· quatro anos de estudo de física, ... descrita pela eletrodinâmica clássica. ... se 1w de...
TRANSCRIPT

TEO VICTOR RESENDE DA SILVA
SOLUÇÃO DAS EQUAÇÕES DE BLOCH ÓPTICAS PARA SISTEMAS ATÔMICOSDE DOIS E TRÊS NÍVEIS UTILIZANDO GPUS
JI-PARANÁ, ROJULHO DE 2017

TEO VICTOR RESENDE DA SILVA
SOLUÇÃO DAS EQUAÇÕES DE BLOCH ÓPTICAS PARA SISTEMAS ATÔMICOSDE DOIS E TRÊS NÍVEIS UTILIZANDO GPUS
Trabalho de Conclusão de Curso apresentadoao Departamento de Física de Ji-Paraná,Universidade Federal de Rondônia, Campus deJi-Paraná, como parte dos quesitos para aobtenção do Título de Bacharel em Física, soborientação do Prof. Dr. Marco Polo Moreno deSouza
JI-PARANÁ, ROJULHO DE 2017

FUNDAÇÃO UNIVERSIDADE FEDERAL DE RONDÔNIACAMPUS DE JI-PARANÁ
DEPARTAMENTO DE FÍSICA DE JI-PARANÁ – DEFIJI
ATA DE AVALIAÇÃO DO TRABALHO DE CONCLUSÃO DE CURSO DO CURSODE BACHARELADO EM FÍSICA.
Aos ___ dias do mês de julho do ano de 2017, às ________, no Auditório do Campus da Unir
de Ji-Paraná, reuniu-se a Banca Julgadora composta pelo professor orientador Dr. Marco Polo
Moreno de Souza e pelos examinadores Prof. Dr. Walter Trennepohl Júnior e Prof. Dr.
Ricardo de Sousa Costa, para avaliarem o Trabalho de Conclusão de Curso, do Curso de
Bacharelado em Física, intitulado “SOLUÇÃO DAS EQUAÇÕES DE BLOCH ÓPTICAS
PARA SISTEMAS ATÔMICOS DE DOIS E TRÊS NÍVEIS UTILIZANDO GPUS”, do
discente Teo Victor Resende da Silva. Após a apresentação, o candidato foi arguido pelos
integrantes da Banca Julgadora por _____ minutos. Ao final da arguição, a Banca Julgadora,
em sessão reservada, _________________ o candidato com nota _____, em uma avaliação de
0 (zero) a 10 (dez). Nada mais havendo a tratar, a sessão foi encerrada às ___ horas e ____
minutos, dela sendo lavrada a presente ata, assinada por todos os membros da Banca
Julgadora.
_______________________________________________________
Prof. Dr. Marco Polo Moreno de Souza – DEFIJI/CJP/UNIROrientador
_______________________________________________________
Prof. Dr. Walter Trennepohl Júnior – DEFIJI/CJP/UNIR
_______________________________________________________
Prof. Dr. Ricardo de Sousa Costa – DEFIJI/CJP/UNIR

4
AGRADECIMENTOS
A todo corpo docente da Unir pelo aprendizado proporcionado até aqui em quase
quatro anos de estudo de Física, Matemática e ciência em geral, com gratidão especial
ao orientador deste trabalho, Prof. Marco Polo, pelo profissionalismo e disposição carac-
terísticos que permitiram a conclusão da monografia e o entendimento de diversos temas
intrincados.
Aos colegas de curso, quase todos mais novos que eu, mas que me acolheram como
se fosse jovem como eles.
A James Hetfield, John Paul Jones, Robert Plant, Jimmy Page, David Gilmour,
Roger Waters, Esperanza Spalding, Brian May e, in memorian, Freddy Mercury e Ch-
ris Cornell pelas músicas que tocavam ao fundo durante a produção do texto, ou nos
momentos de descanso entre parágrafos.
Aos muitos divulgadores e divulgadoras que despertaram o meu interesse pela
ciência nos anos 1990, luzes de razão que nos atuais tempos de obscurantismo crescente
se fazem talvez ainda mais necessárias.

5
Your father’s lightsaber. This is the weapon of a Jedi Knight. Not as clumsy
or random as a blaster. An elegant weapon, for a more civilized age.—Obi-Wan Kenobi, para Luke Skywalker, Uma Nova Esperança

6
RESUMO
As equações de Bloch ópticas descrevem a interação da matriz densidade com um campo
eletromagnético ao longo do tempo. Abordamos neste trabalho a solução dessas equações
para sistemas atômicos de dois e três níveis interagindo com um trem de pulsos de laser
ultracurtos. Utilizamos o método Runge-Kutta de 4a ordem para solução dos sistemas
de equações diferenciais para o problema. Adotamos parâmetros compatíveis com vapor
atômico de rubídio. Como o deslocamento Doppler é um efeito importante em um vapor
atômico, efetuamos a distribuição Maxwell-Boltzmann das velocidades. Para um perfil
Doppler adequado do vapor atômico de rubídio na temperatura ambiente a faixa de velo-
cidades calculadas vai de -600 a 600 m/s. Também estudamos um sistema de três níveis
do tipo Λ, variando a taxa de repetição do laser pulsado. A solução computacional destes
últimos dois casos se torna custosa e demorada para um programa sequencial comum, mas
tem uma natureza obviamente paralelizável. O uso de unidades de processamento gráfico
(GPUs) para problemas computacionais paralelizáveis tem se difundido nos últimos anos
nas mais diversas áreas da ciência, como por exemplo em problemas físicos envolvendo
simulações de Monte Carlo. Comparamos o desempenho das soluções das equações de
Bloch na forma tradicional sequencial e suas alternativas paralelas na plataforma CUDA,
com placas de vídeo nVidia. O uso dessa tecnologia aplicada a problemas físicos paraleli-
záveis pode significar ganhos de tempo da ordem de dezenas ou até centenas, dependendo
da natureza e do tamanho do problema.
Palavras-chave: equações de Bloch; transições em vapor atômico; paralelização na GPU

7
LISTA DE TABELAS
4.1 Configuração das camadas eletrônicas em átomos alcalinos. . . . . . . . . . 34
6.1 GPUs nVidia utilizadas nos testes. . . . . . . . . . . . . . . . . . . . . . . 58
6.2 Máquinas distintas e suas combinações CPUxGPU. . . . . . . . . . . . . . 58
6.3 Comparações CPUxGPU das máquinas em operação e o respectivo tama-
nho do array de velocidades a partir do qual o tempo de execução na GPU
é menor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
6.4 Fator de ganho de tempo da GPU em relação à CPU no cálculo dos dados
de variação da frequência. . . . . . . . . . . . . . . . . . . . . . . . . . . . 65

8
LISTA DE FIGURAS
2.1 Distribuição Maxwell-Boltzmann do isótopo 85Rb . . . . . . . . . . . . . . 22
2.2 Transição de dois fótons . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.3 Sistema atômico de três níveis com EIT . . . . . . . . . . . . . . . . . . . . 26
3.1 Campo elétrico para um trem de pulsos . . . . . . . . . . . . . . . . . . . . 30
3.2 Ilustração de um pulso com envoltória e largura de 100 fs. . . . . . . . . . 31
3.3 Transformada de Fourier do pulso. . . . . . . . . . . . . . . . . . . . . . . 31
4.1 Energia de ionização em função do número atômico Z . . . . . . . . . . . . 35
4.2 Estruturas fina e hiperfina do rubídio. . . . . . . . . . . . . . . . . . . . . . 37
4.3 Representação de um sistema atômico de três níveis do tipo Λ. . . . . . . . 41
4.4 Representação de um sistema atômico de três níveis tipo cascata. . . . . . 43
5.1 Estrutura simplificada de uma CPU . . . . . . . . . . . . . . . . . . . . . . 46
5.2 Estrutura simplificada de um cluster de computadores para processamento
paralelo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.3 Esquema simplificado de uma GPU atual, com hieraquia de memória dos
SMs e interface com a CPU. . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.4 Esquema simplificado da distribuição de blocos por multiprocessador de
uma GPU. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
6.1 População ρ22 em função do tempo, com variações de Ω0. Utilizados como
parâmetros γ22 = 2π × 5MHz, δ = 0, γ12 = γ22/2, valores realistas para a
transição 5S → 5P do rubídio. . . . . . . . . . . . . . . . . . . . . . . . . . 53
6.2 População ρ22 em função do tempo, com variações de δ . . . . . . . . . . . 54
6.3 Variação temporal das populações ρ22 e ρ33 . . . . . . . . . . . . . . . . . . 55
6.4 Distribuição das populações ρ22 e ρ33 por velocidade . . . . . . . . . . . . . 56
6.5 Comparativo entre tempos de execução na CPU e na GPU variando-se o
número de pulsos do laser . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
6.6 Evolução do tempo de execução variando-se o número de threads na GPU
e o número de iterações na CPU. . . . . . . . . . . . . . . . . . . . . . . . 60
6.7 Tempo de execução em função do número de threads executadas na GPU. . 61

9
6.8 Tempo de execução em função da proporção threads/bloco . . . . . . . . . 62
6.9 Tempo de execução em função do número threads para um bloco. . . . . . 62
6.10 Valores absolutos da diferença entre a solução da distribuição população
ρ22 entre a CPU e a GPU. . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
6.11 Tempo de execução em função do tamanho do array de velocidades para
i5 4460 e dois exemplos extremos: a placa de menor poder computacional
dos testes, GT210, e a superior GTX 760 Ti. . . . . . . . . . . . . . . . . . 64
6.12 Tempo de execução para o problema em cada hardware utilizado. . . . . . 66
6.13 População ρ33 e σ12 em função da variação da frequência de repetição . . . 67

10
CONTEÚDO
1 Introdução 17
2 Transições atômicas 21
2.1 Níveis de energia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.2 Interação com radiação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3 Taxas de transição e regras de seleção . . . . . . . . . . . . . . . . . . . . . 23
2.4 Interação com dois fótons . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.5 Transparência eletromagneticamente induzida . . . . . . . . . . . . . . . . 25
3 Lasers pulsados 27
3.1 Histórico do laser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2 Emissão estimulada, ganho de laser e inversão de população . . . . . . . . 27
3.3 Laser pulsado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3.1 Representação do campo elétrico . . . . . . . . . . . . . . . . . . . 29
4 Sistemas atômicos 33
4.1 Átomos alcalinos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.2 Estrutura fina e hiperfina . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.3 O átomo de rubídio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4 As equações de Bloch ópticas . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.5 Sistema de dois níveis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.6 Sistema de três níveis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.6.1 Tipo Λ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.6.2 Tipo cascata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5 Paralelismo em unidades de processamento gráfico 45
5.1 Programação serializada . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.1.1 Arquitetura da CPU . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.2 Programação paralela . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.3 Paralelismo em placas gráficas . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.3.1 Arquitetura da GPU . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.3.2 Programação paralela em CUDA-C . . . . . . . . . . . . . . . . . . 49

11
6 Resultados 53
6.1 Dinâmica de populações em átomos de três níveis em cascata . . . . . . . . 53
6.2 Solução na GPU para átomos de dois níveis . . . . . . . . . . . . . . . . . 57
6.2.1 Publicações e participações em eventos . . . . . . . . . . . . . . . . 64
6.3 Solução na GPU para átomos de três níveis do tipo Λ . . . . . . . . . . . . 64
7 Conclusões 69
Apêndice 1: Código fonte C de programa para solução das equações de
Bloch em um sistema atômico de três níveis 75
Apêndice 2: Código fonte C de programa que distribui as populações por
velocidade em um sistema atômico de três níveis 81
Apêndice 3: Código fonte C de programa para medições na CPU envol-
vendo a solução para sistemas de dois níveis 87
Apêndice 4: Código fonte CUDA-C de programa para medições na GPU
envolvendo a solução para sistemas de dois níveis 91
Apêndice 5: Banner apresentado no ENF 2016 96
Apêndice 6: Resumo da apresentação no ENF 2016 97
Apêndice 6: Resumo da apresentação para o grupo de pesquisa Estrutura
da Matéria e Física Computacional 99
Anexo 1: Aceitação ENF 2016 101
Anexo 2: Código fonte CUDA-C para a solução para sistemas de três níveis
tipo Λ na GPU 103
Anexo 3: Código fonte C++ para a solução para sistemas de três níveis
tipo Λ na CPU 113

12
1 INTRODUÇÃO
A interação dos átomos com radiação é um tema estudado desde o início do século
XX e os primórdios da Mecânica Quântica. O modelo atômico de Bohr já propunha níveis
quantizados de energia para o átomo de hidrogênio. Modelos mais elaborados com base
na equação de Schrödinger chegaram a resultados semelhantes, embora com as devidas
correções posteriores que não eram compatíveis com o modelo simples de Bohr [1, 2].
Os conceitos de emissão e absorção já eram propostos teoricamente por Einsten
desde a década de 1910. Sua aplicação prática nas décadas de 1950 e 1960 permitiu o
surgimento do laser, que ampliou ainda mais as possibilidades de estudo da interação dos
sistemas atômicos com campos eletromagnéticos, inclusive com efeitos coerentes. Os lasers
pulsados e sua alta potência de emissão contribuíram ainda mais com a área, especialmente
os lasers mode-locked com largura temporal dos pulsos da ordem de femtossegundos [3, 4].
A dinâmica de sistemas atômicos pode ser descrita pelo formalismo da matriz den-
sidade, aplicando o conceito de populações fracionárias nos diferentes estados de energia.
As equações de Bloch ópticas, um conjunto de equações diferenciais acopladas, descrevem
a evolução temporal dessas populações e dos demais elementos da matriz densidade, as
coerências entre os estados [5, 6].
Embora para alguns casos mais simples as equações de Bloch tenham solução
analítica, para outros a solução é numérica e trabalhosa. Para sistemas atômicos de dois
níveis as equações de Bloch consistem em um par de equações diferenciais acopladas. Já
para sistemas atômicos de três níveis o sistema tem seis equações diferenciais acopladas.
Abordamos ambos os casos de forma analítica e numérica neste trabalho.
A aplicação das equações de Bloch ópticas a grandes volumes de dados é de solução
numérica demorada, mesmo com uso de computadores pessoais e estações de trabalho
atuais, com processadores da geração mais recente. Conforme se discute à frente, esse
é um fator a se considerar na distruição Maxwell-Boltzmann das velocidades do vapor
atômico ou em uma ampla faixa variação de frequências incidentes.
Entretanto, cada item de tais volumes de dados considerados, sejam as velocida-
des individuais ou as frequências, são calculáveis de maneira independente. Esse fato
torna tais problemas paralelizáveis, e a aplicação de computação paralela passa a ser uma
escolha adequada para melhora do tempo de execução do programa usado para a solu-

13
ção. Soluções paralelas de processamento são alternativas de custo bastante inferior à
cara supercomputação desde os anos 1990, com os clusters e computação distribuída pela
Internet [7, 8].
Nos anos recentes, a programação de softwares para solução de problemas científi-
cos complexos tem utilizado o paralelismo em placas gráficas de vídeo (graphical processing
units - GPUs), quando aplicável. Tais dispositivos permitem ganhos significativos no de-
sempenho com um custo de aquisição e operação relativamente baixo [7, 9, 10].
Nesse contexto, tratamos neste trabalho a solução das equações de Bloch ópticads
para sistemas atômicos de dois e três níveis de um vapor atômico de rubídio em interação
com um laser de pulsos ultracurtos, utilizando a programação serializada tradicional e o
paralelismo na GPU, comparando os resultados quantitativamente, buscando estabelecer
cenários no qual a computação paralela na GPU se torna uma alternativa barata e eficiente
para problemas físicos paralelizáveis e que demandam alto desempenho ou tempo de
execução.
Iniciamos a discussão com a ambientação teórica do tema. No primeiro capítulo
apresentamos as transições atômicas e alguns efeitos relevantes da interação de átomos
com radiação. O segundo capítulo abrange um breve histórico e uma introdução ao laser
e ao laser pulsado, e a sua representação do campo elétrico.
No terceiro capítulo abordamos sistemas atômicos, especialmente átomos alcalinos,
a estrutura fina e hiperfina, o átomo de rubídio e a determinação das equações de Bloch
para sistemas atômicos de dois e três níveis do tipo cascata e do tipo Λ.
O quarto capítulo encerra a fundamentação teórica com uma breve explanação
sobre o paralelismo em GPUs e sua distinção em relação à programação serializada tra-
dicional, enquanto explana sobre as diferenças nas arquiteturas de cada modelo, antes de
demonstrar exemplos práticos de códigos equivalentes.
No quinto e último capítulo apresentamos os resultados obtidos para três diferentes
contextos, sempre com parâmetros compatíveis com vapor atômico do isótopo 85Rb em
interação com um trem de pulsos ultracurtos de laser.
Primeiramente, estudamos a dinâmica de populações para átomos de três e dois ní-
veis, com a solução numérica das equações de Bloch em cada caso, a distribuição Maxwell-
Boltzmann das velocidades no vapor atômico e a discussão dos efeitos ópticos e atômicos
envolvidos nos resultados, em conformidade com a literatura científica na área.

14
Em seguida, investigamos a solução em GPUs para a distribuição Maxwell-Boltzmann
de átomos de dois níveis, ao lado da solução serializada tradicional, com a comparação
temporal quantificada das duas soluções, visando a aplicação em problemas físicos para-
lelizáveis.
Por último, obtemos a solução na GPU de um sistema atômico de três níveis do tipo
Λ com transparência eletromagneticamente induzida, uma extensão do problema anterior
para uma situação física mais realista em um tópico de estudo mais recente.

15
2 TRANSIÇÕES ATÔMICAS
2.1 NÍVEIS DE ENERGIA
O modelo atômico de Bohr já previa que o átomo possui níveis quantizados de
energia. Como nesse modelo o elétron orbita o núcleo como em um sistema planetário
de miniatura, Bohr assumiu que apenas certas órbitas eram permitidas. O elétron assim
saltaria de uma órbita permitida para outra, apenas assim perdendo energia, emitindo
essa energia correspondente como luz em um comprimento de onda específico [6]. Os
níveis de energia do hidrogênio no modelo de Bohr são dados por sua conhecida fórmula
En =mee
4
8n2h2ε20
(2.1)
ondeme é a massa do elétron, n o chamado número quântico principal, ε0 a permissividade
do vácuo, e a carga elétrica elementar e h a constante de Planck.
O resultado de Bohr é equivalente ao da solução da equação de Schrödinger inde-
pendente do tempo para átomos de um elétron, descontadas correções como da estrutura
fina, estrutura hiperfina, efeito Zeeman e do spin do elétron [2].
2.2 INTERAÇÃO COM RADIAÇÃO
Os três processos a se considerar na interação de átomos com radiação, conside-
rando apenas transições de um fóton, são de interesse direto para este trabalho:
1. um átomo pode sair de um estado excitado para um estado de menor energia emi-
tindo um fóton, na chamada emissão espontânea;
2. um átomo pode absover um fóton e fazer a transição de um estado de menor para
um estado de maior energia, a chamada absorção;
3. átomos podem emitir fótons sob a influência de radiação, na chamada emissão esti-
mulada [2].

16
Para este trabalho, e como a abordagem usual da área, tratamos o campo de
radiação classicamente, e o sistema atômico quanticamente, já que a densidade de fó-
tons mesmo em um campo relativamente fraco pode ser aproximada como uma variável
contínua, descrita pela eletrodinâmica clássica. Essa abordagem também é chamada de
semiclássica [2, 6].
Entretanto, o vapor atômico contido em um recipiente contém, no mínimo, energia
térmica a ser considerada na interação com radiação. Tendo em vista a velocidade do
movimento dos átomos que compõe o vapor se faz necessário aplicar o efeito Doppler no
fenômeno. Se em um referencial estacionário o átomo absorve radiação na frequência ω0,
um átomo com velocidade v absorve energia quando δ = ωc − ω0 = kv. A fração de
átomos no intervalo de velocidades entre v e dv é
f(v)dv =
√M
2πkBTexp
(−Mv2
2kBT
)dv (2.2)
para um átomo de massa M na temperatura T [6]. kB é a constante de Boltzmann. Na
Figura 2.1, temos a fração de átomos em função da distribuição das velocidades para o
átomo de rubídio.
Figura 2.1: Distribuição Maxwell-Boltzmann do isótopo 85Rbpara T = 300K. O eixo vertical representa a fração de átomospara cada velocidade

17
2.3 TAXAS DE TRANSIÇÃO E REGRAS DE SELEÇÃO
Tanto para a emissão espontânea quanto para a absorção descritas na seção ante-
rior, o fóton emitido ou absorvido tem uma frequência angular ω, que pela conservação
de energia satisfaz a relação
~ω = Ej − Ei (2.3)
onde Ej é a energia do estado superior, e Ei a energia do estado menos energético [12].
O Hamiltoniano dependente do tempo que descreve a perturbação para uma interação de
dipolo elétrico com um campo ~E(t) é
H ′ = −e~r · ~E(t) (2.4)
sendo −e~r o operador de dipolo elétrico do átomo que, no caso, é representado apenas
pelo elétron que reage à interação [6, 12].
Pela regra de ouro de Fermi, a taxa de transição Wij entre os estados i e j é
proporcional ao quadrado do elemento de matriz Mij da perturbação, ou seja,
Wij =2π
~|Mij|2g(~ω), (2.5)
onde g(~ω) é a densidade de estados, isto é, o número de estados na faixa de energias de
E a E + dE. A definição do elemento de matriz é
Mij = 〈j| H ′ |i〉 . (2.6)
Considerando que a amplitude E0 do campo elétrico ~E(t) é constante no átomo
dado o pequeno tamanho do átomo em relação ao comprimento de onda da luz incidente,
e definindo o momento de dipolo elétrico µij como
µij = −e 〈j| r |i〉 , (2.7)
sendo r a componente de ~r na direção de ~E, podemos escrever concisamente o elemento
de matriz como
Mij = µijE0. (2.8)
O elemento de matriz acima leva às regras de seleção. Por tais regras, se os

18
estados não as satisfazem, a taxa de transição de dipolo elétrico será zero, e a transição
é chamada de transição proibida. Caso a transição obedeça às regras de seleção se trata
de uma transição permitida.
2.4 INTERAÇÃO COM DOIS FÓTONS
Supondo um sistema de dois níveis de energia, E1 o estado fundamental e E2 o
estado excitado, em interação com um fóton de energia
~ω =1
2(E2 − E1), (2.9)
fica evidente que tal fóton não leva à transição entre os estados. Entretanto, se dois fótons
com a mesma energia ~ω interagem com o mesmo sistema, a transição para E2 se torna
possível, desde que as regras de seleção sejam obedecidas [13].
Em outro caso possível, dois fótons de frequências diferentes, ω1 e ω2, interagem
simultaneamente com o sistema, são absorvidos e promovem a transição, ressonante em
ω1 + ω2 [14].
Ambos os casos são retratados na Figura 2.2, e envolvem a definição de um estado
virtual entre o estado fundamental e |1〉 e o estado excitado |2〉. Entretanto, tal estado
virtual não é um estado intermediário real.
Tais interações múltiplas não se limitam a dois fótons, existindo ainda interações
multifóton para três fótons ou mesmo para n fótons [15]. Para este trabalho, nos limitamos
à discussão dos casos de um e dois fótons.
Para a amplitude de probabilidade da absorção de um ou dois fótons, primeiros
definimos a frequência de Rabi [6]
Ω =µijE
~(2.10)
onde µij é o momento de dipolo da transição, mencionado na seção anterior. Assim, a
probabilidade da transição por absorção de um fóton é [15]
p1 = 2π~Ω2tg(ω) (2.11)
onde g(ω) é a densidade de estados. A probabilidade cresce linearmente com o tempo.

