ana rosa marques an alise de per s de utiliza˘c~ao em ...§ão.pdf · palavras-chave m aquinas de...
TRANSCRIPT

Universidade de AveiroDepartamento deEletronica, Telecomunicacoes e Informatica,
2016
Ana Rosa MarquesGoncalves
Analise de perfis de utilizacao em sistemas deauto-aprendizagem


Universidade de AveiroDepartamento deEletronica, Telecomunicacoes e Informatica,
2016
Ana Rosa MarquesGoncalves
Analise de perfis de utilizacao em sistemas deauto-aprendizagem
Dissertacao apresentada a Universidade de Aveiro para cumprimento dosrequisitos necessarios a obtencao do grau de Mestre em Sistemas de In-formacao, realizada sob a orientacao cientıfica da Doutora Ana Maria Per-feito Tome, Professora Associada do Departamento de Eletronica, Tele-comunicacoes e Informatica da Universidade de Aveiro e do Doutor LuısAntonio Arsenio Descalco, Professor Auxiliar do Departamento de Ma-tematica da Universidade de Aveiro.


o juri / the jury
presidente / president Doutor Jose Manuel Neto VieiraProfessor Auxiliar do Departamento de Eletronica, Telecomunicacoes e Informatica
da Universidade de Aveiro
vogais / examiners committee Doutor Luıs Miguel Almeida da SilvaProfessor Auxiliar Convidado do Departamento de Matematica da Universidade de
Aveiro
Doutora Ana Maria Perfeito TomeProfessora Associada do Departamento de Eletronica, Telecomunicacoes e In-
formatica da Universidade de Aveiro


agradecimentos /acknowledgements
Comeco por agradecer aos meus orientadores, os Professores Ana MariaTome e Luıs Descalco pelo que me ensinaram, pela disponibilidade e apoio.Quero tambem agradecer as minhas chefias na PT Inovacao e aPonto.C/Maisis pela compreensao durante os dois primeiros anos destaaventura.As minhas meninas Adriana e Clara por em tantas ocasioes deixarem “amama trabalhar”e por, em outras tantas nao deixarem. Sem elas esta de-manda nao teria o mesmo sabor.Ao meu marido Fabio, por estar sempre a meu lado. Por me incentivar eacreditar em mim.Agradeco aos meus pais e ao meu irmao todo o amor e apoio dados duranteestes anos. Agradeco a todos os me ajudaram a concluir este trabalho.


palavras-chave maquinas de vetores de suporte, aprendizagem supervisionada, dados nao-equilibrados
resumo Um Sistema Tutor Inteligente (STI) e um programa de computador quetem como objetivo apoiar o aluno na sua aprendizagem. A aplicacao webdo projeto SIACUA e um STI desenhado para o apoio ao estudo autonomoem disciplinas de Calculo.Neste trabalho foram adicionadas algumas funcionalidades a aplicacao webSIACUA. Das funcionalidades implementadas realcamos a possibilidade decriacao de cursos sem recurso a um programador e a geracao de dois tiposde relatorio sobre a utilizacao da propria aplicacao. A primeira tem comoobjetivo facilitar o uso da aplicacao pelos professores. Quanto aos relatorios,um apresenta o numero de vezes que cada topico foi escolhido para estudo eo outro apresenta por questao, o numero de vezes que foi respondida assimcomo as taxas de erro e acerto.Ainda no ambito deste trabalho procuramos prever o sucesso ou insucessode um aluno com base na sua utilizacao desta aplicacao. Recolhemos dadospara as disciplinas de Calculo 2 e Calculo 3. Do processamento dos dadosrecolhidos extraımos um conjunto de caracterısticas e aplicamos algoritmosde aprendizagem nao supervisionada e supervisionada. Os algoritmos trei-nados foram o K-Means, vizinhos mais proximos e maquina de vetores desuporte (SVM). Para os dados de Calculo 2, o classificador SVM Linearcom reducao do numero de caracterısticas foi o que apresentou melhoresresultados. Como os dados de Calculo 3 nao eram equilibrados qualquer umdos classificadores mostrou pouca capacidade de discriminacao entre alunosaprovados e alunos reprovados. Assim, abordamos variantes do classifica-dor SVM Linear para conjuntos de dados nao equilibrados. Os resultadosmostram a importancia da utilizacao de tecnicas especıficas para dados naoequilibrados.


keywords support vector machines, unsupervised learning, unbalanced data sets
abstract An Intelligent Tutor System (ITS) is a computer program aimed to supportstudents in their learning process. The SIACUA project’s web application isan ITS designed to support the autonomous study in Calculus courses.Within the scope of this work new functionalities were added to the SIACUAweb application. We highlight two of those functionalities: the possibilityof courses creation without the intervention of a programmer and reportsresuming the use of the application. With the first functionality it is ex-pected that more teachers consider to prepare new study materials for thestudents. And the reports are useful to know for instance which topics arechosen more often as well as statistics about the answers in order to detectpossible misleading questions.Besides that we tried to predict the success or failure of a student basedon the data collected during student SICUA interaction. The data con-cerning two courses (Calculus 2 and Calculus 3) were analyzed: a set ofcharacteristics was extracted and unsupervised and supervised learning al-gorithms were applied. The algorithms were K-Means, nearest neighborsand support vector machines (SVM). Considering the Calculus 2 data, theclassifier SVM Linear with reduction of the number of characteristics wasthe one that presented better results. As the Calculus 3 data was unba-lanced any of the classifiers showed little discrimination capacity betweenapproved and failed students. So, variants of the Linear SVM classifier forunbalanced data sets were approached. The results show the importance ofusing specific techniques for unbalanced data.


Conteudo
Conteudo i
Lista de Figuras iii
Lista de Tabelas v
Introducao 1
1 SIACUA 31.1 Aplicacao web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.1.1 Modelo do domınio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.1.2 Modelo do aluno . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.1.3 Modelo do tutor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2 Novas funcionalidades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.2.1 Relatorios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.2.2 Construcao de arvores e de cursos . . . . . . . . . . . . . . . . . . . . 9
Construcao de arvores . . . . . . . . . . . . . . . . . . . . . . . . . . . 10Construcao de cursos de pronto-a-vestir . . . . . . . . . . . . . . . . . 11
1.2.3 Gestao do estado das questoes MEGUA . . . . . . . . . . . . . . . . . 121.2.4 Conjuntos de questoes sobre uma dada materia . . . . . . . . . . . . . 131.2.5 Pre-requisitos e sugestao de estudo . . . . . . . . . . . . . . . . . . . . 13
1.3 Contexto de utilizacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.4 Sobre a extracao de caracterısticas . . . . . . . . . . . . . . . . . . . . . . . . 15
2 Aprendizagens nao supervisionada e supervisionada 192.1 Espaco Multidimensional . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.1.1 Normalizacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20Normalizacao min-max . . . . . . . . . . . . . . . . . . . . . . . . . . 20Normalizacao z-score . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.2 Aprendizagem nao supervisionada . . . . . . . . . . . . . . . . . . . . . . . . 202.2.1 Medidas de distancia . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.2.2 K-Means . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
Limitacoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.2.3 Avaliacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.3 Aprendizagem supervisionada . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.3.1 Vizinhos mais proximos . . . . . . . . . . . . . . . . . . . . . . . . . . 23
Limitacoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
i

2.3.2 SVM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24Dados linearmente separaveis . . . . . . . . . . . . . . . . . . . . . . . 24Dados nao linearmente separaveis . . . . . . . . . . . . . . . . . . . . . 25
2.3.3 SVM Linear e eliminacao de caracterısticas . . . . . . . . . . . . . . . 262.3.4 Classificacao por voto maioritario . . . . . . . . . . . . . . . . . . . . . 26
2.4 Aprendizagem supervisionada: dados nao equilibrados . . . . . . . . . . . . . 272.4.1 DEC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272.4.2 SMOTE + DEC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.4.3 SVM e a geracao de instancias . . . . . . . . . . . . . . . . . . . . . . 292.4.4 z-SVM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.5 Aprendizagem supervisionada: avaliacao . . . . . . . . . . . . . . . . . . . . . 312.5.1 Medidas de desempenho . . . . . . . . . . . . . . . . . . . . . . . . . . 31
Curva ROC e area abaixo da curva . . . . . . . . . . . . . . . . . . . . 332.5.2 Validacao cruzada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.5.3 Comparacao de classificadores . . . . . . . . . . . . . . . . . . . . . . . 34
3 Analise dos dados 353.1 Caracterizacao dos dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.1.1 Descricao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.2 Pre-analise: perspetiva de dia . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.2.1 O caso de Calculo 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363.2.2 O caso de Calculo 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.3 Perspetiva do utilizador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383.3.1 Aprendizagem nao supervisionada . . . . . . . . . . . . . . . . . . . . 423.3.2 Aprendizagem supervisionada . . . . . . . . . . . . . . . . . . . . . . . 43
Vizinhos mais proximos . . . . . . . . . . . . . . . . . . . . . . . . . . 43Maquinas de Vetores de Suporte (SVM) . . . . . . . . . . . . . . . . . 45SVM para dados nao equilibrados . . . . . . . . . . . . . . . . . . . . 48Grupos de classificadores . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.4 Comparacao de classificadores . . . . . . . . . . . . . . . . . . . . . . . . . . . 513.5 Perspetiva perguntas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.5.1 Aprendizagem nao supervisionada . . . . . . . . . . . . . . . . . . . . 563.6 Conclusao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4 Conclusoes e trabalho futuro 59
A Listagem de caracterısticas 63A.1 Caracterısticas por dia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63A.2 Caracterısticas por aluno . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63A.3 Caracterısticas por questao . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
B Resultados aprendizagem supervisionada 67
C Resultados dos testes de hipoteses 70C.1 Calculo 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70C.2 Calculo 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Bibliografia 86
ii

Lista de Figuras
1.1 Exemplo da pagina de estudo autonomo do SIACUA. . . . . . . . . . . . . . 41.2 Representacao generica do modelo do domınio: UC - unidade curricular, A -
assunto, T - tema e C - conceito. . . . . . . . . . . . . . . . . . . . . . . . . . 51.3 Modelo do aluno sem e com respostas submetidas. . . . . . . . . . . . . . . . 61.4 Exemplo de relatorio com a taxa de acerto a cada uma das questoes MEGUA. 81.5 Exemplo de relatorio sobre o acesso aos diferentes topicos. . . . . . . . . . . . 91.6 Exemplos de duas arvores de conhecimento e curso de pronto-a-vestir. . . . . 101.7 Criacao de arvore. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.8 Criacao de curso de pronto-a-vestir. . . . . . . . . . . . . . . . . . . . . . . . 111.9 Area de estudo autonomo de curso de pronto-a-vestir. . . . . . . . . . . . . . 121.10 Gestao de questoes MEGUA. . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.1 Vizinhos mais proximos. Figura adaptada de [1]. . . . . . . . . . . . . . . . . 232.2 SVM Linear. Figuras adaptadas de [2]. . . . . . . . . . . . . . . . . . . . . . . 252.3 SVM nao linear. Figuras adaptadas de [2]. . . . . . . . . . . . . . . . . . . . . 252.4 Treino do mesmo conjunto de dados nao equilibrado com SVM Linear e SVM
Linear com pesos associados as classes. . . . . . . . . . . . . . . . . . . . . . . 282.5 Geracao de instancias. Figuras adaptadas de [3]. . . . . . . . . . . . . . . . . 292.6 Geracao de instancias por SMOTE e SMOTE SVM. . . . . . . . . . . . . . . 302.7 Exemplo de curvas ROC. A curva C1 representa um classificador com melhor
desempenho do que aquele representado pela curva C2. . . . . . . . . . . . . . 33
3.1 Calculo 2, 2014/2015: numero total de alunos por dia. . . . . . . . . . . . . . 373.2 Calculo 3, 2015/2016: numero total de alunos por dia. . . . . . . . . . . . . . 373.3 Calculo 3, 2015/2016: Graficos de bigodes das caracterısticas associadas ao
numero de dias e ao tempo de estudo. . . . . . . . . . . . . . . . . . . . . . . 383.4 Calculo 2, 2014/2015: Heatmap da matriz correlacao; apenas estao assinaladas
as correlacoes que sao > 0.95. . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.5 Calculo 2, 2014/2015: Histogramas das caracterısticas gerais. . . . . . . . . . 413.6 Calculo 3, 2015/2016: Histogramas das caracterısticas gerais. . . . . . . . . . 413.7 Calculo 2, 2014/2015: tempo de resposta vs tempo de analise. . . . . . . . . . 423.8 Calculo 3, 2015/2016: tempo de resposta vs tempo de analise. . . . . . . . . . 423.9 Calculo 2: curvas ROC para avaliacao do desempenho na reducao do numero
de caracterısticas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.10 Calculo 3: curvas ROC para avaliacao do desempenho na reducao do numero
de caracterısticas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
iii

3.11 Calculo 2, 2014/2015: Heatmap da matriz correlacao. . . . . . . . . . . . . . 543.12 Calculo 3, 2015/2016: Heatmap da matriz correlacao. . . . . . . . . . . . . . 543.13 Dados referentes aos alunos avaliados. . . . . . . . . . . . . . . . . . . . . . . 553.14 Dados referentes aos alunos avaliados: medias de tempo. . . . . . . . . . . . . 55
iv

Lista de Tabelas
1.1 Utilizacao da aplicacao SIACUA na disciplina de Calculo 2, com e sem com-ponente de avaliacao. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.2 Sequencia de acoes reais que se concretizam numa resposta valida. . . . . . . 161.3 Sequencia de acoes que traduzem uma resposta valida. . . . . . . . . . . . . . 16
2.1 Matriz confusao. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.1 Numero de alunos por disciplina e grupo. . . . . . . . . . . . . . . . . . . . . 383.2 Calculo 3: medidas de avaliacao de desempenho do classificador vizinhos mais
proximos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.3 Calculo 3: medidas de avaliacao de desempenho do classificador vizinhos mais
proximos aplicado aos dados com reducao do numero de caracterısticas. . . . 453.4 Resumo dos parametros considerados nas simulacoes com SVM Linear e SVM
RBF. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.5 Calculo 2: resultados obtidos nas simulacoes para reducao do numero de ca-
racterısticas com SVM Linear; dados normalizados com z-score. . . . . . . . . 473.6 Calculo 2: resultados da eliminacao recursiva de caracterısticas. . . . . . . . . 473.7 Calculo 3: resultados da eliminacao recursiva de caracterısticas. . . . . . . . . 483.8 Parametros determinados para as simulacoes com DEC apos geracao de
instancias. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 493.9 Calculo 3: resultados obtidos para as simulacoes classificacao por voto. . . . . 503.10 Acuracia obtida com os varios classificadores. . . . . . . . . . . . . . . . . . . 513.11 Valor de g obtido com os varios classificadores. . . . . . . . . . . . . . . . . . 523.12 Numero de questoes MEGUA por disciplina e nıvel. . . . . . . . . . . . . . . 533.13 Numero de respostas por disciplina e grupo de utilizadores. . . . . . . . . . . 533.14 Resultados obtidos por aprendizagem nao supervisionada. . . . . . . . . . . . 56
B.1 Resultados obtidos por treino do classificador vizinhos mais proximos. . . . . 67B.2 Resultados obtidos por treino do classificador vizinhos mais proximos aplicado
aos dados com reducao do numero de caracterısticas. . . . . . . . . . . . . . . 67B.3 Resultados obtidos por treino do classificador SVM Linear. . . . . . . . . . . 68B.4 Resultados obtidos por treino do classificador SVM com kernel RBF. . . . . . 68B.5 Resultados obtidos por treino do classificador DEC com SVM Linear. . . . . 68B.6 Calculo 2: resultados obtidos por previsao do conjunto de dados original usando
o classificador DEC treinado com dados gerados. . . . . . . . . . . . . . . . . 68B.7 Calculo 3: resultados obtidos por previsao do conjunto de dados original usando
o classificador DEC treinado com dados gerados. . . . . . . . . . . . . . . . . 69
v

B.8 Resultados obtidos aplicando a abordagem z-SVM. . . . . . . . . . . . . . . . 69
C.1 Calculo 2: comparacao entre os classificadores vizinhos mais proximos. . . . . 70C.2 Calculo 2: comparacao entre os classificadores SVM Linear e z-SVM. . . . . . 71C.3 Calculo 2: comparacao entre os classificadores DEC com geracao de instancias
por SMOTE e SMOTE SVM. . . . . . . . . . . . . . . . . . . . . . . . . . . . 72C.4 Calculo 2: comparacao entre os classificadores SVM Linear e SVM com kernel
RBF. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73C.5 Calculo 2: comparacao entre os classificadores ERC e RFECV. . . . . . . . . 74C.6 Calculo 2: comparacao entre o classificador DEC e o classificador
SMOTE+DEC normalizacao min-max. . . . . . . . . . . . . . . . . . . . . . . 74C.7 Calculo 2: comparacao entre diferentes classificadores. . . . . . . . . . . . . . 75C.8 Calculo 3: comparacao entre os classificadores vizinhos mais proximos, quanto
a acuracia. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76C.9 Calculo 3: comparacao entre os classificadores vizinhos mais proximos, quanto
ao valor de g. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77C.10 Calculo 3: comparacao entre os classificadores SVM Linear e SVM com kernel
RBF, quanto a acuracia. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77C.11 Calculo 3: comparacao entre os classificadores SVM Linear e SVM com kernel
RBF, quanto valor de g. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78C.12 Calculo 3: comparacao entre os classificadores ERC e RFECV, quanto a acuracia. 78C.13 Calculo 3: comparacao entre os classificadores ERC e RFECV, quanto ao valor
de g. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79C.14 Calculo 3: comparacao entre os classificadores DEC com geracao de instancias
por SMOTE e SMOTE SVM, quanto a acuracia. . . . . . . . . . . . . . . . . 80C.15 Calculo 3: comparacao entre os classificadores DEC com geracao de instancias
por SMOTE e SMOTE SVM, quanto ao valor de g. . . . . . . . . . . . . . . 81C.16 Calculo 3: comparacao entre os classificadores SVM Linear e z-SVM, quanto a
acuracia. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82C.17 Calculo 3: comparacao entre os classificadores SVM Linear e z-SVM, quanto
ao valor de g. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83C.18 Calculo 3: comparacao entre o classificador DEC e o classificador S.SVM+DEC
normalizacao min-max, quanto a acuracia. . . . . . . . . . . . . . . . . . . . . 84C.19 Calculo 3: comparacao entre o classificador DEC e o classificador S.SVM+DEC
normalizacao z-score, quanto ao valor de g. . . . . . . . . . . . . . . . . . . . 84C.20 Calculo 3: comparacao entre diferentes classificadores quanto a acuracia. . . . 85C.21 Calculo 3: comparacao entre diferentes classificadores quanto ao valor de g. . 85
vi

Introducao
Um Sistema Tutor Inteligente (STI) e um programa de computador que tem como objetivoapoiar o aluno na sua aprendizagem. Uma das motivacoes para a utilizacao destes sistemasassenta no consenso que existe sobre a eficacia da tutoria individual [4]. A capacidade queum STI tem de indicar, de imediato, ao aluno se uma determinada a tarefa foi realizada comsucesso e crucial. Isto porque a tutoria individual e mais eficaz precisamente porque ocorrecomo resposta direta a uma necessidade do aluno.
Considerando que e possıvel proporcionar um STI por aluno numa sala de aula, os STIconseguem reunir as vantagens de um ambiente de aprendizagem em grupo e de uma tutoriaum para um [4].
A aplicacao web do projeto SIACUA [5] e um STI de apoio ao estudo autonomoem disciplinas de matematica. Cada uma das disciplinas e disponibilizada na aplicacaopara estudo sob a forma de topicos que sao o proprio currıculo da disciplina. Existemquestoes associadas aos varios itens do currıculo, podendo cada questao estar associada aum ou mais itens. O estudo da materia e proporcionado atraves da analise e resolucaodestas questoes. Para cada disciplina ou curso, a zona da aplicacao em que sao dispo-nibilizadas questoes associadas a topicos da materia designamos por area de estudo autonomo.
A disponibilizacao de um novo curso era uma tarefa morosa e que implicava a intervencaode um programador conhecedor do sistema. Era portanto necessario agilizar o processo deintroducao de um novo curso na plataforma. Nesse sentido, e no ambito deste trabalho,desenvolvemos uma nova funcionalidade na aplicacao que permite disponibilizar novos cursosna plataforma sem ser necessaria a intervencao de um programador. Alem de util para osprofessores que ja utilizam o SIACUA, esta funcionalidade podera incentivar mais professoresa usar a aplicacao.
Ainda no contexto deste trabalho, realcamos a disponibilizacao de dois relatorios deutilizacao da aplicacao. Estes relatorios estao disponıveis na area de gestao da aplicacao.Um dos relatorios apresenta o numero de vezes que cada topico foi escolhido para estudo. Ooutro relatorio apresenta por questao, o numero de vezes que foi respondida assim como astaxas de erro e acerto.
Na Universidade de Aveiro, e incentivada a utilizacao da aplicacao web SIACUA emdisciplinas de Calculo, nomeadamente Calculo 2 e Calculo 3 lecionadas pelo Departamentode Matematica da mesma instituicao. O aluno, quando pretende estudar uma determinadamateria escolhe esse topico na area de estudo autonomo sendo-lhe apresentada uma questaorelacionada. Com base nas respostas dadas pelo aluno as varias questoes, o sistema calculao conhecimento do aluno a cada um dos topicos do currıculo do curso. Para este calculo sao
1

utilizadas redes Bayesianas ou de crenca. Por exemplo, se no topico Derivadas o aluno tiverum valor de 70% significa que o sistema cre com 70% de probabilidade que o aluno conheceo topico Derivadas.
Quisemos perceber se a utilizacao da aplicacao web SIACUA contribui para o sucessodos alunos a disciplina. Em [5], os resultados indicam nao existir uma correlacao entre aclassificacao dos alunos e o conhecimento calculado pelo sistema. E os habitos de utilizacaoda aplicacao podem ser relacionados com o sucesso ou insucesso a disciplina? Sera que aregularidade do estudo, isto e, se o estudo e realizado ao longo do semestre ou apenas emdeterminados momentos, tem influencia no sucesso dos alunos?
O sistema mantem um registo do uso da aplicacao. Analisando esses registos, cruzandocom a informacao dos alunos aprovados e reprovados, sera possıvel obter um modelo quedescreva os alunos e permita prever o seu sucesso? Analisamos os dados de utilizacao daaplicacao procurando determinar se e possıvel prever o sucesso ou insucesso de um alunocom base nesses registos. Recorremos a diferentes visualizacoes da informacao assim como aalgoritmos de aprendizagem nao supervisionada e supervisionada. Como um dos conjuntosde dados e nao equilibrado abordamos tambem estrategias de classificacao adequadas paradados nao equilibrados [6].
Organizacao interna
Alem desta introducao, a dissertacao e constituıda por 4 capıtulos e apendices. NoCapıtulo 1 apresentamos a aplicacao web do projeto SIACUA assim como desenvolvimen-tos realizados sobre a aplicacao no ambito desta dissertacao. No Capıtulo 2 descrevemosalgumas tecnicas de analise de dados assim como alguns algoritmos de aprendizagem naosupervisionada e supervisionada. No Capıtulo 3 apresentamos a analise dos resultados ob-tidos por aplicacao das tecnicas abordadas anteriormente. Terminamos com as conclusoese trabalho futuro. Em apendice apresentamos a lista exaustiva de todas as caracterısticasconsideradas, assim como resultados obtidos por aplicacao dos algoritmos e por avaliacaoestatıstica do desempenho dos varios algoritmos.
2

Capıtulo 1
SIACUA
Neste capıtulo comecamos por uma breve apresentacao da aplicacao SIACUA, com enfasenos modelos de domınio e utilizador. Para uma descricao detalhada da aplicacao consultar,por exemplo, o trabalho de dissertacao de Madalena Fonseca [7]. A seccao seguinte introduzos desenvolvimentos realizados na aplicacao no ambito deste trabalho de dissertacao. Segue-se a descricao do contexto em que a aplicacao foi utilizada e em que foram recolhidos osdados cuja analise se apresenta neste trabalho. Terminamos este capıtulo com a explicacaodo processamento realizado sobre os dados de modo a permitir a sua analise.
1.1 Aplicacao web
O SIACUA - Sistema Interativo de Aprendizagem por Computador, Universidade deAveiro - e um projeto de apoio ao ensino e uma ferramenta para o estudo autonomo emmatematica [5, 8]. No ambito deste projeto tem vindo a ser desenvolvida uma aplicacao webcomummente designada aplicacao SIACUA. Esta aplicacao e um sistema aberto em que cadaaluno pode aceder e praticar os topicos de um curso, obtendo retorno imediato sobre o seudesempenho.
A Figura 1.1 apresenta a pagina de estudo autonomo para um dos cursos disponıveisna aplicacao: Calculo 3. Cada item (assunto, tema ou conceito) do curso Calculo 3 estarepresentado nesta pagina atraves de hiperligacoes. Seguindo cada uma dessas hiperligacoese apresentada uma questao ao aluno. Para cada item que constitui o currıculo do cursoe apresentada uma barra de progresso. Esta barra representa o desempenho do aluno noitem associado. Este desempenho e determinado com base nas respostas dadas as questoesassociadas aos itens.
O aluno tem ainda a possibilidade de indicar que questao quer treinar. Sempre queuma questao e apresentada ao aluno, e indicado qual o seu numero. Assim, usando a area“Procurar Exercıcios”, o aluno pode praticar uma questao especıfica. Esta funcionalidadepermite, por exemplo, ao aluno esclarecer duvidas que tenham surgido ao resolver umdeterminado problema junto de um professor ou de colegas e pode ser tambem usada emcontexto de aula pelo professor, propondo questoes para resolucao em grupo.
A forma de interacao principal entre o aluno e o sistema consiste em selecionar itens eresponder a questoes selecionadas aleatoriamente pelo proprio sistema. Sempre que o alunosubmete uma resposta, sabe imediatamente se a resposta esta correta ou incorreta, ficando a
3
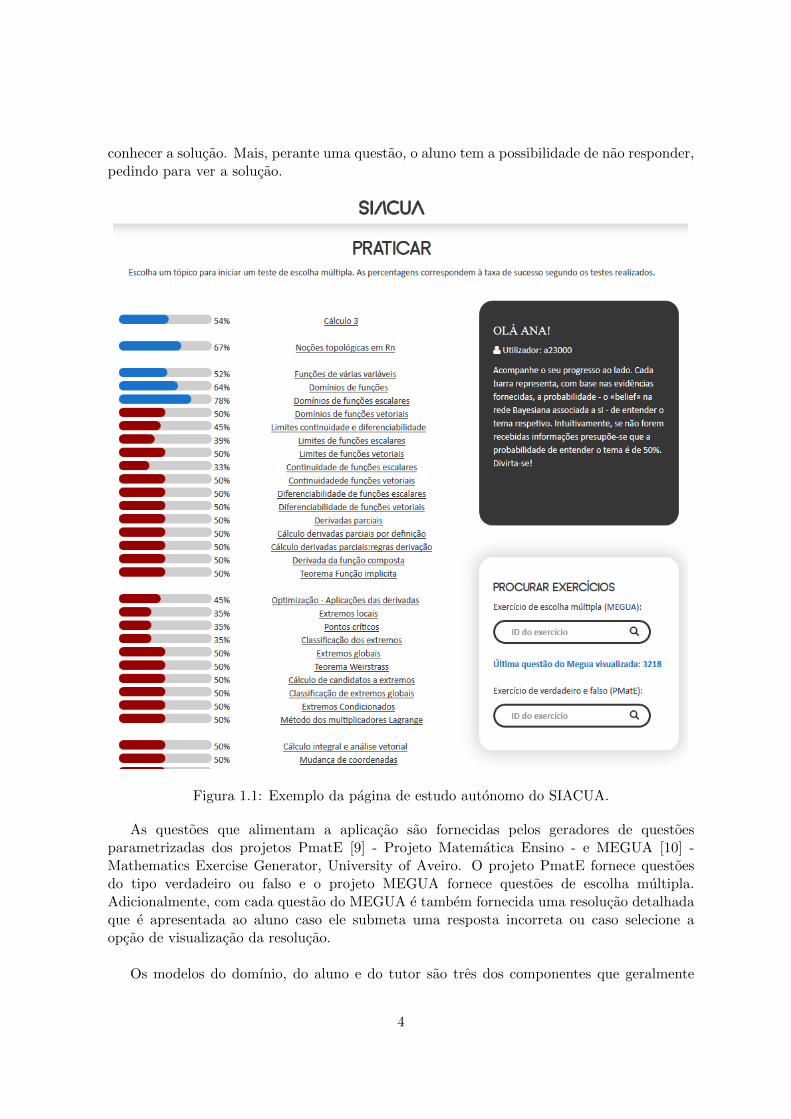
conhecer a solucao. Mais, perante uma questao, o aluno tem a possibilidade de nao responder,pedindo para ver a solucao.
Figura 1.1: Exemplo da pagina de estudo autonomo do SIACUA.
As questoes que alimentam a aplicacao sao fornecidas pelos geradores de questoesparametrizadas dos projetos PmatE [9] - Projeto Matematica Ensino - e MEGUA [10] -Mathematics Exercise Generator, University of Aveiro. O projeto PmatE fornece questoesdo tipo verdadeiro ou falso e o projeto MEGUA fornece questoes de escolha multipla.Adicionalmente, com cada questao do MEGUA e tambem fornecida uma resolucao detalhadaque e apresentada ao aluno caso ele submeta uma resposta incorreta ou caso selecione aopcao de visualizacao da resolucao.
Os modelos do domınio, do aluno e do tutor sao tres dos componentes que geralmente
4

compoem um sistema tutor inteligente [4]. Apresentamos cada um dos modelos no contextoda aplicacao SIACUA.
1.1.1 Modelo do domınio
Um modelo do domınio contem uma lista das pecas que sao relevantes para o conhecimentonaquele domınio: e o mapa de conceitos. O metodo mais comum para a construcao do modelodo domınio e atraves de especialistas. Para a definicao dos modelos do domınio recorreu-se,no caso do SIACUA, aos professores das diferentes unidades curriculares.
No SIACUA os grandes domınios sao as unidades curriculares. Assim, temos o domınioda unidade curricular (ou disciplina ou curso) composto por assuntos; cada assunto e definidopor um conjunto de temas e a cada tema existe um conjunto de conceitos associados.
Consideremos as seguintes premissas:
• existe uma relacao hierarquica entre disciplina, assunto, tema e conceito;
• um mesmo conceito apenas esta agregado a um assunto, e assim por diante.
Assente nestas premissas, um domınio de conhecimento pode ser representado atraves deum grafo direcionado acıclico - uma arvore - em que os arcos representam uma relacao decomposicao/agregacao. A Figura 1.2 exemplifica esta representacao.
UC
A1 A2
T1.1 T1.2
C1.1.1 C1.2.1 C1.2.2 C2.1.1
T2.1
1
2
3
4
5
6 7
8
9
10
Figura 1.2: Representacao generica do modelo do domınio: UC - unidade curricular, A -assunto, T - tema e C - conceito.
Adicionalmente, existe uma nocao de ordem entre os assuntos, dentro de um mesmoassunto entre os temas e dentro de um mesmo tema entre os conceitos. Esta nocao concretiza-se num numero de ordem associado a cada no da arvore de conceitos que traduz a ordemtemporal em que as materias sao lecionadas. O numero de ordem de cada item do modelo dodomınio representado na Figura 1.2 esta indicado ao lado de cada no, a negrito.
1.1.2 Modelo do aluno
O modelo do aluno deve ser uma representacao dinamica do conhecimento “emergente”doaluno. Idealmente, deveria incluir todas as caracterısticas do aluno (comportamento econhecimento) que podem ter influencia na sua aprendizagem. Deste modo, o modelo e naoso uma representacao do conhecimento do aluno, mas funciona como fonte de informacaosobre o aluno [4].
5

