utilizaÇÃo de redes neurais artificiais e … · kappa em um processo kraft de cozimento de...
TRANSCRIPT

1
Programa de Pós-graduação em Engenharia
UTILIZAÇÃO DE REDES NEURAIS ARTIFICIAIS E TECNOLOGIA FT-NIR PARA PREDIÇÃO DO NÚMERO
KAPPA EM UM PROCESSO KRAFT DE COZIMENTO DE MADEIRA EM INDÚSTRIA DE CELULOSE
RONALDO NEVES RIBEIRO
Dissertação apresentada ao Centro Universitário do Leste de Minas Gerais para obtenção do Título de Mestre em Engenharia Industrial.
Coronel Fabriciano 2007

i
RONALDO NEVES RIBEIRO
UTILIZAÇÃO DE REDES NEURAIS ARTIFICIAIS E TECNOLOGIA FT-NIR PARA PREDIÇÃO DO NÚMERO
KAPPA EM UM PROCESSO KRAFT DE COZIMENTO DE MADEIRA EM INDÚSTRIA DE CELULOSE
Dissertação apresentada ao Centro Universitário do Leste de Minas Gerais para obtenção do Título de Mestre em Engenharia Industrial. Área de Concentração: Engenharia Industrial Orientadora: DSc. Andréa Oliveira S. da Costa Co-Orientador: Dr. Roselito Albuquerque Teixeira
Coronel Fabriciano 2007

ii
A história é vivida para frente, porém é escrita em retrospecto. Sabemos o fim antes de considerarmos o início, e jamais podemos recapturar totalmente o que deveríamos saber apenas no começo.
(Cicely Verônica Wedgwood)

iii
Dedico este trabalho a toda minha família e amigos.

iv
AGRADECIMENTOS Agradeço a Deus e a nosso Senhor Jesus Cristo pelas Bênçãos e Amor incondicional
durante toda minha vida.
Agradeço aos Meus Pais, Sr. Élvio Ribeiro Camargo a Sra. Nadir Neves Camargo,
que diante de sua humildade como seres humanos me concederam a vida e
ensinamentos valiosos sobre a mesma.
Agradeço ao meu irmão, José Antônio Ribeiro, pelo apoio, conselhos,
companheirismo, amizade e pela sua busca constante em estar por perto mesmo
diante de minhas limitações de tempo.
Agradeço à minha família e amigos que souberam entender os momentos ausentes
para dedicação às atividades do mestrado.
Agradeço aos meus colegas de trabalho na Cenibra, que cada um em sua forma
pessoal, me transferiram força e apoio nesta jornada, não se limitando em nenhum
momento, a prestar qualquer apoio solicitado.
Agradeço a Professora Êny Paula pelo apoio constante na elaboração deste trabalho.
Agradeço aos colaboradores deste trabalho Luciana e Walaston, pelo apoio técnico,
aquisições dos dados de processo e sugestões preciosas.
Agradeço aos meus alunos de graduação entre os anos de 2005 a 2007, que souberam
entender minhas limitações de disponibilidade de tempo.
Agradeço aos Professores Andréa Costa e Roselito de Albuqueque pelas valiosas
orientações, críticas, paciência e principalmente pela amizade.
Agradeço a todos os Professores do Mestrado que foram a base para realização deste
trabalho.
Agradeço aos Professores e Amigos Rodrigo Cássio e Fabrício Fernandes, pelo
companheirismo, pela amizade e apoio durante a realização deste trabalho.
Agradeço ao amigo Nilton César pela presença quase constante nos finais de semana.
Agradeço ao Júlio Cezar por participar das idéias e colaborar com continuamente
com o trabalho e ao Eng. Luis Gonzaga por dedicar seu tempo quando solicitado.
Agradeço ao Leonardo Figueirêdo, pelo apoio constante e companheirismo.
Agradeço a todos os Colegas do Mestrado que foram companheiros e encararam a
busca deste objetivo.

v
RESUMO O objetivo deste trabalho é propor um modelo matemático para predição do grau de
cozimento (#Kappa) em um digestor contínuo para uma planta de celulose com
processo de produção tipo Kraft, que utiliza como matéria prima eucalipto do tipo
Grandis. Foi explorada a modelagem através de redes neurais artificiais, com a
utilização de variáveis de processo de uma planta real. A tecnologia FT-NIR
(Fourier Transform Near Infrared) foi usada para identificar os cavacos de madeira
que entram no processo de cozimento. Associada a esta tecnologia, foi utilizada uma
técnica de análise multivariada denominada PCA (Principal Components Analysis)
para redução da dimensionalidade dos padrões de entrada do modelo. Foram
utilizadas como entradas do modelo neural, variáveis de processo e as análises
associadas aos espectros de freqüência da absorbância do infravermelho nos cavacos
de madeira. Uma rápida abordagem sobre o processo do tipo Kraft foi necessária
para melhorar o entendimento do problema. Foram realizados testes utilizando
métodos de otimização paramétrica não-linear para o treinamento do modelo neural.
Os resultados mostraram uma boa adequação na utilização destas técnicas para
predição de variáveis no ramo industrial, especialmente o grau de cozimento em um
digestor contínuo. O modelo desenvolvido é capaz de predizer a variável #Kappa,
possibilitando ações operacionais mais proativas e conseqüente redução da
variabilidade desta. Apesar da complexidade do processo de cozimento, das
inúmeras variáveis que interferem no grau de cozimento e o comportamento não
linear dos digestores, a modelagem baseada em redes neurais ofereceu coeficientes
de correlação satisfatórios entre os valores preditos e efetivamente medidos no
processo.

vi
ABSTRACT
The main objective of this work is the proposition of a mathematical model for
prediction of the cooking degree (Kappa number) in a continuous digester for a pulp
mill running Kraft production process, which utilizes Eucalyptus Grandis as raw
material. Mainly modeling through artificial neural networks utilizing process
variables from a real plant was explored in this work. The FT-NIR (Fourier
Transform Near Infrared) technology was utilized to identify the wood chips entering
the cooking process. In association with this technology, it was utilized a
multivariated analysis technique named PCA (Principal Components Analysis), for
reduction of the dimensionality of the model’s input standards. Process variables and
analyses associated to the infrared absorbency frequency spectra in the wood chips
were utilized as input to the neural model.
A rapid introduction to the Kraft process was necessary for better understanding of
the problem. Several tests utilizing various methods of nonlinear parametric
optimization for training of the neural model were conducted. The results showed
adequacy for utilization of these techniques for variable prediction in the industrial
field, especially the cooking degree in a continuous digester. The developed model is
capable of predicting the Kappa variable with a certain advance, thus enabling more
proactive operational actions and consequent reduction of the variability of this
variable. In spite of the complexity of the cooking process, the countless variables
influencing the degree of cooking and the nonlinear behavior of the digester, the
modeling based on neural networks provided good correlation coefficients between
the predicted values and those actually measured in the process.

vii
SUMÁRIO
1 INTRODUÇÃO ................................................................................................. 18
1.1 Revisão e Motivação.................................................................................. 18
1.2 Organização dos capítulos.......................................................................... 23
2 CARACTERÍSTICAS DA MADEIRA E DESCRIÇÃO DO PROCESSO DE FABRICAÇÃO DE CELULOSE (ETAPAS DE MOVIMENTAÇÃO DE MADEIRA, PICAGEM E COZIMENTO)........................................................ 25
2.1 O processo de produção de celulose Kraft ................................................. 25
2.2 Características da madeira ......................................................................... 28
2.3 Caracterização da madeira utilizada na Cenibra ........................................ 36
2.4 Sistema de recebimento e manuseio da madeira........................................ 40
2.4.1 Preparação de cavacos........................................................................ 40 2.5 Cozimento (polpeamento).......................................................................... 43
2.6 Digestor ...................................................................................................... 44
2.7 Número Kappa (#Kappa)........................................................................... 51
2.8 Variabilidade das Linhas de Produção....................................................... 52
3 ANÁLISE DOS COMPONENTES PRINCIPAIS (PCA)................................. 54 3.1 Introdução .................................................................................................. 54
3.2 Dedução das Componentes Principais ....................................................... 55
3.3 Escolha do número de Componentes Principais ........................................ 59
3.4 Comentários finais ..................................................................................... 61
4 A TECNOLOGIA FT-NIR (Fourrier Transform Near Infrared) ..................... 62 4.1 Introdução .................................................................................................. 62
4.2 Absorbância e absorção da luz................................................................... 62
4.3 A espectroscopia no infravermelho próximo por Transformada de Fourier
(FT-NIR) ................................................................................................................ 64
4.4 A Transformada de Fourier........................................................................ 66
4.5 Técnicas de pré-tratamento matemático empregadas ao FT-NIR.............. 68
4.6 Aplicações em indústrias de celulose e papel ............................................ 68
4.7 Conclusões ................................................................................................. 70
5 REDES NEURAIS ARTIFICIAIS (RNA) ........................................................ 71 5.1 Introdução .................................................................................................. 71
5.2 Modelo de um neurônio artificial............................................................... 72
5.3 Função de ativação..................................................................................... 74

viii
5.4 Arquitetura das RNAs................................................................................ 75
5.5 Projeto de uma RNA .................................................................................. 77
5.6 Aprendizado supervisionado...................................................................... 78
5.7 Algoritmo de treinamento Back-propagation ............................................ 81
5.7.1 Função de ativação............................................................................. 82 5.7.2 Taxa de aprendizagem........................................................................ 83 5.7.3 Modos de treinamento seqüencial e por lote...................................... 83 5.7.4 Critérios de parada ............................................................................. 84
5.8 Redes de múltiplas camadas (MLP)........................................................... 84
5.9 Métodos de primeira e segunda ordem ...................................................... 86
5.10 Generalização em uma RNA...................................................................... 87
5.11 Early Stopping (parada antecipada) ........................................................... 89
5.12 Conclusões ................................................................................................. 91
6 METODOLOGIA E RESULTADOS................................................................ 92 6.1 Introdução .................................................................................................. 92
6.2 O problema estudado ................................................................................. 94
6.3 Preparação dos dados e procedimentos para os testes das RNAs .............. 95
6.3.1 Planejamento dos testes ..................................................................... 95 6.3.2 Tratamento dos dados ........................................................................ 97
6.4 Apresentação de Dados, utilização de análise de componentes principais
para definição de variáveis de entrada aplicadas a rede neural artificial ............... 99
6.5 Implementação da RNA........................................................................... 102
6.6 Comparação dos resultados obtidos ......................................................... 104
6.6.1 Primeira geração de resultados RNA_01_PCA1 ............................. 105 6.6.2 Segunda geração de resultados RNA_02_PCA2 ............................. 108 6.6.3 Terceira geração de resultados (RNA _03_PCA3) .......................... 111 6.6.4 Quarta geração de resultados (RNA_04_PCA4).............................. 114 6.6.5 Quinta Geração de resultados (RNA_05_ NIR)............................... 117 6.6.6 Testes com Early Stopping.............................................................. 124 6.6.7 Simulador de processos.................................................................... 126
7 COMENTÁRIOS FINAIS............................................................................... 128 7.1 Conclusões ............................................................................................... 128
7.2 Sugestões para trabalhos futuros.............................................................. 129

ix
LISTA DE FIGURAS
Figura 2.1 Principais etapas envolvidas na rota produtiva Kraft .................... 27
Figura 2.2 Diagrama cíclico do processo recuperação Kraft .......................... 28
Figura 2.3 Ilustração de uma parede de células e organização das fibras ...... 30
Figura 2.4 Estrutura de um tronco .................................................................. 31
Figura 2.5 Tipos de nós quanto a aderência: A- Nó vivo, B- Nó morto ......... 32
Figura 2.6 Rendimento do Eucalyptus grandis para um processo em produção
com #Kappa 16............................................................................... 36
Fig. 2.7 Características da madeira da Cenibra (histograma de densidade).. 39
Fig. 2.8 Características da madeira da Cenibra (histograma de AE) .......... 39
Figura 2.9 Digestor contínuo - Cenibra .......................................................... 46
Figura 2.10 Digestor contínuo para cozimento Kraft (Lo-Solids) ..................... 49
Figura 2.11 Processo de cozimento Lo-Solids com 04 diferentes zonas de
cozimento ...................................................................................... 50
Figura 2.12 Histograma de #Kappa .................................................................. 53
Figura 3.1 (a) Dados originais nas coordenadas X1 e X2; (b) Os eixos dos
componentes principais Y1 e Y2 ................................................... 57
Figura 3.2 Dados projetados nos dois eixos principais: (a) Primeiro componente
principal contendo”ou “explicando” a maior parte da variação nos
dados; (b) Segundo componente principal, contendo a menor parte da
variação nos dados ......................................................................... 57
Figura 3.3 Representação dos escores dos autovalores de cada fator (método do
Diagrama de autovalores) .............................................................. 60
Figura 4.1 Absorbância do meio ..................................................................... 63
Figura 4.2 Espectro Eletromagnético .............................................................. 65
Figura 5.1 Modelo de um neurônio artificial................................................... 73
Figura 5.2 Funcões de ativação: (a) Função limiar, (b) Função linear, (c) Função
Linear por partes, (d) Função Sigmoidal tangente hiperbólica ............... 75
Figura 5.3 Rede alimentada adiante com uma única camada de neurônios .............. 76
Figura 5.4 Rede alimentada adiante totalmente conectada com uma camada oculta 77
Figura 5.5 Método de aprendizagem supervisionada com professor ........................ 79

x
Figura 5.6 Método de aprendizagem por correção de erros, grafo de fluxo de sinal 79
Figura 5.7 Diagrama em blocos de uma RNA, resultando em um único neurônio na
camada de saída ....................................................................................... 80
Figura 5.8 Rede MLP Típica com duas camadas intermediárias .............................. 85
Figura 5.9 Problema de ajuste do modelo ................................................................ 89
Figura 5.10 Comportamento dos erros de treinamento e validação para uma RNA. 90
Figura 6.1 Gráfico de correlação entre o desvio padrão de #Kappa e AE da madeira da
Cenibra .................................................................................................... 94
Figura 6.2 Exemplo de espectro de freqüência de cavacos de madeira, obtidos usando a
técnica FT-NIR ........................................................................................ 97
Figura 6.3 Estrutura de todos os modelos testados ................................................... 103
Figura 6.4: Estrutura de todos os modelos testados RNA _01_PCA1........................ 106
Figura 6.5 Simulação da RNA algoritmo TRAINSCG - Teste RNA _01_PCA1 ..... 106
Figura 6.6 Simulação da RNA algoritmo TRAINBR para o teste RNA _01_PCA1. 107
Figura 6.7 Simulação da RNA algoritmo TRAINLM - Teste RNA _01_PCA1 ....... 107
Figura 6.8 Simulação da RNA algoritmo TRAINGD - Teste RNA _01_PCA1 ....... 107
Figura 6.9: Simulação da RNA algoritmo TRAINGDM -Teste RNA _01_PCA1..... 108
Figura 6.10: Estrutura de todos os modelos testados RNA _02_PCA2........................ 109
Figura 6.11 Simulação da RNA algoritmo TRAINSCG - Teste RNA _02_PCA2 .... 109
Figura 6.12 Simulação da RNA algoritmo TRAINBR - Teste RNA _02_PCA2....... 110
Figura 6.13 Simulação da RNA algoritmo TRAINLM - Teste RNA _02_PCA2 ..... 110
Figura 6.14 Simulação da RNA algoritmo TRAINGD - Teste RNA _02_PCA2 ....... 110
Figura 6.15 Simulação da RNA algoritmo TRAINGDM – Teste RNA _02_PCA2 ... 111
Figura 6.16: Estrutura de todos os modelos testados RNA _03_PCA3........................ 112
Figura 6.17 Simulação da RNA algoritmo TRAINSCG - Teste RNA _03_PCA3 ..... 112
Figura 6.18 Simulação da RNA algoritmo TRAINBR - Teste RNA _03_PCA3 ....... 113
Figura 6.19 Simulação da RNA algoritmo TRAINLM - Teste RNA _03_PCA3 ...... 113
Figura 6.20 Simulação da RNA algoritmo TRAINGD - Teste RNA _03_PCA3 ....... 113
Figura 6.21 Simulação da RNA algoritmo TRAINGDM - Teste RNA _03_PCA3.... 114
Figura 6.22: Estrutura de todos os modelos testados RNA _04_PCA4........................ 115
Figura 6.23 Simulação da RNA algoritmo TRAINSCG - Teste RNA _04_PCA4 ..... 115
Figura 6.24 Simulação da RNA algoritmo TRAINBR - Teste RNA _04_PCA4........ 116
Figura 6.25 Simulação da RNA algoritmo TRAINLM - Teste RNA _04_PCA4 ....... 116
Figura 6.26: Simulação da RNA algoritmo TRAINGD - Teste RNA _04_PCA4 ....... 116
Figura 6.27: Simulação da RNA algoritmo TRAINGDM - Teste RNA _04_PCA4.... 117

xi
Figura 6.28: Estrutura de todos os modelos testados RNA _05_NIR........................... 118
Figura 6.29 Simulação da RNA algoritmo TRAINSCG - Teste RNA _05_PCA5 ..... 118
Figura 6.30: Simulação da RNA algoritmo TRAINBR - Teste RNA _05_PCA5........ 119
Figura 6.31: Simulação da RNA algoritmo TRAINLM - Teste RNA _05_PCA5 ....... 119
Figura 6.32: Simulação da RNA algoritmo TRAINGD - Teste RNA _05_PCA5 ....... 119
Figura 6.33: Simulação da RNA algoritmo TRAINGDM - Teste RNA _05_PCA5.... 120
Figura 6.34: Correlação linear da melhor rede obtida .................................................. 121
Figura 6.35: Tendência dos valores do #Kappa no treinamento com o algoritmo
TRAINSCG.............................................................................................. 122
Figura 6.36: Comparação da variável #Kappa predito e medido para o melhor modelo
obtido........................................................................................................ 123
Figura 6.37 Histograma dos dados de treinamento...................................................... 123
Figura 6.38: Arquitetura RNA que apresentou melhor resultado (10x6x1) ................ 124
Figura 6.39 Resposta com Early Stopping, RNA com melhor resultado na validação 125
Figura 6.40 Janela de entrada de dados para predição do #Kappa ............................. 127

xii
LISTA DE TABELAS
Tabela 2.1 Evolução da classificação da madeira na Cenibra ....................... 37
Tabela 2.2 Curvas de correção linear de características da madeira ............. 38
Tabela 6.1 Variâncias dos componentes principais ....................................... 100
Tabela 6.2 Componentes principais ............................................................... 101
Tabela 6.3 Resumo dos resultados dos testes ................................................ 126

xiii
LISTA DE ABREVIATURAS E SIGLAS
ABRAF Associação Brasileira de Produtores de Florestas Plantadas
AA Álcali Ativo
AE Álcali Efetivo
AHex´s Ácidos hexenurônicos
ATT Álcali Total Titulável
CA Corrente Alternada
CENIBRA Celulose Nipo Brasileira SA
CLP Controlador lógico programável
CPs Componentes principais
CR Caldeira de recuperação
CSTR Continuous Stirred Tank Reactor
DB Densidade Básica
FT-NIR Fourier Transform Near Infrared
IR Infrared
ISO International Standartization Organization
ITC Isothermal Coocking
IV Radiação Infravermelha
L Lume celular
LBR Licor branco
LM Lamela média
LN Licor Negro
LPD Licor preto diluído
MATLAB® Matrix Laboratory
MIX Mistura de madeira de diferentes qualidades

xiv
MLP Multilayer Perceptron
NIR Near Infrared
#Kappa Número Kappa
PCA Principal Components Analyses
PLS Regressão multivariada (Projection to Latent Struccture)
PM Parede primária
RD Rendimento depurado
RDH Rapid Displacement Heating
RNAs Redes Neurais Artificias
S1 Primeira camada da parede secundária
S2 Segunda camada da parede secundária
S3 Terceira camada da parede secundária
SCG Gradiente Conjugado Escalonado
SG Siringila/guaiacila
TAPPI Technical Association for the Pulp, Paper and converting Industy
tSA/d Tonelada seca ao ar por dia
UV Radiação Ultravioleta
VCP Votorantim Celulose e Papel

xv
LISTA DE SÍMBOLOS
dL/dt Variação do teor de lignina nos cavacos de madeira em função do tempo
k Taxa de variação de temperatura dependente da reação
C Concentração de álcali efetivo do licor de cozimento
L Teor de lignina contida nos cavacos
H Fator H - Junção dos efeitos do tempo e temperatura no processo de cozimento
t0 Tempo inicial de circulação
kr Coeficiente de reação relativa
N Abreviação de Normal (Química)
x Vetor aleatório x
y Vetor aleatório y
z Transformação z
x1, x2, xp Vetor de variáveis x
y1, y2, yp Vetor de variáveis y
n, m Linhas e colunas de uma matriz
Iλ Autovalor associado a matriz identidade
det Determinante
xT Vetor aleatório x transposto
µ Vetor de médias
Σ Matriz de covariância
λ1 , λ2,, λp Autovalores da matriz
T1u Varáveis transpostas da linha 1 de uma matriz
11u , , 21u P1u Variáveis de uma matriz

xvi
x , , , 1x 2x px Vetores de uma matriz
UT Matriz U transposta
Var Variância
Cov Covariância
i , j Direções de um vetor
S Desvio padrão
S2 Quadrado do desvio padrão
X , Y Média aritmética
σ Desvio padrão
estY Valor do vetor Y estimado
r Coeficiente de correlação
f Freqüência
C0 Velocidade das ondas
λ Comprimento de onda
I0 Intensidade de uma onda
v Velocidade
c Velocidade da luz
h Constante de Planck
γ Radiação gama
α Coeficiente de absorção
ca Concentração de absorbância
f(x) Função
wx Freqüência angular
( )⋅ϕ Função de ativação
k Neurônio k

xvii
x1, x2,..., xn Sinais de entrada
wk1, wk2, ..., wkm Pesos sinápticos do neurônio k
vk Saída do combinador linear
bk Bias
yk Sinal de saída do neurônio
δ Gradiente local
( )nw ji∆ Variação da correção no peso do neurônio j na iteração n
η Taxa de aprendizagem
( )niδ Gradiente local do neurônio j na iteração n
)(nyi Sinal de entrada i do neurônio j na iteração n
S1 Variável de saída do digestor - #Kappa medido
E1Representa a temperatura na circulação de homogeneização após o aquecimento do licor de cozimento
E2Representa a temperatura na circulação de cozimento antes do aquecimento de licor de cozimento
E3Representa a temperatura na circulação de homogeneização antes do aquecimento de licor de cozimento
E4 Representa o Alcali Total Titulável
E5 Representa o Alcali Residual
E6 Representa a sulfididade do licor branco de cozimento
E7 Relação lignina por kilograma de celulose
CP1, CP2, CP3Componentes principais que representam a matriz de dados analisados pelo FT-NIR

18
1 INTRODUÇÃO
1.1 Revisão e Motivação
Para o período entre 2005 a 2008, a previsão para crescimento do mercado
de celulose (polpa química) será de aproximadamente 3,3% ao ano, representando 5
milhões de toneladas mundiais para o novo montante. Aproximadamente 95% desse
crescimento ocorrerá na América Latina, significando que esta região produzirá 25%
do mercado mundial (LANSDELL, 2006, p.1). No Brasil espera-se um crescimento
nesse período de 1,9 milhões de toneladas o que representa 41% do crescimento
mundial.
Para essa produção, o Brasil conta com a ajuda das condições climáticas e
uma engenharia florestal desenvolvida. As indústrias de celulose alcançam hoje
patamares elevados de produção e qualidade, competindo em níveis até mesmo
superiores ao mercado mundial. Desde o plantio da madeira até o processo de
cozimento e produto final, os sistemas automatizados têm sido amplamente
utilizados, o que gera uma alta escala produtiva, com custos mais baixos.
Diante desta estimativa de crescimento do setor de celulose, vale ressaltar
que de acordo com o relatório anual da ABRAF (2007) isto não significará em
impactos ambientais, pois as florestas ocuparão áreas já desmatadas e ainda por
vários projetos de fomento florestal. No entanto, este crescimento é uma grande
oportunidade de novos desenvolvimentos tecnológicos nos processos de fabricação,
para os sistemas que os controlam e ainda o crescimento da economia do país.
O processo de polpação pode ser considerado o coração de uma planta de
celulose, pois neste se dá o cozimento da madeira para separar as fibras dos demais
componentes. O digestor é o equipamento responsável pelo cozimento e apresenta
uma série de fatores que podem ser considerados como distúrbios nesta etapa.
Atendendo as constantes necessidades dos usuários de melhorias
operacionais, melhorias no desempenho dos equipamentos, nos processos e na
qualidade do produto acabado, surge a oportunidade para o desenvolvimento de

19
ferramentas de simulação que permitam testes off-line, sem colocar em risco a
operacionalidade da produção (FERNANDES & CASTRO, 2000, p3729).
Em indústrias de celulose e papel, os digestores são os equipamentos mais
críticos operacionalmente, pois sofrem influências das múltiplas variáveis de entrada.
Estes equipamentos podem ser classificados como reatores especiais, heterogêneos e
complexos do ponto de vista de entendimento operacional. Nestes ocorrem muitas
reações químicas, além de possuírem variáveis de processo de difícil medição.
A necessidade de estudar e ou predizer seu comportamento através de
modelagem matemática tem sido o motivo de inúmeras pesquisas ao longo dos anos
(HARKONEN, 1987); (MICHELSEN & FOSS, 1996); (QIAN et al., 1997); (AL-
AWAMI & SYDRAK, 1998); (WISNEWSKI & DOYLE III, 1998); (DOYLE III &
KYIHAN, 1999); (FERREIRA et al., 2000); (WISNEWSKI, 2001); (AGUIAR,
2001); (QUEIROZ et al., 2004); (KAYIHAN, 2002); (CARDOSO et al., 2002);
(POLIT et al., 2002); (POUGATCH et al., 2005); (DUFOUR et al., 2005) e
(PADHIYAR et al., 2006).
O pioneiro nestas pesquisas foi Vroon (1957). Este autor introduziu o
conceito do fator H, que ainda hoje continua sendo utilizado. Neste caso, temperatura
e tempo de cozimento foram agrupados em uma única variável. A partir dos estudos
de Vroon outros estudos e modelos foram desenvolvidos para o fator H (BUGAGER
et al., 1979) e (MARQUES et al., 1979).
Em todos os processos químicos de produção de celulose, as variáveis
tempo de cozimento e temperatura de deslignificação são consideradas as mais
importantes, pois afetam diretamente a remoção de lignina e a qualidade do produto
final (MARQUES et al., 1979). Estas variáveis se relacionam de forma inversa, ou
seja, quanto maior a temperatura, menor o tempo de cozimento.
Segundo Bugager et al. (1979), o uso do fator H para controlar o cozimento
é questionável e deve ser usado com restrições para madeira de eucalipto, pois um
mesmo fator H, usando tempo e temperaturas diferentes, foi obtido para celulose
com rendimentos depurados e #Kappa variados.
Variações da densidade da madeira de eucalipto ocorrem em níveis de
estrutura anatômica, composição química e propriedades físicas, podendo ser
detectadas diferenças significativas inter e intra-específicas (TOMAZELLO, 1994).

20
A densidade básica tem se mostrado um bom índice universal para a qualidade da
madeira (FOEKEL & MENOCHELLI, 1990), sendo esta propriedade a que mais
oferece informações sobre as demais características deste material (GARCIA, 1995).
Essas características influenciam diretamente no resultado do cozimento da madeira,
ou ainda influenciam diretamente no #Kappa.
Blake (2004) analisa as influências da densidade básica da madeira na
qualidade da polpação Kraft e nas características da polpa. Foram analisados os
requerimentos de carga de álcali para polpação, o rendimento do processo, as
características do licor residual, a branqueabilidade e as propriedades físico-
mecânicas da polpa branqueada. Vale ressaltar que este estudo não propôs um
modelo matemático dessas influências.
Estudos realizados com diferentes espécies de eucaliptos não encontraram
correlações bem definidas entre a densidade básica da madeira e a demanda de carga
de álcali ou o rendimento do processo (MOKFIENSKI, 2003).
Este trabalho busca identificar e propor um modelo que correlacione as
alterações do número #Kappa em função das variações na química da madeira,
identificadas pela análise da absorbância de luz do infravermelho próximo nos
cavacos de Eucalyptus Grandis em uma planta de celulose que utiliza o processo
Kraft. Esta técnica é denominada FT-NIR (Fourier Transform Near Infrared).
Também são utilizadas técnicas multivariadas como exemplo o PCA (Principal
Componentes Analyses) para redução da matriz de dados gerada pelo FT-NIR. A
modelagem é feita utilizando inteligência artificial, as RNAs (Redes Neurais
Artificiais) .
Alguns trabalhos mostram que as medições por espectroscopia, têm
apresentado bons resultados nas medições de variáveis em processos industriais.
Gomes (2007) descreve as principais aplicações nos diversos ramos industriais. Em
medições dos componentes dos cavacos de madeira, vários trabalhos mostram um
bom desempenho desta técnica de medição (SKOGLUND, et al., 2004); (HOANG et
al., 2005); (SANTOS et al., 2006); ( FACKLER et al., 2006) e (CALDEIRAA et al.,
2007).
Neste trabalho, foi utilizado um equipamento (ANTARIS) para medir o
comprimento de onda da absorção de luz infravermelho próximo NIR (Near

21
Infrared) nos cavacos de madeira. Este equipamento gera um espectro de freqüência,
que é analisado por Transformada de Fourier. A combinação desta medição e sua
análise, forma a tecnologia FT-NIR (Fourier Transform Near Infrared).
Estas informações sobre os cavacos de madeira obtidas pelo FT-NIR, são
tratadas por técnicas estatísticas multivariadas, para serem utilizadas como parte das
variáveis de entrada de um modelo empírico que utiliza inteligência artificial (Redes
Neurais) para predição do #Kappa na saída do processo de polpação (cozimento).
Foram utilizadas também outras variáveis de entrada consideradas pela
prática operacional de grande influência no processo de cozimento.
Os modelos, até então encontrados na literatura, têm utilizado predição do
#Kappa nos digestores contínuos, mas não utilizando as mesmas variáveis propostas
neste trabalho, especialmente os dados do FT-NIR. Os trabalhos que mais se
aproximam são o de Blake (2004), que analisa somente uma variável como entrada
para o seu modelo, a densidade da madeira via a técnica FT-NIR, e o de Aguiar &
Filho (2000), que propôs um modelo utilizando redes neurais, mas não utiliza as
características da madeira como entrada de seu modelo.
Os analisadores FT-NIR apresentam um conceito de medição diferente da
instrumentação analítica convencional, pois empregam tecnologia óptica e eletrônica
aliada ao conceito matemático da Transformada de Fourier. Os princípios físicos
básicos envolvidos são os da absorção. O termo Transformada de Fourier refere-se
ao método de obtenção do espectro, que essencialmente é um processo de modulação
ou codificação, seguido de uma demodulação (COHN & RIBEIRO, 2002).
Os analisadores por absorção de radiação infravermelha ou simplesmente
analisadores infravermelhos (IV ou IR) são aplicáveis às substâncias constituídas por
moléculas hetero atômicas, ou seja, aquelas formadas por no mínimo dois átomos de
espécies diferentes. Estas substâncias absorvem a radiação IV em determinadas
faixas, coincidentes com as freqüências de vibração das moléculas.
CaldeiraA et al. (2007) apresenta bons resultados com testes experimentais
através da avaliação do desempenho do equipamento NIR, com medições on-line e
utilizou destas informações, associadas com um modelo de regressão multivariada
(PLS), para análise do teor seco e densidade básica em cavacos.

