weka pentaho day2014-fidelis
TRANSCRIPT

1
Minerando seu Data Warehouse (WEKA)
Marcos Vinicius Fidelis
Analista de Informática – Universidade Estadual de Ponta GrossaProfessor – Universidade Tecnológica Federal do Paraná

2
Agenda● Comparação DW x DM● KDD e fases● Data Mining● Motivação● Tarefas de DM● Classificação● Regressão● Árvore de Decisão – C4.5 ● WEKA● Histórico● Formato ARFF● Datsets● Explorer● Screenshots de classificadores● Módulos Pentaho● Seleção de atributos● Experimenter● Avaliação de classificadores e privacidade● Usos de DM● DM é perigoso!● Cursos● Considerações Finais

3
Módulos Pentaho
A Suite Pentaho OSBI é composta pelo Pentaho BI Server, Pentaho Data Integration, Pentaho Analysis, Pentaho Reporting, Pentaho Dasboards e Pentaho Data Mining.– Pentaho Data Integration: Ta mbém conhecido como Kettle é uma solução robusta para integração de dados, recomendada
para processos de ETL (do inglês Extract, Transfomation and Load) responsáveis por popular um Data Warehouse, Migração de base de dados e Integração entre Aplicações. Não deixa nada a desejar para os principais player’s do mercado.
– Pentaho Analysis: Também conhecido como Mondrian é um poderoso motor olap, baseado em uma arquitetura ROLAP, onde pode-se utilizar os principais SGBD’s do mercado. Possui diversas funcionalidades, como, camada de metadados, linguagem MDX, cache em memória, tabelas agregadas e muito mais.
– Pentaho Reporting: Este módulo da suite comtempla duas ferramentas, uma ferramenta de geração de relatórios, também conhecida como JFreeReport e outra para geração de metadados, a qual permite a criação Ad-Hoc de relatórios via web browser.
– Pentaho Dashboards: Este módulo da suite permite a criação de paineis de controle, mais conhecidos como Dashboards e através dele é possivel reunir em uma mesma tela, os principais indicadores de um departamento ou de toda a empresa.
– Pentaho Data Mining: Também conhecido como Weka é o módulo mais antigo da suite e possui poderosos recursos para mineração de dados.

4
Uma comparação DW x DM
● Data Warehouse pode ser definido como uma coleção de dados, orientados por assunto, integrados, variáveis com o tempo e não voláteis, para dar suporte ao processo de tomada de decisão.
● Data Mining é extração inteligente de dados. De acordo com alguns especialistas, o Data Warehouse, fornece memória mas não inteligência.
● A mineração de dados é uma ferramenta que permite adicionar inteligência à memória que a organização possui, permitindo realizar descobertas importantes dentro de grandes volumes de dados;– Data Warehouse é repositório “centralizado de dados”. O Data Warehouse integra os
dados corporativos de uma empresa em um “único repositório”;
– Data Mining não é uma evolução do Data Warehouse. A Mineração de Dados surgiu no início dos anos 90, a partir da reunião de idéias proveniente de diferentes áreas como Inteligência Artificial, Banco de Dados, Estatística, e Visualização de Dados. A principal motivação para o surgimento da Mineração de Dados encontra-se no fato de as organizações estarem armazenando de forma contínua uma enorme quantidade de dados a respeito de seus negócios nas últimas décadas. ;
●

5
Uma comparação DW x DM● Data Mining não depende do Data Warehouse, mas obtém-se melhores
resultados quando aplicados em conjunto. Especialistas definem Data Warehouse como um depósito central de dados, extraído de dados operacionais, em que a informação é orientada a assuntos, não volátil e de natureza histórica. Devido a essas características, Data Warehouses tendem a se tornar grandes repositórios de dados extremamente organizados, facilitando a aplicação do Data Mining;
● Cada empresa deve saber escolher qual das técnicas é importante para o seu negócio. (Uma, outra ou as duas);
● Data Warehouse aliado a ferramentas estatísticas desempenham papel semelhante ao Data Mining, mas não descobrem novos padrões de comportamento (a não ser empiricamente).
● Já o Data Mining descobre novos padrões de comportamento dos dados.

6
Knowledge Discovery in Databases (KDD)
“O processo não trivial de identificar em grandes conjuntos de dados, padrões que sejam válidos, novos, úteis e compreensíveis, buscando melhorar o entendimento de um problema ou um procedimento de tomada de decisão. (Fayyad et al. 1996)
KDD utiliza algoritmos de Data Mining para extrair padrões classificados como “conhecimento”.
Incorpora também tarefas como escolha do algoritmo adequado, processamento e amostragem de dados e interpretação de resultados;
Torture os dados até eles confessarem.

