monitoração de rede - di.ufpe.brsuruagy/cursos/gerencia-mp/2015-gr-2-monitoracaore... ·...
TRANSCRIPT

MONITORAÇÃO DE REDE
Prof. José Augusto Suruagy Monteiro

Capítulo 2 de William Stallings. SNMP, SNMPv2,
SNMPv3, and RMON 1 and 2, 3rd. Edition.
Addison-Wesley, 1999.
Baseado em slides do Prof. Chu-Sing Yang
(Department of Electrical Engineering – National
Cheng Kung University)
2

Roteiro
Introdução
Arquitetura de monitoração de rede
Monitoração de desempenho
Monitoração de falhas
Monitoração de contabilização
3

Introdução
Monitoração de rede
Observa e analisa o status e comportamento dos sistemas finais, sistemas intermediários e sub-redes que compõem a configuração a ser gerenciada
Principais áreas de projeto
Acesso à informação de monitoramento Como definir a informação de monitoramento
Como levar a informação de um recurso até um gerente
Projeto de mecanismos de monitoramento Qual o melhor modo de obter informações dos recursos
Aplicação da informação monitorada Como a informação monitorada é usada nas diversas áreas
funcionais de gerenciamento
4

Roteiro
Introdução
Arquitetura de monitoração de rede
Monitoração de desempenho
Monitoração de falhas
Monitoração de contabilização
5

Informação de Monitoração de Rede
Informação estática
Caracteriza a configuração atual e os seus elementos Número e identificação de portas em um roteador
É tipicamente gerada pelo elemento envolvido
A informação é disponibilizada a um gerente por um agente ou um proxy
Informação dinâmica
Relacionada a eventos na rede Uma mudança de estado de uma máquina de protocolo
Transmissão de um pacote numa rede
É coletada e armazenada pelo elemento de rede responsável pelos eventos correspondentes
6

Informação de Monitoração de Rede
Informação estatística
É derivada da informação dinâmica
Número médio de pacotes transmitidos por unidade de
tempo
É gerada por qualquer sistema que tenha acesso às
informações dinâmicas correspondentes
7

Organização de uma base de
informações de gerência 8

Arquitetura Funcional da Monitoração
de Rede 9

Sistema de
Monitoração de Rede
Aplicação de monitoração
Inclui as funções da monitoração de rede que são visíveis aos usuários
Monitoração de desempenho, de falhas e de contabilização
Função gerente
Módulo que efetua a função básica de monitoramento de recuperar informação de outros elementos
Função agente
Reúne e registra informações de gerência para um ou mais redes
Comunica a informação ao monitor
Objetos gerenciados
É a informação de gerência que representa os recursos e suas atividades
Agente de monitoramento
Módulo adicional responsável pelas informações estatísticas
Gera resumos e análises estatísticas da informação de gerência
10

Recursos gerenciados
Monitor de rede
Inclui software agente e
um conjunto de objetos
gerenciados
Monitora a carga em si
mesmo e na rede
Instrumentado para
monitorar a quantidade
de tráfego de gerência
de rede que entra e sai
do monitor
11

