apostilacsd
DESCRIPTION
apostila csdTRANSCRIPT

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 1
CONFIABILIDADE DE SISTEMAS DIGITAIS
Prof. Benício José de Souza

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 2
Conteúdo: I. Conceitos Fundamentais .QUALIDADE/CONFIABILIDADE/DISPONIBILIDADE .NÍVEIS DE UM SISTEMA DIGITAL .CICLO DE VIDA DE UM SISTEMA .CONTROLE DE QUALIDADE II. Falhas e suas manifestações .MANIFESTAÇÃO DAS FALHAS .DISTRIBUIÇÕES DAS FALHAS III. Técnicas de Confiabilidade .PREVENÇÃO DAS FALHAS .TÉCNICAS DE DETECÇÃO DE FALHAS .CONFIABILIDADE DE SISTEMAS IV. Técnicas de Disponibilidade .MASCARAMENTO DAS FALHAS .REDUNDÂNCIA DINÂMICA V. Técnicas de Manutenibilidade/Testabilidade .PRODUÇÃO .TESTES DE ACEITAÇÃO .TESTABILIDADE VI. Confiabilidade do Software .MODELAGEM DA CONFIABILIDADE DO SOFTWARE .SOFTWARE TOLERANTE A FALHAS REFERÊNCIAS: [1] O’Connor, Patrick D.T. - “ Practical Reliability Engineering” John Wiley, 1994 terceira edição. [2] Daniel P. Siewiorek; Robert S. Swarz-"Reliable Computer Design"
Digital Press,1992 [3] Musa, J. D., Iannino A. Okumoto, K. – “Software Reliability Measure-ment, Prediction, Aplication” - McGraw-Hill , 1987 [3] Hoang Pham - "Software Reliability"
Spring-Verlag, 2000

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 3
I. CONCEITOS FUNDAMENTAIS QUALIDADE POR PROJETO 1.1- QUALIDADE :Totalidade das características e atributos de um produto ou serviço, responsáveis pela satisfação das necessidades especificadas ou implícitas do momento e do futuro.(ANSI/ASQC). 1.2- NIVEIS DE COMPETÊNCIA NA PRODUÇÃO : N1-Problemas são encontrados. O otimismo permite que muitos deles possam ser propagados. Um grande número deles terminam como problemas no campo. N2-Problemas são encontrados. O Controle da Qualidade é usado para diagnosti-car e corrigir a raiz dos problemas. Essa informação é realimentada no início da cadeia produtiva de modo que os mesmos problemas não reapareçam. N3-Problemas são prevenidos. Problemas potenciais e suas raízes são identifica-das antes da ocorrência. Otimizações posicionam o projeto o mais longe possível de todos os problemas potenciais. Essa informação é alimentada no início da ca-deia produtiva a fim de assegurar que o problema não seja introduzido. USA/Japão 1970/
PROJETO FABRICAÇÃO OPERAÇÃO
???
? ?
?
= problemas
1980/
PROJETO FABRICAÇÃO OPERAÇÃO? ?= problemas
C.Q.
?
1990/1980
PROJETO FABRICAÇÃO OPERAÇÃO
REF. Don Clausing ; Bruce H. Simpson-"QUALITY BY DESIGN" Quality Progress jan. 1990

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 4
1.3- MUDANÇAS DE ATITUDE velha nova Solução de problemas Prevenção de problemas Quantificação da confiabilidade redução da "inconfiabilidade" Automação do desperdício Eliminação do desperdício .Pensar em termos de como se pode projetar ou fabricar melhores produtos, não apenas resolver problemas ou evitá-los. .Enfocar "o que vai bem" e não "o que vai mal". .Empregar "Análise de modos e efeitos dos sucessos" em lugar de "análise dos modos e efeitos das falhas”, ou "Análise de árvore de sucesso” em lugar de "Aná-lise de árvore de falhas". .Definir os requisitos do cliente/consumidor e fornecer um pouco mais, não só exatamente o solicitado ou o que é competitivo. .Otimizar os resultados ou atributos desejados, não somente incorporá-los. .Minimizar o custo total(custo de propriedade) sem comprometimento da quali-dade, e não apenas realizar estudos de custo/desempenho. DIFERENTES ÊNFASES DO CONTROLE DE QUALIDADE % correções N3 N1, N2 -24 PROJETO FABRICAÇÃO 0 OPERAÇÃO +3 mês Exercício: O gráfico acima esquematiza a porcentagem de correções efetuadas durante o desenvolvimento de um produto. Uma das curvas é típica do nível N3 e a outra dos níveis N1 e N2. Comparar as características desses níveis de competência.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 5
1.4- ASPECTOS DA PRODUÇÃO
PREVENÇÃO DE PROBLEMAS
ENGENHARIA DA QUALIDADE
QFD JIT
.Engenharia da Qualidade- Otimização das funções críticas do processo de produ-ção de modo a satisfazer tanto quanto possível os valores mais desejados pelo cliente, e ainda a minimização do custo total. .Propagação da função qualidade-(QFD-Quality Function Deployment) Maneiras sistemáticas de auxilio na identificação dos requisitos do cliente e sua propagação em todas as áreas da empresa, permanecendo sempre fiel às neces-sidades do cliente. O QFD auxilia a identificação dos parâmetros críticos que de-vem ser otimizados pela Engenharia da Qualidade. .Fabricação acionada pela encomenda-(JIT-Just In Time) A fabricação é "puxada pela encomenda ou demanda" ao invés de "empurrada pela fábrica". O JIT necessita de boa qualidade dos produtos para poder funcionar. O JIT não é "entrega em tempo". Tenta eliminar os estoques de reposição, não funcionando, portanto para produtos de baixa qualidade. .Estágios da produção • PROPAGAÇÃO DOS REQUISITOS DESENVOLVIMENTO • ESTABELECIMENTO DO MELHOR PROJETO • VERIFICAÇÃO DO PROJETO • VALIDAÇÃO DO PROJETO • VALIDAÇÃO DOS PROCESSOS DE PRODUÇÃO • CURVA DE APRENDIZADO COMPLETA PRODUÇÃO

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 6
2- CONFIABILIDADE 2.1- CONCEITOS CONFIABILIDADE -Medida da capacidade de um item desempenhar uma função requerida sob condições preestabelecidas por um determinado período de tem-po.(ISO-8402). MTTF-"Mean Time To Failure"-Tempo médio (ou Tempo Esperado) para o item falhar. MANUTENIBILIDADE -Medida da facilidade(menor custo) com que um item é re-parado. MTTR-"Mean Time To Repair"-Tempo médio de reparo. DISPONIBILIDADE -Fração do tempo em que o item está operacional. MTBF-"Mean Time Between Failures"-Tempo médio entre falhas. MTBF=MTTF+MTTR A=MTTF/MTBF (disponibilidade assintótica) TOLERÂNCIA A FALHAS -Capacidade de execução correta de um algoritmo na presença de falhas ou defeitos. 2.2 - CUSTOS:
.CUSTO TOTAL PARA OPERAÇÃO DO SISTEMA DURANTE n ANOS.
C=I+S P
Di i
ii
n
( )11 +=∑
I=Custo de Aquisição D=Taxa de desconto anual Si=Custo da i-ésima manutenção anual Pi=número de falhas esperadas no ano i OBS.- Esse modelo não considera a perda por falta de qualidade. Na realidade o custo é sempre decrescente com o aumento da qualidade.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 7
2.3 CICLO DE VIDA DE UM SISTEMA ESTÁGIO FONTES DE ERROS TÉCNICAS DE DETECÇÃO •Especificação Projeto do algoritmo . Simulação e projeto Especificações formais Verificação da consistência •Protótipo Projeto do algoritmo . Teste de estímu-
lo/resposta Fiação e montagem "Timing" Falha de componente •Fabricação Fiação e montagem . Teste de sistema ,("Burn-In") Falha de componente Diagnósticos •Instalação Montagens . Teste de sistema Falha de componente Diagnósticos •Operação Falha de componente . Diagnósticos Erros operacionais Flutuações ambientais 2.4- ESTÁGIO DE FABRICAÇÃO DO HARDWARE
MONTAGEM
PAINÉIS
TESTE DE
PAINÉIS
MONTAGEM
CARTÕES C.I.
INSPEÇÃO ETESTE DOSCARTÕES C.I.
MONTAGEM DO
SISTEMA
FABRICAÇÃO DE
CARTÕES C.I.
TESTE DOS
CARTÕES C.I.
INSPEÇÃO DE
COMPONENTES

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 8
TESTE DE MATURIDADE DO PROJETO (DMT)- Estimativa do MTTF de um novo produto antes da fabricação em serie.("RUN-IN"). Procedimento: (a)-Operar um conjunto de amostras das partes em teste por um período prolon-gado de tempo(6 a 8 unidades por 2 a 4 meses) em condições que simulam o ambiente de operação no campo. (b)-Observar, registrar e classificar as falhas de acordo com fatores do tipo: mo-do, tempo, causa ambiental. As falhas similares são agrupadas com freqüência de ocorrência decrescente. (c)-Investigar e corrigir as causas das falhas. (d)-Avaliar o MTTF. ( Θ0=MTTF desejado) (e)-Continuar o procedimento até que o MTTF atinja o valor Θ0 . ESTÁGIO DE FABRICAÇÃO DO SOFTWARE O software de um equipamento é construído utilizando-se algum modelo de CICLO DE VIDA estudado na Engenharia de Software, como por exemplo, o mo-delo clássico CASCATA, PROTOTIPAÇÃO, ESPIRAL, UNIFICADO, etc.. Em geral esses modelos não estipulam método de avaliação quantitativa da con-fiabilidade do software. Do ponto de vista qualitativo o processo de produção do software não difere conceitualmente do processo do hardware nos estágios de projeto. Desse modo, o controle de qualidade do software é representado pelos diversos procedimentos de avaliação estabelecidos para os estágios do ciclo de vida. Exemplo: MODELO ESPIRAL Exercício: Identificar no modelo espiral de desenvolvimento do software os as-pectos relacionados com o controle de qualidade. Detalhar o modelo antes disso.
PLANEJAMENTO ANÁLISE DOS RISCOS AVALIAÇÃO DO CLIENTE ENGENHARIA

