técnicas de mineração de dados aplicadas a sistemas de recomendação
DESCRIPTION
Ministrante: Joel Pinho Lucashttp://saspi2.com/palestras/ver/17TRANSCRIPT

1
TÉCNICAS DE MINERAÇÃO DE DADOS APLICADAS A
SISTEMAS DE RECOMENDAÇÃO
Joel Pinho Lucas
Universidad de Salamanca
Programa de Doctorado en Informática y Automática

2
Índice
Contextualização
Sistemas de Recomendação
Mineração de Dados
Regras de Associação
Classificação Baseada em Associação
Proposta de uma Metodologia
Validação no Sistema PSiS

3
Contextualização
Estipula-se que o volume de informação disponível nomundo duplica a cada 20 meses (Breese, et. al.)
A tecnologia atual permite o armazenamento epublicação de grandes volumes de dados
Atualmente existe maior dificuldade em processar eextrair de informação útil de bases de dados

4
Contextualização
Bancos de dados podem esconder conhecimento valiosoe útil à tomada de decisão, planejamento e gestão
Exemplo: a rede Wal-Mart conta com uma base de dadosna qual se executa 25 milhões de transações ao dia (ano2001)

5
Contextualização
Sistemas de Comercio Eletrônico (E-commerce):
• O “boom de informação’’ existente atualmente semanifesta através de uma imensa quantidade deprodutos a venda
• Usuários apresentam dificuldade em selecionar ecomprar produtos
• Necessitam apresentar seus produtos de maneirapersonalizada
• Utilizam sistemas de recomendação para fazer sugestõesde produtos e proporcionar a escolha dos mesmos(Thabtah et. al.)

6
Sistemas de Recomendação
“If I have 3 million customers on the Web, I should have 3 million storeson the Web.” – Jeff Bezos, Amazon.com
Surgiram na área de e-commerce para proporcionarsugestões de produtos e prover informação para auxiliarna escolha de produtos
Têm como meta a criação de uma nova loja personalizadaa cada cliente (Thabtah et. al.)
Diminuem as dificuldades do usuário em encontrarprodutos (itens) ou serviços de sua preferência

7
Sistemas de Recomendação
Tendem a proporcionar um aumento nas vendas
Atualmente também podem ser utilizados em outras áreas(bibliotecas virtuais, portais científicos, sistemas de e-learning, etc.)
Podem apresentar-se na forma de sugestões e tambémcomo informações de resumo de acessos, críticas ouopiniões

8
Sistemas de Recomendação
Instituem o conceito de comunidade de usuários (perfis)
Exemplos: MovieLens, Video Recommender, Amazon, etc.
Arquitetura composta por três elementos principais:histórico de dados, dados de entrada e um ou maisalgoritmos

9
Avaliações de Usuários
Expressam informação acerca do interesse dos usuariosnos itens do sistema
Podem ser de dois tipos:
Explícita (feedback ativo): obtidas através de ratings e/oucomentários
Implícita (feedback passivo): obtidas de maneira indireta(subjetiva) utilizando-se timing logs, registros de compras,de navegação, etc.

Figura: Exemplo de avaliação explícita 10

11
Tipos de Sistemas de Recomendação
Métodos Baseados em Conteúdo
Métodos Baseados em Filtragem Colaborativa
Baseados em Memória (Baseados no Usuário)
Baseados em Modelo (Baseados em Itens)

12
Métodos Baseados em Conteúdo
Figura: Exemplo de método aplicado em conteúdo

13
Métodos Baseados em Filtragem Colaborativa
Figura: Exemplo de um sistema baseado em filtragem colaborativa

14
Limitações
Dificilmente consegue-se ter opiniões acerca da maioria dos produtos em sistemas de comércio eletrônico atuais (Sarwar et. al)
Usuários de sistemas de e-commerce conseguem avaliar apenas 1% dos produtos disponíveis (Sarwar et. al)
Avaliações de usuários podem ser aplicadas apenas noem domínios de informação homogêneo

