mobile web-browser reconnaissanceee03124/files/pdi.pdfresumo actualmente a indústria de telefones...
TRANSCRIPT

FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO
Mobile Web-Browser Reconnaissance
João Miguel de Carvalho Magalhães
Relatório de Preparação para a DissertaçãoMestrado Integrado em Engenharia Electrotécnica e de Computadores
Major Telecomunicações
Orientador: Professor Doutor Miguel Pimenta Monteiro
Co-orientador: Mestre Pedro Fortuna
Julho 2010

c© João Magalhães, 2010

Resumo
Actualmente a indústria de telefones móveis está a sofrer um forte desenvolvimento onde já épossível a um utilizador, através do seu telefone móvel, aceder à Web, consultar o email, reproduzirconteúdo multimédia, entre outras coisas que normalmente só eram possíveis em computadorestradicionais. Este facto está a levar que cada vez mais utilizadores comecem a usar o telefonepara aceder à Internet substituindo este o computador tradicional. Com este incremento súbito donúmero de acessos, aumenta também o risco de se verificar fraudes na Web, como por exemplo oClick Fraud. É de forma a detectar a Click Fraud que surge este projecto.
Neste documento, começamos então por fazer uma introdução dos intervenientes no projectoassim como uma introdução do problema a resolver. De forma a dar a conhecer a problemática dotema foi desenvolvido um capítulo sobre publicidade online onde foram analisados os diferentestipo de publicidade na Internet, aos modelos de negócio existentes onde se englobou os váriosmodelos de receitas e o volume de negócio.
Feita esta análise foi efectuada uma análise à problemática do Click Fraud assim como dastécnicas mais usadas para o praticar. Feita esta contextualização do problema percebe-se entãoqual a importância das técnicas de identificação de browsers para a detecção do Click Fraud. Dessaforma foram analisadas as características dos Browsers Móveis assim como assimiladas as suaslimitações e particularidades. De forma complementar foram também analisadas as característicasdas plataformas mais vulgares no acesso à internet por meio móvel. Para concluir, procedeu-se à investigação das técnicas de identificação de browsers que pudessem ser utilizadas para aidentificação de browsers móveis.
i

ii

Abstract
Today the mobile phone industry is undergoing a strong development where is already possiblefor a user, via their mobile phone, access the Web, check email, play media content among otherthings that usually is only possible in traditional computers. This is leading more and more usersto start using the phone for Internet access replacing this way the traditional computer. With thissudden increase in the number of mobile Internet accesses, it also increases the risk of fraud onthe Web, such as Click Fraud. This project was born from the need to detect Click Fraud.
In this document, we begin by making an issue of the project participants as well as an in-troduction to the problem that need to be solved. In order to make known the problems of ClickFraud was developed a chapter on online advertising where we analyzed the different types ofadvertising on the Internet to existing business models which included the various revenue modelsand the business revenue.
Following this analysis it was examined the issue of Click Fraud as well as the most usedtechniques for its practice. Once the contextualization of the problem is done we realize theimportance of the browser identification techniques in the detection of Click Fraud. That way weanalyzed the characteristics of Mobile Browsers and assimilated their limitations and peculiarities.In a complementary way were also analyzed the characteristics of the most common platformsused in the Internet access via mobile. To conclude, we proceeded to investigate the browseridentification techniques that could be used to identify mobile browsers.
iii

iv

Agradecimentos
Desejo agradecer ao meu orientador, Mestre Pedro Fortuna por toda a simpatia e apoio pres-tado.
v

vi

Conteúdo
1 Introdução 11.1 Apresentação da AuditMark . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Introdução do Problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.3 Objectivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.4 Estrutura do Documento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Publicidade Online 32.1 Tipos de Publicidade Online . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Publicidade Via Web . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.1.2 Publicidade Via E-mail . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Modelos de Negócio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2.1 Modelos de Receita . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.2.2 Volume de Negócio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3 Click Fraud . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.4 Conclusão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3 Browsers de Plataformas Móveis 113.1 Plataformas Móveis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.2 Browsers Moveis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.3 Conclusão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4 Reconhecimento de Browsers 214.1 Técnicas de Reconhecimento de Browers . . . . . . . . . . . . . . . . . . . . . 21
4.1.1 Análise dos Cabeçalhos HTTP . . . . . . . . . . . . . . . . . . . . . . . 224.1.2 Document Object Model . . . . . . . . . . . . . . . . . . . . . . . . . . 244.1.3 HTTP Persistent Connections . . . . . . . . . . . . . . . . . . . . . . . 26
4.2 Funcionamento do AuditService da AuditMark . . . . . . . . . . . . . . . . . . 274.2.1 Módulo de recolha de dados . . . . . . . . . . . . . . . . . . . . . . . . 274.2.2 Módulo Audit-PI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.2.3 Módulo de processamento de dados . . . . . . . . . . . . . . . . . . . . 29
4.3 Conclusão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5 Conclusão 315.1 Proposta de Solução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315.2 Planificação do Trabalho a Desenvolver . . . . . . . . . . . . . . . . . . . . . . 325.3 Conclusão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
Referências 34
vii

