o objetivo deste módulo é apresentar a arquitetura atual...
TRANSCRIPT

O objetivo deste módulo é apresentar a arquitetura atual da Internet, baseada em endereços
IPv4.
Para isso será abordado o conceito de sistemas autônomos (Autonomous System – AS) que
é a forma de organização lógica da Internet.
Em seguida, serão vistos os protocolos de roteamento usados na Internet e nas redes
privadas. Os protocolos de roteamento são utilizados para configurar automaticamente as
rotas dos roteadores que formam os backbones da Internet e também as redes privadas.
1

Do ponto de vista físico, a infraestrutura de redes IP pode ser dividida em 3 níveis: usuário,
acesso e núcleo (também chamado de core ou backbone).
A infraestrutura nível núcleo (backbone) corresponde geralmente a equipamentos e enlaces
de alta capacidade pertencentes a operadoras de telecomunicação. Exemplos de tecnologias
de comunicação nesse nível são o ATM, SDH, Gigabit-Ethernet. Nesse nível, os dados
transportados pelos enlaces são agregados, isto é, eles correspondem a dados de uma
grande quantidade de usuários.
Os equipamentos utilizados no backbone são geralmente muito caros para serem utilizados
ao nível de usuário. Dessa forma, é necessário criar um nível intermediário, com
equipamentos mais baratos e velocidades inferiores, a fim de permitir que usuários se
conectem ao backbone. Esse nível intermediário é denominado nível de acesso. Um
exemplo de tecnologia de nível acesso é o ADSL, conforme mostrado na figura. O ADSL
permite que a conexão de rede utilizada pelos usuários seja uma simples linha telefônica. A
linha telefônica tem uma capacidade muito inferior àquele utilizada no backbone, de forma
que múltiplas linhas telefônicas precisam ser multiplexadas para atingir uma velocidade
compatível com o backbone.
O equipamento de rede responsável por multiplexar as linhas é denominado: DSLAM: Digital
Subscriber Line Access Multiplexer. Geralmente o próprio DSLAM é um equipamento
intermediário, sendo necessário ainda um outro nível de multiplexagem realizado por um
equipamento denominado B-RAS (Broadband Remote Access Server).
2

Além da multiplexagem, o B-RAS é responsável por autenticar e policiar o tráfego do usuário.
O protocolo de autenticação geralmente é o PPPoE (Point-to-Point over Ethernet) ou PPPoA
(Point-to-Point over ATM), de acordo com a tecnologia utilizada no nível backbone.
A infraestrutura de rede de nível usuário corresponde a tecnologia de comunicação que
conecta um usuário ou a uma rede privada até a rede de acessp. Os equipamentos desse
nível são comumente chamados de CPE: Customer Premises Equipment ou RG: Residential
Gateway. No caso do ADSL, o CPE é um modem que conecta a rede do usuário a uma linha
multiplexada pelo DSLAM.
Conforme mostra a figura, uma rede backbone pode interligar multiplas redes de acesso. Os
backbones, por sua vez são conectados entre si, formado uma grande rede formada por
inúmeras operadoras.
A rede Internet é uma rede que segue esse princípio. As redes backbones que formam a
Internet podem ser de várias origens: redes de empresas de telecomunicação (com fins
comerciais), redes do governo e redes de pesquisa. Independente de sua origem, todas
essas redes precisam seguir um padrão comum de funcionamento, a fim de que sejam
interoperáveis. Esse padrão de funcionamento é baseado no conceito de sistemas
autônomos e protocolos de roteamento padronizados.
3
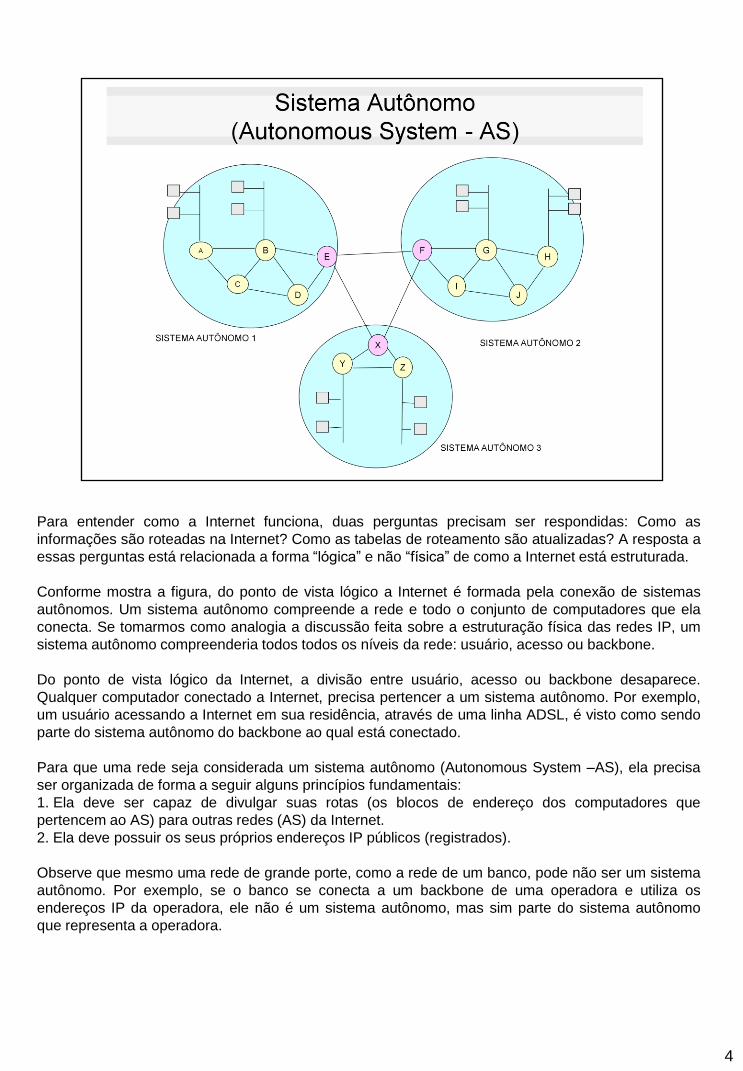
Para entender como a Internet funciona, duas perguntas precisam ser respondidas: Como as
informações são roteadas na Internet? Como as tabelas de roteamento são atualizadas? A resposta a
essas perguntas está relacionada a forma “lógica” e não “física” de como a Internet está estruturada.
Conforme mostra a figura, do ponto de vista lógico a Internet é formada pela conexão de sistemas
autônomos. Um sistema autônomo compreende a rede e todo o conjunto de computadores que ela
conecta. Se tomarmos como analogia a discussão feita sobre a estruturação física das redes IP, um
sistema autônomo compreenderia todos todos os níveis da rede: usuário, acesso ou backbone.
Do ponto de vista lógico da Internet, a divisão entre usuário, acesso ou backbone desaparece.
Qualquer computador conectado a Internet, precisa pertencer a um sistema autônomo. Por exemplo,
um usuário acessando a Internet em sua residência, através de uma linha ADSL, é visto como sendo
parte do sistema autônomo do backbone ao qual está conectado.
Para que uma rede seja considerada um sistema autônomo (Autonomous System –AS), ela precisa
ser organizada de forma a seguir alguns princípios fundamentais:
1. Ela deve ser capaz de divulgar suas rotas (os blocos de endereço dos computadores que
pertencem ao AS) para outras redes (AS) da Internet.
2. Ela deve possuir os seus próprios endereços IP públicos (registrados).
Observe que mesmo uma rede de grande porte, como a rede de um banco, pode não ser um sistema
autônomo. Por exemplo, se o banco se conecta a um backbone de uma operadora e utiliza os
endereços IP da operadora, ele não é um sistema autônomo, mas sim parte do sistema autônomo
que representa a operadora.
4

Um AS é uma rede (coleção de roteadores e computadores) que segue uma arquitetura
WAN. Para que a rede de uma instituição possa ser transformada em AS, ela primeiro,
precisa obter um conjunto mínimo de endereços IP públicos (registrados) junto as
autoridades da Internet.
Quando uma instituição se torna um AS, ela passa a ter seus próprios endereços IP, isto é, os
endereços utilizados na rede não são obtidos de provedores, mas pertencem a própria
instituição. A topologia de uma rede AS possui dois tipos de roteadores: internos e de borda.
Os roteadores internos são utilizados para interconectar as redes do AS. As redes internas ao
AS podem ser a diversas filiais de uma empresa ou os clientes de uma operadora de
telecomunicações. O roteador de borda é utilizado para conectar o AS a outros AS que
compõem a Internet. Observe que os roteadores internos precisam conhecer como os vários
prefixos estão distribuídos entre as várias redes que pertencem ao AS. Já o roteador de
borda (indicado como B, na figura), pode simplesmente divulgar rotas agregadas para os
outros AS da internet. Por exemplo, ao invés de divulgar os vários prefixos 200.17.1.0/24,
200.17.1.0/24, 200.17.1.130/24, etc., ele pode divulgar simplesmente a rota 200.17.0.0/16.