A modelacao do aluno e o processo de recolha de informacao relevante de modo a inferir oestado atual do conhecimento do aluno assim como a representacao dessa mesma informacaode modo a que o modelo do tutor consiga orientar/apoiar o aluno na sua aprendizagem.Existem varias abordagens quanto a construcao do modelo do aluno [11]. Duas dessaspossıveis abordagens sao: sobreposicao e redes Bayesianas.
Sobreposicao - E um dos modelos de aluno mais comum e assume que o conhecimentoque um aluno tem do domınio e correto mas incompleto. Assim, o modelo do aluno e umsubconjunto do modelo do domınio (que reflete o nıvel de conhecimento do aluno). Nestemodelo do aluno, tradicionalmente cada conceito tem atribuıdo um valor binario (0 ou 1),indicando se o aluno sabe ou nao esse conceito. Existem outros modelos em que a cadaconceito e atribuıda uma medida quantitativa tal como a probabilidade de o aluno saber umdeterminado conceito.
Uma das desvantagens deste modelo e nao permitir representar nem o conhecimentoerrado (equıvocos) que o aluno possa ter adquirido, nem as diferentes necessidades cogniti-vas [11].
Redes Bayesianas - Uma rede Bayesiana (ou rede de crenca) e um grafo orientadoacıclico (sobre grafos consultar, por exemplo [12]) no qual os nos representam variaveisaleatorias e os arcos representam a relacao causal entre as variaveis traduzida numa de-pendencia probabilıstica. A cada no e associada uma probabilidade condicionada pelos nospredecessores. Esta estrutura causal permite uma melhor percecao da interacao entre asvariaveis e a previsao dos efeitos de alteracoes externas. As redes Bayesianas sao uma ferra-menta bastante usada para representar e raciocinar sobre a incerteza em modelos de aluno(sobre redes Bayesianas consultar, por exemplo [13, 14]).
No modelo do aluno, as redes Bayesianas permitem representar diferentes dimensoes doaluno como conhecimentos, equıvocos ou emocoes [11].
No SIACUA sao usadas estas duas abordagens para a construcao do modelo doaluno [11, 15]. A estrutura da rede Bayesiana e dada pelo modelo do domınio, assumindo-seinicialmente que o aluno sabe os diferentes conceitos com 50% de certeza. Sempre que oaluno responde a uma questao a rede e enriquecida com a resposta: no evidencia.
a)
A
T1 T2
C1.2 C2.1 C2.2
T3
C1.3C1.1 C3.3C3.2C3.1
b)
A
T1 T2
C1.2 C2.1 C2.2
T3
C1.3C1.1 C3.3C3.2C3.1
Q1 Q3Q2 Q4 Q5
Figura 1.3: Modelo do aluno sem e com respostas submetidas.
6

Consideremos a rede da Figura 1.3 a). Nesta figura, o modelo do aluno coincide com omodelo do domınio pois ainda nao existe qualquer resposta. Os nos do grafo correspondema variaveis aleatorias binarias. Para definir a rede Bayesiana indicamos as probabilidadesassociadas a cada no. Por exemplo
P (C1.1 = 1) = 0.5, P (C1.2 = 1) = 0.5, P (C1.3 = 1) = 0.5
P (C1.1 = 0) = 0.5, P (C1.2 = 0) = 0.5, P (C1.3 = 0) = 0.5
sendo analogo para os restantes nos folha. Estas probabilidades representam a crenca noconhecimento. Isto e, cre-se com 50% de certeza que o aluno conhece o conceito C1.1.
Inicialmente, ou seja, sem qualquer evidencia do conhecimento do aluno, a crenca e de50% em todos os nos folha. Intuitivamente se conclui que se a crenca no conhecimento e de50% nesses nos, a crenca no conhecimento nos nos intermedios e na raiz e tambem de 50%.
Como referido, sempre que o aluno responde a uma questao (correta ou incorretamente) eadicionada uma evidencia do conhecimento do aluno a rede, tal como ilustrado na Figura 1.3b) em que o aluno ja submeteu cinco respostas. Como cada questao tem associados a sium ou mais itens (sempre nos folha), o no evidencia e adicionado a rede ligado as folhascorrespondentes. Ao adicionar um no evidencia o conhecimento do aluno e propagado pelarede. E atraves deste mecanismo que o sistema consegue fornecer ao aluno informacao sobreo seu desempenho. Assim, para cada conceito, o respetivo conhecimento do aluno e traduzidonuma barra de progresso.
A partir do momento em que e adicionado o primeiro no evidencia, a rede deixa de seruma arvore. Salientamos que a rede e dinamica, crescendo a medida que sao adicionadasmais evidencias.
As probabilidades condicionadas associadas aos nos evidencia sao calculadas usando osparametros nıvel, ındice de discriminacao, slip, guess e o peso de cada conceito associado aquestao. Resumidamente, o parametro nıvel indica o nıvel de dificuldade da questao, slip e aprobabilidade de um aluno responder de forma errada conhecendo os conceitos que a questaoenvolve e guess e a probabilidade de o aluno acertar ao acaso (ou seja, responder corretamentedesconhecendo os conceitos); o ındice de discriminacao traduz o quanto a questao permitedistinguir alunos. Para responder corretamente a uma questao assume-se ser necessario terconhecimento a um ou mais conceitos; cada um desses conceitos cobertos pela questao temum peso associado. Todos estes parametros sao definidos pelo autor das questoes, com basena sua experiencia (para mais detalhes consultar [5, 8]).
1.1.3 Modelo do tutor
Uma das funcoes do modelo do tutor e determinar a forma como sao escolhidas as questoesa apresentar ao aluno. Descrevemos esse processo em seguida.
Sempre que o aluno escolhe estudar determinado conceito a aplicacao recolhe todas asquestoes de ambos os projetos MEGUA e PmatE, que tenham associadas a si esse conceito (ouconceitos seus descendentes na arvore de conceitos). Nesta atividade de recolha das questoessao descartadas todas as questoes que tenham associadas a si conceitos mais avancados que oconceito selecionado. Isto e, sao descartadas todas as questoes que possam abordar conceitoscom numero de ordem superior (ainda nao lecionados). Do conjunto de questoes determinadoe escolhida aleatoriamente uma questao para apresentar ao aluno. Adicionalmente, durante
7

uma sessao de estudo e mantido um registo das questoes a que o aluno ja submeteu resposta.Com base neste registo e ainda possıvel garantir que a mesma questao nao e apresentada aoaluno mais do que uma vez numa mesma sessao de estudo.
1.2 Novas funcionalidades
Nesta seccao descrevemos funcionalidades desenvolvidas no ambito deste trabalho de dis-sertacao. Salientamos que a evolucao da aplicacao SIACUA ocorreu principalmente ao nıveldas funcionalidades disponıveis para professores, nomeadamente os relatorios de utilizacao dosistema e a possibilidade de criar novos cursos sem a ajuda de um programador. A expec-tativa e que estas facilitem o uso da aplicacao pelos professores, fazendo com que seja usadaem mais disciplinas.
1.2.1 Relatorios
Na area dedicada aos professores foi disponibilizada uma funcionalidade que permite ageracao de dois relatorios. Atraves da sua consulta sera possıvel ao professor monitorizaralguns indicadores ao longo do perıodo de lecionacao da disciplina. Estes relatorios saogerados com base nos registos de atividade recolhidos. O primeiro indica o numero de vezesque cada conceito foi escolhido explicitamente. O outro mostra a taxa de acerto para cadaquestao MEGUA.
Figura 1.4: Exemplo de relatorio com a taxa de acerto a cada uma das questoes MEGUA.
A Figura 1.4 apresenta um relatorio com a taxa de acerto a questoes do MEGUA desdeo inıcio do primeiro semestre do ano letivo 2016/2017 ate a data em que foi feita a consulta,
8

a 5/10/2016. Por cada questao apresenta a taxa de acerto a questao. Permite identificarquestoes mal formuladas ou com um grau de dificuldade inadequado.
Figura 1.5: Exemplo de relatorio sobre o acesso aos diferentes topicos.
A Figura 1.5 apresenta um relatorio dos conceitos de Calculo 3 com mais cliques desde oinıcio do primeiro semestre do ano letivo 2016/2017 ate a data em que foi feita a consulta,a 5/10/2016. Para cada topico apresenta o numero de “cliques”, isto e, o numero de vezesque foi selecionado explicitamente aquele topico de estudo. Este relatorio permite identificarquais os topicos que os alunos procuram estudar mais.
1.2.2 Construcao de arvores e de cursos
Uma das evolucoes para a aplicacao idealizadas pela equipa responsavel pelo SIACUApassa pela flexibilizacao do processo de criacao e disponibilizacao de novos cursos na aplicacaoweb. O que se pretende e a possibilidade de construir cursos a partir de arvores (ou mapas)de conceitos existentes. Aos cursos assim criados designamos por cursos de pronto-a-vestir.Consideremos as arvores representadas nas alıneas a) e b) da Figura 1.6. Estas arvorespodem corresponder ou nao a unidades curriculares (ou cursos).
Suponhamos que foi definido um curso cujo currıculo aborda o assunto A1 da arvore comraiz em UC1 e o assunto A′2 da arvore com raiz em UC2. Entao o modelo do domınio parao novo curso pode ser representado pela arvore da alınea c) da Figura 1.6. Para adicionareste curso na aplicacao web basta criar um curso de pronto-a-vestir composto por ramos de
9

a) b)
UC1
A1 A2
T1.1 T1.2
C1.1.1 C1.2.1 C1.2.2 C2.1.1
T2.1
UC2
A'1 A'3
T'1.1 T'2.1
C'2.1.3
PV
A1
T1.1 T1.2
C1.1.1 C1.2.1 C1.2.2
T'2.1
C'2.1.3C'2.1.1C'2.1.2
A'2
C'2.1.1C'2.1.2
T'3.1
A'2
T'1.2
c)
Figura 1.6: Exemplos de duas arvores de conhecimento e curso de pronto-a-vestir.
arvores existentes. Caso alguma das arvores nao exista e necessario introduzi-la no sistema.
Construcao de arvores
Para a introducao de arvores no sistema foi desenvolvida uma funcionalidade para criare manter arvores de conceitos. Na Figura 1.7 podemos ver o formulario de criacao de umaarvore.
Figura 1.7: Criacao de arvore.
Este formulario e composto por duas areas. A primeira, de caracterısticas gerais, permitedefinir:
• Nome identificador: campo de preenchimento obrigatorio com a chave identificadora daarvore;
• Nome descritivo: campo de preenchimento obrigatorio com o nome que aparecera nasinterfaces graficas, devendo por isso ser um nome descritivo da arvore;
10

• Descricao: campo de preenchimento opcional, que podera conter informacao adicionalsobre a arvore.
Na segunda area e introduzida a arvore de conceitos, no a no. Cada no e definido porquatro campos: identificador numerico, chave, nome descritivo e peso. A relacao hierarquicaentre os nos assim como o numero de ordem vem naturalmente da estrutura em arvore quegraficamente o utilizador constroi.
Tal como indicado, o objetivo desta funcionalidade e facilitar a introducao e manutencaode arvores no sistema SIACUA. O processo fica facilitado porque:
• deixa de ser necessario o programador introduzir as arvores manualmente na base dedados dando mais autonomia ao professor;
• apesar de a definicao de cada no da arvore ser pouco amigavel e possıvel a partir deuma unica interface introduzir ou editar uma arvore.
Construcao de cursos de pronto-a-vestir
Antes de avancarmos para a criacao de cursos de pronto-a-vestir explicamos brevementeo que, ate agora, tem sido necessario para adicionar um curso a aplicacao SIACUA. Alem daarvore com o modelo do domınio e preciso criar o conjunto de paginas e logica para esse novocurso. Ou seja, e necessario mais uma vez o programador intervir. Ora, pretende-se que oprofessor seja autonomo na criacao de novos cursos. Assim, foi necessario implementar ummecanismo que, a partir de informacao presente na base de dados, disponibilize na aplicacaoweb os cursos existentes ao utilizador. Este mecanismo tem a capacidade de construir a redeBayesiana e calcular o conhecimento para qualquer curso de pronto-a-vestir.
Figura 1.8: Criacao de curso de pronto-a-vestir.
A Figura 1.8 apresenta a interface de criacao do curso. Alem da chave identificadora docurso, e possıvel definir aqui o texto que surge na pagina com informacoes sobre o curso.
11

Para a definicao do modelo do domınio basta adicionar o numero de nos pretendidos(filhos diretos da raiz que e o curso) e para cada um selecionar o ramo e indicar o respetivopeso. Notamos que num curso de pronto-a-vestir, por enquanto, apenas existe area de estudoautonomo. Num curso adicionado manualmente e possıvel incluir outros conteudos.
Na Figura 1.9 podemos ver parte da pagina de estudo autonomo para o curso criado.
Figura 1.9: Area de estudo autonomo de curso de pronto-a-vestir.
Neste exemplo, o conhecimento nas duas sub-arvores e calculado usando as respetivas redesBayesianas. Foi implementado um mecanismo para que o conhecimento se propague tambempara a raiz do curso de pronto-a-vestir, tendo em conta o peso das respetivas sub-arvores.Note-se que, ao criar um curso pronto-a-vestir, ficam disponıveis as questoes cujos conceitosassociados ocorrem todos na arvore do novo curso. Este novo mecanismo permite assim umare-utilizacao muito simples das questoes criadas, noutros contextos de aprendizagem.
1.2.3 Gestao do estado das questoes MEGUA
Tal como referido anteriormente, o gerador de questoes parametrizadas do projeto ME-GUA [10] e um dos fornecedores dos problemas disponıveis na aplicacao SIACUA. Quandouma questao do MEGUA esta concluıda pode ser exportada do MEGUA para o sistemaSIACUA, ficando automaticamente disponıvel na aplicacao SIACUA, na area de estudoautonomo.
Uma necessidade sentida pelos professores e a de poder definir se uma determinada questaodo MEGUA deve ou nao estar disponıvel para estudo. Nesse sentido foi adicionado um novocampo a tabela com as questoes oriundas do MEGUA e que indica o estado da questao.Sempre que uma questao e exportada do MEGUA para o SIACUA fica no estado “naovalidado”. As questao invalidas estao automaticamente indisponıveis.
Para fazer a gestao (do estado) das questoes do MEGUA no sistema SIACUA foi desen-volvida uma nova funcionalidade da area de professor. A Figura 1.10 apresenta a interfacegrafica para gestao da disponibilidade das questoes MEGUA. Nesta pagina o professor podevalidar questoes mantendo-as indisponıveis, validar e disponibilizar questoes, ou ainda inva-lidar questoes.
12

Figura 1.10: Gestao de questoes MEGUA.
1.2.4 Conjuntos de questoes sobre uma dada materia
Uma tarefa que geralmente consome muito tempo a um professor e a de preparar os testes.No sentido de facilitar o processo de escolher os exercıcios a constar num teste, e garantindoque determinados conceitos sao cobertos, foi criado um servico no SIACUA. Este servicopermite recolher conjuntos de questoes. O servico espera quatro parametros:
• num questions: o numero de questoes que pretende; o servico devolve, no maximo estenumero de exercıcios, escolhendo aleatoriamente de entre os exercıcios disponıveis;
• course: o nome identificador da arvore ou mapa de conceitos;
• concept id: o numero identificador do conceito na arvore course;
• exstate: indica quais os estados das questoes que se pretende.
O servico recolhe todas as questoes associadas ao no concept id da arvore course oua seus descendentes, garantindo que questoes que envolvam conceitos mais avancados (comnumero de ordem superior) nao sao contempladas. Das questoes recolhidas, sao selecionadasnum questions questoes aleatoriamente. Caso o numero de exercıcios encontrados seja igualou inferior a num questions sao devolvidos todos os exercıcios recolhidos.
1.2.5 Pre-requisitos e sugestao de estudo
Em [5] e indicada como possıvel melhoria do sistema SIACUA a inclusao de sugestoesdirigidas ao aluno com base no seu desempenho. Neste contexto foi implementado um meca-
13

nismo rudimentar de sugestao de topicos de estudo. Esta sugestao e dada ao aluno quando,apos este ter respondido a uma questao, o conhecimento em algum dos conceitos associadosa questao e inferior a um limiar. O aluno pode escolher seguir a sugestao ou nao, ficandoregistado se o aluno seguiu a sugestao dada. Pretende-se recolher informacao que permitaavaliar a recetividade dos alunos a este tipo de sugestoes.
De modo a implementar este mecanismo de sugestao de topicos de estudo no modelo dotutor a rede Bayesiana foi enriquecida com a relacao de pre-requisito (entre conceitos).
1.3 Contexto de utilizacao
Foram recolhidos dados de utilizacao relativos aos cursos de Calculo 2 lecionado no segundosemestre do ano letivo 2014/2015 e Calculo 3 lecionado no primeiro semestre do ano letivo2015/2016. Em ambas as disciplinas o conhecimento calculado pela aplicacao pode contribuirpara o resultado final da avaliacao de cada um dos alunos.
No caso de Calculo 3, no documento sobre a avaliacao e referido que “Os estudantes saoincentivados a utilizar a plataforma SIACUA (http://siacua.web.ua.pt/) para apoio ao estudoautonomo. Dois topicos no SIACUA ficam em modo de avaliacao durante uma semana emdatas a anunciar nas aulas.”
Para Calculo 2, podemos ler no respetivo dossier pedagogico, que “Na plataformaSIACUA os alunos poderao submeter-se a avaliacao nos capıtulos Transformada de Laplace,Equacoes Diferenciais, Series Numericas e Series de Potencias. Neste caso serao utilizadas asbarras de progresso de conhecimento de cada um dos capıtulos.”No final, esta componentepode contar ate um valor (5%) da nota final do aluno, sendo que esta componente edesconsiderada caso se verifique que prejudica a nota final do aluno.
Por experiencia, os docentes sabem que geralmente a maioria dos alunos nao estuda re-gularmente nem utiliza as ferramentas disponibilizadas, a nao ser que veja efeito direto nanota final a disciplina. Assim, e apesar de a aplicacao SIACUA ser uma aplicacao para oauto diagnostico e estudo autonomo, foi incentivado o uso da aplicacao introduzindo-a comocomponente de avaliacao.
Por curiosidade analisamos a utilizacao da aplicacao SIACUA durante o segundo semestredo ano letivo 2015/2016, na disciplina de Calculo 2. Neste caso nao houve componente deavaliacao associada ao SIACUA. O que verificamos foi uma utilizacao reduzida comparativa-mente ao segundo semestre de 2014/2015, tal como se pode observar na Tabela 1.1.
2014/2015 2015/2016
numero de utilizadores do tipo aluno 327 20
numero medio de respostas por questao MEGUA 36.4 1.3
numero medio de alunos por dia de estudo 17.8 1.4
Tabela 1.1: Utilizacao da aplicacao SIACUA na disciplina de Calculo 2, com e sem componentede avaliacao.
Por analise do dados apresentados na Tabela 1.1 verificamos que o facto de existir ou naocomponente de avaliacao associada a aplicacao SIACUA pesa na sua utilizacao. No entanto,
14

seria necessario recolher estes dados de utilizacao para outros cenarios de utilizacao e analisaroutras variaveis, de modo a consolidar qualquer conclusao.
1.4 Sobre a extracao de caracterısticas
Algumas acoes dos utilizadores da aplicacao SIACUA sao registadas na base de dados natabela Logs. Os campos que compoem esta tabela sao os seguintes.
• login: identificador unıvoco do utilizador.
• action: descreve a acao realizada.
• number: quando a acao realizada respeita a uma questao, este campo indica o numeroda questao (no caso de questoes do PmatE identifica o modelo).
• time: timestamp com a hora do servidor em que foi realizada a acao.
• course: indica no contexto de que disciplina foi realizada a acao.
O dados analisados resultam da recolha de registos da tabela de Logs e posteriorprocessamento. O primeiro passo consistiu na recolha dos registos. Para cada disciplinaforam recolhidos todos os registos de utilizadores do tipo aluno no intervalo do perıodoletivo respetivo. Por exemplo, para Calculo 2, segundo semestre 2014/2015, foram recolhidosregistos no intervalo de 11-02-2015 a 14-07-2015. Adicionalmente, foram colocadas restricoesde ordenacao na pesquisa: primeiro por aluno e depois por data (da mais antiga para a maisrecente).
Considerando o campo action, os registos relevantes para a compilacao dos dados sao osque apresentam os valores descritos em seguida.
• acertou_megua: indica que o utilizador respondeu corretamente a uma questao doMEGUA.
• errou_megua: indica que o utilizador respondeu de forma incorreta a uma questao doMEGUA.
• siacua: indica que o utilizador foi redirecionado para a pagina com os topicos deestudo, isto e, a pagina de estudo autonomo; possıveis valores sao siacua_calculo2 esiacua_calculo3.
• viu_questao_megua: indica que foi apresentada uma questao do MEGUA ao utilizador.
• viu_resol_megua: indica que o utilizador solicitou a resolucao de uma questao doMEGUA, nao respondendo explicitamente a essa questao.
A Tabela 1.2 ilustra uma sequencia de registos reais.Analisando essa sequencia e possıvel perceber que o aluno efetuou o login na aplicacao
no contexto do curso Calculo 2. Apos o login o aluno procurou a area de estudo autonomoe escolheu um topico. O sistema escolheu aleatoriamente uma questao a colocar, tendo sidoescolhida a questao do MEGUA com o identificador 3061. Verificamos que o aluno, cerca de
15

action number time
1 login calculo2 0 2015-05-25 10:59:42.087
2 estudo autonomo 0 2015-05-25 10:59:44.693
3 siacua calculo2 0 2015-05-25 10:59:44.943
4 viu questao megua 3061 2015-05-25 10:59:56.257
5 viu resol megua 3061 2015-05-25 11:17:02.773
6 siacua calculo2 0 2015-05-25 11:30:31.580
Tabela 1.2: Sequencia de acoes reais que se concretizam numa resposta valida.
17 minutos apos lhe ter sido apresentada a questao, escolheu ver a resolucao sem responder.Na analise da resolucao o aluno despendeu cerca de 13 minutos.
A sequencia de mensagens de 3 a 6 representa um momento de estudo do aluno, concreti-zado numa resposta a uma questao: o aluno escolheu um topico, foi apresentada uma questao,o aluno analisou a pergunta e respondeu, tendo ainda oportunidade de analisar o resultado.A Tabela 1.3 ilustra as sequencias de mensagens validas.
# Acoes possıveis Descricao
1 viu_questao_megua Momento em que comeca a ser visualizada a questao.
2
acertou_megua Momento que foi submetida a resposta e iniciada avisualizacao do resultado ou resolucao. A diferenca detempo entre este instante e o momento anterior indica otempo que o utilizador necessitou para responder a questao.
errou_megua
viu_resol_megua
3 siacua Momento em que a visualizacao do resultado ou resolucao ter-mina. A diferenca de tempo entre este instante e o momentoanterior indica o tempo que o utilizador necessitou para es-tudar o resultado ou resolucao.
Tabela 1.3: Sequencia de acoes que traduzem uma resposta valida.
Foi desenvolvido um script em Java para, a partir destes registos, recolher todas as res-postas validas. Cada resposta contem a seguinte informacao:
• numero identificador da questao do MEGUA que foi respondida;
• momento (timestamp) em que foi visualizada a questao;
• login identificador do utilizador que submeteu a resposta;
• o tempo despendido, em segundos, para submeter a resposta; isto e, o tempo passadoentre a apresentacao da questao ao utilizador e a submissao da resposta;
16

• o tempo despendido, em segundos, para analisar o resultado; corresponde ao tempopassado entre a apresentacao do resultado e pedido do utilizador para continuar e voltara pagina principal da area de estudo autonomo;
• o resultado: 0 - errou, 1 - acertou, 2 - viu resolucao sem responder.
Estes registos sao processados posteriormente de modo a obter as caracterısticas por aluno,por questao MEGUA e por dia de estudo.
17

18

Capıtulo 2
Aprendizagens nao supervisionada esupervisionada
As tecnicas de aprendizagem nao supervisionada, tambem designadas de clustering, saolargamente usadas na exploracao de dados. Perante dados recolhidos e sobre os quais aindapouco se sabe, e comum que o primeiro passo na sua analise seja tentar identificar grupos deobjetos semelhantes. Os algoritmos de aprendizagem supervisionada, tambem designados poralgoritmos de previsao, sao usados sobre conjuntos de dados que tem etiquetas associadas.No caso de os dados terem associadas classes, os algoritmos designam-se por algoritmos declassificacao. Tipicamente, o algoritmo aprende um modelo com base em parte dos dadosclassificados, testa esse modelo nos restantes dados classificados e usa o modelo determinado(quando o modelo tem um desempenho considerado satisfatorio) para prever a classe deobjetos desconhecidos.
Este capıtulo esta organizado do seguinte modo. Na seccao 2.1 introduzimos o modelode dados. Na seccao seguinte descrevemos um dos algoritmos classicos de aprendizagem naosupervisionada. As seccoes 2.3 e 2.4 abordam tecnicas de aprendizagem supervisionada comenfase nos classificadores de superfıcie de decisao. A ultima seccao deste capıtulo abordaa tematica da avaliacao de classificadores e da comparacao de desempenho de diferentesmodelos.
2.1 Espaco Multidimensional
Cada objeto do conjunto de dados e um ponto num espaco multidimensional. A repre-sentacao algebrica de cada objeto e um vetor
x =[x1 x2 . . . xM
]T. (2.1)
Cada entrada do vetor corresponde a um valor duma das caracterısticas do objeto. Adimensao M do espaco e o numero total de caracterısticas que descrevem o objeto.
19

2.1.1 Normalizacao
Na maioria da aplicacoes do mundo real as caracterısticas xi tem gamas de valores diferen-tes. Por isso e comum efetuar uma transformacao dos valores que se designa por normalizacaodos dados. Esta transformacao consiste no mapeamento dos valores de cada caracterısticaem valores pertencentes a um intervalo especificado. E particularmente util em algoritmos deaprendizagem em que sao usadas medidas de distancia [2]. Diferentes medidas de distanciasao abordadas na seccao 2.2.1.
Normalizacao min-max
A normalizacao min-max e uma transformacao linear dos dados que mapeia cada valor xinum valor x′i no intervalo desejado. Esta transformacao preserva a relacao entre os valoresoriginais.
Sejam minxi e maxxi o menor e maior valores que ocorrem para uma caracterıstica. Seja[a, b] o intervalo pretendido. Cada valor xi e mapeado no valor x′i ∈ [a, b] segundo a expressao
x′i =xi −minxi
maxxi −minxi(b− a) + a . (2.2)
E usual o intervalo selecionado ser o intervalo [0, 1].
Normalizacao z-score
Neste caso, os valores de uma caracterıstica sao normalizados com base na media xi e nodesvio padrao sxi . A expressao para a normalizacao de um valor xi e a seguinte
x′i =xi − xisxi
. (2.3)
Este metodo e util quando se desconhecem os valores maximo e mınimo que ocorrem paraa caracterıstica xi ou quando existem outliers que influenciem a normalizacao min-max.
2.2 Aprendizagem nao supervisionada
O objetivo da aprendizagem nao supervisionada e a identificacao de grupos no conjuntode dados. Objetos dum mesmo grupo sao semelhantes entre si e distintos dos objetos per-tencentes a outros grupos. A definicao de semelhanca e baseada em medidas de distancia.Quanto menor a distancia, maior a semelhanca.
2.2.1 Medidas de distancia
Tendo dois objetos x e z num espaco multidimensional de dimensao M existem diversasformas de medir a distancia entre eles.
• Euclidiana
d(x, z) =√
(x1 − z1)2 + (x2 − z2)2 + . . .+ (xM − zM )2 =
√√√√ M∑i=1
(xi − zi)2 (2.4)
20

• Manhattan
d(x, z) = |x1 − z1|+ |x2 − z2|+ . . .+ |xM − zM | =M∑i=1
|xi − zi| (2.5)
• Chebyshev
d(x, z) = max {|x1 − z1|, |x2 − z2|, . . . , |xM − zM |} = max |xi−zi|, i = 1, . . . ,M (2.6)
• Minkowski
d(x, z) = p√|x1 − z1|p + |x2 − z2|p + . . .+ |xM − zM |p = p
√√√√ M∑i=1
|xi − zi|p (2.7)
A distancia de Minkowski e equivalente a distancia de Manhattan quando p = 1, aeuclidiana quando p = 2 e a de Chebyshev quando p→∞.
Todas as medidas referidas tem o valor zero quando se trata do mesmo objeto, isto e,d(x,x) = 0. Portanto, num processo de decisao o valor mınimo corresponde ao objeto maisproximo.
2.2.2 K-Means
O K-Means [16] e um algoritmo de aprendizagem nao supervisionada em que cada objetopertence a um so grupo.
O algoritmo e iniciado com o numero K de grupos que se pretende. Em seguida saoescolhidos K objetos como sendo os representantes iniciais dos K potenciais grupos. Estaescolha pode ser aleatoria ou seguir algum criterio como, por exemplo, tentar escolher objetosque estejam equidistantes uns dos outros. Ao representante de um grupo da-se o nome decentroide. Apos a escolha dos K centroides, repetem-se os dois passos seguintes ate que oscentroides se mantenham inalterados.
1. Incluir cada objeto do conjunto de dados no grupo representado pelo centroide maisproximo.
2. Com base nos objetos pertencentes a cada grupo, recalcular o respetivo centroide.
O centroide e um ponto no espaco M -dimensional que, geralmente, e a media dos objetosdo grupo. O centroide pode nao ser um elemento do conjunto de dados. Os centroides finaissao os representantes de cada um dos grupos.
Para medir a qualidade dos grupos encontrados, e usada uma funcao objetivo, cujo valorse pretende minimizar. O que se pretende minimizar e a inercia interna de cada grupo, oua soma dos quadrados das distancias entre cada ponto e o centro do grupo a que pertence.No entanto, esta medida nao e apropriada quando os grupos nao sao convexos ou tem formasalongadas [17].
21

Dados K grupos e um conjunto de dados com N elementos, a funcao objetivo a minimizar,nas variaveis binarias ukj , e dada por
K∑k=1
N∑j=1
ukj d(xj , ck)2 (2.8)
em que ck e o centroide do grupo k e ukj e um elemento da matriz U de dimensoes K×N . Asentradas da matriz U sao definidas do modo seguinte: ukj = 0, se o elemento j nao pertenceao grupo k e ukj = 1, se o elemento j pertence ao grupo k.
Limitacoes
Uma das fragilidades do algoritmo K-Means e que o resultado final e influenciado pelaescolha dos centroides iniciais. Uma forma de a ultrapassar e executar o algoritmo diversasvezes, escolhendo a cada execucao, um conjunto diferente de K centroides iniciais.
Outra das limitacoes deste algoritmo e o facto de ser sensıvel a presenca de outliers. Istoacontece porque a media e uma estatıstica sensıvel a outliers [18].
2.2.3 Avaliacao
No caso de aprendizagem nao supervisionada o silhouette [19] e uma das medidas maisusadas. Este coeficiente traduz o quao semelhante um objeto i e ao seu grupo A, comparandocom a semelhanca ao grupo mais proximo B, permitindo escolher o numero de grupos quemelhor se adequa aos dados. Por grupo mais proximo entendemos aquele que apresenta amenor media das distancias de i a cada um dos objetos de B.
Consideremos uma particao dos dados em grupos obtida por aplicacao de um algoritmode aprendizagem nao supervisionada. Para um objeto i pertencente ao grupo A, o coeficientesilhouette e dado pela expressao
si =b− a
max{a, b}(2.9)
em que a e a media das distancias internas (distancia do objeto aos restantes elementos domesmo grupo) e b e a media das distancias ao grupo mais proximo B. Este coeficiente apenasesta definido quando a cardinalidade de A e maior que um. Da definicao acima verifica-seque si ∈ [−1, 1]. Quando si esta proximo de 1 significa que a media das distancias internas emuito mais pequena que a media das distancias para o grupo mais proximo. Entao pode-seafirmar que o objeto i foi corretamente atribuıdo ao grupo A. Se si e aproximadamente 0entao a e b sao aproximadamente iguais. Neste caso nao e claro se se deveria atribuir o objetoi ao grupo A ou ao grupo B. Se si e proximo de −1, a e muito maior que b. Ou seja, o objetoi esta em media mais proximo de B do que de A. Tal indica que seria mais correto atribuiro objeto ao grupo B.
A media dos coeficientes e uma medida da validade dos grupos encontrados pelo algoritmode aprendizagem nao supervisionada, sendo usada tambem para comparar diferentes solucoes.
s =
∑Ni=1 siN
. (2.10)
22

