probabilidades e estatística - notas de apoio às aulas teóricas - paulo soares
TRANSCRIPT

DEPARTAMENTO DE MATEMÁTICA
Probabilidades e Estatística
Notas de apoio às aulas teóricas
Paulo Soares
14 de Setembro de 2010

Programa
Revisões de Estatística Descritiva e de Análise Combinatória1.
Noções de probabilidade
Experiências aleatórias. Espaço de resultados. Acontecimentos.1.
Noção de probabilidade: interpretações de Laplace, frequencista e subjectivista. Axiomática de probabilidade
e teoremas decorrentes.
2.
Probabilidade condicional.3.
Teoremas da probabilidade composta e da probabilidade total. Teorema de Bayes. Acontecimentos
independentes.
4.
2.
Variáveis aleatórias
Variável aleatória. Função de distribuição.1.
Variáveis aleatórias discretas. Função (massa) de probabilidade.2.
Variáveis aleatórias contínuas. Função densidade de probabilidade.3.
Vectores aleatórios bidimensionais. Funções de distribuição conjunta e marginais.4.
Vectores aleatórios discretos e contínuos. Distribuições conjunta, marginais e condicionais. Independência
entre variáveis aleatórias.
5.
3.
Distribuições de probabilidade e características
Valor esperado de uma variável aleatória e de uma função de uma variável aleatória.1.
Momentos simples e centrais. Desvio padrão e coeficiente de variação.2.
Moda e quantis.3.
Distribuições discretas: Uniforme, Bernoulli, Binomial, Hipergeométrica, Geométrica e Poisson.4.
Distribuições contínuas: Uniforme, Exponencial e Normal.5.
4.
Complementos das distribuições de probabilidade
Valor esperado de uma função de um par aleatório discreto e contínuo. Covariância e correlação. Valor
esperado e matriz de covariâncias de um par aleatório. Valor esperado condicional e propriedades.
1.
Relações entre distribuições.2.
Convergência em distribuição e Teorema Central do Limite. Aplicações.3.
5.
Amostragem e estimação pontual
Estatística Descritiva e Inferência Estatística. Amostragem aleatória. Estatísticas.1.
Estimação pontual: estimador e estimativa. Propriedades dos estimadores.2.
Método da máxima verosimilhança.3.
Momentos da média amostral e de variâncias amostrais. Distribuições amostrais da média e variância numa
população normal. Distribuições do qui-quadrado e t-Student.
4.
6.
Estimação por intervalos
Noções básicas. Método pivotal.1.
Intervalos de confiança para parâmetros de populações normais.2.
Intervalos de confiança para parâmetros de populações não normais uniparamétricas.3.
7.
Testes de hipóteses
Noções básicas.1.
Testes de hipóteses para parâmetros de populações normais.2.
Testes de hipóteses para parâmetros de populações não normais uniparamétricas.3.
Teste de ajustamento do qui-quadrado de Pearson.4.
8.
Introdução à regressão linear simples
Modelos de regressão.1.
Método dos mínimos quadrados em regressão linear simples.2.
Propriedades dos estimadores dos mínimos quadrados.3.
Inferências no modelo de regressão linear simples.4.
Coeficiente de determinação e análise de resíduos na avaliação do modelo.5.
9.

2. Noções de probabilidade
2.1 Experiências aleatórias. Espaço de resultados.Acontecimentos.
DefiniçãoUm procedimento ou conjunto de circunstâncias que produza resultadosobserváveis e para o qual:
se conhecem todos os resultados possíveis previamente à sua realização,1.mas não é possível prever o resultado de cada realização,2.
diz-se uma experiência aleatória.
DefiniçãoO conjunto formado por todos os resultados possíveis de uma experiência aleatóriadiz-se o seu espaço de resultados (Ω).
Exemplo - Algumas experiências aleatóriasE1 : lançamento de um dado cúbico
E2 : lançamento de duas moedas
E3 : lançamento de uma moeda até sair "cara"
E4 : ensaio da duração de uma lâmpada nova
DefiniçãoUm qualquer subconjunto de Ω diz-se um acontecimento.
Seja Ω = {ω1, …, ωn, …} um espaço de resultados. Destaquemos alguns acontecimentos
notáveis:
∅ acontecimento impossível
{ωi} acontecimento elementar
Ω acontecimento certo
DefiniçãoO conjunto de todos os acontecimentos definidos num espaço de resultados diz-se oespaço de acontecimentos de uma experiência aleatória (𝒜 ).

Um espaço de acontecimentos é uma σ-álgebra, ou seja:
A ∈ 𝒜 ⇒ A‾ ∈ 𝒜 ;1.
A1, …, An, … ∈ 𝒜 ⇒ ⋃i=1
+∞Ai ∈ 𝒜 .2.
DefiniçãoUma função P : 𝒜 → ℝ diz-se uma função de probabilidade. Para um qualquer
acontecimento A ∈ 𝒜 , o número real P(A) diz-se a probabilidade da ocorrência
de A.
DefiniçãoO terno (Ω, 𝒜 , P) diz-se o espaço de probabilidade de uma experiência aleatória.
2.2 Noção de probabilidade: interpretações de Laplace,frequencista e subjectivista. Axiomática de probabilidade eteoremas decorrentes.
Como definir uma função de probabilidade ou como interpretar o conceito deprobabilidade?Não há uma definição de probabilidade! É antes um conceito primitivo que tem tido,ao longo do tempo, diferentes interpretações.
Interpretação de Laplace (1749-1827)
Consideremos um espaço de resultados formado por n resultados (#Ω = n) e A ∈ 𝒜 tal
que #A = nA.
Então
P(A) =#A
#Ω=nA
n.
Limitações
Ω finito.
Resultados equiprováveis.
Interpretação frequencista
Considerem-se n repetições de uma experiência aleatória e seja nA o número de
ocorrências de um acontecimento A nessas n repetições. Então
P(A) = limn→ +∞
nA
n.
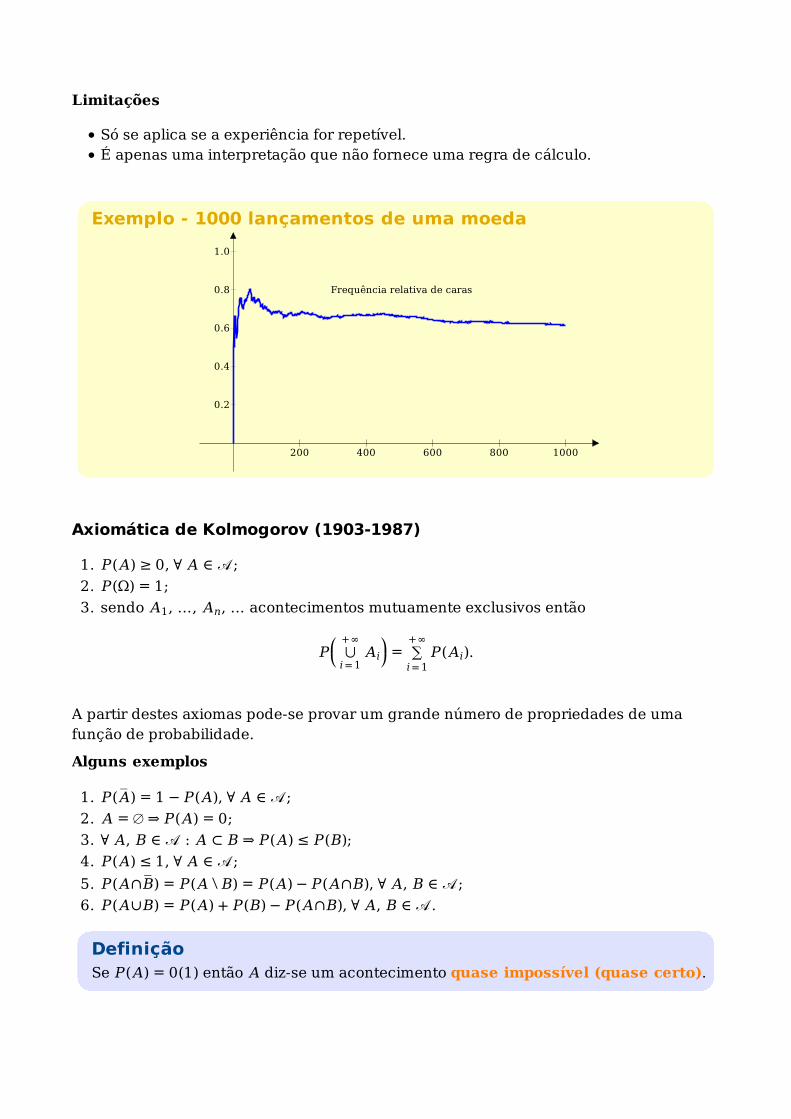
Limitações
Só se aplica se a experiência for repetível.É apenas uma interpretação que não fornece uma regra de cálculo.
Exemplo - 1000 lançamentos de uma moeda
Axiomática de Kolmogorov (1903-1987)
P(A) ≥ 0, ∀ A ∈ 𝒜 ;1.
P(Ω) = 1;2.
sendo A1, …, An, … acontecimentos mutuamente exclusivos então3.
P⎛⎝⎜ ⋃i=1
+∞Ai
⎞⎠⎟ = ∑
i=1
+∞P(Ai).
A partir destes axiomas pode-se provar um grande número de propriedades de umafunção de probabilidade.
Alguns exemplos
P(A‾ ) = 1 − P(A), ∀ A ∈ 𝒜 ;1.
A = ∅ ⇒ P(A) = 0;2.
∀ A, B ∈ 𝒜 : A ⊂ B ⇒ P(A) ≤ P(B);3.
P(A) ≤ 1, ∀ A ∈ 𝒜 ;4.
P(A∩B‾ ) = P(A ∖ B) = P(A) − P(A∩B), ∀ A, B ∈ 𝒜 ;5.
P(A∪B) = P(A) + P(B) − P(A∩B), ∀ A, B ∈ 𝒜 .6.
DefiniçãoSe P(A) = 0(1) então A diz-se um acontecimento quase impossível (quase certo).
Frequência relativa de caras
200 400 600 800 1000
0.2
0.4
0.6
0.8
1.0

Cálculo de probabilidades em espaços de resultados finitos
Seja Ω = {ω1, …, ωn}. Quantos acontecimentos podemos definir?
Seja A = {ω1*, …, ωk
*} ⊂ Ω.
P(A) = P(
⋃i=1
k
{ωi*})
= ∑i=1
kP({ωi
*})
Caso particular: resultados equiprováveis P({ωi}) = 1 / n, ∀ i.
P(A) =k
n=
#A
#Ω
2.3 Probabilidade condicional.Não vimos ainda como levar em conta no cálculo de probabilidades o facto de aocorrência de um acontecimento poder afectar a probabilidade de outrosacontecimentos ocorrerem.
DefiniçãoSeja B ∈ 𝒜 tal que P(B) > 0. A probabilidade condicional da ocorrência de A
dado que B ocorreu é definida por
P(A ∣∣ B) =P(A∩B)
P(B), ∀ A ∈ 𝒜 .
Toda a probabilidade é condicional!
TeoremaSeja B ∈ 𝒜 tal que P(B) > 0 e defina-se a função P(• ∣∣ B) de 𝒜 em ℝ. Então
(Ω, 𝒜 , P(• ∣∣ B)) é um espaço de probabilidade.
Como consequência do teorema anterior todas as propriedades de uma função de
probabilidade são satisfeitas por P(• ∣∣ B).
Alguns exemplos
P(A‾ ∣∣ B) = 1 − P(A ∣∣ B), ∀ A ∈ 𝒜 ;1.
P(∅ ∣∣ B) = 0;2.
∀ A1, A2 ∈ 𝒜 : A1 ⊂ A2 ⇒ P(A1 ∣∣ B) ≤ P(A2 ∣∣ B);3.
P(A1∪A2 ∣∣ B) = P(A1 ∣∣ B) + P(A2 ∣∣ B) − P(A1∩A2 ∣∣ B), ∀ A1, A2 ∈ 𝒜 .4.
2.4 Teoremas da probabilidade composta e daprobabilidade total. Teorema de Bayes. Acontecimentos

independentes.Uma aplicação das probabilidades condicionais
P(A∩B) = P(A)P(B ∣∣ A), se P(A) > 0
= P(B)P(A ∣∣ B), se P(B) > 0
Teorema da probabilidade compostaP(A1∩A2∩…∩An) = P(A1)×P(A2 ∣∣ A1)×…
…× P(An−1 ∣∣ A1∩A2∩…∩An−2)×
× P(An ∣∣ A1∩A2∩…∩An−1)
DefiniçãoUma sucessão de acontecimentos A1, …, An tais que
Ai∩A j = ∅, ∀ i ≠ j1.
⋃i=1
nAi = Ω2.
diz-se uma partição do espaço de resultados Ω.
Teorema da probabilidade totalSendo A1, …, An uma partição de Ω então
P(B) = ∑i=1
nP(B ∣∣ Ai)P(Ai), ∀ B ∈ 𝒜 .
Teorema de Bayes (1702-1761)Sendo A1, …, An uma partição de Ω e B ∈ 𝒜 tal que P(B) > 0, então
P(Ak ∣∣ B) =P(B ∣∣ Ak)P(Ak)
∑i=1n P(B ∣∣ Ai)P(Ai)
, ∀ k = 1, …, n.
DefiniçãoOs acontecimentos A e B dizem-se independentes se e só se P(A∩B) = P(A)P(B).
Notas:
A e B independentes ⇒ P(A ∣∣ B) = P(A), se P(B) > 0 e P(B ∣∣ A) = P(B), se P(A) > 0;1.
todo o acontecimento é independente de ∅ e Ω.2.
Poderão dois acontecimentos disjuntos serem independentes?3.

DefiniçãoSeja H ∈ 𝒜 tal que P(H) > 0. Dois acontecimentos A e B dizem-se
condicionalmente independentes (dado H) se e só se
P(A∩B ∣∣ H) = P(A ∣∣ H)P(B ∣∣ H).
Para mais do que dois acontecimentos é possível definir várias formas de independência.
DefiniçãoOs acontecimentos A1, …, An dizem-se completamente independentes se e só se
P(A1∩…∩An) = ∏i=1
nP(Ai);
análogo para qualquer subconjunto com n − 1 acontecimentos;
…
quaisquer dois acontecimentos distintos são independentes.