Recursos em um sistema agente
Configuração mais
comum para monitorar
outros elementos de
rede
Sistemas gerente e
agente compartilham:
Protocolo de
gerenciamento de
rede
MIB
12
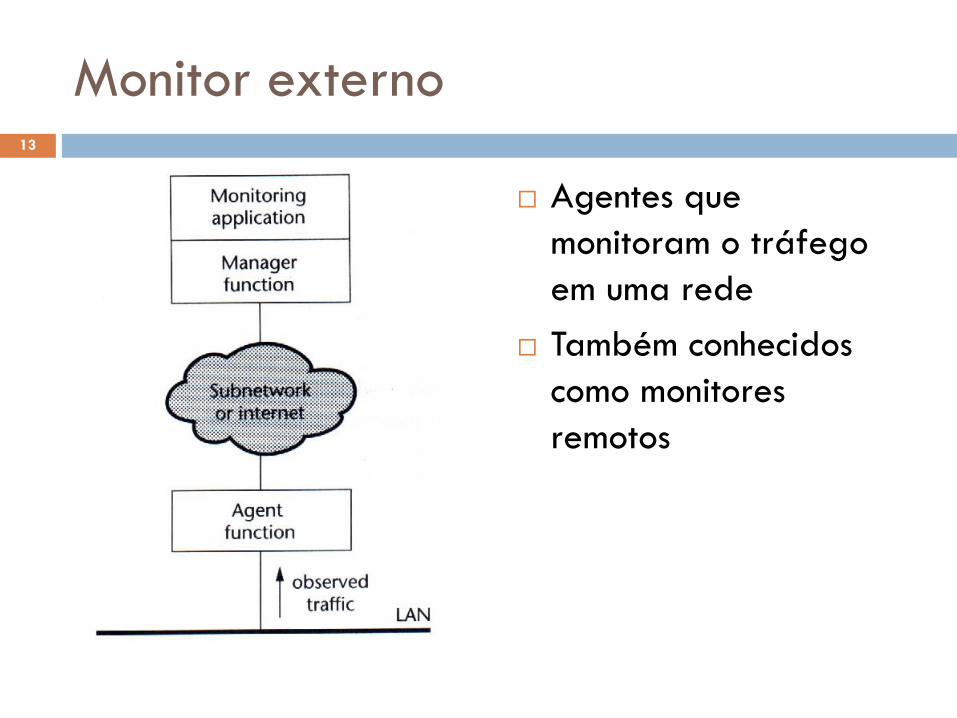
Monitor externo
Agentes que
monitoram o tráfego
em uma rede
Também conhecidos
como monitores
remotos
13

Agente Monitor Proxy
Proxy = intermediário
Necessário quando
elementos de rede
não compartilham o
mesmo protocolo de
gerência com o
monitor de rede
14

Polling 15
Informações uteis para o monitoramento de rede são coletadas e armazenadas por agentes e disponibilizadsa para um ou mais sistemas gerente
Polling
É uma interação consulta-resposta entre um gerente e um agente
O gerente consulta um agente e solicita os valores de diversos elementos de informação
É usado para gerar um relatório para um usuário e para responder a consultas específicas do usuário

Polling 16
Gerente
Consulta um agente e pede os valores de diversos elementos de informação
Obtém a configuração que está gerenciando
Obtém periodicamente uma atualização das condições
Investiga uma área em detalhes após ter sido alertado de um problema
Agente
Responde com informações da sua MIB
Relata informação que corresponde a um determinado critério
Provê ao gerente informação sobre a estrutura da MIB no agente

Relato de Ocorrência de Evento 17
Agente pode gerar um relato
Periodicamente para informar ao gerente o seu estado atual
Quando ocorrer algum evento significativo ou incomum
Gerente
Fica escutando, aguardando informação que chega
Pré-configura ou seta a periodicidade de envio de relatos
Benefícios
Útil para detectar problemas assim que ocorrerem
Mais eficiente que o polling para monitorar objetos cujos estados ou valores mudam de forma relativamente infrequente

Polling vs. Relato de Evento 18
Fatores a serem considerados:
Quantidade de tráfego de rede gerado por cada um dos métodos
Robustez em situações críticas
Atraso para notificar o gerente da rede
Quantidade de processamento nos dispositivos gerenciados
Compromissos entre a transferência confiável e não confiável
As aplicações de monitoração de rede que estão sendo suportadas
As contingências necessárias caso o dispositivo notificador falhe antes de enviar o relato
Em geral
Abordagem do SNMP: polling
Sistemas de gerenciamento de telecomunicações: ambos

Roteiro
Introdução
Arquitetura de monitoração de rede
Monitoração de desempenho
Monitoração de falhas
Monitoração de contabilização
19

