perspectivas - edisciplinas.usp.br · perspectivas 17_ko18,22.htm 2. 3 ... considere o...
TRANSCRIPT


Perspectivas
2https://www.glassdoor.com/Jobs/Intel-Corporation-fpga-Jobs-EI_IE1519.0,17_KO18,22.htm

3
“Quão rápido um sistema computacional pode executar um
programa single-threaded para realizar um trabalho útil”
Samuel H. Fuller e Lynette Millet em The Future of Computing Performance: Game Over or Next Level?

4
"Por que se importar com o desempenho na computação?"
"O que é workload?"
"O quanto tem melhorado o desempenho dos computadores?"

Importância de melhorar o desempenho na computação
5
1. Capacidade computacional
• Possibilitar computações que previamente eram impraticáveis ou que valessem a pena
2. Desempenho escala mais rapidamente que o custo
• Melhor custo-desempenho possibilita que a computação seja usada onde previamente era economicamente inviável
Exemplo: Não é vantajoso computar a previsão do tempo de amanhã se isso leva 24 horas, entretanto, se torna razoável se o tempo necessário for de 12 horas.

Forma desejável de medir desempenho
6
1. Avaliar desempenho se baseando em um workloadsignificativo;
2. Fabricantes de computadores: deveriam analisar seus projetos tendo como base workloads atuais e estimativas de workloads futuros dos consumidores;
3. Consumidores: se basear em seus workloads para considerar melhor opção dentre computadores disponíveis.
⇒ Isso leva tempo e é caro, levando muitas pessoas a optarem por pacotes de benchmarks padronizados.

Desempenho
7
Métrica: algo que pode ser medido
Objetivo: avaliar o quão bom/ruim é uma arquitetura
Exemplos:– Tempo de execução de um programa;
– Número de programas executados por segundo;
– Ciclos por instruções do programa;
– Energia consumida por um programa.
Como podemos comparar? Medir?

Desempenho (2)
8
• Medir, Relatar e Resumir
• Fazer escolhas inteligentes
• Ver além do sensacionalismo do mercado
• Ponto fundamental para compreender as reais necessidades de um sistema
Por que alguns hardwares são melhores que outros para diferentes programas?
Quais fatores do desempenho do sistema são relacionados ao hardware?
(exemplo: Eu preciso de um novo equipamento ou de um novo sistema operacional?
Qual é o papel do conjunto de instruções (ISA) no desempenho?

Desempenho (3)Por Hennessy & Patterson
9
• Perspectiva de compra– Dada um conjunto de computadores, qual deles tem:
• Melhor desempenho?
• Menor custo?
• Melhor custo-benefício?
• Perspectiva de projeto– Defrontado com opções de projeto, em qual delas:
• Se extraí o melhor desempenho?
• Menor custo?
• Melhor custo-benefício?
• Ambas requerem– Base para comparação
– Métricas de avaliação
• Objetivo é entender implicações de custo x desempenho de escolhas arquiteturais

Desempenho de uma CPU
10
• Complexo de se avaliar
• Maior complexidade e escala dos softwares modernos
• Ampla disponibilidade de técnicas para melhoria de desempenho
• Recursos da CPU: múltiplos núcleos, O3, Branchprediction, inúmeras unidades funcionais, etc.

Desempenho de uma CPU (2)
11
• É impossível tendo em posse apenas o manual do conjunto de instruções determinar a velocidade de execução de um sistema
Exemplo 1:
Supondo que um programa tenha 1900 instruções de LOAD e cada uma delas demora 3 ciclos de clock para serem executadas, o tempo para execução dessas instruções seria de:
1900 x 3 ciclos de clock?

Exemplo 2
12
Fatorial em Sistema Embarcado

Exemplo 2
13
• Processador LEON3
– SPARC V8
– 50 MHz
– 128 MB RAM
– 16 KB cache D/I
• Standalone (s/ SO)
– Setup n = 3
– Estimativa: 78 ciclos de clock
– Real: ~175 ciclos de clock.• Stalls de memória

Desempenho de uma CPU (3)
14
• Desempenho é um dos fatores mais importantes para os projetistas de arquiteturas
O que fundamentalmente determina o desempenho de um computador?

Trade-off: latência versus vazão
15
Qual dos aviões tem maior desempenho?
• Tempo para realizar a tarefa - latência
– Quanto tempo cada avião leva para completar a tarefa de "transportar"?
• Tarefas por dia, hora, semana, segundo - vazão
– Quantas pessoas podem ser transportadas por hora?
Do sentido genérico “o fato de só se poder ter uma de duas coisas (the trade-off betweenefficiency and quality, por exemplo), ou “o ponto, o grau até onde se pode alcançar ambas”

Explorando exemplo
16
• Tempo do Concorde vs. Boeing 754?– Concorde é 2170 km/h / 980 km/h = 2,2 vezes mais rápido
= 6,5 horas / 3 horas
• Vazão do Concorde vs. Boeing 747?– Concorde é 44 / 72,3 = 0,61 "vezes mais rápido"– Boeing é 77,3 / 44 = 1.60 "vezes mais rápido"
• Boeing é 1,6 vezes (60%) mais rápido em termos de vazão
• Concorde é 2,2 vezes (120%) mais rápido em termos de tempo de voo (latência)
Foco primário no tempo de execução de um único trabalho
Inúmeras instruções em um programa => Vazão de instruções é importante!

Latência x Vazão
17
• Tempo de resposta (latência)– Tempo entre o início e o fim de uma tarefa
– Diminuir o tempo de resposta quase sempre melhora a vazão
• Vazão (throughput)– Quantas tarefas simultâneas um sistema pode executar?
– Qual é a taxa média de execução de tarefas?
– Quanto trabalho está sendo feito?
• Latência vs vazão– O que melhora se?
• Se atualizarmos um computador com um novo processador?
• Se um novo computador for acrescentado a um laboratório?

