções de BI criadas,
conforme a necessidade. Porém vale a pena ressaltar que uma solução de BI não será livre de

103
custos, pois ainda existem outros custos associados como: hardware, implementação da
solução, manutenção, treinamento, migração de dados, entre outros.
Para a realização de trabalhos futuros, alguns itens podem complementar ou dar
continuidade a este trabalho como:
a) análise dos dados incluídos do data warehouse, permitindo assim, a obtenção de
informações e conhecimento sobre a transferência de recursos do governo federal para
os estados e municípios. Neste caso, também sendo necessário a criação de novos
cubos de dados, gráficos e relatórios adicionais, possibilitando tentar estabelecer uma
relação entre as transferências e as populações dos estados e municípios brasileiros;
b) inclusão de dados no data warehouse relativos ao PIB de cada município e dos
partidos políticos que assumiram cada prefeitura, os governos dos estados e o governo
federal em cada ano, para assim, possibilitar uma análise mais precisa da qualidade da
transferência de recursos do governo federal, e se os critérios adotados têm relação
com o PIB ou partidos políticos;
c) criação de dashboards para permitir comparações entre regiões ou informações
consolidadas por projetos ou localização geográfica. Exploração de outras ferramentas
Pentaho como: Community Dashboard Framework (CDF), para criação de
dashboards de forma facilitada; Pentaho Analyzer para análise de cubos OLAP; Entre
outras com propósitos diversos, sendo que estas podem ser encontradas em Pentaho
(2012d).

104
REFERÊNCIAS
BOUMAN, R.; DONGEN, J. V. Pentaho Solutions: Business Intelligence and Data
Warehousing with Pentaho and MySQL. Indianapolis, Indiana, USA: Wiley Publishing, 2009.
BRASIL. Controladoria-Geral da União. Portal da Transparência - Dados do Portal.
Disponível em: <http://www.portaldatransparencia.gov.br/sobre/Origem.asp> Acesso em: 17
jun. 2012a.
BRASIL. Controladoria-Geral da União. Portal da Transparência - Download de
Consultas. Disponível em: <http://www.portaldatransparencia.gov.br/planilhas/> Acesso em:
17 jun. 2012b.
BRASIL. Controladoria-Geral da União. Portal da Transparência - Glossário. Disponível
em: <http://www.portaldatransparencia.gov.br/glossario/DetalheGlossario.asp?letra=t>
Acesso em: 17 jun. 2012c.
BRASIL. Controladoria-Geral da União. Portal da Transparência - Sobre o Portal.
Disponível em: <http://www.portaldatransparencia.gov.br/sobre/> Acesso em: 17 jun. 2012d.
BRASIL. Controladoria-Geral da União. Portal da Transparência - Sobre o Portal - O que
você encontra no Portal. Disponível em:
<http://www.portaltransparencia.gov.br/sobre/OQueEncontra.asp> Acesso em: 30 jul. 2012e.
CARVALHO, Luiz Alfredo Vidal de. Datamining: A Mineração de Dados no Marketing,
Medicina, Economia, Engenharia e Administração. São Paulo, SP: Érica, 2001.
CHAUDHURI, Surajit; DAYAL, Umeshwar; NARASAYYA, Vivek. An overview of
business intelligence technology. Communications of the ACM, New York, USA, v. 54, n.
8, p. 88-98, ago. 2011. Disponível em:
<http://delivery.acm.org/10.1145/1980000/1978562/p88-
chaudhuri.pdf?ip=189.26.130.197&acc=OPEN&CFID=75668290&CFTOKEN=95664262&_
_acm__=1333460546_603f9f0da642ffdd23592b958edfb471>. Acesso em: 02 abr. 2012.
INMON, William H. Como construir o Data Warehouse. 2 ed. Rio de Janeiro, RJ: Campus,
1997.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Área Territorial Oficial.
Disponível em:
<http://www.ibge.gov.br/home/geociencias/cartografia/default_territ_area.shtm> Acesso em:
28 set. 2012a.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Censo Demográfico 2010.
Disponível em: <http://www.ibge.gov.br/home/estatistica/populacao/censo2010/default.shtm>
Acesso em: 17 jun. 2012b.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Contagem da População
2007. Disponível em:

