banco de dados e inteligência empresarial
DESCRIPTION
Banco de dados e Inteligência empresarialTRANSCRIPT

( 4 )
Gestão do Conhecimento – Segurança e Gerenciamento de
Banco dos Dados


Caro (a) aluno (a)!
Esta unidade tem como objetivo proporcionar uma visão geral sobre banco de dados e algumas de suas carac-terísticas, como também apresentar as definições básicas dos sistemas gerenciadores de banco de dados. A unida-de contempla também uma introdução aos conceitos de data warehouse e mineração de dados como elemento do processo de descoberta de conhecimento em banco de dados (KDD).
Gestão do conhecimento
Gerenciador de banco de dados
Bancode Dados
Modelagem
Sistemas
Data Warehouse
Mineração Dados

70
Ban
co d
e D
ados
eIn
telig
ênci
a E
mpr
esar
ial
Bancos de Dados (BD) e Sistemas Gerenciadores de Bancos de Dados (SGBD) são um componente essencial na sociedade moderna, a maioria de nós encontra diariamente diversas atividades que envolvem alguma interação com um banco de dados. Por exemplo, quando vamos a um banco efe-tuar um pagamento, quando fazemos uma reserva em um hotel ou em uma companhia aérea, é certo que essas ativida-des envolverão um sistema que estará acessando um banco de dados. Até mesmo a compra de algum produto em super-mercado atualiza automaticamente o banco de dados que mantêm o controle de estoque dos itens.
Conforme Elmasri (2010), os bancos de dados e sua tec-nologia têm um impacto importante sobre o uso crescente dos computadores. Considerando negócios, comércio eletrônico, engenharia, medicina entre tantas outras áreas de conheci-mento, é possível afirmar que os bancos de dados possuem influência crítica na operação dos mesmos.
Sabemos que um banco de dados é uma coleção de dados relacionados, representando algum aspecto do mundo real, representa uma coleção logicamente coerente de dados com algum significado inerente. São projetados e construídos para receber dados com uma finalidade específica.
Por outro lado, um sistema gerenciador de banco de dados é uma coleção de programas que permite ao usuário criar e manter um banco de dados. O sistema gerenciador de banco de dados é um conjunto de softwares de uso geral que facilita processo de definição, construção, manipulação e compartilhamento de banco de dados entre diversos usuá-rios e aplicações.

Ges
tão
do C
onhe
cim
ento
–Ba
nco
de D
ados
e G
eren
ciad
or d
e Ban
co d
e Dad
os
71
Software para processar consultas e aplicações
Programas de aplicação e consultas
Usuários e Programadores
Definição do Banco de Dados Armazenado (Metadados)
Banco de Dados Armazenado
Software para acessar dados armazenados
Sistema gerenciador de Banco de Dados
Sistema de Banco de dados
Acima é apresentado um modelo conceitual simplificado de um ambiente de sistema de banco de dados com seus elementos, adaptado de Elmasri (2010).
4.1
Elementos do Sistema de Banco de Dados
Definir um banco de dados envolve especificar os tipos, estruturas e restrições dos dados a serem armazena-dos, por exemplo:

72
Ban
co d
e D
ados
eIn
telig
ênci
a E
mpr
esar
ial
• Metadado: consiste na definição ou informação descritiva do banco de dados também é armazenada pelo sistema gerenciador em forma de catálogo ou dicionário.
• Construção: consiste no processo de armazenar os dados em algum meio controlado pelo sistema gerenciador.
• Manipulação: consiste na inclusão de funções como consulta ao banco de dados para recuperar dados espe-cíficos e atualizações do banco de dados.
• Compartilhamento: consiste na definição das per-missões para que diversos usuários e programadores acessem o banco de dados de forma simultânea.
Um programa de aplicação acessa o banco de dados ao enviar consultas ou solicitações de dados ao sistema geren-ciador, uma consulta normalmente resulta na recuperação de alguns dados, uma consulta, também denominada de transa-ção, pode fazer que alguns dados sejam lidos e outros, grava-dos no banco de dados.
Outras funções importantes fornecidas pelo sistema gerenciador de banco de dados incluem proteção do banco de dados e sua manutenção por um longo período.
A proteção inclui “proteção do sistema” contra defeitos ou falhas de hardware ou software e “proteção de segurança” contra acesso não autorizado ou malicioso.
Um banco de dados de grande porte pode ter um ciclo de vida de muitos anos, de modo que o sistema gerenciador precisa ser capaz de manter o sistema, permitindo que ela evolua à medida que os requisitos mudam com o tempo.

