concurso mainframe ibm2011 parte1
DESCRIPTION
Concurso Mainframe Ibm2011 Parte1TRANSCRIPT

Concurso Mainframe IBM 2011 - BrasilParte 1
Tempo para conclusão – aproximadamente 2 horas
Ajuda
Você poderá achar as referências abaixo úteis para a conclusão das tarefas:
– z/OS v1.11 Information Center:
http://publib.boulder.ibm.com/infocenter/zos/v1r11/index.jsp
Começou o Concurso!Nesta etapa, você conhecerá algunsprocedimentos usando o editor ISPF!
Algumas tarefas básicas serão passadas e,ao final, você deverá rodar um executável!

CONHECENDO OS TIPOS DE DATASETS
Conforme visto na ambientação, um data set pode ser sequencial ou particionado. O que isto significa, afinal de contas?
Dataset Sequencial:
Este tipo de dataset contém dados que são acessados em sequência. Cada acesso depende do outro e ocorre na ordem em que é inserido, no estilo FIFO (first in first out – primeiro a entrar, primeiro a sair).
Dataset Particionado:
Este tipo de dataset pode conter vários membros, como uma pasta pode contar várias subpastas. Cada membro pode conter uma JCL, uma biblioteca ou até mesmo um executável. Cada dado pode ser acessado separadamente.
Brincando com o Dataset Sequencial
Você vai começar copiando um dataset sequencial já existente.
No menu principal do ISPF, entre na opção 3 (Utilities) e 3 (Copy/Move). Você estará no menu Move/Copy. Escolha a opção C (copy) e no campo Name digite 'ZOS.BR.PARTE1.HMR'.
Sua tela deverá estar assim:
Dê Enter!

Agora, na próxima tela, digite no campo Name o caminho 'IBMxxxx.PARTE1.HMR' (substitua IBMxxxx por seu user ID).
Dê Enter novamente!
Como o dataset 'IBMxxxx.PARTE1.HMR' não foi criado ainda, o sistema pergunta se você deseja alocá-lo e como isso será feito. Digite a opção 1 para criá-lo conforme o dataset de origem. Dê Enter.

Dê F3 até retornar ao menu principal do ISPF.
Entre no menu 3 (Utilities) e 4 (Dslist).No campo Dsname Level escreva IBMxxxx e pressione Enter para visualizar todos os datasets que
você possui.
Digite e no espaço na frente do dataset que você criou (IBMxxxx.PARTE1.HMR) e dê dois Enter para
abri-lo.
Você visualizará um arquivo cheio de caracteres. No campo Command digite os seguintes comandos, cada um seguido de um Enter:
CHANGE 1 / ALL
CHANGE 2 _ ALL
CHANGE 3 \ ALL
CHANGE 4 - ALL
CHANGE 5 | ALL
CHANGE 6 ( ALL
CHANGE 0 A ALL
CHANGE ? E ALL
CHANGE + O ALL
CHANGE > U ALL
CHANGE 9 P ALL
CHANGE } M ALL
CHANGE 8 S ALL

A sintaxe do comando CHANGE:
CHANGE [palavra_antiga] [palavra_nova] ALL
ou
CHANGE [palavra_antiga] [palavra_nova]
O ALL indica que todas as palavras que baterem com a [palavra_antiga] que o editor encontrar deverão ser trocadas.
É, nossa equipe é bem humorada!De qualquer forma, percebeu o queaconteceu? Você inseriu comandos que substituiram um caracter pelo outro. Este comando é muito usadopara substituir caracteres e palavras
no editor ISPF.
Ok, agora chega de brincar!Vamos para tarefa seguinte, você
precisa alocar um dataset particionadoe aprender um pouco mais sobre o
editor ISPF!