3. Variáveis aleatórias
3.1 Variável aleatória. Função de distribuição.
Em geral, há interesse apenas numa ou mais características dos resultados de umaexperiência aleatória.
1.
Há ainda interesse em abandonar a formalização particular de cada experiênciaaleatória e levar o cálculo de probabilidades para um campo mais familiar — aanálise de funções reais de variável real.
2.
⇓
Variáveis aleatórias
ExemploConsidere uma caixa com 4 peças boas (B) e 5 peças defeituosas (D). Suponha que
são retiradas 2 peças dessa caixa.Espaço de resultados: Ω = {BB, BD, DB, DD}
P(BB) = 49×3
8= 1
6
P(BD) = 49×5
8= 5
18= 5
9×4
8= P(DB)
P(DD) = 59×4
8= 5
18
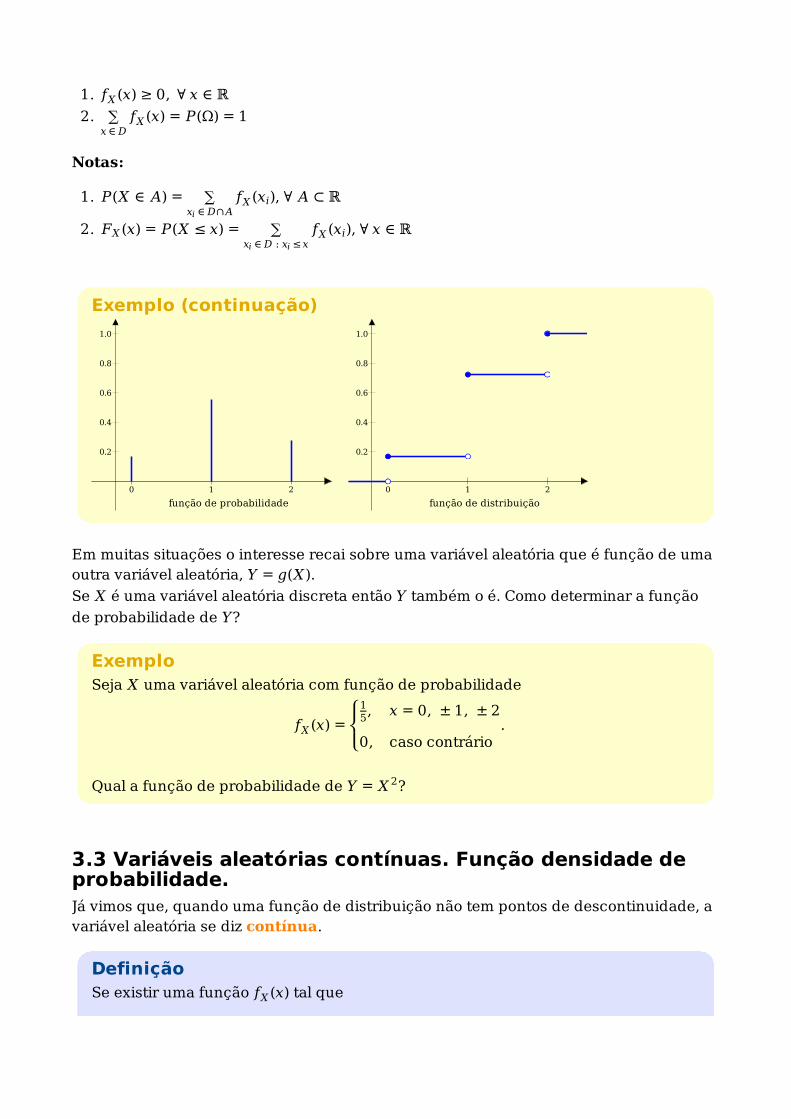
Exemplo (continuação)Seja X="número de peças defeituosas nas 2 extracções".
P(X = 0) = P(BB) = 16
P(X = 1) = P(BD) + P(DB) = 59
P(X = 2) = P(DD) = 518
Note-se que P(X = 0) + P(X = 1) + P(X = 2) = P(Ω) = 1.
DefiniçãoSeja (Ω, 𝒜 , P) um espaço de probabilidade. Uma função X : Ω → ℝ diz-se uma
variável aleatória.
∀ A ⊂ ℝ : P(X ∈ A) = P(X−1(A)) = P(B) em que B = {ω ∈ Ω : X(ω) ∈ A} ∈ 𝒜
Definição
Seja X uma variável aleatória. A função de distribuição de X é definida por
FX (x) = P(X ≤ x), ∀ x ∈ ℝ.
Caracterização de uma função de distribuição
∀ (x, y) ∈ ℝ2 : x < y ⇒ FX (x) ≤ FX (y) (função não decrescente)1.
limx→ −∞
FX (x) = 0 e limx→ +∞
FX (x) = 12.
limx→x
0+FX (x) = FX (x0), ∀ x0 ∈ ℝ (função contínua à direita)3.
Outras propriedades de uma função de distribuição
0 ≤ FX (x) ≤ 1, ∀ x ∈ ℝ1.
P(X = x) = FX (x) − FX (x−), ∀ x ∈ ℝ2.
Tipos de variáveis aleatórias
Seja D o conjunto (numerável) dos pontos de descontinuidade de FX (x).
D ≠ ∅ e P(X ∈ D) = 1 ⇒ a variável aleatória diz-se discreta.1.
D = ∅ ⇒ a variável aleatória diz-se contínua.2.
D ≠ ∅ e P(X ∈ D) < 1 ⇒ a variável aleatória diz-se mista.3.
3.2 Variáveis aleatórias discretas. Função (massa) deprobabilidade.Seja D o conjunto de valores de uma variável aleatória discreta X .
DefiniçãoA função (massa) de probabilidade de X é definida por
fX (x) ={
P(X = x), x ∈ D
0, x ∉ D.
Algumas propriedades da função de probabilidade
-1 1
0.5
1.0
-1 1
0.5
1.0
-1 1
0.5
1.0
fX (x) ≥ 0, ∀ x ∈ ℝ1.
∑x∈ D
fX (x) = P(Ω) = 12.
Notas:
P(X ∈ A) = ∑xi ∈ D∩A
fX (xi), ∀ A ⊂ ℝ1.
FX (x) = P(X ≤ x) = ∑xi ∈ D : xi ≤x
fX (xi), ∀ x ∈ ℝ2.
Exemplo (continuação)
Em muitas situações o interesse recai sobre uma variável aleatória que é função de umaoutra variável aleatória, Y = g(X).
Se X é uma variável aleatória discreta então Y também o é. Como determinar a função
de probabilidade de Y?
ExemploSeja X uma variável aleatória com função de probabilidade
fX (x) =⎧
⎨
⎩
⎪
⎪
15, x = 0, ± 1, ± 2
0, caso contrário.
Qual a função de probabilidade de Y = X 2?
3.3 Variáveis aleatórias contínuas. Função densidade deprobabilidade.Já vimos que, quando uma função de distribuição não tem pontos de descontinuidade, avariável aleatória se diz contínua.
DefiniçãoSe existir uma função fX (x) tal que
0 1 2
0.2
0.4
0.6
0.8
1.0
função de probabilidade
0 1 2
0.2
0.4
0.6
0.8
1.0
função de distribuição

FX (x) = ⌠⌡−∞
x
fX (t)dt, ∀ x ∈ ℝ
então fX (x) diz-se a função densidade de probabilidade da variável aleatória X .
Algumas propriedades
fX (x) ≥ 0, ∀ x ∈ ℝ1.
P(X ∈ A) = ⌠⌡A
fX (x)dx, ∀ A ⊂ ℝ2.
P(X ∈ ℝ) = ⌠⌡−∞
+∞fX (x)dx = 13.
P(X = a) = 0, ∀ a ∈ ℝ4.
fX (x) = dFX(x)dx
nos pontos onde FX é diferenciável5.
No caso contínuo uma variável Y = g(X) pode ser de qualquer tipo e é, em geral, mais
simples recorrer à função de distribuição.
ExemploSejam X uma variável aleatória contínua com função densidade de probabilidade
fX (x) ={
1, x ∈ ]0, 1[
0, caso contrário.
Quais as funções densidade de probabilidade de Y = log X e de Z = − 3X 2?
No exemplo anterior ambas as transformações são bijectivas. Mesmo quando não é esseo caso, a função de distribuição pode conduzir à resolução do problema.
ExemploSejam X uma variável aleatória contínua com função densidade de probabilidade
fX (x) > 0, ∀ x ∈ ℝ, e Y = X 2. Qual a função de distribuição de Y?
3.5 Vectores aleatórios bidimensionais. Funções dedistribuição conjunta e marginais.O que vimos atrás sobre a função de distribuição generaliza-se facilmente para o estudosimultâneo de duas variáveis aleatórias.
DefiniçãoSeja (X , Y) uma variável aleatória bidimensional. Então
FX ,Y (x, y) = P(X ≤ x, Y ≤ y), ∀ (x, y) ∈ ℝ2

diz-se a função de distribuição conjunta de (X , Y).
Algumas propriedades da função de distribuição conjunta
0 ≤ FX ,Y (x, y) ≤ 1, ∀ (x, y) ∈ ℝ21.
FX ,Y (x + Δx , y + Δy) ≥ FX ,Y (x, y), ∀ Δx , Δy ≥ 02.
limx, y→ +∞
FX ,Y (x, y) = 13.
limx→ −∞
FX ,Y (x, y) = 0 e limy→ −∞
FX ,Y (x, y) = 04.
A partir do conhecimento do comportamento conjunto de (X , Y) é também possível
analisar separadamente X e Y uma vez que limx→ +∞
FX ,Y (x, y) = FY (y) e
limy→ +∞
FX ,Y (x, y) = FX (x).
3.6 Vectores aleatórios discretos e contínuos.Distribuições conjunta, marginais e condicionais.Independência entre variáveis aleatórias.
DefiniçãoSeja (X , Y) uma variável aleatória bidimensional discreta. Então
fX ,Y (x, y) = P(X = x, Y = y), ∀ (x, y) ∈ ℝ2
diz-se a função de probabilidade conjunta de (X , Y).
ExemploTiram-se duas cartas ao acaso de um baralho de 52 cartas. Sejam X o número de
figuras (reis, damas ou valetes) e Y o número de ases obtidos.
Determine a função de probabilidade conjuntas do par aleatório (X , Y) e calcule os
valores da função de distribuição conjunta nos pontos (0, 1.5), (3, 1) e (5, 4).
Y / X 0 1 2
0 105 / 221 72 / 221 11 / 221
1 24 / 221 8 / 221 0
2 1 / 221 0 0
DefiniçãoSeja (X , Y) uma variável aleatória bidimensional contínua. Se existir uma função
fX ,Y (x, y) tal que

FX ,Y (x, y) = ⌠⌡−∞
x⌠⌡−∞
y
fX ,Y (u, v)dv du, ∀ (x, y) ∈ ℝ2
então ela diz-se a função densidade de probabilidade conjunta de (X , Y).
Notas:
⌠⌡ℝ
⌠⌡ℝ
fX ,Y (x, y)dy dx = 11.
fX ,Y (x, y) ≥ 0, ∀ (x, y) ∈ ℝ22.∂FX ,Y (x, y)
∂x∂ y= fX ,Y (x, y), ∀ (x, y) ∈ ℝ2 nos pontos onde FX ,Y é diferenciável3.
ExemploNum sistema formado por duas componentes, sejam X e Y as variáveis aleatórias
que representam as durações, em anos, da primeira e da segunda componentes,respectivamente. A função densidade de probabilidade conjunta de (X , Y) é dada
por
fX ,Y (x, y) ={
e−x− y , x > 0 e y > 0
0, x ≤ 0 ou y ≤ 0
Qual é a probabilidade de ambas as componentes durarem no máximo 2 anos?1.Qual é a probabilidade da primeira componente durar mais do dobro do tempoque a segunda?
2.
DefiniçãoSeja (X , Y) uma variável aleatória bidimensional. Então
fX (x) = ∑yfX ,Y (x, y)
⎛⎝⎜ = ⌠
⌡ℝfX ,Y (x, y)dy
⎞⎠⎟, ∀ x ∈ ℝ
e
fY (y) = ∑xfX ,Y (x, y)
⎛⎝⎜ = ⌠
⌡ℝfX ,Y (x, y)dx
⎞⎠⎟, ∀ y ∈ ℝ
dizem-se as funções (densidade) de probabilidade marginais de X e Y,
respectivamente.
DefiniçãoSeja (X , Y) uma variável aleatória bidimensional. Então

fX ∣∣Y = y(x) =fX ,Y (x, y)
fY (y), ∀ x ∈ ℝ e ∀ y ∈ ℝ : fY (y) > 0
e
fY ∣∣X =x(y) =fX ,Y (x, y)
fX (x), ∀ y ∈ ℝ e ∀ x ∈ ℝ : fX (x) > 0
dizem-se as funções (densidade) de probabilidade condicionais de X dado
Y = y e de Y dado X = x, respectivamente.
DefiniçãoDuas variáveis aleatórias, X e Y, dizem-se independentes se para todo A, B ⊂ ℝ os
acontecimentos X ∈ A e Y ∈ B são independentes, isto é, se
P(X ∈ A, Y ∈ B) = P(X ∈ A)P(Y ∈ B).
TeoremaAs variáveis aleatórias X e Y são independentes se e só se
FX ,Y (x, y) = FX (x)FY (y), ∀ (x, y) ∈ ℝ2.
TeoremaAs variáveis aleatórias X e Y são independentes se e só se
fX ,Y (x, y) = fX (x)fY (y), ∀ (x, y) ∈ ℝ2.
Qual o efeito da independência sobre as distribuições condicionais das variáveisaleatórias?
TeoremaSe X e Y são variáveis aleatórias independentes então as variáveis aleatórias
U = g(X) e V = h(Y) são também independentes.

4. Distribuições de probabilidade ecaracterísticas
4.1 Valor esperado de uma variável aleatória.
A função de distribuição ou a função (densidade) de probabilidade são descriçõesprobabilísticas completas de uma variável aleatória.Pode-se ainda quantificar aspectos particulares do comportamento da variávelaleatória através do cálculo de algumas medidas numéricas.
DefiniçãoO valor esperado ou esperança matemática da variável aleatória X é definido por
E[X] = ∑ixi fX (xi)
⎛⎝⎜ = ⌠
⌡ℝxfX (x)dx
⎞⎠⎟,
caso exista.
Nota: o valor esperado de uma variável aleatória não é necessariamente um valor dessavariável assim como o centro de massa de um corpo pode não pertencer ao própriocorpo.
Generalização: E[g(X)] = ∑ig(xi)fX (xi)
⎛⎝⎜ = ⌠
⌡ℝg(x)fX (x)dx
⎞⎠⎟.
Algumas propriedades do valor esperado
E[c] = c, ∀ c ∈ ℝ1.
E[aX + b] = aE[X] + b, ∀ (a, b) ∈ ℝ2 (operador linear)2.
4.2 Momentos simples e centrais. Desvio padrão ecoeficiente de variação.
DefiniçãoO momento simples de ordem k da variável aleatória X é definido por
μk = E[Xk
], caso exista.
O momento central de ordem k da variável aleatória X é definido por
Mk = E[(X − E[X])k], caso exista.
Notas:
É possível relacionar os momentos simples com os centrais1.M1 = 02.

