monitoramento de tráfego veicular terrestre usando análise...
TRANSCRIPT

Universidade de BrasíliaInstituto de Ciências Exatas
Departamento de Ciência da Computação
Monitoramento de Tráfego Veicular Terrestre UsandoAnálise de Movimento em Imagens Sequenciais
Esther Arraes GrigatiFelipe Braga Camargo Dias
Monografia apresentada como requisito parcialpara conclusão do Bacharelado em Ciência da Computação
OrientadorProf. Dr. Flávio de Barros Vidal
Brasília2015

Universidade de Brasília — UnBInstituto de Ciências ExatasDepartamento de Ciência da ComputaçãoBacharelado em Ciência da Computação
Coordenador: Prof. Dr. Homero Luiz Pícollo
Banca examinadora composta por:
Prof. Dr. Flávio de Barros Vidal (Orientador) — CIC/UnBProf. Dr. Camilo Chang Dórea — CIC/UnBProf. Dr. Aletéia Patrícia Favacho de Araújo — CIC/UnB
CIP — Catalogação Internacional na Publicação
Grigati, Esther Arraes.
Monitoramento de Tráfego Veicular Terrestre Usando Análise de Movi-mento em Imagens Sequenciais / Esther Arraes Grigati, Felipe BragaCamargo Dias. Brasília : UnB, 2015.101 p. : il. ; 29,5 cm.
Monografia (Graduação) — Universidade de Brasília, Brasília, 2015.
1. Segmentação de Movimento, 2. Fluxo Ótico, 3. Análise de Trânsito,4. Fluxo de Veículos.
CDU 004.4
Endereço: Universidade de BrasíliaCampus Universitário Darcy Ribeiro — Asa NorteCEP 70910-900Brasília–DF — Brasil

Universidade de BrasíliaInstituto de Ciências Exatas
Departamento de Ciência da Computação
Monitoramento de Tráfego Veicular Terrestre UsandoAnálise de Movimento em Imagens Sequenciais
Esther Arraes GrigatiFelipe Braga Camargo Dias
Monografia apresentada como requisito parcialpara conclusão do Bacharelado em Ciência da Computação
Prof. Dr. Flávio de Barros Vidal (Orientador)CIC/UnB
Prof. Dr. Camilo Chang Dórea Prof. Dr. Aletéia Patrícia Favacho de AraújoCIC/UnB CIC/UnB
Prof. Dr. Homero Luiz PícolloCoordenador do Bacharelado em Ciência da Computação
Brasília, 13 de Julho de 2015

Resumo
A obtenção de informações a respeito do fluxo de veículos terrestres em rodoviasé um problema para quaisquer entidades que desejem utilizar essas informações, sejapara projetar melhorias na infraestrutura, seja para planejar manutenções nas vias. Acrescente presença de câmeras digitais nos ambientes urbanos e nas imediações de rodoviasrepresenta um estímulo à criação de aplicações que obtêm a partir de imagens sequenciaisinformações úteis à análise de trânsito. Este projeto propõe a detecção de movimentode veículos em sequências de imagens para determinar a quantidade e a classificação deveículos presentes em cada imagem.
Palavras-chave: Segmentação de Movimento, Fluxo Ótico, Análise de Trânsito, Fluxode Veículos.
i

Abstract
The acknowledgement of terrestrial vehicle flow data in highways configures a problemto whomever entities that want to use that data in order to project upgrades in the infras-tructure or to better plan the maintenance in those roads. The growing number of digitalcameras in urban environments and at highway premises represents a strong motivationfor the design of applications that gather relevant information on traffic analysis fromimage sequences. This project’s proposal is to detect and extract vehicle movement fromimage sequences in order to measure the amount and determine the type of vehicles ineach image.
Keywords: Motion Tracking, Optical Flow, Traffic Analysis, Vehicle Flow.
ii

Sumário
1 Introdução 11.1 Justificativa e Apresentação do Problema . . . . . . . . . . . . . . . . . . 11.2 Objetivos Gerais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Objetivos Específicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.4 Estrutura deste Trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Revisão Bibliográfica 32.1 Segmentação em Imagens . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Watershed . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.1.2 K-means . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.1.3 Segmentação de Movimento . . . . . . . . . . . . . . . . . . . . . . 5
3 Análise de Trânsito 133.1 Detecção por Modelos Geométricos e Estimação de Movimento via Filtro
de Kalman Extendido (EKF) . . . . . . . . . . . . . . . . . . . . . . . . . 133.2 Detecção por Background Subtraction, Rastreamento por Template Mat-
ching e Classificação por Forma de Blocos. . . . . . . . . . . . . . . . . . . 153.3 Detecção, Rastreamento e Classificação em Tempo Real através de Carac-
terísticas Estáveis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4 Metodologia Proposta 214.1 Inicialização . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214.2 Conversão da Imagem para Níveis de Cinza . . . . . . . . . . . . . . . . . 214.3 Escolha de Pontos Relevantes . . . . . . . . . . . . . . . . . . . . . . . . . 224.4 Fluxo Ótico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234.5 Cálculo de Atributos do Vetor de Deslocamento . . . . . . . . . . . . . . . 234.6 Exclusão de Pontos Estáticos . . . . . . . . . . . . . . . . . . . . . . . . . 244.7 Avaliação da Similaridade dos Pontos . . . . . . . . . . . . . . . . . . . . . 244.8 Agrupamento de Vetores Similares . . . . . . . . . . . . . . . . . . . . . . . 254.9 Remoção de Pontos Dispersos . . . . . . . . . . . . . . . . . . . . . . . . . 26
5 Resultados 275.1 Base de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285.2 F-measure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295.3 Discussão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
6 Conclusão 42
iii

Referências 43
iv

Lista de Figuras
2.1 Segmentação de grãos de arroz em imagem com variações de iluminação [16]. 32.2 Exemplo do processo que a aplicação do algoritmo Watershed produz [25]. 42.3 Exemplo dos resultados produzidos pela aplicação do K-means [25]. . . . . 52.4 Exemplo de uma imagem com a diferença entre dois quadros consecutivos. 62.5 Exemplo do deslocamento de uma imagem. . . . . . . . . . . . . . . . . . . 82.6 Duas curvas deslocadas de um vetor h. . . . . . . . . . . . . . . . . . . . . 8
3.1 Figura para ilustrar o conceito de orientação de um veículo [9]. . . . . . . . 143.2 Figura para ilustrar o conceito de modelo de Ackermann para carros [9]. . . 143.3 Figura que mostra a sequência de um objeto detectado sendo processado
antes de ser passado ao rastreador [12]. . . . . . . . . . . . . . . . . . . . . 163.4 Exemplo de uma situação que precede o cruzamento de trajetórias de veí-
culos [12]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163.5 Exemplo de uma situação onde existe cruzamento de trajetórias de veícu-
los [12]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173.6 Figura que ilustra o processo de separação de blocos fundidos, em que a
região de corte é a região onde o procedimento de separação de blocos cortao bloco maior, adaptado de [12]. . . . . . . . . . . . . . . . . . . . . . . . . 17
3.7 À esquerda, tem-se um ângulo de captura mais tradicional, com a câmeramais elevada. À direita, tem-se o ângulo a ser atacado, mais baixo e commais oclusão, adaptado de [13]. . . . . . . . . . . . . . . . . . . . . . . . . 18
3.8 Passos do processo de ajuste e calibração do sistema ao ambiente alvo [13]. 193.9 Respectivamente da esquerda para a direita, os processos de Background
Subtraction e de seleção de pontos relevantes a rastrear [13]. . . . . . . . . 193.10 Processo de criação de elemento em ação [13]. . . . . . . . . . . . . . . . . 193.11 Exemplos de classificação de veículos, onde os números seguidos de "T"
representam objetos classificados como caminhões [13]. . . . . . . . . . . . 20
4.1 Fluxograma do algoritmo proposto. . . . . . . . . . . . . . . . . . . . . . . 22
5.1 Exemplo de imagens de saída do conjunto M30. . . . . . . . . . . . . . . . 275.2 Exemplo de imagens de saída do conjunto M30-HD. . . . . . . . . . . . . . 285.3 Exemplo de imagens dos dois conjuntos de dados. . . . . . . . . . . . . . . 295.4 Exemplo da área válida nas imagens dos dois conjuntos de dados. Os
veículos das áreas em vermelho devem ser desconsiderados na detecção. . . 29
v

Lista de Tabelas
3.1 Resultados da contagem de veículos obtidos por Guerrero, adaptado de [9]. 153.2 Resultados de recall obtidos por Guerrero, adaptado de [9]. . . . . . . . . . 153.3 Resultados obtidos por Huang, adaptado de [12]. . . . . . . . . . . . . . . . 173.4 Resultados obtidos por Kanhere, adaptado de [13]. . . . . . . . . . . . . . 20
5.1 Melhores resultados obtidos para o conjunto de imagens M30. . . . . . . . 315.2 Resultados obtidos no dataset M30 para tamV izinhanca igual a 80. . . . . 315.3 Resultados obtidos no dataset M30 para tamV izinhanca igual a 100. . . . 325.4 Resultados obtidos no dataset M30 para tamV izinhanca igual a 120. . . . 335.5 Resultados obtidos no dataset M30 para tamV izinhanca igual a 140. . . . 345.6 Resultados obtidos no dataset M30 para tamV izinhanca igual a 160. . . . 355.7 Melhores resultados obtidos para o conjunto de imagens M30-HD. . . . . . 365.8 Resultados obtidos no dataset M30-HD para tamV izinhanca igual a 120. . 365.9 Resultados obtidos no dataset M30-HD para tamV izinhanca igual a 140. . 375.10 Resultados obtidos no dataset M30-HD para tamV izinhanca igual a 160. . 385.11 Resultados obtidos no dataset M30-HD para tamV izinhanca igual a 180. . 395.12 Resultados obtidos no dataset M30-HD para tamV izinhanca igual a 200. . 405.13 Comparação de resultados de recall . . . . . . . . . . . . . . . . . . . . . . 41
vi

Capítulo 1
Introdução
1.1 Justificativa e Apresentação do ProblemaSegundo a Comissão Eletrotécnica Internacional (IEC) [17], o conceito de Smart Cities,
isto é “cidades inteligentes”, é uma vertente de trabalho crescente no cenário de pesquisasmundial. O uso de câmeras e sensores para a captura de informações a serem utilizadasem sistemas que representam essa ideia é essencial, logo aplicações que se utilizam destasformas de coleta de dados têm se popularizado.
O processo que transforma a administração de uma cidade na direção de uma maneirasistemática e inteligente, como é proposto pela ideologia de Smart Cities, começa comesforços destinados a criação de sistemas voltados ao benefício dos cidadãos e do meioambiente. A criação e gerência competente de redes de água, energia elétrica, gás ede saneamento, de sistemas de transporte, comunicação e de elementos como hospitais,delegacias e corpo de bombeiros são indispensáveis à eficácia, à sustentabilidade e à própriasobrevivência da cidade como todo [17].
O desenvolvimento bem sucedido de uma cidade inteligente depende de uma combi-nação harmônica, centralizada e gerenciável de todos os sistemas essenciais à manutençãodos serviços básicos à população. É possível estender a administração a cada vez mais ser-viços uma vez que o sistema central é confiável [6]. O enfoque deste trabalho será o ramode estudo relacionado à automatização de serviços de gerência e controle de transportes.
No contexto nacional, o processo de contagem de veículos é utilizado para diversosfins, como estimativas de fluxo para levantamentos de como e onde melhorar a infra-estrutura. Este procedimento é feito por meio de funcionários, pessoal destacado para atarefa de realizar contagens que sirvam de amostras para alimentar modelos estatísticosde estimação de fluxo, ou mesmo por simples extrapolação. Logo, foi encontrada umademanda por projetos que envolvam a contagem de veículos de maneira automática, quepode ser mais robusta, por não ter limitações quanto ao horário de trabalho e, ainda,eliminar o fato de poder haver falta de variedade de informações devido aos curtos períodosde coleta.
O trabalho proposto por Kanhere e Birchfield [13] tem como um de seus objetivosprincipais realizar contagem de veículos, e compará-la com os valores obtidos através dacontagem manual para estimar sua capacidade e precisão. Os trabalhos propostos porGuerrero [9] e Huang e Liao [12] possuem como objetivo realizar detecção, rastreamento eclassificação de veículos automaticamente. A presença de esforços de pesquisa com estes
1

objetivos fortalece a hipótese de que é possível se utilizar destes meios para se produzirsistemas automáticos de detecção e contagem de veículos.
1.2 Objetivos GeraisO objetivo geral deste trabalho é a implementação de um sistema automatizado que
seja capaz de prover melhorias no processo de contagem de veículos em rodovias utilizandosegmentação de movimento em sequências de imagens.
1.3 Objetivos EspecíficosEntre os objetivos específicos do trabalho, pode-se destacar:
1. Contagem absoluta de veículos.
2. Classificação dos veículos em pequenos, médios ou grandes.
Busca-se atingir tais objetivos através da aplicação de conceitos em Visão Computa-cional, tais como a segmentação de imagens e as técnicas de Fluxo Ótico e Clustering.
1.4 Estrutura deste TrabalhoEste documento possui mais cinco capítulos em sua estrutura. No Capítulo 2 é feita
uma breve revisão bibliográfica de conceitos teóricos que embasam os métodos elabora-dos no decorrer do projeto. O Capítulo 3 contém uma amostra dos principais trabalhosdesenvolvidos na área de análise de trânsito. No Capítulo 4 é apresentada a metodolo-gia desenvolvida para proporcionar uma resolução ao problema proposto. O Capítulo 5apresenta uma análise dos resultados obtidos a partir do sistema criado. Para finalizar,no capítulo 6, encontram-se algumas conclusões do projeto e os trabalhos futuros.
2

