oportunidades e desafios para projetos de big data… · como referência a esses dados massivos,...
TRANSCRIPT

1
UNIVERSIDADE FEDERAL DO RIO DE JANEIRO
INSTITUTO COPPEAD DE ADMINISTRAÇÃO
CÉSAR WAKO SUZUKI
OPORTUNIDADES E DESAFIOS PARA
PROJETOS DE BIG DATA: um estudo de
caso da parceria Petrobras EMC²
RIO DE JANEIRO
2016

2
CÉSAR WAKO SUZUKI
OPORTUNIDADES E DESAFIOS PARA PROJETOS DE BIG
DATA: um estudo de caso da parceria Petrobras EMC²
RIO DE JANEIRO
2016
Dissertação de Mestrado apresentada ao
Programa de Pós-Graduação em
Administração, Instituto COPPEAD de
Administração, Universidade Federal do
Rio de Janeiro, como parte dos requisitos
necessários à obtenção do título de Mestre
em Administração
Orientador: Profª. Drª. Elaine Tavares
Rodrigues

3

4
Dedico este trabalho a minha família,
que esteve junto comigo em todos os momentos,
demonstrando paciência quando não pude passear,
carinho quando encontrei dificuldades,
e admiração quando mostrei o resultado!

5
AGRADECIMENTOS
Agradeço à minha família, pelo amor.
À minha orientadora, pela confiança.
Ao meu chefe, pelo suporte e incentivo.
Aos professores, pela sabedoria passada.
Ao Instituto COPPEAD, pela oportunidade única.
Aos meus colegas, pelas experiências inesquecíveis.
À Petrobras e à EMC pela cooperação e tempo dedicado.
E, não menos importante, aos leitores. Desejo a estes uma ótima experiência!!!

6
RESUMO
Mídias Sociais, câmeras de segurança, GPS, sensores espalhados em equipamentos
eletrônicos, logs de acessos de Internet. Nunca se produziu tanto dado como atualmente.
Esta infinidade de dados, advindos das mais diversas fontes, estão fluindo numa
velocidade incomparável. Neste contexto, surge uma tecnologia que promete fazer uso
desses dados, extraindo informações relevantes às empresas em tempo real: Big Data.
Quais oportunidades essa nova tecnologia oferece? Quais desafios podem ser encontrados
ao se optar pela sua adoção? Com o intuito de responder essas perguntas, este trabalho
teve como foco um estudo de caso do desenvolvimento de três projetos de pesquisa de
Big Data na Petrobras, em parceria com centro de pesquisa da EMC2. Para efeito de
comparação, foram levantadas nove oportunidades e nove desafios, os quais foram
tratadas como categorias analíticas. Posteriormente foram identificadas dez
oportunidades, das quais cinco conferem com as categorias analíticas desenvolvidas e
cinco foram consideradas oportunidades emergentes deste estudo. Referente aos desafios,
seis deles coincidem com as categorias apresentadas e dois surgiram durante o estudo. As
oportunidades, no caso analisado, giraram em torno da otimização operacional, através
da construção de modelos preditivos que incorrem na possibilidade de traçar um plano de
manutenção baseada na condição e melhorias em processos da cadeia de suprimentos. Já
o maior desafio esteve nos problemas relacionados à custódia e gestão dos dados. A
principal contribuição da pesquisa reside no estudo de projetos desenvolvidos em
organizações e empresas de TI, onde as primeiras podem transpor desafios técnicos e as
últimas terem a chance de desenvolver projetos que podem vir a ser transformados em
produtos com valor de mercado.
Palavras-chave: Tecnologia da informação; Big Data; Indústria de óleo e gás; Petrobras,
EMC².

7
ABSTRACT
Social media, security cameras, GPS, scattered sensors in electronic equipment, Internet
access logs. We never produced as much data as today. This plethora of data, coming
from different sources, are flowing in an unrivaled speed. In this context, a technology
emerges that promises to make use of these data, extracting relevant information to
companies in real time: Big Data. Which opportunities this new technology offers? What
challenges can be found to opt for its adoption? In order to answer these questions, this
study focused on a case study of the development of three big research projects by
Petrobras, in partnership with research center EMC². For comparison, it was raised nine
challenges and nine opportunities, which were treated as analytical categories. Later ten
opportunities were identified, of which five confer with the developed analytical
categories and five were considered emerging opportunities in this study. Regarding the
challenges, six of them coincide with the categories presented and two arose during the
study. The opportunities in the analyzed case, centered on the operational optimization
through the construction of predictive models that incur the possibility of drawing up a
maintenance plan based on the condition and improvements in processes of the supply
chain. And the biggest challenge was the problems related to the custody (ownership) and
management of data. The main contribution of the research lies in the study of projects
developed in IT organizations and businesses, where the former can overcome technical
challenges and the last have the chance to develop projects that may be processed into
products with market value.
Key words: Information Technology, Big Data, Oil & gas, Petrobras, EMC².

8
SUMÁRIO
1. INTRODUÇÃO .................................................................................................................... 9
1.1. OBJETIVO GERAL .................................................................................................................. 10
1.2. OBJETIVOS ESPECÍFICOS ........................................................................................................ 11
1.3. RELEVÂNCIA ......................................................................................................................... 11
1.4. DELIMITAÇÃO DO ESTUDO ..................................................................................................... 12
2. REFERENCIAL TEÓRICO ............................................................................................. 14
2.1. BREVE HISTÓRICO DA EVOLUÇÃO DA ANÁLISE DE DADOS ..................................................... 14
2.2. O QUE É BIG DATA ................................................................................................................ 17
2.3. OPORTUNIDADES ADVINDAS DO USO DO BIG DATA ................................................................ 24
2.4. DESAFIOS NA IMPLEMENTAÇÃO DO BIG DATA ...................................................................... 32
3. MÉTODO ............................................................................................................................ 41
4. OS PROJETOS ANALISADOS ........................................................................................ 49
5. OPORTUNIDADES E DESAFIOS NO DESENVOLVIMENTO DE PROJETOS DE
BIG DATA NA PETROBRAS ................................................................................................................ 54
6. CONSIDERAÇÕES FINAIS ............................................................................................. 69
7. REFERÊNCIAS.................................................................................................................. 75
ANEXOS ................................................................................................................................................... 85
ANEXO I – ROTEIRO DE PESQUISA ................................................................................................. 85
ANEXO II – LISTA DE DEFINIÇÕES DE BIG DATA ....................................................................... 86

9
1. INTRODUÇÃO
Já não é de hoje que as organizações veem na informação grande fonte de vantagem
competitiva. Utilizando-se de dados para obter informações relevantes que podem ajudar
na otimização operacional, refinar a tomada de decisão, alimentar sistemas antifraudes e
muitos outros exemplos, as organizações podem obter vantagens competitivas
(DAVENPORT, 2014).
Nesse contexto, surge o conceito de data analytics, que consiste basicamente na aplicação
de tratamento estatístico em dados coletados, com o intuito de gerar previsões e insights
dando sentido a esses dados, transformando-os em informação que ajudam na tomada de
decisões e planejamento estratégico das empresas (CHEN ET AL., 2012).
Segundo Galbraith (2014), empresas utilizam grande bancos de dados há anos e, através
de técnicas como “data mining”, aplicam algoritmos que buscam correlações entre esses
dados, com o intuito de gerar insights que possam vir a trazer vantagens competitivas
frente aos seus concorrentes. Porém, o volume, a forma e a fonte de dados existentes
atualmente são bem diferentes de antigamente. No princípio, dados eram coletados
através de instrumentos como pesquisas, faturas de cartões, comprovantes de transações
e armazenados em bancos de dados (databases) de forma estruturada. Assim, muitas
vezes, o limitante era a falta de dados para gerar informações úteis/relevantes.
Hoje, muito devido à facilidade e velocidade de troca de informações advindo da criação
da internet, aliado à grande capacidade de armazenamento existente, dados estão sendo
extraídos das mais diversas fontes, como fotos de celulares, mapas de GPS, vídeos de
câmeras de segurança, áudio de call centers, e-mails, redes sociais e blogs, de forma
instantânea (Galbraith, 2014).
Portanto, o principal desafio agora é selecionar os dados que possam gerar informações
relevantes, dentro de tantas fontes possíveis e gerar o modelo/algoritmo/ferramenta que
melhor interprete esses dados (HARRIOTT, 2013).
Como referência a esses dados massivos, surgiu o termo Big Data1, que para Boudreau
(2012) é muito mais do que simplesmente uma grande quantidade de dados estruturados
1 Um conjunto de tecnologias capazes de armazenar, limpar, tratar, processar, analisar e extrair valor de
conjuntos de dados que são difíceis de processar com tecnologias tradicionais. Será detalhado mais a frente.

10
ou não2, e sim de dar sentido a eles. Portanto, além da habilidade de coletar uma
imensidão de dados, Big Data trata também de usá-los de forma a entender melhor como
o mundo funciona.
Shaw (2014) corrobora Boudreau ao afirmar que a verdadeira revolução trazida pelo Big
Data não está no impressionante volume de dados obtidos em tempo real e na capacidade
de armazenamento, mas na criação e aperfeiçoamento das técnicas de análise (algoritmos)
desses dados e na velocidade de processamento que os computadores proporcionam na
aplicação desses algoritmos. A isto se soma a capacidade de se utilizar dados de diversos
tipos de bases de dados e fontes de informação, possibilitando maximizar sua utilidade.
Schmarzo (2013) destaca a capacidade do Big Data de prover análise de dados em tempo
real, possibilitando o desenvolvimento de modelos de previsão e o monitoramento de todo
o ambiente de negócios, refinando, assim, a tomada de decisões gerenciais e modificando
de forma drástica a estrutura das organizações.
Nesse contexto, surgem as perguntas que norteiam todo o desenvolvimento deste presente
trabalho: Quais oportunidades e desafios estão presentes em projetos de Big Data?
1.1. OBJETIVO GERAL
O objetivo geral deste estudo foi identificar oportunidades e desafios para o
desenvolvimento de projetos de Big Data. Mais especificamente, analisou-se o caso da
Petrobras para conhecer o que motivou a empresa a implementar o Big Data e quais
desafios ela precisou superar para isto.
2 Dados estruturados são dados que contém uma organização para serem recuperados. É como se fossem
etiquetas, linhas e colunas que identificam diversos pontos sobre aquela informação. Já dados não
estruturados referem-se a dados que não se encaixam nesse padrão (linhas e colunas), como por exemplo
vídeos, e-mails, áudios e comentários de redes sociais.

11
1.2. OBJETIVOS ESPECÍFICOS
Muito se fala sobre o Big Data hoje, porém, no Brasil, ela ainda é uma tecnologia pouco
difundida. A literatura acadêmica na área de administração da informação é também ainda
pouco desenvolvida, pois uma vez que se trata de soluções tecnológicas relativamente
recentes, seu estudo na perspectiva gerencial ainda está sendo iniciado (NETO, 2015).
Assim, optou-se por fazer um levantamento teórico de oportunidades e desafios
potenciais para adoção de Big Data, estabelecendo categorias de análise para estudar o
caso da Petrobras. Posteriormente, de posse destas categorias, uma pesquisa de campo foi
realizada para se identificar as oportunidades e barreiras encontradas no caso da
Petrobras.
Assim, os objetivos específicos da pesquisa de campo foram:
A) Fazer um levantamento das oportunidades, identificadas pela Petrobras, que
levaram a utilização do Big Data.
B) Identificar os desafios enfrentados pela Petrobras ao adotar essa nova tecnologia.
C) Comparar os achados com os estudos acadêmicos sobre o assunto, buscando
ampliar o conhecimento sobre implementação de Big Data, ainda que de forma
exploratória.
1.3. RELEVÂNCIA
Mídias Sociais, sensores em celulares, sensores em automóveis, câmeras de filmagens,
chamadas de call centers - nunca se produziu tantos dados como atualmente. A
possibilidade de extrair insights a partir dessa imensidão de fontes faz com que o Big
Data, aliado à computação em nuvem (cloud computing), seja um dos assuntos mais
debatidos hoje na área da Tecnologia da Informação (DAVENPORT, 2006;
SCHMARZO, 2013).
Ao se realizar uma busca ao termo Big Data na Business Source Complete (EBSCOhost),
foram encontrados 26.455 artigos, destes 9.688 presentes em revistas acadêmicas.
Restringindo a pesquisa somente ao ano de 2015, o resultado é 7.357 artigos encontrados,

12
sendo 3.470 publicações em revistas acadêmicas. Ou seja, mais de um terço das
publicações acadêmicas se concentraram nesse ano, corroborando a importância atribuída
à pesquisa deste tema atualmente. Entretanto, uma leitura rápida dos títulos disponíveis
permite identificar que o conhecimento científico produzido sobre o assunto é
preponderantemente técnico. A perspectiva gerencial da implementação de Big Data
ainda não foi corretamente explorada na literatura.
Números ainda mais impressionantes foram divulgados pelo grupo Gartner3, em seu site,
no segundo semestre de 2015. Segundo eles, estima-se que mais de 75% das empresas de
todos os segmentos pretendem investir em Big Data até 2017, e cerca de 4,4 milhões de
empregos serão criados para suportar essa demanda já em 2016, sendo 1,9 milhões deles
localizados nos Estados Unidos (GARTNER, 2015).
Já a opção pelo setor de óleo e gás, deu-se devido aos altos investimentos alocados em
tecnologia da informação, especialmente em Big Data que segundo a Newswire (2015)
foi algo em torno de $ 3,5 bilhões. Além disso, seus produtos sofrem grandes oscilações
de preços, envolvem grandes custos de produção e operacionais e apresentam problemas
típicos de Big Data (alto volume de dados, advindos de diversos sensores e em alta
velocidade).
Através dos números acima, pode-se ter uma ideia da importância do Big Data.
Entretanto, por se tratar de um conjunto de tecnologias novas trazidas para o contexto
organizacional, não se pode partir da premissa de que as oportunidades e desafios
anteriormente encontradas na implementação de sistemas de informação serão os mesmos
para Big Data. Torna-se relevante estudar as oportunidades advindas de seu uso, assim
como os desafios que podem ser encontrados pelas empresas que optam pela sua adoção,
pois tratando-se de uma tecnologia nova, poder acompanhar o desenvolvimento de
projetos na área e comparar com a literatura, não só servirá de base para outros estudos,
mas também pode ajudar as outras empresas a compreender melhor essa ferramenta.
1.4. DELIMITAÇÃO DO ESTUDO
3 Uma das empresas de consultoria mais conceituadas na área de TI.

13
A pesquisa desenvolvida teve como base um estudo de caso numa empresa pública do
setor de petróleo - a Petrobras, compreendendo o período de 2014 ao início de 2016. Os
três projetos estudados na Petrobras estão em fase de desenvolvimento, não sendo
possível a coleta de resultados da adoção destes projetos. Novos desafios ainda poderão
surgir, mas como se tratam de projetos de desenvolvimento longos, não é necessário
esperar até o final para que o caso apresentado possa já trazer conhecimento sobre os
processos de implementação de Big Data.
Os três projetos tratam de uma inciativa do Centro de Pesquisas e Desenvolvimento
Leopoldo Américo Miguez de Mello (Cenpes) e da EMC², assim outras inciativas que
possam existir em outras áreas e subsidiárias da cia não foram contempladas.

14
2. REFERENCIAL TEÓRICO
Este capítulo está subdividido em quatro partes. A primeira busca fazer uma breve linha
evolutiva da análise de dados, para entendermos um pouco melhor o porquê de existir
tantas definições diferentes para o Big Data e o que levou ao seu surgimento. As demais
partes, tratam da definição do termo Big Data, das oportunidades e desafios para sua
implementação, os quais motivam as empresas a buscarem cada vez mais a sua utilização
e influenciam o sucesso de sua implementação.
2.1. BREVE HISTÓRICO DA EVOLUÇÃO DA ANÁLISE DE DADOS
Um grande número de dados não estruturados e complexos, anteriormente descartados,
tornam-se úteis no processo decisório de negócios. Os dados são correlacionados a fim
de buscar padrões que não seriam evidentes ao serem analisados com sistemas de banco
de dados ou ferramentas de software tradicionais. A este novo processo, dá-se o nome
Big Data Analytics (SIMON, 2013).
Em termos acadêmicos, os estudos relativos à Business Intelligence and Analytics
(BI&A) e Big Data Analytics tem crescido significativamente. Sendo assim, faz-se
necessário uma breve explanação dos conceitos de BI&A utilizados nesse estudo.
Analisando a evolução e aplicações do BI&A, Chen et al. (2012) propuseram um modelo
evolutivo que classifica as iniciativa em BI&A 1.0, 2.0 e 3.0.
BI&A 1.0:
BI&A 1.0 emerge do campo da gestão de dados, sendo dependente de tecnologias de
coleta, extração e análise de dados (ETL)4. Popularizado na década de 1990, o BI&A 1.0
foi largamente adotado para análise e integração de dados coletados pelas empresas e
armazenados em sistemas de banco de dados relacionais (RDBMS)5. Para tanto, o
conjunto de dados analisados são, geralmente, estruturados.
4 Termo em inglês para “Extraction, Transformation and Load”. 5 Termo em inglês para “Relational Database Management System”.

15
Compõe a categoria de BI&A 1.0 os sistemas de gestão e armazenamento de dados,
ferramentas ETL, processamento analítico online (OLAP)6 e ferramentas de relatórios.
Também estão inseridos os sistemas de gestão de desempenho de negócios (BPM)7 e
ferramentas de mineração de dados essenciais na associação e segmentação dos dados,
possibilitando, assim, a detecção de anomalias e a confecção de modelagens utilizáveis
em diversos setores de negócios.
Segundo Sallam et al. (2011), algumas características fundamentais para o
desenvolvimento das plataformas deste tipo de Business Analytics são: relatórios,
dashboards, queries ad hoc, sistemas de rastreamento de buscas para utilização em
inteligência de negócios, OLAP, ferramentas de visualização interativa, scorecards,
modelagem preditiva, mineração de dados.
BI&A 2.0:
O BI&A 2.0 surge como uma extensão do advento da web 2.0. Segundo O’Reilly (2004):
Web 2.0 é a mudança para uma internet como plataforma, e um
entendimento das regras para obter sucesso nessa nova
plataforma. Entre outras, a regra mais importante é desenvolver
aplicativos que aproveitem os efeitos de rede para se tornarem
melhores quanto mais são usados pelas pessoas, aproveitando a
inteligência coletiva.
O advento da web 2.0 forneceu não só os seus bancos de dados relacionais tradicionais,
como também logs de usuários, detalhamentos destes usuários através de IPs, cookies,
buscas recorrentes e padrões de compra. Para O’Reilly (2005), a atividade dos usuários
em mídias sociais, fóruns, blogs, grupos online, eventos virtuais ou jogos online gerou
também um imenso volume de informações atraentes para diversos tipos de negócios.
Novos objetos de análise trouxeram uma real mudança na forma como as organizações
lidam com esses dados e como podem usar essas informações. O BI&A 2.0, através de
suas ferramentas de análise, amplia o conhecimento sobre esses novos dados, e é capaz
de informar e identificar novas áreas de atuação e oportunidades de negócios.
6 Termo em inglês para Online Analytic Processing. Local onde os dados são analisados e processados
gerando informações essenciais ao negócio. 7 Termo em inglês Business Performance Management.

16
Ao trabalhar com informações em tempo real, O BI&A 2.0 procura fornecer informações
precisas no momento em que as empresas mais precisam. A análise de dados estruturados,
não estruturados e complexos, advindos da web 2.0, demandam novas aplicações de
softwares e tecnologias aplicadas aos processos de negócios. Diferentemente do BI&A
1.0, não são utilizados somente banco de armazenamento de dados tradicionais, mas sim
de dados on-line com o auxílio do OLTP8 e do Real Time ETL9.
BI&A 3.0
A mobilidade é uma realidade cada vez mais presente em todos os segmentos de mercado,
por isso, o BI&A 3.0 atua no sentido de permitir que as empresas se adaptem a uma nova
realidade de negócios.
Dispositivos móveis de alto desempenho, infraestrutura de transmissão de dados rápida e
confiável e os avanços tecnológicos dos sistemas móveis fazem do BI&A 3.0 um nicho
de mercado e investimento promissor. Com ele, é possível ter pronto acesso às
informações de BI&A de determinada empresa e concorrentes a qualquer momento ou
lugar, facilitando a análise, cruzamento de dados e tomada estratégica de decisões.
Por fim, a tabela a seguir resume as principais características do BI&A 1.0, 2.0 e 3.0
segundo Gartner BI Hype Cicle (2015):
8 OLTP: Online Transaction Processing basicamente é o processamento de transações em tempo real
através de sistemas como o Enterprise Resource Planning (ERPs).
9 Real Time ETL consiste na extração, transformação e carga de dados em tempo real. Através deste sistema
é possível integrar os dados em tempo real, sendo realizado em intervalos curtos de tempo.

