reconhecimento de padrões aplicado à bioinformática
TRANSCRIPT

Reconhecimento de Padrões aplicado à Bioinformática
Dr. Leandro Carrijo CintraCNPTIA – Embrapa Informática Agropecuária
Curso de Verão 2010
BioinformáticaUSP

CNPTIA - Centro Nacional de Pesquisas Tecnológicas em Informática para a Agricultura
• Responsabilidades: • Execução de projetos de pesquisa que objetivam ampliar a participação
tecnológica na agropecuária• Execução de projetos de TI críticos para a Embrapa
• Laboratórios: • Novas Tecnologias • Software Livre• Geotecnologias• Modelagem Agroambiental• Inteligência Computacional• Bioinformática• Organização da Informação Digital• Redes, Conectividade e Alto Desempenho

Reconhecimento de padrões: Definições
• O ato de observar os dados brutos e tomar uma ação baseada na categoria de um padrão, Duda et al. [1]
• É uma área de pesquisa que tem por objetivo a classificação de objetos (padrões) em um número de categorias ou classes Theodoridis & Koutroumbas [2]

Aplicações
• Biometria • Reconhecimento de faces, voz, digitais, etc...
• Processamento de linguagem escrita e falada• Aplicações na análise do mercado financeiro• Aplicações médicas• Descobrimento de novos fármacos• Controle de qualidade industrial

Aplicações em Bioinformática
• Predição de Genes• Detecção de exons e introns• Predição de estrutura secundária de proteínas• Detecção de homologia entre proteínas• Detecção de genes ortólogos/parólogos• Determinação de redes gênicas

Conceitos básicos
• Exemplo(padrão, instância): um objeto único do mundo a partir do qual um modelo será aprendido, ou sobre o qual um modelo será usado (predição).
Ex: uma célula, um atleta, uma face, um caracter, etc...
• Característica (atributo, variável): uma quantidade descrevendo um exemplo (padrão). Ex: altura, peso, expressão de um gene, etc...

Conceitos básicos
• Vetor de características (vetor de features): uma lista de características que descreve um exemplo. Ex: (peso, altura), fatores de expressão gênica em genes
• Classe: um atributo especial no vetor de características que permite a identificação dos padrões.
Ex: (45, 1.56, jóquei) • Conjunto de exemplos: é constituído pelos vetores de
características de um conjunto de exemplos. – Conjunto de treinamento– Conjunto de teste

Exemplo 1
• Considere o caso onde as instâncias (padrões) são jóqueis e jogadores de basquete. Poderíamos ter como conjunto de exemplos:
• (51, 1.51, jóquei)• (80, 1.92, jogBasq)• (53, 1.54, jóquei)• (52, 1.56, jóquei)• (51, 1.50, jóquei)• (88, 2.12, jogBasq)

Exemplo 2(scatterplot)
?

Overfitting
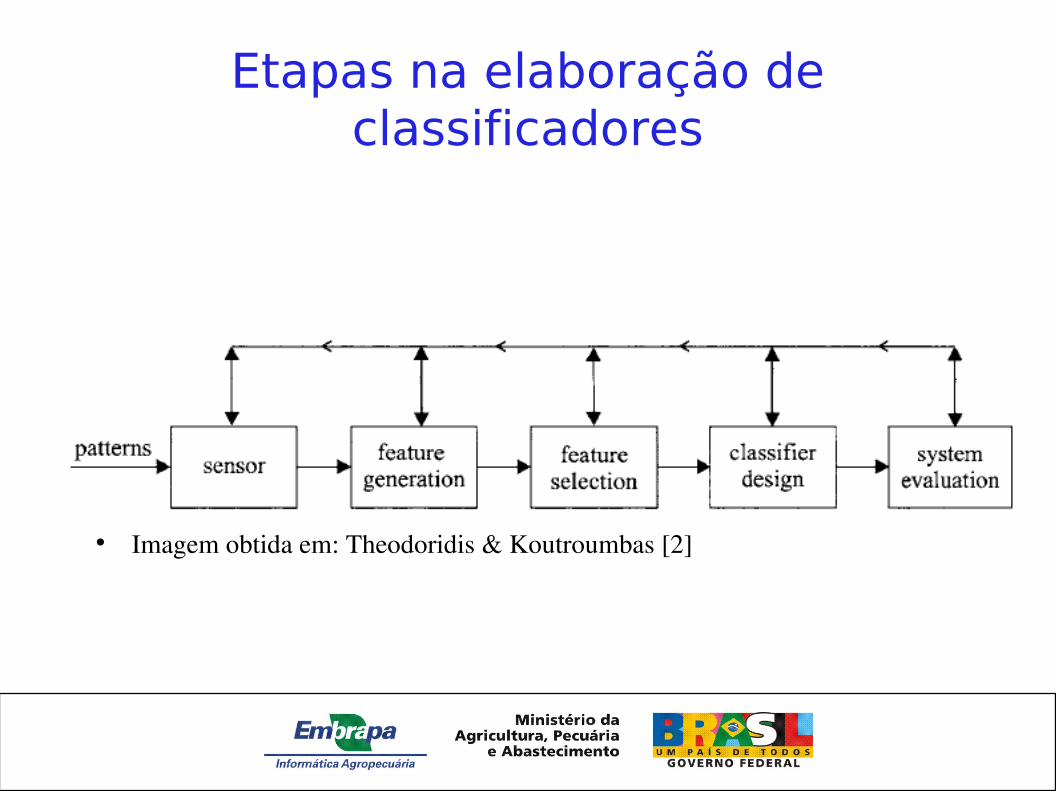
Etapas na elaboração de classificadores
• Imagem obtida em: Theodoridis & Koutroumbas [2]

