classificação de pacientes com diplegia espástica ... · sistema de diagnóstico e apoio à...
TRANSCRIPT

Classificação de Pacientes com Diplegia EspásticaBaseada em Padrões de Marcha
Francisco Nunes dos Santos Alves Fernandes
Dissertação para obtenção do Grau de Mestre em
Engenharia Mecânica
Orientadores: Prof. Susana Margarida da Silva VieiraProf. Filipa Oliveira da Silva João
Júri
Presidente: Prof. Paulo Jorge Coelho Ramalho OliveiraOrientador: Prof. Susana Margarida da Silva Vieira
Vogal: Prof. António Prieto Veloso
Junho 2017

ii

Este trabalho é dedicado a toda a minha família que sempre me apoiou incondicionalmente durante
toda esta jornada. Um especial obrigado aos meus pais e irmã Joana e aos meus avós António
Silvano e Maria Marques.
iii

iv

Agradecimentos
Gostaria de deixar uma nota de apreço por todos os que participaram na elaboração desta tese, nome-
adamente a Professora Susana Vieira, e os meus colegas Marta Fernandes, Cátia Salgado, Ricardo
Pacheco e o Nuno Costa.
Um agradecimento a Faculdade de Motricidade Humana e em especial a professora Filipa João pela
colaboração. Finalmente um grande agradecimento ao António Henriques, Miguel Roque e o Guilherme
Leite que foram os meus companheiro durante toda a jornada.
v

vi

Resumo
A diplegia espástica pertence a um grupo de distúrbios crónicos do movimento que se manifestam
na infância, sendo facilmente diagnosticado, no entanto a identificação do subgrupo de diagnóstico é
complexa. A análise através de ensaios biomecânicos de marcha permite a obtenção de informação
cinemática e cinética assim como medidas quantitativas que possibilitam a criação de algoritmos e
métodos essenciais ao suporte de diagnóstico clínico. No entanto, a análise e diagnóstico médico
em Portugal ainda é baseado na avaliação qualitativa dos dados cinemáticos, levando assim a um
critério subjetivo caracterizado por falta de precisão e repetição. Neste trabalho utilizaram-se técnicas
de clustering de forma a identificar variáveis significativas assim como padrões que caracterizem a
tipificação da patologia utilizando os dados cinemáticos e cinéticos, com o propósito de elaborar um
sistema de diagnóstico e apoio à decisão de classificação clínica de doentes por grupo baseado em
padrões de marcha.
Desta dissertação resultaram quatro classificadores,um para distinguir pacientes de referência, ou sem
qualquer problema de marcha, dos pacientes com distúrbios, os restantes três são específicos para
doentes com diplegia espástica, e são referentes a 3, 4 e 5 grupos, identificados e validados por um
conjunto de índices de validação, nomeadamente o Silhouette, Dunn, Davies Bouldin e Xie-Beni.
Palavras-chave: Paralisia Cerebral, Diplegia Espástica, Classificador, Classificação de do-
entes, Apoio à Decisão Médica
vii

viii

Abstract
Spastic diplegia belongs to a group of chronic movement disorders that appear in early childhood (ce-
rebral palsy). It manifests itself as an easily identifiable gait disorder. Instrumented gait analysis gives
detailed information and quantitative measurements for clinician’s diagnostic support. However, pattern
recognition in Portugal from clinicians is still based on qualitative assessment of the kinematic data using
only the sagittal plane. It lacks precision and repetition. Therefore, the aim is to combine pattern recog-
nition and quantitative kinematic/Kinetic data in order to devise a diagnostic decision support system
with clinically useful classification of sagittal gait patterns in spastic diplegia.
Four classifiers were created in this dissertation. One of those is intended to distinguish reference pa-
tients without any walking problems from patients with disorders. The remaining three are specific for
patients with spastic diplegia, and refer to 3, 4 and 5 distinguished groups, whose values come from
cluster validation index .
Palavras-chave: Cerebral Palsy, Spastic diplegia, Classifier, Gait patterns, Group Identifica-
tion, Decision Support System
ix

x

Conteúdo
xi

xii

Lista de Tabelas
xiii

xiv

Lista de Figuras
xv

xvi

Capítulo 1
Introdução
1.1 Apoio à Decisão Clínica
Com a evolução da tecnologia e o constante aumento das informações disponíveis no pré-diagnóstico
médico surgiu uma necessidade crescente de um ’Sistema de Apoio à Decisão Clínica’. American Me-
dical Association refere-se a estes como "Os sistemas de apoio à decisão (CDSSs) são sistemas de
informação concebidos para melhorar a tomada de decisões clínicas. As características dos pacien-
tes individuais são combinadas com uma base de conhecimentos informatizados, e os algoritmos de
software geram recomendações específicas do paciente."[? ]
Este sistemas funcionam como um meio de complementação do diagnóstico promovendo a repeti-
bilidade de método, reduzindo deste modo a subjetividade e ambiguidade associada ao diagnóstico e
decisão médica. A introdução destes métodos na medicina moderna contribui para um melhoramento
da qualidade dos serviços prestados aos pacientes e implicitamente um aumento na qualidade de vida,
através da personalização e automatização na avaliação da condição médica.
1.2 Revisão Bibliográfica
Paralisia Cerebral é uma patologia que tem vindo a ser muito investigada nos últimos cem anos, ten-
tando melhorar o diagnóstico e tratamento através de um aumento do conhecimento deste distúrbio.
Uma definição aceite é que Cerebral palsy - CP ou em português Paralisia Cerebral, descreve um grupo
de perturbações permanentes no desenvolvimento de movimento e postura, causando limitações nas
atividades. Estes são distúrbios não progressivos que ocorreram no cérebro do feto ou infantil. Os
distúrbios motores da paralisia cerebral são acompanhados por distúrbios de percepção, sensorias,
cognitivos, comunicativos e comportamentais, manifestando-se através de epilepsia e por problemas
músculo-esqueléticos secundários [? ].
Segundo a APCL Associação de Paralisia Cerebral de Lisboa existem três tipos de problemas mais
comuns em Paralisia Cerebral:
• Ataxia - Caracterizada por diminuição da tonicidade muscular, incoordenação dos movimentos e
1

equilíbrio deficiente, devido a lesões no cerebelo ou das vias cerebelosas.
• Atetose/Distonia - Este caracteriza-se por movimentos involuntários e variações na tonicidade
muscular resultantes de lesões dos núcleos situados no interior dos hemisférios cerebrais (Sis-
tema Extra-Piramidal).
• Espasticidade - Caracterizado por paralisia e aumento de tonicidade dos músculos resultante de
lesões no córtex ou nas vias daí provenientes. Pode haver um lado do corpo afectado (hemiparé-
sia), os 4 membros (tetraparésia) ou mais os membros inferiores (diplegia)[? ].
Esta tese foca-se no último caso referido, mais especificamente o caso de diplegia espástica.
Muito estudos foram desenvolvidos na classificação dos padrões de marcha na diplegia espástica,
os quais divergem essencialmente no método sendo uns qualitativos, ou seja, baseados em observa-
ções de dados médicos sem recurso a dados estatísticos e por oposição os quantitativos.
Nesta tese o estudo apresentado em 2004 [? ] servirá como referência para comparação de resul-
tados obtidos, uma vez que é considerado o benchmark para a tipificação da diplegia espástica e onde
são definidos 5 padrões de marcha diferentes:
• True equinus;
• Jump gait;
• Apparent equinus;
• Crouch gait;
• Assymetrical gait, este é caracterizado por apresentar diagnósticos diferentes para cada membro
inferior.
Este estudo baseou-se em dados do plano sagital referentes a pélvis, anca, joelho e tornozelo [? ].
Vários estudos quantitativos foram também realizados [? ? ? ? ? ] . Estes recorrem a métodos
sistemáticos baseados em estatística e técnicas de clustering para classificação.
Em 1983 utilizando a técnica kth nearest neighbour clustering e com dados referentes à anca (nos eixos
x, y e z ), ao joelho(no eixo x) e ao tornezelo (no eixo z) concluiu a existência de 4 grupos distintos [? ].
O’Malley et al. (1997) [? ] utilizando k means chegou a um número de 5 grupos distintos baseado em
comprimento do passo, cadência, comprimento da perna e idade.
Um ano mais tarde baseando-se em dados cinemáticos relativos a anca, joelho e tornozelo, O’Byrne
utilizando a mesma técnica de clustering chegou a 8 grupos [? ].
Em 2007 um estudo feito por Toro com recurso a hierarchical clustering conduziu a um número de 13
grupos baseando-se em dados cinemáticos referentes a anca, joelho e tornozelo [? ].
Dois anos depois, num estudo levado a cabo por Carriero, utilizando a técnica de cluster ’c-means’, e
com recurso a técnica ’PCA’, (Análise das Componentes Principais) concluiu que é possível combinar
estas duas ferramentas de modo a chegar a uma classificação quantitativa dos doentes com paralesia
cerebral [? ].
2

1.3 Objetivos
Como mencionado na secção anterior, a classificação de padrões de marcha em pacientes com diple-
gia espástica tem sido largamente estudada tanto qualitativamente, através do reconhecimento clínico,
como quantitativamente, com base em análise estatística e recurso a algoritmos computacionais. Em-
bora todos estes estudos tenham sido feitos existe uma grande lacuna quanto à definição de método e
do número de grupos distintos. Com este trabalho será realizado um estudo transversal baseado em 26
crianças com paralisia cerebral. Este vai ser realizado com base em resultados de ensaios biomecâni-
cos provenientes do Laboratório de Biomecânica e Morfologia Funcional da Faculdade de Motricidade
Humana da Universidade de Lisboa. Com recurso a estes dados o objetivo é contribuir para colmatar
estas lacunas, através da criação de um método capaz de classificar e identificar os agrupamentos de
padrões de marcha na diplegia espástica, levando em conta os requisitos de aplicações do mundo real.
1.4 Contribuições
Com esta tese pretende-se encontrar um classificador capaz de distinguir com uma eficácia de 100%
pacientes com diplegia espástica de pacientes sem perturbações na marcha. Será criado um método
capaz de identificar grupos distintos e classificar pacientes de acordo com os padrões mencionados
anteriormente. Futuramente vai ser publicado em jornal de biomecânica demonstrando o método obtido.
1.5 Estrutura da Tese
Esta tese divide-se em 5 partes distintas. Numa primeira instância fez-se um enquadramento geral e
breve de definição do problema. No capítulo 2 vai ser explicado em que consistem os ensaios biomecâ-
nicos bem como o seu papel no diagnóstico médico. Refere-se ainda os dados de uma maneira geral
bem como a problemática. No capitulo 3, vão ser explicadas em detalhe as técnicas utilizadas, sendo
no seguinte capítulo apresentados resultados provenientes da aplicação destas. Por fim, no capítulo 5
capitulo vão ser sintetizados os principais resultados e apresentadas as conclusões.
3

4

Capítulo 2
Diagnóstico Clínico Baseado em
Ensaios Biomecânicos
De acordo com Schwarz et al.(2013) [? ] podemos definir a a biomecânica como a mecânica apli-
cada aos sistemas biológicos determinando as informações básicas que proporcionam conhecimento
necessário para o entendimento das influências mecânicas. A Biomecânica possui duas componentes:
• Cinemática- Esta está relacionada com as características dos movimentos, tendo como base para
a sua análise uma perspetiva temporal e espacial. Sendo postas de parte as referências relativas
às forças que atuam. Num sentido mais prático, este tipo de análise tem como foco a rapidez,
altura e distância de um movimento.
• Cinética- Esta componente foca-se nas forças que são necessárias ao movimento.
A combinação das informações derivadas de uma análise biomecânica do movimento permite-nos re-
construir o movimento de uma forma detalhada e complexa. Que pode ser utilizada como suporte ao
diagnóstico, permitindo uma análise mais pormenorizada tendo em conta a possibilidade de obter in-
formações que estão subjacentes ao movimento e não podem ser detetadas através de um diagnóstico
visual. De acordo com a definição de biomecânica, podemos dizer que um ensaio biomecânico se trata
de um teste feito ao sistema biológico que permite obter informações necessárias para o diagnóstico
médico.
A análise clínica e instrumentada da marcha (CGA-Clinical Gait Analysis) é uma ferramenta impor-
tante para a tomada de decisão de intervenção cirúrgica, nomeadamente em crianças com Paralisia Ce-
rebral (PC). Estudos reportam alterações substanciais (acima de 50%) nas decisões cirúrgicas quando
as recomendações de clínicos experientes são seguidas de uma CGA, evitando gastos desnecessários
e eventuais resultados negativos derivados de procedimentos cirúrgicos inadequados [? ]. Em alguns
países como Inglaterra e Austrália, esta análise tem sido aplicada. Apesar disto em Portugal todo o di-
agnóstico é feito apenas com base na observação médica levando a uma falta de precisão e repetição
e em casos mais extremos erros de diagnóstico detetados já em situações pré-operatórias, operatórias
e pós-operatórias. Com esta tese pretende-se minimizar este problema através da criação de um clas-
5

sificador baseado em dados biomecânicos. Numa fase inicial, criar um modelo capaz de diferenciar
padrões de marcha saudáveis de não-saudáveis. Numa segunda parte, parte fulcral da tese, contribuir
para padronizar o número de grupos existentes bem como tentar encontrar um método padrão de cri-
ação de um classificador que possa ser um suporte médico no diagnóstico. Para o desenvolvimento
desta tese foram utilizados dados biomecânicos fornecidos pelo laboratório de biomecânica da FMH -
Faculdade de Motricidade Humana.
2.1 Caracterização e Recolha dos Dados
Os dados mencionados anteriormente são referentes a 25 crianças com marcha normal, que durante
esta tese foram considerados como referência, e 26 com diplegia espástica perfazendo um conjunto
total de 51 crianças. Os dados referentes aos doentes com diplegia espástica, ou seja, os pacientes
que apresentam anomalia na marcha, são referentes a crianças com idades até aos 18 anos e que
foram acompanhadas pelo menos 2 anos.
Como já foi referido,oa dados foram obtidos através do laboratório de biomecânica da FMH - Fa-
culdade de Motricidade Humana com recurso a um sistema optoeletrónico composto por 15 câmaras
(Qualisys Oqus 300, Qualisys AB, Gothenburg, Sweden) recolhendo com uma frequência de amostra-
gem de 100 Hz; a força de reação do solo (FRS) foi recolhida através de duas plataformas de força
Kistler (9281B e 9283U014) e uma AMTI. Foram colocados nos sujeitos 37 marcas refletoras e 4 clus-
ters de marcas de forma a possibilitar a reconstrução tridimensional de 12 segmentos corporais, dos
quais 7 foram utilizados nesta análise (pélvis, coxas, pernas e pés). Foi pedido às crianças que ca-
minhassem naturalmente ao longo de um corredor, até se obterem pelo menos 5 ciclos completos de
dados cinemáticos e cinéticos.
Estes ensaios fornecem-nos dados cinemáticos e cinéticos, que nos dão informação referente a três
planos, sagital, frontal(coronal) e transversal. Os dados cinemáticos fornecidos dão nos informação do
segmento pélvis e das articulações da anca, joelho e tornozelos:
Estes são calculados como a rotação entre o ângulo distal em relação ao segmento proximal. A
unidade de medida utilizada é o grau [o].
Os dados cinéticos são calculados através da dinâmica inversa, usando as equações de Newton-
Euler do movimento, e representam os momentos internos com todos os segmentos excepto a pélvis.
Ou seja:
• Anca;
• Joelho;
• Tornozelo;
A unidade utilizada nestes dados é de momentos, ou torque, [N/m]. As imagens abaixo mostram os
planos e segmentos considerados.
6

Figura 2.1: Planos de movimentos [? ] Figura 2.2: Segmentos considerados [? ]
Os gráficos que se seguem apresentam a vermelho com linha contínua as médias de cada segmento
em cada eixo, das crianças de referência, ou seja aqueles que apresentam padrões de marcha sem
perturbações. Por outro lado a linha preta tracejada apresenta os mesmos dados mas referente aos
pacientes com diplegia espástica.
7
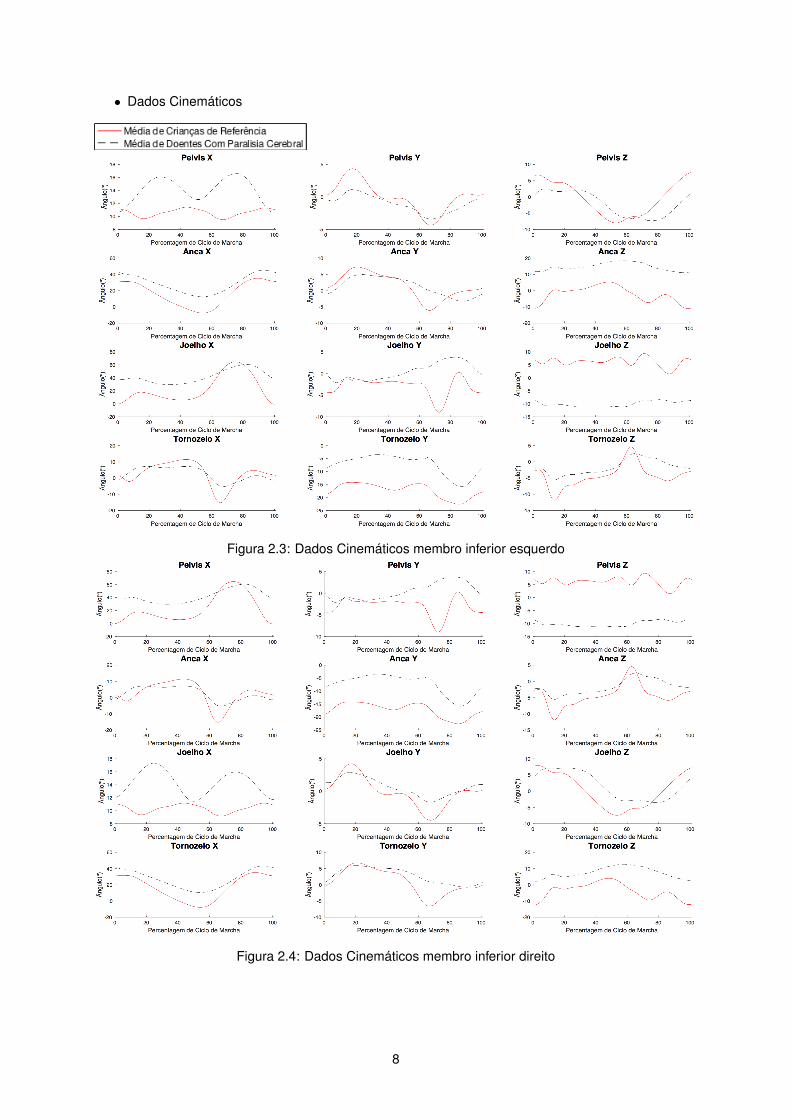
• Dados Cinemáticos
Figura 2.3: Dados Cinemáticos membro inferior esquerdo
Figura 2.4: Dados Cinemáticos membro inferior direito
8

• Dados Cinéticos
Figura 2.5: Dados Cineticos membro inferior esquerdo
Figura 2.6: Dados Cineticos membro inferior direito
9

2.2 Formulação do Problema
2.2.1 Classificador Doente/ Não Doente
O primeiro problema que surge trata-se de definir cada pessoa como apresentando uma marcha sem
anomalias ou com anomalia. Este enquadra-se numa secção de problemas binário, uma vez que
cada paciente tem apenas duas hipóteses de classificação. Para tal vai ser criado um classificador
supervisionado, uma vez que se sabe à priori qual a classificação de cada doente. O classificador
atribuirá a cada paciente :
• Tipo 0 - Considerado pessoa saudável pelo classificador.
• Tipo 1 - Considerado paciente com anomalia na marcha ou pessoa não saudável pelo classifica-
dor.
2.2.1.1 Grupo de Estudo
Para esta problemática foram considerados todos os dados disponíveis tanto os de referência como
os com paralisia cerebral. E começou-se pelos dados de cinemática, e uma vez que se obteve os
resultados pretendidos utilizando exclusivamente estes não foram utilizados os dados cinéticos. Estes
dados foram sendo selecionados de acordo com a evolução da performance do classificador.
Na secção dos Resultados vai ser explicitado e demonstrado o subconjunto que conduziu ao melhor
classificador.
2.2.1.2 Tratamento de Dados
Numa primeira abordagem vai ser feita uma redução de variáveis através de uma transformação no
espaço de coordenadas com recurso a técnica PCA, que se traduz como Análise dos Principais Com-
ponentes. Esta técnica transforma os dados originais em novos dados projetando-os em novos eixos
de acordo com as direções de maior variância dos dados e truncando estes novos dados de acordo
com um thresholdd de variância Para tal, foi utilizada a ferramenta pca do MATLAB (Versão R2016a,
Mathworks, Inc., Natick, MA, USA). Para complementar esta transformação foi utilizada a ferramenta
Sequential Forward Selection, para seleção das variáveis, utilizando a ferramenta do MATLAB sfs. Esta,
através da combinação dos diferentes PC, componentes principais, provenientes da análise PCA, sele-
ciona a melhor combinação de variáveis através da minimização do critério de erro, neste caso através
da maximização da exatidão do modelo criado.
Todas estas técnicas mencionadas vão ser explicadas em maior detalhe na secção que se segue,
para ilustrar o processo segue-se a Figura ??.
10

Figura 2.7: Esquema do processo: Classificador doente/não-Doente
2.2.2 Classificador de Tipos Diplegia Espástica - Não Supervisionado
Numa segunda abordagem vai ser criado um classificador capaz de definir cada paciente com anomalia
na marcha, ou seja, exclusivamente os pacientes com diplegia espástica, em diferentes grupos.Trata-se
de um problema mais complexo uma vez que, ao contrário do primeiro, há a criação de um classificador
não supervisionado, dado que não se conhece à partida a classificação inerente a cada paciente,
agravado pelo facto de como já foi mencionado no primeiro capítulo, não é consensual o número de
grupos existentes aquando da classificação de doentes com diplegia espástica.
2.2.2.1 Grupo de Estudo
Para a análise deste problema foram considerados todos os pacientes com diplegia espástica à dispo-
sição. E tal como para o classificador anterior, todos os dados cinemáticos e dada a falta de informação
de um dos pacientes que reduziria mais o grupo de estudo e a escassez de tempo os dados cinéticos
não foram considerados. Nestes dados foi feita uma divisão por paciente, na qual, o lado esquerdo
foi considerado para criação dos centros de clusters e do classificador. Por sua vez, o lado direito foi
considerado como novos dados, ou novos pacientes, sendo estes usados na validação do classificador.
Esta escolha foi feita tendo em conta a possibilidade de comportamentos assimétricos dos membros
inferiores de cada paciente, ou seja, poderem apresentar diagnósticos clínicos diferentes.
2.2.2.2 Seleção do Número de Grupos
Para que fosse possível a criação de um classificador, houve a necessidade de rotular os dados. Para tal
foi usada uma técnica de classificação K-means. Esta originou um novo problema que está associado
a uma das grandes desvantagens desta técnica de clustering, trata-se da imposição da definição do
número de grupos à priori. Para tal, foram utilizados índices de validação de cluster, estes avaliam a
performance da classificação conduzindo-nos e indicando-nos o valor ou valores mais adequados de
acordo com métricas que caracterizam cada um destes índices.
2.2.2.3 Tratamento de Dados
O tratamento de dados foi idêntico ao do primeiro classificador. Passando por duas etapas, a primeira
uma transformação no espaço de coordenadas PCA enquanto que numa segunda fase foi feito recurso
11

a ferramenta Sequential Feature Selectiondo MATLAB para seleção destas mesmas variáveis.
Figura 2.8: Esquema do processo: Classificador dos pacientes por grupos
2.2.3 Classificador de Tipos Diplegia Espástica - Supervisionado
Por último vai ser criado um classificador capaz de definir cada paciente com anomalia na marcha, ou
seja, exclusivamente as crianças com diplegia espástica, em diferentes grupos. Este tem em comum
os dados e o propósito do classificador anterior e o processo do primeiro, visto ser supervisionado. A
classificação utilizada para que fosse possível criar um classificador deste tipo foi obtida através de uma
comparação direta com os resultado do artigo [? ].
2.2.3.1 Grupo de Estudo
Para a análise deste problema, tal como no classificador que se antecede, foram considerados todos
as crianças com diplegia espástica à disposição. Isto porque o problema é o mesmo diferenciado-se os
dois casos apenas na abordagem e processo que os dados são sujeitos.
2.2.3.2 Tratamento de Dados
O tratamento de dados vai ser igual aos demais classificadores, passando num a primeira fase por uma
transformação no espaço de coordenadas PCA enquanto que numa segunda fase foi feito recurso a
ferramenta Sequential Feature Selection do MATLAB para seleção destas mesmas variáveis. Como já
referido o processo é identico ao do primeiro classificador, como tal pode ser observado na Figura ??.
12

