arquitetura e organização de processadores aulas 9 e 10 ...flavio/ensino/cmp237/aula09.pdf ·...
TRANSCRIPT

CMP237
Universidade Federal do Rio Grande do SulInstituto de Informática
Programa de Pós-Graduação em Computação
Arquitetura e Organização de Processadores
Aulas 9 e 10
Memória cache

CMP237
1. IntroduçãoTendências tecnológicas
Capacidade Velocidade (latência)Lógica: 2x em 3 anos 2x em 3 anosDRAM: 4x em 3 anos 2x em 10 anosDisco: 4x em 3 anos 2x em 10 anos
DRAMAno Tamanho Tempo acesso1980 64 Kb 250 ns1983 256 Kb 220 ns1986 1 Mb 190 ns1989 4 Mb 165 ns1992 16 Mb 145 ns1995 64 Mb 120 ns
1000:1! 2:1!

CMP237
Tendências tecnológicas
Hiato de desempenho (latência) entre processador e memória DRAM
µProc60% / ano(2X / 1.5 anos)
DRAM9% / ano(2X / 10 anos)1
10
100
1000
DRAM
CPU
hiato cresce 50%a cada ano
Perf
orm
ance
“Lei de Moore”
1980
1981
1983
1982
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
Tempo

CMP237
Hierarquia de memória
Bloco de controle
Blocooperac.
Memória
Processador
Mem
ória
MemóriaMemória
Mem
ória
• objetivo: oferecer ilusão de máximo tamanho de memória, com mínimo custo emáxima velocidade
• cada nível contém cópia de parte da informação armazenada no nível superiorseguinte
Mais lentaMais rápidaVelocidade:MaiorMenorTamanho:Mais baixoMais altoCusto:

CMP237
Tecnologias na hierarquia de memória
• Acesso randômico– tempo de acesso é o mesmo para todas as posições– DRAM: Dynamic Random Access Memory
• alta densidade, baixa potência, barata, lenta• dinâmica: precisa de um “refresh” regular
– SRAM: Static Random Access Memory• baixa densidade, alta potência, cara, rápida• estática: conteúdo dura “para sempre”(enquanto houver alimentação)
• Acesso “não-tão-randômico”– tempo de acesso varia de posição para posição e de tempos em tempos– exemplos: disco, CD-ROM
• Acesso sequencial– tempo de acesso varia linearmente com a posição (p.ex. fita)

CMP237
Hierarquia de memória
Bloco de controle
Blocooperac.
Memóriasecundária
(disco)
Processador
Registrad.
Memóriaprincipal(DRAM)
Cache2º nível(SRAM)
On-C
hipC
ache
0,1 1 2-5 10-20 10.000.000 (10 ms)Velocidade (ns):
100 16 K 512 K 256 M GsTamanho (bytes):

CMP237
Hit e miss
• Hit: dado aparece em algum bloco no nível superior (junto ao processador)
– Hit Ratio: a fração de acessos à memória resolvidos no nível superior– Hit Time: tempo de acesso ao nível superior, que consiste de
tempo de acesso à memória RAM + tempo para determinar hit/miss• Miss: dado precisa ser buscado de um bloco no nível inferior
– Miss Ratio = 1 – (Hit Ratio)– Miss Penalty: tempo gasto para substituir um bloco no nível superior +
tempo para fornecer o bloco ao processador• Hit Time << Miss Penalty

CMP237
Hierarquia de memória
Como a hierarquia é gerenciada?• Registradores <-> memória
– pelo compilador• cache <-> memória principal
– pelo hardware• memória principal <-> disco
– pelo hardware e pelo sistema operacional (memória virtual)– pelo programador (arquivos)

CMP237
Princípio de localidade
• Hierarquia de memória funciona devido ao princípio de localidade– todos os programas repetem trechos de código e acessam repetidamente
dados próximos
• localidade temporal: posições de memória, uma vez acessadas, tendem a ser acessadas novamente no futuro próximo
• localidade espacial: endereços em próximos acessos tendem a ser próximos de endereços de acessos anteriores
Probabilidadede referência
Espaço de endereçamento0 2n - 1

