tipos de dependência entre variáveis aleatórias e …veronica/dependence/book.pdftipos de...
TRANSCRIPT

Tipos de Dependência entre Variáveis Aleatórias e Teoria
de Cópulas
Autor: Márcio Luis Lanfredi ViolaSupervisora: Profa. Dra. Verónica Andrea González-López
Instituto de Matemática, Estatística e Computação Científica (IMECC-UNICAMP)
Dezembro/2009

Sumário
1 Tipos de Dependência entre Variáveis Aleatórias 1
1.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Funções Totalmente Positivas e Totalmente Negativas . . . . . . . . . . . . . 2
1.3 Dependência do Quadrante Positivo (e Negativo) e do Octante . . . . . . . 9
1.3.1 Variáveis Aleatórias Estocasticamente Crescentes e Decrescentes,
Dependência Crescente na Cauda à Direita e Dependência Decres-
cente na Cauda à Esquerda . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.4 Variáveis Aleatórias Negativamente Associadas . . . . . . . . . . . . . . . . . 17
1.5 Implicações e Contra-exemplos envolvendo os Conceitos de Dependência . 19
1.6 Tabelas referentes ao Capítulo . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2 Teoria de Cópulas 27
2.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2 Cópula e Teorema de Sklar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.3 Cópulas Arquimedianas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.4 Cópulas Multivariadas e a Transformada de Laplace . . . . . . . . . . . . . . 45
3 Variável BIPIT 55
3.1 Variáveis PIT e BIPIT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.2 Propriedades da função K . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4 Tau de Kendall 67
4.1 Concordância . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
i

5 Kendall Plot 79
5.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.2 Construção do Kendall Plot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
5.2.1 QQplot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
5.2.2 Kendall Plot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
5.3 Resultados e Fundamentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
Referências Bibliográficas 94
ii

Lista de Figuras
2.1 Scatterplots: Dados exponenciais independentes (primeira figura); dados exponenciais
independentes transformados pelas acumuladas (segunda figura). . . . . . . . . . . . 30
2.2 Gerador φ não estrito e pseudo-inversa φ[−1] para a cópula Arquimediana W . . . . . 44
2.3 Gerador φ estrito e pseudo-inversa φ[−1] para a cópula Arquimediana Π. . . . . . . . 45
3.1 QQplot entre a amostra Hi = H(xi, yi) da BIPIT H associada distribuição normal
bivariada do Exemplo 3.1 e uma amostra U1, . . . , U100 com distribuição U(0, 1). . . 56
3.2 QQplot das amostras das BIPITS H e H1: H1, . . . ,Hn e H11, . . . ,H1n respec-
tivamente, n = 100, onde Hi = H(ui, vi) = uivi sendo ui, vi amostras de U(0, 1)
e H1i = H(x1i, y1i) = F1(x1i)G1(y1i) sendo x1i com distribuição exp(2) e y1i com
distribuição exp(10). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.3 Funções distribuição de Kendall das cópulas M (linha cheia preta), W (linha cheia
cinza) e família de Gumbel para θ = 1, 3, 7 (primeira figura); família de Clayton
para θ = 1, 3, 4 (segunda figura). . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.4 Funções λ(v), v ∈ I, das cópulas M (linha cheia preta), W (linha cheia cinza)
e família de Gumbel para θ = 1, 3, 7 (primeira figura); família de Clayton para
θ = 1, 3, 4. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.1 QQplots referentes Exemplo 4.5: H0i = Π(ui, vi),H1i = C−0.5(ui, vi),H2i = C2(ui, vi)
com Cθ cópula de Clayton com parâmetro θ (A linha com ponto e tracejado é a di-
agonal principal do gráfico). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
iii

5.1 Gráficos da inversa da função distribuição K−1(p) vs. H(dnpe) ≡ K−1n (p) proveniente
de n = 100 pseudo-observações da cópula 4.2.12 (primeira figura); e Wdnpe:n,K =
E(H(dnpe)), n = 100, sob hipótese da mesma cópula (segunda figura). . . . . . . . . . 88
5.2 Kendall Plot sob hipótese nula de independência para a amostra (x1, y1), . . . , (x100, y100)sendo xi com distribuição exp(2) e yi com distribuição exp(10) com xi gerados de
forma independente de yi. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
5.3 Kendall Plot sob hipótese nula de independência de n = 100 pares de observações do
vetor aleatório (X,Y ) com Y = 1−X. . . . . . . . . . . . . . . . . . . . . . . . . . . 90
5.4 Kendall Plot sob hipótese nula de independência, de n = 100 pares de observações
do vetor aleatório (X,Y ) com Y = X. . . . . . . . . . . . . . . . . . . . . . . . . . . 91
5.5 Kendall Plot sob hipótese nula de cópula de Clayton θ = 2 (Wi:n,K0 referente a
Clayton com θ = 2) de amostras aleatórias de tamanho n = 100 associadas a cópula
de Clayton com os respectivos parâmetros θ = 0.5, 2, 5. . . . . . . . . . . . . . . . . 92
iv

Lista de Tabelas
6.1 Função de probabilidade conjunta de (X1, X2, X3, X4) . . . . . . . . . . . . . . . . . 24
6.2 Função de probabilidade conjunta de X e Y . . . . . . . . . . . . . . . . . . . . . . . 24
6.3 Função de probabilidade conjunta de X e Y . . . . . . . . . . . . . . . . . . . . . . . 24
6.4 Função de probabilidade conjunta de X e Y . . . . . . . . . . . . . . . . . . . . . . . 24
6.5 Função de probabilidade conjunta de (Y1, Y2) . . . . . . . . . . . . . . . . . . . . . . 25
3.1 Algumas famílias paramétricas de cópulas Arquimedianas com seus geradores e es-
paços paramétricos (*na cópula de Clayton o gerador é estrito se θ ≥ 0, caso contrário
é não estrito). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
1.1 Cópulas Arquimedianas da Tabela 3.1 com os respectivos geradores φ e funções dis-
triuição K. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
1.1 Medida de associação τ de Kendall expressa em função do parâmetro θ para algumas
famílias de cópulas Arquimedianas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
1

2

Capítulo 1
Tipos de Dependência entre Variáveis
Aleatórias
1.1 Introdução
Os conceitos e análise de dependência são necessários para o entendimento do modelo a ser
considerado e quando este pode ser aplicado. Isto inclui a análise da estrutura de dependência
conveniente ao modelo e se a dependência do modelo aumenta quando os parâmetros multivariados
aumentam, isto é, um modelo multivariado pode ser analisado a partir das estruturas de dependência
que ele consiga cobrir em relação ao universo das estruturas de dependência possíveis. Assim,
as propriedades de dependência são importantes para a avaliação da adequação de um modelo
particular perante uma dada aplicação ou um conjunto de dados. No entanto, na prática, pode ser
difícil a comprovação das propriedades teóricas assumidas pelos modelos.
O estudo dos vários tipos de dependência é importante pois um dado modelo de cópula pode ser
mais adequado para um tipo de dependência pretendido do que para outro. Por exemplo, há modelos
de cópula que modelam dependências positivas (limitante superior de Fréchet [25]) enquanto que
há modelos de cópula que modelam dependências negativas (limitante inferior de Fréchet [25]).
Há várias formas para definir dependências sendo que há conceitos que podem ser considerados
mais fortes como, por exemplo, dependência MTP2 ou MRR2, e outros que podem ser considerados
1

2
mais fracos como, por exemplo, dependência PQD ou NQD.
1.2 Funções Totalmente Positivas e Totalmente Negativas
As definições dadas a seguir referem-se à funções gerais sendo que a função densidade ou a função
de probabilidade são casos particulares. Nesta seção, por simplicidade, serão dadas as definições e
propriedades utilizando-se funções contínuas. O caso discreto é análogo.
Definição 1.1. Seja uma função f(x) uma função não-negativa definida em χ = χ1×χ2× ...×χnonde cada χi é totalmente ordenado, satisfazendo
f(x ∨ y)f(x ∧ y) ≥ f(x)f(y) (2.1)
onde ∨ e ∧ são operações definidas como sendo
x ∨ y = (max(x1, y1), ....,max(xn, yn))
e
x ∧ y = (min(x1, y1), ....,min(xn, yn));
∀x,y onde x = (x1, ..., xn) e y = (y1, ..., yn). A função densidade que satisfizer (2.1) será denomi-
nada função multivariada totalmente positiva de ordem 2 (“multivariate totally positive of order 2”)
denotada por MTP2. Um vetor aleatório X = (X1, ..., Xn) de n componentes será chamado MTP2
se sua função densidade for MTP2 [27].
A função f(x) que satisfizer a desigualdade (2.1) considerando-se ≤ no lugar de ≥ será chamada
função multivariada totalmente negativa de ordem 2 (“multivariate reverse rule of order 2”) denotada
por MRR2 [28].
Para a análise das definições acima será considerado o caso n = 2. Para este caso, será dada
uma interpretação para cada um dos conceitos citados.
Definição 1.2. Seja uma função f(x, y) não-negativa de duas variáveis definidas em χ = χ1 × χ2
sendo χ1 e χ2 totalmente ordenados. A função será totalmente positiva de ordem r, denotada por
TPr, se para todo x1 < ... < xm, y1 < .... < ym, xi ∈ χ1, yi ∈ χ2, 1 ≤ m ≤ r, o determinante da
matriz quadrada de ordem r, |f(xi, yi)|i,j=1,...,m, 1 ≤ m ≤ r, é definido como sendo [26]

3
|f(xi, yi)|i,j=1,2,...,m =
∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣
f(x1, y1) f(x1, y2) ... f(x1, ym)
f(x2, y1) f(x2, y2) ... f(x2, ym)
. . .
. . .
. . .
f(xm, y1) f(xm, y2) ... f(xm, ym)
∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣∣(2.2)
for não-negativo.
Quando r = 2, a partir da condição de que o determinante (2.2) seja não-negativo, obtém-se
f(x1, x2)f(y1, y2) − f(x1, y2)f(y1, x2) ≥ 0 para toda escolha x1 < x2, y1 < y2, xi ∈ χ1, yi ∈ χ2,
i = 1, 2. Neste caso, a função f(x, y) será totalmente positiva de ordem 2 (“totally positive of order
2”) [27]. Este conceito foi generalizado por meio da Definição 1.1.
Uma função f(x, y), não-negativa, de duas variáveis reais, definidas em χ1 × χ2 sendo χ1 e χ2
totalmente ordenados será totalmente negativa de ordem 2 (“reverse rule of order 2”), denotado por
RR2 se f(x1, x2)f(y1, y2) − f(x1, y2)f(y1, x2) ≤ 0 para toda escolha x1 < x2 e y1 < y2, xi ∈ χ1,
yi ∈ χ2, i = 1, 2 [28].
Quando a função f for uma função densidade, o seu domínio será real, ou seja, χi = R,
i = 1, ...., n.
A condição de dependência positiva f(x1, x2)f(y1, y2) ≥ f(x1, y2)f(y1, x2) significa que é mais
provável que ocorram dois pares com componentes assumindo valores grande-grande ou pequeno-
pequeno do que dois pares com componentes assumindo valores grande-pequeno ou pequeno-grande.
Os conceitos TP2 e RR2 podem ser estendidos. Considere µ uma medida de probabilidade nos
conjuntos de Borel em Rn. Se I1, ..., In forem intervalos em R, define-se µ(I1, ..., In) = µ(I1×...×In).Se I e J forem intervalos em R, I < J se x ∈ I, y ∈ J implicar em x < y . Define-se [2, 23]:
Definição 1.3. Seja µ uma medida de probabilidade em R2. Esta medida será RR2 se
µ(I1, I2)µ(I′1, I
′2) ≤ µ(I1, I
′2)µ(I
′1, I2) para todos os intervalos I1 < I
′1, I2 < I
′2 em R.
Definição 1.4. Seja µ uma medida de probabilidade em Rn, n ≥ 2. Esta medida será RR2 aos
pares se µ(I1, ..., In) for RR2 nos pares Ii, Ij para todo 1 ≤ i < j ≤ n sendo que as demais variáveis
(intervalos) são mantidas fixas. As v.a. X1, ..., Xn (ou o vetor aleatório X ou sua f.d.a F) serão
RR2 aos pares se sua correspondente medida de probabilidade em Rn for RR2 aos pares.

4
A seguir, serão apresentadas algumas propriedades referentes ao conceito MTP2. A demons-
tração das propriedades podem ser encontradas em [27]. As propriedades 1 à 4 são úteis para a
obtenção de funções densidade MTP2 a partir de outras funções densidade MTP2 e as propriedades
5 à 7 são úteis para a obtenção de funções densidade MTP2 a partir de funções densidade PF2 e/ou
TP2.
1. Seja f uma função densidade MTP2 em χ. Então a função densidade marginal, ϕ, em∏ki=1 χi
dada por
ϕ(x1, ..., xk) =∫χn
....
∫χk+1
f(x1, ..., xk, xk+1, ..., xn)dxk+1...dxn
é MTP2;
2. Se f e g forem funções densidade MTP2. Então, a função fg será MTP2;
3. Sejam χ =∏ni=1 χi, ξ =
∏ni=1 ξi, ζ =
∏ni=1 ζi onde χi, ξi e ζi são espaços totalmente ordenados.
Sejam f e g funções densidade MTP2, respectivamente, em ξ × χ e χ× ζ. Define-se,
h(y, z) =∫χ f(y,x)g(x, z)dσ(x), σ = σ1 × ...× σn. Então, h é uma função MTP2 em ξ × ζ;
4. Se f(x) for MTP2, x ∈ χ, ϕ1, ..., ϕn forem todas funções crescentes (ou todas funções de-
crescentes), respectivamente, em χ1, ..., χn e φk(xk)nk=1 forem funções positivas. Então, a
função ψ(x) = ψ(x1, ..., xn) = (∏ni=1 φi(xk))f(ϕ1(x1), ..., ϕn(xn)) será MTP2 em χ;
5. Seja X = (X1, ..., Xn) um vetor aleatório composto por variáveis aleatóriasX1, ..., Xn indepen-
dentes onde cada Xi, i = 1, ..., n, possui função densidade, fXi , PF21. Seja Y = (Y1, ..., Yn)
um vetor aleatório com função densidade conjunta, fY, MTP2 em Rn e suponha que X e Y
são independentes. Então, Z = X + Y possui uma função densidade MTP2;
6. Seja X = (X1, ..., Xn) um vetor aleatório composto por variáveis aleatórias X1, ..., Xn inde-
pendentes onde cada Xi, i = 1, ..., n, possui função densidade, fXi , PF2 e seja Xo uma v.a.
independente de X possuindo função densidade fXo . Define-se Zi = Xi + Xo, i = 1, ..., n.
Então, a função densidade conjunta de Z = (Z1, ..., Zn) é MTP2;
1Uma função f(x) definida em (−∞,∞) é PFr (“Pólya frequency function of order r) se f(x − y) for TPr,
−∞ < x, y < ∞ [26].

5
7. Seja X = (X1, ..., Xn) um vetor aleatório composto por variáveis aleatóriasX1, ..., Xn indepen-
dentes onde cada Xi, i = 1, ..., n possui função densidade, fXi . Seja Xo uma variável aleatória
positiva. Se, para i = 1, ..., n, fXi(u/v) for TP2 em −∞ < u < ∞ e v > 0, ou fXi(uv) for
TP2 em −∞ < u < ∞ e v > 0, então ambos os vetores aleatórios Z = (X1Xo, ..., XnXo) e
W = (X1/Xo, ..., Xn/Xo) terão funções densidade MTP2;
8. Seja X = (X1, ..., Xn) um vetor aleatório possuindo densidade conjunta MTP2. Sejam ψ e ϕ,
ambas funções crescentes (ou ambas funções decrescentes), em Rn. Então,
E[ϕ(X)ψ(X)] ≥ (E[ϕ(X)])(E[ψ(X)]).
Vale observar que, utilizando-se as propriedades 1 e 2, obtém-se a propriedade 3 e que da
propriedade 2, obtém-se: Variáveis aleatórias independentes possuem função densidade conjunta
MTP2.
Da propriedade 1 obtém-se: Se X = (X1, ..., Xn) for MTP2 então qualquer subconjunto formado
pelas componentes de X, por exemplo, (Xi, ..., Xk) será MTP2 onde 2 ≤ i, k < n
E, da propriedade 8, obtém-se que
Cov(ϕ(X), ψ(X)) ≥ 0 (2.3)
a qual sugere a seguinte definição [11, 27]:
Definição 1.5. Seja X = (X1, ..., Xn) um vetor aleatório satisfazendo a expressão (2.3) para qual-
quer par de funções crescentes (ou decrescentes) ψ e ϕ. As componentes de X, X1, ..., Xn, são
denominadas variáveis aleatórias associadas.
Utilizando-se a definição anterior, obtém-se o seguinte resultado:
Teorema 1.1. Seja X = (X1, ..., Xn) um vetor aleatório formado por v.a. associadas e sejam
ϕ1, ..., ϕk funções não-negativas em Rn sendo todas crescentes (ou todas decrescentes). Então,
E
[k∏i=1
ϕi(X)
]≥
k∏i=1
E [ϕi(X)] (2.4)

6
Demonstração: Para a demonstração consulte [27].
Em particular, se ϕi(X) = ϕi(Xi), i = 1, ..., n, a expressão (2.4) do teorema anterior fornece
E[ϕ1(X1)...ϕn(Xn)] ≥n∏i=1
E[ϕi(Xi)] (2.5)
Especialmente, a expressão (2.5) permite demonstrar
P (X1 ≥ c1, ..., Xn ≥ cn) ≥∏ni=1 P (Xi ≥ ci) e P (X1 ≤ c1, ..., Xn ≤ cn) ≥
∏ni=1 P (Xi ≤ ci). Na
próxima seção, tais desigualdades designarão outros tipos de dependência.
Vale observar que a partir do conceito de dependência MTP2 obteve-se o conceito de variáveis
aleatórias associadas. Com isso, o conceito de dependência MTP2 é mais forte do que o conceito
de variáveis aleatórias associadas no sentido de que o primeiro implica no segundo.
A seguir, serão apresentadas algumas propriedades referentes à v.a. associadas [11].
1. Um subconjunto de v.a. associadas é associado;
2. Se dois conjuntos de v.a. associadas forem independentes, então a união será um conjunto de
v.a. associadas;
3. Funções não-decrescentes de v.a. associadas são associadas;
4. Um conjunto formado por uma única v.a. é associado;
5. Variáveis aleatórias independentes são associadas;
6. Se T(k) = (T (k)1 , ..., T
(k)n ) for um vetor aleatório com T
(k)i , i = 1, ..., n, associadas para cada k
e T(k) → T, em distribuição, então as componentes do vetor aleatório T = (T1, ..., Tn) serão
associadas.
Serão apresentados, a seguir, alguns exemplos de funções densidade MTP2 [27].
• Exemplo 1: Seja X = (X1, ..., Xn) uma amostra aletória formada por variáveis aleatórias i.i.d.
Xi, possuindo função densidade f . Então, a densidade conjunta das estatísticas de ordem
X1,n, ..., Xn,n é MTP2;

7
• Exemplo 2: Considere que X = (X1, ..., Xn) ∼ N(0,∑
). Esta distribuição será MTP2 se e
somente se −∑−1 possuir elementos fora da diagonal não-negativos;
• Exemplo 3: A função densidade da Distribuição Logística Multivariada é definida como sendo
f(x1, ..., xn) = n!exp
−
n∑i=1
xi
1 +
n∑i=1
e−xi
−(m+1)
O Núcleo Generalizado de Cauchy é dado por
k(y) =1
(1 +∑n
i=1 yi)α
onde yi > 0, i = 1, ..., n. Este núcleo é TP2 em cada par de variáveis. Com isso, a Distribuição
Logística Multivariada é MTP2 pelas propriedades 2 e 4 referentes à função densidade MTP2;
• Exemplo 4: Seja X1, ..., Xn v.a. independentes com Xi ∼ Gama(αi, βi), αi ≥ 1, βi > 0,
i = 1, ..., n. A função densidade fXi(x) = cixαi−1e−βix , x > 0 é PF2. Se Xo for indepen-
dente de X1, ..., Xn, Xo ∼ Gama(αo, βo), então o vetor Z = (X1 + Xo, ...., Xn + Xo) possui
Distribuição Gamma Multivariada e, pela propriedade 6 referente à função densidade MTP2,
tem-se que a sua densidade conjunta será MTP2;
• Exemplo 5: Seja X1, ..., Xn v.a. independentes com Xi ∼ Gama(αi, βi), αi > 0, βi > 0,
i = 1, ..., n. A função densidade fXi(u/v) = ci(u/v)αi−1e−βi(u/v), é TP2 para u e v positivos.
Se Xo for independente de X1, ..., Xn e Xi ∼ χ2νi
, então o vetor
Z = ((X1/ν1)(Xo/νo)−1, ...., (Xn/νn)(Xo/νo)−1) possuirá Distribuição F Multivariada e, pela
propriedade 7 referente à função densidade MTP2, tem-se que a sua densidade conjunta será
MTP2;
• Exemplo 6: Seja X = (X1, ..., Xn) ∼ N(0, I) e S ∼ χ2, X e S independentes. Seja
Z = (Z1, ..., Zn) = (X1/S, ...,Xn/S). O vetor aleatório Z possui Distribuição de Cauchy
multivariada. Então, (|Z1|, ..., |Zn|) possui densidade conjunta MTP2 considerando o mesmo
argumento do exemplo prévio desde que e−u2/v2 é TP2 com u > 0, v > 0.
A seguir, serão apresentadas algumas propriedades referentes às funções MRR2 [28].

8
1. Se f e g forem funções MRR2. Então, a função fg será MRR2;
2. Se f(x) for MRR2 com x ∈ χ e ϕ1, ..., ϕn forem todas funções crescentes (ou todas funções de-
crescentes), respectivamente, em χ1, ..., χn. Então, a função ψ(x) = ψ(x1, ..., xn)=f(ϕ1(x1), ...ϕn(xn))
será MRR2 em χ;
A seguir, serão apresentados alguns exemplos de distribuições MRR2 [28].
• Exemplo 1: Seja X = (X1, ..., Xn) um vetor aleatório composto por v.a. independentes tais
que Xi ∼ Binomial(ni, pi),∑n
i=1 pi = 1,∑n
i=1Xi = N . A distribuição de X é dada por
PX(x) =N !∏n
i=1 xi! (N −∑n
i=1 xi)!
n∏i=1
pxii
(1−
n∑i=1
pi
)N−Pni=1 xi
(2.6)
onde x = (x1, ..., xn) representa um dado valor que o vetor aleatório X assume e pi ≥ 0,
i = 1, ..., n. Esta distribuição é denominada Distribuição Multinomial e, pode-se mostrar, que
esta é MRR2;
• Exemplo 2: Seja X = (X1, ..., Xn) um vetor aleatório. A função de probabilidade da Dis-
tribuição Hipergeométrica Multivariada é dada por
PX(x) =
[∏ni=1
(Mi
xi
)](M −
∑ni=1Mi
m−∑n
i=1 xi
)(M
m
)−1
(2.7)
com∑n
i=1 xi = m, 0 ≤ xi ≤ Mi, i = 1, ..., n e∑n
i=1Mi = M onde x = (x1, ..., xn) representa
um dado valor que o vetor aleatório X assume. Esta distribuição é MRR2;
• Exemplo 3: Seja X = (X1, ..., Xn) um vetor aleatório. A função densidade da Distribuição de
Dirichlet é dada por
f(x) =Γ(∑n
j=0 θj)∏nj=0 Γ(θj)
1−n∑j=1
xj
θ0−1n∏j=1
xθj−1j (2.8)
onde∑n
j=1 xj ≤ 1, 0 ≤ xj e θj ≥ 1, j = 0, .., n sendo Γ(.) a Função Gama. A Distribuição de
Dirichlet é MRR2.