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 9
2.5 PRINCÍPIO DO CRESCIMENTO DA CONFIABILIDADE ( "Reliability Growth") A confiabilidade de um produto cresce à medida que seu projeto é corrigido e o processo de fabricação é aperfeiçoado. No caso do hardware, existe um limite máximo de confiabilidade (MTTF potenci-al). Esse valor é teoricamente atingido quando restarem apenas falhas ocasiona-das por erros de projeto e portanto restam apenas as possíveis falhas de compo-nentes.
Modelos de Crescimento da Confiabilidade:
. Modelo de Duane E(F)=λTβ
Com base na curva de crescimento de confiabilidade de um determinado produto podem ser estabelecidas três regiões: R: Se uma unidade falhar em um tempo menor que Tr, esta é rejeitada. T: Se uma unidade falhar após Tr, esta é reparada e o teste continua. A: Se uma unidade sobreviver ao teste durante um tempo maior que Tn , esta é aceita. Risco do Consumidor-Probabilidade do MTTF<Θ0 e unidade aceita. Risco do Produtor-Probabilidade do MTTF>Θ0 e unidade rejeitada.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 10
2.6 INSPEÇÃO DE COMPONENTES Pré-seleção de componentes ("screening") antes da montagem das placas. Kb: custo da substituição de um componente a nível de placa Ks: custo de substituição de um componente a nível de sistema Kf: custo de substituição de um componente no campo Estima-se que: Kf=10Ks e Ks=10Kb
Custo X1000$1000
100
10
10 100 1000Número de componentes utilizados anualmente
0.8%
1.2%
2%
4%
%componentesdefeituosos
custo doequipamento automáticode teste
ECONOMIA DA PRE-SELEÇÃO DE COMPONENTES Exercício -Discutir os aspectos ligados à confiabilidade na produção de um software "ïndustrial". • Esquematizar um ciclo de vida do software • Quais as principais semelhanças e diferenças no controle de qualidade com
relação ao hardware. • Que significado poderia ser dado ao MTTF e MTTR no caso do software.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 11
II. FALHAS E SUAS MANIFESTAÇÕES 1.DEFINIÇÕES 1.1- FALHA (1) :Modificação em um componente físico provocada por processo de degradação interna ou por ação do ambiente.("FAILURE"). FALHA (2) :Estado errôneo do hardware ou software resultado de falhas em com-ponentes, interferência física do ambiente, engano do operador ou projeto incor-reto.("FAULT"). 1.2- DEFEITO :Característica( ou parâmetro) de um componente físico, ou de um algoritmo, produzida fora de especificação. 1.3- ERRO :Resultado incorreto produzido por um sistema. 1.4- CATEGORIAS DE FALHAS OU ERROS . PERMANENTE(HARD) :Falha ou erro de manifestação contínua , estável e irre-versível. . INTERMITENTE :Falha ou erro ocasional decorrente de instabilidades de com-ponentes físicos ou defeitos nos algoritmos. . TRANSITÓRIA (SOFT) :Falha ou erro ocasional decorrente de modificações temporárias de condições ambientais.(ex. Interferência Eletromagnética). 1.5- FONTES DE ERROS ERROS TÍPICOS TAXA OCORRÊNCIA .Falhas permanentes .Permanente .Falhas intermitentes .Intermitente .Falhas transitórias .Transitório .Defeitos de projeto .Intermitente Em um sistema predominam as falhas transitórias do hardware somadas com as falhas provocadas por defeitos no software. A fonte das falhas de software é clas-sificada como Defeito de projeto. Esses dois tipos de falhas são os predominantes nos sistemas atuais.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 12
1.6- ORIGENS DOS DEFEITOS EM CIRCUITOS INTEGRADOS .Decorrem dos processos de produção. DEFEITO % RELATIVA (CMOS) % RELATIVA (TTL) STD(SSI,MSI,LSI) .SUPERFÍCIE 38 16 (contaminação,material estranho,...) .CRISTAL 7 7 (imperfeições, trincas,...) .OXIDO 32 14 ("pinholes", defeito passivação,...) .DIFUSÃO 6 8 (anomalia de difusão, defeito de isolação,...) .METALIZAÇÃO 8 51 (curto circuito, circuito aberto,...) .CIRCUITO DE E/S 9 4 ("curtos","leakage" excessivo,...) 1.7- FALHAS A NÍVEL LÓGICO (Modos de falha) .Falhas nos CIs observadas a nível de "pinos", ocasionadas pêlos defeitos inter-nos. -"STUCK-AT" ou "GRAMPEADO":Valores lógicos nos pinos, ou trilhas, permanen-temente em "0" ou "1". -"CURTO":Duas ou mais linhas fisicamente em curto-circuito. Esse tipo de falha é também decorrente de defeitos nas placas de circuito impresso, conectores , ca-bos, etc.. -"ABERTO"-Idem, em circuito aberto. -"RUIDOSO"-Linha com nível lógico instável.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 13
2. DISTRIBUIÇÕES DAS FALHAS DE COMPONENTES 2.1- FUNÇÃO CONFIABILIDADE : R(t)- Probabilidade de um componente não falhar no intervalo de tempo de 0 a t . F(t)=1-R(t) .Distribuição da ocorrência das falhas f(t)=dF(t)/dt .Densidade de probabilidades da distribuição de ocorrência das falhas λ(t)=f(t)/R(t) .Taxa instantânea de falhas TAXA DE FALHAS TÍPICA DE UM COMPONENTE ELETRÔNICO ("CURVA DA BANHEIRA")
λ : taxa de falhas
tempo
período de vidanormal
períododeenvelhecimento
período de mortalidade infantil
2.2- COMPORTAMENTO NO PERÍODO DE VIDA NORMAL λ(t) aproximadamente constante=λ R(t)=exp(-λt) F(t)=1-exp(λt) f(t)=λexp(-λt) (d.p. exponencial) MTTF= 1/λ

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 14
2.3- COMPOSICAO DA TAXA DE FALHAS (PERIODO DE VIDA NORMAL) .MODELO MIL-HDBK-217 λ=ΠL ΠQ (C1ΠT+C2ΠE) ( circuito integrado lógica digital, memória) λ=ΠL ΠQ (λcyc+C1ΠT+C2ΠE) ( memória EEPROM) λ=λbΠEΠAΠQ... Πn (componente discreto) O valor de λ é calculado por essa fórmula em falhas/106horas FATOR FAIXA ΠL "Learning factor" 1:10 (baseado na maturidade do processo de fabricação) ΠQ "Quality factor" 1:150 (baseado no processo de inspeção e C.Q) ΠT "Temperature factor" 0.1:1000 (baseado na temperatura de operação e tipo de CI) ΠE "Enviromental factor" 0.2:10 (baseado no ambiente de operação) C1 ,C2 "Complexity factors" (baseado no encapsulamento, numero de "gates" equivalentes, numero de pi-nos, numero de bits,etc.) ΠL - FATOR DE APRENDIZADO O fator de aprendizado é 10 , nas seguintes condições: (a)-componente novo em produção inicial. (b)-ocorreram muitas mudanças de projeto. (c)-interrupção prolongada da produção. caso contrario, uma vez estabilizado o processo de produção ΠL vale 1. ΠQ - FATOR DE QUALIDADE : .-Definido por classe de componente: ΠQ S- classe A, militar norma MIL-38510 1 B- classe B, militar MIL-35810 2 B1- classe B, militar norma MIL-883 5 B2- classe B- não militar (idem) 10 C- classe C militar norma MIL-38510 16 D- classe D comercial 150 ΠE -.Solicitação ambiental mecânica GB -Imóvel ameno(escritório) 0.2 SF -Orbital(satelite) 0.2

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 15
GF -Imovel fixo 1.0 GM -Portatil 4.0 NS -Naval(encapsulado) 4.0 NU -Naval-superficie 5.0 AI -Aereo- habitado 4.0 AU -Aereo não habitado 6.0 ML -Missil-lançamento 10.0 ΠT -Solicitação por temperatura (CI silício)
ΠT ⎥⎦
⎤⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛−
−=
29811exp1.0
J
ATK
E
MODELO DE ARRHENIUS Leva em conta o fator de velocidade de reação química em função da temperatu-ra de junção.
MTTF1=MTTF2 )}11(exp{21 TTK
EA −
MTTF1 = MTTF a temperatura T1 MTTF2 = MTTF a temperatura T2 EA = Energia de ativação (eV) K=8.617x10-5 eV/0K Constante de Boltzman -FATOR DE ACELERAÇÃO
F=λ1/λ2exp{ ( )}EK T T
A 1 1
1 2
−
ENERGIA DE ATIVAÇÃO Valor característico do tipo de material do CI. EA
TTL,DTL,ECL 0.40 MOS, VHSIC CMOS 0.35 I2L 0.6 GaAs 1.4 TEMPERATURA DE JUNÇÃO TJ=TA+Icc.Vcc.Af.θJA TJ=Temperatura de junção TA=Temperatura ambiente Vcc=Tensão de alimentação Icc=Corrente de alimentação Af=Fator de ventilação (com ventilador=0.75 sem ventilador=1.0) θJA=resistência térmica da pastilha (0K/W) FATOR DE COMPLEXIDADE C1 Depende do número de Gates equivalente (“tamanho do circuito”). Exemplos (MIL-217-F Notice 1)

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 16
Tipo Número de Gates C1 SSI,MSI,LSI (TTL,ECL) 1 a 100 0.0025 101 a 1000 0.005 PLA/PAL 1 a 200 0.010 201 a 1000 0.21 1001 a 5000 0.42 SSI, MSI (MOS) 1 a 100 0.010 101 a 1000 0.020 PLA/PAL (MOS) 1 a 500 0.00085 501 a 2000 0.0017 Microprocessador MOS 8 bits 0.060 16 bits 0.28 32 bits 0.56 ROM Até 16K bits 0.00065 EEPROM 64K a 256K bits 0.0034 DRAM 256K a 1M bits 0.010 SRRAM 256K a 1M bits 0.062 FATOR DE COMPLEXIDADE C2 Depende do tipo de encapsulamento e número de pinos. Exemplos (MIL-217-F Notice 1) todos com encapsulamento de cerâmica quando aplicável. NP é o número de pinos.
Herméticos DIP, PGA, SMT 08.14
2 )(108.2 PNC −×=
DIP Glass Seal 51.15
2 )(100.9 PNC −×=
EXEMPLO : λ : (10-6falhas/hora λb ΠE ΠQ ΠL ΠT C1 C2 ΠR Πcv λ CI bipolar 6.0 5.0 1.0 1.9 0.006 0.002 0.115 Resistor fixo .0015 8.0 5.0 1.6 0.096 Capacitor fixo .003 24.0 1.0 2.0 0.144 - TAXA DE FALHAS DE UMA PLACA :- METODO DE CONTAGEM DE COMPONENTES -Soma dos λs dos componentes. Os valores são tabelados nas normas utilizadas, considerando-se os componentes nas mesmas condições. METODO DE "STRESS" -Soma dos λs dos componentes, calculados um a um conforme as condições de operação de cada componente na placa. OUTROS COMPONENTES

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 17
:soquetes, conectores, furos metalizados, pontos de solda, etc. são contabilizados conforme valores tabelados em normas, e adicionados à taxa de falhas total da placa. ESTIMATIVAS DO MTTF (A partir de ensaio) MÉTODO DE TESTE ACELERADO m=MTTF vida média verdadeira (vida média da população) M=estimativa da vida média N=número de ítens ensaiados T=duração do ensaio h=NT horas de operação dos ítens (número de horas equivalente de ensaio) r=número de falhas observadas α=nível de significância 100(1-α)%=nível de confiança Para distribuição de falhas exponencial e ensaio com reposição
M=h/r m rr
Mα χ α=
+22 22 ( , )
Para ensaio sem reposição
M=h/r m rr
Mα χ α=
222 ( , )
υ χ2(0.05,υ) χ2(0.90,υ) χ2(0.95,υ) 2 0.103 4.605 5.991 4 0.711 7.779 9.448 6 1.635 10.65 12.59 8 2.733 13.36 15.51 10 3.94 15.98 18.31 20 10.85 28.41 31.41 Exercício: Estimar o MTTF com nível de confiança de 0.90 de um componente, a partir dos seguintes dados de ensaios: θJA =100 0C/W (14 pinos,plástico) Temperatura do ensaio=125 0C Af=0.75 Icc=10mA,Vcc=5.0 V MODO DE FALHA ENSAIOS T= 48 168 500 1000 horas M1:0.3eV r= 6 1 1 0 M2:0.5eV r= 8 6 3 1 M3:1.0eV r= 6 1 2 1 N= 40k 34k 6k 5k Exercício Um cartão de interface utiliza 20 CIs CMOS da família 74HC com as seguintes ca-racterísticas:

