uma análise dos novos sistemas de bancos de dados relacionais
TRANSCRIPT

Uma Análise dos Novos Sistemas de Bancos de Dados Relacionais
Escaláveis
Pedro Henrique dos Santos Lemos
Pedro Soares Figueiredo
Projeto de Graduação apresentado ao Curso de
Engenharia de Computação e Informação da
Escola Politécnica, Universidade Federal do Rio
de Janeiro, como parte dos requisitos necessários
à obtenção do título de Engenheiro.
Orientador: Alexandre de Assis Bento Lima
Rio de Janeiro
Março de 2014

UMA ANÁLISE DOS NOVOS SISTEMAS DE BANCOS DE DADOS RELACIONAIS
ESCALÁVEIS
Pedro Henrique dos Santos Lemos
Pedro Soares Figueiredo
PROJETO DE GRADUAÇÃO SUBMETIDO AO CORPO DOCENTE DO CURSO DE
ENGENHARIA DE COMPUTAÇÃO E INFORMAÇÃO DA ESCOLA POLITÉCNICA DA
UNIVERSIDADE FEDERAL DO RIO DE JANEIRO COMO PARTE DOS REQUISITOS
NECESSÁRIOS PARA A OBTENÇÃO DO GRAU DE ENGENHEIRO DE
COMPUTAÇÃO E INFORMAÇÃO.
Examinada por:
______________________________________________
Prof. Alexandre de Assis Bento Lima, D.Sc.
______________________________________________
Profa. Marta Lima de Queirós Mattoso, D.Sc.
______________________________________________
Prof. Ricardo Cordeiro de Farias, Ph.D.
RIO DE JANEIRO, RJ – BRASIL
MARÇO de 2014

iii
Pedro Henrique dos Santos Lemos
Pedro Soares Figueiredo
Uma Análise dos Novos Sistemas de Bancos de Dados
Relacionais Escaláveis/Pedro Henrique dos Santos Lemos e
Pedro Soares Figueiredo. – Rio de Janeiro: UFRJ/ Escola
Politécnica, 2014.
VIII, 58 p.: il.; 29,7 cm.
Orientador: Alexandre de Assis Bento Lima
Projeto de Graduação – UFRJ/ Escola Politécnica/ Curso de
Engenharia de Computação e Informação, 2014.
Referências Bibliográficas: pxx
1. Banco de Dados 2. Modelo Relacional 3. NoSQL 4.
NewSQL. Universidade Federal do Rio de Janeiro, Escola
Politécnica, Curso de Engenharia de Computação e
Informação. III. Título.
Pedro Henrique dos Santos Lemos
Pedro Soares Figueiredo
Uma Análise dos Novos Sistemas de Bancos de Dados
Relacionais Escaláveis/Pedro Henrique dos Santos Lemos e
Pedro Soares Figueiredo. – Rio de Janeiro: UFRJ/ Escola
Politécnica, 2014.
VIII, 58 p.: il.; 29,7 cm.
Orientador: Alexandre de Assis Bento Lima
Projeto de Graduação – UFRJ/ Escola Politécnica/ Curso de
Engenharia de Computação e Informação, 2014.
Referências Bibliográficas: pxx
1. Banco de Dados 2. Modelo Relacional 3. NoSQL 4.
NewSQL. Universidade Federal do Rio de Janeiro, Escola
Politécnica, Curso de Engenharia de Computação e
Informação. III. Título.
Pedro Henrique dos Santos Lemos
Pedro Soares Figueiredo
Uma Análise dos Novos Sistemas de Bancos de Dados
Relacionais Escaláveis/Pedro Henrique dos Santos Lemos e
Pedro Soares Figueiredo. – Rio de Janeiro: UFRJ/ Escola
Politécnica, 2014.
VIII, 58 p.: il.; 29,7 cm.
Orientador: Alexandre de Assis Bento Lima
Projeto de Graduação – UFRJ/ Escola Politécnica/ Curso de
Engenharia de Computação e Informação, 2014.
Referências Bibliográficas: pxx
1. Banco de Dados 2. Modelo Relacional 3. NoSQL 4.
NewSQL. Universidade Federal do Rio de Janeiro, Escola
Politécnica, Curso de Engenharia de Computação e
Informação. III. Título.
Figueiredo, Pedro Soares
Lemos, Pedro Henrique dos Santos
Uma Análise dos Novos Sistemas de Bancos de Dados
Relacionais Escaláveis/Pedro Henrique dos Santos Lemos e
Pedro Soares Figueiredo. – Rio de Janeiro: UFRJ/ Escola
Politécnica, 2014.
XII, 71 p.: il.; 29,7 cm.
Orientador: Alexandre de Assis Bento Lima
Projeto de Graduação – UFRJ/Escola Politécnica/
Curso de Engenharia de Computação e Informação, 2014.
Referências Bibliográficas: p. 66-69
1. Banco de Dados 2. Modelo Relacional 3. NoSQL 4.
NewSQL. I. Lima, Alexandre de Assis Bento II. Universidade
Federal do Rio de Janeiro, Escola Politécnica, Curso de
Engenharia de Computação e Informação. III. Titulo.

iv
AGRADECIMENTOS
Por Pedro Lemos:
Chegar em um momento como esse não é algo fácil. Foram 6 intensos anos,
nos quais inúmeras dificuldades surgiram, muitas coisas foram deixadas de lado, para
que esse momento chegasse, mas principalmente, muitas coisas foram conquistadas
ao longo desses anos, que hoje me fazem ter a certeza que esse tempo não foi em
vão, e sim muito proveitoso. Mas para enfrentar todos os obstáculos e mesmo assim
sentir o prazer dessa conquista, foi necessário uma comunhão de forças, as quais
agradeço aqui nesse momento.
À minha família, principalmente meus pai, Artur e Wania, minhas irmãs,
Larissa e Renata e minha namorada Anália, por todo o apoio e dado durante esse
longo período. Não teria sido fácil, sem a ajuda de vocês, sem o suporte emocional
necessário, para aguentar viradas de noites de estudos, estágios durante o fim de
semana, viagens a trabalho e passar 1 ano morando longe de casa. Obrigado por todo
o amor e carinho que vocês sempre me deram.
Aos amigos de ECI, que fizeram cada dia de faculdade, ser um dia diferente.
Sem vocês, esses anos não seriam os mesmos, e teriam passado muito mais
devagar. Obrigado por me ajudar a levar a faculdade com a seriedade, mas também
com a alegria necessária.
À Fluxo e seus membros, por ter me feito aprender muito mais que
Engenharia. Por me deixar conhecer esse imenso mundo que é o Empreendedorismo.
Sem todos os EMPIs, PAME´s, reuniões de fim de semana, sem ter conhecido todos
vocês, essa faculdade não teria a menor graça. Obrigado por ser minha 2ª casa.
Aos amigo feitos no Porto, obrigado pela grande experiência de ter morado
fora de casa durante 1 ano. Vocês tornaram esse momento, mais incrível do que eu
poderia imaginar.

v
AGRADECIMENTOS
Por Pedro Figueiredo:
Primeiramente, tenho que agradecer à meus pais, Sérgio e Mônica, pelas
primeiras orientações que recebi na vida. O amor, o carinho, o apoio incondicional, a
educação dada e os valores que me passaram fizeram com que tudo o que aconteceu
até aqui fosse possível. Obrigado por me ensinarem a acreditar. À meus irmãos, Lucas
e João Felipe, obrigado por serem os melhores irmãos possíveis.
Aos queridos amigos da turma de 2008 da ECI, agradeço por terem tornado
essa jornada prazerosa, mesmo nos momentos mais difíceis. As salas de estudo,
virtuais e reais, serão lembradas. Todas as outras reuniões, mais ainda! Obrigado por
terem se tornado amigos de verdade. Um agradecimento especial ao Pedro Lemos
pela parceria inestimável na realização deste projeto.
Aos amigos da época de colégio, vocês me ensinaram o significado real da
palavra amizade. Essa foi uma lição incrível! Obrigado pelo apoio de sempre.
Aos companheiros da Plannera, obrigado por terem feito parte da minha vida
profissional. E obrigado por terem me ensinado a “aprender a errar melhor”. ,
E a todos que de alguma forma contribuíram para este momento, agradeço.
Por ambos:
Ao professor Alexandre Assis, agradecemos pelas aulas que eventualmente
levaram à escolha deste tema, pela orientação neste trabalho, pela dedicação em
todas as revisões do texto. E aos demais professores, obrigado por todos os
momentos igualmente inspiradores.

vi
Resumo do Projeto de Graduação apresentado à Escola Politécnica/ UFRJ como parte
dos requisitos necessários para a obtenção do grau de Engenheiro de Computação e
Informação.
Uma Análise dos Novos Sistemas de Bancos de Dados Relacionais Escaláveis
Pedro Henrique dos Santos Lemos
Pedro Soares Figueiredo
Março/2014
Orientador: Alexandre de Assis Bento Lima
Curso: Engenharia de Computação e Informação
Sistemas de Gerência de Bancos de Dados Relacionais (SGBDR) tradicionalmente
são usados como parte da solução de aplicações de Processamento de Transações.
Nos últimos anos, porém, surgiram novas aplicações, geralmente baseadas na Web:
redes sociais, jogos multijogadores online, análise de dados em tempo real, entre
outros. Aplicações bem sucedidas desses tipos são caracterizadas por um alto volume
de interações por segundo e um tempo de resposta baixo, o que demanda requisitos
de escalabilidade e desempenho melhorados dos SGBD. Sistemas NoSQL, uma
classe de SGBD não-relacionais, surgiram para atender a esta demanda, fornecendo
escalabilidade horizontal, em troca de uma consistência relaxada dos dados, chamada
consistência tardia, e da ausência de uma linguagem de consulta de alto nível, como a
SQL, o que dificulta sua adoção em larga escala. Assim, uma nova classe de SGBDR
vem surgindo: os SGBD NewSQL, com suporte a SQL e transações ACID, que se
diferenciam por novas estratégias de implementação, que incluem, entre outras, dados
residentes em memória, escalabilidade horizontal em ambientes com arquitetura de
memória distribuída, e por serem projetados para atender a tipos específicos de
aplicações. Essa nova classe de SGBDR constitui o objeto de análise deste projeto.
Para isso, suas motivações e suas principais características foram estudadas. Para
fins ilustrativos, foram realizados testes de desempenho com um SGBD NewSQL
através da aplicação de um conjunto de benchmarks, que simulam cargas de trabalho
típicas de domínios de aplicações distintos.

vii
Abstract of Undergraduate Project presented to POLI/UFRJ as a partial fulfillment of
the requirements for the degree of Computer and Information Engineer.
Analysis of the New Scalable Relational Database Systems
Pedro Henrique dos Santos Lemos
Pedro Soares Figueiredo
March/2014
Advisor: Alexandre de Assis Bento Lima
Major: Computer and Information Engineering
Relational Database Management Systems (RDBMS) are traditionally used as a part of
Transaction Processing applications. In recent years, however, new Web-based
applications emerged: social networks, online multiplayer games, real-time data
analytics, among others. Successful applications of that kind are characterized by a
high volume of interactions per second and low response time, which demands
improved performance and scalability from DBMS. NoSQL systems, a non-relational
class of DBMS, emerged to fulfill this task, providing horizontal scalability, in exchange
of relaxed data consistency (called eventually consistent systems) and the absence of
a high-level query language, such as SQL, which makes their adoption harder. Thus, a
new class of RDBMS arose: NewSQL, that supports both SQL and ACID-compliant
transactions, and differentiates themselves from traditional RDBMS by presenting new
strategy implementations that include in-memory data storage and horizontal scalability
in shared nothing clusters. They are also designed according to specific application
requirements. NewSQL systems are the object of analysis of this project. Motivations
for their development and main features were studied. For illustrative purposes,
performance evaluation of one NewSQL DBMS was done through the execution of a
set of synthetic benchmarks, simulating a variety of distinguished application workloads.

viii
SUMÁRIO
Capítulo 1 - Introdução ................................................................................................ 1
1.1 Tema ...................................................................................................................... 1
1.2 Justificativa ............................................................................................................ 1
1.3 Objetivo .................................................................................................................. 2
1.4 Metodologia ........................................................................................................... 2
1.5 Organização do Texto ........................................................................................... 3
Capítulo 2 - Fundamentação Teórica .......................................................................... 4
2.1 Estratégias tradicionais para implementação de SGBD ........................................ 4
2.2 Novo Ambiente ...................................................................................................... 5
2.3 Bancos de Dados Distribuídos .............................................................................. 7
2.4 NoSQL ................................................................................................................. 14
2.4.1 Motivação ......................................................................................................... 14
2.4.2 Principais Características ................................................................................. 14
2.4.3 Classificação ..................................................................................................... 15
2.4.4 Problemas ......................................................................................................... 17
2.5 Avaliação de Desempenho em Sistemas de Bancos de Dados .......................... 18
Capítulo 3 - NewSQL ................................................................................................. 21
3.1 NuoDB ................................................................................................................. 22
3.1.1 Visão Geral ....................................................................................................... 22
3.1.2 Arquitetura ........................................................................................................ 23
3.1.2.1 Estrutura em níveis ........................................................................................ 23
3.1.2.2 Os Átomos ..................................................................................................... 25
3.1.2.3 Controle de Concorrência .............................................................................. 26
3.2 VoltDB .................................................................................................................. 27
3.2.1 Visão Geral ....................................................................................................... 27
3.2.2 Arquitetura ........................................................................................................ 28
3.3 MemSQL .............................................................................................................. 31

ix
3.3.1 Visão Geral ....................................................................................................... 31
3.3.2 Arquitetura ........................................................................................................ 31
3.3.2.1 Alocação de Tabelas ..................................................................................... 32
3.3.2.2 Controle de Concorrência .............................................................................. 33
3.3.3 Execução de Consultas .................................................................................... 34
3.3.4 Propriedades ACID ........................................................................................... 35
3.4 Google Spanner ................................................................................................... 36
3.4.1 Visão Geral ....................................................................................................... 36
3.4.2 Arquitetura ........................................................................................................ 37
Capítulo 4 - Avaliação experimental .......................................................................... 39
4.1 OLTP-Bench ........................................................................................................ 39
4.1.1 TPC-C ............................................................................................................... 40
4.1.2 TATP ................................................................................................................. 42
4.1.3 YCSB ................................................................................................................ 44
4.1.4 Twitter ............................................................................................................... 46
4.2 Ambiente de Testes ............................................................................................. 48
4.3 Procedimento Experimental ................................................................................. 49
4.3.1 Objetivo ............................................................................................................. 49
4.3.2 Metodologia ...................................................................................................... 49
4.3.3 Configuração dos SGBD .................................................................................. 51
4.4 Resultados Experimentais ................................................................................... 52
4.4.1 TATP ................................................................................................................. 52
4.4.2 Twitter ............................................................................................................... 54
4.4.3 YCSB ................................................................................................................ 56
4.4.4 TPC-C ............................................................................................................... 58
Capítulo 5 - Conclusão .............................................................................................. 62
5.1 Limitações ............................................................................................................ 63
5.2 Trabalhos Futuros ................................................................................................ 64

x
Referências Bibliográficas ............................................................................................ 66
Anexo A ........................................................................................................................ 70

xi
LISTA DE FIGURAS
Figura 1 – Um sistema de banco de dados distribuído. Adaptado de (ÖZSU,
VALDURIEZ, 2010). ..................................................................................................... 10
Figura 2 - Arquitetura do NuoDB. Adaptado de www.nuodb.com ................................ 25
Figura 3 - Arquitetura do MemSQL. Adaptado de www.memsql.com .......................... 32
Figura 4 - Execução de Consultas no MemSQL. Adaptado de www.memsql.com ...... 35
Figura 5 - Esquema do TPC-C ..................................................................................... 41
Figura 6 - Esquema do TATP ....................................................................................... 43
Figura 7 - Esquema do YCSB ...................................................................................... 45
Figura 8 – Esquema do Twitter .................................................................................... 46
Figura 9 - Resultados TATP - 2 Nós ............................................................................ 53
Figura 10 - Resultados TATP - 4 Nós .......................................................................... 53
Figura 11 - Resultados TATP - 128 Usuários Virtuais .................................................. 54
Figura 12 - Resultados Twitter - 2 Nós ......................................................................... 55
Figura 13 - Resultados Twitter - 4 Nós ......................................................................... 55
Figura 14 - Resultados Twitter - 128 Usuários Virtuais ................................................ 56
Figura 15 - Resultados YCSB - 2 Nós .......................................................................... 57
Figura 16 - Resultados YCSB - 4 Nós .......................................................................... 57
Figura 17 - Resultados YCSB - 128 Usuários Virtuais ................................................. 58
Figura 18 - Resultados TPCC - 2 Nós .......................................................................... 58
Figura 19 - Resultados TPCC - 4 Nós .......................................................................... 59
Figura 20 - Resultados TPCC - 128 Usuários Virtuais ................................................. 59

xii
LISTA DE SIGLAS
ACID – Atomicidade, Consistência, Isolamento e Durabilidade
BASE – Basically Available, Soft-state services with Eventual-Consistency
JDBC – Java Database Connectivity
LDD – Linguagem de Definição de Dados
MV – Máquina Virtual
MVCC – Multi Version Concurrency Control
OLTP – Processamento de Transações em Tempo Real (do inglês, Online Transaction
Processing)
SBD – Sistemas de Bancos de Dados
SBDD – Sistemas de Bancos de Dados Distribuídos
SBDR – Sistemas de Bancos de Dados Relacionais
SGBD – Sistema de Gerência de Banco de Dados
SM – Gerenciador de Armazenamento (do inglês, Storage Manager)
SQL – Linguagem de Consulta Estruturada (do inglês, Structured Query Language)
SSD – Solid State Drives
TE – Motor de Transações (do inglês, Transaction Engine)
TPC – Transaction Processing Performance Council
XML – eXtended Markup Language
YCSB – Yahoo! Cloud Serving Benchmark