Ges
tão
do C
onhe
cim
ento
–Ba
nco
de D
ados
e G
eren
ciad
or d
e Ban
co d
e Dad
os
73
Observe:
O termo "Consulta" ou "Query" que originalmente significa uma pergunta ou uma pesquisa, é usado livremente para todos os tipos de interações com banco de dados, incluindo a modificação dos dados.
Observe:
- BD = Banco de Dados
- SBD = Sistema de Banco de Dados
- SGBD = Sistema Gerenciador de Banco de Dados
Podemos observar que um sistema de banco de dados – SBD – contem o banco de dados – BD – e o sistema gerencia-dor de banco de dados – SGBD.
4.2
Abordagem de Banco de Dados – Características
Diversas características distinguem a abordagem de banco de dados da abordagem muito mais antiga de progra-mação com arquivos.
Saiba Mais- Um arquivo é uma coleção de registros de dados que podem ou não estar ordenados.- Uma Aplicação é um programa de software que possui uma finalidade específica, por exemplo, calcular a nota total de um aluno.

74
Ban
co d
e D
ados
eIn
telig
ênci
a E
mpr
esar
ial
No processamento de arquivo tradicional, cada usu-ário define e implementa os arquivos necessários para uma aplicação de software específica como parte da programação da aplicação.
Para explicar essa característica Elmasri (2010) utili-za como exemplo uma aplicação de sistema escolar, nele um usuário, por exemplo, do departamento de registro acadêmi-co, pode manter arquivo sobre alunos e suas notas.
Os programas para imprimir o histórico escolar de um aluno e inserir novas notas são implementados como parte da aplicação.
Um segundo usuário, por exemplo, o departamento de finanças, pode registrar as mensalidades e os seus pagamen-tos. Observe que embora ambos os usuários estejam interes-sados em dados sobre alunos, cada um deles mantém arqui-vos separados.
Essa redundância na definição e no armazenamento de dados resulta em desperdício de espaço e em esforços redun-dantes para manter dados comuns.
De forma diferente, na abordagem de banco de dados, um único repositório mantém dados que são definidos uma vez e depois acessados por vários usuários. Nos sistemas de arquivos, cada aplicação é livre para nomear os elementos de dados independentemente.
Ao contrário, em um banco de dados, os nomes ou rótulos de dados são definidos uma única vez, e usados repe-tidamente por consultas, transações e aplicações.
As principais características da abordagem de banco de dados versus a abordagem de processamento de arquivo são as seguintes:

Ges
tão
do C
onhe
cim
ento
–Ba
nco
de D
ados
e G
eren
ciad
or d
e Ban
co d
e Dad
os
75
• Natureza de autodescrição de um sistema de banco de dados.
• Isolamento entre programas e dados e abstração de dados.
• Suporte de múltiplas visões dos dados.
• Compartilhamento de dados e processamento de transações multiusuário.
natureza de autodescrição de um sistema de banco de dados
Uma característica fundamental da abordagem de banco de dados é que o seu sistema contém não apenas o próprio banco de dados, mas também uma definição ou des-crição completa de sua estrutura e restrições. A informação armazenada no catálogo é chamada de metadados e descreve a estrutura do banco de dados.
Isolamento entre programas e dados e abs-tração de dados
Diferentemente dos sistemas de arquivos, em que os arquivos de dados estão embutidos nos programas de apli-cação, fazendo com que qualquer mudança em sua estrutu-ra exija alteração em todos os programas que acessam este arquivo, os programas que acessam os sistemas gerenciado-res de banco de dados (SGBD) não exigem tais mudanças, pois existe esta propriedade de independência de dados do programa.
Suporte de múltiplas visões dos dadosUm banco de dados em geral possui muitos usuários,
cada um podendo exigir um ponto de vista (visão) diferen-te do banco de dados. Uma visão pode ser um subconjunto