Classificação Supervisionada versus Não-Supervisionada
• Aprendizado supervisionado: durante a fase de treinamento os algoritmos necessita de exemplos que tenham o rótulo indicando a classe à qual o mesmo pertence.
• Aprendizado nãosupervisionado: os algoritmos não consideram (não necessitam) da classe à qual cada exemplo pertence. Eles fazem o agrupamento (reunião em classes) dos exemplos baseados em alguma métrica de similaridade (função de distância).

Alguns algoritmos...
• Aprendizado supervisionado• Aprendizado bayesiano• Redes Neurais Artificiais (RNAs)• Kvizinhos (kNN Knearest neighbors)• Árvores de decisão• Máquinas de Suporte Vetorial (MSVs)
• Aprendizado nãosupervisionado (clusterização)• Métodos de clusterização hierárquicos (dendogramas)• Kmédias• Redes de Kohonen
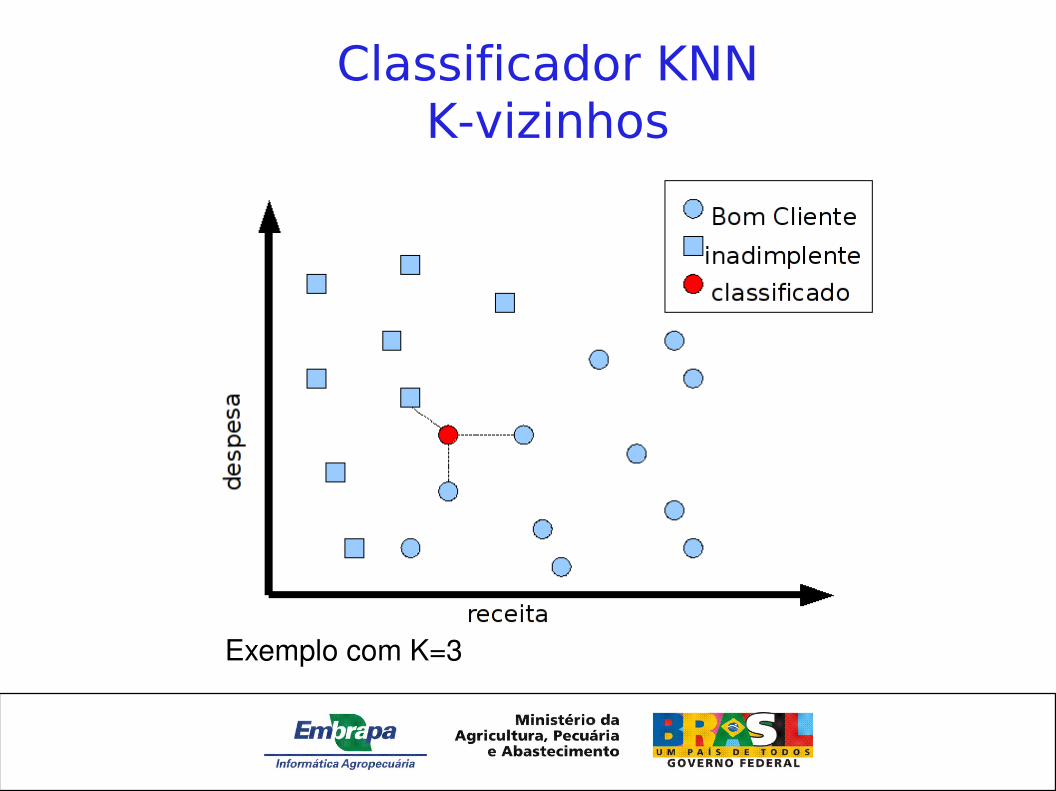
Classificador KNNK-vizinhos
Exemplo com K=3