Comparativo
18
• Dizer que um Computador A é n vezes mais rápido que B significa que:
𝑛 =𝑡𝑒𝑚𝑝𝑜 𝑑𝑒 𝑒𝑥𝑒𝑐𝑢çã𝑜𝐵
𝑡𝑒𝑚𝑝𝑜 𝑑𝑒 𝑒𝑥𝑒𝑐𝑢çã𝑜𝐴

Métrica
19
• Desempenho: definido como o inverso do tempo de execução
𝑑𝑒𝑠𝑒𝑚𝑝𝑒𝑛ℎ𝑜𝐴 =1
𝑡𝑒𝑚𝑝𝑜 𝑑𝑒 𝑒𝑥𝑒𝑐𝑢çã𝑜𝐴
• Dizer que um Computador A é n vezes mais rápido que Btambém significa que (desempenho relativo):
𝑛 =𝑡𝑒𝑚𝑝𝑜 𝑑𝑒 𝑒𝑥𝑒𝑐𝑢çã𝑜𝐵
𝑡𝑒𝑚𝑝𝑜 𝑑𝑒 𝑒𝑥𝑒𝑐𝑢çã𝑜𝐴=
1𝑑𝑒𝑠𝑒𝑚𝑝𝑒𝑛ℎ𝑜𝐵
1𝑑𝑒𝑠𝑒𝑚𝑝𝑒𝑛ℎ𝑜𝐴
=𝑑𝑒𝑠𝑒𝑚𝑝𝑒𝑛ℎ𝑜𝐴𝑑𝑒𝑠𝑒𝑚𝑝𝑒𝑛ℎ𝑜𝐵
= 1 +𝑛
100

Aperfeiçoamento (improvement)
20
• Melhora do desempenho significa incremento:
→ Mais é melhor
• Tempo de execução (ou tempo de resposta) significa decremento:
→ Menos é melhor

Exemplo
21
• Se um computador A executa o programa X em 10 segundos e um computador B executa o mesmo programa em 15 segundos:
→ A é 50% mais rápido que B ou A é 33% mais rápido que B?
Solução:• A afirmação que diz que A é n% mais rápida que B pode ser expressa como:
⇒𝑡𝑒𝑚𝑝𝑜 𝑑𝑒 𝑒𝑥𝑒𝑐𝑢çã𝑜𝐵
𝑡𝑒𝑚𝑝𝑜 𝑑𝑒 𝑒𝑥𝑒𝑐𝑢çã𝑜𝐴= 1 +
𝑛
100
⇒ 𝑛 =𝑡𝑒𝑚𝑝𝑜 𝑑𝑒 𝑒𝑥𝑒𝑐𝑢çã𝑜𝐵 − 𝑡𝑒𝑚𝑝𝑜 𝑑𝑒 𝑒𝑥𝑒𝑐𝑢çã𝑜𝐴 ∗ 100
𝑡𝑒𝑚𝑝𝑜 𝑑𝑒 𝑒𝑥𝑒𝑐𝑢çã𝑜𝐴=
15 − 10 ∗ 100
10= 𝟓𝟎
→ Computador A é 50% mais rápido que B

Tempo de execução
22
• Tempo decorrido (real)– Contagem total do tempo (acesso a disco e memória, E/S e etc.)
– Normalmente não é ideal para fins de comparação
• Interrupções do processo pelo escalonador e tempos imprevisíveis de acesso a E/S
• Tempo de CPU (user + system)
– Não computa E/S e tempo de execução de outros programas (tempo do sistema + usuário)
– Foco deste curso: tempo consumido em linhas de código do “nosso programa”
• Exemplo: comando time do Linux

Ciclos de clock
23
• Ao invés de relatar o tempo de execução em segundos, geralmente é utilizado ciclos:
• "ticks" de clock indicam quando uma atividade inicia
• Ciclo de clock: tempo entre ticks = segundos por ciclo
cycle
seconds
program
cycles
program
seconds
time

• TCLK = Período ou ciclo de clock– Tempo entre dois pulsos de clock
– Segundos por ciclo
• fCLK = Frequência de clock– Ciclos de clock por segundo = 1/T
• 1 Hz = 1 / segundo
• Exemplos:– A frequência de clock de 500 MHz corresponde ao tempo de
ciclo de clock: 1 / (500 * 106) = 2 * 10-9 = 2 nseg
– A frequência de clock de 1 GHz corresponde ao tempo de ciclo de clock: 1 / (109) = 1*10-9 = 1 nseg
Ciclos de clock (2)
24
tick tick

Quantos ciclos de clock são necessários para executar um programa?
25
• Poderíamos assumir que o número de ciclos é igual ao número de instruções?
Essa afirmação é incorreta:Diferentes instruções levam diferentes quantidades de tempo em diferentes arquiteturas
1st in
str
uction
2nd instr
uction
3rd
in
str
uction
4th
5th
6th ...

Números de ciclos variam para diferentes instruções
26
• Multiplicação leva mais tempo que adição;
• Operações de ponto flutuante levam mais tempo que as de inteiro;
• Acessar a memória leva mais tempo que acessar registradores.
clock cycle
opA opB opA opC

Perspectiva do programa
27
• Sua execução envolve:– Um determinado número de instruções;– Um determinado número de ciclos;– Um determinado número de segundos.
• Vocabulário relacionado:– CPI (Ciclos por Instrução)
• Específico para cada instrução de uma dada arquitetura;• Pode ser utilizada como medida de desempenho;• Aplicações com elevada computação de ponto flutuante
geralmente tem maior CPI.
– MIPS (Milhões de instruções por segundo)• Pode ser utilizada como medida para vazão de dados.

Tempo de execução ou Tempo de CPU
28
𝐶𝑃𝑈𝑡𝑖𝑚𝑒 = 𝐶𝑙𝑜𝑐𝑘 𝐶𝑦𝑐𝑙𝑒𝑠 × 𝑇𝐶𝐿𝐾 =𝐶𝑙𝑜𝑐𝑘 𝐶𝑦𝑐𝑙𝑒𝑠
𝑓𝐶𝐿𝐾
– Otimizar o desempenho significa reduzir o tempo de execução (ou CPUtime):
• Reduzir o número de ciclos de clock por programa;
• Reduzir o período de clock;
• Aumentar a frequência de clock. Factível hoje?