2.3 Aprendizagem supervisionada
Quando o conjunto de classes existentes e conhecido, assim como sao conhecidas as classesdos objetos do conjunto de dados, e possıvel aplicar aprendizagem supervisionada. O con-junto de dados classificados e usado para treinar o algoritmo. O objetivo da aprendizagemsupervisionada e atribuir a cada objeto uma classe.
O conjunto de dados e composto pelos pontos no espaco M -dimensional e pelas classesdesses pontos. Formalmente, cada elemento do conjunto de dados e representado por (x, y)onde x representa o vetor de caracterısticas do objeto e y a etiqueta (nome da classe).
2.3.1 Vizinhos mais proximos
Este e um algoritmo de classificacao lazy em que nao ha fase de treino. Os elementosdo conjunto de treino sao o modelo. A classificacao de um objeto desconhecido baseia-se naclassificacao conhecida dos objetos mais proximos daquele que se quer classificar [18].
Classe 0
Classe 1
Figura 2.1: Vizinhos mais proximos. Figura adaptada de [1].
Para classificar um novo objeto o algoritmo procura no conjunto de dados conhecidos osk objetos mais proximos desse novo objeto (os vizinhos). Com base na classe predominantedesses k objetos e estimada a classe do novo objeto. A Figura 2.1 ilustra este algoritmo parauma instancia e diferentes valores de k. Note-se que se k = 3 a classe 1 e atribuıda a instanciaem causa; no entanto, se k = 5 a mesma instancia e atribuıda a classe 0.
O funcionamento do classificador vizinhos mais proximos e determinado pelo valor de k epela medida de proximidade escolhida. A medida de distancia mais popular e a euclidiana.
Limitacoes
A escolha destes dois parametros (valor de k e medida de distancia) tem impacto nodesempenho do algoritmo. Se k for demasiado pequeno o resultado pode ser sensıvel a ruıdoexistente no conjunto de dados de treino. Por outro lado, com um k demasiado grandea vizinhanca podera comecar a incluir objetos que nao estao proximos (de acordo com amedida escolhida) e que naturalmente ate pertencem a outra classe.
Relativamente a escolha da medida de distancia, esta depende do problema em concreto(conjunto de dados). Idealmente, a distancia d a usar e aquela em que, para dois objetos x ey, quanto menor o valor de d(x,y) maior a probabilidade de os dois objetos pertencerem amesma classe.
A abordagem escolhida para determinar a classe de um novo objeto com base nas classesdos objetos vizinhos pode ser relevante para os resultados. A forma mais simples e considerar
23

a classe predominante, ou seja, todos os vizinhos tem o mesmo peso. Outra possibilidadee atribuir um peso a cada um dos vizinhos, sendo esse peso inversamente proporcional adistancia. Sendo d a distancia entre o novo objeto e um objeto de treino, o peso w podeser calculado, por exemplo, segundo a expressao w = 1/d2. A utilizacao de pesos torna aestimacao da classe do novo objeto menos sensıvel ao parametro k.
2.3.2 SVM
O classificador SVM (vem do ingles Support Vector Machines) e considerado um dosclassificadores mais robustos. Permite obter bons resultados mesmo com um conjunto dedados pequeno, sendo ainda insensıvel a dimensao do vetor de caracterısticas [18].
E um classificador para duas classes baseado na regra de decisao seguinte, em que paracada instancia z temos
g(z) =∑i
αiyiK(xi, z) + b⇒ g(z) > 0 y = 1g(z) < 0 y = −1
. (2.11)
Os parametros do classificador determinados pelo treino sao: αi, os vetores de suporte xie respetivas etiquetas yi e b. Notar que os vetores de suporte sao elementos do conjunto detreino que tem associados valores αi diferentes de zero. Os valores αi sao os Lagrangianos doproblema de otimizacao quadratico associado ao treino. Na fase de teste o classificador precisade ter os vetores de suporte (com as etiquetas) e os respetivos Lagrangianos. E K(xi, z) euma funcao de kernel:
• Kernel linear determina que a superfıcie de separacao no espaco multidimensional e umhiperplano. A funcao de kernel define o produto interno no espaco de entrada
K(x, z) = xT z. (2.12)
• Kernel RBF. Neste caso a superfıcie de separacao no espaco multidimensional da entradae nao linear. A funcao de kernel define o produto interno no espaco determinado pelatransformacao Φ(.)
K(x, z) = ΦT (x)Φ(z) = exp(‖x− z‖2
−2γ
). (2.13)
Antes de treinar e preciso escolher o kernel a utilizar e respetivos parametros (o γ no caso doRBF), e o valor de C que determina a largura da margem. A escolha que melhor resultadospermite obter e determinada experimentalmente [2].
Dados linearmente separaveis
Consideremos o problema de classificacao binario no espaco bi-dimensional. O primeirografico da Figura 2.2 ilustra os dados de ambas as classes. Este e um exemplo em que osdados sao linearmente separaveis. Isto significa que, no caso bidimensional, e possıvel tracarlinhas retas a separar os dados das diferentes classes. Estendendo para M -dimensional temoshiperplanos a separar os dados.
24

Característica A
Cara
cte
rís
tica B
Figura 2.2: SVM Linear. Figuras adaptadas de [2].
O classificador procura o melhor hiperplano. No caso da Figura 2.2 e uma linha retaporque o problema e bi-dimensional. O melhor hiperplano e aquele que define uma maiorseparacao dos dados, uma maior margem. Isto permite uma mais correta classificacao dedados futuros. Os outros dois graficos da Figura 2.2 ilustram dois possıveis modelos, sendoque o ultimo tem uma margem maior.
No caso linearmente separavel, os hiperplanos paralelos ao hiperplano de decisao e quedefinem a margem passam pelos vetores de suporte. Estes objetos sao aqueles mais difıceis declassificar, pois sao os que estao mais proximos da fronteira de decisao. Assim, a complexidadedo modelo encontrado e determinada pelo numero de vetores de suporte (e nao pelo numerode caracterısticas).
Dados nao linearmente separaveis
Se os dados nao forem linearmente separaveis nao e possıvel determinar um hiperplanoque separe os dados de ambas as classes. Uma abordagem para determinar o modelo nestescasos assenta na ideia de margem flexıvel. Basicamente, o classificador com kernel linear,durante a fase de treino permite a existencia de alguns erros (objetos mal classificados). Oprimeiro grafico da Figura 2.3 ilustra esta situacao.
Outra abordagem passa pela escolha da funcao de kernel, ao escolher uma funcao de kernelque defina uma relacao nao linear entre os dados, tal como exemplificado no segundo graficoda Figura 2.3.
Característica A
Cara
cte
rís
tica B
Figura 2.3: SVM nao linear. Figuras adaptadas de [2].
25

2.3.3 SVM Linear e eliminacao de caracterısticas
O objetivo e eliminar algumas das caracterısticas de entrada de modo a obter umsubconjunto mınimo de caracterısticas que permite o melhor desempenho na classificacao dasobservacoes. Uma das tecnicas para a selecao de caracterısticas consiste na sua ordenacao,segundo algum criterio, escolhendo depois as que estao no topo da ordenacao.
A equacao de decisao determinada pelo SVM Linear e dada por
g(z) =∑i
αiyixTi z + b⇒ g(z) > 0 y = 1
g(z) < 0 y = −1. (2.14)
Como referido em 2.3.2, parte destes α calculados sao nulos, sendo que os que nao saonulos correspondem aos vetores de suporte. A partir dos Lagrangianos α calcula-se o vetorde pesos w
w =
K∑i=1
αiyixi. (2.15)
Substituindo o calculo do vetor de pesos na equacao de decisao obtemos
g(z) = wT z + b = w1z1 + w2z2 + . . .+ b⇒ g(z) > 0 y = 1g(z) < 0 y = −1
. (2.16)
Se wi for muito proximo de zero a caracterıstica correspondente nao tem influencia.Assim, e possıvel usar o valor absoluto de wi como criterio de ordenacao.
A tecnica de eliminacao recursiva de caracterısticas apresentada em [20] e um processo ite-rativo em que sao progressivamente eliminadas as caracterısticas com peso associado proximode zero, i.e., com menor influencia no processo de decisao. Os passos sao:
1. Treinar o classificador otimizando os pesos da funcao objetivo.
2. Para o criterio de ordenacao de caracterısticas adotado, calcular a posicao de cada uma.
3. Remover a caracterıstica com menor influencia.
A aplicacao recursiva dos passos implica que a dimensao do vetor de caracterısticas doobjeto diminua.
2.3.4 Classificacao por voto maioritario
A motivacao para este tipo de classificacao e a possibilidade de combinar classificadoresconceptualmente diferentes. Sao duas as regras mais comuns de voto: voto maioritario e votopesado. O voto maioritario e feito com base na classe atribuıda por cada classificador; nautilizacao desta regra, e recomendado considerar um numero ımpar de classificadores. O votopesado recorre as probabilidades associadas a cada classe e ao peso atribuıdo a cada um dosclassificadores. Assume-se que os resultados dos classificadores sao independentes. Ilustramosem seguida com exemplos.
26

Suponhamos que sao usados tres classificadores e que se trata de um problema de clas-sificacao binaria. Para uma dada instancia o resultado de cada um dos classificadores e oseguinte:
classificador 1 → classe 0
classificador 2 → classe 0
classificador 3 → classe 1
No caso da regra por voto maioritario, a instancia em causa e atribuıda a classe 0.
Consideremos agora que a cada classificador esta associado um peso; seja w1=1, w2=1 ew3=1. As probabilidades associadas a cada classe sao as seguintes:
classe 0 classe 1
classificador 1 w1 * 0.2 w1 * 0.8
classificador 2 w2 * 0.6 w2 * 0.4
classificador 3 w3 * 0.3 w3 * 0.7
media pesada 0.36 0.64
Sendo a regra de classificacao por voto pesado e atribuıda a classe 1 a instancia.
2.4 Aprendizagem supervisionada: dados nao equilibrados
Em [21] e apresentado o estado da arte, a data de 2009, relativamente a aprendizagemsupervisionada em conjuntos de dados nao equilibrados. Neste artigo e referido que razoesentre classe maioritaria e classe minoritaria como 100, 1000 ou 10000 nao sao incomuns. Noartigo [1], em que sao realizadas diversas simulacoes com diferentes classificadores e diferentesconjuntos de dados, a razao entre a classe maioritaria e a classe minoritaria dos conjuntos dedados usados varia entre 1.14 e 10.
Duas das tecnicas abordadas nessa revisao [21] sao a geracao de instancias da classe mi-noritaria e a atribuicao de diferentes custos a incorreta classificacao de objetos, dependendoda classe a que pertencam. Em [6] e apresentado um resumo de algumas tecnicas que mini-mizam os problemas que surgem quando os dados treinados por SVM nao sao equilibrados.Nas subseccoes seguintes detalhamos algumas dessas tecnicas.
2.4.1 DEC
Apesar da robustez do SVM, quando treinado num conjunto de dados nao equilibrado,este classificador produz modelos com desempenho baixo na classe minoritaria. Isto ocorreporque a fronteira de decisao e enviesada para a classe maioritaria.
DEC [22] vem do ingles Different Error Costs e e uma das tecnicas usadas quandona presenca de dados nao equilibrados ou ruıdo. Assenta na ideia de atribuir um custo aclassificacao incorreta de instancias positivas diferente do custo associado a classificacaoincorreta de instancias negativas. O custo maior e atribuıdo a classificacao incorreta de
27

observacoes da classe minoritaria.
O problema de otimizacao no SVM Linear, considerando a margem flexıvel, e dado por
min
(1
2wTw + C
∑i
ξi
)com yi(w
Txi + b) ≥ 1− ξi e ξi ≥ 0. (2.17)
As variaveis ξi sao variaveis de folga para os elementos mal classificados. O objetivo emaximizar a margem e minimizar o numero de elementos mal classificados. O parametroC controla o compromisso entre estes dois objetivos. Sejam C+ e C− o peso associado aclassificacao incorreta de elementos da classe positiva e da classe negativa, respetivamente.Podemos reescrever a funcao objetivo
min
(1
2wTw + C+
∑i|yi>0
ξi + C−∑i|yi<0
ξi + b
). (2.18)
sujeita as mesmas condicoes que a equacao 2.17.
Conjunto de dados SVM linear SVM linear - DEC
Figura 2.4: Treino do mesmo conjunto de dados nao equilibrado com SVM Linear e SVMLinear com pesos associados as classes.
No artigo [22] nao sao referidos quais os valores de C+ e C− adequados. Em [23] estatecnica e avaliada e e determinado experimentalmente que definindo os custos tais que a suarazao e o inverso da razao entre a cardinalidade das classes permite obter bons resultados.Ou seja, sendo N+ e N− o numero de elementos da classe positiva e da classe negativa,respetivamente, e sendo a classe positiva a classe minoritaria, entao C+/C− = N−/N+.Tendo como exemplo a Figura 2.4, como N+ = 20 e N− = 80 a razao entre C+ e C− e80/20 = 4.
2.4.2 SMOTE + DEC
Os resultados experimentais apresentados em [23] indicam que a utilizam de SMOTEseguida da aplicacao de DEC tem um melhor desempenho. SMOTE, que vem do inglesSynthetic Minority Over-sampling Technique, consiste na geracao de objetos para a classeminoritaria [24]. As novas instancias sao geradas ao longo dos segmentos de reta que unemvizinhos mais proximos da classe minoritaria como ilustrado na Figura 2.5. Deste modo, a
28

regiao de decisao para esta classe torna-se mais abrangente. O processo SMOTE e o que sedescreve em seguida.
Para iniciar, o SMOTE necessita do numero k de vizinhos a considerar e de NS que indicaquanto a classe minoritaria e aumentada. Este valor NS pode ser um qualquer inteiro menorque 100 ou entao multiplos inteiros de 100. Quando NS < 100 sao escolhidos aleatoriamenteNS instancias da classe minoritaria, caso contrario todas as instancias da classe minoritariasao consideradas. Seja T esse conjunto de instancias. Com base no valor de NS e determinadoo numero de objetos a gerar por cada instancia de T , seja ng esse valor.
1. Para cada xi ∈ T
(a) Determina os k vizinhos mais proximos
(b) gerados = 0
(c) Enquanto gerados < ng
i. Escolhe aleatoriamente um vizinho mais proximo de xi.
ii. Multiplica a diferenca entre ambos por um valor aleatorio entre 0 e 1.
iii. Adiciona o resultado a observacao xi.
iv. gerados += 1
O resultado obtido e uma nova instancia, gerada artificialmente, localizadaentre as duas observacoes que lhe deram origem.
2.4.3 SVM e a geracao de instancias
Em [3] e proposta uma tecnica de geracao de instancias da classe minoritaria baseada nosvetores de suporte de um modelo SVM treinado com o conjunto de dados original.
A zona em que sao geradas as novas instancias e aproximada pelos vetores de suporte daclasse minoritaria. Deste modo, as novas instancias surgem ao longo da fronteira de decisao,onde a presenca de objetos e crıtica para a estimacao da melhor equacao de decisao possıvel.A Figura 2.5 ilustra a geracao de instancias por SMOTE SVM.
instância da classe minoritária
vizinho maispróximo da mesmaclasse minoritária
Figura 2.5: Geracao de instancias. Figuras adaptadas de [3].
29

Tal como no SMOTE e necessario indicar o numero k de vizinhos mais proximos e emquanto a classe minoritaria e aumentada, obtendo o numero de instancias que e necessariogerar.
1. Treina um modelo SVM, determinando os vetores de suporte da classe minoritaria.
2. Com base no numero total de instancias a gerar, calcula o numero de instancias quedevem ser geradas por vetor de suporte da classe minoritaria. Seja ng esse valor.
3. Para cada vetor de suporte svi que seja da classe minoritaria
(a) Determina os k vizinhos mais proximos, independentemente da classe
(b) Determina nn o conjunto dos ng vizinhos mais proximos de svi da classe mino-ritaria
(c) Se a maioria dos k vizinhos mais proximos de svi for da classe maioritaria, porcada xj ∈ nn cria uma nova instancia no segmento de reta que une o vetor desuporte svi a xj . E analogo ao SMOTE, as instancias sao geradas por interpolacao.
Caso a maioria dos k vizinhos mais proximos de svi sejam da classe minoritaria,por cada xj ∈ nn cria uma nova instancia na reta que une o vetor de suporte svia xj (a excecao da zona definida pelo segmento de reta). A nova instancia naodista do vetor de suporte svi mais do que a distancia entre svi e xj . Neste casoas instancias sao geradas por extrapolacao.
O objetivo e expandir a classe minoritaria nas zonas em que existem poucas instancias daclasse maioritaria e consolidar a zona de fronteira para a classe minoritaria em zonas em queexistem muitas observacoes da classe maioritaria. A Figura 2.6 ilustra o caso de um conjuntode dados bi-dimensional nao equilibrado e o resultado da geracao de instancias por utilizacaodos metodos SMOTE e SMOTE SVM.
Figura 2.6: Geracao de instancias por SMOTE e SMOTE SVM.
2.4.4 z-SVM
Nesta abordagem [25] comeca por ser treinado um classificador SVM. Posteriormente afronteira de decisao determinada e modificada de modo a corrigir o enviesamento para a classe
30

maioritaria. Recordemos a equacao de decisao.
g(z) =∑i
αiyiK(xi, z) + b⇒ g(z) > 0 y = 1g(z) < 0 y = −1
(2.19)
Separando os vetores de suporte pelas respetivas classes podemos reescrever a equacao dedecisao.
g(z) =∑i|yi>0
αiyiK(xi, z) +∑i|yi<0
αiyiK(xi, z) + b⇒ g(z) > 0 y = 1g(z) < 0 y = −1
(2.20)
No z-SVM a magnitude dos α associados aos vetores de suporte da classe minoritaria eaumentada multiplicando cada um deles por uma constante positiva z.
g(z) = z∑i|yi>0
αiyiK(xi, z) +∑i|yi<0
αiyiK(xi, z) + b⇒ g(z) > 0 y = 1g(z) < 0 y = −1
(2.21)
considerando que a classe positiva e a classe minoritaria.Usando o g como medida de avaliacao, o que se pretende e determinar o valor de z tal
que g seja o maior possıvel.
max
√∑i|yi>0
I(yi × g(z))
P×
∑i|yi<0
I(yi × g(z))
N(2.22)
sendo P e N o numero de elementos da classe positiva e o numero de elementos da classenegativa, respetivamente. I(yi × g(z)) tem valor zero se yi × g(z) < 0 e tem valor 1 casocontrario.
2.5 Aprendizagem supervisionada: avaliacao
Como medir o desempenho de um algoritmo de classificacao? Uma das medidas maisnaturais e a proporcao de objetos corretamente classificados, designada por acuracia. Noentanto, esta medida depende da dimensao dos diferentes grupos [16]. Portanto, podera serconveniente usar diferentes medidas em funcao do problema.
2.5.1 Medidas de desempenho
Apresentamos em seguida algumas das medidas considerando o caso de classificacaobinaria. Por uma questao de simplicidade consideramos a classe positiva + e a classe ne-gativa −. A partir da matriz confusao, como a que e apresentada na Tabela 2.1 e possıvelobter diversas medidas.
Na matriz confusao sao apresentados o numero TP de objetos corretamente identifica-dos como positivos, o numero FP de objetos incorretamente identificados como positivos, onumero TN de objetos corretamente identificados como negativos e FN o numero de objetosincorretamente classificados como negativos. Verificamos a existencia de dois tipos de erro:os falsos positivos (erro do tipo 1) e os falsos negativos (erro do tipo 2). Enumeramos emseguida algumas das medidas do desempenho de um algoritmo de classificacao.
31

Classe prevista Total
+ − objetos
Classe + TP FN P
real − FP TN N
Tabela 2.1: Matriz confusao.
• recall ou sensibilidade e a proporcao de objetos positivos corretamente classificados
r =TP
TP + FN=TP
P(2.23)
• razao de falsos positivos ou false alarm rate e a proporcao de objetos negativos classi-ficados incorretamente
FP
FP + TN=FP
N(2.24)
• razao de falsos negativos e a proporcao de objetos positivos classificados incorretamente
FN
TP + FN=FN
P(2.25)
• especificidade e a proporcao de objetos negativos classificados corretamente
s =TN
TN + FP=TN
N(2.26)
• precisao e a proporcao de objetos classificados como positivos e que de facto o sao
p =TP
TP + FP(2.27)
• acuracia e a proporcao dos objetos corretamente classificados
a =TP + TN
TP + TN + FP + FN=TP + TN
P +N(2.28)
• F-score ou F-measure e a media harmonica que combina precisao e recall
2× r × pp+ r
(2.29)
• taxa de erro e a proporcao dos objetos classificados incorretamente
FP + FN
TP + TN + FP + FN=FP + FN
P +N(2.30)
• media geometrica da especificidade e recall
g =√r × s (2.31)
Esta e uma medida que tem sido usada em situacoes em que os dados nao sao equilibra-dos [23, 25]. Uma vez que a especificidade pode ser lida como a acuracia nas observacoesda classe negativa e a sensibilidade como a acuracia nas de classe positiva, um valorelevado de g indica que o modelo em avaliacao nao esta enviesado no sentido da classemaioritaria.
32

Curva ROC e area abaixo da curva
A curva ROC (do ingles Receiver Operating Characteristic) e uma representacao graficaque ilustra o desempenho de um classificador binario em funcao da variacao do limiar dediscriminacao. A Figura 2.7 ilustra duas curvas ROC correspondentes a classificadores comdiferentes desempenhos.
Razão de falsos positivos
Recall
C1
C2
0
1
1
Figura 2.7: Exemplo de curvas ROC. A curva C1 representa um classificador com melhordesempenho do que aquele representado pela curva C2.
Quanto mais a curva seguir junto ao limite esquerdo e depois junto ao limite superiorda area de desenho da curva, melhor o desempenho do classificador. A diagonal a tracointerrompido corresponde a curva de um classificador com desempenho aleatorio.
A area abaixo da curva (AUC) e um resumo da informacao contida na curva. E umamedida da capacidade de discriminacao do classificador, isto e, da capacidade de classificarcorretamente instancias de ambas as classes. Assim, quanto maior o seu valor, melhor odesempenho do classificador. As curvas ROC e a medida AUC sao muitas vezes as medidasescolhidas para avaliar o desempenho de classificadores [1, 22, 26, 27] .
2.5.2 Validacao cruzada
E uma forma sistematica de avaliar o desempenho de um classificador. Esta abordagem emuitas vezes adotada quando o conjunto de dados e pequeno. Consiste na divisao do conjuntode dados em k subconjuntos de aproximadamente igual tamanho. Em seguida sao realizadask sessoes de treino e teste. Em cada sessao e usado um dos k conjuntos para teste e osrestantes k− 1 para treino, sendo que no final cada objeto e usado o mesmo numero de vezespara treino e exatamente uma vez para teste.
Existem diferentes estrategias para a concretizacao dos subconjuntos de validacao cruzada.Na mais comum os k subconjuntos sao criados de modo a preservar a percentagem de objetosde cada classe, semelhante a existente no conjunto de dados. Esta estrategia e designada porstratified k-fold.
33

2.5.3 Comparacao de classificadores
E natural considerar que o melhor classificador e aquele que apresenta o valor mais elevadode acuracia. No entanto, a diferenca na acuracia de dois classificadores pode nao traduziruma diferenca estatisticamente significativa. Para determinar se essa diferenca e significativaaplicamos um teste estatıstico como o t-teste [28]. A hipotese que colocamos, hipotese nula, eque ambos os classificadores sao iguais. Se pudermos rejeitar esta hipotese podemos concluirque a diferenca entre os dois classificadores e relevante. Nesse caso escolhemos o classificadorcom melhor acuracia.
Sejam MA e MB dois classificadores. Queremos comparar o seu desempenho usando a es-trategia de validacao cruzada. Consideremos cada um dos k subconjuntos em que foi divididoo conjunto de dados para a validacao cruzada. Sejam pAj e pBj a acuracia dos classificadores
MA e MB no subconjunto j, respetivamente. Seja pj = pAj − pBj a diferenca da acuracia parao subconjunto j. A hipotese nula afirma que pj tem media zero.
A media das diferencas da acuracia p e a variancia sao dadas pelas expressoes seguintes.
p =
∑j pj
kσ2 =
∑j(pj − p)2
k − 1j = 1, . . . , k (2.32)
O valor de t-score usado no teste de hipoteses e calculado por√k pσ .
Se t-score ∈ (−tα/2,(k−1), tα/2,(k−1)) a hipotese de ambos os modelos serem iguais e aceite.O valor de t e lido de uma tabela de probabilidades em funcao dos graus de liberdade e donıvel de confianca pretendido.
34

Capıtulo 3
Analise dos dados
Na primeira seccao deste capıtulo apresentamos os dados sobre os quais trabalhamos. Nasseccoes seguintes apresentamos a analise de dados realizada da perspetiva de dia, utilizador eperguntas. Terminamos com uma comparacao entre os varios resultados obtidos e respetivasconclusoes.
3.1 Caracterizacao dos dados
Os dados foram analisados por disciplina. Para cada uma das disciplinas o primeiropasso consistiu em recolher os registos de atividade na aplicacao SIACUA durante o perıodode lecionacao dessa disciplina. Estes registos foram depois processados de modo a obter,para cada utilizador do tipo aluno, uma listagem de todas as respostas dadas aos diferentesproblemas. Este processo esta descrito na Seccao 1.4.
3.1.1 Descricao
Recordamos que cada resposta contem a seguinte informacao:
• numero identificador da questao do MEGUA que foi respondida;
• momento (timestamp) em que foi visualizada a questao;
• login identificador do utilizador que submeteu a resposta;
• o tempo despendido, em segundos, para submeter a resposta; isto e, o tempo passadoentre a apresentacao da questao ao utilizador e a submissao da resposta;
• o tempo despendido, em segundos, para analisar o resultado; corresponde ao tempopassado entre a apresentacao do resultado e pedido do utilizador para continuar e voltara pagina principal da area de estudo autonomo;
• o resultado: 0 - errou, 1 - acertou, 2 - viu resolucao sem responder.
Notamos que ao analisar os dados tendo como ponto de partida as respostas, estamosautomaticamente a considerar apenas os alunos que responderam a pelo menos uma questaodurante o perıodo indicado.
35

