aprendizagem de máquina - eletrica.ufpr.br · • calculando a margem geométrica ... – os...
TRANSCRIPT

Aprendizagem de Máquina
Alessandro L. Koerich
Programa de Pós-Graduação em Engenharia ElétricaUniversidade Federal do Paraná (UFPR)
Máquinas de Vetor de Suporte

Introdução
• Support Vector Machines SVM
• Método supervisionado de aprendizagem para problemas de: – Classificação– Regressão
• Duas ideias principais– Assumindo classes linearmente separáveis, aprende
hiperplanos de separação com margem máxima.– Expande a entrada para um espaço de alta
dimensionalidade para lidar com casos não-linearmente separáveis.

Hiperplano de Separação
• Conjunto de treinamento:– (xi,yi), i=1,2,…,N; yi{+1,-1}
• Hiperplano: wx+b=0– É completamente determinado por (w,b)
onde x=(x1, x2, …, xd), w=(w1, w2, …, wd), wx=(w1x1+w2x2+…+wdxd) produto escalar

Margem Máxima
De acordo com um teorema da teoria de aprendizagem, de todas as possíveis funções de decisão lineares aquela que maximiza a margem do conjunto de treinamento minimizará o erro de generalização.
Isso se tivermos dados o suficiente e assumindo que os dados não são ruidosos!
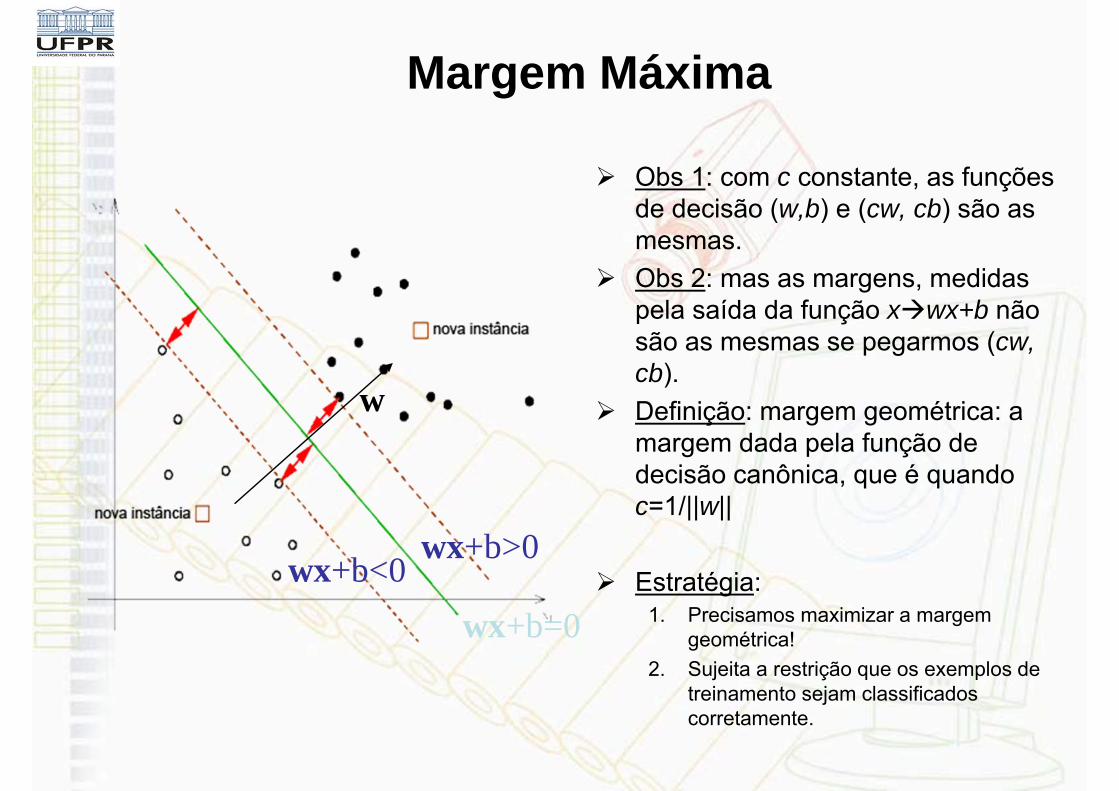
Margem Máxima
Obs 1: com c constante, as funções de decisão (w,b) e (cw, cb) são as mesmas.
Obs 2: mas as margens, medidas pela saída da função xwx+b não são as mesmas se pegarmos (cw, cb).
Definição: margem geométrica: a margem dada pela função de decisão canônica, que é quando c=1/||w||
Estratégia: 1. Precisamos maximizar a margem
geométrica!2. Sujeita a restrição que os exemplos de
treinamento sejam classificados corretamente.
w
wx+b=0
wx+b>0wx+b<0

