mysql - visão geral
TRANSCRIPT

MySQL
Airton LastoriClayton M. Pereira
Strauss Cunha
31-mar-2016
CE-263Prof. José M Parente de OliveiraProf. Ricardo da Silva SantosProfa. Emilia Colonese

● Mercado● Características gerais● Estruturas de armazenamento● Índices● Técnicas para grandes volumes de dados● Conclusão (pontos fracos e fortes)
Agenda
Mercadopopularidade e adoção
4
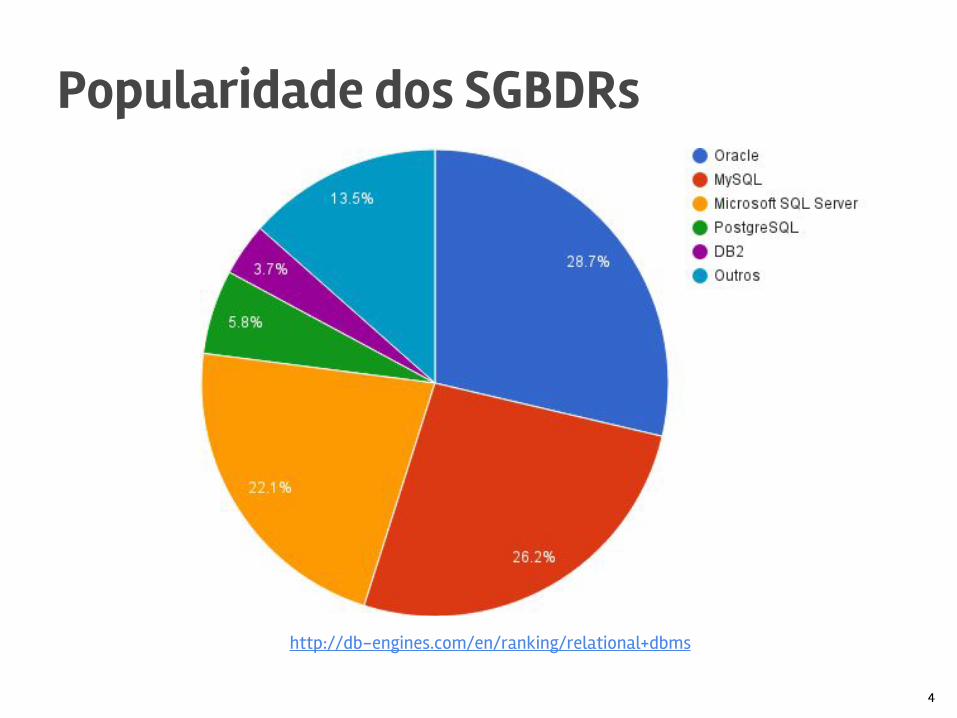
http://db-engines.com/en/ranking/relational+dbms
Popularidade dos SGBDRs
5
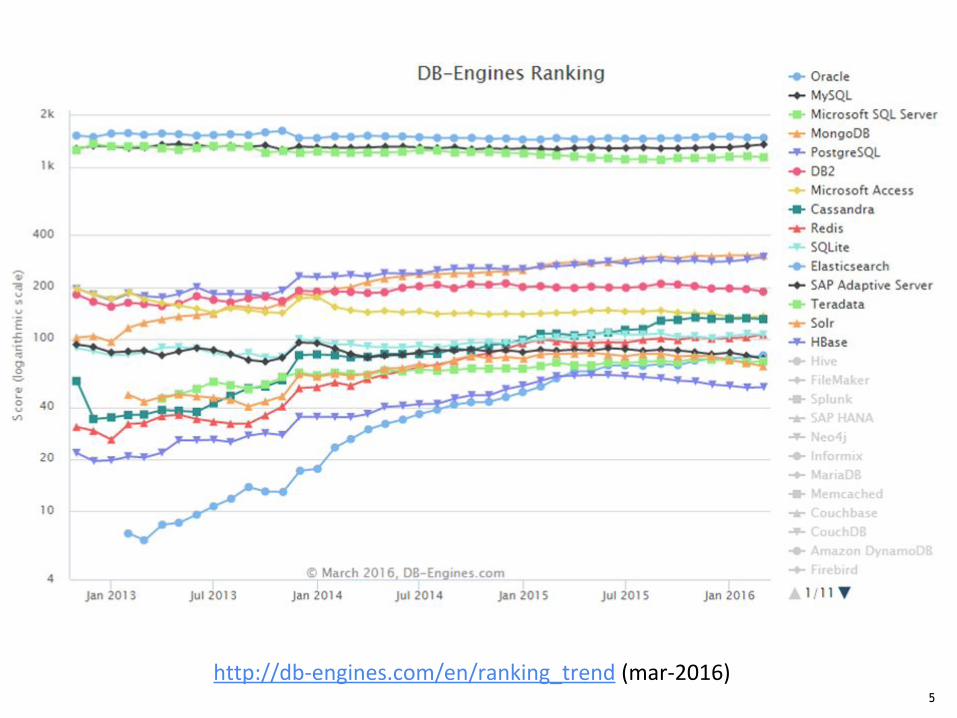
http://db-engines.com/en/ranking_trend (mar-2016)
6
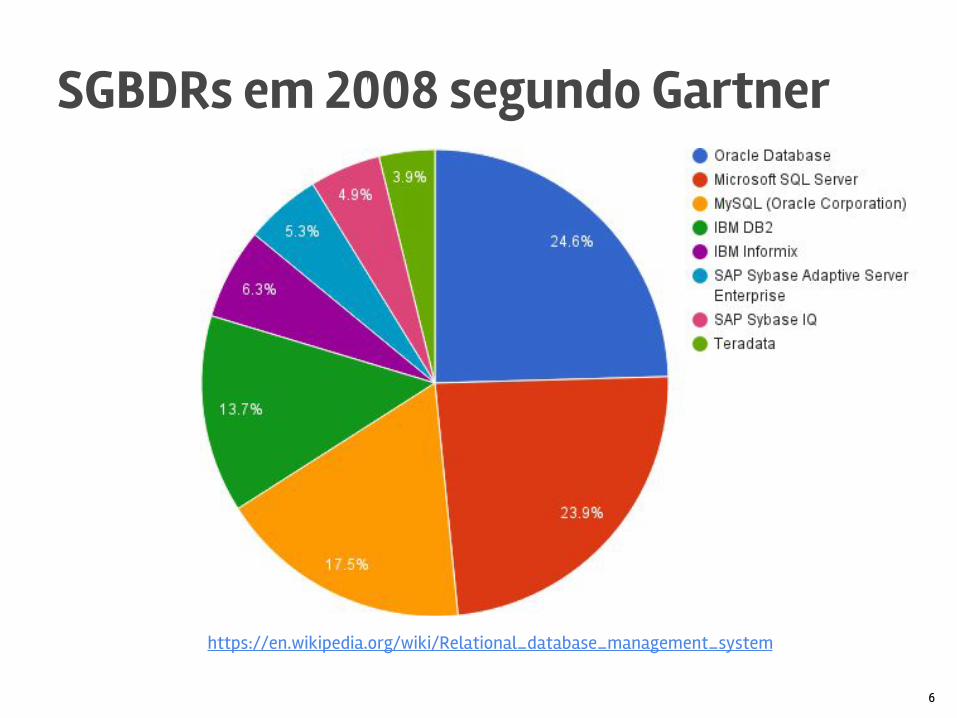
https://en.wikipedia.org/wiki/Relational_database_management_system
SGBDRs em 2008 segundo Gartner

