uma introdução aos sistemas de recomendação:, modelos
TRANSCRIPT

UNIVERSIDADE ESTADUAL DECAMPINAS
Instituto de Matemática, Estatística eComputação Científica
CAMILA JARDIM CAVALCANTE BONILLA
Uma introdução aos sistemas de recomendação:modelos matemáticos, algoritmos e aplicações
Campinas2020

Camila Jardim Cavalcante Bonilla
Uma introdução aos sistemas de recomendação:modelos matemáticos, algoritmos e aplicações
Dissertação apresentada ao Instituto de Mate-mática, Estatística e Computação Científicada Universidade Estadual de Campinas comoparte dos requisitos exigidos para a obtençãodo título de Mestra em Matemática Aplicadae Computacional.
Orientador: Cristiano Torezzan
Este exemplar corresponde à versãofinal da Dissertação defendida pelaaluna Camila Jardim Cavalcante Bo-nilla e orientada pelo Prof. Dr. Cristi-ano Torezzan.
Campinas2020

Ficha catalográficaUniversidade Estadual de Campinas
Biblioteca do Instituto de Matemática, Estatística e Computação CientíficaAna Regina Machado - CRB 8/5467
Bonilla, Camila Jardim Cavalcante, 1992- B641i BonUma introdução aos sistemas de recomendação : modelos matemáticos,
algoritmos e aplicações / Camila Jardim Cavalcante Bonilla. – Campinas, SP :[s.n.], 2020.
BonOrientador: Cristiano Torezzan. BonDissertação (mestrado profissional) – Universidade Estadual de Campinas,
Instituto de Matemática, Estatística e Computação Científica.
Bon1. Sistemas de recomendação (Filtragem da informação). 2. Aprendizado
de máquina. 3. Redução de dimensionalidade (Estatística). 4. Método K-vizinhomais próximo. 5. Árvores de decisão. 6. Redes neurais (Computação). I.Torezzan, Cristiano, 1976-. II. Universidade Estadual de Campinas. Instituto deMatemática, Estatística e Computação Científica. III. Título.
Informações para Biblioteca Digital
Título em outro idioma: An introduction to recommendation systems : mathematicalmodels, algorithms and applicationsPalavras-chave em inglês:Recommender systems (Information filtering)Machine learningDimension reduction (Statistics)K-nearest neighborDecision treesNeural networks (Computer science)Área de concentração: Matemática Aplicada e ComputacionalTitulação: Mestra em Matemática Aplicada e ComputacionalBanca examinadora:Cristiano Torezzan [Orientador]Washington Alves de OliveiraLucas Garcia PedrosoData de defesa: 15-12-2020Programa de Pós-Graduação: Matemática Aplicada e Computacional
Identificação e informações acadêmicas do(a) aluno(a)- ORCID do autor: https://orcid.org/0000-0003-0563-5438- Currículo Lattes do autor: http://lattes.cnpq.br/9408921263160458
Powered by TCPDF (www.tcpdf.org)

Dissertação de Mestrado Profissional defendida em 15 de dezembro de
2020 e aprovada pela banca examinadora composta pelos Profs. Drs.
Prof(a). Dr(a). CRISTIANO TOREZZAN
Prof(a). Dr(a). WASHINGTON ALVES DE OLIVEIRA
Prof(a). Dr(a). LUCAS GARCIA PEDROSO
A Ata da Defesa, assinada pelos membros da Comissão Examinadora, consta no
SIGA/Sistema de Fluxo de Dissertação/Tese e na Secretaria de Pós-Graduação do Instituto de
Matemática, Estatística e Computação Científica.

Ao meu Deus, Aquele que por mim tudo executa.Salmos 57:2

Agradecimentos
Existe um provérbio africano que diz que “é preciso um vilarejo inteiro paracriar uma criança”. Poderíamos facilmente adaptá-lo e dizer que é preciso um vilarejointeiro para formar um mestre. Nesses anos de mestrado foram muitas as pessoas envolvidase que, de uma maneira ou outra, ofereceram suporte para que eu pudesse prosseguir emalcançar meu objetivo.
Em primeiro lugar agradeço ao meu Deus, cuja graça esteve todo o tempo sobremim e que confirmou a obra das minhas mãos.
Agradeço ao meu esposo, Josué, meu cuidador e incentivador. Sei que grandeparte do que sou e do que tenho construído só é possível porque tenho você ao meu lado eo seu amor todos os dias. Essa conquista também é sua.
Agradeço à minha família em todo o seu tamanho: meu pai, minha mãe, meusirmãos, minha sogra, meu sogro e meus cunhados. Obrigada pelo amor, compreensão eincentivo. Agradeço em especial ao meu pai, em quem eu vejo todos os dias o amor peloconhecimento. Obrigada pelo seu apoio sempre fiel e sempre presente.
Agradeço ao meu orientador Prof. Dr. Cristiano Torezzan. Obrigada pelo tempo,paciência, incentivo e interesse genuíno em meu desenvolvimento acadêmico. Me sintohonrada em ter trabalhado de maneira mais próxima com alguém a quem tanto admiro.
Agradeço a todo o corpo de professores e coordenadores do programa doMestrado Profissional em Matemática Aplicada e Computacional do IMECC, em especiala Prof. Dr. Sueli Costa, ao Prof. Dr. Simão Stelmastchuk, ao Prof. Dr. João FredericoMeyer (Joni) e a Prof. Dr. Priscila Rampazzo por seu empenho e esmero na função deprofessores. Agradeço também aos funcionários do IMECC por serem sempre tão solícitose gentis, sobretudo a equipe da secretaria de pós-graduação e da biblioteca.
Agradeço as equipes e aos meus superiores nas empresas onde trabalhei duranteo período do mestrado, Falconi, Mercado Livre e PagSeguro, pela compreensão e apoiodurante os momentos em que era preciso me ausentar para participar das aulas naUNICAMP. Agradeço especialmente a dois grandes amigos que estiveram muito próximosdurante boa parte da jornada, Porto e Wander. Que venham ainda muitos anos deconquistas juntos.
Aos meus amigos que viraram família durante o período do mestrado, vai meuagradecimento já cheio de saudades. Makson, Andrey, Enio e Suellen, a amizade de vocêsfoi um dos grandes fatores de sucesso dessa empreitada (e as muitas horas de desesperopré-prova estudando no “predinho da pós”, só para comemorarmos - ou nos consolarmos -

com pizza da Vila Ré e sorvete do Machuchos no dia seguinte).
Agradeço também aos professores que compõem a banca pela avaliação ecomentários que muito contribuíram para o refinamento do trabalho.
Aos que fizeram parte dessa conquista mas que, por algum motivo, não nomeeinos agradecimentos acima, minha gratidão sincera.

ResumoSistemas de recomendação têm sido amplamente utilizados, sobretudo no ramo do comércioeletrônico, para compilar informações sobre as preferências dos usuários, com o intuitode sugerir itens de maneira personalizada e facilitar a busca por produtos e serviços.Tais sistemas são baseados em modelos matemáticos e algoritmos computacionais, quepermitem processar um grande volume de dados e automatizar as recomendações. Nestetrabalho apresenta-se uma revisão sobre as principais abordagens utilizadas na modelagemdos sistemas de recomendação, denominadas sistemas de filtragem colaborativa e sistemasde filtragem baseada em conteúdo, bem como as métricas de avaliação utilizadas. Otrabalho inclui uma síntese sobre a história dos sistemas de recomendação e exemplosde casos de uso em grandes empresas de tecnologia. São discutidos com mais detalhes osalgoritmos de regressão linear, redução de dimensionalidade de matrizes, K-vizinhos maispróximos, árvores de decisão e redes neurais artificiais. Por fim, apresenta-se a aplicaçãodos algoritmos de K-vizinhos mais próximos, redução de dimensionalidade de matrizese redes neurais artificiais na construção de um sistema de recomendação para uma lojaonline de vestuário.
Palavras-chave: Sistemas de recomendação, aprendizado de máquina, redução de di-mensionalidade de matrizes, K-vizinhos mais próximos, árvores de decisão, redes neuraisartificiais.

AbstractRecommendation systems have been widely used, especially in e-commerce, in order tocompile information on users’ preferences and suggest items in a personalized manner,facilitating the users’ search for products and services. These systems are based onmathematical models and computational algorithms that enable the processing of a largevolume of data and the automation of recommendations. This text reviews the mainmethods used in modeling recommendation systems, that is, collaborative filtering systemsand content based filtering systems, as well as some of the evaluation metrics used. Asynthesis on the history of recommendation systems is included, along with examplesof their use in big technology companies. The algorithms discussed in greater detail arelinear regression, matrix dimensionality reduction, K-nearest neighbors, decision trees,and artificial neural networks. Finally, applications of the algorithms K-nearest neighbors,matrix dimensionality reduction, and artificial neural networks in the construction of arecommendation system for a clothing online store are presented.
Keywords: Recommendation systems, machine learning, matrix dimensionality reduction,K-nearest neighbors, decision trees, artificial neural networks.

Lista de ilustrações
Figura 1 – Exemplo de recomendações de produtos na plataforma Amazon.com . . 19Figura 2 – Exemplo de recomendações de filmes e séries na plataforma de streaming
Netflix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20Figura 3 – Filtragem baseada em conteúdo vs. Filtragem colaborativa . . . . . . . 22Figura 4 – Desenho esquemático de uma base de dados e seus elementos para um
algoritmo de aprendizado de máquina . . . . . . . . . . . . . . . . . . . 33Figura 5 – Desenho esquemático de uma base de dados referente a m músicas e n
características . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34Figura 6 – Resumo das várias categorias de sistemas de recomendação com seus
respectivos algoritmos . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Figura 7 – Gráfico de dispersão para vinte avaliações de dois produtos . . . . . . . 44Figura 8 – Gráfico de dispersão para vinte avaliações de dois produtos, aproximado
por uma reta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44Figura 9 – Estimação da avaliação de A através de uma aproximação unidimensio-
nal do conjunto de dados . . . . . . . . . . . . . . . . . . . . . . . . . . 45Figura 10 – Exemplo de vizinhança para um usuário . . . . . . . . . . . . . . . . . 57Figura 11 – Exemplo de árvore de decisão cujas folhas apresentam a frequência de
compra de um certo produto . . . . . . . . . . . . . . . . . . . . . . . . 66Figura 12 – Exemplo de duas árvores de decisão . . . . . . . . . . . . . . . . . . . . 68Figura 13 – Exemplo de árvore de decisão com dois níveis . . . . . . . . . . . . . . 68Figura 14 – Ilustração de regiões geradas por uma árvore de decisão . . . . . . . . . 69Figura 15 – Árvore de regressão com quatro folhas, representadas pelas regiões R1,
R2, R3 e R4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70Figura 16 – Entropia para uma variável aleatória binária . . . . . . . . . . . . . . . 75Figura 17 – Árvore de regressão finalizada . . . . . . . . . . . . . . . . . . . . . . . 80Figura 18 – Árvore de classificação finalizada . . . . . . . . . . . . . . . . . . . . . 83Figura 19 – Figura esquemática de uma rede neural . . . . . . . . . . . . . . . . . . 86Figura 20 – Rede neural com dois nós na camada de entrada, dois nós na camada
oculta e um nó na camada de saída . . . . . . . . . . . . . . . . . . . . 87Figura 21 – Função de erro para redes com um peso (esquerda) e dois pesos (direita) 89Figura 22 – Função erro e vetor gradiente para w = -4 . . . . . . . . . . . . . . . . 90Figura 23 – Função com um mínimo local e um mínimo global . . . . . . . . . . . . 91Figura 24 – Função degrau unitário versus função sigmoide . . . . . . . . . . . . . . 93Figura 25 – Rede Neural com vieses . . . . . . . . . . . . . . . . . . . . . . . . . . 94

Lista de tabelas
Tabela 1 – Tabela com avaliações dadas por m usuários a n itens . . . . . . . . . 23Tabela 2 – Detalhamento das características dos produtos A, B e C . . . . . . . . 30Tabela 3 – Tabela binária gerada a partir do detalhamento das características dos
produtos A, B e C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30Tabela 4 – Avaliações de filmes: Exemplo 1 . . . . . . . . . . . . . . . . . . . . . . 40Tabela 5 – Variáveis categóricas codificadas . . . . . . . . . . . . . . . . . . . . . . 41Tabela 6 – Avaliações de filmes: Exemplo 3 . . . . . . . . . . . . . . . . . . . . . . 60Tabela 7 – Similaridade entre filmes: Exemplo 3 . . . . . . . . . . . . . . . . . . . 61Tabela 8 – Similaridade entre usuários: Exemplo 4 . . . . . . . . . . . . . . . . . . 63Tabela 9 – Notas para um determinado livro por idade do leitor . . . . . . . . . . 67Tabela 10 – Base de dados D com m observações, n variáveis independentes, e y
categórico com h classes . . . . . . . . . . . . . . . . . . . . . . . . . . 76Tabela 11 – Avaliações para cinco filmes entre as maiores bilheterias da história . . 79Tabela 12 – Árvore de regressão: Primeira iteração com variável ano . . . . . . . . 79Tabela 13 – Avaliações para cinco filmes conforme gênero e distribuidora . . . . . . 81Tabela 14 – Detalhamento de campos da base de dados da ModCloth . . . . . . . . 105Tabela 15 – Detalhamento dos algoritmos aplicados . . . . . . . . . . . . . . . . . . 106Tabela 16 – Comparação de métricas de precisão entre modelos . . . . . . . . . . . 110Tabela 17 – Comparação de top 10 itens recomendados entre modelos . . . . . . . . 111

Lista de algoritmos
2.1 Regressão Linear . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 422.2 Decomposição em valores singulares para mitigação do problema de matrizes
esparsas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 562.3 Decomposição em valores singulares para previsão de avaliações . . . . . . 562.4 K-vizinhos mais próximos em sistemas baseados em conteúdo: Regressão . 642.5 K-vizinhos mais próximos em sistemas baseados em conteúdo: Classificação 642.6 K-vizinhos mais próximos em sistemas de vizinhança: Similaridade entre
usuários . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 652.7 K-vizinhos mais próximos em sistemas de vizinhança: Similaridade entre itens 652.8 Árvore de regressão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 842.9 Árvore de classificação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 852.10 Redes neurais em sistemas baseados em conteúdo . . . . . . . . . . . . . . 1022.11 Redes neurais em sistemas de filtragem colaborativa . . . . . . . . . . . . . 103

Sumário
Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1 SISTEMAS DE RECOMENDAÇÃO: NOÇÕES BÁSICAS . . . . . . 181.1 Revisão histórica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181.2 Casos de destaque no uso de sistemas de recomendação . . . . . . . 181.2.1 Uso em comércio eletrônico: Amazon.com . . . . . . . . . . . . . . . . . . 191.2.2 Uso em plataformas de streaming : Netflix . . . . . . . . . . . . . . . . . . 201.2.3 Uso em redes sociais: Facebook . . . . . . . . . . . . . . . . . . . . . . . 211.3 Objetivos de sistemas de recomendação . . . . . . . . . . . . . . . . 211.4 Modelos básicos em sistemas de recomendação . . . . . . . . . . . . 211.4.1 Sistemas de filtragem colaborativa . . . . . . . . . . . . . . . . . . . . . . 231.4.1.1 Sistemas baseados em vizinhanças . . . . . . . . . . . . . . . . . . . . . . . 231.4.1.2 Sistemas baseados em modelos . . . . . . . . . . . . . . . . . . . . . . . . . 241.4.2 Sistemas de filtragem baseada em conteúdo . . . . . . . . . . . . . . . . . 241.4.3 Comparação entre modelos colaborativos e baseados em conteúdo . . . . . 251.4.4 Outros modelos em sistemas de recomendação . . . . . . . . . . . . . . . 251.5 Como avaliar sistemas de recomendação . . . . . . . . . . . . . . . . 251.5.1 Precisão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261.5.1.1 Precisão em problemas de previsão . . . . . . . . . . . . . . . . . . . . . . . 261.5.1.2 Precisão em problemas de ranking . . . . . . . . . . . . . . . . . . . . . . . 281.5.2 Cobertura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 291.5.3 Diversidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 291.5.4 Novidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2 MODELOS MATEMÁTICOS . . . . . . . . . . . . . . . . . . . . . . 322.1 Introdução ao aprendizado de máquina . . . . . . . . . . . . . . . . . 322.1.0.1 Terminologia e estrutura de dados . . . . . . . . . . . . . . . . . . . . . . . 322.1.0.2 Aprendizado supervisionado e não supervisionado . . . . . . . . . . . . . . . . 342.1.0.3 Dados de treinamento, validação e teste . . . . . . . . . . . . . . . . . . . . 352.2 Introdução à algoritmos para sistemas de recomendação . . . . . . . 362.3 Regressão Linear . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.3.1 Embasamento matemático . . . . . . . . . . . . . . . . . . . . . . . . . . 372.3.2 Aplicação em sistemas de recomendação . . . . . . . . . . . . . . . . . . . 402.4 Redução de dimensionalidade de matrizes . . . . . . . . . . . . . . . 422.4.1 Embasamento matemático . . . . . . . . . . . . . . . . . . . . . . . . . . 442.4.1.1 Fatores latentes: Intuição geométrica . . . . . . . . . . . . . . . . . . . . . . 44

2.4.1.2 Fatoração de matrizes e fatores latentes . . . . . . . . . . . . . . . . . . . . 452.4.1.3 Decomposição em valores singulares . . . . . . . . . . . . . . . . . . . . . . 462.4.1.4 Redução de dimensionalidade utilizando decomposição em valores singulares . . 492.4.2 Aplicação em sistemas de recomendação . . . . . . . . . . . . . . . . . . . 522.4.2.1 Mitigação do problema de matrizes esparsas . . . . . . . . . . . . . . . . . . 522.4.2.2 Previsão de avaliações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 532.5 K-vizinhos mais próximos . . . . . . . . . . . . . . . . . . . . . . . . . 562.5.1 Embasamento matemático . . . . . . . . . . . . . . . . . . . . . . . . . . 572.5.1.1 Regressão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 572.5.1.2 Classificação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 582.5.1.3 Modelos de vizinhança . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 592.5.2 Aplicação em sistemas de recomendação . . . . . . . . . . . . . . . . . . . 592.6 Árvores de decisão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 652.6.1 Embasamento Matemático . . . . . . . . . . . . . . . . . . . . . . . . . . 702.6.1.1 Regressão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 702.6.1.2 Classificação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 732.6.1.3 Sistemas de filtragem colaborativa . . . . . . . . . . . . . . . . . . . . . . . 782.6.2 Aplicação em sistemas de recomendação . . . . . . . . . . . . . . . . . . . 792.7 Redes Neurais Artificiais . . . . . . . . . . . . . . . . . . . . . . . . . . 852.7.1 Embasamento matématico . . . . . . . . . . . . . . . . . . . . . . . . . . 862.7.1.1 Gradiente Descendente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 872.7.1.2 Perceptron . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 912.7.1.3 Algoritmo de Backpropagation . . . . . . . . . . . . . . . . . . . . . . . . . 932.7.2 Aplicação em sistemas de recomendação . . . . . . . . . . . . . . . . . . . 99
3 APLICAÇÕES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1043.1 Apresentação do problema . . . . . . . . . . . . . . . . . . . . . . . . 1043.1.0.1 Estrutura dos dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1043.2 Algoritmos utilizados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1063.2.1 Sistemas de filtragem colaborativa . . . . . . . . . . . . . . . . . . . . . . 1063.2.1.1 Método dos k-vizinhos mais próximos . . . . . . . . . . . . . . . . . . . . . 1073.2.1.2 Decomposição em valores singulares . . . . . . . . . . . . . . . . . . . . . . 1073.2.2 Sistemas de filtragem baseada em conteúdo . . . . . . . . . . . . . . . . . 1083.2.2.1 Método dos k-vizinhos mais próximos . . . . . . . . . . . . . . . . . . . . . 1093.2.2.2 Rede Neural Artificial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1093.3 Discussão de resultados . . . . . . . . . . . . . . . . . . . . . . . . . . 1103.4 Evoluções no estudo do problema . . . . . . . . . . . . . . . . . . . . 112
Conclusão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114

REFERÊNCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116

16
Introdução
O avanço das comunicações digitais e a integração das cadeias de suprimentopropiciaram um grande avanço no comércio digital e o oferecimento de uma enormevariedade de itens de forma online. Segundo dados de abril de 2019 (SCRAPEHERO,2019), o site de comércio eletrônico Amazon.com possuía quase 120 milhões de produtosem sua plataforma ao redor do mundo. Dentre as muitas categorias, a maior era a de“Literatura”, com 44,2 milhões de exemplares. A categoria com o menor número de itensera a de “Ferramentas e melhorias domésticas”, com 3,7 milhões de produtos - ou seja,caso um potencial cliente queira comprar um kit de ferramentas, se deparará com umaescolha entre milhões.
Ainda que mecanismos de busca ajudem a aliviar esse problema ao permitirque o usuário especifique as características do produto no qual tem interesse, negligenciama enorme oportunidade existente através do mapeamento dos interesses do cliente e apersonalização da oferta de produtos.
De forma a atender a necessidade de personalização de ofertas e mitigar ochamado information overload (excesso de informação, que tende a impactar negativamenteo processo de tomada de decisão), foram criados os chamados “sistemas de recomendação”.Essa tecnologia permite extrair as informações mais relevantes de uma grande e dinâmicabase de dados com base nas características dos produtos e no perfil dos usuários.
Além de recomendações de produtos, como no caso da Amazon citado acima,sistemas de recomendação são utilizados também para indicar ao usuário potenciaisconteúdos de interesse. Por exemplo, o jornal americano The New York Times utilizaum sistema de recomendação para sugerir novos artigos aos seus leitores. Plataformas demídia como Netflix e Spotify utilizam esses sistemas para gerar recomendações de filmese músicas. Um caso interessante é também o da plataforma de músicas Pandora, queficou conhecida por seu “Music Genome Project”. O projeto, iniciado há mais de umadécada, analisa as ondas sonoras de músicas a fim de encontrar características como timbree estilo musical. Com uma base de dados onde cada música tem ao final 450 atributosanalisados, a iniciativa promete personalizar a experiência do usuário (PANDORA, 2019).Até mesmo ferramentas de busca como Google e Yahoo utilizam sistemas de recomendaçãopara classificar os resultados de acordo com interesses e buscas anteriormente realizadaspelo usuário (KANE, 2018).
Mas afinal, como funcionam os sistemas de recomendação? Quais são os prin-cipais métodos e modelos conceituais utilizados? Este trabalho busca investigar essasquestões e trazer algumas respostas sob a ótica da matemática aplicada. Assim, o ob-

Introdução 17
jetivo desse texto é abordar certas aplicações de sistemas de recomendação com ênfasena compreensão de alguns dos modelos matemáticos e algoritmos computacionais maisutilizados. No Capítulo 1 apresenta-se uma visão geral sobre sistemas de recomendação,iniciando pela revisão histórica, casos de uso em diferentes segmentos de mercado, osmodelos de sistemas mais utilizados e métricas de avalição de qualidade para sistemas derecomendação. As principais referências utilizadas nesse capítulo foram (AGGARWAL,2016) e (KANE, 2018).
No Capítulo 2 são abordados alguns dos principais algoritmos empregados naconstrução de sistemas de recomendação, oferecendo ao leitor uma breve introdução sobreconceitos básicos no campo de aprendizado de máquina e seguindo para apresentar algunsentre os algoritmos mais utilizados na criação de sistemas de recomendação. Aborda-seo algoritmo do método dos K-vizinhos mais próximos, redução de dimensionalidade dematrizes, árvores de decisão e redes neurais artificiais. As principais referências utilizadasforam (AGGARWAL, 2016), (MARSLAND, 2009), (KANE, 2018), (HASTIE; TIBSHI-RANI; FRIEDMAN, 2017), (GOODFELLOW; BENGIO; COURVILLE, 2016) e (STONE,2020).
No Capítulo 3 apresenta-se o estudo de quatro sistemas de recomendaçãocriados a partir de alguns dos algoritmos discutidos no segundo capítulo, especificamenteos algoritmos dos K-vizinhos mais próximos, redução de dimensionalidade de matrizese redes neurais artificiais. Esses sistemas foram utilizados como estudos de caso, com ointuito de testar os algoritmos estudados e as implementações que foram feitas, na análisede dados reais, obtidos a partir de uma base pública. No Capítulo 4, são apresentadas asconclusões e algumas perspectivas futuras.
Vale salientar que o estudo de sistemas de recomendação tem ramificações eespecificidades que transcendem o escopo dessa dissertação. No entanto, a expectativaé que esse texto possa servir de inspiração para estudantes de matemática, estatística,engenharia ou áreas afins que estiverem interessados em alguns aspectos estruturantes quesão utilizados para modelar tais sistemas.

18
1 Sistemas de recomendação: Noções Bási-cas
1.1 Revisão históricaOs primeiros sistemas de recomendação foram criados no início dos anos 90,
como uma resposta ao crescimento do volume de conteúdo disponível na internet. Um dosprimeiros artigos publicados no assunto, desenvolvido no centro de pesquisa da Xerox, emPalo Alto, em 1992, analisava os problemas decorrentes do uso crescente de comunicaçõeseletrônicas, que terminavam por sobrecarregar o usuário com documentos desnecessáriosou de pouco interesse. No sistema chamado Tapestry os usuários podiam listar critérios defiltragem de conteúdos, como palavras-chave e outros usuários com os quais compartilhavaminteresses. Por exemplo, um usuário poderia solicitar algo como “todos os artigos com apalavra fintech que contém comentários do Ricardo Silva” (GOLDBERG et al., 1992).
Dois anos depois, o projeto GroupLens apresentado na Association for Compu-ting Machinery 1994 Conference on Computer Supported Cooperative Work utilizava umsistema de recomendação de Collaborative Filtering (ou “Filtro Colaborativo” na traduçãoliteral) que permitia aos usuários da rede Usenet encontrar artigos de interesse em meio aum grande volume de informação (RESNICK et al., 1994). O sistema GroupLens, assimcomo o Tapestry, se baseava nas interações de pessoas com opiniões semelhantes paracriar sugestões personalizadas. A diferença entre os dois sistemas se dava uma vez que oGroupLens gerava as recomendações fundamentado nas avaliações de outros usuários, e nãoexigia que o usuário inicial especificasse com quais outros usuários possuía similaridade.
Em 1995 o sistema Ringo foi apresentado na CHI 1995 Proceedings of theSIGCHI Conference on Human Factors in Computing Systems como um Social InformationFiltering que explorava a similaridade entre os interesses musicais de vários usuários pararecomendar ou desaconselhar músicas (SHARDANAND; MAES, 1995).
A partir de 1996, a popularidade de sistemas de recomendação cresceu ra-pidamente, tanto em pesquisas acadêmicas como comercialmente, e várias empresas seespecializaram em construir e comercializar esse tipo de sistema (KONSTAN; RIEDL,2012).
1.2 Casos de destaque no uso de sistemas de recomendaçãoNesta seção são discutidos três casos que estão entre os mais emblemáticos no
uso de sistemas de recomendação em cenários comerciais.

Capítulo 1. Sistemas de recomendação: Noções Básicas 19
1.2.1 Uso em comércio eletrônico: Amazon.com
A plataforma de comércio eletrônico Amazon.com foi uma das pioneiras nouso de sistemas de recomendação de forma comercial. As informações fornecidas pelousuário e utilizadas na construção do sistema podem ser coletadas de maneira explícitae de maneira implícita. Dentre as informações explícitas podem-se considerar as notas,em uma escala de 1 a 5, que o usuário atribui aos produtos que comprou. De maneiraimplícita a empresa consegue coletar informações sobre o comportamento do usuário naplataforma, como por exemplo as categorias dos produtos mais buscados e comprados pelousuário (AGGARWAL, 2016).
Uma vez feito o login do usuário em sua conta Amazon, as recomendaçõessão exibidas logo na primeira página. Na parte superior da Figura 1 são apresentadasrecomendações baseadas nas últimas pesquisas e compras do usuário. Mais abaixo sãovistas recomendações de livros comprados por outros usuários que possuem característicassimilares ao usuário em questão.
Figura 1 – Exemplo de recomendações de produtos na plataforma Amazon.com. Fonte:autora.