9
1.3 Dependência do Quadrante Positivo (e Negativo) e do Octante
Considere X um vetor aleatório de dimensão n (n ≥ 2) com f.d.a. F . Define-se a dependência do
octante superior positivo (“positive upper orthant dependent”) e a dependência do octante inferior
positivo (“positive lower orthant dependent”) [25] como sendo:
Definição 1.6. X = (X1, ..., Xn) ou F possuem dependência do octante superior positivo (PUOD)
se P (Xi > ai, i = 1, ..., n) ≥∏ni=1 P (Xi > ai), ∀a = (a1, ..., an) ∈ Rn.
Definição 1.7. X = (X1, ..., Xn) ou F possuem dependência do octante inferior positivo (PLOD)
se P (Xi ≤ ai, i = 1, ..., n) ≥∏ni=1 P (Xi ≤ ai), ∀a = (a1, ..., an) ∈ Rn.
Se X verifica as Definições 1.6 e 1.7 então X ou F possuem dependência do octante posi-
tivo(“positive orthant dependent”) denotada por POD.
Intuitivamente, a expressão da Definição 1.6 significa que é mais provável que X1, ..., Xn as-
sumam, simultaneamente, valores grandes comparado com o vetor de v.a. independentes com as
mesmas correspondentes distribuições marginais univariadas.
Similarmente, serão enunciados os conceitos de dependência do octante inferior negativo (“nega-
tive lower orthant dependent”), dependência do octante superior negativo (“negative upper orthant
dependent”) e dependência do octante negativo (“negative orthant dependent”) [25].
Definição 1.8. X = (X1, ..., Xn) ou F possuem dependência do octante superior negativo (NUOD)
se P (Xi > ai, i = 1, ..., n) ≤∏ni=1 P (Xi > ai), ∀a = (a1, ..., an) ∈ Rn.
Definição 1.9. X = (X1, ..., Xn) ou F possuem dependência do octante inferior negativo (NLOD)
se P (Xi ≤ ai, i = 1, ..., n) ≤∏ni=1 P (Xi ≤ ai), ∀a = (a1, ..., an) ∈ Rn.
Se X verifica as Definições 1.8 e 1.9 então X ou F possuem dependência do octante negativo
(NOD).
As expressões que compõem as definições 1.6 e 1.7, em geral, para n ≥ 3, não se equivalem (veja
um contra-exemplo na seção 3.2.5). Porém, para n = 2, elas se equivalem. Isto, também, vale para
as definições 1.8 e 1.9. Com isso, definições acima se reduzem, para n = 2, às seguintes:
Seja X = (X1, X2) um vetor aleatório bivariado com f.d.a. F . Então, define-se a dependência
do quadrante positivo (“positive quadrant dependent”) [30, 25] como sendo:

10
Definição 1.10. X ou F possuem dependência do quadrante positivo (PQD) se
P (X1 > a1, X2 > a2) ≥ P (X1 > a1)P (X2 > a2), ∀a1, a2 ∈ R, ou equivalentemente,
P (X1 ≤ a1, X2 ≤ a2) ≥ P(X1 ≤ a1) P(X2 ≤ a2), ∀a1, a2 ∈ R.
A expressão da definição 1.10 representa uma condição de dependência positiva e significa que é
mais provável que X1 e X2 assumam, conjuntamente, valores grandes ou pequenos comparado com
X′1 e X ′
2 onde X1d= X
′1 e X2
d= X′2 sendo X ′
1 e X ′2) v.a. independentes.
Similarmente, será apresentada a dependência do quadrante negativo(“negative quadrant dependent”)
[30, 25] definido a seguir.
Definição 1.11. X ou F possuem dependência do quadrante negativo (NQD) se
P (X1 > a1, X2 > a2) ≤ P (X1 > a1)P (X2 > a2), ∀a1, a2 ∈ R, ou equivalentemente,
P (X1 ≤ a1, X2 ≤ a2) ≤ P(X1 ≤ a1) P(X2 ≤ a2), ∀a1, a2 ∈ R.
A seguir, serão apresentadas algumas propriedades referentes ao conceito de dependência PQD
e NQD [30].
1. O vetor de v.a. (X,X) será PQD para todo X;
2. Se o vetor de v.a. (X,Y ) for PQD, então o vetor (X,−Y ) será NQD;
3. Se o vetor de v.a. (X,Y ) for PQD então o vetor (r(X), s(Y )) será PQD se r e s forem funções
não-decrescentes;
4. Sejam (X1, Y1), ..., (Xn, Yn) pares independentes de v.a. com funções de distribuição F1, ...., Fn.
Sejam r e s funções de n variáveis e sejam X = r(X1, ..., Xn) e Y = s(Y1, ..., Yn). Então:
(a) (X,Y ) será PQD se, para cada i, as seguintes condições forem válidas:
i. Fi é PQD e r, s são concordantes 2 para a i-ésima coordenada ou;
ii. Fi é NQD e r, s são discordantes 3 para a i-ésima coordenada.2Duas funções reais r e s de n variáveis independentes serão concordantes para a i-ésima coordenada se,
considerando-as funções da i-ésima coordenada, deixando as demais fixas, ambas são funções não-decrescentes ou
ambas são funções não-crescentes.3Duas funções reais r e s de n variáveis independentes serão concordantes para a i-ésima coordenada se,
considerando-as funções da i-ésima coordenada, deixando as demais fixas, uma das funções é não-decrescente e a
outra é não-crescente.

11
(b) (X,Y ) será NQD se, para cada i, as seguintes condições forem válidas:
i. Fi é PQD e r, s são discordantes para a i-ésima coordenada ou;
ii. Fi é NQD e r, s são concordantes para a i-ésima coordenada.
5. Sejam (X1, Y1), ..., (Xn, Yn) pares independentes de v.a. com funções de distribuição F1, ...., Fn.
Sejam U e V v.a. independentes e independentes de (X1, Y1), ..., (Xn, Yn) e sejam
X = r(U,X1, ..., Xn) e Y = s(V,X1, ..., Xn). Então, as conclusões dos ítens (a) e (b) na
propriedade 4. continuam válidas.
6. Se (X,Y ) for PQD e se existirem E(XY ), E(X) e E(Y ), então E(XY ) ≥ E(X)E(Y ).
A seguir, serão apresentados alguns exemplos de v.a. PQD [30]. As justificativas dos exemplos
baseiam-se nas propriedades anteriores.
• Exemplo 1: Para qualquer v.a. X e para qualquer função não-decrescente s, o vetor (X, s(X))
será PQD;
• Exemplo 2: (X = U + aZ, Y = V + bZ) será PQD se as constantes a e b tiverem o mesmo
sinal para quaisquer v.a. independentes U , V e Z;
• Exemplo 3: Para quaisquer v.a. independentes X e V , (X,Y = X + V ) será PQD;
• Exemplo 4: (X = r(U,Z), Y = s(V,Z)) será PQD se U , V e Z forem v.a. independentes e r
e s forem funções não-decrescentes em Z (arbitrárias para as demais v.a.).
Agora, serão apresentadas algumas propriedades relativas ao conceito NOD [8]:
1. Qualquer conjunto de v.a. independentes será NOD;
2. Qualquer subconjunto de tamanho ≥ 2 formado por v.a. NOD será NOD;
3. Se X1, ..., Xn forem v.a. NOD e ϕ1, ..., ϕn forem funções Borel-mensuráveis crescentes com
valores reais. Então, ϕ1(X1), ..., ϕn(Xn) serão v.a. NOD;
4. A união de conjuntos independentes de v.a. NOD será NOD.

12
Também, serão apresentados alguns exemplos de distribuições NOD [23].
• Exemplo 1: A Distribuição Multinomial dada por (2.6) é NOD;
• Exemplo 2: A Distribuição Hipergeométrica Multivariada dada por (2.7) é NOD;
• Exemplo 3: A Distribuição de Dirichlet dada por (2.8) é NOD.
1.3.1 Variáveis Aleatórias Estocasticamente Crescentes e Decrescentes,Dependência Crescente na Cauda à Direita e Dependência Decrescentena Cauda à Esquerda
Denotando-se =(F1, ..., Fn) como a classe das distribuições multivariadas que possuem funções
de distribuição marginais F1, ..., Fn, considere X = (X1, X2) um vetor aleatório bivariado possuindo
f.d.a F ∈ =(F1, F2). Define-se:
Definição 1.12. A variável aleatória X2 será estocasticamente crescente (“stochastically increasing”),
denotada por SI, em X1 ou a distribuição condicional F2|1 será estocasticamente crescente (↑) se
P (X2 > x2|X1 = x1) = 1− F2|1(x2|x1) ↑ x1,∀x2 [25].
Se, na Definição 1.12, trocarmos os índices 1 por 2 e 2 por 1, ter-se-á que X1 será SI em X2 ou
F1|2 será SI.
A expressão da definição 1.12 representa uma condição de dependência positiva e significa que
a probabilidade de que X2 ultrapasse um limiar x2 é crescente quando X1 aumentar.
Se, na Definição 1.12, trocarmos ↑ por ↓, a variável aleatória X2 será estocasticamente decres-
centes (“stochastically decreasing”), denotada por SD, em X1 [25].
Há dois conceitos de dependência que podem ser considerados como uma extensão multivariada
do conceito SI (Definição 1.12): dependência positiva através da ordenação estocástica (“positive de-
pendence through the stochastic ordering”) e dependência condicionalmente crescente em sequência
(“conditional increasing in sequence”)[8].
Definição 1.13. O vetor aleatório (X1, ..., Xn) possuirá dependência positiva através da ordenação
estocástica, denotada por PDS, se [X1, ..., Xi−1|Xi = xi] for estocasticamente crescente quando xi
aumentar, para todo i = 1, ..., n.

13
Definição 1.14. O vetor aleatório (X1, ..., Xn) possuirá dependência condicionalmente crescente
em sequência, denotada por CIS, se Xi for estocasticamente crescente em X1, ..., Xi−1 , isto é, se
P (Xi > xi|X1 = x1, ..., Xi−1 = xi−1) ↑ (for crescente em) x1, ..., xi−1, ∀xi, i = 1, ..., n.
Note que, para n = 2, PDS equivale à X2 SI em X1 e X1 SI em X2. Da mesma forma, CIS
equivale à SI.
Os conceitos de v.a. PDS e CIS possuem as seguintes versões para dependência negativa:
dependência negativa através da ordenação estocástica (“negative dependence through the stochastic
ordering”) e dependência condicionalmente decrescente em sequência (“conditional decreasing in
sequence”).
Definição 1.15. O vetor aleatório (X1, ..., Xn) possuirá dependência negativa através da ordenação
estocástica, denotada por NDS, se [X1, ..., Xi−1|Xi = xi] for estocasticamente decrescente em xi,
para todo i = 1, ..., n [23].
Definição 1.16. O vetor aleatório (X1, ..., Xn) possuirá dependência condicionalmente decrescente
em sequência, denotada por CDS, se P (Xi > xi|X1 = x1, ..., Xi−1 = xi−1) ↓ (for decrescente em)
x1, ..., xi−1, ∀xi, i = 1, ..., n [8].
Para v.a. CDS (veja a Definição 1.16) e NOD (veja as Definições 1.8 e 1.9), tem-se a seguinte
propriedade [23]: Sejam Xo, X1, ..., Xn v.a. independentes sendo que cada v.a. possui função den-
sidade ou função de probabilidade PF2. Então, para x fixo, as v.a. condicionais
(X1, ..., Xn|Xo +X1 + ...+Xn = x) são RR2 aos pares e, consequentemente, serão CDS e NOD.
Nas Definições 1.14 e 1.16, ao invés, das v.a. X1, ..., Xi−1 serem condicionadas, respectivamente,
aos valores fixo x1, ..., xi−1, pode-se considerar X1, ..., Xi−1 condicionadas, respectivamente, em
X1 > x1, ..., Xi−1 > xi−1 ou X1 ≤ x1, ..., Xi−1 ≤ xi−1. Dessa forma, tem-se as seguintes definições
[8].
Definição 1.17. As v.a. X1, ..., Xn serão crescentes na cauda à direita em sequência (“right-tail
increasing in sequence”), denotada por RTIS, se P (Xi > xi|X1 > x1, ..., Xi−1 > xi−1) ↑ (for
crescente em) x1, ..., xi−1, ∀xi, i = 1, ..., n.

14
Definição 1.18. As v.a. X1, ..., Xn serão crescentes na cauda à esquerda em sequência (“left-tail
decreasing in sequence”), denotada por LTIS, se P (Xi ≤ xi|X1 ≤ x1, ..., Xi−1 ≤ xi−1) ↑ x1, ..., xi−1,
∀xi, i = 1, ..., n.
Se n = 2, a Definição 1.17 torna-se: A v.a. X2 será crescente na cauda à direita (“right-tail
increasing”), denotada por RTI, em X1 se P (X2 > x2|X1 > x1) = 1−F (x1,x2)1−F1(x1) ↑ x1,∀x2 [25].
Se n = 2, a Definição 1.18 torna-se: A v.a. X2 será crescente na cauda à esquerda (“left-tail
incresing”), denotada por LTI, em X1 se P (X2 ≤ x2|X1 ≤ x1) = F (x1,x2)F1(x1) ↑ x1,∀x2 [8].
As expressões nas Definições 1.17 e 1.18 são condições de dependência positiva. Pela Definição
1.17, para o caso em que n = 2, tem-se que é mais provável que X2 assuma valores grandes quando
X1 aumentar. E, pela Definição 1.18, para o caso em que n = 2, tem-se que é mais provável que X2
assuma valores pequenos quando X1 diminuir.
Se, nas Definições 1.17 e 1.18, a monocidade ↑ for trocada por ↓, ter-se-á os conceitos referentes
à dependência negativa.
Se, na Definição 1.17, a monocidade ↑ for trocada por ↓ tem-se que as v.a. X1, ..., Xn serão
decrescentes na cauda à direita em sequência (“right-tail decreasing in sequence”), denotada por
RTDS, ou seja, P (Xi > xi|X1 > x1, ..., Xi−1 > xi−1) ↓ x1, ..., xi−1, ∀xi, i = 1, ..., n [8] sendo que,
para n = 2, a v.a. X2 será decrescente na cauda à direita (“right-tail decresing”), denotada por
RTD, em X1, ou seja, P (X2 > x2|X1 > x1) = F (x1,x2)F1(x1) ↓ x1,∀x2 [8, 25].
Se, na Definição 1.18, a monocidade ↑ for trocada por ↓ tem-se que as v.a. X1, ..., Xn serão
decrescentes na cauda à esquerda em sequência (“left-tail decreasing in sequence”), denotada por
LTDS, se P (Xi ≤ xi|X1 ≤ x1, ..., Xi−1 ≤ xi−1) ↓ x1, ..., xi−1, ∀xi, i = 1, ..., n [8] sendo que, para
n = 2, a v.a. X2 será decrescente na cauda à esquerda (“left-tail decreasing ”), denotada por LTD,
em X1, ou seja, P (X2 ≤ x2|X1 ≤ x1) = F (x1,x2)F1(x1) ↓ x1,∀x2 [8, 25].
A seguir, algumas propriedades referentes às dependências SI, SD, CDS, RTDS, RTD serão
dadas [8]:
1. X2 será SD em X1 se e somente se X2 for SI em −X1. Além disso, X2 será SD em X1 se e
somente se −X2 for SI em X1;
2. Seja o vetor aleatório (X,Y ) possuindo função densidade f(x, y) satisfazendo

15
∣∣∣∣∣ f(x1, y1) f(x1, y2)
f(x2, y1) f(x2, y2)
∣∣∣∣∣ ≤ 0
para cada escolha x1 < x2, y1 < y2. Então, Y será SD em X;
3. Sejam:
(a) (X1, ..., Xn) um vetor aleatório possuindo função densidade f(x1, ..., xn) que satisfaz
∣∣∣∣∣ f(x1, ..., xi, ..., xj , ..., xn) f(x1, ..., xi, ..., x′j , ..., xn)
f(x1, ..., x′i, ..., xj , ..., xn) f(x1, ..., x
′i, ..., x
′j , ..., xn)
∣∣∣∣∣ ≤ 0 (3.9)
para cada par de variáveis permanecendo as demais fixas onde xi < x′i e xj < x
′j ;
(b) Todas as funções de densidade marginais fk(x1, ..., xk), 1 ≤ k < n satisfazendo (3.9) para
cada par de variáveis permanecendo as demais fixas.
Então, (X1, ..., Xn) será CDS e cada permutação de (X1, ..., Xn) será CDS;
4. Seja o vetor aleatório (X1, ..., Xn) CDS. Então, E(ϕ(Xi)|X1 = x1, ..., Xi−1 = xi−1) será de-
crescente em x1, ..., xi−1 para cada função integrável crescente ϕ;
5. Seja a sequência Xn, n ≥ 1 de vetores aleatórios CDS p-dimensionais com f.d.a. Hn, n ≥ 1tais queHn → H fracamente quando n→∞ ondeH é a f.d.a. do vetor aleatório p-dimensional
X. Então, X será CDS;
6. Qualquer conjunto de v.a. independentes é RTDS;
7. Qualquer subconjunto de v.a. RTDS é RTDS;
8. Se X1, ..., Xn forem v.a. RTDS e ϕ1, ..., ϕn forem funções Borel-mensuráveis crescentes, então
ϕ1(X1), ..., ϕn(Xn) será RTDS;
9. Seja X = (X1, X2). Então, X2 é RTD em X1 ⇔ P (X2 ≥ x2|X1 > x1) ↓ x1 para todo
x2 ⇔ E(ϕ(X2)|X1 > x1) ↓ x1 para toda função real ϕ crescente;

16
10. Seja X2 v.a. RTD na v.a. X1 e seja Z uma v.a. independente de (X1, X2). Definindo
X = X1 + aZ e Y = X2 + bZ, a e b constantes, tem-se que Y é RTD em X;
11. Seja a sequência Xn, n ≥ 1 de vetores aleatórios RTDS p-dimensionais com f.d.a.
Hn, n ≥ 1 tais que Hn → H fracamente quando n→∞ onde H é a f.d.a. do vetor aleatório
p-dimensional X. Então, X será RTDS;
12. Seja (U, V ) RTD e seja Z uma v.a. independente de (U, V ). Definindo ϕ1 e ϕ2, funções
Borel-mensuráveis que mapeiam R2 em R com ϕ1(u, .) crescente em u e ϕ2(., v) crescente em
v. Então, (X,Y ) é RTD onde X = ϕ1(U,Z) e Y = ϕ2(Z, V );
13. Sejam X = (X1, ..., Xn) um vetor aleatório formado por v.a. RTDS, ϕl : R → R uma função
Borel-mensurável crescente para cada l = 1, ..., n. Sejam Z = (Z1, ...Zn) um vetor aleatório
formado por v.a. RTDS sendo X e Z independentes. Definindo Yl = ϕl(Xl) + Zl, l = 1, ..., n,
tem-se que Y1, ..., Yn são RTDS;
14. Sejam
(a) Seja (X1, ..., Xn) um vetor aleatório tal que Fn(x1, ..., xn) = P (X1 > x1, ..., Xn > xn)
satisfaça:
i. ∣∣∣∣∣ Fn(x1, ..., xi, ..., xj , ..., xn) Fn((x1, ..., xi, ..., x′j , ..., xn)
Fn(x1, ..., x′i, ..., xj , ..., xn) Fn((x1, ..., x
′i, ..., x
′j , ..., xn)
∣∣∣∣∣ ≤ 0 (3.10)
para cada par de variáveis permanecendo as demais fixas xi < x′i e xj < x
′j ;
ii. Se F k(x1, ..., xk) = P (X1 > x1, ..., Xk > xk), 1 ≤ k < n, verificar (3.10) para cada
par de variáveis permanecendo as demais fixas;
Então, (X1, ..., Xn) será RTDS e qualquer permutação de (X1, ..., Xn) será RTDS;
A seguir, serão apresentados alguns exemplos relativos à alguns conceitos de dependência apre-
sentados nesta seção [8, 23]:
• Exemplo 1: A Distribuição Multinormal com vetor de médias µ = (µ1, ..., µn) e matriz de
variância-covariância∑
definida positiva é CDS;

17
• Exemplo 2: A Distribuição Multinomial dada por (2.6) é CDS e NDS;
• Exemplo 3: A Distribuição de Dirichlet dada por (2.8) é CDS.
1.4 Variáveis Aleatórias Negativamente Associadas
Definição 1.19. As variáveis aleatórias X1, ..., Xn possuem associação negativa (“negative association”),
denotada por NA, se para cada par de subconjuntos disjuntos A1, A2 de 1, ..., n tem-se
Cov(ϕ(Xi, i ∈ A1), ψ(Xj , j ∈ A2)) ≤ 0 (4.11)
sempre que ϕ e ψ forem funções crescentes [23].
Vale observar que (4.11) continua válida se ϕ e ψ forem funções decrescentes.
A seguir, serão apresentadas algumas propriedades referentes ao conceito de v.a. NA [23].
1. Sejam A1, ..., Am subconjuntos disjuntos de índices 1, ..., n e φ, ..., φm funções crescentes e
positivas. Se as variáveis aleatórias, X1, ..., Xn, forem NA, então:
E
[m∏i=1
φi(Xj , j ∈ Ai)
]≤
m∏i=1
E[φi(Xj , j ∈ Ai)]
2. Um subconjunto de duas ou mais v.a. NA é NA;
3. Um conjunto de v.a. independentes é NA;
4. Funções crescentes definidas em subconjuntos disjuntos de um conjunto de v.a. NA são NA;
5. A união de conjuntos independentes de v.a. NA é NA;
6. Sejam X1, ..., Xn v.a. independentes e suponha que a esperança condicional
E(φ(Xi, i ∈ A)|∑
i∈AXi) seja crescente em∑
i∈AXi, para cada função crescente φ e para
cada subconjunto apropriado A de índices 1, ..., n. Então, a distribuição condicional de
X1, ..., Xn dado∑Xi é NA, quase certamente;

18
7. Sejam X1, ..., Xn v.a. independentes possuindo funções densidade PF2. Então, a distribuição
condicional conjunta de X1, ..., Xn dado∑Xi é NA, quase certamente.
Uma consequência da propriedade 1 é a dada a seguir: Se A1, A2 forem subconjuntos disjuntos
de índices 1, ..., n e x1, ..., xn ∈ R. Então,
P (Xi ≤ xi, i = 1, ..., n) ≤ P (Xi ≤ xi, i ∈ Ai)P (Xj ≤ xj , j ∈ A2)
e
P (Xi > xi, i = 1, ..., n) ≤ P (Xi > xi, i ∈ Ai)P (Xj > xj , j ∈ A2);
Então, em particular, X1, ..., Xn são NOD.
A seguir serão apresentados alguns exemplos de distribuições NA [23].
• Exemplo 1: Seja x = (x1, ..., xn) um conjunto de n números reais. Uma distribuição de
permutação é a distribuição conjunta do vetor X = (X1, ..., Xn) que assume os valores de
todas a n! permutações de x com igual probabilidade, sendo cada probabilidade igual à 1n! ,
n > 1. Temos que uma distribuição de permutação é NA;
• Exemplo 2: A Distribuição Multinomial dada por (2.6) é NA;
• Exemplo 3: A Distribuição Hipergeométrica Multivariada dada por (2.7) é NA;
• Exemplo 4: Seja X = (X1, .., Xn) uma amostra aleatória de uma população. Seja Ri o posto
de Xi, i = 1, ..., n. Como R = (R1, ..., Rn) possui distribuição de permutação, tem-se que R
será NA;
• Exemplo 5: Variáveis aleatórias que possuem distribuições normais negativamente correla-
cionadas são NA;
• Exemplo 6: A Distribuição de Dirichlet dada por (2.8) é NA.