15
Limitações
A limitação mais crítica está relacionada com adispersão de dados (data sparsity)
O número de avaliações necessárias para construirmodelos de predição é inferior ao número de avaliaçõesdisponíveis
Atualmente não é comum utilizar técnicas puramentebaseadas em memória

16
Limitações
A escalabilidade (scalability) também pode ser um fatorcomprometedor para la eficiência de um sistema derecomendação
O problema da “primeira avaliação” (first rater) é
pertinente a todas categorias de métodos
O problema da “ovelha negra” (gray sheep) ocorre,predominantemente, em métodos de filtragemcolaborativa

17
Limitações
Métodos baseados em conteúdo são pouco afetados peladispersão de dados e pelo problema da “ovelha negra”
A falta de mecanismos para extrair propriedades deobjetos Web desfavorece o uso de métodos baseados emconteúdo de maneira pura (Claypool et. al.)
Técnicas de recomendação baseadas em conteúdocostumam ser utilizadas juntos com técnicas de filtragemcolaborativa

18
Limitações
Figura: Exemplo de erro na recomendação

19
Sistemas de Recomendação
Erros que podem ocorrer:
Falsos negativos
Falsos positivos
Técnicas de mineração de dados podem ser aplicadaseficientemente em sistemas de recomendação,entretanto, necessitam ser extendidas para tratarproblemas típicos de tais sistemas (Cheung et al.)

KDD
O termo “Mineração de Dados” é tratado como sinônimoao processo de KDD, como também uma etapa domesmo
Terminologia: KDD (Knowledge Discovery in Databases –Descoberta de Conhecimento em Bancos de Dados)
“Processo não trivial de identificação de padrões válidos,novos, potencialmente úteis e compreensíveis, embutidosnos dados” (Fayyad, 1996)
20

KDD
Permite a extração de informações que dificilmenteseriam identificadas somente realizando consultas emum banco de dados
O sucesso de uma organização passa a depender dahabilidade em manipular sua informação (matéria primaessencial para seu desenvolvimento) (Brauner et al.)
Torna-se eminente a necessidade de um meio de lidarcom grandes volumes de informação e prover maiorautomatização em sua análise
21

23/11/10

23
Mineração de Dados
“The key to success in business is to know somethingthat nobody knows”, Aristotle Onassis (1959)
Destinada a extração de padrões úteis nos dados
É uma area multi-disciplinar (tecnicas provenientes dainteligência artifical, banco de dados, estatística, etc.)
O tipo de padrão a ser encontrado está diretamenterelacionado com o tipo de conhecimento a serdescoberto

23/11/10

Aplicações
Gerência de Marketing
Bioinformática
Detecção de fraudes
Web Mining (Mineração da Web)
Bases de dados estatísticas
Text-Mining
Medicina
Fenômenos metereológicos
Sistemas de recomendação
....
25

26
Classes de Problemas
De acordo com o objetivo de mineração, têm-sediferentes classes de problemas:
Classificação
Agrupamento
Associação

Classificação
Examina características de um registro (ouobjeto) para enquadrá-lo (classificá-lo) em umconjunto pré definido (classe)
Utiliza um conjunto de treinamento para obteras classes
Aprendizado supervisionado
Técnicas (algoritmos): redes neurais, redesbayesianas, árvores de decisão, etc.
27

23/11/10

23/11/10

Agrupamento
Procura segmentar populações heterogêneas emsubgrupos ou segmentos homogêneos
Aprendizado não supervisionado (os grupos nãosão pré definidos)
30
23/11/10

Agrupamento
Similarity is hard to define, but… “We know it when we see it” Dr. E. Keogh
32

Regras de Associação
Foram introduzidas com o objetivo de descreverinformação nova acerca da compra de produtos(market basket analysis)
Identificam itens cuja presença implica a presença deoutros itens em uma mesma transação
Exemplo: quando um cliente compra uma camisasocial, em 70% dos casos ele compra também umagravata. Isso acontece em 13,5% das compras.
Confiança = 70%
Suporte = 13,5%
33

34
Regras de Associação
Aprendizagem não supervisada + objetivo dedescrição
Algoritmos: Apriori, FP-Growth, Basic, ECLAT, DIC,etc.
Possuem a notação A → B, onde A e B são conjuntosde itens

Regras de Associação
O caso mais conhecido: a cadeia Wal-Martidentificou que, às sextas-feiras, as vendasde cervejas cresciam na mesma proporção que asde fraldas
Regras com alto suporte e confiança não sãonecessariamente interessantes
- Padrões óbvios X muitas regras
35

36
Regras de Associação
Exemplo: considerando-se uma compra desupermercado como uma transação.
Supondo uma transação t1, tal que
t1 = {queijo, refrigerante, manteiga}
Pode-se ter as seguintes regras...