Capítulo 1. Sistemas de recomendação: Noções Básicas 20
Sistemas de recomendação geram grande parte da receita da Amazon. Umartigo de 2013 elaborado pela consultoria estratégica McKinsey & Company afirma que35% dos produtos vendidos no site são recomendações geradas pelos sistemas da empresa(MACKENZIE; MEYER; NOBLE, 2013).
1.2.2 Uso em plataformas de streaming : Netflix
Como uma plataforma de streaming de filmes e séries, a Netflix oferece aousuário recomendações baseadas tanto no comportamento do usuário, a exemplo dos últimositens assistidos ou melhores avaliados, quanto no comportamento de outros usuários daplataforma, como as melhores avaliações ou temas mais populares. Abaixo é possível verum conjunto de recomendações baseadas no fato de que o usuário anteriormente haviaassistido ao seriado “The Witcher”.
Figura 2 – Exemplo de recomendações de filmes e séries na plataforma de streaming Netflix.Fonte: autora.
Os sistemas de recomendação da Netflix se tornaram especialmente popularesatravés do Netflix Prize Contest, uma competição patrocinada pela empresa a fim defomentar a discussão e desenvolvimento de sistemas de recomendação com filtragemcolaborativa (mais detalhes sobre sistemas de filtragem colaborativa serão dados naspróximas seções). O objetivo da competição era desenvolver um algoritmo que pudessepredizer as notas dadas por certos usuários a certos filmes. Os prêmios eram entreguesde acordo com as melhorias apresentadas na comparação entre o algoritmo padrão daNetflix e o algoritmo apresentado, ou de acordo com as melhorias quando o algoritmoapresentado era comparado ao algoritmo melhor colocado até o momento. É reconhecidoque o Netflix Prize Contest promoveu contribuições significantes para a pesquisa emsistemas de recomendação (AGGARWAL, 2016).

Capítulo 1. Sistemas de recomendação: Noções Básicas 21
1.2.3 Uso em redes sociais: Facebook
Como outras redes sociais, o Facebook exibe ao usuário sugestões de amizades afim de expandir sua rede de conexões. A idéia desse sistema de recomendação é aprimorara experiência do usuário na plataforma, de forma a encorajar o crescimento e relevânciada rede social para o usuário. Algoritmos como o do Facebook são baseados nas relaçõesestruturais entre usuários, formando uma rede de usuários, e não em notas e avaliações,como nos casos da Amazon.com e Netflix (WOLFRAM, 2013). Com isso, as característicasdesses algoritmos diferem muito dos clássicos algoritmos que tratam do problema depredizer uma nota a partir de uma combinação usuário-item. O leitor que deseja seaprofundar em algoritmos de recomendação baseados em relações estruturais (a exemplodas sugestões de amizade no Facebook e classificação de websites na página de busca doGoogle) pode ler mais sobre o assunto no Capítulo 10 de (AGGARWAL, 2016).
1.3 Objetivos de sistemas de recomendaçãoO objetivo final de um sistema de recomendação sempre será a geração de
receita. Em um cenário de vendas online como na Amazon, recomendações corretasimpactam diretamente no número de itens vendidos e consequentemente na geração dereceita. Para produtos vendidos a partir de assinaturas mensais ou anuais, como Netflix eSpotify, recomendações corretas melhoram a experiência do usuário, o que em consequênciadiminui as chances de que o usuário cancele a sua assinatura. Para redes sociais, comoFacebook e LinkedIn, recomendações de novos amigos aumentam o uso e relevância daplataforma no dia a dia dos usuários, alavancando novas formas de receita como publicidadee serviços financeiros.
De maneira geral, problemas de recomendação podem ser formulados de duasmaneiras: problemas de previsão e problemas de ranking. Problemas de previsão buscamprever a nota dada por um certo usuário a um item específico. De forma mais direta, oobjetivo final desses algoritmos é calcular o valor da nota para uma certa combinaçãousuário-item. Problemas de ranking, por sua vez, têm como objetivo gerar uma lista dosk itens de maior interesse para o usuário. Algoritmos de previsão são mais genéricos nosentido de que, uma vez com as notas de cada combinação usuário-item calculadas, bastaclassificá-las de maneira decrescente para cada usuário e escolher os k primeiros itens(AGGARWAL, 2016).
1.4 Modelos básicos em sistemas de recomendaçãoEntre as estratégias mais populares para a construção de sistemas de recomen-
dação, duas se destacam: Filtragem colaborativa e Filtragem baseada em conteúdo. Um

Capítulo 1. Sistemas de recomendação: Noções Básicas 22
sistema de recomendação pode se basear em uma ou outra estratégia, ou mesmo em umacombinação das duas.
Sistemas de recomendação cuja filtragem é baseada em conteúdo se fundamen-tam na criação de perfis, sendo esses perfis de usuários ou de produtos. Enquanto o perfilde um usuário poderá contar com informações como idade e renda, por exemplo, o perfil deum produto pode levar em conta atributos como marca e ano de lançamento. Um exemplointeressante da aplicação de filtragem baseada em conteúdo na indústria musical é o “MusicGenome Project” (Projeto genoma da música, na tradução literal), do aplicativo Pandora.O projeto conta com um time de musicólogos que é reponsável por coletar centenas deatributos das milhões de músicas disponíveis na plataforma. Considerando o históricode interesse de cada ouvinte, o sistema é capaz de gerar recomendações personalizadas(KOREN; BELL; VOLINSKY, 2009). Essa estratégia é ilustrada no lado esquerdo daFigura 3.
As aplicações de filtragem colaborativa por sua vez não dependem da criaçãode perfis de usuários ou produtos, mas levam em conta a relação entre usuários e ainterdependência entre produtos para gerar recomendações. Interesses do usuário 1 poderãoser recomendados ao usuário 2 na medida em que os usuários 1 e 2 forem similares, conformeilustrado no lado direito da Figura 3.
Figura 3 – Filtragem baseada em conteúdo vs. Filtragem colaborativa. Fonte: (TONDJI,2018)

Capítulo 1. Sistemas de recomendação: Noções Básicas 23
1.4.1 Sistemas de filtragem colaborativa
Através das opiniões de vários usuários sobre vários itens, os sistemas defiltragem colaborativa computam as recomendações. As notas das avaliações feitas pelosusuários para cada item são dispostas em uma matriz mˆ n para m usuários e n itens.Como nem todos os usuários podem comprar ou avaliar todos os n itens, as matrizesutilizadas em algoritmos de filtragem colaborativa tendem a ser esparsas, ou seja, umagrande parte dos elementos da matriz não são especificados. Os elementos especificados damatriz são os elementos para os quais o usuário forneceu alguma informação sobre o item,como por exemplo a nota de uma avaliação.
A Tabela 1 representa uma matriz mˆ n. Nela estão as notas, obtidas a partirde um intervalo discreto de 1 a 5, que foram dadas pelos usuários aos itens em questão.Os itens não especificados, denotados pelo símbolo de interrogação em vermelho, ?, são ositens não avaliados pelos usuários.
Usuário/Item Item A Item B Item C ... Item nUsuário 1 ? ? 4 ... ?Usuário 2 1 4 5 ... ?Usuário 3 ? ? ? ... 4Usuário 4 5 2 3 ... 4
... ... ... ... ... ...Usuário m 3 ? ? ... 2
Tabela 1 – Tabela com avaliações dadas por m usuários a n itens
O conceito central em algoritmos de filtragem colaborativa é o de que oselementos não especificados podem ser calculados a partir das similaridades entre usuáriosou itens. Na grande maioria das vezes, o nível de similaridade entre um grupo de usuáriosou um grupo de itens é muito alto, de forma que podemos deduzir a nota que o usuário 1daria ao item A ao ver a nota que o usuário 2 deu a esse mesmo item, entendendo que osusuários 1 e 2 têm preferências muito parecidas.
Sistemas de filtragem colaborativa podem ser classificados ainda como sistemasbaseados em vizinhanças e sistemas baseados em modelos.
1.4.1.1 Sistemas baseados em vizinhanças
Sistemas baseados em vizinhanças podem ser trabalhados sob o ponto de vistada similaridade entre usuários ou itens. No primeiro caso, a vizinhança V é determinadapelo conjunto dos k usuários mais similares ao usuário i em questão. A fim de prever aavaliação que o usuário i daria ao item j, basta calcular a média ponderada das notasdadas pelos usuários da vizinhança V ao item j. Nesse caso, a similaridade é calculada

Capítulo 1. Sistemas de recomendação: Noções Básicas 24
entre as linhas da matriz mˆn. Por outro lado, sob o ponto de vista da similaridade entreitens, a vizinhança V é determinada pelo conjunto dos k itens mais similares ao item j emquestão. A lógica segue a mesma: a média ponderada das notas dadas pelo usuário i aos kitens mais similares a j será a nota predita para o item j. Aqui, a similaridade é calculadaentre as colunas da matriz mˆ n.
Por sua simplicidade, sistemas baseados em vizinhanças são populares e de fácilimplementação. No entanto, não costumam performar bem em matrizes esparsas, afinal,se existem muitos elementos não especificados o processo de determinar a vizinhançaé comprometido, e os resultados podem não ser confiáveis. Uma alternativa que temsido utilizada para contornar esse problema é a utilização de técnicas de fatoração dematrizes combinadas com algoritmos de otimização, que permitem estimar as avaliaçõesnão especificadas com base na estrutura da matriz (KOREN; BELL; VOLINSKY, 2009).
1.4.1.2 Sistemas baseados em modelos
Sistemas baseados em modelos, por sua vez, utilizam técnicas de aprendizadode máquina e mineração de dados. Uma diferença importante entre os algoritmos baseadosem vizinhanças e os algoritmos baseados em modelos é a de que, no primeiro caso, oscálculos são realizados para um caso por vez, enquanto no segundo, um modelo generalizadoque pode ser aplicado a todo o conjunto de dados é gerado desde o início. Por exemplo,em modelos de vizinhança, selecionamos os k vizinhos mais similares a cada usuário ouitem todas as vezes que quisermos calcular uma nova previsão. Em contrapartida, em umsistema baseado na fatoração de matrizes, as avaliações de todos os usuários para todos ositens é feita simultaneamente.
1.4.2 Sistemas de filtragem baseada em conteúdo
Algoritmos de filtragem baseada em conteúdo utilizam as características deitens ou usuários a fim de gerar recomendações. Levando em conta as características dosprodutos comprados ou melhor avaliados pelo usuário, o modelo é capaz de prever qualnota um usuário possivelmente daria a um item desconhecido.
Sistemas de filtragem baseada em conteúdo são especialmente úteis em situ-ações onde as avaliações de outros usuários são escassas ou não existem, uma vez queutilizam unicamente dados históricos do próprio usuário para o qual a previsão está sendogerada. Além disso, diferentemente dos sistemas de filtragem colaborativa, os modelosgerados por algoritmos de filtragem baseada em conteúdo são específicos para cada usuário(AGGARWAL, 2016). Tome, por exemplo, uma matriz de avaliação inicialmente esparsamˆn, com as notas de m usuários para n itens. Ao executarmos um algoritmo de filtragemcolaborativa, a matriz completa nos trará a estimativa de todas as possíveis avaliações detodos os usuários para todos os itens. De maneira distinta, para performar uma regressão

Capítulo 1. Sistemas de recomendação: Noções Básicas 25
ou classificação baseada em conteúdo, consideramos uma matriz cujas linhas são os itenscomprados ou avaliados especificamente por um usuário, e cujas colunas são as caracterís-ticas desses itens - ou seja, o conteúdo. Dessa forma, os modelos gerados são específicospara o usuário em questão.
1.4.3 Comparação entre modelos colaborativos e baseados em conteúdo
Uma das grandes vantagens de algoritmos baseados em conteúdo é a capa-cidade de gerar recomendações de novos itens para usuários antigos. Basta compilaras características de um novo item e o modelo utilizará informações históricas sobre ocomportamento de compra e avaliação do usuário para predizer se o mesmo irá ou nãogostar da novidade. Em contrapartida, esses modelos tendem a gerar recomendações poucodiversas, já que raramente levam em conta itens pouco familiares ao usuário e não utilizamdados provenientes de outros usuários para enriquecer as recomendações.
Quando consideramos a entrada de novos usuários, sistemas de filtragemcolaborativa tendem a obter melhor performance, uma vez que novos usuários não têmum histórico robusto de compras e avaliações e portanto não existe insumo para gerarrecomendações a esses usuários em um sistema baseado em conteúdo (AGGARWAL, 2016).
1.4.4 Outros modelos em sistemas de recomendação
Apesar dos modelos de filtragem colaborativa e filtragem baseada em conteúdoserem os mais populares no estudo de sistemas de recomendação, existem ainda outros,a exemplo dos sistemas baseados em conhecimento - onde conhecimento prévio e expli-citamente fornecido sobre as preferências do usuário é usado com o propósito de gerarrecomendações - sistemas demográficos e sistemas utilitários. O leitor interessado podeencontrar maiores detalhes sobre esses outros modelos a partir da seção 1.3.3 do primeirocapítulo em (AGGARWAL, 2016).
1.5 Como avaliar sistemas de recomendaçãoComo mencionado anteriormente, o objetivo final de qualquer sistema de
recomendação é gerar receita. Dessa forma, a melhor maneira de avaliar a efetividadede um sistema de recomendação é entender se os itens recomendados são eventualmenteconsumidos. Com esse fim são implementados os populares “testes A/B”, onde um grupode usuários é selecionado e então dividido em dois subgrupos A e B, cada um sendoexposto a um sistema de recomendação diferente e mantendo todas as outras variáveisconstantes. Os subgrupos são então comparados com relação a uma ou mais métricas,como por exemplo a taxa de conversão (um item sugerido que é consumido dentro de

Capítulo 1. Sistemas de recomendação: Noções Básicas 26
um período pré-especificado conta uma conversão). O grupo com melhor performancerepresenta o melhor sistema de recomendação.
No entanto, realizar testes A/B requer acesso a uma rede online que possibilitaque um sistema seja implementado e em seguida seus resultados monitorados. Comoobter acesso a uma rede online não é tarefa trivial, sendo uma oportunidade reservadaapenas àquelas instituições que fornecem os produtos consumidos pelo usuário final, foramdesenvolvidos também testes offline, amplamente utilizados tanto em pesquisa comocomercialmente. De maneira prática, testes offline auxiliam na pré-seleção de sistemas derecomendação que serão implementados de maneira online (GEBREMESKEL; VRIES,2016).
Os algoritmos de sistemas de recomendação implementados no Capítulo 3desse trabalho serão testados de maneira offline. São discutidas a seguir algumas entreas métricas mais populares utilizadas em testes offline para a avaliação de sistemas derecomendação.
1.5.1 Precisão
A precisão de um sistema de recomendação pode ser entendida de duas maneiras.Para sistemas cuja função é predizer as notas das avaliações de uma combinação usuário-item, a precisão será a medidade de quão diferente é a nota predita da nota real. Emcontrapartida, para sistemas cuja função é criar um ranking com os k itens de maiorinteresse para o usuário, a precisão é a medida de quantos itens dentre esses k foramrecomendados corretamente (AGGARWAL, 2016).
1.5.1.1 Precisão em problemas de previsão
Seja D um conjunto de dados totalmente conhecido referentes a m usuários e nitens. Sejam rij a nota real dada pelo usuário i ao item j, e rij a nota dada pelo usuário iao item j predita pelo algoritmo. A diferença entre a nota real e a nota predita será o erropara essa combinação usuário-item. Podemos calcular o erro médio para todo o conjuntode dados D através da fórmula 1.1 abaixo.
MAE “
mÿ
i“1
nÿ
j“1|rij ´ rij|
mn(1.1)
Onde MAE é o erro absoluto médio (do inglês mean average error). O valordo MAE será o valor médio de diferença entre a nota prevista e a nota real para cadacombinação usuário-item no conjunto de dados (KANE, 2018). É possível também encontraro NMAE, que nada mais é do que o MAE normalizado, conforme equação 1.2 (AGGARWAL,

Capítulo 1. Sistemas de recomendação: Noções Básicas 27
2016). Como o valor do MAE normalizado vai de 0 a 1, o resultado do NMAE é talvezmais intuitivo, sendo que quanto mais próximo de zero melhor.
NMAE “MAE
rmax ´ rmin(1.2)
Onde rmax e rmin são a maior e menor nota no conjunto de dados D, respecti-vamente.
Dependendo da aplicação, grandes discrepâncias entre o valor predito e o valorreal são especialmente prejudiciais ao sistema. Por exemplo, imagine uma aplicação naindústria farmacêutica, onde pequenas diferenças entre os volumes das substâncias podemresultar em cenários muito diferentes. Nesses casos, é possível utilizar o erro quadráticomédio (ou apenas MSE, do inglês mean squared error), que por conta do fator quadráticopenaliza de maneira mais acentuada as maiores diferenças entre as predições e os valoresreais (AGGARWAL, 2016). Calcula-se o MSE conforme equação 1.3 abaixo.
MSE “
mÿ
i“1
nÿ
j“1prij ´ rijq
2
mn(1.3)
Através do MSE é possível também encontrar o RMSE, que nada mais é doque a raiz quadrada do MSE. A vantagem de se utilizar o RMSE ao invés do MSE é queo valor do RMSE tem a mesma unidade de medida que as notas dadas pelos usuários.Abaixo são apresentadas as equações para o RMSE e o NRMSE, sendo o último o RMSEnormalizado (KANE, 2018).
RMSE “
g
f
f
f
e
mÿ
i“1
nÿ
j“1prij ´ rijq
2
mn(1.4)
NRMSE “RMSE
rmax ´ rmin(1.5)
É importante lembrar que todas as métricas de precisão discutidas acimasão métricas que calculam o erro entre a predição e o valor real, e devem ser portantominimizadas pelo sistema.

Capítulo 1. Sistemas de recomendação: Noções Básicas 28
1.5.1.2 Precisão em problemas de ranking
Problemas de ranking têm como objetivo criar uma lista de k itens a seremrecomendados para o usuário. A fim de calcular a precisão de um sistema de recomendaçãobaseado em ranking, podemos calcular quantas das recomendações feitas pelo sistemaforam realmente avaliadas pelo usuário. O resultado desse cálculo será o que chamados detaxa de acerto (KANE, 2018).
Por exemplo, suponha que o algoritmo retorne três sugestões de filmes para ousuário: “Gladiador”, “Os Incríveis” e “Como se fosse a primeira vez”. Desses três filmes,o usuário avaliou apenas “Os Incríveis”. Nesse caso, consideramos apenas um acerto. A fimde encontrar a taxa de acerto para todo o sistema, somamos todos os acertos individuaispara cada usuário e dividimos pelo número total de usuários (KANE, 2018).
De maneira geral, seja Ri o conjunto de k itens recomendados pelo algoritmopara um usuário i fixado, e Ai o conjunto de todos os itens que esse mesmo usuário jáavaliou. A taxa de acerto do sistema pode ser calculada conforme 1.6 abaixo.
Taxa de acerto “
mÿ
i“1
kÿ
j“1Cij
m(1.6)
Onde m é o número total de usuários, Cij “ 1 caso o item j P Ri esteja contidotambém em Ai, e Cij “ 0 caso contrário.
Uma outra forma de avaliar a precisão de um sistema de recomendação comfoco em ranking é calcular a correlação entre a posição relativa de um item na lista dos kitens recomendados pelo sistema a um usuário i e a posição relativa desse mesmo item nalista dos k itens mais bem avaliados por esse usuário. Essa correlação pode ser calculadade diversas maneiras, e entre as mais comuns está o coeficiente de correlação de postosSpearman, conforme equação 1.7 abaixo.
ρ “
kÿ
j“1prj ´ rqprj ´ ¯rq
g
f
f
e
kÿ
j“1prj ´ rq
2kÿ
j“1prj ´ ¯rq2
(1.7)
O valor de ρ na equação 1.7 acima varia entre -1 e 1. Quando ρ “ 1 ou ρ “ ´1,temos uma relação monotônica entre as posições relativas em cada uma das listas, sendoque ρ “ 1 representa uma função estritamente crescente (quanto maior a posição relativana lista de itens recomendados, maior a posição relativa na lista dos itens mais bem

Capítulo 1. Sistemas de recomendação: Noções Básicas 29
avaliados) e ρ “ ´1 representa uma função estritamente decrescente. Quando ρ “ 0 nãoexiste correlação monotônica entre as duas listas.
A correlação de Spearman média entre todos os m usuários pode ser calculadaa fim de se ter uma métrica única para todo o sistema.
1.5.2 Cobertura
A cobertura é o percentual de itens que podem ser recomendados através doalgoritmo em comparação com o número total de itens existentes. Por exemplo, quando umlivro novo é lançado na plataforma de comércio eletrônico Amazon.com, ele só aparecerácomo uma recomendação após ser vendido algumas vezes. Isso acontece porque o algoritmoprecisa dessas vendas para presumir algum padrão de compra e avaliação do item. Atéque esse padrão seja estabelecido, existirão itens disponíveis na plataforma que não serãosugeridos pelo sistema de recomendação, diminuindo a métrica de cobertura (KANE,2018).
Considere novamente o conjuntoD de dados conhecidos referentes am usuários en itens. Seja Ti a lista dos k itens recomendados ao usuário i pelo sistema, sendo i “ 1, ...,m.Podemos calcular a cobertura do sistema através da equação 1.8 (AGGARWAL, 2016)(LI, 2019).
Cobertura “|| Ymi“1Ti ||
n(1.8)
Onde n é o número total de itens disponíveis para consumo.
1.5.3 Diversidade
Bons sistemas de recomendação apresentam ao usuário recomendações relevan-tes porém diversas. Recomendar sempre o mesmo produto ou produtos muito similarespode sinalizar um sistema de recomendação relevante, mas pouco diverso. Em contrapar-tida, recomendar uma lista de produtos aleatórios é extremamente diverso, porém pode serpouco relevante. A diversidade pode ser calculada através de uma métrica de similaridadepara cada par de itens. Se a lista de produtos recomendada ao usuário é muito similarentre si, a diversidade é baixa. Do contrário, a diversidade é alta (KANE, 2018).
Podemos calcular a similaridade a cada par de itens em uma lista de k itensrecomendados pelo sistema através da similaridade de cossenos. Para isso, no entanto, énecessário termos informações sobre as características dos itens recomendados. Sejam porexemplo os itens A, B e C três produtos disponíveis para compra e recomendados a umusuário i qualquer. Exemplificamos abaixo com uma tabela os detalhes das característicasde cada um dos produtos.

Capítulo 1. Sistemas de recomendação: Noções Básicas 30
Produto Categoria Faixa de preço MarcaA Infantil Até R$ 25 PomPomB Casa De R$ 25 a R$ 50 ComfortC Infantil De R$ 25 e R$ 50 Comfort
Tabela 2 – Detalhamento das características dos produtos A, B e C
A Tabela 2 acima pode ser transformada em uma tabela binária, conformeTabela 3.
Produto Infantil Casa Até R$ 25 De R$ 25 a R$ 50 PomPom ComfortA 1 0 1 0 1 0B 0 1 0 1 0 1C 1 0 0 1 0 1
Tabela 3 – Tabela binária gerada a partir do detalhamento das características dos produtosA, B e C
Considerando cada linha da Tabela 3 como um vetor, é possível encontraro cosseno do ângulo entre os vetores A e B, B e C e A e C. Vetores muito similaresapontam para direções similares, e o ângulo entre esses vetores se aproxima de zero. Comoo cosseno de zero é 1, quanto mais próximo de 1 é o cosseno do ângulo entre dois vetores,mais similares são esses vetores. Para encontrar uma métrica única de similaridade S paraessa lista de recomendações, podemos somar os valores de cada cosseno e dividir pelonúmero total de itens (três valores de cosseno e três itens nesse exemplo). A métrica dediversidade será igual a D “ 1 ´ S (KANE, 2018). A fim de encontrar uma métrica dediversidade para todo o sistema, basta somar cada Di, sendo i “ 1, ...,m, e dividir por m,o número total de usuários.
1.5.4 Novidade
Novidade é a métrica de quão populares são os itens recomendados. Usuáriostendem a confiar mais em recomendações que incluem pelo menos alguns itens familiares,afinal, itens populares tendem a ser populares exatamente porque são desejados por grandeparte do público. No entanto, ao recomendar apenas itens que estão sempre entre os maisvendidos, o sistema falha em sua missão de apresentar ao usuário produtos que talvez elenão conheça, mas que podem ser muito relevantes. É importante lembrar que o objetivofinal de um sistema de recomendação sempre é gerar receita, e expor o usuário a mais itensrelevantes aumentam as chances de compra. Quanto maior o número de itens popularesem uma lista de recomendações, menor a novidade (KANE, 2018).
Em casos onde existe o acesso a um sistema online, a métrica de novidadepode ser medida através de uma pesquisa onde os usuários respondem se já conheciam ou

Capítulo 1. Sistemas de recomendação: Noções Básicas 31
não os itens recomendados pelo sistema. De maneira offline é possível estimar um valorpara novidade caso o conjunto de dados com as notas para cada combinação usuário-itempossua também a informação de data e hora em que a avaliação foi feita (AGGARWAL,2016). A idéia principal é a de que um sistema que recomenda itens desconhecidos aousuário incentiva ações futuras ao invés de ações no presente. Com isso em mente, édeterminada uma data de corte t0, tal que todas as avaliações feitas após a data de cortesão removidas do conjunto de dados. Além disso, algumas recomendações anteriores à t0também são removidas. Feito isso, o conjunto de dados restante é utilizado para construiro algoritmo de recomendação. Após a construção, o algoritmo é executado e os resultadosanalisados. Para cada item recomendado pelo algoritmo e que foi avaliado antes de t0 amétrica de novidade é penalizada, e para cada item recomendado e avaliado após t0 amétrica de novidade é premiada. A idéia aqui é a de que, se o sistema recomendou itensque já haviam sido avaliados então as recomendações foram óbvias, no sentido de que nãotrouxeram algo novo para o usuário. Do contrário, a métrica de novidade deve aumentar.