22
Segundo Wisnewski & Doyle III (2001) existem vários atributos nos
digestores contínuos que desafiam uma boa modelagem e também são problemas
para um bom controle do equipamento, dentre estes destacam-se:
• a variável #Kappa possui atrasos em sua medição;
• o tempo elevado de atraso entre as variáveis de entrada e seus efeitos no
#Kappa;
• os digestores apresentam comportamento não linear;
• as variações biológicas da química da madeira estão sujeitas à variações
aleatórias não mensuráveis nas componentes como concentração, umidade e
densidade que são as principais fontes de variações contínuas na operação
dos digestores.
Identificar e conhecer as características físicas, químicas e anatômicas da
madeira (cavacos) antes de sua entrada no processo de cozimento e utilizar estas
informações para predição do #Kappa, trará grandes benefícios operacionais para o
processo de produção de celulose.
A madeira sofre influência de vários fatores em um processo de análise de
suas características, além das análises não serem procedimentos triviais, pois são
influenciadas por:
• espécie de madeira (mais importante);
• comportamento do crescimento (em regiões deformadas do tronco, a
constituição da madeira é diferenciada);
• fatores hereditários da árvore;
• ponto de tomada da amostra. Exemplo: cerne ou camada externa lenho
juvenil ou adulto, idade, altura no tronco (na parte inferior o lenho é mais
comprimido), tronco ou ramos, etc.;
• condições e história do armazenamento da madeira antes da sua análise.
• método de preparação da amostra.
O digestor estudado utiliza o processo de cozimento Lo-solids e de acordo
com Marcoccia et al. (1998), este é um processo modificado de polpação que foi
utilizado industrialmente a partir de outubro de 1993.
O objetivo básico do processo Lo-solids é minimizar a concentração de
sólidos oriundos da madeira nas fases de deslignificação principal e residual. Esta

23
rotina apresenta como principiais vantagens em relação aos processos de cozimento
convencionais (ITC – Isothermal Coocking, KobudoMari e Compact Cooking): o
aumento da resistência e viscosidade da polpa, a redução da temperatura de
cozimento e do uso de álcali, uma melhoria na eficiência de lavagem no digestor, um
cozimento mais uniforme, uma melhor desempenho no deslocamento da coluna de
cavacos dentro do digestor e redução na demanda de reagentes químicos no
branqueamento.
Devido a estas vantagens o processo Lo-Solids tem apresentando uma rápida
expansão na sua aplicação industrial no mundo, projetos mais recentes de digestores
tem utilizado esta tecnologia de cozimento, como exemplo os novos projetos de
aumento de capacidade das fábricas da Cenibra, Aracruz, Veracel e VCP (Três
Lagoas).
De acordo com Wisnewski & Doyle III (2001) os digestores exibem
comportamentos não lineares particularmente quando operam com #Kappa baixos,
estes autores afirmam ainda que os estudos e desenvolvimento de modelos para estes
equipamentos não são triviais e demandam muita dedicação.
Diante das adversidades encontradas nos processos industriais, o
desenvolvimento de modelos matemáticos tem sido fonte de estudos de diversos
pesquisadores e a utilização das RNAs (Redes Neurais Artificiais), tem alcançado
bons resultados especialmente em sistemas não lineares, com a maioria utilizando
redes do tipo MLP (Multilayer Perceptron). Nas aplicações em indústrias de
celulose e papel, vários autores têm estudado e descrito sobre estes modelos (GE, et
al., 1998); (LEMMETI et al., 1998); (KASPARIAN & BATUR, 1998); (PREMIER
et al., 1999); (HAYKIN, 2001); (AGUIAR & FILHO, 2001); (YU & GOMM, 2003);
(LAPERRIÈRE et al., 2004); (DUFOUR et al., 2005); (MALMBERG, et al., 2005);
(COSTA, et al., 2005); (RUBINI & YAMAMOTO, 2006) e (BARBER & SCOTT,
2007).
1.2 Organização dos capítulos
No Capítulo 2 são abordadas as características da madeira utilizada na
Cenibra para o processo de fabricação de celulose e a descrição do processo de

24
fabricação de celulose tipo Kraft. Comenta-se também sobre as particularidades do
processo estudado.
No Capítulo 3 são abordados conceitos relativos à Análise de Componentes
Principais (PCA) onde são mostradas as deduções dos componentes principais, a
determinação dos valores através dos autovetores e os conceitos de média aritmética,
correlação, variância e covariância.
O Capítulo 4 trata da técnica FT-NIR (Fourier Transform Near Infrared),
na qual se obtém as informações sobre os cavacos de madeira para informações que
serão utilizadas como parte das variáveis de entrada da rede neural proposta neste
trabalho. É feita uma abordagem sobre a teoria de funcionamento dos sistemas IR
(Infrared) e NIR (Near Infrared) que, associados à Transformada de Fourier, dão
origem à tecnologia FT-NIR. São mostradas também as análises dos dados obtidos.
No Capítulo 5 é feita uma abordagem genérica sobre redes Neurais
Artificiais.
No Capítulo 6 é mostrada a metodologia dos estudos, os resultados obtidos
em função dos testes realizados e também são discutidas algumas características dos
métodos abordados que podem fazer com que os mesmos não encontrem soluções
com capacidades de generalização.
No capítulo 7 são apresentadas as conclusões deste trabalho e as sugestões
de futuras pesquisas.
E finalmente as referências bibliográficas empregadas são listadas.

25
2 CARACTERÍSTICAS DA MADEIRA E DESCRIÇÃO DO PROCESSO
DE FABRICAÇÃO DE CELULOSE (ETAPAS DE MOVIMENTAÇÃO
DE MADEIRA, PICAGEM E COZIMENTO)
2.1 O processo de produção de celulose Kraft
O processo polpa sulfato ou processo Kraft foi desenvolvido em 1879, na
Alemanha, pelo pesquisador Dahl, no qual o polpeamento de madeiras é feito através
de soda e sulfeto de sódio (ASSUMPÇÃO et al., 1988, p.171).
O processo Kraft tem como função dissolver a lignina1, agente ligante das
fibras na madeira, com o objetivo de liberar as fibras com o mínimo de degradação
dos carboidratos (celulose2 e hemicelulose3). Na etapa de cozimento da madeira,
emprega o hidróxido de sódio (NaOH) e o sulfeto de sódio (Na2S) como agente ativo
na reação.
O processo de obtenção de celulose apresenta um subproduto denominado
“licor negro”. Este fluido contém a parte da madeira denominada lignina, combinada
com os reagentes químicos utilizados no início do processo de polpação. Por razões
econômicas e ambientais torna-se estritamente necessária a reutilização deste produto
em um processo denominado recuperação de produtos químicos, que consiste na
elevação do teor de sólidos e em seguida queimá-lo na caldeira de recuperação.
Os fundidos resultantes da queima do LN (Licor Negro) na CR (Caldeira de
Recuperação) são dissolvidos em licor branco fraco com uma concentração entre 20
a 60 g/L. Após a dissolução, a mistura é tratada transformando-se em licor branco,
que é utilizado no início do processo de polpação, fechando assim o ciclo de
recuperação.
1 Lignina é uma substância química, que confere rigidez à parede da célula e, nas partes da madeira, age como um agente permanente de ligação entre as células, gerando uma estrutura resistente ao impacto, compressão e dobra (D’ALMEIDA, 1988, p.76). 2 Celulose é um polissacarídeo formado por unidades do monossacarídeo β-D-glucose, que ligam entre si através dos carbonos 1 e 4, dando origem a um polímero linear (D’ALMEIDA,1988, p.47). 3 Hemicelulose é uma mistura de polímeros polissacarídeos de baixa massa molecular, os quais estão intimamente associados com a celulose no tecido das plantas (D’ALMEIDA,1988, p.68).

26
O processo Kraft, tem como principal vantagem, o sistema de recuperação
dos produtos químicos a ele associado. Por outro lado, apresenta como desvantagens:
o alto custo, as emissões de odores no ambiente, baixa alvura após o cozimento e
consequentemente maior custo de branqueamento com baixo rendimento entre 40 a
50% (ASSUMPÇÃO et al., 1988, p.171).
Após a etapa de cozimento, a polpa que deixa o digestor passa por uma
lavagem de massa marrom. Em seguida, é pré-branqueada e branqueada através de
um processo químico que envolve oxigênio, peróxido de hidrogênio, soda cáustica e
dióxido de cloro. Finalmente a celulose branqueada é enviada para as etapas de
secagem e enfardamento.
Uma boa qualidade da celulose, associada a baixos custos de produção, está
intimamente correlacionada com os bons resultados no processo de polpação, daí a
necessidade de um bom conhecimento e um bom rendimento durante a etapa do
cozimento. Para isto, o #Kappa é uma variável de extrema importância para bons
resultados operacionais.
Costa (2000) descreve as principais etapas envolvidas no processo de
produção de celulose Kraft da seguinte forma:
• preparo das toras de madeira: as toras são transformadas em cavacos por
meio de um processo que envolve a retirada das cascas seguida de uma
etapa para redução de tamanho nas linhas de picagem;
• cozimento dos cavacos de madeira: os cavacos são levados ao digestor
juntamente com o licor branco de cozimento, nesta etapa é utilizado para
aquecimento, o vapor através de troca térmica direta;
• separação da pasta e do licor formados: a etapa de cozimento separa a polpa
celulósica, que é enviada para as etapas seqüentes da linha de fibras, do licor
negro fraco que é enviado ao ciclo de recuperação.
A Figura 2.1 evidencia o processo tipo Kraft de forma simplificada em
diagrama de blocos.

27
Cozimento
Pátio de madeira
Deslignificação
Extração/ Secagem da polpa marrom
Caldeira Biomassa
Evaporação Stripping
Caustificação da Lama de cal
Turbina
Tratamento de água
Caldeira recuperação
Oxidação do Licor Branco
Preparação de Oxigênio
Prod. Químicos (branq.)
Caustificação Licor Verde
Água tratadaÓleo combustível
Cascas e finos
Vapor
Dregs
Cal
Óleo combustível
Oxigênio líquido ou ar
InsumosProdutos químicos de
branqueamento
Celulose
Branqueamento
Lavagem de Polpa marrom
Madeiras
Energia Elétrica Vapor
Licor branco
Gases Odorososconcentrados
Água tratada
Lavagem da Polpa
Licor verde
Rejeitos
Vapor de processo
Figura 2.1: Principais etapas envolvidas na rota produtiva Kraft (PIOTO, 2003)
Durante o processo de recuperação, o licor negro que sai do digestor é
levado a um sistema de evaporadores de múltiplo efeito para que o mesmo aumente o
seu conteúdo de sólidos. O licor mais concentrado é então queimado nas caldeiras de
recuperação. Os sais fundidos resultantes são tratados e retornam à rota produtiva de
celulose na forma de licor branco (NaOH e Na2S). Assim, uma característica
importante deste processo de recuperação dos sais inorgânicos é que as etapas
envolvidas estão correlacionadas de forma a atribuir ao processo global uma natureza
cíclica como mostra a Figura 2.2.

28
Figura 2.2: Diagrama cíclico do processo recuperação Kraft (ASSUMPÇÃO et al., 1988, p.176)
2.2 Características da madeira
A madeira é constituída de vários elementos celulares, unidos entre si, o que
forma tecidos diferenciados conforme a função que desempenham. Carvalho (2005)
afirma que é o conjunto e arranjo do lenho que definem sua estrutura.
Karlson (2006) descreve que a madeira é composta principalmente por três
tipos de materiais: celulose, hemicelulose e lignina e que sua composição relativa
varia de acordo com cada espécie de árvore.
Carvalho (2005) comenta que ainda que todas as madeiras sejam formadas
basicamente pelos mesmos elementos, as modificações de forma, tamanho e arranjo
dos componentes tornam diferentes as estruturas das diversas espécies. Afirma
também que embora exista uma grande variabilidade da madeira dentro da mesma

29
espécie e, até mesmo, dentro de uma mesma árvore, a estrutura básica das madeiras
pertencentes a uma mesma espécie mantém-se constante. Esta característica torna
possível a classificação e a identificação das madeiras através de observações de seus
elementos. Dentro de certos limites, o estudo da estrutura da madeira permite avaliar
as possibilidades de sua aplicação.
As paredes celulares são constituídas de muitas substâncias orgânicas e
inorgânicas. Consideram-se como substâncias orgânicas a lignina, proteínas e
lipídios. Como substâncias protéicas importantes, têm-se a extensina, que dá rigidez
à parede, e a α-expansina, que atua na expansão irreversível da parede. São também
comuns as enzimas peroxidases, fosfatases entre outras (CARVALHO, 2005, p.33).
Substâncias lipídicas como suberina, cutina e ceras tornam a parece celular
impermeável à água. Dentre as substâncias inorgânicas podem ser citados a sílica e o
carbonato de cálcio.
Carvalho (2005) descreve que a parede celular forma-se externamente à
membrana plasmática. As primeiras camadas formadas constituem a parede primária
(PM) (Figura 2.3), onde a deposição das microfibrilas ocorre por intussuscepção, ou
seja, por rearranjo entrelaçado. Entre as paredes primárias de duas células contíguas
está presente a lamela média, ou mediana (LM) (Figura 2.3).
Em muitas células a parede primária é a única que permanece. Em outras,
internamente à parede primária, ocorre a deposição de camadas adicionais que
constituem a parede secundária. Nesta parede, as microfibrilas são depositadas por
aposição, ou seja, por arranjo ordenado. A primeira, a segunda e a terceira camadas
da parede secundária são designadas S1, S2 e S3, respectivamente, sendo delimitadas
pela mudança de orientação da deposição, que varia nas diferentes camadas (Figura
2.3). A camada mais próxima da parede primária é denominada S1, a camada
seguinte é a S2 representa cerca de 70 a 75% do total da parede celular descreve
KOGA (1988). A camada S3 é semelhante a S1 e suas microfibrilas estão dispostas,
aproximadamente, na direção perpendicular ao eixo da fibra de 60° a 90°.
Durante a deposição da parede secundária inicia-se a lignificação. No caso
de células mortas, a parede secundária delimita o lume celular (L).

30
S3 - Camada de entrada da parede secundária
S2 - Camada principal da parede secundária
S1 - Camada de saída da parede secundária PM - Parede primária LM - Lamela média
L - Lume Celular
Figura 2.3 Ilustração de uma parede de células e organização das fibras
De acordo com Carvalho (2005) as paredes diferem em espessura,
composição e propriedades físicas nas diferentes células. A união entre duas células
adjacentes é efetuada através da lamela média (LM) que é constituída principlmdente
por lignina (KOGA, 1988, p. 33). A parede primária é mais espessada que a lamela
média e geralmente se mostra bem mais fina em comparação à parede secundária. A
parede primária possui alto teor de água, cerca de 65%, e o restante, que corresponde
à matéria seca, é composta de 90% de polissacarídeos (30% de celulose, 30% de
hemicelulose e 30% de pectina) e 10% de proteínas (expansina, extensina e outras
glicoproteínas). Impregnações e, ou, depósitos de cutina, suberina e ceras podem
estar presentes na parede primária de algumas células. A parede secundária possui
um teor de água reduzido, devido à deposição de lignina que é um polímero
hidrofóbico. A matéria seca é constituída de 65 a 85% de polissacarídeos (50-80% de
celulose e 5 a 30% de hemicelulose) e 15 a 35% de lignina. A celulose é o maior
componente da parede secundária, estando aparentemente ausentes as pectinas e
glicoproteínas. Embora o processo de lignificação esteja associado à parede
secundária, ele geralmente se inicia na lamela média e parede primária, de modo que
estas também podem conter lignina quando da formação da parede secundária.
Vários fatores caracterizam a madeira e a sua influência nos processos de
polpação. Dentre eles destacam-se:
• Espécie da madeira alimentada no processo:
A espécie de madeira tem grande efeito na qualidade e propriedades da polpa
celulósica. A Cenibra utiliza em suas operações apenas madeira de folhosas,
mais especificamente Eucalipto (híbridos de grandis).

31
De forma geral, a madeira proveniente de folhosas possui, quando
comparadas às madeiras de coníferas, as seguintes características:
° fibras mais curtas (cerca de 1mm de comprimento);
° menor teor de lignina;
° maior teor de xilanas4;
° maior facilidade de impregnação dos cavacos;
° maior facilidade de deslignificação;
° excelentes propriedades de impressão e escrita.
• Qualidade do cerne e alburno;
Observam-se nas caracterizações da madeira, diferenças nas qualidades das
madeiras de cerne e alburno (Figura 2.4). Embora do ponto de vista de
obtenção de celulose esse fato tenha pouco aplicação prática, pois se consome
a tora inteira, é importante destacar que:
• cerne: Possui mais extrativos e lignina, que levam:
° menor rendimento;
° mais pitch que é um depósito adesivo de origem natural (vegetal)
formado em polpa, papel e no maquinário da fábrica;
° dificuldade maior de cozimento e consequentemente de
branqueamento.
• menor permeabilidade (capacidade de absorção de umidade);
• maior dificuldade de impregnação dos cavacos;
Figura 2.4: Estrutura de um tronco, Carvalho (2005)
4 As xilanas são polissacarídeos como um esqueleto linear formado por unidades de xilose conectadas entre si pelos carbonos 1 e 4, através das ligações Beta (β) (D’ALMEIDA,1988, p.70).

32
• Presença de nós na alimentação de cavacos;
Nó é a porção basal de um ramo que se encontra embebida no tronco ou peças
de madeira, provocando na sua vizinhança desvios ou a descontinuidade dos
tecidos lenhosos (CARVALHO, 2005, p.39). O efeito dos nós depende do seu
tamanho, número, distribuição, característica (solto/vazado). A grande
presença de nós tem influência negativa no rendimento do processo, uma vez
que prejudicam as propriedades físico-mecânicas das fibras. Quanto a
aderência o nó pode ser vivo, morto ou solto conforme mostrado na Figura
2.5.
Figura 2.5: Tipos de nós quanto a aderência: A- Nó vivo, B- Nó morto, Carvalho (2005)
• Presença da madeira juvenil e de topo;
Da mesma forma que as diferenças na qualidade de cerne e alburno, embora
do ponto de vista de obtenção de celulose, esse fato tenha pouca aplicação
prática, pois se consome o tronco inteiro, cita-se as seguintes diferenças nas
características de madeira juvenil e de topo:
° menor densidade;
° menor rendimento;
° fibras mais curtas e de paredes mais finas;
° menor comprimento e diâmetro dos elementos de vasos;
° parede celular mais fina;
° maiores ângulos das microfibrilas;
° maior proporção de fibras;
° menor proporção de vasos;
° maior teor de holocelulose.
• Presença de madeira de tensão (crescimento excêntrico);

33
Caracteriza-se por uma medula acentuadamente deslocada do centro do
tronco. Os anéis de crescimento apresentam largura variável e as zonas de
lenho inicial e tardio são pouco diferenciadas. Pode ser provocada pelo vento,
ação da gravidade em árvores que crescem obliquamente, forte insolação
lateral, crescimento unilateral da copa que resulta em suprimento de
nutrientes deficiente em um dos lados (CARVALHO, 2005, p.37).
Em regiões muito acidentadas, como é o caso de algumas áreas de plantio da
Cenibra, pode ocorrer à presença de madeira de tensão, caracterizado pela
presença do crescimento excêntrico, o que favorece as seguintes
características:
° camada gelationosa S3 (Figura 2.3);
° mais celulose e menos lignina;
° maior rendimento;
° mais galactana e menos xilana;
° vasos menores e menos freqüentes;
° densidade mais elevada;
° propriedades de resistência inferiores.
• Idade da madeira;
Do ponto de vista prático, a idade da madeira é um fator de gerenciamento
operacional das florestas e afeta as propriedades de interesse do
processamento das seguintes formas:
° quanto maior a idade da árvore maior será sua densidade;
° quanto maior a idade maior é o RD (rendimento depurado); Queiroz
(2004) conclui em seus experimentos, que a madeira de baixa
densidade apresenta menor requerimento de álcali para produção de
polpa, maior rendimento depurado e viscosidade da polpa mais
elevada.
° quanto maior a idade menor será o consumo específico (capacidade de
conversão e polpa de celulose ou seja m³ de madeira / tonelada polpa).
• Variação na densidade básica da madeira alimentada no cozimento
(densidade a granel dos cavacos);

34
Para a Cenibra, a densidade tem sido um dos únicos fatores utilizados como
característica de qualidade no acompanhamento operacional da fábrica. É
sabido que a densidade afeta de forma significativa no processo de produção
de celulose.
Embora a densidade represente as tendências definidas nas características da
madeira, sabe-se que outros fatores também influenciam essa avaliação e que,
por exemplo, o teor e composição da lignina da árvore poderão afetar muito
as características do processamento, e até mesmo se sobrepondo a tendência
da densidade.
As alterações de densidade na madeira influenciam nas:
° alterações no processo de picagem;
° alterações no dimensionamento dos cavacos;
° alterações na densidade a granel dos cavacos;
° alterações no teor de rejeitos;
° variações no consumo específico de madeira em m³ / tonelada polpa;
° alterações do consumo de álcali efetivo;
° alterações no RD (rendimento depurado);
° variações na viscosidade;
° maior consumo de energia no refino.
De forma geral, a densidade causa vários efeitos em um processo de
cozimento, e consequentemente nos processos de produção de celulose e do
próprio papel, e se relaciona com as seguintes características (QUEIROZ et
al., 2004):
° variação de volume específico aparente;
° variação de resistência à refinação;
° variação de resistência ao rasgo;
° variações nas características de opacidade;
° alterações nas características superficiais;
° alterações na qualidade de impressão;
° variação na resistência à tração;
° variação no alongamento;
° variação da resistência ao arrebentamento;

35
° variação da resistência a dobras;
° variação no peso específico aparente;
° alterações nas propriedades de ligação entre fibras;
• Composição química da madeira alimentada
Espécies de madeira que apresentam as melhores características para a
produção de polpa celulósica são as que possuem maiores teores de
carboidratos (celulose, hemicelulose) menores teores de extrativos, de lignina
e maior relação SG5. siringila/guaiacila.
Composição:
° celulose: 40 a 50%;
° hemicelulose: 20 a 30%;
° lignina (guaiacila, co-polímero siringila-guaiacila): 25 a 35%;
° extrativos (resina, cera, gordura, açúcar, tanino): 2 a 4%;
° cinzas: < 0,5%;
° Mn, Fe, Cu, Co, Zn: afetam o branqueamento que utiliza reagentes
como ozônio (O3) e peróxido de hidrogênio (H2O2), causam perda de
viscosidade e reversão de alvura;
° Ca, Al, Si, Ba, Mg, Mn: causam incrustações na caldeira de
recuperação, evaporadores e lavadores;
° P, N: nutrientes que afetam qualidade do efluente;
° K, Cl, Cr: corrosão entupimentos na caldeira de recuperação;
° Cd, Cu, Ni, As, Hg, Zn, Cr: aumentam toxidez do efluente.
A Figura 2.6 mostra a relação e o rendimento para os principais
componentes do Eucalyptus grandis (COLODETTE, 2004). Considerou-se uma
estimativa para um processo com produção, tomando como referência o #Kappa
igual 16 e rendimento depurado igual a 50%. Pode ser observado que dos 100 Kg de
madeira, aproximadamente 50%, após a etapa de polpação, segue na linha de fibras
como polpa marrom e o restante é extraído como licor negro fraco e é considerado
como perdas, mas no entanto é reaproveitado na etapa de recuperação.
5 Siringila/Guaiacila (S/G) são tipos de lignina presentes na constituição química da madeira.

36
100 Kg Madeira Eucalyptus grandis
Figura 2.6: Rendimento do Eucalyptus grandis para um processo em produção com
#Kappa=16 (COLODETTE, 2004)
2.3 Caracterização da madeira utilizada na Cenibra
Caldeira et al. (2006) descreve que até o ano de 2001, a Cenibra não possuía
nenhum tipo de classificação com objetivo de abastecimento de madeira. Toda a
caracterização realizada limitava-se à conversão de quantidades utilizadas nos
processamentos florestais. A partir de 2001, iniciou-se uma simples caracterização,
dividindo a madeira em leve e pesada. Entre 2003 e 2005, a caracterização por
densidade foi implantada, e a madeira foi dividida em cinco classes conforme Tabela
2.1, utilizadas na confecção de misturas para atender as necessidades de produção.
Em algumas situações, entretanto, observava-se que a densidade não era suficiente
para entendimento dos distúrbios do processo e o manuseio destas cinco classes de
qualidade era bastante oneroso nas operações florestais.
Dessa forma, em 2005 iniciou-se uma nova estratégia de caracterização da
madeira. A área de plantio da Cenibra foi classificada segundo extratos, que são
áreas correspondentes a um material genético homogêneo, de mesma idade, rotação e
região.
Extrativos 2,1 kg
Ligninas 26,7 kg
Hemiceluloses 21,0 kg
Celulose 50,2 kg
Cinzas 0,4 kg
Extrativos 0,25 kg
Ligninas 0,75 kg
Hemiceluloses 8,0 kg
Celulose 41,0 kg
Cinzas 0,1 kg
Extrativos 88%
Ligninas 97%
Hemiceluloses 62%
Celulose 18%
Cinzas 75 %
Madeira
Fibras Marrons (50 kg) Cozimento Kraft com #Kappa 16 Rendimento 50%
(10 kappa x 0,15 x 0,50) Perdas

37
Tabela 2.1: Evolução da classificação da madeira na Cenibra, Caldeira, et al., (2006)
Até 2001 2000 a 2002 2003 a 2005 2006 Classificação por
densidade Classificação por Qualidade
A - <= 450 kg/m3 A
B - = 451 a 480 kg/m3 B
C - = 481 a 510 kg/m3 C
D - > 510 kg/m3
Sem Classificação Média e Peso
E - Desconhecido
Em 2006 iniciou-se a classificação por qualidade da madeira (Tabela 2.1),
sendo:
• Classe A: é a madeira da linha de produção #1, com densidade baixa, menor
teor de lignina e extrativos, rendimentos maiores (estudada neste trabalho);
• Classe B: é madeira da linha de produção #2, com densidade altas, com
maiores teores de lignina e extrativos, rendimentos menores e maior
tolerância para o MIX (mistura de madeira de diferentes qualidades);
• Classe C: é a madeira com características de qualidade maiores que o Limite
máximo permitido.
Através de um projeto de avaliação pré-corte da madeira utilizada na
Cenibra, foi realizada a avaliação do consumo de AE (Álcali Efetivo) e RD
(Rendimento Depurado) para #Kappa igual a 17, através de testes experimentais
(cozimento) em laboratório, utilizando as seguintes condições de cozimento:
• tempo de cozimento: 150 minutos;
• temperatura do digestor: 170 ºC;
• sulfidez: 30 %.
Ao final destes testes, foram analisadas as concentrações dos seguintes
parâmetros de qualidade:
• lignina total, solúvel e insolúvel;
• Extrativos (resinas);
• densidade básica (DB); siringila e guaiacila (S/G).