7
Fases do KDD● Definição do problema● Seleção dos dados● Pré-processamento dos dados● Transformação● Mineração dos dados ● Interpretação/Avaliação

8
Fases do KDD
Seleção dos dados Selecionar ou segmentar dados de acordo com critérios definidos. Seleciona-se os dados que tem relevância para o negócio. Ex:Todas as pessoas que são proprietárias de carros é um subconjunto de dados determinados.
Pré-processamento Estágio de limpeza dos dados,onde informações julgadas desnecessárias são removidas. Ex:O sexo de um paciente gestante. Reconfiguração dos dados para assegurar formatos consistentes (identificação). Ex:sexo = "M" ou "F" sexo = "Masc" ou "Fem"
Transformação Transforma-se os dados em formatos utilizáveis. Alguns algoritmos não manipulam determinados tipos de dados. Depende da técnica de Data Mining usada. Ex:rede neural -> converter valor literal em valor numérico. Disponibilizar os dados de maneira usável e navegável.
Mineração de dados É a verdadeira extração dos padrões de comportamento dos dados. Utilizando a definição de fatos,medidas de padrões, estados e o relacionamento entre eles.
Interpretação e Avaliação Identificado os padrões pelo sistema, estes são interpretados em conhecimentos, os quais darão suporte a tomada de decisões humanas. Ex:Tarefas de previsões e classificações.

9
Utilizando um DW em KDD
Com um DW vários dos passos iniciais do processo de KDD podem ser dispensados ou
acelerados

10
Data Mining
DATA MINING é um processo de busca de dados por PADRÕES anteriormente desconhecidos e uso frequente destes padrões para PREDIZER CONSEQUENCIAS futuras.
É o processo de explorar grandes quantidades de dados à procura de padrões consistentes, como regras de associação ou sequências temporais, para detectar relacionamentos sistemáticos entre variáveis, detectando assim novos subconjuntos de dados. (Wikipedia)

11
Data Mining
Mineração de Dados ou Garimpagem de Dados?
O termo da moda parece ser Mineração de Dados.
Garimpagem de Dados
Normalmente conhecida como Data Mining, erroneamente traduzida no Brasil para Mineração de Dados (o brasileiro pensa em mineração como um buraco aberto no chão, de onde saem toneladas de minério bruto), outro mundo dentro do mundo que é BI. Como DW, é interminável e fundamental para inteligência de negócios em grandes empresas. Leia Freakonomics para entender como estatística e modelagem matemática abrem uma janela de compreensão sobre a realidade (o exemplo de painel na análise da relação livros-estudantes de sucesso é, na minha opinião, a definição mais clara e concisa de Data Mining que eu já vi – e olha que eu vendia SAS…) Depois dele, leia Data Mining Techniques, de Gordon Linoff e Michael Berry. Daí você pode passar para alguma ferramenta: SAS, SPSS, R, Statistica, JMP, Weka…
Fábio de Salles

12
Motivação
● A informatização dos meios produtivos permitiu a geração de grandes volumes de dados– Transações eletrônicas, novos equipamentos e sensores.
● A sombra digital deixada por cada indivíduo aumenta significativamente com o avanço da tecnologia– Posts facebook, twitter, instagram, foursquare, blogs,
smartphones, logs diversos, etc.
● A capacidade de analisar os dados é infinitamente menor que a velocidade de geração dos mesmos dados

13
A internet em um minuto

14
Todos os padrões são interessantes?
Um padrão é interessante se:● Facilmente pode ser compreendido por humanos● É válido em dados de teste com um certo grau
de certeza● Potencialmente útil● Novo● Se valida uma hipótese do usuário

15
Tarefas de Data Mining
• Classificação: aprendizado de uma função que mapeia um dado em uma de várias classes conhecidas.
• Regressão (predição): aprendizado de uma função que mapeia um dado em um valor real.
• Agrupamento (clustering): identificação de grupos de dados onde os dados tem características semelhantes entre si e os grupos tem características diferentes.
• Sumarização: descrição do que caracteriza um conjunto de dados (ex. conjunto de regras).
• Detecção de desvios ou outliers: identificação de dados que deveriam seguir um padrão mas não o fazem.