viii CONTEÚDO

Lista de Figuras
2.1 Diagrama de um modelo de negócio aplicavel à publicidade online . . . . . . . . 62.2 Receitas Anuais com Publicidade Online, nos Estados Unidos da América. . . . . 82.3 Cota de Mercado das maiores agências publicitárias para a Internet . . . . . . . . 8
3.1 Cotas de utilização de Sistemas Operativos para os diferentes continentes . . . . 133.2 Cotas de utilização de Browsers Móveis para os diferentes continentes . . . . . . 153.3 Arquitectura de um Browser . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4.1 Diferenças no uso do método GET entre Internet Explorer e Mozilla Firefox . . . 254.2 Diferenças no uso do método POST entre Internet Explorer e Mozilla Firefox . . 264.3 Arquitectura do AuditService . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
5.1 Diagrama de Gantt do Projecto . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
ix

x LISTA DE FIGURAS

Lista de Tabelas
3.1 Comparação entre Sistemas Operativos Móveis . . . . . . . . . . . . . . . . . . 143.2 Comparação entre Browsers Móveis . . . . . . . . . . . . . . . . . . . . . . . . 18
4.1 Métodos HTTP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234.2 Campos mais vulgares do método GET . . . . . . . . . . . . . . . . . . . . . . 244.3 Comparação das técnicas de identificação de Browsers . . . . . . . . . . . . . . 29
5.1 Lista das Tarefas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
xi

xii LISTA DE TABELAS

Abreviaturas e Símbolos
Web World Wide WebWWW World Wide WebFEUP Faculdade de Engenhartia da Universidade do PortoURI Uniform Resource IdentifierURL Uniform Resource LocatorVoIP Voice over IPTCP Transmission Control ProtocolHTTP Hypertext Transfer ProtocolHTML HiperText Markup LanguageDHTML Dynamic HiperText Markup LanguageCPU Central Processing UnitOS Operating systemJRE Java Runtime EnvironmentRIM Research in MotionROM Read only memoryRAM Random access memoryXML Extensible Markup LanguageCSS Cascading Style SheetsDOM Document Object ModelMIME Multipurpose Internet Mail ExtensionsSSL/TLS Secure Sockets Layer/Transport Layer SecurityGPS Global Positioning SystemFTP File Transfer ProtocolRFC Request for CommentsW3C World Wide Web ConsortiumIETF Internet Engineering Task Force
xiii

xiv ABREVIATURAS E SÍMBOLOS

Capítulo 1
Introdução
Este capítulo tem como objectivo fazer a introdução do tema que irá ser desenvolvido assim
como apresentar a empresa proponente da dissertação e as pessoas responsáveis pelo projecto.
Assim será feita uma descrição do problema a resolver e serão delineados os objectivos propostos
para a resolução do mesmo.
1.1 Apresentação da AuditMark
A AuditMark, é uma start-up que se encontra sediada na UPTEC – Parque da Ciência e Tec-
nologia da Universidade do Porto que tem como base a auditoria de tráfego proveniente de cam-
panhas publicitárias online sendo um dos seus principais temas de trabalho a detecção de Click
Fraud em anúncios publicitários. É neste contexto que se apresenta a proposta de dissertação da
AuditMark sobre o tema “Mobile Web-Browser Reconnaissance”. Os orientadores da dissertação
são o Professor Doutor Miguel Pimenta Monteiro, FEUP, e o Mestre Pedro Fortuna, AuditMark.
1.2 Introdução do Problema
Presentemente está a haver um forte desenvolvimento da indústria de telefones móveis. Assim
já existem telefones telefones que para além da efectuarem chamadas, conseguem aceder à Web,
consultar o email, reproduzir conteúdo multimédia, entre outras coisas que normalmente só eram
possíveis em computadores tradicionais. Este facto está a levar que cada vez mais utilizadores
comecem a usar o telefone para aceder à Internet substituindo este o computador tradicional. Com
este incremento súbito do número de acessos, aumenta também o risco de se verificar fraudes na
Web, como por exemplo o Click Fraud. O ClickFraud é um esquema em que um utilizador clica
em banners publicitários, sem qualquer interesse na publicidade, com o intuito de prejudicar a
empresas publicitada ou obter algum dinheiro. Relativamente aos Web-Browsers de dispositivos
1