Capítulo 3
Classificador Baseado em Ensaios
Biomecânicos
3.1 Clustering
Os algoritmos de Clustering são técnicas não supervisionadas muito utilizadas nos dias que correm não
só pela possibilidade de organizar e categorizar dados, mas também pela possibilidade de compressão
de dados e modelação. Existem várias técnicas de clustering tal como fuzzy C-means clustering, the
mountain custering method, subtractive clustering entre outros. Nesta tese a técnica aplicada foi K-
means[? ] ou hard clustering. Esta técnica vai ser explicada com mais detalhe no seguimento deste
capítulo. O objetivo destas técnicas é dividir o conjunto de dados em grupos ou clusters de modo a que
a semalhança dos elementos no mesmo grupo seja minimizada e a diferença entre diferentes grupos
maximizada.[? ]
3.1.1 K-means
Este método é aplicado em diversas áreas tal como imagem, compressão de dados, pré-processamento
de dados para modelação entre outras aplicações. O algoritmo implícito nesta técnica divide os dados
de um conjunto n de vetores xj , j = 1, ..., n em c grupos Gi, i = 1, ..., c e encontra os centros do cluster,
ou perfil de cada grupo, de modo a que função de custo (distância) seja minimizada. A distância utilizada
neste trabalho foi a Euclidiana para o cálculo desta, a função custo toma a seguinte forma:
J =
c∑i=1
Ji =
c∑i=1
(∑
kixk∈Gi
() ‖xk − ci‖)2)
A função Ji =∑ci=1(
∑kixk∈Gi
() ‖xk − ci‖)2) é a função de custo dentro do grupo i. A partição
dos grupos tipicamente é definida por uma matriz binária com um grau de pertença U(c × n) , onde o
elemento uij é 1 se o vetor xj pertence ao grupo i e caso contrário é 0. A partir do momento que os
centros dos clusters cj estão fixos minimiza-se calcula-se a pertença do elemento uij através de :
13

uij =
1 se ‖xk − ci‖2 para k 6= i
0 caso contrário
A matriz grau de pertença U segue as seguintes propriedades:
c∑i=1
(uij = 1,∀j = 1, ..., n)
c∑i=1
n∑j=1
(uij = n)
Por outro lado se uijestá fixo, então os centros dos clusters são calculados com recurso a:
ci =1
|Gi|∑
k,xkεGi
xk
Trata-se de um algoritmo iterativo. O cálculo dos centros dos clusters bem como a matriz de grau de
pertença U, são calculados várias vezes de modo a minimizar a função de custo seguindo os passos:
1. Inicialização dos centros dos clusters aleatoriamente;
2. Cálculo da matriz de grau de pertença;
3. Atribuição de cada ponto ao centro mais próximo;
4. Atualização dos centros;
5. Repetir os três passos anteriores, até que não haja alteraçõe de membros por centro.
Tal como foi referido no capitulo que se antecede, um dos maiores problemas associados com o uso
desta técnica é a necessidade de definir o número de centros de clusters à priori. Como tal, este
número pode ser definido de acordo com o conhecimento dos dados por parte do utilizador do método
ou, alternativamente, recorrendo a índices de validação. Para a realização deste trabalho recorreu-se a
alguns índices de validação de clusters, matéria que vai ser aprofundada no seguimento.
3.1.2 Índices de Validação
Quando o número real de clusters para um certo conjunto de dados não é conhecido recorre-se a
índices de validação de clusters. Estes têm como objetivo maximizar a semelhança dentro de cada
clusters e ao mesmo tempo maximizar a diferença entre os diferentes grupos. Para chegar ao número
de de clusters, os seguintes métodos foram utilizados, estes tratam-se de Internal Clustering Validation
Measures:
• Silhouette, este índice mede o quão compacto cada grupo e o grau de separação dos diferentes
grupos. Um aumento do valor deste indica um grupo com melhor qualidade. Este é definido como:
1
NC
∑i
{i
xi
∑x∈Ci
b(x)− a(x)max [b(x), a(x)))]
}
14

E o valor ótimo é o valor máximo obtido.
• Davies and Bouldin’s, este índice analisa a coesão do cluster com base na distância entre o
centroide do cluster e dos dados correspondentes a esse cluster e a separação com base na
distância entre centroides. Esta é medida de acordo como a equação:
1
NC
∑i
maxj,j 6=i
i
xi
∑x∈Ci,y 6=x
d(x, ci) +1
xj
∑x∈Cj
d(x,Cj))
/d(ci, cj)
Em que o valor ótimo é o valor mínimo obtido.
• Dunn este identifica se um cluster é compacto e bem separado de acordo com a seguinte formula:
mini
{minj
(minx∈ Ci, y ∈ Cjd(x, y)
maxx,y∈Ckd(x,y)
)}
E o valor ótimo é o valor máximo obtido.
• Xie and Beni’s o objetivo deste é quantificar o rácio entra a variação total do cluster e a separação
dos clusters. [∑i
∑x∈Ci
d2(x, ci))
]/[x ·mini 6=jd2(ci, cj)
]Sendo o valor mais baixo o ótimo.
Nestas equações:
1. X- Corresponde ao conjunto de dados;
2. x- Número de pacientes de X;
3. c- Centros de D;
4. NC- número de clusters;
5. d(x,y)- Distância entre x e y.[? ]
3.2 Redução de Variáveis
Muitas vezes é possível representar os dados, por meio de transformações, de uma forma reduzida de
‘features efetivas’ e ainda assim conseguir reter grande parte da informação contida nos dados iniciais.
Este processo é conhecido como ‘dimensionality reduction’ ou redução da dimensão. Uma das técnicas
mais utilizadas para esta função é o PCA[? ] ‘Principal Component Analysis’, que foi utilizada nesta
tese e vai ser analisado em maior detalhe posteriormente.
3.2.1 PCA-Análise dos componentes principais
É um método estatístico para multivariáveis com objetivo, como já foi salientado anteriormente, reduzir
da dimensão do espaço de observações. Esta redução é conseguida por intermédio da combinação
15

linear das variáveis que caracterizam o objeto de estudo e descarte das combinações que apresentam
menor variância. Assumindo xi, i = 1, ..., n seja a entrada dos dados X a serem considerados. Con-
seguimos encontrar o vetor , vetor unitário, maximizando a variância dos dados após projeta-los em .
Assumindo que X tem média zero tal que:n∑i=1
xi = 0
A projeção dexi em u é definida como o produto interno:
pi = xi · u = xTi u = uTxi
Em que u é um vetor unitário, tal que:
‖u‖ =√utu = 1
Como ambos os vetores apresentam média igual a zero temos que:
n∑i=1
pi =
n∑i=1
utxi = utn∑i=1
xi = ut · 0 = 0
O quadrado de pi é expresso como:
p2i = (uTxi)(xTi u) = uT (xix
Ti )u
E a sua variância :
σ2p(u) =
1
n
n∑i=1
p2i
= ut(1
n
n∑i=1
xixTi )u
= uTRu
Em que R é a matriz de correlação. Através do Multiplicador de Lagrange podemos minimizar a matriz
de variância projetada tal que:
J = uTRu+ λ(1− uTu)
Derivando a equação e igualando a zero obtemos:
∇uJ = 2Ru− 2λu = 0⇔ Ru = λu
Esta condição estacionária implica que λ é o valor próprio da matriz de correlação R eui o vetor
próprio correspondente. Assim ao substituir na formula da variância, esta toma a seguinte forma:
σ2p(u) = uTRu = uTλu = λuTu = λ
16

Com isto concluímos que a projeção da variância tem um máximo igual ao valor próprio da matriz
de correlação R. Isto acontece quando o vetor de projeção u é igual ao vetor próprio correspondente.
Um dado vetor x pode ser expresso utilizando n vetores próprios de R.
x =
n∑i=1
qiui
Onde qi é a projeção de x em u, e é um vetor próprio unitário de R. O índice i é ordenado de forma
a que ui pertença ao valor próprio λi e i = 1, ..., n. Respeitando o constrangimento:
λ1 ≥ ... ≥ λi ≥ ... ≥ λn
No caso referido inicialmente de redução de dimensão retendo dados com maior variância, x pode ser
aproximado por x eliminando n−m termos tal que:
x =
m∑i=1
piui
Esta aproximação tem um erro associado de:
e = x− xn∑
i=m+1
piui
Se cada ui , em que i = 1, ..., n , é ortogonal entre si então o vetor do erro é ortogonal ao vetorx
independentemente do valor de m.
A variância de x é igual a soma das variâncias de x e da variância de e.
σ2x = σ2
x + σ2e = λ1 + ...+ λm + λm+1 + ...+ λm
Assim sendo para que se possa reduzir a dimensão dos dados é necessário primeiramente encon-
trar a matriz de correlação R e os seus valores e vetores próprios. Após isto os dados são projetados
num subespaço calculado pelos vetores próprios correspondentes aos maiores valores próprios.
3.3 Seleção de Variáveis
3.3.1 Sequential forward selection
Para minimizar o erro do modelo foi feita uma seleção de dados, feature selection, através da técnica
Sequential Forward Selection [? ], para tal recorreu-se a ferramenta do Matlab SFS. Sendo, xi, i = 1, ...n
o paciente i, uma feature é o conjunto de variáveis que compõem xi, tal que xi = f1, f2..fn. O
objetivo desta técnica é criar um sub-conjuntoxs ⊂ x composto por algumas das features de x de forma
a minimizar uma função de erro. Originando um total de oXs ⊂ X . A seleção progressiva é um
algoritmo de busca em árvore que vai adicionando gradualmente features até chegar a condição de
17

Figura 3.1: Transformação PCA [? ]
paragem. A imagem que se segue demonstra esquematicamente o funcionamento deste algoritmo,
sendo apresentado em amarelo as features que vão sendo selecionadas a cada iteração.
Figura 3.2: Seleção de variáveis através de SFS
18

3.4 Classificador
O aumento substancial da quantidade de dados gerados e armazenados levou a uma crescente neces-
sidade de técnicas que permitem filtrar e analisar estes dados, para que estes possam ser realmente
úteis. Ao processo de procura e definição de padrões relevantes que possibilitam uma interpretação e
estudo adequado dos dados disponíveis é denominamos por Data Mining. Estas técnicas são extre-
mamente importantes pois permitem não só a análises e previsões de situações futuras como tambem
reduzir o tempo dispendido no processo. Parte fundamental desta tese, é a identificação de padrões,
integrando na técnica de clustering e na criação do classificador. Mais especificamente no classifica-
dor adotado durante esta tese foi Support Vector Machine, SVM[? ] que vai ser explorado com maior
detalhe no seguimento desta seção.
3.4.1 SVM - Support Vector Machine
Trata-se de uma técnica de classificação supervisionada baseada num princípio relativamente simples
de que um conjunto de dados binários pode ser separado e deste modo classificado através de uma
superfície de decisão, fronteira, tentando maximizar esta margem de separação. Esta fronteira varia
de acordo com a dimensionalidade dos dados, para dados bidimensionais esta fronteira tratar-se-á de
uma reta, para dados tridimensionais um plano, ou seja, para dados com dimensãon o hiperplano será
definido em n. O primeiro caso a ter em consideração trata-se de dados linearmente separáveis, o
caso mais simples, no qual um conjunto de dados é separável linearmente por um hiperplano. Sendo
os dados de treino xi ∈ X a respetivamente classificação yi ∈ Y , em que X constitui o espaço dos
dados e Y = {−1,+1}.
Os dados são linearmente separáveis se é possível separar os dados das classes +1 e −1 por meio
de um hiperplano. O qual é definido matematicamente como:
f(x) = wT · x+ b = 0
Na qual w ·x é o produto escalar entre w e x, w é um vetor de pesos ajustável x é o vetor de entrada
e b ∈ < . Com esta função o espaço dos dados X é dividido em duas regiões:
w · x+ b ≥ 0 se yi = +1
w · x+ b < 0 se yi = −1
A partir de f(x) , é possível obter um número infinito de hiperplanos equivalentes, através da multi-
plicação de w e b por uma mesma constante. Como tal o hiperplano ótimo é definido pela margem de
separação ρ , que mede a distância entre o plano e o ponto mais próximo. O hiperplano ótimo é aquele
que maximiza esta diferença, tal como é possível observar na figura que se segue.
19

Figura 3.3: Exemplo de Hiperplano Ótimo detetado com SVM- [? ]
Na imagem que se antecede é possível verificar hiperplano ótimo a vermelho e o exemplo de alguns
hiperplanos existentes dos infinitos possíveis. Assumindo que w∗ e b∗ são os valores que definem este
hiperplano. Este plano é definido como:
w∗ · x+ b∗ = 0
A função que nos dá a distância entre um ponto e o hiperplano ótimo é:
g(x) = w∗ · x+ b∗
Para facilitar a visualização vamos exprimir x como:
x = xp + rw∗
‖w∗‖
Onde xp é a projeção normal de x e r a distância ao hiperplano. Ao definir g(xp) = 0 obtemos:
g(x) = w∗T · x+ b∗ = r‖w∗‖
Ou
r =g(x)
‖w∗‖
O ponto que satizfaz a condição:
w∗ · x+ b ≥ 0 se yi = +1
e
w∗ · x+ b < 0 se yi = −1
É chamado vector de suporte. Este é o mais próximo do hiperplano e define a localização do
hiperplano de separação. A distância algébrica do vetor de suporte x(s) é definida como:
20
r =g(x(s))
‖w∗‖=
+1‖w∗‖ se yi = +1
e
−1‖w∗‖ se yi = −1
A margem de separação entre dados binários ótima é dada por:
ρ = 2r =2
‖w∗‖
A partir disto conclui-se que maximizar a margem de separação equivale a minimizar a norma Eu-
clidiana do vetor de pesos w∗ . Consequentemente esta é definida como:
φ(w) =1
2wTw
Em casos mais complexos nos quais os dados não são linearmente separáveis, ‘slack variables’ são
introduzidas para que penalizem pontos classificados incorretamente.
ρ(ε) =
N∑i=1
εi
Passando deste modo a função objetivo a formular-se através da aglomeração destas duas funções,
assumindo a seguinte forma:
φ(w) =1
2wTw +
N∑i=1
εi
Para o caso de dados não-linearmente separáveis, a função euclidiana é substituída por uma função
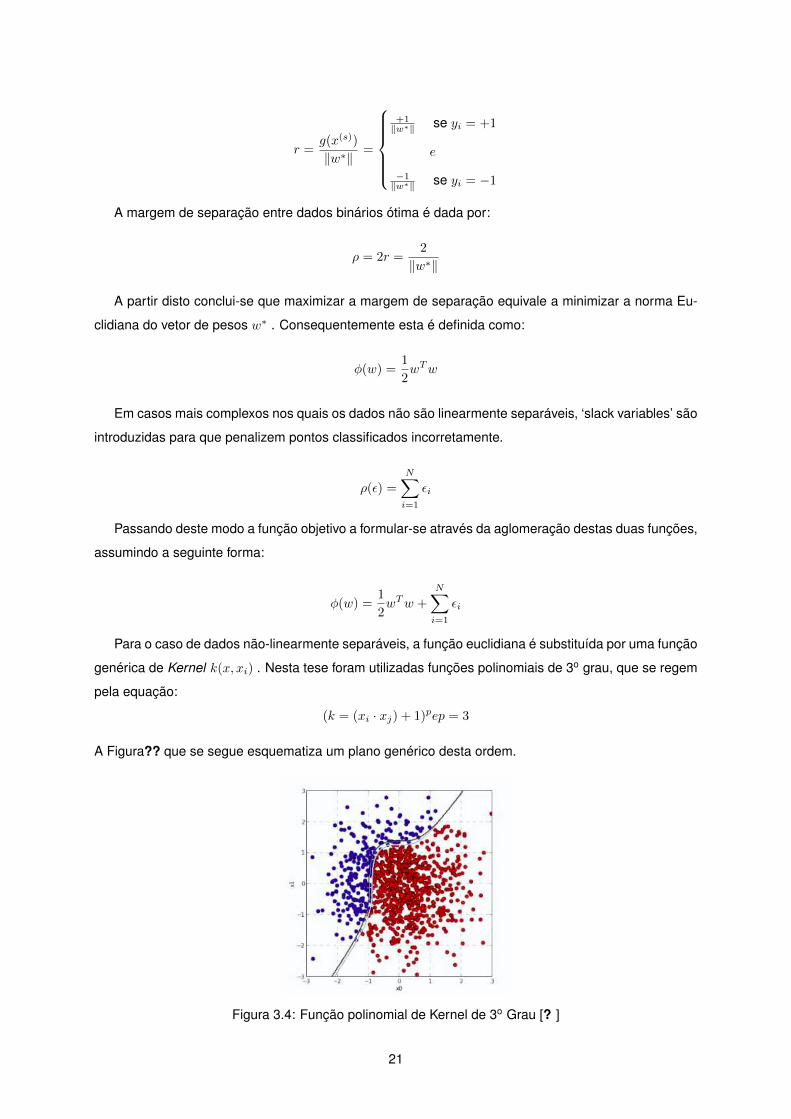
genérica de Kernel k(x, xi) . Nesta tese foram utilizadas funções polinomiais de 3o grau, que se regem
pela equação:
(k = (xi · xj) + 1)pep = 3
A Figura?? que se segue esquematiza um plano genérico desta ordem.
Figura 3.4: Função polinomial de Kernel de 3o Grau [? ]
21
3.4.2 SVM- Support Vector Machine - Problema Multi-Classe
Originalmente, a técnica de SVM foi pensada e implementada para problemas binários através do
método explicado anteriormente. Este conceito foi estendido a problemas de classificação multi-classe.
Para tal existem dois métodos, o primeiro passa pela criação de um número finito de classificadores,
transformando um problema multi-classe em vários sub-problemas binários e finalmente combina-se
estes classificadores criando um classificador final que é o aglomerado de todos estes . O outro método
é considerando todos os dados e formulando uma função de custo e otimizando-a. Durante esta tese
foi utilizado a ferramenta fitecoc do programa MATLAB, que se enquadra no primeiro grupo, e cria um
classificador através de uma técnica one-versus-one. Este treina um classificador diferente para cada
par de diferentes grupos, se tivermos N classes vai criar N(N−1)2 classificadores. Dado um conjunto de
dados T, com os dados de treino xi ∈ X a classificação destes yi ∈ Y , em que X constitui o espaço
dos dados e Y = 1, ..., k. Para os dados de treino ith e a classe jth, o classificador adota a seguinte
forma:
minwij ,bij ,εij1
2(wij)Twij + C
∑εij
E é classificado segundo: (wij)φ(xt) + bij ≥ 1− εitt se yt = i
(wij)φ(xt) + bij ≤ 1 + εitt se yt = j
εijt ≥ 0
A função φ mapeia os dados numa dimensão maior e C é o parâmetro penalizador.
Conduzindo assim a um classificador menos sensível a dados mal balanceados, com o inconveni-
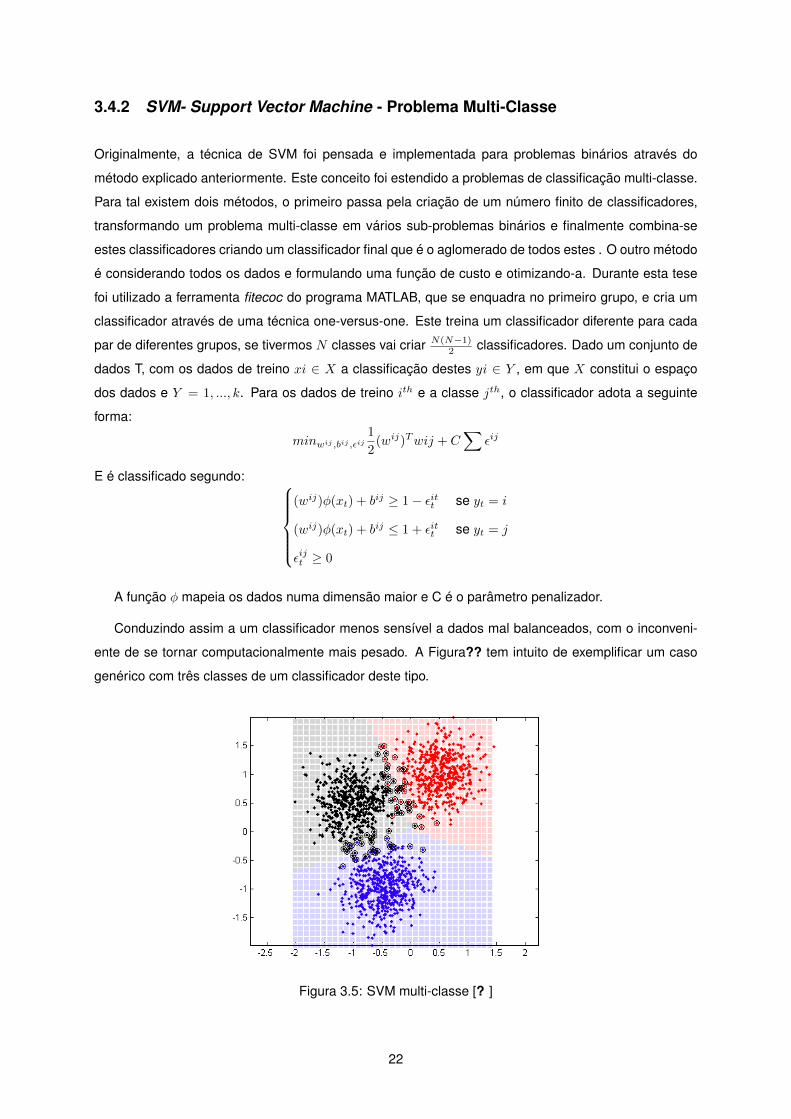
ente de se tornar computacionalmente mais pesado. A Figura?? tem intuito de exemplificar um caso
genérico com três classes de um classificador deste tipo.
Figura 3.5: SVM multi-classe [? ]
22

3.5 Divisão e Validação de Dados
3.5.1 Partição dos dados
Um dos principais problemas na criação do modelo é conseguir com que este tenha dados que tradu-
zam a realidade com maior detalhe possível para que este se possa classificar dados do mundo real
com a precisão e exatidão espectada. Por exemplo, por vezes ao minimizar o erro durante o treino do
modelo podemos estar a condicionar e a piorar a performance do modelo aquando da sua implemen-
tação no mundo real. Para evitar isto, é feita uma partição dos dados em treino e teste. Os dados de
treino servem para criar os modelos enquanto que os de testes são dados que não foram considerados
na criação e servem para validar os modelos. Existem várias técnicas de partição de dados e com estas
advêm algumas vantagens e desvantagens. Conhecendo estas é possível selecionar uma divisão dos
dados mais conveniente para o tipo de dados que se está a lidar. Os dados de treino servem para criar
os modelos enquanto que os de teste, que não são considerados na criação do modelo servem para
compara modelos.
Estes problemas podem persistir, basta haver um caso particular em que os dados teste criem um
modelo com uma boa performance para uns dados de teste específico. Para reduzir esta hipótese os
dados são partidos em subconjuntos. Um caso específico desta partição, e muito utilizado quando os
dados disponíveis são reduzidos, é o caso do Leave-One-Out. Pela razão apresentada este método foi
utilizado nesta tese. Neste caso são criados um número de subconjuntos igual ao número de dados N
disponíveis, no qual são calculados N erros permitindo fazer uma investigação completa dos dados em
relação à sua variação. A figura que segue demonstra um processo de validação cruzada genérica.
Figura 3.6: Validação cruzada [? ]
3.5.2 Validação
Durante toda esta tese tratou-se cada membro inferior de cada paciente de forma independente. Isto
deveu-se, não só pela possibilidade de poderem apresentar comportamentos assimétricos por membro,
mas também para poder avaliar as pernas de forma individual duplicando o tamanho da amostra. Como
tal os dados para criação e teste do modelo são referentes ao membro inferior esquerdo e a validação
23

do membro oposto em dados que nunca foram usados para treinar ou afinar parâmetros do modelo. A
validação tem como objetivo testar a performance do classificador.
3.5.3 Análise de performance
Nesta secção da tese vão ser explicados os indicadores utilizados para o definir e calcular a perfor-
mance de cada classificador criado.
3.5.3.1 Matriz de confusão
Para facilitar a observação dos resultados obtidos é muito comum a utilização da matriz de confusão.
Esta foi criada por Kohavi e Provost em 1998. Nesta matriz cada linha representa o valor real, por sua
vez as colunas representam os valores previstos pelo classificador, permitindo visualizar de um modo
relativamente fácil a performance do classificador em questão. A imagem que se segue é um exemplo
específico para o caso de um classificador binário.
Tabela 3.1: Matriz de Confusão
Classificação do modelo
1 0
Classe Verdadeira1 VP FN
0 FP VN
As iniciais referentes a esta tabela têm o seguinte significado:
• VP-Verdadeiros Positivos, este é caso em que o a classe real 1 é classificada pelo modelo como
1.
• FN- Falsos Negativos, nesta situação o valor real é 1 e foi previsto como sendo 0 por parte do
classificador.
• FP- Falsos Positivos, em oposição ao último caso, neste caso o valor real é 0 e o classificador,
classifica-o como sendo 1.
• VN- Verdadeiros Negativos, por fim a situação na qual o valor real é 0 e o classificador acerta.
24

Estas definições vão ser úteis daqui em diante para que se consiga definir cada indicador de perfor-
mance.
3.5.3.2 Exactidão
Exactidão =V P + V N
V P + V N + FN + FP
3.5.3.3 Precisão
Precisão =V P
V P + FP
3.5.3.4 Sensibilidade
Sensibilidade =V P
V P + FN
3.5.3.5 Especificidade
Especificidade =V N
V N + FP
3.5.3.6 Valor Preditivo Negativo
VPN =V N
V N + FN
3.5.3.7 Falsos Positivos
FP =FP
FP + V N
3.5.3.8 Taxa de Falsa Predição
TFP =FP
FP + V P
3.5.3.9 Taxa de Falsos Negativos
TFN =FN
FN + V P
25