Processando cada uma destas respostas, obtivemos um conjunto de caracterısticas por dia,aluno e questao, sendo que todas as caracterısticas de contagem de tempo foram convertidaspara minutos. Por exemplo, por dia podemos determinar o numero de utilizadores distintosque acedeu a aplicacao e respondeu a alguma questao, o numero de respostas submetidas ouo tempo despendido na aplicacao na area de estudo autonomo. Por questao recolhemos onumero de respostas submetidas em funcao do resultado ou o tempo utilizado para respondera questao. Por aluno calculamos o numero de respostas submetidas ou tempo despendido naarea de estudo autonomo na aplicacao.
Deste modo, e possıvel obter 8 caracterısticas por dia, 12 por questao do MEGUA e 14por utilizador. Apoiados na analise dos dados relativos a utilizacao da aplicacao ao longodo semestre, aumentamos para 42 o numero de caracterısticas associadas ao utilizador aodistinguir as interacoes ocorridas em dias fora dos perıodos de avaliacao e dias de avaliacao.A lista exaustiva das caracterısticas pode ser consultada no Apendice A.
3.2 Pre-analise: perspetiva de dia
O conhecimento calculado pela aplicacao contribui para o resultado final da avaliacao decada um dos alunos, as disciplinas de Calculo 2 e Calculo 3. Assim, nas datas definidas noinıcio do semestre, sao consultados os valores de conhecimento para os topicos em questao [29].
Naturalmente, esta medida influencia a utilizacao da aplicacao ao longo de um semestre.Assim, definindo o perıodo de avaliacao, podemos medir a mesma caraterıstica em perıodode avaliacao e fora dele.
A determinacao dos dias que constituem o perıodo de avaliacao foi realizada de formaobjetiva com base no calendario escolar (perıodos de avaliacao final e de recurso) e de formaempırica com base no numero total de alunos que acederam a aplicacao, por dia.
3.2.1 O caso de Calculo 2
Na disciplina de Calculo 2, no ano letivo de 2014/2015, as datas de consulta do conheci-mento foram 9 de Marco, 9 de Abril e 9 de Junho de 2015.
O grafico da Figura 3.1 apresenta, por dia, o numero total de alunos que responderam apelo menos uma questao. Por observacao do grafico, constatamos que os picos de utilizacaoocorrem claramente em torno das datas de consulta do conhecimento para avaliacao.
Assim, assumimos a seguinte classificacao para os dias de estudo na aplicacao.
• Perıodo de avaliacao, existindo quatro perıodos de avaliacao: 7 a 9 de Marco de 2015,6 a 9 de Abril de 2015, 8 a 9 de Junho de 2015 e de 29 de Junho a 7 de Julho de 2015.
• Fora do perıodo de avaliacao, para os restantes dias.
3.2.2 O caso de Calculo 3
Na disciplina de Calculo 3, no ano letivo de 2015/2016, as datas de consulta do conheci-mento foram 28 de Outubro e 31 de Dezembro de 2015.
O grafico da Figura 3.2 apresenta, por dia, o numero total de alunos que responderam apelo menos uma questao. Por observacao do grafico, constatamos que os picos de utilizacaoocorrem claramente em torno das datas de consulta do conhecimento para avaliacao. Adici-onalmente, verificamos que no inıcio do semestre houve uma grande afluencia a aplicacao.
36
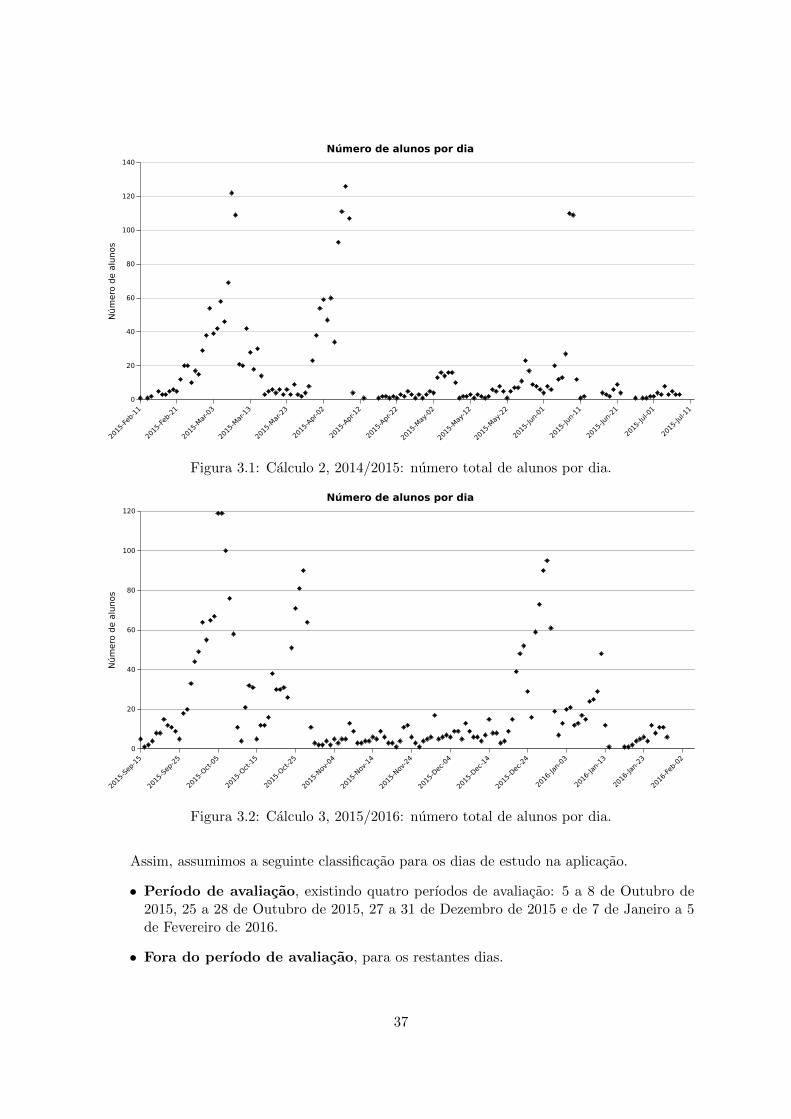
2015
-Feb
-11
2015
-Feb
-21
2015
-Mar
-03
2015
-Mar
-13
2015
-Mar
-23
2015
-Apr
-02
2015
-Apr
-12
2015
-Apr
-22
2015
-May
-02
2015
-May
-12
2015
-May
-22
2015
-Jun-
01
2015
-Jun-
11
2015
-Jun-
21
2015
-Jul-0
1
2015
-Jul-1
1
0
20
40
60
80
100
120
140
Núm
ero
de a
lunos
Número de alunos por dia
Figura 3.1: Calculo 2, 2014/2015: numero total de alunos por dia.
2015-Sep-15
2015-Sep-25
2015-Oct-05
2015-Oct-15
2015-Oct-25
2015-Nov-04
2015-Nov-14
2015-Nov-24
2015-Dec-04
2015-Dec-14
2015-Dec-24
2016-Jan-03
2016-Jan-13
2016-Jan-23
2016-Feb-02
0
20
40
60
80
100
120
Número
de a
lunos
Número de alunos por dia
Figura 3.2: Calculo 3, 2015/2016: numero total de alunos por dia.
Assim, assumimos a seguinte classificacao para os dias de estudo na aplicacao.
• Perıodo de avaliacao, existindo quatro perıodos de avaliacao: 5 a 8 de Outubro de2015, 25 a 28 de Outubro de 2015, 27 a 31 de Dezembro de 2015 e de 7 de Janeiro a 5de Fevereiro de 2016.
• Fora do perıodo de avaliacao, para os restantes dias.
37
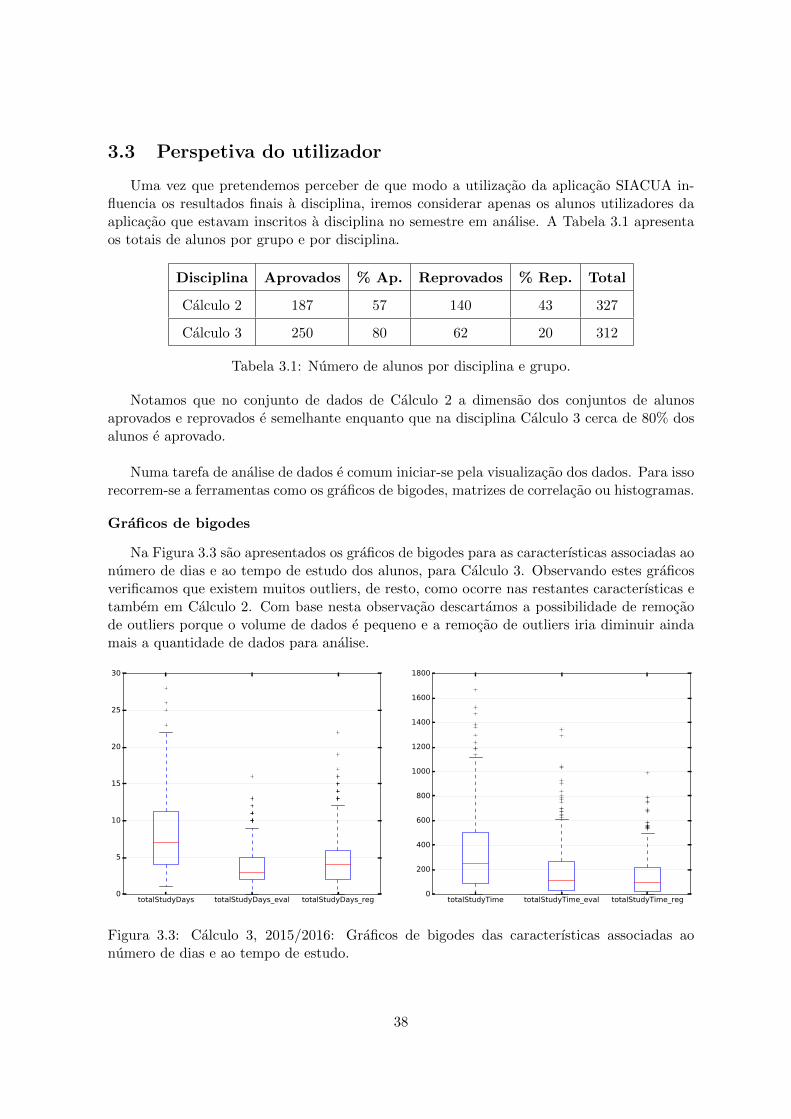
3.3 Perspetiva do utilizador
Uma vez que pretendemos perceber de que modo a utilizacao da aplicacao SIACUA in-fluencia os resultados finais a disciplina, iremos considerar apenas os alunos utilizadores daaplicacao que estavam inscritos a disciplina no semestre em analise. A Tabela 3.1 apresentaos totais de alunos por grupo e por disciplina.
Disciplina Aprovados % Ap. Reprovados % Rep. Total
Calculo 2 187 57 140 43 327
Calculo 3 250 80 62 20 312
Tabela 3.1: Numero de alunos por disciplina e grupo.
Notamos que no conjunto de dados de Calculo 2 a dimensao dos conjuntos de alunosaprovados e reprovados e semelhante enquanto que na disciplina Calculo 3 cerca de 80% dosalunos e aprovado.
Numa tarefa de analise de dados e comum iniciar-se pela visualizacao dos dados. Para issorecorrem-se a ferramentas como os graficos de bigodes, matrizes de correlacao ou histogramas.
Graficos de bigodes
Na Figura 3.3 sao apresentados os graficos de bigodes para as caracterısticas associadas aonumero de dias e ao tempo de estudo dos alunos, para Calculo 3. Observando estes graficosverificamos que existem muitos outliers, de resto, como ocorre nas restantes caracterısticas etambem em Calculo 2. Com base nesta observacao descartamos a possibilidade de remocaode outliers porque o volume de dados e pequeno e a remocao de outliers iria diminuir aindamais a quantidade de dados para analise.
totalStudyDays totalStudyDays_eval totalStudyDays_reg0
5
10
15
20
25
30
totalStudyTime totalStudyTime_eval totalStudyTime_reg0
200
400
600
800
1000
1200
1400
1600
1800
Figura 3.3: Calculo 3, 2015/2016: Graficos de bigodes das caracterısticas associadas aonumero de dias e ao tempo de estudo.
38
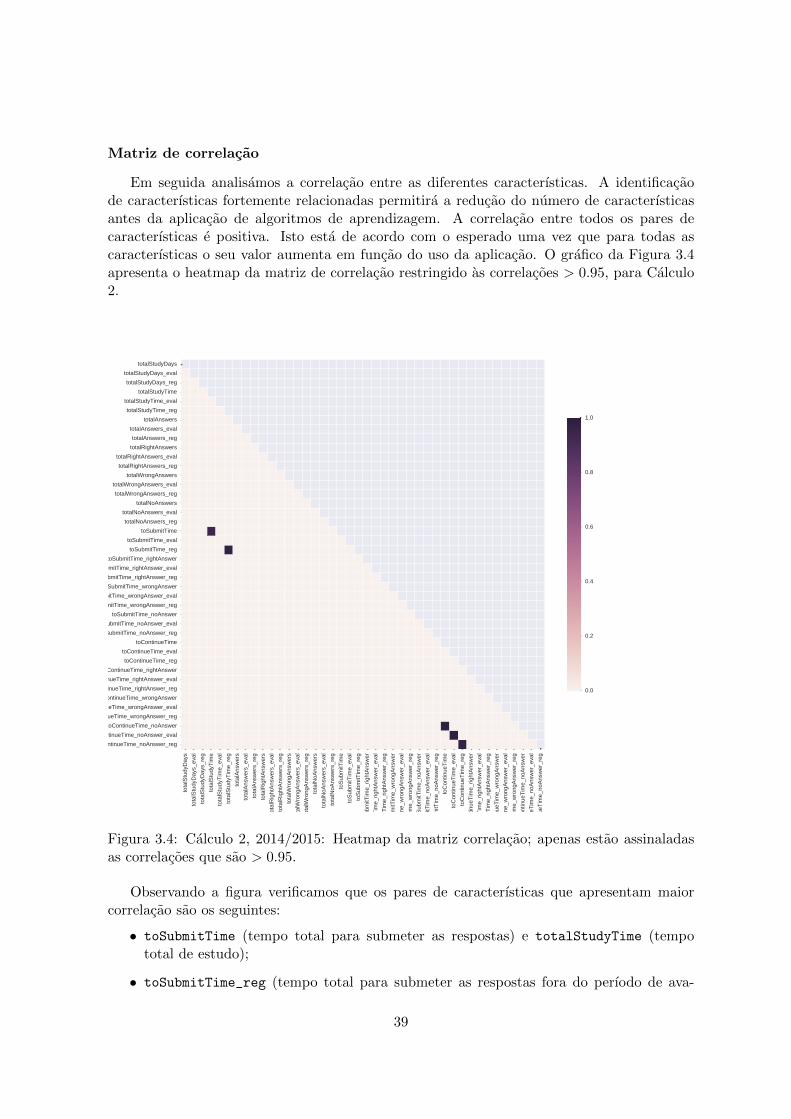
Matriz de correlacao
Em seguida analisamos a correlacao entre as diferentes caracterısticas. A identificacaode caracterısticas fortemente relacionadas permitira a reducao do numero de caracterısticasantes da aplicacao de algoritmos de aprendizagem. A correlacao entre todos os pares decaracterısticas e positiva. Isto esta de acordo com o esperado uma vez que para todas ascaracterısticas o seu valor aumenta em funcao do uso da aplicacao. O grafico da Figura 3.4apresenta o heatmap da matriz de correlacao restringido as correlacoes > 0.95, para Calculo2.
totalStudyDays
totalStudyDays_eval
totalStudyDays_reg
totalStudyTime
totalStudyTime_eval
totalStudyTime_reg
totalAnswers
totalAnswers_eval
totalAnswers_reg
totalRightAnswers
totalRightAnswers_eval
totalRightAnswers_reg
totalWrongAnswers
totalWrongAnswers_eval
totalWrongAnswers_reg
totalNoAnswers
totalNoAnswers_eval
totalNoAnswers_reg
toSubmitTime
toSubmitTime_eval
toSubmitTime_reg
toSubmitTime_rightAnswer
toSubmitTime_rightAnswer_eval
toSubmitTime_rightAnswer_reg
toSubmitTime_wrongAnswer
toSubmitTime_wrongAnswer_eval
toSubmitTime_wrongAnswer_reg
toSubmitTime_noAnswer
toSubmitTime_noAnswer_eval
toSubmitTime_noAnswer_reg
toContinueTime
toContinueTime_eval
toContinueTime_reg
toContinueTime_rightAnswer
toContinueTime_rightAnswer_eval
toContinueTime_rightAnswer_reg
toContinueTime_wrongAnswer
toContinueTime_wrongAnswer_eval
toContinueTime_wrongAnswer_reg
toContinueTime_noAnswer
toContinueTime_noAnswer_eval
toContinueTime_noAnswer_reg
toContinueTime_noAnswer_reg
toContinueTime_noAnswer_eval
toContinueTime_noAnswer
toContinueTime_wrongAnswer_reg
toContinueTime_wrongAnswer_eval
toContinueTime_wrongAnswer
toContinueTime_rightAnswer_reg
toContinueTime_rightAnswer_eval
toContinueTime_rightAnswer
toContinueTime_reg
toContinueTime_eval
toContinueTime
toSubmitTime_noAnswer_reg
toSubmitTime_noAnswer_eval
toSubmitTime_noAnswer
toSubmitTime_wrongAnswer_reg
toSubmitTime_wrongAnswer_eval
toSubmitTime_wrongAnswer
toSubmitTime_rightAnswer_reg
toSubmitTime_rightAnswer_eval
toSubmitTime_rightAnswer
toSubmitTime_reg
toSubmitTime_eval
toSubmitTime
totalNoAnswers_reg
totalNoAnswers_eval
totalNoAnswers
totalWrongAnswers_reg
totalWrongAnswers_eval
totalWrongAnswers
totalRightAnswers_reg
totalRightAnswers_eval
totalRightAnswers
totalAnswers_reg
totalAnswers_eval
totalAnswers
totalStudyTime_reg
totalStudyTime_eval
totalStudyTime
totalStudyDays_reg
totalStudyDays_eval
totalStudyDays
0.0
0.2
0.4
0.6
0.8
1.0
Figura 3.4: Calculo 2, 2014/2015: Heatmap da matriz correlacao; apenas estao assinaladasas correlacoes que sao > 0.95.
Observando a figura verificamos que os pares de caracterısticas que apresentam maiorcorrelacao sao os seguintes:
• toSubmitTime (tempo total para submeter as respostas) e totalStudyTime (tempototal de estudo);
• toSubmitTime_reg (tempo total para submeter as respostas fora do perıodo de ava-
39

liacao) e totalStudyTime_reg (tempo total de estudo fora do perıodo de avaliacao);
• toContinueTime_noAnswer (tempo total para analisar o resultado dos pedidos de vi-sualizacao da resolucao) e toContinueTime (tempo total para analisar o resultado dasrespostas);
• toContinueTime_noAnswer_eval (tempo total para analisar o resultado dos pedidosde visualizacao da resolucao em perıodo de avaliacao) e toContinueTime_eval (tempototal para analisar o resultado das respostas em perıodo de avaliacao);
• toContinueTime_noAnswer_reg (tempo total para analisar o resultado dos pedidos devisualizacao da resolucao fora do perıodo de avaliacao) e toContinueTime_reg (tempototal para analisar o resultado das respostas fora do perıodo de avaliacao).
Realizamos a mesma analise com os dados relativos a Calculo 3 e foram identificados8 pares de caracterısticas com correlacao > 0.95. Nesses 8 pares, alem dos cinco pares decaracterısticas mencionados acima, estavam tambem:
• toSubmitTime_eval (tempo total para submeter as respostas em perıodo de avaliacao)e totalStudyTime_eval (tempo total de estudo em perıodo de avaliacao);
• toSubmitTime (tempo total para submeter as respostas) e toSubmitTime_rightAnswer(tempo total para submeter as respostas corretas);
• toSubmitTime_reg (tempo total para submeter as respostas fora do perıodo de ava-liacao) e toSubmitTime_rightAnswer_reg (tempo total para submeter as respostascorretas fora do perıodo de avaliacao).
Histogramas
Do ponto de vista da classificacao dos alunos, aprovado ou reprovado, desenhamos os his-togramas para as varias caracterısticas. Para a construcao dos histogramas consideramos, porcaracterıstica, a totalidade dos dados para a determinacao dos 10 bins. Em seguida, aplicamosos bins determinados aos dados referentes aos alunos aprovados e reprovados separadamente.Nos histogramas sao apresentados os valores percentuais considerando a totalidade dos alunos.
Analisando as caracterısticas mais gerais que contabilizam numero de dias, tempo enumero de respostas, verificamos que a maioria dos alunos reprovados “cai”no primeiro bin,para Calculo 2, e que o uso da aplicacao durante o perıodo regular de aulas tem um grande im-pacto. Os histogramas para as mesmas caracterısticas e para o conjunto de dados de Calculo3, parecem indicar que os alunos aprovados usam de facto a aplicacao ao longo do semestre.Mas uma vez que os dados desta disciplina nao sao equilibrados e existem cerca de quatrovezes mais aprovados que alunos reprovados, nao podemos retirar informacao relevante desteshistogramas.
Tempo de resposta vs tempo de analise
Sera que se consegue estabelecer alguma relacao entre o tempo necessario para submetera resposta e o tempo despendido a analisar o resultado?
As Figuras 3.7 e 3.8 apresentam os graficos de dispersao entre o tempo para submetera resposta e o tempo de analise do resultado, para Calculo 2 e Calculo 3 respetivamente.
40

0 5 10 15 20 25
valor
0.0%
5.0%
10.0%
15.0%
20.0%
Perc
enta
gem
pelo
tota
l totalStudyDays
aprovados
reprovados
0 2 4 6 8 10 12
valor
0.0%
2.0%
4.0%
6.0%
8.0%
10.0%
12.0%
14.0%
Perc
enta
gem
pelo
tota
l totalStudyDays_eval
aprovados
reprovados
0 2 4 6 8 10 12 14 16 18
valor
0.0%
5.0%
10.0%
15.0%
20.0%
25.0%
Perc
enta
gem
pelo
tota
l totalStudyDays_reg
aprovados
reprovados
0 200 400 600 800 1000 1200 1400
minutos
0.0%
5.0%
10.0%
15.0%
20.0%
Perc
enta
gem
pelo
tota
l totalStudyTime
aprovados
reprovados
0 200 400 600 800 1000
minutos
0.0%
5.0%
10.0%
15.0%
20.0%
25.0%
Perc
enta
gem
pelo
tota
l totalStudyTime_eval
aprovados
reprovados
0 100 200 300 400 500 600 700 800 900
minutos
0.0%
5.0%
10.0%
15.0%
20.0%
25.0%
30.0%
Perc
enta
gem
pelo
tota
l totalStudyTime_reg
aprovados
reprovados
0 50 100 150 200 250 300 350 400 450
valor
0.0%
5.0%
10.0%
15.0%
20.0%
25.0%
Perc
enta
gem
pelo
tota
l totalAnswers
aprovados
reprovados
0 50 100 150 200 250 300 350
valor
0.0%
5.0%
10.0%
15.0%
20.0%Perc
enta
gem
pelo
tota
l totalAnswers_eval
aprovados
reprovados
0 50 100 150 200 250 300
valor
0.0%
5.0%
10.0%
15.0%
20.0%
25.0%
30.0%
35.0%
Perc
enta
gem
pelo
tota
l totalAnswers_reg
aprovados
reprovados
Figura 3.5: Calculo 2, 2014/2015: Histogramas das caracterısticas gerais.
0 5 10 15 20 25 30
valor
0.0%
5.0%
10.0%
15.0%
20.0%
Percentagem pelo total totalStudyDays
aprovados
reprovados
0 2 4 6 8 10 12 14 16
valor
0.0%
5.0%
10.0%
15.0%
20.0%
25.0%
Percentagem pelo total totalStudyDays_eval
aprovados
reprovados
0 5 10 15 20 25
valor
0.0%
5.0%
10.0%
15.0%
20.0%
25.0%
Percentagem pelo total totalStudyDays_reg
aprovados
reprovados
0 200 400 600 800 1000 1200 1400 1600 1800
minutos
0.0%
5.0%
10.0%
15.0%
20.0%
25.0%
30.0%
Percentagem pelo total totalStudyTime
aprovados
reprovados
0 200 400 600 800 1000 1200 1400
minutos
0.0%5.0%
10.0%15.0%20.0%25.0%30.0%35.0%40.0%45.0%
Percentagem pelo total totalStudyTime_eval
aprovados
reprovados
0 200 400 600 800 1000
minutos
0.0%5.0%
10.0%15.0%20.0%25.0%30.0%35.0%40.0%
Percentagem pelo total totalStudyTime_reg
aprovados
reprovados
0 100 200 300 400 500 600 700
valor
0.0%
5.0%
10.0%
15.0%
20.0%
Percentagem pelo total totalAnswers
aprovados
reprovados
0 100 200 300 400 500
valor
0.0%
5.0%
10.0%
15.0%
20.0%
25.0%
30.0%
35.0%
Percentagem pelo total totalAnswers_eval
aprovados
reprovados
0 100 200 300 400 500 600
valor
0.0%5.0%
10.0%15.0%20.0%25.0%30.0%35.0%40.0%
Percentagem pelo total totalAnswers_reg
aprovados
reprovados
Figura 3.6: Calculo 3, 2015/2016: Histogramas das caracterısticas gerais.
Verificamos que independentemente do perıodo (fora ou em perıodo de avaliacao), ha umatendencia para os alunos que despendem mais tempo a tentar resolver as questoes, fazeremuma analise mais cuidadosa do resultado. Esta tendencia e mais clara para a disciplina deCalculo 3.
Apos a analise exploratoria dos dados verificamos que o facto de existir uma componentede avaliacao (mesmo com um peso diminuto) assente no conhecimento que a aplicacao es-tima que o aluno tenha com base nas respostas corretas e incorretas que submete, contribuipara um maior uso da aplicacao SIACUA. Naturalmente, este uso acentuado centra-se nosperıodos de avaliacao. Tambem verificamos que a proporcao de alunos aprovados e reprovadose equilibrada em Calculo 2, enquanto que na disciplina de Calculo 3 o numero de aprovadose bastante superior ao numero de reprovados.
Devido a natureza das varias caracterısticas e natural que estas estejam correlacionadas.No entanto, ha algumas caracterısticas que apresentam correlacao mais forte. Analisando oshistogramas das Figuras 3.5 e 3.6 a caracterıstica relativa ao numero de dias de interacaocom a aplicacao (considerados dias de estudo) fora dos perıodos de avaliacao parece ser um
41
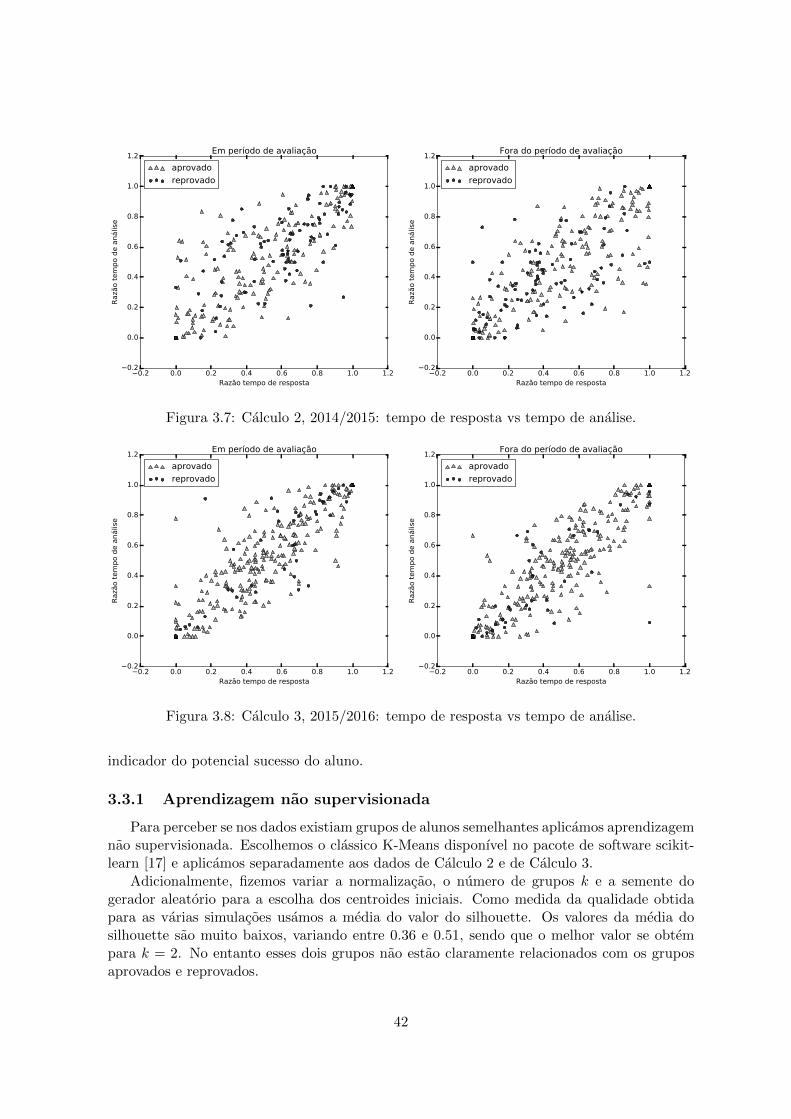
−0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2Razão tempo de resposta
−0.2
0.0
0.2
0.4
0.6
0.8
1.0
1.2
Razã
o tempo de análise
Em período de avaliação
aprovado
reprovado
−0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2Razão tempo de resposta
−0.2
0.0
0.2
0.4
0.6
0.8
1.0
1.2
Razã
o tempo de análise
Fora do período de avaliação
aprovado
reprovado
Figura 3.7: Calculo 2, 2014/2015: tempo de resposta vs tempo de analise.
−0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2Razão tempo de resposta
−0.2
0.0
0.2
0.4
0.6
0.8
1.0
1.2
Razã
o tempo de análise
Em período de avaliação
aprovado
reprovado
−0.2 0.0 0.2 0.4 0.6 0.8 1.0 1.2Razão tempo de resposta
−0.2
0.0
0.2
0.4
0.6
0.8
1.0
1.2
Razã
o tempo de análise
Fora do período de avaliação
aprovado
reprovado
Figura 3.8: Calculo 3, 2015/2016: tempo de resposta vs tempo de analise.
indicador do potencial sucesso do aluno.
3.3.1 Aprendizagem nao supervisionada
Para perceber se nos dados existiam grupos de alunos semelhantes aplicamos aprendizagemnao supervisionada. Escolhemos o classico K-Means disponıvel no pacote de software scikit-learn [17] e aplicamos separadamente aos dados de Calculo 2 e de Calculo 3.
Adicionalmente, fizemos variar a normalizacao, o numero de grupos k e a semente dogerador aleatorio para a escolha dos centroides iniciais. Como medida da qualidade obtidapara as varias simulacoes usamos a media do valor do silhouette. Os valores da media dosilhouette sao muito baixos, variando entre 0.36 e 0.51, sendo que o melhor valor se obtempara k = 2. No entanto esses dois grupos nao estao claramente relacionados com os gruposaprovados e reprovados.
42

3.3.2 Aprendizagem supervisionada
Foram utilizados dois classificadores: o vizinhos mais proximos e o maquina de veto-res de suporte (SVM). Em particular o SVM Linear foi utilizado com objetivos diferentes:classificacao e eliminacao de caracterısticas.
Na analise dos resultados para diferentes algoritmos de classificacao comecamos, na maio-ria das vezes, por utilizar uma implementacao da tecnica de procura exaustiva disponibilizadano pacote de software scikit-learn. Esta tecnica e designada por grid search e procura a me-lhor parametrizacao (em funcao de uma medida de avaliacao) tendo sido dados os intervalospossıveis para os parametros.
Vizinhos mais proximos
Com a totalidade das caracterısticas
No passo inicial de procura do conjunto de parametros que otimiza, tendo como me-dida a acuracia, o resultado do classificador vizinhos mais proximos, exploramos a variacaodo numero de vizinhos e os pesos associados aos vizinhos mais proximos. Fizemos variar onumero de vizinhos k entre 3 e 10; quanto aos pesos, o pacote de software scikit-learn ofereceduas possibilidades: uniforme, em que todos os vizinhos tem igual peso, e peso inversamenteproporcional a distancia, em que quanto menos distante o vizinho esta mais peso esse vizi-nho tem. O scikit-learn disponibiliza diferentes algoritmos para localizar os vizinhos maisproximos. O algoritmo escolhido foi o de procura exaustiva. Isto e, cada objeto a classificar etestado com todos os elementos do conjunto de treino de modo a determinar os vizinhos maisproximos. Relativamente a distancia optamos pela de Minkowski fazendo variar o parametrop associado a potencia na distancia de Minkowski. Ver a Seccao 2.2.1 sobre medidas dedistancia. Adicionalmente experimentamos nao normalizar o conjunto de dados, normalizarcom min-max e normalizar com z-score.
A Tabela B.1 no Apendice B, apresenta o resultado da aplicacao da funcionalidade gridsearch com validacao cruzada do tipo stratified 10-fold. Relativamente ao numero de vizinhos,este variou entre 6 e 9, sendo que para ambos os conjuntos de dados (Calculo 2 e Calculo 3)o algoritmo aplicado aos dados com normalizacao min-max necessitou de menor numero devizinhos. Para Calculo 2, a distancia pesada foi a que obteve melhor acuracia enquanto quepara Calculo 3 foi a distancia uniforme. O valor da acuracia varia entre 0.713 e 0.728 paraos dados da disciplina de Calculo 2 e entre 0.792 e 0.801 para os dados de Calculo 3. Comopara Calculo 3, o numero de elementos em cada caso nao e equilibrado (ver a Tabela 3.1), econveniente considerar outras medidas de avaliacao alem da acuracia. A Tabela 3.2 apresentaos valores de medidas como o recall ou a precisao.
Verificamos que o valor da especificidade e muito baixo indicando que as observacoes daclasse reprovado nao estao a ser corretamente classificadas.
Com um sub-conjunto de caracterısticas
Apesar de o numero de caracterısticas dos dados em analise nao ser considerado elevado,exploramos a reducao do seu numero com base no conjunto de caracterısticas que apre-senta maior correlacao. O processo de determinacao destas caracterısticas esta descrito naSeccao 3.3. Assim, se duas caracterısticas tem correlacao superior a 0.95, eliminamos umadelas.
43

Medidas
Normalizacao Precisao Recall F1-score Especificidade g
nenhuma 0.822 0.944 0.879 0.177 0.409
min-max 0.827 0.936 0.878 0.210 0.443
z-score 0.822 0.960 0.886 0.161 0.393
Tabela 3.2: Calculo 3: medidas de avaliacao de desempenho do classificador vizinhos maisproximos.
No caso dos dados de Calculo 2 as caracterısticas eliminadas foram cinco: tempototal de estudo (totalStudyTime), tempo total de estudo fora dos perıodos de avaliacao(totalStudyTime reg), tempo despendido a analisar a resolucao em caso de pedido devisualizacao da resolucao no global e por perıodos (toContinueTime noAnswer, toCon-tinueTime noAnswer reg, toContinueTime noAnswer eval). Para os dados de Calculo 3,alem destas cinco caracterısticas, foram tambem eliminadas: tempo total de estudo emperıodo de avaliacao (totalStudyTime eval), tempo total despendido para submeter umaresposta correta no global e em perıodo regular (toSubmitTime rightAnswer e toSubmit-Time rightAnswer reg).
Para avaliar se esta reducao significava melhorias de desempenho consideramos o classifi-cador vizinhos mais proximos. Para o conjunto de dados com todas as caracterısticas usamosa parametrizacao determinada anteriormente. Para o conjunto de dados com reducao decaracterısticas comecamos por usar a tecnica grid search para determinar a melhor parame-trizacao neste caso. Tal como anteriormente fizemos variar o numero de vizinhos k (entre3 e 10), variamos o peso associado aos vizinhos mais proximos (uniforme ou inversamenteproporcional a distancia) e o parametro p associado a potencia na distancia de Minkowski. Oalgoritmo escolhido foi tambem o de pesquisa exaustiva.
A Tabela B.2 no Apendice B, apresenta os parametros determinados e a Tabela 3.3 apre-senta, para Calculo 3, o valor de outras metricas alem da acuracia. Para os dados com reducaode caracterısticas o numero de vizinhos variou entre 5 e 9, sendo que para ambos os conjuntosde dados (Calculo 2 e Calculo 3) o algoritmo aplicado aos dados com normalizacao min-maxnecessitou de maior numero de vizinhos. Tambem com esta normalizacao o melhor resultadofoi obtido usando a distancia pesada, tendo a distancia uniforme obtido melhor acuracia nosdados nao normalizados e nos dados normalizados com z-score. A acuracia varia entre 0.713e 0.749 para os dados de Calculo 2, e entre 0.792 e 0.795 para os dados de Calculo 3.
Em seguida comparamos as curvas ROC medias obtidas por validacao cruzada do tipostratified 10-fold. Verificamos que as curvas medias sao bastante semelhantes, tal como sepode observar nas Figuras 3.9 e 3.10 relativas a Calculo 2 e Calculo 3 respetivamente. Combase nestes resultados concluımos que a reducao do numero de caracterısticas com base nacorrelacao nao tem impacto significativo no desempenho do classificador.
44