CMP237
Princípio de localidade
Como explorar o princípio de localidade numa hierarquia de memória?• Localidade Temporal
=> Mantenha itens de dados mais recentemente acessados nos níveis da hierarquia mais próximos do processador
• Localidade Espacial=> Mova blocos de palavras contíguas para os níveis da hierarquia mais
próximos do processador Nível mais
distante
Bloco Y
Nível maispróximo
Bloco X
para processador
do processador

CMP237
Localidade temporal
• usualmente encontrada em laços de instruções e acessos a pilhasde dados e variáveis
• é essencial para a eficiência da memória cache• se uma referência é repetida N vezes durante um laço de
programa, após a primeira referência a posição é sempre encontrada na cache
Tc = tempo de acesso à cacheTm = tempo de acesso à memória principalTce = tempo efetivo de acesso à cache
N Tc + Tm Tm= Tc + Tce = NN
se Tc = 1 ns, Tm = 20 ns, N = 10 Tce = 3 nsN = 100 Tce = 1,2 ns

CMP237
Localidade espacial
módulos de memória principal
210
715
memóriacache
08
19
linha
linha byteendereço de memória

CMP237
Impacto no desempenho
Medindo o impacto do hit ratio no tempo efetivo de acesso
Tc = tempo de acesso à memória cacheTm = tempo de acesso à memória principalTce = tempo efetivo de acesso à memória cache, considerando efeito
dos misses
Tce = Tc + (1 – h) Tm
se Tc = 1 ns, Tm = 20 ns
h = 0.85 0.95 0.99 1.0
então Tce = 4 ns 2 ns 1.2 ns 1 ns

CMP237
Impacto no desempenho
Tempo gasto com um cache miss, em número de instruções executadas
1º Alpha 340 ns / 5.0 ns = 68 clks x 2 instr. ou 136 instruções2º Alpha 266 ns / 3.3 ns = 80 clks x 4 instr. ou 320 instruções3º Alpha 180 ns / 1.7 ns = 108 clks x 6 instr. ou 648 instruções
1/2 X latência x 3 X freqüência clock x 3 X instruções/clock ⇒ ≈ 5 X

CMP237
Impacto no desempenho
• Supondo um processador que executa um programa com:– CPI = 1.1 – 50% aritm/lógica, 30% load/store, 20% desvios
• Supondo que 10% das operações de acesso a dados na memória sejammisses e resultem numa penalidade de 50 ciclos
CPI = CPI ideal + nº médio de stalls por instrução= 1.1 ciclos + 0.30 acessos à memória / instrução
x 0.10 misses / acesso x 50 ciclos / miss= 1.1 ciclos + 1.5 ciclos = 2. 6
• 58 % do tempo o processador está parado esperando pela memória!• um miss ratio de 1% no fetch de instruções resultaria na adição de 0.5
ciclos ao CPI médio
CPI ideal 1.1
Data misses 1.5
Instr.misses 0.5

CMP237
2. Organizações de memória cache
• processador gera endereço de memória e o envia à cache• cache deve
– verificar se tem cópia da posição de memória correspondente– se tem, encontrar a posição da cache onde está esta cópia– se não tem, trazer o conteúdo da memória principal e escolher posição
da cache onde a cópia será armazenada• mapeamento entre endereços de memória principal e endereços de
cache resolve estas 3 questões– deve ser executado em hardware
• estratégias de organização (mapeamento) da cache– mapeamento completamente associativo– mapeamento direto– mapeamento set-associativo

CMP237
Mapeamento completamente associativo
endereço gerado pelo processadormiss: memória é acessada
endereço dado
cache
comparaçãosimultâneacom todosos endereços
hitmemóriaprincipalprocessador

CMP237
Mapeamento completamente associativo
endereço gerado pelo processador
word byte
endereço word 0
hit
w 1 w 2 w 3
cache
comparaçãosimultâneacom todosos endereços
cache organizada em linhas com 4 palavras de 4 bytes
seleciona word e byteprocessador