26
Capítulo 4
Resultados
4.1 Classificador Doente/ Não Doente
4.1.1 Dados
Para este classificador, tal como foi referido anteriormente começou-se por considerar apenas os dados
cinemático à disposição.
Dada a simplicidade do problema estes foram suficientes para construir um classificador capaz de
desempenhar a classificação de um modo eficaz. Os resultados obtidos vão ser apresentados no
seguimento deste capítulo.
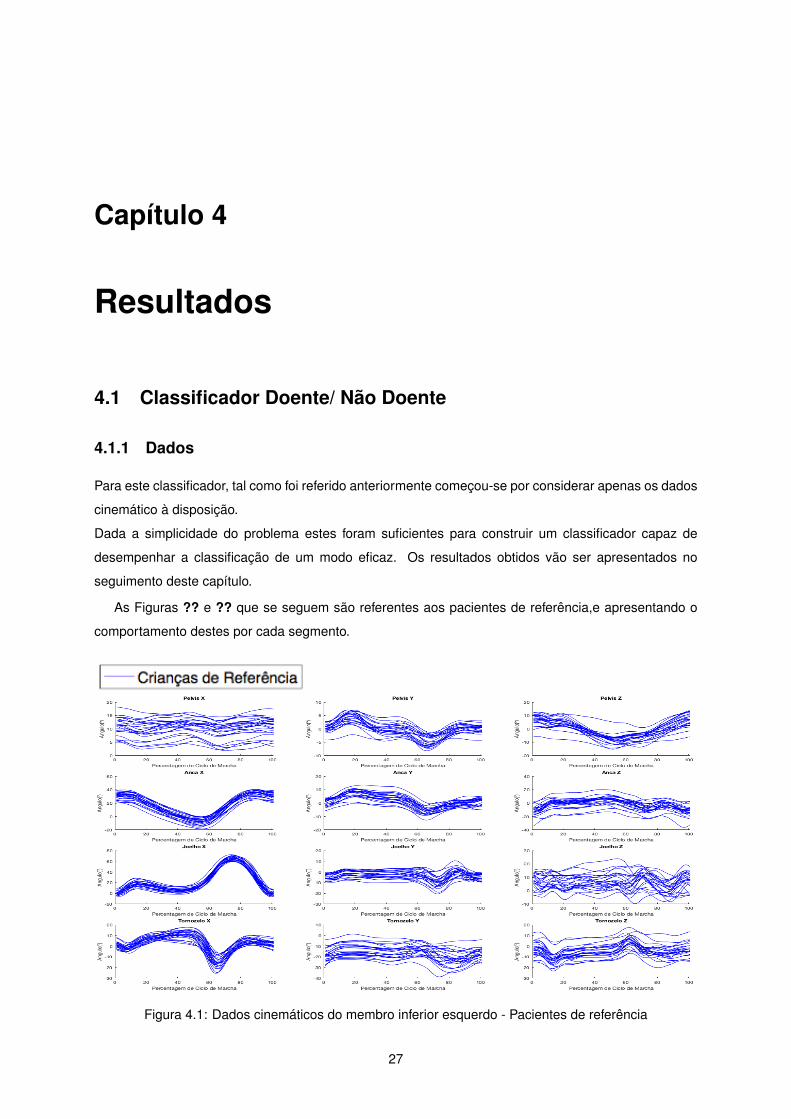
As Figuras ?? e ?? que se seguem são referentes aos pacientes de referência,e apresentando o
comportamento destes por cada segmento.
Figura 4.1: Dados cinemáticos do membro inferior esquerdo - Pacientes de referência
27
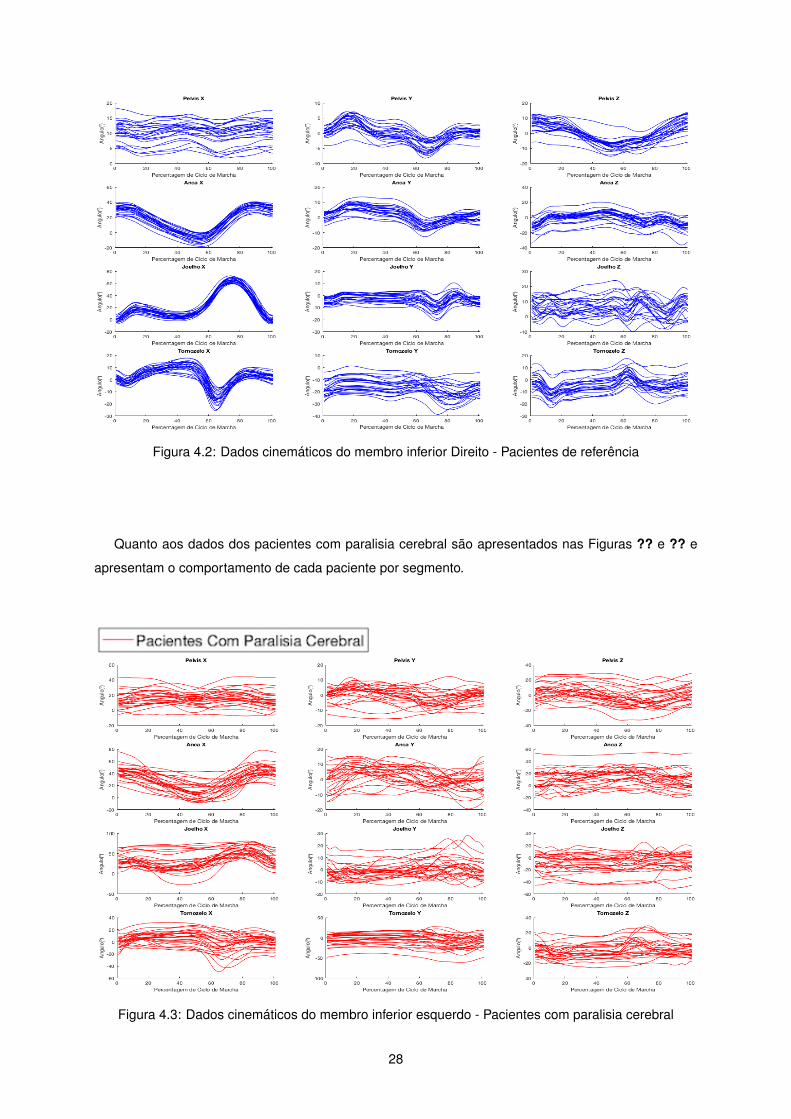
Figura 4.2: Dados cinemáticos do membro inferior Direito - Pacientes de referência
Quanto aos dados dos pacientes com paralisia cerebral são apresentados nas Figuras ?? e ?? e
apresentam o comportamento de cada paciente por segmento.
Figura 4.3: Dados cinemáticos do membro inferior esquerdo - Pacientes com paralisia cerebral
28
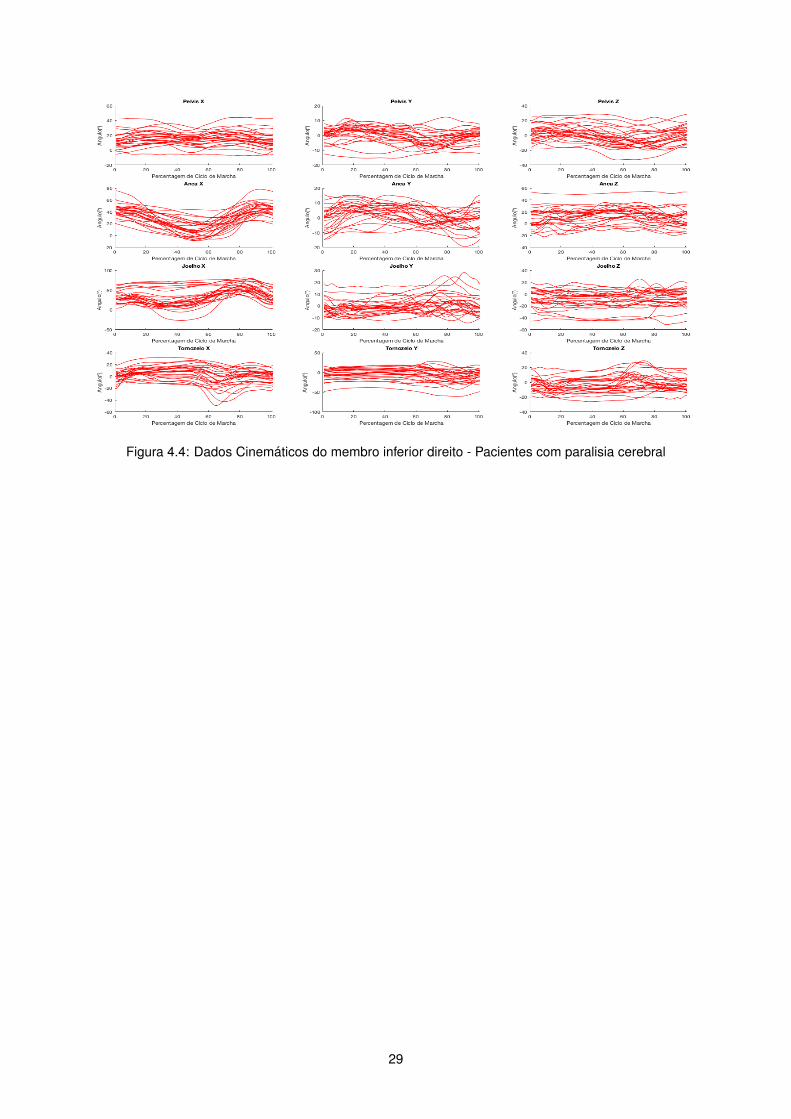
Figura 4.4: Dados Cinemáticos do membro inferior direito - Pacientes com paralisia cerebral
29

4.1.2 Sem Seleção de Variáveis
A primeira abordagem considerada foi a criação de um classificador SVM-Support Vector Machine após
uma redução de variáveis PCA em que foi considerado o critério de redução a variância a 95% sem
qualquer seleção de variáveis. Esta redução resultou num total de 24 Componentes Principais. A
Tabela ?? demonstra as classificações obtidas pelo classificador, com uma exatidão de 92.3%.
Tabela 4.1: Matriz de confusão
Classificação do modelo
1 0
Classe Verdadeira1 24 1
0 3 24
Através da matriz de confusão obtida é possível observar que 24 dos 25 pacientes saudáveis, ou
de referência, são bem classificados. Por sua vez, no caso dos pacientes com problemas associados
aos membros inferiores, 3 dos 27 pacientes são mal classificados. Isto deve-se ao facto de não haver
uma seleção de variáveis, criando redundâncias a nível dos dados e também pelo facto de estes três
pacientes em muitas dos segmento apresentarem comportamentos normais.
30
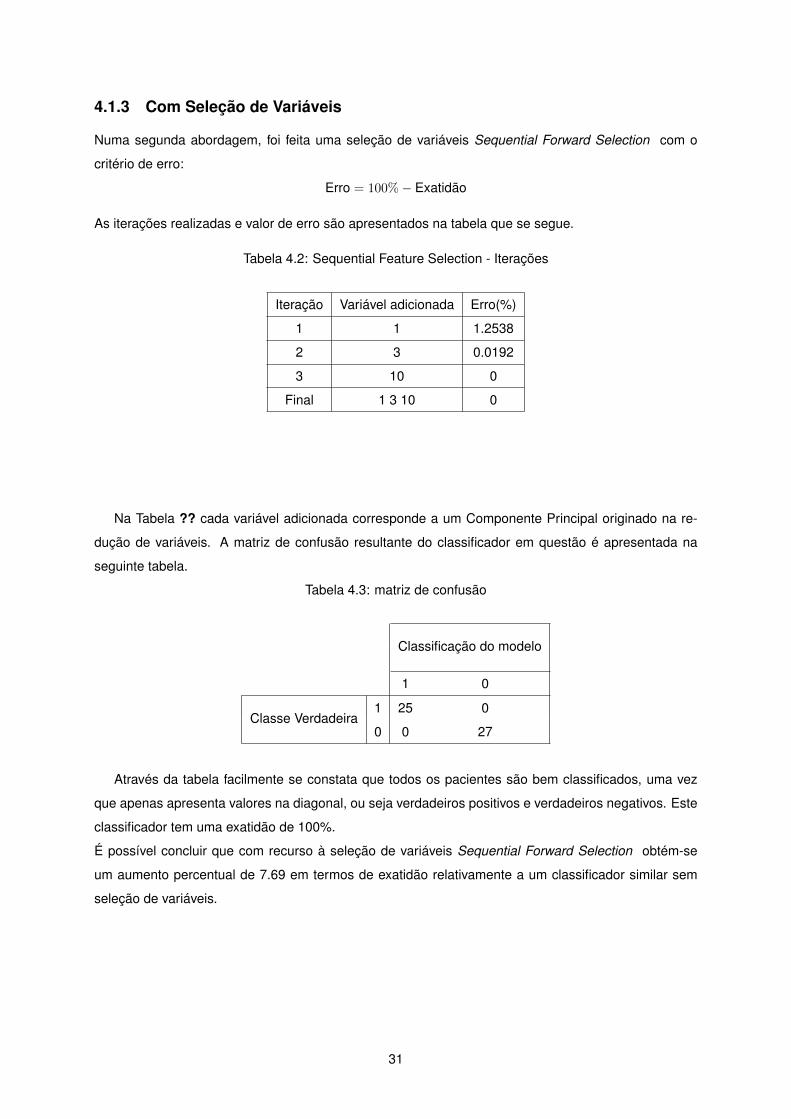
4.1.3 Com Seleção de Variáveis
Numa segunda abordagem, foi feita uma seleção de variáveis Sequential Forward Selection com o
critério de erro:
Erro = 100%− Exatidão
As iterações realizadas e valor de erro são apresentados na tabela que se segue.
Tabela 4.2: Sequential Feature Selection - Iterações
Iteração Variável adicionada Erro(%)
1 1 1.2538
2 3 0.0192
3 10 0
Final 1 3 10 0
Na Tabela ?? cada variável adicionada corresponde a um Componente Principal originado na re-
dução de variáveis. A matriz de confusão resultante do classificador em questão é apresentada na
seguinte tabela.
Tabela 4.3: matriz de confusão
Classificação do modelo
1 0
Classe Verdadeira1 25 0
0 0 27
Através da tabela facilmente se constata que todos os pacientes são bem classificados, uma vez
que apenas apresenta valores na diagonal, ou seja verdadeiros positivos e verdadeiros negativos. Este
classificador tem uma exatidão de 100%.
É possível concluir que com recurso à seleção de variáveis Sequential Forward Selection obtém-se
um aumento percentual de 7.69 em termos de exatidão relativamente a um classificador similar sem
seleção de variáveis.
31
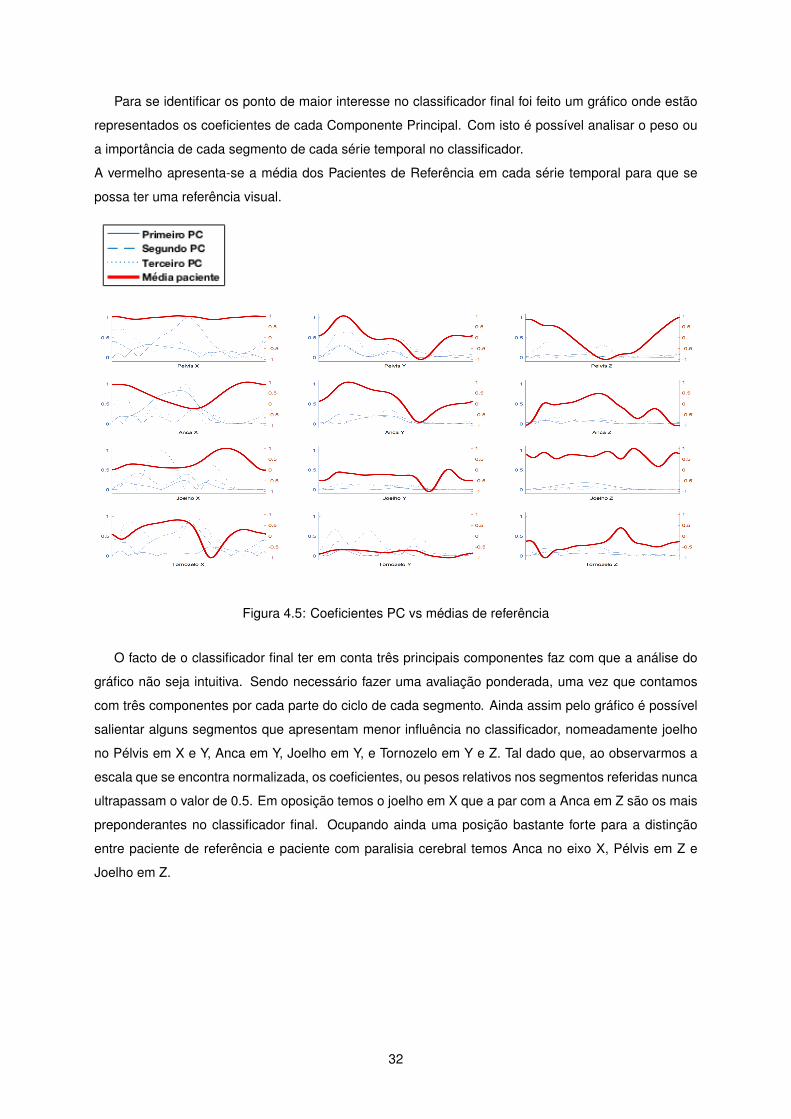
Para se identificar os ponto de maior interesse no classificador final foi feito um gráfico onde estão
representados os coeficientes de cada Componente Principal. Com isto é possível analisar o peso ou
a importância de cada segmento de cada série temporal no classificador.
A vermelho apresenta-se a média dos Pacientes de Referência em cada série temporal para que se
possa ter uma referência visual.
Figura 4.5: Coeficientes PC vs médias de referência
O facto de o classificador final ter em conta três principais componentes faz com que a análise do
gráfico não seja intuitiva. Sendo necessário fazer uma avaliação ponderada, uma vez que contamos
com três componentes por cada parte do ciclo de cada segmento. Ainda assim pelo gráfico é possível
salientar alguns segmentos que apresentam menor influência no classificador, nomeadamente joelho
no Pélvis em X e Y, Anca em Y, Joelho em Y, e Tornozelo em Y e Z. Tal dado que, ao observarmos a
escala que se encontra normalizada, os coeficientes, ou pesos relativos nos segmentos referidas nunca
ultrapassam o valor de 0.5. Em oposição temos o joelho em X que a par com a Anca em Z são os mais
preponderantes no classificador final. Ocupando ainda uma posição bastante forte para a distinção
entre paciente de referência e paciente com paralisia cerebral temos Anca no eixo X, Pélvis em Z e
Joelho em Z.
32
4.2 Classificador de Tipos Diplegia Espástica - Não Supervisio-
nado
4.2.1 Dados
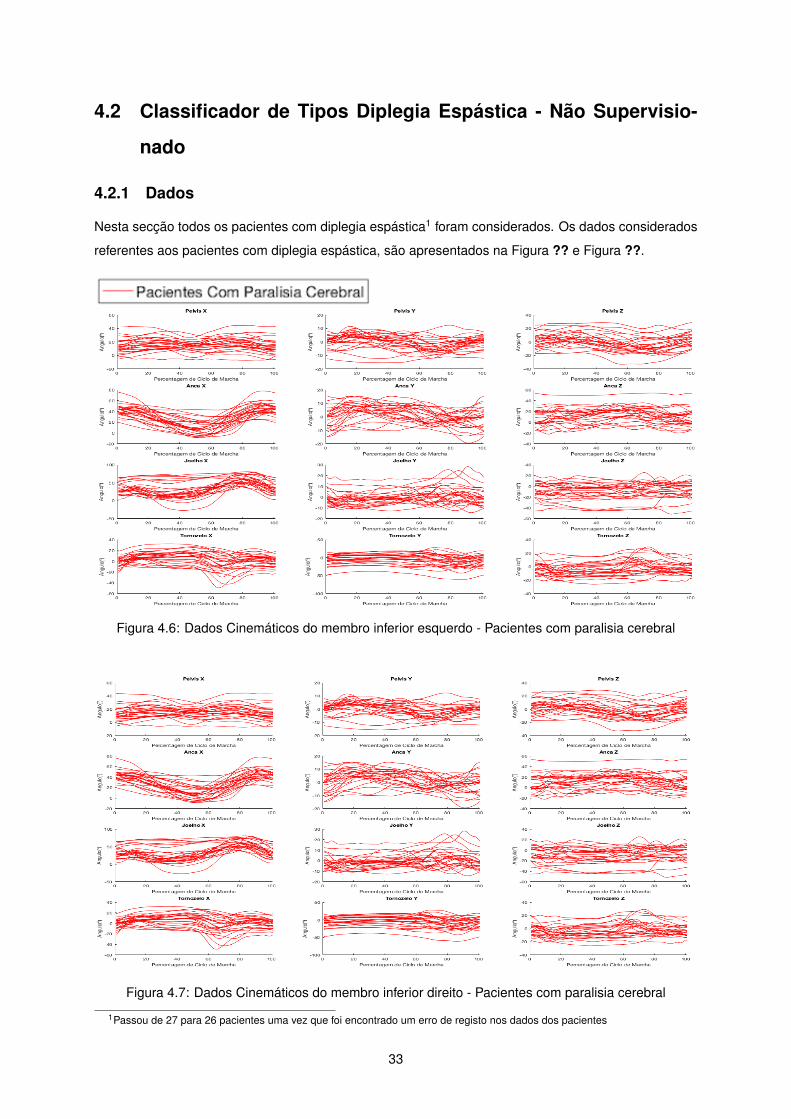
Nesta secção todos os pacientes com diplegia espástica1 foram considerados. Os dados considerados
referentes aos pacientes com diplegia espástica, são apresentados na Figura ?? e Figura ??.
Figura 4.6: Dados Cinemáticos do membro inferior esquerdo - Pacientes com paralisia cerebral
Figura 4.7: Dados Cinemáticos do membro inferior direito - Pacientes com paralisia cerebral
1Passou de 27 para 26 pacientes uma vez que foi encontrado um erro de registo nos dados dos pacientes
33
4.2.2 Índices de Validação
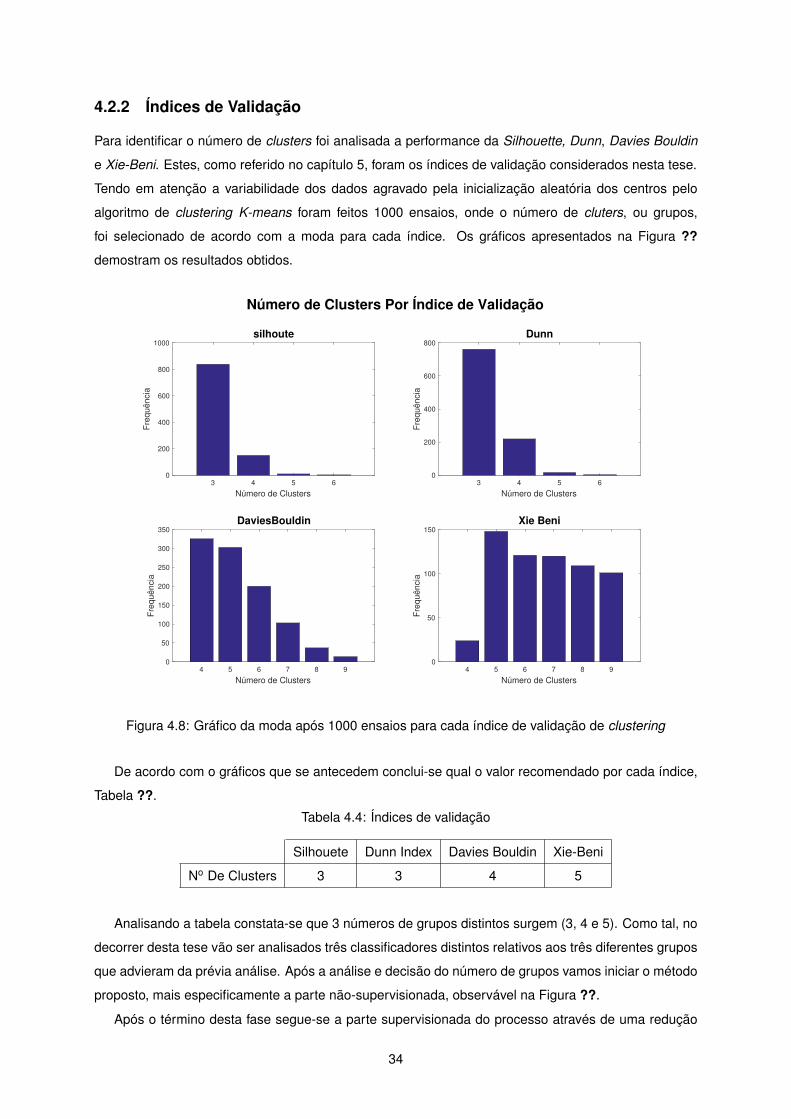
Para identificar o número de clusters foi analisada a performance da Silhouette, Dunn, Davies Bouldin
e Xie-Beni. Estes, como referido no capítulo 5, foram os índices de validação considerados nesta tese.
Tendo em atenção a variabilidade dos dados agravado pela inicialização aleatória dos centros pelo
algoritmo de clustering K-means foram feitos 1000 ensaios, onde o número de cluters, ou grupos,
foi selecionado de acordo com a moda para cada índice. Os gráficos apresentados na Figura ??
demostram os resultados obtidos.
3 4 5 6
Número de Clusters
0
200
400
600
800
1000
Fre
quência
silhoute
3 4 5 6
Número de Clusters
0
200
400
600
800
Fre
quência
Dunn
4 5 6 7 8 9
Número de Clusters
0
50
100
150
200
250
300
350
Fre
quência
DaviesBouldin
Número de Clusters Por Índice de Validação
4 5 6 7 8 9
Número de Clusters
0
50
100
150
Fre
quência
Xie Beni
Figura 4.8: Gráfico da moda após 1000 ensaios para cada índice de validação de clustering
De acordo com o gráficos que se antecedem conclui-se qual o valor recomendado por cada índice,
Tabela ??.
Tabela 4.4: Índices de validação
Silhouete Dunn Index Davies Bouldin Xie-Beni
No De Clusters 3 3 4 5
Analisando a tabela constata-se que 3 números de grupos distintos surgem (3, 4 e 5). Como tal, no
decorrer desta tese vão ser analisados três classificadores distintos relativos aos três diferentes grupos
que advieram da prévia análise. Após a análise e decisão do número de grupos vamos iniciar o método
proposto, mais especificamente a parte não-supervisionada, observável na Figura ??.
Após o término desta fase segue-se a parte supervisionada do processo através de uma redução
34