Para se tornar um AS, a instituição precisa solicitar um conjunto de IPs registrados
junto as autoridades da Internet. O controle global da atribuição de endereços IP é
feito pelo IANA (Internet Assigned Numbers Authority). A IANA é responsável por
designar quantos blocos de endereço estão disponíveis para cada região do
planeta, evitando duplicação ou má distribuição dos endereços. A IANA utiliza 5
autoridades de abrangência regional para agilizar o processo de atribuição dos
endereços em todo o mundo.
Essas autoridades são:
AfriNIC: responsável pela região da África
APNIC: responsável pela região Ásia e Pacífico
ARIN: responsável pela região da América do Norte
LACNIC: responsável pela região da América Latina e algumas ilhas do Caribe
RIPE NCC: responsável pela Europa, Oriente Médio e Ásia Central
Todas vez que uma empresa solicita se tornar um AS, ela precisa receber um
"número de AS", que é único em toda a Internet. A IANA também é responsável por
atribuir os números de AS.

As figuras ilustram informações parciais de dois sistemas autônomos: PUCPR e GOOGLE. A
PUCPR é registrada junto ao LACNIC e o GOOGLE é registrado junto a ARIN. Cada AS
possui um número, que é utilizado para identificar o AS ao nível dos protocolos de
roteamento da Internet. Nesses exemplos, o AS PUCPR possui o número 13522 e o AS
GOOGLE possui o número 15169.
A quantidade de prefixos (blocos de endereços IP contínuos) e endereços IP varia de acordo
com o tamanho da instituição. A PUCPR possui três prefixos e 8192 endereços. O GOOGLE
possui 109 prefixos e 122624 endereços. As entidades de registro (LACNIC, ARIN, etc)
possuem bases de dados que permitem obter de forma online informações sobre um AS. É
possível também consultar bases de dados para determinar todos os prefixos (blocos de
endereços IP) que pertencem a um dado AS.
O plugin gratuito para o firefox, que pode ser obtidon o endereço
http://www.asnumber.networx.ch/, permite identificar o AS de qualquer site da Internet. Os
dados mostrados na figura foram obtidos através desse plugin. Para usar o plugin, basta
entrar em qualquer site da Internet, que o plugin mostra os dados do AS na barra de status,
na parte inferior da janela do firefox. Através do plugin, observamos que o site "pucpr.br"
pertence ao prefixo 200.192.112.0/21, e o site google.com pertence ao prefixo
209.85.128.0/17.
7

Uma instituição pode se tornar um sistema autônomo por diversas razões diferentes.
Operadoras de telecomunicações precisam se tornar sistemas autônomos a fim de poder
prestar a venda de serviços de conectividade para Internet. Nesse caso, a operadora
geralmente possui um backbone de grande porte, como o caso da RNP (que é uma
operadora gratuita para universidades e instituiçõe do governo).
Quando um cliente se conecta a Internet através de um sistema autônomo de uma operadora
de telecomunicações, ele é "visto" pelo restante da Internet como sendo parte da rede da
operadora. Isso significa que o cliente não precisa se preocupar em instalar protocolos de
roteamento em seus roteadores. Essa responsabilidade é do administrador do sistema
autônomo (AS). Como consequência, a rede do cliente pode ser bem mais simples e barata.
Contudo, muitas instituições que não são operadoras de telecomunicações também podem
se tornar AS. Esse é o caso de grandes instituições como bancos, instituições do governo,
universidades e multi-nacionais. A vantagem de ser um AS nesse caso é ter total
independência em relação ao provedor de acesso. Por exemplo, se um grande banco não for
um AS, mas um simples cliente de outro AS, ele precisará trocar todos os endereços IP
registrados de sua rede caso decida trocar de provedor. Além disso, é muito difícil conectar a
rede da empresa a dois ou mais provedores simultaneamente (para garantir redundância),
pois a rede precisaria conter endereços IP de várias operadoras misturados na rede da
instituição.
Dessa forma, os sistemas autônomos podem ser classificados em vários tipos, de acordo
com a finalidade de uso destinada pela instituição que o controla.

Os sistemas autônomos podem ser classificados por dois critérios: o primeiro em relação a sua
permissão de passagem de tráfego de outros AS, e o segundo em relação a forma de relacionamento
comercial com outros AS.
Quanto a pemissão de passagem de tráfego de outros AS, a classificação é a seguinte:
Stub AS: são ligados à Internet através de um único ponto de saída. Também são chamados de
“single-homed”. Esse tipo de AS corresponde geralmente a instituições privadas que não desejam
prestar serviços de telecomunicações para terceiros, apenas se beneficiar da autonomia de ser um
AS. Na figura, o AS 5 é um exemplo de stub AS.
Transit AS : Sistemas Multihomed (com várias conexões) que permitem que o tráfego de outros AS
utilizem suas conexões como passagem. As operadoras que prestam serviços de acesso a Internet
(ISP) são desse tipo.
Non-Transit: São sistemas multihomed, mas que não permitem transporte de tráfego envolvendo
outros AS. Isso significa que apenas o tráfego em que a origem ou o destino é um endereço IP do
próprio AS é permitido. Esse é o caso das instituições privadas que possuem mais de uma conexão
com a Internet (para redundância), mas não desejam que essa conexão seja utilizada para transportar
tráfego de terceiros.
O controle de passagem de tráfego é feito através do protocolo de roteamento entre ASs, que controla
o sentido de divulgação das rotas. Esse tópico será discutido mais adiante, quando falarmos sobre o
BGP, que é o protocolo de roteamento usado na Internet.
Quanto a forma de relacionamento comercial, a classificação é a seguinte:
Relacionamento Peer: Quando dois AS se interconectam de maneira gratuita, visando benefício
mútuo de troca de tráfego, através de um acordo de tráfego multi-lateral (ATM).
Quando o relacionamento é comercial, a conectividade é denominada transit.

A interconexão desordenada de sistemas autônomos em forma de uma malha poderia levar a
um desempenho muito pobre da Internet, devido a uma grande quantidade de saltos. Por
essa razão, foram desenvolvidos locais especiais onde vários sistemas autônomos podem se
conectar utilizando apenas um salto. Esses locais são denominados IXP (Internet Exchange
Point).
Atualmente, a tecnologia mais utilizada para implementar IXP é o Ethernet. O equipamento
usado no IXP nada mais é do que um switch de grande capacidade, que recebe, em suas
portas, as fibras oriundas dos roteadores de borda de vários AS.
Em muitos países a manutenção dos IXP é subsidiada por órgãos públicos. No Brasil além da
denominação IXP (ou PIX, Ponto de Troca de Tráfego), a denominação PTT (PTT: Ponto de
Troca de Tráfego) também é muito usada.
O maior PTT do Brasil é denominado PTTMetro. Esse PPT é mantido pelo Projeto do Comitê
Gestor da Internet no Brasil (CGIbr). Ele permite a interconexão direta entre as redes ASs
que compõem a Internet Brasileira. O PTTMetro possui vários locais de interconexão (PIX). A
figura mostra o PIX Central, localizado em São Paulo, que interconecta vários ASs, como a
USP, a Brasil Telecom e Outros.