19
1.5 Implicações e Contra-exemplos envolvendo os Conceitos de De-
pendência
Teorema 1.2. Todos os tipos de dependências, definidos nas seções anteriores, são invariantes com
respeito às transformações estritamente crescentes sobre as componentes do vetor aleatório.
Demonstração: Para a demonstração consulte [25].
Teorema 1.3. Relações para o caso bivariado:
(a) densidade TP2 ⇒ SI ⇒ LTD, RTI;
(b) LTD ou RTI ⇒ associação ⇒ PQD;
(c) densidade TP2 ⇒ f.d.a. TP2 e função de sobrevivência TP2;
(d) f.d.a TP2 ⇒ LTD e função de sobrevivência TP2 ⇒ RTI.
Demonstração: Para a demonstração consulte [25].
Pelo teorema anterior, observa-se que a dependência TP2 é uma dependência forte pois esta
implica nas dependências SI, LTD, RTI, associação e PQD entre v.a. . A dependência mais fraca é
a PQD.
Teorema 1.4. Relações para o caso multivariado:
(a) um subvetor aleatório de um vetor aleatório associado é associado;
(b) associação ⇒ PUOD e PLOD;

20
(c) PDS ⇒ PUOD e PLOD;
(d) CIS ⇒ associação.
Demonstração: Para a demonstração consulte [25].
A seguir, serão dadas outras implicações entre os conceitos de dependência:
1. Um par de v.a. NQD é NA [23];
2. Um par de v.a. NA é NOD [23];
3. RTDS equivale à NUOD [8];
4. LTI equivale à NQD. Porém, para n ≥ 3, LTIS não implica em NUOD [8];
5. RTIS implica em PUOD [8];
6. Se (X1, X2) for SD, ele será também RTD.
Na sequência, serão dados exemplos de implicações que não são válidas. Na seção 1.6 são
mostradas as tabelas utilizadas em alguns contra-exemplos.
• Contra-Exemplo 1: Para n ≥ 3, NUOD e NLOD não se equivalem [23]
Sejam as v.a. X1, X2 e X3 assumindo valores (0, 1, 1), (1, 0, 1), (1, 1, 0) e (0, 0, 0) sendo que
cada valor assume a probabilidade 1/4. Então,
P (X1 > 0, X2 > 0, X3 > 0) = 0 <18
= P (X1 > 0)P (X2 > 0)P (X3 > 0)
mas
P (X1 ≤ 0, X2 ≤ 0, X3 ≤ 0) =14>
18
= P (X1 ≤ 0)P (X2 ≤ 0)P (X3 ≤ 0);
• Contra-Exemplo 2: Nem v.a. NUOD e nem v.a. NLOD implica em v.a. NA [23]
No contra-exemplo seguinte, X = (X1, X2, X3, X4) será NOD mas não será NA.

21
Seja o vetor aleatório X = (X1, X2, X3, X4) onde cada v.a. Xi possui Distribuição de Bernoulli
com P (Xi = 1) = 0, 5, i = 1, ..., 4. Considere os pares (X1, X2) e (X3, X4) possuindo a mesma
distribuição bivariada. A função de probabilidade conjunta de (X1, X2, X3, X4) é dada pela
Tabela 6.1.
Pode-se verificar que todas as condições NLOD e NUOD são válidas.
Porém, P (Xi = 1, i = 1, ..., 4) > P (X1 = X2 = 1)P (X3 = X4 = 1) viola o conceito NA;
• Contra-Exemplo 3: RTD não implica em LTI [8]
Sejam (X,Y ) duas v.a. tendo função de probabilidade conjunta dada pela Tabela 6.2.
Como P (Y > 0|X ≥ 0) = 310 , P (Y > 0|X ≥ 1) = 44
165 , P (Y > 0|X ≥ 2) = 30165 e
P (Y > 0|X ≥ 3) = 0 tem-se que Y é RTD em X.
Porém, P (Y = 0|X ≤ 0) = 35 >
59 = P (Y = 0|X ≤ 1) e, assim, Y não é LTI em X;
• Contra-Exemplo 4: LTI não equivale à RTD [8]
Para mostrar que LTI não implica em RTD, considere (X,Y ) duas v.a. tendo distribuição
conjunta de probabilidade dada pela Tabela 6.3.
Como P (Y = 0|X ≤ 0) = 25 , P (Y = 0|X ≤ 1) = 1
2 , P (Y = 0|X ≤ 2) = 35 e
P (Y = 0|X ≤ 3) = 35 tem-se que Y é LTI em X.
Porém, P (Y = 1|X > 1) = 0, 30 < 0, 40 = P (Y = 1|X > 2) e, assim, Y não é RTD em X;
• Contra-Exemplo 5: Para n ≥ 3, LTIS não equivale à NUOD [8]
Considere as v.a. X, Y e Z tais que Z condicionado em X ≤ x e Y ≤ y, possui função
densidade
P (Z ≤ z|X ≤ x, Y ≤ y) = 1− exp−z(x+ y) (5.12)
com z > 0. As v.a. X e Y possuem função de distribuição conjunta dada pela Tabela 6.3.
Desde que lado direito de (5.12) é crescente em x e y e, a partir do exemplo supra-citado,
(X,Y ) é LTI e a sequência (X,Y, Z) é LTIS.

22
Porém, desde que
P (Z ≤ z|X ≤ x) = 1− exp−z(x+ 1)
e
P (Z ≤ z|Y ≤ y) = 1− exp−z(y + 3)
segue que
P (X > 2, Y > 0, Z > 2) = e−8−1, 35e−6+0, 45e−4 > 0, 1e−8 = P (X > 2)P (Y > 0)P (Z > 2);
• Contra-Exemplo 6: CDS não implica em RTDS [8]
Para mostrar que CDS não implica em RTDS, considere X1, X2 e X3 v.a. tais que
fX3|X1,X2(x3|x1, x2) = x2e
−x2x3
com x3 > 0. As v.a. X1 e X2 possuem função de probabilidade conjunta dada pela Tabela
6.4.
Como P (X2 > 1|X1 = 0) = 1, P (X2 > 1|X1 = 1) = 13 , P (X2 > 1|X1 = 2) = 1
4 ,
P (X2 > 2|X1 = 0) = 13 , P (X2 > 2|X1 = 1) = 1
3 e P (X2 > 2|X1 = 2) = 0 tem-se que X2 é
SD em X1. Além disso, como P (X3 > x|X1 = x1, X2 = x2) = exp−x2x ↓ x2 tem-se que
(X1, X2, X3) é CDS.
Por outro lado, utilizando-se a identidade
P (C|A ∪B) = P (C|A)P (A)
P (A) + P (B)+ P (C|B)
P (B)P (A) + P (B)
quando P (A ∩B) = 0, P (A) > 0 e P (B) > 0, obtém-se
P (X3 > x|X1 > 0, X2 > 1) =12P (X3 > x|X1 = 1, X2 = 3) + P (X3 > x|X1 = 2, X2 = 2) =
=12(e−3x + e−2x
)enquanto que P (X3 > x|X1 > 1, X2 > 1) = P (X3 > x|X1 = 2, X2 = 2) = e−2x.

23
Como P (X3 > x|X1 > 1, X2 > 1) > P (X3 > x|X1 > 0, X2 > 1), ∀x > 0 tem-se que
(X1, X2, X3) não é RTDS;
• Contra-Exemplo 7: NA não implica em RR2 aos pares, CDS ou NDS [23]
No contra-exemplo seguinte, será mostrado que Y é NA mas não é RR2 aos pares, CDS ou
NDS.
Seja X = (X1, X2, X3) um vetor aleatório possuindo uma função de probabilidade multinomial
trivariada f com probabilidades p1, p2 e p3 estritamente positivas e X1 + X2 + X3 = 3.
Considere o vetor aleatório induzido Y = (Y1, Y2) onde Y1 = X1X2 e Y2 = X3. A função de
probabilidade conjunta de (Y1, Y2) será denotada por g e é dada pela Tabela 6.5.
A Distribuição Multinomial é RR2 aos pares, CDS e NDS [2, 28]. Será mostrado que a função
de probabilidade conjunta g não é nem RR2, nem CDS e nem NDS.
Pela função de probabilidade conjunta g de (Y1, Y2) obtém-se que
P (x) =
∣∣∣∣∣ g(0, 0) g(0, 1)
g(1, 0) g(1, 1)
∣∣∣∣∣ > 0
Então, conclui-se que g não é RR2.
Notando que P (Y2 > 0|Y1 = 0) = 1− P (Y2 = 0|Y1 = 0) < 1 enquanto que
P (Y2 > 0|Y1 = 1) = 1− P (Y2 = 0|Y1 = 1) = 1, conclui-se que Y não é CDS.
Como, para um vetor bivariado, CDS equivale à NDS, segue que Y não é NDS.
Pelas propriedades 7 e 4 da seção 1.4, conclui-se, respectivamente, que X é NA e Y é NA.
Portanto, NA não implica em RR2 aos pares, CDS ou NDS já que Y é NA mas não é RR2,
CDS ou NDS.
Além das implicações, citadas anteriormente, que não são válidas, tem-se, também, que CIS não
implica RTIS [8], RTIS não implica CIS [8].
1.6 Tabelas referentes ao Capítulo

24
Tabela 6.1: Função de probabilidade conjunta de (X1, X2, X3, X4)
Y/X (0,0) (0,1) (1,0) (1,1)
(0,0) 0,0577 0,0623 0,0623 0,0577
(0,1) 0,0623 0,0677 0,0677 0,0623
(1,0) 0,0623 0,0677 0,0677 0,0623
(1,1) 0,0577 0,0623 0,0623 0,0577
Tabela 6.2: Função de probabilidade conjunta de X e Y
Y/X 0 1 2 3
0 0,15 0,10 0,20 0,25
1 0,10 0,10 0,10 0
Tabela 6.3: Função de probabilidade conjunta de X e Y
Y/X 0 1 2 3
0 0,10 0,15 0,20 0,15
1 0,15 0,10 0,05 0,10
Tabela 6.4: Função de probabilidade conjunta de X e Y
Y/X 0 1 2
1 0 0,20 0,30
2 0,20 0 0,10
3 0,10 0,10 0

25
Tabela 6.5: Função de probabilidade conjunta de (Y1, Y2)
Y/X 0 1 2
0 f(0, 3, 0) + f(3, 0, 0) 0 f(1, 2, 0) + f(2, 1, 0)
1 f(0, 2, 1) + f(2, 0, 1) f(1, 1, 1) 0
2 f(0, 1, 2) + f(1, 0, 2) 0 0
3 f(0, 0, 3) 0 0

26

Capítulo 2
Teoria de Cópulas
2.1 Introdução
Desde que Joe (1997) [25] e Nelsen (1999) [31] pela primeira vez introduziram o conceito de cópu-
las para uso em modelagem padrão, tem havido um interesse crescente nesta abordagem. Cópulas
tornaram-se uma ferramenta popular de modelagem multivariada em muitos domínios onde a de-
pendência multivariada é de interesse e o uso da habitual normalidade multivariada está em questão.
Em ciências autuárias cópulas são usadas na modelagem de mortalidade e perdas [13, 14, 15]. Em
finanças, cópulas são usadas na classificação de crédito e modelagem de risco [3, 9, 7]. Em estudos
biomédicos, cópulas são utilizadas na modelagem de eventos correlacionados e riscos competitivos
[37]. Em engenharia, cópulas são utilizadas no controle de processo multivariado e modelagem
hidrológica [16].
Quando se fala em modelagem de dependência, hoje em dia um dos primeiros temas a ser levado
em consideração é a recente teoria de cópulas discutida por Joe [25] e Nelsen [31]. Esta teoria
se torna atrativa devido às cópulas abrangerem um grande leque de estruturas de dependência e
conseguirem modelar completamente a estrutura de dependência dos dados.
A modelagem através da distribuição normal é amplamente utilizada por sua simplicidade
analítica e fácil estimação da matriz de correlação, seu único parâmetro de dependência, e por
conta da vasta gama de estruturas que podem ser modeladas por esta distribuição. Porém algumas
27

28
de suas característica, de simetria e curtose, por exemplo, limitam sua utilização. Como Embrechts
et. al. [10] mostram, há muitos obstáculos à suposição de normalidade. Para os mercados de crédito
e financeiro, o principal é a característica de pequena probabilidade em eventos extremos conjuntos.
Evidências empíricas sugerem que no comportamento destes mercados verificam-se eventos extremos
mais prováveis que os previstos pela distribuição normal, não só nas marginais, mas também em
dimensões superiores. Neste contexto, a modelagem através das cópulas torna-se atraente devido a
sua maior variedade de estruturas de dependência.
A cópula é uma distribuição multivariada cujas marginais são U(0, 1). Seja o vetor aleatório
U = (U1, . . . , Ud) ∈ Id com cópula d-dimensional C, temos
C(u1, . . . , ud) = P (U1 ≤ u1, . . . , Ud ≤ ud), (u1, . . . , ud) ∈ Id
e combinado com o fato de que qualquer v.a. contínua pode ser transformada por sua acumulada
para uma v.a. com distribuição U(0, 1), cópulas podem ser usadas para fornecer uma estrutura de
dependência multivariada separadamente das distribuições marginais. Seja H uma f.d.a. de X =
(X1, . . . , Xd) com marginais F1, . . . , Fd, Sklar [36] mostrou que existe uma cópula C d-dimensional
tal que para todo xi ∈ DomFi,
H(x1, . . . , xd) = C(F1(x1), . . . , Fd(xd)) (1.1)
Como visto, com cópulas pode-se trabalhar a estrutura de dependência em um contexto mul-
tivariado, porém esta dissertação trata apenas do contexto bidimensional, apresentando todos os
resultados para esta dimensão. Também não há impedimento para se trabalhar com o Kendall Plot,
objeto central da tese, em um contexto multivariado, por uma questão de exemplificação trabalha-se
em um contexto bivariado.
A função cópula C associada ao vetor aleatório (X,Y ) também é conhecida como função de-
pendência, já que a cópula contém toda informação de dependência entre as variáveis X e Y . Desta
maneira a utilização da equação (1.1) possibilita trabalhar com a estrutura de dependência de
(X,Y ) de forma livre de medida de escala e locação, restringindo-se apenas ao intervalo [0, 1]. A
característica da informação de dependência que a cópula contém pode ser vista através do seguinte
exemplo.

29
Exemplo 2.1. São geradas duas amostras, de forma independente. Sejam (x1 . . . x100) e (y1 . . . y100)
pseudo observações independentes com distribuição F1(x) = 1− exp(−2x) e F2(y) = 1− exp(−10y)
respectivamente. Observando o scatterplot de X e Y na Figura 2.1 vê-se que não fica evidente a
independência entre essas variáveis. Porém, ao plotar (F1(xi), F2(yi)), as amostras transformadas
pelas respectivas acumuladas F1 e F2, fica evidente a independência entre X e Y . Visto que a cópula
é a distribuição conjunta entre F1(X) e F2(Y ). Mostra-se que a cópula evidencia a verdadeira inde-
pendência existente entre X e Y e como a forma das marginais pode produzir uma falsa impressão
de dependência.
Como a cópula é uma função de (U1, ..., Un) onde Ui = Fi(Xi), i = 1, .., n, observa-se que quando
se tem valores observados de duas v.a. X e Y , a cópula modela a ordem dos valores observados das
v.a. X e Y pois considera-se a f.d.a. de cada v.a. sendo que a ordem da amostra é algo inerente à
esta função. Esta ordem é evidenciada através do Gráfico de Dispersão dos valores uniformizados
F1(x) e F2(y).
2.2 Cópula e Teorema de Sklar
Definição 2.1. Sejam S1 e S2 subconjuntos não vazios de R, função H : S1×S2 → R e o retângulo
B = [x1, x2]× [y1, y2], (xi, yi) ∈ DomH com i, j = 1, 2, . . .. Define-se H-volume de B como
VH(B) = H(x2, y2) + H(x2, y1)−H(x1, y2) + H(x1, y1) (2.2)
Definição 2.2. Uma função H bidimensional é bicrescente se VH(B) ≥ 0, ∀B, com VH(B) dado
pela Definição 2.1.
Exemplo 2.2. Uma função não decrescente marginalmente pode não ser bicrescente. Seja H : I2 →I definida por H(x, y) = max(x, y), temos VH(I2) = −1, ou seja, H não é bicrescente.
Exemplo 2.3. Uma função pode ser bicrescente e decrescente em alguns de seus argumentos. Seja
H : I2 → I definida por H(x, y) = (2x − 1)(2y − 1). Note que VH(B) pode ser reescrito como
VH(B) = (y2 − y1)(4x2 − 4x1) ≥ 0, pois x1 ≤ x2 e y1 ≤ y2 no retângulo B, logo H é bicrescente.
Porém H é uma função decrescente de x para cada y ∈ (0, 1/2) e função decrescente de y para cada
x ∈ (0, 1/2).

30
Figura 2.1: Scatterplots: Dados exponenciais independentes (primeira figura); dados exponenciais
independentes transformados pelas acumuladas (segunda figura).

31
Definição 2.3. Uma aplicação H : S1 × S2 → R é aplanada se H(x, a1) = 0 = H(a1, y), ∀(x, y) ∈S1 × S2, onde ai = minz : z ∈ Si.
Definição 2.4. Uma subcopula é uma função C ′ com as seguintes propriedades:
1. DomC ′ = S1 × S2, onde S1 e S2 são subconjuntos de I contendo 0 e 1;
2. C ′ é aplanada e bicrescente;
3. C ′ é marginalmente uniforme, ou seja, para todo u ∈ S1 e v ∈ S2,
C ′(u, 1) = u e C ′(1, v) = v (2.3)
Exemplo 2.4. Sejam S1 = S2 = 0, 1. A função C ′ : S1 × S2 7−→ R definida por
C ′(0, 0) = C ′(0, 1) = C ′(1, 0) = 0 e C ′(1, 1) = 1
é a mais simples subcopula.
Definição 2.5. Uma cópula é uma subcopula cujo domíno é I2.
Exemplo 2.5. As funções W,M : I2 → I dadas por W (u, v) = max(u + v − 1, 0) e M(u, v) =
min(u, v) são exemplos particulares de cópulas denotadas respectivamente por M e W . É trivial
mostrar que a função M(u, v) é aplanada e marginalmente uniforme. Para verificar que esta função é
bicrescente, considere o retângulo B = [x1, x2]× [y1, y2], x1, x2, y1 e y2 ∈ I, para o caso y2 ≥ x2 ≥ x1
e x1 ≤ y1 ≤ x2 e desta maneira
VM (B) = M(x2, y2)−M(x2, y1)−M(x1, y2) +M(x1, y1) = x2 − y1 ≥ 0
Para os demais casos a demonstração é análoga. A cópula W pertence a classe das cópulas
Arquimedianas e será vista na próxima seção.
Como toda cópula é uma subcopula, os próximos conceitos são apresentados para subcopulas,
logo válidos paracópulass.
Teorema 2.1. Uma subcopula bidimensional C ′ é marginalmente não decrescente.

32
Demonstração. Primeiro, provemos que a aplicação t → C ′(t, y2) − C ′(t, y1), y1, y2 ∈ I, y1 ≤ y2 é
não decrescente. Consideremos T (t) = C ′(t, y2)−C ′(t, y1), se t1 ≤ t2, ti ∈ I, temos T (t2)−T (t1) ≥ 0,
pois
T (t2)− T (t1) = C ′(t2, y2)− C ′(t2, y1)− C ′(t1, y2) + C ′(t1, y1) = V ′C(B)
onde B = [t1, t2] × [y2, y1]. Como C ′ é bicrescente, então V ′C(B) ≥ 0, logo a aplicação é não
decrescente. Analogamente verifica-se que a aplicação T ∗(t) = C ′(x2, t)−C ′(x1, t), x1, x2 ∈ I, x1 ≤x2 é não decrescente. Agora, seja x1 = y1 = 0 nas aplicações T e T ∗, como C ′ é aplanda, segue que
C ′ é marginalmente não decrescente.
Teorema 2.2. Seja C ′ uma subcopula. Então para todo (u, v) ∈ DomC ′,
max(u+ v − 1, 0) ≤ C ′(u, v) ≤ min(u, v) (2.4)
Demonstração. Como C ′ é aplanada, marginalmente uniforme e não decrescente temos
0 = C ′(0, v) ≤ C ′(u, v) ≤ C ′(1, v) = v e 0 = C ′(u, 0) ≤ C ′(u, v) ≤ C ′(u, 1) = u (2.5)
Logo,
C ′(u, v) ≤ min(u, v)
Como C ′ também é bicrescente, então VC′(B) ≥ 0. Sendo B = [u, 1]× [v, 1] temos
VC′(B) = C ′(1, 1) + C ′(u, v)− C ′(u, 1)− C ′(1, v)
= 1 + C ′(u, v)− u− v ≥ 0 (2.6)
Portanto pelas equações (2.5) e (2.6), temos C ′(u, v) ≥ max(u+ v − 1, 0).
Conforme Exemplo 2.5, os limites na equação (2.4) são as cópulas M e W . Então para toda
cópula C e para todo (u, v) ∈ I2,
W (u, v) ≤ C(u, v) ≤M(u, v) (2.7)
A desigualdade (2.7) é denominada desigualdade dos limites de Frechét, a cópula M é nomeada por
limite superior de Frechét e a cópula W por limite inferior de Frechét.
A ligação entre funções distribuição multivariada e suas marginais univariadas é feita pelo Teo-
rema de Sklar apresentado a seguir, por meio das cópulas. O nome cópula foi escolhido para enfatizar
a maneira como a cópula une uma função distribuição conjunta às suas marginais univariadas.

