otimizaÇÃo nÃo linear de grande porte tese … · no presente trabalho propõe-se uma nova...
TRANSCRIPT

MATRIZES QUASE-NEWTON ESPARSAS PARA PROBLEMAS DE OTIMIZAÇÃO NÃO LINEAR DE GRANDE PORTE
Evandro da Silveira Goulart
TESE SUBMETIDA AO CORPO DOCENTE DA COORDENAÇÃO DOS
PROGRAMAS DE PÓS-GRADUAÇÃO DE ENGENHARIA DA UNIVERSIDADE
FEDERAL DO RIO DE JANEIRO COMO PARTE DOS REQUISITOS
NECESSÁRIOS PARA A OBTENÇÃO DO GRAU DE DOUTOR EM CIÊNCIAS
EM ENGENHARIA MECÂNICA.
Aprovada por:
________________________________________________ Prof. José Herskovits Norman, D.Ing.
________________________________________________ Prof. Francisco José da Cunha Pires Soeiro, Ph.D.
________________________________________________ Prof. Susana Scheimberg de Makler, D.Sc.
________________________________________________ Prof. Anatoli Leontiev, Ph.D.
________________________________________________ Prof. Hélcio Rangel Barreto Orlande, Ph.D.
RIO DE JANEIRO, RJ – BRASIL
AGOSTO DE 2005

ii
GOULART, EVANDRO DA SILVEIRA
Matrizes Quase-Newton Esparsas para
Problemas de Otimização Não-Linear de
Grande Porte [Rio de Janeiro] 2005
VIII, 100 p. 29,7 cm (COPPE/UFRJ, D.Sc.,
Engenharia Mecânica, 2005)
Tese - Universidade Federal do Rio de
Janeiro, COPPE.
1. Otimização
2. Programação Não Linear
3. Matrizes Quase-Newton
I. COPPE/UFRJ II. Título (série)

iii
À minha mãe Ilza da Silveira Goulart.

iv
Agradecimentos
Ao professor Herskovits, pela orientação e pelo apoio, fundamentais para a
realização deste trabalho.
Aos colegas do laboratório Optimize (ainda estou devendo um churrasco).
À minha namorada Ana Paula sempre ao meu lado.
À minha família que sempre me apoiou. João Patrício, Vicente, Neida, Fátima,
Mariana, Antônio e Isabela.
À amiga Carmen Nilda por suas idéias mirabolantes (eu pretendo ir à praia este
ano).
Ao CNPq pelo suporte financeiro.

v
Resumo da Tese apresentada à COPPE/UFRJ como parte dos requisitos necessários
para a obtenção do grau de Doutor em Ciências (D. Sc.)
MATRIZES QUASE-NEWTON ESPARSAS PARA PROBLEMAS DE
OTIMIZAÇÃO NÃO-LINEAR DE GRANDE PORTE
Evandro da Silveira Goulart
Agosto /2005
Orientador: José Herskovits Norman
Programa: Engenharia Mecânica
Os métodos Quase-Newton em problemas não-lineares de otimização geram
uma aproximação da derivada segunda da função objetivo, nos casos sem restrições, e
da derivada segunda do lagrangeano, nos casos com restrições. As técnicas Quase-
Newton usualmente geram matrizes definidas positivas. Em problemas de otimização de
grande porte, torna-se inviável a utilização do método de atualização Quase-Newton na
sua forma clássica, pois este exige o armazenamento de uma matriz cheia e um grande
número de operações computacionais. As principais técnicas na literatura que ampliam
a atualização Quase-Newton para problemas grandes são o Método de Memória
Limitada e o Método de Atualização Esparsa. Em certos problemas de otimização, as
derivadas das restrições são esparsas, tornando interessante a utilização de uma
atualização Quase-Newton esparsa. Apresenta-se uma nova técnica de atualização
Quase-Newton esparsa através da minimização de uma função baseada na norma
quadrada de Frobenuis que obedece a condição secante e gera uma matriz definida
positiva. Esta atualização aumenta a esparsidade dos sistemas internos do FAIPA
ampliando a eficiência de solvers esparsos durante a resolução de problemas de grande
porte. Resultados numéricos mostram a boa performance dessa nova técnica associada
ao FAIPA.

vi
Abstract of Thesis presented to COPPE/UFRJ as a partial fulfillment of the
requirements for the degree of Doctor of Science (D. Sc.)
SPARSE QUASI-NEWTON MATRICES FOR LARGE-SCALE PROBLEMS
IN NON-LINEAR OPTIMIZATION
Evandro da Silveira Goulart
August /2005
Advisor: José Herskovits Norman
Department: Mechanical Engineering
Quasi-Newton methods for nonlinear optimization construct a matrix that is an
approximation of the second derivative of the function, in the unconstrained case, and of
the second derivative of the Lagrangian when constraints are considered. Usually, the
quasi-Newton matrix must be positive definite. Classic quasi-Newton updating rules get
full matrices, requiring a very large storage area and a great number of computations,
when the number of variables is large. Several techniques were developed to modify
and extend updating quasi-Newton rules in several ways, to make them suitable for
large problems, for instance, the Limited Memory and the Sparse Quasi-Newton
Updates. The Limited Memory method avoids the storage of the quasi-Newton matrix.
However, for several optimization problems, the constraints Jacobian is sparse, making
interesting the use of sparse quasi-Newton matrices. We present a new updating
technique to obtain positive definite sparse quasi-Newton matrices that minimize a
function based on a squared Frobenius norm. This update increases the sparsity of the
internal systems of FAIPA and allows the use of linear systems solvers for sparse
matrices improving the efficiency for very large-scale problems. We present numerical
results that show a good performance of this new technique when associated with the
internal sparse solver in FAIPA.

vii
ÍNDICE 1 – Introdução e Objetivos 1
1.1 – Considerações Gerais 1
1.1 – Organização dos Capítulos 3
2 – FAIPA: Algoritmo de Pontos Interiores por Arcos Viáveis 7
2.1 – Considerações Gerais 7
2.2 – Algoritmo do FAIPA 13
2.3 – Sistemas Simétricos no FAIPA 16
2.4 – Esparsidade dos Sistemas Internos do FAIPA 17
3 – Técnicas Quase-Newton para Problemas de Grandes Porte 20
3.1 – Introdução 20
3.2 – Introdução aos Métodos Quase-Newton 20
3.2.1 – Método Quase-Newton do tipo DFP 21
3.2.2 – Método Quase-Newton do tipo BFGS 23
3.3 – Métodos de Atualização da Matriz Quase-Newton em Problemas Grandes 24
3.3.1 – Método de Memória Limitada 24
3.3.1.1 – Produto vBk 28
3.3.1.2 – Produto vBu kt 29
3.3.2 – Método de Atualização Esparsa 30
3.3.2.1 – Atualização Esparsa de Toint (1977) 31
3.3.2.2 – Atualização Esparsa de Fletcher (1996) 36
4 – Técnica de Atualização Quase-Newton Diagonal 39
4.1 – Introdução 39
4.2 – Técnica de Atualização Diagonal 39
4.3 – Resolução do Problema 45

viii
5 – Métodos Diretos para Solução de Sistemas Lineares Esparsos 48
5.1 – Introdução 48
5.2 – Método Direto 49
5.3 – Método Direto para Sistemas Esparsos 50
5.4 – Esquemas de Armazenamento de Matrizes Esparsas 54
5.5 – Rotina MA27 (HSL) 57
5.6 – Rotina MA28 (HSL) 59
5.7 – Rotina SSTSTRF/S (CRAY SV1) 60
5.8 – Rotina SGETRF/S (LAPACK) 61
6 – Resultados Numéricos 62
6.1 – Introdução 62
6.2 – CUTEr 63
6.3 – Resultados Numéricos – Interface FAIPA_CUTEr 66
6.4 – Apresentação do Problema HS43_NF 69
6.5 – Comparação entre diferentes solvers internos ao FAIPA 70
6.6 – FAIPA Quase-Newton Esparso 72
6.7 – Problema HS43_NF para auxiliar na comparação entre as técnicas de Atualização
Diagonal, BFGS e Memória Limitada
82
6.8 – Problemas CUTEr para auxiliar na comparação entre as técnicas de Atualização
Diagonal e Memória Limitada
84
7 – Conclusões e Propostas 93
7.1 – Considerações Gerais 93
8 – Referências Bibliográficas 96

1
CAPÍTULO 1
Introdução e Objetivos
1.1– Considerações Gerais
A Otimização trata do problema da busca da melhor alocação de um conjunto
limitado de recursos, escolhendo a alternativa que maximize o lucro ou minimize o
custo, dentre todas aquelas que satisfazem um conjunto específico de restrições.
A otimização pode ser aplicada em numerosas áreas de conhecimento, incluindo:
gestão de cadeias de suprimento (planejamento, produção, distribuição); transporte
(roteiros, gestão de frotas e tripulação); indústria petroquímica (aquisição de materiais,
projeto e operação de refinarias, distribuição); aplicações militares (logística, alocação
de pessoal, operações de guerra); finanças (operação de carteiras, gestão de recursos
financeiros); otimização do projeto de estruturas, veículos terrestres, marítimos e
aeroespaciais, equipamentos para diversas indústrias de processamento em geral [10].
A busca de melhores soluções é um dos grandes objetivos da Engenharia. Desta
forma, a Engenharia tem, cada vez mais, investido na área de otimização para que seja
possível aplicar esta ferramenta em problemas de grande porte. Logo há um grande
interesse em se desenvolver algoritmos de otimização eficientes e robustos [32].
O presente trabalho terá como base o FAIPA (Feasible Arc Interior Point
Algorithm), desenvolvido por HERSKOVITS [24][25][26][27]. Este algoritmo é um
método de Pontos Interiores e Arcos Viáveis que resolve o problema geral de
otimização não-linear, fazendo iterações nas variáveis de projeto e nos multiplicadores
de Lagrange para resolver as condições de otimalidade de Karush-Kuhn-Tucker.

2
Em cada iteração o FAIPA resolve três sistemas lineares internos com a mesma
matriz de coeficientes. Nestes sistemas está incluída a derivada segunda da função
Lagrangiana, ),,( µλxH , ou uma aproximação Quase-Newton ( B ) da mesma.
O FAIPA tem se mostrado confiável e eficiente na solução de problemas de
médio e pequeno porte. Estas características o qualificam para servir como base em
nossos estudos, cujo objetivo é resolver problemas do tamanho requerido pelas
aplicações modernas. O FAIPA vem sendo utilizado em indústrias de primeira linha
assim como em universidades e centros de pesquisa [27].
Em linhas gerais, este trabalho tem como objetivo principal o desenvolvimento
teórico e computacional de técnicas para programação não-linear, baseadas no FAIPA,
para a solução de problemas de grande porte, aproveitando a esparsidade dos sistemas
internos ao FAIPA.
Uma questão que será amplamente abordada diz respeito à atualização da matriz
B no Método Quase-Newton, o qual substitui o cálculo da Hessiana do lagrangeano em
problemas com restrições. Os algoritmos modernos exigem que a matriz B seja definida
positiva, para garantir convergência.
Em problemas com muitas variáveis torna-se inviável a utilização desse método
na sua forma clássica (DFP ou BFGS, por exemplo), pois este exige o armazenamento e
manipulação de uma matriz cheia, de dimensão igual ao número de variáveis. Existem
várias técnicas na literatura que ampliam a atualização Quase-Newton para problemas
grandes. Serão abordadas algumas das principais técnicas: o Método de Memória
Limitada e o Método de Atualização Esparsa.
O Método de Memória Limitada foi desenvolvido inicialmente para problemas
sem restrições e posteriormente estendido para problemas com restrições de caixa. O
FAIPA apresenta uma adaptação para empregar essa técnica em problemas com
quaisquer tipos de restrições não-lineares [16].
Técnicas de atualização esparsas Quase-Newton presentes nos artigos de TOINT
[37][38][39] e FLETCHER [13][14], foram utilizadas como referência na concepção de
uma nova técnica esparsa.
No fim dos anos 70, Toint propôs uma técnica de atualização esparsa para
problemas de grande porte. A técnica Quase-Newton de Toint além de não produzir
uma matriz definida positiva, exige o armazenamento dessa matriz a cada iteração [35].

3
Nos anos 90, Fletcher publicou uma técnica esparsa que não exige o
armazenamento da matriz a cada iteração, pois as informações necessárias para a
atualização são guardadas do mesmo modo que no Método de Memória Limitada. No
entanto, essa técnica além de não gerar matrizes definidas positivas [14], não apresenta
bons resultados numéricos na resolução de problemas de grande porte [35].
No presente trabalho propõe-se uma nova técnica que aproveita o conceito de
memória limitada para armazenar informações do problema durante as iterações e obter
uma matriz B diagonal definida positiva com um reduzido custo computacional.
Essa nova técnica de atualização aumenta a esparsidade dos sistemas lineares
internos do FAIPA, permitindo um melhor aproveitamento de solvers que consideram a
esparsidade de matrizes visando a redução do custo computacional.
Comparou-se o novo método de atualização esparsa e o método de memória
limitada juntamente com o FAIPA.
A solução de problemas de grande porte implica na solução de sistemas lineares
internos ao FAIPA com elevado número de equações. Para resolver tais problemas
integraram-se ao FAIPA técnicas como a utilizada na rotina MA27, desenvolvida pelo
CSE Group [21], utilizada para resolver sistemas de equações lineares simétricos e
esparsos. Essa rotina utiliza o Método Direto baseado numa variante da eliminação
gaussiana para sistemas esparsos [7]. Já foram resolvidos sistemas, junto ao FAIPA,
com 20.000 equações.
Um melhor aproveitamento desses recursos pode ser obtido mediante a
utilização de técnicas de computação de alto desempenho. Uma das alternativas é a
implementação da rotina SSTSTRF/S escrita na linguagem Fortran que resolve sistemas
lineares com estrutura simétrica esparsa através do método direto em ambiente de
computação paralela e vetorial. Ela foi desenvolvida para o ambiente do sistema
operacional UNICOS [4] do computador CRAY SV1, disponível através do Núcleo de
Atendimento em Computação de Alto Desempenho (NACAD-COPPE/UFRJ). Essa
rotina auxiliou na obtenção de resultados importantes com o FAIPA em ambiente de
computação de alto desempenho.
Embora nosso objetivo esteja focado na solução de sistemas esparsos, a Técnica
de Memória Limitada junto ao FAIPA requer o uso de solvers para sistemas densos.
Nesse sentido, para um melhor desempenho da Técnica de Memória Limitada com o

4
FAIPA, foi necessária a implementação do solver para sistemas densos não simétricos
SGETRF/S pertencente ao conjunto de rotinas do LAPACK.
Para testar as novas idéias adicionadas no algoritmo FAIPA, utilizou-se uma
ferramenta computacional chamada CUTEr (Constrained and Unconstrained Testing
Environment revisited) que apresenta uma coleção de problemas testes amplamente
utilizados na literatura [17]. O CUTEr é uma ferramenta que auxilia no projeto e
desenvolvimento de softwares em otimização.
Para utilizar essa ferramenta são necessárias duas etapas: a decodificação e
criação da interface. A plataforma de decodificação CUTEr é disponível para sistemas
operacionais UNIX e LINUX. No presente trabalho utilizou-se o sistema operacional
LINUX durante a etapa de decodificação. A interface é um conjunto de rotinas escritas
em FORTRAN 77 e FORTRAN 90 que fornecem os dados referentes aos problemas
testes e devem ser adaptadas ao algoritmo de otimização (no nosso caso o FAIPA).
1.2 – Organização dos capítulos
O trabalho que segue está organizado em capítulos da seguinte forma:
Capítulo 2 – FAIPA: Algoritmo de Pontos Interiores e de Arcos Viáveis:
Está descrito o algoritmo FAIPA, base deste trabalho, e as alterações no FAIPA
Esparso. Essa alterações fazem parte da implementação de solvers que aproveitam a
esparsidade dos sistemas lineares no intuito de resolver problemas de grande porte.
Capítulo 3 – Técnicas Quase-Newton para Problemas de Grande Porte:
Inicialmente descreve-se o principal método Quase-Newton: o BFGS. Em seguida
são apresentadas algumas técnicas já existentes para solucionar o problema de
atualização da matriz Quase-Newton em problemas de grande porte, tais como o
Método de Memória Limitada e Método de Atualização Esparsa.
Nesse capítulo estão descritas as técnicas esparsas dos artigos de Toint e Fletcher
que foram utilizados como referência na concepção de uma nova técnica esparsa.

5
No entanto, o objetivo principal deste capítulo é mostrar como está inserida, nesse
contexto, uma nova técnica numérica para este tipo de atualização que aproveita a
esparsidade na busca de um melhor rendimento computacional em problemas
considerados de grande porte, além de gerar matrizes atualizadas simétricas positivas
definidas.
Capítulo 4 – Técnica de Atualização Quase-Newton Diagonal:
Detalhamento da nova técnica de atualização Quase-Newton diagonal. Com essa
atualização obtêm-se matrizes positivas definidas que apresentam um padrão esparso
que permite melhorar o desempenho do FAIPA na resolução de problemas com um
grande número de variáveis e de restrições.
Capítulo 5 – Técnicas para Solução de Sistemas de Equações Através de
Métodos Diretos:
São apresentados os fundamentos do método de resolução de sistemas esparsos de
equações lineares utilizado na rotina MA27, MA28 e na rotina SSTSTRF/S, sendo esta
última desenvolvida para o ambiente computacional do computador CRAY SV1.
No entanto, para um melhor desempenho da Técnica de Memória Limitada junto ao
FAIPA, foi necessário a implementação de um solver para sistemas densos. Optou-se
pelo solver SGETRF/S pertencente ao conjunto de rotinas do LAPACK.
Capítulo 6 – Testes Numéricos:
Nesse capítulo, inicialmente descreveu-se a ferramenta CUTEr utilizada para
auxiliar na realização de testes numéricos com o FAIPA e apresentou-se o problema
HS43_NF que também auxiliou na tarefa de realizar testes numéricos.
Em seguida, usando o problema HS43_NF, realizaram-se testes para verificação
do desempenho das rotinas MA27 e MA28 quando implementadas no FAIPA.
Logo depois estão os resultados da Nova Técnica de Atualização Quase-Newton
Esparsa. Comparou-se esta técnica com as atualizações BFGS e de Memória Limitada.

6
Mostraremos os gráficos com as iterações do FAIPA quando este usou cada uma das
técnicas.
Por fim, para a obtenção de resultados com problemas maiores através da
interface CUTEr ou com o problema HS43_NF, utilizou-se um computador AMD Atlon
1800 MHz com 1.5Gb de Memória RAM e, principalmente, o computador CRAY SV1
com 12 processadores e 16Gb de memória RAM para comparar o desempenho da
Técnica Esparsa Diagonal com a de Memória Limitada junto ao FAIPA.
Capítulo 7 – Conclusões e Propostas
Este capítulo apresenta as conclusões sobre os resultados obtidos no Capítulo 6
quando foram comparadas várias técnicas de atualização da matriz Quase-Newton (B),
quando associadas ao FAIPA.
Capítulo 8 – Referências Bibliográficas

7
CAPÍTULO 2
FAIPA: Algoritmo de Pontos Interiores por Arcos Viáveis.
2.1 – Considerações Gerais
O algoritmo de pontos interiores por arcos viáveis (FAIPA) é uma técnica nova
para otimização com restrições de desigualdade e restrições de igualdade. FAIPA requer
um ponto inicial no interior das restrições de desigualdades e gera uma seqüência de
pontos interiores. Quando o problema tem somente restrições de desigualdade a função
objetivo é reduzida em cada iteração. Uma função auxiliar é empregada quando existem
também restrições de igualdade.
O fato de fornecer pontos interiores, até mesmo quando as restrições são não-
lineares, torna o FAIPA uma ferramenta eficiente para projetos de otimização em
engenharia.
Considere o problema de programação não linear com restrições de igualdade e
desigualdade:
⎪⎪⎩
⎪⎪⎨
⎧
===≤
ℜ∈
pi xhemi xgsujeito a
xxfminimize
i
i
n
x
,...,1 ;0)( ,...,1 ;0)(
),(
(2.1)

8
onde: nx ℜ∈ são as variáveis do projeto, ℜ∈)(xf é a função objetivo, mxg ℜ∈)( são
as restrições de desigualdade e pxh ℜ∈)( são as restrições de igualdade.
Denotaremos nxmxg ℜ∈∇ )( e nxpxh ℜ∈∇ )( as matrizes dos gradientes de g e h,
respectivamente, e chamaremos de mℜ∈λ e pℜ∈µ os vetores com os multiplicadores
de Lagrange.
Em (2.2) temos o Lagrangeano do problema (2.1) e em (2.3) temos a Hessiana
do Lagrangeano.
)()()(),,( xhxgxfxl tt µλµλ ++= (2.2)
∑∑==
∇+∇+∇=p
iii
m
iii xhxgxfxL
1
2
1
22 )()()(),,( µλµλ (2.3)
Define-se mxmxG ℜ∈)( uma matriz diagonal tal que )()( xgxG iii = .
O algoritmo FAIPA (Feasible Arc Interior Point Algorithm), proposto por
HERSKOVITS [27], é um método de pontos interiores por arcos viáveis que resolve o
problema geral de otimização não-linear (2.1) fazendo iterações nas variáveis de projeto
x (variáveis primais) e nos multiplicadores de Lagrange (variáveis duais) para resolver
as condições de otimalidade de Karush-Kuhn-Tucker (KKT).
As condições de otimalidade de Karush-Kuhn-Tucker correspondentes ao
problema (2.1) podem ser escritas da seguinte forma:
0)(0
0)(0)(
0)()()(
≤≥
==
=∇+∇+∇
xg
xhxG
xhxgxf
λ
λµλ
(2.4) (2.5) (2.6) (2.7) (2.8)
Um ponto *x é dito estacionário se existe *λ e *µ tal que as igualdades (2.4),
(2.5) e (2.6) são verdadeiras e será um Ponto de KKT se todas as equações (2.4), (2.5),
(2.6), (2.7) e (2.8) são confirmadas.
As condições de KKT constituem um sistema não-linear de equações e
inequações com as incógnitas ),,( µλx . Esse sistema é resolvido considerando as

9
equações (2.4), (2.5) e (2.6) de tal forma que as desigualdades (2.7) e (2.8) sejam
respeitadas.
FAIPA faz iterações de Newton para resolver as equações não-lineares (2.4),
(2.5) e (2.6) nas variáveis primais e duais.
Com o objetivo de garantir convergência para pontos KKT, um sistema é
resolvido de tal forma que as desigualdades (2.7) e (2.8) sejam satisfeitas em cada
iteração.
Seja ),,( µλxLS = e mxmR∈Λ uma matriz diagonal com os termos iii λΛ = .
Com uma iteração de Newton para a resolução de (2.4), (2.5) e (2.6) obtém-se o
seguinte sistema linear:
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡ ∇+∇+∇=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∇∇Λ
∇∇
)()(
)()()( -
00)(0)()(
)()(
0
0
0
xhxG
xhxgxfxx
xhxGxg
xhxgS
t
t λµλ
µµλλ (2.9)
onde ),,( µλx se referem a iteração atual e ),,( 000 µλx se referem ao novo ponto que
será obtido. Podemos considerar BS ≡ , isto é, a uma aproximação Quase-Newton de
),,( µλxL ou considerar, também, IS ≡ , onde I é a identidade.
Considerando que um dos objetivos desse trabalho é propor uma nova técnica de
atualização Quase-Newton, a partir de agora em todos os sistemas do FAIPA que serão
apresentados teremos BS ≡ .
Seja nd ℜ∈0 tal que xxd −= 00 . Através de (2.9) temos:
⎪⎩
⎪⎨
⎧
−=∇
=+∇Λ
−∇=∇+∇+
)()(
0)()(
)()()(
0
00
000
xhdxh
xGdxg
xfxhxgBd
t
t λ
µλ
(2.10)
que independe do valor de 0µ . A resolução do sistema (2.10) fornece a direção 0d além
de uma nova estimativa dos multiplicadores de Lagrange.