Margem Máxima
• De acordo com Obs1, podemos impor que a saída da função para os pontos mais próximos sejam +1 e –1 nos dois lados da função de decisão. Isso remove a liberdade da escala.
• Indicando o exemplo positivo mais próximo como x+ e o negativo mais próximo como x-, isto é:
• Calculando a margem geométrica (que deve ser maximizada):
e as restrições:.
1 e 1 bb wxwx
||||1)(
||||21)
||||||||||||||||(
21
wwxwx
wwx
ww
wx
ww
bbbb
1 para 11 para 1
ii
ii
ybyb
wxwx
iby ii todopara 01)( wx

Margem Máxima
wx+b=0wx+b=1
wx+b=-1
wx+b>1wx+b<1
Dado um conjunto de treinamento com exemplos linearmente separáveis (xi, yi), i=1,2,…,N; yi{+1,-1}
Minimize ||w||2
Sujeito a
Este é um problema de programação quadrática tendo como restrições desigualdades lineares.
Niby ii ,..1 ,01)( wx

Vetores de Suporte
Os exemplos de treinamento que estiverem mais próximos da função de separação são chamados de vetores de suporte.
Qual é a saída da função de decisão para estes exemplos (pontos)?

Resolvendo
• Construa e minimize o Lagrangiano:
• Tire as derivadas com respeito a w e b, iguale-os a 0
– Os multiplicadores de Lagrange i são chamados de ‘variáveis dual’
– Cada exemplo de treinamento tem uma variável dual associada.
Ni
bybL
i
N
iiii
,...1,0 restrição a respeito com
)1)((||||21),,(
1
2
wxww
0)1)((:
0),,(
0),,(
1
1
bycondKKT
ybbL
ybL
iii
N
iii
N
iiii
wx
w
xww
w
parametros são expressos como uma combinação linear dos pontos de treinamento.
Somente SVs terão I diferente de zero.


Resolvendo
• Então,
• Colocando de volta no Lagrangiano para obter a formulação dual
• O dual resultante é resolvido para usando um QP solver:
• b não aparece no dual, entãoele é determinado separadamentea partir das restrições iniciais.
SVi iiiN
i iii yyw xx 1
Niy
yyW
iiN
i i
N
i ijijiN
ji ji
,...1,0,0 :subject to21)( :maximise
1
11,
xx
Dados entram somente na forma de produto escalar!

Classificando Novos Exemplos
• Uma vez encontrados os parâmetros (*, b*) resolvendo a otimização quadrática sobre os exemplos de treinamento, o SVM está pronto para ser usado para classificar novos exemplos.
• Dado um novo ponto (exemplo) x, sua afiliação a classe é sign[f(x, *, b*)], onde
***1
***** ),,( bybybbfSVi iii
N
i iii xxxxxwx
Dados entram somente na forma de produto escalar

Solução
• A solução do SVM, i.e. do problema de programação quadrática com desigualdades lineares como restrições tem a propriedade interessante de que os dados entram somente na forma de produto escalar!
• Produto escalar: dado x=(x1,x2,…,xn) e y=(y1,y2,…,yn), então o produto escalar de x e y é xy=(x1y1+x2y2+…+xnyn).
• Isto é interessante, pois nos permite tornar os SVMsnão-linear sem complicar o algoritmo veja próximo slide.

SVMs Não Lineares
• Transforma x (x)

SVMs Não Lineares
• O algoritmo linear depende somente de xxi, portanto o algoritmo transformado depende somente de (x)(xi)
• Use a função kernel K(x,y) tal que K(x,y)= (x)(y)

Kernels
• Exemplo 1: pontos x,y no espaço de características 2D, transformado para espaço de características 3D
• Exemplo 2:
onde que corresponde a este kernel tem dimensão infinita.
• Nem toda a função pode ser um kernel! A função deve obedecer o Teorema de Mercer.
• Para testar uma nova instância x:
2
22
21
21
2
1
2
1 )()()(),( implica,2)( se ; ; xyyxyxxyx
K
x
xx
x
y
y
x
x
)),(()(1
bKysignf SV
i iii xxx
}2/||||exp{),( 22 yxyx K
(quadrado do produto escalar)

Kernel Trick
• Exemplo1: como separar linearmente estes exemplos de duas classes?
• Solução: Elevando para uma dimensão linearmente separável: R1 R2
– φ(x) = (x,x2)

Kernel Trick
• φ(x) = (x,x2)

Kernel Trick
• Φ: R2 R3
• (x1, x2) (z1, z2, z3) = (x12,√2x1x2, x2
2)

Kernel Trick
• Φ: R2 R3
• (x1, x2) (z1, z2, z3) = (x12,√2x1x2, x2
2)

Kernels

SVM para Classificação
1. Preparar a matriz de dados2. Selecionar a função de kernel a ser empregada3. Executar o algoritmo de treinamento usando
um resolvedor QP para obter os valores de i.4. Novas instâncias podem ser classificadas
usando os valores de i e os vetores de suporte.