FacebookUber
AirbnbYoutubeLinkedinTwitterAlibabaGithub
Casos de uso famosos
7
www.mysql.com/customers

Características Geraishistórico, arquitetura e casos de uso típicos
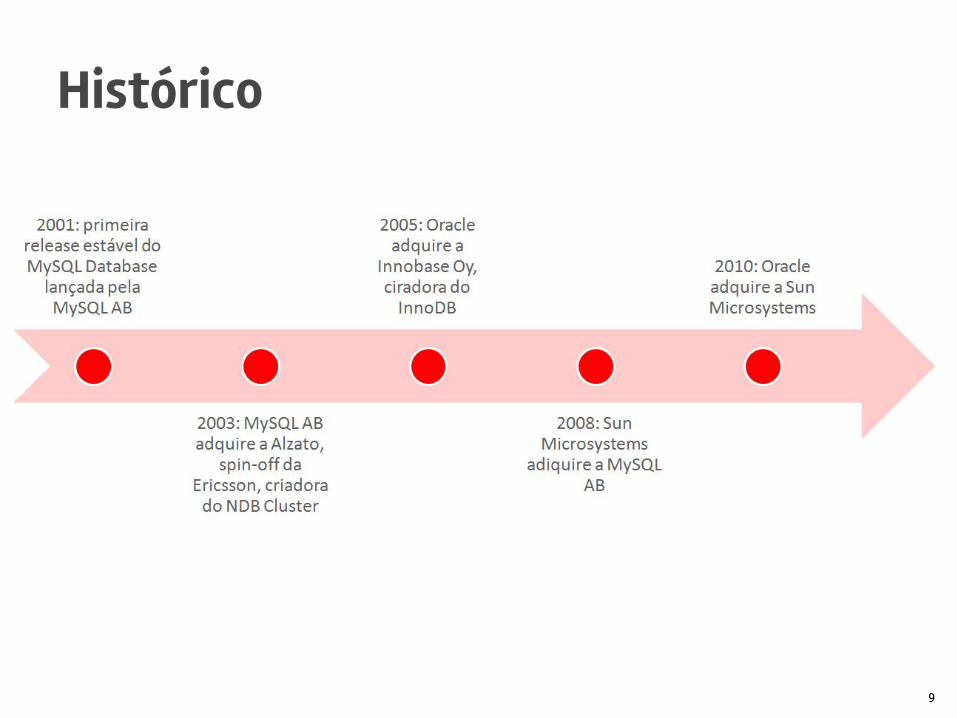
Histórico
9

Arquitetura MySQL Database
10
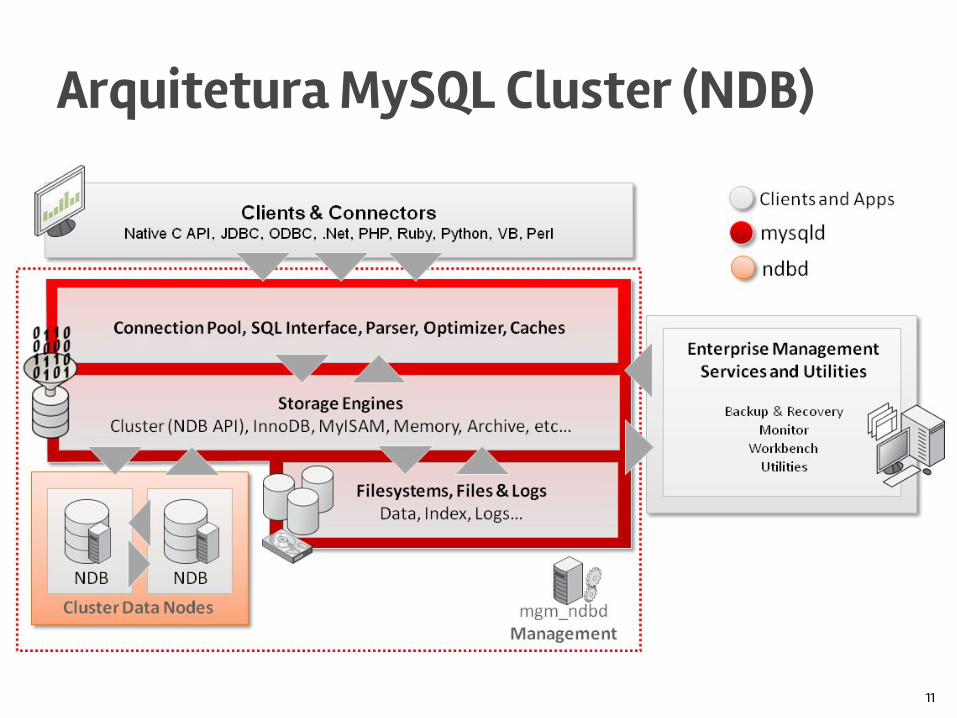
Arquitetura MySQL Cluster (NDB)
11