2 Introdução
móveis estes possuem algumas características que os tornam diferentes dos browsers convencio-
nais. Estes browsers, também chamados de micro-browsers, foram desenvolvidos tendo em conta
as limitações tecnológicas e energéticas que os telefones móveis possuem. Assim, é normal estes
browsers possuírem tecnologias que permitam reduzir a quantidade de dados transferidos ou pro-
cessados. E é tendo por base estes factos que a AuditMark propôs o tema “Mobile Web-Browser
Reconnaissance”, que irá ser dissertado neste documento.
1.3 Objectivos
Para a realização deste projecto foram definidos os seguintes objectivos:
1. O primeiro objectivo centra-se na elaboração de novos perfis de browser para os browsers
móveis mais vulgares. Estes perfis serão posteriormente integrados na base de dados de
perfis já existentes para possibilitar a identificação deste tipo de browsers.
2. O segundo objectivo prende-se com a adaptação de uma solução já existente para a identifi-
cação de browsers para que suporte a identificação de browsers móveis. Assim será neces-
sário efectuar as alterações necessárias para que esta ferramenta já existente possa proceder
à identificação dos browsers móveis.
Com o cumprimento destes dois objectivos dar-se-á por concluído o projecto, integrando no
serviço de auditoria da AuditMark uma ferramenta de detecção de browsers móveis.
1.4 Estrutura do Documento
O documento encontra-se dividido em 5 capítulos.
No primeiro capítulo será feita uma introdução do projecto assim como da empresa propo-
nente, neste caso a AuditMark.
No segundo capítulo será feita uma análise aos diferentes tipos de publicidade na Internet,
com um aprofundar para a publicidade via Web. Neste contexto serão analisados os modelos de
negócio e de receitas existentes assim como o volume de negócio que esta indústria movimenta.
Para finalizar será ainda discutido neste capítulo o conceito de Click Fraud, referindo-se em que é
que consiste e quais as técnicas para o praticar.
No terceiro capítulo do documento serão abordados os Browser Móveis. Serão analisadas
as características das plataformas que os suportam assim como as características possíveis de os
distinguir.
No quarto capítulo serão então abordadas as técnicas de identificação de browsers assim como
realizada uma breve descrição superficial do funcionamento do serviço de auditoria da AuditMark.
No capítulo 5 será delineada uma proposta de trabalho assim como será estabelecido um plano
de trabalho a cumprir durante o projecto. Para finalizar foi elaborada uma conclusão de forma a
analisar o trabalho desenvolvido e apresentado neste documento.

Capítulo 2
Publicidade Online
A Internet é, sem dúvida alguma, uma das formas de comunicação mais populares do globo.
Esse facto advém dos inúmeros serviços disponibilizados através da mesma. Actualmente é pos-
sível consultar o e-mail, fazer transferência de ficheiros, comunicar por voz através da tecnologia
VoIP e, talvez o serviço mais popular, a utilização da World Wide Web. A World Wide Web é
um conjunto de documentos, imagens e outro conteúdo multimédia disponível sobre a forma de
páginas Web que podem ser acedidos através de Uniform Resource Identifiers (URIs) que são úni-
cos para cada página existente. Para aceder ao conteúdo de página Web são utilizados browsers
onde é colocado o URI correspondente, que, através do protocolo HTTP, recolhe o conteúdo da
página desejada do servidor Web. As páginas são geralmente desenvolvidas obedecendo ao proto-
colo HTML para que possam posteriormente ser processados pelos browsers que as reconstroem
para serem visualizadas pelo utilizador. A World Wide Web veio desta forma proporcionar a livre
circulação da informação e ideias, adquirindo assim a popularidade que tem nos dias de hoje.
Para usufruírem dos serviços disponibilizados na Internet, na maioria dos casos, os utiliza-
dores não necessitam de pagar nenhuma taxa à entidade que lhe presta o serviço. No entanto, a
prestação do serviço tem um custo para essa mesma entidade que cresce em conformidade com a
dimensão do serviço prestado. Se aliarmos a isso a popularidade que a Internet possui, torna-se
assim evidente a utilização da publicidade online como forma de suportar financeiramente essas
entidades.
2.1 Tipos de Publicidade Online
Da mesma maneira que existem vários serviços de Internet, existem também diferentes formas
de se fazer publicidade online. Actualmente existem 2 grandes formas de publicidade online
com base no funcionamento de dois serviços de Internet distintos, a World Wide Web e o E-mail.
(Robbin Zeff, 1999)
3