10
Seja a função potencial
∑=
+=p
iii xhcxfcx
1)()(),(φ (2.11)
onde na iteração k, kic é tal que
0)()()(
01 <+ kki
i cxhxh µ , pi ,,2 , 1 K= (2.12)
Está provado [24][25] que kd0 é uma direção de descida de ),( kcxφ .
No entanto 0d não é sempre uma direção viável [27].
Para obter uma direção viável, um vetor negativo é adicionado ao lado direito de
(2.10).
⎪⎩
⎪⎨
⎧
=∇
−=+∇Λ
−∇=∇+∇+
0)()()(
)()()(
dxhxGdxg
xfxhxgBd
t
t ρλλ
µλ
(2.13)
onde ℜ∈ρ é positivo.
Agora, d é uma direção viável desde que 0)( <−=∇ ρdxgti para as restrições
ativas.
Para assegurar que d é também uma direção de descida, é preciso estabelecer
um critério para a obtenção de ρ de tal forma que:
( ) ( )cxdcxd tt ,, 0 φαφ ∇≤∇ (2.14)
com )1,0(∈α , então ( ) 0, <∇ cxd t φ .
Para obter ρ , resolve-se o seguinte sistema auxiliar:

11
⎪⎩
⎪⎨
⎧
=∇
−=+∇Λ
=∇+∇+
0)()()(
0)()(
1
11
111
dxh
xGdxg
xhxgBd
t
t λλ
µλ
(2.15)
Então, podemos considerar que:
10 ddd ρ+= (2.16)
onde temos que a desigualdade (2.14) é obedecida para qualquer 0>ρ se
( ) 0,1 <∇ cxd t φ .
Caso contrário, faz-se
),(),()1(
1
0
cxdcxd
t
t
φφαρ
∇∇−
< , (2.17)
que obedece (2.14).
O algoritmo de pontos interiores de direções viáveis (FDIPA) descrito em [24],
utiliza essa direção d como direção de descida. O procedimento de busca linear procura
um passo t que assegure que o novo ponto )( tdx + satisfaça as restrições de
desigualdade e com um razoável decréscimo na função potencial auxiliar ),,( 00 µλφ x .
No entanto, quando há restrições extremamente não lineares, o comprimento do
passo pode tornar-se muito pequeno acarretando uma convergência mais lenta. Esse fato
é similar ao Efeito Maratos [27].
Basicamente, a idéia para evitar esse problema consiste em fazer uma busca
linear através de um arco de segunda ordem, tangente à direção viável de descida ( d ) e
com curvatura próxima aquela da restrição ativa.
Sendo:
dxgxgdxg tiii
Ii )()()(~ ∇−−+=ω mi ,...,1= (2.18)

12
dxhxhdxh tiii
Ei )()()(~ ∇−−+=ω pj ,...,1= (2.19)
O arco em x é definido da seguinte forma:
dttdxxk~2
1 ++=+ (2.20)
onde d~ é obtido resolvido o sistema (2.21).
⎪⎪⎩
⎪⎪⎨
⎧
−=∇
Λ−=+∇Λ
=∇+∇+
Et
It
dxh
xGdxg
xhxgdB
ω
ωλ
µλ
~~)(
~~)(~)(
0~)(~)(~
(2.21)
O arco empregado no FAIPA é representado na Figura 2.1 onde a restrição
0)( ≤xgi é ativa na iteração kx . Uma vez que kd0 e kd são direções de descida da
função potencial )(xφ em kx , o ângulo com )( kxφ∇− é agudo.
A Figura 2.1 representa o arco viável no caso em que há uma restrição ativa, isto
é gi(xk)=0. HERSKOVITS et al. [27] prova que é possível caminhar a partir de xk ao
longo de um arco até um novo ponto viável com um valor mais baixo da função
objetivo.
Figura 2.1- Arco Viável.
d1
d0
−∇φ (x)
∇g (x)
d
d~Feasible arc
d1ρ
xk
gi(x) = 0

13
Em problemas que utilizam uma direção de busca e apresentam restrições
altamente não lineares, o grau de convergência dos algoritmos pode ser prejudicado, já
que o passo é muito pequeno. Todavia, o algoritmo FAIPA baseado no método de arcos
viáveis não apresenta este problema de convergência, pois ao definir-se o arco leva-se
em consideração a curvatura da restrição, aumentando assim a convergência do
problema para a solução ótima.
2.2 - Algoritmo do FAIPA
O algoritmo de pontos interiores e arcos viáveis para resolver o problema (2.1) será
descrito abaixo de forma resumida, a fim de se conhecer o seu funcionamento.
Parâmetros:
)1,0(∈α e 0>ϕ
Dados Iniciais: 0ax Ω∈ , onde 0
aΩ representa uma região viável.
0>λ , ,mR∈λ
0>µ , ,pR∈µ nxnRB ∈ simétrica definida positiva
0=ic , pRc ∈
Passo 1: Determinação da direção de descida.
(i) Resolva o sistema linear em ( 0d , 0λ , 0µ ), que chamaremos de Sistema (I):
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡∇=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∇∇Λ
∇∇
)(0
)( -
00)(0)()(
)()(
0
0
0
xh
xfd
xhxGxg
xhxgB
t
t
µλ (2.22)

14
onde ,0nRd ∈ , 0
mR∈λ .0pR∈µ
Se 00 =d , Pare.
(ii) Resolva o sistema linear em ( 1d , 1λ , 1µ ), que chamaremos de Sistema (II)::
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∇∇Λ
∇∇
0
0 -
00)(0)()(
)()(
1
1
1
λµλd
xhxGxg
xhxgB
t
t (2.23)
onde ,1nRd ∈ , 1
mR∈λ pR∈1µ , iii λ=Λ , sendo mi ,...,1= .
(iii) Seja a seguinte função potencial
∑=
+=p
iiic xhcxfx
1)()()(φ (2.24)
(iv) Se )(2.1 0 ici µ< , então )(2 0 ici µ−= , pi ,,2,1 K=
(iv) Se ( ) 01 >∇ xd ct φ então:
⎥⎦
⎤⎢⎣
⎡∇
∇−=
)()()1(;min
1
02
20 xdxdd
ct
ct
φφαϕρ (2.25)
Senão:
2
20dϕρ = (2.26)
(v) Determinação da direção de descida d.
10 ddd ρ+= (2.27)
Passo 2: Determinação da direção restaurada d~ .

15
(i) Seja:
dxgxgdxg tiii
Ii )()()(~ ∇−−+=ω mi ,...,1= (2.28)
dxhxhdxh tiii
Ei )()()(~ ∇−−+=ω pj ,...,1= (2.29)
(ii) Resolva o sistema linear em ( µλ ~,~,~d ), que chamaremos de Sistema (III):
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡Λ=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∇∇Λ
∇∇
E
I
t
t
d
xhxGxg
xhxgB
ωω
µλ
~~0
- ~
~~
00)(0)()(
)()( (2.30)
Onde iii λ=Λ , sendo mi ,...,1= .
Passo 3: Busca no arco.
(i) Encontre um passo de comprimento t que satisfaça um de critério de busca
linear baseado na função potencial auxiliar )~( 2dttdxc ++φ
Passo 4: Atualização.
(i) Obter o novo ponto 1+kx :
dttdxxk~2
1 ++=+ (2.31)
(ii) Se o problema em 1+kx verifica o(s) critério(s) de parada do algoritmo:
Pare
Senão
Defina uma nova atualização de λ e B , considerando 0>λ e B simétrica
positiva definida. Então vá para o Passo 1.

16
Algumas alternativas para a atualização de λ e B são discutidos em [22]. Elas
conduzem a algoritmos com diferentes performances em termos da velocidade de
convergência local.
O tamanho dos sistemas lineares (2.22), (2.23) e (2.30) é igual à soma do
número das variáveis mais o número de restrições de desigualdade e de igualdade. Em
[27] prova-se que estes sistemas têm uma solução única.
É importante ressaltar que já foi provado que o algoritmo aqui apresentado tem
convergência global para toda matriz B, simétrica definida positiva, e para
qualquer 0 >λ [27].
2.3 – Sistemas Simétricos no FAIPA
Analisando os sistemas lineares (I), (II) e (III) descritos em (2.22), (2.23) e
(2.30), respectivamente, constata-se que todos são assimétricos. Tornar esses sistemas
simétricos é uma alternativa para obtermos uma redução no custo computacional,
considerando-se que o problema de otimização seja de grande porte e que o algoritmo
faça uso da esparsidade das matrizes.
Considerando a equação (2.32) parte do Sistema (I):
0)()( 00 =+∇Λ λxGdxgt (2.32)
Multiplicando (2.32) por 1−Λ
0)()( 01
0 =Λ+∇ − λxGdxgt (2.33)
Da multiplicação entre as matrizes diagonais 1−Λ e )(xG na verdade resultará
uma matriz )(xΨ também diagonal onde
iiii xgx λ/)()( =Ψ (2.34)

17
Então (2.34) pode ser escrita da seguinte maneira:
0)()( 00 =Ψ+∇ λxdxgt (2.35)
Substituindo (2.35) em (2.22) temos um novo Sistema (I), porém simétrico.
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡∇=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∇Ψ∇
∇∇
)(0
)( -
00)(0)()(
)()(
0
0
0
xh
xfd
xhxxg
xhxgB
t
t
µλ (2.36)
O mesmo procedimento será feito nos demais sistemas (II) e (III).
O Sistema (II), agora simétrico é descrito em (2.37):
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∇Ψ∇
∇∇
0
0 -
00)(0)()(
)()(
1
1
1
ed
xhxxg
xhxgB
t
t
µλ (2.37)
onde me ℜ∈ é um vetor com componentes unitárias, isto é, 1=ie , mi ,...,1= .
O Sistema (III), agora simétrico é descrito em (2.38):
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∇Ψ∇
∇∇
E
I
t
t
d
xhxxg
xhxgB
ωω
µλ
~~0
- ~
~~
00)(0)()(
)()( (2.38)
Além do aproveitamento da simetria e da esparsidade, será proposta uma nova
alternativa de atualização da matriz B .

18
2.4 – Esparsidade dos Sistemas Internos do FAIPA
Uma matriz é considerada esparsa se muitos dos seus elementos são nulos. Uma
outra maneira de considerar se uma matriz é esparsa, é quando existe a possibilidade de
obter vantagens computacionais ao explorar apenas os elementos diferentes de zero
dessa matriz.
O interesse de aproveitar a esparsidade de matrizes tem se intensificado, cada
vez mais, pois esse tipo de estrutura matricial proporciona uma enorme redução do
custo computacional e também devido ao fato de muitos dos problemas em engenharia
serem esparsos [7].
Seja a matriz não simétrica (2.39) que compõem os sistemas (2.22), (2.23) e
(2.30).
00)(0)()(
)()(
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
∇∇Λ
∇∇
xhxGxg
xhxgB
t
t (2.39)
Para analisar a influência da relação entre o número de variáveis n e de
restrições )( pm + no número de elementos nulos da matriz (2.39), montou-se o Gráfico
2.1. No eixo das abscissas temos )/( pmn + e a porcentagem correspondente de
elementos nulos, no eixo das ordenadas.
Considerou-se dois casos no Gráfico (2.1). O primeiro que chamaremos de Caso
1, considera a matriz Quase-Newton nxnB ℜ∈ , a matriz dos gradientes das restrições de
desigualdade nxmxg ℜ∈∇ )( e a matriz com os gradientes de igualdade nxpxh ℜ∈∇ )(
todas elas densas.
No Caso 2 a matriz nxnB ℜ∈ é diagonal e mantém-se nxmxg ℜ∈∇ )( e nxpxh ℜ∈∇ )( densas.
Analisando as informações do Gráfico (2.1) podemos afirmar que no Caso 1 o
número de elementos nulos diminui quando há mais variáveis que restrições.

19
No Caso 2 a matriz (2.39) terá 50% de elementos nulos quando há igualdade
entre o número de variáveis e restrições. Para qualquer outra relação entre variáveis e
restrições haverá um aumento no número de elementos nulos na matriz (2.39).
0
10
20
30
40
50
60
70
80
0,20 0,25 0,33 0,50 1 2 3 4 5
Relação Variáveis/Restrições
Ele
men
tos N
ulos
(%)
Caso 1Caso 2
Gráfico 2.1- Influência da relação entre número de variáveis e de restrições
no número de elementos nulos da matriz (2.39).
No Capítulo 4 será apresentada uma técnica de atualização Quase-Newton que
gera matrizes diagonais. Através do Gráfico 2.1 percebemos que essa atualização irá
aumentar significativamente a esparsidade dos sistemas internos do FAIPA utilizados
em cada iteração e permitindo um melhor aproveitamento ao utilizar solvers que
exploram a estrutura da matriz na resolução de sistemas de equações, no intuito de
reduzir o custo computacional.
Serão implementadas no FAIPA alterações na maneira de armazenar as matrizes
dos sistemas esparsos. As estruturas de dados para armazenamento desse tipo de
matrizes consideram apenas os elementos não nulos. Esse assunto será abordado no
Capítulo 5.

20
CAPÍTULO 3
Técnicas Quase-Newton para Problemas
de Grande Porte
3.1 – Introdução
Antes de abordar o assunto principal desse capítulo, a atualização da matriz
Quase-Newton em problemas de grande porte, iniciaremos com uma breve abordagem
sobre os métodos Quase-Newton, do tipo DFP e do tipo BFGS, que obedecem a
condição secante e geram matrizes definida positiva.
Em seguida serão apresentados os métodos de atualização da matriz Quase-
Newton utilizados na resolução de problemas de otimização que apresentam um grande
número de variáveis de projeto. Por fim, será abordado o tema que trata de uma nova
técnica de atualização esparsa da matriz Quase-Newton.
3.2 – Introdução aos Métodos Quase-Newton
Seja o seguinte problema:
)( xfminimize (3.1)
onde a função 2Cf ∈ , nx ℜ∈ e nxnF ℜ∈ a Hessiana de f ( fF 2∇= ).

21
O método de Newton modificado consiste em encontrar um novo ponto a cada
iteração da seguinte forma:
)( - k1 kkkk xfStxx ∇=+ (3.2)
onde nxnS ℜ∈ é uma matriz simétrica, nf ℜ∈∇ o gradiente da função no ponto e kt é
escolhido de tal forma que minimize )( 1+kxf . Se 1−= FS for a inversa da Hessiana
temos o método de Newton e se IS = , onde I é a matriz identidade, nos temos o
steepest descent.
Através dos métodos Quase-Newton é possível obter uma aproximação nxnH ℜ∈ da inversa da matriz Hessiana, ao invés da exata exigida nos Métodos de
Newton. Essa aproximação é feita obedecendo a Condição Secante descrita em (3.3).
kkk syH =+1 (3.3)
Onde, de acordo com o problema sem restrições (3.1), temos os seguintes
vetores ks e ky :
1+−= kkk xxs (3.4)
)()( 1+∇−∇= kkk xfxfy (3.5)
3.2.1 – Método Quase-Newton do tipo DFP
Nos anos 50, a necessidade de um algoritmo que acelerasse as iterações durante
a resolução de problemas de minimização do tipo (3.1), isto é, que resolvesse
rapidamente com custo computacional reduzido fez com que Davidon [35]
desenvolvesse o primeiro algoritmo Quase-Newton que deu origem ao DFP.
O DFP (Davidon, Fletcher e Powell), um dos primeiros métodos a construir uma
aproximação da inversa da hessiana, foi originalmente proposto por Davidon em 1959, e
posteriormente desenvolvido por Fletcher e Powell em 1963 [35].

22
Seja nxnH ℜ∈ a aproximação da inversa da Hessiana. Então, em cada iteração
temos a seguinte atualização:
kktk
ktkkk
ktk
tkk
kk yHyHyyH
ysssHH −+=+1 (3.6)
Se consideramos a matriz B a aproximação da Hessiana de tal forma que 1−= HB ,
temos em (3.7) a seguinte Condição Secante, também conhecida como Condição Quase-
Newton.
kkk ysB =+1 (3.7)
Onde (3.3) e (3.7) são duais.
Dessa forma, podemos considerar a seguinte atualização da matriz B :
kTk
Tkk
Tkkk
kTkkk
kk syyy
sBsBssBBB +−=+ 1 (3.8)
A equação (3.8) é denominada atualização BFGS da matriz .B
Outra regra de atualização de H é a inversão de 1+kB apresentada na Equação
(3.9). Para isto utiliza-se a fórmula de Sherman-Morrison para se determinar :1+kH
ktk
tkkkk
tkk
ktk
tkk
ktk
kktk
kk sysyHHys
ysss
syyHyHH +
−⎟⎟⎠
⎞⎜⎜⎝
⎛++=+ 11 (3.9)
A equação (3.9) é denominada regra de atualização BFGS da matriz H .

23
3.2.2 – Método Quase-Newton do tipo BFGS
O mais popular dos métodos Quase-Newton é o BFGS, denominado dessa
maneira para referir-se aos idealizadores da técnica: Broyden, Fletcher, Goldfarb e
Shanno.
A atualização BFGS da matriz 1+kB é apresentada em (3.8), onde ks e ky são
descritos em (3.4) e (3.5), respectivamente.
Em problemas sem restrições, a atualização BFGS produzirá uma matriz 1+kB
simétrica definida positiva sempre que a matriz kB também seja definida positiva e que
se verifique, além da Condição Quase-Newton (3.7), a seguinte condição de curvatura:
0>kTk ys (3.20)
Em problemas com restrições, o vetor ky é obtido da seguinte maneira:
),,(),,( 111 kkkxkkkxk xlxly µλµλ ∇−∇= +++ (3.21)
onde l é o lagrangeano da função objetivo.
No entanto, em problemas com restrições, a Hessiana exata do problema não é
necessariamente definida positiva na solução. Portanto, nesses casos, nem sempre é
possível garantir que a matriz B obtida através da atualização BFGS seja definida
positiva. Para superar essa dificuldade, Powell propôs uma modificação da atualização
BFGS [24].
Ele sugeriu que se
kkTkk
Tk sBsys 2.0< (3.22)
então calcula-se φ para obter um novo ky , mantendo-se o mesmo ks .
kTkkk
Tk
kkTk
yssBssBs
−=
8.0φ (3.23)

24
O novo ky é obtido da seguinte maneira:
kkkk sByy )1( φφ −+= (3.24)
E, por fim, com novo vetor ky , além de ks e kB , através da mesma equação
(3.17) temos a atualização de 1+kB para o problema com restrições.
3.3 – Métodos de Atualização da Matriz Quase-Newton em Problemas Grandes
O Método Quase-Newton, na sua forma clássica (BFGS, por exemplo), não pode
ser usado para otimização de problemas grandes, pois gera e, por conseqüência,
manipula matrizes densas, o que torna o custo computacional elevado e inviável. É
possível, no entanto, modificar e estender esse método de diversas maneiras afim de
torná-lo eficiente para a resolução de problemas de grande porte [35].
As principais técnicas para esse tipo de atualização são as seguintes:
Método de Memória Limitada;
Método de Atualização Esparsa;
3.3.1 – Método de Memória Limitada
A técnica de memória limitada, concebida para resolução de problemas de
otimização não linear de grande porte, é baseada no método quase-Newton, permite
aproximar a inversa da matriz Hessiana da função que se deseja minimizar sem a
necessidade de armazenamento dessa matriz. As vantagens deste método estão na
economia no armazenamento em memória e na redução do número de operações [2].