Medidas
Normalizacao Precisao Recall F1-score Especificidade g
nenhuma 0.816 0.956 0.880 0.129 0.351
min-max 0.823 0.948 0.881 0.177 0.410
z-score 0.825 0.944 0.881 0.194 0.427
Tabela 3.3: Calculo 3: medidas de avaliacao de desempenho do classificador vizinhos maisproximos aplicado aos dados com reducao do numero de caracterısticas.
0.0 0.2 0.4 0.6 0.8 1.0Razão de falsos positivos
0.0
0.2
0.4
0.6
0.8
1.0
Sensibilidade
Curvas ROC médias
todas características (area = 0.76)
redução características (area = 0.79)
Figura 3.9: Calculo 2: curvas ROC para ava-liacao do desempenho na reducao do numerode caracterısticas.
0.0 0.2 0.4 0.6 0.8 1.0Razão de falsos positivos
0.0
0.2
0.4
0.6
0.8
1.0
Sensibilidade ou recall
Curvas ROC médias
todas características (area = 0.69)
redução características (area = 0.63)
Figura 3.10: Calculo 3: curvas ROC paraavaliacao do desempenho na reducao donumero de caracterısticas.
Maquinas de Vetores de Suporte (SVM)
Nesta seccao apresentam-se os resultados com o SVM. Ambas as variantes, linear e naolinear, foram utilizadas. Comecou-se com um estudo exploratorio para estimar os parametrosde treino otimo. Em seguida utilizaram-se ambas as variantes para classificar os dois conjuntosde dados. O SVM Linear foi ainda explorado para escolha de caracterısticas. Foram tambemaplicadas variantes de treino para dados nao equilibrados.
Escolha de parametros para treinar
Para o treino de classificadores de superfıcie de decisao comecamos por determinar o valordo parametro C no caso de classificador com kernel linear, e os parametros C e γ no casode classificador com kernel RBF. Para isso usamos a funcionalidade grid search disponıvel nopacote de software scikit-learn, aplicando aos dados sem normalizacao, e aplicando aos dadosnormalizados com z-score e min-max.
Para o classificador SVM Linear e dados de Calculo 2, estes eram os valores sugeridospara o parametro C no final da execucao do grid search: dados sem normalizacao, C = 0.014,dados com normalizacao min-max, C = 0.084 e dados com normalizacao z-score, C = 50.Uma vez que estes valores sao diversos dos encontrados na literatura, procuramos determinarquao melhor era o C sugerido relativamente a um valor mais usual, ou ate relativamente ao
45
valor um, o valor por omissao do pacote de software scikit-learn. Realizamos essa mesmaexperiencia para as restantes situacoes e com base nos resultados obtidos optamos pelaparametrizacao apresentada na Tabela 3.4.
SVM Linear SVM RBF
Disciplina Norm. C C γ
Calculo 2
nenhuma 0.1 4 0.00001
min-max 0.1 1.5 0.5
z-score 1 1 0.001
Calculo 3
nenhuma 0.1 1 0.01
min-max 0.1 1 0.01
z-score 0.1 1 0.01
Tabela 3.4: Resumo dos parametros considerados nas simulacoes com SVM Linear e SVMRBF.
Com esta parametrizacao treinamos os classificadores SVM Linear e SVM com kernel RBFusando uma estrategia de validacao cruzada do tipo stratified 10-fold. As Tabelas B.3 e B.4apresentam os resultados obtidos. No caso dos dados da disciplina de Calculo 2, o treino como classificador SVM com kernel RBF parece obter melhor desempenho do que o treino comSVM Linear. E possıvel verificar que para os dados de Calculo 3 o facto de estes serem naoequilibrados influencia o treino de ambos os classificadores e que estes tem pouca capacidadede discriminar os alunos reprovados.
Eliminacao de caracterısticas
Com base na tecnica descrita em 2.3.3 implementamos um processo de reducao do numerode caracterısticas. A ideia parte do princıpio de que as caracterısticas menos relevantesterao associados coeficientes proximos de zero. Naturalmente, uma questao imediata e adefinicao de “proximo de zero”. Na exploracao que realizamos eliminamos progressivamenteas caracterısticas tais que o valor absoluto do peso associado era inferior a 0.01.
Para treinar os dados optamos pelo classificador SVM Linear disponıvel no scikit-learn,usando validacao cruzada do tipo stratified 10-fold. Para cada uma das normalizacoes quetem estado a ser usadas nas simulacoes usamos o valor C indicado na Tabela 3.4.
O processo iterativo de reducao do numero de caracterısticas, designado ERC, e o que sedescreve em seguida.
Passo 0: O classificador aprende um modelo determinando o peso associado a cadacaracterıstica; e calculada a acuracia.
Passo iterativo: enquanto houver algum peso inferior a 0.01 remove-se a respetiva ca-racterıstica dos dados e repete-se o passo 0.
Passo final: de entre os varios subconjuntos de caracterısticas testados durante o passoiterativo, e determinado aquele que apresenta maior valor de acuracia.
46
A Tabela 3.5 apresenta um resumo dos resultados intermedios obtidos atraves do processoERC, para a disciplina de Calculo 2 e normalizacao z-score.
Iter Caracterıstica removida Coeficiente Acuracia
0 - - 0.737
1 toContinueTime wrongAnswer eval 0.0050 0.731
2 toSubmitTime eval 0.0099 0.731
Tabela 3.5: Calculo 2: resultados obtidos nas simulacoes para reducao do numero de carac-terısticas com SVM Linear; dados normalizados com z-score.
Contabilizamos 16 caracterısticas em comum que fazem parte do modelo final para osdados de ambas as disciplinas, independentemente da normalizacao. Neste conjunto de 16caracterısticas nao existe qualquer uma relativa ao numero de respostas dadas. Ou seja,apenas caracterısticas relativas ao numero de dias de estudo e tempo de estudo (tempo desubmissao, tempo de analise de resultado) sao comuns a todos os modelos finais.
Eliminacao recursiva de caracterısticas: implementacao do scikit-learn
O pacote de software scikit-learn disponibiliza uma implementacao do processo de eli-minacao recursiva de caracterısticas designada RFECV. Neste caso, e tal como em [20], todasas caracterısticas sao progressivamente eliminadas tendo como criterio eliminar a que tem me-nor peso (em valor absoluto) associado. Sempre que e removida uma caracterıstica e calculadaa acuracia ou outra medida de avaliacao que tenha sido indicada. Apos ficar com apenas umacaracterıstica o classificador assume como subconjunto otimo aquele que apresentar o melhorresultado.
Realizamos a simulacao com o RFECV nas mesmas condicoes da simulacao anterior,sendo que a medida de avaliacao de desempenho do classificador foi a acuracia. As Tabela 3.6e 3.7 apresentam os resultados das varias simulacoes. Analisando o numero de caracterısticaseliminadas por cada um dos metodos verificamos que, em geral, o metodo RFECV eliminamaior numero de caracterısticas. Assim, nenhuma caracterıstica e comum aos modelos obtidospara as diferentes normalizacoes dos dados de Calculo 2 e Calculo 3. Se considerarmosapenas os dados normalizados, a caracterıstica relativa ao numero total de dias de estudo(totalStudyDays) faz parte dos modelos determinados para ambas as disciplinas.
ERC RFECV
Norm. Car. Acur. Recall Espec. Car. Acur. Recall Espec.
nenhuma 28 0.749 0.76 0.73 3 0.746 0.77 0.71
min-max 40 0.752 0.80 0.69 25 0.758 0.79 0.71
z-score 40 0.731 0.75 0.70 8 0.719 0.74 0.69
Tabela 3.6: Calculo 2: resultados da eliminacao recursiva de caracterısticas.
47

ERC RFECV
Norm. Car. Acur. Recall Espec. Car. Acur. Recall Espec.
nenhuma 25 0.795 0.97 0.10 1 0.801 1 0
min-max 40 0.801 1 0 1 0.801 1 0
z-score 36 0.795 0.98 0.05 6 0.808 1 0.03
Tabela 3.7: Calculo 3: resultados da eliminacao recursiva de caracterısticas.
A comparacao destes resultados com os da Tabela B.3 indica que a eliminacao de carac-terısticas traz alguma vantagem para os dados de Calculo 2. Para os dados da disciplinaCalculo 3, devido ao facto de nao serem equilibrados, a especificidade obtida apos reducao donumero de caracterısticas, independentemente do metodo, mantem-se muito baixa.
SVM para dados nao equilibrados
Notamos que, ao contrario do que acontece nas descricoes na literatura, no nosso caso aclasse minoritaria e a classe negativa, a classe dos alunos reprovados.
Para as simulacoes com o DEC usamos o parametro class weight de entrada do metodoLinearSVC disponıvel no pacote de software sikit-learn. Fizemos variar a proporcao dos pesosprocurando obter os melhores valores de g e de acuracia.
Realizamos tambem a analise dos dados da disciplina de Calculo 2 com tecnicas de analisede dados nao equilibrados. Notamos que a razao entre o numero de alunos aprovados ealunos reprovados e 1.336. Embora intuitivamente consideremos os dados de Calculo 2 comoequilibrados, em [1], em que e feita uma analise experimental com diversos classificadorestreinados com varios conjuntos de dados nao equilibrados, existem dois conjuntos de dadoscom razoes de equilıbrio inferiores. Para os dados de Calculo 2 sem qualquer normalizacao arazao de pesos selecionada foi 10:9. Isto e, o peso associado a classe negativa e 10 e o pesoassociado a classe positiva e 9. Para os dados normalizados com min-max e z-score a razaode pesos determinada foi 20:17 e 20:13, respetivamente.
Para a disciplina de Calculo 3, a proporcao que melhor resultado obteve com os dadosnao normalizados foi a sugerida em [23]. Assim, para essa simulacao, o peso associado aclasse negativa foi 125 e o peso associado a classe positiva foi 31. Para os dados normalizadosselecionamos a razao de pesos 20:9, ou seja, o peso associado a classe negativa foi 20 e o pesoassociado a classe positiva foi 9.
Na Tabela B.5 apresentamos os resultados obtidos por validacao cruzada do tipo stratified10-fold. A utilizacao de DEC nos dados de Calculo 2 parece nao trazer qualquer vantagemenquanto que nos dados de Calculo 3 e notoria a melhoria na capacidade de detecao deinstancias da classe minoritaria.
Usando a biblioteca imbalanced-learn [30] realizamos varias simulacoes em que primeiroforam geradas instancias para a classe minoritaria, sendo aplicado DEC ao conjunto de dadoscom as novas instancias. Para a geracao de instancias exploramos o SMOTE e o SMOTESVM disponıveis na referida biblioteca, fazendo variar o parametro ratio entre 0.3 e 1 para
48

Calculo 3 e entre 0.8 e 1 para Calculo 2. Este parametro indica a razao entre o numero deelementos da classe minoritaria e da classe maioritaria que devera existir no final da geracaode instancias. Para a aplicacao do DEC usamos o classificador SVM Linear fazendo variaros pesos associados a cada uma das classes. A Tabela 3.8 resume os pesos e razoes quepermitiram obter os melhores resultados aplicando validacao cruzada do tipo stratified 10-fold. Nesta tabela, S.SVM identifica o SMOTE SVM. Realcamos que os conjuntos para avalidacao cruzada foram obtidos apos a geracao de instancias para a classe minoritaria.
Calculo 2 Calculo 3
Norm. Geracao Razao Pesos Razao Pesos
nenhumaS.SVM 1 20:17 0.9 5:3
SMOTE 1 10:9 0.8 5:3
min-maxS.SVM 1 20:19 0.4 20:11
SMOTE 1 20:19 0.8 20:11
z-scoreS.SVM 1 20:19 0.4 20:11
SMOTE 1 20:19 1 20:11
Tabela 3.8: Parametros determinados para as simulacoes com DEC apos geracao de instancias.
Usando a razao de geracao de instancias para a classe minoritaria e os pesos para cada umadas classes obtidos na simulacao anterior (ver Tabela 3.8), realizamos uma nova simulacao emque a geracao de dados foi realizada apos a criacao dos conjuntos para a validacao cruzadado tipo stratified 10-fold. O processo e o que se descreve em seguida.
1. Cria os conjuntos para a validacao cruzada, cv.
2. TN = FN = FP = TP = 0.
3. Para cada treino, teste em cv
(a) Aplica a geracao de instancias a treino obtendo treino′.
(b) Treina o classificador DEC com os dados de treino′.
(c) Com o classificador treinado, preve a classe dos dados em teste.
(d) Atualiza o valor de TN, FN, FP, TP .
4. Calcula a acuracia e o valor de g.
Nas Tabelas B.6 e B.7 apresentamos os resultados obtidos por aplicacao do processoacima descrito nos dados de Calculo 2 e Calculo 3, respetivamente. Verificamos que paraambos os conjuntos de dados, com e sem geracao de instancias da classe minoritaria (vertambem a Tabela B.5), os varios resultados obtidos com DEC sao semelhantes.
Para a realizacao de simulacoes com a tecnica z-SVM foi necessario obter a equacao dedecisao. No pacote de software scikit-learn, ao usar o LinearSVC nao se tem acesso ao α
49
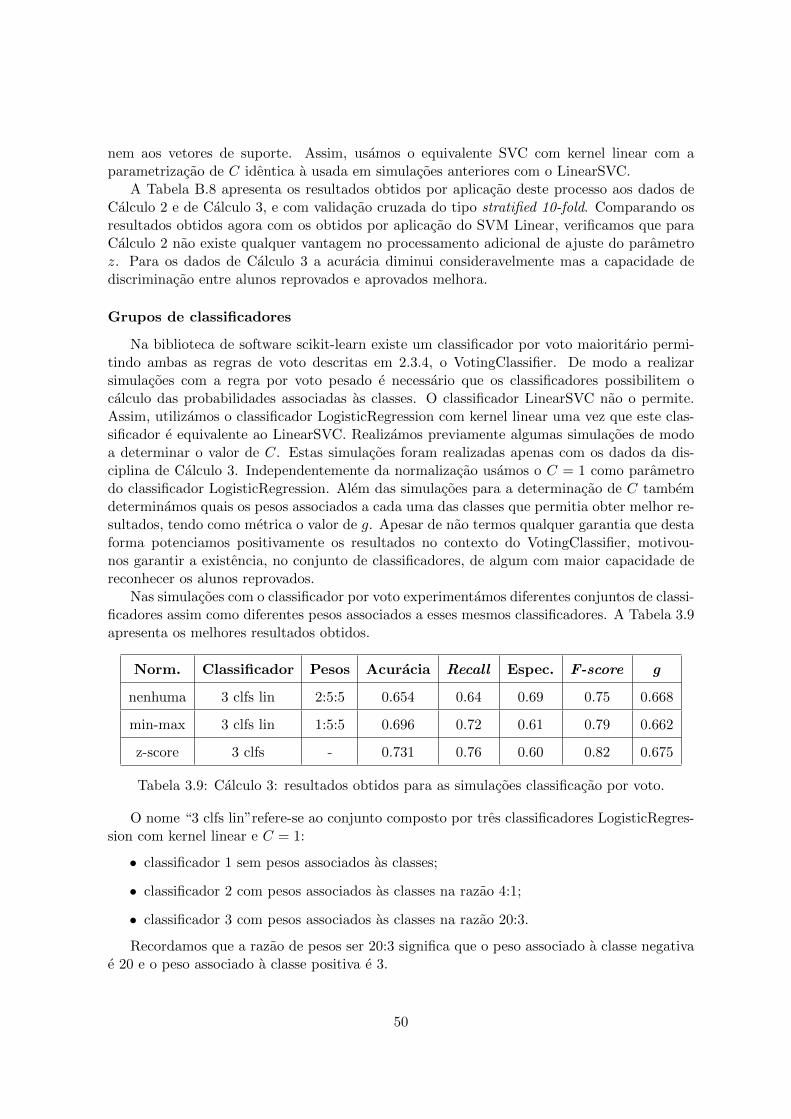
nem aos vetores de suporte. Assim, usamos o equivalente SVC com kernel linear com aparametrizacao de C identica a usada em simulacoes anteriores com o LinearSVC.
A Tabela B.8 apresenta os resultados obtidos por aplicacao deste processo aos dados deCalculo 2 e de Calculo 3, e com validacao cruzada do tipo stratified 10-fold. Comparando osresultados obtidos agora com os obtidos por aplicacao do SVM Linear, verificamos que paraCalculo 2 nao existe qualquer vantagem no processamento adicional de ajuste do parametroz. Para os dados de Calculo 3 a acuracia diminui consideravelmente mas a capacidade dediscriminacao entre alunos reprovados e aprovados melhora.
Grupos de classificadores
Na biblioteca de software scikit-learn existe um classificador por voto maioritario permi-tindo ambas as regras de voto descritas em 2.3.4, o VotingClassifier. De modo a realizarsimulacoes com a regra por voto pesado e necessario que os classificadores possibilitem ocalculo das probabilidades associadas as classes. O classificador LinearSVC nao o permite.Assim, utilizamos o classificador LogisticRegression com kernel linear uma vez que este clas-sificador e equivalente ao LinearSVC. Realizamos previamente algumas simulacoes de modoa determinar o valor de C. Estas simulacoes foram realizadas apenas com os dados da dis-ciplina de Calculo 3. Independentemente da normalizacao usamos o C = 1 como parametrodo classificador LogisticRegression. Alem das simulacoes para a determinacao de C tambemdeterminamos quais os pesos associados a cada uma das classes que permitia obter melhor re-sultados, tendo como metrica o valor de g. Apesar de nao termos qualquer garantia que destaforma potenciamos positivamente os resultados no contexto do VotingClassifier, motivou-nos garantir a existencia, no conjunto de classificadores, de algum com maior capacidade dereconhecer os alunos reprovados.
Nas simulacoes com o classificador por voto experimentamos diferentes conjuntos de classi-ficadores assim como diferentes pesos associados a esses mesmos classificadores. A Tabela 3.9apresenta os melhores resultados obtidos.
Norm. Classificador Pesos Acuracia Recall Espec. F-score g
nenhuma 3 clfs lin 2:5:5 0.654 0.64 0.69 0.75 0.668
min-max 3 clfs lin 1:5:5 0.696 0.72 0.61 0.79 0.662
z-score 3 clfs - 0.731 0.76 0.60 0.82 0.675
Tabela 3.9: Calculo 3: resultados obtidos para as simulacoes classificacao por voto.
O nome “3 clfs lin”refere-se ao conjunto composto por tres classificadores LogisticRegres-sion com kernel linear e C = 1:
• classificador 1 sem pesos associados as classes;
• classificador 2 com pesos associados as classes na razao 4:1;
• classificador 3 com pesos associados as classes na razao 20:3.
Recordamos que a razao de pesos ser 20:3 significa que o peso associado a classe negativae 20 e o peso associado a classe positiva e 3.
50

O nome “3 clfs”refere-se ao conjunto composto por dois classificadores LogisticRegressioncom kernel linear (C = 1) e um classificador SVM com kernel RBF (C = 1 , γ = 0.01):
• classificador 1 linear e sem pesos associados as classes;
• classificador 2 linear e com pesos associados as classes na razao 4:1;
• classificador 3 nao linear e com pesos associados as classes na razao 125:31.
Os resultados apresentados sao ligeiramente melhores que os obtidos treinando o classifi-cador SVM Linear com pesos associados as classes (ver Tabela B.5).
3.4 Comparacao de classificadores
As Tabelas 3.10 e 3.11 apresentam o resumo da acuracia e valor de g obtidos com os variosclassificadores. Identificamos a negrito os melhores resultados.
Calculo 2 Calculo 3
Classificador nenhuma min-max z-score nenhuma min-max z-score
kNN 0.728 0.719 0.713 0.792 0.792 0.801
kNN c/ red. 0.749 0.713 0.716 0.792 0.795 0.795
SVM Linear 0.719 0.749 0.728 0.785 0.801 0.795
ERC 0.725 0.752 0.731 0.795 0.801 0.795
RFECV 0.746 0.758 0.719 0.801 0.801 0.808
SVM RBF 0.731 0.752 0.740 0.801 0.801 0.801
DEC 0.716 0.725 0.734 0.644 0.670 0.587
SMOTE+DEC 0.713 0.722 0.621 0.603 0.628 0.487
S.SVM+DEC 0.694 0.716 0.618 0.641 0.715 0.663
Voto Maior. - - - 0.654 0.696 0.731
z-SVM 0.719 0.728 0.706 0.385 0.401 0.494
Tabela 3.10: Acuracia obtida com os varios classificadores.
Para os dados de Calculo 2 nao normalizados os classificadores RFECV e vizinhos maisproximos com reducao de caracterısticas sao os que apresentam valores mais altos de acuraciae g. Considerando os dados com normalizacao min-max, ambos as versoes do classificadorSVM Linear com reducao de caracterısticas apresentam o melhor desempenho. Para os dadoscom normalizacao z-score, os classificadores SVM com kernel RBF e DEC sao o que obtiverammelhor resultado.
Para os dados de Calculo 3, ha uma clara vantagem na utilizacao de classificadores adap-tados a conjuntos de dados nao equilibrados, a excecao do z-SVM cujos resultados ficamaquem das outras tecnicas utilizadas nas simulacoes. Recordamos que o classificador z-SVM
51
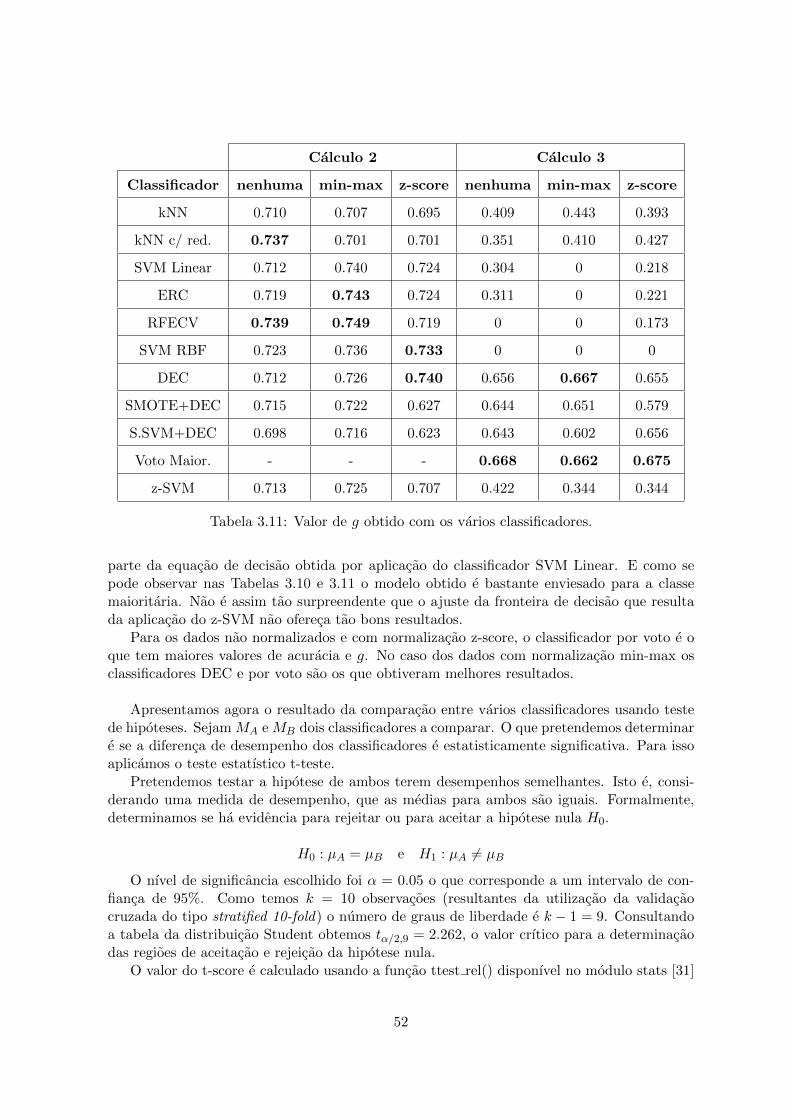
Calculo 2 Calculo 3
Classificador nenhuma min-max z-score nenhuma min-max z-score
kNN 0.710 0.707 0.695 0.409 0.443 0.393
kNN c/ red. 0.737 0.701 0.701 0.351 0.410 0.427
SVM Linear 0.712 0.740 0.724 0.304 0 0.218
ERC 0.719 0.743 0.724 0.311 0 0.221
RFECV 0.739 0.749 0.719 0 0 0.173
SVM RBF 0.723 0.736 0.733 0 0 0
DEC 0.712 0.726 0.740 0.656 0.667 0.655
SMOTE+DEC 0.715 0.722 0.627 0.644 0.651 0.579
S.SVM+DEC 0.698 0.716 0.623 0.643 0.602 0.656
Voto Maior. - - - 0.668 0.662 0.675
z-SVM 0.713 0.725 0.707 0.422 0.344 0.344
Tabela 3.11: Valor de g obtido com os varios classificadores.
parte da equacao de decisao obtida por aplicacao do classificador SVM Linear. E como sepode observar nas Tabelas 3.10 e 3.11 o modelo obtido e bastante enviesado para a classemaioritaria. Nao e assim tao surpreendente que o ajuste da fronteira de decisao que resultada aplicacao do z-SVM nao ofereca tao bons resultados.
Para os dados nao normalizados e com normalizacao z-score, o classificador por voto e oque tem maiores valores de acuracia e g. No caso dos dados com normalizacao min-max osclassificadores DEC e por voto sao os que obtiveram melhores resultados.
Apresentamos agora o resultado da comparacao entre varios classificadores usando testede hipoteses. Sejam MA e MB dois classificadores a comparar. O que pretendemos determinare se a diferenca de desempenho dos classificadores e estatisticamente significativa. Para issoaplicamos o teste estatıstico t-teste.
Pretendemos testar a hipotese de ambos terem desempenhos semelhantes. Isto e, consi-derando uma medida de desempenho, que as medias para ambos sao iguais. Formalmente,determinamos se ha evidencia para rejeitar ou para aceitar a hipotese nula H0.
H0 : µA = µB e H1 : µA 6= µB
O nıvel de significancia escolhido foi α = 0.05 o que corresponde a um intervalo de con-fianca de 95%. Como temos k = 10 observacoes (resultantes da utilizacao da validacaocruzada do tipo stratified 10-fold) o numero de graus de liberdade e k − 1 = 9. Consultandoa tabela da distribuicao Student obtemos tα/2,9 = 2.262, o valor crıtico para a determinacaodas regioes de aceitacao e rejeicao da hipotese nula.
O valor do t-score e calculado usando a funcao ttest rel() disponıvel no modulo stats [31]
52

da biblioteca scipy. Se |t-score| < tα/2,9 entao a hipotese H0 e aceite, ou seja ambos osclassificadores tem desempenhos analogos. Caso contrario, nao ha evidencias que sustentema hipotese nula. A hipotese nula e rejeitada.
No Apendice C sao apresentados os resultados dos testes de hipoteses com classificadorestreinados com os dados de Calculo 2 e Calculo 3. Notamos que a medida de desempenhoconsiderada foi a acuracia. No caso de Calculo 3, alem da acuracia usamos tambem o valorde g.
Resumindo, da avaliacao estatıstica dos resultados da classificacao resultou que em mediaos classificadores tiveram resultados identicos.
3.5 Perspetiva perguntas
Os dados recolhidos sobre as respostas as questoes do MEGUA foram complementadoscom o nıvel de dificuldade atribuıdo pelo autor da questao. A Tabela 3.12 apresenta o numerode questoes existentes por disciplina e nıvel.
Nıvel 1 2 3 4 5
Calculo 2 0 838 31 0 0
Calculo 3 315 471 267 38 0
Tabela 3.12: Numero de questoes MEGUA por disciplina e nıvel.
A semelhanca das caracterısticas de utilizador, tambem foi possıvel obter as caracterısticasda perspetiva das perguntas por alunos aprovados e alunos reprovados. Por exemplo, saberquantas vezes um aluno aprovado respondeu a questao q e quantas vezes esta questao foirespondida por alunos reprovados. Como nos interessa perceber se existe relacao entre o usoda aplicacao SIACUA e a aprovacao dos alunos, reduzimos os dados aqueles que correspondema respostas dadas por alunos avaliados. A Tabela 3.13 apresenta, por grupos de utilizadores,o numero de questoes respondidas e a totalidade de respostas dadas.
Utilizadores avaliados
Questoes Respostas Q. comuns Respostas Resp. Ap. Resp. Rep.
Calculo 2 869 30463 867 30458 20637 9821
Calculo 3 1091 46161 984 45005 39001 5994
Tabela 3.13: Numero de respostas por disciplina e grupo de utilizadores.
Os dados apresentados na tabela parecem indicar que os alunos de Calculo 3 usam maisa aplicacao pois submetem mais respostas. Tambem podemos concluir, pelo menos para osalunos de Calculo 2 uma vez que o conjunto de dados e equilibrado, que os alunos aprovadosusam mais a aplicacao SIACUA.
53

Analise grafica
As Figuras 3.11 e 3.12 apresentam as matrizes de correlacao entre as caracterısticas.Verificamos que para ambas as disciplinas sao os mesmos tres pares de caracterısticas queapresentam maior correlacao:
• rightAnswers e answers;
• toSubmitTime rightAnswer e toSubmitTime;
• toContinueTime noAnswer e toContinueTime;
answ
ers
rightAnswers
wrong
Answers
noAnswers
toSub
mitT
ime
toSub
mitT
ime_
rightAnswer
toSub
mitT
ime_
wrong
Answer
toSub
mitT
ime_
noAnswer
toCon
tinue
Time
toCon
tinue
Time_
rightAnswer
toCon
tinue
Time_
wrong
Answer
toCon
tinue
Time_
noAnswer
toContinueTime_noAnswer
toContinueTime_wrongAnswer
toContinueTime_rightAnswer
toContinueTime
toSubmitTime_noAnswer
toSubmitTime_wrongAnswer
toSubmitTime_rightAnswer
toSubmitTime
noAnswers
wrongAnswers
rightAnswers
answers
0.2
0.4
0.6
0.8
1.0
Figura 3.11: Calculo 2, 2014/2015: Heatmapda matriz correlacao.
answ
ers
rightAnswers
wrong
Answers
noAnswers
toSub
mitT
ime
toSub
mitT
ime_
rightAnswer
toSub
mitT
ime_
wrong
Answer
toSub
mitT
ime_
noAnswer
toCon
tinue
Time
toCon
tinue
Time_
rightAnswer
toCon
tinue
Time_
wrong
Answer
toCon
tinue
Time_
noAnswer
toContinueTime_noAnswer
toContinueTime_wrongAnswer
toContinueTime_rightAnswer
toContinueTime
toSubmitTime_noAnswer
toSubmitTime_wrongAnswer
toSubmitTime_rightAnswer
toSubmitTime
noAnswers
wrongAnswers
rightAnswers
answers
0.2
0.4
0.6
0.8
1.0
Figura 3.12: Calculo 3, 2015/2016: Heatmapda matriz correlacao.
Estes resultados parecem indicar que as respostas corretas sao a maioria e que a maiorparte do tempo despendido para submeter uma resposta e para submeter uma respostacorreta. De facto, este ultimo nao e inesperado uma vez que a maioria das respostasdadas e correta. Interessante verificar que o tempo de analise de resolucao (quandopedida explicitamente pelo utilizador) e o que mais contribui para o tempo necessario paraanalisar o resultado de uma resposta. Sera que os alunos que respondem errado nao sepreocupam em tentar perceber porque responderam errado? Sera que os alunos quandoem duvida preferem ver a resolucao, havendo por isso um menor numero de respostas erradas?
Para obter mais informacao desenhamos os graficos de barras apresentados nas Figu-ras 3.13 e 3.14.
O grafico da Figura 3.13 apresenta a soma de valores para cada uma das caracterısticas.Por analise deste grafico verificamos que o numero de pedidos de visualizacao da resolucao esuperior ao numero de respostas erradas, o que indica que os alunos em caso de duvida, optampor ver a resolucao. O grafico da Figura 3.14 apresenta, para as caracterısticas que refletemtempo, o valor medio por resposta. Analisando este grafico verificamos que, na disciplina deCalculo 2, o tempo medio de submissao de uma resposta correta ou de uma resposta erradanao difere muito. Na disciplina de Calculo 3, o tempo medio de submissao de uma respostacorreta e inferior, em cerca de 40 segundos, relativamente ao tempo de submissao de uma
54

answers
rightA
nswers
wrongAnswers
noAnswers
toSubmitTim
e
toSubmitTim
e_rightA
nswer
toSubmitTim
e_wrongAnsw
er
toSubmitTim
e_noAnsw
er
toContinueTim
e
toContinueTim
e_rightA
nswer
toContinueTim
e_wrongAnsw
er
toContinueTim
e_noAnsw
er
0
20000
40000
60000
80000
Cálculo 2, 2014/2015Cálculo 3, 2015/2016
Figura 3.13: Dados referentes aos alunos avaliados.
avg_
toSu
bmitT
ime
avg_
toSu
bmitT
ime_
right
Answer
avg_
toSu
bmitT
ime_
wro
ngAns
wer
avg_
toSu
bmitT
ime_
noAns
wer
avg_
toCon
tinue
Tim
e
avg_
toCon
tinue
Tim
e_rig
htAns
wer
avg_
toCon
tinue
Tim
e_wro
ngAns
wer
avg_
toCon
tinue
Tim
e_no
Answer
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Cálculo 2, 2014/2015Cálculo 3, 2015/2016
Figura 3.14: Dados referentes aos alunos avaliados: medias de tempo.
resposta incorreta. Sera que o numero de questoes faceis, na perspetiva dos alunos, e maiorem Calculo 3? Ainda por analise do grafico da Figura 3.14, verificamos que em ambas asdisciplinas, o tempo medio de analise da resolucao no caso de resposta errada e inferior emmais de 60 segundos relativamente ao caso em que o aluno pede para ver a solucao semresponder a questao. Podemos inferir que o aluno quando escolhe esta opcao esta de factointeressado na resolucao detalhada do problema.
55