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 18
Screening: classe B1, encapsulamento cerâmico, 16 pinos, potência dissipada em cada CI igual a 65mW, resistência térmica junção/encapsulamento de 31 oC/W e complexidades C1=0.020 e C2=0.010. a) Calcular a taxa de falhas desse cartão quando instalado em um trem em uma gaveta com ventilação forçada na qual a temperatura permanece em 32 oC. b) Calcular a taxa de falhas desse cartão quando instalado em um trem em uma gaveta sem ventilação forçada na qual a temperatura permanece em 52 oC. III- TÉCNICAS DE CONFIABILIDADE 1.DEFINIÇÕES 1.1- CONFINAMENTO DE FALHA :Quando a falha ocorre é desejável limitar a a-brangência de seus efeitos. O confinamento da falha é o método de limitar o es-palhamento dos efeitos da falha em uma determinada área do sistema. 1.2- DETECÇÃO DE FALHAS : Muitas falhas provocam sintomas. A detecção é um método de tornar observável algum sintoma da falha. 1.3- MASCARAMENTO DE FALHAS : São técnicas empregadas para esconder os sintomas de uma falha. 1.4- RE-TENTATIVA("RETRY") :Em muitos casos “tentar outra vez a operação de um sistema” pode ser bem sucedida. Isso ocorre, por exemplo, quando a falha é transitória. 1.5- RECONFIGURAÇÃO : Substituição de uma parte falha do sistema por uma outra parte redundante. Pode ocorrer com ou sem degradação das funções do sistema . 1.6- RECUPERAÇÃO : Processo de eliminação dos efeitos das falhas ou dos erros. 1.7- REINÍCIO("RESTART/RESET") :Recuperação a partir de um estado inicial bem definido("frio"),ou de um estado intermediário muito anterior("morno") ou bem recente("quente"). 1.8- REPARO : Substituição de componente falho e reinício bem sucedi-do(REINTEGRAÇÃO) do componente no sistema(em geral "frio"."cold start"). .CENARIO DE UM PROCESSO DE DETECÇÃO/REPARO Falha Falha MTBF MTTD MTTR MTTF
DET. DIAG. RECON REC. REIN
MTBF: Tempo médio entre falhas MTTD: Tempo médio para a detecção de falhas. MTTF: Tempo esperado para a próxima falha, a partir do instante que o sistema é reiniciado.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 19
2. PREVENÇÃO DE FALHAS ("FAULT-AVOIDANCE") 2.1- DEFINIÇÃO :Conjunto de técnicas destinadas a aumentar o Tempo Médio para Falhar (MTTF) de um sistema. São técnicas que procuram maximizar o MTTF dos componentes físicos , minimizar o número de defeitos no projeto e proteger o sistema da ação do ambiente. 2.2- MODELO MIL-217 :Otimização de λ=ΠL . ΠQ (C1ΠT +C2ΠE ) ΠL : Utilização de componentes com uma história de uso bem conheci-da. ΠQ : Utilização de componentes de melhor qualidade,inspeção de com-ponentes e "burn-in" dos equipamentos. C1,C2 : Simplificação do projeto e otimização da memória. A utilização de componentes de alta integração(LSI,VLSI) tende a diminuir a taxa de falhas se comparada com um sistema MSI de mesma complexidade. Por exemplo: processador PDP-8 : λ[PDP-8(MSI)]=325x λ[PDP-8(LSI)] Melhoria do ambiente do sistema. -Filtros de Linha -Blindagem eletromagnética -Aterramentos -Isolação(acoplamento óptico, fibra óptica,..) -Amortecimento de vibrações -Proteções contra umidade e poluição ΠT : Diminuição da temperatura de operação do sistema. Em geral realizada por remoção do ar aquecido por ventiladores. Em alguns casos por trocadores de calor com fluido liquido(freon,p.ex). Utilizando-se o fator de aceleração de Arrenhius observa-se que λ(40o)=3.0xλ(30o) (com EA =1.0 eV). Uma regra que pode ser adotada é a de que o MTTF quase dobra a cada 10o de diminuição da temperatura de operação de um componente. Por exemplo , valores simulados para um PDP-8 mostram que: temperatura ambiente MTTF (interna ao gabinete) 50o C( sem ventilação) 3555 h 40o C(c/ventiladores) 5980 h

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 20
3. DETECÇÃO DE FALHAS 3.1- DEFINIÇÃO :Mecanismo pelo qual se observa a presença de uma falha ou erro baseado em sintomas presentes nos sinais ou na informação fornecidos por um componente. - FATOR DE COBERTURA :Porcentagem de todas as falhas possíveis de um com-ponente detectáveis pelo mecanismo. - FALHAS DE MODO COMUM :Falhas simultâneas em dois componentes duplica-dos que produzem erros idênticos. 3.2- MÉTODOS BASICOS PARA DETECÇÃO DE FALHAS DUPLICAÇÃO/COMPARAÇÃO
x
y1
y2
DETECTOR
E1
E2
d=0: y1=y2
1: y1~y2 CODIFICAÇÃO/VERIFICAÇÃO
CODIFICADOR DECODIFICADORX Xc X
d=0: Xc é código
1: Xc não é código

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 21
4.CÓDIGOS PARA DETECÇÃO DE ERROS 4.1- DEFINIÇÕES : .Dada uma palavra de n bits, com k bits de informação e r bits de redundância (n=k+r) pode-se construir um conjunto de 2k palavras que constitui um código de redundância k/n. U(x): Número de 1s em uma palavra x Z(x): Número de zeros em uma palavra x .d(x1,x2) : Distância Hamming entre x1 e x2 d(x1,x2)=U(x1⊕x2) .Códigos Separados: Quando os r bits redundantes podem ser identificados. .Códigos Não-Separados:(caso contrário) 4.2- CÓDIGOS M de N: .São códigos Não-Separados nos quais devem comparecer exatamente M 1s em uma palavra de N bits. 4.3- CÓDIGOS DE PARIDADE: ("HORIZONTAL") .As palavras são subdivididas em campos C de n bits. Para cada campo é acres-centado um bit de paridade p cujo valor é definido por: U(C)=par[impar] → p=0 U(C)=impar[par] → p=1 paridade PAR[IMPAR] .TÉCNICAS UTILIZADAS: ESQUEMA COBERTURA (a).Bit por palavra .todos erros de 1 bit .todos erros de número impar de bits (b).bit por byte .todos erros de 1 bit .todos erros com número impar de bits por byte (c).Entrelaçado .todos erros de 1 bit .todos erros de número impar de bits por campo .grande número de erros múltiplos adjacentes (d).Por pastilha .(idem entrelaçado)

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 22
.PRINCIPAIS APLICAÇÕES: -Paridade em memórias(RAM e PROM) -Paridade em vias paralelas (Dados, Endereços e Controle) -Paridade em comunicação serial (ex. USART) 4.4- CÓDIGOS ARITMÉTICOS: .São códigos A(x) tais que A(x*y)=A(x)*A(y). Onde * é uma operação aritmética e x,y são palavras não codificadas. Dois exemplos deste tipo de código são: . AN : Os códigos são gerados muliplicando-se o operando (N) por um módulo (A) não potência de 2. É um código do tipo Não-Separado. Na verificação são corretos os casos em que o resultado é divisível por N. . RESIDUO: São códigos Separados onde o campo de verificação R(N) é calculado por R(N)=N mod m. A verificação pode ser efetuada por comparação. 4.5- CÓDIGOS CÍCLICOS (CRC):São geralmente empregados em comunicação serial(por exemplo em controladores de disco magnético). Na forma Separada, blocos de comprimento fixo("frames") são transmitidos seguidos por um campo que contem o resto da divisão do "frame" por um polinômio gerador. Na recepção a verificação é efetuada pela divisão do "frame" e resto pelo mesmo polinômio gerador. Se T(x)=F(x)+xkR(x) então T(x) G(x) =constante R(x)= resto da divisão de F(x) por G(x) A cobertura deste tipo de código depende do polinômio gerador(grau r). Os mais comuns são os CRC-32 que utilizam r=32. Em geral permite a detecção de: -Qualquer número de erros em bits adjacentes de comprimento :r -Qualquer número impar de bits errados -A probabilidade de não detectar erro de um bit qualquer é menor ou igual a :2-r . 5.OUTROS MÉTODOS DE DETECÇÃO 5.1- PARIDADE("VERTICAL") :Para cada bloco de comprimento b palavras( de n bits) de valor constante, é incluída uma palavra de verificação(n bits) igual à so-matória módulo2 de todas as palavras do bloco. Inclui os bits de paridade "hori-zontal" se existirem. A verificação é efetuada recalculando-se a somatória e com-parando-se o resultado com a palavra de paridade "vertical". Este esquema é mais utilizado em memórias tipo PROM ou "mask-ROM", com a verificação realizada periodicamente pelo software. 5.2- "CHECKSUMS" :São esquemas semelhantes à paridade vertical, com o uso de somatória aritmética,desprezando o "vai-um". É empregado em memórias tipo PROM, na movimentação de blocos de dados entre memórias RAM ou em comuni-cação paralela. 5.3- "WATCHDOG TIMERS / TIME-OUT" : Os WDTs são "Timers" que provocam interrupções não mascaráveis se não forem desativados periodicamente pela UCP. São utilizados para verificar padrões temporais de execução de um softwa-re. O "Time-Out" é um esquema mais utilizado em protocolos de comunicação para evitar esperas indefinidas de mensagens. São implementados geralmente pela programação de um relógio de tempo real(despertador).

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 23
.Exercícios: -Projetar um circuito de geração e verificação que exemplifique cada uma das formas de codificação dos itens 4.2 a 4.5. - Esquematizar o projeto(software e hardware) de um WDT para um micropro-cessador, com intervalo de interrupções programável. Sugerir um critério para desativação do WDT que verifique o funcionamento da UCP. 6. CONFIABILIDADE DE SISTEMAS .Modelos de Redes de Confiabilidade REPRESENTAÇÃO: Os NÓS representam elementos de um sistema que falham (e/ou são reparados) de forma estatisticamente independente dos demais. Os RAMOS representam uma lógica de dependência funcional entre os elementos.
E1 (x1)
E2 (x2)
E3 (x3)
MODELO PROBABILÍSTICO: Xn=<x1,x2,...,xN> representa os possíveis estados ocupados pelo sistema. A cada elemento associa-se uma variável aleatória binária xi , com a seguinte convenção: xi =0 Elemento Ei normal. xi =1 Elemento Ei falho. p{Ei normal}=p{xi =0}=pi p{Ei falho}=p{xi =1}=1-pi =qi Os eventos nesse espaço de estados são representados por funções f(X) que reú-nem os estados nos quais o sistema é considerado normal [f(X)=0] ou falho [f(X)=1]. Esses eventos são necessariamente disjuntos e coletivamente exausti-vos . exemplo: Esta-dos Xn
Sistema Probabilidades (As variáveis xi são indepen-dentes)
n x1 x2 x3 f(X) 0 0 0 0 0:normal p1p2p3 1 0 0 1 1:falho p1p2q3 2 0 1 0 0:normal p1q2p3 3 0 1 1 1:falho p1q2q3 4 1 0 0 0:normal q1p2p3 5 1 0 1 1:falho q1p2q3 6 1 1 0 1:falho q1q2p3 7 1 1 1 1:falho q1q2q3

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 24
p{sistema normal}=p{f(X)=0}=p1p2p3+p1q2p3+q1p2p3=(p1+p2-p1p2)p3