1
Capítulo 1 - Introdução
1.1 Tema
Este projeto traz os resultados de um estudo sobre as novas tecnologias utilizadas
para implementação de Sistemas de Gerência de Bancos de Dados Relacionais
(SGBDR), conjuntamente denominadas NewSQL.
1.2 Justificativa SGBDR tradicionalmente são usados como parte da solução de aplicações com
grande número de transações. Nos últimos anos, porém, surgiram uma variedade de
novas aplicações, geralmente baseadas na Web: redes sociais online, jogos
multijogadores, comércio eletrônico a nível global, mensageiros instantâneos, etc.
Aplicações bem sucedidas desses tipos são caracterizadas por um alto volume de
interações por segundo e, normalmente, espera-se que o tempo de resposta seja
muito baixo, o que demanda requisitos de escalabilidade e desempenho melhorados
dos SGBD (STONEBRAKER,2011). As estratégias de implementação dos SGBDR
atuais (armazenamento baseado em disco, arquitetura centralizada, entre outros) são
um empecilho para atender a esses requisitos. Uma abordagem do tipo “dividir para
conquistar” para o problema da escalabilidade, como fragmentar os dados em uma
arquitetura distribuída, por exemplo, tem um custo elevado de manutenção em um
SGBDR. O aprimoramento de tecnologias de hardware, como processadores mais
rápidos, memórias com mais capacidade (e que ficaram, ao mesmo tempo, mais
baratas), e novas formas de armazenamento não-volátil, como os Solid State Drives
(SSD), também devem ser consideradas. Bases de dados residentes unicamente em
memória passam a ser uma opção, por exemplo.
Por isso, surgiu o movimento NoSQL. Sistemas NoSQL visam atender a
problemas específicos, através de modelos de dados distintos, como: orientados a

2
grafos (adequados a uma rede social, por exemplo), a documentos (adequados a
sistemas web que utilizam estruturas tipo XML ou JSON, por exemplo) e
armazenamento chave-valor (um exemplo seria uma espécie de cache). O problema é
que esse tipo de sistema provê um maior desempenho em troca de “relaxar” a
consistência, sendo tardiamente consistentes, e não possuem uma linguagem de
consulta unificada, como o SQL, o que pode tornar complexo o acesso aos dados,
podendo até inviabilizar a decisão de adoção desse tipo de tecnologia.
Assim, pesquisadores como STONEBRAKER et al.(2007) sugerem soluções
que mantenham o Modelo Relacional, as transações ACID (Atomicidade,
Consistência, Isolamento e Durabilidade) e a SQL, reduzindo “custos de transição”,
mas que, ao mesmo tempo, tenham arquiteturas e estratégias de implementações
projetadas para atender a necessidades específicas, pois assim evitam sobrecargas
induzidas por recursos que existem em SGBDR tradicionais e, muitas vezes, são
desnecessárias, pois estes tendem a ser generalistas (“uma aplicação para tudo”). A
esse conjunto de novas soluções deu-se o nome NewSQL.
1.3 Objetivo
O objetivo principal deste projeto é realizar um estudo sobre as novas tecnologias para
SGBDR denominadas NewSQL, mostrando desde os motivos da sua concepção até
os detalhes de funcionamento de algumas dessas ferramentas, passando pelas
principais diferenças entre o NewSQL e os SGBDR tradicionais. Um outro objetivo é
verificar, através de experimentos, o desempenho de alguns dos novos SGBDR. Para
tanto, uma ferramenta (NuoDB) foi analisada com a utilização de quatro benchmarks
com características bastante distintas.
1.4 Metodologia
As seguintes etapas foram realizadas para a conclusão deste estudo:

3
I. Levantamento de material didático, a fim de realizar um estudo
aprofundado sobre as tecnologias de bancos de dados NewSQL.
II. Pesquisa exploratória de diversos conceitos de bancos de dados e do
cenário atual, tentando entender o porquê da necessidade de novas
tecnologias.
III. Planejamento e organização de um ambiente de testes para realização
de quatro benchmarks entre um sistema NewSQL e um SGBDR atual.
IV. Escolha de ferramentas NewSQL para avaliação de desempenho.
V. Avaliação das ferramentas selecionadas através da execução dos
benchmarks escolhidos.
VI. Análise dos resultados obtidos.
1.5 Organização do Texto
Este projeto está organizado da seguinte forma: no Capítulo 2 são apresentadas as
características dos SGBDR tradicionais e as demandas das novas aplicações, que não
conseguem ser atendidas por esses sistemas de forma satisfatória. Além disso, são
apresentados conceitos de bancos de dados distribuídos e uma breve descrição das
tecnologias NoSQL, uma das primeiras alternativas aos SGBDR tradicionais. Também
há uma breve introdução a métodos para avaliação de desempenho em SGBD, e
quais características específicas podem ser medidas por eles. No Capítulo 3 é
apresentado o conceito de NewSQL e algumas ferramentas desenvolvidas são
analisadas. O Capítulo 4 descreve os experimentos realizados e seus resultados.
O Capítulo 5 conclui o projeto.

4
Capítulo 2 - Fundamentação Teórica
2.1 Estratégias tradicionais para implementação de SGBD Os SGBD tradicionais, especialmente os que suportam aplicações que executam
processamento de transações em linha (OLTP, do inglês “On-line Transaction
Processing”), possuem uma série padrão de recursos, tais como suporte ao modelo de
dados Relacional (SGBDR), estruturas para armazenamento de dados em disco,
controle de concorrência entre transações e recuperação de falhas através de
arquivos de log (HARIZOPOULOS et al., 2008). Alguns destes recursos já faziam
parte do “System R” (STONEBRAKER et al., 2007), SGBD Relacional lançado na
década de 1970, quando as bases de dados eram muito maiores que a quantidade de
memória principal disponível em um servidor de banco de dados e o custo de um
computador apropriado para tais bases era altíssimo.
Duas das principais características desses sistemas são a utilização da
linguagem SQL para consultas (devido ao modelo Relacional) e a garantia das
propriedades ACID em suas transações. A primeira possui vantagens como: promover
a independência dos dados, ser uma linguagem de alto nível, declarativa, amplamente
disseminada na comunidade (fazendo parte do currículo de praticamente todos os
cursos ligados à Computação), proporcionar relativa facilidade de aprendizado e
compreensão e ser uma linguagem independente de plataforma, sendo suportada por
basicamente todos os SGBDR.
As propriedades ACID garantem aos usuários a execução correta e consistente
de suas transações. São transações atômicas, pois todas as suas operações são
executadas com sucesso, ou, em caso de alguma falha, todas são desfeitas;
consistentes, pois toda transação leva o banco de dados de um estado consistente a
outro estado consistente, respeitando as restrições de integridade; isoladas, pois,
caso ocorram transações concorrentes, uma transação não interfere no resultado da

5
outra, permitindo que o resultado da execução paralela das transações seja o mesmo
obtido caso as mesmas tivessem sido executadas sequencialmente; e duráveis, pois,
em caso de sucesso, as alterações causadas pela transação são persistidas mesmo
em caso de falhas. Esse tipo de garantia é crucial para o bom funcionamento de
sistemas OLTP como, por exemplo, sistemas bancários e de compras de passagens
aéreas. Por isso, nestes sistemas, o benefício de garantir a consistência dos dados
por muitas vezes acaba sendo superior à perda de desempenho induzida pela
sobrecarga causada por alguns mecanismos de controle de concorrência.
Devido, em grande parte, à estas características, os SGBDR ainda são
amplamente utilizados. Esta ampla utilização, nos últimos 40 anos, levou seus
desenvolvedores a desenvolvê-los como ferramentas que podem ser utilizadas por
qualquer tipo de aplicação que necessite de persistência de dados (“one size fits all” -
(STONEBRAKER, CENTINTEMEL, 2005)). O cenário, no entanto, vem mudando
desde a década de 2000, conforme mostra a próxima seção.
2.2 Novo Ambiente O principal mercado a ser atendido pelos SGBDR, na época em que foram criados,
era o de aplicações transacionais OLTP, mais especificadamente o de processamento
de dados de negócios (STONEBRAKER et al. 2007), como por exemplo sistemas para
compra de passagens de avião. De forma diferente do cenário atual, este tipo de
operação não era realizado diretamente pelo cliente através da Internet, já que a
mesma ainda nem existia. Nos EUA, por exemplo, as transações eram realizadas por
operadores profissionais especializados, contatados por telefone, que então
manipulavam o banco de dados com sua aplicação cliente, através de um terminal,
para fazer a reserva com operações simples.

6
Apesar de parecer que ter um sistema único para todas as aplicações possa
ser fantástico, do ponto de vista financeiro e operacional, a perspectiva sobre os
SGBDR vem mudando (STONEBRAKER et al., 2007).
Nos últimos anos uma enorme quantidade de outros mercados surgiu,
incluindo motores de busca na Web, redes sociais e o mercado de comunicação
móvel, entre outras aplicações em tempo real, fazendo com que o cenário OLTP dos
dias atuais seja claramente distinto: existem dispositivos, em escala global,
constantemente conectados à Internet, como smartphones e tablets, que são
potenciais geradores de transações. Considerando o exemplo da reserva de
passagens de avião mencionado anteriormente, por exemplo: hoje esse objetivo pode
ser alcançado enquanto se toma um café. Basta que se disponha de um dispositivo
móvel conectado a Internet. Essa comodidade, associada a um mundo dinâmico em
que as pessoas desejam a todo momento que suas solicitações sejam atendidas com
rapidez, levanta duas demandas em relação aos SGBDR: maior vazão (em número de
transações por unidade de tempo) e alta disponibilidade, normalmente alcançada na
forma de replicação (STONEBRAKER, 2011).
Além das mudanças nas aplicações que utilizam SGBD e no contexto
informacional que estamos, podemos citar também uma grande mudança no cenário
dos hardwares utilizados. Segundo STONEBRAKER et al. (2007) os processadores
modernos são bem mais rápidos, e executam transações em microssegundos, os
discos rígidos aumentaram significativamente de tamanho, e novas tecnologias de
armazenamento não-volátil foram desenvolvidas, como os SSD (do inglês, Solid State
Drive ), que possuem tempos de resposta bastante reduzidos. Além disso, o custo da
memória principal diminuiu, e já é possível ter servidores com capacidade suficiente
para tornar possível a implantação de bases de dados residentes unicamente em
memória principal (STONEBRAKER, WEISBERG, 2013). Some-se a isso o fato de
que aglomerados (do inglês clusters) de computadores, constituídos de dezenas ou
até mesmo milhares de computadores comuns interconectados, ganharam grande

7
popularidade como solução para aumentar a capacidade de processamento disponível
a baixo custo, e este cenário se torna ainda mais factível.
Mas é claro que os SGBDRs atuais não são idênticos aos lançados inicialmente.
Ao longo dos anos, diversas melhorias já foram implantadas como arquiteturas de
memória compartilhada, índices baseados em mapas de bits, suporte para tipos de
dados definidos pelo usuário entre outros (STONEBRAKER et al., 2007). Ainda assim,
parte desse esforço de desenvolvimento introduziu uma série de sobrecargas em uma
tentativa de tornar o sistema genérico o suficiente para atender a múltiplos casos de
uso, quando soluções especializadas com foco em escalabilidade e distribuição de
dados podem ser mais adequadas a algumas organizações.
2.3 Bancos de Dados Distribuídos
Um dos principais objetivos de um SGBD é permitir independência dos dados
armazenados em relação à aplicação que os consome, ou seja, retirar as lógicas de
armazenamento, acesso e controle aos dados da própria aplicação e passar essas
responsabilidades a um software especializado. A forma mais simples de se conseguir
isso é instalando uma instância de um SGBD em um servidor, esteja ele localizado no
próprio centro de dados (do inglês datacenter) da organização ou em uma Máquina
Virtual (MV) de uma operadora de serviços de computação em nuvem. Esta solução
pode, a princípio, ser mais simples de administrar, porém apresenta o mesmo
problema inerente a outras aplicações que seguem uma arquitetura centralizada: há
um ponto de falha único, o que pode levar à indisponibilidade do serviço.
Além disso, empresas que utilizem um SBD centralizado para integrar seus
dados podem ter filiais em todo o mundo. Isso levanta algumas questões
interessantes: Como garantir uma maior disponibilidade desses dados? Nenhuma
empresa gostaria que os dados de seus usuários (potencialmente milhões deles) não

8
estejam disponíveis por causa da falha de um computador, sob o risco de grandes
prejuízos financeiros.
Também é razoável assumir que se uma empresa deste porte guardar um
histórico das transações comerciais de todos os seus usuários desde que o sistema
entrou em funcionamento, por exemplo, possuirá dados da ordem de grandeza de
alguns terabytes ou petabytes. Como um único servidor de banco de dados se sai ao
lidar com bases de dados dessa magnitude (e, possivelmente, com muitas transações
concorrentes)? Além disso, se uma hipotética empresa X tem filiais em São Paulo e
Tóquio, por exemplo, será que os dados disponíveis a respeito da filial de São Paulo
são relevantes para a equipe situada em Tóquio?
Para resolver o primeiro problema, alguns SGBD, como o MySQL 1 ou o
PostgreSQL2, ao longo dos seus ciclos de desenvolvimento, introduziram mecanismos
de replicação de dados. Um exemplo normalmente suportado é a replicação do tipo
mestre-escravo, onde o computador configurado como mestre armazena em um
arquivo de log todas as tuplas que foram atualizadas e depois propaga as
modificações para o(s) computador(es) escravo(s). Assim, se o mestre falhar um
escravo pode assumir sua função. Essa é uma solução que acarreta grande
redundância de dados, se baseando em cópias de uma base de dados inteira. Se
mestre e escravos forem executados por servidores localizados no mesmo espaço
físico, ainda há um risco de uma catástrofe natural, por exemplo, tornar a operação do
serviço indisponível. Se, por outro lado, estes servidores estiverem separados
geograficamente, a latência da comunicação entre eles pela rede pode vir a se tornar
um fator importante para a degradação do desempenho, que é diretamente
proporcional à distância.
1 http://dev.mysql.com/doc/refman/5.7/en/replication.html, acessado pela primeira vez em 27/02/2014 2 http://www.postgresql.org/docs/9.3/static/high-availability.html, acessado pela primeira vez em 27/02/2014

9
Com respeito à segunda questão, existe um limite físico para acomodar bases
de dados muito grandes, a própria capacidade de armazenamento do servidor. Uma
possível solução para esse problema seria migrar a base de dados para um servidor
com maior capacidade de armazenamento, o que é conhecido como escalabilidade
vertical (STONEBRAKER et al.,2007). Esta solução envolve a compra de
equipamentos caros e cujo incremento de desempenho é limitado, pois chega um
ponto em que não há como melhorá-lo através de novas atualizações de hardware.
Além disso, implica em deixar o servidor inoperante durante o tempo em que a
migração acontece, sendo este possivelmente o maior prejuízo. Uma alternativa à
escalabilidade vertical é aumentar a capacidade de processamento de dados ao
adicionar mais servidores a um aglomerado de computadores que, conjuntamente,
possuem uma capacidade de processamento superior ao de um único servidor com
muitos recursos. Aumentar o desempenho ao adicionar mais nós ao aglomerado é
conhecido como escalabilidade horizontal.
Estas são algumas das razões que motivaram a pesquisa e o desenvolvimento
de sistemas de bancos de dados distribuídos. Antes de definir o que são sistemas de
bancos de dados distribuídos, porém, deve-se definir o que são sistemas distribuídos
em geral.
Um sistema computacional distribuído pode ser definido como “um número de
elementos de processamento autônomos (não necessariamente homogêneos),
interconectados por uma rede de computadores, que cooperam para realizar as
tarefas que lhes foram atribuídas”. Nessa definição, “elementos de processamento”
são “dispositivos capazes de executar um programa por conta própria” (ÖZSU,
VALDURIEZ, 2010).
Nesse caso, podem ser distribuídos: a lógica de processamento, conforme a
definição anterior implicitamente sugere; as funções de um computador, que podem
ser delegadas a componentes de hardware ou software distintos; os próprios dados e
também o controle da execução de um determinado programa, que pode ser realizado

10
por diversos computadores ao invés de um único (ÖZSU, VALDURIEZ, 2010). Do
ponto de vista de sistemas de bancos de dados, todos esses modos de distribuição
são importantes.
Assim, ÖZSU e VALDURIEZ (2010) definem banco de dados distribuído como
“uma coleção de múltiplos bancos de dados, logicamente inter-relacionados e
distribuídos por uma rede de computadores”. Um Sistema de Gerência de Bancos de
Dados Distribuídos (SGBDD) então é definido como “o software que permite a
gerência de bancos de dados distribuídos e torna a distribuição transparente para os
usuários”. O nome Sistema de Banco de Dados Distribuído (SBDD) também é utilizado
como referência ao conjunto formado pelo banco de dados distribuído e seu SGBDD e
aplicações associadas.
É importante ressaltar que um SBDD não é uma coleção de arquivos que
podem ser armazenados individualmente nos nós de uma rede de computadores. Em
um SBDD, além de logicamente relacionados, deve haver estrutura comum entre
esses arquivos, e o acesso deve ser feito por uma interface comum (ÖZSU,
VALDURIEZ, 2010). A Figura 1 demonstra o que foi dito:
Figura 1 – Um sistema de banco de dados distribuído. Adaptado de (ÖZSU, VALDURIEZ, 2010).