37
Regras de Associação
ID Regra
1 queijo → refrigerante, manteiga
2 queijo → refrigerante
3 queijo → manteiga
4 refrigerante → queijo, manteiga
5 refrigerante → queijo
6 refrigerante → manteiga
7 manteiga → queijo, refrigerante
8 manteiga → queijo
9 manteiga → refrigerante
10 queijo, refrigerante → manteiga
11 queijo, manteiga → refrigerante
12 refrigerante, manteiga → queijo
Tabela: Possíveis regras geradas a partir de t1
23/11/10

23/11/10

40
Classificação Baseada em Associação
Consiste em um método alternativo de classificação, ondeas regras de associação são utilizadas dentro de umcontexto de predição
Atualmente dispõem-se de poucos classificadoresassociativos eficientes, tais como CBA, CPAR, MCAR, CMARe TFPC (Thabtah et al.)
Quando um objeto é classificado, suas propriedades sãoconfrontadas com os termos antecedentes das regras deassociação do modelo criado
É necessário que o termo consequente de uma Regra deClassificação se restrinja a um único atributo (A → class)

41
Classificação Baseada em Associação
Vantagens dos classificadores associativos:
A construção de um modelo de associação costuma sermais eficiente que a de um modelo de classificação
Vários estudos (Liu et al) (Thabtah et. al) (Yin y Han)apontam que a CBA proporciona maior precisão quemétodos de classificação tradicionais
O output de um algoritmo de regras de associação é defácil compreensão a ser humano (Sarwar et. al)

42
Classificação Baseada em Associação
Exemplo de regras de classificação:
R1: (atr2, g) → (atr3, classeA)
R2: (atr1, h) → (atr3, classeB)
R3: {(atr1, b) AND (atr2, g)} → (atr3, classeA)
ID atr1 atr2 class
1 a f ?
2 a g ?
3 b h ?
4 b g ?
5 c g ?
Tabela: Conjunto de treinamento:

43
Algoritmo CBA-Fuzzy
Adaptado para sistemas de recomendação (menosfalsos positivos)
Desenvolvido com base no algoritmo CBA disponívelma biblioteca LUKS-KDD
Utiliza lógica Fuzzy

44
Lógica Fuzzy
Extensão da lógica booleana que admite valoresintermediários entre 0 (falso) e 1 (verdadeiro)
Lida com dados vagos ou imprecisos
Cada valor representa um grau de pertinência deum elemento a um dado conjunto (valor em [0, 1])
Cada conjunto possui uma função para indicar ograu de pertinência de elementos

45
Lógica Fuzzy
Áreas de Aplicação:
Robótica
Sistemas Especialista
Jogos
Sistemas de apoio à tomada decisão
Sistemas de recomendação
...
Utilização prática:
Metrô de Sendai no Japão (1988)
Ar-condicionado
Câmeras fotográficas
...

46
Lógica Fuzzy
Jovem Meia Idade Idoso Baixo Médio Alto
X1 0 1 0 1 0 0
X2 0 1 0 1 0 0
X3 0 1 0 1 0 0
X4 0 1 0 0 1 0
x5 0 1 0 0 0 1
Idade Salário
X1 36 820
X2 38 910
X3 36 930
X4 43 2100
x5 59 4000
Tabela 1: Dados Tabela 2: Valores de pertinência na lógica Crisp
Jovem Meia Idade Idoso Baixo Médio Alto
X1 0.5 0.5 0 0.8 0.2 0
X2 0.4 0.6 0 0.7 0.3 0
X3 0.5 0.5 0 0.6 0.4 0
X4 0 1 0 0 1 0
x5 0 0.5 0.5 0 0 1
Tabela 3: Valores de pertinência fuzzy