105
<http://www.ibge.gov.br/home/estatistica/populacao/contagem2007/default.shtm> Acesso
em: 17 jun. 2012c.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Contagem da População
2007. Disponível em:
<http://www.ibge.gov.br/home/estatistica/populacao/contagem2007/popmunic2007layoutTC
U14112007.xls> Acesso em: 17 jun. 2012d.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Estimativa da População
2005. Disponível em:
<ftp://ftp.ibge.gov.br/Estimativas_Projecoes_Populacao/Estimativas_2005/UF_Municipio.zi>
Acesso em: 17 jun. 2012e.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Estimativa da População
2006. Disponível em:
<ftp://ftp.ibge.gov.br/Estimativas_Projecoes_Populacao/Estimativas_2006/UF_Municipio.zi>
Acesso em: 17 jun. 2012f.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Estimativa da População
2008. Disponível em:
<http://www.ibge.gov.br/home/estatistica/populacao/estimativa2008/POP_2008_TCU.pdf>
Acesso em: 17 jun. 2012g.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Estimativa da População
2009. Disponível em:
<http://www.ibge.gov.br/home/estatistica/populacao/estimativa2009/POP_2009_TCU.pdf>
Acesso em: 17 jun. 2012h.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Estimativa da População
2011. Disponível em:
<ftp://ftp.ibge.gov.br/Estimativas_Projecoes_Populacao/Estimativas_2011/tab_Municipios_T
CU.zip> Acesso em: 17 jun. 2012i.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Estimativas de
População. Disponível em:
<http://www.ibge.gov.br/home/estatistica/populacao/estimativa2011/default.shtm> Acesso
em: 17 jun. 2012j.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Informações Sociais,
Demográficas e Econômicas. Disponível em:
<http://www.ibge.gov.br/home/disseminacao/eventos/missao/informacoessociais.shtm>
Acesso em: 17 jun. 2012k.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. O IBGE. Disponível em:
<http://www.ibge.gov.br/home/disseminacao/eventos/missao/instituicao.shtm> Acesso em:
17 jun. 2012l.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA. Primeiros resultados do
Censo 2010. Disponível em:

106
<http://www.ibge.gov.br/home/estatistica/populacao/censo2010/primeiros_resultados/populac
ao_por_municipio_zip.shtm> Acesso em: 17 jun. 2012m.
KIMBALL, Ralph; ROSS, Margy. The data warehouse toolkit: guia completo para
modelagem dimensional. Rio de Janeiro: Campus, 2002.
MACHADO, Felipe Nery Rodrigues. Tecnologia e Projeto de Data Warehouse. 2. ed. São
Paulo, SP: Érica, 2006.
OXFORD UNIVERSITY PRESS. Oxford Dictionaries Online. Definition of suite.
Disponível em: < http://oxforddictionaries.com/definition/american_english/suite> Acesso
em: 20 out. 2012.
PENTAHO. Console do Usuário. Disponível em:
<http://demo.pentaho.com/pentaho/Home/> Acesso em: 29 abr. 2012a.
PENTAHO. Metadata Business Model Overview. Disponível em:
<http://wiki.pentaho.com/display/ServerDoc2x/01.+Metadata+Business+Model+Overview/>
Acesso em: 05 mai. 2012b.
PENTAHO. Pentaho Classic Engine. Disponível em:
<http://reporting.pentaho.com/classic_engine.php/> Acesso em: 02 mai. 2012c.
PENTAHO. Pentaho Community Home. Disponível em: <http://community.pentaho.com/>
Acesso em: 05 mai. 2012d.
PENTAHO. Pentaho Kettle Project. Disponível em: <http://kettle.pentaho.com/> Acesso
em: 24 mar. 2012e.
PENTAHO. Pentaho Mondrian Project. Disponível em: <http://mondrian.pentaho.com/>
Acesso em: 24 mar. 2012f.
PENTAHO. Pentaho Report Designer. Disponível em:
<http://reporting.pentaho.com/report_designer.php/> Acesso em: 02 mai. 2012g.
PENTAHO. Pentaho Reporting Project. Disponível em: <http://reporting.pentaho.com/>
Acesso em: 24 mar. 2012h.
PENTAHO BI Platform CE. Versão 3.9.0 [S.l.]: Source Forge, 2011. Disponível em:
<http://sourceforge.net/projects/pentaho/files/Business%20Intelligence%20Server/3.9.0-
stable/>. Acesso em: 17 jun. 2012.
PENTAHO Data Integration CE: Spoon. Versão 4.2.0 [S.l.]: Source Forge, 2011. Disponível
em: <http://sourceforge.net/projects/pentaho/files/Data%20Integration/4.2.0-stable/>. Acesso
em: 17 jun. 2012.
PENTAHO Design Studio CE. Versão 4.0.0 [S.l.]: Source Forge, 2011. Disponível em:
<http://sourceforge.net/projects/pentaho/files/Design%20Studio/4.0.0-stable/>. Acesso em: 17
jun. 2012.

