€¦ · Índice....
TRANSCRIPT

Tivoli Application Dependency DiscoveryManagerVersão 7.3
Guia do Usuário
IBM

Nota
Antes de utilizar estas informações e o produto suportado por elas, leia as informações em “Avisos” napágina 263.
Aviso da Edição
Esta edição se aplica à versão 7, liberação 3 do IBM® Tivoli Application Dependency Discovery Manager (número doproduto 5724-N55) e a todas as liberações e modificações subsequentes, até que seja indicado de outra forma emnovas edições.© Copyright International Business Machines Corporation 2006, 2016.

Índice
Figuras.................................................................................................................. v
Tabelas............................................................................................................... vii
Sobre Estas Informações...................................................................................... ixConvenções usadas neste centro de informações..................................................................................... ixTermos e definições.................................................................................................................................... ix
Capítulo 1. Usando................................................................................................ 1Console de Gerenciamento de Descoberta.................................................................................................1
Iniciando o Console de Gerenciamento de Descoberta........................................................................1Escopos da Descoberta.......................................................................................................................... 2Listas de Acesso..................................................................................................................................... 6Executando Descobertas..................................................................................................................... 13Gerenciando Descobertas....................................................................................................................15Reconciliando Itens de Configuração..................................................................................................79
Portal de Gerenciamento de Dados.......................................................................................................... 84Tarefas de Descoberta......................................................................................................................... 84Tarefas de Topologia............................................................................................................................92Tarefas Analíticas................................................................................................................................. 96Tarefas de Administração.................................................................................................................. 105Tarefas de Gerenciamento de Domínio.............................................................................................109
Portal de Acesso a Dados........................................................................................................................ 116Efetuar Login...................................................................................................................................... 116Desconectando-se............................................................................................................................. 117Área de janela do painel.....................................................................................................................117Pesquisa............................................................................................................................................. 118Executando procura sugestiva...........................................................................................................118Executando procura normal.............................................................................................................. 118Executando procura avançada.......................................................................................................... 119Visualizando Detalhes do Componente.............................................................................................119Comparando componentes............................................................................................................... 120Visualizando Relacionamento............................................................................................................121Área de janela de detalhes................................................................................................................ 121Área de janela Visualizar comparação...............................................................................................121Comparação de Componentes: área de janela de resultados..........................................................122Área de janela Relacionamento.........................................................................................................122
Referência da Interface com o Usuário.................................................................................................. 123Janelas e Controles do Console de Gerenciamento de Descoberta................................................ 123Janelas e Controles do Portal de Gerenciamento de Dados............................................................ 143
Cenários de Tarefas.................................................................................................................................181Configurando uma Descoberta.......................................................................................................... 181Estendendo Servidores Customizados..............................................................................................187
Aplicativos de Negócios.......................................................................................................................... 189Introdução aos aplicativos de negócios............................................................................................ 191Estrutura do aplicativo de negócios.................................................................................................. 192Criando aplicativos de negócios com padrões de agrupamento......................................................194Criando aplicativos de negócios com descritores de aplicativos..................................................... 198Criando aplicativos de negócios com API Java.................................................................................203
iii

Exibindo aplicativos de negócios.......................................................................................................215Processamento de padrões de agrupamento................................................................................... 216Ferramenta bizappscli.................................................................................................................. 233Configurando as entradas do arquivo collation.properties...................................................248Criação de log.....................................................................................................................................250Migração da 7.2.2 e conversão automática de antigos aplicativos de negócios............................. 251Integrando aplicativos de negócios com outros produtos Tivoli......................................................255Cenários de exemplo..........................................................................................................................255
Avisos............................................................................................................... 263Marcas Registradas................................................................................................................................. 264
iv

Figuras
1. Janela Priorização do Atributo....................................................................................................................82
2. Topologia com a opção HigherUp selecionada........................................................................................ 230
3. Topologia com as opções HigherUp e HigherDown selecionadas.......................................................... 230
4. Topologia com a opção LowerDown selecionada.................................................................................... 231
5. Topologia com as opções LowerDown e LowerUp selecionadas............................................................ 231
6. Topologia somente com a opção HigherUp selecionada.........................................................................232
7. Topologia com as opções HigherUp e HigherDown selecionadas.......................................................... 232
8. Topologia somente com a opção LowerDown selecionada.....................................................................233
9. Topologia com as opções LowerDown e LowerUp selecionadas............................................................ 233
v

vi

Tabelas
1. Informações do Escopo da Descoberta........................................................................................................2
2. Tipos de Componentes, Campos e Listas Necessários para a Entrada da Lista de Acesso .......................7
3. Modelos de servidor customizado predefinidos........................................................................................ 23
4. Formato do Arquivo de Diretiva.................................................................................................................. 35
5. Variáveis de Ambiente do Arquivo de Diretiva........................................................................................... 36
6. Objetos de Mapa de Destino para o Servidor Customizado.......................................................................40
7. Objetos de Mapa de Destino para o Sistema de Computador .................................................................. 42
8. Informações do Histórico de Descoberta...................................................................................................53
9. Atributos BiDi.............................................................................................................................................. 67
10. Elementos e Atributos do Descritor de Aplicativo de Base..................................................................... 72
11. Elementos e Atributos do Descritor de Aplicativo do Componente........................................................ 73
12. Localizações do Descritor de Aplicativo Padrão...................................................................................... 75
13. Descrição do Aplicativo.............................................................................................................................76
14. Topologias Especializadas........................................................................................................................93
15. Topologias Especializadas......................................................................................................................116
16. .................................................................................................................................................................119
17. Itens da Guia Descoberta....................................................................................................................... 123
18. .................................................................................................................................................................127
19. Tipos de Componentes, Campos e Listas Necessários para a Entrada da Lista de Acesso ................ 127
20. Ícones da ferramenta da barra de ferramentas de topologia .............................................................. 154
21. Itens de Menu Pop-up dos Aplicativos de Negócios............................................................................. 155
22. Detalhes da guia Rotas........................................................................................................................... 156
23. Métodos de API de padrão de agrupamento......................................................................................... 205
vii

24. Gerenciamento de planejamento padrão.............................................................................................. 206
25. Métodos de gerenciamento de execução de padrão.............................................................................207
26. Elementos e atributos de configuração de camadas.............................................................................225
viii

Sobre Estas Informações
O propósito desta versão do documento em PDF é fornecer os tópicos relacionados do centro deinformações em um formato para impressão.
Convenções usadas neste centro de informaçõesNa documentação do IBM Tivoli Application Dependency Discovery Manager (TADDM) determinadasconvenções são usadas. Elas são usadas para se referir às variáveis e caminhos dependentes do sistemaoperacional, ao diretório COLLATION_HOME e ao local do arquivo collation.properties, que éreferenciado em toda a documentação do TADDM, incluindo as mensagens.
Variáveis e caminhos dependentes de sistemas operacionais
Neste centro de informações, as convenções UNIX são usadas para especificar as variáveis de ambiente epara notação de diretório.
Ao usar a linha de comandos Windows, substitua $variable por %variable% para variáveis de ambiente esubstitua todas as barras (/) por barras invertidas(\) nos caminhos de diretórios.
Se estiver usando shell bash em um sistema Windows, é possível usar as convenções UNIX.
Diretório COLLATION_HOME
O diretório-raiz do TADDM também é chamado de diretório COLLATION_HOME.
Em sistemas operacionais como AIX ou Linux, a localização padrão para a instalação do TADDM é odiretório /opt/IBM/taddm. Portanto, neste caso, o diretório$COLLATION_HOME é /opt/IBM/taddm/dist.
Nos sistemas operacionais Windows, a localização padrão para a instalação do TADDM é o diretórioc:\IBM\taddm. Portanto, neste caso, o diretório %COLLATION_HOME% é c:\IBM\taddm\dist.
Localização do arquivo collation.properties
O arquivo collation.properties contém as propriedades de servidor do TADDM e inclui comentáriossobre cada uma das propriedades. Está localizado no diretório $COLLATION_HOME/etc.
Termos e definiçõesConsulte a lista de termos e definições a seguir para aprender sobre os conceitos importantes no IBMTivoli Application Dependency Discovery Manager (TADDM).
coleção de acessosUma coleção que é usada para controlar o acesso a itens de configuração e permissões paramodificar itens de configuração. É possível criar coleções de acessos apenas quando a segurança denível de dados estiver ativada.
descoberta assíncronaNo TADDM, a execução de um script de descoberta em um sistema de destino para descobrirsistemas que não podem ser acessados diretamente pelo servidor do TADDM. Como essa descobertaé executada manual e separadamente de uma descoberta credenciada típica, ela é chamada de"assíncrona".
aplicativo de negóciosUma coleção de componentes que fornece uma funcionalidade de negócios que você pode utilizarinterna, externamente ou com outros aplicativos de negócios.
© Copyright IBM Corp. 2006, 2016 ix

CIConsulte o item de configuração.
coletaNo TADDM, um grupo de itens de configuração.
item de configuração (CI)Um componente da infraestrutura de TI que esteja sob controle do gerenciamento de configuração eesteja, portanto, sujeito a um controle formal de mudanças. Cada CI no banco de dados do TADDMtem um objeto persistente e um histórico de mudanças associado a ele. Sistemas operacionais,interfaces L2 e bancos de dados do tamanho do buffer pool são exemplos de CIs.
descoberta credenciadaVarredura de sensor do TADDM que descobre informações detalhadas a respeito dos seguintes itens:
• Cada sistema operacional no ambiente de tempo de execução. Essa varredura é também conhecidacomo descoberta de Nível 2 e requer credenciais do sistema operacional.
• A infraestrutura de aplicativos, componentes de software implementados, servidores físicos,dispositivos de rede, sistemas virtuais e dados de host utilizados no ambiente de tempo deexecução. Essa varredura é também conhecida como descoberta de Nível 3 e requer credenciais dosistema operacional e credenciais do aplicativo.
descoberta sem credencialVarredura de sensor do TADDM que descobre informações básicas a respeito dos sistemas ativos docomputador no ambiente de tempo de execução. Essa varredura é também conhecida comodescoberta de Nível 1 e não requer credenciais.
Portal de Gerenciamento de DadosA interface do usuário do TADDM baseada na Web para visualização e manipulação dos dados em umbanco de dados do TADDM. Essa interface com o usuário é aplicável a uma implementação doservidor de domínio, a uma implementação do servidor de sincronização e a cada servidor dearmazenamento em uma implementação do servidor de fluxo. A interface com o usuário é muitosemelhante em todas as implementações, embora em uma implementação do servidor desincronização, ela tenha algumas funções adicionais para incluir e sincronizar domínios.
descobrir encadeamento do trabalhadorNo TADDM, um encadeamento que executa sensores.
Console de Gerenciamento de DescobertaA interface com o usuário cliente do TADDM para gerenciar descobertas. Esse console é conhecidotambém como o Console do Produto. Ele é aplicável a uma implementação de servidor de domínio e aservidores de descoberta em uma implementação de servidor de fluxo. A função do console é amesma nessas duas implementações.
servidor de descobertasUm servidor do TADDM que executa sensores em uma implementação do servidor de fluxo, mas nãotem um banco de dados próprio.
domínioNo TADDM, um subconjunto lógico da infraestrutura de uma empresa ou outra organização. Osdomínios podem delinear limites organizacionais, funcionais ou geográficos.
servidor de domínioUm servidor do TADDM que executa sensores em uma implementação do servidor de domínio e quetem um banco de dados próprio.
implementação do servidor de domínioUma implementação do TADDM com um servidor de domínio. Uma implementação do servidor dedomínio pode ser parte de uma implementação do servidor de sincronização.
Na implementação do servidor de domínio, as seguintes propriedades de servidor do TADDM devemser configuradas para o seguinte valor:
com.collation.cmdbmode=domain
x Sobre Estas Informações

ativar o contextoO conceito de movimentação contínua de uma UI de produto Tivoli para outra UI de produto Tivoli(em um console diferente ou no mesmo console ou interface de portal) com conexão única e com a UIdestino posicionada no ponto adequado para os usuários continuarem a tarefa.
Descoberta de nível 1Varredura de sensor do TADDM que descobre informações básicas a respeito dos sistemas ativos docomputador no ambiente de tempo de execução. Essa varredura também é conhecida comodescoberta sem credencial porque ela não requer nenhuma credencial. Ela usa o sensor de Varredurade Pilhas e o sensor de Escopo do IBM® Tivoli® Monitoring. A descoberta de nível 1 é muito superficial.Ela coleta apenas o nome do host, o nome do sistema operacional, o endereço IP, o nome de domíniocompleto e o endereço do Controle de Acesso à Mídia (MAC) de cada interface descoberta. Alémdisso, a descoberta do endereço do MAC é limitada a sistemas Linux on System z® e Windows. Adescoberta de nível 1 não descobre sub-redes. Para qualquer interface de IP descoberta que nãopertença a uma sub-rede existente que for descoberta durante a descoberta do Nível 2 ou Nível 3,novas sub-redes são criadas com base no valor da propriedadecom.collation.IpNetworkAssignmentAgent.defaultNetmask no arquivocollation.properties.
Descoberta de nível 2A varredura do sensor do TADDM que descobre informações detalhadas sobre cada sistemaoperacional no ambiente de tempo de execução. Essa varredura também é conhecida comodescoberta com credenciais e ela requer credenciais do sistema operacional. A descoberta de Nível 2coleta nomes de aplicativos e os nomes do sistema operacional e números de porta que estãoassociados a cada aplicativo em execução. Se um aplicativo tiver estabelecido uma conexão deTCP/IP com um outro aplicativo, essas informações são coletadas como uma dependência.
Descoberta de nível 3A varredura do sensor do TADDM que descobre informações detalhadas sobre a infraestrutura doaplicativo, componentes de software implementados, servidores físicos, dispositivos de rede,sistemas virtuais e dados de host que são usados no ambiente de tempo de execução. Essa varreduratambém é conhecida como descoberta com credenciais e ela requer credenciais do sistemaoperacional e credenciais do aplicativo.
ocupação variadaNo TADDM, uma instalação do TADDM usada pelo provedor de serviços ou fornecedor de TI paradescobrir diversos ambientes de cliente. Além disso, o provedor de serviços ou o fornecedor de TIpode ver os dados de todos os ambientes de cliente, mas, dentro de cada um desses, apenas osdados específicos do respectivo cliente podem ser exibidos na interface com o usuário ouvisualizados nos relatórios desse ambiente.
Console do ProdutoConsulte Console de Gerenciamento de Descoberta.
descoberta baseada em scriptNo TADDM, o uso, em uma descoberta credenciada, dos mesmos scripts de sensor fornecidos pelossensores em suporte para descoberta assíncrona.
SEConsulte equivalente do servidor.
equivalente do servidor (SE)Uma unidade representativa da infraestrutura de TI, definida como um sistema de computador (comconfigurações padrão, sistemas operacionais, interfaces de rede e interfaces de armazenamento)com software de servidor instalado (como um banco de dados, servidor da Web ou servidor deaplicativos). O conceito de equivalente de servidor também inclui rede, armazenamento e outrossubsistemas que fornecem serviços para o funcionamento ideal do servidor. Um equivalente doservidor depende do sistema operacional:
Sistema operacional Número aproximado de CIs
Windows 500
AIX 1000
Sobre Estas Informações xi

Sistema operacional Número aproximado de CIs
Linux 1000
HP-UX 500
Dispositivos de rede 1000
servidor de armazenamentoUm servidor do TADDM que processa dados de descoberta recebidos dos servidores de descoberta eos armazena no banco de dados do TADDM. O servidor de armazenamento primário coordena osservidores de descoberta e todos os outros servidores de armazenamento e funciona como umservidor de armazenamento. Todos os servidores de armazenamento que não são primários sãochamados de servidores de armazenamento secundário.
implementação do servidor e fluxoUma implementação do TADDM com um servidor de armazenamento primário e ao menos umservidor de descoberta. Este tipo de implementação pode também incluir um ou mais servidores dearmazenamento secundário opcionais. O servidor de armazenamento primário e os servidores dearmazenamento secundário compartilham um banco de dados. Os servidores de descobertas nãotêm banco de dados.
Neste tipo de implementação, os dados de descoberta fluem em paralelo a partir de diversosservidores de descoberta para o banco de dados do TADDM.
Em uma implementação de servidor de fluxo, a seguinte propriedade de servidor do TADDM deve serconfigurada para um dos seguintes valores:
• com.collation.taddm.mode=DiscoveryServer• com.collation.taddm.mode=StorageServer
Para todos os servidores, exceto o servidor de armazenamento primário, as seguintes propriedades(para o nome do host e número de porta do servidor de armazenamento primário) devem também serconfiguradas:
• com.collation.PrimaryStorageServer.host• com.collation.PrimaryStorageServer.port
Caso a propriedade com.collation.taddm.mode esteja configurada, a propriedadecom.collation.cmdbmode não deve ser configurada ou sua linha deve ser comentada.
servidor de sincronizaçãoUm servidor do TADDM que sincroniza dados de descoberta de todos os servidores de domínio naempresa e tem seu próprio banco de dados. Este servidor não descobre dados diretamente.
implementação do servidor de sincronizaçãoUma implementação do TADDM com um servidor de sincronização e duas ou mais implementaçõesdo servidor de domínio, cada um dos quais possui seu próprio banco de dados local.
Nesse tipo de implementação, o servidor de sincronização copia os dados de descoberta de diversosservidores de domínio, um domínio por vez, em um processo de sincronização em lote.
Em uma implementação do servidor de sincronização, as seguintes propriedades do servidor doTADDM devem ser configuradas para o seguinte valor:
com.collation.cmdbmode=enterprise
Este tipo de implementação está obsoleto. Portanto, em uma nova implementação do TADDM em quemais de um servidor é necessário, use a implementação do servidor de fluxo. Um servidor desincronização pode ser convertido para se tornar um servidor de armazenamento primário para umaimplementação do servidor de fluxo.
xii Sobre Estas Informações

Banco de dados do TADDMNo TADDM, o banco de dados em que os dados de configurações, dependências e histórico demudanças estão armazenados.
Cada servidor do TADDM, exceto os servidores de descoberta e servidores de armazenamentosecundário, tem seu próprio banco de dados. Os servidores de descobertas não têm banco de dados.Servidores de armazenamento compartilham o banco de dados do servidor de armazenamentoprimário.
servidor TADDMUm termo genérico que pode representar qualquer um dos seguintes termos:
• servidor de domínio em uma implementação do servidor de domínio• servidor de sincronização em uma implementação do servidor de sincronização• servidor de descoberta em uma implementação do servidor de fluxo• servidor de armazenamento (incluindo o servidor de armazenamento primário) em uma
implementação do servidor de fluxo
sistema de destinoNo processo de descoberta do TADDM, o sistema a ser descoberto.
descoberta de utilizaçãoVarredura do sensor do TADDM que descobre informações de utilização para o sistema host. Umadescoberta de utilização requer credenciais do sistema operacional.
Sobre Estas Informações xiii

xiv Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Capítulo 1. Usando
Console de Gerenciamento de DescobertaO Console de Gerenciamento da Descoberta é a interface com o usuário do cliente IBM Tivoli ApplicationDependency Discovery Manager (TADDM) para gerenciar descobertas. Esse console é conhecido tambémcomo o Console do Produto. Ele é aplicável a uma implementação de servidor de domínio e a servidoresde descoberta em uma implementação de servidor de fluxo. A função do console é a mesma nessas duasimplementações.
Iniciando o Console de Gerenciamento de DescobertaO Console de Gerenciamento de Descoberta é uma interface com o usuário baseada em Java que vocêinicia a partir de um navegador da web.
Antes de IniciarCertifique-se de que seu navegador esteja configurado para usar um Java™ Runtime Environmentsuportado, e que seu computador atenda a todos os requisitos de hardware e software do cliente TADDM.Para obter mais informações, consulte o Guia de instalação do TADDM.
Procedimento
Para iniciar o Console de Gerenciamento de Descoberta, conclua as seguintes etapas:1. Abra um navegador da Web e digite a URL e o número da porta do sistema em que instalou o servidor
TADDM. O número de porta padrão é 9430.Por exemplo:
http://system.company.com:9430
A Página de Ativação do TADDM é exibida. Certifique-se de que todos os serviços no Console doAdministrador foram iniciados.
2. Opcional: Para usar uma conexão SSL, conclua as seguintes etapas:
a. No título do Console de Gerenciamento de Descoberta, selecione Mostrar Opções do SSL.b. Clique em Fazer Download de Truststore para fazer download de truststore e selecionar um
diretório no qual salvar o arquivo de truststore.c. Na caixa de entrada à direita do link Fazer Download do Truststore , insira o nome do diretório
que contém o arquivo de truststore.3. Clique em Iniciar Console de Gerenciamento de Descoberta. A janela Download de Arquivo é
exibida.4. Na janela Download de Arquivo, clique em Abrir. A janela Login é exibida.5. No campo Nome do Usuário, digite o nome do usuário para conectar ao servidor TADDM. Utilize uma
conta de usuário que foi criada durante a instalação ou a conta do administrador padrão. O nome deusuário do administrador padrão é administrador.
6. No campo Senha, digite a senha para o nome de usuário digitado. A senha para o nome de usuário doadministrador padrão é collation.
7. No campo Servidor, digite o nome completo do servidor a acessar. O campo Servidor é pré-preenchido com o nome do servidor padrão.
8. No campo Porta, digite o número de porta para o servidor. O campo Porta é pré-preenchido com onúmero de porta padrão.
© Copyright IBM Corp. 2006, 2016 1

9. Opcional: Selecione Estabelecer uma Sessão Segura (SSL) para criptografar todos os dados,incluindo o nome de usuário e a senha, antes de transmitir pela rede. Para usar o SSL, você deve tersalvo o truststore do servidor quando instalou o cliente do Console de Gerenciamento de Descoberta.
10. Clique em Login. A janela do cliente do Console de Gerenciamento de Descoberta é exibida.
O que Fazer Depois
Importante: Para obter informações adicionais sobre como efetuar login no Console de Gerenciamentode Descoberta com uma conexão SSL, consulte o Guia de Resolução de Problemas do TADDM.
Escopos da DescobertaÉ possível usar um escopo de descoberta para identificar os dispositivos, sistemas do computador eoutros componentes em sua infraestrutura que você deseja que o servidor acesse. É necessárioconfigurar pelo menos um escopo antes de executar uma descoberta.
É possível especificar os conjuntos de escopos da descoberta usando endereços IP, intervalos deendereços IP ou sub-redes para definir o limite das redes que podem ser acessadas durante adescoberta. Um escopo pode ser tão pequeno quanto um único endereço IP, ou tão grande quanto umintervalo de endereços IP ou uma rede Classe C. Para varrer intervalos de sub-redes maiores que umarede Classe C, consulte Carregando um Escopo de Descoberta a Partir de um Arquivo para obter maisinformações. É possível também excluir dispositivos específicos do escopo.
Quando houver um firewall entre o servidor e os sistemas que você deseja que sejam descobertos emoutra área de sua rede, configure o firewall para permitir o acesso na porta SSH (porta 22) e configureuma âncora. Consulte “Âncoras e Gateways” na página 43, para obter informações adicionais. A tabela aseguir lista e descreve as informações que são exibidas para um conjunto de escopos de descoberta naárea de janela Escopo, na guia Conjuntos de Escopos:
Tabela 1. Informações do Escopo da Descoberta
Informaçõesdo Escopo daDescoberta
Descrição
Método Especifica se inclui ou exclui o endereço IP, o intervalo de endereços IP ou a sub-rede.
Tipo O tipo de endereço especificado, entre as seguintes opções:Sub-rede
Uma sub-rede IP, por exemplo, 255.255.255.0.Intervalo
Intervalo do endereço IP, por exemplo, 1.2.3.4 - 1.2.3.10Host
Endereço IP, por exemplo, 1.2.3.4.
Valor O endereço IP, o intervalo de endereços IP ou a sub-rede reais.
Descrição Uma descrição ou nome do host fornecidos pelo usuário do escopo da descoberta.
Nota: Um escopo ou um grupo de escopos não é um identificador, mas uma coleção de endereços IPindividuais. Portanto, se você restringir a configuração, por exemplo, Entrada de Acesso ou Perfil deDescoberta para um escopo ou um grupo de escopos, ela se aplica a todos os endereços IP incluídosnaquele escopo ou grupo de escopos. Isso também significa que quando um determinado endereço IPfor incluído em muitos escopos ou grupos de escopos e você restringir a configuração para apenas umdeles, a restrição para o IP específico sempre se aplica, independentemente do escopo, ou grupo deescopos, que é usado para descoberta.
Configurando um EscopoÉ possível usar o Console de Gerenciamento de Descoberta para configurar um conjunto de escopos.
2 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Procedimento
Importante: A criação de escopos muito grandes pode levar a problemas de desempenho, incluindotravamento do servidor.
Para configurar um conjunto de escopos e um escopo, conclua as seguintes etapas a partir do Console deGerenciamento de Descoberta:1. Na barra de menus, clique em Descoberta > Escopo.
A área de janela Escopo é exibida.2. Para definir um novo conjunto de escopos de descoberta, clique em Incluir Conjunto.
A janela Nome do Conjunto de Escopos é exibida.3. No campo Nome, digite o nome para o novo conjunto de escopos.
Importante: Os nomes de conjunto de escopos não podem conter os caracteres a seguir:
• '• .• /
Nota: Se você estiver gerenciando diversos domínios com um servidor de sincronização, assegure-sede que cada nome de conjunto de escopos seja exclusivo em todos os domínios gerenciados pelomesmo servidor. Usar o mesmo nome de conjunto de escopos em mais de um domínio pode causarproblemas ao gerar relatórios.
4. Clique em OK. O novo conjunto de escopos é exibido na lista Conjuntos de Escopos.5. Para incluir o escopo e o conteúdo no conjunto de escopos, selecione o conjunto de escopos que você
acabou de criar e clique em Incluir.A janela Incluir Escopo é exibida.
6. Para incluir as configurações para o escopo, conclua uma das etapas a seguir:
• Selecione Sub-rede na lista Tipo de IP e digite o endereço IP da máscara de sub-rede no campoEndereço IP. Este deve ser um valor exclusivo dentro do conjunto de escopos.
• Selecione Intervalo na lista Tipo de IP e digite os endereços IP inicial e final no campo EndereçosIP. Este deve ser um valor exclusivo dentro do conjunto de escopos.
• Selecione Host na lista Tipo de IP e digite o endereço IP do host no campo Endereço IP ou digite onome do host no campo Nome do Host. Este deve ser um valor exclusivo que existe dentro doconjunto de escopos.
Importante: Se o IP e o nome do host estiverem definidos e não corresponderem entre si, o IP temprecedência. O nome do host é tratado apenas como uma "descrição".
7. Para excluir dispositivos e hosts de seu escopo, clique em Incluir Exclusão e conclua uma dasseguintes etapas:
• Na lista Tipo de IP, selecione Sub-rede e digite o endereço IP da sub-rede no campo Endereço IP.• Na lista Tipo de IP, selecione Intervalo e digite os endereços IP inicial e final no campo Endereço
IP.• Na lista Tipo de IP, selecione Host e digite os endereços IP inicial e final no campo Endereço IP.
8. Para salvar o escopo, clique em OK. O novo escopo é exibido na lista.
Configurando um grupo de escoposÉ possível usar o Console de Gerenciamento da Descoberta para configurar um grupo de escopos.
Procedimento
1. Para incluir o grupo de conjuntos de escopos, conclua as etapas a seguir:a) Na área de janela Funções, clique em Descoberta > Escopo e selecione a guia Grupos de Escopos.b) Para criar um novo grupo de escopos vazio, clique em Incluir Conjunto. A janela Nome do Grupo
de Escopos é exibida.
Capítulo 1. Usando 3

c) No campo Nome, digite MyGroup como o nome para o novo grupo de escopos.d) Clique em OK. O nome MyGroup é exibido na lista Grupos de Escopos.
2. Para incluir conjuntos de escopos existentes no grupo de escopos, conclua as etapas a seguir:a) Na lista de Grupos de Escopos na guia Grupos de Escopos, selecione MyGroup e clique em Incluir.
A janela Incluir conjuntos de escopos no Grupo é exibida.b) Selecione os conjuntos de escopo que deseja incluir no grupo.c) Clique em Incluir.
Os novos conjuntos de escopos são exibidos na lista.
Alterando um EscopoÉ possível usar o Console de Gerenciamento de Descoberta para alterar um escopo de descobertaexistente.
Procedimento
Importante: A criação de escopos muito grandes pode levar a problemas de desempenho, incluindotravamento do servidor.
Para alterar um escopo de descoberta existente, conclua as seguintes etapas a partir do Console deGerenciamento de Descoberta:1. Na barra de menus, clique em Descoberta > Escopo.
A área de janela Escopo é exibida.2. Na lista Conjuntos de Escopos, selecione um conjunto de escopos.
A lista de escopos para esse conjunto de escopos está listada à direita.3. Na lista de escopos, selecione um escopo e clique em Editar.
A janela Editar Escopo é exibida.4. Para alterar as configurações para o escopo, conclua uma das etapas a seguir:
• Para alterar uma sub-rede, digite o endereço IP da sub-rede no campo Endereço IP. Este deve serum valor exclusivo dentro do conjunto de escopos. Continue com a Etapa 5.
• Para alterar um intervalo de dispositivos, digite os endereços IP inicial e final no campo EndereçoIP. Este deve ser um valor exclusivo dentro do conjunto de escopos. Continue com a Etapa 5.
• Para alterar um dispositivo específico, digite o endereço IP ou o nome completo do host no campoNome do Host. Este deve ser um valor exclusivo dentro do conjunto de escopos. Continue com aEtapa 6.
5. Para excluir dispositivos e hosts do escopo de descoberta, clique em Incluir Exclusão e conclua umadas seguintes etapas:
• Na lista Tipo de IP, selecione Sub-rede e digite o endereço IP da sub-rede no campo Endereço IP.• Na lista Tipo de IP, selecione Intervalo e digite os endereços IP inicial e final no campo Endereço
IP.6. Para salvar o escopo, clique em OK. As novas alterações são aplicadas ao escopo.
Alterando um grupo de escoposÉ possível usar o Console de Gerenciamento da Descoberta para mudar um grupo de escopos dedescoberta existente.
Procedimento
Para mudar um grupo de escopos de descoberta existente, conclua as etapas a seguir no Console deGerenciamento da Descoberta:1. Na barra de menus, clique em Descoberta > Escopo e selecione a guia Grupos de Escopo.2. Na lista de grupos de escopo, selecione o grupo que você deseja editar.
4 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

• Para excluir um conjunto de escopos do grupo de escopos, selecione os conjuntos de escopos quedeseja excluir e clique em Excluir a partir de um grupo.
• Para incluir um conjunto de escopos para um grupo de escopos, clique em Incluir no grupo. Ajanela Incluir Escopo é aberta. Selecione conjuntos de escopos que deseja incluir no grupo deescopos e clique em Incluir.
Excluindo um EscopoÉ possível usar o Console de Gerenciamento de Descoberta para excluir um escopo.
Procedimento
Para excluir um escopo, conclua as seguintes etapas a partir do Console de Gerenciamento deDescoberta:1. Na barra de menus, clique em Descoberta > Escopo
A área de janela Escopo é exibida.2. Na lista Conjuntos de Escopos, selecione o conjunto de escopo que contém o escopo que você deseja
excluir.Os escopos para tal conjunto de escopos são listados à direita.
3. Na lista de escopos, selecione um escopo e clique em Excluir Conjunto.Uma janela de mensagem é exibida.
4. Para excluir o escopo, clique em Sim.O escopo é excluído do conjunto de escopos.
Excluindo um Conjunto de EscoposÉ possível usar o Console de Gerenciamento de Descoberta para excluir um conjunto de escopos.
Procedimento
Para excluir um conjunto de escopos, conclua as seguintes etapas a partir do Console de Gerenciamentode Descoberta:1. Na barra de menus, clique em Descoberta > Escopo
A área de janela Escopo é exibida.2. Na lista Conjuntos de Escopos, selecione o conjunto de escopos que deseja excluir e clique em
Excluir Conjunto.Uma janela de mensagem é exibida.
3. Para excluir o conjunto de escopos, clique em Sim.O conjunto de escopos é excluído.
Excluindo um grupo de escoposÉ possível usar o Console de Gerenciamento da Descoberta para excluir um grupo de escopos.
Procedimento
Para excluir um grupo de escopos, conclua as etapas a seguir no Console de Gerenciamento daDescoberta:1. Na barra de menus, clique em Descoberta > Escopo. A área de janela Escopo é exibida.2. Selecione a guia Grupo de Escopos.3. Na lista Grupos de Escopos, selecione o grupo de escopos que contém o escopo que você deseja
excluir. Os conjuntos de escopos para tal grupo de escopos são listados à direita.4. Na lista de escopos, selecione um escopo e clique em Excluir Grupo. Uma janela de mensagem é
exibida.5. Para excluir o grupo de escopos, clique em Sim. O grupo de escopos é excluído.
Capítulo 1. Usando 5

Listas de AcessoA lista de acesso é uma coleta de todos os nomes de usuário, senhas e cadeias de comunidades SNMP(Protocolo Simples de Gerenciamento de Rede) que o servidor utiliza ao acessar os itens de configuraçãoem sua infra-estrutura. É necessário configurar esta lista para os Itens de Configuração que você desejadescobrir. Ao usar o sensor de Varredura de Pilhas para descoberta de menos credencial, uma lista deacesso não é necessária.
Sobre Esta Tarefa
Os nomes de usuário, senhas e cadeias de comunidades, se necessário, são categorizados por cada tipode dispositivo ou aplicativo de software e, opcionalmente, restritos pelo escopo. Por exemplo, todos osnomes de usuário e senhas para todos os sistemas do computador são armazenados como um grupo etodos os nomes de usuário e senhas para todos os bancos de dados são armazenados como outro grupo.
Ao acessar um dispositivo, o servidor seqüencialmente utiliza cada nome de usuário e senha (ou cadeiade comunidade) no grupo através de um escopo particular (endereço IP por sub-rede) até o dispositivoconceder a permissão de servidor para acessá-lo. Por exemplo, ao acessar um sistema do computador, oservidor utiliza o primeiro nome de usuário e senha especificados na lista de acesso para sistemas docomputador. Se o nome de usuário e senha estiverem incorretos para um sistema do computadorparticular, o servidor automaticamente utilizará o próximo nome de usuário e senha especificados na listade acesso para um sistema do computador.
Como você digita uma lista de nomes de usuários e senhas (ou cadeias de comunidades) para cada tipode item de configuração, não é necessário especificar um nome de usuário e senha para um item deconfiguração particular. Quando especificar todos os nomes de usuários e senhas para cada tipo dedispositivo, defina o escopo para cada par de nome de usuário e senha. O servidor automaticamentetenta cada nome de usuário e senha até que a combinação correta seja localizada. A lista de acessocriada é usada pelo Console de Gerenciamento de Descoberta e é criptografada e armazenada no bancode dados.
Se o dispositivo que você está descobrindo for um dispositivo de rede capaz de ser gerenciado através doprotocolo SNMP, digite uma cadeia da comunidade SNMP no campo de Comunidade. Se estiver utilizandoo SNMP para um dispositivo Cisco, será necessário selecionar o elemento de rede SNMP e digitar umacadeia de comunidade SNMP no campo Comunidade para o dispositivo Cisco.
Para cada entrada do Sistema do Computador na lista de acesso, existe a opção de especificar um dostipos de autenticação a seguir:
• padrão• senha• PKI (Infraestrutura da Chave Pública)
Se você selecionar a autenticação padrão, a autenticação baseada em chave SSH será tentada primeiro,usando a senha para o passphrase chave, se necessário. Se a autenticação baseada em chave não forbem-sucedida, a autenticação do nome de login e da senha será tentada. Se o tipo de autenticação desenha for selecionado, apenas a autenticação de senha será tentada. De forma semelhante, se PKI forselecionado, apenas a autenticação baseada em chave será tentada. Recomenda-se configurar o tipo deautenticação para a nova entrada da lista de acesso que está sendo incluída se você conhecer o tipo. Sevocê não conhecer o tipo de autenticação, o comportamento padrão poderá levar a várias tentativas delogin inválidas que poderão, às vezes, resultar no bloqueio da conta.
Nos casos em que seu administrador do sistema configurou o SSH com o método de autenticação delogin e senha, inicie o Console de Gerenciamento de Descoberta com a opção Estabelecer uma SessãoSegura (SSL) ativada antes de configurar a lista de acesso. Essa opção criptografa todos os dados,incluindo nomes de usuários e senhas da lista de acesso antes de os dados serem transmitidos entre oConsole de Gerenciamento de Descoberta e o servidor.
Incluindo uma Nova Entrada da Lista de AcessoÉ possível incluir uma nova entrada da lista de acesso usando o Console de Gerenciamento deDescoberta. As etapas para incluir uma nova entrada da lista de acessos variam, com base no tipo de
6 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

componente que você deseja incluir. Use a Descoberta > Lista de Acesso para incluir uma nova entradada lista de acesso. Também é possível incluir programaticamente novas entradas da lista de acesso,utilizando a API Java.
Sobre Esta Tarefa
Se você desejar incluir programaticamente novas entradas da lista de acesso ou se tiver um aplicativo deterceiros e desejar gerenciar identidades ou alterar a senha, use a API Java para executar essa tarefa.Para ver os métodos de API Java, consulte o tópico Gerenciando listas de acesso no Developer Guide doSDK do TADDM.
Procedimento
Para incluir uma nova entrada da lista de acesso usando o Console de Gerenciamento de Descoberta,conclua as seguintes etapas:1. Na barra de menus, clique em Descoberta > Lista de Acesso.
A área de janela Lista de Acesso é exibida.2. Para incluir uma nova entrada na lista de acesso, clique em Incluir.
O bloco de notas Detalhes de Acesso é exibido.3. Na lista Tipo de Componente, selecione o tipo de componente que deseja descobrir.4. Para todos os tipos de componentes diferentes de Elemento de Rede (SNMP), conclua as seguintes
etapas:a) No campo Nome, digite o nome da entrada da lista de acesso.b) No campo Nome do Usuário, digite o nome do usuário para efetuar login no componente que
deseja descobrir.
Ao especificar uma conta de usuário de domínio do Windows, o nome do domínio e o nome dousuário devem ser separados por uma barra invertida (\), conforme mostrado no exemplo a seguir:DOMAIN\username.
c) No campo Senha, digite a senha para efetuar login no componente que você deseja descobrir.d) No campo Confirmar Senha, digite novamente a senha para efetuar login no componente que
deseja descobrir.5. Clique em OK para salvar as informações.
A área de janela Lista de Acesso é exibida com as novas informações.6. Etapas adicionais podem ser necessárias com base no tipo de componente selecionado. A tabela a
seguir identifica os tipos de componentes e os campos e listas adicionais que você deve completarpara a entrada da lista de acesso.
Tabela 2. Tipos de Componentes, Campos e Listas Necessários para a Entrada da Lista de Acesso
Tipos de Componentes Campos e Listas
Servidor de Aplicativos, Banco de Dados,Servidores do Sistema de Mensagens
NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidor.
SenhaSenha para acessar o servidor.
FornecedorO fornecedor do servidor ou banco de dados.
Capítulo 1. Usando 7

Tabela 2. Tipos de Componentes, Campos e Listas Necessários para a Entrada da Lista de Acesso(continuação)
Tipos de Componentes Campos e Listas
Servidor CSM NomeNome para identificar o dispositivo na lista deacesso.
SenhaSenha para acessar o servidor.
Nome do UsuárioNome do usuário para acessar o servidor.
Dispositivo Cisco NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o dispositivo.
SenhaA senha para o dispositivo Cisco, se vocêestiver usando o protocolo Telnet, SSH1 ouSSH2.
Ativar SenhaA ativação da senha do dispositivo Cisco, sevocê estiver usando o protocolo Telnet, SSH1ou SSH2.
Confirmar Ativar SenhaA ativação da senha do dispositivo Cisco, sevocê estiver usando o protocolo Telnet, SSH1ou SSH2.
O sensor Cisco IOS exige que o sensor SNMPesteja estabelecido e em funcionamento comrelação ao dispositivo. Se o seu sensor Cisco IOSestiver usando um protocolo Telnet e nãosolicitar um nome de usuário, digite padrão nocampo Nome do Usuário.
Cisco Works NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidor.
SenhaSenha para acessar o servidor.
8 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Tabela 2. Tipos de Componentes, Campos e Listas Necessários para a Entrada da Lista de Acesso(continuação)
Tipos de Componentes Campos e Listas
Sistema de Computador, Sistema de Computador(Windows)
Tipo de AutenticaçãoO tipo de autenticação para o sistema decomputador.
NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o sistema decomputador.
SenhaSenha para acessar o sistema decomputador.
CCMS (Computing Center Management System) NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidor SAPCCMS.
ID do ClienteO ID do cliente do servidor SAP CCMS.
SenhaSenha para acessar o servidor SAP CCMS.
Soluções de Alta Disponibilidade NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidorVeritas Cluster.
SenhaSenha para acessar o servidor Veritas Cluster.
IBM Tivoli Monitoring NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o TivoliEnterprise Portal Server.
SenhaSenha para acessar o Tivoli Enterprise PortalServer.
Capítulo 1. Usando 9
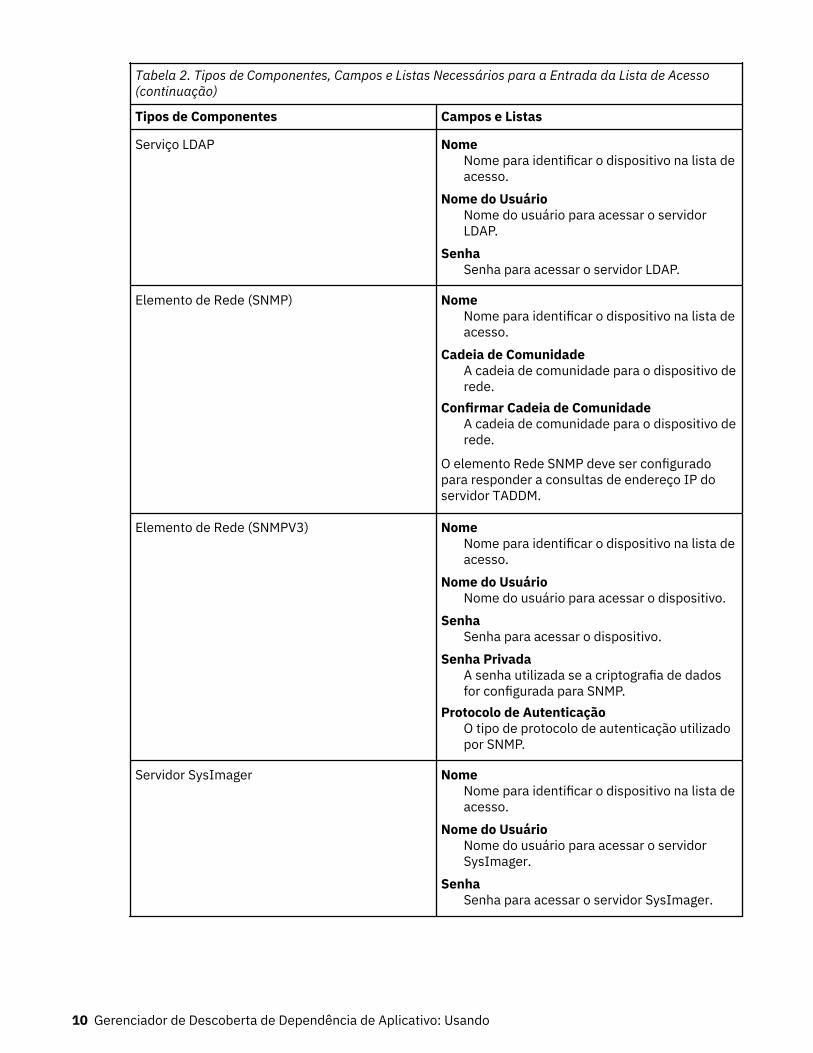
Tabela 2. Tipos de Componentes, Campos e Listas Necessários para a Entrada da Lista de Acesso(continuação)
Tipos de Componentes Campos e Listas
Serviço LDAP NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidorLDAP.
SenhaSenha para acessar o servidor LDAP.
Elemento de Rede (SNMP) NomeNome para identificar o dispositivo na lista deacesso.
Cadeia de ComunidadeA cadeia de comunidade para o dispositivo derede.
Confirmar Cadeia de ComunidadeA cadeia de comunidade para o dispositivo derede.
O elemento Rede SNMP deve ser configuradopara responder a consultas de endereço IP doservidor TADDM.
Elemento de Rede (SNMPV3) NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o dispositivo.
SenhaSenha para acessar o dispositivo.
Senha PrivadaA senha utilizada se a criptografia de dadosfor configurada para SNMP.
Protocolo de AutenticaçãoO tipo de protocolo de autenticação utilizadopor SNMP.
Servidor SysImager NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidorSysImager.
SenhaSenha para acessar o servidor SysImager.
10 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Tabela 2. Tipos de Componentes, Campos e Listas Necessários para a Entrada da Lista de Acesso(continuação)
Tipos de Componentes Campos e Listas
Servidor de Diretórios System Landscape NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o Servidor deDiretórios System Landscape.
SenhaSenha para acessar o Servidor de DiretóriosSystem Landscape.
7. Para configurar as limitações do escopo, clique na guia Limitações do Escopo.A página Limitações do Escopo é exibida.
8. Na página Limitações do Escopo, conclua uma das seguintes etapas:
• Para utilizar as informações de acesso em todos os componentes de todo o escopo de descoberta,clique em Escopo Inteiro.
• Para restringir a aplicação de informações de acesso específicas para determinados sistema, cliqueem Limitar ao escopo selecionado ou Limitar aos grupos de escopo selecionados. Em seguida,selecione o conjunto de escopos ou o grupo de escopos para os quais você deseja restringir oacesso. A entrada da lista de acesso é utilizada apenas ao descobrir o escopo selecionado. Aodescobrir um conjunto de escopos ou grupo de escopos diferente, a entrada da lista de acessos nãoé usada. Esse método evita tentativas de login inválidas que podem resultar no bloqueio do usuárioà conta.
9. Para salvar a nova entrada da lista de acesso, clique em OK.
Alterando uma Entrada da Lista de AcessoÉ possível alterar uma entrada da lista de acesso existente usando o Console de Gerenciamento deDescoberta. As etapas para alterar uma entrada da lista de acesso dependem do tipo de componente quevocê deseja incluir. Use a Descoberta > Lista de Acesso para alterar uma entrada da lista de acessoexistente. Também é possível modificar entradas da lista de acesso existentes programaticamente,usando a API Java.
Sobre Esta Tarefa
Se desejar gerenciar programaticamente as entradas de sua lista de acesso ou se tiver um aplicativo deterceiro e desejar gerenciar identidades ou alterar a senha, por exemplo, poderá usar a API Java parafazer isso. Para ver os métodos de API Java, consulte o tópico Gerenciando listas de acesso no DeveloperGuide do SDK do TADDM.
Procedimento
Para alterar uma entrada da lista de acesso usando o Console de Gerenciamento de Descoberta, concluaas seguintes etapas:1. Na barra de menus, clique em Descoberta > Lista de Acesso.
A área de janela Lista de Acesso é exibida.2. Na lista, selecione a entrada que você deseja alterar e clique em Editar.
O bloco de notas Detalhes de Acesso é exibido, com os campos Tipo de Componente, Nome e Nomede Usuário desativados. Não é possível alterar essas configurações.
3. Se desejar alterar as informações de senha, clique em Alterar e conclua as etapas a seguir:a) No campo Senha, digite a senha a ser registrada no componente que deseja descobrir.
Capítulo 1. Usando 11

b) No campo Confirmar Senha, redigite a senha a ser registrada no componente que desejadescobrir.
4. Para configurar as limitações do escopo, clique na guia Limitações do Escopo.A página Limitações do Escopo é exibida.
5. Na página Limitações do Escopo, conclua uma das seguintes etapas:
• Para utilizar as informações de acesso em todos os componentes de todo o escopo de descoberta,clique em Escopo Inteiro.
• Para restringir a aplicação de informações de acesso específicas para determinados sistema, cliqueem Limitar ao escopo selecionado ou Limitar aos grupos de escopo selecionados. Em seguida,selecione o conjunto de escopos ou o grupo de escopos para os quais você deseja restringir oacesso. A entrada da lista de acesso é utilizada apenas ao descobrir o escopo selecionado. Aodescobrir um conjunto de escopos ou grupo de escopos diferente, a entrada da lista de acessos nãoé usada. Isso evita tentativas de login inválidas que podem resultar no bloqueio do usuário à conta.
6. Para salvar a nova entrada da lista de acesso, clique em OK.
Movendo uma Lista de Acesso Entre ServidoresÉ possível mover uma lista de acesso de um servidor TADDM para outro servidor TADDM.
Sobre Esta TarefaNão é possível mover uma lista de acesso para ou de um servidor de armazenamento ou de um servidorde armazenamento secundário.
Para mover uma lista de acesso de um servidor TADDM para outro, conclua as seguintes etapas:
Procedimento
1. Abra uma janela de linha de comandos no servidor TADDM a partir do qual você deseja mover a listade acesso.
2. No diretório $COLLATION_HOME/bin, use o seguinte comando para gravar a lista de acesso em umarquivo criptografado:Nos sistemas operacionais Linux, AIX, e Linux on System z:
authconfig.sh -u $username -p $password -d -f $filename
No sistema operacional Windows:
authconfig.bat -u username -p password -d -f filename
3. Copie o arquivo criptografado criado pelo comando authconfig e o arquivo TADDMSec.propertiesa partir do diretório $COLLATION_HOME/etc/ para o servidor TADDM para o qual você deseja mover(servidor de destino). Assegure-se de não sobrescrever o arquivo TADDMSec.properties existenteno servidor de destino.
4. No servidor TADDM para o qual você moveu os arquivos, a partir do diretório $COLLATION_HOME/bin, use o seguinte comando:Nos sistemas operacionais Linux, AIX, e Linux on System z:
authconfig.sh -u $username -p $password -m -f $filename –k $key_filename [-o] [-e $output_filename]
No sistema operacional Windows:
authconfig.bat -u username -p password -m -f filename -k key_filename [-o] [-e output_filename]
em que:-f filename
Esse valor especifica o nome e o local do arquivo criptografado que foi criado na etapa 2.
12 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

-k key_filenameEsse valor especifica o nome e o local do arquivo TADDMSec.properties que você copiou doservidor TADDM de origem. O arquivo TADDMSec.properties no servidor de destino não podeser usado ao mover uma lista de acesso que foi criptografada pelo servidor de origem.
Opcional: -oA ação padrão ao mover uma lista de acesso entre servidores é mesclar a lista de acesso dearquivos criptografados com a lista de acesso no servidor de destino. Em seguida, a listacombinada é salva no banco de dados.
Para sobrescrever a lista de acesso atual no servidor de destino com a lista de acesso no arquivocriptografado, inclua a opção -o.
Opcional: -e output_filenameSe você não desejar gravar imediatamente na lista de acesso a partir do arquivo criptografado noservidor de destino, inclua a opção -e. A opção -e criptografa novamente a lista de acesso em umarquivo de saída usando a chave de criptografia do servidor de destino. Você deve especificar umnome para o arquivo recriptografado e um local para ele no servidor de destino. Essa opção nãosalva nenhuma entrada da lista de acesso no arquivo criptografado no banco de dados no servidorde destino.
O que Fazer DepoisSe você selecionou a opção -e ao mover listas de acesso entre servidores, poderá mover o arquivonovamente criptografado posteriormente para o banco de dados do servidor de destino. Ao mover oarquivo novamente criptografado para o banco de dados, use o seguinte comando, em que filename é onome e o local do arquivo novamente criptografado:Nos sistemas operacionais Linux, AIX, e Linux on System z:
authconfig.sh -u $username -p $password -m -f $filename [-o]
No sistema operacional Windows:
authconfig.bat -u username -p password -m -f filename [-o]
O -o é opcional e se comporta exatamente conforme descrito no procedimento anterior. Assegure-se deomitir a opção -k. O arquivo TADDMSec.properties no servidor remoto não pode ser usado para movero arquivo novamente criptografado para o banco de dados.
Executando DescobertasApós configurar um escopo inicial para a descoberta e estabelecer uma lista de acesso para seussistemas de computação, você está pronto para executar uma descoberta básica. Também é possívelexecutar uma descoberta Windows não administrador para a qual não é necessário fornecer a conta doadministrador.
Executando uma Descoberta BásicaApós configurar um escopo inicial para a descoberta e estabelecer uma lista de acesso para seussistemas de computação, você está pronto para executar uma descoberta básica.
Importante: Executar uma descoberta contra um escopo muito grande pode levar a problemas dedesempenho, inclusive travamento do servidor.
Para executar uma descoberta, conclua as seguintes etapas do Console de Gerenciamento deDescoberta:
1. Na barra de menus, clique em Descoberta > Visão Geral. A área de janela Visão Geral é exibida.2. Para iniciar a descoberta, clique em Executar Descoberta. A janela Executar Descoberta é exibida.3. Na janela Executar Descoberta, selecione Elementos de Escopos Selecionados no menu Escopo e
selecione na árvore os escopos a serem incluídos na descoberta. É possível executar a descoberta emrelação a elementos de escopo, conjuntos de escopos e grupos de escopos.
Capítulo 1. Usando 13

4. Na lista Perfil, selecione o perfil de descoberta a ser utilizado durante a execução da descoberta.Consulte “Utilizando Perfis de Descoberta” na página 53 para obter informações adicionais sobreperfis de descoberta.
5. Para executar a descoberta, clique em OK.
Depois de iniciar uma descoberta e enquanto a descoberta estiver em execução, você poderá visualizar aVisão Geral da Descoberta para visualizar detalhes de sua descoberta.
Consulte “Configurando uma Descoberta” na página 181 para obter uma abordagem orientada ao cenáriopara a descoberta.
Redescobrindo Itens de ConfiguraçãoVocê pode usar a opção Redescobrir para atualizar um item de configuração (CI) que já foi descobertopela descoberta credenciada.
Antes de Iniciar
A opção Redescobrir está disponível no Portal de Gerenciamento de Dados. Use essa opção pararedescobrir o CI sem passar pelo processo de descoberta completo.
Antes de poder redescobrir itens de configuração, deve-se editar a propriedade a seguir no arquivocollation.properties:com.collation.rediscoveryEnabled=true
Os valores válidos são true e false. O padrão é false. Altere o valor para true para ativar a funçãode redescoberta.
Se algum IC for descoberto chamando o sensor principal apenas devido ao qual o IC écriado, a propriedade a seguir deve ser configurada como true:
com.collation.isRediscoveryViaMainSensorOnly=true
Os valores válidos dessa propriedade são true e false. O padrão é falso.
Sobre Esta Tarefa
A opção Redescoberta utiliza informações armazenadas pela descoberta completa anterior para darorigem à redescoberta. Valores iniciais antigos podem fornecer resultados imprevisíveis. Nos exemplos aseguir, as alterações após uma descoberta completa podem causar um valor inicial inválido, e aredescoberta pode falhar ou pode obter dados incompletos:
• As informações de destino que o sensor utiliza foram alteradas (endereço IP, ligação de porta etc.)• O modelo de dados subjacente foi alterado. Essa situação é típica com liberações e manutenção, como
uma nova liberação, fix pack ou uma correção temporária.• O sensor muda significativamente, o que afeta as informações do valor inicial que estão armazenadas.
Planeje uma descoberta completa de todos CIs após os principais aplicativos de manutenção, como ainstalação de uma correção temporária, fix pack ou nova liberação, em vez de usar a opçãoRedescoberta. Fazendo isso, você assegura que os valores iniciais sejam mantidos em um níveladequado para a redescoberta funcionar corretamente.
Importante:
• A redescoberta não é um método de longo prazo para manter CIs atualizadas.• Para a redescoberta de uma coleção customizada, o processo é diferente. Uma coleção customizada
em si não pode ser redescoberta, mas os elementos que pertencem a ela podem ser. Ao selecionaruma coleção customizada para redescoberta, os elementos que pertencem a ela e que podem serredescobertos são automaticamente redescobertos.
• No TADDM 7.3.0.3 e mais recente, é possível redescobrir somente os objetos de nívelsuperior.
14 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Procedimento
1. No Portal de Gerenciamento de Dados, vá para a área de janela esquerda inferior ComponentesDescobertos.
2. Selecione os CIs que você deseja redescobrir.3. Clique em Ações > Redescobrir.4. A redescoberta começa somente depois do último sensor usado para descobrir o CI particular. Ela não
inicia sensores de recebimento de dados para descoberta mais profunda. Para executar umadescoberta completa, use Executar Descoberta no Console do Produto.
ResultadosDepois de concluir uma redescoberta e visualizar o histórico da descoberta no Console do Produto, vocêvê que os sensores executaram, mas o perfil e os campos de escopo ficam em branco. A redescobertacria um perfil dinâmico sempre que você executar uma redescoberta.
Gerenciando DescobertasÉ possível usar o Console de Gerenciamento de Descoberta para gerenciar o processo de descoberta.
Capturando Resultados de Descoberta no Servidor de DescobertasEm uma implementação de servidor de fluxo, os dados de descoberta circulam do servidor dedescobertas para o servidor de armazenamento primário. Esses dados são processados e armazenadosno banco de dados no servidor de armazenamento primário. Alternativamente, é possível capturar earmazenar essas informações no sistema de arquivos no servidor de descoberta. Essas informaçõespodem ser analisadas e transferidas para o servidor de armazenamento para processamento earmazenamento posteriores.
Sobre Esta TarefaPara capturar as informações de descoberta no servidor de descobertas, conclua as seguintes etapas:
Procedimento
1. Na descoberta $COLLATION_HOME/var, crie um diretório nomeado topo para armazenar asinformações de descoberta. Quando uma descoberta é executada, os resultados são armazenados emum diretório exclusivo criado no diretório $COLLATION_HOME/var/topo. Por exemplo, o diretório$COLLATION_HOME/var/topo/74i9x86th.
2. Para armazenar as informações no banco de dados, conclua as seguintes etapas:a) Copie o diretório gerado para o servidor de armazenamento. A mesma versão do TADDM deve ser
instalada no servidor de armazenamento e no servidor de descobertas.b) Execute o seguinte comando:
api.sh -u username -p password find "IMPORT data_directory"
em que data_directory é o diretório a partir do qual os dados são importados.Por exemplo:
api.sh -u administrator -p collation find "IMPORT /tmp/74i9x86th"
O script api.sh está localizado no diretório $COLLATION_HOME/sdk/bin.
O servidor de descobertas não pode persistir as informações no banco de dados durante umadescoberta até que o diretório $COLLATION_HOME/var/topo seja excluído.
Em uma implementação de servidor de domínio, o servidor de domínio tem seu próprio banco dedados. Para um servidor de domínio independente, as informações de uma descoberta podem sercapturadas no servidor usando as etapas anteriores.
3. Para listar o conteúdo de objetos armazenados, execute o seguinte comando:
api.sh -u username -p password find "LIST data_directory"
Capítulo 1. Usando 15

em que data_directory é o diretório que contém os dados a serem analisados. Geralmente, este é omesmo diretório que aquele para o qual você exportou os dados de descoberta, por exemplo,
api.sh -u administrator -p collation find "LIST /tmp/74i9x86th"
O conteúdo dos objetos armazenados é listado em $COLLATION_HOME/log/services/ApiServer.log.
Há um limite para a quantidade de dados registrada em cada mensagem. Para objetos grandes, o valorda propriedade com.collation.log.msg.size deve ser aumentado acima do valor padrão de100000.
Carregando um Escopo de Descoberta de um ArquivoÉ possível usar o comando loadscope para gerenciar e carregar o escopo de descoberta a partir de umarquivo.
Sobre Esta Tarefa
Importante: A criação de escopos grandes pode levar a problemas de desempenho, incluindotravamento do servidor.
O exemplo a seguir mostra o formato do comando loadscope:
loadscope.jy [-d] [-q] [-C] -u username -p password clearAll | (clearScopename) | (clearScopeSetname) | ([-s ScopeSetName | -g ScopeGroupName] load [scopefile])
O script loadscope.jy está no diretório $COLLATION_HOME/bin.
A lista a seguir descreve as opções do comando loadscope:-d
Liga a criação de log de depuração detalhada.-q
Carrega o escopo sem sincronização.
É possível usar essa opção ao carregar diversos escopos. Certifique-se de não usar o sinalizador -qcom o final, de forma que a sincronização possa então ocorrer.
Importante: No TADDM 7.3.0.3 e mais recente, essa opção é ignorada. Como odesempenho da sincronização do escopo melhorou significantemente, essa opção não é maisnecessária.
-CEsse parâmetro faz o arquivo loadscope.jy excluir o escopo. Entretanto, ele não exclui oScopeElements designado para o escopo que será posteriormente removido por um agente doconstrutor de topologia.
-u usernameO nome de usuário para acessar o servidor TADDM. Esse parâmetro é obrigatório para operações decarregamento.
-p senhaA senha para o nome de usuário. Esse parâmetro é obrigatório para operações de carregamento.
clearAllExclui todos os conjuntos de escopos e o grupo de escopos.
clearScopeExclui o conjunto de escopos ou o grupo de escopos.
clearScopeSet
Importante: Descontinuado.
Exclui o conjunto de escopos ou o grupo de escopos.
16 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

-s ScopeSet ou -g ScopeGroupScopeSet é o nome do conjunto de escopos usado para carregar os elementos de escopo.ScopeGroup é o nome do grupo de escopos usado para carregar os conjuntos de escopos. Esseparâmetro é obrigatório para operações de carregamento.
Importante: Os nomes de conjunto de escopos não podem conter os caracteres a seguir:
• '• .• /
loadCarrega os elementos do escopo no sistema, substituindo elementos existentes por novos elementos.
scopefileO arquivo que contém os elementos a seguir:
• Os elementos do escopo caso você deseje carregar um conjunto de escopos usando o parâmetro -sScopeSet.
• Os conjuntos de escopos no caso de desejar carregar um grupo de escopos usando o parâmetro -gScopeGroup.
Esse parâmetro é obrigatório para operações de carregamento.
Carregando um conjunto de escopos de um arquivo
O exemplo a seguir mostra como carregar um arquivo de descoberta usando o comando loadscope:
% loadscope.jy -u administrator -p cmdb -s Windows load /tmp/scopefile
Um arquivo do escopo consiste em entradas no seguinte formato:
scope,[exclude_scope:exclude_scope...],[description]
Um arquivo de escopo pode conter qualquer número de escopos, usando qualquer combinação dosseguintes tipos de escopo:
• Escopos de sub-rede (por exemplo, 1.2.3.4/255.255.255.0)• Escopos de endereço (por exemplo, 1.2.3.4)• Escopos de intervalo (por exemplo, 1.2.3.4-5.6.7.8)
Importante: A seguir, estão detalhes sobre o formato de arquivo do escopo:
• Apenas endereços IP são válidos no arquivo do escopo. Nomes do host não podem ser usados.• Cada elemento do escopo existe em uma linha separada.• Os escopos de endereço não devem incluir exclusões.• O caractere de e comercial (&) não é permitido no parâmetro [description].• As entradas serão ignoradas se não forem válidas.• Você pode inserir linhas de comentários prefixadas com o sinal numérico (#).
O texto de amostra a seguir é um arquivo de escopo de amostra:
# This is a comment10.10.10.10,,10.10.10.20,,10.10.10.30,,10.10.10.0/255.255.255.0,10.10.10.2:10.10.10.3,10.10.10.2-10.10.10.9,10.10.10.4:10.10.10.5,10.10.10.88,,10.10.10.999,,
Capítulo 1. Usando 17

Carregando um grupo de escopos de um arquivoUm arquivo do escopo consiste em entradas no seguinte formato, que descreve um único grupo deescopos:
scopeSetName1scopeSetName2...scopeSetNameNem que scopeSetNameN é o nome de um conjunto deescopos existente que deve ser incluído no grupo.
Importante: Cada nome de conjunto de escopos é colocado em uma linha separada. Você podeinserir linhas de comentários prefixadas com o sinal numérico (#).
Use os comandos a seguir para carregar e excluir conjuntos de escopos e grupos de escopos:
• Carregando um conjunto de escopos:
loadscope.jy -u <username> -p <password> -s <ScopeSet> load <scopefile>
• Carregando um grupo de escopos:
loadscope.jy -u <username> -p <password> -g <ScopeGroup> load <scopefile>
• Excluindo um conjunto de escopos ou um grupo de escopos:
loadscope.jy -u <username> -p <password> clearScope <name>
• Excluindo todos os conjuntos de escopos e grupos de escopos:
loadscope.jy -u <username> -p <password> clearAll
Exportando Escopos para Uso em um Outro Servidor TADDMUse o comando api.sh para exportar escopos.
Sobre Esta Tarefa
Para exportar conjuntos de escopos e grupos de escopos em um formato XML, execute o comando aseguir:
api.sh -u -p find --depth=5 Scope
Localize o script api.sh no diretório $COLLATION_HOME/sdk/bin.
Restrição: Escopos exportados com o comando api.sh não podem ser importados em outro servidorTADDM. Use o comando datamover.sh|bat para mover escopos entre os servidores TADDM.
Para manter a integridade de dados, você deve mover os dados entre as mesmas versões de servidoresTADDM.
Criando e Gerenciando Modelos de Servidor CustomizadoÉ possível criar servidores customizados para descobrir e categorizar servidores que, por padrão, não sãosuportados pelo TADDM. Essa é uma técnica avançada para configurar o TADDM para descobrirservidores que ele não conhece por padrão.
Sobre Esta TarefaSua infraestrutura pode conter aplicativos de software e tipos de servidores, como servidores Java, quenão são categorizados automaticamente pelo TADDM. Todo processo do servidor com uma porta deatendimento TCP que não é reconhecida é classificado em uma categoria Servidor Desconhecido. Osservidores desconhecidos não são exibidos na topologia e não podem aproveitar a maioria das funções.
18 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Você, porém, obtém informações básicas como o nome e dados de tempo de execução sobre o servidordesconhecido.
É possível definir um servidor customizado para criar um modelo que configure as regras de associaçãopara o servidor customizado. Durante uma descoberta, qualquer servidor desconhecido é categorizadoautomaticamente como um servidor customizado desse tipo se as informações de tempo de execuçãocorresponderem aos critérios definidos no modelo. Todos os arquivos de configuração utilizados peloservidor customizado também serão automaticamente capturados, se especificados nos modelos.
Um modelo de servidor customizado predefinido, chamado "Ignorar todos os processos nãocorrespondidos", ignora quaisquer processos que não sejam correspondidos por outro modelo. Umamelhoria no desempenho é obtida usando-se esse modelo, mas se você desejar procurar por servidoresdesconhecidos usando a funcionalidade Processos Desconhecidos, deverá assegurar-se de que essemodelo não esteja ativado. Por padrão, o modelo "Ignorar todos os processos não correspondidos" nãoestá ativado.
Os servidores customizados são exibidos na topologia e é possível visualizar detalhes sobre eles. Emboraesses detalhes não sejam tão completos quanto aqueles fornecidos para servidores suportados, definirservidores customizados permite que todos os componentes em sua infraestrutura participem natopologia e em comparações. É possível gerenciar servidores customizados na janela ServidoresCustomizados.
No TADDM 7.3.0.2 e mais recente, o atributo hierarchyType é configurado para cadamodelo de servidor customizado. Ele é usado para definir mais detalhadamente os objetos de origem e dedestino dos relacionamentos para atravessar na seção passagem da configuração de padrão deagrupamento. O valor desse atributo é criado com base nos nomes de modelos. Todos os espaços sãoremovidos e as letras iniciais de palavras separadas são configuradas para maiúsculas. Por exemplo, omodelo do IBM Tivoli Enterprise Console possui o atributo hierarchyType configurado paraIBMTivoliEnterpriseConsole, e o modelo do CA iTechnology iGateway possui o hierarchyTypeconfigurado para CAITechnologyIGateway.
No TADDM 7.3.0.3, e mais recente, é possível ativar a criação de itens temporários, o que é útilna criação de modelos de servidor customizado. Para detalhes, consulte o tópico Configurando para adescoberta de itens temporários no Guia do Administrador do TADDM.
Incluindo Servidores CustomizadosUm modelo de servidor customizado contém critérios descritivos que são utilizados para designarprocessos do servidor desconhecido ao servidor customizado. Você especifica seus critérios ao definir omodelo para o servidor customizado no Console de Gerenciamento de Descoberta.
Sobre Esta Tarefa
As informações a seguir associadas aos processos em execução são analisadas para corresponderem aoprocesso para um servidor customizado particular:
Nome do programaO nome do programa executável.
Nome do serviço do WindowsO nome de um serviço do sistema operacional Windows.
ArgumentoOs argumentos transmitidos ao programa.
AmbienteAs variáveis de ambiente configuradas para o programa.
PortaO número da porta TCP na qual o processo está atendendo.
Os detalhes dos critérios e das informações gerais do servidor customizado incluem o nome, o tipo deservidor e os critérios de identificação para o servidor customizado. Para visualizar detalhes sobre esseservidor desconhecido, dê um clique duplo em um servidor desconhecido na Topologia e clique na guiaTempo de Execução.
Capítulo 1. Usando 19

Você pode, então, utilizar estas informações para criar um critério de procura para um servidorcustomizado utilizando as Informações Gerais e a guia Critérios da janela Detalhes do ServidorCustomizado.
Procedimento
Para incluir um servidor customizado, conclua as seguintes etapas do Console de Gerenciamento deDescoberta:
1. Na área de janela Funções, clique em Descoberta > Servidores Customizados.A área de janela Servidores Customizados é exibida.
2. Na área de janela Servidores Customizados, clique em Incluir.O notebook Detalhes do Servidor Customizado é exibido.
3. No campo Nome, digite o nome do servidor customizado.4. Na lista Tipo, selecione o tipo de servidor customizado que está incluindo.5. Em Ação, conclua uma das seguintes etapas:
• Clique em Descobrir se desejar descobrir todas as instâncias do servidor.• Clique em Ignorar se desejar suprimir a descoberta de todas as instâncias do servidor.
6. Para ativar a definição do servidor customizado, clique em Ativado.7. Para selecionar um ícone a associar com o servidor customizado, clique em Navegar e selecione o
ícone que deseja utilizar.8. Em Critérios de Identificação, conclua uma das seguintes etapas:
• Para corresponder a todos os critérios de identificação, clique em Todos os Critérios.• Para corresponder a qualquer um dos critérios de identificação, clique em Qualquer Critério.
9. Conclua as seguintes etapas para definir os critérios para o servidor customizado:a) Na primeira lista, selecione o tipo de critério.b) Na segunda lista, selecione o operador.c) No campo fornecido, digite o argumento de texto para o tipo de critério e o operador.
10. Para remover os critérios de identificação, clique em Remover.11. Para definir novos critérios, clique em Incluir Critério.12. Para incluir arquivos de configuração, clique na guia Arquivos de Configuração.
A página Arquivos de Configuração é exibida.13. Na página Arquivos de Configuração, clique em Incluir.
A janela Caminho de Procura para Capturar Arquivo é exibida.14. Na lista Tipo, selecione um dos tipos de arquivos a capturar:
• Arquivo de Configuração• Módulo de Software• Diretório/Arquivo do Descritor de Aplicativos
15. Na lista Caminho da Procura, selecione um dos seguintes caminhos da procura para o arquivo deconfiguração:/
A raiz do sistema de arquivos.$PWD
O diretório de trabalho atual do programa em execução.$Home
O diretório inicial do ID do usuário do programa em execução.C:
Um diretório em seu computador local.
20 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

%ProgramFiles%O diretório de arquivos do programa.
%SystemRoot%O diretório raiz do sistema
Digite o caminho e o nome do arquivo do arquivo de configuração na caixa de texto ou digite *(asterisco) para especificar todos os arquivos no diretório selecionado.
16. Para capturar o conteúdo do arquivo de configuração, clique em Capturar conteúdo do arquivo e,opcionalmente, especifique o número máximo de bytes do arquivo de configuração capturado.
17. Para recursar através da estrutura de diretório para procurar o arquivo especificado, selecioneRecursar procura de diretório (se usar o TADDM 7.3.0.3 ou mais recente) ou Recursar conteúdo dodiretório (se usar o TADDM 7.3.0.2 ou anterior).
18. Para salvar as configurações para o servidor customizado, clique em OK.
Editando um Servidor CustomizadoÉ possível usar o Console de Gerenciamento de Descoberta para editar um servidor customizado.
Procedimento
Para editar um servidor customizado, conclua as seguintes etapas do Console de Gerenciamento deDescoberta:1. Na área de janela Funções, clique em Descoberta > Servidores Customizados.
A área de janela Servidores Customizados é exibida.2. Na área de janela Servidores Customizados, clique em Editar.
O bloco de notas Detalhes do Servidor Customizado é exibido, com os campos Nome e Tipodesativados. Estes campos não podem ser alterados.
3. Para alterar os outros campos no bloco de notasDetalhes do Servidor Customizado, consulte“Incluindo Servidores Customizados” na página 19.
4. Para atualizar as informações sobre o servidor customizado que você acabou de alterar, execute outradescoberta.Para melhorar a velocidade do processo de descoberta, limite o escopo ativo da descoberta ao novocomponente.
Copiando um Servidor CustomizadoÉ possível criar um novo servidor customizado com base em um existente. Isto é feito copiando-se umservidor listado na área de janela Servidores Customizados e atribuindo-lhe um nome exclusivo.
Procedimento
Para copiar um servidor customizado, conclua as seguintes etapas a partir do Console de Gerenciamentode Descoberta:1. Na área de janela Funções, clique em Descoberta > Servidores Customizados.
A área de janela Servidores Customizados é exibida.2. Na área de janela Servidores Customizados, selecione o servidor customizado que deseja copiar e
clique em Copiar.A janela Configurar Nome é exibida.
3. No campo Nome, digite o nome para o novo servidor customizado.4. Para salvar o novo servidor customizado, clique em OK.
Excluindo um Servidor CustomizadoÉ possível usar o Console de Gerenciamento de Descoberta para excluir um servidor customizado.
Capítulo 1. Usando 21

Procedimento
Para excluir um servidor customizado, conclua as seguintes etapas a partir do Console de Gerenciamentode Descoberta:1. Na área de janela Funções, clique em Descoberta > Servidores Customizados.
A área de janela Servidores Customizados é exibida.2. Na área de janela Servidores Customizados, selecione o servidor customizado que deseja excluir e
clique em Excluir.Uma janela de mensagem é exibida.
3. Para excluir o servidor customizado, clique em Sim na janela de mensagem.4. Para confirmar a exclusão, certifique-se de que o servidor customizado não esteja listado na área de
janela Servidores Customizados.
Reposicionando Entradas do Servidor CustomizadoÉ possível alterar a ordem em que os servidores customizados são listados na área de janela ServidoresCustomizados. A ordem da lista é importante porque a correspondência do modelo é aplicada da partesuperior para a parte inferior na lista de servidores customizados e pára na primeira correspondência. Porexemplo, um modelo mais genérico corresponde a todos os servidores de um tipo específico e ummodelo mais específico corresponde apenas a servidores que possuem um argumento de cadeiaespecífico. Após um servidor ter correspondência com uma categoria de servidores, o servidorcustomizado é removido da lista de servidores desconhecidos. Um servidor não pode ser membro demais de uma categoria ao mesmo tempo, mesmo se o servidor corresponder a critérios de váriosservidores customizados na lista. Alterar a ordem da lista pode fazer com que o processo do servidorcorresponda a um servidor customizado diferente.
Procedimento
Para reposicionar entradas da área de janela Servidores Customizados, conclua as seguintes etapas apartir do Console de Gerenciamento de Descoberta:1. Na área de janela Funções, clique em Descoberta > Servidores Customizados.
A área de janela Servidores Customizados é exibida.2. Na área de janela Servidores Customizados, selecione o servidor customizado que deseja
reposicionar e conclua uma das etapas a seguir:
• Para mover o servidor para cima na lista de entrada, clique em Mover para Cima.• Para mover o servidor para baixo na lista de entrada, clique em Mover para Baixo.
Ativando o Modelo IgnorarÉ possível ativar o modelo predefinido "Ignorar Todos os Processos Não Correspondidos" que ignoramquaisquer processos que não correspondam a outro modelo.
Antes de IniciarAtivar esse modelo resulta em ignorar padrões de servidores desconhecidos. Antes de ativá-lo, assegure-se de que não deseja identificar servidores desconhecidos usando a funcionalidade ProcessosDesconhecidos.
Procedimento
Para ativar o modelo que ignora todos os processos não correspondentes, conclua as seguintes etapas apartir do Console de Gerenciamento de Descoberta:1. Na área de janela Funções, clique em Descoberta > Servidores Customizados.
A área de janela Servidores Customizados é exibida.2. Na área de janela Servidores Customizados, selecione o modelo de servidor customizado "Ignorar
Todos os Processos Não Correspondidos". Clique em Editar.A janela Detalhes do Servidor Customizado é exibida.
22 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

3. Clique em Ativado.4. Clique em OK.
Modelos predefinidosO TADDM inclui muitos modelos de servidor customizado predefinidos que estão prontos para utilizaçãoimediata. É possível usa-los em seu próprio ambiente para descobrir software adicional.
Pré-RequisitosAntes de começar a usar os modelos de servidor customizado, certifique-se de que os valoresbuildforge.exe e buildforge;NODEM são incluídos na propriedade forcedServerList noarquivo collation.properties da seguinte maneira:
com.collation.platform.os.WindowsOs.forcedServerList=w3wp;nserver;amqzxma0;bipservice;buildforge.execom.collation.platform.os.UnixOs.forcedServerList=amqzxma0;vxconfigd;clstrmgr;bipbroker;libvirtd;buildforge;NODEM
Novos modelos no TADDM 7.3.0.2No TADDM 7.3.0.2, muitos modelos estão prontos para utilização imediata. No entanto, deve-seutilizar esses modelos com cuidado. Depois de fazer upgrade para o TADDM 7.3.0.2, revise a lista demodelos manualmente e decida quais deles podem ser usados com segurança. Dependendo da suaconfiguração, não executar esta etapa pode resultar em geração de duplicatas.Por exemplo, em uma liberação anterior do TADDM, o modelo JavaServer foi desativado e vocêdecidiu não para a descoberta AppServers com base em Java utilizando os modelos customizadosporque usou descoberta de Nível 3 para conseguir isso. Nessa, se você deixar os novos modelosativados, duplicatas poderão ser criadas.
Nota: No caso de migração do TADDM 7.3.0 ou 7.3.0.1, os seguintes modelos serão movidos para ofinal da lista de servidores customizados para que os servidores desconhecidos possam sercategorizados primeiro como servidores dos tipos que são especificados por mais modelosespecíficos listados anteriormente.
• IBM WebSphere Liberty Profile• Tomcat• JavaServer• Ignorar todos os processos não correspondidos
Lista de modelos de servidor customizadoA tabela a seguir contém a lista de todos os modelos de servidor customizado que estão disponíveispara uso imediato. Ela especifica se o modelo está ativado por padrão e qual classe de objeto eledescobre. Se uma extensão for criada para um modelo, ela também será listada na tabela. Osmodelos são classificados na ordem alfabética. Se um modelo possui uma extensão, o nome daextensão é especificado na coluna Nome.
Tabela 3. Modelos de servidor customizado predefinidos
Nome Ativado porpadrão
Classe de objeto de descoberta
AppDynamics Controller Sim AppServer
Watchdog Aternity Sim AppServer
BlackBerry Enterprise Server Sim AppServer
Agente Patrol BMC Sim AppServer
BroadVision Sim AppServer
Business Objects Enterprise Sim AppServer
CA iTechnology iGateway Sim AppServer
Capítulo 1. Usando 23

Tabela 3. Modelos de servidor customizado predefinidos (continuação)
Nome Ativado porpadrão
Classe de objeto de descoberta
Cisco Data Center NetworkManager
Sim AppServer
CollationProcesses Sim AppServer
Compaq Insight Manager Agent Sim AppServer
ConnectDirect Sim AppServer
Dell OpenManage Agents Sim AppServer
Hitachi Hi-Track Monitor Sim AppServer
HP Discovery & DependencyMapping Inventory
Sim AppServer
HP SiteScope Sim AppServer
HP System ManagementHomepage Software
Sim AppServer
Servidor HTTP Sim WebServer
IBM Build Forge Agent Sim AppServer
IBM Build Forge Server Sim AppServer
IBM Cognos 7 PowerPlay Sim AppServer
IBM Cognos BusinessIntelligence
Sim AppServer
IBM Cognos Impromptu Sim AppServer
IBM Communications Server Sim AppServer
IBM Content Analytics Sim AppServer
IBM Endpoint Manager forSoftware Use Analysis
Sim AppServer
IBM Enterprise Integrator Sim AppServer
IBM InfoSphere Data Stage Sim AppServer
IBM InfoSphere Guardium Sim AppServer
IBM License Metric Tool Sim AppServer
IBM Netcool/Impact Server Sim AppServer
IBM Netcool/Impact UI Server Sim AppServer
IBM Netcool/OMNIbus Sim DatabaseServer
IBM Security AppScanEnterprise
Sim AppServer
IBM Security Directory Server Sim AppServer
24 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Tabela 3. Modelos de servidor customizado predefinidos (continuação)
Nome Ativado porpadrão
Classe de objeto de descoberta
IBM Tivoli Business Service Manager Sim AppServer
IBM Tivoli Enterprise Console Sim AppServer
IBM Tivoli EnterpriseMonitoring Server
Sim AppServer
IBM Tivoli Enterprise PortalServer
Sim AppServer
IBM Tivoli Monitoring Agent Sim AppServer
IBM Tivoli MonitoringWarehouse Proxy Agent
Sim AppServer
IBM Tivoli Storage ManagerClient Acceptor Deamon
Sim AppServer
Centro de Operações do IBMTivoli Storage Manager
Sim J2EEServer
IBM Tivoli Storage ManagerServer
Sim AppServer
IBM Tivoli Storage ManagerStorage Agent
Sim AppServer
IBM WebSphere Liberty Profile Sim J2EEServer
Portal IBM WebSphere Sim J2EEServer
IBM WebSphere VoiceResponse
Sim AppServer
Ignorar todos os processos nãocorrespondidos
Não AppServer
InetDaemon Sim AppServer
JavaServer Sim AppServer
Agente Legato Networker Sim AppServer
ManageEngine AppManager Sim AppServer
ManageEngine OpManager Sim AppServer
McAfee IntruShield Sim AppServer
McAfee Network SecurityCentral Manager
Sim AppServer
McAfee Network SecurityManager
Sim AppServer
Microsoft Biz Talk Sim AppServer
MySql
Extension: mysql.py.
Sim DatabaseServer
Capítulo 1. Usando 25

Tabela 3. Modelos de servidor customizado predefinidos (continuação)
Nome Ativado porpadrão
Classe de objeto de descoberta
Netegrity-Siteminder Sim AppServer
Agente de operações OpenView Sim AppServer
Oracle EMAgent Sim AppServer
OracleStrayProcesses Sim AppServer
Outros Agentes Compaq Sim AppServer
PaperClip Internet eXpressPackage Translator System
Sim AppServer
PostgreSQL Sim DatabaseServer
Serviço de spooler de impressão Não AppServer
Progress OpenEdge UnifiedBroker
Sim AppServer
Quadstone Sim AppServer
Solução ARS Sim AppServer
Serviço de registro remoto Não AppServer
RIM BlackBerry Sim AppServer
ServiceNow MID Server Sim AppServer
SiebelGateway Sim AppServer
SiebelServer Sim AppServer
SSHServer Sim AppServer
Agente antivírus Symantec Sim AppServer
Tableau Server - APIServer Sim AppServer
Tableau Server - DataServer Sim AppServer
Tableau Server - VizQLServer Sim AppServer
Tomcat Sim J2EEServer
Unicenter AutoSys JobManagement Agent
Sim AppServer
Serviços integrados do UNIX Sim AppServer
Verint Extraction Engine Sim AppServer
WebMethods Integration Server8.2
Sim AppServer
WebMethods Integration Server9.6
Sim AppServer
Serviços integrados do Windows Sim AppServer
YSoft SafeQ CMLNode Sim AppServer
26 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Tabela 3. Modelos de servidor customizado predefinidos (continuação)
Nome Ativado porpadrão
Classe de objeto de descoberta
YSoft SafeQ CRSNode Sim AppServer
YSoft SafeQ ORSNode Sim AppServer
YSoft SafeQ ReplicatorNode Sim AppServer
Criando e Gerenciando Modelos de Sistema de ComputadorÉ possível customizar como os sistemas de computador e outros dispositivos são descobertos criandomodelos de sistema de computador. Um modelo de sistema de computador pode especificarinformações adicionais que você deseja reunir a partir de um tipo de sistema descoberto e podeespecificar a classe de modelo a ser usada para uma categoria de dispositivo descoberto.
Sobre Esta Tarefa
É possível definir um modelo de sistema de computador para especificar informações sobre um tipo desistema de computador ou um dispositivo de rede, incluindo informações adicionais a serem reunidasdurante a descoberta. Use um modelo de sistema de computador se desejar customizar como umdeterminado tipo de sistema ou de dispositivo é tratado, ou para reunir informações adicionais que osensor não descobre por padrão.
Incluindo um Modelo do Sistema de Computador em um Sistema OperacionalUm modelo do sistema de computador pode especificar informações sobre um sistema operacionalespecífico que você deseja descobrir. Use esse tipo de modelo de sistema de computador se você desejardescobrir detalhes adicionais além das informações coletadas por um sensor de sistema operacional.
Sobre Esta TarefaCriando um modelo de sistema de computador para um sistema operacional, é possível especificararquivos de configuração adicionais que você deseja que sejam incluídos nas informações reunidasdurante a descoberta.
Procedimento
Para incluir um modelo de sistema de computador em um sistema operacional:1. Na área de janela Funções do Console de Gerenciamento de Descoberta, clique em Descoberta >
Sistemas de Computador.A área de janela Sistemas de Computador é exibida.
2. Na área de janela Sistemas do Computador, clique em Incluir.A janela Detalhes do Sistema de Computador é exibida.
3. No campo Nome, digite um nome para o modelo de sistema de computador.Esse é o nome que aparecerá na lista da área de janela Sistemas de Computador.
4. No campo Ação, selecione Descobrir para especificar se os sistemas de computadorcorrespondentes ao modelo devem ser descobertos.
5. Para ativar o modelo, clique em Ativado.Apenas modelos ativados são usados para detectar sistemas correspondentes.
6. Para selecionar um ícone a associar ao modelo do sistema do computador, clique em Navegar eselecione o ícone que deseja utilizar.O ícone selecionado será usado para representar sistemas de computador descobertos quecorrespondem ao modelo na UI do TADDM.
7. Selecione Sistema Operacional para especificar que você está criando um modelo de sistemaoperacional.
Capítulo 1. Usando 27

8. No campo Identificando Critérios, selecione o sistema operacional apropriado na lista.O modelo corresponderá a todos os sistemas de computador em execução no sistema operacionalespecificado.
9. Clique na guia Arquivos de Configuração.A página Arquivos de Configuração é exibida.
10. Na página Arquivos de Configuração, clique em Incluir.A janela Caminho de Procura para Capturar Arquivo é exibida.
11. Na lista Caminho da Procura, selecione um dos seguintes caminhos da procura para o arquivo deconfiguração:/
A raiz do sistema de arquivos.$PWD
O diretório de trabalho atual do programa em execução.$Home
O diretório inicial do ID do usuário do programa em execução.C:
Um diretório em seu computador local.%ProgramFiles%
O diretório de arquivos do programa.%SystemRoot%
O diretório raiz do sistema
No campo de texto, digite o caminho e o nome do arquivo de configuração que deseja capturar oudigite um asterisco (*) para especificar todos os arquivos no diretório selecionado.
12. Para capturar o conteúdo do arquivo de configuração especificado, selecione Capturar Conteúdo doArquivo. Se você desejar limitar a quantidade de dados capturados, selecione Limitar Tamanho doArquivo Capturado em e especifique o número máximo de bytes do arquivo de configuraçãocapturado.
13. Para procurar o arquivo especificado em subdiretórios do local especificado, selecione Recursarprocura de diretório (se usar o TADDM 7.3.0.3 ou mais recente) ou Recursar procura de diretório(se usar o TADDM 7.3.0.2 ou anterior).
14. Depois de concluída a especificação das informações para o modelo de sistema de computador,clique em OK.
15. Opcional: É possível estender a descoberta de sistemas operacionais com comandos ou scriptsJython.Para obter informações sobre como estender modelos de sistema de computador, consulte“Estendendo Modelos do Servidor Customizado e do Sistema do Computador” na página 32.
O que Fazer DepoisO novo modelo está disponível imediatamente; não é necessário reiniciar o servidor TADDM. Asinformações especificadas serão usadas para exibir os sistemas de computador correspondentes nainterface com o usuário TADDM; quaisquer arquivos de configuração especificados no modelo estãodisponíveis na guia Arquivos de Configuração para os sistemas descobertos.
Incluindo um Modelo de Sistema de Computador em um Dispositivo de RedeUm modelo de sistema de computador para um dispositivo de rede especifica a classe do objeto demodelo para uso por dispositivos SNMP descobertos, como roteadores e comutadores. Use esse tipo demodelo se desejar fornecer uma identificação mais precisa de uma classe de dispositivo SNMP ou sedesejar tratar um dispositivo SNMP como um sistema de computador.
Procedimento
Para incluir um modelo de sistema de computador em um dispositivo de rede:
28 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