Indicadores de desempenho 20
Dificuldades na escolha e uso de indicadores:
Há muitos indicadores em uso
O significado de muitos indicadores ainda não estão claramente compreendidos
Alguns indicadores são suportados apenas por alguns fabricantes
Muitos indicadores não são adequados para comparação uns com os outros
Indicadores são precisamente medidos mas incorretamente interpretados
O cálculo dos indicadores toma um tempo excessivo e os resultados finais são difíceis de ser usados para controlar o ambiente

Indicadores de desempenho 21
Orientados a serviço (mais alta prioridade)
Disponibilidade (availability)
Tempo de resposta
Ausência de erros (accuracy)
Orientados a eficiência
Vazão (throughput)
Utilização

Disponibilidade 22
Percentual do tempo em que um sistema de rede, um componente ou uma aplicação está disponível para um usuário
Baseia-se na confiabilidade dos componentes individuais de uma rede
MTBF (Mean Time Between Failures): tempo médio entre falhas
MTTR (Mean Time To Repair): tempo médio até o conserto
Disponibilidade: A =𝑀𝑇𝐵𝐹
𝑀𝑇𝐵𝐹+𝑀𝑇𝑇𝑅

Disponibilidade de um sistema 23
A disponibilidade de um sistema depende da
disponibilidade dos seus componentes individuais e
da organização do sistema
Existência ou não de componentes redundantes

Disponibilidade de um sistema 24
Conexões em série:
Conexões em paralelo:
Indisponibilidade =1-A =0,02
Indisponibilidade do sistema em paralelo
=0,02 x 0,02 = 0,0004
A(paralelo) = 1- 0,0004
=0,9996
A = 0,98
A(serial)=0,98 x 0,98
=0,96

Disponibilidade: Exemplo 25
Disponibilidade de um sistema com dois links conectando um multiplexador a um host
Períodos normais correspondem a 40% dos pedidos, onde qualquer um dos links dá conta da carga de tráfego
Durante os períodos de pico, os dois links são necessários para dar conta da carga total, mas um link dá conta de 80% da carga máxima.
Af = (capacidade quando 1 link está ativo) * Pr[1 link estar ativo] + (capacidade quando 2 links estão ativos) * Pr[2 links estarem ativos]

Disponibilidade: Exemplo 26
Af = (capacidade quando 1 link está ativo) * Pr[1 link estar ativo] +
(capacidade quando 2 links estão ativos) * Pr[2 links estarem ativos]
Af (período normal) = 1 * [A(1-A) + (1-A)A] + 1 * (A*A) = 0,99
Af (pico) = 0,8 * [A(1-A) + (1-A)A] + 1 * (A)(A) = 0,954
Af = 0,6 * Af (pico) + 0,4 * Af (período normal)
Se A = 0,9 então Af = 0,9684
Portanto, o sistema consegue lidar com 97% das
solicitações de serviço.

Requisitos básicos para
disponibilidade 27
Instalações seguras
Sistemas elétricos (no-break, gerador, etc.)
Diversidade de circuitos
Redundância intra-chassis
Fontes de alimentação duais
Hot swap
Multiprocessadores

Tempo de Resposta 28
Tempo que leva para uma resposta aparecer no terminal do usuário após uma solicitação do mesmo
Custo para obter um tempo de resposta mais curto
Capacidade computacional Aumento na capacidade implica em custo mais elevado
Requisitos concorrentes Prover um tempo de resposta rápido para alguns processos pode
penalizar outros processos
A produtividade melhora quando tempos de resposta rápidos são alcançados
Até 2 segundos de tempo de resposta é aceitável para a maioria das aplicações interativas

Tempo de Resposta para Gráficos 29
Estudo realizado com engenheiros usando um programa de CAD para o projeto de CIs e placas.
A produtividade (volume de transações) aumenta dramaticamente quando o tempo de resposta é inferior a 1 segundo.