107
PENTAHO Metadata Editor CE. Versão 4.0.0 [S.l.]: Source Forge, 2011. Disponível em:
<http://sourceforge.net/projects/pentaho/files/Pentaho%20Metadata/4.0.0-stable/>. Acesso
em: 17 jun. 2012.
PENTAHO Mondrian Schema Workbench CE. Versão 3.3.0.14703 [S.l.]: Source Forge,
2011. Disponível em:
<http://sourceforge.net/projects/mondrian/files/schema%20workbench/3.3.0-stable/>. Acesso
em: 17 jun. 2012.
PENTAHO Report Designer CE. Versão 3.8.2.GA.14313 [S.l.]: Source Forge, 2011.
Disponível em:
<http://sourceforge.net/projects/jfreereport/files/04.%20Report%20Designer/3.8.2-stable/>.
Acesso em: 17 jun. 2012.
POSTGRESQL. JDBC Driver. Disponível em: < http://jdbc.postgresql.org/download.html>
Acesso em: 17 jun. 2012.
SCHEPS, Swain. Business Intelligence for Dummies. 1. ed. Indianapolis, Indiana, USA:
Wiley Publishing, 2008.
SILVA, E.L. da; MENEZES, E. M. Metodologia da Pesquisa e elaboração de Dissertação.
4a Ed. UFSC, Florianópolis, 2005.
THOMSEN, C.; PEDERSEN, T. B. A Survey of Open Source Tools for Business
Intelligence. International Journal of Data Warehousing and Mining, Hershey, PA, USA.
IGI Global. v. 5, n. 3, p.56-75. 2009.
TURBAN, E. et al. Business Intelligence: Um Enfoque Gerencial para a Inteligência do
Negócio. 1. ed. Porto Alegre: ARKMED, 2008.
WEBER, Steven. The success of open source. vol. 368. Cambridge, MA, USA: Harvard
University Press, 2003.
WITHEE, Ken. Microsoft Business Intelligence for Dummies. 1ª ed. Indianapolis, Indiana,
USA: Wiley Publishing, 2010.
WOODSIDE, Joseph M. Business Intelligence and Learning, Drivers of Quality and
Competitive Performance. 2010. 197 f. Tese (Doutorado)-Cleveland State University,
Cleveland, OH, EUA, 2010. Disponível em: <http://etd.ohiolink.edu/send-pdf.cgi/Joseph
Woodside M.pdf?csu1304981512>. Acesso em: 30 mar. 2012.

108
APÊNDICES

109
APÊNDICE A – Script SQL para Criação do Data Warehouse
CREATE TABLE di_tempo (
seq_tempo SERIAL NOT NULL,
ano INTEGER,
PRIMARY KEY(seq_tempo)
);
CREATE TABLE di_projeto (
seq_projeto SERIAL NOT NULL,
cod_funcao BIGINT,
nme_funcao VARCHAR(400),
cod_sub_funcao BIGINT,
nme_sub_funcao VARCHAR(400),
cod_programa BIGINT,
nme_programa VARCHAR(400),
cod_acao BIGINT,
nme_acao VARCHAR(400),
nme_ling_cidada VARCHAR(400),
PRIMARY KEY(seq_projeto)
);
CREATE TABLE di_geo (
seq_geo SERIAL NOT NULL,
cod_mun_ibge INTEGER,
cod_mun_ptransp INTEGER,
nme_municipio VARCHAR(150),
cod_uf INTEGER,
sigla_uf VARCHAR(2),
nme_uf VARCHAR(100),
cod_regiao INTEGER,
nme_regiao VARCHAR(50),
cod_meso INTEGER,
nme_meso VARCHAR(100),
cod_micro INTEGER,
nme_micro VARCHAR(100),
PRIMARY KEY(seq_geo)
);
CREATE TABLE ft_populacao (
seq_tempo INTEGER NOT NULL,
seq_geo INTEGER NOT NULL,
qtd_populacao INTEGER,
vl_transf_habitante DOUBLE PRECISION,
PRIMARY KEY(seq_tempo, seq_geo),
FOREIGN KEY(seq_tempo) REFERENCES di_tempo(seq_tempo),
FOREIGN KEY(seq_geo)
REFERENCES di_geo(seq_geo)
);
CREATE INDEX ft_populacao_FKIndex1 ON ft_populacao (seq_tempo);
CREATE INDEX ft_populacao_FKIndex2 ON ft_populacao (seq_geo);
CREATE INDEX IFK_Rel_10 ON ft_populacao (seq_tempo);
CREATE INDEX IFK_Rel_11 ON ft_populacao (seq_geo);

