professor: lui · criada para todo o banco de dados. já no modelo orientado a documentos, temos um...
TRANSCRIPT

NoSQL e Big Data
Professor: Luis Felipe Leite


O que é o Big Data?

Big Data
Vivemos hoje a era da informação. Em apenasum clique, temos acesso a notícias, dadosfinanceiros, pesquisas, etc.
Essa quantidade exacerbada de informaçãopode ser útil, bem como danosa.

Big Data
Big Data hoje é uma palavra da moda. E com certeza é umconceito transformador.
O conceito dita que, praticamente tudo que fazemos hojeem dia, deixa um rastro digital. E que, esses dados devem epodem ser analisados.
Em resumo, Big Data, pode ser vista como nossahabilidade de tratar e usar essa grande quantidade dedados.

Big Data
Do ínicio da civilização até hoje até 2003, a raçahumana gerou 5 exabytes de dados. Hoje nósproduzimos a mesma quantidade de dados em doisdias. A ideia é que em alguns anos, produziremosessa mesma quantidade a cada minuto.
O facebook em 2013 tinha 1.11 bilhão de usuários.

De onde vem esses dados?
Dados de atividades corriqueiras:● Música digital, dados de smartphones e cartões
de crédito.Dados de conversas.Dados de imagens e vídeos.Dados de sensores.Dados de Internet das Coisas.

O que esses dados nostrazem?
Essa grande quantidade de dados trazemcaracterísticas novas ao novo paradigma de BigData chamadas de os 4 Vs.
● Volume;● Velocidade;● Variedade;● Veracidade

Volume
Volume se refere a questão da quantidade de dadosem si. O grande volume que é gerado a cada minuto eque só aumenta.
Para processar essa quantidade enorme de volumede dados, ferramentas foram ,e estão sendodesenvolvidas, para guardar e analisar esses dadosde forma distribuída.

Velocidade
Velocidade se refere a rapidez que novas informações sãogeradas a cada minuto e como elas se tornam viral nasredes sociais.
A tecnologia hoje permite que esses dados sejamanalisados sem que exista a necessidade de um banco dedados.

Variedade
A variedade de dados que é gerada hoje em dia nostraz formas diferentes de interagir.
No passado, a maioria dos dados eram estruturados(Dados bancários), já hoje, o grande volume está nosnão estruturados. (textos, imagens, voz, etc…)
Com o Big Data, podemos juntar dados variados eanalisá-los juntos.

Veracidade
Muitos dados, pouca confiança

Como usar esse big data?
Embora seja complexo tratar, armazenar eanalisar essa grande quantidade de dados, aindústria e as empresas já descobriram que, sefeito de uma forma direcionada, o uso do big datapode trazer excelentes frutos.

Melhor entendimento declientes

Melhor entendimento declientes
A chave aqui é analisar o que os clientes procuram ecompram para prever futuras vendas.
Foi investigado pelo wallmart que após o Katrina, amaioria dos clientes compravam strawberry poptarts.Antes do furacão a maior venda era cerveja.
Colocar cerveja perto de fraudas durante a noite éuma outra ideia que vem de análises.

Entendimento e otimização deprocessos de negócios
O comércio varejista está tornando seus estoques maissustentáveis e menos custosos baseado em análises dedados de redes sociais, trends e previsões do tempo.
Outro exemplo pode ser visto na melhora de rotas deentrega e distribuição de produtos com base na análise dedados do trânsito em tempo real.

Análises médicas

Análises médicas
O google trends é uma poderosa ferramenta para juntar dadosdiferentes sobre um mesmo assunto e mostrar análisesinteressantes sobre essas correlações.
A cura de doenças pode ser descoberta por profissionais dainformação, em vez de médicos.
É especulado que a cura da Aids já pudesse ter sido descobertase a sociedade de hoje tivesse os meios necessários paraprocessar a quantidade de dados sobre o vírus já disponível.
Genoma humano.

Cumprimento da Lei
Agências governamentais usam big data para preverataques terroristas, bem como ter “insights” sobre áreasperigosas urbanas.
Empresas de cartão de crédito também usam da análise degrandes volumes de dados para ter uma ideia de quandouma compra é uma fraude ou não.