3.5.1 Aprendizagem nao supervisionada
Um dos objetivos da analise dos dados de interacao com a aplicacao da perspetiva dasrespostas dadas pelos alunos, e o de eventualmente afinar parametros como o nıvel de dificul-dade ou de discriminacao. Uma das possibilidades e a aplicacao de teoria de resposta ao itemgeralmente usada em contexto de teste de avaliacao [32]. Outra abordagem e a utilizacao detecnicas de aprendizagem nao supervisionada e supervisionada. Neste seccao abordamos estaultima, mais concretamente aplicamos aprendizagem nao supervisionada de modo a identificaros grupos em que as questoes se dividem. Para isso trabalhamos com diferentes conjuntos dedados, variando as caracterısticas, numa tentativa de melhor descrever as questoes do pontode vista de dificuldade e/ou discriminacao.
• Conjunto 1: todas as caracterısticas;
• Conjunto 2: media do tempo de submissao de respostas corretas e taxa de acerto;
• Conjunto 3: media do tempo de submissao de respostas corretas e taxa de acerto, poralunos aprovados e alunos reprovados.
A Tabela 3.14 apresenta um resumo dos resultados obtidos por aplicacao do algoritmoK-Means. Nao foi realizada qualquer normalizacao dos dados. As colunas Grupo 1 e Grupo2 indicam o numero de elementos dos conjuntos determinados por aplicacao do algoritmoK-Means.
Disciplina Conjunto Grupos Media silhouette Grupo 1 Grupo 2
Calculo 2
Conj. 1 2 0.572 699 170
Conj. 2 2 0.572 533 316
Conj. 3 2 0.420 566 301
Calculo 3
Conj. 1 2 0.419 465 626
Conj. 2 2 0.523 754 337
Conj. 3 2 0.526 154 830
Tabela 3.14: Resultados obtidos por aprendizagem nao supervisionada.
Apesar de estarem previstos 5 graus de dificuldade para as questoes do MEGUA os resul-tados obtidos para o numero de grupos nao sao completamente inesperados. Recordemos queo objetivo da aplicacao SIACUA e o estudo autonomo. Questoes muito faceis ou muito difıceisdesmotivam a maioria dos alunos. Naturalmente nao podemos colocar de lado a possibilidadede as caracterısticas escolhidas nao serem as que melhor traduzem a dificuldade das questoes.
3.6 Conclusao
Verificamos que os alunos fazem um uso da aplicacao bastante diferente em perıodo deavaliacao e fora do perıodo de avaliacao, sendo que existem picos de utilizacao em perıodo de
56

avaliacao. Tambem observamos que os alunos que utilizam a aplicacao SIACUA regularmenteapresentam maior probabilidade de sucesso a disciplina.
Relativamente a aplicacao dos diferentes algoritmos de classificacao no sentido de obterum modelo capaz de prever o sucesso ou insucesso de um aluno com base na sua interacaocom a aplicacao web SIACUA verificamos o seguinte.
• Quando aplicado o algoritmo vizinhos mais proximos, a reducao do numero de ca-racterısticas com base na correlacao nao tem impacto significativo no desempenho doclassificador.
• Consideremos os resultados obtidos por aplicacao do classificador SVM Linear comreducao do numero de caracterısticas com base no peso associado a cada uma aos dadosde Calculo 2. Estes resultados sao ligeiramente melhores comparativamente a aplicacaode SVM Linear com todas as caracterısticas.
• Para os dados de Calculo 2, que podemos considerar como equilibrados, nao e vantajosaa utilizacao de abordagens especıficas para conjuntos de dados nao equilibrados.
• Para Calculo 3, considerando como medida de avaliacao o g, muito usado no caso deconjuntos de dados nao equilibrados, e clara a vantagem na utilizacao de tecnicas paraconjuntos de dados nao equilibrados.
A analise dos dados na perspetiva das respostas dadas tambem permitiu retirar algumasconclusoes.
• No caso de Calculo 2, da totalidade de respostas dadas, 68% foram dadas por alunosaprovados.
• Os alunos que optam por ver a resolucao de um problema estao mesmo interessados emestudar a resolucao detalhada.
• Em regra, os alunos quando em duvida quanto a resposta correta, optam por ver aresolucao detalhada.
Relativamente a classificacao das questoes apenas exploramos a aprendizagem nao super-visionada com o algoritmo K-Means. Os melhores resultados foram obtidos para k = 2 o queparece indicar que as perguntas de dividem em dois grupos.
57

58

Capıtulo 4
Conclusoes e trabalho futuro
No trabalho que apresentamos procuramos prever o sucesso ou insucesso de um aluno auma disciplina de Calculo com base na sua interacao com a aplicacao web SIACUA [5] deapoio ao estudo autonomo. Os dados analisados referem-se as disciplinas de Calculo 2 dosegundo semestre de 2014/2015, e de Calculo 3 do primeiro semestre de 2015/2016, ambaslecionadas pelo Departamento de Matematica da Universidade de Aveiro. Para a disciplinade Calculo 2 existem 327 registos sendo 187 de alunos aprovados e 140 de alunos reprovados.No caso de Calculo 3 sao 312 os registos, sendo 250 de alunos aprovados e 62 de alunosreprovados.
Em ambas as disciplinas a utilizacao da aplicacao contribuıa diretamente para a avaliacaodo aluno. Esse facto contribuiu para uma utilizacao significativa da aplicacao. Ao analisaros dados recolhidos ao longo de cada um dos semestres, verificamos a existencia de picos deutilizacao em torno das datas em que a interacao com a plataforma era avaliada. Com basenesta constatacao podemos considerar as varias caracterısticas de utilizacao em perıodo deavaliacao e fora do perıodo de avaliacao.
Comecamos por uma analise exploratoria dos dados aplicando o algoritmo de aprendiza-gem nao supervisionada K-Means. Os melhores resultados obtidos foram para k = 2. Noentanto, comparando a dimensao destes dois conjuntos com a dimensao dos conjuntos dealunos aprovados e reprovados nao existe uma clara correspondencia.
Em seguida aplicamos o algoritmo de aprendizagem supervisionada vizinhos maisproximos, avaliando a reducao do numero de caracterısticas com base na correlacao. Os re-sultados obtidos indicam que a reducao do numero de caracterısticas com base na correlacaonao tem impacto significativo do desempenho do classificador vizinhos mais proximos, quandoaplicado aos nossos conjuntos de dados.
Outro algoritmos de aprendizagem supervisionada explorado foi o maquina de vetores desuporte (SVM). No caso do SVM usamos as variantes linear e nao linear. Com o classificadorSVM Linear exploramos tambem a reducao de caracterısticas. No caso de Calculo 2 osmelhores resultados foram obtidos com a reducao do numero de caracterısticas com base nopeso associado a cada caracterıstica na equacao de decisao.
Para Calculo 3, como o conjunto de dados para esta disciplina nao e equilibrado, os re-sultados mostram que o SVM tem pouca capacidade de discriminar entre alunos aprovados ealunos reprovados, independentemente de haver reducao do numero de caracterısticas. Para
59

lidar com esta situacao estudamos e aplicamos algumas variantes do SVM Linear para con-juntos de dados nao equilibrados. As variantes aplicadas foram:
• DEC, em que sao atribuıdos diferentes custos a incorreta classificacao dos alunos, de-pendendo do conjunto a que pertence [22];
• geracao de instancias e posterior aplicacao de DEC, sendo que foram usadas duastecnicas de geracao artificial de dados [23]
– SMOTE, em que os novos dados sao gerados sobre os segmentos de reta que unemos vizinhos mais proximos da classe minoritaria [24];
– SMOTE SVM, em que primeiro e treinado o SVM e os novos dados sao criadoscom base nos vetores de suporte da classe minoritaria [3];
• z-SVM que consiste no ajuste da fronteira de decisao determinada por aplicacao doSVM [25].
Os resultados obtidos por aplicacao destes classificadores nos dados de Calculo 3 saosubstancialmente melhores, o que mostra que uso de estrategias para dados nao equilibrados erelevante. Por exemplo, para o classificador DEC, embora o valor da acuracia tenha diminuıdoem media 16%, o valor de g aumentou em media cerca de 48%. Ou seja, a capacidade dediscriminacao entre alunos aprovados e reprovados melhorou consideravelmente.
Das estrategias elencadas acima, a excecao e o z-SVM. Recordamos que o ponto departida para esta abordagem e a fronteira de decisao resultante da aplicacao do SVM Lineare que e muito enviesada. Acreditamos que nestes casos a correcao introduzida pelo z-SVMnao seja suficiente para os seus resultados estarem a par dos resultados obtidos pelos outrosclassificadores para dados nao equilibrados.
Exploramos ainda grupos de classificadores com dois tipos de voto: voto maioritario evoto pesado. Esta foi a abordagem que obteve os melhores resultados com o conjunto dedados de Calculo 3. Para este classificador, a acuracia varia entre 65% e 73% dependendo danormalizacao. O valor de g ronda os 66%.
A excecao do grupo de classificadores, aplicamos as tecnicas para dados nao equilibradostambem aos dados de Calculo 2. Os resultados indicam que nao ha qualquer vantagem em ofazer. De facto, a acuracia diminui em cerca de 3% relativamente aos resultados obtidos poraplicacao do SVM Linear com reducao do numero de caracterısticas.
Os varios resultados da classificacao foram avaliados estatisticamente, considerando paresde classificadores. Resultou que em media os classificadores tiveram resultados identicos, naohavendo algum que se distinguisse dos restantes pela positiva.
De um modo geral os resultados obtidos sao frageis. Acreditamos que o volume de dadosrecolhidos nao e o suficiente para cobrir a diversidade de comportamentos ou habitos deutilizacao da aplicacao. Assim, nao e ainda possıvel prever o sucesso do aluno. No futuropretendemos continuar a recolher e analisar a interacao dos alunos com a aplicacao webSIACUA. Esperamos que com a continuidade deste trabalho seja possıvel prever o sucessoou insucesso de um aluno com base num modelo gerado a partir dos dados recolhidos.
60

A analise dos dados realizada da perspetiva das questoes foi apenas exploratoria. No en-tanto permitiu inferir que, em regra, quando um aluno tem duvidas relativamente a respostacorreta opta por nao responder a questao e ver a resolucao. Tambem podemos verificar queos alunos que optam por ver a resolucao estao de facto interessados em estudar a resolucaodetalhada que e disponibilizada na aplicacao, pois em media, despendem mais tempo na suaanalise do que quando respondem incorretamente. No futuro pretendemos analisar estes dadosdirecionando a investigacao para afinacao dos parametros dificuldade e nıvel de discriminacao.
Por motivos tecnicos, a informacao recolhida considerou apenas as respostas as questoesoriundas do projeto MEGUA [10]. Uma vez que essa dificuldade foi ultrapassada pretendemosrecolher e analisar tambem os dados relativos as respostas a questoes provenientes do projetoPmatE [9].
No ambito deste trabalho foram adicionadas facilidades na aplicacao web SIACUA paraa criacao de cursos sem recurso a um programador, procurando facilitar o seu uso pelosprofessores. Foi tambem disponibilizada uma funcionalidade que permite gerar dois tipos derelatorio, acessıveis a professores, sobre a utilizacao da propria aplicacao. Um dos relatoriosapresenta o numero de vezes que cada topico foi escolhido para estudo. O outro relatorioapresenta por questao, o numero de vezes que foi respondida assim como as taxas de erroe acerto. Com primeiro relatorio pretende-se identificar quais as materias que os alunosmais procuram estudar com o apoio da aplicacao. Serao materias mais difıceis? Com osegundo relatorio o objetivo primario e tentar identificar questoes com taxas de erro ele-vadas. Isto porque questoes nesta situacao poderao necessitar de melhoria, de ser clarificadas.
No modelo do tutor foi implementado um mecanismo de sugestao de estudo aos alunos.No futuro pretendemos evoluir o modelo do tutor com base nos resultados da analise dosdados de utilizacao.
61

62

Apendice A
Listagem de caracterısticas
A.1 Caracterısticas por dia
• day - dia (dia/mes/ano)
• totalStudents - numero de utilizadores naquele dia
• totalAnswers - numero respostas naquele dia
• totalRightAnswers - numero de respostas corretas naquele dia
• totalWrongAnswers - numero de respostas incorretas naquele dia
• totalNoAnswers - numero de pedidos de visualizacao da resolucao naquele dia
• totalStudyTime - tempo total, em minutos, de estudo naquele dia
• totalToSubmitTime - tempo total, em minutos, para submissao de resposta naqueledia
• totalToContinueTime - tempo total, em minutos, de analise do resultado naquele dia
Com base no numero total de alunos e no tempo de estudo por dia, foram definidosdois perıodos: perıodo regular e perıodo de avaliacao (inclui dias em torno dos momentos deavaliacao e epoca de recurso).
A.2 Caracterısticas por aluno
Apenas sao considerados os alunos que se submeteram a avaliacao, isto e, alunos quetambem aparecem na pauta. Foram adicionadas caracterısticas da pauta a cada aluno.
• login - identificador do aluno
• totalStudyDays - numero de dias que o aluno estudou, isto e, em que submeteu pelomenos uma resposta; cada dia e contabilizado apenas uma vez
• totalStudyDays_eval - numero de dias que o aluno estudou em perıodo de avaliacao
• totalStudyDays_reg - numero de dias que o aluno estudou em perıodo regular
63

• totalStudyTime - tempo total, em minutos, de estudo do aluno
• totalStudyTime_eval - tempo total, em minutos, de estudo do aluno em perıodo deavaliacao
• totalStudyTime_reg - tempo total, em minutos, de estudo do aluno em perıodo regular
• totalAnswers - numero de respostas dadas pelo aluno
• totalRightAnswers - numero de respostas corretas dadas pelo aluno
• totalWrongAnswers - numero de respostas incorretas dadas pelo aluno
• totalNoAnswers - numero de pedidos de visualizacao da resolucao
• totalAnswers_eval - numero de respostas dadas pelo aluno em perıodo de avaliacao
• totalRightAnswers_eval - numero de respostas corretas dadas pelo aluno em perıodode avaliacao
• totalWrongAnswers_eval - numero de respostas incorretas dadas pelo aluno em perıodode avaliacao
• totalNoAnswers_eval - numero de pedidos de visualizacao da resolucao em perıodo deavaliacao
• totalAnswers_reg - numero de respostas dadas pelo aluno em perıodo regular
• totalRightAnswers_reg - numero de respostas corretas dadas pelo aluno em perıodoregular
• totalWrongAnswers_reg - numero de respostas incorretas dadas pelo aluno em perıodoregular
• totalNoAnswers_reg - numero de pedidos de visualizacao da resolucao em perıodoregular
• toSubmitTime - tempo total, em minutos, para submeter as respostas
• toSubmitTime_rightAnswer - tempo total, em minutos, para submeter as respostascorretas
• toSubmitTime_wrongAnswer - tempo total, em minutos, para submeter as respostasincorretas
• toSubmitTime_noAnswer - tempo total, em minutos, para submeter os pedidos de vi-sualizacao da resolucao
• toSubmitTime_eval - tempo total, em minutos, para submeter as respostas em perıodode avaliacao
• toSubmitTime_rightAnswer_eval - tempo total, em minutos, para submeter as res-postas corretas em perıodo de avaliacao
64

• toSubmitTime_wrongAnswer_eval - tempo total, em minutos, para submeter as res-postas incorretas em perıodo de avaliacao
• toSubmitTime_noAnswer_eval - tempo total, em minutos, para submeter os pedidosde visualizacao da resolucao em perıodo de avaliacao
• toSubmitTime_reg - tempo total, em minutos, para submeter as respostas em perıodoregular
• toSubmitTime_rightAnswer_reg - tempo total, em minutos, para submeter as respos-tas corretas em perıodo regular
• toSubmitTime_wrongAnswer_reg - tempo total, em minutos, para submeter as respos-tas incorretas em perıodo regular
• toSubmitTime_noAnswer_reg - tempo total, em minutos, para submeter os pedidos devisualizacao da resolucao em perıodo regular
• toContinueTime - tempo total, em minutos, para analisar o resultado das respostas
• toContinueTime_rightAnswer - tempo total, em minutos, para analisar o resultadodas respostas corretas
• toContinueTime_wrongAnswer - tempo total, em minutos, para analisar o resultadodas respostas incorretas
• toContinueTime_noAnswer - tempo total, em minutos, para analisar o resultado dospedidos de visualizacao da resolucao
• toContinueTime_eval - tempo total, em minutos, para analisar o resultado das respos-tas em perıodo de avaliacao
• toContinueTime_rightAnswer_eval - tempo total, em minutos, para analisar o resul-tado das respostas corretas em perıodo de avaliacao
• toContinueTime_wrongAnswer_eval - tempo total, em minutos, para analisar o resul-tado das respostas incorretas em perıodo de avaliacao
• toContinueTime_noAnswer_eval - tempo total, em minutos, para analisar o resultadodos pedidos de visualizacao da resolucao em perıodo de avaliacao
• toContinueTime_reg - tempo total, em minutos, para analisar o resultado das respostasem perıodo regular
• toContinueTime_rightAnswer_reg - tempo total, em minutos, para analisar o resul-tado das respostas corretas em perıodo regular
• toContinueTime_wrongAnswer_reg - tempo total, em minutos, para analisar o resul-tado das respostas incorretas em perıodo regular
• toContinueTime_noAnswer_reg - tempo total, em minutos, para analisar o resultadodos pedidos de visualizacao da resolucao em perıodo regular
65

• Curso - id do curso do aluno
• Epo. Normal - classificacao obtida na epoca normal de avaliacoes
• Epoc. Recurso - classificacao obtida na epoca de recurso
• Nota Final - classificacao final
• Label - etiqueta que pode ter um dos valores: reprovado, aprovado
A.3 Caracterısticas por questao
A caracterıstica nıvel foi obtida da base de dados.
• exid - o numero da questao do MEGUA
• answers - numero de vezes que esta questao foi respondida
• rightAnswers - numero de vezes que a questao foi respondida corretamente
• wrongAnswers - numero de vezes que a questao foi respondida incorretamente
• noAnswers - numero de vezes que a questao nao foi respondida, isto e, foi pedido paraver a resolucao
• toSubmitTime - tempo total, em minutos, para submeter as respostas a esta questao
• toSubmitTime_rightAnswer - tempo total, em minutos, para submeter as respostascorretas a esta questao
• toSubmitTime_wrongAnswer - tempo total, em minutos, para submeter as respostasincorretas a esta questao
• toSubmitTime_noAnswer - tempo total, em minutos, para submeter os pedidos de vi-sualizacao da resolucao a esta questao
• toContinueTime - tempo total, em minutos, para analisar os resultados das respostasa esta questao
• toContinueTime_rightAnswer - tempo total, em minutos, para analisar os resultadosdas respostas corretas a esta questao
• toContinueTime_wrongAnswer - tempo total, em minutos, para analisar os resultadosdas respostas incorretas a esta questao
• toContinueTime_noAnswer - tempo total, em minutos, para analisar os resultados dospedidos de visualizacao da resolucao a esta questao
• nıvel - nıvel de dificuldade da questao, atribuıdo pelo professor
66

Apendice B
Resultados aprendizagemsupervisionada
Disciplina Normalizacao k Pesos Parametro p Acuracia
Calculo 2
nenhuma 8 inv. distancia 1 0.728
min-max 6 inv. distancia 2 0.719
z-score 8 inv. distancia 1 0.713
Calculo 3
nenhuma 9 uniforme 1 0.792
min-max 7 uniforme 3 0.792
z-score 9 uniforme 2 0.801
Tabela B.1: Resultados obtidos por treino do classificador vizinhos mais proximos.
Disciplina Normalizacao k Pesos Parametro p Acuracia
Calculo 2
nenhuma 7 uniforme 3 0.749
min-max 9 inv. distancia 1 0.713
z-score 5 uniforme 2 0.716
Calculo 3
nenhuma 7 uniforme 2 0.792
min-max 9 inv. distancia 2 0.795
z-score 7 uniforme 3 0.795
Tabela B.2: Resultados obtidos por treino do classificador vizinhos mais proximos aplicadoaos dados com reducao do numero de caracterısticas.
67
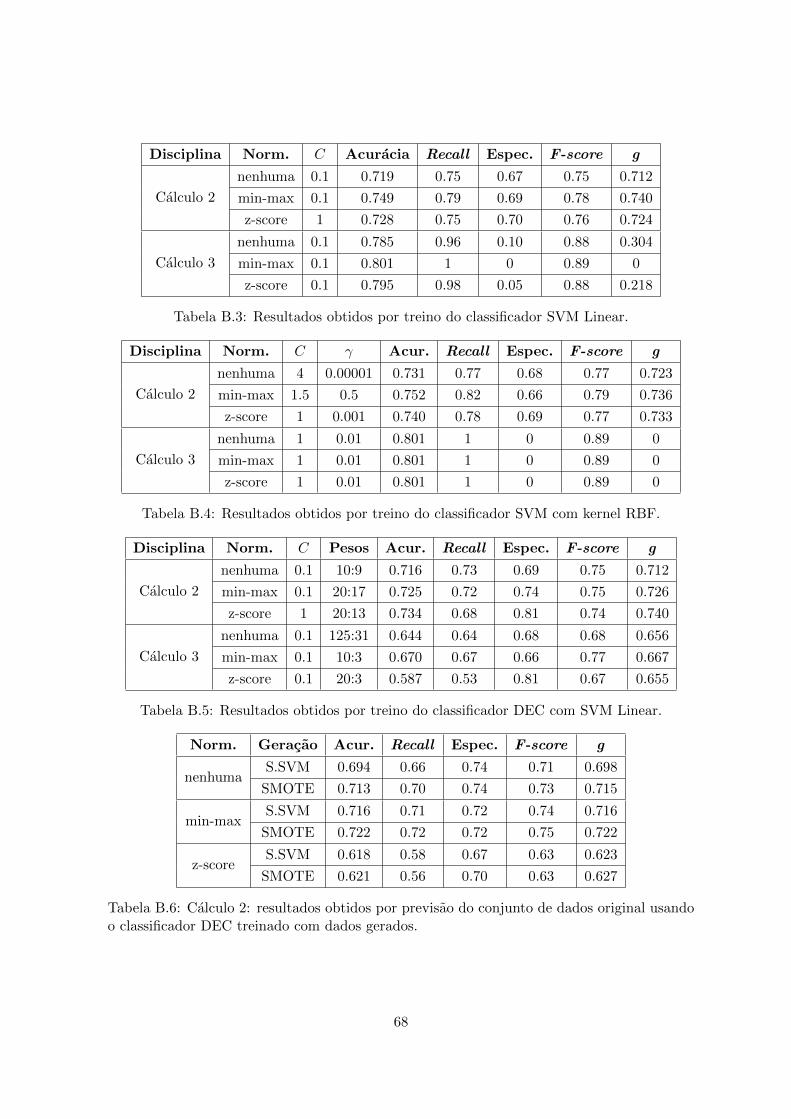
Disciplina Norm. C Acuracia Recall Espec. F-score g
Calculo 2
nenhuma 0.1 0.719 0.75 0.67 0.75 0.712
min-max 0.1 0.749 0.79 0.69 0.78 0.740
z-score 1 0.728 0.75 0.70 0.76 0.724
Calculo 3
nenhuma 0.1 0.785 0.96 0.10 0.88 0.304
min-max 0.1 0.801 1 0 0.89 0
z-score 0.1 0.795 0.98 0.05 0.88 0.218
Tabela B.3: Resultados obtidos por treino do classificador SVM Linear.
Disciplina Norm. C γ Acur. Recall Espec. F-score g
Calculo 2
nenhuma 4 0.00001 0.731 0.77 0.68 0.77 0.723
min-max 1.5 0.5 0.752 0.82 0.66 0.79 0.736
z-score 1 0.001 0.740 0.78 0.69 0.77 0.733
Calculo 3
nenhuma 1 0.01 0.801 1 0 0.89 0
min-max 1 0.01 0.801 1 0 0.89 0
z-score 1 0.01 0.801 1 0 0.89 0
Tabela B.4: Resultados obtidos por treino do classificador SVM com kernel RBF.
Disciplina Norm. C Pesos Acur. Recall Espec. F-score g
Calculo 2
nenhuma 0.1 10:9 0.716 0.73 0.69 0.75 0.712
min-max 0.1 20:17 0.725 0.72 0.74 0.75 0.726
z-score 1 20:13 0.734 0.68 0.81 0.74 0.740
Calculo 3
nenhuma 0.1 125:31 0.644 0.64 0.68 0.68 0.656
min-max 0.1 10:3 0.670 0.67 0.66 0.77 0.667
z-score 0.1 20:3 0.587 0.53 0.81 0.67 0.655
Tabela B.5: Resultados obtidos por treino do classificador DEC com SVM Linear.
Norm. Geracao Acur. Recall Espec. F-score g
nenhumaS.SVM 0.694 0.66 0.74 0.71 0.698
SMOTE 0.713 0.70 0.74 0.73 0.715
min-maxS.SVM 0.716 0.71 0.72 0.74 0.716
SMOTE 0.722 0.72 0.72 0.75 0.722
z-scoreS.SVM 0.618 0.58 0.67 0.63 0.623
SMOTE 0.621 0.56 0.70 0.63 0.627
Tabela B.6: Calculo 2: resultados obtidos por previsao do conjunto de dados original usandoo classificador DEC treinado com dados gerados.
68

Norm. Geracao Acur. Recall Espec. F-score g
nenhumaS.SVM 0.641 0.64 0.65 0.74 0.643
SMOTE 0.603 0.57 0.73 0.70 0.644
min-maxS.SVM 0.715 0.78 0.47 0.81 0.602
SMOTE 0.628 0.61 0.69 0.73 0.651
z-scoreS.SVM 0.663 0.67 0.65 0.76 0.656
SMOTE 0.487 0.40 0.84 0.56 0.579
Tabela B.7: Calculo 3: resultados obtidos por previsao do conjunto de dados original usandoo classificador DEC treinado com dados gerados.
Disciplina Norm. C Acur. Recall Espec. F-score g
Calculo 2
nenhuma 0.1 0.719 0.75 0.68 0.75 0.713
min-max 0.1 0.728 0.74 0.71 0.76 0.725
z-score 1 0.706 0.71 0.71 0.73 0.707
Calculo 3
nenhuma 0.1 0.385 0.36 0.50 0.48 0.422
min-max 0.1 0.401 0.43 0.27 0.54 0.344
z-score 0.1 0.494 0.56 0.21 0.64 0.344
Tabela B.8: Resultados obtidos aplicando a abordagem z-SVM.
69