33
Teorema 2.3. Seja H uma função distribuição conjunta com marginais F e G. Então existe uma
cópula C tal que para todo x, y ∈ R,
H(x, y) = C(F (x), G(y)) (2.8)
Se F e G são contínuas, então C é única; caso contrário, C é unicamente determinada em Im(F )×Im(G). Inversamente, se C é uma cópula e F e G são f.d.a., então a função H definida pela equação
(2.8) é uma função distribuição conjunta com marginais F e G.
Demonstração. A prova segue dos lemas 2.1 e 2.2 apresentados a seguir.
Lema 2.1. Seja H uma função distribuição conjunta com marginais F e G. Então existe uma única
subcopula C ′ tal que
1. DomC ′ = Im(F )× Im(G);
2. ∀x, y ∈ R, H(x, y) = C ′(F (x), G(y))
Demonstração. Sejam (x1, y1), (x2, y2) ∈ DomH. Pela desigualdade triangular, temos
|H(x2, y2)−H(x1, y1)| ≤ |H(x2, y2)−H(x1, y2)|+ |H(x1, y2)−H(x1, y1)|
Considere x1 ≤ x2. Como H é uma função distribuição conjunta, então
0 ≤ H(x2, y2)−H(x1, y2) ≤ F (x2)− F (x1)
por H ser marginalmente decrescente, aplanada, H(x,∞) = F (x) e H(∞, y) = G(y). Uma de-
sigualdade análoga é válida quando x2 ≤ x1. Portanto segue que para qualquer x1, x2 ∈ S1,
|H(x2, y2) − H(x1, y2)| ≤ |F (x2) − F (x1)|. Similarmente para qualquer y1, y2 ∈ S2, |H(x1, y2) −H(x1, y1)| ≤ |G(y2)−G(y1)|, logo
|H(x2, y2)−H(x1, y1)| ≤ |F (x2)− F (x1)|+ |G(y2)−G(y1)| (2.9)
Desta forma, segue que se F (x1) = F (x2) e G(y1) = G(y2), então H(x1, y1) = H(x2, y2) e conse-
quentemente o conjunto de pares (F (x), G(y)),H(x, y) permite definir uma função
(F (x), G(y)) C′→ H(x, y)

34
sendo C ′ única com domínio Im(F ) × Im(G). A prova que a função C ′ é uma subcopula segue
diretamente das propriedades da distribuição conjunta H [22]. Para cada u ∈ Im(F ), existe um
x ∈ R tal que F (x) = u, então
C ′(u, 1) = C ′(F (x), G(∞)) = H(x,∞) = F (x) = u
C ′(u, 0) = C ′(F (x), G(−∞)) = H(x,−∞) = 0
Como H é bicrescente por definição, logo C ′ é bicrescente.
Lema 2.2. Seja C ′ uma subcopula. Então existe uma cópula C tal que C(u, v) = C ′(u, v), ∀(u, v) ∈DomC ′; isto é, qualquer subcopula pode ser extendida a umacópulaa. A extensão é geralmente não
única.
Demonstração. Da equação (2.9) e usando o item 2. do Lema 2.1, concluímos que C ′ é uniforme-
mente contínua em seu domínio Im(F )× Im(G), ou seja,
|C ′(u2, v2)− C ′(u1, v1)| ≤ |u2 − u1|+ |v2 − v1|
Denotemos Im(F ) por S1 e Im(G) por S2.
Da continuidade de C ′ podemos estender C ′ a uma função C ′′, ainda subcopula, com domínio
em S1×S2, onde S1 é o fecho de S1 e S2 é o fecho de S2. O próximo passo é estender a subcopula C ′′
a uma função C com domínio em I2. Para este fim, seja (a, b) ∈ I2, e sejam a1 e a2, respectivamente,
o menor e o maior elemento de S1 que satisfaça a1 ≤ a ≤ a2; e sejam b1 e b2, respectivamente, o
menor e o maior elemento de S2 que satisfaça b1 ≤ b ≤ b2. Se a ∈ S1, defina a1 = a2 = a; e se
b ∈ S2, defina b1 = b2 = b. Desta maneira, sejam
λ1 =
(a− a1)/(a2 − a1), se a1 < a2
1, se a1 = a2
µ1 =
(b− b1)/(b2 − b1), se b1 < b2
1, se b1 = b2
e define-se
C(a, b) = (1− λ1)(1− µ1)C ′′(a1, b1) + (1− λ1)µ1C′′(a1, b2)
+ λ1(1− µ1)C ′′(a2, b1) + λ1µ1C′′(a2, b2). (2.10)

35
É trivial que DomC = I2 e que C(a, b) = C ′′(a, b), ∀(a, b) ∈ DomC ′′. Como λ1 e µ1 são
lineares em a e b, a forma C(a, b) da equação (2.10) é bilinear em (a, b) propriedade que permite
demonstrar que C é aplanada e marginalmente uniforme. Conforme Definição 2.5, para C ser uma
cópula falta provar que C é bicrescente. Seja (c, d) outro ponto em I2 tal que c ≥ a e d ≥ b, e
sejam c1, d1, c2, d2, λ2, µ2 relacionados a c e d assim como a1, b1, a2, b2, λ1, µ1 são relacionados a a e
b. Deve-se provar que VC(B) ≥ 0 para o retângulo B = [a, c]×[b, d]. Diversos casos são considerados
para esta prova. O mais simples dos casos é aquele em que não existe ponto em S1 estritamente
entre a e c e não há ponto em S2 estritamente entre b e d, então temos c1 = a1, c2 = a2, d1 = b1 e
d2 = b2. Substituindo a equação (2.10) e os termos correspondentes para C(a, d), C(c, b) e C(c, d)
na expressão dada pela equação (2.2) para VC(B), temos
VC(B) = VC([a, c]× [b, d]) = (λ2 − λ1)(µ2 − µ1)VC([a1, a2]× [b1, b2]),
de que segue que VC(B) ≥ 0 neste caso, pois c ≥ a e d ≥ b implica λ2 ≥ λ1 e µ2 ≥ µ1.
Outro caso de interesse é quando pelo menos um ponto está em S1 estritamente entre a e c, e
pelo menos um ponto está em S2 estritamente entre b e d, então a < a2 ≤ c1 < c e b < b2 ≤ d1 < d.
Para este caso, substituindo a equação (2.10) e os termos correspondentes para C(a, d), C(c, b) e
C(c, d) na expressão dada pela equação (2.2) para VC(B) e reordenando os termos temos
VC(B) = (1− λ1)µ2VC([a1, a2]× [d1, d2]) + µ2VC([a2, c1]× [d1, d2])
+ λ2µ2VC([c1, c2]× [d1, d2]) + (1− λ1)VC([a1, a2]× [b2, d1])
+ VC([a2, c1]× [b2, d1]) + λ2VC([c1, c2]× [b2, d1])
+ (1− λ1)(1− µ1)VC([a1, a2]× [b1, b2])
+ (1− µ1)VC([a2, c1]× [b1, b2]) + λ2(1− µ1)VC([c1, c2]× [b1, b2]).
O lado direito da expressão acima é a soma de combinações de nove quantidades não negati-
vas, representadas por C-volumes, com coeficientes não negativos, logo é não negativa. Os casos
remanescentes são similares, que completam a prova.
Antes de apresentar o próximo resultado é necessária a definição de quasi-inversa.
Definição 2.6. Seja F uma função distribuição acumulada. Então a quasi-inversa de F é qualquer
função F (−1) com domínio em I tal que

36
1. Se t ∈ Im(F ), então F (−1)(t) = x com x ∈ R tal que F (x) = t, ou seja, ∀t ∈ Im(F ),
F (F (−1)(t)) = t;
2. Se t /∈ Im(F ), então
F (−1)(t) = infx|F (x) ≥ t = supx|F (x) ≤ t.
Corolário 2.1. Sejam H, F,G e C ′ como no Lema 2.1, e sejam F (−1) e G(−1) as quasi-inversas de
F e G, respectivamente. Então para qualquer (u, v) ∈ DomC ′,
C ′(u, v) = H(F (−1)(u), G(−1)(v)) (2.11)
Sejam x ∈ Dom(F ) e y ∈ Dom(G) conforme Teorema 2.3 se u = F (x) e v = G(y), então
x = F (−1)(u) e y = G(−1)(v). Quando F e G são contínuas o Corolário 2.1 é válido para cópulas
e temos U, V com distribuição U(0, 1) onde U = F (X) e V = G(Y ). Deste modo a cópula C é
distribuição conjunta do vetor aleatório (U, V ) com marginais U(0, 1).
Exemplo 2.6. Um método para construção de cópulas é resultante do último corolário. Seja H a
distribuição da independência
H(x, y) = F (x)G(y) (2.12)
com marginais F (x) = 1− exp(−2x) e G(y) = 1− exp(−y), onde as respectivas quasi-inversas são
dada por
F (−1)(u) =
− log(1−u)
2 , se x ≥ 0
0, c.c.
G(−1)(v) =
− log(1− v), se x ≥ 0
0, c.c.
Logo, a cópula associada a H é dada por
C(u, v) = H(F (−1)(u), G(−1)(v))
= FF (−1)(u)GG(−1)(v)
= [1− e−2 log(1−u)/2][1− e− log(1−v)]
= uv

37
Esta cópula recebe a notação especial Π e é denominada cópula produto. Sua estrutura caracteriza
a independência entre as v. a. X e Y quando as f.d.a. F e G são contínuas. Note que se a conjunta
H é definida pela equação (2.12), a estrutura de dependência entre as v.a. X e Y independe de suas
marginais, pois
C(u, v) = H(F (−1)(u), G(−1)(v)) = FF (−1)(u)GG(−1)(v) = uv
pela definição de quasi-inversa (Definição 2.6).
Muito da utilidade de cópulas no estudo de estatísticas não paramétricas deriva do fato que sob
transformações monótonas estritas de v.a. as cópulas são invariantes, ou são alteradas de modo
previsível como visto nos próximos dois resultados.
Teorema 2.4. Sejam X e Y v.a. contínuas com cópula CX,Y . Se α e β são funções estritamente
crescentes na Im(X) e Im(Y ) respectivamente, então Cα(X),β(Y ) = CX,Y .
Demonstração. Sejam F1, G1, F2 e G2 as respectivas distribuições de X,Y, α(X) e β(Y ), respecti-
vamente. Assim, para qualquer x, y ∈ R,
Cα(X),β(Y )(F2(x), G2(y)) = P [α(X) ≤ x, β(Y ) ≤ y] = P [X ≤ α−1(x), Y ≤ β−1(y)]
= CX,Y (F1(α−1(x)), G1(β−1(y))) = CX,Y (F2(x), G2(y))
Desde que X e Y são contínuas, Im(F2) = Im(G2) = I, logo segue que Cα(X),β(Y ) = CX,Y em
I2.
Quando pelo menos uma função, α ou β, é estritamente decrescente, a cópula das v.a. α(X) e
β(Y ) é uma simples transformação de CX,Y .
Teorema 2.5. Sejam X, Y v.a. contínuas com cópula CX,Y e α e β funções estritamente monótonas
na Im(X) e Im(Y ) resprectivamente.
1. Se α é estritamente crescente e β é estritamente decrescente, então
Cα(X),β(Y )(u, v) = u− CX,Y (u, 1− v), u, v ∈ I.

38
2. Se α é estritamente decrescente e β é estritamente crescente, então
Cα(X),β(Y )(u, v) = v − CX,Y (1− u, v), u, v ∈ I.
3. Se α e β ambas são estritamente decrescentes, então
Cα(X),β(Y )(u, v) = u+ v − 1 + CX,Y (1− u, 1− v), u, v ∈ I.
Demonstração. Sejam F1, G1, F2 eG2 as distribuições deX,Y, α(X) e β(Y ) respectivamente. Tomemos
u ∈ Im(F2) e v ∈ Im(G2) tais que u = F2(x) para algum x ∈ Im(F2) = I (devido a v.a. α(X) ser
contínua) e v = G2(y) para algum y ∈ Im(G2) = I (devido a v.a. β(X) ser contínua).
Demonstração item 1.:
Cα(X),β(Y )(u, v) = Cα(X),β(Y )(F2(x), G2(y))(2.8)= P (α(X) ≤ x, β(Y ) ≤ y)
= P (X ≤ α−1(x), Y ≥ β−1(y)) (2.13)
Como,
F2(x) = P (α(X) ≤ x) = P (X ≤ α−1(x)) = F1(α−1(x))
= P (X ≤ α−1(x), Y ≤ β−1(y)) + P (X ≤ α−1(x), Y ≥ β−1(y)) (2.14)
e
G2(y) = P (β(Y ) ≤ y) = P (Y ≥ β−1(y)) = 1−G1(β−1(y))
⇒ G1(β−1(y)) = 1−G2(y) (2.15)
temos
P (X ≤ α−1(x), Y ≤ β−1(y)) = CX,Y (F1(α−1(x)), G1(β−1(y)))
= CX,Y (F2(x), 1−G2(y))
= CX,Y (u, 1− v) (2.16)
onde a segunda igualdade se refere às equações (2.14) e (2.15).

39
Substituindo a equação (2.16) na equação (2.14)
F2(x) = P (X ≤ α−1(x), Y ≥ β−1(y)) + CX,Y (u, 1− v)
⇒ P (X ≤ α−1(x), Y ≥ β−1(y)) = u− CX,Y (u, 1− v) (2.17)
Desta forma, substituindo a equação (2.17) na equação (2.13), se completa a prova.
Demonstração item 2.: análoga a demonstração item 1.
Demonstração item 3.:
Cα(X),β(Y )(u, v) = Cα(X),β(Y )(F2(x), G2(y))(2.8)= P (α(X) ≤ x, β(Y ) ≤ y)
= P (X ≥ α−1(x), Y ≥ β−1(y))
= 1− [P (X ≤ α−1(x)) + P (Y ≤ β−1(y))− P (X ≤ α−1(x), Y ≤ β−1(y))]
= 1− F1(α−1(x))−G1(β−1(y)) + P (X ≤ α−1(x), Y ≤ β−1(y)) (2.18)
Reescrevendo F1(α−1(x)), temos
F1(α−1(x)) = 1− P (X ≥ α−1(x)) = 1− P (α(X) ≤ x) = 1− F2(x) (2.19)
e, analogamente
G1(β−1(y)) = 1−G2(y) (2.20)
Substituindo as equações (2.19) e (2.20) na equação (2.18) e utilizando o Teorema 2.3,
Cα(X),β(Y )(u, v) = 1− [1− F2(x)]− [1−G2(y)] + CX,Y (F1(α−1)(x), G1(β−1(y))
= u+ v − 1 + CX,Y (1− u, 1− v)
2.3 Cópulas Arquimedianas
O termo cópula Arquimediana foi mencionado pela primeira vez na literatura estatística em dois
artigos de Genest & Mackay (1986ab) [17] e [18]. Cópulas Arquimedianas também são mencionadas
por Schweizer and Sklar (1983) [34], mas sem o nome Arquimediana.

40
A Classe das cópulas Arquimedianas abrange uma grande variedade de estruturas de dependên-
cia, incluindo estruturas próprias de estudos financeiros. Algumas questões em finanças exigem
modelos que permitem uma forte dependência entre as perdas extremas (por exemplo, bolsas em
colapso) e ganhos extremos. Em particular, as cópulas Arquimedianas podem assumir dependência
caudal assimétrica, sendo uma propriedade a favor de sua aplicação à modelagem de dados com
estrutura de dependênica assimétrica.
Em estudos financeiros um aspecto importante a ser analisado é a dependência caudal. De-
pendência caudal inferior e superior entre dois mercados financeiros existe quando a probabilidade
de valores conjuntos negativos (positivos) em eventos extremos é maior que a que poderia ser pre-
vista a partir das distribuições marginais. Recentes estudos empíricos mostram que períodos de
turbulência e calma em finanças são caracterizados por diferentes níveis de dependência caudal,
sendo a dependência mais forte sobre a cauda inferior do que na cauda superior.
As cópulas Arquimedianas podem ser construídas facilmente e a forma fechada para sua ex-
pressão é simples. Estas facilidades se devem ao fato da representação da cópula Arquimediana
permitir reduzir o estudo de cópula multivariada ao estudo de uma função univariada denotada por
gerador de uma cópula Arquimediana φ. A seguir esta função é apresentada com mais detalhes.
Definição 2.7. Seja φ : I → [0,∞] uma função contínua e estritamente decrescente tal que φ(1) = 0.
A pseudo-inversa de φ é a função φ[−1] : [0,∞] → I dada por
φ[−1](t) =
φ−1(t), se 0 ≤ t ≤ φ(0)
0, se φ(0) ≤ t ≤ ∞
Note que φ[−1] é contínua e não crescente em [0,∞], e estritamente decrescente em [0, φ(0)].
Além disso,
φ[−1](φ(u)) = u, ∀u ∈ I (3.21)
e
φ(φ[−1](t)) =
t, se 0 ≤ t ≤ φ(0)
φ(0), se φ(0) ≤ t ≤ ∞ = min(t, φ(0))
Finalmente, se φ(0) = ∞, então φ[−1] = φ−1.

41
Lema 2.3. Seja φ e φ[−1] como na Definição 2.7. Seja a função C : I2 → I dada por
C(u, v) = φ[−1](φ(u) + φ(v)) (3.22)
Então C satisfaz duas das três condições para uma cópula, é aplanada e marginalmente uniforme.
Demonstração.
C(u, 0) = φ[−1](φ(u) + φ(0)) = 0
A última igualdade segue da definição de pseudo-inversa, pois φ(u) + φ(0) ≥ φ(0) sendo φ uma
função que assume somente valores positivos.
C(u, 1) = φ[−1](φ(u) + φ(1)) = φ[−1](φ(u))(3.21)= u (3.23)
Analogamente, por simetria, C(0, v) = 0 e C(1, v) = v.
O seguinte lema apresenta uma condição necessária e suficiente para que a função C na equação
(3.22) seja bicrescente, e portanto, uma cópula.
Lema 2.4. Sejam φ,φ[−1] e C satisfazendo as hipóteses do Lema 2.3. Então C é bicrescente, se e
somente se, sempre que u1 ≤ u2,
C(u2, v)− C(u1, v) ≤ u2 − u1 (3.24)
Demonstração. (⇒)
VC([u1, u2]× [v, 1]) = C(u1, v)+C(u2, 1)−C(u1, 1)−C(u2, v) ≥ 0 ⇔ u2−u1 ≥ C(u2, v)−C(u1, v)
Então, a equação (3.24) é equivalente à condição VC([u1, u2]× [v, 1]) ≥ 0 que é sempre válida quando
C é bicrescente.
(⇐) Considere C satisfazendo a equação (3.24). Sejam v1, v2 ∈ I, v1 ≤ v2, temos C(0, v2) = 0 ≤v1 ≤ v2 = C(1, v2). Como C é contínua, desde que φ e φ[−1] também são, existe t ∈ I tal que
C(t, v2) = v1, ou seja, φ(v2) + φ(t) = φ(v1). Então
C(u2, v1)− C(u1, v1) = φ[−1](φ(u2) + φ(v1))− φ[−1](φ(u1) + φ(v1))
= φ[−1](φ(u2) + φ(v2) + φ(t))− φ[−1](φ(u1) + φ(v2) + φ(t))
= φ[−1](φ(C(u2, v2)) + φ(t))− φ[−1](φ(C(u1, v2)) + φ(t))
= C(C(u2, v2), t)− C(C(u1, v2, t))(3.24)
≤ C(u2, v2)− C(u1, v2) ⇔ VC([u1, u2]× [v1, v2]) ≥ 0

42
O próximo teorema mostra que a condição da função C ser bicrescente dada pelo Lema 2.4
também encontra-se relacionada com uma propriedade da função φ, bem como as outras duas
condições para que C seja uma cópula (Lema 2.3).
Deste modo, somente a estrutura da função φ pode determinar se a função C da equação (3.22)
é ou não uma cópula.
Teorema 2.6. Sejam φ e φ[−1] como na Definição 2.7. Então a função C : I2 → I dada pela
equação (3.22) é uma cópula se e somente se φ é convexa.
Demonstração. Como consequência do Lema 2.4 é necessário provar que a equação (3.24) é válida
se e somente se φ é convexa.
(⇒) Observe que a equação (3.24) é equivalente a
u1 + φ[−1](φ(u2) + φ(v)) ≤ u2 + φ[−1](φ(u1) + φ(v))
para u1 ≤ u2, se denotarmos a = φ(u1), b = φ(u2) e c = φ(v), então a equação (3.24) também é
equivalente a
φ[−1](a) + φ[−1](b+ c) ≤ φ[−1](b) + φ[−1](a+ c) (3.25)
onde a ≥ b, por φ ser decrescente, e c ≥ 0.
Supondo a equação (3.24) válida, ou seja, supondo que φ[−1] satisfaça a equação (3.25). Sejam
s, t ∈ [0,∞] tais que 0 ≤ s ≤ t. Se definirmos a = (s+ t)/2, b = s e c = (t− s)/2 na equação (3.25),
temos
φ[−1]
(s+ t
2
)≤ φ[−1](s) + φ[−1](t)
2
Logo φ[−1] é mid-convexa, e desde que φ[−1] é contínua segue que φ[−1] é convexa. O fato de φ[−1]
convexa implica na convexidade de φ.
(⇐) Assuma φ[−1] convexa. Sejam a, b, c ∈ I tais que a ≥ b e c ≥ 0; e seja
0 ≤ γ = (a−b)/(a−b+c) ≤ 1. Deste modo temos a = (1−γ)b+γ(a+c) e b+c = γb+(1−γ)(a+c).
Logo por definição de função convexa,
φ[−1](a) ≤ (1− γ)φ[−1](b) + γφ[−1](a+ c)

43
e
φ[−1](b+ c) ≤ γφ[−1](b) + (1− γ)φ[−1](a+ c)
Somando as duas últimas igualdades resulta na equação (3.25), que completa a prova.
Cópulas da forma apresentada na equação (3.22) são denominadas Cópulas Arquimedianas. A
função φ é denominada gerador de uma cópula Arquimediana. Se φ(0) = ∞, φ é denominada
gerador estrito. Conforme Definição 2.7, φ[−1] = φ−1 e C(u, v) = φ−1(φ(u) + φ(v)) é denominada
cópula Arquimediana estrita. Se φ(0) <∞, φ é denominada gerador não estrito.
Cópulas Arquimedianas podem ser contruídas usando o Teorema 2.6 - apenas encontrando
funções φ com propriedades que satisfaçam sua hipótese - e definindo as correspondentes cópu-
las via equação (3.22). Em outras palavras, a cópula Arquimediana C é unicamente determinada
pelo gerador φ.
Exemplo 2.5.(continuação) Seja φ(t) = 1 − t, ∀t ∈ I, um gerador não estrito (Figura 2.2).
De acordo com a Definição 2.7 φ[−1](t) = φ−1(t) = 1− t, ∀t ∈ I e 0 para t > 1, ou seja, φ[−1](t) =
max(1− t, 0). Gerando a cópula C via equação (3.22), temos
φ−1(φ(u) + φ(v)) = max(1− [(1− u) + (1− v)], 0) = max(u+ v − 1, 0) = W (u, v)
Sendo então a cópula limite inferior de Frechét uma cópula Arquimediana.
Exemplo 2.6.(continuação) Seja φ(t) = − ln(t), ∀t ∈ I, um gerador estrito (Figura 2.3).
Segue da Definição 2.7 que φ[−1](t) = φ−1(t) = exp(−t), 0 ≤ t <∞. Pela equação (3.22), temos
φ−1(φ(u) + φ(v)) = exp(−[(− lnu) + (− ln v)]) = uv = Π(u, v)
Deste modo a cópula produto Π é também Arquimediana.
Exemplo 2.7. Uma grande variedade de famílias paramétricas de cópulas pertence a classe das
cópulas Arquimedianas. Nelsen [31] apresenta uma lista extensa com as famílias de cópulas Arqui-
medianas mais comuns. Algumas destas famílias são apresentadas na Tabela 3.1.
As quatro cópulas apresentam diferenças distintas com relação a estrutura de dependência que
representam. A família de Gumbel apresenta dependência caudal superior, a família de Clayton
apresenta dependência caudal inferior, a família de cópulas 4.2.12 apresenta ambas dependências
caudais e a família de Frank não apresenta dependência caudal, é simétrica em relação a diagonal
secundária.