Para que a rede de uma instituição possa se tornar um AS, algumas regras precisam ser
respeitadas. Conforme dito anteriormente, os roteadores de um AS são classificados em dois
tipos: roteadores internos e roteadores de borda. Os roteadores internos são aqueles que se
conectam apenas a roteadores e computadores no interior do AS. Os roteadores de borda, se
conectam a roteadores de outros AS. Na figura, apenas os roteadores E, F e L são
roteadores de borda. Todos os demais são roteadores internos.
Um roteador interno não precisa ser um muito potente, pois ele precisa conhecer apenas as
rotas para as redes que pertencem ao próprio AS. Já o roteador de borda precisa conhecer
todas as rotas da Internet. Isso faz com que esse roteador seja, geralmente, muito caro. A
quantidade de rotas da Internet, atualmente, é superior a 300.000. Isso faz com que o
roteador de borda tenha que ter uma quantidade razoável de memória, e também bastante
velocidade para consultar as tabelas de roteamento. O roteador será tanto mais caro quanto
maior a velocidade do seu enlace. Se o roteador for de baixa capacidade (com link de menos
de 1 Mbps), ele pode até ser implementado com um equipamento de custo reduzido.
Contudo, se o link do roteador de borda for da ordem de centenas de Mbps, então seu custo
será bastante elevado (dezenas de milhares de dólares).
Roteadores de borda atuais precisam suportar aproximadamente 222.000 rotas (junho 2007)
além de mais 50% para rotas privadas de clientes. A fim de processar essas rotas sem
grande atraso na propagação dos pacotes os roteadores precisam: Muita memória de acesso
rápido e Alta capacidade de processamento. Roteadores com essa capacidade podem ter
custos superiores a U$ 50K.
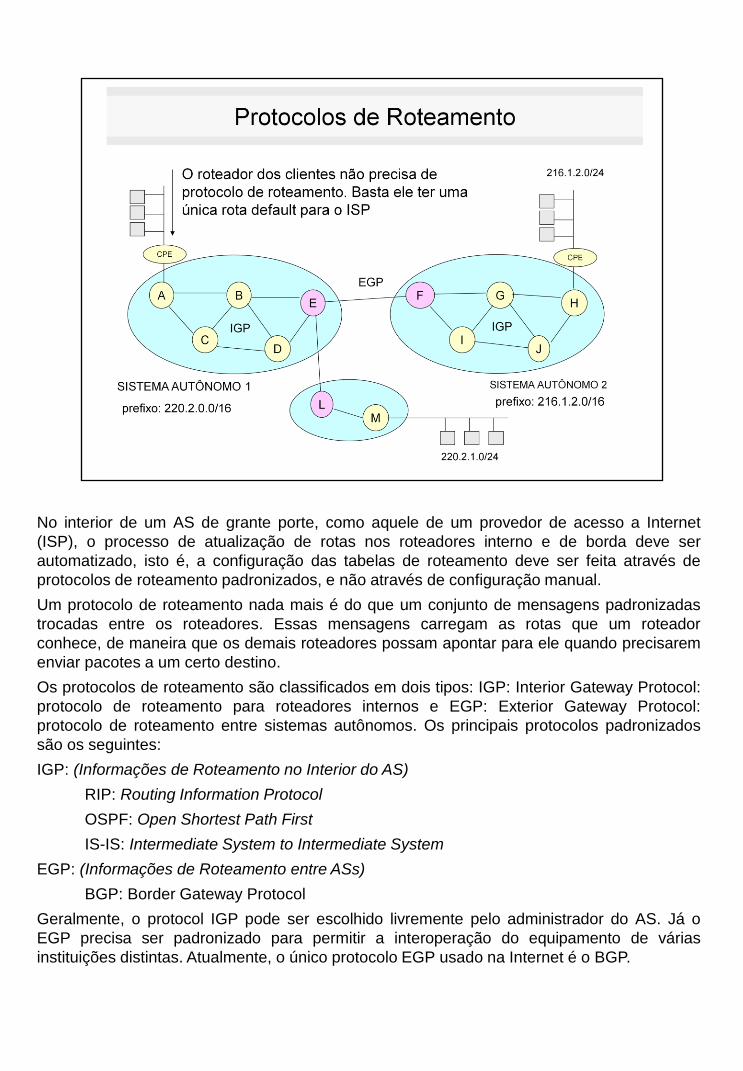
No interior de um AS de grante porte, como aquele de um provedor de acesso a Internet
(ISP), o processo de atualização de rotas nos roteadores interno e de borda deve ser
automatizado, isto é, a configuração das tabelas de roteamento deve ser feita através de
protocolos de roteamento padronizados, e não através de configuração manual.
Um protocolo de roteamento nada mais é do que um conjunto de mensagens padronizadas
trocadas entre os roteadores. Essas mensagens carregam as rotas que um roteador
conhece, de maneira que os demais roteadores possam apontar para ele quando precisarem
enviar pacotes a um certo destino.
Os protocolos de roteamento são classificados em dois tipos: IGP: Interior Gateway Protocol:
protocolo de roteamento para roteadores internos e EGP: Exterior Gateway Protocol:
protocolo de roteamento entre sistemas autônomos. Os principais protocolos padronizados
são os seguintes:
IGP: (Informações de Roteamento no Interior do AS)
RIP: Routing Information Protocol
OSPF: Open Shortest Path First
IS-IS: Intermediate System to Intermediate System
EGP: (Informações de Roteamento entre ASs)
BGP: Border Gateway Protocol
Geralmente, o protocol IGP pode ser escolhido livremente pelo administrador do AS. Já o
EGP precisa ser padronizado para permitir a interoperação do equipamento de várias
instituições distintas. Atualmente, o único protocolo EGP usado na Internet é o BGP.

Para entender a diferença entre os protocolos BGP, OSPF, RIP, etc é necessário, primeiro,
rever alguns conceitos importantes sobre o roteamento.
O primeiro aspecto que precisa ser analisado é como um roteador armazena suas rotas.
Conceitualmente, um roteador utiliza duas tabelas internas a fim de determinar para onde
enviar um pacote para um dado destino: a RIB e a FIB. A RIB (Router Information Base) é o
conjunto completo de rotas configuradas no roteador. Na RIB, é possível ter mais de uma rota
para um mesmo destino.
Independente de quantas rotas existem, um roteador irá sempre utilizar a rota de menor
custo até que essa rota deixe de funcionar, ou uma outra rota seja criada. Por isso, os
roteadores mantém uma outra tabela, mais otimizada denominada FIB. A FIB (Forwarding
Information Base) contém apenas as melhores rotas ativas (as que realmente são utilizadas).
Além disso, a FIB pode conter informações necessárias para simplificar o processo de
encaminhamento dos pacotes para o roteador vizinho (por exemplo, o endereço MAC do
próximo salto para evitar uma consulta ARP desnecessária).
Olhando a figura, vemos que o roteador A conhece duas rotas para chegar até uma rede E,
uma através de B (com custo 2) e outra através de C (com custo 3). Ambas as rotas estão
armazenada em sua RIB, mas apenas a rota de custo 3 está armazenada em sua FIB.

O segundo aspecto que precisa ser analisado é como o roteador representa e descobre suas
rotas. Em redes IP, dois métodos são utilizados: os algoritmos de estado de enlace (link
state) e os algoritmos de vetor de distâncias (distance vector).
No método baseado em estado de enlace, cada roteador possui uma representação completa
da rede ao qual está conectado na forma de um grafo. Isto é, o roteador sabe como os
roteadores estão conectados e qual o custo associado ao enlace de cada roteador. Nesse
método, os roteadores não trocam rotas diretamente, mas sim trocam informações sobre
seus enlaces e a velocidade de seus enlaces. Uma vez criada a representação interna da
rede no roteador, as rotas são calculadas através de um algoritmo de varredura de grafos,
como o Dijkstra, para subsequente preenchimento das tabelas RIB e FIB.
Por outro lado, no método baseado em vetor de distâncias, nenhum roteador possui o
conhecimento completo da rede. Ao invés disso, o roteador possui apenas as rotas, isto é, a
informação do próximo salto e do custo associado para um conjunto de destinos conhecidos
na rede. Nesse método, os roteadores trocam rotas diretamente, não sendo necessário
nenhum tipo de cálculo para determinação das rotas. Apesar do método de vetor de
distâncias parecer mais simples, ele é muito limitado. Nessa abordagem, os roteadores
perdem muito tempo para reparar danos na rede (substituir rotas melhores defeituosas por
rotas alternativas).

Os protocolos de roteamento que seguem o método do vetor de distâncias são baseados na
propagação de rotas, com incremento de custos. Esse método pode ser resumido da
seguinte forma:
A) Os roteadores divulgam as redes a que estão diretamente conectados por seus enlaces
B) Apenas as melhores ofertas são aceitas para cada rede.
C) Quando um roteador recebe uma rota, ele a repassa adiante acrescentando a ela o seu
próprio custo
Na figura, observa-se que o roteador A faz o anúncio de que ele sabe acessar a rede A para
os roteadores B e C. O roteador B repassa o anúncio de acesso ao roteador C, adicionando o
custo do seu próprio enlace na rota. Dessa forma, o roteador C recebe duas ofertas: uma
vinda diretamente de A e outra vinda de B, com o custo acrescido. Nesse caso, a oferta vinda
de B é descartada, e apenas a oferta vinda de A é propagada para D.
Nesse método, as rotas tem um tempo de vida (TTL), e os roteadores re-anunciam
periodicamente suas rotas. As rotas cujo re-anuncio não é recebido dentro do prazo de vida
são desativadas. Nesse caso, as rotas de maior custo previamente ignoradas passam a ser
aceitas (por exemplo, o roteador C passaria a aceitar a oferta de B, caso parasse de receber
a oferta de A).
Conforme dito anteriormente, a desvantagem desse método é que o tempo para reparar rotas
defeituosas pode ser muito alto. O tempo de atualização das rotas é aproximadamente:
nsaltos * TTL. O protocolo RIP segue esse princípio.

Os protocolos de roteamento que seguem o método baseado em estado de enlace são muito
mais eficientes que os de vetor de distância, mas podem exigir roteadores um pouco mais
sofisticados para serem implementados. Nesse método, cada roteador mantém um banco de
dados completo com a descrição de toda topologia da rede (link state database).
Incialmente, nesse método, os roteadores descobrem se existem outros roteadores
(roteadores vizinhos) que suportam o mesmo protocolo através de mensagem Hello. A
mensagem de Hello também é utilizada para verificar se os vizinhos continuam ativos (isto é,
como mensagens de keep alive). Uma vez conhecido seus vizinhos, os roteadores trocam
informações sobre a topologia da rede (roteadores e seus enlaces). Os roteadores parceiros
sincronizam sua base de estado de enlace através de mensagens que transportam anúncios
de novos enlaces (Link State Advertisement - LSA).
Quanto o protocolo é ativado pela primeira vez nos roteadores da rede, existe uma grande
quantidade de informações trocadas. Todavia, após as informações das bases de estado de
enlace terem sido sincronizadas, as mensagens de atualização de estado (LSA) serão
enviadas somente se um novo enlace for adicionado ou removido. Isso faz com que esse tipo
de protocolo seja mais adequado para redes de grande porte. Igualmente, o roteador já
possui localmente todas as informações necessárias para calcular rotas alternativas no caso
de falha de seus vizinhos, fazendo com que a recuperação em caso de falhas seja muito
mais rápida.
Os protocolos OSPF e IS-IS são exemplos de protocolos de estado de enlace.