76
Ban
co d
e D
ados
eIn
telig
ênci
a E
mpr
esar
ial
de banco de dados ou conter um dado virtual que é derivado dos arquivos do banco de dados, mas não estão armazenados explicitamente. Isso é importante, pois para o usuário o que importa é a possibilidade e facilidade de múltiplas visões, não importando se os dados a que se referem estão armaze-nados ou se são derivados.
Compartilhamento de dados e processa-mento de transações multiusuário
Para atender este conceito de multiusuário, o sistema gerenciador de banco de dados deve incluir um software de controle de concorrência para garantir que vários usuários, tentando atualizar o mesmo dado, faça isto de uma maneira controlada, de modo que o resultado destas atualizações seja correto.
Por exemplo, a reserva de um quarto de hotel sendo feita por vários agentes. O sistema precisa garantir que um só agente vai fazer a reserva para uma única pessoa. Esse tipo de aplicação é denominada de “Processamento de Transação Online” também conhecido por OLTP (Online Transaction Processing).
Saiba MaisO dicionário de dados é um arquivo que contém metadados, ou seja, dados dos próprios dados, do qual fazem parte as especificações das estruturas de dados, regras e métodos de acesso e outros detalhes necessários à implementação. Por outro lado, faz-se uso de uma Linguagem de Manipulação de Dados (LMD), cuja finalidade é permitir que os usuários possam acessar ou manipular os dados organizados de acordo com um modelo especifico sobre os mesmos.