4 Publicidade Online
2.1.1 Publicidade Via Web
Este tipo de publicidade consiste na utilização de websites como plataforma publicitária. São
colocados em websites pequenos anúncios que publicitam um produto e encaminham o utilizador
para o website do anunciante. Actualmente o desenvolvimento destes anúncios sofreu uma forma
impulsão conduzindo a que os conteúdos publicitários possam ser alterados dinamicamente com
base no país do utilizador, últimas pesquisas efectuadas ou até pelos sítios Web visitados recen-
temente. Seguidamente serão descritos quais os tipos de anúncios mais comuns nos sítios Web.
(Stern, 2008)
• Banner: Este tipo de anúncio é uma imagem que é colocada no website de forma a chamar
a atenção do utilizador. Mais recentemente são usadas animações em JAVA ou Flash de
forma a tornar os conteúdos expostos mais apelativos e dinâmicos.
• Anúncio Flutuante: É um anúncio que se desloca ao longo da página ficando sempre visível
enquanto o utilizador circula pela página.
• Inline Text: Esta forma de publicidade funciona da seguinte forma: A agência publicitária
coloca, sobre determinadas palavras ou frases do sítio Web expositor, hiper-ligações para o
website do anunciante. De modo a expor a publicidade é normal colocar o respectivo texto
numa cor diferente e aparecer uma pequena imagem ou animação publicitária sempre que
o rato passar por cima do referido texto. Esta forma de publicidade é comum em blogs e
sítios Web com muita informação escrita.
• Anúncio em Vídeo: Este tipo de publicidade pode ser feito de duas formas. A primeira
forma consiste em colocar sobre o vídeo um pequeno banner que acompanha a reprodução
do mesmo. A segunda forma é colocar vídeos publicitários antes do vídeo que o utilizador
pretende visualizar. Este tipo de publicidade tem sofrido uma forte impulsão com o aumento
da informação difundida sobre a forma de vídeo na Internet.
• Trick Banner: O funcionamento é idêntico ao banner tradicional com a diferença de ten-
tar induzir em erro o utilizador. É usual este tipo de banner evidenciar semelhanças com
erros do sistema operativo ou prémios pelo utilizador ser a enésima visita ao sítio Web.
Geralmente este tipo de banner conduz a sítios Web com fins maliciosos.
• Pop-up: Este método consiste em abrir novas janelas com conteúdo publicitário sempre que
o utilizador circula entre páginas. Este método caiu em desuso pois os browsers adoptaram
medidas para prevenir que páginas novas abrissem sem o consentimento do utilizador.
2.1.2 Publicidade Via E-mail
Relativamente à publicidade via E-mail, o processo de publicidade é igualmente simples. O
anunciante envia um E-mail a todos os potenciais interessados no seu produto e espera por uma
eventual interesse por parte do destinatário. Quando a popularidade do e-mail cresceu houve um