17
Quadro 2 – Características e Capacitações do BI&A Evolução do BI&A - Principais Características e
Capacitações (Fonte: CHEN, CHIANG e STOREY, 2012).
2.2. O QUE É BIG DATA
Big Data são ativos de informação de grande volume, velocidade e variedade que exigem
formas custo-efetivas e inovadoras de processamento de informações para uma melhor
percepção e tomada de decisões (GARTNER, 2013).
Por se tratar de um tema relativamente novo, ainda existem muitas divergências sobre a
definição do que é Big Data. Em uma matéria de 2014, publicada no
datascience@berkeley10, de sua relações públicas Jennifer Ducther, mais de quarenta
líderes de setores como moda, alimentação, automobilístico, medicina, marketing
definem o que é Big Data na visão deles. Na tabela abaixo, seguem algumas das respostas.
Nome, posição Definição sobre Big Data
John Akred,
Fundador e CTO da
Silicon Valley Data
Science
É uma tentativa de dar sustento à tomada de decisão através de
insights extraídos da análise de dados, somado a um conjunto
de tecnologias que viabilizem economicamente essa análise de
grande quantidade de dados obtidos de várias fontes diferentes
10 Portal do mestrado em ciência da informação e dados online (Master of Information anda Data Science
Delivered Online).
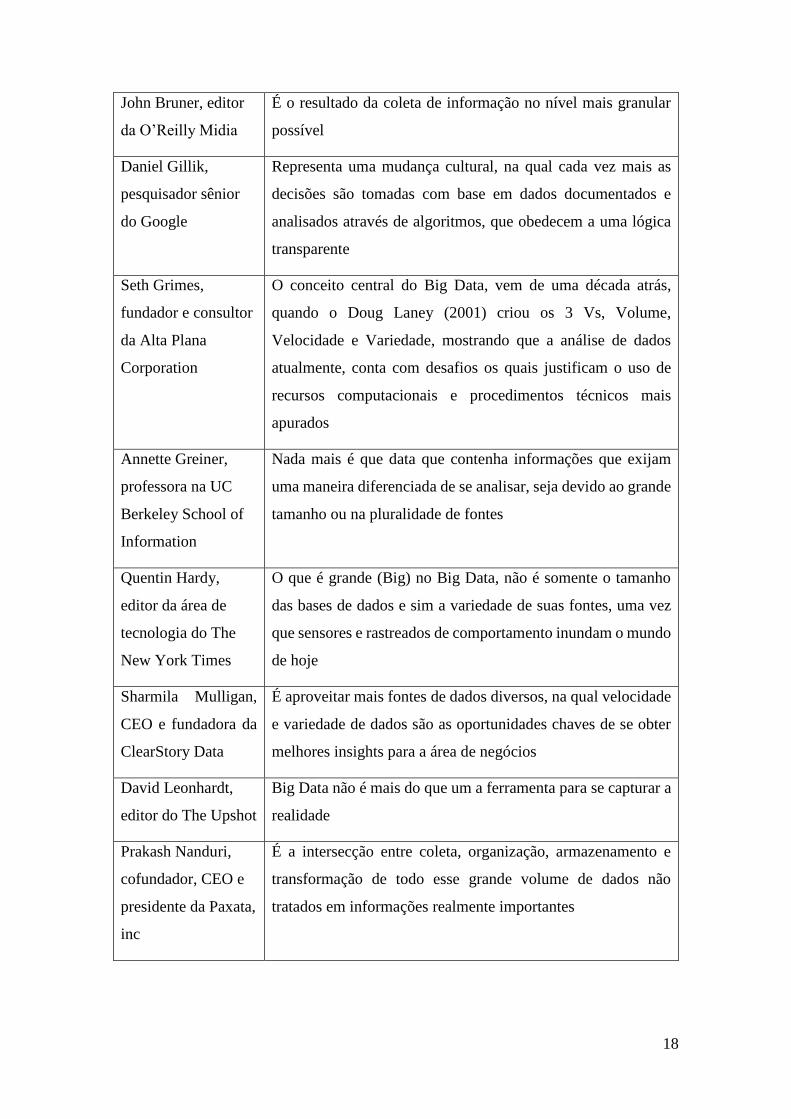
18
John Bruner, editor
da O’Reilly Midia
É o resultado da coleta de informação no nível mais granular
possível
Daniel Gillik,
pesquisador sênior
do Google
Representa uma mudança cultural, na qual cada vez mais as
decisões são tomadas com base em dados documentados e
analisados através de algoritmos, que obedecem a uma lógica
transparente
Seth Grimes,
fundador e consultor
da Alta Plana
Corporation
O conceito central do Big Data, vem de uma década atrás,
quando o Doug Laney (2001) criou os 3 Vs, Volume,
Velocidade e Variedade, mostrando que a análise de dados
atualmente, conta com desafios os quais justificam o uso de
recursos computacionais e procedimentos técnicos mais
apurados
Annette Greiner,
professora na UC
Berkeley School of
Information
Nada mais é que data que contenha informações que exijam
uma maneira diferenciada de se analisar, seja devido ao grande
tamanho ou na pluralidade de fontes
Quentin Hardy,
editor da área de
tecnologia do The
New York Times
O que é grande (Big) no Big Data, não é somente o tamanho
das bases de dados e sim a variedade de suas fontes, uma vez
que sensores e rastreados de comportamento inundam o mundo
de hoje
Sharmila Mulligan,
CEO e fundadora da
ClearStory Data
É aproveitar mais fontes de dados diversos, na qual velocidade
e variedade de dados são as oportunidades chaves de se obter
melhores insights para a área de negócios
David Leonhardt,
editor do The Upshot
Big Data não é mais do que um a ferramenta para se capturar a
realidade
Prakash Nanduri,
cofundador, CEO e
presidente da Paxata,
inc
É a intersecção entre coleta, organização, armazenamento e
transformação de todo esse grande volume de dados não
tratados em informações realmente importantes

19
AnnaLee Saxenian,
decana da UC
Berkeley School of
Information
São dados que não podem ser processados de maneira
convencional, pois são muito grandes, muito velozes ou muito
complexos para serem analisados pelas ferramentas usuais
Quadro 3 – Definições de Big Data segundo personalidades dos negócios (Fonte:
datascience@berkeley, 2014.)
Talvez a definição mais aceita atualmente é a de Doug Laney que escreveu um artigo,
publicado em fevereiro de 2001, em nome da Gartner intitulado “3-D Data Management:
Controlling Data Volume”, no qual foram introduzidos os 3 Vs (Volume, Velocidade, e
Variedade), conceitos largamente utilizados para explicar o fenômeno Big Data até hoje.
Porém, outras empresas de tecnologia como a Microsoft e a Oracle possuem definições
ligeiramente diferentes. Para a Microsoft, Big Data é um termo que descreve a aplicação
de uma grande capacidade computacional, o que se tem de mais moderno em machine
learning e inteligência artificial para processar informações massivas e muitas vezes
altamente complexas (The Big Bang, 2013).
Por outro lado, para a Oracle, Big Data é a soma do tradicional banco de dados relacional
com novas fontes de dados não estruturados, também citando os 3 Vs e acrescentando um
quarto: Valor (Oracle White Paper, 2012).
Para este estudo, foi observado que ao longo do ano de 2015, dos vinte artigos
organizados por ordem de relevância na base de dado EBSCOhost, ao se procurar o termo
Big Data, quinze deles continham descrição clara do conceito de Big Data e dentre eles,
todos citavam pelo menos 3 “Vs” (Volume, Velocidade e Variedade). Portanto, pode-se
inferir que existe uma tendência de chegar a um consenso quanto à definição do termo
Big Data, fazendo-se necessário uma explicação mais detalhada desses “Vs”.
De forma simplificada “Volume” é a quantidade, “Velocidade” é a taxa de transferência
e a “Variedade” é a diversidade de tipos e fontes dos dados (SIMON, 2013, MINELLI,
CHAMBERS e DHIRAJ, 2013; BUHL, ROGLIMGER, MOSER e HEIDEMANN, 2013,
Davenport, 2014; KYUNGHEE, HOGDUIN e ZHANG, 2015; MIN, CHYCYLA e
STEWART, 2015).
O grande volume de dados que caracteriza o Big Data advém da quantidade de transações,
eventos e história que as novas tecnologias nos possibilitam capturar e armazenar. Porém,
Gandomi e Haider (2015) salientam a dificuldade de se estabelecer um parâmetro de qual

20
o tamanho que os dados devem ter para serem considerados “Big”. Primeiro, porque o
que é considerado grande hoje, no futuro com o avanço tecnológico, tende a ficar
pequeno. Segundo, porque determinado tamanho de um conjunto de dados considerado
grande para certos setores é consideravelmente pequeno para outros. Por último, nem
sempre o tamanho do conjunto retrata sua complexidade. Assim, conjuntos menores de
dados podem demandar tecnologias de análise bem mais avançadas dependendo de seu
tipo e complexidade.
Por variedade entende-se a heterogeneidade dos dados, uma vez que um grande avanço
do Big Data foi possibilitar a introdução de dados semiestruturados e não estruturados,
possibilitando integrar e agregar diferentes tipos de dados de diversas fontes para uma
análise mais rica, propiciando insights que antes não eram viáveis (MCAFEE e
BRYNJOLFSSON, 2012).
Para Minelli, Chambers e Dhiraj (2013), dados semiestruturados são aqueles que não se
encaixam em uma estrutura formal de modelo de dados porém, exibem certos padrões
que possibilitam sua ordenação e hierarquização. Como exemplo, pode-se citar as
ligações de call centers que sempre perguntam as mesmas informações pessoais dos
clientes (nome, endereço, entre outras) e suas reclamações. Ainda segundo os mesmos
autores, dados não estruturados são aqueles que não se encaixam em modelos pré-
definidos e/ou não podem ser estruturados em um banco de dados relacional. Inúmeros
tipos de dados não estruturados podem providenciar uma série de informações úteis para
as empresas, como vídeos, áudios, mídias sociais, sensores e dados de Internet
(quantidade e direcionamento de clicks, logs e etc.).
Não menos importante, a velocidade é o quão rápido os dados são criados, inseridos,
acumulados e processados (MINELLI, CHAMBERS e DHIRAJ, 2013) e também se
refere à vinculação de conjuntos de dados que estão vindo com velocidades diferentes e
a mudança repentina das quantidades de informação transferidas quando comparadas ao
ritmo habitual (SICULAR, 2013).
A proliferação de aparelhos digitais, como smartphones e sensores pode nos dar uma ideia
do que representa a velocidade dos dados atualmente, pois eles emitem dados de forma
continua, os quais muitas vezes demandam análise em tempo real para se tornarem
significantes, uma vez que muitos desses dados podem perder importância ao longo do
tempo (GANDOMI e HAIDER, 2015).

21
A IBM11 achou necessário adicionar mais um “V”, a Veracidade, que nada mais é do que
a necessidade de se obter dados verídicos, de acordo com a realidade do momento
analisado, pois dados passados muitas vezes não podem ser considerados verídicos para
o presente, tão pouco para análises preditivas. Portanto, a relevância dos dados coletados
são importantes, assim como a necessidade de verificação deles e seu processamento em
tempo real. Esse ponto é agravado quando não se pode garantir o acesso à dados
completos ou a confiabilidade das fontes, tornando a validade da análise questionável.
Outra importante empresa do setor, a SAS, também sentiu a necessidade de se acrescentar
mais um “V” ao conceito - a Variabilidade que trata da inconsistência dos fluxos de dados,
causando picos periódicos sazonais ou gerados com base em eventos específicos.12
Contudo, esse atributo não é muito citado, devido ao entendimento que ele é uma
característica da velocidade.
E finalmente, o último “V”, o Valor, foi introduzido inicialmente pela Oracle ao destacar
que, apesar do patamar tecnológico que atingimos, propiciar decisões muito mais precisas
e acuradas, extrair valor do uso do Big Data depende ultimamente das pessoas, que devem
se preocupar em aprender a detectar e fazer uso dos insights, aprendendo a fazer as
perguntas certas, reconhecer padrões e prever comportamentos durante a análise dos
dados.13
Ainda quanto ao valor, quanto maior a riqueza de dados, mais importante é saber realizar
as pergunta certas no início de todo o processo de análise, destaca Brow e Eric (2014).
Faz-se necessário o foco para a orientação do negócio, ou seja o valor que a coleta e
análise dos dados trata para ele. Não é viável realizar todo o processo de Big Data se não
se tem questionamentos que auxiliem o negócio de um modo realístico. Igualmente
importante é se ater aos custos envolvidos nessa operação, o valor agregado de todo esse
trabalho desenvolvido, coleta, armazenamento e análise de todos esses dados tem que
compensar os custos financeiros envolvidos (TAURION, 2013).
Esses 3 últimos conceitos (Veracidade, Variabilidade e Valor) ao contrário dos 3
primeiros (Volume, Variedade e Velocidade) originalmente apresentados por Laney
11 Informação extraída do próprio site da empresa disponível em
https://www.ibm.com/developerworks/community/blogs/jfp/entry/big_data_for_dummies23?lang=en
acessado em 27/01/2016. 12 Informação retirada do site da SAS disponível em http://www.sas.com/pt_br/insights/big-data/what-is-
big-data.html acessado em 27/01/2016. 13 Informação retirada do site da Oracle disponível em https://www.oracle.com/big-data/index.html
acessado em 27/01/2016.

22
(2001) são comuns à grande parte das ferramentas de análise de dados que conhecemos,
causando certa relutância a serem aceitos como características intrínsecas ao Big Data.
Por outro lado, Veracidade está sendo cada vez mais comentado na forma do desafio de
validar as informações advindas do Big Data e Valor tem sido usado como o ápice/junção
advinda dos atributos volume, velocidade e variedade.
Mediante o exposto, o conceito de Big Data utilizado neste estudo é:
Um conjunto de tecnologias capazes de armazenar, limpar, tratar, processar, analisar e
extrair valor de conjuntos de dados que são difíceis de processar com tecnologias
tradicionais (e que podem ser definidos por um ou mais V’s do conjunto multidimensional
de V’s), bem como o próprio conjunto de dados que demanda essas tecnologias para
serem analisados.
Uma tabela com as referências utilizadas nesta pesquisa para o entendimento do conceito
de Big Data é apresentada no anexo II.
Definidos os conceitos a serem utilizados de Big Data e apresentada uma breve
contextualização da evolução da análise dos dados, uma vez que este estudo é direcionado
principalmente para pessoas ligadas à área de administração, optou-se por fazer uma
breve introdução à termos mais técnicos relacionados ao Big Data, na forma de um
glossário apresentado a seguir.

23
TERMO DEFINIÇÃO
Algoritmo É a matemática por trás da análise, mais especificamente seria os procedimentos de
cálculo, a lista de instruções para se calcular uma função.
Analytics Uso de algoritmos para extrair informações de dados
Cloud (Nuvem) Termo usado para qualquer recurso computacional oferecido como serviço em rede
(network)
Complex Event
Processing (CEP) Processo que analisa eventos em tempo real
Data Lake Repositório que armazena um grande e variado volume de dados, estruturados e não
estruturados
Data Mining Processo de descobrir padrões, tendências e relações de dados usando "machine
learning"
Framework
(Arcabouço)
É uma abstração que une códigos comuns entre vários projetos de software
provendo soluções para determinados problemas
Grid Servidores ligados em rede para usufruir dos benefícios do paralelismo
Hadoop Framework open-source com capacidade de armazenar dados não estruturados
enormes (HDFS) e processá-los (MapReduce) em GRID
HDFS Sistema de arquivo do Hadoop
HStreaming Add-on do Hadoop que prove CEP
Machine
Learning
Técnica algorítmica de "aprender" com dados empíricos, extraindo informações
suficientes para predizer o resultado de novos dados
MapReduce
Programa escrito quase todo em Java, que permite a "quebra" de um problema em
pequenas partes que são distribuídas em Grid, fazendo com que eles possam ser
solucionados simultaneamente (mapper). Posteriormente ele coleta todos os
resultados e faz a combinação deles (reducer)
NoSQL Database É um termo utilizado para definir um tipo de banco de dados que não segue normas
de tabelas (schemas) determinadas previamente (Not only SQL)
SQL (Structured
Query Language)
Linguagem para armazenar, acessar e manipular dados em um banco de dados
relacional
Quadro – 4 Glossário de termos técnicos (fonte: autor)
Todos os termos acima descritos estão intimamente ligados ao Big Data, uma vez que
grande parte dos dados envolvidos na análise do Big Data são semi ou não estruturados,
ou seja, que não se encaixam em banco de dados SQL. Portanto, para processá-los, foram
criados uma nova linguagem (NoSQL), o algoritmo MapReduce e novos frameworks
como, por exemplo, o Hadoop.
O NoSQL surgiu da necessidade de um desempenho superior e de maior escalabilidade,
uma vez que os bancos de dados relacionais exigem uma distribuição vertical dos
servidores, ou seja, quanto mais dados, mais memória e mais espaço para armazenamento
um servidor precisa. Já no NoSQL, a distribuição é horizontal, fazendo uso do paralelismo
para diminuir a carga exigida de processamento de cada servidor, podendo obter

24
resultados muito melhores com “cpus” menos potentes (MINELLI, CHAMBERS e
DHIRAJ, 2013).
Um grande utilizador do conceito é o Google, que garante maior eficiência e menor custo
utilizando computadores de médio e pequeno porte para distribuição dos dados. Outro
benefício ressaltado pela empresa, é que os bancos de dados NoSQL são mais tolerantes
a erros.
A criação do algoritmo MapReduce e de sua plataforma gratuita mais utilizada o Hadoop
podem ser vistos como os principais responsáveis pelo boom do Big Data, pois somente
através deles que foi possível viabilizar o processamento e, por consequência, a extração
de valiosas informações desse amontoado de dados (SHVACHKO, KUANG, et al.,
2010).
O MapReduce alia o poder do paralelismo com o HDFS (caso for utilizado com o
Hadoop), formando um framework no qual um controlador mestre distribui comandos via
uma função “Mapper” para todos os processos que estão sendo rodados, quebrando um
grande problema em processos menores. Posteriormente, o resultado desses processos são
enviados à uma outra tarefa “Reducer”, a qual sumariza todo o trabalho dos “Mappers”
(MINELLI, CHAMBERS e DHIRAJ, 2013).
Outras plataformas gratuitas como o Hive e o PIG também fazem uso do MapReduce
para processar o Big data, porém a diferença destas para o Hadoop é que elas oferecem
uma interface parecida com o SQL para o HDFS.
2.3. OPORTUNIDADES ADVINDAS DO USO DO BIG DATA
O termo oportunidade pode ser interpretado de várias maneiras, porém para este trabalho,
entende-se por oportunidades quaisquer potenciais benefícios ou vantagens identificados,
que motivem as empresas a adotarem o Big Data.
Para melhor entendimento, este tópico foi dividido em duas partes, serão apresentadas
oportunidades e exemplos de aplicações gerais e, posteriormente, os aplicados na
indústria de óleo e gás.

25
Dado que as empresas que dominam a gestão orientada para dados podem obter
recompensas significativas e se diferenciar de seus concorrentes (CHEN, CHIANG E
STOREY, 2012), fica claro que as maiores oportunidades do uso do Big Data está
relacionado com suas características peculiares que o diferencia dos dados e análises
tradicionalmente usados hoje nas organizações.
Assim, Simon (2013) afirma que o domínio do Big Data permite as organizações
entenderem melhor seu passado, presente e futuro, possibilitando encontrar respostas
sobre o que aconteceu, o que está acontecendo, o que acontecerá e por quê. O autor
destaca que o Big Data pode muito mais do que responder perguntas complexas
predefinidas pois, com o uso de análises preditivas, além de prover insights sobre
problemas existentes, pode-se identificar potenciais problemas que nem se sabia que
existiam. A técnica fomenta uma cultura de experimentação, onde dados podem ser
combinados de formas diferentes na busca de insights interessantes ao negócio.
Halaweh e Massry (2015) também destacam a capacidade do Big Data em identificar
padrões escondidos, que suportam uma tomada de decisão mais refinada, além da melhora
dos processos e a possibilidade de se desenvolver novos modelos de negócios. Outro
ponto bastante importante, é a habilidade de se tomar decisões baseadas em análises de
fatos em tempo real, tornando elas mais sensíveis e efetivas.
O acréscimo de novas fontes de dados, aliado com a capacidade de processá-los
rapidamente e extrair insights que antes não eram possíveis, tornando a construção de
modelos preditivos uma realidade, foram os destaques de Davenport (2014). O autor
também afirma que existe três classes de valor ligadas ao Big Data: redução de custos,
melhora na tomada de decisões e melhora de produtos e serviços.
A figura a seguir tem como objetivo mostrar de forma simplificada o que o Big Data traz
de novo e alguns exemplos de aplicações.

26
Figura – 1 Big Data a Novidade (fonte: Gartner, créditos: Editora de Arte)
Loshin (2013) levantou uma série de oportunidades advindas do uso do Big Data:
Maior assertividade ao se identificar perfil do consumidor, possibilitando a
criação de produtos mais adequados.
Melhora na pesquisa e análise nos setores de manufaturados, possibilitando a
criação de novos produtos.
Melhora no planejamento estratégico e de negócios, gerando inovação e novas
start-ups.
Construção de modelos preditivos, refinando a tomada de decisão, impactando
diretamente em setores como cadeia de suprimentos, no qual otimização do
estoque e previsão de vendas é essencial.

27
Melhora na identificação de fraudes.
Contudo, ainda segundo o autor, todas essas promessas não passam de mera replicação
do que foi prometido pelos promotores do BI. Assim, para ele o diferencial do Big Data
é a profundidade e, por consequência, o valor dos insights providos pelo Big Data, pois
este é suportado por tecnologias como o Hadoop e o MapReduce, capazes de processar
dados que nunca antes foram levados em conta em tempo real (CEP).
Em um estudo realizado em 2012 pela IBM e pela Said Business School, cerca de 49%
dos respondentes afirmaram que a maior oportunidade do Big Data está na capacidade de
se entender melhor os consumidores, pois entendendo melhor seus clientes, é possível
prever como eles vão se comportar no futuro, provendo-lhes melhores produtos e
serviços. Em segundo lugar, ficou a otimização operacional com 18%, seguido de
gerenciamento de risco/financeiro (15%), criação de novos modelos de negócios (14%) e
melhoria em recursos humanos com 4% (YIN e KAYNAK, 2015).
A criação de transparência nas atividades organizacionais que podem ser usados para
aumentar a eficiência e a melhora nos processos de inovação também são benefícios do
uso do Big Data destacados pela McKinsey Global Institute (2011) e Tankard (2012).
Embora intimamente associado aos benefícios já listados, Silva & Campos (2014)
acrescenta ainda a melhora nas previsões de demanda de mercado e a capacidade de
desenvolver vantagens competitivas mais sustentáveis.
Para ilustrar melhor as oportunidades espalhadas nos diversos setores econômicos, segue
um quadro com exemplos de aplicações do Big Data por indústria:

28
INDÚSTRIA APLICAÇÃO
Finanças/Banco
Perfil do consumidor, targeting, vendas cruzadas
Sentiment Analysis, fortalecimento da marca
Inovação de produtos
Detecção de fraudes
Varejo
Serviço personalizado
Otimização dos produtos
Excelência operacional
Melhor alocação de espaço para produtos e publicidade
Saúde
Melhoria na qualidade e eficiência
Detecção de doenças de forma antecipada
Detecção de fraudes
Prevenção de epidemias
Controle de tráfego
Melhoria da capacidade de detectar funis
Melhor alocação de policiais e agentes de trânsito
Maior facilidade de obter informações relevantes de veículos
Melhor distribuição e temporalização de sinais
Maior ajuda na tomada de decisão dos clientes
Turismo Novos serviços e produtos
Processamento de informações de forma mais barata e rápida
Otimização de routing
Telecomunicações Análise de gravações
Melhoria nos planos
Quadro -5 Exemplos de aplicação de Big Data por indústria (Fonte: Adaptado de Big Data Analytics:
Applications and Benefits por K V N Rajesh, 2013)
A redução dos custos e aumento das receitas; o aumento da eficiência operacional; a
melhora na tomada de decisão; a melhora de produtos e serviços já existentes; a melhora
nos processos de inovação e o desenvolvimento de novos produtos e mercados são
oportunidades constantemente citadas por diversos autores que estudam o Big Data,
conforme tabela a seguir.
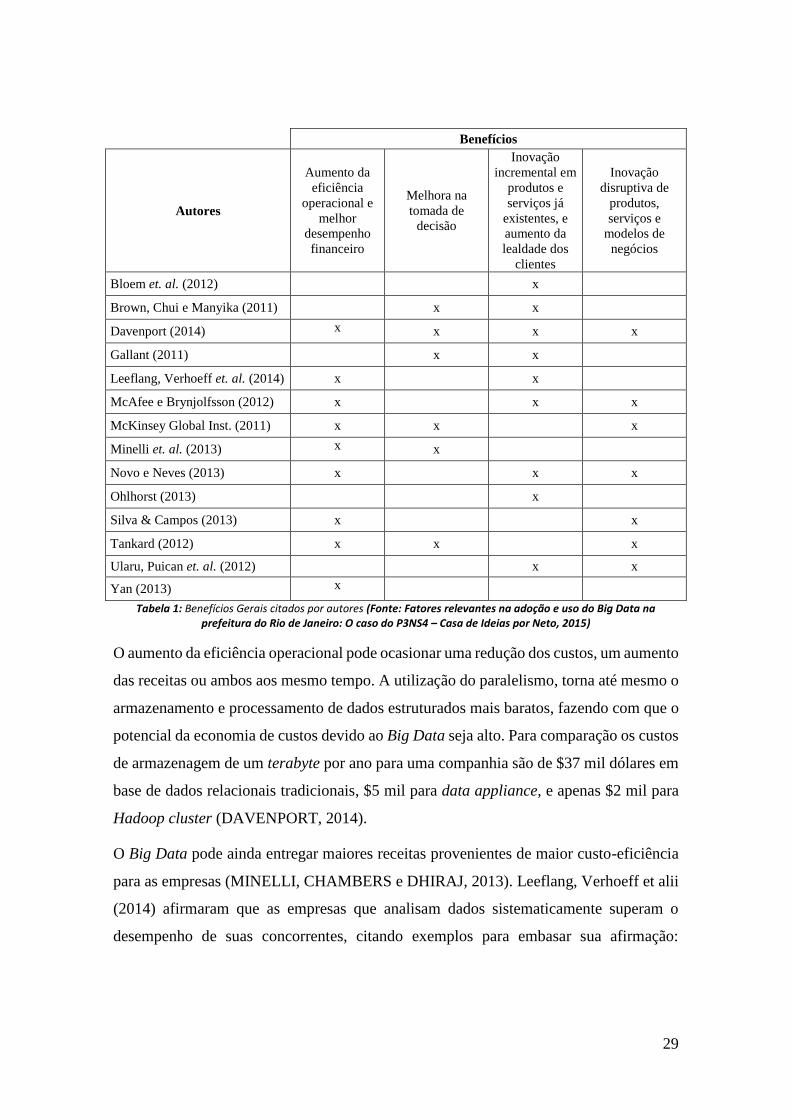
29
Benefícios
Autores
Aumento da
eficiência
operacional e
melhor
desempenho
financeiro
Melhora na
tomada de
decisão
Inovação
incremental em
produtos e
serviços já
existentes, e
aumento da
lealdade dos
clientes
Inovação
disruptiva de
produtos,
serviços e
modelos de
negócios
Bloem et. al. (2012) x
Brown, Chui e Manyika (2011) x x
Davenport (2014) x x x x
Gallant (2011) x x
Leeflang, Verhoeff et. al. (2014) x x
McAfee e Brynjolfsson (2012) x x x
McKinsey Global Inst. (2011) x x x
Minelli et. al. (2013) x x
Novo e Neves (2013) x x x
Ohlhorst (2013) x
Silva & Campos (2013) x x
Tankard (2012) x x x
Ularu, Puican et. al. (2012) x x
Yan (2013) x
Tabela 1: Benefícios Gerais citados por autores (Fonte: Fatores relevantes na adoção e uso do Big Data na prefeitura do Rio de Janeiro: O caso do P3NS4 – Casa de Ideias por Neto, 2015)
O aumento da eficiência operacional pode ocasionar uma redução dos custos, um aumento
das receitas ou ambos aos mesmo tempo. A utilização do paralelismo, torna até mesmo o
armazenamento e processamento de dados estruturados mais baratos, fazendo com que o
potencial da economia de custos devido ao Big Data seja alto. Para comparação os custos
de armazenagem de um terabyte por ano para uma companhia são de $37 mil dólares em
base de dados relacionais tradicionais, $5 mil para data appliance, e apenas $2 mil para
Hadoop cluster (DAVENPORT, 2014).
O Big Data pode ainda entregar maiores receitas provenientes de maior custo-eficiência
para as empresas (MINELLI, CHAMBERS e DHIRAJ, 2013). Leeflang, Verhoeff et alii
(2014) afirmaram que as empresas que analisam dados sistematicamente superam o
desempenho de suas concorrentes, citando exemplos para embasar sua afirmação:

30
Amazon.com (taxa de crescimento anual – AGR14 – 2000-2010: 56,5%), O2 (AGR
29,5%), CapitalOne (AGR 16,6%), Tesco (AGR 11.7%), e progressiva (AGR 6%).
A melhora da tomada de decisão, talvez fora o primeiro motivador para as empresas
criarem mecanismos de análise de dados. Que proposta devemos apresentar para o
cliente? Quais clientes tem maior tendência de deixar de ser clientes rapidamente? Quanto
de estoque devemos manter? Como devemos precificar nossos produtos? Estes tipos de
decisões são facilitadas com Big Data devido ao surgimento dos novos conjuntos de
dados menos estruturados que podem ser aplicados a elas (DAVENPORT, 2014).
Os insights advindos do uso do Big Data tem se mostrado mais profundos e valiosos,
devido à própria característica dos “V,s”, eles envolvem maior quantidade e qualidade de
informações, além de um melhor timing do que antes (MANYIKA, CHUI, et al., 2011;
ZIKOPOULOS, DEROOS, et al., 2012; THE WHITE HOUSE, 2012).
A área de RH pode se beneficiar enormemente ao se obter uma decisão mais assertiva,
seja na hora de se selecionar e admitir novos empregados ou na hora de promovê-los.
(BERSIN, 2013). Outra área que se beneficia muito é a de marketing, pois entendendo
melhor seus consumidores, não só pode-se criar campanhas publicitárias mais eficazes,
como também criar/adaptar produtos e precificar de maneira mais eficiente (LOSHIN,
2013).
A contribuição da tecnologia para a melhora da tomada de decisão pode beneficiar toda
a companhia, e não somente a área de RH e marketing, devido à maior disponibilidade de
dados e a maior capacidade de processá-los. Tradicionalmente, os modelos têm sido
criados usando subconjuntos dos dados chamados de amostra. Uma vez que o modelo é
criado, um segundo conjunto maior de dados é utilizado para testar ou validar o modelo.
Este processo iterativo é frequente. Uma vez que o modelo foi validado, o modelo é
utilizado para avaliar ou analisar todos os dados. Esta é uma abordagem estatística bem
conhecida que tem sido utilizada durante décadas. Com Big Data, cientistas de dados
utilizam uma maior quantidade de dados, ou todos os dados, para criar o modelo. Ao fazer
isto, os cientistas de dados são capazes de introduzir variáveis preditivas no modelo a fim
de aumentar a exatidão do modelo (MINELLI, CHAMBERS e DHIRAJ, 2013).
14 Do inglês, “Anual Growth Rate”.

31
A possibilidade de se trabalhar com 100% do espaço amostral como dito acima, permite
uma maior compreensão do perfil de cada consumidor. Assim, entendendo a fundo seus
anseios, é possível trabalhar de forma ativa, seja na inovação incremental de produtos e
serviços existentes, ou na inovação disruptiva de produtos, serviços e modelos de
negócios (NOVO e NEVES, 2013).
Gallant (2011) ressalta a importância da análise de eventos e da capacidade de criar
sistemas preditivos. Prever a intenção de um cliente de mudar-se para a concorrência tem
muito mais valor do que analisar porque o cliente deixou a empresa. Não que entender os
motivos que levaram a esta decisão do cliente não tenha seu valor, mas poder tomar ações
de contenção, impedindo a saída do cliente, é mais importante do que agir reativamente,
melhorando o que estava errado ou investindo em campanhas caras para tentar trazer o
cliente perdido de volta. Esta mesma visão é compartilhada por Hea (2013) que adiciona
a importância do uso de dados disponíveis em mídias sociais para a capacidade de realizar
estas predições (NOVO e NEVES, 2013).
Especificamente para a indústria de óleo e gás, segundo um estudo publicado pela PR
Newswire US (2015), a indústria de óleo e gás gerou investimentos da ordem de $3,5
bilhões em 2015. A Bain & Company, em um relatório publicado em 2014 já afirmava
que a indústria de petróleo era considera “early adopter” do Big Data e já estava colhendo
benefícios de seu poder de análise de dados, muito devido a sua característica de sempre
lidar com uma grande quantidade de dados, advindos de diversas fontes e muitos deles
obtidos em tempo real (BERTOCCO E PADMANABHAN, 2014).
A Oracle, em uma publicação intitulada “Improving Oil & Gas Performance with Big
Data”, publicada em Abril de 201515, destaca que em todas as etapas do ciclo do petróleo,
desde a exploração, passando pela extração até a produção, assim como em grande parte
das atividades envolvidas em todo o processo, como cadeia de suprimento e marketing,
produzem uma quantidade massiva de dados provenientes de diversas fontes, muitos
deles de forma contínua. Dados de sensores durante a perfuração, produção, transporte e
refino; dados armazenados em sistemas que acompanham a operação; dados de redes
sociais, dados históricos de exploração, distribuição e precificação; dados sísmicos; e
relatórios de ocorrências são alguns exemplos.
15 Disponível em http://www.oracle.com/us/technologies/big-data/big-data-oil-gas-2515144.pdf Acessado
em 20/03/2016

32
Esses fatores levaram a grandes empresas como a Shell a apostarem no Big Data. Em
parceria com a Hewlett-Packard, a Shell instalou sensores ligados por fibra ótica que
transmitem dados sísmicos para servidores mantidos pela Amazon Web Services. Através
da análise desses dados, certos padrões de interferência podem ser identificados em
potenciais bolsões de petróleo. Outra aplicação de Big Data explorada pela empresa é a
utilização de dados de sensores de máquinas com o intuito de estabelecer procedimentos
de manutenção preventiva, evitando quebra e interrupção de funcionamento. Por último,
a Shell ainda faz uso de algoritmos complexos que levam em conta o custo de produção
do combustível, indicadores econômicos, previsões e padrões de clima para construir um
modelo de previsão da demanda, podendo assim alocar de forma mais eficaz recursos e
também precificar seu produto (MARR, 2015).
Portanto, é fato que em uma indústria que envolve alto desenvolvimento tecnológico,
imenso investimento e que seu produto sofre constantes oscilações de preço, uma postura
“data driven” é necessária, pois quanto mais refinada for a tomada de decisão, maior
impacto terá em seus resultados.
Novo e Neves (2013) afirmaram que uma grande empresa de petróleo, conseguiu reduzir
os custos com pessoal em quase 25% e ao mesmo tempo aumentar a produtividade em
5% graças à adoção da tecnologia. Este ganho de eficiência operacional foi possível
utilizando sensores ao longo da linha de produção, enviando dados que eram analisados
em tempo real, permitindo ajustes imediatos na linha, evitando assim intervenções
manuais, que são, em geral, demoradas, caras e perigosas.
Assim, as maiores empresas que prestam serviços de Big Data do mundo, como a Oracle,
a SAS e a EMC, estão cada vez mais focadas na indústria de óleo e gás e apontam as
oportunidades de melhoria da eficiência operacional; maior eficácia na exploração
(inclusive Pré-sal) e refinamento e a possibilidade de um melhor entendimento das
mudanças do mercado como os maiores potenciais de ganho.
2.4. DESAFIOS NA IMPLEMENTAÇÃO DO BIG DATA
Harriott (2013) criou o modelo “Business analytics success pillars” (BASF), representado
na figura 2 que consiste na introdução de fatores responsáveis, segundo o autor, por uma
boa utilização do Big Data numa empresa:

33
“Business Challenges”, que representa entender de forma clara as questões
mais urgentes que necessitam ser respondidas pela análise dos dados, ou
seja, os desafios da empresa/negócio que, quando resolvidos, podem gerar
aumento de receita ou vantagem competitiva.
“Data Foundation”, que remete à importância de se ter uma fonte
válida/confiável de dados. Isso só é possível se os silos de conhecimento
existentes dentro dos departamentos de uma empresa sejam
desconstruídos e a informação flua entre eles de forma rápida e
padronizada. Deve-se buscar uniformizar a “língua” da informação,
estabelecendo o mesmo parâmetro para todas as áreas.
“Analytics Implementation”, que se relaciona com o “como”, ou seja,
como desenvolver e prover a informação de forma a realmente resolver os
desafios da empresa. Para isso, o autor alerta que o mais importante é
sempre focar nos objetivos finais dos usuários da informação (setores,
outros profissionais) e prosseguir com a análise com o intuito de atingi-
los.
“Insight”, que o autor classifica como o fator mais importantes, pois
determina como os analistas transformam dados em informações/insights
úteis. Para isso, eles precisam (através de análise estatísticas) mostrar o
que aconteceu, por que e, por extrapolação, prever o que acontecerá
(tendência).
“Execution and Measurement”, que basicamente é a capacidade de tomar
decisões suportadas pelas informações processadas e acompanhar os
resultados delas de forma a medir a eficácia/eficiência das análises.
“Distributed Knowledge”, que trata do desafio de se utilizar do
conhecimento de toda a organização com o intuito de enriquecer os
insights obtidos dos dados ou ainda processá-los mais rápidos, obtendo
melhores resultados do que se fosse aplicado somente o conhecimento do
analista.
“Innovation”, onde o analista deve sempre buscar formas criativas de
como proceder com a extração da informação e como processá-la de forma
a melhor atender às necessidades da empresa, evitando cair na rotina de

34
providenciar relatórios e mais relatórios, sem nem ao menos saber para
que serve estas informações.
Figura 2 – Modelo de Harriot (BASF) (Fonte: Pillars for Successful Analytics
Implementation)
Também em 2013, uma pesquisa com 140 profissionais de TI de Hong Kong realizada
por Sheila Lam, para o periódico Computer World, apontou que dentre os maiores
desafios que as empresas enfrentaram ao implementarem o Big Data (Tabela 1)
destacaram-se baixa integração entre as diversas ferramentas de dados (48,8%), baixa
qualidade dos dados (39,8%), falta de arquitetura de dados (39%) e confusão quanto à
quem pertence os dados (39%).

35
Baixa integração entre as diversas ferramentas de dados 48,8%
Baixa qualidade dos dados 39,8%
Falta de arquitetura de dados 39,0%
Confusão quanto a quem pertencem os dados 39,0%
Equipe ou habilidades de "Data Science" inadequadas 38,2%
Desafios relacionados ao legado tecnológico 32,5%
Infraestrutura de gerenciamento de dados inadequada 31,7%
Desenvolvimento de novos casos de negócios 24,4%
Inabilidade de atingir a velocidade desejada 14,6%
Conflitos internos/culturais 14,6% Tabela 2 – Desafios imediatos para a implementação do Big Data segundo estudo realizado com
profissionais de TI de Hong Kong (Fonte: Tradução livre de Computer World Hog Kong
Julho/Agosto de 2013)
Analisando a tabela acima, é válido destacar que grande parte dos desafios mencionados
são puramente técnicos e portanto devem ser mais simples de serem solucionados do que
aqueles atribuídos à mudanças culturais (14,6%) ou ao desenvolvimento de novos casos
de negócios (14,6%) (LAM, 2013).
Já para Barton & Court (2012), os principais desafios para uma boa aplicação do Big Data
são:
Ter que lidar com múltiplas fontes de dados, que consiste na escolha dos
dados a serem utilizados (internos e externos), na estrutura do banco de
dados escolhida (como padronizar esses dados) e como agrupar dados de
diferentes formatos em um mesmo database.
Construir modelos que provisionam previsões e otimizações
eficientes/acuradas. Muito mais do que a mera aplicação de ferramental
estatístico nos dados no intuito de identificar correlações e, com isso, fazer
previsões, Big Data trata do desenvolvimento de modelos/algoritmos
construídos a partir de uma oportunidade de negócio identificada, na qual
pode-se utilizar da análise de dados que venham a resultar em melhoria do
desempenho da empresa. Neste quesito, especial atenção quanto à
complexidade do modelo é necessária.
O último desafio elencado pelos autores é a necessidade de se adaptar às
organizações para uma cultura “data driven”, ou seja, alinhar a cultura
organizacional com a aplicação da análise de dados, gerando

36
confiabilidade à ferramenta. Isso pode ser obtido através da sincronização
do fluxo de informação entre analistas e usuários das análises (prover
informações realmente relevantes e atualizadas) e de se prover informação
de forma simples aos usuários finais (os analistas não precisam mostrar o
algoritmo ou dar um monte de informações aos usuários, e sim somente o
resultado da aplicação do modelo em uma interface fácil de ser entendida).
É preciso também desenvolver a capacidade de seus analistas de
explorarem os dados e entender o que os usuários realmente precisam, para
a criação de modelos que melhor traduzam esses dados em informações
relevantes.
Ainda há a dificuldade de, no meio de tanta informação, achar correlações que mostram
mais do que meras casualidades, achar significado para “o por quê” dessas correlações
acontecerem e, consequentemente, achar aplicabilidade para essas informações. Somado
com problemas quanto à preservação da privacidade e a necessidade de conseguir
identificar quem tem os dados que sua empresa necessita e como obter esses dados.
Muitas vezes os dados não estão em silos departamentais dentro de sua empresa e sim
com consumidores, terceiros, outras empresas. Estes são os fatores apontados por
Pentland (2012) como maiores problemas enfrentados por quem quer fazer uso do Big
Data.
Já Galbraith (2014), aponta três principais desafios para as organizações que pretendem
usufruir dos benefícios advindos do uso do Big Data:
Mudanças de poder16 entre os tomadores de decisões que se apoiam em
julgamentos baseados na experiência para aqueles que se baseiam no uso de
tecnologias digitais. Neste tópico, o autor ressalta que é inevitável uma mudança
de poder dentro de toda a estrutura organizacional da empresa para receber e
integrar os novos analistas de dados, de forma que eles possam participar
ativamente na tomada de decisão. Ele ainda defende que, em muitos casos, para
reforçar a autoridade desses novos analistas ou para mediar potenciais conflitos
dentro da organização, a criação do “Chief Data Officer” (CDO) é uma possível
solução.
16 O termo original utilizado pelo autor foi Power Shifts

37
Capacidade de tomada de decisão em tempo real17, pois se a organização contar
com uma capacidade de análise apropriada, elas poderão tomar decisões em tempo
real. Ainda segundo o autor, tomar decisões baseados em análises de fatos que
estão acontecendo em tempo real, impactaria em diversas áreas da organização,
dentre elas: publicidade, gerenciamento de comunidade, desenvolvimento de
novos produtos e gerenciamento da cadeia de suprimentos, uma vez que as
empresas podem envolver seus clientes em conversas sobre suas marcas, obter
ideias de novos produtos e como comercializá-los.
E finalmente, gerar receita da utilização do Big Data. Para o autor, esse tópico
representa tanto um desafio quanto uma oportunidade e está intimamente ligado
ao sucesso ou fracasso dos dois desafios citados anteriormente, pois para ele (o
autor), fazendo a transição adequada da mudança de poder na estrutura de tomada
de decisão da organização e obter a capacidade de tomar essas decisões em tempo
real, naturalmente criará oportunidades de ganho de receita.
Outro modo bastante utilizado para abordar os desafios advindos da implementação do
Big Data é relacioná-los aos “Vs” citados anteriormente, pois ao mesmo tempo que eles
representam grandes oportunidades a serem exploradas, também representam grandes
desafios a serem superados. Yin e Kaynak (2015), discutiram os desafios do Big Data,
baseados no Volume, Variedade, Veracidade, Velocidade e Valor, agrupando esses “5
Vs” em três grupos:
Volume e Variedade: estas duas características se relacionam diretamente com os
requerimentos de hardware e software a serem utilizados. Uma vez que o
problema de espaço de armazenamento e processamento originado por essas
características tem sido em grande parte solucionado por tecnologias baseados em
nuvem18, o processamento dessa quantidade enorme de dados em tempo real ainda
é desafiador, assim programas como o MapReduce e frameworks como o Hadoop
tendem a ultrapassar essas barreiras no futuro.
Veracidade e Velocidade: A combinação desses dois atributos remete à
necessidade de se obter a habilidade de detectar e processar dados online. O fluxo
contínuo de grande quantidade de dados, demanda extremo cuidado e agilidade
ao se selecionar dados relevantes de não relevantes, pois dependendo de como
17 Real-Time Decision Making 18 Por exemplo: Cloud computing, virtualization, storage

38
estes dados são selecionados e processados, eles podem ser corrompidos,
manipulados ou se tornarem obsoletos.
Valor: Apontado pelo autor juntamente com o desafio de se validar (Veracidade)
as informações obtidas, a capacidade de extrair valor (monetizar) do Big Data
depende diretamente da capacidade de se criar um ambiente cooperativo ente
academia, indústria e empresas. Neste tópico, o autor salienta que existe um
enorme “gap” entre o uso ideal do Big Data e o real, e que somente as empresas
e indústria compartilhando seus dados com pesquisadores, e permitindo que esses
publiquem seus estudos, pode acelerar seu desenvolvimento.
Jagadish et al. (2014), em uma abordagem mais técnica, desenvolveram um modelo em
que descrevem o passo a passo do processo de análise do Big Data19. Nesse modelo, os
autores apontaram os seguintes desafios como os mais importantes (divididos por fases):
Aquisição de dados: desafio referente ao procedimento de seleção dos dados a
serem utilizados na análise, ou seja, que filtros usar de forma a não descartar dados
relevantes e não deixar passar inutilidades.
Extração e limpeza das informações: nem sempre os dados processados derivam
informações estruturadas ou informações que possam ser usadas diretamente.
Nestes casos, existe o desafio de se obter as informações desejadas no meio de
grandes volumes de dados processados não estruturados, além de um trabalho de
limpeza desses dados, eliminando possíveis erros e suprindo possíveis faltas.
Integração, agregação e representação: em muitas oportunidades, diversos tipos
de dados diferentes devem ser utilizados para a obtenção da mesma informação.
Além disso, existem diversas maneiras de se construir banco de dados e cada
organização utiliza sua própria arquitetura. Assim, problemas de integração
desses diversos banco de dados, de como homogeneizar essas diversas fontes de
dados e produzir um “padrão” para representar essas informações, de forma que
toda a comunidade possa entendê-las, são grandes desafios.
Modelagem e análise: desafios relacionados ao método de como estruturar e
proceder com a análise do Big Data (querying and mining), levando-se em conta
19 Os autores chamara de Big Data analysis pipeline

39
as características de que o Big Data normalmente é heterogêneo, advindo de fontes
não confiáveis e extremamente dinâmico.
Por fim, vem o desafio de interpretar o resultado da análise desse conjunto de
dados complexos, que depende da capacidade humana.
Os autores ainda enumeram desafios comuns à todas as fases anteriormente descritas:
O primeiro grande desafio é relacionado à heterogeneidade (representado pelo
“V” de Variedade) dos dados, uma vez que os algoritmos usados pelas máquinas
ao se efetuar as análises contam com a entrada de dados homogêneos. Espera-se
ainda, grande dificuldade para gerar metadata válida que descreva com exatidão
a data armazenada de forma automatizada.
O próximo desafio remete à existência de dados inconsistentes ou incompletos,
desafio este presente em qualquer tipo de análise de dados, porém deveras
agravado no uso do Big Data, pois a grande variedade de fontes dos dados pode
significar que a procedência desses dados nem sempre são confiáveis e que eles
nem sempre podem ser obtidos na íntegra. Por outro lado, o grande volume de
dados pode significar que através da redundância e do cruzamento de dados, esse
problema possa ser amenizado.
O terceiro fator é a escala, que apesar do grande avanço que estamos presenciando
na evolução do hardware atualmente, a complexidade dos dados e
consequentemente a exigência de maior capacidade de processamento também
está aumentando. Portanto, mesmo com o advento das tecnologias relacionadas à
nuvem, existe uma grande preocupação sobre a escalabilidade do Big Data, pois
ainda não se chegou uma forma custo-efetiva ótima dessa tecnologia.
O quarto desafio é basicamente o mesmo apontado por Yin e Kaynak (2015), que
é a necessidade de se processar e analisar dados em tempo real.
O penúltimo desafio é bastante discutido atualmente, não só ao se tratar de Big
Data e sim de praticamente todas as tecnologias que tratam de dados,
principalmente após o surgimento da Internet que é a questão da privacidade e
pertencimento dos dados. Serviços online, aplicativos de rastreamento, arquivos
médicos, todos eles se apoderam de nossos dados privados. Como controlar o que

40
será feito com esses dados e como evitar que eles sejam compartilhados, são
problemas amplamente discutidos.
E finalmente, existe a perspectiva humana, que semelhante a escala da tecnologia,
é necessário garantir que os as pessoas possam absorver os resultados dessas
análises. Mais ainda, para garantir essa escalabilidade do ponto de vista humano,
uma forte colaboração dos especialistas (que atualmente são poucos) em
modelagem, compartilhando seus algoritmos e uma arquitetura de visualização
que possibilite acesso e entendimento de todos é bastante desafiador.
Apesar dos inúmeros desafios descritos nessa seção, as empresas acreditam que as
oportunidades advindas do uso do Big Data são uma realidade e que seus benefícios são
imensos, justificando o grande investimento que essas organizações estão fazendo nessa
área.