19
Figura 2.2: Transição do estado fundamental |1〉 para oestado excitado |2〉 após interação com dois fótons no casoa) de dois fótons de mesma frequência e b) em frequênciasdiferentes. O tracejado representa o estado virtual.
Para o caso de dois fótons,
p2 = (2π~)2Ω21Ω2
2tg(ω), (2.12)
sendo Ωi a frequência de Rabi para cada um dos campos incidentes. Para o caso de fótons
iguais, p2 ∝ Ω4 . O fator de divisão ~4 para a absorção de dois fótons mostra que tal
ocorrência é muito mais improvável que a absorção de um único fóton.
2.5 TRANSPARÊNCIA ELETROMAGNETICAMENTE INDUZIDA
A transparência eletromagneticamente induzida (electromagnetically induced trans-
parency - EIT) foi observada inicialmente por Boller et al (1991). Trata-se de um fenômeno
em que um meio opticamente opaco passa a ser transparente para a radiação na frequência
de ressonância [16].
A EIT já foi observada em sistemas atômicos e sólidos [15]. A situação ideal para
observação do fenômeno ocorre em um sistema atômico de três níveis [17, 18, 19]. Sistemas
atômicos dessa espécie são discutidos na seção 4.6, e resultados de cálculos envolvendo
EIT são discutidos na seção 6.3.
O efeito é melhor observado no caso original estudado por Boller. Nessa confi-

20
guração, um sistema atômico de três níveis, |1〉, |2〉 e |3〉 está sob ação de dois campos.
O primeiro, de frequência ω, está acoplado à transição |1〉 −→ |3〉. O segundo campo
coerente, de frequênciaω′ e mais intenso, é acoplado à transição |2〉 −→ |3〉.Nessa configuração, apresentada na Figura 2.3, e sob condições adequadas, o meio
se torna transparente para o campo de frequência ω, não havendo mais absorção [15, 16,
17, 18].
Figura 2.3: Sistema atômico de três níveis sob ação dedois campos eletromagnéticos em uma típica situação emque EIT é observada.
A EIT produzida por um trem de pulsos foi observada experimentalmente por Sau-
tenkov et al (2005), conforme previsto teoricamente [20]. Lasers pulsados são discutidos
na seção 3.2.
Estudos mais recentes mostram que na EIT produzida por um trem de pulsos as
ressonâncias para a transição de um fóton e dois fótons ocorrem simultaneamente [21].

21
3 LASERS PULSADOS
3.1 HISTÓRICO DO LASER
O termo laser é um acrônimo em inglês para amplificação da luz por emissão estimu-
lada de radiação, sendo originário do termo mais antigo maser, que significa amplificação
de micro-ondas por emissão estimulada de radiação. O maser foi proposto em 1954 por
Basov e Prokhorov e no mesmo ano por Townes. O conceito de maser é consequência da
ideia da emissão estimulada proposta por Einstein cerca de quarenta anos antes [3, 4].
O princípio do maser derivou sua versão óptica, conhecida no final dos anos 1950
como maser óptico, após o trabalho de Schawlow e Townes em 1958. Posteriormente, o
termo laser se popularizou em substituição [3].
A principal diferença entre o laser e a luz comum, característica que sua radiação
compartilha com as micro-ondas, em coesão com sua origem no maser, é que a luz dos
lasers é coerente, estando todos os fótons emitidos por seu mecanismo exatamente na
mesma fase [4, 22].
Outra propriedade importante de quase todos os lasers é a colimação, que garante
que a luz do laser fique confinada a um feixe estreito por longas distâncias, e deriva dire-
tamente do processo de construção do mecanismo do laser, que envolve diversas reflexões
e saída do mecanismo pela extremidade do tubo. Apenas fótons alinhados com o eixo do
tubo conseguem sair, já que fótons ligeiramente desalinhados colidem com as paredes do
tubo e não compoem o feixe [4].
3.2 EMISSÃO ESTIMULADA, GANHO DE LASER E INVERSÃO DE POPULAÇÃO
Se um fóton é emitido para o interior de uma cavidade contendo átomos no estado
fundamental, ele pode ser absorvido por um átomo, excitando-o para um estado de energia
mais alto. Caso encontre algum átomo já em um estado excitado de energia, sendo esse
fóton de um comprimento de onda determinado e correto, ele pode estimular o átomo a
emitir um fóton de mesmo comprimento de onda e fase, no mesmo sentido. Assim, essa

22
radiação amplificada é coerente e monocromática [4].
O ganho de laser é a medida do quão bem um meio amplifica os fótons pelo
processo descrito de emissão estimulada. Se um feixe de fótons viaja por um tubo em
uma densidade que permita serem descritos como uma onda eletromagnética, a onda
é amplificada se as emissões estimuladas superam as emissões espontâneas e as perdas
devido à saída do feixe emitido [4].
A energia do sistema de átomos obedece à aproximação clássica da distribuição de
Boltzmann, em caso de equilíbrio térmico, sendo o estado fundamental mais populoso que
os estados excitados. Entretanto, é possível bombear energia para o sistema e provocar
uma situação de desequilíbrio que viola a distruibuição, no processo chamado inversão de
população, onde um estado excitado se torna mais populoso que o estado fundamental
[3, 11].
Como um estado de não equilíbrio, as inversões de população não duram um pe-
ríodo prolongado [11]. Esse processo é necessário para o funcionamento da grande maioria
dos lasers [4].
3.3 LASER PULSADO
Lasers de onda contínua (cw, de continuous-wave) possuem um fluxo constante de
energia, enquanto lasers pulsados comprimem a saída de energia em pequenos picos, que
funcionam como pacotes espaçados de energia. A melhora desejada é na potência de pico.
Por exemplo, se 1W de saída de um laser cw for dividido em dez pulsos de 20ns cada,
a potência do pico pode ser maior que a potência média na ordem de 106, permitindo
aplicações impossíveis para um laser cw, com o mesmo gasto energético [11].
Há uma série de métodos para se produzir um laser pulsado. O mais simples
consiste no chamado Q-switching (ou chaveamento-Q), que funciona por armazenamento
de energia através de inversão de poupulação até um nível em que a energia é liberada
em um pulso único e de alta energia [11].
Há vários tipos de chaveadores-Q, e um particularmente é o do tipo E-O, que usa
um cristal eletro-óptico, chamado célula Pockels, que polariza a luz com uma diferença
de 90o dependendo da voltagem aplicada [11].

23
Em uma adaptação do Q-switching o método de cavity dumping também permite
produzir um laser pulsado, com o uso combinado de um chaveador E-O, pois a alternância
da polarização da luz permite que o laser produza um pulso de alta energia e depois cesse
até novo estímulo [4].
Contudo, para produção dos pulsos ultracurtos abordados nesta monografia a téc-
nica utilizada é o modelocking, que, no domínio do tempo, consiste em um pulso curto
refletido continuamente por espelhos na cavidade. Cada vez que o pulso encontra o espe-
lho parcialmente transmissor um pulso é gerado. A energia é compactada no pulso por
um modulador que pode ser, por exemplo, um chaveador E-O que "abre"uma vez a cada
viagem completa [4, 11].
No domínio da frequência, os diferentes modos longitudinais do laser com suas
pequenas diferenças de frequência oscilam em fase na cavidade do laser. No laser mode-
locked, os modos têm suas fases relativamente associadas e travadas (locked), formando
um pulso que viaja pela cavidade, com pico de energia no ponto onde todos os modos
interferem construtivamente, pois todos os modos recebem a mesma amplificação com a
abertura do chaveamento [4].
3.3.1 Representação do campo elétrico
Uma discussão completa do cálculo do campo elétrico complexo do trem de pul-
sos ultracurtos se encontra em Diels e Rudolph (2006) [23]. Para representar os pulsos
ultracurtos a intervalos constantes, temos que E(t) é dado por [24]
E(t) =N−1∑
n=0
E0(t− nTR)e−i(ωct−nωcTR+n∆φ) (3.1)
onde E0 é uma função que representa a envoltória do pulso, N é a quantidade de pulsos,
ωc é a frequência da onda e ∆φ a diferença de fase pulso-a-pulso. A Figura 3.1 mostra
uma representação gráfica do trem de pulsos com uma escolha arbitrária de parâmetros
para melhor visualização. No problema real em análise, os pulsos têm duração da ordem
de 10−13s, enquanto o tempo entre os pulsos dura 10−8s, o que torna pouco prática a
visualização gráfica trem de pulsos.
Para uma representação realista de E0(t) nos cálculos, podemos representar o pulso

24
Figura 3.1: Representação do campo elétrico para um trem de pulsos. A curva vermelhaé a envoltória dos pulsos.
como uma curva secante hiperbólica na seguinte forma [23]
E0(t) = E0sech
(1,76t
Tp
), (3.2)
onde E0 é a amplitude do campo, Tp é a largura temporal do pulso e a constante 1,76
é uma escolha conveniente para a forma do pulso. Utilizamos essa representação nos
cálculos deste trabalho.
A Figura 3.2 mostra ilustrativamente um pulso de largura temporal 100 fs e a
Figura 3.3 sua transformada de Fourier. O pulso, no domínio da frequência, tem largura
de 5 THz.

25
Figura 3.2: Ilustração de um pulso com envoltória e largura de100 fs.
Figura 3.3: Transformada de Fourier do pulso.

26
4 SISTEMAS ATÔMICOS
No início do século XX já estava estabelecido que o átomo continha elétrons, que
eram em si muito mais leves que o átomo, e que átomos podiam ganhar ou perder elétrons,
afetando a sua carga. Após experimentos de Geiger, Marsden e Rutherford, este último
propôs em 1911 um modelo onde quase toda a massa do átomo estava concentrada em
um pequeno e denso núcleo [2].
Também já era amplamente sabido que qualquer elemento emitia um espectro
luminoso característico, e também que tal espectro era composto por linhas discretas
de emissão, e que os elementos também tinham linhas definidas de absorção. As linhas
de emissão do espectro do hidrogênio eram notórias, organizadas em séries regulares em
várias faixas do espectro eletromagnético [1, 2, 6].
O modelo de Bohr para o átomo de hidrogênio, proposto em 1913, que expandia a
ideia de Rutherford de elétrons orbitando o núcleo como um minúsculo sistema planetário
para um cenário em que apenas algumas órbitas eram permitidas, efetivamente quantizou
níveis de energia e deu conta do espectro discreto do hidrogênio [6].
Embora o modelo orbital fosse útil para explicar as linhas de emissão e absorção
do hidrogênio e alguns outros efeitos naturais [2], mesmo após correções relativísticas de
Sommerfeld a ideia foi superada pelas funções de onda e pelas soluções da equação de
Schrödinger, que ainda permitiu eliminar as distorções do modelo de Bohr-Sommerfeld
para átomos com mais de um elétron [6].
4.1 ÁTOMOS ALCALINOS
Os elétrons de um átomo no estado fundamental se distribuem de uma forma
que minimiza a energia do sistema, não se agrupando todos na camada mais baixa onde
n = 1 devido ao princípio da exclusão de Pauli, que restringe o número de elétrons em
uma dada camada ao estabelecer que dois elétrons não podem ter o mesmo conjunto de
números quânticos. De forma equivalente, podemos dizer que os elétrons se disttribuem
nas camadas obedecendo à distribuição de Fermi-Dirac, uma vez que são férmions, isto é,
partículas de spin semi inteiro [6].

27
Assim, elétrons preenchem as camadas progressivamente conforme o número atô-
mico Z cresce, sendo que para Z = 2, 10, 18, 36... as camadas são completas, formando
os chamados gases nobres (He, Ne, Ar, Kr, ...). Os átomos alcalinos (Li, Na, K, Rb,
...) consistem em um átomo de gás nobre como núcleo mais um elétron na camada mais
externa.
Tabela 4.1: Configuração das camadas eletrônicas emátomos alcalinos.
Elemento Distribuição de elétronsLítio 1s22sSódio 1s22s2p63sPotássio 1s22s2p63s23p64sRubídio 1s22s2p63s23p63d104s24p65sCésio 1s22s2p63s23p63d104s24p64d105s25p66s
Nesse caso, como se vê na Tabela 4.1, o elétron da camada mais externa para
átomos alcalinos mais pesados não está necessariamente na camada subsequente. Podemos
observar tal fato a partir do potássio, onde a camada 4s é preenchida antes da 3d. Isso
se deve aos efeitos de penetração, isto é, o quanto a camada externa "enxerga"a carga
nuclear no núcleo atômico, e blindagem, mais efetiva nas camadas nd que nas camadas
ns, conforme a expressão [2, 6]
E(n, l) = −hc R∞(n− δl)2
, (4.1)
que é uma versão da fórmula correspondente do modelo atômico de Bohr que funciona
especialmente bem para os níveis de energia dos átomos alcalinos. Na expressão, R∞ é a
constante de Rydberg e l o número quântico secundário. O termo δl é chamado defeito
quântico, e é maior para a camada s que para a camada d, levando ao efeito discutido [6].
Átomos alcalinos são de especial interesse por sua energia de ionização. Esta
atinge máximos nos átomos de gases nobres, e mínimos nos átomos alcalinos, conforme
visto na Figura 4.1. Além disso, os estados excitados dos alcalinos podem ser expressos
integralmente pela descrição de seu elétron mais externo, o que torna particularmente
simples a sua análise de espectro óptico em termo de seus estados excitados [1, 2].

28
Figura 4.1: Energia de ionização em função do número atômico Z. Comdados da Tabela Periódica dos Elementos, baseado na figura de Bransdene Joachain [2, p. 305].
4.2 ESTRUTURA FINA E HIPERFINA
A estrutura fina surge de efeitos relativísticos que levam a pequenas divisões nos
níveis de energia do átomo. O método mais comum para cálculo da estrutura fina é
utilizando a teoria de perturbações, o que requer o conceito de spin do elétron e o da
interação spin-órbita [2, 6].
Para a determinação da estrutura fina, iniciamos pela definição do momento an-
gular eletrônico total ~J , que é a soma entre o momento angular orbital ~L e o spin ~S
[6, 12]~J = ~L+ ~S. (4.2)
Para cada configuração eletrônica dos elétrons de valência há uma série de estados
definidos por L, S e J . Os estados LS são chamados termos atômicos, e uma combinação
de J e seus diferentes termos relativos a L e S são chamados níveis, e permitem definir a
notação espectroscópica [12]:
|L, S, J〉 ≡(2S+1) Lj (4.3)
Da Equação 4.2 podemos fazer
~J2 = (~L+ ~S)2
~J2 = ~L2 + 2〈~L · ~S〉+ ~S2
〈~L · ~S〉 =1
2〈 ~J2 − ~L2 − ~S2〉

29
〈~L · ~S〉 |LSJ〉 =~2
2[J(J + 1)− L(L+ 1)− S(S + 1)] |LSJ〉 (4.5)
Como o Hamiltoniano da interação spin-órbita é dado por [12]
Hso = α~L · ~S (4.6)
onde α é uma constante, e a variação de energia devido à interação spin-órbita é o valor
esperado desse Hamiltoniano, em conjunto com a Equação 4.5 tem-se que
Eso = β[J(J + 1)− L(L+ 1)− S(S + 1)] (4.7)
onde β é uma constante. Essa equação indica que para diferentes termos J obtidos pelos
mesmos valores de L e S têm diferentes energias.
Para a estrutura hiperfina se considera o efeito do momento angular total do átomo~F , dado por
~F = ~J + ~I (4.8)
onde ~I é o spin nuclear. O Hamiltoniano da estrutura hiperfina é dado por [6]
HEHF = A~J · ~I (4.9)
onde A é o coeficiente A de Einstein. Logo, variação de energia da estrutura hiperfina é
EEHF = A〈 ~J · ~I〉. (4.10)
Seguindo um procedimento similar ao que conduziu à Equação 4.5 para o termo 〈 ~J · ~I〉,
EEHF = A~2
2[(F + 1)− J(J + 1)− I(I + 1)] (4.11)
A Figura 4.2 apresenta as estruturas fina e hiperfina do rubídio, elemento utilizado
nesta monografia. Para átomos alcalinos, as transições hiperfinas n2S1/2 → n2P1/2 são
as transições D1 e n2S1/2 → n2P3/2 são as transições D2. A absorção e emissão nas
proximidades dessas chamadas linhas D é de interesse especial em espectroscopia e em
física atômica [25].

30
Figura 4.2: Estruturas fina e hiperfina do rubídio.
4.3 O ÁTOMO DE RUBÍDIO
As soluções e dados neste trabalho são compatíveis com vapor atômico de rubídio
(Rb). O Rb é um metal alcalino altamente reativo que ocorre naturalmente em uma
mistura do isótopo 85Rb com o levemente radioativo 87Rb, em minerais de onde também
se extrai outros metais alcalinos como o césio. O 85Rb é o único isótopo estável do
rubídio, o mais abundante naturalmente e cujos parâmetros foram considerados. Possui
37 elétrons, apenas um na última camada, uma massa atômica de 84,911789738u e spin
nuclear 5/2 [26].
Metais alcalinos como o rubídio são muito usados em estudos envolvendo espec-
troscopia por motivos que os tornam uma escolha bastante óbvia na área: o espectro
de absorção é simples, bastante estudado, bem definido e conhecido. Além disso, sua
estrutura simples, com apenas um elétron de valência, permite uma modelagem teórica
detalhada [27].
As linhas D são facilmente alcançáveis na região do infravermelho por lasers de
Ti:safira, cujos parâmetros são adotados nos cálculos adiante [28].

31
4.4 AS EQUAÇÕES DE BLOCH ÓPTICAS
Para um átomo interagindo com um campo eletromagnético se assume que o Ha-
miltoniano tem a forma
H = H0 + V (t) (4.12)
onde H0 é o Hamiltoniano do átomo livre e V (t) é a energia da interação do átomo com
o campo, dada no caso pela aproximação de dipolo elétrico V (t) = −µE(t), considerando
apenas a componente na direção do campo. Logo, o Hamiltoniano se torna
H =N∑
k=1
~ωk |k〉 〈k| − µE(t) (4.13)
sendo ~ωk a energia do estado quântico representado por k. Para a Equação 4.13 usamos
a definição do Hamiltoniano do átomo livre H0 [29]. Assim, adotamos como base os
autoestados de H0, que são bem conhecidos pela solução da equação de Schrödinger.
A matriz densidade se compõe das populações fracionárias dos estados atômicos,
e sua evolução temporal é dada pela equação de Liouville-Neumann [5].
∂ρ
∂t= − i
~[H, ρ] (4.14)
onde ρ é o operador matriz densidade e H é o Hamiltoniano total do sistema. É necessário
considerar ainda na Equação 4.14 os fenomenológicos termos de relaxação dos estados
excitados [15, 29, 30], que chamaremos γij. Assim, a Equação 4.14 para um dado elemento
ij da matriz densidade se torna
ρij = − i~
[H, ρ]ij − γijρij (4.15)
4.5 SISTEMA DE DOIS NÍVEIS
A matriz densidade ρ para um sistema de dois níveis é dada por [6]
ρ = |α〉 〈α| =
c1
c2
[c∗1 c∗2] =
|c1|2 c1c
∗2
c2c∗1 |c2|2
=
ρ11 ρ12
ρ21 ρ22
(4.16)

32
onde ρii são as chamadas populações fracionárias [5, 6], ρij para i 6= j as coerências
representativas da resposta do sistema a uma dada frequência [6] e ck é a amplitude da
função de onda do estado k [12].
Para calcular os elementos ρij da matriz densidade, parte-se da Equação 4.15,
omitindo-se a princípio o termo de relaxação por simplicidade. Assim, por exemplo, para
termo ρ11,
∂
∂t〈1| ρ |1〉 = − i
~〈1| [H, ρ] |1〉
ρ11 = − i~〈1| Hρ− ρH |1〉
ρ11 = − i~
(〈1| Hρ |1〉 − 〈1| ρH |1〉
)
ρ11 = − i~
2∑
k=1
(〈1| H |k〉 〈k| ρ |1〉 − 〈1| ρ |k〉 〈k| H |1〉
)
ρ11 = − i~
2∑
k=1
(〈1| ~ωk |k〉 〈k| − µE |k〉 〈k| ρ |1〉 − 〈1| ρ |k〉 〈k| ~ωk |k〉 〈k| − µE |k〉 |1〉) .
Como µij é o momento de dipolo elétrico da transição |i〉 −→ |j〉, na forma matricial
escrevemos
µ.=
0 µ12
µ12 0
(4.18)
e ρ11 se torna
ρ11 = − i~
(~ω1ρ11 − µ12Eρ21 − ~ω1ρ11 + µ21Eρ13) (4.19a)
ρ11 = iµ12E
~ρ21 − i
µ21E
~ρ12. (4.19b)
A frequência de Rabi Ωij é dada por [6, 30]
Ωij =µijE
~. (4.20)
Portanto, o elemento da matriz densidade ρ11 para um sistema atômico de dois níveis é
dado por
ρ11 = iΩ21ρ21 + c.c.+ γ22ρ22 (4.21)
ao incluirmos novamente o termo de relaxação. O cálculo dos elementos restantes das

33
matriz densidade é semelhante, e pode ser generalizado para os demais termos:
ρ11 = iΩ21(t)ρ21 + c.c.+ γ22ρ22 (4.22a)
ρ22 = iΩ12(t)ρ12 + c.c.− γ22ρ22 (4.22b)
ρ12 = [i(ω2 − ω1)− γ12]ρ12 − iΩ12(t)(1− 2ρ22) (4.22c)
Para simplificar essa representação, utilizamos os seguintes fatos. Uma das pro-
priedades da matriz densidade é que Tr(ρ) = 1 [5], isto é, para um sistema de dois níveis
ρ11 + ρ22 = 1. Também, ρij = ρ∗ji e Ω12 = Ω∗21 ≡ Ω. Definimos ainda ωj − ωi = ωji e
ω21 − ωc = δ, a dessintonia do campo com respeito à ressonância atômica.
Em adição, definimos a variável σij, aplicando a aproximação de onda girante em
extensão ao formalismo da matriz densidade:
σij = ρije−iωct (4.23)
em uma alteração que não afeta as populações fracionárias (quando i = j), mas altera a
representação das coerências [6, 31].
Desta forma, obtemos as equações de Bloch ópticas para um sistema atômico de
dois níveis.
ρ22 = iΩ0(t)σ12 + c.c.− γ22ρ22 (4.24a)
σ12 = (iδ − γ12)σ12 + iΩ0(t)(2ρ22 − 1) (4.24b)
Neste trabalho os cálculos envolvendo sistemas atômicos de dois níveis utilizam as
Equações 4.24.