DefiniçãoA variância da variável aleatória X é definida por
Var[X] = E[(X − μ1)2] = E[(X − E[X])2],
caso exista. O desvio padrão de X é igual a + Var[X]√
.
Algumas propriedades da variância
Var[X] ≥ 01.
Var[c] = 0, ∀ c ∈ ℝ2.
Var[X] = 0 ⇔ P(X = E[X]) = 13.
Var[aX + b] = a2Var[X], ∀ (a, b) ∈ ℝ24.
Var[X] = E[X 2] − (E[X])2 ⇔ M2 = μ2 − μ125.
DefiniçãoO coeficiente de variação da variável aleatória X é definido por
CV =+ Var[X]
√
E[X].
4.3 Moda e quantisPara além das medidas anteriores há outras que não se baseiam em momentos.
Moda(s) de X = argmax x ∈ℝ fX (x)
Mediana de X = Q0.5 : P(X ≤ Q0.5) ≥ 0.5 e P(X ≥ Q0.5) ≥ 0.5.
A mediana é um caso particular de um conjunto de medidas:
DefiniçãoPara 0 < p < 1, o valor Qp diz-se o quantil de ordem p se
P(X ≤ Qp) ≥ p e P(X ≥ Qp) ≥ 1 − p.
No caso contínuo o cálculo de quantis simplifica-se:
Quantil de ordem p de X = Qp : FX (Qp) = ⌠⌡−∞
Qp
fX (x)dx = p
ExemploO jogador A propõe um jogo de dados ao jogador B com as seguintes regras:
o jogador B paga €5 de aposta e lança um dado;se sair 4 ou 5 o jogador B recebe o valor da aposta;

se sair 6 o jogador B ganha €20.
Qual o lucro mais provável do jogador B numa jogada? Será este um jogo justo?
4.4 Distribuições discretas.
Distribuição uniforme discreta.
DefiniçãoSeja X uma variável aleatória que toma valores em D = {x1, …, xn}. Se esses valores
forem equiprováveis então diz-se que a variável tem uma distribuição uniformediscreta nesse conjunto.
X ∼ U({x1, …, xn}) ⇔ fX (x) =⎧
⎨
⎩
⎪
⎪
1n, x ∈ D
0, x ∉ D.
E[X] = ∑i=1
nxi fX (xi) = ∑
i=1
nxi
1
n=
∑i=1n xi
n
Var[X] = E[X 2] − (E[X])2 =∑i=1
n xi2
n−
(
∑i=1n xi
n )
2
Distribuição binomial.
DefiniçãoUma experiência aleatória com apenas dois resultados diz-se um ensaio ou provade Bernoulli.
Seja X ={
1, se ocorreu um "sucesso"
0, se não ocorreu um "sucesso".
A distribuição de X fica definida se conhecermos a probabilidade de "sucesso",
0 < p < 1. Então,
fX (x) =
⎧
⎨
⎩
⎪⎪⎪⎪
p, x = 1
1 − p, x = 0
0, caso contrário
≡{
px(1 − p)1−x , x = 0, 1
0, caso contrário.
DefiniçãoNas condições anteriores diz-se que a variável aleatória X tem uma distribuição de
Bernoulli ou X ∼ Ber(p), com 0 < p < 1.
Facilmente se mostra que E[X] = E[X 2] = p e Var[X] = p(1 − p).
Uma prova de Bernoulli isolada é um caso pouco interessante. No entanto, muitassituações de interesse prático podem ser descritas como sequências de repetições deuma prova desse tipo.
Consideremos uma experiência aleatória que consiste numa sequência de realizaçõesindependentes de uma prova de Bernoulli com probabilidade de sucesso p.
Que variáveis aleatórias poderá ter interesse considerar?
Seja X = "número de sucessos em n realizações da prova".
Temos então que
fX (x) =n
x
⎛⎝⎜
⎞⎠⎟p
x(1 − p)n−x , x = 0, 1, …, n.
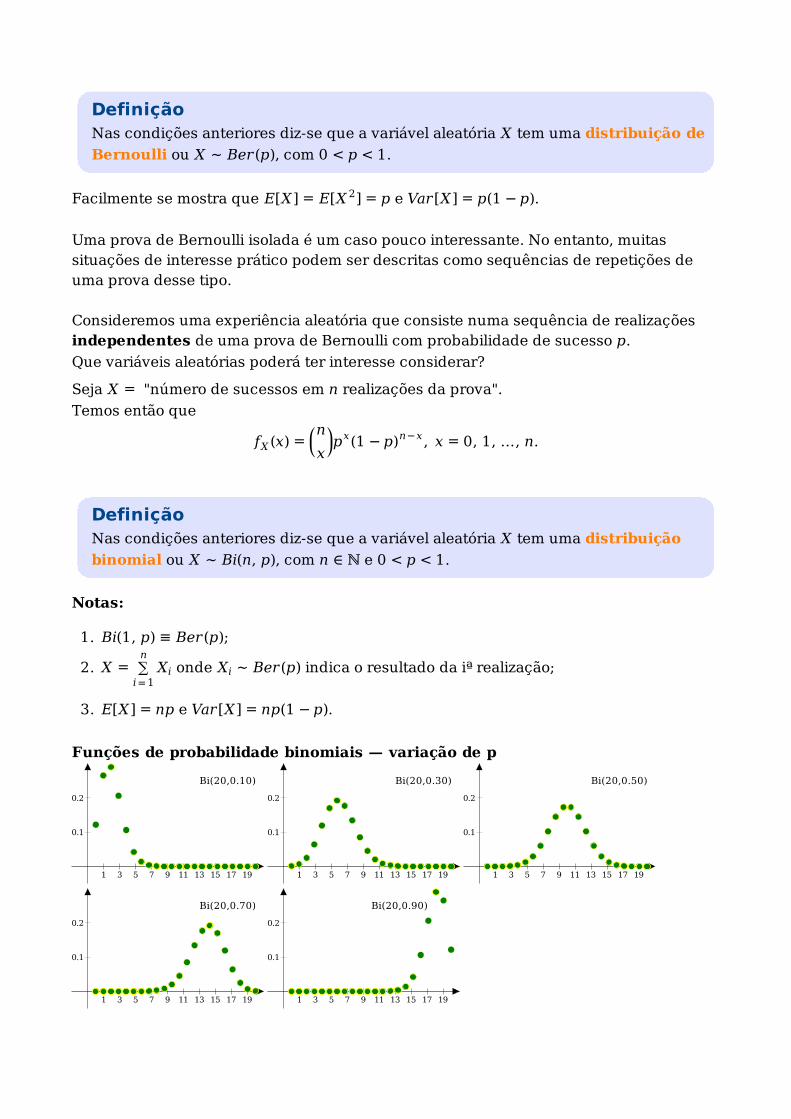
DefiniçãoNas condições anteriores diz-se que a variável aleatória X tem uma distribuição
binomial ou X ∼ Bi(n, p), com n ∈ ℕ e 0 < p < 1.
Notas:
Bi(1, p) ≡ Ber(p);1.
X = ∑i=1
nXi onde Xi ∼ Ber(p) indica o resultado da iª realização;2.
E[X] = np e Var[X] = np(1 − p).3.
Funções de probabilidade binomiais — variação de p
1 3 5 7 9 11 13 15 17 19
0.1
0.2
Bi(20,0.10)
1 3 5 7 9 11 13 15 17 19
0.1
0.2
Bi(20,0.30)
1 3 5 7 9 11 13 15 17 19
0.1
0.2
Bi(20,0.50)
1 3 5 7 9 11 13 15 17 19
0.1
0.2
Bi(20,0.70)
1 3 5 7 9 11 13 15 17 19
0.1
0.2
Bi(20,0.90)

ExemploUm teste de escolha múltipla é formado por 10 questões com 4 alíneas das quaisapenas uma está certa.
Qual a probabilidade desse aluno responder acertadamente a pelo menosmetade das questões?
1.
Se se responder a todas as questões ao acaso, qual é o número mais provável derespostas certas?
2.
Se X ∼ Bi(n, p) representar o número de sucessos numa experiência aleatória do tipo
referido, qual a distribuição do número de insucessos na mesma experiência (Y)? Qual a
relação entre as variáveis aleatórias X e Y?
Distribuição hipergeométrica.
Consideremos uma população de dimensão N formada por objectos de dois tipos: M
com uma característica associada ao "sucesso" e N − M sem essa característica.
Retirada uma amostra de dimensão n dessa população, ao acaso mas sem reposição, seja
X = "número de sucessos na amostra". Então,
fX (x) =
Mx( )
N − Mn − x( )
Nn( )
, x = max (0, n − (N − M)), …, min (n, M).
DefiniçãoNas condições anteriores diz-se que a variável aleatória X tem uma distribuição
hipergeométrica ou X ∼ H(N, M, n), com N ∈ ℕ, 0 < M < N e 0 < n < N.
Notas:
A experiência aleatória referida pode ser vista como uma sequência de n realizações
dependentes de uma prova de Bernoulli mas com probabilidade de sucesso
constante igual a p = MN
;
1.
E[X] = nM
N e Var[X] = n
M
N×
N − M
N×
N − n
N − 1;2.
Se N → + ∞ com p = MN
fixo então E[X] = np, Var[X] → np(1 − p) e ainda
Mx( )
N − Mn − x( )
Nn( )
→n
x
⎛⎝⎜
⎞⎠⎟p
x(1 − p)n−x .
3.
Aplicação: se N tem um valor elevado e N ≫ n então ao longo das realizações da prova
a proporção de sucessos na população tem uma variação pequena e podemos considerarque

X ∼a
Bi(n, p) com p = M / N.
Distribuição geométrica.
Consideremos uma experiência aleatória que consiste numa sequência de realizaçõesindependentes de uma prova de Bernoulli com probabilidade de sucesso p até à
ocorrência do primeiro sucesso.
Seja X = "número de realizações da prova até ao primeiro sucesso".
Temos então que
fX (x) = (1 − p)x−1p, x = 1, 2, ….
DefiniçãoNas condições anteriores diz-se que a variável aleatória X tem uma distribuição
geométrica (ou de Pascal) ou X ∼ Geo(p), com 0 < p < 1.
Notas:
fX (x) é sempre decrescente;1.
E[X] = 1p e Var[X] = 1−p
p2 .2.
FX (x) ={
0, x < 1
1 − (1 − p)k, k ≤ x < k, k ∈ ℕ3.
TeoremaX ∼ Geo(p) ⇒ P(X > i + j ∣∣ X > i) = P(X > j), ∀ i, j = 1, 2, …
Distribuição de Poisson.
DefiniçãoConsideremos a contagem do número de ocorrências de um evento durante umcerto intervalo de tempo (comprimento, área, etc.). Seja N(t) o número de
ocorrências em ]0, t] com N(0) = 0. Se
os números de ocorrências em intervalos disjuntos são independentes;1.P(N(t + Δt) − N(t) = 1) ≈ λΔt;2.
P(N(t + Δt) − N(t) > 1) ≈ 0,3.
então a experiência aleatória diz-se um processo de Poisson com parâmetro
λ ∈ ℝ+.
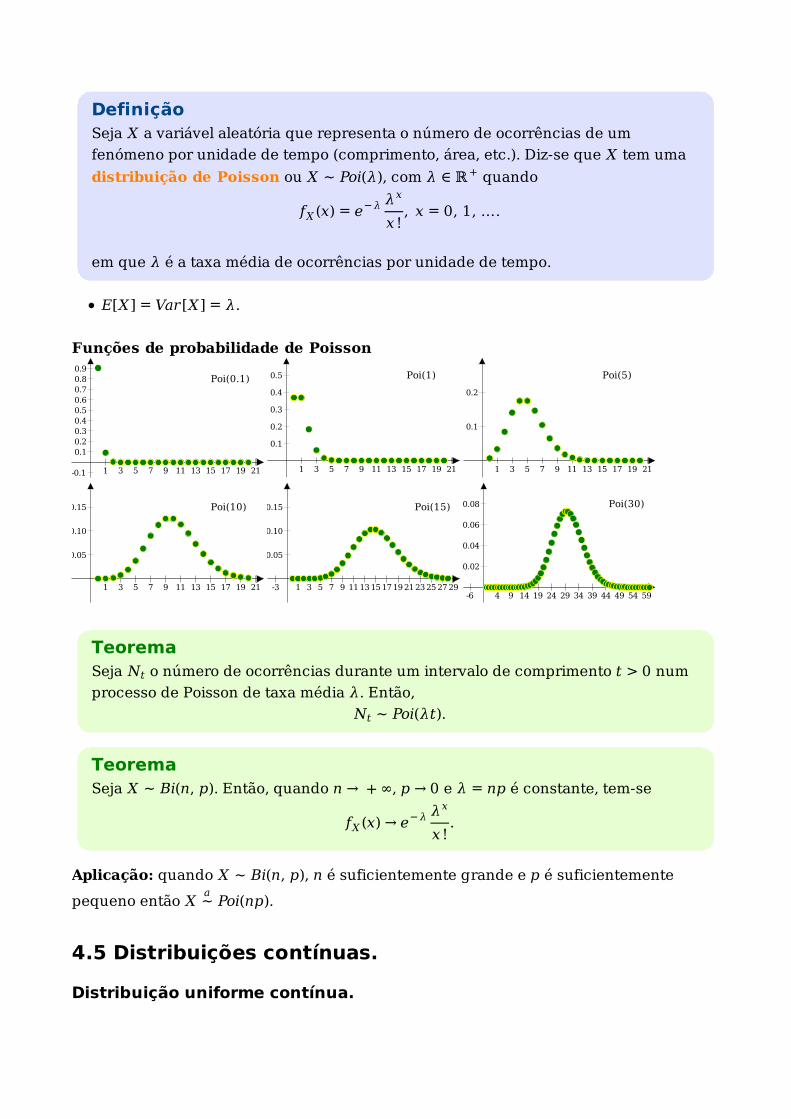
DefiniçãoSeja X a variável aleatória que representa o número de ocorrências de um
fenómeno por unidade de tempo (comprimento, área, etc.). Diz-se que X tem uma
distribuição de Poisson ou X ∼ Poi(λ), com λ ∈ ℝ+ quando
fX (x) = e−λ λx
x !, x = 0, 1, ….
em que λ é a taxa média de ocorrências por unidade de tempo.
E[X] = Var[X] = λ.
Funções de probabilidade de Poisson
TeoremaSeja Nt o número de ocorrências durante um intervalo de comprimento t > 0 num
processo de Poisson de taxa média λ. Então,
Nt ∼ Poi(λt).
TeoremaSeja X ∼ Bi(n, p). Então, quando n → + ∞, p → 0 e λ = np é constante, tem-se
fX (x) → e−λ λx
x !.
Aplicação: quando X ∼ Bi(n, p), n é suficientemente grande e p é suficientemente
pequeno então X ∼a
Poi(np).
4.5 Distribuições contínuas.
Distribuição uniforme contínua.
1 3 5 7 9 11 13 15 17 19 21-0.1
0.10.20.30.40.50.60.70.80.9
Poi(0.1)
1 3 5 7 9 11 13 15 17 19 21
0.1
0.2
0.3
0.4
0.5 Poi(1)
1 3 5 7 9 11 13 15 17 19 21
0.1
0.2
Poi(5)
1 3 5 7 9 11 13 15 17 19 21
0.05
0.10
0.15 Poi(10)
-3 1 3 5 7 9 11131517192123252729
0.05
0.10
0.15 Poi(15)
-6 4 9 14 19 24 29 34 39 44 49 54 59
0.02
0.04
0.06
0.08 Poi(30)