1. No Console de Gerenciamento de Descoberta, clique em Descoberta > Sistemas de Computador.2. Na visualização Sistemas de Computador, clique em Incluir.3. Na janela Detalhes do Sistema de Computador, especifique os detalhes para o novo modelo do
Sistema de Computador.Os campos desta janela são os seguintes:Nome
Um nome exclusivo para identificar o modelo.Ação
Especifica se o modelo é usado para descoberta.Ativado
Especifica se o modelo está ativado. Apenas modelos ativados são usados para detectar sistemascorrespondentes.
ÍconeO ícone usado para identificar o modelo na visualização Sistemas de Computador. Clique emProcurar para ver os ícones disponíveis a partir dos quais escolher.
TipoEspecifica o tipo de objeto correspondente pelo modelo (Sistema Operacional ou MIB). Para umdispositivo de rede, selecione MIB.
Identificando CritériosDefine os critérios usados para corresponder os dispositivos descobertos. É possível definirdiversos critérios. Para corresponder apenas os dispositivos descobertos que satisfazem todos oscritérios definidos, selecione Todos os Critérios; para corresponder dispositivos que satisfazemqualquer dos critérios definidos, selecione Qualquer Critério.
Cada critério tem três partes:
• O operando é o valor do dispositivo descoberto a ser correspondido. Selecione um dosseguintes:Sys OID
O valor SNMP sysObjectID do SNMPv2-MIB::sysObjectID (OID 1.3.6.1.2.1.1.2)Descrição de Sys
O valor SNMP sysDescr do SNMPv2-MIB::sysDescr (OID 1.3.6.1.2.1.1.1)• O operador especifica o tipo de comparação a ser executada (por exemplo, is-greater-than ou
contains.• O valor correspondente especifica o valor para comparar com o operando.
4. Clique em OK para salvar o modelo e feche a janela.O novo modelo aparece na visualização Sistema de Computador.
Nota: A sequência de modelos na visualização Sistemas de Computador é significativa. Durante adescoberta, o algoritmo correspondente irá parar quando atingir o primeiro modelo do Sistema deComputador correspondente do tipo MIB; se o campo Ação deste modelo estiver definido comoDescobrir, esse modelo será usado então para a descoberta. É possível alterar a ordem de modelos nalista clicando nos botões Mover para Cima e Mover para Baixo e clicando em Salvar para salvar suasalterações.
5. Opcional: É possível criar um arquivo de classe de ação que define o tipo de objeto modeloComputerSystem a ser usado para o dispositivo descoberto.Geralmente, um arquivo de classe de ação é usado para especificar o valor do atributo type do objetomodelo ComputerSystem para dispositivos descobertos.
Nota: É possível configurar qualquer valor de atributo no arquivo de classe de ação. No entanto, essevalor pode ser substituído. Por exemplo, a classe de ação configura o fabricante como "IBM", mas osensor SNMP MIB2 descobre que o nome do fabricante é "Cisco". Neste caso, o nome descoberto pelosensor substitui o valor fornecido pelo arquivo de classe de ação. Se for necessário substituir um valor
Capítulo 1. Usando 29

descoberto pelo sensor SNMP MIB2, você deverá usar um script Jython para fazer isso durante umadescoberta.
No diretório $COLLATION_HOME/etc/templates/action, crie um arquivo XML com o mesmonome (sem incluir a extensão) como o modelo de Sistema de Computador. (Por exemplo, para ummodelo chamado Comutador Lucent, o arquivo de classe de ação deveria ser chamado deComutador Lucent.xml.)
O conteúdo do arquivo XML especifica a classe do objeto modelo e os valores de atributo para uso. Oexemplo a seguir especifica a classe do objeto modelo UnitaryComputerSystem, com o atributo typedefinido como Bridge e o atributo manufacturer definido como Lucent:
<?xml version="1.0" encoding="UTF-8"?> <results xmlns="urn:www-collation-com:1.0" xmlns:coll="urn:www-collation-com:1.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:www-collation-com:1.0 urn:www-collation-com:1.0/results.xsd">
<UnitaryComputerSystem array="1" xsi:type= "coll:com.collation.platform.model.topology.sys.UnitaryComputerSystem"> <type>Bridge</type> <manufacturer>Lucent</manufacturer> </UnitaryComputerSystem> </results>
6. Opcional: É possível estender a descoberta de dispositivos SNMP com scripts Jython.Para iniciar um script Jython durante a descoberta, você deve primeiro criar um modelo customizadode Sistema de Computador MIB usando a visualização Sistemas de Computador. É possível criar umarquivo descritor definindo os scripts Jython associados a esse modelo.
Para configurar um script Jython para um modelo existente, acesse o diretório$COLLATION_HOME/etc/templates/commands e crie um novo arquivo descritor com o mesmonome do nome do modelo (por exemplo, Roteador de Fundição). Para o conteúdo do arquivo,especifique o seguinte:
SCRIPT:script_file_path
em que script_file_path é o caminho absoluto e o nome do arquivo do script Jython a ser executado. Épossível definir diversos scripts incluindo diversas entradas SCRIPT em um único arquivo descritor. Épossível incluir comentários no arquivo, iniciando uma linha com o caractere sinal de sustenido (#).
Nota: Para usar scripts Jython para descoberta por meio de uma âncora, coloque o script em umsubdiretório do diretório $COLLATION_HOME/etc/templates. O local padrão é$COLLATION_HOME/etc/templates/extension-scripts.
Para obter mais informações sobre o uso do Jython para acessar os dispositivos SNMP, consulte oGuia do Desenvolvedor do SDK.
Editando um Modelo de Sistema do ComputadorÉ possível usar o Console de Gerenciamento de Descoberta para editar um modelo de sistema decomputador.
Procedimento
Para editar um modelo de sistema de computador, conclua as seguintes etapas a partir do Console deGerenciamento de Descoberta:1. Na área de janela Funções, clique em Descoberta > Sistemas de Computador.
A área de janela Sistemas de Computador é exibida.2. Na área de janela Sistemas do Computador, clique em Editar.
O notebook Detalhes do Sistema do Computador é exibido. Não é possível alterar o Nome para omodelo de sistema do computador.
30 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Copiando um Modelo de Sistema do ComputadorÉ possível criar um novo modelo de sistema do computador com base em um existente. Isto é feitocopiando-se um modelo listado na área de janela Sistemas do Computador e atribuindo-lhe um nomeexclusivo.
Procedimento
Para copiar um modelo de sistema de computador, conclua as seguintes etapas a partir do Console deGerenciamento de Descoberta:1. Na área de janela Funções, clique em Descoberta > Sistemas de Computador.
A área de janela Sistemas do Computador é exibida na área de trabalho.2. Na área de janela Sistemas do Computador, selecione o modelo que deseja copiar e clique em
Copiar.A janela Configurar Nome é exibida.
3. No campo Nome, digite o nome para o novo modelo.4. Para salvar o novo modelo, clique em OK.
Excluindo um Modelo de Sistema do ComputadorÉ possível usar o Console de Gerenciamento de Descoberta para excluir um modelo de sistema decomputador.
Procedimento
Para excluir um modelo de sistema de computador, conclua as seguintes etapas a partir do Console deGerenciamento de Descoberta:1. Na área de janela Funções, clique em Descoberta > Sistemas de Computador.
A área de janela Sistemas de Computador é exibida.2. Na área de janela Sistemas do Computador, selecione o modelo que deseja excluir e clique em
Excluir.Uma janela de mensagem é exibida.
3. Para excluir o modelo, clique em Sim na janela de mensagens.4. Para confirmar a exclusão, certifique-se de que o modelo não esteja listado na área de janela
Sistemas do Computador.
Reposicionando Entradas do Modelo de Sistema do ComputadorÉ possível alterar a ordem em que os modelos de sistema do computador são listados na área de janelaSistemas do Computador. A ordem da lista é importante porque a correspondência do modelo é aplicadada parte superior para a parte inferior na lista de modelos e pára na primeira correspondência. Porexemplo, um modelo mais genérico corresponde a todos os servidores de um tipo específico e ummodelo mais específico corresponde apenas a servidores que possuem um argumento de cadeiaespecífico.
Procedimento
Para reposicionar entradas na área de janela Sistemas de Computador, conclua as seguintes etapas apartir do Console de Gerenciamento de Descoberta:1. Na área de janela Funções, clique em Descoberta > Sistemas de Computador.
A área de janela Sistemas de Computador é exibida.2. Na área de janela Sistemas do Computador, selecione o modelo que deseja reposicionar e conclua
uma das etapas a seguir:
• Para mover o modelo para cima na lista de entrada, clique em Mover para Cima.• Para mover o modelo para baixo na lista de entrada, clique em Mover para Baixo.
Capítulo 1. Usando 31

Estendendo Modelos do Servidor Customizado e do Sistema do ComputadorSua infraestrutura pode conter aplicativos de software e tipos de servidores, como servidores Java, quenão são categorizados automaticamente pelo TADDM. Usando o Console de Gerenciamento deDescoberta, é possível criar modelos de servidor customizado para descobrir e categorizar essesservidores.
Talvez seja necessário também definir um modelo de servidor customizado para um tipo de servidor quejá está descoberto, se você desejar customizar alguns aspectos da maneira que ele é descoberto. Porexemplo, pode ser necessário alterar o ícone de exibição ou capturar arquivos de configuraçãoespecíficos.
Definir um servidor customizado significa que você está criando um modelo que configura as "regras deassociação" para o servidor customizado.
Durante uma descoberta, o TADDM categoriza automaticamente qualquer servidor desconhecido comoum servidor customizado desse tipo se as informações de tempo de execução corresponderem aoscritérios definidos no modelo. Todos os arquivos de configuração utilizados pelo servidor customizadotambém serão automaticamente capturados, se especificados nos modelos.
Criar um modelo de servidor customizado para um aplicativo permite também que o TADDM o exibasubsequentemente como parte da topologia. É possível visualizar detalhes sobre o aplicativo, incluindo aporta de atendimento, informações de tempo de execução e quaisquer arquivos de configuração oudescritores de aplicativos coletados.
Em alguns casos, isso pode não ser suficiente. Por exemplo, pode ser necessário também acessar aversão do produto. Por padrão, o TADDM não é capaz de coletar informações de versão para aplicativosarbitrários do servidor customizado.
É possível usar o TADDM para estender modelos de servidor customizado para coletar informaçõesadicionais, conforme necessário, usando as seguintes abordagens:
• Execute comandos no sistema de destino para preencher qualquer atributo no Modelo de DadosComum para o componente
É possível usar essa abordagem para definir o atributo productVersion, por exemplo. Para obterinformações adicionais, consulte a seção sobre execução de comandos para preencher o Modelo deDados Comum.
• Execute comandos no sistema de destino e armazene o resultado como um arquivo de configuraçãopara o componente
Um uso comum desta abordagem é extrair informações do Registro do Windows. Para obterinformações adicionais sobre execução de comandos para criar um arquivo de configuraçãocustomizado, consulte “Executando Comandos para Criar um Arquivo de Configuração Customizado” napágina 39.
• Execute um script Jython no servidor TADDM.
É possível alterar qualquer informação sobre um componente. A diferença entre esta e a primeiraabordagem é o local em que o código é executado. Isso é mais flexível que a abordagem de CMD. Asextensões do servidor customizado com base em Jython são executadas no servidor TADDM. Essasextensões podem criar novos componentes e definir ExtendedAttributes. Elas também podemconfigurar atributos abaixo do primeiro nível do destino de descoberta.
– Por exemplo, uma extensão com base em CMD pode configurar ComputerSystem.serialNumber ouqualquer outro atributo de primitiva do Sistema de Computador. Uma extensão com base em Jythonpode configurar atributos nas L2Interfaces associadas ao Sistema de Computador.
Limitações
A extensão de modelos de servidor customizado e de sistemas de computador de várias maneiras ésuportada apenas no modo de descoberta regular. A extensão dos modelos de sistema de computador ésuportada somente na descoberta regular. Para extensão de servidor customizado, essa função não ésuportada de todas as maneiras (para extensão) no modo de descoberta assíncrono ou baseado emscript. Para obter mais informações sobre as extensões suportadas no modo de descoberta assíncrono ou
32 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

baseado em script 'Extensão de servidor customizado no modo de descoberta assíncrono e baseado emscript'
Migrando um script para uma nova versão do JythonNo TADDM versão 7.3, duas versões do Jython estão disponíveis. O Jython 2.1 atual está descontinuado,mas ainda usado por padrão. É possível migrar para um novo Jython 2.5.3.
Sobre Esta TarefaAtualmente, scripts e sensores baseados em script usam o Jython 2.1 por padrão, embora ele estejadescontinuado. Para migrar para o Jython 2.5.3, conclua as seguintes etapas.
Procedimento
• Para modificar o script, altere os seguintes interpretadores:
– #!/usr/bin/env ./jython_coll para #!/usr/bin/env ./jython_coll_253– jython_wrap para jython_wrap_253– cjython para cjython_253
• Para modificar os sensores baseados em script, altere o comandoSCRIPT:<script.jy/py> paraSCRIPT[com.ibm.cdb.core.jython253_2.5.3]:<script.jy/py>.
Importante: Não use versões diferentes do Jython em um sensor de modelo. Todos os comandosSCRIPT devem ter o mesmo pacote configurável, o padrão ou o 2.5.3.
Para configurar um script de sensor para usar o Jython 2.5.3, inclua o seguinte código em seucabeçalho:
import sysimport javafrom java.lang import Systemcoll_home = System.getProperty("com.collation.home")jython_home = coll_home + "/osgi/plugins/com.ibm.cdb.core.[jython_1.0.0|jython253_2.5.3]/lib/"sys.path.append(jython_home + "/Lib")sys.prefix = jython_home + "/Lib"
• Para modificar o script que é executado usando UniversalDataAgentConfiguration (quandoparserClassName for JythonParser), inclua o elemento parserBundle, como no seguinteexemplo:
<results> <UniversalDataAgentConfiguration xsi:type="coll:com.collation.platform.model.discovery.agent.UniversalDataAgentConfiguration">...<parserClassName>com.collation.platform.uda.JythonParser</parserClassName> <parserBundle>com.ibm.cdb.core.jython253</parserBundle>
... </UniversalDataAgentConfiguration></results>
• Para modificar o interpretador de script que é executado usando CustomTemplateSensor no descritorCSTTemplate, inclua o elemento engineId, como no seguinte exemplo:
<CTSTemplate>...<engineId>com.ibm.cdb.core.jython253</engineId>...</CTSTemplate>
Estendendo Servidores CustomizadosÉ possível criar um modelo de servidor customizado para um aplicativo para categorizar o aplicativo e,posteriormente, exibi-lo como parte da topologia. Também é possível visualizar detalhes sobre o
Capítulo 1. Usando 33

aplicativo, incluindo a porta de atendimento, informações de tempo de execução e quaisquer arquivos deconfiguração ou descritores de aplicativos que foram coletados.
Sobre Esta TarefaEm alguns casos, entretanto, isso pode não ser suficiente. Por exemplo, pode ser necessário tambémacessar a versão do produto. Por padrão, o TADDM não pode coletar informações de versão paraaplicativos arbitrários de servidor customizado.
No entanto, é possível estender modelos de servidor customizado para coletar informações adicionais,conforme necessário, usando as seguintes abordagens:
• Execute comandos no sistema de destino para preencher qualquer atributo no modelo IBM para ocomponente.
É possível usar essa abordagem para definir o atributo productVersion, por exemplo.• Execute comandos no sistema de destino e armazene o resultado como um arquivo de configuração
para o componente.
Um uso comum desta abordagem é extrair informações do Registro do Windows.• Execute um script Jython no servidor.
É possível alterar qualquer informação sobre um componente. A diferença entre esta e a primeiraabordagem é o local em que o código é executado. Além disso, é possível usar um script Jython parapreencher os atributos estendidos e para criar novos objetos modelo ou relações.
Procedimento
Para definir um servidor customizado, conclua as seguintes etapas:1. Abra o Console de Gerenciamento de Descoberta.2. Crie um modelo de servidor customizado para o aplicativo concluindo as seguintes etapas:
a) Clique em Descoberta > Servidores Customizados na barra lateral.b) Clique em Incluir para definir um novo modelo de servidor customizado.c) Configure as informações gerais e os critérios para o modelo de servidor customizado.d) Configure os arquivos de configuração do servidor customizado.
É possível configurar a captura dos seguintes tipos de arquivos:
• arquivos de configuração• descritores de aplicativos• módulos de software
Para obter informações adicionais sobre descritores de aplicativos, consulte “Descritores deAplicativos” na página 71. Os módulos de software representam módulos de aplicativosimplementados como código executável ou scripts que estão em execução dentro do servidorcustomizado. Este é um nível opcional de detalhe que pode ser incluído na descoberta do seuservidor customizado. Se aplicável, é possível incluir esses módulos de software em Aplicativos deNegócios para um nível mais alto de visibilidade na composição de seus Aplicativos de Negócios.
3. Crie um arquivo de diretiva que contenha os comandos a serem executados e inclua comandos escripts no arquivo descritivo, conforme necessário.
Utilize o formato descrito em Tabela 4 na página 35 ao especificar comandos no arquivo de diretiva.Tabela 5 na página 36 esboça as variáveis de ambiente que podem ser utilizadas no arquivo dediretiva.
Mantenha os comandos o mais simples possível. Se o comando parar durante a execução, o sensoratingirá o tempo limite e o componente não será descoberto.
4. Salve o arquivo de diretiva.
34 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

O arquivo de diretiva deve ter o mesmo nome que o modelo de servidor customizado e deve serarmazenado no seguinte diretório: $COLLATION_HOME/etc/templates/commands. O TADDMaciona diretivas neste diretório usando o nome do modelo de servidor customizado.
O que Fazer Depois
Tabela 4 na página 35 descreve o formato do comando para os arquivos de diretiva.
Tabela 4. Formato do Arquivo de Diretiva
Diretiva Descrição
CMD:variable= path/command É possível definir um comando sequencial. Porexemplo:
CMD:productVersion=/usr/sbin/postconf|awk '/^mail_version/ {print $3}'
Você sempre deve especificar caminhos absolutospara comandos, e deve colocar entre aspas duplas(") comandos ou argumentos que contenhamespaços.
É possível utilizar variáveis de ambienteassociadas ao processo, especificado por$VARIABLE$. Por exemplo:
CMD:productVersion=grep versionNum$TOMCAT_HOME$/config/config.props |awk '{print $2}'
CMD:NOP= path/command É possível executar o comando sem designarresultados a uma variável. Por exemplo:
CMD:NOP=regexport HKLM\Software\Microsoft\InetStp c:\windows\temp\iis.reg /y
CMD:CONFCONTENT. filename= path/command
É possível executar um comando e armazenar osresultados no arquivo de configuraçãocustomizado especificado pelo nome do arquivo.Por exemplo:
CMD:CONFCONTENT.iisREG=cmd.exe /c typec:\windows\temp\iis.reg
Para obter informações adicionais, consulte aseção sobre execução de comandos para criar umarquivo de configuração customizado.
SCRIPT: path/script É possível iniciar scripts Jython (.py). Por exemplo:
SCRIPT:path/command.py
Quando o caminho começa com (/), o TADDMsupõe um caminho absoluto; caso contrário, ocaminho é relativo de $COLLATION_HOME. Paraobter informações adicionais, consulte a seçãosobre a execução de scripts Jython.
Capítulo 1. Usando 35

Tabela 5 na página 36 descreve as variáveis de ambiente disponíveis para uso nos arquivos de diretiva.
Tabela 5. Variáveis de Ambiente do Arquivo de Diretiva
Variável Descrição
$COLL_PROGPATH$ Esta variável é expandida para o nome do diretórioem que o programa está localizado. Por exemplo,se a linha de comandos for /usr/local/bin/foobar -c /etc/foobar.conf, a variável$COLL_PROGPATH$ será expandida para /usr/local/bin.
É possível usar essa variável para isolar seuarquivo de diretiva em casos em que um comandoestá localizado em diferentes diretórios emdiversos computadores.
$COLL_PROGNAME$ Esta variável é expandida para o nome completodo executável. Por exemplo, se a linha decomandos for /usr/local/bin/foobar -c /etc/foobar.conf, a variável$COLL_PROGNAME$ será expandida para /usr/local/bin/foobar. Para executar o comandoapropriado, é possível usar $COLL_PROGPATH$/$COLL_PROGNAME$.
$COLL_CMDLINE$ Esta variável é expandida para a linha decomandos inteira, incluindo todos os argumentos.Por exemplo, se a linha de comandos for /usr/local/bin/foobar -c /etc/foobar.conf, avariável $COLL_CMDLINE$ será expandidapara /usr/local/bin/foobar -c /etc/foobar.conf.
É possível usar essa variável para localizar a versãodo daemon do shell seguro (sshd) em execução emum sistema sem ter que saber onde ele estáinstalado, usando o seguinte comando:
CMD:productVersion=$COLL_PROGPATH$/sshd -V 2>&1 |awk '/version/ {print $3}'
Usando um Script para Estender Extensões de Servidor CustomizadoÉ possível usar shell scripts ou scripts Jython para estender um modelo de servidor customizado (CST). OTADDM copia os scripts definidos no sistema de destino, executa os scripts e retorna os arquivos de saídapara o servidor TADDM.
Importante: A ação de estender extensões de servidor customizado utilizando um script é suportada nomodo de descoberta baseada em script e assíncrona quando a extensão é configurada conformemencionado na seção 'Extensão de servidor customizada no modo de descoberta de script e assíncrona'.
Para iniciar um modelo de servidor customizado usando um script, defina um script principal para ummodelo de servidor customizado especificado. Se necessário, é possível definir um ou mais scriptsadicionais que são usados pelo script principal.
Definição de CST estendido com scripts
Um CST pode ter um arquivo de comando definido no diretório $COLLATION_HOME/etc/templates/commands. O nome do arquivo de comando possui o mesmo nome que o nome do CST. Inclua oscomandos a seguir no arquivo de comando para estender o CST com scripts:
36 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

ASDMAINSCRIPTEsse comando especifica o nome do arquivo de script principal. Ele especifica o script a ser copiado einiciado no sistema de destino.
ASDSCRIPTEsse comando especifica nomes de arquivos de script adicionais, se necessário. Ele especifica scriptsa serem copiados e usados pelo script principal no sistema de destino.
Sintaxe de Comando
Inclua os seguintes comandos no arquivo de comando:ASDMAINSCRIPT:os_discriminator:script_relative_path
A variável os_discriminator define o sistema operacional em que é possível executar o script. Osseguintes valores são válidos:
• AIX• LINUX• SOLARIS• UNIX• WINDOWS• ALL: Use este valor para indicar todos os sistemas operacionais.
A variável script_relative_path define um caminho relativo para um script que inicia a partir dodiretório $COLLATION_HOME. Coloque os scripts em um subdiretório do diretório$COLLATION_HOME/etc/templates/commands.
ASDSCRIPT:os_discriminator:script_relative_pathAs mesmas definições, conforme descrito anteriormente, também se aplicam ao comandoASDSCRIPT.
Exemplo de um arquivo de comando
Um conjunto de scripts é um conjunto de scripts definido com o mesmo atributo os_discriminator. Cadaconjunto de scripts possui um script principal (ASDMAINSCRIPT) e pode ter, se necessário, um ou maisscripts adicionais (ASDSCRIPT). O CST estendido por scripts escolhe o conjunto de scripts maisespecífico para o sistema operacional descoberto.
O exemplo a seguir mostra um arquivo de comando para um CST estendido com scripts:
ASDMAINSCRIPT:AIX:etc/templates/commands/scripts/scriptAix.shASDSCRIPT:AIX:etc/templates/commands/scripts/myTest3.shASDMAINSCRIPT:UNIX:etc/templates/commands/scripts/scriptUnix.shASDSCRIPT:UNIX:etc/templates/commands/scripts/myTest.shASDSCRIPT:UNIX:etc/templates/commands/scripts/myTest2.sh
Esse arquivo de comando define dois conjuntos de script: um para AIX apenas e um para sistemasoperacionais UNIX e similares.
Arquivos Gerados por Script
O TADDM copia os scripts definidos para o sistema de destino e executa o script principal. O scriptprincipal é iniciado no diretório do sistema raiz, mas está localizado em um diretório temporário. Paraobter o local real do script, use o comando dirname $0.
Os scripts e arquivos gerados pelo script, que são armazenados no local temporário no sistema dedestino, são retornados para o servidor TADDM. Os arquivos são colocados no diretório$COLLATION_HOME/var/asdd/{runId}/{targetIp}/{sensorOsgiId}. O nome sensorOsgiIdconsiste no identificador do sensor do servidor de aplicativos customizado (CustomAppSever) e no nomedo modelo. Por exemplo,com.ibm.cdb.discover.sensor.app.customappserver_7.1.0.JavaServer para um CSTJavaServer.
Capítulo 1. Usando 37

Inclua uma extensão Jython em um CST estendido com scriptsPara analisar dados reunidos por um CST estendido com scripts, é possível chamar scripts Jython(extensão .py) automaticamente durante uma descoberta. Para incluir uma extensão Jython em umarquivo de script, você deve incluir o seguinte comando no arquivo de diretiva:SCRIPT:jythonscript_relative_path
O arquivo de diretiva deve ter o mesmo nome do CST e deve ser armazenado no seguinte diretório:$COLLATION_HOME/etc/templates/commands
O TADDM transmite o contexto do sensor do servidor de aplicativos para a linguagem de script usandoum hashmap ou um mapa de destino de script. Esse método ativa o Jython para manipular objetos Java.O mapa de destino do script possui objetos predefinidos que podem ser usados pelo script paraprocessar e transmitir resultados de retorno. Os objetos a seguir estão disponíveis no mapa de destino doscript para um CST estendido com scripts:
• saídas - o objeto <OutputDataSet> da lista• informações do sistema - o objeto de informações do sistema• valor inicial - o objeto CustomAppServerSeed• resultado - o objeto CustomAppServerResult• ambiente - o objeto do ambiente Java HashMap que contém o objeto Mapear <String, String>
O seguinte exemplo mostra uma amostra de código de origem Jython:
...
log = LogFactory.getLogger("com.ibm.cdb.discover.sensor.CustomAppServerScriptSensor")
result = scripttargets.get("result")seed = scripttargets.get("seed");env = scripttargets.get("environment")systeminfo = scripttargets.get("systeminfo")outputDataSetList = scripttargets.get("outputs")
# just print the content of output data set listfor outputDataSet in outputDataSetList: if not outputDataSet.isValid(): log.error("Not valid output data set") continue for outputData in outputDataSet.iterator(): if not outputData.isValid(): log.error("Not valid output data") try: log.info(outputData.getValue()) except ExecutionException, e: log.error("ExecutionException", e)
...
Dica: Para obter mais exemplos de como usar o script Jython para estender um escopo de descoberta,consulte o tópico Estendendo o escopo da descoberta do sensor com o modelo simplificado no DeveloperGuide do SDK do TADDM.
Executando Comandos para Preencher o Modelo de Dados ComumÉ possível executar comandos em um sistema de destino para preencher atributos no Modelo de DadosComum.
Por exemplo, suponha que você tenha gravado um modelo de servidor customizado, chamado postfix,para o agente de transferência de correio postfix. Você deseja utilizar o SDK do TADDM para extrairinformações de software sobre todas as instalações do postfix para que possa planejar atualizações deacordo, mas observa que productVersion não está na saída.
É possível estender o modelo de servidor customizado para capturar estas informações. O comandopostconf exibe a cadeia mail_version e o terceiro campo desta linha contém as informações de versãopara postfix. Portanto, é possível utilizar o comando a seguir para extrair a cadeia de versão:
$ postconf | awk '/^mail_version/ {print $3}'
38 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Para que o TADDM execute o comando, crie um arquivo de diretiva armazenado em$COLLATION_HOME/etc/templates/commands/postfix contendo a linha a seguir:
CMD:productVersion=/usr/sbin/postconf |awk'/^mail_version/ {print $3}'
Nota: Preencher um atributo no Modelo de Dados Comum não o faz aparecer na área de janela Detalhesdo componente, no Console de Gerenciamento de Descoberta. O atributo é, no entanto, armazenado nobanco de dados e pode ser recuperado usando o SDK do TADDM. Para que o atributo apareça na interfacecom o usuário, use uma extensão do arquivo de configuração, conforme descrito na seção sobreexecução de comandos para criar um arquivo de configuração customizado.
• Um atributo no Modelo de Dados Comum, preenchido por uma Extensão de Servidor Customizada, seráexibido no Console de Gerenciamento da Descoberta somente se o Console de Gerenciamento daDescoberta tiver sido projetado para exibir o atributo especificado.
• Preencher atributos não altera os atributos que podem ser exibidos pelo Console de Gerenciamento deDescoberta.
• Saída capturada por diretivas CMD:CONFCONTENT será exibida na guia Arquivos de configuração noConsole de Gerenciamento da Descoberta se o tipo de destino que está sendo descoberto tiver essaguia no Console de Gerenciamento de Descoberta.
Executando Comandos para Criar um Arquivo de Configuração CustomizadoÉ possível executar comandos em um sistema de destino e armazenar resultados em um arquivo deconfiguração customizado.
Você pode fazer isso para registrar uma parte do Registro do Windows em um arquivo de configuração,por exemplo. É possível salvar os resultados em um arquivo de configuração customizado para acessar asinformações usando o Console de Gerenciamento do Discovery.
Nota: Saída capturada por diretivas CMD:CONFCONTENT será exibida na guia Arquivos de configuraçãono Console de Gerenciamento da Descoberta se o tipo de destino que está sendo descoberto tiver essaguia no Console de Gerenciamento de Descoberta.
Por exemplo, suponha que você tenha gravado um modelo de servidor customizado chamadoHomePageWebServer que subcategorize o IIS da Microsoft. É possível criar um arquivo de diretiva com omesmo nome, armazenado no diretório $COLLATION_HOME/etc/templates/commands que contenhaa seguinte linha:
CMD:NOP=reg export HKLM\Software\Microsoft\InetStpc:\windows\temp\iis.reg /y CMD:CONFCONTENT.iisREG=cmd.exe /c type c:\windows\temp\iis.reg
Quando os comandos do arquivo de diretiva forem executados, os resultados da exportação do Registro(reg export) serão armazenados em um arquivo de configuração chamado iisREG.
Limitação: Se você usar a diretiva CMD:CONFCONTENT para ampliar o sensor existente, o sensor doservidor do aplicativo customizado será executado além do sensor existente. Nesse caso, os arquivos deconfiguração são armazenados somente para o sensor que armazena os resultados por último. Porexemplo, se você usar a diretiva para ampliar o sensor do Oracle, ambos os sensores, do Oracle e doservidor de aplicativos customizados serão executados. Se o sensor do Oracle armazena os resultadoscomo últimos, os arquivos de configuração são coletados somente para esse sensor. Se você desejararmazenar os arquivos de configuração que são capturados pelos dois sensores, é possível usar regras depriorização para especificar qual sensor armazenar por último. Por exemplo, para armazenar os arquivosde configuração que são definidos para ambos, o sensor do Oracle e a extensão que você criou, deve-seprimeiro editar a extensão para também coletar todos os arquivos que o sensor do Oracle armazena.Depois, deve-se configurar o sensor do servidor de aplicativos customizados para ter prioridade sobre osensor do Oracle. Como resultado, os arquivos de configuração que são armazenados para o sensor doOracle e extensão são capturados pelo sensor do servidor de aplicativos customizados. Como alternativa,é possível usar extensão do sensor de modelo customizado. A única diferença em comparação com osensor do servidor de aplicativos customizados é que os resultados do sensor existente, por exemplo, o
Capítulo 1. Usando 39

sensor do Oracle, são incluídos na extensão do sensor de modelo customizado. Portanto, não énecessário editar a extensão, mas as regras de priorização ainda se aplicam.
Para obter informações adicionais sobre as regras de priorização, consulte “Incluindo Regras dePriorização em seus Itens de Configuração (Objetos Modelos)” na página 82.
Executando Scripts JythonÉ possível estender modelos do servidor customizado e de sistema do computador chamando os scriptsJython (extensão .py) em um sistema de destino.
O TADDM detecta automaticamente a linguagem de script e transmite o contexto do servidorcustomizado ou do sistema do computador para a linguagem de script usando um hashmap. Isso permiteque o Jython manipule objetos Java.
A estrutura detalhada do script Jython é descrita API de extensões do servidor customizado do Guia dodesenvolvedor de SDK do TADDM. No entanto, a inicialização da seção auxiliar do sensor é diferente paraextensões do modelo de servidor customizado e do modelo do sistema de computador. As seções aseguir fornecem uma descrição dessas diferenças.
Seção sensorhelper do script JythonO script Jython que você usa para estender o servidor customizado e os modelos de sistema docomputador contém a seção sensorhelper. Essa seção inicializa o módulo Python das ferramentas dosensor com informações sobre o destino da descoberta. Dependendo de qual modelo é usado paraestender o escopo da descoberta, ele possui a seguinte forma:
• Inicializando o sensorhelper para um servidor customizado:
(os_handle, result, appserver, seed, log, env)=sensorhelper.init(targets)
• Inicializando o sensorhelper para um sistema de computador:
(os_handle, result, computersystem, seed, log)=sensorhelper.init(targets)
Nota: Não mude a ordem dos elementos nessa seção do script. Caso contrário, ela falha.
Objetos de Mapa de Destino para o Servidor CustomizadoA tabela a seguir lista e descreve os objetos disponíveis no mapa de destinos para o servidorcustomizado.
Tabela 6. Objetos de Mapa de Destino para o Servidor Customizado
Objeto Descrição
os_handle Esse objeto é uma implementação da camada deabstração do TADDM Os. É possível usá-lo paraexecutar comandos remotos.
O método a seguir está disponível:
• executeCommand(String cmd): Executa umcomando em um destino remoto e retorna asaída como uma sequência.
40 Gerenciador de Descoberta de Dependência de Aplicativo: Usando
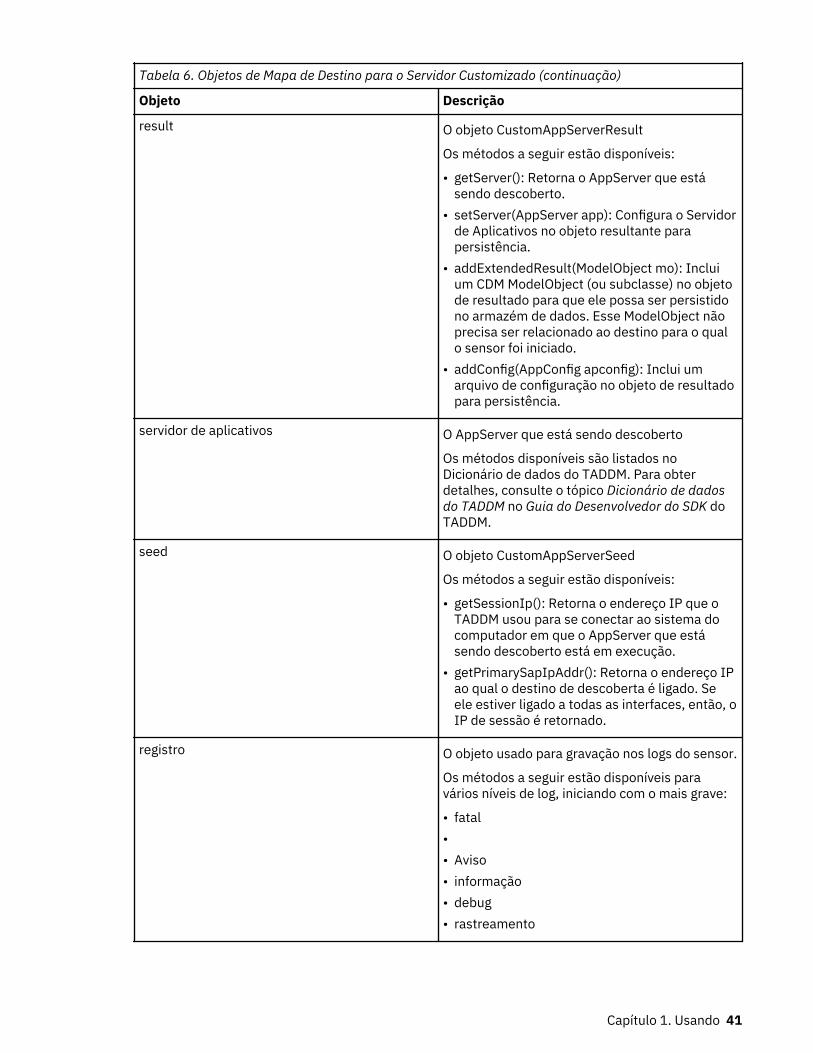
Tabela 6. Objetos de Mapa de Destino para o Servidor Customizado (continuação)
Objeto Descrição
result O objeto CustomAppServerResult
Os métodos a seguir estão disponíveis:
• getServer(): Retorna o AppServer que estásendo descoberto.
• setServer(AppServer app): Configura o Servidorde Aplicativos no objeto resultante parapersistência.
• addExtendedResult(ModelObject mo): Incluium CDM ModelObject (ou subclasse) no objetode resultado para que ele possa ser persistidono armazém de dados. Esse ModelObject nãoprecisa ser relacionado ao destino para o qualo sensor foi iniciado.
• addConfig(AppConfig apconfig): Inclui umarquivo de configuração no objeto de resultadopara persistência.
servidor de aplicativos O AppServer que está sendo descoberto
Os métodos disponíveis são listados noDicionário de dados do TADDM. Para obterdetalhes, consulte o tópico Dicionário de dadosdo TADDM no Guia do Desenvolvedor do SDK doTADDM.
seed O objeto CustomAppServerSeed
Os métodos a seguir estão disponíveis:
• getSessionIp(): Retorna o endereço IP que oTADDM usou para se conectar ao sistema docomputador em que o AppServer que estásendo descoberto está em execução.
• getPrimarySapIpAddr(): Retorna o endereço IPao qual o destino de descoberta é ligado. Seele estiver ligado a todas as interfaces, então, oIP de sessão é retornado.
registro O objeto usado para gravação nos logs do sensor.
Os métodos a seguir estão disponíveis paravários níveis de log, iniciando com o mais grave:
• fatal•• Aviso• informação• debug• rastreamento
Capítulo 1. Usando 41

Tabela 6. Objetos de Mapa de Destino para o Servidor Customizado (continuação)
Objeto Descrição
env O objeto do ambiente HashMap Java. As chavessão as variáveis de ambiente de processos. Osvalores são aqueles das variáveis.
Objetos de Mapa de Destino para o Sistema de ComputadorA tabela a seguir lista e descreve os objetos que estão disponíveis no mapa de destinos para osistema de computador.
Tabela 7. Objetos de Mapa de Destino para o Sistema de Computador
Objeto Descrição
os_handle Esse objeto é uma implementação da camada deabstração do TADDM Os. É possível usá-lo paraexecutar comandos remotos.
O método a seguir está disponível:
• executeCommand(String cmd): Executa umcomando em um destino remoto e retorna asaída como uma sequência.
result O objeto ComputerSystemResult
Os métodos a seguir estão disponíveis:
• getComputerSystem(): Retorna o Sistema deComputador sendo descoberto.
• setComputerSystem(): Configura o Sistema deComputador no objeto de resultado parapersistência.
• addExtendedResult(ModelObject mo): Incluium CDM ModelObject (ou subclasse) no objetode resultado para que ele possa ser persistidono armazém de dados. Esse ModelObject nãoprecisa ser relacionado ao destino para o qualo sensor foi iniciado.
computersystem O ComputerSystem que está sendo descoberto
Os métodos disponíveis são listados noDicionário de dados do TADDM. Para obterdetalhe, consulte o tópico Dicionário de dados doTADDM no Guia do Desenvolvedor de SDK doTADDM.
seed O objeto ComputerSystemSeed
O método a seguir está disponível:
• getIpAddress(): Retorna o endereço IP que oTADDM usa para descobrir o destino.
42 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Tabela 7. Objetos de Mapa de Destino para o Sistema de Computador (continuação)
Objeto Descrição
registro O objeto usado para gravação nos logs do sensor.
Os métodos a seguir estão disponíveis paravários níveis de log, iniciando com o mais grave:
• fatal•• Aviso• informação• debug• rastreamento
Executando o scriptPara executar o script, deve-se criar o arquivo de diretiva e incluir o nome do script Jython, porexemplo:
SCRIPT:myscript.py
Para obter informações adicionais sobre o formato do arquivo de diretiva, consulte “EstendendoServidores Customizados” na página 33.
Por exemplo, é possível executar o script Jython myscript.py incluindo o seguinte comando no arquivode diretiva:
SCRIPT:myscript.py
Criando Novos Objetos e Relacionamentos por meio de Extensões de Servidor CustomizadasÉ possível criar novos objetos e relacionamentos por meio de extensões de servidor customizadas.
Para criar novos objetos e relacionamentos, chame o método addExtendedResult() no objeto deresultado passado ao script. A chamada de método addExtendedResult() utiliza um ModelObjectcomo o parâmetro. Ela pode ser chamada repetidamente se você deseja criar mais de um objeto novo.Pelo menos uma das regras de nomenclatura, definida pelo Modelo de Dados Comum, deve serconfigurada em quaisquer ModelObjects novos que forem incluídos no ExtendedResult paraarmazenamento. A falha em fazer isso fará com o sensor falhe com um "Erro de Armazenamento", pois omecanismo de reconciliação do TADDM não pôde gerar um Identificador Exclusivo Global (GUID) para oModelObject especificado. Para obter informações adicionais, consulte a documentação do Modelo deDados Comum, localizada no arquivo dist/sdk/doc/model/CDMWebsite.zip de seu DVD deinstalação do TADDM.
Extensões de servidor customizadas são iniciadas quando o CustomComputerSystemSensor ou oCustomAppServerSensor é executado. Se o sensor não for executado, a extensão de servidorcustomizada não inicia e os novos objetos e relacionamentos não são criados.
Âncoras e GatewaysÉ possível usar âncoras e gateways para estender descobertas a zonas de rede restritas e para transferiralguns dos processos de descoberta do servidor TADDM para aprimorar o desempenho de descobertageral.
O servidor TADDM usa o protocolo SSH para comunicar diretamente com hosts do computador e outroscomponentes que ele descobre. Entretanto, há dois casos em que o servidor deve se comunicar por meiode um proxy para coletar informações do sistema:
• Ao usar um firewall entre o servidor TADDM e outras seções de sua rede.• Ao descobrir e coletar informações de sistemas Windows.
Capítulo 1. Usando 43

Informações de Requisitos
• Para obter informações sobre os requisitos para gateways do Windows, consulte o tópico Gatewaysdo Windows no Guia de Instalação do TADDM.
• Se você usar âncoras no sistema operacional Windows, para requisitos consulte o tópico Gatewaysdo Windows topic no Guia de Instalação do TADDM.
Restrição: Âncoras são suportadas na edição Cygwin 64 bits no Windows Server 2012 x64 eWindows Server 2008 x64. Porém, o usuário de descoberta e o usuário que iniciar o serviço devemser os mesmos.
• Se você usar âncoras nos sistemas operacionais Linux ou AIX, é possível usar apenas os sistemasque são suportados pelo servidor TADDM. Para requisitos de hardware, consulte o tópico Servidorde descoberta no Guia de Instalação do TADDM.
Executando uma Descoberta Que Requer Âncoras
No exemplo a seguir, o escopo da descoberta é o conjunto de elementos do escopo selecionado paradescoberta na janela Executar Descoberta. Consulte “Executando uma Descoberta Básica” na página 13para obter mais informações.
Ao executar uma descoberta que requer âncoras, assegure que cada âncora esteja incluída no escopo dedescoberta. Por exemplo, para descobrir um destino que está em um conjunto de escopos (por exemplo,scopeset1) atribuído a uma âncora, a âncora e o conjunto de escopos (scopeset1) devem ser incluídos naexecução de descoberta. O conjunto ou os conjuntos de escopos que são designados a cada âncoradevem incluir apenas os endereços IP acessíveis pela âncora. Além disso, se os conjuntos de escoposdesignados ao servidor raiz forem restritos, eles deverão incluir apenas o conjunto de endereços IP que oservidor TADDM pode acessar diretamente, incluindo os endereços IP de quaisquer âncoras definidas.
Balanceamento de carregamento durante uma descoberta
Use as propriedades a seguir para balancear a carga durante uma descoberta:com.ibm.cdb.discover.agents.max
define o número máximo de agentes a ser executado simultaneamente em uma âncora. Estapropriedade pode ter o escopo definido para um perfil ou um servidor âncora específico.O valor padrão é o valor da propriedade com.collation.discover.dwcount.
com.ibm.cdb.discover.workitem.cooldowné uma propriedade geral e define a quantia de tempo, especificada em segundos, que um item detrabalho aguarda antes dele ser processado novamente.O valor padrão é 30.
Configurando ÂncorasÉ possível configurar âncoras para descobertas quando houver um firewall presente.
Sobre Esta TarefaOs dispositivos IP devem responder a pings do servidor TADDM ou a uma âncora para seremdescobertos. Como a maioria dos firewalls não é configurada para redirecionar pings, o servidor TADDMnão consegue executar ping em sistemas por meio de um firewall e não consegue descobri-los. Paraativar a descoberta por meio de um firewall, uma âncora deve ser identificada para ajudar o servidorTADDM com o processo de descoberta.
A âncora deve estar localizada na mesma seção de rede que o destino para descoberta e atender aosmesmos requisitos que o servidor TADDM.
Para poder descobrir sistemas que tenham um firewall entre eles e o servidor TADDM, o servidor TADDMdeve permitir o tráfego SSH na âncora. Assegure-se de que o seu administrador de rede configure ofirewall para ativar o tráfego SSH entre o servidor TADDM e a âncora. Você deve usar o protocolo de redeSSH versão 2 ao trocar os dados.
44 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Nos sistemas Linux e UNIX, a conta de serviço de descoberta possui permissão de execução raiz para ocomando nmap. Assegure-se de que a seguinte linha exista no arquivo de configuração /etc/sudoers:
TADDM_userid ALL=(ALL) NOPASSWD:nmap_path
em que
• TADDM_userid é a conta do serviço de descoberta do TADDM no sistema de âncora.• nmap_path é o caminho completo para o local do comando nmap.
Se o arquivo sudoers contiver uma linha Defaults requiretty, faça um comentário.
A âncora é criada pelo AnchorSensor por meio de uma sessão SSH que se conecta ao sistema definidocomo a âncora. O usuário para a sessão de SSH na primeira entrada do Sistema de Computador (ouSistema de Computador (Windows)) na Lista de Acesso que conclui uma conexão bem-sucedida. Nosistema de âncora, o diretório inicial para esse usuário deverá ser gravável pelo usuário e ter no mínimo1,2 GB de espaço livre. Os arquivos do TADDM, incluindo o SDK Java, são transferidos para esse diretóriousando scp e extraídos. Como esses arquivos contêm código executável, você deve desativar programasantivírus ou configurá-los para permitir que o usuário âncora transfira e extraia esse código. Âncorastambém são reimplementadas automaticamente pelo AnchorSensor após as mudanças de manutençãodo TADDM, como fix packs.
Se a conexão de rede entre o servidor TADDM e o sistema de âncora estiver lenta ou se o servidor TADDMe o servidor de âncora estiverem separados, o AnchorSensor poderá atingir o tempo limite antes deconcluir a criação da âncora. O valor de tempo limite padrão é de 20 minutos. Para alterar o valor detempo limite do AnchorSensor para outro valor, modifique a configuração para o valorcom.collation.discover.agent.AnchorSensor.timeout no arquivo COLLATION_HOME/etc/collation.properties. O valor é em milissegundos, portanto, o valor padrão é 1200000, que é iguala 20 minutos.
Depois que a configuração do firewall estiver concluída, defina a âncora usando o Console deGerenciamento de Descoberta. Quando definir a âncora, você deverá incluí-la no escopo do servidor raiz.O escopo da âncora deve ser restrito aos sistemas dessa seção da rede. Quando a descoberta é iniciada apartir do Console de Gerenciamento de Descoberta, o servidor TADDM implementa os arquivosnecessários para a âncora. Depois que os arquivos forem implementados, a âncora executará adescoberta e retornará os resultados para o servidor TADDM.
Se houver várias zonas ou firewalls, será necessário especificar pelo menos uma âncora em cada zonaadjacente para que as comunicações possam ser transmitidas de cada âncora por meio de cada firewall.Para fazer isso, o tráfego SSH deve ser ativado entre cada par de âncoras adjacentes, começando com oservidor raiz. Cada âncora na próxima sub-rede da rede adjacente deve ser incluída no escopo da âncorana sub-rede anterior. As âncoras encadeadas dessa maneira devem estar em execução no mesmo tipo desistema operacional.
Nota: Se mais de uma âncora estiver especificada em um único escopo e houver conectividade entreelas, o TADDM tentará iniciar o encadeamento de âncoras nessas âncoras. Esse comportamento poderesultar em várias mensagens de erro na GUI e nos logs, mesmo se a âncora for implementadacorretamente.
Consulte “Incluindo uma Âncora ou Gateway” na página 48 para obter informações sobre como definirâncoras usando o Console de Gerenciamento de Descoberta.
Observe também que a interface com o usuário do TADDM não indica em qual zona NAT está um objeto.Para evitar confusão, assegure-se de que os hosts com o mesmo endereço IP em diferentes zonas NATtenham nomes de hosts diferentes, o que possibilita distingui-los. Designe domínios diferentes (porexemplo, nat1.lab.company.com, nat2.lab.company.com) para cada zona NAT. Isso assegura que osnomes completos dos hosts em diferentes zonas NAT sejam exclusivos. Observe que se o mesmoservidor DNS for usado para diferentes zonas NAT com endereços de sub-rede idênticos, entãovisualizações de DNS diferentes deverão ser usadas para cada zona.
Nota: Quando uma âncora ou outro host dual-homed for descoberto por meio de uma descoberta L1, ohost pode ser exibido como uma entrada duplicada na área de infraestrutura física. Essa duplicaçãoocorre porque o host é descoberto duas vezes, uma pelo TADDM e uma pela âncora, e a descoberta L1
Capítulo 1. Usando 45

não fornece informações suficientes para reconciliar as duas descobertas. Para reconciliar as duasentradas como um host, execute uma descoberta L2 ou L3.
Se mais de um servidor de domínio, na implementação do servidor de sincronização, ou servidor dedescoberta, na implementação do servidor de fluxo, usar a mesma máquina como uma âncora na qualexecutar descobertas simultâneas, as seguintes alterações deverão ser feitas:
• Configure a porta da âncora.
1. Na área de janela Âncoras e Gateways do Console de Gerenciamento de Descoberta, clique emConfigurar Porta da Âncora. A janela Editar Número da Porta é exibida.
2. No campo Nº da Porta, digite o número da porta. Assegure-se de que o número da porta sejadiferente para cada servidor TADDM.
3. Clique em OK.• Configure o diretório de âncora.
1. Abra o arquivo $COLLATION_HOME/etc/collation.properties.2. Configure o valor da propriedade com.ibm.cdb.taddm.anchor.root para o nome do diretório de
âncora. Assegure-se de que a propriedade não tenha um comentário e que o diretório seja diferenteem cada servidor TADDM.
O TADDM define um atributo de identificação de local para cada item de configuração (CI) criado noservidor TADDM. Para definir o atributo de identificação local para CIs criados em uma âncora, configureo atributo anchor_location_n no arquivo $COLLATION_HOME/etc/anchor.properties. Asentradas da amostra a seguir do arquivo anchor.properties indicam como as informações de localdas âncoras é definida:
anchor_host_1=192.168.1.13anchor_scope_1=FIRST_SCOPEanchor_zone_1=FIRST_ZONEanchor_location_1=FIRST_LOCATIONanchor_host_2=192.168.2.22anchor_scope_2=SECOND_SCOPEanchor_location_2=SECOND_LOCATIONPort=8497
Se uma identificação de local não for especifica para uma âncora, o local de cada um dos CIs criados naâncora é definido para o local que está especificado para o servidor TADDM ao qual os CIs estãoconectados. Se a identificação do local não for especificada para a âncora ou o servidor TADDM, nenhumainformação de local é definida para esse CI.
Configurando para Descoberta por meio de Firewalls NATÉ possível criar zonas NAT para suportar a descoberta de hosts em uma rede privada atrás de um firewallNAT.
Sobre Esta Tarefa
O TADDM suporta a descoberta de hosts em uma rede privada que usa conversão de endereço de rede(NAT). Uma rede privada, conforme definida por RFC 1918, usa endereços IP privados que ficam dentrode um dos seguintes blocos de endereços:
• 10.0.0.0/8 (10.0.0.0 até 10.255.255.255)• 172.16.0.0./20 (172.16.0.0 até 172.31.255.255)• 192.168.0.0/16 (192.168.0.0 até 192.168.255.255)
Como diferentes redes privadas acessíveis por meio de firewalls NAT podem usar os mesmos endereços,a descoberta de objetos usando esses endereços pode não ser possível para identificar hosts em redesprivadas diferentes como distintos. Por exemplo, dois objetos diferentes podem ser designados aoendereço IP privado 10.10.10.3, pois eles existem em redes privadas diferentes. Quando descoberto pormeio de um firewall NAT, um objeto deverá sobrescrever o outro no banco de dados TADDM.
46 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Esse problema pode ser evitado criando Zonas NAT, que são sequências arbitrárias que você define paraidentificar cada rede privada atingível por meio de NAT. Quando o TADDM descobre um endereço IPdentro de uma rede privada associada a uma zona NAT, ele inclui a sequência da zona como parte doobjeto de endereço IP armazenado. Isso garante que objetos de diferentes redes privadas sejamidentificados de forma não ambígua e armazenados separadamente, mesmo se eles tiverem os mesmosendereços IP em suas redes respectivas.
Procedimento
Para configurar para descoberta por meio de um firewall NAT, conclua as seguintes etapas:1. Crie uma âncora usando o Console de Gerenciamento de Descoberta.
Para suportar a descoberta NAT, você deve especificar um escopo.2. Edite o arquivo $COLLATION_HOME/etc/anchor.properties com um editor de texto.3. Localize as entradas anchor_host_n e anchor_scope_n (em que n é um número) que corresponde
à âncora recém-incluída.4. Inclua uma entrada anchor_zone_n correspondente.
Por exemplo, se você criou um host de âncora com o endereço 9.43.73.184 e o escopo QA_SCOPE, aentrada modificada pode ser a seguinte:
#Last modified on:#Mon Feb 16 16:19:52 PST 2009anchor_host_1=9.43.73.184anchor_scope_1=QA_SCOPEanchor_zone_1=QA_ZONEport=8497
Nota: Alterar um nome de zona NAT pode causar a criação de objetos duplicados associados ao novonome. Portanto, ao nomear uma zona NAT, escolha uma sequência que seja uma descrição simbólicae significativa da rede privada, em vez de um nome derivado do endereço IP ou do nome do host daâncora (que pode ser alterado). Depois de definida a zona NAT e usá-la para descoberta, evite alterá-la.
5. Execute uma descoberta no escopo NAT e um escopo contendo a âncora.No exemplo anterior, isso seria uma descoberta no escopo QA_SCOPE e um escopo contendo oendereço da âncora 9.43.73.184.
Configurando Gateways do WindowsÉ possível configurar gateways do Windows para descoberta quando houver um firewall presente.
Sobre Esta TarefaAmbos, uma âncora e um gateway são necessários para descobrir sistemas Windows com a proteção deum firewall. O servidor TADDM usa o SSH para se comunicar com a âncora atrás de um firewall. A âncora,por sua vez, usa a SSH para se comunicar com o gateway do Windows. O gateway do Windows usa entãoWindows Management Instrumentation (WMI) para descobrir os destinos do Windows. Deve haver umgateway do Windows localizado em cada zona de rede em que você deseja descobrir sistemas Windows.
Consulte “Incluindo uma Âncora ou Gateway” na página 48 para obter informações sobre como definirgateways do Windows usando o Console de Gerenciamento de Descoberta.
Se você estiver usando uma âncora e um gateway no mesmo sistema, para resolver problemas doCygwin, inclua a seguinte entrada no arquivo Collation.properties:com.collation.platform.session.GatewayForceSsh
Especifica se o gateway dever ser forçado a agir independentemente da âncora. Os valores válidossão true e false. Configure o valor como true. Quando o valor for configurado como true, uma sessãoSSH será usada para transferir tráfego entre o gateway e a âncora, em vez de uma sessão local.
Configurando para Descoberta Através de um Firewall Sem uma ÂncoraEm ambientes que tenham vários firewalls, a implementação de uma âncora em cada zona de firewallpode não ser prática.
Capítulo 1. Usando 47

Nessas situações, pode ser mais fácil abrir portas no firewall em vez de implementar âncoras. Paraplataformas não Windows, a lista de portas que devem ser abertas são aquelas necessárias paradescoberta de aplicativo. Como as portas de aplicativos podem ser configuradas, não há uma listapredefinida de portas. Normalmente, abrir todas as portas acima de 1024 deve ser suficiente.
Para sistemas Windows, além das portas de aplicativo, as portas de compartilhamento de arquivos e asportas RPC restritas devem ser abertas:
• 139 RCP Ativar Serviço de Sessão NetBIOS• 445 TCP Ativar SMB sobre TCP• 137 UDP Ativar Serviço de Nomes NetBIOS• 138 UDP Ativar Serviço de Datagrama NetBIOS• 135 TCP Ativar DCOM• 5000 TCP Ativar RPC• 5001 TCP Ativar RPC• 5002 TCP Ativar RPC• 5003 TCP Ativar RPC• 5004 TCP Ativar RPC• 5005 TCP Ativar RPC• 5006 TCP Ativar RPC• 5007 TCP Ativar RPC• 5008 TCP Ativar RPC• [...]• 5099 TCP Ativar RPC• 5100 TCP Ativar RPC
Para limitar o intervalo de portas que a Microsoft utiliza para RPC, consulte http://support.microsoft.com/kb/154596, para obter informações adicionais.
No TADDM 7.3.0.2 e mais recentes, é possível usar a sessão do PowerShell para descobrir ossistemas de destino do Windows. Para essa sessão, a porta 5985 ou a 5986 deve ser aberta. As portaslistadas anteriormente não são necessárias. Se o seu firewall estiver configurado para permitir somentecomunicação limitada, por exemplo, se ele permitir somente as portas do PowerShell, será necessárioconfigurar o sensor Ping para a descoberta ser bem-sucedida. Inclua a propriedadecom.collation.pingagent.ports no arquivo collation.properties e configure o valor como5985, 5986 ou ambos. Para obter detalhes, consulte o tópico Configurando as entradas do arquivocollation.properties na seção Sensor Ping da Referência do sensor do TADDM.
Incluindo uma Âncora ou GatewayÉ possível usar o Console de Gerenciamento de Descoberta para incluir uma âncora ou um gateway.
Procedimento
Para incluir uma âncora ou gateway Windows, conclua as etapas a seguir no Console de Gerenciamentode Descoberta:1. Na área de janela Funções, clique em Descoberta > Âncoras e Gateways.
A área de janela Âncoras e Gateways é exibida.2. Na área de janela Âncoras e Gateways, clique em Incluir.
A janela Incluir Âncora é exibida.3. Na lista Tipo, conclua uma das etapas a seguir:
• Para incluir uma âncora, selecione Âncora.• Para incluir um gateway Windows, selecione Gateway do Windows.
48 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

4. Para identificar a âncora ou gateway Windows, conclua uma das etapas a seguir:
• Para configurar pelo endereço IP, clique em Endereço e, em seguida, digite o endereço IP no campoEndereço.
• Para configurar pelo nome do host, clique em Nome do Host e, em seguida, digite o nome do host nocampo Nome do Host.
5. No Escopo para procurar a seção do host, conclua uma das etapas a seguir:
• Para incluir o escopo de descoberta inteiro, clique em Escopo Inteiro.• Para restringir o escopo usado pela âncora, clique em Limitar aos conjuntos de escopos
selecionados ou em Limitar aos grupos de escopos selecionados e, em seguida, selecione osconjuntos de escopos ou grupos de escopos que deseja incluir.
6. Para salvar a âncora ou o gateway do Windows, clique em OK.
O que Fazer DepoisDepois de incluir uma âncora, você deve incluir o endereço IP ou o nome do host para ele no escopo dedescoberta. Consulte “Configurando um Escopo” na página 2, para obter informações adicionais.
Editando uma Âncora ou GatewayDepois de incluir uma âncora ou um gateway Windows, não é possível alterar o seu tipo, endereço IP ounome do host, mas é possível editar o escopo.
Procedimento
Para editar o escopo de uma âncora ou gateway do Windows, conclua as etapas a seguir no Console deGerenciamento de Descoberta:1. Na área de janela Funções, clique em Descoberta > Âncoras e Gateways.
A área de janela Âncoras e Gateways é exibida.2. Na área de janela Âncoras e Gateways, selecione a âncora ou um gateway que você deseja editar e
clique em Editar Escopo.A janela Incluir Âncora é exibida.
3. Para alterar as configurações do escopo, conclua uma das etapas a seguir:
• Para utilizar as informações de acesso em todos os componentes do conjunto de escopos definidos,clique em Escopo Inteiro.
• Para restringir o aplicativo de informações de acesso específicas para determinados sistemas, cliqueem Limitar aos conjuntos de escopos selecionados ou em Limitar aos grupos de escoposselecionados e, em seguida, selecione o conjunto de escopos ou grupo de escopos para qual desejarestringir o acesso.
4. Para salvar suas alterações, clique em OK.
Excluindo uma Âncora ou GatewayÉ possível usar o Console de Gerenciamento de Descoberta para excluir uma âncora ou gatewayWindows.
Procedimento
Para excluir uma âncora ou gateway Windows, conclua as etapas a seguir no Console de Gerenciamentode Descoberta:1. Na área de janela Funções, clique em Descoberta > Âncoras e Gateways.
A área de janela Âncoras e Gateways é exibida.2. Na área de janela Âncoras e Gateways, selecione a âncora ou o gateway Windows que deseja excluir
e clique em Excluir.Uma janela de mensagem é exibida.
3. Para excluir a âncora ou o gateway do Windows, clique em Sim na janela de mensagens.
Capítulo 1. Usando 49

4. Para confirmar a exclusão, certifique-se de que a âncora ou o gateway do Windows não esteja listadona área de janela Âncoras e Gateways.
Configurando uma Porta de ÂncoraSe a porta de âncora padrão estiver em uso por outro aplicativo, você deve definir um novo número deporta para a âncora.
Sobre Esta Tarefa
Importante: A porta da âncora é uma configuração global para todas as âncoras. Portanto, quando vocêdefinir um novo número de porta para uma âncora, o novo número de porta é designado para todas asâncoras.
Procedimento
Para definir a porta da âncora, conclua as seguintes etapas a partir do Console de Gerenciamento deDescoberta:1. Na área de janela Funções, clique em Descoberta > Âncoras e Gateways.2. Na área de janela Âncoras e Gateways, selecione uma âncora e clique em Configurar Porta de
Âncora.3. No campo Nº da Porta:, digite o número da porta da âncora.4. Para salvar o número da porta, clique em OK.
Parando a ÂncoraUma descoberta pode incluir uma ou mais âncoras. As âncoras devem parar a execução quando foremconcluídas ou se atingirem o tempo limite. Se desejar encerrar o servidor TADDM, deverá encerrartambém cada âncora. Se você não encerrar cada âncora, isso poderá levar a um comportamentoinesperado, incluindo mal desempenho de algumas descobertas.
Procedimento
Se a âncora não parar por si mesma, conclua as seguintes etapas a partir do Console de Gerenciamentode Dados:1. Verifique se os processos da âncora não estão mais em execução digitando o seguinte comando:
% ps -ef |grep -i anchor
Esse comando identifica quaisquer processos de âncora que ainda estejam em execução. Você deveobter a saída semelhante a seguir:
coll 237510.0 0.0 6136 428 ? S Jun02 0:00 /bin/sh local-anchor.sh 8494 <more information here>
2. Pare o processo digitando o seguinte comando:
- % kill-9 23751
Você deveria obter nenhuma saída ou algo semelhante ao seguinte:
root 13561 13486 0 16:19 pts/0 00:00:00grep -i anchor
Planejamentos de DescobertaÉ possível planejar descobertas para assegurar que as informações apresentadas no Console deGerenciamento de Descoberta sejam sempre atuais e exatas.
50 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Sobre Esta Tarefa
Na maioria dos casos, particione o seu ambiente em grupos operacionais e execute descobertas nessessubconjuntos de sua organização. Isto reduz o tempo que leva para concluir uma descoberta particular eleva em conta que seções diferentes de seu ambiente são alteradas em velocidades diferentes.
Se você criar um planejamento para executar uma descoberta, ele ligará o escopo atual àqueleplanejamento. Posteriormente, se desejar incluir uma nova entrada no escopo, será necessário excluir oplanejamento e criar um novo. É possível planejar uma descoberta para executar as seguintes tarefas:
• Identificar grupos operacionais dentro de seu ambiente. Diferentes seções de seu ambienteprovavelmente têm diferentes velocidades de alteração. Identificando grupos operacionais em sua redepelos endereços IP, intervalos do endereço IP e sub-redes, você pode planejar para que partições desua infra-estrutura tenham diferentes planejamentos de descoberta.
• Verifique o histórico de descoberta para determinar quanto tempo geralmente leva para concluirdiferentes tipos de descobertas em seu ambiente.
Os planejamentos de descoberta não podem ser sobrepostos. A primeira descoberta deve ser concluídaantes que uma nova descoberta possa ser iniciada. Se uma descoberta for planejada para ser iniciadaantes que uma descoberta existente tenha sido concluída, a nova descoberta não será iniciada e seráregistrado um erro.
Verifique o histórico de descoberta para fazer uma estimativa do tempo de conclusão típico paradiferentes descobertas para que seja possível evitar potenciais sobreposições de planejamento.
• O planejamento descobre com base nos grupos operacionais identificados por você. Configure amaioria das descobertas planejadas para atualizarem um subconjunto de sua topologia. Por exemplo,dependendo do tamanho de seu ambiente e de suas necessidades operacionais, você poderá planejaruma descoberta completa uma vez a cada 24 horas ou concluir uma descoberta da camada doaplicativo uma vez a cada seis horas.
Ao criar um planejamento de descoberta, você especifica a hora de início e a freqüência de descobertas.É possível também definir o escopo de uma descoberta particular selecionando os elementos do escopo(sub-redes, endereços IP ou intervalos), os componentes ou as visualizações a serem incluídos nadescoberta.
Referências relacionadas“Área de Janela Planejamento ” na página 138É possível visualizar informações de planejamento na área de janela Planejamento.
Incluindo um Planejamento de DescobertaIncluir um planejamento instrui o servidor a executar uma descoberta no tempo definido.
Procedimento
Para incluir um planejamento de descoberta, conclua as seguintes etapas a partir do Console deGerenciamento de Descoberta:
1. Na área de janela Funções, clique em Descoberta > Planejamento.A área de janela Planejamento é exibida.
2. Na área de janela Planejamento, clique em Incluir.O bloco de notas Planejamento de Descoberta é exibido.
3. No campo Nome, digite o nome do planejamento de descoberta.4. No campo Hora de Início (hora do servidor), digite a data e a hora em que deseja que o
planejamento de descoberta seja iniciado.5. Na lista Repetir, selecione a freqüência com que deseja que o planejamento de descoberta seja
executado.6. No campo Cada, digite o valor numérico para o intervalo de tempo.7. Para configurar o escopo do planejamento de descoberta, clique na guia Escopo. A página Escopo é
exibida.
Capítulo 1. Usando 51

8. Selecione os elementos do escopo que deseja incluir. Se você usar o TADDM 7.3.0.3 ou mais recente,selecione uma das opções a seguir:
• Conteúdo dinâmico de escopos e grupos selecionados. Nesse modo, é possívelselecionar somente conjuntos de escopos e grupos de escopos. Eles são resolvidos para uma listade elementos pouco antes de uma descoberta. Isso significa que é possível modificar o conteúdode tais conjuntos de escopos e grupos de escopos e as descobertas de execuções deplanejamento definidas com lista atualizada de elementos de escopo. Como resultado, não énecessário modificar um planejamento sempre que mudar o conteúdo de um conjunto de escoposou um grupo de escopos.
• Elementos selecionados estáticos de escopos e grupos. Nesse modo, é possívelselecionar conjuntos de escopos, grupos de escopos e elementos do escopo únicos. O conteúdode tal escopo é estático, o que significa que somente os elementos escolhidos são descobertos.Se o conjunto de escopos ou o conteúdo do grupo de escopos mudar ao longo do tempo, adescoberta será executada com relação aos elementos que pertenceram ao escopo no momentoda criação do planejamento de descoberta.
9. Na lista Perfil, selecione uma das seguintes opções:
• Para descobrir sistemas de computador ativos no ambiente de tempo de execução, selecioneDescoberta de Nível 1. Este perfil pode ser utilizado para executar a descoberta sem credencial.
• Para descobrir informações detalhadas sobre os sistemas de computador ativos no ambiente detempo de execução, selecione Descoberta de Nível 2.
• Para descobrir a infraestrutura de aplicativo inteira, componentes de software implementados,servidores físicos, dispositivos de rede, LAN virtual e dados do host, selecione Descoberta de Nível3.
10. Para salvar o planejamento de descoberta, clique em OK.
Visualizando Detalhes do Planejamento de DescobertaÉ possível exibir as informações de resumo sobre um planejamento de descoberta na janela Detalhes doPlanejamento de Descoberta.
Procedimento
Para exibir os detalhes para um planejamento de descoberta, conclua as seguintes etapas a partir doConsole de Gerenciamento de Descoberta do Produto:1. Na área de janela Funções, clique em Descoberta > Planejamento.
A área de janela Planejamento é exibida.2. Na área de janela Planejamento, selecione o planejamento para o qual deseja visualizar detalhes e
clique em Detalhes.A janela Detalhes do Planejamento é exibida. Não é possível alterar nenhum dos detalhes para oplanejamento de descoberta. Para ver qual tipo de detalhes são exibidos, acesse “Janela Detalhes doplanejamento” na página 139.
3. Para fechar a janela Detalhes do Planejamento, clique em Fechar.
Excluindo um Planejamento de DescobertaÉ possível excluir um planejamento de descoberta existente.
Procedimento
Para excluir um planejamento de descoberta, conclua as seguintes etapas a partir do Console deGerenciamento de Descoberta:1. Na área de janela Funções, clique em Descoberta > Planejamento.
A área de janela Planejamento é exibida.2. Na área de janela Planejamento, selecione o planejamento que deseja excluir e clique em Excluir.
Uma janela de mensagem é exibida.
52 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

3. Para excluir o planejamento, clique em Sim na janela de mensagem.4. Para confirmar a exclusão, certifique-se de que o planejamento não esteja listado na área de janela
Planejamento.
Visualizando o Histórico de DescobertaCada vez que uma descoberta é executada, o Console de Gerenciamento de Descoberta atualiza aatividade de descoberta e as informações de erro que são exibidas na área de janela Histórico.
Sobre Esta Tarefa
É possível visualizar o histórico de descoberta, incluindo a atividade associada e informações de erro, naárea de janela Histórico. Por padrão, as informações sobre as últimas dez descobertas são exibidas.
Pode demorar muito para recuperar e exibir o histórico de descobertas na área de janela Histórico. Comoalternativa, tente usar Eventos Concluídos do Sensor pela Execução do Relatório BIRT.
A tabela a seguir lista e descreve as informações que são exibidas para cada descoberta.
Tabela 8. Informações do Histórico de Descoberta
Campo Descrição
Hora de Início A data e a hora em que a descoberta foi iniciada.
Hora deConclusão
A data e a hora em que a descoberta foi concluída.
Código deConclusão
O status final da descoberta.
Perfil Utilizado O tipo de perfil utilizado pela descoberta. Pode ser uma das opções a seguir:
• Descoberta de Nível 1• Descoberta de Nível 2• Descoberta de Nível 3• Customizada
Consulte “Utilizando Perfis de Descoberta” na página 53 para obter informaçõesadicionais sobre perfis de descoberta.
Procedimento
Para visualizar um histórico da descoberta, conclua as seguintes etapas a partir do Console deGerenciamento de Descoberta:1. Na área de janela Funções, clique em Descoberta > Histórico.
A área de janela Histórico é exibida.2. Para exibir informações sobre uma descoberta, selecione uma entrada na tabela.
Uma segunda tabela de dados é exibida. Esta tabela fornece uma lista de sensores e o nome do host,endereço IP, data, status e descrição para cada sensor.
3. Para exibir os escopos que estão incluídos na descoberta, clique em Detalhes do Escopo. A janelaLista de Escopos é exibida.
4. Para fechar a janela Lista de Escopos, clique em Cancelar.
Utilizando Perfis de DescobertaOs perfis de descoberta o ajudam a descobrir seu ambiente de TI.
O TADDM descobre e coleta informações de configuração para a infraestrutura inteira de aplicativos,identificando componentes de software implementados, servidores físicos, dispositivos de rede, LANvirtual e dados do host utilizados em um ambiente do datacenter.
Capítulo 1. Usando 53

Por exemplo, configura sensores individuais, gerencia várias configurações do mesmo sensor, pega aconfiguração apropriada com base em um conjunto de critérios e gerencia conjuntos de configuração desensores diferentes a serem aplicados em uma única execução. Você pode também especificar uma listade acesso do perfil de descoberta e ela ser utilizada apenas durante uma descoberta com esse perfilparticular. Uma lista de acesso do perfil de descoberta funciona da mesma maneira que uma lista deacesso geral.
Criando Perfis de DescobertaAo criar perfis de descoberta, os perfis padrão, os sensores padrão e as configurações dos sensorespadrão não são editáveis.
Sobre Esta Tarefa
Quando executa uma descoberta, você deve selecionar um perfil. Se nenhum perfil for selecionado, adescoberta será executada contra o perfil padrão, que é uma descoberta de Nível 3. Para alterar o perfilpadrão, clique em Editar > Preferências e selecione outro perfil.
Procedimento
Para criar perfis de descoberta, conclua as seguintes etapas:1. Na gaveta Descoberta do Console de Gerenciamento de Descoberta, clique em Perfis de
Descoberta.2. Na janela Perfis de Descoberta, clique em Novo.3. Digite o nome do perfil.
O nome do perfil deve ser exclusivo.4. Digite uma descrição para o novo perfil. A descrição é exibida na interface com o usuário com as
páginas Configuração do Sensor, Controle de Acesso e Propriedades da Plataforma.5. Ao criar um novo perfil, é possível usar um perfil existente como base para o novo perfil. Na lista
Clonar o perfil existente, selecione um perfil existente ou selecione Nenhum. Clonar um perfilexistente inclui a configuração do agente, a lista de acesso e a configuração da plataforma.
Há três níveis de perfis de descoberta entre os quais escolher:Descoberta de Nível 1
Este perfil pode ser utilizado para executar a descoberta sem credencial. Ela pode ser utilizadapara descobrir sistemas do computador ativos no ambiente de tempo de execução.
Descoberta de Nível 2Este perfil pode ser utilizado para descobrir informações detalhadas sobre sistemas docomputador ativos no ambiente de tempo de execução.
Descoberta de Nível 3Este perfil pode ser utilizado para descobrir a infraestrutura de aplicativo inteira, componentesde software implementados, servidores físicos, dispositivos de rede, LAN virtual e dados do hostutilizados em um ambiente de tempo de execução. Se você estiver executando uma descobertautilizando qualquer um dos sensores (aplicativo) de camada de Nível 3, sensores do sistema decomputador das plataformas correspondentes devem ser ativados. Por exemplo, o sensor doServidor SQL da Microsoft ou o sensor do Servidor Citrix Server requerem que o sensor dosistema de computador Windows esteja ativado durante a descoberta. Se você executar o sensordo aplicativo sem ativar o sensor do sistema de computador, isso pode causar um erro dearmazenamento do sensor do aplicativo.
6. Clique em OK.O perfil de descoberta é criado e listado com os outros perfis existentes. Os perfis são listados aolado das páginas Configuração do Sensor, Controle de Acesso e Propriedades da Plataforma. Senão conseguir ver os perfis, procure uma barra divisora ao lado da página Configuração do Sensor.Use o mouse para mover a barra divisora para ver a lista de perfis.Ao selecionar um perfil, os detalhes do perfil são exibidos nas páginas Configuração do Sensor,Controle de Acesso e Propriedades da Plataforma.
54 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

7. Na página Configuração do Sensor, selecione um sensor e você poderá criar, ativar e configurarsensores.Ao configurar um sensor, você deve primeiro fazer uma cópia do sensor padrão que faz parte doproduto TADDM. Em seguida, modifique essa cópia. Para fazer uma cópia do sensor padrão, concluaas seguintes etapas:
a. Destaque o sensor que deseja modificar e clique em Novo. O diálogo Criar Configuração éexibido.
b. Nomeie seu novo sensor.Nota: Quando o TADDM usa o nome especificado para acesso de sistema de arquivos, porexemplo, logs, contextos de scripts estáticos, e assim por diante, todos os caracteres especiais ede espaço em branco são removidos do nome.
c. Para ativar sua configuração e desativar a configuração padrão, clique no botão de opções. Agora,é possível modificar a configuração do sensor.
É possível incluir restrições de escopo em um sensor. Uma restrição de escopo significa que quandouma descoberta é executada usando um perfil, o sensor é executado apenas no escopo configuradocom esta restrição de escopo, ou seja, conjuntos de escopos e grupos de escopo selecionados. Porexemplo, se você deseja que o WebSphereSensor para o perfil ProfileTest seja executado no conjuntode escopos da WebSphereDiscovery, crie uma nova configuração de sensor baseada no sensor decélula WebSphere e configure uma restrição de escopo da WebSphereDiscovery. Quando vocêexecutar a descoberta utilizando o perfil ProfileTest, selecione os conjuntos de escopos apropriados(incluindo WebSphereDiscovery) e o sensor de célula do WebSphere é executado apenas no conjuntode escopos de descoberta do WebSphere.
8. Na página Controle de Acesso, é possível incluir, editar ou excluir entradas de controle de acessopara o perfil de descoberta.Qualquer controle de acesso definido na página Controle de Acesso substitui os controles de acessoda lista de acesso principal.
9. Na página Propriedades da Plataforma, é possível incluir, editar ou excluir propriedades para umaplataforma.
10. Clique em Salvar.
Alterando Perfis de DescobertaUse a gaveta Descoberta do Console de Gerenciamento de Descoberta para alterar os perfis dedescoberta.
Procedimento
Para alterar perfis de descoberta, conclua as etapas a seguir:1. Na gaveta Descoberta do Console de Gerenciamento de Descoberta, clique em Perfis de Descoberta.2. Na janela Perfis de Descoberta, selecione o perfil que deseja alterar.
Os perfis são listados ao lado das páginas Configuração do Sensor, Controle de Acesso ePropriedades da Plataforma. Se não conseguir ver os perfis, procure uma barra divisora ao lado dapágina Configuração do Sensor. Use o mouse para mover a barra divisora para ver a lista de perfis.Ao selecionar um perfil, os detalhes do perfil são exibidos nas páginas Configuração do Sensor,Controle de Acesso e Propriedades da Plataforma.
3. Na página Configuração do Sensor, selecione um sensor e você poderá criar, ativar, configurar eexcluir sensores.Ao configurar um sensor, dê um clique duplo no valor que deseja editar. Ao excluir sensores, não épossível excluir sensores padrão.
Importante: Para salvar o valor editado, clique em Enter. Se você clicar em OK depois de editar ovalor, a alteração não será salva.
4. Na página Controle de Acesso, é possível incluir, editar ou excluir entradas de controle de acesso parao perfil de descoberta.
Capítulo 1. Usando 55

Qualquer controle de acesso definido na página Controle de Acesso substitui os controles de acessoda lista de acesso principal.
5. Na página Propriedades da Plataforma, é possível incluir, editar ou excluir propriedades para umaplataforma.
6. Clique em Salvar.
Excluindo Perfis de DescobertaUse a gaveta Descoberta do Console de Gerenciamento de Descoberta para excluir perfis de descoberta.
Procedimento
Para excluir um perfil de descoberta, conclua as etapas a seguir:1. Na gaveta Descoberta do Console de Gerenciamento de Descoberta, clique em Perfis de Descoberta.2. Na janela Perfis de Descoberta, selecione o perfil que deseja excluir. Não é possível excluir um perfil
padrão.Os perfis são listados ao lado das páginas Configuração do Sensor, Controle de Acesso ePropriedades da Plataforma. Se não conseguir ver os perfis, procure uma barra divisora ao lado dapágina Configuração do Sensor. Use o mouse para mover a barra divisora para ver a lista de perfis.
3. Clique em Excluir.É exibida uma mensagem de confirmação.
Planejando Perfis de DescobertaUse a gaveta Descoberta do Console de Gerenciamento de Descoberta para planejar os perfis dedescoberta.
Procedimento
Para criar um planejamento para um perfil de descoberta, conclua as etapas a seguir:1. Na gaveta Descoberta do Console de Gerenciamento de Descoberta, clique em Planejamento.2. Na janela Planejamento, clique em Incluir.3. Na página Detalhes, conclua as etapas a seguir:
a. Digite um nome.b. Selecione uma data e uma hora de início.c. Selecione a opção para repetir a descoberta.
4. Na página Escopo, conclua as etapas a seguir:
a. Selecione um escopo.b. Para o escopo, configure as opções.c. Selecione um perfil.
5. Clique em OK.
Executando uma Descoberta Utilizando PerfisUse a gaveta Descoberta do Console de Gerenciamento de Descoberta para executar uma descobertausando perfis.
Procedimento
Para executar uma descoberta utilizando um perfil, conclua as etapas a seguir:1. Na gaveta Descoberta do Console de Gerenciamento de Descoberta, clique em Visão Geral.2. Na janela Visão Geral, clique em Executar Descoberta.3. Selecione os componentes e os elementos do escopo.4. Selecione um perfil.5. Clique em OK.
56 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

O Programa de Carregamento em MassaO programa de carregamento em massa, que é o arquivo loadidml.sh nos sistemas UNIX e o arquivoloadidml.bat nos sistemas Windows, carrega livros do Discovery Library para o banco de dados doTADDM.
Um manual é um arquivo em formato de manual IdML que contém dados de outros produtos Tivoli. Épossível carregar as informações de um manual no banco de dados TADDM. A coleção de manuais Tivoliestá disponível em http://www.ibm.com/software/brandcatalog/ismlibrary/.
O programa de carregamento em massa lê os livros, importa os dados para o banco de dados do TADDMe registra os resultados no diretório results do programa de carregamento em massa. Além disso, oprograma de carregamento em massa registra mensagens de erro no arquivo $COLLATION_HOME/log/bulkloader.log.
O programa de carregamento em massa é executado nos seguintes tipos de servidor TADDM:
• servidor de domínio em uma implementação do servidor de domínio• servidor de sincronização em uma implementação do servidor de sincronização• servidor de armazenamento (primário ou secundário) em uma implementação do servidor de fluxo
Embora o programa de carregamento em massa esteja disponível em um servidor de descobertas emuma implementação do servidor de fluxo, ele não executa em um servidor de descobertas. Paraassegurar autorizações adequadas, o programa de carregamento em massa deve ser executado pelomesmo ID de usuário que executa os processos do servidor TADDM.
Todos os diretórios usados para armazenar arquivos de log e de resultado devem existir antes daexecução do programa de carregamento em massa. É possível customizar esses diretórios atualizando asdefinições de configuração no arquivo $COLLATION_HOME/etc/bulkloader.properties.
Quando o programa de carregamento em massa for concluído, o servidor TADDM poderá ainda estarprocessamento o manual IdML.
Quando você carregar dados para qualquer objeto da classe LogicalContent ou seus descendentes, otamanho permitido para o conteúdo de conteúdo é 5 MB. Se os dados excederem o limite permitido, elessão recortados e reticências (...) são incluídas no final da sentença.
Consulte também “Carregando padrões de agrupamento” na página 210 e o tópico Ferramenta do IBMDiscovery Library IdML Certification no Discovery Library Adapter Developer's Guide do TADDM.
Executando o Programa de Carregamento em MassaO programa de carregamento em massa fornece o recurso de carregar ou atualizar grandes quantidadesde dados de item de configuração (CI) e dados de relacionamentos no banco de dados do TADDM. Aentrada para o programa de carregamento em massa é um arquivo que contém um documento XMLformatado para Identity Markup Language (IdML). O programa de carregamento em massa também podeser usado para definir um grande número de atributos estendidos.
Sobre Esta TarefaEm uma implementação de servidor de fluxo, o programa de carregamento em massa atualiza dados dobanco de dados no servidor de armazenamento. É possível executar o programa de carregamento emmassa a partir do servidor de armazenamento primário, servidor de armazenamento secundário ou osdois ao mesmo tempo. Em uma implementação de servidor de sincronização, é possível executar oprograma a partir do servidor de sincronização.
Procedimento
Para executar o programa de carregamento em massa, conclua as seguintes etapas:1. Verifique a exatidão do arquivo $COLLATION_HOME/etc/bulkload.properties.
Para aceitar os padrões, não altere nada no arquivo.2. Verifique se o diretório de trabalho e o diretório de resultados mencionados no arquivobulkload.properties são válidos.
Capítulo 1. Usando 57

O diretório de trabalho e o de resultados devem existir antes da execução do programa decarregamento em massa ou este programa não será executado. Se desejar usar diretórios diferentes,você deverá criar esses diretórios manualmente e atualizar o arquivo de propriedades. O programa decarregamento em massa não cria automaticamente esses diretórios.
Para criar os diretórios, use a mesma conta de usuário que inicia e para o servidor TADDM. Se oprograma de carregamento em massa não tiver permissões para ler e gravar nos diretórios ativos e deresultados, ele não poderá ser executado.
3. Execute o programa de carregamento em massa.
• Para sistemas operacionais Windows, o script de carregamento em massa está localizado no arquivo$COLLATION_HOME/bin/loadidml.bat.
• Para todos os outros sistemas operacionais, o script de carregamento em massa está localizado noarquivo $COLLATION_HOME/bin/loadidml.sh.
Use o seguinte comando para executar o programa de carregamento em massa:
./loadidml.sh -o -f path_to_idml_file
Em que:-o
Instrui o programa de carregamento em massa para substituir os arquivos processados e carregaros arquivos IdML.
-f path_to_idml_fileEspecifica o caminho completo para o arquivo de entrada ou um diretório que contém arquivosIdML de entrada. O diretório em que o arquivo de entrada é colocado não deve ser o mesmo que odiretório de trabalho do programa de carregamento em massa. Se um diretório compartilhado forusado para conter o arquivo de entrada, ou se arquivos forem copiados em um diretório local, estediretório não poderá ser igual ao diretório de trabalho, de resultados ou de log do programa decarregamento em massa. Esse parâmetro é obrigatório.
Por exemplo:
./loadidml.sh -o -f /opt/IBM/taddm/dlaxmls/testfile.xml
4. Se o programa de carregamento em massa não for executado, leia as mensagens no arquivobulkload.log. O arquivo de log está localizado no diretório $COLLATION_HOME/log.
Dependendo do tamanho do manual, da capacidade do computador e de outras variáveis, podedemorar bastante tempo para carregar os dados. O programa de carregamento em massa pode nãogravar mensagens no arquivo de log ao esperar que o sistema TADDM armazene informações nobanco de dados. Quando um ou mais registros estiverem armazenados no banco de dados, o arquivode resultados e o arquivo de log serão atualizados com o status. Você não deve cancelar o programade carregamento em massa enquanto ele estiver carregando dados. O programa de carregamento emmassa sai quando o carregamento de dados estiver concluído. Para obter informações sobre comodeterminar se o programa de carregamento em massa está em execução, consulte o tópico Problemasde programa de carregamento em massa no Guia de resolução de problemas do TADDM.
5. Após a execução do programa de carregamento em massa, verifique o arquivo de resultados para verse houve problemas durante o programa.O arquivo de resultados está localizado no diretório resultsdir configurado no arquivobulkload.properties.
Procure um arquivo com uma extensão .results e o mesmo nome que o arquivo IdML. Por exemplo,se o nome do arquivo IdML importado for test.xml, o nome do arquivo de resultados serátest.results. Se o arquivo de resultados estiver vazio, verifique se há erros no arquivo de log.Entradas importantes do arquivo de resultados são marcadas com as tags SUCCESS e FAILURE. Seestatística estiver ativada, a porcentagem de mensagens de êxito também será registrada. As tagsFAILURE são para objetos individuais e não indicam necessariamente uma falha do arquivo inteiro.Objetos marcados como com falha não são armazenados no banco de dados.
58 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

6. Para processar o mesmo manual novamente após o primeiro carregamento inicial, utilize o sinalizador-o ou remova a entrada específica do arquivo processedfiles.list.O arquivo processedfiles.list está localizado no diretório de trabalho especificado no arquivobulkload.properties.
7. Se o programa de carregamento em massa indicar que outro programa de carregamento em massaestiver em execução e este não for o caso, acesse o diretório de trabalho e exclua o arquivo .bllock.Execute o programa de carregamento em massa novamente.O arquivo .bllock é um arquivo oculto em sistemas UNIX porque ele inicia com um ponto (.). Excluaesse arquivo apenas se tiver certeza de que outro programa de carregamento em massa ainda nãoestá em execução.
Leia as informações no arquivo bulkload.log. O arquivo de log pode conter detalhes sobre asmensagens que são exibidas.
8. É possível executar o carregamento em massa no servidor de sincronização, entretanto, existem asseguintes limitações:
• Nenhuma propagação de mudança: Existe um histórico de mudanças semelhante àquele do servidorde domínio, entretanto, não há propagação de mudança. Por exemplo, se você alterar a configuraçãode duplex em uma interface L2, a configuração de duplex não será exibida como uma alteração nosistema do computador. A configuração de duplex é exibida somente como uma mudança nainterface L2.
• Nenhuma agregação de mudança: Quando um atributo muda de A -> B -> A na mesma descoberta(carregamento em massa), a mudança (A -> B) ou (B -> A) não é registrada no relatório do históricode mudanças.
• Reconciliação avançada limitada: O único agente construtor de topologia que é executado noservidor de sincronização é o CrossDomainDependencyAgent. Se a conexão lógica tiver o mesmoendereço IP dos endereços IP 'de' e 'para', ou o host local for usado, oCrossDomainDependencyAgent não criará uma dependência. O Adaptador da Biblioteca deDescoberta (DLA) cria os relacionamentos entre objetos implícitos e explícitos.
ExemploPara a maioria das situações, o uso apenas dos parâmetros -f e -o é suficiente, mas outros parâmetrossão suportados, se necessário. O exemplo a seguir mostra alguns dos parâmetros usados raramente:
./loadidml.sh -f path_to_idml_file -u userid -p passwd -g -c -e -o -b bidirectional_format_on_or_auto -l location tag -loadEAMeta -override -disableIdmlCertificationTool
Em que:-u userid
Especifica o ID do usuário a ser usado para autenticação com o servidor TADDM.O parâmetro -u é opcional. Forneça um ID de usuário apenas se o ID do usuário tiver as permissõescorretas (privilégios completos de atualização e leitura) e estiver definido no servidor TADDM comoum usuário válido.
-p passwdEspecifica a senha usada para autenticação com o servidor TADDM.O parâmetro -p é opcional. Forneça uma senha apenas se o ID de usuário tiver as permissõescorretas (privilégios completos de atualização e leitura) e estiver definida no servidor TADDM comoum usuário válido.
-gEspecifica para utilizar o algoritmo de gravação de gráfico para persistirem os dados no banco dedados.
Essa opção melhora o desempenho de carregamento e é útil para carregar arquivos XML com dadosque possuem grandes matrizes de objetos contidos. Os arquivos IdML de descoberta do Tivoli Storage
Capítulo 1. Usando 59