34
4.6 SISTEMA DE TRÊS NÍVEIS
As equações de Bloch para um sistema atômico de três níveis se definem pelo mesmo
método da seção anterior, com as mesmas definições e aproximações, quando aplicáveis.
O operador de dipolo elétrico µ assume a forma
µ.=
0 µ12 µ13
µ21 0 µ23
µ31 µ32 0
(4.25)
Entretanto, consideramos neste trabalho dois tipos de sistemas atômicos de três
níveis, o tipo Λ e o tipo cascata, discutidos a seguir.
4.6.1 Tipo Λ
Uma representação do sistema tipo Λ é mostrada na Figura 4.3. O estado |3〉 é o
de maior energia. Há duas frequências, ω1 e ω2, para as transições entre |1〉 e |3〉 e entre
|2〉 e |3〉. A transição entre |1〉 e |2〉 é proibida por dipolo elétrico [32].
Figura 4.3: Representação de um sistemaatômico de três níveis do tipo Λ.
Após cálculos semelhantes ao realizado para um sistema de dois níveis, temos as
seguintes equações para os termos da matriz densidade de um sistema de três níveis do

35
tipo Λ.
ρ11 = iΩ31(t)ρ31 + c.c.− γ11ρ33 (4.26a)
ρ22 = iΩ23(t)ρ32 + c.c.− γ22ρ33 (4.26b)
ρ22 = (iΩ31(t)ρ13 + c.c.) + (iΩ32(t)ρ23 + c.c.)− γ33ρ33 (4.26c)
ρ12 = (iω21 − γ12)ρ12 + iΩ13ρ32 − iΩ32ρ13 (4.26d)
ρ13 = (iω31 − γ13)ρ13 + iΩ13(ρ33 − ρ11)− iΩ23ρ12 (4.26e)
ρ23 = (iω32 − γ23)ρ23 + iΩ13(ρ33 − ρ22)− iΩ13ρ21 (4.26f)
Consideramos iguais as frequências de Rabi das duas transições, isto é, Ω31(t) =
Ω23(t) ≡ Ω(t). As taxas de relaxação do estado excitado |3〉 para os estados fundamentais
|1〉 e |2〉 também são tratadas como iguais e γ13 = γ23 ≡ γ, e γ33 = 2γ. Como a transição
|1〉 −→ |2〉 é proibida, γ12 = 0.
Usando as aproximações para os termos σij, adotamos a seguinte notação
ρ12 = σ12ei(ω1−ω2)t
ρ13 = σ13eiωct)
ρ23 = σ23eiωct)
δk = ω3k − ωk
e chegamos às equações de Bloch para um sistema de três níveis Λ adotadas nos cálculos
deste trabalho.
ρ11 = −iΩ(t)σ13 + c.c.− γρ33 (4.28a)
ρ22 = −iΩ(t)σ23 + c.c.− γρ33 (4.28b)
ρ22 = (iΩ(t)σ13 + c.c.) + (iΩ(t)σ23 + c.c.)− 2γρ33 (4.28c)
σ12 = i(δ2 − δ1)σ12 − iΩ(t)σ23 − iΩ(t)σ13 (4.28d)
σ13 = (iδ1 − γ)σ13 + iΩ(t)(ρ33 − ρ11 − σ12) (4.28e)
σ23 = (iδ2 − γ)σ23 + iΩ(t)(ρ33 − ρ22 + σ12) (4.28f)

36
4.6.2 Tipo cascata
Se um dos três estados tem uma energia intermediária entre os outros dois, a
configuração é chamada sistema em cascata, ou escada. Na Figura 4.4 apresentamos um
sistema com essa estrutura, sendo |2〉 o estado intermediário [32].
Figura 4.4: Represen-tação de um sistema atô-mico de três níveis tipocascata.
Os termos da matriz densidade são assim dados por
ρ11 = −iΩ21(t)ρ12 + c.c.+ γ22ρ22 (4.29a)
ρ21 = iΩ21(t)ρ12 − iΩ32(t)ρ23 + c.c.− γ22ρ22 + γ33ρ33 (4.29b)
ρ33 = iΩ32(t)ρ23 + c.c.− γ33ρ33 (4.29c)
ρ12 = (iω21 − γ12)ρ12 − iΩ32(t)ρ13 + iΩ12(t)(ρ22 − ρ11) (4.29d)
ρ23 = (iω32 − γ23)ρ23 − iΩ21(t)ρ13 + iΩ32(t)(ρ33 − ρ22) (4.29e)
ρ13 = i(ω31 − γ13)ρ13 − iΩ023(t)ρ12 + iΩ12(t)ρ23. (4.29f)
Por procedimentos similares aos casos anteriores, chegamos às equações de Bloch

37
para o caso, dadas por
ρ11 = −iΩ21(t)σ12 + c.c.+ γ22ρ22 (4.30a)
ρ21 = iΩ21(t)σ12 − iΩ32(t)σ23 + c.c.− γ22ρ22 + γ33ρ33 (4.30b)
ρ33 = iΩ32(t)σ23 + c.c.− γ33ρ33 (4.30c)
σ12 = [i(δ12 −∆12)− γ12]σ12 − iΩ32(t)σ13 + iΩ12(t)(ρ22 − ρ11) (4.30d)
σ23 = [i(δ23 −∆23)− γ23)]σ23 − iΩ21(t)σ13 + iΩ32(t)(ρ33 − ρ22) (4.30e)
σ13 = [i(δ12 + δ23 −∆12 −∆23)− γ13]σ13 − iΩ023(t)σ12 + iΩ0
12(t)σ23 (4.30f)
sendo δij a dessintonia do campo e ∆ij o deslocamento Doppler para a transição i −→ j.
∆ij é dado por
∆ = kv (4.31)
sendo v a velocidade de um grupo de átomos e k o número de onda, dado por k = 2π/λ,
onde λ é o comprimento de onda do laser.

38
5 PARALELISMO EM UNIDADES DE PROCESSAMENTO GRÁFICO
A popularização dos computadores pessoais para uso cotidiano nos ambientes do-
mésticos ou de trabalho se deu através de microcomputadores, máquinas baseadas no
funcionamento de um microprocessador único chamado unidade central de processamento
(do inglês central processing unit, CPU) [33].
Em paralelo, embora com muitos pontos de contato e evolução compartilhada,
se desenvolve o campo da supercomputação, que visa resolver problemas que demandam
alto poder computacional através dos chamados supercomputadores. Ainda com o mesmo
propósito, mas aproveitando máquinas de arquiteturas diversas interligadas por redes de
computadores, tem-se a computação multinó, cujo principal exemplo é o cluster [7].
A tendência atual da computação de alto desempenho é pelo processamento para-
lelo. Mesmo as CPUs atuais para uso doméstico seguem evoluindo em número de núcleos
paralelos. Como desenvolvimento relativamente recente, há o uso de placas gráficas como
alternativa para computação paralela. Um dos principais motivos é a barreira dos 4 GHz
de frequência de processamento para núcleos de CPU, um limite onde a tecnologia atual
produz muito calor e consome muita energia, tornando a solução cara pelos custos de
resfriamento e de eletricidade [7].
5.1 PROGRAMAÇÃO SERIALIZADA
A maioria das CPUs atuais segue a arquitetura de von Neumann, e executa pro-
gramas através do ciclo de máquina que envolve buscar instruções na memória principal,
interpretá-las e executá-las [7, 34]. Trata-se de um processo simples, mas cada núcleo de
CPU só pode lidar com um ciclo de máquina por vez.
5.1.1 Arquitetura da CPU
A CPU busca suas instruções na memória principal da máquina, mas ao invés de
buscar uma instrução por vez e a executar de imediato, pode buscar blocos de instruções

39
e as armazenar em estruturas de memória chamadas cache. Na chamada hierarquia de
memória, caches se situam acima da memória principal, geralmente integradas ao próprio
processador. Muitas vezes há dois níveis de cache, o mais inferior compartilhado pelos
núcleos da CPU e o superior vinculado a cada núcleo [7].
Na arquitetura das CPUs abordadas neste trabalho, todas Intel x86, pode haver
dois níveis de cache, chamados L1 e L2, por ordem de precedência na hierarquia. Ou-
tras CPUs mais avançadas podem ter ainda outro nível de cache compartilhado entre
os núcleos, chamado L3. A Figura 5.1 apresenta um esquema simplificado da arquite-
tura da CPU para um processador moderno de quatro núcleos, considerando núcleos de
processamento e hierarquia de memória.
Figura 5.1: Estrutura simplificada da hierarquia de memória e processamento deuma CPU atual. Processadores de baixo custo podem ter menos níveis de cache. A ca-pacidade de processar dados é maior com a proximidade do núcleo de processamento,e a capacidade de armazenamento cresce no sentido oposto.
5.2 PROGRAMAÇÃO PARALELA
Com os custos crescentes dos computadores, alternativas paralelas de computação
já eram populares nos anos 1990 com a solução multinó dos clusters, máquinas comuns
interligadas em rede responsáveis cada uma por um bloco de processamento. Um conceito
simples que foi adaptado a níveis de microprocessadores e placas gráficas multinúcleo [7].
A Figura 5.2 mostra um cluster esquematizado.

40
Figura 5.2: Estrutura simplificada de um cluster de computadorespara processamento paralelo.
5.3 PARALELISMO EM PLACAS GRÁFICAS
A programação paralela na GPU exige um entendimento maior do funcionamento
do hardware para aproveitamento melhor do alto desempenho, em contraste com a pro-
gramação tradicional de mesmo nível na CPU [7].
GPUs surgiram no contexto de processamento de gráficos em três dimensões em
ambiente computacional, especialmente para jogos que utilizavam engines 3D [35]. O alto
poder de processamento das GPUs, entretanto, em conjunto com otimização de bibliotecas
de softwares específicas, é usado atualmente em diversas soluções científicas e técnicas de
problemas que demandam desempenho, em diversas áreas do conhecimento, como Física,
Computação, Biologia e Medicina [8].
Em problemas físicos, computação na GPU tem sido usada em diversas áreas como
simulações de Monte Carlo do modelo de Ising [9], simulações de modelos de spin [10],
óptica não-linear [36] e simulações de colisões [37].

41
5.3.1 Arquitetura da GPU
A seção de interesse na arquitetura de uma GPU envolve os streaming multipro-
cessors (SM), ou multiprocessadores de fluxo, unidades de processamento responsáveis
pela execução de códigos em paralelo. A GPU também tem sua hierarquia de memória
própria, e se comunica com a CPU através de uma interface por onde se troca dados nos
dois sentidos [7].
O esquema básico dessa estrutura está na Figura 5.3. A interface entre a GPU e a
CPU funciona numa frequência menor que a capacidade das duas pontas, funcionando, no
termo computacional aplicado ao caso, como um gargalo, sendo um importante fator a se
considerar na escolha da solução computacional a se utilizar. Em alto nível de abstração,
definimos uma função a ser executada na GPU, chamada kernel. Invocamos o kernel
paralelamente através de um grid de até três dimensões de blocos de execução. Cada
bloco possui uma estrutura de até três dimensões de threads. Cada bloco é associado
a um multiprocessador, que executa as threads daquele bloco, como esquematizado na
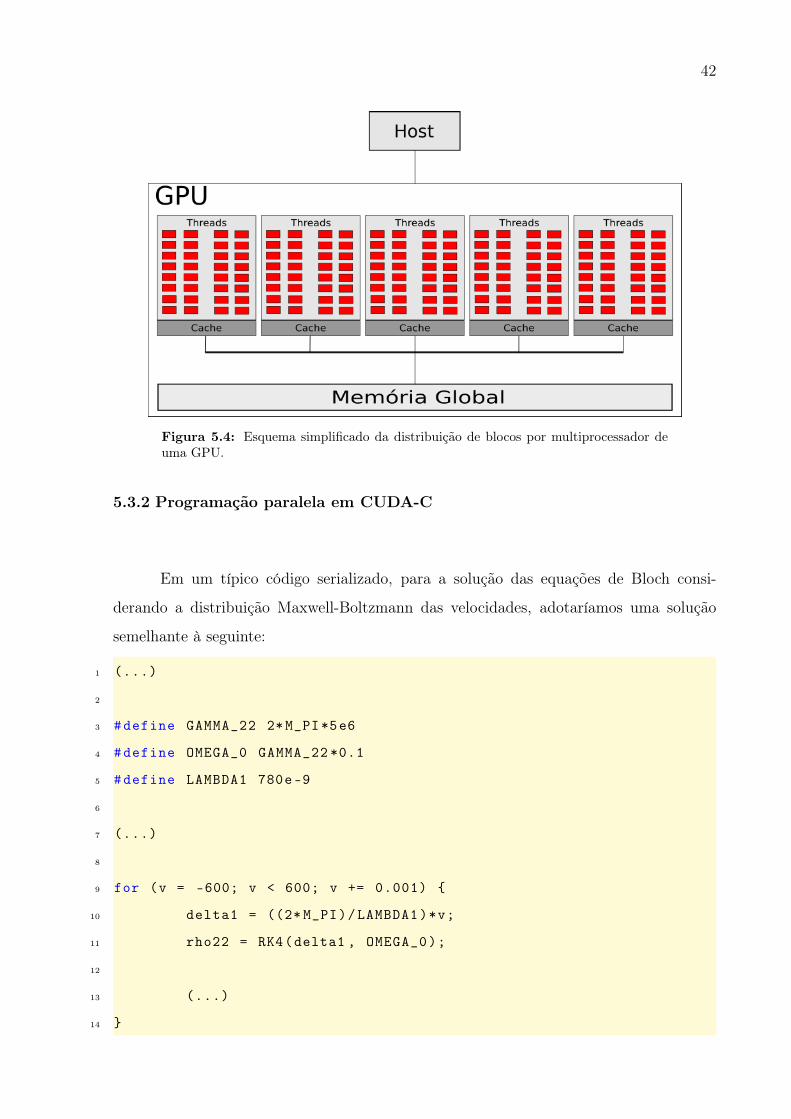
Figura 5.4 [38].
Figura 5.3: Esquema simplificado de uma GPU atual, com hiera-quia de memória dos SMs e interface com a CPU.
42
Figura 5.4: Esquema simplificado da distribuição de blocos por multiprocessador deuma GPU.
5.3.2 Programação paralela em CUDA-C
Em um típico código serializado, para a solução das equações de Bloch consi-
derando a distribuição Maxwell-Boltzmann das velocidades, adotaríamos uma solução
semelhante à seguinte:
1 (...)
2
3 #define GAMMA_22 2*M_PI*5e6
4 #define OMEGA_0 GAMMA_22 *0.1
5 #define LAMBDA1 780e-9
6
7 (...)
8
9 for (v = -600; v < 600; v += 0.001)
10 delta1 = ((2* M_PI)/LAMBDA1)*v;
11 rho22 = RK4(delta1 , OMEGA_0);
12
13 (...)
14

43
Em tal exemplo, o laço de repetição executa sequencialmente 1,2×106 vezes o có-
digo que integra as equações de Bloch, contido na função RK4(). Os termos em maiúsculas
são constantes. Para a paralelização na GPU, primeiramente definimos um kernel que
será executado paralelamente.
1 __global__ void kdmb(float *d_rho22 , float *d_vel)
2 int idx = threadIdx.x + blockIdx.x * blockDim.x;
3 float delta = ((2 * PI) / LAMBDA1)*(d_vel[idx]);
4
5 (...)
6
7 d_rho22[idx] = cuCrealf(rho_22)*exp(-U*U*d_vel[idx]*d_vel[
idx]);
8
A primeira linha abaixo da declaração do método kmdb() define um índice baseado
no número de blocos e threads definidos antes da execução. Após definir as variáveis já
reservando o espaço em memória necessário e antes de invocar o kernel, devemos copiar
os dados da memória principal do computador para a memória da GPU. Para tanto,
utilizamos a função cudaMemcpy() com a opção cudaMemcpyHostToDevice, que nessa
configuração faz a cópia dos dados das variáveis definidas no sistema anfitrição para a
GPU.
É necessário uma variável para uso no sistema anfitrião, por convenção definida
com o prefixo h_ de host, e outra para a GPU com o prefixo d_, de device.
1
2 #define MINV -600
3 #define MAXV 600
4 #define PASSO 0.01
5
6 (...)
7
8 const float ARRAY_SIZE = (MAXV - MINV)/PASSO;
9
10 int main(int argc , char *argv [])
11 (...)

44
12 int size = (ARRAY_SIZE)*sizeof(float);
13 float *h_rho22 = (float*) malloc(size);
14 float *d_rho22;
15 float *h_vel = (float*) malloc(size);
16 float *d_vel;
17
18 (...)
19
20 cudaMemcpy(d_rho22 , h_rho22 , size , cudaMemcpyHostToDevice);
21 cudaMemcpy(d_vel , h_vel , size , cudaMemcpyHostToDevice);
22
23 (...)
24
25
Tal processo leva tempo dependente da frequência de operação do hardware host, e
o trânsito no sentido inverso para tratamento adequado dos dados se dará após os cálculos,
o que deve ser considerado na escolha pela paralelização [8]. Detalhes dessa característica
são discutidos de maneira quantitativa na seção 6.2.
A invocação do kernel procede à execução em paralelo, de acordo com a arquitetura
da GPU, e segue o seguinte padrão.
1 (...)
2 dim3 grid(50, 100);
3
4 (...)
5 kdmb <<<grid , 256>>>(d_rho22 , d_vel);
6 (...)
Nesse exemplo de execuções em blocos de três dimensões, um grid de 5000 conjun-
tos bidimensionais de 256 threads é invocado para execução na GPU. Apesar da abstração
do paralelismo invocar todas as 1,28×106 threads ao mesmo tempo, elas não serão execu-
tadas em sua totalidade de maneira simultânea, estando sujeitas às limitações de memória
nos devidos graus de hierarquia e do número de SMs de cada hardware.
Após a invocação do kernel e execução dos dados em paralelo na GPU, os dados
precisam ser deslocados de volta para a memória principal do computador para o trata-

45
mento de saída dos dados em tela ou arquivo, novamente usando a função cudaMemcpy(),
desta vez com a opção cudaMemcpyDeviceToHost:
1 (...)
2 cudaMemcpy(h_rho22 , d_rho22 , size , cudaMemcpyDeviceToHost);
3
4 for (i = 0; i < ARRAY_SIZE; i++)
5 (...)
6
7 (...)
46
6 RESULTADOS
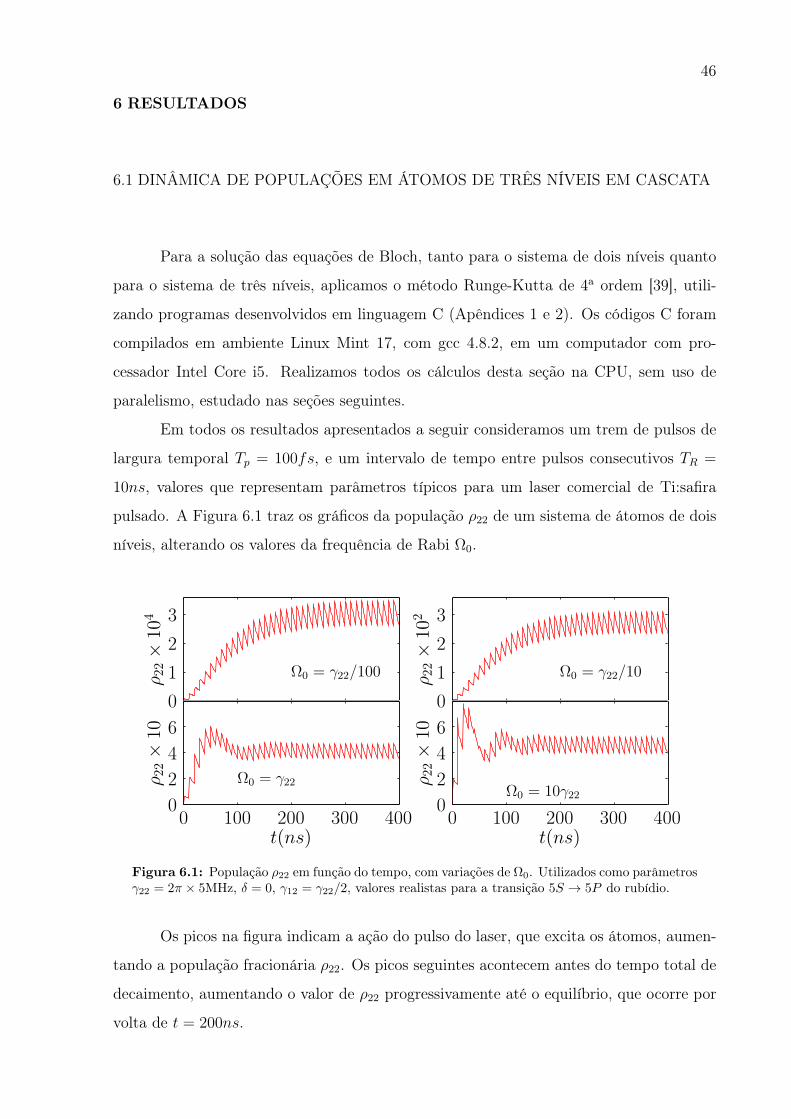
6.1 DINÂMICA DE POPULAÇÕES EM ÁTOMOS DE TRÊS NÍVEIS EM CASCATA
Para a solução das equações de Bloch, tanto para o sistema de dois níveis quanto
para o sistema de três níveis, aplicamos o método Runge-Kutta de 4a ordem [39], utili-
zando programas desenvolvidos em linguagem C (Apêndices 1 e 2). Os códigos C foram
compilados em ambiente Linux Mint 17, com gcc 4.8.2, em um computador com pro-
cessador Intel Core i5. Realizamos todos os cálculos desta seção na CPU, sem uso de
paralelismo, estudado nas seções seguintes.
Em todos os resultados apresentados a seguir consideramos um trem de pulsos de
largura temporal Tp = 100fs, e um intervalo de tempo entre pulsos consecutivos TR =
10ns, valores que representam parâmetros típicos para um laser comercial de Ti:safira
pulsado. A Figura 6.1 traz os gráficos da população ρ22 de um sistema de átomos de dois
níveis, alterando os valores da frequência de Rabi Ω0.
0123
ρ22×
104
Ω0 = γ22/100
0123
ρ22×
102
Ω0 = γ22/10
0 100 200 300 4000246
t(ns)
ρ22×
10
Ω0 = γ22
0 100 200 300 4000246
t(ns)
ρ22×
10
Ω0 = 10γ22
Figura 6.1: População ρ22 em função do tempo, com variações de Ω0. Utilizados como parâmetrosγ22 = 2π × 5MHz, δ = 0, γ12 = γ22/2, valores realistas para a transição 5S → 5P do rubídio.
Os picos na figura indicam a ação do pulso do laser, que excita os átomos, aumen-
tando a população fracionária ρ22. Os picos seguintes acontecem antes do tempo total de
decaimento, aumentando o valor de ρ22 progressivamente até o equilíbrio, que ocorre por
volta de t = 200ns.