CMP237
Mapeamento completamente associativo
• vantagem: máxima flexibilidade no posicionamento de qualquer palavra (ou linha) da memória principal em qualquer palavra (ou linha) da cache
• desvantagens – custo em hardware da comparação simultânea de todos os endereços
armazenados na cache– algoritmo de substituição (em hardware) para selecionar uma linha da
cache como conseqüência de um miss• utilizado apenas em memórias associativas de pequeno tamanho
– tabelas

CMP237
Mapeamento direto
endereço gerado pelo processador
tag índice
tag dado
tag + índice
cache
índice
= ?diferentes
memóriaprincipal
processadoriguais

CMP237
Mapeamento direto
• endereço é dividido em 2 partes– parte menos significativa: índice, usado como endereço na cache onde
será armazenada a palavra– parte mais significativa: tag, armazenado na cache junto com o
conteúdo da posição de memória• quando acesso é feito, índice é usado para encontrar palavra na
cache– se tag armazenado na palavra da cache é igual ao tag do endereço
procurado, então houve hit• endereços com mesmo índice são mapeados sempre para a mesma
palavra da cache

CMP237
Mapeamento direto
• mapeamento: endereço é o módulo do número de blocos na cache
00001 00101 01001 01101 10001 10101 11001 11101
000
Cache
Memory
001
010
011
100
101
110
111
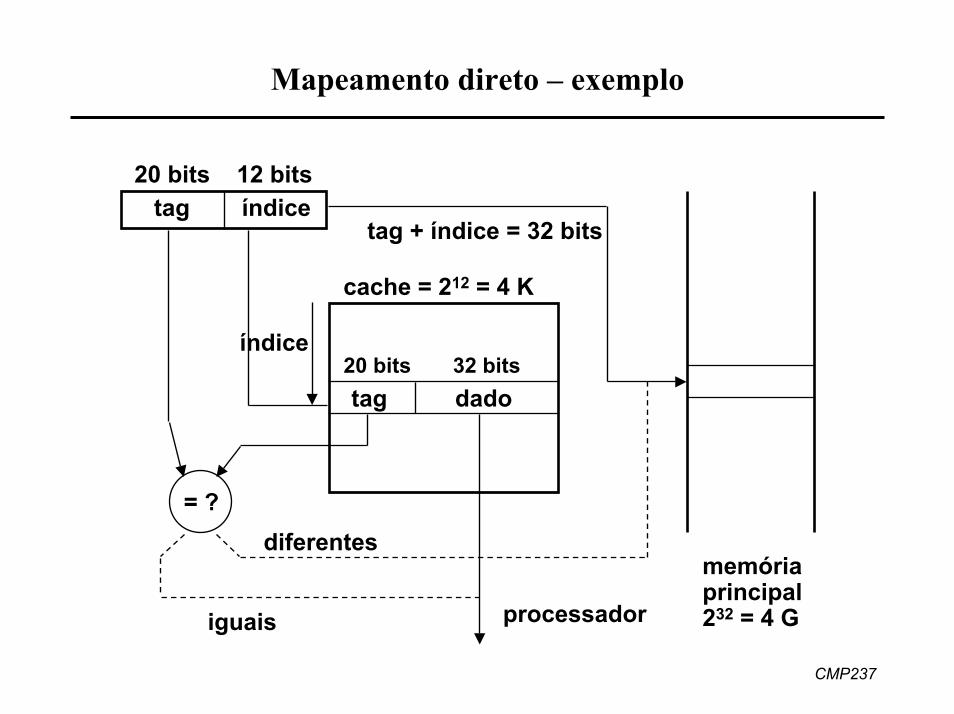
CMP237
Mapeamento direto – exemplo
tag índice20 bits 12 bits
tag dado20 bits 32 bits
tag + índice = 32 bits
cache = 212 = 4 K
índice
= ?diferentes
memóriaprincipal232 = 4 Gprocessadoriguais

CMP237
Mapeamento direto – uso de linhas
Cache IndexCache Tag Exemplo: 0x50 Byte Select931 4 0
1
:
Cache DataByte 0Byte 1Byte 31 :
Byte 32Byte 33Byte 63 :Byte 992Byte 1023 :
0
23
:
0x50
Ex: 0x00Ex: 0x01armazenado comoparte do “estado”da cache
:
Valid Bit Cache Tag
31