Performance no esporte.

Cidades inteligentes
Cidades estão usando big data para prever trânsito, clima,decisões.
Essas previsões podem tornar a cidade em uma smartcity.

O quarto paradigma
Milhares de anos atrás: Ciência empírica, como a naturezafunciona, etc.
Centenas de anos atrás: Já foram criados modelosmatemáticos, modelos e generalizações
Décadas atrás: A descoberta de que usando computadorera possível prever coisas mais rápidas.
Hoje, temos cientistas e sistemas juntando quinquilhõesde dados, explorando as informações (e-science).

E os bancos de dados?
Com essa enorme quantidade de informações, como osbancos de dados podem nos ajudar?
A n t e s, o s b a n c o s e ra m p e n s a d o s ap e n a s e mgerenciamento de dados.
Os bancos durante anos, se desenvolveram, com base nasgrandes empresas, pensando em consistências,integridade, etc….ACID!!

CAP THEOREM
O ACID é nossa base de bancos de dados relacionaisaté hoje.
Esqueça!!
Um cara chamado Brewer, em 2000, afirmou que éimpossível um serviço web prover consistência,disponibilidade e tolerância à partição ao mesmotempo.

CAP Theorem
Consistência: Todos os nós estão vendo a mesma coisa aomesmo tempo.
Disponibilidade: A garantia que cada serviço vai ter aresposta se teve sucesso ou falhou.
Tolerância à partição: O sistema continua funcionandomesmo se houver um erro em um nó, ou parte do sistemaparar de funcionar.

ACID X BASE
BASE é uma forma de entregar o banco da melhor formapossível.
Facebook é um ótimo exemplo se tratando de consistênciaem mão da disponibilidade.
A troca entre os três pilares é feita de forma perto doótimo, relaxando um ou outro fator, dependendo de suaaplicação.

ACID X BASE

CAP Theorem
Então, dada as três características, consistência,disponibilidade e tolerância à partição, você pode ter nomáximo duas para qualquer sistema distribuído.
A questão é qual você vai abrir mão.

NoSQL

NoSQL
Existe uma ideia na internet que os bancos de dadosNoSQL querem acabar com o padrão SQL.
Uma definição mais realista, aponta para uma ideia deuma padrão de armazenamento de dados alternativos aoSQL, oferecendo robustez e principalmente, escalabilidademelhor.

NoSQL
O termo NoSQL foi primeiramente utilizado em 1998 comoo nome de um banco de dados não relacional de códigoaberto.
Seu autor, Carlo Strozzi, alega que o movimento NoSQL "écompletamente distinto do modelo relacional e portantodeveria ser mais apropriadamente chamado "NoREL".

NoSQL
Com a crescente popularização da internet, diversosnovos dados foram surgindo e tratá-los foi se tornandogradualmente mais complexo e sua manutenção cada vezmais cara.
A crescente popularização das redes sociais, a geração deconteúdo por dispositivos móveis bem como o númerocada vez maior de pessoas e dispositivos conectados, fezcom que o trabalho de armazenamento de dados e suaanálise esbarrasse nas questões de escalabilidade ecustos de manutenção desses dados.

NoSQL X Banco de DadosRelacionais
Bancos de dados relacionais tambémfazem escalabilidade, porém, quantomaior o tamanho, mais custoso ele setorna.
Novas máquinas e novos especialistas,fazem a empresa gastar mais do que oesperado.

NoSQL X Banco de DadosRelacionais
Quando tratamos de bancos de dados nãorelacionais, é permitido uma escalabilidademais barata e menos trabalhosa.
A exigência de máquinas mais poderosasnão é mais necessária e sua facilidade demanutenção permite que o banco sejaadministrado por um número menor depessoas.

NoSQL X Banco de DadosRelacionais
Com essa facilidade, os bancos de dadosNoSQL ganham popularidade entre asgrandes empresas.
Características que reúnem a possibilidadede trabalhar com uma gama de dados vindode diferentes origens é um prato cheio pararedes sociais, empresas financeiras, etc.