38
Paralelamente a esse trabalho de classificação da madeira em laboratório,
iniciaram-se as medições através da tecnologia FT-NIR. A tecnologia FT-NIR é uma
metodologia mais rápida e de menor custo, já que são necessárias análises das
características para o volume de todo o maciço florestal da Cenibra.
A primeira parte do trabalho de segregação da madeira constou da criação
das curvas de calibração, nas quais foram obtidas as correlações mostradas na Tabela
2.2, com dados provenientes da caracterização do ano de 2005.
Para amostras desconhecidas e não caracterizadas pelo FT-NIR, foram feitas
extrapolações baseadas na idade, procedência e região de origem da madeira.
Em função dos resultados obtidos, Caldeira et al. (2006) relata que foi
possível selecionar 2 variáveis que passaram a descrever a qualidade madeira. São
eles: densidade e consumo de álcali efetivo para #Kappa 17 (chamado a partir daqui
para simplificação de AE).
Tabela 2.2: Curvas de correção linear de características da madeira (CALDEIRA et al., 2006)
Característica Correlação
AE-Álcali Efeivo (%) 0,623
RD-Rendimento Depurado(%) 0,561
DB- Densidade Básica (kg/m3) 0,778
Lignina(%) 0,230
Extrativos (%) 0,573
Dessa forma, foi possível obter uma visão da distribuição da qualidade da
madeira programada para abastecimento em 2006, representada pelos histogramas na
Figura 2.7 (referentes à densidade) e na Figura 2.8 (correspondente ao AE). Somente
após esta classificação foi possível determinar e reduzir os desvios padrões destas
variáveis, através de alterações de procedimentos operacionais.
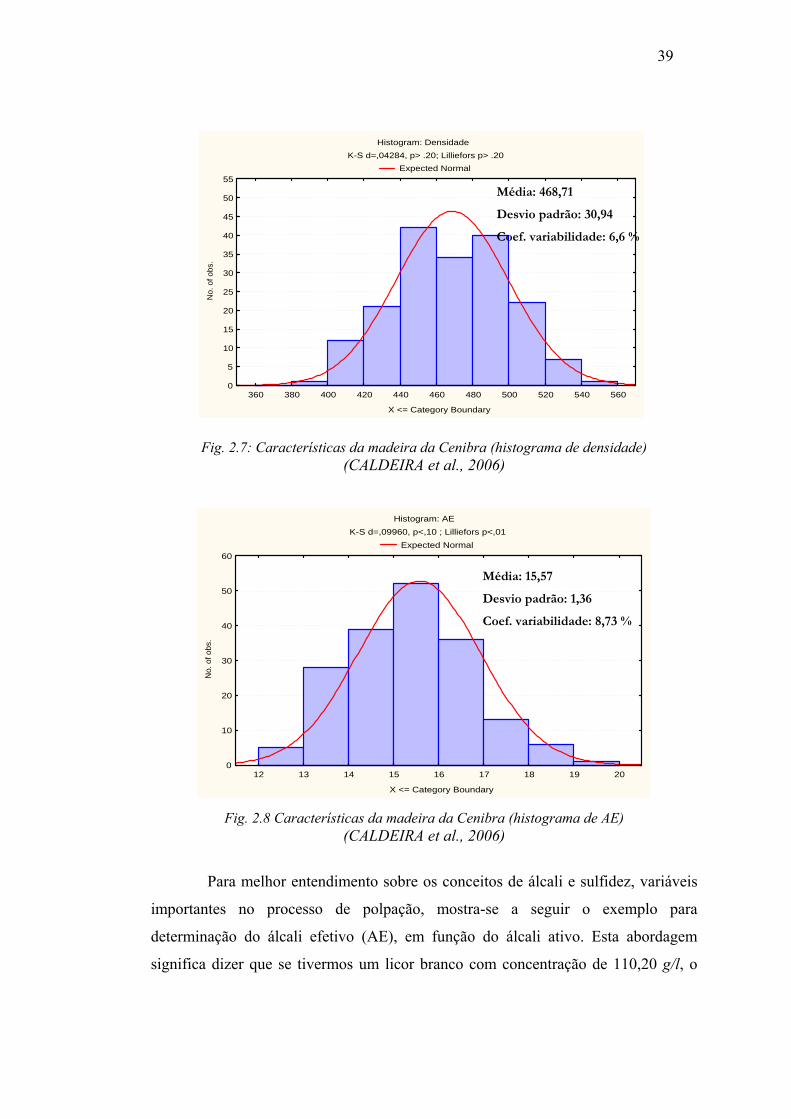
39
Histogram: DensidadeK-S d=,04284, p> .20; Lilliefors p> .20
Expected Normal
360 380 400 420 440 460 480 500 520 540 560
X <= Category Boundary
0
5
10
15
20
25
30
35
40
45
50
55
No.
of o
bs.
Média: 468,71
Desvio padrão: 30,94
Coef. variabilidade: 6,6 %
Fig. 2.7: Características da madeira da Cenibra (histograma de densidade)
(CALDEIRA et al., 2006)
Histogram: AEK-S d=,09960, p<,10 ; Lilliefors p<,01
Expected Normal
12 13 14 15 16 17 18 19 20
X <= Category Boundary
0
10
20
30
40
50
60
No.
of o
bs.
Média: 15,57
Desvio padrão: 1,36
Coef. variabilidade: 8,73 %
Fig. 2.8 Características da madeira da Cenibra (histograma de AE)
(CALDEIRA et al., 2006)
Para melhor entendimento sobre os conceitos de álcali e sulfidez, variáveis
importantes no processo de polpação, mostra-se a seguir o exemplo para
determinação do álcali efetivo (AE), em função do álcali ativo. Esta abordagem
significa dizer que se tivermos um licor branco com concentração de 110,20 g/l, o

40
mesmo terá 97,42 g/l de Álcali Efetivo e 13,77 g/l de NaHS, considerando uma um
percentual de 25% de enxofre.
⎪⎪⎪⎪
⎩
⎪⎪⎪⎪
⎨
⎧
−→⇒⇓
⎩⎨⎧
⇒
+=AElgNaOHlg
Sulfidez
NaOHlgNaHSlg
SNalg
SNaNaOHAtivoAlcalilg
/42,97/65,82)%25(
/77,13/77,13
/55,27 2
/20,1102
2.4 Sistema de recebimento e manuseio da madeira
As fábricas de celulose possuem geralmente pátios de estocagem de
cavacos, a fim de garantir um abastecimento contínuo ao digestor. Manter o nível de
cavacos nos pátios garante um estoque capaz de suprir o processo sem interrupção
momentânea das linhas de abastecimento e picagem.
Algumas empresas utilizam os pátios para estocagem de cavacos por um
período mais longo, a fim de obter propriedades dos cavacos específicas, como é o
caso da eliminação de extrativos e secagem da madeira, o que não é o caso específico
da Cenibra.
2.4.1 Preparação de cavacos
Após o corte da madeira no campo e o seu transporte até a fábrica, a
madeira é conduzida até a mesa receptora de toras nas linhas de picagem, onde
recebe pulverização de água com o objetivo de impedir a geração de suspensão de
particulado (poeira) e remoção de areia. O sistema de arraste das mesas, constituído
por correntes, favorece a remoção de terra, areia, pequenos galhos e um pouco de
casca da madeira recém chegada.

41
Após a mesa receptora, a madeira é conduzida por transportadores de
correias aos tambores descascadores onde, por atrito com a superfície irregular das
paredes internas e entre a própria madeira, ocorre seu descascamento.
Após a saída do tambor descascador a tora de madeira é conduzida ao
picador de disco através de correias transportadoras. O picador é constituído por
facas fixadas em um disco, que gira em alta velocidade. A tora de madeira desce por
uma calha inclinada de encontro com as facas, sendo reduzida à cavacos. Os cavacos
produzidos são enviados em seguida aos pátios de estocagem.
2.4.1.1 Pátio de estocagem
O pátio de estocagem de madeira da linha I da Cenibra é o pátio mais
antigo, portanto com uma concepção menos moderna. O cavaco que chega até o
pátio é conduzido por uma correia transportadora localizada acima do pátio. Possui
uma correia principal que transporta o cavaco desde a saída do picador, onde é
transferido para uma outra correia, que está montada sobre um transportador móvel
que se desloca no sentido longitudinal.
Através da correia móvel o cavaco pode ser descarregado diretamente sobre
o leito do pátio ou ser descarregado em uma outra correia que está no sentido
perpendicular, que por sua vez descarrega na direção dos arrastadores de extração do
pátio, chamado de stocker.
O deslocamento do carro é feito manualmente pelo operador podendo
formar pilhas espaçadas sobre a camada de cavacos existentes no pátio. O formato do
pátio é um retângulo, com 110 metros de comprimento por 30 metros de largura na
base, mantendo esta dimensão até o topo da pilha, que mede 16 metros.
Normalmente o pátio preserva o cavaco espalhado em toda a sua área,
variando, portanto sua altura e conseqüentemente o volume, conforme o ritmo de
produção dos picadores, em relação ao ritmo de produção do digestor.
O cavaco é removido para ser cozido no digestor utilizando arrastadores
instalados na lateral direita do pátio. Na maior parte do tempo, uma correia sobre o
pátio desvia o cavaco sobre os arrastadores deixando o volume armazenado no pátio
como estoque.

42
Com esta logística de operação Caldeira et al. (2006) afirma que
determinadas camadas de cavacos podem permanecer no pátio por um período muito
grande, principalmente as que fazem parte das camadas mais inferiores, enquanto o
cavaco que acaba de entrar no pátio pode ser extraído quase no mesmo instante.
Afirma ainda que não é difícil definir o MIX dos cavacos recém produzidos
quando associados aos cavacos que estão ha mais tempo estocados. Esta situação irá
depender de vários fatores, principalmente quanto ao volume consumido pelo
digestor em relação ao produzido pelos picadores. Maior consumo no digestor,
implica numa maior extração dos cavacos recém chegados ao pátio, devendo ser
completada por mais uma parcela de cavacos estocados anteriormente. À medida que
o pátio abaixa em altura, camadas de cavacos estocados por mais tempo passam a
serem utilizadas. Por outro lado, a diminuição do consumo implica que o pátio irá
ganhar volume. Assim, mais cavacos ficarão estocados, e as camadas mais inferiores
ficarão estocadas por um período muito maior.
Existem períodos do ano em que o volume de cavacos do pátio varia em
virtude de melhor ganho na picagem da madeira. Tradicionalmente, épocas chuvosas
contribuem para uma diminuir o volume dos cavacos no pátio.
Caldeira et al. (2006) relatam que neste tipo de pátio é possível os cavacos
podem sofrer alteração química devido ao tempo de estocagem, como já mencionado
anteriormente. Os cavacos podem ainda sofrer alterações físicas devido à
movimentação freqüente de máquinas de grande porte no pátio, o que provoca a
compactação, quebra e a formação de finos.
2.4.1.2 Extração dos cavacos do pátio para consumo no digestor
A extração dos cavacos para o peneiramento e posteriormente para consumo
no digestor, é realizada através de três arrastadores montados abaixo do pátio,
localizados em pontos longitudinais. Estes arrastadores fazem parte de um
equipamento denominado stocker, e são responsáveis pela extração do cavaco para o
peneiramento e posteriormente para consumo no digestor. São acionados por
cilindros hidráulicos e comandados por um controlador lógico programável (CLP).

43
Uma rosca helicoidal posicionada dentro de uma calha, completa o ciclo de
extração dos cavacos em cada stoker. Quando a calha da rosca está vazia um sinal
de comando, proveniente de uma célula de carga é enviado ao CLP, que por sua vez,
obedecendo a uma programação estabelecida, executa automaticamente os comandos
necessários para a movimentação dos arrastadores (retração e avanço). Os
arrastadores funcionam de forma alternada, ou seja, quando um arrastador estiver
inserido no pátio o outro retrairá e o que estiver retraído tende a avançar. O
retrocesso dos arrastadores traz consigo a porção dos cavacos que alimentam a calha
da rosca e através do helicóide alimenta a correia, rumo ao peneiramento.
O curso de avanço e retrocesso dos arrastadores é de aproximadamente 1,4
m, a distância máxima possível do alcance dos arrastadores dentro do pátio é de 4,0
metros. Diante desta estrutura, pode-se afirmar que os arrastadores estão limitados a
uma área de captação restrita e fixa dentro do pátio, local onde estão montados os
stockers. Portanto, haverá sempre a necessidade de direcionar o cavaco nestes
pontos, seja através da correia transportadora, ou pela alimentação através de
máquina móvel (pá mecânica).
Após a extração pelos stockers, os cavacos são enviados à etapa de
peneiramento para remoção dos finos e dos overs. Em seguida, são transportados ao
processo de cozimento.
2.5 Cozimento (polpeamento)
O processo de cozimento consiste na separação da lignina das fibras
celulósicas, constituintes básicos da madeira. Para efetuá-la, a CENIBRA utiliza o
processo químico Kraft ou Sulfato.
Este processo de cozimento químico usa soda cáustica, compostos de
enxofre (denominado licor branco ou licor de cozimento), temperatura e tempo de
cozimento adequados em um vaso pressurizado, conhecido como digestor. O
digestor estudado neste trabalho possui capacidade volumétrica de 1.000 m³. A
alimentação é feita continuamente pelo topo, com descarga simultaneamente pelo
fundo o tempo de retenção é de aproximadamente 3 horas.

44
Os produtos resultantes do cozimento são as fibras celulósicas, denominadas
massa marrom e uma mistura de matéria orgânica e inorgânica denominada licor
preto fraco. Este licor, após tratamento, é queimado na caldeira de recuperação,
gerando energia e vapor.
Desde a alimentação até a descarga, os cavacos permanecem
aproximadamente 3 horas em regime de cozimento. A massa, antes de ser
descarregada pelo fundo, é pré-lavada dentro do próprio digestor.
Os cavacos que vêm do peneiramento caem em um silo. No silo, é
introduzido vapor de baixa pressão para um pré-aquecimento. No fundo deste silo, os
cavacos passam por uma rosca que funciona como um medidor de cavacos. Em
seguida, passam por um alimentador de baixa pressão, que está localizado na calha
de cavacos para depois caírem no alimentador de alta pressão, onde em contato com
o licor de topo, inicia o processo de circulação. Este licor transportará os cavacos até
o topo do digestor.
Parte deste licor passa por uma peneira localizada no alimentador de alta
pressão e vai para dois filtros. O licor filtrado vai para o tanque de nível e o licor não
filtrado vai para a calha de cavacos, com objetivo de manter o nível desta. Do tanque
de nível o licor retorna à circulação de topo. A mistura de cavaco e licor chegará
direto no separador de topo, que irá extrair parte deste licor para que o mesmo
retorne a circulação de topo. O restante será transportado pelo separador de topo para
dentro do digestor, onde ocorrerá o cozimento dos cavacos, com introdução de vapor
a pressão de 13 Kgf/cm2.
2.6 Digestor
Os digestores são vasos de pressão onde os cavacos de madeira são tratados
com o licor de cozimento, à pressão e temperatura estabelecida, visando a produção
de pasta de celulose (ASSUMPÇÃO et al., 1988, p.235). O ciclo de operação do
cozimento inicia-se com a introdução dos cavacos e do licor no digestor, seguido
pelo aquecimento do conjunto até a temperatura estabelecida, conforme o tipo de

45
cozimento empregado. As variáveis: temperatura, tempo de cozimento e quantidade
de reagentes, promovem a solubilização e separação das fibras.
Para evitar a ebulição o licor de cozimento é necessário que o digestor
trabalhe com uma pressão acima da pressão atmosférica, possibilitando assim
aumento da temperatura de cozimento, uma aceleração nas reações químicas de
deslignificação e maior produtividade no equipamento.
Por ser um material de menor custo, os digestores são em sua maioria,
construídos em aço carbono sendo empregado também, em alguns casos, aço
inoxidável na forma de revestimento. As seções superiores e médias do digestor são
as mais sujeitas a corrosão (ASSUMPÇÃO et al., 1988, p.237).
Digestores de maior porte são mais econômicos que os de pequeno porte,
pois necessitam de quantidades específicas menores de vapor e mão-de-obra. Porém,
atualmente para instalação de novas fábricas, tem surgido uma nova tecnologia
chamada de Compact Cooking, onde há o pré-cozimento do cavaco antes de entrar
no digestor propriamente dito.
Os digestores descontínuos são os empregados na polpação alcalina. Estes
equipamentos possuem aquecimento direto ou indireto, e os processos de cozimentos
empregados por eles mais conhecidos são: Batch e Superbatch.
Nos sistemas descontínuos, também chamados de batelada, existem três
processos com aplicação comercial: RDH (Rapid Displacement Heating),
SuperBatch e EnerBatch. Nos processos RDH e SuperBatch é feito um pré-
tratamento (impregnação) do cavaco com licor negro, visando reduzir o consumo de
vapor e ao mesmo tempo aumentar a sulfidez inicial e reduzir a carga de álcali
efetiva. Já no processo EnerBatch é feito um pré-tratamento do cavaco com licor
branco seguido de um pré-tratamento com licor negro. Todos estes processos
possibilitam uma substancial economia de energia e melhoram a qualidade da polpa
(PIOTTO, 2003, p.201).
Já os digestores contínuos, podem ser classificados em função dos processos
utilizados para o cozimento: Convencional, ITC (Isothermal Cooking), Kobudo-
Mari, Lo-Solids, Compact Cooking. Nestes equipamentos, toda matéria prima de
produção de celulose é introduzida continuamente através de equipamentos

46
especiais, sendo os produtos descarregados, simultaneamente e na mesma proporção,
após o tempo de retenção necessário para acontecer o cozimento da madeira.
A celulose marrom é obtida no digestor contínuo estudado, com objetivo de
produzir de 1288 tSA/d (tonelada seca ao ar por dia). O digestor é um vaso
pressurizado com aproximadamente 60m de altura, 3 m e 6m de diâmetro na parte
superior e inferior, respectivamente (Figura 2.9).
Figura 2.9: Digestor contínuo – Cenibra
Basicamente, durante sua operação, o digestor é mantido continuamente
cheio, sendo alimentado na parte superior com cavacos e licor de cozimento (licor
branco). A polpa de celulose descarregada na parte inferior possui uma consistência
de 10%. O rendimento do processo é da ordem de 50%, ou seja, para cada tonelada
(peso seco) de cavacos alimentados, obtém-se 0,5 tonelada de celulose. A
temperatura de cozimento é aproximadamente 170 ºC a uma pressão do vapor de
alimentação é de 13 kgf/cm² (fundo).
No digestor, processa-se o cozimento da madeira com o licor branco, agente
químico que separa as fibras de celulose dos compostos orgânicos restantes da
madeira que são dissolvidos. Como a lignina é o principal composto a ser separado,
esta etapa é também chamada de deslignificação.

47
Uma consideração importante em processos de cozimento, é Fator H que é
um método desenvolvido por Vroon (1957) para expressar o tempo e a temperatura
de cozimento como uma única variável, é calculado com base na área sob a curva da
velocidade relativa em função do tempo.
A tecnologia de cozimento utilizada atualmente na Cenibra é a chamada Lo-
Solids. O objetivo básico desta metodologia é minimizar a concentração de sólidos
oriundos da madeira nas fases de deslignificação principal e residual, mantendo as
condições necessárias para um processo modificado. A tecnologia Lo-Solids oferece
como benefícios:
• redução de picos de concentração de álcali;
• redução de picos de temperatura;
• mínima concentração de lignina ao final do cozimento;
• máxima sulfidez no início do cozimento.
Segundo Marcoccia et al. (1998) tem-se verificado que a concentração de
sólidos de madeira dissolvidos pode ser reduzida em até 30%. No processo Lo-
Solids, as condições de reação desejáveis são obtidas pela extração do licor negro do
sistema várias vezes durante o processo de polpação. Cada uma das extrações é
seguida de uma injeção de licor para reconstituição das concentrações de reagentes
desejáveis. O cozimento Lo-Solids apresenta muitas vantagens dentre elas, destacam-
se:
• o aumento da resistência e viscosidade da polpa;
• a redução da temperatura de cozimento e do uso de álcali;
• a melhoria na eficiência de lavagem no digestor;
• o cozimento mais uniforme;
• um melhor desempenho no deslocamento da coluna de cavacos
dentro do digestor;
• a redução na demanda de reagentes químicos no branqueamento.
Devido a estas vantagens o processo Lo-Solids tem apresentando uma rápida
expansão na sua aplicação industrial no mundo. Além disto, em várias fábricas
observou-se uma redução no consumo específico de madeira da ordem de 8% , o que
segundo Marcoccia et al. (1998) evidencia o aumento de rendimento devido ao uso
deste processo.

48
Basicamente este tipo de cozimento objetiva:
• estabilizar o perfil de concentrações de carga alcalina ao longo do
cozimento;
• concentrar maior número de íons sulfeto na fase de deslignificação
inicial e no começo da fase principal de remoção de lignina, como
forma de se proteger os carboidratos;
• uniformizar as temperaturas ao longo de cozimento, as quais são
mantidas menores em relação ao que se fazia no passado;
• reduzir a concentração de lignina dissolvida e de íons de sódio,
conseguindo-se isso pela troca constante dos licores conforme vão
sendo extraídos os compostos da madeira;
• processar condições brandas de cozimento e uniformes, levando em
consideração as principais variáveis do processo de cozimento Kraft.
Estes sólidos dissolvidos referem-se à lignina, celulose, hemicelulose,
extrativos, metais e sais minerais, os quais são removidos da madeira e dissolvidos
nos licores extraídos, durante o cozimento. Este processo inicia-se na impregnação,
onde os cavacos recebem o licor de cozimento e são aquecidos até a temperatura de
cozimento. O final da deslignificação refere-se à última zona de cozimento no
digestor.
Conceitualmente a hemicelulose, assim como a celulose, é um
polissacarídeo constituído de vários tipos de unidades de açúcar. Além de ser um
polímero ramificado de cadeia mais curta, possui baixa massa molecular, estrutura
amorfa e tem como principal constituinte a D-xilose (eucalipto), encontrado na
parede da fibra e representa de 20 a 30% da madeira (folhosas).
Sólidos de madeira dissolvidos são removidos do sistema pela extração do
licor de impregnação consumido e/ou pelos múltiplos licores de cozimento
consumidos ao longo do digestor. Em adição aos sólidos de madeira dissolvidos,
água e químicos do cozimento também serão removidos em cada extração. A
quantidade de água e álcali efetivo removido para uma dada extração dependerá do
fluxo de extração e da concentração do licor extraído. A reposição de água deve ser
realizada de maneira a satisfazer as necessidades do sistema hidráulico.

49
A reposição dos químicos do cozimento deve executada de forma a
satisfazer o grau de deslignificação necessário ao longo do digestor. Como resultado,
de licor branco e filtrado de lavagem são adicionados juntos para satisfazer o grau de
cozimento necessário ou em cada ponto onde é efetuada a extração, como afirma
Marcoccia et al. (1998).
Porém, nem todo sólido dissolvido presente no processo de cozimento, pode
ser removido do sistema via extração. Os licores de reposição, licor branco e
reposição de filtrado de lavagem, juntos, têm significativamente mais baixas
concentrações de sólidos de madeira dissolvidos do que os licores remanescentes no
digestor quando se efetua a mistura.
A combinação dos fluxos de reposição, junto com os licores remanescentes,
permanece no sistema após a extração. Ao mesmo tempo a combinação de fluxos de
reposição aumenta a relação líquido/madeira descendente de uma dada extração. A
alta relação líquido/madeira ajuda a diluir algum sólido dissolvido adicional formado
durante a zona de cozimento subseqüente.
A Figura 2.10, mostra um digestor contínuo tipo hidráulico, para processo
de cozimento Kraft com os principais equipamentos do sistema.
Figura 2.10: Digestor contínuo para cozimento Kraft (Lo-Solids)

50
Todo o processo descrito tem como objetivo controlar o grau de cozimento,
ou seja, o teor de lignina residual na massa, medido pelo #Kappa, que é um
parâmetro utilizado como referência para o controle do processo.
No processo de cozimento Lo-Solids, as múltiplas entradas de licor branco e
as múltiplas extrações de licor negro fraco, podem ser rearranjadas de diferentes
formas, dependendo das características individuais de cada digestor. A flexibilidade
inerente do processo de Lo-Solids, permite um controle independente de reações
químicas nas diferentes zonas existentes, conforme a Figura 2.11.
Licor Branco
Zona de Impregnação
Segundo estágio de cozimento
Primeiro estágio de cozimento Licor Branco
Zona de lavagem Licor Branco
Figura 2.11 Processo de cozimento Lo-Solids com 04 diferentes zonas de cozimento
Andritz, 2006
Moczydlower (2002) descreve o digestor, como um vaso de pressão onde os
cavacos e o licor branco são alimentados continuamente pela parte superior. O
cozimento da madeira ocorre do topo até o centro do digestor em fluxo co-corrente.
Do centro até a parte inferior, realiza-se uma operação de lavagem com fluxo em
contra-corrente, a fim de se retirar o licor negro formado. Uma visão esquemática do
digestor de celulose é apresentada na Figura 2.11. Assim, a flexibilidade inerente do
processo permite um controle independente de reações químicas nas diferentes zonas
existentes.

51
A finalidade do cozimento da madeira é separar da sua organização
compacta as fibras que estão unidas pela substância lignina como mencionado
anteriormente. De acordo Assumpção et al. (1988) para a produção de pastas
uniformes, deve-se dar um tratamento químico e térmico idêntico a todas as fibras.
Isto só é possível se os reagentes químicos houverem sido transportados para o
interior dos cavacos. Este transporte é realizado por meio de dois mecanismos
conforme comenta Assumpção et al. (1988): primeiro pela penetração do licor na
madeira devido a um gradiente de pressão hidrostática; e pela difusão de íons ou
outros solutos através da água sob a influência de um gradiente de concentração.
Embora a lignina seja o componente da madeira mais afetado pela polpação
alcalina, todos os carboidratos, incluindo a celulose, são atacados pelo licor de
cozimento composto principalmente de NaOH e Na2S segundo afirma Assumpção et
al. (1988). Estes autores comentam também que as variáveis que controlam o
rendimento, a composição química a as propriedades físicas da pasta produzida
podem ser dividas em dois grupos:
• variáveis associadas com a madeira: espécie, densidade básica (Expressa em
gramas ou quilogramas de madeira seca por centímetro cúbico ou por
decímetro cúbico de madeira verde, respectivamente.), fatores de
crescimento, estocagem e dimensões do cavaco;
• variáveis associadas com a operação do digestor: relação entre massa dos
reagentes e a massa de madeira seca, concentração dos reagentes no licor de
cozimento, sufidez do licor, temperatura e tempo de cozimento.
2.7 Número Kappa (#Kappa)
A qualidade da polpa é usualmente verificada ao final do processo de
cozimento da madeira. Uma maneira tradicional de se realizar esta medida é a
obtenção do #Kappa para o processo. D`Almeida (1988) afirma que a lignina
presente em pasta não branqueada é prontamente oxidada por permanganato de
potássio, enquanto a celulose é muito pouco atacada. Tomando-se esta propriedade,
pode-se definir o #Kappa como sendo o número em ml de solução de permanganato

52
de potássio 0,1N consumido por um grama de pasta absolutamente seca, sob
condições específicas.
O #Kappa foi determinado pela norma TAPPI (Technical Association for
the Pulp, Paper, and converting Industry) T236 cm-85. O #Kappa corrigido foi
obtido após a quantificação dos ácidos hexenurônicos e utilizando-se do fator de
conversão proposto por Li & Gellertedt (1997), no qual 11,9 mmol de Ahexs/kg de
polpa corresponde a uma unidade de Kappa.
Já o procedimento ISO 302:1981, define o #Kappa como o número de ml
de 0,02 mol/l de solução de permanganato de potássio, consumido sobre condições
especificadas em 1 g de polpa (calculada em base seca). Os resultados são corrigidos
para um valor correspondente obtido, quando 50% (massa/massa) de permanganato
de potássio são consumidos no teste.
Na Cenibra existe um instrumento on-line para medição contínua da
variável Kappa no digestor estudado, no entanto, para este trabalho foi adotado o
procedimento de análises laboratoriais, objetivando maior precisão na variável
medida.
2.8 Variabilidade das Linhas de Produção
Através dos dados de processo levantados no período de 01/01/2006 a
15/05/2006, Caldeira et al. (2006) descreve que se observou a variabilidade da linha
de produção, medida pelo desvio padrão do #Kappa do digestor, chegando aos
resultados mostrados na Figura 2.12.
O #Kappa médio no cozimento do processo estudado medido nesse
período, foi de 15,6 com um desvio padrão de 2,42, refletindo em um coeficiente de
variabilidade de 15,56%. Espera-se com a implementação do modelo proposto neste
trabalho, oferecer ao operador uma ferramenta de controle que facilite suas ações
operacionais, para reduzir a variabilidade por informações antecipadas da variável
#Kappa, preditas pelo modelo.
53
Histogram: Kappa Dig1K-S d=,07361, p> .20; Lilliefors p<,10
Expected Normal
10 11 12 13 14 15 16 17 18 19 20
X <= Category Boundary
0
10
20
30
40
50
60
No.
of o
bs.
Figura 2.12 Histograma de #Kappa

54
3 ANÁLISE DOS COMPONENTES PRINCIPAIS (PCA)
3.1 Introdução
A Análise de Componentes Principais (PCA) é uma técnica de análise
multivariada, baseada na combinação linear entre as variáveis analisadas, para
redução de dimensionalidade de matrizes. Quando esta técnica é aplicada à uma
matriz com muitas variáveis de entrada o novo conjunto de variáveis torna-se
ortogonal entre si e, portanto não fica correlacionado com os dados originais, em que
as primeiras componentes, denominadas componentes principais, explicam a maior
parte da variância total existente no conjunto de dados, podendo assim representá-
los.
A Análise de Componentes Principais (também conhecida como a
transformação de Karhnen-Loève na teoria da comunicação) maximiza a taxa de
redução de variância (HAYKIN, 2001, p.433).
A seleção e a extração de características são problemas comuns no
reconhecimento estatístico de padrões. A seleção de características é um processo no
qual o espaço de dados é transformado em um espaço de características. Entretanto,
esta transformação é promovida para reduzir o número de características efetivas,
mantendo o conteúdo das informações dos dados originais. O objetivo é reduzir a
dimensionalidade dos dados em análise e encontrar uma transformação mais
representativa e mais compacta destes.
O método consiste em transformar um vetor aleatório x mR∈ em outro
vetor x nR∈ (para ), projetando x nas n direções ortogonais de maior
variância, ou seja, as componentes principais.
mn ≤
Segundo Johnson (2002), os principais objetivos de se utilizar métodos de
análise estatística multivariada são:
• reduzir os dados ou simplificação estruturada: O caso estudado é
apresentado em uma matriz de espectros de freqüência com uma dimensão
elevada, e a técnica PCA reduzirá a dimensão dos dados, porém sem perda
significativa de informação;

55
• ordenar e agrupar grupos de objetos ou variáveis com características
similares;
• investigar as dependências entre as variáveis: O interesse está na relação
natural entre as variáveis. Se todas as variáveis são independentes ou se há
uma dependência entre elas. Se sim, como;
• criar e testar hipóteses: hipóteses estatísticas formuladas em função de uma
população de parâmetros multivariados são testadas para validar suposições
ou reforçar convicções anteriores;
• prever a relação entre as variáveis com o intuito de anteceder os valores de
uma ou mais variáveis observadas e até mesmo outras variáveis;
Ainda pode-se comentar que a análise de componentes principais é o
cálculo dos autovalores e correspondentes autovetores de uma matriz de variâncias e
covariâncias ou de uma matriz de coeficientes de correlação entre variáveis. Quando
as variáveis, devido a escalas diferentes de mensurações empregadas, não são
diretamente comparadas, torna-se necessário preliminarmente padronizá-las, de
modo que as variáveis transformadas passem a ter média zero e variância unitária.
Com variáveis padronizadas, a matriz de variâncias e covariâncias e a de coeficientes
de correlação tornam-se idênticas.
3.2 Dedução das Componentes Principais
Algebricamente as componentes principais são combinações lineares de p
variáveis originais: x1, x2,...,xp.
Geometricamente, as combinações lineares representam a seleção de um novo
sistema de coordenadas obtidas por rotação do sistema original com x1, x2,...,xp como
eixos. Os novos eixos, y1, y2,...,yp, representam as direções com variabilidade
máxima, permitindo uma interpretação mais simples da estrutura da matriz de
covariância.
De acordo com Tino (2005) a análise dos componentes principais, consiste
numa transformação linear de “m” variáveis originais em “n” novas variáveis, de tal