44
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
t
phi(t
)
0.0 0.5 1.0 1.5 2.0 2.5 3.00.
00.
20.
40.
60.
81.
0
t
phi^
[−1]
(t)
Figura 2.2: Gerador φ não estrito e pseudo-inversa φ[−1] para a cópula Arquimediana W .
nome Cθ(u, v) φθ(t) θ ∈ estrito
Clayton max([u−θ + v−θ − 1]−1/θ
)t−θ−1θ [−1,∞]\0 θ ≥ 0∗
Gumbel exp(−[(− lnu)θ + (− ln v)θ]1/θ) (− ln t)θ [1,∞) sim
Frank −1θ ln
(1 + (e−θu−1)(e−θv−1)
e−θ−1
)− ln e−θv−1
e−θ−1(−∞,∞)\0 sim
4.2.12 (1 + [(u−1 − 1)θ + (u−1 − 1)θ]1/θ)−1(
1t − 1
)θ [1,∞) sim
Tabela 3.1: Algumas famílias paramétricas de cópulas Arquimedianas com seus geradores e espaços
paramétricos (*na cópula de Clayton o gerador é estrito se θ ≥ 0, caso contrário é não estrito).
Nelsen [31] não apresenta nenhum nome especial para a última cópula da Tabela 3.1, logo esta
dissertação refere-se a esta cópula conforme notação deste autor.

45
0.0 0.5 1.0 1.5 2.0 2.5 3.0
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
t
phi(t
)
0 1 2 3 40.
00.
20.
40.
60.
81.
0
t
phi^
[−1]
(t)
Figura 2.3: Gerador φ estrito e pseudo-inversa φ[−1] para a cópula Arquimediana Π.
2.4 Cópulas Multivariadas e a Transformada de Laplace
Conforme já mencionado, para a construção de distribuições contínuas multivariadas, pode-se
utilizar as suas funções densidade marginais univariadas e uma estrutura de dependência multivari-
ada, ou seja, a função de distribuição acumulada conjunta FX pode ser obtida através de suas funções
de distribuição acumulada marginais e da cópula que é uma estrutura de dependência dada por uma
distribuição CX associada à X. Em outras palavras, a cópula é a distribuição multivariada de um
vetor aleatório composto por distribuições marginais univariadas U(0, 1). Para uma distribuição m-
variada F ∈ =(F1(x1), ..., Fm(xm)), onde Fj é a j-ésima função de distribuição marginal univariada,
a cópula associada à F é uma função distribuição C : [0, 1]m −→ [0, 1] que satisfaz
F (x) = C(F1(x1), ..., Fm(xm)) (4.26)
onde x ∈ Rm [25].

46
Se F é uma função de distribuição contínua m-variada com marginais univariadas F1, ..., Fm e
funções quantis F−11 , ..., F−1
m , então C(u) = F (F−11 (u1), ..., F−1
m (um)) é única e verifica (4.26).
Nesta seção, serão utilizadas mistura de potência das f.d.a. univariadas e a Transformada de
Laplace para a construção de uma cópula C. A seguir será definida a Transformada de Laplace.
Definição 2.8. Seja M uma função de distribuição acumulada de uma v.a. não-negativa. A
Transformada de Laplace é definida por
φ(s) =∫ ∞
0e−swdM(w) (4.27)
onde s ≥ 0 [25].
Se πo for a massa de M em 0, então lims→∞φ(s) = φ(∞) = πo. Durante o capítulo, será
assumido que as Transformadas de Laplace correspondem à transformadas de v.a. positivas, isto é,
M(0) = 0 ou, em termos de φ(s), φ(∞) = 0. Isto é devido ao fato de que exp−φ−1(F (x)) será
uma f.d.a. quando F for uma f.d.a. univariada.
Observa-se que a transformada φ é contínua, estritamente decrescente e satisfaz φ(0) = 1. Então,
o funcional inverso φ−1 é estritamente decrescente e satisfaz φ−1(0) = ∞ e φ−1(1) = 0.
Além disso, φ possui derivadas contínuas de todas as ordens e derivadas com sinais alternados,
isto é, (−1)iφ(i)(s) ≥ 0 para todo s ≥ 0 onde φ(i) representa a i-ésima derivada. Esta propriedade
de alternância de sinais na derivada é denominada completamente monótona.
Seja Lm = φ : [0,∞) → [0, 1]|φ(0) = 1, φ(∞) = 0, (−1)jφ(j) ≥ 0, j = 1, ...,m, m = 1, 2, ..., a
classe das funções diferenciáveis, estritamente decrescentes. Considerando a classe
L∗n = w : [0,∞) → [0,∞)|w(0) = 0, w(∞) = ∞, (−1)j−1w(j) ≥ 0, j = 1, ..., n, n = 1, 2, ...,
tem-se que as funções em L∗n são, usualmente, composições da forma ψ−1 φ com ψ, φ ∈ L1 . As
composições do tipo ψ−1 φ ∈ L∗∞ aparecerão na construção de cópulas trivariadas.
A seguir serão apresentados alguns teoremas sobre a classe L∗∞. Estes são úteis pois nos fornecem
a imagem das funções que são o domínio das Transformadas de Lapace. Isto nos possibilita verificar
se o domínio das expresões utilizadas na construção de cópulas é [0,∞).
Teorema 2.7. Seja χ uma Transformada de Laplace. Então χα é completamente monótona para
todo α > 0 se e somente se −ln(χ) ∈ L∗∞.

47
Demonstração: Para a demonstração consulte [25].
Teorema 2.8. Se ψ é uma Transformada de Laplace tal que −ln(ψ) ∈ L∗∞ e φ é outra Transformada
de Laplace, então η(s) = φ(−ln(ψ(s))) é uma Transformada de Laplace.
Demonstração: Para a demonstração consulte [25].
Seja F uma dada f.d.a. univariada. Então, existe uma única f.d.a. G tal que
F (x) =∫ ∞
0Gα(x)dM(α) (4.28)
Comparando (4.27) e (4.28) podemos escrever
F (x) =∫ ∞
0Gα(x)dM(α) = φ(−ln(G(x))) (4.29)
Da expressão (4.29) obtemos G(x) = e−φ−1(F (x)). Para simplificar a notação, o valor x em
G(x) = e−φ−1(F (x)) será suprimido.
Considerando a classe bivariada =(F1, F2), seja Gj = e−φ−1(Fj), j = 1, 2. Então, a expressão a
seguir é uma f.d.a. em =(F1, F2):∫ ∞
0Gα1G
α2 dM(α) = φ(−ln(G1)− ln(G2)) = φ(φ−1(F1) + φ−1(F2)) (4.30)
A cópula obtida considerando que F1 e F2 assumem valores da distribuição U(0, 1) é
C(u1, u2) = φ(φ−1(u1) + φ−1(u2)) (4.31)
A forma (4.31) é denominada Cópula Arquimediana e possui a seguinte propriedade:
Teorema 2.9. A cópula (4.31) possui densidade TP2.
Demonstração: Para a demonstração consulte [25].

48
O teorema anterior fornece a dependência da cópula arquimediana. Como ela possui dependên-
cia TP2, que é uma dependência forte, então, ela, também, possui dependência SI, LTD, RTI, PQD.
Porém, ela poderá ser adequada na modeladem de variáveis aleatórias TP2 e não ser adequada na
modelagem de variáveis aleatórias que possuem algum tipo de dependência mais fraco, por exemplo,
v.a. SI.
Para m f.d.a. univariadas, F1, ..., Fm, uma extensão simples é dada pela f.d.a. multivariada
F = φ(∑m
j=1 φ−1(Fj)) cuja Cópula Arquimediana é,
C(u) = φ(m∑j=1
φ−1(uj)) (4.32)
Uma generalização trivariada de (4.31), no sentido de obter-se mais estruturas de dependência
pois a expressão seguinte envolverá duas Transformadas de Laplace diferentes e, consequentemente,
envolverá mais que um parâmetro, ao contrário da expressão (4.32) que envolve apenas uma Trans-
formada de Laplace, é dada por
C(u) = ψ(ψ−1 φ[φ−1(u1) + φ−1(u2)] + ψ−1(u3)) (4.33)
onde ψ, φ são Transformadas de Laplace e ν = ψ−1 φ ∈ L∗∞.
Note que (4.33) possui funções de distribuição marginais bivariadas nas coordenadas (1, 2) da
forma (4.31) com Transformada de Laplace φ e funções de distribuição marginais bivariadas nas
coordenadas (1, 3) e (2, 3) da forma (4.31) com Transformada de Laplace ψ. Observe que (4.32)
é um caso especial de (4.33) quando ψ = φ. A representação em forma de mistura de funções de
distribuição de (4.33), que generaliza (4.30), é
C(u) =∫ ∞
0
∫ ∞
0Gβ1 (u1)G
β2 (u2)dM2(β, α)Gα3 (u3)dM1(α) (4.34)
onde G1 = G2 = e−φ−1 e G3 = e−ψ
−1 , M1 é a distribuição correspondente à ψ, M2(.;α) é a
distribuição com Transformada de Laplace χα definida por χ−1α (z) = ν−1(−α−1ln(z)).
A expressão (4.34) segue da seguinte representação:

49
∫ ∞
0Gα12(u1, u2)Gα3 (u3)dM1(α)
onde M1 e G3 foram definidas anteriormente e G12(u1, u2) = exp(−ν[φ−1(u1) + φ−1(u2)]).
As seguintes famílias uniparamétrica de Transformada de Laplace (TL) podem ser utilizadas
para a construção de cópulas com o uso das expressões apresentadas anteriormente:
• TLA: φθ(s) = exp(−s1/θ), θ ≥ 1;
• TLB (gamma): φθ(s) = (1 + s)−1/θ, θ ≥ 0;
• TLC (série de potência): φθ(s) = 1− (1− e−s)1/θ, θ > 0;
• TLD (série logarítmica): φθ(s) = −θ−1ln(1− (1− e−θ)e−s), θ > 0.
As correspondentes transformadas inversas são dadas por:
• TLA: φ−1θ (t) = (−ln(t))θ;
• TLB: φ−1θ (t) = t−θ − 1;
• TLC: φ−1θ (t) = −ln(1− (1− t)θ);
• TLD: φ−1θ (t) = −ln
(1−e−θt
1−e−θ
).
onde t = φ(s).
A fim de motivar a construção das Transformadas de Laplace observa-se que a família TLD é
obtida através de uma v.a. cuja função de probabilidade possui a expressão (1−e−θ)i
iθ , i = 1, 2, ... .
Similarmente, a família TLC é obtida através de uma v.a. cuja função de probabilidade é θ−1 para
i = 1 e θ−1∏i−1j=1(j − θ−1) para i = 2, 3, ... .
Além das famílias de Transformadas de Laplace mostradas anteriormente, Joe [25] apresenta
outras famílias.

50
Considerando-se as famílias TLA, TLB, TLC e TLC, pode-se mostrar que −ln(φθ) ∈ L∗∞. Para
as famílias TLA e TLB, a demonstração é direta. E, para as famílias TLC e TLD, demonstra-se
utilizando o Teorema 2.7. Para as demonstrações destes fatos consulte [25].
As famílias de Transformada de Laplace citadas anteriormente podem ser aplicadas na equação
(4.31) obtendo-se os modelos de cópulas bivariadas a seguir.
• Família B1: Modelo de Frank [12]
Este modelo utiliza a Transformada de Laplace φ como sendo a família TLD. A cópula asso-
ciada à este modelo é dada por
C(u, v; δ) = −δ−1ln
(η − (1− e−δu)(1− e−δv)
η
)
onde η = 1− e−δ, 0 ≤ δ <∞.
A função densidade associada à este modelo de cópula é,
c(u, v; δ) =δηe−δ(u+v)
(η − (1− e−δu)(1− e−δv))2
Esta família possui, entre outras, as seguintes propriedades: SI, densidade TP2, reflexão
simétrica 1 [25].
Este modelo engloba o caso das variáveis aleatórias serem independentes quando δ → 0.
• Família B2: Modelo de Kimeldorf e Sampson [29]
Este modelo utiliza a Transformada de Laplace φ como sendo a família TLB. A cópula asso-
ciada a este modelo é dada por
C(u, v; δ) = (u−δ + v−δ − 1)−1/δ
para 0 ≤ δ <∞.1c(u, v|δ) = c(1− u, 1− v|δ), 0 < u, v < 1

51
A sua função densidade é dada por:
c(u, v; δ) = (1 + δ)(uv)−δ−1(u−δ + v−δ − 1)−2−1/δ
Esta família possui, entre outras, as seguintes propriedades: SI, densidade TP2 [25].
Este modelo engloba o caso das v.a. serem independentes quando δ → 0.
• Família B3: Modelo de Joe [24]
Este modelo utiliza a Transformada de Laplace φ como sendo a família TLC. A cópula asso-
ciada a este modelo é dada por
C(u, v; δ) = 1− (uδ + vδ − uδvδ)1/δ
para 1 ≤ δ <∞ onde u = 1− u e v = 1− v.
A sua função densidade é,
c(u, v; δ) = uδ−1vδ−1[δ − 1 + u−δ + v−δ − uδvδ](uδ + vδ − uδvδ)−2+1/δ
Esta família possui, entre outras, as seguintes propriedades: SI, densidade TP2 [25].
Este modelo engloba o caso das v.a. serem independentes quando δ = 1.
• Família B4: Modelo de Gumbel [21]
Este modelo utiliza a Transformada de Laplace φ como sendo a família TLA. A cópula asso-
ciada a este modelo é dada por
C(u, v; δ) = exp(−(uδ + vδ)1/δ)
para 1 ≤ δ <∞ onde u = −ln(u) e v = −ln(v).

52
A função densidade associada à este modelo de cópula é dada por:
c(u, v; δ) = C(u, v; δ)(uv)−1 (uv)δ−1
(uδ + vδ)2−1/δ[(uδ + vδ)1/δ + δ − 1]
Esta família possui, entre outras, as seguintes propriedades: SI, densidade TP2 [25].
Este modelo engloba o caso das v.a. serem independentes quando δ = 1.
Joe [25] apresenta outros modelos de cópulas bivariadas além de extendê-los para variáveis
aleatórias com dependência negativa.
• Família M1: Generalização da família B2
Este modelo utiliza as Transformadas de Laplace ψθ1 e φθ2 como sendo a família TLB. A
cópula associada a este modelo é dada por
C(u1, u2, u3; θ1, θ2) =[(u−θ21 + u−θ22 − 1
)θ1/θ2+ u−θ13 − 1
]−1/θ1
para θ1 ≤ θ2, θ1 ≥ 0 e θ2 ≥ 0.

53
• Família M2: Generalização da família B4
Este modelo utiliza as Transformadas de Laplace ψθ1 e φθ2 como sendo a família TLA. A
cópula associada a este modelo é dada por
C(u1, u2, u3; θ1, θ2) = exp
−((
[−ln(u1)]θ2 + [−ln(u2)]θ2)θ1/θ2
+ [−ln(u3)]θ1)1/θ1
para θ1 < θ2, θ1 ≥ 1 e θ2 ≥ 1.

54

Capítulo 3
Variável BIPIT
3.1 Variáveis PIT e BIPIT
Sabe-se que se X é v.a. unidimensional com f.d.a. F contínua, temos U = F (X), a v.a. transfor-
mada pela acumulada, com distribuição U(0, 1). Porém, para maiores dimensões isto geralmente não
acontece. Suponha (X,Y ) com f.d.a. H, seja H = H(X,Y ), a v.a. transformada pela acumulada
conjunta, geralmente a f.d.a. K de H não é U(0, 1).
Exemplo 3.1. Seja (x1, y1), . . . , (x100, y100) uma amostra aleatória de uma distribuição H normal
bivariada com média µ = (0, 0) e matrix de covariância
Σ =
(1 0.3
0.3 1
)Tomemos a v.a. H = H(X,Y ). O QQplot entre a amostra aleatória da v.a. H calculada
por Hi = H(xi, yi) e uma amostra com distribuição U(0, 1) pode-se concluir que H não seque
distribuição U(0, 1) (Figura 3.1).
O estudo da v.a. H e de sua f.d.a. K é importante, pois ambas contém informação de dependên-
cia sob H(X,Y ), já que dependem apenas da cópula associada a H pelo Teorema 2.3, e não das
marginais F e G,
K(t) = P (H(X,Y ) ≤ t) = P (C(F (X), G(Y )) ≤ t) = P (C(U, V ) ≤ t)
55
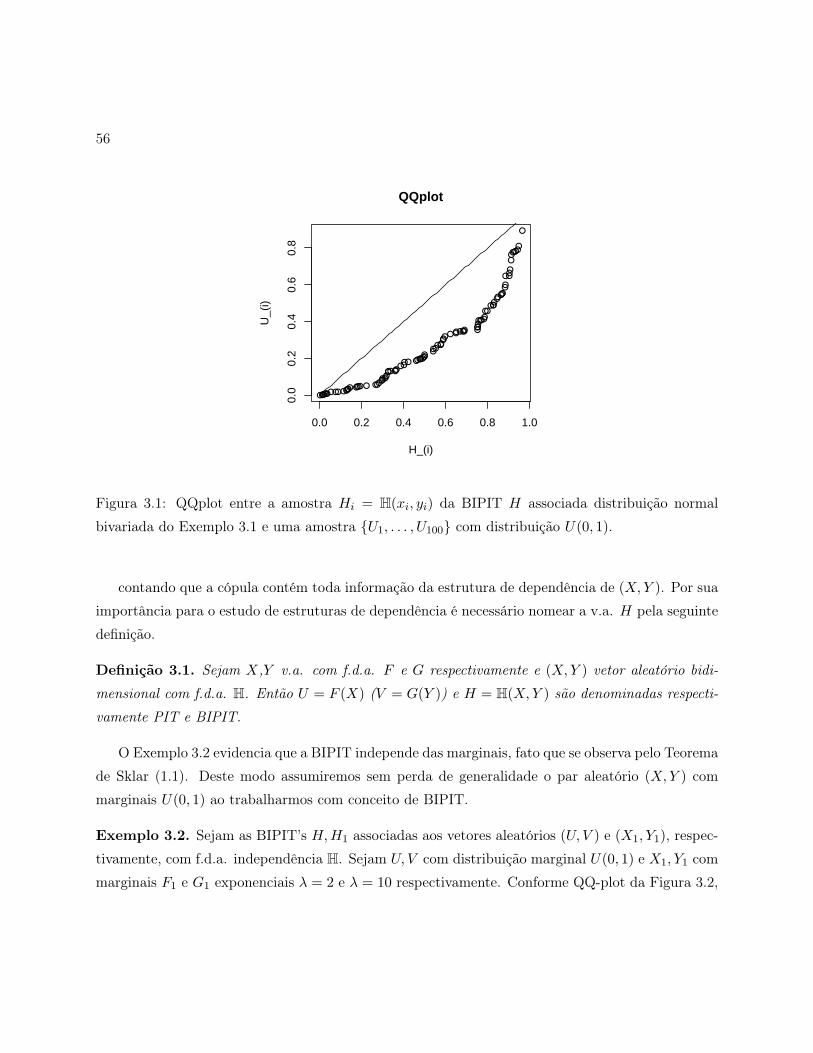
56
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
QQplot
H_(i)
U_(
i)
Figura 3.1: QQplot entre a amostra Hi = H(xi, yi) da BIPIT H associada distribuição normal
bivariada do Exemplo 3.1 e uma amostra U1, . . . , U100 com distribuição U(0, 1).
contando que a cópula contém toda informação da estrutura de dependência de (X,Y ). Por sua
importância para o estudo de estruturas de dependência é necessário nomear a v.a. H pela seguinte
definição.
Definição 3.1. Sejam X,Y v.a. com f.d.a. F e G respectivamente e (X,Y ) vetor aleatório bidi-
mensional com f.d.a. H. Então U = F (X) (V = G(Y )) e H = H(X,Y ) são denominadas respecti-
vamente PIT e BIPIT.
O Exemplo 3.2 evidencia que a BIPIT independe das marginais, fato que se observa pelo Teorema
de Sklar (1.1). Deste modo assumiremos sem perda de generalidade o par aleatório (X,Y ) com
marginais U(0, 1) ao trabalharmos com conceito de BIPIT.
Exemplo 3.2. Sejam as BIPIT’s H,H1 associadas aos vetores aleatórios (U, V ) e (X1, Y1), respec-
tivamente, com f.d.a. independência H. Sejam U, V com distribuição marginal U(0, 1) e X1, Y1 com
marginais F1 e G1 exponenciais λ = 2 e λ = 10 respectivamente. Conforme QQ-plot da Figura 3.2,

57
H e H1 são identicamente distribuídas, evidenciando que a estrutura de dependência da BIPIT é
invariante sob as marginais.
0.0 0.2 0.4 0.6 0.8
0.0
0.2
0.4
0.6
0.8
H_(1i)
H_(
i)
Figura 3.2: QQplot das amostras das BIPITS H e H1: H1, . . . ,Hn e H11, . . . ,H1n respectiva-
mente, n = 100, onde Hi = H(ui, vi) = uivi sendo ui, vi amostras de U(0, 1) e H1i = H(x1i, y1i) =
F1(x1i)G1(y1i) sendo x1i com distribuição exp(2) e y1i com distribuição exp(10).
Os seguintes teoremas apresentam uma expressão para o cálculo da função distribuição K da
BIPIT H = C(X,Y ).
Teorema 3.1. Seja (X,Y ) um vetor aleatório com f.d.a. C e seja K a f.d.a. da v.a. BIPIT,
H ≡ C(X,Y ). Então
K(v) =∫ 1
0E(IC(x, Y ) ≤ v|X = x)dx (1.1)

58
Demonstração.
K(v) = P (C(X,Y ) ≤ v) = E[IC(X,Y ) ≤ v]
= E(E[IC(x, Y ) ≤ v|X = x])
=∫ 1
0E(IC(x, Y ) ≤ v|X = x)dx. (1.2)
Teorema 3.2. Sejam Cx(y) ≡ C(x, y) estritamente crescente e inversível e yx,v ≡ C−1x (v), ∀0 ≤
v ≤ x, 0 < x < 1. Então,
K(v) = v +∫ 1
vC∗(x, yx,v)dx ≡ v − λ(v) (1.3)
onde, C∗(x, y) ≡ ∂C(x,y)∂x e λ(v) ≡ −
∫ 1v C
∗(x, yx,v)dx.
Demonstração. Pela equação (1.1) K(v) pode ser escrito como
K(v) =∫ v
0E(IC(x, Y ) ≤ v|X = x)dx︸ ︷︷ ︸
(1)
+∫ 1
vE(IC(x, Y ) ≤ v|X = x)dx︸ ︷︷ ︸
(2)
.
De acordo com o Teorema 2.2 toda cópula C é limitada superiormente pela cópula maximal
M(x, y) = min(x, y). Então, ∀ 0 ≤ x ≤ v, C(x, y) ≤ v, logo IC(x, Y ) ≤ v = 1 para a região de
integração da integral (1). Desta maneira a integral (1) é igual a v. A integral (2) pode ser reescrita
como
∫ 1
vP (C(x, Y ) ≤ v|X = x)dx
Conforme hipótese, C(x, yx,v) = v para x fixo, e C é marginalmente não decrescente, logo temos
a equivalência C(x, Y ) ≤ v ⇔ Y ≤ yx,v. Então∫ 1
vP (C(x, Y ) ≤ v|X = x)dx =
∫ 1
vP (Y ≤ yx,v|X = x)dx
=∫ 1
v
(∫ yx,v
0c(x, y)dy
)dx
=∫ 1
vC∗(x, yx,v)dx

59
onde c é a densidade de C, c(u, v) ≡ ∂2C∂u∂v (u, v).
Exemplo 3.3. Cópula Produto: Π(x, y) = xy ; x, y ∈ I
Sem a aplicação do Teorema 3.2 temos,
KΠ(v) = P (XY ≤ v) =∫ 1
0P
(X ≤ v
y
)dy
=∫ v
01dy +
∫ 1
v
v
ydy = v − v ln v
Usando o Teorema 3.2 temos Π∗(x, y) = y e Π(x, yx,v) = v, então yx,v = vx . Logo,∫ 1
vΠ∗(x, yx,v)dx =
∫ 1
vyx,vdx =
∫ 1
v
v
xdx = −v ln v
Portanto, KΠ(v) = v − v ln v.
Exemplo 3.4. Cópula Maximal: M(x, y) = min(x, y) ; x, y ∈ I
Observe que KM (v) deve ser calculada através de uma mistura de cópulas, Cα(x, y) = (1− α)xy +
αmin(x, y), 0 ≤ α ≤ 1, chamada Família de Fréchet, porque a Cópula M não satisfaz a hipótese
do Teorema 3.2 pois Mx(y) não é estritamente crescente . Quando α → 1, temos KCα(v) → v e
segue que KM (v) = v.
No Teorema 3.2 yx,v ≡ C−1x (v), 0 ≤ v ≤ x, 0 < x < 1 fixo, representa a segunda coordenada
dos pontos do conjunto de nível v da cópula C dado por
(x, yx,v) ∈ I2|C(x, yx,v) = v
Conforme Nelsen [31], para uma cópula Arquimediana este conjunto de nível v consiste dos pontos
(x, yx,v) pertencentes a curva
φ(x) + φ(yx,v) = φ(v), (x, yx,v) ∈ I2, v > 0 (1.4)
A curva (1.4) pode ser reescrita expressando yx,v em função de x por
yx,v = Lv(x) = φ[−1](φ(v)− φ(x)) = φ−1(φ(v)− φ(x)) (1.5)
sendo a última igualdade garantida pela Definição 2.7.