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 25
FUNÇÃO CONFIABILIDADE R(t): A função confiabilidade de um elemento Ei é a probabilidade deste elemento manter-se operando normalmente, sem nenhuma falha, no intervalo de tempo [0,t]. A confiabilidade de uma rede de elementos é dada por: R(t)=p{f(X(t)=0} substituindo-se pi por Ri(t). No exemplo anterior R(t)=[R1(t)+R2(t)-R1(t)R2(t)]R3(t)
TEMPO MÉDIO PARA FALHAR-MTTF :
∫∞
=0
)( dttRMTTF
No caso de sistemas eletrônicos em geral , adota-se o modelo de taxa de falhas constante λ , de modo que a confiabilidade é dada por:
tetR λ−=)(
DISTRIBUIÇÃO DAS FALHAS- F(t) :É a probabilidade de um elemento falhar pelo menos uma vez no intervalo de tempo [0,t). F(t)=1-R(t) f(t)= (d /dt)F(t) : densidade de probabilidades de F(t)
tetF λ−−=1)( tetf λλ=)(
λ(t)=f(t)/R(t) é a função taxa de falhas [ou "hazard function" h(t) ]. Represen-ta a probabilidade de um elemento falhar no intervalo de tempo t,t+dt dado que o elemento tem operado normalmente no intervalo 0,t. No caso de componente eletrônico com λ constante significa que essa probabili-dade não depente de t, ou seja, o componente ”não tem memória de sua vida”.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 26
DISTRIBUIÇÃO DE POISSON Supor que um componente tenha taxa de falhas constante λ , portanto não tem “memória”, e quando este componente falhar seja substituído por outro novo e idêntico em um tempo de reparo desprezível em relação ao MTTF do componen-te. Nessas condições pode-se modelar uma sucessão de falhas como se fosse uma repetição de falhas de um único componente que fosse recuperado instanta-neamente. A probabilidade de ocorrer k falhas em um período de tempo t é representada por uma distribuição de Poisson da variável aleatória k.
!)()(k
etkPtk λλ −
=
tkE λ=)( valor esperado do número de falhas em um período de tempo t.
tk λσ =)(2 Variância de k.
CÁLCULO DE R(t) DE REDES: ELEMENTOS EM SERIE:
E1 E2 En
∏=
=n
itRitR
1)()(
ELEMENTOS EM PARALELO:
E1
E2
En
∏=
−−=n
itRitR
1))(1(1)(
SISTEMAS k/n: São sistemas constituídos por n elementos em paralelo que e-xigem pelo menos k elementos funcionando para que o sistema funcione. Quando os todos os elementos são idênticos, com confiabilidade R(t), a confiabi-lidade do sistema é dada por:
∑−
=
− −=kn
i
iinin RRCtRs
0, )1()(
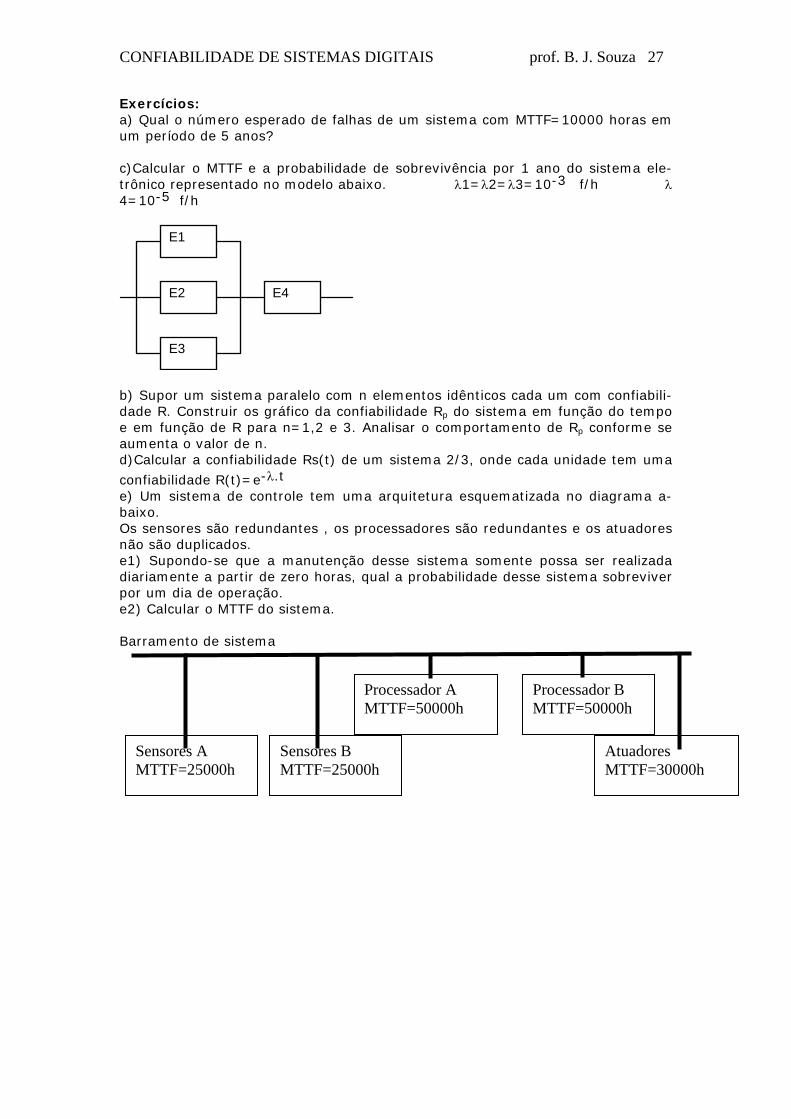
CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 27
Exercícios: a) Qual o número esperado de falhas de um sistema com MTTF=10000 horas em um período de 5 anos? c)Calcular o MTTF e a probabilidade de sobrevivência por 1 ano do sistema ele-trônico representado no modelo abaixo. λ1=λ2=λ3=10-3 f/h λ4=10-5 f/h
E1
E2
E3
E4
b) Supor um sistema paralelo com n elementos idênticos cada um com confiabili-dade R. Construir os gráfico da confiabilidade Rp do sistema em função do tempo e em função de R para n=1,2 e 3. Analisar o comportamento de Rp conforme se aumenta o valor de n. d)Calcular a confiabilidade Rs(t) de um sistema 2/3, onde cada unidade tem uma
confiabilidade R(t)=e-λ.t e) Um sistema de controle tem uma arquitetura esquematizada no diagrama a-baixo. Os sensores são redundantes , os processadores são redundantes e os atuadores não são duplicados. e1) Supondo-se que a manutenção desse sistema somente possa ser realizada diariamente a partir de zero horas, qual a probabilidade desse sistema sobreviver por um dia de operação. e2) Calcular o MTTF do sistema. Barramento de sistema
Sensores A MTTF=25000h
Sensores B MTTF=25000h
Processador A MTTF=50000h
Processador B MTTF=50000h
Atuadores MTTF=30000h

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 28
7. MASCARAMENTO DE FALHAS 7.1- DEFINIÇÃO: São técnicas que, por meio de redundâncias adicionadas a ní-vel lógico ou em nível de módulos ou nível de sistema, permitem que determina-dos modos de falhas internas não provoquem erros na saída. O objetivo dessas técnicas é diminuir a taxa de erros e não a taxa de falhas . Utilizam-se duas técnicas básicas: .Redundância N-modular: Quando a redundância é adicionada nos componentes. .Correção de erros: Quando a redundância é adicionada na informação, de modo que os erros produ-zidos pelas falhas possam ser corrigidos antes de atingir a saída. Nos dois casos, os circuitos podem ou não realizar a detecção da falha. 7.2- REDUNDÂNCIA N-MODULAR: Neste caso, N módulos funcionalmente idênticos realizam simultaneamente a mesma operação. Os resultados produzidos são votados e o "melhor" deles é co-locado na saída. O esquema mais comum é o que utiliza 3 módulos idênticos, e utiliza um votador de maioria(2 em 3) para escolher o valor da saída. Esse méto-do é denominado Redundância Modular Triplicada(TMR-"Triple Modular Redun-dancy").
M1
M2
M3
VOTADORx
y1
y2
y3
y
y1≅y2≅y3≅f(x) y=maioria(y1,y2,y3) maioria(y1,y2,y3)=(y1 e y2) ou (y1 e y3) ou(y2 e y3)

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 29
CONFIABILIDADE DO SISTEMA TMR: R: Confiabilidade de um módulo Rv : Confiabilidade do Votador Considera-se uma rede do tipo 2/3 em serie com o votador: RTMR =Rv (3R2 -2R3 ) Exercício Supondo-se que cada módulo de um sistema TMR tenha uma taxa de falhas cons-tante igual a λ , e o votador tenha uma taxa de falhas constante λv , calcular: (a) a confiabilidade do sistema RTMR(t) (b) o valor do MTTF do sistema TMR . (c)Comparar o MTTF do TMR com o MTTF de um sistema (simplex) constituído por um único módulo. (d)Por quanto tempo o sistema TMR apresentará uma taxa de erros menor que o sistema simplex?
(a) RTMR(t)=e-λv t (3e-2λt -2e-3λt )
(b) MTTFv v
=+
−+
32
23λ λ λ λ
(c) Se λv <<λ então MTTF(TMR)=5/6λ=(5/6)MTTFsimplex (d)Supor λv=k Calcular t1 onde RTMR =Rsimplex .Para t<t1 o TMR é "melhor" e para t>t1 o TMR é "pior". Resolver graficamente para alguns valores de k. 7.3- CORREÇÃO DE ERROS Para a correção de erros são utilizados códigos com redundância suficiente para a correção de t erros e ainda a detecção de p erros.Sendo d a distância do có-digo tem-se: (2t+p+1)=d A classe mais importante é a que utiliza códigos de correção lineares .São códi-gos separados (n,k) onde se acrescenta k bits de paridade aos (n-k) bits de informação.Esses códigos podem ser descritos por uma matriz geradora G e uma matriz de decodificação H. O vetor d com n-k bits de dados é transformado no vetor x com n bits de mo-do que: x=dG (1,n) (1,n-k) ( n-k,n) O vetor x é decodificado de modo que: Hx=s (n-k,n) (n,1) (n-k,1) O vetor s é denominado síndrome. Em geral H é definida de forma que s=0 indica x correto e s ≠0 indica os bits de x a serem corrigidos. Exemplo: código (n=7,k=3) 3 bits de paridade,4 bits de dados <x1,x2,x3,x4,x5,x6,x7>=<d1,d2,d3,d4,p1,p2,p3> p1=d1⊕d2⊕d3 p2=d2⊕d3⊕d4 p3=d1⊕d2⊕d4

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 30
1 0 0 0 1 0 1 G= 0 1 0 0 1 1 1 0 0 1 0 1 1 0 0 0 0 1 0 1 1 Exemplo: código (n=7,k=3) d1 d2 d3 d4 p1 p2 p3 1 1 1 0 1 0 0 H= 1 0 1 1 0 1 0 0 1 1 1 0 0 1 Neste exemplo, s=<s1,s2,s3> quando diferente de 0, indica o número do bit a ser corrigido(caso x contenha um único erro).s=<0,1,1> por exemplo, indica que o bit d4 deve ser corrigido, uma vez que <0,1,1> é a coluna d4 da matriz H. APLICAÇÃO: Os códigos de correção de erros lineares são aplicados principalmente nos siste-mas de memórias RAM ECC. As memórias representam os maiores contribuintes para a taxa de falhas de um computador. Alguns dados de falhas são apresenta-dos abaixo. TAXA DE ERROS X DENSIDADE DA MEMORIA Densidade(bits/pastilha) Taxa típica(% por 1000horas) "Soft" "Hard" 1k 0.001 0.0001 4k 0.02 0.002 16k 0.10 0.011 64k 0.13 0.016 CONFIABILIDADE DA MEMORIA Tipo de Erro MTTF(16Mbyte- pastilhas de 64k bits) Simples "soft"(corrigível) 13.5 dias Simples "hard"(corrigível) 109.7 dias Duplo "soft" 864 dias Duplo "hard" 7021 dias (ref. Electronic Design-setembro 1980) (Dados antigos. A confiabilidade melho-rou muito) SISTEMAS DE MEMORIA COM CORREÇÃO/DETECÇÃO DE ERROS (SEC/DED-"Single Error Correction/Double Error Detection) Esses sistemas utilizam pastilhas de suporte,como por exemplo a AM2960,DP8400(National),etc.compatíveis com expansões da memória. Exercício: -Projetar um sistema de memória de 1Mbyte de dados, para um microcomputa-dor, que utilize o esquema SEC/DED.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 31
7.4- VOTADORES(NIVEL LOGICO) : São circuitos lógicos que realizam a votação de maioria "bit a bit". Podem ser não-sincronizados ou sincronizados. 7.5- MASCARAMENTO DE FALHAS A NIVEL LOGICO Conjunto de técnicas a nível lógico(interno às pastilhas LSI,VLSI principalmen-te)que utilizam códigos corretores de erros e/ou redundâncias lógicas para dimi-nuir a taxa de erros do componente. Em geral as falhas a serem mascaradas são do tipo "grampeadas" em 0 ou 1. Em um tipo de técnica, denominada lógica "interwoven"("inter-fiada"), o circuito é organizado em estágios, de modo que as falhas críticas nas saídas de um está-gio tornam-se subcríticas no estágio seguinte e finalmente mascaradas no estágio final. Cada estágio usa redundância a nível de "gates" e a "fiação" de um estágio para outro obedece determinados padrões pré-estabelecidos. Teoricamente pode-se implementar qualquer tipo de função lógica que tolera um determinado núme-ro de falhas. Tipo de Porta lógica Falha Critica Falha Sub-Critica AND 1→0 0→1 OR 0→1 1→0 NOT 0→1,1→0 Nenhuma NAND →0 0 →1 VOTADOR Nenhuma 0→1,1→0 Exercícios: -Projetar um circuito votador síncrono (combinatório). -Projetar um circuito votador para 3 sinais pulsados de freqüências idênticas, sendo que a defasagem entre os pulsos pode chegar a 10% do período. -Projetar um circuito para a função Z=( ( XY )W ) que tolere 1 falha crítica na entrada.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 32
IV-TÉCNICAS DE DISPONIBILIDADE 1-MODELAGEM 1.1- DISPONIBILIDADE: A função disponibilidade A(t), representa a probabilidade de um sistema estar operando no instante t. A disponibilidade assintótica A é definida por: A=limA(t) t→∞. A pode ser interpretada como a fração do tempo em que o sistema opera nor-malmente. Assim, se A=0,99 significa que o sistema opera normalmente 99% do tempo. 1.2- PROCESSOS DE MARKOV: Um processo de Markov é um processo estocástico definido por um conjunto finito de estados, um conjunto de transições de estado e uma probabilidade asso-ciada a cada transição. Dado que o processo ocupa um estado i, no instante t, a probabilidade da primeira transição ocorrer para um estado j ,representada por pij , não depende dos estados ocupados anteriormente, mas somente do estado i. As probabilidades pij serão representadas por: pij =λij∆t onde λij é uma taxa constante e ∆t um intervalo de tempo tal que pij ∆t <<1. Os processos de Markov serão representados por um diagrama de transições de estados com indicações das taxas ao lado de cada transição.
i
λ
λk1,i
λ
λ
λ
λ
k,i
km,i
i,j1
i,j
i,jn
Para cada estado i, a seguinte condição deve ser satisfeita:
∑=n
nii ,λλ
i
jijip
λλ ,
, =
1, =∑n
nip