2.2 Modelos de Negócio 5
interesse enorme dos publicitários de aderir a esta forma de expor os seus produtos, já que o
envio deste tipo de mensagens é um processo grátis não sendo necessário pagar nenhuma taxa
por e-mail enviado à entidade que presta o serviço. Desta forma foram criadas ferramentas para
enviar mensagens publicitárias para o maior número de endereços de e-mail possível de uma forma
automática. Assim sendo, logo os utilizadores viram as suas caixas de e-mail cheias de e-mails
que não lhes interessava, o vulgar SPAM. Acompanhando as queixas dos utilizadores, as entidades
que prestavam os serviços de E-mail resolveram proporcionar filtros de SPAM aos utilizadores e,
mais recentemente, os principais governos mundiais decidiram agir contra quem o praticasse. Em
2002 a União Europeia redige a directiva 2002/58 que proíbe o uso do SPAM para fins comerciais.
Estabelece também que tem que partir do utilizador a intenção de receber publicidade criando
assim as listas opt-in. É também garantido ao utilizador a possibilidade de a qualquer momento
cessar a sua intenção de receber mais e-mails publicitários.
Devido a todos estes inconvenientes que a publicidade por e-mail possui, para o anunciante
e anunciado, esta possui na actualidade pouco peso no mercado mundial de publicidade online,
sendo este quase totalmente preenchido pela publicidade via Web. No contexto deste trabalho
interessa-nos perceber a publicidade online via Web pelo que será melhor retratada no ponto se-
guinte.
2.2 Modelos de Negócio
Numa forma convencional, se um utilizador tiver a intenção de publicitar um produto seu, re-
corre a uma agência publicitária que o ajuda a anunciar o produto ao seu mercado alvo. De igual
forma pode ser usado o mesmo modelo de negócio na publicidade online. As agências publici-
tárias detêm uma lista de sítios Web onde podem colocar os seus anúncios publicitários sendo os
proprietários dos mesmos compensados financeiramente. Desta forma podemos considerar quatro
actores no processo de publicidade online: (Ferreira, 2008)
• O utilizador - São todos os indivíduos que circulam na Web podendo ou não ter interesse
na publicidade online.
• O anunciante - É a pessoa ou empresa que pretende publicitar algum tipo de conteúdo.
• A agência publicitária - É a empresa que o anunciante contacta para que seja efectuada a
publicidade.
• O sítio Web expositor - É o sítio onde é feita a publicidade.
Na figura 2.1 podemos observar como o processo de publicitar um conteúdo na Web se de-
senvolve.
1 – O anunciante contacta a agência publicitária para publicitar a sua empresa/produto.
2 – A agência publicitária faz um estudo sobre a publicidade necessária e contacta os sítios
Web parceiros para fazer a divulgação.

6 Publicidade Online
3 – O utilizador visualiza a publicidade e interage com a mesma.
4 – O utilizador é redireccionado para o sítio Web da empresa concluindo assim o ciclo de
promoção da empresa/produto.
Figura 2.1: Diagrama de um modelo de negócio aplicavel à publicidade online
Podemos quase considerar os motores de busca como algo indispensável na Web, quer pela
sua necessidade quer pela sua popularidade. Explorando este facto as empresas que desenvolvem
os motores de busca iniciaram-se assim no mercado da publicidade online. Como tal, estas fa-
cilitam ao anunciante a possibilidade de colocar a hiperligação para o seu sítio numa localização
facilmente visível para o utilizador ou melhorar a sua posição nas buscas efectuadas. Algumas
empresas, como a Google AdSense, disponibilizam também que sites expositores coloquem Ads
para promover a publicidade.
2.2.1 Modelos de Receita
Historicamente, os modelos de receita foram sofrendo alterações com base na experiência das
agências de publicidade online e nos requisitos dos anunciantes. Inicialmente era aplicado um
modelo de receita idêntico ao praticado pelas agências de publicidade convencionais mas, pelas
próprias características da Web houve necessidade de inovar. Deste modo existem 3 modelos de
receita principais: Cost per Mile(CPM), Cost per Click (CPC), Cost per Action (CPA). (Ferreira,
2008; Tuzhilin, 2007)
• Cost per Mille (CPM) - Este modelo também é conhecido por Cost per Thousand ou Cost
per Impression. No modelo de receita convencional, o anunciante paga a uma empresa pu-
blicitária por cada impressão efectuada. Transportando para a publicidade online, significa
que o anunciante vai pagar à empresa publicitária em conformidade com o número de vezes
que a publicidade for carregada pelos diversos utilizadores. Na maioria das empresas pu-
blicitárias o acto de recarregamento da página ou outras acções externas não é considerado
como uma impressão, salvaguardando assim os interesses dos anunciantes. Nalguns casos