32
2 Modelos matemáticos
2.1 Introdução ao aprendizado de máquinaAntes de entrarmos no detalhamento matemático dos algoritmos utilizados
em sistemas de recomendação, faremos uma breve introdução sobre as terminologias econceitos de aprendizado de máquina que serão utilizados neste trabalho. Uma referênciamais completa sobre o tema pode ser encontrada em (KUBAT, 2017) e (BISHOP, 2006).
2.1.0.1 Terminologia e estrutura de dados
Esse trabalho ficará restrito ao estudo de dados tabulares estruturados. Nessecaso, assumiremos que os dados necessários para a resolução dos problemas de recomendaçãopodem ser expressos na forma de uma matriz com m linhas e n colunas, cujas informaçõespodem conter dados numéricos, categóricos ou textuais. Assim sendo, por delimitaçãode escopo, não trataremos de dados no formato de imagens, nem mesmo dados nãoestruturados.
De maneira geral, um algoritmo de aprendizado de máquina recebe um conjuntode informações - ao que chamamos atributos de entrada - e nos retorna um conjuntode respostas, também conhecidas como atributos de saída. Os atributos de entrada sãofornecidos ao algoritmo no formato de matrizes mˆn, onde cada linha da matriz representauma observação, também chamada de instância, e possui n colunas. Podemos definir cadaobservação como um vetor xi, i “ 1, ...,m, e cada um dos n elementos do vetor xi dizemrespeito a n variáveis preditivas. O atributo de saída, por sua vez, será um vetor y P Rm.Cada elemento yj do vetor y é uma resposta do algoritmo à observação j da matriz Xmˆn
de atributos de entrada (veja a Figura 4). Idealmente os atributos de entrada devem serindependentes entre si, enquanto o atributo de saída será uma variável dependente, sendocalculada a partir das variáveis preditivas.
No vetor y são armazenadas as previsões dos valores dos atributos de saída feitaspelo algoritmo. Em contrapartida, o vetor atributo alvo y,y P Rm, contém as informaçõesreais e previamente conhecidas. Essas informações são utilizadas na construção do modeloe são o insumo do aprendizado do algoritmo. Na prática, queremos aperfeiçoar esseaprendizado a fim de que y se aproxime ao máximo de y. Chamamos de erro à funçãoque calcula as imprecisões do modelo se baseando nas diferenças entre os vetores y e y(MARSLAND, 2009).
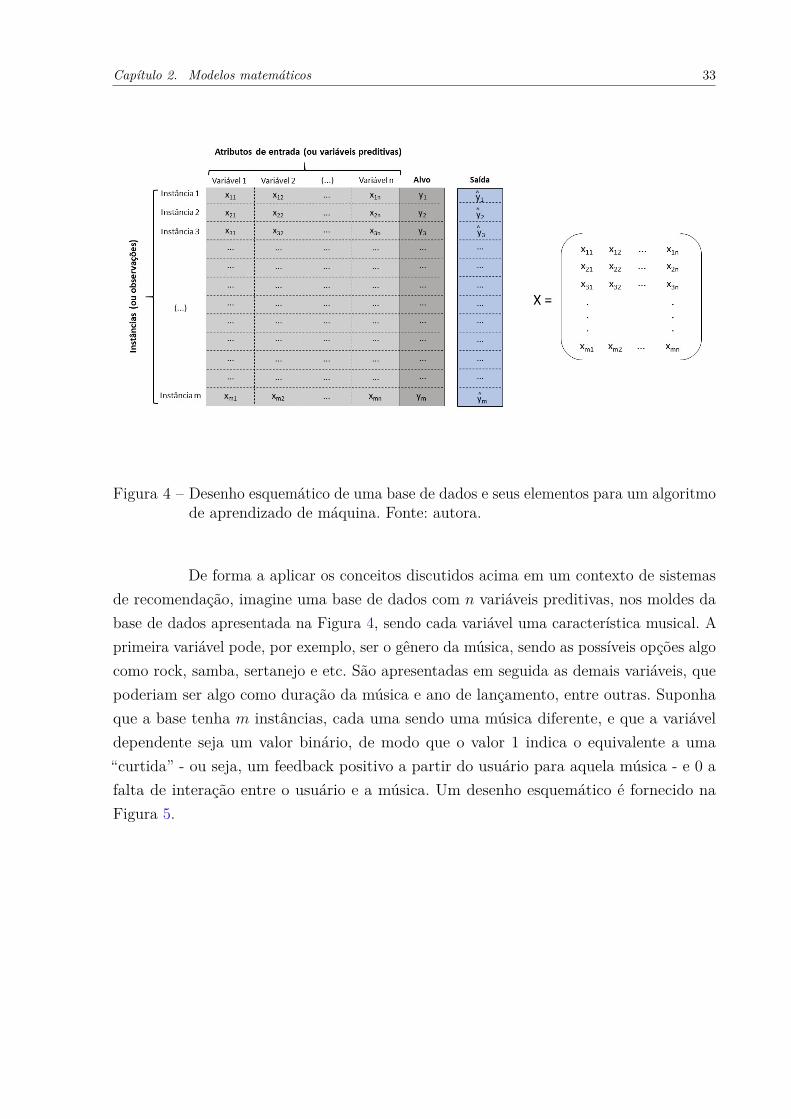
Capítulo 2. Modelos matemáticos 33
Figura 4 – Desenho esquemático de uma base de dados e seus elementos para um algoritmode aprendizado de máquina. Fonte: autora.
De forma a aplicar os conceitos discutidos acima em um contexto de sistemasde recomendação, imagine uma base de dados com n variáveis preditivas, nos moldes dabase de dados apresentada na Figura 4, sendo cada variável uma característica musical. Aprimeira variável pode, por exemplo, ser o gênero da música, sendo as possíveis opções algocomo rock, samba, sertanejo e etc. São apresentadas em seguida as demais variáveis, quepoderiam ser algo como duração da música e ano de lançamento, entre outras. Suponhaque a base tenha m instâncias, cada uma sendo uma música diferente, e que a variáveldependente seja um valor binário, de modo que o valor 1 indica o equivalente a uma“curtida” - ou seja, um feedback positivo a partir do usuário para aquela música - e 0 afalta de interação entre o usuário e a música. Um desenho esquemático é fornecido naFigura 5.

Capítulo 2. Modelos matemáticos 34
Figura 5 – Desenho esquemático de uma base de dados referente a m músicas e n caracte-rísticas. Fonte: autora.
Veja que os vetores y e y referentes ao atributo alvo e ao atributo de saída nãosão completamente iguais. Isso é esperado, uma vez que na maioria dos casos o algoritmonão é capaz de reproduzir os valores do atributo alvo com 100% de precisão. O objetivo doalgoritmo é justamente aprender com os dados previamente conhecidos, de modo a errarcada vez menos em suas previsões, representadas no vetor y.
2.1.0.2 Aprendizado supervisionado e não supervisionado
Os métodos de aprendizado de máquina podem ser classificados em duas princi-pais categorias: o aprendizado supervisionado e o não supervisionado. No aprendizado su-pervisionado é necessário fornecer ao algoritmo o que chamamos de “verdade fundamental”,ou seja, o algoritmo deverá receber algum conhecimento prévio sobre o valor e o tipode atributo de saída esperado. De modo geral, a tarefa do algoritmo é estabelecer umacorrespondência entre os atributos de entrada e os atributos de saída. Por outro lado, paraos algoritmos de aprendizado não supervisionado, não é necessário fornecer qualquer tipode conhecimento prévio sobre o atributo de saída. Nesses casos, o objetivo do algoritmo édescobrir as estruturas implícitas ao conjunto de dados em questão (SONI, 2018).
De forma a ilustrar os conceitos de aprendizado supervisionado e não supervisi-onado, imagine ensinar a uma criança sobre cores. Ao mostrá-la um objeto azul, você diza ela "essa cor é a cor azul", e da mesma maneira com a cor rosa, vermelha, verde, e assimpor diante. Isso é um aprendizado supervisionado, pois as características do atributo de

Capítulo 2. Modelos matemáticos 35
saída são especificadas previamente. Em contrapartida, aprender a falar é um exemplode aprendizado não supervisionado. Nesse caso, a própria criança começa a entender aestrutura de linguagem ao ouvir outras pessoas falarem. Mais tarde, em complemento, acriança pode ter contato com um método supervisionado para aperfeiçoar a fala atravésdo aprendizado de regras gramaticais.
Algoritmos de aprendizado supervisionado são geralmente construídos comoalgoritmos de regressão ou classificação. Algoritmos de regressão tem como objetivo mapearatributos de entrada a um atributo de saída numérico. Por exemplo, dado um conjunto decaracterísticas de clientes, é possível determinar a probabilidade de certo cliente comprarum certo produto através de um algoritmo de regressão. Um caso específico de algoritmosde regressão são os algoritmos de classificação, onde o atributo de saída assume um formatocategórico. Pode-se, por exemplo, utilizar um algoritmo de classificação para recomendara um cliente um próximo destino de férias a partir de suas últimas viagens.
As tarefas mais comuns em aprendizado não supervisionado são clusterização eredução de dimensionalidade. Em clusterização é possível encontrar tendências em dadosde difícil interpretação humana através da criação de clusters, ou seja, grupos de dadosque possuem características semelhantes. Similarmente, a redução de dimensionalidade éutilizada a fim de encontrar quais os fatores latentes em um grupo de dados representadopor uma matriz esparsa, possibilitando a representação dessa matriz de muitas dimensõesatravés de sua decomposição em matrizes de dimensões menores (SONI, 2018) .
2.1.0.3 Dados de treinamento, validação e teste
Durante a construção de um algoritmo de aprendizado de máquina, é necessárioutilizar três conjuntos de dados diferentes: dados de treinamento, dados de validação edados de teste. Os dados de treinamento serão efetivamente utilizados pelo algoritmo parao aprendizado, enquanto os dados de validação e teste ficarão ocultos do aprendizadoe entrarão em uma fase posterior apenas para verificar a precisão do modelo. Os dadosde validação são utilizados para fazer o ajuste fino dos parâmetros do algoritmo com oobjetivo de melhorar sua acurácia, enquanto os dados de teste devem ser usados apenas nomodelo final, completamente especificado, de forma a antecipar o resultado do algoritmosobre dados reais e desconhecidos (ACADEMY, 2021).
De volta ao exemplo da base de dados de características musicais, suponhaque a base de dados com as características musicais previamente conhecidas possua milobservações, ou seja, m “ 1.000. Dispomos então de mil casos onde temos todas ascaracterísticas da música, e ao final um valor binário representando o feedback do usuáriopara aquela música. A fim de construir o algoritmo, separamos uma fração dessas milobservações para serem nossos dados de treinamento. Como sugestão, pode-se utilizarcerca de 70% das observações como dados de treinamento, 5% como validação e 25% como

Capítulo 2. Modelos matemáticos 36
teste. No entanto, esses percentuais podem variar em função do número total de instânciase da natureza do problema.
É importante que sejam utilizados três conjuntos de dados completamentediferentes e construídos de maneira aleatória a fim de minimizar o viés do modelo. Casoseja feita a construção, validação e teste do algoritmo com o mesmo conjunto de dados,durante a fase de teste o algoritmo pode apresentar um desempenho muito bom, o que podenão se confirmar quando for exposto a um conjunto de dados desconhecidos. Essa falsaimpressão se origina do fato de que estamos testando o algoritmo com os mesmos dadosque utilizamos para ensiná-lo, ou seja, o algoritmo tem tudo “decorado”. Esse fenômeno,onde o algoritmo “decora” os dados, é chamado de overfitting, e é algo que queremos evitarao construir um modelo. Se overfitting ocorre o modelo será incapaz de generalizar asregras, o que aumenta o risco de que sejam geradas previsões incorretas (AGGARWAL,2016).
2.2 Introdução à algoritmos para sistemas de recomendaçãoComo discutido no primeiro capítulo, existem de maneira geral duas categorias
em sistemas de recomendação: sistemas cuja filtragem é baseada em conteúdo e sistemasde filtragem colaborativa. Sistemas de filtragem colaborativa são subdivididos em doisgrupos, os sistemas baseados em vizinhança e os baseados em modelos.
Esse trabalho abordará cinco algoritmos de aprendizado de máquina no contextode sistemas de recomendação, sendo eles a regressão linear, o método dos k-vizinhosmais próximos, a redução de dimensionalidade, as árvores de decisão e as redes neuraisartificiais. Alguns algoritmos são comumente utilizados em problemas de recomendação deambas as categorias, enquanto outros, por sua natureza e limitações técnicas, são usadosespecificamente em problemas de apenas uma categoria. No Capítulo 3 é realizada aaplicação dos algoritmos dos k-vizinhos mais próximos, redução de dimensionalidade dematrizes esparsas e redes neurais artificiais.
Na Figura 6 abaixo são esquematizadas as subdivisões de sistemas de reco-mendação e os algoritmos que podem ser utilizados em problemas de cada uma dessassubdivisões.

Capítulo 2. Modelos matemáticos 37
Figura 6 – Resumo das várias categorias de sistemas de recomendação com seus respectivosalgoritmos. Fonte: autora.
Nas seções a seguir serão apresentados os algoritmos citados na Figura 6,procurando enfatizar os aspectos matemáticos por trás de cada um, assim como exemplosno contexto de sistemas de recomendação e os respectivos algoritmos de implementação.
2.3 Regressão LinearO objetivo da regressão linear é encontrar uma equação linear que explique a
relação entre as variáveis de previsão - ou atributos de entrada - e a variável de resposta,a qual também chamamos de atributo de saída.
2.3.1 Embasamento matemático
Neste método, assume-se a hipótese de que a variável alvo, y P Rm, pode serexplicada por meio de uma relação linear com as variáveis de previsão. Definiremos aquicada variável de previsão como xj P R
m, onde j “ 1, 2, ..., n. A relação entre a variávelalvo y e as variáveis de previsão xj pode ser explicada através da equação 2.1:
y “ c0 ` c1x1 ` c2x2 ` ...` cjxj ` ...` cnxn (2.1)
Nesse contexto, um problema de regressão linear consiste em determinar oscoeficientes tc0, c1, ..., cnu que permitem encontrar estimativas que sejam as mais próxi-

Capítulo 2. Modelos matemáticos 38
mas possíveis dos dados conhecidos. O objetivo do modelo é “aprender” com os dadospreviamente conhecidos quais são os coeficientes mais adequados para aquele problema.
Do ponto de vista matemático, cada instância do conjunto de treinamentofornecerá uma equação linear cujas variáveis são os coeficientes tc0, c1, ..., cnu. O conjuntodessas equações forma um sistema linear, que pode ser escrito na forma matricial conformeequação 2.2.
Xc “ y (2.2)
Onde:
X “
»
—
—
—
—
—
—
—
–
1 x11 x12 . . . x1n
1 x21 x22 . . . x2n
1 x31 x32 . . . x3n... ... ... . . .
...1 xm1 xm2 . . . xmn
fi
ffi
ffi
ffi
ffi
ffi
ffi
ffi
fl
c “ tc0, c1, ..., cnu (2.3)
y “ ty1, y2, ..., ynu (2.4)
Sem ă n, ou seja, o número de instâncias do conjunto de treinamento for menordo que o número de variáveis preditivas e consequentemente menor do que o número decoeficientes, o sistema é subdeterminado e acontece o que se chama de hiper-parametrizaçãoda regressão, quando o número de variáveis é maior do que o número de dados.
Se m “ n, o sistema pode admitir uma solução única que, em geral, não servepara o propósito de fazer previsões ou recomendações, visto que há uma interpolação dospontos. Este tipo de modelo explica perfeitamente os dados de treinamento, mas falha naextrapolação dos resultados. Nesse caso ocorre o overfitting, conforme comentado na seção2.1.
O caso interessante e mais desejável em modelos de aprendizagem ocorre quandom ą n, ou seja, o número de instâncias é maior (e preferencialmente bem maior) do queo número de variáveis. Nesse caso o sistema linear é sobredeterminado e, em geral, nãoadmite solução. O que se busca então é um conjunto de coeficientes que melhor se aproximedos dados reais do treinamento.
Formalmente, busca-se encontrar coeficientes que minimizem o erro entreas previsões feitas pelo modelo (armazenadas no vetor y) e os valores alvo observado(armazenados no vetor y). Isso é resolvido através dos métodos do quadrados mínimos.

Capítulo 2. Modelos matemáticos 39
A fim de construir um modelo de regressão linear utilizando o método dosquadrados mínimos, iniciamos pela multiplicação das matrizes na equação 2.2, obtendo osistema abaixo:
$
’
’
’
’
’
’
&
’
’
’
’
’
’
%
c0 ` x11c1 ` x12c2 ` ¨ ¨ ¨ ` x1ncn “ y1
c0 ` x21c1 ` x22c2 ` ¨ ¨ ¨ ` x2ncn “ y2...
c0 ` xm1c1 ` xm2c2 ` ¨ ¨ ¨ ` xmncn “ ym
(2.5)
Em um mundo perfeito, onde todas as variáveis deX que influenciam o resultadode y são conhecidas, o sistema 2.5 apresentaria uma solução. Como esse não é o caso, osistema não apresenta solução e portanto não existe um vetor c que multiplicado à matrizX retorne exatamente os valores em y.
No entanto, é possível encontrar um vetor p que, multiplicado à matriz X,traga resultados muito próximos aos valores reais de y.
Chamemos de y o vetor proveniente da multiplicação de X e p. O objetivoaqui é encontrar o vetor p que minimize o erro ε, ou seja, que minimize a diferença entreos valores reais em y e os valores calculados em y:
ε “ ||y´Xp|| “ ||y´ y|| (2.6)
Como a diferença entre y e y nada mais é do que o vetor gerado por y - y (oqual iremos chamar aqui de e), queremos minimizar a magnitude de e. Sabemos que umavez que y é a multiplicação entre X e p, o vetor y mais próximo que podemos encontrar dey é a projeção de y no subespaço gerado pelos vetores-coluna da matrix X (MARGALIT,2019), então o erro mínimo será:
min}e} “ }y´ projCpXqy} (2.7)
Por definição, o vetor gerado por y´projCpXqy é ortogonal ao subespaço geradopelos vetores-coluna da matrix X, e por consequência pertence ao núcleo de X transposta,XT . Com isso temos que:
XTpy´ projCpXqyq “ 0
XTpy´Xpq “ 0
XTy´XTXp “ 0 (2.8)

Capítulo 2. Modelos matemáticos 40
A equação 2.8 é um sistema linear, e portanto pode-se encontrar o vetor p queirá minimizar o erro ε entre os valores reais do vetor de resposta y e os valores calculadosy, uma vez que XTy e XTX são conhecidos. Com isso é possível encontrar a equaçãolinear que correlaciona os valores de X com a variável dependente y, de acordo com aequação 2.9 abaixo:
yj “ p0 ` p1xj1 ` p2xj2 ` ¨ ¨ ¨ ` pnxjn @j P 1, ...,m (2.9)
2.3.2 Aplicação em sistemas de recomendação
Algoritmos de regressão linear podem ser implementados na construção desistemas de filtragem baseada em conteúdo, onde a matriz Xmˆn compreende n caracte-rísticas de m itens para um usuário u fixo. Cada matriz X corresponderá a um usuárioúnico. Abaixo, exemplificamos a aplicação desse algoritmo.
Exemplo 1. Regressão linear em sistemas baseados em conteúdoConsidere uma base de dados gerada a partir das avaliações dadas por um usuário a umacoleção de filmes, conforme a Tabela 4 abaixo.
Código do Filme Gênero Nacionalidade Avaliação01 Comédia Americano 3,502 Drama Alemão 2,703 Comédia Brasileiro 3,804 Drama Brasileiro 4,1
Tabela 4 – Avaliações de filmes: Exemplo 1
Para cada filme, representado por um código na primeira coluna da tabela, sãofornecidas as informações de gênero e nacionalidade, e por fim a avaliação dada pelousuário, que pode ir de 1 a 5 estrelas. O objetivo da regressão linear, nesse caso, seriaencontrar uma equação linear que relacione as características dos filmes com a avaliaçãodada pelo usuário. Uma vez com essa regra estabelecida, seria possível em teoria predizeras avaliações que o usuário daria a filmes que ele ainda não viu, tendo insumos pararecomendá-los ou não.
A primeira coluna, com o código do filme, é apenas uma coluna de indexaçãousada para referenciar cada filme. As colunas 2 e 3 são as variáveis de previsão, utilizadasna composição da matriz de variáveis de previsão X. A última coluna, com as avaliaçõesdadas pelo usuário, é o atributo alvo y.
Como os valores das colunas 2 e 3 da tabela acima são categóricos, é necessárioprimeiro codificá-los a fim de seguir com a regressão linear. Tomemos o conjunto gerado

Capítulo 2. Modelos matemáticos 41
pelas categorias de gênero G = {Comédia, Drama} e o conjunto gerado pelas categoriasde nacionalidade N = {Americano, Alemão, Brasileiro}. Cria-se uma coluna para cadacategoria. Caso o filme apresente a característica em questão, o elemento aij pertencente àmatriz de variáveis de previsão X, onde i faz referência ao filme e j à categoria, será iguala 1. Caso contrário, aij será igual a 0. Esse conceito é conhecido como “one hot encoding”,e é exemplificado na Tabela 5 abaixo.
Código Comédia Drama Americano Alemão Brasileiro Avaliação01 1 0 1 0 0 3,502 0 1 0 1 0 2,703 1 0 0 0 1 3,804 0 1 0 0 1 4,1
Tabela 5 – Variáveis categóricas codificadas
Uma vez com as variáveis categóricas codificadas, a matriz de variáveis deprevisão X e o vetor do atributo alvo y seriam:
X “
»
—
—
—
—
–
1 0 1 0 00 1 0 1 01 0 0 0 10 1 0 0 1
fi
ffi
ffi
ffi
ffi
fl
y “
»
—
—
—
—
–
3, 52, 73, 84, 1
fi
ffi
ffi
ffi
ffi
fl
É importante mencionar que, apesar de termos incluido colunas para todasas categorias de gênero e nacionalidade em um primeiro momento, devemos retirar umacoluna de cada variável antes de seguir com a regressão. Isso acontece porque a fim deconstruir uma regressão linear as variáveis de previsão devem ser independentes entre si.Ao considerar o caso da variável de gênero, por exemplo, sabe-se que, após a codificação, acoluna “Comédia” somada à coluna “Drama” sempre será igual a 1, ou seja, é possívelinferir o valor da coluna “Drama” sabendo o valor da coluna “Comédia” e vice versa. Issosignifica que as colunas na verdade são combinações lineares e não são independentesentre si. O mesmo acontece no caso da nacionalidade. Ao se retirar uma das colunas,ainda é possível inferir qual o valor da coluna faltante através dos valores das colunasque permanecem (uma vez que a coluna retirada é uma combinação linear das colunasque ficam), o que nos permite seguir com a regressão sabendo que todas as variáveis sãoindependentes entre si. Para esse exemplo, serão retiradas as colunas referentes às variáveisde “Drama” e “Brasileiro”. A nova matriz X será:

Capítulo 2. Modelos matemáticos 42
X “
»
—
—
—
—
–
1 1 00 0 11 0 00 0 0
fi
ffi
ffi
ffi
ffi
fl
Uma vez com o processo acima finalizado, temos uma matriz X compostaapenas por números. O próximo passo é normalizar os dados da matriz. Imagine porexemplo que a matriz em questão tivesse uma coluna com a idade do filme e outra como valor total, em reais, provenientes dos ingressos vendidos nas bilheterias de cinemadurante as semanas de estréia. Enquanto a coluna de idade não passará de talvez 50 ou60 anos, a coluna com o faturamento dos ingressos poderá chegar aos milhões de reais.Se construimos o modelo sem antes normalizar esses dados, a variável de faturamentoterá maior influência no resultado final da regressão, apesar de não necessariamente ser avariável mais importante quando comparada à variável de idade. Por isso, antes de seguirpara a etapa de construção do modelo, é importante normalizar os dados em cada colunade X (LAKSHMANAN, 2019).
Após essa fase de pré-processamento de dados, basta calcular o vetor p utilizandoa equação 2.8. Com os valores dos elementos de p conhecidos, o valor de y referente auma nova observação mj`1 pode ser encontrado a partir da equação 2.9.
No Algoritmo 2.1 apresentamos uma sequência dos principais passos que devemser realizados para um processo de aprendizagem de máquina utilizando regressão linear.
Algoritmo 2.1 Regressão LinearImportar base de dados DDecompor D entre X e yCodificar colunas em X que possuam dados categóricosRemover uma coluna de cada variável categórica codificada em XNormalizar dados em XDividir X e y entre dados de treinamento, dados de validação e dados de testeUtilizando os dados de treinamento, encontrar o vetor p através da equação: XTy ´XTXp “ 0Para uma nova observação cujo índice é j ` 1, encontrar yj`1 através da equação:xj`1 p “ yj`1
2.4 Redução de dimensionalidade de matrizesDiferentemente de algoritmos baseados em conteúdo, onde o conjunto de dados é
organizado de forma que as variáveis preditivas e o atributo alvo são claramente demarcados(vide Figura 4), a construção de algoritmos que lidam com filtragem colaborativa requer

Capítulo 2. Modelos matemáticos 43
que o conjunto de dados assuma a forma de uma matriz Amˆn relativa a m usuários e nitens, onde cada elemento aij é a avaliação dada pelo usuário i ao item j.
Nas aplicações de algoritmos de aprendizado de máquina em situações reais, amatriz de avaliações Amˆn frequentemente assume grandes dimensões (vide caso da Amazon,com milhões de usuários e milhões de itens disponíveis na plataforma). Nesses casos, écomum que uma boa parte das linhas e colunas dessa matriz seja altamente correlacionada,uma vez que o padrão de consumo de muitos usuários tende a ser parecido. Dessa forma,a matriz original possui um alto grau de informações redundantes, e grande parte dainformação presente na matriz A pode ser aproximada através de uma decomposiçãode matrizes de posto reduzido p ă minpm,nq, ou seja, podemos reduzir o número dedimensões analisadas e manter as informações mais importantes da matriz A utilizandoum conjunto menor de dados.
Essa redução de dimensionalidade só é possível uma vez que as correlaçõesentre os itens e/ou usuários na matriz A podem ser explicadas através de fatores latentes,ou seja, características implícitas ao conjunto de dados e que explicam a maior parte desua variância.
A redução de dimensionalidade pode ser aplicada no contexto de sistemas derecomendação de duas formas principais, detalhadas abaixo (AGGARWAL, 2016):
1. Na criação de uma representação da matriz de avaliações, reduzindo a dimensionali-dade de itens ou de usuários. Essa técnica é utilizada para mitigar o problema dematrizes de avaliações esparsas, comumente encontradas em casos reais quando nemtodos os usuários avaliam todos os itens;
2. Na criação de uma representação da matriz de avaliações, porém determinando demaneira simultânea as representações latentes tanto de itens como de usuários. Nessecaso, a matriz de avaliações é completada de uma vez só, sem a necessidade deimplementar nenhum algoritmo adicional.
Iremos iniciar esse capítulo com uma seção sobre a intuição geométrica sobreos fatores latentes, seguida de uma discussão sobre a conexão entre fatoração de matrizes,fatores latentes, e redução de dimensionalidade. Posteriormente abordaremos o uso daredução de dimensionalidade no contexto de sistemas de recomendação, tanto comoferramenta de mitigação do problema de matrizes esparsas como o seu uso exclusivo paracompletar uma matriz de avaliação incompleta.

Capítulo 2. Modelos matemáticos 44
2.4.1 Embasamento matemático
2.4.1.1 Fatores latentes: Intuição geométrica
Considere uma matriz Amˆn. A fim de exemplificar o conceito, trabalharemosmomentâneamente com m “ 20 e n “ 2, ou seja, uma matriz com avaliações de vinteusuários a dois itens específicos, A e B. Suponha também que as avaliações dos dois itenssejam correlacionadas positivamente. Abaixo apresentamos o gráfico de dispersão de duasdimensões, onde o eixo das abcissas representa as avaliações dadas ao item A, e o eixo dasordenadas as do item B.
Figura 7 – Gráfico de dispersão para vinte avaliações de dois produtos. Fonte: autora.
Graças a disposição dos dados, o gráfico de dispersão 7 pode ser aproximadopor uma reta no sentido no qual os dados estão mais “alongados”, conforme abaixo:
Figura 8 – Gráfico de dispersão para vinte avaliações de dois produtos, aproximado poruma reta. Fonte: autora.