No método baseado em estado de enlace, cada roteador constrói uma representação completa da rede na forma de um grafo, conforme indicado na figura. A tabela de roteamento é preenchida através de um algoritmo que varre o grafo e determina as melhores rotas do roteador para cada um dos destinos possíveis (isto é, para cada uma das interfaces dos demais roteadores). O algoritmo mais utilizado para essa finalidade é o Dijikstra. Os principais conceitos desse algoritmo são mostrados na figura. Suponha que o algoritmo está sendo executado no roteador A. O roteador A determina que o melhor caminho para chegar ao roteador C é usar o enlace AC. Dessa forma, ele atribui o custo 1 (em vermelho) para a rota AC. Para chegar até o roteador B, existem duas alternativas: AB com custo 5 ou ACB com custo 4. O roteador decide então que o melhor caminho para chegar até B é ACB, e atribui o custo 4 para o caminho. A partir desse momento, qualquer rota que passe por B utilizará sempre o trajeto ACB, de forma que esse teste não precisa mais ser efetuado. Esse procedimento se repete até que uma rota cada um dos demais destinos da rede seja encontrada. Existem variações no algoritmo Dijikstra. O constrained shortest path first (CSPF) permite impor restrições adicionais ao invés de escolher simplesmente o caminho mais curto. As restrições podem ser de várias naturezas: restringir o uso de enlaces indisponíveis, pouco confiáveis ou muito lentos (menos banda). Duas técnicas são utilizadas: aparar enlaces indesejáveis (eliminá-los do grafo - prunning) e criar uma nova métrica que incorpora outras restrições em seu cálculo. O CSPF deve ser usado com cautela, pois todos os roteadores precisam usar a mesma métrica, ou poderão ser criadas rotas em loop. A versão sem restrições é ainda a mais usada atualmetne. Observe que pela estratégia do Dijikstra, apenas uma rota é escolhida para cada destino. Mesmo quando dois caminhos de custo idêntico são encontrados, o primeiro a ser descoberto é mantido. Em alguns roteadores com suporte ao ECMP (Equal Cost Mutipath), é possível utilizar mais de um caminho quando existem alternativas idênticas de menor custo. Nesse caso, os roteadores procurar efetuam balanceamento de carga entre caminhos de custo idêntico.

Em um protocolo de estado de enlace os roteadores necessitam de memória para armazenas
as informações da topologia da rede e capacidade de processamento para descobrir rotas a
partir do grafo de topologia.
Supondo que n é o número de enlaces total da rede (isto é, a soma de enlaces de todos os
roteadores da rede), então a quantidade de recursos gasta em cada roteador pode ser
estimada da seguinte forma: Memória para armazenar o grafo: cresce linearmente com n.
Capacidade de processamente necessária para varrer o grafo: cresce entre n* log(n) e n^2.
Por essa razão, para prover escalabilidade em redes de grade porte, os protocolos de estado
de enlace adotam o conceito de divisão em áreas, conforme ilustrado pela figura. O objetivo
da divisão em áreas é reduzir a quantidade de informação que cada roteador precisa
conhecer sobre a rede. Nessa abordagem, um roteador tem conhecimento completo apenas
dos roteadores que estão na mesma área que ele, e apenas um sumário das informações
das outras áreas. O sumário das outras áreas nada mais é do que um conjunto de rotas
agregadas (isto é, dependendo dos prefixos, todas as rotas de uma área estrangeira podem
ser representadas por uma única rota).
Nessa abordagem, os roteadores são classificados em dois tipos: os roteadores intra-área e
os roteadores de borda de área (ABR). Os roteadores intra-área trocam informações
completas de estado de enlace dentro de suas áreas. Já os roteadores ABR trocam apenas
rotas sumarizadas com outros ABR.

Conceitualmente, é possível definir um terceiro método de propagação de rotas denominado
vetor de caminho. O método de vetor de caminho é bastante similar ao método de vetor de
distância, contudo, nesse método, uma lista completa de saltos da origem até o destino é
incluída nas ofertas de rota trocadas entre os roteadores.
O objetivo principal dessa lista é evitar a criação de loops. O protocolo BGP, utilizado para
toca de rotas entre sistemas autônomos, segue o princípio do vetor de caminho. Para ilustrar
esse conceito, considere a figura que ilustra uma rede formada por três sistemas autônomos:
SA1, SA2 e SA3. Considere, no exemplo, que o roteador de borda do SA3 (Z) deseja
informar para os demais AS que é possível chegar a rede 200.17.1.0/24 através dele. A
oferta de rota é feita para o roteador E do SA2 e para o roteador F do SA1. A oferta inclui o
vetor de caminho, que é uma lista de sistemas autônomos e não de roteadores. Quando um
roteador de borda recebe uma oferta, ele passa a oferta para frente incluindo também o seu
número de AS no vetor de caminho. Dessa forma, a oferta de acesso a rede 200.17.1.0/24 é
repassada para o roteador F do SA1 pelo roteador E do SA2, incluindo também o código do
SA2.
Observe que no exemplo, o SA2 é um AS do tipo transit, pois ele repassou a oferta de rota do
SA3 para o SA1. Caso o SA2 fosse do tipo non-transit, o repasse da rota não seria feito.

Na seqüência desse módulo serão estudados três protocolos relacionados a configuração de
rotas em redes IP: RIP, OSPF e BGP.
Os protocolos RIP e OSPF são do tipo IGP, isto é, eles são utilizados para troca de
informações de roteamento no interior de um AS. Já o protocolo BGP é um protocolo EGP,
isto é, ele é utilizado para troca de informações entre sistemas autônomos distintos.
Como vimos, o protocolo RIP é do tipo "vetor de distâncias". Esse protocolo é considerado
bastante ineficiente para redes de grande porte, não sendo utilizado, na prática, em sistemas
autônomos de grande porte. Contudo, seu estudo é importante, principalmente para entender
a diferença com relação a outros protocolos.
O OSPF segue o método de "estado de enlace", e é um dos protocolos mais utilizados como
IGP. O outro protocolo bastante usado como IGP é o IS-IS (Intermediate System to
Intermediate System). Nesse módulo, apenas o OSPF será estudado, pois ambos os
protocolos trazem muitas similaridades.
O BGP é o único protocolo utilizado como EGP. Como veremos, esse protocolo é bastante
diferente dos anteriores, pois além de ser do tipo "vetor de caminho", ele é o único que
funciona sobre TCP.

O RIP é um protocolo de roteamento do tipo "vetor de distâncias", originário do conjunto XNS da
Xerox. Existem duas versões de RIP: Versão 1 (RFC 1058) e Versão 2 (RFC 1723). A versão 1 é
muito limitada, e não deve ser mais usada. Esta versão utiliza mensagens em broadcast, e foi
desenvolvida antes da introdução do CIDR (Classless InterDomain Routing). Isto é, nessa versão não
é possível criar rotas com máscaras de subrede. A versão 2 resolveu vários problemas da versão 1.
Ela utiliza mensagens em multicast, ao invés de broadcast. Ela também introduziu o suporte a CIDR.
Na prática, se o RIP for utilizado, ele deverá ser sempre na versão 2. Mesmo a versão 2 do RIP tem
suas limitações. O método de custo suportado pelo RIP é apenas o número de saltos (hop count). Isto
significa que o RIP não consegue levar em conta a capacidade dos enlaces quando está definindo o
custo de uma rota. Outra limitação é que o tamanho máximo de uma rota é de 15 saltos (acima deste
valor, a rede é considerada inalcançável).
Uma rede RIP define dois tipos de elementos: os ativos e os passivos. Os elementos ativos são
capazes de enviar e receber mensagens RIP. Os elementos passivos são capazes apenas de receber
rotas. De maneira geral, numa rede, apenas os roteadores são ativos. Os computadores são sempre
passivos ou não usam RIP.
O RIP é um protocolo encapsulado em mensagens UDP (utiliza a porta padrão 520). O RIP define
dois tipos de mensagem: Requisição - Request (tipo 1): solicita informações de roteamento e
Resposta - Response (tipo 2): envia informações de roteamento. Na prática, o RIP trabalha quase
sempre no modo não solicitado, onde apenas mensagens do tipo Response são enviadas
periodicamente pelos elementos ativos da rede. Cada mensagem response pode transportar no
máximo 25 rotas.