Alocando um Dataset Particionado
Para as próximas etapas, precisaremos criar um dataset particionado.
A partir do painel principal do ISPF, digite 3 (Utilities), dê Enter e entre 2 (data set).
Você será levado para a tela de Data Set Utility. Na linha de opção (no topo), digite A (para alocar um novo dataset). No campo Data Set Name, digite PARTE1.DATA e dê Enter.
Não se esqueça! Data sets são nomeados com identificadores de 1 a 8 caracteres e separados por pontos. Digitando sem aspas, o sistema assumirá automaticamente que o primeiro identificador será seu ID. Desta forma, o dataset que estamos criando deverá ficar como IBMxxxx.PARTE1.DATA.
Digitando 'IBMxxxx.PARTE1.DATA' terá o mesmoResultando que digitando apenas PARTE1.DATA.Sem aspas simples, o sistema assume que seu ID
Será o primeiro identificador, mesmo se vocêNão digitá-lo, enquanto que, entre aspas simples,
Você precisará digitá-lo manualmente.
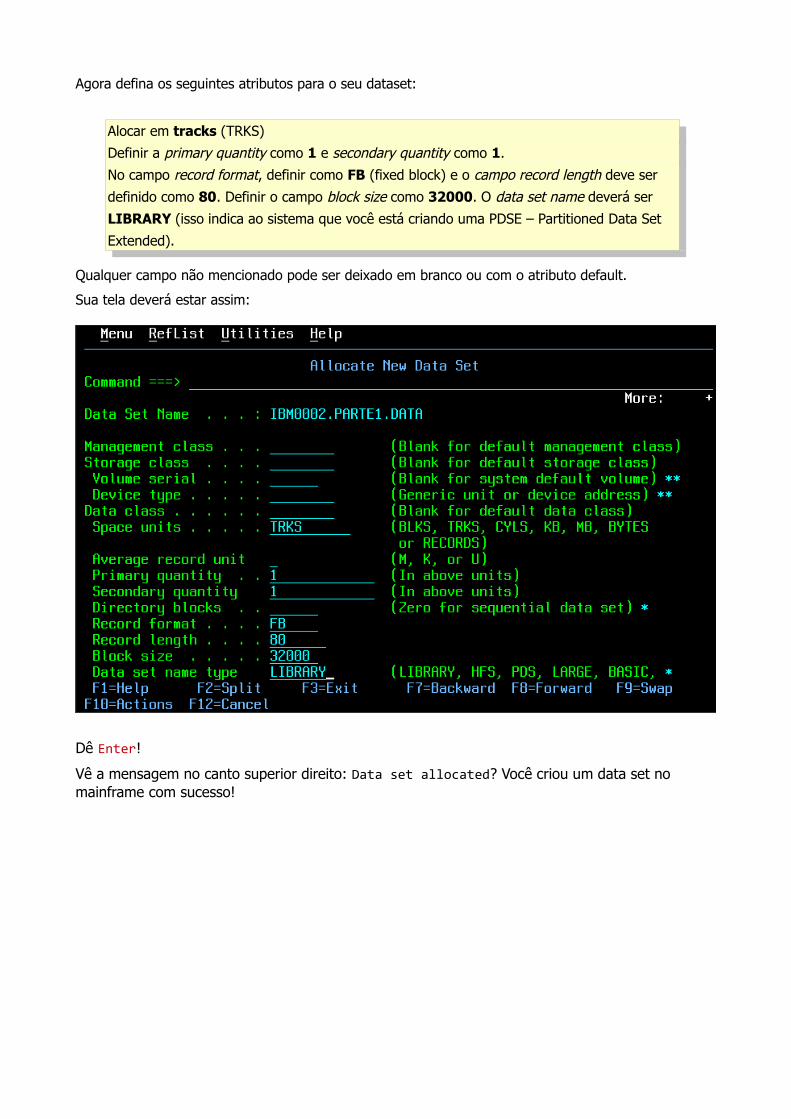
Agora defina os seguintes atributos para o seu dataset:
Alocar em tracks (TRKS)
Definir a primary quantity como 1 e secondary quantity como 1.
No campo record format, definir como FB (fixed block) e o campo record length deve ser
definido como 80. Definir o campo block size como 32000. O data set name deverá ser
LIBRARY (isso indica ao sistema que você está criando uma PDSE – Partitioned Data Set
Extended).
Qualquer campo não mencionado pode ser deixado em branco ou com o atributo default.
Sua tela deverá estar assim:
Dê Enter!
Vê a mensagem no canto superior direito: Data set allocated? Você criou um data set no mainframe com sucesso!