47
Notamos que quando a frequência de Rabi é uma fração da taxa de relaxação do
estado excitado, a evolução da excitação segue de maneira semelhante, apesar da diferença
na ordem de grandeza da população ρ22. Quando, por outro lado, Ω0 é igual ou maior
que γ22, o equilíbrio de ρ22 ainda ocorre próximo de t = 200ns, após decair de um valor
máximo atingido anteriormente.
Além disso, para campos muito intensos, como no caso em que Ω0 = 10γ22, perce-
bemos uma oscilação no valor médio de ρ22, as chamadas oscilações de Rabi, que ocorrem
também na excitação de átomos por lasers contínuos, e se devem ao fato de laser ora ex-
citar os átomos do estado 1 para o estado 2 (absorção) e ora no sentido inverso (emissão
estimulada), alternadamente, em uma frequência igual a Ω/2π [12].
A figura 6.2 apresenta os gráficos da população ρ22 também em um sistema de
átomos de dois níveis, desta vez com variações da dessintonia de campo.
01234
ρ22×
102
δ = 0
0123
ρ22×
103
δ = γ22
0 100 200 300 40001234
t(ns)
ρ22×
103 δ = 2γ22
0 100 200 300 4000123
t(ns)
ρ22×
102
δ = 2πfr
Figura 6.2: População ρ22 em função do tempo, com variações de δ. Faz-se γ22 = 2π × 5Mhz,δ = 0, γ12 = γ22/2 e fr = 100MHz.
Com a definição para a taxa de repetição fr ≡ 1/TR, observamos que quando
δ = 2πfr, a evolução temporal de ρ22 é semelhante à de quando δ = 0. Isso acontece pois
o espectro de um trem de pulsos consiste em um pente de frequências, isto é, um conjunto
de milhares ou milhões de modos discretos de frequência separados por fr. Assim, sempre
que δ = 2πmfr, onde n é um número inteiro, os átomos estarão em ressonância com o
modo m do pente, e portanto serão excitados. Para os demais valores de δ, observamos a
alternância entre interferência destrutiva e construtiva antes do equilíbrio, e a excitação
de uma fração bem menor da população de átomos.

48
A seguir, a Figura 6.3 mostra o resultado alcançado para as populações ρ22 e ρ33
de um sistema atômico de três níveis em cascata, novamente variando Ω0 e δ.
0123
ρ22×
104
Ω0 = γ22/100
0
1
2
ρ33×
104
Ω0 = γ22/10
0246
ρ22×
10
Ω0 = 10γ220
2
4
ρ33×
102
Ω0 = 10γ22
0123
ρ22×
103
δ = γ22
0
2
4ρ
33×
109
δ = γ22
0 100 200 300 4000123
t(ns)
ρ22×
102
δ = 2πfr
0 100 200 300 4000
1
t(ns)
ρ33×
104
δ = 2πfr
Figura 6.3: Variação temporal das populações ρ22 e ρ33. Nas duas primeiras linhas de figurasδ = 0 enquanto variamos a frequência de Rabi. Nas seguintes variamos a dessintonia de campoenquanto Ω0 = γ22/10.
Após, distribuimos as populações de um sistema atômico de três níveis em função
da velocidade. Fazendo ∆ = kv, onde k = 2π/λ, atribui-se λ = 780nm, e se resolve
numericamente as equações e Bloch. Multiplica-se então os valores das populações ρ22 e
ρ33 após t = 400ns pela fração populacional na Equação 2.2.
A Figura 6.4 mostra os resultados para ρ22 e ρ33. Observamos que apenas alguns
grupos de átomos em determinadas velocidades são excitados. Conforme notado por
Aumiller (2009) [40], as populações acompanham a distribuição por velocidade da fração
populacional dos átomos, que apresentamos para o átomo de rubídio na Figura 2.1. A
forma de pente da distribuição se deve à excitação por trem de pulsos.
A estrutura de picos é característica de interferência construtiva. Os picos duplos

49
da Figura 6.4b se devem à alternância entre uma condição de interferência construtiva e
uma de interferência destrutiva. Para o caso da interferência destrutiva, uma vez que a
transição dos estados ocorre em determinado comprimento de onda, o acúmulo do efeito
do pulso com o efeito Doppler tem o efeito inverso ao da excitação na ressonância, fazendo
a população do estado excitado decair. Para o caso, δ1 = 0 e δ2/2π = 100 MHz, e essa
diferença é a responsável pelos picos duplos.
(a)
0
2
4
6
ρ22×
104
(a)
-600 -400 -200 0 200 400 6000
2
4
6
v(m/s)
ρ33×
107
(b)
Figura 6.4: Distribuição das populações (a) ρ22 e (b) ρ33 por velocidade. As mudanças entre acondição construtiva ou destrutiva da interferência gera os picos duplos em (b), devido aos valoresdiferentes das dessintonias de campo: δ1 = 0 e δ2/2π = 100 MHz.

50
6.2 SOLUÇÃO NA GPU PARA ÁTOMOS DE DOIS NÍVEIS
Na seção anterior, a solução para a população ρ22 com aplicação da distribuição
Maxwell-Boltzman de velocidades tem a forma de picos de excitação apresentada na
Figura 6.4a.
O átomo em ressonância, isto é, com δ = 0, oscila na frequência do campo, e um
átomo com velocidade v 6= 0 oscila na frequência ωc + kv 6= ωc [6], supondo ω21 = ωc.
Assim, entre dois pulsos o campo oscila ωcTR vezes, enquanto o átomo oscila (ω21 +
kv)TR vezes. Se a diferença entre esses números de oscilações for um número inteiro, a
interferência é construtiva, então
(ω21 + kv)TR − ωcTR = 2πn, n = 0, 1, 2... (6.1)
Sendo ω21 = ωc,
kvTR = 2πn. (6.2)
Como k = 2π/λ
vn =λ
TRn, n = 0, 1, 2..., (6.3)
que é a condição de interferência construtiva. Portanto, entre dois picos adjacentes a
diferença de velocidades é
∆v =λ
TR(6.4)
Utilizando os parâmetros do problema, isto é, comprimento de onda do campo λ = 780
nm e TR = 10 ns, chegamos a uma diferença de velocidades ∆v = 78 m/s, que é a diferença
de velocidades entre os picos de excitação na Figura 6.4a.
Para calcular esses resultados, integramos a solução para cada uma das velocidades
da distribuição. Para uma precisão da variação de ∆v = 1 m/s , integramos 1000 vezes.
Para uma precisão maior, como ∆v = 0,001 m/s, integramos 106 vezes, o que torna
o problema de solução computacional custosa, embora paralelizável, já que os cálculos
podem ser realizados separadamente.
Realizamos os testes para a solução desse problema em três processadores e cinco
placas de vídeo distintas. A solução na CPU (Apêndice 3) foi desenvolvida em linguagem
C, compilada com GCC 4.8 ou 4.9. A solução na GPU (Apêndice 4) utilizou o framework

51
CUDA-C, compilada com NVCC em versão compatível com cada placa de vídeo testada,
conforme Tabela 6.1.
Tabela 6.1: GPUs nVidia utilizadas nos testes.
Hardware Características Versão do Cuda Capacidade computacionalGT 210 Baixo custo 5.5 1.1GT 310M Plataforma móvel 6.5 1.1GTX 850M Plataforma móvel 7.0 5.0GTX 560 Intermediário 7.0 3.2GTX 760 Ti Intermediário 7.5 5.0
A capacidade computacional da GPU é um nível de processamento que abrange
diferenças na biblioteca CUDA e no hardware das GPUs, conforme o desenvolvimento
incremental da tecnologia dos dispositivos [7].
As três CPUs são exemplos significativos de configurações representativas e cate-
gorizáveis: um Intel Core2Duo, processador legado com sete anos de uso, um Intel i5 M
460, desenvolvido para uso em notebooks, e um Intel i5 4460, processador de potencial
intermediário. As GPUs utilizadas foram todos modelos nVidia compatíveis com Cuda,
apresentados na Tabela 6.1.
Além dos testes em separado, testamos três configurações completas de combina-
ções distintas de CPU e GPU, visando realizar comparações específicas de desempenho e
custo, sendo um computador legado, um computador móvel e um montado com foco em
desempenho, conforme a Tabela 6.2.
Tabela 6.2: Máquinas distintas e suas combinações CPUxGPU.
Hardware CaracterísticasIntel Core2Duo e GT 210 Hardware legadoIntel i5 M 480 e GT 310M NotebookIntel i5 4460 e GTX 760 Ti Configuração para desempenho
Inicialmente, comparamos diretamente os tempos de execução entre todos os hardwa-
res. A comparação é direta e visual, e a princípio deixa evidente a diferença entre os dois
modelos de solução. Atingimos a solução das equações de Bloch novamente pelo método
RK4. Os parâmetros constantes ao longo de todos os testes são a duração do pulso de
100fs, o tempo entre pulsos de 10ns e o passo de integração numérica no intervalo en-
tre pulsos de 2, 5ps. Variamos o número de pulsos (e consequentemente a duração da
interação) e, quando aplicável, a faixa de velocidades da distribuição Maxwell-Boltzmann

52
(exceto quando explicitamente mencionados valores diversos, -600 m/s < v < 600 m/s, e
o passo entre velocidades é 1 m/s).
(a) (b)
Figura 6.5: Comparativo entre tempos de execução na CPU e na GPU variando-se o número depulsos do laser. A diferença entre os tempos comparados nos gráficos é da ordem de 102, como sevê no eixo temporal das duas comparações.
A execução na CPU demonstrada na Figura 6.5a deixa evidente que o RK4 cresce
linearmente em função do tamanho do problema a ser resolvido. A comparação com a
execução na GPU (Figura 6.5b) mostra que a solução do problema na GPU também é
linear, embora a inclinação da reta seja menor por um fator próximo de 90. A GPU não
altera a complexidade do tempo de execução, mas dispende recursos computacionais para
solucioná-lo de maneira mais eficiente.
O gasto de recursos da GPU, entretanto, tem um custo mínimo. O trânsito em
duas vias de dados entre a memória principal do computador e a GPU, na ida para
execução e na volta para exibição dos resultados, gasta tempo nem sempre desprezível
[38], fazendo existir um volume mínimo de dados para o qual o uso da GPU se torna
efetivamente vantajoso. Para o problema em análise, variamos o número de threads na
GPU em paralelo e um número compatível de iterações na CPU. A Figura 6.6 traz os
resultados comparados. Observamos os pontos de interseção entre as curvas, que indicam
quando a solução na GPU se torna temporalmente vantajosa.
Uma vez solucionadas as equações de Bloch para cada velocidade da distribui-
ção Maxwell-Boltzmann do vapor atômico de rubídio, variamos o tamanho da lista de
execução por meio da variação da faixa de velocidades. Utilizamos convencionalmente o
intervalo −600 m/s < v < 600 m/s para as soluções gerais. Para as variações seguintes,

53
Figura 6.6: Evolução do tempo de execução variando-se o número de threads na GPU e o númerode iterações na CPU.
fazemos vmin = −600 m/s e vmax cresce conforme o tamanho do problema, a princípio em
incrementos de 1 m/s. Não utilizamos a distribuição incompleta gerada por essas varia-
ções para nenhum fim, adotando o método somente para a comparação de desempenho
computacional de uma faixa de velocidades de tamanho arbitrário.
Notamos que, conforme esperado, a CPU executa as tarefas individuais mais rapi-
damente, e que a GPU, conforme igualmente postulado e demonstrado extensivamente,
vence conforme o volume de dados tratados cresce. Na Tabela 6.3 expressamos o tamanho
da faixa de velocidades da distribuição Maxwell-Boltzman solucionadas pelas equações de
Bloch para o qual a GPU se torna vantajosa em comparação à GPU.
Tabela 6.3: Comparações CPUxGPU das máquinas em operação e o respectivo tamanho do arrayde velocidades a partir do qual o tempo de execução na GPU é menor.
Hardware comparado Dimensão do arrayIntel Core2Duo x GT 210 27Intel i5 M 480 x GT 310M 28Intel i5 4460 x GTX 760 Ti 55
Vemos nas Figuras 6.7a, 6.7b e 6.7c que a evolução temporal de execução da GPU
é constante para algumas faixas de tamanho do array de velocidades, e o crescimento para
faixa seguinte se dá em degrau, o que é compatível com o percebido por [41]: a latência
é constante enquanto o array a ser executado couber no cache utilizado. Conforme a
faixa cresce, o número de conjuntos de cache em uso cresce, e para cada novo conjunto
usado sobe-se um degrau. Essa característica permite a deduzir reversamente o tamanho

54
do cache [41].
0 5 0 1 0 0 1 5 0 2 0 0 2 5 08 0 09 0 0
1 0 0 01 1 0 01 2 0 01 3 0 01 4 0 01 5 0 01 6 0 01 7 0 0
(a)
0 5 0 1 0 0 1 5 0 2 0 0 2 5 05 0 0
6 0 0
7 0 0
8 0 0
9 0 0
1 0 0 0
(b)
0 1 2 8 2 5 6 3 8 4 5 1 2 6 4 0 7 6 8 8 9 66 0 08 0 0
1 0 0 01 2 0 01 4 0 01 6 0 01 8 0 02 0 0 02 2 0 0
(c)
Figura 6.7: Tempo de execução em função do número de threads executadas na GPU.
As duas formas de resolver o mesmo problema deixam evidente a diferença exis-
tente entre elas. A GPU se destaca sobre a CPU em uma diferença da ordem daquela
entre poucos segundos e dezenas de minutos para o problema em análise, obviamente
paralelizável, o que permanece verdade mesmo quando se compara a placa de vídeo de
entrada GT 210 com o processador i5 4460, de poder intermediário. Estabelecida essa
superioridade, aprofundamos agora a análise do funcionamento comparado entre as GPUs.
Uma vez que se usa as GPUs principalmente por poder de processamento e de-
sempenho, interessa-nos saber as melhores formas de uso de memória e processamento
visando minimizar o tempo de processamento. A primeira variável testada é a configu-
ração blocos x threads. Embora parte da literatura recomende a consideração cuidadosa
da taxa de ocupação do cache como otimização, análises mais detidas como a de Volkov
[42] demonstram que o problema é na verdade mais complexo, o que os testes realizados

55
confirmam.
Na Figura 6.8 variamos o número de threads por bloco. Na Figura 6.9 variamos
também o tamanho do array de velocidades. Vemos algumas constantes em todos os
modelos analisados. O uso de muitas threads por bloco e de muitos blocos de poucas
threads é notoriamente ineficiente. Podemos notar uma faixa onde a relação blocos x
threads é de eficiência semelhante. A tendência de subida entre Nb× 32 e Nb× 256, onde
Nb é o número de blocos, não se confirma integralmente, com máximos locais distintos
nos modelos.
0 5 0 1 0 0 1 5 0 2 0 0 2 5 01 5 0 03 0 0 04 5 0 06 0 0 07 5 0 09 0 0 0
1 0 5 0 0
0 2 5 6 5 1 2 7 6 8 1 0 2 44 0 06 0 08 0 0
1 0 0 01 2 0 01 4 0 01 6 0 01 8 0 02 0 0 02 2 0 02 4 0 02 6 0 0
Figura 6.8: Tempo de execução em função da proporção threads/bloco. Neste resultado o númerode threads é fixo; a variação acontece na quantidade de threads por bloco.
0 2 0 0 4 0 0 6 0 0 8 0 0 1 0 0 04 0 0
5 0 0
6 0 0
7 0 0
1 1 0 1 0 0 1 0 0 06 0 08 0 0
1 0 0 01 2 0 01 4 0 01 6 0 01 8 0 02 0 0 02 2 0 0
Figura 6.9: Tempo de execução em função do número threads para um bloco.
Não é seguro apontar uma solução ótima para a relação blocos x threads, mas é
evidentemente possível indicar uma solução aceitável para o tempo de desempenho na
faixa em que o número de threads fica entre 32 e 256, para um problema com 1024
execuções paralelas.
Interessa-nos, entretanto, não apenas uma solução mais rápida mas, principal-
mente, uma solução correta. A Figura 6.10 traz a comparação entre as populações fra-

56
cionárias ρ22 resultantes do cálculo na GPU e na CPU. Apesar do resultado geral ser
compatível em ambas, há uma diferença a partir do quinto dígito significativo em valores
absolutos.
Identificamos que as funções matemáticas exp e sech retornam valores ligeiramente
diferentes na última casa significativa para suas implementações na biblioteca padrão C
math.h e na biblioteca matemática CUDA C, o que é a fonte dessa diferença nos resultados
entre as soluções.
Figura 6.10: Valores absolutos da diferença entre a solução da distribuição população ρ22 entrea CPU e a GPU.
Por fim, ainda se faz necessário prever o ganho de desempenho do uso de parale-
lismo na GPU para um problema físico mais realista. O uso de uma faixa de velocidades de
103 é um problema que pode ser considerado pequeno, tanto para a solução das equações
de Bloch em outros contextos quando para as GPUs mais recentes. Assim, aumentou-se
a ordem do tamanho da faixa de velocidades até 106.
A Figura 6.11 traz a comparação visual dos tempos de execução. Para um problema
pequeno, da ordem de 103 velocidades, a solução na CPU i5 4460 é vinte vezes mais lenta
que na GTX 760 Ti. O ganho da GT 210, por sua vez, é de apenas 4,5. Quando o
problema é da ordem de 105, a GT 210 é 43 vezes superior ao i5 4460 em desempenho, e a
GTX 760 é cerca de 900 vezes mais rápida. Na faixa de 106 velocidades, a superioridade
da GT 210 sobre a CPU cai para um fator próximo de 30, entretanto a GTX 760 continua
aumentando sua diferença para um fator próximo de 980 vezes.

57
Figura 6.11: Tempo de execução em função do tamanho do array de velocidades para i5 4460 edois exemplos extremos: a placa de menor poder computacional dos testes, GT210, e a superiorGTX 760 Ti.
6.2.1 Publicações e participações em eventos
Da presente seção, o resumoDensity matrix calculations of Doppler-broadened
atomic systems implemented on GPUs foi selecionado para apresentação no Encon-
tro de Física 2016 da SBF em Natal/RN em forma de banner (Apêndices 5 e 6 e Anexo
1). O tema também foi assunto de seminário apresentado ao grupo de pesquisa Estru-
tura da Matéria e Física Computacional do Departamento de Física da UNIR Campus de
Ji-Paraná (Apêndice 7).
6.3 SOLUÇÃO NA GPU PARA ÁTOMOS DE TRÊS NÍVEIS DO TIPO Λ
Para os resultados desta seção utilizamos as equações de Bloch representativas
de um sistema atômico do tipo Λ, conforme discutido na subseção 4.6.1. Alcançamos as
soluções numéricas também através do método RK4, com programa paralelo desenvolvido
em linguagem CUDA-C, compilado com NVCC versão 7.5 (Anexo 2). Para a solução na
CPU, utilizamos um código em linguagem C++ compilado em GCC 4.9 ou em Microsoft
Visual Studio 2015 (Anexo 3).

58
O hardware testado consiste em dois processadores Intel i5, um da série 4200 M e
outro da série 4460. As duas placas de vídeo nVidia utilizadas nos testes foram a GTX
850 M e a GTX 760 Ti.
Integramos as soluções para uma interação com 100 pulsos de duração temporal
Tp = 100 fs e frequência inicial fR = 100 MHz. Nessas condições, variamos fR em
intervalos regulares para cada passo da solução. Outros parâmetros incluem γ/2π = 2,5
MHz, ω1 = 0, ω2/2π = 6,8 GHz e ω3/2π = 384 THz. Para a frequência de Rabi, adotamos
Ω0 = γ/5
Na Figura 6.13 apresentamos a população ρ33 e a coerência σ12 em função da
variação da taxa de repetição δfR. Observamos que ρ33 atinge seu valor máximo e logo
em seguida vai a zero, no mesmo ponto em que σ12 tem seu valor máximo, de acordo com
o esperado, em conformidade com estudos recentes realizados na área [21].
Tais resultados são compatíveis com a transparência eletromagneticamente indu-
zida discutida na seção 2.5 e respectivas referências. O crescimento da população ρ33
ocorre ao se aproximar da ressonância de dois fótons, e vai a zero exatamente nessa res-
sonância, onde σ12 tem seu valor máximo. Nos detalhes (c) e (d) da Figura 6.13 vemos
os picos da ressonância de um fóton.
A melhora de tempo entre a execução na CPU e na GPU varia, neste caso, entre
25 e 40 vezes, dependendo do hardware comparado. A Figura 6.12 traz uma comparação
visual dos dados de execução em cada CPU e GPU utilizada para a solução.
Para este problema não foi possível carregar todos os dados a se calcular na GPU,
o que levou à necessidade de 36 chamadas de kernel, o que reduziu drasticamente o ganho
de performance em relação às soluções da seção anterior. Contudo, o ganho ainda é
significativo, já que a solução na GPU leva mais de uma hora, enquanto a GPU leva
poucos minutos para tratar o problema.
Os hardwares comparados podem ser divididos em um notebook (processador i5
4200 M e GTX 850 M) e um computador com foco em desempenho (i5 4460 e GTX 760i).
Nessa configuração, os fatores de melhora são mostrados na Tabela 6.4.
Tabela 6.4: Fator de ganho de tempo da GPU em relação à CPU no cálculo dos dados de variaçãoda frequência.
Hardware comparado Fator de melhora (TCPU/TGPU)Intel i5 4200 M x GTX 850 M 25Intel i5 4460 x GTX 760 Ti 14

59
i 5 4 2 0 0 M i 5 4 4 6 0 G T X 8 5 0 M G T X 7 6 0 T i01 02 03 04 05 06 07 0
H a r d w a r e
C P U s
G P U s
Figura 6.12: Tempo de execução para o problema em cada hardware utilizado.