47
Lógica Fuzzy
Figura: Exemplo de função triangular (adaptada do Matlab
48
Lógica Fuzzy
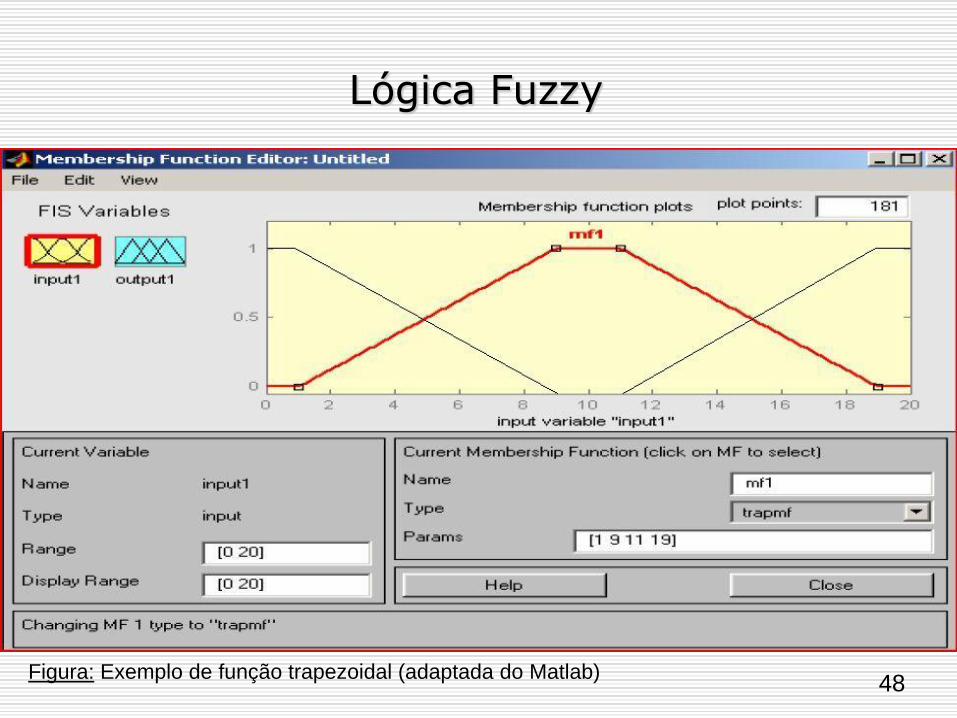
Figura: Exemplo de função trapezoidal (adaptada do Matlab)

49
Fuzzificação
Equal-Width (ex:[10-20[, [20-30], [30-40]) função triangular
Equal-Depth (ex:[10-25[, [25-30], [35-40]): função triangular e trapezoidal
ID Autor Ano País Idade Rating
1 Stephen King [1996-1998[:0.3; [1998-2000[:0.7
FR [25-30[:0.3; [30-33[:0.7 Good
2 Anne Rice [1975-1983[:0.5; [1983-1988[:0.5
ES [30-33[:0.2; [33-35[:0.8 Bad
3 Stephen King [2000-2001[:0.6; [2001-2003[:0.4
UK [33-35[:0.5; [35-37[:0.5 Bad
4 Nora Roberts [1983-1988[:0.8; [1988-1993[:0.2
BR [40-47[:0.7; [47-50[:0.3 Good
Tabela: Exemplo de input ao CBA-Fuzzy

50
Associação Fuzzy
Cada item de uma regra possui um grau de pertinênciaassociado ao conjunto presente no mesmo
O cálculo do suporte e da confiança devem seradaptados
Função de pertinência utilizada para classificação noalgoritmo CBA-Fuzzy

51
Casos de Estudo
Objetivos:
Analisar o comportamento de algoritmos de CBA frente adatos de sistemas de recomendación
Comparar a precisão de algoritmos de CBA com a dealgoritmos de classificação tradicionais
Identificar situações nas quais cada algoritmo pode serutilizado mais eficientemente
Comparar aspectos relacionados com limitações desistemas de recomendação
Bases de dados utilizadas: MovieLens e Book Crossing