11
ÖZSU e VALDURIEZ (2010) também apresentam as quatro características
fundamentais dos SBDD: gerência transparente de dados distribuídos e replicados,
acesso confiável aos dados através de transações distribuídas, desempenho
melhorado e uma maior facilidade em expandir o sistema.
Ao falar em gerência transparente dos dados, o termo transparente significa
uma separação entre semânticas de alto nível e os detalhes de implementação de
baixo nível, ou seja, um sistema transparente ‘esconde’ os detalhes de implementação
dos usuários. Para ilustrar o que isso quer dizer, um exemplo: suponha que a mesma
empresa hipotética X mencionada anteriormente deseje guardar os dados de projetos
executados no Brasil apenas na filial de São Paulo. Isso é possível através de um
procedimento chamado fragmentação, em que cada relação da base de dados pode
ser dividida em um conjunto de fragmentos que serão armazenados em locais
diferentes (ÖZSU, VALDURIEZ, 2010). Se então uma consulta (em SQL, por exemplo)
for submetida ao sistema (distribuído) buscando os registros correspondentes aos
projetos de São Paulo, em um sistema completamente transparente isso poderia ser
feito utilizando a mesma consulta que seria feita caso o sistema fosse centralizado,
sem que o usuário se preocupasse com os detalhes da fragmentação e localização
dos dados.
Em SBDD, para garantir confiabilidade ainda são utilizadas transações,
sequências de operações executadas como ações atômicas que levam o banco de um
estado consistente a outro, mesmo quando diversas dessas transações ocorrem de
forma concorrente (ÖZSU, VALDURIEZ, 2010). Para dar suporte à transações
distribuídas, porém, é necessária a implementação de mecanismos de controle de
concorrência distribuídos e protocolos de segurança distribuídos (logs de recuperação
por exemplo), que são mais complexos que os equivalentes em um cenário
centralizado.
A melhoria de desempenho em SGBDD está baseada no conceito de
localização dos dados, ou seja, os dados devem ser armazenados próximos aos seus

12
pontos de uso reais. Os potenciais benefícios da localização dos dados são: como
cada local é responsável apenas por uma porção dos dados, isso ocasiona um uso
menos intensivo dos recursos computacionais, como da CPU, no servidor; além disso,
a localização reduz o tempo de acesso remoto normalmente envolvido em redes de
longa distância (WAN, do inglês Wide Area Network), permitindo que requisições
sejam servidas com um menor tempo de resposta. Além disso, em sistemas
distribuídos, se torna possível explorar técnicas de processamento paralelo nas formas
inter-consulta e intra-consulta. Paralelismo inter-consulta diz respeito à execução de
múltiplas consultas simultaneamente, enquanto o paralelismo intra-consulta envolve
reescrita de uma consulta feita em um esquema de dados global em um certo número
de subconsultas, cada uma podendo ser executada em locais diferentes (ÖZSU,
VALDURIEZ, 2010).
A última característica apresentada é a maior facilidade com relação à
expansão do sistema, o que torna mais fácil acomodar bases de dados de tamanhos
crescentes. Também existe uma implicação econômica: normalmente é mais barato
acrescentar computadores com configuração mais modesta a um aglomerado de
computadores que tenham o mesmo poder computacional que um único computador
com um nível muito elevado de recursos. (ÖZSU, VALDURIEZ, 2010)
Embora tragam importantes benefícios, o desenvolvimento de SBDD possui
uma série de desafios (ÖZSU, VALDURIEZ, 2010):
O primeiro deles é o próprio projeto do banco de dados, ou seja, determinar
como os dados devem ser divididos entre as possíveis localidades. Existem duas
alternativas neste caso: replicação e fragmentação. A replicação pode ser total (toda a
base replicada em mais de um local) ou parcial (alguns fragmentos são replicados).
Quanto à fragmentação, as decisões mais importantes são: como realizar a
fragmentação em si e qual a melhor alocação destes fragmentos. Além disso, deve
existir uma forma de mapear itens de dados em fragmentos através de uma espécie

13
de “catálogo”, que normalmente é chamado diretório. Um exemplo de questão relativa
à gerência deste diretório pode ser: o mesmo é global ou apenas local?
Outra questão a ser tratada é como realizar o processamento de consultas
distribuídas, o que envolve desenvolver algoritmos que analisem as consultas
recebidas e gerem planos de execução das mesmas com o menor custo,
considerando fatores como a distribuição dos dados e custos de comunicação entre
nós.
O controle de concorrência distribuído, mencionado anteriormente de forma
breve, envolve a sincronização de acessos ao banco de dados distribuído, de forma
que a integridade do mesmo seja mantida, ou seja, múltiplas cópias de dados devem
convergir para o mesmo valor mutuamente. Existem diversas abordagens neste caso
(pessimistas ou otimistas) e este pode ser considerado o problema mais estudado
neste campo de pesquisa.
Finalmente, há a detecção e recuperação de falhas. Replicação de dados
aumenta a redundância e tem o potencial de fazer com que a operação se mantenha
ativa mesmo quando há uma falha. Porém, se uma ou diversas instâncias se tornarem
inacessíveis (por problemas na rede) ou inoperantes, devem existir mecanismos
capazes de identificar quando a falha acontece, manter as demais instâncias
consistentes e atualizadas e, eventualmente, quando os outros computadores (ou a
rede) se recuperarem da falha, o SBDD deve voltar a funcionar normalmente.
Embora a classe de SBDD investigados neste trabalho (NewSQL) seja
relativamente nova, bancos de dados distribuídos e os problemas associados a eles
são estudados há bastante tempo. ROTHNIE et. al. (1980) descrevem o
desenvolvimento de um SBDD chamado SDD-1 com uma linguagem de consulta
chamada Datalanguage. BERNSTEIN e GOODMAN (1981a) propõem um método
para otimização do processamento de consultas no SDD-1. RAM (1989), DAUDPOTA
(1998) sugerem modelos para o problema da alocação de dados. KHAN e AHMAD
(2010) propõem um algoritmo específico para gerenciar dados replicados. Controle de

14
concorrência distribuído foi estudado por (BERNSTEIN,GOODMAN,1981b) e
(CAREY,LIVNY,1988), para dar alguns exemplos.
2.4 NoSQL
2.4.1 Motivação
SGBDR não atendem satisfatoriamente aplicações que poderiam se beneficiar de
escalabilidade horizontal, como as que precisam de capacidade analítica em tempo
real, para citar um exemplo. Para buscar atender esta demanda, surge o NoSQL. Com
a intenção original de se criar sistemas distribuídos escaláveis, com modelos mais
simples que o relacional e com alta disponibilidade, o movimento NoSQL (mais
conhecido hoje em dia como “Not only SQL”) iniciado no final da década de 2000
(STONEBRAKER, 2010) vem crescendo rapidamente e já conta com o mais de 1503
SGBD desenvolvidos.
2.4.2 Principais Características
Uma das características fundamentais dos sistemas NoSQL é a escalabilidade
horizontal baseada em uma arquitetura do tipo memória distribuída com replicação e
fragmentação dos dados em diferentes servidores (CATTELL, 2010). Isso permite que
esses sistemas possam suportar um grande número de operações de leitura/escrita
por segundo, sendo elas normalmente características de sistemas OLTP. Em sua
maioria, esses sistemas NoSQL, diferentemente de SBGDR, não fornecem suporte às
propriedades transacionais ACID. Atualizações, por exemplo, são propagadas para
todo o aglomerado, porém sem saber antecipadamente o momento exato em que
todas as réplicas de um item de dados estarão atualizadas, o que caracteriza um
3 http://nosql-database.org/ , acessado pela primeira vez em 03/12/2013

15
relaxamento na consistência de dados, chamado consistência tardia. Alguns autores
sugerem um novo acrônimo no lugar do ACID, o BASE (do inglês, Basically Available,
Soft State, Eventually Consistent) (CATTELL, 2010), representando uma forma de
sacrificar algumas restrições impostas pelas propriedades ACID para que um sistema
possa conseguir um desempenho e uma escalabilidade muito maiores (CATTELL,
2010). Logo, os SGBD NoSQL operam sobre a relação entre desempenho e
complexidade do modelo, tendendo sempre a aumentar a primeira.
São definidas por CATTELL (2010) seis importantes características dos novos
sistemas NoSQL:
1. Aumento de desempenho de operações simples quando do aumento do
número de nós;
2. Replicação e distribuição de dados em diferentes nós;
3. No lugar do SQL, um protocolo simples de comunicação com o SGBD;
4. Um modelo de controle de concorrência mais “relaxado” do que o
utilizado nos SGBDR tradicionais;
5. Uma distribuição eficiente dos índices e utilização de memória RAM para
armazenamento de dados; e
6. Adição dinâmica de atributos aos registros já existentes na base (pela
não-obrigação de ter esquemas fixos).
2.4.3 Classificação Como sistemas NoSQL não são regulados por nenhum modelo em específico,
partilhando apenas algumas características em comum, foram propostas algumas
classificações para os mesmos, dos quais as principais são (LEAVITT, 2010,
CATTELL, 2010):
Armazém de Pares Chave-Valor. É um sistema que armazena valores
indexados para posterior recuperação através de chaves. Esses sistemas podem

16
utilizar dados estruturados e/ou não estruturados. A escalabilidade nesses sistemas é
obtida através da distribuição das chaves entre os diversos nós. Esses sistemas
geralmente possuem funcionalidades como replicação, versionamento de itens de
dados, entre outras. Os SGBD NoSQL do tipo chave-valor são ideais para aplicações
que possuem um único tipo de objeto a ser guardado, e cujas consultas sejam
baseadas em um único atributo (chave) (CATTELL, 2010). Um exemplo disso seria
um cache de páginas web dinâmicas: páginas que carreguem objetos pesados podem
ser armazenadas em cache para reduzir o tempo de espera do usuário. Por exemplo,
em uma aplicação de comércio eletrônico, a chave poderia ser gerada sobre
parâmetros que identificam um produto. Desde que a geração dessa chave seja
determinística, sempre será possível recuperá-la.
Exemplos de SGBD NoSQL chave-valor são o Voldemort4 e o Redis5.
Orientados à Coluna. Diferentemente dos SGBDR, que armazenam as
informações em tabelas fortemente estruturadas em linhas e colunas, esse tipo de
sistema contém uma tabela extensível de dados minimamente relacionados. Cada
linha desta tabela pode possuir um conjunto próprio de colunas, que não precisa ser
igual aos das demais. A escalabilidade é feita através da distribuição das linhas e
colunas pelos nós, fragmentando inicialmente as colunas de uma tabela (criando-se
“novas” pequenas tabelas e montando grupos de tabelas relacionadas) e depois
fragmentando as linhas dessas tabelas resultantes pela chave primária, com
fragmentação por intervalo. Exemplos de bancos NoSQL orientados à coluna são o
HBASE6 e o Cassandra7.
Baseado em Documento. Esses SGBD armazenam e organizam dados como
uma coleção de documentos, ao invés de tabelas estruturadas com tamanhos
uniformes para cada registro. Sendo assim, os usuários podem adicionar quantos
4 http://www.project-voldemort.com/, acessado pela primeira vez em 15/12/2013 5 http://redis.io/, acessado pela primeira vez em 15/12/2013 6 https://hbase.apache.org/, acessado pela primeira vez em 15/12/2013 7 http://cassandra.apache.org/, acessado pela primeira vez em 15/12/2013

17
atributos forem necessários, de qualquer tamanho, a um documento. A escalabilidade
geralmente é atingida através de leituras sobre réplicas de dados já modificados.
Exemplos de bancos de dados NoSQL baseados em documentos são o SIMPLEDB8
da Amazon e o MongoDB9.
2.4.4 Problemas
As soluções NoSQL chegaram ao mercado como uma alternativa para atender às
necessidades das aplicações que os SGBDR tradicionais têm dificuldade em suprir,
devido aos problemas de escalabilidade e disponibilidade. No entanto, estas soluções
já enfrentam alguns problemas (LEAVITT, 2010), que devem ser bem analisados por
qualquer futuro utilizador, para que seja avaliada a viabilidade de sua utilização.
Complexidade e Sobrecarga
Como os bancos NoSQL não possuem uma linguagem unificada de consulta,
como o SQL, eles necessitam de uma programação manual das consultas, o que pode
não ser uma tarefa viável para aqueles que não saibam ou não desejem codificá-las.
Mais do que isso, ao longo dos anos, tempo de pesquisa e desenvolvimento foi
investido em aprimorar compiladores SQL para gerar planos de execução de
consultas otimizados. Ao desenvolver novos métodos de acesso, perde-se esta
experiência adquirida, e novos trabalhos precisam ser desenvolvidos.
Consistência
Os sistemas NoSQL dão suporte apenas a consistência tardia de dados. Os
usuários devem estar cientes de que há uma troca envolvida. No caso de aplicações
cuja exatidão dos dados é crítica, não ter garantias de consistência pode não ser uma
opção.
8 http://aws.amazon.com/simpledb/, acessado pela primeira vez em 15/12/2013 9 http://www.mongodb.org/, acessado pela primeira vez 15/12/2013

18
Pouca Maturidade da Tecnologia
A maioria das organizações e pessoas não são familiarizados com os sistemas
NoSQL, o que pode atrapalhar na sua adoção no mercado.
Dados esses problemas, principalmente os relacionados à ausência de uma
linguagem como SQL e das propriedades ACID, é que uma nova corrente surgiu na
comunidade de bancos de dados. O movimento NewSQL, termo citado pela primeira
vez em 2011 (ASLETT,2011), argumenta que os problemas dos SGBDR não estão
relacionados à linguagem SQL ou às transações ACID, e sim à algumas limitações
impostas por projetos que datam de vários anos, como uma natureza intrinsecamente
centralizada e armazenamento de dados baseado em disco. No próximo capítulo os
sistemas NewSQL e suas principais características são analisados em maiores
detalhes.
2.5 Avaliação de Desempenho em Sistemas de Bancos de
Dados
SGBD são softwares complexos que, além de exercer uma série de atividades
naturalmente complexas, como manter a consistência dos dados e possuir tolerância a
falhas, devem, preferencialmente, atender também a alguns requisitos não-funcionais,
como ser eficientes no armazenamento de dados e ter alto desempenho. Com a
popularização de sistemas para suporte à inteligência empresarial (do inglês business
intelligence) e à análise de dados em tempo real, esses se tornam fatores ainda mais
relevantes na decisão de adotar ou não uma determinada solução de banco de dados
para atender certas necessidades de negócio. Com uma boa variedade de opções de
SGBD disponíveis, incluindo os de código aberto, é importante que uma pessoa no
papel de tomador de decisão tenha como medir, de alguma, forma um conjunto de
características entre os sistemas candidatos.

19
Medir o desempenho de um SGBD, porém, não é uma tarefa trivial, dado que a
própria definição de desempenho pode ser dada em função de um conjunto de
variáveis diferentes. Para algumas aplicações, que lidem com dados muito sensíveis
ou críticos de alguma forma (um sistema de monitoramento, por exemplo), pode ser
importante que muitas operações de atualização sejam realizadas rapidamente, logo
tendo uma alta vazão (do inglês throughput) de transações por unidade de tempo. Já
para outras, pode ser mais importante que o SGBD a ser avaliado apresente alta
disponibilidade, pois tempo do sistema fora do ar representa prejuízo financeiro
elevado.
Algumas características “gerais”, porém, podem ser avaliadas. BING apud
PAUL (2008) define como propósitos básicos da avaliação de desempenho de SGBD:
1. Dado um único SGBD, descobrir a melhor configuração e ambiente de
operação
2. Estudar dois ou mais sistemas de bancos de dados e realizar uma
comparação sistemática entre eles
Um benchmark é “um conjunto de instruções executáveis usado para medir e
comparar o desempenho quantitativo e relativo de dois ou mais sistemas
gerenciadores de bancos de dados através da execução de experimentos controlados”
(SENG et al., 2004). Os dados gerados pela execução de um benchmark, como vazão,
tempo de resposta, relação preço/desempenho, entre outros, podem ser usados para
representar ou predizer o desempenho de um sistema. Este tipo de informação pode
ajudar grupos de usuários distintos (administradores de banco de dados,
desenvolvedores, gestores, etc.) a tomar decisões a respeito da aquisição de um novo
sistema, ou a encontrar um gargalo na operação de um já existente, por exemplo.
Benchmarks de banco de dados são compostos de bases de teste e cargas de
trabalho (workloads) de teste, podendo ser sintéticos ou empíricos. Um benchmark
sintético simula uma aplicação típica em um domínio pré-determinado e gera uma
carga de trabalho correspondente, enquanto benchmarks empíricos utilizam cenários e

20
dados reais. Embora utilizar cargas de trabalho reais sejam o teste ideal para um
sistema, os custos de implementação do ambiente podem ser maiores que os
benefícios obtidos. Por isso, normalmente, a utilização de benchmarks sintéticos são
soluções preferidas (SENG et al., 2004).
Um dos desafios apresentados por benchmarks sintéticos é a reprodutibilidade
dos testes realizados. Os resultados podem variar de acordo com configurações de
usuário, por exemplo. Assim, resultados alcançados em um ambiente não
necessariamente serão reproduzidos em outro e, por isso, devem ser utilizados como
estimativa, normalmente com o propósito de comparação relativa (SENG et al., 2004).