DefiniçãoSe
fX (x) =⎧
⎨
⎩
⎪
⎪
1b−a
, a ≤ x ≤ b
0, caso contrário
então diz-se que X tem uma distribuição uniforme contínua no intervalo [a, b] ou
X ∼ U(a, b), com a < b ∈ ℝ.
Notas:
E[X] = ⌠⌡a
b
x1
b − adx =
a + b
21.
Var[X] =(b − a)2
122.
Distribuição exponencial.
DefiniçãoSe
fX (x) ={
λe−λx , x ≥ 0
0, x < 0
então diz-se que X tem uma distribuição exponencial ou X ∼ Exp(λ), com λ > 0.
Notas:
FX (x) = ⌠⌡0
xλe−λt dt = [ − e−λt
]0
x= 1 − e−λx , x ≥ 01.
E[X] =1
λ e Var[X] =
1
λ22.
TeoremaX ∼ Exp(λ) ⇒ P(X > s + t ∣∣ X > t) = P(X > s), ∀ s, t ≥ 0
TeoremaSeja X uma variável aleatória que representa o número de ocorrências por unidade
de tempo (comprimento, área, etc.) de um qualquer fenómeno e Y uma outra
variável aleatória que representa o tempo entre ocorrências sucessivas. SeX ∼ Poi(λ) então Y ∼ Exp(λ).
O teorema anterior também se aplica se a variável aleatória representar o tempo até àprimeira ocorrência do fenómeno.
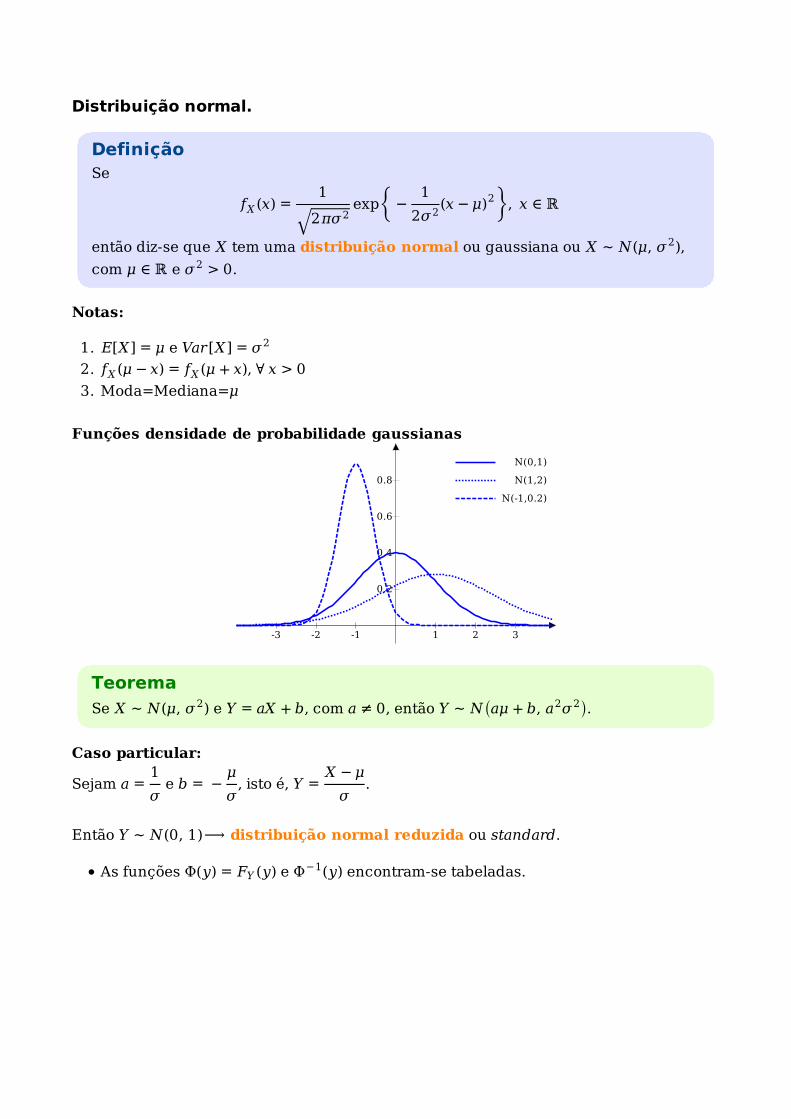
Distribuição normal.
DefiniçãoSe
fX (x) =1
2πσ2√
exp{
−1
2σ2(x − μ)2
}, x ∈ ℝ
então diz-se que X tem uma distribuição normal ou gaussiana ou X ∼ N(μ, σ2),
com μ ∈ ℝ e σ2 > 0.
Notas:
E[X] = μ e Var[X] = σ21.
fX (μ − x) = fX (μ + x), ∀ x > 02.
Moda=Mediana=μ3.
Funções densidade de probabilidade gaussianas
TeoremaSe X ∼ N(μ, σ2) e Y = aX + b, com a ≠ 0, então Y ∼ N(aμ + b, a2σ2
).
Caso particular:
Sejam a =1
σ e b = −
μ
σ, isto é, Y =
X − μ
σ.
Então Y ∼ N(0, 1)⟶ distribuição normal reduzida ou standard.
As funções Φ(y) = FY (y) e Φ−1(y) encontram-se tabeladas.
-3 -2 -1 1 2 3
0.2
0.4
0.6
0.8
N(0,1)
N(1,2)
N(-1,0.2)

5. Complementos das distribuições deprobabilidade
Covariância e correlação. Propriedades.
DefiniçãoSejam X e Y duas variáveis aleatórias. O valor esperado de uma função g(X , Y) é
dado por
E[g(X , Y)] =
⎧
⎨
⎩
⎪⎪⎪⎪
∑x
∑yg(x, y)fX ,Y (x, y), no caso discreto
⌠⌡ℝ
⌠⌡ℝ
g(x, y)fX ,Y (x, y)dy dx, no caso contínuo,
caso exista.
TeoremaSendo X e Y duas variáveis aleatórias então
E[X + Y] = E[X] + E[Y].
TeoremaSe X e Y são variáveis aleatórias independentes então
E[XY] = E[X]E[Y].
DefiniçãoSeja (X1, X2) um par aleatório. O valor esperado condicional de Xi dado X j, com
i ≠ j, é definido por
E[Xi ∣∣ X j = x j] =
⎧
⎨
⎩
⎪⎪⎪⎪
∑xi
xi fXi ∣∣X j =x j (xi), no caso discreto
⌠⌡ℝ
xi fXi ∣∣X j =x j (xi)dxi, no caso contínuo,
caso exista.
TeoremaSendo (X1, X2) um par aleatório tem-se que E[E[Xi ∣∣ X j]] = E[Xi].
DefiniçãoA covariância de X e Y é definida por
Cov[X , Y] = E[(X − E[X])(Y − E[Y])].
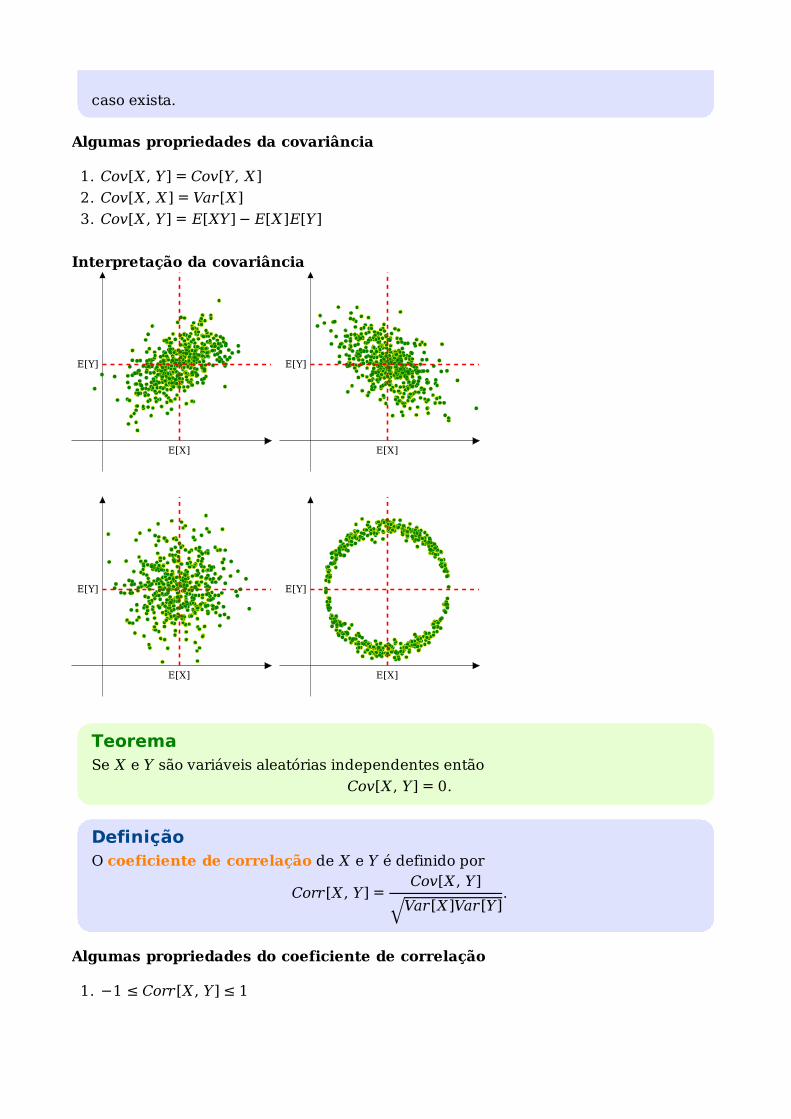
caso exista.
Algumas propriedades da covariância
Cov[X , Y] = Cov[Y, X]1.
Cov[X , X] = Var[X]2.
Cov[X , Y] = E[XY] − E[X]E[Y]3.
Interpretação da covariância
TeoremaSe X e Y são variáveis aleatórias independentes então
Cov[X , Y] = 0.
DefiniçãoO coeficiente de correlação de X e Y é definido por
Corr[X , Y] =Cov[X , Y]
Var[X]Var[Y]√
.
Algumas propriedades do coeficiente de correlação
−1 ≤ Corr[X , Y] ≤ 11.
E[Y]
E[X]
E[Y]
E[X]
E[Y]
E[X]
E[Y]
E[X]

Corr[aX , Y + b] =a
∣∣a∣∣Corr[X , Y], a ≠ 0 e b ∈ ℝ2.
Corr[X , Y] = ± 1 ⇔ Y = aX + b, com a ≠ 0 e b ∈ ℝ3.
Combinações lineares de variáveis aleatórias. Relaçõesentre distribuições.
DefiniçãoSeja X1, …, Xn uma sucessão de variáveis aleatórias. Uma combinação linear
dessas variáveis é uma variável aleatória Y definida por
Y = ∑i=1
nci Xi, com (c1, …, cn) ∈ ℝn.
Algumas propriedades:
E[Y] = ∑i=1
nci E[Xi]1.
Cov[
∑i=1
mci Xi, ∑
j=1
nd j Y j]
= ∑i=1
m∑j=1
nci d j Cov[Xi, Y j]2.
Var[Y] = ∑i=1
nci
2 Var[Xi] + 2 ∑i=1
n∑j> i
ci c j Cov[Xi, X j]3.
TeoremaSejam Xi ∼ Bi(ni, p), i = 1, …, n, variáveis aleatórias independentes. Então
Y = ∑i=1
nXi ∼ Bi
(∑i=1
nni, p)
.
TeoremaSejam Xi ∼ Poi(λi), i = 1, …, n, variáveis aleatórias independentes. Então
Y = ∑i=1
nXi ∼ Poi
(∑i=1
nλi).
TeoremaSejam Xi ∼ N(μi, σi
2), i = 1, …, n, variáveis aleatórias independentes. Então
Y = ∑i=1
nXi ∼ N
(∑i=1
nμi, ∑
i=1
nσi
2)
.

Aproximações entre distribuições: convergência emdistribuição e Teorema do Limite Central.Em geral, não é fácil ou é mesmo impossível determinar a distribuição da soma de umasucessão de variáveis aleatórias independentes!
DefiniçãoUma sucessão de variáveis aleatórias X1, …, Xn, com funções de distribuição
F1, …, Fn, converge em distribuição para uma variável aleatória X (Xn →𝒟X),
quando n → + ∞, se Fn → FX para todo o ponto de continuidade de FX .
Exemplos
H(N, M, n) →𝒟Bi(n, p = M / N) quando N → + ∞, M / N e n constantes;1.
Bi(n, p) →𝒟Poi(λ = np) quando n → + ∞, p → 0 e np é constante.2.
Teorema do limite centralSeja X1, …, Xn, … uma sucessão de variáveis aleatórias não correlacionadas e
identicamente distribuídas com variância finita. Sendo Sn = ∑i=1n Xi, então, quando
n → + ∞,Sn − E[Sn]
Var[Sn]√
⟶𝒟
N(0, 1).
Notas:
E[Sn] = ∑i=1
nE[Xi] = nE[X] e Var[Sn] = ∑
i=1
nVar[Xi] = nVar[X];1.
Para n suficientemente grande, P
⎛
⎝
⎜⎜⎜
Sn − E[Sn]
Var[Sn]√
≤ x
⎞
⎠
⎟⎟⎟
≃ Φ(x).2.
Aplicação
Sejam Xi ∼ Ber(p), i = 1, …, n, variáveis aleatórias independentes e Sn = ∑i=1n Xi. Tem-se
que E[Sn] = np, Var[Sn] = np(1 − p) e, pelo T. L. C.,Sn − np
np(1 − p)√
⟶𝒟
N(0, 1).
Note-se que Sn ∼ Bi(n, p). Para n suficientemente grande então
Sn ∼aN(np, np(1 − p)).
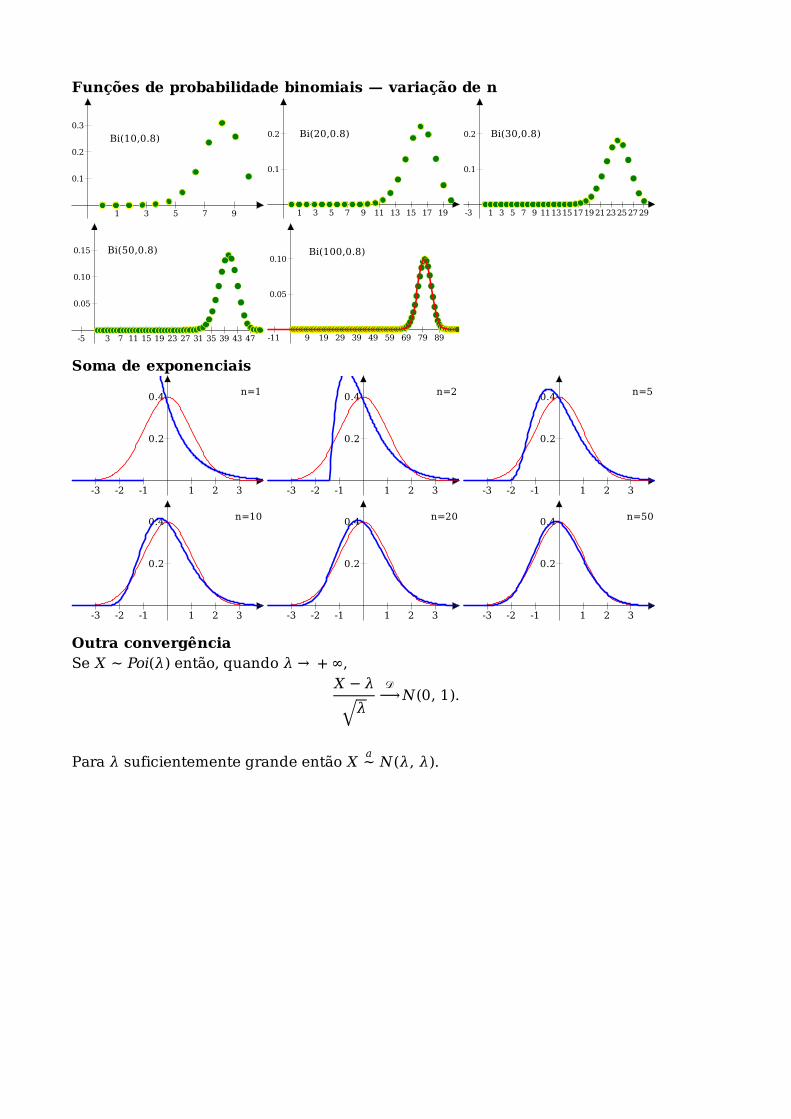
Funções de probabilidade binomiais — variação de n
Soma de exponenciais
Outra convergênciaSe X ∼ Poi(λ) então, quando λ → + ∞,
X − λ
λ√
⟶𝒟
N(0, 1).
Para λ suficientemente grande então X ∼aN(λ, λ).
1 3 5 7 9
0.1
0.2
0.3
Bi(10,0.8)
1 3 5 7 9 11 13 15 17 19
0.1
0.2 Bi(20,0.8)
-3 1 3 5 7 9 11131517192123252729
0.1
0.2 Bi(30,0.8)
-5 3 7 11 15 19 23 27 31 35 39 43 47
0.05
0.10
0.15 Bi(50,0.8)
-11 9 19 29 39 49 59 69 79 89
0.05
0.10Bi(100,0.8)
-3 -2 -1 1 2 3
0.2
0.4 n=1
-3 -2 -1 1 2 3
0.2
0.4 n=2
-3 -2 -1 1 2 3
0.2
0.4 n=5
-3 -2 -1 1 2 3
0.2
0.4 n=10
-3 -2 -1 1 2 3
0.2
0.4 n=20
-3 -2 -1 1 2 3
0.2
0.4 n=50