110
CREATE TABLE ft_recurso_transferido (
seq_geo INTEGER NOT NULL,
seq_tempo INTEGER NOT NULL,
seq_projeto INTEGER NOT NULL,
vl_transferido DOUBLE PRECISION,
PRIMARY KEY(seq_geo, seq_tempo, seq_projeto),
FOREIGN KEY(seq_geo) REFERENCES di_geo(seq_geo),
FOREIGN KEY(seq_tempo) REFERENCES di_tempo(seq_tempo),
FOREIGN KEY(seq_projeto) REFERENCES di_projeto(seq_projeto)
);
CREATE INDEX ft_recurso_transferido_FKIndex1 ON ft_recurso_transferido (seq_geo);
CREATE INDEX ft_recurso_transferido_FKIndex2 ON ft_recurso_transferido (seq_tempo);
CREATE INDEX ft_recurso_transferido_FKIndex3 ON ft_recurso_transferido (seq_projeto);
CREATE INDEX IFK_Rel_07 ON ft_recurso_transferido (seq_geo);
CREATE INDEX IFK_Rel_08 ON ft_recurso_transferido (seq_tempo);
CREATE INDEX IFK_Rel_09 ON ft_recurso_transferido (seq_projeto);

111
APÊNDICE B – Script PL/pgSQL Auxiliar para Execução dos Gráficos
Os scripts abaixo são todos functions e realizam apenas consultas, com o objetivo
de facilitar a criação dos gráficos com a ferramenta Pentaho Design Studio.
.......................................................................................................................................................
CREATE OR REPLACE FUNCTION sem_acento(text)
RETURNS text AS
$BODY$
SELECT translate( $1, text 'åáàãâäéèêëíìîïóòõôöúùüûçÿýñÅÁÀÃÂÄÉÈÊËÍÌÎÏÓÒÕÔÖÚÙÛÜÇÝÑ', text
'aaaaaaeeeeiiiiooooouuuucyynAAAAAAEEEEIIIIOOOOOUUUUCYN')
$BODY$
LANGUAGE sql VOLATILE STRICT;
CREATE OR REPLACE FUNCTION total_populacao_meso_regiao(siglauf character varying, mesoregiao
character varying, valano integer)
RETURNS bigint AS
$BODY$
DECLARE
total BIGINT;
BEGIN
select sum(ep.qtd_populacao) INTO total from ft_populacao ep
inner join di_geo eg on ep.seq_geo=eg.seq_geo
inner join di_tempo et on ep.seq_tempo=et.seq_tempo
where lower(eg.sigla_uf) = lower(siglaUf) and
lower(sem_acento(eg.nme_meso))=lower(sem_acento(mesoRegiao))
and et.ano = valAno;
RETURN total;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_populacao_micro_regiao(siglauf character varying, mesoregiao
character varying, microregiao character varying, valano integer)
RETURNS bigint AS
$BODY$
DECLARE
total BIGINT;
BEGIN
select sum(ep.qtd_populacao) INTO total from ft_populacao ep
inner join di_geo eg on ep.seq_geo=eg.seq_geo
inner join di_tempo et on ep.seq_tempo=et.seq_tempo
where lower(eg.sigla_uf) = lower(siglaUf) and
lower(sem_acento(eg.nme_meso))=lower(sem_acento(mesoRegiao))
and lower(sem_acento(eg.nme_micro))=lower(sem_acento(microRegiao))
and et.ano = valAno;
RETURN total;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;