CMP237
Tamanho da linha x miss ratio
1 KB8 KB16 KB64 KB256 KB
256
40%
35%
30%
25%
20%
15%
10%
5%
0%
Mis
s ra
te
64164Block size (bytes)

CMP237
Tamanho da linha
• em geral, uma linha maior aproveita melhor a localidade espacial MAS– linha maior significa maior miss penalty
• demora mais tempo para preencher a linha– se tamanho da linha é grande demais em relação ao tamanho da cache, miss
ratio vai aumentar• muito poucas linhas
• em geral, tempo médio de acesso = Hit Time x (1 - Miss Ratio) + Miss Penalty x Miss Ratio
MissPenalty
Tamanho da linha
MissRatio explora localidade espacial
poucas linhas: comprometelocalidade temporal
Tempo médiode acesso
Miss Penalty& Miss Ratioaumentam
Tamanho da linhaTamanho da linha

CMP237
Quantos bits tem a cache no total?
• supondo cache com mapeamento direto, com 64 KB de dados, linha com uma palavra, endereços de 32 bits
• 64 KB -> 16 Kpalavras, 214 palavras, neste caso 214 linhas• cada linha tem 32 bits de dados mais um tag (32-14-2 bits) mais
um bit de validade:214 x (32 + 32 -14 -2 +1) = 214 x 49 = 784 x 210 = 784 Kbits
• 98 KB para 64 KB de dados, ou 50% a mais

CMP237
Mapeamento direto
• vantagens– não há necessidade de algoritmo de substituição– hardware simples e de baixo custo– alta velocidade de operação
• desvantagens– desempenho cai se acessos consecutivos são feitos a palavras com mesmo
índice– hit ratio inferior ao de caches com mapeamento associativo
• demonstra-se no entanto que hit ratio aumenta com o aumento dacache, aproximando-se de caches com mapeamento associativo– tendência atual é de uso de caches grandes

CMP237
Mapeamento conjunto – associativo
tag índice
tag dado
= ?
tag dado tag dado tag dado
= ? = ? = ?sim sim
Cache
índice
sim simnão

CMP237
Mapeamento conjunto – associativo
• mapeamento direto: todas as palavras armazenadas na cache devem ter índices diferentes
• mapeamento associativo: linhas podem ser colocadas em qualquer posição da cache
• compromisso: um nº limitado de linhas, de mesmo índice mas diferentestags, podem estar na cache ao mesmo tempo (num mesmo conjunto)
• nº de linhas no conjunto = associatividade

CMP237
Mapeamento conjunto – associativo
• vantagem em relação ao mapeamento completamente associativo: comparadores são compartilhados por todos os conjuntos
• algoritmo de substituição só precisa considerar linhas dentro de um conjunto
• muito utilizado em microprocessadores– Motorola 68040: 4-way set associative– Intel 486: 4-way set associative– Pentium: 2-way set associative

CMP237
Desvantagem da cache conjunto-associativo
• conjunto-associativa N-way X mapeamento direto– dado tem atraso extra do multiplexador– dado vem DEPOIS da decisão Hit/Miss e da seleção do conjunto
• numa cache com mapeamento direto, linha da cache está disponívelANTES da decisão Hit/Miss
– possível assumir um hit e continuar. Recuperar depois se for miss.
Cache DataLinha 0
Cache Tag Valid
: ::
Cache DataLinha 0
Cache TagValid
:: :
Cache Index
Mux 01Sel1 Sel0
Linha
CompareAdr Tag
Compare
OR
Hit

CMP237
Impacto da associatividade da cache
0%
3%
6%
9%
12%
15%
Eight-wayFour-wayTwo-wayOne-way
1 KB2 KB4 KB8 KB
Mis
s ra
te
Associativity 16 KB32 KB64 KB128 KB

CMP237
Fontes de misses
• compulsórios (cold start ou chaveamento de processos, primeira referência): primeiro accesso a uma linha
– é um “fato da vida”: não se pode fazer muito a respeito– se o programa vai executar “bilhões” de instruções, misses compulsórios
são insignificantes• de conflito (ou colisão)
– múltiplas linhas de memória acessando o mesmo conjunto da cache conjunto-associativa ou mesma linha da cache com mapeamento direto
– solução 1: aumentar tamanho da cache– solução 2: aumentar associatividade
• de capacidade– cache não pode conter todas as linhas accessadas pelo programa– solução: aumentar tamanho da cache
• invalidação: outro processo (p.ex. I/O) atualiza memória