Capítulo 2
Revisão Bibliográfica
O campo de estudo de Visão Computacional é uma área vasta dentro das Ciências daComputação. Neste capítulo, são apresentados os conceitos relevantes ao entendimentodos métodos desenvolvidos no projeto, que serão posteriormente descritos.
2.1 Segmentação em ImagensSegundo Gonzalez [10], o conceito de segmentar consiste no processo de subdividir uma
imagem em elementos e objetos constituintes. O nível (classe ou grupo) a que cada objetopertence depende do objetivo da segmentação. Isto é, o processo de segmentação deve serimediatamente interrompido quando um objeto ou elemento de interesse foi detectado [10].
Segundo Szeliski [25], a criação de classes e a distribuição de objetos semelhantesdentre as classes de equivalência criadas configura um problema de agrupamento. Nocontexto da Visão Computacional, existem diversas técnicas e métodos em forma de algo-ritmos que foram desenvolvidos com o objetivo de resolver esse desafio, alguns derivadosdos métodos desenvolvidos na Estatística e outros elaborados levando-se em considera-ção particularidades inerentes ao estudo de processamento digital de imagens [25]. AFigura 2.1 apresenta um exemplo de segmentação em imagens.
Figura 2.1: Segmentação de grãos de arroz em imagem com variações de iluminação [16].
3

Algumas estratégias como Fluxo Ótico [11] e Background Subtraction [22] possuemsimilaridades, tal como o fato de cada uma utilizar-se da presença de movimento comocritério chave para tentar classificar e categorizar os elementos, de modo que elementosque tem algum tipo de movimento são destacados do restante da imagem. É possíveldesenvolver técnicas de agrupamento especificamente para um dado problema utilizando-se de uma combinação de técnicas existentes, como a segmentação por forma geométrica [9]ou por movimento [13]. Dentre os algoritmos que possuem maior popularidade, tem-se oWatershed [3] e o K-Means [15]. O primeiro é um algoritmo de segmentação por detecçãode bordas, e o segundo realiza agrupamento de elementos de forma parametrizada.
2.1.1 Watershed
Segundo Szeliski [25], o algoritmo Watershed é uma técnica relacionada à limiarização,por operar em uma imagem em níveis de cinza. Esta técnica realiza a segmentaçãoda imagem em diversas regiões que agem como bacias de captação. A classificação éfeita tomando-se a abstração de que “chove” na imagem, cada uma das bacias captaria aprecipitação e a agruparia [25].
O processamento do algoritmo consiste no cálculo de alguns pontos mínimos da ima-gem, que servirão de “sementes” para a expansão das regiões. Quando duas regiões que seoriginaram de sementes diferentes se encontram, é definida uma fronteira, e esse conjuntode fronteiras define as regiões segmentadas na imagem. Um exemplo da aplicação doWatershed é apresentado na Figura 2.2.
(a) Imagem inicial, antesdo processamento.
(b) Imagem durante o pro-cesso de inundação das se-mentes.
(c) Imagem após o proces-samento.
Figura 2.2: Exemplo do processo que a aplicação do algoritmo Watershed produz [25].
2.1.2 K-means
Segundo Bishop [4], o K-means é um algoritmo que possui um comportamento di-ferente, pois o número de classes nas quais os objetos serão agrupados depende de umparâmetro pré-definido que é passado ao algoritmo. O parâmetro k define em quantasclasses o algoritmo agrupará os objetos, e a escolha deste parâmetro de maneira coerenteé indispensável ao bom rendimento e acurácia do algoritmo. É comum que sejam feitasbaterias de testes empíricos com diversas variações do valor de k para que o valor sejaconvenientemente escolhido.
O K-means modela a densidade de probabilidades como uma superposição de distri-buições esféricas simétricas, não exigindo nenhuma razão ou modelagem probabilística
4

pré-determinada [4]. O método desenvolvido pelo K-means procura por k classes, cal-culando um centro para cada classe e atualizando os valores associados a esse centro demaneira iterativa. No processo de atualização de cada centro, o algoritmo agrupa maiselementos que se alinhem com as características de cada centro, expandindo as regiões [25].Um exemplo da aplicação do K-means é apresentado na Figura 2.3.
(a) Imagem inicial, antes dacomputação.
(b) Imagem final, com as clas-ses separadas por cor.
(c) Imagem de um gráfico em3D do resultado obtido.
Figura 2.3: Exemplo dos resultados produzidos pela aplicação do K-means [25].
2.1.3 Segmentação de Movimento
Segundo Davies [8], é possível extrair informações dos elementos presentes em sequên-cias de imagens por meio da análise de movimento. Para isso, é necessário estabeleceruma correspondência entre os elementos de um quadro com os elementos do próximo.Esta correspondência pode ser obtida detectando-se as regiões da imagem que não semovimentam e analisando o que sobra, como no Background Subtraction, ou realizando adetecção do movimento em si, como no Fluxo Ótico.
De acordo com Read e Meyer [18], as sequências de imagens são produzidas comuma alta taxa de amostragem, já que é necessário que o olho humano tenha a percep-ção de que o movimento dos objetos da cena é contínuo. Portanto, o número mínimode quadros por segundo utilizado atualmente na captura de vídeos é 24. Desta forma,quadros consecutivos apresentam nível de semelhança bem alto. Isso torna possível obteruma correspondência entre os objetos com a análise das diferenças entre duas imagensconsecutivas [8].
De acordo com Gonzales [10], uma das abordagens mais simples para detectar mudan-ças entre duas imagens é compará-las pixel -a-pixel, obtendo a relação entre as posiçõesdos pixels em um determinado quadro e no quadro seguinte. Isto pode ser realizado com acriação de uma imagem que representa a diferença entre dois quadros consecutivos, comoapresentado na Figura 2.4. Considere uma imagem I composta por pixels (x, y) em quet representa o tempo, como na Equação 2.1.
dij(x, y) =
{1, se |I(x, y, ti)− I(x, y, tj)| > L
0, caso contrário(2.1)
Na Equação 2.1, L representa um limiar especificado. Nessa abordagem, regiões deintensidade constante não fornecem informações de movimento, apenas as bordas com acomponente normal à direção do movimento são capazes de fornecer essas informações [8].Essa ideia, entretanto, pode ser desenvolvida e levar à noção de fluxo ótico.
5

(a) Imagem no tempo ti. (b) Imagem no tempo tj .
(c) Diferença entre as imagens.
Figura 2.4: Exemplo de uma imagem com a diferença entre dois quadros consecutivos.
Fluxo Ótico
Horn e Shunck [11] definem I(x, y, t) como a função que determina a intensidade deum pixel em um determinado quadro, sua expansão pela série de Taylor pode ser escritacomo
I(x+ dx, y + dy, t+ dt) = I(x, y, t) + Ixdx+ Iydy + Itdt+ ε (2.2)
Na Equação 2.2 os termos Ix, Iy e It representam as derivadas parciais de I em relaçãoa x, y e t, respectivamente. Além disso, ε representa os termos de ordem maior ou iguala dois.
Para o cálculo do fluxo ótico ser possível, deve-se assumir que o brilho de um objetoem movimento deve se manter constante. Isto é, um pixel que se deslocou (dx, dy) notempo dt deve ter a mesma intensidade que tinha anteriormente. Essa propriedade podeser escrita como:
I(x, y, t) = I(x+ dx, y + dy, t+ dt) . (2.3)
Comparando as equações 2.2 e 2.3 e fazendo a diferenciação em relação a t, conclui-seque:
Ixdx
dt+ Iy
dy
dt+ It +O(dt) = 0 . (2.4)
6

Na Equação 2.4, O(dt) vale zero quando dt tende a zero. Portanto, é possível afirmarque:
It = −(Ixdx
dt+ Iy
dy
dt
)= −(Ixx+ Iyy) . (2.5)
A velocidade v de cada pixel pode ser escrita na forma:
v = (vx, vy) =
(dx
dt,dy
dt
)= (x, y) . (2.6)
Fazendo a substituição de v na Equação 2.5, a seguinte equação é obtida:
It = −(Ixvx, Iyvy) . (2.7)
Sabendo que o gradiente de I é dado pela equação:
∇I =
(dx
dt,dy
dt
), (2.8)
pode-se escrever a derivada parcial de I em relação a t como:
It = −∇I · v . (2.9)
Então, a componente da velocidade na direção (Ix, Iy) é igual a
|v| = It√Ix
2 + Iy2. (2.10)
A Equação 2.10 representa uma equação escalar e, portanto, não é suficiente paradeterminar as duas componentes do vetor de velocidade desejadas. Além disso, as bordasparalelas à direção do movimento não fornecem informações relevantes ao cálculo do fluxoótico. Neste caso, ∇I será normal a v, logo It será igual a 0.
Uma solução para este problema, proposta por Bruce D. Lucas e Takeo Kanade em1981 [14], consiste em utilizar uma técnica iterativa de estimativa para computar a velo-cidade.
Fluxo Ótico Lucas-Kanade
Segundo Lucas e Kanade [14], f(x) e g(x) são funções que determinam o valor de umpixel na posição determinada pelo vetor x em duas imagens. A Figura 2.5 exemplificaessas funções.
Deseja-se encontrar o vetor de disparidade h que minimiza a distancia entre f(x+ h)e g(x) em uma determinada região de interesse R. Primeiramente, a ideia é desenvolvidapara casos unidimensionais e, só então, é estendida para um número maior de dimensões.
Em casos unidimensionais, deve-se encontrar a disparidade horizontal h entre as curvasf(x) e g(x), tal que g(x) = f(x + h), isso é exemplificado na Figura 2.6. Para valorespequenos de h, pode-se dizer que
f(x) ≈ f(x+ h)− f(x)
h=g(x)− f(x)
h. (2.11)
7

(a) Imagem dada pela função f(x). (b) Imagem dada pela função g(x).
Figura 2.5: Exemplo do deslocamento de uma imagem.
Figura 2.6: Duas curvas deslocadas de um vetor h.
Portanto, o vetor h pode ser escrito da seguinte forma
h ≈ g(x)− f(x)
f ′(x). (2.12)
O valor de h na Equação 2.12 depende do valor de x. Portanto, todo valor que o vetorx assumir implica em um um valor para o vetor h. Para obter uma estimativa de h énecessário calcular a média aritmética de todos os valores de h que foram calculados. Isto
8

é,
h ≈∑x
g(x)− f(x)
f(x)/∑x
1. (2.13)
Assim, é importante observar que o sucesso do algoritmo proposto depende do valorde h, este deve ser pequeno suficiente para que a aproximação feita na Equação 2.12seja adequada. A aproximação linear de f(x) apresentada na Equação 2.11 apresentamelhores resultados em regiões onde f(x) é quase linear. Em regiões em que o valor de|f ′(x)| é alto, a aproximação não é tão efetiva. Para aprimorar o cálculo da média de h,é possível atribuir pesos diferentes a cada termo calculado. Isto pode feito de forma queas regiões que apresentem melhores resultados tenham maior influência no resultado doque as regiões em que a aproximação não é tão precisa. O coeficiente de ajuste, portanto,pode ser calculado de maneira inversamente proporcional ao valor estimado de |f ′(x)|.Uma estimativa para esse valor é escrito na forma:
f ′(x) ≈ g′(x)− f ′(x)
h. (2.14)
Essa aproximação, descrita na Equação em 2.14, pode ser utilizada para criar ocoeficiente de ajuste, o fator constante 1/h é descartado para tal função. Desta forma, ocoeficiente que será utilizado é descrito como
w(x) =1
|g′(x)− f ′(x)|. (2.15)
Utilizando o coeficiente w(x), é possível utilizar uma média ponderada para aperfeiçoaro cálculo do valor médio de h. A equação que realiza esse cálculo pode ser escrita como
h ≈∑x
w(x)[g(x)− f(x)]
f(x)/∑x
w(x). (2.16)
Com a estimativa do valor de h calculada, a função f(x) pode ser deslocada de hunidades, então o procedimento deve ser repetido. Desta forma, os valores de h convergirãopara o melhor valor de h possível.
A iteração pode ser feita de forma similar ao método de Newton-Raphson [19]. Ovalor de h deve começar com zero, isto é, h0 = 0. Os próximos valores de h são dadospela expressão
hk+1 = hk +∑x
w(x)[g(x)− f(x+ hk)]
f(x+ hk)/∑x
w(x) . (2.17)
Para estender o procedimento para mais de uma dimensão, algumas alterações devemser realizadas. Em duas dimensões, a aproximação linear não é feita da forma que foiapresentada, uma vez que o comportamento da Equação 2.12 é indefinido nos casos emque f ′(x) = 0. Isso pode ser resolvido reescrevendo a aproximação linear da Equação2.11 como
f(x+ h) ≈ f(x) + hf ′(x) . (2.18)
9