25
Considerando inicialmente a aproximação BFGS da Hessiana apresentada na
equação (3.22).
kTk
Tkk
kkTk
kTkkk
kk syyy
sBsBssBBB +−=+1 (3.25)
Sendo B a aproximação da Hessiana e os vetores ks e ky descritos em (3.26) e
(3.27), respectivamente
kkk xxs −= +1 (3.26)
)()( 1 kkk xfxfy ∇−∇= + (3.27)
onde )( 1+∇ kxf e )( kxf∇ são os gradientes da função objetivo nos pontos 1+kx e kx
respectivamente.
Segundo [2], é possível representar de forma mais conveniente a regra de
atualização BFGS da equação (3.25). Esta nova forma é conhecida como uma
representação compacta da matriz BFGS e está descrita em (3.28).
Seja 0B uma matriz simétrica positiva definida e assumido-se que os k pares
11 −
=kiii ys satisfazem .0>i
ti ys Seja kB obtida na ésimak atualização de 0B pela fórmula
direta BFGS (3.25), ao tomarmos os pares 11 −
=kiii ys podemos então escrever
[ ] ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡
−−=
−
tk
tk
ktk
kktk
kkk YBS
DLLSBS
YSBBB 0
1
000 (3.28)
sendo
],....,[ 0 kk ssS = (3.29)
],....,[ 0 kk yyY = (3.30)
onde kS e kY são matrizes );( kn×

26
⎩⎨⎧ >
= −−
contrário caso 0 se
)( 11 jiysL j
ti
ijk (3.31)
ijkL )( é uma matriz triangular )( kk ×
],...,[diag 1100 −−= ktk
tk ysysD (3.32)
kD é uma matriz diagonal )( kk × .
Usando o esquema apresentado em [2], ao invés de se considerar os k pares 11 −
=kiii ys para atualizar a matriz ,B é possível tomar somente os m últimos pares.
Durante as primeiras k iterações, quando mk ≤ , as matrizes kS e kY armazenarão os
k pares de vetores s e y . Nas iterações subseqüentes quando mk > , o procedimento
de atualização de kS e kY é alterado de tal forma que sejam removidos os pares s e y
mais antigos e adicionados pares mais novos.
Além disso, assume-se que IB kε=0 , e reformula-se a equação (3.28):
[ ] ⎥⎦
⎤⎢⎣
⎡⎥⎦
⎤⎢⎣
⎡
−−=
−
tk
tkk
ktk
kktkk
kkkkk YS
DLLSS
YSIBεε
εε1
(3.33)
onde:
],....,[ 1−−= kmkk ssS (3.34)
],....,[ 1−−= kmkk yyY (3.35)
são matrizes );( kn×
⎩⎨⎧ >
= +−−+−−
contrário caso 0 se
)( 11 jiysL jmk
timk
ijk (3.36)
ijkL )( é uma matriz triangular );( kk ×

27
],...,[ 11 −−−−= ktkmk
tmkk ysysdiagD (3.37)
kD é uma matriz diagonal e kε um escalar positivo qualquer. Em [3], recomenda-se:
11
11
−−
−−=k
tk
ktk
k sssyε (3.38)
No entanto, em [16], recomenda-se .1=kε
Nesta última formulação as matrizes têm a dimensão relacionada aos últimos m
pares de vetores s e y [(3.34) e (3.35)] e não mais ao total de k iterações como mostrado
em (3.29) e (3.30). A matriz Quase-Newton, ,B continua com a mesma dimensão
).( nn×
Observa-se que a matriz
⎥⎦
⎤⎢⎣
⎡
− ktk
kktk
DLLSBS 0 (3.39)
da equação (3.28) é indefinida.
Porém, sua inversão pode ser feita, utilizando-se o método de fatorização de
Cholesky, da seguinte maneira:
0
0 21
21
21
21
0 ⎥⎥
⎦
⎤
⎢⎢
⎣
⎡−−
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−=⎥
⎦
⎤⎢⎣
⎡−t
k
kkk
kkk
k
ktkk
tkk
VDLD
VDL
DSBSL
LD (3.40)
onde kV é uma matriz triangular inferior que satisfaz
, 10
tkkkk
tk
tkk LDL SBS VV −+= (3.41)
Se 0B é positiva definida e ,1,...,1 ,0 −=≥ kiys iti então kV existe e não é
singular.

28
Logo, tem-se uma nova forma de representar a atualização da matriz Quase-
Newton dada por:
[ ] ⎥⎦
⎤⎢⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−⎥⎥
⎦
⎤
⎢⎢
⎣
⎡−−=
−
tkk
tk
kkk
k
tk
tkkkkkkkk S
Y
VDL
D
VLDDSYIB
εεε 0
0
-1
21
211-
21
21
(3.42)
Nesta última formulação as matrizes têm a dimensão relacionada com os últimos
m pares de vetores s e y, e não mais ao total de k iterações. A matriz Quase-Newton,
,kB continua com a mesma dimensão )( nn × . Na prática sugere-se que 7≤m [2].
A técnica de memória limitada na realidade não armazena a matriz B da iteração
anterior e as informações necessárias estão armazenadas nos vetores S e Y. Como não
há armazenamento, faz-se uso de artifícios para obtenção de produtos entre vetores e a
matriz B.
Usando-se a equação (3.42) serão apresentadas algumas operações envolvendo a
matriz kB . Tais operações serão úteis quando for utilizada a técnica de memória
limitada junto ao algoritmo do FAIPA [10].
As operações destacadas são as seguintes: produto de kB por um vetor v e
produto vBu kt , onde u e v são vetores de dimensão n.
3.3.1.1 - Produto vBk
O produto de kB por um vetor v é determinado da seguinte forma:
- dados: kx , kS , kY , ,kL kD e ;kε
- efetuar a fatorização de Cholesky de tkkkk
tkk LDL SS 1−+ε para se obter . kV
- resolver a equação (3.43):
⎥⎦
⎤⎢⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−⎥⎥
⎦
⎤
⎢⎢
⎣
⎡−=
−
vSvY
VDL
D
VLDDp t
kk
tk
kkk
k
tk
tkkk
ε 0
0
-1
21
211-
21
21
(3.43)

29
- efetuar o produto
[ ]pSY-vεvB kkkkk ε = (3.44)
3.3.1.2 - Produto vBu kt
O produto de vBu kt , onde u e v são vetores de dimensão n é determinado da
seguinte forma:
- dados kS , kY , kL e kD
- define-se kW
[ ]kkkk SYW ε= (3.45)
- calcular ktYu , kk
t Su ε , vY tk e vS t
kkε
- determinar ktWu e vW t
k
- efetuar a decomposição de Cholesky de tkkkk
tk LDL SS 1−+ para obter ; kV
- calcular tk uvε .
- resolver (3.46)
vWVDL
D
VLDD Wu-vuεvBu t
k
kkk
k
tk
tkkkk
ttkk
t 0 0
-1
21
211-
21
21
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−⎥⎥
⎦
⎤
⎢⎢
⎣
⎡−=
−
(3.46)

30
3.3.2 – Método de Atualização Esparsa
É um assunto que foi explorado e abandonado no fim dos anos 70 com Toint
[37][38][39] e ressurgiu no meio da década de 90 com Fletcher [13][14]. Consiste
basicamente no desenvolvimento da atualização Quase-Newton adotando um
determinado padrão de esparsidade para a matriz Hessiana ( 2f∇ ).
Antes de descrevermos as técnicas esparsas de Toint e Fletcher, é necessário
definir a norma de Frobenius, que será utilizada para resolver tais problemas de
atualização.
A norma de Frobenius F
. de uma matriz é definida da seguinte maneira.
Seja M a matriz:
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
nnn
n
MM
MMM
L
MOM
L
1
111
(3.47)
Onde ℜ∈ijM , sendo ni ,...,1= e nj ,...,1= .
Então:
∑∑= =
=n
i
n
jijF
MM1 1
2 (3.48)
ou
∑∑= =
=n
i
n
jijF
MM1 1
22 (3.49)

31
3.3.2.1 – Atualização Esparsa de Toint (1977)
Toint apresenta o problema de atualização esparsa considerando que a matriz
1+kB é a solução do seguinte problema quadrático descrito abaixo:
⎪⎪⎪
⎭
⎪⎪⎪
⎬
⎫
∈∀==
=
−=−
+
++
+
∈++ ∑
+
I i,j0 B eBB
ysBsujeito a
BBBB minimize
ij1k
tkk
kkk
I(i,j)
2ijkijk
2
FkkB 1k
)()(
])()[(
11
1
11
(3.50)
onde
F
⋅ denota a norma de Frobenius;
os vetores ks e ky são 1−−= kkk xxs e )()( 1−∇−∇= kkk xfxfy
0)]([|),( 2 =∇= ijxfjiI
( ) 0][|),( 2 ≠∇= ijxfjiJ
A solução kB é obtida resolvendo um sistema linear com n equações e
conservando o mesmo padrão de esparsidade I .
Em [37], Toint apresenta, além da formulação do problema, o procedimento de
atualização assumindo que a matriz B possui dimensões nn× , esparsa e simétrica onde
seus elementos são números reais. As condições de esparsidade não são aplicadas aos
elementos da diagonal, isto é, eles não podem ser nulos.
O objetivo, então, é obter a matriz 1+kB ( 11 ++ = ktk BB )
EBB kk +=+1 (3.51)
que satisfaça a seguinte condição secante
kkk ysB =+1 (3.52)
onde ks e nk Ry ∈ , e o padrão de esparsidade de kB é mantido em 1+kB .

32
A matriz E é chamada de Matriz de Correção.
As condições de esparsidade podem ser descritas da seguinte maneira:
0)()( 1 == + ijkijk BB (3.53)
desde que os pares ( i , j ) I∈ , sendo I um conjunto de pares inteiros.
Há também um conjunto J que contém os pares não pertencentes a I e
0)( e 0)( 1 ≠≠ + ijkijk BB (3.54)
desde que os pares ( i , j ) J∈ , sendo J um conjunto de pares inteiros. Considera-se
(i,i) J∈ , para todo i.
Para resolver o problema, Toint sugere o seguinte procedimento descrito a seguir
cujo objetivo final é obter a Matriz de Correção.
Considerando a equação (3.51) e a equação secante (3.52) temos:
kkk ysEB =+ )( (3.55)
kkkk sByEs −= (3.56)
Fazendo:
kkk sByr −= (3.57)
Então:
kEsr = (3.58)
Toint sugere a criação de uma matriz descrita em (3.59) que permite reescrever a
equação (3.58).
⎩⎨⎧
∈∀
∈∀=
Iji
JjisjiX j
), ( ,0
), ( , ),( (3.59)

33
Reescrevendo (3.58) temos:
∑=
=n
jijiji XEr
1
, onde ni ,...,1= (3.60)
Seja uma matriz C, podemos considerar a matriz de correção da seguinte forma:
)(5.0 TCCE += (3.61)
O problema pode ser considerado da seguinte forma:
⎪⎪⎪
⎭
⎪⎪⎪
⎬
⎫
=
=+
+
∑=
,...,nionde
rXCCsujeito a
minimize
iijjiij
FE
1
2] )( [
CC 81
n
1j
2T
(3.62)
Da mesma forma que em [19], o lagrangeano da função do problema (3.62) é o
seguinte:
2-] )( [( )2(81),(
1 11 1
22 ∑ ∑∑∑= == =
+−++=Φn
iiij
n
jjiiji
n
i
n
jjiijjiij rXCCCCCCC λλ (3.63)
Diferenciando em relação a ijC temos:
0)(0.5),(=−−+=
∂Φ∂
jijijijiijij
XXCCCC λλλ (3.64)
Sendo ni ,...,1= e nj ,...,1= .
Podemos usar a equação (3.61) para reescrever a (3.64):
0=−− jijijiij XXE λλ (3.65)

34
jijijiij XXE λλ += (3.66)
Substituindo (3.66) em (3.60):
∑=
+=n
jijjijijii XXXr
1])[( λλ , onde ni ,...,1= (3.67)
Que pode ser reescrita:
∑∑==
+=n
jijjij
n
jijii XXXr
11
2 )()( λλ , onde ni ,...,1= (3.68)
Podemos transformar ainda mais a equação (3.68) ao criar a matriz Q da
seguinte forma:
∑=
+=n
kijikijijij XXXQ
1
2 )( δ , onde ni ,...,1= e nj ,...,1= (3.69)
Então temos o seguinte sistema de equações onde a incógnita é λ .
rQ =λ (3.70)
Por fim, com λ , o vetor solução de (3.70), junto a equação (3.66), obtém-se a
matriz de correção.
É possível reescrever resumidamente o processo descrito acima para a resolução
do problema que consiste em encontrar a matriz de correção segundo a técnica esparsa
de Toint:
⎪⎪
⎭
⎪⎪
⎬
⎫
∈∀==
−=
IjiEeEE
sByEssujeito a
E .minimize
ij
tkkkk
FE
), ( 0
50 2
(3.71)

35
Para a resolução de (3.71) define-se a matriz X de dimensões n x n:
⎩⎨⎧
∈∀
∈∀=
Iji
JjisjiX j
), ( ,0
), ( , ),( (3.72)
Em seguida obtém-se a matriz Q da seguinte forma:
ijjiijij iXXXQ δ2:),(+= (3.73)
onde δ é o delta de Kronecker descrito em (3.74).
⎩⎨⎧
≠=
=jiji
ij ,0 ,1
δ (3.74)
De posse da matriz Q é possível resolver o sistema (3.75) e obter o vetor λ para
utilizá-lo em (3.76) e encontrar a matriz de correção E .
kkk sByQ −=λ (3.75)
Então, obtém-se a matriz de correção:
⎩⎨⎧
∈∀+∈∀
=JjiXX
IjiE
jiijij ), ( ,
), ( ,0
ji λλ (3.76)
Agora é possível encontrar a matriz 1+kB definido na equação (3.51).
Dentre as várias desvantagens dessa técnica é que, além de não garantir que 1+kB
seja definida positiva, exige a resolução de um sistema de equações (3.75) com muitas
variáveis [31]. Além disso, é necessário o armazenamento da matriz B a cada iteração.

36
3.3.2.2 – Atualização Esparsa de Fletcher (1996)
Em [14], Fletcher apresenta uma outra maneira para descrever o método de
atualização esparsa. Ele considera, agora, que a matriz 1+kB é a solução do seguinte
problema quadrático:
⎪⎪
⎭
⎪⎪
⎬
⎫
∉∀==
−
+
++
++
JjiBeBBsujeito a
YSBminimize
ijk
tkk
FkkkBK
), ( 0)(
1
11
21
1
(3.77)
onde
F
⋅ denota a norma de Frobenius;
as matrizes kS e kY contém os m diferentes pares is e iy , mi ,...,1= .
],...,[ 1 kmkk ssS +−= (3.78)
],...,[ 1 kmkk yyY +−= (3.79)
os vetores ks e ky são 1−−= kkk xxs e )()( 1−∇−∇= kkk xfxfy
=J 0)]([|),( 2 ≠∇ ijxfji
Ainda em [12], Fletcher mostra que o problema apresenta solução única se kS
satisfaz a condição de independência linear entre as colunas da matriz. Considerando-se
isso, 1+kB pode ser obtida através da solução de um sistema definido positivo, porém
não é garantido, também, que 1+kB seja positiva definida [31].
O sistema (3.80) é proposto por Fletcher em [12] para auxiliar na resolução do
problema (3.77).
wbKPPt = (3.80)
Antes de descrever esse sistema, é preciso apresentar alguns conjuntos, matrizes
e vetores necessários para uma melhor compreensão. Além disso, será introduzido o
operador vec que será utilizado para transformar matrizes em vetores.

37
O conjunto L é definido como aquele que contém os pares que indicam os
elementos da parte triangular inferior de B e que pertencem a J .
JLjiJjiL ⊂≥∈= , ,),( (3.81)
A variável nti representa o número de pares que estão contidas no conjunto L .
O vetor b , de dimensão nti , é a solução do problema, pois nele estão
armazenados os elementos de 1+kB , cujos pares ),( ji pertencem a L .
A matriz Z , de dimensões nn× , é descrita em (3.82)
tkk
tkk SYYSZ += (3.82)
O vetor w , de dimensão nti , é montado a partir da matriz Z da seguinte forma:
LiiZw
LjiZZw
iir
jiijr
∈∀=
∈∀+=
),( ),(
),( ),( (3.83)
onde ntir ,...,1= .
A maneira de obter as matrizes E , de dimensões nn× e que servirão para a
montagem da matriz P , é descrita em (3.84). Para cada par Jji ∈ ), ( , há uma matriz
ijE que possui elemento de valor 1 na posição ), ( ji e zero nas demais posições.
⎩⎨⎧ ∈
=contrário caso ,0 ), ( ,1 Jji
Eij (3.84)
A matriz P , de ordem ntin ×2 , é montada por colunas da seguinte forma:

38
LiiEvec
LjiEEvec
ii
jiij
∈∀
∈∀+
),( ),(
),( ),( (3.85)
Finalmente, a matriz K é formada a partir da soma dos produtos de Kronecker
entre a matriz tkk SS e a matriz identidade Ι . Esse produto está representado em (3.86).
)()( tkk
tkk SSSSK ⊗Ι+Ι⊗= (3.86)
O produto de Kronecker, também conhecido como produto direto ou produto
tensor, é definido em (3.87). Por exemplo, A é uma matriz pn× e C uma matriz
qm× , então o produto de Kronecker de A e C será:
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
=⊗
CaCaCa
CaCaCaCaCaCa
CA
npnn
p
p
L
MMMM
L
L
21
22221
11211
(3.87)
Ao resolver o sistema (3.80), de posse dos valores do vetor b efetua-se a
montagem da matriz 1+kB .
Essa atualização não exige o armazenamento da matriz kB em cada iteração para
obter a matriz 1+kB , uma vez que as informações das iterações anteriores contidas nos
vetores S e Y são suficientes.
O fato de ter que resolver um sistema para se obter a nova matriz 1+kB pode ser
considerado uma desvantagem desse método, pois a dimensão desse sistema é igual ao
número de não zeros ( nti ) contidos na parte triangular inferior da Hessiana que
forneceu o padrão de esparsidade.
No entanto, a grande desvantagem está no fato de que essa atualização não
garante aproximações definidas positivas [14]. Outra desvantagem está no fato de que o
método não apresenta bons resultados na resolução de problemas de grande porte [35].

39
CAPÍTULO 4
Técnica de Atualização
Quase-Newton Diagonal
4.1 – Introdução
No capítulo anterior apresentaram-se algumas técnicas para a obtenção de
matrizes Quase-Newton em problemas grandes. Dentre essas técnicas está a atualização
esparsa, que serviu de inspiração para a concepção de uma técnica nova, a qual
chamaremos de Técnica de Atualização Quase-Newton Diagonal.
Os objetivos dessa nova técnica são:
- Obter uma atualização que gere matrizes definidas positivas;
- Evitar o armazenamento da matriz B a cada iteração;
- Aumentar a esparsidade dos sistemas usados na resolução de problemas de
otimização, reduzindo o custo computacional em problemas de grande porte.
4.2 – Técnica de Atualização Diagonal
Modificando algumas restrições em relação à proposta de Fletcher descrito em
(3.77) no capítulo anterior, temos um novo problema descrito em (4.1), onde 1+kB é a
solução do problema quadrático

40
⎪⎪⎭
⎪⎪⎬
⎫
≠∀==>>
−
+
+
++
jiBeniBsujeito a
YSBminimize
ijk
iik
FkkkBk
0)( ,...,1 0, , )(
1
1
21
1
δδ (4.1)
Onde:
F
⋅ representa a norma de Frobenius;
as matrizes kS e kY contém os q diferentes pares is e iy , qi ,...,1= e em
cada iteração elas são atualizadas de forma semelhante ao Método de
Memória Limitada.
],...,[ 1 kqkk ssS +−= (4.2)
],...,[ 1 kqkk yyY +−= (4.3)
os vetores ky e ks são ),,(),,( 1 kkkxkkkxk xlxly µλµλ −∇−∇= e
1−−= kkk xxs , onde l é o lagrangeano da função objetivo em problemas com
restrições.
n representa a dimensão de 1+kB .
A seguir apresentaremos a nova técnica de atualização esparsa. Sejam as
matrizes B, S e Y descritas em (4.7), (4,8) e (4.9), respectivamente.
Seja B uma matriz diagonal n x n.
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
nv
vv
B
L
MOM
L
0
000
2
1
(4.7)
As matrizes S e Y armazenam q pares de vetores s e y, respectivamente.