56
modo que a primeira nova variável computada seja responsável pela maior variação
possível existente no conjunto de dados. A segunda, pela maior variação possível
restante e assim por diante, até que toda a variação do conjunto tenha sido explicada.
Segundo Howard (2001) do teorema 0)( =− xAIλ possui uma solução
não trivial se e se somente se, 0)det( =− AIλ , e esta equação é chamada de
equação característica de A. Assim, os autovalores de A podem ser encontrados
resolvendo esta equação em λ .
O que realmente interessa é determinar para quais valores de λ o sistema
tem uma solução não trivial. Um valor de λ é chamado de autovalor de A, ou valor
próprio, ou as vezes, valor característico de A. Se λ é um autovalor de A, então cada
solução não trivial é um autovetor de A associado ao autovalor de λ .
Se A é uma matriz n x m (n linhas correspondentes às variáveis e m colunas
correspondentes às amostras) então um vetor não nulo x em nR é chamado um
autovetor de A se Ax é um múltiplo escalar de x, ou seja, xAx λ= para algum
escalar λ . O escalar λ é chamado de autovalor de A e diz-se que x é um autovetor
associado a λ .
Para o PCA geralmente, os dois ou três primeiros autovetores encontrados
explicarão a maior parte da variabilidade presente. Quando o primeiro autovetor
explicar 90 a 95% da variabilidade, isso deve ser encarado com cuidado e verificado
se não estão presentes variáveis com valores de magnitudes muito maiores que as
demais.
Os autovetores correspondem às componentes principais e são os resultados
do carregamento das variáveis originais em cada um deles. Tais carregamentos
podem ser considerados como uma medida da relativa importância de cada variável
em relação às componentes principais e os respectivos sinais, se positivos ou
negativos, indicam relações diretamente e inversamente proporcionais.
A matriz de carregamentos de cada variável nas componentes principais,
quando multiplicada pela matriz original de dados, fornecerá a matriz de contagens
(scores) de cada caso em relação às componentes principais. Esses valores poderão
então ser dispostos num diagrama de dispersão, em que os eixos são as duas
componentes mais importantes, e mostrar o relacionamento entre os casos
condicionados pelas variáveis medidas.
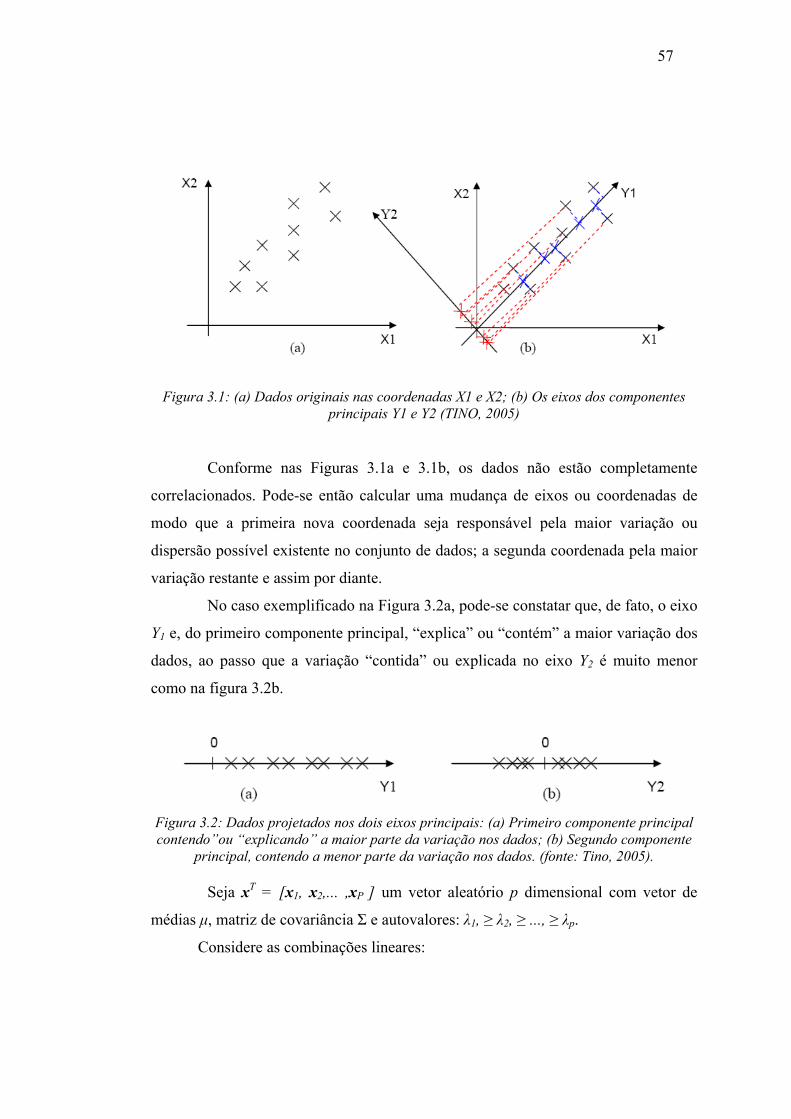
57
Figura 3.1: (a) Dados originais nas coordenadas X1 e X2; (b) Os eixos dos componentes principais Y1 e Y2 (TINO, 2005)
Conforme nas Figuras 3.1a e 3.1b, os dados não estão completamente
correlacionados. Pode-se então calcular uma mudança de eixos ou coordenadas de
modo que a primeira nova coordenada seja responsável pela maior variação ou
dispersão possível existente no conjunto de dados; a segunda coordenada pela maior
variação restante e assim por diante.
No caso exemplificado na Figura 3.2a, pode-se constatar que, de fato, o eixo
Y1 e, do primeiro componente principal, “explica” ou “contém” a maior variação dos
dados, ao passo que a variação “contida” ou explicada no eixo Y2 é muito menor
como na figura 3.2b.
Figura 3.2: Dados projetados nos dois eixos principais: (a) Primeiro componente principal contendo”ou “explicando” a maior parte da variação nos dados; (b) Segundo componente
principal, contendo a menor parte da variação nos dados. (fonte: Tino, 2005).
Seja xT = [x1, x2,... ,xP ] um vetor aleatório p dimensional com vetor de
médias µ, matriz de covariância Σ e autovalores: λ1, ≥ λ2, ≥ ..., ≥ λp.
Considere as combinações lineares:

58
pPP22P11PTpP
pPj22j11jTjj
pP2222112T22
pP1221111T11
xuxuxuxuy
xuxuxuxuy
xuxuxuxuy
xuxuxuxu
+++==
+++==
+++==
+++==
L
M
L
M
L
Ly
ou:
XUY T=
onde:
e
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
P
2
1
y
yy
YM
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
PPP2P1
2P2221
1P1211
uuu
uuuuuu
U
L
MLMM
L
L
com: ( ) ( ) ( ) µuXEuXuEYE T
jTj
Tjj ===
( ) ( ) ( ) juuuXVaruXuVarYVar T
jjTj
Tjj ∑===
( ) ( ) T
jTi
TTiji uuXuX,uVarY,YCov ∑== j
P ,2, 1,ji L=≠ Tendo tudo normalizado com:
[ ]⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
=
Pj
2j
1j
Pj2j1jjTj
u
uu
uuuuuM
L
Define-se, de acordo com Chatfield e Collins (1992):
• A 1.ª componente principal como a combinação linear que maximiza a
variância sujeita à restrição ;
xuT1
)( T1 xuVar 1T
11 =uu
• A 2.ª componente principal como a combinação linear que maximiza a
variância sujeita às restrições e ;
xuT2
)( T2 xuVar 122 =uuT 0),( T
21 =xuxuCov T

59
• A j-ésima componente principal como a combinação linear que maximiza a
variância sujeita às restrições e todo i < j.
xuTj
)( Tj xuVar 1T
j =juu 0),( Tj =xuxuCov T
j
3.3 Escolha do número de Componentes Principais
O método no qual se seleciona ou escolhe os componentes principais é um
dos pontos de grandes discussões técnicas. Vários critérios são relacionados e os
mais conhecidos são:
Critério 1 - Critério de Kaiser (1958)
É provavelmente o critério mais usado. Kaiser (1958) propõe considerar
apenas os autovalores superiores a um, demonstrando que estes seriam os valores
estatisticamente significativos.
Critério 2 - Diagrama de Autovalores
A observação do diagrama de autovalores permite conservar aqueles
situados acima do ponto de mudança ruptura da inclinação da curva da função que
relaciona a ordem e os autovalores. Assim, se dois fatores são associados a
autovalores quase iguais, eles representam a mesma proporção de variabilidade e não
há motivo, a priori, de conservar um e não outro. Inversamente, uma forte
diminuição entre dois autovalores sucessivos leva a conservar na interpretação dos
fatores que a precederam. A Figura 3.3 mostra que há uma alteração brusca no
coeficiente angular da curva após o segundo autovalor. Mostra também que o
primeiro componente principal (PC1) possui uma boa covariância, o que representa
uma maior variância dos dados originais, oferecendo então maior relevância das
informações contidas nos dados. Valores de variância superiores a 1, explicam mais
de 90% dos dados originais.

60
1 2 3 4 5 61,0
1,5
2,0
2,5
3,0
3,5
4,0
Autovalores
Var
iânc
ia
Figura 3.3: Representação dos escores dos autovalores de cada fator (método do Diagrama
de autovalores)
Critério 3 - Fatores Interpretáveis
É um critério empírico, mas não desprovido de sentido, é recomendado por
diferentes autores, em particular Thurstone (1947) que propõem conservar os fatores
que se sabe claramente dar um significado. Faz-se uma análise que tenha uma
coerência com as variáveis que estão sendo avaliadas.
Critério 4 - Simulação de LÉBART (1972)
Para a sua operacionalização, cria-se uma matriz do mesmo tamanho de
números aleatórios, mas que respeitem a mesma distribuição (desvio padrão) e a
mesma média de cada variável da matriz em estudo. Após, faz-se a análise de
componentes principais e obtém-se uma série de autovalores. Este processo é
repetido "n" vezes. Para cada classificação na série de autovalores, conserva-se o
autovalor máximo observado ao longo das "n" simulações. Esses valores máximos
observados representam o limite inferior que deve ser ultrapassado para que um
componente possa ser levado em conta.
Vinte simulações são suficientes para atingir um limiar de significância de
5% (1/20). Sua principal desvantagem é que sua aplicação é mais demorada,
necessitando realizar 20 PCA a partir de dados gerados ao acaso para escolher os
autovalores limites.

61
3.4 Comentários finais
A análise dos componentes principais (PCA) encontra os componentes que
melhor representam o conjunto de dados analisados. É importante ressaltar que o
PCA tem sido aplicado como uma técnica matemática que não requer a especificação
de um modelo estatístico para explicar a estrutura do “erro”. Em particular não é feita
qualquer premissa sobre a distribuição das probabilidades da variável original
comenta Monteiro & Reis (1999).
Como o problema tratado apresenta um sistema que possui muitas entradas,
o PCA foi aplicado para reduzir a dimensionalidade da matriz de dados original.
Neste trabalho, os dados extraídos da análise dos cavacos de madeira,
através da tecnologia FT-NIR, geram um espectro de freqüência com 1557 variáveis
diferentes, após a aplicação do PCA, utilizando a rotina PREPCA do MATLAB®,
optou-se por utilizar o critério do diagrama dos autovalores para a escolha dos
componentes principais mais significativos.

62
4 A TECNOLOGIA FT-NIR (Fourrier Transform Near Infrared)
4.1 Introdução
A obtenção de informações e o conhecimento das variáveis de processo são
imprescindíveis no ajuste dos processos industriais. O Infravermelho Próximo (NIR)
apresenta-se como uma poderosa ferramenta para obtenção de dados, por sua vasta
aplicação.
Gomes (2007) descreve sobre a tecnologia FT-NIR e suas aplicações nas
medições dos diversos tipos de variáveis de processo na indústria.
Apontadas por Gomes (2007), são suas principais vantagens: o grande
potencial na coleta de dados, e possibilidade de uma análise não destrutiva das
amostras (pois a radiação NIR é suficientemente pequena, o que faz com que a
amostra não altere sua estrutura). Se utilizados recursos de transmissão de dados do
tipo fibras óticas, por exemplo, tornam as análises a distâncias mais simples e livres
de vibração e descartam a presença de pessoas em ambientes de riscos ou tóxicos.
A Transformada de Fourier é uma aliada do NIR, pois tem como função
básica decompor ou separar um sinal de diferentes freqüências, com suas respectivas
amplitudes. A junção destas duas técnicas forma a tecnologia FT-NIR (Fourier
Transform Near Infrared).
4.2 Absorbância e absorção da luz
Segundo Jenkins e White (1981), existem dois aspectos importantes quando
um raio de luz passa por um meio, seja ele gasoso, líquido ou sólido. No primeiro, na
medida em que a luz penetra em um meio, a sua intensidade irá diminuir em maior
ou menor proporção. Já no segundo aspecto diz que a velocidade de propagação será
menor no meio do que no espaço livre. A absorção é o principal causa da perda de
intensidade, mas em alguns casos o espalhamento contribui ativamente.

63
Se um meio for diferente do vácuo, o raio que penetra neste meio sofrerá
perda de intensidade, amplitude de ondas e haverá absorção.
Com a lei de Beer-Lambert, pode ser definida a absorbância de um meio
através da equação 4.1:
alcA
II α−− == 1010
0
1
(4.1)
Sendo I0 o raio incidente, I1 o raio emergente, α o coeficiente de absorção, l
espessura do meio e ca a concentração de absorbância do meio.
Logo, a equação 4.2 é definida:
⎟⎟⎠
⎞⎜⎜⎝
⎛=
1
010log
IIA
(4.2)
Com o resultado obtido, a Absorbância do meio pode ser observada na
Figura 4.1.
Figura 4.1: Absorbância do meio
Jenkins e White (1981) observaram que quando a intensidade de todos os
comprimentos de onda é atenuada de maneira semelhante, a substância apresenta

64
uma absorção geral. Mas em grande parte das substâncias onde alguns comprimentos
de onda são absorvidos em relação aos outros, apresentam uma absorção seletiva.
GBC (1995) afirma que toda absorção ocorre a nível molecular. É neste
nível que as moléculas absorvem energia (luz) de determinados comprimentos de
onda. A análise espectrofotométrica tem com base a seletividade na absorção de
energia. Para obtenção de um espectro deve-se medir a quantidade de energia que é
absorvida em função do comprimento de onda, e esta energia e denominada
absorbância.
Hulst (1981) diz que a absorção é a medida da perda de luz do feixe
principal. Quando parte da luz emerge do meio para fora do eixo do raio principal,
da-se o nome de energia espalhada ou difusa. Assim a somatória da absorção e do
espalhamento será o fato da extinção de luz.
4.3 A espectroscopia no infravermelho próximo por Transformada de Fourier
(FT-NIR)
O desenvolvimento computacional trouxe o crescimento de várias técnicas
de obtenção de dados de alta resolução. Dentre estas a Espectroscopia no
Infravermelho Próximo por Transformada de Fourier (FT-NIR) evoluiu na aquisição
de dados, através das análises da radiação espectral, com desenvolvimento de estudos
e pesquisas em diversas áreas. A Transformada de Fourier foi incorporada à
tecnologia NIR com objetivo de decompor ou separar um sinal de diferentes
freqüências, com suas respectivas amplitudes.
Em meados do século XX surgem os primeiros equipamentos comerciais
que utilizavam à espectroscopia de infravermelho para o controle da concentração de
butadieno que era utilizado na síntese de borrachas sintéticas. Esses foram
desenvolvidos durante a Segunda Guerra Mundial.
A espectroscopia no infravermelho possui uma tradição de ser uma análise
que apresenta a ‘impressão digital das substâncias orgânicas’. A absorbância em uma
freqüência particular é característica de um grupo funcional presente no composto
químico. A espectroscopia no IR oferece oportunidades analíticas quase que
ilimitadas para muitas áreas de produção e controle de qualidade.

65
Dessa forma, ela vem ganhando muito espaço nos laboratórios analíticos e
em controle de qualidade dos processos industriais. Isso vem ocorrendo devido ao
baixo custo da instrumentação, à velocidade, à facilidade, à não necessidade de
tratamento da amostra, à baixa quantidade de amostras utilizadas, além de não ser
uma técnica destrutiva e de possuir alta seletividade. Ela também ocorre numa ampla
faixa de aplicações químicas e pode ser usada para determinações qualitativas e
quantitativas conforme descreve Borin (2003).
O infravermelho apresenta divisões que são: Infravermelho próximo com
comprimento de onda de 780 a 2.500 nm e com número de onda de 12.800 a 4.000
cm-1, infravermelho médio com comprimento de onda de 2.500 a 5.000 nm com
número de onda de 4.000 a 200 cm-1 e infravermelho distante com comprimento de
onda de 5.000 a 10.000 nm com número de onda de 200 a 1.000 cm-1 que podem ser
observadas em destaque na Figura 4.2 como descrito no manual da PHILIPS (1981).
Figura 4.2: Espectro Eletromagnético
Scafi e Pasquini (2005) descrevem que o desenvolvimento da
instrumentação está intimamente ligado à necessidade de se obter técnicas capazes de
determinar as propriedades da amostra de forma rápida e simultânea. Além de toda
agilidade na determinação, atualmente deseja-se que a técnica permita algum tipo de

66
classificação, isso se deve a necessidade de comprovar a autenticidade e a qualidade
do produto estudado.
De acordo com Bokobza (1998), a faixa de comprimento de radiação do
infravermelho próximo situa-se entre 780 a 2.500 nm (12.800 a 4.000 cm-1) e que
suas interações provêm de sobretons e combinações de transições associadas á níveis
energéticos vibracionais de grupos de átomos, e sua região de freqüência encontram-
se entre 3,8x1014 a 1,2x1014 hz.
Por definição, um método analítico deve apresentar características que
possibilitam: determinações diretas sem o pré-tratamento na amostra; a obtenção de
resultados em intervalos de tempo em ordem de minutos; operações a longas
distâncias o que torna o instrumento simples e de fácil transporte; verificação de
amostras sejam elas pastas, líquidas ou sólidas para observação de sua autenticidade;
uma análise não-destrutiva e em tempo real.
Os métodos espectroscópicos preenchem as atribuições acima, mas há
problemas em relação à seletividade e limites de detecção. Assim o controle de
qualidade de processo ganha com a possibilidade contribuições em novas
metodologias.
Vale salientar que os instrumentos baseados na tecnologia FT-NIR
necessitam de uma calibração e ajustes iniciais, ou seja, quando instalados pela
primeira vez no processo, ou em laboratórios, é necessário que sejam feitas amostras
e gerada uma curva de calibração e o FT-NIR aprenderá a partir desta curva
comparado com padrões laboratoriais.
4.4 A Transformada de Fourier
Jean-Baptiste Joseph Fourier estudou e desenvolveu uma transformada
integral em que sua função é expressa em termos de funções de base, onde a soma ou
integral de funções senoidais são multiplicadas por coeficientes (amplitudes).
Variações são diretamente relacionadas a esta transformada, dependendo do tipo de
função que se deseja transformar.
Os sinais eletromagnéticos são basicamente compostos por uma sucessão de
ondas de diferentes freqüências, por exemplo, um sinal Doppler (ultra-som). Um

67
sinal de ressonância nuclear magnética, o sinal de infravermelho, o sinal de rádio
freqüência são constituídos de diferentes freqüências e fases. Esses podem ser
analisados através de espectro de freqüências ou da Transformada de Fourier.
O critério de Nyquist tem uma alta relevância quanto ao uso da
transformada, pois este determina que a freqüência de amostragem (freqüência de
Nyquist) de um sinal, precisa ser no mínimo o dobro da maior freqüência presente
neste sinal.
A Equação 4.3 e 4.4 demonstram a Transformada de Fourier de uma função
f(x) e a transformada inversa respectivamente:
( )[ ] ( ) ( ) dxexfwFxfF tjwx
x−∞
∞−∫=≡ (4.3)
( )[ ] ( ) ( ) xxwi
xx dwewFxfwFF xπ
π21
21 −∞
∞−
− ∫=≡(4.4)
Onde wx = 2πfx é a freqüência angular é dada em rd/seg, e j= 1− .
Para que uma função da Transformada de Fourier seja integrável e finita,
esta deve obedecer a seguinte Equação 4.5:
∫∞
∞−∞<dxxf |)(|
(4.5)
A da Transformada de Fourier associada à espectroscopia nos traz novas
maneiras de identificação de variáveis de processo como exemplo a Transformada de
Fourier - Infravermelho Próximo (FT-NIR -Fourier transform Near infrared).
As técnicas para análises quantitativas surgem com o avanço da
espectroscopia NIR. Isso ocorre com a combinação da Transformada de Fourier e a
geometria empregada pelos espectrofotômetros que utilizam o interferômetro de
Michelson comenta Eikrem (1990). As análises de Fourier possibilitam uma
interpretação das informações extraídas da tecnologia NIR.

68
4.5 Técnicas de pré-tratamento matemático empregadas ao FT-NIR
A interpretação dos dados gerados (espectros de freqüência) pelo FT-NIR
requer a utilização de métodos multivariados. Estes métodos são utilizados para
tradução de informações de difícil avaliação, para dados com menor
dimensionalidade e de mais fácil manipulação.
A relação matemática (modelo de calibração) entre os valores químicos e os
dados espectrais vem sendo analisada pela regressão por mínimos quadrados parciais
(PLS), que são pré-tratamentos matemáticos aplicados aos dados espectrais como
descrito por Morgano et al. (2007).
Outro método muito empregado na análise dos espectros NIR é a Análise de
Componentes Principais (PCA) que consiste na projeção dos dados originais de
grande dimensão espacial para dimensões menores. Seu objetivo é transformar dados
complexos para que as informações mais importantes e relevantes se tornem mais
fáceis de visualizar.
Neste trabalho foi utilizado o PCA seguindo o critério do “diagrama de
autovalores” para determinação dos componentes principais que representam as
informações analisadas pelo FT-NIR, como apresentado no capítulo 3.
4.6 Aplicações em indústrias de celulose e papel
Várias aplicações do Infravermelho Próximo por Transformada de
Fourier têm surgido nos diferentes seguimentos na indústria. De acordo com Gomes
(2007) a aplicação da espectroscopia no infravermelho próximo vem crescendo ao
longo dos anos na medição de varáveis nas indústrias. Principalmente nas indústrias
de Papel e Celulose, Petroquímica, Álcool, Açúcar, entre outras.
Caldeira et al. (2007) descrevem as aplicações do NIR na indústria de papel
e celulose para medição de teor de umidade e densidade básica em amostras de
cavacos. Obter uma resposta rápida sobre a composição dos cavacos de madeira faz
com que a qualidade do produto final (celulose) seja garantida. Para isto, foi
instalado para testes na linha produtiva da VCP, um equipamento Direct-LigthTM

69
System 6.500 para obter de informações on line sobre a densidade e o teor seco dos
cavacos. Estes testes mostraram que a tecnologia FT-NIR, pode ser utilizada também
on line.
Os benefícios com o uso desta técnica permitem a indústria melhorar o
controle do consumo específico de madeira, reduzir a variabilidade do #Kappa,
controlar e reduzir na carga de álcali ativo dosada no digestor. Também obter
resultados do teor seco e densidade básica dos cavacos, antes do processar a madeira
no processo de produção de celulose.
Algumas das variáveis que são analisadas pelo NIR na indústria de celulose
e papel:
• Teor de umidade de cavacos de madeira;
• Densidade básica da madeira;
• Teor de álcali dos licores banco e verde;
• Lignina contida nos cavacos de madeira;
• Ácidos hexenurônicos (AHex´s6);
• Viscosidade na polpa celulósica.
De acordo com Cohn & Ribeiro (2002) as variáveis medidas pelo NIR
apresentam uma taxa de correlação linear maior do que 0,9 comparando com
medições laboratoriais. E ainda existem outras variáveis que podem ser medidas com
o auxílio do NIR na indústria de papel e celulose, por exemplo: A medição do teor de
lignina dos ácidos hexenurônicos (AHex´s), viscosidade na polpa celulósica, essas
são utilizadas no processo de branqueamento da polpa Kraft CaldeiraA et al. (2007).
Baseado nestes princípios, a espectroscopia no Infravermelho Próximo por
Transformada de Fourier (FT-NIR) passou a ser uma técnica muito utilizada para
várias análises laboratoriais de variáveis dos processos industriais (COHN e
RIBEIRO, 2002); (BORIN, 2003); (CIENFUEGOS, 2003); (PASQUINI, 2003);
(KARLSSON, 2006) e (CALDEIRA et al., 2007).
Gomes (2007) relaciona as principais aplicações desta tecnologia nos
demais segmentos industriais.
6 Ácidos Hexenurônicos: durante cozimentos Kraft, os grupos ácidos 4-O-metilglucurônicos, das cadeias laterais da xilana, são convertidos para ácidos Hexenurônicos (A HEX). Madeiras como Eucaliptos são grandes fontes destes ácidos, devido ao seu teor de xilanas.

70
4.7 Conclusões
A espectroscopia de infravermelho próximo (NIR) tem sido utilizada para
medição de diversas variáveis industriais e se apresenta como uma importante
ferramenta para medição de variáveis de difícil medição, com boas perspectivas na
realização de análises em tempo real.
Esta se apresenta como uma tecnologia em ascensão, em função das
diversas aplicações em desenvolvimento nos diversos ramos da indústria.

71
5 REDES NEURAIS ARTIFICIAIS (RNA)
5.1 Introdução
De acordo com Haykin (2001) uma rede neural é um processador
paralelamente distribuído constituído de unidades de processamento simples, que
têm a propensão natural para armazenar conhecimento experimental e torná-lo
disponível para uso futuro. Ela se assemelha ao cérebro em dois aspectos:
• o conhecimento é adquirido pela rede a partir de seu ambiente através de um
processo de aprendizagem;
• forças de conexão entre neurônios, conhecidas como pesos sinápticos, são
utilizadas para armazenar o conhecimento adquirido.
Segundo Braga et al. (2000) as RNAs são sistemas paralelos distribuídos
compostos por unidades de processamento simples (nós) que calculam determinadas
funções matemáticas (normalmente não-lineares). Tais unidades são dispostas em
uma ou mais camadas e interligadas por um grande número de conexões, geralmente
unidirecionais.
Na maioria dos modelos estas conexões estão associadas a pesos, os quais
armazenam o conhecimento representado no modelo e servem para ponderar a
entrada recebida por cada neurônio da rede. O funcionamento destas redes é
inspirado em uma estrutura física do cérebro humano.
As RNAs têm sido utilizadas para solução de vários problemas
computacionais e pode-se afirmar que esta utilização se dá em função das seguintes
propriedades:
• não-linearidade;
• mapeamento de entrada;
• adaptabilidade;
• generalização.
As RNAs são capazes de solucionar problemas mais complexos em função
de sua característica natural e do paralelismo interno inerente de sua arquitetura. Por
isto, apresentam possibilidade de maior desempenho comparada com os modelos

72
convencionais. A solução de problemas utilizando RNAs, passam pelos
procedimentos:
• inicialmente é apresentado o problema (os dados de entrada);
• a RNA extrai automaticamente as características destas informações;
• aprendem com estas informações e sugerem um resultado.
A capacidade de reconhecer padrões não apresentados à RNA no período de
treinamento é denominada capacidade de generalização e é uma característica
importante para estes modelos. De acordo com Figueirêdo (2006) as RNAs são
capazes de extrair informações não apresentadas de forma explícita através de
exemplos. Assim, são capazes de atuar como mapeadores universais de funções
multivariáveis.
As RNAs também possuem a capacidade de auto-organização e de
processamento temporal, que associado às demais características, as transformam em
uma ferramenta extremamente atraente e poderosa na solução de problemas
complexos. Especialmente no ramo industrial, vários autores têm utilizado destas
técnicas (Ge , et al., 1998); (LEMMETI et al., 1998); (KASPARIAN, 1998);
(PREMIER et al., 1999); (HAYKIN, 2001); (AGUIAR & FILHO, 2001); (YU &
GOMM, 2003); (LAPERRIÈRE et al., 2004); (DUFOUR et al., 2005);
(MALMBERG, et al., 2005); (COSTA, et al., 2005); (RUBINI & YAMAMOYO,
2006); (FIGUEIRÊDO, 2006) e (BARBER & SCOTT, 2007).
5.2 Modelo de um neurônio artificial
De acordo com Haykin (2001) um neurônio é uma unidade de processamento
de informação que é fundamental para a operação de uma RNA. A descrição do
modelo do neurônio proposto por McCulloch e Pitts (1969) resultou em um modelo
com n terminais de entrada x1, x2,...,xn (que representam os dendritos) e apenas um
terminal de saída y (representando o axônio). Para emular o comportamento das
sinapses, os terminais de entrada do neurônio têm pesos acoplados wk1, wk2, ...,wkm
cujos valores podem ser positivos ou negativos. O efeito de uma sinapse particular i
no neurônio é dado por xiwi. Os pesos determinam em que grau o neurônio deve

73
considerar sinais de disparo que ocorrem naquela conexão. Uma descrição do
neurônio artificial é mostrada na Figura 5.1.
Bias
Figura 5.1: Modelo de um neurônio artificial
Neste modelo não-linear (Figura 5.1), podem ser identificados três
elementos básicos:
• Sinapses: ou conexão de entrada, caracterizadas por pesos ou forças próprias.
Um sinal xj na entrada da sinapse j, conectada ao neurônio k é multiplicado pelo
peso sináptico wkj;
• Junção aditiva: responsável pela soma ponderada dos sinais de entrada;
• Função de ativação: restringe a amplitude da saída de um neurônio, limita o
intervalo permissível de amplitude do sinal de saída. Podem ser do tipo linear e
não-linear. Tipicamente o intervalo normalizado da amplitude da saída de um
neurônio é escrito como o intervalo unitário fechado [0, 1] ou alternativamente [-
1, 1].
O modelo neuronal apresentado na Figura 5.1 inclui também um bias
aplicado externamente, representado por bk. O bias tem o efeito de aumentar (se
bk>0), ou diminuir (se bk<0) a entrada líquida da função de ativação.
Em termos matemáticos, pode-se descrever um neurônio ‘k’ escrevendo o
seguinte par de equações (5.1) e (5.2):
j
m
jkjk xwv ∑
=
=1
(5.1)
Σ
wk1
wk2
wknxn
x2
x1
bk
Função de ativação
( )⋅ϕ vkSinais
de entrada Saída
M M ykJunção aditiva
Pesos sinápticos