Capítulo 2. Modelos matemáticos 45
A reta representada na Figura 8 é um vetor latente que explica o sentido demaior variância nas avaliações dos itens A e B. Através da aproximação dada por esse vetorlatente, é possível representar os pontos pAvaliaçãoA, AvaliaçãoBq como uma só dimensão,indicando apenas a localização de cada ponto na reta. Através desse sistema, podemosrepresentar dados bidimensionais de maneira unidimensional, reduzindo a dimensionalidadedo conjunto de dados inicial. Nesse exemplo, a aproximação dos dados por uma reta significaque a matriz de dados original possui posto p “ 1 (AGGARWAL, 2016).
Além disso, suponha que tenhamos as coordenadas da reta que aproxima oconjunto de dados e a avaliação para apenas um dos itens. Podemos aproximar a avaliaçãopara o segundo item ao calcular a interseção dessa reta com um hiperplano de dimensão p(que no caso desse exemplo é uma reta unidimensional). De fato, as avaliações desconhecidasem um conjunto de dados podem ser aproximadas se tivermos pelo menos p avaliaçõesconhecidas para o usuário em questão (AGGARWAL, 2016). Veja que, nesse exemplo, sea avaliação do item B é 60 para um usuário específico, a avaliação do item A pode seraproximada como 39, conforme exemplificado pela figura abaixo.
Figura 9 – Estimação da avaliação de A através de uma aproximação unidimensional doconjunto de dados. Fonte: autora.
É importante notar que métodos de redução de dimensionalidade baseados emfatores latentes são construídos a partir de correlações e redundâncias nos dados. Se oconjunto de dados não possui nenhum tipo de redundância não é possível encontrar fatoreslatentes e portanto esses métodos não podem ser utilizados.
2.4.1.2 Fatoração de matrizes e fatores latentes
Uma das formas de entender e construir a redução de dimensionalidade dematrizes é através de sua fatoração. Considere uma matriz Amˆn cujos elementos são todos

Capítulo 2. Modelos matemáticos 46
conhecidos. Seja p ă minpm,nq o posto dessa matriz. A matriz A pode ser aproximadaatravés da decomposição:
A « UpΣpVTp (2.10)
Onde Up é uma matriz mˆ p, Σp é uma matriz pˆ p e Vp é uma matriz nˆ p.Realizando a multiplicação entre Up e Σp simplificamos a equação 2.10, conforme abaixo:
A « U 1pVTp (2.11)
Onde U 1p continua sendo uma matriz mˆ p (apesar de possuir elementos comvalores diferentes de Up) e Vp não é modificada. Cada coluna de U 1p representa um dos pvetores que formam uma base para o espaço coluna de A, e cada linha j de Vp possui oscoeficientes que, quando combinados aos vetores coluna de U 1p, se transformam na colunaj de A. Podemos também considerar as colunas de Vp como os vetores que formam abase para o espaço linha de A e as linhas de U 1p como os coeficientes correspondentes(AGGARWAL, 2016).
Trazendo esse conceito ao universo de sistemas de recomendação, cada linha ida matriz U 1p consiste em um vetor ui P R
p que nos diz a tendência do usuário i em A
de se identificar com cada um dos p fatores latentes. Da mesma forma, cada coluna j emV Tp consiste em um vetor vj P R
p que explica a relação entre um item j e cada um dosfatores latentes. Com isso em mente, a estimativa da nota aij da avaliação de um usuárioi ao item j pode ser facilmente encontrada através do produto interno entre a linha de U 1preferente ao usuário i e a coluna de V T
p referente ao item j, conforme equação 2.12:
aij “ vjT ui (2.12)
Existem vários métodos de fatoração de matrizes que permitem a construçãoda fatoração da matriz A como detalhado anteriormente, e entre eles está a decomposiçãopor valores singulares, que será discutida abaixo. Uma vez com a base teórica da fatoraçãoesclarecida, vamos seguir para definir a relação entre fatoração de matrizes e redução dedimensionalidade através de fatores latentes.
2.4.1.3 Decomposição em valores singulares
Seja A uma matriz mˆ n. Sabemos que, se m “ n e A possuir uma base deautovetores, A pode ser decomposta em três matrizesM , Λ eM´1, ondeM é a matriz cujas

Capítulo 2. Modelos matemáticos 47
colunas são os autovetores de A e Λ é uma matriz diagonal cuja diagonal é composta pelosautovalores de A (BOLDRINI et al., 1986). Essa decomposição é chamada de decomposiçãoespectral.
Agora, no caso em que m ‰ n ou que não seja possível encontrar uma base deautovetores de A, ainda assim é possível decompor a matriz A através da decomposiçãoem valores singulares. Nesse caso, A será decomposta nas três matrizes U , Σ e V T , onde Ué a matriz cujas colunas são os autovetores de AAT , Σ é a matriz diagonal cuja diagonal écomposta pela raiz quadrada dos autovalores de AAT (que também são autovalores deATA), e V é a matriz cujas colunas são os autovetores de ATA (vide equação 2.13 abaixo).
A “ UΣV T (2.13)
Para fins de demonstração, seja A uma matriz mˆ n com posto p. É evidenteque ATA é uma matriz nˆ n e simétrica. Além disso, ATA é semi-definida positiva(GUNDERSEN, 2018), como demonstrado abaixo:
G “ ATA
xTGx “ xTATAx
xTGx “ pAxqTAx
xTGx “ ||Ax||2
xTGx ě 0 (2.14)
Como uma matriz simétrica, podemos afirmar que ATA admite uma baseortonormal de autovetores, e pode então ser decomposta conforme abaixo:
ATA “ V ΛV ´1
ATA “ V ΛV T (2.15)
Onde a segunda igualdade acima se deve ao fato de que V é a matriz nˆ ncujas colunas são os autovetores ortonormais de ATA, e como uma matriz ortormal a suainversa é igual à transposta. Como mencionado anteriormente, Λ é a matriz diagonal nˆ ncujos elementos não nulos são os autovalores de ATA.
Como ATA é semi-definida positiva, todos os seus autovalores são maiores ouiguais a zero. Ao considerarmos a raiz quadrada desses autovalores, encontramos o que cha-mamos de valores singulares, costumariamente denotados pela letra σ (GUNDERSEN,2018).

Capítulo 2. Modelos matemáticos 48
Sabemos então que, para um autovetor vi P Rn qualquer de ATA:
ATAvi “ λivi “ σ2i vi (2.16)
Vamos definir um vetor ui P Rm de forma que ui “
Avi
σi. Por construção, ui
será um autovetor de AAT , conforme demonstrado abaixo:
AATui “ AATAvi
σi
AATui “ AATAvi1σi
AATui “ Aσ2i vi
1σi
AATui “ σ2i
Avi
σi
AATui “ λiui (2.17)
Onde a terceira igualdade acima decorre de que vi é autovetor de ATA, entãoATAvi “ λivi “ σ2
i vi.
Além disso, ui é um vetor unitário, como provamos abaixo.
}ui} “ 1a
u21i ` u
22i ` ...` u
2mi “ 1
u21i ` u
22i ` ...` u
2mi “ 1
uTi ui “ 1
Avi
σi
T Avi
σi“ 1
viTAT
σi
Avi
σi“ 1
viTATAvi
σ2i
“ 1
viTσ2
i vi
σ2i
“ 1
viTvi “ 1
1 “ 1 (2.18)
Uma vez que vi é um vetor ortonormal.

Capítulo 2. Modelos matemáticos 49
Concatenando os vetores ui para todo i “ 1, ...,m, formamos a matriz Umˆm,cujas colunas são formadas pelos vetores ui. Temos que U será igual ao produto dasmatrizes Amˆn, Vnˆn e Σ´1
nˆm, onde Σmˆn é a matriz diagonal cujos elementos não nulossão as raizes quadradas dos autovalores de ATA, que também são autovalores de AAT ,uma vez que ambas as matrizes possuem os mesmos autovalores diferentes de zero. Comisso temos que:
U “ AV Σ´1
UΣ “ AV Σ´1Σ
UΣ “ AV
UΣV ´1“ AV V ´1
UΣV T“ A (2.19)
Uma vez que V é ortonormal e sua inversa é igual a transposta (GUNDERSEN,2018).
Provamos então que qualquer matriz Amˆn pode ser decomposta nas matrizesUmˆm, Σmˆn e V T
nˆn.
Convencionalmente, os autovetores em U e V são ordenados conforme seusvalores singulares correspondentes em Σ, de maneira decrescente.
2.4.1.4 Redução de dimensionalidade utilizando decomposição em valores singulares
Como discutido anteriormente, graças ao alto grau de informações redundantesna matriz de avaliações Amˆn, grande parte da informação presente na matriz pode seraproximada através de uma decomposição de matrizes de posto p ă minpm,nq. O objetivoé reduzir o número de dimensões analisadas sem perder as informações mais importantesda matriz A.
A fim de entender qual a perda de informação relativa à redução de uma oumais dimensões, calculamos a matriz de covariância de A. A covariância é a medida dograu de interdependência entre duas variáveis, ou seja, caso duas variáveis sejam altamentecorrelacionadas, a covariância será alta. A covariância será nula caso as duas variáveissejam independentes entre si (HUI, 2019).
A matriz de covariância será uma matriz simétrica, cuja diagonal é a variânciade uma variável com relação à ela mesma.
A fim de ilustrar a aplicação dessa decomposição no contexto de sistemas derecomendação, tomemos como exemplo a matriz Amˆn de m usuários e n itens, tal queo elemento aij é a nota dada pelo usuário i ao item j. Vamos centralizar a matriz A

Capítulo 2. Modelos matemáticos 50
subtraindo de cada elemento a média de todas as notas dadas àquele item (média doselementos na coluna j), de forma que a média dos valores em cada coluna é zero. Paravariáveis centralizadas, a covariância entre duas variáveis a e b pode ser calculada atravésdo valor esperado da multiplicação entre elementos das duas variáveis, conforme equação2.20:
covpa,bq “ Erabs (2.20)
E a variância de uma variável com relação a ela mesma é calculada da mesmaforma:
varpaq “ covpa, aq “ Eraas (2.21)
Reescrevendo as equações 2.20 e 2.21 na forma matricial para n variáveis comm elementos cada, é possível encontrar a matriz de covariância de A, denotada abaixo porCA (HUI, 2019):
CA “1nATA (2.22)
Sabemos que qualquer matriz A pode ser decomposta utilizando a decomposiçãopor valores singulares. Seja então A “ UΣV T :
CA “1npUΣV T
qTpUΣV T
q
CA “1npV ΣTUT
qpUΣV Tq
CA “1nV ΣT
pUTUqΣV T
CA “1nV ΣTΣV T
CA “1nV Σ2V T
CA “ VΣ2
nV T
CA “ V DV T (2.23)
Onde D acima é a matriz Σ2
n. Como os elementos da diagonal da matriz Σ
são os valores singulares da matriz A e que por sua vez são convencionalmente ordenadosde forma decrescente, podemos afirmar que os valores singulares de maior valor estão

Capítulo 2. Modelos matemáticos 51
diretamente relacionados às variáveis de A que possuem a maior variância, ou seja, quedetém o maior nível de informação.
De fato, uma das propriedades da matriz de covariância é que a variância de Aé o traço de CA, que consequentemente é o traço da matriz diagonal D, como demonstradoabaixo (OLIVEIRA, 2016):
traçopCAq “ traçopV DV Tq
traçopCAq “ traçopDV V Tq
traçopCAq “ traçopDIq
traçopCAq “ traçopDq (2.24)
Como D “Σ2
n, o que decorre da afirmação acima é que podemos calcular a
proporção da variância de A relativa a cada valor singular σi através da razão entre σ2i
e a soma dos quadrados dos valores singulares em Σ. Dessa forma, sabendo os valoressingulares da matriz A, é possível eliminar as variáveis redundantes - ou seja, aquelas quepossuem os menores valores singulares e consequentemente representam pouca variânciados dados - e reconstruir a matriz A˚, que é a aproximação da matriz A, através damultiplicação das matrizes Up, Σp e Vp truncadas após a remoção de variáveis redundantes.A idéia é manter apenas os vetores latentes do conjunto de dados. Além disso, é possívelutilizar um processo iterativo para estimar os elementos faltantes na matriz A em situaçõesonde A não é completamente especificada (AGGARWAL, 2016).
Voltemos ao exemplo inicial da matriz A20ˆ2 com as avaliações de vinte usuáriosa dois itens A e B. Encontramos as duas matrizes quadradas AAT e ATA e seus respectivosautovalores não nulos, que são 79.668, 4 e 5.339, 6. Com isso, podemos calcular a proporçãopσi
da variância dos dados relativa a cada valor singular σi de A, conforme abaixo:
pσ1 “79.668, 42
p79.668, 42 ` 5.339, 62q
pσ1 “ 0, 996
pσ2 “5.339, 62
p79.668, 42 ` 5.339, 62q
pσ2 “ 0, 005
Veja que o vetor latente relativo ao primeiro valor singular representa 99,6%da variância nos dados de A. Com isso, podemos representar a matriz A como uma matriz

Capítulo 2. Modelos matemáticos 52
de posto p “ 1, removendo as colunas e linhas de U , Σ e V relativas ao segundo valorsingular em Σ. A nova matriz A˚ será representada a partir da multiplicação entre asmatrizes U20ˆ1, Σ1ˆ1 e V2ˆ1.
Agora veja que, realizando os cálculos, o vetor linha em V2ˆ1T é o vetor
p0, 653, 1q. Esse é o vetor latente representado nas Figuras 8 e 9 como a reta que melhoraproxima o conjunto de dados em A.
2.4.2 Aplicação em sistemas de recomendação
Como comentado anteriormente, a redução de dimensionalidade em sistemas derecomendação pode ser aplicada de duas formas principais: como ferramenta para mitigaro problema de matrizes esparsas ou como forma de prever avaliações desconhecidas deusuários a itens. Abaixo abordaremos ambas as aplicações em um contexto de sistemas derecomendação.
2.4.2.1 Mitigação do problema de matrizes esparsas
O objetivo do uso de redução de dimensionalidade para mitigar o problema dematrizes esparsas é o de redimensionar uma matriz esparsa Amˆn em uma matriz Rmˆp,com p ă n, de forma que Rmˆp seja completamente especificada. A partir dessa novamatriz é possível por exemplo estabelecer vizinhanças entre usuários (grupos de usuáriossimilares entre si) ou criar árvores de decisão, sem o problema de dados desconhecidos.
O primeiro passo a fim de construir uma representação de menor dimensãoda matriz A é calcular a matriz de covariância n ˆ n entre as colunas de A, a qualdenominaremos CA. Como A é uma matriz esparsa, o cálculo de CA é feito utilizandoapenas as linhas referentes aos usuários que possuem avaliações para os dois itens emquestão. No caso em que não existem usuários em comum entre dois itens, a covariânciaentre esses itens é considerada zero (AGGARWAL, 2016).
Uma vez com a matriz de covariância construída, aplicamos a decomposiçãoespectral em CA conforme abaixo:
CA “ V DV T (2.25)
Encontramos os p autovalores responsáveis pela maior parte da variância noconjunto de dados, conforme discussão na seção anterior. Seja Vp a matriz nˆ p resultanteda eliminação das n´ p colunas de V que menos contribuem com a variância nos dados.
Iremos calcular a contribuição de cada avaliação observada em A na projeçãoem cada vetor latente de Vp, e então encontrar a média dessas contribuições para cada

Capítulo 2. Modelos matemáticos 53
item. Seja gi a i-ésima coluna da matriz Vp. Ao j-ésimo elemento de gi chamaremos gji.Seja auj um elemento conhecido da matriz esparsa de avaliações A, sendo auj a avaliaçãorelativa ao usuário u e o item j. Temos então que a contribuição de auj no vetor latente gié a multiplicação aujgi. Se definirmos o conjunto Iu como o conjunto de todas as avaliaçõesconhecidas para o usuário u, a contribuição média rui do usuário u no vetor latente gi écalculada através da equação 2.26 abaixo (AGGARWAL, 2016):
rui “
ř
jPIurujgji
|Iu|(2.26)
Uma vez com rui calculado para todos os m usuários e todos os p vetoreslatentes, construimos a matriz Rmˆp, tal que R “ rruismˆp. A partir dessa nova matriz Rcompletamente especificada podem ser aplicados algoritmos como k-vizinhos mais próximosou árvores de decisão, métodos esses que serão abordados nas próximas sessões.
2.4.2.2 Previsão de avaliações
Pode-se também utilizar a redução de dimensionalidade em sistemas de reco-mendação de maneira exclusiva, sem aplicar o uso de qualquer outro algoritmo. O objetivoaqui é utilizar os fatores latentes em um conjunto de dados de forma a calcular a previsãode uma avaliação aij inicialmente desconhecida.
Exemplo 2. Redução de dimensionalidade para previsão de avaliações
Seja A uma matriz mˆ n gerada a partir das notas dadas por m usuários a nprodutos diferentes. Suponha que as notas variem de 1 a 5, de forma discreta. Como nemtodos os usuários deram notas a todos os produtos, alguns elementos da matriz A estãofaltando. Abaixo é exemplificada a matriz A para uma amostra de 5 usuários e 3 produtos.
A “
»
—
—
—
—
—
—
–
2 2 ?4 3 1? 4 52 1 44 5 2
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
Queremos encontrar valores para os dois elementos faltantes, mais especifica-mente os elementos a31 e a13, onde aij representa a nota dada pelo usuário i ao item j.Uma vez com a matriz completa, podemos usar os valores de a31 e a13 para decidir se éinteressante recomendar o item 1 ao terceiro usuário e o item 3 ao primeiro usuário.
Vamos inicialmente preencher os valores desconhecidos em A com a média decada coluna, gerando a matriz A1.

Capítulo 2. Modelos matemáticos 54
A1 “
»
—
—
—
—
—
—
–
2 2 34 3 13 4 52 1 44 5 2
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
Aplicando a decomposição em valores singulares em A1 obtemos as matrizes U ,Σ e V , como demonstrado abaixo. Temos então que A1 “ U ˆ Σˆ V T , onde:
U “
»
—
—
—
—
—
—
–
0, 337 0, 234 ´0, 042 0, 775 ´0, 4790, 389 ´0, 502 ´0, 648 ´0, 258 ´0, 3320, 579 0, 347 0, 435 ´0, 516 ´0, 2950, 334 0, 561 ´0, 517 0 0, 5530, 536 ´0, 508 0, 348 0, 258 0, 516
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
Σ “
»
—
—
—
—
—
—
–
11, 90 0 00 3, 82 00 0 1, 370 0 00 0 0
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
V T“
»
—
–
0, 568 0, 601 0, 562´0, 368 ´0, 425 0, 827´0, 736 0, 676 0, 020
fi
ffi
fl
Percebe-se que o primeiro valor singular de 11,90 representa 89, 6% da variânciaem A1, conforme demonstrado abaixo:
11, 902
11, 902 ` 3, 822 ` 1, 372 “ 89, 6%
Se tomarmos o primeiro e o segundo valor singular, eliminando o terceiro,contamos com 98, 8% da variância. Vamos eliminar o terceiro valor singular de 1,37, ereconstruir a matriz A1 utilizando U5ˆ2, Σ2ˆ2 e V3ˆ2, de forma a encontrar A2:
U5ˆ2 “
»
—
—
—
—
—
—
–
0, 337 0, 2340, 389 ´0, 5020, 579 0, 3470, 334 0, 5610, 536 ´0, 508
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl

Capítulo 2. Modelos matemáticos 55
Σ2ˆ2 “
«
11, 90 00 3, 82
ff
V T2ˆ3 “
«
0, 568 0, 601 0, 562´0, 368 ´0, 425 0, 827
ff
Como A2 “ U5ˆ2 ˆ Σ2ˆ2 ˆ VT
2ˆ3, temos que A2 é:
A2 “
»
—
—
—
—
—
—
–
1, 95 2, 03 2, 993, 33 3, 59 1, 013, 43 3, 60 4, 961, 47 1, 48 4, 004, 34 4, 66 1, 98
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
Veja que apesar da redução de dimensionalidade a variação entre os valoresde A1 e A2 é pequena. Embora a decomposição original tenha dimensionalidade 3 (trêsvalores singulares), podemos realizar a decomposição truncada com dimensão 2 (sem omenor valor singular) iterativamente de forma a completar a matriz A original e encontraros valores de a13 e a31. O benefício de realizar a decomposição truncada é a de que dessaforma o sistema requer menos esforço computacional, o que é muito importante em casosonde existem milhões de usuários e milhões de itens.
Vamos substituir os elementos a13 e a31 que eram desconhecidos na matriz Aoriginal pelos valores em A2, ou seja, os valores encontrados após a decomposição truncadaem duas dimensões:
A2 “
»
—
—
—
—
—
—
–
2 2 2, 994 3 1
3, 43 4 52 1 44 5 2
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
Aplicando a decomposição truncada com posto p “ 2 novamente, chegamos naseguinte matriz A3:
A3 “
»
—
—
—
—
—
—
–
2, 03 1, 98 2, 993, 33 3, 59 1, 053, 75 3, 71 4, 971, 57 1, 38 4, 034, 37 4, 66 1, 96
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl

Capítulo 2. Modelos matemáticos 56
Veja que os valores de a13 e a31 pouco mudaram de A2 para A3. A idéia é realizaresse processo iterativamente para Ai, até que a diferença entre os valores desconhecidosentre iterações subsequentes seja muito pequena, de forma que esses valores se estabilizem.Baseado nisso, podemos decidir ou não por sugerir esses itens aos usuários em questão.
O Algoritmo 2.2 resume os passos para utilizar a decomposição em valoressingulares para a mitigação do problema de matrizes esparsas. De maneira similar, oAlgoritmo 2.3 define as etapas necessárias para utilização da decomposição em valoressingulares a fim de prever avaliações.
Algoritmo 2.2 Decomposição em valores singulares para mitigação do problema dematrizes esparsasImportar matriz de avaliações AEncontrar matriz de covariância CAAplicar decomposição espectral em CA e definir os p autovalores responsáveis pela maiorparte da variânciaDefinir Vp como a matriz com apenas os p maiores vetores latentesCalcular a contribuição média do usuário u no vetor latente gi através da equação:
rui “
ř
jPIuruj gji
|Iu|(2.27)
Construir a matriz R “ rruismˆp completamente especificada
Algoritmo 2.3 Decomposição em valores singulares para previsão de avaliaçõesImportar matriz de avaliações APreencher valores não especificados com a média de cada coluna em AEncontrar a matriz de valores singulares ΣDefinir o número k de dimensões a serem reduzidas em A de acordo com a variânciados valores singulares em ΣRemover da matriz Σ as linhas e colunas referentes aos k valores singulares definidos nopasso anterior, assim como suas respectivas colunas em U e linhas em V T
Encontrar a matriz A˚ através da multiplicação de U , Σ e V T truncados após reduçãode k dimensõesSubstituir os valores não especificados de A pelos seus respectivos valores em A˚, eaplicar a decomposição truncada novamente. Seguir esse processo iterativamente até aconvergência dos valores inicialmente não especificados
2.5 K-vizinhos mais próximosO método dos k-vizinhos mais próximos, também conhecido como KNN do
inglês k-nearest neighbors, se utiliza da distância entre instâncias para fazer as previsões.Nesse método, são criadas vizinhanças para cada instância, e a estimativa do resultado deuma instância específica é calculada com base nos resultados de sua vizinhança.

Capítulo 2. Modelos matemáticos 57
Observe, por exemplo, a Figura 10. Seja o usuário em vermelho o usuário parao qual gostaríamos de predizer uma certa avaliação. Definimos então uma vizinhança paraesse usuário como sendo o grupo de k usuários mais próximos a ele (grupo de usuáriosem amarelo na figura). As predições do algoritmo serão baseadas no comportamento dosusuários que fazem parte dessa vizinhança.
Figura 10 – Exemplo de vizinhança para um usuário. Fonte: autora
2.5.1 Embasamento matemático
O método dos k-vizinhos mais próximos pode ser utilizado tanto em análises deregressão como de classificação, sendo que essas duas aplicações seguem costumariamenteuma abordagem de sistemas baseados em conteúdo. Além disso, o método pode sertambém aplicado em sistemas de filtragem colaborativa baseados em vizinhança, onde épossível calcular a similaridade entre usuários e/ou itens a fim de prever uma avaliaçãodesconhecida.
2.5.1.1 Regressão
Seja a base de dados D um conjunto de m tuplas {xi , yi}, i = 1, ..., m, ondem é o número total de observações, xi P R
n, sendo n o número de variáveis de previsão, eyi P R. Seja xt a nova observação para a qual queremos encontrar uma previsão yt.
Em um primeiro momento, calcula-se a distância di entre o vetor xt e cadavetor xi, i “ 1, 2, ...,m. O cálculo da distância pode ser feito de várias formas, sendo asmais comuns a distância euclidiana e o ângulo entre vetores.

Capítulo 2. Modelos matemáticos 58
Dado um certo k P Z, com k ą 0, são selecionados os k vetores xi mais próximosa xt (daí o nome do método, k-vizinhos mais próximos), ou seja, os k vetores xi com amenor distância di. Para encontrar a previsão yt, usa-se a média ponderada pela distânciados valores de yi para todo xi P Npxt, kq, sendo Npxt, kq o conjunto gerado pelos k vetoresmais próximos a xt.
yt “
ÿ
xiPNpxt,kq
wiyi
ÿ
xiPNpxt,kq
wi(2.28)
Onde wi é a função peso. Como queremos dar um peso menor a vetores maisdistantes de xt, a função peso deve ser inversamente proporcional à distância di. Caso diseja o ângulo entre xi e xt, podemos assumir wi “ cos di, uma vez que quanto maior oângulo, menor o cosseno do ângulo entre os vetores. Caso di seja a distância euclidianaentre xi e xt, é possível determinar wi “
1d2i
, por exemplo (KANE, 2018).
2.5.1.2 Classificação
Seja a base de dados D um conjunto de m tuplas {xi , yi}, i = 1, ..., m, onde mé o número total de observações, xi P R
n, sendo n é o número de variáveis de previsão, eyi é uma variável categórica pertencente a um conjunto de classes C “ tc1, c2, ...chu, ondeh o número total de classes. Seja xt a nova observação para a qual queremos encontraruma previsão yt, ou seja, queremos prever qual será a classe de xt.
Da mesma maneira que na análise de regressão, calcula-se primeiro a distânciadi entre o vetor xt e cada vetor xi, i “ 1, 2, ...,m.
Dado um certo k P Z, com k ą 0, são selecionados os k vetores xi com amenor distância di. Para encontrar a previsão yt, verificamos a qual classe pertence cadaxi P Npxt, kq, sendo Npxt, kq o conjunto gerado pelos k vetores mais próximos a xt. Aprevisão yt será a classe cj que irá maximizar a equação 2.29 abaixo:
yt “ argmaxcjPtc1,c2,...,chu
ÿ
xiPNpxt,kq
F pyi, cjq (2.29)
Onde F pyi, cjq “ 1 se yi “ cj e F pyi, cjq “ 0 caso contrário.
O operador argmax faz referência aos argumentos que maximizam a funçãoÿ
xiPNpxt,kq
fpyi, cq. Em outras palavras, a função 2.29 procura retornar a classe cj que
maximiza o somatório, que nada mais é do que a classe mais frequente no conjuntoNpxt, kq (BATISTA; SILVA, 2009).