41
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=
nqn
q
ss
ssS
L
MOM
L
1
111
(4.8)
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=
nqn
q
yy
yyY
L
MOM
L
1
111
(4.9)
A função que será minimizada é a seguinte:
2 F
YBS −=Φ (4.10)
Substituindo (4.7), (4.8) e (4.9) em (4.10) temos:
2
1
111
1
1111
0
0
Fnqn
q
nqn
q
n yy
yy
ss
ss
v
v
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=Φ
L
MOM
L
L
MOM
L
O (4.11)
Realizando a multiplicação seguida da subtração das matrizes em (4.11) temos:
2
11
11111111
Fnqnqnnnn
ysvysv
ysvysv
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−
−−=Φ
L
MOM
L
(4.12)
A norma de Frobenius da matriz em (4.12) será, então:
22111
211
211111
)( )(
)( )(
nqnqnnn
nnn
ysvysv
ysvysv
−++−+
+−++−=Φ
L
MM
L
(4.13)

42
Logo:
22221111
21
21
2111
21
221111111
211
21
2 2
2 2
nqnqnqnnqnqqqq
nnnnnn
yysvsvyysvsv
yysvsvyysvsv
+−+++−+
++−+++−=Φ
L
MM
L
(4.14)
Sob a forma matricial, a equação (4.14) é reescrita em (4.15):
[ ]
[ ]
[ ]
[ ]
[ ] [ ]
0
0 2
0
0 2
0
0
0
0
0
0
0
0
1
1
1
11
111
11
1
1
11
1
11
1
111
1
1
1
11
1
11
1
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
++⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡+
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−
−⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡−
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
+
+⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=Φ
nq
q
nqq
n
n
nq
q
nq
q
n
nn
n
nnq
q
nq
q
n
nnn
n
y
yyy
y
yyy
y
y
s
svv
y
y
s
svv
v
v
s
s
s
svv
v
v
s
s
s
svv
MLLML
MOL
LMOL
MOOL
LMOOL
(4.15)
Se considerarmos o vetor v, as matrizes jD e os vetores jY , onde qj ,...,1= ,
poderemos reescrever a equação (4.15):
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
nv
vv M
1
(4.16)

43
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=
nj
j
s
sD
0
01
j O (4.17)
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=
qj
j
y
yY M
1
j (4.18)
Reescrevendo (4.15) considerando (4.16), (4.17) e (4.18), então:
q11
qq11
qq11
2 2
YYYY
YDvYDv
vDDvvDDv
Tq
T
TT
TT
+++
−−−
++=Φ
L
L
L
(4.19)
Se considerarmos agora a matriz Q , o vetor b e o escalar c, descritos em (4.20),
(4.21) e (4.22), respectivamente, podemos reescrever (4.19).
∑=
×=q
jjDQ
1
22 (4.20)
∑=
×=q
jjjYDb
12 (4.21)
∑=
=q
jj
tj YYc
1 (4.22)
Por fim, reescrevendo (4.19), obtemos a seguinte função quadrática:
cbvQvvv TT 0.5 )( +−=Φ (4.23)

44
Podemos afirmar que o problema (4.1) é equivalente ao de minimizar uma
função quadrática, como a que temos apresentada na equação (4.23), com restrições na
variável v , onde δ≥iv , 0>δ e ni ,...,1= .
Então, podemos reescrever o problema (4.1) da seguinte maneira:
⎪⎭
⎪⎬⎫
=>≥
+−=Φ
nivsujeito a
cbvQvvvminimize
i
tt
v
,...,1 0
5.0 )(
δ (4.24)
onde
a nova matriz atualizada é diagonal, onde nivB iii ,...,1 == ;
n representa a dimensão de B , isto é, o número de variáveis do problema
original .
δ é uma constante;
a matriz Q
∑=
×=m
jjDQ
1
22 (4.25)
onde jD uma matriz diagonal:
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
=
nj
j
j
j
S
SS
D
L
MOM
L
0
0
2
1
(4.26)
o vetor b
∑=
×=m
jjjYDb
12 (4.27)

45
onde jY é o seguinte vetor:
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
=
nj
j
j
j
y
yy
YM2
1
(4.28)
o vetor c
∑=
=m
jj
tj YYc
1 (4.29)
Sendo qj ,...,1= , onde q é o número de pares de vetores ks e ky armazenados
nas matrizes kS e kY respectivamente descritas em (4.2) e (4.3), onde ambas possuem
dimensão qn× .
As matrizes kS e kY são atualizadas de modo semelhante ao Método de
Memória Limitada, onde são armazenados os vetores ks e ky , sendo calculados da
seguinte forma (nos problemas com restrições): 1−−= kkk xxs e
),,(),,( 1 kkkx
kkkx
k xlxly µλµλ −∇−∇= , onde l é o lagrangeano da função objetivo.
4.3 – Resolução do Problema
Para a resolução do problema através das condições de otimalidade de KKT é
necessário ter o gradiente da função objetivo e o gradiente das restrições.
O gradiente da função )(vΦ é obtido facilmente:
bQvv )( −=Φ∇ (4.30)
Para obtenção do gradiente das restrições, temos que:

46
ii vg −= δ , ni , ... ,1= (4.31)
então
[ ]nk ggvg ∇⋅⋅⋅∇=∇ 1)( (4.32)
onde i
i vgg
∂∂
=∇ , ni ,...,1= .
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
−
=∇
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡−
=∇
1
00
, ,
0
01
1M
LM
ngg (4.33)
O gradiente das restrições será:
Ivg k -)( =∇ (4.34)
A partir das condições de otimalidade de Karush-Kuhn-Tucker para o problema
(4.24) temos as equações (4.35) e (4.36)
0)(1
=∇+Φ∇ ∑=
n
iiik gv λ (4.35)
0)( =ikT vg λ (4.36)
Considerando a equação (4.35) temos:
0 =−− iiiii bvQ λ , ni , ... ,1= (4.37)
A partir da equação (4.36) temos:

47
0)-( =iiv λδ , ni , ... ,1= (4.38)
Através da análise das informações de (4.37) e (4.38), podemos considerar as
seguintes situações:
1) Se 0 =iλ , então
0 =− iiii bvQ , ni , ... ,1= (4.39)
ii
ii Q
bv = , ni , ... ,1= (4.40)
2) Se 0 >iλ
δ=iv , ni , ... ,1= (4.41)
Portanto, o vetor solução do problema (4.24) pode ser obtido a partir da equação
(4.40) considerando-se δ>iv . Caso contrário, se δ≤iv faz-se δ=iv .

48
CAPÍTULO 5
Métodos Diretos para Solução de
Sistemas Lineares Esparsos
5.1 – Introdução
No presente capítulo são abordados alguns conceitos sobre Métodos Diretos e
como eles podem ser utilizados em situações nas quais o problema é considerado
esparso.
Descreve-se de maneira sucinta, como as rotinas MA27, MA28 e SSTSTRF/S
utilizam o conhecimento da esparsidade para obter a solução, através do Método Direto,
em sistemas simétricos e não simétricos. A MA27 e a MA28 são utilizadas em
computadores seqüenciais. A SSTSTRF/S é parte da biblioteca de rotinas disponíveis
no computador CRAY SV1 e permite o uso de processamento em paralelo.
No entanto, o Método de Memória Limitada junto ao FAIPA efetua a resolução
de sistemas lineares densos, o que torna inviável o uso de solvers específicos para
sistemas esparsos. Por isso fez-se a implementação da rotina SGETRF/S que resolve
sistemas densos pelo método direto e pertencente ao LAPACK. Além disso, essa rotina
poderia ser utilizada tanto em computadores seqüenciais como em ambiente de alto
desempenho com o computador CRAY SV1.

49
5.2 – Método Direto
Consideremos o sistema
cAx = (5.1)
em que A é uma matriz quadrada de dimensão n não singular, nRx ∈ é a variável do
problema e nRb∈ .
Métodos Diretos usam uma fatoração dos coeficientes da matriz A para facilitar
a obtenção da solução de sistemas do tipo (5.1).
A fatoração mais comum para sistemas não simétricos é a do tipo LU , onde a
matriz A (ou uma permutação dela) é expressa como o produto das matrizes L e U ,
onde L é triangular inferior e U é triangular superior.
Desse modo, podemos ter:
LUPAQ = (5.2)
onde P e Q são matrizes de permutação obtidas de tal forma a manter a estabilidade
numérica.
Após a fatoração, a solução pode ser apresentada de uma maneira sucinta
observando duas etapas principais: uma substituição direta (5.3) e outra de substituição
inversa (5.4).
PcLy = (5.3)
yUz = (5.4)
A solução x é obtida em (5.5) realizando-se a permutação de z .
Qzx = (5.5)
O uso dessa fatoração LU para resolver sistemas de equações é usualmente
chamada de Eliminação Gaussiana.

50
Se a matriz A é simétrica positiva definida, é normal usar uma fatoração (5.6)
conhecida como Fatoração de Cholesky.
tt LLPAP = (5.6)
Para o caso de matrizes simétricas em geral é usada a fatoração (5.7).
tt LDLPAP = (5.7)
Se em (5.7) a matriz A é indefinida, para que a decomposição seja estável, é
preciso que a matriz D seja diagonal com blocos, onde cada bloco possui ordem 1 ou 2,
e L é triangular inferior unitária [15].
5.3 – Método Direto para Sistemas Esparsos
A utilização da esparsidade no intuito de viabilizar a resolução de sistemas com
grande número de variáveis requer o aumento dos cuidados no momento da
manipulação dos elementos da matriz desse sistema [7]. Dentre esses cuidados podemos
citar alguns destaques:
Controle do número de elementos nulos que passam a ser não nulos após a
fatoração (Ordenamento).
Predição da localização dos elementos não nulos e também daqueles elementos
nulos que poderão vir a ser não nulos (Fatoração Simbólica).
Esquema de armazenamento que faz uso somente dos elementos não nulos.
Manipular, durante a fatoração, apenas os elementos não nulos.
O processo da Eliminação Gaussiana quando utilizado em sistemas esparsos
pode provocar a perda do padrão de esparsidade, isto é, permitir a inserção de elementos
não nulos em posições antes ocupadas por elementos nulos [29]. Um exemplo clássico é
o das matrizes apresentadas em (5.9) e (5.11) onde o ordenamento das linhas e das

51
colunas é extremamente efetivo para a manutenção da esparsidade da matriz durante a
Eliminação Gaussiana [9].
Considerando:
LUA = (5.8)
Se o padrão de esparsidade da matriz A for considerada como em (5.9)
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
××××
××××××
=A (5.9)
então, após a fatoração, a matriz que contém LU terá o padrão de esparsidade alterado
como em (5.10). Os símbolos ⊗ representam os não nulos inseridos no lugar de
elementos nulos no padrão original.
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
×⊗⊗×⊗×⊗×⊗⊗××××××
=LU (5.10)
No entanto, se for feito um reordenamento de linhas e colunas de tal forma que a
matriz reordenada passe a ter o padrão apresentado em (5.11) a fatoração preservará o
padrão de esparsidade de tal forma que não haverá inserção de elementos não nulos
como em (5.10).
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
××××××××××
=A (5.11)

52
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
××××××××××
=LU (5.12)
A etapa de Fatoração Simbólica consiste em determinar a localização dos não
nulos em L e U , além de preparar a estrutura de dados para armazenagem e alocação
de memória para esses não nulos.
A Fatoração Numérica utiliza os valores numéricos dos elementos e realiza a
fatoração LU com pivoteamento que garanta a estabilidade numérica do processo.
Para matrizes simétricas definidas positivas, na etapa de Ordenamento utiliza-se
o algoritmo de Grau Mínimo. Para matrizes não simétricas ou simétricas indefinidas é
comum utilizar-se o Critério de Markovitz.
O algoritmo de Grau Mínimo escolhe o elemento i da diagonal de tal forma que
o número de não zeros na linha e coluna i é minimizado.
O Critério de Markowitz escolhe o elemento kija ( k indica a iteração) de tal
forma a minimizar a expressão (5.13), na qual temos kir representando o número de não
zeros na linha i e kjc representando o número de não zeros na coluna j .
)1min()1min( −− kj
ki cr (5.13)
Além disso, o Critério de Markowitz exige um controle da estabilidade
numérica, chamada Escolha Limite de Pivô que consiste em aceitar para pivô da
iteração k qualquer elemento kija que satisfaça o critério descrito pela desigualdade
(5.14), onde u ( 10 ≤< u ) é o parâmetro limite [7].
kik
kkk aua ≥ (5.14)
Na prática, o valor 1.0=u e considerado satisfatório e dá bastante liberdade
para se escolher o pivô em termos da esparsidade da matriz [7].
Em linhas gerais, a solução de (5.1) pode ser dividida em quatro fases [15]:

53
1) Fase de Pré-Ordenamento: que explora a estrutura;
2) Fase de Análise: onde a estrutura da matriz é analisada para produzir um
ordenamento e uma estrutura de dados satisfatórios para uma fatoração eficiente. Nessa
etapa é determinada a seqüência de pivoteamento. Muitas vezes referem-se a essa fase
com Fatoração Simbólica ou também de Ordenamento;
3) Fase de Fatoração: onde é efetuada a fatoração numérica, isto é, são
computados os fatores, baseada na seqüência de pivoteamento definida na fase de
Análise;
4) Fase de Solução: onde os fatores são usados para resolver o sistema através de
substituição direta e seguida de uma substituição inversa.
Quando o sistema (5.1) é simétrico, as Fases 2 e 3 terão comportamentos
diferenciados para os casos em que a matriz A é definida positiva ou indefinida.
Para matrizes simétricas definidas positivas, a seqüência de pivoteamento pode
ser obtida usando somente o padrão de esparsidade, isto é, durante a fase de análise não
há manipulação computacional de números reais e na fase de fatoração a seqüência de
pivoteamento pode ser usada sem modificações.
Em problemas onde a matriz é simétrica indefinida, é possível alterar a
seqüência de pivoteamento, caso seja necessário durante a fatoração, para manter a
estabilidade numérica. Isso quer dizer que as Fase 2 e 3 são realizadas conjuntamente,
podendo ser consideradas uma fase só.
Se o sistema for não simétrico as Fase 2 e 3 são realizadas conjuntamente, e
também podem ser consideradas uma fase só.
Há rotinas que utilizam o Método Direto onde a Fase 4 permite resolver
repetidamente várias vezes o sistema para diferentes vetores c , obtendo dessa forma
uma maior eficiência computacional.
A Fase 3 (ou uma combinação das Fases 2 e 3) normalmente requer mais tempo
computacional. A fase mais rápida é a Fase 4. Em sistemas densos, a Fase 1 não é
utilizada [15].
Dentre os Métodos Diretos para sistemas esparsos podemos destacar o Método
Multifrontal, que é uma generalização do Método Frontal, pois faz uso de múltiplas

54
matrizes frontais. O método foi implementado por Duff e Reid em 1982 e representa um
avanço significativo na solução direta de sistemas esparsos [6].
O Método Frontal tem suas origens na solução de problemas de análise
estrutural através do Método dos Elementos Finitos. Inicialmente considerava sistemas
simétricos definidos positivos e posteriormente foi estendido para sistemas não
simétricos [6].
O Método Multifrontal pode ser usado tanto em sistemas indefinidos não
simétricos como também em sistemas indefinidos simétricos. Além disso, o método
aplica-se também em sistemas com matrizes que são simétricas quanto a sua estrutura,
mas não quanto aos seus valores [6].
5.4 – Esquemas de Armazenamento de Matrizes Esparsas
Existe uma grande variedade de tipos de armazenamento de matrizes esparsas
dentre os quais podemos citar:
- Esquema Coordenado
- Esquema CSC (Compressed Sparse Column)
O Esquema Coordenado tem como característica apresentar dois tipos de
armazenagem: uma Parte Primária e uma Parte Secundária. A Parte Primária é
constituída por um vetor de reais contendo todos os elementos não nulos da matriz (que
chamaremos de AC). A Parte Secundária corresponde a dois vetores de inteiros que
contém os índices de linha (IRN) e de coluna (ICN) dos elementos não nulos.
Quando comparado com outros esquemas, o coordenado necessita de um espaço
de armazenagem relativamente elevado e, além disso, operações com matrizes esparsas
não são implementadas de uma forma eficiente usando este esquema. Por essa razão o
Esquema Coordenado é habitualmente usado apenas como input/output entre rotinas de
manipulação de matrizes esparsas e o usuário.

55
O Esquema Coordenado é o tipo de armazenagem usado como interface das
rotinas MA28 e MA27 para resolução de sistemas de equações lineares com matrizes
esparsas [21].
O Esquema CSC (Compressed Sparse Column) armazena as informações da
matriz também em três vetores que chamaremos de AMAT, ROWIND e COLSTR.
O vetor AMAT armazena os elementos diferentes de zero da matriz. O vetor
ROWIND contém os índices da coluna de cada elemento armazenado no vetor AMAT.
O vetor COLSTR contém informações referentes ao número de elementos diferentes de
zero contidos em cada coluna da matriz que se deseja armazenar.
Por exemplo, seja uma matriz A de dimensões n x n, com nz elementos
diferentes de zero.
Os vetores AMAT e ROWIND terão dimensão nz. O vetor COLSTR terá
dimensão n+1.
Para entender o armazenamento das informações contidas em COLSTR vamos
considerar o valor da posição i nesse vetor e seja nzci o número de não zeros da coluna
i-1 da matriz A. Então o valor na posição i do vetor COLSTR será (nzci+1).
Convenciona-se que sempre a primeira posição desse vetor será igual a 1 e a última
posição tenha o valor nz+1.
O Esquema CSC é muito usado por muitos solvers esparsos [4], dentre os quais
está o SSTSTRF/S disponível no computador CRAY SV1.
O Esquema CSC, em relação ao Coordenado, geralmente necessita um espaço
menor para o armazenamento das informações de uma mesma matriz não simétrica de
dimensões nxn .
Por exemplo, se considerarmos nz o número de elementos diferentes de zero
dessa matriz, os vetores AMAT e ROWIND teriam dimensão nz e o terceiro vetor
(COLSTR) apresentaria dimensão n+1. Enquanto isso, no Esquema Coordenado todos
os vetores teriam dimensão nz.

56
Seja, por exemplo, a seguinte matriz:
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=
dgecf
gfbea
A
000
000
22
2
11
1
(5.15)
Se o armazenamento for feito através do Esquema Coordenado teremos os
seguintes vetores: AC, IRN e ICN. O vetor AC contém os elementos da matriz que são
diferentes de zero. Os vetores IRN e ICN contém os índices das linhas e das colunas,
respectivamente, de cada um dos elementos diferentes de zero da matriz A.
Então o esquema de armazenamento coordenado para a matriz não simétrica
(5.15) será:
[ ]222111 gfegfedcbaAC = (5.16)
[ ] 4342214321IRN = (5.17)
[ ] 2214344321ICN = (5.18)
Se considerarmos a matriz descrita em (5.15) simétrica, isto é, 21 ee = , 21 ff = e
21 gg = , então o esquema de armazenamento coordenado será o seguinte :
[ ]111 gfedcbaAC = (5.19)
[ ] 2214321IRN = (5.20)
[ ] 4344321ICN = (5.21)

57
Seja o armazenamento da matriz não simétrica (2.15) seguindo o Esquema CSC.
Então teremos:
[ ]dgecfgfbeaAMAT 211222= (5.22)
[ ] 4213243241 ROWIND = (5.23)
[ ] 118631COLSTR = (5.24)
5.5 – Rotina MA27 (HSL)
A Harwell Subroutine Library (HSL) [21] apresenta uma coleção de rotinas
escritas na linguagem Fortran para computação científica de grande porte. A rotina
MA27, que integra essa coleção, resolve sistemas de equações lineares simétricos e
esparsos do tipo:
RHSAX = (5.25)
onde:
A é uma matriz quadrada de ordem n , esparsa, simétrica e não
necessariamente definida.
RHS matriz que contém os nrhs vetores c que compõem o lado direito.
X é a matriz que contém as nrhs soluções.
1≥nrhs .
A rotina MA27, desenvolvida a partir da MA17 e escrita na linguagem Fortran,
foi implementada em 1982 por Duff e Reid, e foi o primeiro código a utilizar a técnica
multifrontal. Em 1993 os mesmos autores da MA27 desenvolveram a MA47 também
baseada no Método Multifrontal, porém a MA47 não apresentava um bom desempenho
em determinadas situações. Por este motivo nunca foi considerada sucessora da MA27
[18].

58
Em 2000, Duff anuncia o desenvolvimento da MA57, a rotina sucessora da
MA27. Dentre as atualizações dessa nova rotina podem ser citadas a utilização das
rotinas BLAS Nível 3 (Basic Linear Álgebra Program) e o fim do uso de blocos
COMMON da linguagem FORTRAN [18].
Durante a fase de análise na MA27, os pivôs poderão ser selecionados
considerando-se apenas o padrão de esparsidade caso a matriz seja definida positiva. Se
a matriz for indefinida, a ordem de pivoteamento pode ser modificada durante a
fatoração de tal forma que obedeça a um critério de estabilidade.
Para a seleção da seqüência de pivoteamento que assegure a preservação da
esparsidade é utilizado o algoritmo de grau mínimo.
A MA27 permite que, após a realização das etapas de análise e de fatoração, a
etapa de solução possa ser chamada repetidamente para resolver o sistema usando
diferentes vetores c .
Vejamos três esquemas possíveis para utilizar a MA27:
1) Apenas um tipo de matriz A e somente um vetor b . Nesse caso para resolver
o problema a rotina utiliza apenas uma etapa de análise (representado por An ), uma
etapa de fatoração (representado por Ft ) e uma etapa de solução (representado por
Sol ).
cAx = SolFtAn || (5.26)
2) Diferentes matrizes A , porém apresentando o mesmo padrão de esparsidade.
A rotina utiliza apenas uma etapa de análise ( An ), e sucessivas etapas de fatoração e
solução.
111 cxA =
222 cxA =
333 cxA =
SolFtSolFtSolFtAn |||||| (5.27)

59
3) Mesma matriz A e diferentes vetores b . Apenas uma etapa de análise, uma
etapa de fatoração e sucessivas etapas de solução.
11 cAx =
22 cAx =
33 cAx =
SolSolSolFtAn |||| (5.28)
O sistema gerado pelo FAIPA e que é descrito no Capítulo 2, pode ser
considerado simétrico. O esquema (5.28) será utilizado para a solução dos sistemas
internos ao FAIPA.
A implementação da rotina MA27 fez-se necessário para que o FAIPA pudesse
resolver sistemas com um número elevado de variáveis com o aproveitamento da
esparsidade.
5.6 – Rotina MA28 (HSL)
A MA28 integra também a coleção de rotinas escritas na linguagem Fortran para
computação científica de grande porte da Harwell Subroutine Library (HSL) [21]. A
rotina MA28 difere da MA27 no fato de ter sido desenvolvida para resolver sistemas de
equações não lineares assimétricos e esparsos. Esses sistemas são do tipo:
RHSAX = (5.29)
Onde:
A é uma matriz quadrada de ordem n , esparsa, não simétrica.
RHS contém os nrhs vetores c que compõem o lado direito.
X é a matriz que contém as nrhs soluções.
1≥nrhs .