74
( )kkk bvy +=ϕ (5.2)
Onde x1, x2,...,xn são os sinais de entrada; wk1, wk2, ..., wkn são os pesos sinápticos do
neurônio k; vk é a saída do combinador linear devido aos sinais de entrada; bk é o
bias; ( )⋅ϕ é a função de ativação; e yk é o sinal de saída do neurônio.
5.3 Função de ativação
A função de ativação ( )⋅ϕ é responsável pela definição da saída do neurônio
em função de seu nível interno de ativação vk. Os tipos de função de ativação mais
utilizadas são:
• Função limiar: ilustrada na Figura 5.2(a). A saída no neurônio é dada
pela Equação 5.3.
( )⎭⎬⎫
⎩⎨⎧
<≥+
=0 para 0,0 para,1
vv
vϕ (5.3)
• Função linear: ilustrada na Figura 5.2(b). A saída no neurônio é dada
pela Equação 5.4.
( ) vv αϕ = (5.4)
Sendo α um número real que define a saída linear para os valores de v .
• Função linear por partes: ilustrada na Figura 5.2(c). A saída no neurônio
é dada pela Equação 5.5.
( )⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
≤<<
≥+=
0 para 0,10 para ,
1 para,1
vvu
vvϕ (5.5)
• Função sigmoidal logística: a saída no neurônio é dada pela Equação 5.6.
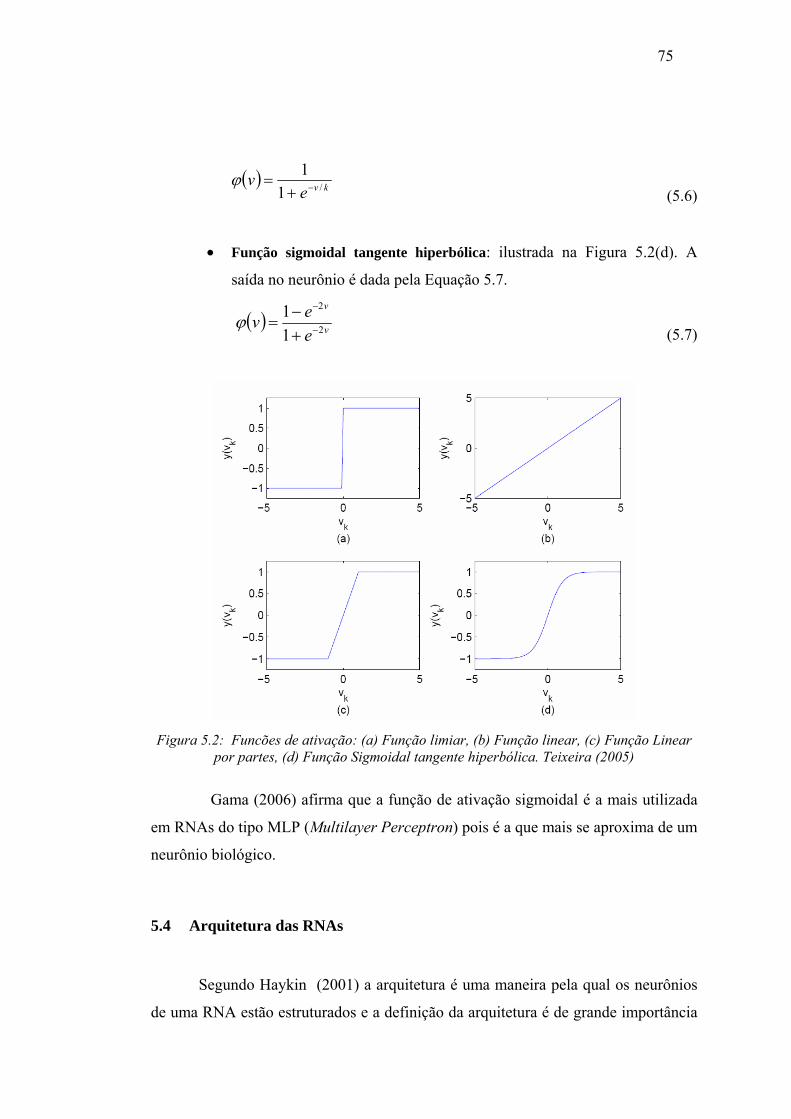
75
( ) kvev /1
1−+
=ϕ (5.6)
• Função sigmoidal tangente hiperbólica: ilustrada na Figura 5.2(d). A
saída no neurônio é dada pela Equação 5.7.
( ) v
v
eev 2
2
11
−
−
+−
=ϕ (5.7)
Figura 5.2: Funcões de ativação: (a) Função limiar, (b) Função linear, (c) Função Linear
por partes, (d) Função Sigmoidal tangente hiperbólica. Teixeira (2005)
Gama (2006) afirma que a função de ativação sigmoidal é a mais utilizada
em RNAs do tipo MLP (Multilayer Perceptron) pois é a que mais se aproxima de um
neurônio biológico.
5.4 Arquitetura das RNAs
Segundo Haykin (2001) a arquitetura é uma maneira pela qual os neurônios
de uma RNA estão estruturados e a definição da arquitetura é de grande importância

76
na sua concepção, uma vez que ela restringe o tipo de problema que pode ser tratado
pela RNA. Podem-se identificar três tipos de arquitetura:
• redes alimentadas adiante (feedforward) de uma única camada;
• redes alimentadas adiante de múltiplas camadas (Multilayer
Feedforward Networks);
• redes recorrentes.
Redes com uma única camada de nós só conseguem resolver problemas
linearmente separáveis. Redes recorrentes, por sua vez, são mais apropriadas para
resolver problemas que envolvem processamento temporal. Fazem parte da definição
da arquitetura os seguintes parâmetros: número de camadas da rede, número de nós
da camada escondida, tipo de conexão entre os nós e a topologia da rede.
As RNAs de uma única camada possuem uma camada de entrada contendo
nós fonte e uma única camada de saída, com nós computacionais. A camada de
entrada não é considerada no número de camadas pelo fato dos neurônios de entradas
serem especiais, cuja função é distribuir cada uma das entradas da rede (sem
modificá-las) a todos os neurônios da camada seguinte. A Figura 5.3 ilustra as redes
feedforward de uma única camada.
Figura 5.3: Rede alimentada adiante com uma única camada de neurônios,Haykin (2001)
As RNAs alimentadas adiante de múltiplas camadas diferem-se pela presença
de uma ou mais camadas intermediárias. A função dos neurônios da camada
escondida é extrair as estatísticas de ordem elevada (HAYKIN, 2001, p.183). Uma
Camadas de saídas de neurônios
Camadas de entrada de neurônios fonte

77
RNA é dita totalmente conectada quando cada um dos nós de uma camada da rede
está conectado a todos os nós da camada adjacente seguinte. Entretanto, se alguns
dos elos de comunicação (conexões sinápticas) estiverem faltando na rede, pode-se
dizer que ela está parcialmente conectada. A Figura 5.4 mostra um exemplo de RNA
alimentada adiante, com duas camadas totalmente conectadas. As RNAs alimentadas
adiante com múltiplas camadas (Multilayer Feedforward Networks) comumente
denominadas de MLP (Multilayer Perceptron), são as redes mais difundidas na
literatura e que serão utilizadas neste trabalho.
Camada de entrada de nós
fonte
Camada de neurônios
ocultos
Camada de neurônios de
saída
Figura 5.4: Rede alimentada adiante totalmente conectada com uma camada oculta
Haykin (2001)
5.5 Projeto de uma RNA
Segundo Haykin (2001) o projeto de uma RNA passa pelas seguintes etapas:
• seleção da arquitetura com definição da quantidade de nós de entrada,
nós escondidos e nós de saída;
• treinamento da RNA a partir de um conjunto de dados do processo;
• validação da rede treinada a partir da avaliação das respostas da rede
mediante a apresentação de dados não utilizados durante o treinamento,
ou seja, avaliação de sua capacidade de generalização.

78
5.6 Aprendizado supervisionado
As propriedades de uma RNA de fundamental importância são: a habilidade
de aprender a partir de seu ambiente e a habilidade de melhorar o seu desempenho
através da aprendizagem. Uma rede neural aprende acerca de seu ambiente através de
um processo iterativo de ajustes aplicados a seus pesos sinápticos e níveis de bias.
Idealmente, a rede se torna mais instruída sobre o seu ambiente após cada iteração do
processo de aprendizagem. Uma definição de aprendizagem no contexto das redes
neurais foi expressa por Haykin (2001): “Aprendizagem é um processo pelo qual, os
parâmetros livres de uma rede neural são adaptados através de um processo de
estimulação pelo ambiente no qual a rede está inserida. O tipo de aprendizagem é
determinado pela maneira pela qual a modificação dos parâmetros ocorre”. Esta
definição do processo de aprendizagem implica na seqüência de eventos:
• a rede neural é estimulada pelo ambiente;
• a rede neural sofre modificações nos seus parâmetros livres como
resultado desta estimulação;
• a rede neural responde de uma maneira nova ao ambiente, devido às
modificações ocorridas na sua estrutura interna.
De acordo com Braga et al. (2000) diversos métodos desenvolvidos para
treinamento de RNAs podem ser agrupados em dois paradigmas principais:
aprendizado supervisionado e aprendizado não supervisionado.
O método mais comum de aprendizado utilizado no treinamento de RNAs é
o aprendizado supervisionado (Figura 5.5), esta metodologia possui esse nome
porque as entradas e saídas desejadas para a rede são fornecidas por um supervisor
(professor) externo. O objetivo é ajustar os parâmetros da rede de forma a encontrar
uma ligação entre os pares de entrada e saída.
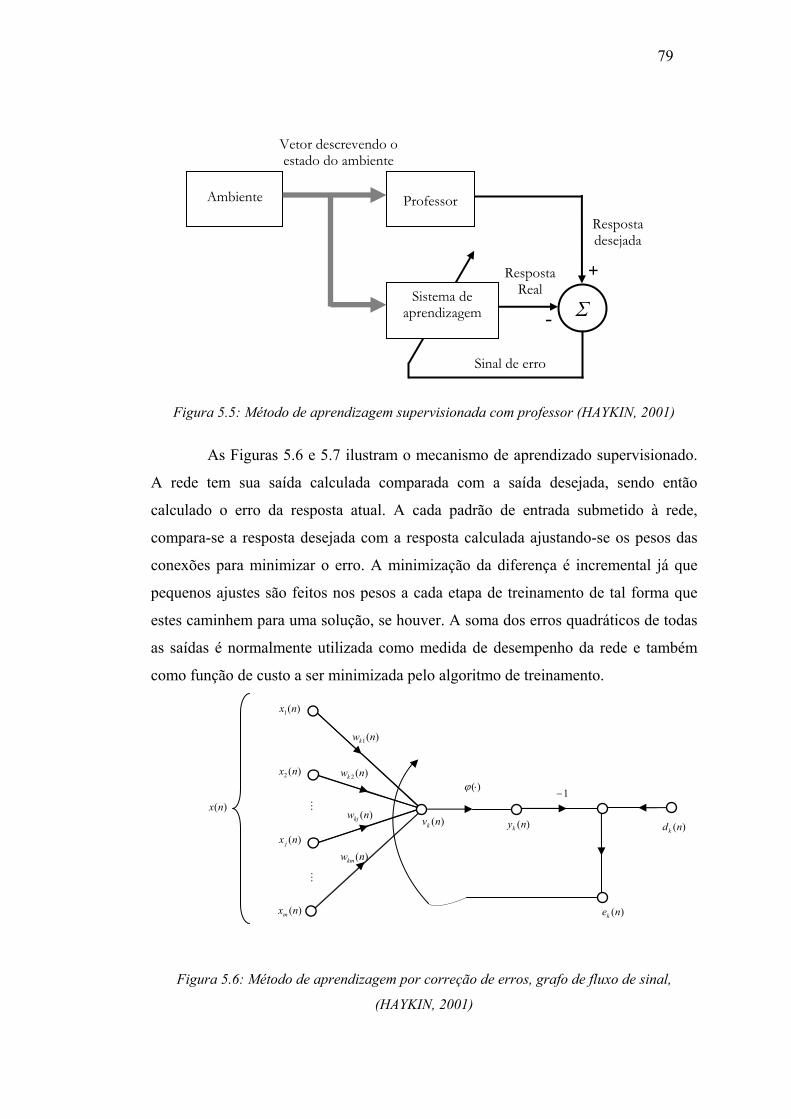
79
Vetor descrevendo o estado do ambiente
Figura 5.5: Método de aprendizagem supervisionada com professor (HAYKIN, 2001)
As Figuras 5.6 e 5.7 ilustram o mecanismo de aprendizado supervisionado.
A rede tem sua saída calculada comparada com a saída desejada, sendo então
calculado o erro da resposta atual. A cada padrão de entrada submetido à rede,
compara-se a resposta desejada com a resposta calculada ajustando-se os pesos das
conexões para minimizar o erro. A minimização da diferença é incremental já que
pequenos ajustes são feitos nos pesos a cada etapa de treinamento de tal forma que
estes caminhem para uma solução, se houver. A soma dos erros quadráticos de todas
as saídas é normalmente utilizada como medida de desempenho da rede e também
como função de custo a ser minimizada pelo algoritmo de treinamento.
Figura 5.6: Método de aprendizagem por correção de erros, grafo de fluxo de sinal,
(HAYKIN, 2001)
Resposta desejada
Ambiente
Σ -
Professor
Sistema de aprendizagem
+Resposta Real
Sinal de erro
)(nyk
)(1 nx
)(2 nx
)(nx j
)(nxm
)(nx)(nvk
1−)(⋅ϕ
)(nek
)(ndk
)(1 nwk
)(2 nwk
M
M
)(nwkj
)(nwkm

80
Vetor de
Figura 5.7: Diagrama em blocos de uma RNA, resultando em um único neurônio na camada
de saída, (HAYKIN, 2001)
Os exemplos mais conhecidos de algoritmos para aprendizado
supervisionado são: a regra delta proposta por Wildrow & Hoff (1960) e a sua
generalização para redes de múltiplas camadas, o algoritmo backpropagation
desenvolvido por Rumelhart et al. (1986).
A adaptação por correção de erros procura minimizar a diferença entre a
saída calculada pela rede e a saída desejada, ou seja, o erro da resposta atual da rede.
O termo do erro deve ser escrito como mostrado na Equação 5.8. ( )nek
( ) ( ) ( )nyndne kkk −= (5.8)
Onde é a saída desejada e ( )ndk ( )nyk é a resposta atual calculada pela rede no
intente de tempo t. A forma genérica para alteração dos pesos por correção de erros é
apresentada na Equação 5.9:
( ) ( ) ( ) ( )txtetwtw iii η+=+1 (5.9)
Onde η é a taxa de aprendizado e xi(t) é a entrada para o neurônio i no tempo t.
De acordo com Equação 5.9, o ajuste dos pesos deve ser proporcional ao
produto do erro pelo valor de entrada naquele instante do tempo.
dk(n)
ΣNeurônio de
saída k
yk(n) x(n)
ek(n) Rede de múltiplas camadas
alimentada adiante
entrada Uma ou mais camadas de
neurônios oculto - +

81
5.7 Algoritmo de treinamento Back-propagation
O algoritmo back-propagation é o mais utilizado no treinamento de RNAs
de multicamadas do tipo MLP com uma ou mais camadas escondidas. Este algoritmo
foi proposto por Rumelhart et al. (1986) e citado por Haykin (2001).
O algoritmo de retropropagação de erro, ou simplesmente retropropagação
(back-propagation), utiliza pares de entrada/saída desejada para ajustar os pesos da
RNA, por meio de um mecanismo de correção de erro.
O treinamento através do algoritmo back-propagation ocorre de duas
formas:
• fase de propagação: é utilizada para definir a saída da rede para um dado
padrão de entrada, mantendo os pesos sinapticos fixos. O fluxo segue no
sentido entrada/saída;
• fase de retropropagação: esta fase utiliza a saída desejada e a saída
calculada pela RNA na fase de propagação, para ajustes dos pesos das
conexões da rede. O fluxo de sinal de erro é inverso ao fluxo na fase de
propagação.
O cálculo dos ajustes dos pesos pelo algoritmo de retropropagação do erro é
dado pelas seguintes relações:
1. Cálculo da correção dos pesos, pela regra delta proposta por WILDROW e
HOFF (1960) é mostrada na Equação 5.10.
( ) ( ) )(nynnw iiji ηδ=∆ (5.10)
Sendo:
( )nw ji∆
Correção no peso do neurônio j na iteração n;
η Taxa de aprendizagem;
( )niδ Gradiente local do neurônio j na iteração n;
)(nyi Sinal de entrada i do neurônio j na iteração n;

82
2. Cálculo do gradiente local, Equação 5.11:
• para um neurônio j na camada de saída;
( ) ( ) ))((' nvnen jjj ϕδ = (5.11)
Sendo o erro entre a entrada e saída do neurônio j e a saída desejada
da iteraçao n, é a derivada da função de ativação do neurônio j em
relação a saída linear do neurônio, , na iteração n.
( )nej
))((' nv jϕ
)(nv j
• para um neurônio j na camada intermediária, Equação 5.12;
( ) )()())((' nwnnvn kjk
kjj ∑= δϕδ (5.12)
Sendo a derivada da função de ativação do neurônio j em relação a saída
linear do neurônio na iteração n e
))((' nv jϕ
)()( nwn kjk
k∑δ é a soma ponderada dos gradientes
locais da camada seguinte na iteração n.
Como aparece o termo nas Equações 5.11 e 5.12 do cálculo do
gradiente local, isso significa que as funções de ativação utilizadas em uma RNA do
tipo MLP devem ser diferenciáveis.
))((' nv jϕ
5.7.1 Função de ativação
O cálculo do δ (gradiente local) para cada neurônio do perceptron de
múltiplas camadas requer o conhecimento da função de ativação )(⋅ϕ associada
aquele neurônio. Para que haja esta derivação necessita-se que a função )(⋅ϕ seja
contínua (HAYKIN, 2001, p.195). Em termos básicos, a diferenciabilidade é uma
única exigência que a função de ativação deve satisfazer. Um exemplo de uma
função de ativação não-linear, continuamente diferenciável normalmente utilizada
nos perceptrons de múltiplas camadas é a não-linearidade sigmóide; descreve-se duas

83
formas desta função:
• função logística;
• função tangente hiperbólica.
5.7.2 Taxa de aprendizagem
O algoritmo back-propagation fornece uma “aproximação” para a trajetória
no espaço de pesos calculada pelo método da descida mais íngreme. Quanto menor
for o parâmetro da taxa de aprendizagem η , menor serão as variações dos pesos
sinápticos da rede, de uma iteração para a outra e mais suave será a trajetória no
espaço de pesos (HAYKIN, 2001, p.196). Por outro lado, se fizermos o parâmetro da
taxa de aprendizagem
w∆
η muito grande para acelerar a taxa de aprendizagem, as
grandes alterações nos pesos sinápticos resultantes podem tornar a rede instável
(oscilatória).
Um método simples para aumentar a taxa de aprendizagem, evitando o
perigo da instabilidade, é alterar a “regra delta generalizada” mostrada na Equação
5.13, incluindo um termo de momento como mostrado por Rumelhart et al. (1986):
( ) ( ) )()(1 nynnwnw ijjiji ηδα +−∆=∆ (5.13)
Sendo α um número positivo chamado de constante de momento, ele controla o laço
de realimentação que age em torno de ( )nwji∆ .
A equação 5.13 é chamada de regra delta generalizada.
5.7.3 Modos de treinamento seqüencial e por lote
É chamado de época a apresentação de todos os padrões do conjunto de
treinamento à rede. De acordo com Haykin (2001), para um dado conjunto de
treinamento, o algoritmo back-propagation pode ser executado de dois modos
distintos.

84
• modo seqüencial que é também de modo on-line, no qual o ajuste de
pesos é realizado após a apresentação de cada padrão à rede. Neste
modo, considerando um conjunto de treinamento com m padrões, ao
final de uma época terão sido realizados m ajustes nos pesos;
• modo por lote ou batelada que é também chamado modo batch, no qual
o ajuste de pesos é realizado após a apresentação de todos os padrões à
rede. Ainda considerando um conjunto de treinamento com m padrões,
ao final de uma época será realizado apenas um ajuste nos pesos, porém
este ajuste considera os erros obtidos em todos os padrões.
5.7.4 Critérios de parada
Haykin (2001) descreve que não existe critérios de parada bem formalizados
para o algoritmo back-propagation, mas sim, critérios de parada razoáveis do ponto
de vista prático e que são normalmente empregados. Alguns dos critérios são:
• pelo valor da norma euclidiana do vetor gradiente: o algoritmo converge
quando a norma euclidiana do vetor gradiente atinge um limiar
especificado;
• pelo valor da taxa de variação do erro médio quadrático: o algoritmo
converge quando a taxa de variação do erro médio quadrático por época
for suficientemente pequena;
• pela capacidade de generalização da rede: neste caso deve ser usado um
conjunto de padrões, segregado do conjunto total de padrões, para
validação.
5.8 Redes de múltiplas camadas (MLP)
As redes neurais de uma só camada resolvem apenas problemas linearmente
separáveis. A solução de problemas não linearmente separáveis passa pelo uso de
redes com uma ou mais camadas intermediárias, ou escondidas. Segundo Cybenko
(1989) uma rede com uma camada intermediária pode implementar qualquer função

85
contínua. A utilização de duas camadas intermediárias permite a aproximação de
qualquer função.
As redes com múltiplas camadas são conhecidas como MLPs (Multilayer
Perceptron) e apresentam um poder computacional muito maior do que aquele de
uma rede sem camada intermediária. A precisão obtida e a implementação da função
objetivo dependem do número de nós utilizados nas camadas intermediárias.
A Figura 5.8 mostra o grafo arquitetural de uma MLP com duas camadas
ocultas e uma camada de saída. A rede aqui representada é totalmente conectada. Isto
significa que um neurônio em qualquer camada da rede está conectado a todos os
neurônios da camada anterior. O fluxo do sinal através da rede progride para frente,
da esquerda para a direita e de camada em camada.
Figura 5.8 Rede MLP típica com duas camadas intermediárias, Haykin, 2001
Em uma rede MLP o processamento realizado por cada nó é definido pela
combinação dos processamentos realizados pelos nodos da camada anterior que estão
conectados a ele. Quando se segue da primeira camada intermediária em direção a
camada de saída, as funções implementadas se tornam cada vez mais complexas
(FIGUEIRÊDO, 2006, p.72).
O número de nós nas camadas intermediárias é em geral definido
empiricamente. Este número depende fortemente da distribuição dos padrões de
treinamento e validação da rede.
Conexões
Camadas Intermediárias
Camadas de Camada de Entrada Saída

86
De acordo com Braga et al. (2000) o número de neurônios na camada
intermediária depende dos fatores:
• número de amostras de treinamento;
• quantidade de ruído presente nos exemplos;
• complexidade da função a ser aprendida;
• distribuição estatística dos dados de treinamento.
Existem problemas que necessitam apenas de uma unidade de entrada e de
uma unidade de saída, e outros que podem precisar de várias unidades
intermediárias. O número de unidades intermediárias pode também, em alguns casos,
crescer exponencialmente com o número de entradas. A solução neural mais
eficiente é aquela em que o número de unidades cresce apenas proporcionalmente
com o aumento do número de unidades de entrada.
Para a solução de problemas práticos de reconhecimento de padrões, aloca-
se para a rede um número de unidades intermediárias suficientes para a solução do
problema. Deve-se ter cuidado para não utilizar unidades demais, o que pode levar a
rede a memorizar os padrões de treinamento, em vez de extrair características gerais
que permitirão a generalização ou o reconhecimento de padrões não vistos durante o
treinamento (overfitting), nem um número muito pequeno, que pode forçar a rede a
gastar tempo em excesso tentando encontrar uma representação ótima, sem
apresentar convergência durante o treinamento (underfitting).
5.9 Métodos de primeira e segunda ordem
Como mostrado por Haykin (2001) no desenvolvimento do algoritmo back-
propagation, o treinamento de redes neurais de multicamadas é um problema de
otimização não-linear de uma função de custo, que mede o erro quadrático médio
calculado pela saída da rede neural frente a uma saída desejada.
A literatura mostra vários métodos de otimização não-lineares que podem
ser aplicados ao problema de treinamento de redes neurais para minimização do erro.
O algoritmo back-propagation é uma implementação baseada no método do
gradiente, em que o vetor de parâmetros (pesos) é ajustado na direção oposta ao do

87
vetor gradiente. Este método é classificado como um método indireto de primeira
ordem já que utiliza apenas a informação do gradiente (primeira derivada) da função
de custo para o ajuste dos pesos da rede.
Os métodos de primeira ordem são conhecidos pela baixa eficiência no
tratamento de problemas de larga escala, pois apresentam taxas de convergência
muito pobres, especialmente em regiões próximas a mínimos locais descrito por
Iyoda (2000). Do ponto de vista da direção de busca, o método do gradiente pode ser
interpretado como sendo ortogonal a uma aproximação linear da função de custo em
determinado ponto descrevem Edgar e Himmelblau (1988).
Nos métodos indiretos de segunda ordem, além do vetor gradiente da função
objetivo, faz-se também o uso da matriz Hessiana (matriz de derivadas de segunda
ordem) da função erro. Na literatura referente a otimização não-linear, uma classe de
algoritmos de segunda ordem é apontada como apropriada para problemas de larga
escala afirma Silva (1998). De acordo com Takahashi (2006) apesar de notadamente
superiores aos métodos de primeira ordem, os métodos de segunda ordem também
apresentam desvantagens, sendo a principal delas o alto custo computacional
associado ao cálculo e armazenamento da matriz Hessiana.
Jones et al. (2005) descreve que um dos algoritmos de segunda ordem mais
rápidos para o treinamento de RNAs de tamanho moderado é o algoritmo proposto
por Levenberg Marquardt, uma variação do método de Newton que aproxima
localmente a superfície de erro por uma função quadrática, mas que simplifica o
cálculo da matriz Hessiana usando apenas a matriz Jacobiana (Matriz de derivadas de
primeira ordem com relação aos pesos e termos de polarização da RNA).
5.10 Generalização em uma RNA
Capacidade de generalização em RNA é a capacidade desta, devidamente
treinada, responder coerentemente a padrões desconhecidos. Ao termo “padrões
desconhecidos” fica subentendido que seja um conjunto de padrões extraído da
mesma população dos conjuntos de dados de treinamento, ou seja, dados com
mesmas características estatísticas dos padrões de treinamento.

88
Segundo Teixeira (2001) a capacidade de generalização não é uma
propriedade inerente às RNAs, ou seja, ela não é facilmente obtida simplesmente
submetendo a rede à fase de treinamento. Braga et al. (2000) descrevem que alguns
fatores devem ser levados em consideração para se obter uma RNA com elevada
capacidade de generalização e basicamente esta generalização sofre a influências:
• do tamanho e representatividade estatística do conjunto de dados de
treinamento;
• da arquitetura da rede neural;
• da complexidade fisica do problema abordado.
Não existe uma regra para escolher o tamanho do conjunto de treinamento.
Cada problema abordado requer uma quantidade de amostras capaz de representá-lo.
Este parâmetro não é de simples estimativa dado que o domínio do problema nem
sempre é conhecido a priori.
A escolha da arquitetura do modelo neural adequada à complexidade do
problema é um dos maiores desafios no estudo da capacidade de generalização.
Modelos com arquiteturas muito grandes elevam sua complexidade. Quando a
complexidade do modelo é maior que a necessária para modelar o problema, a rede
tende a ficar super-ajustada aos dados de treinamento, respondendo inadequadamente
aos padrões de validação e testes.
Este fenômeno de super-ajuste do modelo aos dados de treinamento é
comumente chamado de overfitting e, reduz a capacidade de um modelo generalizar.
Porém, se a complexidade do problema supera a complexidade do modelo, este não é
capaz de descrever e representar o domínio do problema, caracterizando assim o
fenômeno de sub-ajuste ou underfitting. A Figura 5.9 ilustra o que pode ocorrer com
o erro de generalização quando sob os efeitos de sub ajuste e super ajuste aos dados e
treinamento.
Nas Figuras 5.9a, b e c, a função geradora é uma senóide que varia de 0 a 2π
que foi contaminada por um ruído de média 0 e desvio padrão 1. Apenas os pontos
nas figuras foram submetidos às RNAs para treinamento.
A Figura 5.9(a) mostra uma RNA que não foi capaz de modelar toda a
complexidade do problema, gerando um modelo neural pobre em termos de
generalização. Já na Figura 5.9(c) o modelo neural criado superou a complexidade da

89
função geradora, passando a modelar o ruído presente nos dados, ficando também
mal ajustado à função geradora. Apenas na Figura 5.9(b) o ajuste do modelo está
compatível com a complexidade do problema e nota-se que a RNA buscou modelar a
função geradora.
(5.9a) Underfitting
(5.9b) Ajuste Adequado
(5.9c) Overerfitting
Figura 5.9: Problema de ajuste do modelo – ( HAYKIN, 2001)
Braga et al. (2000), Teixeira (2001) e Takahashi (2006), afirmam que os
fenômenos de underfitting e overfitting afetam a capacidade de generalização das
RNAs e buscar um equilíbrio pode ser uma tarefa árdua. Esses fenômenos sofrem
influências pelo tamanho do conjunto de treinamento, pelo número de épocas de
treinamento, e também pelo número de parâmetros livres (pesos) da RNA.
De acordo com Haykin (2001) uma RNA que é projetada para generalizar
bem, produzirá um mapeamento correto de entrada - saída mesmo quando as
entradas forem um pouco diferentes dos exemplos utilizados para o treinamento da
rede. Se uma rede é treinada em excesso, ela perde a habilidade de generalizar entre
padrões de entrada – saída similares.
5.11 Early Stopping (parada antecipada)
O método de treinamento com parada antecipada (Early Stopping) é uma
técnica de treinamento baseada na divisão dos padrões em pelo menos dois conjuntos
distintos de dados, mas com mesma representatividade estatística. Estes conjuntos
são chamados normalmente de conjuntos de treinamento e de validação que após um

90
período de estimação (treinamento) os pesos sinápticos e os níveis dos bias, do
perceptron de múltiplas camadas são todos fixos e a rede opera no seu modo direto
para frente. O erro de validação é então medido por cada exemplo do subconjunto de
validação. Quando a fase de validação é completada, a estimação (treinamento) é
reiniciada para um novo período e o processo é repetido.
O erro de treinamento deve ser monotonicamente decrescente a partir do
início do treinamento, que deve ser interrompido no momento que este erro começa a
crescer com os padrões de validação, embora o erro de treinamento ainda seja
decrescente (TAKAHASHI, 2006, p.27). Esta sintonia indica que o treinamento está
levando a rede a uma condição de sobre ajuste e para evitá-lo o treinamento é
interrompido e os parâmetros da RNA na época anterior são considerados como os
parâmetros finais obtidos com o treinamento.
A Figura 5.10 mostra o comportamento dos erros de treinamento e de
validação com dados ruidosos. Teixeira (2006) comenta que o processo de
treinamento pode ser dividido em duas partes. Na primeira parte, caracterizada pelo
início do treinamento até o ponto de mínimo da curva erro de validação, a rede se
adapta somente às características principais dos dados, ou seja, aprende a função
geradora. Na segunda parte, na medida em que o treinamento prossegue o ruído
também começa a ser mapeado pela rede.
Erro de ValidaçãoErro de Treinamento
Err
o
Épocas
Figura 5.10: Comportamento dos erros de treinamento e validação para uma RNA –
(HAYKIN, 2001, p.243)

91
5.12 Conclusões
Este capítulo exibiu os conceitos fundamentais de um sistema de
processamento paralelo distribuído denominado redes neurais artificiais. De acordo
com a literatura estudada a inteligência artificial tem se mostrado uma ótima
ferramenta para solução de problemas lineares e não-lineares.
As redes neurais têm se mostrado uma poderosa ferramenta no
desenvolvimento de modelos baseados na modelagem empírica e apresentam uma
boa capacidade de representar as não linearidades dos processos industriais.
Assim como todo sistema, os modelos baseados em RNAs possuem
vantagens e desvantagens, mas é uma ferramenta que tem tido uma vasta utilização
pela diversidade em suas aplicações.
Sua fácil utilização e sua baixa sensibilidade a ruídos tornam-nas mais
flexíveis que os modelos convencionais para lidar com a solução de problemas.