Tipos de bancos NoSQL
Bancos de dados orientado àcolunas;Bancos de dados chave valor;Bancos de dados orientados adocumento;Bancos de dados de grafos.

Bancos de dados orientados àcoluna.
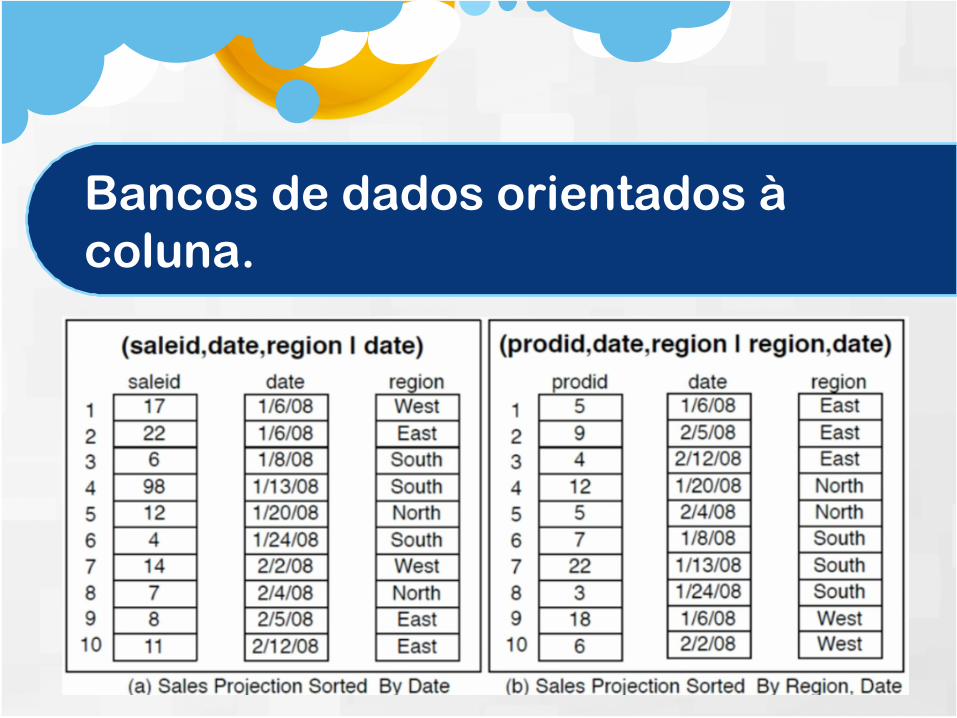
O banco de dados orientados à coluna veio como foco em análise.
O quest ionamento aqui é na forma dearmazenamento dos dados.
Em vez de ter todos os dados em tuplas e depoisem outra tupla e assim adiante, você armazenaem colunas.

Bancos de dados orientados àcoluna.
Você pode ter os dados armazenados emcolunas para analisar em uma dimensão.
Os recortes verticais são mais importantes doque recortes horizontais.
Esses banco de dados focam na performanceatravés de recortes verticais.
Monet DB

Bancos de dados orientados àcoluna.
Bancos de dados orientados àcoluna.

Bancos de dados orientados àdocumentos
Nós usamos muitos documentos, muitostambém em formatos xml.
Em vez de pegar esses documentos,transformar em uma tabela eguardar. Pega o documento em xmlmesmo e guarda.