Productivity Center e do Tivoli Configuration Manager são exemplos do arquivo com grandes matrizesde objetos contidos. Outros arquivos também podem se beneficiar deste algoritmo. O algoritmo degravação de gráfico grava lotes de objetos no banco de dados de uma vez. O número de objetosgravados é influenciado pela configuração do tamanho do cache no arquivo bulkload.properties.Atenção ao usar esse algoritmo, pois há limitações.
Restrição: Devido às limitações de API atuais, o arquivo IdML deve ter tokens de origem presentespara cada objeto a fim de executar a gravação de gráfico. Tokens de origem, entretanto, são um valoropcional em um arquivo XML IdML. Portanto, se a opção -g for fornecida e nenhum token de origemestiver disponível para um objeto, um token de origem fictício será automaticamente gerado paraesse objeto usando o ID do objeto necessário a partir do arquivo XML. Os tokens de origem simuladosnão são exibidos como tokens de ativação no contexto. No entanto, os tokens de origem simuladossão exibidos para atributos do objeto individuais e no arquivo de log de carregamento em massa. Essecomportamento é uma parte normal do algoritmo.
Se um único elemento não satisfizer as regras de nomenclatura ou se falhar ao ser gravado no bancode dados por qualquer motivo, o gráfico inteiro ou um subconjunto de elementos poderá falhar aopersistir. Mensagens de erro indicando o objeto específico que causou a falha não estão disponíveisdevido a limitações atuais. Execute o arquivo sem a opção -g para identificar um problema.
Determinados arquivos IdML reutilizam valores do token de origem para mais de um objeto. Enquantoadmissível no IdML, esses arquivos não podem ser processados com a opção -g devido a limitaçõesatuais. Arquivos que reutilizam tokens de origem entre objetos devem ser carregados sem a opção -g.
A gravação de gráfico requer memória adicional no cliente e no servidor. Se um erro de "falta dememória" ocorrer, reduza a configuração do tamanho do cache no arquivo de propriedades ou nãouse a opção -g.
Recursos abstratos não são suportados durante a gravação de gráfico. Processe os arquivos quecontêm essas características sem a opção -g. Os atributos estendidos são suportados durante agravação de gráfico.
-cEspecificado para copiar os arquivos de origem IdML para o diretório em massa de trabalho eprocessá-los lá. Este método pode levar a atrasos ao copiar arquivos grandes.
-eEspecifica que as informações de erro do carregamento de dados são disponibilizadas no código deretorno do programa. Por padrão, o programa de carregamento em massa retorna o código de saída 0,mesmo se ocorrer um erro ao carregar os dados. O parâmetro -e instrui o programa a retornar ocódigo 5 quando ocorre um erro ao carregar os dados. Observe que o código de retorno do próprioprograma de carregamento em massa tem prioridade mesmo se o parâmetro -e estiver especificado.Por exemplo, se o programa de carregamento em massa não puder se conectar ao servidor TADDM, ocódigo retornado conterá estas informações.
-b bidirectional_format_on_or_autoEspecifica se o suporte bidirecional está ativado, desativado ou é configurado automaticamente. Asopções para o sinalizador bidirecional são on e auto. Quando o sinalizador bidirecional é on, vocêpode configurar os parâmetros bidirecionais para cada Sistema de Software de Gerenciamentoutilizando os perfis bidirecionais predefinidos. Quando o sinalizador bidirecional estiver definido comoauto, a transformação bidirecional é ativada e o formato bidirecional é detectado automaticamente.
Se estiver usando SSH, não especifique on para o sinalizador bidirecional. Quando você escolher onpara o sinalizador bidirecional e utilizar SSH, a janela de configuração bidirecional de carregamentoem massa não será exibida. Sem completar os campos na janela de configuração bidirecional decarregamento em massa, você não poderá configurar os parâmetros bidirecionais.
-l location tagEspecifica um valor de tag de local ao carregar arquivos IdML. Cada item de configuração carregado apartir do arquivo IdML possui seu valor de tag de local designado. Se mais de um arquivo IdML estiverpresente no mesmo diretório cada arquivo requerer uma tag de local exclusiva, é necessário carregaros arquivos separadamente. Certifique-se de que o valor
60 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

com.ibm.cdb.locationTaggingEnabled no arquivo COLLATION_HOME/etc/collation.propertes esteja definido para true.
Para obter mais informações sobre a tag de localização, consulte o tópico Configurando a tag delocalização no Guia do administrador do TADDM.
-loadEAMeta
Nota: A sinalização é relacionada aos metadados de atributos estendidos.
Força o carregador em massa a ignorar valores e a armazenar apenas os metadados de atributosestendidos. Um novo atributo é incluído em atributos definidos anteriormente para a mesma classeCDM nos metadados. O tipo para o novo atributo nos metadados do atributo está configurado como'String'.
Se -loadEAMeta for transmitido, os metadados de atributos estendidos podem ser definidos com osmanuais a seguir:
• Manuais IdML regulares• Manuais IdML apenas com definições de metadados.
Se ambos forem transmitidos, a opção -loadEAMeta tem precedência sobre a opção -g e o modo degravação de gráfico é ignorado.
ExemploPara a parte a seguir do arquivo de origem IdML, o programa de carregamento em massa com aopção -loadEAMeta define os atributos estendidos myExtAttr1, myExtAttr2 emyExtAttrInCategory para o tipo de componente WindowsComputerSystem. O atributomyExtAttrInCategory é definido na categoria myExtAttrCategory.
<cdm:sys.windows.WindowsComputerSystem id="9.10.10.10-WindowsSystem" sourceToken="ip_address=9.10.10.10"> <cdm:extension> <cdm:extattr name="myExtAttr1">value1</cdm:extattr> <cdm:extattr name="myExtAttr2">value2</cdm:extattr> <cdm:extattr category="myExtAttrCategory" name="myExtAttrInCategory">value3</cdm:extattr> </cdm:extension> ...</cdm:sys.windows.WindowsComputerSystem>
-override
Nota: A sinalização é relacionada aos metadados de atributos estendidos.
Se esta sinalização for transmitida com a sinalização -loadEAMeta, ela força a redefinição do tipo deatributo, no caso de o atributo já estar definido e seu tipo for diferente de 'String'.
Exemplo
./loadidml.sh -f /opt/IBM/taddm/dlaxmls/testfile.xml -u admin -p password -g -c -o -b auto -l tag
-disableIdmlCertificationToolEspecifica para desativar a validação de manuais IdML antes do processamento dos manuais peloprograma de carregamento em massa.
O Arquivo de Propriedades de Carregamento em MassaO arquivo de propriedades de carregamento em massa está localizado no diretório$COLLATION_HOME/etc/bulkload.properties. Esse arquivo fornece ao programa de carregamentoem massa informações que são necessárias para carregar o arquivo IdML no banco de dados TADDM.
A lista a seguir descreve as propriedades do arquivo $COLLATION_HOME/etc/bulkload.propertiese seus valores padrão. Você não deve alterar nada no arquivo se desejar aceitar os padrões.
Capítulo 1. Usando 61

com.ibm.cdb.bulk.numcopies=1Esta propriedade especifica o número de cópias do arquivo a ser copiado.
com.ibm.cdb.bulk.workdir=bulkEsta propriedade especifica o diretório que o programa de carregamento em massa usa para copiararquivos antes de carregá-los. Consulte a opção "-c" e a propriedadecom.ibm.cdb.bulk.createworkingcopy. O diretório padrão é relativo ao diretório de nível superior dodiretório referido pela variável de ambiente $COLLATION_HOME.
Não copie o arquivo IdML para o diretório $COLLATION_HOME, uma vez que esse local faz com que oprocesso de carregamento falhe.
com.ibm.cdb.bulk.workdir.cleanup=falseEsta propriedade especifica se o diretório de trabalho deve ser limpo após o processo decarregamento ser concluído.
com.ibm.cdb.bulk.processedfiles.cleanup=30Esta propriedade especifica o número de dias a manter os arquivos na lista de arquivos processados.
com.ibm.cdb.bulk.retrycount=5Esta propriedade especifica o número de vezes para tentar carregar um arquivo novamente se onúmero permitido de carregamentos em massa simultâneos, que é 10 por padrão, for excedido.
com.ibm.cdb.bulk.retrydelay=60Esta propriedade especifica o número de segundos a aguardar antes de tentar carregar um arquivonovamente, enquanto uma descoberta está em andamento.
com.ibm.cdb.bulk.resultsdir=bulk/resultsEsta propriedade especifica o diretório para manter os arquivos de resultados criados quando umarquivo IdML é carregado no banco de dados TADDM. O diretório padrão é relativo ao diretório denível superior referido pela variável $COLLATION_HOME.
com.ibm.cdb.bulk.apiservertimeout=60Esta propriedade especifica o número de segundos antes do servidor de API retornar um erro e oprograma de carregamento em massa parar o processamento.
com.ibm.cdb.bulk.stats.enabled=falseEsta propriedade especifica se a reunião de estatísticas do programa de carregamento em massa forexecutada. Ativar as estatísticas diminui o desempenho e aumenta os tamanhos dos arquivos de log ede resultados.
com.ibm.cdb.bulk.log.success.results=trueEsta propriedade especifica se os objetos gravados com êxito são registrados no arquivo deresultados. A criação de log reduzida pode melhorar o desempenho reduzindo a saída.
com.ibm.cdb.bulk.allocpoolsize=1024Esta propriedade especifica a quantia máxima de memória que pode ser alocada para o processo doUtilitário de Carregamento em Massa. Esse é um valor Xmx que é passado para a classe Java principaldo Utilitário de Carregamento em Massa. Especifique o valor em megabytes.
com.ibm.cdb.bulk.cachesize=2000Esta propriedade especifica o número de objetos a serem processados em uma única operação degravação ao executar a gravação do gráfico. Aumentar este número melhora o desempenho no riscode executar sem memória no cliente ou no servidor. Altere esse número apenas quando informaçõesespecíficas estiverem disponíveis para indicar que o processamento de um arquivo com um cachemaior fornece benefícios ao desempenho. A configuração do tamanho de cache atualmente não podeser superior a 4.000.
com.ibm.cdb.bulk.createworkingcopy=trueEsta propriedade especifica para primeiro copiar o arquivo de origem IdML para o diretório em massae, em seguida, continuar a processar o arquivo copiado.
com.ibm.cdb.bulk.forceUniqueSourceTokens=trueEsta propriedade especifica se tokens de origem exclusivos são criados pelo utilitário decarregamento em massa. O valor padrão é true. Para desativar a criação de tokens de origemexclusivos, defina o valor como false.
62 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Essa propriedade será usada apenas se a gravação de gráfico estiver ativada.
Ao usar o utilitário de gravação, objetos de nível inferior com tokens de origem duplicados podem nãoser exibidos corretamente quando ativados no contexto. Quando essa propriedade estiver definidacomo true, um número de índice será anexado a um token de origem duplicado para garantirexclusividade.
com.ibm.cdb.bulk.idmlcertificationtool.disabled=trueEsta propriedade especifica se a Ferramenta de Certificação IdML é usada para validar os manuaisIdML antes de seu processamento. Por padrão a ferramenta de certificação está desativada.
com.ibm.cdb.bulk.idmlcertificationtool.toolongattrhandling=errorEsta propriedade especifica como a Ferramenta de Certificação IdML manipula valores de atributosCDM muito longos. Os valores a seguir são suportados:
• error - o valor padrão, relata valores de atributos CDM muito longos como erros.• warn - relata valores de atributos CDM muito longos como avisos.• ignore - ignora problemas com valores de atributos CDM muito longos.
Por padrão, valores de atributos muito longos são relatados como erros e o processamento demanuais IdML é parado com um erro de análise sintática. Quando a propriedade é configurada parawarn ou ignore, o programa de utilitário de carregamento em massa não é parado.
É aconselhável não ignorar o problema com valores de atributos muito longos. Embora os valores deatributos muito longos sejam truncados e armazenados no banco de dados TADDM, eles podemcausar inconsistência de informações. Isso pode levar a um comportamento inesperado do TADDM eprodutos que são integrados com o TADDM.
Esta propriedade é usada apenas quando a Ferramenta de Certificação IdML é ativada.
Códigos de Retorno do Carregamento em MassaOs códigos de retorno a seguir são configurados para que, se estiver gravando um script cron ou algumoutro script que chame o programa de carregamento em massa, você possa determinar o status docarregamento em massa e como o carregamento em massa saiu.
Em uma linha de comandos, você vê os seguintes códigos de retorno e suas mensagens.
0O programa foi concluído. Isso não significa que tudo foi carregado. Verifique o arquivo de resultadospara obter estas informações.
1Ocorreu algum erro, mas ele é desconhecido. Verifique o arquivo bulkload.log no diretório logpara ver se há informações adicionais.
2Uma propriedade básica do ambiente necessária para executar o programa de carregamento emmassa não foi configurada.
3Foi fornecido um parâmetro da linha de comandos que não é válido. É o próprio parâmetro ou osdados fornecidos com o parâmetro que não estão corretos. Corrija o comando e tente novamente.
4O ID do usuário ou a senha não estava correto e o programa de carregamento em massa não pôdeefetuar login. Isso acontece quando um parâmetro -u -p incorreto foi fornecido ao programa decarregamento em massa.
5O arquivo XML que estava sendo processado continha erros, mas o programa de carregamento emmassa continuou a processar o arquivo.
6O arquivo XML que estava sendo processado continha erros e fez com que o programa decarregamento em massa parasse o processamento do arquivo.
Capítulo 1. Usando 63

7O analisador XML falhou ao analisar o arquivo XML e o processamento do programa de carregamentoem massa parou.
8O servidor de API retornou um erro, mas o programa de carregamento em massa conseguiu recuperare continuar.
9O servidor de API retornou um erro e o programa de carregamento em massa parou o processamento.
10Pode ser executada apenas uma cópia do programa de carregamento em massa de cada vez. Umacópia já estava em execução, portanto, esta cópia não pode ser executada.
11Uma descoberta está em processamento e o programa de carregamento em massa está bloqueado enão pode ser executado. Com base no que está configurado no arquivo de propriedades, o programade carregamento em massa tenta ser executado novamente, mas se este erro for retornado, ele teráesgotado as tentativas de repetições.
12Uma descoberta está em processamento e o programa de carregamento em massa está bloqueado enão pode ser executado. Com base no que está configurado no arquivo de propriedades, o programade carregamento em massa tenta ser executado novamente, mas se este erro for retornado, ele teráesgotado as tentativas de repetições.
13Há uma propriedade especificada no arquivo de entrada para o programa de carregamento em massaque não é válida.
14O arquivo já foi processado conforme registrado no arquivo processedfiles.list no diretório detrabalho do programa de carregamento em massa. Utilize o parâmetro de substituição -o paraforçar o processamento do arquivo ou edite processedfile.list e remova da lista a entrada paraeste arquivo.
15O servidor de API não foi iniciado e o programa de carregamento em massa não pôde se conectar.
16Os arquivos de propriedades para linguagens bidirecionais estavam vazios.
Boas Práticas para Utilizar o Programa de Carregamento em MassaVocê deve carregar diversos arquivos de entrada na ordem correta (de acordo com o horário oualfabeticamente), atualizar seus arquivos mais recentes e remover arquivos do seu diretóriocompartilhado antes que eles expirem do arquivo de lista processado.
Há duas abordagens que controlam a ordem em que vários arquivos de entrada de um diretório sãocarregados. Uma opção é carregar cada arquivo individualmente, carregando os arquivos na ordemcorreta. A abordagem poderá ser necessária se a única diferença entre os nomes de arquivos for umregistro de data e hora no nome do arquivo. Uma segunda opção é alterar os nomes dos arquivos paraincluir sequências de ordenação alfabética. Essas cadeias de ordenação são, então, definidas para oprograma de carregamento em massa utilizando o arquivo processOrder.list. O arquivoprocessOrder.list não existe, portanto, você deve criá-lo manualmente. O programa decarregamento em massa processa arquivos que correspondem à primeira sequência de ordenação emprimeiro lugar, à segunda sequência de ordenação em segundo lugar e assim por diante. Se mais de umarquivo corresponder à mesma cadeia de ordenação, uma ordem de processamento dentro desse gruponão será assegurada.
Para arquivos de atualização, geralmente, apenas o arquivo de atualização mais recente deve sercarregado. Para arquivos de atualização e delta, o arquivo de atualização deve, geralmente, ser carregadoprimeiro e, em seguida, os arquivos delta são carregados na seqüência na qual foram gerados. Paraarquivos delta apenas, eles devem ser carregados na seqüência na qual foram gerados.
64 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Um diretório compartilhado utilizado para arquivos de entrada deve ser mantido de maneira adequada.Os arquivos de entrada carregados devem ser removidos do diretório compartilhado antes de seremexpirados do arquivo da lista processada. Se um arquivo permanecer no diretório após ser expirado dalista processada, ele será recarregado, talvez carregando dados mais antigos.
Desempenho frequente de ajuste de banco de dados durante os carregamentos iniciais de manuaisDLA
O TADDM requer manutenção do banco de dados para otimizar o uso de recursos e melhorar odesempenho de consultas SQL. O programa de carregamento em massa do TADDM (arquivoloadidml.sh para sistemas UNIX ou loadidml.bat para sistemas Windows) lê e atualiza os objetosde banco de dados ao mover dados dos manuais DLA no banco de dados TADDM. A manutenção bem-sucedida requer:
• Carregamento dos dados representativos no banco de dados que é usado posteriormente para cálculode estatísticas.
• Executação da manutenção do banco de dados TADDM de acordo com o tópico Manutenção do bancode dados no Guia do Administrador do TADDM, para reunir as estatísticas do banco de dados.
Executar manutenção do banco de dados frequentemente, durante carregamentos iniciais de manuaisDLA melhora o desempenho e reduz o tempo que as consultas SQL (SELECT, UPDATE, DELETE) levampara ser executadas com relação ao banco de dados. Após os carregamentos iniciais dos manuais DLA,esse processo não é necessário porque as estatísticas do banco de dados são válidas.
Realizando a manutenção do banco de dados durante os carregamentos iniciais de manuais DLA.O exemplo a seguir se refere aos manuais DLA z/OS.
1. Carregue cada tipo de um manual de uma de suas LPARs menores (BASE, TASK, DB2, IMS, CICS,ZOS, MQ, WAS).
2. Execute a manutenção do banco de dados para reunir estatísticas do banco de dados. Para o DB2,é necessário executar instruções RUNSTATS/REORG.
3. Carregue todos os manuais de suas LPARs menores (BASE, TASK, DB2, IMS, CICS, ZOS, MQ, WAS).4. Execute a manutenção do banco de dados novamente para atualizar as estatísticas do banco de
dados.5. Carregue todos os manuais de uma de suas LPARs maiores (BASE, TASK, DB2, IMS, CICS, ZOS,
MQ, WAS).6. Execute a manutenção do banco de dados novamente para atualizar as estatísticas do banco de
dados.7. Carregue o restante dos manuais. Execute a manutenção do banco de dados online durante o
processo de carregamento em massa a cada duas horas para reunir as estatísticas de banco dedados mais recentes.
Utilizando o Suporte BiDi (Bidirecional) para Sensores e o Programa de Carregamento em MassaO suporte de linguagem bidirecional é fornecido para os idiomas Árabe e Hebraico.
O texto bidirecional é armazenado e processado em diferentes ambientes (plataformas) e com diferenteslayouts. Esse texto bidirecional pode ser introduzido no TADDM por meio da descoberta do sensor,manuais IdML, carregamento em massa ou APIs. A transformação de layout bidirecional deve ser usadapara transformar de um formato de layout externo no formato de layout bidirecional padrão TADDM.
Suporte Bidirecional para Sensores
Para lidar com dados descobertos e que contêm dados bidirecionais com formatos diferentes, énecessário transformar o formato bidirecional de todos os dados bidirecionais descobertos em umformato padrão bidirecional. Seguindo os padrões Unicode, os valores de parâmetros de FormatoBidirecional Padrão são:
• Tipo de Texto: Implícito• Direção do Texto: Da esquerda para a direita (LTR)
Capítulo 1. Usando 65

• Sinalizador de troca simétrica: Sim• Indicador de Forma Bidirecional: Não Formado• Indicador Numérico Bidirecional: Nominal
É possível ativar ou desativar a Transformação Bidirecional para os sensores de dados.
O formato bidirecional é configurado de uma das seguintes maneiras:
• Configuração do formato bidirecional utilizado pelo sistema externo antes da descoberta. É necessárioespecificar explicitamente este formato bidirecional do método antes da execução de uma descoberta.
• Descoberta automática do padrão do formato bidirecional utilizado pelo sistema externo durante adescoberta. Esse formato bidirecional do método é identificado com base nos atributos de dados e nosatributos do sistema externo, ou em ambos, que são descobertos pelo sensor. A identificação doformato bidirecional baseia-se no algoritmo, levando em conta algumas ou todas as informações oudados que são descobertos pelo sensor do sistema externo.
Durante a configuração de descoberta, é possível especificar quais dessas duas opções de formato vocêprefere. Se preferir a primeira, é possível também especificar o Perfil Bidirecional a ser utilizado durante adescoberta.
Suporte Bidirecional para o Programa de Carregamento em Massa
Os adaptadores de descoberta criam os arquivos IdML na biblioteca Descoberta. Os Adaptadores deDescoberta gravam dados na Biblioteca de Descoberta. Os dados descobertos podem conter dadosbidirecionais. Neste caso, é necessária uma transformação bidirecional para esses dados paratransformar os dados para o formato bidirecional padrão.
O suporte bidirecional para os dados IdML é fornecido no programa de Carregamento em Massa. Oprograma de Carregamento em Massa configura o formato bidirecional necessário para os dadoscarregados dos arquivos IdML, dependendo da configuração bidirecional do usuário. É possível configuraro formato bidirecional para cada Sistema de Software de Gerenciamento ou usar uma opção de detecçãode formato bidirecional automática. Consulte “Configurando o formato bidirecional para o programa decarregamento em massa” na página 68 para obter mais informações.
Criando um Perfil BidirecionalO suporte de linguagem bidirecional é fornecido para os idiomas Árabe e Hebraico.
Sobre Esta TarefaSe você precisar configurar BiDi para sensores ou para o programa de Carregamento em Massa, deverácriar um perfil Bidirecional. Você usa o perfil BiDi para:
• Designar um nome para cada formato Bidirecional específico. A lista a seguir inclui os atributos quepodem ser selecionados para cada perfil:
– Tipo de texto– Orientação– Troca simétrica– Ajuste– Ajuste numérico
• Reutilize o Perfil Bidirecional em várias configurações; configuração do sensor e configurações doprograma de carregamento em massa.
• É possível selecionar diferentes atributos bidirecionais e qualquer alteração nesses atributos serárefletida na configuração do sensor ou no programa de carregamento em massa.
Procedimento
Para criar um perfil bidi, conclua as seguintes etapas:1. Efetue login com um ID de usuário que forneça permissão de atualização.
66 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

2. Na barra de menus, clique em Editar > Perfis Bidi.3. Para incluir uma nova configuração de perfil bidirecional, clique em Incluir.4. Na área de janela Perfil Bidi, conclua os seguintes campos:
a) Digite um nome de perfil. O nome do perfil pode conter espaços e suporta caracteres NLS.b) Opcional: Insira uma breve descrição para este perfil.c) Selecione os atributos BiDi nas listas drop-down. Use a tabela a seguir para ajudar em suas
seleções:
Tabela 9. Atributos BiDi
Parâmetro Valores DescriçãoConfiguração Padrão Comentário
Tipo de Texto I Implícito (Lógico) I (Implícito)
V Visual
Orientação do Texto L Da Esquerda para a Direita L (daEsquerdapara aDireita)
R Da Direita para a Esquerda
C Contextual da Esquerda paraa Direita
D Contentual da Direita para aEsquerda
Troca Simétrica Y Troca simétrica ativada Y (Sim)
N Troca simétrica desativada
Ajuste S O texto está ajustado N (Nãoajustado)
Aplicávelapenas a scriptsem árabeN O texto não está ajustado
I Ajuste inicial
M Ajuste médio
F Ajuste final
B Ajuste isolado
Ajuste Numérico H Hindi (Nacional) N (Nominal) Aplicávelapenas a scriptsem árabeC Contextual
N Nominal
5. Clique em OK para salvar o novo perfil BiDi.
Configurando o Formato Bidirecional para DescobertaPara exibir dados descobertos com dados bidirecionais em formatos bidirecionais diferentes, o processode descoberta TADDM transforma os dados bidirecionais em um formato.
Antes de Iniciar
Configurar o formato bidirecional para descoberta é um processo de duas etapas: selecionar um sensor edefinir a opção de configuração.
Procedimento
Para configurar formato bidirecional para descoberta, conclua as seguintes etapas:1. Efetue login com um ID de usuário que forneça permissão de atualização.
Capítulo 1. Usando 67

2. Na barra de menus, clique em Editar > Configuração Bidirecional.3. Para incluir um novo formato bidirecional para descoberta, clique em Incluir.4. Selecione um nome de sensor para descoberta.5. Selecione uma das três opções para configuração:
Transformação bidirecional DESLIGADAO suporte para o formato bidirecional está desativado. Esta é a opção padrão.
Descoberta bidirecional automáticaO suporte para o formato bidirecional está ativado. O formato bidirecional é detectadoautomaticamente.
Transformação bidirecional LIGADAO suporte para o formato bidirecional está ativado. Se selecionar esta opção, você poderáselecionar um perfil bidirecional da lista.
6. Para salvar o formato bidirecional para descoberta, clique em OK.
Configurando o formato bidirecional para o programa de carregamento em massaPara exibir dados descobertos com dados bidirecionais em formatos bidirecionais diferentes, o processode descoberta TADDM transforma os dados bidirecionais em um formato.
Antes de Iniciar
O script loadidml.sh é usado para iniciar e executar o programa Utilitário de Carregamento em Massa apartir de uma linha de comandos em sistemasLinux ou AIX. O script precisa de vários parâmetros da linhade comandos:
-h hostname-u user id-p password-f path+filename-b on/auto/file
Essa opção é utilizada para ativar e configurar o suporte para BiDi para o programa de carregamentoem massa, de acordo com os seguintes parâmetros:
• On: Ativar a transformação para BiDi• Auto: Ativar a transformação para BiDi automática• file: Ativar e configurar o IC importado utilizando o arquivo de configuração de BiDi
Esse parâmetro também é utilizado para ativar e configurar o suporte para BiDi para o programa decarregamento em massa:On
Com esse parâmetro, uma janela de configuração BiDi é exibida e você pode configurar um perfilBiDi para cada Sistema de Software de Gerenciamento (MSS). É possível configurar o MSSutilizando um Perfil Bidirecional predefinido ou selecionando um Perfil Bidirecional Automáticopara ligar a transformação bidirecional automática para este MSS. Usando –b ON, é possível abriruma janela para ver a GUI de configuração BiDi de Carregamento em Massa. Não é possível usaressa opção ao usar o Secure Shell para iniciá-la. Esta opção é manual, portanto, não pode serutilizada quando você deseja executar o programa de Carregamento em Massa de formasilenciosa.
AutoCom este parâmetro, a transformação bidirecional é ativada e o formato bidirecional é detectadoautomaticamente sem nenhuma interação.
fileCom este parâmetro, a configuração bidirecional para cada MSS é realizada utilizando-se umarquivo de configuração bidirecional. Crie esse arquivo, bidiconfig.properties no caminho$COLLATION_HOME/etc.
68 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

No arquivo de configuração bidirecional, configure cada MSS para um Perfil Bidirecional pré-criado: MSS_Name = BiDI_PROFILE_NAME. Esta opção requer que o MSS e sua configuraçãobidirecional sejam incluídos no arquivo de configuração bidirecional antecipadamente. Paraconfigurar qualquer MSS usando a opção “–b file” que já foi carregada no banco de dados TADDM,o perfil especificado no arquivo de configuração BiDi é substituído pela configuração especificadano banco de dados TADDM. O aviso a seguir será impresso no arquivo bulkload.log:
"Aviso BIDI: O MSS_NAME possui duas configurações bidirecionais. O perfil especificado no arquivo de propriedades substituiráa configuração especificada no CMDB"
Procedimento
Conclua as etapas a seguir para configurar o formato bidirecional para o programa de Carregamento emMassa:1. Efetue login com um ID de usuário que forneça permissão de atualização.2. Na barra de menus, clique em Editar > Perfil Bidi e inclua um novo perfil BiDi.3. Execute o script loadidml usando a opção BiDi ‘-b' e passe um dos seguintes parâmetros para esta
opção:
• Auto
loadidml.sh –u administrator –p collation –b auto–f /sampleidml.xml
• On
loadidml.sh –u administrator –p collation –b on–f /sampleidml.xml
• file
Por exemplo: loadidml.sh –u administrator –pcollation –b file –f /sampleidml.xml
Reconfigurando o Perfil Bidirecional para um MSS CarregadoÉ possível reconfigurar o perfil bidirecional para um MSS carregado.
Procedimento
Conclua as etapas a seguir para reconfigurar o formato bidirecional para um MSS carregado:1. Na barra de menus, clique em Editar > MSS2. Na Lista do Sistema de Software de Gerenciamento, selecione o MSS e clique em Editar.3. Selecione uma das seguintes opções:
• Outro perfil bidirecional que foi criado anteriormente.• Perfil Bidirecional Automático para ligar a Transformação Bidirecional Automática.• Vazio para desativar a Transformação Bidirecional.
4. Clique em OK.
Programa Utilitário de Delta BooksAo invés de carregar o manual DLA completo quando ocorrem mudanças de dados, o TADDM fornece apossibilidade de gerar e carregar apenas o manual delta. Com o programa utilitário de manuais delta, épossível gerar conjuntos de manuais delta IdML que contêm delta ou mudanças entre os dois conjuntosde manuais. Em situações típicas, o programa aumenta significativamente a velocidade do processo decarregamento de manuais.
O programa utilitário delta books é implementado nos arquivos a seguir:
Capítulo 1. Usando 69

• Para UNIX:
$COLLATION_HOME/tools/deltabooks/deltabooks.tar
• Para Windows:
$COLLATION_HOME/tools/deltabooks/deltabooks.zip
Consulte também o tópico Ferramenta do IBM Discovery Librar IdML Certification no Discovery LibraryAdapter Developer's Guide do TADDM
Carregando Livros DLA no TADDMÉ possível usar o procedimento a seguir para carregar os livros DLA no TADDM.
Procedimento
1. Execute o z/OS DLA em um conjunto de destinos para reunir os livros DLA.2. Carregue a saída de descoberta no TADDM.3. Após os livros terem sido alterados, execute a ferramenta z/OS DLA novamente nos mesmos destinos.4. Use o utilitário delta books para executar a primeira e a segunda saída do z/OS DLA, reunidas na etapa
1 a 3.5. Carregue os delta books no TADDM.
Conceitos relacionados“O Programa de Carregamento em Massa” na página 57O programa de carregamento em massa, que é o arquivo loadidml.sh nos sistemas UNIX e o arquivoloadidml.bat nos sistemas Windows, carrega livros do Discovery Library para o banco de dados doTADDM.
Usando o programa utilitário delta booksDepois de reunir os livros DLA e carregá-los no TADDM, é possível usar o programa utilitário delta bookspara gerar livros delta.
Procedimento
1. Para usar o programa utilitário delta books, extraia os seguintes archives:
• Para UNIX:
$COLLATION_HOME/tools/deltabooks/deltabooks.tar
• Para Windows:
$COLLATION_HOME/tools/deltabooks/deltabooks.zip
2. Execute o script deltabooks.sh ou o arquivo em lote deltabooks.bat com a seguinte sintaxe:
deltabooks.sh|bat -f <fully qualified path to directory that contains first discovery output>-t <fully qualified path to directory that contains the second discovery output>-o <fully qualified path to directory for the delta books> [-verbose] [-allowReversedOrder]
em que:
• O parâmetro -verbose ativa a saída detalhada.
• O parâmetro -allowReversedOrder permite inverter a ordem de comparação dosmanuais de modo que os manuais da primeira descoberta sejam mais recentes do que os manuaiscorrespondentes da segunda descoberta.
Nota: Esse parâmetro está disponível no TADDM 7.3.0.2 e posterior.
Exemplo: deltabooks.sh -f /first_output/ -t /second_output/ -o /delta_books/
70 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

3. Revise a saída de manuais delta para ter certeza de que todos os manual-pares foram processados.Especialmente, procure as linhas que contêm as seguintes mensagens:
• Falha ao gerar manual delta• Falha ao gerar manuais delta
Descritores de AplicativosÉ possível usar descritores de aplicativos para associar componentes a aplicativos de negócios eespecificar mais detalhes sobre os aplicativos.
Visão Geral dos Descritores de AplicativosDescritores de Aplicativos IBM fornecem automação completa do processo de descoberta, criando emantendo aplicativos de negócios e sua composição.
Um descritor de aplicativo é uma tag de aplicativo que mapeia um sistema de computador, servidor deaplicativos ou módulo para um aplicativo de negócios. Usando descritores de aplicativos, é possívelidentificar um componente de um aplicativo de negócios no momento do desenvolvimento. Quando osdescritores de aplicativos são descobertos, eles são usados para associar automaticamentecomponentes com aplicativos de negócios, além de eliminar a modelagem manual e a manutenção decomposições do aplicativo de negócios.
Um descritor de aplicativo é um arquivo XML colocado em um local especificado que especifica ossistemas de computador, servidores de aplicativo (contêineres) ou módulos, e os associa a aplicativos denegócios. É possível mapear diversos módulos de uma vez ou mapear um contêiner inteiro (como umservidor IBM WebSphere).
Os arquivos $COLLATION_HOME/log/services/TopologyBuilder.log e $COLLATION_HOME/log/agents/AppDescriptorAgent.log contêm mensagens de log relevantes ao processamento dosarquivos de descritor de aplicativo.
As seguintes estratégias podem ser utilizadas para criar e implementar descritores de aplicativos:
Durante a implementaçãoA definição do aplicativo durante o desenvolvimento e a implementação é a abordagemrecomendada. Com esta abordagem, você pode capturar as informações mais exatas e completassobre o pacote de módulos em aplicativos de negócios.
Após a implementaçãoÉ possível incluir descritores de aplicativos para módulos implementados após a implementaçãoinicial, criando os descritores e então, implementando-os no sistema de arquivos no computador dedestino.
Há dois tipos de descritores de aplicativos:
Descritor de aplicativo de baseContém informações gerais sobre um aplicativo. O descritor de aplicativo de base é opcional.
Descritor de aplicativo do componenteContém informações sobre um sistema de computador específico, servidor de aplicativos ou móduloimplementado em um servidor.
É necessário designar um único nome de aplicativo no descritor de aplicativo de base e no descritor deaplicativo de componente. Este nome único é utilizado para correlacionar todos os descritores deaplicativos descobertos para um aplicativo específico.
Restrição: Descritores de aplicativos usados para aplicativo de negócios não são suportados pelossensores de descoberta assíncrona ou baseada em scripts. Durante a descoberta baseada em scripts ouassíncrona, os descritores de aplicativo não são descobertos.
Descritor de aplicativo de baseO descritor de aplicativos base contém informações gerais sobre um padrão de agrupamento e, narealidade, também sobre um aplicativo de negócios, tal como a descrição, a URL, o contato e outrasinformações.
Capítulo 1. Usando 71

Como o descritor de aplicativo de base contém informações gerais, ele não é requerido para descobrir umaplicativo.
Importante: Os aplicativos de negócios são criados automaticamente mesmo sem um arquivo dodescritor de aplicativos base se um arquivo do descritor de aplicativos do componente for fornecido econtém uma tag app-instance-name. O nome que é usado para o aplicativo de negócios é a tag app-instance-name do arquivo do descritor de aplicativos do componente. Além disso, o descritor deaplicativos base sem qualquer descritor de aplicativo do componente com um nome de aplicativocorrespondente não aciona a criação de um padrão de agrupamento e, como resultado, um aplicativo denegócios.
É necessário somente um descritor de aplicativos base para cada aplicativo. Em casos em que mais deum descritor é utilizado, o sistema utiliza aquele com o registro de data e hora mais recente.
O descritor de aplicativos base pode ser implementado em qualquer diretório do descritor de qualquercomponente do aplicativo.
A tabela a seguir descreve a estrutura do descritor de aplicativo de base:
Tabela 10. Elementos e Atributos do Descritor de Aplicativo de Base
Elemento Descrição e atributos
base-app-descriptor O elemento-raiz para o descritor de aplicativo de base.
app-instance O elemento para as informações sobre a instância do aplicativo.
nome (Obrigatório) O nome da instânciado aplicativo.
grouping-pattern O nome do padrão deagrupamento que inclui adefinição do aplicativo denegócios.
descrição Uma descrição da instância doaplicativo.
url A URL apontando para oaplicativo.
contact Um nome de contato ou outrasinformações para o aplicativo(Isso não é importado noTADDM).
O fragmento XML a seguir mostra um exemplo do descritor de aplicativo de base:
<base-app-descriptor> <app-instance name="application_name" grouping-pattern="grouping_pattern_name" description="application_description" url="application_url" contact="contact_name"/></base-app-descriptor>
Descritor de aplicativo do componenteO descritor de aplicativo do componente contém informações sobre um sistema de computadorespecífico, um servidor ou um módulo implementado dentro de um servidor, junto com informaçõessobre a participação do componente dentro do aplicativo.
Os componentes podem incluir sistemas do computador, servidores de banco de dados, servidores JavaEE ou módulos dentro de servidores. É possível usar um descritor separado para cada módulo ou umúnico descritor para todos os módulos dentro de um servidor.
72 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Um descritor de aplicativo do componente deve ser implementado no diretório de descritores de cadaservidor que seja um componente do aplicativo de negócios ou que contenha módulos que sejamcomponentes do aplicativo de negócios. Use descritores de aplicativos do componente em vez dossensores WebSphere ou Weblogic para incluir os componentes Java EE em um aplicativo de negóciospara obter uma granularidade mais precisa para as dependências descobertas. Para obter maisinformações, consulte Melhores Práticas para Descobrir Aplicativos de Negócios na wiki do TADDM, emhttps://github.com/TADDM/taddm-wiki/wiki/Business-Application-Mapping
Um descritor de aplicativos é um XML com o seguinte formato:
<component-app-descriptor app-instance-name="instance_name" grouping-pattern> <component-descriptor type="component_type" name="component_name" marker-module="true|false"/></component-app-descriptor>
Os elementos e atributos do arquivo descritor de aplicativo do componente são os seguintes:
Tabela 11. Elementos e Atributos do Descritor de Aplicativo do Componente
Elemento dedescritor docomponente
Descrição e atributos
component-app-descriptor
O elemento-raiz para o descritor de aplicativo de componentes.
app-instance-name
(Obrigatório) O nome da instância do aplicativo.
grouping-pattern
O nome do padrão de agrupamento que inclui a definição doaplicativo de negócios.
Capítulo 1. Usando 73

Tabela 11. Elementos e Atributos do Descritor de Aplicativo do Componente (continuação)
Elemento dedescritor docomponente
Descrição e atributos
component-descriptor
(Obrigatório) O elemento para as informações do componente.
tipo (Obrigatório) Um descritor de componente pode se aplicar a umsistema do computador (host), um servidor em sua totalidade ou amódulos individuais dentro do servidor. O atributo type especificaeste relacionamento e pode ter um dos valores a seguir:
• host – um sistema de computador.• servidor – um servidor de software, por exemplo, um servidor de
aplicativos.• módulo – um módulo de software implementado em um servidor.• implementável – qualquer componente que está implementado
em um servidor.
nome O nome do componente. Obrigatório quando o atributo type estiverconfigurado como módulo ou implementável.
marker-module
(Opcional) Um tipo especial de definição de módulo para domíniosJava EE. Quando um módulo é indicado como um módulo demarcador, servidores gerenciados pelo Java EE dentro do domínioque inclui o módulo de marcador são tratados como tendo todos seusmódulos incluídos no aplicativo. Para outros tipos de servidores desoftware que não são servidores de aplicativos como domínios JavaEE, o módulo marcador indica que todos os componentesimplementados no servidor que inclui o módulo marcador sãoincluídos no aplicativo de negócios. É possível especificar os valores aseguir para o módulo marcador:
• verdadeiro• falso
Nota: Para remover um componente de um aplicativo de negócios que foi criado com um descritor deaplicativo do componente, você deve editar o aplicativo de negócios no Portal de Gerenciamento deDados.
Localizações do Descritor de AplicativoA localização do diretório que contém os descritores de aplicativos depende do tipo de componente e daconfiguração do sistema.
Um arquivo descritor de aplicativo é um XML colocado em um local específico que depende do tipo dedescritor de aplicativo. O nome do arquivo não é significativo, mas ele deve terminar com aextensão .xml.
Nota: Assegure-se de que a conta de serviço TADDM tenha acesso ao local de qualquer descritor deaplicativo que você queira usar.
Durante a descoberta, o servidor TADDM verifica descritores de aplicativo, como a seguir:
• Para descritores de aplicativos base, o arquivo descritor de aplicativo pode ser colocado no diretório dodescritor de aplicativo de qualquer componente que faça parte do aplicativo.
74 Gerenciador de Descoberta de Dependência de Aplicativo: Usando
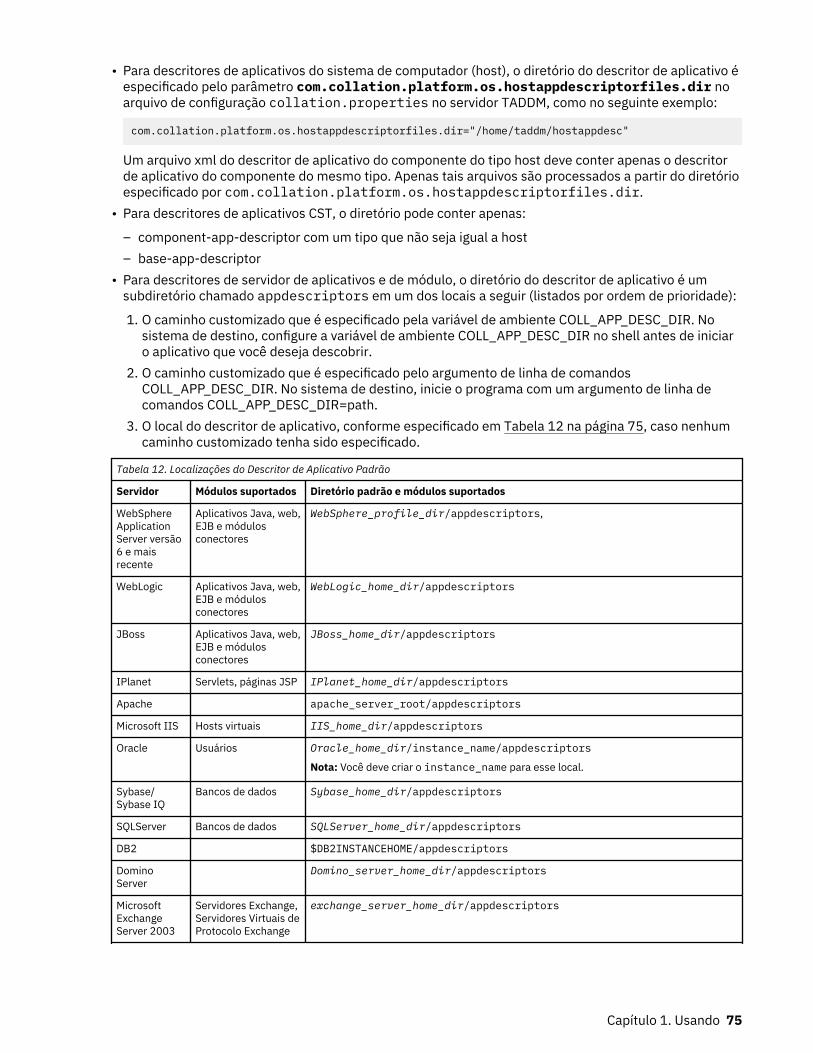
• Para descritores de aplicativos do sistema de computador (host), o diretório do descritor de aplicativo éespecificado pelo parâmetro com.collation.platform.os.hostappdescriptorfiles.dir noarquivo de configuração collation.properties no servidor TADDM, como no seguinte exemplo:
com.collation.platform.os.hostappdescriptorfiles.dir="/home/taddm/hostappdesc"
Um arquivo xml do descritor de aplicativo do componente do tipo host deve conter apenas o descritorde aplicativo do componente do mesmo tipo. Apenas tais arquivos são processados a partir do diretórioespecificado por com.collation.platform.os.hostappdescriptorfiles.dir.
• Para descritores de aplicativos CST, o diretório pode conter apenas:
– component-app-descriptor com um tipo que não seja igual a host– base-app-descriptor
• Para descritores de servidor de aplicativos e de módulo, o diretório do descritor de aplicativo é umsubdiretório chamado appdescriptors em um dos locais a seguir (listados por ordem de prioridade):
1. O caminho customizado que é especificado pela variável de ambiente COLL_APP_DESC_DIR. Nosistema de destino, configure a variável de ambiente COLL_APP_DESC_DIR no shell antes de iniciaro aplicativo que você deseja descobrir.
2. O caminho customizado que é especificado pelo argumento de linha de comandosCOLL_APP_DESC_DIR. No sistema de destino, inicie o programa com um argumento de linha decomandos COLL_APP_DESC_DIR=path.
3. O local do descritor de aplicativo, conforme especificado em Tabela 12 na página 75, caso nenhumcaminho customizado tenha sido especificado.
Tabela 12. Localizações do Descritor de Aplicativo Padrão
Servidor Módulos suportados Diretório padrão e módulos suportados
WebSphereApplicationServer versão6 e maisrecente
Aplicativos Java, web,EJB e módulosconectores
WebSphere_profile_dir/appdescriptors,
WebLogic Aplicativos Java, web,EJB e módulosconectores
WebLogic_home_dir/appdescriptors
JBoss Aplicativos Java, web,EJB e módulosconectores
JBoss_home_dir/appdescriptors
IPlanet Servlets, páginas JSP IPlanet_home_dir/appdescriptors
Apache apache_server_root/appdescriptors
Microsoft IIS Hosts virtuais IIS_home_dir/appdescriptors
Oracle Usuários Oracle_home_dir/instance_name/appdescriptors
Nota: Você deve criar o instance_name para esse local.
Sybase/Sybase IQ
Bancos de dados Sybase_home_dir/appdescriptors
SQLServer Bancos de dados SQLServer_home_dir/appdescriptors
DB2 $DB2INSTANCEHOME/appdescriptors
DominoServer
Domino_server_home_dir/appdescriptors
MicrosoftExchangeServer 2003
Servidores Exchange,Servidores Virtuais deProtocolo Exchange
exchange_server_home_dir/appdescriptors
Capítulo 1. Usando 75

Tabela 12. Localizações do Descritor de Aplicativo Padrão (continuação)
Servidor Módulos suportados Diretório padrão e módulos suportados
ServidorCustomizado
Fornecido pelousuário por meio dadefinição do modelo
Fornecido pelo usuário por meio da definição do modelo
ClusterVeritas
VS_home_dir/appdescriptors
No caso de servidores gerenciados, como servidores Java EE, que são gerenciados pelo domínio Java EE,o local do diretório do descritor de aplicativo está no nível do Servidor Administrativo ou do Gerenciadorde Domínio. O conteúdo especificado nesse diretório é utilizado como o superconjunto de todos osmapeamentos possíveis para todos os servidores gerenciados. Para cada servidor gerenciado(dependendo de quais módulos forem descobertos como implementados), o descritor de aplicativo éprocessado para a inclusão daqueles módulos no aplicativo.
Exemplo de Descritores de AplicativosÉ possível visualizar informações do aplicativo para um descritor de aplicativo de amostra.
A tabela a seguir descreve detalhes de um aplicativo de amostra:
Tabela 13. Descrição do Aplicativo
Detalhe
Aplicativo Gerenciamento de Ordemm
Instância Teste
Servidores • Três servidores Apache• Dois servidores WebLogic (gerenciados em um domínio)• Um servidor customizado (Gateway de Cumprimento da Ordem)• Um processo Java customizado (Programa de Correio Automático)• Uma Instância Oracle
Módulos • Conteúdo estático• Arquivo WAR• Arquivo EAR• Arquivo RAR (comunica-se com o módulo Gateway)• Módulo Gateway virtual• jar automailer• Esquema do DB
Host • Três sistemas de servidor da Web• Dois sistemas de servidor de aplicativos• Um sistema de servidor de gateway de Cumprimento de Ordem• Um sistema do servidor de banco de dados Oracle
O descritor de aplicativo base do aplicativo de amostra é armazenado no arquivo oms_coll_desc.xml,colocado no diretório do descritor de aplicativo de qualquer componente de aplicativo:
<base-app-descriptor> <app-instance name="Order Management-Staging" description="Order Entry application - staging" url="http://orderentry.stage.lab.com"
76 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

contact="John Public" /></base-app-descriptor>
O descritor de aplicativo do componente do sistema de computador que hospeda o servidor Apache éarmazenado no arquivo apache_host_coll_desc.xml no local especificado pelo parâmetrocom.collation.platform.os.hostappdescriptorfiles.dir no arquivo de configuraçãocollation.properties. Descritores de aplicativos de host adicionais estão presentes em cadasistema de computador incluído no aplicativo de negócios:
<component-app-descriptor grouping-pattern="Order Management-Staging" app-instance-name="Order Management-Staging-Web Tier" > <component-descriptor type="host" name="staging.example.com" marker-module="true" /></component-app-descriptor>
O descritor de aplicativo do componente WebLogic é armazenado no arquivo wls_coll_desc.xml dodiretório WebLogic_home_dir/appdescriptors:
<component-app-descriptor grouping-pattern="Order Management-Staging" app-instance-name="Order Management-Staging-Order Processing Server" > <!-- order.war --> <component-descriptor type="module" name="WebLogicWebModule:order" marker-module="false" /> <!-- orderejb.ear --> <component-descriptor type="module" name="WebLogicWebModule:orderejb" marker-module="false" /> <!-- ofg.rar --> <component-descriptor type="module" name="WebLogicWebModule:ofg" marker-module="false" /></component-app-descriptor>
O descritor de aplicativo do componente Gateway de Cumprimento de Ordem, armazenado no arquivoofg_coll_desc.xml do diretório especificado no modelo de servidor customizado:
<component-app-descriptor grouping-pattern="Order Management-Staging" app-instance-name="Order Management-Staging-Order Fulfillment Gateway" > <component-descriptor type="server" name="n/a" marker-module="false" /></component-app-descriptor>
O descritor de aplicativo do componente para o processo de correio automático Java é armazenado noarquivo am_coll_desc.xml no diretório especificado no modelo de servidor customizado:
<component-app-descriptor grouping-pattern="Order Management-Staging" app-instance-name="Order Management-Staging-Order Processing Automailer"> <component-descriptor type="module" name="automailer.jar" marker-module="false" /> <component-descriptor type="module" name="login.jar" marker-module="false" /></component-app-descriptor>
Capítulo 1. Usando 77

O descritor de aplicativo do componente para o esquema de banco de dados Oracle é armazenado noarquivo ora_coll_desc.xml do diretório $ORACLE_HOME/appdescriptors:
<component-app-descriptor grouping-pattern="Order Management-Staging" app-instance-name="Order Management-Staging-Order Processing DB"> <component-descriptor type="module" name="ORDER" marker-module="false" /> <component-descriptor type="module" name="OFG" marker-module="false" /> <component-descriptor type="module" name="ADMIN" marker-module="false" /></component-app-descriptor>
O descritor de aplicativo do componente para o servidor Apache é armazenado no arquivoapache_coll_desc.xml do diretório Apache_server_home_dir/appdescriptors no servidorApache. Descritores de aplicativos adicionais estão presentes em cada servidor Apache que faça parte doaplicativo Gerenciamento de Ordens:
<component-app-descriptor grouping-pattern="Order Management-Staging" app-instance-name="Order Management-Staging-Web Tier"> <component-descriptor type="module" name="/opt/apache13/htdocs/ordermgt/" marker-module="false" /></component-app-descriptor>
Suprimindo Avisos de SensorÉ possível filtrar mensagens de aviso selecionadas, quando o mesmo conjunto de avisos é reportado cadavez que a descoberta é executada.
Sobre Esta TarefaOs sensores produzem mensagens de aviso quando alguns dados da descoberta não são coletados. Vocêpode filtrar as mensagens sobre os problemas que já são conhecidos.
Restrição: A filtragem de mensagem de aviso é possível somente para códigos de aviso do TADDM eoutros identificadores independentes de idioma, como códigos de erro do sistema operacional queconstituem uma mensagem de aviso. As partes da mensagem que dependem do idioma localizado nãopodem ser filtradas.
No arquivo collation.properties, inclua uma lista de mensagens de aviso que você deseja filtrarpara a propriedade com.ibm.cdb.discover.suppressedWarnings. Esse lista consiste em códigosde aviso de sensor ou comandos do SO que fazem parte de uma mensagem de aviso. Os códigos ecomandos devem ser separados por ponto e vírgula. Comece a lista com os códigos de aviso CTJTD.
As configurações de filtragem não afetam os IPs e escopos que tiverem sua própria versão com escopodefinido para essa propriedade.
• Para filtrar avisos para IP específico ou escopo, anexe o endereço IP ou nome do escopo à propriedade:
com.ibm.cdb.discover.suppressedWarnings.<IP>=<filter>;<filter>;...
com.ibm.cdb.discover.suppressedWarnings.<scopename>=<filter>;...• Para filtrar todas as mensagens de aviso, use um asterisco (*) como um filtro.• Para incluir um ponto e vírgula no filtro, use a sequência a seguir: \\;
Exemplos
Importante: Digite os códigos de aviso e comandos em uma linha.
78 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

• O exemplo a seguir mostra os avisos especificados de filtragem para um sistema de computador dedestino ou um escopo da descoberta:
com.ibm.cdb.discover.suppressedWarnings.1.2.3.4=CTJTD0808W;CTJTD0737Wcom.ibm.cdb.discover.suppressedWarnings.myscope=cat /proc/cpuinfo | grep core id;CTJTD0762W;0x32bf
• O exemplo a seguir mostra todos os avisos de filtragem para o sistema de computador de destino:
com.ibm.cdb.discover.suppressedWarnings.1.2.3.4=*
• O exemplo a seguir mostra a filtragem de uma mensagem que contém ponto e vírgula:
com.ibm.cdb.discover.suppressedWarnings=LANG=C\\; psrinfo -p
Nota: Também é possível especificar a propriedade com.ibm.cdb.discover.suppressedWarningsvia Console do Produto na janela de Propriedades da Plataforma de Perfis de Descoberta. Quando a caixade opção Incluído da propriedade com.ibm.cdb.discover.suppressedWarnings está selecionada,essa propriedade substitui as configurações de filtragem do arquivo collation.properties quando adescoberta é executada com esse perfil de descoberta.
Reconciliando Itens de ConfiguraçãoOs itens de configuração (ICs) são reconciliados para determinar se um IC recém-descobertocorresponde a um IC que está armazenado no banco de dados TADDM. Este processo elimina aduplicação no banco de dados TADDM.
A reconciliação de novos dados ocorre automaticamente quando ocorrem os seguintes eventos:
• Após executar uma descoberta, mas antes de os ICs recém-descobertos serem armazenados no bancode dados TADDM, o processo de reconciliação inicia. Este processo elimina duplicatas e reduz o tempode processamento geral para ICs descobertos. O processo é executado para sistemas de computadordescobertos por vários sensores do TADDM e para sistemas de computador carregados a partir dosadaptadores da biblioteca de descoberta (DLAs).
• Durante o armazenamento do objeto, o gerenciador de topologia mescla os ICs com base nas regras denomenclatura correspondentes.
• Periodicamente, os agentes do construtor de topologia são executados para desempenhar umareconciliação mais complexa. Este método inclui a mesclagem de ICs existentes, a criação derelacionamentos e a remoção de quaisquer ICs duplicados não cobertos pelos eventos anteriores.
Priorização de DadosÉ possível usar a priorização para ordenar dados recebidos no banco de dados TADDM. A priorização usaregras definidas para determinar qual origem de dados tem prioridade sobre outras origens de dados aoatualizar atributos do item de configuração (IC). Este método assegura que os ICs reconciliadoscontenham valores de atributo de uma origem de dados predefinida.
Dados para ICs podem ser fornecidos para o TADDM a partir de diversas origens. As diversas origenspodem incluir vários sensores, o Console de Gerenciamento de Descoberta, a API ou adaptadores dabiblioteca de descoberta (DLAs). A priorização de dados usa regras para criar uma lista ordenada deorigens de dados.
Pré-requisitos para Usar a Priorização
As condições a seguir devem existir antes do uso das regras de priorização:
• A priorização ocorre somente quando os dados são gravados e não afeta dados existentes.• A priorização pode ocorrer somente ao carregar origens de dados em um único banco de dados. Dados
de domínio cruzado, tais como dados combinados no servidor de sincronização, não podem serpriorizados.
Capítulo 1. Usando 79

• As regras de priorização e de origens de dados podem ser definidas antes ou após dados de umaorigem específica serem carregados no banco de dados TADDM. A exclusão de uma origem de dadosnão afeta dados no banco de dados.
• A priorização pode ser aplicada somente entre dois ICs que são reconhecidos pelo sistema como omesmo item. Quando o mesmo IC é gravado no banco de dados usando diferentes regras denomenclatura ou diferentes valores para o atributo, o sistema visualiza o IC como dois itens separados.A priorização não é aplicada aos dados entre dois ICs diferentes.
Os dados de IC que não requerem priorização não precisam de uma definição de origem de dados parasalvar dados no banco de dados TADDM. Em muitos casos, não é necessário fornecer nenhuma origem dedados ou regra de prioridade para um IC. A priorização não é necessária, por exemplo, se somente umaorigem de dados relata informações sobre esse IC ou se as origens de dados que fornecem dados parauma classe são todas igualmente confiáveis.
Definições de Regra de Prioridade
As regras de prioridade para origens de dados podem ser definidas para a classe inteira ou para umatributo individual para uma classe. Os dois níveis não podem ser usados ao mesmo tempo em qualquerclasse de IC única.
• As regras de prioridade podem ser alteradas a partir do nível de classe para o nível de atributo ou donível de atributo para o nível de classe para uma determinada classe de IC.
• A alteração das regras de prioridade ou dos níveis de prioridade altera as definições no banco de dadosTADDM. Quando as novas regras são aplicadas aos dados recebidos, pode haver um atraso antes que osistema reflita completamente as definições de prioridade alteradas para uma determinada classe deIC.
Regras de Prioridade no Nível da ClasseAs regras de prioridade no nível da classe fornecem uma lista ordenada de origens de dados para aclasse inteira. A prioridade das origens de dados é determinada por suas posições na lista. A primeiraorigem de dados na lista possui a prioridade mais alta, a segunda origem de dados na lista tem asegunda prioridade mais alta e assim por diante. Os dados podem ser gravados no banco de dados apartir de uma origem de dados que não é definida em uma regra de prioridade. No entanto, os dadospodem ser sobrescritos por qualquer origem de dados definida por uma regra de prioridade, porqueela possui a prioridade mais baixa para essa classe. Sempre que a origem de dados recebida possuiuma prioridade mais alta, ela atualiza os dados no banco de dados (a classe inteira ou um atributoespecífico). Se a origem de dados recebida possui uma prioridade inferior à origem de dados quepossui os dados no banco de dados, os dados recebidos são ignorados, para a classe ou para umdeterminado atributo.
Regras de Prioridade no Nível do AtributoRegras de prioridade de atributo individuais se comportam da mesma maneira que regras no nível daclasse. Com uma exceção, a lista ordenada específica de origens de dados se aplica somente a umdeterminado atributo da classe. Cada atributo na classe pode ter uma lista ordenada diferente deorigens de dados. O número de atributos em uma classe que podem ser priorizados usando apriorização no nível do atributo possui uma limitação de 192 caracteres. Portanto, o número realdepende dos atributos que são selecionados para serem priorizados. O Console de Gerenciamento deDescoberta impinge o limite e informa que foi feita uma tentativa de priorizar atributos individuais emexcesso.
Alteração do atributo para regras de prioridade no nível da classeSe regras de priorização forem alteradas a partir do atributo no nível da classe após os dados serempersistidos no banco de dados, as informações detalhadas sobre qual origem de dados forneceu qualvalor de atributo não serão preservadas na próxima vez que os dados forem carregados. Em vez disso,uma das origens de dados fornecidas para os dados existentes será selecionada como o proprietáriopara todos os dados no IC. Essa origem de dados é usada na comparação com a origem de dadosrecebida para determinar se os dados no IC devem ser atualizados. Esta ação ocorre porque apriorização no nível da classe requer que todos os dados em um IC venham de um único provedor.
80 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Nenhuma regra de prioridade definidaSe nenhuma regra de prioridade for definida, os dados mais recentes recebidos no sistemaatualizarão os dados existentes.
Regras de prioridade definidas após os dados estarem no banco de dadosSe as regras de prioridade forem incluídas após os dados estarem no banco de dados, os dadosexistentes receberão a prioridade mais baixa no sistema. Os dados existentes são sobrescritos pelosdados recebidos, independentemente da prioridade das origens de dados recebidas. Após os dadosserem gravados usando as novas regras, a priorização se aplicará às atualizações futuras.
Regras de prioridade são excluídas após os dados no banco de dadosSe regras de prioridade forem excluídas após os dados estarem no banco de dados, quaisquer dadosrecebidos atualizarão os dados existentes.
Sistema de Software de Gerenciamento (Identificador)
Quando dados são salvos no banco de dados TADDM, um identificador do sistema de software degerenciamento (MSS) é fornecido para definir a identidade do provedor de dados. O sistema tentaautomaticamente corresponder o identificador de MSS de um provedor de dados com definições deorigem de dados que foram definidas para priorização. Se for feita uma correspondência entre umidentificador de MSS e uma origem de dados, todas as regras de prioridade que contiverem essa origemde dados serão aplicadas aos dados recebidos. A área de janela Detalhes no Console de Gerenciamentode Descoberta exibe o sistema de software de gerenciamento (MSS) que fornece dados sobre umdeterminado IC.
Códigos de Cores para Itens de Configuração com Regras de PrioridadeNa janela Priorização de Atributo, é possível criar uma origem de dados e regras de priorização paraitens de configuração. Os itens de configuração são codificados por cor, dependendo de quais regras depriorização estão associadas aos atributos.
Os itens de configuração na janela Priorização do Atributo são codificados por cor para mostrar se asregras são aplicadas aos itens de configuração.
As cores a seguir são exibidas na janela:
• Na área de janela Itens de Configuração, o nome de classe do IC é destacado em azul se qualquer umde seus atributos possuir regras de prioridade designadas a ele. Se um nome de classe de IC nãoestiver destacado, não há regras definidas para nenhum de seus atributos.
• Na área de janela Lista de Origens de Dados do TADDM, o nome da origem de dados está em verde seele possui um identificador de MSS associado. O nome estará em azul se não possuir identificador deMSS associado. Esta situação ocorre se a origem de dados não foi armazenada ou se a entrada daorigem de dados não foi definida corretamente e não possui MSS correspondente.
• Na área de janela superior direita, nas colunas Nome do Atributo e Objeto de Origem, a linha do atributoé destacada de acordo com o esquema a seguir:
– Destacada em azul se ela possui regras de prioridade associadas a ela.– Destacada em amarelo se o objeto de origem a partir do qual ela herda o atributo possuir regras de
prioridade associadas a ele.– O atributo não é destacado se nenhuma regra de prioridade estiver designada a ele e ele não herda
nenhuma regra.
Figura 1 na página 82 mostra que o atributo adminState é destacado em amarelo. O IC denominadoAgente tem regras de prioridade definidas para o atributo adminState. O IC TWSAgent herda seuatributo adminState desse IC (Agente). O atributo accessMethod não possui regras designadas a ele enão herda nenhuma regra.
Capítulo 1. Usando 81

Figura 1. Janela Priorização do Atributo
Incluindo Regras de Priorização em seus Itens de Configuração (Objetos Modelos)É possível usar o Console de Gerenciamento de Descoberta para priorizar atributos para itens deconfiguração. A priorização determina qual origem de dados tem prioridade sobre outras origens dedados ao atualizar atributos do item de configuração (IC).
Procedimento
Para priorizar os atributos para itens de configuração (ICs), conclua as etapas a seguir:1. No Console de Gerenciamento de Descoberta, clique em Editar > Regras de Priorização.2. Na área de janela Lista de Origens de Dados do TADDM, clique em Incluir. A janela Incluir Origem de
Dados é exibida.3. Selecione uma das origens de dados a seguir:
• Criar uma Origem de Dados para Descoberta
82 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Selecione esta opção para criar uma origem de dados que é reunida a partir de todos os sensores.Os valores não podem ser alterados e somente uma origem de dados deste tipo pode ser criada nosistema. O nome da origem de dados é TADDMALLDISCOVERY.
• Criar uma Origem de Dados para Topologia
Selecione esta opção para criar uma origem de dados do construtor de topologia do TADDM. Osvalores não podem ser alterados. O nome da origem de dados é TADDMALLTOPOB.
• Criar uma Origem de Dados Customizada
(Antes do fix pack 4) Insira os valores nos campos a seguir:
– Nome do Produto– Nome do Host– Opcional: Nome do Fabricante– Opcional: Descrição– Opcional: Designação de MSS
Insira valores nos seguintes campos:
– Nome do Produto– Nome do subcomponente– Instância do subcomponente– Opcional: Descrição
Nota: Esta opção é recomendada antes de todas as outras opções, uma vez que abrange todos oscasos de uso conhecidos.
O 'Nome do produto', o 'Nome do sobcomponente' e a 'Instância do subcomponente' devem serinseridos conforme exibidos no sistema de software de gerenciamento (MSS), com as mesmascapitalização, ortografia e pontuação. O MSS é exibido em Editar>MSS no Console de descoberta.
• Criar uma origem de dados de MSS
Selecione um dos métodos a seguir para inserir a Designação de MSS:
– Digite as entradas de nome do produto e do host exatamente conforme exibido no sistema desoftware de gerenciamento (MSS). O nome deve ter a mesma capitalização, ortografia epontuação.
– Alternativamente, a partir da lista Designação de MSS (Opcional), selecione o nome de MSSapropriado. Essa lista inclui o nome de MSS que está associado a cada sensor. Todos os nomesde MSS que você definiu são exibidos nessa lista. Os nomes de MSS que resultam docarregamento de dados dos manuais IdML ou do programa de carregamento em massa tambémsão exibidos.
Nota: A Atribuição MSS é opcional. Se você não especificar nenhum valor no campo, pode usaruma configuração global a partir do arquivo etc/attrpriorot.properties. O conteúdo doarquivo deve estar em conformidade com o formato a seguir:
<MSS>=<PRIORITY>
em que <MSS> é o nome do MSS e <PRIORITY> é a prioridade da origem de dados, 1 representa aprioridade mais alta. Por exemplo:
IBM:TADDM:ds.ibm.com:Discovery:WindowsComputerSystemSensor=10
4. Clique em OK para salvar a nova origem de dados.5. Na área de janela Itens de Configuração, selecione um objeto modelo. Os atributos que estão
associados a este objeto modelo são exibidos na área de janela adjacente. Selecione um nome doatributo para designar à nova origem de dados. O objeto modelo e o nome do atributo, ou nomes, que
Capítulo 1. Usando 83

você selecionou são destacados em azul na parte superior da área de janela Regras de Priorizaçãopara Item de Configuração e Atributo.
6. Na área de janela Lista de Origens de Dados do TADDM, selecione a origem de dados. Clique emCopiar. A origem de dados move para a área de janela Regras de Priorização para Item deConfiguração e Atributo.
7. Opcional: Selecione a caixa de seleção Definir Priorização no Nível da Classe para aplicar estapriorização a todos os atributos para o objeto modelo selecionado.
8. A área de janela Regras de Priorização para Item de Configuração e Atributo lista as origens de dadosque são copiadas. Para mover a origem de dados para a posição desejada, selecione-a e clique emMover Para Cima ou Mover Para Baixo. Quanto mais alta a posição nesta área de janela, mais alta aprioridade para essa origem de dados.
9. Clique em OK para salvar as informações.
Portal de Gerenciamento de DadosO Portal de Gerenciamento de Dados é a interface com o usuário baseada na web do IBM TivoliApplication Dependency Discovery Manager (TADDM) para visualização e manipulação dos dados em umbanco de dados TADDM. Essa interface com o usuário é aplicável a uma implementação do servidor dedomínio, a uma implementação do servidor de sincronização e a cada servidor de armazenamento emuma implementação do servidor de fluxo. A interface com o usuário é muito semelhante em todas asimplementações, embora em uma implementação do servidor de sincronização, ela tenha algumasfunções adicionais para incluir e sincronizar domínios.
Tarefas de DescobertaÉ possível usar o Portal de Gerenciamento de Dados para configurar descobertas.
Nota: O Portal de Gerenciamento de Dados ativa a configuração apenas de escopos de descoberta econjuntos de escopo. Para executar operações nos grupos de escopos, consulte “Área de Janela Escopo”na página 125.
Configurando um EscopoÉ possível usar o Portal de Gerenciamento de Dados para configurar um conjunto de escopos e umescopo.
Procedimento
Importante: A criação de escopos muito grandes pode levar a problemas de desempenho, incluindotravamento do servidor.
Para configurar um conjunto de escopos e um escopo, usando o Portal de Gerenciamento de Dados,conclua as seguintes etapas:1. Na barra de menus, clique em Descoberta > Escopo.
A área de janela Escopo é exibida.2. Para definir um novo conjunto de escopos da descoberta, clique em Novo Conjunto de Escopos.
A janela "Novo Conjunto de Escopos" é exibida.3. No campo Nome, digite o nome para o novo conjunto de escopos.
Importante: Os nomes de conjunto de escopos não podem conter os caracteres a seguir:
• '• .• /
4. Clique em OK.O novo conjunto de escopos é exibido na lista Conjuntos de Escopos.
84 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

5. Para incluir o escopo e o conteúdo no conjunto de escopos, selecione o conjunto de escopos recém-criado e clique em Novo.A janela "Novo Escopo" é exibida.
6. Para incluir as configurações para o escopo, conclua uma das etapas a seguir:
• No painel Incluir, selecione Sub-rede na lista e execute um dos seguintes procedimentos:
– No campo Endereço, digite o endereço IP da máscara de sub-rede.– Mova a régua de controle para o endereço IP da máscara de sub-rede.
A máscara de sub-rede inserida deve ter um valor exclusivo dentro do conjunto de escopos.• No painel Incluir, selecione Intervalo na lista e no campo Endereços, digite o primeiro e o último
endereços IP do intervalo. Os valores inseridos devem ser exclusivos dentro do conjunto deescopos.
• No painel Incluir, selecione Host na lista e execute um dos seguintes procedimentos:
– No campo Endereços, digite o endereço IP do host.– No campo Descrição/Nome do Host, digite o nome do host.
Os valores inseridos devem ser exclusivos dentro do conjunto de escopos.
Importante: Se o endereço IP e o nome do host estiverem definidos e não corresponderem entre si,o endereço IP terá precedência e o nome do host será tratado apenas como uma descrição.
7. Para excluir dispositivos e hosts do escopo, no painel Exclusões, clique em Incluir e conclua uma dasseguintes etapas:
• Selecione Sub-rede na lista e execute um dos seguintes procedimentos:
a. No campo Endereço, digite o endereço IP da máscara de sub-rede.b. Mova a régua de controle para o endereço IP da máscara de sub-rede.
• Selecione Intervalo na lista e digite o primeiro e o último endereços IP do intervalo.• Selecione Host na lista e digite o endereço IP do nome do host.
8. Para salvar o escopo, clique em OK.O novo escopo é exibido na lista.
Alterando um EscopoÉ possível usar o Portal de Gerenciamento de Dados para alterar um escopo de descoberta existente.
Procedimento
Importante: A criação de escopos muito grandes pode levar a problemas de desempenho, incluindotravamento do servidor.
Para alterar um escopo de descoberta existente, usando o Portal de Gerenciamento de Dados, conclua asseguintes etapas:1. Na barra de menus, clique em Descoberta > Escopo.
A área de janela Escopo é exibida.2. Na lista Conjuntos de Escopos, selecione um conjunto de escopos.
A lista de escopos para esse conjunto de escopos está listada à direita.3. Na lista de escopos, selecione um escopo e clique em Editar.
A janela "Editar Escopo" é exibida.4. Para alterar as configurações para o escopo, conclua uma das etapas a seguir:
• Para alterar uma sub-rede, no campo Endereço, digite o endereço IP da sub-rede. O valor da sub-rede inserido deve ser um valor exclusivo dentro do conjunto de escopos. Continue com a Etapa 5.
Capítulo 1. Usando 85

• Para alterar um intervalo de dispositivos, no campo Endereço, digite o primeiro e o último endereçosIP do intervalo. Os valores inseridos devem ser exclusivos dentro do conjunto de escopos. Continuecom a Etapa 5.
• Para alterar um dispositivo específico, no campo Endereço, digite o endereço IP, ou no campoDescrição/Nome do Host, digite o nome completo do host. Os valores inseridos devem serexclusivos dentro do conjunto de escopos. Continue com a Etapa 6.
5. Para excluir dispositivos e hosts do escopo de descoberta, no painel Exclusões, clique em Incluir econclua uma das seguintes etapas:
• Selecione Host na lista e digite o endereço IP do nome do host.• Selecione Sub-rede na lista e digite o endereço IP da sub-rede.• Selecione Intervalo na lista e digite o primeiro e o último endereços IP do intervalo.
6. Para salvar o escopo, clique em OK. As novas alterações são aplicadas ao escopo.
Excluindo um EscopoÉ possível usar o Portal de Gerenciamento de Dados para excluir um escopo.
Procedimento
Para excluir um escopo, usando o Portal de Gerenciamento de Dados, conclua as seguintes etapas:1. Na barra de menus, clique em Descoberta > Escopo.
A área de janela Escopo é exibida.2. Na lista Conjuntos de Escopos, selecione o conjunto de escopos que contém o escopo que deseja
excluir.A lista de escopos para esse conjunto de escopos está listada à direita.
3. Na lista de escopos, selecione um escopo e clique em Excluir.Uma janela de mensagem é exibida.
4. Para excluir o escopo, clique em Sim.O escopo é excluído do conjunto de escopos.
Excluindo um Conjunto de EscoposÉ possível usar o Portal de Gerenciamento de Dados para excluir um conjunto de escopos.
Procedimento
Para excluir um conjunto de escopos, usando o Portal de Gerenciamento de Dados, conclua as seguintesetapas:1. Na barra de menus, clique em Descoberta > Escopo.
A área de janela Escopo é exibida.2. Na lista Conjuntos de Escopos, selecione o conjunto de escopos que deseja excluir e clique em
Excluir Conjunto de Escopos.Uma janela de mensagem é exibida.
3. Para excluir o conjunto de escopos, clique em Sim.O conjunto de escopos é excluído.
Incluindo Servidores CustomizadosÉ possível usar o Portal de Gerenciamento de Dados para incluir servidores customizados.
Procedimento
Para incluir um servidor customizado, conclua as seguintes etapas a partir do Portal de Gerenciamento deDados:
1. Na área de janela Funções, clique em Descoberta > Servidores Customizados.A área de janela Servidores Customizados é exibida.
86 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

2. Na área de janela Servidores Customizados, clique em Novo.A guia Informações Gerais e Critérios do bloco de notas Detalhes do Servidor Customizado éexibida.
3. Para ativar a definição do servidor customizado, clique em Ativado.4. No campo Nome, digite o nome do servidor customizado.5. Na lista Tipo, selecione o tipo de servidor customizado que está incluindo.6. Para configurar a ação, conclua uma das seguintes etapas:
• Clique em Descobrir se desejar descobrir todas as instâncias do servidor.• Clique em Ignorar se desejar suprimir a descoberta de todas as instâncias do servidor.
7. Para selecionar um ícone a associar com o servidor customizado, clique em Navegar e selecione oícone que deseja utilizar.
8. No painel Critérios de Identificação, conclua uma das seguintes etapas:
• Para corresponder a todos os critérios de identificação, clique em Todas as seguintes condiçõesforem atendidas (lógica AND).
• Para corresponder a todos os critérios de identificação, clique em Qualquer uma das seguintescondições for atendida (lógica OR).
9. Conclua as seguintes etapas para definir os critérios para o servidor customizado:a) Na primeira lista, selecione o tipo de critério.b) Na segunda lista, selecione o operador.c) No campo fornecido, digite o argumento de texto para o tipo de critério e o operador.
10. Para incluir o novo critério, clique em +.11. Para incluir arquivos de configuração, clique na guia Arquivos de Configuração.
A página Arquivos de Configuração é exibida.12. Na página Arquivos de Configuração, clique em Novo.
A janela Caminho de Procura para Capturar Arquivo é exibida.13. Na lista Tipo, selecione um dos tipos de arquivos a capturar:
• Arquivo de Configuração• Módulo de Software• Diretório/Arquivo do Descritor de Aplicativos
14. Na lista Caminho da Procura, selecione um dos seguintes caminhos da procura para o arquivo deconfiguração:/
A raiz do sistema de arquivos.$PWD
O diretório de trabalho atual do programa em execução.$HOME
O diretório inicial do ID do usuário do programa em execução.C:
Um diretório em seu computador local.%ProgramFiles%
O diretório de arquivos do programa.%SystemRoot%
O diretório-raiz do sistema.
Digite o caminho e o nome do arquivo do arquivo de configuração na caixa de texto ou digite *(asterisco) para especificar todos os arquivos no diretório selecionado.
15. Para capturar o conteúdo do arquivo de configuração, clique em Capturar conteúdo do arquivo e,opcionalmente, especifique o número máximo de bytes do arquivo de configuração capturado.
Capítulo 1. Usando 87

16. Para recursar através da estrutura de diretório para procurar o arquivo especificado, selecioneRecursar procura de diretório (se usar o TADDM 7.3.0.3 ou mais recente) ou Recursar conteúdo dodiretório (se usar o TADDM 7.3.0.2 ou anterior).
17. Para salvar as configurações para o servidor customizado, clique em OK.
Editando um Servidor CustomizadoÉ possível usar o Portal de Gerenciamento de Dados para editar um servidor customizado.
Procedimento
Para editar um servidor customizado, conclua as seguintes etapas usando o Portal de Gerenciamento deDados:1. Na área de janela Funções, clique em Descoberta > Servidores Customizados.
A área de janela Servidores Customizados é exibida.2. Na área de janela Servidores Customizados, clique em Editar.
O bloco de notas Detalhes do Servidor Customizado é exibido, com os campos Nome e Tipodesativados. Estes campos não podem ser alterados.
3. Para alterar os outros campos no bloco de notasDetalhes do Servidor Customizado, consulte“Incluindo Servidores Customizados” na página 86.
4. Para atualizar as informações sobre o servidor customizado que você acabou de alterar, execute outradescoberta.Para melhorar a velocidade do processo de descoberta, limite o escopo ativo da descoberta ao novocomponente.
Copiando um Servidor CustomizadoÉ possível criar um servidor customizado com base em um existente. Isto é feito copiando-se um servidorlistado na área de janela Servidores Customizados e atribuindo-lhe um nome exclusivo.
Procedimento
Para copiar um servidor customizado, conclua as seguintes etapas a partir do Portal de Gerenciamento deDados:1. Na área de janela Funções, clique em Descoberta > Servidores Customizados.
A área de janela Servidores Customizados é exibida.2. Na área de janela Servidores Customizados, selecione o servidor customizado que deseja copiar e
clique em Copiar.A janela Detalhes do Servidor Customizado é exibida.
3. No campo Nome, digite o nome do novo servidor customizado.4. Se apropriado, digite novos valores para uma ou mais propriedades do novo servidor customizado.5. Para salvar o novo servidor customizado, clique em OK.
Excluindo um Servidor CustomizadoÉ possível usar o Portal de Gerenciamento de Dados para excluir um servidor customizado.
Procedimento
Para excluir um servidor customizado, conclua as seguintes etapas a partir do Portal de Gerenciamentode Dados:1. Na área de janela Funções, clique em Descoberta > Servidores Customizados.
A área de janela Servidores Customizados é exibida.2. Na área de janela Servidores Customizados, selecione o servidor customizado que deseja excluir e
clique em Excluir.Uma janela de mensagem é exibida.
3. Para excluir o servidor customizado, clique em Sim na janela de mensagem.
88 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

4. Para confirmar a exclusão, certifique-se de que o servidor customizado não esteja listado na área dejanela Servidores Customizados.
Trabalhando com padrões de agrupamentoNa área de janela Padrões de Agrupamento, no Portal de Gerenciamento de Dados, é possível criar,exibir e editar padrões de agrupamento. Padrões de agrupamento podem ser usados para ter os seus CIsagrupados automaticamente em coleções customizadas de aplicativos de negócios de tipo, coleções oucoleções de acesso.
Para obter detalhes, consulte “Criando aplicativos de negócios com padrões de agrupamento” na página194.
Veja também os tópicos Gerenciando padrões de agrupamento e Mantendo padrões de agrupamentousando a API REST no Guia do Desenvolvedor SDK do TADDM.
Visualizando o Histórico de DescobertaCada vez que uma descoberta é executada, o Portal de Gerenciamento de Dados atualiza a atividade dedescoberta e as informações de erro que são exibidas na área de janela Histórico.
Sobre Esta Tarefa
É possível visualizar o histórico de descoberta, incluindo a atividade associada e informações de erro, naárea de janela Histórico. Por padrão, as informações sobre as últimas dez descobertas são exibidas.
Pode demorar muito para recuperar e exibir o histórico de descobertas na área de janela Histórico. Comoalternativa, tente usar Eventos Concluídos do Sensor pela Execução do Relatório BIRT.
Procedimento
Para visualizar um histórico da descoberta, conclua as seguintes etapas a partir do Portal deGerenciamento de Dados:1. Na área de janela Funções, clique em Descoberta > Histórico.
A área de janela Histórico é exibida.2. Para exibir informações sobre uma descoberta, selecione uma entrada na tabela.
Uma segunda tabela de dados é exibida. Esta tabela fornece uma lista de sensores e o nome do host,endereço IP, data, status e descrição para cada sensor.
3. Para exibir os escopos que estão incluídos na descoberta, clique em Detalhes do Escopo. A janelaLista de Escopos é exibida.Para fechar a janela Lista de Escopos, clique em Fechar.
4. Para exibir informações sobre um evento, selecione o evento e clique em Detalhes do Evento. Ajanela Evento de Descoberta é exibida.Para fechar a janela Evento de Descoberta, clique em Fechar.
Identificando Servidores DesconhecidosÉ possível identificar servidores desconhecidos em execução em um sistema de computador e usar essasinformações para criar um modelo de servidor customizado que você pode usar para descobertas futuras.
Sobre Esta Tarefa
Os servidores desconhecidos são identificados após uma descoberta por um agente de construção detopologia. O agente de construção de topologia é executado em segundo plano periodicamente,dependendo do valor da frequência configurada, portanto os servidores desconhecidos podem não serreconhecidos imediatamente após a conclusão de uma descoberta. A cada quatro horas é a frequênciapadrão na qual o agente de construção de topologia é executado.
Para configurar a frequência do agente de segundo plano, configure a seguinte propriedade no arquivocollation.properties:
com.ibm.cdb.topobuilder.groupinterval.background=frequency
Capítulo 1. Usando 89

em que frequency é a frequência, em horas, do agente de segundo plano. O valor padrão é 4.0.
Procedimento
Para identificar servidores desconhecidos, conclua as seguintes etapas no Portal de Gerenciamento deDados:1. Na área de janela Componentes Descobertos, selecione um ou mais sistema de computador que você
deseja marcar para servidores desconhecidos.2. Clique em Ações > Servidores Desconhecidos.
A área de janela Servidores Desconhecidos é exibida.3. Para criar um servidor customizado com base em um servidor desconhecido, selecione um servidor
desconhecido e clique em Criar Servidor Customizado.O servidor desconhecido permanecerá marcado como desconhecido até depois que um modelo deservidor customizado tiver sido criado no servidor desconhecido e uma descoberta executada.
Fundindo Manualmente Itens de Configuração DescobertosA fusão manual é o processo no qual você combina dois ou mais objetos do item de configuração (CI) emum CI. É possível usar esse processo para remover CIs duplicados.
Antes de Iniciar
Ao fundir os CIs, um único CI é selecionado na lista de CIs a serem fundidos. Esse CI é chamado de CI"durável" e é retido no final da operação de fusão. Os outros CIs são chamados de CIs "temporários" esão excluídos no final da operação de fusão.
As seguintes regras se aplicam à fusão manual de CIs:
• Apenas CIs do mesmo tipo podem ser fundidos.• Quando os CIs são fundidos, apenas os atributos de tipos primitivos (por exemplo, sequência e número
inteiro) são transferidos do CI temporário para o CI durável. Essa transferência ocorrerá apenas se o CIdurável já não tiver um valor para esse atributo. Matrizes e objetos associados ao CI temporário não sãotransferidos.
• Quando um CI temporário for excluído, todos os CIs relacionados também serão excluídos. Porexemplo, se um CI ComputerSystem for excluído, então o CI do sistema operacional no sistema decomputador e todas as instalações de software no sistema operacional serão excluídas.
• Se um CI designado como um objeto temporário for, posteriormente, redescoberto ou recarregado pormeio do recurso de carregamento em massa, ele atualizará o objeto durável. Esse método não resultaem uma segunda instância do CI.
• A fusão não é atualmente suportada para Sistemas de Negócio ou Aplicativos de Negócios.
Aviso: Não exiba/navegue em um CI temporário quando o processo de mesclagem está emandamento. Isso pode fazer com que o arquivo error.log rastreie exceções de um ponto nulo ecom que a mesclagem falhe sem exibir uma mensagem de erro.
Procedimento
Para fundir CIs, conclua as seguintes etapas no Portal de Gerenciamento de Dados:1. Execute um dos seguintes:
• Na área de janela Componentes Descobertos, selecione os CIs que deseja fundir. Clique em Ações> Fundir.
• Em uma visualização de topologia, selecione os CIs que deseja fundir, clique com o botão direito domouse neles e selecione Fundir.
A janela Fundir Componente é exibida.2. Na lista Nome de Exibição, selecione o CI a ser retido no final da fusão (CI durável). Clique em Marcar
como Durável.
90 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