de variáveis e criação de um classificador com e sem seleção de variáveis. Foram testadas estas
duas hipóteses para se conseguir precisar a influência desta seleção de variáveis na performance
do classificador. Nas próximas secções os resultados que foram obtidos vão ser apresentados em
diferentes secções diferindo no número de grupos.
35
4.2.3 Classificador - 3 Grupos
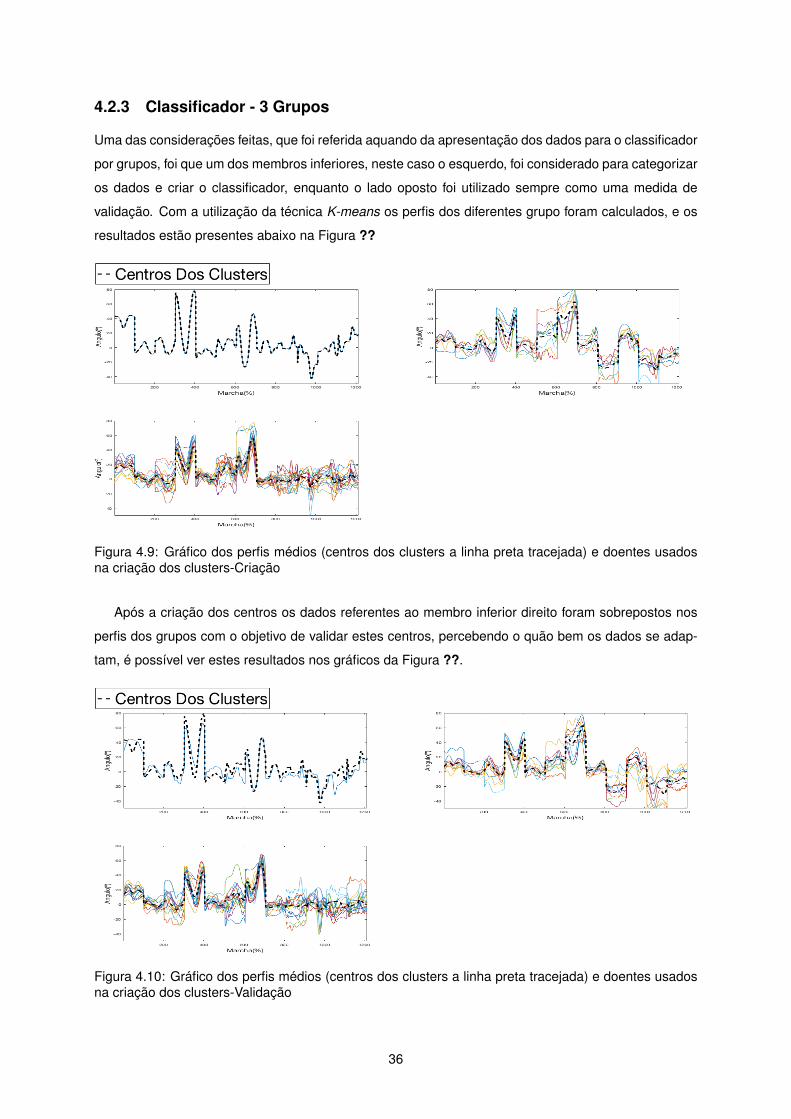
Uma das considerações feitas, que foi referida aquando da apresentação dos dados para o classificador
por grupos, foi que um dos membros inferiores, neste caso o esquerdo, foi considerado para categorizar
os dados e criar o classificador, enquanto o lado oposto foi utilizado sempre como uma medida de
validação. Com a utilização da técnica K-means os perfis dos diferentes grupo foram calculados, e os
resultados estão presentes abaixo na Figura ??
Figura 4.9: Gráfico dos perfis médios (centros dos clusters a linha preta tracejada) e doentes usadosna criação dos clusters-Criação
Após a criação dos centros os dados referentes ao membro inferior direito foram sobrepostos nos
perfis dos grupos com o objetivo de validar estes centros, percebendo o quão bem os dados se adap-
tam, é possível ver estes resultados nos gráficos da Figura ??.
Figura 4.10: Gráfico dos perfis médios (centros dos clusters a linha preta tracejada) e doentes usadosna criação dos clusters-Validação
36
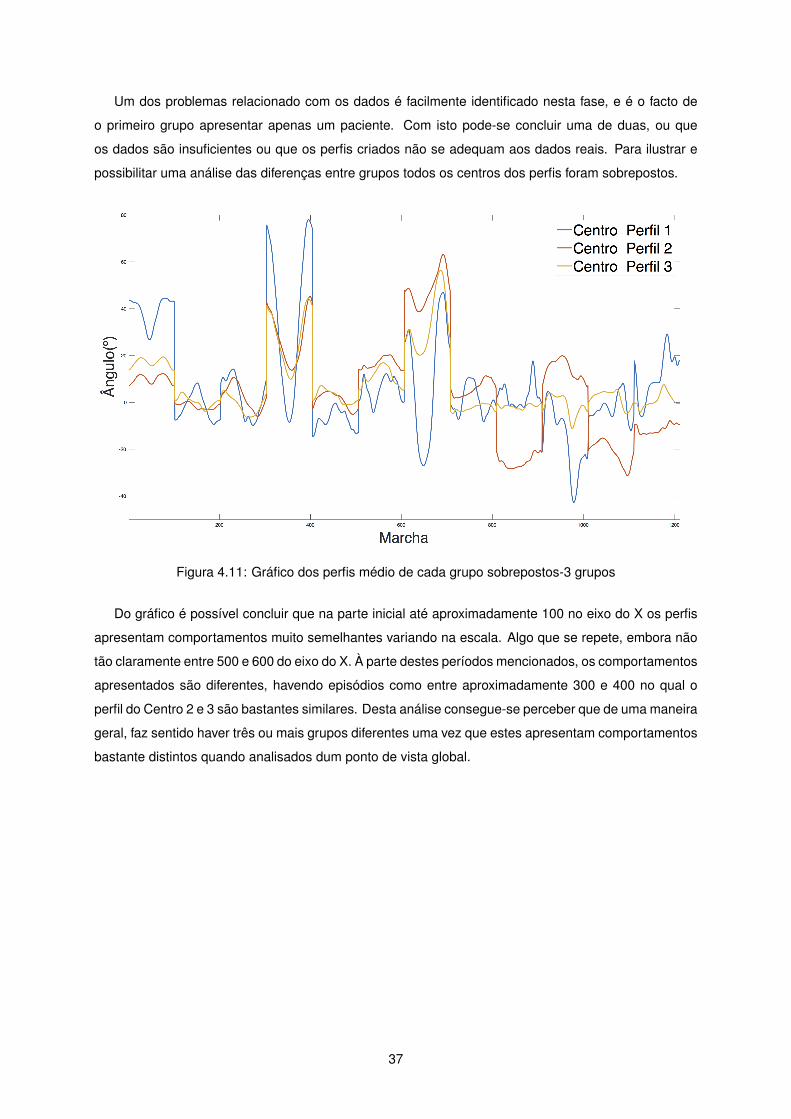
Um dos problemas relacionado com os dados é facilmente identificado nesta fase, e é o facto de
o primeiro grupo apresentar apenas um paciente. Com isto pode-se concluir uma de duas, ou que
os dados são insuficientes ou que os perfis criados não se adequam aos dados reais. Para ilustrar e
possibilitar uma análise das diferenças entre grupos todos os centros dos perfis foram sobrepostos.
Figura 4.11: Gráfico dos perfis médio de cada grupo sobrepostos-3 grupos
Do gráfico é possível concluir que na parte inicial até aproximadamente 100 no eixo do X os perfis
apresentam comportamentos muito semelhantes variando na escala. Algo que se repete, embora não
tão claramente entre 500 e 600 do eixo do X. À parte destes períodos mencionados, os comportamentos
apresentados são diferentes, havendo episódios como entre aproximadamente 300 e 400 no qual o
perfil do Centro 2 e 3 são bastantes similares. Desta análise consegue-se perceber que de uma maneira
geral, faz sentido haver três ou mais grupos diferentes uma vez que estes apresentam comportamentos
bastante distintos quando analisados dum ponto de vista global.
37

4.2.3.1 Classificador Sem Seleção de Variáveis
Em primeira instância foi criado um classificador sem que para isso houvesse uma seleção de variáveis.
Para os dados de criação foram obtidos os resultados que se seguem.
Criação - Membro Inferior Esquerdo
Tabela 4.5: Matriz de confusão
Classificação do modelo
1 2 3
ClasseVerdadeira
1 0 0 1
2 0 3 5
3 0 0 17
Pela análise direta é possível observar que o classificador para as duas primeiras classes apre-
senta resultados de classificação muito baixos. No primeiro caso, pode ser justificado pela reduzida
representatividade de dados relativos a esse grupo.
Por este problema ser mais complexo, comparativamente a problemática anterior, houve uma ne-
cessidade de estabelecer critérios de performance por grupo. Como tal chegou-se aos seguintes apre-
sentados na Figura ??.
Tabela 4.6: Resultado do classificador- criação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 96.15 / 0 100 96.15 0 / 100
2 80.77 100 37.5 100 78.26 0 0 62.50
3 76.92 73.91 100 33.33 100 66.67 66.67 0
Traduzindo-se numa exatidão geral de 76.92%.
38
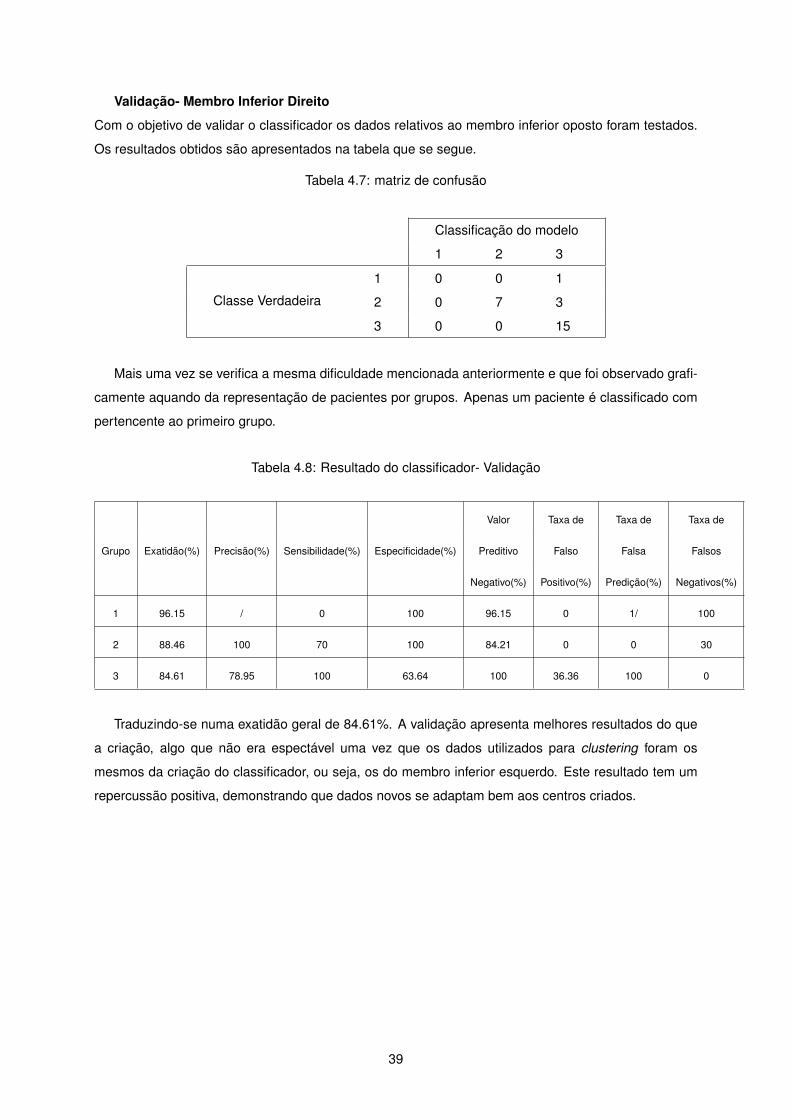
Validação- Membro Inferior Direito
Com o objetivo de validar o classificador os dados relativos ao membro inferior oposto foram testados.
Os resultados obtidos são apresentados na tabela que se segue.
Tabela 4.7: matriz de confusão
Classificação do modelo
1 2 3
Classe Verdadeira
1 0 0 1
2 0 7 3
3 0 0 15
Mais uma vez se verifica a mesma dificuldade mencionada anteriormente e que foi observado grafi-
camente aquando da representação de pacientes por grupos. Apenas um paciente é classificado com
pertencente ao primeiro grupo.
Tabela 4.8: Resultado do classificador- Validação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 96.15 / 0 100 96.15 0 1/ 100
2 88.46 100 70 100 84.21 0 0 30
3 84.61 78.95 100 63.64 100 36.36 100 0
Traduzindo-se numa exatidão geral de 84.61%. A validação apresenta melhores resultados do que
a criação, algo que não era espectável uma vez que os dados utilizados para clustering foram os
mesmos da criação do classificador, ou seja, os do membro inferior esquerdo. Este resultado tem um
repercussão positiva, demonstrando que dados novos se adaptam bem aos centros criados.
39
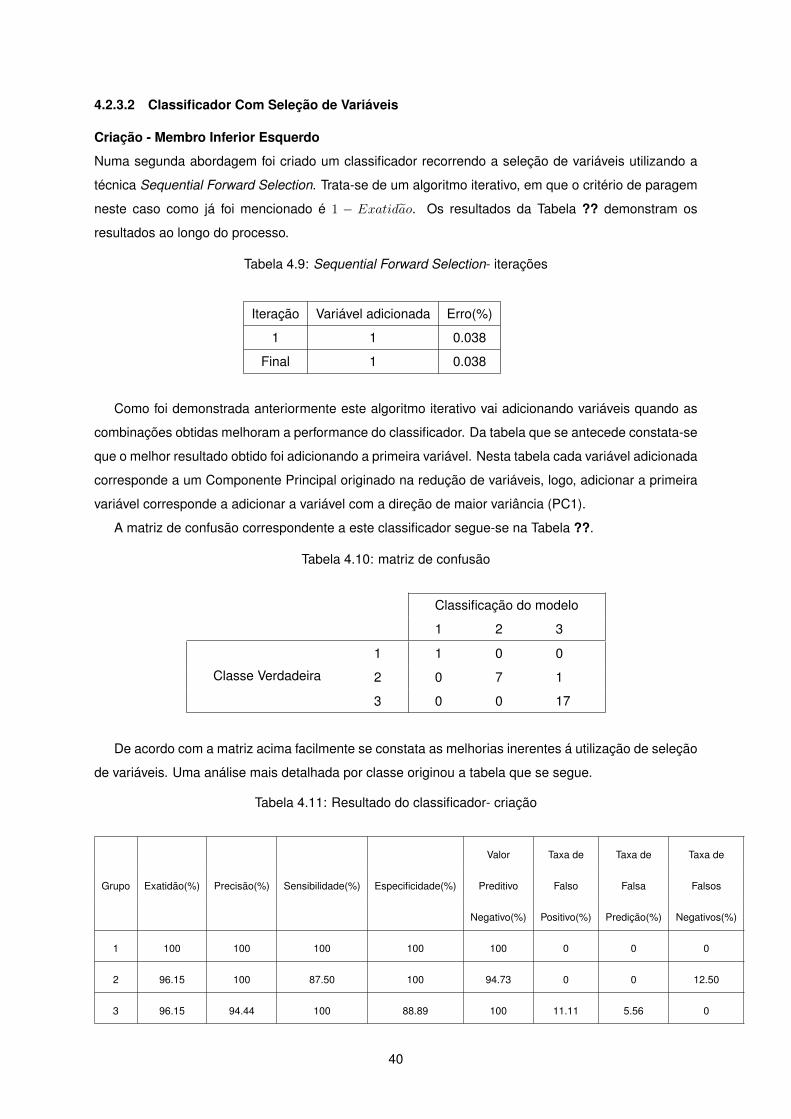
4.2.3.2 Classificador Com Seleção de Variáveis
Criação - Membro Inferior Esquerdo
Numa segunda abordagem foi criado um classificador recorrendo a seleção de variáveis utilizando a
técnica Sequential Forward Selection. Trata-se de um algoritmo iterativo, em que o critério de paragem
neste caso como já foi mencionado é 1 − Exatidao. Os resultados da Tabela ?? demonstram os
resultados ao longo do processo.
Tabela 4.9: Sequential Forward Selection- iterações
Iteração Variável adicionada Erro(%)
1 1 0.038
Final 1 0.038
Como foi demonstrada anteriormente este algoritmo iterativo vai adicionando variáveis quando as
combinações obtidas melhoram a performance do classificador. Da tabela que se antecede constata-se
que o melhor resultado obtido foi adicionando a primeira variável. Nesta tabela cada variável adicionada
corresponde a um Componente Principal originado na redução de variáveis, logo, adicionar a primeira
variável corresponde a adicionar a variável com a direção de maior variância (PC1).
A matriz de confusão correspondente a este classificador segue-se na Tabela ??.
Tabela 4.10: matriz de confusão
Classificação do modelo
1 2 3
Classe Verdadeira
1 1 0 0
2 0 7 1
3 0 0 17
De acordo com a matriz acima facilmente se constata as melhorias inerentes á utilização de seleção
de variáveis. Uma análise mais detalhada por classe originou a tabela que se segue.
Tabela 4.11: Resultado do classificador- criação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 100 100 100 100 100 0 0 0
2 96.15 100 87.50 100 94.73 0 0 12.50
3 96.15 94.44 100 88.89 100 11.11 5.56 0
40
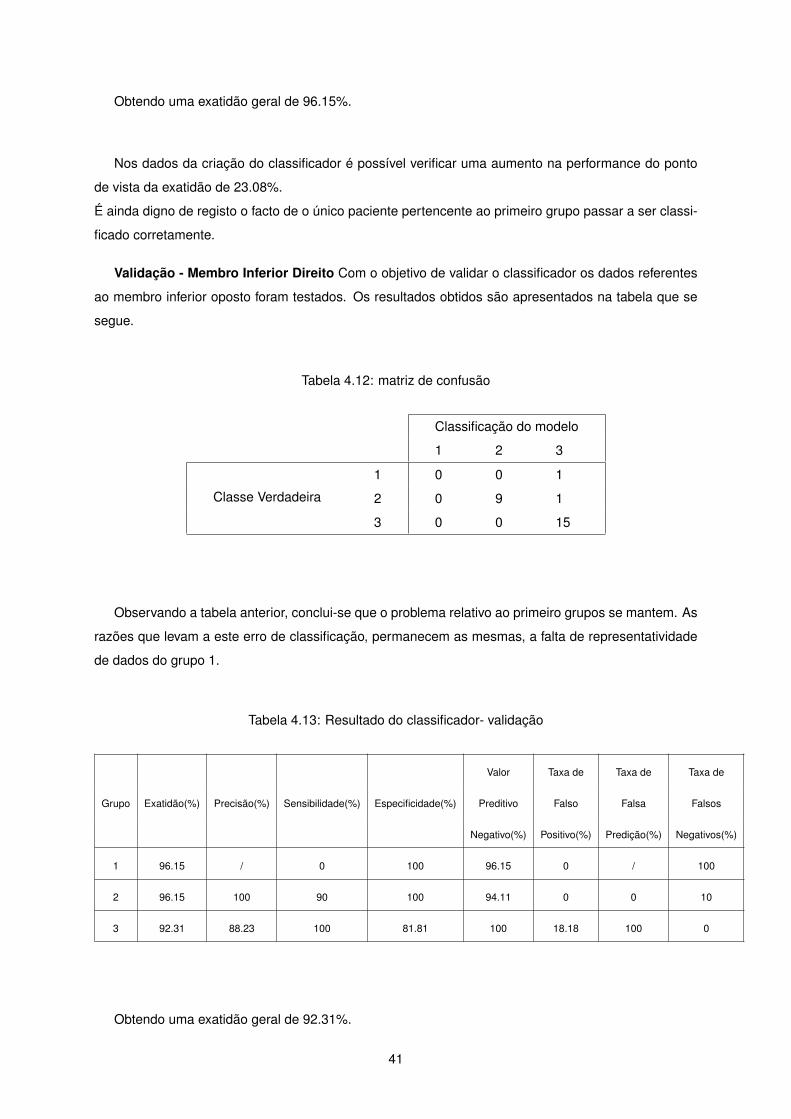
Obtendo uma exatidão geral de 96.15%.
Nos dados da criação do classificador é possível verificar uma aumento na performance do ponto
de vista da exatidão de 23.08%.
É ainda digno de registo o facto de o único paciente pertencente ao primeiro grupo passar a ser classi-
ficado corretamente.
Validação - Membro Inferior Direito Com o objetivo de validar o classificador os dados referentes
ao membro inferior oposto foram testados. Os resultados obtidos são apresentados na tabela que se
segue.
Tabela 4.12: matriz de confusão
Classificação do modelo
1 2 3
Classe Verdadeira
1 0 0 1
2 0 9 1
3 0 0 15
Observando a tabela anterior, conclui-se que o problema relativo ao primeiro grupos se mantem. As
razões que levam a este erro de classificação, permanecem as mesmas, a falta de representatividade
de dados do grupo 1.
Tabela 4.13: Resultado do classificador- validação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 96.15 / 0 100 96.15 0 / 100
2 96.15 100 90 100 94.11 0 0 10
3 92.31 88.23 100 81.81 100 18.18 100 0
Obtendo uma exatidão geral de 92.31%.
41

Figura 4.12: Coeficientes PC vs médias de referência - 3 grupos
O gráfico ?? tem uma análise mais direta comparativamente ao ?? uma vez que apenas o classifi-
cador final depende exclusivamente de um único componente principal. Assim sendo é possível dizer
que os segmentos mais preponderantes são o Joelho em Z, o Tornozelo em Y e em partes do ciclo o
Joelho em X. É possível dizer que em termos de eixo, o Y é o menos influente na decisão do nosso
classificador, há excepção do Tornozelo, que contraria totalmente a tendência.
42

4.2.4 Classificador- 4 Grupos
Considerando a existência de quatro grupos distintos e com recurso á técnica de agrupamento cluste-
ring K-means foi originada a Figura ??.
Figura 4.13: Gráfico dos perfis médios (centros dos clusters a linha preta tracejada) e doentes usadosna criação dos clusters-Criação 4 grupos
Após a criação dos centros, os dados referentes ao membro inferior direito foram sobrepostos nos
perfis dos grupos com o objetivo de os validar. Na Figura ?? são apresentados os resultados obtidos.
Figura 4.14: Gráfico dos perfis médios (centros dos clusters a linha preta tracejada) e doentes usadosna criação dos clusters-Validação 4 grupos
Uma das vantagens presentes comparativamente aos dados dos 3 grupos observáveis graficamente
deve-se ao facto de haver uma maior distribuição do pacientes na criação dos grupos. Apesar disto é
possível ver sempre um grupo dominante, neste caso o segundo grupo que corresponde ao gráfico
superior direito. Apesar disto, nos dados utilizados na validação, observa-se um problema similar ao do
verificado no problema com 3 grupos distintos, que se prende ao facto de um dos grupos apresentar
apenas um paciente. Finalmente verifica-se ainda a escassez de elementos no quarto grupo, sendo
43
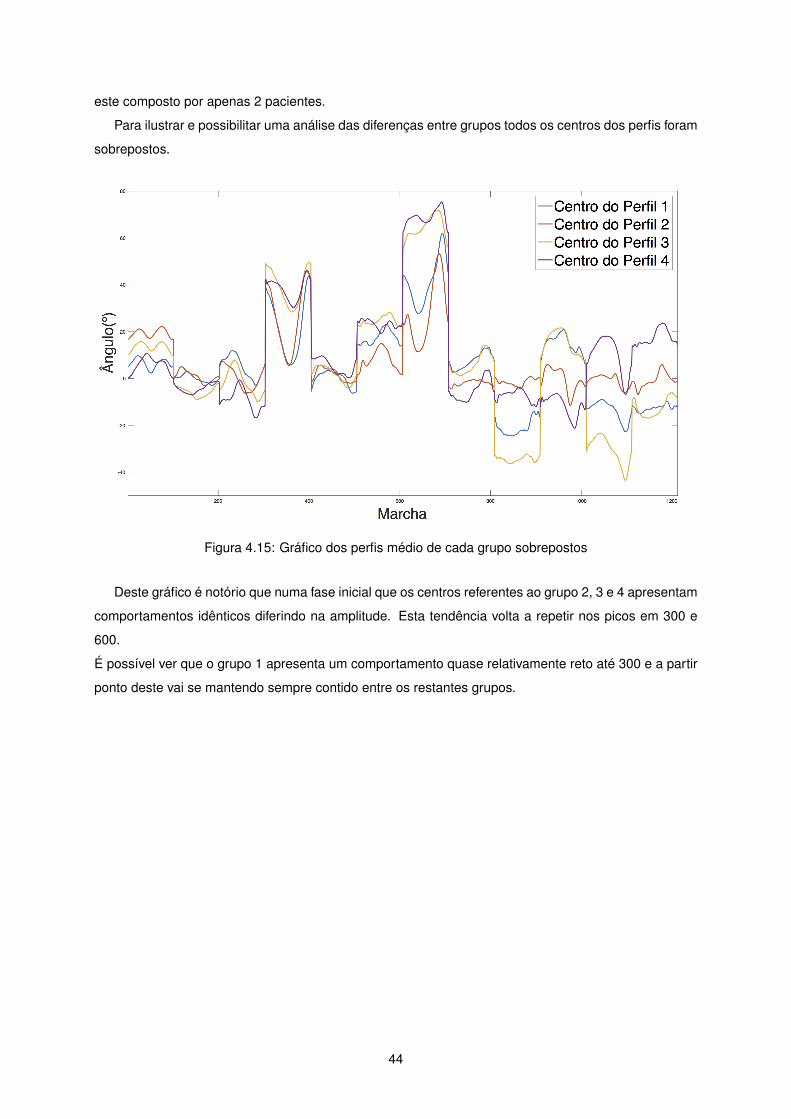
este composto por apenas 2 pacientes.
Para ilustrar e possibilitar uma análise das diferenças entre grupos todos os centros dos perfis foram
sobrepostos.
Figura 4.15: Gráfico dos perfis médio de cada grupo sobrepostos
Deste gráfico é notório que numa fase inicial que os centros referentes ao grupo 2, 3 e 4 apresentam
comportamentos idênticos diferindo na amplitude. Esta tendência volta a repetir nos picos em 300 e
600.
É possível ver que o grupo 1 apresenta um comportamento quase relativamente reto até 300 e a partir
ponto deste vai se mantendo sempre contido entre os restantes grupos.
44