41
3. MÉTODO
O presente estudo tem caráter exploratório devido ao pouco conhecimento acumulado
sobre implementação de Big Data em organizações, especialmente no Brasil. O método
escolhido foi o do estudo de caso, por ser recomendado a estudos exploratórios e em fase
inicial de investigação (YIN, 1989). O estudo de caso se caracteriza como um tipo de
pesquisa cujo objeto é uma unidade que se analisa profundamente (GODOY, 1995).
Assim, esse modelo tem se tornado uma estratégia utilizada quando os pesquisadores
procuram responder "como" e "por que" os fenômenos ocorrem, quando o investigador
tem pouco controle sobre os eventos, e quando o foco da pesquisa é um fenômeno inserido
em algum contexto da vida real (YIN, 1989) – características bem próximas da presente
pesquisa.
3.1. Petrobras, Cenpes e TIC
A Petrobras é uma sociedade anônima de capital aberto, cujo maior acionista é a União
(representada pela Secretaria do Tesouro Nacional). Presente em 19 países, opera em
diversos campos: exploração e produção, refino, comercialização, transporte,
petroquímica, distribuição de derivados, gás natural, energia elétrica, gás-química e
biocombustíveis.20
Sua missão é atuar na indústria de petróleo e gás de forma ética, segura e rentável, com
responsabilidade social e ambiental, fornecendo produtos adequados às necessidades dos
clientes e contribuindo para o desenvolvimento do Brasil e dos países onde atua. Já sua
visão para 2030 é ser uma das cinco maiores empresas integradas de energia do mundo e
a preferida de seus públicos de interesse.
Presente em 19 países a Petrobras conta 725.447 acionistas em 2015, ano em que seus
investimentos foram da ordem de R$ 76,3 bilhões e sua receita de vendas foi de R$ 321,6
bilhões, obtendo um lucro líquido de R$ -34,8 bilhões. A empresa ainda conta com 78.470
funcionários, 122 plataformas de produção, 16 refinarias e reservas provadas de 13,3
20 Informações retiradas do site da Petrobras (www.petrobras.com.br), dados de dezembro de 2014.

42
bilhões de barris de óleo equivalentes. Sua produção diária é de 2 milhões 787 mil barris
de óleo equivalente por dia e 2 milhões 26 mil barris de derivados por dia. Conforme
representado na figura a seguir.
Figura 3 – Estatísticas Petrobras (Fonte: http://www.petrobras.com.br21)
O Centro de Pesquisas e Desenvolvimento Leopoldo Américo Miguez de Mello (Cenpes),
localiza-se na Cidade Universitária, campus da Universidade Federal do Rio de Janeiro
(UFRJ), com uma área de aproximadamente 300 mil m2 e quase 50 anos de existência.
Foi criado com a intenção de ser responsável por coordenar todas as pesquisas científicas
e tecnológicas na empresa, recolhendo e sistematizando sua documentação, além de
coordenar trabalhos relativos a estudos de patentes. Em Abril de 2014, o Cenpes contava
com 1950 profissionais, somando investimentos na ordem de US$ 566 milhões em
pesquisa e desenvolvimento desde 2008, tornando-se um dos maiores complexos de
pesquisa aplicada à indústria de energia do mundo.22
As atividades de tecnologia da informação e telecomunicações estão presentes desde a
fundação da Petrobras, em 1953, a partir da implantação dos primeiros sistemas de
21 Dados dos resultados do exercício de 2014/ Última atualização: Dezembro de 2014. Não inclui os
escritórios de representação 22 Informações retirada no site da Petrobras: http://www.petrobras.com.br/fatos-e-dados/cenpes-tecnologia-
para-superar-desafios-em-60-anos-de-petrobras.htm

43
comunicação telefônica. Naquela ocasião, a área era denominada Divisão de
Telecomunicações (DITEL) e estava ligada ao Gabinete da Presidência. No entanto
somente em 2008 foi criada a Gerência Executiva da Tecnologia da Informação e
Telecomunicações (TIC).
A TIC é a maior unidade da área de serviços da Petrobras, com mais de 11 mil
colaboradores, sendo responsável pela integração de toda a Companhia. A formação
dessa unidade teve como objetivo gerar para a Petrobras economias de escala e de escopo
e reduzir o tempo de entrega de serviços e soluções, através da integração dos processos
e serviços de tecnologia da informação e de telecomunicações.
3.2. A parceria estratégia com a EMC²
Presente em 86 países, a EMC é líder mundial em auxiliar empresas e provedores de
serviços a otimizar suas operações e fornecer ITaaS (IT as a service, TI como serviço). A
computação em nuvem é fundamental para essa transformação. Com produtos e serviços
inovadores, a EMC acelera a jornada rumo à computação em nuvem, ajudando os
departamentos de TI a armazenar, gerenciar, proteger e analisar seu ativo mais valioso –
a informação – de um modo mais ágil, confiável e barato.
Com mais de 70.000 colaboradores ao redor do mundo, em 2014 a empresa ocupou a
posição 128 da Fortune 500 e declarou uma receita de $24,4 bilhões. Dentre seus
principais clientes estão bancos de atuação global e empresas líderes de serviços
financeiros, fabricantes, organizações de assistência médica e ciências biomédicas,
provedores de serviços de Internet e telecomunicações, linhas aéreas e empresas de
transporte, instituições de ensino e órgãos públicos.
Atualmente, a Dell está em processo de compra da EMC Corp, numa transação de
aproximadamente $67 bilhões, tratando-se da maior aquisição da história na área de TI.
O Centro de Pesquisa e Desenvolvimento do Brasil (BRDC) foi criado em 2012 no Parque
Tecnológico do Rio, no campus da Universidade Federal do Rio de Janeiro. A unidade,
cuja principal atividade é a realização de pesquisas aplicadas relacionadas com o Big Data
e com desafios encontrados na indústria de óleo e gás, abriga um centro de investigações

44
aplicada, laboratórios de desenvolvimento de soluções e o primeiro Executive Briefing
Center (EBC) da América Latina.
A missão do BRDC é criar tecnologias revolucionárias a fim de solucionar os desafios
relevantes da indústria. Sua visão é ser um excelente provedor de IP para a EMC, um dos
principais contribuintes para o sucesso global da EMC em óleo e gás, ser o provedor
número um de IP Big Data para a indústria de óleo e gás, ser a primeira opção na América
Latina para pesquisas de Big Data e ser o modelo de sucesso para futuros centros de P&D
da EMC.
O BRDC da EMC² estabeleceu parceria estratégica com o Cenpes, de fundamental
importância durante o desenvolvimento dos projetos estudados, pois recaiu sobre o
Centro de Pesquisa da EMC2 a responsabilidade sob parte técnica do tratamento e limpeza
dos dados utilizados. Assim, o Cenpes proveu os desafios que precisava tratar com Big
Data e a EMC2 colaborou na parte técnica dos projetos. A parceria realizada será
explicada em detalhes mais adiante nesta dissertação.
3.2. Coleta e análise de dados
Análise documental e entrevistas semiestruturadas foram os instrumentos utilizados neste
estudo para coleta de dados, após a realização da pesquisa bibliográfica. Foram realizadas
quatro entrevistas semiestruturadas com os líderes dos projetos de Big Data. Como fontes
documentais, foram utilizados áudios de palestras, sites, apresentações em power point e
textos fornecidos pelas empresas envolvidas (Petrobras e EMC²).
Com o intuito de melhor entender as empresas envolvidas e fazer uma breve introdução
das mesmas, foram consultados os seus respectivos sites23. Para detalhar os três projetos
de Big Data desenvolvidos pela Petrobras, utilizou-se de dois áudios de palestras de um
de seus idealizadores, uma ministrada em um encontro organizado pela Harvard Business
Review do Brasil em 2013 e a outra - dois anos depois - no Instituto COPPEAD de
Administração, além de documentos e apresentações eletrônicas cedidas pela própria
23 www.petrobras.com.br e www.emc.com

45
Petrobras e uma entrevista semiestruturada com o responsável geral dos projetos,
realizada em meados de 2015.
Para aprofundar na identificação das oportunidades e desafios apresentados no uso do Big
Data pela Petrobras, cerne deste presente estudo, optou-se por realizar três entrevistas
semiestruturadas, duas com os representantes da EMC² nos projetos e uma novamente
com o responsável geral do projeto, o qual representa a Petrobras e mais especificamente
Centro de Pesquisas e Desenvolvimento (Cenpes).
As entrevistas foram classificadas como semiestruturadas, devido ao fato de que todas
partiram de três tópicos básicos a serem desenvolvidos com base em um roteiro básico,
apresentado no Anexo 1. Os tópicos abordados foram:
Definição de Big Data.
Fatores que motivaram a Petrobras a optarem pelo uso do Big Data
(Oportunidades identificadas)
Principais dificuldades esperadas e encontradas durante o desenvolvimento dos
projetos.
Porém, para cada entrevistado foram o roteiro de entrevista foi adaptado, de acordo com
seu papel e competência atribuída nos projetos. Novamente esses “sub roteiros”
representavam tópicos a serem discutidos durante as entrevistas, cabendo ao entrevistador
formular as perguntas e aprofundar a discussão ao longo de sua execução.
As entrevistas ocorreram entre o 2015 e início de 2016 e foram entrevistados o
representante do Cenpes nos projetos (duas vezes), que ao mesmo tempo é o responsável
geral dos projetos e os especialistas da EMC² responsáveis pelos projetos 1 e projetos 3 e
4, conforme tabela a seguir. Dos cinco envolvidos nos projetos das duas empresas, três
responsáveis foram entrevistados.
Entrevistado Empresa Papel Número de entrevistas
RG Petrobras Responsável geral dos projetos 2
LP1 EMC² Líder do projeto 1 1
LP2 EMC² Líder dos projetos 2 e 3 1 Tabela 3: Tabela dos entrevistados para o caso (Fonte: autor)
O objetivo de não se fazer uma entrevista rigorosamente estruturada foi o de explorar os
tópicos básicos de forma bastante aberta, devido ao caráter exploratório da pesquisa. De

46
acordo com as respostas, poderia-se aprofundar o tema, evitando assim, a indução das
respostas e favorecendo a discussão de oportunidades e desafios não tratados na literatura.
Para a análise de dados, os itens mencionados na literatura como oportunidades e desafios
para o uso de Big Data foram tratados como categorias analíticas, representados nas
tabelas a seguir:

47
Oportunidades Autores
Capacidade de se armazenar, analisar grandes volumes
de informação
Davenport (2014), Minelli et al. (2013), Novo
e Neves (2013), Silva e Campos (2014),
Taurion (2012), McAfee e Brynjolfsson
(2012), Simon (2013), Loshin (2013), Gallant
(2011)
Análise de informação em tempo real
Davenport (2014), Minelli et al. (2013), Novo
e Neves (2013), Silva e Campos (2014),
Taurion (2012), McAfee e Brynjolfsson
(2012), Simon (2013), Loshin (2013), Gallant
(2011)
Capacidade de se integrar dados de diversas fontes e
tipos
Davenport (2014), Minelli et al. (2013), Novo
e Neves (2013), Silva e Campos (2014),
Taurion (2012), McAfee e Brynjolfsson
(2012), Simon (2013), Loshin (2013), Gallant
(2011)
Obtenção de novos insights
Davenport (2014), Manyika et al. (2011),
Harriott (2013), Simon (2013), Loshin
(2013), Gallant (2011)
Melhora na tomada de decisão
Brown, Chui e Manyika (2011), Davenport
(2014), Gallant (2011), Minelli et al. (2013),
Tankard (2012)
Aumento da eficiência operacional e melhor
desempenho financeiro
Leeflang, Verhoeff et. al. (2014), Davenport
(2014), McAfee e Brynjolfsson (2012),
Minelli et. al. (2013), Novo e Neves (2013),
Silva & Campos (2013), Tankard (2012), Yan
(2013)
Inovação incremental em produtos e serviços já
existentes, e aumento da lealdade dos clientes
Bloem et. al. (2012), Brown, Chui e Manyika
(2011), Davenport (2014), Gallant (2011),
Leeflang, Verhoeff et. al. (2014), McAfee e
Brynjolfsson (2012), Novo e Neves (2013),
Ohlhorst (2013) Ularu, Puican et. al. (2012)
Inovação disruptiva de produtos, serviços e modelos de
negócios
Davenport (2014), McAfee e Brynjolfsson
(2012), McKinsey Global Inst. (2011), Novo
e Neves (2013), Silva & Campos (2013),
Tankard (2012), Ularu, Puican et. al. (2012)
Construção de modelos preditivos
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Taurion (2012), Novo e
Neves (2013), Gallant (2011), Loshin (2013),
Rajesh (2013), Simon (2013)
Tabela 4: Oportunidades citados por autores (Fonte: autor)

48
Desafios Autores
Validade e qualidade dos dados
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Taurion (2012), McAfee
e Brynjolfsson (2012), Simon (2013),
Harriott (2013), Lam (2013), Barton e Court
(2012), Yin e Kaynak (2015), Jagadish et al.
(2014)
Modelar algoritmos que produzam informações
pertinentes
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Simon (2013), Harriott
(2013), Lam (2013), Barton e Court (2012),
Jagadish et al. (2014)
Interpretar os dados de maneira eficiente
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Taurion (2012), McAfee
e Brynjolfsson (2012), Simon (2013),
Harriott (2013), Yin e Kaynak (2015),
Jagadish et al. (2014), Galbraith (2014),
Falta de especialistas "cientistas de dados"
Davenport (2014), Manyika et al. (2011),
Taurion (2012), Simon (2013), Minelli et al.
(2013), Jagadish et al. (2014), Barton & Court
(2012), Lam (2013)
Dificuldade de se migrar de um perfil "modo driven"
para "data driven"
Davenport (2014), Harriott (2013), Lam
(2013), Barton & Court (2012)
Custódia, gerenciamento dos dados
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Taurion (2012), McAfee
e Brynjolfsson (2012), Simon (2013), Lam
(2013), Jagadish et al. (2014)
Segurança dos dados
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Taurion (2012), McAfee
e Brynjolfsson (2012), Simon (2013)
Infraestrutura de TI
Davenport (2014), Taurion (2012), Simon
(2013), Jagadish et al. (2014), Yin e Kaynak
(2015), Lam (2013)
Dificuldade de se extrair valor
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Simon (2013), Harriott
(2013), Yin e Kaynak (2015), Taurion (2012)
Tabela 5: Desafios citados por autores (Fonte: autor)
Ou seja, buscou-se nos dados coletados trechos que confirmassem estes itens como
oportunidades e desafios e também procurou-se identificar oportunidade e desafios
emergentes, que não foram apontados na revisão literária, mas que estiveram presentes
no caso da Petrobras. As categorias analíticas estabelecidas a priori e a posteriori geraram
então as proposições desta pesquisa exploratória.

49
4. OS PROJETOS ANALISADOS
Algumas peculiaridades quanto à iniciativa de implementar o Big Data na Petrobras
devem ser levadas em conta ao estudar esse casso.
A primeira é que são projetos de pesquisa desenvolvidos por iniciativa de um líder no
Cenpes e não envolve a entrega de um “produto final”, pois como se trata de projetos de
pesquisa, eles podem ou não dar origem a “entregáveis”, dependendo do resultado da
pesquisa e da capacidade da empresa de aproveitá-lo. Outro ponto de destaque é que os
projetos foram desenvolvidos por uma parceria entre a Petrobras (através do Cenpes e da
TIC) e a EMC, não existindo uma relação cliente-fornecedor entre as partes, ou seja, sem
contrapartida financeira. A parceria realizada será explicada em detalhes mais adiante
nesta dissertação.
A seguir, os projetos são aplicados detalhadamente.
Projeto 1: Centro de monitoramento e diagnóstico (análise dos dados dos sensores
das turbo máquinas).
Projeto 2: Análise de dados da cadeia de suprimentos e inventários (Logística e
Supply Chain).
Projeto 3: Análise dos dados sísmicos (Prospecção).
1) Centro de monitoramento e diagnóstico (CMD)
Uma plataforma de petróleo conta com, em média, seis mil sensores, emitindo uma
enorme quantidade de dados. A análise destes dados pode ajudar a melhor as operações
das plataformas. Esta ideia deu origem ao centro de monitoramento e diagnóstico, pois
hoje os parques termoelétricos Petrobras contam com quinze turbinas, setenta turbo
geradores, cinquenta moto geradores, totalizando a geração de mais de cinco mil
megawatts. Tudo isso gera uma quantidade massiva de dados.
Com o tempo, essas máquinas exigem paradas para manutenção preventiva, o que
culmina na interrupção da operação. O atraso dessa parada pode resultar em danos nos
equipamentos e, por consequência, em manutenção corretiva, acarretando interrupções

50
não programadas e aumentando os gastos, que consistem na despesa para o conserto
acrescidos do prejuízo da interrupção de funcionamento.
Portanto, o momento de realização das paradas preventivas é essencial. Por um lado, se
ela for feita prematuramente, incide o significante custo da paralisação da operação. Por
outro lado, caso ela seja adiada em demasia, a empresa incorrerá em risco de danificar o
equipamento, comprometendo toda a operação e estendendo ainda mais o tempo de
parada.
Assim, o principal papel do CMD é otimizar essas paradas. Analisando dados desses
sensores, a CMD pode entender o comportamento de geradores, identificar anomalias e
prever falhas, melhorando significantemente a eficiência dos mesmos, reduzindo o tempo
de parada, eliminando paradas desnecessárias e potenciais defeitos no equipamento.
Em suma, a Petrobras está buscando basicamente:
Monitoramento contínuo e integrado de sensores dos equipamentos;
Acompanhamento, em tempo real, da eficiência térmica e elétrica dos
equipamentos;
Diagnóstico da causa raiz de eventos críticos, para correção e prevenção de
defeitos;
Prognóstico, em tempo real, de possíveis desvios de desempenho.
2) Logística e Cadeia de Suprimentos
A Logística equivale a cerca de 40% dos custos na indústria de petróleo. Na Petrobras
isso não é diferente. São mais de R$ 11 bilhões em estoques, totalizando mais de 80 mil
itens e 2 mil pedidos diários para mais de 300 destinos diferentes. A complexidade
Logística da empresa impõe diversos desafios, o que faz com que a Petrobras busque
incessantemente melhorias nos processos.
Por isso, a empresa investe em um projeto de Big Data específico para a Logística do
armazém, que consiste em todo o processo de transporte de materiais entre o armazém e
as plataformas. Esses transportes podem ser terrestres ou marítimos e seguem as seguintes
etapas:
Recebimento – chegada do equipamento.

51
Armazenagem – estocagem.
Atendimento da demanda, que se subdivide em tratamento do pedido,
consolidação das caixas e entrega dos itens na plataforma.
Os problemas ocorridos em cada etapa descrita acima são numerosos. Contudo, os mais
destacados são o longo lead-time e o estoque excessivo. O lead-time - tempo entre o
pedido e a chegada da peça à plataforma - hoje varia entre 7 e 15 dias, quando a meta é
um lead-time de 5 dias. Vale lembrar que, dependendo da falha que se deseja reparar, o
lead-time pode representar tempo de interrupção de atividades nas plataformas.
Já o estoque excessivo tem relação com a necessidade de produção ininterrupta. A parada
da produção devido à indisponibilidade de peças de reposição pode significar um prejuízo
de milhões de reais. Por este motivo, a Petrobras mantém um grande estoque com a
finalidade de disponibilizar peças de reposição e evitar paradas na produção. Contudo, o
estoque da empresa está avaliado em cerca de R$ 11 bilhões, o que faz a gerência
questionar se esse estoque é excessivo ou não.
Para atenuar esses e outros problemas, a empresa investe em um projeto de Big Data que
busca prioritariamente:
Identificar gargalos nos processos de logística e cadeia de suprimentos;
Reduzir lead time;
Estimar como melhorar o atendimento;
Evitar perdas por paradas na plataforma;
Otimizar o estoque;
Avaliar a probabilidade de falta de materiais para reposição, assim como, a
probabilidade da utilização de um material em determinado período de tempo.
Em outras palavras, o objetivo final do projeto é otimizar o processo nos armazéns de
forma a atender as plataformas de maneira satisfatória, reduzindo o tempo de entrega e
os estoques.
Para atingir esses objetivos, o projeto de Big Data alia informações do SAP, do sistema
de reserva e transporte de carga, que envolve não só a análise dos dados existentes da

52
operação, como a criação de um modelo preditivo. A criação de um modelo preditivo se
justifica porque o banco de dados da empresa não contém as informações necessárias para
cobrir todos os cenários possíveis da operação. Sendo assim, o objetivo é identificar o
comportamento em cada etapa no atendimento da demanda, desde o recebimento até a
entrega do material na plataforma.
O modelo ajudará a companhia a criar todos os cenários possíveis da operação,
permitindo a empresa calcular a probabilidade de ocorrência de eventos, buscar
alternativas para melhorar o atendimento, identificar gargalos no processo, otimizar o
estoque, assim como estimar os lead-time esperados de acordo com o comportamento da
demanda.
3) Otimização da Produção
Em qualquer empresa, otimizar a produção é sempre um dos objetivos e um desafio
constante.
No processo produtivo da Petrobrás, encontram-se diversos sensores nos poços, nas
plataformas e nos barcos de apoio, por exemplo. Com essa massa de dados à disposição,
abriu-se a possibilidade de utilizá-los, através de Big Data, para melhorar o modelo
preditivo de produção e preventivo contra falhas.
Um dos problemas que podem ocorrer no processo produtivo são as chamadas “golfadas”.
Isto acontece quando o padrão de escoamento se torna intermitente. O fluido não gira
constantemente, os separadores enfrentam problemas e não conseguem operar,
precisando parar. Além disso, grandes variações de pressão também causam problemas
na plataforma, que não está preparada para receber, em separado, água, óleo ou gás, e sim
uma mistura destes componentes. Alguns motivos para a golfada são a maneira como o
óleo está no reservatório ou o quanto é injetado no reservatório para facilitar a retirada do
óleo.
Outro problema comum à produção são as formações de hidratos, uma espécie de
congelamento de CO2, dentro da plataforma. Isto acontece porque, em águas profundas,
a 2 mil metros de profundidade, a temperatura é baixa e a pressão é alta. Quando os
hidratos se formam, é necessário injetar um equipamento para limpar esse acúmulo de

53
CO2 congelado. Com o auxílio de Big Data, espera-se antever a formações de hidrato
para poder realizar a limpeza antes de uma situação crítica.
Com a prevenção e previsão de erros, objetiva-se manter a plataforma operando no ponto
ótimo. Hoje na Petrobras já existem projetos com este objetivo, mas que não trabalham
com Big Data. Com a análise de grande quantidade de dados, espera-se conseguir atuar
em um horizonte maior, como médio e longo prazo, até mesmo em função da
característica de disposição dos equipamentos, com a plataforma em alto mar e as
máquinas de conserto em terra.
Para operacionalizar a prevenção de erros, a tentativa é obter correlação entre as variáveis
que afetam a produção para acompanhamento proativo dos KPIs (Indicadores Chaves de
Produção). Além disso, busca-se também encontrar correlações não óbvias entre as
variáveis.24
Assim, o Big Data neste projeto foi aplicado para utilizar os dados dos diversos sensores
espalhados nos poços, nas plataformas e nos barcos de apoio, com o intuito de:
Melhorar o modelo preditivo de produção e preventivo contra falhas.
Evitar paradas advindas de problemas como “golfadas”.
Antever a formações de hidrato para poder realizar a limpeza antes de uma
situação crítica.
Manter a plataforma operando no ponto ótimo.
24 Todas as informações sobre os projetos foram obtidas através da análise de documentos fornecidos pela
Petrobras e de palestras ministradas pelo Dr. Ismael dos Santos no COPPEAD e em congresso da HBR.