Capítulo 2. Modelos matemáticos 59
2.5.1.3 Modelos de vizinhança
Em sistemas de filtragem colaborativa baseados em vizinhança, onde possuímosuma matriz Amˆn com as avaliações de m usuários a n itens, cada linha relativa a umusuário (ou coluna relativa a um item) é vista como um vetor x. Calcula-se a distância dovetor relativo ao usuário (ou item) para o qual queremos prever a avaliação (vetor xi) etodos os outros vetores xu.
Trabalhemos a seguir com o cenário de similaridade entre usuários. Seja Pipjqo conjunto dos k usuários mais próximos ao usuário i cujas avaliações para o item j sãoconhecidas. Note que wui é a função similaridade entre os vetores correspondentes aousuário u e o usuário i. Podemos encontrar a previsão da avaliação aij do usuário i aoitem j conforme abaixo:
aij “
ÿ
uPPipjq
wuiauj
ÿ
uPPipjq
wui(2.30)
Em casos onde Amˆn é uma matriz esparsa, pode-se construir a matriz comple-tamente especificada Rmˆp com posto p ă n, conforme discutido na seção 2.4.2, subseção“Mitigação do problema de matrizes esparsas”. A partir da matriz R calcula-se a vizinhançaPipjq. Uma vez com a vizinhança definida, voltamos à matriz A e aplicamos a equação2.30 para encontrar a previsão aij (AGGARWAL, 2016).
2.5.2 Aplicação em sistemas de recomendação
O algoritmo de k-vizinhos mais próximos possui aplicações tanto em sistemasde filtragem baseada em conteúdo como em sistemas de filtragem colaborativa baseadosem vizinhança.
Em sistemas baseados em conteúdo o conjunto de dados D compreende umamatriz Xmˆn, com m observações que apresentam n características cada. A matriz Xrepresenta um único usuário u, sendo necessárias r matrizes X para gerar recomendaçõespara r usuários diferentes. Já no caso de sistemas de vizinhança a matriz Xmˆn será umamatriz cujos elementos representam as notas dadas por m usuários a n itens.
Enquanto em sistemas baseados em conteúdo a similaridade entre vetores sempreserá feita entre itens (similaridade linha a linha), em sistemas baseados em vizinhançaé possível encontrar uma previsão yt em termos da similaridade entre usuários (linha alinha) ou entre itens (coluna a coluna). Mais detalhes sobre a implementação de cadamétodo serão dados a seguir.

Capítulo 2. Modelos matemáticos 60
Exemplo 3. K-vizinhos mais próximos em sistemas baseados em conteúdo
Considere um conjunto de dados D referente a m filmes, com três característicascada. Para cada filme temos as informações de gênero, nacionalidade, e número de anosdesde a data de lançamento até hoje. Sabemos também se o usuário gostou ou não de cadafilme, sendo 1 um indicador de que o usuário gostou do filme e 0 caso contrário.
Queremos saber se o usuário irá gostar ou não de um novo filme, “O PoderosoChefão III”, um drama americano lançado em 1990. A Tabela 6 abaixo exemplifica essecaso.
Código do Filme Gênero Nacionalidade Idade Avaliação01 Comédia Americano 15 102 Drama Alemão 3 003 Comédia Brasileiro 7 004 Drama Brasileiro 9 105 Drama Americano 30 ?
Tabela 6 – Avaliações de filmes: Exemplo 3
Após codificar as duas colunas categóricas (gênero e nacionalidade) a matriz Xresultante será:
X “
»
—
—
—
—
—
—
–
1 0 1 0 0 150 1 0 1 0 31 0 0 0 1 70 1 0 0 1 90 1 1 0 0 30
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
A fim de evitar viés na construção do modelo iremos excluir as colunas relativasao gênero drama e à nacionalidade brasileira, e normalizar as colunas.
X “
»
—
—
—
—
—
—
–
1 1 0 150 0 1 31 0 0 70 0 0 90 1 0 30
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
X “
»
—
—
—
—
—
—
–
0, 707 0, 707 0 0, 4220 0 1 0, 084
0, 707 0 0 0, 1970 0 0 0, 2530 0, 707 0 0, 844
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl

Capítulo 2. Modelos matemáticos 61
Calculamos a distância entre o vetor xt e cada vetor xi relativo aos filmes jáavaliados pelo usuário. Para esse exemplo, tomamos di “ cos θi, sendo θi o ângulo entrext e xi, i “ 1, ..., 4. Os cálculos estão na Tabela 7 abaixo.
i xt xi cos θi1 (0, 0,707, 0, 0,844) (0,707, 0,707, 0, 0,422) 0,7162 (0, 0,707, 0, 0,844) (0, 0, 1, 0,084) 0,0643 (0, 0,707, 0, 0,844) (0,707, 0, 0, 0,197) 0,2064 (0, 0,707, 0, 0,844) (0, 0, 0, 0,253) 0,767
Tabela 7 – Similaridade entre filmes: Exemplo 3
Tomando um k “ 2 arbritrário, vemos pela Tabela 7 que os dois vetores maispróximos de xt são os vetores x4 e x1. Vamos calcular o valor esperado de yt conformeequação 2.29.
yt “ argmaxcjPt0,1u
ÿ
xiPNpxt,kq
F pyi, cjq
Considerando cj “ 1:
yt “ F py1, 1q ` F py4, 1q
yt “ F p1, 1q ` F p1, 1q
yt “ 1` 1
yt “ 2 (2.31)
Considerando cj “ 0:
yt “ F py1, 0q ` F py4, 0q
yt “ F p1, 0q ` F p1, 0q
yt “ 0` 0
yt “ 0 (2.32)
A condição que maximiza a função 2.29 é quando cj “ 1, então concluímos queo filme “O Poderoso Chefão” é uma boa recomendação para o usuário.
Exemplo 4. K-vizinhos mais próximos em sistemas de vizinhança
Considere a matriz Mmˆn abaixo cujas entradas amn representam as notasdadas por m usuários a n itens diferentes, m P t1, 2, 3, 4, 5u e n P t1, 2, 3, 4u. As notas

Capítulo 2. Modelos matemáticos 62
são dadas em uma escala de 1 a 5, sendo 1 a pior nota e 5 a melhor. Perceba que algunsdos elementos de M são desconhecidos, e denotados pelo símbolo ?. Esses elementosrepresentam itens que não foram avaliados pelo usuário em questão.
M “
»
—
—
—
—
—
—
–
1 ? 4 53 4 3 42 3 5 ?? 5 3 13 ? 2 4
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
Vamos calcular o elemento a34, ou seja, a nota que o usuário três daria aoquarto item. Isso pode ser feito de duas formas: usando a similaridade entre usuários ou asimilaridade entre itens.
Similaridade entre usuários: Iniciaremos os cálculos da similaridade entreusuários centralizando os vetores-linha da matriz M , ou seja, subtraindo de cada elementoo valor médio de sua respectiva linha de forma que a média de todas as linhas seja igual azero. A idéia aqui é diminuir o viés que possa existir quando usuários diferentes avaliamos itens em escalas diferentes. Por exemplo, considere uma escala de avaliações de 1 a 5,sendo 1 a pior nota e 5 a melhor. Pode ser que o usuário i costume dar nota 3 apenas parafilmes que ele realmente não gostou. Do contrário, esse usuário costuma dar notas 4 ou 5.Em contrapartida o usuário i` 1 é mais crítico, e dá nota 3 a itens que gostou, porém nãoadorou. Para evitar que o modelo seja construído de forma enviezada, centralizamos asnotas de cada usuário de forma que todas estejam na mesma escala. É importante notarque a centralização se baseia apenas nos elementos especificados de cada vetor-linha.
M “
»
—
—
—
—
—
—
–
´2, 3 ? 0, 7 1, 7´0, 5 0, 5 ´0, 5 0, 5´1, 3 ´0, 3 1, 7 ?
? 2 0 ´20 ? ´1 1
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
Em seguida, calculamos a similaridade entre usuários. A similaridade é cal-culada com base apenas nos elementos avaliados por ambos os usuários. Por exemplo,como o primeiro usuário avaliou os itens 1, 3 e 4 e o terceiro usuário avaliou os itens 1,2 e 3, a similaridade entre esses dois usuários será calculada com base nas notas dadaspara os itens 1 e 3 apenas. Da mesma maneira como no exemplo 3 iremos calcular asimilaridade entre usuários a partir do cosseno do ângulo entre os vetores correspondentesa cada usuário - quanto mais próximo de 1 o cosseno do ângulo for, mais similares sãoos usuários. Como queremos calcular a nota dada pelo terceiro usuário ao quarto item, atabela abaixo apresenta a similaridade entre o terceiro usuário e todos os outros.

Capítulo 2. Modelos matemáticos 63
Usuário i u3 ui cos θi1 (-1,3, 1,7) (-2,3, 0,7) 0,812 (-1,3, -0,3, 1,7) (-0,5, 0,5, -0,5) -0,194 (-0,3, 1,7) (2, 0) -0,175 (-1,3, 1,7) (0, -1) -0,79
Tabela 8 – Similaridade entre usuários: Exemplo 4
Tomando um k “ 2 arbitrário, vemos que os usuários mais similares ao usuário3 e que possuem uma avaliação para o item 4 são os usuários 1 e 4 (caso algum desses doisusuários não tivesse avaliado o item 4, usaríamos o próximo usuário mais similar cujaavaliação para o item 4 é especificada). Para encontrar o valor de a34 podemos fazer a médiados valores de a14 e a44, ponderada pela similaridade entre os usuários, conforme equação2.30. A função wui nesse exemplo é o cosseno do ângulo entre os vetores correspondentesao usuário u e o usuário i.
aij “
ÿ
uPPipjq
wuiauj
ÿ
uPPipjq
wui
a34 “w13a14 ` w43a44
w13 ` w43
a34 “p0, 81ˆ 1, 7q ` p´0, 17ˆ´2q
p0, 81´ 0, 17qa34 “ 2, 68 (2.33)
Veja que 2,68 é um valor acima de zero (e portanto acima da média) e tambémacima das notas dadas pelo terceiro usuário a qualquer outro item que ele tenha avaliado,e consequentemente deve ser uma boa recomendação para esse usuário.
Similaridade entre itens: Os passos a serem seguidos a fim de calcular a34
através da similaridade entre itens são os mesmos passos detalhados anteriormente, coma diferença de que todos devem ser pautados nos vetores-coluna da matriz M, e não emseus vetores-linha. Nesse caso, os vetores serão centralizados com base na média das notasde cada coluna, assim a média de todas as colunas será zero. Além disso, o ângulo entrevetores deverá ser calculado com base nos vetores-coluna da matriz M centralizada. Aequação 2.2.19 permanece a mesma, com a diferença de que ao invés de Pipjq será usadoo conjunto Pjpiq com os k itens mais próximos ao item j cujas avaliações para o usuário isão especificadas. O valor de wtj será o cosseno do ângulo entre os vetores correspondentesao item t e o item j.
O Algoritmo 2.4 detalha os passos necessários para a implementação do método

Capítulo 2. Modelos matemáticos 64
dos k-vizinhos mais próximos em um problema de regressão. Mais adiante, o Algoritmo2.5 aborda as etapas para a utilização do algoritmo em problemas de classificação, maisespecificamente em sistemas de recomendação baseados em conteúdo. Os algoritmos 2.6 e2.7 apresentam a implementação do algoritmo em sistemas de recomendação baseados emvizinhança, abordando a similaridade entre usuários e então a similaridade entre itens.
Algoritmo 2.4 K-vizinhos mais próximos em sistemas baseados em conteúdo: RegressãoImportar base de dados DDecompor D entre X e yCodificar colunas em X que possuam dados categóricosRemover uma coluna de cada variável categórica codificada em XNormalizar dados em XDividir X e y entre dados de treinamento, dados de validação e dados de testeDeterminar um valor para kUtilizando os dados de treinamento, calcular a distância entre o vetor xt, para o qualqueremos encontrar uma previsão yt, e cada vetor xi, i “ 1, 2, ...,mEncontrar os k vetores xi mais próximos ao vetor xt, definindo a vizinhança Npxt, kqde xtDeterminar a função peso wi de maneira inversamente proporcional à distância entrevetoresA fim de encontrar yt, calcular a média dos valores de yi ponderada por wi para todosos k vetores em Npxt, kq, conforme equação abaixo:
yt “
ř
xiPNpxt,kqwiyi
ř
xiPNpxt,kqwi
Algoritmo 2.5 K-vizinhos mais próximos em sistemas baseados em conteúdo: ClassificaçãoImportar base de dados DDecompor D entre X e yCodificar colunas em X que possuam dados categóricosRemover uma coluna de cada variável categórica codificada em XNormalizar dados em XDividir X e y entre dados de treinamento, dados de validação e dados de testeDeterminar um valor para kUtilizando os dados de treinamento, calcular a distância entre o vetor xt, para o qualqueremos encontrar uma previsão yt, e cada vetor xi, i “ 1, 2, ...,mEncontrar os k vetores xi mais próximos ao vetor xt, definindo a vizinhança Npxt, kqde xtA previsão yt será a classe cj que irá maximizar a equação:
yt “ argmaxcjPtc1,c2,...,chu
ÿ
xiPNpxt,kq
F pyi, cjq
Onde Epyi, cjq “ 1 se yi “ cj e Epyi, cjq “ 0 caso contrário

Capítulo 2. Modelos matemáticos 65
Algoritmo 2.6 K-vizinhos mais próximos em sistemas de vizinhança: Similaridade entreusuáriosImportar matriz de avaliações MCentralizar vetores-linha de MDeterminar um valor para kPara encontrar a projeção da avaliação aij com relação ao usuário i e o item j, calculara similaridade wui entre a linha correspondente ao usuário i e todas as outras linhasEncontrar os k usuários mais similares ao usuário i com avaliações especificadas para oitem j, definindo assim o conjunto PipjqO valor de aij será a média dos valores das avaliações ponderada por wui para todos osk usuários em Pipjq, conforme equação abaixo:
aij “
ÿ
uPPipjq
wuiauj
ř
uPPipjqwui
Algoritmo 2.7 K-vizinhos mais próximos em sistemas de vizinhança: Similaridade entreitensImportar matriz de avaliações MCentralizar vetores-coluna de MDeterminar um valor para kPara encontrar a projeção da avaliação aij com relação ao usuário i e o item j, calculara similaridade wtj entre a coluna correspondente ao item j e todas as outras colunasEncontrar os k itens mais similares ao item j com avaliações especificadas para o usuárioi, definindo assim o conjunto PjpiqO valor de aij será a média dos valores das avaliações ponderada por wtj para todos osk itens em Pjpiq, conforme equação abaixo:
aij “
ÿ
tPPjpiq
wtjait
ř
tPPjpiqwtj
2.6 Árvores de decisãoAlgoritmos baseados em árvores de decisão são algoritmos utilizados tanto em
problemas de classificação como em problemas de regressão. Sua denominação deve-se àestrutura de gráfico em formato de árvore, com uma raiz, nós e folhas (vide Figura 11abaixo).

Capítulo 2. Modelos matemáticos 66
Figura 11 – Exemplo de árvore de decisão cujas folhas apresentam a frequência de comprade um certo produto. Fonte: autora.
O nó de maior hierarquia em uma árvore de decisão é chamado de raiz, sendorepresentado na figura acima pela pergunta “Idade > 30?”. A partir da raiz existem ligações(ramos) para outros nós, chamados de nós internos, ou filhos. Nós que não são conectadosa nenhum outro nó são chamados de folhas. O processo de decisão (ou classificação) érealizado com base no valor das folhas. No exemplo acima, o modelo se baseia em váriascaracterísticas de clientes a fim de definir, para um determinado cliente e um dado produto,qual a frequência de compra mais provável. Por exemplo, P1 pode ser igual a 1 comprapor mês, P2 a 2 compras por mês, P3 a três compras por mês e P4 a 4 compras por mês.Com essas informações, uma empresa é capaz de fazer recomendações mais assertivas aseus clientes.
De maneira geral, a construção de uma árvore de decisão envolve os seguintespassos:
1. Escolha das variáveis que serão utilizadas para a definição dos nós, desde a raiz atéo último nó;
2. Definição das regras que irão dividir os dados a partir de um determinado nó, combase no valor da variável que define o nó;
3. Definição das regras que definem quando um determinado ramo deve ser encerrado,formando uma folha, ou deve se dividir em novos nós;
4. Definição do valor predito para a variável alvo em cada folha.
No primeiro passo devem ser escolhidas as variáveis mais relevantes para adefinição dos nós. Nos algoritmos de árvore de decisão para regressão, isso é feito através

Capítulo 2. Modelos matemáticos 67
da mensuração da menor distorção quadrática (MSE, do inglês Minimum Squared Error),definida por:
MSE “mÿ
i“1pyi ´ yiq
2 (2.34)
Onde yi é o i-ésimo elemento da variável alvo y e yi a respectiva predição. OMSE dependerá da variável preditiva em questão e de seu respectivo valor de corte, e deveráser calculado para cada variável considerando um conjunto de valores de corte distintos.O par variável-valor de corte com o menor MSE deve ser escolhido para a definição dopróximo nó.
A título de exemplo, considere os dados da Tabela 9, que relacionam a idade enotas atribuídas por leitores para um determinado livro. Suponha que desejamos construiruma árvore de decisão para predizer a nota em função da variável idade.
Idade Nota12 414 517 518 419 420 323 425 326 329 330 235 438 341 149 252 353 160 265 1
Tabela 9 – Notas para um determinado livro por idade do leitor
Na Figura 12 são apresentadas duas árvores de decisão para esse problema. Naprimeira, o nó raiz divide os dados tendo como corte a idade de 31 anos, resultando emum MSE de 17,4. Na segunda, usando a idade de 19,5 anos como corte, o MSE é 14,4. Ouseja, a segunda árvore é melhor do que a primeira.

Capítulo 2. Modelos matemáticos 68
Figura 12 – Exemplo de duas árvores de decisão. Fonte: autora.
Podemos incluir um novo ramo na segunda árvore ao incluir, por exemplo, umnovo nó que divide os dados mais uma vez, agora tendo como linha de corte a idade de38,5 anos. Isso é ilustrado na Figura 13. Nesse caso, o MSE da nova árvore será de 7,4,ou seja, bem melhor que a segunda árvore da Figura 12. Esse processo pode ser repetidoiterativamente até atingir o limite do número de ramos. No entanto, nesse processo deramificação da árvore, deve-se atentar para evitar o overfitting.
Figura 13 – Exemplo de árvore de decisão com dois níveis. Fonte: autora.
Cada árvore ilustrada na Figura 12 divide os dados em duas regiões, R1 eR2, e a predição em cada região pode ser dada, por exemplo, pela média das notas dasobservações pertencentes àquela região, conforme ilustrado na Figura 14.

Capítulo 2. Modelos matemáticos 69
Figura 14 – Ilustração de regiões geradas por uma árvore de decisão. Fonte: autor.
Esse processo pode ser generalizado para considerar várias variáveis e valoresde corte, gerando distintas regiões Ru, onde a predição em cada região será dada pelamédia dos valores da variável alvo correspondentes às observações pertencentes aquelaregião.
A popularidade dos algoritmos baseados em árvores de decisão se deve a algunsfatores, entre eles a maneira como as soluções são apresentadas de forma a facilitar avisualização e o entendimento. Uma vez tendo a árvore construída, o usuário conseguevisualizar exatamente a combinação de variáveis que leva a cada decisão. Do ponto de vistaprático as árvores de decisão são aplicáveis tanto a problemas de regressão, cuja variáveldependente é numérica, quanto a problemas de classificação, cuja variável dependente écategórica (MARSLAND, 2009).
Entre as dificuldades encontradas na construção e implementação de árvoresde decisão está a tendência ao overfitting, principalmente quando o número de folhasna árvore é alto. Isso acontece quando o algoritmo “memoriza” os dados previamenteconhecidos e perde a capacidade de previsão para novas observaçoes (LAST; MAIMOM;MINKOV, 2002). Além disso, pequenas variações nos dados utilizados na construção domodelo podem gerar árvores muito diferentes entre si (LAST; MAIMOM; MINKOV, 2002).Técnicas de “poda” da árvore, como por exemplo limitar o número de folhas ou de níveis,podem atenuar esses efeitos (MARSLAND, 2009).

Capítulo 2. Modelos matemáticos 70
2.6.1 Embasamento Matemático
2.6.1.1 Regressão
Existem várias estratégias para se construir uma árvore de decisão (ROKACH;MAIMON, 2015), dentre elas destacaremos, neste trabalho, o algoritmo CART. O métodoCART, acrônimo para Classification and Regression Trees, nos permite construir árvorestanto para dados numéricos, em casos de algoritmos de regressão, como para dadoscategóricos em algoritmos de classificação (MARSLAND, 2009). Na sequência apresentamosuma breve introdução sobre a construção de uma árvore de regressão utilizando o métodoCART. Uma referência mais completa pode ser encontrada em (MARSLAND, 2009),(HASTIE; TIBSHIRANI; FRIEDMAN, 2017) e (ROKACH; MAIMON, 2015).
A título de exemplo, considere a árvore representada na Figura 15, gerada apartir de uma base de dados D. Seja D um conjunto de m observações, com n variáveisindependentes e uma variável alvo, similar ao ilustrado na Figura 4. Cada observação édefinida como um vetor xi P R
n, onde i “ 1, ...,m. O j-ésimo elemento xij do vetor xi
corresponde ao valor da variável j para a observação i, sendo j “ 1, ..., n. A variável alvoé denotada pelo vetor y P Rm.
A árvore do lado direito da Figura 15 divide os dados em quatro regiões.Para toda observação xi em uma região Ru, sendo u “ 1, 2, 3, 4, o valor yi predito peloalgoritmo será o mesmo. Em outras palavras, para qualquer ponto pxi1, xi2q dentro de R1,por exemplo, o valor de yi será o mesmo (DOMKE, 2010).
Figura 15 – Árvore de regressão com quatro folhas, representadas pelas regiões R1, R2,R3 e R4. Fonte: autora.
Como todo yi relativo a um vetor xi em uma região Ru tem o mesmo valor,teremos ao fim u valores distintos para yi. Para encontrar o valor de yi para cada região u

Capítulo 2. Modelos matemáticos 71
que minimiza o MSE, ou seja, que minimiza a diferença entre yi e yi, devemos resolver oproblema 2.35 abaixo:
yi “ argminyi
ÿ
xiPRu
pyi ´ yiq2 (2.35)
Manipulando o somatório da equação 2.35 teremos:
S “ÿ
xiPRu
pyi ´ yiq2
S “ÿ
xiPRu
py2i ´ 2yiyi ` y2
i q
S “ÿ
xiPRu
y2i ´ 2yi
ÿ
xiPRu
yi `ÿ
xiPRu
y2i
S “ Ny2i ´ 2yi
ÿ
xiPRu
yi `ÿ
xiPRu
y2i (2.36)
Onde N no primeiro termo é o número de vetores xi na região Ru. Paraminimizar S em 2.36, podemos diferenciar com relação a yi:
BS
Byi“ 2Nyi ´ 2
ÿ
xiPRu
yi (2.37)
Igualando a equação 2.37 a zero, concluímos que o valor de yi que minimiza oerro é a média de todos os pontos yi que correspondem aos vetores xi em Ru:
BS
Byi“ 0
2Nyi ´ 2ÿ
xiPRu
yi “ 0
2Nyi “ 2ÿ
xiPRu
yi
yi “
ř
xiPRuyi
N(2.38)
A partir dos cálculos acima, já estabelecemos que o valor de yi a ser inferidopelo modelo para qualquer xi pertencente a uma região Ru será a média de todos os valoresyi relativos a xi em Ru (DOMKE, 2010). No entanto, precisamos definir quais serão essasregiões Ru do modelo, e isso implica em definir quais variáveis irão em cada um dos nós,em qual ordem, e qual será o valor de corte que será usado em cada nó para definir os

Capítulo 2. Modelos matemáticos 72
ramos. Para exemplificar esse processo, considere o exemplo da Figura 15. Veja que aprimeira variável definida para ocupar a posição de nó raiz foi a variável j1. Se j1 é maiordo que k, sendo k o valor de corte da variável j1 no nó raiz, então o vetor xi pertencerá àregião R4. Do contrário, seguimos para investigar o valor de j2. Se j2 é maior do que ovalor de corte g, então o vetor xi pertencerá à R3. Caso contrário, seguimos para verificarnovamente o valor de j1, porém agora no terceiro nó e não mais no nó raiz. Se j1 for maiordo que a nota de corte s então xi pertence à R2, e se finalmente nenhuma dessas condiçõesfoi satisfeita, xi pertence à região R1.
A fim de iniciar os cálculos que estabelecerão as regiões Ru definiremos o vetorvj como o vetor-coluna relativo à variável independente vj, j “ 1, ..., n, e vij como oelemento i do vetor vj. Seja s o valor de corte relativo à variável vj. Como s P R, existeminfinitas possibilidades de escolha para um valor de corte. No entanto, existem apenasalguns valores de s que otimizam a construção da árvore de decisão. Dado um j qualquer,ordenamos os elementos de vj em ordem crescente e definimos os valores médios entrecada par (vij,vpi`1qj) (DOMKE, 2010). Ao fim, teremos m ´ 1 possibilidades de s paracada vj. O cálculo de s é exemplificado abaixo para um valor j fixo:
s11 “v1j ` v2j
2s12 “
v2j ` v3j
2...
s1pm´1q “vpm´1qj ` vmj
2
Sendo m o número de observações no conjunto de dados D.
Seguimos a fim de determinar dois conjuntos, T1 e T2, tal que:
T1pj, sq “ txi, xij ď su T2pj, sq “ txi, xij ą su (2.39)
Os conjuntos T1 e T2 dividem os dados da base de dados D em duas regiões.Sejam y1 e y2 os valores de yi preditos para cada uma dessas duas regiões. Queremosencontrar j e s que irão minimizar o erro entre o valor predito de yi e o valor real yi:
argminj,s
rargminy1
ÿ
xiPT1pj,sq
pyi ´ y1q2` argmin
y2
ÿ
xiPT2pj,sq
pyi ´ y2q2s (2.40)
Como demonstrado anteriormente, os valores de y1 e y2 que minimizam ostermos internos da equação 2.41 são as médias dos valores de yi para todo xi pertencente

Capítulo 2. Modelos matemáticos 73
aos conjuntos T1pj, sq e T2pj, sq. A fim de definir o par pj, sq que irá minimizar o valorda equação 2.41, para todo j P p1, 2, ..., nq calcula-se qual o erro entre y1 e y2 e o valorreal yi. Como y1 e y2 dependem da escolha de s, esse cálculo deverá ser feito m´ 1 vezespara cada j P p1, 2, ..., nq. Ao fim da primeira iteração, uma matriz pm´ 1q ˆ n poderáser construída, onde cada valor eij será o erro relativo à variável vj com o respectivo valorde corte s1i. O par pi, jq com o menor valor será escolhido para definir a variável que irá nopróximo nó da árvore, assim como o valor de corte (HASTIE; TIBSHIRANI; FRIEDMAN,2017).
Uma vez com a primeira variável e o valor de corte definidos, repetimos oprocesso nas duas regiões resultantes da divisão, e assim por diante.
Uma árvore muito grande e que leva em consideração muitas variáveis podelevar ao overfitting. Isso acontece porque o algoritmo passa a contar como relevantesvariáveis que não necessariamente contribuem para o valor do atributo alvo, tomandocasos específicos como regras a serem seguidas. Para evitar esse fenômeno. técnicas depoda podem ser aplicadas. Uma forma fácil de podar a árvore é configurar o processo paraque as iterações sejam interrompidas quando o número de observações em uma regiãochegar a um valor mínimo estabelecido. Existem outros métodos de poda de árvores dedecisão, entre eles o Cost Complexity Criterion. A idéia é que nós internos de uma árvoresejam retirados e, a cada nó eliminado, um custo é calculado. A sequência de sub-árvorescom custo mínimo é a árvore definitiva. Mais detalhes sobre Cost Complexity Criterionpodem ser encontrados em (HASTIE; TIBSHIRANI; FRIEDMAN, 2017).
2.6.1.2 Classificação
Um dos algoritmos mais populares na construção de árvores de classificação éo algoritmo ID3, criado por J. Ross Quinlan (MARSLAND, 2009), e será abordado emmais detalhes nos próximos parágrafos.
A fim de entender o algoritmo ID3, é necessário compreender alguns conceitosfundamentais sobre “Teoria da Informação”. De maneira simples, a teoria da informação éum campo da matemática aplicada que consiste em estudar a quantidade de informaçãoexistente em um sinal (GOODFELLOW; BENGIO; COURVILLE, 2016).
Uma das idéias fundamentais em teoria da informação é a de que saber daocorrência de um evento improvável nos traz mais informação do que saber da ocorrênciade um evento provável. Por exemplo, se alguém disser algo como “isso aconteceu no dia emque o sol nasceu”, não é possível captar nenhuma informação que nos ajude a especificarque dia foi esse, uma vez que o sol nasce todos os dias. Agora, se a mesma pessoa nos disser“isso aconteceu no dia em que houve um eclipse”, que é um evento muito mais improváveldo que o nascer do sol, temos muito mais informação que nos ajude a determinar a data àqual a pessoa se refere.