3. Os CIs restantes são fundidos na ordem em que são exibidos na lista Nome de Exibição. Para alterar aprioridade, selecione um CI e clique em Mover para Cima ou Mover para Baixo para alterar a ordem.
4. Clique em OK para salvar as informações.
O que Fazer DepoisAs informações relativas a operações de fusão são registradas no arquivo $COLLATION_HOME/log/services/ReconciliationMerge.log.
Se dois CIs forem fundidos por engano tentando redescobrir ou recarregar, o objeto temporário resultarána atualização do objeto durável e não recriará o CI temporário original. O CI durável deve ser excluído eos CIs duráveis e temporários, redescobertos ou recarregados.
Excluindo Manualmente Itens de Configuração MescladosSe você não desejar mais itens de configuração mesclados manualmente, será possível excluí-losmanualmente e descobrir os itens de configuração originais novamente. Se dois ICs forem mesclados porengano juntos ou se objetos-filhos duplicados forem exibidos, será possível excluí-los manualmente.
Procedimento
Para excluir manualmente ICs mesclados, conclua as etapas a seguir a partir do portal de gerenciamentode dados:1. Na área de janela Componentes Descobertos, selecione o IC (objeto durável) que deseja excluir.2. Clique em Ações > Excluir. A janela Excluir Itens é exibida.3. Na janela Excluir Itens, selecione o IC e clique em Ok. Se o IC for usado por um outro componente,
uma janela de confirmação será exibida.4. Clique em OK para excluir o IC.
O que Fazer DepoisExecute uma descoberta para ver os ICs originais.
Criando ComponentesÉ possível criar um componente usando o assistente Criar Componente.
Sobre Esta TarefaAs páginas específicas exibidas no assistente Criar Componente dependem do tipo de componente quevocê está criando.
Procedimento
Para criar um componente, conclua as seguintes etapas:1. Na barra de menus, clique em Editar > Criar Componente.
A página Informações Gerais do assistente Criar Componente é exibida.2. No campo Nome, digite o nome do componente.3. Na lista Tipo, selecione o tipo do componente a ser criado.4. Clique em Avançar.
A próxima página do assistente Criar Componente é exibida.5. Dependendo do tipo de componente a ser criado, páginas diferentes do assistente Criar
Componente são exibidas.Conclua quaisquer das seguintes tarefas apropriadas:
• Na página Informações do Servidor do assistente Criar Componente, conclua as seguintes tarefas:
a. Na lista Disponível, selecione os computadores que deseja incluir.b. Clique em Incluir.
• Na página Informações de IP do assistente Criar Componente, conclua as seguintes tarefas:
Capítulo 1. Usando 91

a. No campo Nome do Host, digite o nome do host do computador que deseja incluir.b. No campo Endereço IP, digite o endereço IP do computador a ser incluído. Se apropriado, mova
a régua de controle para especificar a máscara de sub-rede.c. Clique em Incluir.
6. Clique em Avançar.A página Informações Administrativas do assistente Criar Componente é exibida.
7. Opcional: Especifique algumas ou todas as seguintes informações:
• Contato Administrativo• Contato de Escalação• Número de Rastreamento• Site• Nome do Grupo• Notas
8. Se um ou mais atributos estendidos tiver sido definido para o tipo de componente que você estácriando, clique em Avançar.A página Atributos Estendidos do assistente Criar Componente é exibida.
9. Opcional: Na página Atributos Estendidos, especifique um valor para um ou mais dos atributosestendidos listados.
10. Clique em Concluir.
Editando ComponentesÉ possível editar um componente existente.
Sobre Esta TarefaAs páginas específicas exibidas no bloco de notas Editar Componente dependem do tipo de componenteque você está editando.
Procedimento
Para editar um componente, conclua as seguintes etapas:1. Na área de janela Componentes Descobertos, selecione o componente que você deseja editar.2. Clique em Ações > Editar.
O bloco de notas Editar Componente é exibido.3. Clique na guia que contém as informações que deseja editar.
Dependendo do tipo de componente que você está editando, algumas das seguintes guias estãodisponíveis:
• Informações Gerais• Informações do Servidor• Informações de IP• Informações Administrativas• Atributos Estendidos
4. Atualize as informações do componente.5. Clique em OK.
Tarefas de TopologiaÉ possível usar o Portal de Gerenciamento de Dados para visualizar informações da topologia gráfica.
92 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Exibindo uma Topologia de Visão GeralUma topologia de visão geral contém todos os itens de configuração em uma categoria. Uma topologia devisão geral pode ser visualizada no Portal de Gerenciamento de Dados usando a função Topologia.
Procedimento
Para exibir uma topologia de visão geral, conclua as seguintes etapas no Portal de Gerenciamento deDados:1. Na área de janela Funções, clique em Topologia.2. Clique em Aplicativos de Negócios.
Uma topologia de visão geral para o item é exibida.
ResultadosAo executar uma nova descoberta ou fazer alterações no servidor de sincronização, como incluir umaplicativo de negócios ou um serviço, o servidor de sincronização não reflete automaticamente asalterações no Portal de Gerenciamento de Dados. As alterações mais recentes podem ser visualizadasrecarregando-se a visualização.
Exibindo uma Topologia EspecializadaÉ possível visualizar uma topologia especializada para itens de configuração (IC) de determinados tiposno portal de gerenciamento de dados.
Sobre Esta Tarefa
As topologias especializadas estão disponíveis para diversos tipos de IC. É possível ativar essastopologias a partir da área de janela Componentes Descobertos. Tabela 14 na página 93 lista astopologias especializadas e os tipos de IC para os quais elas estão disponíveis.
Tabela 14. Topologias Especializadas
Nome da Topologia Tipo de IC
Topologia do AIX Sistema de computador AIX
Topologia do BladeCenter sistema de computador de subtipo BladeCenter
Topologia Física do Aplicativo de Negócios aplicativo de negócios, vApp, Sistema SAP, SiebelEnterprise
Topologia de Software do Aplicativo deNegócios
aplicativo de negócios, vApp, Sistema SAP, SiebelEnterprise
Topologia do Farm Citrix Farm Citrix
Topologia do Cluster CSM Cluster de Gerenciamento da Configuração
Topologia do Cluster CSM L2 Cluster de Gerenciamento da Configuração
Topologia de dep. do sistema do ClusterCSM Topologia
Cluster de Gerenciamento da Configuração
Topologia do Exchange 2007 Grupo Exchange 2007
Topologia do Cluster HACMP Cluster HACMP
Topologia de HMC e LPAR Sistema de computador System p
Topologia do Sistema Virtual HyperV Sistema de computador Windows
Topologia do Cluster MQ Cluster do WebSphere MQ
Topologia do MSCluster Cluster Microsoft
Topologia Oracle ASM Oracle Automatic Storage Management (ASM)
Capítulo 1. Usando 93
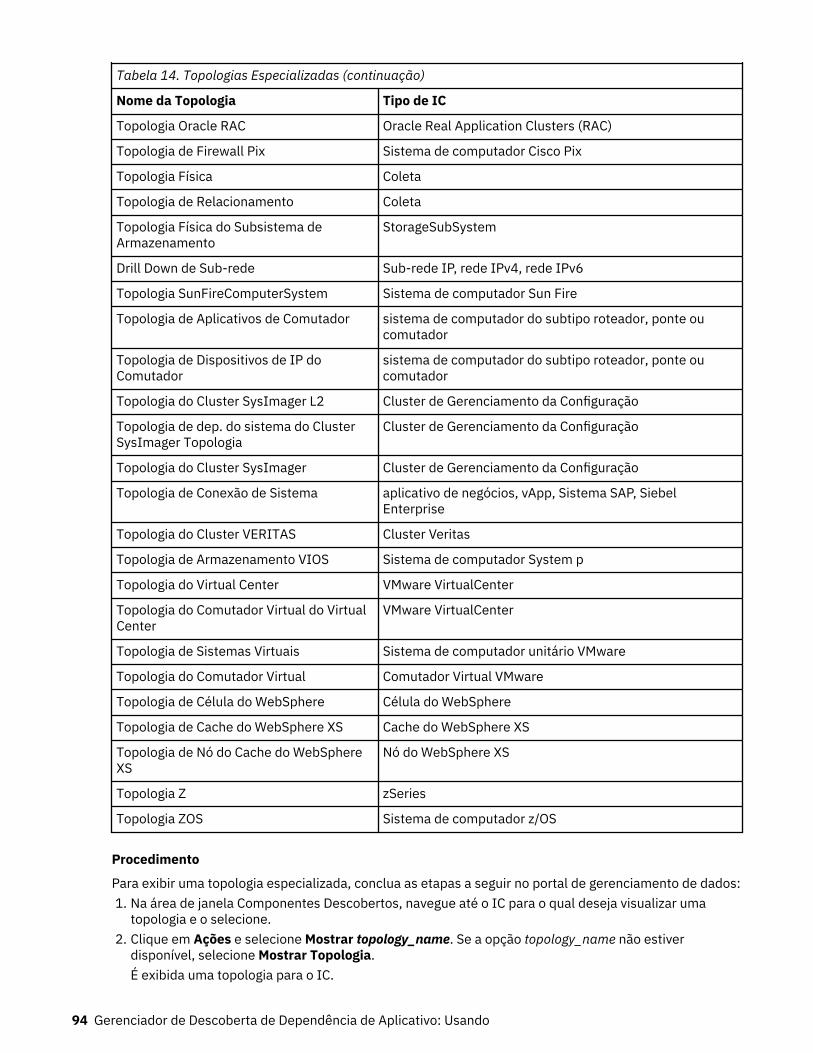
Tabela 14. Topologias Especializadas (continuação)
Nome da Topologia Tipo de IC
Topologia Oracle RAC Oracle Real Application Clusters (RAC)
Topologia de Firewall Pix Sistema de computador Cisco Pix
Topologia Física Coleta
Topologia de Relacionamento Coleta
Topologia Física do Subsistema deArmazenamento
StorageSubSystem
Drill Down de Sub-rede Sub-rede IP, rede IPv4, rede IPv6
Topologia SunFireComputerSystem Sistema de computador Sun Fire
Topologia de Aplicativos de Comutador sistema de computador do subtipo roteador, ponte oucomutador
Topologia de Dispositivos de IP doComutador
sistema de computador do subtipo roteador, ponte oucomutador
Topologia do Cluster SysImager L2 Cluster de Gerenciamento da Configuração
Topologia de dep. do sistema do ClusterSysImager Topologia
Cluster de Gerenciamento da Configuração
Topologia do Cluster SysImager Cluster de Gerenciamento da Configuração
Topologia de Conexão de Sistema aplicativo de negócios, vApp, Sistema SAP, SiebelEnterprise
Topologia do Cluster VERITAS Cluster Veritas
Topologia de Armazenamento VIOS Sistema de computador System p
Topologia do Virtual Center VMware VirtualCenter
Topologia do Comutador Virtual do VirtualCenter
VMware VirtualCenter
Topologia de Sistemas Virtuais Sistema de computador unitário VMware
Topologia do Comutador Virtual Comutador Virtual VMware
Topologia de Célula do WebSphere Célula do WebSphere
Topologia de Cache do WebSphere XS Cache do WebSphere XS
Topologia de Nó do Cache do WebSphereXS
Nó do WebSphere XS
Topologia Z zSeries
Topologia ZOS Sistema de computador z/OS
Procedimento
Para exibir uma topologia especializada, conclua as etapas a seguir no portal de gerenciamento de dados:1. Na área de janela Componentes Descobertos, navegue até o IC para o qual deseja visualizar uma
topologia e o selecione.2. Clique em Ações e selecione Mostrar topology_name. Se a opção topology_name não estiver
disponível, selecione Mostrar Topologia.É exibida uma topologia para o IC.
94 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Exportando uma TopologiaÉ possível exportar a topologia exibida atualmente para um arquivo de imagem.
Procedimento
Para exportar uma topologia, conclua as seguintes etapas no Portal de Gerenciamento de Dados:1. Na área de janela Funções, clique em Topologia.2. Clique em Aplicativos de Negócios.
Uma topologia de visão geral para o item é exibida.
3. Clique no ícone .A janela Exportar Topologia é exibida.
4. Selecione o tipo de arquivo para o qual deseja exportar a topologia.As seguintes opções estão disponíveis:
• Formato JPEG (tipo de arquivo é JPG)• Portable Network Graphics (tipo de arquivo é PNG)• Scalable Vector Graphics (tipo de arquivo é SVG)
5. Se solicitado, para os tipos de arquivo JPG e PNG, especifique a resolução de imagem digitando aaltura e a largura da imagem.Para algumas topologias, resoluções maiores podem ser necessárias para Clarity. A resolução máximaé 9999 x 9999 pixels. Para o tipo de arquivo SVG, a altura e a largura da imagem são irrelevantes.
Nota: Ao exportar topologias de aplicativo de negócios para o tipo de arquivo SVG, épossível usar uma API da linha de comandos dedicada, a ferramenta bizappscli, que gera arquivosmenores e permite compactar o arquivo para o formato .zip para reduzir ainda mais o tamanho doarquivo. Para obter detalhes, consulte “Ações para exportar topologias para o formato SVG” na página247.
6. Clique em Exportar.Dependendo da configuração do seu navegador, será solicitado que você salve o arquivo de imagemou a imagem será exibida no navegador.
Definindo manualmente dependências entre itens de configuraçãoVocê pode definir dependências entre itens de configuração (CIs) criando um arquivo de definição XML.Você define uma consulta de seleção de SQL dentro do arquivo de definição para selecionardependências. As dependências são automaticamente criadas e exibidas na topologia e a área de janelade Detalhes no Portal de Gerenciamento de Dados.
Procedimento
1. No servidor TADDM, crie um arquivo definition_filename.xml no diretório$COLLATION_HOME/etc/dependencies. Para implementações corporativas, os arquivos dedefinição customizados devem ser armazenados no servidor de armazenamento primário.
2. Edite o arquivo definition_filename.xml. Esse arquivo deve conter os atributos a seguir:Rótulo
Um nome de definição curto.Tipo
Um tipo de dependência como um nome de classe de dependência. Por exemplo,app.dependencies.ServiceDependency.
Descrição (opcional)Uma breve descrição das dependências.
Capítulo 1. Usando 95

ConsultaUma consulta SQL que deve retornar pelo menos duas colunas contendo aliases de origem edestino. Os aliases contêm um par de Identificadores Exclusivos Globais (GUIDs) que são usadaspara criar uma dependência entre os CIs.
O arquivo de definição XML deve ser compatível com o arquivo de definição do esquema XML (XSD). Oarquivo schema.xsd está localizado no diretório $COLLATION_HOME/etc/dependencies.
O construtor de topologia constrói as relações e dependências entre os itens descobertos. Oconstrutor de topologia executa uma lista de agentes em intervalos especificados. Depois de o agenteexecutar a consulta, o TADDM constrói as dependências definidas customizadas.
Quando as dependências não estão mais válidas, são automaticamente excluídas. A remoção doarquivo definition_filename.xml, deixa as dependências já criadas intactas, mas a alteração daconsulta pode levar à remoção das dependências criadas.
Para remover dependências customizadas indesejadas crie uma consulta vazia conforme mostrado noexemplo a seguir.
ExemploO arquivo example.xml está no diretório $COLLATION_HOME/etc/dependencies e mostra as etapaspara definir um arquivo de definição de dependência customizado.
<dependency xsi:noNamespaceSchemaLocation="schema.xsd"> <label>Example</label> <type>app.dependencies.ApplicationToApplicationDependency</type> <query>SELECT guid_x AS SOURCE, guid_x AS TARGET FROM appsrvr WHERE 0 = 1</query></dependency>
Tarefas AnalíticasÉ possível usar o Portal de Gerenciamento de Dados para executar analítica e gerar relatórios.
Exibindo Informações de Comparação de ComponentesÉ possível criar um relatório de Comparação de Componentes no Portal de Gerenciamento de Dados.
Sobre Esta Tarefa
É possível comparar dois ou mais componentes do mesmo tipo e criar um relatório com base nacomparação. Estão disponíveis dois modos de comparação, básico e profundo, que irão comparar oselementos dos componentes de uma maneira básica ou de uma maneira aprofundada e com drill down. Otipo de comparação feito é determinada pelos componentes selecionados.
Ao comparar as coleções customizadas, só é possível comparar duas a cada vez. No modo básico, oselementos essenciais da coleção são comparados, tais como atributos de Coleção Customizada (comodisplayName, hierarchyType, Atributos estendidos), CoreCIs displayName (agrupados por tierName eTipo), Número de Nós (agrupados por tierName e Tipo) e as informações de GroupingPattern básicas(Nome e Atributos Estendidos). No modo profundo, além de comparar os elementos do modo básico, éfeita a comparação do displayName para todos os Nós (agrupados por TierName e Tipo).
Procedimento
Para exibir um relatório de Comparação de Componentes, conclua as seguintes etapas a partir do Portalde Gerenciamento de Dados:1. Na área de janela Funções, clique em Analítica > Comparação de Componentes para definir os
parâmetros para um relatório de comparação de componentes.A guia Comparação de Componentes da área de janela Comparação de Componentes é exibida.
2. Na seção Componentes, conclua as seguintes etapas:a) Na lista Versão, selecione a versão da descoberta em comparação com aquela em que deseja
executar a comparação de componentes.
96 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

b) Na lista Disponível, selecione os componentes que deseja comparar.c) Clique em Incluir.d) Opcional: Para configurar o componente como a chave com a qual comparar todos os outros
componentes, selecione um componente incluído e clique em Configurar como Chave.Você pode configurar um componente como chave nos casos em que tem um componenteconhecido que tem uma configuração correta.Este componente age como o mestre em relação ao qual todos os outros componentes incluídossão comparados. Quando um componente com uma configuração diferente da da chave éencontrado, o aplicativo ressalta o componente e a configuração diferente na cor vermelha. Noscasos em que você não escolhe uma chave, o primeiro componente é automaticamente designadocomo a chave. Isso pode acontecer quando não há um componente bom conhecido com o qualcomparar. Por exemplo, pode haver um cluster que está tendo problemas, mas você não sabequais servidores são bons ou ruins.
3. Selecione as opções para a comparação de componentes.a) Para Nível, selecione Profundo ou Básico.b) Para Incluir Serviços de Infraestrutura, selecione Sim ou Não.c) Para os Componentes Disponíveis, selecione Sim ou Não.
4. Para executar o relatório, clique em Executar Relatório.O relatório é exibido na guia Resultados da área de janela Comparação de Componentes.
5. Clique na guia Resultados para visualizar a área de janela Comparação de Componentes:Resultados.
Exibindo um Relatório do Histórico de MudançasÉ possível exibir um relatório do histórico de mudanças para todos os itens de configuração (CIs)descobertos no Portal de Gerenciamento de Dados usando a função Analítica.
Sobre Esta Tarefa
Nota: O atributo de etiqueta de um CI não é configurado quando o CI é descoberto. Ele é configuradopela primeira vez quando você altera o nome exibido do CI a partir do nome com o qual ele foi criado. Norelatório do histórico de mudanças, o campo que exibe o valor da etiqueta antigo fica em branco depoisde você alterar a etiqueta do CI pela primeira vez.
É possível excluir elementos específicos do relatório de histórico de mudanças configurando o arquivo aseguir:
$COLLATION_HOME/etc/changeserver.xml
Em geral, incluir um elemento no changeserver.xml resulta em sua exclusão do histórico demudanças, mas considere as regras de configuração a seguir:
• Se você incluir um nome de classe sem atributos, essa classe, suas classes de especialização e todas asclasses contidas nela serão ignoradas.
• Se você incluir uma classe com atributos, os atributos e as classes de especialização dessa classe serãoignorados.
• Se você incluir um nome de pacote, esse pacote inteiro e todos os pacotes filhos serão ignorados.• Se você incluir um nome de atributo, esse atributo será ignorado em todas as classes.
Ao configurar os objetos e atributos a serem ignorados, especifique os nomes de API e nomes de objetoscom uma letra iniical maiúscula, por exemplo, WindowsService, e os nomes de atributros com umaletra inicial minúscula, por exemplo, processId.
Depois de fazer mudanças no arquivo changeserver.xml, você deve reiniciar o servidor TADDM paraque as mudanças entrem em vigor.
Capítulo 1. Usando 97

Procedimento
Para exibir as informações do histórico de mudanças, conclua as etapas a seguir:1. Na área de janela Funções, clique em Analítica.2. Clique no item Histórico de Mudanças.
A área de janela Histórico de Mudanças é exibida.3. Especifique um intervalo de tempo para o relatório preenchendo a seção Intervalo de Tempo.
É possível especificar um intervalo de tempo absoluto ou relativo. Se o horário de início e o horário deencerramento forem iguais, nenhuma informação do histórico de mudanças será exibida.
4. No painel Componentes, a partir da lista Tipo de Componente, selecione o tipo de componentesobre o qual você deseja criar um relatório do histórico de mudanças.Na lista Componentes Disponíveis, todos os componentes do tipo selecionado são exibidos.
5. Na lista Componentes Disponíveis, clique em cada componente que você deseja incluir no relatórioe clique em Incluir.Os componentes incluídos são exibidos na lista Componentes Incluídos.
6. Clique em Executar Relatório.Os resultados do relatório são exibidos na guia Resultados.
7. Se o valor antigo e o novo valor forem valores de texto e tiverem mais de 100 caracteres, eles serãotruncados no relatório. Para ver os valores completos, clique em Mostrar Detalhes.
8. Para comparar valores de texto novos e antigos que tenham mais de 100 caracteres, clique emMostrar Diferenças.As linhas que diferem entre os dois valores são exibidas. Para cada diferença, as seguintesinformações são exibidas:
• número da linha• tipo de mudança (incluída, removida ou alterada)• novo valor• valor antigo
Para salvar as mudanças em um arquivo, clique em Salvar. Para fechar a janela, clique em Fechar.9. Para classificar o relatório por atributo, clique no título da coluna para esse atributo. Por exemplo, é
possível classificar o relatório por data clicando no título da coluna Data. Clicar dentro de um títuloaltera a ordem de classificação para o atributo entre crescente e decrescente. É possível tambémalterar a largura da coluna clicando na linha do título em qualquer borda da coluna e arrastando-apara a esquerda ou para a direita.
10. Para exportar o conteúdo da tabela de resultados para um arquivo, clique em Exportar.A janela "Exportar Relatório como" é exibida.
11. Na lista Salvar como, selecione o tipo de arquivo para o qual deseja exportar as informações natabela de resultados.Os formatos de arquivos disponíveis são:
• PDF• CSV• XML
Nota: Se você estiver usando o navegador Microsoft Internet Explorer e estiver conectando usandouma sessão segura, não será possível exportar as informações do relatório para um arquivo. Asseguintes alternativas estão disponíveis:
• Use um navegador da Web alternativo.• Use o Tivoli Common Reporting para visualizar e administrar relatórios.
12. Para exportar o relatório, clique em Exportar.
98 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

O seu navegador abrirá o arquivo exportado com base na preferência de manipulação de arquivoespecificada para esse formato de arquivo.
Trabalhando com Consultas CustomizadasÉ possível criar consultas para relatórios que são baseados em dados descobertos que estãoarmazenados no banco de dados TADDM.
Na área de janela Consulta Customizada do Portal de Gerenciamento de Dados, é possível formular umaconsulta simples selecionando componentes e especificando critérios. Essa consulta semelhante a SQLretorna visualizações de uma única tabela para o componente especificado no banco de dados TADDM.Esses dados podem estar em um formato diferente do que é exibido na área de janela Detalhes, porqueeles mostram os valores brutos do banco de dados, não os valores formatados exibidos na área de janelaDetalhes.
A guia Consultas Salvas da área de janela Consulta Customizada exibe consultas customizadasexistentes.
Nota: Os dados necessários para a lista Tipo de Componente na guia Editar Consulta devem sercarregados para que essa opção esteja disponível. Esse processo ocorre em segundo plano, iniciandoquando você efetua logon na interface do Portal de Gerenciamento de Dados e pode levar vários minutospara ser concluído. Se você tentar acessar a lista Tipo de Componente imediatamente após efetuarlogon, talvez seja necessário aguardar a conclusão do carregamento.
Criando uma Consulta CustomizadaÉ possível criar uma consulta customizada ou é possível fazer uma cópia de uma consulta existente,alterar as propriedades, conforme for necessário, e salvá-la como uma nova consulta customizada.
Sobre Esta Tarefa
Ao criar uma consulta customizada, você deve especificar um tipo de componente. Os objetos das listasde Tipo de Componente são localizados por descobertas do TADDM. Se não tiver ocorrido nenhumadescoberta do TADDM, nenhuma informação de componente estará disponível e, portanto, não serápossível criar uma consulta customizada.
Ao selecionar um tipo de componente, os atributos padrão para esse tipo de componente são exibidos. Épossível alterar o conjunto de atributos padrão para um componente.
Procedimento
Para criar uma consulta customizada, conclua as seguintes etapas no Portal de Gerenciamento de Dados:1. Na área de janela Funções, clique em Analítica > Consulta Customizada.
A área de janela Consulta Customizada é exibida.2. Execute um dos seguintes:
• Clique em Nova. A guia Nova Consulta é exibida.• Na guia Consultas Salvas, selecione a consulta customizada que deseja copiar e clique em Copiar.
A guia Editar Consulta é exibida.3. No campo Nome, digite o nome da consulta customizada.4. Na lista Tipo de Componente, selecione um tipo de componente.
Nota: Se estiver copiando uma consulta customizada existente, não será possível alterar o tipo decomponente da nova consulta customizada.
Os atributos padrão para esse tipo de componente são exibidos.5. Selecione Corresponder Todos os Critérios ou Corresponder Quaisquer Critérios para especificar
um AND lógico ou um OR lógico para vários critérios de comparação.6. Especifique critérios para corresponder a um ou mais dos atributos exibidos. Os atributos exibidos
dependem do tipo de componente para o qual você está criando uma consulta customizada. Para cadacritério a ser especificado, conclua as seguintes etapas:
Capítulo 1. Usando 99

a) Selecione um tipo de critério. Os tipos de critérios disponíveis dependem do tipo de atributo.b) No campo de valor de atributo, especifique um valor de critério. À medida que você digita um valor
de atributo para um atributo de sequência, uma lista de sugestões pode ser apresentada. Se vocêselecionar uma sugestão na lista, esse valor será colocado no campo de valor de atributo.As sugestões de valor de atributo são exibidas onde o texto inserido forma qualquer parte do nomede um item de configuração descoberto pelo TADDM. Este campo não faz distinção entremaiúsculas e minúsculas.
Nota: Os critérios "diferente de" e "!=" não correspondem valores nulos. Eles correspondem qualquervalor de atributo não nulo que seja diferente daquele fornecido. O valor de atributo não pode conterum caractere " “ " (aspas) ou " ' " (apóstrofo), por exemplo, nc"10.
7. Para executar a consulta customizada antes de salvá-la, clique em Executar Consulta.A execução da consulta possibilita examinar os resultados e assegurar que a consulta seja executadaconforme esperado antes de salvá-la.
8. Para salvar a consulta customizada, clique em Salvar.
Configurando Atributos de Consulta CustomizadaÉ possível configurar os atributos usados em uma consulta customizada.
Procedimento
Para configurar atributos de consulta customizada, conclua as seguintes etapas no Portal deGerenciamento de Dados:1. Na área de janela Funções, clique em Analítica > Consulta Customizada.
A área de janela Consulta Customizada é exibida.2. Execute um dos seguintes:
• Clique em Nova. A guia Nova Consulta é exibida. Na lista Tipo de Componente, selecione ocomponente para o qual deseja criar uma consulta customizada.
• Na guia Consultas Salvas, selecione a consulta customizada que deseja copiar e clique em Copiar.A guia Editar Consulta é exibida.
• Na guia Consultas Salvas, selecione a consulta customizada que deseja editar e clique em Editar.A guia Editar Consulta é exibida.
3. Clique em Configurar.A janela Configurar Atributos é exibida. Por padrão, a lista Atributos Disponíveis exibe todos osatributos disponíveis para o componente selecionado. Para filtrar os Atributos exibidos, no campoFiltro, digite o nome de um atributo, ou parte do nome de um atributo. Apenas atributos quecorrespondam ao texto inserido serão exibidos na lista Atributos Disponíveis.
4. Para incluir um atributo na consulta customizada, execute um dos seguintes procedimentos:
• Na lista Atributos Disponíveis, selecione o atributo que deseja incluir e clique em Incluir.• Na lista Atributos Disponíveis, dê um clique duplo no atributo que deseja incluir.
O atributo é exibido na lista Atributos Incluídos.5. Para remover um atributo da consulta customizada, execute um dos seguintes procedimentos:
• Na lista Atributos Incluídos, selecione o atributo que deseja remover e clique em Remover.• Na lista Atributos Incluídos, dê um clique duplo no atributo que deseja remover.
O atributo é removido da lista Atributos Incluídos.6. Para restaurar a lista Atributos Incluídos com os atributos padrão para o tipo de componente atual,
clique em Restaurar Padrões.7. Para salvar os atributos atualmente na lista Atributos Incluídos como a lista padrão de atributos para
o tipo de componente atual, clique em Salvar como Padrões.8. Clique em OK.
100 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Executando uma Consulta CustomizadaÉ possível executar uma consulta customizada existente, visualizar os resultados em uma tabela evisualizar informações adicionais sobre cada um dos objetos listados nos resultados da consulta.
Procedimento
Para executar uma consulta customizada e visualizar os resultados, conclua as seguintes etapas no Portalde Gerenciamento de Dados:1. Na área de janela Funções, clique em Analítica > Consulta Customizada.
A área de janela Consulta Customizada é exibida.2. Execute um dos seguintes:
• Na guia Consultas Salvas, selecione uma consulta e clique em Executar Consulta.• Na guia Editar Consulta, clique em Executar Consulta.• Na guia Editar Consulta, assegure-se de que na lista Tipo de Componente, um componente tenha
sido selecionado. Clique em Executar Consulta.
Nota: Não é necessário especificar um nome para executar uma consulta customizada, mas você deveespecificar um nome para salvar uma consulta customizada.
A guia Resultados é exibida. As colunas exibidas na tabela correspondem aos atributos selecionadosna consulta.
3. Para visualizar informações detalhadas sobre um objeto listado nos resultados da consulta, na área dejanela Resultados, selecione um resultado da consulta e clique em Detalhes.O bloco de notas Detalhes é exibido.
4. Para visualizar os relacionamentos de um objeto listado nos resultados da consulta, na área de janelaResultados, selecione um resultado da consulta e clique em Explorar.Um gráfico de topologia centralizado do nó do objeto é exibido.
5. Para incluir um objeto listado nos resultados da consulta na lista de componentes a ser comparada,selecione um resultado da consulta e clique em Marcar para Comparação.A janela Comparação de Componentes é exibida contendo o componente selecionado. Paracontinuar com a comparação de componentes, conclua as etapas a seguir:
a. Na área de janela Consulta Customizada, clique no segundo componente a ser comparado.
Importante: Não é necessário fechar a janela Comparação de Componentes antes de clicar emoutro componente na área de janela Consulta Customizada.
A janela Comparação de Componentes é exibida contendo o segundo componente selecionado.b. Repita esta etapa para todos os componentes adicionais que você deseja comparar.c. Na janela Comparação de Componentes, selecione os componentes que deseja comparar e clique
em Comparar. A área de janela Comparação de Componentes é exibida.
Para obter informações adicionais sobre comparação de componentes, consulte “ExibindoInformações de Comparação de Componentes” na página 96 e “Área de Janela Comparação deComponentes: Resultados” na página 159.
6. Para visualizar o histórico de mudanças de um objeto listado nos resultados da consulta, na área dejanela Resultados, selecione um resultado da consulta e clique em Mudanças.O histórico de mudanças do objeto é exibido.
7. Para exportar os resultados da consulta para um arquivo (por exemplo, Adobe Portable DocumentFormat, Comma Separated Values ou XML), conclua as seguintes etapas:a) Na área de janela Resultados, selecione um resultado da consulta e clique em Salvar.
A área de janela Exportar é exibida.b) Na lista Formato, selecione o formato no qual deseja salvar os resultados da consulta.c) Clique em Salvar.
Capítulo 1. Usando 101

Nota: Se você estiver usando o navegador Microsoft Internet Explorer e estiver conectando usandouma sessão segura, não será possível exportar as informações do relatório para um arquivo. Asseguintes alternativas estão disponíveis:
• Use um navegador da Web alternativo.• Use o Tivoli Common Reporting para visualizar e administrar relatórios.
Editando uma Consulta CustomizadaÉ possível editar as propriedades de uma consulta customizada.
Procedimento
Para editar uma consulta customizada, conclua as seguintes etapas no Portal de Gerenciamento deDados:1. Na área de janela Funções, clique em Analítica > Consulta Customizada.
A área de janela Consulta Customizada é exibida.2. Na guia Consultas Salvas, selecione a consulta customizada que você deseja editar.3. Clique em Editar.
A guia Editar Consulta é exibida.4. Configure novos valores para alguns ou todos os atributos exibidos.
Nota: Não é possível alterar o tipo de componente da consulta.5. Para executar a consulta customizada antes de salvá-la, clique em Executar Consulta.
A execução da consulta nesse ponto possibilita o exame dos resultados e assegura que a consulta foiexecutada conforme esperado antes de salvá-la.
6. Para salvar a consulta editada, clique em Salvar.
Excluindo uma Consulta CustomizadaÉ possível excluir uma consulta customizada da tabela de consultas salvas.
Procedimento
Para excluir uma consulta customizada da lista de consultas salvas, conclua as seguintes etapas no Portalde Gerenciamento de Dados:1. Na área de janela Funções, clique em Analítica > Consulta Customizada.
A área de janela Consulta Customizada é exibida.2. Na guia Consultas Salvas, selecione a consulta customizada que você deseja excluir.3. Clique em Excluir.
A consulta customizada é removida da tabela de consultas salvas.
Exibindo Informações de Resumo do InventárioÉ possível exibir um resumo do inventário no Portal de Gerenciamento de Dados usando a funçãoAnalítica.
Procedimento
Para exibir informações de resumo do inventário, conclua as etapas a seguir:1. Na área de janela Funções, clique em Analítica.2. Clique no item Resumo do Inventário.
A área de janela Resumo do Inventário é exibida.3. Clique em uma entidade na coluna Tipo de Componente ou Detalhe do Inventário.
A área de janela Detalhes do Inventário é exibida.4. Na área de janela Detalhes do Inventário, selecione um componente e clique em um dos seguintes
botões, dependendo do tipo de informação que deseja exibir:
102 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

• Clique em Detalhes para exibir a área de janela Detalhes para o componente selecionado.• Clique em Alterações para exibir a área de janela Histórico de Mudanças para o componente
selecionado.• Clique em Salvar para salvar o relatório Resumo do Inventário para o componente selecionado.• Clique em Marcar Para Comparação para incluir este componente na lista de componentes a serem
comparados. A janela Comparação de Componentes é exibida contendo o componenteselecionado. Para continuar com a comparação de componentes, conclua as etapas a seguir:
a. Na área de janela Detalhes do Inventário, clique no segundo componente a ser comparado.
Importante: Não é necessário fechar a janela Comparação de Componentes antes de clicar emoutro componente na área de janela Detalhes do Inventário.
A janela Comparação de Componentes é exibida contendo o segundo componente selecionado.b. Repita esta etapa para todos os componentes adicionais que você deseja comparar.c. Na janela Comparação de Componentes, selecione os componentes que deseja comparar e
clique em Comparar. A área de janela Comparação de Componentes é exibida.
Importante: Para obter informações adicionais sobre comparação de componentes, consulte“Exibindo Informações de Comparação de Componentes” na página 96 e “Área de JanelaComparação de Componentes” na página 158.
Nota: Com a segurança em nível de dados ativada, quando você tiver restringido o acesso aos ICs eexecutar o relatório de resumo de inventário, pode ver uma lista completa de ICs como se você tivessedireitos administrativos. Mas não pode ver nenhum detalhe sobre os ICs restritos. A mensagem"Acesso negado" é exibida ao tentar exibir, por exemplo, a área de janela Detalhes ou o Histórico deMudanças.
Exibindo Informações do Histórico de Mudanças Usando o Resumo de InventárioÉ possível exibir o histórico de mudanças para um item de configuração selecionado no Portal deGerenciamento de Dados usando a função Resumo de Inventário.
Procedimento
Para exibir as informações do histórico de mudanças, conclua as etapas a seguir:1. Na área de janela Funções, clique em Analítica.2. Clique no item Resumo do Inventário.
A área de janela Resumo de Inventário é exibida.3. Na área de janela Resumo de Inventário, clique em uma entidade na coluna Tipo de Componente ou
Detalhe do Inventário.A área de janela Detalhes do Inventário é exibida.
4. Na área de janela Detalhes do Inventário, clique em uma entidade na coluna Nome de Exibição eclique em Alterações.A área de janela Histórico de Mudanças é exibida.
5. Para exibir as informações do histórico de mudanças para um timeframe específico, especifique ointervalo de tempo para o relatório concluindo a seção Timeframe. É possível especificar um intervalode tempo absoluto ou relativo. Digite as datas e horas iniciais e finais para o período que deseja norelatório.
6. Clique em Mostrar Alterações para exibir informações do histórico de mudanças para o timeframeespecificado.
Exibindo Informações de Resumo do AplicativoÉ possível exibir as informações de detalhes de resumo do seu aplicativo e o histórico no Portal deGerenciamento de Dados usando a função Analítica.
Capítulo 1. Usando 103

Procedimento
Para exibir um resumo de seus aplicativos de negócios, conclua as etapas a seguir:1. Na área de janela Funções, clique em Analítica.2. Clique no item Resumo do Aplicativo.
A área de janela Resumo do Aplicativo é exibida.3. Na área de janela Resumo do Aplicativo, selecione uma entidade na coluna Nome do Aplicativo e
execute uma das seguintes etapas:
• Clique em Detalhes para exibir a área de janela Detalhes de Resumo do Aplicativo.• Clique em Alterar para exibir a área de janela Histórico de Mudanças.• Clique em Topologia do Software para exibir a topologia do software para o aplicativo de negócios.• Clique em Topologia Física para exibir a topologia do hardware utilizada pelo aplicativo de negócios.• Clique em Inventário para exibir a área de janela Resumo de Inventário.• Clique em Marcar Para Comparação para incluir este componente na lista de componentes a serem
comparados.
A janela Comparação de Componentes é exibida contendo o componente selecionado. Paracontinuar com a comparação de componentes, conclua as etapas a seguir:
a. Na área de janela Resumo do Aplicativo, clique no segundo componente a ser comparado.
Importante: Não é necessário fechar a janela Comparação de Componentes antes de clicar emoutro componente na área de janela Resumo do Aplicativo.
A janela Comparação de Componentes é exibida contendo o segundo componente selecionado.b. Repita esta etapa para todos os componentes adicionais que você deseja comparar.c. Na janela Comparação de Componentes, selecione os componentes que deseja comparar e
clique em Comparar. A área de janela Comparação de Componentes é exibida.
Para obter informações adicionais sobre comparação de componentes, consulte “ExibindoInformações de Comparação de Componentes” na página 96 e “Área de Janela Comparação deComponentes” na página 158.
Exibindo Informações sobre o Inventário do SistemaÉ possível exibir um relatório de inventário do sistema para todos os itens de configuração (CIs)descobertos no Portal de Gerenciamento de Dados usando a função Analítica.
Procedimento
Para exibir informações sobre o inventário do sistema, conclua as etapas a seguir:1. Na área de janela Funções, clique em Analítica.2. Clique no item Inventário do Sistema.
A área de janela Inventário do Sistema é exibida.3. Para classificar o relatório por atributo, clique no título da coluna para esse atributo. Por exemplo, é
possível classificar o relatório por tamanho de memória clicando no título da coluna Tamanho deMemória. Clicar dentro de um título altera a ordem de classificação para o atributo entre crescente edecrescente. É possível também alterar a largura da coluna clicando na linha do título em qualquerborda da coluna e arrastando-a para a esquerda ou para a direita.
4. Para exportar o conteúdo da tabela de resultados para um arquivo, clique em Salvar.A janela Exportar Relatório é exibida.
5. Na lista Tipo de Arquivo, selecione o tipo de arquivo para o qual deseja exportar as informações sobreo inventário do sistema.Os formatos de arquivos disponíveis são:
104 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

• CSV• XML
6. Para exportar o relatório, clique em Exportar.O seu navegador abre o arquivo exportado com base na preferência de manipulação de arquivoespecificada para esse formato de arquivo.
Exibindo Informações sobre o Inventário do Servidor de SoftwareÉ possível exibir um relatório de inventário do servidor de software para todos os itens de configuração(CIs) descobertos no Portal de Gerenciamento de Dados usando a função Analítica.
Procedimento
Para exibir informações sobre o inventário do servidor de software, conclua as etapas a seguir:1. Na área de janela Funções, clique em Analítica.2. Clique no item Inventário do Servidor de Software.
A área de janela Inventário do Servidor de Software é exibida.3. Para classificar o relatório por atributo, clique no título da coluna para esse atributo.
Por exemplo, é possível classificar o relatório por versão clicando no título da coluna Versão. Clicardentro de um título altera a ordem de classificação para o atributo entre crescente e decrescente. Épossível também alterar a largura da coluna clicando na linha do título em qualquer borda da coluna earrastando-a para a esquerda ou para a direita.
Nota: Os dados do relatório são recuperados do banco de dados, uma página de cada vez, e algunsvalores exibidos são gerados para exibição. Dependendo dos dados incluídos em uma determinadapágina, podem ocorrer resultados de classificação inesperados.
4. Para exportar o conteúdo da tabela de resultados para um arquivo, clique em Salvar.A janela Exportar Relatório é exibida.
5. Na lista Tipo de Arquivo, selecione o tipo de arquivo para o qual deseja exportar as informações sobreo inventário do servidor de software.Os formatos de arquivos disponíveis são:
• PDF• CSV• XML
Nota: Se você estiver usando o navegador Microsoft Internet Explorer e estiver conectando usandouma sessão segura, não será possível exportar as informações do relatório para um arquivo. Asseguintes alternativas estão disponíveis:
• Use um navegador da Web alternativo.• Use o Tivoli Common Reporting para visualizar e administrar relatórios.
6. Para exportar o relatório, clique em .O seu navegador abre o arquivo exportado com base na preferência de manipulação de arquivoespecificada para esse formato de arquivo.
Tarefas de AdministraçãoÉ possível usar o Portal de Gerenciamento de Dados para executar tarefas de administração.
Criando UsuáriosQuando o registro baseado em arquivo é usado para gerenciamento de usuário, é possível criar um novousuário e designar funções a esse usuário.
Procedimento
Para criar um usuário, conclua as etapas a seguir:
Capítulo 1. Usando 105

1. Inicie o Portal de Gerenciamento de Dados.2. Clique em Administração > Usuários.
Uma lista de usuários é exibida.3. Clique em Criar Usuário.
A janela Criar Usuário é exibida.4. Insira as seguintes informações para o novo usuário nos seguintes campos:
• Nome do Usuário• Endereço de E-mail• Senha (duas vezes para confirmação)• Tempo Limite da Sessão (em minutos)
Para um tempo limite de sessão ilimitado para o Console de Gerenciamento de Descoberta, o valorde tempo limite da sessão é -1.
É possível configurar um valor de tempo limite da sessão para cada usuário na área de janelaUsuários do Portal de Gerenciamento de Dados, configurando o valor de Tempo Limite da Sessão(em minutos).
5. Designe funções ao novo usuário.Para cada função designada, execute as seguintes etapas:a) Marque a caixa de seleção para essa função.b) Especifique o escopo da função selecionando uma ou mais coleções de acessos.
6. Clique em Criar Usuário.O usuário é incluído. A lista de usuários é exibida novamente, com o novo usuário incluso na lista.
Editando UsuáriosQuando o registro baseado em arquivo é usado para gerenciamento de usuário, é possível alterar asinformações para um usuário existente.
Sobre Esta Tarefa
Além de alterar os detalhes do usuário (endereço de e-mail, senha e tempo limite da sessão), também épossível alterar as permissões de acesso designando diferentes funções e coleções de acessos.
Procedimento
Para editar um usuário, conclua as etapas a seguir:1. Inicie o Portal de Gerenciamento de Dados.2. Clique em Administração > Usuários.
Uma lista de usuários é exibida.3. Clique no nome de usuário que você deseja editar e, em seguida, clique em Editar.
As informações para o usuário são exibidas.4. Altere os detalhes do usuário conforme necessário:
• Endereço de e-mail.• Nova senha (duas vezes para confirmação).• Nova data de expiração de senha. Se for especificada uma data que não é válida, a expiração seráconfigurada para 90 dias a partir da data atual.
• Tempo limite da sessão (em minutos).5. Altere as funções e permissões de acesso para atender a seus requisitos de segurança.6. O botão no qual você clica para salvar suas mudanças depende das propriedades alteradas:
• Para salvar as propriedades de Detalhe do Usuário, clique em Alterar
106 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

• Para salvar as propriedades de Alterar Senha, clique em Alterar Senha• Para salvar as propriedades de Alterar Designação de Função, clique em Alterar Função
Excluindo UsuáriosQuando o registro baseado em arquivo é usado para gerenciamento de usuário, é possível excluir umusuário criado.
Sobre Esta Tarefa
Restrição: O administrador não pode ser excluído.
Procedimento
Para excluir um usuário, conclua as etapas a seguir:1. Inicie o Portal de Gerenciamento de Dados.2. Clique em Administração > Usuários.
Uma lista de usuários é exibida.3. Selecione o usuário que você deseja excluir e clique em Excluir.
Uma janela de confirmação é exibida.4. Clique em OK.
O usuário é excluído.
Criando Grupos de UsuáriosQuando o registro baseado em arquivo é usado para gerenciamento de usuário, é possível criar um novogrupo de usuários.
Procedimento
Para criar um grupo de usuários, conclua as seguintes etapas:1. Inicie o Portal de Gerenciamento de Dados.2. Clique em Administração > Grupos de Usuários.
A área de janela Grupos de Usuários é exibida.3. Clique em Criar Grupo.
A área de janela Criar Grupo é exibida.4. Na área de janela Criar Grupo, selecione os usuários para seu grupo de usuários.5. Designe funções ao novo grupo de usuários.
Para cada função designada, execute as seguintes etapas:a) Marque a caixa de seleção para essa função.b) Especifique o escopo da função selecionando uma ou mais coleções de acessos.
6. Clique em OK.O grupo de usuários é incluído. A lista de grupos de usuários é exibida novamente, com o novo grupode usuários incluso na lista.
Editando Grupos de UsuáriosQuando o registro baseado em arquivo é usado para gerenciamento de usuário, é possível alterar asinformações para um grupo de usuários existente.
Sobre Esta Tarefa
Além de incluir ou remover usuários em um grupo de usuários, também é possível alterar as permissõesde acesso designando diferentes funções e coleções de acessos.
Capítulo 1. Usando 107

Procedimento
Para editar um grupo de usuários, execute as seguintes etapas:1. Inicie o Portal de Gerenciamento de Dados.2. Clique em Administração > Grupos de Usuários.
Uma lista de grupos de usuários é exibida.3. Selecione o nome de usuário do grupo de usuários que você deseja alterar e clique em Editar.
A área de janela Editar Grupos de Usuários é exibida.4. Inclua ou remova usuários do grupo de usuários.5. Se os requisitos de segurança do grupo de usuários foram alterados, altere as funções e permissões
de acesso conforme necessário.6. Clique em OK.
Suas mudanças são salvas.
Excluindo Grupos de UsuáriosQuando o registro baseado em arquivo é usado para gerenciamento de usuário, é possível excluir umgrupo de usuários criado.
Procedimento
Para excluir um grupo de usuários, conclua as etapas a seguir:1. Inicie o Portal de Gerenciamento de Dados.2. Clique em Administração > Grupos de Usuários.
A área de janela Grupos de Usuários é exibida.3. Selecione o grupo de usuários que você deseja excluir e clique em Excluir.
Uma janela de confirmação é exibida.4. Clique em OK.
O grupo de usuários é excluído.
Criando FunçõesSe as funções predefinidas não forem suficientes para suas necessidades, será possível criar uma novacom as permissões que você escolher.
Procedimento
Para criar uma nova função, conclua as etapas a seguir:1. Inicie o Portal de Gerenciamento de Dados.2. Clique em Administração > Funções.
Uma lista de funções é exibida.3. Clique em Criar Função.
A janela Criar Função é exibida.4. Digite um nome para a nova função, em seguida, selecione as permissões que você deseja conceder.5. Clique em Criar Função.
A lista de funções é exibida novamente, com a nova função inclusa na lista.
Editando FunçõesÉ possível editar uma função para configurar suas permissões.
Sobre Esta Tarefa
Restrição: As funções predefinidas (administrador, operador e supervisor) não podem ser editadas.
108 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Procedimento
Para criar uma nova função, conclua as etapas a seguir:1. Inicie o Portal de Gerenciamento de Dados.2. Clique em Administração > Funções.3. Na lista de funções, selecione a função que você deseja editar e, em seguida, clique em Editar.4. Na janela Editar Função, selecione as permissões que você deseja conceder.5. Clique em OK.
A lista de funções é atualizada para mostrar as mudanças.
Excluindo FunçõesÉ possível excluir uma função que não é mais necessária.
Sobre Esta Tarefa
Restrição: As funções predefinidas (administrador, operador e supervisor) não podem ser excluídas.
Procedimento
Para excluir uma função, conclua as etapas a seguir:1. Inicie o Portal de Gerenciamento de Dados.2. Clique em Administração > Funções.
Uma lista de funções é exibida.3. Clique em Excluir próximo à função que você deseja excluir.
A função é excluída.
Tarefas de Gerenciamento de DomínioA implementação do servidor de sincronização fornece a funcionalidade TADDM para toda a empresa,além de permitir que vários domínios sejam gerenciados por um único servidor de sincronização.
Incluindo um Domínio em sua EmpresaÉ possível usar a área de janela Resumo do Domínio para incluir um novo domínio em sua empresa.
Sobre Esta Tarefa
Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Procedimento
Para incluir um domínio em sua empresa, conclua as etapas a seguir:1. Clique em Gerenciamento de Domínio > Resumo de Domínio.
A área de janela Resumo de Domínio é exibida.2. Na área de janela Resumo de Domínio, clique em Novo.
A área de janela Incluir Domínio é exibida.3. Na área de janela Incluir Domínio, insira as informações de domínio.4. Para aplicar as informações digitadas, clique em OK.
Alterando um Domínio em sua EmpresaÉ possível usar a área de janela Resumo de Domínio para atualizar as informações para um domínio emsua empresa.
Sobre Esta Tarefa
Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Capítulo 1. Usando 109

Procedimento
Para alterar as informações de domínio para um domínio existente, conclua as etapas a seguir:1. Clique em Gerenciamento de Domínio > Resumo de Domínio.
A área de janela Resumo de Domínio é exibida.2. Na área de janela Resumo de Domínio, selecione o Domínio a ser alterado e clique em Editar.
A área de janela Editar Domínio é exibida.3. Na área de janela Editar Domínio, atualize as informações de domínio.4. Para assegurar que o Portal de Gerenciamento de Dados possa contatar o domínio usando as
informações especificadas na seção Detalhes do Domínio, clique em Conexão de Teste.Uma janela de confirmação é exibida para informar se a conexão foi ou não bem-sucedida.
5. Se você alterou as informações de domínio e desejar salvá-las sem sair da área de janela EditarDomínio, clique em Salvar Alterações.As alterações são salvas e a área de janela Editar Domínio permanece aberta.
6. Se você alterou as informações de domínio e desejar salvá-las e voltar à área de janela Resumo deDomínio, clique em Aplicar.As alterações são salvas e a área de janela Resumo de Domínio é exibida.
Excluindo um Domínio de sua EmpresaSe não for mais necessário coletar informações sobre um domínio específico, você poderá usar a área dejanela Resumo de Domínio no Portal de Gerenciamento de Dados para excluir esse domínio de suaempresa.
Sobre Esta Tarefa
Para excluir um domínio, você deve efetuar logon no Portal de Gerenciamento de Dados como um usuárioque tenha a permissão de tempo de execução de Administrador. Quando um domínio é excluído do bancode dados TADDM, todas as coleções de acesso que precisam ser excluídas deverão ser excluídasmanualmente usando a API ou o script api.sh. Se o domínio que está excluindo tiver políticas deautorização para coleções de acessos que foram sincronizadas para o banco de dados do servidor desincronização, você deverá remover manualmente o acesso a essas coleções de acessos usando o Portalde Gerenciamento de Dados.
Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Procedimento
Para excluir um domínio de sua empresa, conclua as etapas a seguir:1. Na área de janela Resumo de Domínio, selecione um domínio.2. Para excluir o domínio, clique em Excluir.
É exibido um prompt para confirmar se você deseja excluir o domínio selecionado.3. Clique em OK.
A exclusão do domínio pode demorar para ser concluída, mas ela é executada como uma tarefa emsegundo plano para que você continue a usar o Portal de Gerenciamento de Dados. O progresso datarefa é exibido na lista Domínio, ao lado do domínio que você está excluindo. Quando a operação deexclusão for concluída, o domínio será excluído de sua empresa e removido da tabela Resumo deDomínio.
Movendo um Domínio para Outro Servidor de SincronizaçãoUse a área de janela Resumo de Domínio para mover um domínio de um servidor de sincronização paraoutro.
Antes de IniciarAo mover um domínio, primeiro assegure que ele esteja ativo e em execução.
110 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Sobre Esta Tarefa
Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Procedimento
Para mover um domínio de um servidor de sincronização para outro, conclua as seguintes etapas:1. No Portal de Gerenciamento de Dados em execução no primeiro servidor de sincronização, clique em
Gerenciamento de Domínio > Resumo de Domínio.A área de janela Resumo de Domínio é exibida.
2. Na área de janela Resumo de Domínio, clique em Excluir. O domínio é excluído do primeiro servidorde sincronização.
Importante: Se você tiver um grande banco de dados, esse processo poderá levar algumas horas. Aárea de janela Status de Domínio exibe que a operação de exclusão está em andamento até ela serconcluída.
3. No Portal de Gerenciamento de Dados em execução no segundo servidor de sincronização, clique emGerenciamento de Domínio > Resumo de Domínio. A área de janela Resumo de Domínio é exibida.
4. Na área de janela Resumo de Domínio, clique em Novo.A área de janela Incluir Domínio é exibida.
5. Na área de janela Incluir Domínio, insira as informações de domínio.6. Para aplicar as informações digitadas, clique em OK. O domínio é movido para o novo servidor de
sincronização.
O que Fazer DepoisDepois de incluir o domínio, ele deve ser completamente sincronizado para ter seus recursos incluídos noservidor de sincronização. O domínio da interface com o usuário deve ser reiniciado para que ele possaautenticar para o novo servidor de sincronização.
Atualizando as Informações de Domínio no Banco de Dados TADDMQuando o status de um domínio em sua empresa for alterado, será possível exibir as informaçõesatualizadas na área de janela Resumo de Domínio.
Sobre Esta Tarefa
Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Procedimento
Para atualizar as informações de domínio no banco de dados TADDM, conclua as seguintes etapas:1. Clique em Gerenciamento de Domínio > Resumo de Domínio.
A área de janela Resumo de Domínio é exibida.2. Na área de janela Resumo de Domínio, selecione o domínio para o qual deseja que as informações
sejam enviadas para o banco de dados TADDM.3. Clique em Atualizar na área de janela Resumo de Domínio.
O status de disponibilidade dos domínios em sua empresa que são atualizados no banco de dadosTADDM.
Iniciando um Console de Gerenciamento de DescobertaEmbora não haja um Console de Gerenciamento de Descoberta para o servidor de sincronização, épossível acessar o Console de Gerenciamento de Descoberta de quaisquer dos domínios na empresa apartir do servidor de sincronização.
Sobre Esta Tarefa
Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Capítulo 1. Usando 111

Procedimento
Para iniciar um Console de Gerenciamento de Descoberta para um domínio em sua empresa, conclua asseguintes etapas:1. Opcional: Se você estiver usando Firefox versão 3.0 ou posterior, assegure-se de que o protocolo de
criptografia TLS 1.0 esteja ativado em suas configurações do navegador.Para ativar o TLS 1.0 no Firefox 3.6:a) Clique em Ferramentas > Opções.b) Na janela Opções, clique em Avançado.c) Clique na guia Criptografia.d) Selecione Usar TLS 1.0.
2. Clique em Gerenciamento de Domínio > Resumo de Domínio.A área de janela Resumo de Domínio é exibida.
3. Assegure-se de que o domínio para o qual deseja acessar o Console de Gerenciamento de Descobertatenha um ícone de cadeado aberto ao lado do nome do domínio, especificando que ele aceitaconexões não seguras.
4. Selecione o domínio para o qual deseja iniciar o Console de Gerenciamento de Descoberta.5. Clique em Iniciar.
O Console de Gerenciamento de Descoberta do domínio selecionado é exibido.
Iniciando um Console de Gerenciamento de Descoberta em Modo SeguroDepois que conexões seguras tiverem sido configuradas, será possível ativar uma conexão segura com oConsole de Gerenciamento de Descoberta para qualquer um dos domínios na empresa a partir do Portalde Gerenciamento de Dados, em execução no servidor de sincronização.
Antes de IniciarCertifique-se de que seu navegador esteja configurado para usar um Java Runtime Environmentsuportado, e que seu computador atenda a todos os requisitos de hardware e software do cliente TADDM.Para obter mais informações, consulte o Guia de instalação do TADDM.
Sobre Esta Tarefa
Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Procedimento
Para configurar definições de conexão SSL e iniciar um Console de Gerenciamento de Descoberta emmodo seguro para um domínio em sua empresa, conclua as seguintes etapas:1. Clique em Gerenciamento de Domínio > Resumo de Domínio.
A área de janela Resumo de Domínio é exibida.2. Na área de janela Resumo de Domínio, selecione o domínio para o qual deseja iniciar o Console de
Gerenciamento de Descoberta em modo seguro.3. Opcional: Se necessário, configure as definições de conexão SSL.
Você deve concluir esta etapa em uma das seguintes situações:
• As definições de conexão SSL não foram configuradas. Essa etapa deve ser concluída para que vocêpossa iniciar o Console de Gerenciamento de Descoberta em modo seguro. (Se ainda não tiverconfigurado as definições de conexão SSL, o botão Iniciar em Modo Seguro não é ativado).
• A lista de domínios gerenciados foi alterada. Nessa situação, você deve repetir a configuração dasdefinições de conexão SSL para atualizar o truststore (especialmente se algum domínio tiver sidoincluído).
Para configurar as definições SSL, conclua as seguintes etapas:
a) Clique em Configurações de Conexão SSL.
112 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

A janela Configurações de Conexão SSL é exibida.b) Clique em Fazer Download do Truststore. Anote o diretório no qual deseja salvar o arquivo de
armazenamento confiável.
Importante: Não altere o nome do arquivo de armazenamento confiável.
O arquivo de armazenamento confiável é transferido por download usando uma conexão segura.c) No campo Diretório para o Truststore, digite o diretório no qual salvou o arquivo de
armazenamento confiável, sem o separador de caminho final.Por exemplo, se você salvou o arquivo de armazenamento confiável como
C:\domain_certs\Domain.cert
insira o diretório do truststore como
C:\domain_certs
d) Clique em OK.As informações do arquivo de armazenamento confiável são salvas em um cookie do navegador esão usadas ao iniciar uma conexão segura.
Para desativar conexões não seguras e forçar o uso de conexões SSL, configurecom.collation.security.enforceSSL como true. O valor padrão para esta propriedade é false.
4. Opcional: Se você estiver usando Firefox versão 3.0 ou posterior, assegure-se de que o protocolo decriptografia TLS 1.0 esteja ativado em suas configurações do navegador.Para ativar o TLS 1.0 no Firefox 3.6:a) Clique em Ferramentas > Opções.b) Na janela Opções, clique em Avançado.c) Clique na guia Criptografia.d) Selecione Usar TLS 1.0.
5. Na área de janela Resumo de Domínio, assegure-se de ter selecionado o domínio para o qual desejainiciar o Console de Gerenciamento de Descoberta em modo seguro.
6. Clique em Iniciar em Modo Seguro. Se for solicitado a aceitar um certificado de segurança, vocêdeverá fazê-lo. Será solicitado a aceitar um certificado de segurança apenas na primeira vez em que seconectar ao domínio.O seu navegador tenta abrir confignia.jnlp.
Nota: Se o botão Iniciar em Modo Seguro não estiver ativado, você deverá configurar as definições deconexão SSL conforme descrito na etapa “3” na página 112.
7. Se o seu navegador solicitar que você especifique como deseja usar confignia.jnlp, execute umdos seguintes procedimentos:a) Abra confignia.jnlp com o Java Web Start.b) Salve o arquivo confignia.jnlp localmente. Para ativar o Console de Gerenciamento de
Descoberta posteriormente, abra confignia.jnlp com o Java Web Start.O Console de Gerenciamento de Descoberta do domínio selecionado é inicializado usando SSL eexibido.
Especificando a Sincronização On DemandA sincronização on demand pode ser feita por meio da sincronização completa ou da sincronizaçãoincremental usando o Portal de Gerenciamento de Dados em execução em um servidor de sincronização.
Sobre Esta Tarefa
Com a sincronização completa, todos os itens de configuração em um domínio são sincronizados para obanco de dados do servidor de sincronização. Com a sincronização incremental, apenas os itens deconfiguração que foram alterados no domínio são sincronizados para o banco de dados do servidor desincronização.
Capítulo 1. Usando 113

Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Procedimento
Para especificar a sincronização entre o banco de dados do servidor de sincronização e o banco de dadosdo servidor de domínio, conclua as seguintes etapas:1. Na área de janela Funções, do Portal de Gerenciamento de Dados, clique em Gerenciamento de
Domínio > Sincronizar.A área de janela Sincronizar é exibida.
2. Na seção Domínios da área de janela Sincronizar, clique no domínio que deseja sincronizar.A área de janela Sincronizar é exibida contendo informações sobre o domínio selecionado.
3. Na seção Sincronização On Demand, selecione Executar Sincronização Completa se desejar executara sincronização completa entre o banco de dados do servidor de sincronização e o banco de dados doservidor de domínio. Caso contrário, a sincronização incremental será executada.
4. Para iniciar a sincronização imediatamente, clique em Iniciar.5. Para parar a sincronização, clique em Parar.
Especificando uma Sincronização PlanejadaÉ possível especificar a sincronização planejada em vez de executar a sincronização on demand usando oPortal de Gerenciamento de Dados em execução no servidor de sincronização. A sincronização planejadaé sempre incremental, ou seja, apenas aqueles itens de configuração que foram alterados no domínio sãosincronizados para o banco de dados do servidor de sincronização.
Sobre Esta Tarefa
Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Procedimento
Para configurar um tempo específico para a ocorrência da sincronização, conclua as etapas a seguir:1. Na área de janela Funções do Portal de Gerenciamento de Dados, clique em Gerenciamento de
Domínio > Sincronizar.A área de janela Sincronizar é exibida.
2. Na seção Domínios da área de janela Sincronizar, clique no domínio que deseja sincronizar.A área de janela Sincronizar é exibida contendo informações sobre o domínio selecionado.
3. Na seção Sincronização Planejada, clique em Nova.A área de janela Período do Planejamento é exibida.
4. Digite o nome do planejamento.5. Digite a hora em que deseja que a sincronização comece.6. Na lista no campo Repetir, selecione o intervalo no qual executar a sincronização. As opções são: por
hora, diário ou semanal.A opção selecionada é exibida próxima à caixa de entrada no campo Cada.
7. No campo Cada, digite um valor numérico ou as especificações Repetir para passar entre cadasincronização.
8. Para salvar as informações, clique em Incluir.A área de janela Sincronizar é exibida com as novas informações na tabela que está na seçãoSincronização Planejada.
9. Para retornar à área de janela Sincronizar sem salvar as informações, clique em Cancelar.
Visualizando o Status da SincronizaçãoÉ possível visualizar o status da sincronização e um log da sincronização para os domínios em suaempresa usando o Portal de Gerenciamento de Dados em execução no servidor de sincronização.
114 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Sobre Esta Tarefa
Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Procedimento
Para visualizar o status da sincronização para um domínio específico, desempenhe as seguintes etapas:1. Na área de janela Funções do Portal de Gerenciamento de Dados, clique em Gerenciamento de
Domínio > Sincronizar.A área de janela Sincronizar é exibida.
2. Na seção Domínios da área de janela Sincronizar, clique no domínio que deseja sincronizar.A área de janela Sincronizar é exibida contendo informações sobre o domínio selecionado.
3. Na seção Hora da Última Sincronização, clique em Visualizar Detalhes da Sincronização.A área de janela Status da Sincronização é exibida contendo o status da sincronização e um log dasincronização.
Excluindo uma Sincronização PlanejadaSe você não desejar mais que uma sincronização planejada ocorra, poderá excluir esse planejamento desincronização usando o Portal de Gerenciamento de Dados em execução no servidor de sincronização.
Sobre Esta Tarefa
Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Procedimento
Para excluir uma sincronização planejada de um domínio em sua empresa, conclua as etapas a seguir:1. Na área de janela Funções do Portal de Gerenciamento de Dados, clique em Gerenciamento de
Domínio > Sincronizar.A área de janela Sincronizar é exibida.
2. Na seção Domínios da área de janela Sincronizar, clique no domínio que deseja sincronizar.A área de janela Sincronizar é exibida contendo informações sobre o domínio selecionado.
3. A partir da tabela na seção Sincronização Planejada, selecione o planejamento que deseja excluir.4. Clique em Excluir.
O planejamento para esse domínio é removido da tabela.
Exibindo Informações sobre o Inventário da EmpresaUsando o Portal de Gerenciamento de Dados em execução no servidor de sincronização, é possível exibirum relatório de inventário para o domínio local ou quaisquer dos domínios remotos incluídos em suaempresa.
Sobre Esta Tarefa
Essa tarefa está disponível para implementações do servidor de sincronização apenas.
Procedimento
Para exibir um resumo do inventário, conclua as etapas a seguir:1. Na área de janela Funções, clique em Analítica e execute um dos seguintes procedimentos:
• Para exibir um resumo do inventário para o domínio local, clique em Resumo do Inventário (local).A área de janela Resumo de Inventário é exibida.
• Para exibir um resumo do inventário para qualquer um dos domínios remotos em sua empresa,clique em Resumo do Inventário (domínio). A seção Domínio da área de janela Resumo deInventário é exibida, contendo uma lista Domínio. Se você selecionou Resumo de Inventário
Capítulo 1. Usando 115

(domínio), clique no domínio (na lista Domínio) para o qual deseja exibir o resumo de inventário. Aárea de janela Resumo de Inventário é exibida.
2. Na área de janela Resumo de Inventário, clique em uma entidade na coluna Tipo de Componente ouDetalhe do Inventário.A área de janela Detalhes do Inventário é exibida.
3. Na área de janela Detalhes do Inventário, selecione um componente e clique em um dos seguintesbotões, dependendo do tipo de informação que deseja exibir:
• Clique em Detalhes para exibir a área de janela Detalhes para o componente selecionado.• Clique em Alterações para exibir a área de janela Histórico de Mudanças para o componente
selecionado.• Clique em Salvar para salvar o relatório Resumo do Inventário para o componente selecionado.• Clique em Marcar Para Comparação para incluir este componente na lista de componentes a serem
comparados. A área de janela Comparação de Componentes é exibida contendo o componenteselecionado. Para continuar com a comparação de componentes, conclua as etapas a seguir:
a. Na área de janela Detalhes do Inventário, clique no segundo componente a ser comparado.
Importante: Não é necessário fechar a janela Comparação de Componentes antes de clicar emoutro componente na área de janela Detalhes do Inventário.
A janela Comparação de Componentes é exibida contendo o segundo componente selecionado.b. Repita esta etapa para todos os componentes que deseja comparar.c. Na janela Comparação de Componentes, selecione os componentes que deseja comparar e
clique em Comparar. A área de janela Comparação de Componentes é exibida.
Importante: Os mesmos dados descobertos em mais de um domínio remoto são exibidos apenas noresumo do inventário para um determinado domínio remoto.
Portal de Acesso a DadosO Portal de acesso a dados do TADDM é a interface com o usuário baseada na web do IBM® TivoliApplication Dependency Discovery Manager (TADDM), usada para visualizar os dados em um banco dedados do TADDM. Essa interface com o usuário está disponível com a implementação do servidor dedomínio, com a implementação do servidor de sincronização e com cada servidor de armazenamento emuma implementação do servidor de fluxo.
Efetuar LoginVocê deve ter credenciais de login válidas para efetuar login no Portal de acesso a dados. Caso seja umnovo usuário, entre em contato com a equipe de administração para obter credenciais.
Procedimento
Pré-requisito:
• Credenciais Válidas em Credenciais• Navegador Compatível. Os nagevadores a seguir suportam o Portal de acesso da dados do TADDM:
Tabela 15. Topologias Especializadas
Pesquisador Versão
BR Mais recente (11.x)
Firefox Último (61.x)
Cromado Mais Recente (70.x)
1. Abra um navegador da web e digite qualquer uma das URLs a seguir:
116 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Para httphttp://<PSS/SSS IP>:9430/dap
Para httpshttps://<PSS/SSS IP>:9431/dap
Nota: O Portal de acesso a dados pode ser acessado nos serviços de armazenamento primário ousecundário.
2. Na página do Portal de acesso a dados do TADDM, insira seu ID de usuário e senha.3. Clique em Login.
Para problemas relacionados ao login, consulte a seção 'Resolução de problemas'.
Desconectando-sePara sair, conclua as etapas a seguir:
Procedimento
1. Acesse a barra de navegação e clique no perfil do usuário.2. Clique em Sair.
Área de janela do painelO painel exibe todos os itens de configuração disponíveis no CMDB do TADDM por meio de um gráfico depizza. Esse gráfico fornece flexibilidade para visualizar rapidamente os detalhes do IC. Cada fatia dográfico de pizza representa uma categoria de item de configuração e pode ser identificada por um calloutcorrespondente.
A seguir, estão os principais recursos do gráfico de pizza:
• Cada fatia do gráfico de pizza representa um item de configuração.• Cada fatia é ilustrada com cores distintas.• É possível clicar em cada fatia para explodir e explorar os detalhes relacionados.• Cada fatia possui callouts que descrevem o nome do item de configuração e sua contagem.• No gráfico de pizza, os links de itens de configuração são listados.
Customização do gráfico
Por padrão, todos os itens de configuração disponíveis são mostrados no gráfico de pizza e o tamanho dafatia depende da contagem do item de configuração. Portanto, os itens de configuração com contagemmais baixa geralmente não estão claramente visíveis no gráfico de pizza. Nesse cenário, é possível ocultaros itens de configuração que possuem grande contagem para visualizar o gráfico atualizado. Além disso, épossível visualizar o gráfico de pizza em tela cheia. No modo tela cheia, é possível explorar o gráfico depizza ampliado no qual até mesmo as pequenas fatias ficam notavelmente visíveis.
Para ocultar um item de configuração, clique nos links do item de configuração no gráfico de pizza. Demaneira semelhante, é possível exibir quaisquer itens de configuração.
Explorando detalhes de um item de configuração
Para explorar informações detalhadas para um item de configuração, clique na fatia correspondente nográfico de pizza. Um novo gráfico de pizza aparecerá e exibirá os detalhes dos itens de configuração. Essenovo gráfico ilustrará as subcategorias do item de configuração. É possível clicar novamente nas fatias donovo gráfico para explorar ainda mais. A lista de inventários exibe o componente relacionado e seusdetalhes associados. É possível clicar nos links do componente para visualizar os detalhes relacionados.
Nota: Os links de componentes estarão ativos apenas para os itens de configuração suportados. Paraoutros itens de configuração, os links de componentes não estarão ativos.
Capítulo 1. Usando 117

Imprimir e fazer download
Gráfico de pizza
Na janela do painel, é possível fazer o download de um gráfico de pizza em diversos formatos, taiscomo JPEG, PNG, SVG e PDF.
Na área de janela do gráfico de pizza, clique no ícone de menu para escolher o formato que vocêdeseja fazer download. Também é possível imprimir um gráfico diretamente.
Resultado do inventárioÉ possível fazer download dos resultados de inventário em dois formatos de saída: CSV e PDF.
PesquisaA funcionalidade de procura consulta os componentes que pertencem a várias classes, como sistema decomputador, servidor de aplicativos e servidor de banco de dados e exibe os seguintes detalhes doscomponentes:
Nome de exibição, Rótulo, Nome, Nome completo do domínio, Endereço numérico.
Utilizando a operação de procura, é possível executar as procuras Sugestiva, Normal e Avançada.
Executando procura sugestivaO campo de procura sugere uma lista de componentes, com base no que é digitado no campo de procura.Por exemplo, ao digitar ra, os itens de configuração (IC) iniciados com ra serão exibidos na listasuspensa.
Procedimento
1. No campo Procurar, digite um ou dois caracteres alfabéticos ou dígitos iniciais (no caso de endereçoIP) do detalhe do componente que deseja procurar.
Uma lista de sugestões é exibida.2. Opcional: é possível clicar em uma das categorias a seguir para filtrar os resultados da procura.
Todos : Exibe todos os resultados correspondentes.Servidor de aplicativos: exibe resultados relacionados ao Servidor de aplicativos.Sistema de cálculo: exibe o resultado relacionado ao sistema de cálculo.Bancos de dados : exibe resultados relacionados aos bancos de dados.
3. Na lista, clique no item que deseja visualizar.4. O resultado da procura é exibido.
Nota: Por padrão, 10 resultados são exibidos por página.
Executando procura normalNa procura normal, é possível procurar rapidamente um componente por seu nome ou endereço IP.
Procedimento
1. No campo Procurar, digite o nome ou endereço IP do componente que deseja procurar.É exibida uma lista de componentes correspondentes.
2. Clique no item que deseja visualizar.Alternativamente, clique no ícone Procurar.
3. O resultado da procura é exibido.
Nota: Por padrão, 10 resultados são exibidos por página.
118 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Executando procura avançadaO recurso de procura avançada ajuda a usar critérios específicos para procurar itens de configuração. Épossível procurar itens de configuração usando uma combinação de palavras-chave, seus valores,operadores e caracteres curinga.
Procedimento
1. No campo Procurar, insira os critérios para procura. Os critérios de procura são uma combinação depalavras-chave, seu valor e operadores. Para obter mais informações, consulte exemplos.
A seção a seguir fornece uma lista de palavras-chave e operadores disponíveis:Palavras-chave
Tabela 16.
Palavras-chave Detalhe
Nome Nome de Exibição
PI Endereço IP
FQDN Nome Completo do Domínio
Data Última hora de modificação
Finalidade doOs operadores disponíveis são (=) (<=) (>=) (&)
Nota: Use * como um caractere curinga.2. Clique no ícone Procurar ou pressione Enter.3. O resultado da procura exibe uma lista de componentes correspondentes aos critérios de procura.
Nota: Por padrão, 10 resultados são exibidos por página.
Exemplos de critérios de procura e combinação1. name=taddm.Isso listará os resultados que têm “taddm” como o nome de exibição.2. name=taddm.Isso listará somente os resultados cujo nome de exibição começa com "taddm".3. name= * taddm.Isso listará os resultados que têm o nome de exibição terminado somente com "addm".4. name=*taddm* & fqdn=taddm.lab.com.Isso listará os resultados cujo nome de exibição contém taddm e que têm o valor fqdn comotaddm.lab.com.5. ip=aa.bb.cc.dd.Isso listará os resultados que têm "aa.bb.cc.dd" como endereço IP6. date>=2019-01-16Isso listará os resultados cuja data da Última atualização é maior ou igual a 2019-01-16
Visualizando Detalhes do ComponenteÉ possível visualizar vários valores de atributo de um componente.
Procedimento
Para visualizar os detalhes de atributos ou valores de um componente, conclua as etapas a seguir:1. No campo Procurar, digite os detalhes do componente que deseja procurar. Para obter mais
resultados, consulte a seção 'Procurar'.
Capítulo 1. Usando 119

2. Na lista Resultados da procura, clique no componente que deseja visualizar. O resultado da procuraexibe uma tabela com os seguintes atributos:
• Nome do Componente• Tipo de Componente• Tipo• Endereço IP• Última Atualização• Ações
3. No cabeçote componente, clique no link do componente correspondente a ser visualizado. Umapágina de detalhes exibe todos os atributos do componente.
Comparando componentesÉ possível comparar os itens de configuração e visualizar seus atributos semelhantes e diferentes. Ummáximo de cinco itens de configuração com o mesmo Tipo podem ser comparados.
Procedimento
Para comparar os componentes, conclua as etapas a seguir:1. No campo Procurar, digite os detalhes do componente. É exibida uma lista de componentes
correspondentes.2. Na lista Componentes, clique em um Componente que deseja comparar. É exibida uma tabela de
componentes correspondentes.
Nota: É possível clicar em qualquer uma das categorias a seguir para filtrar os resultados da procura:Todos
Exibir todos os resultados correspondentesServidor de aplicativos
Exibir os itens relacionados ao servidor de aplicativosSistema do computador
Exibe os itens relacionados ao sistema de computadorBancos de dados
Exibe os itens relacionados aos bancos de dadosRede
Exibe os itens relacionados à redeCluster
Exibe itens relacionados ao cluster3. É possível comparar componentes usando uma das maneiras a seguir:
• Utilizando a área de janela Detalhes:
a. No Resultado da procura, clique em qualquer link de componente que você deseja comparar. Aárea de janela de detalhes será exibida.
b. Clique em Incluir para comparar.c. Clique no link resultado da procura nas trilhas de navegação. A área de janela Resultado da
procura será exibida.d. Na lista de componentes, clique no link componente similar e clique em INCLUIR para
comparar.e. Acesse a Etapa 4.
• Usando a Área de Janta de Resultado da Procura :
a. Na área de janela resultado da procura, selecione as caixas de seleção dos componentescorrespondentes que você deseja comparar.
120 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

b. Clique em Incluir para comparar.c. Acesse a Etapa 4.
4. Clique em Visualizar Comparação . A área de janela de comparação é exibida.5. Na área de janela Visualizar comparação, configure os critérios para a comparação. Para obter mais
detalhes, consulte a seção Área de janela Visualizar comparação.6. Opcional: caso deseje remover qualquer componente da lista de comparação, clique no ícone de
Lixeira correspondente.7. Clique em Comparar agora para iniciar a comparação. A área de janela Resultados da Comparação
exibe o resultado.
Visualizando RelacionamentoEsta página mostra o relacionamento entre classes de tipos iguais ou diferentes. Cada relacionamentopossui uma definição ou um tipo. Esses tipos de relacionamentos diferentes transportam umadeterminada semântica, que diz respeito ao tipo de associação entre as instâncias de recursos.
Procedimento
Para visualizar o relacionamento de um componente, conclua as etapas a seguir:1. No campo Procurar, digite os detalhes do componente (como, sistema do componente, servidor de
banco de dados, servidor de aplicativos ou endereço IP) que deseja procurar. É exibida uma lista decomponentes correspondentes.
2. Na lista Componentes, clique em um Componente que deseja comparar. A área de janela Resultadoda procura exibe uma tabela com os atributos a seguir:
• Nome do Componente• Tipo de Componente• Tipo• Endereço IP• Última Atualização• Ações
3. No cabeçote Ações, clique no link Visualizar relacionamento do componente que deseja visualizar.
Área de janela de detalhesA área de janela Detalhes mostra os atributos do item de configuração (IC). No lado esquerdo da área dejanela, são listados os atributos disponíveis. É possível clicar em qualquer atributo para visualizar osdetalhes correspondentes.
Área de janela Visualizar comparaçãoA área de janela Comparação de componentes contém as opções a seguir:
Definir como ChaveConfigura um componente como principal para fazer a comparação com o outro componente.
Ícone de lixeiraRemove o componente da lista de comparação.
DESFAZERInclui novamente o componente excluído recentemente na lista de comparação.
NívelDefine a profundidade do relatório de comparação; a opção Profundo mostra mais detalhes do que aopção Básica.
BásicoSelecione esta opção para obter informações gerais de configuração, como configurações de númerode porta e diretórios.
Capítulo 1. Usando 121

ProfundoSelecione esta opção para obter informações adicionais sobre os módulos instalados em servidoresApache, objetos de aplicativos implementados (como EJBs) e recursos (como JDBC e JMS) emservidores WebLogic.
Incluir Serviços de InfraestruturaOs componentes de infraestrutura são configurados para se comunicarem com vários serviços, comoum serviço DNS ou um serviço de sistema de arquivos NFS.Ao selecionar Sim, o TADDM procura todas as diferenças na dependência de serviço entre os Cis(Componentes) comparados.
Nota: Por padrão, essa opção é NO . Se você tiver selecionado Sistema de cálculo na página deprocura, essa opção não estará disponível.
Incluir SistemaIncluir sistema compara os sistemas físicos nos quais o software reside, além de comparar o softwaredo servidor.Ao selecionar Sim, além de comparar o software do servidor, o resultado da procura tambémmostrará o sistema físico no qual o software reside. Por exemplo, ao selecionar Sim durante acomparação de banco de dados, o TADDM comparará o banco de dados e o sistema operacional.Ao selecionar Não, o resultado da procura mostrará somente os detalhes do servidor de software.
Nota: Por padrão, essa opção é NO .
Incluir Lista CompletaÉ possível usar uma das três maneiras a seguir para visualizar o relatório de comparação:Semelhantes: é possível ver os atributos semelhantes.Mudanças: é possível ver os atributos diferentes.Ambos: é possível ver atributos semelhantes e diferentes.
Comparação de Componentes: área de janela de resultadosA área de janela Resultado de comparação exibe tabelas com detalhes de comparação.
Os atributos semelhantes e diferentes dos componentes são agrupados separadamente. Cada tabelacompreende três colunas; a primeira coluna mostra os nomes de Atributos, a segunda coluna mostra osvalores de atributos do componente principal e a terceira coluna mostra os valores de atributos do outrocomponente.
A cor da coluna do componente principal é azul e a cor da coluna do outro componente é verde. Porpadrão, 10 resultados são exibidos por página. Na parte inferior, é possível localizar o número total deitens de configuração para a procura. Com base na seleção Incluir lista completa, a área de janelaResultado de comparação é exibida:
SemelhanteTabela com atributos que têm valores semelhantes para os componentes principal e não principal.
Ou
AlteraçõesTabela com atributos que têm valores diferentes para os componentes principal e não principal.
Ou
AmbasDuas tabelas, uma com valores de atributos semelhantes e outra com valores de atributos diferentes.
Área de janela RelacionamentoA área de janela Relacionamento mostra os atributos a seguir:
Nome do Relacionamento
122 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

• Representa as relações da instância de origem com a instância de destino e vice-versa. Por exemplo,um dos tipos de relacionamento no CDM é manages, que representa que a instância de origemparticipa de uma função de controle na instância de recurso de destino no relacionamento
IC Relacionado
• Representa a instância de origem ou de destino em relação ao IC selecionado
Origem ou Destino
• Cada instância de relacionamento possui uma origem e um destino, que são as funções dorelacionamento. O número de instâncias que podem participar de cada função é importante. Algunsrelacionamentos permitem a participação de apenas uma instância. Outros permitem qualquer númerode instâncias. O número de instâncias que podem participar de cada função é conhecido como acardinalidade do relacionamento.
Referência da Interface com o UsuárioAs interfaces com o usuário do TADDM são o Console de Gerenciamento de Descoberta e o Portal deGerenciamento de Dados. As janelas específicas que estão disponíveis em qualquer uma dessas duasinterfaces com o usuário dependem do tipo de implementação do TADDM.Console de Gerenciamento de Descoberta
A interface com o usuário cliente do TADDM para gerenciar descobertas. Esse console é conhecidotambém como o Console do Produto. Ele é aplicável a uma implementação de servidor de domínio e aservidores de descoberta em uma implementação de servidor de fluxo. A função do console é amesma nessas duas implementações.
Portal de Gerenciamento de DadosA interface do usuário do TADDM baseada na Web para visualização e manipulação dos dados em umbanco de dados do TADDM. Essa interface com o usuário é aplicável a uma implementação doservidor de domínio, a uma implementação do servidor de sincronização e a cada servidor dearmazenamento em uma implementação do servidor de fluxo. A interface com o usuário é muitosemelhante em todas as implementações, embora em uma implementação do servidor desincronização, ela tenha algumas funções adicionais para incluir e sincronizar domínios.
Janelas e Controles do Console de Gerenciamento de DescobertaO Console de Gerenciamento de Descoberta exibe informações a partir de um servidor de descoberta.
A Tabela 17 na página 123 descreve os itens que podem ser visualizados na guia Descoberta da área dejanela Funções do Console de Gerenciamento de Descoberta.
Tabela 17. Itens da Guia Descoberta
Item da guia Descoberta Descrição
Visão Geral Exibe o status atual da descoberta. É possívelexecutar uma descoberta, monitorar o progressoda descoberta e examinar erros. Também épossível parar uma descoberta, visualizar um logde descoberta e visualizar o log de escopo.
Escopo Descreve o intervalo de endereços IP que édescoberto durante o processo de descoberta. Ointervalo de endereços IP é descoberto utilizando-se endereços IP, intervalos de endereços IP e sub-redes. É possível modificar o escopo incluindo,editando ou removendo entradas. Os conjuntos deescopos podem ser agrupados em grupos deescopos. É possível modificar grupos de escoposao incluir e remover conjuntos de escopos.
Capítulo 1. Usando 123

Tabela 17. Itens da Guia Descoberta (continuação)
Item da guia Descoberta Descrição
Lista de Acesso Exibe a lista de acesso definida para o servidor.Uma lista de acesso é uma coleta de nomes deusuário, senhas e cadeias de comunidades doProtocolo Simples de Gerenciamento de Rede(SNMP) utilizada pelo servidor para acessar osdestinos de descoberta em sua infraestrutura.Você pode incluir, editar e excluir entradas na listade acesso.
Servidores Customizados Exibe os servidores customizados. Você podeincluir, editar, copiar ou excluir servidorescustomizados.
Sistemas do Computador Exibe todos os modelos criados para customizar adescoberta de Sistemas do Computador. O usuáriopode criar modelos para customizar a descobertade um Sistema do Computador.
Âncoras e Gateways Exibe as âncoras e os gateways em suainfraestrutura. As âncoras são utilizadas paradescobrir entidades dentro de áreas de rederestritas sem requerer um servidor dedicado naárea. Os gateways são necessários para adescoberta não superficial de servidores Windows.Eles não são necessários para a descoberta semcredencial (Perfil de Descoberta 1) de servidoresWindows. É possível incluir ou excluir âncoras egateways e também especificar a porta decomunicação.
Planejamento Exibe os planejamentos de descoberta, queinstruem o servidor a executar uma descoberta emum momento definido. É possível incluir novosplanejamentos, editar planejamentos existentes ouremover um planejamento conforme necessário.
Histórico Exibe informações do histórico sobre descobertaspassadas. É possível exibir a atividade e asmensagens de erro associadas a cada descoberta.
Perfis de Descoberta Exibe todos os perfis de descoberta que sãoutilizados durante o processo de descoberta.
Área de Janela Visão GeralÉ possível visualizar informações de descoberta na área de janela Visão Geral. É possível visualizar a áreade janela Visão Geral enquanto uma descoberta está em execução.
A área de janela Visão Geral contém as informações e os botões a seguir:
ID da DescobertaExibe o ID de cada descoberta atualmente em execução. Para visualizar informações sobre umadescoberta específica, selecione o ID dessa descoberta na lista. Quando nenhuma descoberta estiverem execução, o valor Nova Descoberta será exibido.
StatusExibe o status da descoberta.
Componentes LocalizadosExibe o número de componentes descobertos.
124 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Sensores em ExecuçãoExibe o número de sensores que estão em execução.
ProgressoUma tabela com informações relacionadas ao progresso, incluindo uma lista de sensores e os nomesdo host, endereços IP e datas correspondentes.
Mostrar Apenas Itens de StatusFiltra a tabela pelo status selecionado na lista.
InformaçõesExibe informações sobre o sensor selecionado.
Executar DescobertaSolicita que você selecione um escopo e um perfil com o qual deve iniciar uma descoberta.
Detalhes do EscopoExibe informações sobre o escopo.
Registro de DescobertaSolicita que você insira uma sequência na qual pesquisar o log de descoberta.
Área de Janela EscopoÉ possível gerenciar informações de escopo usando a área de janela Escopo.
A área de janela Escopo contém as informações sobre conjuntos de escopos e grupos de escopos. A guiaConjuntos de Escopos contém as informações a seguir:
Conjuntos de escoposUma coleta lógica de nomes do host, endereços IP, intervalos de endereços IP ou sub-redes.
MétodoEspecifica se inclui ou exclui o endereço IP, o intervalo de endereços IP ou a sub-rede.
TipoO tipo de endereço especificado, que inclui os seguintes valores:
• Sub-rede - uma sub-rede IP, como 255.255.255.0• Intervalo - intervalo do endereço IP, como 1.2.3.4 - 1.2.3.10• Endereço - endereço IP, como 1.2.3.4
ValorO endereço IP, o intervalo de endereços IP ou a sub-rede reais.
Descrição/nome do hostUma descrição fornecida pelo usuário do escopo de descoberta.
Incluir ConjuntoCria um conjunto de escopos e o inclui na lista de conjuntos de escopos.
Excluir ConjuntoExclui um conjunto de escopos e o remove da lista de conjuntos de escopos.
IncluirCria um escopo e o inclui na tabela.
EditarEdita os atributos de um escopo.
ExcluirExclui um escopo e o remove da tabela.
A guia Grupos de Escopos contém as informações a seguir:
Grupos de escoposOs grupos de conjuntos de escopos existentes. Um conjunto de escopos pode ser um membro dediversos grupos de escopos.
Conjuntos de escoposEspecifica a lista de conjuntos de escopos que são membros de um grupo de escopos selecionado.
Capítulo 1. Usando 125

Incluir GrupoCria um grupo de escopos e o inclui na lista de grupos de escopos.
Excluir GrupoExclui um grupo de escopos e o remove da lista de grupos de escopos.
Incluir no grupoInclui conjuntos de escopos nos grupos de escopos selecionados.
Excluir do grupoExclui um conjunto de escopos do grupo de escopos e o remove da tabela.
Janela Incluir EscopoÉ possível incluir um escopo em um conjunto de escopos e um novo grupo de conjuntos de escoposusando a janela Incluir Escopo.
Ao criar um escopo, é possível especificar um host individual, uma sub-rede ou um intervalo deendereços IP. Para excluir hosts individuais do escopo, inclua uma exclusão nesse host.
Acesse Descoberta > Escopo> e selecione a guia Conjuntos de escopos. A janela Incluir Escopo éaberta.
A janela Incluir Escopo contém as seguintes informações:
Tipo de IPEspecifique o formato do endereço IP ou o nome do host que deseja incluir. Os valores válidos são:
• Sub-rede• Intervalo• Host
Endereço IPEspecifique o endereço IP no formato apropriado, dependendo do valor Tipo de IP.
DescriçãoEspecifique uma descrição do host.
Incluir ExclusãoExibe campos nos quais você especifica os detalhes de hosts que deseja excluir do escopo.
RemoverRemove a exclusão.
Quando desejar incluir novos grupos de conjuntos de escopos, acesse Descoberta > Escopo e selecione aguia Grupos de Escopos. A janela Incluir Escopo contém as seguintes informações:Grupos de Escopo
A lista de grupos de escoposConfigurações do Escopo
A lista de conjuntos de escopos que são membros de um grupo de escopos escolhido.
Para incluir conjuntos de escopos em um grupo de escopos, clique em Incluir no Grupo e selecione osconjuntos de escopos que deseja incluir em um grupo.
Área de Janela Lista de AcessoÉ possível gerenciar informações de escopo usando a área de janela Lista de Acesso.
A área de janela Lista de Acesso contém as seguintes informações:Tipo
O tipo da entrada da lista de acesso.Nome
O nome da entrada da lista de acesso.Nome do Usuário
O nome do usuário para efetuar login no componente a ser descoberto.
126 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Restrições do Conjunto de EscoposInformações sobre os escopos aos quais o acesso ao componente é restrito, se aplicado.
Tabela 18.
Campo Descrição
Incluir Incluir detalhes do acesso na lista de acesso.
Editar Edita detalhes de acesso existentes.
Excluir Exclui detalhes de acesso existentes.
Mover para Cima Move os detalhes de acesso selecionados uma posição acima nalista de acesso.
Mover para Baixo Move os detalhes de acesso selecionados uma posição abaixo nalista de acesso.
Janela Detalhes de AcessoÉ possível gerenciar informações de escopo usando a janela Detalhes de Acesso.
A janela Detalhes de Acesso contém as seguintes guias:
• Informações de Acesso• Limitação de Escopo
Os campos exibidos na guia Informações de Acesso dependem do valor selecionado na lista Tipo deComponente. A tabela a seguir identifica os tipos de componentes e os campos e listas adicionais quevocê deve completar para a entrada da lista de acesso.
Tabela 19. Tipos de Componentes, Campos e Listas Necessários para a Entrada da Lista de Acesso
Tipos de Componentes Campos e Listas
Servidor de Aplicativos, Banco de Dados,Servidores do Sistema de Mensagens
NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidor.
SenhaSenha para acessar o servidor.
FornecedorO fornecedor do servidor ou banco de dados.
Servidor CSM NomeNome para identificar o dispositivo na lista deacesso.
SenhaSenha para acessar o servidor.
Nome do UsuárioNome do usuário para acessar o servidor.
Capítulo 1. Usando 127