Conclusão
• Os SVMs aprendem fronteiras de decisão lineares (como os perceptrons)– Busca o hiperplano que maximiza a margem– O hiperplano ótimo vem a ser uma combinação linear dos
vetores de suporte
• Transforma problemas não lineares em um espaço de mais alta dimensão usando funções de kernel
• Então há uma chance maior de que neste espaço transformado, as classes serão linearmente separáveis.

SVM Soft Margin
• Entretanto, assim como outros algoritmos de aprendizagem, o SVM está sujeito a dois problemas:
– Outliers– Exemplos com erros de rotulação.
• Nestes caso o SVM irá falhar, mas….

SVM Soft Margin
• Mesmo se o conjunto de treinamento não for linearmente separável…
• A abordagem tradicional é permitir que a margem de decisão comete uns poucos erros (alguns pontos podem ficar dentro da margem ou no lado errado).
• Isso tem um custo para cada exemplo classificado incorretamente, que depende de quão longe ele está em atender as restrições impostas pela margem.

SVM Soft Margin
• Uma modificação da ideia de margem máxima que permite exemplos com erros de rotulação.
• Se não existir um hiperplano que possa particionar os exemplos positivos (+1) e negativos (-1), o método Soft Margin escolherá um hiperplano que particione os exemplos o melhor possível, enquanto ainda maximiza a distância para os exemplos separáveis.
• Este método introduz variáveis de folga (ξi), as quais medem o erro de classificação (ou sensibilidade) do exemplo xi

SVM Soft Margin
• A restrição então é modificada:
e passamos para a seguinte restrição:
• A função objetiva então é aumentada por uma função que penaliza ξi diferentes de zero e a otimização se torna um compromisso entre uma margem larga e uma penalidade de erro pequena.
• Se a função de penalização for linear, o problema de otimização se torna:
Niby ii ,..1 ,01)( wx
Niby iii ,..1 ,1)( wx

SVM Soft Margin
sujeito a:
• E o dual…
Niby
Cw
ii
n
iibw
,..1 ,01)(
21min
1
2
,,
wx
0,
1)(21maxmin
11 1
2
,,,
ii
n
iiiiii
n
i
n
iiibw
bxwyCw

Parâmetros
• A efetividade do SVM depende da seleção do kernel, dos parâmetros do kernel e do parâmetro soft margin C.
• O kernel mais usando é o Gaussiano (ou RBF). – Neste caso, os parâmetros gamma () e C são
selecionados através de um grid-search com valores crescentes dos parâmetros (libsvm).
– Grid search testa valores de cada parâmetro dentrode uma faixa específica de busca, usando passosgeométricos.

Parâmetros
– Grid search é computacionalmente cara!
– O modelo deve ser avaliado em muitos pontos dentro do grid para cada parâmetro.
– Exemplo:• Se considerarmos 10 intervalos de busca e um função
Gaussiana como kernel com 2 parâmetros (C e gamma),• O modelo deve ser avaliado em 10*10 = 100 pontos do grid.• Se for utilizada validação cruzada, este número é
multiplicado pelo número de folds (4 a 10).

Limitações
• O SVM é aplicável diretamente somente para problemas binários (duas classes).
• Assim, para utilizá-lo em problemas multi-classes, deve ser feita uma redução para diversos problemas binários.

SVM Multi-Classes
• Reduzir o problema multi-classes para múltiplos problemas binários de classificação
– Estratégia um-contra-todos (one-versus-all): construir classificadores binários que distinguem entre uma das classes e as demais.
– Estratégia um-contra-um (one-versus-one): construir um classificador para cada par de classes.
• É a estratégia usada na LIBSVM!

SVM Multi-Classes
• Estratégia um-contra-todos (one-versus-all, one-versus-rest, one-against-all): construir classificadores binários que distinguem entre uma das classes e as demais.
– Para C classes são construídos C classificadores– Usa-se como contra-exemplos os exemplos de todas as outras
classes.– A classificação de novas instâncias é feita usando a estratégia o-
vencedor-ganha (winner-takes-all)– O classificador com a maior saída atribui a classe.

SVM Multi-Classes
• Estratégia um-contra-um (one-versus-one, pairwise): construir um classificador para cada par de classes.
– Para C classes são construídos C(C-1)/2 classificadores.– A classificação é feita por uma estratégia de votação
maioria vence (max-wins voting), onde cada classificador atribui uma das duas classes para a instância.
– A classe mais votada determina a classificação da instância.

SVM Multi Classes
• Exemplo: 4 classes

SVM Multi Classes
• Exemplo: 4 classes– Estratégia um-contra-um: 4(4-1)/2 = 6 classificadores

SVM Multi Classes
• Exemplo: 4 classes– Estratégia um-contra-um: 4(4-1)/2 = 6 classificadores

SVM Multi Classes
• Exemplo: 4 classes– Estratégia um-contra-todos: 4 classificadores