Capítulo 2. Modelos matemáticos 74
Seja X uma variável aleatória, e x um dos estados possíveis para essa variável.A informação contida no evento X = x é definida pela equação 2.41 abaixo:
Ipxq “ ´ logP pxq (2.41)
Onde P pxq é a probabilidade de que X = x. A unidade de medida de Ipxqdepende da base do logaritmo utilizado para calcular Ipxq. Para base e, a unidade demedida é em nats. Para base 2, a unidade de medida seria em bits ou shannons. De formaintuitiva, 1 nat seria o total de informação que se ganha ao observar um evento comprobabilidade 1/e.
Enquanto a equação 2.41 nos traz a informação contida em um evento conside-rando um único resultado (no caso, X = x), é possível calcular a quantidade de informaçãopara uma distribuição de probabilidade completa utilizando o conceito de “Entropia”,conforme equação 2.42 abaixo:
HpXq “ EX„P rIpxqs “ ´EX„P rlogP pxqs (2.42)
Segundo a equação 2.42, a entropia H de uma variável aleatória X que seguea distribuição P é o valor esperado de informação para um evento proveniente dessadistribuição (GOODFELLOW; BENGIO; COURVILLE, 2016).
A entropia também pode ser vista sob o ponto de vista de incerteza. Paradistribuições quase determinísticas, cujo resultado pode ser inferido com quase 100% decerteza, a entropia será baixa (lembre-se do exemplo do nascer do sol: como ocorre tododia, saber que o sol nasceu quase não nos traz nenhuma informação). Agora imagine umavariável aleatória X cuja distribuição P é uniforme (por exemplo no caso de jogar umamoeda, onde temos 50% de probabilidade de cara e 50% de coroa). Nesse caso a entropiaserá alta, uma vez que temos um alto nível de incerteza.
O gráfico na figura 16 ilustra a relação entre probabilidade e entropia para umavariável aleatória binária com dois possíveis resultados: x1 e x2.

Capítulo 2. Modelos matemáticos 75
Figura 16 – Entropia para uma variável aleatória binária. Fonte: autora.
Seja o eixo horizontal a probabilidade de x1. Então, quando ppx1q “ 0 temosque ppx2q “ 1, e a entropia será:
HpXq “ ´EX„P rlogP pxqs
HpXq “ ´ÿ
xPX
ppxqfpxq
HpXq “ ´pppx1q log ppx1q ` ppx2q log ppx2qq
HpXq “ ´p0` 1 log 1q “ 0 Nats
O mesmo pode ser calculado caso ppx1q “ ppx2q “ 0, 5:
HpXq “ ´pppx1q log ppx1q ` ppx2q log ppx2qq
HpXq “ ´p0, 5 log 0, 5` 0, 5 log 0, 5q “ 0, 69 Nats
Como ilustrado acima, o pico de entropia para uma variável aleatória bináriase dá quando ambos os possíveis resultados tem probabilidade de 50%, ou seja, quando onível de incerteza é máximo.
De volta à construção de árvores de classificação, utilizamos o conceito deentropia para definir qual será a estrutura da árvore, ou seja, sua raiz, nós, ramos e folhas.O algoritmo ID3 calcula qual o ganho de informação (quanto maior a entropia da variávelmaior o ganho de informação) para cada variável independente. A variável que estará nopróximo nó é a variável com o maior ganho de informação.

Capítulo 2. Modelos matemáticos 76
Seja a base de dados D um conjunto de m tuplas {xi , yi}, i “ 1, ...,m, onde mé o número total de observações, xi P R
n, sendo n o número de variáveis de independentese yi é uma variável categórica, pertencente a um conjunto de classes C “ tc1, c2, ...chu,sendo h o número total de classes. Definiremos vj como o vetor-coluna relativo à variávelindependente vj , j “ 1, 2, ...n, e xij como o elemento do vetor xi correspondente à variávelvj.
v1 v2 v3 ... vn y
x11 x12 x13 ... x1n c1x21 x22 x23 ... x2n c1... ... ... ... ... ...
xpm´1q1 xpm´1q2 xpm´1q3 ... xpm´1qn c3xm1 xm2 xm3 ... xmn ch
Tabela 10 – Base de dados D com m observações, n variáveis independentes, e y categóricocom h classes
Calculamos o ganho de informação de cada variável independente vj em D
conforme a equação 2.43 abaixo:
GanhopS, jq “ EntropiapSq ´ÿ
fPvj
|Sf ||S|
EntropiapSf q (2.43)
Onde S é o conjunto de todos os vetores xi em D, |S| é a contagem de todasas linhas (ou observações) em S, Sf é o subconjunto de S cujas linhas tem valor f para avariável vj, e |Sf | é a contagem de todas as linhas (ou observações) em Sf .
Para se calcular a entropia de S utilizamos a equação 2.44 abaixo:
EntropiapSq “ ´ÿ
cPS
ppcq log ppcq (2.44)
EntropiapSq “ ´ppc1q log ppc1q ´ ppc2q log ppc2q ´ ppc3q log ppc3q ´ . . .´ ppchq log ppchq
Na primeira iteração do algoritmo, |S| será igual am. Agora tomemos a primeiravariável independente, v1, e calculemos a entropia de cada subconjunto Sf . Voltemos àTabela 10, porém dessa vez com m “ 4 e preenchendo com valores a coluna referente a v1:
v1 v2 v3 ... vn y
a1 x12 x13 ... x1n c1a3 x22 x23 ... x2n c1a3 x32 x33 ... x3n c3a2 x42 x43 ... x4n ch

Capítulo 2. Modelos matemáticos 77
Existem apenas três classes de valores em v1, f “ a1, a2 e a3. Com isso,Sa1, Sa2 e Sa3 serão:
Sa1
v1 v2 v3 ... vn y
a1 x12 x13 ... x1n c1
Sa2
v1 v2 v3 ... vn y
a2 x42 x43 ... x4n ch
Sa3
v1 v2 v3 ... vn y
a3 x22 x23 ... x2n c1a3 x32 x33 ... x3n c3
As entropias de Sa1 , Sa2 e Sa3 podem ser calculadas da mesma forma como foicalculada a entropia de S (equação 2.44), a única diferença é que ao invés de utilizar todoo conjunto S, as entropias agora serão calculadas a partir de subconjuntos de S. O númerode observações em cada subconjunto Sf será o valor de |Sf |.
Finalmente, o ganho de informação em S da variável v1 será:
GanhopS, jq “ EntropiapSq ´ÿ
fPvn
|Sf ||S|
EntropiapSf q (2.45)
Substituindo os subconjuntos do exemplo na equação 2.45:
GanhopS, 1q “ EntropiapSq
´ p|Sa1||S|
EntropiapSa1q `|Sa2||S|
EntropiapSa2q `|Sa3||S|
EntropiapSa3qq
Na primeira iteração do algoritmo, o ganho é calculado conforme a equaçãoacima para todas as n variáveis vj . A variável com o maior ganho será a variável escolhidapara o nó raiz.
Estarão ligados ao nó raiz um número r de ramos, de acordo com o númerototal de classes existentes na variável definida para representar o nó. Por exemplo, seo maior ganho fosse comprovado ser o ganho referente a v1, então teríamos três ramosa partir do nó raiz: c1, c2 e c3. Isolando cada uma dessas três classes na base de dados,

Capítulo 2. Modelos matemáticos 78
obtemos os três subconjuntos já ilustrados anteriormente: Sa1 , Sa2 e Sa3 . A iteração é feitamais uma vez para cada ramo, calculando os ganhos relativos a cada subconjunto paracada variável independente.
Existem vários critérios para determinar o interrompimento desse processoiterativo, como número mínimo de elementos em cada folha, profundidade da árvore,ou quando existe apenas uma classe em y em um subconjunto Sf (e quando esse éo caso adiciona-se uma folha representando essa classe) (GOODFELLOW; BENGIO;COURVILLE, 2016).
2.6.1.3 Sistemas de filtragem colaborativa
A fim de trabalhar com árvores de decisão em sistemas de filtragem colaborativa,nos deparamos com dois desafios. O primeiro é delimitar quais são as variáveis preditivase qual é a variável de saída, uma vez que em uma matriz de avaliações Amˆn as variáveisde previsão e de saída não estão claramente definidas como em modelos baseados emconteúdo. O segundo é o problema de matrizes esparsas. Uma vez que um grande númerode usuários não terá avaliações conhecidas para vários itens, onde encaixá-los em umapotencial bifurcação na árvore?
Podemos tratar o primeiro problema se definirmos como variável de respostaum item por vez e construirmos n árvores. Por exemplo, se queremos prever qual seráa avaliação de um usuário para o item 1, correspondente à primeira coluna em Amˆn,construimos a árvore de decisão usando todas as colunas da matriz A como variáveis deprevisão, com exceção da primeira coluna, que será tratada como variável de resposta. Aofim teremos n árvores diferentes. Essas árvores serão utilizadas conforme o item para oqual queremos prever uma avaliação.
O segundo problema pode ser tratado utilizando o método de mitigação doproblema de matrizes esparsas através da redução de dimensionalidade da matriz A,método esse discutido na seção 2.4.2. Novamente, se queremos prever qual será a avaliaçãode um usuário para o item 1, tomamos todas as outras colunas da matriz A, que agoraserá uma matriz mˆ pn´ 1q e encontramos a matriz completamente especificada Rmˆp,p ă pn´ 1q. Tomamos as p colunas de R como sendo as variáveis de previsão, e a colunarelativa ao item 1 como a variável de saída. Construimos a árvore utilizando, a partir dessenovo conjunto de dados, as linhas relativas aos usuários cujas avaliações para o item 1 sãoconhecidas. Ao final teremos n árvores, cada uma relativa a um item. A fim de fazermosprevisões para um usuário u com relação ao item i, utilizamos a árvore construída para oitem i a partir das matrizes completamente especificadas (AGGARWAL, 2016).

Capítulo 2. Modelos matemáticos 79
2.6.2 Aplicação em sistemas de recomendação
Discutiremos a seguir dois exemplos de regressão e classificação para sistemasbaseados em conteúdo.
Exemplo 5. Árvore de regressão
Entre os filmes com as maiores bilheterias da história, cinco foram selecionadose são apresentados na tabela abaixo:
Filme Ano Bilheteria (USD Milhões) AvaliaçãoAvengers: Endgame 2019 2.797,8 4,2
Avatar 2009 2.789,7 3,9Titanic 1997 2.187,5 4,9
Star Wars: The Force Awakens 2015 2.068,2 2,5Jurassic World 2015 1.671,7 3,1
Tabela 11 – Avaliações para cinco filmes entre as maiores bilheterias da história
Queremos construir uma árvore de regressão a partir dos dados na tabela acima.Vamos primeiro analisar a variável v1, relativa ao ano de lançamento do filme. Ordenamosos filmes do mais antigo ao mais novo, e encontramos os candidatos à ponto de corte s1:
Ano Avaliação s1 Valor de s1
1997 4,92009 3,9 s11 20032015 2,5 s12 20122015 3,1 s13 20152019 4,2 s14 2017
Tabela 12 – Árvore de regressão: Primeira iteração com variável ano
Para s11 “ 2003, teremos os seguintes subconjuntos T1pj, sq e T2pj, sq:
T1pano, 2003q1997 4,9
T2pano, 2003q2009 3,92015 2,52015 3,12019 4,2
Como T1pano, 2003q possui apenas uma observação, y1 “ 4, 9 e portanto y1 ´
y1 “ 4, 9´ 4, 9 “ 0, ou seja, o erro relativo à T1pano, 2003q é zero. Já em T2pano, 2003q,

Capítulo 2. Modelos matemáticos 80
a média das avaliações será y2 “ 3, 43, e a soma dos erros quadrados será 1, 79. A somados erros relativos a T1pano, 2003q e T2pano, 2003q será então 0` 1, 79 “ 1, 79.
Esse processo é repetido para os outros três candidatos à ponto de corte paraa variável de ano. Depois, a mesma coisa é feita para a variável de bilheteria. Ao fim,podemos compilar os erros conforme tabela abaixo:
Erros para cada conjunto pvj, s1qs Ano Bilheterias11 1,79 3,05s12 1,99 0,71s13 3,24 3,14s14 3,24 3,24
Como o menor erro é relativo ao ponto de corte s12 da variável bilheteria,sabemos que o nó raiz da árvore será correspondente a essa variável. O ponto de corte s12para a variável bilheteria é o valor 2.127, 85. Existem três bilheterias maiores que 2.127, 85e que formam o primeiro subconjunto, e duas menores ou iguais a 2.127, 85, formando osegundo subconjunto. Seguimos para uma segunda iteração do algoritmo, agora performandoos mesmos passos acima, porém nos dois subconjuntos resultantes da primeira iteração.Ao final, a árvore de regressão possuirá a seguinte forma:
Figura 17 – Árvore de regressão finalizada. Fonte: autora.
Perceba que a árvore apresentada acima poderia ser podada de forma a evitaroverfitting. Poderíamos por exemplo limitar a profundidade da árvore a apenas dois níveis,ao invés de três, que é o que a árvore completa possui. Caso a limitação de dois níveisfosse realizada, filmes com bilheteria maior que US$ 2.488.600.000,00 seriam avaliados em

Capítulo 2. Modelos matemáticos 81
3, 9` 4, 9` 4, 23 “ 4, 3, ou seja, a média das avaliações de todos os filmes cuja bilheteria
está acima do ponto de corte.
Exemplo 6. Árvore de classificação
Considere a tabela abaixo referente a cinco filmes de diferentes gêneros edistribuidoras. Na coluna de avaliação, o valor 1 corresponde a uma “curtida”, ou seja,uma manifestação de interesse por parte do usuário.
Gênero Distribuidor AvaliaçãoAção Disney 1Ação 20th Century 1Drama 20th Century 0Ficção Disney 0Ficção Universal 1
Tabela 13 – Avaliações para cinco filmes conforme gênero e distribuidora
Vamos calcular a entropia relativa ao conjunto S, ou seja, o conjunto de dadoscompleto. Temos que |S| é cinco, porque temos cinco observações. Além disso, dentre ascinco observações, três tem avaliação 1 e duas tem avaliação 0, portanto a probabilidadepp1q “ 3{5 e a probabilidade pp0q “ 2{5. Calculemos a entropia de S (note que estamosusando log na base 2, então o valor da entropia se dá em bits).
EntropiapSq “ ´ppc1q log ppc1q ´ ppc2q log ppc2q
EntropiapSq “ ´p3{5q logp3{5q ´ p2{5q logp2{5q
EntropiapSq “ 0, 97bits
A fim de definir qual variável irá no nó raiz da árvore, vamos primeiramenteencontrar o ganho de informação relativo à variável de gênero. Existem três classes navariável de gênero: ação, drama e ficção. A partir dessas três classes, criamos três subgruposSação, Sdrama e Sficção, conforme abaixo:
SaçãoGênero Distribuidora AvaliaçãoAção Disney 1Ação 20th Century 1
SdramaGênero Distribuidora AvaliaçãoDrama 20th Century 0

Capítulo 2. Modelos matemáticos 82
SficçãoGênero Distribuidora AvaliaçãoFicção Disney 0Ficção Universal 1
É preciso calcular o tamanho e a entropia de cada subgrupo. Para calcular otamanho, é só contar o número de observações em cada conjunto. Com isso temos que|Sação|“ 2, |Sdrama|“ 1 e |Sficção|“ 2. Pode-se calcular a entropia da mesma forma comofizemos com o conjunto completo de dados, S, utilizando a equação 2.44.
EntropiapSaçãoq “ ´ÿ
cPSação
ppcq log ppcq
EntropiapSaçãoq “ ´ppc1q log ppc1q ´ ppc2q log ppc2q
EntropiapSaçãoq “ ´pp1q log pp1q ´ pp0q log pp0q
EntropiapSaçãoq “ ´1 log 1´ 0 log 0
EntropiapSaçãoq “ 0
EntropiapSdramaq “ ´pp1q log pp1q ´ pp0q log pp0q
EntropiapSdramaq “ ´0 log 0´ 1 log 1
EntropiapSdramaq “ 0
EntropiapSficçãoq “ ´pp1q log pp1q ´ pp0q log pp0q
EntropiapSficçãoq “ ´0, 5 log 0, 5´ 0, 5 log 0, 5
EntropiapSficçãoq “ 1 bit
Podemos agora calcular o ganho de informação da variável gênero, conformeequação 2.43.
GanhopS, gêneroq “ EntropiapSq ´ÿ
fPvj
|Sf ||S|
EntropiapSf q (2.46)
GanhopS, gêneroq “ 0, 97´ p25 ˆ 0` 15 ˆ 0` 2
5 ˆ 1q
GanhopS, gêneroq “ 0, 57
O mesmo processo é repetido para a variável distribuidora, onde encontramosque o Ganho(S, distribuidora) é 0,17, que é menor do que o ganho da variável gênero.

Capítulo 2. Modelos matemáticos 83
Escolhemos portanto a variável gênero para o nó raiz, que terá três ramos: ação, drama eficção. A partir desses três ramos seguimos com uma segunda iteração, agora em cada umdos subconjuntos Sação, Sdrama e Sficção. Caso o subconjunto de dados referente a uma certaclasse apresente apenas observações com a mesma avaliação, uma folha será adicionadacom o valor dessa avaliação e a segunda iteração para essa classe estará completa. Casocontrário, como para esse exemplo o conjunto de dados S possui apenas duas variáveisindependentes, já fica claro que a variável dos nós do segundo nível da árvore será adistribuidora, uma vez que na primeira iteração já foram criados subconjuntos cuja variávelgênero é fixa em cada um.
Ao fim do processo, a árvore de classificação será conforme abaixo:
Figura 18 – Árvore de classificação finalizada. Fonte: autora.
São apresentados a seguir dois algoritmos que resumem os principais passospara a construção de árvores de regressão e classificação.

Capítulo 2. Modelos matemáticos 84
Algoritmo 2.8 Árvore de regressãoImportar base de dados DDecompor D entre X e yCodificar colunas em X que possuam dados categóricosRemover uma coluna de cada variável categórica codificada em XNormalizar dados em XDividir X e y entre dados de treinamento, dados de validação e dados de testeUtilizando os dados de treinamento, definir a primeira variável a ser testada para o nóraiz como v1Ordenar o conjunto de dados de treinamento de maneira crescente conforme os valoresem v1Encontrar os m´ 1 candidatos à ponto de corte s1Definir os primeiros conjuntos T1 e T2 de acordo com o primeiro s1Para cada conjunto definido acima, calcular yu, u “ 1, 2, conforme equação abaixo:
yu “
ř
xiPTuyi
N
Encontrar a soma dos erros quadrados entre yu e yi para T1 e T2Repetir o processo acima para todos os outros candidatos à ponto de corte s1, e depoisrepetir o mesmo processo para as outras variáveis vjDefinir a variável e o valor de s1 com o menor erro como variável e ponto de corte aserem utilizados no nó da árvoreRealizar esse processo iterativamente para cada subdivisão resultante da última definiçãode variável nó e ponto de corte

Capítulo 2. Modelos matemáticos 85
Algoritmo 2.9 Árvore de classificaçãoImportar base de dados DDecompor D entre X e yCodificar colunas em X que possuam dados categóricosRemover uma coluna de cada variável categórica codificada em XNormalizar dados em XDividir X e y entre dados de treinamento, dados de validação e dados de testeUtilizando os dados de treinamento, calcular a entropia total do conjunto de dadosatravés da equação abaixo:
EntropiapSq “ ´ÿ
cPS
ppcq log ppcq
Definir a primeira variável a ser testada para o nó raiz como v1Calcular as entropias Sf de cada subgrupo relativo aos valores da variável v1Calcular o ganho de informação da variável v1 através da equação abaixo:
GanhopS, jq “ EntropiapSq ´ÿ
fPvj
|Sf ||S|
EntropiapSf q
Repetir esse processo para as outras variáveis, e definir como variável do nó raiz a quepossui o maior ganho de informaçãoRealizar esse processo iterativamente para cada subdivisão resultante da última definiçãode variável nó
2.7 Redes Neurais ArtificiaisAs redes neurais artificiais tem marcado presença em vários dos desenvolvi-
mentos mais modernos e empolgantes de inteligência artificial. Por sua alta versatilidade,ficaram conhecidas como "aproximadoras universais de funções"(AGGARWAL, 2016),podendo ser aplicadas tanto em problemas de classificação como regressão.
Apesar da versatilidade, o maior “trunfo” das redes neurais está na forma comoaprendem, simulando a maneira como o próprio cérebro humano adquire conhecimento.Através do fortalecimento ou enfraquecimento dos sinais sinápticos entre neurônios, océrebro é capaz de consolidar ou não o nosso entendimento a partir de um estímulo externo.Da mesma forma, o aprendizado de algoritmos baseados em redes neurais é feito atravésdo ajuste dos pesos entre os neurônios de uma rede.
Os neurônios (também chamados nós) de uma rede neural são organizados emcamadas que podem ser de três tipos: camada de entrada, camadas ocultas e camada desaída. Os nós de cada camada são ligados aos nós da próxima camada através de conexões,sendo que cada conexão possui um peso, conforme ilustrado na Figura 19.

Capítulo 2. Modelos matemáticos 86
Figura 19 – Figura esquemática de uma rede neural. Fonte: autora.
Denominamos I a quantidade total de nós xi na camada de entrada, J o númerototal de nós zj na camada oculta, e K o número total de nós yk na camada de saída.Na figura acima o esquema foi desenhado considerando a observação t de um total de Tobservações. Cada conexão terá peso wmn, onde m representa o índice do nó inicial e n oíndice do nó final (STONE, 2020).
O valor total de entrada em um nó é denominado u e também é chamado deinput total. O input u é a soma dos produtos dos valores dos nós da camada anterior eseus respectivos pesos. Designamos a cada nó uma função de ativação fpuq, de forma quea saída desse nó (ou output) é igual ao resultado da aplicação fpuq no input total u.
De maneira genérica, uma rede neural é treinada através do fornecimento deinputs aos nós na camada de entrada. Esses inputs alimentarão uma função de ativaçãofpuq, e o resultado dessa aplicação será o output desses nós. Para cada nó na próximacamada, somamos os produtos entre o output dos nós da camada de entrada e os pesos dasconexões entre esses nós e o nó da camada atual. Essa soma de produtos será o input totaldos nós da camada oculta, que por sua vez alimentará uma nova função de ativação quegerará o output desses nós. Esse processo é realizado em todos os nós de todas as camadasaté chegar nos nós da camada de saída. O erro entre os outputs dos nós da camada desaída e o respectivo valor real é calculado, e o valor desse erro é utilizado para atualizaros pesos da rede. Esse processo é feito iterativamente até que o erro esteja dentro de umvalor desejado.
2.7.1 Embasamento matématico
Como mencionado anteriormente, o valor do erro calculado ao fim de umaiteração é utilizado para atualizar os pesos de toda a rede. O objetivo final sempre é

Capítulo 2. Modelos matemáticos 87
minimizar o erro entre o valor de um output calculado pela rede neural e seu valor real.
Apesar da existência de dezenas de algoritmos de minimização, um algoritmoamplamente utilizado na minimização de funções em problemas de aprendizado de máquinaé o gradiente descendente, que será abordado a seguir.
2.7.1.1 Gradiente Descendente
Considere a rede neural apresentada a seguir, com dois nós na camada deentrada, dois nós na camada oculta, um nó na camada de saída e um peso para cadaconexão entre nós:
Figura 20 – Rede neural com dois nós na camada de entrada, dois nós na camada oculta eum nó na camada de saída. Fonte: autora.
Seja yt o valor real do nó de saída para a observação t e yt o output calculadopela rede neural. O valor dos inputs em z1t e z2t para a observação t serão:
z1t “ x1tw11 ` x2tw21
z2t “ x1tw12 ` x2tw22 (2.47)
O output yt será uma função de z1t e z2t:
yt “ fpz1tqw3 ` fpz2tqw4 (2.48)
De maneira didática, consideremos um total de observações T “ 2. Construimosentão duas equações para yt, tal que t P r1, T s:

Capítulo 2. Modelos matemáticos 88
y1 “ fpz11qw3 ` fpz21qw4
y1 “ fpx11w11 ` x21w21qw3 ` fpx11w12 ` x21w22qw4 (2.49)
y2 “ fpz12qw3 ` fpz22qw4
y2 “ fpx12w11 ` x22w21qw3 ` fpx12w12 ` x22w22qw4 (2.50)
O objetivo é encontrar os pesos que minimizem o erro da equação e aproximemyt e yt ao máximo. Seja yt = yt. Como os valores de x1t, x2t e yt são conhecidos para cadaiteração t, possuímos duas equações e seis variáveis desconhecidas (os pesos w11, w12, w21,w22, w3 e w4). Nota-se, com isso, que seria necessário termos várias observações a fim dedefinir os valores dos pesos e treinar a rede. Considere a inclusão, por exemplo, de maisum neurônio na camada oculta. Criaríamos então três novas conexões e, portanto, trêsnovos pesos a serem treinados.
Essa complexidade se torna ainda mais relevante se considerarmos que as redesneurais aplicadas em problemas reais podem ter alguns milhares (se não milhões) deparâmetros a serem determinados através de treinamento (MOCANU et al., 2018). Essescenários originam problemas de otimização não linear com muitas variáveis, e podem sertrabalhados com algoritmos iterativos como o método do gradiente descendente.
Para compreender, intuitivamente, como o gradiente descendente por ser utili-zado para treinar os pesos de uma rede neural, consideremos f1t “ fpz1tq e f2t “ fpz2tq.Definimos o vetor ft como o vetor com os outputs dos nós da camada oculta para cada obser-vação t, tal que f1 “ pf11, f21q e f2 “ pf12, f22q. Construimos também o vetor wj “ pw3, w4q.O valor de yt será então o produto interno entre os vetores ft e wj. Podemos reescrever asequações 2.49 e 2.50 da seguinte forma:
y1 “ f1 ¨wj (2.51)
y2 “ f2 ¨wj (2.52)
Uma forma padrão de se calcular o erro Et entre yt e yt é:
Et “12pyt ´ ytq
2 (2.53)
Como yt “ ft ¨wj “ f1tw3 ` f2tw4, temos que:

Capítulo 2. Modelos matemáticos 89
Et “12pyt ´ pf1tw3 ` f2tw4qq
2 (2.54)
O erro total da rede neural da Figura 20 será então a soma dos erros Et parat P r1, T s:
E “12
Tÿ
t“1pyt ´ pf1tw3 ` f2tw4qq
2
E “12
Tÿ
t“1pyt ´ ft ¨wjq
2 (2.55)
Os valores de yt são conhecidos. Os valores de ft dependem de x1t, x2t edas variáveis de peso w11, w12, w21, w22. Agrupemos todos os pesos da rede em um vetorw “ pw11, w12, w21, w22, w3, w4q. Como x1t e x2t também são conhecidos, chegamos àconclusão de que o erro total da rede é uma função dos seis pesos da rede, ou seja, emtermos do vetor w. A seguir são apresentados dois exemplos de gráficos do erro E emtermos dos pesos da rede, o primeiro considerando uma rede com apenas um peso (umarede neural com um nó de entrada e um nó de saída), e o segundo considerando uma redecom dois pesos. Para redes com mais do que dois pesos o gráfico do erro passa a ter maisdo que três dimensões.
Figura 21 – Função de erro para redes com um peso (esquerda) e dois pesos (direita).Fonte: autora.