60
Figura 6.13: População ρ33 (a) e σ12 (b) em função da variação da frequência de repetição.Notamos o decréscimo abrupto de ρ33 após o máximo no mesmo ponto onde σ12 é máxima. Abaixotemos o detalhe em torno da origem de (a) e o detalhe em torno da origem de (c).

61
7 CONCLUSÕES
Estudamos sistemas atômicos de dois e três níveis, e suas transições induzidas por
um trem de pulsos ultracurtos, determinando as equações de Bloch ópticas que descrevem
a evolução temporal das populações atômicas de cada estado excitado.
Solucionamos numericamente os sistemas de equações através do método Runge-
Kutta de 4a ordem, com parâmetros compatíveis com vapor atômico de rubídio e com
um laser de Ti:safira pulsado, de forma que o intervalo temporal entre os pulsos (10 ns)
é inferior ao tempo de vida do estado excitado. Sendo assim, observamos que
• os picos populacionais variam em magnitude com o tempo até atingir o equilíbrio,
quando as sequências de picos assumem valores constantes;
• para campos relativamente pouco intensos, quando a frequência de Rabi é uma
fração da taxa de relaxação do estado excitado correspondente, os picos seguem em
crescimento até atingirem o equilíbrio por volta de t = 200ns;
• para campos mais intensos (Ω(t) é igual ou maior que γ22), o equilíbrio é atingido
também por volta de t = 200ns, embora após decair de um valor máximo atingido
anteriormente;
• na variação da dessintonia de campo, há modos discretos de frequência de ressonân-
cia dados por δ = 2πnfr onde n é um número inteiro;
• existe uma excitação seletiva ligada a velocidades específicas da distribuição Maxwell-
Boltzmann, fenômeno vinculado ao efeito doppler.
Em relação à utilização da GPU da solução para átomos de dois níveis com consi-
deração da distribuição de velocidades, notamos que:
• a GPU se destaca em ganho de tempo para o problema em análise mesmo na com-
paração entre placas de baixo custo e processadores de desempenho intermediário;
• há um tamanho mínimo de problema paralelizável a partir do qual a GPU se torna
vantajosa;
• o uso cuidadoso do cache e da configuração de grids e threads tem relação direta
com o ganho de desempenho;

62
• diferenças nas implementações das bibliotecas matemáticas padrão C e CUDA C
dificultam a comparação em problemas mais precisos;
• o uso para problemas que demandem maior precisão pode exigir a definição de
funções matemáticas próprias com a precisão necessária.
Por último, observamos nos resultados a existência de transparência eletromag-
neticamente induzida (EIT) na ressonância após variação da taxa de repetição do laser
pulsado. Quanto à solução na GPU para essa variação da taxa de repetição no sistema Λ
do laser pulsado em uma faixa de -2 a 2 MHZ a partir da ressonância, percebemos que:
• a GPU é vantajosa por um fator grande, mas bastante inferior ao problema da
distribuição Maxwell-Boltzmann das velocidades;
• o fator de melhora do tempo de execução é inferior devido ao volume de dados a se
tratar, que excede as especificações das arquiteturas das GPUs utilizadas;
• o problema pode ser melhor tratado aplicando-se GPUs distribuídas em cluster,
como sugestão para trabalhos posteriores.

63
REFERÊNCIAS
[1] EISBERG, Robert; RESNICK, Robert.Quantum Physics of Atoms, Molecules,
Solids, Nuclei and Particles. Second Edition. JohnWiley & Sons. New York, 1985.
[2] BRANSDEN, B H; JOACHAIN, C J. Physics of atoms and molecules. Longman
Scientific & Technical. Essex, 1983.
[3] HAKEN, H. Light, vol. 2: Laser Light Dynamics. North Holland Pysics Pu-
blishing. Amsterdam, 1985.
[4] CSELE, Mark. Fundamentals of Light Sources and Lasers. John Wiley & Sons.
2004.
[5] SAKURAI, J J; NAPOLITANO, Jim. Mecânica Quântica Moderna. 2a edição.
Bookman. Porto Alegre, 2013.
[6] FOOT, Christopher J. Atomic Physics. Oxford University Press. Oxford, 2004.
[7] COOK, Shane. Cuda Programming: A developer’s guide to parallel compu-
ting with GPUs. Morgan Kaufman. 2013.
[8] HWU, Wen-Mei W (editor). GPU computing gems emerald edition. Elsevier,
2011.
[9] BLOCK, Benjamin; VIRNAU, Peter; PREIS, Tobias. Multi-GPU acceletrated
multi-spin Monte Carlo simulations of the 2D Ising model. Computer Physics
Communications 181, 2010, 1549-1556.
[10] WEIGEL, Martin. Simulating spin models on GPU. Computer Physics Commu-
nications 182, 2011, 1833-1836. Wen-Mei W. Hwu (editor). GPU computing gems
emerald edition. Elsevier, 2011.
[11] HITZ, Breck; EWING, J J; HECHT, Jeff. Introduction to Laser Technology. 3a
Edição. IEEE Press. 1991.
[12] FOX, Mark. Quantum Optics: An Introduction. Oxford University Press. Ox-
ford, 2006.

64
[13] MURTI, Y.; Vijavan, C. Essentials of Nonlinear Optics. Ane Books. Nova Delhi,
2014.
[14] SUTHERLAND, Richard L. Handbook of Nonlinear Optics. 2a Edição. Marcel
Dekker. Nova York, 2003.
[15] BOYD, Robert W. Nonlinear Optics. 3a Edição. Academic Press. Cambridge, 2008.
[16] BOLLER, K J; IMAMOGLU, A; HARRIS, S E. Observation of Electromagne-
tically Induced Transparency. Physical Review Letters, Volume 66, Number 20.
Stanford, 1991.
[17] SCULLY, Marlan O; ZUBAIRY, M. Suhail. Quantum Optics. Cambridge Univer-
sity Press. Cambridge, 1997
[18] NEW, Geoffrey. Nonlinear Optics. Cambridge University Press. Cambridge, 2011.
[19] FLEISCHHAUER, Michael; IMAMOGLU, Atac; MARANGOS, Jhonatan
P.Electromagnetically induced transparency: Optics in coherent media.
Reviews of Modern Physics, Volume 77, 2005.
[20] SAUTENKOV, Vladimir A, et. al. Electromagnetically induced transparency
in rubidium vapor prepared by a comb of short optical pulses. Physical
Review A, 71, 063804, 2005.
[21] MORENO, Marco P; VIANNA, Sandra S. Coherence induced by a train of
ultrashort pulses in a Λ-type system. Journal of the Optical Society of America
B 28(5):1124. 2011
[22] CHANG, Willian S C. Principles of Lasers and Optics. Cambridge University
Press. 2005.
[23] DIELS, Jean-Claude Diels; RUDOLPH, Wolfgang. Ultrashort laser pulse pheno-
mena: Fundamentals, techniques and applications on a femtosecond time
scale. Academic Press, 2a Ed. Albuquerque, 2006.
[24] CUNDIFF, S T. Phase stabilization of ultrashort optical pulses. J. Phys. D:
Appl. Phys. 35, R43–R59, 2002.

65
[25] WELLER, Lee et al. Absolute absorption on rubidium D1 line: including
resonant dipole-dipole interactions. Journal of Physics B: Atomic, Molecular
and Optical Physics, v. 44, n. 19, p. 195006, 2011.
[26] STECK, Daniel A. Rubidium 85 D Line Data. Revisão 2.1.6. Disponível em
http://steck.us/alkalidata. 20 de setembro de 2013.
[27] STIENKEMEIER, F et al. Spectroscopy of alkali atoms (Li, Na, K) attached
to large helium clusters. Z. Phys. D 38, 253—263, 1996.
[28] TAKAHASHI, Y. et al. Spectroscopy of Alkali Atoms and Molecules in Superfluid
Helium. Physical Review Letters, Volume 71, number 7, 1993.
[29] SOARES, A A; ARAUJO, Luís E E. Coherent accumulation of excitation in
the electromagnetically induced transparency of an ultrashort pulse train.
Physical Review A 76, 043818, 2007.
[30] TEMKIN, R J. Excitation of an atom by a train of short pulses. J. Opt. Soc.
Am. B, Vol. 10, No. 5, 1993.
[31] EINWOHNER, T H; WONG, J; GARRISON, J C Analytical solutions for la-
ser excitation of multilevel systems in the rotating-wave approximation.
Physical Review A, Volume 14, Number 4, 1976.
[32] PURI, Ravinder R. Mathematical Methods of Quantum Optics. Springer. Ber-
lim, 2001.
[33] WEBER, Raul Fernando. Arquitetura de Computadores Pessoais. 2a edição.
Sagra Luzzatto. Porto Alegre, 2003.
[34] BROOKSHEAR, J Glenn. Ciência da Computação: Uma visão Abrangente.
5a edição. Bookman. Porto Alegre, 2000.
[35] SANDERS, Jason; KANDROT, Edward. CUDA by example: An introduction
to general-purpouse GPU programming. Addison-Wesley, 2010.
[36] DEMETER, G. Solving the Maxwell-Bloch equations for resonant nonlinear
optics using GPUs. Computer Physics Communications 184.4, 2013.

66
[37] HERMAN, Everton, et. al. Multi-GPU and Multi-CPU Parallelization for
Interactive Physics Simulations. Euro-Par 2010 Parallel Processing, 2010, 235-
246.
[38] CHENG, John; GROSSMAN, Max; MCKERCHER, Ty. Professional CUDA C
Programming. Wrox, Indianapolis, 2014.
[39] RUGGIERO, Márcia A. Gomes; LOPES, Vera Lúcia da Rocha. Cálculo numérico:
aspectos teóricos e computacionais. 2a edição. Makron Books. São Paulo, 1996.
[40] AUMILER, D; BAN T; PICHLER, G. Time dynamics of a multilevel system
excited by a train of ultrashort pulses. Physical Review A 79. 2009
[41] WONG, H, et. al. Demystifying GPU Microarchitecture through Microben-
chmarking. In: Performance Analysis of Systems & Software (ISPASS), 2010 IEEE
International Symposium on. IEEE, 2010. p. 235-246.
[42] VOLKOV, V. Better performance at lower occupancy. UC Berkeley, 2010.

67
APÊNDICE 1: CÓDIGO FONTE C DE PROGRAMA PARA SOLUÇÃO
DAS EQUAÇÕES DE BLOCH EM UM SISTEMA ATÔMICO DE TRÊS
NÍVEIS EM CASCATA
1 #include <math.h>
2 #include <complex.h>
3 #include <stdio.h>
4
5 #define GAMMA_22 2*M_PI*5e6
6 #define GAMMA_33 2*M_PI *660e3
7 #define GAMMA_23 2*M_PI *3.33 e6
8 #define GAMMA_13 2*M_PI *330e3
9 #define GAMMA_12 GAMMA_22 *0.5
10 #define GAMMA_M 0
11 #define PSI 1
12 #define DELTA GAMMA_22
13 #define DELTAM (2* M_PI)/(1e-8)
14 #define RHO11_0 1
15 #define OMEGA_CW 0.01* GAMMA_22
16 #define OMEGA_M 0.01* GAMMA_33
17 #define FILENAME "r3l -res -d_G22 -ocw_G22_10 -om_G33_10.txt"
18 // Tamanho do passo de tempo
19 #define H 5e-15
20 //Tempo maximo
21 #define MAX 4e-7
22 //Tempo do pulso
23 #define Tp 1e-13
24 // Intervalo entre inicio e reinicio dos pulsos
25 #define Tr 1e-8
26
27 double complex rhodot11(float omegacw , double complex sigma12 ,
28 double complex rho22 , double complex rho11 , double complex rho11_0);
29
30 double complex rhodot22(float omegacw , float omegam ,
31 double complex sigma12 , double complex sigma23 , double complex rho22 ,
32 double complex rho33);
33
34 double complex rhodot33(float omegam , double complex sigma23 ,
35 double complex rho33);
36
37 double complex sigmadot12(float deltam , float DELTAcw ,
38 double complex sigma12 , double complex sigma13 , float omegam ,
39 float omegacw , double complex rho22 , double complex rho11);
40
41 double complex sigmadot23(float deltacw , float DELTAm ,
42 double complex sigma23 , double complex sigma13 , float omegam ,
43 float omegacw , double complex rho33 , double complex rho22);

68
44
45 double complex sigmadot13(float deltacw , float deltam , float DELTAcw ,
46 float DELTAm , double complex sigma23 , double complex sigma13 ,
47 double complex sigma12 , float omegam , float omegacw);
48
49 double omega0_t(double o0, double t);
50
51 int main (void)
52 double complex rho11 = RHO11_0;
53 double complex rho22 = 0, rho33 = 0, sigma12 = 0;
54 double complex sigma23 = 0, sigma13 = 0;
55 double complex k1 , k2 , k3 , k4 , l1, l2, l3, l4, m1, m2, m3, m4;
56 double complex n1 , n2 , n3 , n4 , o1, o2, o3, o4, p1, p2, p3, p4;
57 double t=0.0, tp = 0.0, tr = 0.0, h, omega_0 , omegam , grav = 0.0;
58 char pulse = 1;
59 FILE *arq;
60
61 printf ("\n%s\n", FILENAME);
62 arq = fopen(FILENAME , "w");
63 fpr intf (arq , "t (ns)\trho11\trho22 (x1e6)\trho33");
64
65 // RK4
66 while (t < MAX)
67 if (pulse == 1) h = H;
68 else h = H*1;
69
70 // Estabelece a distancia Tr e o reinicio do pulso
71 if (tr < Tr)
72 tr += h;
73
74 else
75 tr = 0.0;
76 pulse = 1;
77
78
79 // Estabelece a duracao do pulso
80 if ((pulse == 1) && (tp < Tp))
81 tp += H;
82
83 else
84 tp = 0.0;
85 pulse = 0;
86
87
88 // Encontra omega_0 em funcao do tempo
89 omega_0 = omega0_t(OMEGA_CW *(Tr/Tp), tr);
90 omegam = omega0_t(OMEGA_M *(Tr/Tp), tr);
91
92 k1 = rhodot11(omega_0 , sigma12 , rho22 , rho11 , RHO11_0);

69
93 l1 = rhodot22(omega_0 , omegam , sigma12 , sigma23 , rho22 , rho33);
94 m1 = rhodot33(omegam , sigma23 , rho33);
95 n1 = sigmadot12(DELTAM , DELTA , sigma12 , sigma13 , omegam ,
96 omega_0 , rho22 , rho11);
97 o1 = sigmadot23(DELTAM , DELTA , sigma23 , sigma13 , omegam ,
98 omega_0 , rho33 , rho22);
99 p1 = sigmadot13(DELTAM , DELTAM , DELTA , DELTA , sigma23 , sigma13 ,
100 sigma12 , omegam , omega_0);
101
102 k2 = rhodot11(omega_0 , sigma12 + (h/2)*n1, rho22 + (h/2)*l1,
103 rho11 + (h/2)*k1 , RHO11_0);
104 l2 = rhodot22(omega_0 , omegam , sigma12 + (h/2)*n1,
105 sigma23 + (h/2)*o1, rho22 + (h/2)*l1 , rho33 + (h/2)*m1);
106 m2 = rhodot33(omegam , sigma23 + (h/2)*o1 , rho33 + (h/2)*m1);
107 n2 = sigmadot12(DELTAM , DELTA , sigma12 + (h/2)*n1,
108 sigma13 + (h/2)*p1, omegam , omega_0 , rho22 + (h/2)*l1,
109 rho11 + (h/2)*k1);
110 o2 = sigmadot23(DELTAM , DELTA , sigma23 + (h/2)*o1,
111 sigma13 + (h/2)*p1, omegam , omega_0 , rho33 + (h/2)*m1,
112 rho22 + (h/2)*l1);
113 p2 = sigmadot13(DELTAM , DELTAM , DELTA , DELTA ,
114 sigma23 + (h/2)*o1, sigma13 + (h/2)*p1,
115 sigma12 + (h/2)*n1, omegam , omega_0);
116
117 k3 = rhodot11(omega_0 , sigma12 + (h/2)*n2, rho22 + (h/2)*l2,
118 rho11 + (h/2)*k2 , RHO11_0);
119 l3 = rhodot22(omega_0 , omegam , sigma12 + (h/2)*n2,
120 sigma23 + (h/2)*o2, rho22 + (h/2)*l2 , rho33 + (h/2)*m2);
121 m3 = rhodot33(omegam , sigma23 + (h/2)*o2 , rho33 + (h/2)*m2);
122 n3 = sigmadot12(DELTAM , DELTA , sigma12 + (h/2)*n2,
123 sigma13 + (h/2)*p2, omegam , omega_0 , rho22 + (h/2)*l2,
124 rho11 + (h/2)*k2);
125 o3 = sigmadot23(DELTAM , DELTA , sigma23 + (h/2)*o2,
126 sigma13 + (h/2)*p2, omegam , omega_0 , rho33 + (h/2)*m2,
127 rho22 + (h/2)*l2);
128 p3 = sigmadot13(DELTAM , DELTAM , DELTA , DELTA ,
129 sigma23 + (h/2)*o2, sigma13 + (h/2)*p2,
130 sigma12 + (h/2)*n2, omegam , omega_0);
131
132 k4 = rhodot11(omega_0 , sigma12 + h*n3, rho22 + h*l3,
133 rho11 + h*k3 , RHO11_0);
134 l4 = rhodot22(omega_0 , omegam , sigma12 + h*n3, sigma23 + h*o3,
135 rho22 + h*l3 , rho33 + h*m3);
136 m4 = rhodot33(omegam , sigma23 + h*o3 , rho33 + h*m3);
137 n4 = sigmadot12(DELTAM , DELTA , sigma12 + h*n3, sigma13 + h*p3,
138 omegam , omega_0 , rho22 + h*l3, rho11 + h*k3);
139 o4 = sigmadot23(DELTAM , DELTA , sigma23 + h*o3, sigma13 + h*p3,
140 omegam , omega_0 , rho33 + h*m3, rho22 + h*l3);
141 p4 = sigmadot13(DELTAM , DELTAM , DELTA , DELTA ,

70
142 sigma23 + h*o3, sigma13 + h*p3, sigma12 + h*n3,
143 omegam , omega_0);
144
145 rho11 += (h/6)*(k1 + 2.0*k2 + 2.0*k3 + k4);
146 rho22 += (h/6)*(l1 + 2.0*l2 + 2.0*l3 + l4);
147 rho33 += (h/6)*(m1 + 2.0*m2 + 2.0*m3 + m4);
148 sigma12 += (h/6)*(n1 + 2.0*n2 + 2.0*n3 + n4);
149 sigma23 += (h/6)*(o1 + 2.0*o2 + 2.0*o3 + o4);
150 sigma13 += (h/6)*(p1 + 2.0*p2 + 2.0*p3 + p4);
151
152 if (grav == 0.0)
153 fpr intf (arq , "\n%e\t%e\t%e\t%e", t/1e-9, creal(rho11),
154 creal(rho22), creal(rho33));
155
156 printf ("\n%e\t%e\t%e\t%e\t%e", t/1e-9, creal(rho11), creal(rho22),
creal(rho33),
157 creal(rho11) + creal(rho22) + creal(rho33));
158
159 if (grav >= 1e-9) grav = 0.0;
160 else grav += h;
161
162 t += h;
163
164 fc lose (arq);
165
166 return 0;
167
168
169 double complex rhodot11(float omegacw , double complex sigma12 ,
170 double complex rho22 , double complex rho11 , double complex rho11_0)
171 return -I*omegacw*sigma12 + conj(-I*omegacw*sigma12) +
172 PSI*GAMMA_22*rho22 - GAMMA_M *( rho11 - rho11_0);
173
174
175 double complex rhodot22(float omegacw , float omegam ,
176 double complex sigma12 , double complex sigma23 , double complex rho22 ,
177 double complex rho33)
178 return I*omegacw*sigma12 + conj(I*omegacw*sigma12) -
179 I*omegam*sigma23 + conj(-I*omegam*sigma23) -
180 (GAMMA_22 + GAMMA_M)*rho22 + GAMMA_33*rho33;
181
182
183 double complex rhodot33(float omegam , double complex sigma23 ,
184 double complex rho33)
185 return I*omegam*sigma23 + conj(I*omegam*sigma23) -
186 (PSI*GAMMA_33 + GAMMA_M)*rho33*0 - GAMMA_33*rho33;
187
188
189 double complex sigmadot12(float deltacw , float DELTAcw ,

71
190 double complex sigma12 , double complex sigma13 , float omegam ,
191 float omegacw , double complex rho22 , double complex rho11)
192 return (I*( deltacw - DELTAcw) - GAMMA_12 - GAMMA_M)*sigma12 -
193 I*omegam*sigma13 + I*omegacw *(rho22 -rho11);
194
195
196 double complex sigmadot23(float deltam , float DELTAm ,
197 double complex sigma23 , double complex sigma13 , float omegam ,
198 float omegacw , double complex rho33 , double complex rho22)
199 return (I*( deltam + DELTAm) - GAMMA_23 - GAMMA_M)*sigma23 +
200 I*omegacw*sigma13 + I*omegam *(rho33 -rho22);
201
202
203 double complex sigmadot13(float deltacw , float deltam , float DELTAcw ,
204 float DELTAm , double complex sigma23 , double complex sigma13 ,
205 double complex sigma12 , float omegam , float omegacw)
206 return (I*( deltacw + deltam + DELTAcw - DELTAm) - GAMMA_13 -
207 GAMMA_M)*sigma13 + I*omegacw*sigma23 - I*omegam*sigma12;
208
209
210 double omega0_t(double o0, double t)
211 double a = 1/cosh (1.76*(t/Tp));
212 return o0*a;
213