A figura mostra o formato de uma mensagem RIP versão 2. Conforme mencionado
anteriormente, as mensagens RIP são encapsuladas no protocolo UDP. A mensagem RIP
possui três seções principais:
Cabeçalho: inclui os campos Command e Version. O valor 1 no campo Command indica
request e o valor 2 indica response. O valor 2 no campo Version indica que é a versão 2 do
RIP.
Autenticação: O campo Família de Endereços possui o valor fixo 0xFFFF para identificar a
seção de autenticação. O campo tipo de Autenticação utiliza um byte para identificar um dos
três modos de autenticação suportados pelo RIP: Message Digest (16 bytes MD5 da
mensagem), Password Simples (senha de 6 bytes), Message Digest Key e Sequence
Number (HMAC com chave secreta). O código de autenticação de até 16 bytes é
transportado no final da seção.
Entrada de Rotas. Essa seção possui uma lista de até 15 entradas de rotas. Cada entrada de
rota é composto pelos campos Família de Endereços (indica se é IPv4, por exemplo), Tag de
Rota (número usado para diferenciar rotas internas de externas), Endereço de Base (e.g.
200.0.0.0), Máscara de Subrede (e.g. 255.255.255.0), Endereço do Gateway (e.g.,
200.0.0.1), e Métrica (e.g., 2). Um valor de métrica igual a 16 indica que a rota está inativa.
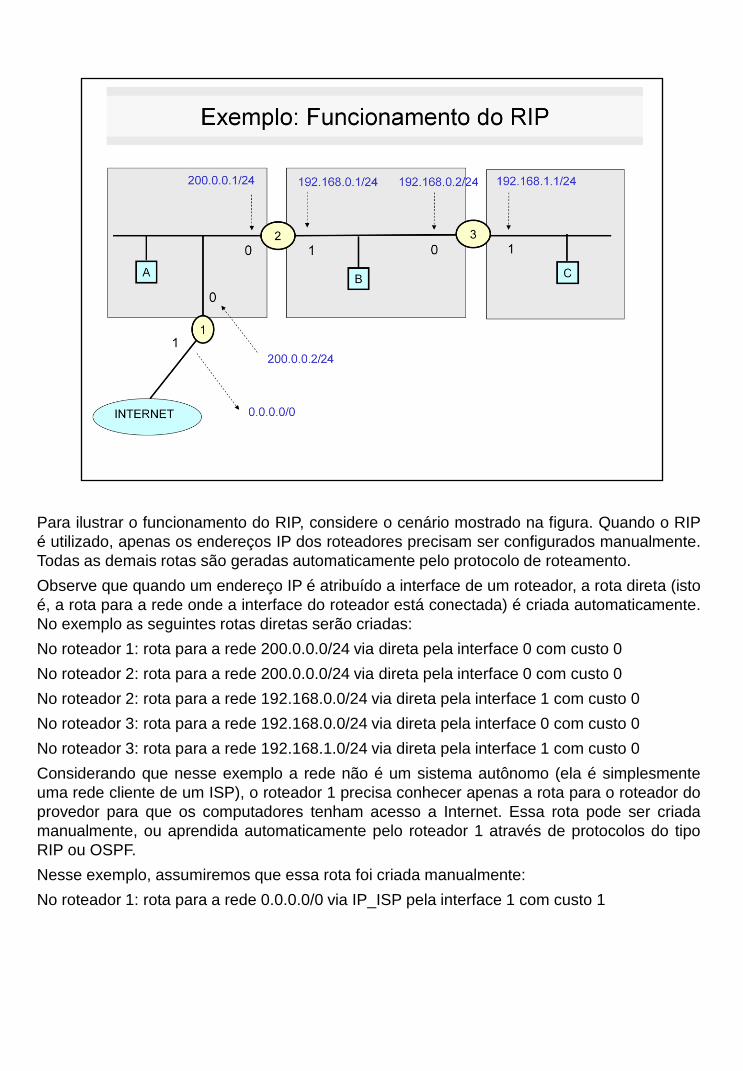
Para ilustrar o funcionamento do RIP, considere o cenário mostrado na figura. Quando o RIP
é utilizado, apenas os endereços IP dos roteadores precisam ser configurados manualmente.
Todas as demais rotas são geradas automaticamente pelo protocolo de roteamento.
Observe que quando um endereço IP é atribuído a interface de um roteador, a rota direta (isto
é, a rota para a rede onde a interface do roteador está conectada) é criada automaticamente.
No exemplo as seguintes rotas diretas serão criadas:
No roteador 1: rota para a rede 200.0.0.0/24 via direta pela interface 0 com custo 0
No roteador 2: rota para a rede 200.0.0.0/24 via direta pela interface 0 com custo 0
No roteador 2: rota para a rede 192.168.0.0/24 via direta pela interface 1 com custo 0
No roteador 3: rota para a rede 192.168.0.0/24 via direta pela interface 0 com custo 0
No roteador 3: rota para a rede 192.168.1.0/24 via direta pela interface 1 com custo 0
Considerando que nesse exemplo a rede não é um sistema autônomo (ela é simplesmente
uma rede cliente de um ISP), o roteador 1 precisa conhecer apenas a rota para o roteador do
provedor para que os computadores tenham acesso a Internet. Essa rota pode ser criada
manualmente, ou aprendida automaticamente pelo roteador 1 através de protocolos do tipo
RIP ou OSPF.
Nesse exemplo, assumiremos que essa rota foi criada manualmente:
No roteador 1: rota para a rede 0.0.0.0/0 via IP_ISP pela interface 1 com custo 1

Após a ativação do RIP em um roteador, todas as rotas conhecidas pelo roteador são
propagadas. É possível configurar o RIP para propagar rotas a partir de todas as suas
interfaces, ou apenas de interfaces específicas. Por exemplo, no roteador 1, pode-se desejar
propagar rotas pela interface interna do roteador, mas bloquear o envio de mensagens RIP
para interface conectada ao provedor.
A figura ilustra o funcionamento do RIP no processo de propagação da rota local
192.168.1.0/24. Uma mensagem de RIP response é enviada em broadcast (RIPv1) ou
multicast (RIPv3) pelo roteador 3 para toda a rede 192.168.0.0/0. Essa rota é recebida pelo
computador B e também pelo roteador 2. Caso o computador B tenha o serviço RIP ativado,
uma rota dinâmica será criada em sua tabela de roteamento.
O roteador 2, por sua vez, repassa a oferta de rota recebida de 3 adicionando o valor 1 ao
custo. A oferta feita pelo roteador 2 será recebida pelo computador A e também pelo roteador
1.
Caso o roteador 1 tenha o protocolo RIP ativado em sua interface externa, a oferta da rota
será repassada também para o provedor (no caso, como 192.168.1.0/24 corresponde a uma
subrede de endereços privados, o administrador não deve ativer o RIP na interface externa,
para evitar que essa rota seja propagada).
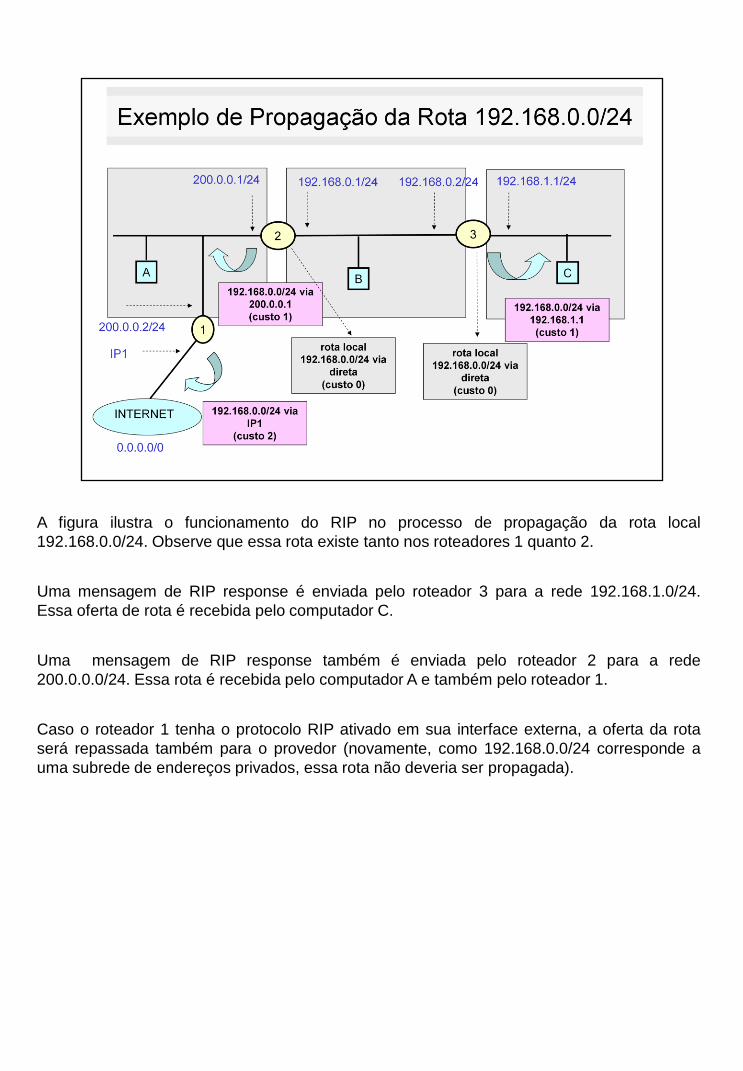
A figura ilustra o funcionamento do RIP no processo de propagação da rota local
192.168.0.0/24. Observe que essa rota existe tanto nos roteadores 1 quanto 2.
Uma mensagem de RIP response é enviada pelo roteador 3 para a rede 192.168.1.0/24.
Essa oferta de rota é recebida pelo computador C.
Uma mensagem de RIP response também é enviada pelo roteador 2 para a rede
200.0.0.0/24. Essa rota é recebida pelo computador A e também pelo roteador 1.
Caso o roteador 1 tenha o protocolo RIP ativado em sua interface externa, a oferta da rota
será repassada também para o provedor (novamente, como 192.168.0.0/24 corresponde a
uma subrede de endereços privados, essa rota não deveria ser propagada).
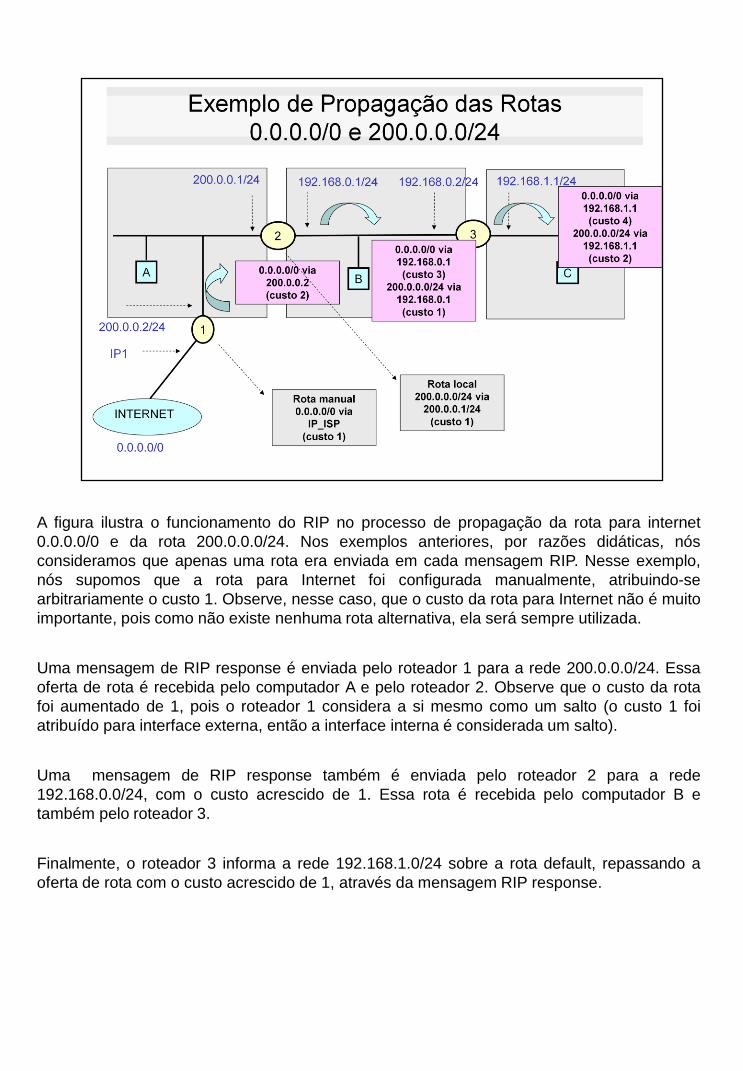
A figura ilustra o funcionamento do RIP no processo de propagação da rota para internet
0.0.0.0/0 e da rota 200.0.0.0/24. Nos exemplos anteriores, por razões didáticas, nós
consideramos que apenas uma rota era enviada em cada mensagem RIP. Nesse exemplo,
nós supomos que a rota para Internet foi configurada manualmente, atribuindo-se
arbitrariamente o custo 1. Observe, nesse caso, que o custo da rota para Internet não é muito
importante, pois como não existe nenhuma rota alternativa, ela será sempre utilizada.
Uma mensagem de RIP response é enviada pelo roteador 1 para a rede 200.0.0.0/24. Essa
oferta de rota é recebida pelo computador A e pelo roteador 2. Observe que o custo da rota
foi aumentado de 1, pois o roteador 1 considera a si mesmo como um salto (o custo 1 foi
atribuído para interface externa, então a interface interna é considerada um salto).
Uma mensagem de RIP response também é enviada pelo roteador 2 para a rede
192.168.0.0/24, com o custo acrescido de 1. Essa rota é recebida pelo computador B e
também pelo roteador 3.
Finalmente, o roteador 3 informa a rede 192.168.1.0/24 sobre a rota default, repassando a
oferta de rota com o custo acrescido de 1, através da mensagem RIP response.