Tabela 19. Tipos de Componentes, Campos e Listas Necessários para a Entrada da Lista de Acesso(continuação)
Tipos de Componentes Campos e Listas
Dispositivo Cisco NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o dispositivo.
SenhaA senha para o dispositivo Cisco, se vocêestiver usando o protocolo Telnet, SSH1 ouSSH2.
Ativar SenhaA ativação da senha do dispositivo Cisco, sevocê estiver usando o protocolo Telnet, SSH1ou SSH2.
Confirmar Ativar SenhaA ativação da senha do dispositivo Cisco, sevocê estiver usando o protocolo Telnet, SSH1ou SSH2.
O sensor Cisco IOS exige que o sensor SNMPesteja estabelecido e em funcionamento comrelação ao dispositivo. Se o seu sensor Cisco IOSestiver usando um protocolo Telnet e não solicitarum nome de usuário, digite padrão no campoNome do Usuário.
Cisco Works NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidor.
SenhaSenha para acessar o servidor.
Sistema de Computador, Sistema de Computador(Windows)
Tipo de AutenticaçãoO tipo de autenticação para o sistema decomputador.
NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o sistema decomputador.
SenhaSenha para acessar o sistema de computador.
128 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Tabela 19. Tipos de Componentes, Campos e Listas Necessários para a Entrada da Lista de Acesso(continuação)
Tipos de Componentes Campos e Listas
CCMS (Computing Center Management System) NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidor SAPCCMS.
ID do ClienteO ID do cliente do servidor SAP CCMS.
SenhaSenha para acessar o servidor SAP CCMS.
Soluções de Alta Disponibilidade NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidorVeritas Cluster.
SenhaSenha para acessar o servidor Veritas Cluster.
IBM Tivoli Monitoring NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o TivoliEnterprise Portal Server.
SenhaSenha para acessar o Tivoli Enterprise PortalServer.
Serviço LDAP NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidor LDAP.
SenhaSenha para acessar o servidor LDAP.
Capítulo 1. Usando 129
Tabela 19. Tipos de Componentes, Campos e Listas Necessários para a Entrada da Lista de Acesso(continuação)
Tipos de Componentes Campos e Listas
Elemento de Rede (SNMP) NomeNome para identificar o dispositivo na lista deacesso.
Cadeia de ComunidadeA cadeia de comunidade para o dispositivo derede.
Confirmar Cadeia de ComunidadeA cadeia de comunidade para o dispositivo derede.
O elemento Rede SNMP deve ser configurado pararesponder a consultas de endereço IP do servidorTADDM.
Elemento de Rede (SNMPV3) NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o dispositivo.
SenhaSenha para acessar o dispositivo.
Senha PrivadaA senha utilizada se a criptografia de dados forconfigurada para SNMP.
Protocolo de AutenticaçãoO tipo de protocolo de autenticação utilizadopor SNMP.
Servidor SysImager NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o servidorSysImager.
SenhaSenha para acessar o servidor SysImager.
Servidor de Diretórios System Landscape NomeNome para identificar o dispositivo na lista deacesso.
Nome do UsuárioNome do usuário para acessar o Servidor deDiretórios System Landscape.
SenhaSenha para acessar o Servidor de DiretóriosSystem Landscape.
A guia Limitações de Escopo contém as seguintes informações:
130 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Escopo inteiroSe selecionado, especifica que os detalhes do acesso não são limitados pelo escopo. Esse é o valorpadrão.
Limite para conjuntos de escopos selecionadosSe selecionado, especifica que os detalhes de acesso são limitados aos conjuntos de escoposselecionados.
Limite para grupos de escopo selecionadosSe selecionado, especifica que os detalhes de acesso são limitados aos grupos de escoposselecionados.
Área de Janela Servidores CustomizadosÉ possível gerenciar servidores customizados na área de janela Servidores Customizados.
A área de janela Servidores Customizados contém as informações e os botões a seguir:
AtivadoEspecifica se o TADDM age em correspondências com esse modelo de servidor customizado durantea descoberta. Os valores são: true ou false.
ÍconeO ícone associado ao servidor customizado.
NomeO nome do servidor customizado.
TipoO tipo de servidor customizado:
• AppServer• Java EE Server• Servidor da Web• Servidor de Banco de Dados
Cada um dos quatro tipos de servidor customizado genérico listados acima pode ser usado para criarum modelo para a descoberta de tipos de servidor que o TADDM não categoriza automaticamente.Durante a descoberta, todo servidor desconhecido é identificado como um servidor customizadodesse tipo, se as informações de tempo de execução correspondem aos critérios especificados nomodelo e nenhum outro sensor ativado existente corresponde a esses critérios. Esses tipos podemtambém ser executados se o sensor TADDM correspondente for executado e falhar.
Servidores do Tipo Sensor
Os Tipos restantes correspondem aos sensores que são executados no ambiente. Esses modelos deservidor customizado do tipo sensor são executados somente em conjunto com um sensor bem-sucedido existente e destinam-se a estender a descoberta de um servidor, customizando certosaspectos de como o sensor descobre o servidor. Consulte o Capítulo 15 "Extensões de ServidoresCustomizados" , para obter informações adicionais.
Se um sensor credenciado e um servidor customizado forem executados para o mesmo destinodurante uma ou mais descobertas, devido à natureza diferente dos dados descobertos semcredenciais, os objetos criados pelo CST podem não reconciliar com artefatos criados pelo sensor.
AçãoA ação a executar durante a descoberta:Descobrir
Inclui os servidores customizados que correspondem ao modelo localizado durante a descobertano TADDM e remove o servidor do relatório de servidor desconhecido.
IgnorarRemove servidores customizados que correspondem ao modelo localizado durante a descobertado relatório de servidor desconhecido.
Capítulo 1. Usando 131

Arquivos de ConfiguraçãoO caminho para os arquivos de configuração com os quais o servidor customizado está associado.
Janela Detalhes do Servidor CustomizadoÉ possível criar, editar ou visualizar um servidor customizado na janela Detalhes do ServidorCustomizado.
A janela Detalhes do Servidor Customizado contém as seguintes guias:
• Informações Gerais e Critérios• Arquivos de Configuração
A guia Informações Gerais e Critérios contém as informações e os botões a seguir:
NomeO nome do servidor customizado.
TipoO tipo de servidor customizado:
• AppServer• Java EE Server• Servidor da Web• Servidor de Banco de Dados
Cada um dos quatro tipos de servidor customizado genérico listados acima pode ser usado para criarum modelo para a descoberta de tipos de servidor que o TADDM não categoriza automaticamente.Durante a descoberta, todo servidor desconhecido é identificado como um servidor customizadodesse tipo, se as informações de tempo de execução correspondem aos critérios especificados nomodelo e nenhum outro sensor ativado existente corresponde a esses critérios. Esses tipos podemtambém ser executados se o sensor TADDM correspondente for executado e falhar.
Servidores do Tipo Sensor
Os Tipos restantes correspondem aos sensores que são executados no ambiente. Esses modelos deservidor customizado do tipo sensor são executados somente em conjunto com um sensor bem-sucedido existente e destinam-se a estender a descoberta de um servidor, customizando certosaspectos de como o sensor descobre o servidor. Consulte a seção "Desenvolvendo extensões deservidor customizado" no Developer Guide do SDK TADDM para obter mais informações.
Limitação: Não é possível usar sensores baseados em script para criar extensões de servidorcustomizado.
Se um sensor credenciado e um servidor customizado forem executados para o mesmo destinodurante uma ou mais descobertas, devido à natureza diferente dos dados descobertos semcredenciais, os objetos criados pelo CST podem não reconciliar com artefatos criados pelo sensor.
AçãoA ação a executar durante a descoberta:Descobrir
Inclui os servidores customizados que correspondem ao modelo localizado durante a descobertano TADDM e remove o servidor do relatório de servidor desconhecido.
IgnorarRemove servidores customizados que correspondem ao modelo localizado durante a descobertado relatório de servidor desconhecido.
AtivadoEspecifica se o TADDM age em correspondências com esse modelo de servidor customizado durantea descoberta. Os valores são: true ou false.
ÍconeO ícone associado ao servidor customizado.
132 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Nota: Para alguns tipos de servidores customizados, o ícone pode não ser exibido na área de janelaComponentes Descobertos, na área de janela Detalhes e na área de janela ServidoresCustomizados do Portal de Gerenciamento de Dados.
PesquisarSolicita que você selecione uma imagem a ser usada como o ícone para o servidor customizado.
Identificando CritériosEspecifique como deseja que os conjuntos de condições sejam tratados. As opções disponíveis são:
• Todas as seguintes condições forem atendidas (lógica AND)• Qualquer uma das seguintes condições for atendida (lógica OR)
Lista de CritériosEspecifique o tipo de critério para o conjunto de condições. Os tipos válidos são:Nome do programa
O nome do programa executável.Nome do serviço do Windows
O nome de um serviço do sistema operacional Windows.Argumento
Os argumentos transmitidos ao programa.Ambiente
As variáveis de ambiente configuradas para o programa.Porta
O número da porta TCP na qual o processo está atendendo.Lista de Operadores
Especifique o operador para o conjunto de condições. Os operadores válidos são:
• é• não é• contém• não contém• começa com• não começa com• termina com• não termina com• expressão regular
A guia Arquivos de Configuração contém as informações e os botões a seguir:Nomes de Arquivos
Lista os arquivos de configuração com os quais o servidor customizado é associado.Incluir
Inclui um arquivo de configuração na tabela.Editar
Edita o arquivo de configuração selecionado.Remover
Remove o arquivo de configuração selecionado da tabela.Campo Argumento de Texto
Especifique o argumento de texto para o critério.Remover
Remove o critério.Incluir Critério
Inclui um critério.
Capítulo 1. Usando 133

Janela Caminho da Procura para Arquivo de CapturaÉ possível incluir um arquivo de configuração em um servidor customizado ou um sistema de computadorna janela Caminho da Procura para Arquivo de Captura.
A janela Caminho da Procura para Arquivo de Captura contém as informações e os botões a seguir:Tipo
Especifique o tipo de arquivo a ser capturado. Os valores válidos são:
• Arquivo de Configuração• Módulo de Software• Diretório/Arquivo do Descritor de Aplicativos
Caminho da ProcuraEspecifique o caminho da procura para o arquivo de captura. Deve-se especificar os detalhes doarquivo em dois campos.
• No primeiro campo, especifique o caminho para o diretório que deseja procurar. Também é possívelselecionar os seguintes valores predefinidos:/
A raiz do sistema de arquivos.$PWD
O diretório de trabalho atual do programa em execução.$HOME
O diretório inicial do ID do usuário do programa em execução.C:
Um diretório em seu computador local.%ProgramFiles%
O diretório de arquivos do programa.%SystemRoot%
O diretório-raiz do sistema.
Nota: O asterisco (*) não é permitido nesse campo.• No segundo campo, especifique algumas informações sobre o arquivo de configuração que você
deseja localizar. É possível digitar o nome do arquivo, a extensão do arquivo, por exemplo, *.txtou um asterisco * para procurar todos os arquivos no diretório especificado.
Capturar conteúdo do arquivoEspecifique se deseja capturar o conteúdo do arquivo de configuração.
Limitar tamanho do arquivo capturado emEspecifique o número máximo de bytes do arquivo de configuração capturado.
Recursar procura de diretórioEspecifique se deseja recursar através da estrutura de diretório, incluindo todos os subdiretórios paraprocurar pelo arquivo de configuração.
Importante: Se desejar capturar o conteúdo do arquivo, antes de selecionar a opção de recursar,certifique-se de que os dados que você deseja capturar não sejam muito grandes. Por exemplo,verifique se os subdiretórios não contêm discos inteiros. Não insira / no primeiro campo e * nosegundo campo Caminho da procura porque isso pode levar a erros de falta de memória e tempolimite. No caso de dados grandes, é possível usar a opção Limitar tamanho do arquivo capturado a.
Nota: No TADDM 7.3.0.2, ou anterior, o nome dessa caixa de seleção é Recursar conteúdo dodiretório.
OKSalva as alterações e fecha a janela.
CancelarDescarta as alterações e fecha a janela.
134 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Área de Janela Sistemas de ComputadorÉ possível gerenciar sistemas de computador usando a área de janela Sistemas de Computador.
A área de janela Sistemas de Computador contém as seguintes informações:Ativado
Especificado se o modelo de sistema de computador estiver ativado durante a descoberta.Ícone
Exibe o ícone que representa o modelo de sistema de computador.Nome
Exibe o nome do modelo de sistema de computador.Tipo
Exibe o tipo do modelo de sistema de computador.Ação
Especifica se o sistema de computador deve ser descoberto ou ignorado.Arquivos de Configuração
Exibe o arquivo de configuração associado ao modelo de sistema de computador.Salvar
Salva a ordem da lista de modelos do sistema de computador.Incluir
Inclui um modelo de sistema de computador.Editar
Edita o modelo de sistema de computador selecionado.Copiar
Copia os detalhes do modelo de sistema de computador selecionado para um novo modelo desistema de computador. Você deverá fornecer o nome do novo modelo de sistema de computador.
ExcluirExclui o modelo de sistema de computador selecionado.
Mover para CimaMove o modelo de sistema de computador selecionado uma posição acima na lista de modelos desistema de computador.
Mover para BaixoMove o modelo de sistema de computador selecionado uma posição abaixo na lista de modelos desistema de computador.
Janela Detalhes do Sistema de ComputadorÉ possível criar, editar ou visualizar um sistema de computador na janela Detalhes do Sistema deComputador.
A janela Detalhes do Sistema de Computador contém as seguintes guias:
• Informações Gerais e Critérios• Arquivos de Configuração
A guia Informações Gerais e Critérios contém as informações e os botões a seguir:
NomeO nome do sistema de computador.
AçãoA ação a executar durante a descoberta:Descobrir
Inclui os sistemas de computador que correspondem ao modelo encontrado durante adescoberta em TADDM e remove o sistema do relatório de servidor desconhecido.
Capítulo 1. Usando 135

IgnorarRemove sistemas de computador que correspondem ao modelo encontrado durante a descobertado relatório de servidor desconhecido.
AtivadoEspecifica se o TADDM age em correspondências com esse modelo de sistema de computadordurante a descoberta. Os valores são: true ou false.
ÍconeO ícone associado ao sistema de computador.
PesquisarSolicita que você selecione uma imagem a ser usada como o ícone para o sistema de computador.
Sistema OperacionalEspecifica se o sistema de computador está executando um sistema operacional.
MIBEspecifica se o sistema de computador é um Management Information Base (MIB).
Identificando CritériosEspecifique como deseja que os conjuntos de condições sejam tratados. Os itens exibidos nestaseção dependem do tipo do sistema de computador.
Se o sistema de computador estiver executando um sistema operacional, será possível especificarapenas um critério, com base no sistema operacional em execução no sistema de computador.
Se o sistema de computador for um MIB, as opções disponíveis serão:
• Todos os Critérios• Qualquer Critério
Lista de CritériosEspecifique o tipo de critério para o conjunto de condições.
Os tipos válidos para um sistema de computador do sistema operacional são:Sistema Operacional
O sistema operacional do sistema de computador.
Os tipos válidos para um sistema de computador MIB são:SysOID
O valor SysOID para o sistema de computador MIB.Descrição de Sys
O valor de descrição Sys para o sistema de computador MIB.
Lista de OperadoresEspecifique o operador para o conjunto de condições.
O tipo válido para um sistema de computador do sistema operacional é:
• é
Os tipos válidos para um sistema de computador MIB são:
• é• não é• contém• não contém• começa com• não começa com• termina com• não termina com• expressão regular
136 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Campo Argumento de TextoEspecifique o argumento de texto para o critério. Esse botão é ativado apenas quando o tipo dosistema de computador for MIB.
Lista de Sistemas OperacionaisEspecifique o sistema operacional do sistema de computador. Essa lista é ativada apenas quando otipo do sistema de computador for sistema operacional. Os valores válidos são:
• Linux• SunOS• AIX• HP-UX• Windows• OpenVMS• Tru64• Darwin
RemoverRemove o critério. Esse botão é ativado apenas quando o tipo do sistema de computador for MIB.
Incluir CritérioInclui um critério na lista de critérios. Esse botão é ativado apenas quando o tipo do sistema decomputador for MIB.
A guia Arquivos de Configuração é ativada apenas quando o tipo do sistema de computador for sistemaoperacional. A guia Arquivos de Configuração contém as informações e os botões a seguir:Nomes de Arquivos
Lista os arquivos de configuração com os quais o sistema de computador está associado.Incluir
Inclui um arquivo de configuração na tabela.Editar
Edita o arquivo de configuração selecionado.Remover
Remove o arquivo de configuração selecionado da tabela.
Área de Janela Âncoras e GatewaysÉ possível especificar informações sobre âncoras e gateways do Windows na área de janela Âncoras eGateways.
A área de janela Âncoras e Gateways contém as informações e os botões a seguir:
TipoO tipo de âncora ou gateway. Os tipos incluem gateway Windows e servidor âncora.
EndereçoO endereço IP da âncora ou host gateway Windows.
PortaA porta usada para comunicação entre o servidor TADDM e os hosts de âncora.
Configuração do EscopoUtilize o escopo de descoberta inteiro ou limite o escopo ao conjunto especificado.
Janela Incluir ÂncoraÉ possível criar, editar ou visualizar uma âncora ou gateway Windows na janela Incluir Âncora.
A janela Incluir Âncora contém as seguintes informações:
TipoExibe o tipo da âncora. Os valores válidos são:
Capítulo 1. Usando 137

• Âncora• Gateway do Windows
Configurar porEspecifique se deseja definir a âncora por endereço IP ou nome do host. Dependendo do valorselecionado, o campo Endereço ou o campo Nome do Host é exibido.
EndereçoEspecifique o endereço IP da âncora.
Nome do HostEspecifique o nome do host da âncora.
Escopo inteiroEspecifica se a âncora pode ser pesquisada em todos os escopos da descoberta.
Limite para conjuntos de escopos selecionadosEspecifica se a âncora pode ser pesquisada apenas em um escopo da descoberta específico. Você ésolicitado a selecionar os conjuntos de escopos de descoberta.
Limite para grupos de escopo selecionadosEspecifica se a âncora pode ser pesquisada apenas em um escopo da descoberta específico. Você ésolicitado a selecionar os grupos de escopos de descoberta.
Área de Janela PlanejamentoÉ possível visualizar informações de planejamento na área de janela Planejamento.
A área de janela Planejamento contém as informações e os botões a seguir:
NomeExibe o nome do planejamento.
Próxima DescobertaExibe quando ocorrerá a próxima descoberta.
Ciclo de RepetiçãoExibe a duração do ciclo de repetição. Os valores válidos são:
• Nenhum• Por Hora• Diariamente• Semanal• Mensal
Perfil UtilizadoO tipo de perfil utilizado pela descoberta. Pode ser uma das opções a seguir:
• Descoberta de Nível 1• Descoberta de Nível 2• Descoberta de Nível 3• Customizada
Janela Planejamento de DescobertaÉ possível usar a janela Planejamento de descoberta para incluir um planejamento de descoberta.
A janela Planejamento de Descoberta contém as informações e os botões a seguir:
A guia Detalhes contém as informações e os botões a seguir:Nome
O nome do planejamento.Hora de Início (hora do servidor)
A hora de início da descoberta.
138 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

RepetirA duração do ciclo de repetição. Os valores válidos são:
• Nenhum• Por Hora• Diariamente• Semanal• Mensal
Ao selecionar um ciclo de repetição, é possível especificar um valor numérico para o ciclo, porexemplo, 3 horas ou 4 dias.
A guia Escopo contém as informações e os botões a seguir:
EscopoO escopo da descoberta. No TADDM 7.3.0.3, e mais recente, é possível escolher as duas opções aseguir:
Conteúdo dinâmico de escopos e grupos selecionadosÉ possível selecionar somente conjuntos de escopos e grupos de escopos. Nesse modo, osconjuntos de escopos e os grupos de escopos são resolvidos para uma lista de elementos poucoantes de uma descoberta. Isso significa que é possível modificar o conteúdo de tais conjuntos deescopos e grupos de escopos e as descobertas de execuções de planejamento definidas com listaatualizada de elementos de escopo. Como resultado, não é necessário modificar umplanejamento sempre que mudar o conteúdo de um conjunto de escopos ou um grupo deescopos.
Elementos selecionados estáticos de escopos e gruposÉ possível selecionar conjuntos de escopos, grupos de escopos e elementos do escopo únicos. Oconteúdo de tal escopo é estático, o que significa que somente os elementos escolhidos sãodescobertos. Se o conjunto de escopos ou o conteúdo do grupo de escopos mudar ao longo dotempo, a descoberta será executada com relação aos elementos que pertenceram ao escopo nomomento da criação do planejamento de descoberta.
PerfilO tipo do perfil de descoberta que a descoberta usa.
Janela Detalhes do planejamentoÉ possível usar a janela Detalhes do planejamento para visualizar os detalhes de um planejamento dedescoberta.
NomeO nome do planejamento.
Hora de Início (hora do servidor)A hora de início da descoberta.
FrequênciaA frequência com que a descoberta é executada.
Nome do PerfilO nome do perfil de descoberta que a descoberta usa.
EscoposO escopo da descoberta planejada.
Nota: No TADDM 7.3.0.3, e mais recente, essas informações são substituídas porConjuntos de escopos e Elementos do escopo.
Configurações do EscopoA lista de conjuntos de escopos e grupos da descoberta planejada. Essas informações estãodisponíveis somente quando você seleciona a opção Conteúdo dinâmico de escopos e gruposselecionados na guia Escopo durante a criação do escopo.
Capítulo 1. Usando 139

Elementos do EscopoA lista de elementos do escopo da descoberta planejada. Essas informações estão disponíveissomente quando você seleciona a opção Elementos estáticos selecionados de escopos e grupos naguia Escopo durante a criação do escopo.
Área de Janela HistóricoÉ possível visualizar o histórico de descoberta na área de janela Histórico.
A área de janela Histórico contém as informações e os botões a seguir:
Hora de InícioA data e a hora em que a descoberta foi iniciada.
Hora de ConclusãoA data e a hora em que a descoberta foi concluída.
Código de ConclusãoO status final da descoberta.
Perfil UtilizadoO tipo de perfil utilizado pela descoberta. Pode ser uma das opções a seguir:
• Descoberta de Nível 1• Descoberta de Nível 2• Descoberta de Nível 3• Customizada
Detalhes do EscopoAtiva a exibição de informações sobre o escopo usado. Quando os detalhes do escopo estiveremativados, as seguintes informações são exibidas:Sensor
Exibe o nome do sensor usado.Nome/IP do Host
Exibe o nome do host ou o endereço IP do destino descoberto.Data
Exibe a hora e a data da descoberta.Status
Exibe o status da descoberta.Descrição
Exibe informações sobre as informações descobertas se a descoberta foi concluída ouinformações de erro se a descoberta encontrou problemas.
InformaçõesExibe informações de visão geral sobre a descoberta, o destino e as informações salvas ou oserros recebidos.
Área de Janela Perfis de DescobertaÉ possível gerenciar informações de perfil de descoberta usando a área de janela Perfis de Descoberta.
A área de janela Perfis de Descoberta contém as seguintes guias:
• Configuração do Sensor• Controle de Acesso• Propriedades da Plataforma
A área de janela Perfis de Descoberta contém as seguintes informações:Nome
O nome do perfil de descoberta.Novo
Inclui um perfil de descoberta.
140 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

SalvarSalva as alterações feitas no perfil de descoberta selecionado.
ExcluirExclui o perfil de descoberta selecionado.
DescriçãoExibe informações de descrição sobre o perfil de descoberta selecionado.
A guia Configuração do Sensor contém as seguintes informações sobre o perfil de descobertaselecionado:Ativado
Exibe se a configuração do sensor está ativada ou desativada.Nome do Sensor
Exibe o nome da configuração do sensor.Tipo
Exibe o tipo da configuração do sensor.Restrições de Escopo
Exibe restrições do escopo associado à configuração do sensor, se houver.Descrição
Exibe uma descrição da configuração do sensor.Configurar
Configura a configuração do sensor selecionada.Novo
Inclui uma configuração do sensor para a tabela Configuração do Sensor.Excluir
Exclui a configuração do sensor selecionada da tabela Configuração do Sensor.Limpar Tudo
Limpa todas as configurações do sensor da tabela Configuração do Sensor.Selecionar Tudo
Seleciona todas as configurações do sensor da tabela Configuração do Sensor.
A guia Controle de Acesso contém as seguintes informações sobre o perfil de descoberta selecionado:
TipoO tipo da entrada da lista de acesso.
NomeO nome da entrada da lista de acesso.
Nome do UsuárioO nome do usuário para efetuar login no componente a ser descoberto.
Restrições de EscopoInformações sobre os conjuntos de escopos e grupos de escopos para os quais o acesso aocomponente está restrito, se aplicado.
NovoInclui detalhes do acesso à lista de acesso.
EditarEdita os detalhes de acesso selecionado.
ExcluirExclui os detalhes de acesso selecionado.
A guia Propriedades da Plataforma contém as seguintes informações sobre o perfil de descobertaselecionado:Incluído
Especifica se o conjunto de propriedades da plataforma deve ser incluído.
Capítulo 1. Usando 141

NomeExibe o nome das propriedades da plataforma.
ValorExibe o comando especificado pelas propriedades da plataforma.
Restrições de EscopoExibe restrições do escopo associadas às propriedades da plataforma, se houver.
EditarEdita as propriedades da plataforma selecionada.
Limpar TudoLimpa todas as propriedades da plataforma.
Selecionar TudoSeleciona todas as propriedades da plataforma.
Janela Criar Novo PerfilÉ possível criar um perfil de descoberta na janela Criar Novo Perfil.
A janela Criar Novo Perfil contém as seguintes informações:
Nome do PerfilDigite o nome do perfil.
DescriçãoDigite uma descrição do perfil.
Clonar Perfil ExistenteSe você desejar criar um novo perfil com base nas propriedades de um perfil existente, poderá clonarum perfil existente. Na lista, selecione o perfil que você deseja clonar.
OKSalva o novo perfil e fecha a janela.
CancelarDescarta as alterações e fecha a janela.
Janela Criar ConfiguraçãoÉ possível criar uma configuração do sensor na janela Criar Configuração.
A janela Criar Configuração contém as seguintes informações:
NomeDigite o nome da configuração do sensor.
DescriçãoDigite uma descrição da configuração do sensor.
TipoExibe o tipo da configuração do sensor.
Ativar ConfiguraçãoEspecifica se a configuração do sensor está ativada para uso.
Executar Descoberta Baseada em ScriptEspecifica se a descoberta baseada em script é executada.
Tabela de ConfiguraçãoAs seguintes informações sobre propriedades de configuração são listadas:
• Nome• Valor
Sem RestriçõesEspecifica que nenhuma restrição de escopo se aplica a esta configuração do sensor.
142 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Incluir RestriçõesEspecifica que as restrições de escopo se aplicam a esta configuração do sensor. Você será solicitadoa selecionar o escopo que deseja aplicar a esta configuração do sensor.
OKSalva as informações de configuração do sensor e fecha a janela.
CancelarDescarta as informações de configuração do sensor e fecha a janela.
Janela Editar Propriedades da PlataformaÉ possível editar uma propriedade da plataforma na janela Editar Propriedades da Plataforma.
Se você alterar o valor de uma propriedade desta janela, deverá marcar também a caixa de seleçãoIncluído para salvar esse valor. Por exemplo, se você alterar o valor da propriedadecom.ibm.cdb.discover.PreferScriptDiscovery para true, o valor de true não será salvo, amenos que você marque também a caixa de seleção Incluído para a propriedade.
A janela Editar Propriedades da Plataforma contém as seguintes informações:
Nome da PropriedadeDigite o comando usado pela propriedade da plataforma.
Sem RestriçõesEspecifica que nenhuma restrição de escopo se aplica a esta propriedade da plataforma.
Incluir RestriçõesEspecifica que restrições de escopo se aplicam a esta propriedade da plataforma. Você serásolicitado a selecionar o escopo que deseja aplicar a esta propriedade da plataforma.
Janelas e Controles do Portal de Gerenciamento de DadosO Portal de Gerenciamento de Dados exibe informações a partir de um servidor de armazenamento.
Item de Menu Alterar SenhaÉ possível alterar a senha no Portal de Gerenciamento de Dados.
Para alterar a senha, clique em Arquivo > Alterar Senha. Digite sua senha atual e, em seguida, digite econfirme sua nova senha.
Sua nova senha se tornará ativa na próxima vez em que você efetuar logon no Portal de Gerenciamentode Dados.
Área de janela de detalhesA área de janela Detalhes exibe informações detalhadas sobre um objeto selecionado.
É possível exportar as informações da área de janela de detalhes, clicando no ícone Exportar Detalhes. Épossível exportar essas informações em XML, arquivo PDF ou formato CSV. Alternativamente, clique emArquivo > Exportar Detalhes no menu.
Nota: O ícone para alguns servidores customizados pode não ser exibido na área de janela Detalhes.
Área de Janela Componentes DescobertosDepois de executar uma descoberta, é possível usar a área de janela Componentes Descobertos paravisualizar uma lista de componentes descobertos e ativar visualizações com informações maisdetalhadas sobre os componentes.
Usando a área de janela Componentes Descobertos, é possível executar as seguintes tarefas:
• Localizar um item de configuração (CI) navegando para ele por meio do link Resumo do Inventário oudo link Consulta Customizada.
• Localizar um CI digitando o nome todo ou parte do nome no campo Filtro. Os CIs, dentro da categoriaatual, que contêm o texto filtrado são exibidos. Não é possível usar símbolos de caracteres curingacomo parte do texto de filtro.
Capítulo 1. Usando 143

• A página avança ou retrocede por meio da lista de CIs exibidos. Também é possível especificar onúmero de uma página específica para exibir e configurar o número de CIs a serem exibidos em cadapágina.
• Clique no nome de um CI para exibir informações sobre ele na área de janela Detalhes.• Marque a caixa de seleção ao lado do nome do CI para selecioná-lo. É possível selecionar um ou mais
CIs por vez.• Selecione uma ação na lista Ações para executar uma ação em um ou mais CIs selecionados.• Clique em Carrinho de Compras para incluir os CIs selecionados no carrinho de compras. Adicionando
CIs ao carrinho de compras, você pode executar ações em diversos CIs se eles existirem na hierarquiado Resumo de Inventário ou estiverem na lista Consulta Customizada.
• Remova um ou todos os CIs do carrinho de compras.• Mostre os componentes dependentes, o tipo de componentes contidos no relacionamento dependente
e veja como os componentes foram criados.
Nota: O ícone para alguns servidores customizados pode não ser exibido na área de janela ComponentesDescobertos.
A área de janela Componentes Descobertos contém as seguintes informações:Carrinho de Compras
Exibe o conteúdo do carrinho de compras. Se o conteúdo do carrinho de compras estiver sendoexibido atualmente, ele retorna à visualização do componente descoberto.
AçõesSe um ou mais CIs estiverem selecionados ou o carrinho de compras não estiver vazio, a lista conteráações válidas. As ações exibidas dependem do número e do tipo de CI selecionado ou contido nocarrinho de compras. Algumas das seguintes ações são exibidas:Incluir no carrinho de compras
Inclui o CI ou os CIs selecionados no carrinho de compras.Histórico de Mudanças
Exibe uma área de janela para gerar um relatório do Histórico de Mudanças. Um relatório doHistórico de Mudanças identifica alterações nos componentes durante um período de tempoespecificado.
Comparar Entre VersõesExibe uma área de janela em que é possível gerar um relatório que compare o componenteselecionado com versões anteriores do mesmo componente.
Comparar ComponentesExibe uma área de janela em que é possível comparar os componentes selecionados com outroscomponentes semelhantes.
ExcluirExclui o CI ou os CIs selecionados.
EditarExibe a janela Editar Componente.
Esvaziar carrinhoEsvazia o carrinho de compras.
ExplorarExibe, usando o assistente de topologia centralizada do nó, um gráfico detalhando asdependências entre os CIs.
MesclarMescla os CIs selecionados.
RedescobrirRedescobre o CI ou os CIs selecionados.
Remover do carrinho de comprasRemove o CI ou os CIs selecionados do carrinho de compras.
144 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Mostrar DependênciasExibe a janela Dependências.
Mostrar DetalhesExibe informações detalhadas sobre o componente selecionado na área de janela Detalhes.
Mostrar Resumo de InventárioExibe o resumo do inventário para aplicativos de negócios ou coleções selecionados.
Mostrar Topologia de Conexão de SistemaExibe um relatório gráfico de qualquer sistema de computador conectado diretamente.
Mostrar TopologiaExibe o gráfico de topologia.
Mostrar Topologia ci_typeExibe uma topologia especializada para um tipo de IC específico.
Servidores DesconhecidosExibe uma área de janela em que é possível visualizar os servidores desconhecidos em execuçãono sistema de computador. É possível definir um servidor customizado com base em um servidordesconhecido para que ele possa ser descoberto.
Consultas CustomizadasContém consultas customizadas salvas. É possível selecionar um ou mais CIs retornados por umaconsulta customizada.
Resumo de InventárioContém CIs, agrupados nas seguintes categorias:
• Servidores de Aplicativos• Clusters• Composições• Sistemas do Computador• Servidores Customizados• Servidores de Banco de Dados• Servidores de Sistemas de Mensagens• Elementos de Rede• Outros Servidores• Serviços• Armazenamento• IPs Desconhecidos• Servidores da Web
Nota: Com a segurança em nível de dados ativada, quando você tiver acesso restrito a ICs, na área dejanela Componentes Descobertos é possível ver apenas os ICs aos quais você tem acesso, incluindoaplicativos de negócios e coleções.
Exibe a primeira página.
Exibe a página anterior.Campo Número da Página
É possível inserir o número da página que você deseja exibir.
Exibe a página seguinte.
Capítulo 1. Usando 145

Exibe a última página.
Exibe a janela "Alterar o Tamanho da Página" na qual você pode selecionar o número de CIs a seremexibidos em cada página.
Área de Janela Servidores DesconhecidosDepois de executar uma descoberta, é possível usar a área de janela Servidores Desconhecidos paravisualizar uma lista de servidores desconhecidos em execução em um sistema de computador e definirum servidor customizado com base em um servidor desconhecido.
Os servidores desconhecidos são identificados após uma descoberta por um agente de construção detopologia. O agente de construção de topologia é executado em segundo plano periodicamente,dependendo do valor da frequência configurada, portanto os servidores desconhecidos podem não serreconhecidos imediatamente após a conclusão de uma descoberta. A cada quatro horas é a frequênciapadrão na qual o agente de construção de topologia é executado.
Por essa razão, se você estiver executando o Relatório de Servidores Desconhecidos antes de o agente deconstrução da topologia ser concluído, o relatório poderá não listar todos os servidores desconhecidos.
A área de janela Servidores Desconhecidos contém as seguintes informações:Detalhes
Exibe os detalhes do servidor desconhecido selecionado.Criar Servidor Customizado
Cria um servidor customizado com base no servidor desconhecido selecionado.Excluir
Exclui o servidor desconhecido selecionado.Comando
O nome do programa executável.Argumentos
Os argumentos transmitidos ao programa.Portas
O número da porta TCP na qual o processo está atendendo.Nome do Serviço
O nome de um serviço do sistema operacional Windows.
Janela Mesclar ComponenteDepois de executar uma descoberta, é possível usar a janela Mesclar Componente para combinar dois oumais itens de configuração (CIs) em um.
A janela Mesclar Componente contém as seguintes informações:CI Durável
Exibe o nome do CI que é retido no final da operação de mesclagem.CI(s) Temporário(s)
Exibe o nome de CIs que são excluídos no final da operação de mesclagem.Mover para Cima
Eleva a prioridade do CI selecionado.Mover para Baixo
Reduz a prioridade do CI selecionado.Marcar como Durável
Define o CI selecionado como o CI durável.Nome de Exibição
Lista os CIs temporários selecionados para a operação de mesclagem.
146 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Janela DependênciasÉ possível usar a janela Dependências para criar ou excluir um componente dependente.
A janela Dependências contém as seguintes informações:Novo
Exibe a janela Incluir Dependência.Excluir
Exclui o componente dependente selecionado.Dependente
Exibe o nome dos outros componentes no relacionamento de dependência.Tipo
Exibe o tipo dos outros componentes no relacionamento de dependência.Criado Por
Exibe como a dependência foi criada de forma incluída ou descoberta manualmente.
Janela Incluir DependênciaÉ possível usar a janela Incluir Dependência para criar um relacionamento de dependência.
Selecione o componente para o qual você deseja criar um relacionamento na área de janelaComponentes Descobertos e, em seguida, selecione o componente de destino na janela IncluirDependências. Existem dois tipos de relacionamentos, provedor ou relacionamento dependente.
A janela Incluir Dependências contém as seguintes informações:
ProvedorClique em Provedor e selecione um componente de destino na lista. O componente inicialselecionado na área de janela Componentes Descobertos agora é um provedor para o componente dedestino selecionado.
DependenteClique em Dependente e selecione um componente de destino na lista. O componente inicialselecionado na área de janela Componentes Descobertos agora é dependente do componente dedestino selecionado.
A lista a seguir mostra o tipo de dependências que é possível ter entre os componentes:
• AppServer -> AppServer• AppServer -> AppServerCluster• AppServer -> Service• AppServer -> ComputerSystem• ComputerSystem -> AppServer• ComputerSystem -> AppServerCluster
DescobertaÉ possível exibir informações de resumo do domínio para todos os domínios em seu ambiente clicandonos itens listados em Descoberta na área de janela Funções.
É possível exibir os seguintes tipos de informações de descoberta:
• Informações de escopo• Informações do servidor customizado• Informações da entidade de negócios
Área de Janela EscopoÉ possível gerenciar informações de escopo para os domínios em seu ambiente ao configurar conjuntosde escopos.
Nota: Para configurar grupos de escopos, consulte “Área de Janela Escopo” na página 125 no Console deGerenciamento da Descoberta.
Capítulo 1. Usando 147

A área de janela Escopo contém as seguintes informações:
Novo conjunto de escoposCria um conjunto de escopos e o inclui na lista de conjuntos de escopos.
Excluir conjunto de escoposExclui um conjunto de escopos e o remove da lista de conjuntos de escopos.
Conjuntos de escoposUma coleta lógica de nomes do host, endereços IP, intervalos de endereços IP ou sub-redes.
NovoCria um escopo e o inclui na tabela.
EditarEdita os atributos de um escopo.
ExcluirExclui um escopo e o remove da tabela.
MétodoEspecifica se inclui ou exclui o endereço IP, o intervalo de endereços IP ou a sub-rede.
TipoO tipo de endereço especificado, que inclui os seguintes valores:
• Sub-rede - uma sub-rede IP, como 255.255.255.0• Intervalo - intervalo do endereço IP, como 1.2.3.4 - 1.2.3.10• Endereço - endereço IP, como 1.2.3.4
ValorO endereço IP, o intervalo de endereços IP ou a sub-rede reais.
Descrição/nome do hostUma descrição fornecida pelo usuário do escopo de descoberta.
Área de Janela Servidores CustomizadosÉ possível gerenciar informações do servidor customizado para os domínios em seu ambiente.
Nota: O ícone para alguns servidores customizados pode não ser exibido na área de janela ServidoresCustomizados.
A área de janela Servidor Customizado contém as seguintes informações:
NovoCria um servidor customizado e o inclui na lista de servidores customizados.
EditarEdita os atributos de um servidor customizado.
CopiarCria um servidor customizado com base em um já existente.
ExcluirExclui um servidor customizado da lista de servidores customizados.
MoverAltera a ordem na qual os servidores customizados são listados.
#Exibe o número de um servidor customizado.
AtivadoExibe se um servidor customizado está ativo ou não.
NomeExibe o nome de um servidor customizado.
148 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

TipoExibe o tipo de um servidor customizado.
AçãoExibe se as instâncias de um servidor são descobertas ou ignoradas.
Arquivo de ConfiguraçãoExibe os arquivos de configuração associados, se houver.
Janela Detalhes do Servidor CustomizadoÉ possível usar a janela Detalhes do Servidor Customizado para criar ou editar um servidor customizadousando o Portal de Gerenciamento de Dados.
A área de janela Detalhes do Servidor Customizado contém as seguintes guias:
• Informações Gerais e Critérios• Arquivos de Configuração
A guia Informações Gerais e Critérios da área de janela Detalhes do Servidor Customizado contém asseguintes seções:
• Informações Gerais sobre o Servidor• Identificando Critérios
A seção Informações Gerais sobre o Servidor contém as informações e os botões a seguir:
AtivadoSe selecionado, especifica que o servidor customizado está ativado.
ÍconeExibe um ícone para o servidor customizado.
PesquisarExibe as imagens disponíveis que podem ser usadas como um ícone para o servidor customizado.
NomeExibe o nome do servidor customizado.
TipoExibe o tipo do servidor customizado.
AçãoEspecifica se o servidor customizado deve ser descoberto ou ignorado por descobertas.
A seção Identificando Critérios contém as informações e os botões a seguir:
Executar a ação quandoEspecifique como deseja que os conjuntos de condições sejam tratados. As opções disponíveis são:
• Todas as seguintes condições forem atendidas (lógica AND)• Qualquer uma das seguintes condições for atendida (lógica OR)
Lista de Tipos de CritériosEspecifique o tipo de critério para o conjunto de condições. Os tipos válidos são:Nome do programa
O nome do programa executável.Nome do serviço do Windows
O nome de um serviço do sistema operacional Windows.Argumento
Os argumentos transmitidos ao programa.Ambiente
As variáveis de ambiente configuradas para o programa.Porta
O número da porta TCP na qual o processo está atendendo.
Capítulo 1. Usando 149

Lista de OperadoresEspecifique o operador para o conjunto de condições. Os operadores válidos são:
• é• não é• contém• não contém• começa com• não começa com• termina com• não termina com• expressão regular
Campo Argumento de TextoEspecifique o argumento de texto para o conjunto de condições.
+Inclui um conjunto de condições.
-Remove o conjunto de condições.
A guia Arquivos de Configuração da área de janela Detalhes do Servidor Customizado contém asinformações e os botões a seguir:Novo
Inclui um arquivo de configuração.Editar
Edita o arquivo de configuração selecionado.Copiar
Copia o arquivo de configuração selecionado.Excluir
Exclui o arquivo de configuração selecionado.Tipo
Exibe o tipo de arquivo de configuração.Caminho da Procura
Exibe o caminho da procura do arquivo de configuração.Nome do Arquivo
Exibe o nome do arquivo de configuração.OK
Salva as alterações e fecha a janela.Cancelar
Descarta as alterações e fecha a janela.
Janela Caminho da Procura para Arquivo de CapturaÉ possível usar a janela Caminho da Procura para Arquivo de Captura para especificar um caminho deprocura para um arquivo de captura usando o Portal de Gerenciamento de Dados.
A janela Caminho da Procura para Arquivo de Captura contém as informações e os botões a seguir:Tipo
Especifique o tipo de arquivo a ser capturado. Os valores válidos são:
• Arquivo de Configuração• Módulo de Software• Diretório/Arquivo do Descritor de Aplicativos
150 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Caminho da ProcuraEspecifique o caminho da procura para o arquivo de captura. Os valores válidos são:/
A raiz do sistema de arquivos.$PWD
O diretório de trabalho atual do programa em execução.$HOME
O diretório inicial do ID do usuário do programa em execução.C:
Um diretório em seu computador local.%ProgramFiles%
O diretório de arquivos do programa.%SystemRoot%
O diretório-raiz do sistema.Nome do Arquivo
Especifique o caminho e o nome do arquivo de captura na caixa de texto ou digite * (asterisco) paraespecificar todos os arquivos no diretório selecionado.
Capturar conteúdo do arquivoEspecifique se deseja capturar o conteúdo do arquivo de configuração.
Limitar tamanho do arquivo capturado emEspecifique o número máximo de bytes do arquivo de configuração capturado.
Recursar procura de diretórioEspecifique se deseja recursar através da estrutura de diretório, incluindo todos os subdiretórios paraprocurar pelo arquivo.
Nota: No TADDM 7.3.0.2, ou anterior, o nome da caixa de seleção é Recursar conteúdo do diretório.
OKSalva as alterações e fecha a janela.
CancelarDescarta as alterações e fecha a janela.
Janela Mover Antes/ApósÉ possível usar a janela Mover Antes/Após para alterar a ordem na qual os servidores customizados sãolistados na área de janela Servidores Customizados do Portal de Gerenciamento de Dados.
A janela Mover Antes/Após contém as informações e os botões a seguir:Mover
Especifique se o servidor customizado a ser movido deve ser movido antes ou após o servidorcustomizado selecionado.
Tabela de Servidor CustomizadoLista os servidores customizados em ordem decrescente.
#Exibe a posição do servidor customizado.
NomeExibe o nome do servidor customizado.
OKSalva as alterações e fecha a janela.
CancelarDescarta as alterações e fecha a janela.
Área de janela Padrões de AgrupamentoÉ possível criar padrões de agrupamento e visualizar informações sobre os padrões em seu ambiente.
Capítulo 1. Usando 151

Esta área de janela foi movida para a seção Analytics do Portal de Gerenciamento de Dados noTADDM 7.3.0.2. Para ver o conteúdo da área de janela Padrões de Agrupamento, consulte “Área de janelaPadrões de Agrupamento” na página 164.
Área de Janela Status dos Grupos de Agentes de TopologiaÉ possível usar a área de janela Status dos Grupos de Agentes de Topologia para assegurar que osdados provenientes da descoberta mais recente estejam prontos e tenham sido processados por todos osagentes de topologia apropriados.
Os agentes de topologia, que estão reunidos em grupos, são executados em intervalos especificados.Após a conclusão de uma descoberta, você deve aguardar os agentes serem concluídos para assegurarque todos os dados tenham sido processados. Esse processamento inclui a limpeza de objetos de bancode dados não reconciliados e relacionamentos de topologia incompletos.
As informações na área de janela Status dos Grupos de Agentes de Topologia são reconfiguradasquando o TADDM é reiniciado.
Cada grupo inclui um conjunto diferente de agentes de topologia. Os seguintes grupos estão definidos noTADDM por padrão:
DescobertaA frequência de execução do grupo de descoberta não está definida. O grupo inclui os seguintesagentes de topologia:
• CustomAppServerTopoAgent
O grupo de descoberta é definido pela seguinte entrada no arquivo collation.properties:
com.ibm.cdb.topobuilder.groupinterval.discovery=
Nota: O valor padrão em horas está vazio, impedindo o agente de executar.
Segundo PlanoO grupo de segundo plano é executado a cada quatro horas. O grupo inclui os seguintes agentes detopologia:
• DatabaseServerCleanupAgent• HostDependencyAgent• L2Agent• RuntimeCleanupAgent
O grupo de segundo plano é definido pela entrada a seguir no arquivo collation.properties:
com.ibm.cdb.topobuilder.groupinterval.background=4.0
LimpezaO grupo inclui os seguintes agentes de topologia:
• ObjectsWithoutAliasesCleanupAgent• PersobjCleanupAgent• AliasesCleanupAgent
As propriedades para este grupo são descritas no tópico Propriedades de agentes de limpeza no Guiado Administrador do TADDM.
O grupo de limpeza é definido pela seguinte entrada no arquivo collation.properties:
com.ibm.cdb.topobuilder.groupinterval.cleanup=4.0
DependênciaO grupo de dependência é executado a cada 30 minutos. Os grupos incluem os seguintes agentes detopologia:
152 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

• AppDefinitionAgent• AppDescriptorAgent• AppServerClusterAgent• AppTemplateAgent• CDPAgent• CitrixAgent• CMClusterDependencyAgent• CMSDISAgent• CompositeCreationAgent• ComputerSystemConsolidationAgent• ComputerSystemTypeAgent• ConnectionDependencyAgent2• DerivedAppToAppDependencyAgent• DerivedSwitchToDeviceDependencyAgent• DiscoveryLogCleanupAgent• DNSDependencyAgent• DNSServiceAgent• DominoClusterDomainAgent• DominoConnectionAgent• ExchangeDependencyAgent• ExchangeServer2007Agent• GenericAppAgent• HACMPDependencyAgent• HISAgent• HostStorageConnectionAgent• IpNetworkAssignmentAgent• J2EEServerDeploymentAgent• JBossClusterAgent• JDBCDependencyAgent• LDAPServiceAgent• MQServerAgent• MSClusterAgent• NFSDependencyAgent• ObjectDisplayNameAgent• OracleAppClusterAgent• OracleDependencyAgent• PortAppScanConsolidationAgent• SAPDependencyAgent• SoftwareHostReferenceAgent• VCSDependencyAgent• VmwareVirtualCSConsolidationAgent• WebConnectionDependencyAgent• WeblogicClusterAgent
Capítulo 1. Usando 153

• WebLogicServerDeploymentAgent• WebSphereConnectionDependencyAgent
O grupo de dependência é definido pela seguinte entrada no arquivo collation.properties:
com.ibm.cdb.topobuilder.groupinterval.dependency=0.5
On DemandO grupo On Demand resulta da criação de um aplicativo de negócios.
O grupo OnDemand é definido pela seguinte entrada no arquivo collation.properties:
com.ibm.cdb.topobuilder.groupinterval.bizapps=4.0
A área de janela Status dos Grupos de Agentes de Topologia contém as seguintes informações:
IntegraçãoO grupo de integração executa a cada seis horas. O grupo inclui OSLCAgent que integra TADDM aoServiços de Registro que é construído mediante especificação OSLC. Ele também incluiOSLCAutomationAgent, que se conecta aos Provedores de Serviço de Automação de Execução OSLCpara fazer download e criar conjuntos de escopos com endereços IP de terminais de outros produtos.
O intervalo de tempo entre as execuções é especificado na entrada a seguir no arquivocollation.properties:
com.ibm.cdb.topobuilder.groupinterval.integration=6.0
AtualizarAtualiza as informações na área de janela Status dos Grupos de Agentes de Topologia.
Nome do GrupoExibe o nome do grupo de agentes de topologia.
Última ConclusãoExibe o horário da última conclusão.
ConcluídoExibe se o grupo de agentes de topologia concluiu a execução. Um ícone com marcação verde éexibido para um grupo de agentes de topologia que foi concluído. Nenhum ícone é exibido se umgrupo de agentes de topologia estiver em execução ou não tiver sido iniciado desde o início maisrecente do TADDM.
TopologiaDepois de executar uma descoberta para capturar informações sobre sua infraestrutura, é possível usar oPortal de Gerenciamento de Dados para visualizar informações de topologia gráfica para todos osdomínios em seu ambiente ao clicar nos itens que são listados sob Topologia na área de janela Funçõesno Portal de Gerenciamento de Dados.
A topologia utiliza objetos gráficos para representar cada componente dentro de uma categoria e linhaspara representar os relacionamentos entre componentes. São utilizados ícones para representarcomponentes.
Os elementos que são conectados com o IC (item de configuração) que você clicou por último sãodestacados em verde.
A tabela a seguir lista e descreve os ícones da ferramenta da barra de ferramentas para visualizações detopologia:
Tabela 20. Ícones da ferramenta da barra de ferramentas de topologia
Ícone de ferramentas Descrição
Visualizar um componente individual dentro do gráfico de topologia.
154 Gerenciador de Descoberta de Dependência de Aplicativo: Usando
Tabela 20. Ícones da ferramenta da barra de ferramentas de topologia (continuação)
Ícone de ferramentas Descrição
Selecione um grupo de componentes clicando e arrastando o retângulo deseleção.
Panoramizar o gráfico de topologia. Após clicar no ícone de panoramização,use o cursor para arrastar a visualização para rolar ao redor do gráfico detopologia quando o zoom é usado.
Aumentar zoom em uma seção retangular da topologia. Após clicar nozoom no ícone de retângulo, utilize o cursor para desenhar um retângulo nográfico para selecionar a região de zoom.
Aumentar zoom na topologia.
Diminuir zoom da topologia.
Ajustar a topologia inteira dentro da área de trabalho. Esta ferramenta é útilpara visualizar todos os componentes sem ter que rolar.
Mostrar/ocultar a visão geral da topologia. A visão geral da topologia é umacópia escalada de todo o gráfico de topologia. A parte do gráfico detopologia que está sendo visualizada atualmente é marcada com umretângulo na visão geral da topologia.
Mostrar alterações. Esse botão é usado para destacar os componentes queforam alterados. É possível usar a janela Destacar mudanças para definir operíodo de tempo que deseja usar para verificar se há mudanças.
Exporte a topologia para um arquivo de imagem.
Destaque o CoreCI. Esse botão é usado para destacar um ou mais ICsprincipais.
Customize o filtro para CustomCollections (ou seja, Aplicativos deNegócios, Coleções de Acesso e Coleções).
Janela Aplicativos de NegóciosÉ possível visualizar gráficos de topologia de aplicativos de negócios na janela Infraestrutura física noPortal de Gerenciamento de Dados.
Para ver um menu de ações disponíveis para um objeto da topologia, selecione e clique com o botãodireito do mouse no objeto.
A tabela a seguir descreve as ações disponíveis para aplicativos de negócios.
Tabela 21. Itens de Menu Pop-up dos Aplicativos de Negócios
Item de menu Descrição
Incluir no carrinho de compras Inclui o componente selecionado no carrinho de compras.
Mostrar Detalhes Exibe informações detalhadas sobre o componente selecionado naárea de janela Detalhes.
Mostrar Topologia Exibe a topologia para o aplicativo de negócios.
Editar Exibe a janela Editar Componente.
Excluir Exclui o componente selecionado.
Redescobrir Redescobre o componente selecionado.
Capítulo 1. Usando 155
Tabela 21. Itens de Menu Pop-up dos Aplicativos de Negócios (continuação)
Item de menu Descrição
Comparar Entre Versões Exibe uma área de janela em que é possível gerar um relatório quecompare o componente selecionado com versões anteriores domesmo componente.
Explorar Ativa o assistente de topologia centralizada do nó, que pode serusado para criar um gráfico de topologia centralizada do nó.
Histórico de Mudanças Exibe uma área de janela para gerar um relatório do Histórico deMudanças. Um relatório do Histórico de Mudanças identificaalterações para componentes durante um período de tempoespecificado.
Comparar Componentes Exibe uma área de janela em que é possível comparar oscomponentes selecionados com outros componentessemelhantes.
Filtro Exibe a área de Filtro, na qual você pode selecionar filtrar tipos deelementos.
Área de janela de detalhes do Caminho do Aplicativo de NegóciosÉ possível visualizar a área de janela de detalhes do Caminho do Aplicativo de Negócios na topologia doaplicativo de negócios.
Para abrir a área de janela de detalhes do Caminho do Aplicativo de Negócios, no gráfico, clique com obotão direito em uma borda do caminho e escolha a opção Mostrar Detalhes.
A guia Rotas contém informações detalhadas sobre as rotas. Cada caminho tem pelo menos uma rota.Rotas podem conter um ou mais segmentos. Os detalhes sobre cada segmento de uma rota são exibidosem tabelas separadas, que contêm os elementos a seguir:
Tabela 22. Detalhes da guia Rotas.
Item Descrição
Objeto de Origem O objeto de origem do relacionamento oudependência.
Relacionamento e Dependência O tipo de uma conexão entre os nós. Orelacionamento é um tipo básico de uma conexãoque resulta da estrutura de modelo de DadosComuns. A dependência representa uma família dedependências que podem ser customizadas e queexistem como elementos de banco de dadosseparados. Também é possível definir suaspróprias dependências, consulte “Definindomanualmente dependências entre itens deconfiguração” na página 95.
Objeto de Destino O objeto de destino do relacionamento oudependência.
Direção da passagem A direção da passagem de um determinadorelacionamento ou dependência. Para obterdetalhes, consulte “Atravessando relações duranteo processamento padrão” na página 229.
Referências relacionadas“Estrutura do aplicativo de negócios” na página 192
156 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

A estrutura do aplicativo de negócios é criada automaticamente, com base em uma definição de padrãode agrupamento e nas definições de seletores de padrão de agrupamento.
Janela Exportar TopologiaÉ possível exportar a topologia exibida atualmente para um arquivo de imagem.
A janela Exportar Topologia exibe as seguintes informações:
Tipo de ArquivoO tipo de arquivo para o qual exportar a topologia. As seguintes opções estão disponíveis:
• Portable Network Graphics (*.png)• Scalable Vector Graphics (*.svg)• Formato JPEG (*.jpg)
AlturaA altura da imagem exportada.
LarguraA largura da imagem exportada.
ExportarExporta a topologia para um arquivo de imagem.
CancelarCancela a exportação da topologia.
Filtrando uma topologiaÉ possível incluir um filtro para o gráfico de topologia exibido de uma CustomCollection, ou seja, paraAplicativos de Negócios, Coletas de Acesso e Coleções. É possível filtrar (ocultar) um único ou diversosnós em um gráfico de topologia ou cada nó de um tipo selecionado.
Sobre Esta Tarefa
Restrição: Um filtro permanece selecionado (ou desmarcado) durante uma sessão, o que significa queele não é aplicado durante a inicialização nem é salvo de uma sessão para outra.
Dica: Quando um gráfico de topologia exibe nós conectados que possuem nós ocultos (filtrados) entreeles, a conexão entre os nós é uma linha tracejada.
Procedimento
Para filtrar um gráfico de topologia usando a opção barra de ferramentas da topologia, conclua as etapasa seguir no Portal de Gerenciamento de Dados:1. Na área de janela Funções, clique em Topologia.2. Clique em Aplicativos de Negócios.
Uma topologia de visão geral para o item é exibida. Se a topologia exibida não for umaCustomCollection, o botão de filtro será desativado.
3. Clique em Filtrar na barra de ferramentas da topologia.A janela Filtrar é exibida com todos os filtros disponíveis selecionados.
4. Assegure-se de que o tipo de filtro ou sub-filtro que deseja aplicar seja selecionado.
Importante: As opções de filtro são agrupadas por tipo. Selecionar uma opção de filtro, por exemplo'Db2 Database', exclui todos os nós de topologia individuais desse tipo.
5. Clique em OK para visualizar a topologia filtrada.Para filtrar um gráfico de topologia usando o menu de contexto:6. Ao visualizar o gráfico de topologia CustomCollection, selecione um nó ou um número de nós a serem
filtrados e clique com o botão direito do mouse.O menu de Contexto é exibido.
7. Selecione Ocultar nós ou Ocultar tipos.
Capítulo 1. Usando 157

Isso oculta o nó ou nós selecionados, ou o grupo inteiro de nós do mesmo tipo.Para exibir um gráfico de topologia inteiro e não filtrado:8. Ao visualizar o gráfico de topologia CustomCollection, desative o Filtro.
AnalíticaÉ possível executar analítica e gerar relatórios clicando nos itens listados em Analítica na área de janelaFunções do Portal de Gerenciamento de Dados.
É possível desempenhar as seguintes tarefas, utilizando as funções de analítica e de geração derelatórios:
• Executar consultas• Exibir informações sobre o inventário, aplicativos, histórico de mudanças e serviços• Gerar relatórios customizados e interativos
Área de Janela Comparação de ComponentesÉ possível executar um relatório Comparação de Componentes para reunir informações sobre oscomponentes em seu domínio.
A área de janela Comparação de Componentes contém as seguintes seções:
ComponentesEsta seção contém informações sobre o componente no qual você deseja executar a comparação decomponentes.
OpçõesEsta seção contém informações sobre o tipo de comparação que você deseja executar.
A seção Componentes contém as seguintes informações e botões:
VersãoA versão da descoberta.
DisponívelA lista de componentes em seu ambiente. É possível filtrar os componentes da lista com base notexto digitado no campo Filtrar. É possível percorrer a lista de componentes usando os botões depágina seguinte e página anterior.
IncluídoComponentes que você deseja que sejam incluídos no relatório de comparação.
IncluirMove os componentes selecionados da lista Disponível para a lista Incluído.
RemoverMove os componentes selecionados da lista Incluído para a lista Disponível.
Configurar como ChaveDefine o componente selecionado da lista Incluído como a chave com a qual comparar todos osoutros componentes.
A seção Opções contém as seguintes informações e seleções de botões:
NívelO nível do relatório de comparação de componentes gerado, entre os seguintes níveis:Básico
Selecione esta opção para informações gerais de configuração, como configurações de número daporta ou diretórios.
ProfundoSelecione esta opção para obter informações adicionais sobre módulos instalados em servidoresApache e objetos de aplicativos implementados (como EJBs) e recursos (como JDBC e JMS) emservidores WebLogic.
158 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Incluir Serviços de InfraestruturaOs componentes de infraestrutura são configurados para se comunicarem com vários serviços, comoum serviço DNS ou um serviço do sistema de arquivos NFS. Selecionar Incluir Serviços ao compararcomponentes do banco de dados, por exemplo, faz com que o TADDM encontre todas as diferençasnas dependências de serviço entre os componentes que são comparados.
Esta opção está desligada por padrão. Ela está indisponível em casos em que o componente inicialselecionado é um sistema do computador.
Incluir SistemaSelecionar Incluir Sistema compara os sistemas físicos nos quais o software reside, além decomparar o software do servidor. Selecionar Incluir Sistema ao comparar um banco de dados, porexemplo, faz com que o TADDM compare o banco de dados e o sistema de computador no qual obanco de dados está em execução. Ao incluir sistemas na comparação de componentes, os sistemasdevem ter o mesmo tipo. Se os sistemas tiverem tipos diferentes (por exemplo, Windows e AIX), elesnão poderão ser incluídos na comparação.
Esta opção está desligada por padrão. Ela está indisponível em casos em que o componente inicialselecionado é um sistema do computador.
Executar RelatórioCria o relatório Comparação de Componentes.
Área de Janela Comparação de Componentes: ResultadosA área de janela Comparação de Componentes: Resultados contém uma comparação dos atributos deconfiguração de dois ou mais componentes.
A área de janela Comparação de Componentes: Resultados contém as seguintes seções:
Entidades de ConfiguraçãoUma lista hierárquica de todos os atributos de configuração comuns dos componentes incluídos nacomparação.
ComponentesDois ou mais componentes, apresentados um por coluna, detalhando as informações de configuraçãoe de parâmetro. Você pode varrer os resultados para executar uma comparação rápida. A segundacoluna contém os valores do componente chave, com valores chave realçados na cor dourada. Orestante das colunas representa os demais componentes que participam da comparação.
Cada linha representa um atributo de configuração para um determinado tipo de componente. O valordo componente chave para um atributo é examinado e é comparado com os outros valores docomponente e criará uma linha se alguma diferença for localizada ao se utilizar as seguintesconvenções:
• Os valores que são diferentes da chave são realçados na cor vermelha.• Quando um valor é o mesmo que o valor chave, a célula é deixada em branco.• Quando todos os componentes correspondem ao valor chave, a linha não é exibida. Uma linha é
criada apenas quando uma diferença é localizada.• Quando o valor de uma célula em qualquer componente que não seja o chave contém [Not Set],
este atributo foi configurado na chave, mas não no componente particular. De modo oposto, quandoa chave contém [Not Set] para um atributo, isso significa que ele foi configurado para outroscomponentes, mas não no componente chave.
• Para exibir uma caixa de diálogo destacando alterações específicas, é possível clicar nos valoresque estão sublinhados.
Um valor total de verificação é calculado quando localiza diferenças no conteúdo do arquivo deconfiguração comparado à chave e coloca esse número (um link, realçado na cor azul) na tabela deresultados.
O aplicativo não lista o conteúdo do arquivo real nos resultados. Clicar em um número da soma deverificação causa uma comparação de arquivos on-demand, criando uma comparação linha por linhado conteúdo do arquivo de configuração.
Capítulo 1. Usando 159

Área de Janela Histórico de MudançasÉ possível exibir um histórico de mudanças para um único ambiente de domínios ou para todos osdomínios em seu ambiente de sincronização no Portal de Gerenciamento de Dados.
A área de janela Histórico de Mudanças contém as seguintes guias:
• Histórico de Mudanças• Resultados
A guia Histórico de Mudanças contém as seguintes seções:
• Intervalo de Tempo• Componentes
Nota: Mudanças feitas nos membros de coleções customizadas não são exibidas no relatório Histórico deMudanças. Para obter informações adicionais, consulte o tópico Problemas do Portal de Gerenciamentode Dados no Guia de Resolução de Problemas do TADDM.
A seção Intervalo de Tempo da área de janela Histórico de Mudanças contém as seguintes informações:
Configurar Data PorEspecifique o tipo de intervalo de tempo desejado. As opções são:Intervalo de Tempo Relativo
É possível especificar o período de tempo do relatório Histórico de Mudanças digitando o númerode meses, semanas, dias ou horas. O relatório Histórico de Mudanças contém dados iniciadoscom o número de meses, semanas, dias ou horas que você especifica e encerrados com dados dotempo presente.
Intervalo de Tempo AbsolutoÉ possível especificar a data e hora exatas delimitando o início e o final do relatório Histórico deMudanças.
DeA data e a hora a partir das quais deseja iniciar o relatório Histórico de Mudanças.
Caixa de entrada de intervalo de tempoEspecifica o período de tempo para o qual mostrar as mudanças. As opções são: meses, semanas,dias ou horas.
Data de InícioÉ possível especificar a data precisa delimitando o início do relatório do histórico de mudanças.
Hora de InícioÉ possível especificar a hora precisa delimitando o início do relatório do histórico de mudanças.
Data de EncerramentoÉ possível especificar a data precisa delimitando o término do relatório do histórico de mudanças.
Horário de EncerramentoÉ possível especificar a hora precisa delimitando o término do relatório do histórico de mudanças.
A seção Componentes da guia Histórico de Mudanças contém as seguintes informações:
Tipo de ComponenteÉ possível selecionar componentes do software de infraestrutura, de serviços de infraestrutura, dacamada de rede e da camada do sistema.
Componentes DisponíveisLista todos os componentes disponíveis do tipo de componente escolhido que você pode escolher.
IncluirInclui o componente selecionado na lista Componentes Incluídos.
RemoverRemove o componente selecionado da lista Componentes Incluídos.
Componentes InclusosLista os componentes incluídos que você já escolheu.
160 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Executar RelatórioGera um relatório do histórico de mudanças com base nas opções escolhidas.
A tabela de mudanças da guia Resultados contém as seguintes informações:
TipoO tipo de componente alterado.
ComponenteO identificador para o componente específico que foi alterado.
AlterarA ação de alteração, que pode ser uma das ações a seguir:
• Criado• Atualizado• Excluído
DataA data e hora em que a mudança foi detectada pela descoberta do TADDM.
AtributoO atributo de componente que foi alterado.
AntigoO valor antes da alteração ocorrida.
NovoO valor após a alteração ocorrida.
ExportarExporta os resultados para um arquivo. É possível salvar os resultados como um arquivo .pdf, .csvou .xml.
Janela Pop-up Histórico de MudançasÉ possível exibir um histórico de mudanças para um componente selecionado no Portal deGerenciamento de Dados.
A área de janela Histórico de Mudanças contém as seguintes seções:
• Intervalo de Tempo• Uma tabela de alterações
A seção Intervalo de Tempo da área de janela Histórico de Mudanças contém as seguintes informações:
Configurar Data PorEspecifique o tipo de intervalo de tempo desejado. As opções são:Intervalo de Tempo Relativo
É possível especificar o período de tempo do relatório Histórico de Mudanças digitando o númerode meses, semanas, dias ou horas. O relatório Histórico de Mudanças contém dados iniciadoscom o número de meses, semanas, dias ou horas que você especifica e encerrados com dados dotempo presente.
Intervalo de Tempo AbsolutoÉ possível especificar a data e hora exatas delimitando o início e o final do relatório Histórico deMudanças.
DeA data e a hora a partir das quais deseja iniciar o relatório Histórico de Mudanças.
Caixa de entrada de intervalo de tempoEspecifica o período de tempo para o qual mostrar as mudanças. As opções são: meses, semanas,dias ou horas.
Mostrar AlteraçõesExibe as alterações conforme especificado.
Capítulo 1. Usando 161

A tabela de mudanças da área de janela Histórico de Mudanças contém as seguintes informações:
TipoO tipo de componente alterado.
ComponenteO identificador para o componente específico que foi alterado.
AlterarA ação de alteração, que pode ser uma das ações a seguir:
• Criado• Atualizado• Excluído
DataA data e hora em que a mudança foi detectada pela descoberta do TADDM.
AtributoO atributo de componente que foi alterado.
AntigoO valor antes da alteração ocorrida.
NovoO valor após a alteração ocorrida.
Área de Janela Consulta CustomizadaÉ possível gerenciar informações de consulta customizada na área de janela Consulta Customizada.
A área de janela Consulta Customizada contém a guia Consulta Salva e, dependendo das tarefas quevocê está executando, ela pode conter algumas das seguintes guias adicionais:
• Nova Consulta• Editar Consulta• Resultados
A guia Consulta Salva da área de janela Consulta Customizada contém as seguintes informações:
NovoCria uma consulta customizada e a inclui na lista de consultas customizadas.
EditarEdita os atributos da consulta customizada selecionada.
CopiarCria uma consulta customizada com base naquela selecionada.
ExcluirExclui a consulta customizada selecionada da lista de consultas customizadas.
Executar ConsultaExecuta a consulta customizada selecionada.
NomeExibe o nome de uma consulta customizada.
DescriçãoExibe uma descrição de uma consulta customizada.
A guia Resultados da área de janela Consulta Customizada contém as seguintes informações:
DetalhesExibe os detalhes para o componente.
ExplorarExibe a topologia centralizada do nó para o componente.
162 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

AlteraçõesExibe o histórico de mudanças para o componente.
Marcar para ComparaçãoInclui o componente selecionado na lista de componentes a serem comparados.
Incluir no carrinho de comprasInclui os componentes selecionados no carrinho de compras contido na área de janela ComponentesDescobertos.
SalvarExporta um relatório para um arquivo PDF, CSV ou XML.
Área de Janela Resumo de Inventário: Guia InventárioÉ possível exibir detalhes do componente na área de janela Detalhes do Inventário no Portal deGerenciamento de Dados.
A guia Inventário na área de janela Resumo de Inventário contém as seguintes informações:
Ícone AtualizarAtualiza a área de janela com os dados mais recentes do servidor.
Ícone de filtroEspecifica quais condições aplicar à visualização de inventário. As opções são:
• Todos os componentes (Mostra todos os componentes.)• Componentes ativos (Mostra os componentes que foram atualizados desde a data e horaespecificadas.)
• Componentes inativos (Mostra os componentes que não foram atualizados desde a data e horaespecificadas.)
• Marcadores (Mostra itens de configuração superficiais que usam ManagedSystemName como umaregra de nomenclatura.)
Para componentes ativos e inativos, você deve selecionar uma data e hora. O componente estaráativo se tiver sido atualizado após o período selecionado. O componente estará inativo se não tiversido atualizado após o período selecionado. Clique em Aplicar para aplicar as configurações de filtrona visualização.
Tipo de ComponenteO tipo de componente, incluindo servidores da Web, servidores de aplicativos, servidores de banco dedados e sistemas.
Detalhe do InventárioUm resumo do número de cada tipo de componente. Clique no ícone de tipo de componente paraabrir a guia de detalhes do componente.
Área de Janela Resumo de Inventário: Guia DetalhesÉ possível exibir informações detalhadas sobre o inventário para os sistemas em sua empresa.
É possível navegar por essa área de janela a partir da área de janela Resumo de Inventário.
A guia de detalhes na área de janela Detalhes do Inventário contém as seguintes informações:
Nome de ExibiçãoO nome do componente de aplicativo ou do componente de inventário.
PaiO tipo de componente.
Última AtualizaçãoA data e hora em que o componente foi modificado pela última vez.
DetalhesExibe detalhes sobre o aplicativo ou o componente de inventário correspondente.
ExplorarExibe a topologia centralizada do nó para o aplicativo ou o componente de inventário correspondente.
Capítulo 1. Usando 163

AlteraçõesExibe o histórico de mudanças para o aplicativo ou o componente de inventário correspondente.
SalvarCria um arquivo contendo as informações exibidas na área de janela Detalhes do Inventário.
Marcar para ComparaçãoInclui o componente selecionado na lista de componentes a serem comparados.
Incluir no carrinho de comprasInclui os componentes selecionados no carrinho de compras contido na área de janela ComponentesDescobertos.
ExcluirExclui uma linha selecionada do relatório. Exibe a janela Excluir Componente que mostra todos ositens selecionados e suas dependências. A partir daqui, é possível selecionar e confirmar os itens quedeseja excluir.
Excluir TudoExclui todas as linhas do relatório.
Depois de confirmar a exclusão, o processo exclui todos os componentes. Essa tarefa pode demorarbastante para ser processada e é executada como uma tarefa assíncrona, em segundo plano. Paraconfirmar que os componentes foram excluídos, clique no ícone Atualizar para visualizar o inventárioatual.
Área de janela Padrões de AgrupamentoÉ possível criar padrões de agrupamento e visualizar informações sobre os padrões em seu ambiente.
As informações especificadas na área de janela Padrões de Agrupamento são usadas peloBizAppsAgent como um critério de entrada para criar automaticamente padrões de agrupamento.
Nota: A área de janela Padrões de Agrupamento é na seção Analytics do Portal deGerenciamento de Dados no TADDM 7.3.0.2 e posterior. Se você usar uma versão anterior da liberaçãoTADDM 7.3, esta área de janela fica na seção Descoberta.
Nota: Para exibir a área de janela Padrões de agrupamento com seu conteúdo, deve-se ter apermissão de Atualização concedida para o DefaultAccessCollection.
Opções de Padrões de Agrupamento
A área de janela Padrões de Agrupamento contém as seguintes opções:Novo...
Cria um padrão de agrupamento e o inclui na lista de padrões de agrupamento.Editar...
Edita os atributos de um padrão de agrupamento.Copiar
Copia o padrão de agrupamento selecionado. Por padrão, o novo padrão é denominado Cópia denome do padrão copiado, mas é possível alterá-lo. Por padrão, a cópia não é ativada paraprocessamento.
ExcluirExclui um padrão de agrupamento e o remove da lista de padrões de agrupamento.
ExecuçãoInicia o padrão de agrupamento no horário mais próximo possível sem ter que esperar pelo tempo deexecução planejado. Essa opção é ativada apenas para os padrões que estão ativados.
PararPara os padrões que estão atualmente em execução. Essa opção é ativada somente para os padrõesque têm o status de execução Em andamento.
Atualizar VisualizaçãoAtualiza a lista de padrões de agrupamento, incluindo as informações de status da execução.
164 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

AtivarAtiva ou desativa o padrão de agrupamento selecionado ou todos.
Filtrar...Permite filtrar padrões de agrupamento por seus nomes. Digite o nome inteiro ou parte do nome dopadrão que você deseja localizar. A procura faz distinção entre maiúsculas e minúsculas. Os seguintescaracteres curinga são permitidos:
• * - corresponde a qualquer número de ocorrências de qualquer caractere, ele seráautomaticamente incluído no final da consulta
• ? -corresponde a uma ocorrência de qualquer caractere
Por exemplo, se deseja exibir todos os padrões que possuem modelo em seus nomes, digite*modelo. Os resultados contêm os seguintes tipos de nomes:
• O nome inicia com modelo, por exemplo, modelo_padrão.• modelo está no meio do nome, por exemplo janelas modelo de servidor customizado.• O nome termina com modelo, por exemplo comp_sys_modelo.
Informações da tabela de Padrões de Agrupamento
A tabela de Padrões de Agrupamento contém as seguintes informações:Nome
Exibe o nome de um padrão de agrupamento.Tipo
Exibe o tipo de um padrão de agrupamento. Os tipos válidos são Aplicativo de Negócios, Coleção deAcesso e Coleção.
AtivadoAtiva o padrão de agrupamento a ser processado. Se essa caixa de seleção não estiver marcada, opadrão não estará ativado para processamento.
DescriçãoExibe uma descrição de um padrão de agrupamento.
Última execuçãoEspecifica a última vez em que o padrão foi executado.
Próxima execuçãoEspecifica a próxima vez em que o padrão será executado.
Status da execuçãoEspecifica o status da execução. Por exemplo, se um padrão estiver sendo processado, o status seráEm andamento. Se o padrão estiver configurado para ser excluído do processamento, o status seráNão ativado.
Criar um novo assistente de Padrão de AgrupamentoUsando o assistente Criar novo Padrão de Agrupamento, é possível criar um padrão de agrupamento dotipo Aplicativo de Negócios, Coleção de Acesso ou Coleção.
Dependendo dos detalhes específicos do padrão de agrupamento que está sendo criado, algumas outodas as páginas a seguir são exibidas no assistente Criar um novo padrão de agrupamento:
• Informações Gerais• Seletores• Informações Administrativas
A página Informações Gerais contém algumas, ou todas, as seguintes informações:Nome
Exibe o nome do padrão de agrupamento.Tipo de padrão
Exibe o tipo do padrão de agrupamento.
Capítulo 1. Usando 165

Tipo de compatibilidadeEsta opção é ativada apenas se a propriedadecom.ibm.cdb.serviceinfrastructure.earlier.ver.compatibility for configurada comotrue. Ela exibe o tipo para o qual a antiga entidade de agrupamento é convertida. O tipo decompatibilidade é baseado em um Tipo Padrão escolhido:
• Coleção - somente o tipo de compatibilidade Coleção está disponível.• Coleção de Acessos - somente o tipo de compatibilidade Coleção de Acessos está
disponível.• Aplicativo de Negócios - os tipos a seguir estão disponíveis:
– Aplicativo de Negócios– Serviço de Negócios.
PlanejamentoExibe o planejamento do padrão de agrupamento. Se você criou seus próprios planejamentos, elesestarão na lista.
ConfiguraçãoExibe a configuração do padrão de agrupamento. Se você criou suas próprias configurações, elasestarão na lista.
DescriçãoExibe uma descrição do padrão de agrupamento.
URLExibe uma URL associada ao padrão de agrupamento.
A página Seletores contém algumas ou todas as informações a seguir:Novo
Cria uma regra. Ao clicar em Novo, as seguintes informações estarão disponíveis:
• Nome do seletorEspecifica um nome para o novo seletor.
• Nome da camadaEspecifica o nome da camada. Ao inserir qualquer nome nesse campo, todos os objetos que sãolocalizados pelo seletor são incluídos nesta camada. O nome da camada inserido aqui temprecedência sobre os nomes das camadas que são especificados na configuração da camada.
• DescriçãoDescrição do seletor.
• Visualizações da regra de seleçãoExibe a consulta que é usada para selecionar o CI principal e a expressão de nome doagrupamento. Ao clicar em Escolher..., as seguintes informações estão disponíveis:
– Tipo de seleçãoDefine o tipo de seleção. É possível escolher entre os três tipos de seleção, a seleção deconsulta MQL, a seleção de consulta SQL e seleção com base em instâncias.
– ConsultaDefine a consulta que seleciona CIs principais ou os elementos que você selecionoumanualmente como CIs principais.
– Expressão de nome do agrupamentoDefine a expressão que gera o identificador de coleção.
– Tamanho da amostra de testeDefine o número de CIs principais que estão incluídos no teste. Essa opção é útil quandosua consulta localizar vários CIs principais. Ao limitar o número de CIs principais, o testenão leva muito tempo para ser concluído.
– TesteTesta se o tipo de seleção escolhido e a expressão de nome do agrupamento são válidos.
166 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

ExcluirExclui o seletor selecionado.
DesativadoCria uma versão de rascunho de um seletor. Seletores desativados não são usados peloBizAppsAgent na construção de coleções customizadas.
Modelo de passagem de dadosDefine como o seletor atravessa dependências.A opção Usar modelo de passagem de dependência permite a passagem de dados.As opções Higher Up e Lower Down determinam se os ICs conectados acima ou abaixo da cadeia dedependência do IC principal são incluídos na coleção customizada gerada.As opções Higher Down e Lower Up determinam se os ICs conectados abaixo ou acima na cadeia dedependências de ICs já incluídos também são incluídos na coleção customizada gerada.
A página Informações Administrativas contém algumas, ou todas, as seguintes informações:Contato Administrativo
Exibe um contato administrativo para o padrão de agrupamento.Contato de Escalação
Exibe o contato de escalada para o padrão de agrupamento.Número de Rastreamento
Exibe o número de rastreamento para o padrão de agrupamento.Site
Exibe informações de site para o padrão de agrupamento.Nome do Grupo
Exibe um nome de grupo para o padrão de agrupamento.Notas
Exibe notas para o padrão de agrupamento.Tarefas relacionadas“Criando padrões de agrupamento” na página 194É possível criar novos padrões de agrupamento na área de janela Padrões de Agrupamento, no Portal deGerenciamento de Dados.
Área de Janela Resumo de AplicativoÉ possível exibir informações de resumo de aplicativos para os domínios em seu ambiente no Portal deGerenciametno de Dados.
A área de janela Resumo do Aplicativo contém as seguintes informações:
SalvarExporta um relatório para um arquivo PDF, CSV ou XML.
Nome do AplicativoO nome do aplicativo de negócios.
Nome do DomínioO nome de domínio em que o aplicativo de negócios está localizado.
GruposExibe informações associadas aos grupos funcionais em seu ambiente.
AlteraçõesExibe o histórico de mudanças para seu aplicativo de negócios.
DetalhesExibe detalhes em seu aplicativo de negócios.
ExplorarExibe a topologia centralizada do nó para o aplicativo.
Capítulo 1. Usando 167

Topologia de SoftwareExibe a topologia de software para o aplicativo.
Topologia FísicaExibe a topologia física para o aplicativo.
InventárioExibe o resumo do inventário para o aplicativo.
Marcar para ComparaçãoInclui o componente selecionado na lista de componentes a serem comparados.
Incluir no carrinho de comprasInclui os componentes selecionados no carrinho de compras contido na área de janela ComponentesDescobertos.
Área de Janela Inventário do SistemaO relatório Inventário do Sistema mostra detalhes para todos os sistemas do computador em seuambiente. Ele contém informações da área de janela Detalhes. É possível exportar esse relatório em XML,arquivo PDF ou formato CSV. Ao exportar este relatório, você exporta apenas as informações que sãoexibidas na visualização atual.
A área de janela Inventário do Sistema contém as seguintes informações:
NomeO nome do componente.
ModeloO modelo do componente.
Tipo de CPUO tipo de processador instalado no componente.
Contagem da CPUO tamanho do processador.
Tamanho da MemóriaA quantidade de memória no componente em bytes.
FabricanteO fabricante do componente.
SalvarExporta um relatório para um arquivo PDF, CSV ou XML.
Incluir no carrinho de comprasInclui os componentes selecionados no carrinho de compras contido na área de janela ComponentesDescobertos.
Este relatório suporta a paginação.
Área de Janela Inventário do Servidor de SoftwareO relatório Inventário do Servidor de Software mostra detalhes para todo o software para o aplicativo emexecução no componente.
A área de janela Inventário do Servidor de Software contém as seguintes informações:
SalvarExporta um relatório para um arquivo PDF, CSV ou XML.
NomeO nome do componente.
TipoO tipo do componente, como Db2Instance, OracleInstance.
VersãoA versão do software em execução no componente.
168 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Nome de ExibiçãoO nome do componente como ele é exibido na lista Componentes Descobertos.
Incluir no carrinho de comprasInclui os componentes selecionados no carrinho de compras contido na área de janela ComponentesDescobertos.
Área de Janela Relatórios BIRTÉ possível incluir, fazer download, excluir e executar relatórios BIRT na área de janela Relatórios BIRT doPortal de Gerenciamento de Dados.
A área de janela Relatórios BIRT contém as seguintes informações:Nome
Exibe o nome de um relatório.Descrição
Exibe uma descrição do relatório.Executar Relatório
Exibe um relatório que foi implementado no mecanismo de tempo de execução BIRT do TADDM.Novo
Implementa um novo arquivo de design de relatório para o mecanismo de tempo de execução BIRTdo TADDM.
ExcluirExclui um arquivo de design de relatório que foi implementado no mecanismo de tempo de execuçãoBIRT do TADDM.
AtualizarRecarrega a lista de relatórios BIRT implementados.
DownloadFaz download de um arquivo de design de relatório implementado a partir do servidor TADDM para oseu computador para edição ou clonagem.
AdministraçãoÉ possível gerenciar as informações de administração para os domínios em seu ambiente no consolePortal de Gerenciamento de Dados.
As informações de administração a seguir podem ser gerenciadas para os domínios em seu ambiente:
• Grupos de Usuários• Usuários• Funções
Área de Janela Grupos de UsuáriosÉ possível exibir informações do usuário de administração para sua empresa.
A área de janela Grupos de Usuários exibe as seguintes informações:
Nome do GrupoO nome do grupo de usuários.
UsuáriosO nome do usuário no grupo.
FunçõesAs funções concedidas ao usuário no grupo.
Criar GrupoCrie um novo grupo de usuários e inclua esse grupo de usuários na tabela de Banco de Dados deDomínio.
Capítulo 1. Usando 169

ExcluirExclui um grupo de usuários e remove esse grupo de usuários da tabela de Banco de Dados deDomínio. Este botão está disponível para usuários logados como administradores ou usuários comuma função que possui permissão de administrador.
EditarAltera a senha de um grupo de usuários. Este botão está disponível para usuários logados comoadministradores ou usuários com uma função que possui permissão de administrador.
Janelas Criar Grupo de Usuários e Editar Grupo de UsuáriosÉ possível criar ou editar um grupo de usuários para os usuários dentro de cada domínio em seuambiente.
A janela Criar Grupo de Usuários e a janela Editar Grupo de Usuários contêm as seguintes seções:
• Informações Gerais• Designação do Grupo de Usuários• Designação de Função
A seção Informações Gerais exibe as seguintes informações:
Nome do GrupoO nome do grupo de usuários. Na janela Editar Grupo de Usuários, esse campo contém o nome dogrupo de usuários que você está editando.
A seção Designação do Grupo de Usuários exibe as seguintes informações:
Usuários DisponíveisUma lista dos usuários que podem estar neste grupo de usuários.
IncluirInclui um usuário no grupo de usuários.
RemoverRemove um usuário do grupo de usuários.
Usuários IncluídosLista dos usuários selecionados para estarem no grupo de usuários.
A seção Designação de Função exibe as seguintes informações:
AtribuirA caixa de opção para atribuir uma função.
Nome da FunçãoO nome da função para este usuário.
PermissõesO nome do tipo de permissões para este usuário.
Coletas de AcessoA caixa de opção para especificar coletas de acesso.
Área de Janela UsuáriosÉ possível exibir informações sobre o usuário administrativo de sua empresa na área de janela Usuáriosdo Portal de Gerenciamento de Dados.
As informações exibidas dependem do tipo de autenticação que você está usando, conforme definido napropriedade com.collation.security.usermanagementmodule.
Se estiver usando a autenticação baseada em arquivo padrão, todos os usuários serão exibidos.
Se estiver usando autenticação baseada em LDAP ou VMM, a área de janela Usuários terá um campo deprocura e os usuários serão exibidos com base nos critérios de procura inseridos. Para listar todos osusuários (até o limite de procura definido pelo arquivo collation.properties), no campo de procura,insira o caractere "*".
A área de janela Usuários exibe as seguintes informações:
170 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

UsuárioO nome do usuário.
FunçõesAs funções concedidas ao usuário.
Endereço de E-mailO endereço de e-mail do usuário.
Tempo Limite da SessãoO valor de tempo limite da sessão (em minutos) designado a este usuário.
Criar UsuárioCria um novo usuário e o inclui na tabela.
ExcluirExclui um usuário e o remove da tabela Usuários. Este botão está disponível para usuários logadoscomo administradores ou usuários com uma função que possui permissão de administrador.
EditarAltera a senha de um usuário. Este botão está disponível para usuários logados como administradoresou usuários com uma função que possui permissão de administrador.
Janela Criar UsuárioÉ possível criar usuários para os domínios dentro de seu ambiente na janela Criar Usuário do Portal deGerenciamento de Dados.
A janela Criar Usuário contém as seguintes seções:
• Informações Gerais• Designação de Função
A seção Informações Gerais exibe as seguintes informações:
Nome do UsuárioO nome do usuário.
Endereço de E-mailO endereço de e-mail do usuário.
SenhaA senha para a conta do usuário.
Confirmar SenhaA senha de confirmação para a conta do usuário.
Tempo Limite da Sessão (Minutos)O valor de tempo limite da sessão (em minutos) é designada ao usuário.
A seção Designação de Função exibe as seguintes informações:
AtribuirA caixa de opção para atribuir uma função.
Nome da FunçãoO nome da função para este usuário.
PermissõesO nome do tipo de permissões para este usuário.
Coletas de AcessoA caixa de opção para especificar coletas de acesso.
Área de Janela FunçõesÉ possível exibir informações da função de administração para sua empresa no Portal de Gerenciamentode Dados usando a área de janela Funções. Esta função está disponível para usuários com login efetuadocomo administrador ou usuários com uma função que possua permissão de administrador.
A área de janela Funções contém as seguintes informações:
Capítulo 1. Usando 171

FunçõesO nome da função (por exemplo, administrador ou operador).
Nome do AplicativoO nome do aplicativo.
PermissõesO tipo de permissões incluídas pela função.
Criar FunçãoCria uma nova função e a inclui na tabela.
EditarEdita as permissões incluídas por uma função.
ExcluirExclui uma função e a remove da tabela.
Janela Criar FunçãoÉ possível criar uma função para os usuários no Portal de Gerenciamento de Dados usando a funçãoAdministração. Esta função está disponível para usuários com login efetuado como administrador ouusuários com uma função que possua permissão de administrador.
Nome da FunçãoO nome da função que está sendo criada.
A janela Criar Função contém uma seção Permissões com as seguintes informações:
Caixa de opçãoA caixa de opção correspondente ao tipo de função e ao aplicativo que estão sendo criados.
TipoO tipo de função. Por exemplo, Leitura, Atualização, Descoberta ou Administração.
AplicativoO aplicativo definido para esta função.
OKCria a função depois que as informações são digitadas.
CancelarRetorna à área de janela Funções.
Janela Editar FunçãoÉ possível editar uma função existente no Portal de Gerenciamento de Dados usando a funçãoAdministração. Esta função está disponível para usuários com login efetuado como administrador ouusuários com uma função que possua permissão de administrador.
As funções predefinidas (administrador, operador e supervisor) não podem ser editadas.
A janela Criar Função contém uma seção Permissões com as seguintes informações:
Caixa de opçãoA caixa de opção correspondente ao tipo de função e ao aplicativo que estão sendo criados.
TipoO tipo de função. Por exemplo, Leitura, Atualização, Descoberta ou Administração.
AplicativoO aplicativo definido para esta função.
OKAplica as alterações à função depois de especificar as informações.
CancelarRetorna à área de janela Funções sem fazer nenhuma alteração.
Área de Janela Resumo de Servidores TADDMA área de janela Resumo de Servidores TADDM no Portal de Gerenciamento de Dados (em execução emuma implementação do servidor de fluxo) contém informações sobre os servidores de descoberta e os
172 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

servidores de armazenamento em seu ambiente. Nessa área de janela, é possível executar váriasoperações nos servidores de descoberta, servidor de armazenamento primário e servidores dearmazenamento secundários.
Esta área de janela está disponível apenas no Portal de Gerenciamento de Dados em execução em umaimplementação de servidor de fluxo.
A área de janela Resumo de Servidores TADDM contém os seguintes botões:
AtualizarAtualiza a lista de servidores de descobertas e servidores de armazenamento.
AtivarConecta ao servidor de descobertas ou servidor de armazenamento selecionado. É possível conectarao servidor de descobertas ou servidor de armazenamento em modo seguro ou não seguro.
A área de janela Resumo de Servidores TADDM contém uma tabela com os seguintes campos:
Nome do HostExibe o nome do host do servidor de descobertas ou servidor de armazenamento.
TipoExibe o tipo de servidor de descobertas e de servidor de armazenamento.
StatusExibe o status do servidor de descobertas e do servidor de armazenamento.
Membro do Conjunto de ArmazenamentoExibe se o servidor de armazenamento é usado para manipular carga de trabalho de descoberta.
Número da ConstruçãoExibe o ID da construção em execução no servidor de descobertas e no servidor de armazenamento.
Assistente Criar ComponenteUsando o assistente Criar Componente, é possível criar um componente.
Dependendo dos detalhes específicos do componente que você está criando, algumas ou todas asseguintes páginas serão exibidas no assistente Criar Componente:
• Informações Gerais• Informações do Servidor• Informações de IP• Informações Administrativas• Atributos Estendidos
A página Informações Gerais contém algumas, ou todas, as seguintes informações:Nome
Digite o nome do componente.Tipo
Selecione o tipo de componente.
A página Informações do Servidor contém algumas, ou todas, as seguintes informações:Disponível
Lista o conteúdo disponível. O conteúdo pode ser selecionado a partir das listas de tipos deservidores existentes.
IncluídoLista o conteúdo incluído.
IncluirInclui o item selecionado na lista Incluído e o remove da lista Disponível.
RemoverRemove o item selecionado da lista Incluído e o inclui na lista Disponível.
A página Informações de IP contém algumas, ou todas, as seguintes informações:
Capítulo 1. Usando 173