72
APÊNDICE 2: CÓDIGO FONTE C DE PROGRAMA QUE DISTRIBUI
AS POPULAÇÕES POR VELOCIDADE EM UM SISTEMA ATÔMICO DE
TRÊS NÍVEIS EM CASCATA
1 #include <math.h>
2 #include <complex.h>
3 #include <stdio.h>
4 #include <string.h>
5
6 // Constantes
7
8 #define GAMMA_22 2*M_PI*5e6
9 #define GAMMA_33 2*M_PI *660e3
10 #define GAMMA_23 2*M_PI *3.33 e6
11 #define GAMMA_13 2*M_PI *330e3
12 #define GAMMA_12 GAMMA_22 *0.5
13 #define GAMMA_M 0
14 #define PSI 1
15 #define DELTA 0.0
16 #define DELTAM 0
17 #define DELTAM_32 2*M_PI *20e6
18 // Pop. inicial de rho11
19 #define RHO11_0 1
20 #define OMEGA_CW 0.1* GAMMA_22
21 #define OMEGA_M 0.1* GAMMA_33
22 #define FILENAME "r3l -res -ocw_G22_10 -om_G33_10.txt"
23 // Tamanho do passo de tempo
24 #define H 5e-15
25 //Tempo maximo
26 #define MAX 4e-7
27 //Tempo do pulso
28 #define Tp 1e-13
29 // Intervalo entre inicio e reinicio dos pulsos
30 #define Tr 1e-8
31
32 // U = sqrt(M/(2*kb*T))
33 #define U 4.13e-3
34 #define LAMBDA1 780e-9
35 #define LAMBDA2 780e-9
36 #define MINV -600.0
37 #define MAXV 600.0
38
39 double complex rhodot11(float omegacw , double complex sigma12 ,
40 double complex rho22 , double complex rho11 ,
41 double complex rho11_0)
42 return -I*omegacw*sigma12 + conj(-I*omegacw*sigma12) +
43 PSI*GAMMA_22*rho22 - GAMMA_M *( rho11 - rho11_0);

73
44
45
46 double complex rhodot22(float omegacw , float omegam ,
47 double complex sigma12 , double complex sigma23 ,
48 double complex rho22 ,double complex rho33)
49 return I*omegacw*sigma12 + conj(I*omegacw*sigma12) -
50 I*omegam*sigma23 + conj(-I*omegam*sigma23) -
51 (GAMMA_22 + GAMMA_M)*rho22 + GAMMA_33*rho33;
52
53
54 double complex rhodot33(float omegam , double complex sigma23 ,
55 double complex rho33)
56 return I*omegam*sigma23 + conj(I*omegam*sigma23) -
57 (PSI*GAMMA_33 + GAMMA_M)*rho33*0 - GAMMA_33*rho33;
58
59
60 double complex sigmadot12(float deltacw , float DELTAcw ,
61 double complex sigma12 , double complex sigma13 , float omegam ,
62 float omegacw , double complex rho22 , double complex rho11)
63 return (I*( deltacw - DELTAcw) - GAMMA_12 - GAMMA_M)*sigma12 -
64 I*omegam*sigma13 + I*omegacw *(rho22 -rho11);
65
66
67 double complex sigmadot23(float deltam , float DELTAm ,
68 double complex sigma23 , double complex sigma13 , float omegam ,
69 float omegacw , double complex rho33 , double complex rho22)
70 return (I*( deltam + DELTAm) - GAMMA_23 - GAMMA_M)*sigma23 +
71 I*omegacw*sigma13 + I*omegam *(rho33 -rho22);
72
73
74 double complex sigmadot13(float deltacw , float deltam ,
75 float DELTAcw , float DELTAm , double complex sigma23 ,
76 double complex sigma13 , double complex sigma12 , float omegam ,
77 float omegacw)
78 return (I*( deltacw + deltam + DELTAcw - DELTAm) - GAMMA_13 -
79 GAMMA_M)*sigma13 + I*omegacw*sigma23 - I*omegam*sigma12;
80
81
82
83 double omega0_t(double o0, double t)
84 double a = 1/cosh (1.76*(t/Tp));
85 return o0*a;
86
87
88 double p(int v)
89 return (U/sqrt(M_PI))*exp(-(U*U)*(v*v));
90
91
92 int main (void)

74
93 double complex rho11 = RHO11_0;
94 double complex rho22 = 0, rho33 = 0, sigma12 = 0;
95 double complex sigma23 = 0, sigma13 = 0;
96 double complex k1 , k2 , k3 , k4 , l1, l2, l3, l4, m1, m2, m3, m4;
97 double complex n1 , n2 , n3 , n4 , o1, o2, o3, o4, p1, p2, p3, p4;
98 double t=0.0, tp = 0.0, tr = 0.0, h, omega_0 , omegam;
99 char pulse = 1, filev [100];
100 FILE *arqv;
101 float v;
102 double DELTA1 , DELTA2;
103
104 printf (".");
105 // Arquivo de dados da distribuicao por velocidade
106 sprintf(filev , "r5 -L1_%.0f-L2_%.0f.txt", LAMBDA1 /1e-9,
107 LAMBDA2 /1e-9);
108 arqv = fopen(filev , "w");
109 fpr intf (arqv , "v (m/s)\trho22\trho33");
110
111 for (v = MINV; v <= MAXV; v += 7.8)
112 DELTA1 = ((2* M_PI)/LAMBDA1)*v;
113 DELTA2 = ((2* M_PI)/LAMBDA2)*v;
114
115 // RK4
116 while (t < MAX)
117 // Aplica o menor passo no interior do pulso
118 // No intervalo entre pulsos aplica o fator multiplicador
119 if (pulse == 1)
120 h = H;
121 else h = H*100;
122
123 // Estabelece a distancia Tr e o reinicio do pulso
124 if (tr < Tr)
125 tr += h;
126 else
127 tr = 0.0;
128 pulse = 1;
129
130
131 // Estabelece a duracao do pulso
132 if ((pulse == 1) && (tp < Tp))
133 tp += H;
134
135 else
136 tp = 0.0;
137 pulse = 0;
138
139
140 // Encontra omega_0 em funcao do tempo
141 omega_0 = omega0_t(OMEGA_CW *(Tr/Tp), tr);

75
142 omegam = omega0_t(OMEGA_M *(Tr/Tp), tr);
143
144 k1 = rhodot11(omega_0 , sigma12 , rho22 , rho11 , RHO11_0);
145 l1 = rhodot22(omega_0 , omegam , sigma12 , sigma23 , rho22 , rho33);
146 m1 = rhodot33(omegam , sigma23 , rho33);
147 n1 = sigmadot12(DELTAM ,DELTA1 , sigma12 , sigma13 , omegam ,
148 omega_0 , rho22 , rho11);
149 o1 = sigmadot23(DELTAM_32 , DELTA2 , sigma23 , sigma13 , omegam ,
150 omega_0 , rho33 , rho22);
151 p1 = sigmadot13(DELTAM_32 , DELTAM , DELTA1 , DELTA2 , sigma23 ,
152 sigma13 , sigma12 , omegam , omega_0);
153
154 k2 = rhodot11(omega_0 , sigma12 + (h/2)*n1, rho22 + (h/2)*l1,
155 rho11 + (h/2)*k1 , RHO11_0);
156 l2 = rhodot22(omega_0 , omegam , sigma12 + (h/2)*n1,
157 sigma23 + (h/2)*o1, rho22 + (h/2)*l1 , rho33 + (h/2)*m1);
158 m2 = rhodot33(omegam , sigma23 + (h/2)*o1 , rho33 + (h/2)*m1);
159 n2 = sigmadot12(DELTAM , DELTA1 , sigma12 + (h/2)*n1,
160 sigma13 + (h/2)*p1, omegam , omega_0 , rho22 + (h/2)*l1,
161 rho11 + (h/2)*k1);
162 o2 = sigmadot23(DELTAM_32 , DELTA2 , sigma23 + (h/2)*o1,
163 sigma13 + (h/2)*p1, omegam , omega_0 ,
164 rho33 + (h/2)*m1 , rho22 + (h/2)*l1);
165 p2 = sigmadot13(DELTAM_32 , DELTAM , DELTA1 , DELTA2 ,
166 sigma23 + (h/2)*o1, sigma13 + (h/2)*p1,
167 sigma12 + (h/2)*n1, omegam , omega_0);
168
169 k3 = rhodot11(omega_0 , sigma12 + (h/2)*n2, rho22 + (h/2)*l2,
170 rho11 + (h/2)*k2 , RHO11_0);
171 l3 = rhodot22(omega_0 , omegam , sigma12 + (h/2)*n2,
172 sigma23 + (h/2)*o2, rho22 + (h/2)*l2 , rho33 + (h/2)*m2);
173 m3 = rhodot33(omegam , sigma23 + (h/2)*o2 , rho33 + (h/2)*m2);
174 n3 = sigmadot12(DELTAM , DELTA1 , sigma12 + (h/2)*n2,
175 sigma13 + (h/2)*p2, omegam , omega_0 , rho22 + (h/2)*l2,
176 rho11 + (h/2)*k2);
177 o3 = sigmadot23(DELTAM_32 , DELTA2 , sigma23 + (h/2)*o2,
178 sigma13 + (h/2)*p2, omegam , omega_0 ,
179 rho33 + (h/2)*m2 , rho22 + (h/2)*l2);
180 p3 = sigmadot13(DELTAM_32 , DELTAM , DELTA1 , DELTA2 ,
181 sigma23 + (h/2)*o2, sigma13 + (h/2)*p2,
182 sigma12 + (h/2)*n2, omegam , omega_0);
183
184 k4 = rhodot11(omega_0 , sigma12 + h*n3, rho22 + h*l3,
185 rho11 + h*k3 , RHO11_0);
186 l4 = rhodot22(omega_0 , omegam , sigma12 + h*n3, sigma23 + h*o3,
187 rho22 + h*l3 , rho33 + h*m3);
188 m4 = rhodot33(omegam , sigma23 + h*o3 , rho33 + h*m3);
189 n4 = sigmadot12(DELTAM , DELTA1 , sigma12 + h*n3,
190 sigma13 + h*p3, omegam , omega_0 , rho22 + h*l3,

76
191 rho11 + h*k3);
192 o4 = sigmadot23(DELTAM_32 , DELTA2 , sigma23 + h*o3,
193 sigma13 + h*p3, omegam , omega_0 , rho33 + h*m3,
194 rho22 + h*l3);
195 p4 = sigmadot13(DELTAM_32 , DELTAM , DELTA1 , DELTA2 ,
196 sigma23 + h*o3, sigma13 + h*p3, sigma12 + h*n3,
197 omegam , omega_0);
198
199 rho11 += (h/6)*(k1 + 2.0*k2 + 2.0*k3 + k4);
200 rho22 += (h/6)*(l1 + 2.0*l2 + 2.0*l3 + l4);
201 rho33 += (h/6)*(m1 + 2.0*m2 + 2.0*m3 + m4);
202 sigma12 += (h/6)*(n1 + 2.0*n2 + 2.0*n3 + n4);
203 sigma23 += (h/6)*(o1 + 2.0*o2 + 2.0*o3 + o4);
204 sigma13 += (h/6)*(p1 + 2.0*p2 + 2.0*p3 + p4);
205
206 t += h;
207 //while RK4
208
209 // Gravacao em arquivo da pop em funcao da velocidade
210 fpr intf (arqv , "\n%.0f\t%e\t%e", v, creal(rho22)*p(v),
211 creal(rho33)*p(v));
212 printf ("\n%.0f\t%.0f\t%e\t%e",v/10 + 60, v, creal(rho22)*p(v),
213 creal(rho33)*p(v));
214
215 t = 0.0;
216 tr = 0.0;
217 tp = 0.0;
218 rho11 = RHO11_0;
219 rho22 = 0;
220 rho33 = 0;
221 sigma12 = 0;
222 sigma23 = 0;
223 sigma13 = 0;
224 //for
225 fc lose (arqv);
226 return 0;
227

77
APÊNDICE 3: CÓDIGO FONTE C DE PROGRAMA PARA MEDIÇÕES
NA CPU ENVOLVENDO A SOLUÇÃO PARA SISTEMAS DE DOIS NÍ-
VEIS
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <math.h>
4 #include <complex.h>
5 #include <time.h>
6
7 #define PI 3.14159265359f
8
9 const float GAMMA_22 = 2*PI*5e6;
10 const float GAMMA_12 = 2*PI*5e6*0.5; // GAMMA22 /2
11 const float OMEGA_0 = 2*PI*5e6*0.1; // GAMMA22 /10
12
13 #define DELTA 0
14 #define H 5e-15f
15 #define MAX 4e-7f
16 #define Tp 1e-13f
17 #define Tr 1e-8f
18 #define U 4.13e-3f // U = sqrt(M/(2*kb*T))
19 #define LAMBDA1 780e-9f
20 #define MINV -600.0f
21 #define MAXV 599.0f
22 #define PASSO 1.0f
23
24 float p(int v)
25 return exp(-(U*U)*(v*v));
26
27
28 float complex f_sigmadot(float complex sigma_12 ,
29 float complex rho_22 , float delta , float omega_0);
30
31 float complex f_rhodot(float complex sigma_12 , float complex rho_22 , float omega_0);
32
33 float complex RK4(float delta , float omega_t0);
34
35 float omega0_t(float e0 , float t);
36
37
38 int main(void)
39 const float delta_mult = ((2*PI)/LAMBDA1);
40 float v;
41 float delta1;
42 float complex rho22;
43 FILE *arqp , *arqt;

78
44 clock_t start , end;
45 float htimedif;
46
47 printf ("Executando na CPU");
48 //CPU
49 time(&start);
50 arqp = fopen("pop_cpu_40p.txt", "w");
51 fpr intf (arqp , "v (m/s)\trho22");
52
53 for (v = MINV; v <= MAXV; v += PASSO)
54 delta1 = delta_mult*v;
55 rho22 = RK4(delta1 , OMEGA_0);
56 fpr intf (arqp , "\n%.0f\t%e", v, creal(rho22)*p(v));
57 printf ("\nCPU %.0f\t%e", v, creal(rho22)*p(v));
58
59
60 fc lose (arqp);
61 time(&end);
62 htimedif = difftime(end , start);
63
64 printf ("\nTempo na CPU: %.1f s",
65 htimedif);
66
67 arqt = fopen("timediff.txt", "w");
68 fpr intf (arqt , "CPU");
69 fpr intf (arqt , "%f", htimedif);
70 fc lose (arqt);
71
72 return 0;
73
74
75 float complex f_sigmadot(float complex sigma_12 ,
76 float complex rho_22 , float delta , float omega_0)
77 return (I*delta - GAMMA_12)*sigma_12 -
78 I*omega_0 *(1 - 2* rho_22);
79
80
81 float complex f_rhodot(float complex sigma_12 , float complex rho_22 ,
82 float omega_0)
83 float complex i_omega_sig = I*omega_0*sigma_12;
84
85 float complex rho_22_dot = -(GAMMA_22*rho_22)
86 + i_omega_sig + conj(i_omega_sig);
87
88 return rho_22_dot;
89
90
91 float complex RK4(float delta , float omega_t0)
92 const float O0 = omega_t0 *(Tr/Tp);

79
93 float complex rho_22 = 0;
94 float complex sigma_12 = 0;
95 float complex k1s , k2s , k3s , k4s;
96 float complex k1r , k2r , k3r , k4r;
97 float t=0, tr = 0.0f, omega_0 , h=H;
98
99 while (t < MAX)
100 if (tr >= Tr)
101 tr = 0.0f;
102 h = H;
103
104 else if ((tr >= Tp*6) && (omega_0 != 0))
105 h = H*500;
106 omega_0 = 0;
107
108
109 if (tr < Tp*6)
110 omega_0 = omega0_t(O0 , tr - Tp*3);
111
112 k1s = f_sigmadot(sigma_12 , rho_22 , delta , omega_0);
113 k1r = f_rhodot(sigma_12 , rho_22 , omega_0);
114
115 k2s = f_sigmadot(sigma_12 + (h/2)*k1s ,
116 rho_22 + (h/2)*k1r , delta , omega_0);
117 k2r = f_rhodot(sigma_12 + (h/2)*k1s ,
118 rho_22 + (h/2)*k1r , omega_0);
119
120 k3s = f_sigmadot(sigma_12 + (h/2)*k2s ,
121 rho_22 + (h/2)*k2r , delta , omega_0);
122 k3r = f_rhodot(sigma_12 + (h/2)*k2s ,
123 rho_22 + (h/2)*k2r , omega_0);
124
125 k4s = f_sigmadot(sigma_12 + h*k3s ,
126 rho_22 + h*k3r , delta , omega_0);
127 k4r = f_rhodot(sigma_12 + h*k3s ,
128 rho_22 + h*k3r , omega_0);
129
130 sigma_12 += (h/6)*(k1s + 2.0* k2s + 2.0* k3s + k4s);
131 rho_22 += (h/6)*(k1r + 2.0* k2r + 2.0* k3r + k4r);
132
133 t += h;
134 tr += h;
135
136
137 return rho_22;
138
139
140 float omega0_t(float o0 , float t)
141 float a = 1/coshf (1.76*(t/Tp));

80
142 return o0*a;
143

81
APÊNDICE 4: CÓDIGO FONTE CUDA-C DE PROGRAMA PARA MEDI-
ÇÕES NA GPU ENVOLVENDO A SOLUÇÃO PARA SISTEMAS DE DOIS
NÍVEIS
1 #include <stdlib.h>
2 #include <stdio.h>
3 #include <math.h>
4 #include <complex.h>
5 #include <cuComplex.h>
6 #include "cuda_runtime.h"
7 #include "device_launch_parameters.h"
8
9 #define MINV -500
10 #define MAXV 500
11 #define PASSO 1 // Determina o tamanho do array
12 #define THREADN 250
13 #define BLOCKX 4
14 #define BLOCKY 1
15 #define LAMBDA1 780e-9
16 #define U 4.13e-3
17
18 #define PI 3.14159265359
19
20 #define GAMMA_22 2*PI*5e6
21 #define GAMMA_12 GAMMA_22 *0.5
22 #define OMEGA_0 GAMMA_22 *0.1
23 #define H 5e-15f
24 #define MAX 4e-7f
25 #define Tp 1e-13f
26 #define Tr 1e-8f
27 #define FILENAME "rG-L780.txt"
28
29 const float ARRAY_SIZE = (MAXV - MINV)/PASSO;
30
31 __device__ cuFloatComplex cMultFloat(cuFloatComplex comp , float mult)
32 return cuCmulf(make_cuFloatComplex(mult , 0), comp);
33
34
35 __device__ cuFloatComplex f_sigmadot(cuFloatComplex s12 ,
36 cuFloatComplex r22 , float delta , float omega_0)
37
38 cuFloatComplex i_delta = make_cuFloatComplex (0, delta);
39 cuFloatComplex g12s12 = cMultFloat(s12 , -GAMMA_12);
40 cuFloatComplex i_omega = make_cuFloatComplex (0, -omega_0);
41 cuFloatComplex omega_rho = cMultFloat(r22 , -2);
42
43 cuFloatComplex res = cuCmulf(i_delta , s12);

82
44 res = cuCaddf(res , g12s12);
45 res = cuCaddf(res , i_omega);
46 omega_rho = cuCmulf(i_omega , omega_rho);
47 res = cuCaddf(res , omega_rho);
48
49 return res;
50
51
52
53 __device__ cuFloatComplex f_rhodot(cuFloatComplex s12 ,
54 cuFloatComplex r22 , float omega_0)
55
56 cuFloatComplex i_omega = make_cuFloatComplex (0, omega_0);
57 cuFloatComplex g22r22 = cMultFloat(r22 , -GAMMA_22);
58 cuFloatComplex i_omega_sig = cuCmulf(i_omega , s12);
59 cuFloatComplex res = cuCaddf(g22r22 , i_omega_sig);
60 res = cuCaddf(res , cuConjf(i_omega_sig));
61
62 return res;
63
64
65
66 __global__ void kdmb(float *d_rho22 , float *d_vel)
67 int idx = threadIdx.x + (blockIdx.y*gridDim.x + blockIdx.x)*blockDim.x;
68 float delta = ((2 * PI) / LAMBDA1)*( d_vel[idx]);
69 cuFloatComplex rho_22 = make_cuFloatComplex (0, 0);
70 cuFloatComplex sigma_12 = make_cuFloatComplex (0, 0);
71 cuFloatComplex k1s , k2s , k3s , k4s;
72 cuFloatComplex k1r , k2r , k3r , k4r;
73 float t = 0.0f, tr = 0.0f, omega_0 , h = H;
74
75 while (t < MAX)
76 if (tr > Tr)
77 tr = 0.0f;
78 h = H;
79
80 else if (tr > Tp)
81 h = H*500;
82
83
84 omega_0 = OMEGA_0 *(Tr / Tp)*(1 / cosh (1.76*( tr / Tp)));
85
86 k1s = f_sigmadot(sigma_12 , rho_22 , delta , omega_0);
87 k1r = f_rhodot(sigma_12 , rho_22 , omega_0);
88
89 k2s = f_sigmadot(cuCaddf(sigma_12 , cMultFloat(k1s , h / 2)),
90 cuCaddf(rho_22 , cMultFloat(k1r , h / 2)),
91 delta , omega_0);
92 k2r = f_rhodot(cuCaddf(sigma_12 , cMultFloat(k1s , h / 2)),

83
93 cuCaddf(rho_22 , cMultFloat(k1r , h / 2)),
94 omega_0);
95
96 k3s = f_sigmadot(cuCaddf(sigma_12 , cMultFloat(k2s , h / 2)),
97 cuCaddf(rho_22 , cMultFloat(k2r , h / 2)),
98 delta , omega_0);
99 k3r = f_rhodot(cuCaddf(sigma_12 , cMultFloat(k2s , h / 2)),
100 cuCaddf(rho_22 , cMultFloat(k2r , h / 2)),
101 omega_0);
102
103 k4s = f_sigmadot(cuCaddf(sigma_12 , cMultFloat(k3s , h)),
104 cuCaddf(rho_22 , cMultFloat(k3r , h)),
105 delta , omega_0);
106 k4r = f_rhodot(cuCaddf(sigma_12 , cMultFloat(k3s , h)),
107 cuCaddf(rho_22 , cMultFloat(k3r , h)),
108 omega_0);
109
110 sigma_12 = cuCaddf(sigma_12 ,
111 cMultFloat(cuCaddf(cuCaddf(cuCaddf(k1s , cMultFloat(k2s , 2)),
112 cMultFloat(k3s , 2)), k4s), h/6));
113 rho_22 = cuCaddf(rho_22 ,
114 cMultFloat(cuCaddf(cuCaddf(cuCaddf(k1r , cMultFloat(k2r , 2)),
115 cMultFloat(k3r , 2)), k4r), h/6));
116
117 t += h;
118 tr += h;
119
120
121 d_rho22[idx] = cuCrealf(rho_22)*((U/sqrt(PI))*exp(-U*U*d_vel[idx]*d_vel[idx]));
122
123
124 int main(int argc , char *argv [])
125 int i;
126 int size = (ARRAY_SIZE)*sizeof(float);
127 float *h_rho22 = (float*) malloc(size);
128 float *d_rho22;
129 float *h_vel = (float *) malloc(size);
130 float *d_vel;
131 float v;
132 FILE *arqp , *arqt;
133 cudaEvent_t start , stop;
134 float time;
135 int threads=THREADN;
136 dim3 grid(BLOCKX , BLOCKY);
137
138 if (argc > 2)
139 threads = atoi(argv [2]);
140
141