● Web, Mobile e embarcado● Muitas conexões simultâneas● Transações curtas em tempo e em operações
◦ Máximo poucos segundos◦ COMMITs intermediários
● Dados mais quentes cabem em memória RAM● Se pensar em uma arquitetura Big Data
(lambda), MySQL vai aparecer no Speed Layer com mais frequência
Uso típico do MySQL
12

Estruturas de Armazenamentostorage engines, InnoDB, limites

As estruturas de armazenamento vão mudar de acordo com o Storage Engine, definido por tabela.
CREATE TABLE … ENGINE=MyISAM
Criará uma tabela do “tipo” MyISAM, considerado um padrão simples, rápido para leituras, mas problemático para escritas.
Se não for explicitado, será usado o default (InnoDB).
Storage Engines
14

Se aproxima dos demais SGBDRs de mercado:ACIDTransaçõesLock em nível de linhaFKs para integridade referencial
Dados fisicamente organizados em índices clusterizados B+Tree.
Os dados das linhas da tabela são armazenados nas folhas da árvore, organizada pela sua chave primária.
InnoDB
15
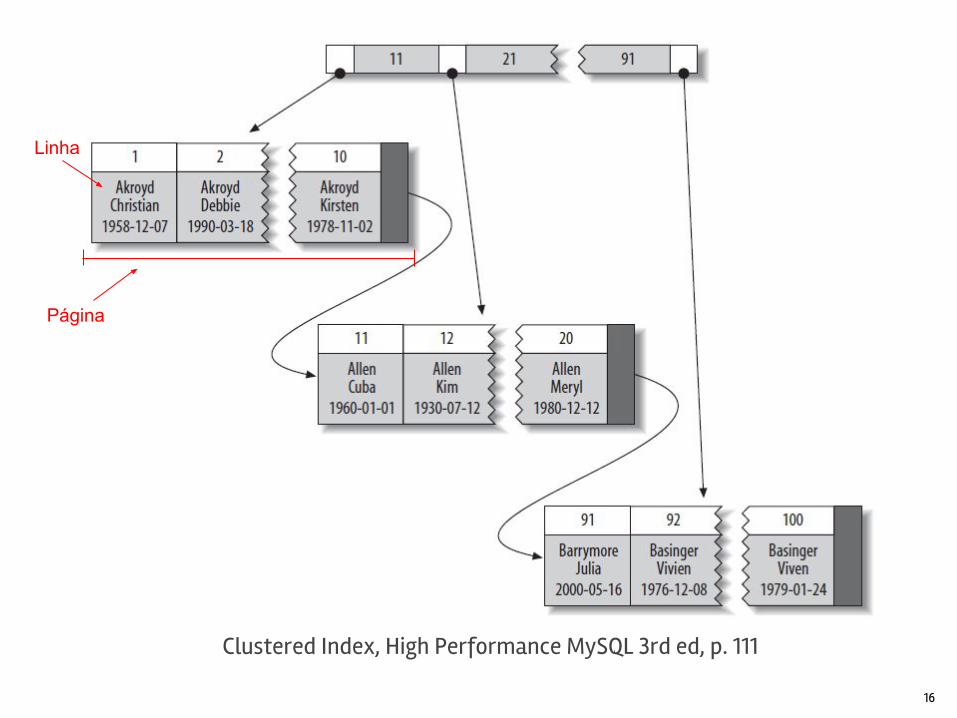
16
Clustered Index, High Performance MySQL 3rd ed, p. 111
Linha
Página