Nome do HostDigite o nome do host do computador a ser incluído.
endereço IPDigite o endereço IP do computador que deseja incluir. Se apropriado, mova a régua de controle paraespecificar a máscara de sub-rede.
IncluirInclui o nome do host especificado e informações do endereço IP para a lista de endereços IP.
RemoverRemove o endereço IP selecionado da lista.
Endereço IPO endereço IP do computador.
Máscara de Sub-redeA máscara de sub-rede do computador.
Nome do HostO nome do host do computador.
A página Informações Administrativas contém algumas, ou todas, as seguintes informações:Contato Administrativo
Digite um contato administrativo para o componente.Contato de Escalação
Digite um contato de escalação para o componente.Número de Rastreamento
Digite um número de rastreamento para o componente.Site
Digite informações do site para o componente.Nome do Grupo
Digite um nome de grupo para o componente.Notas
Digite notas para o componente.
A página Atributos Estendidos contém um campo para cada atributo estendido definido. Os atributosestendidos são agrupados por uma categoria. Cada categoria possui uma guia separada. Para cadaatributo, digite o valor do atributo estendido.
Janela Definir Atributos EstendidosÉ possível criar, visualizar e excluir atributos estendidos.
A janela Definir Atributos Estendidos exibe as seguintes informações:
Tipo de ComponenteSelecione o tipo de componente para o qual deseja criar ou visualizar um atributo estendido.
NovoCria um novo atributo estendido para o tipo de componente selecionado.
ExcluirExclui o atributo estendido selecionado para o tipo de componente selecionado.
Nome do Atributo EstendidoExibe o nome do atributo estendido.
Tipo de Atributo EstendidoExibe o tipo do atributo estendido.
CategoriaExibe a categoria do atributo estendido.
Nome do Atributo Estendido HerdadoExibe o nome do atributo estendido herdado.
174 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Herdado da ClasseExibe a classe a partir da qual o atributo estendido é herdado.
Janela Criar Novo Atributo EstendidoÉ possível criar atributos estendidos.
A janela Criar Novo Atributo Estendido exibe as seguintes informações:
Nome do atributo estendidoDigite o nome do atributo estendido.
Tipo de atributo estendidoSelecione o tipo de atributo estendido. Os seguintes valores estão disponíveis:
• Cadeia• Caractere• Ponto de flutuação de precisão dupla• Ponto de flutuação• Inteiro• Booleano• Número inteiro curto• Número inteiro longo
Categoria do atributo estendidoSelecione a categoria do atributo estendido. É possível selecionar uma categoria existente ou acategoria do tipo novo.
Área de Janela Resumo do DomínioA área de janela Resumo do Domínio do Portal de Gerenciamento de Dados (em execução no servidor desincronização) contém informações sobre os domínios em seu ambiente. A partir desta área de janela, épossível executar várias operações nos domínios.
Esta área de janela está disponível apenas no Portal de Gerenciamento de Dados em execução em umservidor de sincronização.
A seção Resumo do Domínio Distribuído contém os seguintes botões:
NovoInclui um domínio em sua empresa.
EditarEdita o domínio selecionado em sua empresa.
ExcluirExclui o domínio selecionado de sua empresa.
AtualizarAtualiza as informações da tabela Resumo do Domínio para o domínio selecionado.
IniciarInicia um Console de Gerenciamento de Descoberta para um domínio em sua empresa.
Iniciar em Modo SeguroInicia um Console de Gerenciamento de Descoberta para um domínio em sua empresa usando umaconexão SSL segura.
Configurações de Conexão SSLExibe as configurações de conexão SSL.
A área de janela Resumo de Domínio contém uma tabela com os seguintes campos:
DomínioO nome deste domínio.
Capítulo 1. Usando 175

Nome do HostO nome do host para este domínio.
Última SincronizaçãoA hora da última sincronização para este domínio.
Status do DomínioStatus do host.
Áreas de Janela Incluir Domínio e Editar DomínioÉ possível usar as áreas de janela Incluir Domínio e Editar Domínio no Portal de Gerenciamento deDados, executando em um servidor de sincronização, para trabalhar com os domínios que compõem suaempresa ou alterá-los. É possível usar essas áreas de janela para incluir um domínio em sua empresa oualterar um domínio existente.
Essas áreas de janela estão disponíveis apenas no Portal de Gerenciamento de Dados em execução emum servidor de sincronização.
As áreas de janela Incluir Domínio e Editar Domínio contêm as seguintes seções:
• Detalhes do Domínio: Utilize esta seção para digitar informações que descrevam o domínio que vocêestá incluindo ou alterando.
• Detalhes do Administrador: Utilize esta seção para digitar informações sobre os contatos para estedomínio.
Importante: Para incluir um domínio ou alterar um domínio existente, você deve efetuar login no Portalde Gerenciamento de Dados como um usuário que tenha a permissão de tempo de execução deAdministrador.
A seção Detalhes do Domínio das áreas de janela Incluir Domínio e Editar Domínio contém os seguintescampos:
Nome do Domínio(Obrigatório) O nome do domínio.
Endereço do Servidor(Obrigatório) O nome completo do host ou o endereço IP do servidor TADDM.
Porta de Atendimento(Necessária) A porta de atendimento do servidor TADDM. Use a porta de registro de serviço entreservidores do domínio. Pata obter o valor, use o valor da propriedadecom.ibm.cdb.service.registry.interserver.port do servidor de domínio no arquivo$COLLATION_HOME/etc/collation.properties. O valor padrão é 4160.
Na área de janela Editar Domínio, os campos são preenchidos com os valores atuais.
A seção Detalhes do Administrador das áreas de janela Incluir Domínio e Editar Domínio contém osseguintes campos:
NomeO nome do administrador de domínio.
ContatoO contato para o domínio.
Contato de EscalaçãoO nome do contato de escalação para o domínio.
NotasNotas do usuário sobre o domínio.
As áreas de janela Incluir Domínio e Editar Domínio contêm os seguintes botões:
Incluir Domínio(Área de janela Incluir Domínio apenas) Inclui este domínio.
Salvar Alterações(Área de janela Editar Domínio apenas) Salva as informações alteradas.
176 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Aplicar(Área de janela Editar Domínio) Salva as informações alteradas e retorna à área de janela Resumo doDomínio.
CancelarRetorna à área de janela Resumo do Domínio sem salvar qualquer informação.
Área de Janela SincronizarSincronizar um banco de dados do servidor de domínio com o banco de dados do servidor desincronização exige o uso da área de janela Sincronizar no Portal de Gerenciamento de Dados.
Esta área de janela está disponível apenas no Portal de Gerenciamento de Dados em execução em umservidor de sincronização.
A área de janela Sincronizar contém as quatro seções a seguir:Domínio
Contém os nomes dos domínios na empresa.Sincronização On Demand
Utilize esta seção para imediatamente iniciar ou parar a sincronização.Sincronização Planejada
Utilize esta seção para planejar a sincronização do novo domínio. As informações de sincronizaçãoque são digitadas na área de janela Período do Planejamento são exibidas em uma tabela.
Hora da Última SincronizaçãoUtilize esta seção para visualizar os detalhes da sincronização. Você pode precisar clicar em Atualizarpara atualizar o horário da última sincronização.
Na seção Sincronização On Demand contém a caixa de seleção e os botões a seguir:
Executar Sincronização completaEspecifica se deve executar a sincronização completa entre o banco de dados do servidor desincronização e o banco de dados do servidor de domínio.
IniciarInicia a sincronização.
PararPára a sincronização.
A seção Sincronização Planejada contém os campos e botões a seguir:
NomeO nome do planejamento.
Próxima SincronizaçãoA hora da próxima sincronização planejada.
Ciclo de RepetiçãoEspecifica com que frequência a sincronização ocorre. As opções são: diário, por hora ou semanal.
IntervaloOs valores do Ciclo de Repetição em número entre cada sincronização. Por exemplo, um Ciclo deRepetição diário e um Intervalo de 2 significa que se passam 2 dias entre cada sincronização.
NovoPlaneja a sincronização.
ExcluirRemove o planejamento da tabela Sincronização Planejada.
A seção Hora da Última Sincronização contém o botão a seguir:
Visualizar Detalhes da SincronizaçãoExibe o status da sincronização (SyncStatus) e um log da sincronização.
Capítulo 1. Usando 177

Área de Janela Período do PlanejamentoSe você desejar planejar a sincronização, em vez de executar uma sincronização on-demand, use a áreade janela Período do Planejamento no Portal de Gerenciamento de Dados (em execução no servidor desincronização) para especificar o nome do planejamento e com que frequência a sincronização deveocorrer.
Esta área de janela está disponível apenas no Portal de Gerenciamento de Dados em execução em umservidor de sincronização.
A área de janela Período do Planejamento contém os seguintes campos:
Nome(Obrigatório) O nome do planejamento.
Iniciar(Obrigatório) O ícone do calendário para especificar a hora para iniciar a sincronização.
RepetirEspecifica com que frequência a sincronização ocorre. As opções são: nenhum, por hora, diário ousemanal.
A CadaObrigatório quando o campo Repetir não estiver definido como Nenhum. O número de valores deespecificação de Repetição entre cada sincronização. Por exemplo, configurar Repetir para 'diário' e ACada para '2 dias' significa que se passam 2 dias entre cada sincronização.
NovoInclui o novo período de sincronização na tabela Sincronização Planejada na área de janelaSincronização.
CancelarFecha a área de janela Período do Planejamento sem incluir um novo período de sincronização.
Procurando um Componente por Nome ou Endereço IPÉ possível usar o campo Procurar na parte superior do Portal de Gerenciamento de Dados para procurarcom rapidez componentes descobertos por nome ou endereço IP. É possível, então, filtrar a lista decomponentes correspondentes e executar ações sobre componentes diretamente da página deresultados da procura.
Sobre Esta TarefaA função de procura procura componentes que pertençam a quaisquer das seguintes subclasses:
• ComputerSystem• AppServer• Serviço• ITSystem
Procedimento
Para procurar um componente descoberto por nome ou endereço IP:1. No campo Procurar, digite a sequência desejada.
É possível procurar por componente usando quaisquer dos vários identificadores básicos:
• Nome de exibição• Rótulo• Nome• Nome de domínio completo• Endereço IP numérico
178 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

A função Procurar procura esses atributos por quaisquer ocorrências da sequência especificada. Porexemplo, se você procurar por raleigh.ibm.com, todos os componentes cujos nomes completos dedomínio incluam raleigh.ibm.com serão encontrados.
Nota: Se precisar localizar um componente usando um atributo diferente, será possível usar umaconsulta customizada (disponível a partir da área de janela Consulta Customizada da guia Analítica).
2. Clique em Procurar.Depois que a procura estiver concluída, os resultados serão exibidos no painel Resultados daProcura. Se uma procura resultar em diversos resultados, eles serão exibidos em uma tabela na áreade trabalho de diversos resultados. Se uma procura resultar em apenas um resultado, ele será exibidona área de trabalho de resultado único.
3. Se a procura retornou mais de um resultado de procura, será possível usar a área de janela Filtrospara restringir os resultados da procura aos componentes de seu interesse.É possível restringir a tabela de resultados por tipo de componente. Para ver apenas componentes deum tipo específico, clique no tipo de objeto de modelo na lista Tipo de Componente. A lista mostra ostipos de todos os componentes correspondentes à sequência de procura.
4. Para executar uma ação em um componente diretamente da área de janela Resultados da Procura,execute um dos seguintes:
• Na área de trabalho de diversos resultados, selecione uma linha na tabela e clique em uma dasações disponíveis:Detalhes
Mostra informações detalhadas sobre o componente.Dependências
Mostra informações de dependência do componente.Explorar
Abre a visualização de topologia centralizada do nó para o componente.Alterações
Mostra o histórico de mudanças do componente.Marcar para Comparação
Inclui o componente na lista de componentes a serem comparados.• Na área de trabalho de resultado único, clique na lista suspensa de componentes e clique em uma
das ações disponíveis:Excluir
Exclui o componente.Explorar
Abre a visualização de topologia centralizada do nó para o componente.Alterações
Mostra o histórico de mudanças do componente.Marcar para Comparação
Inclui o componente na lista de componentes a serem comparados.
O que Fazer DepoisDepois de procurar um componente por nome ou endereço IP, os resultados da procura serão exibidos naárea de trabalho de resultado único ou em uma tabela na área de trabalho de diversos resultados.
Área de Janela Resultados da Procura: Área de Trabalho Diversos ResultadosSe uma pesquisa resultar em diversos resultados, os resultados serão exibidos em uma tabela na área detrabalho de diversos resultados, na área de janela Resultados da Procura. Para abrir um resultado emuma área de trabalho de resultado único, dê um clique duplo nesse resultado na área de trabalho dediversos resultados.
A área de trabalho de diversos resultados, na área de janela Resultados da Procura, contém as seguintesinformações:
Capítulo 1. Usando 179

Lista FiltrosRestringe os resultados da procura exibindo componentes apenas do tipo selecionado na tabela naárea de trabalho de diversos resultados.
ComponenteO nome completo do domínio do componente.
Tipo de ComponenteO tipo do objeto modelo do componente.
Correspondências da ProcuraO atributo que contém a sequência correspondente e o valor de atributo completo (com asubsequência correspondente destacada).
A área de trabalho de diversos resultados, na área de janela Resultados da Procura, contém os seguintesbotões:Detalhes
Mostra informações detalhadas sobre o componente.Dependências
Mostra informações de dependência do componente.Explorar
Abre a visualização de topologia centralizada do nó para o componente.Alterações
Mostra o histórico de mudanças do componente.Marcar para Comparação
Inclui o componente na lista de componentes a serem comparados.Incluir no carrinho de compras
Inclui os componentes selecionados no carrinho de compras contido na área de janela ComponentesDescobertos.
Área de Janela Resultados da Procura: Área de Trabalho Resultado ÚnicoSe uma procura resultar em apenas um resultado, o resultado será exibido na área de trabalho única, naárea de janela Resultados da Procura. Para uma procura que proporciona mais de um resultado, dê umclique duplo no resultado na área de trabalho de diversos resultados para abrir esse resultado na área detrabalho de resultado único.
A área de trabalho de resultado único, na área de janela Resultados da Procura, contém as seguintesinformações:Trilha de Navegação
Exibe sua posição dentro da estrutura de resultados da procura. Para retornar à área de trabalho dediversos resultados, clique em Resultados da Procura.
Lista Suspensa de ComponentesLista as ações que podem ser executadas no componente atual.Excluir
Exclui o componente.Explorar
Abre a visualização de topologia centralizada do nó para o componente.Alterações
Mostra o histórico de mudanças do componente.Marcar para Comparação
Inclui o componente na lista de componentes a serem comparados.Informações do Componente
Exibe informações sobre o tipo de componente e a hora da atualização mais recente.
A área de trabalho de resultado único, na área de janela Resultados da Procura, contém as seguintesguias:
180 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Guia DependênciasA área de trabalho de resultado único inclui a guia Dependências, que exibe informações de dependênciapara o resultado da procura.
A guia Dependências, na área de trabalho de resultado único, contém as seguintes informações:Explorador de Dependências
Restringe a lista de dependências exibindo componentes apenas do tipo selecionado.Componente
O nome completo do domínio do componente.Tipo de Componente
O tipo do objeto modelo do componente.
A guia Dependências, na área de trabalho de resultado único, contém os seguintes botões:Detalhes
Mostra informações detalhadas sobre o componente selecionado.Dependências
Mostra informações de dependência para o componente selecionado.Explorar
Abre a visualização de topologia centralizada do nó para o componente selecionado.Alterações
Mostra o histórico de mudanças do componente selecionado.Marcar para Comparação
Inclui o componente selecionado na lista de componentes a serem comparados.
Guia Relatórios BIRTA área de trabalho de resultado único inclui a guia Relatórios BIRT, que exibe os relatórios BIRTrelevantes para o resultado da procura.
A guia Relatórios BIRT, na área de trabalho de resultado único, contém as seguintes informações:Lista Descrição
Lista os relatórios BIRT, se houver, que são relevantes para o resultado da procura.Área de Janela Relatório
Exibe o relatório selecionado.
Cenários de TarefasEsses cenários de tarefas fornecem instruções para concluir algumas das tarefas comuns que os usuáriosexecutam com o IBM Tivoli Application Dependency Discovery Manager (TADDM). Os dados e osparâmetros incluídos nesses cenários são exemplos apenas e não representam padrões do sistema.
Configurando uma DescobertaÉ possível usar o Console de Gerenciamento de Descoberta para configurar uma descoberta.
Sobre Esta TarefaNeste cenário, deseja-se descobrir informações sobre os seguintes sistemas do computador que estãoatrás de um firewall:
• Um sistema Windows com um nome do host de windows1.• Um sistema Windows com um nome do host de windows2.• Um sistema Linux com um nome do host de linux1.
Este cenário possui seis etapas principais:
1. Configurando o escopo2. Configurando a lista de acesso
Capítulo 1. Usando 181

3. Incluindo gateways4. Incluindo âncoras5. Executando a descoberta6. Visualizando os detalhes
Etapa 1: Configurar o EscopoPara configurar o escopo de uma descoberta, efetue login como um supervisor ou administrador, econclua as seguintes etapas a partir do Console de Gerenciamento de Descoberta ou do Portal deGerenciamento de Dados.
Procedimento
Para configurar o escopo de uma descoberta, efetue login como um supervisor ou administrador, econclua as seguintes etapas a partir do Console de Gerenciamento de Descoberta ou do Portal deGerenciamento de Dados:
1. Na área de janela Funções, clique em Descoberta > Escopo e selecione a guia Conjuntos de Escopo.A área de janela Escopo é exibida.
2. Execute um dos seguintes:
• Na área de janela Escopo do Console de Gerenciamento de Descoberta, clique em IncluirConjunto. A janela Nome do Conjunto de Escopos é exibida.
• Na área de janela Escopo do Portal de Gerenciamento de Dados, clique em Novo Conjunto deEscopos. A janela Novo Conjunto de Escopos é exibida.
3. No campo Nome, digite MyScope como o nome para o novo conjunto de escopos.
Nota: Se você estiver gerenciando diversos domínios com um servidor de sincronização, assegure-sede que cada nome de conjunto de escopos seja exclusivo em todos os domínios gerenciados pelomesmo servidor. Usar o mesmo nome de conjunto de escopos em mais de um domínio pode causarproblemas ao gerar relatórios.
4. Clique em OK. O nome MyScope é exibido na lista Conjuntos de Escopos.5. Execute um dos seguintes:
• Na lista de conjuntos de escopos do Console de Gerenciamento de Descoberta, selecioneMyScope e clique em Incluir. A janela Incluir Escopo é exibida.
• Na lista de conjuntos de escopos do Portal de Gerenciamento de Dados, selecione MyScope eclique em Novo. A janela Novo Escopo é exibida.
6. Execute um dos seguintes:
• Na janela Incluir Escopo do Console de Gerenciamento de Descoberta, conclua as seguintesetapas:
a. Na lista Tipo de IP, selecione Host.b. No campo Nome do Host, digite windows1 (supondo que o servidor TADDM possa consultarwindows1 em DNS).
c. Clique em OK. O novo escopo é exibido na lista.
• Na janela Novo Escopo do Portal de Gerenciamento de Dados, conclua as seguintes etapas:
a. Na lista Endereço, selecione Host.b. No campo Descrição/Nome do Host, digite windows1 (supondo que o servidor TADDM possa
consultar windows1 em DNS).c. Clique em OK. O novo escopo é exibido na lista.
7. Execute um dos seguintes:
• Na lista de conjuntos de escopos do Console de Gerenciamento de Descoberta, selecioneMyScope e clique em Incluir. A janela Incluir Escopo é exibida.
182 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

• Na lista de conjuntos de escopos do Portal de Gerenciamento de Dados, selecione MyScope eclique em Novo. A janela Novo Escopo é exibida.
8. Execute um dos seguintes:
• Na janela Incluir Escopo do Console de Gerenciamento de Descoberta, conclua as seguintesetapas:
a. Na lista Tipo de IP, selecione Host.b. No campo Nome do Host, digite windows2 (supondo que o servidor TADDM possa consultarwindows2 em DNS).
c. Clique em OK. O novo escopo é exibido na lista.
• Na janela Novo Escopo do Portal de Gerenciamento de Dados, conclua as seguintes etapas:
a. Na lista Endereço, selecione Host.b. No campo Descrição/Nome do Host, digite windows2 (supondo que o servidor TADDM possa
consultar windows2 em DNS).c. Clique em OK. O novo escopo é exibido na lista.
9. Execute um dos seguintes:
• Na lista de conjuntos de escopos do Console de Gerenciamento de Descoberta, selecioneMyScope e clique em Incluir. A janela Incluir Escopo é exibida.
• Na lista de conjuntos de escopos do Portal de Gerenciamento de Dados, selecione MyScope eclique em Novo. A janela Novo Escopo é exibida.
10. Execute um dos seguintes:
• Na janela Incluir Escopo do Console de Gerenciamento de Descoberta, conclua as seguintesetapas:
a. Na lista Tipo de IP, selecione Host.b. No campo Nome do Host, digite linux1 (supondo que o servidor TADDM possa consultarlinux1 em DNS).
c. Clique em OK. O novo escopo é exibido na lista.
• Na janela Novo Escopo do Portal de Gerenciamento de Dados, conclua as seguintes etapas:
a. Na lista Endereço, selecione Host.b. No campo Descrição/Nome do Host, digite linux1 (supondo que o servidor TADDM possa
consultar linux1 em DNS).c. Clique em OK. O novo escopo é exibido na lista.
Incluindo grupo de escoposAo configurar o escopo de uma descoberta, é possível incluir o grupo de conjuntos de escopos e incluirconjuntos de escopos existentes no grupo de escopos.
Procedimento
1. Para incluir o grupo de conjuntos de escopos, conclua as etapas a seguir:a) Na área de janela Funções, clique em Descoberta > Escopo e selecione a guia Grupos de Escopos.b) Para criar um novo grupo de escopos vazio, clique em Incluir Conjunto. A janela Nome do Grupo
de Escopos é exibida.c) No campo Nome, digite MyGroup como o nome para o novo grupo de escopos.d) Clique em OK. O nome MyGroup é exibido na lista Grupos de Escopos.
2. Para incluir conjuntos de escopos existentes no grupo de escopos, conclua as etapas a seguir:a) Na lista de Grupos de Escopos na guia Grupos de Escopos, selecione MyGroup e clique em Incluir.
A janela Incluir conjuntos de escopos no Grupo é exibida.
Capítulo 1. Usando 183

b) Selecione os conjuntos de escopo que deseja incluir no grupo.c) Clique em Incluir.
Etapa 2: Configurar a Lista de AcessoApós configurar o escopo para a sua descoberta, você deve fornecer informações de acesso para ossistemas de computador que incluiu. Essas informações ativam a comunicação entre o TADDM e aquelessistemas de computador durante o processo de descoberta.
Procedimento
Para configurar a lista de acesso para sua descoberta, conclua as seguintes etapas a partir do Console deGerenciamento de Descoberta:1. Na área de janela Funções, clique em Descoberta > Lista de Acesso. A área de janela Lista de Acesso
é exibida.2. Para incluir uma entrada para acessar sistemas Windows, clique em Incluir. O bloco de notas
Detalhes de Acesso é exibido.3. Na página Informações de Acesso, conclua as seguintes informações:
a) No menu Tipo de Componente, selecione Sistema do Computador (Windows).b) No campo Nome, digite windows para identificar a entrada na lista de tarefas.c) No campo Nome de usuário, digite administrador, que é o ID do usuário para acessar ambos os
sistemas Windows.d) Nos campos Senha e Confirmar Senha, digite password1, que é a senha correspondente paraadministrador.
4. Opcional: Na página Limitações de Escopo é possível escolher a limitação para os escoposselecionados para esta entrada de acesso. É possível escolher as caixas de seleção a seguir:
• Escopo inteiro - este é o valor padrão para entrada de acesso, não há limitações.• Limitar aos conjuntos de escopos selecionados e Limitar aos grupos de escopos selecionados -
Escolha os conjuntos de escopos ou grupos de escopos. A entrada da lista de acesso é usada apenasao descobrir o conjunto de escopos ou o grupo de escopos selecionado.
5. Clique em OK. Os novos detalhes de acesso estão incluídos na lista.6. Para incluir uma entrada para acessar o sistema Linux, clique em Incluir. O bloco de notas Detalhes
de Acesso é exibido.7. Na página Informações de Acesso, conclua as seguintes informações:
a) No menu Tipo de Componente, selecione Sistema do Computador.b) No campo Nome, digite linux para identificar a entrada na lista de tarefas.c) No campo Nome de usuário, digite linuxusr, que é o ID do usuário para acessar o sistema Linux.d) Nos campos Senha e Confirmar Senha, digite linuxusr, que é a senha correspondente paralinuxusr.
8. Opcional: Na página Limitações de Escopo é possível escolher a limitação para os escoposselecionados para esta entrada de acesso. É possível escolher as caixas de seleção a seguir:
• Escopo inteiro - este é o valor padrão para entrada de acesso, não há limitações.• Limitar aos conjuntos de escopos selecionados e Limitar aos grupos de escopos selecionados -
Escolha os conjuntos de escopos ou grupos de escopos. A entrada da lista de acesso é usada apenasao descobrir o conjunto de escopos ou o grupo de escopos selecionado.
9. Clique em OK. Os novos detalhes de acesso estão incluídos na lista.
Etapa 3: Incluir GatewaysEste cenário inclui a descoberta de sistemas Windows. Para descobrir informações sobre sistemasWindows em execução em seu ambiente, você deve especificar um sistema Windows para funcionarcomo um servidor de gateway. Este servidor gateway deve permitir acesso SSH a partir do servidorTADDM que pode exigir mudanças de regras em seu firewall.
184 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Procedimento
Para especificar um servidor gateway, conclua as seguintes etapas a partir do Console de Gerenciamentode Descoberta:1. Na área de janela Funções, clique em Descoberta > Âncoras e Gateways. A área de janela Âncoras e
Gateways é exibida.2. Na lista Âncoras e Gateways, clique em Incluir. A janela Incluir Âncora é exibida.3. Na lista Tipo, selecione Gateway do Windows.4. Clique em Nome do Host para configurar o servidor de gateway por seu nome do host.5. No campo Nome do Host, digite gateway_server, que é o nome do servidor de gateway a utilizar
para a descoberta de sistemas Windows especificados na configuração do escopo.6. Clique em OK para salvar as informações e retornar à área de janela Âncoras e Gateways.7. Depois que o servidor gateway for incluído, você deve fornecer credenciais de acesso a ele. Para
incluir credenciais de acesso ao gateway_server, clique em Descoberta > Lista de Acesso econclua as seguintes etapas:a) No menu Tipo de Componente, selecione Sistema do Computador (Windows).b) No campo Nome, digite gateway para identificar a entrada na lista de tarefas.c) No campo Nome de usuário, digite administrador, que é o ID do usuário para acessargateway_server.
d) Nos campos Senha e Confirmar Senha, digite gatewaypass, que é a senha correspondente paraadministrador.
e) Clique em OK. Os novos detalhes de acesso estão incluídos na lista.
Etapa 4: Incluir ÂncorasNeste cenário, existe um firewall entre o servidor TADDM e outra seção de sua rede, portanto énecessário ativar as descobertas por meio de firewalls. Para fazer isso, você deve especificar pelo menosum sistema de computador em cada seção da rede que esteja protegida por um firewall. Este sistema docomputador é conhecido como âncora.
Procedimento
Para especificar uma âncora, conclua as seguintes etapas a partir do Console de Gerenciamento deDescoberta:1. Na área de janela Funções, clique em Descoberta > Âncoras e Gateways. A área de janela Âncoras e
Gateways é exibida.2. Na lista Âncoras e Gateways, clique em Incluir. A janela Incluir Âncora é exibida.3. Na lista Tipo, selecione Âncora.4. Para configurar a âncora pelo seu nome do host, clique em Nome do Host.5. No campo Nome do Host, digite anchor_server, que é o nome da âncora a ser usado para descobrir
o sistema Linux especificado ao definir o escopo.6. Clique em OK para salvar as informações e para retornar à área de janela Âncoras e Gateways.7. Após a âncora ser incluída, é necessário incluí-la no seu conjunto de escopos. Para incluir a âncora no
seu conjunto de escopos, conclua as seguintes etapas:a) Na área de janela Funções, clique em Descoberta > Escopo.
A área de janela Escopo é exibida.b) Na lista Conjuntos de Escopos, selecione MyScope e, em seguida, clique em Incluir. A janela
Incluir Escopo é exibida.c) Na lista Tipo de IP, selecione Host.d) No campo Nome do Host, digite anchor_server.e) Clique em OK. O novo escopo é exibido na lista.
Capítulo 1. Usando 185

8. Após incluir a âncora no seu conjunto de escopos, você deve fornecer credenciais de acesso para ela.Para incluir credenciais de acesso para anchor_server, clique em Descoberta > Lista de Acesso econclua as etapas a seguir:a) No menu Tipo de Componente, selecione Sistema do Computador. Se o servidor âncora for um
servidor Windows, selecione Sistema de Computador (Windows).b) Para identificar a entrada na lista de tarefas, digite âncora no campo Nome.c) No campo Nome de Usuário, digite administrador, que é o ID do usuário para acessaranchor_server. Se o servidor de âncora for um servidor Windows, então, a conta deve terprivilégios de administrador.
d) Nos campos Senha e Confirmar Senha, digite anchorpass, que é a senha correspondente aancrusr.
e) Clique em OK. Os novos detalhes de acesso estão incluídos na lista.9. Clique em OK para salvar as informações e para retornar à área de janela Âncoras e Gateways.
Etapa 5: Executar a DescobertaVocê está pronto para executar sua descoberta.
Procedimento
Para executar uma descoberta, conclua as seguintes etapas a partir do Console de Gerenciamento deDescoberta:1. Na área de janela Funções, clique em Descoberta > Visão Geral. A área de janela Visão Geral é
exibida.2. Na área de janela Visão Geral, clique em Executar Descoberta. A janela Executar Descoberta é
exibida.3. A partir do menu de opções Escopo, selecione Elementos do Escopo Selecionados. Uma árvore de
escopos é exibida.4. Na árvore, selecione MyScope, que é o escopo definido especificado para a descoberta.5. A partir da lista de Perfis, selecione Descoberta de Nível 2. Além de descobrir sistemas de
computador, uma Descoberta de Nível 2 também descobre aplicativos que correspondem aosmodelos de servidor customizados.
6. Clique em OK para executar a descoberta. O processo de descoberta pode demorar alguns minutos. Épossível monitorar o progresso de sua descoberta na área de janela Visão Geral.
O que Fazer DepoisDepois que a descoberta for concluída, será possível visualizar informações sobre componentesdescobertos na área de janela Componentes Descobertos do Portal de Gerenciamento de Dados.
Etapa 6: Visualizar os DetalhesAgora, é possível visualizar todos os detalhes sobre os sistemas de computador que foram descobertos.
Procedimento
Para visualizar os detalhes de sistemas desconhecidos, conclua as seguintes etapas no Portal deGerenciamento de Dados:1. Na área de janela Componentes Descobertos, conclua uma das seguintes etapas:
• Navegue para os sistemas de computador descobertos que você deseja visualizar, por exemplo,Resumo de Inventário > Sistemas de Computador > Windows > windows1
• No campo Filtro, digite alguns ou todos os nomes do sistema de computador que você desejavisualizar; por exemplo, windows1.
2. Para visualizar os detalhes de windows1, clique duas vezes em sua entrada na área de janelaComponentes Descobertos. As propriedades do sistema de computador são exibidas na área dejanela Detalhes. A página Geral é exibida por padrão.
186 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

3. Para visualizar outros detalhes para windows1, clique nas guias localizadas na parte superior da áreade janela Detalhes.
4. É possível executar as ações selecionadas em um sistema de computador a partir da área de janelaComponentes Descobertos. Para executar uma ação em windows1, marque a caixa de seleção aolado do nome do sistema de computador e clique em Ações > action_name.
O que Fazer DepoisPara obter informações adicionais sobre a abordagem flexível para descoberta, consulte o documentoTADDM's Flexible Approach to Discovery em http://www.ibm.com/software/brandcatalog/ismlibrary/.
Estendendo Servidores CustomizadosEsta seção inclui um cenário de exemplo para estender um servidor customizado.
Etapa 1: Criar um Modelo de Servidor CustomizadoÉ possível criar um modelo de servidor customizado para estender um servidor customizado.
Para criar um modelo de servidor customizado, execute as seguintes tarefas:
Definir as Informações Gerais do ServidorA primeira etapa na criação de um modelo de servidor customizado é definir as informações gerais doservidor.
Procedimento
Para definir as informações gerais do servidor, execute as seguintes etapas a partir do Console deGerenciamento de Descoberta:1. Na área de janela Funções, clique em Descoberta > Servidores Customizados.
A área de janela Servidores Customizados é exibida.2. Para incluir um novo modelo de servidor customizado, clique em Novo.
O bloco de notas Detalhes do Servidor Customizado é exibido.3. No campo Nome, digite myServer, que é o nome do novo servidor customizado que você está
incluindo.4. Na lista Tipo, selecione AppServer, que é o tipo de servidor que está sendo incluído.5. Para descobrir o myServer AppServer, clique em Descobrir.6. Para ativar a definição do servidor customizado, clique em Ativado.
O que Fazer DepoisVocê deve especificar os critérios de identificação para myServer.
Especificar os Critérios de IdentificaçãoA segunda etapa na criação de um modelo de servidor customizado é especificar os critérios deidentificação.
Antes de IniciarVocê deve definir as informações gerais do servidor para o servidor customizado antes de especificar oscritérios de identificação.
Sobre Esta TarefaOs critérios de identificação são regras que são utilizadas para classificar um processo genéricodescoberto em um processo conhecido. Durante a descoberta, os seguintes atributos podem seravaliados para determinar se um CST corresponde:
• nome do programa• nome do serviço do Windows• argumentos
Capítulo 1. Usando 187

• variáveis de ambiente• todas as portas associadas
Procedimento
Para especificar os critérios de identificação, execute as seguintes etapas a partir da página InformaçõesGerais e Critérios do bloco de notas Detalhes do Servidor Customizado:1. Na seção Critérios de Identificação, clique em Todos os Critérios.
Essa etapa assegura que todos os critérios correspondam ao processo para corresponder a esse CST.2. Na primeira lista na seção Critérios de Identificação, selecione Nome do Programa.3. Na segunda lista na seção Critérios de Identificação, selecione termina-com.4. No campo junto ao segundo menu, digite java.5. Para incluir outro argumento na lista de critérios de identificação, clique em Incluir Critério.
Uma nova linha é incluída na seção Critérios de Identificação.6. Na primeira lista da seção Critérios de Identificação, selecione Porta.7. Na segunda lista da seção Critérios de Identificação, selecione é.8. No campo ao lado da segunda lista, digite 1098.
Essa etapa é importante porque você sabe que o processo usa a porta 1098.
O que Fazer DepoisOpcional: Depois de especificar todos os critérios de identificação, clique na guia Arquivos deConfiguração para abrir a página Arquivos de Configuração e inclua os arquivos de configuração nosdetalhes do servidor customizado.
Opcional: Incluir Arquivos de ConfiguraçãoApós concluir a página Informações Gerais & Critérios, você pode incluir arquivos de configuração parao servidor customizado. Essa etapa é opcional, entretanto, executando essas etapas, um arquivo deconfiguração é coletado a partir do sistema sempre que o CST corresponder.
Procedimento
Para incluir um arquivo de configuração, execute as seguintes etapas na página Arquivos deConfiguração do bloco de notas Detalhes do Servidor Customizado:1. Clique em Incluir para incluir um arquivo de configuração.
A janela Editar Arquivo de Captura é exibida.2. Na lista Tipo, selecione Arquivo de Configuração. Essa etapa especifica que o tipo de arquivo que
você está incluindo é um arquivo de configuração.3. Na lista Caminho da Procura, selecione "/" para especificar que o arquivo de configuração está
localizado no diretório-raiz.4. No campo Caminho de Procura, digite /configfiles/myServer.conf. Essa etapa especifica o
local do arquivo de configuração.5. Clique em Capturar conteúdo do arquivo.6. Clique em Limitar tamanho do arquivo capturado a.7. No campo Bytes, digite 10000 para limitar o tamanho do arquivo capturado a 10.000 bytes.8. Para salvar as informações do arquivo de configuração e fechar a janela Editar Arquivo de Captura,
clique em OK.O novo arquivo de configuração é exibido na página Arquivos de Configuração do notebook Detalhesdo Servidor Customizado.
9. Para salvar os critérios para o servidor customizado e retornar à área de janela ServidoresCustomizados, clique em OK. O Servidor de Aplicativos myServer é exibido na lista de servidorescustomizados.
188 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Etapa 2: Criar um Arquivo de DiretivaApós concluir o bloco de notasDetalhes do Servidor Customizado, você pode criar um arquivo dediretiva. Um arquivo de diretiva contém comandos e scripts que capturam atributos adicionais que nãoforam descobertos anteriormente. Criar um arquivo de diretiva é opcional, mas é uma etapa necessárianeste cenário, pois você precisa coletar a productVersion para myServer.
Procedimento
Para criar um arquivo de diretiva, conclua as seguintes etapas:1. Abra um editor de texto e digite o seguinte comando:
CMD:productVersion=cat /configfiles/myServer.conf|grep"^version"|awk'{print $2}'
2. Salve o arquivo no diretório $COLLATION_HOME/etc/templates/commands/myServer.
Etapa 3: Executar DescobertaAgora, é necessário executar uma descoberta. Esta etapa é necessária porque os servidorescustomizados devem ser descobertos para o modelo criado.
Sobre Esta TarefaConsulte “Configurando uma Descoberta” na página 181 para obter instruções completas sobre comoexecutar uma descoberta.
Aplicativos de NegóciosUm aplicativo de negócios é uma coleção de componentes que fornece uma funcionalidade de negóciosque você pode usar internamente, externamente ou com outros aplicativos de negócios. Você pode criaraplicativos de negócios de componentes individuais, que estão relacionados uns com os outros.
Por exemplo, Gerenciamento de Pedido, Gerenciamento de Inventário e Faturamento são aplicativos denegócios que podem usar componentes individuais como um servidor de aplicativos Java EE, LDAP e umbanco de dados que é executado no servidor Solaris.
O aplicativo de negócios é um tipo de coleção customizada. Também é possível criar os seguintes tiposde coleções customizadas:
• Coleção, que é um grupo de todos os recursos que você pode selecionar de acordo com as suasnecessidades.
• Coleção de acessos, que é uma coleção que é usada para controlar o acesso aos itens de configuração(CIs) e permissões para modificar itens de configuração. É possível criar coleções de acesso apenasquando a segurança de nível de dados estiver ativada. Para obter informações adicionais, consulte otópico Permissões no Guia do Administrador do TADDM.
Os métodos a seguir são fornecidos para criar aplicativos de negócios:
• Usar padrões de agrupamento no Portal de Gerenciamento de Dados.• Usar descritores de aplicativos.• Usar padrões de agrupamento que são criados com API Java e carregados pelo programa de
carregamento em massa.
Os aplicativos de negócios nas liberações anteriores do TADDM
Nas versões anteriores do TADDM, um aplicativo de negócios era uma coleta simples de CIsdesconectados. Estes CIs poderiam ser apenas elementos de nível superior de Modelo de Dados Comum.Eles foram agrupados em grupos de elementos funcionais do mesmo tipo. Cada CI teve que ser incluídoexplicitamente a um aplicativo de negócios, como uma instância ou utilizando uma regra de MQL. Issorequeria que o usuário soubesse exatamente quais elementos formavam o aplicativo de negócios e quaisobjetos dependentes o usuário deveria incluir no aplicativo de negócios.
Capítulo 1. Usando 189

Nova abordagem para gerar aplicativos de negócios usando padrões de agrupamento
Com essa liberação do TADDM, a abordagem para criar aplicativos de negócios muda radicalmente. Umaplicativo de negócios é agora um gráfico de CIs conectados de tipos que você especifica. Os elementosmais importantes ao construir aplicativos de negócios são CIs principais. CIs principais fornecem valor denegócios principal para o aplicativo de negócios específico, por exemplo, aplicativo Java Platform,Enterprise Edition ou um banco de dados. Eles são os únicos elementos que você deve incluirmanualmente (por MQL ou consulta SQL, um conjunto de instâncias de CI ou como arquivos de descritorde aplicativo) ou usando API (no caso de cenários de integração). Todos os outros elementos queconstituem a infraestrutura de apoio para o aplicativo de negócios são incluídos automaticamentepercorrendo relações e dependências que são descobertos e armazenados no TADDM. É possível decidirquais as relações são atravessadas e quais são ignoradas. Também é possível decidir quais CIs de todosos objetos atravessados são usados para compor o aplicativo de negócios resultante.
Como você não pode ter certeza de que todas as dependências necessárias já estão descobertas earmazenadas no TADDM ou porque pode haver dependências que têm significado estritamente comerciale não podem ser descobertas automaticamente, é possível especificar mais de um CI principal para cadaaplicativo de negócios. É possível criar muitas consultas para selecionar vários CIs principais ou épossível usar CustomSqlDependencyAgent para criar mais dependências entre objetos relacionados.Se você usar o agente, não precisará criar mais consultas.
Um padrão de agrupamento consiste em consultas que selecionam CIs principais, a fórmula que calcula onome de aplicativos de negócios a partir dos CIs principais e uma descrição que define a forma como osobjetos dependentes são atravessados. Padrões de agrupamento são processados automaticamente deacordo com o planejamento que você define e coleções customizadas são geradas como resultado. Cadavez que um padrão de agrupamento é processado, todas as consultas são processadas, todas asdependências são atravessadas e a estrutura do aplicativo de negócios é gerada, de acordo com os CIs eas relações existentes. Como resultado, todas as mudanças ambientais na estrutura do aplicativo denegócios são automaticamente capturadas e refletidas quando o padrão de agrupamento é processado.Por exemplo, se um novo servidor de aplicativos ou uma nova máquina virtual é descoberta, ela é incluídaautomaticamente no aplicativo de negócios. Se um CI foi modificado ou removido, por exemplo, umsistema de computador virtual foi movido para outro hypervisor, as alterações são aplicadasautomaticamente, ou seja, o sistema de computador virtual é removido do aplicativo que continha ohypervisor.
Em liberações anteriores, um modelo de aplicativo poderia produzir apenas um aplicativo de negócios.Agora, é possível criar não apenas um aplicativo de negócios a partir de um padrão de agrupamento, mastambém é possível criar muitos aplicativos de negócios a partir de um padrão ou um pequeno conjunto depadrões. Como resultado, é fácil generalizar padrões de agrupamento para produzir instâncias deaplicativos de negócios para diversos ambientes, por exemplo, o aplicativo implementado nos ambientesde produção, teste, garantia de qualidade e de desempenho. Para conseguir isso, uma expressão denome do agrupamento é criada. É possível usá-la para fornecer uma fórmula para calcular o nome de umaplicativo de negócios a partir de seu CI principal. Por exemplo, é possível usar as convenções denomenclatura para extrair partes específicas de nomes de CIs ou qualquer atributo existente que denoteo propósito de um ambiente específico. Também é possível extensão essa generalização. Por exemplo, épossível criar um padrão de agrupamento que gere todos os aplicativos de negócios de um determinadotipo, como Java Platform ou aplicativos Enterprise Edition, em todos os ambientes de implementação.
Para obter informações adicionais sobre configuração de padrões de agrupamento e processamento depadrões de agrupamento de controle, consulte “Processamento de padrões de agrupamento” na página216.
Nota: Aplicativos de negócios que são criados com a configuração padrão contêm apenas objetos de nívelalto e de nível médio. Portanto, alguns tipos de CI, que eram objetos de alto nível no TADDM 7.2.2, nãosão mais objetos de alto nível na versão 7.3.0. Como resultado, eles não são incluídos em aplicativos denegócios. Os novos objetos de alto nível são SComputerSystem, SSoftwareServer, SLogicalGroup,SPhysicalFile, SSoftwareInstallation, SFunction. O novo objeto de nível intermediário éSDeployableComponent. Além disso, no novo modelo, não há nenhum tipo OperatingSystem, seusatributos foram mesclados na classe simple.SComputerSystem.
190 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Introdução aos aplicativos de negóciosAntes de criar seus aplicativos de negócios, deve-se planejá-los cuidadosamente. Essas orientaçõesgerais podem ajudar o Cliente a decidir como construir seus aplicativos de negócios.
Selecionando os ICs principaisOs CIs principais são o ponto de início de seu aplicativo de negócios. Deve-se primeiro decidir qual é afunção de seu aplicativo de negócios e, em seguida, selecionar o IC principal apropriado. Umaplicativo geralmente consiste em elementos que constituem o próprio aplicativo e na infraestruturana qual ele está implementado. Se estiver criando um aplicativo de negócios para middleware, porexemplo, um banco de dados ou um servidor de aplicativos, é aconselhável selecionar o objetoimplementável mais alto, não os elementos de infraestrutura. A infraestrutura é o que você desejadescobrir. O objeto é o mais alto quando ele está no nível superior da hierarquia e nenhum outroobjeto depende dele. Por exemplo, é possível selecionar um aplicativo Java Platform, EnterpriseEdition, que é implementado em um servidor WebSphere. O objeto implementável mais alto é umbom início na maioria dos casos.Em alguns casos, é possível selecionar um sistema de computador como o CI principal, por exemplo,se o sistema de computador não hospedar qualquer componente de software. Caso contrário, seránecessário ser muito cauteloso em tais opções, porque essa seleção gerará aplicativos muitograndes, que poderão ser difíceis de exibir e que poderão fazer com que o servidor TADDM falhe comuma condição de falta de memória.Se estiver criando um aplicativo de negócios para um servidor independente no qual nenhum objetopode ser implementado, será possível selecionar este servidor como o CI principal.
O tamanho de um aplicativo de negóciosO tamanho de seu aplicativo de negócios depende de suas necessidades. Não há nenhum limite parao número de nós que podem ser criados, mas tenha em mente que quanto maior o aplicativo, maior atopologia e mais memória é necessária. Os aplicativos muito grandes têm pouco valor, porque vocêserá incapaz de exibi-los e analisá-los. O tamanho máximo da topologia é limitado pela memória. Paraevitar o travamento do servidor TADDM, uma verificação de segurança é implementada. O limitedepende das configurações de tamanho de heap Java máximo atual para o processo de JVM doTomcat (TADDM 7.3.0) ou para o processo de JVM do Liberty (TADDM 7.3.0.1 e mais recente). Asconfigurações são definidas com base em uma função linear (25 * M / 32) - 200, em que M é otamanho de heap Java máximo. Por exemplo, a topologia que possui 600 nós requer 1 GB de heap. Atopologia que possui 3.000 nós requer 4 GB de heap. O limite se aplica a todas as topologias que sãosimultaneamente exibidas em vários navegadores, não apenas para o usuário atual.Para assegurar que a topologia não seja muito grande, é possível criar um aplicativo, configurar oparâmetro maxHopsLimit para um valor inferior, por exemplo 2 e analisar o aplicativo resultante. Sevocê perceber que a passagem não é grande o suficiente, será possível definir esse parâmetro comum valor mais alto. É possível analisar quais relações e dependências são incluídas, como os dadossão transferidos. Em seguida, é possível incluir mais elementos se você achar que o aplicativo nãopossui componentes importantes, ou filtrar alguns dos elementos que são insignificantes para o seuaplicativo. Para incluir e filtrar as dependências e relações, use a configuração do padrão deagrupamento.O tamanho dos aplicativos de negócios é correlacionado aos planejamentos de sua execução. Ointervalo no qual o processo de construção é iniciado deve ser maior que o tempo total de construçãodo aplicativo. Por exemplo, se você tiver um aplicativo grande, que é construído para algumas horas,aumente o intervalo para, por exemplo, 20 horas.
PlanejamentosOs aplicativos são reconstruídos nos intervalos especificados. O intervalo padrão é a cada 4 horas.Considere quais mudanças são feitas em seus aplicativos de negócios, e com que frequência, econfigure o intervalo em conformidade. Se um aplicativo for crítico para seus negócios, configure-opara ser executado com mais frequência, por exemplo, a cada dia ou duas vezes por dia. Se umaplicativo for menos importante, será possível defini-lo para ser executado com menos frequência,por exemplo, uma vez por semana. É melhor quando nem todos os seus aplicativos são reconstruídosao mesmo tempo. No entanto, se você tem certeza de que tem encadeamentos suficientes paraprocessar todos os padrões de agrupamento, poderá planejá-los para execução ao mesmo tempo. Sevocê planeja seus planejamentos com cuidado, poderá evitar uma situação em que não há
Capítulo 1. Usando 191

encadeamentos disponíveis para o processamento de padrões de agrupamento, o que pode fazercom que um aplicativo crítico fique esperando ser atualizado.Use a ferramenta bizappscli para configurar as programações do aplicativo.Ajuste o planejamento para o tamanho do aplicativo de negócios, conforme especificado na seçãoanterior.
Referências relacionadas“Configurando o tamanho máximo de topologias exibidas” na página 215A exibição de grandes topologias consome muita memória e pode até travar o servidor TADDM. Paraevitar isso, uma verificação de segurança é implementada. Também é possível configurar o tamanhomáximo da topologia, dependendo de suas necessidades, no arquivo collation.properties.“Configuração dos padrões de agrupamento” na página 216É possível controlar o processo de criação de aplicativos de negócios usando a configuração de padrõesde agrupamento. A configuração permite incluir ou excluir as relações escolhidas durante a passagem dedados e as classes escolhidas dos aplicativos de negócios resultantes. Também é possível alterar adireção de dependência para relações definidas no Modelo de Dados Comum e designar camadas aoselementos de aplicativo de negócios.“Ações para gerenciar planejamentos de padrão de agrupamento” na página 239Ao usar a ferramenta bizappscli, é possível criar e modificar os planejamentos de padrões deagrupamento.
Estrutura do aplicativo de negóciosA estrutura do aplicativo de negócios é criada automaticamente, com base em uma definição de padrãode agrupamento e nas definições de seletores de padrão de agrupamento.
Para obter detalhes, consulte “Criando padrões de agrupamento” na página 194.
A estrutura de aplicativos de negócios possui um formato de um gráfico direcionado. Os elementosgráficos são denominados Nós e o as bordas dos gráficos são chamadas Caminhos.Aplicativo de negócios
O aplicativo de negócios é representado por uma nova classe no Modelo de Dados Comum chamada
com.collation.platform.model.topology.customCollection.CustomCollection
CustomCollection tem um significado mais amplo e pode representar não apenas aplicativos denegócios, mas também outros tipos de coleções que não têm significado estritamente comercial. Oatributo hierarchyType define o significado de cada coleção customizada. Atualmente, esseatributo pode ter três valores: Business Application, Collection, e Access Collection. A Coleção deAcessos é usada pelo TADDM para controlar o acesso a alguns conjuntos de dados. Para obter maisinformações sobre segurança no nível de dados, veja o tópico Permissions no TADDM Administrator'sGuide.
Nós do aplicativo de negóciosUm nó do aplicativo de negócios sempre aponta para apenas um componente, que geralmente é umitem de configuração. O nó é representado por uma nova classe no Modelo de Dados Comumchamada com.collation.platform.model.topology.customCollection.Node.Um nó não está visível no Portal de Gerenciamento de Dados. Isso significa que ao exibir a área dejanela de detalhes para um determinado nó, a área de janela de detalhes de um componente ao qualo nó está conectado é exibida.Para estes tipos de elementos que são menos importantes ou irrelevantes para a estrutura geral, osnós não são criados. Esses elementos são chamados de elementos de nível baixo e geralmente nãosão itens de configuração, por exemplo, endereço IP, sistema operacional, processo, CPU.
Caminhos de aplicativos de negóciosUm caminho de aplicativo de negócios é uma conexão entre dois nós de aplicativo de negócios. Ocaminho é representado por uma nova classe no Modelo de Dados Comum chamadacom.collation.platform.model.topology.customCollection.Path. O caminho é sempre
192 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

direcionado de acordo com a direção de dependência dos objetos. Isso significa que o objetodependente aponta para o objeto do qual ele depende.Um caminho contém informações sobre os nós de origem e de destino, e sobre uma rota a partir deum nó de origem para um nó de destino.Caminhos representam relações ou dependências entre objetos de origem e destino, mas elestambém podem representar subgráficos inteiros. Os subgráficos incluem todos os nós que não foramincluídos como nós no aplicativo de negócios, conforme definido na configuração de composição dopadrão de agrupamento que gerou o aplicativo de negócios específico. Todos os elementos que sãoexcluídos pela configuração de composição e as relações entre eles são armazenados comoinformações detalhadas para apenas um caminho entre um par específico de objetos. É possívelvisualizar esses detalhes na área de janela de detalhes do caminho.Dois objetos podem ser conectados por mais de uma rota. Por exemplo, dependência direta entre osobjetos de origem e de destino, relação direta entre objetos de origem e de destino e uma rota queconecta um par de objetos de nível baixo por meio de um conjunto de relações e dependências. Noentanto, todos os objetos que foram incluídos durante a passagem são representados por apenas umcaminho e os dados detalhados (o atributo XD) contêm informações adicionais para cada rota.Para obter detalhes sobre caminhos de aplicativos de negócios, consulte “Área de janela de detalhesdo Caminho do Aplicativo de Negócios” na página 156.
A classe CustomCollection não tem relações com nós e caminhos, mas a classe Nó e a classe Caminhotêm relações com a classe CustomCollection. Se você deseja consultar todos os nós ou caminhos parauma coleção customizada específica, consulte esses nós ou caminhos, o atributo pai do que aponta parauma coleção customizada específica. Por exemplo:
select * from Path em que parent.guid == 'DED47778C834ABAFBA6A55137D1A8B'
Consultando rotasCada CI pode ter dados adicionais que são armazenados como XML, juntamente com o objeto. Oatributo que contém dados XML é chamado XD. No caso de um objeto de caminho, este atributoarmazena informações detalhadas sobre objetos de nível baixo que foram atravessados durante ageração de aplicativos de negócios, mas que foram excluídos pela configuração de composição. Eletambém armazena informações detalhadas sobre esses objetos. Para obter detalhes sobre aconfiguração de composição, consulte “Configuração de composição” na página 222.O seguinte exemplo mostra um resultado a partir da consulta de um objeto de caminho:
<Path array="1" guid="F92431E223E637ECAC3775DD54AA0AC2" lastModified="1413539533336" parent="DED47778CBA834ABAFBA6A55137D1A8B" xsi:type="coll:com.collation.platform.model.topology.customCollection.Path"> <sourceNodeGuid>5B2C7E013F4A3E948080405446FC38DD</sourceNodeGuid> <targetNodeGuid>24EEC97B70F43039AE2EC88C31D96B56</targetNodeGuid> <displayName>1.0.0.0/24 - 1.0.0.7</displayName> <bidiFlag>3</bidiFlag> <XD> <xml> <routes> <instance> <routeStart/> <fromObjectGuid>1AA04147456D3FB3811DDC1425732B56</fromObjectGuid> <relationshipType>net.IpInterface(ipNetwork) -> relation.Networks -> net.IpNetwork</relationshipType>
<toObjectGuid>EB377A0AB0BA35E9A78688FACEFE181E</toObjectGuid>
<fromObjectGuid>1AA04147456D3FB3811DDC1425732B56</fromObjectGuid> <relationshipType>net.IpInterface(parent) -> relation.Contains -> sys.ComputerSystem(ipInterfaces)</relationshipType>
<toObjectGuid>4FF04D906FD8354298DCB2F9116AD0C3</toObjectGuid> </instance>
Capítulo 1. Usando 193

</routes> </xml> </XD> <isPlaceholder>false</isPlaceholder> <status>1</status> <statusChangeTime>1413539533336</statusChangeTime></Path>
Para consultar dentro do atributo XD, você pode utilizar um novo operador eval. Por exemplo, paraconsultar caminhos que contêm um objeto específico como um objeto de nível baixo, use a seguinteconsulta:
select * from Path where XD eval'/xml/routes/instance[fromObjectGuid=\"1AA04147456D3FB3811DDC1425732B56\"]'
Para obter informações adicionais sobre MQL e o operador eval, consulte o tópico Linguagem deConsulta do Modelo no SDK Developer's Guide do TADDM.
Nota: Cada rota possui segmentos. Um segmento consiste em dois nós que são conectados por umrelacionamento ou dependência. Se o número de segmentos excede o limite que é definido napropriedade com.ibm.cdb.serviceinfrastructure.path.max.length, a rota não é criada. Paraobter detalhes, consulte “Configurando as entradas do arquivo collation.properties” na página 248.
Criando aplicativos de negócios com padrões de agrupamentoÉ possível criar aplicativos de negócios definindo padrões de agrupamento no Portal de Gerenciamentode Dados.
Criando padrões de agrupamentoÉ possível criar novos padrões de agrupamento na área de janela Padrões de Agrupamento, no Portal deGerenciamento de Dados.
Procedimento
Para criar um novo padrão de agrupamento, conclua as etapas a seguir:1. Abra Portal de Gerenciamento de Dados.2. Na área de janela Funções, clique em Descoberta se TADDM 7.3.0 ou 7.3.0.1 for usado, ou em
Analytics, se TADDM 7.3.0.2 ou mais recente for usado.3. Clique em Padrões de Agrupamento. A tabela Padrões de Agrupamento é exibida.4. Clique em Nova. A área de janela Informações Gerais da janela Criar Novo Padrão de Agrupamento
é exibida.5. No campo Nome, especifique um nome de padrão de agrupamento. O nome pode ser alterado para
um nome diferente e ele não precisa ser exclusivo.6. Selecione o tipo de padrão e selecione o tipo de compatibilidade de padrão se aplicável.
a) Os tipos de padrão a seguir estão disponíveis:
• Aplicativo de Negócios, que é uma coleção de componentes que fornece umafuncionalidade de negócios que pode ser usada internamente, externamente ou com outrosaplicativos de negócios.
• Coleção de Acessos, que é uma coleção usada para controlar o acesso aos itens deconfiguração (ICs) e as permissões para modificá-los quando a segurança em nível de dadosestiver ativada.
• Coleção, que é um grupo de quaisquer recursos que podem ser selecionados de acordo comsuas necessidades.
b)É possível selecionar o tipo de compatibilidade de padrão somente quando a compatibilidade como modo da versão anterior estiver ativado. Esse tipo determina o tipo para o qual a antiga entidadede agrupamento é convertida. Para obter mais informações sobre o processo de conversão,
194 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

consulte “Migração da 7.2.2 e conversão automática de antigos aplicativos de negócios” napágina 251.O tipo de compatibilidade é baseado em um tipo de padrão escolhido:
• Coleção - somente o tipo de compatibilidade Coleção está disponível.• Coleção de Acessos - somente o tipo de compatibilidade Coleção de Acessos está
disponível.• Aplicativo de Negócios - os tipos a seguir estão disponíveis:
– Aplicativo de Negócios.– Serviço de Negócios.
7. Especifique o valor da opção Planejamento. Esse é o momento em que os aplicativos de negóciossão gerados. É possível escolher entre os valores predefinidos ou alterar o momento usando aferramenta bizappscli.
8. Especifique o valor para a opção Configuração. É possível escolher entre os valores predefinidos oualterar a configuração usando a ferramenta bizappscli. A ferramenta permite modificar opçõesavançadas do processo de construção do aplicativo de negócios.
9. Opcional: Insira uma breve descrição na área Descrição.10. Opcional: Se aplicável, no campo URL, especifique a URL que vincula ao aplicativo de negócios.11. Clique em Avançar. A área de janela Seletores é exibida.
Nota: É possível criar uma versão de rascunho de um seletor selecionando a caixa de seleçãoDesativado. Tal seletor não é usado pelo BizAppsAgent na construção de coleções customizadas.
12. Clique em Novo para incluir um seletor e insira o nome do seletor.13.
Opcional: No campo Nome da Camada, especifique o nome da camada do seletor. Para obter maisinformações, consulte “Camadas de aplicativo de negócios” na página 252.
14. Opcional: Insira a descrição do seletor na área Descrição.15. Defina regras de seleção. Clique em Escolher...16. Clique em Escolher... para editar o método de seleção de ICs principais e expressão de nome do
agrupamento. Uma nova janela será exibida.a) Escolha o tipo de seleção de IC principal. Os métodos a seguir estão disponíveis:
• Consulta MQL - insira uma consulta na área de texto. O "SELECT * FROM" inicial já estacodificado permanentemente, portanto, é necessário especificar apenas a tabela de origem e ascondições opcionais. Para obter mais informações, consulte o tópico Visão geral do Idioma daConsulta de Modelo no SDK Developer's Guide.
• Consulta SQL - insira uma consulta na área de texto. O "SELECT * FROM" inicial já estacodificado permanentemente, portanto, é necessário especificar apenas a tabela de origem e ascondições opcionais. Para esse tipo de consulta, use os nomes de visualização do banco dedados de bloco de construção, e não nomes de tabela, por exemplo,BB_COMPUTERSYSTEM40_V WHERE NAME_C like 'test%'.
• Seleção baseada em instância - selecione ICs manualmente da lista de todos os ICsdescobertos.
Nota: É possível definir consultas customizadas ao clicar em Obter a partir de modelos.Consultas customizadas podem ser salvas e reutilizadas em outros seletores.
b) Edite o campo Expressão do nome do agrupamento. Insira a expressão do nome doagrupamento para o seletor ou deixe o valor padrão "${patternName}". O valor padrãoconfigura o nome da coleção gerada como o nome do padrão do agrupamento.Para obter mais informações sobre expressão de nome do agrupamento, consulte “Expressão denome do agrupamento” na página 211.
c) Opcional: Clique em Testar para verificar se o método de seleção e a expressão de nome doagrupamento são válidos. Se houver um erro, o campo relevante será destacado e a mensagem de
Capítulo 1. Usando 195

erro detalhada será indicada pela dica de ferramenta. Se não houver erros de validação, é possívelver os resultados de amostra. Para cada IC principal, um nome calculado da coleção customizadaestá incluído. Se a expressão do nome do agrupamento não for aplicável para alguns dos CIsprincipais, por exemplo, quando um atributo não é configurado para o objeto, um aviso é exibido.Coleções customizadas não são criadas para tais ICs principais.
Nota: Mesmo se você não testar a consulta e a expressão do nome do agrupamento, elas sãovalidadas automaticamente quando você salva o padrão de agrupamento inteiro. Se houver algumerro, o padrão de agrupamento não será salvo,, a menos que o erro faça referência ao seletordesativado.
d) Clique em OK para aceitar as mudanças e fechar a janela de diálogo.O status de validação de cada seletor é representado por um ícone na lista de seletores. É possívelmover o mouse sobre o ícone para ver uma mensagem da dica de ferramenta com detalhes.
17. Selecione ou limpe as opções relativas ao Modelo de Passagem de Dependência, que afeta como osICs relacionados são incluídos na coleção.
• Limpe a opção Modelo de Passagem de Dependência para ignorar as dependências depassagem do IC principal. Nesse caso, coleções customizadas que são geradas por este seletorconsistem apenas em ICs especificados pela consulta do seletor.
• Se você selecionar a opção Modelo de Passagem de Dependência, as opções a seguir estarãodisponíveis:
– Higher Up - atravessar as dependências de cima. Quando você seleciona essa opção, oBizAppsAgent atravessa todos os objetos, dos quais um CI principal específico depende etodos os outros objetos que dependem desses objetos. Por exemplo, o BizAppsAgentatravessa de um hypervisor até todos os sistemas de computador que estão hospedados nelee, em seguida, até todos os servidores de aplicativos que estão hospedados nesses sistemasde computador.
– Higher Down - atravessar as dependências de cima e, em seguida, de baixo. É possívelselecionar esta opção somente quando a opção HigherUp estiver selecionada. Com a opçãoHigher Down selecionada, BizAppsAgent passa por todos os objetos que encontra enquantoatravessa as dependências de baixo para cima.
– Lower Down - atravessar as dependências de baixo. Quando você seleciona esta opção,BizAppsAgent atravessa todos os objetos, dos quais depende um IC principal específico, etodos os outros objetos dos quais dependem esses objetos. Por exemplo, o BizAppsAgentatravessa do servidor da web até um sistema de computador hosting, do qual o servidor da webdepende e, em seguida, vai do sistema de computador até um hypervisor hosting, do qual osistema de computador depende.
– Lower Up - atravessar as dependências de baixo e, em seguida, de cima. É possível selecionaresta opção somente quando a opção LowerDown estiver selecionada. Com a opção Lower Upselecionada, BizAppsAgent passa por todos os objetos que encontra enquanto atravessa asdependências de baixo.
18. Opcional: É possível incluir mais seletores nesse padrão de agrupamento clicando em Novo erepetindo as etapas 12 - 17.
19. Opcional: É possível revisar outros seletores desse padrão de agrupamento ao clicar em um seletorna lista à esquerda da janela. É possível então mudar os detalhes de cada seletor.
20. Opcional: É possível remover um seletor ao selecioná-lo na lista à esquerda da janela e clicar emExcluir.
21. Clique em Avançar. A área de janela Informações Administrativas é exibida.22. Opcional: Especifique as informações apropriadas na área de janela Informações Administrativas.23. Opcional: Clique em Avançar. A área de janela Atributos Estendidos é exibida.
Nota: Esta área de janela será exibida somente se os atributos estendidos para o tipo Padrão deAgrupamento forem definidos.
196 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Para saber mais sobre os atributos estendidos e suas definições, consulte o tópico Atributosestendidos no TADDM SDK Developer's Guide.
24. Opcional: Especifique as informações apropriadas na área de janela Atributos Estendidos. Essesatributos estendidos são copiados nas coleções customizadas geradas.
Notas:
• Não é necessário incluir definições de atributos estendidos no tipo de coleção customizadaexplicitamente. As definições necessárias são criadas automaticamente pelo BizAppsAgentdurante a geração de coleções customizadas.
• Quando definições dos atributos estendidos são clonadas automaticamente do Padrão deAgrupamento para um tipo de Coleção Customizada, o tipo de cada atributo estendido é ampliadopara String para evitar perda de dados durante o cast de valores existentes.
• Toda vez que os padrões de agrupamento são processados, os valores de atributo estendidoexistentes de uma coleção customizada são atualizados. As mudanças manuais nos atributosestendidos propagados de uma coleção customizada são perdidas na próxima execução do padrãode agrupamento. Se coleções customizadas criadas a partir de um único padrão de agrupamentodevem ter um atributo estendido que pode ser customizado para cada coleção customizada deforma independente, então, é necessário definir um atributo estendido dedicado para o tipoCustomCollection com um nome e categoria groupingPattern exclusivos.
25. Clique em Concluir para fechar o assistente e enviar o padrão de agrupamento recém-criado. Atabela Padrões de Agrupamento é atualizada automaticamente.
Referências relacionadas“Ferramenta bizappscli” na página 233É possível usar a ferramenta bizappscli CLI para gerenciar padrões de agrupamento, planejamentosde processamento de padrão de agrupamento, configurações padrão e a execução de padrões deagrupamento.
É possível usar a ferramenta para criar relatórios para analisar o conteúdo de aplicativos denegócios.
É possível usar a ferramenta para exportar o gráfico da topologia do aplicativo de negócios parao formato SVG.
Exibindo padrões de agrupamentoÉ possível exibir detalhes dos padrões de agrupamento na área de janela Padrões de Agrupamento noPortal de Gerenciamento de Dados.
Sobre Esta Tarefa
Nota: Para exibir a área de janela Padrões de agrupamento com seu conteúdo, deve-se ter apermissão de Atualização concedida para o DefaultAccessCollection.
Procedimento
Para exibir as informações de padrões de agrupamento, conclua as etapas a seguir:1. Na área de janela Funções, clique em Descoberta se TADDM 7.3.0 ou 7.3.0.1 for usado, ou em
Analytics, se TADDM 7.3.0.2 ou mais recente for usado.2. Clique em Padrões de Agrupamento. A tabela Padrões de Agrupamento é exibida.3. Opcional: Se durante o processamento do padrão de agrupamento pelo BizAppsAgent ocorrerem
erros, um ícone de aviso será exibido. Para ver a mensagem de erro detalhada, mova o mouse sobre oícone ou clique no botão Editar para abrir a guia Informações Gerais.
Nota: Quando um padrão de agrupamento é processado e ocorre um erro durante os cálculos de CIprincipal, por exemplo, a consulta fornecida é inválida, o processamento desse padrão deagrupamento é abandonado. O conteúdo de coleções customizadas de nenhum seletor não écalculado, portanto, coleções customizadas permanecem inalteradas. Outros padrões deagrupamento são processados normalmente.
Capítulo 1. Usando 197

O que Fazer Depois
• É possível atualizar a lista de padrões de agrupamento que são exibidos na tabela Padrões deAgrupamento. Clique em Atualizar Visualização.
• É possível classificar os padrões de agrupamento na tabela Padrões de Agrupamento. Por exemplo,para classificar os padrões de agrupamento por tipo, clique na coluna Tipo.
Editando padrões de agrupamentoÉ possível editar um padrão de agrupamento existente na área de janela Padrões de Agrupamento, noPortal de Gerenciamento de Dados.
Procedimento
Para editar um padrão de agrupamento existente, conclua as etapas a seguir:1. Na área de janela Funções, clique em Descoberta se TADDM 7.3.0 ou 7.3.0.1 for usado, ou em
Analytics, se TADDM 7.3.0.2 ou mais recente for usado.2. Clique em Padrões de Agrupamento. A tabela Padrões de Agrupamento é exibida.3. Selecione o padrão que deseja editar e clique em Editar.4. Edite um ou mais atributos padrão.
Para saber mais sobre a UI para edição de atributos de um padrão de agrupamento e os seusseletores, consulte “Criando padrões de agrupamento” na página 194. Para modificar seletores dopadrão de agrupamento, acesse a guia Seletores.
5. Para salvar as alterações, clique em OK.
Excluindo padrões de agrupamentoÉ possível excluir um padrão de agrupamento existente na área de janela Padrões de Agrupamento, noPortal de Gerenciamento de Dados.
Procedimento
Para excluir um padrão de agrupamento existente, conclua as etapas a seguir:1. Na área de janela Funções, clique em Descoberta se TADDM 7.3.0 ou 7.3.0.1 for usado, ou em
Analytics, se TADDM 7.3.0.2 ou mais recente for usado.2. Clique em Padrões de Agrupamento. A tabela Padrões de Agrupamento é exibida.3. Selecione o padrão que deseja excluir e clique em Excluir.4. Para salvar as alterações, clique em OK.
O padrão de agrupamento selecionado é removido.
Criando aplicativos de negócios com descritores de aplicativosDescritores de aplicativos em versões anteriores do TADDM foram usados para ajudar a automatizar oprocesso de descoberta, criação e manutenção de aplicativos de negócios. Agora, eles são uma parteimportante de um novo mecanismo de Composição do Aplicativo de Negócios. Novos padrões deagrupamento são criados ciclicamente e os padrões de agrupamento existentes são modificadosciclicamente usando dados de descritores de aplicativos descobertos.
Usar descritores de aplicativos em sistemas de computador e servidores de software permite a inclusãoautomática desses sistemas de computador, servidores, juntamente com outros componentesimplementados neles e módulos de software em um aplicativo de negócios específico. É possível incluirtal sistema e seus componentes em um aplicativo de negócios apenas ao colocar um arquivo XML dodescritor de aplicativo apropriado no local predefinido ou no local especificado no arquivocollation.properties. Não é necessário usar a UI do TADDM ou qualquer configuração. ArquivosXML descritores de aplicativos são lidos durante uma descoberta de infraestrutura do TADDM regular.Após esse processo, o agente do descritor de aplicativo, junto com o agente do aplicativo de negócios,processa periodicamente todos os descritores descobertos e gera seletores apropriados ou padrões deagrupamento, se necessário, a partir desses descritores descobertos. Os seletores ou padrões de
198 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

agrupamento gerados são então processadas pelo agente de aplicativo de negócios, que gera aplicativosde negócios de destino.
Seletores são gerados juntos pelo AppDescriptorAgent e o BizAppsAgent. OAppDescriptorAgent apenas cria novos padrões de agrupamento a partir de novos descritores deaplicativos. Essa é a única tarefa que ele executa. Ele não atualiza os seletores com base nos descritoresde aplicativos para os padrões de agrupamento existentes. O BizAppsAgent atualiza tais seletores paratodos os nomes de aplicativos de negócios que foram gerados a partir de um padrão de agrupamentoespecífico. Para ter certeza de que os padrões de agrupamento contêm dados atualizados, quando elessão criados, eles são processados ciclicamente pelo BizAppsAgent. Durante o processamento de umpadrão de agrupamento específico, o BizAppsAgent primeiramente processa tipos de seletor diferentesdaquele baseado em descritores de aplicativos. Quando o agente conclui a criação de todos os aplicativosde negócios, ele coleta os seus nomes e atualiza seletores com base em descritores de aplicativos. Porexemplo, o agente cria novos seletores, modifica seletores existentes ou remove um seletor se odescritor de aplicativo foi removido.
Para criar padrões de agrupamento e seletores com base em descritores de aplicativos, todos osdescritores de aplicativos que são armazenados no banco de dados TADDM são lidos e agrupados pelonome do aplicativo de negócios de destino. Para cada aplicativo de negócios, uma lista de componentes egrupos funcionais designados a eles é criada usando ICs que são fornecidos nos descritores deaplicativos do componente. Essa lista é, então, dividida pelos nomes de grupos funcionais, e seletoresespecíficos são criados para cada grupo funcional. O nome do grupo funcional é usado como um nome dacamada no seletor gerado. Para obter informações adicionais sobre configuração de camadas, consulte“Configuração de camadas” na página 224.
Se o descritor de aplicativos base fornece o nome do padrão de agrupamento, esse padrão deagrupamento é atualizado com a nova lista de seletores ou um novo padrão de agrupamento é criado. Seo padrão de agrupamento não for fornecido, o agente verifica se o aplicativo de negócios de destinoexiste. Se ele existe, o agente localiza o padrão de agrupamento que gerou esse aplicativo de negócios(ele pode ser o padrão de agrupamento para um aplicativo de negócios ou um padrão de agrupamentomais geral que gera um grupo de aplicativos de negócios) e anexa os seletores gerados a esse padrão deagrupamento. Se o aplicativo de negócios de destino não existe, um novo padrão de agrupamento écriado para gerar apenas esse único aplicativo de negócios. Se um descritor de aplicativo do componenteespecífico foi removido da máquina de destino e esta mudança foi refletida no banco de dados do TADDMapós a descoberta, o BizAppsAgent remove esses componentes dos seletores existentes. Se, após essamodificação, o seletor ficar vazio, ele também será removido. Se um padrão de agrupamento não contivermais nenhum seletor, ele será desativado e, como resultado, removido do processamento.
Nota: Ao definir um padrão de agrupamento para muitos descritores de aplicativos do componente, eledeverá ser o mesmo para o descritor de aplicativos base e descritores de aplicativos do componenteassociados. Se os descritores de aplicativos de componentes avançados definirem padrões deagrupamentos, nenhum padrão será criado, mesmo se o descritor de aplicativos base não padrão deagrupamento algum.
É possível visualizar os seletores e padrões de agrupamento gerados pelo descritor de aplicativo usandoa UI do TADDM. No entanto, como os seletores do tipo de descritor de aplicativo são geradosautomaticamente, você não pode modificá-los ou excluí-los. É possível modificar somente o modelo depassagem de dependência para eles.
Na liberação atual, descritores de aplicativos são armazenados em uma nova classe denominadaBizAppDescriptor. Durante a migração, todos os descritores de aplicativos existentes sãotransformados nessa nova classe. Os padrões de agrupamento que são gerados durante a migração usamesses descritores de aplicativos migrados.
As seguintes estratégias podem ser utilizadas para criar e implementar descritores de aplicativos:
• Defina o aplicativo durante o desenvolvimento e implementação. Com esta abordagem, é possívelcapturar as informações mais precisas e completas sobre o pacote de módulos em aplicativos denegócios.
• Depois que o aplicativo já estiver no lugar (criando os descritores e colocando-os no local apropriadonos sistemas de computador de destino), é possível implementar descritores de aplicativos.
Capítulo 1. Usando 199

Etapa 1: Criando o descritor de aplicativos baseA primeira etapa na criação do aplicativo Finanças é criar o descritor de aplicativo de base.
Sobre Esta TarefaO descritor de aplicativo de base contém informações gerais sobre o aplicativo, como a versão einformações de contato. Somente um descritor de aplicativo de base é necessário para o aplicativoFinanças. Se mais de um descritor for implementado, então, aquele com o registro de data e hora maisrecente será processado pelo TADDM.
Importante: Você não precisa utilizar uma convenção de nomenclatura específica para arquivos XML. Aousar extensões .xml e implementar os arquivos no diretório do descritor de aplicativo apropriado, elessão processados pelo TADDM.
Na versão anterior do TADDM, o descritor de aplicativos base permitido para especificar a definição doaplicativo dentro dos descritores de aplicativos base. Isso não é mais suportado. Todas as seções dedefinição do aplicativo agora são ignoradas durante o processamento do agente descritor de aplicativo. Amensagem de aviso apropriada é impressa nos logs.
Nota: O descritor de aplicativos base define apenas informações gerais sobre o aplicativo de negócios.Essas informações são armazenadas em um padrão de agrupamento que é usado para criar um aplicativode negócios de destino. No entanto, padrões de agrupamento e aplicativos de negócios devem ter oconteúdo, e, portanto, descritores de aplicativos base devem ser acompanhados por descritores deaplicativos do componente. Um descritor de aplicativos base sozinho não pode criar um padrão deagrupamento ou um aplicativo de negócios.
Procedimento
Para criar o descritor de aplicativo de base para o aplicativo Finanças, conclua as seguintes etapas:1. Usando um editor de texto, abra o arquivo finance_base_app_desc.xml.2. No arquivo .xml, especifique o seguinte esquema:
<base-app-descriptor> <app-instance name="Finance" grouping-pattern="Finance1" version="1.0" description="All components of the finance application" url="http://finance.acme.com" contact="John Doe"/></base-app-descriptor>
É necessário especificar um valor apenas para o campo app-instance name. Todos os outroscampos são opcionais.
3. Salve o arquivo .xml.
Etapa 2: Criando os descritos do aplicativo do componenteApós criar o descritor de aplicativo de base, é necessário criar os descritores de aplicativos docomponente.
Sobre Esta TarefaO descritor de aplicativo do componente contém informações sobre um sistema de computadorespecífico ou componente e módulo de servidor, ou um software implementado dentro de um servidor esoftware implementado dentro de um servidor, juntamente com informações sobre a participação daentidade no aplicativo de negócios. As entidades podem incluir sistemas de computador, servidores debanco de dados, servidores Java EE, os módulos dentro de um servidor, tais como aplicativos da web,Archives Corporativos e páginas JSP ou outros componentes implementados nos servidores.
Os descritores de aplicativo do componente têm o esquema a seguir:
<component-app-descriptor app-instance-name="Finance" grouping-pattern="Finance1"> <component-descriptor
200 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

type="server" name="htdocs" functional-group="deprecated" marker-module="true" /></component-app-descriptor>
Nota: O atributo grouping-pattern é opcional.
O component-descriptor possui os atributos a seguir:tipo
É possível especificar quatro valores de tipo:
• host - usado ao incluir sistemas de computador em um aplicativo de negócios.• server - usado ao incluir servidores de software ou servidores de aplicativo de software em um
aplicativo de negócios.• module - usado ao incluir módulos de software implementados no servidor para um aplicativo de
negócios.• deployable - usado ao incluir outros componentes gerais implementados no servidor para um
aplicativo de negócios.
nomeUsado para especificar o módulo de software ou componente implementado que é selecionado paraum aplicativo de negócios. O valor deste atributo depende do valor da sinalização marker-module.
Nota: Para sistemas de computador e servidores de software, este atributo não é usado.
functional-groupDescontinuado. Este atributo é suportado apenas para fornecer compatibilidade com descritores deaplicativos antigos. Uma camada especial (TADDM 7.3.0) ou uma camada manual (TADDM 7.3.0.1 eposterior) é criada com um nome igual a esse valor. Para obter mais informações sobre camadasespeciais e manuais, consulte o tópico Compatibilidade de entidades de negócios com versõesanteriores no Guia do Administrador do TADDM.Não é aconselhável usar esse atributo, mas sim confiar em regras de camadas regulares. Para obtermais informações, consulte “Camadas de aplicativo de negócios” na página 252.
marker-moduleUma sinalização booleana que indica se o módulo de software selecionado ou componenteimplementado é um "marcador" ou não. Os valores permitidos são true ou false.
• Se um módulo de software é usado como um "marcador", todos os módulos de softwareimplementados no servidor ou domínio do servidor são incluídos no aplicativo de negócios atravésdo seletor do padrão de agrupamento quando um módulo com esse nome é encontrado. Se oservidor for um servidor do gerenciador de implementação do WebSphere, todos os módulos desoftware implementados em todos os servidores em todos os nós no WebSphere Cell gerenciadopor este gerenciador de implementação são incluídos no aplicativo de negócios através do seletordo padrão de agrupamento. Da mesma forma, se o servidor for o servidor de administração doWebLogic, todos os módulos de software do domínio gerenciado por este servidor são incluídos noaplicativo de negócios através do seletor do padrão de agrupamento.
• Se um componente implementado denotado por type="deployable" é usado como um"marcador", todos os componentes implementados no servidor são incluídos no aplicativo denegócios através do seletor do padrão de agrupamento.
Pode haver diversas seções component-descriptor em um único descritor de aplicativo docomponente. Como resultado, é possível definir diversos elementos a serem incluídos no aplicativo denegócios sem criar diversos arquivos.
Os componentes a seguir são incluídos no aplicativo de negócios Finanças que é fornecido como umexemplo:
• O servidor da web Apache nomeado "apache_server1".• O servidor IBM WebSphere nomeado "j2ee_websphere1".
Capítulo 1. Usando 201

• A instância do DB2 nomeada "my_db2".
Como esses componentes estão em diferentes máquinas físicas, um descritor de aplicativo docomponente deve ser criado para cada componente do aplicativo Finanças.
Etapa 2a: Criando o Descritor para o Servidor ApacheConclua as etapas a seguir para criar o descritor de aplicativo do componente para o servidor Apache.
Procedimento
Conclua as seguintes etapas para criar o servidor de aplicativos do componente para o servidor Apache:1. Abra um editor de texto e crie o arquivo apache_coll_desc.xml.2. No arquivo apache_coll_desc.xml, especifique o seguinte esquema:
<component-app-descriptor app-instance-name="Finance"> <component-descriptor type="module" name="mod_ldap" marker-module="false" /></component-app-descriptor>
3. Salve o arquivo apache_coll_desc.xml no diretório apache_server_root/appdescriptors noservidor Apache.
4. Reinicie o servidor Apache.
Etapa 2b: Criando o Descritor para o Servidor IBM WebSphereConclua as etapas a seguir para criar o descritor de aplicativo do componente para o servidor IBMWebSphere.
Procedimento
Conclua as seguintes etapas para criar o servidor de aplicativos do componente para o servidor IBMWebSphere:1. Abra um editor de texto e crie o arquivo websphere_coll_desc.xml.2. No arquivo websphere_coll_desc.xml, especifique o seguinte esquema:
<component-app-descriptor app-instance-name="Finance"> <component-descriptor type="module" name="FinanceEJB" marker-module="false" /></component-app-descriptor>
3. Salve o arquivo websphere_coll_desc.xml no diretório WebSphere_profile_dir/appdescriptors no servidor WebSphere.
4. Reinicie o servidor WebSphere.
Etapa 2c: Criando o Descritor para a Instância do DB2Conclua as etapas a seguir para criar o descritor de aplicativo do componente para a instância do DB2.
Procedimento
Conclua as seguintes etapas para criar o descritor de aplicativo do componente para a instância do DB2:1. Abra um editor de texto e crie o arquivo db2_coll_desc.xml.2. No arquivo db2_coll_desc.xml, especifique o seguinte esquema:
<component-app-descriptor app-instance-name="Finance"> <component-descriptor type="module" name="Finance"
202 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

marker-module="false" /></component-app-descriptor>
3. Salve o arquivo db2_coll_desc.xml no diretório $DB2INSTANCEHOME/appdescriptors nosistema de computador em que a instância do DB2 está localizada.
Etapa 3: Executando uma descobertaApós concluir os descritores de aplicativos, é necessário executar uma descoberta. Esta etapa énecessária porque todos os componentes do aplicativo Finanças devem ser descobertos antes de vocêpoder organizá-los em um aplicativo de negócios.
Sobre Esta TarefaConsulte “Configurando uma Descoberta” na página 181 para obter instruções completas sobre comoexecutar uma descoberta.
Restrição: Descritores de aplicativos usados para aplicativo de negócios não são suportados pelossensores de descoberta assíncrona ou baseada em scripts. Durante a descoberta baseada em scripts ouassíncrona, os descritores de aplicativo não são descobertos.
Etapa 4: Visualizando o aplicativo de negóciosApós concluir os descritores de aplicativos e executar uma descoberta, é possível visualizar detalhessobre o aplicativo de negócios Finanças.
Procedimento
Para visualizar detalhes sobre o aplicativo de negócios Finanças, conclua as seguintes etapas a partir doConsole de Gerenciamento de Descoberta:1. Na área de janela Funções, clique em Topologia > Finanças.
A área de janela Aplicativos de Negócios - Finanças é exibida. A área de janela Aplicativos deNegócios - Finanças contém os seguintes componentes:
• apache_server1• j2ee_websphere1• my_db2
2. Na área de janela Aplicativos de Negócios - Finanças, selecione apache_server1.Detalhes sobre apache_server1 são exibidos na área de janela Detalhes.
3. Para visualizar detalhes sobre os componentes j2ee_webspere1 ou my_db2, selecione o íconeapropriado na área de janela Aplicativos de Negócios – Finanças. Detalhes sobre o componenteselecionado são exibidos na área de janela Detalhes.
Referências relacionadas“Configurando o tamanho máximo de topologias exibidas” na página 215A exibição de grandes topologias consome muita memória e pode até travar o servidor TADDM. Paraevitar isso, uma verificação de segurança é implementada. Também é possível configurar o tamanhomáximo da topologia, dependendo de suas necessidades, no arquivo collation.properties.
Criando aplicativos de negócios com API JavaÉ possível criar e gerenciar aplicativos de negócios usando a API Java. Também é possível carregarpadrões de agrupamento no banco de dados TADDM usando o programa de carregamento em massa.
Gerenciando padrões de agrupamento usando API JavaOs métodos de padrão de agrupamento permitem a criação, modificação, exclusão e recuperação depadrões de agrupamento junto com seus seletores.
Os padrões de agrupamento definem regras que são usadas para construir aplicativos de negócios.Padrões são aplicados periodicamente ao banco de dados TADDM para criar aplicativos de negócios,coleções ou coleções de acessos.
Capítulo 1. Usando 203