112
CREATE OR REPLACE FUNCTION total_populacao_municipio(seqgeo integer, valano integer)
RETURNS bigint AS
$BODY$
DECLARE
total BIGINT;
BEGIN
select sum(ep.qtd_populacao) INTO total from ft_populacao ep
inner join di_geo eg on ep.seq_geo=eg.seq_geo
inner join di_tempo et on ep.seq_tempo=et.seq_tempo
where eg.seq_geo = seqGeo
and et.ano = valAno;
RETURN total;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_populacao_regiao(nomeregiao character varying, valano integer)
RETURNS bigint AS
$BODY$
DECLARE
total BIGINT;
BEGIN
select sum(ep.qtd_populacao) INTO total from ft_populacao ep
inner join di_geo eg on ep.seq_geo=eg.seq_geo
inner join di_tempo et on ep.seq_tempo=et.seq_tempo
where lower(eg.nme_regiao) = lower(nomeRegiao) and et.ano = valAno;
RETURN total;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_populacao_uf(siglauf character varying, valano integer)
RETURNS bigint AS
$BODY$
DECLARE
total BIGINT;
BEGIN
select sum(ep.qtd_populacao) INTO total from ft_populacao ep
inner join di_geo eg on ep.seq_geo=eg.seq_geo
inner join di_tempo et on ep.seq_tempo=et.seq_tempo
where lower(eg.sigla_uf) = lower(siglaUf) and et.ano = valAno;
RETURN total;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_meso_regiao(siglauf character varying, mesoregiao
character varying, valano integer)
RETURNS numeric AS
$BODY$
DECLARE
total NUMERIC;
BEGIN
select sum(x.vl_transferido) INTO total from ft_recurso_transferido x

113
inner join di_geo y on y.seq_geo=x.seq_geo
inner join di_tempo z on z.seq_tempo=x.seq_tempo
where lower(y.sigla_uf) = lower(siglaUf) and z.ano = valAno and
lower(sem_acento(y.nme_meso))=lower(sem_acento(mesoRegiao));
RETURN total;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_micro_regiao(siglauf character varying, mesoregiao
character varying, microregiao character varying, valano integer)
RETURNS numeric AS
$BODY$
DECLARE
total NUMERIC;
BEGIN
select sum(x.vl_transferido) INTO total from ft_recurso_transferido x
inner join di_geo y on y.seq_geo=x.seq_geo
inner join di_tempo z on z.seq_tempo=x.seq_tempo
where lower(y.sigla_uf) = lower(siglaUf) and z.ano = valAno and
lower(sem_acento(y.nme_meso))=lower(sem_acento(mesoRegiao))
and lower(sem_acento(y.nme_micro))=lower(sem_acento(microRegiao));
RETURN total;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_por_estado(regiaoparam character varying)
RETURNS SETOF record AS
$BODY$
BEGIN
RETURN QUERY select CAST(sem_acento(g.nme_uf) as VARCHAR) as REGIAO,
t.ano as ANO,
CAST(sum(r.vl_transferido)/1000 as BIGINT) as TOTAL_TRANSFERIDO
from public.ft_recurso_transferido r
inner join public.di_geo g on g.seq_geo=r.seq_geo
inner join public.di_tempo t on t.seq_tempo=r.seq_tempo
where g.nme_uf is not null and lower(g.nme_regiao)=lower(regiaoParam)
group by t.ano, REGIAO, g.sigla_uf
order by t.ano ASC, REGIAO;
RETURN;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_por_estado(regiaoparam character varying, valano
integer)
RETURNS SETOF record AS
$BODY$
BEGIN
RETURN QUERY select CAST(sem_acento(g.nme_uf) as VARCHAR) as REGIAO,
CAST(sum(r.vl_transferido)/1000 as BIGINT) as TOTAL_TRANSFERIDO,
total_populacao_uf(g.sigla_uf, t.ano) as POPULACAO,