Capítulo 2. Modelos matemáticos 90
Como discutido inicialmente, o objetivo é encontrar o vetor w que minimize oerro da rede neural. Fazendo uma conexão com a Figura 21 acima, queremos encontrar ovalor de w que nos leve ao ponto mais baixo nos gráficos apresentados, valor esse que aquichamaremos de wmin.
Através do algoritmo do gradiente descendente, iniciamos as iterações com umvetor peso w0, sendo w0 um vetor com pesos de valor arbitrário. Calculamos então o vetorgradiente da função erro com relação a w (ou seja, ∇Ew) no ponto w0. O vetor gradientesempre aponta para a direção onde a função cresce mais rápido, e ao chegar no pontomáximo ou mínimo o vetor gradiente possui magnitude zero. Ora, se o gradiente apontapara a direção onde a função cresce mais rápido, o vetor oposto ao vetor gradiente apontapara a direção onde a função diminui mais rápido, o que poderá nos ajudar a minimizar oerro.
Considere o gráfico à esquerda da Figura 21. Se tomamos um valor de warbitrário tal que w “ ´4, o vetor oposto ao vetor gradiente nesse ponto apontará para adireção do valor de w onde a função Epwq é minima, conforme figura abaixo:
Figura 22 – Função erro e vetor gradiente para w = -4. Fonte: autora.
O algoritmo então atualizará o valor de w de tal forma que o vetor w dapróxima iteração esteja um pouco mais próximo de wmin, conforme equação abaixo:
wnovo “ wvelho ´ ε∇Ew, (2.56)

Capítulo 2. Modelos matemáticos 91
onde ε representa a taxa de aprendizado, ou seja, o tamanho do passo dado emcada iteração na direção oposta ao gradiente. Veja que a diferença entre wnovo e wvelho
depende diretamente do valor de ∇Ew. Quando o peso w ainda está muito longe de wmin,a magnitude de ∇Ew é maior, e damos passos maiores em direção ao ponto mínimo deEpwq. Quando já estamos próximos a wmin, a magnitude de ∇Ew é menor, e com isso adiferença entre wnovo e wvelho também é menor.
Se a taxa de aprendizado é muito pequena, quase não há diferença entre wnovo
e wvelho, e o algoritmo precisa de muitas iterações para chegar ao ponto mínimo. Noentanto, se a taxa de aprendizado é muito alta, podemos ir de um ponto a outro entreduas iterações e “pular” wmin.
As atualizações no vetor w são feitas até a convergência, ou seja, até que oerro total da rede atinja um valor assintóticamente ótimo.
Dependendo da natureza da função de erro, o algoritmo do gradiente descen-dente pode nos levar ao ponto w onde o erro atinge um mínimo local, e não o mínimoglobal da função. Veja por exemplo o caso abaixo:
Figura 23 – Função com um mínimo local e um mínimo global. Fonte: autora.
A boa notícia é que redes neurais raramente sofrem do problema de mínimoslocais, uma vez que suas superfícies tendem a possuir muitos mínimos locais com a mesmaprofundidade, e que por sua vez são quase tão profundos quanto o mínimo global (STONE,2020). Isso fortalece ainda mais o uso do gradiente descendente na construção de redesneurais.
2.7.1.2 Perceptron
Existem inúmeras arquiteturas de redes neurais que se utilizam de váriascombinações de nós e camadas. A mais simples é o Perceptron, modelo desenvolvido nasdécadas de 1950 e 1960.

Capítulo 2. Modelos matemáticos 92
A arquitetura básica do Perceptron consiste em vários nós de entrada e apenasum nó de saída. O nó de saída possui algo que chamamos de threshold, que é um limiteque determina o valor do output desse nó. A função de ativação do nó de saída no casode um Perceptron é uma função degrau unitário, conforme demonstrado na equação 2.57.Caso o input total u seja maior do que o threshold θ, o output do nó de saída sera igual a1. Caso contrário, será zero.
fpuq “
$
&
%
1, u ą θ
0, u ď θ(2.57)
Ao adicionarmos camadas ocultas ao Perceptron, construimos o que é chamadode Multilayer Perceptron (MLP). O problema com um MLP é que, para treiná-lo atravésdo gradiente descendente, é preciso calcular a derivada da função degrau de forma aencontrar o gradiente da função erro. Como a função degrau possui uma descontinuidadequando u “ θ, não existe derivada nesse ponto. Por esse motivo, precisamos utilizar umafunção contínua e diferenciável. Existem várias opções de funções de ativação para os nósde uma rede neural, e entre as mais comuns está a função sigmoide, que é similar a funçãodegrau unitário porém sem a descontinuidade:
fpxq “L
1` e´kx (2.58)
Onde L é o valor máximo da curva e o argumento ´kx dita a inclinação datransição. Como estamos procurando uma função similar à função degrau unitário, afunção sigmoide fpuq utilizada será:
fpuq “1
1` e´u (2.59)
A derivada da função sigmoide com relação ao input total u será df
du“ fpuqp1´
fpuqq. Na figura abaixo apresentamos do lado esquerdo a função degrau unitário, e dolado direito a função sigmoide.

Capítulo 2. Modelos matemáticos 93
Figura 24 – Função degrau unitário versus função sigmoide. Fonte: autora.
A função sigmoide é especialmente importante por flexibilizar os tipos deoutputs que a rede neural pode calcular. Se todos os nós possuem funções de ativaçãolineares, a composição das funções lineares ao longo das várias camadas ainda é uma funçãolinear, ou seja, a adição de camadas pode não acrescentar um valor significativo à redeneural. No entanto, ao adicionar uma camada cuja função ativação é a função sigmoide,conseguimos reproduzir funções não lineares. De fato, uma rede com três camadas de nóssigmoides ou mais é capaz de reproduzir funções que uma rede com apenas duas camadasde unidades sigmoides não consegue (STONE, 2020).
Além disso, não é preciso que os nós nas camadas de entrada e de saída te-nham funções de ativação não lineares. O teorema de aproximação universal, provadoem sua versão inicial com a função sigmoide por George Cybenko em 1989, afirma queem uma rede neural onde a propagação dos inputs acontece da esquerda para a direita(também chamada de feed-forward network, que será discutida mais profundamente nospróximos parágrafos) apenas uma camada oculta com um número finito, mas suficiente-mente grande, de nós cuja função de ativação é não linear é suficiente para aproximarqualquer função contínua em um subconjunto compacto em Rn (STONE, 2020).
2.7.1.3 Algoritmo de Backpropagation
Aplicaremos os conceitos do algoritmo de gradiente descendente, a arquiteturaPerceptron e Multilayer Perceptron e a função sigmoide ao que chamamos de algoritmo deBackpropagation, que é efetivamente a forma pela qual uma rede neural “aprende”.
Considere a rede neural da Figura 25. Nessa rede neural temos I “ 2, J “ 3 eK “ 1. Os inputs dos nós xit na camada de entrada são ui, e da mesma forma os inputsda camada oculta são uj e da camada de saída uk. Vamos definir as funções de ativação

Capítulo 2. Modelos matemáticos 94
dos nós das camadas de entrada e de saída como sendo a função identidade, ou seja,fpuq “ u. A função de ativação na camada oculta será a função sigmoide, de forma quefpujq “ p1` e´ujq
´1.
Veja que adicionamos dois nós nas camadas de entrada e oculta cujo valor é -1.Esses nós são os “vieses” da rede neural, e têm um papel muito parecido com o papel daconstante em uma regressão linear, auxiliando o modelo a se ajustar ao conjunto de dados.Aqui, consideramos que o input desses dois nós é o valor -1, e o peso entre esses nós e acamada seguinte é designado br, onde r “ j para o nó na camada de entrada e r “ k parao nó na camada oculta.
Figura 25 – Rede Neural com vieses. Fonte: autora.
Os inputs serão propagados na rede neural da esquerda para a direita, ou seja,indo para a frente, ao que chamamos de “forward propagation”. Esse movimento configurauma rede do tipo feed-forward, ou na tradução literal, uma rede de alimentação direta.
Para analisar o forward propagation, tomemos uma observação t. O input totaldos nós da camada de entrada serão uit, e como a função de ativação desses nós é linear,temos que o output xit “ uit.
Uma vez que a alimentação da rede é feita da esquerda para a direita, sabemosque o input total nos nós na camada oculta será a soma dos produtos dos outputs dacamada de entrada e seus respectivos pesos, conforme equação 2.60:
ujt “Iÿ
i“1wijxit ´ bj (2.60)
Definindo xI`1 “ ´1 e wI`1,j “ bj, simplificamos a equação:

Capítulo 2. Modelos matemáticos 95
ujt “I`1ÿ
i“1wijxit (2.61)
Seguindo a mesma lógica, o input total no nós da camada de saída será:
ukt “J`1ÿ
j“1wjkzjt (2.62)
Sabemos que zjt “ fjpujtq e ykt “ fkpuktq. Construimos então a equação de yktconforme abaixo:
ykt “ fkpuktq
ykt “ fkpJ`1ÿ
j“1wjkzjtq
ykt “ fkpJ`1ÿ
j“1wjkfjpujtqq
ykt “ fkpJ`1ÿ
j“1wjkfjp
I`1ÿ
i“1wijxitqq (2.63)
O valor do output do nó de saída depende então da combinação entre os inputstotais nos nós de entrada, as funções de ativação de cada nó e de todos os pesos da rede.Isso define o que chamamos de forward propagation de inputs.
Uma vez com os inputs propagados da camada de entrada para a camadade saída (de trás para a frente), vamos atualizar os pesos da rede neural através de ummecanismo que faz o caminho contrário, indo da camada de saída para a camada deentrada, chamado de algoritmo de “backpropagation” de erros.
Sabemos que, pelo algoritmo do gradiente descendente, a atualização dos pesosda rede é feita utilizando a equação 2.82:
wnovo “ wvelho ´ ε∇Ew (2.64)
Onde:
∇Ew “ pBE
Bw11,BE
Bw12, . . . ,
BE
BwJ`1,Kq (2.65)

Capítulo 2. Modelos matemáticos 96
Tomemos um peso wjk entre a camada oculta e a camada de saída. Seja ∆wjkta diferença entre wjkvelho
e wjknovo para o peso wjk na observação t. Temos então que:
∆wjkt “ ´εBEtBwjk
(2.66)
Como a função erro depende do valor de ykt, que por sua vez é uma função deukt, e sendo ukt uma função de wjk e zjt, pela regra da cadeia temos que:
∆wjkt “ ´εBEtBukt
BuktBwjk
(2.67)
Vamos definir a variação do erro Et na observação t com relação ao input uktno nó de saída yk como o termo δkt “
BEtBukt
.
Sabemos que ukt “J`1ÿ
j“1wjkzjt, e portanto para um wjk fixo Bukt
Bwjk“ zjt. Com
isso, concluímos que:
∆wjkt “ ´εδktzjt (2.68)
Ou seja, a atualização dos pesos entre a camada oculta e a camada de saídadepende do termo δkt do respectivo nó na camada de saída, iniciando o movimento depropagação “de trás pra frente”, o algoritmo de backpropagation.
Por definição, δkt “BEtBukt
. Como já mencionado anteriormente, a função errodepende do valor de ykt, que por sua vez é uma função que depende unicamente do valorde ukt. Podemos então aplicar a regra da cadeia em δkt:
δkt “BEtBukt
δkt “BEtBykt
dyktdukt
(2.69)
Como a função de ativação da camada de saída é a função identidade ykt “ ukt,temos que dykt
dukt“ 1. Além disso, Et “ p1{2qpykt ´ yktq2, e
BEtBykt
“ pykt ´ yktq. Temos entãoque δkt “ pykt ´ yktq ˆ 1 “ pykt ´ yktq.
Disso, concluímos que:

Capítulo 2. Modelos matemáticos 97
∆wjkt “ ´ε δkt zjt∆wjkt “ ´ε pykt ´ yktq zjt (2.70)
E para todas as observações t P r1, T s:
∆wjk “ ´εTÿ
t“1pykt ´ yktq zjt (2.71)
O que conclui a lógica de atualização dos pesos entre a camada oculta e acamada de saída. Nos falta agora definir o processo de atualização dos pesos entre acamada oculta e a camada de entrada. Seguindo a mesma lógica aplicada anteriormente,tomemos um peso wij entre a camada de entrada e a camada oculta. Seja ∆wijt a diferençaentre wijvelho
e wijnovo para o peso wij na observação t. Temos então que:
∆wijt “ ´εBEtBwij
(2.72)
Sabemos que a função erro depende do valor de ykt. O valor de ykt é uma funçãode ukt, que por sua vez é a soma dos produtos de zjt e os pesos wjk. Sabemos tambémque o valor de zjt é a aplicação da função sigmoide no input ujt, e que ujt é a soma dosprodutos de xit e os pesos wij. Podemos concluir então que pela regra da cadeia:
∆wijt “ ´εBEtBwij
∆wijt “ ´εBEtBujt
BujtBwij
(2.73)
Vamos definir a variação do erro Et na observação t com relação ao input ujt
no nó da camada oculta zj como o termo δjt “BEtBujt
. Como ujt “I`1ÿ
i“1wijxit, para um wij
fixo, BujtBwij
“ xit. Com isso, concluímos que:
∆wijt “ ´εδjtxit (2.74)
Provamos novamente que a atualização dos pesos acontece de frente para trás,sendo que a diferença entre os pesos novos e velhos para um peso entre a camada deentrada e a camada oculta depende do termo δjt do respectivo nó na camada oculta.

Capítulo 2. Modelos matemáticos 98
Por definição, δjt “BEtBujt
. Aplicando a regra da cadeia temos que:
δjt “BEtBujt
δjt “BEtBzjt
dzjtdujt
(2.75)
A função de ativação da camada oculta é a função sigmoide, então zjt “
fpujtq “ p1´ e´ujtq´1. Com isso, a derivada dzjt
dujt“ zjtp1´ zjtq.
Para encontrar BEtBzjt
é preciso lembrar que o erro Et depende do resultado detodos os nós ykt da camada de saída, que são uma função dos inputs ukt. Além disso,sabemos também que o output zjt de cada nó na camada oculta contribui para o resultadode todos os nós da camada de saída. Então:
BEtBzjt
“
Kÿ
k“1
BEtBukt
BuktBzjt
(2.76)
Como ukt “J`1ÿ
j“1wjkzjt,
BuktBzjt
“ wjk para um zjt fixo. Além disso, BEtBukt
“ δkt
por definição. Com isso temos que:
BEtBzjt
“
Kÿ
k“1δktwjk (2.77)
Substituindo na equação 2.75:
δjt “ zjtp1´ zjtqKÿ
k“1δktwjk (2.78)
Finalmente, concluímos que para uma observação t:
∆wijt “ ´εzjtp1´ zjtqKÿ
k“1δktwjkxit (2.79)
E para todas as observações t P r1, T s:
∆wij “ ´εTÿ
t“1zjtp1´ zjtq
Kÿ
k“1δktwjkxit (2.80)
Concluindo o processo para atualizar todos os pesos da rede.

Capítulo 2. Modelos matemáticos 99
2.7.2 Aplicação em sistemas de recomendação
Por serem extremamente flexíveis, algoritmos de redes neurais podem ser usadostanto em problemas de filtragem baseada em conteúdo quanto em problemas de filtragemcolaborativa baseados em modelos.
Em problemas de filtragem baseada em conteúdo, as redes neurais podemser construídas para atender problemas de regressão ou de classificação. Nesses casos, amatriz de variáveis de previsão Xmˆn terá m observações e n características. Em casos deregressão, o vetor com os elementos de saída y P Rm possuirá os valores das avaliações decada observação. Para problemas de classificação, os elementos do vetor y serão a classe àqual a observação pertence.
Agora, em problemas de filtragem colaborativa, a matriz Xmˆn será uma matrizde avaliações de m usuários a n itens. Como nem todos os usuários deram uma nota atodos os itens, muitos elementos são desconhecidos. Podemos usar a rede neural de forma acompletar essa matriz iterativamente, criando n redes onde cada um dos itens é o atributode saída em cada uma das redes. Por exemplo, a primeira rede neural seria construida deforma que a variável v1 seria o atributo de saída, e os valores das variáveis v2 a vn seriamos inputs da camada de entrada. Isso pode ser feito n vezes, com n redes neurais diferentes.Ao fim, os valores desconhecidos da matriz original podem ser substituidos pelos outputsde cada instância nas n redes neurais.
Exemplo 7. Redes neurais em sistemas baseados em conteúdo
A fim de discutir problemas de regressão, vamos retomar o exemplo 1. Nesseexemplo temos quatro filmes e suas informações de gênero e nacionalidade, e ao fim ovalor das avaliações dadas pelo usuário para cada um.
Após codificação das variáveis, chegamos à Tabela 5. A matriz de variáveis deprevisão e o vetor do atributo de saída são:
X “
»
—
—
—
—
–
1 0 1 0 00 1 0 1 01 0 0 0 10 1 0 0 1
fi
ffi
ffi
ffi
ffi
fl
y “
»
—
—
—
—
–
3, 52, 73, 84, 1
fi
ffi
ffi
ffi
ffi
fl
Dadas as características do conjunto de dados, podemos construir uma redeneural em cuja camada de entrada teremos cinco nós com entradas binárias. Podemos

Capítulo 2. Modelos matemáticos 100
então adicionar uma camada oculta com um número inicial J de nós, e apenas um nóna camada de saída que será o valor da avaliação do usuário dadas as características dofilme. Podemos determinar as funções de ativação de cada camada, assim como o númerode camadas ocultas e o número de nós em cada uma de forma a diminuir o erro entre osvalores calculados de y e os valores reais conhecidos y.
Vamos abordar agora um caso de classificação. Considere o exemplo 3 e osfilmes descritos na Tabela 3. Nesse caso, o atributo de saída é binário, indicando se ousuário gostou ou não do filme.
Existem algumas poucas diferenças com relação ao caso anteriormente citadode regressão. A primeira é que o conjunto de dados é diferente, e possui a coluna de idadedo filme. Em redes neurais é muito importante normalizar os valores dos inputs antesde alimentá-los à rede neural, facilitando o processo de aprendizado do algoritmo. Apóscodificação das variáveis de classe e normalização dos inputs, teríamos seis nós na camadade entrada. Continuaríamos com apenas um nó na camada de saída, porém o valor dooutput yi para a observação i seria um valor entre yi 0 e 1. Para valores de yi maiores queum threshold θ, consideraríamos a avaliação como 1. Do contrário, a avaliação seria 0.
Para um número de classes maior (por exemplo se quiséssemos determinar,dadas as características do usuário, se o usuário é do tipo A, B, C ou D e recomendaritens baseados nessa informação), teríamos um camada de saída com quatro nós, e aofim da iteração a rede neural nos traria uma probabilidade entre 0 e 1 de que o usuáriopertence a cada uma dessas classes. A classe com a maior probabilidade será a classe paraa qual designamos o usuário.
Exemplo 8. Redes neurais em sistemas de filtragem colaborativa baseadosem modelosComo já discutido anteriormente, matrizes de avaliação utilizadas em sistemas de filtragemcolaborativa tendem a ser esparsas, uma vez que nem todos os usuários deram notas atodos os itens existentes em uma plataforma.
Já discutimos com detalhes como é possível mitigar esse problema através daredução de dimensionalidade, criando uma matriz de menor dimensionalidade completa-mente especificada. O maior problema aqui é a perda de interpretabilidade causada poressa redução de dimensões, o que dificulta o entendimento dos resultados gerados por essealgoritmo.
Uma outra forma de completar matrizes esparsas é através do uso de redesneurais a fim de completá-las iterativamente (AGGARWAL, 2016). Considere a matrizA do exemplo 2, tal que A é uma matriz mˆ n gerada a partir das notas dadas por musuários a n produtos diferentes. As notas variam de 1 a 5, de forma discreta. Abaixoexemplificamos a matriz A para uma amostra de 5 usuários e 3 produtos.

Capítulo 2. Modelos matemáticos 101
A “
»
—
—
—
—
—
—
–
2 2 ?4 3 1? 4 52 1 44 5 2
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
A primeira coisa a se fazer é preencher os elementos faltantes com as médias decada coluna. A fim de tornar o resultado ainda mais robusto, é possível primeiro centralizarcada coluna tal que a média de cada uma é zero, e então os elementos faltantes, que serãoa média de cada coluna, também serão zero, conforme matriz abaixo:
A “
»
—
—
—
—
—
—
–
´1 ´1 01 0 ´20 1 2´1 ´2 11 2 ´1
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
Como alternativa, poderíamos também empregar um algoritmo simples comopor exemplo k-vizinhos mais próximos a fim de preencher a matriz pela primeira vez.
A partir dessa primeira matriz completa, elegemos a primeira coluna relativaao primeiro item como o vetor dos atributos de saída, e usamos o restante da matriz, quejá está completa, como a matriz das variáveis de previsão. Por exemplo, no caso da matrizA, a matriz X de variáveis de previsão e o vetor y dos atributos de saída seriam:
X “
»
—
—
—
—
—
—
–
´1 00 ´21 2´2 12 ´1
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
y “
»
—
—
—
—
—
—
–
´11?´11
fi
ffi
ffi
ffi
ffi
ffi
ffi
fl
Usaríamos então as observações para as quais o respectivo elemento no vetor yé conhecido como conjunto de dados de treinamento da rede neural (nesse exemplo seriamas observações das linhas 1, 2, 4 e 5), e as observações para as quais o respectivo elemento

Capítulo 2. Modelos matemáticos 102
em y não é especificado como as observações para as quais queremos prever o valor de y(a linha 3).
Montamos então a primeira rede neural, com dois nós na camada de entrada,referentes aos valores dos itens nas colunas 2 e 3 da matriz X, e um nó na camada desaída para a previsão do valor de y. Após empregar a rede neural para a previsão do valorde y, substituimos o terceiro elemento da primeira coluna de A por y, reservamos esseresultado, e seguimos a fim de realizar o mesmo processo novamente, agora considerando aterceira coluna de A como o vetor de atributos de saída e as colunas 1 e 2 a fim de formara matriz de variáveis de previsão.
Esse processo é realizado n vezes, sendo n o número de itens (ou colunas) paraas quais existe um elemento não especificado. Após a finalização desse processo, teremosuma nova matriz Amˆn cujas entradas não especificadas foram atualizadas. O processo éentão realizado uma segunda vez, e é feito até que os valores dos elementos desconhecidosinicialmente convirjam.
Com a matriz A completa, podemos decidir quais itens devem ser sugeridos aquais usuários.
A seguir apresentamos dois algoritmos. O primeiro resume os passos para aconstrução de uma rede neural aritifical em sistemas baseados em conteúdo. Logo emseguida, apresentamos um algoritmo que detalha a implementação de uma rede neural emsistemas de filtragem colaborativa.
Algoritmo 2.10 Redes neurais em sistemas baseados em conteúdoImportar matriz de variáveis de previsão X e vetor do atributo de saída yNormalizar colunas em XDividir X e y entre dados de treinamento, dados de validação e dados de testeDefinir a topologia da rede neural da seguinte forma: camada de entrada com n neurônios,camada de saída com um neurônio para problemas de regressão e c neurônios paraproblemas de classificação, onde c é o número total de classes do conjunto de dados.Defina t camadas ocultas com s neurônios cada, onde t e s podem ser ajustados a fimde melhorar a performance do algoritmoUtilizando as observações para as quais o valor em y é especificado, treinar a rede neuralusando o algoritmo do gradiente descendente:
wnovo “ wvelho ´ ε∇Ew (2.81)
Após treino do algoritmo, realizar a previsão dos valores não especificados em y

Capítulo 2. Modelos matemáticos 103
Algoritmo 2.11 Redes neurais em sistemas de filtragem colaborativaImportar matriz de avaliações ACentralizar vetores-coluna de A e preencher elementos faltantes com a média de cadacoluna, ou seja, zeroPara a primeira iteração, determinar a primeira coluna de A como o vetor y com osatributos de saída, e as outras colunas formam a matriz X de variáveis de previsãoDefinir a topologia da rede neural da seguinte forma: camada de entrada com n-1neurônios, camada de saída com um neurônio, e t camadas ocultas com s neurônioscada, onde t e s podem ser ajustados a fim de melhorar a performance do algoritmoDefinir as funções de ativação para os neurônios em cada camadaUtilizando as observações para as quais o valor em y é especificado, treinar a rede neuralusando o algoritmo do gradiente descendente:
wnovo “ wvelho ´ ε∇Ew (2.82)
Após treino do algoritmo, realizar a previsão dos valores não especificados em yReserve o vetor ynovo e repita o processo para as n´ 1 colunas faltantes, construindo anova matriz AnovaRepita os passos acima até que os valores na matriz A convirjam

104
3 Aplicações
3.1 Apresentação do problemaO objetivo dessa seção é apresentar ao leitor diferentes aplicações de alguns dos
algoritmos discutidos no segundo capítulo. Para tal, iremos explorar os dados relativos aosclientes do e-commerce americano ModCloth, especializado na venda de roupas femininas.O objetivo é criar sistemas de recomendação utilizando diferentes algoritmos porém com omesmo fim: apresentar ao cliente recomendações de novos itens com a intenção de aumentaras vendas e ampliar a percepção de valor do cliente sobre a loja.
3.1.0.1 Estrutura dos dados
A base de dados utilizada nas aplicações a serem discutidas foi originalmenteapresentada por Rishabh Misra, Mengting Wan e Julian McAuley na décima segundaconferência sobre sistemas de recomendações da Association for Computing Machinery(MISRA; WAN; MCAULEY, 2018). Em sua estrutura original, possui as avaliações de47.958 usuários sobre 1.378 itens. As avaliações seguiam notas de 1 a 5. O usuário com omenor número de itens avaliados avaliou apenas uma peça de roupa, enquanto o usuárioque avaliou o maior número de itens avaliou 27 peças. No total, a base original possui82.790 avaliações.
O detalhamento dos campos da base de dados original é apresentado na Tabela14.

Capítulo 3. Aplicações 105
Campo Detalhamento Exemploitemid Código numérico representando o item
avaliado125442
waist Número representando a medida da cin-tura do usuário
31
size Número representando a medida geraldo usuário
11
quality Avaliação de 1 a 5, em um intervalodiscreto, feita pelo usuário ao item emquestão
3,0
cup size Informação categórica representando amedida do busto do usuário
dd/e
hips Número representando a medida do qua-dril do usuário
36
bra size Número representando outra medida dobusto do usuário
34
category Categoria do item em questão Dressesbust Número representando ainda outra me-
dida do busto do usuário36
height Altura do usuário no sistema imperial 5ft 7inusername Nome do usuário bivislength Informação categórica sobre compri-
mento do itemjust right
fit Informação categória sobre tamanho doitem
small
userid Código numérico representando o usuá-rio que fez a avaliação
575252
shoe size Número representando o tamanho dospés do usuário
9,0
shoe width Informação categórica sobre a largurados pés do usuário
average
reviewsummary Para as avaliações onde o usuário escre-veu algum texto com detalhamentos, oresumo desse texto
"Suits my body type!"
reviewtext O texto escrito pelo usuário detalhandoa avaliação
"From the other reviews itseems like this dress eitherworks for your body type orit doesn’t..."
Tabela 14 – Detalhamento de campos da base de dados da ModCloth
A fim de diminuir o tamanho da base de dados para agilizar os testes, alémde evitar a criação de um viés nos resultados por conta de itens que tiveram apenas umaou poucas avaliações, a base original foi filtrada a fim de manter apenas as avaliaçõesreferentes a itens que tinham sido avaliados por pelo menos 500 usuários. Além disso,foram removidos alguns campos cuja qualidade dos dados estava muito comprometida

Capítulo 3. Aplicações 106
(informações mal escritas ou faltando), e feita a conversão do campo de altura do usuário,com unidades em pés e polegadas, para o sistema métrico em centímetros.
Após esse processo de limpeza e formatação dos dados, a base gerada possui41.855 avaliações relativas a 50 itens (todos com pelo menos 500 avaliações cada) e 30.174usuários. Dos campos originais, foram mantidas as colunas de item_id, category, user_id,height, size, hips, bra size e quality.
Todo o tratamento de dados e implementação dos algoritmos foram realizadosutilizando a linguagem de programação Python.
3.2 Algoritmos utilizadosAo todo foram empregados quatro algoritmos para a criação de dois sistemas
de filtragem colaborativa e dois sistemas de filtragem baseada em conteúdo, conformeTabela 15.
Tipo de sistema de recomendação AlgoritmoFiltragem colaborativa Método dos k-vizinhos mais próximosFiltragem colaborativa Decomposição em valores singulares
Filtragem baseada em conteúdo Método dos k-vizinhos mais próximosFiltragem baseada em conteúdo Redes neurais artificiais
Tabela 15 – Detalhamento dos algoritmos aplicados
O objetivo foi utilizar o mesmo conjunto de dados nos quatro algoritmos, nospermitindo comparar os resultados tanto entre os dois tipos de filtragem como entre ostipos de algoritmos empregados em cada filtragem.
3.2.1 Sistemas de filtragem colaborativa
Para os sistemas de filtragem colaborativa foi utilizado o pacote de ferramentasSurprise, um pacote desenvolvido para uso em Python e que facilita muitíssimo a aplicaçãode algoritmos de filtragem colaborativa na construção de sistemas de recomendação. Emambos os casos a única variável considerada nas aplicações foi a variável de quality paracada combinação usuário-item. Perceba que a matriz usuário-item utilizada nos algoritmosde filtragem colaborativa possui as avaliações de 30.174 usuários sobre 50 itens, dessaforma possuindo 50 ˆ 30.174 “ 1.508.700 elementos. No entanto, temos apenas 41.855avaliações especificadas, o que quer dizer que 97,2% dos valores da matriz são desconhecidos,configurando uma matriz esparsa.