54
5. OPORTUNIDADES E DESAFIOS NO DESENVOLVIMENTO DE
PROJETOS DE BIG DATA NA PETROBRAS
Para a análise de dados desta pesquisa, optou-se por usar de comparação entre a literatura
e as informações coletadas durante as entrevistas, na tentativa de melhor compreender as
oportunidades e desafios levantados, e aferir se o que é descrito em textos acadêmicos
pode ser verificado na prática. Adicionalmente, buscou-se identificar também
peculiaridades destes desafios e oportunidades e fatores emergentes ainda não descritos
na literatura. Em resumo, levantou-se algumas categorias de análise levantadas no
referencial teórico, sintetizadas nas tabelas 4 e 5, e na pesquisa de campo, buscou-se
verificar a existência destas oportunidades e desafios e de outras oportunidades e desafios
emergentes.
Apesar da indústria do petróleo ser bastante conservadora, no que tange ao Big Data ela
pode ser considerada uma “early adopter”. Porém, no caso específico da Petrobras, essa
tecnologia era pouco difundida, como retrata o trecho a seguir, parte da entrevista feita
com o representante do Cenpes e responsável geral (RG) dos três projetos de pesquisa
estudados neste caso.
Há uns 3 anos atrás25 recebi uma visita do pessoal do MIT aqui junto com o
pessoal do ITA, primeira vez que ouvi falar de Big Data... Eu na época
confesso a você que não sabia nada do que era Big Data, não tinha a menor
ideia, achava que Big Data era muito dado... Aí eles me pediram para falar
sobre Big Data na Petrobras. Como eu não sabia qual era o assunto eu fui lá e
apresentei a área de (sísmica) na reunião onde eles tem muitos dados. Não
consegui traçar nenhum diálogo com o pessoal porque eu percebi que o que eu
falei não era o que eles queriam ouvir. (RG)
Por outro lado, a EMC instalou o seu Centro de Pesquisa e Desenvolvimento do Brasil
(BRDC), com o principal objetivo de realizar pesquisas na área de Big Data focada na
indústria de óleo e gás, conforme os trechos a seguir.
...a indústria de óleo e gás é uma indústria com cara de Big Data porque todas
as etapas dela (...) têm Big Data de algum jeito. Na parte de exploração os
dados são gigantes, são altas quantidades de dados. Então você tem muito
dado, é o tal do volume do Big Data. Ela está no comecinho. Depois disso,
quando você vai para fazer perfuração e tal, você tem dados que, por exemplo,
podem ser super reais, porque durante a perfuração você tem dados em
streaming, você tem que ajustar aquilo. De repente tem a parte de velocidade
do dado. E na hora em que você está produzindo você tem zilhões de fontes de
dados diferentes que vão te dar... Se você olhar para uma plataforma é uma
25 Refere-se a 2013.

55
cidade inteligente. Também coordeno o projeto de cidades inteligentes, assim
é uma cidade inteligente, você tem que em última análise tudo é (sensoriado)
e você poderia ter aquilo tudo entrado num grande lago, num repositório de
dados e você toma decisões que são melhores porque você está olhando o todo
e não cada um só o seu processo, a produção na produção, a mecânica na
mecânica, o moço da comida na comida, a água na água, enfim, você pode
integrar isso tudo. Então você tem a tal da variedade dos dados, tem muita
informação. A indústria de óleo e gás é uma indústria que é naturalmente de
Big Data. (LP1)
...o mercado de óleo e gás tem essa característica de ter um volume de dados
crescente, e característica de big data ao longo de todo processo... No caso, a
gente focou na parte de “up stream”, que é a parte de exploração e produção
de óleo e gás. Então você tem um volume muito grande de dados no início do
processamento, que são os dados sísmicos... Mais à frente, depois dessa parte
de início que você tem esses dados todos que precisam ser processados por
algoritmos pesados que demoram um bom tempo para gerar um resultado, se
tem um uso de HPC, hard perfomance computing nessa fase. Você encurta o
processamento disso por algum tempo, você mede isso em barril de óleo...Você
consegue transferir isso para valor de mercado facilmente... Nessa fase
seguinte você tem integração desses dados sísmicos com vários outros tipos de
dados. Então tem uma diversidade de dados que precisam ser integrados muito
grande, e isso é outra característica de big data, o volume... Aqui você tem a
variedade dos dados e uma etapa crítica que precisa de apoio, são muitas
hipóteses que estão sendo feitas, o estudo muitas vezes de integração entre
vários profissionais para poder trabalhar e a produtividade disso é muito
importante, você integrar bem esses dados. Então tinha o segundo V
aparecendo aqui. Depois tem um momento onde você vai furar, perfurar os
poços, e também, quando você começa a produzir, você tem dado chegando
continuamente. Então o terceiro V que é o V da velocidade aparece nessa fase
final, que você tem uma parte de engenharia, de construção lá e de produção,
que precisa tratar stream de dado chegando o tempo todo e juntar isso com meu
histórico de dados para ter a melhor decisão naquele momento. (LP2)
As iniciativas em Big Data da Petrobras podem ser consideradas, de certa forma, ainda
tímidas, mediante as oportunidades do setor. O depoimento a baixo mostra como
começou os projetos, na Petrobras.
Aí um outro dia, uma vez, passando aqui pelo centro, a Karin, que é o símbolo
lá da EMC, esteve aqui no Brasil falando que eles estavam criando um centro
de data science aqui, que eles queriam fazer pesquisas junto com a Petrobras.
Eu levei essa ideia aqui para a gerência e a gente acabou criando esses
primeiros projetos depois de muito tempo de conversa, de ver o que as pessoas
estavam fazendo na área e aí a gente percebeu valor nesse negócio e fomos a
alguns clientes internos da Petrobras para poder vender o projeto. Então a gente
foi falar com o pessoal do Geope, que é parte de gestão integrada de operações,
sobre o assunto, mesmo sem ser ainda especialista no assunto e nem nada, a
gente foi comentar com eles essa ideia de usar informações dos dados que a
gente tinha para tentar melhorar a qualidade das soluções que a gente tinha até
o momento. (RG)
De maneira geral, a abordagem da Petrobras em relação ao Big Data foi de identificar
problemas do dia a dia, principalmente das áreas de operação e logística e, com o auxílio
da EMC, verificar se existia a possibilidade de aplicar alguma solução de Big Data a esses

56
problemas. Seguem trechos que descrevem o passo a passo do processo de identificação
dessas oportunidades.
A gente fez uma série de seminários onde tinham pessoas do Cenpes, do centro
de pesquisa, onde eles enxergavam... Eles lá já estavam começando com
iniciativas na área de Big Data, então eles convidaram pessoas que eles
achavam que tinham problemas que se pareciam com Big Data, e a gente fez
uma sequência de seminários, apresentou umas tecnologias e falando mesmo
desse papel de especialista e depois dessa sequência de seminários a gente foi
aprofundando qual seriam os projetos que seriam mais interessantes da gente
fazer em parceria. Aí a gente tinha a presença das pessoas do Cenpes e das
pessoas da TI Petrobras. No final disso a gente começou com uma lista grande,
onde a gente foi reduzindo por interesse da área fim, quantidade de dado
disponível porque assim, às vezes é um dado sigiloso e a gente não trabalharia
dentro da Petrobras, a gente não era contratado Petrobras. (LP1)
...já existia uma vertical de óleo e gás na EMC, um segmento para colocar os
nossos produtos na área de óleo e gás, e a gente teve gente que veio desse setor,
o Tim Voyt, que era o nosso diretor de negócios aqui, ele veio dessa área - já
tinha um bom conhecimento de alguns casos que pareciam interessantes, e
outras pessoas da própria vertical também. Agora, os casos que foram
escolhidos, quando a gente foi trabalhar com a Petrobras especificamente, a
gente teve várias sessões, muita discussão e estamos com uma quantidade
razoável de possíveis projetos, resultado dessas conversas e foram escolhidos
esses 3 casos, que foram os desenvolvidos. (LP2)
No trechos a seguir, os entrevistados reforçam que a Petrobras, assim como toda a
indústria de óleo e gás per si, possuem problemas clássicos de Big Data e o ponto crucial
que motivou a empresa a recorrer a esse ferramental foi a oportunidade de se otimizar a
produção.
O outro projeto foi de otimização da produção onde a gente tenta estudar o
comportamento da planta, a situação em que ela está e tentar prever a
ocorrência de problemas futuros como geração de hidratos, geração de
“golfadas”, situações anômalas que prejudicam a produção de óleo. Então isso
também foi abordado junto com os colegas do Geope... Esse é um problema
do dia a dia deles, otimizar a produção e a gente colocou que seria interessante
tentar fazer alguma iniciativa de pesquisa nessa área. (RG)
...uma área que foi inicialmente levantada foi isso daí, da operação de
plataformas, porque a operação de uma plataforma é um sistema complexo
com milhares de variáveis correlacionadas e muitas das vezes a otimização,
não digo nem a otimização, mas o controle da operação num ponto ideal, é
uma tarefa difícil porque você projeta a plataforma para um ponto de
operação... Isso se reflete basicamente nas perdas de produção que você ...
Como o objetivo é você fazer a planta próximo do seu ponto máximo ótimo de
operação, para você ter a maior eficiência possível, isso se torna um problema
naturalmente importante. ... como que a gente pode olhar para os dados da
planta que refletem o estado em que ela está e tentar correlacionar o estado
atual dela com (...) eventuais problemas indicados no passado e ver se a gente
consegue antever esses problemas no futuro. Um problema clássico de Big
Data. (RG)
Você pode pensar, por exemplo, em usar todos os sensores disponíveis - a parte
de dados para fazer projetos, por exemplo, de otimização da produção. Hoje
em dia o cara que olha o óleo ele olha o óleo, o cara que olha o gás, ele olha
gás, não tem assim um indicador holístico de dizer "olha, tudo bem, vou

57
diminuir a produção de gás, mas vou aumentar a de óleo". Então existe, você
pode trabalhar e otimizar a produção... (LP1)
Esse tipo de aplicação é bastante condizente com o que a maioria dos autores destacam
como um ponto forte do Big Data: a capacidade de se processar uma infinidade de dados,
vindo de diversas fontes, nesse caso, milhares de sensores e uma séries de relatórios
operacionais. Através de algoritmos, construir um modelo preditivo que possa através da
análise desses dados, apontar possíveis problemas que possam vir a acontecer no futuro.
Outra oportunidade identificada, foi tentar aplicar o Big Data em um problema que já foi
tratado com outras ferramentas analíticas e comparar resultados, como descrito a seguir.
Já tinha tido uma iniciativa na Petrobras para fazer um gestão da manutenção
de tubos geradores, mas o approach utilizado não era de Big Data. Era um
approach meramente estatístico, porque o pessoal de operação e manutenção
tem esse problema. É um calcanhar de Aquiles deles - eles têm que garantir o
máximo de tempo de funcionamento dos tubos geradores e eles já tinham
iniciado vários projetos tentando melhorar a vida útil desse equipamento,
diminuir o downtime, essas coisas todas. E a gente entendeu que poderia ser
interessante fazer um projeto que tentasse resolver o mesmo problema com as
técnicas de Big Data. Então esse foi um dos projetos selecionados. (RG)
...a gente tem uma plataforma que é uma cidade que precisa ter seu próprio
gerador de energia. Então eles usam o que eles chamam de turbo geradores.
Turbo geradores nada mais são do que turbinas iguais às de avião. Eles têm
turbinas daquele jeito, parte a vapor e tal. Eles precisam gerar energia. Você
imagina que você está (aqui no nosso pré-sal) a 200 km da costa, você não
pode ficar sem energia porque as pessoas vão morrer lá dentro. Não é assim
tão desesperador, mas você vai parar de produzir petróleo, por exemplo, se
você não tiver energia. Então a gente fez projetos de manutenção preditiva que
é dizer quando aquela máquina vai dar problema antecipadamente, uma
semana antes, dizer "esse sintoma...” (LP1)
Esse projeto, em específico, mostra que apesar de existirem muitas semelhanças na
aplicação do Big Data e outras ferramentas de tratamento de dados, o grande diferencial
do primeiro frente ao último é que, muitos dados que não eram levados em conta,
principalmente pela incapacidade da tecnologia usada não ser capaz de processá-los,
podem ser usados para aprimorar a análise e revelar importantes insights. Levando tudo
isso em conta, mais uma vez os anseios da Petrobras corroboram o que os autores
estudados na revisão bibliográfica concluíram, quando afirmaram que muitas empresas
procuram o Big Data na esperança de se utilizar do crescente volume de dados como
forma de se obter insights para dar mais suporte a decisões mais eficientes e assertivas.
O último projeto está ligado aos potenciais benefícios que o Big Data pode trazer na
melhoria da cadeia de suprimentos, em especial na logística de transporte da Petrobras,
como descrito abaixo. Isto naturalmente está ligado a melhoria da eficiência operacional.

58
E o último projeto que a gente criou foi o de logística aplicado à gerencia de
estoques do (AIP) onde a gente... É um problema clássico voltado para Big
Data porque essa gestão de tempo, de estoques, tempo de entrega chamado
“lead time” são problemas clássicos de otimização em geral e é natural que
você possa tentar técnicas de Big Data para você, por exemplo, tentar descobrir
as melhores opções, melhores perfis de compra de equipamentos, tudo isso
para tentar reduzir esse tempo de entrega nas plataformas. (RG)
...ele tinha um projeto lá de estudar o lead time, ou seja, o lead time médio do
tempo de entrega dos pedidos das embarcações no caso da Petrobras. E esse
lead time historicamente é considerado alto e a ideia desse projeto era se
descobrir o valor ideal para esse lead time da forma que a gente conseguisse
sempre baixar esse tempo aumentando a eficiência... Então é complexo. Você
tem um problema de roteamento envolvido, tem um problema de maximização
do container, ou seja, você quer mandar o máximo possível de material pelos
barcos, mas os barcos têm limitação. Então a gente construiu um modelo de
simulação que pelo menos não otimiza nada, mas me dá respostas sobre as
decisões que eu venha a tomar quando eu faço, por exemplo, aumento da frota
de barcos ou redução da frota de barcos. ... O outro problema é esse que falei,
dado que você tem que comprar essas coisas, qual é o melhor fornecedor para
te fornecer o equipamento tal na data tal, num prazo tal, ou seja, esse tipo de
estudo é que é importante lá para o cara decidir quem vai comprar. Além disso
a gente também espera modelar toda essa cadeia de suprimento para ter um
simulador mais real porque é muito difícil escrever um problema de otimização
com tantas variáveis e com tantos... Não é que seja impossível, mas é bem
difícil de você montar um simulador só na base de variáveis que você tem, que
não são só variáveis continuas, tem categóricas e outros tipos de variáveis que
são ruins para você modelar num processo qualquer. (RG)
...você pode trabalhar na parte logística, porque a logística de uma companhia,
principalmente a nossa que a maioria é off shore, é uma loucura, porque você
tem que levar comida, água, todas as peças, você tem barco, armazéns que tem
fortunas sentadas lá dentro porque não pode faltar. Então a parte logística vira
um problema combinatorial que é Big Data, não tem jeito. (LP1)
Enfim, todas as oportunidades citadas estão alinhadas com o que vem sendo apontado
como principais pontos fortes do Big Data e justificam o interesse da Petrobras em fazer
uso dessa nova tecnologia, reforçado nas palavras a seguir.
...modelo preditivo de manutenção, especialmente para equipamentos caros.
Você não vai fazer um modelo preditivo pra acompanhar o funcionamento de
uma lâmpada de luz, mas tu vai fazer para um compressor... Esse é um ponto.
No caso especifico nosso de reservatório e refinaria acompanhar o pós
operação para saber se alguma anomalia está acontecendo com a planta antes
de você de fato saber do problema é importante... Predição e manutenção
baseada na condição. (RG)
Nos nossos projetos que a gente teve com a Petrobras até focaram um pouco
mais nessa parte final, muito dado chegando, tratamento de histórico de dados
na área de manutenção preditiva, de otimização e de logística, estava nessa fase
final... (LP2)
Porém, aliados à essas grandes oportunidades, são esperados grandes desafios, os quais
são detalhados pelos entrevistados mais adiante.
O desafio mais citado entre os três entrevistados foi sem dúvida a gestão dos dados (Data
ownership e Data management), o qual também é apontado por quase todos dos experts

59
em Big Data referenciados neste trabalho. Nesse contexto, destacam-se a importância de
se ter uma figura de poder como o CDO (do inglês Chief Data Officer), capaz de fornecer
dados pertencentes às mais diversas áreas da organização para os profissionais que fazem
a análise, o maior controle da gestão dos dados, ou seja, como garantir a relevância e a
qualidade dos dados, além do problema quanto à segurança e legislação sobre esses dados,
conforme trechos a seguir.
Pra falar a verdade, a gente não tinha noção da dificuldade que seria a questão
dos dados, porque aqui na Petrobras (acho que isso são problemas de empresas
grandes) existe a questão da TIC que é a “custodiante” dos dados, mas não é a
dona dos dados. Existe a automação que é quem coleta as informações, mas
também não é dona do dado. Existe o dono do dado que é o cliente, que é o
gerente da plataforma, gerente do ativo, que é o dono do dado e quem pode
liberar o acesso ao dado para qualquer um. Então a gente tem 3 atores aí com
os quais a gente tem que “interfaciar” sendo que o nosso projeto tinha uma
característica mais complicada ainda, que o acesso aos dados tinha que ser
garantido para o pessoal de fora da Petrobras. Então esse foi o grande
problema, um dos grandes problemas foi conseguir negociação do acesso aos
dados porque, convencer as pessoas de que o dado é importante e que ele tem
valor e que eu posso em prol da Petrobras compartilhar essa informação para
ter resultado, não foi uma tarefa fácil. Nossos projetos, a maioria deles tem em
torno de 18 meses de duração, não sei se tem algum de 24, mas de 15 a 20
meses e mais ou menos a gente ficou nessa briga pelos projetos em torno de 8
meses, para arrumar o dado e coisa e tal. (RG)
Um outro problema que existe é que a gestão do dado é de um ator e o cara que
tem os dados... Não existe uma padronização, uma preocupação com o valor
da informação. Então eu diria que a gente tem muito dado que a gente nem
sabe... Isso é meio difícil de colocar abertamente, mas muita coisa a gente
armazena e não sabe nem para que está armazenando. O dado está sendo
adquirido, mas eu acho que a gente tinha que ter uma postura diferente em
relação ao dado e saber por que a gente está adquirindo cada dado, qual é o
valor daquele dado, quem usa aquele dado, isso tudo tem que ser revisto. Acho
que a grande contribuição para esse projeto, espero que seja criar uma nova era
na Petrobras e a oportunidade da criação do que a gente chama na área do Big
Data do Chief Data Office, algum camarada ou alguma área de gestão de dados
que esteja colocada com um papel maior do que ela tem hoje dentro da
estrutura organizacional da Petrobras. (RG)
...a gente tinha essas dificuldades da obtenção do dado por ele ser muito
sensível, é comum dar uma insegurança para banco, enfim. Acho que isso seria
um desafio. (LP1)
Então tem questão de transmissão de dados, toda essa parte. Tem questão de
segurança do dado que precisa ser tratado também, o volume de dados muitas
vezes você vai tratar com informações que são... Por exemplo, dado sísmico é
crucial para a empresa. Ele já é crucial quando você adquire, depois que
interpreta então ele tem um valor muito importante. (LP2)
Para o Responsável Geral dos projetos, este desafio de se obter os dados é o maior de
todos no caso da Petrobras, ao ser indagado sobre uma possível solução, ele apontou a
criação de um CDO. Porém, como constatado no trecho a seguir, na visão dele esse
problema é muito mais complexo.

60
A estrutura é um problema organizacional porque veja, de que grupo vai ser o
Chief Data Officer? Vai ser o cara do negócio que debaixo dele tem um outro
cara que é o cara da TIC, que não está na mesma estrutura da área de negócio,
é uma estrutura paralela? Ou está dentro do cara da TIC e ele não está na
estrutura do negócio? Ou o pessoal da automação, vai estar na automação, que
também não está no negócio e também não está na TIC? Quer dizer, a
colocação desse elemento que eu acho, defendo que esteja no negócio, ela
envolve alguns problemas porque ela tinha que ter também a infra da TIC para
tocar e quando você faz uma organização vertical como a Petrobras tem hoje,
de área da TIC, área do EP, área de abastecimento, área de finanças, essa
verticalização dificulta porque o data science é transversal a todo mundo e aí é
que é a grande dificuldade. Por isso para mim isso teria que ser um cara do
negócio, mas que tivesse a autoridade sobre as outras áreas, é aí que é um
modelo de gestão complicado e eu não conheço o assunto nem para propor.
(RG)
Além do problema de custódia, segurança e gestão dos dados, outro desafio encontrado,
pode ser considerado dois lados de uma mesma moeda: encontrar especialistas. De um
lado a Petrobras via a parte de tratamento dos dados e modelagem como um grande
desafio, que foi resolvido pela EMC, através do esforço conjunto de seus líderes de
projeto com o envolvimento de especialistas do Instituto Alberto Luiz Coimbra de Pós-
Graduação e Pesquisa de Engenharia da Universidade Federal do Rio de Janeiro (COPPE
– UFRJ) e da Pontifícia Universidade Católica do Rio de Janeiro (PUC – RJ). Do outro,
a parceira EMC necessitava de especialistas que pudessem descrever com precisão os
problemas a serem resolvidos, ou seja, o que eles realmente precisavam que os modelos
fizessem.
Essa “moeda” impacta diretamente tanto no gerenciamento de riscos do projeto, pois
como nem uma parte, nem outra possui uma visão geral do projeto, e sim domínio de
partes do mesmo, dificulta identificar e prever possíveis problemas durante sua execução,
quanto na qualidade das soluções, uma vez que sem o envolvimento de especialistas dos
problemas, muitas informações são ignoradas.
O lado da Petrobras coincide com um grande desafio encontrado por muitas empresas que
optaram por utilizar do Big Data. Conforme foi levantado anteriormente, a dificuldade de
se encontrar um “data scientist” capaz não só de realizar a modelagem, mas também
interpretar os resultados dela, obtendo os insights desejados é enorme. Por isso, muitas
dessas empresas, assim como a própria Petrobras, optam por contratar serviços
especializados como o da EMC. Essa “frustração” de não ser nem especialista na área de
petróleo, nem da área de Big Data, dificultando a gestão dos projetos, tal como a
expectativa de se deparar com dificuldades na parte mais teórica (matemática) do

61
ferramental, que logo foi suprida pela parceira (EMC), ficam claras nas seguintes
declarações do RG.
Tem um outro problema também que eu poderia dizer, aí mais um problema
meu como gestor dos projetos, coordenador geral dos projetos, que é o fato de
eu não ser especialista nas áreas de petróleo, sou especialista em computação
gráfica, matemática e HPC... Sempre, a gente sabe conversar, mas um projeto
de Big Data como esse, você precisa mais do que isso, você precisa ter
idealmente vivência do problema. Isso faz toda a diferença quando você
procura uma solução de analytcs para seu problema. (RG)
Nossos especialistas não entendem o problema do Big Data, até pensar em
riscos para eles é muito complexo. Pra mim é complexo, apesar de entender do
ponto de vista de desenvolvimento de sistemas e arquitetura de software e um
pouco de Big Data que estou entendendo hoje, falar em questão de riscos numa
gestão de projetos é uma coisa muito tranquila para mim, entretanto mapear
esses riscos no problema que a gente está atacando é que é difícil. Por outro
lado, para os especialistas como não conhecem e não tem ideia de como o
projeto evoluiu, como vai evoluir, até porque se os caras são especialistas em
petróleo, não são especialistas em software, não é? Eles não conseguem
também enxergar os riscos, essa é um ponto crítico em qualquer projeto para o
sucesso, ter a gerência dos riscos bem administrada, bem controlada. (RG)
A gente esperava uma dificuldade na parte teórica, mas a EMC teve a
competência, posso dizer assim, de trazer outros pesquisadores da área de
computação, de estatística, que são da COPPE e da PUC do Rio de Janeiro que
estão dando apoio à parte teórica na formulação. Então a dificuldade natural
que a gente esperava em relação à tratamento dos dados sempre vai existir
porque você tem milhares de maneira de resolver o problema... (RG)
...o fato da gente não conhecer o assunto. Boa parte do projeto a gente levou
treinando o nosso pessoal. Isso foi uma parte bem interessante que a EMC fez
de trazer aqui alguns especialistas deles e fazerem casos junto com a gente,
mostrarem algumas soluções e isso permitiu que a gente ganhasse tempo no
conhecimento sobre o problema. (RG)
No tocante à EMC, uma maior aproximação dos usuários finais dos produtos poderia ser
uma solução adequada, porém o fato de se tratar de projetos de pesquisas e não de um
contrato para entrega de um produto, toda a comunicação durante o trabalho baseou-se
entre o Cenpes, a TIC e a EMC, excluindo-se os potenciais usuários finais do
desenvolvimento, conforme trechos a seguir.
...tive um problema que era a dificuldade assim do contato com o usuário final,
porque as pessoas que estavam engajadas desde o começo que era mais a parte
de TI e centro de pesquisa e tal, eu achei que tive menos contato do que era
necessário com o usuário final que seria o cara que entende da turbo máquina
mesmo, achei que teve um gap. (LP1)
...tinha projeto de logística que envolvia um tanto de conhecimento de
domínio, muito dado... O dado era um dado mais difícil de entender porque
tinham coisas lá, a gente tinha que interagir com o pessoal da própria Petrobras.
Nem sempre encontra a pessoa certa que vai te explicar o que é tal tabela, o
que tem ali, qual é realmente o significado daquilo. São várias inconsistências,
na forma como também as pessoas descreviam o processo. (LP2)
No processo de otimização em que atuei tinha um volume muito grande de
dados já coletados, eram dados mais uniformes, mas tinham várias