52
Dados de MovieLens
Sistema de recomendação de filmes disponível sem custospara fins acadêmicos pelo GroupLens
Composto de avaliações de usuários acerca de 1.682filmes
Inicialmente continha aproximadamente 100.000avaliações feitas por 943 usuários
Depois do pré-processamento restaram 14.587 registrosno arquivo de entrada

53
Dados de MovieLens
Dados de Usuários
Sexo
Binario
Edad
Num.
Ocupación
String
Postal
Num.
Dados de Filmes
Título
String
ID
Num.
Gênero (19 atributos)
Binário
ID
Num.
Dados de Opiniões
ID Usuario
Num.
ID
Num.
Puntuación
Num. (1 - 5)
ID Usuario
Num.
ID
Num.
ID Usuario
Num.
ID
Num.
Puntuação
Num. (1 - 5)
ID Filme
Num.
ID Usuario
Num.
ID
Num.
Sexo
Binario
Edad
Num.
Ocupação
String
Sexo
Binário
Idade
Num.

54
Pré-Processamento
*Puntuação
Binário
ID
Num.
Sexo Usuário
Binário
*Idade Usuário
- < 18
- [18, 25[
- [25, 35[
- [35, 45[
- [45, 50[
- [50, 56[
- > 56
Ocupação Usuário
String
Título Filme
String
*Gênero Filme
String

55
Dados de Book Crossing
Dados de avaliações acerca de livros coletados (porZiegler et. al) da comunidade de Book Crossing
Inicialmente continha 1.149.780 de avaliações acercade 271.379 livros
278.858 usuários realizaram avaliações explícitas (de1 a 10) e implícitas
Depois do pré-processamento restaram 433.671registros

56
Dados de Book Crossing
Dados de UsuáriosDados de Livros
Título
String
ISBN
Num.
Ano Pub.
Num.
ID
Num.
Dados das Avaliações
Pontuação
Num. (1 - 10)
ISBN
Num.
User ID
Num.
ID
Num.
Lugar
String
Idade
Num.
Autor
String
Editora
String
User ID
Num.
ID
Num.
ISBN
Num.
User ID
Num.
ID
Num.

57
Pré-Processamento
*Avaliação
bin
ID
Num.
*Idade Usuário
- < 16
- [16 - 20]
- [21 - 25]
- [26 - 30]
- [31 - 35]
- [36 - 40]
- [41 - 45]
- [46 - 50]
- > 50
Lugar Usuário
String
Ano de Publicação
- < 1980
- [1981 - 1990]
- [1991 - 1995]
- [1996 - 2000]
- [2001 - 2004]
Autor do Livro
String

58
Pré-Processamento
O conjunto de dados foi dividido em dois:
lugares agrupados em estados dos EUA (25.523registros)
lugares agrupados por países (8.926 registros)
Derivou-se mais 2 conjuntos de dados: manteve-seapenas os 10 valores mais frequentes nos atributosAutor e País/Estado Estados dos EUA com 10 valores distintos (6.270 registros)
Países com 10 valores distintos (3.238 registros)

Analisando a Precisão
DadosRede
BayesianaC4.5 CBA CPAR CMAR cd*
MovieLens 81,95% 82,88% 81,4% 74,07% 83,28% 0,86
BCrossing World 80,87% 80,21% 79,47% 73,25% 59,55% 0,062
BCrossing World10 80,51% 79,98% 81,28% 79,86% 33,51% 0,36
BCrossing USA 80,23% 81,31% 80,23% 78,15% 67,30% 0,18
BCrossing USA10 81,53% 80,82% 81,56% 76,71% 56,86% 0,7
Tabela: Precisão registrada nos algoritmos
59
*cd = coeficiente de dispersão = num reg./produto dos valores distintos

Falsos Positivos
DadosRede
BayesianaC4.5 CBA CBA-Fuzzy
MovieLens 47,7% 42,6% 32,22% 32,08%
BCrossing World 45,15% 39,9% 23,03% 31,89%
BCrossing World10 40,3% 42,45% 33,83% 32,88%
BCrossing USA 47,45% 41,55% 20,43% 18,89%
BCrossing USA10 48,25% 44% 34,66% 28,63%
Tabela: Falsos Positivos gerados
60