60
A MA28 também permite que, após a realização das etapas de análise e de
fatoração, a etapa de solução possa ser chamada repetidamente para resolver o sistema
usando diferentes vetores c .
O sistema gerado pelo FAIPA, descrito no Capítulo 2, é originalmente
assimétrico. O esquema (5.26) será utilizado para a solução dos sistemas internos ao
FAIPA.
A implementação da rotina MA28 fez-se necessário para que o FAIPA pudesse
resolver sistemas não simétricos com um número elevado de variáveis com o
aproveitamento da esparsidade.
5.7 – Rotina SSTSTRF/S (CRAY SV1)
Desenvolvida para o sistema operacional UNICOS (derivado do sistema
operacional UNIX System V) do CRAY SV1, a rotina SSTSTRF/S é formada por duas
subrotinas principais: a SSTSTRF e a SSTSTRS [4].
Considerando o sistema descrito em (5.29), a rotina SSTSTRF/S realiza através
do método direto a resolução dos sistemas considerando as matrizes esparsas com
simetria de posição. Essa rotina apresenta, basicamente, quatro fases de execução [4]:
1) Reordenamento;
2) Fatoração Simbólica;
3) Determinação da seqüência de execução dos nós e do armazenamento exigido
para as matrizes frontais;
4) Fatoração numérica.
A rotina SSTSTRS resolve o sistema após a fatoração realizada pela SSTSTRF.
Na etapa de solução é possível resolver o sistema utilizando diferentes vetores que
compõem a matriz RHS , descrita em (5.29).
A implementação dessa rotina foi realizada para um melhor desempenho do
FAIPA em ambiente de alto desempenho, pois a SSTSTRF/S foi desenvolvida para
aproveitar ao máximo o ambiente de computação paralela e vetorial do CRAY SV1.

61
5.7 – Rotina SGETRF/S (LAPACK)
As rotinas LAPACK estão escritas em linguagem Fortran77 e permitem resolver
sistemas de equações lineares. Estão disponíveis rotinas para matrizes densas e de
banda, porém não existem opções para matrizes esparsas [4].
A rotina SGETRF/S é formada por duas subrotinas principais: a SGETRF e a
SGETRS.
Considerando o sistema:
RHSAX = (5.30)
Onde:
A é uma matriz densa quadrada de ordem n .
RHS contém os nrhs vetores c que compõem o lado direito.
X é a matriz que contém as nrhs soluções.
1≥nrhs .
Considerando o sistema descrito em (5.30), a rotina SGETRF realiza uma
fatoração LU utilizando pivoteamento com permutação de linhas.
A rotina SGETRS resolve o sistema após a fatoração realizada pela SGETRF.
Nessa etapa é possível resolver o sistema utilizando diferentes vetores que compõem a
matriz RHS .
O fato de poder ser utilizada tanto em máquinas seqüenciais como em um
computador de alto desempenho, como o CRAY SV1, tornou essa rotina muito mais
interessante, pois permitiu um melhor desempenho do FAIPA, ao resolver sistemas
densos, nos dois tipos de ambiente computacional.

62
CAPÍTULO 6
Resultados Numéricos
6.1 – Introdução
No presente capítulo, inicialmente é descrita a ferramenta CUTEr utilizada para
auxiliar na realização de testes numéricos com o FAIPA. Foram resolvidos alguns
problemas sem restrições e com restrições que indicam a funcionalidade da interface
CUTEr junto ao FAIPA.
Em seguida é feita a apresentação do problema HS43_NF que também auxiliará
na tarefa de realizar testes numéricos e foi escrito na linguagem FORTRAN 90.
Na etapa seguinte, através do problema HS43_NF, realizaram-se testes para
verificação do desempenho das rotinas MA27 e MA28 quando implementadas no
FAIPA. Essas rotinas permitem a resolução de sistemas lineares esparsos de grande
porte.
Logo depois, estão os resultados da Nova Técnica de Atualização Quase-Newton
Diagonal. Foram feitas comparações com as atualizações BFGS e de Memória
Limitada. Mostraremos os gráficos com as iterações do FAIPA quando este usou cada
uma das técnicas. Nessa etapa foram utilizados problemas de Hock e Schittkowski [28]
escritos na Linguagem Matlab.
Por fim, para a obtenção de resultados com problemas maiores através da
interface CUTEr ou com o HS43_NF, utilizou-se um computador AMD Atlon 1800
MHz com 1.5Gb de Memória RAM e, principalmente, o computador CRAY SV1 com
12 processadores e 16Gb de memória RAM. O acesso ao computador CRAY SV1 foi

63
feito através do NACAD-COPPE/UFRJ (Núcleo de Atendimento em Computação de
Alto Desempenho).
6.2 – CUTEr
O CUTEr (Constrained and Unconstrained Testing Environment revisited) [17]
é uma ferramenta que auxilia no projeto e desenvolvimento de softwares em otimização.
Para utilizar essa ferramenta são necessárias duas etapas: a decodificação e
criação da interface.
A plataforma de decodificação CUTEr é disponível para sistemas operacionais
UNIX e LINUX. No presente trabalho utilizou-se o sistema operacional LINUX durante
a etapa de decodificação.
A interface é um conjunto de rotinas escritas em FORTRAN 77 e FORTRAN 90
que devem ser adaptadas ao algoritmo de otimização para fornecer os dados referentes
aos problemas testes.
Os problemas testes disponíveis para a utilização na plataforma CUTEr durante
a etapa de decodificação estão escritos na linguagem SIF (Standard Input Format). A
plataforma CUTEr decodifica os arquivos SIF. O formato SIF é baseado na estrutura
chamada Separabilidade Parcial em Grupo. Uma função é dita parcialmente separável
em grupos se:
1) Puder ser escrita sob a forma:
( ) ( )( )∑=
=ng
iii xgxf
1
α (6.1)
onde ng é o número de grupos.
2) Cada função de grupo ( )αig for duas vezes continuamente diferenciável na
variável α .

64
3) A função
( ) [ ]( )∑∈
−+=ij
iti
jjjii bxaxyx
τ
ωα , (6.2)
é conhecida como i-ésimo grupo.
4) Cada um dos índices iτ é um subconjunto de ,,1 neK , onde ne é o número
de funções elemento não linear.
5) Cada função elemento não linear jy for duas vezes continuamente
diferenciável na variável [ ]jx .
6) O gradiente ia de cada função elemento linear iti bxa − é, em geral, esparsa.
7) Os ji,ω são conhecidos como peso.
O decodificador do CUTEr é utilizado para realizar a conversão do arquivo,
relativo a cada problema que está no formato SIF, para um conjunto de arquivos no
formato de dados (.dat) e Fortran77 (.f).
Uma interface entre o FAIPA e os arquivos gerados após a decodificação foi
escrita para que os problemas disponíveis na biblioteca CUTEr pudessem ser
otimizados.
A interface consiste em dois conjuntos distintos de arquivos. Um dos conjuntos
apresenta arquivos fixos, escritos na linguagem Fortran 77, que farão a manipulação dos
dados relativos a cada problema de otimização com restrições ou sem restrições. O
outro conjunto de arquivos será alterado para cada problema e depende do processo de
decodificação. Neste último conjunto, além dos arquivos em Fortran 77 há também um
arquivo dat que contém dados do problema, por exemplo, o ponto x inicial.

65
Para problemas sem restrições os arquivos fixos utilizados são os seguintes:
unames.f Obtêm o nome do problema e suas variáveis.
usetup.f Obtêm do arquivo dat os dados do problema que será minimização.
ufn.f Fornece o valor da função.
ugr.f Fornece o valor do gradiente da função.
Para problemas com restrições os arquivos fixos utilizados são os seguintes:
cnames.f Obtêm o nome do problema e suas variáveis.
csetup.f Obtêm do arquivo dat os dados do problema que será minimização.
cfn.f Fornece o valor da função e das restrições.
cgr.f Fornece o valor do gradiente da função e das restrições.
Para cada problemas, os arquivos gerados após a decodificação são os seguintes:
elfun.f Fornece valores das funções elemento não linear e respectivas derivadas.
group.f Fornece valores das funções de grupo e respectivas derivadas.
range.f Transforma variáveis elementares em internas.
outsdif.dat Contêm os dados do problema que será minimização.

66
6.3 – Resultados Numéricos – Interface FAIPA_CUTEr
Para verificar a funcionalidade da interface FAIPA_CUTEr foram
disponibilizados vários problemas sem restrições e com restrições.
Serão apresentados inicialmente nas Tabelas 6.1(a), 6.1(b) e 6.1(c) os resultados
de problemas resolvidos através do FAIPA com a interface de problemas teste CUTEr.
Nessa etapa a configuração do FAIPA utilizada foi a seguinte: atualização BFGS e
LAPACK Denso. A coluna nprob indica o número do problema na interface.
nprob nome variáveis restrições nbox )( xf iterações f eval.
101 HS01 2 0 1 1.24518E-05 37 69
103 HS03 2 0 1 4.65462E-10 17 18
104 HS04 2 0 2 2.6667E+00 6 7
105 HS05 2 0 4 -1.9232E+00 6 8
106 HS06 2 1 0 7.8888E-29 10 12
107 HS07 2 1 0 -1.7321E+00 15 35
108 HS08 2 2 0 -1.0000E+00 7 9
109 HS09 2 1 0 -5.0000E-01 6 7
110 HS10 2 1 0 -1.0000E+00 8 9
111 HS11 2 1 0 -8.4984E+00 11 13
112 HS12 2 1 0 -3.0000E+01 8 12
113 HS13 2 1 2 1.0010E+00 28 30
115 HS15 2 2 1 3.6038E+02 10 11
117 HS17 2 2 3 1.0000E+00 11 12
118 HS18 2 2 4 5.0000E+00 10 11
119 HS19 2 2 4 -6.9618E+03 16 22
121 HS21 2 1 4 -9.9960E+01 11 13
122 HS22 2 2 0 1.0000E+00 8 10
123 HS23 2 5 4 2.000E+00 11 12
124 HS24 2 3 2 -1.000E+00 15 18
126 HS26 3 1 0 2.8124E-07 20 45
127 HS27 3 1 0 4.0000E-02 20 30
Tabela 6.1(a): Problemas HS – FAIPA_CUTEr.

67
nprob nome variáveis restrições nbox )( xf iterações f eval.
128 HS28 3 1 0 0.0000E+00 4 6
129 HS29 3 1 0 -2.2627E+00 11 12
130 HS30 3 1 6 1.0000E+00 10 12
131 HS31 3 1 6 6.0000E+00 10 12
132 HS32 3 2 3 1.0000E+00 8 9
133 HS33 3 2 4 -4.5857E+00 14 17
134 HS34 3 2 6 -8.34032E-01 13 16
135 HS35 3 1 3 1.1111E-01 8 10
136 HS36 3 1 6 -3.3000E+03 14 18
137 HS37 3 2 6 -3.4560E+03 17 20
138 HS38 4 0 8 1.0357E-10 19 32
139 HS39 4 2 0 -1.0000E+00 14 14
140 HS40 4 3 0 -2.5000E-01 7 8
141 HS41 4 1 8 1.9259E+00 14 15
142 HS42 4 2 0 1.3858E+01 9 12
143 HS43 4 3 0 -4.4000E+01 12 16
144 HS44 4 6 4 -1.5000E+01 21 27
145 HS45 5 0 10 1.000E+01 24 25
147 HS47 5 3 0 1.36007E-10 29 72
148 HS48 5 2 0 1.60237E-29 4 11
149 HS49 5 2 0 7.0712E-06 17 23
150 HS50 5 3 0 3.23904E-12 17 32
151 HS51 5 3 0 0.0000E+00 3 7
152 HS52 5 3 0 5.3266E+00 6 9
153 HS53 5 3 10 4.0930E+00 7 9
156 HS56 7 4 0 -3.4560E+00 15 22
159 HS59 2 3 4 -6.7495E+00 17 18
160 HS60 3 1 6 3.2568E-02 10 13
163 HS63 3 2 3 9.6172E+02 11 14
164 HS64 3 1 3 6.2998E+03 21 23
165 HS65 4 2 6 9.5353E-01 14 15
166 HS66 4 2 6 5.18163E-01 9 10
171 HS71 4 2 8 1.7014E+01 11 13
172 HS72 4 2 8 7.2767E+02 34 40
173 HS73 4 3 4 2.9894E+01 17 19
Tabela 6.1(b): Problemas HS - FAIPA_CUTEr.

68
nprob nome variáveis restrições nbox )( xf iterações f eval.
174 HS74 4 5 8 5.1265E+03 13 14
175 HS75 4 5 8 5.1744E+03 32 37
176 HS76 4 3 4 -4.6818E+00 10 11
177 HS77 5 2 0 2.4151E-01 16 24
178 HS78 5 3 0 -2.9197E+00 8 10
179 HS79 5 3 0 7.8777E-02 12 14
180 HS80 5 3 10 5.3950E-02 8 9
181 HS81 5 3 10 5.3950E-02 10 12
183 HS83 5 6 10 -3.0665E+04 15 18
184 HS84 5 6 10 -5.2803E+06 21 22
186 HS86 5 10 5 -3.2349E+01 18 24
193 HS93 6 2 6 1.3508E+02 12 14
195 HS95 6 4 12 1.5619E-02 8 10
196 HS96 6 4 12 1.5619E-02 8 10
197 HS97 6 4 12 3.1358E+00 18 21
198 HS98 6 4 12 3.1358E+00 28 35
199 HS99 7 2 14 -8.3108E+08 13 27
200 HS100 7 4 0 6.8063E+02 15 17
204 HS104 8 6 16 3.9511E+00 28 29
207 HS107 9 6 8 5.0550E+03 16 21
208 HS108 9 13 1 5.0000E-01 14 17
210 HS110 10 0 20 -4.5778E+01 7 8
212 HS112 10 3 10 -4.6414E+01 19 20
218 HS118 15 29 30 6.6270E+02 45 54
Tabela 6.1(c): Problemas HS - FAIPA_CUTEr.

69
6.4 - Apresentação do Problema HS43_NF
Para testar as implementações no FAIPA, alterou-se o problema HS43 [28] para
permitir a mudança do número de variáveis e de restrições de tal forma a obtermos um
problema com um número elevado de variáveis.
O problema HS43 original tem 4 variáveis e 3 restrições. O novo problema, que
denominamos de HS43_NF, poderá ter o seu número de variáveis e de restrições
expandido por um valor nf definido pelo usuário.
Seja o problema HS43 original com restrições:
432124
23
22
21 721552)( xxxxxxxxxf +−+−+++= (6.3)
)8()( 432124
23
22
211 xxxxxxxxxg +−+−−−−−−= (6.4)
)2210()( 4124
23
22
212 xxxxxxxg ++−−−−−= (6.5)
)225()( 42123
22
213 xxxxxxxg ++−−−−−= (6.6)
Então, o problema HS43_NF pode ser definido da seguinte maneira:
( ) ∑=
−−−−−− +−+−+++=nf
iiiiiiiii xxxxxxxxxf
14142434
24
214
224
234 721552 (6.3)
Com restrições:
( ) )8( 414243424
214
224
23423 jjjjjjjjj xxxxxxxxxg +−+−−−−−−= −−−−−−− (6.4)
( ) )2210( 43424
214
224
23413 jjjjjjj xxxxxxxg ++−−−−−= −−−−− (6.5)
( ) )225( 424342
142
242
343 jjjjjjj xxxxxxxg ++−−−−−= −−−−− (6.6)
onde j = 1, ... nf .

70
6.5 – Resultados Numéricos – Comparação entre diferentes resolvedores internos
ao FAIPA.
Utilizou-se o problema HS43_NF para auxiliar na comparação entre os solvers
que resolvem em cada iteração os sistemas internos ao FAIPA. O solver, que
chamaremos de Denso Original, foi programado inicialmente no FAIPA e utiliza o
Método Direto para resolver sistemas densos não simétricos. Foi feita uma comparação
deste com os solvers MA27 e MA28.
Os resultados obtidos foram os seguintes:
FAIPA nf variáveis restrições tempo (s) ordem do sistemaDenso Original 174
MA28 59 MA27
100 400 300 17
700
Denso Original 770
MA28 210 MA27
150 600 450 62
1050
Denso Original 2334
MA28 545 MA27
200 800 600 141
1400
Denso Original 9158
MA28 1980 MA27
300 1200 900 464
2100
Denso Original 97215
MA28 9826 MA27
500 2000 1500 2238
3500
Denso Original -
MA28 84240 MA27
1000 4000 3000 19372
7000
Tabela 6.2: Problemas HS43_NF
De posse desses valores, foi possível obter os gráficos 6.1 e 6.2. No gráfico 6.1
estão plotados os tempos para a resolução de cada problema de acordo com o valor de nf
escolhido considerando os diferentes resolvedores implementados no FAIPA. O gráfico

71
6.2 indica o número de vezes em que a solução do problema com a MA27 é mais rápida
em relação aos outros resolvedores considerando a resolução, através do FAIPA, do
problema HS43_NF.
Com o solver Denso Original não foi possível resolver o problema com nf 1000.
HS43_NF
10
100
1000
10000
100000
0 100 200 300 400 500 600 700 800 900 1000 1100
NF
tem
po (s
)
OriginalMA28MA27
Gráfico 6.1
05
10
15202530
354045
0 100 200 300 400 500 600 700 800 900 1000 1100
NF
Original / MA27
MA28 / MA27
Gráfico 6.2