62
combinações, tinha problemas de performance, escalabilidade para ver e tinha
o próprio caso de uso, a necessidade de ter uma proximidade com o usuário
final lá da ponta. Algo que eu aprendi, se a gente tivesse tido a oportunidade
de ter tido contato tanto num projeto quanto no outro, envolvimento já de quem
usa lá na ponta logo no início, talvez a gente até pudesse ter tido resultados até
mais relevantes... (LP2)
Ao contrário do esperado, durante as entrevistas, poucos problemas estritamente técnicos
foram apontados. Dentre eles, ainda destacam-se a falta de padronização dos dados
coletados, a segurança da informação e a dificuldade de se escrever um problema de
otimização com tantas variáveis foram os mais críticos.
O maior motivo para o impacto dos problemas técnicos serem minimizados neste caso,
foi sem dúvida o envolvimento da parceira EMC e seus especialistas. Além disso, o
paralelismo é hoje uma tecnologia acessível e de relativo baixo custo.
O principal motivo para o paralelismo representar redução de custo é que ele está
associado à mudança de plataforma para armazenamento e processamento de dados, que
passa de uma grande e potente plataforma de dados estruturados para o uso de múltiplos
servidores (DAVENPORT, 2014).
Apesar disto, o entrevistado LP2 destaca que usar do paralelismo e obter escalabilidade
não são dificuldades triviais e, por isso, continua sendo desafiador, conforme trecho a
seguir.
Tecnicamente, tem o problema clássico de escalabilidade. Os problemas são
grandes e você tem que dar um jeito de saber quebrá-los bem para você poder
acelerar, poder botar paralelismo, essencialmente está falando de big data,
envolve paralelismo, e envolve também a questão de você aplicar... Se fala
muito em ciência de dados, o que é, já fui em outras entrevistas e perguntavam
o que o cientista de dados precisa ter, e a minha resposta sempre foi “o cientista
de dados precisa ser um cientista”, ele precisa saber formular hipóteses, validar
hipóteses, saber ser capaz de isolar variáveis para ver qual é a influência de
uma coisa na outra. Então é um processo cientifico só que você está usando a
computação do processo num volume de dados muito grande que te ajuda a
poder trabalhar e você consegue fazer ciência com um apoio computacional
grande. Diria que esse enfoque, (seria a inclusão) do máximo que você pode
de poder computacional que vai se tornando mais barato na medida em que as
máquinas estão se tornando mais baratas, mas envolve muito de engenharia
também que é você poder quebrar os problemas e desenvolver soluções
paralelas não é algo trivial. Exige uma formação diferente. (LP2)
O último desafio citado foi uma certa dificuldade de se apresentar o valor de forma
atrativa para o setor estratégico da Petrobras. Sendo uma tecnologia relativamente nova,
existiam poucos resultados consolidados de projetos semelhantes, além do fato de ser

63
difícil de se quantificar os benefícios diretos da aplicação do Big Data, conforme
comentário do entrevistado LP1.
...o fato de eles serem muito conservadores é o desafio de trabalhar com dados
muito sensíveis e claro, de fazer com que uma indústria que já tem "tanto
sucesso", se abrisse para o fato de que tinha alguma coisa nova que podia
revolucionar a vida deles. Até porque assim, eles usam tecnologia de ponta o
tempo inteiro. Então de repente chegam uns caras aqui dizendo que tem esse
Big Data que vai mudar a minha vida, o cara diz "claro que não, já tenho aqui
meu super cluster que trouxe uma porção de coisas então não preciso disso".
(LP1)
A questão da custódia e, por consequência, do acesso aos dados foi o grande desafio a ser
superado. A essência de qualquer ferramenta de análise de dados, tão como o Big Data é
o acesso aos dados, porém o que foi relatado por todos os entrevistados foi uma grande
dificuldade de se obter esses dados, pois muitas vezes os “donos” desses dados não são
os mesmo que armazenam (tem a custódia), que também não são os mesmos que coletam
esses dados. Assim, para obtê-los, foi necessário garantir a permissão desses três agentes,
o que acabou tomando muito tempo. Além disso, como se tratou de uma parceria, ou seja,
envolveu uma empresa externa a Petrobras, muitos dados foram tratados como sigilosos,
o que dificultou ainda mais sua obtenção.
Um fato especial aconteceu durante a realização desse trabalho, que foi a explosão da
crise da Petrobras e da queda do preço do barril de petróleo. Contudo, diferente do
esperado, pode-se dizer que esses fatores não só não afetaram os projetos como, de certa
forma, contribuíram positivamente à realização dos mesmos, conforme as afirmações
abaixo.
...nesse momento de crise isso é uma coisa importante porque agora qualquer
incremento de produtividade ou qualquer economia que você faça é
importante, pelo momento da crise atual de petróleo. (LP1)
Talvez a continuação, o engajamento ou a venda dessas coisas tenha tido algum
efeito, mas para o projeto de pesquisa em si não vi nenhum problema. (LP1)
Os projetos, o que a gente teve se torna até mais relevantes para a Petrobras
porque são coisas que ajudam a diminuir custo e quando se está no contexto
de petróleo em baixa, reduzir custo é muito importante, evitar perdas, por
exemplo, na produção. Você poder evitar perda na manutenção das máquinas,
evitar perdas na logística. Então são coisas que estão no coração do que precisa
ser pensado. Diria que na disposição, digamos assim, houve todo um turbilhão
no contexto da Petrobras, inclusive questões políticas sobre o processo, não só
a questão do preço do petróleo. Não sei como vai ser a continuidade, mas diria
que houve dificuldades no início para questões até burocráticas para ter o dado
e do acesso ao usuário final que pesaram mais até no resultado final, digamos

64
de atrapalhar um pouco mais o resultado final, do que realmente o que
aconteceu do preço do petróleo ter caído. (LP2)
Talvez devido ao fato dos três projetos de pesquisa terem sido desenvolvidos em sistema
de parceria, consequentemente, não envolvendo custos adicionais à Petrobras, uma vez
que a EMC não recebeu nenhum pagamento e os profissionais do Cenpes e da TIC
envolvidos somente dedicaram suas horas de trabalho ao projeto, foi possível dar
continuidade sem maiores problemas aos trabalhos.
No entanto, transformá-los em produto final e implementá-los de fato exigem
investimentos massivos seja em treinamento, ou mesmo em equipamento.
Em resumo, o estudo do caso da Petrobras, mostra algumas oportunidades e desafios
enfrentados pela empresa no desenvolvimento de projetos de Big Data
A Petrobras gera um grande volume de dados em fluxo contínuo, além de demandar a
integração de diferentes tipos de dados, dando origem a problemas clássicos de Big Data.
Assim, a Petrobras se torna uma empresa extremamente atrativa para projetos de big data.
Além disto, a empresa atua num mercado altamente promissor para soluções de Big Data,
o que fez com que a EMC desenvolvesse um Centro de Pesquisa no Brasil para
desenvolvimento de soluções para o setor de Óleo e Gás.
No processo de comparação entre as oportunidades identificadas durante o
desenvolvimento dos projetos pela Petrobras com as citadas pelos autores estudados
(Tabela 4), foi possível identificar cinco confirmações:
A possibilidade de se aplicar o Big Data para problemas já tratados por estatísticas
convencionais, permitindo a incorporação de novos dados que não eram
considerados antes. Essa oportunidade se enquadra nas categorias analíticas
“Capacidade de se armazenar, analisar grandes volumes de informação”
apontados pelos autores Davenport (2014), Minelli et al. (2013), Novo e Neves
(2013), Silva e Campos (2014), Taurion (2012), McAfee e Brynjolfsson (2012),
Simon (2013), Loshin (2013), Gallant (2011) e “Capacidade de se integrar dados
de diversas fontes e tipos” mencionados pelos autores Davenport (2014), Minelli
et al. (2013), Novo e Neves (2013), Silva e Campos (2014), Taurion (2012),
McAfee e Brynjolfsson (2012), Simon (2013), Loshin (2013) e Gallant (2011),
culminando na obtenção de informações mais precisas e aprofundadas.

65
Otimização da produção e melhoria na cadeia de suprimentos, que se enquadram
na categoria “aumento da eficiência operacional e melhor desempenho
financeiro”, descrita por Leeflang, Verhoeff et. al. (2014), Davenport (2014),
McAfee e Brynjolfsson (2012), Minelli et. al. (2013), Novo e Neves (2013), Silva
& Campos (2013), Tankard (2012) e Yan (2013).
Construção de modelos preditivos para previsão de problemas e para manutenção,
que se encaixa perfeitamente na categoria “Construção de modelos preditivos”
referida por Davenport (2014), Manyika et al. (2011), Minelli et al. (2013),
Taurion (2012), Novo e Neves (2013), Gallant (2011), Loshin (2013), Rajesh
(2013) e Simon (2013).
As duas últimas oportunidades podem ser consideradas causa e consequência, pois
a obtenção de novos insights possibilita o refinamento da tomada de decisão,
ambos citados de maneira expressa nas categorias analíticas “Obtenção de novos
insights” tratados por Davenport (2014), Manyika et al. (2011), Harriott (2013),
Simon (2013), Loshin (2013), Gallant (2011) e “Melhora da tomada de decisão”
descritos por Brown, Chui e Manyika (2011), Davenport (2014), Gallant (2011),
Minelli et al. (2013) e Tankard (2012).
No quesito oportunidades emergentes deste estudo, optou-se por separar as oportunidades
para a Petrobras, das oportunidades da parceira EMC², uma vez que se trata de uma
peculiaridade deste estudo tratar de um caso sobre o desenvolvimento de projetos de
pesquisa através de parceria. Assim, temos:
Oportunidades emergentes para a Petrobras:
Na parceria com a EMC, possibilidade de se ter acesso a data scientists e de se
estudar possíveis soluções para seus problemas.
Seleção de portfólio de projetos com base no interesse da área fim, na quantidade
de dados disponível e no acesso aos dados (não expuseram dados sigilosos).
Para a EMC²:
Os projetos desenvolvidos podem gerar produtos de valor para o mercado.
Acesso aos dados para poder desenvolver modelos e posteriormente transformá-
los em produtos.
Assim, das nove categorias analíticas, somente três não foram confirmadas nesta
pesquisa: Análise de informação em tempo real, Inovação incremental em produtos e

66
serviços já existentes, e aumento da lealdade dos clientes e Inovação disruptiva de
produtos, serviços e modelos de negócios.
Sobre as oportunidades para desenvolvimentos de projetos de Big Data, é possível
apontar as seguintes proposições:
P1: Algumas condições existentes na organização relacionadas aos problemas que
possui e aos dados que tem acesso favorecem o desenvolvimento de projetos de Big
Data.
A existência de alto volume de dados, de dados em fluxo contínuo e de diversos tipos que
podem ser integrados são fatores que motivam o desenvolvimento de projetos de Big
Data. Soma-se a isto, a existência de problemas clássicos de big data na instituição.
P2: Big Data é uma oportunidade de se tratar de forma diferente problemas já
tratados por estatísticas convencionais, podendo favorecer a otimização da
produção, a melhoria na cadeia de suprimentos e as atividades de manutenção.
Big data, ao permitir que novos dados sejam incorporados na análise de problemas que já
eram tratados por estatísticas convencionais, permite o desenvolvimento de modelos
preditivos, de simulações e a obtenção de novos insights.
P3: Parcerias entre Centros de Pesquisa de empresas de TI e de empresas que
desejem desenvolver soluções de Big Data são favorecidas pela atratividade das
soluções para o setor.
Empresas que atuem em setores com grande potencial para aplicações de Big Data podem
estabelecer parcerias com centros de pesquisa de empresas de TI para desenvolver
soluções que lhes sejam úteis e que possam ser, posteriormente, comercializadas pelas
empresas de TI. Estas parcerias podem dar às empresas acesso à cientistas de dados, e
podem se transformar em laboratórios de desenvolvimentos de soluções para a empresa
de TI. A seleção do portfólio para estas parceiras deve levar em consideração a existência
e o acesso aos dados e o interesse das áreas fins na solução.

67
No que tange aos desafios, foram constatados que seis desafios levantados durante o caso,
foram abordados de forma direta ou indireta na literatura estudada (Tabela 5):
A falta de padronização de dados remete à categoria analítica “Validade e
qualidade dos dados”, enunciada pelos autores Davenport (2014), Manyika et al.
(2011), Minelli et al. (2013), Taurion (2012), McAfee e Brynjolfsson (2012),
Simon (2013), Harriott (2013), Lam (2013), Barton e Court (2012), Yin e Kaynak
(2015) e Jagadish et al. (2014).
O problema de escrever um problema de otimização com tantas variáveis pode ser
enquadrado na categoria “Modelar algoritmos que produzam informações
pertinentes”, descrita pelos autores Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Simon (2013), Harriott (2013), Lam (2013), Barton e Court
(2012) e Jagadish et al. (2014).
Segurança da informação, que se refere a categoria homônima “Segurança da
informação” tratada pelos autores Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Taurion (2012), McAfee e Brynjolfsson (2012) e Simon
(2013).
A falta de uma figura que possua a autoridade sobre o acesso aos dados coletados,
facilitando sua obtenção e uma melhor comunicação entre os entes que coletam,
armazenam e os “donos dos dados” são problemas clássicos retratados na
categoria “Custódia, gerenciamento de dados” citado por Davenport (2014),
Manyika et al. (2011), Minelli et al. (2013), Taurion (2012), McAfee e
Brynjolfsson (2012), Simon (2013), Lam (2013) e Jagadish et al. (2014).
Dificuldade de obtenção dos dados, seja pela sensibilidade da informação, seja
pela falta de organização e completude dos dados ou ainda pela falta de
comunicação entre os três entes supracitados - coletor, custodiante e dono do
dado. Isto está ligado com as categorias ”Custódia, gerenciamento de dados”
referido por Davenport (2014), Manyika et al. (2011), Minelli et al. (2013),
Taurion (2012), McAfee e Brynjolfsson (2012), Simon (2013), Lam (2013),
Jagadish et al. (2014) e “Validade e qualidade dos dados” descrita por Davenport
(2014), Manyika et al. (2011), Minelli et al. (2013), Taurion (2012), McAfee e
Brynjolfsson (2012), Simon (2013), Harriott (2013), Lam (2013), Barton e Court
(2012), Yin e Kaynak (2015) e Jagadish et al. (2014).

68
Estrutura organizacional – onde encaixar o CDO, apesar deste item não ser tratado
diretamente em nenhuma categoria analítica construída, ele foi abordado por
Harriott (2013), como parte do problema de “Custódia, gerenciamento de dado”.
Dois desafios emergiram durante o estudo do caso:
Como os projetos foram feitos entre centros de pesquisa, faltavam especialista em
óleo e gás que pudessem descrever com precisão os problemas a serem resolvidos.
Por não ser um contrato de prestação de serviço, não há envolvimento dos usuários
finais das soluções.
Dificuldade de mostrar para a alta direção da Petrobras o valor estratégico dos
projetos, pois a tecnologia ainda é nova. Isto é influenciado pela dificuldade de
medir o valor das soluções, que também é um desafio para a EMC poder lançar
produtos no mercado.
Todavia, as categorias Interpretar os dados de maneira eficiente, Dificuldade de se migrar
de um perfil "modo driven" para "data driven", Dificuldade de se extrair valor, Falta de
especialistas "cientistas de dados"e Infraestrutura de TI não foram identificadas no
presente estudo, destacando que a minimização do impacto das duas últimas (Dificuldade
de se extrair valor, Falta de especialistas "cientistas de dados"e Infraestrutura de TI) muito
se deve ao modelo de parceria aplicado nestes projetos, conforme citado anteriormente.
Sobre os desafios para desenvolvimentos de projetos de Big Data, é possível apontar as
seguintes proposições:
P4: Projetos de Big Data enfrentam desafios ricos, relacionados à qualidade do
dados, à dificuldades de modelagem e à segurança da informação.
A falta de padronização de dados, a dificuldade de escrever problemas de otimização com
um grande número de variáveis e as dificuldades associadas à segurança da informação
são desafios presentes em projetos de Big Data.

69
P5: Projetos de Big Data enfrentam desafios de gestão, relacionados à gestão dos
dados, às reformulações das estruturas organizacionais e à especificidades
decorrentes das parcerias Interorganizacionais criadas para o desenvolvimento dos
projetos.
Os desafios de gestão dos dados e a dificuldade de obter dados na organização marcam
projetos de Big Data. As revisões necessárias na estrutura organizacional para inclusão
de novos cargos e competências também merece atenção. Por fim, é preciso gerir os
projetos de Big Data de acordo com as especificidades das parcerias desenvolvidas, que
determinam que recursos serão alocados no desenvolvimento e de que forma.
6. CONSIDERAÇÕES FINAIS
Após análise da literatura e dos dados obtidos sobre os projetos desenvolvidos na área
pela Petrobras, pode-se concluir que, de fato, existem muitas oportunidades para a
aplicação do Big Data na indústria de óleo e gás, tal como inúmeros desafios.
Não só na indústria de óleo e gás, foco deste estudo, como em diversos outros setores, o
Big Data tem sido explorado por empresas, vide o enorme investimento relacionado às
tecnologias envolvidas.
A contribuição principal desta pesquisa reside na investigação de projetos realizados por
centros de pesquisa sem contrapartida financeira, mas que representam oportunidades
para diferentes organizações.
Ao se investigar oportunidades identificadas pela Petrobras durante o desenvolvimento
dos seus projetos, cinco delas se mostraram bastante alinhadas com a literatura abordada
neste presente estudo: a aplicar Big Data para problemas já tratados por estatísticas
convencionais, permitindo a incorporação de novos dados que não eram considerados
antes; a otimização da produção e melhoria na cadeia de suprimentos, que se enquadram
na categoria “aumento da eficiência operacional e melhor desempenho financeiro”; a
criação de modelos preditivos para previsão de problemas e para manutenção; a
possibilidade de melhoria da tomada de decisão e a obtenção de novos insights.
Além dessas oportunidades, mais quatro oportunidades emergiram durante esta pesquisa.
Para a Petrobras, na parceria com a EMC, existiu a possibilidade de se ter acesso à data

70
scientists, para se estudar possíveis soluções para seus problemas e de se selecionar um
portfólio de projetos com base no interesse da área fim, na quantidade de dados disponível
e no acesso aos dados (sem a exposição de dados sigilosos). Já por parte da EMC², os
projetos desenvolvidos podem gerar produtos de valor para o mercado, além de se obter
o acesso aos dados para poder desenvolver modelos e, posteriormente, transformá-los em
produtos.
Houve consenso na opinião dos entrevistados no sentido de destacar a oportunidade de
aplicação do Big Data na otimização operacional como o principal benefício vislumbrado
na adoção desta ferramenta no contexto da Petrobras.
Todavia, uma série de desafios foram encontrados nas tentativas de explorar os benefícios
destes projetos. Muitos desses desafios já estavam presentes na adoção de outras
tecnologias de análise de dados como o BI e o Analytics. Porém, as características
representadas pelos “Vs” do Big Data escalonam esses problemas, seja quanto à
complexidade da tecnologia a ser usada, quanto à exigência da própria capacidade
humana de interpretação.
Equacionando todos esses fatores, os principais players da indústria de óleo e gás, como
a BP, a Shell, a Schlumberger e a Halliburton, fizeram significativos investimentos na
área, ao contrário do que se esperava de um setor relativamente conservador, apostando
pesado no potencial do Big Data fornecer insights que possam vir a impactar
profundamente na eficiência destas empresas, culminando em corte de custos.
Acompanhando esse desenvolvimento, a EMC estabeleceu o BRDC e focou no
desenvolvimento de pesquisas relacionadas ao Big Data na área de óleo e gás,
aproximando-se naturalmente da Petrobras.
Assim, no segundo eixo deste estudo que gira em torno de quais desafios a Petrobras
encontrou durante o desenvolvimento de seus projetos de pesquisa em Big Data, foram
identificados oito itens, dos quais seis estão de acordo com os citados pelos autores: falta
de padronização de dados; a dificuldade de escrever um problema de otimização com
tantas variáveis (modelar algoritmos que produzam informações pertinentes); a segurança
da informação; gestão de dados (ownership e management); dificuldade de obtenção dos
dados (ligado intimamente com data ownership e validade/qualidade dos dados), e as
dificuldades de adequação da estrutura organizacional,.