Ges
tão
do C
onhe
cim
ento
–Ba
nco
de D
ados
e G
eren
ciad
or d
e Ban
co d
e Dad
os
77
4.3
Arquiteturas de um Sistema Gerenciador de Banco de dados
As primeiras arquiteturas usavam mainframes para executar o processamento principal e de todas as funções do sistema, incluindo os programas aplicativos, programas de interface com o usuário, bem como a funcionalidade dos SGBDs. Essa é a razão pela qual a maioria dos usuários fazia acesso aos sistemas via terminais que não possuíam poder de processamento, apenas a capacidade de visualização.
Conforme explica Gordon (2006), todos os processa-mentos eram feitos remotamente, apenas as informações a serem visualizadas e os controles eram enviados do mainfra-me para os terminais de visualização, conectados a ele por redes de comunicação.
Como os preços de hardware foram decrescendo, mui-tos usuários trocaram seus terminais por computadores pes-soais (PC) e estações de trabalho.
No começo os SGBDs usavam esses computadores da mesma maneira que usavam os terminais, ou seja, o SGBD era centralizado e toda sua funcionalidade, execução de pro-gramas aplicativos e processamento da interface do usuário eram executados em apenas uma máquina.
Gradualmente, os SGBDs começaram a explorar a dis-ponibilidade do poder de processamento no lado do usuário, o que levou à arquitetura cliente-servidor.
78
Ban
co d
e D
ados
eIn
telig
ênci
a E
mpr
esar
ial
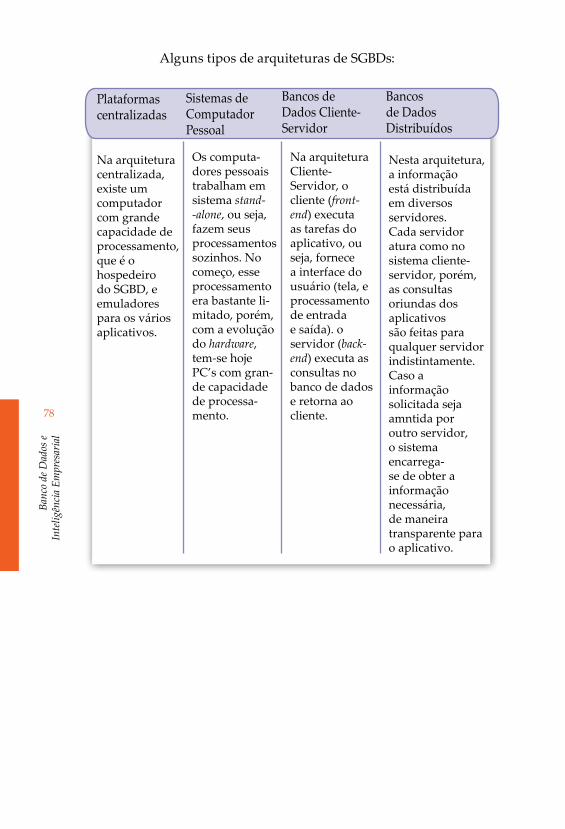
Alguns tipos de arquiteturas de SGBDs:
Na arquitetura centralizada, existe um computador com grande capacidade de processamento, que é o hospedeiro do SGBD, e emuladores para os vários aplicativos.
Os computa-dores pessoais trabalham em sistema stand--alone, ou seja, fazem seus processamentos sozinhos. No começo, esse processamento era bastante li-mitado, porém, com a evolução do hardware, tem-se hoje PC’s com gran-de capacidade de processa-mento.
Na arquitetura Cliente-Servidor, o cliente (front-end) executa as tarefas do aplicativo, ou seja, fornece a interface do usuário (tela, e processamento de entrada e saída). o servidor (back-end) executa as consultas no banco de dados e retorna ao cliente.
Nesta arquitetura, a informação está distribuída em diversos servidores.Cada servidor atura como no sistema cliente-servidor, porém, as consultas oriundas dos aplicativos são feitas para qualquer servidor indistintamente. Caso a informação solicitada seja amntida por outro servidor, o sistema encarrega-se de obter a informação necessária, de maneira transparente para o aplicativo.
Plataformas centralizadas
Sistemas de Computador Pessoal
Bancos de Dados Cliente-Servidor
Bancos de Dados Distribuídos

Ges
tão
do C
onhe
cim
ento
–Ba
nco
de D
ados
e G
eren
ciad
or d
e Ban
co d
e Dad
os
79
4.4
Vantagens no uso de Sistemas de Banco de Dados
Como aprendemos no conteúdo já estudado, os siste-mas de banco de dados proporcionam algumas vantagens para as empresas quanto ao aspecto de utilizar as informa-ções como vantagem competitiva. Na gestão do conhecimen-to é importante que as informações estejam disponíveis de forma precisa e no momento certo para que decisões corretas sejam tomadas.
Abaixo são apresentadas algumas dessas vantagens com suas especificações.
• Redução ou Eliminação de Redundâncias
A redundância ocorre quando um mesmo campo exis-te de forma simultânea em diferentes em sistemas. No sis-tema de banco de dados, os dados que eventualmente são comuns a mais de um sistema, são compartilhados por eles, permitindo o acesso a uma única informação sendo consul-tada por vários sistemas, eliminando, dessa forma, a privati-zação dos dados.
• Eliminação de Inconsistências
A inconsistência ocorre quando um mesmo campo tem valores diferentes em sistemas diferentes. Portanto, como no sistema de banco de dados o armazenamento da informação está em um único local, está garantido um único valor para o dado em seu respectivo campo.