Apendice C
Resultados dos testes de hipoteses
Para todos os testes aqui apresentados o nıvel de significancia e α = 0.05 e tα/2,9 = 2.262.
C.1 Calculo 2
Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
kNN, sem norm. 0.728 kNN, min-max 0.719 0.5101 H0 e aceite
kNN, sem norm. 0.728 kNN, z-score 0.713 0.5495 H0 e aceite
kNN, sem norm. 0.728 kNN, red semnorm.
0.749 -1.2967 H0 e aceite
kNN, sem norm. 0.728 kNN, red min-max 0.713 0.6778 H0 e aceite
kNN, sem norm. 0.728 kNN, red z-score 0.716 0.5687 H0 e aceite
kNN, min-max 0.719 kNN, z-score 0.713 0.2985 H0 e aceite
kNN, min-max 0.719 kNN, red semnorm.
0.749 -1.4952 H0 e aceite
kNN, min-max 0.719 kNN, red min-max 0.713 0.3984 H0 e aceite
kNN, min-max 0.719 kNN, red z-score 0.716 0.1710 H0 e aceite
kNN, z-score 0.713 kNN, red semnorm.
0.749 -1.3386 H0 e aceite
kNN, z-score 0.713 kNN, red min-max 0.713 0.0109 H0 e aceite
kNN, z-score 0.713 kNN, red z-score 0.716 -0.1474 H0 e aceite
kNN, red semnorm.
0.749 kNN, red min-max
0.713 2.4560 H0 e rejeitada
kNN, red semnorm.
0.749 kNN, red z-score. 0.716 1.2710 H0 e aceite
kNN, red min-max 0.713 kNN, red z-score 0.716 -0.1344 H0 e aceite
Tabela C.1: Calculo 2: comparacao entre os classificadores vizinhos mais proximos.
A Tabela C.1 apresenta o resultado da comparacao de desempenho entre os classificadores
70

vizinhos mais proximos, abreviado kNN, tendo como medida do desempenho a acuracia. Eindicado se os dados foram normalizados ou se houve reducao do numero de caracterısticas,abreviado red.
Analisando o resultado dos varios testes comparativos confirmamos que a reducao decaracterısticas com base na correlacao nao traduz um melhor desempenho do classificadorvizinhos mais proximos treinado com os dados de Calculo 2. Para este classificador o valormais alto para a acuracia foi obtido com reducao de caracterısticas e normalizacao min-max.
A Tabela C.2 apresenta o resultado da comparacao de desempenho entre os classificadoresSVM Linear e z-SVM. Recordamos que o z-SVM e um ajuste posterior da equacao de decisaodeterminada com o SVM Linear.
Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
Linear, sem norm. 0.719 Linear, min-max 0.749 -1.6691 H0 e aceite
Linear, sem norm. 0.719 Linear, z-score 0.728 -0.5144 H0 e aceite
Linear, sem norm. 0.719 z-SVM, sem norm. 0.719 0.0079 H0 e aceite
Linear, sem norm. 0.719 z-SVM, min-max 0.728 -0.4656 H0 e aceite
Linear, sem norm. 0.719 z-SVM, z-score 0.706 0.9317 H0 e aceite
Linear, min-max 0.749 Linear, z-score 0.728 3.2864 H0 e aceite
Linear, min-max 0.749 z-SVM, sem norm. 0.719 1.9383 H0 e aceite
Linear, min-max 0.749 z-SVM, min-max 0.728 1.3422 H0 e aceite
Linear, min-max 0.749 z-SVM, z-score 0.706 2.9382 H0 e rejeitada
Linear, z-score 0.728 z-SVM, sem norm. 0.719 0.6704 H0 e aceite
Linear, z-score 0.728 z-SVM, min-max 0.728 -0.0051 H0 e aceite
Linear, z-score 0.728 z-SVM, z-score 0.706 1.7739 H0 e aceite
z-SVM, sem norm. 0.719 z-SVM, min-max 0.728 -0.3876 H0 e aceite
z-SVM, sem norm. 0.719 z-SVM, z-score 0.706 0.8356 H0 e aceite
z-SVM, min-max 0.728 z-SVM, z-score 0.706 1.0840 H0 e aceite
Tabela C.2: Calculo 2: comparacao entre os classificadores SVM Linear e z-SVM.
Os resultados indicam que, pelo menos para os dados de Calculo 2, o processamentoadicional que o classificador z-SVM implica nao traduz uma melhoria significativa nodesempenho do classificador SVM Linear. Destes classificadores, o que obteve melhoracuracia foi o SVM Linear com normalizacao min-max.
A Tabela C.3 apresenta o resultado da comparacao de desempenho do classificador DEC,quando treinado com instancias geradas por SMOTE e SMOTE SVM (alem de instanciasreais). Verificamos que o desempenho e independente da tecnica de geracao de instanciasescolhida.
71
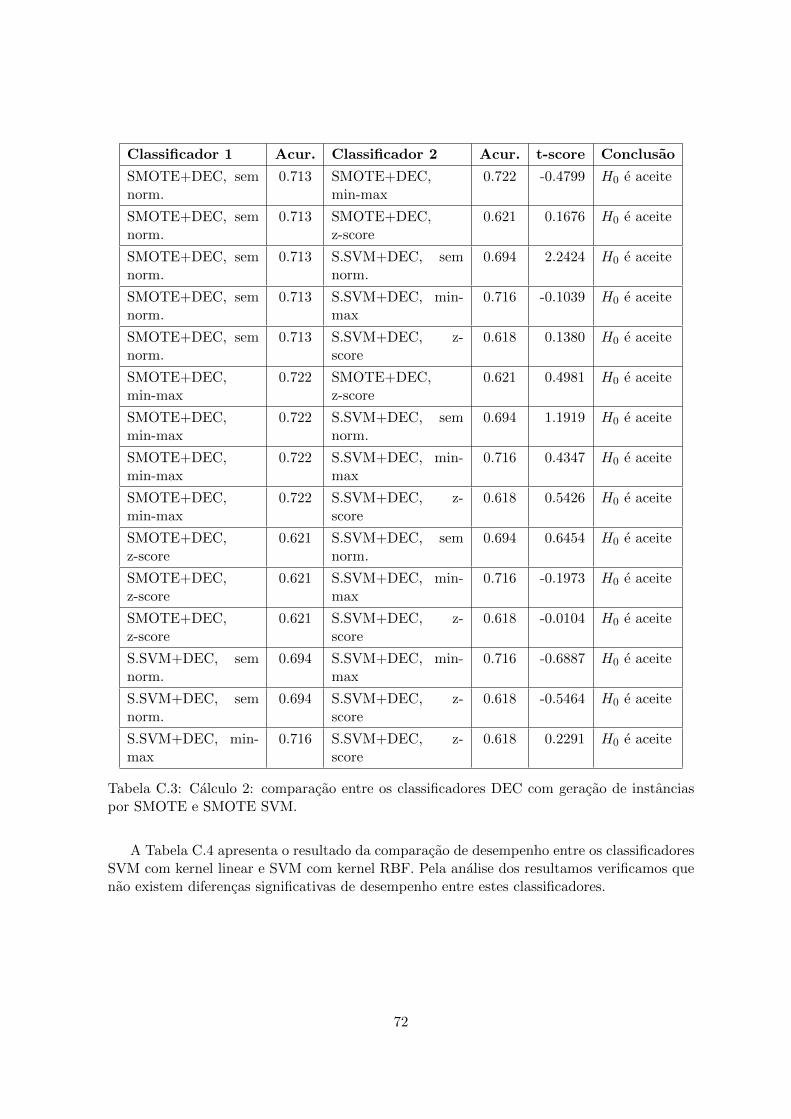
Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
SMOTE+DEC, semnorm.
0.713 SMOTE+DEC,min-max
0.722 -0.4799 H0 e aceite
SMOTE+DEC, semnorm.
0.713 SMOTE+DEC,z-score
0.621 0.1676 H0 e aceite
SMOTE+DEC, semnorm.
0.713 S.SVM+DEC, semnorm.
0.694 2.2424 H0 e aceite
SMOTE+DEC, semnorm.
0.713 S.SVM+DEC, min-max
0.716 -0.1039 H0 e aceite
SMOTE+DEC, semnorm.
0.713 S.SVM+DEC, z-score
0.618 0.1380 H0 e aceite
SMOTE+DEC,min-max
0.722 SMOTE+DEC,z-score
0.621 0.4981 H0 e aceite
SMOTE+DEC,min-max
0.722 S.SVM+DEC, semnorm.
0.694 1.1919 H0 e aceite
SMOTE+DEC,min-max
0.722 S.SVM+DEC, min-max
0.716 0.4347 H0 e aceite
SMOTE+DEC,min-max
0.722 S.SVM+DEC, z-score
0.618 0.5426 H0 e aceite
SMOTE+DEC,z-score
0.621 S.SVM+DEC, semnorm.
0.694 0.6454 H0 e aceite
SMOTE+DEC,z-score
0.621 S.SVM+DEC, min-max
0.716 -0.1973 H0 e aceite
SMOTE+DEC,z-score
0.621 S.SVM+DEC, z-score
0.618 -0.0104 H0 e aceite
S.SVM+DEC, semnorm.
0.694 S.SVM+DEC, min-max
0.716 -0.6887 H0 e aceite
S.SVM+DEC, semnorm.
0.694 S.SVM+DEC, z-score
0.618 -0.5464 H0 e aceite
S.SVM+DEC, min-max
0.716 S.SVM+DEC, z-score
0.618 0.2291 H0 e aceite
Tabela C.3: Calculo 2: comparacao entre os classificadores DEC com geracao de instanciaspor SMOTE e SMOTE SVM.
A Tabela C.4 apresenta o resultado da comparacao de desempenho entre os classificadoresSVM com kernel linear e SVM com kernel RBF. Pela analise dos resultamos verificamos quenao existem diferencas significativas de desempenho entre estes classificadores.
72

Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
Linear, sem norm. 0.719 Linear, min-max 0.749 -1.6691 H0 e aceite
Linear, sem norm. 0.719 Linear, z-score 0.728 -0.5144 H0 e aceite
Linear, sem norm. 0.719 RBF, sem norm. 0.731 -0.7419 H0 e aceite
Linear, semnorm.
0.719 RBF, min-max 0.752 -2.2961 H0 e rejeitada
Linear, sem norm. 0.719 RBF, z-score 0.740 -0.8207 H0 e aceite
Linear, min-max 0.749 Linear, z-score 0.728 3.2864 H0 e rejeitada
Linear, min-max 0.749 RBF, sem norm. 0.731 1.0896 H0 e aceite
Linear, min-max 0.749 RBF, min-max 0.752 -0.2781 H0 e aceite
Linear, min-max 0.749 RBF, z-score 0.740 0.4415 H0 e aceite
Linear, z-score 0.728 RBF, sem norm. 0.731 -0.1734 H0 e aceite
Linear, z-score 0.728 RBF, min-max 0.752 -1.9338 H0 e aceite
Linear, z-score 0.728 RBF, z-score 0.740 -0.5521 H0 e aceite
RBF, sem norm. 0.731 RBF, min-max 0.752 -1.2053 H0 e aceite
RBF, sem norm. 0.731 RBF, z-score 0.740 -0.3956 H0 e aceite
RBF, min-max 0.752 RBF, z-score 0.740 0.7140 H0 e aceite
Tabela C.4: Calculo 2: comparacao entre os classificadores SVM Linear e SVM com kernelRBF.
A Tabela C.5 apresenta o resultado da comparacao de desempenho entre os classifica-dores SVM com kernel linear treinados com dados com menor numero de caracterısticas.Verificamos que os classificadores SVM com kernel linear treinados com menor numero decaracterısticas apresentam melhor desempenho quando treinados com dados normalizadoscom min-max. Essa diferenca de desempenho apenas e significativa relativamente ao desem-penho dos mesmos classificadores treinados com dados normalizados com z-score. Destesclassificadores o RFECV com normalizacao min-max foi o que obteve maior valor de acuracia.
A Tabela C.6 apresenta o resultado da comparacao de desempenho entre o classificadorDEC e o classificador SMOTE+DEC normalizacao min-max. Pelos resultados apresentados,concluımos que, no caso dos dados de Calculo 2, a geracao de instancias nao acresce vantagemao treino dos dados com o classificador DEC. Verificamos ainda que a geracao de instanciasantes do treino do classificador DEC nao melhora significativamente o seu desempenho. Destesclassificadores aquele que apresenta maior acuracia e o DEC com normalizacao z-score.
73
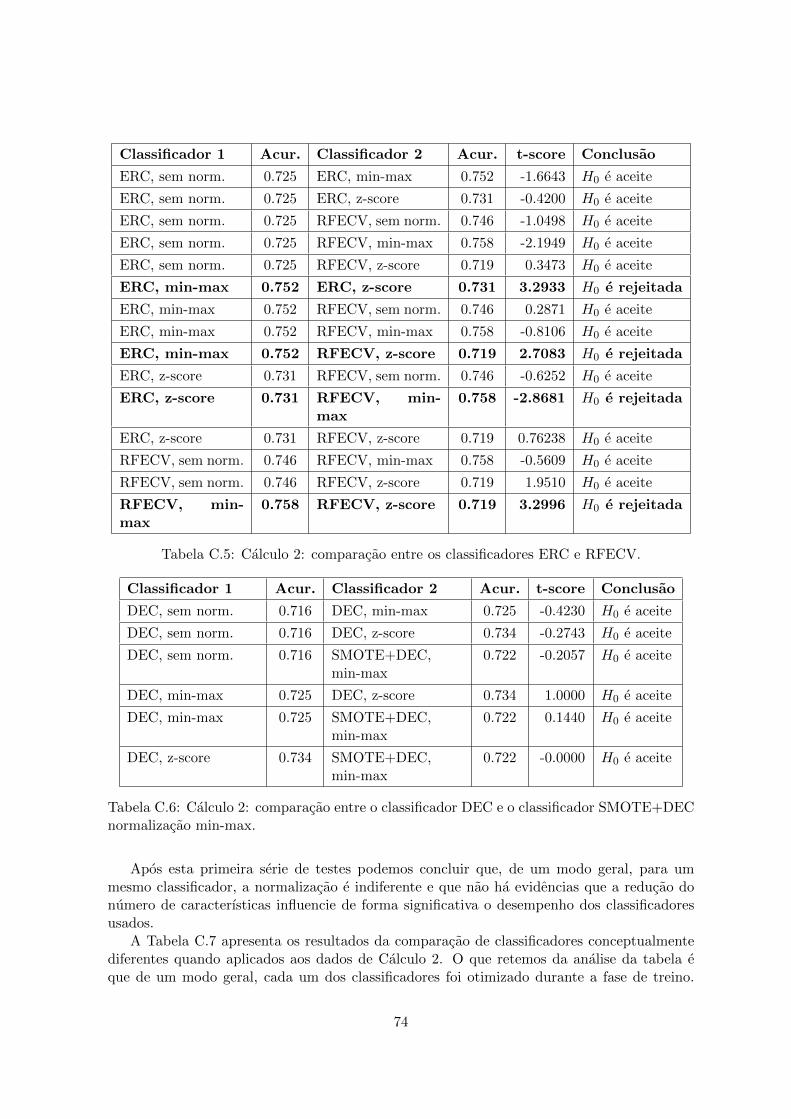
Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
ERC, sem norm. 0.725 ERC, min-max 0.752 -1.6643 H0 e aceite
ERC, sem norm. 0.725 ERC, z-score 0.731 -0.4200 H0 e aceite
ERC, sem norm. 0.725 RFECV, sem norm. 0.746 -1.0498 H0 e aceite
ERC, sem norm. 0.725 RFECV, min-max 0.758 -2.1949 H0 e aceite
ERC, sem norm. 0.725 RFECV, z-score 0.719 0.3473 H0 e aceite
ERC, min-max 0.752 ERC, z-score 0.731 3.2933 H0 e rejeitada
ERC, min-max 0.752 RFECV, sem norm. 0.746 0.2871 H0 e aceite
ERC, min-max 0.752 RFECV, min-max 0.758 -0.8106 H0 e aceite
ERC, min-max 0.752 RFECV, z-score 0.719 2.7083 H0 e rejeitada
ERC, z-score 0.731 RFECV, sem norm. 0.746 -0.6252 H0 e aceite
ERC, z-score 0.731 RFECV, min-max
0.758 -2.8681 H0 e rejeitada
ERC, z-score 0.731 RFECV, z-score 0.719 0.76238 H0 e aceite
RFECV, sem norm. 0.746 RFECV, min-max 0.758 -0.5609 H0 e aceite
RFECV, sem norm. 0.746 RFECV, z-score 0.719 1.9510 H0 e aceite
RFECV, min-max
0.758 RFECV, z-score 0.719 3.2996 H0 e rejeitada
Tabela C.5: Calculo 2: comparacao entre os classificadores ERC e RFECV.
Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
DEC, sem norm. 0.716 DEC, min-max 0.725 -0.4230 H0 e aceite
DEC, sem norm. 0.716 DEC, z-score 0.734 -0.2743 H0 e aceite
DEC, sem norm. 0.716 SMOTE+DEC,min-max
0.722 -0.2057 H0 e aceite
DEC, min-max 0.725 DEC, z-score 0.734 1.0000 H0 e aceite
DEC, min-max 0.725 SMOTE+DEC,min-max
0.722 0.1440 H0 e aceite
DEC, z-score 0.734 SMOTE+DEC,min-max
0.722 -0.0000 H0 e aceite
Tabela C.6: Calculo 2: comparacao entre o classificador DEC e o classificador SMOTE+DECnormalizacao min-max.
Apos esta primeira serie de testes podemos concluir que, de um modo geral, para ummesmo classificador, a normalizacao e indiferente e que nao ha evidencias que a reducao donumero de caracterısticas influencie de forma significativa o desempenho dos classificadoresusados.
A Tabela C.7 apresenta os resultados da comparacao de classificadores conceptualmentediferentes quando aplicados aos dados de Calculo 2. O que retemos da analise da tabela eque de um modo geral, cada um dos classificadores foi otimizado durante a fase de treino.
74
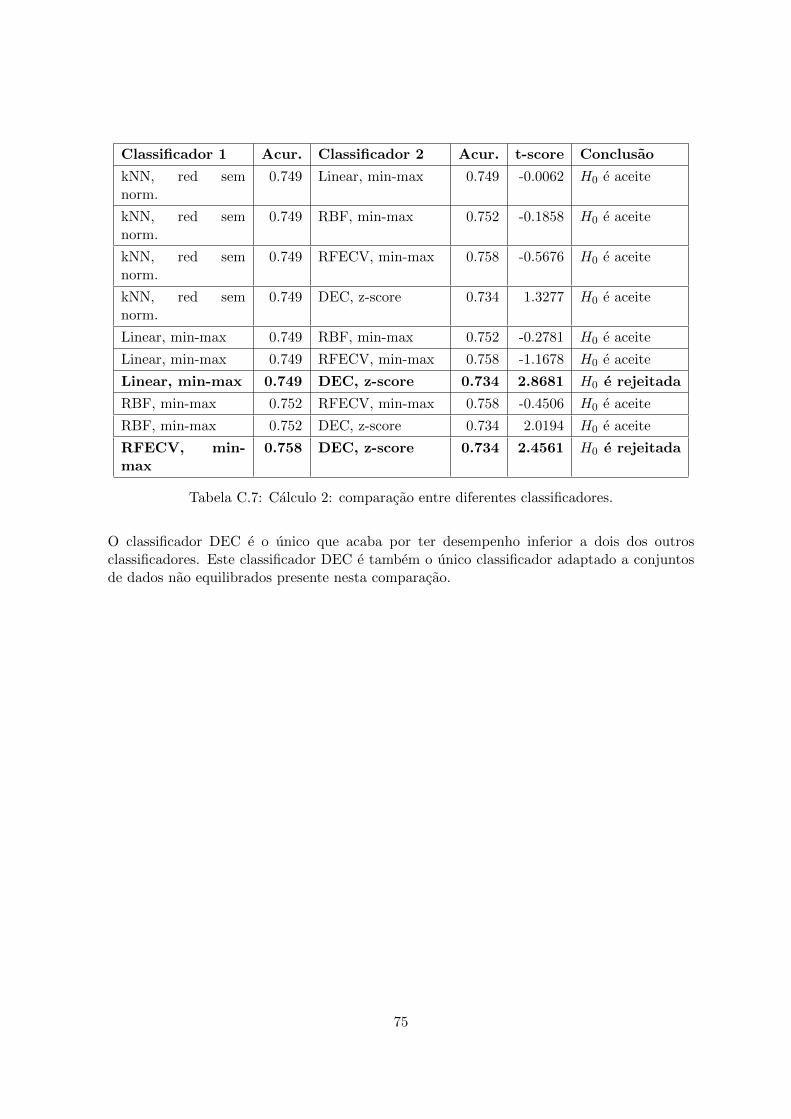
Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
kNN, red semnorm.
0.749 Linear, min-max 0.749 -0.0062 H0 e aceite
kNN, red semnorm.
0.749 RBF, min-max 0.752 -0.1858 H0 e aceite
kNN, red semnorm.
0.749 RFECV, min-max 0.758 -0.5676 H0 e aceite
kNN, red semnorm.
0.749 DEC, z-score 0.734 1.3277 H0 e aceite
Linear, min-max 0.749 RBF, min-max 0.752 -0.2781 H0 e aceite
Linear, min-max 0.749 RFECV, min-max 0.758 -1.1678 H0 e aceite
Linear, min-max 0.749 DEC, z-score 0.734 2.8681 H0 e rejeitada
RBF, min-max 0.752 RFECV, min-max 0.758 -0.4506 H0 e aceite
RBF, min-max 0.752 DEC, z-score 0.734 2.0194 H0 e aceite
RFECV, min-max
0.758 DEC, z-score 0.734 2.4561 H0 e rejeitada
Tabela C.7: Calculo 2: comparacao entre diferentes classificadores.
O classificador DEC e o unico que acaba por ter desempenho inferior a dois dos outrosclassificadores. Este classificador DEC e tambem o unico classificador adaptado a conjuntosde dados nao equilibrados presente nesta comparacao.
75

C.2 Calculo 3
As Tabelas C.8 e C.9 apresentam o resultado da comparacao de desempenho entre osclassificadores vizinhos mais proximos, abreviado kNN, tendo como medidas de desempenhoa acuracia e o valor de g, respetivamente. E indicado se os dados forma normalizados ou sehouve reducao do numero de caracterısticas, abreviado red.
Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
kNN, sem norm. 0.792 kNN, min-max 0.792 -0.0054 H0 e aceite
kNN, sem norm. 0.792 kNN, z-score 0.801 -0.7613 H0 e aceite
kNN, sem norm. 0.792 kNN, red sem norm. 0.792 0.0000 H0 e aceite
kNN, sem norm. 0.792 kNN, red min-max 0.795 -0.2758 H0 e aceite
kNN, sem norm. 0.792 kNN, red z-score 0.795 -0.1550 H0 e aceite
kNN, min-max 0.792 kNN, z-score 0.801 -0.7512 H0 e aceite
kNN, min-max 0.792 kNN, red sem norm. 0.792 0.0079 H0 e aceite
kNN, min-max 0.792 kNN, red min-max 0.795 -0.2654 H0 e aceite
kNN, min-max 0.792 kNN, red z-score 0.795 -0.3007 H0 e aceite
kNN, z-score 0.801 kNN, red sem norm. 0.792 1.0077 H0 e aceite
kNN, z-score 0.801 kNN, red min-max 0.795 0.9912 H0 e aceite
kNN, z-score 0.801 kNN, red z-score 0.795 0.4409 H0 e aceite
kNN, red sem norm. 0.792 kNN, red min-max 0.795 -0.3007 H0 e aceite
kNN, red sem norm. 0.792 kNN, red z-score. 0.795 -0.2046 H0 e aceite
kNN, red min-max 0.795 kNN, red z-score 0.795 -0.0079 H0 e aceite
Tabela C.8: Calculo 3: comparacao entre os classificadores vizinhos mais proximos, quanto aacuracia.
Analisando os resultados apresentados verificamos que a reducao do numero de carac-terısticas com base na correlacao nao significa melhor desempenho do classificador vizinhosmais proximos, quando treinado com os dados de Calculo 3 e independentemente da medidade desempenho considerada. Para este classificador o valor mais alto para a acuracia foiobtido sem reducao de caracterısticas e normalizacao z-score; o valor mais alto de g foi obtidotambem sem reducao de caracterısticas e normalizacao min-max.
Nas Tabelas C.10 e C.11 apresentamos os resultados relativos a comparacao de desempe-nho dos classificadores SVM de kernel linear e SVM de kernel RBF.
Quanto a acuracia nao existe diferenca significativa entre os classificadores. Quanto aovalor de g, de um modo geral, parece haver vantagem na utilizacao do classificador SVMLinear sem normalizacao dos dados.
76
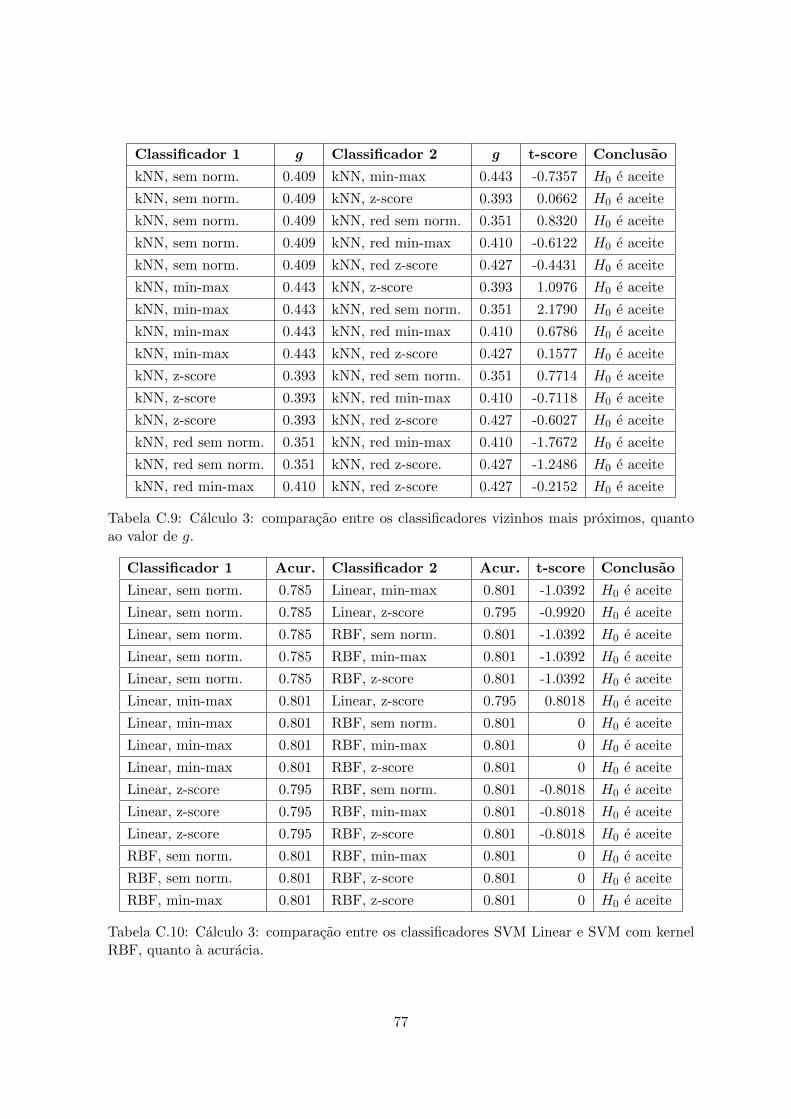
Classificador 1 g Classificador 2 g t-score Conclusao
kNN, sem norm. 0.409 kNN, min-max 0.443 -0.7357 H0 e aceite
kNN, sem norm. 0.409 kNN, z-score 0.393 0.0662 H0 e aceite
kNN, sem norm. 0.409 kNN, red sem norm. 0.351 0.8320 H0 e aceite
kNN, sem norm. 0.409 kNN, red min-max 0.410 -0.6122 H0 e aceite
kNN, sem norm. 0.409 kNN, red z-score 0.427 -0.4431 H0 e aceite
kNN, min-max 0.443 kNN, z-score 0.393 1.0976 H0 e aceite
kNN, min-max 0.443 kNN, red sem norm. 0.351 2.1790 H0 e aceite
kNN, min-max 0.443 kNN, red min-max 0.410 0.6786 H0 e aceite
kNN, min-max 0.443 kNN, red z-score 0.427 0.1577 H0 e aceite
kNN, z-score 0.393 kNN, red sem norm. 0.351 0.7714 H0 e aceite
kNN, z-score 0.393 kNN, red min-max 0.410 -0.7118 H0 e aceite
kNN, z-score 0.393 kNN, red z-score 0.427 -0.6027 H0 e aceite
kNN, red sem norm. 0.351 kNN, red min-max 0.410 -1.7672 H0 e aceite
kNN, red sem norm. 0.351 kNN, red z-score. 0.427 -1.2486 H0 e aceite
kNN, red min-max 0.410 kNN, red z-score 0.427 -0.2152 H0 e aceite
Tabela C.9: Calculo 3: comparacao entre os classificadores vizinhos mais proximos, quantoao valor de g.
Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
Linear, sem norm. 0.785 Linear, min-max 0.801 -1.0392 H0 e aceite
Linear, sem norm. 0.785 Linear, z-score 0.795 -0.9920 H0 e aceite
Linear, sem norm. 0.785 RBF, sem norm. 0.801 -1.0392 H0 e aceite
Linear, sem norm. 0.785 RBF, min-max 0.801 -1.0392 H0 e aceite
Linear, sem norm. 0.785 RBF, z-score 0.801 -1.0392 H0 e aceite
Linear, min-max 0.801 Linear, z-score 0.795 0.8018 H0 e aceite
Linear, min-max 0.801 RBF, sem norm. 0.801 0 H0 e aceite
Linear, min-max 0.801 RBF, min-max 0.801 0 H0 e aceite
Linear, min-max 0.801 RBF, z-score 0.801 0 H0 e aceite
Linear, z-score 0.795 RBF, sem norm. 0.801 -0.8018 H0 e aceite
Linear, z-score 0.795 RBF, min-max 0.801 -0.8018 H0 e aceite
Linear, z-score 0.795 RBF, z-score 0.801 -0.8018 H0 e aceite
RBF, sem norm. 0.801 RBF, min-max 0.801 0 H0 e aceite
RBF, sem norm. 0.801 RBF, z-score 0.801 0 H0 e aceite
RBF, min-max 0.801 RBF, z-score 0.801 0 H0 e aceite
Tabela C.10: Calculo 3: comparacao entre os classificadores SVM Linear e SVM com kernelRBF, quanto a acuracia.
77
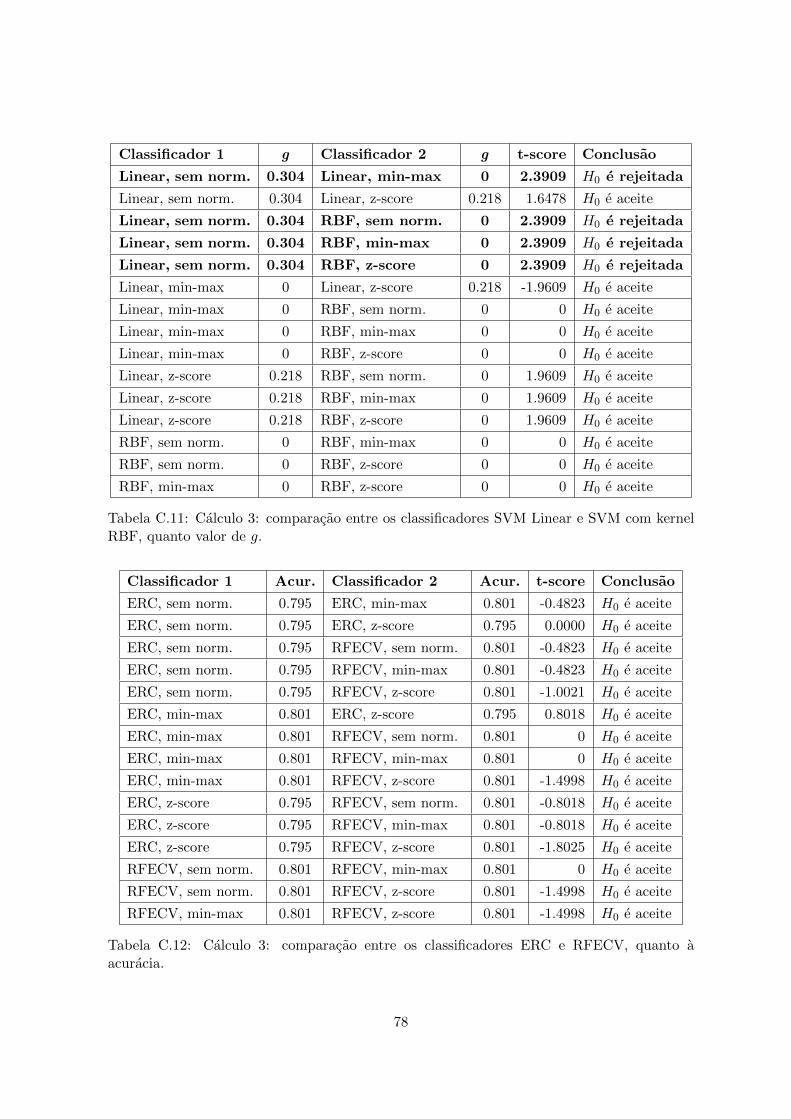
Classificador 1 g Classificador 2 g t-score Conclusao
Linear, sem norm. 0.304 Linear, min-max 0 2.3909 H0 e rejeitada
Linear, sem norm. 0.304 Linear, z-score 0.218 1.6478 H0 e aceite
Linear, sem norm. 0.304 RBF, sem norm. 0 2.3909 H0 e rejeitada
Linear, sem norm. 0.304 RBF, min-max 0 2.3909 H0 e rejeitada
Linear, sem norm. 0.304 RBF, z-score 0 2.3909 H0 e rejeitada
Linear, min-max 0 Linear, z-score 0.218 -1.9609 H0 e aceite
Linear, min-max 0 RBF, sem norm. 0 0 H0 e aceite
Linear, min-max 0 RBF, min-max 0 0 H0 e aceite
Linear, min-max 0 RBF, z-score 0 0 H0 e aceite
Linear, z-score 0.218 RBF, sem norm. 0 1.9609 H0 e aceite
Linear, z-score 0.218 RBF, min-max 0 1.9609 H0 e aceite
Linear, z-score 0.218 RBF, z-score 0 1.9609 H0 e aceite
RBF, sem norm. 0 RBF, min-max 0 0 H0 e aceite
RBF, sem norm. 0 RBF, z-score 0 0 H0 e aceite
RBF, min-max 0 RBF, z-score 0 0 H0 e aceite
Tabela C.11: Calculo 3: comparacao entre os classificadores SVM Linear e SVM com kernelRBF, quanto valor de g.
Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
ERC, sem norm. 0.795 ERC, min-max 0.801 -0.4823 H0 e aceite
ERC, sem norm. 0.795 ERC, z-score 0.795 0.0000 H0 e aceite
ERC, sem norm. 0.795 RFECV, sem norm. 0.801 -0.4823 H0 e aceite
ERC, sem norm. 0.795 RFECV, min-max 0.801 -0.4823 H0 e aceite
ERC, sem norm. 0.795 RFECV, z-score 0.801 -1.0021 H0 e aceite
ERC, min-max 0.801 ERC, z-score 0.795 0.8018 H0 e aceite
ERC, min-max 0.801 RFECV, sem norm. 0.801 0 H0 e aceite
ERC, min-max 0.801 RFECV, min-max 0.801 0 H0 e aceite
ERC, min-max 0.801 RFECV, z-score 0.801 -1.4998 H0 e aceite
ERC, z-score 0.795 RFECV, sem norm. 0.801 -0.8018 H0 e aceite
ERC, z-score 0.795 RFECV, min-max 0.801 -0.8018 H0 e aceite
ERC, z-score 0.795 RFECV, z-score 0.801 -1.8025 H0 e aceite
RFECV, sem norm. 0.801 RFECV, min-max 0.801 0 H0 e aceite
RFECV, sem norm. 0.801 RFECV, z-score 0.801 -1.4998 H0 e aceite
RFECV, min-max 0.801 RFECV, z-score 0.801 -1.4998 H0 e aceite
Tabela C.12: Calculo 3: comparacao entre os classificadores ERC e RFECV, quanto aacuracia.
78