60
Para v = 0, o conjunto (x, yx,v) ∈ I2|C(x, yx,v) = 0 é chamado conjunto zero de C e denotado
por Z(C). Para as cópulas Arquimedianas com gerador estrito, por exemplo para família de Frank
(Tabela 3.1), Z(C) é composto pelos dois segmentos de reta 0×I e I×0 de acordo com Definição
2.5. Para as cópulas Arquimedianas com gerador não estrito, por exemplo para família de Clayton
θ ≥ 0 (Tabela 3.1), Z(C) tem área positiva e é limitado pelos segmentos 0 × I e I × 0 e pela
curva φ(x) + φ(yx,v) = φ(0), isto é, yx,v = L0(x) chamada curva zero de C.
O Corolário a seguir fornece ferramentas para facilitar o cálculo da f.d.a. K de BIPIT assoaciada
a uma classe particular de cópulas, as cópulas Arquimedianas que serão o foco desta dissertação.
Em sua demonstração é usado o conceito de curva de nível de cópulas Arquimedianas.
Corolário 3.1. Seja C uma cópula Arquimediana gerada por φ ∈ Ω. A f.d.a. K da v.a. BIPIT,
H ≡ C(X,Y ), é dada por:
K(v) = v − φ(v)φ′(v+)
(1.6)
onde, φ′(v+), denota a derivada a direita de φ em v e Ω o espaço dos geradores φ.
Demonstração. Utilizaremos o Teorema 3.2 para demonstrar que λ(v) = φ(v)φ′(v) usando os conceitos
de curva de nível e conjunto de nível de uma cópula Arquimediana C.
C∗(x, y) ≡ ∂C(x, y)∂x
=(φ′(x) +
∂φ(y)∂x
)φ[−1]′ (φ(x) + φ(y)) = φ′(x)φ[−1]′ (φ(x) + φ(y))
então,
C∗(x, yx,v) = φ′(x)φ[−1]′(φ(x) + φ(yx,v))(1.5)= φ′(x)φ[−1]′(φ(v)) =
φ′(x)φ′(φ−1(φ(v)))
=φ′(x)φ′(v)
.
para v > 0.
Para o caso v = 0 temos (x, yx,v), os pontos pertencentes ao conjunto zero da cópula C, dados
não somente pela curva L0(x) da equação (1.5), mas pertencentes ao conjunto
(x, yx,v)|x ∈ I e yx,v = 0︸ ︷︷ ︸(1)
∪(x, yx,v)|y ∈ I e x = 0︸ ︷︷ ︸(2)
∪(x, yx,v)|φ(x) + φ(yx,v) ≥ φ(0)︸ ︷︷ ︸(3)

61
Se (x, yx,v) ∈ (1), temos
C∗(x, yx,v) = φ′(x)φ[−1]′(φ(x) + φ(yx,v)) = φ′(x)φ[−1]′(φ(x) + φ(0))
=φ′(x)
φ′(φ[−1](φ(x) + φ(0)))=φ′(x)φ′(0)
usando a Definição 2.7. Por simetria, para o conjunto (2) segue idêntico resultado.
E se (x, yx,v) ∈ (3), temos
φ(x) + φ(yx,v) ≥ φ(x) + φ(0)− φ(x) = φ(0)
então,
C∗(x, yx,v) = φ′(x)φ[−1]′(φ(x) + φ(yx,v))
=φ′(x)
φ′(φ[−1](φ(x) + φ(yx,v)))
=φ′(x)φ′(0)
usando a Definição 2.7.
Deste modo segue que,
λ(v) = −∫ 1
v
φ′(x)φ′(v)
dx =φ(v)φ′(v)
, v ∈ I.
Logo, para v ∈ I temos K(v) = v − λ(v) = v − φ(v)φ′(v) considerando φ diferenciável em v.
Se φ não for diferenciável em v, temos φ′(v) ≡ φ′(v+), pois v ≤ x por hipótese do Teorema 3.2.
Concluindo, K(v) = v − φ(v)φ′(v+)
para qualquer gerador φ de cópula Arquimediana C.
Exemplo 3.5. A Tabela 1.1 apresenta as funções distribuição K, calculadas por meio do Corolário
3.1, de algumas cópulas Arquimedianas.
Como visto no Exemplo 2.7, a cópula de Clayton C−1 é a cópula minimal W , então substituindo
θ = −1 na função distribuição K de Clayton temos
KW (v) = 1, ∀v ∈ [0, 1]

62
cpula φθ(v) Kθ(v)
Clayton v−θ−1θ v + v
θ (1− vθ)
Gumbel (− ln v)θ v − v ln vθ
Frank − ln e−θv−1e−θ−1
v +θe−θv ln e−θv−1
e−θ−1
e−θv−1
4.2.12(
1v − 1
)θv +
v2( 1v−1)θ
Tabela 1.1: Cópulas Arquimedianas da Tabela 3.1 com os respectivos geradores φ e funções dis-
triuição K.
Do mesmo modo usando θ = 1 na função distribuição K de Gumbel temos
KΠ(v) = v − v ln v, ∀v ∈ [0, 1]
3.2 Propriedades da função K
Esta seção apresenta propriedades para K relativas a uma ordenação estocástica definida a seguir.
Definição 3.2. A ordem estocástica ordinária entre duas v.a. contínuas X1 e X2 com f.d.a. F1 e
F2 respectivamente é denotada por X1 ≺st X2 equivalente a
F1(x) ≥ F2(x), ∀x ∈ R.
Definição 3.3. A ordem estocástica de Kendall entre dois vetores aleatórios contínuos (X1, Y1) e
(X2, Y2) com f.d.a. H1 e H2 respectivamente e denotada como
(X1, Y1) ≺k (X2, Y2) ou H1(X1, Y1) ≺st H2(X2, Y2)
representa a ordenação estocástica entre as BIPIT’s H1 ≡ H1(X1, Y1) e H2 = H2(X2, Y2), ou seja,
H1 ≺st H2.
Esta ordem estocástica é chamada Kendall devido a estar associada ao coeficiente populacional
da medida de associação tau de Kendall estudada no próximo capítulo. Também existe uma asso-
ciação entre a função K e a medida tau de Kendall, que será apresentada no próximo capítulo, por
isso K é chamada frequentemente de função distribuição de Kendall [32].

63
O teorema abaixo valida os limites de Frechét também para a ordem estocástica de Kendall.
Teorema 3.3. Sejam K a f.d.a. da v.a. BIPIT H ≡ C(X,Y ) e a função λ(v), v ∈ I, definida pelo
Teorema 2.3.
KM (v) ≤ K(v) ≤ KW (v), ou seja, v ≤ K(v) ≤ 1, v ∈ I; (2.7)
λW (v) ≤ λ(v) ≤ λM (v), ou seja, v − 1 ≤ λ(v) ≤ 0, v ∈ I. (2.8)
Demonstração. Equação (2.7): É trivial que K(v) ≤ 1 com K(v) f.d.a. Sendo C(x, y) não de-
crescente marginalmente, temos C∗(x, y) positiva, logo λ(v) ≡ −∫ 1v C
∗(x, yx,v)dx ≤ 0, deste modo
K(v) = v − λ(v) ≥ v.
Equação (2.8): Provada equação (2.7) temos
v ≤ K(v) ≤ 1 ⇔ v ≤ v − λ(v) ≤ 1 ⇔ v − 1 ≤ λ(v) ≤ 0
Corolário 3.2. Os limites de Frechét são válidos para a ordem estocástica de Kendall
W ≺k C ≺k M
Exemplo 3.6. As Figuras 3.3 e 3.4 ilustram o Teorema 3.3 e o Corolário 3.2 mostrando KM ≤K ≤ KW e λW (v) ≤ λ(v) ≤ λM (v) para as funções K das cópulas de Gumbel e Clayton. Além de
também ilustrarem a ordenação estocástica de Kendall para as famílias de Clayton e Gumbel com
θ ≤ θ∗ ⇒ KCθ≥ KCθ∗ , ou seja Cθ ≺k Cθ∗ .
Tal ordenação é confirmada através das formas analíticas das funções K apresentadas no Exem-
plo 3.5 para a fámília de Clayton e Gumbel.
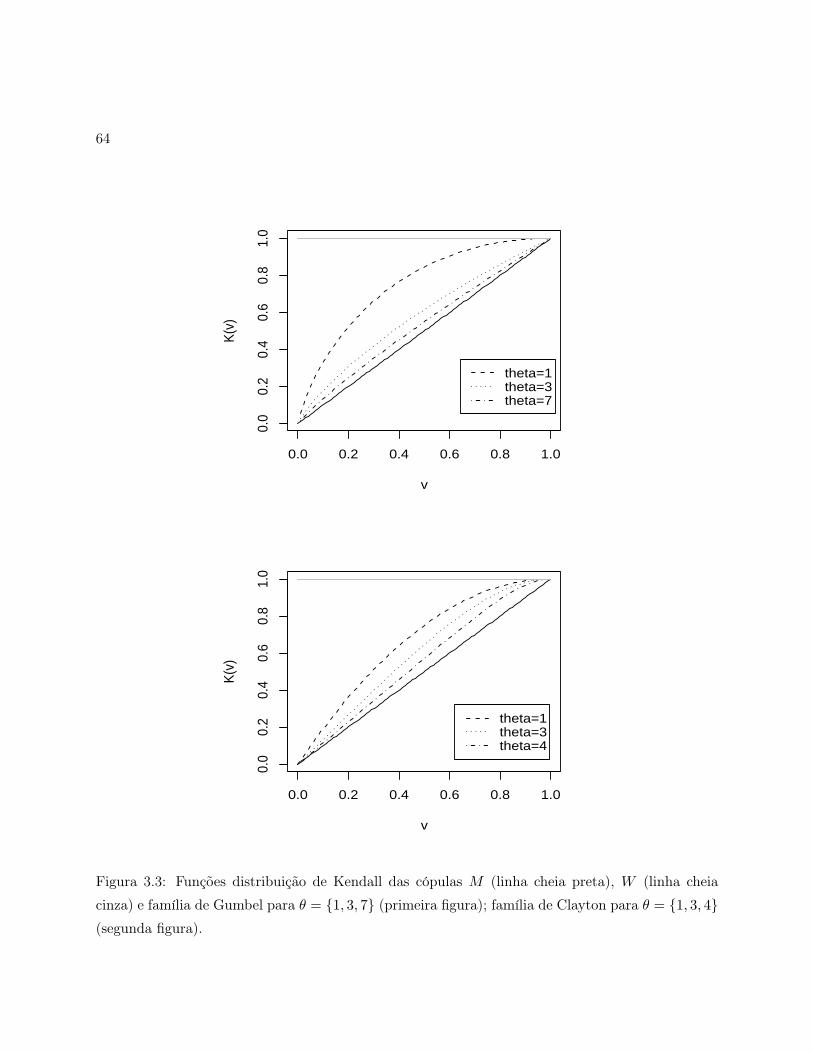
64
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
v
K(v
)
theta=1theta=3theta=7
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
v
K(v
)
theta=1theta=3theta=4
Figura 3.3: Funções distribuição de Kendall das cópulas M (linha cheia preta), W (linha cheia
cinza) e família de Gumbel para θ = 1, 3, 7 (primeira figura); família de Clayton para θ = 1, 3, 4(segunda figura).

65
0.0 0.2 0.4 0.6 0.8 1.0
−1.0
−0.5
0.0
0.5
1.0
v
lam
bda(
v)
theta=1theta=3theta=7
0.0 0.2 0.4 0.6 0.8 1.0
−1.0
−0.5
0.0
0.5
1.0
v
lam
bda(
v)
theta=1theta=3theta=7
Figura 3.4: Funções λ(v), v ∈ I, das cópulas M (linha cheia preta), W (linha cheia cinza) e família
de Gumbel para θ = 1, 3, 7 (primeira figura); família de Clayton para θ = 1, 3, 4.

66

Capítulo 4
Tau de Kendall
Este capítulo explorará a cópula como objeto de estudo de dependência ou associação entre
duas variáveis por meio do coeficiente tau de Kendall. Porém, primeiramente, será apresentado o
conceito e algumas propriedades desta medida de associação.
4.1 Concordância
Informalmente, um par de variáveis aleatórias é concordante se grandes valores de uma variável
estão associados a grandes valores da outra variável ou se pequenos valores de uma variável estão
associados a pequenos valores da outra variável. E o par é discordante caso contrário. Formalmente,
concordância é definida por:
Definição 4.1. Sejam (x, y) e (x, y) duas observações de um vetor (X,Y ) de v.a. contínuas. Diz-se
que estas observações são
concordantes se(y − y)(x− x)
> 0
discordantes se(y − y)(x− x)
< 0
Tau de Kendall é uma medida de associação definida em termos da concordância pela diferença
entre a probabilidade dos pares concordantes e discordantes.
67

68
Definição 4.2. Sejam (X1, Y1) e (X2, Y2) vetores aleatórios i.i.d. com a mesma f.d.a. H. Então
o coeficiente populacional Tau de Kendall de um vetor (X,Y ) de v.a. contínuas com f.d.a. H é
definido por
τ ≡ P [(X1 −X2)(Y1 − Y2) > 0]− P [(X1 −X2)(Y1 − Y2) < 0] (1.1)
Teorema 4.1. Sejam (X1, Y1), (X2, Y2) vetores independentes de v.a. contínuas com função dis-
tribuição conjunta H1,H2 respectivamente, com marginais comuns F (de X1, X2) e G (de Y1, Y2),
C1, C2 as respectivas cópulas de (X1, Y1) e (X2, Y2) e seja
Q ≡ P [(X1 −X2)(Y1 − Y2) > 0]− P [(X1 −X2)(Y1 − Y2) < 0]
denominada função de concordância, então
Q ≡ Q(C1, C2) ≡ 4∫∫
I2C2(u, v)dC1(u, v)− 1
Demonstração. Como P [(X1 − X2)(Y1 − Y2) < 0] = 1 − P [(X1 − X2)(Y1 − Y2) > 0], a função Qpode ser reescrita por Q = 2P [(X1 −X2)(Y1 − Y2) > 0]− 1, onde
P [(X1 −X2)(Y1 − Y2) > 0] = P (X1 > X2, Y1 > Y2)︸ ︷︷ ︸(1)
+P (X1 < X2, Y1 < Y2)︸ ︷︷ ︸(2)
(1) = P (X2 < X1, Y2 < Y1) =∫∫
R2
P (X2 < x, Y2 < y)dC1(F (x), G(y))
=∫∫
R2
C2(F (x), G(y))dC1(F (x), G(y)) =∫∫
I2C2(u, v)dC1(u, v)
(2) = P (X2 > X1, Y2 > Y1) =∫∫
R2
P (X2 > x, Y2 > y)dC1(F (x), G(y))
=∫∫
R2
[1− F (x)−G(y) + C2(F (x), G(y))] dC1(F (x), G(y))
=∫∫
I2[1− u− v + C2(u, v)] dC1(u, v) =
∫∫I2C2(u, v)dC1(u, v)
A última igualdade segue de U, V serem U(0, 1), logo E(U) = E(V ) = 12 .
Deste modo,
P [(X1 −X2)(Y1 − Y2) > 0] = 2∫∫
I2C2(u, v)dC1(u, v)

69
Então segue que
Q = 4∫∫
I2C2(u, v)dC1(u, v)− 1
O próximo resultado estabelece uma ligação entre a medida tau de Kendall entre duas v.a. X
e Y e a cópula C associada a estas variáveis por meio da função de concordância.
Teorema 4.2. Sejam X,Y v.a. contínuas com cópula C e seja H ≡ C(F (X), G(Y )) a sua v.a.
BIPIT com f.d.a. K. O coeficiente populacional tau de Kendall é dado por
τ ≡ Q(C,C) ≡ 4∫∫
I2C(u, v)dC(u, v)− 1 = 4E(C(U, V ))− 1 (1.2)
e pode ser reescrito por
τ = 3− 4∫ 1
0K(t)dt (1.3)
Demonstração. A prova da equação (1.2) segue da Definição 4.2 e do Teorema 4.1.
Da equação (1.2) temos
τ = 4E(H)− 1 = 4∫ 1
01−K(t)dt− 1 = 3− 4
∫ 1
0K(t)dt
Como a v.a. BIPIT H ∈ [0, 1] não assume valores negativos, então E(H) =∫ 10 1−K(t)dt
Assim como a função distribuição K de uma BIPIT associada a uma cópula Arquimediana é
expressa em função do gerador φ, tau de Kendall também é expresso em função de φ para cópulas
Arquimedianas.
Corolário 4.1. Sejam X,Y v.a. contínuas com cópula Arquimediana C gerada por φ. O coeficiente
populacional τ de Kendall é dado por
τ = 1 + 4∫ 1
0
φ(t)φ′(t)
dt (1.4)
Demonstração. Seja a BIPIT H ≡ C(F (X), G(Y )) com f.d.a. K. Pelo Teorema 4.2, equação (1.3)
τ(1.6)= 3− 4
∫ 1
0t− φ(t)
φ′(t)dt = 1 + 4
∫ 1
0
φ(t)φ′(t)
dt

70
Exemplo 4.1. Se Cθ é um membro da família de Frank (Tabela 3.1), devido a complexidade
de resolução da integral na equação (1.4), o cálculo de τ torna-se mais adequado via integração
numérica. Para as demais famílias Arquimedianas citadas nesta dissertação a integral na equação
(1.4) é de simples resolução, sendo então possível encontrar uma função de θ que expresse a medida
de associação τ de Kendall, tais expressões encontram-se na Tabela 1.1.
familia Arquimediana τ = f(θ)
Clayton τ = θθ+2
Gumbel τ = θ−1θ
4.2.12 τ = 1− 23θ
Tabela 1.1: Medida de associação τ de Kendall expressa em função do parâmetro θ para algumas
famílias de cópulas Arquimedianas.
Exemplo 4.2. Desde que a cópula M possui como suporte a diagonal v = u em I2 e possui
marginais U(0, 1), segue que se g é função integrável cujo domínio é I2, então∫∫I2g(u, v)dM(u, v) =
∫ 1
0g(u, u)du
Similarmente, desde que W possui como suporte a diagonal secundária v = 1− u, temos∫∫I2g(u, v)dW (u, v) =
∫ 1
0g(u, 1− u)du
Logo, temos
τΠ = Q(Π,Π) = 4∫∫
I2uvdΠ(u, v)− 1 = 4
∫ 1
0uvdudv − 1 = 0
τM = Q(M,M) = 4∫∫
I2min(u, v)dM(u, v)− 1 = 4
∫ 1
0udu− 1 = 1
τW = Q(W,W ) = 4∫∫
I2max(u+ v − 1, 0)dW (u, v)− 1 = 4
∫ 1
00du− 1 = −1
A cópula M é chamada cópula maximal por estabelecer relação de dependência perfeitamente
positiva entre as variáveis X,Y , como pode ser evidenciado pelo valor τM = 1, ou seja, probabilidade

71
1 de queX e Y sejam concordantes. O contrário acontece para a cópulaW , chamada cópula minimal
por estabelecer relação de dependência perfeitamente negativa entre as variáveis X,Y , τW = −1, ou
seja, a discordância das variáveis X e Y é certa. O Teorema a seguir mostra a unicidade da relação
de dependência perfeita negativa e positiva com respeito às cópulas.
Teorema 4.3. O coeficiente populacional tau de Kendal associado a cópula C pela equação (1.2) é
igual a 1, se e somente se, a cópula C é M . E τ = −1, se e somente se, C = W .
Demonstração. (⇐) A prova que τW e τM são iguais a −1 e 1 respectivamente segue do Exemplo
4.2.
(⇒) Agora considerando X,Y,X ′, Y ′ com distribuição U(0, 1) e sejam (X,Y ) e (X ′, Y ′) i.i.d.
com f.d.a. cópula C. A seguir a demonstração será dada como consequência de uma sequência de
afirmações:
a) τ = 1 ⇒ C = M
1. τ = 1 ⇒ X = Y com probabilidade 1;
2. X = Y ⇒ C(x, y) = min(x, y)
b) τ = −1 ⇒ C = W
1. τ = −1 ⇒ Y = 1−X com probabilidade 1;
2. Y = 1−X ⇒ C(x, y) = max(x+ y − 1, 0)
Demonstração a):