A figura mostra como ficaria a tabela de roteamento dos roteadores 2 e 3, após a estabilização da criação das rotas pelo RIP. A última coluna da tabela indica se a rota foi criada localmente (isto é, de forma manual pela atribuição de um endereço IP para interface do roteador) ou através do RIP. Em todos os cenários de RIP ilustrados anteriormente, nós omitimos todas as mensagens de rota que seriam ignoradas pelo roteador. Observe que, se um roteador receber uma oferta de rota com um custo superior aquele que ele já possui em sua tabela, a mensagem será ignorada.
As rotas criadas pelo RIP não são permanentes. Elas precisam ser renovadas periodicamente, caso contrário, elas serão consideradas inativas (terão seu custo alterado para 16) e serão posteriormente removidas nas tabelas de roteamento.
Após a criação das rotas nos roteadores, as mensagens RIP response continuam a ser enviadas de forma periódica a cada 30 segundos. Esse procedimento é necessário, pois ele é utilizado para detectar de forma automática a ocorrência de falhas na rede. Se um roteador deixar de receber a oferta de uma rota por mais do que 180 segundos (isto é, se 6 mensagens RIP forem perdidas em seqüência) a rota será considerada obsoleta, e seu custo será elevado para 16. O temporizador que controla quando a rota se torna obsoleta denomina-se “time-out timer”.
Se após esse período, o roteador continuar sem receber a oferta da rota por mais 120 segundos, a rota será removida da tabela de roteamento. O temporizador que controla a remoção das rotas é denominado “garbage collection timer”.

O OSPF é um protocolo de estado de enlace, considerado mais eficiente e escalável que o RIP. Além de ser mais escalável, uma diferença importante do OSPF em relação ao RIP é que ele permite utilizar parâmetros mais genéricos para cálculo das métricas das rotas (como levar em conta a velocidade dos enlaces), ao invés de usar simplesmente o número de saltos. Diferente do RIP que é encapsulado em UDP, o OSPF é encapsulado diretamente no IP (protocolo tipo 89). O OSPF para redes IPv4 está na versão 2, e é definido pelas RFCs 2328 e 1246.
As mensagens OSPF são mostradas na figura. De acordo com seu tipo, elas podem ser transmitidas em unicast ou multicast. Os seguintes endereços de multicast são reservados para o uso do OSPF: 224.0.0.5 e 224.0.0.6. O multicast é utilizado sempre que a mesma mensagem puder interessar a mais do que um roteador simultaeamente. As mensagens OSPF são as seguintes (listadas na seqüência mais comum de uso): 1.Hello: usada para descobrir vizinhos e manter o relacionamento entre eles 2.Database Description (Descrição da Base de Dados): lista um diretório de entradas de estado de enlace 3.Link State Request (Solicitação do Estado de Enlace): requisita uma ou mais informações específicas de estado de enlace 4.Link State Update (Atualização do Estado de Enlace): envia a informação de uma ou mais entradas de estado de enlace (LSA - Link State Advertisement) 5.Link State Acknowledge (Reconhecimento do Estado de Enlace): confirma o recebimento seguro da informação de estado de enlace.
28