Criando um membro para o Dataset
Um membro pode ser qualquer coisa – código de programa, saída de programa, dados
binários ou simplesmente texto.
➔ Dê F3 até voltar ao menu principal do ISPF Primary Option Menu.
➔ Selecione a opção 3 (Utilities)
➔ Selecione a opção 3 (Move/Copy)
O dataset de onde vamos copiar os dados se chama ZOS.BR.PARTE1.DATA. Neste dataset, os dados
estão inseridos no próprio, ao invés de inseridos em um membro dentro do dataset.
➔ No topo do painel, escolha a opção C (de cópia) no campo Option
Você criou um dataset, mas até o momentonão há nada dentro! Vamos copiar um
membro com informações sobre o estoquedas lojas cadastradas.
Temos um cadastro de produtos que as lojas vendem em nosso site.
Precisamos prever quanto de lucro eles terão com o estoque disponibilizado.

➔ Escreva 'ZOS.BR.PARTE1.DATA' no campo Name embaixo de From Other Partitioned or Sequential Data Set
Como você irá escrever o nome completo do dataset, é necessário colocar ele entre aspas simples.
Pressione Enter para ir ao próximo painel, onde você irá indicar para onde o conteúdo deste dataset
deverá ser copiado.
Embaixo da seção normeada To Other Partitioned or Sequential Data Set escreva o nome do
dataset que você recém criou no campo Name.
Neste momento, não há membros em seu dataset. Se você especificar um nome de membro que não
existe, o z/OS vai automaticamente criar um novo membro e copiar os dados para o mesmo.
Chamaremos o novo membro de PRODLIST.
Escreva o nome do membro para onde os dados serão copiados entre parênteses depois do nome do
dataset. Ficará assim: PARTE1.DATA(PRODLIST)

Pressione Enter! Se tudo foi preenchido corretamente, deverá aparecer uma mensagem no canto
superior direito da sua tela com os dizeres Data set copied.
➔ Dê F3 até o menu Utility
➔ Selecione a opção 4 (Dslist)
No campo Dsname Level escreva IBMxxxx e pressione Enter para visualizar todos os datasets que
você possui.
Digite b no espaço na frente do dataset que você criou (IBMxxxx.PARTE1.DATA) para abri-lo.
Lembra do que eu falei antes, sobrecolocar o nome do dataset entre aspassimples? Neste caso, queremos copiar
o dataset para um dataset que começa como seu ID, portanto você pode digitar tanto'IBMxxxx.ZOS.PARTONE(PRODLIST)'
quantoZOS.PARTONE(PRODLIST)

Dentro do dataset IBMxxxx.PARTE1.DATA(PRODLIST) você verá o novo membro, PRODLIST, que você
copiou de nosso dataset sequencial. Digite e no espaço à frente do membro para editar.

Usando o editor do ISPF para manipular o texto
Agora você está no editor de texto do ISPF text editor, vendo os dados do membro PRODLIST:
Alguns comandos podem ser digitados na linha de comando, no topo da tela (ou na parte inferior,
dependendo de como está configurado seu ISPF). O editor do ISPF mostra um aviso constatando que o
comando UNDO não está disponível até você habilitar o RECOVERY ON (the UNDO command is not
available until you change your edit profile using the command RECOVERY ON). Para se
livrar dessa mensagem, você pode inserir tanto o comando RECOVERY ON quanto RESET e pressionar
Enter. O comando RECOVERY ON habilita o modo de RECOVERY, enquanto o comando RESET apenas
reseta a tela.
Neste espaço, você também pode inserir bpara apenas visualizar o membro, ou d para deletá-lo. Você pode deletar o membro e
copiá-lo novamente, caso erre algo e queiracomeçar de novo.