61
Metodologia Híbrida de Recomendação
Figura: Modelo de recomendação

62
Metodologia Híbrida de Recomendação
Encontrar grupos de usuários
Utiliza as últimas transações do usuários
Baseado em filtragem colaborativa
Aplica-se um algoritmo de agrupamento (K-means)
Associa-se uma lista ordenadas de itens para cada grupo
Um modelo CBA-Fuzzy off-line
Construído através da versão adaptada de CBA
Input: últimas transações de usuários + “atributo grupo”
Output: um conjunto de regras de classificaçao associando atributosde usuários e itens

63
Metodologia Híbrida de Recomendação
Runtime do Sistema de Recomendação
Input: última transação do usuário ativo (métodbaseado em conteúdo)
Etapa intermediária: resulta em 1 ou mais grupos deusuários previstos para o atributo classe (através dalógica fuzzy)
Output: os primeiros itens da lista ordenada (de 1 oumais grupos)

64
Aplicação no Sistema PSiS
Figura: Tela principal do PSiS (http://gecad.isep.ipp.pt:9090/psis)

Links de Interesse
Weka, University of Waikato (www.cs.waikato.ac.nz/ml/weka)
Machine Learning Repository, University of California – Irvine (http://archive.ics.uci.edu/ml/)
KDnuggets (www.kdnuggets.com)
LUCSKDD Software Library - Liverpool University (http://www.csc.liv.ac.uk/~frans/KDD/Software/)
GroupLens - University of Minnesota, USA (http://www.grouplens.org/)
65

66
Bibliografia
Breese, J.S., Heckerman, D., Kadie, C.: Empirical analysis of predictive algorithmsfor collaborative filtering. 43--52 (1998)
Thabtah, F., Cowling, P., Peng, Y.: Mcar: multi-class classification based onassociation rule. In: AICCSA ’05: Proceedings of the ACS/IEEE 2005 InternationalConference on Computer Systems and Applications, Washington, DC, USA, IEEEComputer Society (2005)
Sarwar, B.M., Karypis, G., Konstan, J.A., Reidl, J.: Item-based collaborativefiltering recommendation algorithms. In: World Wide Web. 285--295 (2001)
Cheung, K.W., Kwok, J.T., Law, M.H., Tsui, K.C.: Mining customer product ratingsfor personalized marketing. Decision Support Systems 35(2), 231--243 (2003)
Agrawal, R., Imielinski, T., Swami, A.N.: Mining association rules between sets ofitems in large databases. In Buneman, P., Jajodia, S., eds.: Proceedings of the1993 ACM SIGMOD International Conference on Management of Data,Washington, D.C. 207 -- 216 (1993)
Lee, C.H., Kim, Y.H., Rhee, P.K.: Web personalization expert with combiningcollaborative filtering and association rule mining technique. Expert Systems Appl.21(3), 131--137 (2001)

67
Bibliografia
Liu, B., Hsu, W., Ma, Y.: Integrating classification and association rule mining.In: Knowledge Discovery and Data Mining. 80--86 (1998)
Li, W., Han, J., Pei, J.: CMAR: Accurate and efficient classification based onmultiple class-association rules. In: ICDM. 369--376 (2001)
Lin, W.; Alvarez, S.; Ruiz, C. Efficient adaptive-support association rule miningfor recommender systems. (2002)
Yin, X., Han, J.: Cpar: Classification based on predictive association rules. In:SIAM International Conference on Data Mining (SDM’03). 331--335 (2003)
Coenen, F., Leng, P.H., Zhang, L.: Threshold tuning for improved classificationassociation rule mining. In: PAKDD. 216--225 (2005)
Wang, Y., Xin, Q., Coenen, F.: A novel rule ordering approach in classificationassociation rule mining. In: The 5th International Conference on MachineLearning and Data Ming (MLDM’2007), Springer LNAI 4571, 339--348 (2007)