Conforme discutimos anteriormente, os protocolos de estado de enlace, como o OSPF, adotam o
conceito de divisão em áreas, a fim de diminuir os recursos de memória e processamento gastos no
roteador. As áreas são organizadas em uma hierarquia de dois níveis: área zero: backbone do AS e
demais áreas: conectadas ao backbone. Se uma única área for utilizada, a quantidade de roteadores
é limitada (menos que 200 para roteadores legados).
Quando a divisão em áreas é adotada, os roteadores recebem a seguinte denominação:
Roteadores Intra-Area: Conhecem apenas a topologia de rede do interior de sua própria área.
Roteadores de Fronteira de Área (ABR): Conhecem duas ou mais áreas aos quais estão diretamente
conectados. Esse roteadores efetuam agregação de rotas utilizando CIDR (a agregação pode ser
ativada ou não).
Roteadores de Fronteira de AS (ASBR): Trocam informações com outros AS e podem pertencer a
qualquer área.
As áreas do OSPF podem ainda, ser dos seguintes tipos:
Áreas Stub: Utilizadas para proteger roteadores com pouca capacidade de CPU ou memória. Esse
tipo de área é configurada no ABR, que propaga apenas uma rota padrão para os demais roteadores
da área.
Not So Stubby Area (NSSA): Uma LSA especial denominada LSA-NSSA é utilizada para propagar
rotas de uma área Stub para outras áreas que não suporte OSPF (por exemplo RIP). Essa
mensagem tem um campo adicional que permite apontar uma gateway diferente do roteador
anunciante.
Enlaces Virtuais: Permitem criar enlaces virtuais (não físicos) usados para aumentar a conectividade
da malha OSPF. Exemplo: interconectar duas áreas adjacentes utilizando um roteador que não tem
interface direta com a Área 0.
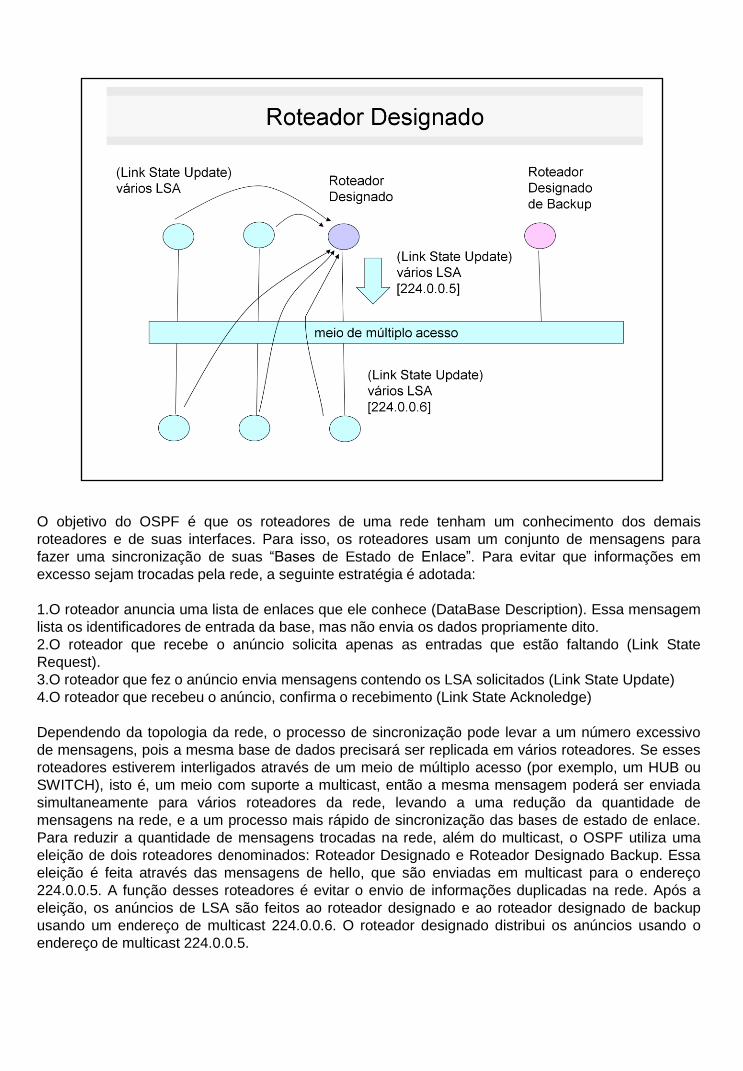
O objetivo do OSPF é que os roteadores de uma rede tenham um conhecimento dos demais
roteadores e de suas interfaces. Para isso, os roteadores usam um conjunto de mensagens para
fazer uma sincronização de suas “Bases de Estado de Enlace”. Para evitar que informações em
excesso sejam trocadas pela rede, a seguinte estratégia é adotada:
1.O roteador anuncia uma lista de enlaces que ele conhece (DataBase Description). Essa mensagem
lista os identificadores de entrada da base, mas não envia os dados propriamente dito.
2.O roteador que recebe o anúncio solicita apenas as entradas que estão faltando (Link State
Request).
3.O roteador que fez o anúncio envia mensagens contendo os LSA solicitados (Link State Update)
4.O roteador que recebeu o anúncio, confirma o recebimento (Link State Acknoledge)
Dependendo da topologia da rede, o processo de sincronização pode levar a um número excessivo
de mensagens, pois a mesma base de dados precisará ser replicada em vários roteadores. Se esses
roteadores estiverem interligados através de um meio de múltiplo acesso (por exemplo, um HUB ou
SWITCH), isto é, um meio com suporte a multicast, então a mesma mensagem poderá ser enviada
simultaneamente para vários roteadores da rede, levando a uma redução da quantidade de
mensagens na rede, e a um processo mais rápido de sincronização das bases de estado de enlace.
Para reduzir a quantidade de mensagens trocadas na rede, além do multicast, o OSPF utiliza uma
eleição de dois roteadores denominados: Roteador Designado e Roteador Designado Backup. Essa
eleição é feita através das mensagens de hello, que são enviadas em multicast para o endereço
224.0.0.5. A função desses roteadores é evitar o envio de informações duplicadas na rede. Após a
eleição, os anúncios de LSA são feitos ao roteador designado e ao roteador designado de backup
usando um endereço de multicast 224.0.0.6. O roteador designado distribui os anúncios usando o
endereço de multicast 224.0.0.5.

Todas as mensagens OSPF possuem um cabeçalho comum, conforme indicado na figura. A versão atual do OSPF é a 2. O tipo da mensagem identifica qual mensagem OSPF está sendo transportada após o cabeçalho.
Um roteador OSPF deve ter um identificador único em todo o sistema autônomo. Essa identificação é feita através de dois campos do cabeçalho: identificador de roteador e identificador de área. O identificador de roteador é, por recomendação, o menor endereço IP do roteador. O identificador de área identifica a área OSPF a qual a interface que enviou a mensagem pertence. Esse parâmetro é configurado pelo administrador do roteador.
Assim como o RIPv2, o OSPF permite incluir informações de autenticação nas mensagens OSPF, para evitar que roteadores “mal-intecionados” ou “mal-configurados” contaminem a base de estados de enlace da rede. Os campos Tipo de Autenticação, Dados de Autenticação, ID de Chave, Tamanho da Autenticação e Número de Seqüência, estão todos relacionados ao processo de autenticação. Os seguintes tipos de autenticação são suportados:
tipo 0: sem autenticação (os campos de autenticação são ignorados) tipo 1: senha simples (utiliza uma senha de 64 bits não criptografada) tipo 3: autenticação criptográfica MD5

A mensagem Hello permite detectar novos vizinhos (roteadores com suporte a OSPF) e
verificar se eles estão ativos. As mensagens Hello são enviadas em intervalos de 10
segundos. Caso um roteador deixe de enviar mensagens Hello por mais do que 40 segundos,
ele é considerado inativo.
As mensagens Hello também são usadas para eleger o roteador designado. Quando o
serviço OSPF é configurado em um roteador, o administrador de rede pode setar um valor de
“Prioridade do Roteador”, que é transportado na mensagem Hello. O roteador com maior
prioridade é eleito. Caso haja empate, o desempate entre prioridades é feito para o roteador
com ID mais alto (o ID é geralmente o menor endereço IP do roteador).
A mensagem Hello também carrega a lista de todos os vizinhos conhecidos pelo roteador. Os
vizinhos são identificados pelo seu ID (menor endereço IP).

A mensagem database description transporta um sumário da base de estados de enlace.
Cada entrada da base corresponde a informação sobre um enlace de um roteador da rede. O
anúncio completo de uma entrada da base é denominado LSA (Link State Advertisement).
A mensagem database description não transporta todos os dados da entrada, somente seu
cabeçalho. Por isso, a mensagem é composta por uma lista de “LSA Headers”. O objetivo
dessa mensagem é oferecer uma lista de tudo o que o roteador conhece sobre a rede. Se
algum roteador estiver interessado em obter mais informações sobre um dado enlace, então
ele precisará fazer uma solicitação explícita do LSA desejado, utilizando a mensagem “Link
State Request”.
O campo MTU indica o tamanho máximo do pacote que a interface que enviou a mensagem
é capaz de transportar sem fragmentação. O campo opções traz diversas informações sobre
a interface, como o suporte a multicast e a capacidade de criar circuitos.
O LSA Header possui vários campos, mas o mais importante é o identificador de estado de
enlace, que nada mais é do que o endereço IP da interface sobre a qual é possível solicitar
mais informações.
33

A mensagem de Link State Update pode transporte um ou mais anúncios de estado de
enlace (LSA). No OSPF são utilizados 4 tipos de LSA:
Tipo 1: Router-Link Entry. Correspondem a anúncios de enlaces de roteador. São produzidos
por todos os roteadores e são espalhados dentro de uma única área.
Tipo 2: Network-Link Entry. Correspondem a anúncios de enlaces de rede. São produzidos
pelo roteador designado e são espalhados em uma única área.
Tipo 3 e 4: Summary-Link Entry. Correspondem a anúncios resumidos de enlace. São
produzidos pelos roteadores de fronteira de área ABR. Descrevem rotas para destinos em
outras áreas e para os roteadores de fronteira de AS.
Tipo 5: Autonomous System External Link Entry. Correspondem a anúncios de enlace
oriundos de outros sistemas autônomos. São produzidos pelos roteadores de fronteira AS e
são espalhados por todos as áreas.

A mensagem de reconhecimento de estado de enlace (link state acknowledge), é enviada
pelos roteadores que receberam anúncios de estado de enlace (LSA), através de mensagens
de link update.
Essa mensagem é muito similar a mensagem de descrição de base dados (database
description), pois ela é formada por uma lista de LSA headers que estão sendo confirmados.
Uma vez que todo os processo de sincronização foi encerrado, todas as mensagens OSPF,
com exceção da mensagem Hello, param de ser enviadas. Novas mensagens de database
description, link state update e link state acknowledge só serão enviadas em duas situações:
quando um roteador apresentar falha na rede ou quando um novo enlace for descoberto por
algum roteador da rede.
O caso de falha é detectado através das mensagens Hello. Quando um roteador percebe que
algum de seus vizinhos parou de enviar mensagens Hello por mais do que 40 segundos, ele
considera que os enlaces do vizinho estão inativos, e envia mensagens para os demais
roteadores informado apenas essa alteração. O mesmo acontece quando um novo roteador é
introduzido na rede.