114
CAST(sum(r.vl_transferido)/total_populacao_uf(g.sigla_uf, t.ano) as BIGINT) as
VALOR_TRANS_HAB_ANO
from public.ft_recurso_transferido r
inner join public.di_geo g on g.seq_geo=r.seq_geo
inner join public.di_tempo t on t.seq_tempo=r.seq_tempo
where g.nme_uf is not null and lower(g.nme_regiao)=lower(regiaoParam)
and t.ano = valAno
group by REGIAO, g.sigla_uf, t.ano
order by REGIAO;
RETURN;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_por_meso_regiao(siglauf character varying)
RETURNS SETOF record AS
$BODY$
BEGIN
RETURN QUERY select CAST(sem_acento(g.nme_meso) as VARCHAR) as REGIAO,
t.ano as ANO,
CAST(sum(r.vl_transferido)/1000 as BIGINT) as TOTAL_TRANSFERIDO
from public.ft_recurso_transferido r
inner join public.di_geo g on g.seq_geo=r.seq_geo
inner join public.di_tempo t on t.seq_tempo=r.seq_tempo
where g.nme_meso is not null
and g.sigla_uf = siglaUf
group by t.ano, g.sigla_uf, REGIAO
order by t.ano, REGIAO;
RETURN;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_por_meso_regiao(siglauf character varying, valano
integer)
RETURNS SETOF record AS
$BODY$
BEGIN
RETURN QUERY select CAST(sem_acento(g.nme_meso) as VARCHAR) as MESOREGIAO,
CAST(sum(r.vl_transferido)/1000 as BIGINT) as TOTAL_TRANSFERIDO,
total_populacao_meso_regiao(g.sigla_uf, g.nme_meso, t.ano) as POPULACAO,
CAST(sum(r.vl_transferido)/total_populacao_meso_regiao(g.sigla_uf, g.nme_meso, t.ano) as BIGINT)
as VALOR_TRANS_HAB_ANO
from public.ft_recurso_transferido r
inner join public.di_geo g on g.seq_geo=r.seq_geo
inner join public.di_tempo t on t.seq_tempo=r.seq_tempo
where g.nme_meso is not null
and t.ano = valAno and g.sigla_uf = siglaUf
group by g.sigla_uf, g.nme_meso, t.ano
order by g.nme_meso;
RETURN;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;

115
CREATE OR REPLACE FUNCTION total_transferido_por_micro_regiao(siglauf character varying,
mesoparam character varying, valano integer)
RETURNS SETOF record AS
$BODY$
BEGIN
RETURN QUERY select CAST(sem_acento(g.nme_micro) as VARCHAR) as MICROREGIAO,
CAST(sum(r.vl_transferido)/1000 as BIGINT) as TOTAL_TRANSFERIDO,
total_populacao_micro_regiao(g.sigla_uf, g.nme_meso, g.nme_micro, t.ano) as POPULACAO,
CAST(sum(r.vl_transferido)/total_populacao_micro_regiao(g.sigla_uf, g.nme_meso, g.nme_micro,
t.ano) as BIGINT) as VALOR_TRANS_HAB_ANO
from public.ft_recurso_transferido r
inner join public.di_geo g on g.seq_geo=r.seq_geo
inner join public.di_tempo t on t.seq_tempo=r.seq_tempo
where g.nme_meso is not null
and t.ano = valAno and lower(g.sigla_uf) = lower(siglaUf) and sem_acento(lower(g.nme_meso)) =
sem_acento(lower(mesoParam))
group by g.sigla_uf, g.nme_meso, g.nme_micro, t.ano
order by g.nme_micro;
RETURN;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_por_micro_regiao(siglauf character varying,
mesoparam character varying)
RETURNS SETOF record AS
$BODY$
BEGIN
RETURN QUERY select CAST(sem_acento(g.nme_micro) as VARCHAR) as REGIAO,
t.ano as ANO,
CAST(sum(r.vl_transferido)/1000 as BIGINT) as TOTAL_TRANSFERIDO
from public.ft_recurso_transferido r
inner join public.di_geo g on g.seq_geo=r.seq_geo
inner join public.di_tempo t on t.seq_tempo=r.seq_tempo
where g.nme_meso is not null
and lower(g.sigla_uf) = lower(siglaUf) and sem_acento(lower(g.nme_meso)) =
sem_acento(lower(mesoParam))
group by g.sigla_uf, g.nme_meso, g.nme_micro, t.ano
order by t.ano, REGIAO;
RETURN;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_por_municipio(siglauf character varying, mesoparam
character varying, microparam character varying)
RETURNS SETOF record AS
$BODY$
BEGIN
RETURN QUERY select CAST(sem_acento(g.nme_municipio) as VARCHAR) as REGIAO,
t.ano as ANO,
CAST(sum(r.vl_transferido)/1000 as BIGINT) as TOTAL_TRANSFERIDO
from public.ft_recurso_transferido r
inner join public.di_geo g on g.seq_geo=r.seq_geo
inner join public.di_tempo t on t.seq_tempo=r.seq_tempo