92
6 METODOLOGIA E RESULTADOS
6.1 Introdução
De acrdo com Pasquini et al. (2007) a demanda por resultados analíticos,
que são empregados na definição da qualidade da madeira que se destina a produção
de celulose e papel, tem aumentado continuamente. Alguns fatores influenciam esta
demanda. São eles:
• A preocupação constante com a qualidade da matéria prima que chega ao
pátio de cavacos e é destinada ao processo produtivo;
• As pesquisas de melhoria genética associada à necessidade de clones cada
vez mais perfeitos;
• E os critérios de segregação separando a madeira por diferentes
características próprias.
A busca de técnica para aprimoramento da qualidade da madeira que chega
ao processo de cozimento tem gerado um número elevado de pesquisas, não só no
âmbito do desenvolvimento genético, mas também com a utilização de técnicas de
espectroscopia no infravermelho próximo (PASQUINI et al., 2007). Este é um
método rápido, não destrutivo e que demanda pouca quantidade de amostras, as quais
precisam ser submetidos a procedimentos mínimos e rápidos de pré-tratamento.
Em testes realizados no laboratório da Cenibra, foram analisadas várias
amostras de cavacos de diferentes clones e diferentes regiões e em datas distintas. As
análises feitas com o equipamento FT-NIR (Antaris) foram utilizadas como parte das
variáveis para composição do conjunto de dados de entrada do modelo proposto
neste trabalho. Este modelo objetiva predizer a variável #Kappa em um digestor
contínuo de cozimento de madeira.
Em cada amostra de cavaco analisada pelo equipamento denominado FT-
NIR é gerado um conjunto de informações de aproximadamente 1.557 variáveis
correspondentes ao espectro de freqüência do comprimento de onda (ν) de 4.000 a
10.000 cm-1. O FT-NIR utiliza a Transformada de Fourrier para melhor avaliação
deste espectro de freqüência e estes espectros são informações de difícil

93
interpretação. Para melhor utilização desta metodologia faz-se necessária a utilização
de técnicas multivariadas para redução da dimensionalidade da matriz gerada. A
técnica utilizada no presente trabalho foi o PCA (Principal Componentes Analysis)
descrito no capítulo 3.
As informações dos espectros de freqüência referem-se à absorbância do
infravermelho no cavaco, ou seja, a quantidade de luz infravermelha que cada
amostra de cavaco absorve. Através desta absorbância muitas informações sobre os
cavacos de madeira podem ser conhecidas. Vários pesquisadores abordam este tema
(SKOGLUND, et al., 2004); (PASQUINI, et al., 2007) e (CALDEIRAA et al., 2007).
O FT-NIR é capaz de identificar nos cavacos variáveis importantes para o
processo de cozimento, tais como: lignina total, densidade básica, teor seco, teor de
extrativos e ainda reconhecer diferentes materiais genéticos de madeira de eucalipto.
Todas estas variáveis são de grande influência no processo de cozimento conforme
descrito por vários pesquisadores (BARRICHELO, 1976); (LEE, 1997); (SIDRAK,
1998); (FERNANDES, 1999); (DOYLE III, 1999); (CARDOSO et al., 2002);
(BLAKE et al., 2004); (CALDEIRA et al., 2006) e (PASQUINI, et al., 2007).
Baseado nestas informações sobre os cavacos, decidiu-se estudar as
influências destes espectros de freqüência no processo de cozimento, especialmente
no #Kappa. Para isto, o modelo estudado utiliza destas informações, dentre outras
variáveis de processo que influenciam no grau de cozimento do digestor, para
predição da variável #Kappa na saída deste equipamento.
Testes realizados no laboratório de qualidade da Cenibra utilizando a
tecnologia FT-NIR, indicaram uma alta correlação entre a variabilidade da qualidade
da madeira (AE) e a variabilidade do processo de cozimento, ou seja, variações no
espectro de freqüência da madeira que entra no processo de cozimento apresentam
correlações com as variações do grau de cozimento. Esta constatação subsidiou a
decisão para a utilização destas análises para composição do grupo das variáveis de
entrada do modelo proposto neste trabalho.
A Figura 6.1 mostra a curva de correlação linear entre o desvio padrão de
#Kappa e o desvio padrão de álcali (AE).
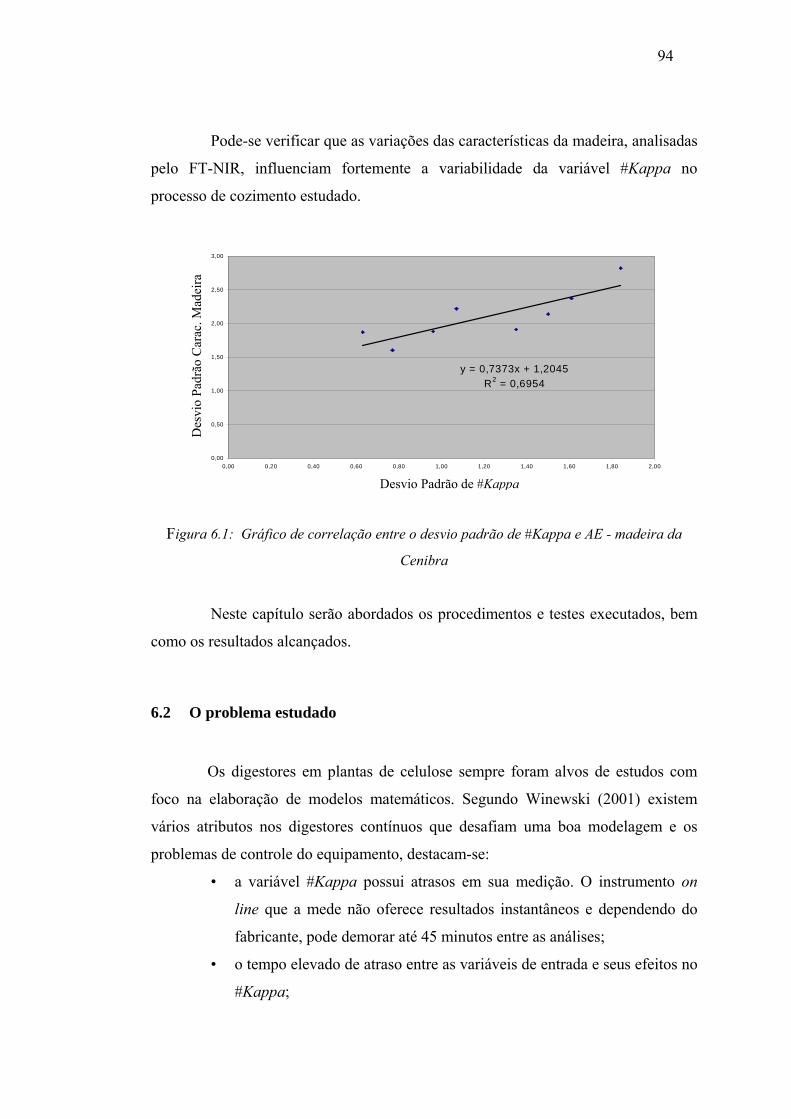
94
Pode-se verificar que as variações das características da madeira, analisadas
pelo FT-NIR, influenciam fortemente a variabilidade da variável #Kappa no
processo de cozimento estudado.
Desvio padrão de kappa / Desvio padrão Alc Mad L1
y = 0,7373x + 1,2045R2 = 0,6954
0,00
0,50
1,00
1,50
2,00
2,50
3,00
0,00 0,20 0,40 0,60 0,80 1,00 1,20 1,40 1,60 1,80 2,00
Des
vio
Padr
ão C
arac
. Mad
eira
Desvio Padrão de #Kappa
Figura 6.1: Gráfico de correlação entre o desvio padrão de #Kappa e AE - madeira da
Cenibra
Neste capítulo serão abordados os procedimentos e testes executados, bem
como os resultados alcançados.
6.2 O problema estudado
Os digestores em plantas de celulose sempre foram alvos de estudos com
foco na elaboração de modelos matemáticos. Segundo Winewski (2001) existem
vários atributos nos digestores contínuos que desafiam uma boa modelagem e os
problemas de controle do equipamento, destacam-se:
• a variável #Kappa possui atrasos em sua medição. O instrumento on
line que a mede não oferece resultados instantâneos e dependendo do
fabricante, pode demorar até 45 minutos entre as análises;
• o tempo elevado de atraso entre as variáveis de entrada e seus efeitos no
#Kappa;

95
• os digestores apresentam comportamento não linear;
• as variações biológicas da química da madeira estão sujeitas à variações
aleatórias não mensuráveis nas componentes como concentração,
umidade, densidade que são as principais fontes de variações contínuas
na operação dos digestores.
No digestor estudado com o ritmo de produção normal, o cavaco que entra
sai do equipamento como polpa de celulose 3 horas depois. Isto significa que a
variável #Kappa possui um atraso de aproximadamente 3 horas em relação a entrada,
pois esta é medida na saída do digestor.
As ações operacionais para correção dos desvios desta variável somente
podem ser feitas após sua medição. Isto significa muitas intervenções do operador
com um tempo de atraso grande, o que na prática gera uma variabilidade no #Kappa.
Este trabalho propõe um modelo que em função das características da
madeira, analisadas pela técnica FT-NIR, e das variáveis de processo que de acordo
com a experiência operacional, mais influenciam no resultado do cozimento, seja
capaz de predizer o #Kappa logo que o cavaco entra no digestor.
Identificar e conhecer as características físicas, químicas e anatômicas da
madeira (cavacos) antes de sua entrada no processo de cozimento, e utilizar destas
informações para predição do #Kappa trará grandes benefícios operacionais para o
processo de produção de celulose.
6.3 Preparação dos dados e procedimentos para os testes das RNAs
6.3.1 Planejamento dos testes
Para obtenção dos resultados foi criada uma metodologia para testes das
RNAs, seguindo os seguintes procedimentos:
• RNA _01_PCA1
• Aplicado PCA em toda a matriz de entrada (dados do FT-NIR mais
dados de processo), escolhidos os 17 PCs (Componentes Principais)
mais significativos. Uma nova matriz de PCs foi formada e a partir

96
desta matriz foram feitos todos os testes das RNAs, conforme descrito
na metodologia, subitem 6.6.1.
• RNA _02_PCA2
• separado a matriz de dados de processo, da matriz de dados gerados
pelo FT-NIR (absorbância de IV) dos cavacos de madeira;
• aplicado a técnica de redução de dimensionalidade com retorno de 25
PCs. Em seguida foram unificadas as matrizes de dados de processo
com a matriz de retorno de 25 PCs e formando uma matriz única.
• RNA_03_PCA3
• idem ao procedimento RNA_02_PCA2, no entanto com retorno da
matriz de absorbância dos cavacos (FT-NIR) com 15 PCs.
• RNA_04_PCA4
• idem ao procedimento RNA_02_PCA2, no entanto com retorno da
matriz de absorbância dos cavacos (FT-NIR) com 10 PCs.
• RNA_05_NIR
• separado a matriz de dados de processo, da matriz de dados gerados
pelo FT-NIR (absorbância de IV) dos cavacos de madeira;
• aplicado á técnica de redução de dimensionalidade com retorno de 3
PCs, em seguida foram unificadas as matrizes de dados de processo
com a matriz de retorno de 3 PCs, formando uma matriz única e
treinadas as RNAs.
Para todos os procedimentos relacionados foram treinadas RNAs utilizando
os algoritmos de otimização paramétrica7: Levenberg Marquadt, gradiente conjugado
escalonado, regularização Bayssiana, gradiente decrescente e gradiente decrescente
com momentum. Para as simulações foram utilizadas rotinas do MATLAB® que
simulam estes métodos de busca;
Também foram treinadas RNAs com os seguintes número de neurônios na
camada escondida: 3, 4, 5, 6, 7, 8, 9, 10, 12, 15, 20, 25, 30, 35, 40;
E ainda foram treinadas 300 redes para cada teste, sendo que dentre estas a
7 Otimização paramétrica: a partir do conjunto de dados de aproximação, e fixada a função de aproximação );(. θg , como encontrar um valor ótimo para o vetor de parâmetros .pR∈θ

97
que obteve melhor resultado foi a validada.
6.3.2 Tratamento dos dados
Utilizando a tecnologia FT-NIR para análise dos cavacos de madeira, pôde-
se obter os espetros de freqüência demonstrados na Figura 6.1.
0,0
0,2
0,4
0,6
0,8
1,0
1,2
Comprimento de Onda
Ab
sorb
ânci
a
Amostra 1
Amostra 2Amostra 3
Amostra 4Amostra 5
Amostra 6Amostra 7Amostra 8
Amostra 9Amostra 10
Amostra 11Amostra n10.000cm-14.000cm-1
2.500nm 1.000nm
Figura 6.2: Exemplo de espectro de freqüência de cavacos de madeira, obtidos
usando a técnica FT-NIR
Como já descrito, a matriz de dados gerada pelo FT-NIR possui uma alta
dimensionalidade, assim, foi necessário aplicar uma técnica estatística multivariada
de análise de dados denominada PCA (Principal Components Analysis), para
redução da dimensão da matriz em uma representação mais tratável, sob o ponto de
vista computacional.
Os cavacos de madeira (padrões analisados) geram uma matriz de dados n x
m (1557 x 1) onde n é o espectro de freqüência que o FT-NIR e m representa as
amostras dos cavacos.
Os dados utilizados para este estudo foram coletados aleatoriamente no
período de setembro de 2006 a março de 2007.

98
O equipamento denominado FT-NIR modelo “Nicolet Antaris” instalado no
laboratório do setor de qualidade da Cenibra foi utilizado para obter a absorbância de
luz do infravermelho próximo dos cavacos em análises feitas no período estudado.
Desta forma, considera-se as análises para este trabalho feitas Off Line. Tecnologias
para medição online ainda encontram-se em desenvolvimento e não estão disponíveis
comercialmente no mercado.
Em avaliação de outros modelos propostos para digestores contínuos
observa-se trabalhos similares, sendo o que mais se aproxima, são os estudos de
Aguiar (2000). Em seu trabalho, iniciou estudos com 22 variáveis de entrada e
concluiu com a proposta de apenas 9 variáveis de entrada para seu modelo, foram
escolhidas aquelas que possuem forte correlação com o #Kappa destacando: o álcali
e a sulfidez do licor de cozimento, temperatura e o fator H nas diferentes zonas do
cozimento. A técnica de modelagem aplicada por Aguiar (2000) foi a de RNA (Rede
Neural Artificial), utilizando redes do tipo MLPs (Multilayer Perceptron). Vale
ressaltar que o modelo proposto por Aguiar (2000) não incluía as análises do FT-NIR
como padrões de entrada.
Para compor o grupo de variáveis de entrada do modelo proposto neste
trabalho, foram utilizadas as sugestões de Aguiar (2000), a experiência operacional
em função de anos de operação do digestor estudado e as análises feitas pelo FT-NIR
nos cavacos de madeira, ou seja, os principais fatores que influenciam o #Kappa,
analisados por anos de conhecimentos adquiridos pela equipe de operação da área do
digestor da Celulose Nipo Brasileira SA. (Cenibra), e pela pesquisa nos modelos já
desenvolvidos por outros pesquisadores (HARKONEN, 1987); (MICHELSEN &
FOSS, 1996); (QIAN et al., 1997); (AL-AWAMI & SIDRAK, 1998); (WISNEWSKI
& DOILE III, 1998); DOYLE III & KYIAHAN, 1999); (FERREIRA et al., 2000);
(WISNEWSKI et al., 2001); (AGUIAR, 2000); (AGUIAR & FILHO, 2001);
(QUEIROZ et al., 2004); (KAYIHAN, 2002); (CARDOSO et al., 2002); (POLIT et
al., 2002); (POUGATCH et al., 2005); (DUFOUR et al., 2005) e (PADHIYAR,
2006).
Foi feita uma avaliação global do conjunto de dados e eliminados os
outliers, ou seja, aqueles dados cujo comportamento não seguem o comportamento
geral para mais de uma variável. Esta etapa consistiu em uma análise criteriosa e

99
visual na matriz de dados disponível. Uma análise do histograma dos dados foi
utilizada para facilitar a identifição dos outliers.
Um total de 160 padrões foi utilizado para obtenção do modelo neural.
Dentre estes, 111 foram utilizados para treinamento e 49 para validação.
6.4 Apresentação de Dados, utilização de análise de componentes principais
para definição de variáveis de entrada aplicadas a rede neural artificial
Os dados (padrões) definidos como entradas para desenvolvimento do
modelo neural seguiram os procedimentos estabelecidos no item 6.3.
Durante todas as etapas dos testes foram mantidas como entradas 7 variáveis
de processo e a estas foram associados os dados do FT-NIR, com diferentes números
de PCs de acordo com os procedimentos estabelecidos. São as variáveis:
• E1 a temperatura na circulação de homogeneização após o aquecimento
do licor de cozimento;
• E2 a temperatura na circulação de cozimento antes do aquecimento de
licor de cozimento;
• E3 a temperatura na circulação de homogeneização antes do
aquecimento de licor de cozimento;
• E4 o Alcali Total Titulável (AT);
• E5 o Alcali Residual (AR);
• E6 a sulfididade (sulfidez) do licor Branco de cozimento;
• E7 a relação lignina por Kilograma de celulose;
Inicialmente foram utilizados os dados do FT-NIR e os dados de processo
para formar uma única matriz, e sobre esta matriz total, foi aplicada a ferramenta
estatística PCA. Os 17 CPs (Componentes Principais) mais significativos foram
escolhidos e apresentados à RNA para treinamento e validação.
Para segunda apresentação de dados no desenvolvimento do modelo, foi
separado as variáveis de processo dos dados do FT-NIR, em seguida aplicado PCA
somente nos dados do FT-NIR, foram escolhidos os 25 CPs mais significativos e a
estes foram adicionados às 7 variáveis de processo. Uma matriz total de 32 variáveis
foi formada e utilizada como entrada para treinamento e validação da RNA.

100
A terceira apresentação de dados para desenvolvimento do modelo, seguiu o
segundo procedimento, no entanto, foram utilizados os 15 CPs mais significativos,
retornados da aplicação do PCA nos dados FT-NIR. Uma matriz total de 22 entradas
foi formada e utilizada para treinamento e validação da RNA.
A quarta apresentação de dados para desenvolvimento do modelo, também
seguiu o segundo e terceiro procedimento, desta vez utilizados os 10 CPs mais
significativos. Uma matriz total de 17 entradas foi formada e utilizada para
treinamento e validação da RNA.
Analisando as respostas da aplicação de PCA na matriz de dados do FT-NIR
e os testes nos diversos modelos estudados, pôde-se perceber através dos
procedimentos mostrados no item 6.3.1 (RNA_01_PCA1, RNA_02_PCA2,
RNA_03_PCA3, RNA_04_PCA4) que estes modelos não apresentavam resultados
expressivos. Foi estão necessário reavaliar o procedimento de tratamento dos dados
do FT_NIR e para isto, foi utilizado o método de escolha dos CPs denominado
“Diagrama de Autovalores” como descrito na seção 3.3. Uma nova composição da
matriz de dados de entrada da RNA foi elaborada formando a quinta apresentação de
dados para desenvolvimento do modelo. Uma nova matriz de dados foi apresentada à
RNA, composta dos 3 CPs mais significativos, retornados da aplicação do PCA nos
dados FT-NIR, mais 7 variáveis de processo. Uma matriz total de 10 entradas foi
formada e utilizada para treinamento e validação da RNA como na primeira geração
de resultados.
A Tabela 6.1 mostra valores de variância dos dados do FT-NIR.
Tabela 6.1: Variâncias dos componentes principais
Variância (%) Somatório acumulado das variâncias
1488,432 1488,432 63,56655 1551,99855 4,106359 1556,104909 0,62289 1556,727799 0,139754 1556,867553 0,067604 1556,935157 0,027346 1556,962503 0,011637 1556,97414
.
.
.
.
.
.

101
Valores e variância superiores a 1%, somente são observados nos três
primeiros PCs, isto explica mais de 90% dos dados originais. No entanto, somente
estes, possuem relevância para a matriz de dados, e foram utilizados para compor a
matriz de dados final apresentada à RNA para treinamento e validação durante esta
etapa dos testes, denominada procedimento RNA_05_NIR.
A Tabela 6.2 apresenta os 3 CPs mais significativos obtidos, sendo que é
mostrado apenas uma parte dos dados devido a sua dimensão.
Estes componentes principais mostrados na Tabela 6.2 foram associados
aos dados de processo de cozimento (7 variáveis) e formado a matriz na qual foi
utilizada para o treinamento da rede neural.
Tabela 6.2: Componentes principais
Padrão 1 Padrão 2 Padrão 3 Padrão 4 Padrão 5 Padrão 6 Padrão n CP1 -7,49192 28,21503 -8,34711 -36,1454 -22,3949 -66,3442 ... CP2 12,98745 1,151334 4,07441 2,76574 2,239127 9,24616 ... CP3 -0,23153 0,672787 -0,25518 1,237489 -1,21237 -2,77446 ...
Em função de praticidade, somente foram mostrados neste trabalho a
composição do conjunto de entrada de dados referentes a quinta geração de
resultados, pois foi esta a combinação que apresentou melhores resultados para o
modelo testado.
CP1, CP2, CP3, são os componentes principais que representam a matriz de dados
analisados pelo FT-NIR (dados de absorbância do NIR, extraídos dos cavacos de
madeira).
Também foram feitos testes utilizando a decimação dos dados, entretanto,
apesar de reduzir consideravelmente o número de variáveis de entrada da RNA, os
resultados não foram satisfatórios. A técnica PCA se mostrou, para este caso, mais
atrativa, pois apresentou melhores resultados no modelo final.
A massa de dados que foi apresentada à RNA durante todas as etapas dos
treinamentos embora tenha sidos os mesmos padrões (total de 160), foram de forma
aleatória, ou seja, cada treinamento teve uma randomização dos dados de entrada.

102
6.5 Implementação da RNA
Uma vez realizado o tratamento nos dados que descreve a qualidade da
madeira, as informações do processo são associadas a estes dados e empregadas
como entradas das redes neurais testadas. Neste estudo são empregadas redes tipo
MLP com 2 camadas. O número de neurônios na camada intermediária (ou
escondida) foi definido durante a etapa de treinamento, sendo este um parâmetro
empregado na busca de melhores modelos.
Durante os testes, uma camada intermediária produziu melhores resultados e
quando aumentado o número de camadas intermediárias, o modelo apresentou uma
redução considerável no coeficiente de correlação linear entre a variável medida e a
predita.
A função de ativação implementada que apresentou melhores resultados foi
a “sigmoidal tangente hiperbólica” usualmente tratada no programa comercial
(software de simulação) MATLAB® como TANSIG. Outras funções (sigmoidal
logística) também foram testadas, mas foram descartadas, por não apresentarem
melhorias nos resultados.
A ordem com que os padrões foram apresentados à RNA influenciou os
resultados. As redes treinadas com conjuntos em ordem aleatória apresentaram
melhor qualidade de predição do que aquelas treinadas com dados ordenados, isto
também pôde ser observado por Aguiar (2000).
De acordo com Haykin (2001) as redes MLP (Multilayer Perceptron), têm
sido aplicadas com sucesso para resolver diversos problemas de difíceis soluções
através de treinamento supervisionado com o algoritmo de retropropagação de erro
(Error Back propagation). Basicamente, a aprendizagem por retropropagação de erro
consiste em dois passos através das diferentes camadas de rede, o de propagação e
retropropagação, como mostrado no item 5.7.
Neste trabalho foi utilizado o algoritmo de retropropagação
(backpropagation) proposto por Rumelhart et al. (1986). Este é o algoritmo mais
utilizado em treinamentos de redes neurais de multicamadas utiliza pares de entrada-
saída proveniente do modelo de tal forma que os pesos possam ser ajustados por um
método de correção de erros.

103
Os conjuntos de dados (entradas e saída das redes) foram normalizados antes
de se iniciar o processo de obtenção dos modelos. A escolha dos dados empregados
no treinamento das redes e os usados na validação do modelo foram aleatórios. A
Figura 6.3 evidencia a estrutura de todos os modelos testados.
Rede Neural
Amostra de cavaco de madeira
PCAVariáveis
operacionais
Espectro de freqüência FT-NIR
Predição do #Kappa
Figura 6.3: Estrutura de todos os modelos testados
As rotinas de otimização paramétricas utilizadas neste estudo, foram de
primeira e segunda ordem, sendo que através da utilização do software de simulação
MATLAB®, utilizou-se:
• TRAINSCG: esta rotina emprega o método de treinamento do gradiente
conjugado escalonado foi elaborado por Moller (1993) sendo introduzida
uma nova variação no algoritmo de gradiente conjugado (Gradiente
Conjugado Escalonado – SCG) que evita a busca unidimensional a cada
iteração utilizando uma abordagem de Levenberg-Marquardt cujo
objetivo é fazer um escalonamento do passo de ajuste α.
Este algoritmo de treinamento é um método de segunda ordem que utiliza
informações sobre a derivada segunda da função de custo (erro).
• TRAINBR: esta rotina (Regularização Baysiana) envolve a modificação
da função objetivo, geralmente utilizada, que é o somatório dos erros
quadráticos médio das respostas da rede. O objetivo da modificação é
melhorar a capacidade de generalização do modelo. Este tipo de método
de treinamento foi proposto por MacKay (1992). É assumido que os pesos
e os bias da rede são variáveis randômicas que seguem uma distribuição

104
Gaussiana e os parâmetros estão relacionados às variâncias associadas
com essas distribuições.
• TRAINLM: esta rotina, assim como o método de Newton, é bastante
eficiente quando estamos tratando de redes que não possuem mais do que
algumas centenas de conexões a serem ajustadas. Isto se deve,
principalmente, ao fato de que estes algoritmos necessitam armazenar
uma matriz quadrada cuja dimensão é da ordem do número de conexões
da rede.
• TRAINGD: esta rotina emprega o método do gradiente descendente, que
atualiza os pesos e os bias de acordo com o gradiente descendente.
• TRAINGDM: é o método do gradiente descendente com momento, que
atualiza os pesos e os bias de acordo com o gradiente descendente com
momento.
Após a implementação da RNA vários testes foram executados na busca de
obter os melhores resultados, o item 6.6 detalha os testes e resultados encontrados.
Os subitens 6.6.5 e 6.6.6, mostram os melhores resultados obtidos durante todas as
etapas de desenvolvimento dos testes. Ainda no subitem 6.6.6 uma extrapolação dos
testes é mostrada, na qual houve uma melhora significativa nos resultados de
predição da variável #Kappa.
6.6 Comparação dos resultados obtidos
Foram considerados um total de 160 padrões (pares de entradas/saídas), para
obtenção dos modelos. Deste total são escolhidos aleatoriamente 70% para etapa de
treinamento e 30% para a de validação do modelo. Como mencionado anteriormente,
a escolha de quais padrões foram empregados no treinamento e quais foram
empregados na validação foi aleatória.
Um tempo de retenção (ou tempo de residência) igual a 3 horas foi
calculado em função da velocidade de alimentação do digestor. Ou ainda,
considerou-se que após 3 horas de alimentação do cavaco, a polpa gerada desta
alimentação sairá do equipamento. Esta informação foi considerada na elaboração do

105
conjunto de dados originais. Assim, o #Kappa (variável a ser predita) considerado
para cada conjunto de entradas é avaliado 3 horas depois do momento que as
entradas são verificadas na planta industrial.
Em uma situação ótima, deseja-se que o valor predito para o #Kappa seja
exatamente igual ao valor real. Isto nos leva a uma correlação linear igual a 1 (100%)
entre o #Kappa real e o predito. Sabe-se ainda que, para sistemas reais e complexos,
como é o caso do digestor estudado, esta correlação dificilmente será alcançada. O
que se faz na prática é buscar modelos que se aproximem ao máximo desta meta.
Além disso, deseja-se modelos que possam ser empregados no
acompanhamento do processo em tempo real, ou seja, modelos que funcionem como
sensores virtuais (soft sensor) para a variável estudada. Neste sentido, a validação
dos modelos indica a capacidade do modelo para desempenhar este papel.
Os dados de validação simulam as novas condições (ou novos dados)
operacionais que serão gerados pela planta industrial, uma vez que não são usados na
estimação dos parâmetros do modelo. Ou ainda, embora o desempenho da rede no
teste de treinamento seja importante, mais significativo é o obtido no teste de
validação.
Os testes das RNAs tiveram uma seqüência baseada no procedimento
proposto no subitem 6.3.1, objetivando utilizar vários algoritmos de treinamento e
diferentes números de neurônios na camada escondida para se obter uma comparação
entre os resultados alcançados.
6.6.1 Primeira geração de resultados RNA_01_PCA1
Aplicado PCA em todos os padrões de entradas juntos, ou seja, os dados de
absorbância dos cavacos (dados do FT-NIR) juntos com os dados de processo,
escolhido os 17 CPs mais significativos, formando uma matriz única (17 x 160), e a
partir desta foram treinadas RNAs utilizando os algoritmos otimização paramétrica:
TRAINSCG, TRAINBR, TRAINLM, TRAINGD e TRAINGDM do Toolbox de
RNAs do MATLAB® na versão 7.0.0 (R.14).
A Figura 6.4 apresenta a estrutura do modelo treinado, na qual se utilizou de
uma matriz única para treinamento da RNA.