CMP237
Fontes de misses
20%
Mis
s ra
te p
er ty
pe
2%
4%
6%
8%
10%
12%
14%
1 4 8 16 32 64 128
One-way
Two-way
Cache size (KB) Four-way
Eight-way
Capacity
misses compulsórios não aparecem
misses de capacidade (parte “branca”da curva) dependem do tamanho dacache
misses de conflito: dependem daassociatividade e do tamanho da cache

CMP237
Quantidade de misses segundo a fonte
Mapeam. direto Conj.-associat. N-way Complet. associativa
Missescompulsórios
Tamanho da cache
Misses de capacidade
Misses de invalidação
Grande Médio Pequeno
Mesmo Mesmo Mesmo
Misses de conflito Alto Médio Zero
Baixo Médio Alto
Mesmo Mesmo Mesmo

CMP237
3. Mecanismos de fetch e escrita
• estratégias para fetch de palavras ou linhas da memória principal– fetch por demanda– prefetch
• fetch por demanda– fetch da linha quando ocorre miss– estratégia mais simples, não exige hardware adicional
• prefetch– fetch da linha antes que ela seja necessária– p.ex: prefetch da linha i+1 quando a linha i é inicialmente referenciada– alternativa: prefetch da linha i+1 quando ocorre miss da linha i

CMP237
Operações de escrita
• leitura na cache não afeta conteúdo não há discrepância entrecache e memória principal
• escrita na cache: cópias da palavra na cache e na memória principal podem ter valores diferentes
• valores deveriam ficar iguais em razão de:– acessos de E/S feitos através da memória principal– acessos à memória principal por múltiplos processadores
• tempo médio de acesso à cache é aumentado pela necessidade de atualizações da memória principal
• mecanismos de coerência de escrita– write-through– write-back

CMP237
Mecanismo write-through
• write-through: cada escrita na cache é repetida imediatamente na memória principal
• escrita adicional na memória principal aumenta tempo médio de acesso à cache
• estatisticamente apenas 5% a 34% dos acessos à memória são escritas

CMP237
Mecanismo write-through
Tempo médio de acesso à cache Tma é dado porTma = Tc + (1 – h) Tb + w (Tm – Tc)
ondeTc = tempo de acesso à cache h = hit ratioTb = tempo de leitura de uma linha da memória principalTm = tempo de acesso a uma palavra da memória principalw = probabilidade de que acesso seja de escrita
supondoTc = 1 ns, Tb = Tm = 10 ns, h = 0.98, w = 0.2
Tma = 3,0 ns, sendo 0,2 ns devido a misses e 1,8 ns devido ao write-through

CMP237
Write-Through com Write Buffer
ProcessadorCache
DRAM
Write Buffer
• Write Buffer é necessário entre cache e memória principal– processador: escreve dados na cache e no write buffer– controlador de memória: escreve conteúdo do buffer na memória
• Write buffer é uma FIFO– típico número de posições = 4– funciona bem se: freqüência de escritas << 1 / ciclo escrita DRAM
• problema– freqüência de escritas > 1 / ciclo escrita DRAM– saturação do Write Buffer

CMP237
Saturação do Write Buffer
• freqüência de escritas > 1 / ciclo escrita DRAM– se esta condição existe por um longo período de tempo (porque tempo de
ciclo da CPU é rápido demais e/ou ocorrem muitas instruções store em seqüência):
• Write-Buffer terá overflow, não importa quão grande ele seja• solução para saturação do Write Buffer
– usar cache com write-back– instalar uma cache de segundo nível (L2)
ProcessadorCache
Write Buffer
DRAML2Cache