Bancos de dados orientados àdocumentos
MongoDB e CouchDB seguem essa ideia.
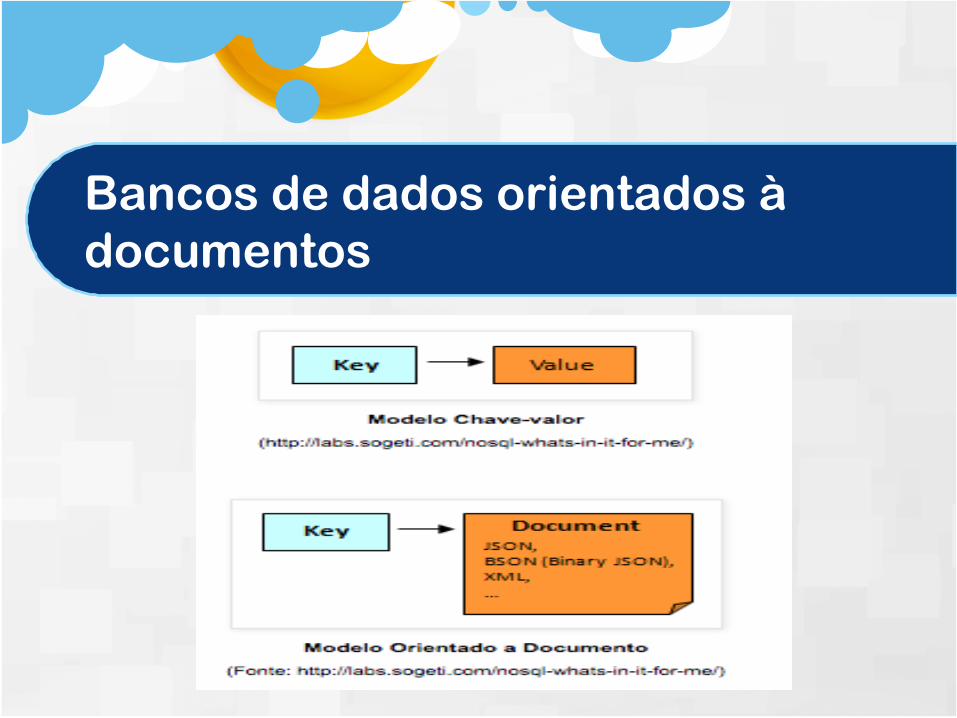
Este modelo armazena uma coleção dedocumentos. No caso, um documento érepresentado como um objeto, que possuium código único e um conjunto decampos, que podem ser strings, listas ououtros objetos aninhados.

Bancos de dados orientados àdocumentos
As estruturas desses campos se parecem com aestrutura dos campos no modelo Chave-valor (Key-value).
No modelo Chave-valor, uma única tabela hash écriada para todo o banco de dados. Já no modeloorientado a documentos, temos um conjunto dedocumentos (objetos) e em cada documento temosum conjunto de chaves (campos) cada um com suachave (key).
Bancos de dados orientados àdocumentos

Bancos de dados orientados àdocumentos
Uma característica importante deste modelo é que ele nãodepende de um esquema rígido, ou seja, não há obrigaçãode uma estrutura fixa. Sendo assim, pode-se fazer umaatualização na estrutura do documento sem causarnenhum problema com ao banco de dados.
Por exemplo, a adição de novos campos ao documento nãocausará nenhum problema no banco. Essa facilidade eflexibilidade em atualizar a estrutura dos documentos éuma das grandes e principais vantagens do modeloorientado a documentos.

Bancos de dados orientados àdocumentos
As codificações em uso incluem XML, YAML, JSON eBSON, assim como formas binárias, como imagens, PDF,documentos do Microsoft Office (MS Word, Excel) e assimpor diante.

Bancos de dados de Grafos
Neo4J é o mais conhecido banco de dados de grafos.
Os bancos de dados relacionais não permitem que osdados sejam representados através de grafos de umamaneira natural.
Algumas pesquisas dessa forma, podem se tornarextremamente complexas ou até mesmo impraticáveis.
● O uso de grafos pode facilitar e muito a aquisição dealguns resultados.

Bancos de dados de Grafos

Bancos de dados de Grafos
Analisando o grafo, se quisermos saber quem viajou para omesmo lugar que o Ricardo, basta descobrimos osrelacionamento de saída dele, que sejam do tipo VIAJOU,com isso, temos as cidades pelas quais Ricardo viajou.

Bancos de dados de Grafos
Podemos também realizar a complexa pesquisa sugeridaanteriormente, para saber por onde passaram (morando ouviajando) as pessoas que passaram por Nova York.Novamente, podemos percorrer o grafo tendo como pontode partida Nova York, porém, agora percorrendo os doitipos de relacionamentos (MOROU e VIAJOU) de chegada àcidade. Com isso, teremos nosso resultado.

Bancos de dados de Grafos

Bancos de dados de Grafos
Outros exemplos.

Até a próxima aula.