6. Amostragem e estimação pontual
Estatística descritiva e Inferência Estatística. Amostragemaleatória. Estatísticas.
DefiniçãoUma população é um conjunto de objectos ou indíviduos que têm pelo menos umacaracterística (variável estatística) em comum.
Exceptuando a realização de censos e casos em que as populações são pequenas não é,em geral, desejável ou mesmo possível conhecer todos os elementos de uma população!
DefiniçãoUma amostra é um qualquer subconjunto de uma população.
Notação: x1, …, xn — amostra observada de dimensão n
Como escolher uma amostra que represente bem uma população?
Amostragem aleatória simples ou amostragem casual1.Amostragem aleatória por conglomerados2.Amostragem aleatória estratificada3.Amostragem determinística4.…5.
DefiniçãoA amostragem aleatória simples é um método de amostragem em que todos oselementos de uma população têm a mesma probabilidade de serem seleccionados.
Descrição da amostra → Estatística descritiva
Descrição da população → Inferência estatística
ObjectivoEstudo de uma variável estatística numa população
⇕ Estatística paramétrica ⇕
Estudo de uma variável aleatória X com distribuição conhecida, fX (x; θ), mas em que
θ ∈ Θ ⊂ ℝk tem um valor desconhecido.
Nota: θ é um vector de parâmetros e Θ é o espaço paramétrico (conjunto de valores
possíveis para θ).
DefiniçãoUma amostra aleatória simples é uma sucessão de variáveis aleatóriasX = (X1, …, Xn) independentes e identicamente distribuídas de acordo com a

distribuição da variável estatística da população.
Nota: cada amostra observada é uma concretização particular da amostra aleatória!
Qual é a informação amostral?
os valores da amostra observada;1.a distribuição da amostra aleatória:2.
fX(x1, …, xn; θ) = ∏i=1
nfXi
(xi; θ) = ∏i=1
nfX (xi; θ)
O que fazer com a informação amostral?Em geral, essa informação é resumida através do cálculo de estatísticas.
DefiniçãoUma estatística é uma função da amostra aleatória, ou seja, dada a amostraaleatória X = (X1, …, Xn) uma estatística T é dada por T = T(X) = g(X1, …, Xn).
Alguns exemplos comuns:
X‾ =∑i=1
n Xi
n — média amostral;1.
S2 =∑i=1
n (Xi − X‾ )2
n − 1 — variância amostral (corrigida);2.
Sn2 =
∑i=1n (Xi − X‾ )2
n — variância amostral;3.
X(1) = min (X1, …, Xn) — mínimo amostral;4.
X(n) = max (X1, …, Xn) — máximo amostral.5.
Notação:
T(X) — estatística (X‾ , S2, …)1.
t(x) — valor observado da estatística (x‾, s2, …)2.
Estimação pontual: estimador e estimativa. Propriedadesdos estimadores.Estimação pontual ≡ cálculo, a partir de uma amostra observada, de valores plausíveis
para os parâmetros da distribuição da variável estatística de interesse numa população.
DefiniçãoUm estimador pontual de um parâmetro θ é uma qualquer função da amostra
aleatória que não dependa de parâmetros cujo valor seja desconhecido (estatística).

DefiniçãoUma estimativa pontual de um parâmetro θ é um valor observado de um
estimador pontual desse parâmetro.
ExemploSeja X1, …, Xn uma amostra aleatória de uma população com distribuição N(μ, σ2).
Alguns estimadores possíveis para μ são:
X‾ — média amostral1.
mediana amostral2.moda amostral3.X(1) + X(n)
2 — centro do intervalo de variação amostral4.
Como comparar diferentes estimadores?
DefiniçãoUm estimador pontual T de um parâmetro θ diz-se centrado se e só se
E[T] = θ, ∀ θ ∈ Θ.
Nota: dθ[T] = E[T] − θ é o desvio ou enviesamento do estimador.
ExemploSeja X1, …, Xn uma amostra aleatória de uma população X . Então,
X‾ é um estimador centrado de E[X];1.
S2 ( = Sn−12
) é um estimador centrado de Var[X];2.
qual é o problema de Sn2?3.
A B
C D

DefiniçãoO erro quadrático médio de um estimador pontual T de um parâmetro θ é
definido por
EQM[T] = E[(T − θ)2].
Notas:
EQM[T] = Var[T] + dθ2[T]1.
Se T é um estimador centrado então EQM[T] = Var[T]2.
DefiniçãoSejam T1 e T2 dois estimadores pontuais de um parâmetro θ. Diz-se que T1 é mais
eficiente do que T2 se
EQM[T1] ≤ EQM[T2], ∀ θ ∈ Θ
e∃ θ ∈ Θ : EQM[T1] < EQM[T2].
Método da máxima verosimilhança.Retomemos a distribuição amostral
fX(x1, …, xn; θ) = ∏i=1
nfXi
(xi; θ) = ∏i=1
nfX (xi; θ).
No caso discreto, quando o valor de θ é conhecido, esta função dá-nos a probabilidade
de se observar qualquer ponto amostral (x1, …, xn).
DefiniçãoA função ℒ (θ; x) ≡ fX(x; θ) diz-se a função de verosimilhança.
DefiniçãoO valor
θ
E[T] dθ(T)
Var[T]

θ = argmax θ ∈Θℒ (θ; x)
diz-se a estimativa de máxima verosimilhança do parâmetro θ.
Notas:
O estimador associado, quando é determinável analiticamente, diz-se o respectivoestimador de máxima verosimilhança;
1.
Frequentemente é mais conveniente maximizar logℒ (θ; x).2.
ExemploSeja X1, …, Xn uma amostra aleatória de uma população com distribuição Geo(p),
com 0 < p < 1. Determine o estimador de máxima verosimilhança do parâmetro p e
de q = P(X > 1).
Teorema (Invariância dos estimadores de máximaverosimilhança)
Seja θ o estimador de máxima verosimilhança de um parâmetro θ ∈ Θ ⊂ ℝk e g uma
função de ℝk em ℝp com p ≤ k. Então, o estimador de máxima verosimilhança de
g(θ) é g(θ).
Momentos da média amostral e de variâncias amostrais.Distribuições amostrais da média e variância numapopulação normal. Distribuições do qui-quadrado et-Student.Já vimos que E[X‾ ] = E[X]. Temos ainda que Var[X‾ ] = Var[X] / n. Para melhor se avaliar a
estimação de um parâmetro é importante conhecer a distribuição amostral de umestimador ou estatística.
TeoremaSeja X1, …, Xn uma amostra aleatória de uma população N(μ, σ2). Então
X‾ ∼ N(
μ,σ2
n )⇔
X‾ − μσn
√
∼ N(0, 1)
Para populações não normais, se a amostra for suficientemente grande, podemos aplicaro Teorema do Limite Central, obtendo-se:
X‾ − E[X]
Var[X]n√
∼a
N(0, 1) ⇔ X‾ ∼a
N(
E[X],Var[X]
n ).
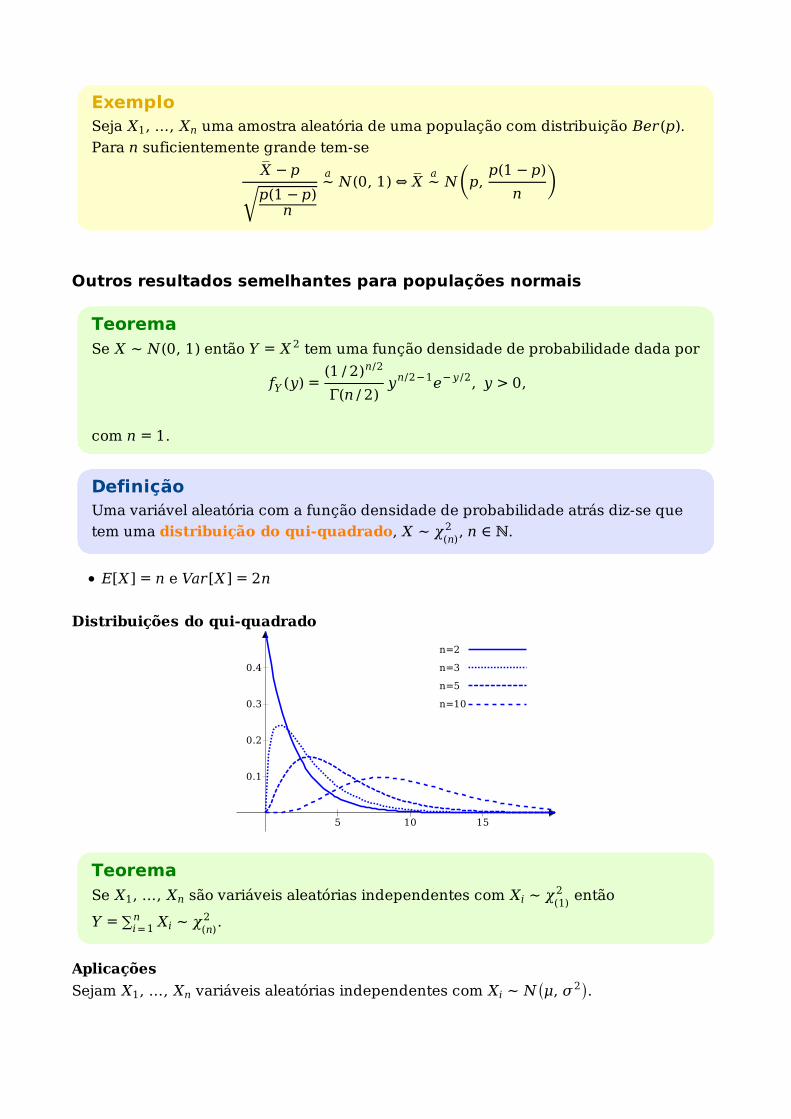
ExemploSeja X1, …, Xn uma amostra aleatória de uma população com distribuição Ber(p).
Para n suficientemente grande tem-se
X‾ − p
p(1 − p)n√
∼a
N(0, 1) ⇔ X‾ ∼a
N(
p,p(1 − p)
n )
Outros resultados semelhantes para populações normais
TeoremaSe X ∼ N(0, 1) então Y = X 2 tem uma função densidade de probabilidade dada por
fY (y) =(1 / 2)n/2
Γ(n / 2)yn/2−1e− y /2, y > 0,
com n = 1.
DefiniçãoUma variável aleatória com a função densidade de probabilidade atrás diz-se que
tem uma distribuição do qui-quadrado, X ∼ χ(n)2 , n ∈ ℕ.
E[X] = n e Var[X] = 2n
Distribuições do qui-quadrado
TeoremaSe X1, …, Xn são variáveis aleatórias independentes com Xi ∼ χ
(1)2 então
Y = ∑i=1n Xi ∼ χ
(n)2 .
Aplicações
Sejam X1, …, Xn variáveis aleatórias independentes com Xi ∼ N(μ, σ2).
5 10 15
0.1
0.2
0.3
0.4
n=2
n=3
n=5
n=10
Então
∑i=1n (Xi − μ)2
σ2∼ χ(n)
2 ;1.
∑i=1n (Xi − X‾ )2
σ2=
(n − 1)S2
σ2∼ χ(n−1)
2 .2.
DefiniçãoUma variável aleatória com a função densidade de probabilidade
fX (x) =Γ(
n + 12 )
nπ√
Γ(n2)
(1 +
x2
n )
−n+12
, x ∈ ℝ
diz-se que tem uma distribuição t-Student, X ∼ t(n), n ∈ ℕ.
E[X] = 0, n ≥ 2 e Var[X] = nn−2
, n ≥ 3, X ⟶𝒟
N(0, 1)
Distribuições t-Student
TeoremaSe X ∼ N(0, 1) e Y ∼ χ
(n)2 são variáveis aleatórias independentes então
X
Y / n√
∼ t(n).
Aplicação
Seja X1, …, Xn uma amostra aleatória de uma população N(μ, σ2). Então
X‾ − μ
Sn
√
∼ t(n−1)
-3 -2 -1 1 2 3
0.1
0.2
0.3
0.4 N(0,1)
t(2)
t(5)
t(20)