21
Capítulo 3 - NewSQL
Os SGBD NoSQL buscam alternativas para melhorar a escalabilidade e o
desempenho dos SBD atuais. No entando, isto é conseguido, em detrimento da
utilização da SQL e das propriedades ACID para as transações. Para muitos, houve
uma grande perda nessa troca, pois não apresentar garantias integrais para a
consistência dos dados, assim como ter que recodificar métodos de acesso, não é
interessante.
Por isso novas pesquisas foram e continuam sendo feitas para conseguir
encontrar uma combinação perfeita entre escalabilidade e consistência. Para sistemas
empresariais que lidam com dados de alto nível, como instituições financeiras,
companhias aéreas e outras mais, essa não é uma questão simples. Apesar de existir
hoje a necessidade de aumentar a escalabilidade de seus sistemas, e, principalmente,
a velocidade de respostas aos clientes, garantir a consistência e a durabilidade das
informações é essencial. E para continuar com essas propriedades, usando os
SGBDR tradicionais, existem algumas possibilidades. Uma delas é adquirir um
servidor com maior capacidade de processamento (escalabilidade vertical). Outra
possibilidade é fragmentar a base manualmente, o que, além de um processo de difícil
manutenção (já que eventualmente será necessário redistribuir os fragmentos), pode
demandar que alguma lógica de acesso aos dados seja incluído no código da
aplicação, por exemplo, o que é exatamente uma prática que se deseja evitar ao
utilizar um SGBD.
Nesse contexto, surgiram os sistemas NewSQL (ASLETT, 2011) que designa
uma nova classe de SGBD que buscam promover a mesma melhoria de desempenho
e escalabilidade dos sistemas NoSQL enquanto mantêm o suporte à linguagem SQL e
às propriedades ACID, que tem ampla adoção com os SGBDR tradicionais.

22
STONEBRAKER e CATTEL (2011) definem cinco características de um SGBD
NewSQL:
1. Linguagem SQL como meio de interação entre o SGBD e a aplicação;
2. Suporte para transações ACID;
3. Controle de concorrência não bloqueante, para que as leituras e escritas
não causem conflitos entre si;
4. Arquitetura que forneça um maior desempenho por nó de processamento;
5. Arquitetura escalável, com memória distribuída e com capacidade de
funcionar em um aglomerado com um grande número de nós.
Diferente dos SGBDR tradicionais, que eram considerados soluções para
qualquer tipo de aplicação, os SGBD NewSQL utilizam uma estratégia diferente. Cada
novo sistema desenvolvido visa atender a uma necessidade específica. Ou seja, os
sistemas NewSQL tentam dividir as novas demandas em diferentes nichos de
mercado e buscam alcançá-los de forma separada, terminando com o antigo conceito
de ter um único sistema que sirva para qualquer tipo de aplicação.
Nas seções seguintes são apresentadas as demandas de aplicações que
alguns desses sistemas buscam atender, assim como as principais decisões de
implementação tomadas para esse fim.
3.1 NuoDB
3.1.1 Visão Geral
NuoDB é um SGBD NewSQL em memória que tem como foco a utilização em
ambientes de dados geo-distribuídos, sendo direcionado para empresas que precisam
expandir suas bases de dados para múltiplos servidores mas não querem perder os
benefícios da álgebra relacional e das propriedades ACID.

23
Para garantir escalabilidade, o NuoDB define uma arquitetura para bases de
dados distribuídas aproveitando dois dos maiores recentes avanços tecnológicos,
como processadores de múltiplos núcleos e memória estendida.
3.1.2 Arquitetura
O NuoDB possui uma arquitetura distribuída com uma abordagem de cache
distribuído e durável (do inglês, durable distributed cache), baseada em replicação sob
demanda (NuoDB Bloor Report, 2013). Para o NuoDB, só existe o suporte ao modo
replicação total dos dados armazenados. Além disso, o NuoDB não realiza
fragmentação da base de dados entre os nós de um aglomerado. Os nós de
processamento formam um cache distribuído em uma rede ponto-a-ponto. Portanto,
em um dado momento, múltiplas cópias de um item de dados podem estar disponíveis
em memória (o que permite balanceamento de carga nas requisições realizadas),
assim como não estar em nenhum nó, devendo ser trazido do disco. Esses conceitos
são mais detalhados nas próximas seções.
3.1.2.1 Estrutura em níveis
O NuoDB é estruturado em 3 diferentes níveis: administrativo, de processamento e de
armazenamento. A separação entre os níveis de processamento e de armazenamento
é o que busca dar escalabilidade ao sistema. Ao separar esses dois níveis, a
durabilidade do sistema passa a ser uma tarefa separada do processamento de
transações, o que permite configurar ambas as propriedades de forma separada.
Assim o desempenho pode ser aumentado, sem causar impacto em como e onde os
dados são armazenados (NuoDB Bloor Report, 2013). Cada nível é representado por
uma instância de NuoDB, rodando um dos processos detalhados a seguir:
O nível de processamento consiste em motores de transação, doravante
denominados de TE (do inglês, transaction engine). Esse nível é responsável por

24
garantir as propriedades Atomicidade, Consistência e o Isolamento do ACID, deixando
a durabilidade para ser garantida pelo nível de armazenamento.
O nível de armazenamento é responsável pela Durabilidade e também por
disponibilidade. É uma fonte de dados sempre ativa e consistente. É constituído de
gerentes de armazenamento, doravante denominados de SM (do inglês, storage
managers). Cada um destes SM possui acesso a um espaço em disco chamado
“arquivo”, que contém uma cópia de toda a base de dados. Um SM pode servir
qualquer item de dados a um TE a partir deste arquivo. Por isso, embora existam
diferentes instâncias físicas da mesma base de dados, o conjunto formado por eles
representam uma única instância lógica, transparente para o usuário.
O nível administrativo é responsável por garantir escalabilidade horizontal por
demanda e o balanceamento de carga. Cada nó possui um agente local. Juntos, os
agentes formam uma rede ponto-a-ponto, que recebe o nome de Domínio (NuoDB
Technical WhitePaper, 2013). Para cada domínio, existem um ou mais agentes da
rede chamados brokers. Um broker é um tipo especial de agente, encarregado das
funções administrativas, e somente através dos brokers é possível gerenciar (iniciar,
parar ou migrar) as bases de dados, inicializar, terminar e obter os logs dos TE e dos
SM e monitorar todo o sistema para saber se tudo está ocorrendo como o esperado.
Na Figura 2, é mostrado um exemplo de arquitetura do NuoDB em 5
computadores, com dois SM e dois TE. Nesse exemplo, o broker possui um servidor
dedicado. A base está replicada em dois SM, garantindo que caso um processo SM
falhe, a base de dados continue funcionando normalmente no outro SM.

25
Figura 2 - Arquitetura do NuoDB. Adaptado de www.nuodb.com
3.1.2.2 Os Átomos
Tendo explicado o que são cada um dos níveis da arquitetura, é necessário ir mais a
fundo e explicar como eles são constituídos de fato. E para isso um novo conceito
precisa ser definido, o de Átomos. Mesmo parecendo uma base de dados SQL, o mais
certo ao definir o NuoDB seria chamá-lo de uma base de dados de objetos distribuída,
com uma camada SQL no topo (NuoDB Technical WhitePaper, 2013). Por trás dessa
camada toda a lógica opera em objetos denominados Átomos, que são objetos auto-
coordenados que podem representar qualquer tipo de informação como por exemplo,
dados, metadados, esquemas, índices e outras mais. Esses objetos facilitam a
comunicação interna e a implementação do cache. O nível de processamento
transacional é responsável por fazer o mapeamento entre o conteúdo SQL e os
devidos Átomos.
Além do conteúdo da base de dados, existe outro tipo de átomo, o chamado
“Átomo de Catálogo”, que é utilizado para buscar os demais átomos entre os
processos correntes. Quando da criação da base de dados, e da ativação do primeiro
TE, um objeto é diretamente colocado no seu cache, o Catálogo Mestre. O Catálogo
Mestre indica onde todos os elementos da base de dados podem ser descobertos. É

26
através desses catálogos que qualquer TE sabe onde um átomo está disponível.
Quando um átomo de dados é requisitado a um TE, ele é buscado na seguinte ordem:
no cache do próprio TE (informação do catálogo local), no cache de outros TE e,
finalmente, se não estiver em nenhum destes, requisitado a um SM para que o mesmo
busque no disco.
Essa abstração de todos os dados em Átomos serve para simplificar o modelo
de durabilidade do NuoDB. Todo os acessos na arquitetura são feitos através dos
átomos, e todos eles são guardados como pares de chave-valor.
3.1.2.3 Controle de Concorrência
Os Átomos ajudam o NuoDB a garantir a durabilidade do sistema, mas eles não são
responsáveis por gerenciar conflitos ou consistência. E, sem isso, o NuoDB não teria
como garantir as propriedade ACID. Para isso, ele utiliza o protocolo Multi-Version
Concurrency Control (MVCC). Esse protocolo funciona guardando versões diferentes
de itens de dados. Além disso, todas as atualizações e remoções de dados geram
novas versões dos mesmos. Os motores de transação, TE, são caches e, dentro
deles, estão diferentes versões de um mesmo dado. Após uma atualização, a nova
versão fica pendente até que a transação associada a ela tenha realizado com
sucesso a sua efetivação.
Como todas as modificações de versões são guardadas em cache, nada de
fato é imediatamente modificado no meio de armazenamento persistente (disco por
exemplo). Assim o sistema pode usar uma abordagem otimista para comunicar as
modificações para todo os interessados e, caso necessário, desfazer a transação,
deixando a última atualização no cache de lado. Junto com o MVCC o NuoDB possui
um modelo de visibilidade da base de dados, chamado de Isolamento Instantâneo
(Snapshot Isolation). Esse modelo permite obter uma visão constante da base de
dados no exato momento em que uma transação se inicia.

27
Porém, mesmo com o MVCC e o Isolamento Instantâneo, ainda teríamos
problemas caso duas transações tentassem fazer modificações em um mesmo valor
simultaneamente. Nesses casos, em atualizações ou remoções de dados, o NuoDB
utiliza uma TE como mediadora, denominada Presidente (do inglês, Chairman), que
define por ordem temporal, qual transação irá concluir e qual não irá ser realizada. É
importante notar que para cada átomo existe uma TE funcionando como Presidente, e
essa TE deve ser uma que possui o átomo em seu cache.
Duas características importantes do NuoDB são o modo como garante
escalabilidade, através da abordagem baseada em replicação sobre demanda, e por
possuir uma certa elasticidade, podendo dinamicamente aumentar ou diminuir o
tamanho do domínio, simplesmente adicionando ou retirando nós e processos TE e
SM.
3.2 VoltDB
3.2.1 Visão Geral VoltDB é um SGBDD com armazenamento em memória principal, em conformidade
com as propriedades ACID e que utiliza uma arquitetura de memória distribuída.
VoltDB implementa um projeto similar ao do H-Store (KALLMAN et al.,2008), seu
predecessor, que foi utilizado como protótipo em pesquisa acadêmica. Uma restrição é
imposta pelo VoltDB: a necessidade da base de dados caber integralmente em
memória. Os benefícios originários desta decisão são: garantir que não haja
sobrecargas, evitando inserir recursos para gerência de acesso a armazenamentos
baseados em disco, e um menor tempo de busca aos dados (justamente por ser em
memória, em comparação a armazenamento em disco). Em compensação, é
necessário que a capacidade de memória principal do servidor seja suficientemente
grande para acomodar os dados da aplicação a qualquer momento.

28
O propósito do VoltDB é ser mais rápido que os SGBDR tradicionais em uma
certa classe de aplicações em tempo real, como manter o estado de partidas de jogos
online, negociações eletrônicas e a localização de anúncios em páginas web
(STONEBRAKER,WEISBERG,2013). A motivação para o desenho da arquitetura do
VoltDB se baseia em eliminar as fontes de sobrecarga mostradas em
(HARIZOPOULOS et al., 2008), a saber: sobrecargas com gerências de
buffer,múltiplas linhas de execução (multi-threading), bloqueios de registros e arquivos
de logs com escritas adiantadas (write-ahead logs).
3.2.2 Arquitetura O ambiente de utilização adequado para o VoltDB é proporcionado por um
aglomerado de computadores (STONEBRAKER,WEISBERG, 2013). Nesse ambiente,
o VoltDB pode realizar fragmentações horizontais para cada tabela, alocando os
fragmentos para diferentes nós do aglomerado. A fragmentação é apropriada para
tabelas grandes que são acessadas ou atualizadas frequentemente. Para tabelas
menores e que sofrem poucas atualizações, também é suportada a opção de replicá-
las integralmente em todos os nós, o que é mais apropriado.
Quando fragmentada, a definição da localização dos fragmentos de uma tabela
é dada por uma função hash aplicada a um dos seus atributo da tabela o que é
indicado em um “catálogo”. Um catálogo no VoltDB é um conjunto pré-compilado de
instruções SQL utilizado para criar ou recuperar uma base de dados. Nele, geralmente
constam instruções LDD (Linguagem de Definição de Dados) com as definições dos
esquemas e dos fragmentos, além de procedimentos armazenados, que podem ser
escritos em SQL ou Java (no momento da escrita deste projeto, estas são as
linguagens suportadas) e compilados junto com o catálogo. Além disso, cada
fragmento é replicado K+1 vezes, de acordo com o conceito de K-safety (indica a
quantidade de réplicas redundantes que podem falhar e o sistema continuar ativo). O

29
valor padrão de K é igual a zero, e este pode ser modificado no arquivo de
configuração da aplicação.
Para o VoltDB, uma transação é implementada como um procedimento
armazenado registrado junto ao sistema (STONEBRAKER, WEISBERG,2013).
Consultas ad-hoc são compiladas em tempo real em procedimentos armazenados
temporários. As transações são analisadas em tempo de compilação, categorizadas e
armazenadas junto ao sistema. As categorias de transações são:
i. Transações de um único nó: neste caso, as transações utilizam apenas
fragmentos que pertencem ao mesmo nó;
ii. Transações “tiro-único”: são transações compostas de diversas
declarações SQL que podem ser executadas em paralelo em múltiplos
nós, pois envolvem diversos fragmentos por exemplo;
iii. Transações gerais: além de envolver múltiplos nós, são compostas de
múltiplas fases, onde cada fase deve ser completada antes da próxima.
Um usuário executa uma transação ao invocar um procedimento armazenado
correspondente e fornecendo parâmetros em tempo de execução. O VoltDB executa
todas as transações em ordem determinística: quando uma transação for do tipo nó
único, é enviada a um “controlador do nó”, no nó correto, que é responsável por
fornecer uma organização sequencial de todas as transações deste tipo. As
transações são então executadas, sequencialmente, sem que haja necessidade de
realizar bloqueios. As transações que pertencem às demais categorias são enviadas a
um tipo especial de controlador, o “controlador global”, que é responsável por definir
um ordenamento sequencial das mesmas. As declarações SQL destes tipos de
transações devem ser enviadas aos nós corretos, onde elas serão inseridas no fluxo
de transações de nós únicos (STONEBRAKER, WEISBERG, 2013). Se, ao projetar
uma aplicação e o esquema da base de dados associado, as transações forem

30
majoritariamente locais em relação aos fragmentos, é possível tirar proveito de um
maior grau de paralelismo com essa solução.
Em cada nó, uma instância do VoltDB é executada através de uma única
thread, o que elimina a sobrecarga que existe quando é preciso gerenciar recursos
compartilhados em ambientes com múltiplas threads. Como todos os dados devem
caber em memória principal, também não há necessidade de existir um buffer, que,
em sistemas baseados em disco, faria cache de dados. O VoltDB garante durabilidade
desses dados através de dois recursos: instantâneos (snapshots) e logs de comandos.
Um instantâneo é uma cópia completa do conteúdo da base de dados, em um
determinado momento no tempo, que é gravada em disco. Instantâneos podem ser
criados manualmente, através de uma ferramenta administrativa do VoltDB (voltadmin),
ou automaticamente, através de intervalos de tempo definidos no arquivo de
configuração. O problema surge caso uma falha ocorra entre a criação de dois
instantâneos: caso o intervalo programado para criação de um instantâneo seja de 10
minutos, por exemplo, e uma falha ocorra no instante t=12 minutos, todas as
transações que ocorreram entre 10 e 12 minutos serão perdidas. Por este motivo, o
VoltDB permite que seja habilitado o recurso de log de comandos, que nada mais é
que um log de todas as transações executadas, escrito no disco em intervalos de
tempo configuráveis (modo assíncrono) ou antes de cada transação sofrer uma
efetivação (modo síncrono). Desta forma, caso ocorra uma falha, o servidor pode
recuperar o estado da base de dados primeiramente pelo último instantâneo
atualizado e, depois, recriando as transações descritas no log.
Alta disponibilidade no VoltDB é alcançada através da replicação de dados.
Quando uma transação é executada, ela é primeiramente enviada para todas as
réplicas, que a processam em paralelo. “Como o controle de concorrência é
determinístico, a transação terá sucesso ou irá falhar em todos os nós, dispensando
sincronização adicional” (STONEBRAKER,WEISBERG,2013). Os nós trocam então
mensagens entre si para indicar que permanecem funcionais e, caso haja um

31
problema com algum deles, este seja desconectado: até K réplicas podem falhar antes
de um aglomerado parar de operar totalmente.
3.3 MemSQL
3.3.1 Visão Geral
O SGBD MemSQL começou a ser desenvolvido em Janeiro de 2011 por dois ex-
funcionários do Facebook, que imaginavam existir uma nova possível maneira de dar
ao SQL escalabilidade e velocidade. O resultado foi um SGBD distribuído em
memória, que é consultado através de uma interface SQL, tendo como foco aplicações
transacionais, e que também apresenta capacidade para execução de análises de
dados em tempo real. Os setores que estão se destacando na utilização do MemSQL
são os serviços financeiros, as telecomunicações e os serviços de propaganda
(ASLETT, 2012).
3.3.2 Arquitetura
O MemSQL possui uma arquitetura distribuída organizada em dois níveis de nós,
Agregadores e Folhas:
Agregadores trabalham como gerentes de consultas, recebendo-as e
distribuindo-as entre os nós folhas. Após as consultas serem executadas pelos nós
folhas, os agregadores combinam os resultados e os retornam para o usuário. Além
disso, a fragmentação dos dados entre os nós folhas também é controlada pelo
agregador. Os agregadores armazenam apenas metadados.
Agregador Mestre (MA) É responsável pelo monitoramento do aglomerado.
Todo aglomerado precisa ter no mínimo um MA para poder ser iniciado. O agregador
mestre trata de todas as operações LDD a serem feitas no banco de dados. Todas as
bases de dados, tabelas, adição e remoção de nós e rebalanceamento dos
fragmentos são feitas através do agregador mestre.