4.2.4.1 Classificador Sem Seleção de Variáveis
Criação - Membro Inferior Esquerdo
Em primeira instância foi criado um classificador sem que para isso houvesse uma seleção de variáveis.
Para os dados de criação os resultados que se seguem foram obtidos.
Tabela 4.14: matriz de confusão
Classificação do modelo
1 2 3 4
Classe Verdadeira
1 1 3 0 0
2 0 17 0 0
3 2 0 0 1
4 0 0 0 2
Esta tabela possibilita ver que os pacientes dos grupos dois e quatro são distinguidos dos restantes
facilmente, algo que não se verifica nos outros grupos.
Como foi referido anteriormente, uma análise mais pormenorizada por grupo foi feita para que se
perceba a performance do classificador por classe. Estes são apresentados na Tabela ??
Tabela 4.15: Resultado do classificador- criação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 80.76 33.33 25 90.91 86.96 9.09 66.67 75
2 88.46 85 100 66.67 100 33.33 15 0
3 88.46 / 0 100 88.46 0 / 35.33
4 96.15 66.67 59 95.83 100 4.17 33.33 0
Obtendo uma exatidão geral de 76.92%.
45
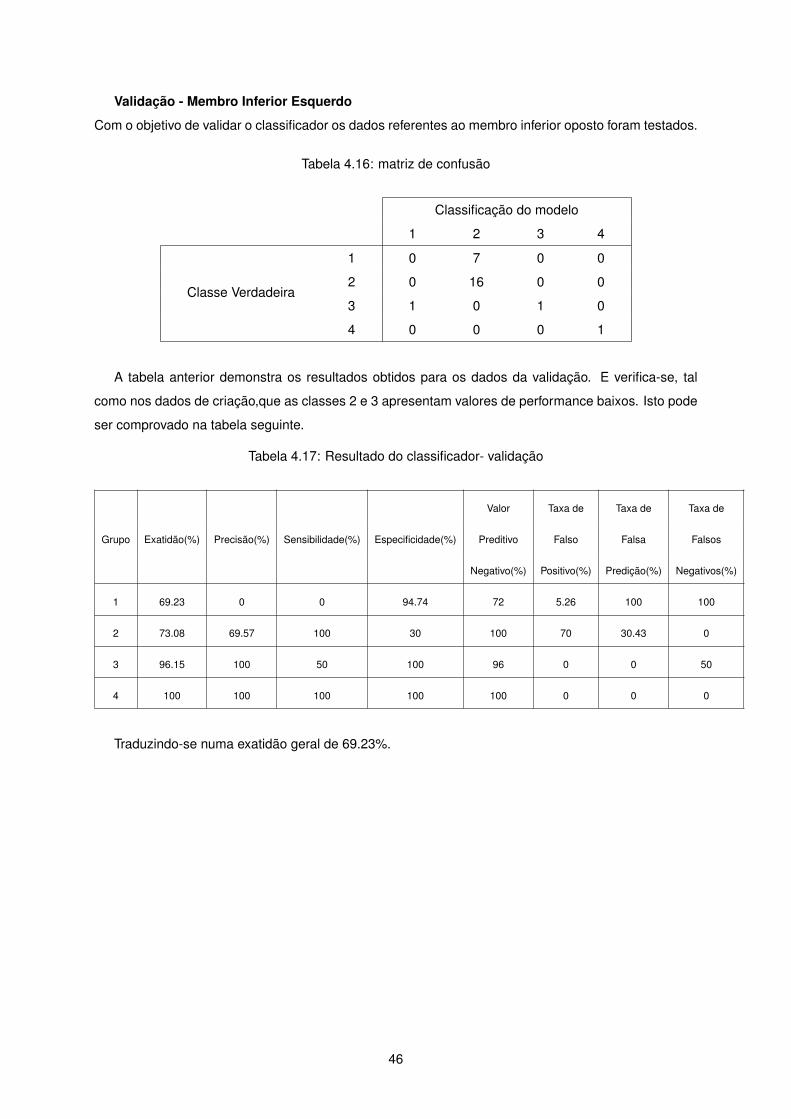
Validação - Membro Inferior Esquerdo
Com o objetivo de validar o classificador os dados referentes ao membro inferior oposto foram testados.
Tabela 4.16: matriz de confusão
Classificação do modelo
1 2 3 4
Classe Verdadeira
1 0 7 0 0
2 0 16 0 0
3 1 0 1 0
4 0 0 0 1
A tabela anterior demonstra os resultados obtidos para os dados da validação. E verifica-se, tal
como nos dados de criação,que as classes 2 e 3 apresentam valores de performance baixos. Isto pode
ser comprovado na tabela seguinte.
Tabela 4.17: Resultado do classificador- validação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 69.23 0 0 94.74 72 5.26 100 100
2 73.08 69.57 100 30 100 70 30.43 0
3 96.15 100 50 100 96 0 0 50
4 100 100 100 100 100 0 0 0
Traduzindo-se numa exatidão geral de 69.23%.
46

4.2.4.2 Classificador Com Seleção de Variáveis
Criação - Membro Inferior Esquerdo Numa segunda aproximação foi criado um classificador havendo
uma seleção de variáveis utilizando a técnica Sequential Forward Selection. Os resultados do processo
iterativo seguem-se na Tabela ??.
Tabela 4.18: Sequential Forward Selection- Iterações
Iteração Variável adicionada Erro(%)
1 1 0
Final 1 0
Pela tabela anterior consegue-se constatar que utilizando apenas uma variável se obtém um erro
de classificação zero. Nesta tabela cada variável adicionada corresponde a uma Componente Principal
originado na redução de variáveis.
A tabela que se segue corresponde à matriz de confusão resultante deste classificador.
Tabela 4.19: matriz de confusão
Classificação do modelo
1 2 3 4
Classe Verdadeira
1 4 0 0 0
2 0 17 0 0
3 0 0 3 0
4 0 0 0 3
Pela matriz de confusão é notória a melhoria obtida pela utilização da seleção de variáveis, estes
traduzem-se na melhorias nos indicadores tidos em conta e apresentados a seguir.
Tabela 4.20: Resultado do classificador- criação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 100 100 100 100 100 0 0 0
2 100 100 100 100 100 0 0 0
3 100 100 100 100 100 0 0 0
4 100 100 100 100 100 0 0 0
Obtendo uma exatidão geral de 100%.
47
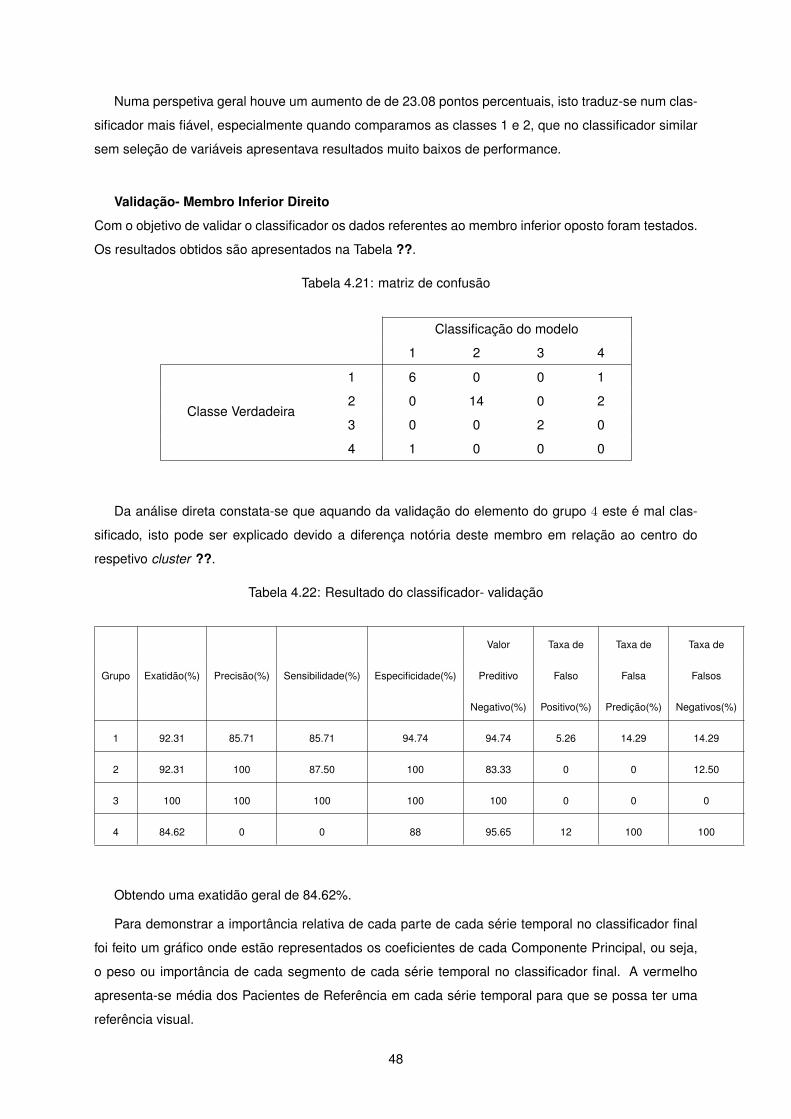
Numa perspetiva geral houve um aumento de de 23.08 pontos percentuais, isto traduz-se num clas-
sificador mais fiável, especialmente quando comparamos as classes 1 e 2, que no classificador similar
sem seleção de variáveis apresentava resultados muito baixos de performance.
Validação- Membro Inferior Direito
Com o objetivo de validar o classificador os dados referentes ao membro inferior oposto foram testados.
Os resultados obtidos são apresentados na Tabela ??.
Tabela 4.21: matriz de confusão
Classificação do modelo
1 2 3 4
Classe Verdadeira
1 6 0 0 1
2 0 14 0 2
3 0 0 2 0
4 1 0 0 0
Da análise direta constata-se que aquando da validação do elemento do grupo 4 este é mal clas-
sificado, isto pode ser explicado devido a diferença notória deste membro em relação ao centro do
respetivo cluster ??.
Tabela 4.22: Resultado do classificador- validação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 92.31 85.71 85.71 94.74 94.74 5.26 14.29 14.29
2 92.31 100 87.50 100 83.33 0 0 12.50
3 100 100 100 100 100 0 0 0
4 84.62 0 0 88 95.65 12 100 100
Obtendo uma exatidão geral de 84.62%.
Para demonstrar a importância relativa de cada parte de cada série temporal no classificador final
foi feito um gráfico onde estão representados os coeficientes de cada Componente Principal, ou seja,
o peso ou importância de cada segmento de cada série temporal no classificador final. A vermelho
apresenta-se média dos Pacientes de Referência em cada série temporal para que se possa ter uma
referência visual.
48
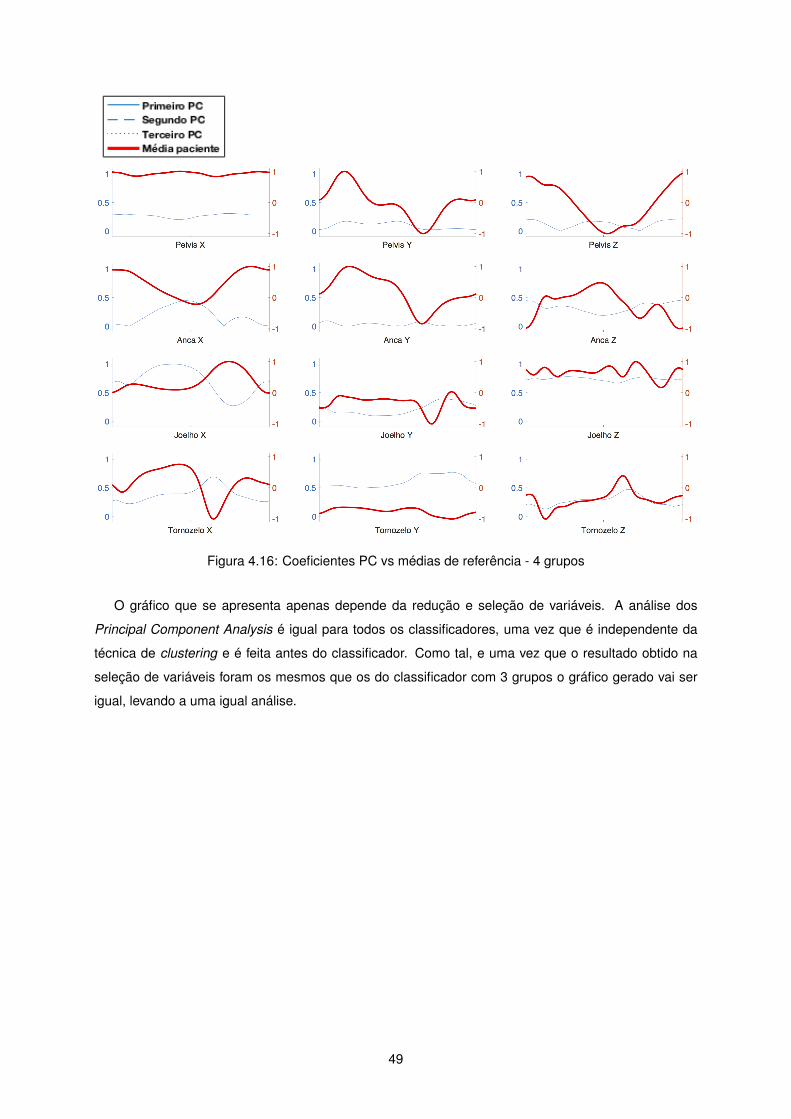
Figura 4.16: Coeficientes PC vs médias de referência - 4 grupos
O gráfico que se apresenta apenas depende da redução e seleção de variáveis. A análise dos
Principal Component Analysis é igual para todos os classificadores, uma vez que é independente da
técnica de clustering e é feita antes do classificador. Como tal, e uma vez que o resultado obtido na
seleção de variáveis foram os mesmos que os do classificador com 3 grupos o gráfico gerado vai ser
igual, levando a uma igual análise.
49
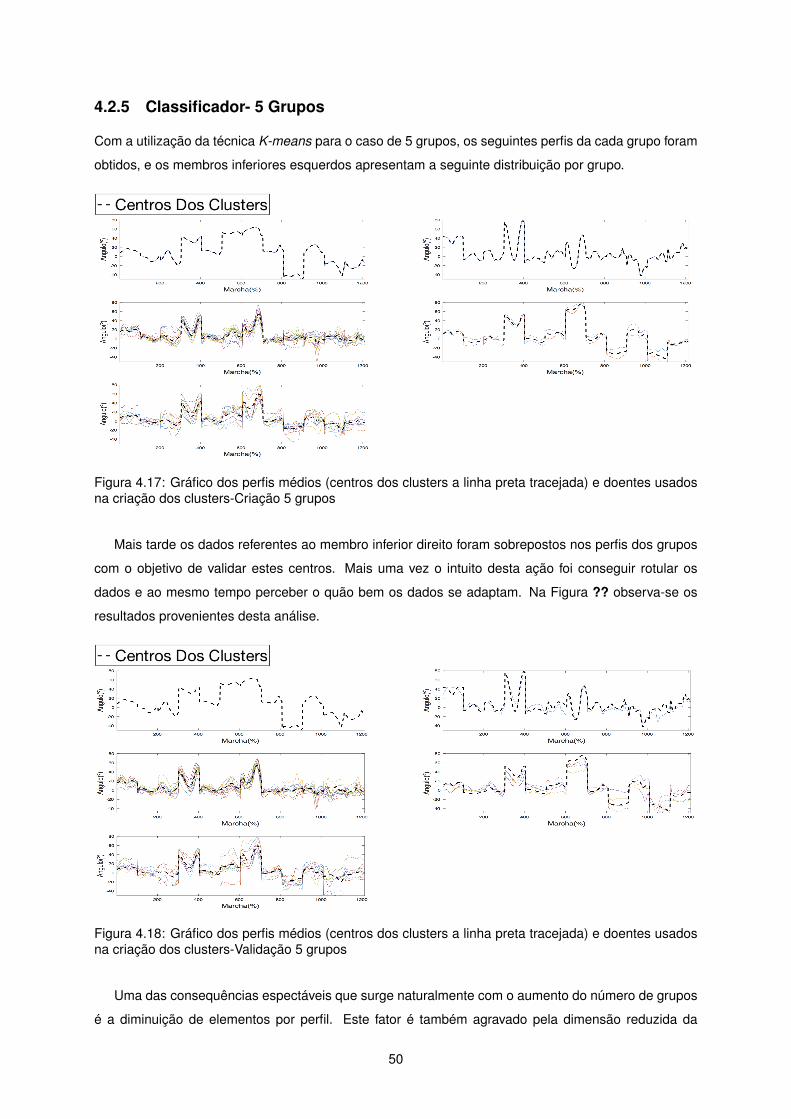
4.2.5 Classificador- 5 Grupos
Com a utilização da técnica K-means para o caso de 5 grupos, os seguintes perfis da cada grupo foram
obtidos, e os membros inferiores esquerdos apresentam a seguinte distribuição por grupo.
Figura 4.17: Gráfico dos perfis médios (centros dos clusters a linha preta tracejada) e doentes usadosna criação dos clusters-Criação 5 grupos
Mais tarde os dados referentes ao membro inferior direito foram sobrepostos nos perfis dos grupos
com o objetivo de validar estes centros. Mais uma vez o intuito desta ação foi conseguir rotular os
dados e ao mesmo tempo perceber o quão bem os dados se adaptam. Na Figura ?? observa-se os
resultados provenientes desta análise.
Figura 4.18: Gráfico dos perfis médios (centros dos clusters a linha preta tracejada) e doentes usadosna criação dos clusters-Validação 5 grupos
Uma das consequências espectáveis que surge naturalmente com o aumento do número de grupos
é a diminuição de elementos por perfil. Este fator é também agravado pela dimensão reduzida da
50
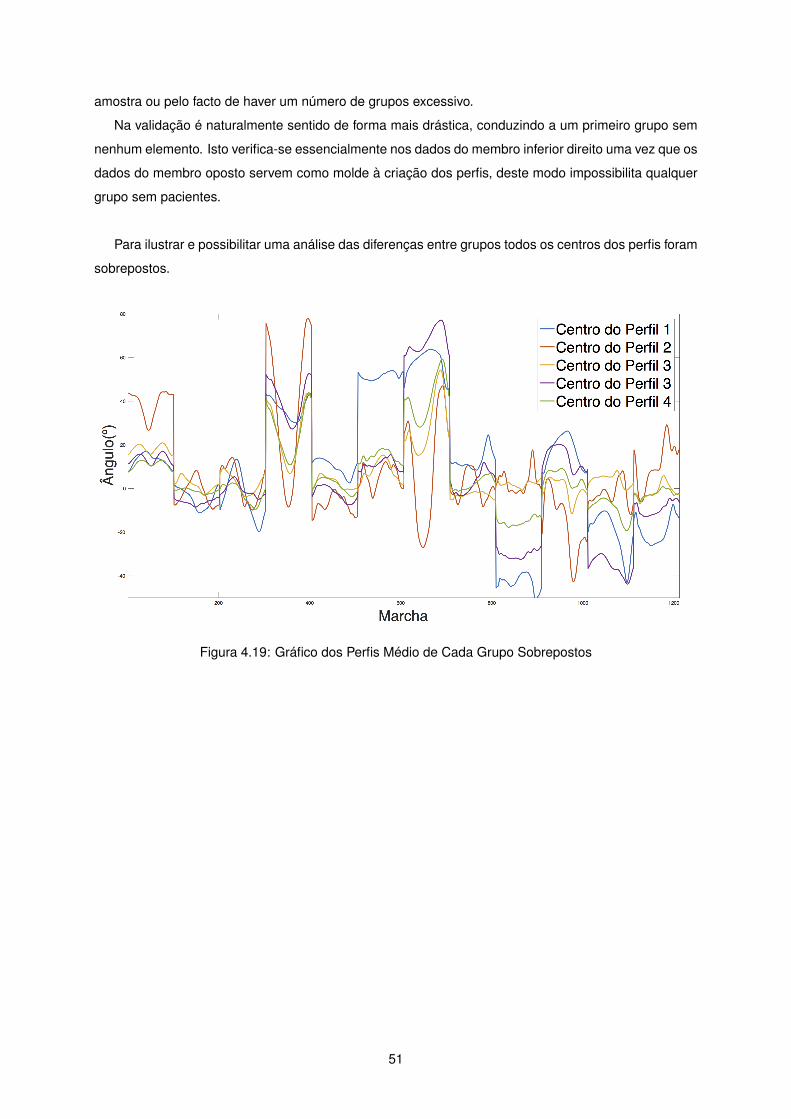
amostra ou pelo facto de haver um número de grupos excessivo.
Na validação é naturalmente sentido de forma mais drástica, conduzindo a um primeiro grupo sem
nenhum elemento. Isto verifica-se essencialmente nos dados do membro inferior direito uma vez que os
dados do membro oposto servem como molde à criação dos perfis, deste modo impossibilita qualquer
grupo sem pacientes.
Para ilustrar e possibilitar uma análise das diferenças entre grupos todos os centros dos perfis foram
sobrepostos.
Figura 4.19: Gráfico dos Perfis Médio de Cada Grupo Sobrepostos
51
4.2.5.1 Classificador sem Seleção de Variáveis
Criação - Membro Inferior Esquerdo Em primeira instância foi criado um classificador sem que para
isso houvesse uma seleção de variáveis. Para os dados de criação os resultados que se seguem foram
obtidos.
Tabela 4.23: matriz de confusão
Classificação do modelo
1 2 3 4 5
Classe Verdadeira
1 0 0 0 0 1
2 0 0 0 0 1
3 0 0 11 0 1
4 0 0 0 0 2
5 0 0 2 0 8
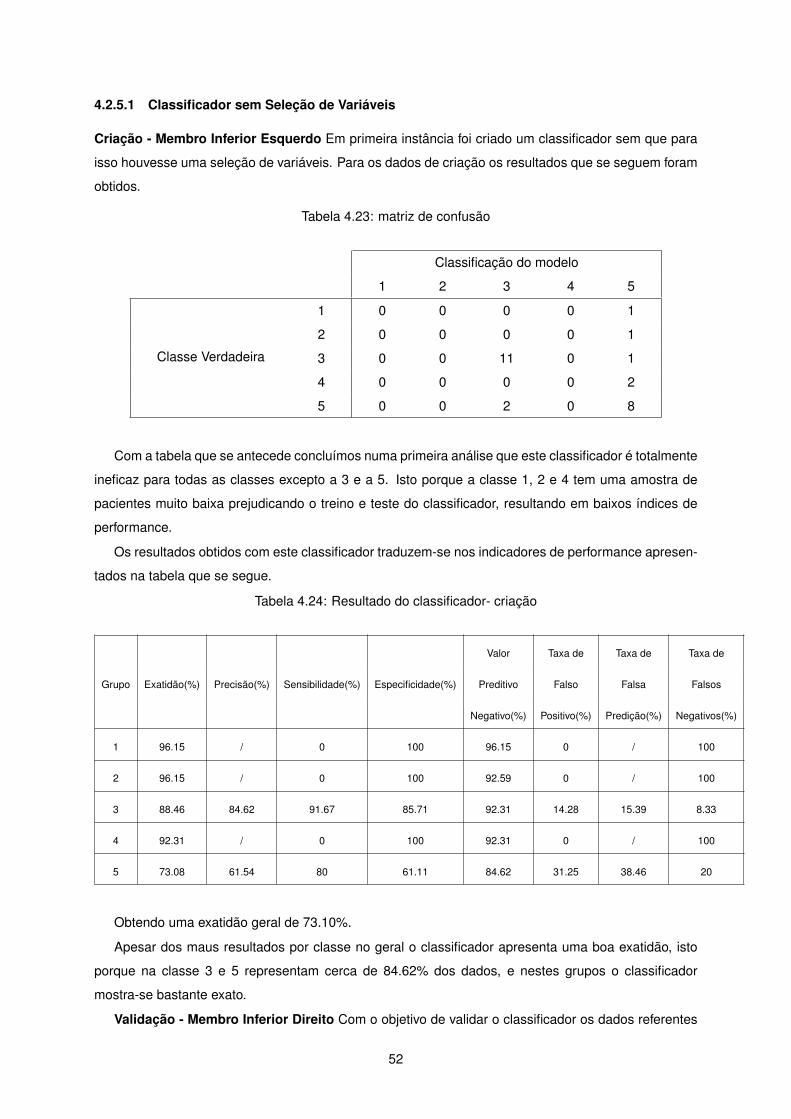
Com a tabela que se antecede concluímos numa primeira análise que este classificador é totalmente
ineficaz para todas as classes excepto a 3 e a 5. Isto porque a classe 1, 2 e 4 tem uma amostra de
pacientes muito baixa prejudicando o treino e teste do classificador, resultando em baixos índices de
performance.
Os resultados obtidos com este classificador traduzem-se nos indicadores de performance apresen-
tados na tabela que se segue.
Tabela 4.24: Resultado do classificador- criação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 96.15 / 0 100 96.15 0 / 100
2 96.15 / 0 100 92.59 0 / 100
3 88.46 84.62 91.67 85.71 92.31 14.28 15.39 8.33
4 92.31 / 0 100 92.31 0 / 100
5 73.08 61.54 80 61.11 84.62 31.25 38.46 20
Obtendo uma exatidão geral de 73.10%.
Apesar dos maus resultados por classe no geral o classificador apresenta uma boa exatidão, isto
porque na classe 3 e 5 representam cerca de 84.62% dos dados, e nestes grupos o classificador
mostra-se bastante exato.
Validação - Membro Inferior Direito Com o objetivo de validar o classificador os dados referentes
52
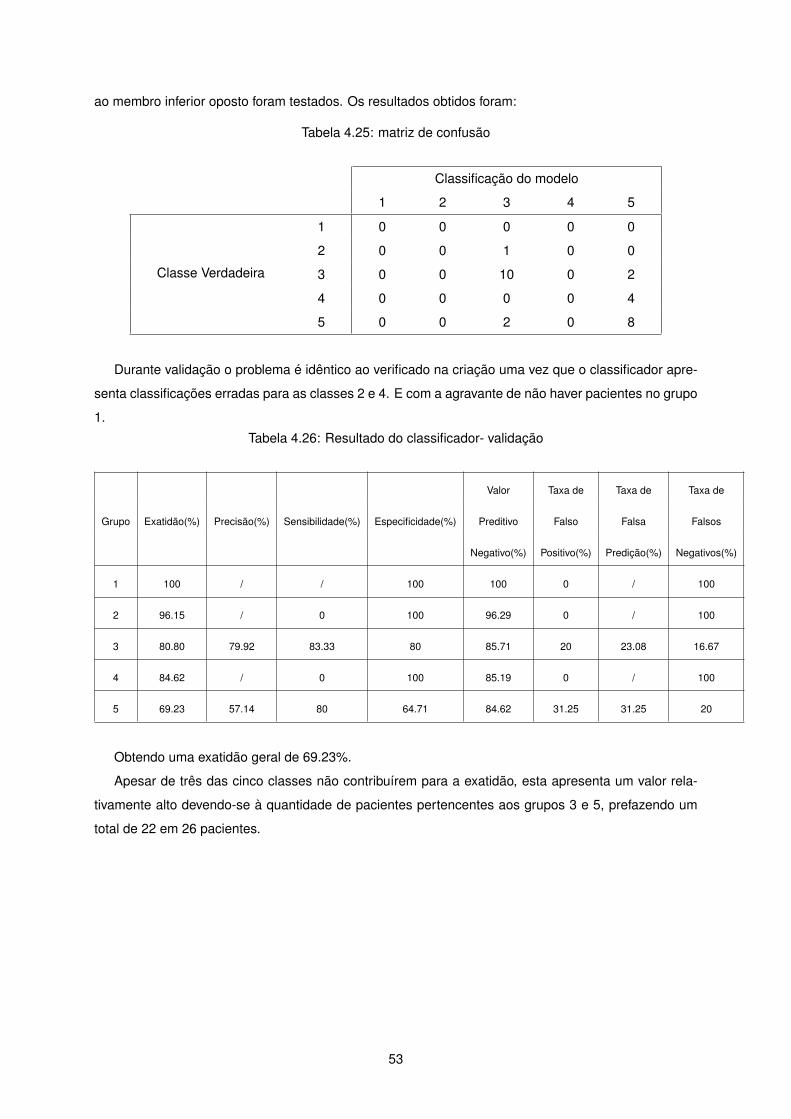
ao membro inferior oposto foram testados. Os resultados obtidos foram:
Tabela 4.25: matriz de confusão
Classificação do modelo
1 2 3 4 5
Classe Verdadeira
1 0 0 0 0 0
2 0 0 1 0 0
3 0 0 10 0 2
4 0 0 0 0 4
5 0 0 2 0 8
Durante validação o problema é idêntico ao verificado na criação uma vez que o classificador apre-
senta classificações erradas para as classes 2 e 4. E com a agravante de não haver pacientes no grupo
1.
Tabela 4.26: Resultado do classificador- validação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 100 / / 100 100 0 / 100
2 96.15 / 0 100 96.29 0 / 100
3 80.80 79.92 83.33 80 85.71 20 23.08 16.67
4 84.62 / 0 100 85.19 0 / 100
5 69.23 57.14 80 64.71 84.62 31.25 31.25 20
Obtendo uma exatidão geral de 69.23%.
Apesar de três das cinco classes não contribuírem para a exatidão, esta apresenta um valor rela-
tivamente alto devendo-se à quantidade de pacientes pertencentes aos grupos 3 e 5, prefazendo um
total de 22 em 26 pacientes.
53