O objetivo, então, se torna achar o valor de h que minimiza a diferença entre as curvas,apresentada na equação
E =∑x
[f(x+ h)− g(x)]2 . (2.19)
Para minimizar o erro em relação a h, deve-se igualar a derivada parcial de E emrelação a h a zero:
0 =∂E
∂h(2.20)
≈ ∂
∂h
∑x
[f(x) + hf ′(x)− g(x)]2 (2.21)
=∑x
2f ′(x)[f(x) + hf ′(x)− g(x)] . (2.22)
Logo, da Equação 2.22 é possível concluir que
h ≈
∑x
f ′(x)[g(x)− f(x)]∑x
f ′(x)2. (2.23)
Essa equação corresponde à encontrada na Equação 2.16 para o caso bidimensional.Neste caso, o coeficiente w(x) é igual a f ′(x)2. Portanto, a forma iterativa do procedimentoque corresponde a 2.17 é dada por
h0 = 0 (2.24)
hk+1 = hk +
∑x
w(x)f ′(x+ hk)[g(x)− f(x+ hk)]∑x
w(x)f ′(x+ hk)2. (2.25)
O método apresentado por Lucas e Kanade pode ser estendido para relacionar duasimagens que se relacionam por qualquer transformação linear, tais como rotação e mu-dança de escala, e não apenas por uma simples translação. Uma relação linear pode serescrita como
g(x) = f(Ax+ h), (2.26)
em que A representa uma matriz contendo a transformação linear entre f(x) e g(x). Nestecaso, a minimização que deve ser feita é similar à da equação 2.19. Ajustando o valor dafunção f , a minimização é dada por
E =∑
x[f(xA+ h)− g(x)]2 . (2.27)
10

Agora, o objetivo é encontrar a matriz de ajuste ∆A e ∆h. Para isso, é necessárioutilizar a aproximação:
f(x(A+ ∆A) + (h+ ∆h)) ≈ f(xA+ h) + (x∆A+ ∆h)∂
∂xf(x) . (2.28)
Derivando a Equação 2.28 em relação às variáveis de minimização e igualando o resul-tado a zero, é gerado um sistema de equações lineares.
Para generalizar o algoritmo para duas ou mais dimensões, o erro apresentado naEquação 2.19 deve ser minimizado. A diferença é que, na Equação 2.28, x e h são vetoresn-dimensionais. A aproximação linear deve ser feita de forma análoga à feita na Equação2.18. Portanto, a aproximação é escrita como
f(x+ h) ≈ f(x) + h∂
∂xf(x) . (2.29)
Nesta equação, ∂/∂x representa o gradiente com relação a x, dado pelo vetor
∂
∂x=
[∂
∂x1,∂
∂x2, · · · , ∂
∂xn
]TA minimização de E é feita de maneira análoga à minimização realizada na Equa-
ção 2.22, portanto:
0 =∂E
∂h(2.30)
≈ ∂
∂h
∑x
[f(x) + h
∂f
∂x− g(x)
]2(2.31)
=∑x
2∂f
∂x
[f(x) + h
∂f
∂x− g(x)
]. (2.32)
Dessa forma, o valor de h pode ser calculado por
h =
[∑x
(∂f
∂x
)T
[g(x)− f(x)]
][∑x
(∂f
∂x
)T (∂f
∂x
)]−1. (2.33)
Esta equação é análoga à Equação 2.23, que é utilizada no caso unidimensional. Nocaso n-dimensional também é possível gerar uma função de recorrência para calcular ovalor de h de forma iterativa.
Esta abordagem apresenta restrições quanto ao tamanho do deslocamento, já que aaproximação feita na Equação 2.11 só é válida para valores pequenos de h. Portanto, asolução gerada por Lucas e Kanade [14] se restringe a situações em que o deslocamentoé pequeno. Uma solução para esse problema consiste em utilizar uma estratégia multi-resolução. Dessa forma, o fluxo ótico é calculado um um nível de baixa resolução e ainformação é propagada para os demais níveis. Essa solução é conhecida como FluxoÓtico Lucas-Kanade Piramidal e foi implementada por Jean-Yves Bouguet em 2000 [5].
11

Fluxo Ótico Lucas-Kanade Piramidal
Bouguet [5] define I e J como duas imagens bidimensionais em níveis de cinza, emque I(x, y) representa o valor do pixel na posição x = [x y]T , u = [ux uy]
T um ponto naimagem I e d = [dx dy]
T o vetor de deslocamento de um ponto. O objetivo do algoritmoé encontrar um ponto v = u+d = [ux + dx uy + dy]
T de forma que I(u) e J(v) sejamsimilares.
Para isso, é importante definir a representação piramidal de uma imagem. I0 é oprimeiro nível da imagem, de forma que I0 = I. Os próximos níveis são denotados porIL, com L = 1, 2, · · · , e são calculados de forma recursiva da seguinte maneira:
IL(x, y) =1
4IL−1(2x, 2y)+
1
8(IL−1(2x− 1, 2y) + IL−1(2x+ 1, 2y) + IL−1(2x, 2y − 1) + IL−1(2x, 2y + 1))+
1
16(IL−1(2x− 1, 2y − 1) + IL−1(2x+ 1, 2y + 1)+
IL−1(2x− 1, 2y + 1) + IL−1(2x+ 1, 2y + 1)).
O método do fluxo ótico de Lucas-Kanade piramidal é iterativo. Assim, o fluxo óticoé calculado inicialmente no maior nível da pirâmide (Lm), que corresponde à imagem coma menor resolução, e em seguida nos níveis subsequentes, até chegar no nível 0.
A cada iteração são calculados os vetores uL, gL−1 e dL. O vetor uL é dado pelo valordo ponto u na imagem IL. Ele é obtido pela expressão uL = u/2L. Já gL−1 é o vetor dedeslocamento estimado para a próxima iteração (L− 1). Assim, ele é calculado com baseno vetor estimado na iteração L e no vetor de deslocamento efetivo dessa mesma iteração.É obtido por meio da fórmula gL−1 = 2(gL + dL). Dessa forma, para obter o vetor dedeslocamento efetivo, é necessário encontrar o valor de dL que minimiza a Equação 2.34.
ε(dL) =
uLx+ωx∑
x=uLx−ωx
uLy +ωy∑
y=uLy−ωy
(IL(x, y)− JL(x+ gLx + dLx , y + gLy + dLy ))2 (2.34)
Na Equação 2.34, ωx e ωy são dois números naturais utilizados para construir umavizinhança de tamanho (2ωx + 1)× (2ωy + 1) em que a similaridade entre os dois pontosde I e J é avaliada. O vetor de deslocamento resultante pode, então, ser calculado como:
d =Lm∑L=0
2LdL. (2.35)
Assim, basta fazer a operação v = u+d para encontrar os pontos v na imagem J quese assemelham aos pontos u da imagem I.
12

Capítulo 3
Análise de Trânsito
Segundo Buch, Velastin e Orwell [6], a análise automática das atividades de tráfegourbano tem aumentado nos últimos anos. Isto ocorre, em parte, devido ao maior númerode câmeras e outros sensores, infraestrutura melhorada e a consequente maior acessibi-lidade aos dados. Adicionalmente, o avanço de técnicas analíticas para o processamentode sequências de imagens e outros tipos de dados, alinhado com o aumento no poder deprocessamento das máquinas, tem possibilitado que novas aplicações surjam com grandefrequência [6].
Existe uma variedade de abordagens que podem ser usadas para a análise de trá-fego utilizando-se de sequências de imagens. Serão apresentadas algumas delas, como otrabalho de Guerrero [9] em 2013, o trabalho de Huang [12] em 2004, e o trabalho deKanhere [13] em 2008, todos com suas respectivas propostas.
Esta seção de análise tem por objetivo contextualizar a proposta de trabalho e apre-sentar de forma breve algumas outras técnicas que são utilizadas na resolução de proble-mas semelhantes aos enfrentados na implementação do projeto. Também é importanteregistrar os resultados obtidos pelo trabalho de Guerrero [9], que será revisitado paracomparação na Seção 5.3 deste trabalho.
3.1 Detecção por Modelos Geométricos e Estimação deMovimento via Filtro de Kalman Extendido (EKF)
Uma das propostas mais recentes em relação à área de análise automatizada de trânsitotem incorporado à detecção o desafio de estimar a orientação dos objetos detectados [24].A estimação de orientação dos objetos é feita após o passo da detecção e pode consistir devariadas técnicas e embutir conceitos de implementações de processos de aprendizagemde máquina e inteligência artificial.
A primeira abordagem que será revisada utiliza-se de modelos geométricos para adetecção e uma combinação de técnicas após essa fase, utilizando-se o EKF e a estimaçãode orientação feita através da construção de um modelo de Ackermann [7] para os objetosdetectados para realizar o passo do rastreamento dos objetos [9].
O maior desafio para este tipo de projeto é a incorporação do cálculo e estimação dasorientações dos objetos de maneira precisa. Para um ser humano, é algo intuitivo e relati-vamente simples detectar movimentos e, subsequentemente à essa detecção, realizar uma
13

associação de tendência de orientação e atribuir àquele objeto detectado alguns atributossubjetivos, como velocidade e direção de seu movimento. Na Figura 3.1 mostra-se comoum ser humano é capaz de detectar e estimar os atributos de volume e de orientação deum veículo em um ambiente urbano.
Figura 3.1: Figura para ilustrar o conceito de orientação de um veículo [9].
O ser humano é capaz de produzir através de percepção, intuito, instinto e inferênciaslógicas a noção de que existe um objeto em movimento e inferir em qual direção estemovimento se apresenta. Esta noção é de difícil construção para máquinas [9].
Para o processo de detecção do projeto, utiliza-se de modelos geométricos dos objetos aserem detectados, embutindo neste processo informações de semântica e de agrupamentodos objetos. Para isso existem três classes básicas de modelos, um para veículos médios,um para veículos pesados e um último para veículos leves.
Essa abordagem utiliza-se das técnicas descritas por Sudowe e Leibe [23] para obter dassequências de imagens detectores utilizados na construção do modelo que é posteriormentefornecido ao módulo de rastreamento do projeto. Uma detecção consiste de uma entidadeque possui um timestamp, que é o momento em que foi gerado, que se refere ao índice daimagem na sequência, possui um par de coordenadas xt e yt que definem sua posição emduas dimensões e um atributo θt que define o ângulo de orientação do objeto detectado.
Para o processo de rastreamento é utilizado um vetor de medida calculado para cadaobjeto detectado, que, além das coordenadas xt e yt e do ângulo de orientação θt, temem sua composição o ângulo da direção do veículo φt e os valores de aceleração linear vte angular at, assim como proposto no modelo de Ackermann [7] para carros, apresentadona Figura 3.2.
Figura 3.2: Figura para ilustrar o conceito de modelo de Ackermann para carros [9].
14

Os resultados de Guerrero, 2013 [9] foram gerados a partir de três bases de dados: aM-30 que é um conjunto de imagens sobre uma rodovia, a M-30-HD que é sobre mesmarodovia do M-30, porém com uma câmera de maior qualidade de captura e por últimoo Urban1 que possui imagens de baixa resolução de um ambiente urbano. Os seguintesvalores, que foram obtidos para a detecção de objetos com o projeto citado acima, mostramque a estratégia proposta era viável. Segue na Tabela 3.1 os valores de contagem deveículos. Na Tabela 3.2 tem-se os valores máximos de recall, que é um parâmetro calculadopor meio da análise de dois atributos: verdadeiros positivos e falsos negativos. O valor derecall é calculado como apresentado na Equação 3.1.
recall =V P
V P + FN(3.1)
Na Tabela 3.1 as entradas da linha EKF sem pose representam a quantidade de carroscontados utilizando o Filtro Extendido de Kalman puro. As entradas de EKF com poserepresentam os resultados obtidos pelo Filtro Extendido de Kalman aliado ao cálculo daorientação de veículo proposto por Guerrero em 2013 [9].
Tabela 3.1: Resultados da contagem de veículos obtidos por Guerrero, adaptado de [9].M-30 M-30-hd Urban1
Anotado 256 235 237EKF - sem pose 300 353 877EKF - com pose 290 339 789
Na Tabela 3.2 as entradas da linha de detecção representam os valores de recall obtidospela detecção geométrica. As entradas da linha EKF sem pose representam os valoresobtidos utilizando o Filtro Extendido de Kalman puro. Já as entradas de EKF com poserepresentam os valores obtidos pelo Filtro Extendido de Kalman aliado ao cálculo daorientação de veículo proposto por Guerrero em 2013 [9].
Tabela 3.2: Resultados de recall obtidos por Guerrero, adaptado de [9].M-30 M-30-hd Urban1
Detecção 0,2384 0,4044 0,5132EKF - sem pose 0,2916 0,5074 0,6518EKF - com pose 0,3009 0,5241 0,6616
Pode-se observar que em ambos os casos a adição do processamento e da avaliaçãodos atributos relacionados com a orientação do veículo apresentaram ganhos em relaçãoà aplicação do EKF sozinho.
3.2 Detecção por Background Subtraction, Rastrea-mento por Template Matching e Classificação porForma de Blocos.
Este trabalho consiste em um sistema que propõe resolver todos os passos que existementre a obtenção da sequência de imagens como entrada e a entrega de um catálogo de
15

objetos detectados, rastreados e classificados como saída. O desenvolvimento de sistemasde trânsito inteligente é importante para a boa administração e manutenção de rodovias,projeto de soluções de trânsito e de novas rodovias baseado na análise do mesmo. Oprojeto tem como objetivo prover informações acerca dos seguintes temas [12]:
1. Detecção de fluxo do tráfego.
2. Determinação de velocidade dos veículos.
3. Determinação das tendências de mudanças de faixa.
4. Distribuição das classes de veículos no fluxo de determinada rodovia.
A proposta consiste em um sistema que realiza a detecção de objetos através da téc-nica de Background Subtraction [22], assim obtendo blocos de pixels que são, após umprocessamento de retirada de ruído, atribuição de um identificador e filtragem de tama-nho, passados a um sistema de rastreamento. A extração e o processamento de um objetodetectado podem ser observadas na Figura 3.3.
Figura 3.3: Figura que mostra a sequência de um objeto detectado sendo processado antesde ser passado ao rastreador [12].
O rastreador realiza uma busca pelo bloco previamente detectado na imagem seguintee, a cada iteração, guarda valores para calcular a trajetória do objeto. Os mapas detrajetória são usados para detectar oclusão e para determinar quais as tendências demovimentação entre as faixas da rodovia, como apresentado nas Figuras 3.4 e 3.5.
Figura 3.4: Exemplo de uma situação que precede o cruzamento de trajetórias de veícu-los [12].
Quando as trajetórias de dois objetos se cruzam, existe um tratamento para tal. Essetratamento consiste em um procedimento que procura por um ponto de corte dentro dogrande bloco que agora os dois objetos formam juntos. Baseado nas formas que os doiselementos possuíam antes de se fundirem, é procurado no bloco maior um casamentopara cada um dos blocos fundadores, de maneira a cortar o bloco grande e obter os dois
16