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 33
. PROBABILIDADE DE OCUPAÇÃO DOS ESTADOS: Serão considerados apenas os processos de Markov representados por cadeias simples. Uma cadeia simples contem um número finito de estados e é irredutível, ou seja, todos os estados são alcançáveis a partir de qualquer estado. Assim não existem estados absorventes (terminais). A probabilidade de ocupação πi(t) é a probabilidade do processo ser encontrado no estado i no instante t . Esses valores podem ser calculados resolvendo-se o seguinte sistema de equações diferenciais:
[ ]Atdt
td )()( ππ= com a condição: π i
i
t∑ =( ) 1
onde π(t) é um vetor linha [π0(t) π1(t)...... πn(t)] e [A] é uma matriz definida da seguinte forma:
jijiA ,, λ= para i≠j ∑≠
−=ik
kiiiA ,, λ
Na condição limite, t→∞ tem-se que dπ(t)/dt=0 de modo que: π[A]=0. Nesse caso πi(t) será representado simplesmente por πi. TEMPOS DE ESPERA NOS ESTADOS Quando um estado i é alcançado o processo permanece nesse estado por um pe-ríodo de tempo ti aleatório. Esse tempo de espera tem distribuição exponencial dada por:
)exp(1)( tttp ii λ−−=≤
O valor médio Ti do tempo de espera é portanto i
iTλ1
=
TEMPOS DE RECORRÊNCIA O tempo de recorrência de um estado i é o tempo que o processo leva para re-tornar ao estado i , medido a partir do instante que o processo chegou ao estado i pela última vez. Esse tempo tem uma distribuição mais complexa, mas o valor médio pode ser calculado pela expressão:
i
iii
Tmπ
=,
TEMPOS DE PRIMEIRA PASSAGEM O tempo de primeira passagem de um estado i para um estado j é o tempo que o processo leva para chegar ao estado j pela primeira vez, medido a partir do ins-tante que o processo chegou ao estado i. Esse tempo tem uma distribuição mais complexa, mas o valor médio pode ser calculado resolvendo-se o sistema recursi-vo:
∑≠
+=jk
jkkiiji mpTm ,,,

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 34
1.3- CÁLCULO DA DISPONIBILIDADE DE UM SISTEMA: Um sistema pode ser modelado por um processo de Markov onde os estados re-presentam as situações operacionais em que o sistema pode ser encontrado. Es-sas situações podem ser estado normal ou estado falho ou estado degradado. As taxas λij representam taxas de falhas de elementos e as taxas µij representam taxas de reparo dos elementos do sistema. Nessas condições a função disponibili-
dade A(t) pode ser calculada por: A(t)= ∑∈Di
i t)(π ,onde D é um subconjunto
de estados para os quais se considera que o sistema , como um todo, esta ope-rando normalmente. EXEMPLO 1: Calcular a disponibilidade de um equipamento com MTTF=1000 ho-ras e tempo médio de reparo MTTR=1 hora.
0: normal 1: falho
λ
µ
Esse sistema pode ser representado por um modelo de Markov com dois estados: 0-normal e 1-falho. O sistema transita de 0 para 1 quando ocorre uma falha, que se supõe com taxa constante λ. O sistema transita de 1 para 0 quando é comple-tado o reparo do sistema. A taxa de reparo é suposta igual a µ reparos/hora. λ01=λ=10-3 falhas/h µ10=µ=1 reparo/h -λ λ π=[π0 π1] [A]= µ -µ O sistema de equações diferenciais para esse caso fica:
)()()(10
0 ttdt
td µπλππ+−= 1)()( 10 =+ tt ππ

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 35
resolvendo-se o sistema:
])(exp[)(0 tt µλµλ
λµλ
µπ +−+
++
=
])(exp[)(1 tt µλµλ
λµλ
λπ +−+
−+
=
Em equilíbrio (valores assintóticos) tem-se que π[A]=0 Com a condição : π0+π1=1 obtém-se: π0=µ / (λ+µ) e π1=λ / (λ+µ) A disponibilidade assintótica é a probabilidade do sistema ser encontrado no esta-do 0 (normal) depois de um tempo muito grande. A=π0 e portanto A=µ/(λ+µ) ou A= MTTF / (MTTF+MTTR) A=0,9990 (99,9%). EXEMPLO 2: Calcular a disponibilidade de um sistema duplicado,onde cada equi-pamento tem um MTTF=1000 horas e o tempo médio de reparo para um ou dois equipamentos é de 1 hora (MTTR=1 hora). Modelo de 3 estados: estado 0:E1 e E2 normais estado 1:E1 ou E2 falho estado 2:E1 e E2 fa-lhos.
0:normal 1:operacional 2:falho
2λλ
µµ
A transição do estado 0 para o estado 1 representa a falha de E1 ou E2.Como as taxas de falha são idênticas (MTTF1=MTTF2=1/λ) λ01=2λ . A transição de 1 para 2 representa a falha de apenas 1 equipamento e λ12=λ. [A]= -2λ 2λ 0 π[A]=0 e ∑πi=1 -µ -(λ+µ) λ µ 0 -µ obtém-se:

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 36
π µλ µ
02
=+
π λµλ µ λ µ
1 22
=+ +( )( )
π λλ µ λ µ
2 22
2
=+ +( )( )
A = + =+
+ +=π π µ λµ
λ µ λ µ0 1 3
20 999998
2
( )( ).
Exercícios: a)Calcular a disponibilidade de um sistema duplicado com duas unidades idênti-cas de MTTF=1000 horas cada uma e com tempos médios de reparo iguais a 1 hora para uma unidade e 2 horas para duas unidades falhas simultaneamente. b)Recalcular a disponibilidade de um sistema definido no exercício anterior, na situação em que o reparo de duas unidades falhas simultaneamente é executa-do, primeiro repondo-se uma das unidades, em seguida religando-se o sistema e finalmente repondo-se a outra unidade. c) Um servidor dual é configurado com dois computadores idênticos, uma unidade de discos espelhados (UD) e um sistema de comunicações de dados (SisCom) conforme o esquema abaixo.Os dados de confiabilidade desse sistema são: MTTF(horas) MTTR(horas) Computador 50000 1 UD 20000 1 SisCom 10000 2 C1) Calcular a disponibilidade assintótica desse servidor. C2) Calcular o tempo médio entre duas intervenções consecutivas de manuten-ção(Reparo de uma parte qualquer do servidor). C3) Calcular o MTTF do sistema. Bar UD SERVIDOR
Computador A Computador B SisCom

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 37
1.4- CONCEITOS SOBRE TÉCNICAS DE DISPONIBILIDADE Um sistema pode ser encontrado em três principais estados: normal degradado ou falho. Em geral considera-se o sistema disponível mesmo que este não realize todas as funções previstas para o estado normal, quando este se encontra em um estado degradado. A disponibilidade é aplicável portanto a cada função inde-pendente do sistema. Em relação a cada uma das funções, a disponibilidade pode ser melhorada com um aumento da confiabilidade (maior MTTF) dos recursos ne-cessários para a realização da função e melhoria dos mecanismos de recuperação dos recursos falhos(menor MTTR). PRINCIPAIS EVENTOS NA OPERAÇÃO DO SISTEMA
SISTEMA NORMAL manutenção
falha mascaramento detecção (esgotamento da redundância) (transitória) retentativa (permanente) diagnostico isolação reconfiguração (esgotamento da redundância) reinicio recuperação (falha catastrófica) SISTEMA DEGRADADO Reparo reintegração
SISTEMA FALHO

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 38
2-ARQUITETURAS TOLERANTES A FALHAS 2.1- TIPOS DE ARQUITETURAS : As arquiteturas de computadores em aplicações que exigem alta confiabilidade podem ser inicialmente classificadas conforme a aplicação exija operação ininter-rupta (non-stop) ou não. No primeiro caso estão as aplicações em controle de processos críticos(veículos de transporte, geração e distribuição de energia, con-trole de tráfego, comutação telefônica,etc.). O segundo caso inclui o processa-mento de dados em geral. A principal diferença nestes dois tipos de sistemas reside no tempo disponível pa-ra reintegração dos elementos de reserva. Em um sistema de operação ininter-rupta os elementos de reserva devem permanecer ligados , com status perma-nentemente atualizados e prontos para entrarem em operação imediata ("hot -standby"). Nos demais sistemas a reserva pode eventualmente permanecer desli-gada(ou como é mais freqüente, realizando outras tarefas), de modo que sua reintegração pode causar uma parada temporária do sistema("cold-standby"). Quanto à principal técnica de projeto da arquitetura em função da aplicação tem-se: Sistema não interrompivel (non-stop) a)MASCARAMENTO DE FALHAS b)REDUNDANCIA N-MODULAR sistema interrompível a)REDUNDANCIA N-MODULAR No caso da redundância N-modular um esquema geral dessas arquiteturas pode ser representado da seguinte forma:
M1
M2
M N+R
CHAVE
N+R
/
N
x
y1
y2
yN+R
DETECTOR(comutador)
VOTADOR
s1
s2
s N
y