72
6.6 – Resultados Numéricos – FAIPA Quase-Newton Esparso.
Com a implementação da nova técnica de atualização esparsa feita na linguagem
Matlab, os resultados obtidos foram comparados com o FAIPA nas opções de
atualização de B através dos métodos Esparso, Memória Limitada, Quase-Newton, e
também considerando B sempre igual a matriz Identidade. Foram utilizados problemas
de Schittkowski [28]. Considerou-se igual a 7 a variável m que indica o número de
pares de vetores ks e ky utilizados na técnica de Memória Limitada. No entanto, na
técnica de atualização esparsa, considerou-se a variável m igual a 5.
Diagonal Mem. Lim. BFGS B=Identidade Prob. nvar ncstr Função iter. Função iter. Função iter. Função iter.HS01 2 0 7,1224E+00 300 1,3833E-05 37 2,0060E-07 36 8,3188E+00 300HS02 2 0 8,1451E-01 300 5,0427E-02 15 5,0428E-02 16 9,5098E-01 300HS03 2 0 3,0579E-04 300 3,6499E-04 14 3,5879E-04 15 9,8812E-04 300HS04 2 0 2,6667E+00 4 2,6667E+00 4 2,6667E+00 4 2,6667E+00 5 HS05 2 0 -1,913E+00 6 -1,913E+00 4 -1,913E+00 4 -1,913E+00 6 HS06 2 1 1,6798E-15 14 7,1808E-13 10 2,3268E-07 9 1,4402E-06 14 HS07 2 1 -1,732E+00 12 -1,732E+00 11 -1,732E+00 11 -1,732E+00 23 HS08 2 2 -1,000E+00 9 -1,000E+00 9 -1,000E+00 9 -1,000E+00 9 HS09 2 1 -4,999E-01 6 -5,000E-01 5 -5,000E-01 5 -4,999E-01 92 HS10 2 1 -1,000E+00 9 -1,000E+00 7 -1,000E+00 7 -1,000E+00 9 HS11 2 1 -8,498E+00 6 -8,498E+00 6 -8,498E+00 6 -8,498E+00 13 HS12 2 1 -2,999E+01 4 -3,000E+01 4 -3,000E+01 4 -2,998E+01 4 HS13 2 1 1,0021E+00 21 - - 1,0004E+00 14 - - HS14 2 2 1,3935E+00 6 1,3935E+00 7 1,3935E+00 7 1,3935E+00 6 HS15 2 2 3,0652E+02 6 3,0651E+02 6 3,0656E+02 6 3,0650E+02 7 HS16 2 2 2,4914E-01 51 2,5012E-01 18 2,5249E-01 18 2,5892E-01 21 HS17 2 2 1,0001E+00 15 1,0000E+00 19 1,0000E+00 20 1,0000E+00 28 HS18 2 2 5,0000E+00 14 5,0000E+00 12 5,0001E+00 13 5,0001E+00 49 HS19 2 2 -6,961E+03 83 -6,961E+03 76 -6,961E+03 114 -6,961E+03 65 HS20 2 3 3,8199E+01 9 3,8199E+01 10 3,8199E+01 9 3,8199E+01 9 HS21 2 1 -9,996E+01 4 -9,996E+01 4 -9,996E+01 4 -9,995E+01 7 HS22 2 2 1,0000E+00 9 1,0000E+00 10 1,0000E+00 10 1,0000E+00 9 HS23 2 5 2,0000E+00 9 2,0000E+00 9 2,0000E+00 9 2,0000E+00 9 HS24 2 3 -1,000E+00 4 -1,000E+00 4 -1,000E+00 4 -1,000E+00 4
Tabela 6.3 - Problemas HS.
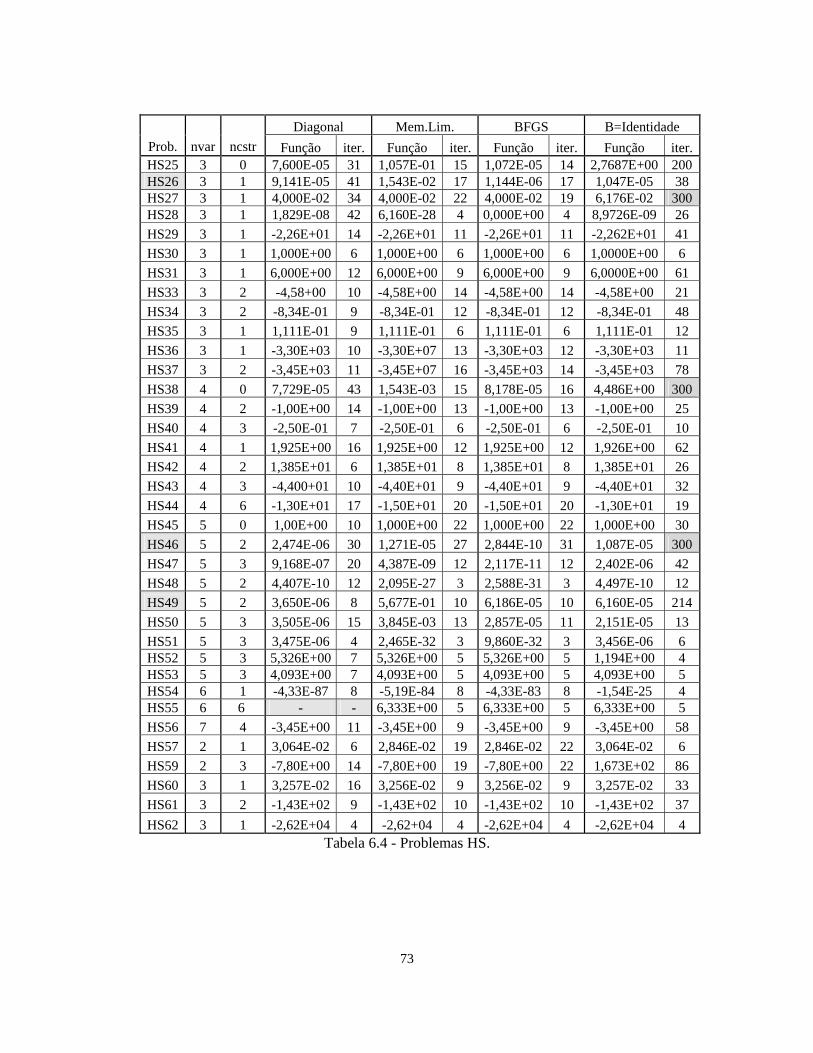
73
Diagonal Mem.Lim. BFGS B=Identidade Prob. nvar ncstr Função iter. Função iter. Função iter. Função iter.HS25 3 0 7,600E-05 31 1,057E-01 15 1,072E-05 14 2,7687E+00 200HS26 3 1 9,141E-05 41 1,543E-02 17 1,144E-06 17 1,047E-05 38 HS27 3 1 4,000E-02 34 4,000E-02 22 4,000E-02 19 6,176E-02 300HS28 3 1 1,829E-08 42 6,160E-28 4 0,000E+00 4 8,9726E-09 26 HS29 3 1 -2,26E+01 14 -2,26E+01 11 -2,26E+01 11 -2,262E+01 41 HS30 3 1 1,000E+00 6 1,000E+00 6 1,000E+00 6 1,0000E+00 6 HS31 3 1 6,000E+00 12 6,000E+00 9 6,000E+00 9 6,0000E+00 61 HS33 3 2 -4,58+00 10 -4,58E+00 14 -4,58E+00 14 -4,58E+00 21 HS34 3 2 -8,34E-01 9 -8,34E-01 12 -8,34E-01 12 -8,34E-01 48 HS35 3 1 1,111E-01 9 1,111E-01 6 1,111E-01 6 1,111E-01 12 HS36 3 1 -3,30E+03 10 -3,30E+07 13 -3,30E+03 12 -3,30E+03 11 HS37 3 2 -3,45E+03 11 -3,45E+07 16 -3,45E+03 14 -3,45E+03 78 HS38 4 0 7,729E-05 43 1,543E-03 15 8,178E-05 16 4,486E+00 300HS39 4 2 -1,00E+00 14 -1,00E+00 13 -1,00E+00 13 -1,00E+00 25 HS40 4 3 -2,50E-01 7 -2,50E-01 6 -2,50E-01 6 -2,50E-01 10 HS41 4 1 1,925E+00 16 1,925E+00 12 1,925E+00 12 1,926E+00 62 HS42 4 2 1,385E+01 6 1,385E+01 8 1,385E+01 8 1,385E+01 26 HS43 4 3 -4,400+01 10 -4,40E+01 9 -4,40E+01 9 -4,40E+01 32 HS44 4 6 -1,30E+01 17 -1,50E+01 20 -1,50E+01 20 -1,30E+01 19 HS45 5 0 1,00E+00 10 1,000E+00 22 1,000E+00 22 1,000E+00 30 HS46 5 2 2,474E-06 30 1,271E-05 27 2,844E-10 31 1,087E-05 300HS47 5 3 9,168E-07 20 4,387E-09 12 2,117E-11 12 2,402E-06 42 HS48 5 2 4,407E-10 12 2,095E-27 3 2,588E-31 3 4,497E-10 12 HS49 5 2 3,650E-06 8 5,677E-01 10 6,186E-05 10 6,160E-05 214HS50 5 3 3,505E-06 15 3,845E-03 13 2,857E-05 11 2,151E-05 13 HS51 5 3 3,475E-06 4 2,465E-32 3 9,860E-32 3 3,456E-06 6 HS52 5 3 5,326E+00 7 5,326E+00 5 5,326E+00 5 1,194E+00 4 HS53 5 3 4,093E+00 7 4,093E+00 5 4,093E+00 5 4,093E+00 5 HS54 6 1 -4,33E-87 8 -5,19E-84 8 -4,33E-83 8 -1,54E-25 4 HS55 6 6 - - 6,333E+00 5 6,333E+00 5 6,333E+00 5 HS56 7 4 -3,45E+00 11 -3,45E+00 9 -3,45E+00 9 -3,45E+00 58 HS57 2 1 3,064E-02 6 2,846E-02 19 2,846E-02 22 3,064E-02 6 HS59 2 3 -7,80E+00 14 -7,80E+00 19 -7,80E+00 22 1,673E+02 86 HS60 3 1 3,257E-02 16 3,256E-02 9 3,256E-02 9 3,257E-02 33 HS61 3 2 -1,43E+02 9 -1,43E+02 10 -1,43E+02 10 -1,43E+02 37 HS62 3 1 -2,62E+04 4 -2,62+04 4 -2,62E+04 4 -2,62E+04 4
Tabela 6.4 - Problemas HS.
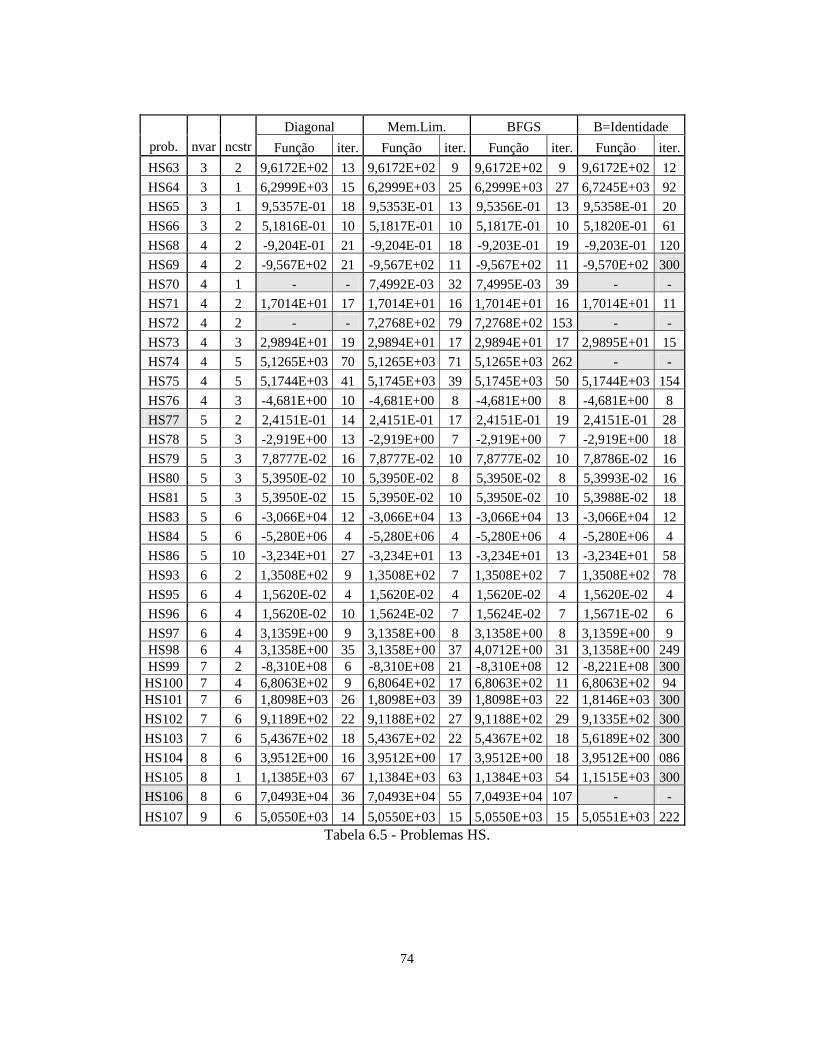
74
Diagonal Mem.Lim. BFGS B=Identidade prob. nvar ncstr Função iter. Função iter. Função iter. Função iter.HS63 3 2 9,6172E+02 13 9,6172E+02 9 9,6172E+02 9 9,6172E+02 12 HS64 3 1 6,2999E+03 15 6,2999E+03 25 6,2999E+03 27 6,7245E+03 92 HS65 3 1 9,5357E-01 18 9,5353E-01 13 9,5356E-01 13 9,5358E-01 20 HS66 3 2 5,1816E-01 10 5,1817E-01 10 5,1817E-01 10 5,1820E-01 61 HS68 4 2 -9,204E-01 21 -9,204E-01 18 -9,203E-01 19 -9,203E-01 120HS69 4 2 -9,567E+02 21 -9,567E+02 11 -9,567E+02 11 -9,570E+02 300HS70 4 1 - - 7,4992E-03 32 7,4995E-03 39 - - HS71 4 2 1,7014E+01 17 1,7014E+01 16 1,7014E+01 16 1,7014E+01 11 HS72 4 2 - - 7,2768E+02 79 7,2768E+02 153 - - HS73 4 3 2,9894E+01 19 2,9894E+01 17 2,9894E+01 17 2,9895E+01 15 HS74 4 5 5,1265E+03 70 5,1265E+03 71 5,1265E+03 262 - - HS75 4 5 5,1744E+03 41 5,1745E+03 39 5,1745E+03 50 5,1744E+03 154HS76 4 3 -4,681E+00 10 -4,681E+00 8 -4,681E+00 8 -4,681E+00 8 HS77 5 2 2,4151E-01 14 2,4151E-01 17 2,4151E-01 19 2,4151E-01 28 HS78 5 3 -2,919E+00 13 -2,919E+00 7 -2,919E+00 7 -2,919E+00 18 HS79 5 3 7,8777E-02 16 7,8777E-02 10 7,8777E-02 10 7,8786E-02 16 HS80 5 3 5,3950E-02 10 5,3950E-02 8 5,3950E-02 8 5,3993E-02 16 HS81 5 3 5,3950E-02 15 5,3950E-02 10 5,3950E-02 10 5,3988E-02 18 HS83 5 6 -3,066E+04 12 -3,066E+04 13 -3,066E+04 13 -3,066E+04 12 HS84 5 6 -5,280E+06 4 -5,280E+06 4 -5,280E+06 4 -5,280E+06 4 HS86 5 10 -3,234E+01 27 -3,234E+01 13 -3,234E+01 13 -3,234E+01 58 HS93 6 2 1,3508E+02 9 1,3508E+02 7 1,3508E+02 7 1,3508E+02 78 HS95 6 4 1,5620E-02 4 1,5620E-02 4 1,5620E-02 4 1,5620E-02 4 HS96 6 4 1,5620E-02 10 1,5624E-02 7 1,5624E-02 7 1,5671E-02 6 HS97 6 4 3,1359E+00 9 3,1358E+00 8 3,1358E+00 8 3,1359E+00 9 HS98 6 4 3,1358E+00 35 3,1358E+00 37 4,0712E+00 31 3,1358E+00 249HS99 7 2 -8,310E+08 6 -8,310E+08 21 -8,310E+08 12 -8,221E+08 300HS100 7 4 6,8063E+02 9 6,8064E+02 17 6,8063E+02 11 6,8063E+02 94 HS101 7 6 1,8098E+03 26 1,8098E+03 39 1,8098E+03 22 1,8146E+03 300HS102 7 6 9,1189E+02 22 9,1188E+02 27 9,1188E+02 29 9,1335E+02 300HS103 7 6 5,4367E+02 18 5,4367E+02 22 5,4367E+02 18 5,6189E+02 300HS104 8 6 3,9512E+00 16 3,9512E+00 17 3,9512E+00 18 3,9512E+00 086HS105 8 1 1,1385E+03 67 1,1384E+03 63 1,1384E+03 54 1,1515E+03 300HS106 8 6 7,0493E+04 36 7,0493E+04 55 7,0493E+04 107 - - HS107 9 6 5,0550E+03 14 5,0550E+03 15 5,0550E+03 15 5,0551E+03 222
Tabela 6.5 - Problemas HS.

75
Diagonal Mem.Lim. BFGS B=Identidade Prob. nvar ncstr Função iter. Função iter. Função iter. Função iter.
HS108 9 13 -5,000E-01 14 -5,000E-01 20 -5,000E-01 20 6,4036E-11 15 HS109 9 10 5,3621E+03 8 5,3621E+03 8 5,3621E+03 8 5,3621E+03 8 HS110 10 0 -4,577E+01 5 -4,577E+01 4 -4,577E+01 4 -4,577E+01 4 HS111 10 3 -4,776E+01 21 -4,776E+01 34 -4,776E+01 35 -4,776E+01 300HS112 10 3 -4,774E+01 8 -4,771E+01 11 -4,770E+01 11 -4,770E+01 38 HS113 10 8 2,4267E+01 31 2,4267E+01 28 2,4267E+01 24 2,4268E+01 53 HS114 10 11 -1,768E+03 99 -1,768E+03 105 -1,768E+03 116 -1,5534+03 150HS116 13 15 9,7589E+01 33 9,7588E+01 65 9,7589E+01 53 4,8883E-05 49 HS117 15 5 3,2349E+01 30 3,2349E+01 56 3,2349E+01 50 3,2349E+01 73 HS118 15 29 6,6482E+02 30 6,6483E+02 51 6,6483E+02 46 6,6506E+02 300HS119 16 8 2,4490E+02 44 2,4490E+02 100 2,4490E+02 77 3,7452E+04 300
Tabela 6.6 - Problemas HS.
Quando utilizou-se a atualização esparsa para resolver os problemas HS01,
HS02 e HS03, a convergência foi muito lenta e extrapolou o limite de 300 iterações.
Para a resolução dos problemas HS07, HS26, HS46, HS49, HS77, HS106 e HS114 foi
necessário alterar os critérios de parada e o número de pares de vetores ks e ky . Com
os problemas HS55, HS70 e HS72 não foi possível encontrar a solução.
Do Gráfico 6.3 ao Gráfico 6.14 estão representados de uma forma mais clara as
informações das Tabelas 6.3, 6.4, 6.5 e 6.6. Nesses gráficos foram plotados as iterações
que o FAIPA efetuou para resolver os problemas HS utilizando diferentes configurações
para a atualização da matriz B: a BFGS, a Diagonal (Esparsa) e de Memória Limitada.
Através desses gráficos podemos perceber que a atualização esparsa apresenta na
grande maioria dos casos um bom comportamento com relação ao número de iterações
quando comparado com os demais métodos utilizados.
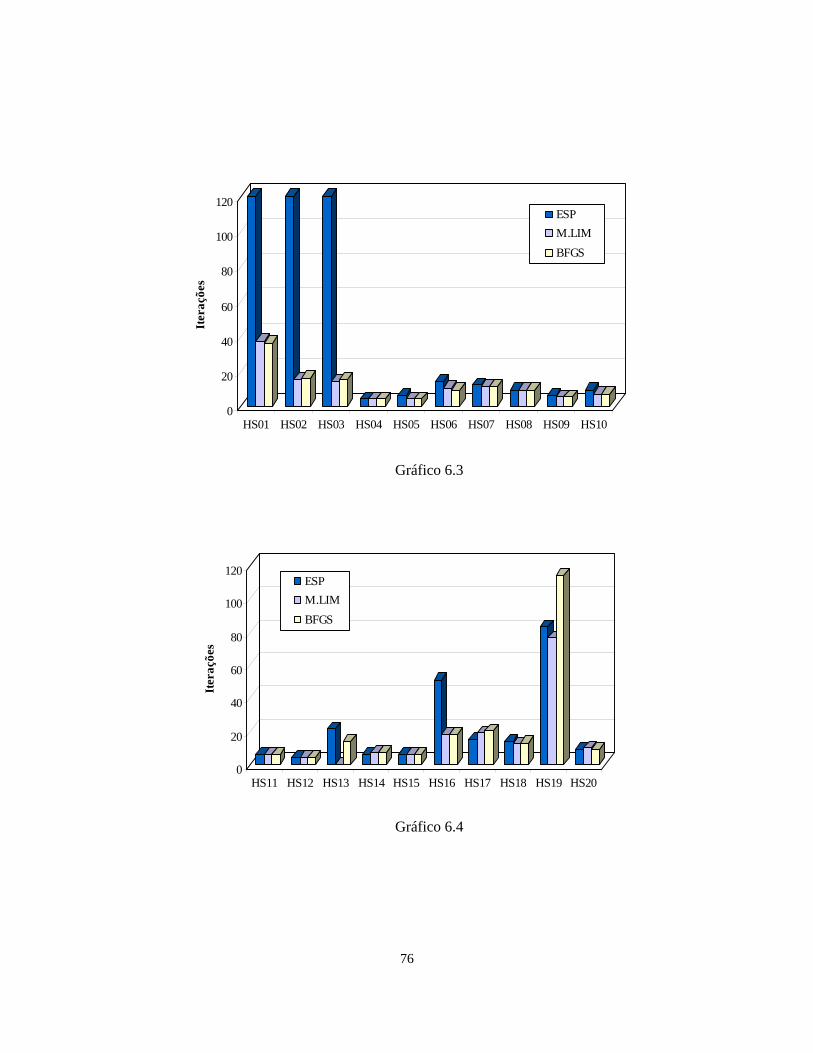
76
0
20
40
60
80
100
120It
eraç
ões
HS01 HS02 HS03 HS04 HS05 HS06 HS07 HS08 HS09 HS10
ESPM.LIMBFGS
Gráfico 6.3
0
20
40
60
80
100
120
Iter
açõe
s
HS11 HS12 HS13 HS14 HS15 HS16 HS17 HS18 HS19 HS20
ESPM.LIMBFGS
Gráfico 6.4