➔ Digite i na coluna de comando, na primeira linha, conforme a tela apresentada
abaixo.
➔ Aperte Enter.
Uma linha em branco foi criada embaixo do cabeçalho Loja do Mario.
Vamos inserir um novo produto, o livro Como Jogar Tenis, na linha criada. O codigo é BK145, o preço
de custo é R$ 4,00 e o preço de venda é R$ 8,99. O estoque inicial será de 25 unidades.
O formato de cada linha no membro deve seguir esta ordem:Codigo_Produto Nome_Produto Preço_Custo Preço_Venda Qtd_Estoque
Preços estão representados em reais (R$).
➔ Digite os detalhes do novo produto, seguindo a indentação das colunas na linha em
branco que você criou.
➔ Pressione Enter.
DICA: Para indentar, utilize a barra de espaço até chegar na coluna desejada, ou seu membro poderá
ficar desconfigurado. Para visualizar as colunas, digite COLS na primeira linha de asteriscos. Isso pode
ser de grande ajuda!
Seu dataset deverá ficar assim:
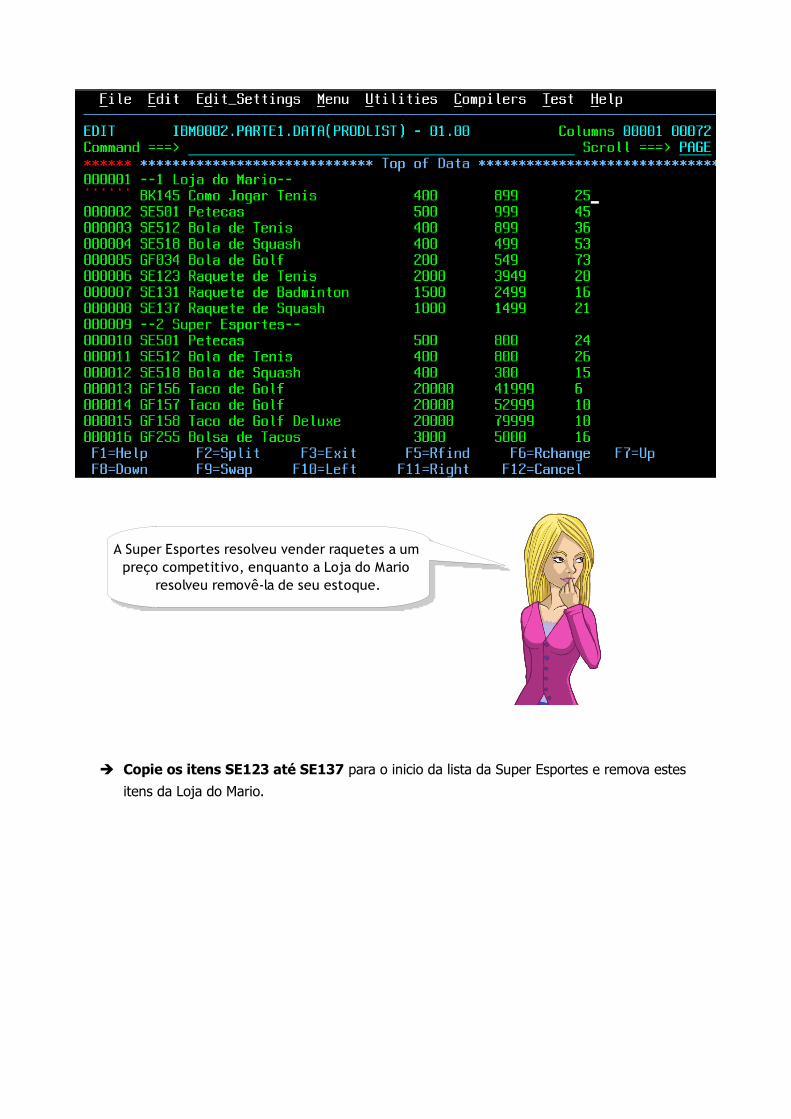
➔ Copie os itens SE123 até SE137 para o inicio da lista da Super Esportes e remova estes
itens da Loja do Mario.
A Super Esportes resolveu vender raquetes a um preço competitivo, enquanto a Loja do Mario
resolveu removê-la de seu estoque.