Função de distância
• Distância Euclidiana, Distância de Mahalanobis, Distância de Manhattan...
• Distância é um número que caracteriza a separação entre dois objetos
• Sejam a, b, c três objetos quaisquer, então a medida de distância deve satisfazer a 3 requisitos:– Ser nãonegativa: d(a,b) ≥ 0– Ser comutativa: d(a,b)=d(b,a)– Satisfazer a desigualdade triangular: d(a,b)+d(b,c) ≥ d(a,c)

Distância Euclideana
• A distância Euclidiana entre dois padrões a=(a1, a2, ..., an) e b=(b1, b2, ..., bn) no espaço ℝn é definida por:
• Atribui a mesma importância para cada dimensão (característica)
d E a ,b=∑i=1
i=n
ai−bi2
d E a ,b= x0−x12 y0− y1
2
a=(x0,y0)
b=(x1,y1)

Distância de Mahalanobis
• A distância estatística ou distância Mahalanobis entre dois padrões a=(a1, a2, ..., an) e
b=(b1, b2, ..., bn) no espaço ℝn é definida por:
• Onde é a matriz de covariância das variáveis. • Pode atribuir um peso (importância) diferente para
cada dimensão
d M a ,b=a−b ∑−1a−bt
−1

Exemplos de distâncias
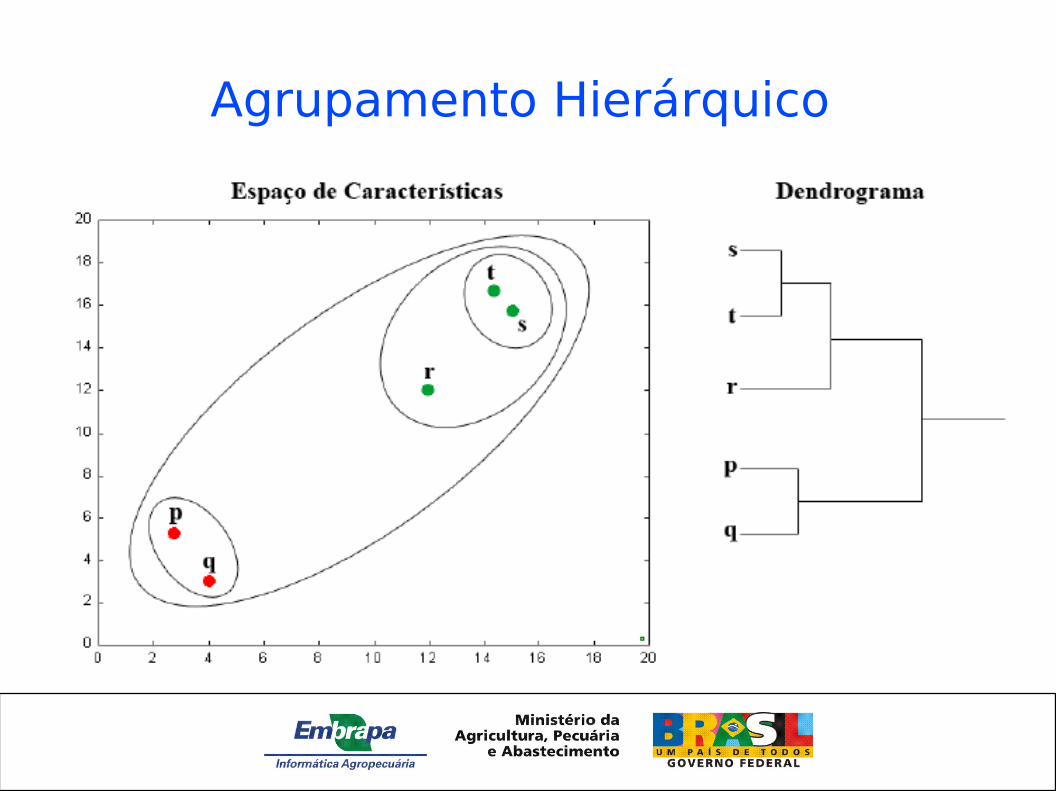
Agrupamento Hierárquico

Como definir a distância entre clusters?