Para o classificador SVM Linear com reducao do numero de caracterısticas, os resultadosapresentados na Tabela C.12 mostram que e indiferente a abordagem usada, quando a medidade desempenho e a acuracia. Quando a medida de desempenho e o valor de g, analisando aTabela C.13 verificamos que a abordagem ERC sem normalizacao dos dados permite melhordesempenho.
Classificador 1 g Classificador 2 g t-score Conclusao
ERC, sem norm. 0.311 ERC, min-max 0 2.3934 H0 e rejeitada
ERC, sem norm. 0.311 ERC, z-score 0.221 1.6919 H0 e aceite
ERC, sem norm. 0.311 RFECV, semnorm.
0 2.3934 H0 e rejeitada
ERC, sem norm. 0.311 RFECV, min-max 0 2.3934 H0 e rejeitada
ERC, sem norm. 0.311 RFECV, z-score 0.173 2.1023 H0 e aceite
ERC, min-max 0 ERC, z-score 0.221 -1.9609 H0 e aceite
ERC, min-max 0 RFECV, sem norm. 0 0 H0 e aceite
ERC, min-max 0 RFECV, min-max 0 0 H0 e aceite
ERC, min-max 0 RFECV, z-score 0.173 -1.4986 H0 e aceite
ERC, z-score 0.221 RFECV, sem norm. 0 1.9609 H0 e aceite
ERC, z-score 0.221 RFECV, min-max 0 1.9609 H0 e aceite
ERC, z-score 0.221 RFECV, z-score 0.173 0.9769 H0 e aceite
RFECV, sem norm. 0 RFECV, min-max 0 0 H0 e aceite
RFECV, sem norm. 0 RFECV, z-score 0.173 -1.4986 H0 e aceite
RFECV, min-max 0 RFECV, z-score 0.173 -1.4986 H0 e aceite
Tabela C.13: Calculo 3: comparacao entre os classificadores ERC e RFECV, quanto ao valorde g.
Quando comparamos o desempenho relativamente a acuracia do classificador DEC trei-nado apos a geracao de instancias da classe minoritaria, em mais de metade dos testes ahipotese H0 e rejeitada. Como podemos observar na Tabela C.14 nao e facil concluir sobreo impacto no desempenho da utilizacao dos geradores SMOTE e SMOTE SVM, no entanto,parece que de um modo geral, o gerador SMOTE SVM obtem melhor desempenho quando amedida e a acuracia.
79

Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
SMOTE+DEC,sem norm.
0.603 SMOTE+DEC,min-max
0.628 -0.7085 H0 e aceite
SMOTE+DEC,sem norm.
0.603 SMOTE+DEC,z-score
0.487 4.4738 H0 e rejeitada
SMOTE+DEC,sem norm.
0.603 S.SVM+DEC,sem norm.
0.641 -2.4422 H0 e rejeitada
SMOTE+DEC,sem norm.
0.603 S.SVM+DEC,min-max
0.715 -3.6832 H0 e rejeitada
SMOTE+DEC,sem norm.
0.603 S.SVM+DEC,z-score
0.663 -2.0000 H0 e aceite
SMOTE+DEC,min-max
0.628 SMOTE+DEC,z-score
0.487 3.6717 H0 e rejeitada
SMOTE+DEC,min-max
0.628 S.SVM+DEC, semnorm.
0.641 -0.2875 H0 e aceite
SMOTE+DEC,min-max
0.628 S.SVM+DEC,min-max
0.715 -2.8218 H0 e rejeitada
SMOTE+DEC,min-max
0.628 S.SVM+DEC,z-score
0.663 -1.2727 H0 e aceite
SMOTE+DEC,z-score
0.487 S.SVM+DEC,sem norm.
0.641 -4.9018 H0 e rejeitada
SMOTE+DEC,z-score
0.487 S.SVM+DEC,min-max
0.715 -5.9974 H0 e rejeitada
SMOTE+DEC,z-score
0.487 S.SVM+DEC, z-score
0.663 -4.8727 H0 e rejeitada
S.SVM+DEC, semnorm.
0.641 S.SVM+DEC, min-max
0.715 2.0399 H0 e aceite
S.SVM+DEC, semnorm.
0.641 S.SVM+DEC,z-score
0.663 -0.5856 H0 e aceite
S.SVM+DEC,min-max
0.715 S.SVM+DEC, z-score
0.663 4.3147 H0 e rejeitada
Tabela C.14: Calculo 3: comparacao entre os classificadores DEC com geracao de instanciaspor SMOTE e SMOTE SVM, quanto a acuracia.
Esta comparacao de classificadores, mas tendo como medida de desempenho o valor deg, revela que a escolha da tecnica de geracao de instancias e indiferente. Tal como se podeobservar na Tabela C.15 nao existem diferencas significativas entre os classificadores.
80
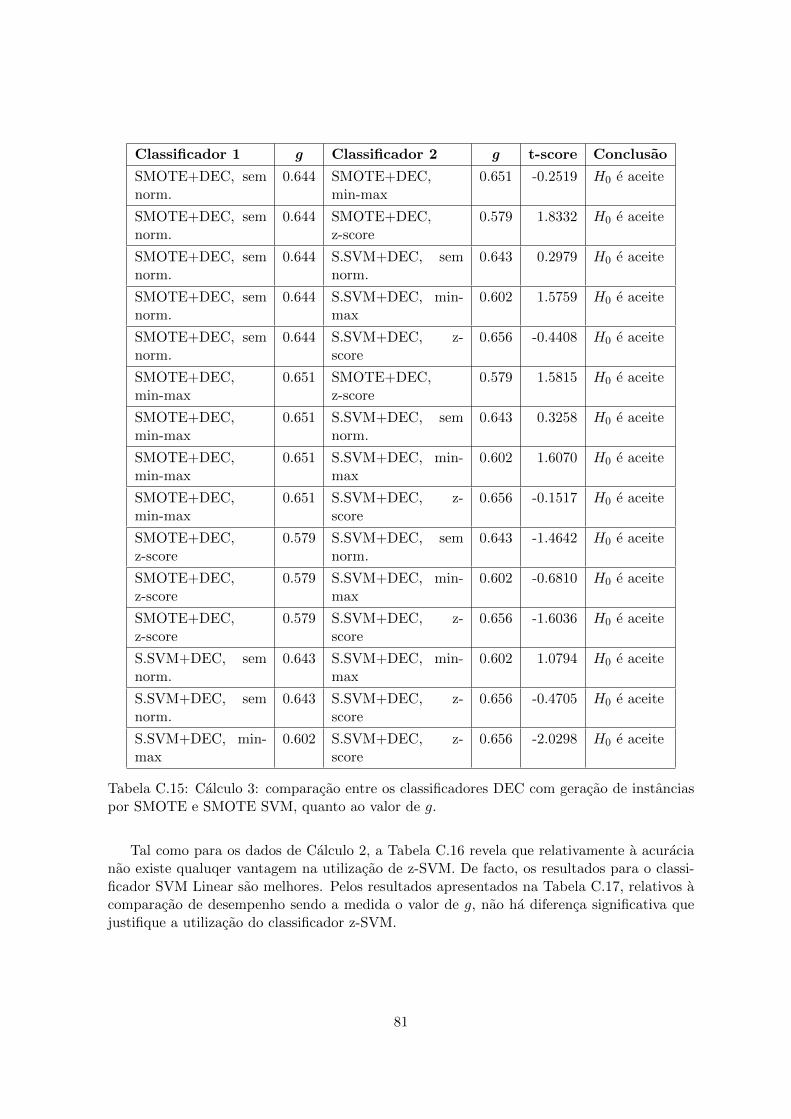
Classificador 1 g Classificador 2 g t-score Conclusao
SMOTE+DEC, semnorm.
0.644 SMOTE+DEC,min-max
0.651 -0.2519 H0 e aceite
SMOTE+DEC, semnorm.
0.644 SMOTE+DEC,z-score
0.579 1.8332 H0 e aceite
SMOTE+DEC, semnorm.
0.644 S.SVM+DEC, semnorm.
0.643 0.2979 H0 e aceite
SMOTE+DEC, semnorm.
0.644 S.SVM+DEC, min-max
0.602 1.5759 H0 e aceite
SMOTE+DEC, semnorm.
0.644 S.SVM+DEC, z-score
0.656 -0.4408 H0 e aceite
SMOTE+DEC,min-max
0.651 SMOTE+DEC,z-score
0.579 1.5815 H0 e aceite
SMOTE+DEC,min-max
0.651 S.SVM+DEC, semnorm.
0.643 0.3258 H0 e aceite
SMOTE+DEC,min-max
0.651 S.SVM+DEC, min-max
0.602 1.6070 H0 e aceite
SMOTE+DEC,min-max
0.651 S.SVM+DEC, z-score
0.656 -0.1517 H0 e aceite
SMOTE+DEC,z-score
0.579 S.SVM+DEC, semnorm.
0.643 -1.4642 H0 e aceite
SMOTE+DEC,z-score
0.579 S.SVM+DEC, min-max
0.602 -0.6810 H0 e aceite
SMOTE+DEC,z-score
0.579 S.SVM+DEC, z-score
0.656 -1.6036 H0 e aceite
S.SVM+DEC, semnorm.
0.643 S.SVM+DEC, min-max
0.602 1.0794 H0 e aceite
S.SVM+DEC, semnorm.
0.643 S.SVM+DEC, z-score
0.656 -0.4705 H0 e aceite
S.SVM+DEC, min-max
0.602 S.SVM+DEC, z-score
0.656 -2.0298 H0 e aceite
Tabela C.15: Calculo 3: comparacao entre os classificadores DEC com geracao de instanciaspor SMOTE e SMOTE SVM, quanto ao valor de g.
Tal como para os dados de Calculo 2, a Tabela C.16 revela que relativamente a acuracianao existe qualuqer vantagem na utilizacao de z-SVM. De facto, os resultados para o classi-ficador SVM Linear sao melhores. Pelos resultados apresentados na Tabela C.17, relativos acomparacao de desempenho sendo a medida o valor de g, nao ha diferenca significativa quejustifique a utilizacao do classificador z-SVM.
81
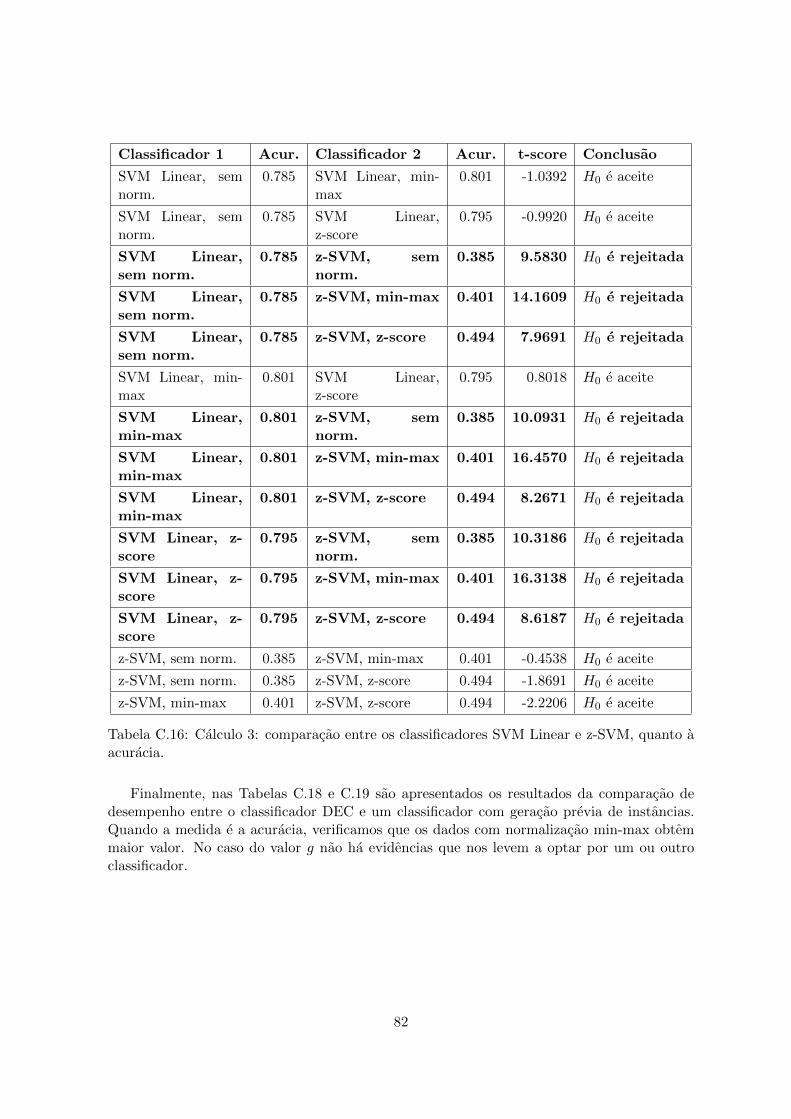
Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
SVM Linear, semnorm.
0.785 SVM Linear, min-max
0.801 -1.0392 H0 e aceite
SVM Linear, semnorm.
0.785 SVM Linear,z-score
0.795 -0.9920 H0 e aceite
SVM Linear,sem norm.
0.785 z-SVM, semnorm.
0.385 9.5830 H0 e rejeitada
SVM Linear,sem norm.
0.785 z-SVM, min-max 0.401 14.1609 H0 e rejeitada
SVM Linear,sem norm.
0.785 z-SVM, z-score 0.494 7.9691 H0 e rejeitada
SVM Linear, min-max
0.801 SVM Linear,z-score
0.795 0.8018 H0 e aceite
SVM Linear,min-max
0.801 z-SVM, semnorm.
0.385 10.0931 H0 e rejeitada
SVM Linear,min-max
0.801 z-SVM, min-max 0.401 16.4570 H0 e rejeitada
SVM Linear,min-max
0.801 z-SVM, z-score 0.494 8.2671 H0 e rejeitada
SVM Linear, z-score
0.795 z-SVM, semnorm.
0.385 10.3186 H0 e rejeitada
SVM Linear, z-score
0.795 z-SVM, min-max 0.401 16.3138 H0 e rejeitada
SVM Linear, z-score
0.795 z-SVM, z-score 0.494 8.6187 H0 e rejeitada
z-SVM, sem norm. 0.385 z-SVM, min-max 0.401 -0.4538 H0 e aceite
z-SVM, sem norm. 0.385 z-SVM, z-score 0.494 -1.8691 H0 e aceite
z-SVM, min-max 0.401 z-SVM, z-score 0.494 -2.2206 H0 e aceite
Tabela C.16: Calculo 3: comparacao entre os classificadores SVM Linear e z-SVM, quanto aacuracia.
Finalmente, nas Tabelas C.18 e C.19 sao apresentados os resultados da comparacao dedesempenho entre o classificador DEC e um classificador com geracao previa de instancias.Quando a medida e a acuracia, verificamos que os dados com normalizacao min-max obtemmaior valor. No caso do valor g nao ha evidencias que nos levem a optar por um ou outroclassificador.
82

Classificador 1 g Classificador 2 g t-score Conclusao
SVM Linear,sem norm.
0.304 SVM Linear,min-max
0 2.3909 H0 e rejeitada
SVM Linear, semnorm.
0.304 SVM Linear,z-score
0.218 1.6478 H0 e aceite
SVM Linear, semnorm.
0.304 z-SVM, sem norm. 0.422 -1.2016 H0 e aceite
SVM Linear, semnorm.
0.304 z-SVM, min-max 0.344 -1.3158 H0 e aceite
SVM Linear, semnorm.
0.304 z-SVM, z-score 0.344 -1.0385 H0 e aceite
SVM Linear, min-max
0 SVM Linear,z-score
0.218 -1.9609 H0 e aceite
SVM Linear,min-max
0 z-SVM, semnorm.
0.422 -5.2584 H0 e rejeitada
SVM Linear,min-max
0 z-SVM, min-max 0.344 -5.6607 H0 e rejeitada
SVM Linear,min-max
0 z-SVM, z-score 0.344 -4.2270 H0 e rejeitada
SVM Linear, z-score
0.218 z-SVM, semnorm.
0.422 -2.6485 H0 e rejeitada
SVM Linear, z-score
0.218 z-SVM, min-max 0.344 -2.7911 H0 e rejeitada
SVM Linear,z-score
0.218 z-SVM, z-score 0.344 -2.0480 H0 e aceite
z-SVM, sem norm. 0.422 z-SVM, min-max 0.344 -0.0890 H0 e aceite
z-SVM, sem norm. 0.422 z-SVM, z-score 0.344 0.1362 H0 e aceite
z-SVM, min-max 0.344 z-SVM, z-score 0.344 0.3398 H0 e aceite
Tabela C.17: Calculo 3: comparacao entre os classificadores SVM Linear e z-SVM, quanto aovalor de g.
As Tabelas C.20 e C.21 apresentam os resultados da comparacao de classificadores con-ceptualmente diferentes, quanto a acuracia e quanto ao valor de g. Analisando o resultado dostestes de hipoteses em que a medida de desempenho considerada e a acuracia, verificamos queos classificadores por voto e DEC com geracao de instancias por SMOTE SVM sao aquelesque apresentam pior desempenho.
Relativamente ao valor de g, os classificadores por voto e DEC sao aqueles que apresentammaior competencia na discriminacao entre alunos reprovados e alunos aprovados.
83

Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
DEC, sem norm. 0.644 DEC, min-max 0.670 -0.9417 H0 e aceite
DEC, sem norm. 0.644 DEC, z-score 0.587 1.8200 H0 e aceite
DEC, sem norm. 0.644 S.SVM+DEC, min-max
0.715 -2.2481 H0 e aceite
DEC, min-max 0.670 DEC, z-score 0.587 3.6259 H0 e rejeitada
DEC, min-max 0.670 S.SVM+DEC, min-max
0.715 -1.6566 H0 e aceite
DEC, z-score 0.587 S.SVM+DEC,min-max
0.715 -3.5936 H0 e rejeitada
Tabela C.18: Calculo 3: comparacao entre o classificador DEC e o classificador S.SVM+DECnormalizacao min-max, quanto a acuracia.
Classificador 1 g Classificador 2 g t-score Conclusao
DEC, sem norm. 0.656 DEC, min-max 0.667 -0.2993 H0 e aceite
DEC, sem norm. 0.656 DEC, z-score 0.655 -0.0473 H0 e aceite
DEC, sem norm. 0.656 S.SVM+DEC, z-score
0.656 -0.1323 H0 e aceite
DEC, min-max 0.667 DEC, z-score 0.655 0.3309 H0 e aceite
DEC, min-max 0.667 S.SVM+DEC, z-score
0.656 0.1867 H0 e aceite
DEC, z-score 0.655 S.SVM+DEC, z-score
0.656 -0.0790 H0 e aceite
Tabela C.19: Calculo 3: comparacao entre o classificador DEC e o classificador S.SVM+DECnormalizacao z-score, quanto ao valor de g.
84
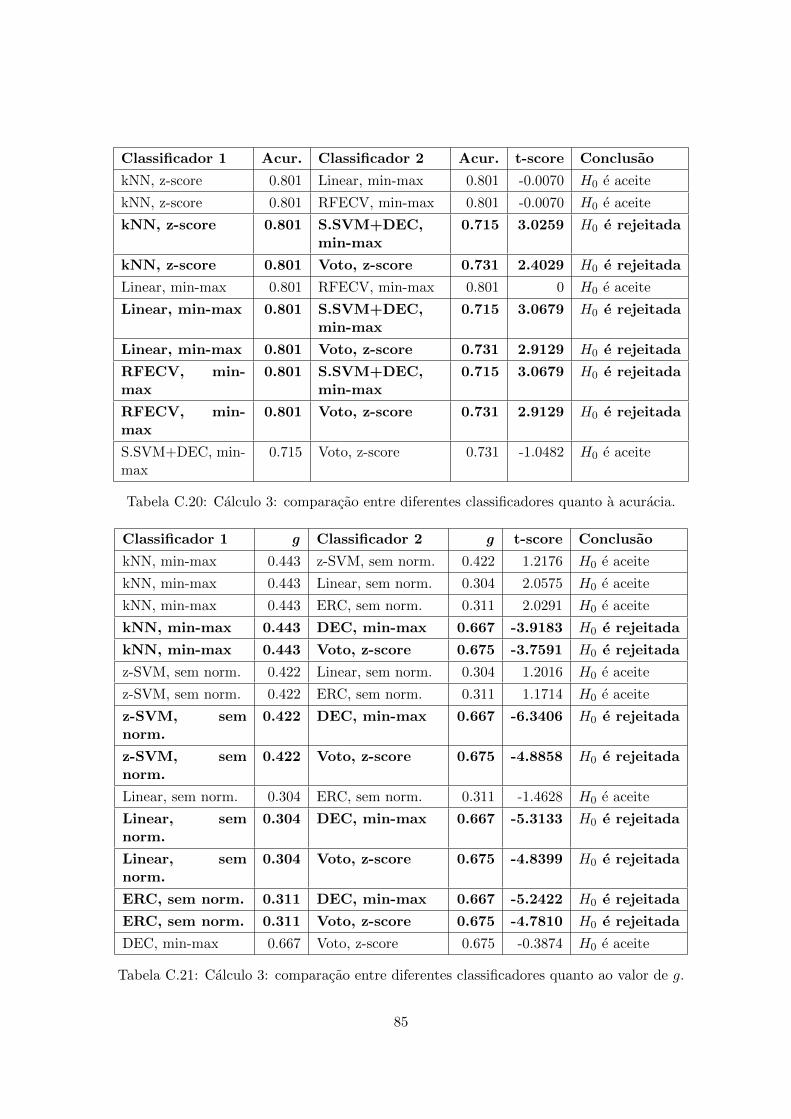
Classificador 1 Acur. Classificador 2 Acur. t-score Conclusao
kNN, z-score 0.801 Linear, min-max 0.801 -0.0070 H0 e aceite
kNN, z-score 0.801 RFECV, min-max 0.801 -0.0070 H0 e aceite
kNN, z-score 0.801 S.SVM+DEC,min-max
0.715 3.0259 H0 e rejeitada
kNN, z-score 0.801 Voto, z-score 0.731 2.4029 H0 e rejeitada
Linear, min-max 0.801 RFECV, min-max 0.801 0 H0 e aceite
Linear, min-max 0.801 S.SVM+DEC,min-max
0.715 3.0679 H0 e rejeitada
Linear, min-max 0.801 Voto, z-score 0.731 2.9129 H0 e rejeitada
RFECV, min-max
0.801 S.SVM+DEC,min-max
0.715 3.0679 H0 e rejeitada
RFECV, min-max
0.801 Voto, z-score 0.731 2.9129 H0 e rejeitada
S.SVM+DEC, min-max
0.715 Voto, z-score 0.731 -1.0482 H0 e aceite
Tabela C.20: Calculo 3: comparacao entre diferentes classificadores quanto a acuracia.
Classificador 1 g Classificador 2 g t-score Conclusao
kNN, min-max 0.443 z-SVM, sem norm. 0.422 1.2176 H0 e aceite
kNN, min-max 0.443 Linear, sem norm. 0.304 2.0575 H0 e aceite
kNN, min-max 0.443 ERC, sem norm. 0.311 2.0291 H0 e aceite
kNN, min-max 0.443 DEC, min-max 0.667 -3.9183 H0 e rejeitada
kNN, min-max 0.443 Voto, z-score 0.675 -3.7591 H0 e rejeitada
z-SVM, sem norm. 0.422 Linear, sem norm. 0.304 1.2016 H0 e aceite
z-SVM, sem norm. 0.422 ERC, sem norm. 0.311 1.1714 H0 e aceite
z-SVM, semnorm.
0.422 DEC, min-max 0.667 -6.3406 H0 e rejeitada
z-SVM, semnorm.
0.422 Voto, z-score 0.675 -4.8858 H0 e rejeitada
Linear, sem norm. 0.304 ERC, sem norm. 0.311 -1.4628 H0 e aceite
Linear, semnorm.
0.304 DEC, min-max 0.667 -5.3133 H0 e rejeitada
Linear, semnorm.
0.304 Voto, z-score 0.675 -4.8399 H0 e rejeitada
ERC, sem norm. 0.311 DEC, min-max 0.667 -5.2422 H0 e rejeitada
ERC, sem norm. 0.311 Voto, z-score 0.675 -4.7810 H0 e rejeitada
DEC, min-max 0.667 Voto, z-score 0.675 -0.3874 H0 e aceite
Tabela C.21: Calculo 3: comparacao entre diferentes classificadores quanto ao valor de g.
85

Bibliografia
[1] L. Zhou and Kin Keung Lai. Benchmarking binary classification models on data sets withdifferent degrees of imbalance. Frontiers of Computer Science in China, 3(2):205–216,2009.
[2] J. Han. Data Mining: Concepts and Techniques. Morgan Kaufmann Publishers Inc., SanFrancisco, CA, USA, 2005.
[3] H.M. Nguyen, E.W. Cooper, and K. Kamei. Borderline over-sampling for imbalanceddata classification. Int. J. Knowl. Eng. Soft Data Paradigm., 3(1):4–21, April 2011.
[4] H.S. Nwana. Intelligent tutoring systems: an overview. Artificial Intelligence Review,4(4):251–277, 1990.
[5] L. Descalco, P. Carvalho, J.P. Cruz, P. Oliveira, and D. Seabra. Computer-assisted inde-pendent study in multivariate calculus. In EDULEARN15 Proceedings, 7th InternationalConference on Education and New Learning Technologies, pages 3352–3360. IATED, 6-8July 2015.
[6] R. Batuwita and Vasile P. Class Imbalance Learning Methods for Support Vector Machi-nes. (eds H. He and Y. Ma), John Wiley & Sons, Inc., 2013.
[7] M.M. Fonseca. Modelo bayesiano do aluno no calculo com varias variaveis. Master’sthesis, Departamento de Matematica, Universidade de Aveiro, 2014.
[8] L. Descalco, P. Carvalho, J.P. Cruz, P. Oliveira, and D. Seabra. Using bayesian networksand parametrized questions in independent study. In EDULEARN15 Proceedings, 7thInternational Conference on Education and New Learning Technologies, pages 3361–3368.IATED, 6-8 July 2015.
[9] Pmate: Projeto matematica ensino. pmate.ua.pt. [Online; accessed 28-June-2016].
[10] Megua. cms.ua.pt/megua. [Online; accessed 28-June-2016].
[11] K. Chrysafiadi and M. Virvou. Review: Student modeling approaches: A literature re-view for the last decade. Expert Systems with Applications, 40(11):4715–4729, September2013.
[12] D.M. Cardoso, J. Szymanski, and M. Rostami. Matematica Discreta. Escolar Editora,2009.
[13] F.V. Jensen and T.D. Nielsen. Bayesian Networks and Decision Graphs. Springer Pu-blishing Company, Incorporated, 2nd edition, 2007.
86

[14] T. Koski and J. Noble. Bayesian Networks: An Introduction. John Wiley and Sons,2009.
[15] E. Millan and J.L. Perez-de-la Cruz. A bayesian diagnostic algorithm for student mo-deling and its evaluation. User Modeling and User-Adapted Interaction, 12(2):281–330,2002.
[16] M. Bramer. Principles of Data Mining (Undergraduate Topics in Computer Science).Springer-Verlag New York, Inc., Secaucus, NJ, USA, 2007.
[17] scikit learn. Usear guide. scikit-learn.org/stable/user_guide.html. [Online; ac-cessed 28-June-2016].
[18] X. Wu, V. Kumar, J. Ross Quinlan, J. Ghosh, Q. Yang, H. Motoda, G.J. McLachlan,A. Ng, B. Liu, P.S. Yu, Z.H. Zhou, M. Steinbach, D.J. Hand, and D. Steinberg. Top 10algorithms in data mining. Knowl. Inf. Syst., 14(1):1–37, December 2007.
[19] P. Rousseeuw. Silhouettes: A graphical aid to the interpretation and validation of clusteranalysis. J. Comput. Appl. Math., 20(1):53–65, November 1987.
[20] I. Guyon, J. Weston, S. Barnhill, and V. Vapnik. Gene selection for cancer classificationusing support vector machines. Mach. Learn., 46(1-3):389–422, March 2002.
[21] H. He and E.A. Garcia. Learning from imbalanced data. IEEE Trans. on Knowl. andData Eng., 21(9):1263–1284, September 2009.
[22] K. Veropoulos, C. Campbell, and N. Cristianini. Controlling the sensitivity of supportvector machines. In Proceedings of the International Joint Conference on AI, pages55–60, 1999.
[23] R. Akbani, S. Kwek, and N. Japkowicz. Applying support vector machines to imbalan-ced datasets. In In Proceedings of the 15th European Conference on Machine Learning(ECML, pages 39–50, 2004.
[24] N.V. Chawla, K.W. Bowyer, L.O. Hall, and W.P. Kegelmeyer. Smote: Synthetic minorityover-sampling technique. J. Artif. Int. Res., 16(1):321–357, June 2002.
[25] T. Imam, K.M. Ting, and J. Kamruzzaman. z-svm: An svm for improved classificationof imbalanced data. In Proceedings of the 19th Australian Joint Conference on ArtificialIntelligence: Advances in Artificial Intelligence, AI’06, pages 264–273, Berlin, Heidelberg,2006. Springer-Verlag.
[26] A. Kowalczyk and B. Raskutti. One class svm for yeast regulation prediction. SIGKDDExplor. Newsl., 4(2):99–100, December 2002.
[27] B. Raskutti and A. Kowalczyk. Extreme re-balancing for svms: A case study. SIGKDDExplor. Newsl., 6(1):60–69, June 2004.
[28] P.N. Tan, M. Steinbach, and V. Kumar. Introduction to Data Mining, (First Edition).Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 2005.
87

[29] L. Descalco and P. Carvalho. Using parameterized calculus questions for learning andassessment. In 2015 10th Iberian Conference on Information Systems and Technologies(CISTI), pages 1–5, June 2015.
[30] G. Lemaıtre, F. Nogueira, and C.K. Aridas. Imbalanced-learn: A python toolbox totackle the curse of imbalanced datasets in machine learning. CoRR, abs/1609.06570,2016.
[31] scipy.org. Statistical functions. /docs.scipy.org/doc/scipy/reference/stats.html.[Online; accessed 12-August-2016].
[32] F.B. Baker. The basics of item response theory. ERIC Clearinghouse on Assessment andEvaluation, 2nd ed. edition, 2001.
88