Figura 3.5: Exemplo de uma situação onde existe cruzamento de trajetórias de veícu-los [12].
Figura 3.6: Figura que ilustra o processo de separação de blocos fundidos, em que aregião de corte é a região onde o procedimento de separação de blocos corta o blocomaior, adaptado de [12].
elementos novamente e prosseguir com a análise. Este comportamento é exemplificado naFigura 3.6.
O projeto gerou resultados experimentais, após baterias de testes com sequências deimages que contavam com a presença de elementos de oclusão. A Tabela 3.3 apresenta emsua coluna Tipo as letras A,B, ...G que são subdivisões de um vídeo de 463 segundos quefoi usado como base de dados para geração destes resultados.Os valores entre parêntesesrepresentam o número de veículos que foram afetados de alguma forma por oclusão emcada subdivisão. O valor médio geral de acerto nestas sequências foi de 91,5%.
Tabela 3.3: Resultados obtidos por Huang, adaptado de [12].Tipo Total Percentual de acertoA 206 (11) 98 %B 34 (8) 66 %C 14 71 %D 10 (5) 93 %E 6 (2) 75 %F 9 (2) 91 %G 3 (2) 80 %
17

3.3 Detecção, Rastreamento e Classificação em TempoReal através de Características Estáveis
A abordagem deste trabalho visa lidar com um problema que é inerente à implan-tação dos sistemas de controle e de colhimento de informações de tráfego via análise desequências de imagens, o posicionamento das câmeras e suas variações [13].
É destacado que existem, em algumas situações, problemas gerados pela expectativa,na maioria das implementações existentes, de que a câmera fique em uma posição vertical-mente superior à da rodovia. Os custos de instalação e manutenção deste tipo de aparelhopodem ser elevados se não há postes ou prédios que estejam convenientemente posiciona-dos. O projeto propõe uma implementação que trabalhe com ângulos mais abrangentes epontos de vista onde a captura ocorre mais próxima ao solo. A Figura 3.7 ilustra atravésde um mapa de características as diferenças entre os pontos vista:
Figura 3.7: À esquerda, tem-se um ângulo de captura mais tradicional, com a câmeramais elevada. À direita, tem-se o ângulo a ser atacado, mais baixo e com mais oclusão,adaptado de [13].
O projeto propõe um algoritmo que consiste de três etapas, as quais são calibraçãodo ambiente, detecção e rastreamento dos objetos. A fase de calibração consiste em umasérie de ajustes manuais no sistema para que ele possa identificar as bordas das rodovias,dado que, como proposto, o sistema deve ser robusto com ângulos de captura alternativosaos usuais. A Figura 3.8 ilustra como esse processo é feito:
O sistema faz detecção e o rastreamento dos objetos da imagem utilizando-se do ras-treador de Lucas-Kanade [14] e utiliza o processo de Background Subtraction [22] paraeliminar ruído, pontos que não se movem e sombras. Os pontos que são usados comoentrada para as funções são selecionados através da técnica de Good Features to Track.Ambos os processos são providos por funções da biblioteca OpenCV [2], usadas em suasformas padrão no projeto. A Figura 3.9 ilustra esses processos para um objeto.
Após o estabelecimento e refinamento dos objetos a serem analisados, o projeto propõeuma reconstrução em 3 dimensões dos objetos, usando as características estáveis de cada
18

Figura 3.8: Passos do processo de ajuste e calibração do sistema ao ambiente alvo [13].
Figura 3.9: Respectivamente da esquerda para a direita, os processos de BackgroundSubtraction e de seleção de pontos relevantes a rastrear [13].
um deles. É feito um processo de filtragem de características que gera dois grupos distintosde características, as estáveis e as instáveis. Os atributos do modelo do objeto reconstruídosão utilizados para catalogar os veículos em classes, que são duas: carros e caminhões. AFigura 3.10 mostra um objeto se tornando um elemento no sistema e mostra exemplos dadetecção e classificação dos veículos no sistema em execução:
Figura 3.10: Processo de criação de elemento em ação [13].
Após a separação dos elementos nos dois grupos de veículos, é realizada uma contagempara fins de computar os resultados gerais das classificações realizadas pelo sistema. Aseguir tem-se três frames exemplos para ilustrar como o sistema faz as classificações. Sãoagrupados pontos relevantes e é analisada a silhueta criada por estes grupos a fim declassificar o objeto como carro ou caminhão.:
Os resultados para o projeto são calculados de forma que todos os veículos que foramsegmentados, são avaliados quanto ao rastreamento e a classificação, logo os valores mos-trados para o passo de classificação desconsideram os erros de detecção. Na Tabela 3.4tem-se a coluna Sequência, que enumera os conjuntos de imagens sequenciais que foramutilizados no projeto. Na coluna seguinte, Veículos e (caminhões), há a apresentaçãodos números gerais de veículos rastreados e o número dos que são especificados comocaminhões. Na terceira coluna, Segmentados e (rastreados), tem-se a correspondênciaentre o que foi detectado e rastreado. As colunas de falsos positivos e classificação sãoauto-explicativas.
19

(a) (b) (c)
Figura 3.11: Exemplos de classificação de veículos, onde os números seguidos de "T"representam objetos classificados como caminhões [13].
Tabela 3.4: Resultados obtidos por Kanhere, adaptado de [13].
Sequência Veículos e(caminhões)
Segmentados e(rastreados) Falsos Positivos Classificados
L1 627 (50) 610 (97%) 3 99,2%L2 492 (56) 481 (98%) 18 97,3%L3 325 (38) 298 (92%) 6 97,2%L4 478 (57) 456 (95%) 8 98,5%L5 217 (14) 209 (96%) 7 98,1%L6 102 (20) 97 (95%) 1 98,0%L7 157 (29) 146 (93%) 6 96,8%S1 104 (7) 98 (93%) 5 97,1%S4 43 (3) 39 (91%) 3 97,6%S8 113 (8) 107 (95%) 4 98,2%S9 51 (5) 47 (92%) 6 94,1%
As implementações propostas pelos três trabalhos revisados, Guerrero [9] em 2013,Huang [12] em 2004 e Kanhere [13] em 2008, seguem abordagens distintas para a cons-trução de um sistema que realiza a análise de informações de tráfego de veículos. Com oestudo das principais técnicas de segmentação em imagens e com a revisão das técnicase dos problemas dos trabalhos analisados neste capítulo, foi possível desenvolver a me-todologia utilizada para a construção do sistema proposto por este trabalho. O próximocapítulo apresenta detalhadamente os métodos utilizados pelo algoritmo desenvolvido.
20

Capítulo 4
Metodologia Proposta
O algoritmo proposto nesta seção para segmentar veículos em imagens de rodovias emtempo real é apresentado em forma de fluxograma na Figura 4.1. O algoritmo processaas imagens iterativamente e em sequência. Os dados são processados sequencialmenteentre os módulos, de forma que a saída de cada módulo é utilizada como entrada para opróximo.
4.1 InicializaçãoO sistema construído recebe como entrada, via linha de comando, um diretório con-
tendo uma sequência de imagens do tipo RGB no formato JPG e um arquivo de imagemopcional no formato JPG que será utilizado como uma máscara para as imagens que serãolidas.
As imagens do diretório são indexadas numericamente, o que permite que a leituraseja feita iterativamente. Além de armazenar a imagem assim que ela é lida, imagem queé chamada de imagem atual, também é necessário armazenar a imagem lida na iteraçãoimediatamente anterior, que é chamada de imagem anterior.
4.2 Conversão da Imagem para Níveis de CinzaTanto a imagem atual quanto a imagem anterior precisam ser convertidas em imagens
em escala de cinza para a execução das funções que serão aplicadas posteriormente.Sejam I uma imagem RGB e G uma imagem em níveis de cinza. Assim, I(x, y) e
G(x, y) representam o valor do pixel na posição x = [x y]T da imagem. O valor do pixelem I(x, y) é uma tupla composta por três valores, o valor no canal vermelho, no canalverde e no canal azul da imagem. Esses valores são representados por IR(x, y), IG(x, y) eIB(x, y), respectivamente.
A conversão da imagem para níveis de cinza é realizada para as duas imagens, aimagem atual e a imagem anterior. Para cada valor de x e y da imagem sendo convertida,é aplicada a Equação 4.1 para obter a imagem em níveis de cinza correspondente [1].
G(x, y) = 0, 299 · IR(x, y) + 0, 587 · IG(x, y) + 0, 114 · IB(x, y) (4.1)
21

Figura 4.1: Fluxograma do algoritmo proposto.
4.3 Escolha de Pontos RelevantesNo método escolhido para a solução da proposta apresentada, é necessário procurar os
pontos de uma imagem na seguinte. Apesar de ser possível utilizar todos os pixels de umaimagem para realizar essa busca, isso não é necessário. Esse fato ocorre porque a maioria
22

dos objetos de uma imagem não se move. Portanto, é possível minimizar os recursoscomputacionais gastos ao selecionar apenas alguns pixels da imagem para rastrear.
Para implementar essa escolha de pontos relevantes, foi utilizada a abordagem deGood Features to Track, proposta por Jianbo Shi e Carlo Tomasi em 1994 [20]. A pro-posta apresentada por eles consiste em criar uma medida para avaliar a qualidade doscantos de uma imagem. O valor da qualidade é calculado para cada pixel da imagem eé analisado posteriormente. Os pixels que não atingem um valor mínimo de qualidadesão descartados. Os pixels restantes são ordenados de acordo com o valor da qualidadeem ordem decrescente. Em seguida, para cada pixel da lista, seus pontos vizinhos sãoremovidos da lista, de forma que reste apenas o ponto com maior qualidade na vizinhança.
O resultado desta etapa é um vetor de pontos que contém os pixels relevantes paraa próxima etapa do algoritmo. Os pontos desse vetor são, em sua maioria, pixels quecompõem bordas de veículos que se movimentam na imagem.
4.4 Fluxo ÓticoO problema a ser resolvido tem como forte característica o movimento dos objetos que
se deseja detectar. É possível afirmar que todo movimento que se detecta nas imagensé oriundo de veículos. Portanto, é possível utilizar um método de segmentação de movi-mento para obter pontos da imagem que correspondem a veículos. O método utilizadopara isso foi o fluxo ótico Lucas-Kanade piramidal.
A função utilizada para calcular o fluxo ótico recebe como entrada o vetor de pontoscalculado na etapa anterior e as imagens atual e anterior em níveis de cinza. Então, ofluxo ótico é calculado de forma a procurar os pontos do vetor fornecido, que pertencemà imagem anterior, na imagem atual.
Essa função tem como retorno dois vetores, um contendo os pontos da imagem anteriore outro contendo os pontos correspondentes na imagem atual. Dessa forma, é possívelobter os vetores de deslocamento para todos os pontos considerados como relevantes.
4.5 Cálculo de Atributos do Vetor de DeslocamentoNesta etapa, os dois vetores resultantes da etapa anterior são utilizados para extrair
alguns atributos do vetor de deslocamento que serão utilizados nas próximas etapas. Osatributos calculados foram o módulo do vetor de deslocamento e seu ângulo.
O módulo do vetor foi calculado por meio da distância euclidiana entre os pontosanteriores e atuais. Isto é, para todo ui = [ux uy]
T pertencente ao vetor de pontosanteriores e vi = [vx vy]
T pertencente ao vetor de pontos atuais, o módulo do vetor dedeslocamento di é dado por:
|di| =√
(ux − vx)2 + (uy − vy)2 . (4.2)
23