Capítulo 3. Aplicações 107
3.2.1.1 Método dos k-vizinhos mais próximos
Para gerar as recomendações através do método dos k vizinhos mais próximos,utilizamos o algoritmo KNNWithMeans do pacote Surprise. Conforme documentaçãodo algoritmo (HUG, 2015), a similaridade é calculada entre usuários de maneira padrão(da mesma forma como foi discutido no exemplo 4 do Capítulo 2). Definimos a funçãosimilaridade como sendo o cosseno do ângulo entre os vetores relativos a cada usuário.Além disso, a nota média de cada usuário é utilizada para centralizar os vetores-linhada matriz usuário-item, de maneira a diminuir o possível viés quando usuários diferentesavaliam o mesmo item em escalas diferentes.
A avaliação centralizada de cada usuário para cada item não avaliado é calculadaentão com base na equação 2.30. A fim de encontrar as avaliações não centralizadas, bastasomar a nota média de cada usuário a todas as avaliações centralizadas estimadas peloalgoritmo.
De maneira padrão, o algoritmo KNNWithMeans utiliza k = 40, ou seja, sãoconsiderados no máximo 40 usuários entre os usuários mais similares ao usuário em questão.Em outras palavras, o número máximo de usuários na vizinhança do usuário u será 40.Lembre-se que, para que um usuário v seja considerado no conjunto de usuários similaresao usuário u a fim de estimar a avaliação do usuário u ao item i, a avaliação do usuário vao item i precisa ser especificada. Além disso, no momento da geração da vizinhança parao usuário u são considerados apenas usuários cuja similaridade com o usuário u é positiva.Caso não exista nenhum usuário v na vizinhança de u para avaliação ao item i, a soma nonumerador da equação 2.30 será zero e a estimativa da avaliação do usuário u será apenasnota média desse usuário, considerando todos os itens já avaliados por ele.
3.2.1.2 Decomposição em valores singulares
Utilizamos o algoritmo SVD do pacote Surprise para gerar as recomendaçõesutilizando o método da decomposição em valores singulares. A fim de aplicar a decomposiçãoem valores singulares a uma matriz, é preciso que essa matriz esteja completamenteespecificada, ou seja, as 97,2% avaliações não conhecidas precisariam ser substituídas comalgum tipo de valor inicial a fim de iniciarmos o processo de decomposição. Poderíamosrealizar o processo de inicialização da matriz substituindo cada elemento desconhecidopela média de avaliações de cada item (conforme trabalhado no exemplo 2), no entanto,dado o tamanho da matriz (30.174 ˆ 50), trabalhar dessa forma tornaria o algoritmoextremamente pesado e lento.
A fim de mitigar esse problema, o algoritmo SVD do pacote Surprise trabalhacom a criação do modelo utilizando apenas as avaliações especificadas. A fim de determinaros fatores latentes e consequentemente os vetores ui e vj necessários para estimar a

Capítulo 3. Aplicações 108
avaliação aij de um usuário i a um item j (conforme equação 2.12), é feita a otimizaçãoda seguinte equação abaixo (KOREN; BELL; VOLINSKY, 2009):
minpv˚,u˚q “ÿ
i,jPK
paij ´ vjT uiq
2` λp|vj|2`|ui|2q (3.1)
Onde λ “ 0, 02 e é uma constante responsável pela regularização do modelo.O conjunto K é o conjunto de todos os pares de usuários e itens pi, jq para os quaisconhecemos as avaliações aij. Para o conjunto de dados trabalhado nesse capítulo, onúmero de elementos em K é 41.855.
Ao invés de calcular as avaliações desconhecidas aij simplesmente através doproduto interno entre ui e vj, adicionamos ao algoritmo um ajuste que diz respeito aos“vieses” implícitos às avaliações conhecidas. Esses vieses são responsáveis por quantificara tendência de alguns itens serem melhor avaliados do que outros (como por exemploquando a percepção popular de uma marca é melhor do que de outra) e a tendência dealguns usuários serem mais ou menos críticos em suas avaliações.
Ao final, a avaliação aij calculada pelo algoritmo seguirá a seguinte equaçãoabaixo:
aij “ µ` bi ` bj ` vjT ui (3.2)
Onde µ é a média geral das avaliações conhecidas, para todos os usuários etodos os itens. A constante bi é o viés do usuário em questão, e a constante bj é o viés doitem em questão. Por exemplo, suponha que estejamos trabalhando com uma matriz deavaliações normalizada, para a qual a média global µ é zero. Sabemos que o usuário i émais crítico e tende a dar notas -0,5 pontos mais baixas que a média. Além disso, o itemj é bem avaliado pelo mercado, e por isso costuma receber avaliações 1 ponto acima damédia. Se o produto interno vj
T ui tem a nota 2,5 como resultado, podemos somar a issoos valores µ “ 0, bi “ ´0, 5 e bj “ 1, chegando ao resultado final aij “ 3.
Substituindo a equação 3.2 na equação 3.1, concluímos que a função a serotimizada será:
minpv˚,u˚q “ÿ
i,jPK
paij ´ µ´ bi ´ bj ´ vjT uiq
2` λp|vj|2`|ui|2`b2
i ` b2jq (3.3)
3.2.2 Sistemas de filtragem baseada em conteúdo
Construímos dois sistemas de filtragem baseada em conteúdo. Através dasinformações conhecidas sobre cada usuário (foram utilizadas as variáveis height, size, hips

Capítulo 3. Aplicações 109
e bra size), foram construídos modelos utilizando o método dos k-vizinhos mais próximose também redes neurais artificiais.
Como alguns dos valores para as características de alguns usuários estavamfaltando, os elementos desconhecidos foram preenchidos com a média dos valores paracada item. Por exemplo, se a altura para certo usuário era desconhecida, preenchemos essevalor com a média das alturas de todos os usuários. Essa técnica nos permite seguir com acriação do modelo sem comprometer o volume de informação que possuímos - se fôssemosexcluir da análise cada usuário para o qual falta alguma informação, a base de dados finala ser utilizada pelo modelo seria muito menor do que a original.
3.2.2.1 Método dos k-vizinhos mais próximos
A fim de aplicar o algoritmo dos k-vizinhos mais próximos em um sistema defiltragem baseada em conteúdo, utilizamos o pacote KNeighborsRegressor da bibliotecasklearn. Definimos o problema como uma regressão, ou seja, assim como nos algoritmos desistema de filtragem colaborativa discutidos acima, a avaliação estimada aij do usuário iao item j será considerada como um número real entre 1 e 5.
A função utilizada para calcular a similaridade entre usuários foi a distânciaeuclidiana entre os vetores correspondentes a cada usuário, sendo que o vetor ci referenteàs características do usuário i possui quatro elementos numéricos, um elemento para cadacaracterística. A base foi normalizada de forma que todas as variáveis estivessem na mesmaescala. Assim como no sistema de filtragem colaborativa, utilizamos k = 40.
Foram criados 50 modelos, um para cada um dos itens na base de dados. Entreos 50 itens, foram listados todos os itens j não avaliados por cada um dos 30.174 usuários.Para cada item não avaliado pelo usuário, aplicamos o modelo correspondente a fim deestimar a nota que esse usuário daria ao item em questão (perceba aqui que, enquantocriamos apenas um modelo para gerar todas as avaliações desconhecidas nos sistemas defiltragem colaborativa, foi necessário criar um modelo por item nos sistemas de filtragembaseada em conteúdo).
3.2.2.2 Rede Neural Artificial
Para construir a rede neural artificial utilizada nesse sistema de recomendação,utilizamos a biblioteca para deep learning em Python, chamada Keras. Assim como emtodos os outros algoritmos já discutidos, o modelo foi construído de forma que o outputseja um número real entre 1 e 5, configurando um problema de regressão.
Após algumas tentativas, a topologia que apresentou os melhores resultados foidefinida, sendo que a camada de entrada possui 4 neurônios (um para cada característicade cada usuário), a primeira camada oculta possui 8 neurônios, a segunda camada oculta

Capítulo 3. Aplicações 110
possui 20 neurônios, e a camada de saída possui apenas um neurônio, por se tratar de umproblema de regressão. A função de ativação dos neurônios em todas as camadas ocultasfoi definida como a função sigmóide.
Da mesma forma como no modelo baseado em conteúdo criado a partir dosk-vizinhos mais próximos, os atributos de entrada foram normalizados antes de seremutilizados na rede neural. Além disso, também é necessário criar 50 modelos, um modelopara um dos 50 itens. Para cada item j não avaliado por um usuário i, utilizamos ascaracterísticas desse usuário como input no modelo do item correspondente, de maneiraque o output será um valor entre 1 e 5 relativo à nota aij estimada da avaliação do usuárioi ao item j.
3.3 Discussão de resultadosComo todos os quatro sistemas de recomendação foram modelados como
problemas de regressão, foram calculados para cada algoritmo o erro absoluto médio(MAE), o erro absoluto médio normalizado (NMAE), a raiz do erro quadrático médio(RMSE) e a raiz do erro quadrático normalizada (NRMSE), todos discutidos na seção1.5.1 do Capítulo 1. Uma vez que essas métricas calculam o erro médio entre o valor realda avaliação e a estimativa apresentada pelo modelo, todas precisam ser minimizadas. OMAE apresenta o erro na mesma escala do conjunto original de avaliações, ou seja, de 1 a 5.O NMAE é normalizado, portanto vai de 0 a 1 e quanto mais próximo de zero, melhor. ORMSE também possui a mesma escala do conjunto original de avaliações, porém penalizade maneira mais acentuada as maiores diferenças entre as previsões e os valores reais. ONRMSE é o RMSE normalizado, portanto também vai de 0 a 1 e deve ser mais próximode zero. Os resultados são apresentados na Tabela 16.
Algoritmo MAE NMAE RMSE NRMSEKNN filtro colaborativo 0,7645 0,1911 1,0087 0,2522SVD filtro colaborativo 0,7686 0,1921 0,9456 0,2364
KNN baseado em conteúdo 0,7859 0,1965 0,9536 0,2384RNA baseada em conteúdo 0,7962 0,1991 0,9503 0,2376
Tabela 16 – Comparação de métricas de precisão entre modelos
Em todos os modelos utilizamos o método da validação cruzada 5-fold, ouseja, o conjunto original de dados utilizado para treinar os algoritmos foi dividido em 5subconjuntos mutuamente exclusivos (sem nenhuma sobreposição entre si), e o algoritmofoi treinado usando cada um desses subconjuntos de dados de treinamento e testado nos5 subconjuntos de dados de teste correspondentes. As métricas de precisão foram então

Capítulo 3. Aplicações 111
calculadas para cada subconjunto, e a média entre os cinco valores foi considerada como amédia final do indicador no conjunto de dados para aquele algoritmo.
Podemos concluir a partir das métricas na Tabela 16 que, enquanto o sistemade filtro colaborativo construído com o algoritmo dos k-vizinhos mais próximos (KNN)possui um erro médio total menor do que os outros, sua métrica NRMSE é a maior entretodos, indicando que as previsões geradas são pouco uniformes, com pontos de grandediscrepância entre o valor previsto e o valor real da avaliação. Em contrapartida, o sistemade filtro colaborativo utilizando a decomposição em valores singulares (SVD) tem o segundomenor NMAE e o menor NRMSE, indicando um que o erro médio total é um poucomaior do que o KNN filtro colaborativo, porém o sistema gera previsões de maneira maisuniforme, ou seja, minimiza as grandes discrepâncias entre os valores reais e os valoresprevistos pelo sistema.
No geral, os sistemas de filtro colaborativo parecem apresentar melhores resul-tados do que os sistemas baseados em conteúdo. No entanto, nenhum sistema se destacadafortemente, uma vez que as diferenças nas métricas de previsão dos quatro sistemas sãopequenas.
Além das métricas de precisão, comparamos também os top 10 itens recomenda-dos pelos quatro sistemas. Um usuário aleatório foi selecionado, e as top 10 recomendaçõespara esse usuário em cada um dos sistemas é apresentada abaixo.
Ranking KNN colaborativo SVD colaborativo KNN conteúdo RNA conteúdo1 A A A B2 B E F A3 C K B F4 D L I D5 E M H M6 F N K C7 G B Q T8 H O R L9 I P D K10 J D S H
Tabela 17 – Comparação de top 10 itens recomendados entre modelos
Os itens A, B e D foram recomendados para o usuário em todos os algoritmos.Os itens F, H e K foram recomendados por três algoritmos. Os itens C, E, I, L e M foramrecomendados por dois algoritmos, o os outros nove itens restantes foram recomendadospor apenas um algoritmo.

Capítulo 3. Aplicações 112
3.4 Evoluções no estudo do problemaNa implementação dos algoritmos acima discutidos o problema foi definido
como um problema de regressão, ou seja, cada avaliação prevista será um número realentre 1 a 5. Outra maneira de trabalhar o problema seria analisá-lo como um problema declassificação, onde cada nota de 1 a 5 seria uma classe, algo como 1 sendo equivalente a "nãogostei"e 5 equivalendo a "gostei muito". Em um ambiente real, poderia ser realizado umteste A/B onde um grupo de usuários recebe recomendações geradas por um algoritmo deregressão e outro grupo por um algoritmo de classificação. Pode-se comparar a performancedos dois grupos, ou seja, qual grupo com o maior índice de interação entre os usuários e ositens recomendados.
Além disso, a performance dos algoritmos baseados em conteúdo depende muitodas variáveis de entrada utilizadas, e isso é especialmente importante uma vez que cadasegmento possui variáveis mais e menos relevantes que levam a tomada de decisão porseus clientes. Se as variáveis consideradas no modelo têm pouca relação com a tomada dedecisão do usuário, o modelo invariavelmente apresentará resultados ruins. Nas aplicaçõesde sistemas baseados em conteúdo discutidas nesse capítulo todas as variáveis diziamrespeito às medidas do usuário, mas podem ser utilizadas variáveis que dizem respeito porexemplo à idade, localização geográfica, o valor médio gasto pelo usuário na plataforma,entre outros.
Ademais, existem variáveis específicas ao algoritmo escolhido que devem sersintonizadas a fim de aprimorar os resultados. No algoritmo dos k-vizinhos mais próximos,por exemplo, podemos variar a função utilizada para calcular a similaridade entre usuáriosou itens, além de refinar o número k de usuários a serem considerados na vizinhança de umcerto usuário. Na construção de uma rede neural, podemos trabalhar funções de ativaçãodiferentes da função sigmóide, como a função ReLu a função Softmax, usada na camada desaída para problemas de classificação. Além disso, é possível modificar a própria topologiada rede neural, assim como a função utilizada para calcular o erro e ajustar os pesos.
Finalmente, pode-se criar um sistema de recomendação que utilize vários dosalgoritmos discutidos em conjunto. É possível, por exemplo, aplicar a decomposição porvalores singulares a fim de mitigar uma matriz esparsa, a transformando em uma matriz demenor dimensionalidade completamente especificada, e então aplicar essa nova matriz emoutro algoritmo. Isso poderia ser feito antes da aplicação do método dos k-vizinhos maispróximos no sistema de filtro colaborativo, de forma que a determinação da vizinhança deum usuário é realizada com uma matriz completamente especificada ao invés da matrizesparsa original. Outra possibilidade para sistemas de filtragem colaborativa é criar váriasmatrizes de avaliações de m usuários a n itens, cada uma sendo gerada a partir de umalgoritmo diferente, e usar todas as previsões aij de um usuário i a um item j de cadaalgoritmo e combiná-las, usando por exemplo uma média ponderada, a fim de encontrar a

Capítulo 3. Aplicações 113
previsão final.

114
Conclusão
Nessa dissertação apresentamos uma revisão sobre os principais modelos desistemas de recomendação, dando destaque aos conceitos matemáticos que sustentamos algoritmos computacionais utilizados na construção desses modelos. Como forma deilustrar os modelos com base em dados reais, implementamos os algoritmos e realizamosquatro estudos de casos para comparar os resultados.
O estudo contemplou uma revisão sobre as duas estratégias mais utilizadas naconstrução de sistemas de recomendação, a filtragem colaborativa e a filtragem baseada emconteúdo. Do ponto de vista computacional, foram enfatizados os principais algoritmos deaprendizado de máquina supervisionado, com especial atenção para os aspectos matemáticosda regressão linear, redução de dimensionalidade e decomposição SVD de matrizes, K-vizinhos mais próximos, árvores de decisão e, finalmente, redes neurais artificiais.
Como forma de aplicar os conceitos estudados, construimos modelos utilizandoalguns dos algoritmos e propomos sistemas de recomendação baseados em um caso real,com o objetivo de recomendar produtos para um site de venda de vestuário online. Osresultados de cada algoritmo foram analisados sob a perspectiva dos indicadores de erroabsoluto médio (MAE) e a raíz do erro quadrático médio (RMSE).
Um assunto interessante e que pode ser abordado em trabalhos futuros é orelevante problema de recomendação em redes sociais, conceito usado por exemplo pararecomendar novas amizades ou conteúdo em plataformas como o Facebook, Instagram,Youtube. Em geral, esses sistemas de recomendação são construídos a partir das relaçõesestruturais entre usuários, classificando os nós e arestas da rede formada e baseando-se emcaracterísticas típicas de redes (ou grafos), como o número de conexões que chegam a umnó específico.
Outra perspectiva muito relevante é o aspecto ético envolvido na implementaçãode um sistema de recomendação, uma vez que esse tipo de sistema é capaz de incentivar ereforçar certos padrões de comportamento. Poderia um sistema de recomendação controlaras ações do usuário? Se sim, quais os perigos inerentes ao uso de sistemas de recomendação?Existe um problema de invasão de privacidade no momento da coleta dos dados quealimentam os sistemas de recomendação? Todos esses questionamentos são de sumaimportância para indivíduos ou empresas que almejam utilizar sistemas de recomendaçãoe podem suscitar trabalhos acadêmicos relevantes, por exemplo, na área de fairness.
Do ponto de vista pessoal, a execução desse trabalho trouxe grande satisfação,uma vez que nos permitiu um estudo mais aprofundado sobre os conceitos matemáticosque embasam alguns dos algoritmos de inteligência artificial mais utilizados hoje em dia.

Conclusão 115
Nas empresas por onde passei foram algumas as vezes em que utilizamos algoritmos deaprendizado de máquina a fim de resolver um problema real, mas admito que muitas dessasaplicações eram realizadas sem um entendimento adequado dos conceitos matemáticosque regram o comportamento desses algoritmos. Além disso, vi grande valor em direcionaro estudo a problemas de recomendação, assunto bastante discutido tanto em círculosacadêmicos quanto corporativos.

116
Referências
ACADEMY, C. Training Set vs Validation Set vs Test Set. 2021. Disponível em:<https://www.codecademy.com/articles/training-set-vs-validation-set-vs-test-set>.Citado na página 35.
AGGARWAL, C. C. Recommender Systems: The textbook. [S.l.]: Springer, 2016. Citado21 vezes nas páginas 17, 19, 20, 21, 24, 25, 26, 27, 29, 31, 36, 43, 45, 46, 51, 52, 53, 59, 78,85 e 100.
BATISTA, G. E. A. P. A.; SILVA, D. F. How k-Nearest Neighbor Parameters Affect itsPerformance. In: Argentine Symposium on Artificial Intelligence. [S.l.: s.n.], 2009. p. 1–12.Citado na página 58.
BISHOP, C. M. Pattern Recognition and Machine Learning. [S.l.]: Springer, 2006. Citadona página 32.
BOLDRINI, J. L.; COSTA, S. I. R.; FIGUEIREDO, V. L.; WETZLER, H. G. AlgebraLinear. [S.l.]: HARBRA Ltda, 1986. Citado na página 47.
DOMKE, J. Statistical Machine Learning: Trees. 2010. Disponível em: <https://people.cs.umass.edu/~domke/courses/sml2010/08trees.pdf>. Citado 3 vezes naspáginas 70, 71 e 72.
GEBREMESKEL, G. G.; VRIES, A. P. de. Recommender systems evaluations: Offline,online, time and a/a test. Working Notes of the Conference and Labs of the EvaluationForum 2016, p. 642–656, 2016. Citado na página 26.
GOLDBERG, D.; NICHOLS, D.; OKI, B. M.; TERRY, D. Using Collaborative Filteringto Weave an Information Tapestry. Communications of the ACM, v. 35, n. 12, p. 61–70,1992. Citado na página 18.
GOODFELLOW, I.; BENGIO, Y.; COURVILLE, A. Deep Learning. [S.l.]: The MITPress, 2016. Citado 4 vezes nas páginas 17, 73, 74 e 78.
GUNDERSEN, G. Proof of the Singular Value Decomposition. 2018. Dis-ponível em: <https://gregorygundersen.com/blog/2018/12/20/svd-proof/#1-gram-matrices-as-positive-semi-definite>. Citado 2 vezes nas páginas 47e 49.
HASTIE, T.; TIBSHIRANI, R.; FRIEDMAN, J. The Elements of Statistical Learning:Data Mining, Inference, and Prediction. [S.l.]: Springer, 2017. Citado 3 vezes nas páginas17, 70 e 73.
HUG, N. k-NN inspired algorithms. 2015. Disponível em: <https://surprise.readthedocs.io/en/stable/knn_inspired.html>. Citado na página 107.
HUI, J. Machine Learning — Singular Value Decomposition (SVD) Principal ComponentAnalysis (PCA). 2019. Disponível em: <https://bit.ly/3rvUXZk>. Citado 2 vezes naspáginas 49 e 50.

Referências 117
KANE, F. Building Recommending Systems with Machine Learning and AI. [S.l.]: SundogEducation, 2018. Citado 8 vezes nas páginas 16, 17, 26, 27, 28, 29, 30 e 58.
KONSTAN, J. A.; RIEDL, J. Recommender systems: from algorithms to user experience.Springer Science+Business Media B.V. 2012, 2012. Citado na página 18.
KOREN, Y.; BELL, R.; VOLINSKY, C. Matrix Factorization Techniques forRecommender Systems. Computer, v. 42, n. 8, p. 42–49, 2009. Citado 3 vezes nas páginas22, 24 e 108.
KUBAT, M. An Introduction to Machine Learning. [S.l.]: Springer, 2017. Citado napágina 32.
LAKSHMANAN, S. How, When and Why Should You Normalize / Standardize /Rescale Your Data? 2019. Disponível em: <https://medium.com/@swethalakshmanan14/how-when-and-why-should-you-normalize-standardize-rescale-your-data-3f083def38ff>.Citado na página 42.
LAST, M.; MAIMOM, O.; MINKOV, E. Improving stability of decision trees. InternationalJournal of Pattern Recognition and Artificial Intelligence, 2002. Citado na página 69.
LI, S. Evaluating A Real-Life Recommender System, Error-Based andRanking-Based. 2019. Disponível em: <https://towardsdatascience.com/evaluating-a-real-life-recommender-system-error-based-and-ranking-based-84708e3285b>.Citado na página 29.
MACKENZIE, I.; MEYER, C.; NOBLE, S. How retailers can keep up with consumers.2013. Disponível em: <https://www.mckinsey.com/industries/retail/our-insights/how-retailers-can-keep-up-with-consumers>. Citado na página 20.
MARGALIT, D. Interactive Linear Algebra. [S.l.]: Georgia Institute of Technology, 2019.Citado na página 39.
MARSLAND, S. Machine Learning: An Algorithmic Perspective. [S.l.]: CRC Press, 2009.Citado 5 vezes nas páginas 17, 32, 69, 70 e 73.
MISRA, R.; WAN, M.; MCAULEY, J. Decomposing fit semantics for product sizerecommendation in metric spaces. RecSys ’18: Proceedings of the 12th ACM Conferenceon Recommender Systems, 2018. Citado na página 104.
MOCANU, D. C.; MOCANU, E.; STONE, P.; NGUYEN, P. H.; GIBESCU, M.; LIOTTA,A. Scalable training of artificial neural networks with adaptive sparse connectivity inspiredby network science. Nature Communications 9, 2018. Citado na página 88.
OLIVEIRA, J. V. de. Estudo da decomposição em valores singulares e análise doscomponentes principais. In: . [S.l.: s.n.], 2016. Citado na página 51.
PANDORA. About the Music Genome Project. 2019. Disponível em: <https://www.pandora.com/about/mgp>. Citado na página 16.
RESNICK, P.; IACOVOU, N.; SUCHAK, M.; BERGSTROM, P.; RIEDL, J. GroupLens:An Open Architecture for Collaborative Filtering of Netnews. Proceedings of ACM 1994Conference on Computer Supported Cooperative Work, v. 1, p. 175–186, 1994. Citado napágina 18.

Referências 118
ROKACH, L.; MAIMON, O. Data mining with decision trees: theory and applications.[S.l.]: World Scientific, 2015. Citado na página 70.
SCRAPEHERO. How Many Products Does Amazon Sell? – April 2019. 2019. Disponívelem: <https://www.scrapehero.com/number-of-products-on-amazon-april-2019/>.Citado na página 16.
SHARDANAND, U.; MAES, P. Social Information Filtering: Algorithms for Automating“Word of Mouth”. CHI ’95 Proceedings of the SIGCHI Conference on Human Factors inComputing Systems, v. 1, p. 210–217, 1995. Citado na página 18.
SONI, D. Supervised vs. Unsupervised Learning. 2018. Disponível em: <https://towardsdatascience.com/supervised-vs-unsupervised-learning-14f68e32ea8d>. Citado 2vezes nas páginas 34 e 35.
STONE, J. V. Artificial Intelligence Engines: A Tutorial Introduction of the Mathematicsof Deep Learning. [S.l.]: Sebtel Press, 2020. Citado 4 vezes nas páginas 17, 86, 91 e 93.
TONDJI, L. N. Web Recommender System for Job Seeking and Recruiting. Tese(Doutorado), 02 2018. Citado na página 22.
WOLFRAM, S. Data Science of the Facebook World. 2013. Disponível em:<https://writings.stephenwolfram.com/2013/04/data-science-of-the-facebook-world/>.Citado na página 21.