Os cadastros deverão ficar organizados conforme o exemplo abaixo:
A Loja do Mario agora vende artigos de Golf, enquanto a Super Esportes removeu estes artigos
de seu estoque.
Vamos alterar o cadastro mais uma vez!

➔ Copie os itens GF156 até GF912 para o final da Loja do Mario e remova estes itens da
Super Esportes.
Os dados deverão ficar parecidos com os do exemplo abaixo:
Temos um novo vendedor disponibilizandoprodutos no nosso site. Precisamos adicioná-lo
em nosso cadastro!

➔ Adicione no final do texto o vendedor abaixo e seu respectivo estoque.
--5 Livraria Agatha--
BK046 / Recordes do Esporte / 10,00 / 14,99 / 67
BK145 / Como Jogar Tenis / 4,00 / 9,99 / 104
BK232 / Regras do Golf / 4,00 / 7,99 / 57
BK245 / Aumente Suas Vantagens / 4,00 / 12,99 / 117
BK267 / Fundamentos do Futebol / 16,00 / 24,99 / 97
BK332 / Corrida de Esquilos Amadora / 1,00 / 4,99 / 206
Agora seu dataset deverá ficar conforme a imagem abaixo:
➔ Escreva SAVE na linha de comando
Seu dataset foi salvo!

Rodando um executavel
Vamos rodar um programa que leia o dataset e retorne um log com o valor total do estoque da Loja!
Para isso, será necessário copiar um job para o seu dataset e submetê-lo.
Muito bom!Agora o controle de estoque está completo!
Próximo passo é rodar um executável queirá ler o conteúdo do nosso dataset!

INTRODUÇÃO AO JCL
Job Control Language (JCL) é como você descreve esta informação ao z/OS, onde um job representa
uma tarefa.
Para cada job que você submete, você precisa falar ao z/OS onde encontrar a entrada (input)
apropriada, como processar a entrada (isto é, qual programa ou quais programas serão rodados) e o
que fazer com o output resultante. Use o JCL para transmitir esta informação para o z/OS através de
uma série de comandos conhecidos como JOB CONTROL STATEMENT (JCL).
Dentro de cada job, os comandos de controle são agrupagos em dois passos. Um passo consiste em
todo o controle necessário para rodar um programa.
Se o job precisa rodar mais de um programa, o job pode conter um passo diferente para cada um dos
programas.
Job Control Statements
Cada job deverá conter:
- Um JOB statement (ou declaração JOB) marcando o início do job para designar um nome.
Esta declaração também é usada para providenciar informações administrativas, incluindo
segurança, contabilização e identificação de informação. Cada job tem uma e apenas uma
declaração JOB.
- Pelo menos uma declaração EXEC (execute), marcando o início de um passo, um nome
para o passo e o programa ou procedimento a ser executado. Você pode adicionar vários
parâmetros para a declaração EXEC para customizar o modo como o programa irá executar e
as condições nas quais ele deverá ser executado.
Como você faria para executar uma tarefa designada a você?
Eu dividiria ela em vários passos, cada um completando uma parte do todo.
Às vezes posso precisar de diferentes ferramentas para cada passo.