2.2 Modelos de Negócio 7
este tipo de modelo pode ser bastante lesivo para o anunciante pois o utilizador pode não
ver a publicidade, mas o anunciante irá ter que pagar por essa impressão.
• Cost per Click (CPC) - Este modelo também é conhecido por Pay per click (PPC). Com
as necessidades dos anunciantes que o CPM não conseguia garantir surgiu este modelo de
receita mais adequado à publicidade online via Web. Ao contrário do CPM o anunciante
só irá pagar se o Ad publicitário receber um clique e for redireccionado com sucesso para
o sítio do anunciante. Desta forma é garantido que o anunciante só irá pagar pelo número
de utilizadores que virem a sua publicidade embora, mesmo assim, não garanta que existe
interesse por parte dos utilizadores. Este é o modelo de receita implementado nos Motores
de Busca onde o anunciante pede para ser colocada a sua publicidade em resposta a palavras-
chave usadas nas pesquisas dos utilizadores. É derivado desse facto, e das mais valias que
este modelo possui, que este é o principal modelo de receita usado na publicidade online.
• Cost per Action (CPA) - Este modelo também é conhecido por Cost Per Acquisition. Este
modelo de receita consiste em só haver pagamento por parte do anunciante quando uma
determinada acção é executada, sendo esta acção previamente acordada entre a agência
publicitária e o anunciante. Este é sem dúvida o modelo que mais benificia o anunciante
pois este consegue garantir o interesse do utilizador na sua publicidade. Para a agencia
publicitária este é o modelo que menos a benificia pois fica dependente do interesse que o
produto publicitado gere no utilizador.
Existem outros modelos de receita menos importantes pelo que serão descritos seguidamente
de forma sucinta.
• Cost Per Visitor (CPV) - O anunciante paga por cada vez que um utilizador chega ao seu
Website através de um Ad publicitário.
• Cost Per View (CPV) - O anunciante paga por cada vez o utilizador visualiza a publicidade.
É usado nos Ads do tipo Pop-up e Ad de Vídeo.
• Cost Per Lead (CPL) - É uma particularização do CPA onde o anunciante paga pelo numero
de utilizadores que completa um processo de inscrição (por exemplo: Newsletter).
• Cost Per Order (CPO) - É uma particularização do CPA onde o anunciante paga pelo
número de utilizadores que completam uma compra ou encomenda com sucesso.
• Cost Per Engagement (CPE) - É uma particularização do CPA onde o anunciante paga
pelo número de interacções que o Ad publicitário sofre por parte de utilizadores. Este tipo
de Ads é geralmente do tipo "banner"com pequenos jogos para cativar o utilizador.
2.2.2 Volume de Negócio
A popularidade da publicidade online é hoje uma forma bastante lucrativa de fazer publicidade.
Segundo o estudo do Interactive Advertising Bureau (PricewaterhouseCoopers, 2010) a receita

8 Publicidade Online
com a publicidade online têm vindo a aumentar com um volume de negócio a ascender aos 22,6
milhares de milhão de dólares (Figura 2.2) nos Estados Unidos da América. Apesar de uma
ligeira quebra nas receitas no ano de 2009, estes números vêm provar a adesão das empresas a
publicitarem os seus produtos através deste tipo de publicidade.
Figura 2.2: Receitas Anuais com Publicidade Online, nos Estados Unidos da América.
Grande parte destas receitas provêm dos motores de busca que possuem modelos de negócio
orientados de forma a rentabilizar a informação que disponibilizam aos utilizadores que os uti-
lizam. Observando a figura 2.3 podemos observar que relativamente às empresas publicitárias
verificamos a supremacia da Google, que através da DoubleClick e do GoogleAdSense, consegue
uma cota de 56,5% no mercado de publicidade através de Ads (Attributor, 2008).
Figura 2.3: Cota de Mercado das maiores agências publicitárias para a Internet
2.3 Click Fraud
Tal como foi abordado anteriormente o modelo de receita mais usado é o CPC, onde os anun-
ciantes pagam pelo número de cliques que a publicidade sofreu. Este modelo apesar da sua po-