80
Ban
co d
e D
ados
eIn
telig
ênci
a E
mpr
esar
ial
• Compartilhamento dos Dados
Permite a utilização simultânea e segura de um dado, por mais de uma aplicação ou usuário, independente da ope-ração que esteja sendo realizada.
Deve ser observado apenas o processo de atualiza-ção concorrente, para não gerar erros de processamento, por exemplo, atualizar simultaneamente o mesmo campo do mesmo registro.
• Restrições de Segurança
Define para cada usuário o nível de acesso a ele conce-dido, por exemplo, consulta, consulta e gravação ou sem aces-so, ao arquivo e ou campo do banco de dados. Esse recurso impede que pessoas não autorizadas utilizem ou atualizem um determinado arquivo ou campo.
• Padronização dos Dados
Permite que os campos armazenados na base de dados sejam padronizados segundo um determinado formato de armazenamento, por exemplo, padronização de tabela, con-teúdo de campos entre outros, e ao nome de variáveis seguin-do critérios padrões preestabelecido pela empresa.
• Independência dos Dados
Representa a forma física de armazenamento dos dados no sistema de banco de dados e a recuperação das informações pelos programas de aplicação. Essa recuperação deverá ser totalmente independente da maneira com que os dados estão fisicamente armazenados.

Ges
tão
do C
onhe
cim
ento
–Ba
nco
de D
ados
e G
eren
ciad
or d
e Ban
co d
e Dad
os
81
• Manutenção da Integridade
Permite que os campos armazenados no sistema de banco de dados sejam padronizados segundo um determina-do formato de armazenamento, por exemplo, padronização de tabela, conteúdo de campos, entre outros. É padronizado também o nome de variáveis, seguindo critérios padrões pre-estabelecidos pela empresa.
4.5
Modelagem de Dados
Modelo de dados é um conjunto de regras utilizadas para descrever os dados, seus inter-relacionamentos, bem como aspectos semânticos, ou seja, relativos aos seus signifi-cados e, restrições de integridade. Os modelos de dados mais utilizados atualmente são o modelo relacional, o modelo enti-dade-relacionamento e o modelo orientado a objeto.
Estes modelos são usados para descrever as estruturas dos dados nos níveis conceitual e externo. Em nível conceitu-al executa-se o projeto conceitual (esquema conceitual, usan-do, por exemplo, o modelo entidade-relacionamento) e o pro-jeto lógico (esquema lógico, usando, por exemplo, o modelo relacional).
Abaixo a lista dos principais modelos de dados:
MODeLOS De DADOS
EntidadeRelacionamento Redes Orientados
a objetosRelacionalHierárquico

82
Ban
co d
e D
ados
eIn
telig
ênci
a E
mpr
esar
ial
4.6Visão Geral de Data Warehouse
Conforme já estudamos, aprendemos que um Banco de Dados (BD) é formado por uma coleção de dados relaciona-dos e, um Sistema de Banco de Dados (SBD) como um banco de dados e um software de banco de dados juntos. Um Data Warehouse (DW) também é uma coleção de informações bem como um sistema de suporte. Contudo, existe uma distinção clara, ou seja, os bancos de dados tradicionais são transacio-nais, podendo ser: relacionais ou orientados a objetos ou em rede ou hierárquicos, enquanto que os data warehouses pos-suem a característica distintiva de servir principalmente para aplicações de apoio à decisão. Os mesmos são otimiza-dos para recuperação de dados e não para processamento de transação de rotina.
Como os data warehouses têm sido desenvolvidos em diversas organizações para atender necessidades particula-res, não existe uma definição canônica para o terma, explica Elmasri (2010). Contudo os data warehouses são muito distintos dos bancos de dados tradicionais em sua estrutura, funciona-mento, desempenho e finalidade.
W. H. Inmon tem sido reconhecido como o primeiro a utilizar o nome data warehouse (Armazém de Dados) e carac-terizou-o como uma coleção de dados orientada a assunto, integrada, não volátil, variável no tempo par e como suporte às decisões gerenciais.
Os data warehouses oferecem acesso a dados para ana-lises complexas, descoberta de conhecimentos e tomadas de decisões. Eles fornecem suporte para demandas de alto desempenho sobre os dados e informações de uma organi-zação.