72
τ = 1 ⇒ P [(X −X ′)(Y − Y ′) > 0] = 1
⇒∫∫
I2[P (X > x, Y > y) + P (X < x, Y < y)] dC(x, y) = 1
⇒∫∫
I2[1− FX(x)− FY (y) + 2C(x, y)] dC(x, y) = 1
⇒∫∫
I2[2C(x, y) + 1− x− y] dC(x, y) = 1
⇒∫∫
I2[2C(x, y) + 1− x− y] dC(x, y) = 1 ⇒ 2C(x, y) + 1− x− y = 1
⇒ C(x, y) =x+ y
2
Aplicando os limites de Fréchet,
C(x, y) =x+ y
2≤ min(x, y) ⇔ X = Y com probabilidade 1
logo,
C(x, y) = P (X ≤ x, Y ≤ y,X = Y ) = P (X ≤ min(x, y)) = min(x, y)
Demonstração b):
τ = −1 ⇒ P [(X −X ′)(Y − Y ′) < 0] = 1
⇒∫∫
I2[P (X > x, Y < y) + P (X < x, Y > y)] dC(x, y) = 1 (1.5)
Como,
P (X > x) = P (X > x, Y < y) + P (X > x, Y > y)
⇒ P (X > x, Y < y) = (1− x)− C(x, y) = y − C(x, y)
e,
P (X < x) = P (X < x, Y < y) + P (X < x, Y > y)

73
⇒ P (X < x, Y > y) = x− C(x, y)
Substituindo na equação (1.5), temos
x+ y − 2C(x, y) = 1 ⇒ C(x, y) =x+ y − 1
2
Por limites de Fréchet,
max(x+ y − 1, 0) ≤ x+ y − 12
⇔ Y = 1−X com probabilidade 1
logo,
C(x, y) = P (X < x, Y < y, Y = 1−X) = P (1− y ≤ X ≤ x)
= F (x)− F (1− y) =
x+ y − 1, se 0 ≤ 1− y ≤ x ≤ 1
0, se caso contrario.
com F denotando a f.d.a. da v.a. X.
Desta forma temos, C(x, y) = max(x+ y − 1, 0).
Exemplo 4.3. O caso particular θ = −1 da família de Clayton é a cópula minimal, pois para este
caso τ = −1 conforme Exemplo 4.1.
No início deste capítulo foi visto que o tau de Kendall é uma medida de associação expressa em
termos da concordância, agora veremos que este coeficiente também é uma medida de concordância
que apresenta as propriedades desta.
Definição 4.3. Uma medida numérica κ de associação entre duas v.a. contínuas X e Y cuja cópula
é C é uma medida de concordância se satisfaz as seguintes propriedades
1. κ é definida para todo par X,Y de v.a. contínuas;
2. −1 ≤ κX,Y ≤ 1, κX,X = 1 e κX,−X = −1;
3. κX,Y = κY,X ;
4. Se X,Y são independentes, então κX,Y = 0;
5. κ−X,Y = κX,−Y = −κX,Y ;

74
6. Se C1 e C2 são cópulas tais que C1(u, v) ≤ C2(u, v), ∀(u, v) ∈ I2, então κC1 ≤ κC2 ;
7. Se (Xn, Yn) é uma sequência de v.a. contínuas com cópulas Cn, e se Cn converge ponto
a ponto a C, então limn→∞ κCn = κC .
Teorema 4.4. Se X,Y são v.a. contínuas com cópula C, então o coeficiente populacional τ de
Kendall satisfaz as propriedades da Definição 4.3, enquadrando-se como medida de concordância.
Demonstração. Cada item da Definição 4.3 é demonstrado separadamente. 2. Como τ é definido
na equação (1.1) por uma diferença de probabilidades, então −1 ≤ τ ≤ 1 e utilizando demonstração
do Teorema 4.5 temos τX,X = τM e τX,−X = τW e por sua vez, pelo Teorema 4.3, temos τM = 1 e
τW = −1.
3. Como CX,Y = CY,X , e por (3.1) temos τ como função da cópula C, então τX,Y = τY,X .
4. Vide Exemplo 4.2.
5. Seja W = −X, pelo Teorema 2.5 temos que CW,Y é dada em função de CX,Y por CW,Y (u, v) =
v − CX,Y (1− u, v),logo
τW,Y = Q(CW,Y , CW,Y ) = 4∫∫
I2−v + CX,Y (1− u, v)dCX,Y (1− u, v)− 1
Aplicando a transformação z = 1− u,
4∫ 1
0
∫ 1
0v − CX,Y (z, v)dCX,Y (z, v)− 1 = −4
∫∫I2CX,Y (z, v)dCX,Y (z, v) + 1 = −τX,Y
A última igualdade deve-se ao fato de que Z = 1− U é U(0, 1), pois U é U(0, 1).
Analogamente temos τX,−Y = −τX,Y .
6. Segue da definição de τ dada pelo Teorema 4.2 e pela função concordância Q (Teorema 4.1) ser
não decrescente em cada argumento.
7. Seja τ ≡ Q(C,C) conforme Teorema 4.2, como Cn → C e Cn é limitada pela cópula Maximal
M , usando o Teorema da Convergência Dominada de Lebesgue temos
limn→∞
τn = limn→∞
4∫∫
I2Cn(u, v)dCn(u, v)− 1 = 4
∫∫I2C(u, v)dC(u, v)− 1 = Q(C,C) = τ
Pelo Exemplo 4.2 foi visto que τW = −1 e τM = 1. Mas o resultado abaixo nos permite verificar
que se uma v.a. Y é uma função crescente da v.a. X, existindo então uma dependência perfeita

75
positiva entre estas variáveis então caracteriza-se CX,Y = M . De maneira análoga, para Y função
decrescente de X caracteriza-se CX,Y = W . Por meio da medida de concordância τ verifica-se este
resultado.
Teorema 4.5. Seja κ medida de concordância para v.a. contínuas X e Y .
1. Se Y é quase certamente uma função crescente de X, então κX,Y = κM = 1;
2. Se Y é quase certamente uma função decrescente de X, então κX,Y = κW = −1;
Demonstração. Primeiro, por intermédio de τ , como um particular exemplo de medida de con-
cordância, se provam que se Y é quase certamente uma função crescente de X sendo (X,Y ) com
cópula C, então C = M e que se Y é quase certamente uma função decrescente de X, então C = W .
Sejam (X,Y ) e (X1, Y1) duas realizações i.i.d. com f.d.a. H, f não decrescente, X = f(Y ) e
X1 = f(Y1) com probabilidade 1.
Como P [(X − X1)(Y − Y1) ≥ 0] + P [(X − X1)(Y − Y1) < 0] = 1, pela equação (1.1) temos
τ = 2P [(X −X1)(Y − Y1) ≥ 0]− 1, onde
P [(X −X1)(Y − Y1) ≥ 0] = P [(X −X1)(Y − Y1) ≥ 0, Y = f(X), Y1 = f(X1)]
= P [(X −X1)(f(X)− f(X1)) ≥ 0] = 1
A última igualdade deve-se ao fato de f não decrescente.
Logo, τ = 2 × 1 − 1 = 1 e pelo Teorema 4.3 temos C = M . Considerando f não crescente, do
mesmo modo, obtém-se τ=-1, e consequentemente, C = W .
Pelo item 6. da Definição 4.3 e pelos limites de Fréchet, W ≤ C ≤ M , temos κW ≤ κ ≤ κM e
como pelo item 2., −1 ≤ κ ≤ 1, então κM = 1 e κW = −1.
A medida de concordância tau de Kendall nomeia o método gráfico de ajuste de cópulas ap-
resentado no próximo capítulo, chamado Kendall Plot. Embora o Kendall Plot seja detalhado no
próximo capítulo, há a necessidade de uma breve introdução de seu conceito neste capítulo para a
justificativa de seu nome. O Kendall Plot pode ser interpretado como um teste gráfico de cópulas
baseado em um QQplot entre duas v.a. BIPIT’s H ≡ C(U, V ) e H0 ≡ C0(U, V ) com cópulas C

76
desconhecida e C0 conhecida. Se o QQplot diagnosticar H e H0 identicamente distribuídas, então
a BIPIT H está associada a cópula C0. Caso contrário, o Kendall Plot revela uma informação a
respeito entre a relação dos coeficientes populacionais τ de Kendall associados às cópulas C e C0.
Esta relação entre τ de Kendall e Kendall Plot se deve ao fato da associação entre τ e K por τ ser
uma função de K (Teorema 4.2). Então pela equação (1.3) temos,
K(w) ≥ K0(w), ∀ 0 ≤ w ≤ 1 ⇒ τ ≤ τ0 (1.6)
ou então, conforme Definição 3.3 temos,
(X,Y ) ≺k (X0, Y0) ⇒ τ ≤ τ0 (1.7)
Assim justificando o nome da ordem ≺k como ordem estocástica de Kendall.
No contexto do QQplot as v.a. BIPIT’s H e H0 são vistas como quantis de suas respectivas
distribuições K e K0, ou seja, os n pontos (Hi,H0i) do QQplot são dados por Hi = K−1(pi) e
H0i = K−10 (pi), ∀ 0 = p1 < . . . < pn = 1. Como K e K0 são f.d.a., logo a implicação (1.6) é
equivalente a
Hi ≤ H0i, ∀ 1 ≤ i ≤ n⇒ τ ≤ τ0 (1.8)
Exemplo 4.4. A recíproca da equação (1.8) nem sempre é válida. Seja a cópula C dada por
C(u, v) = min(CM (u, v), 1/4+CW (u, v)) com KC(t) = max(t, (3/4) bt+ 3/4c) (Nelsen (2003) [32]),
temos Π(u, v) ≤ C(u, v), ∀ (u, v) ∈ I2, deste modo pela propriedade 6. da Definição 4.3, temos
τΠ ≤ τC , porém KC(1/e) = 3/4 > 2/e = KΠ(1/e), ou seja, não é verdade que Π ≺k C.
Exemplo 4.5. Conforme Exemplo 3.6 a família de Clayton segue a ordem estocástica de Kendall, ou
seja, θ ≤ θ∗ ⇒ Cθ ≺k Cθ∗ , então pela implicação (1.7) temos τθ ≤ τθ∗ . A Figura 4.1 mostra o QQplot
de (H0,H1) e (H0,H2) com H0 v.a. BIPIT associada a cópula Π, H1 e H2 as v.a. BIPIT associadas
a cópula de Clayton com θ1 = −0.5 e θ2 = 2 respectivamente. Conforme ordenação estocástica
de Kendall para a família de Clayton, observa-se que os gráficos referentes a θ1 = −0.5 e θ2 = 2
encontram-se respectivamente abaixo e acima da diagonal principal, ou seja, H(1i) ≤ H0i ≤ H(2i),
caracterizando τθ1 < τ0 < τθ2 . De maneira geral, sendo H v.a. BIPIT de uma determinada cópula
C, os QQplot’s (H0,H) situados acima da diagonal principal revelam uma estrutrua de dependência
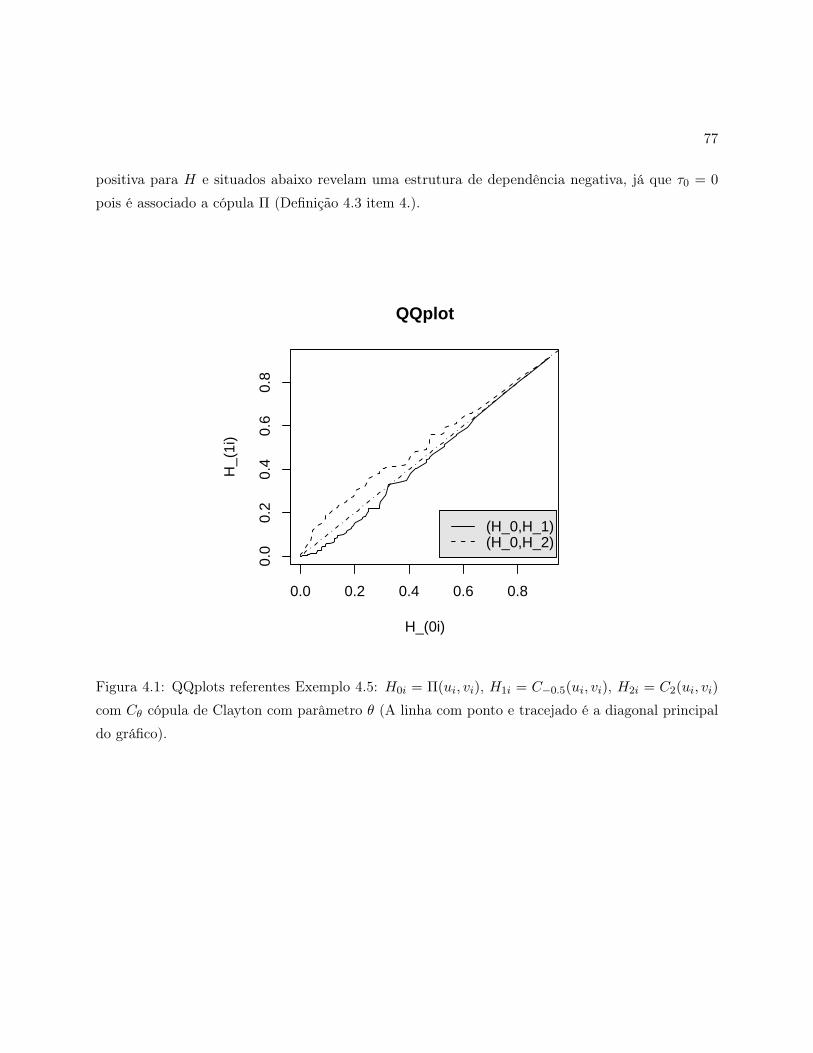
77
positiva para H e situados abaixo revelam uma estrutura de dependência negativa, já que τ0 = 0
pois é associado a cópula Π (Definição 4.3 item 4.).
0.0 0.2 0.4 0.6 0.8
0.0
0.2
0.4
0.6
0.8
QQplot
H_(0i)
H_(
1i)
(H_0,H_1)(H_0,H_2)
Figura 4.1: QQplots referentes Exemplo 4.5: H0i = Π(ui, vi), H1i = C−0.5(ui, vi), H2i = C2(ui, vi)
com Cθ cópula de Clayton com parâmetro θ (A linha com ponto e tracejado é a diagonal principal
do gráfico).

78

Capítulo 5
Kendall Plot
5.1 Introdução
Em meio a um recente estudo de ferramentas para o ajuste de cópulas ainda há a necessidade
de um mecanismo simples e eficiente para a modelagem de dependência. A motivação para a
criação deste mecanismo partiu do mais simples modo para o ajuste de distribuições: o gráfico
QQplot. Porém em cópulas trabalha-se num contexto multivariado diferentemente do QQplot.
Este problema é resolvido usando a v.a. BIPIT que traduz um problema multivariado ao contexto
univariado preservando as características da estrutura de dependência dos dados. Neste contexto
Genest & Frave (2007) utilizam o gráfico QQplot usando a v.a. BIPIT para a modelagem de cópulas
e denominam esta ferramenta gráfica por Kendall Plot. Assim como o QQplot padrão compara os
quantis amostrais aos quantis teóricos da normal padrão, o gráfico proposto compara os quantis
amostrais aos quantis teóricos sob hipótese nula de uma específica função distribuição K de uma
v.a. BIPIT H associada a uma cópula C. Quando os quantis teóricos sob hipótese nula referem-se a
cópula da independência Π (Exemplo 2.6), o gráfico proposto mostra se há evidência de dependência
entre as variáveis. Esta foi a primeira proposta do Kendall Plot sugerida por Genest e Boies(2003).
Este capítulo também apresenta a relação existente entre a medida de concordância tau de
Kendall e o gráfico Kendall Plot, sendo por essa razão o gráfico denominado desta maneira.
79

80
5.2 Construção do Kendall Plot
O Kendall Plot é uma adaptação do gráfico de normalidade. Sua construção é similar ao QQplot,
porém usando o conceito de BIPIT.
5.2.1 QQplot
Uma maneira gráfica de verificar se uma amostra aleatória univariada X1, . . . , Xn é Gaussiana
é comparar os quantis amostrais com os quantis teóricos de uma normal padrão. O QQplot é o
gráfico dos pares (Zdnpie:n, X(dnpie)), onde dnpie denota o menor inteiro maior ou igual a npi, a
sequêcia X(dnpie), 0 ≤ p1 < . . . < pn ≤ 1 corresponde às estatísticas de ordem da amostra e
Zdnpe:n ≡ E(Z(dnpie)) onde Z1, . . . , Zn é uma amostra aleatória com distribuição normal padrão.
Sendo Fn a f.d.a. empírica da v.a. X dada por
Fn(Xi) =1
n− 1#j 6= i : Xj ≤ Xi (2.1)
observa-se que a estatística de ordem X(i) ≡ X(dnpie) é definida como o pi-quantil amostral de uma
amostra de tamanho n. Mais especificamente, de acordo com a equação (2.1), para todo 1 ≤ i ≤ n
e denotando i ≡ dnpie, temos
Fn(X(i)) =i− 1n− 1
≡ pi (2.2)
com 0 = p1 < . . . < pn = 1. E de acordo com Sen & Singer [35], sendo F a f.d.a da v.a. X, temos
X(dnpe) → F−1(p), ∀p ∈ [0, 1]
em probabilidade e quase certamente quando n→∞(para demonstração veja apêndice 2). Ou seja,
é garantida a convergência do quantil amostral ao quantil teórico da distribuição. Deste modo a
convergência de Zdnpe:n ≡ E(Z(dnpe)) ao quantil teórico da normal padrão é garantida pelo Teorema
da Convergência Dominada [22]
limn→∞
E(Z(dnpe)
)= E
(limn→∞
Z(dnpe)
)= E[φ−1(p)] = φ−1(p)

81
pois ∀n, |Z(dnpe)| ≤ Y , com v.a. Y seguindo distribuição Exp(λ), λ ∼= 0.
Logo, para n suficientemente grande se os pontos (Z(dnpie), X(dnpie)), 0 = p1 < . . . < pn = 1
concentram-se sob a diagonal principal, então pode-se concluir que a f.d.a. da v.a. X é a f.d.a. da
normal padrão.
O QQplot é utilizado não somente para verificar se uma amostra aleatória univariada X1, . . . , Xncom distribuição desconhecida F segue distribuição normal, mas também para testar se esta amostra
segue qualquer outra distribuição F0, isto é,
H0 : F (x) = F0(x), ∀ x ∈ DomF
H1 : F (x) 6= F0(x), para pelo menos um valor de x ∈ DomF
O procedimento para este teste também é baseado em uma comparação quantílica, assim como
para o teste com a distribuição normal padrão sob hipótese nula. Considere pi, 0 = p1 < . . . < pn =
1. Para cada pi há dois quantis a considerar: E(Y(dnpie)) sob hipótese de que Y segue distribuição
F0, o pi-quantil teórico sob hipótese nula, e conforme equação (2.2) F−1n (pi) = X(i) ≡ Xdnpie, o pi-
quantil amostral. Logo, se para n suficientemente grande o gráfico dos pares (E(Y(dnpie)), F−1n (pi)),
concentra-se sob a diagonal principal, então a v.a. X segue distribuição F0.
5.2.2 Kendall Plot
Seja uma amostra aleatória bivariada (X1, Y1), . . . , (Xn, Yn). É necessário transformar esta
amostra bivariada em uma amostra univariada que contenha as mesmas informações de dependên-
cia da amostra original para que se possa trabalhar com o conceito do QQplot com a finalidade
de ajustar estruturas de dependência, ou seja, cópulas. A melhor maneira de transformar dados
bivariados em univariados preservando a estrutura de dependência é utilizar a BIPIT desses dados.
Como desconhece-se a distribuição dos dados, se trabalha com a BIPIT empírica H definida pela
distribuição empírica Hn dada por
Hi ≡ Hn(Xi, Yi) =1
n− 1#j 6= i : Xj ≤ Xi, Yj ≤ Yi (2.3)
Desta maneira a hipótese a ser testada pelo Kendall Plot é dada por
H′0 : K(H) = K0(H), ∀H ∈ I
H′1 : K(H) 6= K0(H), para pelo menos um valor de H ∈ I (2.4)

82
onde K é a f.d.a. desconhecida da BIPIT H e K0 a f.d.a. a ser testada.
A hipótese (2.4) funciona como hipótese auxiliar, pois o objetivo principal é testar a estrutura
de dependência dos dados, logo
H0 : C = C0 vs. H1 : C 6= C0 (2.5)
onde a BIPIT H está associada a cópula desconhecida C com distribuição desconhecida K e C0 com
distribuição K0 é a cópula a ser testada. Sob a hipótese nula a BIPIT H está associada a cópula
C0 e segue distribuição K0, portanto a estrutura de dependência dos dados bivariados associados a
H é modelada pela cópula C0.
Deve-se tomar cuidado ao usar o Kendall Plot, pois as hipóteses (2.4) e (2.5) não são equivalentes,
a não rejeição de H′0 não implica na não rejeição de H0. Temos H0 ⊂ H′
0, pois a implicação
C 6= C∗ ⇒ K 6= K∗ é falsa e para sua verificação veja exemplo a seguir.
Exemplo 5.1. Considere uma distribuição pertencente a classe de distribuições do valor-extremo,
cujas cópulas (veja Capéraà, Fougéres e Genest (1997, 2000) [4] e [5]) são da forma
CA(u, v) = exp
[log(uv)A
log(u)log(uv)
]para alguma função convexa A : [0, 1] → [1/2, 1], tal que A(0) = A(1) = 0 e A(w) ≥ max(w, 1−
w), ∀ 0 ≤ w ≤ 1 e sendo a função A definida como gerador da cópula do valor-extremo C. De
acordo com Ghoudi, Khoudraji e Rivest [20] a v.a. BIPIT H = CA(U, V ) é distribuída por
KA(w) = w − (1− τA)w log(w), ∀ 0 ≤ w ≤ 1
onde
τA =∫ 1
0
w(1− w)A(w)
dA′(w)
é o valor populacional de tau de Kendall, desde que A é convexa. Então, se duas distribuições
do valor-extremo com geradores A 6= A∗ verificam τA = τA∗ , logo KA = KA∗ , ou seja, a cópula
do valor-extremo CA não é unicamente determinada por sua f.da. KA. Mas esta questão não
será preocupante nesta dissertação, já que trabalhamos com a classe de cópulas Arquimedianas
bivariadas para a qual as hipóteses (2.4) e (2.5) são equivalentes, já que para esta família a cópula