4.2.5.2 Classificador Com Seleção de Variáveis
Criação - Membro Inferior Esquerdo
Numa segunda aproximação foi criado um classificador havendo uma seleção de variáveis utilizando
a técnica Sequential Forward Selection. Os resultados ao longo das iterações estão representados na
próxima tabela.
Tabela 4.27: Sequential Feature Selection- Iterações
Iteração Variável adicionada Erro(%)
1 1 0
Final 1 0
Com esta tabela percebe-se que o algoritmo teve apenas uma iteração até obter o valor de erro
mínimo e consequentemente uma variável. Nesta tabela cada variável adicionada corresponde a uma
Componente Principal.
A Tabela ?? corresponde a matriz de confusão deste classificador.
Tabela 4.28: matriz de confusão
Classificação do modelo
1 2 3 4 5
Classe Verdadeira
1 1 0 0 0 0
2 0 1 0 0 0
3 0 0 12 0 0
4 0 0 0 2 0
5 0 0 0 0 10
Como era espectável pelo resultado proveniente da tabela 5.27 todos os pacientes da criação são
bem classificados. Traduzindo-se nos resultados da tabela seguinte.
54
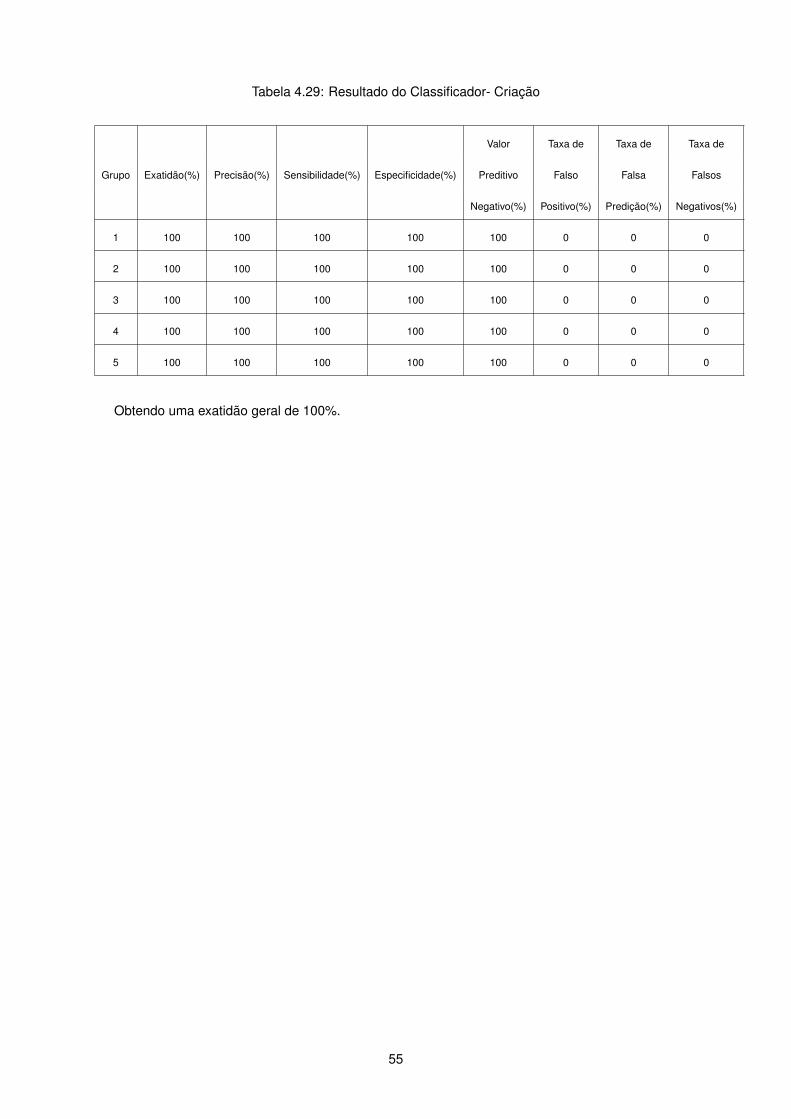
Tabela 4.29: Resultado do Classificador- Criação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 100 100 100 100 100 0 0 0
2 100 100 100 100 100 0 0 0
3 100 100 100 100 100 0 0 0
4 100 100 100 100 100 0 0 0
5 100 100 100 100 100 0 0 0
Obtendo uma exatidão geral de 100%.
55
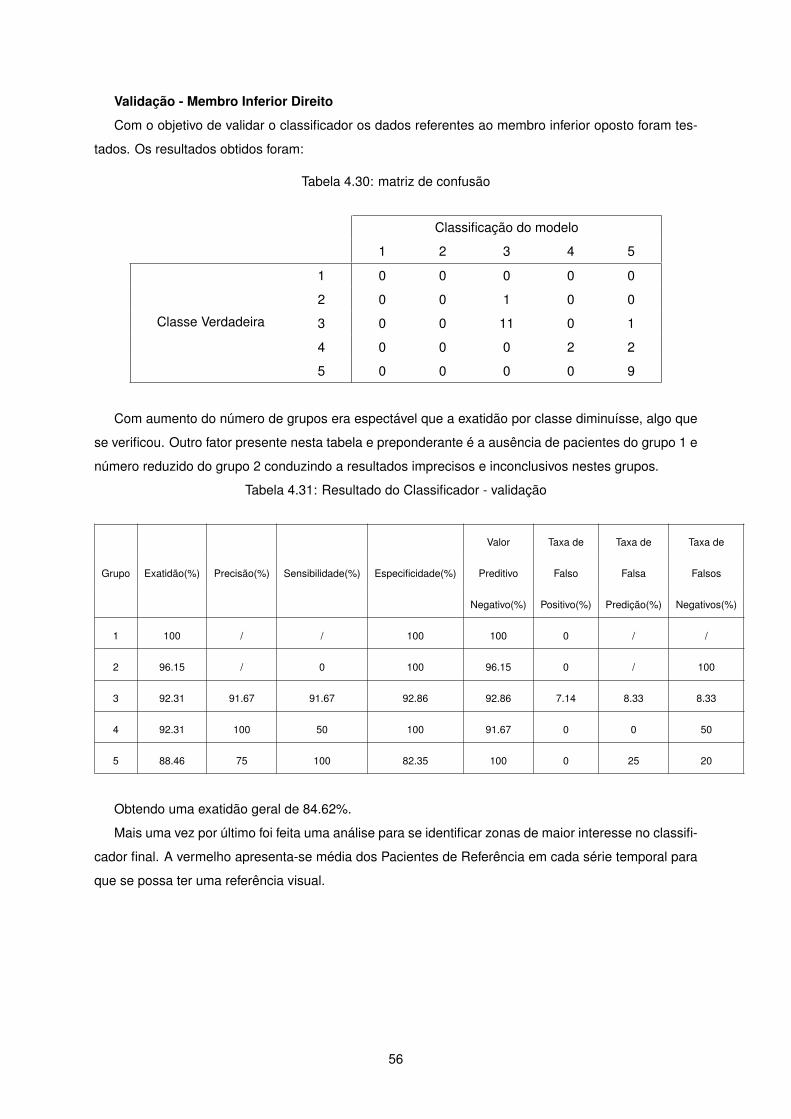
Validação - Membro Inferior Direito
Com o objetivo de validar o classificador os dados referentes ao membro inferior oposto foram tes-
tados. Os resultados obtidos foram:
Tabela 4.30: matriz de confusão
Classificação do modelo
1 2 3 4 5
Classe Verdadeira
1 0 0 0 0 0
2 0 0 1 0 0
3 0 0 11 0 1
4 0 0 0 2 2
5 0 0 0 0 9
Com aumento do número de grupos era espectável que a exatidão por classe diminuísse, algo que
se verificou. Outro fator presente nesta tabela e preponderante é a ausência de pacientes do grupo 1 e
número reduzido do grupo 2 conduzindo a resultados imprecisos e inconclusivos nestes grupos.
Tabela 4.31: Resultado do Classificador - validação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 100 / / 100 100 0 / /
2 96.15 / 0 100 96.15 0 / 100
3 92.31 91.67 91.67 92.86 92.86 7.14 8.33 8.33
4 92.31 100 50 100 91.67 0 0 50
5 88.46 75 100 82.35 100 0 25 20
Obtendo uma exatidão geral de 84.62%.
Mais uma vez por último foi feita uma análise para se identificar zonas de maior interesse no classifi-
cador final. A vermelho apresenta-se média dos Pacientes de Referência em cada série temporal para
que se possa ter uma referência visual.
56
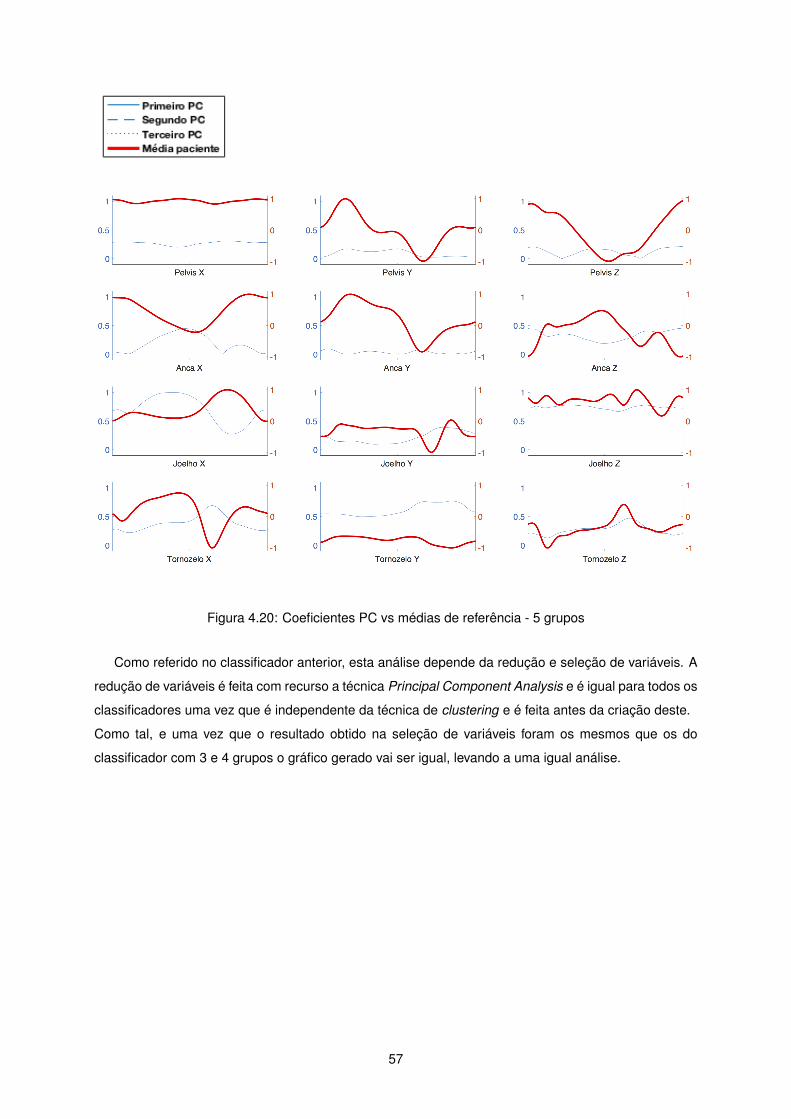
Figura 4.20: Coeficientes PC vs médias de referência - 5 grupos
Como referido no classificador anterior, esta análise depende da redução e seleção de variáveis. A
redução de variáveis é feita com recurso a técnica Principal Component Analysis e é igual para todos os
classificadores uma vez que é independente da técnica de clustering e é feita antes da criação deste.
Como tal, e uma vez que o resultado obtido na seleção de variáveis foram os mesmos que os do
classificador com 3 e 4 grupos o gráfico gerado vai ser igual, levando a uma igual análise.
57

4.2.6 Síntese de Resultados
A Tabela ?? que se segue resume os resultados obtidos permitindo uma comparação mais fácil destes.
Para efeitos de comparação apenas se considerou as exatidões relativas ao classificador, para que esta
análise se torna-se fácil e intuitiva.
Tabela 4.32: Resultados - Síntese
Exatidão
Classificador Não supervisonado Classificador supervisonadoCriação Validação Criação Validação
3 Grupos 79.62% 84.62% 96.15% 92.31%4 Grupos 79.62% 69.23% 100% 84.62%5 Grupos 73.10% 69.23% 100% 84.62%
Facilmente se constata a importância da seleção da variáveis na performance do classificador. Em
todos os casos apresentou uma melhoria notável.
4.3 Validação
Para perceber a aplicabilidade e enquadramento dos resultados foi feita uma comparação qualitativa
entre as classificações obtidas e demonstrados anteriormente, através de clustering, e os resultados
do estudo levado a cabo pela Rodda [? ]. Este estudo foi feito apenas com dados do plano sagital,
para possibilitar esta comparação foram retirados apenas os segmentos dos ciclos de marcha de cada
paciente correspondentes a este plano, apesar disto os classificadores criados tem em conta os dados
dos três planos. Como mencionado no Capítulo 1, este estudo é considerado o benchmark para a
tipificação da diplegia espástica tornando válida esta comparação.
A Figura ?? foi retirado do artigo [? ] e ilustra os diferentes comportamentos por diferente segmento de
cada grupo.
58
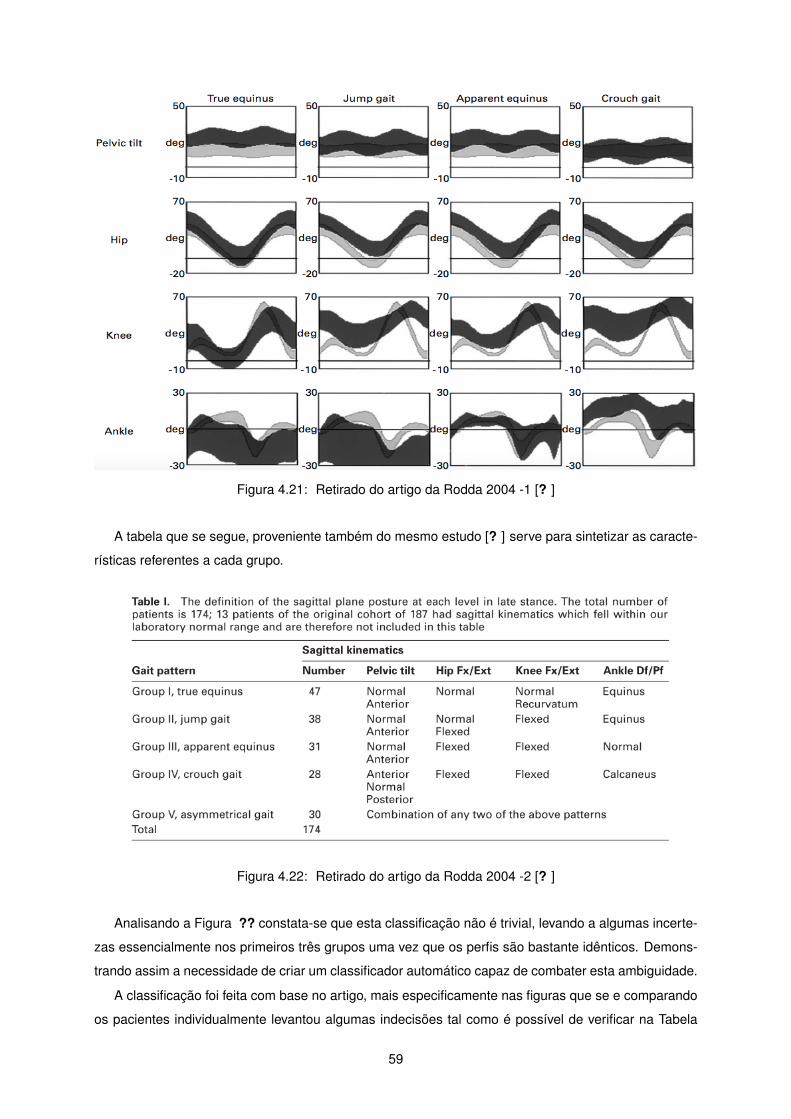
Figura 4.21: Retirado do artigo da Rodda 2004 -1 [? ]
A tabela que se segue, proveniente também do mesmo estudo [? ] serve para sintetizar as caracte-
rísticas referentes a cada grupo.
Figura 4.22: Retirado do artigo da Rodda 2004 -2 [? ]
Analisando a Figura ?? constata-se que esta classificação não é trivial, levando a algumas incerte-
zas essencialmente nos primeiros três grupos uma vez que os perfis são bastante idênticos. Demons-
trando assim a necessidade de criar um classificador automático capaz de combater esta ambiguidade.
A classificação foi feita com base no artigo, mais especificamente nas figuras que se e comparando
os pacientes individualmente levantou algumas indecisões tal como é possível de verificar na Tabela
59
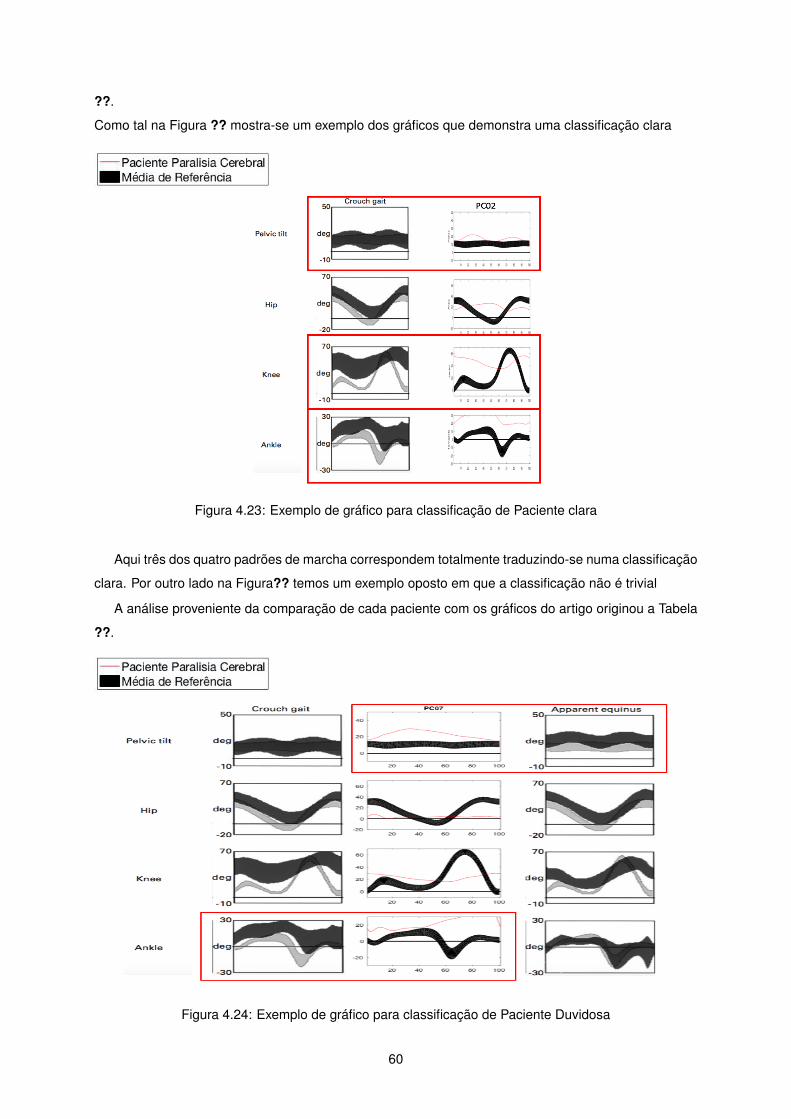
??.
Como tal na Figura ?? mostra-se um exemplo dos gráficos que demonstra uma classificação clara
Figura 4.23: Exemplo de gráfico para classificação de Paciente clara
Aqui três dos quatro padrões de marcha correspondem totalmente traduzindo-se numa classificação
clara. Por outro lado na Figura?? temos um exemplo oposto em que a classificação não é trivial
A análise proveniente da comparação de cada paciente com os gráficos do artigo originou a Tabela
??.
Figura 4.24: Exemplo de gráfico para classificação de Paciente Duvidosa
60