2.3 Click Fraud 9
pularidade possui vernerabilidades em relação ao crime electrónico. (Kshetri, 2010) Devido à
característica do modelo não é possível classificar de uma forma inequívoca se os cliques que a
publicidade sofreu foram ou não de clientes interessados na publicidade. Desta incerteza surge a
Click Fraud. A Click Fraud consiste em provocar, de forma automática (usando scripts ou aplica-
ções) ou manual, cliques em anúncios publicitários de forma intencional, mas sem qualquer inte-
resse na publicidade exposta. Este tipo de fraude pode ter vários objectivos, desde gerar prejuízos
aos anunciantes, gerar lucros aos sítios expositores ou tentar denegrir a qualidade da publicidade
prestada. Segundo a ClickForensics, uma empresa de auditoria do tráfego Web, a quantidade de
cliques fraudulentos tem vindo a aumentar gradualmente ao longo do ano, acabando o ano de 2009
com uma taxa de 15,3% cliques fraudulentos entre os cliques analisados. (ClickForensics, 2010)
A Click Fraud pode ser efectuada de duas maneiras distintas. Através da simulação de browsers
ou através do uso de browsers.
• Através da simulação de browsers - Neste caso, os pedidos feitos ao servidor Web nunca imi-
tam um pedido de um browser real de uma maneira completa. Como tal é possível detectar
inconsistências na estrutura do pedido que permite suspeitar do clique analisado. Uma das
técnicas para verificar a consistência dos pedidos é através de técnicas de reconhecimento
de browers, que será o tema principal deste trabalho de dissertação.
• Através do uso de browsers - Como o browser não é simulado o seu comportamento é
autêntico no que diz respeito à estrutura do pedido. Para tal serão precisas técnicas diferentes
para podermos detectar possíveis cliques fraudulentos como por exemplo a análise aos IPs
dos cliques ou a identificação dos utilizadores através das sessões Web.
De seguida serão descritas algumas das técnicas usadas para a prática de Click Fraud. (Ferreira,
2008; ClickForensics, 2010)
• Cliques Manuais - A prática de Click Fraud através de cliques manuais consiste em o utili-
zador, manualmente, clicar nos anúncios dos anúncios, sendo este é o método mais básico
para a prática da Click Fraud. Para o utilizador torna-se fácil mascarar a sua intenção al-
terando o seu IP com regularidade ou mudando de browser. A única desvantagem para o
utilizador é a quantidade enorme de tempo que necessita disponibilizar para o clique nos
anúncios.
• Ferramentas de Clique Automático - As ferramentas de clique automático são pequenos
programas ou scripts que clicam de uma forma automática nos anúncios de um determinado
endereço. Estes scripts são muito mais eficientes, em comparação com o método de cliques
manuais, e podem ser sofisticados o suficiente para mudar de endereço IP, mudar de browser
ou percorrer uma lista de proxies a cada clique que faz.
• Click Farms - Click Farms são grupos de pessoas que são pagas para clicarem nos anúncios
publicitários agindo como utilizadores vulgares. As pessoas são contratadas para clicarem
nos anúncios em troca de uma pequena quantia de dinheiro. Este método de Click Fraud é

10 Publicidade Online
muito difícil de ser detectado pois os utilizadores são reais e geralmente eles ficam a circular
pelos sítios Web dos anunciantes para aumentar a credibilidade do clique. Este método está
a sofrer um forte desenvolvimento em alguns países do terceiro-mundo e países asiáticos.
• Botnets - As Botnets são grupos de computadores que foram infectados por malware e por
isso se encontram comprometidos. Esses computadores são chamados zombies. Desse facto
advém, que se torna possível a um agente que tenha conhecimento dos computadores infec-
tados, controlar os mesmos para fins ilícitos. No caso da Click Fraud é possível colocar
vários computadores em diferentes partes do mundo a executar ferramentas de clique auto-
mático, aumentando assim a probabilidade de serem considerados como cliques lícitos.
• Affiliate Programs - Este método tem algumas semelhanças com o Click Farms. Neste caso,
os utilizadores são seduzidos a inscreverem-se num sítio Web onde lhes é disponibilizado
um número de anúncios que podem clicar por dia. Sempre que cumprir esse requisito o
utilizador recebe pontos para trocar por produtos ou uma pequena quantia monetária. Desta
maneira, apesar de não haver interesse por parte do utilizador, fica muito difícil de suspeitar
que os cliques fazem Click Fraud.
2.4 Conclusão
A publicidade online é sem dúvida uma mais-valia para as agências publicitárias, sendo tal
comprovado pelo elevado volume de negócio por ela movimentado. A grande parte das agên-
cias publicitárias usam o modelo de receitas Cost Per Click, um modelo muito popular e bem
aceite pelos anunciantes. Mas este modelo de receitas possui um problema, pois é não possível
saber com toda a certeza qual a intenção do utilizador que clicou no ad. Daí surge o problema da
Click Fraud onde utilizadores maliciosos podem tentar ganhar dinheiro indevidamente ou preju-
dicar intencionalmente o anunciante. Como tal torna-se imperativo o controlo da legalidade dos
cliques cobrados aos anunciantes através de técnicas de identificação de Click Fraud. Nesta parte
concluiu-se que o problema da Click Fraud ainda está longe de estar resolvido e ainda é necessário
investigar e desenvolver novos métodos de a controlar.