116
where g.nme_meso is not null
and lower(g.sigla_uf) = lower(siglaUf) and sem_acento(lower(g.nme_meso)) =
sem_acento(lower(mesoParam))
and sem_acento(lower(g.nme_micro)) = sem_acento(lower(microParam))
group by g.sigla_uf, g.nme_meso, g.nme_micro, g.nme_municipio, g.seq_geo, t.ano
order by t.ano, REGIAO;
RETURN;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_por_municipio(siglauf character varying, mesoparam
character varying, microparam character varying, valano integer)
RETURNS SETOF record AS
$BODY$
BEGIN
RETURN QUERY select CAST(sem_acento(g.nme_municipio) as VARCHAR) as MUNICIPIO,
CAST(sum(r.vl_transferido)/1000 as BIGINT) as TOTAL_TRANSFERIDO,
total_populacao_municipio(g.seq_geo, t.ano) as POPULACAO,
CAST(sum(r.vl_transferido)/total_populacao_municipio(g.seq_geo, t.ano) as BIGINT) as
VALOR_TRANS_HAB_ANO
from public.ft_recurso_transferido r
inner join public.di_geo g on g.seq_geo=r.seq_geo
inner join public.di_tempo t on t.seq_tempo=r.seq_tempo
where g.nme_meso is not null
and t.ano = valAno and lower(g.sigla_uf) = lower(siglaUf) and sem_acento(lower(g.nme_meso)) =
sem_acento(lower(mesoParam))
and sem_acento(lower(g.nme_micro)) = sem_acento(lower(microParam))
group by g.sigla_uf, g.nme_meso, g.nme_micro, g.nme_municipio, g.seq_geo, t.ano
order by g.nme_municipio;
RETURN;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_por_regiao()
RETURNS SETOF record AS
$BODY$
BEGIN
RETURN QUERY select g.nme_regiao AS REGIAO,
t.ano as ANO,
CAST(sum(r.vl_transferido)/1000 as BIGINT) as TOTAL_TRANSFERIDO
from public.ft_recurso_transferido r
inner join public.di_geo g on g.seq_geo=r.seq_geo
inner join public.di_tempo t on t.seq_tempo=r.seq_tempo
where nme_regiao is not null
group by t.ano, REGIAO
order by t.ano ASC, REGIAO;
RETURN;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_por_regiao(valano integer)

117
RETURNS SETOF record AS
$BODY$
BEGIN
RETURN QUERY select g.nme_regiao AS REGIAO,
CAST(sum(r.vl_transferido)/1000 as BIGINT) as TOTAL_TRANSFERIDO,
total_populacao_regiao(g.nme_regiao, t.ano) as POPULACAO,
CAST(sum(r.vl_transferido)/total_populacao_regiao(g.nme_regiao, t.ano) as BIGINT) as
VALOR_TRANS_HAB_ANO
from public.ft_recurso_transferido r
inner join public.di_geo g on g.seq_geo=r.seq_geo
inner join public.di_tempo t on t.seq_tempo=r.seq_tempo
where nme_regiao is not null
and t.ano = valAno
group by REGIAO, t.ano
order by REGIAO;
RETURN;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_regiao(nomeregiao character varying, valano integer)
RETURNS numeric AS
$BODY$
DECLARE
total NUMERIC;
BEGIN
select sum(x.vl_transferido) INTO total from ft_recurso_transferido x
inner join di_geo y on y.seq_geo=x.seq_geo
inner join di_tempo z on z.seq_tempo=x.seq_tempo
where lower(y.nme_regiao) = lower(nomeRegiao) and z.ano = valAno;
RETURN total;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;
CREATE OR REPLACE FUNCTION total_transferido_uf(siglauf character varying, valano integer)
RETURNS numeric AS
$BODY$
DECLARE
total NUMERIC;
BEGIN
select sum(x.vl_transferido) INTO total from ft_recurso_transferido x
inner join di_geo y on y.seq_geo=x.seq_geo
inner join di_tempo z on z.seq_tempo=x.seq_tempo
where lower(y.sigla_uf) = lower(siglaUf) and z.ano = valAno;
RETURN total;
END;
$BODY$
LANGUAGE plpgsql VOLATILE;

118
ANEXO

119
ANEXO A – Exemplo de Origem dos Dados
Arquivo CSV com os códigos do IBGE das regiões, unidades da federação, meso
regiões, micro regiões e municípios brasileiros de forma hierárquica.
Arquivo XLS com dados populacionais de todos os municípios brasileiros para o
ano de 2007.
120
Arqui CSV, aberto no Microsoft Excel, relativo a transferência de recursos do governo federal
em 2011.