Tempo de execução (2)
29
𝐶𝑃𝑈𝑡𝑖𝑚𝑒 =𝑆𝑒𝑐𝑜𝑛𝑑𝑠
𝑃𝑟𝑜𝑔𝑟𝑎𝑚=
𝐼𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛𝑠
𝑃𝑟𝑜𝑔𝑟𝑎𝑚×
𝐶𝑦𝑐𝑙𝑒𝑠
𝐼𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛×
𝑆𝑒𝑐𝑜𝑛𝑑𝑠
𝐶𝑦𝑐𝑙𝑒
𝐶𝑃𝑈𝑡𝑖𝑚𝑒 =𝑆𝑒𝑐𝑜𝑛𝑑𝑠
𝑃𝑟𝑜𝑔𝑟𝑎𝑚= 𝐼𝐶 × 𝐶𝑃𝐼 × 𝑇𝐶𝐿𝐾 =
𝐼𝐶 × 𝐶𝑃𝐼
𝑓𝐶𝐿𝐾
– Ciclos por Instrução• CPI = Clock Cycles / Instruction Count
– Instruções por Ciclos• IPC = 1 / CPI

Tempo de execução (3)
30
𝐶𝑃𝑈𝑡𝑖𝑚𝑒 = 𝐶𝑙𝑜𝑐𝑘 𝐶𝑦𝑐𝑙𝑒𝑠 × 𝑇𝐶𝐿𝐾 =𝐶𝑙𝑜𝑐𝑘 𝐶𝑦𝑐𝑙𝑒𝑠
𝑓𝐶𝐿𝐾
– Onde: Clock cycles = 𝒊=𝟏
𝒏(𝑪𝑷𝑰𝒊 𝒙 𝑰𝒊)
⇒ CPU time = σ𝒊=𝟏𝒏 𝑪𝑷𝑰𝒊 × 𝑰𝒊 × 𝑻𝑪𝑳𝑲
CPI = 𝒊=𝟏
𝒏(𝑪𝑷𝑰𝒊 × 𝑭𝒊) Onde Fi =
𝐼𝑖𝐼𝐶
, “frequência da instrução”
⇒ CPU time = IC x CPI x TCLK = IC x σ 𝑪𝑷𝑰𝒊 × 𝑭𝒊 × 𝑻𝑪𝑳𝑲

Exemplo
31
• Calcule os CPI e o tempo da CPU para executar um programa composto por 100 instruções nas proporções descritas pela tabela. A CPU tem clock de 500 MHz.
• Solução:
• CPI = 0.43 * 1 + 0.21 * 4 + 0.12 * 4 + 0.12 * 2 + 0.12 * 2 = 2.23
• CPU time = IC * CPI + Tclock = 100 * 2.23 * 2 ns = 446 ns
CPI = 𝒊=𝟏
𝒏(𝑪𝑷𝑰𝒊 × 𝑭𝒊)
CPU time = IC x CPI x TCLK

MIPS – Millions of instructions per second
32
• Milhões de instruções por segundo
𝑀𝐼𝑃𝑆 =𝐼𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛 𝐶𝑜𝑢𝑛𝑡
𝐸𝑥𝑒𝑐𝑢𝑡𝑖𝑜𝑛 𝑡𝑖𝑚𝑒 × 106
• Onde:
𝐸𝑥𝑒𝑐𝑢𝑡𝑖𝑜𝑛 𝑡𝑖𝑚𝑒 =𝐼𝐶 × 𝐶𝑃𝐼
𝑓𝐶𝐿𝐾
𝑀𝐼𝑃𝑆 =𝑓𝐶𝐿𝐾
𝐶𝑃𝐼 × 106

Lei de Amdahl
33
F F'S
Como calcular o aumento de desempenho ou speedup?
Speedup devido a um aperfeiçoamento E:
t t'
t' = 1 – F + F’ ⇒ t' = 1 – F + F/S
𝑆𝑝𝑒𝑒𝑑𝑢𝑝(𝐸) =𝐸𝑥𝑒𝑐𝑡𝑖𝑚𝑒𝑤𝑖𝑡ℎ𝑜𝑢𝑡 𝐸
𝐸𝑥𝑒𝑐𝑡𝑖𝑚𝑒𝑤𝑖𝑡ℎ 𝐸=
𝑃𝑒𝑟𝑓𝑜𝑟𝑚𝑎𝑛𝑐𝑒𝑡𝑖𝑚𝑒𝑤𝑖𝑡ℎ 𝐸
𝑃𝑒𝑟𝑓𝑜𝑟𝑚𝑎𝑛𝑐𝑒𝑡𝑖𝑚𝑒 𝑤𝑖𝑡ℎ𝑜𝑢𝑡 𝐸

Lei de Amdahl (2)
34
• Suponha que E acelera uma fração F da tarefa por um fator S e o restante da tarefa não é afetado. Assim:
𝐸𝑥𝑒𝑐𝑡𝑖𝑚𝑒(𝐸) = ( 1 − 𝐹 +𝐹
𝑆) × 𝐸𝑥𝑒𝑐𝑡𝑖𝑚𝑒 𝑤𝑖𝑡ℎ𝑜𝑢𝑡 𝐸
𝑆𝑝𝑒𝑒𝑑𝑢𝑝 𝑤𝑖𝑡ℎ 𝐸 =1
1 − 𝐹 +𝐹𝑆
Exectime(E) / Exectime (wo E) = 1 / Speedup(E)