77
0
5
10
15
20
25
30
35
40
45It
eraç
ões
HS21 HS22 HS23 HS24 HS25 HS26 HS27 HS28 HS29 HS30
ESPM.LIMBFGS
Gráfico 6.5
0
5
10
15
20
25
30
35
40
45
Iter
açõe
s
HS31 HS32 HS33 HS34 HS35 HS36 HS37 HS38 HS39 HS40
ESPM.LIMBFGS
Gráfico 6.6
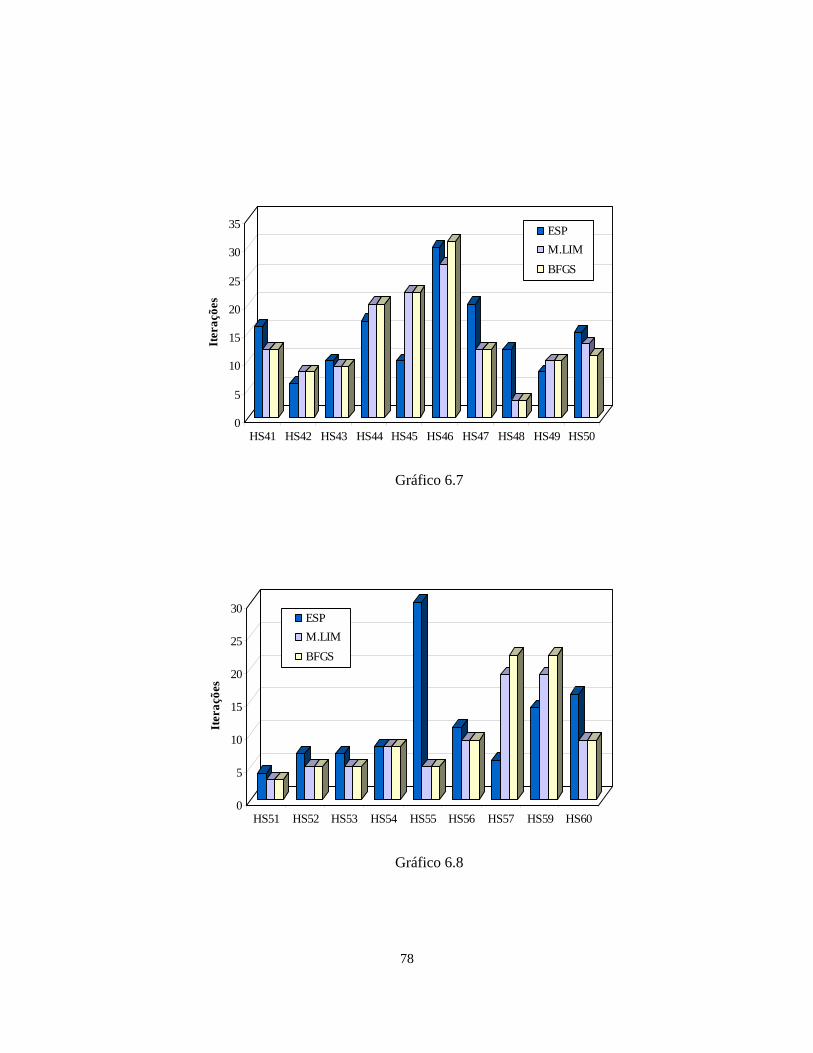
78
0
5
10
15
20
25
30
35It
eraç
ões
HS41 HS42 HS43 HS44 HS45 HS46 HS47 HS48 HS49 HS50
ESPM.LIMBFGS
Gráfico 6.7
0
5
10
15
20
25
30
Iter
açõe
s
HS51 HS52 HS53 HS54 HS55 HS56 HS57 HS59 HS60
ESPM.LIMBFGS
Gráfico 6.8
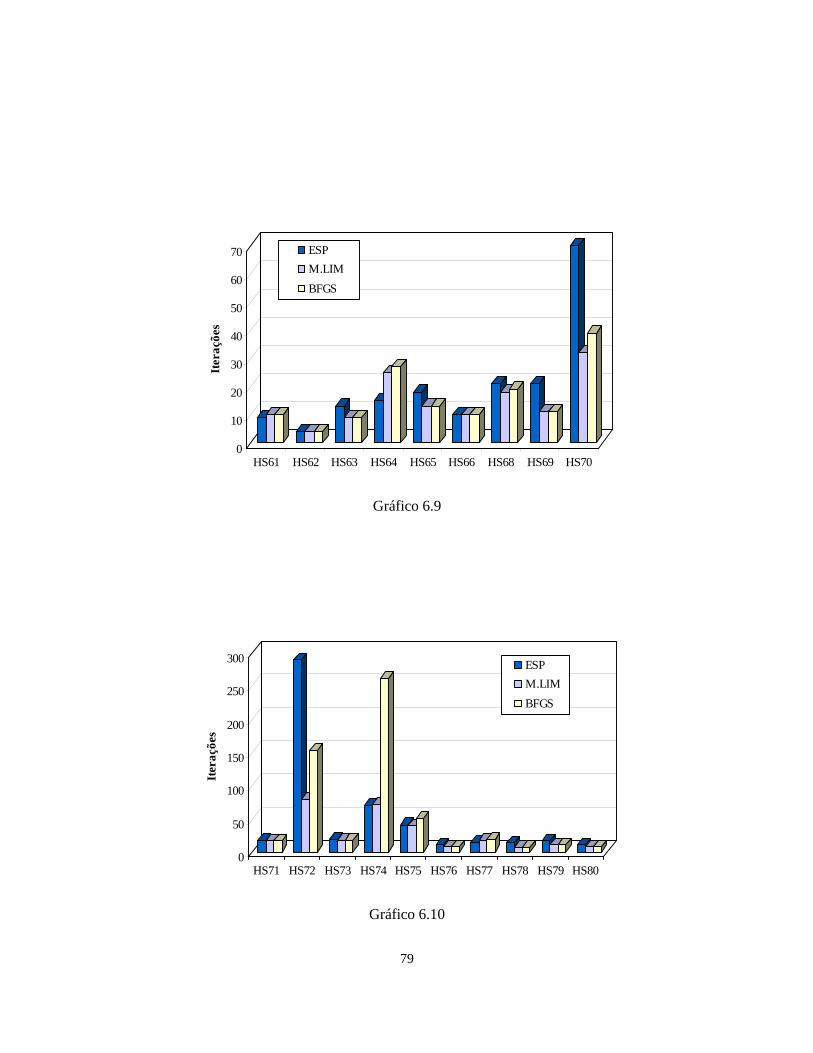
79
0
10
20
30
40
50
60
70
Iter
açõe
s
HS61 HS62 HS63 HS64 HS65 HS66 HS68 HS69 HS70
ESPM.LIMBFGS
Gráfico 6.9
0
50
100
150
200
250
300
Iter
açõe
s
HS71 HS72 HS73 HS74 HS75 HS76 HS77 HS78 HS79 HS80
ESPM.LIMBFGS
Gráfico 6.10
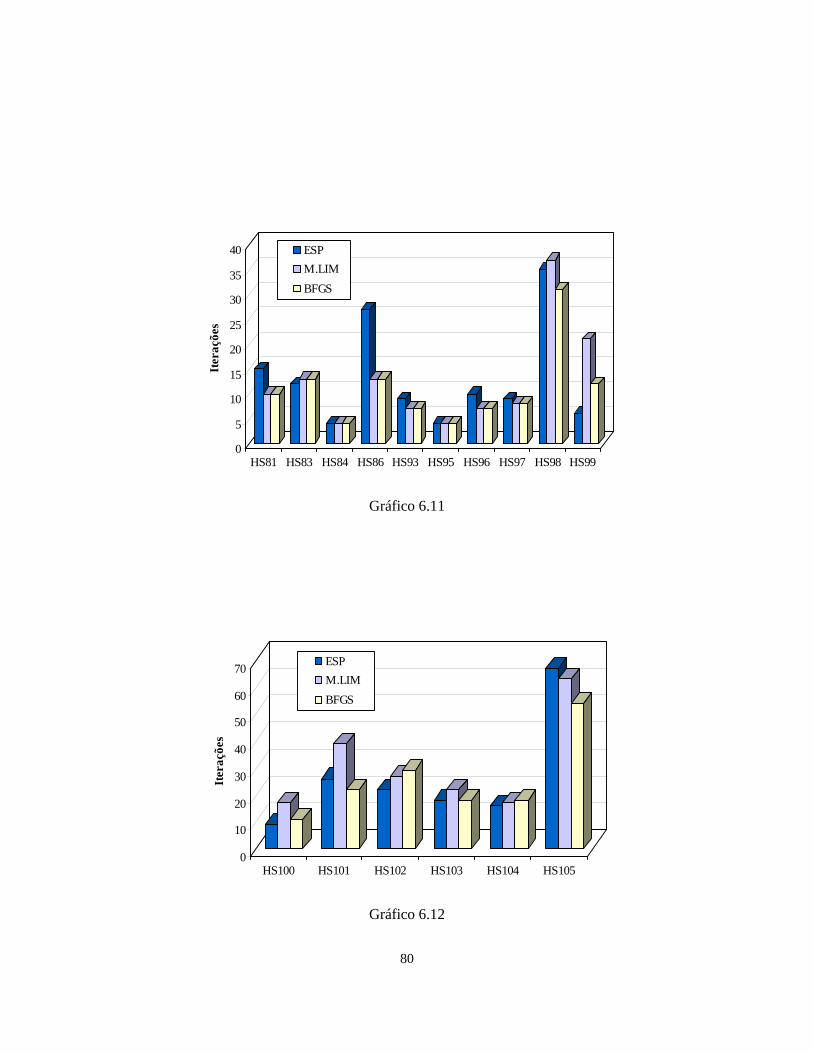
80
0
5
10
15
20
25
30
35
40
Iter
açõe
s
HS81 HS83 HS84 HS86 HS93 HS95 HS96 HS97 HS98 HS99
ESPM.LIMBFGS
Gráfico 6.11
0
10
20
30
40
50
60
70
Iter
açõe
s
HS100 HS101 HS102 HS103 HS104 HS105
ESPM.LIMBFGS
Gráfico 6.12

81
0
20
40
60
80
100
120It
eraç
ões
HS106 HS107 HS108 HS109 HS110 HS111
ESPM.LIMBFGS
Gráfico 6.13
0
20
40
60
80
100
120
Iter
açõe
s
HS112 HS113 HS114 HS116 HS117 HS118 HS119
ESPM.LIMBFGS
Gráfico 6.14
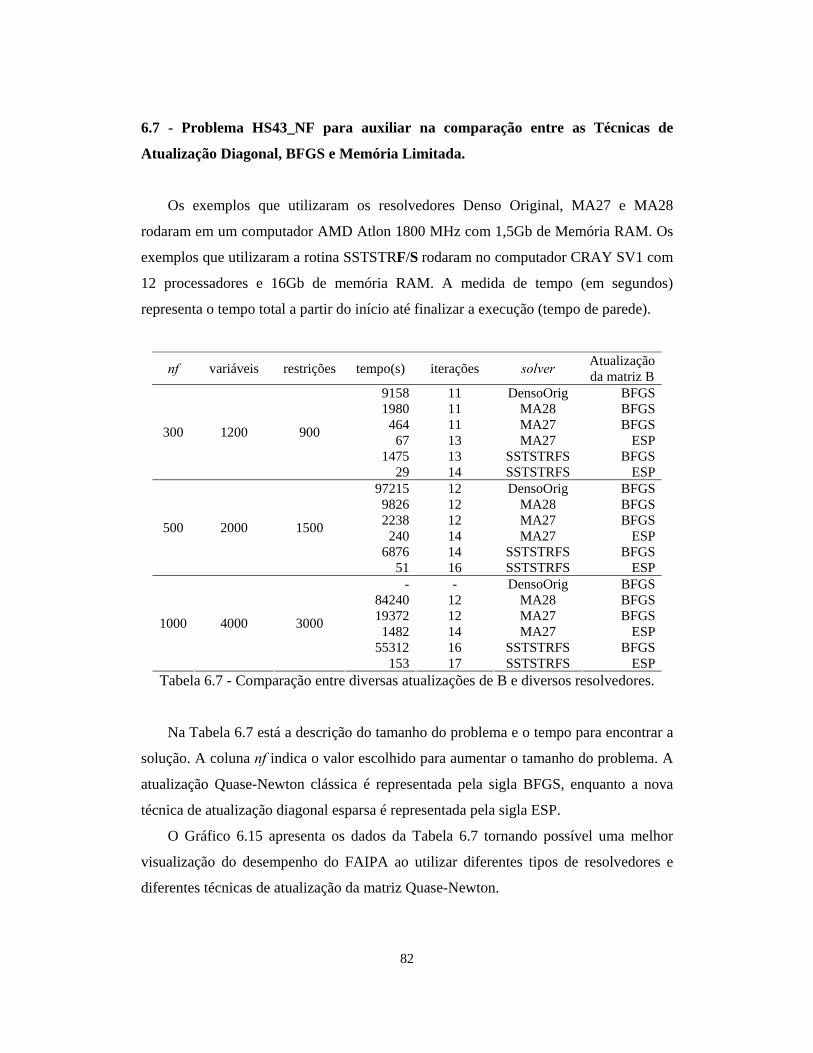
82
6.7 - Problema HS43_NF para auxiliar na comparação entre as Técnicas de
Atualização Diagonal, BFGS e Memória Limitada.
Os exemplos que utilizaram os resolvedores Denso Original, MA27 e MA28
rodaram em um computador AMD Atlon 1800 MHz com 1,5Gb de Memória RAM. Os
exemplos que utilizaram a rotina SSTSTRF/S rodaram no computador CRAY SV1 com
12 processadores e 16Gb de memória RAM. A medida de tempo (em segundos)
representa o tempo total a partir do início até finalizar a execução (tempo de parede).
nf variáveis restrições tempo(s) iterações solver Atualização da matriz B
9158 11 DensoOrig BFGS1980 11 MA28 BFGS
464 11 MA27 BFGS67 13 MA27 ESP
1475 13 SSTSTRFS BFGS
300 1200 900
29 14 SSTSTRFS ESP97215 12 DensoOrig BFGS9826 12 MA28 BFGS2238 12 MA27 BFGS
240 14 MA27 ESP6876 14 SSTSTRFS BFGS
500 2000 1500
51 16 SSTSTRFS ESP- - DensoOrig BFGS
84240 12 MA28 BFGS19372 12 MA27 BFGS1482 14 MA27 ESP
55312 16 SSTSTRFS BFGS
1000 4000 3000
153 17 SSTSTRFS ESPTabela 6.7 - Comparação entre diversas atualizações de B e diversos resolvedores.
Na Tabela 6.7 está a descrição do tamanho do problema e o tempo para encontrar a
solução. A coluna nf indica o valor escolhido para aumentar o tamanho do problema. A
atualização Quase-Newton clássica é representada pela sigla BFGS, enquanto a nova
técnica de atualização diagonal esparsa é representada pela sigla ESP.
O Gráfico 6.15 apresenta os dados da Tabela 6.7 tornando possível uma melhor
visualização do desempenho do FAIPA ao utilizar diferentes tipos de resolvedores e
diferentes técnicas de atualização da matriz Quase-Newton.

83
10
100
1000
10000
100000
300 500 1000
NF
Tem
po (s
)
MA28/BFGSSSTSTRFS/BFGSMA27/BFGSMA27/ESPSSTSTRFS/ESP
Gráfico 6.15 – Desempenho do FAIPA para resolver o problema HS43_NF
utilizando a atualização Esparsa e BFGS.
Considerando valores maiores de nf, a atualização BFGS deixa de ser viável
devido ao seu alto custo computacional. Nesses casos iremos comparar as técnicas
Diagonal e de Memória Limitada através do CRAY SV1. O FAIPA_Esparso nesse caso
usou o solver SSTSTRF/S enquanto o FAIPA com a opção Memória Limitada usou o
solver SGETRF/S do LAPACK. A redução no tempo quando se utiliza a técnica
diagonal esparsa é muito grande. Os dados dessa comparação estão na Tabela 6.8.
nf variáveis restrições iter F tempo(s) CPUtime(s)
1500 6000 4500 16 66000 32832 294636,4
2000 8000 6000 17 88000 13164 107678,7MemLim
3000 12000 9000 15 132000 83586 821123,2
1500 6000 4500 16 66000 257 1039,1
2000 8000 6000 16 88000 412 1118,6Diagonal
3000 12000 9000 13 132000 759 2121,5
Tabela 6.8 - Comparação entre as atualizações Diagonal Esparsa e Memória Limitada.
Destaque para os tempos para resolver o problema nf 3000.
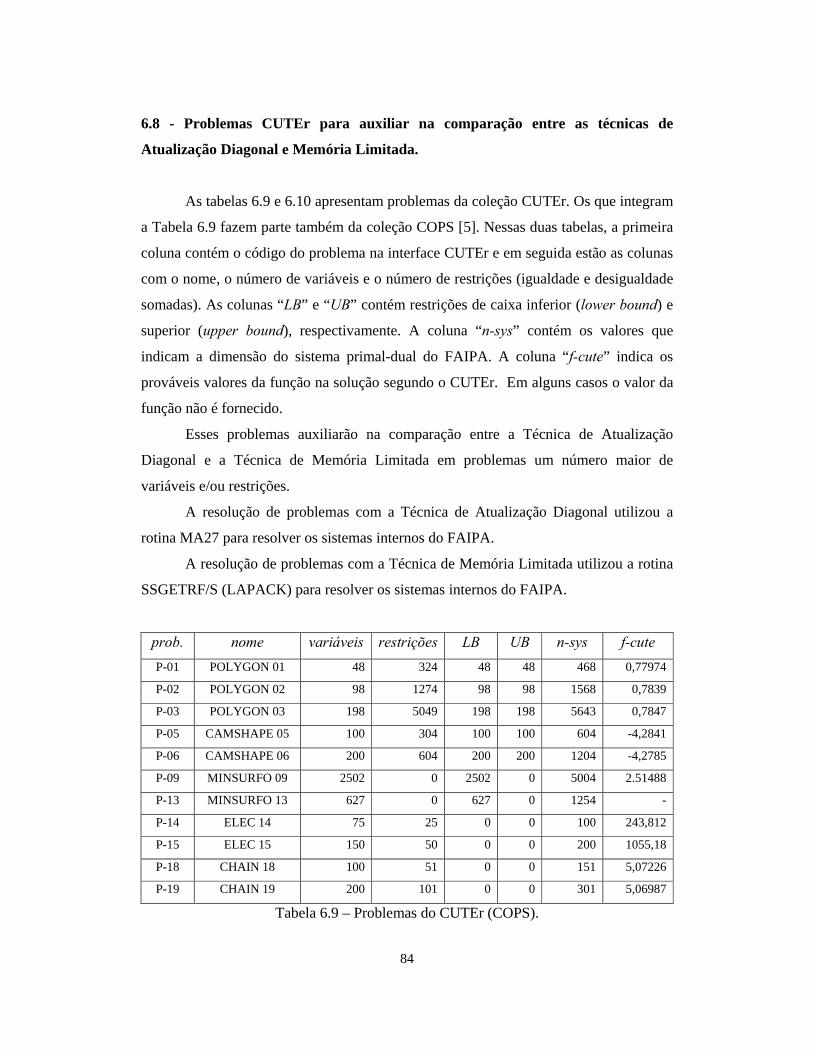
84
6.8 - Problemas CUTEr para auxiliar na comparação entre as técnicas de
Atualização Diagonal e Memória Limitada.
As tabelas 6.9 e 6.10 apresentam problemas da coleção CUTEr. Os que integram
a Tabela 6.9 fazem parte também da coleção COPS [5]. Nessas duas tabelas, a primeira
coluna contém o código do problema na interface CUTEr e em seguida estão as colunas
com o nome, o número de variáveis e o número de restrições (igualdade e desigualdade
somadas). As colunas “LB” e “UB” contém restrições de caixa inferior (lower bound) e
superior (upper bound), respectivamente. A coluna “n-sys” contém os valores que
indicam a dimensão do sistema primal-dual do FAIPA. A coluna “f-cute” indica os
prováveis valores da função na solução segundo o CUTEr. Em alguns casos o valor da
função não é fornecido.
Esses problemas auxiliarão na comparação entre a Técnica de Atualização
Diagonal e a Técnica de Memória Limitada em problemas um número maior de
variáveis e/ou restrições.
A resolução de problemas com a Técnica de Atualização Diagonal utilizou a
rotina MA27 para resolver os sistemas internos do FAIPA.
A resolução de problemas com a Técnica de Memória Limitada utilizou a rotina
SSGETRF/S (LAPACK) para resolver os sistemas internos do FAIPA.
prob. nome variáveis restrições LB UB n-sys f-cute P-01 POLYGON 01 48 324 48 48 468 0,77974
P-02 POLYGON 02 98 1274 98 98 1568 0,7839
P-03 POLYGON 03 198 5049 198 198 5643 0,7847
P-05 CAMSHAPE 05 100 304 100 100 604 -4,2841
P-06 CAMSHAPE 06 200 604 200 200 1204 -4,2785
P-09 MINSURFO 09 2502 0 2502 0 5004 2.51488
P-13 MINSURFO 13 627 0 627 0 1254 -
P-14 ELEC 14 75 25 0 0 100 243,812
P-15 ELEC 15 150 50 0 0 200 1055,18
P-18 CHAIN 18 100 51 0 0 151 5,07226
P-19 CHAIN 19 200 101 0 0 301 5,06987
Tabela 6.9 – Problemas do CUTEr (COPS).

85
prob. nome variáveis restrições LB UB n-sys f-cute P-34 KSIP 34 20 1001 0 0 1021 0,57579
P-35 YAO 35 2000 2000 1 0 4001 197,705
P-37 BIGGSB1 37 5000 0 4999 4999 14998 0,015
P-47 GASOIL 47 1301 1298 3 0 2602 0,005236
P-48 CVXBQP1 48 100 0 100 100 300 227,25
P-49 BIGGSB1 49 100 0 99 99 298 0,015
P-53 SVANBERG 53 100 100 100 100 400 166,1972
P-54 GASOIL 54 2601 2598 3 0 5202 0,005236
P-55 CVXBQP1 55 1000 0 1000 1000 3000 -
P-56 BIGGSB1 56 1000 0 999 999 2998 0,015
P-57 GILBERT 57 1000 1 1 0 1002 482,0273
P-60 SVANBERG 60 1000 1000 1000 1000 4000 1671,43
Tabela 6.10 – Problemas do CUTEr.
Para uma melhor compreensão dos resultados, os problemas foram divididos em
quatro grupos.
O Grupo 1 é formado pelos problemas: ELEC 14, ELEC 15, CHAIN 18,
CHAIN 19, CAMSHAPE 05 e CAMSHAPE 06.
O Grupo 2 é formado pelos problemas: POLYGON 01, POLYGON 02,
POLYGON 03, MINSURFO 09 e MINSURFO 13.
O Grupo 3 é formado pelos problemas: KSIP 34, CVXBQP 48, BIGGSB1 49,
SVANBERG 53 e GILBERT 57.
O Grupo 4 é formado pelos problemas: YAO 35, BIGGSB1 37, GASOIL 54,
CVXBQP1 55, SVANBERG 60 e GASOIL 47.