71
Durante as entrevistas foram descobertos dois desafios: como os projetos foram feitos
entre centros de pesquisa, faltavam especialista em óleo e gás que pudessem descrever
com precisão os problemas a serem resolvidos. Por não ser um contrato de prestação de
serviço, não há envolvimento dos usuários finais das soluções, e houve dificuldade de
mostrar para a alta direção da Petrobras o valor estratégico dos projetos, pois a tecnologia
ainda é nova. Isto é influenciado pela dificuldade de medir o valor das soluções, que
também é um desafio para a EMC poder lançar produtos no mercado.
Dentre os desafios citados, na opinião dos entrevistados a dificuldade de se obter os
dados, seja pela dispersão e incompletude destes, seja pela forte proteção dos silos
informacionais, transformou o desafio de gestão e custódia de dados o maior desafio.
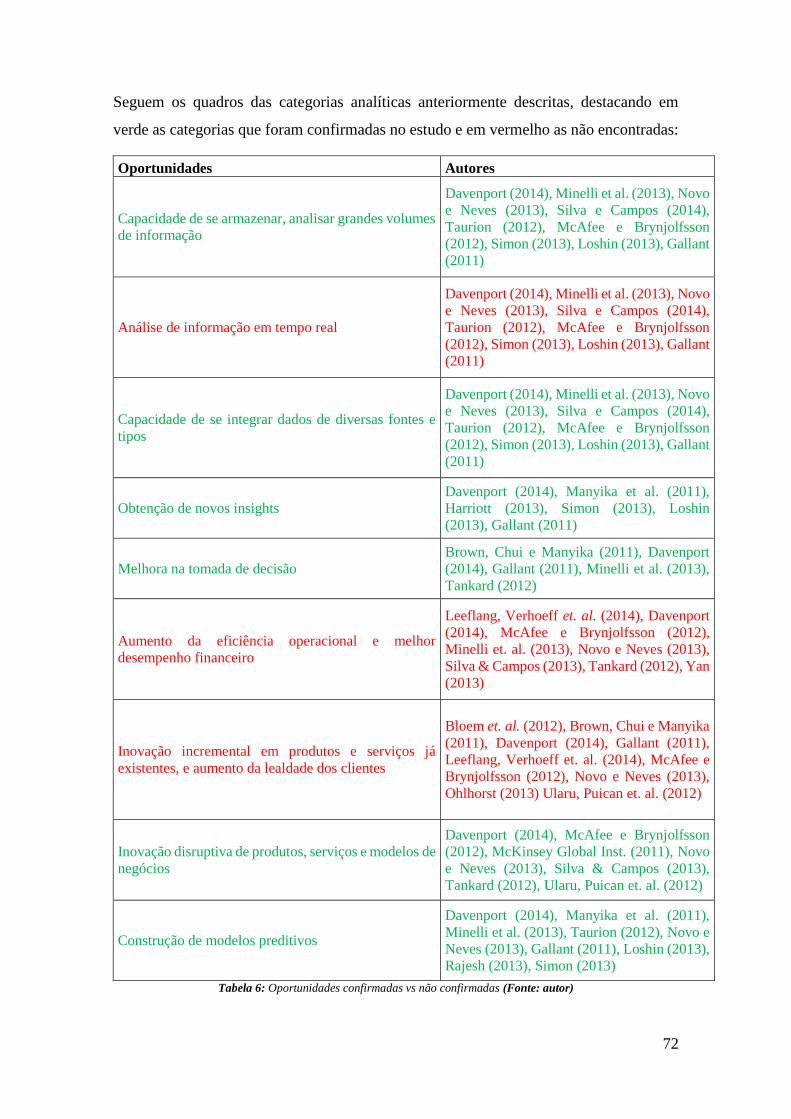
72
Seguem os quadros das categorias analíticas anteriormente descritas, destacando em
verde as categorias que foram confirmadas no estudo e em vermelho as não encontradas:
Oportunidades Autores
Capacidade de se armazenar, analisar grandes volumes
de informação
Davenport (2014), Minelli et al. (2013), Novo
e Neves (2013), Silva e Campos (2014),
Taurion (2012), McAfee e Brynjolfsson
(2012), Simon (2013), Loshin (2013), Gallant
(2011)
Análise de informação em tempo real
Davenport (2014), Minelli et al. (2013), Novo
e Neves (2013), Silva e Campos (2014),
Taurion (2012), McAfee e Brynjolfsson
(2012), Simon (2013), Loshin (2013), Gallant
(2011)
Capacidade de se integrar dados de diversas fontes e
tipos
Davenport (2014), Minelli et al. (2013), Novo
e Neves (2013), Silva e Campos (2014),
Taurion (2012), McAfee e Brynjolfsson
(2012), Simon (2013), Loshin (2013), Gallant
(2011)
Obtenção de novos insights
Davenport (2014), Manyika et al. (2011),
Harriott (2013), Simon (2013), Loshin
(2013), Gallant (2011)
Melhora na tomada de decisão
Brown, Chui e Manyika (2011), Davenport
(2014), Gallant (2011), Minelli et al. (2013),
Tankard (2012)
Aumento da eficiência operacional e melhor
desempenho financeiro
Leeflang, Verhoeff et. al. (2014), Davenport
(2014), McAfee e Brynjolfsson (2012),
Minelli et. al. (2013), Novo e Neves (2013),
Silva & Campos (2013), Tankard (2012), Yan
(2013)
Inovação incremental em produtos e serviços já
existentes, e aumento da lealdade dos clientes
Bloem et. al. (2012), Brown, Chui e Manyika
(2011), Davenport (2014), Gallant (2011),
Leeflang, Verhoeff et. al. (2014), McAfee e
Brynjolfsson (2012), Novo e Neves (2013),
Ohlhorst (2013) Ularu, Puican et. al. (2012)
Inovação disruptiva de produtos, serviços e modelos de
negócios
Davenport (2014), McAfee e Brynjolfsson
(2012), McKinsey Global Inst. (2011), Novo
e Neves (2013), Silva & Campos (2013),
Tankard (2012), Ularu, Puican et. al. (2012)
Construção de modelos preditivos
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Taurion (2012), Novo e
Neves (2013), Gallant (2011), Loshin (2013),
Rajesh (2013), Simon (2013)
Tabela 6: Oportunidades confirmadas vs não confirmadas (Fonte: autor)

73
Desafios Autores
Validade e qualidade dos dados
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Taurion (2012), McAfee
e Brynjolfsson (2012), Simon (2013),
Harriott (2013), Lam (2013), Barton e Court
(2012), Yin e Kaynak (2015), Jagadish et al.
(2014)
Modelar algoritmos que produzam informações
pertinentes
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Simon (2013), Harriott
(2013), Lam (2013), Barton e Court (2012),
Jagadish et al. (2014)
Interpretar os dados de maneira eficiente
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Taurion (2012), McAfee
e Brynjolfsson (2012), Simon (2013),
Harriott (2013), Yin e Kaynak (2015),
Jagadish et al. (2014), Galbraith (2014),
Falta de especialistas "cientistas de dados"
Davenport (2014), Manyika et al. (2011),
Taurion (2012), Simon (2013), Minelli et al.
(2013), Jagadish et al. (2014), Barton & Court
(2012), Lam (2013)
Dificuldade de se migrar de um perfil "modo driven"
para "data driven"
Davenport (2014), Harriott (2013), Lam
(2013), Barton & Court (2012)
Custódia, gerenciamento dos dados
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Taurion (2012), McAfee
e Brynjolfsson (2012), Simon (2013), Lam
(2013), Jagadish et al. (2014)
Segurança dos dados
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Taurion (2012), McAfee
e Brynjolfsson (2012), Simon (2013)
Infraestrutura de TI
Davenport (2014), Taurion (2012), Simon
(2013), Jagadish et al. (2014), Yin e Kaynak
(2015), Lam (2013)
Dificuldade de se extrair valor
Davenport (2014), Manyika et al. (2011),
Minelli et al. (2013), Simon (2013), Harriott
(2013), Yin e Kaynak (2015), Taurion (2012)
Tabela 7: Desafios confirmados vs não confirmados (Fonte: autor)
Sobre as principais limitações desta pesquisa, a primeira é referente ao método utilizado,
pois trata-se de um caso único e exploratório. Portanto, os resultados desta pesquisa não
são generalizáveis. As proposições apresentadas ainda precisam ser validadas em
pesquisas futuras (YIN, 1989).

74
A segunda é que, por ser uma tecnologia ainda em desenvolvimento, as oportunidades e
desafios apresentados por estudiosos relativos ao uso do Big Data podem sofrer
alterações.
E, por último, o presente caso tem uma peculiaridade, pois se trata de projetos de pesquisa
decorrentes de uma parceria interinstitucional. Novamente a extrapolação dos achados
para outras realidades deve considerar as características das parcerias e relações
comerciais subjacentes a implementação.
Vale destacar que, em decorrência dessa peculiaridade em especial, a demanda por
especialistas capazes de prover soluções técnicas complexas por parte da Petrobras foi
suprida pela parceira EMC, mas foi necessária uma maior aproximação desses
especialistas com os especialistas da Petrobras, com o intuito de que estes pudessem
descrever com precisão os problemas a serem resolvidos, ou seja, o que eles realmente
precisavam que os modelos fizessem. Porém criou-se um desafio não previsto na
literatura que foi o impacto tanto no gerenciamento de riscos do projeto, pois como nem
uma parte, nem outra possui uma visão geral do projeto, e sim domínio de partes do
mesmo, dificultando identificar e prever possíveis problemas durante sua execução,
quanto na qualidade das soluções, uma vez que sem o envolvimento de especialistas dos
problemas, muitas informações são ignoradas.
Como sugestão de estudos futuros, sugere-se estudos de caso em contextos distintos sobre
implementação de Big Data, como forma de acumular maior conhecimento sobre estas
implementações. Pode-se também realizar pesquisas qualitativas com profissionais que
lideram estas implementações, de forma a explorar oportunidades e desafios que eles
veem encontrando nestas implementações.

75
7. REFERÊNCIAS
ALLES, MG. Drivers of the Use and Facilitators and Obstacles of the Evolution of Big
Data by the Audit Profession. Accounting Horizons. Junho, 2015.
BARTON, Dominic e COURT, David. Making Advanced Analytics Work for You.
Harvard Business Review online, outubro, 2012.
BAZZOTTI, C.; GARCIA, E.; A Importância do Sistema de Informação Gerencial na
gestão empresarial para tomada de decisões. Ciências Sociais Aplicadas em
Revista, 2006.
BEAUDRY, A; PINSONNEAULT, A. Understanding Users Responses to Information
Technology: A Coping Model of User Adaption. MIS Quarterly, v. 29, n. 3, p. 493-
534, sep., 2005.
BEATH, Cynthia M.; QUADGRAS, Anne e ROSS, Jeanne. You May Not Need Big Data
After All. Harvard Business Review online, dezembro, 2013.
Big Bang, The: How the big data explosion is changing the world.; Microsoft News
Center, 2013. Disponível em <http://www.microsoft.com/en-
us/news/features/2013/feb13/02-11bigdata.aspx> Acesso em: setembro de 2015.
BINGI, P.; SHARMA, M.K.; GODLA, J.K.; Critical Issues affecting an ERP
Implementation. IS Management. 1999
BIEDERMAN, David. Big Data. The Journal of Commerce, março, 2013.
BOTTLES, Kent; BEGOLI, Edmon e WORLEY, Brian. Understanding the Pros and
Cons of Big Data Analytics. Physician Executive, julho/agosto, 2014.
BOUDREAU, Kevin. Big Data Solves Big Problems. Harvard Business Review online,
outubro, 2012.
BOYD, D.; CRAWFORD, K.; Critical questions for Big Data: provocations for a cultural,
technological and scholarly phenomenon. Information, Comunication & Socety,
2012.
BROWN, B.; CHUI, M.; MANYIKA, J.; Are you ready for the era of ‘big data’?
McKinsey Quartertly. Outubro, 2011.

76
BROWN, D. E.. What’s the difference between Business Intelligence and Big Data?
Disponível em Eric D. BROWN: http://ericbrown.com/whats-difference-business-
intelligence-big-data.htm Aessado em 05 de junho de 2014.
BROWN-LIBURD, H; ISSA, H; LOMBARDI, D. Behavioral Implications of Big
Data's Impact on Audit Judgment and Decision Making and Future Research
Directions. Accounting Horizons. 29, 2, 451-468, June 2015. ISSN: 08887993.
BRYNJOLFSSON, Erik e MCAFEE, Andrew. Big Data’s Management Revolution.
Harvard Business Review online, setembro, 2012.
CHEN, H.; CHIANG, R.H.L.; STOREY, V.C.; Business Intelligence and Analyics: From
Big Data o Big Impact. MIS Quarterly, 2012.
CRESWELL, J. Qualitative inquiry and research design: Choosing among five
traditions. Thousand Oaks, CA: Sage, 1998.
Current State of Business Analytics, The: Where do we go from here? Bloomberg
Businessweek Research Services, 2011. Disponível em
<http://www.sas.com/resources/asset/busanalyticsstudy_wp_08232011.pdf>.
Acessado em: março 2015.
DAVENPORT, ; PATIL, D. J. Data Scientist: the sexiest job of the 21st century. Harvard
Business School, 2012.
DAVENPORT, T. Big data at work: dispelling the myths, uncovering the opportunities.
Boston: Harvard Business School Publiching Corporation, 2014.
DAVENPORT, T. H. Competing on Analytics. [S.l.]: Harvard Business School, 2006.
DAVENPORT, T.; BARTH, P.; BEAN, R. How 'Big data' is different. MIT Sloan
Management Review, July 2012.
DE MAURO, A; GRECO, M; GRIMALDI, M. What is Big Data? A Consensual
Definition and a Review of Key Research Topics. AIP Conference Proceedings.
1644, 1, 97-104, Feb. 9, 2015. ISSN: 0094243X.
DEAN, J.; GHEMAWAT, S.; MapReduce: Simplified Data Processing on large clusters.
Communications of the ACM, 2008.
DEVLIN, B.; ROGERS, S.; MYERS, J. Big Data Comes of Age. EMA and 9sight
Consulting Report, 2012.

77
DHOLAKIA, R.R.; DHOLAKIA, N. Scholarly Research in Marketing: Trends and
Challenges in the Era of the Big Data. Disponível em <uri.edu>. Acesso em: 20 julho
2014.
DUTCHER, J.; What Is Big Data? 2014. Disponível em
<https://datascience.berkeley.edu/what-is-big-data/> acessado em janeiro de 2016.
ERICKSON, Scott e ROTHBERG, Helen. Big Data and Knowledge Management:
Establishing a Conceptual Foundation. The Electronic Journal of Knowledge
Management, Volume 12, Issue 2 (pp101-111).
FANG, L.; PATRECIA, S. Critical Success Factors in ERP Implementation. Jönköping
International Business School, 2005. Disponível em: <diva-portal.org> Acesso em:
14 junho 2014.
FINNEY, S.; CORBETT, M. ERP Implementation: A Compilation and Analysis of
Critical Success Factors. Business Process Management Journal, 2007.
FRIEDMAN, H; MARLEY, A. Big Data or Small Data: That is the Question.
Workforce Solutions Review. 6, 6, 4-6, Nov. 2015. ISSN: 21546975.
FREEMAN, L. 2013 in review: Big data, bigger expectations? 2013. Disponível em
<http://blogs.computerworld.com/big-data/23266/2013-review-big-data-cfbdcw>
Acesso em julho de 2014.
FRUCHTERMAN, Jim. Big Data Means More Than Big Profits. Harvard Business
Review online, março, 2013.
GALBRAITH, JR. ORGANIZATION DESIGN CHALLENGES RESULTING FROM
BIG DATA. Journal of Organization Design. 3, 1, 2-13, Jan. 2014. ISSN: 2245408X.
GALLANT,. TIBCO CEO: How Real-Time Computing Will Change the Landscape.
ComputeWorld, 2011.
GALLIERS, R.D.; LEIDNER, D.E. Strategic Information Management. 3ª ed, Oxford,
UK. Elsevier Science, 2003.
GANDOMI, A; HAIDER, M. Beyond the hype: Big data concepts, methods, and
analytics. International Journal of Information Management. 35, 2, 137-144, Apr.
2015. ISSN: 02684012.

78
GARTNER. Glossário de TI, 2012. Disponível em http://www.gartner.com/it-
glossary/big-data/ Acessado em 20/03/2015
GARTNER. Symposium/ITxpo 2015 realizado no início de Outubro em Orlando
www.gartner.com/newsroom Acessado em 20/12/2015
GIDDENS, A; PIERSON, C. Conversations with Anthony Giddens: making sense of
modernity. Cambridge: Polity Press, 1998.
GODOY, Arlida Schmidt. Introdução à pesquisa qualitativa e suas
possibilidades. Rev. adm. empres. [online]. 1995, vol.35, n.2, pp. 57-63.
GOTH, G. Bringing Big Data to the Big Tent. Communications of the ACM. 58, 7, 17-
19, Julho 2015.
GROVES, P.; KAYYALI, B.; KNOTT, D.; VAN KUIKEN, S. The ‘big data’ revolution
in healthcare: Accelerating value and innovation. McKinsey & Company.
Disponível em <www.mckinsey.com> Acesso em: 20 junho 2014.
GUEST, G.; BUNCE, A.; JOHNSON, L. How Many Interviews Are Enough? An
Experiment with Data Saturation and Variability Field Methods, v. 18, n. 1, p. 59-
82, 2006.
GUPTA, R.; GUPTA, S.; SINGHAL, A. Big Data: Overview. International Journal of
Computer Trends and Technology, v.9, n.5, 2014.
GUZZO, RA; et al. Big Data Recommendations for Industrial–Organizational
Psychology. Industrial & Organizational Psychology, Dezembro,. 2015.
HABTE, ML; et al. The Big Data Dilemma: Compliance for the Health Professional in
an Increasingly Data-Driven World. Journal of Health Care Compliance. 17, 3,
5-12, May 2015. ISSN: 15208303.
HALAWEH, M; EL MASSRY, A. Conceptual Model for Successful Implementation of
Big Data in Organizations. Journal of International Technology & Information
Management. 24, 2, 21-34, Apr. 2015. ISSN: 15435962.
HARRIOTT, Jesse. 7 Pillars for Successful Analytics Implementation. Marketing
Insights, spring, 2013.

79
HENRY, R; VENKATRAMAN, S. BIG DATA ANALYTICS THE NEXT BIG
LEARNING OPPORTUNITY. Academy of Information & Management Sciences
Journal. 18, 2, 17-29, June 2015. ISSN: 15325806.
HJ, ROBERTS, PRN, BARRAR; MRPII implementation: key factors for success.
Computer Integrated Manufacturing Systems, 1992.
HOLLAND, C.P.; LIGHT, B.; GIBSON, N. A Critical Success Factors Model for
Enterprise Resource Planning Implementation. ECIS, 1999. Disponível em <
http://www.christopherholland.co.uk/> Acesso em setembro 2015.
IVES, B.; OLSON, M. H. User Involvement and MIS Success: A Review of Research.
Management Science, v. 30, n. 5, p. 586-603, 1984.
JAGADISH, H; et al. Big Data and Its Technical Challenges. Communications of the
ACM. 57, 7, 86-94, July 2014. ISSN: 00010782.
JOBS, CG; AUKERS, SM; GILFOIL, DM. THE IMPACT OF BIG DATA ON YOUR
FIRMS MARKETING COMMUNICATIONS: A FRAMEWORK FOR
UNDERSTANDING THE EMERGING MARKETING ANALYTICS
INDUSTRY. Academy of Marketing Studies Journal. 19, 2, 81-92, June 2015.
ISSN: 15282678.
JOHNSON, Jeanne E. Big Data + Big Analytics = Big Opportunity. Financial Executive
july/august 2012.
JUAN, Z; XIONGSHENG, Y; APPELBAUM, D. Toward Effective Big Data Analysis
in Continuous Auditing. Accounting Horizons, Junho, 2015.
JUN, S; PARK, S; JANG, D. A Technology Valuation Model Using Quantitative Patent
Analysis: A Case Study of Technology Transfer in Big Data Marketing. Emerging
Markets Finance & Trade. 51, 5, 963-974, Sept. 2015. ISSN: 1540496X.
KRAUT, R. Effects of technological change: Quality of employment. In: HARTMANN,
H.; KRAUT, R.; TILLY, L. (Eds.). Computer chips and paper clips: Technology
and women's employment. Washington, DC: National Academy Press, p. 127-165,
1986.
KYUNGHEE, Y; HOOGDUIN, L; Li, Z. Big Data as Complementary Audit Evidence.
Accounting Horizons. Junho, 2015.

80
LABRINIDIS, A.; JAGADISH, H.V. Challenges and Opportunities with Big Data.
Proceedings of the VLDB Endowment, Vol. 5, No. 12, 2012. Disponível em:
<vldb.org> Acesso em: junho 2014.
LAM, S. IS BIG DATA TOO BIG TO HANDLE? (cover story). ComputerWorld Hong
Kong. 15-17, Julho, 2013.
LANEY, D. 3-D Data Management: Controlling Data Volume, Velocity and Variety.
META Group Research Note, 2001. Disponível em <http://goo.gl/Bo3GS> Acesso
em: junho 2014.
LEEFLANG, P.S.H.; VERHOEF, P.C.; DAHLSTRÖM, P.; FREUNDT, T. Challenges
and Solutions for Marketing in a Digital Era. European Management Journal,
n.32, p.1-12, 2014. Elsevier. Disponível em: <http://goo.gl/z1uBzT> Acesso em:
maio 2014.
LYYTIEN, K.; HIRSCHHEIM, R. Information Systems Failures: A Survey and
Classification of the Empirical Literature. Oxford Surveys in Information
Technology (4), 1987, pp. 257-309.
MAJCHRZAK, A.; COTTON, J. A Longitudinal Study of Adjustment to Technological
Change: From Mass to Computer-Automated Batch Production. Journal of
Occupational Psychology, v. 61, n. 1, p. 43-66, 1988.
MARR, B. Big Data In Big Oil: How Shell Uses Analytics To Drive Business Success
Forbes May, 2015.
MCAFEE, A.; BRYNJOLFSSON, E. Big Data: The Management Revolution. Harvard
Business Review, 2012. Disponível em <hbr.org> Acesso em: abril 2014.
MILLINGTON, B; MILLINGTON, R. 'The Datafication of Everything': Toward a
Sociology of Sport and Big Data. Sociology of Sport Journal. 32, 2, 140-160, June
2015. ISSN: 07411235.
MILLER, C.C. Data Science: the numbers of our lives. The New York Times, 11 Abril
2013. Disponível em <biostat.jhsph.edu> Acesso: maio 2014.
MIN, C; CHYCHYLA, R; STEWART, T. Big Data Analytics in Financial Statement
Audits. Accounting Horizons. 29, 2, 423-429, June 2015. ISSN: 08887993.

81
MINELLI, M.; CHAMBERS, M.; DHIRAJ, A. Big Data Big Analytics: Emerging
Business Intelligence and Analytic trends for today's businesses. Hoboken: John Wiley
and Sons Inc., 2013.
MORGAN, J. P. The Proliferation of Data. Challenges and Opportunities. Money
Management Executive, junho, 2012.
MURRAY, M.; COFFIN, G. A Case Study analysis of factors for success in ERP System
implementations. Proceedings of the Seventh Americas Conference on Information
Systems, Boston, p.1012–1018, 2001.
NAH, F.F.H.; LAU, J.L.S.; KUANG J. Critical Factors for Successful Implementation of
Enterprise Systems, 2001. Disponível em <http:/www.emerald-library.com/ft>
Acesso em: abril 2014.
NETO, A. M. F. Fatores relevantes na adoção e uso de Big Data na Prefeitura do Rio de
Janeiro: O caso do P3NS4 - Casa de ideias. Rio de Janeiro, 2015.
NOVO, R.; NEVES, J. M. S. D. Inovação na inteligência analítica por meio do Big
data: característica de diferenciação da abordagem tradicional. VIII Workshop de Pós-
graduação e Pesquisa do Centro Paula Souza. São Paulo: [s.n.]. 2013. p. 32-44.
OHLHORST, F. Big Data Analytics: Turning Big data into Big money. [S.l.]: Wiley,
2013.
Oracle: Big Data for the Enterprise. Oracle White Paper, Junho de 2013. Disponível em
< http://www.oracle.com/us/products/database/big-data-for-enterprise-519135.pdf>
Acesso: setembro 2015.
O’REILLY, T. 2005. “What Is Web 2.0? Design Patterns and Business Models for the
Next Generation of Software.” Disponível em:
http//www.oreillynet.com/pub/a/oreilly/tim/News/2005/09/30/what-is-web-20.html
Acesso em 30 de setembro de 2015.
ORLIKOWSKI, W. J. Using Technology and Constituting Structures: A Practice Lens
for Studying Technology in Organizations. Organization Science, v. 11, n. 4, p. 404-
28, jul./ ago., 2000.
PENTLAND, Alex. Big Data’s Biggest Obstacles. Harvard Business Review online,
outubro, 2012.