Lei de Amdahl (3)
35
• Ideia básica: torne o caso comum mais rápido
• Lei de Amdahl: O ganho de desempenho que pode ser obtido melhorando uma determinada parte do sistema é limitado pela fração de tempo que essa parte é utilizada durante a sua operação.– FraçãoE = a fração do tempo de computação na máquina
original que pode ser convertida para tirar vantagem de alguma melhoria
– SpeedupE = a melhoria obtida pela execução "acelerada"
• O speedup total é dado por:
𝑆𝑝𝑒𝑒𝑑𝑢𝑝𝑡𝑜𝑡𝑎𝑙 =𝐸𝑥𝑒𝑐𝑡𝑖𝑚𝑒(𝑤𝑜 𝐸)𝐸𝑥𝑒𝑐𝑡𝑖𝑚𝑒(𝐸)
=1
1 − 𝐹𝑟𝑎𝑐𝑡𝑖𝑜𝑛𝐸 +𝐹𝑟𝑎𝑐𝑡𝑖𝑜𝑛𝐸𝑆𝑝𝑒𝑒𝑑𝑢𝑝𝐸

Lei de Amdahl (3)
36
Speedup limitado pela parte serial do programa. Se 95% for paralelizável, teoricamente o máximo de speedup possível é de 20x.

Exemplo
37
Considere o aperfeiçoamento de uma CPU resultando em computação dez vezes mais rápida em relação a CPU original. Esta CPU é ocupada com computação apenas 40% de todo tempo. Qual é o speedup total obtido pela introdução da melhoria?
• Solução:– Caso comum: 40% da computação
– FraçãoE = 0.4
– SpeedupE = 10
– 𝑆𝑝𝑒𝑒𝑑𝑢𝑝𝑡𝑜𝑡𝑎𝑙 =1
1 −𝐹𝑟𝑎𝑐𝑡𝑖𝑜𝑛𝐸 +𝐹𝑟𝑎𝑐𝑡𝑖𝑜𝑛
𝐸
𝑆𝑝𝑒𝑒𝑑𝑢𝑝𝐸
=1
1 −0.4 +0.4
10
= 𝟏.𝟓𝟔

Base para avaliação
38
Workload da aplicação alvo
Conjuntos completos de benchmarks
Benchmarks com kernels pequenos
Microbenchmarks
PRÓSCONTRAS
• representativos
• Muito específico• Não portável• Difícil de executar
ou medir
• Portáveis• Amplamente
usados• Maior variação de
workloads
• Menos representativos
• Fácil de "enganar"
• Fácil de ser executado. Até mesmo no ciclo de desenvolvimento
• Identifica máximo desempenho (pico) e possíveis gargalos
• "Pico" pode estar muito longe do desempenho da aplicação

Métricas de desempenho
39
Controle do datapath
Unidades Funcionais
Transístores, Fios e Pinos
Aplicação
Linguagem de Programação
Compilador
ISA• (milhões) de instruções por segundo – MIPS• (milhões) de (FP) operações por segundo – MFLOP/s
• Respostas por mês• Operações úteis por segundo
• Megabyte por segundo• Ciclos por segundo (freq. de clock)
Cada métrica tem um lugar e um propósito, e cada uma pode ser mal utilizada.

Aspectos do desempenho da CPU
40
𝐶𝑃𝑈𝑡𝑖𝑚𝑒 =𝑆𝑒𝑐𝑜𝑛𝑑𝑠
𝑃𝑟𝑜𝑔𝑟𝑎𝑚=
𝐼𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛𝑠
𝑃𝑟𝑜𝑔𝑟𝑎𝑚×
𝐶𝑦𝑐𝑙𝑒𝑠
𝐼𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛×
𝑆𝑒𝑐𝑜𝑛𝑑𝑠
𝐶𝑦𝑐𝑙𝑒
CPUtime = IC x CPI x TCLK
IC (# Instruções) CPI Clock Period
Programa X
Compilador X ( X )
Conj. de Instruções
X X X
Organização X X
Tecnologia X
# Instr
CPI
Clock period

Questões de desempenho com pipelining
41
• O pipelining aumenta a vazão de instruções (número de instruções concluídas por unidade de tempo), mas não reduz o tempo de execução (latência) de uma única instrução.

Questões de desempenho com pipelining
42
• Pipelining geralmente aumenta ligeiramente a latência de cada instrução devido ao desequilíbrio entre os estágios do pipeline e overhead no seu controle.
– O desequilíbrio entre os estágios de pipeline reduz o desempenho, pois a frequência de clock não pode ser maior do que o tempo necessário para o estágio mais lento.
– O overhead do pipeline surge pelo atraso no uso dos registradores do pipeline e do clock skew (atraso no sinal do clock nos latches). Assim: ciclo de clock > atraso dos registradores + clock skew

Métricas com pipeline
43
• IC = Instruction Count
• # Clock Cycles = IC + # Stall Cycles+ LL
LL = Latência dos Latches de Pipeline = ns - 1 ns = Número de estágios do pipeline
• CPI = Clock por Instrução = # Clock Cycles / IC CPI = (IC + #Stall Cycles + LL ) / IC
• MIPS = fclock / (CPI * 106)

Exemplo
44
• IC = Instruction Count = 5
• # Clock Cycles = IC + # Stall Cycles+ LL
# Clock Cycles = 5 + 3 + 4 = 12
• CPI = (IC + #Stall Cycles + LL ) / IC= 12 / 5 = 2.5
• MIPS = fclock / (CPI * 106) = 500 Mhz/2.4*106 = 208.3

Métricas com pipeline (2)
45
• Vamos considerar n iterações de um loop composto por m instruções e k stalls por iteração.
• ICper_iter = m
• #Clock Cycles = ICper_iter + #Stall Cyclesper_iter + LL
• CPIper_iter = (ICper_iter + #Stall Cyclesper_iter + LL ) / ICper_iter
= ( m + k + LL ) / m
• MIPS = fclock / (CPIper_iter * 106)

Métricas com pipeline (assintótica)
46
• Vamos considerar n iterações de um loop composto por m instruções e k stalls por iteração.
• ICAS = m * n
• #Clock Cycles = ICAS + #Stall CyclesAS + LL
• CPIper_iter = lim n→∞(ICAS+ #Stall CyclesAS + LL ) / ICAS
= lim n→∞ ( m*n + k*n + LL ) / m*n=(m+k)/m
• MIPS = fclock / (CPIAS* 106)

Questões de desempenho com pipelining (2)
47
• O CPI ideal em um processador pipelined seria 1, mas os stalls causam degradação no desempenho. Assim, temos:
CPIpipe_medio = Ideal CPI + Pipe Stall Cycles per Instruction
= 1 + Pipe Stall Cycles per Instruction
• Ciclos de Stalls no pipeline são devidos a:1. Hazards estruturais;
2. Hazards de dados;
3. Hazard de controle;
4. Stalls de memória.