106
Amostra de cavacos de madeira
PCA Predição do #Kappa
Rede Neural
Matriz de 17 x 160
Variáveis operacionais
7 variáveis de processo
Matriz Total
Espectro de freqüência FT-NIR 1557 espectros de
freqüência FT-NIR
Figura 6.4: Estrutura do modelo testado RNA01_PCA_01
As Figuras 6.5 a 6.9 mostram a evolução dos testes para todos os métodos
de otimização utilizados, quando variados o número de neurônios na camada
intermediária, tanto para a etapa de treinamento quanto para a validação da RNA.
Os resultados podem ser observados nos gráficos mostrados nas Figuras 6.5
a 6.9.
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.5: Simulação da RNA com o algoritmo TRAINSCG-Teste RNA _01_PCA1

107
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.6: Simulação da RNA com o algoritmo TRAINBR - Teste RNA _01_PCA1
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.7: Simulação da RNA com o algoritmo TRAINLM - Teste RNA _01_PCA1
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.8: Simulação da RNA com o algoritmo TRAINGD- Teste RNA _01_PCA1
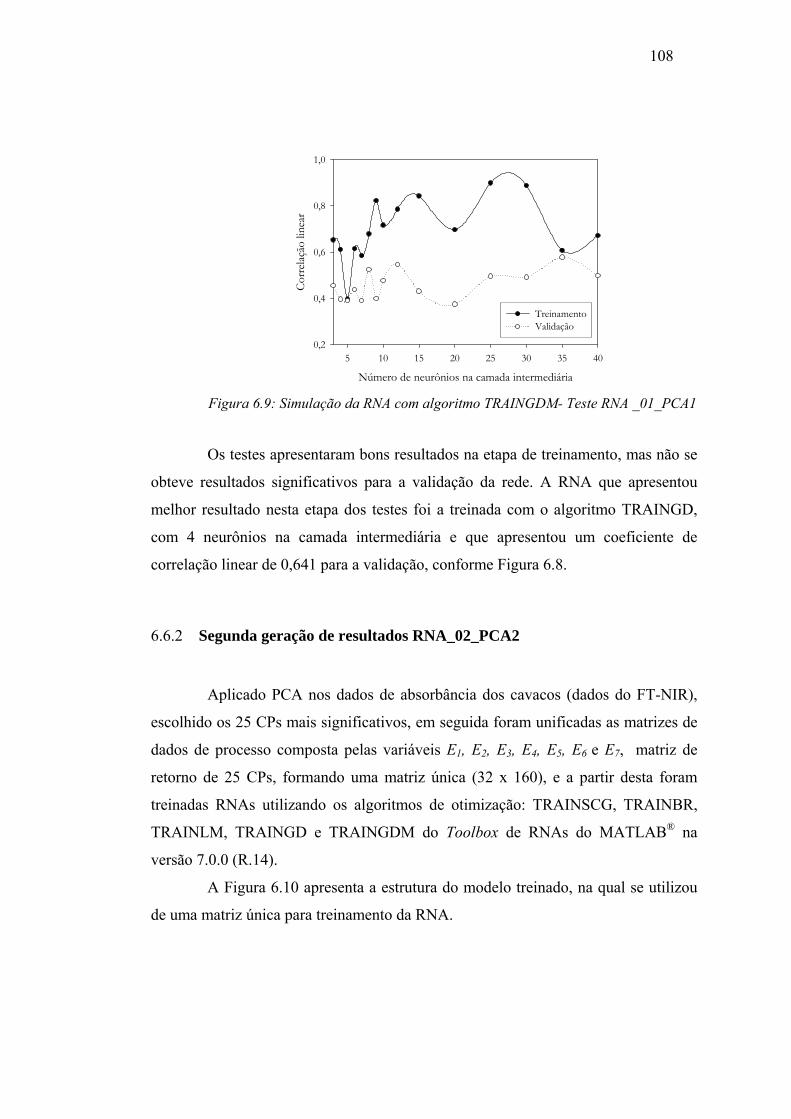
108
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaç
ão li
near
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.9: Simulação da RNA com algoritmo TRAINGDM- Teste RNA _01_PCA1
Os testes apresentaram bons resultados na etapa de treinamento, mas não se
obteve resultados significativos para a validação da rede. A RNA que apresentou
melhor resultado nesta etapa dos testes foi a treinada com o algoritmo TRAINGD,
com 4 neurônios na camada intermediária e que apresentou um coeficiente de
correlação linear de 0,641 para a validação, conforme Figura 6.8.
6.6.2 Segunda geração de resultados RNA_02_PCA2
Aplicado PCA nos dados de absorbância dos cavacos (dados do FT-NIR),
escolhido os 25 CPs mais significativos, em seguida foram unificadas as matrizes de
dados de processo composta pelas variáveis E1, E2, E3, E4, E5, E6 e E7, matriz de
retorno de 25 CPs, formando uma matriz única (32 x 160), e a partir desta foram
treinadas RNAs utilizando os algoritmos de otimização: TRAINSCG, TRAINBR,
TRAINLM, TRAINGD e TRAINGDM do Toolbox de RNAs do MATLAB® na
versão 7.0.0 (R.14).
A Figura 6.10 apresenta a estrutura do modelo treinado, na qual se utilizou
de uma matriz única para treinamento da RNA.
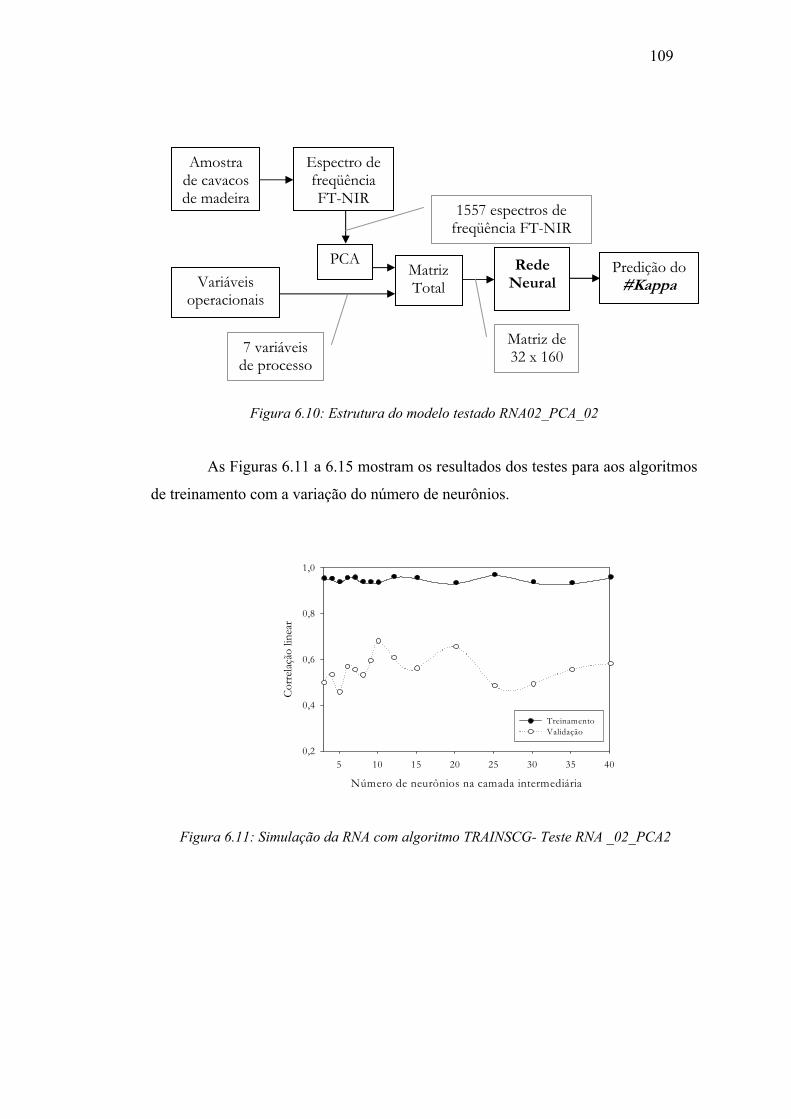
109
Amostra de cavacos de madeira
Predição do #Kappa
Espectro de freqüência FT-NIR
Matriz Total
Rede Neural
Matriz de 32 x 160
1557 espectros de freqüência FT-NIR
PCAVariáveis
operacionais
7 variáveis de processo
Figura 6.10: Estrutura do modelo testado RNA02_PCA_02
As Figuras 6.11 a 6.15 mostram os resultados dos testes para aos algoritmos
de treinamento com a variação do número de neurônios.
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaç
ão li
near
0,2
0,4
0,6
0,8
1,0
Treinamento Validação
Figura 6.11: Simulação da RNA com algoritmo TRAINSCG- Teste RNA _02_PCA2

110
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.12: Simulação da RNA com algoritmo TRAINBR- Teste RNA _02_PCA2
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.13: Simulação da RNA com o algoritmo TRAINLM - Teste RNA _02_PCA2
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaç
ão li
near
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.14: Simulação da RNA com o algoritmo TRAINGD - Teste RNA _02_PCA2
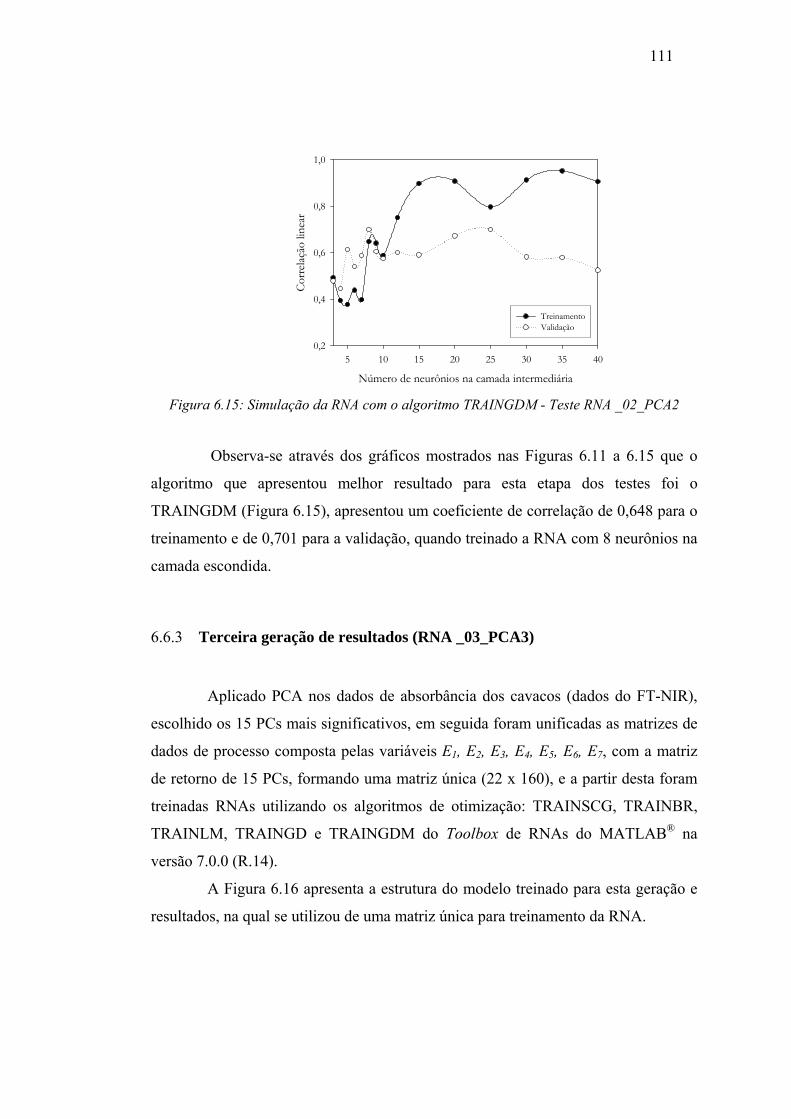
111
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaç
ão li
near
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.15: Simulação da RNA com o algoritmo TRAINGDM - Teste RNA _02_PCA2
Observa-se através dos gráficos mostrados nas Figuras 6.11 a 6.15 que o
algoritmo que apresentou melhor resultado para esta etapa dos testes foi o
TRAINGDM (Figura 6.15), apresentou um coeficiente de correlação de 0,648 para o
treinamento e de 0,701 para a validação, quando treinado a RNA com 8 neurônios na
camada escondida.
6.6.3 Terceira geração de resultados (RNA _03_PCA3)
Aplicado PCA nos dados de absorbância dos cavacos (dados do FT-NIR),
escolhido os 15 PCs mais significativos, em seguida foram unificadas as matrizes de
dados de processo composta pelas variáveis E1, E2, E3, E4, E5, E6, E7, com a matriz
de retorno de 15 PCs, formando uma matriz única (22 x 160), e a partir desta foram
treinadas RNAs utilizando os algoritmos de otimização: TRAINSCG, TRAINBR,
TRAINLM, TRAINGD e TRAINGDM do Toolbox de RNAs do MATLAB® na
versão 7.0.0 (R.14).
A Figura 6.16 apresenta a estrutura do modelo treinado para esta geração e
resultados, na qual se utilizou de uma matriz única para treinamento da RNA.

112
Amostra de cavacos de madeira
Predição do #Kappa
Espectro de freqüência FT-NIR
Matriz Total
Rede Neural
Matriz de 22 x 160
1557 espectros de freqüência FT-NIR
PCAVariáveis
operacionais
7 variáveis de processo
Figura 6.16: Estrutura do modelo testado RNA03_PCA_03
As Figuras 6.17 a 6.21 mostram a evolução dos testes para todos os métodos
de otimização utilizados, quando variados o número de neurônios na camada
intermediária, tanto para a etapa de treinamento quanto para a validação da RNA.
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaç
ão li
near
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.17: Simulação da RNA com o algoritmo TRAINSCG - Teste RNA _03_PCA3

113
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaç
ão li
near
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.18: Simulação da RNA com o algoritmo TRAINBR - Teste RNA _03_PCA3
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.19: Simulação da RNA com o algoritmo TRAINLM - Teste RNA _03_PCA3
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
Treinamento Validação
Figura 6.20: Simulação da RNA com o algoritmo TRAINGD- Teste RNA _03_PCA3

114
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.21: Simulação da RNA com o algoritmo TRAINGDM - Teste RNA _03_PCA3
Observa-se através dos gráficos mostrados nas Figuras 6.17 a 6.21 que o
algoritmo que apresentou melhor resultado para esta etapa dos testes foi o
TRAINGDM (Figura 6.21), apresentou um coeficiente de correlação de 0,767 para o
treinamento e de 0,705 para a validação, quando treinado a RNA com 6 neurônios na
camada escondida.
Observa-se também que algoritmo de otimização TRAINSCG apresenta
resultados similares para a validação, com uma RNA com 12 neurônios na camada
intermediária (Figura 6.17). Apresentou um coeficiente de correlação de 0,947 para o
treinamento e de 0,701 para a validação.
6.6.4 Quarta geração de resultados (RNA_04_PCA4)
Aplicado PCA nos dados de absorbância dos cavacos (dados do FT-NIR),
escolhido os 10 PCs mais significativos, em seguida foram unificadas as matrizes de
dados de processo composta pelas variáveis E1, E2, E3, E4, E5, E6, E7, com a matriz
de retorno de 10 PCs, formando uma matriz única (17 x 160), e a partir desta foram
treinadas RNAs utilizando os algoritmos de treinamento: TRAINSCG, TRAINBR,
TRAINLM, TRAINGD e TRAINGDM do Toolbox de RNAs do MATLAB® na
versão 7.0.0 (R.14).
A Figura 6.22 apresenta a estrutura do modelo treinado para esta geração e
resultados, na qual se utilizou de uma matriz única para treinamento da RNA.

115
Amostra de cavacos de madeira
Predição do #Kappa
Espectro de freqüência FT-NIR
Matriz Total
Rede Neural
Matriz de 17 x 160
1557 espectros de freqüência FT-NIR
PCAVariáveis
operacionais
7 variáveis de processo
Figura 6.22: Estrutura do modelo testado RNA04_PCA_04
As Figuras 6.23 a 6.27 mostram os resultados dos testes para aos algoritmos
de treinamento com a variação do número de neurônios.
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.23: Simulação da RNA com o algoritmo TRAINSCG- Teste RNA _04_PCA4

116
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.24: Simulação da RNA com o algoritmo TRAINBR - Teste RNA _04_PCA4
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.25: Simulação da RNA com o algoritmo TRAINLM - Teste RNA _04_PCA4
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.26: Simulação da RNA com o algoritmo TRAINGD - Teste RNA _04_PCA4

117
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaç
ão li
near
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.27: Simulação da RNA com o algoritmo TRAINGDM - Teste RNA _04_PCA4
Observa-se através dos gráficos mostrados nas Figuras 6.23 a 6.27 que o
algoritmo que apresentou melhor resultado para esta etapa dos testes foi o
TRAINGD (Figura 6.26), apresentou um coeficiente de correlação de 0,704 para o
treinamento e de 0,771 para a validação, quando treinado a RNA com 10 neurônios
na camada escondida.
6.6.5 Quinta Geração de resultados (RNA_05_ NIR)
Aplicado PCA nos dados de absorbância dos cavacos (dados do FT-NIR),
escolhido os 3 PCs mais significativos com variância maior que 1% (Tabela 6.1), em
seguida foram unificadas as matrizes de dados de processo com a matriz dos 3
componentes mais relevantes, foi formado uma nova matriz composta pelas variáveis
E1, E2, E3, E4, E5, E6, E7, CP1, CP2, CP3, formando uma matriz única (10 x 160), e a
partir desta foram treinadas RNAs utilizando os algoritmos de treinamento:
TRAINSCG, TRAINBR, TRAINLM, TRAINGD e TRAINGDM do Toolbox de
RNAs do MATLAB® na versão 7.0.0 (R.14).
A Figura 6.28 apresenta a estrutura do modelo treinado para esta geração e
resultados, na qual se utilizou de uma matriz única para treinamento da RNA.

118
Amostra de cavacos de madeira
Predição do #Kappa
Espectro de freqüência FT-NIR
Matriz Total
Rede Neural
Matriz de 10 x 160
1557 espectros de freqüência FT-NIR
PCAVariáveis
operacionais
7 variáveis de processo
Figura 6.28: Estrutura do modelo testado RNA05_NIR
Pode-se observar através dos gráficos mostrados nas Figuras 6.29 a 6.33 que
o algoritmo que apresentou melhor resultado, ou seja, um coeficiente de correlação
para o teste de validação de 0,8174 foi o TRAINSCG (Figura 6.29), quando treinado
a RNA com 6 neurônios na camada escondida.
Estas Figuras 6.29 a 6.33 também evidenciam que os algoritmos com menor
número de neurônios na camada escondida apresentam melhores resultados, embora
em alguns casos obtenham-se bons resultados com número elevado de neurônios na
camada escondida. Para efeitos de simplicidade, são evitados modelos com número
elevado de neurônios nesta camada.
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
treinamentovalidação
0,8174
Figura 6.29: Simulação da RNA com o algoritmo TRAINSCG - Teste RNA _05_NIR

119
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidacao
Figura 6.30: Simulação da RNA com o algoritmo TRAINBR - Teste RNA _05_NIR
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.31: Simulação da RNA com o algoritmo TRAINLM - Teste RNA _05_NIR
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaçã
o lin
ear
0,2
0,4
0,6
0,8
1,0
TreinamentoValidaçao
Figura 6.32: Simulação da RNA com o do algoritmo TRAINGD - Teste RNA _05_NIR
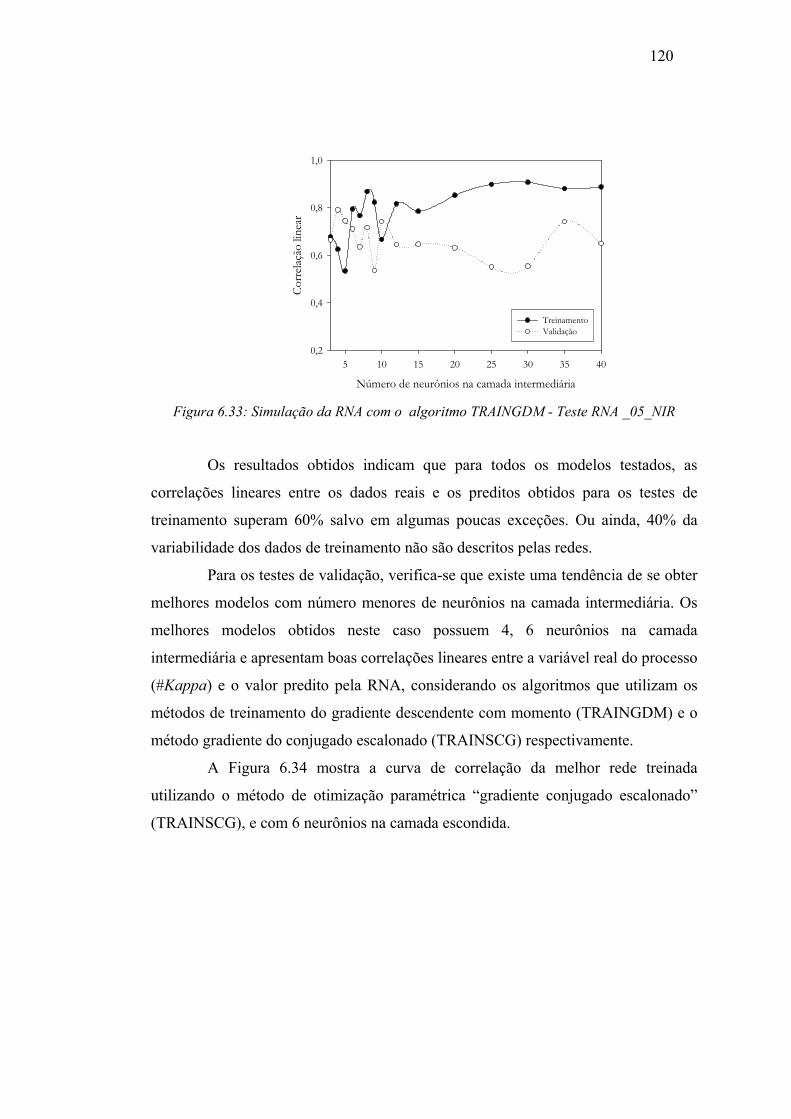
120
Número de neurônios na camada intermediária
5 10 15 20 25 30 35 40
Corr
elaç
ão li
near
0,2
0,4
0,6
0,8
1,0
TreinamentoValidação
Figura 6.33: Simulação da RNA com o algoritmo TRAINGDM - Teste RNA _05_NIR
Os resultados obtidos indicam que para todos os modelos testados, as
correlações lineares entre os dados reais e os preditos obtidos para os testes de
treinamento superam 60% salvo em algumas poucas exceções. Ou ainda, 40% da
variabilidade dos dados de treinamento não são descritos pelas redes.
Para os testes de validação, verifica-se que existe uma tendência de se obter
melhores modelos com número menores de neurônios na camada intermediária. Os
melhores modelos obtidos neste caso possuem 4, 6 neurônios na camada
intermediária e apresentam boas correlações lineares entre a variável real do processo
(#Kappa) e o valor predito pela RNA, considerando os algoritmos que utilizam os
métodos de treinamento do gradiente descendente com momento (TRAINGDM) e o
método gradiente do conjugado escalonado (TRAINSCG) respectivamente.
A Figura 6.34 mostra a curva de correlação da melhor rede treinada
utilizando o método de otimização paramétrica “gradiente conjugado escalonado”
(TRAINSCG), e com 6 neurônios na camada escondida.

121
Figura 6.34: Correlação linear da melhor rede obtida
A Figura 6.35 evidencia a curva de tendência de treinamento da melhor rede
obtida, pode-se observar que a RNA apresenta um baixo resíduo e um baixo RMSE
(Root Mean Square Errors) durante a etapa de treinamento. O coeficiente de
correlação linear nesta etapa, entre a variável medida e a predita pela RNA, foi de
0,9276% e um RMSE de 0,2092.
Os resultados de RMSE apresentados são em função da raiz quadrada do erro
quadrático médio (RMSE), dado pela Equação 6.1 (HAYKIN, 2001, p.225) :
∑∑==
−=M
kkk
N
nnynd
NRMSE
1
2
1))()((
21
(6.1)
Onde é a saída desejada do neurônio de saída k para a amostra n, ) é a
saída fornecida pela rede neural e N o número de padrões.
)(ndk (nyk

122
De acordo com Aguirre (2004) o índice RMSE mede o erro da predição livre
do modelo com relação a média dos dados reais e índices de RMSE superiores a 1,
significa que a resposta do modelo é pior que a média temporal dos dados.
A análise da Figura 6.35 evidencia também, que para todos os modelos
testados, as correlações lineares entre os dados reais e preditos obtidos para os testes
de treinamento superam 90%. Ou ainda, apenas 10% da variabilidade dos dados de
treinamento não são descritos pelas redes nesta etapa. Para os testes de validação,
verifica-se que existe uma tendência de se obter melhores modelos com menor
número neurônios.
5 10 15 20 25-5
0
5
10
15
20
#Kappa medido no processo#Kappa predito pela RNAResíduos
Núm
ero
Kap
pa
Padrões apresentados à RNA no Treinamento
Correlaçao=0,9276
RMSE=0,2092
Figura 6.35: Tendência dos valores do #Kappa no treinamento com o algoritmo TRAINSCG
Uma RNA com arquitetura de 10 x 6 x 1 produziu melhores resultados
durante a validação. A Figura 6.36 evidencia a curva de tendência de validação da
melhor rede obtida. Através do gráfico pode-se observar uma boa capacidade de
resposta do modelo treinado, pois os valores preditos pela RNA acompanham a
tendência dos valores reais da variável #Kappa medidos no processo.
Uma correlação linear de 0,8174 pode ser observada na Figura 6.36, quando
comparadas as variáveis #Kappa predito e medido, é evidenciado ainda os resíduos
durante esta etapa de validação do modelo.

123
5 10 15 20 25-5
0
5
10
15
20
25
#Kappa Medido no Processo#Kappa Predito pela RNAResíduos
Núm
ero
Kap
pa
Padrões apresentados à RNA
Correlaçao=0,8174
Figura 6.36: Comparação da variável #Kappa predito e medido para o melhor modelo
obtido
A Figura 6.37 apresenta o histograma dos dados de treinamento onde a
maior parte dos dados analisados, encontra-se com valores de #Kappa entre 14 a 18.
Observa-se também que ocorreram valores entre 10 e 22, ou seja, foram
apresentados padrões de #Kappa para a rede, com uma faixa ampla sugerindo que na
presença de informações operacionais compreendidos dentro desta faixa, RNA terá
capacidade de reconhecê-los satisfatoriamente. No entanto, acredita-se que a
apresentação de um maior número de padrões à rede, poderia melhorar ainda mais os
resultados alcançados.
Figura 6.37: Histograma dos dados de treinamento

124
A Figura 6.38 mostra a arquitetura da RNA que apresentou melhor correlação
linear na validação, possui uma arquitetura 10 x 6 x 1, apresenta 10 entradas, 6
neurônios na camada intermediária e um na camada de saída.
E1
E2
E3
E4
E5
E6 #Kappa
E7
PC1
PC2
PC3
CAMADA DE ENTRADA
DE NÓS DE FONTE
CAMADA DE NEURÔNIOS
OCULTOS
CAMADA DE NEURÔNIOS
DE SAÍDA
Figura 6.38: Arquitetura RNA que apresentou melhor resultado (10x6x1)
Pode-se observar com os resultados mostrados nos subitens 6.6.2 a 6.6.5,
que o aumento de CPs para representação do conjunto de padrões do FT-NIR não
traz melhorias nos resultados da predição do #Kappa, ou seja, poucos componentes
principais são suficientes para representarem o conjunto de padrões mostrados pelas
análises do FT-NIR.
6.6.6 Testes com Early Stopping
Após obter os melhores resultados utilizando o método de otimização
paramétrica do gradiente do conjugado escalonado (rotina do MATALAB®,
TRAINSCG), foi aplicado no treinamento o Early Stopping na tentativa de melhorar
o modelo encontrado, os resultados são evidenciados nas Figuras 6.39.
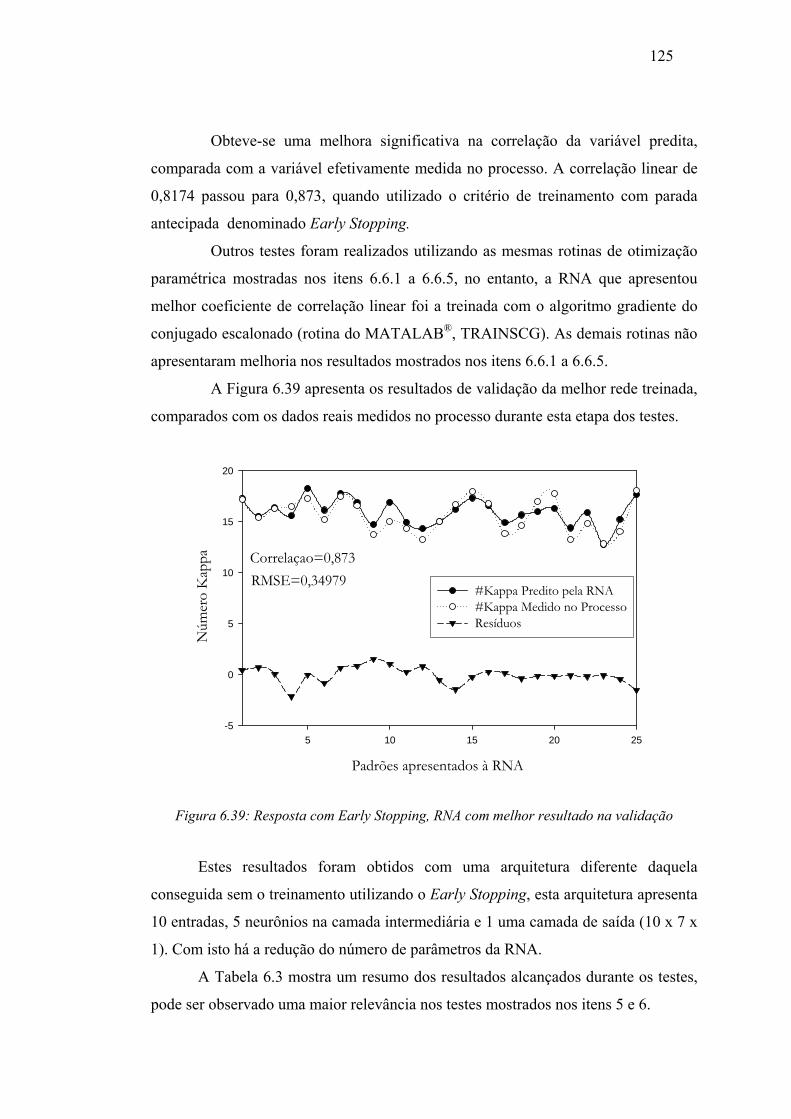
125
Obteve-se uma melhora significativa na correlação da variável predita,
comparada com a variável efetivamente medida no processo. A correlação linear de
0,8174 passou para 0,873, quando utilizado o critério de treinamento com parada
antecipada denominado Early Stopping.
Outros testes foram realizados utilizando as mesmas rotinas de otimização
paramétrica mostradas nos itens 6.6.1 a 6.6.5, no entanto, a RNA que apresentou
melhor coeficiente de correlação linear foi a treinada com o algoritmo gradiente do
conjugado escalonado (rotina do MATALAB®, TRAINSCG). As demais rotinas não
apresentaram melhoria nos resultados mostrados nos itens 6.6.1 a 6.6.5.
A Figura 6.39 apresenta os resultados de validação da melhor rede treinada,
comparados com os dados reais medidos no processo durante esta etapa dos testes.
5 10 15 20 25-5
0
5
10
15
20
#Kappa Predito pela RNA#Kappa Medido no ProcessoResíduos
Núm
ero
Kap
pa
Padrões apresentados à RNA
Correlaçao=0,873RMSE=0,34979
Figura 6.39: Resposta com Early Stopping, RNA com melhor resultado na validação
Estes resultados foram obtidos com uma arquitetura diferente daquela
conseguida sem o treinamento utilizando o Early Stopping, esta arquitetura apresenta
10 entradas, 5 neurônios na camada intermediária e 1 uma camada de saída (10 x 7 x
1). Com isto há a redução do número de parâmetros da RNA.
A Tabela 6.3 mostra um resumo dos resultados alcançados durante os testes,
pode ser observado uma maior relevância nos testes mostrados nos itens 5 e 6.