7. Estimação por intervalos
Noções básicas. Método pivotal.Calculada uma estimativa pontual de um parâmetro como avaliar a qualidadedessa estimativa?
Complementar uma estimativa pontual de um parâmetro com um intervalo devalores que, com maior "confiança", contenha o valor desconhecido do parâmetronuma população.
Como construir esses intervalos?
Usar funções adequadas de estimadores pontuais e as suas distribuições amostrais.
Seja X1, …, Xn uma amostra aleatória de uma população N(μ, σ2) em que o valor de σ2 é
conhecido.
Não é difícil mostrar que X‾ é o estimador de máxima verosimilhança de μ. Já vimos
também que X‾ ∼ N(μ, σ2 / n) ou, equivalentemente, que
X‾ − μσn
√
∼ N(0, 1).
Fixado 0 < γ < 1 determinemos a e b tais que
P(a < n
√
X‾ − μ
σ< b
)= γ.
Como a solução não é única é necessário introduzir um critério adicional. Se tomarmos,
por mera conveniência, a = − b temos então que b = Φ−1(
1+γ2 ).
Resolvendo as duas desigualdades anteriores em ordem a μ obtém-se
P
⎛
⎝
⎜⎜⎜X‾ − b
σ
n√
< μ < X‾ + bσ
n√
⎞
⎠
⎟⎟⎟
= γ.
∴ IACγ(μ) =
⎤
⎦
⎥⎥⎥X‾ − b
σ
n√
, X‾ + bσ
n√
⎡
⎣
⎢⎢⎢, com b = Φ−1
(1+γ
2 ).
Outras soluções — intervalos unilaterais:
a = − ∞ e b = Φ−1(γ) ⇒ IACγ(μ) =
⎤
⎦
⎥⎥⎥
− ∞, X‾ + bσ
n√
⎡
⎣
⎢⎢⎢

a = Φ−1(1 − γ) e b = + ∞ ⇒ IACγ(μ) =
⎤
⎦
⎥⎥⎥X‾ + a
σ
n√
, + ∞
⎡
⎣
⎢⎢⎢
AplicaçãoSuponhamos que σ = 1 e que se observou uma amostra de dimensão n = 100 tal que
x‾ = 10. Para γ = 0.95 tem-se b = Φ−1(0.975) = 1.96 e
IC0.95(μ) = ]9.804, 10.196[.
Será que podemos afirmar queP(9.804 < μ < 10.196) = 0.95?
γ é uma probabilidade associada ao intervalo aleatório de confiança, ou seja, é a
proporção de intervalos de confiança obteníveis que contêm o valor desconhecidodo parâmetro.γ é o nível de confiança associado ao intervalo de confiança, ou seja, uma medida da
confiança que podemos ter de que esse intervalo numérico contenha, de facto, ovalor desconhecido do parâmetro.
DefiniçãoO conjunto (infinito) de todas as amostras possíveis de serem obtidas numapopulação designa-se por espaço amostral e será representado por 𝒳 .
DefiniçãoSeja X = (X1, …, Xn) uma amostra aleatória de uma população com distribuição
fX (x; θ). Um intervalo ]I(X), S(X)[, com I(x) ≤ S(x) ∀ x ∈ 𝒳 , diz-se um intervalo
aleatório de confiança para θ.
se I(X) (S(X)) não depende da amostra aleatória então o intervalo diz-se unilateral à
esquerda (direita);
1.
dada uma amostra observada x a concretização do intervalo aleatório de confiança,
]I(x), S(x)[, é um intervalo numérico designado por intervalo de confiança.
2.
DefiniçãoSeja ]I(X), S(X)[ um intervalo aleatório de confiança para um parâmetro θ. Se
P(I(X) < θ < S(X)) = γ, ∀ θ ∈ Θ
então γ diz-se o nível de confiança do intervalo aleatório de confiança.
O que há de geral no exemplo inicial? ⇒ Método da variável fulcral ou método
pivotal

DefiniçãoUma função da amostra aleatória e do parâmetro de interesse, θ, que não depende
de quaisquer outros parâmetros com valores desconhecidos e cuja distribuição écompletamente conhecida diz-se uma variável fulcral ou pivô para o parâmetro θ.
E se o valor de σ2 for também desconhecido?
Neste caso a variável aleatória, que já vimos anteriormente,
X‾ − μ
Sn
√
∼ t(n−1)
é uma variável fulcral para μ e a construção de intervalos de confiança segue os mesmos
passos do exemplo anterior.
Intervalos de confiança para parâmetros depopulações normais.
IC para a variância de uma população normal
Já vimos atrás que (n − 1)S2
σ2∼ χ
(n−1)2 . Como anteriormente, determinemos a e b tais que
P(a <
(n − 1)S2
σ2< b
)= γ, para 0 < γ < 1.
Agora a distribuição da variável fulcral não é simétrica!
Possível solução — intervalo central ou de caudas iguais:
determinar a tal que Fχ(n−1)2 (a) = 1−γ
2;1.
determinar b tal que Fχ(n−1)2 (b) = 1 −
1−γ2
= 1+γ2
.2.
P(a <
(n − 1)S2
σ2< b
)= P
(
(n − 1)S2
b< σ2 <
(n − 1)S2
a )= γ
∴ IACγ(σ2) =
]
(n − 1)S2
b,
(n − 1)S2
a [
Duas populações normaisSejam X1, 1, …, X1,n1 e X2, 1, …, X2,n2 duas amostras aleatórias independentes de
populações N(μ1, σ12) e N(μ2, σ2
2), respectivamente.

Já vimos que X‾ i ∼ N(μi, σi2 / ni). Como X‾ 1 e X‾ 2 são variáveis aleatórias independentes
então
X‾ 1 − X‾ 2 ∼ N(μ1 − μ2,
σ12
n1+σ2
2
n2 ).
Equivalentemente,
(X‾ 1 − X‾ 2) − (μ1 − μ2)
σ12
n1+σ2
2
n2√
∼ N(0, 1),
que pode servir como variável fulcral para μ1 − μ2 quando σ12 e σ2
2 são conhecidas.
Quando os valores de σ12 e σ2
2 são também desconhecidos pode-se mostrar que, se
σ12 = σ2
2, então
(X‾ 1 − X‾ 2) − (μ1 − μ2)
(n1 − 1)S12 + (n2 − 1)S2
2
n1 + n2 − 2 (1n1
+ 1n2)√
∼ t(n1 +n2 −2).
No caso mais geral não é conhecida uma solução exacta mas, se as amostras foremsuficientemente grandes, pode-se usar uma variável fulcral com uma distribuiçãoaproximada
(X‾ 1 − X‾ 2) − (μ1 − μ2)
S12
n1+S2
2
n2√
∼aN(0, 1).
É claro que, neste último caso, os intervalos têm níveis de confiança aproximados!
Intervalos de confiança para parâmetros depopulações não normais uniparamétricas.
Em geral, a obtenção de variáveis fulcrais não é fácil!Com amostras grandes é muitas vezes suficiente o cálculo de intervalos com níveisde confiança aproximados recorrendo, por exemplo, ao Teorema do Limite Central.
Seja X1, …, Xn uma amostra aleatória de uma população com distribuição fX (x; θ), com n
suficientemente grande, e Sn = ∑i=1n Xi. Pelo T. L. C. temos que
Sn − E[Sn]
Var[Sn]√
=X‾ − E[X‾ ]
Var[X‾ ]√
=X‾ − E[X]
Var[X]n√
∼aN(0, 1).
Uma vez que E[X] e Var[X] dependem de θ a variável anterior pode ser usada como
uma variável fulcral aproximada para θ.

ExemploSeja X1, …, Xn uma amostra aleatória de uma população com distribuição Ber(p).
Para n suficientemente grande temos então
X‾ − p
p(1 − p)n√
∼aN(0, 1).
Fixado 0 < γ < 1 então com a = Φ−1(
1+γ2 ) tem-se
P
⎛
⎝
⎜⎜⎜⎜
− a <X‾ − p
p(1 − p)n√
< a
⎞
⎠
⎟⎟⎟⎟
= γ.
Exemplo (cont.)∣
∣
∣∣∣∣∣
X‾ − p
p(1 − p)n√
∣
∣
∣∣∣∣∣
< a ⇔(X‾ − p)2
p(1 − p)n
< a2 ⇔
⇔(
1 +a2
n )p2 −
(2X‾ +
a2
n )p + X‾
2< 0
Como (1 + a2
n ) > 0 então o intervalo aleatório de confiança aproximado é da forma
]k1, k2[ onde k1 e k2 são as soluções da equação do segundo grau associada à
inequação anterior.
Exemplo (cont.)Uma solução mais simples: pode-se mostrar ainda que
X‾ − p
X‾ (1 − X‾ )n√
∼aN(0, 1).
Com esta variável fulcral aproximada tem-se
IACγ(p) ≃⎤
⎦
⎥⎥X‾ − a
X‾ (1 − X‾ )
n√, X‾ + a
X‾ (1 − X‾ )
n√
⎡
⎣
⎢⎢,
com a = Φ−1(
1+γ2 )

8. Testes de hipóteses
Noções básicas.Nos dois capítulos anteriores vimos como usar os dados observados para determinarum valor ou um conjunto de valores plausíveis para um parâmetro cujo valor numapopulação é desconhecido.Nas primeiras secções deste capítulo o procedimento inverte-se: escolhido um valorou um conjunto de valores possíveis para um parâmetro vamos avaliar se os dadosobservados suportam ou não essa escolha.Por fim, iremos analisar uma questão de uma natureza diferente: o ajustamento deuma distribuição a uma variável aleatória.
Procedimento geral de um teste de hipóteses paramétricasSeja X = (X1, …, Xn) uma amostra aleatória de uma população com distribuição fX (x; θ),
θ ∈ Θ.
1. Hipóteses paramétricas
Hipótese nula: H0 : θ ∈ Θ0
Hipótese alternativa: H1 : θ ∈ Θ1
com Θ = Θ0∪Θ1 e Θ0∩Θ1 = ∅.
Tipos de hipóteses:
H : θ = θ0 — hipótese simples
H : θ ≠ θ0
H : θ > θ0 ou H : θ ≥ θ0 — hipóteses compostas
H : θ < θ0 ou H : θ ≤ θ0
2. Estatística de teste
Escolha de uma estatística de teste adequada T(X) cuja distribuição sob H0 seja
conhecida e que, de alguma forma, meça a maior ou menor concordância entre os dadose a hipótese H0.
3. Região crítica
Admitindo que H0 é verdadeira, define-se uma região C ⊂ ℝ tal que a P(T(X) ∈ C ∣∣ H0)

seja pequena.
4. Aplicação do teste de hipóteses
Observada uma amostra x = (x1, …, xn) calcula-se T(x) e é tomada uma decisão:
— se T(x) ∈ C rejeita-se H0;
— caso contrário não se rejeita H0.
Avaliação de um teste de hipótesesNuma decisão sobre uma hipótese H0 há dois tipos de erros possíveis:
Erro de tipo I: rejeitar H0 quando H0 é verdadeira
Erro de tipo II: não rejeitar H0 quando H0 é falsa
Sejam
α(θ) = P(rejeitar H0 ∣∣ H0 verdadeira) = P(T(X) ∈ C ∣∣ θ ∈ Θ0) e
β(θ) = P(não rejeitar H0 ∣∣ H0 falsa) = P(T(X) ∉ C ∣∣ θ ∈ Θ1).
DefiniçãoA potência de um teste de hipóteses é definida por
P(rejeitar H0 ∣∣ θ) ={
α(θ), θ ∈ Θ0
1 − β(θ), θ ∈ Θ1
.
DefiniçãoO nível de significância de um teste de hipóteses é definido por
supθ ∈Θ0
P(rejeitar H0 ∣∣ θ) = supθ ∈Θ0
α(θ).
Testes de hipóteses para parâmetros de populaçõesnormais.
Testes de hipóteses para a média
Seja X1, …, Xn uma amostra aleatória de uma população N(μ, σ2) em que o valor de σ2 é
conhecido.
1. H0 : μ = μ0 contra H1 : μ ≠ μ0

Estatística de teste: Z0 = n√
X‾ −μ0
σ∼
μ=μ0N(0, 1)
Para definir a região crítica fixa-se o nível de significância do teste, α, ou seja, a
probabilidade dessa região sob H0.
Cα ={
x‾ ∈ ℝ :∣
∣∣ n√
x‾ − μ0
σ
∣
∣∣ > Φ−1⎛
⎝⎜1 −α
2
⎞⎠⎟}
Decisão: se z0 ∈ Cα então rejeita-se H0 para qualquer nível de significância superior ou
igual a α.
Nota: z0 =∣
∣∣ n√
x‾ − μ0
σ
∣
∣∣ ≤ Φ−1⎛
⎝⎜1 −α
2
⎞⎠⎟ ⇔
⇔ μ0 − Φ−1⎛⎝⎜1 −
α
2
⎞⎠⎟
σ
n√
≤ x‾ ≤ μ0 + Φ−1⎛⎝⎜1 −
α
2
⎞⎠⎟
σ
n√
⇔
⇔ x‾ − Φ−1⎛⎝⎜1 −
α
2
⎞⎠⎟
σ
n√
≤ μ0 ≤ x‾ + Φ−1⎛⎝⎜1 −
α
2
⎞⎠⎟
σ
n√
z0 ∉ Cα ⇔ μ0 ∈ IC1−α(μ), ou seja, não se rejeita H0 a um nível de significância α se e
só se μ0 pertence ao IC1−α(μ)!
Alternativa — Cálculo do valor-p
DefiniçãoO valor-p é a probabilidade sob H0 de a estatística de teste tomar valores tão ou
mais desfavoráveis a H0 do que o seu valor observado, ou seja, o menor nível de
significância que conduz à rejeição de H0.
Neste caso o valor-p é calculado como
2min {P(Z0 > z0), P(Z0 ≤ z0)} = 2P(Z0 > ∣∣z0∣∣) = 2(1 − Φ(∣∣z0∣∣)).
Pela definição anterior rejeita-se H0 para níveis de significância superiores ao valor-p e
não se rejeita no caso contrário.
o cálculo do valor-p permite que se prescinda de fixar previamente o nível designificância de um teste de hipóteses.
2. H0 : μ ≤ μ0 contra H1 : μ > μ0
Estatística de teste: Z0 = n√
X‾ − μ0
σ∼
μ=μ0N(0, 1)

Região crítica: Cα ={
x‾ ∈ ℝ : n√
x‾ − μ0
σ> Φ−1(1 − α)
}
Valor-p: P(Z0 > z0)
Nota: este teste de hipóteses também se aplica às hipóteses H0 : μ = μ0 contra
H1 : μ = μ1, com μ1 > μ0.
3. H0 : μ ≥ μ0 contra H1 : μ < μ0
Estatística de teste: Z0 = n√
X‾ − μ0
σ∼
μ=μ0N(0, 1)
Região crítica: Cα ={
x‾ ∈ ℝ : n√
x‾ − μ0
σ< Φ−1(α)
}
Valor-p: P(Z0 < z0)
Nota: este teste de hipóteses também se aplica às hipóteses H0 : μ = μ0 contra
H1 : μ = μ1, com μ1 < μ0.
Quando o valor de σ2 é também desconhecido, todas as hipóteses anteriores podem ser
testadas usando a estatística de teste
T = n√
X‾ − μ
S∼ t(n−1).
A construcão dos testes de hipóteses é inteiramente análoga aos casos anteriores.
Testes de hipóteses para a variância
Neste caso recorre-se à variável fulcral usada no Cap. 7 para σ2 e na construção dos
testes de hipóteses segue-se o procedimento que vimos atrás. No entanto, pode-sepensar que a assimetria da distribuição da estatística de teste introduz novasdificuldades. Vejamos, num exemplo, que isso não acontece.
Consideremos a construção de um teste para as hipóteses H0 : σ2 = σ02 contra
H1 : σ2 ≠ σ02.
Estatística de teste: Q0 =(n − 1)S2
σ02
∼σ2 =σ
02
χ(n−1)2
Qual deverá ser a forma da região crítica?
Sob H0 é de esperar que a estatística tome valores em torno de E[Q0] = n − 1. Logo,
valores que se afastem dessa medida de localização da distribuição χ(n−1)2 , quer para
valores elevados quer para valores próximos de 0, fornecem evidência contra a hipótesenula, ou seja,