Questões de desempenho com pipelining (3)
48
• Pipeline Speedup
𝑃𝑖𝑝𝑒𝑙𝑖𝑛𝑒𝑠𝑝𝑒𝑒𝑑𝑢𝑝 =𝐴𝑣𝑒. 𝐸𝑥𝑒𝑐. 𝑇𝑖𝑚𝑒 𝑈𝑛𝑝𝑖𝑝𝑒𝑙𝑖𝑛𝑒𝑑
𝐴𝑣𝑒.𝐸𝑥𝑒𝑐.𝑇𝑖𝑚𝑒 𝑃𝑖𝑝𝑒𝑙𝑖𝑛𝑒𝑑=
=𝐴𝑣𝑒. 𝐶𝑃𝐼 𝑈𝑛𝑝.
𝐴𝑣𝑒. 𝐶𝑃𝐼 𝑃𝑖𝑝𝑒×𝐶𝑙𝑜𝑐𝑘 𝐶𝑦𝑐𝑙𝑒 𝑈𝑛𝑝.
𝐶𝑙𝑜𝑐𝑘 𝐶𝑦𝑐𝑙𝑒 𝑃𝑖𝑝𝑒

Questões de desempenho com pipelining (4)
49
• Se ignorarmos o overhead nos ciclos de pipelining e assumirmos que os estágios estão perfeitamente balanceados, o tempo de ciclo de clock de dois processadores podem ser iguais, então:
𝑷𝒊𝒑𝒆𝒍𝒊𝒏𝒆𝒔𝒑𝒆𝒆𝒅𝒖𝒑 =𝐴𝑣𝑒. 𝐶𝑃𝐼 𝑈𝑛𝑝.
1+𝑃𝑖𝑝𝑒 𝑆𝑡𝑎𝑙𝑙 𝐶𝑦𝑐𝑙𝑒𝑠 𝑝𝑒𝑟 𝐼𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛
• Caso simples: Todas as instruções consomem o mesmo número de ciclos de clock, que devem ser iguais ao número de estágios de pipeline (profundidade do pipeline):
𝑷𝒊𝒑𝒆𝒍𝒊𝒏𝒆𝒔𝒑𝒆𝒆𝒅𝒖𝒑 =𝑃𝑖𝑝𝑒𝑙𝑖𝑛𝑒 𝐷𝑒𝑝𝑡ℎ
1+𝑃𝑖𝑝𝑒 𝑆𝑡𝑎𝑙𝑙 𝐶𝑦𝑐𝑙𝑒𝑠 𝑝𝑒𝑟 𝐼𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛
• Se não houver stalls no pipeline (caso ideal), isto leva ao resultado intuitivo de que o pipelining pode melhorar o desempenho pela profundidade do pipeline.

Questões de desempenho com pipelining (5)
50
• Qual é o impacto no desempenho dos desvios condicionais?
𝑷𝒊𝒑𝒆𝒍𝒊𝒏𝒆𝒔𝒑𝒆𝒆𝒅𝒖𝒑 =𝑃𝑖𝑝𝑒𝑙𝑖𝑛𝑒 𝐷𝑒𝑝𝑡ℎ
1 + 𝑃𝑖𝑝𝑒 𝑆𝑡𝑎𝑙𝑙 𝐶𝑦𝑐𝑙𝑒𝑠 𝑝𝑒𝑟 𝐼𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛 𝑑𝑢𝑒 𝑡𝑜 𝐵𝑟𝑎𝑛𝑐ℎ𝑒𝑠
𝑷𝒊𝒑𝒆𝒍𝒊𝒏𝒆𝒔𝒑𝒆𝒆𝒅𝒖𝒑 =𝑃𝑖𝑝𝑒𝑙𝑖𝑛𝑒 𝐷𝑒𝑝𝑡ℎ
1 + 𝐵𝑟𝑎𝑛𝑐ℎ 𝐹𝑟𝑒𝑞𝑢𝑒𝑛𝑐𝑦 × 𝐵𝑟𝑎𝑛𝑐ℎ 𝑃𝑒𝑛𝑎𝑙𝑡𝑦

Hierarquia de memória: definições
51
• Hit: dado encontrado em bloco do nível superior
• Hit Rate: taxa de sucesso em relação ao número total de acessos à memória.
𝑯𝒊𝒕 𝑹𝒂𝒕𝒆 =#ℎ𝑖𝑡𝑠
#𝑚𝑒𝑚𝑜𝑟𝑦 𝑎𝑐𝑐𝑒𝑠𝑠𝑒𝑠
• Hit time: tempo para acessar o dado no nível superior da hierarquia, incluindo o tempo necessário para decidir se a tentativa de acesso irá resultar em um sucesso (hit) ou falta (miss).