84
142 cudaEventCreate (&start);
143 cudaEventCreate (&stop);
144 cudaEventRecord(start , 0);
145
146 v = MINV;
147 for (i = 0; i < ARRAY_SIZE; i++)
148 h_vel[i] = v;
149 v += PASSO;
150
151
152 cudaMalloc((void **)&d_rho22 , size);
153 cudaMalloc((void **)&d_vel , size);
154
155 cudaMemcpy(d_rho22 , h_rho22 , size , cudaMemcpyHostToDevice);
156 cudaMemcpy(d_vel , h_vel , size , cudaMemcpyHostToDevice);
157
158 kdmb <<<grid , threads >>>(d_rho22 , d_vel);
159
160 cudaMemcpy(h_rho22 , d_rho22 , size , cudaMemcpyDeviceToHost);
161
162 arqp = fopen("pop_gpu_40p_10e6.txt", "w");
163 fpr intf (arqp , "v (m/s)\trho22");
164
165 for (i = 0; i < ARRAY_SIZE; i++)
166 fpr intf (arqp , "\n%.3f\t%e", h_vel[i], h_rho22[i]);
167
168
169 fc lose (arqp);
170
171 cudaEventRecord(stop , 0);
172 cudaEventSynchronize(stop);
173 cudaEventElapsedTime (&time , start , stop);
174
175 printf ("\nTempo na GPU: %3.3f ms \n", time);
176
177 arqt = fopen("timediffGPU_210_1e3.txt", "w");
178 fpr intf (arqt , "GPU");
179 fpr intf (arqt , "\n%f", time);
180 fc lose (arqt);
181
182 cudaFree(d_rho22);
183 cudaFree(d_vel);
184
185 return 0;
186

85

86
APÊNDICE 5: BANNER APRESENTADO NO ENF 2016
Density matrix calculations of Doppler-broadened atomic systemsimplemented on GPUs
Teo Victor R. da Silva and Marco P. M. de SouzaDepartamento de Fısica, Universidade Federal de Rondonia, Ji-Parana/RO, Brazil
AbstractNumerical calculations of the density matrix elements are a time-consuming computational problem, due tothe Doppler broadening that demands the inclusion of the contribution of many group velocities. We usegraphical processing units (GPUs) to accelerate these calculations by parallelism, for the interaction of rubid-ium vapor with a resonant train of ultrashort laser pulses of 100MHz repetition rate. We consider a two-levelatomic system, and solve the Bloch equations in time domain with the standart 4th order Runge-Kutta method.We compare the performance of five Nvidia GPUs and a Core i5 4460 CPU. There is a relative difference be-low 2.2 × 10−5 for the results presented by GPU and CPU. For the GeForce 760 Ti, it is necessary 55 groupvelocities to be faster than CPU. The maximum speedup is 960× for 106 group velocities, which should beuseful for more realistic problems, where the CPU calculations can take several days.
Hardware
Hardware Characteristics CUDA version Compute capacityGT 210 Low cost 5.5 1.1GT 310M Mobile 6.5 1.1GTX 850M Mobile 7.0 5.0GTX 560 Intermediary 7.0 3.2GTX 760 Ti Intermediary 7.5 5.0
Hardware CharacteristicsIntel Core2Duo and GT 210 Legacy hardwareIntel i5 M 480 and GT 310M LaptopIntel i5 4460 and GTX 760 Ti Performance configuration
TheoryThe Bloch equations describe the time evolution of the density matrix elements when interacting with electro-magnetic fields. For a two level system,
ρ11 = −iΩ0(t)σ12 + c.c. + γ22ρ22 (1a)ρ22 = iΩ0(t)σ12 + c.c.− γ22ρ22 (1b)σ12 = (iδ − γ12)σ12 + iΩ0(ρ22 − ρ11) (1c)
The eletric field of the ultrashort train of pulses is
E(t) =
N−1∑
N=0
E0(t− nTR)e−i(ωct−nωcTR+n∆φ) (2)
We represent the pulse envelopment with a hyperbolic secant function
E0(t) = E0sech
(1,76t
Tp
)(3)
GPU architecture
Figure 1: Source: Ref [7]
GPU execution model
Figure 2: Source: Ref [8]
Results• We solve the Bloch equations with parameters compatible with Rubidium vapor of 85Rb isotope, interacting
with a standard commercial pulsed Ti:sapphire laser.
• Numerical calculations with Runge-Kutta 4th order (RK4) method.
• CPU tests are performed with a C code,and the GPU tests with CUDA-C.
• The solution has the form of excitation peaks
- 6 0 0 - 4 0 0 - 2 0 0 0 2 0 0 4 0 0 6 0 00 , 0 0
0 , 0 2
0 , 0 4
0 , 0 6
0 , 0 8
ρ 22
V e l o c i t y ( m / s ) 0 5 0 1 0 0 1 5 0 2 0 0 2 5 002 0 04 0 06 0 08 0 0
1 0 0 01 2 0 01 4 0 01 6 0 0
Exec
ution
time (
ms)
G P U t h r e a d n u m b e r o r C P U i t e r a t i o n s
I n t e l C o r e 2 D u o I n t e l i 5 M 4 8 0 I n t e l i 5 4 4 6 0 G T 2 1 0 G T 3 1 0 M G T X 7 6 0 T i
• We integrate the solution for each velocity on the distribution.
• The RK4 method has a linear time complexity running on a traditional CPU code. The GPU code maintainsthe time complexity, but has an overall better performance.
• For architectural reasons, there is a minimum number of group velocities for the GPU to become a betteroption.
0 2 5 6 5 1 2 7 6 8 1 0 2 405 0 0
1 0 0 01 5 0 02 0 0 02 5 0 0
Exec
ution
time (
ms)
T h r e a d s p e r b l o c k
4 0 p u l s e s 1 0 0 p u l s e s
G T X 8 5 0 - 1 0 2 4 t h r e a d s
1 0 3 1 0 4 1 0 5 1 0 61 0 - 1
1 0 0
1 0 1
1 0 2
1 0 3
1 0 4
Exec
ution
time (
s)V e l o c i t i e s a r r a y s i z e
G T X 7 6 0 T i G T 2 1 0 i 5 4 4 6 0
• The solution of the Bloch equations for 103 group velocities is still a small problem for an adequate GPUx-CPU comparison.
• We solved for bigger problem sizes, up to 106 group velocities.
• GeForce GTX 760 Ti GPU is 980 times faster than as Intel Core i5 4460 CPU.
• The execution time keeps reducing with the increasing of group velocities
Conclusions• GPUs improve the execution time for the problem under analysis even comparing low-cost entry options as
Nvidia GT 210 over a compatible code running on a intermediary CPU as Intel i5 4460.
• There is a minimum problem size for the GPU became advantageous.
• The use of the cache units and the grids, blocks and threads configuration has a direct impact on the perfor-mance improvement.
• The comparisons in this work arbitrarily change the size or precision of the group velocities array, butthe performance improvement should be useful for more realistic physics problems, like velocity-selectivetransitions in multilevel atomic systems.
Forthcoming ResearchModern CPUs are multicore systems, and a fairer comparison should consider this, but the quadcore i5 would,on best case scenario, be four times faster. There are differences on the implementations of mathematical li-braries on the two languages, leading to slight differences, of a maximum module of the order of 10−5. Resultsdemanding superior precision, which is the case for this subject, can force the definition of more appropriatemathematical functions.
References[1] R. J. Temkin. J. Opt. Soc. Am. B, Vol. 10, No. 5, 1993.
[2] S. T. Cundiff. J. Phys. D: Appl. Phys. 35, R43R59, 2002.
[3] Jean-Claude Diels, Wolfgang Rudolph. Academic Press, 2ł Ed. Albuquerque, 2006.
[4] Everton Hermann, et. al. Euro-Par 2010 Parallel Processing, 2010, 235-246.
[5] G. Demeter. Computer Physics Communications 184.4, 2013.
[6] Benjamin Block, Peter Virnau, Tobias Preis. Computer Physics Communications 181, 2010, 1549-1556.
[7] D. B. Kirk and W. W. Hwu, Programming Massively Parallel Processors, Elsevier, Waltham, 2013.
[8] J. Cheng, M. Grossman and T. McKercher, Professional CUDA C Programming, John Wiley and Sons,Indianapolis, 2014.

87
APÊNDICE 6: RESUMO DA APRESENTAÇÃO NO ENF 2016
Density matrix calculations of Doppler-broadened atomic systemsimplemented on GPUs
Teo Victor Resende da Silva and Marco P. M. de SouzaDepartamento de Fısica, Universidade Federal de Rondonia, Ji-Parana - RO, Brazil.
Important subjects in non-linear optics involving resonant interactions between lasers andatomic vapors has been very studied in recent years. We can mention the parametric four-wave mixing, the electromagnetically induced transparency, the photon echo and the slowlight, for example. The Doppler broadening is usually the main contribution to the opticalresponse of an atomic vapor. Thus, the numerical calculations of the density matrix ele-ments must include the contribution of many group velocities, leading to time-consumingcomputations. On the other hand, graphical processing units (GPUs) has been exten-sively used in various fields of science, like molecular dynamics, magnetohydrodynamicssimulations, Maxwell-Bloch equations, Monte Carlo simulations, and various others. Inthis work, we use GPUs to accelerate the calculations of the density matrix of the problemof a Doppler-broadened rubidium vapor in the presence of a resonant train of ultrashortpulses of 100 MHz repetition rate. We solve the Bloch equations in the time domain forthe 5S1/2 → 5P3/2 transition by using the standard fourth-order Runge-Kutta method.We use the Cuda cores of the GPUs to solve the Bloch equations for different atomicgroup velocities in parallel, while the CPU does it serially. We compare the performanceof five GPUs and a Core i5 4460 CPU, where the results present a relative difference below2.2×10−5. For the Geforce GTX 760 Ti, it is necessary 55 group velocities to this GPU tobe faster than the CPU. The maximum speedup is 960×, reached for 106 group velocities.This speedup should be useful in more realistic problems, like velocity-selective transitionsin multilevel atomic systems, where the calculations on CPU for different group velocitiesand laser frequencies can lead several days.
1

88
APÊNDICE 7: RESUMO DA APRESENTAÇÃO PARA O GRUPO DE PES-
QUISA ESTRUTURA DA MATÉRIA E FÍSICA COMPUTACIONAL
ESTRUTURA DA MATÉRIA E FÍSICA
COMPUTACIONAL
Resumo: As equações de Bloch descrevem a interação da matriz densidade com um
campo eletromagnético ao longo do tempo. Abordamos neste trabalho a solução
dessas equações para um sistema atômico de dois níveis interagindo com um trem de
pulsos de laser ultracurtos. Utilizamos o método Runge-Kutta de 4ª ordem para
solução do sistema de equações. Adotamos parâmetros compatíveis com vapor
atômico de rubídio. Como nos interessa o deslocamento Doppler, efetuamos a
distribuição Maxwell-Boltzmann das velocidades. Para um perfil Doppler adequado
do vapor atômico de rubídio a faixa de velocidades calculadas vai de -600 a 600 m/s.
A solução computacional se torna custosa e demorada para um programa sequencial
comum, mas tem uma natureza obviamente paralelizável. O uso de unidades de
processamento gráfico (GPUs) para problemas computacionais paralelizáveis tem se
difundido nos últimos anos nas mais diversas áreas da ciência, como por exemplo em
problemas físicos envolvendo simulações de Monte Carlo. Realizamos testes em
placas NVIDIA, usando a plataforma CUDA em linguagem C. Comparamos o
desempenho em três processadores (CPUs) e quatro GPUs distintas para estabelecer
uma diferença entre os métodos e o ganho de desempenho ao se utilizar a paralelização
na GPU. Identificamos uma melhora máxima de 980x no tempo de execução na
comparação entre uma placa GTX 960 Ti e um processador Intel i5 4460. A melhora
no tempo se estabelece, em ordens menores, mesmo se utilizando uma placa de baixo
custo como a GT 210 em comparação a um processador intermediário como o i5 4460.
27 de abril de 2016, quarta-feira, 10 h
Laboratório Didático de Física e Química do
Departamento de Física de Ji-Paraná - UNIR
Seminário de Grupo
Teo Victor Resende da Silva
Departamento de Física - UNIR
Solução das equações de Bloch para
sistemas atômicos de dois níveis via GPUs

89
ANEXO 1: ACEITAÇÃO ENF 2016
15/06/2016 ENF2016
https://sec.sbfisica.org.br/eventos/enf/2016/sys/comprovantefinal_pt.asp?traId=1&aut=235156 1/1
Encontro de Física 2016 03 a 07 de setembro de 2016, Natal, RN
Declaração
Declaramos que o trabalho Density matrix calculations of Dopplerbroadened atomic systemsimplemented on GPUs de autoria de Teo Victor Resende da Silva, Marco P. M. de Souza foiaceito para apresentação no(a) Encontro de Física 2016 no período de 03 a 07 de setembro de 2016,Natal, RN.
Apresentador: Marco P. M. de Souza (Universidade Federal de Rondônia (UNIR))Inscrição/Trabalho: 146/1
A forma de apresentação será informada em breve. São Paulo, 15 de junho de 2016
Comitê OrganizadorENF2016

90
ANEXO 2: CÓDIGO FONTE CUDA-C PARA A SOLUÇÃO PARA SISTE-
MAS DE TRÊS NÍVEIS TIPO Λ NA GPU
1 #include "cuda_runtime.h"
2 #include "device_launch_parameters.h"
3 #include "math.h"
4
5 #include <stdio.h>
6 #include <iostream >
7 #include <time.h>
8 #include "cuComplex.h"
9
10 // Desenvolvido por Marco Polo Moreno de Souza em 01/06/2017
11
12 #define Pi 3.141592653589793
13
14 #define blocks 100
15 #define threads 128
16
17 #define varredura 36
18
19 #define q33 (2*Pi*5e6)
20 #define q13 (0.5* q33)
21 #define q12 0
22 #define phi 0
23
24 #define fr0 100e6 //Taxa de repeticao (SI)
25 #define Tp 100e-15 // Largura de temporal do fento (SI)
26 #define Pulsos 100
27
28 #define PontosFemto 10
29 #define Passo 5 //em unidades de Hz
30
31 #define Omega (0.2* q33/(fr0*Tp))
32
33 #define w1 0
34 #define w2 (2*Pi *6800e6)
35 #define w3 (2*Pi*384 e12)
36 #define w (2*Pi*384 e12)
37 #define d 0
38
39 #define CUDA_ERROR_CHECK
40 #define CudaCheckError () __cudaCheckError(__FILE__ , __LINE__)
41
42 inline void __cudaCheckError(const char *file , const int line)
43
44 #ifdef CUDA_ERROR_CHECK

91
45 cudaError err = cudaGetLastError ();
46 if (cudaSuccess != err)
47
48 fpr intf (stderr , "cudaCheckError () failed at %s:%i : %s\n",
49 file , line , cudaGetErrorString(err));
50 system("pause");
51 exit(-1);
52
53 #endif
54
55 return;
56
57
58 __device__ void f(double a11 , double a22 , double a33 ,
59 double a12 , double b12 , double a13 ,
60 double b13 , double a23 , double b23 ,
61 int j, double &saida , double alpha) // sistema de 3
niveis
62
63 if (j==1) saida = 2*Omega *(cos(alpha)*b13 -sin(alpha)*a13) +0.5* q33*a33
;
64 if (j==2) saida = 2*Omega *(cos(alpha)*b23 -sin(alpha)*a23) +0.5* q33*a33
;
65 if (j==3) saida = 2*Omega *(sin(alpha)*(a13+a23)-cos(alpha)*(b13+b23)) -q33*a33
;
66
67 if (j==4) saida = -(w2-w1)*b12+Omega*(cos(alpha)*(b13+b23)-sin(alpha)*(a13+a23))-a12*
q12;
68 if (j==5) saida = (w2-w1)*a12+Omega*(cos(alpha)*(a23 -a13)+sin(alpha)*(b23 -b13))-b12*
q12;
69
70 if (j==6) saida = -(d-w1)*b13+Omega*cos(alpha)*b12+Omega*sin(alpha)*(a12+a11 -a33)-
a13*q13;
71 if (j==7) saida = (d-w1)*a13+Omega*sin(alpha)*b12+Omega*cos(alpha)*(a33 -a11 -a12)-
b13*q13;
72 if (j==8) saida = -(d-w2)*b23 -Omega*cos(alpha)*b12+Omega*sin(alpha)*(a12+a22 -a33)-
a23*q13;
73 if (j==9) saida = (d-w2)*a23 -Omega*sin(alpha)*b12+Omega*cos(alpha)*(a33 -a22 -a12)-
b23*q13;
74
75
76 __global__ void Kernel(double *a11 , double *a22 , double *a33 , double *a12 , double *b12 ,
double *a13 , double *b13 , double *a23 , double *b23 , int *jj)
77
78 // Paralelizacao na taxa de repeticao (variavel fr)
79
80 const int nucleos = blocks*threads;
81 int n,j,k,N,g;
82 double teste;

92
83 double k11_1 ,k11_2 ,k11_3 ,k11_4;
84 double k22_1 ,k22_2 ,k22_3 ,k22_4;
85 double k33_1 ,k33_2 ,k33_3 ,k33_4;
86 double ka12_1 ,ka12_2 ,ka12_3 ,ka12_4;
87 double kb12_1 ,kb12_2 ,kb12_3 ,kb12_4;
88 double ka13_1 ,ka13_2 ,ka13_3 ,ka13_4;
89 double kb13_1 ,kb13_2 ,kb13_3 ,kb13_4;
90 double ka23_1 ,ka23_2 ,ka23_3 ,ka23_4;
91 double kb23_1 ,kb23_2 ,kb23_3 ,kb23_4;
92 double c11 ,c22 ,c33;
93 double c12 ,c13 ,c23;
94 double d12 ,d13 ,d23;
95 double x1,x2,x3,z1 ,z2;
96 double h,t,Tr,fr,alpha;
97
98 int i = blockDim.x * blockIdx.x + threadIdx.x;
99
100 fr = fr0 + (i + nucleos*jj[0])*Passo;
101
102 t = 0;
103 N = -1;
104 Tr = 1/fr;
105 g = PontosFemto;
106 h = Tp/g;
107 //d = w3 - w;
108
109 c11 = c22 = c33 = 0;
110 c12 = c13 = c23 = 0;
111 d12 = d13 = d23 = 0;
112
113
114 for (n=1; n<=2* Pulsos +1; n++) //loop pulsos
115
116 if (n % 2 == 0)
117
118 N = N + 1;
119
120 alpha = -N*w*Tr + N*phi;
121
122 for (k=1; k<=g; k++) //loop tempo
123
124 t = t + h;
125
126 for (j=1; j<=9; j++)
127
128 f(a11[i],a22[i],a33[i],a12[i],b12[i],a13[i],b13[i
],a23[i],b23[i],j,teste ,alpha);
129
130 if (j==1) k11_1=teste; if (j==2) k22_1=teste;

93
if (j==3) k33_1=teste;
131 if (j==4) ka12_1=teste; if (j==5) kb12_1=teste;
if (j==6) ka13_1=teste;
132 if (j==7) kb13_1=teste; if (j==8) ka23_1=teste;
if (j==9) kb23_1=teste;
133
134
135 for (j=1; j<=9; j++)
136
137 f(a11[i]+ k11_1*h/2,a22[i]+ k22_1*h/2,a33[i]+k33_1*
h/2,a12[i]+ ka12_1*h/2,b12[i]+ kb12_1*h/2,a13[i
]+ ka13_1*h/2,b13[i]+ kb13_1*h/2,
138 a23
[
i
]+
ka23_1
*
h
/2,
b23
[
i
]+
kb23_1
*
h
/2,
j
,
teste
,
alpha
)
;
139 if (j==1) k11_2=teste; if (j==2) k22_2=teste;
if (j==3) k33_2=teste;
140 if (j==4) ka12_2=teste; if (j==5) kb12_2=teste;
if (j==6) ka13_2=teste;
141 if (j==7) kb13_2=teste; if (j==8) ka23_2=teste;
if (j==9) kb23_2=teste;
142
143
144 for (j=1; j<=9; j++)
145
146 f(a11[i]+ k11_2*h/2,a22[i]+ k22_2*h/2,a33[i]+k33_2*
h/2,a12[i]+ ka12_2*h/2,b12[i]+ kb12_2*h/2,a13[i
]+ ka13_2*h/2,b13[i]+ kb13_2*h/2,

94
147 a23
[
i
]+
ka23_2
*
h
/2,
b23
[
i
]+
kb23_2
*
h
/2,
j
,
teste
,
alpha
)
;
148 if (j==1) k11_3=teste; if (j==2) k22_3=teste;
if (j==3) k33_3=teste;
149 if (j==4) ka12_3=teste; if (j==5) kb12_3=teste;
if (j==6) ka13_3=teste;
150 if (j==7) kb13_3=teste; if (j==8) ka23_3=teste;
if (j==9) kb23_3=teste;
151
152
153 for (j=1; j<=9; j++)
154
155 f(a11[i]+ k11_3*h,a22[i]+k22_3*h,a33[i]+k33_3*h,
a12[i]+ ka12_3*h,b12[i]+ kb12_3*h,a13[i]+ ka13_3
*h,b13[i]+ kb13_3*h,
156 a23
[
i
]+
ka23_3
*
h
,
b23
[
i
]+