Já o ângulo de cada vetor de deslocamento di é calculado como definido pela Equação4.3.
θi =
arctan
(vx−ux
vy−uy
)se vy 6= uy
90o se vy = uy e vx > ux−90o caso contrário
(4.3)
O valor do ângulo é calculado de forma que −90o ≤ θi ≤ 90o. É importante observarque o ângulo calculado determina a direção do vetor de deslocamento e não é suficientepara determinar o sentido do vetor. Se necessário, o sentido do vetor pode ser obtido pormeio da análise dos sinais obtidos na subtração de vx por ux e na subtração de vy por uy.
4.6 Exclusão de Pontos EstáticosA maioria dos pontos contidos nos vetor de pontos anteriores e no de pontos atuais são
pontos que pertencem à borda de um veículo. No entanto, existem alguns pontos nessesvetores que pertencem a outros objetos que não se movem. Então, torna-se necessáriodesconsiderar pontos com esse comportamento.
Foram considerados pontos estáticos aqueles cujo módulo do vetor de deslocamentoteve valor inferior a um pixel. Esses pontos devem ser removidos dos vetores que armaze-nam os pontos. Dessa forma, é possível evitar que os pontos estáticos sejam consideradosparte de um veículo ao executar a etapa de agrupamento de pontos.
4.7 Avaliação da Similaridade dos PontosCom os vetores de deslocamento já calculados, é necessário separá-los em diferentes
grupos de forma que cada grupo contenha os vetores pertencentes a um veículo. Nestaetapa, os vetores de deslocamento são agrupados de acordo com sua similaridade. Por-tanto, cada grupo criado deve conter elementos similares entre si e, além disso, elementosque são diferentes daqueles que pertencem a outros grupos.
Três critérios foram utilizados para avaliar a similaridade de pontos, os quais foram avizinhança, a diferença entre os módulos dos vetores de deslocamento e a diferença entreos ângulos desses vetores. O processo de agrupamento é feito a cada quadro, e não há anoção de rastreamento além de duas imagens consecutivas.
A vizinhança de um ponto vi = [vx vy]T , que pertence ao vetor de pontos atuais, é
definida por um quadrado com centro em vi e lado de tamanho tamV izinhanca. Portanto,pode ser criada uma função V (vi,vj) que define se dois pontos são vizinhos, como vistona definição 4.4. Se a função tem resultado um, os pontos são considerados vizinhos.
V (vi,vj) =
{1 se |vjx − vix| ≤ tamV izinhanca/2 e |vjy − viy| ≤ tamV izinhanca/20 caso contrário
(4.4)A similaridade entre os módulos dos dois vetores de deslocamento pode ser calculada
de maneira análoga. É possível criar uma função M(di,dj) para avaliar tal similaridade.Para criar essa função, é necessário definir um valor máximo para a diferença entre os
24

módulos, esse valor será chamado de modMaximo. A função definida na Equação 4.5tem como resultado 1 se os vetores de deslocamento são similares em relação aos seusmódulos e 0 se não são.
M(di,dj) =
{1 se ||dj| − |di|| ≤ modMaximo0 caso contrário (4.5)
De maneira análoga, o cálculo da similaridade dos ângulos de dois vetores de deslo-camento foi feito por meio da criação de uma função A(di,dj). O valor máximo para adiferença do ângulo de forma que dois vetores sejam considerados similares com respeitoao ângulo foi chamado de angMaximo. A função definida na Equação 4.6 tem comoresultado 1 se os vetores são similares em relação ao ângulo e 0 se eles não são.
A(di,dj) =
{1 se |θj − θi| ≤ angMaximo0 caso contrário (4.6)
Então, com o auxílio das funções apresentadas nas Equações 4.4, 4.5 e 4.6, define-seque dois vetores de deslocamento são similares se eles são vizinhos e se seus módulos eângulos são similares. Isso pode ser observado também na Equação 4.7, que tem resultado1 quando os vetores são similares e 0 quando não são.
S(vi,vj,di,dj) = V (vi,vj) ·M(di,dj) · A(di,dj) (4.7)
4.8 Agrupamento de Vetores SimilaresNesse cenário, com os critérios de similaridade definidos, é possível agrupar os vetores
de deslocamento para obter quais pontos correspondem a quais veículos. Esse agrupa-mento é realizado iterativamente. No início da execução, não existe grupo algum, portantoos pontos não pertencem a um grupo.
Nesta etapa, os valores máximos para os parâmetros tamV izinhanca, modMaximo eangMaximo não foram utilizados com o mesmo valor dentro de toda a imagem, já que oponto de vista da câmera nas imagens influencia o tamanho aparente dos veículos quandomedido em pixels. Veículos mais próximos da câmera apresentam tamanho maior que osveículos mais distantes.
Para resolver esse problema, a imagem foi dividida em quatro regiões, em que cadaregião tem a mesma largura da imagem original e um quarto de sua altura. Na região emque os veículos estão mais próximos da câmera, o valores dos parâmetros tamV izinhanca,modMaximo e angMaximo não foram alterados. Em cada região seguinte, os valoresdesses parâmetros foram decrescidos em dez por cento. Essa razão de decrescimento foideterminada empiricamente no decorrer do desenvolvimento do projeto de acordo com aanálise da redução do tamanho aparente dos veículos da imagem.
Para cada ponto vi pertencente ao vetor de pontos atuais, é verificado se ele é similara todos os outros pontos vj do vetor por meio do método descrito na etapa anterior. Istoé, o algoritmo verifica se o valor de S(vi,vj,di,dj) é igual a um. Caso seja, existem trêssituações possíveis que podem ocorrer. Caso a função tenha como resultado valor zero,nada é feito.
25

A primeira situação acontece quando o ponto vj já pertence a um grupo. Neste caso,o ponto vi deve ser adicionado a esse grupo. Na segunda situação, o ponto vi é o quepertence a um grupo. Analogamente, o ponto vj deve ser adicionado a esse grupo. Naterceira situação, tanto vi quanto vj não pertencem a um grupo. Neste caso, um novogrupo deve ser criado e os pontos vi e vj, adicionados a ele.
Para cada grupo obtido, então, são calculados o centro e o raio médios do grupo com oobjetivo de determinar uma área circular que contém o veículo a que o grupo corresponde.O centro médio de cada grupo c = [cx cy]
T é calculado como a média ponderada dos valoresdas coordenadas x e y separadamente de cada ponto vi = [vix viy]
T que pertence ao grupo.Seja n o número de pontos que pertence a um grupo, o centro desse grupo pode ser obtidopor meio da Equação 4.8.
cx = 1n
n−1∑i=0
vix
cy = 1n
n−1∑i=0
viy
(4.8)
Por outro lado, o raio r do grupo é calculado como a média ponderada das distânciasde cada ponto vi ao centro do grupo. A Equação 4.9 apresenta como esse raio é calculado.
r =1
n
n−1∑i=0
√(vix − cx)2 + (viy − cy)2 (4.9)
Ao final da execução, a função que agrupa os vetores retorna um vetor contendo todosos grupos criados, em que cada grupo contém os pontos atuais que pertencem ao grupo eos pontos anteriores correspondentes.
4.9 Remoção de Pontos DispersosCom os grupos já determinados e seu centro e seu raio já calculados, é possível de-
terminar uma área aproximada para um veículo. No entanto, podem existir ainda algunspontos que, de fato, não pertencem ao veículo, porém foram selecionados pelo algoritmode agrupamento. Isto é observado quando um ponto do grupo está muito mais distantedo centro que todos os outros. Esse tipo de ponto foi chamado de ponto disperso. Paramelhorar a precisão da área de um veículo, os pontos dispersos de um grupo foram remo-vidos.
A remoção pode ser feita de maneira simples, utilizando apenas o valor da distânciaEuclidiana entre e o centro e cada ponto vi pertencente ao grupo. Para cada ponto deum grupo, a distância é calculada. Se o valor da distância for superior a 150% do valordo raio, o ponto é removido do grupo. Esse valor foi determinado empiricamente ao longodo desenvolvimento do projeto com a observação do padrão de distribuição dos pontos deum veículo em relação ao seu centro.
É importante observar que os valores do raio e do centro não são recalculados a cadaexclusão de ponto, apenas ao final de todas as remoções de um mesmo grupo. O processoé repetido para cada grupo existente no vetor de grupos.
26

Capítulo 5
Resultados
O programa desenvolvido com base no algoritmo representado pelo fluxograma da Fi-gura 4.1, como observado anteriormente, tem como resultado um vetor contendo gruposde vetores de deslocamento correspondentes a um veículo. Para cada iteração do algo-ritmo, o número de grupos foi salvo em um arquivo texto de forma que cada linha doarquivo tenha o número de grupos de uma imagem.
O programa também apresenta como saída duas janelas, uma que os vetores de deslo-camento aplicados na imagem e outra que desenha os grupos obtidos em cada imagem emfunção do seu centro e raio. Exemplos dessa saída podem ser vistos nas Figuras 5.1 e 5.2.As imagens de saída são utilizadas apenas para ilustrar o funcionamento do algoritmo emcada imagem, os dados gerados são salvos para serem analisados posteriormente.
(a) Imagem do conjunto de dadosM30 com os vetores de deslocamentodesenhados em verde.
(b) Imagem do conjunto de dadosM30 com o desenho dos grupos emamarelo.
Figura 5.1: Exemplo de imagens de saída do conjunto M30.
O número de grupos em cada imagem foi comparado com o número de veículos realde cada imagem, fornecido junto nos arquivos da base de dados. Os arquivos contendo asinformações relativas aos veículos em cada imagem foram transformados em um arquivotexto no mesmo formato do arquivo resultante do programa criado. Isso foi feito com oobjetivo de criar uma forma de avaliação para os resultados obtidos.
Um novo programa foi, então, criado para comparar os resultados obtidos com as infor-mações reais dos veículos. Dessa forma, foi possível calcular o número de falsos positivos,falsos negativos, verdadeiros positivos e verdadeiros negativos para cada imagem.
27

(a) Imagem do conjunto de dadosM30-HD com os vetores de desloca-mento desenhados em verde.
(b) Imagem do conjunto de dadosM30-HD com o desenho dos gruposem amarelo.
Figura 5.2: Exemplo de imagens de saída do conjunto M30-HD.
O número total de falsos positivos, falsos negativos, verdadeiros positivos e verdadeirosnegativos de uma execução do programa foram utilizados para calcular os valores deprecision e recall. Estes valores são utilizados para calcular o valor do F-measure, que foia medida utilizada para avaliar o método proposto e implementado.
É importante observar que, até o momento, não foram definidos valores para o tamanhoda vizinhança e a diferença máxima em módulo e ângulo que dois vetores podem ter eainda serem considerados iguais. Esses valores são utilizados no cálculo da similaridadede dois vetores, como apresentado nas Equações 4.4, 4.5 e 4.6.
Os valores dos parâmetros de similaridade não são os mesmos para todas as imagens.Por isso, foi decidido deixar esses parâmetros variáveis. Para determinar os melhores valo-res para eles, foi criado um script que executa o programa diversas vezes com combinaçõesdiferentes desses valores.
5.1 Base de DadosA base de dados utilizada neste trabalho é denominada GRAM Road-Traffic Moni-
toring (GRAM-RTM), ela foi criada para ser utilizada como teste em programas querealizam a detecção de múltiplos veículos em tempo real [9]. Ela é composta por trêsconjuntos de imagens, um chamado M30, um chamado M30-HD e o terceiro chamadoUrban1. Este não se encaixa no escopo do projeto, portanto não foi utilizado.
O conjunto de imagens M30 é composto por 7520 imagens, que foram gravadas emum dia ensolarado com uma câmera Nikon Coolpix L20. As imagens têm resolução de640× 480 e foram obtidas a uma taxa de 30 imagens por segundo.
O conjunto de imagens M30-HD é composto por 9390 imagens, estas gravadas em umdia nublado com uma câmera Nikon DX3100. As imagens foram obtidas a uma taxa de30 imagens por segundo e possuem resolução de 1280× 720.
Todos os veículos da base de dados foram anotados manualmente, e as anotaçõesfornecidas em um arquivo XML. A Figura 5.3 apresenta exemplos de imagens dos doisconjuntos de imagens. A Figura 5.4 mostra a área das imagens que foi considerada válida.Os veículos das áreas em vermelho não foram anotados, portanto qualquer detecção feitanessas áreas deve ser desconsiderada.
28