Hierarquia de memória: definições (2)
52
• Miss: os dados precisam ser tomados de um nível mais baixoMiss Rate: taxa de falta em relação ao número total de acessos à memória.
𝑴𝒊𝒔𝒔 𝑹𝒂𝒕𝒆 =#𝑚𝑖𝑠𝑠𝑒𝑠
#𝑚𝑒𝑚𝑜𝑟𝑦 𝑎𝑐𝑐𝑒𝑠𝑠𝑒𝑠
• Hit Rate + Miss Rate = 1
• Miss Penalty: tempo necessário para acessar um nível mais baixo e substituir o bloco no nível superior.
• Miss Time:Miss Time = Hit Time + Miss Penalty
• Hit Time << Miss Penalty

Tempo médio de acesso a memória
53
• AMAT = Hit Rate * Hit Time + Miss Rate * Miss Time
onde:
Miss Time = Hit Time + Miss Penalty
Hit Rate + Miss Rate = 1
⇒ AMAT = Hit Time + Miss Rate * Miss Penalty

Avaliação de desempenho: Impacto da hierarquia de memória no CPUtime
54
• CPUtime = (CPU exec cycles + Memory stall cycles) x TCLK
onde
TCLK = T período de tempo de ciclo de clock
CPU exec cycles = IC x CPIexec
IC = Instruction Count
(CPIexec inclui instruções da ULA e Load/Store)Memory stall cycles = IC x Misses per instr x Miss Penalty
⇒ CPUtime = IC x (CPIexec + Misses per instr x Miss Penalty) x TCLK
onde:
Misses per instr = Memory access per instruction x Miss rate
⇒ CPUtime = IC x (CPIexec + MAPI x Miss rate x Miss Penalty) x TCLK

Avaliação de desempenho: Impacto da hierarquia de memória no CPUtime
55
⇒ CPUtime = IC x (CPIexec + MAPI x Miss rate x Miss Penalty) x TCLK
Vamos considerar uma cache ideal (100% hits):
CPUtime = IC x CPIexec x TCLK
Vamos considerar um sistema sem cache (100% misses):
CPUtime = IC x ( CPIexec + MAPI x Miss penalty) x TCLK

Avaliação de desempenho: Impacto da hierarquia de memória e stalls no pipeline no CPUtime
56
⇒ CPUtime = IC x (CPIexec + MAPI x Miss rate x Miss Penalty) x TCLK
Colocando tudo junto: Vamos considerar os stalls devido aos hazards no pipeline:
CPUtime = IC x ( CPIexec + Stalls per instr + MAPI x Miss penalty) x TCLK

Desempenho da cache
57
• Tempo médio de acesso a memória:
AMAT = Hit Time + Miss Rate * Miss Penalty
• Como melhorar o desempenho da cache:
– Reduzir o tempo de hit;
– Reduzir a taxa de miss;
– Reduzir a penalidade do miss.


O que é?
59
• Ato de executar um programa de computador, um conjunto de programas ou outras operações a fim de avaliar o desempenho relativo de um objeto, normalmente executando uma série de testes padrão.
• O benchmarking geralmente é associado à avaliação das características de desempenho do hardware do computador.
• Os benchmarks fornecem um método de comparação do desempenho de vários subsistemas em diferentes arquiteturas de chip / sistema.

Histórico das técnicas de Benchmark
60
• Início (meados de 1960)– Tempo de execução de uma única instrução;
– Tempo médio de execução de instrução (Gibson, 1970);
– MIPS puro (1/AIT ~ 1/(Tempo médio de instrução)).
• Programas simples (Início de 1970)– Benchmarks sintéticos (Whetstone);
– Kernels (Livermore Loops).
• Desempenho relativo (Fim de 1970)– VAX 11/780 = One-MIPS.
• Comparativo com IBM360
• Apenas marketing: ~ 500 mil instruções/s – VAX-MIPS
– MFLOPs.

Histórico das técnicas de Benchmark
61
• Aplicações "reais" (a partir de 1989):
– SPEC CPU C/C++/Fortran;
• Científico, computação irregular
• 89, 92, 95, 2000, 2006 e 2017
– Dhrystone;
– MiBench;
– EEMBC;
– TPC;
– LINPACK;
– Bonnie++: filesystem and hard drive benchmark;
– Phoronix Test Suite: open-source cross-platformbenchmarking suite for Linux;
– BDTI (Berkeley Design Technology) Benchmarks

Armadilhas
62

Qual é o significado do gráfico?Baseado no SPECint2017
63

Importância de saber comparar
64
• Benchmark versus workloads reais?
• Workloads reais seriam a melhor forma de medir o desempenho entre diferentes arquiteturas
– Geralmente essa abordagem é infactível¹:
• Aplicação em desenvolvimento: custo para executar partes críticas do software em computadores com diferentes especificações é caro (tempo + $$).
• Aplicação pronta para ser implantada: como saber o desempenho de uma aplicação sobre diferentes condições do workload (aplicação web por exemplo) antes de ser implantada? Há riscos de falhas por falta de capacidade em atender demanda? Como avaliar isso? É preciso prever.
¹ Planning for Web Services: Metrics, Models, and MethodsBenchmark and Performance Tests – Chapter 7Person Education

Importância de saber comparar (2)
65
• A técnica de benchmark é o principal método para medir o desempenho de uma máquina física¹.
– Execução de um conjunto de programas representativosem diferentes computadores e redes e medir os resultados.
– Os resultados são usados para avaliar o desempenho de um determinado sistema com um workload bem definido.
– Bons benchmarks têm objetivos de desempenho e workloads bem definidos, que são mensuráveis e reprodutíveis.
¹ U. Krishnaswamy and I. Scherson, “A Framework for Computer PerformanceEvaluation Using Benchmark Sets,” IEEE Trans. Computers, vol. 49,no. 12, Dec. 2000.

Importância de saber comparar (3)
66
• Tipos de benchmark– Kernels: pequenos pedaços de aplicações reais;
• Úteis para avaliar mudanças arquiteturais. Exemplo: diferentes implementações de uma unidade de divisão de PF.
– Toy programs: com cerca de 100 linhas de código, como algoritmos de ordenação quicksort, bublesort, etc.
• Podem avaliar CPU e padrão de acesso à memória, por exemplo.
– Sintéticos: executam um conjunto de operações que tentam corresponder ao comportamento de uma aplicação real, como o Dhrystone e EEMBC.
– Suíte: oferecem variedade de aplicações. Permitemavaliar diversos aspectos de um computador.