95
kb23_3
*
h
,
j
,
teste
,
alpha
)
;
157 if (j==1) k11_4=teste; if (j==2) k22_4=teste;
if (j==3) k33_4=teste;
158 if (j==4) ka12_4=teste; if (j==5) kb12_4=teste;
if (j==6) ka13_4=teste;
159 if (j==7) kb13_4=teste; if (j==8) ka23_4=teste;
if (j==9) kb23_4=teste;
160
161
162 a11[i] = a11[i] + h*( k11_1 /6+ k11_2 /3+ k11_3 /3+ k11_4 /6)
; a22[i] = a22[i] + h*( k22_1 /6+ k22_2 /3+ k22_3 /3+
k22_4 /6);
163 a33[i] = a33[i] + h*( k33_1 /6+ k33_2 /3+ k33_3 /3+ k33_4 /6)
;
164 a12[i] = a12[i] + h*( ka12_1 /6+ ka12_2 /3+ ka12_3 /3+ ka12_4 /6)
; b12[i] = b12[i] + h*( kb12_1 /6+ kb12_2 /3+ kb12_3 /3+
kb12_4 /6);
165 a13[i] = a13[i] + h*( ka13_1 /6+ ka13_2 /3+ ka13_3 /3+ ka13_4 /6)
; b13[i] = b13[i] + h*( kb13_1 /6+ kb13_2 /3+ kb13_3 /3+
kb13_4 /6);
166 a23[i] = a23[i] + h*( ka23_1 /6+ ka23_2 /3+ ka23_3 /3+ ka23_4 /6)
; b23[i] = b23[i] + h*( kb23_1 /6+ kb23_2 /3+ kb23_3 /3+
kb23_4 /6);
167
168 //loop tempo
169
170
171
172 if (n % 2 == 1)
173
174 t = t + (Tr-Tp);
175 x1 = (w2-w1)*(Tr-Tp);
176 x2 = (d -w1)*(Tr -Tp);
177 x3 = (d -w2)*(Tr -Tp);
178 z1 = q33*(Tr-Tp);
179 z2 = q12*(Tr-Tp);
180
181 c11 = a11[i] + 0.5* a33[i]*(1-exp(-z1));

96
182 c22 = a22[i] + 0.5* a33[i]*(1-exp(-z1));
183 c33 = a33[i]*exp(-z1);
184 c12 = (a12[i]*cos(x1)-b12[i]*sin(x1))*exp(-z2);
185 d12 = (a12[i]*sin(x1)+b12[i]*cos(x1))*exp(-z2);
186 c13 = (a13[i]*cos(x2)-b13[i]*sin(x2))*exp( -0.5*z1);
187 d13 = (a13[i]*sin(x2)+b13[i]*cos(x2))*exp( -0.5*z1);
188 c23 = (a23[i]*cos(x3)-b23[i]*sin(x3))*exp( -0.5*z1);
189 d23 = (a23[i]*sin(x3)+b23[i]*cos(x3))*exp( -0.5*z1);
190
191 a11[i] = c11; a22[i] = c22; a33[i] = c33;
192 a12[i] = c12; a13[i] = c13; a23[i] = c23;
193 b12[i] = d12; b13[i] = d13; b23[i] = d23;
194
195
196 //loop pulsos
197
198
199
200 int main()
201
202 clock_t begin , end;
203 double time_spent;
204 begin = clock();
205
206 FILE *arquivo;
207 arquivo=fopen("dados.dat","w");
208 const int nucleos = blocks*threads;
209
210 cudaDeviceProp prop;
211 int count;
212
213 cudaGetDeviceCount (&count);
214 for (int s=0;s<count;s++)
215
216 cudaGetDeviceProperties (&prop ,s);
217 printf ("General information\n");
218 printf ("%s", prop.name);
219 printf (", Compute Capability %d.%d\n", prop.major , prop.minor);
220 printf ("Clock rate: %d MHz\n", int(prop.clockRate /1000));
221 printf ("Kernel execition timeout: ");
222 if (prop.kernelExecTimeoutEnabled) printf ("Enabled\n");
223 else printf ("
Disabled\n
");
224 printf ("Max threads per block: %d\n", prop.maxThreadsPerBlock);
225 printf ("Max thread dimensions: (%d, %d, %d)\n", prop.maxThreadsDim [0],
prop.maxThreadsDim [1], prop.maxThreadsDim [2]);
226 printf ("Max grid dimensions: (%d, %d)\n", prop.maxGridSize [1], prop.
maxGridSize [2]);

97
227 printf ("Multiprocessor count: %d\n", prop.multiProcessorCount);
228 printf ("Shared memory per MP: %ld kb\n", prop.sharedMemPerBlock /1024);
229 printf ("Registers per MP: %d\n", prop.regsPerBlock);
230 printf ("Warp size: %ld\n\n", prop.warpSize);
231 // printf ("Total Global Memory: %d\n\n", prop.totalGlobalMem);
232
233
234 printf ("Blocks = %d\n", blocks);
235 printf ("Threads = %d\n\n", threads);
236
237 printf ("Calculando ...\n");
238
239 double a11[nucleos ]; double a22[nucleos ];
240 double a33[nucleos ];
241 double a12[nucleos ]; double b12[nucleos ];
242 double a23[nucleos ]; double b23[nucleos ];
243 double a13[nucleos ]; double b13[nucleos ];
244 int jj[1];
245 double soma ,dfr;
246
247 double *dev_a11; double *dev_a22;
248 double *dev_a33;
249 double *dev_a12; double *dev_b12;
250 double *dev_a13; double *dev_b13;
251 double *dev_a23; double *dev_b23;
252 int *dev_jj;
253
254 cudaMalloc((void **)&dev_a11 , nucleos * sizeof(double)); cudaMalloc((void **)&
dev_a22 , nucleos * sizeof(double));
255 cudaMalloc((void **)&dev_a33 , nucleos * sizeof(double));
256 cudaMalloc((void **)&dev_a12 , nucleos * sizeof(double)); cudaMalloc((void **)&
dev_b12 , nucleos * sizeof(double));
257 cudaMalloc((void **)&dev_a23 , nucleos * sizeof(double)); cudaMalloc((void **)&
dev_b23 , nucleos * sizeof(double));
258 cudaMalloc((void **)&dev_a13 , nucleos * sizeof(double)); cudaMalloc((void **)&
dev_b13 , nucleos * sizeof(double));
259 cudaMalloc((void **)&dev_jj , 1 * sizeof(int));
260
261 fpr intf (arquivo , "fr rho11 rho22 rho33 sigma12\n");
262 for (int pp=-varredura; pp <=varredura -1; pp++)
263
264 jj[0] = pp;
265
266 for (int q=0;q<=nucleos -1;q++)
267
268 a11[q] = 0.5; a22[q] = 0.5;
269 a33[q] = 0;
270 a12[q] = 0; b12[q] = 0;
271 a13[q] = 0; b13[q] = 0;

98
272 a23[q] = 0; b23[q] = 0;
273
274
275 cudaMemcpy(dev_a11 , a11 , nucleos * sizeof(double), cudaMemcpyHostToDevice
); cudaMemcpy(dev_a22 , a22 , nucleos * sizeof(double),
cudaMemcpyHostToDevice);
276 cudaMemcpy(dev_a33 , a33 , nucleos * sizeof(double), cudaMemcpyHostToDevice
);
277 cudaMemcpy(dev_a12 , a12 , nucleos * sizeof(double), cudaMemcpyHostToDevice
); cudaMemcpy(dev_b12 , b12 , nucleos * sizeof(double),
cudaMemcpyHostToDevice);
278 cudaMemcpy(dev_a23 , a23 , nucleos * sizeof(double), cudaMemcpyHostToDevice
); cudaMemcpy(dev_b23 , b23 , nucleos * sizeof(double),
cudaMemcpyHostToDevice);
279 cudaMemcpy(dev_a13 , a13 , nucleos * sizeof(double), cudaMemcpyHostToDevice
); cudaMemcpy(dev_b13 , b13 , nucleos * sizeof(double),
cudaMemcpyHostToDevice);
280 cudaMemcpy(dev_jj , jj, 1 * sizeof(int), cudaMemcpyHostToDevice);
281
282 Kernel <<<blocks ,threads >>>(dev_a11 , dev_a22 , dev_a33 , dev_a12 , dev_b12 ,
dev_a13 , dev_b13 , dev_a23 , dev_b23 , dev_jj);
283 CudaCheckError ();
284
285 // cudaDeviceSynchronize waits for the kernel to finish , and returns
286 // any errors encountered during the launch.
287 cudaDeviceSynchronize ();
288
289 cudaMemcpy(a11 , dev_a11 , nucleos * sizeof(double), cudaMemcpyDeviceToHost
); cudaMemcpy(a22 , dev_a22 , nucleos * sizeof(double),
cudaMemcpyDeviceToHost);
290 cudaMemcpy(a33 , dev_a33 , nucleos * sizeof(double), cudaMemcpyDeviceToHost
);
291 cudaMemcpy(a12 , dev_a12 , nucleos * sizeof(double), cudaMemcpyDeviceToHost
); cudaMemcpy(b12 , dev_b12 , nucleos * sizeof(double),
cudaMemcpyDeviceToHost);
292 cudaMemcpy(a13 , dev_a13 , nucleos * sizeof(double), cudaMemcpyDeviceToHost
); cudaMemcpy(b13 , dev_b13 , nucleos * sizeof(double),
cudaMemcpyDeviceToHost);
293 cudaMemcpy(a23 , dev_a23 , nucleos * sizeof(double), cudaMemcpyDeviceToHost
); cudaMemcpy(b23 , dev_b23 , nucleos * sizeof(double),
cudaMemcpyDeviceToHost);
294
295 printf ("*%d ", jj[0]);
296 for (int q=0; q<=nucleos -1; q++)
297
298 dfr = (q + jj[0]* nucleos)*Passo;
299 soma = a11[q] + a22[q] + a33[q];
300 printf ( "%d %.12f %.12f %.12f %.12f\n", q, a11[q],
a22[q], a33[q], soma);

99
301 fpr intf (arquivo , "%.12f %.12f %.12f %.12f %.12f\n", dfr , a11[q],
a22[q], a33[q], sqrt(a12[q]*a12[q]+b12[q]*b12[q]));
302
303
304
305 cudaFree(dev_a11);cudaFree(dev_a22);
306 cudaFree(dev_a33);
307 cudaFree(dev_a12);cudaFree(dev_b12);
308 cudaFree(dev_a13);cudaFree(dev_b13);
309 cudaFree(dev_a23);cudaFree(dev_b23);
310 cudaFree(dev_jj);
311
312 // cudaDeviceReset must be called before exiting in order for profiling and
313 // tracing tools such as Nsight and Visual Profiler to show complete traces.
314 cudaDeviceReset();
315
316 end = clock();
317 time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
318 if (time_spent <=60) printf ("\nTempo de execucao = %f s\n\n", time_spent);
319 if (time_spent > 60 && time_spent <= 3600) printf ("\nTempo de execucao = %f min\n\n
", time_spent /60);
320 if (time_spent >3600) printf ("\nTempo de execucao = %f h\n\n", time_spent /3600);
321
322 printf ("\a");
323 system ("pause");
324 fc lose (arquivo);
325

100
ANEXO 3: CÓDIGO FONTE C++ PARA A SOLUÇÃO PARA SISTEMAS
DE TRÊS NÍVEIS TIPO Λ NA CPU
1 #include <stdio.h>
2 #include <math.h>
3 #include <time.h>
4 #include <iostream >
5
6 //31 -05 -2010
7 // Reescrito em 25/03/2017
8 // calculos numericos na presenca do campo
9 // calculos analiticos no decaimento
10 //Plota Populacoes e coerencias vs fr
11 // Efeito apos passagem de apenas N pulsos
12 //Para sistemas em lambda
13
14 const double Pi = 3.141592654;
15
16 const double q33 = (2*Pi)*5e6;
17 const double q13 = 0.5* q33;
18 const double q12 = 0;
19 const double phi = 0;
20
21 const double fr0 = 100e6; //Taxa de repeticao (SI)
22 const double Tp = 100e-15; // Largura de temporal do fento (SI)
23 const double Omega = 0.2* q33/(fr0*Tp);
24 const int Pulsos = 100;
25
26 const double PassoFemto = 10;
27 const double Passo = 5; //em unidades de Hz
28 const int Varredura = 450000; //em unidades do Passo
29
30 const double w1 = 0;
31 const double w2 = 2*Pi*6800e6;
32 const double w3 = 2*Pi*384 e12;
33 const double w = 2*Pi*384 e12;
34
35 double x1,x2,x3,z1 ,z2,saida;//soma ,
36 double d,h,t;
37 double Tr,fr,a10 ,a20 ,a30 ,alpha;
38 int n,j,k,g,N,p;
39
40 double a11 ,a22 ,a33 ,a12 ,b12 ,a13 ,b13 ,a23 ,b23;
41 double c11 ,c22 ,c33 ,c12 ,c13 ,c23 ,d12 ,d13 ,d23;
42 double k11_1 ,k11_2 ,k11_3 ,k11_4;
43 double k22_1 ,k22_2 ,k22_3 ,k22_4;
44 double k33_1 ,k33_2 ,k33_3 ,k33_4;

101
45 double ka12_1 ,ka12_2 ,ka12_3 ,ka12_4;
46 double kb12_1 ,kb12_2 ,kb12_3 ,kb12_4;
47 double ka13_1 ,ka13_2 ,ka13_3 ,ka13_4;
48 double kb13_1 ,kb13_2 ,kb13_3 ,kb13_4;
49 double ka23_1 ,ka23_2 ,ka23_3 ,ka23_4;
50 double kb23_1 ,kb23_2 ,kb23_3 ,kb23_4;
51
52 void f(double a11 ,double a22 ,double a33 ,
53 double a12 ,double b12 ,double a13 ,
54 double b13 ,double a23 ,double b23 ,int i) // sistema Lambda
55
56 if (i==1) saida = 2*Omega *(cos(alpha)*b13 -sin(alpha)*a13) +0.5* q33*a33
;
57 if (i==2) saida = 2*Omega *(cos(alpha)*b23 -sin(alpha)*a23) +0.5* q33*a33
;
58 if (i==3) saida = 2*Omega *(sin(alpha)*(a13+a23)-cos(alpha)*(b13+b23)) -q33*a33
;
59
60 if (i==4) saida = -(w2-w1)*b12+Omega*(cos(alpha)*(b13+b23)-sin(alpha)*(a13+a23))-a12*
q12;
61 if (i==5) saida = (w2-w1)*a12+Omega*(cos(alpha)*(a23 -a13)+sin(alpha)*(b23 -b13))-b12*
q12;
62
63 if (i==6) saida = -(d-w1)*b13+Omega*cos(alpha)*b12+Omega*sin(alpha)*(a12+a11 -a33)
-0.5*a13*q33;
64 if (i==7) saida = (d-w1)*a13+Omega*sin(alpha)*b12+Omega*cos(alpha)*(a33 -a11 -a12)
-0.5*b13*q33;
65 if (i==8) saida = -(d-w2)*b23 -Omega*cos(alpha)*b12+Omega*sin(alpha)*(a12+a22 -a33)
-0.5*a23*q33;
66 if (i==9) saida = (d-w2)*a23 -Omega*sin(alpha)*b12+Omega*cos(alpha)*(a33 -a22 -a12)
-0.5*b23*q33;
67
68
69 main()
70
71 clock_t begin , end;
72 double time_spent;
73 begin = clock();
74
75 FILE *arquivo;
76 arquivo=fopen("dados.dat","w");
77
78 fpr intf (arquivo , "tempo rho11 rho22 rho33 sigma12\n");
79
80 a10 = 0.5; // populacao inicial do estado 1
81 a20 = 0.5; // populacao inicial do estado 2
82 a30 = 0; // populacao inicial do estado 3
83
84 a11 = a10; a22 = a20; a33 = a30;

102
85 a12 = 0; b12 = 0; a13 = 0;
86 b13 = 0; a23 = 0; b23 = 0;
87
88 d = w3 - w;
89
90 for (p=-Varredura; p<= Varredura; p++)
91
92 t = 0;
93 N = -1;
94 fr = fr0 + p*Passo;
95 Tr = 1/fr;
96
97 for (n=1; n<=2* Pulsos +1; n++)
98
99 // printf ("*");
100 if (n % 2 == 0)
101
102 N = N + 1;
103 g = PassoFemto;
104 h = (1/ double(g))*Tp;
105
106 alpha = -N*w*Tr + N*phi;
107
108 for (k=1; k<=g; k++)
109
110 t = t + h;
111
112 for (j=1;j<=9;j++)
113
114 f(a11 ,a22 ,a33 ,a12 ,b12 ,a13 ,b13 ,a23 ,b23 ,j);
115
116 if (j==1) k11_1=saida; if (j==2) k22_1=
saida; if (j==3) k33_1=saida;
117 if (j==4) ka12_1=saida; if (j==5) kb12_1=
saida; if (j==6) ka13_1=saida; if (j
==7) kb13_1=saida;
118 if (j==8) ka23_1=saida; if (j==9) kb23_1=
saida;
119
120
121 for (j=1;j<=9;j++)
122
123 f(a11+k11_1*h/2,a22+k22_1*h/2,a33+k33_1*h
/2,a12+ka12_1*h/2,b12+kb12_1*h/2,a13+
ka13_1*h/2,b13+kb13_1*h/2,
124 a23
+
ka23_1
*

103
h
/2,
b23
+
kb23_1
*
h
/2,
j
)
;
125 if (j==1) k11_2=saida; if (j==2) k22_2=
saida; if (j==3) k33_2=saida;
126 if (j==4) ka12_2=saida; if (j==5) kb12_2=
saida; if (j==6) ka13_2=saida; if (j
==7) kb13_2=saida;
127 if (j==8) ka23_2=saida; if (j==9) kb23_2=
saida;
128
129
130 for (j=1;j<=9;j++)
131
132 f(a11+k11_2*h/2,a22+k22_2*h/2,a33+k33_2*h
/2,a12+ka12_2*h/2,b12+kb12_2*h/2,a13+
ka13_2*h/2,b13+kb13_2*h/2,
133 a23+
ka23_2
*
h
/2,
b23
+
kb23_2
*
h
/2,
j
)
;
134 if (j==1) k11_3=saida; if (j==2) k22_3=
saida; if (j==3) k33_3=saida;
135 if (j==4) ka12_3=saida; if (j==5) kb12_3=
saida; if (j==6) ka13_3=saida; if (j
==7) kb13_3=saida;
136 if (j==8) ka23_3=saida; if (j==9) kb23_3=
saida;
137
138

104
139 for (j=1;j<=9;j++)
140
141 f(a11+k11_3*h,a22+k22_3*h,a33+k33_3*h,a12
+ka12_3*h,b12+kb12_3*h,a13+ka13_3*h,
b13+kb13_3*h,
142 a23+
ka23_3
*
h
,
b23
+
kb23_3
*
h
,
j
)
;
143 if (j==1) k11_4=saida; if (j==2) k22_4=
saida; if (j==3) k33_4=saida;
144 if (j==4) ka12_4=saida; if (j==5) kb12_4=
saida; if (j==6) ka13_4=saida; if (j
==7) kb13_4=saida;
145 if (j==8) ka23_4=saida; if (j==9) kb23_4=
saida;
146
147
148 a11 = a11 + h*( k11_1 /6+ k11_2 /3+ k11_3 /3+ k11_4
/6); a22 = a22 + h*( k22_1 /6+ k22_2 /3+ k22_3
/3+ k22_4 /6);
149 a33 = a33 + h*( k33_1 /6+ k33_2 /3+ k33_3 /3+ k33_4
/6);
150 a12 = a12 + h*( ka12_1 /6+ ka12_2 /3+ ka12_3 /3+ ka12_4
/6); b12 = b12 + h*( kb12_1 /6+ kb12_2 /3+ kb12_3
/3+ kb12_4 /6);
151 a13 = a13 + h*( ka13_1 /6+ ka13_2 /3+ ka13_3 /3+ ka13_4
/6); b13 = b13 + h*( kb13_1 /6+ kb13_2 /3+ kb13_3
/3+ kb13_4 /6);
152 a23 = a23 + h*( ka23_1 /6+ ka23_2 /3+ ka23_3 /3+ ka23_4
/6); b23 = b23 + h*( kb23_1 /6+ kb23_2 /3+ kb23_3
/3+ kb23_4 /6);
153
154
155
156 if (n % 2 == 1)
157
158 t = t + (Tr-Tp);
159 x1 = (w2-w1)*(Tr-Tp);

105
160 x2 = (d -w1)*(Tr -Tp);
161 x3 = (d -w2)*(Tr -Tp);
162 z1 = q33*(Tr-Tp);
163 z2 = q12*(Tr-Tp);
164
165 c11 = a11 + 0.5* a33*(1-exp(-z1));
166 c22 = a22 + 0.5* a33*(1-exp(-z1));
167 c33 = a33*exp(-z1);
168 c12 = (a12*cos(x1)-b12*sin(x1))*exp(-z2);
169 d12 = (a12*sin(x1)+b12*cos(x1))*exp(-z2);
170 c13 = (a13*cos(x2)-b13*sin(x2))*exp(-0.5*z1);
171 d13 = (a13*sin(x2)+b13*cos(x2))*exp(-0.5*z1);
172 c23 = (a23*cos(x3)-b23*sin(x3))*exp(-0.5*z1);
173 d23 = (a23*sin(x3)+b23*cos(x3))*exp(-0.5*z1);
174
175 a11 = c11; a22 = c22; a33 = c33;
176 a12 = c12; a13 = c13; a23 = c23;
177 b12 = d12; b13 = d13; b23 = d23;
178
179
180
181 fpr intf (arquivo ,"%12.10f %12.10f %12.10f %12.10f %12.10f %12.10f %12.10f
%12.10f %12.10f %12.10f %12.10f %12.10f %12.10f %12.10f %12.10f\n",
182 p*Passo ,a11 ,a22 ,a33 ,sqrt(a12*a12+b12*b12),sqrt(a13*a13+b13*b13),
183 sqrt(a23*a23+b23*b23) ,0.5*a11 +0.5* a22+a12 ,0.5* a11 +0.5*a22 -a12 ,a12 ,b12 ,a13 ,
b13 ,a23 ,b23);
184
185 a11 = a10; a22 = a20; a33 = a30;
186 a12 = 0; b12 = 0; a13 = 0;
187 b13 = 0; a23 = 0; b23 = 0;
188
189
190 fc lose (arquivo);
191 printf ("\a");
192
193 end = clock();
194 time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
195 if (time_spent <=60) printf ("\nTempo de execucao = %f s\n\n", time_spent);
196 if (time_spent > 60 && time_spent <= 3600) printf ("\nTempo de execucao = %f min\n\n
", time_spent /60);
197 if (time_spent >3600) printf ("\nTempo de execucao = %f h\n\n", time_spent /3600);
198