16
Classificação
Encontrar um método para prever a classe de uma instância a partir de instâncias pré-classificadas
Dado um conjunto de pontos das classes (V)erde e (A)zul
Qual é a classe para o novo ponto (D)esconhecido ?
Ponto de classe desconhecida

17
Regressão Linear
w0 + w1 x + w2 y >= 0 Regressão calcula wi a partir dos dados
para minimizar o erro

18
Árvore de decisão
IF X > 5 THEN A ELSE IF Y > 3 THEN A ELSE IF X > 2 THEN V ELSE A
● Cada nó interno é um teste em um atributo
● Cada ramo representa um valor de teste● Cada folha representa uma classe
● Novas instâncias são classificadas seguindo o caminho que leva da raiz até a folha.

19
Árvore de decisão
● Algoritmo
a)Escolher um atributo
b)Estender a árvore adicionando um ramo para cada valor de atributo
c)Passae os exemplos para as folhas (tendo em conta o valor do atributo escolhido)
d)Para cada nó folha – se todos os exemplos são da mesma classe, associar esta classe ao nó folha, caso contrário repetir os passos a, b e c.

20
WEKA
● Desenvolvido na Universidade de Waikato, NZ– Mineração de Dados e Aprendizado de Máquina– Escrito em JAVA
– Distribuído por meio da licença de software livre da GNU
– Utilizada com diferentes propósitos
– Ensino, pesquisa, aplicações

21
WEKA @ pentaho● Data mining with Weka ● (One-of-the-many)
– Definition: Extraction of implicit, previously unknown, and potentially useful information from data.
● Goal: improve marketing, sales, and customer support operations, risk assessment etc. – Who is likely to remain a loyal customer? – What products should be marketed to which prospects? – What determines whether a person will respond to a certain offer?
– How can I detect potential fraud?
● Central idea: historical data contains information that will be useful in the future – (patterns => generalizations)
● Data Mining employs a set of algorithms that automatically detect patterns and regularities in data

22
História
● 1992 – submissão do projeto ao governo de NZ (Ian Witten)
● 1993 – aprovado pelo governo● 1994 – Primeira versão (principalmente em C)● 1996 – Primeira versão pública – WEKA 2.1● 1997 – Convertido para Java● 1998 – WEKA 3 (completamente Java)● 2006 – O projeto foi incorporado ao Pentaho

23
Pentaho Data Mining
● Pentaho Data Mining, é baseado no projeto WEKA, é um conjunto de ferramentas para aprendizado de máquina e mineração de dados.
● Seu amplo conjunto de classificação, regressão, regras de associação, e algoritmos de agrupamento pode ser usado para ajudá-lo a entender o negócio melhor e também ser explorado para melhorar o desempenho futuro através de análises preditivas.
● Possui 3 versões principais– WEKA 3.4 – versão estável criada em 2003 – para corresponder
com o que está descrito na 2 ª edição do livro de Witten e Frank livro Mineração de Dados (publicado 2005). Esta versão está congelada.
– WEKA 3.6 – versão estável criada em 2008 – referente a 3a edição – última (3.6.11)
– WEKA 3.7 – versão de desenvolvimento

24
Wheather: Jogar ou não jogar?@relation weather
@attribute outlook {sunny, overcast, rainy}@attribute temperature real@attribute humidity real@attribute windy {TRUE, FALSE}@attribute play {yes, no}
@datasunny,85,85,FALSE,nosunny,80,90,TRUE,noovercast,83,86,FALSE,yesrainy,70,96,FALSE,yesrainy,68,80,FALSE,yesrainy,65,70,TRUE,noovercast,64,65,TRUE,yessunny,72,95,FALSE,nosunny,69,70,FALSE,yesrainy,75,80,FALSE,yessunny,75,70,TRUE,yesovercast,72,90,TRUE,yesovercast,81,75,FALSE,yesrainy,71,91,TRUE,no

25
ARFF – Data types
● @attribute empName string● @attribute empSalary numeric● @attribute empGender {male, female}● @atttribute empDob date "yyyy-MM-dd"

26
Outros datasets para treinar
Linha 1 Linha 2 Linha 3 Linha 40
2
4
6
8
10
12
Coluna 1
Coluna 2
Coluna 3

27
PDI - Extração de dados do Facebook com a suíte Pentaho
http://www.devmedia.com.br/extracao-de-dados-do-facebook-com-a-suite-pentaho/25523

28
Weka – Explorer

29
Visualização Gráfica

30
Avaliando cada atributo

31
Classificador ZeroRO classificador ZeroR prevê a classe mais frequente para atributos categóricos e a média para Atributos numéricos. Útil para servir de “baseline” para avaliação de outros classificadores.