Berkeley Design Technology -Benchmarks
67
• Consultoria especializada para ajudar executivos de empresas, engenheiros e "product marketers" a criar e usar processadores embarcados, software e ferramentas.
• BDTI desenvolve benchmarks desde 1994
• Utilizados para:
– Auxiliar no desenvolvimento de processadores;
– Avaliar desempenho de processadores embarcados;
– Escolher processor já existente para aplicação embarcada:desempenho x custo x consumo de energia.

Berkeley Design Technology -Benchmarks
68
• Licença incluí:– Especificação técnica detalhada de referência que descreve
o(s) benchmark(s) e fornece diretrizes de implementação;
– Documentação do código do benchmark em linguagem de alto nível (geralmente em C ou MATLAB);
– Quando relevante, implementação(s) de referência em linguagem assembly para um processador representativo;
– Vetores de teste para verificar a funcionalidade do benchmark;
– Treinamento e suporte técnico.
• BDTI exige revisão e certificação de implementações de benchmark antes que qualquer dado de referência possa ser divulgado.

SPEC
69
• Dois dos mais populares benchmarks são os desenvolvidos pela Standard Performance Evaluation Corporation:– SPECint (92, 95, 2000, 2006 e 2017)
– SPECfp (92, 95, 2000, 2006 e 2017)
• Indexa resultados em sua página spec.org
• Duas classes: processor-intesive and graphics-intensive
• Dois tipos de computação: inteiros e ponto-flutante
• Programas reais modificados para serem portáveis e minimizar o efeito do I/O no desempenho

SPEC
70
• Inteiros: programas desenvolvidos em C/C++
• Ponto flutuante: prog. desenvolvidos em C/C++ e Fortran.
• Útil para benchmark de processadores para sistemasDesktop multi-core e servidores single-core.
• Característica das implementações: emprego de bibliotecas estáticas
SPECrate
10 integer benchmarks
10 floating point benchmarks
10 integer benchmarks
13 floating point benchmarks
SPECint2017
SPECfp2017
SPECspeed

71

Benchmarks para servidores
72
• Orientados a vazão de dados
– Taxa de processamento dos processadores do SPEC CPU (mesmo multicores) e é convertida em um índice, o SPECrate.
• Mede paralelismo a nível de requisição;
• SPEC oferece outros benchmarks para medir desempenho a nível de paralelismo de threads usando OpenMP e MPI.
– Atividade de I/O em servidores é significativa, tendo a SPEC desenvolvido o SPECSFS para medir a vazão e tempo de resposta entre nós de processamento (avalia I/O entre disco e rede sobre NFS -Network File System)
– Outra ferramenta: SPECWeb
• Simular múltiplos clientes requisitando páginas estáticas edinâmicas do servidor.

Benchmarks para servidores
73
• Transaction Processing Council (TPC): afere o desempenho de servidores medindo a capacidade dos sistemas em gerenciar transações em bancosde dados (acessos e atualizações).
– Foco em transações em ATM de bancos e reservas aéreas
– Criado em meados de 1980 por um grupo de engenheiros interessados em desenvolver benchmarks realísticos e corretos para transação de processos (TP).
– Medida em transações por segundo, incluindo:
• A própria vazão.
• Tempo de resposta.– Se timeout é atingido, fração da vazão é descartada.

Reportando desempenho
74
• O princípio que guia a medição de desempenho é a: reprodutibilidade.– Outro experimentador deve ter condições de repetir o
experimento e chegar nos mesmos resultados (método científico).
• Características– SPEC:
• Exige extensiva descrição do computador;
• Exige todas as flags de compilação;
• Exige configuração padrão e otimizada;
• Gera resultados gerados em tabelas e gráficos.
– TPC• Exige resultados auditados por fonte confiável
• Custo da informação (todo o ambiente: terminais, equipamentos de comunicação, software, backup... por 3 anos).

Sumário de desempenho
75
• Uma vez escolhida uma métrica de desempenho em conjunto com a suíte de benchmark, é ideal haver condições de sintetizar o resultado em um único número.– Como comparar diferentes computadores dessa
maneira?• Média aritmética: matematicamente incorreta para esse tipo de
análise.
• Média ponderada: também incorreta.
• Média geométrica: a média geométrica a única média correta quando resulta em média normalizada, este é o resultado que está presente em relações com os valores de referência.¹
¹ Fleming, Philip J.; Wallace, John J. (1986). «How not to lie with statistics: the correct way to summarize benchmark
results». Communications of the ACM. 29 (3): 218–221.doi:10.1145/5666.5673

Exemplo
76
• Suponha que o SPECRatio do computador A em um benchmark é 1.25 vezes mais rápido que B. Então, teríamos que:

Exemplo
77
Últimas duas colunas:Relação entre tempos de execução é igual a da entre as SPECRatio⇒ Computador de referência é irrelevante na performance relativa

Interpretando resultados
78
• Números de desempenho são aproximações do desempenho absoluto dos sistemas
• Indíces de benhmarks confiáveis são muito melhores do que desempenho baseados em "peak rate", que são geralmente calculados sobre operações sem muito propósito (instruções simples em MIPS ou MFLOPs, por exemplo).
• Gráficos
– eixo X é a escala de tempo, geralmente, por ano
– eixo Y é a escala logarítmica de desempenho normalizada para cerca de 1985 (primeiras medições de desempenho)

Benchmarks
79Fonte: Samuel H. Fuller e Lynette Millet em The Future of Computing Performance: Game Over or Next Level?

Benchmarks
80Fonte: Samuel H. Fuller e Lynette Millet em The Future of Computing Performance: Game Over or Next Level?

Armadilhas
81
• Benchmarks: Kernels, Toy programs e Sintéticos são desacreditados hoje (H&P):– Susceptíveis a otimização de compiladores
• Diferentes flags de compilação. Que aparentemente só funcionam para otimizar o código dos benchmarks (tendem a não funcionar em uma aplicação real).
– Podem ser executados em diferentes condições:• Com permissão de modificação de código fonte.
• Fabricantes de benchmarks passaram a orientar o uso de um compilador e flags específicas. Além de restringir a modificação do código fonte com opções de:– Não permitirem.
– Tornarem a modificação impossível (benchmark grandes).
– Permitirem desde que não mude o valor dos resultados.