126
Tabela 6.3: Resumo dos resultados dos testes
item Testes
Método de
otimização
paramétrica
Correlação
Linear na
validação
Neurônios na Camada
escondida
1 RNA_01_PCA1 TRAINGD 0,641 4
2 RNA_02_PCA2 TRAINGDM 0,701 8
3 RNA_03_PCA3 TRAINGDM 0,705 6
4 RNA_04_PCA4 TRAINGD 0,771 10
5 RNA_05_NIR TRAINSCG 0,8174 6
6 Early Stopping TRAINSCG 0,873 7
6.6.7 Simulador de processos
Como ferramenta de apoio à tomada de decisões operacionais, foi
desenvolvido um simulador para predição da variável #Kappa baseado na RNA em
questão, desenvolvido através do software MATLAB® na versão 7.0.0 (R.14).
O simulador tem como entradas as variáveis mostradas no subitem 6.6.5. A
simulação do processo acontece baseando-se em uma análise dos espectros de
freqüência dos cavacos de entrada do digestor, feita pelo FT-NIR e pela entrada
manual de dados conforme mostrado na Figura 6.40, esta ilustra os parâmetros de
entrada do simulador.
Após inseridas todas as informações requeridas (dados de entrada), o
comando “Load” carrega estas informações na matriz e dados de entrada da RNA em
seguida um comando “Carrega” busca os parâmetros da melhor RNA treinada.
Acionando o comando “Simula” o modelo fará a predição do #Kappa e o mostrará
na tela.
O simulador é capaz de predizer a variável #Kappa com um índice de
correlação linear de 0,8174, quando utilizado os parâmetros da RNA mostrada no
item 6.6.5.

127
Figura 6.40: Janela de entrada de dados para predição do #Kappa
Quando utilizados os parâmetros da RNA mostrada no item 6.6.6, esta é
capaz de predizer a variável #Kappa com coeficiente de correlação linear de 0,873.
Esta rede foi treinada utilizando o algoritmo gradiente do conjugado escalonado
(rotina do MATALAB®, TRAINSCG) com critério de parada Ealy Stopping.

128
7 COMENTÁRIOS FINAIS
7.1 Conclusões
A tecnologia FT-NIR vem se mostrado uma importante ferramenta de
análises de variáveis industriais e combinada com as redes neurais, se mostrou viável
na elaboração de modelos para digestores em fábricas de celulose com processos do
tipo Kraft.
A seqüência de testes levou à exaustão o treinamento das redes neurais. O
melhor modelo foi escolhido em função da melhor correlação linear obtida entre a
variável medida e a variável predita.
Basicamente foram treinadas RNAs com uma quantidade de 15 diferentes
números de neurônios na camada escondida. Foram utilizados 5 algoritmos de
treinamento diferentes, sendo estes algoritmos de otimização paramétrica de primeira
e segunda ordem. Os resultados obtidos são similares, com uma pequena melhora
nos resultados para os de segunda ordem.
Para cada número de neurônios na camada escondida e cada algoritmo de
otimização paramétrica, foram treinadas 300 diferentes redes, sendo que destas a que
apresentou melhor resultado foi validada.
O melhor modelo obtido é capaz de predizer a variável #Kappa, com um
coeficiente de correlação linear de 0,8174 em relação a variável efetivamente
medida. Isto mostra um resultado satisfatório e oferece ao operador uma informação
antecipada, para que o mesmo possa intervir no processo e consequentemente
controlar melhor as variabilidades do #Kappa no processo de cozimento.
A utilização do critério parada antecipada Early Stopping, melhorou a
correlação linear entre as variáveis predita e medida, de 0,8174 para 0,873, se
mostrando como uma boa ferramenta para contribuição durante as etapas de
treinamento dos modelos.
A técnica multivariada PCA, se mostrou uma boa ferramenta para redução
da dimensionalidade de matrizes com número elevado de padrões de entrada.
Acredita-se que quantidade de padrões utilizados (total de 160) foi um fator

129
determinante para os resultados do modelo. Acredita-se também que com um volume
maior de padrões seja possível obter um modelo que possa apresentar melhores
coeficientes de correlação na predição do #Kappa.
Digestores contínuos de cozimento de madeira em processos do tipo Kraft,
embora apresentem atributos que desafiam uma boa modelagem, podem ser
estudados utilizando várias técnicas dentre elas as RNAs se mostram capazes de
oferecer bons modelos matemáticos.
As redes neurais artificiais têm se apresentado como ferramenta necessária
e importante no contexto industrial. Sua capacidade de aprendizado e de predizer
resultados, quando submetidas a padrões desconhecidos, as transformam em
interessante opção nas soluções dos problemas industriais.
7.2 Sugestões para trabalhos futuros
Como propostas para trabalhos futuros têm-se:
• testar outras arquiteturas de redes para o sistema proposto;
• utilizar um maior número de padrões para treinar novas RNAs;
• ampliar a abrangência deste trabalho para demais variáveis no processo
de fabricação de celulose, ou seja, aquelas variáveis de difícil medição
com os métodos já existentes, como exemplo viscosidade, umidade dentre
outras;
• implementar o modelo que apresentou melhor resultado em uma
ferramenta mais robusta operacionalmente;
• Instalar um sistema de medição FT-NIR online no processo produtivo e
desenvolver um modelo também com predição online.

130
REFERÊNCIAS BIBLIOGRÁFICAS
ABRAF, Anuário Estatístico da ABRAF: ano base 2006 / ABRAF. – Brasília 2007.
81p.
ANDRITZ. Kraft Mill Business. Cenibra Lo-Level/Lo-Solids – Apostila de
Treinamento. Belo Oriente. 2006, 224p.
AL-AWAMI, L.; SIDRAK Y. Understending th dynamic behavior of Kamyr
digesters. ISA Transactions, 37. p. 53-64. 1998.
AGUIAR, H. C. I. L. Modelagem de digestores Kraft contínuo: Redes neurais e
modelos híbridos. 2000. 173p. Dissertação de mestrado – Universidade Estadual de
Campinas –UNICAMP. Campinas Fevereiro de 2000.
AGUIAR, H. C.; FILHO R. M. Neural network and hybrid model: a discussion
about different modeling techniques to predict pulping degree with industrial
data. Chemical Engineering Science; p. 565-570; 2001.
AGUIRRE, L. Introdução à identificação de Sistemas: técnicas lineares e não-
lineares aplicadas a sistemas reais. UFMG, Editora UFMG - Belo Horizonte,
Minas Gerais, 2 edition, 2004.
ASSUMPÇÃO, R. M. V.; PINHO, M. R. R.; CAHEN, R.; PHILIPP, P. “Polpação
química”. Celulose e Papel. Tecnologia de Fabricação de Pasta Celulósica,
Volume 1, 2ª edição, Capítulo 6. São Paulo: IPT-SENAI, 1988.
BARBER, V. A.; SCOTT, G. M. Dynamic modeling of a paper machine software
development. TAPPI Journal, vol. 6, no. 1, January 2007.

131
BARBER, V. A.; SCOTT, G. M. Dynamic modeling of a paper machine part II:
evaluation of wet-end model dynamics. TAPPI Journal, vol. 6, no. 1, February
2007.
BARRICHELO, L. E. G.; FOEKEL, C. E. B.; AHEN, R. Estudos para produção
de celulose de sulfato de seis espécies de eucalipto. IPEF, n.12, p. 77 – 95, junho
1976.
BLAKE, S. C. S. Influência da densidade básica da madeira na qualidade da
polpa Kraft de clones híbridos, Eucalyptus Grandis W. Hill ex Maiden X
Eucalyptus Urophylla S. T. Blake; R. Árvore, Viçosa, v.28, p.901-909, 2004.
BOKOBZA, L. Near Infrared Spectroscopy, .J. Near Infrared Spesctrosc., 6, p. 3-
17, 1998.
BORIN, A. Aplicação de Quimiometria e Espectroscopia no Infravermelho no
Controle de Qualidade de Lubrificantes, Dissertação Mestrado, 2003-
Universidade Estadual de Campinas – Instituto de Química – LAQQA., 2003.
BRAGA, A. P.; LUDERMIR, T. B.; CARVALHO, A. C. P. L. F. Redes Neurais
Artificiais: Teoria e Aplicações. LTC – Livros Técnicos e Científicos Editora S.A.,
2000.
BUGAGER, S.; CAHEN, R.; A. F. & PINHO, M. R. R. Fator-H – Parâmetro
válido para polpação de eucalipto. O Papel, São Paulo: p.35-49. 1979.
CALDEIRA, R. L. A.; FIGUEIREDO A. B. D.; NETO, J. A.; CARLECH, R. P.;
PAIVA, J. M. Influência da Variabilidade da Madeira no Processo de Cozimento
da Cenibra: Proposta de Segregação por Classes de Qualidade. Curso de Pós-
graduação Latu Sensu em Tecnologia de Celulose e Papel (UFV). Belo Oriente,
Cenibra, 2006.

132
CALDEIRAA, A. F.; ROCHA, A. P.; SANTOS, C. V. C.; ALMEIDA. C.; PATELLI,
J. E.; CALVOSA, P. S. P; SACON, V. NIR On Line: An Innovation in the VCP
Wood Yard. Colóquio internacional de celulose e papel, Março 2007, Belo
Horizonte, Brasil. CARDOSO, V. C.; FIZZO, S. M. B.; ROSA, C. A. B.; FOEKEL, C. E. B; ASSIS, T.
F; OILVEIRA, P. Otimização das condições do cozimento kraft de eucalyptus
globulus em função do teor de lignina da madeira. In: 35º Congresso e Exposição
Anual de Celulose e Papel da ABTCP, 2002.
CARVALHO, A. M. M. L. Estrutura Anatômica e Química da Madeira, Parte I;
Curso de pós-graduação lato Sensu em tecnologia de celulose e papel. Universidade
Federal de Viçosa; Engenharia Florestal; Viçosa, MG; 2005; 44p.
CHATFIELD, C.; COLLINS, A. J. Introduction to multivariate analysis. London:
Chapman & Hall, 1992.
CIENFUEGOS, F. Introdução à fotocolorimetria e espectrofotometria. São
Paulo: ALTEC manual; 1995.
CIENFUEGOS, F. Análise Instrumental: Conceitos e Avanços da Análise no
Infravermelho, Revista Química e Derivados, São Paulo, ano 35, N°413, p. 40-46,
março 2003.
COLODETTE, J. L. Química da Madeira; Curso de pós-graduação lato Sensu em
tecnologia de celulose e papel. Universidade Federal de Viçosa; Engenharia
Florestal; Viçosa, MG; 2004.
COHN, P. E. e RIBEIRO, R. N. Medição “on line” do alcali total nos licores
branco e verde empregando tecnologia FT-NIR. In: 35º Congresso e Exposição
Anual de Celulose e Papel da ABTCP, 2002.

133
COLUZZI, DJ. Fundamentals of dental lasers: science and instruments. Dent Clin N Am 2004; 48(4)751-770.
COSTA, A. O. S. Alternativas para o Controle de um Sistema de Evaporadores
de Múltiplo Efeito. 2000. Dissertação (Mestrado em Engenharia Química) –
Programa de Engenharia Química do Instituto Alberto Luis Coimbra de Pós-
Graduação e Pesquisa em Engenharia - PEQ-COPPE-UFRJ, Rio de Janeiro, RJ.
COSTA, A. O. S.; SOUZA, M. B.; BISCAIA, E. C.; LIMA, H. L. Monitoring
particulate material formation in a kraft furnace recovery boiler. Tappi Journal,
vol. 4. no. 4, 2005.
CYBENKO, G. Continuous Valued Neural Networks With Two Hidden Layers
Are Sufficient. Technical Report, Department of Computer Science, Tufts
University, 1988.
CYBENKO, G. Approximation by Superpositions of a Sigmoid Function.
Mathematics of Control, Signals and Systems, 2:303-314, 1989.
D`ALMEIDA, M. L. O. Celulose e Papel. Tecnologia de fabricação de pasta
celulósica. Volume 1, 2ª edição, Capítulo 3. São Paulo: IPT-SENAI, 1988.
DOYLE III, F. J.; KYIHAN, F. Reaction profile control of the continuous pulp
digester. Chemical Engineering Science, 54 (1999) 2679 -2688.
DUFOUR, S.; BHARTIYA, S.; DHURJATI P. S.; DOYLE III, F. J. Neural
network-based software sensor: training set design and application to a
continuous pulp digester. Control Engineering Pratice 13. p. 135-143; 2005.
EDGAR, T. F.; HIMMELBLAU, D. M. Optimization of chemical processes; Mc
Graw Hill Book Company; New York, NY, 1ª ediçao, 1998.

134
EIKREM, L. O. Process Fourier Transform Infrared Spectroscopy, Anal.
Chem.,9, 107-109, 1990.
ESBENSEN, K. H. Multivariate data analysis – In Practice: 5th Edition. Oslo:
CAMO, 2002, 598p.
FACKLER, K.; GRADINGER, C.; HINTERSTOISSER, B.; MESSNER, K.;
SCHWANNINGER, M. Lignin degradation by white rot fungi on spruce wood
shavings during short-time solid-state fermentations monitored by near
infrared spectroscopy. Enzyme and Microbial Technology 39 p.1476–1483, 2006.
FERNANDES, N. C. P. and CASTRO, José A. A. M. “Steady-state simulation of a
continuous moving bed reactor in pulp and paper industry”. Chemichal
Engineering Science, 2000, p3729-3738.
FERREIRA, C. R. S.; GOMIDE, J. L.; OLIVEIRA, R. C.; COLODETTE, J. L.;
NETO, H. F. Estudos de otimização do perfil de temperatura na polpação.
Congresso Internacional de Celulose e Papel; 2000.
FIGUEIRÊDO, L. S. Modelagem e simulação do processo de caustificação. Curso
de Pós-graduação Latu Sensu em Tecnologia de Celulose e Papel (UFV). Belo
Oriente, Cenibra, 2006.
FOEKEL, C. E.; MOURA, E.; MENOCHELLI, S. Densidade Básica: sua
verdadeira utilização como índice de qualidade da madeira de eucalipto para
produção de celulose. In. CONGRESSO FLORESTAL BRASILEIRO, 6, Campos
do Jordão, 1990, Anais ... p. 719-728.
FUNKQUIST, J. Grey box identification of a continuous digester - distributed
parameter process. STFI (Swidish Pulp and Paper Research Institute), Box 5604, S-
114 86 Stockholm, Sweden. Copyright © 1997 Elsevier Science, LTD.

135
GAMA, L. F, A. Análise de componentes principais para redução de
dimensionalidade das entradas em redes neurais artificiais. 2006. 96p.
Monografia (conclusão de curso Engenharia Elétrica) – Centro Universitário do leste
de Minas Gerais UNILESTE-MG. Cel. Fabriciano Julho de 2006.
GARCIA, C. B. Anatomia, composição e propriedade de 5 madeiras paraguaias.
1995. 126f. Dissertação (Mestrado em Ciência Florestal) – Universidade Federal de
Viçosa,Viçosa, 1995.
GARCIA, C. "Modelagem e Simulação" Editora: USP - 1997;
GBC.In: Introduction to UV-Visible spectroscopy. GBC UV-VIS Cintra 10/20/40
Spectrometer Operation Manual. Dandenong: GBC Scientific Equipment Pty Ltd
1996;1;1-3.
Ge, S. S.; HANG, C. C.; ZHANG, T. Z. Nonlinear adaptive control using neural
networks and its aplication to CSTS systems. Journal of process control 9, p 313-
323, 1998.
GOMES, F. F. V. Aplicações do Infravermelho Próximo por Transformada de
Fourier (FT-NIR) na medição de variáveis na indústria. Coronel Fabriciano,
UNILESTE-MG, junho de 2007, 51 p.
GOMIDE, J. L. Caracterização tecnológica para produção de celulose da nova
geração de clones de Eucalyptus do Brasil. R. Árvore, Viçosa, v.29, p.129-137,
2005.
GOMIDE, J. L. Tecnologia e química da produção de celulose. Curso de pós-
graduação Latu Senso em tecnologia de celulose e papel; Universidade Federal de
Viçosa; 2006.
HAYKIN, S. Neural Networks – A Comprehensive Foundation. New York: Macmillan Publishing Company, 1994.

136
HAYKIN, S. Redes Neurais: princípios e práticas; trad. Paulo Martins Engel. -
2.ed. – Porto Alegre: Bookman 2001.
JENKINS, F. A.; WHITE, H. E. Fundamentals of optics. 4th, ed. Auckland: McGranw-Hill; 1981.
HARKONEN, E. J. A mathematical model for two-phase flow in a continuous
digester; Research engineer, Kamyr; TAPPI Journal, dec. 1987, Sweden.
HOANG, V.; BHARDWAJ, N. K.; NGUYEN, K. L. A FTIR method for
determining the content of hexeneuronic acid (hexA) and Kappa number of a
high-yield kraft pulp. Carbohydrate Polymers 61 (2005) 5–9. 2005.
HOWARD, A.; RORRES C. Álgebra Linear com Aplicações / Anton Howad e Cris
Rorres; trad. Claus Ivo Doering. – 8. ed. – Porto Alegre: Bookman, 2001.
HULST, V. Light scattering by small particles. New York: Dover; 1981.
IYODA, E. M.; Inteligência computacional no projeto automático de redes
neurais híbridas e redes neurofuzzy heterogêneas. Dissertação de mestrado,
programa de pós-graduação da faculdade de Engenharia Elétrica e Computação,
Universidade Federal de Campinas, 2000.
JOHNSON, R. A.; WICHERN D. W. Applied Multivariate Statistical Analysis,
Fifth Edition, cp. 1 – Aspects of Multivariate Analysis, cp. 2 – Matrix Algebra and
Random Vectors, cp. 8 – Principal Components, 2002.
JONES, D. M.; WATTSON, J.; BROWN, K. J. Comparison of hot rolled steel
mechanical property prediction models using linear multiple regression, non-
linear multiple regression and non-linear artificial neural networks. Ironmaking
and Steelmaking, 32(5):435 442, 2005.

137
KAISER, H. F. The Varimax critéria for analytical rotation in factor analysis.
Psychometrica, 23: 141-151, 1958.
KARLSSON, H. AB Lorentzen &Wettre. FIBER GUIDE; Fiber analysis and
process applications in pulp and paper industry. Sweden, 2006.
KASPARIAN, V.; BATUR C. Model reference based neural network adaptative
controller. ISA Transactions 37, 1998 21-39.
KAYIHAN, F. A stochastic continuous digester model to capture transition,
compaction an chip size distribution effects. IETek – Integrated Engineering
Technologies; 2002.
KOGA, M. E. T. Celulose e Papel. Tecnologia de fabricação de pasta celulósica.
Volume 1, 2ª edição, Capítulo 2. São Paulo: IPT-SENAI, 1988.
LANSDELL, O.; CREUS, A.; BONA, E. PPPC (Pulp and Paper Products Council)
Report; Supply and Demand MARKET PULP, April, 2006.
LAPERRIÈRE, L.; LEDUC, C.; DANEAULT C.; BÉDARD, P. Chip properties
analysis for predicting bleaching requirements for TMP pulps. TAPPI Journal,
vol. 3, no. 12, December 2004.
LEMMETI, A.; LEIVISKÄ, K.; SUTINEN, R. Kappa number prediction based
on cooking liquor measurements, Report A No 5, May 1998.
LEE, J. H.; RAJA, A. Subspace Identification Based Inferential Control of A
Continuous Pulp Digester; PSE '97-ESCAPE-7 Joint Conference, Computeres
chem.. Eng, Vol. 21, Suppl., pp. S1143-S1148, 1997, Elsevier Science Ltd.

138
LI, J.; GELLERSTEDT, G.; On the structural significance of kappa number
measurement. In: INTERNATIONAL SYMPOSIUM WOOD PULPING
CHEMICAL, 9.; Montreal, 1997. Proceedings. Montreal: TAPPI, 1997. p.56-71
LJUNG, L. (1987). System Identification – Theory of the user. Prentice-Hall
International, New Jersey.
MACKAY, D. J. C. Bayesian interpolation. Neural Computation. vol. 4, p. 415-
447, 1992.
MALMBERG, B.; EDWARDS, L.; LUNDBORG, S.; AHLROTH,; M.
WARNQVIST. B. Prediction of dust composition and amount in kraft recovery
boilers. TAPPI Journal, March 2005.
MARCOCCIA. B. S.; STROMBERG. B. & PROUGH. J. R. Achieving major
increases in hardwood yield with Lo-Solids. In: BREAKING THE PULP YIELD
BARRIER SYMPOSIUM. Atlanta. TAPPI. 1998.
MARQUES, A. R.; FOEKEL, C. E. B. & OLIVERA. L. M. Otimização da relação
tempo-temperatura na produção de celulose Kraft de Eucalypts Urophilla de
origem híbrida. In: Anais do XII Congresso Anual de Cleulose e Papel da ABTCP.
p. 5-15. São Paulo, 1979.
MICHELSEN, F. A.; FOSS, B. A. A dynamic model of the interaction between
the chemical reactions and the residence time in a continuous digester. TAPPI
Journal, vol. 79: no. 4. Ap. 1996.
MOCZYDLOWER, D. Modelagem e Controle de um Digestor Contínuo de
Celulose. 2002. Dissertação (Mestrado em Engenharia Química) – Programa de
Engenharia Química do Instituto Alberto Luis Coimbra de Pós-Graduação e Pesquisa
em Engenharia - PEQ-COPPE-UFRJ, Rio de Janeiro, RJ.

139
MOKFIENSKI, A. Importância da densidade e do teor de carboidratos totais da
madeira de eucalipto no desempenho da linha de fibras. In: Colóquio
internacional sobre celulose Kraft de Eucalipto, 2003, Viçosa. p. 15-38.
MOLLER, M. F. A scaled conjugate gradient algorithm for fast supervised
learning. Neural Networks, Vol. 6, pp. 525-533, 1993;
MONTEIRO, L. R.; REIS, S. F. Princípios de Morfometria Geométrica. Holos
Editora, Ribeirão Preto, Brasil,1999,198p.
MORGANO, M. A.; FARIA, C. G.; FERRÃO, M. F.; FERREIRA, M. M. C.
Determinação de açúcar total em café cru por espectroscopia no infravermelho
próximo e regressão por mínimos quadrados parciais, Química
Nova, vol.30 nº.2, São Paulo, 2007.
PADHIYAR, N.; GUPTA, A.; GAUNTAM, A.; BHARTIYA, S.; DOYLE III, F. J.;
DASH, S.; GAIKWAD, S. Nonlinear inferential multi-rate control of kappa
number at multiple locations in a continuous pulp digester. Journal of Process.
2006.
PASQUINI, J. L. Caracterização tecnológica para produção de celulose da nova
geração de clones de Eucalyptus do Brasil. R. Árvore, Viçosa, v.29, p.129-137,
2005.
PASQUINI, C.; CARNEIRO, C. J. G.; BOMFIM, P. M. Desenvolvimento e
validação de modelos multivariados empregando espectrometria no
infravermelho próximo para estimativa de características da madeira de
Eucalipto. R. O Papel, São Paulo, Março 2007, p. 71-83, 2007.
PHILIPS NV Gloeilampenfabrieken. Manual de Iluminação. Eindhoven: 1981.
PIOTTO, Z. C. Eco-eficiência na indústria de celulose e papel - estudo de caso.

140
2003. Tese. Escola Politécnica da Universidade de São Paulo. São Paulo SP, 2003,
379p.
POLIT, M.; ESTABEM, M.; LABAT, P. A fuzzy model for an anaerobic digester,
comparison with experimental results. Enginneering Aplications of Artificial
Intelligence 15; p. 385-390; 2002.
POUGACTH, K.; SALCUDEAN, M.; GARTSHORE, I. A numerical model of the
reacting multiphase flow in a pulp digester; Aplpied Mathematical Modelling 30
(2006), p. 209-230; march 2005.
PREMIER, G. C.; DINSDALE, R.; GUWY, A. J.; HAWKES, F. R.; HAWKES, D.
L.; WILCOX, S. J. A comparison of the ability of blackbox of arx structure to
represent a fluidized bed anaerobic digestion process. Wat. Res. Vol.33, no. 4, pp.
1027-1037, 1999.
QIAN Y.; LIU H.; ZHANG X.; TESSIER P. J. C.; Optimization of a wood chip
refining process based on fuzzy relational models. Computers Chemical
Engineering, vol. 21; Suppl., p. S1137-S1142, 1997. Elsevier Science LTD.
QUEIROZ, S. C. S.; GOMIDE, J. L.; COLODETTE, J. L.; OLIVEIRA, R. C.
Influência da Densidade Básica da madeira na qualidade da polpa Kraft de
clones híbridos de Eucalyptus grandis W. Hill ex Maiden X Eucalyptus urophila
S. T. Blake; R. Árvore, Viçosa-MG, v.28, n.6, p.901-909, 2004.
RUBINI, B. R.; YAMAMOTO, C. Development of predictive oxygen
delignification models using kinetic expressions and neural networks. TAPPI
Joournal, vol. 5, no. 4, 2006.
RUMELHART, D. E.; HILTON, G. E.; WILLIANS, R.J. Learning representations
by back-propagating errors. Nature, 323:533-536, 1986.

141
RUMELHART, D. E. and McCLELLAND, editors. Parallel distributed process:
explorations in the microstructure cognition, v. 1; Foundation Mit Press. (1986).
SANTOS, R. B.; SOUZA, L. C.; GOMIDE, J. L. Utilização de cavacos para
análises por espectrometria de infravermelho próximo (NIR). Revista O Papel, nº
5, ano 2006, p. 84-88. SP.
SCAFI, S. H. F.; PASQUINI, C. Sistema de Monitoramento em Tempo Real de
Destilação de Petróleo e Derivados Empregando a Espectroscopia no
Infravermelho Próximo. 2005. 196p. Dissertação (Doutorado) – Universidade
Estadual de Campinas. Campinas, 2005.
SKOGLUND, A.; KESSLER, W.; KESSLER, R. W.; BRUNDIN, A.;
MANDENIUS, C. F. On-line spectroscopic measurements of wood chips before a
continuous digester. Chemometrics and Intelligent Laboratory Systems, 70 (2004),
p.129– 135.
SHIN, N. H.; STROTROMBERG, B. Impact of Cooking Conditions On Pulp
Yield And Other Parameters, Andritz Inc. 13 Pruyn’s Island Drive, Glens Falls,
NY 12801
SIDRAK, Y.; AWAMI, A. L. Understanding the dynamic behavior of Kamyr
digesters, ISA Transactions 37 (1998) 53 – 64.
SILVA, L. N. C. Análise e síntese de estratégias de aprendizado para redes
neurais artificiais. Dissertação de Mestrado, Programa de Pós-Graduação da
Faculdade de Engenharia Elétrica e de Computação - Universidade Estadual de
Campinas, 1998.
SPIEGEL, M. R. Schaum’s Outline of Theory and Problems of Estatistics: 13th
Edition. Brasil: McGraw-Hill, inc, 1979, 580p.

142
TAKAHASHI, H, J. Predição de propriedades mecânicas de aços de alta
resistência microligados utilizando técnicas de inteligência computacional. 2006.
128p. Dissertação de Mestrado – Centro Universitário do Leste de Minas Gerais
UNILESTE-MG. Cel. Fabriciano Dezembro de 2006.
TEIXEIRA, R. A. Treinamento de Redes Neurais Artficais Através de
Otimização Multiobjetivo: Uma Abordagem para o Equilíbrio entre a
Polarização e a Variáncia. Tese de Doutorado, Programa de Pós-Graduação em
Engenharia Elétrica - Universidade Federal de Minas Gerais, 2001.
TEIXEIRA, R. A. Redes Neurais Artificiais. Notas de Aula. Centro Universitário
do Leste de Minas Gerais, Brasil, 2005.
TAPPI (Technical Association for the Pulp, Paper, and converting Industry) T236 cm-85.
THURSTONE, L. L. Multiple factor analysis. Chicago, University of Chicago Press, 1947.
TINO, V. F. Utilização de análise de componentes principais na regulagem de
máquinas de injeção plástica, 2005, 79p, Dissertação (Mestrado) – Universidade
Federal do Rio de Janeiro, Rio de Janeiro, 2005.
TOMAZELLO, F. M. Formação e caracterização da estrutura anatômica da
madeira de Eucalyptus. In. Curso de processamento mecânico e secagem da
madeira de Eucalyptus. Piracicaba, IPEF, 1994.
VILELA, R. R. Descrição e balanço de massa de um digestor Lo-Solids. Coronel
Fabriciano: UNILESTE, 2006. (Monografia final do curso de Engenharia Mecânica).
VROON, K. E. (1957). The “H” Factor: A mean of expressing cooking times and
temperature as a single variable. Pulp and Paper Canada, 58(3), 228-231.
YU, D. L.; GOMM, J. B. Implementation of neural network predictive control to

143
a multivariable chemical reactor. Control Engineering Practice 11. p. 1315-1323,
2003.
WILDROW, B.; HOFF, M. E. Adaptative switching circuits. Institute of Radio
Engineers, Western Electronic Show and Convention, 1960.
WISNEWSKI P. A.; DOYLE III, F. J.; KAYAHAN, F. A Fundamental
continuous pulp digester model for simulation and control. IEEE Transactions of
Control Systems Technology, 1998.
WISNEWSKI P. A.; DOYLE III, F. J. Control structure selection and model
predictive control of the Weyerhaeuser digester problem; J. Proc. Cont. Vol. 8.
Nos. 5 6, pp. 487 - 495. 1998; 1998 Elsevier Science Ltd.
WISNEWSKI P. A.; DOYLE III; F. J. Model-Based Predictive Control Studies
for a Continuous Digester, IEEE Transactions of Control Systems Technology, vol.
9, No. 3, May 2001.