Componentes do tempo de resposta 30

Ausência de Erros (Accuracy) 31
Percentual de tempo que não ocorrem erros na
transmissão e entrega de informação
Mecanismos de correção de erros embutidos em
protocolos
Enlace de dados e TCP
Monitoração da taxa de erros pode identificar
Um enlace com falhas intermitentes
Existência de uma fonte de ruído ou interferência

Vazão (Throughput) 32
Taxa na qual ocorrem os eventos orientados a aplicação
É uma medida orientada a aplicação
No. de transações de um dado tipo num certo intervalo de tempo
No. de sessões de usuário para alguma aplicação durante um certo intervalo de tempo
No. de chamadas em um ambiente de comutação de circuito
É útil rastrear estas medidas ao longo do tempo
Identificação de problemas de desempenho

Utilização 33
Percentual em uso da capacidade teórica de um
recurso (ex., multiplexador, linha de transmissão,
switch)
É uma medida mais detalhada do que a vazão
Usada para pesquisar potenciais gargalos e áreas
de congestionamento
O tempo de resposta normalmente cresce
exponencialmente à medida que cresce a utilização
de um recurso

Análise simples de eficiência 34

Função de Monitoração de
Desempenho 35
Componentes da monitoração de desempenho
Medição de desempenho Coleta estatísticas sobre o tráfego e tempos da rede
Realizado por módulos agentes que observam o comportamento dos nós Nó. de conexões, tráfego por conexão
Monitor externo (remoto) Transfere a carga de processamento de nós operacionais para
sistemas dedicados
Análise de desempenho Consiste de software para reduzir e apresentar os dados
Geração de tráfego sintético Permite observar a rede sob uma carga controlada

Relatórios de medição de desempenho
em uma LAN 36
Matriz de comunicação dos hosts
Matriz de comunicação de grupos
Histograma de tipo de pacotes
Histograma de tamanho dos pacotes de dados
Distribuição de vazão-utilização
Histograma do tempo entre chegadas de pacotes
Histograma do atraso de obtenção do canal
Histograma do atraso de comunicação
Histograma da contagem de colisões
Histograma da contagem das transmissões

Perguntas em relação a possíveis erros
ou ineficiências 37
O tráfego está igualmente distribuído entre os usuários da rede ou há pares O-D com tráfego pesado?
Qual é o percentual de cada tipo de pacote? Há algum tipo de pacote com alta frequência não esperada indicando um erro ou ineficiência do protocolo?
Qual é a distribuição dos tamanhos dos pacotes de dados?
Quais são as distribuições do tempo de aquisição de canais e de transmissão? Estes tempos são excessivos?
As colisões são um fator em conseguir transmitir os pacotes, indicando um hardware ou protocolos com defeito?
Quais são a utilização e a vazão dos canais?

Perguntas em relação ao crescimento
da carga de tráfego 38
Qual é o efeito da carga de tráfego na utilização, vazão e retardos?
Quando a carga de tráfego começa a degradar o desempenho do sistema?
Qual o compromisso entre estabilidade, vazão e atraso?
Qual é a capacidade máxima do canal em condições normais de operação?
Quantos usuários ativos são necessários para atingir este máximo?
Pacotes mais longos aumentam ou diminuem a vazão e o atraso?
Como o tamanho constante de pacotes afeta a utilização e o atraso?

Medições Estatísticas vs. Exaustivas 39
Quando um agente está monitorando uma carga
de tráfego pesada, pode não ser prático coletar
todos os dados (exaustivo).
Monitora o número total de pacotes num dado
intervalo de tempo para cada par O-D na LAN
Amostra o fluxo de tráfego para estimar o valor
da variável aleatória
Métodos estatísticos: probabilidades

Roteiro
Introdução
Arquitetura de monitoração de rede
Monitoração de desempenho
Monitoração de falhas
Monitoração de contabilização
40

Monitoração de Falhas 41
Objetivo:
Identificar uma falha assim que possível após sua ocorrência e identificar a sua causa de modo que possa ser tomada uma ação reparadora
Problemas com a observação de falhas
Falhas não observáveis
Certas falhas são inerentemente não observáveis localmente
Existência de impasse entre processos cooperativos distribuídos pode não ser observável localmente
Falhas parcialmente observáveis
O defeito em um nó pode ser observável mas insuficiente para localizar o problema
Nó pode não responder devido a um defeito em algum protocolo de baixo nível
Incerteza na observação
Falta de resposta de um dispositivo remoto pode significar que o dispositivo está travado, a rede está particionada ou congestionamento causou o atraso da resposta ou o temporizador local está com defeito.