(a) Imagem do conjunto de dadosM30.
(b) Imagem do conjunto de dadosM30-HD.
Figura 5.3: Exemplo de imagens dos dois conjuntos de dados.
(a) Imagem do conjunto de dadosM30.
(b) Imagem do conjunto de dadosM30-HD.
Figura 5.4: Exemplo da área válida nas imagens dos dois conjuntos de dados. Os veículosdas áreas em vermelho devem ser desconsiderados na detecção.
5.2 F-measureF-measure é uma medida utilizada para avaliar o desempenho da classificação de
amostras [21]. O cálculo do F-measure é dado pela média harmônica das medidas deprecision e recall, como apresentado na Equação 5.1. O valor resultante desse cálculoé um número entre zero e um. Quanto mais próximo de um for o valor de F-measure,melhor é considerado o método de classificação. Assim, quanto mais próximo de zero for,pior ele é considerado.
F = 2 · precision · recallprecision+ recall
(5.1)
Os valores de precision e recall são calculados com base no número de falsos negativos,falsos positivos e verdadeiros positivos. No contexto da segmentação de veículos, um falsonegativo ocorre quando o algoritmo não indica a presença de um veículo que está naimagem. O falso positivo ocorre quando o algoritmo detecta a presença de um veículoem uma posição quando, na verdade, não existe veículo no local indicado. O verdadeiropositivo ocorre quando há detecção correta de um veículo. Já o verdadeiro negativo ocorrequando não há detecção de veículos em locais que não existem veículos na imagem.
O valor de precision é calculado com base no número total de verdadeiros positivos efalsos positivos de acordo com a Equação 5.2. Seu valor indica a taxa de amostras obtidas
29

que são relevantes.
precision =V P
V P + FP(5.2)
O valor de recall é calculado com base no número total de verdadeiros positivos e defalsos negativos como indicado na expressão 5.3. O valor obtido representa a taxa dasamostras relevantes que são obtidas.
recall =V P
V P + FN(5.3)
5.3 DiscussãoTodos os parâmetros receberam cinco valores diferentes para a realização de testes.
Assim, todo parâmetro tem um valor inicial e um valor de incremento que é utilizadoquatro vezes. Os valores iniciais para os parâmetros foram escolhidos empiricamente aolongo do desenvolvimento do projeto. Os valores dos incrementos foram escolhidos deforma que os resultados nos valores de F-measure tivessem diferença relevante a cadamudança.
Para o primeiro conjunto de imagens, chamado de M30 [9], o valor de tamV izinhanca éinicialmente 80. Após isso, ele é incrementado em vinte unidades. O valor demodMaximoé iniciado com 8 e incrementado em duas unidades. Já o valor de angMaximo é iniciadocom 3 e incrementado de uma unidade.
Os parâmetros do segundo conjunto de imagens, que têm altura 50% maior que asimagens do primeiro conjunto, foram escolhidos de forma a respeitar essa proporção.
Os resultados obtidos para o primeiro conjunto de imagens podem ser vistos nas Ta-belas 5.2 a 5.6. Já os do segundo conjunto, nas Tabelas 5.8 a 5.12. Os maiores valores deF-measure foram destacados.
A adição de uma métrica para avaliar o desempenho da segmentação foi fundamentalpara o desenvolvimento do sistema. Com a utilização do valor de F-measure, foi possíveldeterminar quais técnicas implementadas apresentavam melhorias para o sistema e quaisnão.
Com a realização dos vários testes para os diferentes valores dos parâmetros utilizados,tamV izinhanca, modMaximo e angMaximo, foi possível determinar a melhor configura-ção do sistema para cada tipo de imagem. Isso é fundamental para melhorar os resultadosobtidos a partir do programa.
Analisando os resultados obtidos, apresentados nas Tabelas 5.1 a 5.12, é possível ob-servar que os melhores valores de F-measure ocorrem quando os valores de precision erecall são mais parecidos. Quando um desses valores é bem alto, porém o outro não étanto, o valor do F-measure não é muito alto. Esse comportamento torna o F-measureuma medida apropriada para avaliar a segmentação de veículos.
Os resultados dos testes realizados no primeiro conjunto de imagens são apresentadosnas Tabelas 5.2 a 5.6. A Tabela 5.1 apresenta os maiores valores de F-measure obtidosem cada conjunto de testes realizados.
30

Tabela 5.1: Melhores resultados obtidos para o conjunto de imagens M30.tamV izinhanca modMaximo angMaximo F-measure80 16 6 0,79578100 16 6 0,80728120 16 6 0.81040140 16 4 0,81326160 16 4 0,81614
A Tabela 5.2 apresenta os resultados da execução para os valores possíveis dos parâ-metros modMaximo e angMaximo quando tamV izinhanca é igual a 80. O melhor valorde F-measure observado foi 0,79578.
Tabela 5.2: Resultados obtidos no dataset M30 para tamV izinhanca igual a 80.modMaximo angMaximo Precision Recall F-measure
8
3 0.66511 0.88806 0.760594 0.72906 0.85130 0.785455 0.76713 0.81843 0.791956 0.77748 0.81045 0.793627 0.79924 0.78790 0.79353
10
3 0.66563 0.88818 0.760974 0.72984 0.85132 0.785915 0.76825 0.81846 0.792566 0.77864 0.81037 0.794197 0.80078 0.78765 0.79416
12
3 0.66641 0.88818 0.761484 0.73061 0.85116 0.786295 0.76932 0.81838 0.793096 0.77987 0.81026 0.794787 0.80199 0.78737 0.79461
14
3 0.66743 0.88815 0.762134 0.73205 0.85107 0.787095 0.77092 0.81815 0.793846 0.78163 0.80998 0.795557 0.80397 0.78703 0.79541
16
3 0.66790 0.88821 0.762464 0.73267 0.85107 0.787455 0.77138 0.81809 0.794056 0.78218 0.80986 0.795787 0.80458 0.78686 0.79562
A Tabela 5.3 contém os resultados para os valores possíveis demodMaximo e angMaximoquando tamV izinhanca é igual a 100. Neste caso, o melhor valor de F-measure observadofoi 0,80728.
31