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 39
A reserva operacional é um conjunto de R unidades em condições de substituir qualquer uma das N unidades ativas do sistema. Qualquer uma das unidades tem a capacidade de realizar um conjunto de funções essenciais f1,f2,...fn e um conjunto de funções auxiliares a1,a2,...ax. As funções essenciais devem ser instaladas em todas as N+R unidades, enquanto que as funções auxiliares podem ser distribuídas de uma forma qualquer entre elas. Quando uma unidade ativa que realiza uma função auxiliar ai é substituída por uma outra que não contém essa função, a operação do sistema pode ficar degra-dada. Esse tipo de degradação é denominado degradação suave ("gracefull de-gradation"). AÇÃO DO DETECTOR/COMUTADOR (DC): Este elemento opera associado ao votador, realizando principalmente a função de reconfiguração do sistema. O algoritmo do elemento DC pode ser representado por: .Enquanto existir reserva disponível: .Se ( y i ≠y)e(yk=y)e(Mk não interligada) então : .desliga Mi .interliga Mk Esse algoritmo aplica-se ao caso em que toda a reserva permanece on-line-ligada. Existem entretanto outras possibilidades quanto à operação da reserva: .On-line-Ligada (reintegração totalmente automática) .On-line-Desligada (reintegração totalmente automática) .Off-line (reintegração parcialmente manual) CONFIABILIDADE DO SISTEMA O sistema evolui passando por um estado de esgotamento da reserva , perda do limiar de consenso do votador e finalmente para o estado falho. Para sistemas sem reparo a função confiabilidade tem um limite superior que pode ser expresso por:
Rs Rvcd C N R i Rm RmN R i i
i
p
= + −+ −
=∑ ( , ) ( )( ) 1
0
p= ⎣N/2⎦+R R:número de unidades de reserva Rm=Confiabilidade de um módulo Exercício Construir um gráfico de Rs em função de Rm , supondo Rvcd=1 e N=3, para os seguintes valores de R: R=0: Rs=Rm : sistema simplex R=0: sistema TMR R=1 : 1 unidade de reserva On-line-ligada R=2 : 2 unidades reserva On-line-ligadas Para R=0,1,2 qual o valor mínimo de Rm tal que a confiabilidade do sistema Rs é maior que a confiabilidade do sistema simplex (R s>R m)? 2.2- EXEMPLOS DE CONFIGURAÇÕES a) SISTEMAS DUAIS : R= ∞, Off-line-desligada

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 40
(Votador):Comparação 1/2 ou 2/2("Dual-Fail safe") MÉTODOS DE RECONFIGURAÇÃO (1): A unidade ativa roda programa de diagnóstico continuamente. Se detectar alguma falha, comuta a chave para a outra unidade que passa a ser a unidade ativa. (2): As duas unidades rodam auto-teste. Quando ocorrer simultaneamente dis-crepância na saída das duas unidades e detecção de falha na unidade ativa, o comparador realiza a comutação. Caso ocorra detecção de erro nas duas unida-des, ambas rodam um programa de diagnóstico. A unidade que conseguir passar pelo diagnóstico primeiro, assume o controle como unidade ativa. (3):A unidade ativa controla um "watchdog timer". Se falhar na desativação do WDT, a outra unidade assume o controle automaticamente. (4):Um circuito de arbitragem externo contém uma constante que é continua-mente comparada com valores produzidos pelas duas unidades. Se a unidade ati-va não produzir um resultado correto o árbitro realiza a comutação. MÉTODOS DE SINCRONIZAÇÃO (1): nível de relógio .Utiliza relógio comum ou relógios duplicados com amarração de fase. (2): nível de instrução. As unidades de controle dos dois processadores realizam um protocolo de comunicação de dados dentro do ciclo de cada instrução. As fa-ses dos ciclos de instrução são ajustadas com a introdução de ciclos de "wait". (3): nível de cálculos .Os resultados de cálculos das duas unidades são transmiti-dos a um comparador.Além da comparação,este gera sinais de interrupção para a unidade mais rápida a fim de atrasa-la. (4): nível de software .As unidades trocam mensagens contendo resultados de cálculos para comparação.O protocolo de comunicação do tipo envia/aguarda mensagens permite a sincronização dos dois processos. b) SISTEMAS N-MODULARES MÉTODOS DE RECONFIGURAÇÃO (1): NMR/Simplex. Inicialmente a configuração é NMR(N impar)..Quando uma u-nidade falha, esta e uma outra unidade vão para a reserva. Assim um sistema TMR passa para Simplex sempre que uma unidade falha. (2) "Self-Purge". Inicialmente todas as unidades são conectadas ao votador. À medida que falham, estas vão sendo removidas para a reserva. (3) Redundância Híbrida. Corresponde ao esquema geral definido em 2.1. MÉTODOS DE SINCRONIZAÇÃO (idem, sistemas duais) MÉTODOS DE VOTAÇÃO O elemento que está sendo denominado VOTADOR pode na realidade realizar qualquer outra função de escolha de resultados produzidos pelas unidades. Entre estas pode ser utilizada por exemplo uma votação adaptativa onde o "número de votos" de cada unidade varia dinamicamente. Entretanto os vários esquemas de

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 41
votação geralmente utilizam um número impar de unidades para evitar o proble-ma de empate. Um outro tipo de escolha, mais utilizado quando o número de unidades é par, corresponde a estágios sucessivos de comparações. Por exemplo, um sistema com 4 unidades pode utilizar um esquema 2/4, em uma configuração denominada DUAL-DUAL. V- TÉCNICAS DE MANUTENIBILIDADE 1. ASPECTOS DA MANUTENÇÃO DE SISTEMAS As técnicas de manutenibilidade visam minimizar principalmente dois fatores: o MTTR e a taxa de falso alarme . O falso alarme corresponde às chamadas para manutenção originadas principal-mente por diagnóstico incorreto e falhas transitórias. Alguns levantamentos reali-zados mostram que a taxa de falso alarme chega a ser de duas a quatro vezes a taxa efetiva de falhas no sistema. Quanto à manutenção propriamente dita, duas distribuições são mais importan-tes: a distribuição dos tempos de reparo (TTR) e a distribuição de horas de traba-lho para o reparo(H.H). Essas distribuições são distintas uma vez que em geral, quando um técnico gasta mais de um certo número de horas para reparar o sis-tema um outro técnico mais experiente é enviado ao campo, e assim sucessiva-mente. As distribuições típicas desses tempos são esquematizadas abaixo. % MTTR=4.4 25 mediana=2.0 20 15 20% das chamadas geram reparos entre 0 e 1 hora 10 5 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 >20 TTR % 35% 10 media=6.3 9 mediana=3.0 8 7 6 5 4 3 2 1 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 >20 HH

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 42
2 - PROJETO P/ MANUTENIBILIDADE Algumas técnicas de projeto podem ser empregadas visando minimizar o MTTR e a taxa de falso alarme. O MTTR depende essencialmente dos procedimentos de detecção e diagnóstico das falhas implementados no sistema. Em sistemas de alta disponibilidade o diagnóstico é preferencialmente realizado em diferentes níveis, conforme os procedimentos de reparo utilizados. O nível mais alto de diagnóstico é realizado em nível de UNIDADE DE REPARO EM CAMPO (URC). Uma vez diagnosticada a URC falha, a manutenção é efetuada por simples substituição .Essa substituição, dependendo da configuração do sistema, pode ser realizada automaticamente se houver reserva "on-line". A URC falha é consertada em laboratório e novamente adicionada à reserva, ou simplesmente descartada, dependendo do porte da URC. O conserto da unidade depende de níveis de diagnóstico mais refinados, realizados "off-line”, com auxílio manual. A facilidade de detecção de falhas e conserto de uma URC está direta-mente relacionada a um atributo de projeto denominado TESTABILIDADE . A questão do falso alarme esta associada à qualidade e precisão do diagnóstico em nível de URC, e aos procedimentos de retentativa implementados. Neste úl-timo caso, a retentativa procura eliminar os falsos diagnósticos de falhas perma-nentes. A maior parte das falhas ocorridas em um sistema é de natureza transitó-ria, sendo que uma dificuldade importante neste caso é distinguir uma falha tran-sitória de uma falha intermitente. As principais recomendações de projeto visando a manutenibilidade podem ser resumidas da seguinte forma: - Projeto estruturado com ênfase na modularidade. - Isolação de ambientes de subsistemas independentes. - Auto-Testes nos subsistemas(mecanismos de detecção/correção/diagnóstico). - Observabilidade e controlabilidade de estados internos dos módulos. - Relatórios de estatísticas de falhas e erros. - Minimização do uso de equipamentos externos(p.ex. Analisadores lógicos). - Projeto do empacotamento que facilite a substituição(sem desenergização do sistema). - Reparo baseado em reposição(sem "swap" de módulos). - Emprego de processadores independentes para diagnóstico(eventualmente re-motos) 3. TESTABILIDADE 3.1 CONCEITO A testabilidade de um módulo (hardware ou software)corresponde à facilidade com que este pode ser testado. Uma conclusão sobre o funcionamento correto do módulo, para todas as entradas, ou a identificação dos componentes internos que estão falhos ou com defeitos, são os principais aspectos relacionados com a testabilidade. 3.2 TESTE E DIAGNÓSTICO A NÍVEL LÓGICO No nível lógico a testabilidade está relacionada com a observabilidade e controla-bilidade dos estados internos do circuito. A observação dos estados internos pode ser realizada diretamente por meio de pinos de teste ou fiação de alguns sinais para conectores, por exemplo, ou indiretamente através dos sinais de saí-da.(Obs.- No primeiro caso, as recomendações mais indicadas podem ser vistas nas apostilas dos laboratórios digitais). A observação indireta, através das saídas, consiste em calcular um conjunto de entradas que produzem na saída um valor igual ao estado interno a ser observa-do. Algumas técnicas são propostas, como por exemplo os cálculos por diferença booleana para circuitos combinatórios.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 43
3.3 PROJETO ESTRUTURADO DE CIRCUITOS SEQÜENCIAIS No caso de circuitos seqüenciais o projeto pode ser realizado de modo que todos os sinais de estado fiquem reunidos em um registrador de deslocamento com carga e saídas paralelas (Ao invés de espalhar-se os estados em Flip-Flops). Em operação normal, o registrador de estados é atualizado por meio de carga pa-ralela. No modo "teste”, o registrador pode ser carregado pela entrada serial ("Scan In"), permitindo a controlabilidade externa do circuito. A leitura serial ("Scan Out") permite a observabilidade dos estados através de um único fio. Essa técnica, empregada, por exemplo, já nos computadores IBM 4341 e é de-nominada técnica LSSD("Level Sensitive Scan Design").