32
Folhas possuem uma arquitetura de memória distribuída e armazenam os
dados do banco. Recebem as consultas dos nós agregadores e as executam. Um nó
folha não sabe da existência dos outros, pois o protocolo de controle de concorrência
só atua em um nó, e não entre eles.
A arquitetura do MemSQL, exemplificada na Figura 3, foi projetada para alocar
a maior quantidade de trabalho para os nós folhas, possibilitando a escalabilidade do
aglomerado e um melhor desempenho das consultas ao aumentar o número de nós
folhas disponíveis. Essa adição de nós pode ser feita de forma dinâmica, sem a
necessidade de reiniciar nenhum agregador ou folha do aglomerado. Ao adicionar
folhas, o balanceamento dos dados é feito de forma automática, desde que haja
memória disponível para executar a operação.
Figura 3 - Arquitetura do MemSQL. Adaptado de www.memsql.com
3.3.2.1 Alocação de Tabelas
Quanto à alocação de dados, o MemSQL suporta dois tipos de tabelas: as tabelas
replicadas, criadas a partir do uso da expressão “REFERENCE”, e as tabelas
distribuídas (fragmentadas). As replicadas, como o próprio nome diz, são copiadas em
todos os nós folhas do aglomerado. As tabelas fragmentadas são distribuídas entre os
nós do aglomerado através das chaves de fragmentação (SK, do inglês, Shard Keys) e
das chaves estrangeiras de fragmentação (FSK, do inglês, Foreign Shard Keys),

33
fazendo com que registros com valores iguais para o atributo de fragmentação estejam
sempre no mesmo fragmento, o que facilita a execução de operações de junção. O
resultado da criação padrão de uma tabela no MemSQL (ou seja, se a expressão
CREATE TABLE for utilizada sem nenhum modificador) é: criar uma tabela
fragmentada, dividida em um total de fragmentos igual a oito vezes o número de nós
folhas ativos no aglomerado. Esse valor pode ser modificado ao incluir o modificador
PARTITIONS N na expressão, onde N é o número de fragmentos total desejado.
As definições das chaves de fragmentação são guardadas pelos Agregadores,
que as utilizam na hora de alocar as consultas, enviadas pelo cliente, aos nós folhas.
Para fragmentar uma tabela, o MemSQL tem suporte às fragmentações
primária e derivada. A fragmentação primária pode ser realizada por qualquer atributo
da tabela que seja especificado como chave de fragmentação (se nenhum for atribuído,
a chave de fragmentação padrão é a chave primária). A fragmentação derivada é uma
estratégia para tentar alocar, em um mesmo nó, fragmentos que possuam o mesmo
valor de chave estrangeira, e é definida usando a chave estrangeira de fragmentação.
Para qualquer tabela, somente um modo pode ser usado. Além disso, quando são
utilizadas chaves estrangeiras de fragmentação, para qualquer operação de junção
(entre as tabelas A e B, onde B referencia A, por exemplo), a condição de junção deve
ser que a chave estrangeira de fragmentação de B seja igual a chave de fragmentação
de A, para quaisquer pares de tabelas.
3.3.2.2 Controle de Concorrência
Para o controle de concorrência, o MemSQL utiliza o protocolo MVCC em conjunto
com índices não bloqueantes, a fim de garantir um melhor desempenho em cenários
com operações concorrentes, sem que haja uma degradação da consistência. Assim,
as operações de leitura não bloqueiam as operações de escrita e vice-versa. Esta

34
configuração favorece o uso do MemSQL em aplicações de escrita intensa, ou que
tenham uma proporção semelhante para as operações de escrita e leitura.
Para aumentar o grau de concorrência, o MemSQL suporta apenas transações
formadas por uma única consulta. Além disso, se uma transação utiliza dados de
diferentes fragmentos do banco, uma nova transação é aberta para cada fragmento,
ou seja, caso uma consulta de leitura ou escrita falhe em um fragmento, o SGBD irá
desfazer somente essa consulta, permitindo que as consultas nos demais fragmentos
continuem a ser executadas. Tal característica precisa ser tratada de maneira
cuidadosa pelo desenvolvedor de aplicações, pois pode levar a sérias inconsistências
no banco de dados.
O SGBD MemSQL pode dinamicamente adicionar novos nós ao aglomerado
para aumentar a capacidade de armazenamento ou o poder de processamento. A
fragmentação nos novos nós é feita automaticamente e o aglomerado faz o re-
balanceamento dos dados automaticamente também.
3.3.3 Execução de Consultas
As consultas submetidas ao MemSQL são compiladas e convertidas em códigos C++.
Em seguida, são armazenadas em um cache de consultas. Quando uma nova
consulta é recebida, o MemSQL verifica se já existe código C++ para ela no cache. Tal
fato pode ocorrer se uma consulta idêntica em estrutura, mas possivelmente diferente
quanto aos parâmetros, tiver sido recebida recentemente pelo SGBD. O MemSQL
consegue então reutilizar o código previamente compilado, alterando somente os
valores dos parâmetros e reduzindo significativamente o tempo de processamento. O
cache de consultas não armazena resultados de execuções de consultas anteriores.
Isso limitaria o reaproveitamento a casos em que as consultas são idênticas em
relação tanto à estrutura quanto aos valores dos parâmetros.

35
Ao receber uma requisição, o Agregador Mestre, verifica na tabela hash que
contém os planos de consulta (cache de consultas), se a consulta atual está presente.
Caso esteja, os parâmetros são passados para o código já compilado e a consulta é
executada. Caso contrário, a consulta é compilada em código C++ e adicionada na
tabelas de planos de consulta. Esse processo está demonstrada na Figura 4.
Figura 4 - Execução de Consultas no MemSQL. Adaptado de www.memsql.com
3.3.4 Propriedades ACID
Para garantir a durabilidade da base de dados, a configuração do MemSQL
utiliza três importantes variáveis, definidas como durability, transaction_buffer e
snapshot_trigger_size10. A primeira, quando recebe valor zero, faz com que nenhum
log e/ou instantâneo da base de dados seja guardado em disco, e depois que o
sistema sai do ar, todos os dados alocados se perdem. A base de dados e as
definições das tabelas, porém, são persistidos. O buffer de transações é o buffer do
log de transações de cada base de dados. Quando o tamanho deste buffer atinge o
valor determinado pela variável transaction_buffer, as alterações, até então em
memória, são escritas no disco. Por padrão, o MemSQL escreve as mudanças no
disco de forma assíncrona. Quando a variável transaction_buffer é colocada em zero,
a durabilidade do banco de dados é realizada de forma síncrona, ou seja, todos os
10 www.developers.memsql.com, acessado pela primeia vez em 20/01/2014

36
logs são escritos em disco com a efetivação da transação. Atualmente, o MemSQL
suporta somente o nível de isolamento read-committed e cada uma das requisições é
executada em uma transação independente.
3.4 Google Spanner
3.4.1 Visão Geral
BigTable é “um sistema de armazenamento distribuído para dados estruturados que
foi projetado para ter uma escalabilidade que o permita gerenciar bases de dados
extensas: petabytes de dados espalhados em milhares de servidores comuns”
(CHANG et al., 2006). Ele foi utilizado em diversos projetos do Google e o artigo
publicado (CHANG et al., 2006) foi considerado um dos trabalhos seminais na área de
NoSQL.
BigTable, porém, apresenta alguns problemas, especificamente em “aplicações
que tenham esquemas complexos e em evolução ou que precisem de uma forte
consistência na presença de replicação em redes de longa distância” (CORBETT et al.,
2012). Para isso, o Google desenvolveu o Spanner, um SGBD escalável, multi-versão
(cada versão de um item de dados recebe uma estampa temporal no momento de
uma efetivação), distribuído globalmente e com replicação síncrona. Spanner também
suporta uma linguagem de consulta que é baseada no SQL. De acordo com
CORBETT et al. (2012), este é o primeiro sistema a distribuir dados em escala global e
suportar transações distribuídas com consistência externa (do inglês externally-
consistent distributed transactions). Em um SGBDD, a ordem em que as transações
são completadas no tempo definem uma única escala de execução (schedule) serial,
chamado a escala de execução externa. Um sistema provê consistência externa se
garantir que a escala de execução a ser usada para processar um conjunto de
transações for igual a escala de execução externa (GIFFORD,1982).

37
Em um alto nível de abstração, Spanner pode ser definido como “um banco de
dados que fragmenta os dados entre um conjunto de muitas máquinas de estado
Paxos em centros de dados espalhados por todo o mundo” (CORBETT et al., 2012).
Uma máquina de estados Paxos consiste em um método de implementar um sistema
distribuído com tolerância a falha através da replicação de servidores e comunicação
entre os nós, utilizando para isso uma família de protocolos para resolver o problema
de consenso, chamada de Paxos. O nome foi dado em homenagem ao sistema
empregado pelos habitantes da ilha de Paxos, na Grécia, para manter o Parlamento
funcionando ainda que seus moradores alternassem com frequência nos cargos de
parlamentares (LAMPORT, 1998). No Spanner, a replicação serve aos propósitos de
manter uma alta disponibilidade global e localização geográfica (dos clientes). Além
disso, automaticamente refaz a fragmentação dos dados sob demanda, conforme a
quantidade de dados aumenta ou o número de servidores muda, além de migrá-los
entre os servidores em resposta a falhas ou para balanceamento de carga (CORBETT
et al., 2012).
3.4.2 Arquitetura
Spanner é organizado em um conjunto de zonas, que representam o conjunto de
locais em que os dados podem ser replicados. Zonas podem ser adicionadas ou
removidas conforme um centro de dados é colocado em serviço ou desligado,
respectivamente. Uma zona tem um zonemaster e diversos spanservers (variando
tipicamente de cem a diversos milhares). O zonemaster atribui dados aos spanservers,
que servem dados aos clientes(CORBETT et al., 2012).
Cada spanserver é responsável por cerca de cem a mil instâncias de uma
estrutura de dados chamada tablet. O estado de um tablet é armazenado em um
sistema de arquivos distribuído chamado Colossus.
Suporte a replicação é alcançado ao implementar uma máquina de estados
Paxos sobre um tablet. Cada máquina de estados armazena metadados e o log do

38
tablet correspondente. Para cada réplica a que é atribuída a condição de líder, o
spanserver também implementa um gerente de transações que dá suporte as
transações distribuídas.
Spanner utiliza o protocolo de Efetivação em Duas Fases (2PC, do inglês, Two-
Phase Commit) sobre as máquinas Paxos para realizar o controle de concorrência
distribuído. CORBETT et al. (2012) acreditam que “é melhor que programadores de
aplicações lidem com problemas de desempenho devido ao uso excessivo de
transações do que ter sempre que codificar em torno da falta de transações”.
Em um universo (um ambiente de implantação do Spanner), podem ser criadas
uma ou mais bases de dados. Cada base de dados pode conter um número ilimitado
de tabelas, que contém linhas, colunas e valores, cada um com seus respectivos
conjuntos de versões. A linguagem de consulta utilizada não é detalhada, mas se
parece com SQL com algumas extensões (CORBETT et al., 2012).

39
Capítulo 4 - Avaliação experimental
Neste capítulo, é apresentada uma abordagem para verificar o desempenho
apresentado por ferramentas NewSQL. A título de ilustração, uma das ferramentas
apresentadas no capítulo anterior foi escolhida, e esta foi submetida a aplicação de um
conjunto de testes planejados a partir de quatro benchmarks distintos. A seção 4.1
descreve o conjunto de benchmarks utilizados e uma suíte de testes que simplifica a
execução dos mesmos. A seção 4.2 descreve o ambiente de testes utilizado. A seção
4.3 descreve os objetivos e a metodologia utilizadas para a execução do procedimento
experimental. A seção 4.4 conclui o capítulo apresentando os resultados obtidos e as
análises pertinentes.
4.1 OLTP-Bench
OLTP-Bench é uma suíte de testes, para execução de benchmarks de SGBDs
relacionais com cargas de trabalho focadas em aplicações OLTP e processamento
Web (DIFALLAH et al., 2013). Neste caso, uma carga de trabalho é a implementação
de um benchmark existente ou criado pela equipe. O OLTP-Bench reúne 15
benchmarks, com cargas de trabalho diferenciadas e agrupadas em 4 tipos de
domínios de aplicações. Entre esses benchmarks o TPC-C, TATP, YCSB e Twitter
foram utilizados nesse trabalho por representarem uma gama bem diferenciada de
aplicações.
O OLTP-Bench, além de agrupar vários benchmarks já muito utilizados, conta
com algumas facilidades para sua utilização (DIFALLAH, et al., 2013) como
extensibilidade, suporte para controle da distribuição das transações, definição de
taxas de desempenho alvo, e suporte para vários SGBDs, através da interface JDBC
(Java Database Connectivity).

40
DIFALLAH, et al., (2013), dividem os benchmarks encontrados nesta suíte de
testes em três tipos:
i. Benchmarks Transacionais, com transações de escrita intensa e
relacionamentos complexos.
ii. Benchmarks orientados à Web, com características de redes sociais,
com operações baseadas em grafos de relações muitos para muitos.
Esses benchmarks levam em consideração dados disponíveis
publicamente para simular uma aplicação real.
iii. Benchmarks de teste funcional, com intenção de testar funcionalidades
individuais de determinado SGBD.
Para os experimentos foram utilizados os três tipos de benchmarks definidos
acima, utilizando o TPC-C e o TATP como benchmarks transacionais, o Twitter como
orientado à web e o YCSB (Yahoo! Cloud Serving Benchmark) como de teste funcional.
4.1.1 TPC-C
O benchmark TPC-C (TPC, 2010), publicado pelo TPC (Transaction Processing
Performance Council) é o padrão atual para avaliação de desempenho de sistemas
OLTP tradicionais. O benchmark simula um ambiente onde uma série de usuários
virtuais, ou terminais na nomenclatura do benchmark, executam múltiplas transações
em uma base de dados, simulando uma aplicação de processamento de pedidos em
um armazém.
Este é um benchmark com características de cargas de trabalho intensivas em
escrita e muitas transações concorrentes.
O tamanho da base de dados do TPC-C varia de acordo com o número de
armazéns. Todas as tabelas (com exceção da tabela Item), tem sua cardinalidade
influenciadas pela quantidade de armazéns. O esquema da base de dados do TPC-C
é mostrada na Figura 5:

41
Figura 5 - Esquema do TPC-C
Entre as transações contidas no benchmark estão inclusão de novos pedidos,
entrega de pedidos, contagem de estoque, registro de pagamentos e controle de
situação dos pedidos.
Essas transações são executadas de acordo com uma distribuição de
frequência pré-definida, que pode ser alterada pelo usuário (no OLTP-Bench). Para os
testes realizados nesse trabalho, utilizamos a distribuição padrão das transações que
seguem o seguinte modelo:
i. Transações New-Order (~45%): Inserção de um novo pedido na base de
dados,
ii. Transações Payment (~43%): Inserção de um registro de pagamento no
histórico.
iii. Transações Order Status (~4%): Consulta para saber se o pedido foi
processado.
iv. Transações Stock Level (~4%): Consulta para saber quais itens possuem
um baixo nível de estoque.

42
v. Transações Delivery (~4%): Um item é removido do estoque e a situação
do pedido é atualizada.
É importante salientar que as descrições acima são uma declaração de alto
nível dos objetivos pretendidos com cada uma das transações. Cada uma dessas
transações, na verdade, é responsável por representar uma lógica de negócios
complexa, sendo compostas de várias operações SQL.
A métrica utilizada pelo TPC-C para avaliação do desempenho dos SGBD é o
número de transações do tipo New-Order que são executadas por minuto (tpmC)
enquanto as demais transações acontecem simultaneamente no sistema.
A implementação do TPC-C contida na suíte de testes OLTP-Bench se
diferencia da especificação original, pois omite o “tempo de pensamento” que os
submetedores de transações demoram antes de iniciar cada transação. Assim, cada
submetedor realiza transações ininterruptamente, e com isso somente um pequeno
número de conexões paralelas é necessário para saturar o servidor.
Para este benchmark, foi utilizado o fator 16 durante a fase de carga, o que é
equivalente a ter 16 armazéns distintos. A base de dados equivalente tem 1,3 GB.
4.1.2 TATP
O benchmark TATP (Telecommunication Application Transaction Processing) simula
uma típica aplicação de telecomunicações (IBM Software Group, 2009). O esquema
da sua base de dados foi modelado de maneira semelhante a um banco de dados
central que contém dados sobre os assinantes de telefonia móvel que estão
autorizados a usar as tecnologias GSM (Global System for Mobile Communications) e
o WCDMA (Wide Band Code Division Multiple Access).