Constata-se pela anca pertencia Apparent Equinus e pelo tornozelo apresenta um padrão de Crouch
Gait. Enquanto que nas restantes segmentos poderia pertencer em qualquer um dos lados. Este é
apenas um exemplo, e foram pacientes como este que levaram a classificações como pertencente a
um de dois grupos.
Tabela 4.33: Classificação baseada no artigo [? ]
Membro Inferior Esquerdo Membro Inferior Direito
ID Grupo ID GrupoPC02 Crouch Gait PC02 Crouch GaitPC03 Crouch Gait PC03 Crouch GaitPC04 Apparent Equinus PC04 Crouch GaitPC05 Crouch Gait PC05 Crouch GaitPC06 Jump Gait/Crouch Gait PC06 Crouch GaitPC07 True Equinus/Crouch Gait PC07 Jump GaitPC08 Jump Gait/Crouch Gait PC08 Jump GaitPC09 True Equinus/Apparent Equinus PC09 Apparent Equinus*PC10 True Equinus/Crouch Gait PC10 Crouch Gait/Apparent EquinusPC11 Crouch Gait PC11 Crouch GaitPC12 True Equinus/Apparent Equinus PC12 Apparent Equinus*PC13 Apparent Equinus PC13 Crouch Gait/ Apparent EquinusPC14 True Equinus* PC14 True EquinusPC16 True Equinus* PC16 True EquinusPC17 Apparent Equinus* PC17 Crouch Gait/Apparent Equinus*PC18 True Equinus PC18 True EquinusPC19 True Equinus/Apparent Equinus PC19 True EquinusPC20 Apparent Equinus PC20 Jump GaitPC21 Apparent Equinus PC21 Crouch Gait/ ApparentEquinus*PC22 Apparent Equinus PC22 True Equinus/ Jump GaitPC23 True Equinus PC23 True Equinus/ Jump GaitPC24 Crouch Gait PC24 Crouch GaitPC26 True Equinus PC26 Jump Gait/True EquinusPC28 True Equinus PC28 True EquinusPC29 Apparent Equinus PC29 Crouch GaitPC30 Jump Gait/ Crouch Gait PC30 Crouch Gait
As classificações mais dúbias referentes a Tabela ?? encontram-se assinaladas com asterisco ou
em caso de poder estar entre dois grupos a classificação apresenta as duas hipóteses.
61
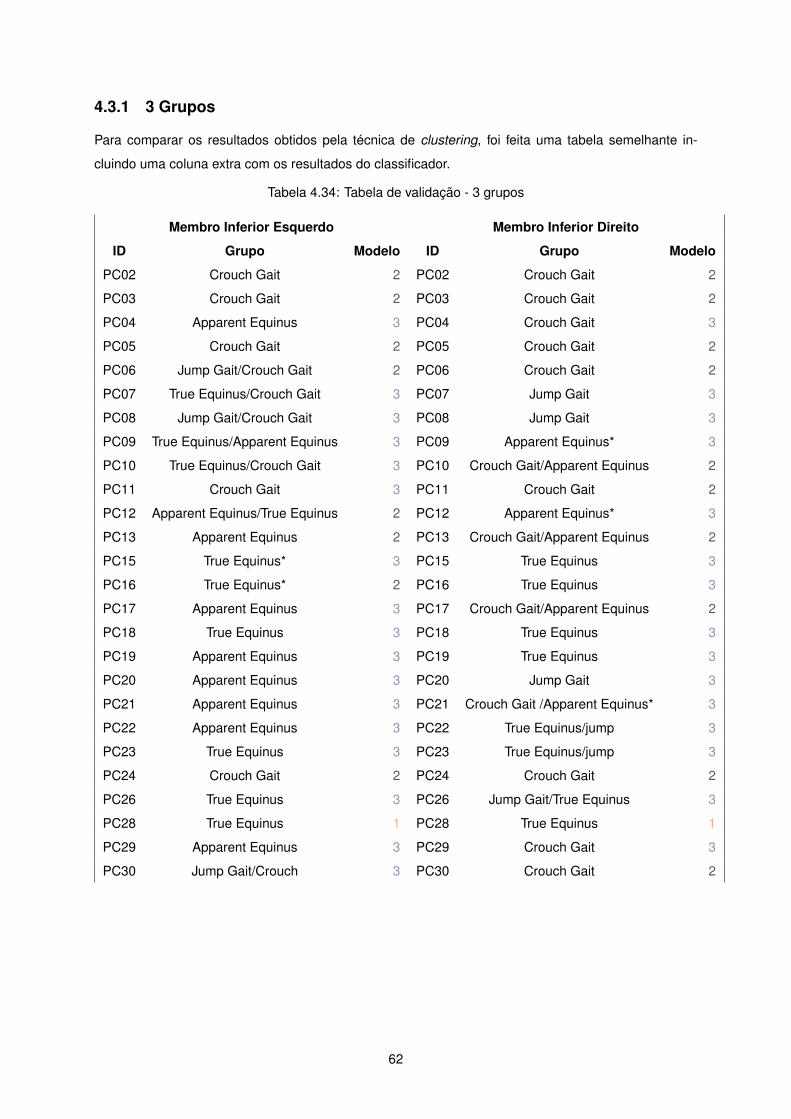
4.3.1 3 Grupos
Para comparar os resultados obtidos pela técnica de clustering, foi feita uma tabela semelhante in-
cluindo uma coluna extra com os resultados do classificador.
Tabela 4.34: Tabela de validação - 3 grupos
Membro Inferior Esquerdo Membro Inferior Direito
ID Grupo Modelo ID Grupo Modelo
PC02 Crouch Gait 2 PC02 Crouch Gait 2
PC03 Crouch Gait 2 PC03 Crouch Gait 2
PC04 Apparent Equinus 3 PC04 Crouch Gait 3
PC05 Crouch Gait 2 PC05 Crouch Gait 2
PC06 Jump Gait/Crouch Gait 2 PC06 Crouch Gait 2
PC07 True Equinus/Crouch Gait 3 PC07 Jump Gait 3
PC08 Jump Gait/Crouch Gait 3 PC08 Jump Gait 3
PC09 True Equinus/Apparent Equinus 3 PC09 Apparent Equinus* 3
PC10 True Equinus/Crouch Gait 3 PC10 Crouch Gait/Apparent Equinus 2
PC11 Crouch Gait 3 PC11 Crouch Gait 2
PC12 Apparent Equinus/True Equinus 2 PC12 Apparent Equinus* 3
PC13 Apparent Equinus 2 PC13 Crouch Gait/Apparent Equinus 2
PC15 True Equinus* 3 PC15 True Equinus 3
PC16 True Equinus* 2 PC16 True Equinus 3
PC17 Apparent Equinus 3 PC17 Crouch Gait/Apparent Equinus 2
PC18 True Equinus 3 PC18 True Equinus 3
PC19 Apparent Equinus 3 PC19 True Equinus 3
PC20 Apparent Equinus 3 PC20 Jump Gait 3
PC21 Apparent Equinus 3 PC21 Crouch Gait /Apparent Equinus* 3
PC22 Apparent Equinus 3 PC22 True Equinus/jump 3
PC23 True Equinus 3 PC23 True Equinus/jump 3
PC24 Crouch Gait 2 PC24 Crouch Gait 2
PC26 True Equinus 3 PC26 Jump Gait/True Equinus 3
PC28 True Equinus 1 PC28 True Equinus 1
PC29 Apparent Equinus 3 PC29 Crouch Gait 3
PC30 Jump Gait/Crouch 3 PC30 Crouch Gait 2
62

Foi analisada o número de vezes que cada grupo era classificado no mesmo grupo pelo classificador
para a criação, e o seguinte gráfico foi obtido
Figura 4.25: Classificação por Grupo - 3 clusters
Pelo gráfico constata-se que o grupo um só tem um paciente, não definindo nenhuma classe em
específico. Por outro lado, a conclusão mais importante a que este gráfico conduz é o facto de haver
dois conjuntos distintos o Crouch Gait classificado como 2, dos restantes grupos classificados como
3. Esta diferença surge naturalmente, tendo em conta os perfis da Figura ??, percebe-se que a maior
diferença surge nestes dois grupos.
63
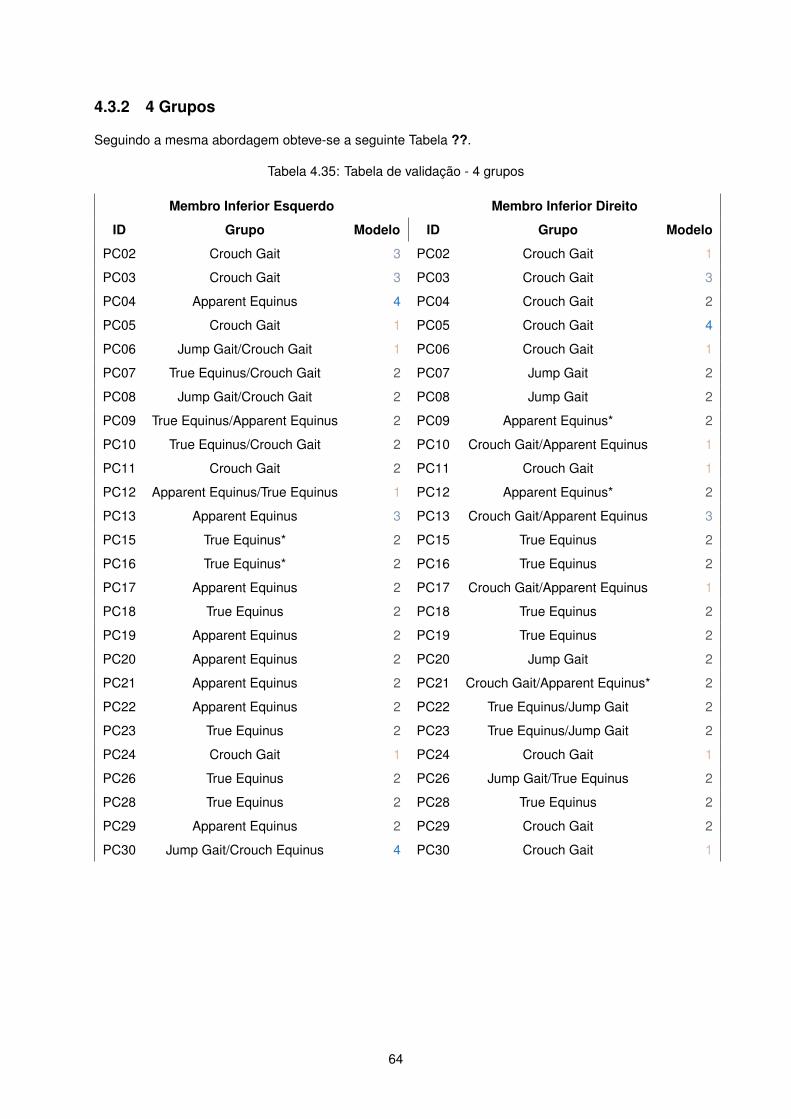
4.3.2 4 Grupos
Seguindo a mesma abordagem obteve-se a seguinte Tabela ??.
Tabela 4.35: Tabela de validação - 4 grupos
Membro Inferior Esquerdo Membro Inferior Direito
ID Grupo Modelo ID Grupo Modelo
PC02 Crouch Gait 3 PC02 Crouch Gait 1
PC03 Crouch Gait 3 PC03 Crouch Gait 3
PC04 Apparent Equinus 4 PC04 Crouch Gait 2
PC05 Crouch Gait 1 PC05 Crouch Gait 4
PC06 Jump Gait/Crouch Gait 1 PC06 Crouch Gait 1
PC07 True Equinus/Crouch Gait 2 PC07 Jump Gait 2
PC08 Jump Gait/Crouch Gait 2 PC08 Jump Gait 2
PC09 True Equinus/Apparent Equinus 2 PC09 Apparent Equinus* 2
PC10 True Equinus/Crouch Gait 2 PC10 Crouch Gait/Apparent Equinus 1
PC11 Crouch Gait 2 PC11 Crouch Gait 1
PC12 Apparent Equinus/True Equinus 1 PC12 Apparent Equinus* 2
PC13 Apparent Equinus 3 PC13 Crouch Gait/Apparent Equinus 3
PC15 True Equinus* 2 PC15 True Equinus 2
PC16 True Equinus* 2 PC16 True Equinus 2
PC17 Apparent Equinus 2 PC17 Crouch Gait/Apparent Equinus 1
PC18 True Equinus 2 PC18 True Equinus 2
PC19 Apparent Equinus 2 PC19 True Equinus 2
PC20 Apparent Equinus 2 PC20 Jump Gait 2
PC21 Apparent Equinus 2 PC21 Crouch Gait/Apparent Equinus* 2
PC22 Apparent Equinus 2 PC22 True Equinus/Jump Gait 2
PC23 True Equinus 2 PC23 True Equinus/Jump Gait 2
PC24 Crouch Gait 1 PC24 Crouch Gait 1
PC26 True Equinus 2 PC26 Jump Gait/True Equinus 2
PC28 True Equinus 2 PC28 True Equinus 2
PC29 Apparent Equinus 2 PC29 Crouch Gait 2
PC30 Jump Gait/Crouch Equinus 4 PC30 Crouch Gait 1
64

Seguiu-se a mesma metodologia de análise, originando o Gráfico ??.
Figura 4.26: Classificação por Grupo - 4 clusters
Através do gráfico e da classificação percebe-se que os grupos 3 e 4 têm baixa representatividade,
isto pode ser explicado por pacientes com padrões intermédios que não se enquadram em nenhum dos
padrões standart. Mais uma vez existe uma separação entre Crouch Gait dos restantes, pelas razões
já mencionadas.
65
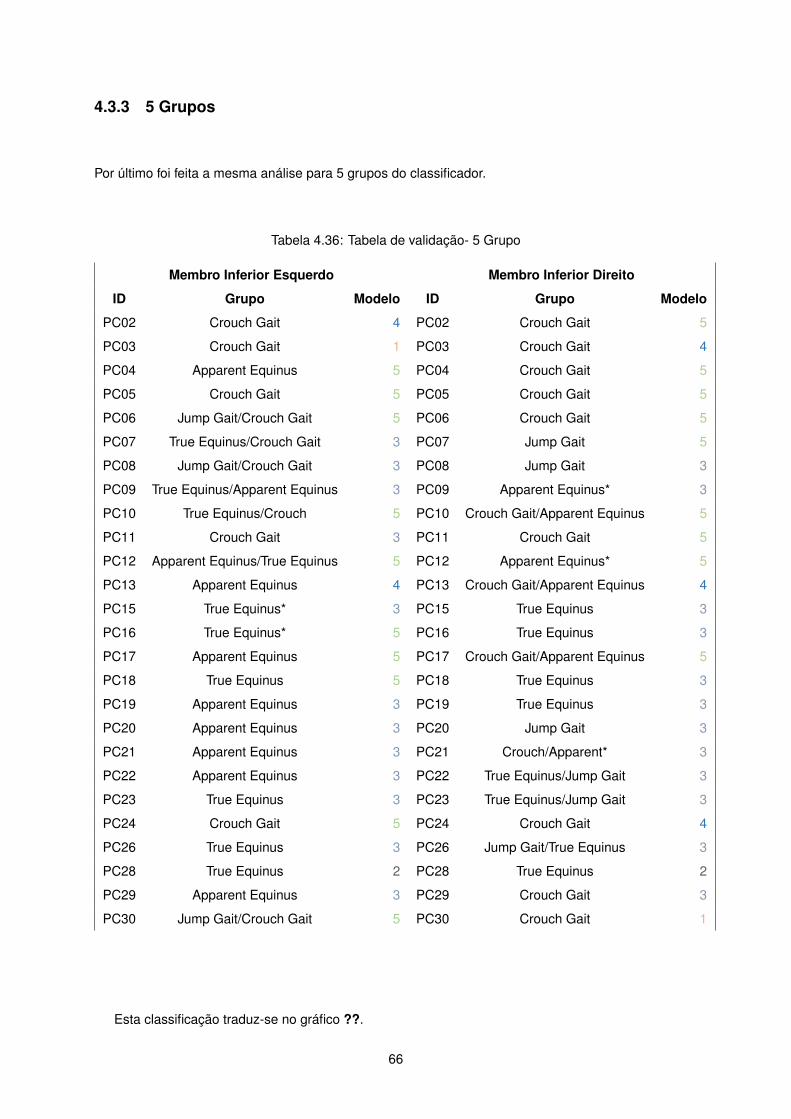
4.3.3 5 Grupos
Por último foi feita a mesma análise para 5 grupos do classificador.
Tabela 4.36: Tabela de validação- 5 Grupo
Membro Inferior Esquerdo Membro Inferior Direito
ID Grupo Modelo ID Grupo Modelo
PC02 Crouch Gait 4 PC02 Crouch Gait 5
PC03 Crouch Gait 1 PC03 Crouch Gait 4
PC04 Apparent Equinus 5 PC04 Crouch Gait 5
PC05 Crouch Gait 5 PC05 Crouch Gait 5
PC06 Jump Gait/Crouch Gait 5 PC06 Crouch Gait 5
PC07 True Equinus/Crouch Gait 3 PC07 Jump Gait 5
PC08 Jump Gait/Crouch Gait 3 PC08 Jump Gait 3
PC09 True Equinus/Apparent Equinus 3 PC09 Apparent Equinus* 3
PC10 True Equinus/Crouch 5 PC10 Crouch Gait/Apparent Equinus 5
PC11 Crouch Gait 3 PC11 Crouch Gait 5
PC12 Apparent Equinus/True Equinus 5 PC12 Apparent Equinus* 5
PC13 Apparent Equinus 4 PC13 Crouch Gait/Apparent Equinus 4
PC15 True Equinus* 3 PC15 True Equinus 3
PC16 True Equinus* 5 PC16 True Equinus 3
PC17 Apparent Equinus 5 PC17 Crouch Gait/Apparent Equinus 5
PC18 True Equinus 5 PC18 True Equinus 3
PC19 Apparent Equinus 3 PC19 True Equinus 3
PC20 Apparent Equinus 3 PC20 Jump Gait 3
PC21 Apparent Equinus 3 PC21 Crouch/Apparent* 3
PC22 Apparent Equinus 3 PC22 True Equinus/Jump Gait 3
PC23 True Equinus 3 PC23 True Equinus/Jump Gait 3
PC24 Crouch Gait 5 PC24 Crouch Gait 4
PC26 True Equinus 3 PC26 Jump Gait/True Equinus 3
PC28 True Equinus 2 PC28 True Equinus 2
PC29 Apparent Equinus 3 PC29 Crouch Gait 3
PC30 Jump Gait/Crouch Gait 5 PC30 Crouch Gait 1
Esta classificação traduz-se no gráfico ??.
66
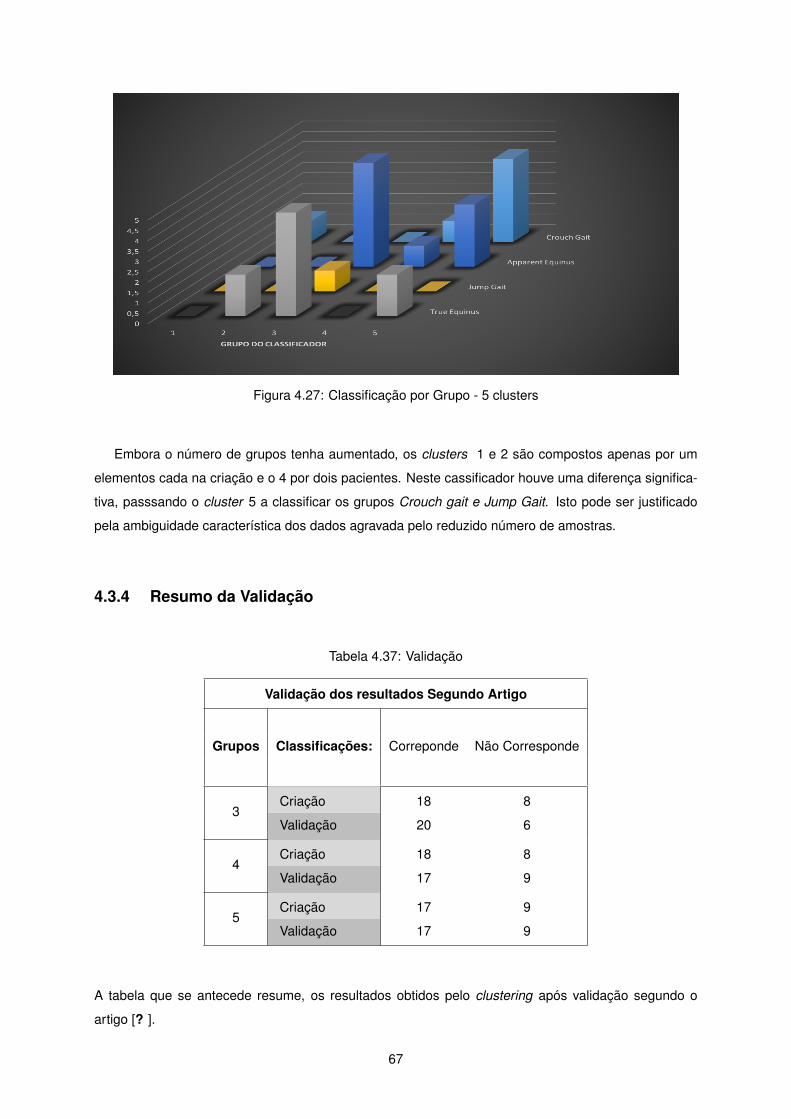
Figura 4.27: Classificação por Grupo - 5 clusters
Embora o número de grupos tenha aumentado, os clusters 1 e 2 são compostos apenas por um
elementos cada na criação e o 4 por dois pacientes. Neste cassificador houve uma diferença significa-
tiva, passsando o cluster 5 a classificar os grupos Crouch gait e Jump Gait. Isto pode ser justificado
pela ambiguidade característica dos dados agravada pelo reduzido número de amostras.
4.3.4 Resumo da Validação
Tabela 4.37: Validação
Validação dos resultados Segundo Artigo
Grupos Classificações: Correponde Não Corresponde
3Criação 18 8
Validação 20 6
4Criação 18 8
Validação 17 9
5Criação 17 9
Validação 17 9
A tabela que se antecede resume, os resultados obtidos pelo clustering após validação segundo o
artigo [? ].
67
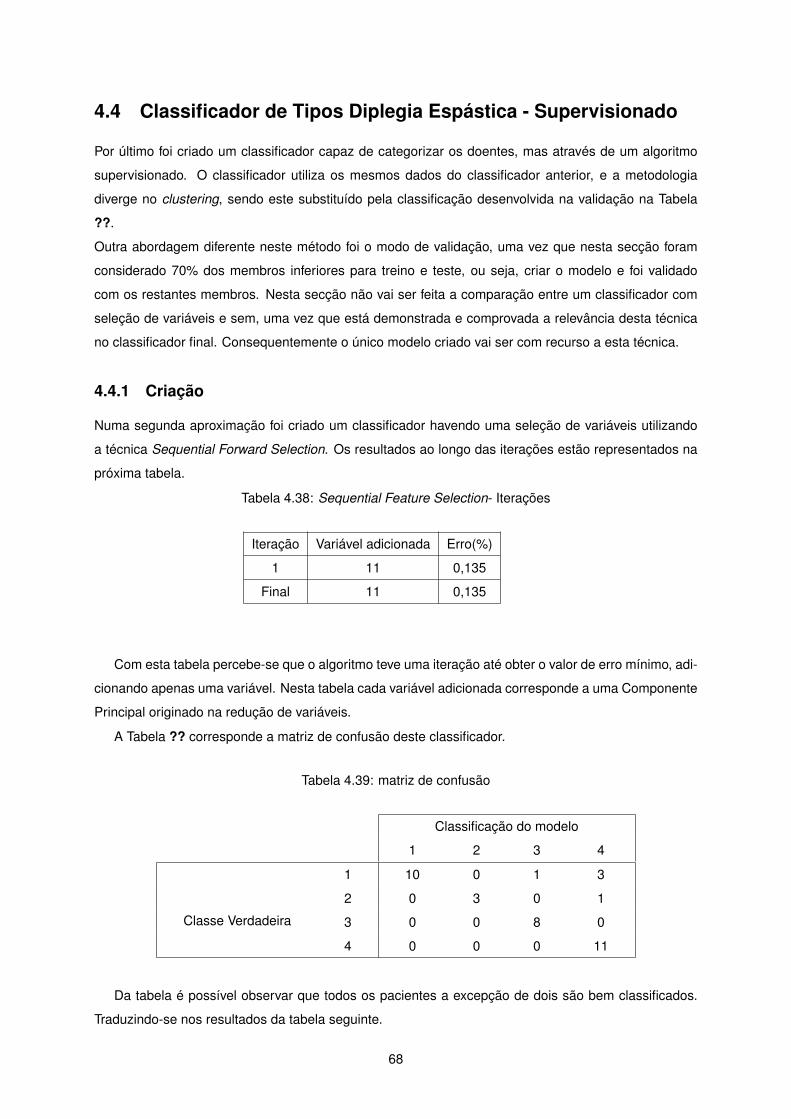
4.4 Classificador de Tipos Diplegia Espástica - Supervisionado
Por último foi criado um classificador capaz de categorizar os doentes, mas através de um algoritmo
supervisionado. O classificador utiliza os mesmos dados do classificador anterior, e a metodologia
diverge no clustering, sendo este substituído pela classificação desenvolvida na validação na Tabela
??.
Outra abordagem diferente neste método foi o modo de validação, uma vez que nesta secção foram
considerado 70% dos membros inferiores para treino e teste, ou seja, criar o modelo e foi validado
com os restantes membros. Nesta secção não vai ser feita a comparação entre um classificador com
seleção de variáveis e sem, uma vez que está demonstrada e comprovada a relevância desta técnica
no classificador final. Consequentemente o único modelo criado vai ser com recurso a esta técnica.
4.4.1 Criação
Numa segunda aproximação foi criado um classificador havendo uma seleção de variáveis utilizando
a técnica Sequential Forward Selection. Os resultados ao longo das iterações estão representados na
próxima tabela.
Tabela 4.38: Sequential Feature Selection- Iterações
Iteração Variável adicionada Erro(%)
1 11 0,135
Final 11 0,135
Com esta tabela percebe-se que o algoritmo teve uma iteração até obter o valor de erro mínimo, adi-
cionando apenas uma variável. Nesta tabela cada variável adicionada corresponde a uma Componente
Principal originado na redução de variáveis.
A Tabela ?? corresponde a matriz de confusão deste classificador.
Tabela 4.39: matriz de confusão
Classificação do modelo
1 2 3 4
Classe Verdadeira
1 10 0 1 3
2 0 3 0 1
3 0 0 8 0
4 0 0 0 11
Da tabela é possível observar que todos os pacientes a excepção de dois são bem classificados.
Traduzindo-se nos resultados da tabela seguinte.
68
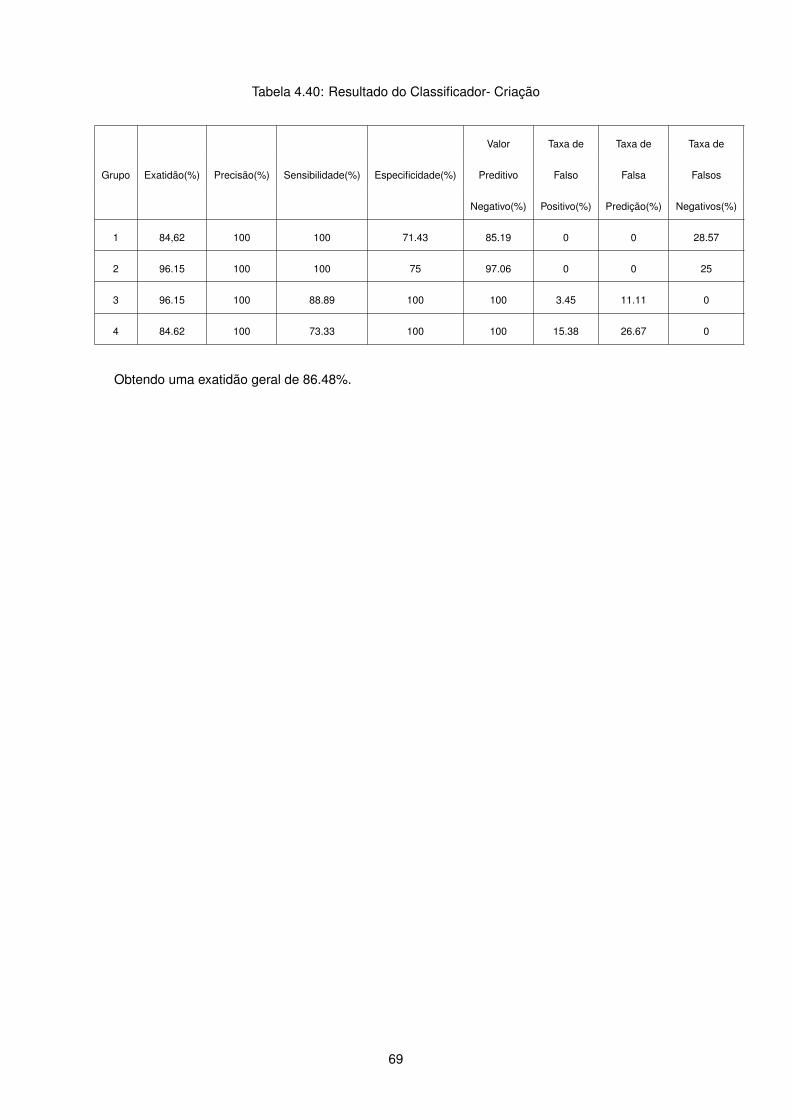
Tabela 4.40: Resultado do Classificador- Criação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 84,62 100 100 71.43 85.19 0 0 28.57
2 96.15 100 100 75 97.06 0 0 25
3 96.15 100 88.89 100 100 3.45 11.11 0
4 84.62 100 73.33 100 100 15.38 26.67 0
Obtendo uma exatidão geral de 86.48%.
69