Ges
tão
do C
onhe
cim
ento
–Ba
nco
de D
ados
e G
eren
ciad
or d
e Ban
co d
e Dad
os
83
4.7
Características de um Data Warehouse
• Orientação por Assunto
O dado é inserido no Data Warehouse decorrente de um ambiente operacional, na grande maioria das vezes. O Data Warehouse é sempre um armazenamento de dados transfor-mados, separados fisicamente do ambiente operacional e da fonte do dado utilizado na aplicação.
As diferenças entre aplicações orientadas por proces-sos e funções e as orientadas por assunto estão no conteúdo dos dados e no nível de detalhes dos mesmos.
No Data Warehouse são incluídos somente os dados que devem ser usados no processo de suporte à decisão (DSS), também denominados de sistema de informação executiva (EIS), enquanto no ambiente operacional as aplicações con-têm dados para satisfazer imediatamente as requisições que podem ou não ser usadas para análise de suporte a decisão.
Orientada por assunto
Credibilidade dos dadosVariação no Tempo
Localização
ParticionamentoIntegração
Granularidade Não Volatilidade

84
Ban
co d
e D
ados
eIn
telig
ênci
a E
mpr
esar
ial
• Integração
Os dados antes de estarem no banco do DW, geralmen-te encontram-se armazenados em vários padrões de codi-ficação, isso se deve aos inúmeros sistemas existentes nas empresas, e que eles tenham sido codificados por diferentes analistas.
Portanto, os mesmos dados podem estar em formatos diferentes. Por meio da integração, padronizam-se em uma representação única os dados de todos os sistemas que for-marão a base de dados do DW.
Por isso, grande parte do trabalho na construção de um DW está na análise dos sistemas operacionais e dos dados que eles contêm.
• Variação no tempo
Em um DW é normal um horizonte de tempo bem superior ao dos sistemas transacionais, que exigem que as informações armazenadas, excluídas, atualizadas e consulta-das sejam em tempo de segundos.
Isso é bastante lógico porque num sistema transacional a finalidade é de fornecer as informações no momento exato, já no Data Warehouse, o principal objetivo é analisar o comporta-mento das mesmas durante um período de tempo maior.
É importante considerar que os dados existentes em um DW são como fotografias (snapshots) e não podem ser atu-alizados, pois seus dados refletem um estado em um deter-minado momento do tempo, já nos sistemas operacionais os registros são atualizados constantemente.
• Não Volatilidade
No Data Warehouse existem somente duas operações, a carga inicial e as consultas dos usuários finais (front-ends) aos dados. Isso pode ser afirmado porque a maneira como os

Ges
tão
do C
onhe
cim
ento
–Ba
nco
de D
ados
e G
eren
ciad
or d
e Ban
co d
e Dad
os
85
dados são carregados e tratados é completamente diferente dos sistemas transacionais.
Enquanto nesses sistemas temos vários controles e atu-alizações de registros, em um DW, tem-se somente inserção e consulta de dados.
Deve-se considerar que os dados sempre passam por filtros antes de serem inseridos no DW. Uma vez que partici-pam de um ambiente de DW, os dados são dispostos de forma diferente à representação de um sistema transacional.
Sobre a não volatilidade Inmon afirma: “Em outras palavras, a maior parte dos dados é física e radicalmente alte-rada quando passam a fazer parte do DW. Do ponto de vista de integração, não são mais os mesmos dados do ambiente operacional. À luz destes fatores, a redundância de dados entre os dois ambientes raramente ocorre, resultando em menos de um por cento de duplicações”.
• Localização
Os dados em um DW podem estar fisicamente armaze-nados em função de dois conceitos:
a) Centralizada em um único local, o banco de dados (BD) supre informação a um DW integrado, e desta forma maximizando o poder de processamento e agili-zando a busca dos dados. Esse tipo de armazenamento é utilizado frequentemente, porém existe a inconveni-ência de investimentos em hardware para comportar a base de dados muito volumosa, e o poderio de proces-samento elevado, a fim de atender satisfatoriamente as consultas simultâneas de muitos usuários.
b) Distribuído em vários locais, o armazenando das informações é realizado por áreas de interesse. Por exemplo, os dados da gerência financeira num servi-