Tabela 5.3: Resultados obtidos no dataset M30 para tamV izinhanca igual a 100.modMaximo angMaximo Precision Recall F-measure
8
3 0.69630 0.88082 0.777774 0.76573 0.83694 0.799755 0.80911 0.79745 0.803246 0.82304 0.78765 0.804957 0.84696 0.75908 0.80062
10
3 0.69718 0.88085 0.778324 0.76696 0.83663 0.800285 0.81091 0.79694 0.803866 0.82523 0.78675 0.805537 0.84962 0.75793 0.80116
12
3 0.69807 0.88087 0.778894 0.76832 0.83649 0.800965 0.81286 0.79683 0.804776 0.82717 0.78644 0.806297 0.85190 0.75748 0.80192
14
3 0.69920 0.88079 0.779564 0.76987 0.83624 0.801695 0.81460 0.79627 0.805336 0.82903 0.78590 0.806897 0.85373 0.75680 0.80235
16
3 0.69975 0.88076 0.779894 0.77061 0.83624 0.802095 0.81541 0.79621 0.805706 0.82995 0.78582 0.807287 0.85465 0.75664 0.80266
32
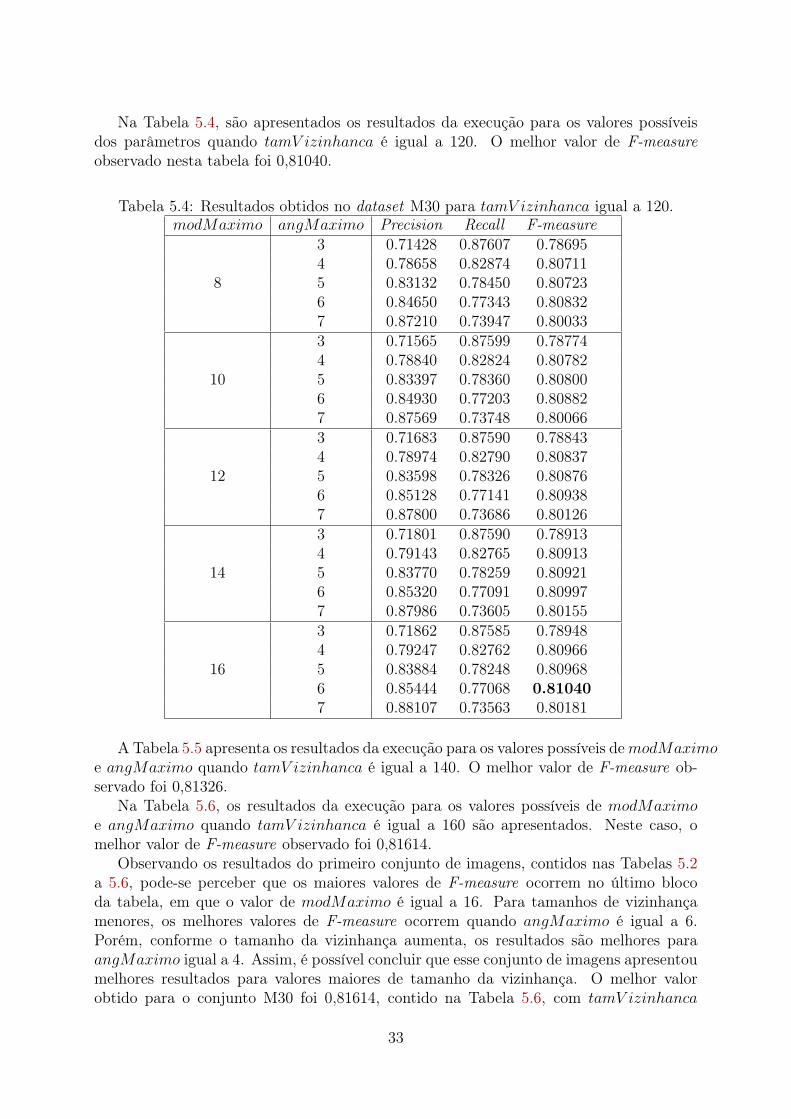
Na Tabela 5.4, são apresentados os resultados da execução para os valores possíveisdos parâmetros quando tamV izinhanca é igual a 120. O melhor valor de F-measureobservado nesta tabela foi 0,81040.
Tabela 5.4: Resultados obtidos no dataset M30 para tamV izinhanca igual a 120.modMaximo angMaximo Precision Recall F-measure
8
3 0.71428 0.87607 0.786954 0.78658 0.82874 0.807115 0.83132 0.78450 0.807236 0.84650 0.77343 0.808327 0.87210 0.73947 0.80033
10
3 0.71565 0.87599 0.787744 0.78840 0.82824 0.807825 0.83397 0.78360 0.808006 0.84930 0.77203 0.808827 0.87569 0.73748 0.80066
12
3 0.71683 0.87590 0.788434 0.78974 0.82790 0.808375 0.83598 0.78326 0.808766 0.85128 0.77141 0.809387 0.87800 0.73686 0.80126
14
3 0.71801 0.87590 0.789134 0.79143 0.82765 0.809135 0.83770 0.78259 0.809216 0.85320 0.77091 0.809977 0.87986 0.73605 0.80155
16
3 0.71862 0.87585 0.789484 0.79247 0.82762 0.809665 0.83884 0.78248 0.809686 0.85444 0.77068 0.810407 0.88107 0.73563 0.80181
A Tabela 5.5 apresenta os resultados da execução para os valores possíveis demodMaximoe angMaximo quando tamV izinhanca é igual a 140. O melhor valor de F-measure ob-servado foi 0,81326.
Na Tabela 5.6, os resultados da execução para os valores possíveis de modMaximoe angMaximo quando tamV izinhanca é igual a 160 são apresentados. Neste caso, omelhor valor de F-measure observado foi 0,81614.
Observando os resultados do primeiro conjunto de imagens, contidos nas Tabelas 5.2a 5.6, pode-se perceber que os maiores valores de F-measure ocorrem no último blocoda tabela, em que o valor de modMaximo é igual a 16. Para tamanhos de vizinhançamenores, os melhores valores de F-measure ocorrem quando angMaximo é igual a 6.Porém, conforme o tamanho da vizinhança aumenta, os resultados são melhores paraangMaximo igual a 4. Assim, é possível concluir que esse conjunto de imagens apresentoumelhores resultados para valores maiores de tamanho da vizinhança. O melhor valorobtido para o conjunto M30 foi 0,81614, contido na Tabela 5.6, com tamV izinhanca
33
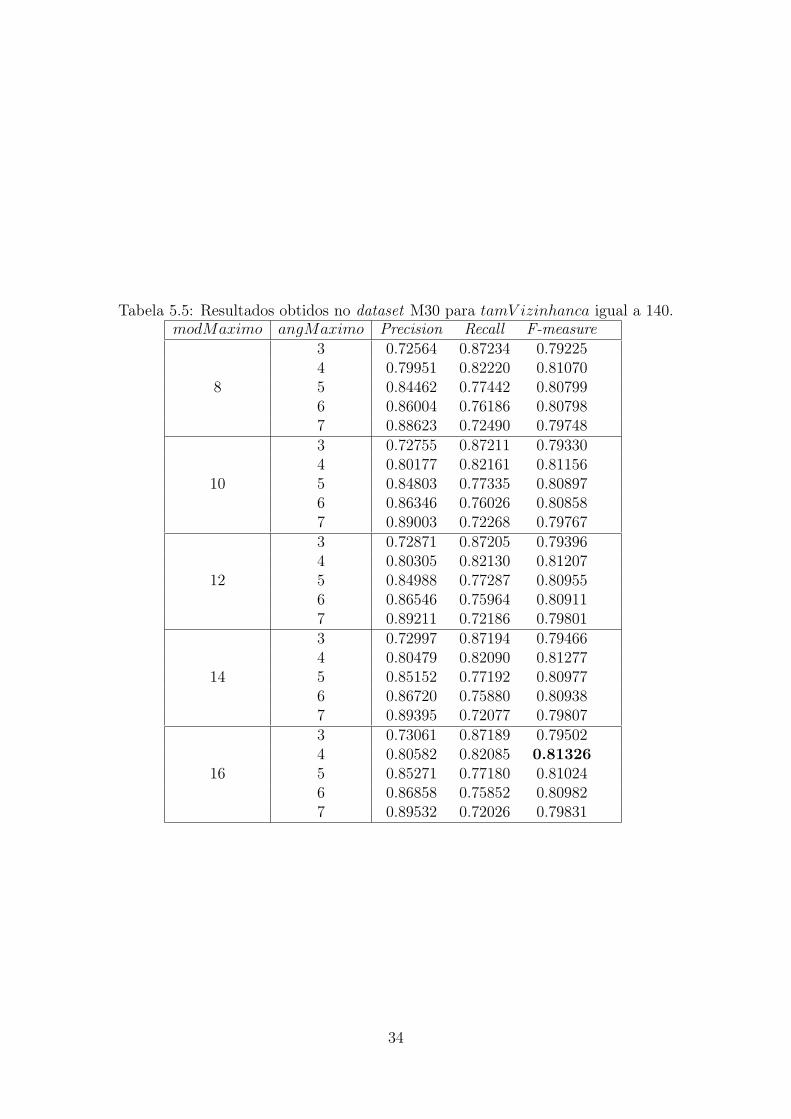
Tabela 5.5: Resultados obtidos no dataset M30 para tamV izinhanca igual a 140.modMaximo angMaximo Precision Recall F-measure
8
3 0.72564 0.87234 0.792254 0.79951 0.82220 0.810705 0.84462 0.77442 0.807996 0.86004 0.76186 0.807987 0.88623 0.72490 0.79748
10
3 0.72755 0.87211 0.793304 0.80177 0.82161 0.811565 0.84803 0.77335 0.808976 0.86346 0.76026 0.808587 0.89003 0.72268 0.79767
12
3 0.72871 0.87205 0.793964 0.80305 0.82130 0.812075 0.84988 0.77287 0.809556 0.86546 0.75964 0.809117 0.89211 0.72186 0.79801
14
3 0.72997 0.87194 0.794664 0.80479 0.82090 0.812775 0.85152 0.77192 0.809776 0.86720 0.75880 0.809387 0.89395 0.72077 0.79807
16
3 0.73061 0.87189 0.795024 0.80582 0.82085 0.813265 0.85271 0.77180 0.810246 0.86858 0.75852 0.809827 0.89532 0.72026 0.79831
34
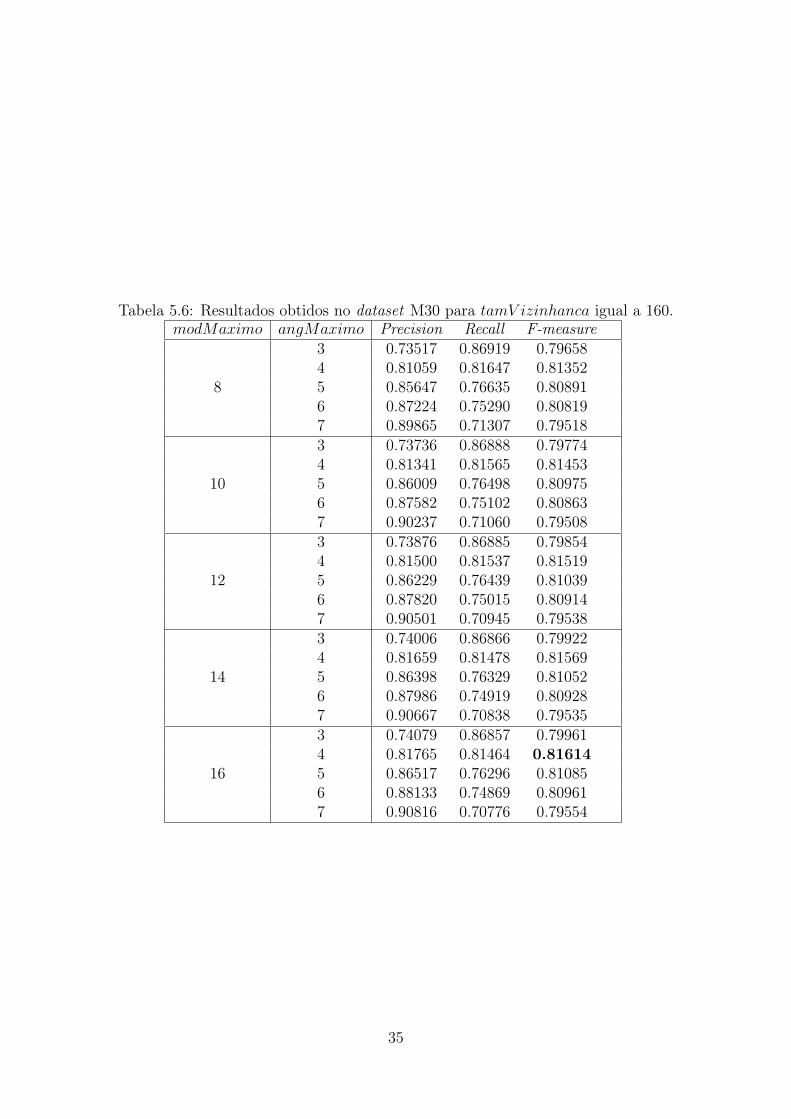
Tabela 5.6: Resultados obtidos no dataset M30 para tamV izinhanca igual a 160.modMaximo angMaximo Precision Recall F-measure
8
3 0.73517 0.86919 0.796584 0.81059 0.81647 0.813525 0.85647 0.76635 0.808916 0.87224 0.75290 0.808197 0.89865 0.71307 0.79518
10
3 0.73736 0.86888 0.797744 0.81341 0.81565 0.814535 0.86009 0.76498 0.809756 0.87582 0.75102 0.808637 0.90237 0.71060 0.79508
12
3 0.73876 0.86885 0.798544 0.81500 0.81537 0.815195 0.86229 0.76439 0.810396 0.87820 0.75015 0.809147 0.90501 0.70945 0.79538
14
3 0.74006 0.86866 0.799224 0.81659 0.81478 0.815695 0.86398 0.76329 0.810526 0.87986 0.74919 0.809287 0.90667 0.70838 0.79535
16
3 0.74079 0.86857 0.799614 0.81765 0.81464 0.816145 0.86517 0.76296 0.810856 0.88133 0.74869 0.809617 0.90816 0.70776 0.79554
35
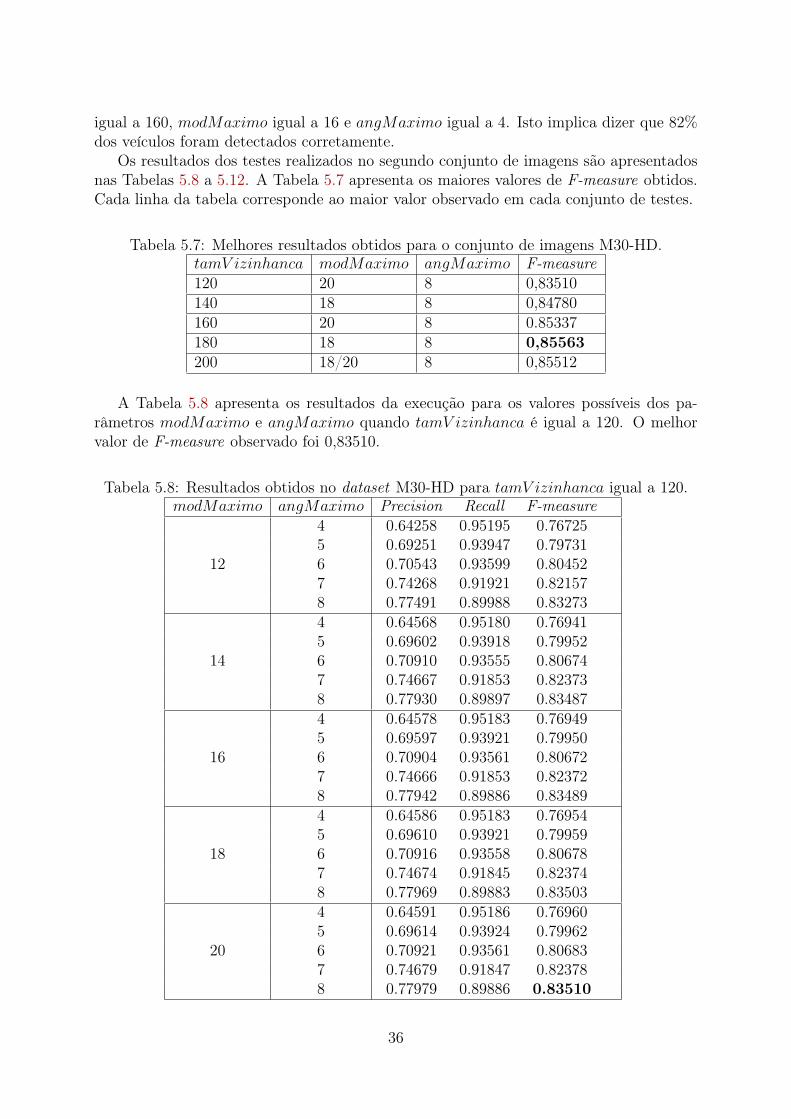
igual a 160, modMaximo igual a 16 e angMaximo igual a 4. Isto implica dizer que 82%dos veículos foram detectados corretamente.
Os resultados dos testes realizados no segundo conjunto de imagens são apresentadosnas Tabelas 5.8 a 5.12. A Tabela 5.7 apresenta os maiores valores de F-measure obtidos.Cada linha da tabela corresponde ao maior valor observado em cada conjunto de testes.
Tabela 5.7: Melhores resultados obtidos para o conjunto de imagens M30-HD.tamV izinhanca modMaximo angMaximo F-measure120 20 8 0,83510140 18 8 0,84780160 20 8 0.85337180 18 8 0,85563200 18/20 8 0,85512
A Tabela 5.8 apresenta os resultados da execução para os valores possíveis dos pa-râmetros modMaximo e angMaximo quando tamV izinhanca é igual a 120. O melhorvalor de F-measure observado foi 0,83510.
Tabela 5.8: Resultados obtidos no dataset M30-HD para tamV izinhanca igual a 120.modMaximo angMaximo Precision Recall F-measure
12
4 0.64258 0.95195 0.767255 0.69251 0.93947 0.797316 0.70543 0.93599 0.804527 0.74268 0.91921 0.821578 0.77491 0.89988 0.83273
14
4 0.64568 0.95180 0.769415 0.69602 0.93918 0.799526 0.70910 0.93555 0.806747 0.74667 0.91853 0.823738 0.77930 0.89897 0.83487
16
4 0.64578 0.95183 0.769495 0.69597 0.93921 0.799506 0.70904 0.93561 0.806727 0.74666 0.91853 0.823728 0.77942 0.89886 0.83489
18
4 0.64586 0.95183 0.769545 0.69610 0.93921 0.799596 0.70916 0.93558 0.806787 0.74674 0.91845 0.823748 0.77969 0.89883 0.83503
20
4 0.64591 0.95186 0.769605 0.69614 0.93924 0.799626 0.70921 0.93561 0.806837 0.74679 0.91847 0.823788 0.77979 0.89886 0.83510
36

A Tabela 5.9 contém os resultados para os valores possíveis demodMaximo e angMaximoquando tamV izinhanca é igual a 140. Neste caso, o melhor valor de F-measure observadofoi 0,84780.
Tabela 5.9: Resultados obtidos no dataset M30-HD para tamV izinhanca igual a 140.modMaximo angMaximo Precision Recall F-measure
12
4 0.66205 0.94946 0.780125 0.71588 0.93350 0.810336 0.73223 0.92887 0.818917 0.77416 0.90726 0.835448 0.81113 0.88275 0.84543
14
4 0.66543 0.94922 0.782395 0.71982 0.93303 0.812676 0.73657 0.92817 0.821347 0.77869 0.90600 0.837548 0.81624 0.88085 0.84731
16
4 0.66559 0.94925 0.782505 0.71994 0.93306 0.812766 0.73671 0.92820 0.821447 0.77899 0.90591 0.837678 0.81683 0.88070 0.84757
18
4 0.66561 0.94928 0.782535 0.72006 0.93309 0.812856 0.73683 0.92820 0.821527 0.77921 0.90594 0.837818 0.81722 0.88076 0.84780
20
4 0.66556 0.94928 0.782505 0.71999 0.93309 0.812816 0.73675 0.92823 0.821487 0.77907 0.90594 0.837738 0.81714 0.88082 0.84779
Na Tabela 5.10, são apresentados os resultados da execução para os valores possíveisdos parâmetros quando tamV izinhanca é igual a 160. O melhor valor de F-measureobservado nesta tabela foi 0,85337.
A Tabela 5.11 apresenta os resultados da execução para os valores possíveis demodMaximoe angMaximo quando tamV izinhanca é igual a 180. O melhor valor de F-measure ob-servado foi 0,85563.
Na Tabela 5.12, os resultados da execução para os valores possíveis de modMaximoe angMaximo quando tamV izinhanca é igual a 200 são apresentados. Neste caso, omelhor valor de F-measure observado foi 0,85512.
É possível observar nos resultados do conjunto M30-HD que os valores de recall re-sultantes são mais altos em comparação com o conjunto de imagens anterior, no entantoo valores de precision foram um pouco mais baixos. Isso indica que o número de falsosnegativos foi baixo no conjunto M30-HD, porém o número de falsos positivos foi alto.
37

Tabela 5.10: Resultados obtidos no dataset M30-HD para tamV izinhanca igual a 160.modMaximo angMaximo Precision Recall F-measure
12
4 0.67649 0.94700 0.789215 0.73307 0.92808 0.819136 0.75208 0.92211 0.828467 0.79756 0.89640 0.844098 0.83659 0.86576 0.85093
14
4 0.68010 0.94673 0.791575 0.73747 0.92758 0.821686 0.75675 0.92111 0.830887 0.80274 0.89484 0.846298 0.84242 0.86354 0.85285
16
4 0.68034 0.94676 0.791745 0.73766 0.92758 0.821796 0.75696 0.92099 0.830967 0.80304 0.89464 0.846378 0.84310 0.86328 0.85307
18
4 0.68033 0.94679 0.791745 0.73775 0.92758 0.821856 0.75707 0.92099 0.831037 0.80334 0.89464 0.846538 0.84359 0.86330 0.85333
20
4 0.68027 0.94682 0.791715 0.73769 0.92761 0.821826 0.75699 0.92105 0.831007 0.80324 0.89467 0.846498 0.84360 0.86336 0.85337
38