4.4.2 Validação- Membro Inferior Direito
Os dados dos membros não considerados na criação foram mais tarde testados com o objetivo de
validar o classificador obtendo-se a seguinte matriz de confusão presente na Tabela ??.
Tabela 4.41: matriz de confusão supervionada
Classificação do modelo
1 2 3 4
Classe Verdadeira
1 0 0 0 0
2 0 0 1 1
3 0 0 2 2
4 0 0 1 8
Traduzindo-se na tabela
Tabela 4.42: Resultado do Classificador supervisionado- validação
Valor Taxa de Taxa de Taxa de
Grupo Exatidão(%) Precisão(%) Sensibilidade(%) Especificidade(%) Preditivo Falso Falsa Falsos
Negativo(%) Positivo(%) Predição(%) Negativos(%)
1 100 / / 100 100 0 / /
2 92.31 / 0 100 86.67 0 / 100
3 84.62 50 50 81.82 81.82 18.18 50 50
4 84.62 72.73 88.89 50 75 50 27.27 11.11
Obtendo uma exatidão geral de 66.67%.
70
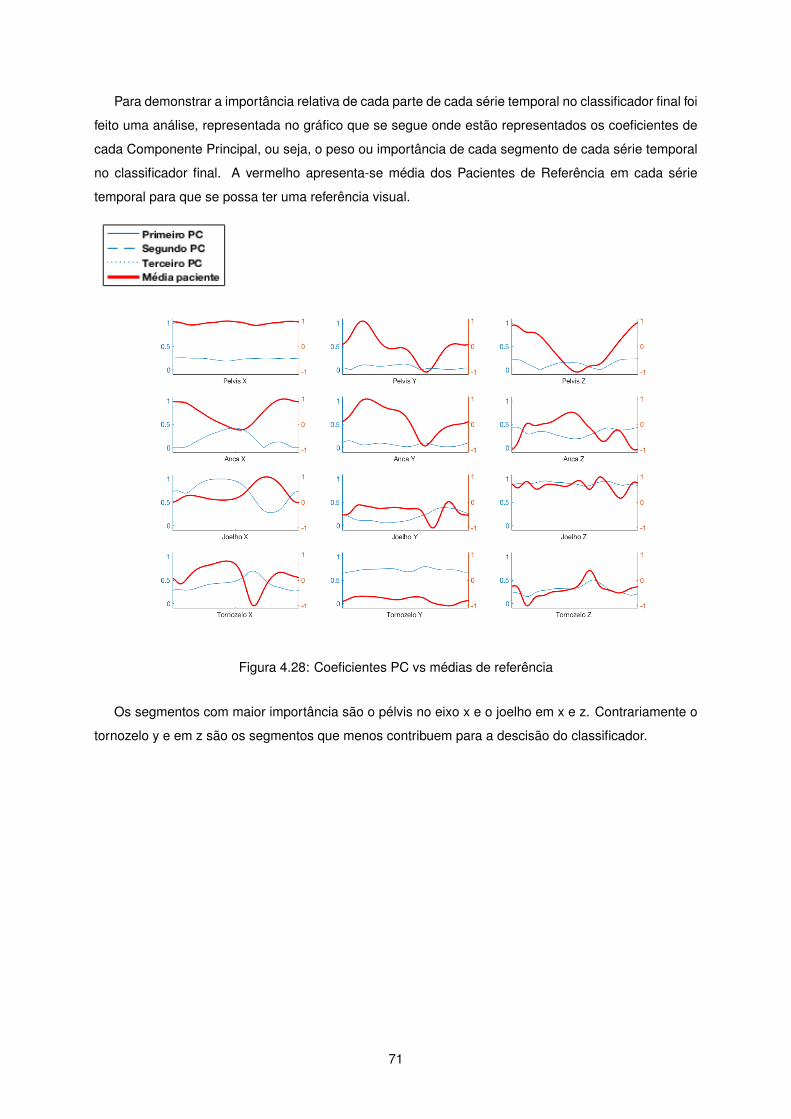
Para demonstrar a importância relativa de cada parte de cada série temporal no classificador final foi
feito uma análise, representada no gráfico que se segue onde estão representados os coeficientes de
cada Componente Principal, ou seja, o peso ou importância de cada segmento de cada série temporal
no classificador final. A vermelho apresenta-se média dos Pacientes de Referência em cada série
temporal para que se possa ter uma referência visual.
Figura 4.28: Coeficientes PC vs médias de referência
Os segmentos com maior importância são o pélvis no eixo x e o joelho em x e z. Contrariamente o
tornozelo y e em z são os segmentos que menos contribuem para a descisão do classificador.
71

72

Capítulo 5
Conclusão
Após conclusão desta dissertação é imprescindível salientar alguns itens. Destes o primeiro a referir
é a importância da seleção de variáveis, que em todos os casos estudados melhorou notoriamente
os resultados. Não esquecendo o papel fundamental desempenhado pela redução de variáveis, que
tornou possível esta análise, uma vez que seria impraticável considerar todos as variáveis de cada
paciente. Ainda tornando possível identificar os pontos do ciclo de maior interesse.
No que toca ao dados disponíveis, é importante fazer uma análise cuidadosa, uma vez que toda a tese
assenta nestes. A primeira observação que se pode fazer, é o número de dados limitado.
Ao trabalhar com classificadores não supervisionados, torna-se imprescindível uma base de dados
mais extensa, para que os padrões encontrados sejam fidedignos.
Por fim, quero salientar a complexidade associada ao problema e aos dados que vem evidenciada na
performance obtida na validação do classificador supervisionado. Para este tipo de técnica, caso os
dados e os problemas não fossem bastante complexos os valores de performance expectados são
bastante elevados. Por fim, quanto ao número de grupos não é fácil precisar, pois existe alguma
ambiguidade nos índices de validação, e a amostra de pacientes não se revelou grande o suficiente
para que todos os grupos fossem representados de forma significativa.
Embora todas as dificuldade sentidas é importante mencionar a possibilidade de criar uma ferramenta
muito importante no auxílio médico, reduzindo o risco de erro no diagnóstico.
5.1 Principais Contribuições
Com este trabalho foi possível chegar a um classificador automático que possibilita a distinção entre
indivíduos com marcha sem perturbações dos pacientes com diplegia espástica.
Foi possível estabelecer classificadores automáticos capazes de distinguir alguns padrões de marcha
em pacientes com diplegia espástica. Estes classificadores só foram possíveis de criar por via de um
método desenvolvido que pode ser aplicado a novas bases de dados e deste modo criar um classifica-
dor cada vez mais preparado para o caso real.
73

5.2 Trabalho Futuro
Num futuro trabalho seria essencial abordar a temática recorrendo aos dados cinéticos, tentando per-
ceber se é possível combinar as informações obtidas de modo a criar um classificador mais robusto.
Com este trabalho possibilita-se uma nova abordagem a este problema que necessita de ser aplicada
a bases de dados mais extensas e transformado num programa mais intuitivo para facilitar a utilização
dos médicos, sendo muito útil na seleção das possíveis intervenções cirúrgicas. Tornando se essen-
cial no auxílio ao diagnóstico por parte de médicos menos experientes É necessário ainda salientar a
importância de uma participação por parte médica ou de especialistas na área mais assídua para que
fosse feita a ponte entre a realidade médica e as técnicas aplicadas.
74

Bibliografia
[] A. Garg, N. Adhikari, H. McDonald, M. P. Rosas-Arellano, P. Devereaux, J. Beyene, J. Sam, and
R. B. Haynes. Effects of Computerized Clinical Decision. American Medical Association, 293(10):
1223–1238, 2005. doi: 10.1001/jama.293.10.1223.
[] P. Rosenbaum, N. Paneth, A. Leviton, M. Goldstein, M. Bax, D. Damiano, B. Dan, and B. Jacobsson.
A report: The definition and classification of cerebral palsy April 2006. Developmental Medicine
and Child Neurology, 49(SUPPL.109):8–14, 2007. ISSN 00121622. doi: 10.1111/j.1469-8749.
2007.tb12610.x.
[] APCL. APCL tipos mais comuns de paralisia cerebral, 2017. URL http://www.apcl.org.pt/.
[] J. M. Rodda, H. K. Graham, L. Carson, M. P. Galea, and R. Wolfe. Sagittal gait patterns in spas-
tic diplegia. The Journal of bone and joint surgery. British volume, 86(2):251–258, 2004. ISSN
0301620X. doi: 10.1302/0301-620X.86B2.13878.
[] A. M. Wong, S. R. Simon, and R. A. Olshen. Statistical analysis of gait patterns of persons with
cerebral palsy. Statistics in Medicine, 2(February):345–354, 1983.
[] M. J. O’Malley, M. F. Abel, D. L. Damiano, and C. L. Vaughan. Fuzzy clustering of children with
cerebral palsy based on temporal-distance gait parameters. IEEE transactions on rehabilitation
engineering : a publication of the IEEE Engineering in Medicine and Biology Society, 5(4):300–9,
1997. ISSN 1063-6528. doi: 10.1109/86.650282. URL http://www.ncbi.nlm.nih.gov/pubmed/
9422455.
[] O. Byrne, M. John, and O. Brien. Quantitative analysis and classification of gait patterns in cerebral
palsy using a three-dimensional motion analyzer. Journal of child neurology, 13(3):101–108, 1998.
[] B. Toro, C. J. Nester, and P. C. Farren. Cluster analysis for the extraction of sagittal gait patterns
in children with cerebral palsy. Gait and Posture, 25(2):157–165, 2007. ISSN 09666362. doi:
10.1016/j.gaitpost.2006.02.004.
[] A. Carriero, A. Zavatsky, J. Stebbins, T. Theologis, and S. J. Shefelbine. Determination of gait pat-
terns in children with spastic diplegic cerebral palsy using principal components. Gait and Posture,
29(1):71–75, 2009. ISSN 09666362. doi: 10.1016/j.gaitpost.2008.06.011.
75

[] F. Dalmolin, I. Saulo, T. Lemos, P. Filho, I. Andrieli, M. Cortes, I. Maurício, V. Brun, I. Carlos, R. Cau-
duro, I. João, and E. W. Schossler. Biomecânica óssea e ensaios biomecânicos -fundamentos
teóricos. Biomecânica óssea e ensaios biomecânicos -fundamentos teóricos Bone biomechanics
and biomechanics essays -theoretical foundations. Ciência Rural, 439439:1675–1682, 2013. ISSN
0103-8478. doi: 10.1590/S0103-84782013000900022.
[] R. M. Kay, S. Dennis, S. Rethlefsen, R. A. Reynolds, D. L. Skaggs, and V. T. Tolo. The effect
of preoperative gait analysis on orthopaedic decision making. Clinical orthopaedics and related
research, 372:217–222, 2000.
[] Jucielle Queiroz. planos e cortes 2, 2017. URL http://s3.amazonaws.com/magoo/
ABAAAfoJYAI-2.jpg. [Online; accessed May 2, 2017].
[] Fix Flat Feet. Anterior pelvic tilt, 2017. URL https://www.fixflatfeet.com/
anterior-pelvic-tilt/. [Online; accessed May 2, 2017].
[] S. P. Lloyd. Least Squares Quantization in PCM. IEEE Transactions on Information Theory, 28(2):
129–137, 1982. ISSN 15579654. doi: 10.1109/TIT.1982.1056489.
[] J.-S. R. Jang, C.-T. Sun, and E. Mizutani. Neuro-Fuzzy And Soft Computing Jang: a computational
approach to learning and machine intelligence, 1997.
[] Y. Liu, Z. Li, H. Xiong, X. Gao, and J. Wu. Understanding of intenal clustering validation measures.
IEEE Internatinal Conference on Data mining, pages 911–916, 2010. ISSN 1550-4786. doi: 10.
1109/ICDM.2010.35.
[] K. Pearson. On lines and planes of closest fit to systems of points in space. The London, Edinburgh,
and Dublin Philosophical Magazine and Journal of Science, 2(1):559–572, 1901. ISSN 1941-5982.
doi: 10.1080/14786440109462720. URL http://dx.doi.org/10.1080/14786440109462720.
[] Sebastian Raschka. Machine learning faq, 2017. URL https://sebastianraschka.com/faq/
docs/lda-vs-pca.html. [Online; accessed May 2, 2017].
[] A. W. Whitney. A direct method of nonparametric measurement selection. IEEE Trans. Comput.,
20(9):1100–1103, Sept. 1971. ISSN 0018-9340. doi: 10.1109/T-C.1971.223410. URL http://dx.
doi.org/10.1109/T-C.1971.223410.
[] C. Cortes and V. Vapnik. Support-Vector Networks. Machine Learning, 20(3):273–297, 1995. ISSN
15730565. doi: 10.1023/A:1022627411411.
[] Cairo Lúcio. Técnicas de redes neurais para o problema de reconhecimento de caracteres:
Um estudo comparativo, 2017. URL https://www.researchgate.net/figure/267918631_fig1_
Fig-1-O-hiperplano-otimo-separando-os-dados-com-a-maxima-margem-r-os. [Online; ac-
cessed May 2, 2017].
[] Xu Cui. Svm (support vector machine) with libsvm, 2017. URL http://www.alivelearn.net/?p=
912. [Online; accessed May 2, 2017].
76

[] analyticsvidhya. k-fold cross validation, 2017. URL https://www.analyticsvidhya.com/
wp-content/uploads/2015/05/kfolds.png. [Online; accessed May 2, 2017].
77

78

Apêndice A
Gráficos utilizados para classificação
Em anexo segue os gráficos utilizados para classificação de de pacientes segundo o artigo [? ]. Dados
referentes aos membros inferiores esquerdos.
Figura A.1: Classificação Membro Inferior esquerdo 1
79
Figura A.2: Classificação Membro Inferior esquerdo 2
Figura A.3: Classificação Membro Inferior esquerdo 3
80

Figura A.4: Classificação Membro Inferior esquerdo 4
81
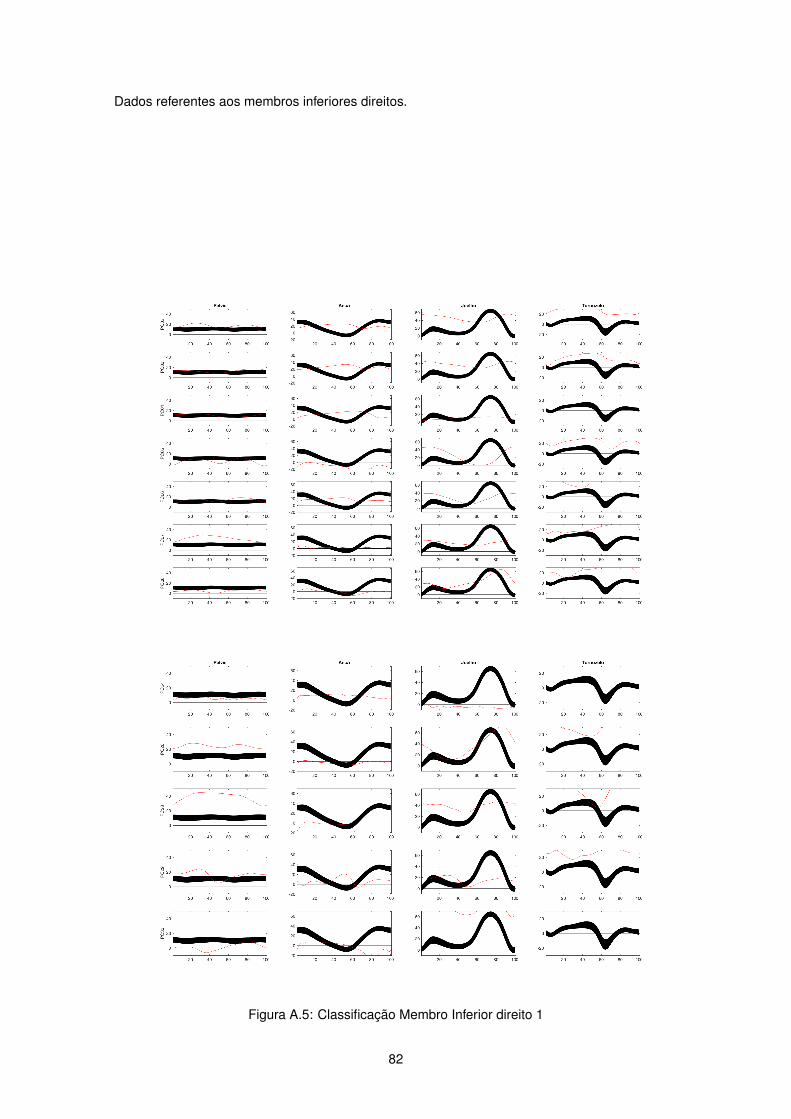
Dados referentes aos membros inferiores direitos.
Figura A.5: Classificação Membro Inferior direito 1
82
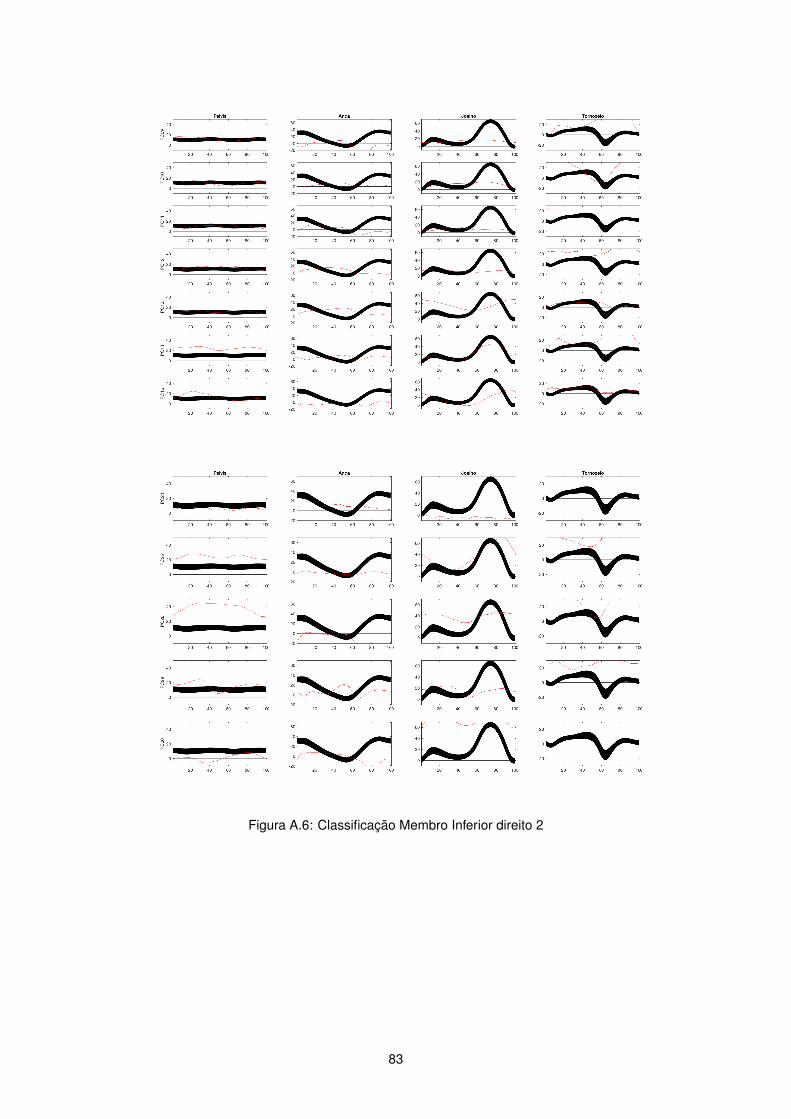
Figura A.6: Classificação Membro Inferior direito 2
83
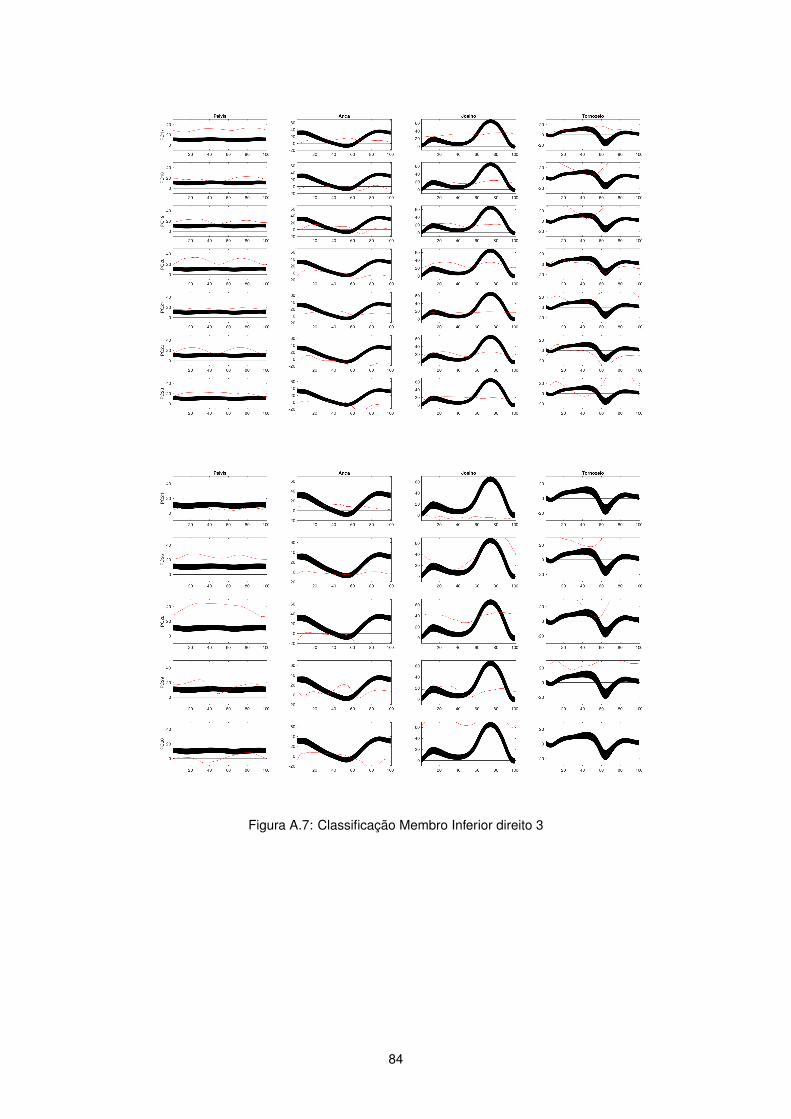
Figura A.7: Classificação Membro Inferior direito 3
84
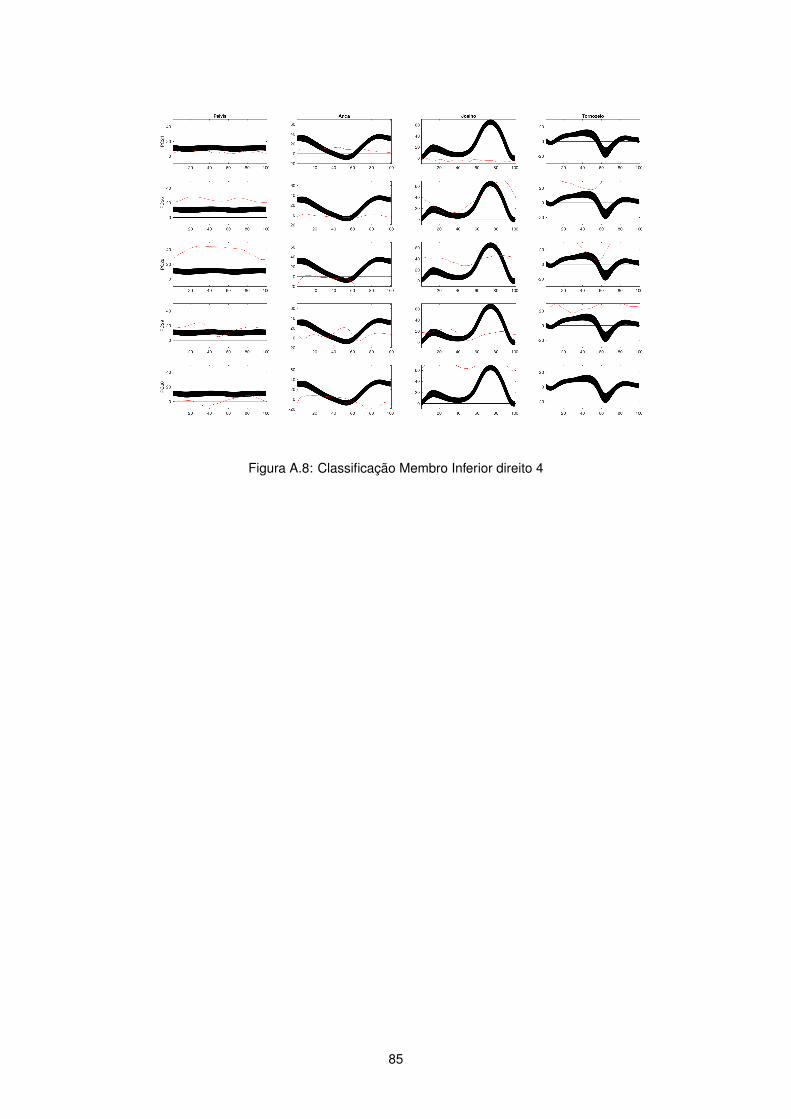
Figura A.8: Classificação Membro Inferior direito 4
85

86