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 44
VI CONFIABILIDADE DO SOFTWARE 1. CONCEITOS Os erros produzidos por um sistema são de um modo geral originados por quatro motivos principais: as falhas de componentes, solicitações físicas externas não previstas, entradas imprevistas, operação imprópria e defeitos de projetos. Os erros devidos ao software exclusivamente podem ser considerados como causa-dos basicamente por defeitos de projeto("bugs"). Em outras palavras, o software sem defeito não falha. As duas principais técnicas de combate aos erros de um sistema, como a preven-ção de falhas("fault avoidance") e a tolerância à falhas ("fault tolerance"), podem ser empregadas para o projeto do software. A prevenção de falhas no caso signi-fica a realização de um projeto do software acompanhado de um rígido controle de qualidade. Neste caso as técnicas de verificação e validação (V&V) estudadas pela Engenharia de Software representam fundamentalmente técnicas de preven-ção de falhas, ou mais apropriadamente, prevenção de defeitos de projeto. Entretanto, do mesmo modo que a prevenção de falhas no hardware não garante a infalibilidade deste, a produção de software com "zero defeitos" ainda pode ser considerada na prática um objetivo muito longe de ser atingido, e muitos conside-ram por motivos muito fortes que esse objetivo é na realidade inatingível, exceto eventualmente para uma classe de software de baixa complexidade e de produ-ção altamente automatizada. As técnicas de tolerância à falhas no software têm por objetivo minimizar a taxa de erros do sistema provocadas por falhas no software. Não se conhece ainda al-guma técnica que possa de fato eliminar essas falhas e, ainda como no hardware, o que se procura com a tolerância à falhas é obter um sistema com uma probabi-lidade de apresentar erros dentro de certos limites pré-estabelecidos. Esses re-quisitos dependem principalmente da aplicação do sistema e de uma relação cus-to/beneficio aceitável. 2. ERROS DO SOFTWARE A fim de se caracterizar alguns conceitos relativos ao software será adotado um modelo simples de um software em geral, definido por uma especificação e um conjunto de algoritmos. A especificação é um mapeamento do tipo Y=f(X), onde Y é um espaço das saídas, X é o espaço das entradas, mais comumente denomi-nado de Domínio das Entradas, e f uma função bem definida pela especificação. Os algoritmos são construções do software que visam realizar a função f de mo-do que Y = Ak(X), onde Ak é o algoritmo candidato. Nesse caso, uma falha do software é um resultado yi=Ak(xi) tal que yi≠f(xi). O que convém destacar nes-sa definição é que não se define falha de software se não for dada uma especifi-cação. Ou de outra forma, um software definido simplesmente por Y=Ak(X), passa a ser a própria especificação, de modo que este "deve se comportar como se comporta”. Não produz erros. Em situações nas quais o único usuário é o pró-prio programador, a questão da existência ou não de erros é "pessoal”. Em sis-temas de alguma aplicação geral, entretanto a questão da especificação e conse-qüentemente dos erros assume um aspecto muito importante. Uma característica particular do software é que a ocorrência das falhas é deter-minadas por um subconjunto de pontos do domínio das entradas X para os quais este responde incorretamente. Se a probabilidade de ocorrência de uma dessas entradas for muito pequena é possível que o software não venha a falhar durante todo seu período de operação. Corresponde aproximadamente a falhas transitó-rias, intermitentes ou "sensíveis a padrões" no caso do hardware. O perfil operacional do software é uma distribuição de probabilidades definida so-bre o domínio X. Conforme o ambiente de operação do software esse perfil pode se alterar.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 45
3. CONFIABILIDADE DO SOFTWARE Existe alguma controvérsia quanto às formas de quantificar a confiabilidade do software. Intuitivamente ou por analogia ao hardware, aceita-se dizer que quanto mais tempo um software permanece em execução sem apresentar falhas , maior é sua confiabilidade. Um outro aspecto também geralmente aceito é que mais cedo ou mais tarde o software falha, ou seja não é perfeito. Com essas duas premissas em mente po-de-se definir uma função confiabilidade R(t) para o software como sendo a pro-babilidade deste ser executado sem apresentar falhas desde o início de operação (t=0) até o instante considerado. Durante esse intervalo de tempo, se o soft-ware não sofrer alterações, a curva R(t) deve ser decrescente. A variável t con-siderada aqui foi o "tempo de execução" e pode não corresponder necessariamen-te ao tempo real , nos casos em que o sistema não opera ininterruptamente. Quando a operação do software é mais caracterizada pelo número de execuções ("rodadas"), a função confiabilidade pode ser expressa na forma R(n), indicando a probabilidade do software ser executado sem apresentar erros até a enésima rodada. Os parâmetros associados à confiabilidade do software podem ser definidos por uma confiabilidade assintótica, ou seja, limite de R(n) para n tendendo a infinito,
estimada por Rnfn
=
onde n é o número de execuções realizadas e nf o número de execuções nas quais o software apresentou falhas. Um outro parâmetro é o MTTF, ou seu inverso λ correspondente à taxa de fa-lhas. O tempo médio para falhar MTTF , por analogia ao hardware, mede o tempo mé-dio que o software demora em apresentar uma falha. O estudo da confiabilidade resume-se essencialmente na busca de métodos para predição e estimativa desses parâmetros, com base em modelos "a priori" da fun-ção confiabilidade e testes do tipo "caixa preta" realizados sobre o software. Esses estudos podem ser vistos por exemplo na referência [ Musa]. Uma das principais dificuldades específicas do software, com respeito à modela-gem para estimativa da confiabilidade, reside na aplicação do princípio do cresci-mento da confiabilidade("Reliability Growth"). No caso do hardware é mais fácil aceitar-se a hipótese de que quanto mais o hardware é testado, sua confiabilidade aumenta (A tendência é eliminar os defei-tos do projeto que causam falhas). No software entretanto observa-se uma situ-ação muito comum em que a correção de um defeito acaba na realidade introdu-zindo outros, às vezes em maior quantidade do que os corrigidos. Com relação à modelagem da confiabilidade do software , essa consideração pode levar a mode-los intratáveis e não muito úteis. Com o aperfeiçoamento das técnicas de manu-tenção do software, e em geral de todo o processo de produção, a tendência é assumir-se o princípio de crescimento da confiabilidade à medida que o software é testado e defeitos são corrigidos. Isso viabiliza também a utilização de modelos mais adequados e úteis. Para efeito de exemplificação será considerado aqui o modelo Logaritmo-Poisson desenvolvido por Musa [3]. Nesse modelo a taxa de falhas de um software de-cresce à medida que as falhas ocorrem. Toda vez que uma falha ocorre o softwa-re é modificado com a finalidade de corrigi-lo e evitar que esse tipo de falha ve-nha ocorrer novamente. Assim: λ(µ)=λ0exp(-θµ) onde: µ(t) : número médio de falhas observadas até o instante t

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 46
t : tempo acumulado de execução. λ0 : taxa de falhas inicial. θ : intensidade de decréscimo da taxa de falhas. t: tempo de execução. Nesse modelo a taxa de falhas decresce à medida que o software é corrigido. Du-rante a fase de depuração do software os instantes de ocorrência das falhas são registrados, o número de falhas acumulado é contabilizado e com esses valores pode se estimar os parâmetros θ e λ0 . Com esses parâmetros pode-se calcular a taxa de falhas correspondente ao início da fase de operação. Nessa fase, a taxa de falhas permanece constante até a primeira falha, quando então o software so-fre uma manutenção e a taxa melhora de acordo com os mesmos parâmetros θ e λ0. Nesse aspecto a diferença quanto à falha de um componente do hardware, com taxa de falhas inicial λh é que quando este componente falhar será substituído por um outro com a mesma taxa . Um módulo de software com taxa de falhas inicial λ0, quando falhar será substituído por um outro módulo (corrigido) com taxa λs menor que a anterior. Esse modelo exige uma detecção de falhas per-feita. Esse tipo de modelagem poderá corresponder a uma aproximação aceitável na medida em que a equipe de manutenção tenha o mesmo perfil da equipe de pro-dução("mesmo θ ") e o perfil operacional do software corresponda em boa apro-ximação ao perfil operacional utilizado na fase de depuração e testes. Para se estimar os parâmetros do modelo é necessário registrar os instantes de ocorrência das falhas t1, t2, ..., ti, ...tme . (medidos no relógio de tempo de exe-cução). Com esses valores anotados é possível utilizar o método dos mínimos quadrados para a estimativa dos parâmetros.
θµλλ −= 0lnln
ri : estimativa de λ no instante de ocorrência da falha i . Pode ser calculada pelo valor de ti e do número de falhas observadas até esse instante (µ=i ). Os parâ-
metros pode ser estimados plotando-se os pontos irri ×−= θ0lnln e traçan-
do-se a “reta média”. (regressão linear simples).
)1ln(1)( 0 +×= tt θλθ
µ 1
)(0
0+×
=t
tθλ
λλ
F
Pλλ
θµ ln1
=∆ )11(1
PFt
λλθ−=∆
Pλ : Taxa de falhas no instante atual (presente).
Fλ : Taxa de falhas em um instante futuro.
t∆ : Tempo esperado de teste para que a taxa de falhas atinja o valor Fλ
supondo-se que atualmente a taxa de falhas é Pλ .
µ∆ : Numero de falhas adicionais esperadas no teste para que a taxa de fa-
lhas atinja o valor Fλ supondo-se que atualmente a taxa de falhas é Pλ .
)]()([exp()( itttR µµ −−=
Confiabilidade do software no instante t dado que a última falha observada (e portanto a última modificação) ocorreu no instante ti .

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 47
Exercício: Um servidor tem uma arquitetura ilustrada na figura abaixo.i Rede Local Disco SERVIDOR A aplicação é um serviço de cartório utilizado na autenticação de documentos. Cada análise de documento é realizada apenas por um dos computadores SWx ou SWy, não havendo comunicação entre eles para efeito da aplicação. Foram experimentados dois programas para o serviço , o ADx e o ADy. No primeiro mês foi utilizado o ADx instalado nos dois computadores. Para cada falha observada o instante de ocorrência foi anotado, o relógio foi parado e o fornecedor do softwa-re realizou uma modificação com o propósito de corrigir algum problema. En-quanto o fornecedor não providenciava uma nova versão os erros subseqüentes eram ignorados .No segundo mês procedeu-se da mesma forma para avaliar o software ADy. Os instantes anotados são os seguintes: (horas) t1 t2 t3 T4 t5 t6 t7 t8 t9 t10 Fim
teste
ADx 0.1 0.2 0.6 1.2 2.4 21.0 52.0 205.0 510.0 700.0 720.0
(horas) t1 t2 t3 T4 t5 t6 t7 t8 t9 t10
ADy 0.5 1.0 1.1 2.2 3.5 5.0 12.0 32.0 58.0 210.0 720.0
a)Avaliar a confiabilidade dos dois softwares. b) Se apenas um dos softwares tiver que ser utilizado no servidor, qual deve ser a melhor escolha entre ADx e ADy ?. Considerar que em operação a ocorrência de falha no aplicativo obriga cada documento ser analisado manualmente, de modo que o custo da falha é bastante alto.Além disso, o fornecedor prestará as-sistência técnica por um período de 2 anos. c) Calcular a probabilidade desse servidor sobreviver por um mês de operação (720 horas), considerando que é utilizado apenas o software escolhido no item 3. instalado nos dois computadores. d) Calcular a probabilidade desse servidor sobreviver durante o terceiro mês de operação (720 horas) considerando que SWx=ADx e SWy=ADy foram instala-dos logo após os dois primeiros meses de testes. Utilizar o modelo logaritmo-Poisson
θµλµλ −= e0
)( θµλλ −= 0lnln ou θµλλ +−=− 0lnln
ti instante da falha ri taxa de falhas instantânea estimada (falhas por inter-valo de tempo)
Computador A SWx
Computador B SWy Roteador

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 48
i ti ADx ri ADx -ln ri ADx
ti ADy ri Ady -ln ri ADy
1 0.1 1/0.1=10.0 -2.3 0.5 2.0 -0.69 2 0.2 1/(0.2-0.1)=10.0 -2.3 1.0 2.0 -0.69 3 0.6 1/(0.6-0.2)=2.50 -0.9 1.1 10.0 -2.3 4 1.2 1/(1.2-0.6)=1.66 -0.5 2.2 0.91 0.09 5 2.4 1/(2.4-1.2)=0.83 0.18 3.5 0.77 0.26 6 21.0 1/(21-
2.4)=0.054 2.9 5.0 0.67 0.4
7 52.0 1/(52-21)=0.0322
3.4 12.0 0.14 1.97
8 205.0 1/(205-52)=0.0065
5.0 32.0 0.05 3
9 510.0 1/(510-205)=0.0033
5.7 58.0 0.038 3.3
10 700.0 1/(700-510)=0.0053
5.2 210.0 0.0066 5
(fim) 720.0 1/(720-510)=0.0048
5.3 720.0 0.0015 6.5