Controle de qualidade do cimento

Análise do movimento celular

Resultados

Weka
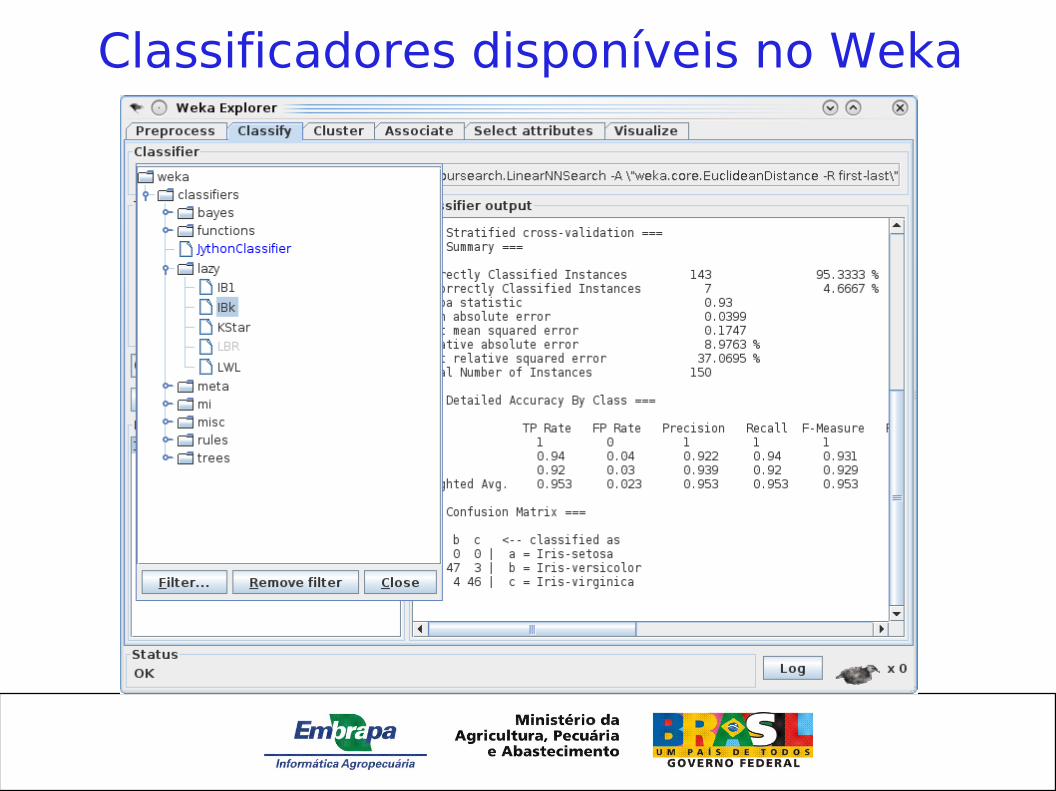
Classificadores disponíveis no Weka