Cα ={
s2 ∈ ℝ+ : q0 < Fχ
(n−1)2
−1 (α / 2)∨ q0 > Fχ
(n−1)2
−1 (1 − α / 2)}
.
Testes de hipóteses sobre a igualdade das médias de duas populaçõesnormais
Nesta secção não há grandes novidades! Para testar hipóteses que envolvam a diferençade médias de duas populações normais, μ1 − μ2, utilizam-se as variáveis fulcrais
descritas na Secção 7.2. A construção dos testes de hipóteses segue as linhas que foramesboçadas anteriormente.
Testes de hipóteses para parâmetros de populações nãonormais uniparamétricas.Tal como na construção de intervalos de confiança, também aqui só iremos considerartestes de hipóteses aproximados baseados em estatísticas de teste obtidas pela aplicaçãodo Teorema do Limite Central, ou seja,
X‾ − E[X]
Var[X]n√
∼a
N(0, 1),
para n suficientemente grande.
Um exemplo deverá ser suficiente para que o procedimento geral seja bem entendido!
ExemploUm fabricante de lâmpadas afirma que o tempo médio de vida das suas lâmpadas é
de 1×103 horas, no mínimo. Numa amostra de 120 lâmpadas retiradas ao acaso da
produção desse fabricante observou-se um tempo total de vida de 112×103 horas.
Admitindo que o tempo de vida de uma lâmpada, em milhares de horas, segue umadistribuição exponencial, avalie a afirmação do fabricante.
Seja X = (X1, …, Xn) uma amostra aleatória de uma população com distribuição Exp(λ),
λ > 0.
Hipóteses
H0 : 1 / λ ≥ 1 contra H1 : 1 / λ < 1
Estatística de teste
Como a dimensão da amostra é suficientemente grande podemos utilizar
T0 = n√ (X‾ − 1) ∼
aN(0, 1),
Região crítica

Tendo em conta as hipóteses e a estatística de teste, a região crítica deverá ter a forma
C = {x‾ ∈ ℝ+ : t0 < Φ−1(α)}.
Assim o valor-p é dado por P(T0 ≤ t0).
Aplicação do teste de hipóteses
Como ∑i=1120 xi = 112 tem-se t0 = 120
√(112 / 120 − 1) ≃ − 0.73.
O valor-p é igual a P(T0 ≤ − 0.73) = 1 − Φ(0.73) = 1 − 0.7673 = 0.2327.
Conclusões
deve-se rejeitar H0 para níveis de significância superiores a 0.2327 e não rejeitar no
caso contrário;
1.
não há evidência suficiente para rejeitar a afirmação do fabricante de lâmpadas aosníveis de significância mais usuais (0.01-0.1).
2.
Teste de ajustamento do qui-quadrado de Pearson.Nos procedimentos estatísticos que vimos até aqui admitiu-se que a distribuição davariável aleatória de interesse era conhecida a menos do valor de um ou maisparâmetros. Iremos agora encarar esse pressuposto como uma hipótese estatística cujaplausibilidade se pretende avaliar.
Consideremos uma amostra aleatória de dimensão n extraída de uma população X com
distribuição fX (x) desconhecida. Pretende-se então testar as hipóteses
H0 : X ∼ fX0(x) contra H1 : X ∼/ fX
0(x).
Comecemos por criar uma partição do contradomínio de X , A1, …, Ak, na qual se
agrupam os dados observados.
Sejam pi0 = P(X ∈ Ai ∣∣ H0) e Oi o número de observações na amostra agrupadas na
classe Ai, i = 1, …, k.
Sob H0, Oi ∼ Bi(n, pi0) e defina-se Ei = E[Oi ∣∣ H0] = npi
0. Note-se que
∑ i=1k Oi = ∑i=1
k Ei = n∑i=1k pi
0 = n.
Uma forma de avaliar a plausibilidade de H0 consiste em comparar as frequências
observáveis, Oi, com as frequências esperadas sob H0, Ei. Para isso utiliza-se a
estatística do qui-quadrado de Pearson
Q2 = ∑i=1
k (Oi − Ei)2
Ei∼a
χ(k−1)2 .
Classes oi
(0, 1] 71
(1, 2] 27
(2, 3] 12
(3, 4] 6
(4, 5] 2
(5, 6] 2
120
Para um nível de significância α a região crítica é, naturalmente,
Cα ={
q2 ∈ ℝ+ : Q2 > Fχ
(k−1)2
−1 (1 − α)}
.
Uma vez que se trata de um teste aproximado é necessário que se verifiquem asseguintes condições:
todas as classes com Ei ≥ 1;1.
pelo menos 80% das classes com Ei ≥ 5.2.
Quando isto não acontece procede-se a um agrupamento das classes.
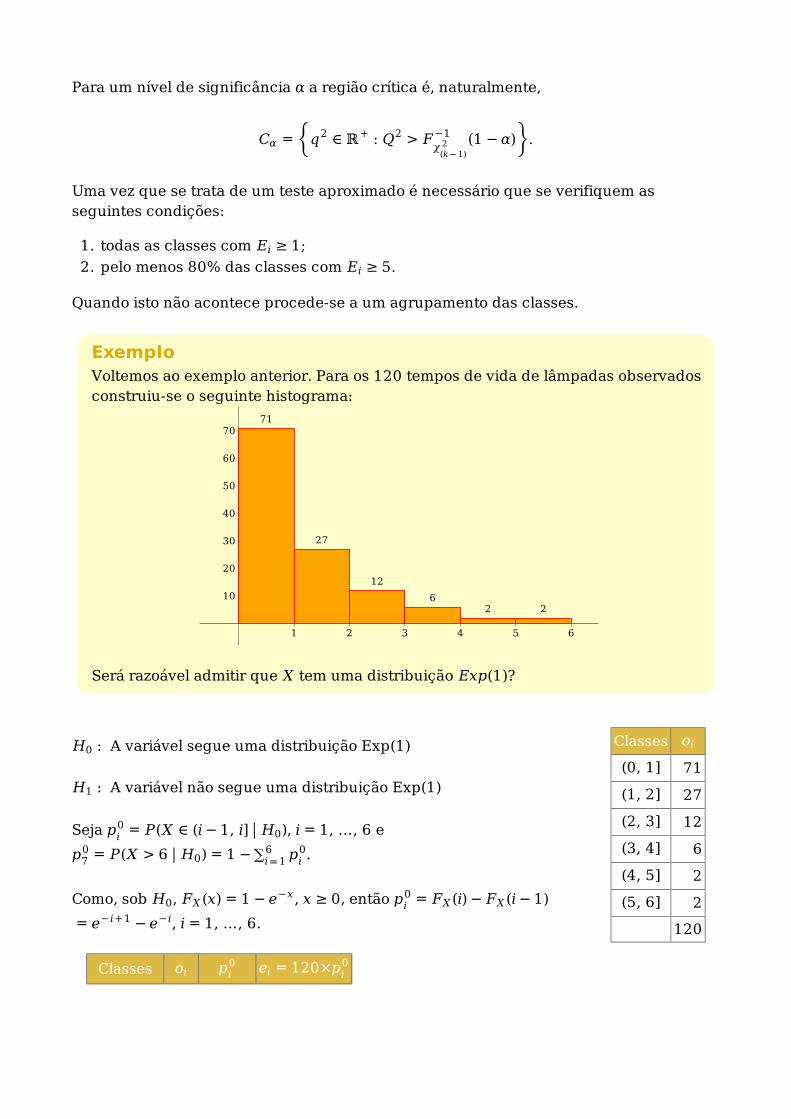
ExemploVoltemos ao exemplo anterior. Para os 120 tempos de vida de lâmpadas observadosconstruiu-se o seguinte histograma:
Será razoável admitir que X tem uma distribuição Exp(1)?
H0 : A variável segue uma distribuição Exp(1)
H1 : A variável não segue uma distribuição Exp(1)
Seja pi0 = P(X ∈ (i − 1, i] ∣∣ H0), i = 1, …, 6 e
p70 = P(X > 6 ∣∣ H0) = 1 − ∑i=1
6 pi0.
Como, sob H0, FX (x) = 1 − e−x , x ≥ 0, então pi0 = FX (i) − FX (i − 1)
= e−i+1 − e−i, i = 1, …, 6.
Classes oi pi0 ei = 120×pi
0
1 2 3 4 5 6
10
20
30
40
50
60
7071
27
12
62 2
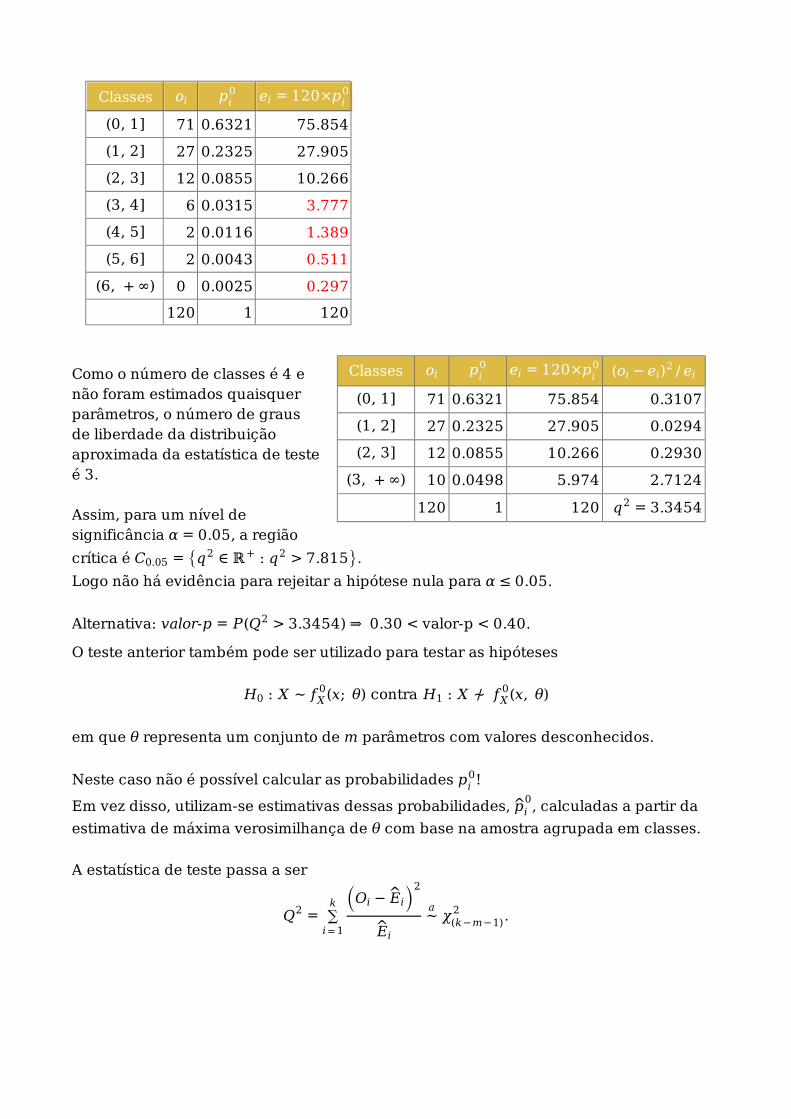
Classes oi pi0 ei = 120×pi
0 (oi − ei)2 / ei
(0, 1] 71 0.6321 75.854 0.3107
(1, 2] 27 0.2325 27.905 0.0294
(2, 3] 12 0.0855 10.266 0.2930
(3, + ∞) 10 0.0498 5.974 2.7124
120 1 120 q2 = 3.3454
Classes oi pi0 ei = 120×pi
0
(0, 1] 71 0.6321 75.854
(1, 2] 27 0.2325 27.905
(2, 3] 12 0.0855 10.266
(3, 4] 6 0.0315 3.777
(4, 5] 2 0.0116 1.389
(5, 6] 2 0.0043 0.511
(6, + ∞) 0 0.0025 0.297
120 1 120
Como o número de classes é 4 enão foram estimados quaisquerparâmetros, o número de grausde liberdade da distribuiçãoaproximada da estatística de testeé 3.
Assim, para um nível designificância α = 0.05, a região
crítica é C0.05 = {q2 ∈ ℝ+ : q2 > 7.815}.
Logo não há evidência para rejeitar a hipótese nula para α ≤ 0.05.
Alternativa: valor-p = P(Q2 > 3.3454) ⇒ 0.30 < valor-p < 0.40.
O teste anterior também pode ser utilizado para testar as hipóteses
H0 : X ∼ fX0(x; θ) contra H1 : X ∼/ fX
0(x, θ)
em que θ representa um conjunto de m parâmetros com valores desconhecidos.
Neste caso não é possível calcular as probabilidades pi0!
Em vez disso, utilizam-se estimativas dessas probabilidades, pi0, calculadas a partir da
estimativa de máxima verosimilhança de θ com base na amostra agrupada em classes.
A estatística de teste passa a ser
Q2 = ∑i=1
k (Oi − Ei)
2
Ei
∼a
χ(k−m−1)2 .
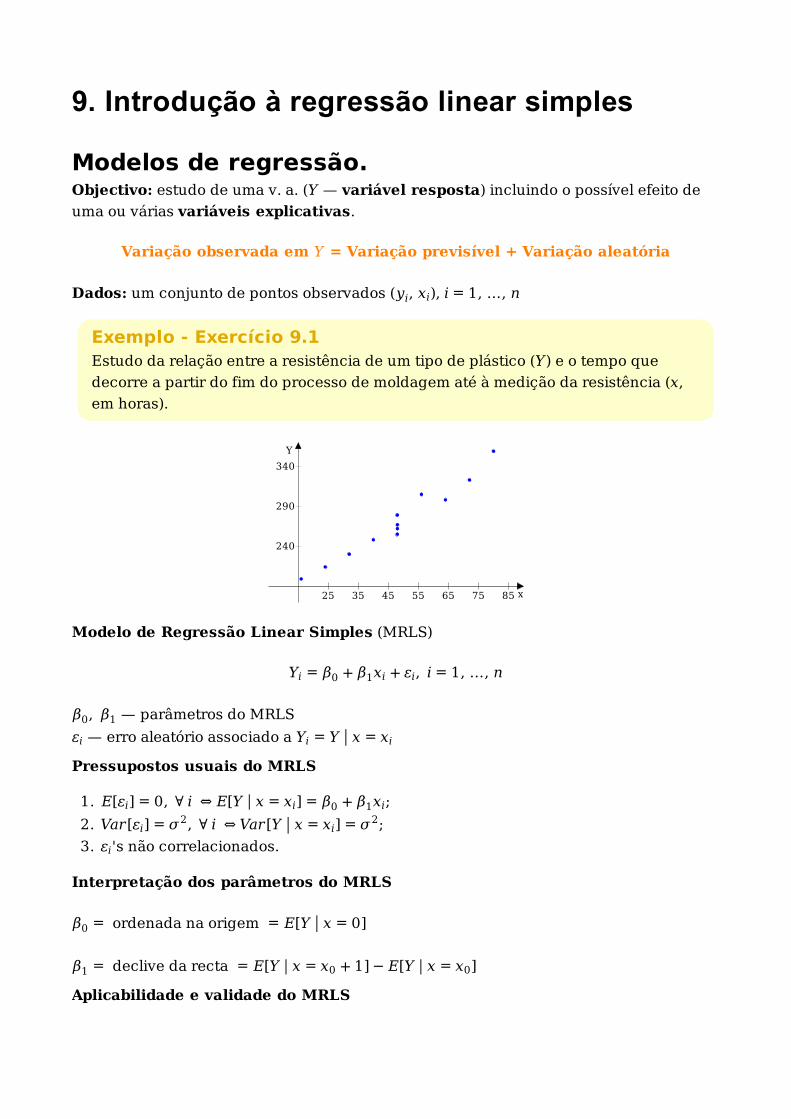
9. Introdução à regressão linear simples
Modelos de regressão.Objectivo: estudo de uma v. a. (Y — variável resposta) incluindo o possível efeito de
uma ou várias variáveis explicativas.
Variação observada em Y = Variação previsível + Variação aleatória
Dados: um conjunto de pontos observados (yi, xi), i = 1, …, n
Exemplo - Exercício 9.1Estudo da relação entre a resistência de um tipo de plástico (Y) e o tempo que
decorre a partir do fim do processo de moldagem até à medição da resistência (x,
em horas).
Modelo de Regressão Linear Simples (MRLS)
Yi = β0 + β1xi + ɛi, i = 1, …, n
β0, β1 — parâmetros do MRLS
ɛi — erro aleatório associado a Yi = Y ∣∣ x = xi
Pressupostos usuais do MRLS
E[ɛi] = 0, ∀ i ⇔ E[Y ∣∣ x = xi] = β0 + β1xi;1.
Var[ɛi] = σ2, ∀ i ⇔ Var[Y ∣∣ x = xi] = σ2;2.
ɛi's não correlacionados.3.
Interpretação dos parâmetros do MRLS
β0 = ordenada na origem = E[Y ∣∣ x = 0]
β1 = declive da recta = E[Y ∣∣ x = x0 + 1] − E[Y ∣∣ x = x0]
Aplicabilidade e validade do MRLS
25 35 45 55 65 75 85
240
290
340
x
Y
Método dos mínimos quadrados em regressão linearsimples.
SQ(β0, β1) = ∑i=1
nɛi
2 = ∑i=1
n(Yi − β0 − β1xi)
2
(β0, β1) = argmin SQ(β0, β1) — estimador de mínimos quadrados
⎧
⎨
⎩
⎪⎪
⎪⎪
∂SQ(β0, β1)
∂ β0= 0
∂SQ(β0, β1)
∂ β1= 0
⇔
⎧
⎨
⎩
⎪⎪
⎪⎪
β1 =∑
i = 1n xiYi −nx‾Y‾
∑i = 1n x
i2 −nx‾ 2
β0 = Y‾ − β1x‾
Equação de regressão estimada: E[Y ∣∣ x] = β0 + β1x
Alternativa: método da máxima verosimilhança
Pressuposto adicional:
ɛi ∼ N(0, σ2), i = 1…, n ⇔ Yi ∼ N(β0 + β1xi, σ2
)