A maioria dos programas requerem dados de entrada ou geram dados de saída, e
geralmente contém:
- Uma ou mais declarações DD (data definition), para identificar e descrever os dados de
entrada e saída a serem usados neste passo. Esta declaração pode ser usada para requerer
um dataset criado previamente, para definir um novo dataset ou para definir e especificar as
características do arquivo de saída, ou output.
Cada job control statement tem cinco campos:
1. Um campo identifier, que é tipicamente duas barras (//). A linha inteira será tratada
como comentário se as barras duplas forem seguidas de um asterisco (//*).
2. Um campo name, identificando a declaração de forma que ela possa ser referida mais
tarde.
3. Um campo operation, identificando o tipo de declaração, i.e. JOB, EXEC, DD.
4. Um campo parameter
5. Qualquer informação seguindo o campo parameter é tratada como comentário e é
ignorada.
Declarações JCL podem ser escritas até a coluna 71. Você pode estar se perguntando o porque deste
formato. Historicamente, o JCL era lido usando cartões perfurados de 80 colunas, sendo as últimas 8
utilizadas para numerar as linhas.
O layout do JCL pode parecer um pouco confuso quando você se deparar com ele pela primeira vez.
Por sorte, o editor ISPF pode disponibilizar os texto destacando a sintaxe, é só digitar o comando
HILITE JCL (ou HILITE AUTO) quando for editar um membro JCL.

Agora que você já sabe copiar membros para o seu dataset, vamos fazer isso de novo, agora copiando
um membro que contém um JCL.
Para mais informações sobre JCL, você pode fazer uma busca na seção JCL Reference do documento
MVS encontrado no z/OS Information Center.
➔ Copie o membro 'ZOS.BR.PARTE1.JCL(CONTAJCL)' para
'IBMxxxx.PARTE1.JCL(CONTAJCL)' – se você copiar este membro sem ter criado o dataset
ainda, o sistema irá perguntar se você quer criá-lo e ainda lhe dá a opção de criar com as
mesmas configurações do dataset de origem. Escolha a opção 1 (tela abaixo). Fácil demais,
não?
➔ Acesse este membro em modo de edição e faça as alterações necessárias especificadas
nos comentários do próprio arquivo.
➔ Com as alterações necessárias feitas, digite SUB na linha de comando e dê enter. Isso irá
submeter o seu JCL.

Vamos ver a saída deste JCL para descobrir o que deu errado e consertar.
Algo saiu errado!Aparentemente temos um erro no nosso JOB.
Se os comandos não estiverem corretos,ele nunca executará o nosso programa!

USANDO SDSF
Nesta seção, você pode perceber que será necessário ficar pulando de uma aplicação para outra. Um
exemplo é o editor de texto com o JCL e o SDSF que será usado para ler o log gerado. Pode ser
frustrante ficar entrando e saindo das aplicações, portanto vamos ensinar como contornar isso.
Coloque o cursor na linha superior de sua tela. Pressionando F2 fará com que sua tela se
divida exatamente onde se encontra o seu cursor, mostrando duas telas separadas por uma
linha horizontal pontilhada. Você poderá apertar F9 para trocar de tela.
SDSF
System Display and Search Facility (SDSF) fornece a informação que você precisa para
monitorar, gerenciar e controlar um sistema z/OS.
Você pode usar o SDSF para visualizar o log do sistema e o status dos jobs que estão
rodando no sistema ou que terminaram de rodar, incluíndo qualquer output destes jobs que
ainda não foram descartados.
Você pode acessar o SDSF pelo painel principal do ISPF usando o comando SD.
No SDSF, use a opção DA para visualizar os jobs ativos, incluindo qualquer tarefa iniciada,
que são um tipo de job especial.
ST pode ser usado para visualizar o status dos jobs que estão ativos, dos que ainda serão
processados e daqueles que já completaram.
Uma vez que você esteja vendo a lista de status dos jobs, no campo de comando é possível
definir um filtro para visualizar apenas os jobs que você possui digitando OWNER IBMxxxx
Para reverter a ação e visualizar todos os jobs, digite:OWNER *
É incrível a diferença queisto pode fazer na horade executar as tarefas!