Padrões de agrupamento especificam seletores que definem pontos de início e regras de passagem detopologia que são executados para criar os aplicativos de negócios resultantes, coleções ou coleções deacessos. Um seletor define a forma de se selecionar itens de configuração do banco de dados TADDM.
Os itens de configuração selecionados se tornam objetos chamados 'ICs principais'. Por exemplo, osseletores do tipo MQL ou SQL contêm uma consulta que retorna a lista desses ICs principais. Usandoesses objetos e aplicando o modelo de passagem de relacionamentos para eles, o processo deconstrução de coleção é iniciado.
Importante: A data e a hora em todos os servidores TADDM devem estar sincronizadas.
Atributos de padrão de agrupamentoCada padrão de agrupamento deve consistir nos seguintes atributos:nome
O nome do padrão de agrupamento.hierarchyType
O tipo de resultado que esse padrão define. Os valores permitidos para o tipo de hierarquia são"BusinessApplication", "Collection" e "AccessCollection". Dependendo do valor do tipo dehierarquia, a coleção do tipo apropriado será criada após a passagem de topologia.
Atributos seletoresCada padrão de agrupamento especifica um ou mais seletores com os atributos a seguir:nome
O nome do seletor.parent
O padrão de agrupamento pai contendo este seletor. Seletores nunca existem sozinhos. Elessempre fazem parte de padrões de agrupamento.
isDisabledUma opção para criar uma versão de rascunho de um seletor. Seletores desativados não sãousados pelo BizAppsAgent na construção de coleções customizadas.
tipoO tipo de seletor. A lista a seguir contém os valores permitidos:
• MQL (0) - a consulta MQL é usada para definir itens de configuração de ponto de início para esteseletor,
• SQL (1) - a consulta SQL é usada para definir itens de configuração de ponto de início para esteseletor,
• Descritor de aplicativo (2) - o descritor de aplicativo define os itens de configuração de ponto deinício para este seletor,
• Manual (3) - somente os itens de configuração selecionados manualmente são usados comoponto de início para este seletor.
queryPara seletores do tipo MQL ou SQL, este campo é obrigatório. Ele contém a sequência deconsultas apropriada que é usada para selecionar os itens de configuração do ponto de início. Emcaso de uma consulta SQL, o usuário pode usar qualquer sintaxe suportada pelo banco de dadosem que o servidor TADDM está instalado. Somente instruções SELECT válidas são aceitáveisdurante a criação do padrão de agrupamento. Quaisquer outras instruções SQL, por exemplo,INSERT, UPDATE, DELETE, DROP, falharão com a exceção que denota uma sintaxe de consultainválida. Em caso de consultas MQL, não há validação de consulta.
GroupingNameExpressionA definição de uma regra usada para gerar uma expressão de nome do agrupamento das coleçõesque são criadas usando este seletor.
useTraversalTemplateUma sinalização booleana que define se este seletor especifica o modelo de passagem. O modelode passagem define regras de topologia durante a construção de coleções. Se a sinalizaçãouseTraversalTemplate não for configurada, os elementos da coleção construídos a partir
204 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

deste seletor conterão somente os elementos de ponto de início (itens de configuração principais;por exemplo, itens de configuração localizados pelo uso de consultas MQL ou SQL). Nenhum outroelemento será passado e incluído em uma coleção. Se a sinalização useTraversalTemplate forconfigurada para true, as regras definidas nos campos goHigherUp, goHigherDown,goLowerDown, goLowerUp serão usadas para definir o padrão de passagem.
goHigherUpUma sinalização booleana que especifica se a passagem passa pelos relacionamentos edependências que apontam para o item de configuração atual até o item de configuração maisalto, que é a origem do relacionamento ou dependência. Em seguida, a passagem continua portodos os relacionamentos e dependências que apontam para o item de configuração atual, a partirdos itens de configuração de origem dessas dependências e relacionamentos.
goHigherDownUma sinalização booleana que especifica se a passagem passa pelos relacionamentos edependências que apontam do item de configuração atual ao item de configuração de destino.Essa regra só é usada se a passagem atingir o item de configuração atual usando pelo menos umaetapa da regra goHigherUp.
goLowerDownUma sinalização booleana que especifica se a passagem passa pelos relacionamentos edependências que apontam a partir do item de configuração atual para baixo para o item deconfiguração inferior, que é o destino do relacionamento ou dependência. Depois, a passagemcontinua por todos os relacionamentos e dependências que apontam do item de configuraçãoatual ao item de configuração de destino dessas dependências e relacionamentos.
goLowerUpUma sinalização booleana que especifica se a passagem passa pelos relacionamentos edependências que apontam para o item de configuração atual a partir do item de configuração deorigem superior. Essa regra só é usada se a passagem atingir o item de configuração atual usandopelo menos uma etapa da regra goLowerDown.
Métodos de API de padrões de agrupamento
A tabela a seguir lista os métodos de padrões de agrupamento e fornece as descrições desses métodos.
Tabela 23. Métodos de API de padrão de agrupamento
Método Descrição
createGroupingPattern(GroupingPattern pattern) Cria o padrão de agrupamento com os parâmetrose seletores especificados. O único parâmetropattern contém a definição de padrão deagrupamento a ser criada junto com todos os seusseletores.
getAllGroupingPatterns() Recupera todos os padrões de agrupamentoexistentes no banco de dados do TADDM.
getGroupingPattern(Guid guid) Recupera o padrão de agrupamento com guidespecificado.
removeGroupingPattern(Guid guid) Exclui o padrão de agrupamento com guidespecificado.
updateGroupingPattern(GroupingPattern pattern) Atualiza o padrão de agrupamento especificado.
Os métodos de padrão de agrupamento fornecem um meio de se controlar a criação, a modificação, aexclusão e a recuperação de planejamentos.
Capítulo 1. Usando 205

Planejamentos de padrão de agrupamento
Atributos de planejamento padrãoCada planejamento padrão deve consistir nos seguintes atributos:nome
O nome do planejamento usado para identificar o planejamento. Embora não seja necessário queo nome seja exclusivo, é aconselhável não criar diversos planejamentos com o mesmo nome.
ExecutionGroupIdO nome do grupo de execução do qual este planejamento faz parte.A criação de um planejamento com o grupo de execução não significa automaticamente quenenhum novo conjunto de encadeamentos será criado em qualquer um dos servidores dearmazenamento. Isso é controlado separadamente pelas propriedades em cada servidor dearmazenamento.
descriçãoA descrição do planejamento.
Atributos adicionais de planejamento padrãoAlém disso, cada planejamento padrão deve consistir em um dos atributos a seguir:intervalInMinutes
Com que frequência (em minutos) o planejamento é disparado.oucronExpression
Expressão no formato cron que fornece controle aprimorado sobre ciclos de execução depadrões.
Nota: Para usar métodos de planejamento padrão via JavaAPI, inúmeros arquivos jar adicionaisdevem estar disponíveis no caminho de classe de cliente da API. É possível localizar estes arquivosjar no diretório TADDM_HOME/lib (também chamado LIB):
• LIB/schedules.jar• LIB/quartz/c3p0-0.9.1.1.jar• LIB/quartz/quartz-2.2.1.jar• LIB/quartz/quartz-jobs-2.2.1.jar
A tabela a seguir lista os métodos de gerenciamento de planejamento padrão e fornece as descriçõesdesses métodos:
Tabela 24. Gerenciamento de planejamento padrão
Método Descrição
getPatternSchedules() Recupera todos os planejamentos existentes no banco dedados TADDM
addSchedule(PatternScheduleschedule)
Cria um novo planejamento padrão
updateSchedule(PatternScheduleschedule)
Permite alterar as configurações de planejamento
removeSchedule(Guid guid, booleanforceToDefault)
Exclui o planejamento com guid especificado. Quando oplanejamento já está associado a qualquer padrão, oparâmetro forceToDefault permite controlar se essespadrões serão alterados para um planejamento padrão ou se ométodo falhará.
removeSchedule(Guid guid) Método abreviado para remover o planejamento padrão, iguala removeSchedule(guid, false)
206 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Tabela 24. Gerenciamento de planejamento padrão (continuação)
Método Descrição
getDefaultSchedule() Recupera detalhes do planejamento padrão
changeDefaultSchedule(Stringexpression, boolean isCronExpression)
Permite alterar a expressão de planejamento padrão. Asinalização isCronExpression define se o parâmetro deexpressão é uma expressão cron de expressão de intervalo(como 1s 2d 3h 4m)
changeDefaultSchedule(int interval Permite alterar o planejamento padrão passando o intervaloem minutos.
getExecutionGroupsInfo() Recupera informações sobre todos os grupos de execuçãodefinidos nos planejamentos, junto com detalhes deencadeamentos disponíveis em cada servidor dearmazenamento para cada grupo
Controle manual de execução de padrões
Para um padrão de agrupamento, os métodos fornecem maneiras de listar padrões que estão sendoexecutados atualmente, além de detalhes de suas próximas execuções. Os métodos também fornecemmeios para o início 'ad hoc' do processamento de padrões ou interrupção dos que estão sendoexecutados.
Mesmo que os métodos de API sejam chamados com relação a um certo servidor de armazenamento, oprocessamento real é solicitado com relação aos respectivos grupos de execução nos conjuntos deencadeamentos dos servidores de armazenamento. Portanto:
• As informações relacionadas ao status do processamento podem ser obtidas de qualquer servidor esempre contêm informações completas (mesmo se o servidor de armazenamento específico nãofornecer recursos para os grupos de execução).
• O processamento real do padrão pode ocorrer em um servidor de armazenamento diferente do usadopara solicitar tal processamento.
• A execução do padrão pode ser interrompida a partir de qualquer servidor de armazenamento, mesmose um padrão estiver sendo processado por um servidor diferente do usado para causar a interrupção.
A tabela a seguir lista métodos de gerenciamento de execução de padrão e fornece as descrições dessesmétodos:
Tabela 25. Métodos de gerenciamento de execução de padrão
Método Descrição
getPatternRunInfo(Guid guid) Para um determinado padrão, guid fornece informaçõesrelacionadas à execução de padrão (como próximo tempode execução).
getPatternsRunInfo() Fornece informações relacionadas à execução de padrãopara todos os padrões definidos no banco de dadosTADDM.
getPatternsInRun() Fornece informações sobre todos os padrões sendoprocessados no momento, junto com informações deexecução como servidor de armazenamento real no qual opadrão está sendo processado.
Capítulo 1. Usando 207

Tabela 25. Métodos de gerenciamento de execução de padrão (continuação)
Método Descrição
runPatternNow(GroupingPattern pattern,boolean waitForCompletion);runPatternNow(String patternName,boolean waitForCompletion);runPatternNow(Guid patternGuid, booleanwaitForCompletion)
Conjunto de métodos que permite iniciar imediatamente aexecução do padrão. O padrão pode ser chamado de(respectivamente):
• objeto de padrão (obtido anteriormente via, porexemplo, DataApi)
• nome de padrão• GUID de padrão
A sinalização waitForCompletion determina se ométodo espera o padrão ser processado ou se ele éconcluído após a solicitação de execução.
runPatternsNow(GroupingPattern[]patterns, boolean waitForCompletion);runPatternsNow Guid patternsGuids[],boolean waitForCompletion)
Esses métodos são semelhantes ao runPatternNow, maspermitem a execução de diversos padrões. A sinalizaçãowaitForCompletion determina se uma função espera oprocessamento do último padrão ser concluído ou se ela éconcluída imediatamente após todas as execuções depadrão serem solicitadas.
runAllPatternsForGroup(StringexecutionGroupId, booleanwaitForCompletion)
Permite executar todos os padrões associados aosplanejamentos de um determinado grupo de execução(normalmente essa é uma maneira rápida de processartodos os padrões)
interruptPatternNow(String patternName);interruptPatternNow(Guid patternGuid);interruptPatternNow(GroupingPatternpattern)
Conjunto de métodos que permite parar o processamentode um determinado padrão (caso o padrão esteja sendoprocessado no momento)
refreshJobs() Atualiza e reinicia todos os planejamentos para todos ospadrões definidos no banco de dados TADDM.
Criando um padrão de agrupamento
Para criar um padrão de agrupamento, conclua as seguintes etapas:
1. Crie um objeto Padrão de Agrupamento e configure os valores para os campos name ehierarchyType.
2. Crie uma matriz de objetos de seletor e configure seus parâmetros para definir as regras de criação decoleção.
3. Anexe todos os seletores ao padrão de agrupamento configurando o campo parent do seletor com opadrão de agrupamento e configurando os seletores de padrão de agrupamento para a matriz deseletores.
4. Crie um padrão usando o método de API de padrão de agrupamento createGroupingPattern.
Excluindo um padrão de agrupamento
Para excluir padrões de agrupamento, use um comando removeGroupingPattern na API de padrão deagrupamento. O comando aceita o parâmetro guid, que identifica exclusivamente o padrão deagrupamento. A exclusão do padrão de agrupamento também exclui todos os seletores anexados.
Exemplo: criando, recuperando e excluindo seletores e padrões de agrupamento
O exemplo a seguir cria um padrão de agrupamento e seus seletores:
208 Gerenciador de Descoberta de Dependência de Aplicativo: Usando
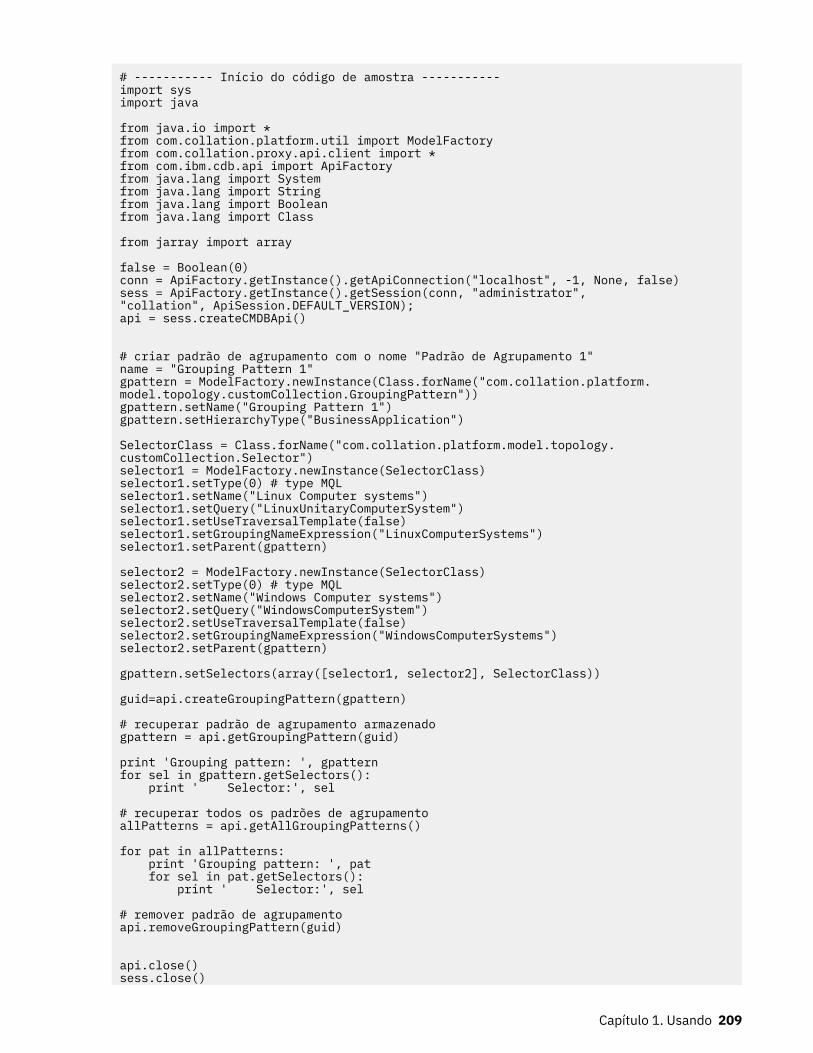
# ----------- Início do código de amostra -----------import sysimport java
from java.io import *from com.collation.platform.util import ModelFactoryfrom com.collation.proxy.api.client import *from com.ibm.cdb.api import ApiFactoryfrom java.lang import Systemfrom java.lang import Stringfrom java.lang import Booleanfrom java.lang import Class
from jarray import array
false = Boolean(0)conn = ApiFactory.getInstance().getApiConnection("localhost", -1, None, false)sess = ApiFactory.getInstance().getSession(conn, "administrator", "collation", ApiSession.DEFAULT_VERSION);api = sess.createCMDBApi()
# criar padrão de agrupamento com o nome "Padrão de Agrupamento 1"name = "Grouping Pattern 1"gpattern = ModelFactory.newInstance(Class.forName("com.collation.platform.model.topology.customCollection.GroupingPattern"))gpattern.setName("Grouping Pattern 1")gpattern.setHierarchyType("BusinessApplication")
SelectorClass = Class.forName("com.collation.platform.model.topology.customCollection.Selector")selector1 = ModelFactory.newInstance(SelectorClass)selector1.setType(0) # type MQLselector1.setName("Linux Computer systems")selector1.setQuery("LinuxUnitaryComputerSystem")selector1.setUseTraversalTemplate(false)selector1.setGroupingNameExpression("LinuxComputerSystems")selector1.setParent(gpattern)
selector2 = ModelFactory.newInstance(SelectorClass)selector2.setType(0) # type MQLselector2.setName("Windows Computer systems")selector2.setQuery("WindowsComputerSystem")selector2.setUseTraversalTemplate(false)selector2.setGroupingNameExpression("WindowsComputerSystems")selector2.setParent(gpattern)
gpattern.setSelectors(array([selector1, selector2], SelectorClass))
guid=api.createGroupingPattern(gpattern)
# recuperar padrão de agrupamento armazenadogpattern = api.getGroupingPattern(guid)
print 'Grouping pattern: ', gpatternfor sel in gpattern.getSelectors(): print ' Selector:', sel
# recuperar todos os padrões de agrupamentoallPatterns = api.getAllGroupingPatterns()
for pat in allPatterns: print 'Grouping pattern: ', pat for sel in pat.getSelectors(): print ' Selector:', sel
# remover padrão de agrupamentoapi.removeGroupingPattern(guid)
api.close()sess.close()
Capítulo 1. Usando 209

System.exit(0)
# ----------- Fim do código de amostra -----------
Exemplo de consultas MQL de API
Os exemplos a seguir mostram como procurar vários padrões usando consultas MQL de API.Localizando todos os aplicativos de negócios para um determinado padrão de agrupamento
api.sh -u user -p pass find "select * from CustomCollection where groupingPattern.guid == '9C704FF849993840B89FBECA5E183AFA'"api.sh -u user -p pass find "select * from CustomCollection where groupingPattern.name == 'GP'"
Localizando todos os nós e caminhos para um determinado aplicativo de negócios
api.sh -u user -p pass find "select * from Node where parent.guid=='B71A946FEA753FB38B57B65775DA6519'"api.sh -u user -p pass find "select * from Path where parent.guid=='B71A946FEA753FB38B57B65775DA6519'"
Localizando todos os nós que apontam para um determinado IC
api.sh -u user -p pass find "select * from Node where sourceGuid == '785614419CED31ACB24989A24F8ED52A'" api.sh -u user -p pass find "select * from Node where displayName contains 'NC9128109078'"
Localizando um aplicativo de negócios compatível com versões anteriores geradas a partir de umnovo aplicativo de negócios
Primeiro, use a consulta a seguir para reunir alguns dados iniciais com base no novo aplicativo denegócios:
api.sh -u user -p pass find "select backwardCompatibleBusinessAppGuid, hierarchyType, originalBusinessAppType from CustomCollection where guid == 'B71A946FEA753FB38B57B65775DA6519'"
Como resultado, você obtém o GUID do aplicativo compatível com versões anteriores e informaçõessobre qual classe consultar. Para um aplicativo de negócios migrado, o campooriginalBusinessAppType contém estas informações, caso contrário, hierarchyType apontarápara ele.Com essas informações, é possível consultar o aplicativo compatível com versões anteriores usando aseguinte consulta:
api.sh -u user -p pass find "select * from Application where guid == '9EA1FAD9B4153000BD21CB2967ADB3DB'"
Carregando padrões de agrupamentoO programa de carregamento em massa pode ser usado para carregar padrões de agrupamento no bancode dados TADDM. Quando os padrões de agrupamento são carregados no banco de dados do TADDM,eles podem ser inspecionados e, opcionalmente, modificados no Portal de Gerenciamento de Dados.
O programa de carregamento em massa suporta o carregamento de manuais IdML com objetosGroupingPattern e Seletor. Quando manuais contêm objetos GroupingPattern e Seletor, as limitações aseguir se aplicam:
• O programa de carregamento em massa deve operar no modo gráfico, ou seja, a opção de linha decomandos -g deve ser especificada.
• Cada manual deve ajustar o cache do carregador em massa. Isso significa que o manual IdML inteiroque contém objetos GroupingPattern e Seletor deve ser carregado de uma vez. Se seus manuais foremmuito grandes, divida-os ou aumente o cache de carregamento em massa. O tamanho da cache édefinido pela propriedade com.ibm.cdb.bulk.cachesize no arquivo $COLLATION_HOME/etc/bulkload.properties.
210 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Consulte também o tópico Programa de carregamento em massa no Guia do Usuário do TADDM.
Expressão de nome do agrupamentoO campo GroupingNameExpression do seletor é usado para gerar expressões de nome doagrupamento das coleções customizadas, por exemplo, aplicativos de negócios que são geradas peloBizAppsAgent.
A coleção customizada apropriada é construída para cada IC principal definido pela consulta do seletor. Aexpressão de nome do agrupamento da coleção customizada é gerado para cada IC principal.
A customização avançada do grupo pode ser permitida definindo-se o campoGroupingNameExpression como um padrão que possa extrair valores de atributo dos ICs principais.Esse padrão também pode executar correspondências de expressão regular nos ICs principais, em vez deapenas fornecer nomes de texto estáticos. A GroupingNameExpression suporta a sintaxe ApacheVelocity limitada para fornecer tal flexibilidade ao definir expressões de nome de agrupamento dascoleções customizadas geradas.
Dica: Para obter detalhes sobre objetos do modelo, por exemplo, atributos e relacionamentos, consulte adocumentação do CDM fornecida com o TADDM. Ela encontra-se no diretório cdm/datadictionary/cdm/misc/CDM.htm.
Há duas variáveis predefinidas no padrão GroupingNameExpression:$coreCI
Esta variável representa o item de configuração principal sendo processado por BizAppsAgent. Elapode ser usada para extrair atributos do IC principal. Por exemplo, $coreCI.displayName obtém oatributo displayName de cada IC principal e coloca seu valor na expressão de nome doagrupamento gerada.
$utilsEsta variável representa os utilitários disponíveis nos padrões. Os métodos de utilitário a seguir estãodisponíveis:
• $utils.regex(inputText, regexPattern1 [, ..., regexPatternN]) - um método queextrai a parte do atributo inputText usando padrões de expressão regular definidos nos atributosregexPattern1..N. A extração é executada usando grupos correspondentes de expressãoregular. Portanto, atributos regexPattern1..N devem definir pelo menos um grupocorrespondente. Padrões de expressão regular sem nenhum grupo correspondente são inválidos eresultam em erro.
Nota: Nenhum grupo correspondente, por exemplo, "abc(?:\d+)", é ignorado. Portanto, esseexemplo é inválido, já que não contém pelo menos um grupo correspondente.
O conteúdo do primeiro grupo correspondente que correspondeu com sucesso ao texto de entradaé selecionado como resultado. Por exemplo, para o texto de entrada "abc-1234-def" e o padrão"[A-Z]+-(\d+)|[a-z]+-\d+-(\w+)", o segundo grupo correspondente (\w+) que captura asubsequência "def" é selecionado, pois o primeiro não corresponde à entrada.
Os padrões de expressão regular regexPattern1..N são correspondidos na sequência 1 a N, atéque a primeira correspondência seja localizada.
• $utils.or(expression1, ..., expressionN) - um método que avalia todas as expressõese seleciona o primeiro resultado da expressão que não é nulo como seu resultado.
Por exemplo, se a propriedade $coreCI.description não tiver um valor e a propriedade$coreCI.name for configurada para um valor válido, utils.or($coreCI.description,$coreCI.name) retornará o resultado da expressão $coreCI.name como seu resultado. O errode que a propriedade $coreCI.description não está disponível não é relatado, como seria, seapenas o $coreCI.description fosse usado.
• $utils.toUpper(inputText) - um método que converte o valor de atributo inputText emcaracteres maiúsculos.
• $utils.toLower(inputText) - um método que converte o valor de atributo inputText emcaracteres minúsculos.
Capítulo 1. Usando 211

• $utils.trim(inputText) - um método que remove todos os caracteres de espaço em brancoiniciais e finais do valor de atributo inputText.
• $utils.replace(inputText, pattern, substitute) - um método que substitui todas assubsequências do atributo inputText correspondentes ao padrão pelo substituto. O atributopattern é um padrão de expressão regular que pode incluir grupos correspondentes. O atributosubstitute pode referenciar os grupos correspondentes definidos no atributo pattern usando$1 para o primeiro grupo correspondente, $2 para o segundo grupo correspondente, e assim pordiante.
Nota: Se o símbolo do dólar ($) ou uma barra invertida (\) forem usados na sequência desubstituição, eles deverão ser escapados incluindo-se outra barra invertida como prefixo para asequência. Por exemplo, na chamada $utils.replace($coreCI.name, "some pattern","abc\$123"), o substituto é um texto estático "abc$123" que inclui o símbolo do dólar, pois essesímbolo foi escapado usando-se a combinação \$ (portanto, $123 não faz referência ao grupocorrespondente 123). Os textos substitutos que contêm o símbolo do dólar ou a barra invertidasozinhos, por exemplo "abc$def" ou "abc\def", são inválidos, pois o símbolo do dólar e a barrainvertida não foram escapados pela inclusão da barra invertida como prefixo. Neste caso, os textossubstitutos válidos são "abc\$def" e "abc\\def".
Exemplos
• Para um padrão de agrupamento com os elementos a seguir:
– hierarchyType: BusinessApplication,– seletor com consulta MQL: SELECT * FROM Database,– GroupingNameExpression: $coreCI.displayName,
a expressão de nome do agrupamento gerada é o valor do atributo displayName de cada IC principal.Se os nomes de exibição forem exclusivos, aplicativos de negócios separados com a expressão denome do agrupamento configurada para o nome de exibição desse IC principal serão criados para cadaIC principal selecionado pela consulta do seletor.
• Para um padrão de agrupamento com os elementos a seguir:
– hierarchyType: BusinessApplication,– selector with MQL query: SELECT * FROM J2EEApplication WHERE name contains'_EDT-',
– GroupingNameExpression: eDayTrader,
um aplicativo de negócios único com a expressão de nome do agrupamento eDayTrader contendotodos os ICs principais e seus objetos dependentes é criado.
• Para um padrão de agrupamento com os elementos a seguir:
– hierarchyType: BusinessApplication,– selector with MQL query: SELECT * FROM Database WHERE name starts-with 'prod_',– GroupingNameExpression: BizApp-${utils.regex("${coreCI.name}", "prod_(.*)")}-${coreCI.label},
e para o IC principal com o nome "prod_EDT1" e o rótulo "trader1", a expressão de nome doagrupamento gerada é BizApp-EDT1-trader1.
Todas as coleções customizadas parciais que são geradas para ICs principais com um nomecorrespondente, por exemplo, EDT1, e um rótulo correspondente, por exemplo, trader1, serãodesignadas a uma única coleção de aplicativos de negócios com expressão de nome do agrupamento,por exemplo, BizApp-EDT1-trader1. Isso permite uma designação dinâmica e o agrupamento deitens de configuração, além de seus objetos relacionados aos aplicativos de negócios, com base emqualquer combinação de atributo correspondente.
212 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Sintaxe Apache Velocity
O padrão GroupingNameExpression suporta sintaxe Apache Velocity limitada e é validado durante acriação. As validações a seguir são impingidas:
• Nenhuma diretiva #include ou #parse é permitida no padrão.• As variáveis $coreCI e $utils estão predefinidas e prontas para serem usadas no padrão, mas não
podem ser redefinidas. Outras variáveis podem ser definidas e usadas no padrão usando a diretiva#set.
• Na variável $coreCI, somente o acesso à propriedade é permitido. Nenhuma chamada de método, porexemplo, getters e setters, são permitidas. O resultado do acesso à propriedade para a variável$coreCI deve ser uma sequência ou outro tipo de dado simples, como Boolean, int, long, float, double.Especialmente, ele não pode ser um objeto do modelo ou matriz. O acesso às propriedades $coreCIque são objetos do modelo ou matrizes para obter suas propriedades ou elementos é permitido quandoo resultado não é um objeto do modelo ou matriz.
Exemplos:
– $coreCI.name é permitido.– $coreCI.OSRunning.name é permitido. É usado para acessar OSRunning, que é um objeto do
modelo do tipo OperatingSystem para obter a propriedade name.– $coreCI.OSInstalled[1].name é permitido. Ele é usado para acessar o segundo elemento de
uma matriz de elementos OperatingSystem para obter a propriedade name do elemento.– $coreCI não é permitido. $coreCI é um objeto do modelo.– $coreCI.OSRunning não é permitido.– $coreCI.OSInstalled não é permitido. Ele resulta em uma matriz de objetos do modelo.– $coreCI.OSInstalled[1] não é permitido. O resultado de OSInstalled[1] é um objeto do
modelo OperatingSystem.– $coreCI.setName("test") não é permitido.– $coreCI.getName() - não é permitido.– $coreCI.hasName() - não é permitido. No entanto, a construção equivalente #if($coreCI.name) ... #end é permitida. Além disso, $utils.or($coreCI.name,$coreCI.otherProperty, ...) pode ser usado para selecionar a primeira propriedade queexiste e está configurada.
– $coreCI.test() - não é permitido. Nenhuma outra chamada de método é permitida também.
• Na variável $utils, somente chamadas de método definidas são permitidas:
– $utils.regex(inputText, regexPattern1 [, ..., regexPatternN])
Valores nulos não são permitidos nos atributos regexPattern1..N. Cada regexPattern devedefinir pelo menos um grupo correspondente. O atributo inputText pode ser nulo quando achamada $utils.regex não for a última chamada na cadeia resultante na inserção de seuresultado no texto final. Por exemplo, se essa chamada $utils.regex tentando acessar apropriedade $coreCI não configurada for aninhada na chamada $utils.or, ela não gerará um erroquando o $utils.or puder selecionar qualquer outro valor de expressão não nulo como resultado.Em todos os outros casos, essa chamada $utils.regex resultará em erro.
– $utils.toUpper(inputText)– $utils.toLower(inputText)– $utils.trim(inputText)– $utils.replace(inputText, pattern, substitute)
Os atributos pattern e substitute devem ser sequências válidas não nulas. O atributo patterndeve ser um padrão de expressão regular válido. O atributo substitute deve ser uma substituiçãoválida ou um padrão de substituição com escape apropriado do símbolo do dólar ($) e da barrainvertida (\), além do uso apropriado dos grupos correspondentes.
Capítulo 1. Usando 213

– $utils.or(expression1, ..., expressionN)
Atributos de expressão podem ser nulos quando a expressão inteira que envolve a chamada$utils.or é avaliada para um valor não nulo.
A lista a seguir contém expressões exemplares, em que a propriedade $coreCI.name é válida, apropriedade $coreCI.description não está configurada e a propriedade $coreCI.instanceIDnão existe. A propriedade $coreCI.instanceID pode ser uma propriedade que não existe, no casode um $coreCI atual ser do tipo ComputerSystem, que não tem a propriedade instanceID (apropriedade instanceID é uma propriedade válida de AppServers) e assim por diante.
- $utils.or($coreCI.description, $coreCI.instanceID) - não válido. Resulta em erroporque é avaliado para um valor nulo.
- $utils.or($coreCI.description, $coreCI.instanceID, "default") - válido. Mesmoque a propriedade description não esteja configurada e a propriedade instanceID não exista,o último atributo será o texto estático "default" e a chamada $utils.or inteira será avaliadacom sucesso para esse valor.
- $utils.or($coreCI.description, $coreCI.instanceID, $utils.name) - válido.Mesmo que a propriedade description não esteja configurada e a propriedade instanceID nãoexista, a propriedade name será válida e a chamada $utils.or inteira será avaliada para um valorválido de $coreCI.name.
- $utils.or($utils.or($coreCI.description, $coreCI.instanceID), "default") -válido. Mesmo que a chamada interna $utils.or($coreCI.description,$coreCI.instanceID) for avaliada para um valor inválido, a chamada externa $utils.or e, aomesmo tempo, a expressão inteira serão avaliadas para um valor válido "default".
- $utils.or($utils.toUpper($coreCI.description),$utils.regex($coreCI.instanceID, "prod_(.*)",$utils.toLower($coreCI.name)) - válido. Embora as chamadas$utils.toUpper($coreCI.description) e $utils.regex($coreCI.instanceID, ...)não sejam válidas, a chamada externa $utils.or e, ao mesmo tempo, a expressão inteira, serãoavaliadas para um valor válido de $utils.toLower($coreCI.name).
Exemplos
- BizApp-$utils.or($utils.regex($utils.toLower($coreCI.label,)"appserver-(.+)"), $regex($coreCI.description, "application servernumber (\d+)"), "default")
• Para o IC principal { label="AppServer123", name="CS-123",description="..." }, o resultado será "BizApp-123" - extraído do atributo$coreCI.label.
• Para o IC principal { label=null, name="CS-123", description="This is anapplication server number 123. Installed mod...." }, o resultado será"BizApp-123" - extracted from $coreCI.description attribute.
As chamadas de método $utils.or a seguir podem ser aninhadas:
- BizApp-$utils.or($utils.or($coreCI.name, $coreCI.label,$utils.regex($coreCI.description, "name: (\S+)")), "default")
- BizApp-$utils.or($utils.regex($coreCI.name, "prod_(.*)|test_(.*)"),$utils.regex($coreCI.keyName, "systemA-(\\d+)|systemC-(\\d+)|system?-?-(.*)"), "default")
- BizApp-$utils.or($utils.regex($coreCI.name, "test_(.*)", "test1_(.*)"),$utils.regex($coreCI.keyName, "prod1_(.*)", "prod_(.*)"), "default")
- BizApp-$utils.or($coreCI.primarySAP.fqdn,$coreCI.primarySAP.primaryIpAddress.dotNotation,$coreCI.primarySAP.primaryIpAddress.byteNotation,$coreCI.primarySAP.primaryIpAddress.stringNotation, "unknown")
214 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

- Equivalente à #set($ip = $coreCI.primarySAP.primaryIpAddress)BizApp-$utils.or($coreCI.primarySAP.fqdn, $ip.dotNotation, $ip.byteNotation,$ip.stringNotation, "unknown") precedente
Exibindo aplicativos de negóciosApós você gerar seus aplicativos de negócios, é possível visualizá-los na janela ComponentesDescobertos.
Procedimento
1. Abra Portal de Gerenciamento de Dados.2. Na janela Componentes Descobertos, clique em Grupos e em Aplicativos de Negócios.3. Selecione o aplicativo que deseja exibir.4. Na lista Ações, selecione Mostrar Topologia.
Configurando o tamanho máximo de topologias exibidasA exibição de grandes topologias consome muita memória e pode até travar o servidor TADDM. Paraevitar isso, uma verificação de segurança é implementada. Também é possível configurar o tamanhomáximo da topologia, dependendo de suas necessidades, no arquivo collation.properties.
O tamanho da topologia é definido pelo número de nós. Isso é determinado dinamicamente, dependendodas atuais configurações de tamanho de heap Java máximo para o processo de JVM do Tomcat (TADDM7.3.0) ou para o processo de JVM do Liberty (TADDM 7.3.0.1 e posterior). As configurações são definidascom base em uma função linear (25 * M / 32) - 200, em que M é o tamanho de heap Java máximo.Por exemplo:
• 600 nós de topologia são permitidos no heap de 1 GB, que é uma configuração padrão.• 3000 nós são permitidos no heap de 4 GB.
Nota: Este limite está relacionado com todas as topologias que são simultaneamente exibidas em váriosnavegadores que estão conectados ao Portal de Gerenciamento de Dados em um único servidor TADDM.O limite não se aplica somente ao usuário atual. Memória é liberada quando você efetua logout, abre umaoutra topologia ou quando uma sessão expira.
Quando a topologia que você deseja exibir é muito grande, a mensagem de aviso a seguir é exibida nolugar da topologia:
O gráfico solicitado excedeu o número de nós permitido.
Para evitar esse tipo de erro, aumente o tamanho de heap máximo para processos de JVM do Tomcat(TADDM 7.3.0) ou para processos de JVM do Liberty (TADDM 7.3.0.1 e posterior) alterando o valor dapropriedade com.collation.Tomcat.jvmargs (TADDM 7.3.0) oucom.collation.Liberty.jvmargs (TADDM 7.3.0.1 e posterior).
Opções de configuração
Use as propriedades a seguir para customizar o tamanho máximo de heap Java.com.collation.topology.maxnodes
Define o número máximo de nós que podem ser visualizados em uma topologia. Essa propriedadedefine o tamanho da topologia mais precisamente do que as configurações padrão. Configure essapropriedade no arquivo collation.properties, quando as configurações padrão não foremsuficientes para exibir topologias.Configure o valor no seguinte formato: 1000. Nesse exemplo, o número máximo de nós é 1000. Osvalores que são muito altos podem levar a erros de Falta de Memória. Se algumas topologiascausarem erros de Falta de Memória, configure essa propriedade para um valor menor.
com.collation.Tomcat.jvmargs (somente TADDM 7.3.0)Define opções da JVM para o Portal de Gerenciamento de Dados. Essa propriedade pode ser usadapara definir o tamanho máximo de heap. Configure essa propriedade no arquivo
Capítulo 1. Usando 215

collation.properties, quando as configurações padrão não forem suficientes para exibirtopologias.Configure o valor no seguinte formato: -Xmx2048M. Nesse exemplo, o tamanho máximo de heap é2048 MB (2 GB). É possível usar qualquer valor.Após alterar a propriedade, reinicie o servidor TADDM.
com.collation.Liberty.jvmargsDefine opções da JVM para o Portal de Gerenciamento de Dados. Essa propriedade pode ser usadapara definir o tamanho máximo de heap. Configure essa propriedade no arquivocollation.properties, quando as configurações padrão não forem suficientes para exibirtopologias.Configure o valor no seguinte formato: -Xmx2048M. Nesse exemplo, o tamanho máximo de heap é2048 MB (2 GB). É possível usar qualquer valor.Após alterar a propriedade, reinicie o servidor TADDM.
Processamento de padrões de agrupamentoÉ possível controlar o mecanismo de processamento de padrões de agrupamento e, assim, controlar oprocesso de geração de aplicativos de negócios.
Configuração dos padrões de agrupamentoÉ possível controlar o processo de criação de aplicativos de negócios usando a configuração de padrõesde agrupamento. A configuração permite incluir ou excluir as relações escolhidas durante a passagem dedados e as classes escolhidas dos aplicativos de negócios resultantes. Também é possível alterar adireção de dependência para relações definidas no Modelo de Dados Comum e designar camadas aoselementos de aplicativo de negócios.
A configuração de padrões de agrupamento é armazenada em formato XML no banco de dados. Épossível exportar a configuração para o arquivo XML e importá-la do arquivo XML.
Os padrões de agrupamento podem ser designados para a configuração padrão e uma configuraçãocustomizada. A configuração padrão se aplica a todos os padrões de agrupamento e é carregada quandoo TADDM é iniciado, mas a configuração customizada tem uma prioridade maior. Isso significa que,quando um padrão de agrupamento é anexado a uma configuração customizada, a configuração padrãose aplica em todos os casos que não são especificados pela configuração do padrão de agrupamentocustomizado. Para obter mais detalhes sobre como criar configurações customizadas, consulte“Anexando uma configuração customizada a um padrão de agrupamento” na página 227.
O arquivo de configuração XML consiste nas seguintes seções:general
contém configuração que define detalhes de nível de criação de log adicionais e número máximo dehops.
compositionConfigurationdefine estes elementos que ficam visíveis como elementos do aplicativo de negócios. As subseções aseguir estão disponíveis:
• includeInComposition• excludeFromComposition
traversalConfigurationpermite excluir ou incluir determinadas relações ou dependências durante o processo de criação deaplicativos de negócios. As subseções a seguir estão disponíveis:
• excludedRelationships• includedRelationships
camadasusado para criar nomes de grupo funcional em aplicativos de negócios que são compatíveis comversões anteriores.
216 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

directionsdenota a direção da dependência para relações definidas no Modelo de Dados Comum. Pode fazerparte somente da configuração padrão.
A configuração a seguir é um trecho da configuração padrão:
<?xml version="1.0" encoding="UTF-8"?><xml> <tiers> ... <tier> <name>Computer Systems</name> <rule> <className>ComputerSystem</className> </rule> </tier>...</tiers> <traversalConfiguration> <excludedRelationships> <exclude relation="{any}" source="customCollection.CustomCollection" target="{any}"/> <exclude relation="{any}" source="customCollection.GroupingPattern" target="{any}"/> <exclude relation="{any}" source="{any}" target="customCollection.GroupingPattern"/> <exclude relation="{any}" source="customCollection.Path" target="{any}"/>... </excludedRelationships> </traversalConfiguration> <compositionConfiguration> <includeInComposition> <include type="simple.SComputerSystem"/> <include type="simple.SDeployableComponent"/> <include type="simple.SFunction"/> <include type="simple.SGroup"/> <include type="simple.SSoftwareServer"/> </includeInComposition> <excludeFromComposition> <exclude type="customCollection.GroupingPattern" /> <exclude type="app.FunctionalGroup" /> </excludeFromComposition> </compositionConfiguration> <directions> <forwardRelationships> <forward relation="only relation.Provides" source="sys.blade.BladeCenterManagementModule" target="sys.blade.Alert"/> <forward relation="only relation.Provides" source="sys.vmware.VMWareVirtualSwitch" target="sys.vmware.VMWarePortGroup"/> <forward relation="only relation.Provides" source="app.AppServer" target="app.JVM"/>... </forwardRelationships> <reverseRelationships> <reverse relation="only app.dependencies.SwitchToDevice" source="{any}" target="{any}"/> <reverse relation="only relation.ControlsAccess" source="{any}" target="{any}"/> <reverse relation="only relation.Contains" source="{any}" target="{any}"/>... </reverseRelationships> </directions></xml>
Para cada tipo de configuração, uma origem, um destino ou uma classe de relação podem ser definidosdas seguintes formas:
• Qualquer tipo ("{any}") - corresponde a qualquer classe do Modelo de Dados Comum.• Nome da classe – corresponde a uma determinada classe e todas as suas subclasses.• Somente nome de classe( only) - corresponde somente a uma determinada classe, sem nenhuma de
suas subclasses.
Exemplos:
Capítulo 1. Usando 217

• <exclude relation="{any}" source="sys.ComputerSystem" target="{any}"/>
Exclui da passagem todos os tipos de relações do ComputerSystem e todas as suas subclasses paraqualquer classe de destino do Modelo de Dados Comum.
• <exclude relation="only relation.InvokedThrough" source="app.messaging.mq.MQLocalQueue" target="app.messaging.mq.MQChannel"/>
Exclui da passagem uma relação InvokedThrough (mas não suas subclasses) entre MQLocalQueue eMQChannel (e suas subclasses).
É possível fornecer um nome de classe como um nome de classe curto ou um nome completo de classe.Por exemplo, é possível usar sys.linux.LinuxUnitaryComputerSystem ao invés decom.collation.platform.model.topology.sys.linux.LinuxUnitaryComputerSystem. Onome da classe não faz distinção entre maiúsculas e minúsculas.
Configuração geralA seção geral do arquivo de configuração define detalhes do nível de criação de log adicionais e númeromáximo de hops.
Exemplo:
<general> <maxHopsLimit>10</maxHopsLimit> <firstTierOnly>true</firstTierOnly> <infoLevel>GENERAL</infoLevel> </general>
A configuração geral consiste nos parâmetros a seguir:
maxHopsLimitEste parâmetro define quão longe do IC principal o mecanismo de composição pode ir durante aconstrução de um aplicativo. O valor define o número de elementos.
Importante: Os elementos que não estão visíveis como os elementos do aplicativo de negócios nãosão ignorados. Para obter mais informações, consulte “Configuração de composição” na página 222.
O valor padrão deste parâmetro é 10.
firstTierOnlyEste parâmetro especifica quantas camadas são processadas em busca de elementos especificados.Este parâmetro só é aplicado à configuração XML do padrão de agrupamento. Os elementos que sãolocalizados pelo seletor do padrão de agrupamento são designados a camadas com base nascondições especificadas pelas camadas. Quando esse parâmetro é configurado como true, e oselementos correspondem às condições de uma camada, as camadas restantes são ignoradas.Quando esse parâmetro for configurado como false, mesmo quando os elementos quecorrespondem as condições de uma camada forem localizados, outras camadas também serãoprocessadas. Portanto, é possível que um elemento seja designado a várias camadas se elecorresponder a todas as condições delas.O valor padrão deste parâmetro é true.
infolevelEste parâmetro especifica o nível de detalhes dos logs quando o nível INFO está configurado. Porexemplo, ele permite obter mais detalhes para os aplicativos de negócios nos arquivos de log semalternar para o nível DEBUG. Os níveis a seguir estão disponíveis:
• NOINFO - nenhuma informação.• DEFAULT - informações sobre o início e a parada de apenas um aplicativo de negócios.• GENERAL - as informações PADRÃO e os dados do IC principal.• DETAILS - as informações GERAIS e os detalhes da rota de passagem do mecanismo de
composição.• MAXINFO - nível máximo de detalhes, atualmente igual ao nível DETALHES.
218 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Configuração de passagemA configuração de passagem consiste em relações incluídas e excluídas entre os objetos.
Por padrão, todos os CIs existentes e suas relações são atravessados durante a composição do aplicativode negócios. Os aplicativos de negócios são compostos durante o processamento do padrão deagrupamento. No entanto, se você usar a configuração de passagem, algumas das relações podem serignoradas do processamento. Isso significa que o compositor não vai além nos relacionamentosexcluídos. Ela se aplica a um relacionamento implícito, que são as relações que são definidas no Modelode Dados Comum, ou relações explícitas, que podem vincular quaisquer ICs e podem ser criadas usandoa API ou UI do TADDM. No entanto, as relações explícitas que são geradas para as relações implícitasusando o script explicitrel.sh são ignoradas por padrão, e não podem ser configuradas.
No exemplo a seguir, as duas primeiras identificações relation excluem completamente o tipo de ICinteiro excluindo todas as relações de entrada e saída. A terceira identificação relation exclui apenasuma relação simples.
Exemplo:
<traversalConfiguration> <excludedRelationships> <exclude relation="{any}" source="admin.AdminInfo" target="{any}"/> <exclude relation="{any}" source="{any}" target="admin.AdminInfo"/> <exclude relation="only relation.DeployedTo" source="app.j2ee.J2EEApplication" target="app.j2ee.websphere.WebSphereCell"/> ... <includedRelationships> <include relation="{any}" source="admin.AdminInfo" target="{any}"/> <include relation="{any}" source="{any}" target="admin.AdminInfo"/> ...
A configuração de passagem consiste nos parâmetros a seguir:excludedRelationships
Este parâmetro contém uma série de relacionamentos excluídos.includedRelationships
Este parâmetro contém uma série de relacionamentos incluídos. Embora todos os relacionamentossejam incluídos por padrão, esse parâmetro é útil no caso de uma configuração de padrão deagrupamento, quando você deseja incluir uma relação que foi excluída da configuração padrão.
Os parâmetros excludedRelationships e includedRelationships contêm os elementos a seguir:relation
O nome da relação ou tipo de dependência.origem
O nome do tipo de objeto de origem da relação. Se você não desejar definir qualquer fonte específica,poderá configurar o valor como {any}.
No TADDM 7.3.0.2 e posterior, também é possível incluir o atributo hierarchyType deum objeto modelo na origem da relação para ser mais específico. Após o nome do tipo de objeto deorigem da relação, inclua dois pontos (:) e o valor do atributo hierarchyType. Por exemplo,source="app.AppServer:IBMTivoliEnterpriseConsole".A fim de se certificar sobre o valor correto do atributo hierarchyType, é possível consultar o CI deum determinado tipo, usando as APIs do TADDM.
No TADDM 7.3.0.3 e mais recente, também é possível incluir o atributohierarchyDomain de um objeto modelo na origem da relação para ser mais específico. Após onome do tipo de objeto de origem da relação, inclua dois pontos (:) e o valor do atributohierarchyDomain. Quando estiver aplicando esse filtro, deve-se também incluir o valor do atributohierarchyType. Por exemplo,source="simple.SSoftwareServer:app.placeholder.client.remote.
Capítulo 1. Usando 219

Unknown", em que app.placeholder.client.remote é o valor do atributo hierarchyDomain eUnknown é o valor do atributo hierarchyType. O atributo hierarchyType é sempre especificadono final e é separado do atributo hierarchyDomain com um ponto.Também é possível usar um asterisco (*), que representa uma ou mais partes integrais do nome dedomínio ou o atributo hierarchyType. Exemplos:
source="simple.SSoftwareServer:app.placeholder.*.Unknown"source="simple.SSoftwareServer:app.placeholder.client.remote.*"
alvoO nome do tipo de objeto de destino da relação. Se você não desejar definir nenhum destinoespecífico, poderá configurar o valor como {any}.
No TADDM 7.3.0.2 e posterior, também é possível incluir o atributo hierarchyType deum objeto modelo no destino da relação para ser mais específico. Após o nome do tipo de objeto dedestino da relação, inclua dois pontos (:) e o valor do atributo hierarchyType. Por exemplo,target="app.AppServer:MySql".A fim de se certificar sobre o valor correto do atributo hierarchyType, é possível consultar o CI deum determinado tipo, usando as APIs do TADDM.
No TADDM 7.3.0.3 e mais recente, também é possível incluir o atributohierarchyDomain de um objeto modelo no destino da relação para ser mais específico. Após onome do tipo de objeto de destino da relação, inclua dois pontos (:) e o valor do atributohierarchyDomain. Quando estiver aplicando esse filtro, deve-se também incluir o valor do atributohierarchyType. Por exemplo,target="simple.SSoftwareServer:app.placeholder.server.local.Java", em queapp.placeholder.server.local é o valor do atributo hierarchyDomain e Java é o valor doatributo hierarchyType. O atributo hierarchyType é sempre especificado no final e é separadodo atributo hierarchyDomain com um ponto.Também é possível usar um asterisco (*), que representa uma ou mais partes integrais do nome dedomínio ou o atributo hierarchyType. Exemplos:
target="simple.SSoftwareServer:*.placeholder.*.Java"target="simple.SSoftwareServer:app.placeholder.*"
direçãoA direção da passagem da dependência definida para um relacionamento específico. Os seguintesvalores estão disponíveis:
• UP: A regra de exclusão ou inclusão é aplicada somente quando a direção atual da passagem estáacima da cadeia de dependência, com início a partir do tipo de objeto de origem.
• DOWN: A regra de exclusão ou inclusão é aplicada somente quando a direção atual da passagem estáabaixo da cadeia de dependência, com início a partir do tipo de objeto de origem.
• UP_AFTER_DOWN: A regra de exclusão ou inclusão é aplicada somente quando a direção atual dapassagem está abaixo e depois acima da cadeia de dependência, com início a partir do tipo deobjeto de origem. Ela é equivalente à opção LowerUp selecionada no Portal de Gerenciamento deDados.
• DOWN_AFTER_UP: A regra de exclusão ou inclusão é aplicada somente quando a direção atual dapassagem está acima e depois abaixo da cadeia de dependência, com início a partir do tipo deobjeto de origem. Ela é equivalente à opção HigherDown selecionada no Portal de Gerenciamentode Dados.
A configuração de passagem está relacionada à direção de relação definida no Modelo de Dados Comum(a configuração de direção relações não é levada em consideração). No entanto, no caso de dependênciasexplícitas a passagem leva em consideração a direção porque a classe de origem e de destino não érestrita pelo Modelo de Dados Comum (qualquer classe pode ser usada como uma origem ou destino darelação explícita).
220 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Mais exemplos
• Ignorar uma relação específica entre um par de objetos específicos.
<exclude relation="relation.RunsOn" source="sys.OperatingSystem" target="sys.ComputerSystem"/>
• Ignorar qualquer relação, para a qual uma classe específica é uma origem.
<exclude relation="{any}" source="net.BindAddress" target="{any}"/>
• Ignorar qualquer relação, para a qual uma classe específica é um destino.
<exclude relation="{any}" source="{any}" target="net.BindAddress"/>
• Ignorar uma relação, mas não suas subclasses.
Nota: dev.RealizesExtent é uma subclasse de relation.Realizes e é processada mesmo querelation.Realizes seja ignorado.
<exclude relation="only relation.Realizes" source="sys.FileSystem" target="sys.FileSystem"/>
• Ignorar qualquer relação, para a qual o objeto IBM Tivoli Enterprise Console do tipo deobjeto AppServer é uma origem.
<exclude relation="{any}"source="app.AppServer:IBMTivoliEnterpriseConsole" target="{any}"/>
Nota: Para obter mais informações sobre o atributo hierarchyType de modelos de servidorcustomizado, consulte “Criando e Gerenciando Modelos de Servidor Customizado” na página 18.
• Ignorar uma relação específica entre um par de objetos específicos. Além disso, a relação éignorada apenas quando ela é localizada durante a passagem de objetos abaixo da cadeia dedependência.
<exclude relation="relation.RunsOn" source="app.AppServer" target="sys.ComputerSystem" direction="DOWN"/>
Se esta regra de exclusão for incluída na configuração padrão, que é anexada a um padrão onde o CIComputerSystem é o CI principal (ponto de início da passagem), então todos os AppServers(aplicativos) executados neste CI principal serão incluídos na topologia, porque os AppServersdependem do ComputerSystem. Outros AppServers conectados com os AppServers já incluídostambém poderão ser incluídos na topologia por meio das dependências do IpConnection. No entanto, aregra de exclusão fornecida no exemplo será aplicada quando o mecanismo da passagem tentar incluiro ComputerSystems host no qual estes AppServers estiverem sendo executados. Nesse caso, a relaçãoAppServer->RunsOn->ComputerSystem é atravessada para baixo e a regra de exclusão é aplicada.
• Ignorando qualquer relação, para a qual o destino é um objeto com tipo SSoftwareServer etem o atributo hierachyDomain configurado para app.placeholder.client.remote e o atributohierarchyType configurado para Unknown.
<exclude relation="{any}" source="{any}" target="simple.SSoftwareServer:app.placeholder.client.remote.Unknown"/>
Também é possível configurar BizAppsAgent para atravessar apenas conjunto específico de relações.Por exemplo:
<excludedRelationships><exclude source="{any}" target="{any}" relation="{any}"/></excludedRelationships><includedRelationships><include target="{any}" source="sys.SystemPComputerSystem" relation="relation.Virtualizes"/><include target="{any}" source="sys.linux.LinuxUnitaryComputerSystem"
Capítulo 1. Usando 221

relation="relation.Virtualizes"/><include target="{any}" source="only sys.ComputerSystem" relation="relation.Virtualizes"/></includedRelationships>
Configuração de composiçãoConfiguração de composição consiste em objetos que são incluídos em aplicativos de negócios eexcluídos deles.
Se não for especificado de outra forma na configuração de composição, todos os objetos serão excluídosda composição do aplicativo de negócios por padrão. A configuração padrão inclui subclasses deinterfaces de alto nível que incluem sistemas de computador, servidores de software e componentes quesão implementados neles, funções e diversos tipos de agrupamentos, por exemplo, clusters ou células.Aplicativos de negócios são afetados pela configuração de composição após sua construção. Os objetosexcluídos são filtrados no aplicativo de negócios, mas ainda é possível visualizá-los na área de janela dedetalhes Caminho.
Exemplo:
<compositionConfiguration> <includeInComposition> <include type="simple.SComputerSystem"/> <include type="simple.SDeployableComponent"/> <include type="simple.SFunction"/> <include type="simple.SGroup"/> <include type="simple.SSoftwareServer"/> </includeInComposition> <excludeFromComposition> <exclude type="customCollection.GroupingPattern"/> <exclude type="process.AccessCollection"/> </excludeFromComposition></compositionConfiguration>
A configuração de composição consiste nos parâmetros a seguir:includeInComposition
Este parâmetro contém uma série de identificações include que especificam os nomes dos tipos deModelo de Dados Comum. Somente objetos dos tipos incluídos e seus subtipos podem sercomponentes de aplicativos de negócios.
excludeFromCompositionEste parâmetro contém uma série de identificações exclude. Isso permite excluir alguns subtiposdos tipos incluídos. Por exemplo, é possível incluir a ramificação do tipo SGroup com duas exceções,GroupingPattern e AccesCollection, como no exemplo anterior.
É possível incluir todos os ICs atravessados no aplicativo de negócios especificando o valor "{any}"para o parâmetro type na identificação include. Consulte o exemplo a seguir:
<compositionConfiguration> <includeInComposition> <include type="{any}"/> </includeInComposition></compositionConfiguration>
Configuração da direção de relaçõesA configuração de direção de relações dedica uma direção de dependência para relações definidas noModelo de Dados Comum.
Nota: A configuração de direção de relações pode ser parte da configuração padrão apenas. Ela não podeser alterada para um padrão de agrupamento específico.
As relações entre ICs são sempre transferidas com base nas direções de dependência. Por exemplo, oServiço de Aplicativos sempre depende do ComputerSystem de hosting porque ele não pode serexecutado sem ele. Se o ComputerSystem for encerrado, o Servidor de Aplicativo não pode funcionar semele e também é encerrado. Mas o ComputerSystem não depende do Application Server porque seufuncionamento não é afetado desativando-se o Application Server. Relações no Modelo de Dados Comum
222 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

nem sempre são alinhadas com a direção de dependência de objetos. A propósito deste tipo deconfiguração é ativar a reversão das relações particulares durante a passagem de dados.
Exemplo:
<directions> <reverseRelationships> <reverse relation="only relation.GroupMemberOf" source="{any}" target="{any}"/> <reverse relation="only relation.Provides" source="{any}" target="{any}"/> ... <forwardRelationships> <forward relation="only relation.Provides" source="sys.blade.BladeCenterManagementModule" target="sys.blade.Alert"/> <forward relation="only relation.Provides" source="sys.vmware.VMWareVirtualSwitch" target="sys.vmware.VMWarePortGroup"/> ...
A configuração de direção de relações consiste nos seguintes parâmetros:reverseRelationships
Este parâmetro é usado para inverter direções de relação do Modelo de Dados Comum. Isso significaque o mecanismo de composição do aplicativo de negócios atravessa sua relação na direção oposta àdefinida no Modelo de Dados Comum. Deve-se fornecer valores para os parâmetros a seguir:
• relation - o nome da relação ou dependência do Modelo de Dados Comum.• source - o nome do tipo de objeto de origem da relação. Em caso de dependência, somente o valor"{any}" será permitido.
• target - o nome do tipo de objeto de destino da relação. Em caso de dependência, somente ovalor "{any}" será permitido.
forwardRelationshipsEste parâmetro permite incluir algumas exceções nos relacionamentos invertidos. No exemploanterior, a relação Provides foi invertida, mas duas exceções foram definidas na seçãoforwardRelationships.
Se um tipo de relação específico não estiver incluído na configuração padrão, ele será tratado comoalinhado com a dependência do objeto. Por exemplo, como relation.Uses é alinhado por padrão coma sua dependência, esse elemento não é necessário na configuração:
<forward relation="relation.Uses" source="{any}" target="{any}"/>
No entanto, a configuração deve conter exceções para um par específico de classes, por exemplo:
<reverse relation="only relation.Uses" source="app.db.oracle.OracleDataFile" target="app.db.oracle.OracleTableSpace"/>
A configuração da direção também pode conter tipos de relações que devem ser revertidas para todas assuas ocorrências no Modelo de Dados Comum. Por exemplo, a relação Gerencia deve ser revertidaglobalmente:
<reverse relation="only relation.Manages" source="{any}" target="{any}"/>
No entanto, quaisquer exceções devem ser incluídas no elemento forwardRelationships:
<forward relation="only relation.Manages" source="sys.HMC" target="sys.ComputerSystem"/>
É possível mudar as direções apenas para as classes para as quais uma relação está definida. Não épossível alterar a direção de uma relação para as subclasses de classes para as quais a relação estádefinida. Por exemplo, uma relação sys.OperatingSystem -> relation.RunsOn ->sys.ComputerSystem não pode ser revertida para sys.linux.Linux -> relation.RunsOn ->sys.linux.LinuxUnitaryComputerSystem. No entanto, é possível incluir ou excluir a passagem derelação dessa maneira.
Capítulo 1. Usando 223

Configuração de camadasUm dos propósitos da criação da configuração padrão de agrupamento customizado é definir as camadasque são designadas para os elementos de grupos criados. Os elementos de cada grupo criado peloBizAppsAgent podem ser divididos em camadas.
A configuração para uma camada contém um nome de camada e um conjunto de regras com condições.As definições de camadas são processadas na ordem definida. A primeira camada, para a qual pelomenos uma regra atende a todas as condições definidas para um determinado item de configuração, édesignada a um elemento.
Nota: É possível controlar quantas camadas são processadas usando o parâmetrofirstTierOnly, que é especificado na seção geral da configuração de padrão. Para obter detalhes,consulte “Configuração geral” na página 218.
A configuração customizada que é específica para um determinado padrão de agrupamento é processadaantes da configuração padrão.
O exemplo a seguir mostra a configuração da camada simples com a definição de camadas paraelementos nos grupos criados. Essa também é a configuração da camada padrão.
<tiers> <tier> <name>Computer Systems</name> <rule> <className>ComputerSystem</className> </rule> </tier> <tier> <name>App Servers</name> <rule> <className>AppServer</className> </rule> </tier> </tiers>
O exemplo a seguir mostra a configuração da camada avançado com a definição de camadas paraelementos nos grupos criados.
<tiers> <tier> <name>My tier name</name> <rule> <className>ComputerSystem</className> <displayName type="wildcard">*.pl</displayName> </rule> <rule> <className type="strict">LinuxUnitaryComputerSystem</className> <displayName type="wildcard">*ibm*</displayName> </rule> </tier> <tier> <name>Windows Computer Systems</name> <rule> <className>WindowsComputerSystem</className> </rule> <rule> <className type="regexp">.*ComputerSystem</className> <expression> <pattern>$CI.OSRunning.OSName</pattern> <match type="regexp">.*Windows.*</match> </expression> </rule> <rule> <hierarchyType type="strict">WindowsComputerSystem</hierarchyType> </rule> </tier>
Para obter mais informações sobre elementos de configuração, consulte “Elementos e atributos deconfiguração de camadas” na página 225.
Conceitos relacionados“Camadas de aplicativo de negócios” na página 252
224 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Camadas de aplicativo de negócios são grupos de elementos do aplicativo de negócios semelhantes. Elassão usadas para criar grupos funcionais para integrar o TADDM com outros produtos e para assegurar acompatibilidade com aplicativos de negócios que foram criados no TADDM 7.2.2.
Elementos e atributos de configuração de camadasConsulte a tabela a seguir para aprender sobre os elementos e atributos da configuração da camada quepode ser customizada.
Tabela 26. Elementos e atributos de configuração de camadas.
Elemento Descrição e atributos
camadas O elemento-raiz para a definição de camadas. Cada definição de camada deve sercolocada sob este elemento.
tier O elemento para a definição de camada.
nome (Requerido) O elemento para a definição de nome de camada. Ele deve sercolocado sob a definição de camada.
rule O elemento para a definição de regra de camada. Ele deve ser colocado sob adefinição de camada. Pelo menos uma regra é obrigatória. Diversas regras parauma definição de camada são permitidas. Neste caso, o operador lógico OR éincluído entre elas. O elemento rule requer pelo menos um elemento decondição: className, displayName ou hierarchyType. Se as condiçõesforem combinadas, o operador lógico AND é incluído entre elas.
className (Opcional) O elemento para a condição de regra de camada com relação a umnome de classe. Apenas um elemento por regra é permitido. Se mais elementosforem necessários, é necessário criar uma nova regra para a definição de camada.Use apenas nomes de classe curtos, por exemplo ComputerSystem.
tipo (Opcional) Define como a condição definida é tratada. Os valores aseguir são possíveis:
• strict - o valor padrão. A classe CDM do IC (Item deConfiguração) deve ser a classe fornecida ou herdar dela. Apenasnomes de classe curtos são permitidos, por exemplo,ComputerSystem.
• wildcard - o nome da classe curto deve corresponder. Estevalor permite usar o sinal de asterisco (*) (zero ou maiscaracteres) e o ponto de interrogação (?) (zero ou um caractere).A herança é ignorada.
• regexp - o nome da classe curto deve corresponder à expressãoregular fornecida. A herança é ignorada.
displayName (Opcional) O elemento para a condição de regra de camada com relação a umnome de exibição. Apenas um elemento por regra é permitido.
tipo (Opcional) Define como a condição definida é tratada. Os valores aseguir são possíveis:
• strict - o valor padrão. O nome de exibição deve ser igual aovalor fornecido.
• wildcard - o nome de exibição deve corresponder. Este valorpermite usar o sinal de asterisco (*) (zero ou mais caracteres) e oponto de interrogação (?) (zero ou um caractere).
• regexp - o nome de exibição deve corresponder à expressãoregular fornecida.
Capítulo 1. Usando 225
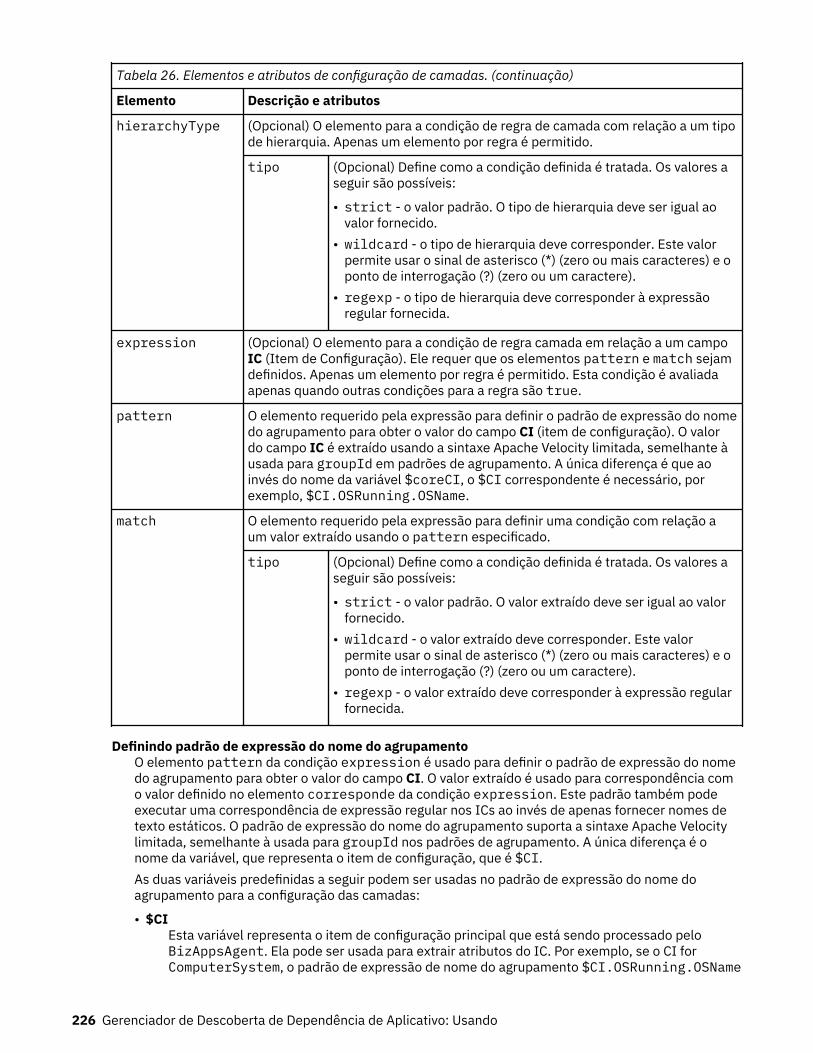
Tabela 26. Elementos e atributos de configuração de camadas. (continuação)
Elemento Descrição e atributos
hierarchyType (Opcional) O elemento para a condição de regra de camada com relação a um tipode hierarquia. Apenas um elemento por regra é permitido.
tipo (Opcional) Define como a condição definida é tratada. Os valores aseguir são possíveis:
• strict - o valor padrão. O tipo de hierarquia deve ser igual aovalor fornecido.
• wildcard - o tipo de hierarquia deve corresponder. Este valorpermite usar o sinal de asterisco (*) (zero ou mais caracteres) e oponto de interrogação (?) (zero ou um caractere).
• regexp - o tipo de hierarquia deve corresponder à expressãoregular fornecida.
expression (Opcional) O elemento para a condição de regra camada em relação a um campoIC (Item de Configuração). Ele requer que os elementos pattern e match sejamdefinidos. Apenas um elemento por regra é permitido. Esta condição é avaliadaapenas quando outras condições para a regra são true.
pattern O elemento requerido pela expressão para definir o padrão de expressão do nomedo agrupamento para obter o valor do campo CI (item de configuração). O valordo campo IC é extraído usando a sintaxe Apache Velocity limitada, semelhante àusada para groupId em padrões de agrupamento. A única diferença é que aoinvés do nome da variável $coreCI, o $CI correspondente é necessário, porexemplo, $CI.OSRunning.OSName.
match O elemento requerido pela expressão para definir uma condição com relação aum valor extraído usando o pattern especificado.
tipo (Opcional) Define como a condição definida é tratada. Os valores aseguir são possíveis:
• strict - o valor padrão. O valor extraído deve ser igual ao valorfornecido.
• wildcard - o valor extraído deve corresponder. Este valorpermite usar o sinal de asterisco (*) (zero ou mais caracteres) e oponto de interrogação (?) (zero ou um caractere).
• regexp - o valor extraído deve corresponder à expressão regularfornecida.
Definindo padrão de expressão do nome do agrupamentoO elemento pattern da condição expression é usado para definir o padrão de expressão do nomedo agrupamento para obter o valor do campo CI. O valor extraído é usado para correspondência como valor definido no elemento corresponde da condição expression. Este padrão também podeexecutar uma correspondência de expressão regular nos ICs ao invés de apenas fornecer nomes detexto estáticos. O padrão de expressão do nome do agrupamento suporta a sintaxe Apache Velocitylimitada, semelhante à usada para groupId nos padrões de agrupamento. A única diferença é onome da variável, que representa o item de configuração, que é $CI.As duas variáveis predefinidas a seguir podem ser usadas no padrão de expressão do nome doagrupamento para a configuração das camadas:
• $CIEsta variável representa o item de configuração principal que está sendo processado peloBizAppsAgent. Ela pode ser usada para extrair atributos do IC. Por exemplo, se o CI forComputerSystem, o padrão de expressão de nome do agrupamento $CI.OSRunning.OSName
226 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

extrai o campo OSName do OperatingSystem (OSRunning) que é executado em umdeterminado ComputerSystem.
• $utilsEssa variável representa os utilitários disponíveis em padrões de expressão do nome doagrupamento. Para obter mais informações, consulte “Expressão de nome do agrupamento” napágina 211.
Anexando uma configuração customizada a um padrão de agrupamentoÉ possível criar sua própria configuração customizada do padrão de agrupamento e conectá-lo a padrõesde agrupamento.
Sobre Esta Tarefa
A configuração dos padrões de agrupamento controla como os aplicativos de negócios serão construídos.É possível criar uma configuração customizada quando se deseja alterar o processo padrão. Por exemplo,é possível excluir determinadas relações e configurar a propriedade maxHopsLimit para um valorinferior para reduzir o tamanho de seu aplicativo. É possível criar suas próprias camadas se você estiverintegrando o TADDM com outros produtos. Consulte “Configuração dos padrões de agrupamento” napágina 216 para obter informações detalhadas sobre cada seção da configuração do padrão deagrupamento.
Importante: A seção somente da configuração que pode ser customizada para um padrão deagrupamento específico é a configuração direção. Esta seção sempre se aplica a todos os padrões deagrupamento, portanto, ao modificá-la, todos os padrões são afetados.
Para criar uma configuração customizada e conectá-la a um padrão de agrupamento, execute asseguintes etapas.
Procedimento
1. Crie um arquivo de configuração XML. As abordagens a seguir são possíveis:
• É possível criar um arquivo vazio, salvá-lo como o arquivo XML, por exemplo, my_config.xml, efornecer o conteúdo.
• É possível exportar a configuração padrão para um novo arquivo e modificar o conteúdo existente.Execute a ferramenta bizappscli no diretório<taddm_installation_directory>dist/sdk/bin, conforme a seguir:
bizappscli.sh exportDefaultConfiguration -f file name
A opção -f define o arquivo de destino onde a configuração padrão é exportada. O exemplo aseguir mostra como exportar a configuração padrão para o arquivo my_config.xml:
bizappscli.sh exportDefaultConfiguration -f my_config.xml
Nota: Os exemplos neste tópico são válidos para os sistemas operacionais Linux e UNIX. Se vocêestiver usando o sistema operacional Windows, execute a ferramenta no formatobizappscli.bat.
2. Dependendo de suas necessidades, forneça o conteúdo personalizado do arquivo que você criou ouexportou.
3. Import a nova configuração para o banco de dados executando a ferramenta bizappscli da seguintemaneira:
bizappscli.sh importConfiguration -c configuration name -f file name
A opção -c especifica o nome da nova configuração, a qual pode ser selecionada, então, na lista detodas as configurações no Portal de Gerenciamento de Dados. A opção -f define um arquivo de
Capítulo 1. Usando 227

origem a partir do qual a configuração é importada. O exemplo a seguir mostra como importar aconfiguração custom_config no arquivo my_config.xml:
bizappscli.sh importConfiguration -c custom_config -f my_config.xml
4. Anexe a configuração a um padrão de agrupamento. É possível usar a ferramenta bizappscli ou oPortal de Gerenciamento de Dados.
• Ferramenta bizappscliPara anexar uma configuração a um padrão de agrupamento usando a ferramentabizappscli, execute a ferramenta da seguinte maneira:
bizappscli.sh attachConfiguration -c configuration name -n pattern name | -g pattern GUID
Use a opção -n ou -g. A opção -n define o nome do padrão de agrupamento. A opção -gdefine o GUID do padrão de agrupamento.O exemplo a seguir mostra como anexar a configuração custom_config a um padrão deagrupamento nomeado my_pattern:
bizappscli.sh attachConfiguration -c custom_config -n my_pattern
Nota: É possível anexar uma configuração a apenas um padrão por vez. Se você deseja anexar amesma configuração a mais padrões, repita o procedimento.
• Portal de Gerenciamento de DadosPara anexar uma configuração a um padrão de agrupamento usando o Portal de Gerenciamentode Dados, execute as seguintes etapas:
a. Abra Portal de Gerenciamento de Dados.b. Na área de janela Funções, clique em Descoberta se TADDM 7.3.0 ou 7.3.0.1 for usado, ou
em Analytics, se TADDM 7.3.0.2 ou mais recente for usado.c. Clique em Padrões de Agrupamento.d. Selecione o padrão para o qual deseja designar a configuração e clique em Editar.e. Na lista Configuração, selecione a configuração que você criou, por exemplo
custom_config.f. Clique em OK.
O que Fazer DepoisSe você deseja que a configuração padrão seja anexada de volta ao padrão que você customizou, seránecessário remover a configuração customizada. Execute a ferramenta bizappscli da seguintemaneira:
bizappscli.sh detachConfiguration -n pattern name | -g pattern GUID
Use a opção -n ou -g. A opção -n define o nome do padrão de agrupamento. A opção -g define o GUIDdo padrão de agrupamento.O exemplo a seguir mostra como remover a configuração customizada de um padrão de agrupamentonomeado my_pattern:
bizappscli.sh detachConfiguration -n my_pattern
Tarefas relacionadas“Definindo uma configuração do padrão de agrupamento” na página 259Saiba como customizar um aplicativo de negócios configurando camadas, invertendo relações eimportando configurações usando a ferramenta bizappscli.Referências relacionadas“Ações para gerenciar a configuração do padrão de agrupamento” na página 242
228 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Ao usar a ferramenta bizappscli, é possível exportar e importar configurações de padrão deagrupamento completos ou suas seções específicas.
Atravessando relações durante o processamento padrãoTodos os elementos de um aplicativo de negócios são atravessados e alinhados de acordo com a direçãode dependência entre objetos. É possível visualizar a direção de passagem em uma topologia.
Os objetos que estão localizados na topologia acima de outros objetos sempre dependem deles. Porexemplo, um servidor de aplicativos é sempre localizado acima de um sistema de computador host. Issosignifica que o servidor de aplicativos depende do sistema de computador. A direção de uma relação queliga estes dois CIs é representada na topologia por uma seta que aponta a partir do servidor deaplicativos até o sistema de computador.
Para cada seletor, é possível decidir quais objetos dependentes atravessar. Primeiro, escolha uma dasduas opções a seguir:
• Atravessar dependências para baixo (LowerDown). Quando você seleciona esta opção, BizAppsAgentatravessa todos os objetos, dos quais depende um IC principal específico, e todos os outros objetos dosquais dependem esses objetos. Por exemplo, o BizAppsAgent atravessa do servidor da web até umsistema de computador hosting, do qual o servidor da web depende e, em seguida, vai do sistema decomputador até um hypervisor hosting, do qual o sistema de computador depende.
• Atravessar dependências para cima (HigherUp). Quando essa opção é selecionada, o BizAppsAgentatravessa todos os objetos dos quais um CI principal específico depende e todos os outros objetos quedependem desses objetos. Por exemplo, o BizAppsAgent atravessa de um hypervisor até todos ossistemas de computador que estão hospedados nele e, em seguida, até todos os servidores deaplicativos que estão hospedados nesses sistemas de computador.
Com estas duas opções, você pode atravessar as relações em apenas uma direção estritamente definida,que é para cima ou para baixo. No entanto, quando você mover um nível para cima ou para baixo do CIprincipal, também é possível incluir relações de processamento na direção oposta. Por exemplo, oBizAppsAgent pode iniciar a partir de um sistema de computador específico, ir para baixo para o seuhypervisor hosting, e, em seguida, ir para cima para todos os outros sistemas de computador virtuaishospedados. Para ativar relações de processamento na direção oposta, use as seguintes opções:
• HigherDown. É possível selecionar esta opção somente quando a opção HigherUp estiver selecionada.Quando você seleciona a opção Higher Down, BizAppsAgent passa por todos os objetos que encontraenquanto atravessa as dependências de baixo para cima.
• LowerUp. É possível selecionar esta opção somente quando a opção LowerDown estiver selecionada.Quando você seleciona a opção Lower Up, BizAppsAgent passa por todos os objetos que encontraenquanto atravessa as dependências de baixo.
Diagramas
Os diagramas a seguir mostram o uso das opções de passagem. Um círculo vermelho representa um ICprincipal. As setas representam a direção da dependência. Os círculos azuis representam objetos que sãoincluídos no aplicativo de negócios quando uma determinada opção é selecionada.
Capítulo 1. Usando 229

HigherUp
Figura 2. Topologia com a opção HigherUp selecionada.
HigherUp e HigherDown
Figura 3. Topologia com as opções HigherUp e HigherDown selecionadas.
230 Gerenciador de Descoberta de Dependência de Aplicativo: Usando
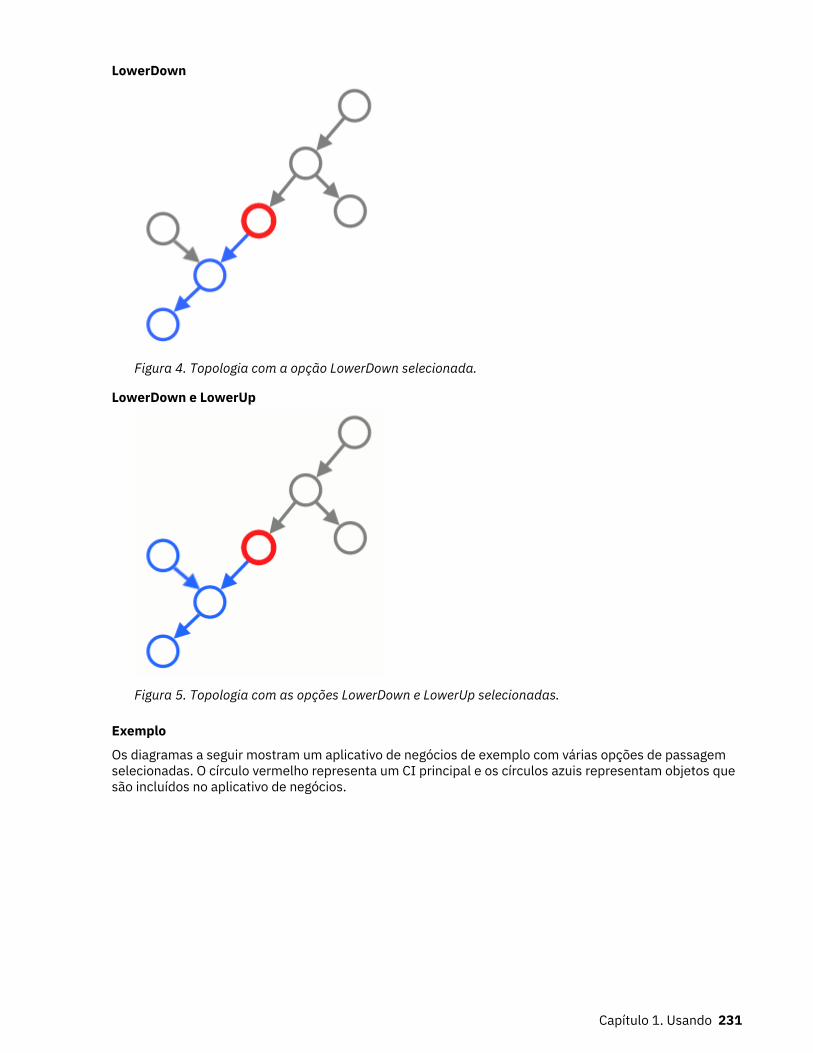
LowerDown
Figura 4. Topologia com a opção LowerDown selecionada.
LowerDown e LowerUp
Figura 5. Topologia com as opções LowerDown e LowerUp selecionadas.
Exemplo
Os diagramas a seguir mostram um aplicativo de negócios de exemplo com várias opções de passagemselecionadas. O círculo vermelho representa um CI principal e os círculos azuis representam objetos quesão incluídos no aplicativo de negócios.
Capítulo 1. Usando 231

Atravessando dependências com a opção HigherUp
Figura 6. Topologia somente com a opção HigherUp selecionada.
Atravessando dependências com as opções HigherUp e HigherDown
Figura 7. Topologia com as opções HigherUp e HigherDown selecionadas.
232 Gerenciador de Descoberta de Dependência de Aplicativo: Usando
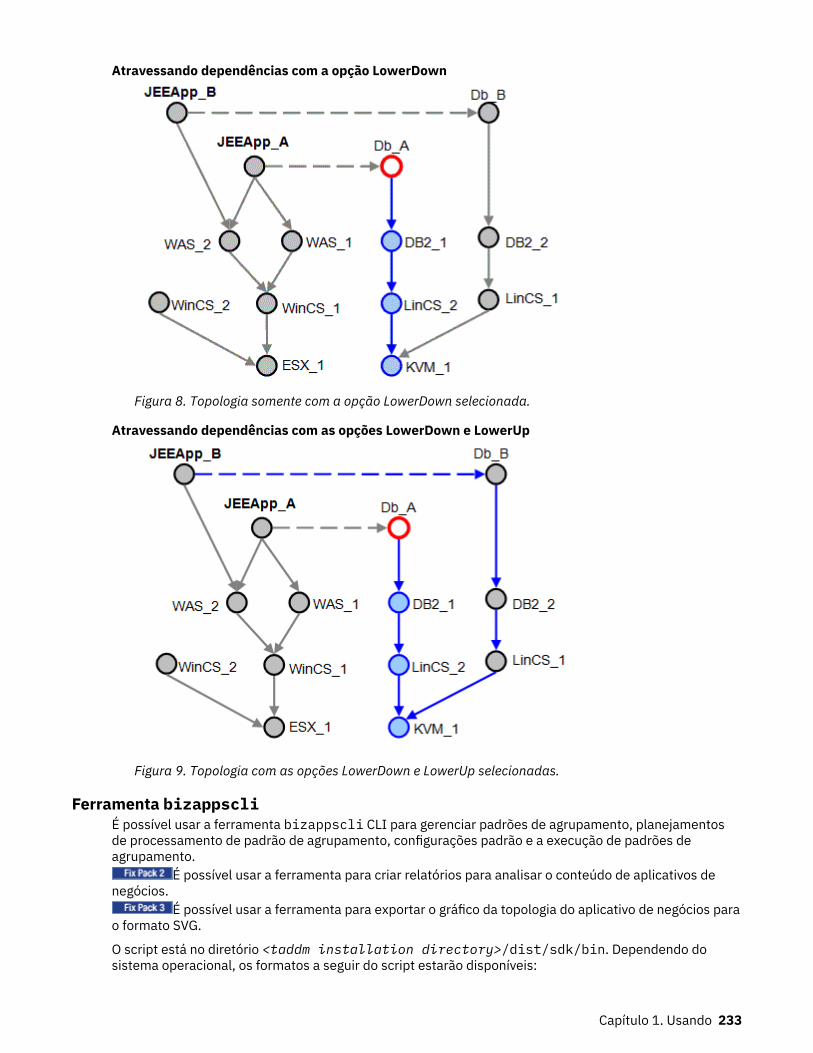
Atravessando dependências com a opção LowerDown
Figura 8. Topologia somente com a opção LowerDown selecionada.
Atravessando dependências com as opções LowerDown e LowerUp
Figura 9. Topologia com as opções LowerDown e LowerUp selecionadas.
Ferramenta bizappscliÉ possível usar a ferramenta bizappscli CLI para gerenciar padrões de agrupamento, planejamentosde processamento de padrão de agrupamento, configurações padrão e a execução de padrões deagrupamento.
É possível usar a ferramenta para criar relatórios para analisar o conteúdo de aplicativos denegócios.
É possível usar a ferramenta para exportar o gráfico da topologia do aplicativo de negócios parao formato SVG.
O script está no diretório <taddm installation directory>/dist/sdk/bin. Dependendo dosistema operacional, os formatos a seguir do script estarão disponíveis:
Capítulo 1. Usando 233

• Para Linux, AIX e Linux on System z - bizappscli.sh.• Para Windows - bizappscli.bat.
Nota: Na seção da ferramenta bizappscli, o formato bizappscli.sh é usado em todos os exemplos.Se você trabalhar no sistema operacional Windows, lembre-se de usar o formato bizappscli.bat.
Importante: Para usar a ferramenta bizappscli, deve-se ter a permissão de Atualizaçãoconcedida para o DefaultAccessCollection.
Para executar a ferramenta bizappscli, deve-se especificar uma ação e opções. As opções a seguir seaplicam a todas as ações:
• -H, --hostname <arg> - define o nome do host. O valor padrão é 0.0.0.0. Se você usar o parâmetro -T, deve-se também especificar o parâmetro -H.
• -P, --port <arg> - define a porta. O valor padrão é 9433.• -p, --password <arg> - define a senha do usuário do TADDM.• -T, --truststore <arg> - define o local do arquivo de armazenamento confiável,jssecacerts.cert, com um certificado para conexão com o servidor TADDM. Esse parâmetro éobrigatório para conexão segura com o TADDM. Se você usar esse parâmetro, deve-se tambémespecificar o parâmetro -H.
• -u, --user <arg> - define o nome do usuário do TADDM.
Nota: Quando os valores das opções contiverem espaços, deve-se colocar os valores entre aspas duplas,por exemplo "meu padrão de agrupamento". Caso contrário, a ferramenta interpreta uma palavradepois do primeiro espaço como o nome da ação, e um erro será gerado.
Para ver todas as ações disponíveis, execute o script sem argumentos. Para ver uma descrição de umaação, use o seguinte script:
bizappscli.sh help -a <action>
Por exemplo, bizappscli.sh help -a listPatterns.
É possível usar a ferramenta bizappscli.sh para controlar o processamento de padrões deagrupamento. Diversos padrões podem ser processados em um único servidor de armazenamento que,por padrão, é o servidor de armazenamento primário e também em servidores de armazenamentomúltiplos.
Grupos de execuçãoOs padrões são processados dentro de um conjunto de encadeamentos denominado ExecutionGroup.Cada servidor de armazenamento pode dedicar encadeamentos a um determinado grupo deexecução, que se torna parte de um conjunto de encadeamentos de diversos servidores, que depoisprocessa padrões. O tamanho do conjunto de encadeamentos define como muitos padrões podemser executados em paralelo. Cada padrão pode ser processado por cinco encadeamentos ao mesmotempo, o que é controlado pelo mecanismo ExecutionGroup.Se em um determinado momento, houver mais padrões de agrupamento que requeremprocessamento do que a capacidade do grupo de execução permite, os padrões pendentes sãoexecutados no tempo mais próximo possível após um dos encadeamentos do grupo de execução setornar disponível. Um novo grupo de execução é criado quando há pelo menos um planejamento quese refere ao nome do grupo de execução. No entanto, quando o grupo de execução é criado, ele deveser ativado em cada servidor de armazenamento que deve fazer parte do grupo de execução, e otamanho do conjunto de encadeamentos precisa ser configurado separadamente em cada servidor dearmazenamento.Por padrão, há um grupo de execução disponível chamado default. O grupo é configurado para tersomente um encadeamento em execução no servidor de armazenamento primário (ele não precisaser ativado no servidor primário). Outros grupos de execução podem ser criados para assegurar queos padrões de mais alta prioridade sempre possuam encadeamentos disponíveis. Todos os padrõesque são executados dentro de grupos de execução possuem a mesma prioridade e, portanto, umpadrão pode bloquear o processamento de outro se nenhum encadeamento inativo estiver disponível
234 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

dentro do grupo. A criação de outro grupo de execução constitui a criação de outro conjunto deencadeamentos.É possível ativar o processamento dos grupos de execução em servidores de armazenamentosecundário além do servidor de armazenamento primário. Em cada servidor de armazenamentosecundário, configure a propriedade a seguir no arquivo collation.properties como true:
com.ibm.cdb.internalscheduling.bizapps.<GROUP NAME>.enabled=true
<GROUP NAME> é o nome do grupo que você deseja ativar. Por exemplo, para ativar o grupo padrão,defina a seguinte propriedade:
com.ibm.cdb.internalscheduling.bizapps.default.enabled=true
Planejamentos de execuçãoPadrões são executados de acordo com seu planejamento. Cada padrão deve ser associado a umplanejamento durante a criação. Um objeto de planejamento contém informações sobre quando, oucom que frequência, o padrão é processado e qual grupo de execução é usado para esseprocessamento. Por padrão, somente um planejamento chamado padrão será criado, com umintervalo padrão configurado para cada 4 horas. Este planejamento padrão é associado ao grupo deexecução padrão.Se você migrou aplicativos de negócios do TADDM 7.2.2, o intervalo padrão será o mesmo que o valorda propriedade com.ibm.cdb.topobuilder.groupinterval.bizapps. É possível verificar ovalor dessa propriedade no arquivo collation.properties.Planejamentos podem ser baseados em intervalos ou na expressão cron.Intervalo
Um planejamento baseado em intervalos aciona o processamento padrão periodicamente comintervalos definidos. O primeiro processamento é acionado após o primeiro intervalo de tempopassar após o servidor TADDM ser iniciado.
CronUm planejamento baseado em cron pode ser criado ao especificar a expressão cron, que permiteplanejamentos mais complexos, como "toda quinta-feira, às 18:00'.
Para obter mais informações sobre os intervalos e expressões cron, consulte “Ações para gerenciarplanejamentos de padrão de agrupamento” na página 239.
Teste manual padrão únicoÉ possível testar um padrão único manualmente fora do planejamento definido.Uma execução manual sempre aciona uma execução no grupo de execução de acordo com oplanejamento definido. Como encadeamentos de grupo de execução podem ser difundidos paradiversos servidores, o encadeamento que é usado para processamento pode estar em um servidoralém do usado para iniciar o processamento.A execução manual não altera o planejamento definido que é associado ao padrão. No entanto, comoqualquer padrão pode ser processado somente uma vez ao mesmo tempo, se um padrão estiver emexecução porque foi acionado por um planejamento definido, a execução manual falhará. Quando oprocessamento padrão for interrompido, o processamento seguinte será iniciado de acordo com oplanejamento definido.Quando um padrão é executado manualmente e uma execução automática é planejada ao mesmotempo, a execução planejada é executada assim que possível. Isso significa que a execução planejadaé executada quando a execução manual é concluída e há um encadeamento livre disponível no grupode execução associado.
Configurando as propriedades da ferramenta bizappsclicom.ibm.taddm.bizappscli.jvmArgs=-Xmx1024M
Essa propriedade define as opções da Java virtual machine para o uso da ferramenta bizappscli.Se não houver memória suficiente para executar a ferramenta, é possível aumentar o tamanho deheap máximo dos processos da Java virtual machine modificando o valor dessa propriedade no
Capítulo 1. Usando 235

arquivo $COLLATION_HOME/sdk/etc/collation.properties. Por exemplo, exportar topologiasde aplicativo de negócios para o formato SVG pode requerer mais memória do que a definida nasconfigurações padrão.Configure o valor no formato a seguir: -Xmx1024M. Nesse exemplo, o tamanho de heap máximo é1024 MB (1 GB).
Ações para gerenciar padrões de agrupamentoAo usar a ferramenta bizappscli, é possível exportar e importar padrões de agrupamento e controlarcomo eles são executados.
É possível usar as ações a seguir, por exemplo, ao copiar padrões de agrupamento entre ambientes dedesenvolvimento, teste ou produção.
exportPatterns
Esta ação exporta as definições de padrão de agrupamento. É possível importá-las posteriormente para amesma ou outra instância TADDM. É possível customizar separadamente o modo de exportação daconfiguração (a opção -C) e o planejamento (a opção -S). Os seguintes valores estão disponíveis:
• NEVER - a configuração associada ou planejamento nunca é exportado.• ALWAYS - a configuração associada ou planejamento é sempre exportado.• NONDEFAULT - a configuração associada ou planejamento é exportado se ele não for um padrão.
As seguintes opções estão disponíveis:
• -C, --configurationExportMode <arg> - define o modo de exportação da configuração. O valorpadrão é NONDEFAULT.
• -f, --filename <arg> - define o arquivo de destino no qual os padrões são exportados. Se você nãoespecificar um caminho, o arquivo será criado no diretório atualmente em funcionamento. Se você nãoespecificar este arquivo, os resultados serão impressos na saída padrão.
• -g, --guid <arg> - define o GUID do padrão.• -n, --name <arg> - define o nome do padrão.• -S, --scheduleExportMode <arg> - define o modo de exportação do planejamento. O valor padrão éNONDEFAULT.
Por exemplo, para exportar um padrão de agrupamento com o nome gp2 para um arquivonew_pattern.xml sem um planejamento, execute a ferramenta da seguinte maneira:
bizappscli.sh exportPatterns -n gp2 -f new_pattern.xml -S NEVER
importPatterns
Esta ação carrega as definições de padrão de agrupamento que foram exportadas para um arquivo XML.Se for necessário, as definições conterão planejamentos definidos e definições de configuração. Épossível customizar o modo de importação do padrão (a opção -I), o planejamento (a opção -S) e aconfiguração (a opção -C). A lista a seguir contém os valores disponíveis.
Nota: Na descrição a seguir dos valores disponíveis, o objeto representa um padrão, planejamento ouconfiguração, dependendo de qual opção for usada.
• DEFAULT - para planejamento e configuração, esta opção anexa o padrão ao objeto padrão. Dadosimportados são ignorados.
• ATTACH - procura objetos existentes por nome. Se o objeto for encontrado, o padrão, planejamento ouconfiguração é anexado a ele. Se o objeto não for encontrado, o comando falhará. Os dados importadossão ignorados.
• CREATE - cria um objeto. Se um objeto com o mesmo nome existir, o comando falhará.• UPDATE - procura objetos existentes por nome e os atualiza com os dados importados. Se um objeto
não existir, ele será criado.
236 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