43
Ao contrário do TPC-C, este benchmark possui cargas de trabalho
principalmente de leitura, com transações curtas (poucas operações SQL) e não
conflitantes.
O esquema da base de dados utilizada pelo TATP é mostrado na Figura 6:
Figura 6 - Esquema do TATP
São pré-definidas sete transações a serem realizadas, as quais inserem,
atualizam, removem e selecionam dados na base de dados. Durante o tempo de
execução, o número de vezes em que cada transação ocorre segue a distribuição de
transações pré-definida pelo usuário. Para esse projeto, foram utilizadas as seguintes
distribuições:
Transação de Leitura (~80%):
i. Transações Get Access Data (~35%): Seleciona os dados para validação
de acesso, com probabilidade de sucesso de 62,5%.

44
ii. Transações Get New Destination (~10%): Seleciona o corrente destino do
encaminhamento de chamadas, com probabilidade de sucesso de 23,9%.
iii. Transações Get Subscriber Data (~35%): Seleciona um registro da tabela
Subscriber, com probabilidade de sucesso de 100%.
Transações de Escrita (~20%):
iv. Transações Delete Call Forwarding (~2%): Remove um registro de
encaminhamento de chamadas, com probabilidade de sucesso de
31,25%.
v. Transações Insert Call Forwarding (~2%): Adiciona um novo registro de
encaminhamento de chamadas, com probabilidade de sucesso de
31,25%.
vi. Transações Update Location (~14%): Atualiza a localidade do assinante,
com probabilidade de sucesso de 100%.
vii. Transações Update Subscriber Data (~2%): Atualiza dados do perfil do
assinante, com probabilidade de sucesso de 62,5%.
O processo de carga dos dados para este benchmark foi realizado utilizando
fator de carga 10, o que é equivalente a inserir um milhão de assinantes. A base de
dados resultante tem 740 MB.
4.1.3 YCSB
O Yahoo! Cloud Serving Benchmark (YCSB) contém um conjunto de cargas de
trabalho simples, micro benchmarks, que representam aplicações com operações
simples mas que necessitam de grande escalabilidade. Esse benchmark foi
desenvolvido para comparar o PNUTS (COOPER et al.,2008), um SGBD próprio do
Yahoo!, com outros SGBD em nuvem, principalmente os NoSQL (SILBERSTEIN et al.,
2010). Seu desenvolvimento foi iniciado pois os bancos NoSQL que estavam surgindo
tinham modelos de dados diferentes entre si (já explicados na seção 2.4), o que

45
dificultava a comparação através dos benchmarks existentes, como o TPC-C, por
exemplo.
O YCSB possui uma única tabela, chamada usertable, detalhada na Figura 7,
sobre a qual as cargas de trabalho são executadas. O benchmark já vem com 6
cargas de trabalho pré-definidas, onde as operações na base de dados e suas
frequências mudam de acordo com o escolhido. Além dos existentes, o YCSB permite
que novas cargas de trabalho sejam criados estendendo a classe CoreWorkload de
onde todos os demais foram criados. Com isso, podem ser criadas carga de trabalho
personalizadas, para atender a necessidades específicas.
Figura 7 - Esquema do YCSB
Com todas essas possibilidades diferentes de testes, o YCSB já foi utilizado em
estudos anteriores para explorar a troca entre disponibilidade, consistência e
fragmentação e também o aumento de desempenho utilizando SGBD em memória
(CURINO, et al., 2012).
Para o processo de carga de dados deste benchmark, foi utilizado o fator 600,
que é equivalente a inserir 600.000 registros na tabela usertable. A base de dados
resultante tem 766 MB. A carga de trabalho utilizada foi 50% escrita e 50% leitura.

46
4.1.4 Twitter
Inspirado pelo micro-blog de mesmo nome, este benchmark é parte integrante do
OLTP-Bench, e não uma implementação da especificação de um benchmark
preexistente. Foi criado “com base em um instantâneo, anônimo, do grafo social do
Twitter de agosto de 2009, contendo 51 milhões de usuários e quase dois bilhões de
relacionamentos do tipo ‘X segue Y’ ” (DIFALLAH et al.,2013).
O benchmark possui um gerador de cargas de trabalho sintéticos que é
baseado em uma aproximação das consultas e transações necessárias para
representar as funcionalidades da aplicação original. O esquema da base do Twitter é
mostrado na Figura 8 :
Figura 8 – Esquema do Twitter

47
Uma breve explicação sobre o que representam as entidades acima pode ser
necessária:
O Twitter 11 é um sistema em que usuários postam mensagens de curta
extensão (limitados a 140 caracteres), chamados tweets. Usuários podem formar uma
rede social entre si “seguindo” uns aos outros. Essa é uma relação assimétrica no
grafo, pois usuário X seguir Y não garante que Y siga X. Um tweet postado por um
usuário é visto por seus seguidores em seus feeds, uma listagem de publicações em
ordem decrescente quanto ao tempo de publicação, da mais recente para a mais
antiga. Existem outras características, mas obviamente este benchmark não se propõe
a ser uma representação exata do sistema, e sim uma aproximação relativamente
precisa do tipo de carga de trabalho que o mesmo suporta regularmente.
As transações que o compõem, assim como a frequência de ocorrência padrão
de cada uma, estão detalhadas a seguir:
i. GetTweet (~0,07%): recupera um tweet pelo seu id
ii. GetTweetsFromFollowing (~0,07%): recupera os tweets de um conjunto de
usuários seguidos por outro
iii. GetFollowers (~7,67%): recupera os seguidores (f2) de um determinado
usuário, identificado por (f1)
iv. GetUserTweets (~91,26%): recupera todos os tweets pelo id de usuário
v. InsertTweet(~0,92%): insere um registro na tabela added_tweets
Baseado no julgamento dos desenvolvedores, de que esse conjunto é
representativo da carga de trabalho do sistema original, essa composição foi a mesma
utilizada durante a execução do benchmark.
11 www.twitter.com, acessado pela primeira vez em 05/02/2014

48
Para o processo de carga de dados deste benchmark, foi utilizado o fator 150,
que é equivalente a inserir 75.000 usuários. A base de dados resultante tem
aproximadamente 1,1 GB.
4.2 Ambiente de Testes Para realizarmos os testes desse projeto, inicialmente foi utilizado o ambiente EC212
da Amazon, com a utilização de Máquinas Virtuais (MV) do tipo micro instância. Porém,
esse tipo de instância, por ter menos de 10% da memória recomendada para
utilização dos SGBD testados e por serem indicadas para aplicações que requisitam
picos momentâneos de desempenho (o que é essencialmente diferente dos
benchmarks, que estressam constantemente o sistema), foi abandonada. Portanto,
optamos pela montagem de um aglomerado heterogêneo composto de notebooks
pessoais.
Nesse aglomerado, utilizamos 4 computadores com as seguintes
configurações:
i. Sistema Operacional Ubuntu 12.04, 4 GB de RAM e processador Intel
Core i5, 300 GB de disco rígido. Identificado como “Computador 1”
ii. Sistema Operacional Ubuntu 12.04, 4 GB de RAM e processador Intel
Core i3, 300 GB de disco rígido. Identificado como “Computador 2”
iii. Sistema Operacional Ubuntu 12.04, 4 GB de RAM e processador Intel
Core i5, 300 GB de disco rígido. Identificado como “Computador 3”
iv. Sistema Operacional OS Mavericks, 4 GB de RAM e processador Intel
Core i5, 500 GB de disco rígido. Identificado como “Computador 4”
Todos os computadores estão conectados por uma rede Ethernet 100 Mbps. O
Computador 4 foi responsável por fazer o papel de cliente, ou seja, pela invocação ao
benchmark. A carga de trabalho foi direcionada a uma instância do SGBD em um
12 http://aws.amazon.com/ec2/, acessado pela primeira vez em 10/01/2014

49
computador diferente, o Computador 3, que foi responsável por representar a camada
administrativa do SGBD, ou seja, a que recebe requisições e as distribui conforme
necessário. Com isso, pretende-se que haja o fator comunicação entre nós presente
em todas as configurações possíveis.
4.3 Procedimento Experimental
4.3.1 Objetivo
O objetivo dos testes realizados é verificar o desempenho de um SGBD NewSQL sob
cargas de trabalho sintéticas que simulam operações de aplicações diferentes. Para
isso, foram utilizados os benchmarks TPC-C, TATP, YCSB e Twitter. Os testes
avaliaram a aceleração obtida ao se aumentar gradativamente o número de nós no
aglomerado. Foram utilizadas configurações com um, dois e quatro nós, descritas
abaixo:
i. Um nó: Computador 3 como servidor
ii. Dois nós: Computadores 3 e 2 como servidores
iii. Quatro nós: Computadores 1,2,3 e 4 como servidores
4.3.2 Metodologia O SGBD NewSQL avaliado é o NuoDB. Excluindo-se o Google Spanner, por ser
proprietário, e, portanto, indisponível para testes, a decisão foi tomada entre os outros
três SGBD apresentados no Capítulo 3. Justifica-se a escolha do NuoDB por ser o
único entre eles a possuir uma edição (não-comercial) sem nenhuma restrição para
testes, chamada “edição desenvolvedor”13. A versão utilizada foi a 2.0.3.
13 http://www.nuodb.com/explore/newsql-cloud-database-editions/compare-editions, acessado pela primeira vez em: 10/01/2014

50
Para cada uma das configurações do aglomerado, foram realizados testes
variando o número de terminais do benchmark entre 4 e 128, dobrando o número a
cada teste. Terminais simulam usuários virtuais enviando requisições simultâneas ao
sistema.
Para cada um dos testes foram realizadas três rodadas de execuções e
obteve-se a média do número de operações processadas por unidade de tempo entre
elas. Exemplo: Para 1 nó utilizando 4 terminais, foram feitas 3 medições.
OLTP-Bench se encarrega de três fases da execução de um benchmark:
criação da base, carga de dados e execução, devendo a fase ser indicada em tempo
de execução através do parâmetro apropriado, durante a invocação do programa (--
create, --load ou –execute). Os parâmetros mínimos que devem ser usados são: o
nome do benchmark escolhido e o arquivo de configuração do mesmo. O arquivo de
configuração do benchmark é um XML em que são definidos: os detalhes da conexão
JDBC,o fator de carga (número que define a quantidade de registros que serão
inseridos durante o processo de carga da base, particular de cada benchmark),
número de terminais (para a fase de execução), além de outros parâmetros que
regulam a execução, como quais as transações disponíveis por benchmark e a
composição das mesmas (frequência em que são utilizadas, devem somar 100%),
tempo de execução do experimento e a taxa (em requisições/seg.) pretendida. Um
exemplo deste arquivo pode ser visto no Anexo A.
Para cada benchmark disponível, existe um exemplo de arquivo de
configuração incluído no diretório samples do OLTP-Bench. Para cada par (SGBD
testado, benchmark escolhido), foi feita uma cópia de um arquivo de exemplo,
correspondente ao benchmark correto, na qual os valores de conexão foram editados
de acordo. Para todos os experimentos, o tempo de execução foi de 60 segundos.
Testes preliminares demonstraram que o valor padrão do parâmetro taxa (10.000)
limitava o resultado obtido, então o valor foi aumentado para 100.000, como limite

51
superior. As configurações particulares de cada benchmark são as mesmas
mencionadas nas seções 4.1.1 a 4.1.4.
Além disso, OLTP-Bench guarda os resultados da execução, em local
especificado, em um conjunto de cinco arquivos: uma cópia das configurações do
benchmark utilizadas para aquela execução (*.ben.cnf), uma cópia das configurações
do SGBD no momento da execução (*.db.cnf), resumo dos resultados (*.summary),
listagem das transações realizadas (identificadas por um id que corresponde à posição
em que aparecem no arquivo de configuração) e o tempo de duração de cada uma
(*.raw) e um resultado agregado por intervalos de tempo (*.res).
A “janela” de tempo utilizada para agregar os resultados (no arquivo .res) pode
ser definida em tempo de execução passando o parâmetro –s à chamada do
executável oltpbenchmark. Para poder acompanhar o resultado a cada segundo, foi
usado o valor 1.
Desses arquivos, foram obtidos os seguintes dados: número médio de
requisições por segundo, latência média e número máximo de requisições realizadas.
Para os dois primeiros, a média entre as três rodadas foi obtida e utilizada como valor
de comparação. Para o último, o maior valor encontrado foi o utilizado para
comparação.
4.3.3 Configuração dos SGBD
Os testes para o SGBD NuoDB foram realizados em duas etapas. Na primeira, a cada
nó adicionado ao aglomerado um processo TE era iniciado nesse novo nó, totalizando
4 nós com 4 TE ao final dos experimentos. Posteriormente, foram feitos testes
replicando a base original, ou seja, através da adição de novos processos SM nos nós
do aglomerado. No total, foram testadas as 6 configurações mostradas abaixo:
i. 1 TE e 1 SM: 1 TE e 1 SM no Computador 3;
ii. 2 TE e 1 SM: 1 TE e 1 SM no Computador 3, 1 TE no Computador 2;

52
iii. 4 TE e 1 SM: 1 TE em cada computador, 1 SM no Computador 3;
iv. 2 TE e 2 SM: 1 TE e 1 SM em cada um dos Computadores 2 e 3;
v. 4 TE e 2 SM: 1 TE em cada computador, 1 SM no Computador 2, 1 SM
no Computador 3 ; e
vi. 4 TE e 4 SM: 1 TE e 1 SM em cada um dos computadores.
Os testes com replicação das bases foram realizados para verificar se os TE
são os únicos responsáveis pelo aumento de desempenho, ou se há benefícios
adicionais ao acrescentar processos SM. O aumento do número de TE aumenta o
tamanho do cache distribuído. O aumento no número de SM aumenta o número de
réplicas do banco de dados utilizados no cenário.
A suíte de testes OLTP-Bench já possui os scripts de criação apropriados para
cada uma das bases base de dados para o NuoDB. Portanto, modificações não foram
necessárias para executar os procedimentos de criação e carga das bases de dados
de cada benchmark realizado. O processo de carga de dados foi realizado com os
fatores de carga apresentado nas seções 4.1.1 a 4.1.4.
4.4 Resultados Experimentais
4.4.1 TATP Para uma configuração de dois nós no aglomerado, duas possibilidades foram
comparadas, uma com a utilização de um SM e outra com 2 SM. Podemos perceber,
na Figura 9, que com o aumento do número de usuários virtuais no sistema, existe um
decréscimo no desempenho da configuração com 2 SM, pois quanto maior o número
de SM mais comunicações entre eles são realizadas para manter a consistência entre
os átomos replicados nos arquivos físicos.
Para uma configuração de quatro nós no aglomerado, 3 possibilidades foram
comparadas, uma com a utilização de uma SM, outra com 2 SM e outra com 4 SM.