Similarmente, você pode filtrar a lista de jobs por nome digitando:PREFIX ABC*
o que deverá mostrar apenas os jobs cujo nome comece com as letras ABC.
Para remover este filtro, entre:PREFIX *
É possível usar ambos os filtros owner e prefix ao mesmo tempo.
Estes filtros são úteis pois mostram apenas os jobs com os quais você irá querer trabalhar.
Porém, esteja ciente de que o SDSF lembra os filtros que você está usando. Se você não
está vendo o job que procura, remova os filtros para que todos os jobs sejam visíveis.
Nos painéis DA e ST você é apresentado com uma lista de jobs. Use as teclas F7 e F8 para
subir ou descer na lista.
Para visualizar mais informações a respeito de um job em particular, é possível usar o
comando S ao lado do job, na coluna da esquerda, e pressionar Enter.
Isso irá disponibilizar alguns dados a respeito da execução deste job.
Caso queira visualizar o output separadamente, você pode digitar ? no lugar de S. Você
poderá então usar S para selecionar o output individualmente.
Use a tecla PF3 para sair desta tela e retornar à anterior.
Lembre-se, se você esquecer os filtros configurados, poderá acabar comuma lista em branco. O ISPF lembra
os filtros entre sessões, porém por padrão ele não os mostra, portanto cuidado para
não fazer uma pesquisa com o filtro configuradoerrado. Para visualizar os filtros que você está
usando, vá para o menu Options no topo da tela e escolha a opção 5 para visualizá-las.

➔ Na lista de Status, filtre-a de forma a mostrar apenas os seus jobs. Isso ajuda a organizar as
coisas!
Agora que você já está um pouco mais familiarizado com o SDSF, procure pela saída com o nome do seu JCL.Use o comando S na frente desta saída para visualizar.

O texto que você está visualizando mostra o que aconteceu no sistema quando seu job foi submetido.
Através dele, é possível identificar onde tudo deu errado.

Você encontrará mensagens de erro no final deste texto, sob o título de STMT NO. MESSAGE. Preste
bem atenção, os erros que ele indica podem ter sido gerados todos pelo mesmo motivo.
Dica: Procure por exemplos de JCL pela internet e estude sua sintaxe. Você poderá achar isto bem útil
para concluir esta tarefa!
Identifique o problema, faça a correção necessária no seu JCL e submeta-o novamente. Se estiver tudo
certo, após submeter ele deverá retornar o código MAXCC = 0. Caso contrário, volte e reveja os
comandos novamente. O erro poderá ser gerado pelo JCL incorreto, porém se o seu arquivo PRODLIST
estiver errado, ele também retornará mensagem de erro do programa (provavelmente um MAXCC=3).
Leia e interprete o log do SDSF com calma.
Se tudo correr bem, seu log deverá se parecer com isto!
Em stepname ele informa os passos que foram executados no job e, em RC (return code), o código de
execução - que identifica se este passo deu certo (00) ou errado (qualquer outro número ou FLUSH).

Vá para o menu principal do ISPF e entre nos menus 3 (Utility) e 4 (Dslist), respectivamente.
No campo Dsname Level, digite IBMxxxx e dê Enter.
Um novo dataset foi criado pelo programa executado, o 'IBMxxxx.IBMxxxx.P1'! Digite b à frente do
dataset e dê Enter para ver seu conteúdo.
Agora você precisa enviar para nossa equipe o seu dataset!
Volte para o menu principal do ISPF e escolha a opção 6 – command.
Entre o comando abaixo:
XMIT N1.JUDGE9 DA('IBMxxxx.IBMxxxx.P1')
Exemplo:
Depois de submeter este dataset, você já pode começar a Parte 2! Baixe a documentação no site do
Concurso Mainframe IBM 2011 e boa sorte! =)
Ok! Agora que corrigiu o erro, o programaexecutou e gerou um arquivo de saída com a
soma do valor do estoque!

Nossa equipe irá verificar se seu programaexecutou corretamente. Caso seja um dos
250 primeiros a terminar corretamente,vou lhe enviar uma camiseta!
Você já fez muito! Agora sabe criar datasetsE membros no mainframe, além de submeter
JCLs e executar programas!
Você já adquiriu experiências quecertamente o destacarão aos olhos
de contratadores!
Existem muitas empresas como a nossa que usamo mainframe para operações em larga-escala. Aatual geração de programadores mainframe estágradualmente se aposentando, portanto grandes
empresas estão buscando profissionais com conhecimento em mainframe.
Parabéns pela sua conquista!Nos vemos na Parte 2!