Monitoração de Falhas 42
Problemas no isolamento de falhas a um dado componente:
Múltiplas causas em potencial
O uso de múltiplas tecnologias causam aumento na quantidade de pontos e tipos de defeitos
Demasiadas observações relacionadas
Um único defeito pode gerar diversos defeitos secundários
Interferência entre o diagnóstico e procedimentos locais de recuperação
Os procedimentos locais de recuperação podem destruir importantes evidências a respeito da natureza da falha, desabilitando o diagnóstico
Ausência de ferramentas de testes automatizados
Os testes para isolar falhas são difíceis e custosos para administrar

Monitoração de Falhas 43

Monitoração de Falhas 44
x

Monitoração de Falhas 45

Funções de Monitoração de Falhas 46
Detecção de falhas
Agente relata erros de forma independente para um ou mais gerentes
Agente mantém um registro de eventos significativos e erros
Critérios para emitir um relato de falha
Evita sobrecarga
Antecipação de falhas
Estabelecendo limiares
Taxa de perda de pacotes
Uma interface de usuário efetiva

Testes para o isolamento de falhas 47
Teste de conectividade
Teste de integridade dos dados
Teste de integridade do protocolo
Teste de saturação dos dados
Teste de saturação da conexão
Teste de tempo de resposta
Teste de loopback
Teste funcional
Teste de diagnóstico

Roteiro
Introdução
Arquitetura de monitoração de rede
Monitoração de desempenho
Monitoração de falhas
Monitoração de contabilização
48

Monitoração de contabilização 49
Registra o uso de recursos da rede pelos usuários
Um sistema de contabilização interno avalia o uso total dos recursos e determina o custo dos recursos compartilhados para cada departamento
Sistema oferece um serviço público
Recursos que podem ser sujeitos a contabilização
Recursos de comunicação
LANs, WANs, linhas alugadas, linhas discadas, sistemas de PBX
Hardware
Estações de trabalho e servidores
Software e sistemas
Software de aplicações e utilitários em servidores, centro de dados e sites de usuários finais
Serviços
Incluem todos os serviços comerciais de comunicação e informação

Coleta de Dados de Contabilização 50
Baseada nos requisitos da organização
Dados de contabilização relacionados com comunicação podem ser coletados e mantidos em cada usuário
Identificação do usuário
Receptor
Número de pacotes
Nível de segurança
Identifica as prioridades de transmissão e processamento
Carimbos de tempo
Associados com cada evento de transmissão e processamento
Temos de início e término de transações
Códigos de status da rede
Indica a natureza de qualquer erro ou mau funcionamento detectado
Recursos utilizados

Resumo 51

Resumo 52
Monitoração de rede é o aspecto mais fundamental do gerenciamento automático de rede
Coleta informação sobre o status e comportamento dos elementos de rede
Informação estática
Informação dinâmica
Informação estatística
Agente coleta informação local de gerência e transmite para um ou mais NMS
Cada NMS inclui software de aplicação de gerência de rede mais software para comunicação com agentes

Resumo 53
Monitoração de desempenho
Disponibilidade
Tempo de resposta
Ausência de erros
Vazão
Utilização
Monitoração de falhas
Identifica falhas assim que possível
Identifica a causa da falha e toma ação corretiva
Função de monitoração de falha é complicada
Monitoração de contabilização
Coleta informação de uso de cada um dos recursos