As seguintes opções estão disponíveis:
• -C, --configurationImportMode <arg> - define o modo de importação de uma configuração. Ovalor padrão é CREATE.
• -f, --filename <arg> - define o arquivo de origem do qual os padrões são importados.• -I, --patternImportMode <arg> - define o modo de importação de um padrão. O valor padrão éCREATE.
• -r, --filter <arg> - seleciona os padrões que são importados do arquivo de origem. O valor dessaopção é o nome do padrão de agrupamento. É possível, opcionalmente, usar um ponto de interrogação(?) e um asterisco (*) como um curinga. Por exemplo, para importar padrões que possuem nomes quecomeçam com a letra "c", especifique o valor c*.
• -S, --scheduleImportMode <arg> - define o modo de importação do planejamento. O valor padrão éCREATE.
• -X, --prefix <arg> - define uma frase opcional que pode ser usada como prefixo para os nomes dospadrões, planejamentos e configurações importados.
Importante: A opção -f é requerida.
Por exemplo, para importar um padrão que foi salvo no arquivo my_pattern.xml, inclua a seu nome oprefixo 10_Jun e certifique-se de que o planejamento padrão será designado a ele, execute a ferramentada seguinte maneira:
bizappscli.sh importPatterns -f my_pattern.xml -X 10_Jun -S DEFAULT
restoreExamplePatterns
Esta ação recria as definições de padrão de exemplo que ficam disponíveis após a instalação do TADDM.É possível usar as opções de modo de importação a seguir para especificar como importar padrões deexemplo :
• -C, --configurationImportMode <arg> - define o modo de importação da configuração. O valorpadrão é CREATE.
• -I, --patternImportMode <arg> - define o modo de importação do padrão. O valor padrão éCREATE.
• -S, --scheduleImportMode <arg> - define o modo de importação do planejamento. O valor padrão éCREATE.
• -X, --prefix <arg> - define uma frase opcional que pode ser usada como prefixo para os nomes dospadrões, planejamentos e configurações importados.
Por exemplo, para restaurar os padrões de agrupamento do exemplo padrão e certificar-se de que aconfiguração padrão está designada a eles, execute a ferramenta da seguinte maneira:
bizappscli.sh restoreExamplePatterns -C DEFAULT
listPatterns
Esta ação lista os padrões de agrupamento e informações gerais sobre eles. Por padrão, ela exibe o ID dogrupo de execução, nome do planejamento, nome do padrão de agrupamento e o horário da próximaexecução do padrão.
As seguintes opções estão disponíveis:
• -A, --sort - classifica os resultados por grupos de execução e planejamentos.• -C, --showConfig - mostra as configurações dos padrões.• -F, --dateFormat <arg> - especifica o formato de data. O formato padrão é M/d/yy h:mm a, por
exemplo, 03/25/15 2:38 PM. Para outros formatos de data, procure informações sobre a classe JavaSimpleDateFormat.
• -g, --guid <arg> - limita os resultado a um padrão específico.
Capítulo 1. Usando 237

• -G, --showGuids - mostra os GUIDs dos padrões.• -N, --hideNames - oculta os nomes dos padrões. Essa opção é normalmente usada com a opção -G.• -S, --separator <arg> - define o separador dos valores. O separador padrão é um espaço, " ".
Por exemplo, para exibir informações sobre apenas um padrão com o GUID00000000000000000000000000000000 e incluir as informações de um fuso horário ao horário dapróxima execução do padrão, execute a ferramenta da seguinte maneira:
bizappscli.sh listPatterns -g 00000000000000000000000000000000 -F "M/d/yy h:mm a z"
Sample output:
EXECUTION_GROUP SCHEDULE_NAME PATTERN_NAME NEXT_EXECUTION_TIMEdefault schedule1 my_pattern1 7/16/15 3:38 AM GMT-12:00
showPatternsRunning
Esta ação lista as tarefas que estão atualmente em execução em todos os planejadores e as instânciasdesses planejadores. Por padrão, apenas o nome do padrão de agrupamento que está sendo executado éexibido. As seguintes opções estão disponíveis:
• -G, --showGuids - mostra os GUIDs dos padrões.• -I, --showServerID - mostra o servidor de processamentos.• -N, --hideNames - oculta os nomes dos padrões. Essa opção é normalmente usada com a opção -G.• -S, --separator <arg> - define o separador dos valores. O separador padrão é um espaço, " ".
Por exemplo, o comando a seguir exibe os GUIDs e o servidor que processa os padrões de agrupamento.Além disso, os valores são separados por ponto e vírgula (;) para distinguir os valores que têm espaçosnos nomes.
bizappscli.sh showPatternsRunning -G -I -S ;
Sample output:
00000000000000000000000000000000;my pattern 1;taddmserverA.ibm.com11111111111111111111111111111111;my pattern 2;taddmserverB.ibm.com22222222222222222222222222222222;my pattern 3;taddmserverA.ibm.com
runPattern
Esta ação planeja um padrão para ser executado imediatamente quando um encadeamento estiverdisponível. As seguintes opções estão disponíveis:
• -e, --executionGroupId <arg> - define o nome do grupo de execução do qual os padrões sãoexecutados.
• -g, --guid <arg> - define o GUID do padrão.• -l, --infoLevel <arg> - define o nível dos detalhes dos arquivos de log. Os seguintes valores estão
disponíveis:
– NOINFO - nenhuma informação.– DEFAULT - informações apenas sobre como iniciar e parar o aplicativo de negócios.– GENERAL - as informações PADRÃO e os dados do IC principal.– DETAILS - as informações GERAIS e os detalhes da rota de passagem do mecanismo de
composição.– MAXINFO - nível máximo de detalhes, atualmente igual ao nível DETALHES.
Se você não especificar nenhum valor, o nível de detalhes é o mesmo que na configuração do padrão deagrupamento que é executado.
• -n, --name <arg> - define o nome do padrão.
238 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

• -w, --wait - define se é necessário aguardar até que o padrão termine a execução. O valor padrão paraessa opção é false.
Importante: Uma das opções a seguir é requerida: -e, -g ou -n.
Por exemplo, para planejar o padrão com o nome meu padrão 5 para executar quando umencadeamento estiver disponível e configurar os detalhes do arquivo de log para o nível mais alto,execute a ferramenta da seguinte maneira:
bizappscli.sh runPattern -n "my pattern 5" -l MAXINFO
stopPatternRun
Esta ação para a tarefa atualmente em execução. As seguintes opções estão disponíveis:
• -g, --guid <arg> - define o GUID do padrão que você deseja parar.• -n, --name <arg> - define o nome do padrão que você parar.
Importante: Uma das opções a seguir é requerida: -g ou -n.
Por exemplo, para parar um padrão com o GUID 00000000000000000000000000000000, execute aferramenta da seguinte maneira:
bizappscli.sh stopPatternRun -g 00000000000000000000000000000000
deletePatterns
Esta ação remove um ou mais padrões. Além disso, todas as futuras execuções planejadas são limpas. Asseguintes opções estão disponíveis:
• -f, --filter <arg> - define os nomes dos padrões a remover. É possível, opcionalmente, usar umponto de interrogação (?) e um asterisco (*) como um curinga. Por exemplo, para importar padrões quepossuem nomes que começam com a letra "c", especifique o valor c*.
• -g, --guid <arg> - define o GUID do padrão que você deseja remover.
Importante: Uma das opções a seguir é requerida: -f ou -g.
Por exemplo, para remover todos os padrões de agrupamento que possuem nomes que começam com aletra "p", execute a ferramenta da seguinte maneira:
bizappscli.sh deletePattern -f p*
Ações para gerenciar planejamentos de padrão de agrupamentoAo usar a ferramenta bizappscli, é possível criar e modificar os planejamentos de padrões deagrupamento.
createSchedule
Esta ação cria planejamentos. As seguintes opções estão disponíveis:
• -c, --cronExpression<arg> - define o intervalo usando a expressão cron. Para obter maisinformações sobre o formato da expressão cron, consulte a documentação do Quartz Scheduler emhttp://quartz-scheduler.org/documentation/quartz-2.x/tutorials/tutorial-lesson-06.
Nota: As expressões cron não são compatíveis com o formato usado pelo daemon cron no Linux eoutros sistemas operacionais UNIX. Há um sexto campo obrigatório adicional para representar ossegundos.
• -d, --description <arg> - define a descrição do planejamento.• -e, --executionGroupId <arg> - define o ID do grupo de execução. O ID do grupo de execução
padrão é default.• -i, --interval <arg> - define o intervalo de execução em horas.
Capítulo 1. Usando 239

• -l, --misfireLimit <arg> - define quanto tempo um padrão pode esperar para ser executado antesde ser ignorado pelo processamento e um aviso ser registrado. O aviso contém as informações de que opadrão não foi iniciado. Para evitar isso, é possível criar mais conjuntos de encadeamentos ou modificaros planejamentos de seus padrões. O valor desta opção é expresso em minutos. O valor padrão é 60. Sevocê não deseja modificar a configuração e, ao mesmo tempo, não deseja que os padrões sejamignorados, defina essa opção para um valor mais alto. Também é possível modificar esse limite usandoa propriedade com.ibm.cdb.internalscheduling.bizapps.schedule name.misfirepropriedade no arquivo collation.properties.
• -n, --name <arg> - define o nome do planejamento. É possível criar dois ou mais planejamentos com omesmo nome. No entanto, isso não é recomendado porque pode gerar confusão.
Importante: A opção -n é necessária e também deve-se usar a opção -c ou -i.
Exemplos:
• Para criar um planejamento que é denominado a cada três horas e que é executado no intervalode 3 horas, execute a ferramenta da seguinte maneira:
bizappscli.sh createSchedule -n "every three hours" -i 3
• Para criar um planejamento que é denominado toda meia-noite e que é executado todos os dias àmeia-noite, execute a ferramenta da seguinte maneira:
bizappscli.sh createSchedule -n "every midnight" -c "0 0 0 * * ?"
• Para criar um planejamento que é denominado aos sábados e que é executado todos os sábados às20h, execute a ferramenta da seguinte maneira. A opção -d inclui uma descrição para esclarecer o usodo planejamento.
bizappscli.sh createSchedule -n "Saturdays" -c "0 0 20 ? * SAT" -d "every Saturday at 8 PM"
listSchedules
Esta ação lista todos os planejamentos. Por padrão, ela exibe o ID do grupo de execução, o nome doplanejamento, o intervalo em que o planejamento será executado e a descrição do planejamento, se forfornecida.
As seguintes opções estão disponíveis:
• -G, --showGuids - exibe os GUIDs dos planejamentos.• -N, --hideNames - oculta os nomes dos planejamentos. Essa opção é normalmente usada com a
opção -G.• -S, --separator <arg> - define o separador dos valores. O separador padrão é um espaço, " ".
Por exemplo, para listar todos os planejamentos com seus GUIDs e separar os valores com a barra (/),execute a ferramenta da seguinte maneira:
bizappscli.sh listSchedules -G -S /
Sample output:
GUID EXECUTION_GROUP NAME INTERVAL DESCRIPTION00000000000000000000000000000000/default/every three hours/INTERVAL: 3h11111111111111111111111111111111/default/default/INTERVAL: 4h22222222222222222222222222222222/default/Saturdays/CRON: 0 0 20 ? * SAT/"every Saturday at 8 PM"33333333333333333333333333333333/default/every midnight/CRON: 1 1 1 * * ?
updateSchedule
Esta ação atualiza a configuração do planejamento. As seguintes opções estão disponíveis:
240 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

• -c, --cronExpression <arg> - define o novo intervalo usando a expressão cron.• -d, --description <arg> - define a nova descrição do planejamento.• -e, --executionGroupId <arg> - define o novo ID do grupo de execução. O ID do grupo de execução
padrão é default.• -g, --guid <arg> - define o GUID do planejamento que você deseja atualizar.• -i, --interval <arg> - define o novo intervalo de execução em horas.• -l, --misfireLimit <arg> - define quanto tempo um padrão pode esperar para ser executado antes
que um aviso seja registrado. O aviso contém informações de que o padrão não foi iniciado. Paraimpedir que esses avisos sejam registrados, é possível criar mais conjuntos de encadeamentos oumodificar os planejamentos de seus padrões. O valor desta opção é expresso em minutos. Se você nãodeseja modificar sua configuração, e ao mesmo tempo, não deseja que os alertas sejam registrados,configure essa opção para um valor mais alto.
• -n, --name <arg> - define o novo nome do planejamento.
Importante: A opção -g é requerida.
Exemplos:
• Para renomear um planejamento com o GUID 00000000000000000000000000000000 paranew_schedule, execute a ferramenta da seguinte maneira:
bizappscli.sh updateSchedule -g 00000000000000000000000000000000 -n "new schedule"
• Para desativar o planejamento com o GUID 00000000000000000000000000000000, especifique ovalor OFF para a opção -i. A opção -d inclui uma descrição para esclarecer o uso do planejamento.
bizappscli.sh updateSchedule -g 00000000000000000000000000000000 -i OFF -d "on demand only"
changeDefaultSchedule
Esta ação modifica o planejamento padrão sem especificar o GUID. As seguintes opções estãodisponíveis:
• -c, --cronExpression <arg> - define o novo intervalo usando a expressão cron.• -i, --interval <arg> - define o novo intervalo em horas.
Importante: Uma das opções a seguir é requerida: -c ou -i.
Por exemplo, para alterar o planejamento padrão para executar todos os dias à meia-noite em vez de acada 4 horas, execute a ferramenta da seguinte maneira:
bizappscli.sh changeDefaultSchedule -c "0 0 0 * * ?"
deleteSchedule
Esta ação exclui um planejamento com um GUID específico. Não é possível remover o planejamentopadrão. As seguintes opções estão disponíveis:
• -f, --forceToDefault - força o planejamento a ser removido mesmo se ele estiver designado a umpadrão de agrupamento. A programação padrão é usada no lugar. Se você não usa essa opção e desejaremover um planejamento que é designado a um padrão de agrupamento, ocorrerá um erro e oplanejamento não será removido.
• -g, --guid <arg> - define o GUID do planejamento que você deseja remover.
Importante: A opção -g é requerida.
Capítulo 1. Usando 241

Por exemplo, para excluir um planejamento com um GUID 00000000000000000000000000000000,mesmo se ele estiver designado a um padrão de agrupamento, execute a ferramenta da seguintemaneira:
bizappscli.sh deleteSchedule -f -g 00000000000000000000000000000000
resetSchedules
Esta ação reconfigura todos os planejamentos de padrão de agrupamento. Isso significa que quandohouver um determinado número de tarefas a serem processadas, e algumas delas forem iniciadas ealgumas enfileiradas, todos as tarefas serão reiniciadas. Os padrões de agrupamento que já estão sendoprocessados não são parados, mas os padrões que estão enfileirados não são iniciados. Quando osplanejamentos são configurados para serem executados em intervalos, os intervalos são reiniciados. Porexemplo, se um intervalo é definido para 3 horas, e você reiniciá-lo, o planejamento será executado 3horas após você executar a ação resetSchedules. Quando um planejamento tem um conjunto deexpressão cron, nada muda. Talvez isso seja necessário quando são feitas mudanças de SQL diretas nospadrões de agrupamento.
Essa ação não tem opções adicionais.
Para reconfigurar todos os planejamentos, execute a ferramenta da seguinte maneira:
bizappscli.sh resetSchedules
Ações para gerenciar a configuração do padrão de agrupamentoAo usar a ferramenta bizappscli, é possível exportar e importar configurações de padrão deagrupamento completos ou suas seções específicas.
exportConfiguration
Esta ação exporta uma configuração do padrão de agrupamento. As seguintes opções estão disponíveis:
• -c, --config <arg> - define o nome da configuração que você deseja exportar.• -f, --filename <arg> - define o arquivo de destino no qual a configuração é exportada. Se você nãoespecificar um caminho, o arquivo será criado no diretório atualmente em funcionamento. Se você nãoespecificar o nome do arquivo, os resultados serão impressos na saída padrão.
• -l, --general - exporta a seção geral da configuração.• -m, --composition - exporta a seção de composição da configuração.• -t, --tiers - exporta a seção de camadas da configuração.• -v, --traversal - exporta a seção de passagem da configuração.
Importante: A opção -c é requerida.
Por exemplo, para exportar as seções de composição e passagem da configuração com o nome config2para o arquivo composition_traversal.xml, execute a ferramenta da seguinte maneira:
bizappscli.sh exportConfiguration -c config2 -f composition_traversal.xml -m -v
importConfiguration
Esta ação importa uma configuração do padrão de agrupamento. As seguintes opções estão disponíveis:
• -c, --config <arg> - define o nome da configuração que você deseja importar.• -f, --filename <arg> - define o arquivo de origem do qual a configuração é importada.• -U, --allowUpdate - atualiza a configuração existente se você estiver importando um arquivomodificado em vez de um novo.
Importante: As opções -c e -f são requeridas.
242 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Por exemplo, para importar a configuração com o nome custom1 a partir do arquivo db_tiers.xml,execute a ferramenta da seguinte maneira:
bizappscli.sh importConfiguration -c custom1 -f db_tiers.xml
exportDefaultConfiguration
Esta ação exporta a configuração padrão do padrão de agrupamento. Por padrão, a composição geral,camadas e seções de passagem da configuração padrão são exportados, a seção de direção é ignorada.As seguintes opções estão disponíveis:
• -d, --directions - exporta a seção de direção da configuração.
Importante: Se você deseja exportar a configuração padrão para editá-la e utiliza-la como umaconfiguração customizada para um padrão de agrupamento específico, não use a opção -d. Aconfiguração de direção sempre é aplicada a todos os padrões de agrupamento, e não é possívelcustomizá-la para um padrão de agrupamento específico.
• -f, --filename <arg> - define o arquivo de destino no qual a configuração padrão é exportada. Sevocê não especificar um caminho, o arquivo será criado no diretório atualmente em funcionamento. Sevocê não especificar o nome do arquivo, os resultados serão impressos na saída padrão.
• -l, --general - exporta a seção geral da configuração.• -m, --composition - exporta a seção de composição da configuração.• -t, --tiers - exporta a seção de camadas da configuração.• -v, --traversal - exporta a seção de passagem da configuração.
Por exemplo, para exportar as instruções e seções gerais da configuração padrão para o arquivodir_gen.xml, execute a ferramenta da seguinte maneira:
bizappscli.sh exportDefaultConfiguration -d -l -f dir_gen.xml
importDefaultConfiguration
Esta ação importa a configuração padrão do padrão de agrupamento. Está disponível a seguinte opção:
• -f, --filename <arg> - define o arquivo de origem do qual a configuração padrão é importada.
Importante: A opção -f é requerida.
Por exemplo, para importar a configuração padrão do arquivo my_default_config.xml, execute aferramenta da seguinte maneira:
bizappscli.sh importDefaultConfiguration -f my_default_config.xml
deleteConfiguration
Esta ação remove uma configuração do padrão de agrupamento. Está disponível a seguinte opção:
• -c --config <arg> - define o nome da configuração que você deseja excluir.
Importante: A opção -c é requerida.
Por exemplo, para excluir uma configuração com o nome test_config, execute a ferramenta daseguinte maneira:
bizappscli.sh deleteConfiguration -c test_config
attachConfiguration
Esta ação designa a configuração existente do padrão de agrupamento a um padrão de agrupamentoespecífico. As seguintes opções estão disponíveis:
Capítulo 1. Usando 243

• -c, --config <arg> - define o nome da configuração.• -g, --guid <arg> - define o GUID do padrão de agrupamento.• -n, --patternname <arg> - define o nome do padrão de agrupamento.
Importante: A opção -c é requerida e deve-se também usar a opção -g ou -n.
Por exemplo, para anexar uma configuração com o nome custom_config para um padrão deagrupamento nomeado pattern1, execute a ferramenta da seguinte maneira:
bizappscli.sh attachConfiguration -c custom_config -n pattern1
Nota: Não é possível usar essa ação para anexar a configuração padrão a um padrão para o qual vocêcriou uma configuração customizada. Se você desejar voltar para a configuração padrão, deverá removera configuração customizada do padrão de agrupamento. Consulte a próxima seção.
detachConfiguration
Esta ação remove uma configuração customizada de um padrão de agrupamento. As seguintes opçõesestão disponíveis:
• -g, --guid <arg> - define o GUID do padrão de agrupamento.• -n, --patternname <arg> - define o nome do padrão de agrupamento.
Importante: Uma das opções a seguir é requerida: -g ou -n.
Por exemplo, para remover uma configuração customizada de um padrão de agrupamento com GUID00000000000000000000000000000000, execute a ferramenta da seguinte maneira:
bizappscli.sh detachConfiguration -g 00000000000000000000000000000000
listConfigurations
Esta ação lista as configurações de padrão de agrupamento. Por padrão, ele exibe somente os nomes deconfiguração.
As seguintes opções estão disponíveis:
• -G, --showGuids - mostra os GUIDs das configurações.• -n, --patternGuid <arg> - mostra a configuração que está anexada a um padrão de agrupamentoespecífico.
• -s, --showPatterns - lista todas as configurações com todos os padrões de agrupamento que estãoatualmente anexados a eles.
Por exemplo, para gerar uma lista de configurações e padrões de agrupamento que são anexados a elas,execute a ferramenta da seguinte maneira:
bizappscli.sh listConfigurations -s
Sample output:
Configuration: custom1Attached patterns:pattern1pattern2
Configuration: config2Attached patterns:gp1gp2
Ações para gerenciar grupos de execuçãoAo usar a ferramenta bizappscli, é possível exibir grupos de execução.
244 Gerenciador de Descoberta de Dependência de Aplicativo: Usando
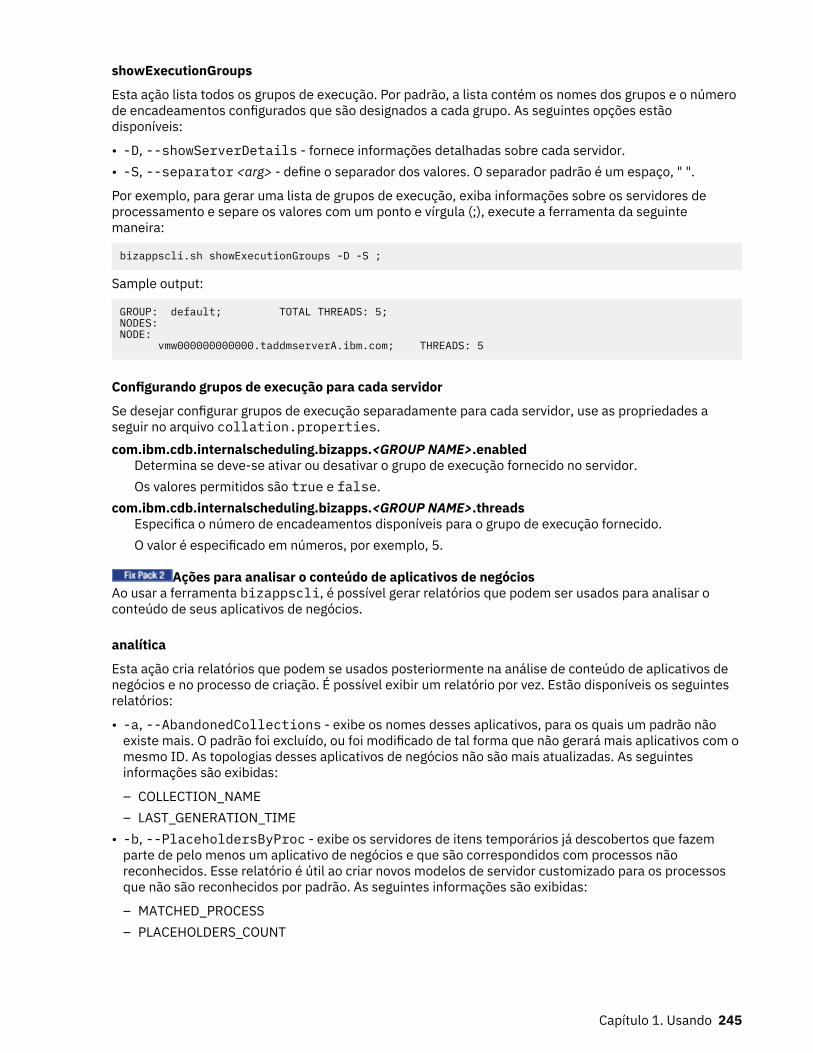
showExecutionGroups
Esta ação lista todos os grupos de execução. Por padrão, a lista contém os nomes dos grupos e o númerode encadeamentos configurados que são designados a cada grupo. As seguintes opções estãodisponíveis:
• -D, --showServerDetails - fornece informações detalhadas sobre cada servidor.• -S, --separator <arg> - define o separador dos valores. O separador padrão é um espaço, " ".
Por exemplo, para gerar uma lista de grupos de execução, exiba informações sobre os servidores deprocessamento e separe os valores com um ponto e vírgula (;), execute a ferramenta da seguintemaneira:
bizappscli.sh showExecutionGroups -D -S ;
Sample output:
GROUP: default; TOTAL THREADS: 5;NODES:NODE: vmw000000000000.taddmserverA.ibm.com; THREADS: 5
Configurando grupos de execução para cada servidor
Se desejar configurar grupos de execução separadamente para cada servidor, use as propriedades aseguir no arquivo collation.properties.com.ibm.cdb.internalscheduling.bizapps.<GROUP NAME>.enabled
Determina se deve-se ativar ou desativar o grupo de execução fornecido no servidor.Os valores permitidos são true e false.
com.ibm.cdb.internalscheduling.bizapps.<GROUP NAME>.threadsEspecifica o número de encadeamentos disponíveis para o grupo de execução fornecido.O valor é especificado em números, por exemplo, 5.
Ações para analisar o conteúdo de aplicativos de negóciosAo usar a ferramenta bizappscli, é possível gerar relatórios que podem ser usados para analisar oconteúdo de seus aplicativos de negócios.
analítica
Esta ação cria relatórios que podem se usados posteriormente na análise de conteúdo de aplicativos denegócios e no processo de criação. É possível exibir um relatório por vez. Estão disponíveis os seguintesrelatórios:
• -a, --AbandonedCollections - exibe os nomes desses aplicativos, para os quais um padrão nãoexiste mais. O padrão foi excluído, ou foi modificado de tal forma que não gerará mais aplicativos com omesmo ID. As topologias desses aplicativos de negócios não são mais atualizadas. As seguintesinformações são exibidas:
– COLLECTION_NAME– LAST_GENERATION_TIME
• -b, --PlaceholdersByProc - exibe os servidores de itens temporários já descobertos que fazemparte de pelo menos um aplicativo de negócios e que são correspondidos com processos nãoreconhecidos. Esse relatório é útil ao criar novos modelos de servidor customizado para os processosque não são reconhecidos por padrão. As seguintes informações são exibidas:
– MATCHED_PROCESS– PLACEHOLDERS_COUNT
Capítulo 1. Usando 245

• -c, --Counts - exibe o número de nós e caminhos de aplicativos de negócios. Este relatório ajuda adetectar anomalias rapidamente, como aplicativos muito grandes ou muito pequenos. As seguintesinformações são exibidas:
– COLLECTION_NAME– NODES_COUNT– PATHS_COUNT– LAST_GENERATION_TIME
• -e, --ForRegeneration - exibe os aplicativos nos quais os nós de membros referem-se aos nós queforam excluídos depois da última geração de aplicativo. Tais aplicativos contêm conteúdodesatualizado e deverá ser gerado novamente. As seguintes informações são exibidas:
– COLLECTION_NAME– NODES_COUNT
• -h, --AllPlaceholders - exibe todos os servidores de marcador que fazem parte de aplicativos denegócios. Este relatório fornece informações detalhadas sobre cada servidor de marcador. As seguintesinformações são exibidas:
– MARCADOR– MATCHED_PROCESS– HOST– LAST_STORE_TIME– COLLECTION_NAME
• -n, --PlaceholdersNeverDiscovered - exibe os servidores de marcador que fazem parte de pelomenos um aplicativo de negócios e que não contêm quaisquer informações do host. Geralmente, essesservidores fazem parte de um ambiente que ainda não foi descoberto, ou de um ambiente externo, porexemplo, nuvem. As seguintes informações são exibidas:
– MARCADOR– COLLECTION_NAME
• -o, --UnusedRoutes - exibe as rotas que foram atravessadas mas não foram usadas nos caminhos deconstrução. As relações que são representadas por essas rotas podem ser excluídas da passagem naconfiguração do padrão de agrupamento. Analise cuidadosamente as rotas que são usadas, porque elaspodem ser usadas novamente quando novos dados forem introduzidos. As seguintes informações sãoexibidas:
– RELATION_TYPE– COUNT
• -r, --Routes - exibe rotas que são usadas para gerar aplicativos de negócios. Rotas não são exibidasna topologia, mas elas constroem os caminhos que são exibidos na topologia. Ao incluir a opção -g, épossível exibir as rotas para um aplicativo específico. As seguintes informações são exibidas:
– RELATION_TYPE– SOURCE_TYPE– TARGET_TYPE– COUNT
• -w, --PlaceholdersToRediscover - exibe os servidores de marcador que fazem parte de pelomenos um aplicativo de negócios e que contém hosts, mas nenhum processo correspondente. Issosignifica que o host do servidor de marcador está no escopo da descoberta, mas as informações sobreprocessos de tempo de execução não reconhecidos já foram excluídas. As seguintes informações sãoexibidas:
– MARCADOR– HOST
246 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

– LAST_STORE_TIME– COLLECTION_NAME
É possível usar as opções a seguir ao criar relatórios com a ação analytics:
• -A, --sortAsc <arg> - classifica os nomes dos aplicativos de negócios em ordem alfabética. Osvalores possíveis são true e false. O valor padrão é false.
• -g, --guid <arg> - define o GUID de um aplicativo. É possível usá-lo para limitar a saída de alguns dosrelatórios a um aplicativo de negócios específico.
• -G, --showGuids - mostra os GUIDs dos objetos, em que um objeto pode ser um aplicativo, marcador,processo ou host.
• -m, --maxRows <arg> - limita a saída para o número de linhas especificado.• -R, --showPattern - exibe os nomes de padrões de agrupamento. Os valores possíveis são true efalse. O valor padrão é false.
• -S, --separator <arg> - define o separador dos valores. O separador padrão é um espaço, " ".
Exemplos1. O comando a seguir exibe um relatório que contém informações sobre o número de nós e caminhosde um aplicativo com o GUID 00000000000000000000000000000000:
bizappscli.sh analytics -c -g 00000000000000000000000000000000
Sample output:
COLLECTION_NAME COLLECTION_GUID NODES_COUNT PATHS_COUNT LAST_GENERATION_TIMEpattern_1 00000000000000000000000000000000 2 2 07/09/2015 07:57:07
2. O comando a seguir exibe um relatório que contém informações sobre todos os servidores demarcador e também especifica os GUIDs dos objetos:
bizappscli.sh analytics -h -G
Sample output:
PLACEHOLDER PLACEHOLDER_GUID MATCHED_PROCESS PROCESS_GUID HOST HOST_GUID LAST_STORE_TIME COLLECTION_NAME COLLECTION_GUID23.23.23.23:9550 11111111111111111111111111111111 kdsmain 22222222222222222222222222222222 23.23.23.23 3333333333333333333333 30/08/2015 06:27:53 my_app2 44444444444444444444444444444444
Consulte também o tópico Configurando para descoberta de itens temporários no Guia do Administradordo TADDM.
Ações para exportar topologias para o formato SVGAo usar a ferramenta bizappscli, é possível exportar a sua topologia de aplicativo de negócios para oformato SVG.
exportTopology
Essa ação exporta a topologia de aplicativo de negócios para o formato SVG. As seguintes opções estãodisponíveis:
• -f, --filename <arg> - define o arquivo de destino para o qual a topologia é exportada. Se você nãoespecificar um caminho, o arquivo será criado no diretório atualmente em funcionamento. Se o arquivocom o nome especificado existir, ele será sobrescrito. Se você não especificar o nome do arquivo, osresultados serão impressos na saída padrão.
• -g, --guid <arg> - define o GUID do aplicativo de negócios.• -n, --name <arg> - define o nome do aplicativo de negócios.
Capítulo 1. Usando 247

• -z, --zip - compacta o arquivo de destino para o formato .zip. A extensão .zip é incluídaautomaticamente. É possível usá-la somente com a opção -f.
Importante: Uma das opções a seguir é requerida: -g ou -n.
Por exemplo, para exportar a topologia do aplicativo de negócios denominada my_app para o arquivo desaída denominado my_app_graph.svg, execute a ferramenta da maneira a seguir:
bizappscli.sh exportTopology -n my_app -f my_app_graph.svg
Limitação: A topologia do aplicativo de negócios sempre é exportada com os CIs principais destacados.Se desejar que os CIs mudados, não os CIs principais, sejam destacados, siga o procedimento descrito notópico “Exportando uma Topologia” na página 95.
Dica: Quando a topologia exportada é exibida, os rótulos de CI que são longos são truncados. Paravisualizar os rótulos integrais, passe o mouse sobre um nó de CI no gráfico para exibir a dica deferramenta, na qual é possível localizar o rótulo integral e a GUID. Um visualizador em conformidade como padrão SVG 1.1 é necessário, por exemplo, o navegador da web Mozilla Firefox.
Propriedades relacionadas
Quando você tiver grandes aplicativos de negócios, poderá ser necessário modificar os valores padrãopara as seguintes propriedades:
• com.ibm.taddm.bizappscli.jvmArgs=-Xmx1024MEssa propriedade define as opções da Java virtual machine para o uso da ferramenta bizappscli. Senão houver memória suficiente para executar a ferramenta, é possível aumentar o tamanho de heapmáximo dos processos da Java virtual machine modificando o valor dessa propriedade no arquivo$COLLATION_HOME/sdk/etc/collation.properties.
• com.collation.view.maxnodes=500Esta propriedade especifica o número máximo de nós que podem ser visualizados em um gráfico detopologia no Data Management Portal. É possível modificar o valor padrão no arquivo$COLLATION_HOME/dist/etc/collation.properties.
Configurando as entradas do arquivo collation.propertiesÉ possível configurar as entradas a seguir relacionadas aos aplicativos de negócios no arquivocollation.properties.
com.ibm.cdb.serviceinfrastructure.deadlock.retry.countDefine o número de tentativas de armazenar uma transação antes de ela falhar. QuandoBizAppsAgent é executado simultaneamente em diversos encadeamentos, pode ocorrer umconflito no banco de dados. Para evitar isso, as tentativas de armazenar uma transação são repetidas.Quando o número de tentativas excede o número especificado por esta propriedade, a transaçãofalha.O valor padrão é 30.
com.ibm.cdb.serviceinfrastructure.deadlock.retry.timeEspecifica o tempo limite antes de todas as tentativas de armazenamento de uma transaçãofalharem.O valor padrão é 7200, expresso em segundos (ou seja, 2 horas).
com.ibm.cdb.serviceinfrastructure.path.max.lengthDefine o comprimento máximo de um caminho de aplicativo de negócios, que é o número máximo desegmentos em uma rota do caminho do aplicativo de negócios.O valor padrão é 9.Rotas longas podem indicar que os dados no banco de dados estão divididos e podem levar a umenorme número de consultas. Nesse caso, a configuração da propriedade para um valor menormelhora o desempenho da construção de grandes aplicativos.Para obter mais informações sobre caminhos e rotas, consulte “Estrutura do aplicativo de negócios”na página 192.
248 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

com.ibm.cdb.serviceinfrastructure.afterprocessing.cleansourcesDetermina se as origens de elementos que são usadas para construir aplicativos de negócios sãoexcluídas após a construção ser concluída. Se essa propriedade estiver configurada para TRUE, osdados temporários do aplicativo de negócios não serão excluídos.O valor padrão é TRUE.Se você configurar esta propriedade para FALSE, o desempenho será consideravelmente reduzido.
com.ibm.cdb.serviceinfrastructure.sources.transaction.bufferDefine o número de elementos de origem que são armazenados em uma transação.O valor padrão é 1000.Se você observar que há muitos conflitos quando grandes aplicativos de negócios são processados,diminua o valor dessa propriedade.
com.collation.Tomcat.jvmargs (somente TADDM 7.3.0)Define opções da JVM para o Portal de Gerenciamento de Dados. Essa propriedade pode ser usadapara definir o tamanho máximo de heap. Configure essa propriedade no arquivocollation.properties, quando as configurações padrão não forem suficientes para exibirtopologias.Configure o valor no seguinte formato: -Xmx2048M. Nesse exemplo, o tamanho máximo de heap é2048 MB (2 GB). É possível usar qualquer valor.Após alterar a propriedade, reinicie o servidor TADDM.
com.collation.Liberty.jvmargsDefine opções da JVM para o Portal de Gerenciamento de Dados. Essa propriedade pode ser usadapara definir o tamanho máximo de heap. Configure essa propriedade no arquivocollation.properties, quando as configurações padrão não forem suficientes para exibirtopologias.Configure o valor no seguinte formato: -Xmx2048M. Nesse exemplo, o tamanho máximo de heap é2048 MB (2 GB). É possível usar qualquer valor.Após alterar a propriedade, reinicie o servidor TADDM.
com.collation.topology.maxnodesDefine o número máximo de nós que podem ser visualizados em uma topologia. Essa propriedadedefine o tamanho da topologia mais precisamente do que as configurações padrão. Configure essapropriedade no arquivo collation.properties, quando as configurações padrão não foremsuficientes para exibir topologias.Configure o valor no seguinte formato: 1000. Nesse exemplo, o número máximo de nós é 1000. Osvalores que são muito altos podem levar a erros de Falta de Memória. Se algumas topologiascausarem erros de Falta de Memória, configure essa propriedade para um valor menor.Consulte também “Configurando o tamanho máximo de topologias exibidas” na página 215.
com.collation.topology.autozoom.thresholdDefine o tamanho mínimo de topologia (definido por uma série de nós) que é necessário para umatopologia ter zoom feito automaticamente quando exibida. Topologias menores são exibidas para seajustarem ao modo de visualização. Essa propriedade melhora a capacidade de leitura de grandestopologias.O valor padrão é 200.
com.ibm.cdb.serviceinfrastructure.earlier.ver.compatibilityDetermina se deve-se criar objetos dos tipos de grupos descontinuados quando aplicativos denegócios antigos forem convertidos usando padrões de agrupamento.O valor padrão é TRUE para o cenário de upgrade e FALSE para o cenário de nova instalação.Para obter mais informações, consulte “Migração da 7.2.2 e conversão automática de antigosaplicativos de negócios” na página 251.
com.ibm.cdb.serviceinfrastructure.compatAPI.preserveFunctionalGroupsDetermina o processo de nomenclatura de grupos funcionais quando aplicativos de negócios que sãocompatíveis com versões anteriores são criados.
Capítulo 1. Usando 249

Se você configurar essa propriedade para true, grupos funcionais terão os mesmos nomes quenomes de camadas. No entanto, as condições a seguir devem ser atendidas:
• O padrão de agrupamento migrado deve ter o atributo useMigratedTierNames configurado paratrue.
• O seletor deve ter o atributo tierName configurado.
Se você configurar esta propriedade para false, os nomes de grupos funcionais serão configuradosusando a configuração de padrão de agrupamento.O valor padrão é true.Para obter mais informações, consulte “Camadas de aplicativo de negócios” na página 252 e“Configuração de camadas” na página 224.
com.ibm.cdb.internalscheduling.bizapps.<GROUP NAME>.enabledDetermina se deve-se ativar ou desativar o grupo de execução fornecido no servidor.Os valores permitidos são true e false.
com.ibm.cdb.internalscheduling.bizapps.<GROUP NAME>.threadsEspecifica o número de encadeamentos disponíveis para o grupo de execução fornecido.O valor é especificado em números, por exemplo, 5.
com.ibm.cdb.internalscheduling.bizapps.schedule name.misfireDefine quanto tempo um padrão pode esperar para ser executado antes de ser ignorado peloprocessamento e um aviso ser registrado. O aviso contém as informações de que o padrão não foiiniciado. Para evitar isso, é possível criar mais conjuntos de encadeamentos ou modificar osplanejamentos de seus padrões.O valor padrão é 60, expresso em minutos.Esta propriedade é definida por planejamento. Por exemplo, se você desejar alterar o valor destapropriedade para o planejamento denominado default, modifique o nome da propriedade daseguinte maneira:
com.ibm.cdb.internalscheduling.bizapps.default.misfire
Se você não deseja modificar a configuração e, ao mesmo tempo, não deseja que os padrões sejamignorados, defina essa propriedade para um valor mais alto.
Nota: Também é possível ajustar essa definição usando a opção misfireLimit da açãocreateSchedule da ferramenta bizappscli. Para obter detalhes, consulte “Ações para gerenciarplanejamentos de padrão de agrupamento” na página 239.
Criação de logQuando aplicativos de negócios são gerados, arquivos de log também são criados e armazenados nodiretório $COLLATION_HOME/log. Quando se tem problemas relacionados aos aplicativos de negócios,os arquivos de log podem ajudar a solucioná-los.
Há dois tipos de logs criados para aplicativo de negócios.Logs criados quando se trabalha com padrões de agrupamento e aplicativos de negócios no Portal deGerenciamento de Dados
• Mensagens de log estão no arquivo log/tomcat.log (TADDM 7.3.0) e no arquivo log/wlp.log(TADDM 7.3.0.1 e posterior).
• Mensagens de erro estão nos arquivos log/error.log, log/tomcat.log (TADDM 7.3.0) e log/wlp.log (TADDM 7.3.0.1 e posterior).
Logs criados quando se trabalha com mecanismo de composição de aplicativos de negócios epadrões de execução a partir da lista de padrões
É recomendado ativar a divisão de criação de log para o mecanismo de composição de aplicativos denegócios, de modo que os logs sejam divididos em arquivos separados. Ela aprimora a legibilidade.Para ativar a divisão de criação de log, configure a propriedadecom.ibm.taddm.log.split.bizapp para true no arquivo collation.properties. Se essa
250 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

propriedade for configurada para false, todos os arquivos de log serão colocados no arquivo log/services/PatternsSchedulingService.log.
• Mensagens de log estão nos seguintes diretórios:
– Arquivo log/services/PatternsSchedulingService.log - contém logs gerais domecanismo de planejamento, sem informações de padrões específicos.
– dist/log/bizapps/<pattern>/<starttime>.log - contém arquivos de log separados paracada padrão de agrupamento e seu tempo de processamento. As pastas <pattern> são criadaspara cada padrão de agrupamento no formato [pattern name-GUID], por exemplo J2EE Apppattern-F12AC23451AB3A4FAF58E9187ABF1169. Dentro das pastas de padrão, é possívellocalizar arquivos de log criados para cada processamento de padrão de agrupamento no formato[time of generation in milliseconds].log, por exemplo 1416408057548.log.
• As mensagens de erro estão no arquivo log/error.log e nos mesmos arquivos que contêmmensagens de log.
Para alterar o nível de log, modifique a propriedade com.collation.log.level.vm.Topology noarquivo collation.properties. Para alterar o nível INFO, também é possível usar a configuração depadrões de agrupamento. Para obter mais informações, consulte o tópico Propriedades de criação de logno Guia do Administrador do TADDM e “Configuração geral” na página 218.
Migração da 7.2.2 e conversão automática de antigos aplicativos de negóciosQuando você faz upgrade do TADDM 7.2.2 para uma versão superior, todos os aplicativos de negócios sãoconvertidos automaticamente nos padrões de agrupamento de acordo com um conjunto específico deregras.
Conversão automática
Um novo padrão de agrupamento é criado para cada aplicativo. Posteriormente, o BizAppsAgent geranovas coleções customizadas a partir desses padrões de agrupamento. O novo conteúdo de coleçõescustomizadas (um conjunto de itens de configuração) é o mesmo que o conteúdo das coleções originaiscorrespondentes.
Nota: Aplicativos de negócios podem conter apenas objetos de alto nível e de nível médio. Portanto,alguns tipos de CI, que eram objetos de alto nível no TADDM 7.2.2, não são mais objetos de alto nível naversão 7.3.0. Como resultado, eles não são incluídos em aplicativos de negócios. Os novos tipos de altonível são SComputerSystem, SSoftwareServer, SLogicalGroup, SPhysicalFile, SSoftwareInstallation,SFunction. O novo tipo de nível intermediário é SDeployableComponent. Além disso, não há nenhum tipoOperatingSystem no novo modelo. Seus atributos foram mesclados na classe simple.SComputerSystem.
As regras a seguir se aplicam quando antigos aplicativos de negócios são convertidos em padrões deagrupamento:
• O tipo padrão é configurado de acordo com um tipo de grupo.
– Os grupos do aplicativo de negócios e os tipos de serviço de negócios são convertidos em padrões deagrupamento do tipo de aplicativo de negócios.
– O grupos do tipo de coleta são convertidos em padrões de agrupamento do tipo coleção.– Os grupos do tipo de coleção de acesso são convertidos em padrões de agrupamento do tipo de
coleção de acesso.• Seletores de um novo padrão de agrupamento são criados para refletir o conteúdo do grupo antigo
correspondente.
– O seletor de consulta MQL é criado para cada regra em um grupo.– O seletor baseado em instância é criado e contém todos os ICs que são selecionadas manualmente
como o conteúdo do grupo.– Os seletores não usam Modelo de Passagem de Dependência, de maneira que apenas CIs
selecionados por cada seletor são incluídos, sem incluir dependências automaticamente.
Capítulo 1. Usando 251

– Grupos funcionais são convertidos em seletores separados com um nome de camada configuradopara o nome do grupo funcional. As camadas não são visíveis para os usuários, mas são usadasdurante a criação de entidades de negócios compatíveis com versões anteriores para recuperar aestrutura dos grupos funcionais original.
• A expressão de nome de agrupamento é configurada como o nome da coleção original, de maneira quea nova coleção customizada tenha o mesmo nome.
• Antigas entidades de agrupamento migradas não são removidas do banco de dados.
Nota: Se ocorrer um erro durante a migração, as entidades de agrupamento são migradas mesmo assim.O padrão de agrupamento afetado é marcado com um ponto de exclamação na lista e a descrição do erroé exibida na janela Editar. Todos os seletores inválidos são marcados.
Compatibilidade de novas coleções customizadas com versões anteriores
Alguns tipos de modelo presentes em versões anteriores do TADDM foram descontinuadas na novaabordagem para aplicativos de negócios. Esses tipos são Application, Collection, AccessCollection,BusinessSystem e FunctionalGroup. No entanto, é possível criar objetos desses tipos para assegurar acompatibilidade.
Para ativar a conversão compatível, use a propriedadecom.ibm.cdb.serviceinfrastructure.earlier.ver.compatibility no arquivocollation.properties. O valor padrão dessa propriedade é TRUE para o cenário de upgrade e FALSEpara o cenário de nova instalação.
Nota: Os grupos do antigo tipo não são exibidos na IU. Eles podem ser listados somente usando API.
Para assegurar que o conteúdo antes e depois da conversão seja o mesmo, camadas especiais (TADDM7.3.0) ou camadas manuais (TADDM 7.3.0.1 e posterior) vinculadas aos seletores são introduzidas. Osnomes de camadas são iguais aos nomes de grupos funcionais. Os nomes de grupos funcionais definidosnos arquivos descritores de aplicativo também são convertidos em camadas especiais ou manuais.Gravas à conversão de compatibilidade, os elementos a seguir são preservados:
• O tipo de antigas entidades de agrupamento. Isso é vital para diferenciar entre serviços de negócios eaplicativos de negócios, pois ambos são convertidos em um padrão do tipo de aplicativo de negócios.
Nota: A limitação a seguir é válida somente no TADDM 7.3.0 e não se aplica ao TADDM 7.3.0.1 eposterior.
Essa função refere-se somente às entidades migradas, portanto, somente padrões de agrupamentomigrados podem ser convertidos de volta em serviços de negócios. Padrões de agrupamento criadosmanualmente do tipo de aplicativo de negócios são sempre convertidos de volta para antigosaplicativos de negócios.
• A estrutura dos grupos funcionais de aplicativo de negócios.
Nota: A limitação a seguir é válida somente no TADDM 7.3.0 e não se aplica ao TADDM 7.3.0.1 eposterior.
No entanto, um IC pode ser designado a apenas uma camada, por isso, no caso de aplicativos denegócios antigos compatíveis com uma versão anterior, um único IC não pode ser compartilhado entrediversos grupos. Se um IC for compartilhado entre vários grupos, ele será removido de todos os grupos,exceto um.
Camadas de aplicativo de negóciosCamadas de aplicativo de negócios são grupos de elementos do aplicativo de negócios semelhantes. Elassão usadas para criar grupos funcionais para integrar o TADDM com outros produtos e para assegurar acompatibilidade com aplicativos de negócios que foram criados no TADDM 7.2.2.
Os grupos funcionais que são criados a partir de camadas têm os mesmos nomes que os das camadas. Ascamadas são criadas com base nos traços de negócios dos elementos do aplicativo de negócios. Porexemplo, uma camada pode conter todos os sistemas de computador. Outra camada pode conter todosos servidores de aplicativos. E a terceira camada pode conter todos os aplicativos Java Platform,
252 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Enterprise Edition. A designação de ICs para camadas específicas é baseada em regras que são definidaspor usuários em arquivos de configuração.
TADDM 7.3.0Camadas especiais
Há dois tipos de camadas, regular e especial. Camadas especiais são projetadas exclusivamentepara os tipos de aplicativos de negócios a seguir:
• Aquelas que foram migradas do TADDM 7.2.2.• Aquelas que foram criadas a partir dos descritores de aplicativos e que possuem nomes de
grupos funcionais configurados.
Camadas são usadas para criar grupos funcionais com os mesmos nomes que os nomes de camadassomente se todas as condições a seguir forem atendidas:
• A propriedade com.ibm.cdb.serviceinfrastructure.compatAPI.preserveFunctionalGroups é configurada como true no arquivo collation.properties.
• O padrão de agrupamento migrado tem o atributo useMigratedTierNames configurado paratrue.
• O seletor tem o atributo tierName configurado.
Se as condições anteriores não forem atendidas, os nomes de camadas e, como resultado, os nomesde grupos funcionais serão configurados usando a configuração de padrão de agrupamento. Paraobter mais informações, consulte “Configuração de camadas” na página 224.
Camadas especiais têm a seguinte característica:
• Camadas especiais têm precedência sobre as camadas regulares. Se existir uma camada especial, onome da camada regular será ignorado.
• Camadas especiais se aplicam somente ao IC principal (por padrão, aplicativos de negóciosmigrados contêm somente IC principal, e não Modelos de Passagem de Dependência).
• Camadas especiais podem ser desativadas globalmente ao configurando o parâmetrocom.ibm.cdb.serviceinfrastructure.compatAPI.preserveFunctionalGroups como false no arquivo collation.properties.
• Camadas especiais podem ser desativadas por padrão de agrupamento único no Portal deGerenciamento de Dados.
TADDM 7.3.0.1
Há dois tipos de camadas, regular e manual.Camadas regulares
Nomes de camadas regulares são calculados usando a configuração de padrão de agrupamento.Para obter mais informações, consulte “Configuração de camadas” na página 224.
Camadas manuaisÉ possível configurar camadas manuais para seletores manualmente no Portal de Gerenciamentode Dados, na área de janela Padrões de Agrupamento. No entanto, camadas manuais sãoconfiguradas automaticamente para os seguintes tipos de padrões de agrupamento:
• Aquelas que foram migradas do TADDM 7.2.2.• Aquelas que foram criadas a partir de descritores de aplicativo e têm nomes de grupo funcionalconfigurados.
Camadas manuais têm precedência sobre camadas regulares. Se existir uma camada manual, onome da camada regular será ignorado.
Casos especiais na conversão automática de aplicativos de negócios antigosDurante a migração automática e a conversão de entidades de agrupamento antigas como aplicativos denegócios, coleções, coleções de acesso e serviços de negócios, casos especiais podem ocorrer.
Capítulo 1. Usando 253

Regras MQL incorretas
Durante a migração de regras MQL, todas as consultas são testadas para validade. Se uma consulta MQLfor inválida, o seletor baseado em instâncias adicionais é criado no padrão de agrupamento. O seletorcontém todos os ICs do grupo migrado. O seletor MQL com consulta MQL inválida também é criado, masé marcado como desativado e não é processado pelo agente. Padrões de agrupamento com seletoresinválidos serão destacados no Portal de Gerenciamento de Dados, permitindo que os usuários encontremfacilmente e corrijam as consultas MQL inválidas.
Nota: Consultas MQL inválidas são raras. No entanto, devido a Mudanças de Modelo na versão maisrecente do TADDM, algumas consultas MQL podem não ser mais válidas.
Regras MQL e o conteúdo de aplicativos de negócios
O algoritmo de migração executa a regra MQL de cada aplicativo de negócios (ou grupo funcional) ecompara os resultados com o conteúdo do aplicativo de negócios. Todos os ICs que fazem parte doconteúdo do aplicativo de negócios, mas não foram retornados por qualquer uma das consultas MQL sãoincluídos no seletor baseado em instâncias.
Nota: Este algoritmo é usado apenas se a sinalização Substituir todo o conteúdo existente pelo novoconteúdo não estiver configurada.
Regras MQL para aplicativos de negócios antigos
Regras MQL que operam em aplicativos de negócios antigos, por exemplo, "select * fromCollection", são tratadas como regras com consultas MQL inválidas. Os dois seletores a seguir sãocriados para tais regras:
• Seletor MQL que contém a mesma consulta MQL. Ele é marcado como inválido e está desativado.• O seletor baseado em instâncias que contém todos os ICs resultantes.
Ele é causado pela diferença entre o novo modelo com base nos padrões de agrupamento e no modelo deaplicativos de negócios antigo. Portanto, é impossível converter automaticamente uma consulta MQL queretorna aplicativos de negócios antigos em uma consulta que retorna coleções customizadascorrespondentes.
Descontinuação do aplicativo de negócios antigo
Todos os tipos de entidades de agrupamento são automaticamente migrados nos padrões deagrupamento durante a atualização do TADDM 7.2.2. Após a migração, eles não excluídos devido aosrequisitos para assegurar a compatibilidade com uma versão anterior (eles são necessários paraintegração com sistemas externos). Eles são descontinuados e ocultos de um usuário. Um usuário podeexecutar apenas um conjunto restrito de operações neles por meio da API.
Mecanismo de vinculação automatizada
O mecanismo de vinculação automatizada assegura a consistência de relações entre as coleçõescustomizadas migradas e os aplicativos de negócios originais.
Os aplicativos de negócios podem ser partes de outros aplicativos de negócios. Por exemplo:
• Um serviço de negócios pode conter aplicativos.• Uma coleção de acessos pode conter coleções.• Um aplicativo pode conter serviços de negócios.
Após a conversão de aplicativos de negócios para novas coleções customizadas por meio de padrões deagrupamento, novas coleções customizadas estão contidas em todos os lugares nos quais os aplicativosde negócios antigos estavam contidos.
Exemplo
1. Aplicativo de Negócios com o nome BA1 (BusinessApplication:A1) contém a coleção C1(Collection:C1).
254 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

2. Durante a fase de migração da instalação, novos padrões de agrupamento,(GroupingPattern:BA1 e GroupingPattern:C1) são criados automaticamente com base emaplicativos de negócios antigos.
3. O CustomCollection:BA1 recém-gerado contém CustomCollection:C1.
Migração de aplicativos de negócios vazios
A função principal dos aplicativos de negócios é agrupar os elementos de infraestrutura existentes emuma entidade que possui designação de negócios comum. O novo modelo com base em padrões deagrupamento não permite definir coleções customizadas vazias porque elas são inúteis em relação à suadesignação. No entanto, o modelo de aplicativo de negócios antigo permitiu a criação de aplicativos denegócios vazios. Para não perder nenhum dado, o TADDM também é capaz de converter aplicativos denegócios vazios.
Para converter aplicativos de negócios vazios, um padrão de agrupamento é criado. Ele então éconfigurado para criar uma coleção customizada que contém apenas o padrão de agrupamento em si.Entretanto, os padrões de agrupamento não podem ser incluídos no conteúdo da coleção customizada.Portanto, o padrão de agrupamento é automaticamente removido e a coleção customizada está vazia.
Este é apenas um mecanismo para assegurar a compatibilidade com versões anteriores e não se destinaa ser usado deliberadamente. Aplicativos de negócios vazios são muitas vezes criados devido àconcepção errada sobre aplicativos de negócios. Por exemplo, os aplicativos de negócios não sãodestinados a representar aplicativos que são concebidos como aplicativos do Sistema Operacional(programas).
Seletores baseados em instâncias em um padrão de agrupamento
Os aplicativos de negócios podem ter o conteúdo a seguir:
• Conteúdo que é não abrangido por regras MQL ou abrangido por regras MQL inválidas.• Conteúdo que é abrangido por regras MQL, mas do tipo aplicativo de negócios.
Tal conteúdo é colocado em seletores baseados em instâncias.
Para serviços de negócios, coleções e coleções de acesso, um seletor baseado em instâncias é criado porgrupo. Para aplicativos de negócios, o seletor baseado em instâncias é criado para cada grupo funcional.
Integrando aplicativos de negócios com outros produtos TivoliÉ possível integrar aplicativos de negócios com outros produtos Tivoli.
Uma nova função foi introduzida para ativar a integração entre o TADDM e os produtos que leem dados doTADDM usando o DataApi ou diretamente do banco de dados TADDM usando SQL. Para aprender sobreesta função, consulte o tópico Compatibilidade de entidades de negócios com versões anteriores no Guiado Administrador do TADDM.
Cenários de exemploSaiba como criar um aplicativo de negócios a partir de vários seletores e vários aplicativos de negócios apartir de um padrão de agrupamento, e como customizar a configuração do padrão de agrupamento.
Criando aplicativo de negócios simples e incluindo dependências manuaisSaiba como criar um aplicativo de negócios simples baseado em aplicativo Java Platform, EnterpriseEdition, e como incluir dependências manuais entre os componentes.
Sobre Esta Tarefa
No exemplo a seguir, um banco de dados com dados de amostra é usado. O banco de dados contém oscomponentes a seguir:
• WebSphere Cell com alguns servidores e aplicativos Java Platform, Enterprise Edition implementados• Servidores JBoss com alguns aplicativos
Capítulo 1. Usando 255

• Sistemas de computador, alguns dos quais fazem parte de um ambiente virtual• Bancos de dados DB2• Servidores da web• Outros componentes
O primeiro objetivo desta tarefa é criar um aplicativo de negócios simples baseado em um aplicativo JavaPlatform, Enterprise Edition. O segundo objetivo desta tarefa é incluir componentes no aplicativo denegócios existente, criando outro seletor ou incluindo dependências manuais entre componentes.
Procedimento
1. Abra Portal de Gerenciamento de Dados.2. Na área de janela Funções, clique em Descoberta se TADDM 7.3.0 ou 7.3.0.1 for usado, ou em
Analytics, se TADDM 7.3.0.2 ou mais recente for usado.3. Clique em Padrões de Agrupamento. A tabela Padrões de Agrupamento é exibida.4. No campo de nome, insira EDay Trader.5. Configure o tipo de padrão para Aplicativo de Negócios.6. Para a opção Planejamento, escolha Todo sábado à noite.7. No campo Descrição, insira Aplicativo EDay Trader e clique em Avançar.8. Clique em Novo para incluir um seletor.9. No campo Nome, insira EDay Trader's J2EE App.
10. No campo Descrição, insira Aplicativo EDay Trader J2EE e clique em Escolher.11. No editor de consulta, selecione Baseado em Instância como tipo de seleção.12. Navegue em seu banco de dados, selecione os componentes que você quer que sejam ICs principais,
clique em Incluir e clique em OK.13. Opcional: Para ver os resultados, clique em Testar.14. Clique em OK. Você está na janela Criar um Novo Padrão de Agrupamento novamente.15. Para ativar a passagem de dados, certifique-se de que a caixa de seleção Usar Modelo de Passagem
de Dependência esteja selecionada. Selecione as opções Higher Down e Lower Up e limpe asoutras.
16. Clique em Concluir.Gerando aplicativo de negócios manualmente17. Para ver o novo aplicativo de negócios, não é necessário esperar o tempo de planejamento para a
geração. É possível gerar o aplicativo manualmente.a) Abra a área de janela Padrões de Agrupamento.b) Selecione o padrão de agrupamento que você criou em clique em Executar.c) Aguarde um momento e clique em Atualizar Visualização.d) Para visualizar o novo aplicativo de negócios, acesse a área de janela Componentes Descobertos.
Criando um novo seletor e incluindo-o no aplicativo de negócios EDay Trader.18. Se você observar que alguns componentes não fazem parte do aplicativo de negócios que você criou,
é possível incluí-los criando um novo seletor. Os elementos ausentes para o aplicativo de negóciosEDay Trader são o banco de dados do DB2 e o Web Server. Primeiro, crie um novo seletor com obanco de dados de DB2 usado pelo aplicativo EDay Trader.a) Na área de janela Padrões de Agrupamento, selecione o padrão EDay Trader e clique em Editar.b) Acesse a guia Seletores e clique em Novo.c) No campo Nome, insira Banco de Dados EDay Trader e clique em Escolher.d) Escolha o IC principal da mesma forma que nas etapas 11 e 12. Inclua o banco de dados ausente.e) Não altere a expressão de nome do agrupamento, ela deve gerar o mesmo nome que o seletor
anterior. Dessa forma, as composições criadas a partir desses dois seletores são mescladas emum aplicativo de negócios. Clique em OK.
256 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

f) Para confirmar suas mudanças, clique em OK.g) Para ver o aplicativo de negócios atualizado, gere novamente o padrão de agrupamento e acesse a
área de janela Componentes Descobertos.Criando dependências manuais19. O servidor da web ainda não faz parte do novo aplicativo de negócios, e não há conexão entre o
aplicativo Java Platform, Enterprise Edition e o banco de dados. No entanto, em vez de criar váriosseletores, é possível criar dependências manuais entre o aplicativo Java Platform, Enterprise Editione o banco de dados DB2 e entre o aplicativo Java Platform, Enterprise Edition e o Web Server.a) Inclua o aplicativo Java Platform, Enterprise Edition no carrinho de compras clicando nele com o
botão direito na topologia e selecionando a opção Incluir no Carrinho de Compras.b) Na área de janela Componentes Descobertos, clique em Carrinho de Compras e selecione a caixa
de seleção do aplicativo.c) Na lista Ações, selecione Mostrar Dependências.d) Clique em Novo, selecione Dependente e navegue para o banco de dados que deseja incluir.
Clique em OK.e) Para incluir a dependência para o Web Server, clique em Novo, selecione Provedor e navegue
para o servidor. Clique em OK.f) Clique em Fechar.
Nota: Com as dependências manuais criadas, você não precisa mais do seletor adicional criado naetapa 18. Acesse a área de janela Padrões de Agrupamento, selecione o padrão EDay Trader eclique em Editar. Na guia Seletores, selecione o seletor Banco de Dados EDay Trader e cliqueem Excluir para removê-lo ou selecione a caixa de seleção Desativado para que ele não sejaprocessado.
Criando muitos aplicativos de negócios a partir de um padrão de agrupamentoSaiba como criar um padrão de agrupamento universal que gere muitos aplicativos de negóciosautomaticamente.
Sobre Esta Tarefa
No exemplo a seguir, um banco de dados com dados de amostra é usado. O banco de dados contém oscomponentes a seguir:
• WebSphere Cell com alguns servidores e aplicativos Java Platform, Enterprise Edition implementados• Servidores JBoss com alguns aplicativos• Sistemas de computador, alguns dos quais fazem parte de um ambiente virtual• Bancos de dados DB2• Servidores da web• Outros componentes
O objetivo desta tarefa é criar um aplicativo de negócios separado para cada aplicativo Java Platform,Enterprise Edition implementado em cada servidor de aplicativos no ambiente de exemplo. Não é precisocriar padrões de agrupamento separados para eles; um é suficiente. Além disso, quando você inclui umaplicativo no banco de dados após ter criado o padrão de agrupamento, um aplicativo de negócios ainda écriado automaticamente para tal aplicativo.
Procedimento
1. Abra Portal de Gerenciamento de Dados.2. Na área de janela Funções, clique em Descoberta se TADDM 7.3.0 ou 7.3.0.1 for usado, ou em
Analytics, se TADDM 7.3.0.2 ou mais recente for usado.3. Clique em Padrões de Agrupamento. A tabela Padrões de Agrupamento é exibida.4. No campo de nome, insira Aplicativos J2EE Genéricos.
Capítulo 1. Usando 257

5. Configure o tipo de padrão para Aplicativo de Negócios.6. Para a opção Planejamento, escolha Todos os dias à 1h.7. No campo Descrição, insira Aplicativos J2EE Genéricos e clique em Avançar.8. Crie um novo seletor. No campo Nome, insira Seletor J2EE Genérico.9. No campo Descrição, insira Seletor criando Aplicativo de Negócios separado paracada aplicativo J2EE e clique em Escolher.
10. No editor de consulta, selecione Consulta MQL como o tipo de seleção; no campo Consulta, insira2EEApplication WHERE domain is-null.
11. A expressão de nome do agrupamento é resolvida para um nome de aplicativo de negócios, que éuma chave exclusiva que identifica aplicativos de negócios. Portanto, ela não pode ser resolvida paraum nome de padrão, já que somente um aplicativo de negócios seria criado. Para evitar isso, épossível usar o nome do aplicativo Java Platform, Enterprise Edition como a expressão de nome doagrupamento. No campo Expressão de Nome do Agrupamento, insira a expressão a seguir:
${coreCI.displayName}
Para ver os resultados, clique em Testar.Os nomes são longos. Para diminuí-los, no lugar do atributo displayName, é possível usar o atributoname:
${coreCI.name}
Para ver os resultados, clique em Testar.É possível ainda alterar alguns dos nomes, por exemplo, aqueles que têm nome do arquivo ear. Épossível remover a extensão .ear usando a expressão a seguir:
$utils.regex(${coreCI.name}, "(.*)\.ear", "(.*)" )
Nessa expressão, a expressão "(.*)\.ear" remove a extensão .ear do nome do arquivo, e onome resultante é a parte restante do nome do arquivo. A expressão "(.*)" deixa o nome comoestá. Para ver os resultados, clique em Testar.Não é necessário modificar os nomes de qualquer outra forma. No entanto, há aplicativos com omesmo nome de diferentes ambientes, por exemplo, os ambientes de teste e produção. Paradistingui-los, é possível incluir em seus nomes um prefixo com o nome de domínio JBoss ou nome doWebSphere Cell. Use a expressão a seguir:
$utils.or($coreCI.parent.parent.name, $coreCI.parent.parent.displayName)$utils.regex(${coreCI.name}, "(.*)\.ear", "(.*)" )
O WebSphere Cell tem sempre o atributo name configurado, portanto, a expressão$coreCI.parent.parent.name retorna todos os nomes do WebSphere Cell. Nem sempre esse é ocaso para um domínio JBoss, no qual, às vezes, o atributo displayName está configurado. Use aexpressão or para que o primeiro argumento não nulo seja retornado para cada aplicativo. Para veros resultados, clique em Testar.Você ainda pode obter mais informações, por exemplo, tipo de servidor e um prefixo, para distinguirfacilmente os aplicativos baseados em Java Platform, Enterprise Edition dos outros. Para incluir oprefixo, insira J2EE na frente da expressão:
J2EE $utils.or($coreCI.parent.parent.name, $coreCI.parent.parent.displayName)$utils.regex(${coreCI.name}, "(.*)\.ear", "(.*)" )
Para incluir o tipo de servidor, use a expressão a seguir:
J2EE [${coreCI.parent.productName}] $utils.or($coreCI.parent.parent.name, $coreCI.parent.parent.displayName)$utils.regex(${coreCI.name}, "(.*)\.ear", "(.*)" )
O tipo de servidor é obtido do atributo productName de servidores de aplicativos. Como servidoresde aplicativos são pais dos aplicativos Java Platform, Enterprise Edition, a expressão que gera o tipode servidor está entre colchetes. Para ver os resultados, clique em Testar.
258 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Os nomes de tipo de servidor são muito longos. É possível remover a palavra Application do nomedo tipo de servidor usando a seguinte expressão:
J2EE [$utils.regex($coreCI.parent.productName, "(.*) Application.*", "(.*)")] $utils.or($coreCI.parent.parent.name, $coreCI.parent.parent.displayName)$utils.regex(${coreCI.name}, "(.*)\.ear", "(.*)" )
Se o nome contiver a palavra Application, ela será removida pela expressão "(.*)Application.*". Se o nome não contém tal palavra, a expressão "(.*)") deixa como está. Paraver os resultados, clique em Testar.Os resultados parecem bons. Clique em OK.
12. Para salvar o novo padrão de agrupamento, clique em Avançar e em Concluir.
O que Fazer DepoisPara ver os novos aplicativos de negócios, abra a área de janela Padrões de Agrupamento, selecione opadrão de agrupamento criado e clique em Executar. Aguarde um momento e clique em AtualizarVisualização. Após o padrão de agrupamento ter sido gerado, é possível visualizar os novos aplicativosde negócios na área de janela Componentes Descobertos.
Definindo uma configuração do padrão de agrupamentoSaiba como customizar um aplicativo de negócios configurando camadas, invertendo relações eimportando configurações usando a ferramenta bizappscli.
Sobre Esta Tarefa
O ambiente neste cenário de exemplo contém os seguintes elementos:
• Serviços da web do IIS versão 7• Os módulos IIS que são implementados nos serviços da web do IIS• Instâncias do Oracle• Os sistemas de computador nos quais os servidores de aplicativos são executados.
O objetivo desta tarefa é criar um aplicativo de negócios que mostra as relações de módulos do IIS emapear essas relações para os serviços da web do IIS no qual esses módulos são implementados. Asrelações que são cobertas por este aplicativo são:
• Dependências transacionais de módulos do IIS• As relações dos serviços da web do IIS pai para estes módulos• As relações de todos os servidores de aplicativos que são localizados pelo padrão de agrupamento
deste aplicativo para os sistemas de computador nos quais esses servidores de aplicativos sãoexecutados.
Nota: A relação entre o módulo IIS e a instância do Oracle é suportada para o TADDM 7.3.0.2 eposterior.
Ao mesmo tempo, os módulos IIS são excluídos do aplicativo de negócios, mas suas relações sãomapeadas para os serviços da web do IIS.
Além disso, os elementos desse aplicativo de negócios são agrupados em três camadas - o primeiro paraserviços da web do IIS (camada BL), o segundo para instâncias do Oracle (camada DB) e o terceiro paratodos os outros elementos, incluindo sistemas de computador (camada grupo funcional comum). Osnomes de camadas são especificados para criar grupos funcionais para ativar a integração com produtoscomo o Tivoli Business Service Manager, onde grupos funcionais são necessários.
Procedimento
1. Inverta a direção da passagem para qu as relações entre os serviços da web do IIS e as instâncias doOracle sejam descobertas. Os módulos IIS têm relações de saída para os módulos de serviços da webdo IIS e as instâncias do Oracle. Se os módulos do IIS forem filtrados, a relação entre o serviço da webdo IIS e a instância do Oracle não poderá ser criada. No entanto, é possível reverter a direção de
Capítulo 1. Usando 259

passagem para que o serviço da web do IIS tenha relação de saída para o módulo IIS. Nesse caso,mesmo que o módulo seja excluído do aplicativo, a passagem não será interrompida e a relação entreo serviço da web do IIS e a instância do Oracle será criada.Para conseguir isso, deve-se modificar a configuração de direção. Como não é possível modificar aconfiguração de direção para um padrão de agrupamento escolhido, deve-se modificar a configuraçãopadrão aplicada a todos os padrões de agrupamento.a) Exporte a configuração padrão utilizando a ferramenta bizappscli. Não é necessário exportar a
configuração inteira. É possível exportar apenas a configuração de direção.No diretório <taddm installation directory>/dist/sdk/bin, execute a ferramentabizappscli com as opções a seguir:
bizappscli.sh exportDefaultConfiguration -d -f default_directions.xml
em que a opção -d especifica apenas a exportação de direções, e a opção -fdefault_directions.xml cria um arquivo que poderá ser editado. O arquivo XML é criado nodiretório dist/sdk/bin.
b) Abra o arquivo default_directions.xml. Modifique o final do arquivo de modo que as relaçõesDeployedTo sejam as mesmas que no exemplo a seguir:
<reverse relation="only relation.DeployedTo" source="simple.SLogicalGroup" target="simple.SDeployableComponent"/><reverse relation="only relation.DeployedTo" source="app.SoftwareModule" target="app.AppServer"/>
Salve as mudanças.2. Crie uma configuração customizada para seu padrão de agrupamento. Crie um arquivo XML e nomeie-
o, por exemplo, config.xml. Inclua o seguinte conteúdo em seu arquivo:
<xml xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="defaultPatternConfiguration.xsd"> <general> <maxHopsLimit>2</maxHopsLimit> <firstTierOnly>true</firstTierOnly> <infoLevel>GENERAL</infoLevel> </general> <compositionConfiguration> <excludeFromComposition> <exclude type="com.collation.platform.model.topology.app.web.iis.IIsModule"/> </excludeFromComposition> </compositionConfiguration> <tiers> <tier> <name>DB</name> <rule> <className>OracleInstance</className> </rule> </tier> </tiers> <traversalConfiguration> <excludedRelationships> <exclude relation="{any}" source="{any}" target="{any}"/> </excludedRelationships> <includedRelationships> <include relation="only relation.DeployedTo" source="app.web.iis.IIsModule" target="app.web.iis.IIsWebService"/> <include relation="app.dependencies.TransactionalDependency" source="app.web.iis.IIsModule" target="app.db.oracle.OracleInstance"/> <include relation="only relation.RunsOn" source="app.AppServer" target="sys.ComputerSystem"/> </includedRelationships> </traversalConfiguration></xml>
Nota: A opção firstTierOnly está disponível no TADDM 7.3.0.1 e posterior.
Essas seções de configuração possuem as seguintes funções:
260 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

• <general> - o parâmetro maxHopsLimit especifica que dois níveis de relações são atravessados,iniciando com os módulos IIS, porque o modelo de passagem de dados é ativado somente para oseletor que consulta os módulos IIS.
• <compositionConfiguration> - exclui o módulo IIS do aplicativo de negócios.• <tiers> - especifica que todos os objetos localizados na instância do Oracle fazem parte da
camada denominada DB.• <traversalConfiguration> - impede todas as relações sejam atravessadas, exceto as relações
entre os módulos IIS e os serviços da web do IIS, entre os módulos IIS e a instância do Oracle eentre todos os servidores e seus hosts.
3. Importe todas as suas mudanças, executando a ferramenta bizappscli na seguinte ordem:
a. Importar a configuração direção padrão:
bizappscli.sh importDefaultConfiguration -f default_direction.xml
b. Importar a configuração customizada:
bizappscli.sh importConfiguration -U -c custom_config -f config.xml
em que:
• -U - atualiza a configuração existente se você estiver importando um arquivo modificado em vezde um arquivo novo.
• -c custom_config - define o nome de sua configuração customizada.4. Crie um padrão de agrupamento e defina dois seletores.
a) Abra Portal de Gerenciamento de Dados.b) Na área de janela Funções, clique em Descoberta se TADDM 7.3.0 ou 7.3.0.1 for usado, ou em
Analytics, se TADDM 7.3.0.2 ou mais recente for usado.c) Clique em Padrões de agrupamento e, em seguida, em Novo.d) Especifique o nome, o tipo padrão e o planejamento.e) Na lista Configuração, selecione custom_config. É a configuração customizada que você criou para
seu padrão de agrupamento. Clique em Avançar.
Nota: Como alternativa, quando o padrão de agrupamento foi criado, é possível conectar aconfiguração customizada a ele, executando a ferramenta bizappscli com as seguintes opções apartir do diretório dist/sdk/bin:
bizappscli.sh attachConfiguration -c custom_config -n my_pattern | -g 00000000000000000000000000000000
em que my_pattern é o nome do seu padrão de agrupamento, e00000000000000000000000000000000 é o GUID do seu padrão de agrupamento. Use a opção -n ou -g.
f) Crie o primeiro seletor. No campo Nome do seletor, digite BL_module.
g)Deixe o campo Nome da camada vazio. Se você especificar qualquer valor neste campo, todos osobjetos que forem localizados por este seletor serão designados a essa camada. Os módulos IISsão excluídos do aplicativo de negócios, e portanto, não precisam fazer parte de qualquer camada.No entanto, se este campo estiver vazio, mas você anexou uma camada customizada à suaconfiguração de padrão de agrupamento, a configuração será aplicada. Todos os objetos que sãolocalizados pelo seletor e que atendem aos requisitos que são especificados na configuração dacamada são designados à camada especificada. Neste caso, conforme especificado naconfiguração custom_config, todos os objetos localizados na instância do Oracle são designadosa uma camada denominada DB.
h) Especifique a consulta MQL a seguir:
SELECT * FROM IIsModule WHERE ((lower(name) == '/bl')) and (!(parent.
Capítulo 1. Usando 261

productVersion) starts-with '7')
Esta consulta procura por módulos IIS que têm o nome '/bl' e são uma parte do serviço da webdo IIS versão 7.
i) No campo Expressão do nome do agrupamento, digite My App.j) Ative a opção Modelo de passagem de dados e selecione todas as opções de passagem para
localizar dependências entre os módulos IIS e outros objetos.k) Crie o segundo seletor. No campo Nome do Seletor, digite BL.
l)No campo Nome da camada, digite BL. Todos os serviços da web do IIS que são encontrados poreste seletor são parte dessa camada.
m) Especifique a consulta MQL a seguir:
SELECT * FROM IIsWebService WHERE (exists (lower(modules.name) == '/bl')) and (!(productVersion) starts-with '7')
Esta consulta procura os serviços da web do IIS pai dos módulos especificados para o primeiroseletor.
n) No campo Expressão do nome do agrupamento, digite My App.o) Desative a opção Modelo de passagem de dados. Como resultado, nenhuma dependência dos
serviços da web do IIS será localizada. No entanto, os hosts desses serviços da web do IIS serãolocalizados pela consulta especificada para o primeiro seletor, porque todas as opções depassagem são selecionadas.
p) Clique em Avançar.q) Opcional: Especifique as informações administrativas.r) Clique em Concluir.
O que Fazer DepoisAguarde a execução planejada do seu padrão de agrupamento. Como alternativa, é possível executá-lomanualmente, selecionando-o na lista de padrões de agrupamento no Portal de Gerenciamento de Dadose clicando em Executar. Após um tempo, é possível exibir a topologia no Portal de Gerenciamento deDados em Topologia.Referências relacionadas“Configuração dos padrões de agrupamento” na página 216É possível controlar o processo de criação de aplicativos de negócios usando a configuração de padrõesde agrupamento. A configuração permite incluir ou excluir as relações escolhidas durante a passagem dedados e as classes escolhidas dos aplicativos de negócios resultantes. Também é possível alterar adireção de dependência para relações definidas no Modelo de Dados Comum e designar camadas aoselementos de aplicativo de negócios.“Ferramenta bizappscli” na página 233É possível usar a ferramenta bizappscli CLI para gerenciar padrões de agrupamento, planejamentosde processamento de padrão de agrupamento, configurações padrão e a execução de padrões deagrupamento.
É possível usar a ferramenta para criar relatórios para analisar o conteúdo de aplicativos denegócios.
É possível usar a ferramenta para exportar o gráfico da topologia do aplicativo de negócios parao formato SVG.
262 Gerenciador de Descoberta de Dependência de Aplicativo: Usando

Avisos
Estas informações foram desenvolvidas para produtos e serviços oferecidos nos Estados Unidos. Épossível que a IBM não ofereça os produtos, serviços ou recursos discutidos nesta publicação em outrospaíses. Consulte um representante IBM local para obter informações sobre produtos e serviçosdisponíveis atualmente em sua área. Qualquer referência a produtos, programas ou serviços IBM nãosignifica que apenas aquele produto, programa ou serviço IBM possam ser utilizados. Qualquer produto,programa ou serviço funcionalmente equivalente, que não infrinja nenhum direito de propriedadeintelectual da IBM poderá ser utilizado em substituição a este produto, programa ou serviço. Entretanto,a avaliação e verificação da operação de qualquer produto, programa ou serviço não IBM são deresponsabilidade do Cliente.
A IBM pode ter patentes ou solicitações de patentes pendentes relativas a assuntos descritos nestapublicação. O fornecimento desta publicação não lhe garante direito algum sobre tais patentes. Pedidosde licença devem ser enviados, por escrito, para:
Gerência de Relações Comerciais e Industriais da IBM BrasilAv. Pasteur, 136-148BotafogoRio de Janeiro, RJCEP 22290-240
Para pedidos de licença relacionados a informações de DBCS (Conjunto de Caracteres de Byte Duplo),entre em contato com o Departamento de Propriedade Intelectual da IBM em seu país ou envie pedidosde licença, por escrito, para:
Intellectual Property LicensingLegal and Intellectual Property LawIBM Japan, Ltd.1623-14, Shimotsuruma, Yamato-shiKanagawa 242-8502 Japan
O parágrafo a seguir não se aplica a nenhum país em que tais provisões não estejam de acordo com alegislação local:
A INTERNATIONAL BUSINESS MACHINES CORPORATION FORNECE ESTA PUBLICAÇÃO "NO ESTADO EMQUE SE ENCONTRA", SEM GARANTIA DE NENHUM TIPO, SEJA EXPRESSA OU IMPLÍCITA, INCLUINDO,MAS A ELAS NÃO SE LIMITANDO, AS GARANTIAS IMPLÍCITAS DE NÃO INFRAÇÃO, COMERCIALIZAÇÃOOU ADEQUAÇÃO A UM DETERMINADO PROPÓSITO.
Alguns países não permitem a exclusão de garantias expressas ou implícitas em certas transações;portanto, essa disposição pode não se aplicar ao Cliente.
Essas informações podem conter imprecisões técnicas ou erros tipográficos. São feitas alteraçõesperiódicas nas informações aqui contidas; tais alterações serão incorporadas em futuras edições destapublicação. A IBM pode, a qualquer momento, aperfeiçoar e/ou alterar o(s) produto(s) e/ou programa(s)descritos nesta publicação, sem aviso prévio.
Referências nestas informações a websites não IBM são fornecidas apenas por conveniência e nãorepresentam de forma alguma um endosso a esses websites. Os materiais contidos nesses websites nãofazem parte dos materiais desse produto IBM e a utilização desses Websites é de inteiraresponsabilidade do Cliente.
A IBM pode utilizar ou distribuir as informações fornecidas da forma que julgar apropriada sem incorrerem qualquer obrigação para com o Cliente.
Licenciados deste programa que desejam obter informações sobre este assunto com objetivo de permitir:(i) a troca de informações entre programas criados independentemente e outros programas (incluindoeste) e (ii) a utilização mútua das informações trocadas, devem entrar em contato com:
© Copyright IBM Corp. 2006, 2016 263

Gerência de Relações Comerciais e Industriais da IBM BrasilAv. Pasteur, 138-146BotafogoRio de Janeiro, RJCEP 22290-240
Tais informações podem estar disponíveis, sujeitas a termos e condições apropriadas, incluindo emalguns casos o pagamento de uma taxa.
O programa licenciado descrito nesta publicação e todo o material licenciado disponível são fornecidospela IBM sob os termos do Contrato com o Cliente IBM, do Contrato Internacional de Licença doPrograma IBM ou de qualquer outro contrato equivalente.
Todos os dados de desempenho aqui contidos foram determinados em um ambiente controlado.Portanto, os resultados obtidos em outros ambientes operacionais podem variar significativamente.Algumas medidas podem ter sido tomadas em sistemas em nível de desenvolvimento e não há garantiade que estas medidas serão iguais em sistemas geralmente disponíveis. Além disso, algumas medidaspodem ter sido estimadas por extrapolação. Os resultados reais podem variar. Os usuários destedocumento devem verificar os dados aplicáveis para seu ambiente específico.
As informações relativas a produtos não IBM foram obtidas junto aos fornecedores dos respectivosprodutos, de seus anúncios publicados ou de outras fontes disponíveis publicamente. A IBM não testouestes produtos e não pode confirmar a precisão de seu desempenho, compatibilidade nem qualqueroutra reivindicação relacionada a produtos não IBM. Dúvidas sobre os recursos de produtos não IBMdevem ser encaminhadas diretamente a seus fornecedores.
Todas as declarações relacionadas aos objetivos e intenções futuras da IBM estão sujeitas a alteração oucancelamento sem aviso prévio e representam apenas metas e objetivos.
Estas informações contêm exemplos de dados e relatórios utilizados nas operações diárias de negócios.Para ilustrá-los da forma mais completa possível, os exemplos incluem nomes de indivíduos, empresas,marcas e produtos. Todos estes nomes são fictícios e qualquer semelhança com os nomes e endereçosutilizados por uma empresa real é mera coincidência.
Se estas informações estiverem sendo exibidas em cópia eletrônica, as fotografias e ilustrações coloridaspodem não aparecer.
Marcas RegistradasIBM, o logotipo IBM e ibm.com são marcas ou marcas registradas da International Business MachinesCorp., registradas em vários países no mundo todo. Outros nomes de produtos e serviços podem sermarcas registradas da IBM ou de outras empresas. Uma lista atual de marcas registradas da IBM estádisponível na Web em "Informações de Copyright e Marcas Registradas" em http://www.ibm.com/legal/copytrade.shtml.
Adobe é uma marca ou marca registrada da Adobe Systems Incorporated nos Estados Unidos e/ou emoutros países.
Java e todas as marcas registradas e logotipos baseados em Java são marcas ou marcasregistradas da Oracle e/ou suas afiliadas.
Linux é uma marca registrada de Linus Torvalds nos Estados Unidos e/ou em outros países.
Microsoft e Windows são marcas registradas da Microsoft Corporation nos Estados Unidos e/ou emoutros países.
UNIX é uma marca registrada do The Open Group nos Estados Unidos e em outros países.
264 Avisos

Outros nomes de empresas, produtos e serviços podem ser marcas registradas ou marcas de serviço deterceiros.
Avisos 265

266 Gerenciador de Descoberta de Dependência de Aplicativo: Usando


IBM®