ℒ (β0, β1, σ2 ∣∣ y) = ∏i=1
n 1
2πσ2√
e− 1
2σ2 (yi −(β0 + β1xi ))2
os estimadores de máxima verosimilhança de β0 e β1 coincidem com os anteriores e
σMV2 =
∑i=1n
(Yi − (β0 + β1xi))2
n.
Propriedades dos estimadores dos mínimos quadrados.
β1 =∑i=1
n xiYi − nx‾Y‾
∑i=1n xi
2 − nx‾2=
∑i=1n xiYi − ∑i=1
n x‾Yi
∑i=1n xi
2 − nx‾2= ∑
i=1
nkiYi
onde ki =(xi − x‾)
∑ j=1n x j
2 − nx‾2.
Tem-se que ∑i=1
nki =
∑i=1n (xi − x‾)
∑ j=1n x j
2 − nx‾2= 0 e ∑
i=1
nkixi =
∑i=1n xi(xi − x‾)
∑ j=1n x j
2 − nx‾2= 1.
E[β1] = ∑i=1
nkiE[Yi] = ∑
i=1
nki(β0 + β1xi) = β1.
β0 = Y‾ − β1x‾ =∑i=1
n Yi
n− ∑
i=1
nx‾kiYi = ∑
i=1
n
(
1
n− x‾ki)
Yi = ∑i=1
nwiYi
com ∑i=1n wi = 1 e ∑i=1
n wixi = 0 ⇒ E[β0] = β0.
Pode-se ainda mostrar que E[σ MV2
] =n − 2
nσ2.
Logo,
σ2 =
∑i=1n
(Yi − (β0 + β1xi))
2
n − 2é um estimador centrado de σ2.
Inferências no modelo de regressão linear simples.Inferências sobre β1

β1 − β1
σ2
∑ xi2 − nx‾2√
∼ t(n−2) - variável fulcral para β1
Hipóteses importantes: H0 : β1 = 0 contra H1 : β1 ≠ 0
Inferências sobre β0
β0 − β0
(1n + x‾2
∑ xi2 − nx‾2)
σ2
√
∼ t(n−2) - variável fulcral para β0
Estimação da resposta esperada: E[Y0] = E[Y ∣∣ x = x0] = β0 + β1x0
Estimador pontual: E[Y0] = β0 + β1x0 (centrado!)
(β0 + β1x0) − (β0 + β1x0)
(1n +
(x‾ − x0)2
∑ xi2 − nx‾2)
σ2
√
∼ t(n−2) - variável fulcral para E[Y0]
Nota: as inferências podem não ser válidas fora do intervalo de valores de x considerado
— extrapolação.
Coeficiente de determinação e análise gráfica de resíduosna avaliação do modelo.Há um grande número de técnicas para avaliar a qualidade do ajustamento de umMRLS. Vejamos algumas das mais simples.
Sendo yi = β0 + β1xi pode mostrar-se que
∑ (yi − y‾)2 = ∑ (yi − yi)2
+ ∑ (yi − y‾)2
⇔
⇔ ∑ (yi − y‾)2 = ∑ (yi − β0^ − β1
^xi)
2+ (β1
^)
2∑ (xi − x‾)2 ⇔
⇔ SQT = SQE + SQR ⇔
⇔ variação total em Y=variação devida ao erro aleatório + variação explicada pelo
MRLS
Coeficiente de determinação: R2 = SQRSQT
= 1 − SQESQT
— proporção da variação em Y
explicada pelo MRLS
Por definição 0 ≤ R2 ≤ 1.
R2 → 1 — indica um bom ajustamento do MRLS
R2 → 0 — indica um mau ajustamento do MRLS
R = + R2√ — coeficiente de correlação empírico
Resíduos:
ri = yi − yi = yi − (β0 + β1xi), i = 1, …, n
Gráficos de ri versus xi ou yi são úteis para detectar violações dos pressupostos do
MRLS:
dependência nos erros;1.heterogeneidade da variância;2.falta de normalidade;3.observações discordantes.4.
Exercício 9.1
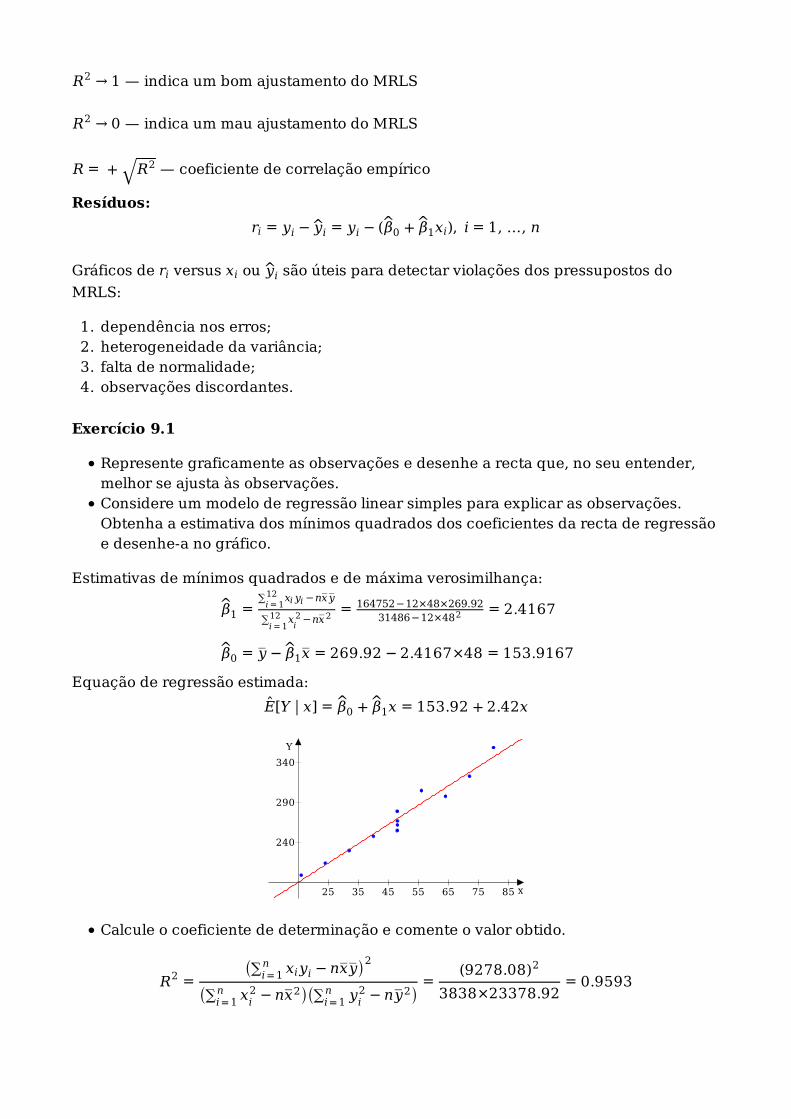
Represente graficamente as observações e desenhe a recta que, no seu entender,melhor se ajusta às observações.Considere um modelo de regressão linear simples para explicar as observações.Obtenha a estimativa dos mínimos quadrados dos coeficientes da recta de regressãoe desenhe-a no gráfico.
Estimativas de mínimos quadrados e de máxima verosimilhança:
β1 =∑
i = 112 xi yi −nx‾ y‾
∑i = 112 x
i2 −nx‾ 2
= 164752−12×48×269.9231486−12×482 = 2.4167
β0 = y‾ − β1x‾ = 269.92 − 2.4167×48 = 153.9167
Equação de regressão estimada:
E[Y ∣∣ x] = β0 + β1x = 153.92 + 2.42x
Calcule o coeficiente de determinação e comente o valor obtido.
R2 =(∑i=1
n xiyi − nx‾y‾)2
(∑i=1n xi
2 − nx‾2)(∑i=1
n yi2 − ny‾ 2
)=
(9278.08)2
3838×23378.92= 0.9593
25 35 45 55 65 75 85
240
290
340
x
Y

Isto é, 95.93% da variabilidade total da resistência do plástico é explicada pelo modelode regressão com o tempo decorrido entre a moldagem e a medição da resistência.
Proceda ao teste da hipótese "O coeficiente angular é nulo". Qual o interesse destahipótese? Relacione-o com o valor do coeficiente de determinação obtido atrás.
Hipóteses: H0 : β1 = 0 versus H1 : β1 ≠ 0.
Estatística do teste:
T =β1 − β1
σ2
∑i xi2 − 10x‾2√
∼β1 =0
t(10),
cujo valor observado é dado por t0 = 15.35.
Valor-p: p = 2×P(T0 > 15.35) = 2.81×10−8. Note-se que p < 0.001 = 2×0.0005 pois
Ft(10)−1 (0.9995) = 4.587.
Conclusão: Rejeita-se H0 para níveis de significância de pelo menos 2.81×10−8, ou
seja, há evidência contra H0, isto é, o tempo decorrido entre a moldagem e a medição da
resistência influencia significativamente a resistência do plástico.
Calcule o intervalo de confiança a 95% para o valor esperado da resistência obtida48 horas depois de concluída a moldagem. Acha legítimo usar o mesmoprocedimento tratando-se de um período de 10 horas em vez de 48 horas? Justifiquea sua resposta.
Variável fulcral para E[Y ∣∣x = x0] = β0 + β1x0:
W =(β0 + β1x0) − (β0 + β1x0)
(1n +
(x‾ − x0)2
∑i xi2 − nx‾2)
σ2
√
∼ t(10)
Intervalo aleatório de confiança para E[Y ∣∣x = x0] a 95%:
(β0 + β1x0) ± Ft(10)−1 (0.975)
(
1
n+
(x‾ − x0)2
∑i xi2 − nx‾2)
σ2
√
P( − 2.228 < W < 2.228) = 0.95 pois Ft(10)−1 (0.975) = 2.228
Estimativa pontual:
E[Y ∣∣x = 48] = 153.91 + 2.4167×48 = 269.91
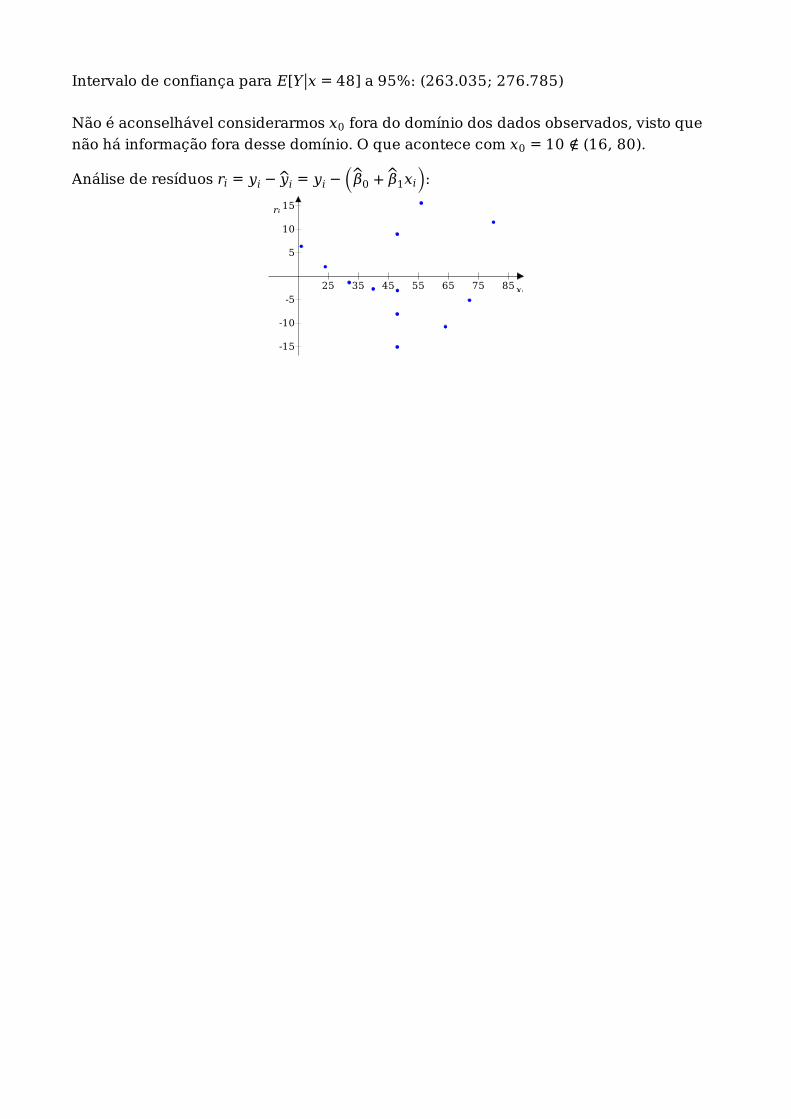
Intervalo de confiança para E[Y ∣∣x = 48] a 95%: (263.035; 276.785)
Não é aconselhável considerarmos x0 fora do domínio dos dados observados, visto que
não há informação fora desse domínio. O que acontece com x0 = 10 ∉ (16, 80).
Análise de resíduos ri = yi − yi = yi − (β0 + β1xi):
25 35 45 55 65 75 85
-15
-10
-5
5
10
15
xi
ri