innodb_flush_at_trx_commitdouble_bufferinnodb_logfile_sizeTamanho de Página: 4, 8, 16, 32, 64KB
● páginas menores podem ajudar na performance em dispositivos com tamanhos de blocos menores (SSD)
● dev.mysql.com > Doc > Refman > 5.7 > En > Innodb-restrictions
Tamanho da Linha: depende do Row format● innodb_default_row_format: DYNAMIC, COMPACT, REDUNDANT,
COMPRESSED● Definido por tabela: CREATE TABLE. ALTER TABLE● dev.mysql.com > Doc > Refman > 5.7 > En > Innodb-physical-record
Configurações flexíveis para Escrita
17

Índicesestruturas suportadas

Índices também dependem do storage engine Há vários tipos Nem todos Storage Engines suportam todos índices Implementações não são padronizadas
InnoDB (padrão) já possui os dados armazenados em B+Tree referenciada pela PK (índice clusterizado). Também suporta índices secundários: B+Tree, Hash, Fulltext e R-Tree (spatial).
Índices B+Tree tornam rápidas Buscas e Ordenações.
Vários tipos
19

Técnicas especiaispara grandes volumes de dados

Recurso que permite dividir os dados de uma tabela em arquivos separados no filesystem, de acordo com alguma regra.
O MySQL suporta partições por regras baseadas em chave, lista, range e hash. Também suporta subpartições.
Particionamento
21
dev.mysql.com/doc/refman/5.7/en/partitioning.html

Criar índices envolvendo mais colunas que as utilizadas pelo otimizador, a fim de evitar que o arquivo de dados seja lido.
Desta forma apenas o índice será lido para recuperar os dados desejados, evitando acesso ao arquivo de dados, e a performance será maior.
Covering Indexes
22
Covering Index, High Performance MySQL 3rd ed, p. 120

Colunas adicionais que contém o resultado de algum cálculo ou função sobre os dados das demais colunas.
Podem ser persistidas no arquivo de dados (stored) ou calculadas on-the-fly (virtual).
mysql> ALTER TABLE t ADD new_col INT GENERATED ALWAYS AS (a - b) VIRTUAL;
mysql> SELECT * FROM t;+----+------+------+---------+| a | b | c | new_col |+----+------+------+---------+| 11 | 3 | 14 | 8 |+----+------+------+---------+
Podem ser indexadas!
Generated Columns
23

Vertical (scale up)hardware mais potente
Horizontal (scale out)mais máquinas (Cluster, Cloud)
Tipos de Escalabilidade
24
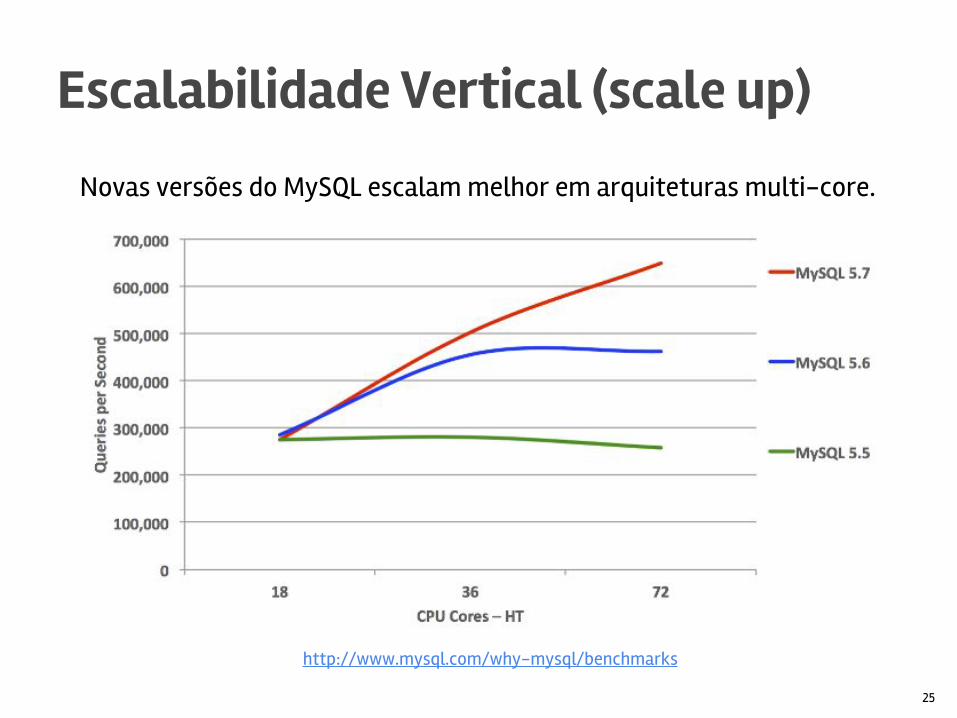
Novas versões do MySQL escalam melhor em arquiteturas multi-core.
Escalabilidade Vertical (scale up)
25
http://www.mysql.com/why-mysql/benchmarks