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 49
4. SOFTWARE TOLERANTE A FALHAS A tolerância a falhas no software é um conjunto de técnicas que visam detectar a ocorrência de falhas no software durante sua execução e não permitir que as es-sas falhas venham produzir erros no sistemas. Os defeitos no software são defei-tos de projeto que não foram detectados na fase de testes, de modo que para um certo subconjunto do domínio das entradas Xe, o algoritmo implementado produz um resultado Ye=A(Xe) ≠f(Xe) ou seja, fora da especificação. Durante a execução do software se ocorre uma dessas entradas em Xe o softwa-re deverá falhar, e o resultado incorreto em Ye poderá propagar-se no sistema e produzir erro na saída. O problema é que esse subconjunto Xe é desconhecido e o fato dos resultados Ye serem diferentes de f(Xe) somente podem ser reconhe-cidos por um observador ideal ("oráculo") externo que conheça e calcule correta-mente a função f . As técnicas de tolerância a falhas propostas são na realidade formas de minimizar a geração de erros, de modo que o sistema tolere um certo número de fa-lhas(causadas por defeitos), mascarando essas falhas e não permitindo que ve-nham a produzir erros. As principais técnicas de tolerância à falhas no software são denominadas Blocos de Recuperação("Recovery Blocks") e n-Versões(n-Version") propostas inicialmente por Horning e Avizienis respectivamente. Essas técnicas utilizam três conceitos amplamente empregados no caso do hardware que são, a detecção de falhas, redundância e independência. A redundância e independência , no ca-so, comparecem associadas no conceito de diversidade. A diversidade apoia-se na hipótese de que dados dois algoritmos Ai e Aj para a mesma especificação f(X) e Se yi(x)=Ai(x)≠f(x) e yj(x)=Aj(x)≠f(x) então p(yi=yj)< ε caso Ai e A j forem o suficientemente diversificados. Os dois algoritmos podem estar incorretos para uma mesma entrada x ,entretanto a probabilidade de produzirem resultados incorretos, porem idênticos, pode ser muito baixa. Esta hipótese sozinha pode contornar o problema da detecção de falhas. Resta entretanto, uma vez detectada a falha, produzir um resultado pelo menos aceitá-vel na sadia, que pode não ser o especificado. Se essa situação ocorrer diz-se o sistema degradou-se, mas não de forma drástica("gracefull degradation"). 4.1 O ESQUEMA DE BLOCOS DE RECUPERAÇÃO Um Bloco de Recuperação(BR) é constituído por uma lista ordenada de algo-ritmos diversificados Y=Ai(X), i=2,..n e um Teste de Aceitação T(y). O resultado produzido pelo BR é o primeiro resultado y da lista tal que T(y) é verdadeiro, ou um erro detectado caso nenhum algoritmo produza um resultado aceitável. Uma forma proposta de representar um BR e que preserva a estrutura de blocos da maior parte das linguagens de programação, pode ser ilustrada por:

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 50
ensure <T(y)> by <y=A1(x)> else by <y=A2(x)> . . else by <y=An(x)> else error A última cláusula significa que nenhum dos algoritmos produziu um resultado a-ceitável, segundo o critério T, e neste caso o erro é fatal, porem detectado. O en-cadeamento de blocos pode ser obtido substituindo-se qualquer <Ai(x)> por um BR interno. Uma saída else error de um bloco interno provoca automaticamen-te uma saída deste tipo no bloco que o envolve. O projeto de um BR envolve a construção do teste de aceitação, que deve ser o mais simples possível para que a possibilidade de falhas no teste seja minimiza-da, e a construção de algoritmos alternativos para implementar a especificação f(X). Em geral essas duas questões são muito dependentes do problema, de forma que se torna difícil encontrar um método geral para resolve-las. O projeto do teste de aceitação pode ser encaminhado a partir da especificação , procurando-se estabelecer uma condição necessária para y=f(x) simples de im-plementar. Por exemplo, se a função f for à geração de uma lista y ordenada crescente a partir de uma lista de números x, uma condição necessária para y é que: y[1]≤:y[2] ≤ :.... ≤:y[n]. Essa condição não é suficiente uma vez que é possível que os valores da lista y sejam distintos dos valores da lista x, por defei-tos no algoritmo de ordenação. Entretanto pode ser um teste de aceitação efici-ente para esses algoritmos. A utilização dos BR pode estar associada também ao desempenho do software. Nos casos em que se dispõe de algoritmos com diferentes desempenhos em ter-mos de tempo de processamento utilizado, porém com precisões inversamente proporcionais. O BR pode ser utilizado ordenando-se os algoritmos com desem-penho decrescentes (e possivelmente com precisões crescentes). 4.2 O ESQUEMA DE n-VERSÕES Este esquema emprega n algoritmos diversificados Ai(X) e uma função y= escolha (y1,y2,...,yn). Os algoritmos são executados em paralelo e os resultados transmitidos a um vo-tador que decide a partir dos n resultados um valor y de consenso, ou se não existir tal consenso, um valor mediano, um valor mais seguro ou simplesmente uma indicação de falha, conforme as características da aplicação. Como no caso dos testes de aceitação, aqui a escolha do valor mais apropriado entre os n resul-tados é também dependente do problema, e é importante que a função escolha seja a mais simples possível. Em muitas aplicações, como em controle de processos, os resultados yi dos algo-ritmos são valores binários, por exemplo, comandos para abrir ou fechar uma válvula. Nestes casos, basta um número impar de versões para que o votador possa decidir por maioria simples o comando que deve ser efetuado(o que não significa que esteja correto). O problema de construção de algoritmos diversificados é semelhante ao dos BR. Em primeiro lugar é necessário garantir-se no mínimo a consistência da especifi-cação, que é comum às varias versões. Se a especificação estiver incorreta, o que corresponde aos modos de falha comum no caso do hardware, pouco poderá ser afirmado sobre os resultados a serem produzidos pelo sistema. A partir de uma mesma especificação o primeiro nível de diversidade a ser tenta-do é o emprego de soluções diversificadas para o problema, o que nem sempre é

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 51
possível. Às vezes é preferível utilizar-se uma mesma solução que comprovada-mente é a melhor. O segundo nível de diversidade corresponde ao nível de algoritmo propriamente dito, que em geral é bastante dependente das estruturas de dados empregadas. Se as estruturas de dados, formas de codificação da informação, etc., forem con-venientemente diversificada, uma mesma solução poderá produzir algoritmos su-ficientemente diversos. O terceiro nível corresponde à diversificação das linguagens de programação utili-zadas. Muitos enganos são cometidos nessa passagem, do algoritmo para o códi-go, e se as linguagens forem bastante diversas, PASCAL e ASSEMBLER por e-xemplo, é possível evitar-se que enganos deste tipo sejam idênticos. Possíveis defeitos de compiladores e outras ferramentas de desenvolvimento podem ser mais facilmente contornados. Além de todas essas providências, uma outra que tem sido experimentada é a utilização de equipes distintas para o desenvolvimento de cada uma das versões. O emprego deste nível de diversidade ainda é controvertido, uma vez que é difícil garantir que a metodologia de desenvolvimento utilizada pelas equipes seja sufi-cientemente distinta. A "cultura tecnológica" das várias equipes é em geral muito semelhante. Por outro lado, o número de experimentos deste tipo é pequeno, da-do o elevado custo que representam. No entanto tem sido utilizada em aplicações muito criticas, como por exemplo em reatores nucleares. O esquema de n-Versões é mais apropriado para o processamento paralelo, loca-lizando-se cada versão em um processador. O votador neste caso pode ser im-plementado diretamente por um votador em hardware, quando a função escolha é suficientemente simples, ou por um programa localizado em um outro proces-sador de entrada/sadia, ou ainda replicado nos n processadores. Neste último caso, nada impede que tenham implementações também diversifi-cadas. De qualquer forma, uma característica dos votadores é que exigem uma razoável sincronização entre as diferentes versões, uma vez que sua ação depende da dis-ponibilidade dos n resultados para que possa decidir. Um esquema de sincronização pode ser implementado do seguinte modo : Quan-do cada versão termina o seu cálculo, esta envia o resultado ao votador. O vota-dor por sua vez aguarda a chegada de um número suficiente de resultados, para então produzir o resultado final. Considerando-se ainda as possíveis falhas no hardware de cada processador, é importante que as esperas sejam controladas por "time-out”, evitando-se esperas indefinidas. A necessidade deste tipo de sin-cronismo é um fator limitante no nível de diversidade das versões. Para um de-sempenho aceitável do sistema os tempos envolvidos devem ser o suficientemen-te balanceados. A versão mais lenta determina o desempenho do sistema, o que pode ser crítico em aplicações de tempo real. Em geral, utiliza-se ainda um mesmo tipo de processador, com recursos idênticos que também limita o uso de versões muito distintas [quanto aos recursos exigi-dos(tamanho da memória principalmente)]. Uma outra forma de sincronização, que em algumas aplicações pode ser menos rígida, consiste na simples atualização em locais preestabelecidos, do resultado produzido pelas n versões. O votador neste caso periodicamente consulta esses resultados e toma sua decisão. Esse esquema também depende de um certo e-quilíbrio de tempos por parte das diferentes versões. 4.3 COMBINAÇÃO BR+NV Algumas formas de combinação entre os esquemas de BR e NV são ainda possí-veis. Um exemplo é o chamado de Blocos de Recuperação por Consenso. Par-te-se de um esquema NV, onde cada versão contém uma lista de alternativas. Em uma primeira iteração, a primeira alternativa de cada versão é executada e os resultados passados para o votador. Este verifica se existe um consenso, ou re-

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 52
sultados idênticos em pelo menos duas versões, o que será então o resultado fi-nal. Senão existir consenso, o votador executa um Teste de Aceitação para o "melhor" dos n resultados e adota este caso aceitável. Se a primeira iteração não for bem sucedida, uma segunda é tentada, neste caso utilizando a segunda alternativa de cada versão, e assim sucessivamente até, no pior caso, uma indicação de falha seja produzida pelo votador, o que correspon-de a uma situação de "esgotamento da redundância”. Este esquema tem a vanta-gem de exigir apenas um teste de aceitação, em relação ao caso em que cada uma das n-versões fosse implementada por um esquema BR puro. No entanto o problema do teste de aceitação continua sendo dependente de problema, com a necessidade de se estabelecer, para cada caso, o que viria a ser um "melhor re-sultado". 5. MODELAGEM DO SOFTWARE TOLERANTE A FALHAS Em sistemas onde o projeto tem objetivos rígidos de confiabilidade e/ou disponi-bilidade, é importante adotar-se alguns critérios quanto à confiabilidade do soft-ware. Assim, se for considerado que o software e' um dos componentes de um processador, a taxa de falhas deste processador será em primeira análise igual à soma das taxas de falhas do hardware e do software λs + λh ,ou seja, estes componentes estão em "serie" em uma rede de confiabilidade. Quando na mode-lagem do sistema considera-se apenas a taxa de falhas do hardware está sendo assumido implicitamente que ,ou o software é perfeito, ou que apresenta uma taxa de falhas desprezível em relação à do hardware. Entretanto no caso mais geral é necessário utilizar-se uma estimativa ou previsão da taxa de falhas do software e verificar o que pode ser melhorado se necessário. A alternativa de construção de software tolerante a falhas, dentro dos esquemas vistos anteriormente deve enfrentar evidentemente o problema de custos.

CONFIABILIDADE DE SISTEMAS DIGITAIS prof. B. J. Souza 53
Exercício a) Uma aplicação instalada nesse servidor utilizou duas variantes distintas X e Y provenientes de dois fornecedores. A variante X foi instalada no computador A e a Y no computador B e, por meio de conversão de formatos, X e Y podem aces-sar dados em quaisquer dos discos A e B. A aplicação foi testada por um deter-minado período e sempre que uma falha foi detectada em uma variante o forne-cedor realizou uma correção específica para aquele problema. Os instantes de fa-lha anotados foram: (horas) t1 t2 t3 T4 t5 t6 t7 t8 t9 t10 Fim
teste
X 1.6 4.4 8.8 16.2 28.4 48.5 81.6 136.
2 226.2
374.6 500.0
(horas)
Y 0.001
0.003
0.010
0.028
0.078
0.214
0.581
1.581
4.300
11.689
50.0
Avaliar a confiabilidade dos dois softwares no instante de fim de teste.(Utilizar o modelo de crescimento de confiabilidade Log-Poisson). b) Supor que após o período de testes as variantes X e Y vão continuar a serem atualizadas pelos fornecedores sempre que uma falha for observada, durante to-do o tempo de vida dessa aplicação que deve ser de 20000 horas. Foi implemen-tado um teste de aceitação T que pode ser incorporado nas duas variantes. Na avaliação (off-line) de T forma utilizados 100 testes independentes e algumas modificações, tendo sido observada apenas uma falha de T. Do ponto de vista exclusivamente de confiabilidade quais das seguintes configu-rações de software é melhor, supondo que deva ser instalada após o período de teste e permanecer até o final. (Justificar quantitativamente).
a) X em A e B. b) Y em A e B c) X em A e Y em B d) Bloco de recuperação XTYT tanto em A quanto em B.