86
Ban
co d
e D
ados
eIn
telig
ênci
a E
mpr
esar
ial
Ambiente Operacional
Aplicação A: 0,1Aplicação B: M,FAplicação C: H,M
A diferença dos dados num Sistema Operacional e no Data Warehouse
Data Warehouse
M, F
dor, dados de marketing em outro e dados da conta-bilidade em um terceiro lugar. Essa visão tende a ser uma opção interessante para quem precisa de bastante desempenho, pois dessa forma minimiza a sobrecar-ga de um único servidor, e as consultas serão sempre atendidas em tempo satisfatório.
• Particionamento
O particionamento dos dados é a repartição dos dados em unidades físicas separadas que podem ser tratadas de forma independente.
• Credibilidade dos Dados
Para manter a credibilidade é importante procurar sempre evitar dados que não sejam provenientes de fontes seguras, pois estes dados geram relatórios de má qualidade, prejudicando a tomada de decisão e causando altos riscos para a tomada de decisão de um negócio.
Operacional
atualizaҫão
inserҫão
consulta
carga consulta
Data Warehouse
exclusão
Na figura acima são apresentadas as formas de operaҫão que ocorrem nos Sistemas Transacionais e no Data Warehouse. Observe que no DW não ocorrem atualizaҫỡes e exclusỡes.

Ges
tão
do C
onhe
cim
ento
–Ba
nco
de D
ados
e G
eren
ciad
or d
e Ban
co d
e Dad
os
87
• Granularidade
A granularidade é definida no ambiente de DW, como o nível de detalhe ou de resumo dos dados existentes num Data Warehouse. Quanto maior for o nível de detalhes, menor será o nível de granularidade, ou seja, um DW com informa-ções sintéticas será reconhecido por seu alto índice de granu-laridade. O nível de granularidade afeta diretamente o volu-me de dados armazenados no DW, e ao mesmo tempo o tipo de consulta e a velocidade de resposta.
4.8
Conceitos de Mineração de Dados
Em relatórios como o popular “Gartner Report” a mine-ração de dados tem sido aclamada como uma das principais tecnologias para o suporte nas tomadas de decisão. Induzido pelo próprio nome, a mineração de dados consiste em desco-brir, ou “minerar”, novas informações em termos de padrões