Sugestão de leitura

Processamento de Microarray

Clusterização
• Genes com funções relacionados tendem a ter padrões de expressão similares
• A clusterização dos genes possibilita inferir a função de genes desconhecidos a partir de outros genes conhecidos que estejam no mesmo cluster
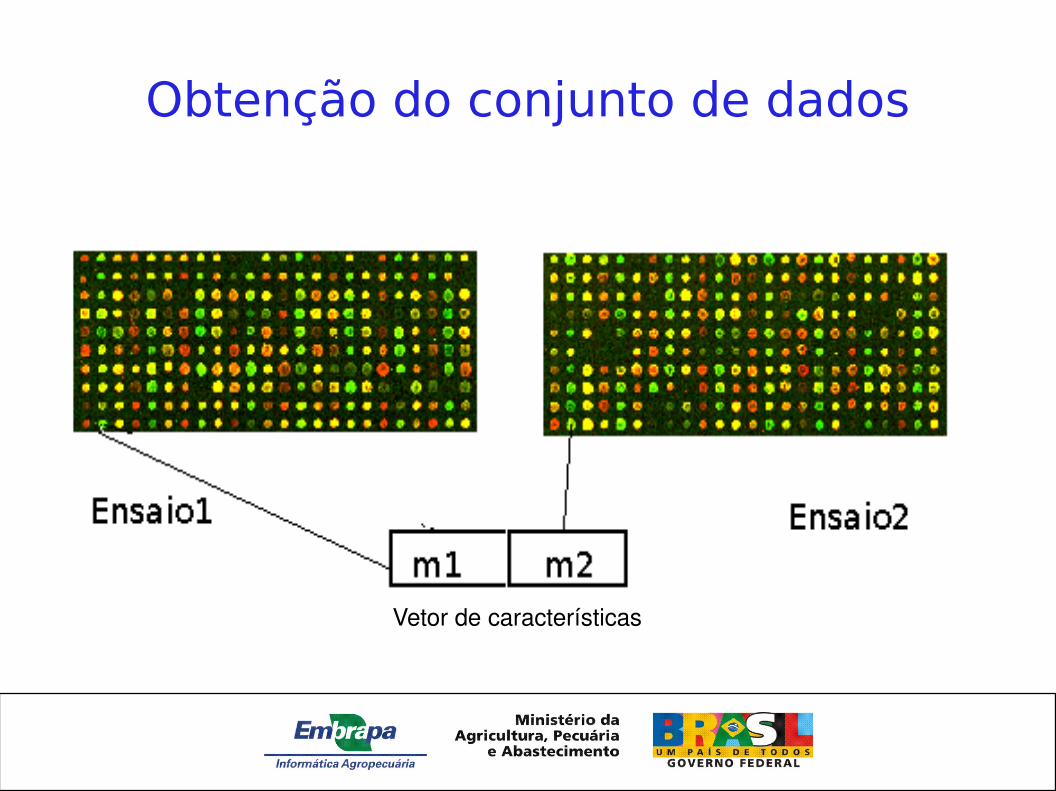
Obtenção do conjunto de dados
Vetor de características

Resultado esperado

Pré-processamento
• Filtros na imagem• Eliminação de spots vazios• Normalização• Desconsiderar genes com pouca variabilidade em
suas intensidades de expressão

Exemplo de alguns experimentos
Banco de dados descrição6220 ORF de S. Cerevisiae em 15 instantes
112 genes em 9 instantes6500 genes humanos em 40 tumores e 22 normais
Cho's dataIyes's data 9800 cDNAs em 12 instantesWen's dataColon cancer dataFonte: Jiang et al.[3]

Identificação de motifs
• Criatividade para gerar os dados de entrada para os algoritmos de classificação!!!!
• Pequenas cadeias inseridas nas regiões promotoras que são utilizadas como âncoras para os fatores de transcrição
• Tipicamente com tamanhos entre 6 e 20 bp• Apresenta algumas posições muito conservadas e
outras bastante mutáveis• Ex: CG{C|G}{A|C|G|T}TA

Representação de um motif
• Representação por consenso: CGSNTA• Onde S representa C ou G• N representa qualquer base
• Representação pela matriz PSSM – Position Specific Scoring Matrix
• É uma matriz com tamanho 4xL, onde L é o tamanho do motif
• Cada elemento uij da matriz representa a frequência relativa que a base i ocorre na posição j do motif

Similaridade com a matriz PSSM
x=ACAGTATou
x=ATCGGA
Quão similar ao motif são as sequências abaixo?
S x =∑i=1
l
∑b=A
T
x ib logf ib
pb
xib=1 se a base b encontrase na posição i da sequência
xib=0 caso contráriopb pobabilidade da base b fib um valor na posicao ib da matriz PSSM

Referências
• [1] R. O. Duda and P.E. Hart and D. G. Stork; Pattern Classification, WhileyInterscience, 2000
• [2] S. Theodoridis and K. Koutroumbas; Pattern Recognition. Academic Press, 1999
• [3] D. Jiang, C. Tang and ª Zhang; Cluster Analyis for Gene Expression Data: A Survey. IEEE Tans on Knowledge and Data Engineering, 16(11): 13701386, 2004

Referências
• [4] Shaun Mahony, et al.; Selforganizing neural networks to support the discovery of DNAbinding motifs; Neural Networks 19: 950962, 2006
• [5] Alan WeeChung Liew, Hong Yan and Megsu Yang; Pattern recognition techniques for the emerging field of bionformatics: A review; Pattern Recognition, 38: 20552073, 2005