53
Podemos perceber na Figura 10 o mesmo padrão mostrado na Figura 9, explicado
pelo maior número de comunicações entre as réplicas da base de dados. Esse fator se
agrava, quanto maior for o número de usuários virtuais fazendo requisições ao SGBD.
Figura 9 - Resultados TATP - 2 Nós
Figura 10 - Resultados TATP - 4 Nós
A Figura 11 demonstra um comparativo de desempenho entre as três
configurações testados: NuoDB com um, dois e quatro SM, fixando o número de
usuários virtuais simultâneos em 128.
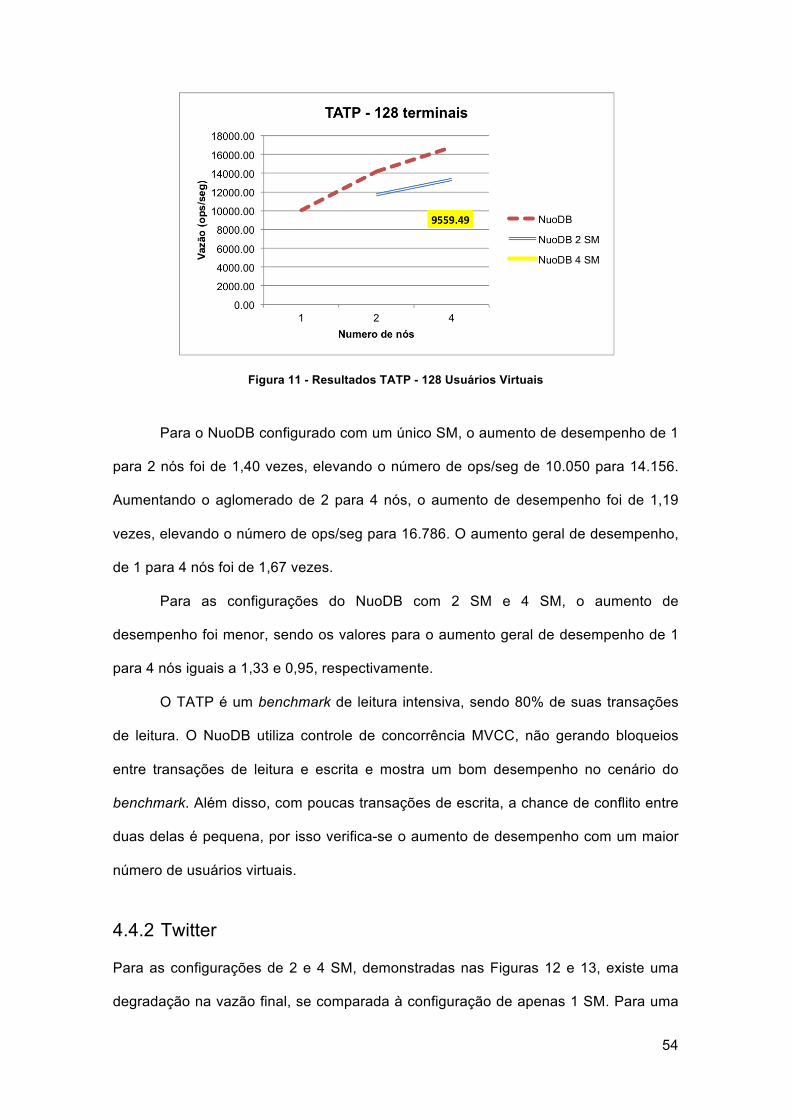
54
Figura 11 - Resultados TATP - 128 Usuários Virtuais
Para o NuoDB configurado com um único SM, o aumento de desempenho de 1
para 2 nós foi de 1,40 vezes, elevando o número de ops/seg de 10.050 para 14.156.
Aumentando o aglomerado de 2 para 4 nós, o aumento de desempenho foi de 1,19
vezes, elevando o número de ops/seg para 16.786. O aumento geral de desempenho,
de 1 para 4 nós foi de 1,67 vezes.
Para as configurações do NuoDB com 2 SM e 4 SM, o aumento de
desempenho foi menor, sendo os valores para o aumento geral de desempenho de 1
para 4 nós iguais a 1,33 e 0,95, respectivamente.
O TATP é um benchmark de leitura intensiva, sendo 80% de suas transações
de leitura. O NuoDB utiliza controle de concorrência MVCC, não gerando bloqueios
entre transações de leitura e escrita e mostra um bom desempenho no cenário do
benchmark. Além disso, com poucas transações de escrita, a chance de conflito entre
duas delas é pequena, por isso verifica-se o aumento de desempenho com um maior
número de usuários virtuais.
4.4.2 Twitter Para as configurações de 2 e 4 SM, demonstradas nas Figuras 12 e 13, existe uma
degradação na vazão final, se comparada à configuração de apenas 1 SM. Para uma
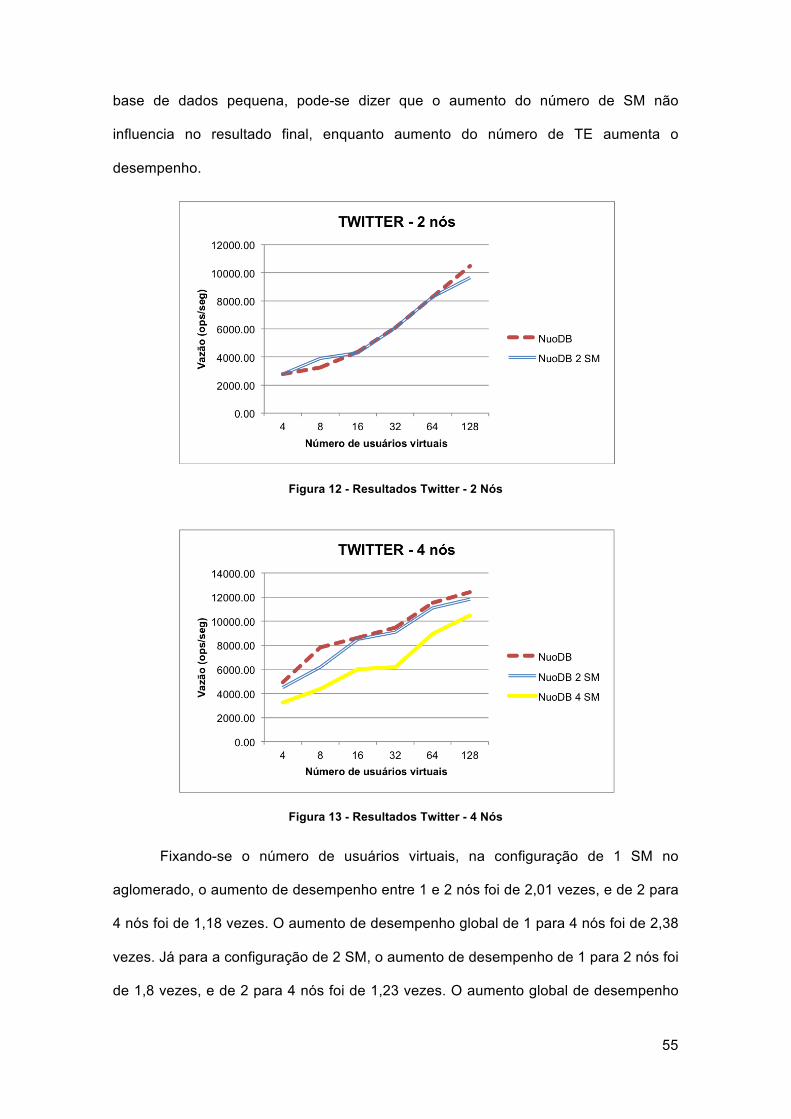
55
base de dados pequena, pode-se dizer que o aumento do número de SM não
influencia no resultado final, enquanto aumento do número de TE aumenta o
desempenho.
Figura 12 - Resultados Twitter - 2 Nós
Figura 13 - Resultados Twitter - 4 Nós
Fixando-se o número de usuários virtuais, na configuração de 1 SM no
aglomerado, o aumento de desempenho entre 1 e 2 nós foi de 2,01 vezes, e de 2 para
4 nós foi de 1,18 vezes. O aumento de desempenho global de 1 para 4 nós foi de 2,38
vezes. Já para a configuração de 2 SM, o aumento de desempenho de 1 para 2 nós foi
de 1,8 vezes, e de 2 para 4 nós foi de 1,23 vezes. O aumento global de desempenho
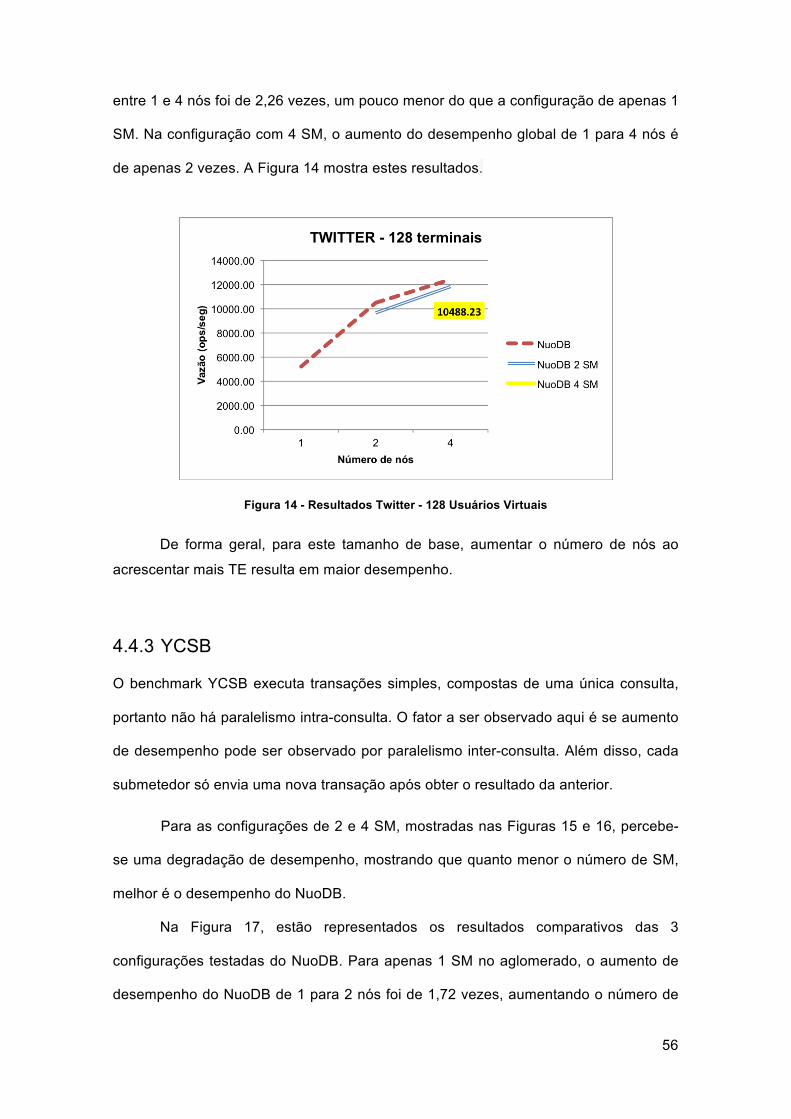
56
entre 1 e 4 nós foi de 2,26 vezes, um pouco menor do que a configuração de apenas 1
SM. Na configuração com 4 SM, o aumento do desempenho global de 1 para 4 nós é
de apenas 2 vezes. A Figura 14 mostra estes resultados.
Figura 14 - Resultados Twitter - 128 Usuários Virtuais
De forma geral, para este tamanho de base, aumentar o número de nós ao
acrescentar mais TE resulta em maior desempenho.
4.4.3 YCSB O benchmark YCSB executa transações simples, compostas de uma única consulta,
portanto não há paralelismo intra-consulta. O fator a ser observado aqui é se aumento
de desempenho pode ser observado por paralelismo inter-consulta. Além disso, cada
submetedor só envia uma nova transação após obter o resultado da anterior.
Para as configurações de 2 e 4 SM, mostradas nas Figuras 15 e 16, percebe-
se uma degradação de desempenho, mostrando que quanto menor o número de SM,
melhor é o desempenho do NuoDB.
Na Figura 17, estão representados os resultados comparativos das 3
configurações testadas do NuoDB. Para apenas 1 SM no aglomerado, o aumento de
desempenho do NuoDB de 1 para 2 nós foi de 1,72 vezes, aumentando o número de
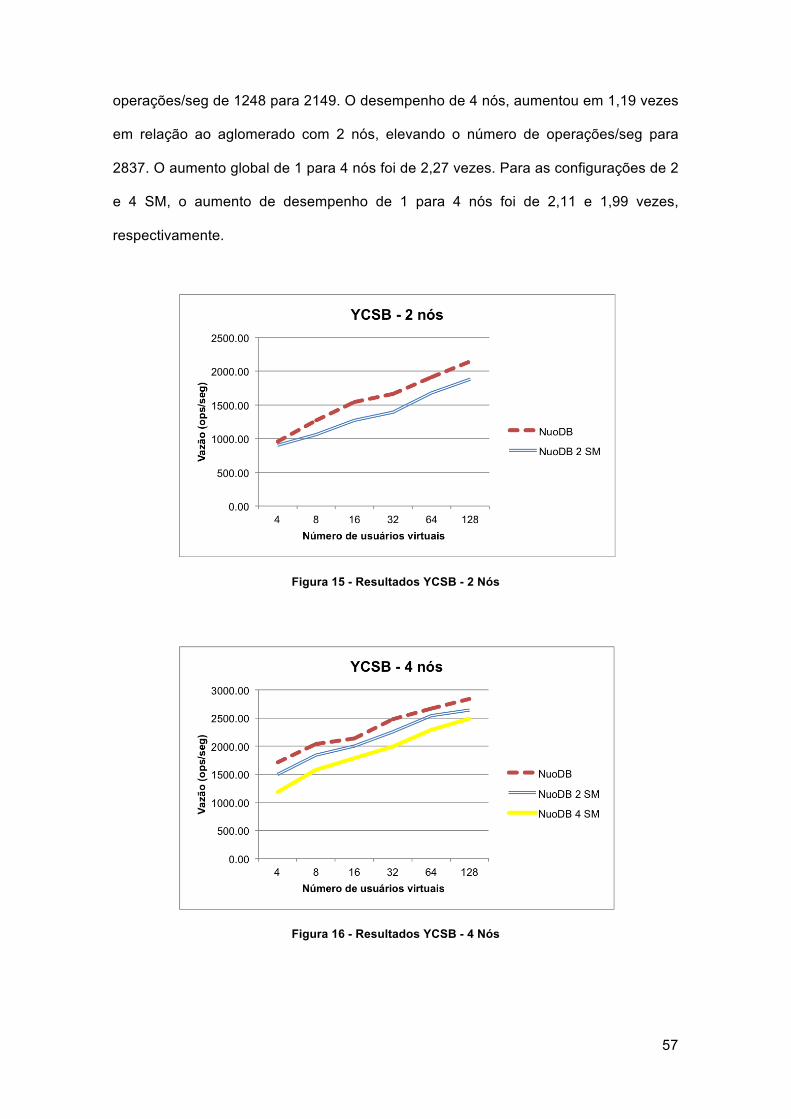
57
operações/seg de 1248 para 2149. O desempenho de 4 nós, aumentou em 1,19 vezes
em relação ao aglomerado com 2 nós, elevando o número de operações/seg para
2837. O aumento global de 1 para 4 nós foi de 2,27 vezes. Para as configurações de 2
e 4 SM, o aumento de desempenho de 1 para 4 nós foi de 2,11 e 1,99 vezes,
respectivamente.
Figura 15 - Resultados YCSB - 2 Nós
Figura 16 - Resultados YCSB - 4 Nós
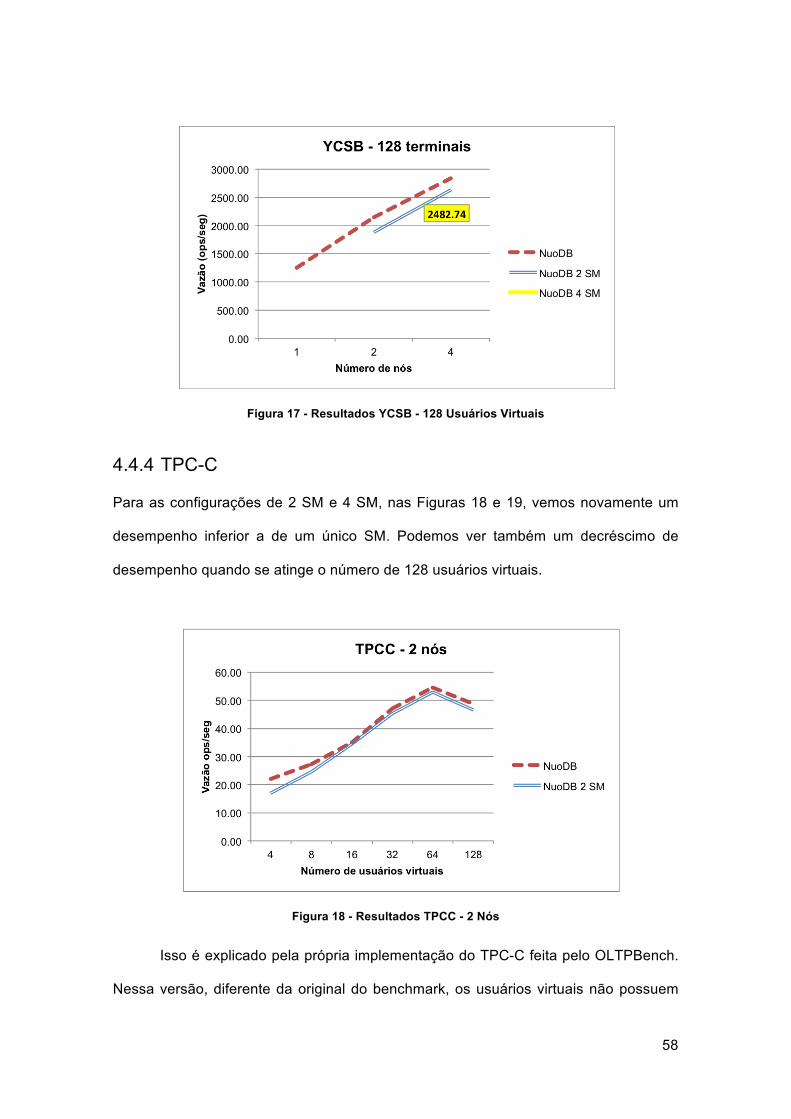
58
Figura 17 - Resultados YCSB - 128 Usuários Virtuais
4.4.4 TPC-C Para as configurações de 2 SM e 4 SM, nas Figuras 18 e 19, vemos novamente um
desempenho inferior a de um único SM. Podemos ver também um decréscimo de
desempenho quando se atinge o número de 128 usuários virtuais.
Figura 18 - Resultados TPCC - 2 Nós
Isso é explicado pela própria implementação do TPC-C feita pelo OLTPBench.
Nessa versão, diferente da original do benchmark, os usuários virtuais não possuem
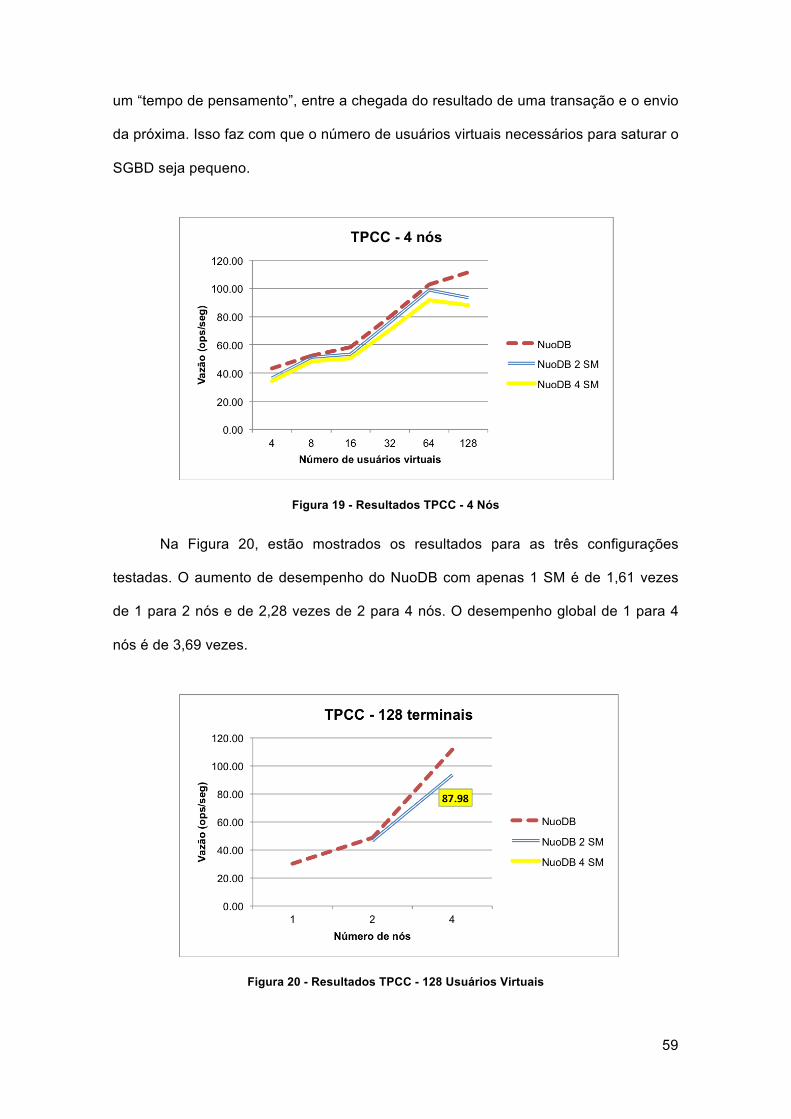
59
um “tempo de pensamento”, entre a chegada do resultado de uma transação e o envio
da próxima. Isso faz com que o número de usuários virtuais necessários para saturar o
SGBD seja pequeno.
Figura 19 - Resultados TPCC - 4 Nós
Na Figura 20, estão mostrados os resultados para as três configurações
testadas. O aumento de desempenho do NuoDB com apenas 1 SM é de 1,61 vezes
de 1 para 2 nós e de 2,28 vezes de 2 para 4 nós. O desempenho global de 1 para 4
nós é de 3,69 vezes.
Figura 20 - Resultados TPCC - 128 Usuários Virtuais