32
Classificador J48 (C4.5) – Árvore de Decisão
33
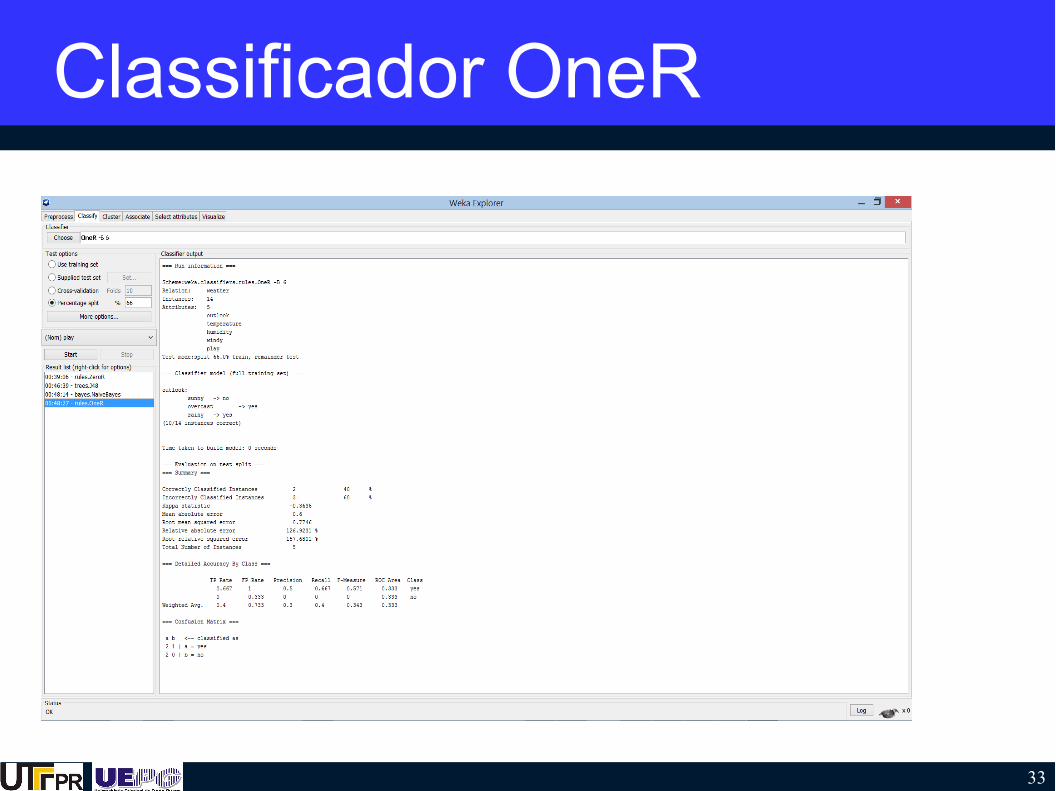
Classificador OneR

34
Database Iris

35
Iris - ZeroR

36
Iris - J48

37
Iris - OneR

38
Output source code
Linha 1 Linha 2 Linha 3 Linha 40
2
4
6
8
10
12
Coluna 1
Coluna 2
Coluna 3

39
Outras abordagens para classificadores
● Bayes– Calcula a probabilidade de que um novo dado
pertença a alguma classe previamente determinada
● Rules● Genetic Algorithms● Neural Net● Ensemble● E muitos outros.

40
Select Attributes
● Seleção de Atributos – realizado no pré-processamento dos dados
● Usado para investigar quais atributos (subconjuntos deles) são mais preditivos
● AttributeSelection em 2 etapas:– Um método de busca
– Um método de avaliação
● Flexibilidade: (quase) qualquer combinação de busca/avaliação

41
Experimenter
● permite a comparação de diferentes estratégias de aprendizagem.
● Para problemas de classificação e regressão● Resultados escritos em um arquivo ou base de dados● Opções de avaliação: cross-validation, curva de
aprendizagem, hold-out● Pode ser executado com diferentes configurações de
parâmetros● Teste de significância acoplado

42
Como avaliar classificadores?
● Acurácia● Custo/benefício total – quando diferentes
erros envolvem diferentes custos● Curvas de Lift e ROC● Erro em predições numéricas
Quanto confiável são os resultados previstos?

43
Data Mining e privacidade
● Data Mining busca PADRÕES e não PESSOAS.
● Soluções técnicas podem limitar a invasão de privacidade– Substituir informações sigilosas com um id anônimo
– Fornecer saídas aleatórias
– Utilizar rótulos em instâncias que escondam o real significado.