86
Para cada problema será apresentado o número de iterações, o tempo (em
segundos) e o valor da função de acordo com a solução obtida com cada uma das
técnicas consideradas na comparação. De posse dos valores das iterações e do tempo de
cada problema, foram criados gráficos para visualizar melhor os resultados de cada
grupo de problemas.
As tabelas 6.11, 6.12, 6.13 e 6.14 apresentam os resultados obtidos com os
grupos 1, 2, 3 e 4 respectivamente. A coluna δ contém os valores desse parâmetro da
atualização diagonal considerado em cada problema.
Atualização Diagonal Memória Limitada
nome n_sys δ it. t (s) f it. t (s) f ELEC 14 100 1 119 6 243,813 183 2 243,813
ELEC 15 200 1 291 30 1055,18 458 20 1055,18
CHAIN 18 151 0,1 537 4 5,0772 1585 48 5,0732
CHAIN 19 301 0,1 679 21 5,0775 2000 369 5,0768
CAMSHAPE 05 604 0,01 19 1 -4,2841 35 181 -4,2840
CAMSHAPE 06 1204 0,01 7 1 -4,2782 10 404 -4,2769
Tabela 6.11 – Resultados obtidos com os problemas do Grupo 1.
Atualização Diagonal Memória Limitada
nome n_sys δ it. t (s) f it. t (s) f POLYGON 01 468 0,01 28 1 -0,77967 42 112 -0,77971
POLYGON 02 1568 0,01 30 10 -0,78368 25 2704 -0,78338
POLYGON 03 5643 0,01 37 56 -0,78453 18 18172 -0,78443
MINSURFO 09 5004 1 56 71 2,52 178 231600(*) 2,52705
MINSURFO 13 1254 1 195 18 2,5291 147 3131 2,5289
Tabela 6.12 – Resultados obtidos com os problemas do Grupo 2.

87
Atualização Diagonal Memória Limitada
nome n_sys δ it. t (s) f it. t (s) f KSIP 34 1021 0,1 21 3 0,57579 22 679 0,57581
CVXBQP1 48 300 0,1 15 0 227,250 89 41 227,253
BIGGSB1 49 298 0,1 819 3 0,01509 72 33 0,01508
SVANBERG 53 400 1 52 2 166,197 43 56 166,197
GILBERT 57 1002 1 71 25 482,027 77 1 482,027
Tabela 6.13 – Resultados obtidos com os problemas do Grupo 3.
Atualização Diagonal Memória Limitada
nome n_sys δ it. t (s) f it. t (s) f YAO 35 4001 0,1 30 224 227,074 - - -
BIGGSB1 37 14998 0,1 881 4632 0,01592 1 43000 (*) 0,6711
GASOIL 54 5202 0,01 380 4809 0,005241 37 43000 (*) 34,1902
CVXBQP1 55 3000 0,1 31 7 22522,5 116 43000 (*) 102553
BIGGSB1 56 2998 0,1 881 201 0,01592 919 415200 0,01582
SVANBERG 60 4000 0,1 311 717 1671,43 34 43000 (*) 1936,58
GASOIL 47 2602 0,01 179 486 0,005241 37 43000 (*) 34,1902
Tabela 6.14 – Resultados obtidos com os problemas do Grupo 4. Os tempos com a
indicação (*) atingiram o limite máximo de 12 horas.
Ao resolver os problemas da Tabela 6.11 ELEC 14 e ELEC 15 com a Técnica de
Atualização Diagonal, foi necessário um menor número de iterações em relação a
Técnica de Memória Limitada. Com os problemas CHAIN 18, CHAIN 19,
CAMSHAPE 05 e CAMSHAPE 06 a Técnica de Memória Limitada apresentou mais
iterações que a Técnica de Atualização Diagonal. A Técnica de Memória Limitada foi
mais rápida que a esparsa nos problemas ELEC 14 e 15, e mais demorada nos demais
problemas da Tabela 6.11.

88
Na Tabela 6.12 a Técnica de Atualização Diagonal foi mais rápida em todos os
casos. A Técnica de Memória Limitada ao resolver o MINSURFO 09 demorou mais de
dois dias para obter a solução, enquanto a Técnica Esparsa resolveu em 71 segundos.
Na Tabela 6.13 os problemas KSIP 34 e CVXBQP1 48 ao serem resolvidos com
a Técnica Esparsa apresentaram menos iterações e menor tempo. No entanto o
BIGGSB1 49 apresentou muitas iterações para atingir a solução, mesmo assim com
tempo menor que o obtido com Memória Limitada. A Técnica de Memória Limitada foi
bem mais rápida que a Atualização Diagonal ao resolver o GILBERT 57.
Na Tabela 6.14 a Técnica de Atualização Diagonal foi significativamente mais
rápida que a Memória Limitada. Com a Diagonal, nenhum dos problemas foi resolvido
com mais de duas horas. Com Memória Limitada considerou-se um limite de doze horas
para término da execução. A exceção foi o problema BIGGSB1 56, o qual foi permitido
obter a solução após cinco dias aproximadamente. O problema YAO 35, que não
apresenta ponto inicial viável, ao ser resolvido com Memória Limitada, um ponto viável
é obtido, porém a execução é encerrada sem apresentar nenhuma iteração.
Percebe-se que, com o aumento do tamanho dos problemas, a Técnica de
Memória Limitada exige um tempo cada vez maior que a Técnica de Atualização
Diagonal, tornando-a inviável em computadores seqüenciais.
Uma desvantagem da Técnica Quase-Newton Diagonal é a determinação do
valor δ mais adequado para cada problema. No entanto, a rapidez com a qual essa
técnica permite a atualização de B em problemas grandes, a torna interessante em
estudos que visam melhorar ainda mais a sua eficiência na resolução de problemas de
otimização de grande porte.
A seguir estão os gráficos que apresentam o número de iterações e o tempo (em
segundos) para cada problema.
Nesses gráficos, a indicação ESP se refere à Técnica de Atualização Diagonal,
enquanto que a indicação ML se refere à Técnica de Memória Limitada.

89
0200400600800
100012001400160018002000
Iter
açõe
s
ELEC 14
ELEC 15
CHAIN 1
8
CHAIN 19
CAMSHAPE 05
CAMSHAPE 06ESP
ML
Gráfico 6.16 – Comparação entre a Atualização Diagonal e Memória Limitada
considerando o número de iterações utilizando os problemas da Tabela 6.7
050
100150200250300350400450
Tem
po (s
)
ELEC 14
ELEC 15
CHAIN 1
8
CHAIN 19
CAMSHAPE 05
CAMSHAPE 06ESP
ML
Gráfico 6.17 – Comparação entre a Atualização Diagonal e Memória Limitada
considerando o tempo para atingir a solução, utilizando os problemas da Tabela 6.7

90
020406080
100120140160180200
Iter
açõe
s
POLYGON 01
POLYGON 02
POLYGON 03
MINSURFO 09
MINSURFO 13
ESP
ML
Gráfico 6.18 – Comparação entre a Atualização Diagonal e de Memória Limitada
considerando o número de iterações utilizando os problemas da Tabela 6.8
0500
100015002000250030003500400045005000
Tem
po (s
)
POLYGON 01
POLYGON 02
POLYGON 03
MINSURFO
09
MINSURFO
13
ESP
ML
Gráfico 6.19 – Comparação entre a Atualização Diagonal e Memória Limitada
considerando o tempo para atingir a solução, utilizando os problemas da Tabela 6.8

91
0100200300400500600700800900
Iter
açõe
s
KSIP 34
CVXBQP1 48
BIGGSB1 4
9
SVANBERG 53
GILBERT 57
ESP
ML
Gráfico 6.20 – Comparação entre a Atualização Diagonal e Memória Limitada
considerando o número de iterações utilizando os problemas da Tabela 6.9
0
100
200
300
400
500
600
700
Tem
po (s
)
KSIP 34
CVXBQP1 48
BIGGSB1 4
9
SVANBERG 53
GILBERT 57
ESP
ML
Gráfico 6.21 – Comparação entre a Atualização Diagonal e Memória Limitada
considerando o tempo para atingir a solução, utilizando os problemas da Tabela 6.9

92
0100
200300400
500600700
800900
1000
Iter
açõe
s
YAO 35
BIGGSB1 3
7
GASOIL 54
CVXBQP1 55
BIGGSB1 5
6
SVANBERG 60
GASOIL 47
ESP
ML
Gráfico 6.22 – Comparação entre a Atualização Diagonal e de Memória Limitada
considerando o número de iterações utilizando os problemas da Tabela 6.10
0
2000
4000
6000
8000
10000
12000
14000
16000
Tem
po (s
)
YAO 35
BIGGSB1 3
7
GASOIL 54
CVXBQP1 55
BIGGSB1 5
6
SVANBERG 60
GASOIL 47
ESP
ML
Gráfico 6.23 – Comparação entre a Atualização Diagonal e Memória Limitada
considerando o tempo para atingir a solução, utilizando os problemas da Tabela 6.10

93
CAPÍTULO 7
Conclusões e Propostas
Obteve-se uma atualização Quase-Newton que produz matrizes esparsas e
definidas positivas para que algoritmos de otimização, como o FAIPA, possam garantir
convergência. Além disso, a Técnica de Atualização Diagonal apresenta um reduzido
custo computacional e aumenta o número de elementos nulos da matriz do sistema
primal-dual do FAIPA, permitindo um melhor aproveitamento de solvers esparsos
reduzindo ainda mais o custo computacional ao resolver problemas de grande porte.
Em linguagem Matlab foram feitos os primeiros testes que confirmaram a
viabilidade da técnica, pois se obteve bons resultados, em problemas pequenos, quando
comparada com as técnicas de atualização BFGS e Memória Limitada. Em poucos
casos a convergência foi lenta (HS01, HS02 e HS03) ou não apresentou solução (HS55,
HS70 e HS72).
Simultaneamente a essa etapa, foi feita a implementação da ferramenta CUTEr
(basicamente em Linguagem FORTRAN 90) que permite resolver problemas pequenos,
médios e de grande porte juntamente com o FAIPA. Inicialmente foram resolvidos
problemas pequenos do tipo HS [28] para certificar-se de que a interface estava
funcionando e posteriormente auxiliar no fornecimento de problemas de grande porte.
Quando foi feita a comparação com problemas maiores (HS43_NF) as Tabelas 6.7
e 6.8 [22] indicaram uma superioridade da Técnica de Atualização Diagonal, com
relação a redução no tempo necessário para resolver cada problema, quando comparada
com as técnicas BFGS e Memória Limitada.

94
Na Tabela 6.8 [22] foram executados problemas maiores em ambiente de
computação de alto desempenho (CRAY SV1). O destaque dessa tabela é o valor nf =
3000 que gera um problema cujos sistemas lineares internos ao FAIPA apresentam
21000 equações. Ao utilizar Memória Limitada para resolver esse problema obteve-se a
solução em 83586 segundos, enquanto com a Técnica de Atualização Diagonal o tempo
foi de 759 segundos, em ambos os casos o número de iterações foram parecidos. Com o
BFGS Clássico, mesmo em ambiente de computação de alto desempenho, não foi
possível obter resultados com problemas desse porte.
Ao utilizar a ferramenta CUTEr com problemas amplamente utilizado para testar
algoritmos de otimização, como o FAIPA, preparou-se um conjunto de problemas para
comparar as Técnicas de Memória Limitada e a Técnica de Atualização Diagonal.
Nessa etapa foi utilizado um computador AMD 1800MHz 1.5Gb, pois o computador
CRAY SV1 estava desativado definitivamente.
Os resultados contidos nas Tabelas 6.11, 6.12 e 6.13 indicaram que a Técnica
Quase-Newton de Atualização Diagonal geralmente apresenta desempenho melhor no
que diz respeito ao tempo consumido para a resolução desses problemas, apresentando,
de modo geral, bons resultados quanto ao número de iterações.
Na Tabela 6.14 a Técnica de Atualização Diagonal destacou-se muito quanto à
rapidez para obter a solução em problemas com um número maior de equações. Nesse
conjunto de problemas a Técnica Diagonal não apresentou nenhuma situação em que
houvesse necessidade de mais de duas horas para encontrar a solução.
A Técnica de Memória Limitada se mostrou muito demorada quando se trata de
problemas com um número maior de equações como os apresentados na Tabela 6.14.
Em todos os problemas dessa tabela não é possível obter solução com um tempo inferior
a doze horas. Possivelmente a resolução de cada um desses problemas se prolongará por
um dia ou mais, haja vista que no problema SVANBERG 60 essa técnica demorou
aproximadamente cinco dias para encontrar a solução.
Apesar do bom desempenho apresentado pela Técnica de Atualização Diagonal,
alguns ajustes podem ser feitos para melhorar essa técnica. Dentre elas está o modo de
obtenção do parâmetro que precisa ser feita com uma técnica que funcione em todos os
casos.

95
A utilização de computadores de alto desempenho como o ALTIX SGI,
disponível a partir de junho de 2005 através do Núcleo de Atendimento em Computação
de Alto Desempenho (NACAD-COPPE/UFRJ), permitirá um melhor aproveitamento
das técnicas apresentadas nesse trabalho, uma vez que o computador CRAY SV1 foi
desativado em novembro de 2004.

96
CAPÍTULO 8
Referências Bibliográficas
[1] BURDAKOV, O. P., MARTÍNEZ, J. M. and PILOTTA, E. A., “A Limited-Memory
Multipoint Symmetric Secant Method for Bound Constrained Optimization”, Annals of
Operations Research, v. 117, pp. 51-70, Kluwer Academics Publishers, Netherdlands,
2003.
[2] BYRD R. H., NOCEDAL J., and SCHNABEL R. B., “Representations of Quasi-
Newton Matrices and Their use in Limited Memory Methods”, Mathematical
Programming v. 63, pp. 129-156, 1994.
[3] CANELAS, A., Técnicas de Ponto Interior para Sistemas de Equações e
Otimização Não-Linear, Tese de M.Sc., COPPE/UFRJ, Rio de Janeiro, RJ, Brasil,
2005.
[4] CRAYDOC, Scientific Libraries User’s Guide, Cray Inc., USA, 2002.
[5] DOLAN, E.D., MORÉ, J.J. and MUNSON, T.S., Benchmarking Optimization
Software with COPS 3.0, Technical Report ANL/MCS-TM-273, Argonne National
Laboratory, Illinois, USA, February, 2004.

97
[6] DUFF, I.S. and REID, J.K., The “Multifrontal Solution of Indefinite Sparse
Symmetric Linear Equations”, ACM Transactions on Mathematical Software v. 9, n. 3,
pp. 302-325, Sep. 1983.
[7] DUFF, I.S., ERISMAN, A.M. and REID, J.K., Directs Methods for Sparse
Matrices. Oxford, England, Oxford University Press, 1986.
[8] DUFF, I.S., Direct Methods, Technical Report RAL-TR-1998-054, Rutherford
Appleton Laboratory, 1998.
[9] DUFF, I.S., Matrix Methods, Technical Report RAL-TR-1998-076, Rutherford
Appleton Laboratory, 1998.
[10] DUBEUX, V.J.C., Técnicas de Programação Não-Linear para Otimização de
Grande Porte, Tese de D.Sc., COPPE/UFRJ, Rio de Janeiro, RJ, Brasil, 2005.
[11] DENNIS, J. E. and SCHNABEL, R. B., Numerical Methods for Unconstrained
Optimization and Nonlinear Equations. New York, Prentice-Hall, 1983.
[12] DONGARRA, J. J., DUFF, I. S., SORENSEN, D. C. and VORST, H. A., Solving
Linear Systems on Vector and Shared Memory Computers. Philadelphia, USA, SIAM,
1993.
[13] FLETCHER, R., “An Optimal Positive Definite Update for Sparse Hessian
Matrices”, SIAM Journal on Optimization, v. 5, n. 1, pp. 192-218, Feb. 1995.
[14] FLETCHER, R., GROTHEY, A. and LEYFFER, S., Computing Sparse Hessian
and Jacobian Approximations with Hereditary Properties, Tech. Report, Department of
Mathematics, University of Dundee, 1996.
[15] GEORGE, A. and LIU, J.W.H, Computer Solution of Large Sparse Positive
Definite Systems, Englewood Cliffs, New Jersey, Prentice-Hall, 1981.

98
[16] GOLDFELD, P., DUARTE, A. and HERSKOVITS, J., “A Limited Memory
Interior Points Technique for Nonlinear Optimization”. ECCOMAS 96, Paris, França,
September, 1996.
[17] GOULD, N.I.M., ORBAN, D. and TOINT, P.L., General CUTEr and SifDec
Documentation, England, 2002. http://hsl.rl.ac.uk/cuter-www
[18] GOULD, I.M. and SCOTT, J.A., A numerical evaluation of HSL packages for
direct-solution of large sparse, symmetric linear systems of equations, Technical Report
RAL-TR-2003-019, Rutherford Appleton Laboratory, 2003.
[19] GREENSTADT, J., “Variations on Variable Metric Methods”, Mathematics of
Computation, v. 24, pp.1-22, 1970.
[20] GRIEWANK, A. and TOINT, P.L., “Numerical Experiments with Partially
Separable Optimization Problems Quasi-Newton Matrices and Their use in Limited
Memory Methods”, Lecture Notes in Mathematics, v. 1066, pp. 203-220, Springer,
Berlin, 1984.
[21] HARWELL SUBROUTINE LIBRARY, A catalogue of subroutines (HSL 2000)
AEA Technology, Harwell, Oxfordshire, England, 2002.
[22] HERSKOVITS, J. N. and GOULART, E., “Sparse Quasi-Newton Matrix for Large
Scale Problems in Non-Linear Optimization”. XXV CILAMCE 2004, in CD, Recife,
Brasil, November, 2004.
[23] HERSKOVITS, J. N. and GOULART, E., “Sparse Quasi-Newton Matrices for
Large Scale Non-Linear Optimization” WCSMO6 - 6th World Congress on Structural
and Multidiciplirnary Optimization, in CD, Rio de Janeiro, Brazil, May 2005.

99
[24] HERSKOVITS, J., “A view on Nonlinear Optimization”, J. Herskovits (ed.),
Advances in Structural Optimization, pp. 71-116, Holland, KLUWER Academic
Publishers, June 1995.
[25] HERSKOVITS, J. and SANTOS, G., “Feasible Arc Interior Point Algorithms for
Nonlinear Optimization”. Fourth World Congress on Computational Mechanics, in CD-
ROM, Buenos Aires, Argentina, June, 1998.
[26] HERSKOVITS, J., “A Feasible Directions Interior Point Technique for Nonlinear
Optimization”, JOTA-Journal of Optimization Theory and Aplications, v. 99, pp. 121-
146, October, 1998.
[27] HERSKOVITS, J., MAPPA, P., GOULART, E. and MOTA SOARES, C.M.,
“Mathematical programming models and algorithms for engineering design
optimization”, Journal of Computational Methods in Applied Mechanics and
Engineering, v. 194, pp. 3244-3268, 2005.
[28] HOCK, W. and SCHITTKOVSKI, K., Lecture Notes in Economics and
Mathematical Systems, Berlin, Germany, Springer-Verlag, 1981.
[29] JÚDICE, J.J. e PATRÍCIO,J.M., Sistemas de Equações Lineares, Departamento de
Matemática da Universidade de Coimbra, 1996.
[30] LUENBERGER, D, G, Linear and Nonlinear Programming. 2 ed. Canada,
Addison Wesley Publishing Company, 1984.
[31] LUKSAN, L. and SPEDICATO, E., “Variable Metric Methods for Unconstrained
Optimization and Nonlinear Least Squares”, Journal of Computational and Applied
Mathematics, v. 124, pp. 61-95, 2000.
[32] MAPPA, P.C., FAIPA_SAND, Uma Técnica para Otimização e Análise
Simultâneas, Tese de D.Sc., COPPE/UFRJ, Rio de Janeiro, RJ, Brasil, 2004.

100
[33] MARTINEZ, J. M., “Practical quasi-Newton methods for solving nonlinear
systems”, Journal of Computational and Applied Mathematics, v. 124, pp. 97-121,
2000.
[34] NOCEDAL, J., Large Scale Unconstrained Optimization, in The State of the Art in
Numerical Analysis, pp. 311-338, Oxford University Press, 1997.
[35] NOCEDAL, J. and WRIGHT, S.J., Numerical Optimization, Springer Series in
Operations Research, New York, Springer, 1999.
[36] NOCEDAL, J. and MARAZZI, M., “Wedge trust region methods for derivative
free optimization”, Mathematical Programming, v. 91, n. 2, pp. 289-30, 2002.
[37] TOINT, Ph.L., “On Sparse and Symmetric Matrix Updating Subject to a Linear
Equation”, Mathematics of Computation, v. 31, n. 140, pp. 954-961, Oct. 1977.
[38] TOINT, P.L., “A Sparse Quasi-Newton Update Derived Variattionally With a
Nondiagonally Weighted Frobenius Norm”, Mathematics of Computation, v. 37, n. 156,
pp. 425-433, Oct. 1981.
[39] TOINT, P.L., “A Note About Sparsity Exploiting Quasi-Newton Updates”,
Mathematical Programming, v. 21, pp. 172-181, 1981.