82
Po-Chieh, H; Po-Sen, H. WHEN BIG DATA GETS SMALL. International Journal of
Organizational Innovation. 8, 2, 100-117, Oct. 2015. ISSN: 19431813.
POZZEBON, M.; PINSONNEAULT, Alain. Challenges in Conducting Empirical Work
Using Structuration Theory: Learning from IT Research. Organization Studies, v.
26 n. 9, p. 1353-376, 2005.
PR, N. Big Data in Oil & Gas Market 2015-2025: Forecasts by Spending Type
(Hardware, Software, Services & Salaries) and Application Area (Upstream,
Midstream, Downstream & Administration). PR Newswire US. Dec. 9, 2015.
RAMESH, CR; et al. A REPORT ON REDUCING DIMENSIONS FOR BIG DATA
USING KERNEL METHODS. Journal of Theoretical & Applied Information
Technology. 80, 2, 296-303, Oct. 15, 2015. ISSN: 19928645.
REED, DA; DONGARRA, J. Exascale Computing and Big Data. Communications of the
ACM. 58, 7, 56-68, July 2015. ISSN: 00010782.
SALLAM, R. L., RICHARDSON, J., HAGERTY, J. E HOSTMANN, B. 2011. “Magic
Quadrant for Business Intelligence Platforms,” Gartner Group, Stamford, CT.
SCHMARZO, B. Big data: understanding how data powers Big Business. Indianapolis:
John Wiley & Sons, Inc., 2013.
SHAPIRO, Gregory P. Big Data Hype (and Reality). Harvard Business Review online,
outubro, 2012.
SHAW, Jonathan. Why “Big Data” Is a Big Deal. Harvard Magazine online, abril, 2014.
SHVACHKO, K. et al. The Hadoop distributed file system. 26th IEEE Symposium on
Mass Storage Systems and Technologies. [S.l.]: [s.n.]. 2010.
SICULAR, S. Gartners’ Big Data definition consists of three pats, not to be confused with
Three “V’s”. Gartner Inc., 2013. Disponível em
<http://www.forbes.com/sites/gartnergroup/2013/03/27/gartners-big-data-
definition-consists-of-three-parts-not-to-be-confused-with-three-vs/> Acesso em:
junho 2015.
SIMON, P. Too Big too Ignore. Hoboken: John Wiley & sons Inc., 2013.
SPONSELLER, S. Enabling Big Data Benefits Across the Oil and Gas Supply Chain.
Pipeline & Gas Journal. 242, 4, 61-78, Apr. 2015. ISSN: 00320188.

83
STANCIU, V. Consideraţii privind auditul financiar în era Big Data. : Considerations
Regarding Financial Audit in the Big Data Era. Audit Financiar. 13, 128, 3-71,
Aug. 2015. ISSN: 15835812.
TANKARD, C. Big data security. Netwrok security, p. 5-8, July 2012.
TAURION,. Você realmente sabe o que é Big data? IBM, 12 Agosto 2012.
<https://www.ibm.com/developerworks/community/blogs/ctaurion/entry/voce_r
ealmente_sabe_o_que_e_big_data?lang=en>. Acesso em: 2 Maio 2015.
TAURION, C. Entrevista com Cezar Taurion: O estágio atual do Big Data no Brasil.
Disponível em IBM:
https://www.ibm.com/developerworks/community/blogs/bigdata/entry/entrevista
_com_cezar_taurion_o_estagio_atual_do_big_data_no_brasil?lang=en;
Acessado em 06 de junho de 2014.
TENE, O.; POLONETSKY, J. Big Data for All: Privacy and User Control in the age of
Analytics. Northwestern Journal of Technology and Intellectual Property, v.11,
n.5, Abril, 2013.
THE 2011 IBM TECH TRENDS REPORT: Tech Trends of today. Skills for tomorrow.
2011. Disponível em
<http://ai.arizona.edu/mis510/other/2011IBMTechTrendsReport.pdf>. Acesso em:
março 2015.
TOLE, AA. Big Data Challenges. Database Systems Journal. 4, 3, 31-40, July 2013.
ISSN: 20693230.
VASARHELYI, MA; KOGAN, A; TUTTLE, BM. Big Data in Accounting: An
Overview. Accounting Horizons. 29, 2, 381-396, June 2015. ISSN: 08887993.
WARREN, J; MOFFITT, KC; BYRNES, P. How Big Data Will Change Accounting.
Accounting Horizons. 29, 2, 397-407, June 2015. ISSN: 08887993.
YAN, J. Big data, Bigger opportunities. 2012 President Management Council Inter-
agency Rotation Program. [S.l.]: [s.n.]. 2013.
YEO, K.T. Critical Failure Factors in Information System Projects. International
Journal of Project Management, Elsevier, 2002.

84
YEOH, W; KORONIUS, A. Critical success factors for business intelligence systems.
Journal of Computer Information Systems, pp.23-32, 2010.
YIN, R.K. Case Study Research: Design and Methods. Sage Publications Inc., 19
YIN, S; KAYNAK, O. Big Data for Modern Industry: Challenges and Trends [Point of
View]. Proceedings of the IEEE. 103, 2, 143-146, Feb. 2015. ISSN: 00189219.
YONG, Cat. Big data - the quest to know the unknown. Enterprise Innovation online,
maio, 2013.

85
ANEXOS
ANEXO I – ROTEIRO DE PESQUISA
Foram utilizados dois roteiros para nortear as entrevistas realizadas, o primeiro tratou da
coleta das informações pertinentes ao caso em geral, referente a primeira entrevista
realizada com o Responsável Geral dos projetos, o segundo trata especificamente das
oportunidades e desafios do Big Data.
Roteiro 1:
1) Identificar a experiência da Petrobras com o Big Data.
2) Motivação da Petrobras em se buscar o Big Data.
3) Buscar informações detalhadas sobre cada projeto de pesquisa.
4) Papel da EMC² nos projetos.
5) Influência da crise atual da Petrobras nos projetos.
Roteiro 2:
1) Funcionamento da parceria EMC² e Petrobras.
2) Oportunidades a serem exploradas.
3) Processo de seleção dos projetos.
4) Desafios previstos e desafios encontrados.
À partir desses dois roteiros, foram criadas perguntas durante as entrevistas com o
objetivo de se obter respostas não induzidas, abrangendo cada tópico em profundidade.
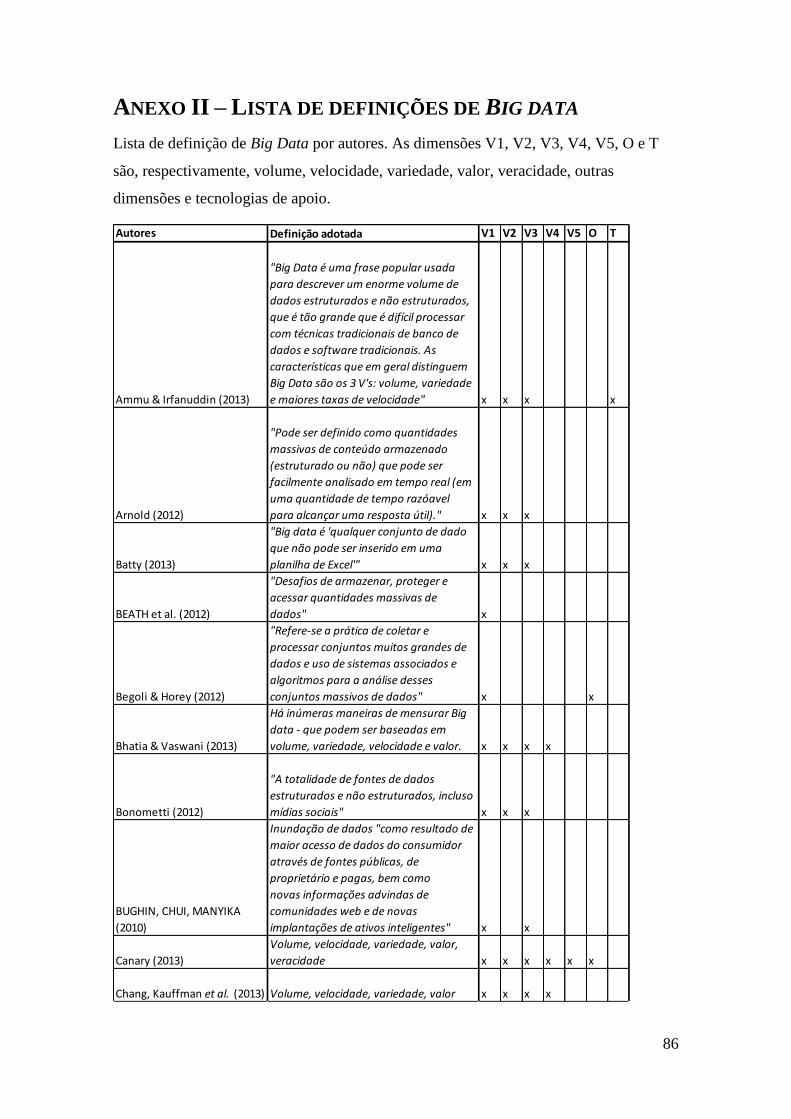
86
ANEXO II – LISTA DE DEFINIÇÕES DE BIG DATA
Lista de definição de Big Data por autores. As dimensões V1, V2, V3, V4, V5, O e T
são, respectivamente, volume, velocidade, variedade, valor, veracidade, outras
dimensões e tecnologias de apoio.
Autores Definição adotada V1 V2 V3 V4 V5 O T
Ammu & Irfanuddin (2013)
"Big Data é uma frase popular usada
para descrever um enorme volume de
dados estruturados e não estruturados,
que é tão grande que é difícil processar
com técnicas tradicionais de banco de
dados e software tradicionais. As
características que em geral distinguem
Big Data são os 3 V's: volume, variedade
e maiores taxas de velocidade" x x x x
Arnold (2012)
"Pode ser definido como quantidades
massivas de conteúdo armazenado
(estruturado ou não) que pode ser
facilmente analisado em tempo real (em
uma quantidade de tempo razóavel
para alcançar uma resposta útil)." x x x
Batty (2013)
"Big data é 'qualquer conjunto de dado
que não pode ser inserido em uma
planilha de Excel'" x x x
BEATH et al. (2012)
"Desafios de armazenar, proteger e
acessar quantidades massivas de
dados" x
Begoli & Horey (2012)
"Refere-se a prática de coletar e
processar conjuntos muitos grandes de
dados e uso de sistemas associados e
algoritmos para a análise desses
conjuntos massivos de dados" x x
Bhatia & Vaswani (2013)
Há inúmeras maneiras de mensurar Big
data - que podem ser baseadas em
volume, variedade, velocidade e valor. x x x x
Bonometti (2012)
"A totalidade de fontes de dados
estruturados e não estruturados, incluso
mídias sociais" x x x
BUGHIN, CHUI, MANYIKA
(2010)
Inundação de dados "como resultado de
maior acesso de dados do consumidor
através de fontes públicas, de
proprietário e pagas, bem como
novas informações advindas de
comunidades web e de novas
implantações de ativos inteligentes" x x
Canary (2013)
Volume, velocidade, variedade, valor,
veracidade x x x x x x
Chang, Kauffman et al. (2013) Volume, velocidade, variedade, valor x x x x

87
Autores Definição adotada V1 V2 V3 V4 V5 O T
Chen & Zhang (2014)
Big Data é uma coleção de conjuntos de
dados muito grandes com uma grande
diversidade de tipos de modo que torna-
se difícil processo usando abordagens de
processamento de dados mais
modernas ou plataformas de
processamento de dados tradicionais. x x x x
Chen, Chiang & Storey (2012)
"Descreve os conjuntos de dados e
técnicas analíticas em aplicações que
são tão grandes (de terabytes para
exabytes) e complexas (de sensor a
dados de mídias sociais) que eles
requerem únicas e avançadas
tecnologias de armazenamento de
dados, administração, análise e
visualização."
x x x x
Cumbley & Church (2013)
Grande parte do debate sobre Big Data
tem sido impulsionada pelo tamanho
(...) Impressionante como são, grande
quantidade de dados eletrônicos é de
pouca utilidade em si. Uma parte
importante do movimento de Big Data
são as novas tecnologias que vem sendo
usadas para extrair informações
significativas (...) volumes de dados
atuais não estão sendo impulsionadas
por dados estruturados tradicionais,
mas por uma explosão de dados não
estruturados ou semi-estruturados. x x x
Davenport (2012)
Dados demasiadamente volumosos ou
muito desestruturados para serem
gerenciados e analisados através de
meios tradicionais x x x
Deloitte (2013)
Volume, Velocidade, variedade,
veracidade, viabilidade, valor x x x x x x
Emerald Group (2013)
"Identifica[...] Big Data [...] como os 3
V's: volume, variedade e velocidade" x x x

88
Autores Definição adotada V1 V2 V3 V4 V5 O T
Evers (2014)
"Big Data, de um ponto de vista
organizacional, são dados de múltiplas
fontes e bases de dados, incluindo
estruturado, bem como dados não
estruturados. (...) Do ponto de vista
tecnológico, Big data engloba grandes
volumes, variedade e velocidade de
dados que não podem ser corretamente
processados e analisadas por meio de
técnicas convencionais, e, assim, inclui
técnicas avançadas necessárias para
processar esses dados, tais como o
processamento paralelo." x x x x
Fernandes, O'Connor &
Weaver (2015)
"Big Data pode ser definid por suas
características básicas, por vezes
referida como os 3 V's: volume,
velocidade e variedade" x x x
Freitas Junior & Maçada
(2014)
Observa-se que foram apresentadas
citações de autores mais recentes, que
vêm estudando o tema nos últimos três
anos, assim, com base no quadro acima,
pode-se notar uma similaridade nos
conceitos, que podem ser sintetizados
como sendo um grande volume de
dados estruturados ou não, de fontes
diversas, que devem ser gerenciados e
analisados de forma peculiar. x x x
French (2012)
"A disponibilidade de vastas
quantidades de dados de todos os tipos
e o aumento de velocidade e poder de
máquinas para analisar esses dados" x x x
Gantz & Reinsel (2012)
"'Tecnologias de Big Data' descreve uma
nova geração de tecnologias e
arquiteturas, concebidas para extrair
economicamente valor de volumes
muito grandes de uma ampla variedade
de dados, permitindo a alta velocidade
de captura, descoberta, e / ou análise. x x x x x
Gartner Group (2012)
“Big Data, em geral, é definido como
ativos de alto volume, velocidade e
variedade de informação que exigem
custo-benefício, de formas inovadoras
de processamento de informações para
maior visibilidade e tomada de decisão.” x x x x

89
Autores Definição adotada V1 V2 V3 V4 V5 O T
Gobble (2013)
"Quando são tão grandes [os dados]
que os sistemas tradicionais não
conseguem lidar." x x
Gordon-Murdane (2012)
"Não é apenas aumento na quantidade
e tipos de dados, é também
melhores ferramentas para armazenar,
agregar, combinar, analisar, e extrair
novas idéias." x x
Griffin (2012)
"É importante notar que big data é
muito mais do que mídias sociais. É
dados estruturados e não estruturados
residindo em bases de dados em
múltiplas regiões geográficas. É texto em
formulários Web e PDFs, e é
email e todas as formas de outros
documentos." x
Grunes & Stcke (2015)
Big data é frequentemente caracterizada
por quatro "Vs": volume, velocidade,
variedade e valor. x x x x
HBR (2013)
"Big Data" é um termo usado para
descrever o novo volume, variedade e
velocidade de dados que agora enfrenta
empresas x x x
IBM (2014)
"Volume, velocidade, variedade e
veracidade" x x x x
Jacobs (2009)
"Big data deve ser definida em qualquer
ponto no tempo, como 'dados cujo
tamanho nos obriga a olhar para além
dos métodos experimentados e
verdadeiros que são predominantes
naquela época'. Hoje em dia, isso pode
significar que os dados é muito grande
para ser colocado em um banco de
dados relacional" x
Kaisler, Armour at al. (2013)
"Características de Big Data:" variedade,
volume, velocidade, valor, complexidade x x x x x
Katal, Wazid & Goudar (2013)
"Big data pode ser definida com as
seguintes propriedades associadas a
ele:" variedade, volume, velocidade,
variabilidade, complexidade, valor x x x x x x
Kraska (2013)
"É quando o aplicativo normal da
tecnologia atual não permite aos
usuários obter no tempo correto, com
custo eficaz e com respostas de
qualidade a perguntas orientadas por
dados." x x x

90
Autores Definição adotada V1 V2 V3 V4 V5 O T
Kumar & Vidhyalakshmi
(2012)
"Volume, variedade e velocidade são os
três principais fatores de Big Data" x x x
Kwon, Lee & Shin (2014)
"Caracterizado em volume, variedade,
velocidade e valor, 'big data' é
considerado por profissionais da
indústria como o próximo 'blue ocean' de
oportunidades de negócios. Definimos
grandes tecnologias de análise de dados
(por exemplo, banco de dados e
ferramentas de mineração de dados) e
técnicas (por exemplo, métodos
analíticos) que uma empresa pode
empregar para analisar dados em
grande escala, dados complexos para
várias aplicações de modo a aumentar o
desempenho da empresa em várias
dimensões" x x x x x
Leeflang, Verhoef et al.
(2014)
"Por big data queremos dizer conjuntos
de dados tão grande e complexo que se
torna difícil para processar usando
ferramentas de gerenciamento de banco
de dados tradicionais ou aplicações de
processamento de dado" x x x x
Lima Junior (2012)
"Big data" refere-se ao conjunto de
dados (dataset) cujo tamanho está
além da habilidade de ferramentas
típicas de banco de dados em capturar,
gerenciar e analisar." x x
Lohr (2012)
"Refere-se à inundação crescente de
dados digitais de muitas fontes,
incluindo a internet, sensores biológicos
e industriais, videos, email e redes
sociais de comunicação." x x
Lopez (2012)
"Existem muitas definições de big data ,
mas a maioria dos especialistas
concordam em três características
fundamentais: volume, velocidade e
variedade. Outro aspecto chave,
frequentemente negligenciado, é custo." x x x
Lyon (2014)
"...huge volume, consisting of terabytes
or petabytes of data; high velocity, being
created in or near real time; extensive
variety, both structured and
unstructured;..." x x x
Maçada & Canary (2013) Apresentado em tabela x x x x x

91
Autores Definição adotada V1 V2 V3 V4 V5 O T
Madden (2012)
"Dados que são em grandes
quantidades, muito rápidos e muito
difíceis para as ferramentas atuais de
processamento" x x x x
Mahrt & Scharkow (2013)
"Denotam um maior conjunto de dados
ao longo do tempo, conjuntos de dados
estes que são grandes demais para
serem manipulados por infraestruturas
de armazenamento e processamento
regulares" x x
MANYIKA et al.
(2011)
"Conjunto de dados cujo tamanho está
além da habilidade de típicas
ferramentas de software de base de
dados para capturar, armazenar,
administrar e analisar"
Marshall (2012)
"Muito grande para ser observado de
perto" x
Michael & Miller (2013)
"Big Data reúne não apenas grandes
quantidades de dados, mas também
vários tipos de dados que anteriormente
nunca teria sido consideradas em
conjunto. Estes fluxos de dados exigem
cada vez maior velocidade de
processamento, mas devem ser
armazenados economicamente" x x x x
Minelli et al. (2013)
"A indústria tem uma definição
evoluindo em torno de Big Data que está
definido por três dimensões:
1. Volume
2. Variedade
3. Velocity" x x x
More, Chaudhary et al. (2013)
"'Big Data' refere-se a conjuntos de
dados, cujo tamanho é além da
capacidade de captura, armazenagem,
gerenciamento e análise do típico
software de banco de dados" x x
NewVantagePartners (2013)
"Big Data é um termo usado para
descrever conjuntos de dados tão
grandes, tão complexos ou que
requeiram tratamento rápido (...) que se
tornam difícil ou impossível de trabalhar
com o uso de gestão de banco de dados
padrão ou ferramentas analíticas.
Manipulando conjuntos de dados como
estes muitas vezes exigem software
maciçamente paralelo em execução em
dezenas, centenas ou até milhares de
servidores" x x x x

92
Autores Definição adotada V1 V2 V3 V4 V5 O T
Novo & Neves (2013)
"Comparando os exemplos aqui listados
é possível identificar as três dimensões
do big data (volume, velocidade e
variedade) presentes" x x x
Pospiech & Feldens (2012)
"Um desafio de uma relação
desfavorável entre dados disponíveis e
tecnologias de informação ou conceitos
atuais." x x
Preimesberger (2011)
"Um crescente número de conjunto de
dados empresariais de tamanhos
colossais e toda a tecnologia necessária
para criar, armazenar, cruzar,
analisar, arquivar e recuperar esses
dados empresariais." x x x x
PwC (2014)
A recente onda de informação eletrônica
produzida em maior volume por um
número crescente de fontes (ou seja,
não apenas os dados coletados por uma
organização particular no curso de
negócios normal). x x
Raghupathi & Raghupathi
(2014)
"Por definição, Big data em saúde refere-
se a dados de saúde electrônicos tão
grandes e complexos que é difícil (ou
impossível) de gerenciar com software e
/ ou hardware tradicional; nem podem
ser facilmente gerenciadas com
ferramentas e métodos de gestão de
dados tradicionais ou comuns" x x x x
Ribeiro (2014)
A abordagem de Big Data está
apoiada em quatro outros fatores de
sustentação, conhecidos como os 4 Vs
do
Big Data: Volume, Variedade,
Velocidade e Veracidade (...)Uso de
tecnologias específicas, tais como
processamento de
rotinas em paralelo e ferramentas
para otimização como Hadoop e
MapReduce, HDFS, além de
abordagens de MachineLearning e
Analytics. x x x x x
Rogers (2011)
"Conjuntos de dados que não podem
mais ser facilmente administrados ou
analisados com ferramentas, métodos
ou infraestruturas tradicionais ou
comuns de administração de dados." x x

93
Autores Definição adotada V1 V2 V3 V4 V5 O T
Silva & Campos (2014)
As definições existentes na literatura
para o Big Data convergem para os
seguintes fatos, a utilização de
diferentes fontes, tipos de dados e
características que se refere ao volume,
variedade e velocidade x x x
Singh & Singh (2012)
"Conjunto de dados que continuam a
crescer tanto que torna difícil de
administrá-los usando conceitos e
ferramentas existentes de administração
de base de dados." x x
Tabuena (2012)
"Big data não é apenas sobre tamanho.
Big data é realmente sobre ferramentas
de dados do tipo analytics." x x
Tankard et al (2012)
"Refere-se à quantidade de informações
cada vez maiores que as organizações
estão armazenando, processando e
analisando, devido ao crescente número
das fontes de informações em uso." x x
Taurion (2012)
O que é Big Data? Outro dia escrevi um
post com uma fórmula simples para
conceitualizálo. Big Data = volume +
variedade + velocidade. Hoje adiciono
mais dois “V”s: veracidade e valor. x x x x x
TechAmerica Foundation
(2012)
"Big Data é um termo que descreve
grandes volumes de alta velocidade,
complexo e variáveis de dados que
exigem técnicas e tecnologias avançadas
para permitir a captura,
armazenamento, distribuição, gestão e
análise da informação" x x x x
Tole (2013)
"Os 3 V's de Laney [volume, velocidade e
variedade] [...] representam elementos-
chave que são considerados vitais sobre
as características dos sistemas de Big
Data. (...) Depois dos 3 V's de Laney,
"mais dois" V's de [valor e veracidade]
foram adicionados como aspectos
fundamentais dos sistemas de Big
Data". x x x x x

94
Autores Definição adotada V1 V2 V3 V4 V5 O T
Ularu, Puican et al. (2012)
Há uma série de definições sobre Big
Data em circulação no mundo, mas
consideramos que o mais importante é
aquela que cada líder dá aos dados de
sua empresa. A maneira que Big Data é
definida tem implicação na estratégia de
uma empresa. Cada líder tem que definir
o conceito, a fim de trazer vantagem
competitiva para a empresa. x x x x x x x
Villars, Olofson & Eastwood
(2011)
(...) é possível que alguns funcionários
brilhante em sua organização lidem
efetivamente com a variedade muitos
dados, volume, e os problemas de
velocidade. Por definição, a taxa de
crescimento Big Data excede as
capacidades de infra-estrutura de TI
tradicional e representa grande parte de
computação e gerenciamento de dados
de problemas para os clientes. x x x x
Xexeo (2013)
Há consenso de que três dessas
características, as iniciadas pelos três
‘Vs’, são as principais: volume,
velocidade e variedade (...) A partir
desses três ‘Vs’, diversos autores
propõem ainda outros conceitos, como
veracidade, variabilidade ou valor. x x x x x x
Yan (2013)
Um esclarecimento a ser feito nas
discussões sobre o conceito de Big data é
que o termo pode se referir tanto a
grandes e/ou diversas bases de dados,
ou para tecnologias de lidar com esses
tipos de conjuntos de dados. x x x