83
C é unicamente determinada pela função K. Este fato se deve a função distribuição K de uma
cópula Arquimediana C ser definida em função do gerador φ desta cópula (Corolário 3.1). E pela
construção de uma cópula Arquimediana (equação 3.22) observa-se que o gerador φ a determina
unicamente.
Assim como o QQplot, o Kendall Plot realiza uma comparação quantílica. Compara-se os
quantis amostrais de K aos quantis teóricos de K0 sob hipótese nula. Os pi-quantis amostrais são
representados por H(dnpie) ≡ H(i) e os pi-quantis teóricos denotados por Wdnpie:n,K0= E(H0
(dnpie)) ≡Wi:n,K0 sendo pi definido como na equação (2.2). Os resultados da próxima seção permitem verificar
que H(dnpie) e E(H0(dnpie)) realmente representam o pi-quantil amostral e teórico da distribuição sob
hipótese nula K0.
Sejam H0(1) ≤ . . . ≤ H0
(n) estatísticas de ordem de uma amostra aleatória H01 , . . . ,H
0n da BIPIT
H0 com distribuição K0, pela definição de densidade de uma estatística de ordem em Casella &
Berger [6].
Wi:n,K0 ≡ E(H0(i)) = n
(n− 1i− 1
)∫ 1
0wK0(w)i−11−K0(w)n−idK0(w) (2.6)
A integral em questão não possui primitiva, portanto foi calculada por integração numérica
através do comando integrate do software estatístico R. Este comando realiza integração numérica
para variável unidimensional através de um método de quadratura adaptativa baseado nas rotinas
dqags e dqagi em Piessens & Doncker-Kapenga [33]. Este algoritmo não funciona bem para inte-
grandos que assumem valores constantes (em particular, próximos de zero) em todo seu domínio.
O integrando em questão é composto por um produto de potências (que dependem de n) de valores
entre 0 e 1, apresentando então valores muito próximos de zero em todo seu domínio, e sendo de-
crescente em n. Portanto para grandes valores de n, por exemplo n > 200, para algumas funções
K0, por exemplo Kπ, a integração usando integrate não corresponde ao valor esperado. Como o
Kendall Plot, assim como o QQplot, é uma ferramenta assintótica foi necessário recorrer a outro
método de integração adaptativa para o cálculo de Wi:n,K0 para um grande tamanho amostral. Veja
apêndice 4 para maiores detalhes do método de integração numérica.
Os passos para construção do Kendall Plot, listados a seguir, são semelhantes ao do QQplot.
1. Para cada 1 ≤ i ≤ n, calcula-se a BIPIT empírica Hi como na equação (2.3);

84
2. Ordena-se Hi: H(1) ≤ . . . ≤ H(n), igualdades são possíveis;
3. Para cada 1 ≤ i ≤ n, calcula-se Wi:n,K0 pela equação (2.6);
4. Plotar os pares (Wi:n,K0 , H(i)), 1 ≤ i ≤ n.
5.3 Resultados e Fundamentos
Esta seção apresenta os resultados teóricos necessários para a validade do Kendall Plot como
método assintótico para comparação de quantis, bem como exemplos decorrentes da teoria para
auxiliar na interpretação do gráfico Kendall Plot. Um dos resultados evidencia a relação existente
entre Kendall Plot e τ de Kendall.
Definição 5.1. Sejam H1, . . . , Hn calculados pela equação (2.3) realizações da BIPIT H = H(X,Y )
com função distribuição de Kendall K. A função distribuição empírica Kn dos Hi’s é dada por
Kn(v) =1n
n∑i=1
IHi ≤ v (3.7)
Teorema 5.1. A função distribuição empírica de Kendall Kn converge em probabilidade à função
distribuição de Kendall K sendo a convergência válida também para as inversas, ou seja,
Kn(v)p→ K(v) e K−1
n (p)p→ K−1(p), ∀v, p ∈ I
quando n→∞.
Demonstração. Seja (X1, Y1), . . . , (Xn, Yn) uma amostra aleatória com f.d.a. cópula C e H1, . . . , Hn,calculados pela equação (2.3), realizações da BIPIT H = C(X,Y ). Provemos que a distribuição
de Hi, P (Hi ≤ v), converge a K(v) = PC(X,Y ) ≤ v e que a função distribuição empírica Kn
dos Hi’s, dada pela equação (3.7), é um estimador√n-consistente de K(v), ou seja, no limite a
esperança do estimador converge a esperança de K(v) e no limite a variância do estimador é nula.
Consequentemente seguem as convergências em probabilidade.
EKn(v) = E[IH1 ≤ v] = P (H1 ≤ v) (3.8)
Dados X1 e Y1 com distribuição U(0, 1) sendo (X1, Y1) com f.d.a. cópula C. Seja (x1, y1)
uma realização de (X1, Y1), pela equação (2.3) temos que a quantidade (n− 1)H1 é distribuida de

85
acordo com uma binomial com parâmetros (n− 1) e C(x1, y1). Desta maneira a função geradora de
momentos condicional a (x1, y1) de H1 é dada por 1 − C(x1, y1) + C(x1, y1)et/(n−1)(n−1). Como
H1 = Cn(X1, Y1) → C(X1, Y1) quando n tende ao infinito, onde Cn denota a cópula empírica, segue
do teorema da convergência dominada de Lebesgue que E(et bH1) converge a EetC(X1,Y1) quando n
tende ao infinito. Portanto, assintoticamente, H1 tem a mesma distribuição que C(X1, Y1), ou seja,
limn→∞
P (H1 ≤ v) = K(v) (3.9)
Logo, pela equação (3.8) temos
E[Kn(v)] → K(v)
quando n→∞.
V ar[Kn(v)] = V ar
[1n
n∑i=1
IHi ≤ v
]= V ar[IH1 ≤ v]/n+ (n− 1)Cov(IH1 ≤ v, IH2 ≤ v)/n
sendo IH1 ≤ v e IH2 ≤ v v.a. de Bernoulli identicamente distribuídas com parâmetro p(v) =
P (H1 ≤ v), logo a variância de Kn(v) pode ser escrita como
p(v)1− p(v)/n+ (n− 1)[P (H1 ≤ v, H2 ≤ v)− p(v)2]/n (3.10)
Usando o termo de ordem 1/n da transformada de Laplace-Stieljes bivariada [1] de
P (H1 ≤ v1, H2 ≤ v2)− P (H1 ≤ v1)P (H2 ≤ v2) (3.11)
mostra-se que
P (H1 ≤ v, H2 ≤ v)− P (H1 ≤ v)2 = k(v)k(v)R(v)− 2vK(v)/n+ o(1/n) (3.12)
onde K(v) = 1−K(v), k(v) = K ′(v) é a densidade de H = C(X,Y ) e
R(v) = E[Cmin(X1, X2),min(Y1, Y2) − v2|C(X1, Y1) = C(X2, Y2) = v]
Para detalhes veja Genest & Rivest [19].

86
Como a distribuição de H1 no limite é dada por K(v)(equação 3.9) e substituindo a equação
(3.12) na equação (3.10), então uma aproximação de ordem o(1/n) para a variância de Kn(v) é
dada por
[K(v)K(v) + k(v)k(v)R(v)− 2vK(v)]/n
E deste modo
limn→∞
V ar[Kn(v)] = 0
e completa-se a prova.
O corolário a seguir é de extrema importância para a característica assintótica do Kendall Plot
mostrando que H(dnpe) e Wdnpe:n,K convergem ao p-quantil teórico da verdadeira distribuição K e
ao p-quantil teórico sob hipótese nula de distribuição K0 respectivamente.
Corolário 5.1. Sejam H1, . . . , Hn realizações da BIPIT H, H1, . . . ,Hn amostra aleatória de
H com f.d.a. K, Kn como na Definição 5.1 e 0 ≤ p ≤ 1, então
H(dnpe) = K−1n (p)
p→ K−1(p) (3.13)
e
Wdnpe:n,K ≡ E(H(dnpe)
)→ K−1(p) (3.14)
quando n→∞.
Demonstração. Demonstração da equação (3.13):
De acordo com a Definição 5.1 pode-se considerar H(dnpe) = K−1n (p), logo a convergência segue do
Teorema 5.1. Demonstração da equação (3.14):
limn→∞
Wdnpe:n,K ≡ limn→∞
E(H(dnpe)
)= E
(limn→∞
H(dnpe)
)= E[K−1(p)] = K−1(p)
Por |H(dnpe)| ≤ 1, ∀n e a convergência quase certa,
H(dnpe)n→∞→ K−1(p)
demonstrada por Sen & Singer [35] (veja Apêndice .2), a igualdade entre limite da esperança e
esperança do limite é garantida pelo Teorema da Convergência Dominada [22].

87
Exemplo 5.2. A Figura 5.1 ilustra a convergência da BIPIT empírica H(dnpe) ≡ K−1n (p) eWdnpe:n,K ≡
E(H(dnpe)) a K−1(p), inversa da distribuição acumulada da BIPIT H. Usa-se no exemplo a BIPIT
H associada a cópula 4.2.12 (Tabela 3.1) que possibilita o cálculo direto da inversa K−1(p). Esta
cópula Arquimediana torna-se uma exceção frente que a distribuição das demais cópulas Arquime-
dianas não apresentam uma forma fechada para o cálculo da inversa da distribuição.
O Corólário 5.1 confirma o mencionado na seção 5.2.2, ou seja, que os elementos do Kendall
Plot, H(i) e Wi:n,K0 ≡ E(H0(i)), representam respectivamente o pi-quantil da distribuição K (descon-
hecida)e o pi-quantil da distribuição sob a hipótese nula K0 para n suficientemente grande. Logo, se
os pontos (Wi:n,K0 , H(i)) concentram-se sob a diagonal principal evidencia-se que a BIPIT H segue
distribuição K0, ou seja, a não rejeição da hipótese nula do Kendall Plot. Este fato é verificado
formalmente através do corolário abaixo.
Corolário 5.2. Os pares (Wi:n,K0 , H(i)) do gráfico Kendall Plot concentram-se ao longo da curva
p 7→ K−1K0(p), ∀p ∈ I. (3.15)
Demonstração. Reparametrizando p = K0(w) temos w = K−10 (p), w ∈ I, então
(K−10 (p),K−1(p)) = (w,K−1K0(w))
logo os pontos do Kendall Plot se comportam como os pontos do gráfico w 7→ K−1K0(w).
Exemplo 2.1 (continuação)
O gráfico dos pontos (Wi:n,K0 , H(i)), 1 ≤ i ≤ n, de acordo com a equação (3.15) concentra-se ao
longo da diagonal principal sob a hipótese nula, ou seja, quando K = K0. A Figura 5.2 mostra o
Kendall Plot dos dados simulados no Exemplo 2.1 sob a hipótese nula de independência, ou seja,
K0(v) = KΠ(v) (veja Exemplo 3.3), evidenciando independência nos dados.
Exemplo 5.3. O gráfico dos pontos (Wi:n,K0 , H(i)), 1 ≤ i ≤ n, de acordo com a equação (3.15)
concentra-se sob o eixo horizontal - H(i) = 0, 1 ≤ i ≤ n - quando o vetor aleatório (X,Y ) testado
está associado a cópula minimal W (veja Exemplo 2.5). Como KW (v) = 1, ∀v ∈ I (Exemplo 3.5),
de acordo com a definição de quasi-inversa (Definição 2.6) temos K−1W (p) = 0, ∀p ∈ I. A Figura 5.3
apresenta o Kendall Plot para as observações do vetor aleatório (X,Y ) sendo Y = 1 − X que de
acordo com demonstração do Teorema 4.3, CX,Y = W .

88
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
K_n^−1
K^
−1
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
W_i:n,K
K^
−1
Figura 5.1: Gráficos da inversa da função distribuição K−1(p) vs. H(dnpe) ≡ K−1n (p) proveniente de
n = 100 pseudo-observações da cópula 4.2.12 (primeira figura); e Wdnpe:n,K = E(H(dnpe)), n = 100,
sob hipótese da mesma cópula (segunda figura).
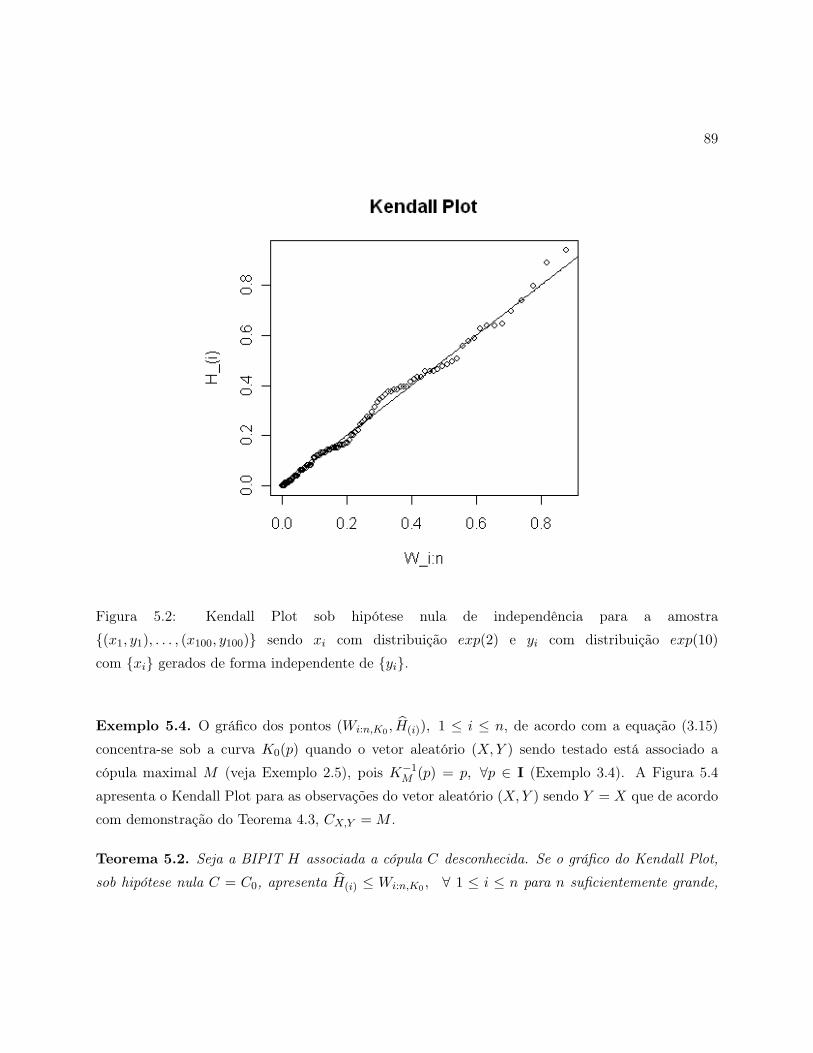
89
Figura 5.2: Kendall Plot sob hipótese nula de independência para a amostra
(x1, y1), . . . , (x100, y100) sendo xi com distribuição exp(2) e yi com distribuição exp(10)
com xi gerados de forma independente de yi.
Exemplo 5.4. O gráfico dos pontos (Wi:n,K0 , H(i)), 1 ≤ i ≤ n, de acordo com a equação (3.15)
concentra-se sob a curva K0(p) quando o vetor aleatório (X,Y ) sendo testado está associado a
cópula maximal M (veja Exemplo 2.5), pois K−1M (p) = p, ∀p ∈ I (Exemplo 3.4). A Figura 5.4
apresenta o Kendall Plot para as observações do vetor aleatório (X,Y ) sendo Y = X que de acordo
com demonstração do Teorema 4.3, CX,Y = M .
Teorema 5.2. Seja a BIPIT H associada a cópula C desconhecida. Se o gráfico do Kendall Plot,
sob hipótese nula C = C0, apresenta H(i) ≤ Wi:n,K0 , ∀ 1 ≤ i ≤ n para n suficientemente grande,

90
Figura 5.3: Kendall Plot sob hipótese nula de independência de n = 100 pares de observações do
vetor aleatório (X,Y ) com Y = 1−X.
então τC ≤ τC0 .
Demonstração. De acordo com as convergências de H(i) e Wi:n,K evidenciadas pelo Corolário 5.1 e
pela relação entre v.a. BIPIT e tau de Kendall estabelecida na equação (1.8), para n suficientemente
grande temos
H(i) ≤Wi:n,K0 , ∀ 1 ≤ i ≤ n⇒ τC ≤ τC0 (3.16)
A recíproca da equação (3.16) nem sempre é válida, veja Exemplo 4.4.

91
Figura 5.4: Kendall Plot sob hipótese nula de independência, de n = 100 pares de observações do
vetor aleatório (X,Y ) com Y = X.
Exemplo 5.5. Simulamos três amostras aleatórias de tamanho n = 150 da cópula de Clayton
com os respectivos parâmetros θ = 0.5, 2, 5 e construímos os Kendall Plot’s sob hipótese nula
de Clayton θ = 2 (Figura 5.5). Conforme esperado o plot dos dados com θ = 2 encontra-se sob a
diagonal principal, e observa-se que os dados com θ = 0.5 e θ = 5 encontram-se respectivamente
abaixo e acima do plot para θ = 2, conforme esperado de acordo com a ordenação estocástica de
Kendall para a família de Clayton (veja Exemplo 4.5).

92
Figura 5.5: Kendall Plot sob hipótese nula de cópula de Clayton θ = 2 (Wi:n,K0 referente a Clayton
com θ = 2) de amostras aleatórias de tamanho n = 100 associadas a cópula de Clayton com os
respectivos parâmetros θ = 0.5, 2, 5.

93

94

Referências Bibliográficas
[1] Abramowitz, M., and Stegun, I. E. Handbook of Mathematical Functions. New York,
USA: Dover, 1972.
[2] Block, H. W., Savits, T. H., and Shahed, M. Some concepts of negative dependence.
The Annals of Probability, 10 (1982), 765–772.
[3] Bouyè, E., Durrleman, V., Bikeghbali, A., Riboulet, G., and T., R. Copulas for
finance Ű a reading guide and some applications. Working paper, Goupe de Recherche Opéra-
tionnelle, Crédit Lyonnais (2000).
[4] Capéeraà, P., Fougères, A. L., and Genest, C. A nonparametric estimation procedure
for bivariate extreme value copulas. Biometrika 84 (1997), 567–577.
[5] Capéeraà, P., Fougères, A. L., and Genest, C. Bivariate distributions with given
extreme value attractor. Journal of Multivariate Analysis 72 (2000), 30–49.
[6] Casella, G., and Berger, R. L. Statistical Inference. Belmont, California, USA: Duxbury
Press, 1990.
[7] Cherubini, U., Luciano, E., and Vecchiato, W. Copula Methods in Finance. John Wiley
& Sons, 2004.
[8] Ebrahimi, N., and Ghosh, M. Multivariate negative dependence. Communications in
Statistics, 4 (1981), 307–337.
95

96
[9] Embrechts, P., Lindskog, F., and McNeil, A. Modelling Dependence with Copulas and
Applications to Risk Management. Handbook of Heavy Tailed Distribution in Finance. Elsevier,
2003.
[10] Embrechts, P., McNeil, A., and Straumann, D. Correlation and dependence in risk
management: properties and pitfalls. Risk Management: Value at Risk and Beyond. Cambridge:
Cambridge University Press, 2002.
[11] Esary, J. D., Proschan, F., and Walkup, D. W. Association of random variables, with
applications. The Annals of Mathematical Statistics 44 (1967), 1466–1474.
[12] Frank, M. J. On the simultaneous associativity of f(x, y) and x + y − f(x, y). Aequationes
Mathematicae 19 (1979), 194–226.
[13] Frees, E., Carriere, J., and Valdez, E. Annuity valuation with dependent mortality.
Journal of Risk and Insurance 63 (1996), 229–261.
[14] Frees, E., and Valdez, E. Understanding relationships using copulas. North American
Actuarial Journal 2, 1 (1998), 1–25.
[15] Frees, E., and Wang, P. Credibility using copulas. North American Actuarial Journal 9, 2
(2005), 31–48.
[16] Genest, C., and Frave, A. C. Everything you always wanted to know about copula mod-
eling but were afraid to ask. Journal of Hydrologic Engineering 12 (2007), 347–368.
[17] Genest, C., and MacKay, J. Copules archimédiennes et familles de lois bidimensionnelles
dont les marges sont données. Canad. J. Statist. 14 (1986a), 145–159.
[18] Genest, C., and MacKay, J. The joy of copulas: Bivariate distributions with uniform
marginals. Amer. Statist. 40 (1986b), 280–285.
[19] Genest, C., and Rivest, L. P. Statistical inference procedures for bivariate archimedean
copulas. Journal of the American Statistical Association 88 (1993), 1034–1043.
[20] Ghoudi, K., Khoudraji, A., and Rivest, L. Propriétés statistiques des copules de valeurs
extrêmes bidimensionnelles. The Canadian Journal of Statistics 26 (1998), 187–197.

97
[21] Gumbel, E. J. Distributions des valeurs extrêmes en plusieurs dimensions. Publ. Inst. Statist.
Univ. Paris 9 (1960), 171–173.
[22] James, B. R. Probabilidade: um Curso em Nível Intermediário, 2a ed. Projeto Euclides. Rio
de Janeiro, Brasil: IMPA, 2002.
[23] Joag-Dev, K., and Proschan, F. Negative association of random variables with applica-
tions. The Annals of Statistics 11 (1983), 286–295.
[24] Joe, H. Parametric family of multivariate distributions with given margins. Journal of Mul-
tivariate Analysis 46 (1993), 262–282.
[25] Joe, H. Multivariate Models and Dependence Concepts. Chapman & Hall, 1997.
[26] Karlin, S. Total Positivity, vol. I. California, USA: Stanford University Press, 1968.
[27] Karlin, S., and Rinnot, Y. Classes of orderings of measures and related correlation in-
equalities, i. multivariate totally positive distributions. Journal of Multivariate Analysis 10
(1980), 467–498.
[28] Karlin, S., and Rinnot, Y. Classes of orderings of measures and related correlation inequal-
ities, ii. multivariate reverse rule distributions. Journal of Multivariate Analysis 10 (1980),
499–516.
[29] Kimeldorf, G., and Sampson, A. R. Uniform representations of bivariate distributions.
Comm. statist. 4 (1975), 617–627.
[30] Lehmann, E. L. Some concepts of dependence. The Annals of Mathematical Statistics 37
(1966), 1137–1153.
[31] Nelsen, R. An Introduction to Copulas. Lecture Notes in Statistics 139. New York, USA:
Springer-Verlag, 1999.
[32] Nelsen, R., Quesada-Molina, J., Rodrigues-Lallena, J., and Ubeda-Flores, M.
Kendall distribution functions. Statistics & Probability Letters 65 (2003), 263–268.

98
[33] Piessens, R., Doncker-Kapenga, E., Uberhuber, C., and Kahaner, D. Quadpack: a
subroutine package for automatic integration. New York, USA: Springer-Verlag, 1983.
[34] Schweizer, B., and Sklar, A. Probabilistic Metric Spaces. New York, USA: North-Holland,
1983.
[35] Sen, P. K., and Singer, J. M. Large Sample Methods in Statistics: an introduction with
applications. New York, USA: Chapman and Hall, 1993.
[36] Sklar, A. Fonctions de répartition à n dimensions et leurs marges. Publ. Inst. Statist. Univ.
Paris 8 (1959), 229–231.
[37] Wang, W., and Wells, M. T. Model selection and semiparametric inference for bivariate
failure-time data. J. Amer. Statist. Assoc. 95 (2000), 62–72.