Armadilhas (2)
82
• EEMBC (Eletronic Design News EmbeddedMicroprocessor Benchmark Consortium) desenvolveu um conjunto de 41 kernels para uso de predição de desempenho para diferentes aplicações:
– Automotiva/Industrial;
– Consumidor;
– Rede;
– Automação comercial e telecomunicação.
• Esforço para o desenvolvimento de benchmark mais confiável: não susceptível a otimização de compilação, alocação aleatória da memória, bibliotecas estáticas ...
• O fato de trabalharem com kernels e limitadas opções de relatório ainda gera controvérsias e a faz não ter boa reputação nesse mercado (H&P).

Exemplo: Como comprometer uma comparação
83
• O mesmo programa C sendo executado em duas arquiteturas
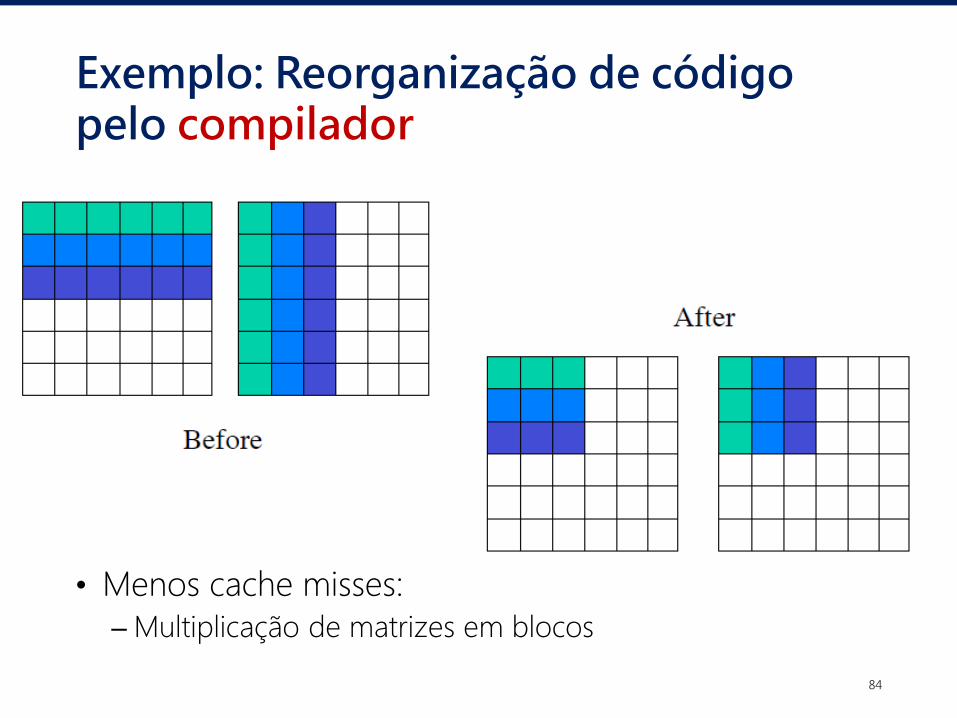
Exemplo: Reorganização de código pelo compilador
84
• Menos cache misses:
– Multiplicação de matrizes em blocos

A curva exponencial das inovações tecnológicas que conduzem à Singularidade, conforme previsto por Ray Kurzweil na Time Magazine (2005) 85
“Há alguns anos, pesquisamos o que
pensavam os maiores especialistas em IA
do mundo. E uma das perguntas que
fizemos foi:
‘Em qual ano você acha que haverá 50%
de probabilidade de termos conseguido a
inteligência de máquinas com nível
humano?’
(...) E a resposta foi em média 2040 ou
2050 (...)
Poderá acontecer muito mais tarde ou mais
cedo, a verdade é que ninguém sabe.”
Nick Bostrom filósofo e futurologista, em palestra no TED em 2015

Considerações
86
• Benchmarks medem todo o sistema:
– Aplicação;
– Compilador, gerenciamento de memória, ...;
– Sistema operacional;
– Arquitetura;
– Organização.
• Tempo nos benchmarks são sensíveis a:
– Alinhamento da cache
– Padrão de acesso à memória
– Localização de dados em disco

Considerações (2)
87
• Benchmarks populares geralmente refletem workloads de "ontem“
– E sobre os programas que as pessoas usam hoje?
– Resistem a "benchmark engineering" ou "benchmarketing"?• Uma vez que um benchmark se torne padronizado e
popular, há uma tremenda pressão para melhorar o desempenho por otimizações direcionadas.
• Pequenos kernels ou programas que passam seu tempo em uma pequena quantidade de código são particularmente vulneráveis
• Em média 70% de todos os programas do SPEC2000 haviam sido "invalidados" no lançamento do SPEC2006.

Considerações (3)
88
• A partir de 2005
– Desempenho single-threaded entra em uma nova era de melhorias modestas;
– Frequência de clock era o maior componente para melhora do desempenho:• Maior frequência implica em maior dissipação de potência;
• Potência consumida pelos chips cresceu exponencialmente e teve que ser repensada.

Considerações (4)
89
–Otimistas x Pessimistas
• Tendência de Kurzweill continuará (otimismo);
• Arquitetura single-threaded e CMOS próximos de atingir seus limites (International Technology Roadmap for Semiconductors - ITRS);
• Programação multi-thread não tem sido amplamente bem sucedida para melhorar eficiência no paralelismo;
• Tecnologias alternativas ainda continuam insuficientes pela dificuldade de adoção.

Referências
90
• Cap. 1: J. Hennessey, D. Patterson,"Computer Architecture: a quantitative approach“ 4 th Edition, Morgan-Kaufmann Publishers.
• Outras espalhadas pelo texto