O BGP (Border Gateway Protocolol) é um protocolo de roteamento por vetor de caminho.
Seu uso é padronizado para sincronização de rotas entre sistemas autônomos (AS). A versão
atualmente utilizada do BGP é a 4, definida na RFC 1771. A motivação para criação do BGP
foi segmentar a Internet em domínios (ASs) administrados independentemente. Sem essa
divisão, a quantidade de rotas divulgadas na Internet seria incrivelmente alta, levando a um
colapso da rede. Graças ao BGP, é possível divulgar apenas rotas agregadas para fora de
um AS.
O BGP é um protocolo mais restritivo do que o OSPF, uma vez que nesse modelo, deseja-se
ter um controle mais apurado de quais rotas são divulgadas e para quem. Por essa razão, o
BGP foi desenvolvido sobre o TCP (porta padrão 179). De forma semelhante ao OSPF, o
BGP utiliza um cabeçalho padrão seguido de 5 tipos de mensagem distintos.
Open (Tipo 1): inicia uma sessão e negocia recursos opcionais entre um par de roteadores
BGP
Update (Tipo 2): anuncia informações de roteamento de um roteador BGP para outro
Notification (Tipo 3): usada para indicar problemas com as mensagens Open ou Update
KeepAlive (Tipo 4): utilizada para verificar se o parceiro está ativo
Route-Refresh (Tipo 5): requisita que um roteador BGP re-anuncie todas as suas rotas

O cabeçalho BGP contém apenas quatro campos: Marcador, Tamanho da Mensagem, Tipo de Mensagem e Versão.
O campo Marcador de 16 bytes existe por razões históricas, e sua principal função é marca o início de uma mensagem BGP. Todas as mensagens BGP trazem esse campo preenchido com 0xff....ff.
O campo tamanho tem 2 bytes, mas o tamanho máximo de uma mensagem BGP é 4096 bytes.
O campo Tipo de 1 byte define um dos cinco tipos possíveis de mensagem BGP.
Um segmento TCP pode transmitir várias mensagens BGP simultaneamente. Por exemplo, é possível ter em um único segmento uma mensagem Keep Alive e várias mensagens Update. Mesmo nesse caso, o cabeçalho BGP precisa ser repetido para cada mensagem.

A mensagem OPEN é utilizada para estabelecer um canal de comunicação BGP entre um roteador e seu parceiro. Os parceiros BGP não são descobertos como no caso do OSPF, mas indicados pelo administrador do roteador durante o processo de configuração do BGP. Isso acontece porque no BGP estamos falando de troca de rotas entre redes pertencentes a instituições diferentes. Então, somente aquelas instituições que possuem algum tipo de acordo, irão participar de uma negociação BGP. Os campos da mensagem Open são os seguintes:
Identificador de AS: número de 16 bits obtido junto a autoridade de registro (e.g. 61033) ou atribuído de forma privada (para comunicação entre AS de uma mesma instituição isolados da Internet). Os números de AS privado devem estar entre 64512 a 65535.
Tempo de Suspensão: determina o tempo que o roteador espera (em segundos) sem keep alive, antes de considerar a sessão (isto é, o roteador parceiro) como morta. Geralmente as mensagens de Keep Alive são enviadas a cada 30 segundos, e o tempo de suspensão é de 90 segundos (isto é, a perda de 3 mensagens consecutivas indica que o roteador deve estar inoperante).
Identificador de BGP: é o endereço IP da interface do roteador
Parâmetros Opcionais: seguem o formato TLV (Tipo – Tamanho – Valor). Existem inúmeras opções disponíveis, com por exemplo, opções de autenticação e capacidades adicionais - AS 4 bytes.

A mensagem de update permite adicionar ou remover novas rotas. Ela é composta de 3
seções: Rotas Retiradas (Withdraw Routes), Atributos de Caminho (Path Attributes) e
Informações de Acesso a Camada de Rede (NLRI - Network Layer Reachability Information).
A seção de rotas retiradas só será utilizada caso o roteador deseje remover a oferta de rotas
feitas anteriormente. Caso não haja rotas a serem retiradas, o valor do campo "Tamanho das
Rotas Retiradas" é zero. As rotas removidas são identificas pelo seu prefixo, utilizando dois
campos: Tamanho (Número de Bits do Prefixo, similar a máscara de subrede) e o Prefixo. Por
exemplo, para remover a rota 200.1.2.0/24 o BGP informaria: Tamanho igual a 24 e Prefixo
igual a 200.1.2. Bits iguais a zero são sempre adicionados para que o prefixo seja múltiplo de
8.
A seção de atributos de caminho e informações de acesso a camada de rede [NLRI] estão
diretamente relacionadas. A seção de atributos de caminho define um conjunto de atributos
que é comum a todas as rotas anunciadas pela mensagem UPDATE. As rotas anunciadas,
propriamente ditas, são listadas na seção NLRI na forma de uma lista de prefixos,
representados de forma idêntica ao da seção de rotas retiradas, isto é, com os campos
Tamanho e Prefixo.
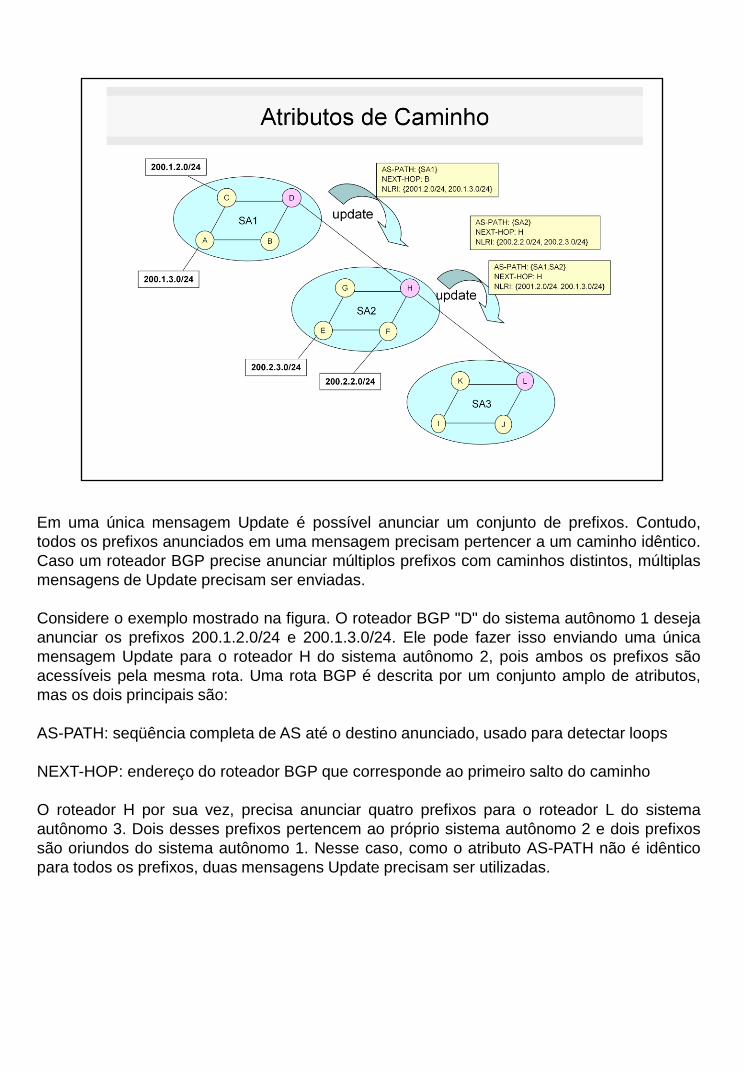
Em uma única mensagem Update é possível anunciar um conjunto de prefixos. Contudo,
todos os prefixos anunciados em uma mensagem precisam pertencer a um caminho idêntico.
Caso um roteador BGP precise anunciar múltiplos prefixos com caminhos distintos, múltiplas
mensagens de Update precisam ser enviadas.
Considere o exemplo mostrado na figura. O roteador BGP "D" do sistema autônomo 1 deseja
anunciar os prefixos 200.1.2.0/24 e 200.1.3.0/24. Ele pode fazer isso enviando uma única
mensagem Update para o roteador H do sistema autônomo 2, pois ambos os prefixos são
acessíveis pela mesma rota. Uma rota BGP é descrita por um conjunto amplo de atributos,
mas os dois principais são:
AS-PATH: seqüência completa de AS até o destino anunciado, usado para detectar loops
NEXT-HOP: endereço do roteador BGP que corresponde ao primeiro salto do caminho
O roteador H por sua vez, precisa anunciar quatro prefixos para o roteador L do sistema
autônomo 3. Dois desses prefixos pertencem ao próprio sistema autônomo 2 e dois prefixos
são oriundos do sistema autônomo 1. Nesse caso, como o atributo AS-PATH não é idêntico
para todos os prefixos, duas mensagens Update precisam ser utilizadas.

Nesse módulo, nós apresentamos o conceito de sistemas autônomos e protocolos de
roteamento. O uso de protocolos de roteamento é bastante comum em empresas de grande
porte e obrigatório em operadoras que prestam serviço de acesso a Internet.
Em redes de pequeno porte é ainda possível configurar roteadores manualmente, ou utilizar
um protocolo de roteamento simples, como o RIP.
Para redes de grande porte, contudo, os protocolos de roteamento trazem a vantagem de
serem capazes de corrigir rotas de forma dinâmica e automática. Isto é, se existir caminhos
alternativos, os protocolos de roteamento são capazes de ativar rotas de maior custo no caso
de falhas físicas ou mesmo de software das rotas de menor custo.
Para os alunos que desejarem procurar mais informações sobre a organização da Internet
em sistemas autônomos, recomenda-se a consulta dos seguintes endereços:
http://logbud.com/visual_trace (rastreamento de rotas entre AS)
http://www.asnumber.networx.ch/ (plugin de AS para o firefox)
http://www.bgp4.as/internet-exchanges (IXP no mundo)
http://bgplay.routeviews.org/bgplay/ (visualização de rotas entre AS)
41