88
Ban
co d
e D
ados
eIn
telig
ênci
a E
mpr
esar
ial
ou regras com base em grandes quantidades de dados. Para ser útil na prática, a mineração de dados precisa ser executa-da de modo eficiente em grandes arquivos e banco de dados. É vasto o campo da mineração de dados que utiliza tecnologias avançadas na elaboração de softwares tais como, aprendizado de máquinas, redes neurais e algorítmos genéricos.
A mineração de dados pode ser usada junto com os Data Warehouse (DW) para ajudar com certos tipos de deci-são, pode também ser aplicada a Banco de Dados operacio-nais (BD) com transações individuais.
Para tornar a mineração de dados mais eficiente, o DW deve possuir uma coleção de dados agregada ou resumida. A mineração ajuda na extração de novos padrões significa-tivos que não podem ser necessariamente encontrados ape-nas ao consultar ou processar dados ou metadados no data warehouse.
Portanto as aplicações de mineração de dados devem ser fortemente consideradas desde cedo, juntamente com o projeto do DW.
4.9
Mineração de Dados e a Descoberta do Conhecimento – (KDD)
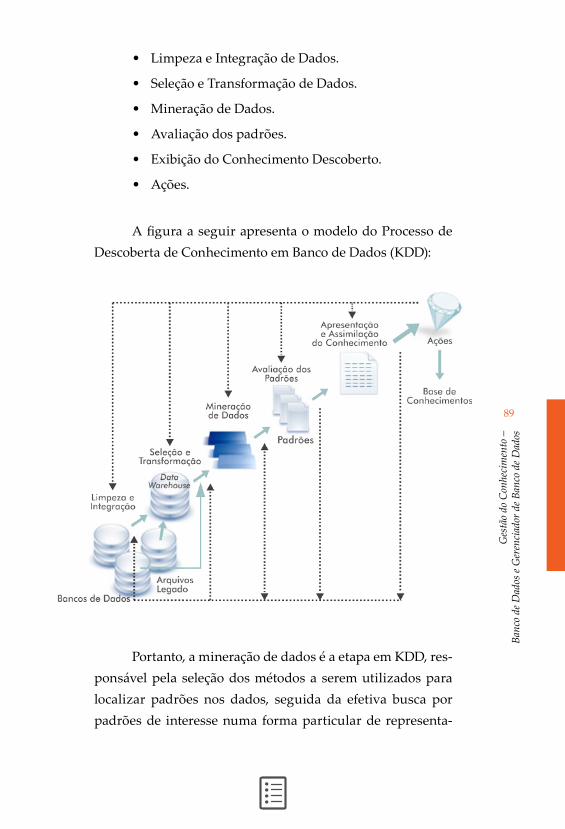
A descoberta do conhecimento nos banco de dados é conhecida como KDD que é abreviação de “Knowledge Dis-covery in Databases” e normalmente é mais abrangente que a mineração de dados. O processo da descoberta do conheci-mento compreende seis fases:
Ges
tão
do C
onhe
cim
ento
–Ba
nco
de D
ados
e G
eren
ciad
or d
e Ban
co d
e Dad
os
89
• Limpeza e Integração de Dados.
• Seleção e Transformação de Dados.
• Mineração de Dados.
• Avaliação dos padrões.
• Exibição do Conhecimento Descoberto.
• Ações.
A figura a seguir apresenta o modelo do Processo de Descoberta de Conhecimento em Banco de Dados (KDD):
Portanto, a mineração de dados é a etapa em KDD, res-ponsável pela seleção dos métodos a serem utilizados para localizar padrões nos dados, seguida da efetiva busca por padrões de interesse numa forma particular de representa-

90
Ban
co d
e D
ados
eIn
telig
ênci
a E
mpr
esar
ial
ção, juntamente com a busca pelo melhor ajuste dos parâme-tros do algorítmo para a tarefa em questão.
A cada dia, as bases de dados das organizações vêm assumindo maiores proporções, e extraindo informação útil, a partir dessa grande quantidade de dados passou a ser uma tarefa fundamental. Infelizmente, a extração realizada ape-nas por consultas rotineiras dos usuários não mais satisfaz a esta necessidade e são necessárias outras formas de extração para que informações sejam descobertas a partir desta massa de dados, principalmente aquelas ocultas, imperceptíveis à intuição ou aos olhos humanos.
Conforme observa Mendonça (2002), nesse cenário a mineração de dados surgiu como uma solução extremamente útil às organizações que querem melhor explorar a informa-ção que possuem em seus repositórios de dados.
Um claro exemplo de mineração de dados é o caso de um distribuidor de produtos, que a partir de sua base de dados com informações sobre seus clientes e as compras dos mesmos, pode traçar perfis de grupos de clientes, e até mesmo de cada cliente individualmente, classificando-os como dese-jar, por exemplo, frequência nas compras.