CMP237
Mecanismo write-back
• write-back: linha da cache só é escrita de volta na memória principal quando precisa ser substituída
• estratégia mais simples: escrita é feita mesmo que linha não tenha sido alterada
Tma = Tc + (1 – h) Tb + (1 – h) Tbonde o segundo termo (1–h) Tb é devido à escrita
• estratégia alternativa: só escrever de volta se linha foi alteradaexige um bit de tag para indicar modificações na linha
Tma = Tc + (1 – h) Tb + wb (1 – h) Tbonde wb = probabilidade de que linha tenha sido alterada

CMP237
4. Substituição de linhas
• quando ocorre um miss, uma nova linha precisa ser trazida da memória principal para a cache
• cache com mapeamento direto não precisa escolher qual linha dacache será substituída
• cache completamente associativa: pode-se escolher qualquer uma das linhas
• cache conjunto-associativa: deve-se escolher uma linha dentro de um conjunto fixado pelo índice
• algoritmo de substituição precisa ser implementado em hardware

CMP237
Algoritmos de substituição
substituição randômica• escolha de uma linha ao acaso para ser substituída• exemplo de implementação em hardware: contador
– contador é incrementado a cada ciclo do relógio– quando substituição é necessária, escolhe-se linha cujo endereço é igual ao
valor atual do contador– cache completamente associativa: contador de n bits se cache tem 2n
linhas– cache conjunto-associativa: contador de 2 bits numa cache com
associatividade = 4
first-in first-out (FIFO)• remover a linha que está há mais tempo na cache• implementação evidente: fila de endereços de linha

CMP237
Algoritmos de substituição
LRU – Least Recently Used• linha a ser substituída é aquela que há mais tempo não é referenciada• implementação mais simples em hardware: contador associado a cada
linha– quando hit ocorre, contador da linha correspondente é zerado– demais contadores são incrementados– linha com contador com valor mais alto é a substituída
• outras implementações– pilha de registradores– matriz de referência– métodos aproximativos

CMP237
5. Hierarquia de caches
• caches integradas dentro de um processador têm limitação de tamanho
• miss penalty na cache é muito grande, pela diferença entre os tempos de acesso da cache e da memória principal
• solução: caches em dois ou três níveis– cache integrada (L1, de primeiro nível) é de tamanho pequeno, p.ex. 8
Kbytes, e tempo de acesso menor– cache secundária (L2) tem tamanho maior, p.ex. 256 Kbytes, e tempo de
acesso maior• processadores recentes têm cache de terceiro nível (L3)
– cache L3 fora do chip do processador, cache L2 dentro• misses podem ocorrer em referências a qualquer nível de cache• transferências entre níveis de cache apresentam mesmos problemas e
possíveis soluções já discutidos

CMP237
6. Caches de dados e instruções
• dados e instruções: cache unificada x caches separadas• vantagens das caches separadas
– política de escrita só precisa ser aplicada à cache de dados– caminhos separados entre memória principal e cada cache, permitindo
transferências simultâneas (p.ex. num pipeline)– estratégias diferentes para cada cache: tamanho total, tamanho de linha,
organização• caches separadas são usadas na maioria dos processadores, no nível
L1• caches unificadas nos níveis L2 e L3

CMP237
Caches de dados e instruções
memória principal
cache instr. cache dados
instruções dados
unidadede acessoà memória
unidadede fetchde instr.
pipeline de instruções
processador

CMP237
Problemas com caches separadas
• código auto-modificável• instruções e dados colocados em posições próximas de memória
duas cópias da mesma linha estarão nas duas caches
• necessidade de controle adicional

CMP237
7. Medindo desempenho
• desempenho da cache depende ...– da organização (mapeamento)– do tamanho da cache e das linhas– do algoritmo de substituição– dos mecanismos de escrita e de fetch– dos programas sendo executados
• métodos de obtenção de estimativas de desempenho– simulação trace-driven– medida direta– modelagem matemática

CMP237
Medindo desempenho
• simulação trace-driven– programas típicos são executados– facilidade de trace do processador é usada para interromper após cada
instrução e registrar endereços de memória gerados pela instrução– registro é utilizado numa simulação– exige-se simulação de grande nº de instruções ( > 1 M )
• medida direta– hardware de monitoração permite coleta das referências à memória– registro é então utilizado na simulação– vantagem: todas as referências são coletadas, mesmo aquelas executadas
por trechos protegidos de código