44
Áreas nas quais DM é aplicado de maneira satisfatória● Retenção de clientes: identificação de perfis para determinados produtos, venda
cruzada;● Bancos: identificar padrões para auxiliar no gerenciamento de relacionamento
com o cliente;● Cartão de Crédito: identificar segmentos de mercado, identificar padrões de
rotatividade;● Cobrança: detecção de fraudes;● Telemarketing: acesso facilitado aos dados do cliente;● Eleitoral: identificação de um perfil para possíveis votantes;● Medicina: indicação de diagnósticos mais precisos;● Segurança: na detecção de atividades terroristas e criminais;● Auxílio em pesquisas biométricas;● RH: identificação de competências em currículos;● Tomada de Decisão: filtrar as informações relevantes, fornecer indicadores de
probabilidade.

45
O uso de DM permite:
● Um supermercado melhore a disposição de seus produtos nas prateleiras, através do padrão de consumo de seus clientes;
● Uma companhia de marketing direcione o envio de mensagens promocionais, obtendo melhores retornos;
● Uma companhia de marketing direcione o envio de mensagens promocionais, obtendo melhores retornos;
● Empresas planejem melhor a logística de distribuição dos seus produtos, prevendo picos nas vendas;
● Empresas possam economizar identificando fraudes;● Agências de viagens possam aumentar o volume de vendas
direcionando seus pacotes a clientes com aquele perfil;

46
Mining Big Data using Weka 3
● http://www.cs.waikato.ac.nz/ml/weka/bigdata.html● “Recent versions of Weka 3.7 also provide access
to new packages for distributed data mining. The first new package is called distributedWekaBase. It provides base "map" and "reduce" tasks that are not tied to any specific distributed platform. The second, called distributedWekaHadoop, provides Hadoop-specific wrappers and jobs for these base tasks. In the future, there could be other wrappers - for example for Spark.”

47
Limitações
● Algoritmos tradicionais precisam ter todos os dados na memória
● Solução– Incremental schemes – Stream algorithms – MOA (Massive Online Analysis)
● http://moa.cs.waikato.ac.nz/

48
Escândalo dos cartões corporativos
• Caso 3:
– {“Locação de automóvel sem condutor”,”R$1000-R$1500”} -> {“Sec.Esp. De Políticas de Promoção da Igualdade Racial”}
• suporte = 1,15% e confiança = 86,67%
• Ressalta-se que esse exemplo é exatamente o pivô das discussões sobre cartões, configurado no aluguel de carros em viagens.

49
Cursos – 5 semanas
Linha 1 Linha 2 Linha 3 Linha 40
2
4
6
8
10
12
Coluna 1
Coluna 2
Coluna 3

50
Cursos

51
Onde conseguir mais informações?
● http://weka.pentaho.com/ ● http://www.cs.waikato.ac.nz/ml/weka/ ● Mineração de Dados - Conceitos, Aplicações e Experimentos com Weka
– http://www.lbd.dcc.ufmg.br/colecoes/erirjes/2004/004.pdf
● Conceitos, Aplicações e Experimentos com Weka – UFPR– www.inf.ufpr.br/aurora/disciplinas/ERBD/ERBD10.pptx
● Sítio da IBM– Mineração de dados com WEKA, Parte 1: Introdução e regressão
● http://www.ibm.com/developerworks/br/opensource/library/os-weka1/
– Mineração de dados com o WEKA, Parte 2: Classificação e armazenamento em cluster● http://www.ibm.com/developerworks/br/opensource/library/os-weka2/
● Data Mining: Practical Machine Learning Tools and Techniques, Third Edition (The Morgan Kaufmann Series in Data Management Systems)
● KDnuggets– news, software, jobs, courses,…– www.KDnuggets.com
● ACM SIGKDD – data mining association– www.acm.org/sigkdd

52
Conclusão
● DM é necessário para tratar conjuntos grandes de dados.● DM é um processo que permite compreender o
comportamento dos dados.● DM é uma etapa dentro do processo de KDD, embora
atualmente DM e KDD seja encarada como a mesma atividade.
● Cuidado com o overfitting (para quando o modelo estatístico se ajusta em demasiado ao conjunto de dados/amostra).
● Pode ser bem aplicado em diversas áreas de negócios como auxiliar no processo decisório.

53
Contato
Obrigado a todos!
Marcos Vinicius Fidelis