● O MySQL possui um recurso nativo de Replicação.● O modelo mais utilizado é Master-Slave assíncrono, que
possibilita escalabilidade de leituras com menor complexidade. ● Usar o storage engine BLACKHOLE no Master para criar
servidores de Relay ajuda escalar escritas.● Escalar escritas em ambientes distribuídos é mais difícil,
envolve sincronização, gerenciamento de locks, resolução de conflitos, etc.
● O MySQL Cluster escala escritas através de replicação síncrona e auto-sharding, porém depende da adequação das tabelas para Storage Engine NDB.
● É possível ter algum ganho de escala de escritas com InnoDB usando plugins como Galera Cluster ou Group Replication.
Escalabilidade Horizontal (scale out)
26

Não possui todas funcionalidades que outros SGBDRsEvitar transações complexas diretamente no SGBDViews materializadas (apenas simulação)
Faltam índices especializadosExpression, Partial, Reverse, Bitmap, GiST, GIN, FOT...
Faltam algumas funcionalidades SQL ANSIIntersect, Except, Merge joins, Common Table Expressions, Windowing Functions, Parallel Query, Data Domain CHECK (apenas simulação ou datatype ENUM)
Conclusão - Pontos Fracos 1/2
27

Poucas funcionalidades OLAP nativasdepende de plugins externos (ex. InfoBright, InfiniDB) e não homologado por algumas aplicações empacotadas de BI
Escalabilidade vertical limitada a hardwares commodityDifícil de escalar escritas horizontalmente
depende de usar relay servers ou storage engine NDB Clusterdepende de uso de técnicas de sharding na aplicação
Não há muitos DBAs "de carreira"comum no mundo SQL Server, Oracle e DB2
Conclusão - Pontos Fracos 2/2
28

Open Source (GPL v2)Fácil de usar e instalar
Fácil de automatizar gerenciamento de múltiplas instâncias
Excelente performance OLTP (leituras e escritas)Muitas conexões simultâneasTransações curtas e em grande volume
Integra muito bem com outras tecnologias Open SourceAlta maturidade e popularidade
Replicação simples e flexívelMuito usada para escalar leituras
Multi-plataformaDesenvolvido e suportado pela Oracle
Conclusão - Pontos Fortes
29

Manual de Referência do MySQLhttp://dev.mysql.com/doc/refman/5.7/en/
Schwartz, Baron, Peter Zaitsev, and Vadim Tkachenko. High performance MySQL: Optimization, backups, and replication. " O'Reilly Media, Inc.", 2012.
DB-Engineshttp://db-engines.com/en/ranking_trend
Wikipediahttps://en.wikipedia.org/wiki/Comparison_of_relational_database_management_systems
https://en.wikipedia.org/wiki/Relational_database_management_system
Referências
30