Tabela 5.11: Resultados obtidos no dataset M30-HD para tamV izinhanca igual a 180.modMaximo angMaximo Precision Recall F-measure
12
4 0.68761 0.94463 0.795885 0.74647 0.92316 0.825476 0.76747 0.91651 0.835397 0.81541 0.88612 0.849308 0.85657 0.85065 0.85360
14
4 0.69135 0.94427 0.798265 0.75092 0.92237 0.827866 0.77234 0.91534 0.837787 0.82060 0.88415 0.851198 0.86252 0.84819 0.85530
16
4 0.69148 0.94427 0.798355 0.75104 0.92246 0.827976 0.77266 0.91531 0.837967 0.82102 0.88389 0.851308 0.86316 0.84787 0.85545
18
4 0.69140 0.94430 0.798305 0.75116 0.92249 0.828056 0.77271 0.91522 0.837957 0.82126 0.88386 0.851418 0.86362 0.84778 0.85563
20
4 0.69139 0.94436 0.798315 0.75122 0.92255 0.828126 0.77269 0.91528 0.837967 0.82110 0.88383 0.851318 0.86343 0.84776 0.85552
39
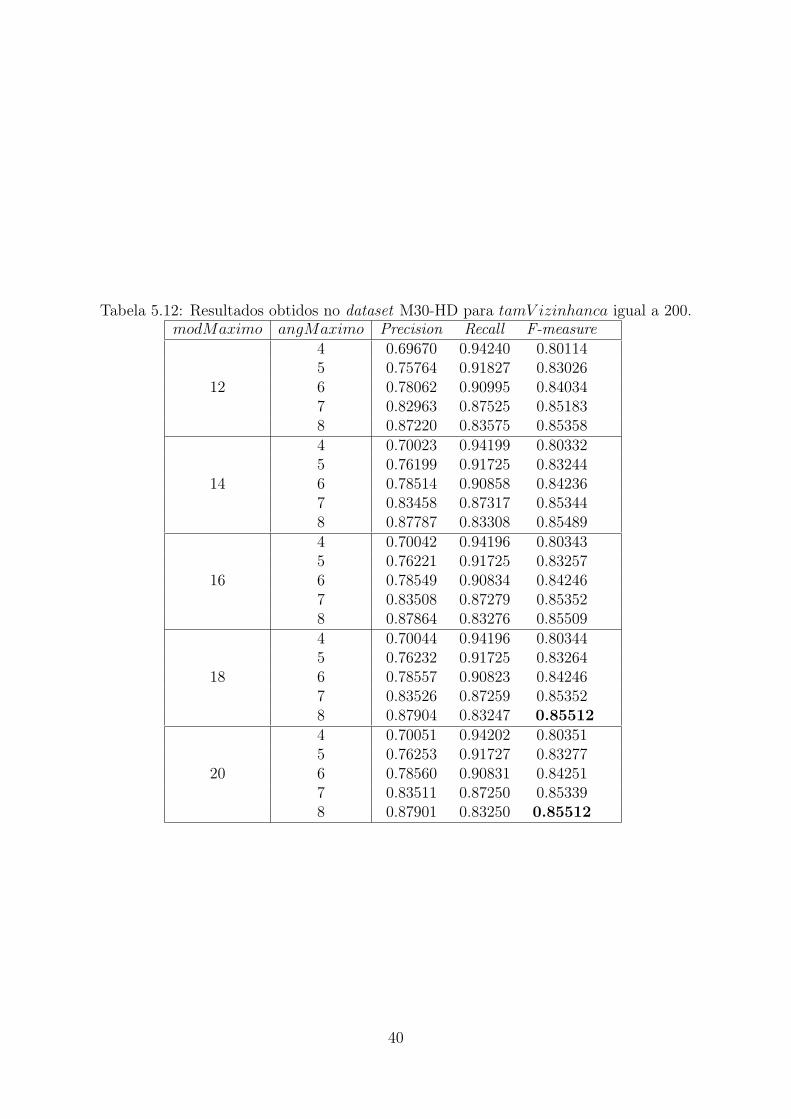
Tabela 5.12: Resultados obtidos no dataset M30-HD para tamV izinhanca igual a 200.modMaximo angMaximo Precision Recall F-measure
12
4 0.69670 0.94240 0.801145 0.75764 0.91827 0.830266 0.78062 0.90995 0.840347 0.82963 0.87525 0.851838 0.87220 0.83575 0.85358
14
4 0.70023 0.94199 0.803325 0.76199 0.91725 0.832446 0.78514 0.90858 0.842367 0.83458 0.87317 0.853448 0.87787 0.83308 0.85489
16
4 0.70042 0.94196 0.803435 0.76221 0.91725 0.832576 0.78549 0.90834 0.842467 0.83508 0.87279 0.853528 0.87864 0.83276 0.85509
18
4 0.70044 0.94196 0.803445 0.76232 0.91725 0.832646 0.78557 0.90823 0.842467 0.83526 0.87259 0.853528 0.87904 0.83247 0.85512
20
4 0.70051 0.94202 0.803515 0.76253 0.91727 0.832776 0.78560 0.90831 0.842517 0.83511 0.87250 0.853398 0.87901 0.83250 0.85512
40

Assim como no M30, houve uma tendência de haver melhores resultados nos blocosfinais das tabelas, em que o valor de modMaximo é maior. Entretanto, eles não seconcentraram em apenas um bloco da tabela, os melhores resultados oscilaram entre oscasos em que modMaximo é igual a 18 e os em que ele é igual a 20. Isso ocorreu porque avariação de duas unidades no valor desse parâmetro não teve muita influência nos valoresde F-measure. O maior valor obtido para o M30-HD é dado com tamV izinhanca iguala 180, modMaximo igual a 18 e angMaximo igual a 8. Nesta situação, o valor de F-measure foi igual a 0,85563. Isto implica dizer que 86% dos veículos foram detectadoscorretamente.
Os maiores valores de F-measure obtidos, 0,81614 e 0,85563, são valores bem próximosde um. Portanto, o método proposto foi útil para resolver o problema de segmentarveículos em vias cujo movimento principal é dado por veículos.
O artigo apresentado na Seção 3.1 utiliza a mesma base de dados usada neste tra-balho para avaliar os resultados obtidos no processo de contagem de veículos. A Tabela5.13 apresenta os maiores valores de recall obtidos tanto neste trabalho quanto no artigopublicado por Guerrero [9] para os conjuntos de imagens M30 e M30-HD.
Tabela 5.13: Comparação de resultados de recallM30 M30-HD
Guerrero [9] 0,3009 0,5241Programa implementado 0,8882 0,9519Diferença bruta 0,5873 0,4278
É possível observar na Tabela 5.13 que os valores de recall obtidos neste trabalhoforam maiores. Isso ocorre porque o número de falsos negativos contabilizados nos doisconjuntos de imagens foi baixo. Como a técnica utilizada para realizar a segmentação dosveículos foi o Fluxo Ótico, o programa desenvolvido não apresenta muitos falsos negativos,uma vez que há detecção de veículos sempre que existe movimento nas imagens.
41

Capítulo 6
Conclusão
O objetivo inicial deste projeto era implementar um sistema automatizado para rea-lizar contagem de veículos em rodovias. Foram utilizadas técnicas simples, que se mos-traram eficazes para a resolução do problema. O uso do Fluxo Ótico foi essencial parasegmentar os veículos, já que essa técnica é muito útil em situações em que há deslo-camento do objeto que se deseja detectar. Outro ponto fundamental para o sucesso doalgoritmo foi realizar o agrupamento de pontos de acordo com sua similaridade, uma vezque vetores de um mesmo veículo foram agrupados de forma a pertencerem ao mesmogrupo.
Uma boa detecção e segmentação de veículos são fundamentais para sistemas quedesejam extrair informações de trânsito, tais como número de veículos, tipos dos veículos,etc. Em sistemas que realizam a obtenção dessas informações, em geral, a segmentaçãode veículos é o primeiro passo feito.
Para melhorar os resultados obtidos, são sugeridos executar testes com variação maiornos valores dos parâmetros, aumentar o número de subregiões em que imagem é dividaou analisar a conveniência de novas métricas para a inserção de elementos em um grupo.
Como cada grupo corresponde a um veículo, uma evolução natural deste trabalho é aextração de informações a partir dos dados contidos nos grupos criados em cada imagem.Podem ser obtidos, por exemplo, a velocidade de um veículo, o seu tamanho, o sentidodo seu movimento e a quantidade de veículos em cada faixa.
42

Referências
[1] Miscellaneous Image Transformations - OpenCV 2.4.11.0 documenta-tion. http://docs.opencv.org/modules/imgproc/doc/miscellaneous_transformations.html, 2014. [Online; acessado 26-06-2015]. 21
[2] Open Source Computer Vision. http://docs.opencv.org/, 2014. [Online; acessado28-06-2015]. 18
[3] Serge Beucher and Christian Lantuéjoul. Use of watersheds in contour detection.International Workshop on image processing: Real-time Edge and Motion detec-tion/estimation, September 1979. 4
[4] Cristopher M. Bishop. Pattern Recognition and Machine Learning. Springer, NewYork, 2006. 4, 5
[5] Jean-Yves Bouguet. Pyramidal implementation of the Lucas Kanade feature tracker.Intel Corporation, Microprocessor Research Labs, 2000. 11, 12
[6] Norbert Buch, Sergio A. Velastin, and James Orwell. A Review of Computer VisionTechniques for the Analysis of Urban Traffic. IEEE Transactions on IntelligentTransportations Systems. Vol. 12, No 3, September 2011, 2011. 1, 13
[7] S. Cameron and P. Proberdt. Advanced guided vehicles, aspects of the oxford agvproject. World Scientific, Singapore, 1994. 13, 14
[8] Roy Davies. Computer and Machine Vision: Theory, Algorithms, Practicalities.Morgan Kaufmann, Egham, Surrey, UK, 2012. 5
[9] Ricardo Guerrero-Gomez-Olmedo , Roberto Lopez-Sastre , Saturnino Maldonado-Bascon , Antonio Fernandez-Caballero. Vehicle Tracking by Simultaneous Detec-tion and Veiwpoint Estimation. 5th International Work-conference on the InterplayBetween Natural and Artificial Computation, IWINAC 2013, Mallorca, Spain, June10-14, 2013., 2013. v, vi, 1, 4, 13, 14, 15, 20, 28, 30, 41
[10] Rafael C. Gonzalez and Richard E. Woods. Digital Image Processing. Prentice Hall,2002. 3, 5
[11] Berthold K. P. Horn and Brian G. Shunck. Determining optical flow. ArtificialIntelligence, pages 185–203, 1981. 4, 6
[12] C. L. Huang and W. C. Liao. A vision-based vehicle identification system. Proc.17th Int. Conf. Pattern Recog, page 364–367, 2004. v, vi, 1, 13, 16, 17, 20
43

[13] N. K. Kanhere and S. T. Birchfield. Real-time incremental segmentation and trackingof vehicles at low camera angles using stable features. IEEE Trans. Intell. Transp.Syst., vol. 9, no. 1, page 148–160, 2008. v, vi, 1, 4, 13, 18, 19, 20
[14] Bruce D. Lucas and Takeo Kanade. An iterative image registration technique withan application to stereo vision. Proceedings of Imaging Understanding Workshop,pages 121–130, April 1981. 7, 11, 18
[15] J. MacQueen. Some methods for classification and analysis of multivariate observati-ons. Proc. of the fifth Berkeley Symposium on Mathematical Statistics and Probability,1:281–297, 1967. 4
[16] MATLAB. Image Segmentation - MATLAB & Simulink. http://www.mathworks.com/discovery/image-segmentation.html, 2014. [Online; acessado 06-10-2014]. v,3
[17] White Paper. Orchestrating infrastructure for sustainable Smart Cities. InternationalElectrotechnical Commission, 2014. 1
[18] Paul Read and Mark-Paul Meyer. Restoration of motion picture film. Butterworth-Heinemann, 2000. 5
[19] Márcia A. Gomes Ruggiero and Vera Lúcia da Rocha Lopes. Cálculo Numérico -Aspectos Teóricos e Computacionais. Pearson Education, 1996. 9
[20] Jianbo Shi and Carlo Tomasi. Good features to track. Computer Vision and PatternRecognition, 1994. Proceedings CVPR ’94., 1994 IEEE Computer Society Conferenceon, pages 593–600, June 1994. 23
[21] Jianbo Shi and Carlo Tomasi. Evaluation: From precision, recall and f-measureto roc, informedness, markedness and correlation. Journal of Machine LearningTechnologies, 2:37–63, February 2011. 29
[22] Chris Stauffer and W.E.L. Grimson. Adaptive background mixture models for real-time tracking. Computer Vision and Pattern Recognition, 1999. IEEE ComputerSociety Conference on., 2:–252 Vol. 2, 1999. 4, 16, 18
[23] P. Sudowe and B. Leibe. Efficient use of geometric constraints for sliding-windowobject detection. International Conference on Computer Vision Systems, 2011. 14
[24] Savarese S. Fei-Fei L Sun, M. Su. H. A multi-view probabilistic model for 3d objectclasses. CVPR, 2009. 13
[25] Richard Szeliski. Computer Vision: Algorithms and Applications. Springer, 2010. v,3, 4, 5
44