60
Para todos os benchmarks testados podemos enumerar 2 importantes
ocorrências:
i. A configuração do NuoDB com apenas 1 SM é a que tem melhor
desempenho. Isso se deve ao fato de que, com 2 e 4 SM, existe uma
maior comunicação entre os SM para que os átomos estejam
consistentes entre si.
ii. Mesmo não existindo uma aceleração linear do desempenho quando se
aumenta o número de nós no aglomerado de 1 para 2 nós e de 2 para 4
nós, observou-se um aumento de desempenho quanto maior o número
de TE utilizados no sistema. É importante lembrar que para cada nó no
aglomerado, sempre existe um TE.
Uma das justificativas para criação dos NewSQL, inclusive do NuoDB, era dar
a possibilidade de se escalar a base de dados horizontalmente, dado que
escalabilidade é um dos requisitos das novas demandas do mercado apresentadas no
Capítulo 1, e que a opção pela escalabilidade vertical não é viável financeiramente
falando, além de chegar a um limite de capacidade de aumento de desempenho.
Nos testes realizados, tentou-se verificar se essa escalabilidade horizontal
realmente era fornecida pelo SGBD testado, o NuoDB. Nos benchmarks realizados,
podemos perceber um aumento de desempenho de acordo com o aumento do número
de nós e processos TE que eram iniciados no sistema. Isso mostra que, para o
ambiente testado, o NuoDB obteve escalabilidade horizontal.
Com as limitações desse projeto, apresentadas no Capítulo a seguir, ainda não é
possível ter certeza até que ponto de fato o NuoDB fornece uma escalabilidade
horizontal. Para isso novo trabalhos devem ser feitos, como mostra o Capítulo final

61
desse trabalho. Porém esse projeto, já mostra uma boa perspectiva do que pode
acontecer em ambientes maiores e mais realistas.

62
Capítulo 5 - Conclusão
A Internet alterou substancialmente a forma como as pessoas se relacionam. Novos
modelos de negócios e de prestação de serviços que surgiram na última década
culminaram com a criação de aplicações que antes não eram possíveis de imaginar.
Redes sociais online ou serviços de mensagem instantânea se tornaram comuns, e o
conhecimento e ferramentas para desenvolvê-las estão disponíveis para qualquer um.
Qual, então, pode ser a diferença entre um caso bem sucedido e outro não?
Aplicações como as mencionadas são consideradas aplicações em tempo real,
com requisitos de baixo tempo de resposta. Para isso é necessário que a camada de
acesso aos dados, ou seja, o SGBD, apresente um desempenho adequado.
Neste projeto, foram apresentados os motivos que levam os SGBDR
tradicionais a não atenderem a esses requisitos apropriadamente. Novas soluções
foram introduzidas. Ainda assim, os anos de pesquisa e desenvolvimento investidos
em aprimorar recursos como os mecanismos de controle de concorrência e
compiladores da linguagem SQL, que tem ampla adoção no mercado, mostraram que
alternativas aos SGBDR tradicionais não precisam abandonar o Modelo Relacional
para alcançar estes objetivos. Este projeto se propôs a analisar alguns dos SGBD
chamados NewSQL, que são projetados para atender a nichos de mercados
específicos. Por sua vez, esta característica guia as escolhas de estratégias de
implementação tomadas por estes SGBD. Portanto, este projeto buscou mostrar
algumas dessas estratégias de implementação e as razões por trás dessas escolhas.
A título de ilustração, o desempenho do NuoDB (um SGBD NewSQL) foi
avaliado através de quatro benchmarks, que impõem cargas de trabalho distintas
(escrita intensiva, leitura intensiva e uma carga balanceada) ao SGBD, executado em
um pequeno aglomerado de computadores.

63
Considerando os resultados obtidos, observou-se uma melhoria geral na
quantidade de transações realizadas por segundo ao adicionar nós ao aglomerado,
assim como incluir maior número de usuários virtuais. Portanto, nos cenários
planejados, pode-se afirmar que a escalabilidade horizontal foi alcançada. É
importante ressaltar que, devido à arquitetura apresentada pelo NuoDB, que é,
simplificadamente, um cache distribuído, não é possível analisar a influência de um
projeto de fragmentação adequado no resultado final. Se o sistema adotado fosse
similar ao MemSQL, por exemplo, seria preciso que o projetista da base de dados
considerasse o problema da fragmentação e da alocação de fragmentos para obter o
melhor desempenho com as consultas utilizadas pela aplicação.
A experiência obtida com os SGBD NewSQL também mostra que ainda
existem algumas limitações de funcionalidade nos mesmos. Atualizações (patches)
são lançados com frequência para incluir correções de erros e ampliar a
compatibilidade com instruções SQL.
5.1 Limitações Um conjunto de fatores delimitaram o escopo e desenvolvimento deste projeto. São
eles:
i. Por limitações de recursos, os procedimentos experimentais apresentados
foram realizados utilizando computadores pessoais. Os mesmos possuem
capacidade de memória principal disponível inferiores aos valores
recomendados pelos fabricantes dos SGBD analisados. Isso, porém, não
impede a execução dos testes, mas limita os tamanhos das bases de
dados utilizadas que possam ser inteiramente armazenadas em memória.
Estas bases de dados, portanto, não se propõem a ser uma representação
exata da aplicação correspondente a cada benchmark realizado, mas
servem ao propósito de comparação.

64
ii. O número de computadores disponíveis para os procedimentos
experimentais também é limitado. Por isso o número de nós do aglomerado
é, no máximo, quatro. Em um cenário de implantação real, esse número
poderia ser muito maior. Além disso, os computadores seriam
interconectados por tecnologias de transmissão de dados na rede mais
avançadas, como Ethernet Gigabit. Por isso, o fator comunicação na rede
deve ser pequeno, porém não desprezível.
iii. As execuções nos benchmarks foram limitadas a duração de um minuto.
Isso permitiu que, quando erros ocorressem, fossem feitas as depurações
necessárias, e novas execuções realizadas, além de obter maior
diversidade nos resultados (múltiplas opções de números de usuários
virtuais, por exemplo). Essa duração, porém, não é a mais adequada, de
acordo com os desenvolvedores dos benchmarks. Alguns recomendam que
as execuções tenham duração de duas ou mais horas, por exemplo, o que
inviabilizaria obter a quantidade de execuções distintas apresentadas.
5.2 Trabalhos Futuros Este projeto mostra uma abordagem prática para avaliação de desempenho em SGBD
NewSQL. Esta abordagem, porém, não é exaustiva, pois outras possibilidades de
estudo podem ser conduzidas a partir desta.
Em primeiro lugar, as condições já apresentadas podem ser ampliadas. Por
exemplo, para o mesmo planejamento de testes realizados, outros valores de
parâmetros podem ser aplicados: o tempo de duração do experimento, composição
das transações de cada benchmark, número de usuários virtuais, entre outros. Um
estudo sobre ajustes finos no NuoDB também pode ser conduzido.
Além disso, um estudo mais aprofundado pode ser feito a partir da inclusão de
um maior número de SGBD NewSQL na comparação, e como as diferentes

65
estratégias de implementação adotadas por estes influenciam nos resultados de
desempenho. Outros benchmarks disponíveis podem ser incluídos.
A influência de outros fatores nos resultados também podem ser estudadas,
como: características específicas de hardware (processadores, memória, discos,
equipamentos de rede) ou de software (diferentes implementações do mesmo
benchmark).

66
Referências Bibliográficas
ASLETT, M., “How will the database incumbents respond to NoSQL and NewSQL?”, 451
Analyst Report, Abr., 2011
BERNSTEIN, P., GOODMAN, N., et al., 1981a, “Query Processing in a System for Distributed
Databases (SSD-1)”, ACM Transactions on Database Systems, v.6, pp. 602-625
BERNSTEIN, P., GOODMAN, N., 1981b, “Concurrency Control in Distributed Database
Systems”, Computing Surveys, v.13, n.2, Jun, pp. 185-221
CAREY, M., LIVNY, M., 1988, “Distributed Concurrency Control Performance: A Study of
Algorithms, Distribution, and Replication”. In: Proceedings of the 14th Very Large Database
Conference, pp. 13-25
CATTELL, R., 2010, “Scalable SQL and NoSQL Data Stores”. In: ACM SIGMOD Record, v. 39,
pp 12-27, Dez.
CHA, M., HADDADI, H., 2010, “Measuring User Influence in Twitter: The Million Follower
Fallacy”. In: Proceedings of the 4th International AAAI Conference on Weblogs and Social Media
CHANG, F., DEAN, J. et al., 2006, “Bigtable: A Distributed Storage System for Structured Data”,
ACM Transactions on Database Systems, v. 26, n.4, Jun, pp. 1-26
COOPER, B., RAMAKRISHNAN, R., et al., “PNUTS: Yahoo!’s Hosted Data Serving Platform”.
In: Proceedings of the VLDB Endowment, vol. 1, no.2, pp. 1277-1288, Ago. 2008
CORBETT, J., DEAN, J., et al., 2012, “Spanner: Google’s Globally-Distributed Database”. In:
Proceedings of OSDI'12: Tenth Symposium on Operating System Design and Implementation,
pp. 251-264, Hollywood, CA, Out., 2012.
CURINO, C., PAVLO, A., et al., 2012, “Benchmarking OLTP/Web Databases in the Cloud: the
OLTP-Bench Framework”. In: CloudDB’12 Proceedings of the Fourth International Workshop on
Cloud Data Management, pp 17-20.

67
DAUDPOTA, N., 1998, “Five Steps to Construct a Model of Data Allocation for Distributed
Database Systems”, Journal of Intelligent Information Systems, v.11, pp-153-168
DIFALLAH, D., CURINO, C., et al., “OLTP-Bench: An Extensible Testbed for Benchmarking
Relational Databases”. In: Proceedings of the Very Large Database Endowment, vol.7, no. 4, pp.
277-288, Dez.2013
GIFFORD,D., “Information Storage in a Decentralized Computer System”. In: Tech. Rep. CSL-
81-8,Xerox PARC, 1982
HARIZOPOULOS, S., ABADI, D., et al., 2008, “OLTP Through the Looking Glass, and What We
Found There”, In: Proceedings of the 2008 ACM SIGMOD International Conference of
Management Data, pp 981-992.
HOWARD, P., 2013, “NuoDB InDetail”, Bloor Report. Disponível em: go.nuodb.com/bloor-
report-request.html. Acesso em: 5 dez 2013
IBM Software Group Information Management, “Telecommunication Application Transaction
Processing (TATP) Benchmark Description”, 2009. Disponível em:
http://tatpbenchmark.sourceforge.net/TATP_Description.pdf . Acesso em: 10 fev. 2014
KALLMAN, R., KIMURA, H., “H-Store: A High-Performance, Distributed Main Memory
Transaction Processing System”. In: Proceedings of the VLDB Endowment, v.1, pp.1496-1499,
Ago., 2008
KHAN, S., AHMAD, I., 2010, “Replicating Data Objects in Large Distributed Database Systems:
An Axiomatic Game Theoretic Mechanism Design Approach”, Distributed and Parallel
Databases, v. 28, Dez, pp. 187-218
LAMPORT, L., 1998, “The Part-Time Parliament”, ACM Transactions on Computer Systems, v.
16, n. 2, Mai, pp. 133-169
LEAVITT, N., 2010, “Will NoSQL Databases Live Up to Their Promise?”, IEEE Computer
Society, v. 43, Feb, pp 12-14.

68
LIM, H., HAN, Y., et al., 2013, “How to Fit when No One Size Fits”, In: The 6th Biennial
Conference on Innovative Data Systems Research (CIDR).
NUODB, “NuoDB Emergent Architechture”, 2013. Disponível em:
http://go.nuodb.com/rs/nuodb/images/ Greenbook_Final.pdf. Acesso em: 10 dez. 2013
NUODB, 2013, “Technical Whitepaper”, v.1 (Out). Disponível em: http://go.nuodb.com/white-
paper.html. Acesso em: 5 dez. 2013
OZSU, M., VALDURIEZ, P., “Principles of Distributed Database Systems , 3 ed., London,
Springer, 2010.
PAUL,S., “Database Systems Performance Evaluation Techniques”, 2008. Disponível em:
http://www1.cse.wustl.edu/~jain/cse567-08/ftp/db/index.html. Acesso em: 27 fev. 2014
RAM., S, 1989, “A Model for Designing Distributed Database Systems”, Information and
Management, v. 17, n. 3, (Out), pp.169-180
ROTHNIE, J., BERNSTEIN, P., et al., 1980, “Introduction to a System for Distributed Databases
(SDD-1)”, ACM Transactions on Database Systems, v. 5, n. 1, (Mar), pp. 1-17
SELTZER, M., 2008, “Beyond Relational Databases”, Communications of the ACM, v. 51, n.
27(Jul), pp. 52-58
SENG, J., YAO, S. B., HEVNER, A. R., 2004, “Requirements-driven database systems
benchmark method”, Decision Support Systems, v. 38, pp 629-648
SILBERSTEIN, A., COOPER, B., et al., “Benchmarking Cloud Serving Systems with YCSB”. In:
Proceedings of the 1st ACM Symposium on Cloud Computing, pp 143-154, Indianapolis, IN,
Jun. 2010.
STONEBRAKER, M., 2010, “SQL Databases v. NoSQL Databases”, Communications of the
ACM, v. 53, n.4(Abr), pp 10-11.

69
STONEBRAKER, M., 2011, “New Opportunities for New SQL”, Communications of the ACM,
v.55, n. 11(Nov), pp. 10-11
STONEBRAKER, M., ABADI, D., et al., 2007, “The End of an Architectural Era (It´s Time for a
Complete Rewrite)”. In: Proceedings of the 33rd International Conference on Very Large
Database, pp 1150-1160.
STONEBRAKER, M., CATTELL, R., 2011, “10 Rules for Scalable Performance in ‘Simple
Operation’ Datastores”, Communications of the ACM, v. 54, n. 6(Jun), pp 72-80
STONEBRAKER, M., CETINTEMEL, U., 2005, “One Size Fits All: An Idea Whose Time Has
Come and Gone”. In: Proceedings of the International Conference on Data Engineering, pp 2-11.
STONEBRAKER, M., WEISBERG, A., 2013, “The VoltDB Main Memory DBMS”, Bulletin of the
IEEE Computer Society Technical Committee on Data Engineering, vol. 36,n.2,pp.21-27
TPC, “TPC Benchmark C Standard Specification”, 2010. Disponível em:
http://www.tpc.org/tpcc/spec/tpcc_current.pdf . Acesso em: 8 fev. 2014

70
Anexo A
Exemplo de arquivo de configuração do OLTP-Bench:
<?xml version="1.0"?>
<parameters>
<!-- Connection details -->
<dbtype>nuodb</dbtype>
<driver>com.nuodb.jdbc.Driver</driver>
<DBUrl>jdbc:com.nuodb://server:port/tatp</DBUrl>
<username>user</username>
<password>password</password>
<isolation>TRANSACTION_SERIALIZABLE</isolation>
<!-- Scalefactor increases the number of subscribers -->
<scalefactor>100</scalefactor>
<!-- The workload -->
<terminals>10</terminals>
<works>
<work>
<time>300</time>
<rate>10000</rate>
<weights>2, 35, 10, 35, 2, 14, 2</weights>
</work>
</works>
<!-- Procedures declaration -->
<transactiontypes>
<transactiontype>
<name>DeleteCallForwarding</name>
</transactiontype>
<transactiontype>
<name>GetAccessData</name>
</transactiontype>
<transactiontype>

71
<name>GetNewDestination</name>
</transactiontype>
<transactiontype>
<name>GetSubscriberData</name>
</transactiontype>
<transactiontype>
<name>InsertCallForwarding</name>
</transactiontype>
<transactiontype>
<name>UpdateLocation</name>
</transactiontype>
<transactiontype>
<name>UpdateSubscriberData</name>
</transactiontype>
</transactiontypes>
</parameters>