Capítulo 3
Browsers de Plataformas Móveis
Ao longo desta década a indústria de telefones móveis tem sofrido um forte desenvolvimento,
disponibilizando aos utilizadores cada vez mais aplicações e funcionalidades. Este facto justifica-
se essencialmente com a necessidade do utilizador ter acesso a funcionalidades que só estão dispo-
níveis em computadores ou dispositivos específicos, como por exemplo o GPS. Assim a indústria
de telefones móveis viu como uma oportunidade de negócio o desenvolvimento dos seus telefo-
nes de forma possibilitar aplicações e funcionalidades que normalmente só estariam disponíveis
noutros produtos. Aliando às novas funcionalidades o conceito de mobilidade inerente a este tipo
de produtos é assim proporcionado ao utilizador uma comodidade e simplicidade que não se en-
contrava antes. Deste desenvolvimento surgiram os SmartPhones. Os SmartPhones são telefones
móveis de última geração que possuem sistemas operativos próprios e para além de todas as fun-
cionalidades inerentes a um telefone móvel, possuem ainda acesso à Internet, leitura de diferentes
tipos de multimédia, acesso ao e-mail, entre outras funcionalidades que normalmente não estão
associados aos telefones. Da mesma forma que num computador convencional, um SmartPhone
para aceder à Web necessita de um Web Browser. Este tipo de browsers, devido às caracterís-
ticas dos telefones, possui algumas limitações ao nível tecnológico, pelo que são normalmente
designados como Mobile-Browsers ou Micro-Browser.
Desta forma torna-se evidente a necessidade de fazer uma análise aos diferentes browsers
que estes dispositivos móveis usam de forma a possibilitar a identificação dos mesmos. Assim,
neste capítulo, será efectuada uma análise aos browsers mais utilizados em dispositivos móveis
assim como às diferentes plataformas que os suportam. Para concluir e vir de encontro ao que
irá ser desenvolvido posteriormente será efectuada ainda uma análise aos vários emuladores de
SmartPhone disponíveis.
11

12 Browsers de Plataformas Móveis
3.1 Plataformas Móveis
As plataformas móveis ou sistemas operativos móveis são, de uma maneira similar aos siste-
mas operativos convencionais, um conjunto de software que regula a forma como as aplicações
superiores e os utilizadores interagem com o hardware do computador. O sistema operativo é as-
sim responsável pela gestão de todos os recursos de hardware do dispositivo controlando vários
aspectos como por exemplo como a memória é utilizada pelas aplicações ou como o CPU deve
responder a diferentes aplicações. De uma certa forma um sistema operativo funciona como uma
ponte entre as aplicações e o hardware, possibilitando assim que as aplicações lhe acedam sem
haver necessidade de conhecer detalhes técnicos e também como um gestor permitindo que diver-
sas aplicações sejam executadas no mesmo dispositivo. Actualmente podemos encontrar Sistema
Operativos em diversos tipos de dispositivos desde computadores, SmartPhones, consolas de jogos
ou mesmo um simples sensores.
Relativamente aos sistemas operativos móveis estes encontram-se actualmente numa fase de
desenvolvimento bastante acentuada devido aos avanços tecnológicos que os telefones móveis têm
sofrido. Assim este tipo de plataforma surge com a tarefa de possibilitar que um simples telefone
móvel se comporte como um computador de secretária tentando contornar e controlar as suas limi-
tações tecnológicas e energéticas. Este segundo aspecto é sem dúvida o ponto que mais influência
no desenvolvimento dos telefones e suas aplicações. Não é possível para um dispositivo móvel
acomodar um sistema operativo que consuma demasiados recursos impossibilitando o utilizador
de o usufruir sem problemas energéticos. Assim aos sistemas operativos móveis acresce a gestão
dos escassos recursos energéticos que o dispositivo disponibiliza balanceando constantemente o
consumo energético em função das necessidades das aplicações de forma a maximizar o tempo de
carga da bateria.
Observando a forte expansão que o mercado de SmartPhones tem sofrido nos anos mais re-
centes, várias empresas têm oferecido aos utilizadores diferentes sistemas operativos para os seus
dispositivos móveis. Esta concorrência possibilitou assim uma variedade muito grande de siste-
mas operativos móveis, o que não se verifica para os seus congéneres “fixos”. Segundo podemos
ver na figura 3.1, num estudo global realizado pela Quantcast sobre as tendências do tráfego Web
móvel, temos um número de sistemas operativos móveis com cotas de utilização significativas
relativamente grande (Quantcast, 2010).
Deste estudo podemos retirar que nos países mais desenvolvidos existe uma forte utilização
de sistemas operativos mais recentes como é exemplo o iOS da Apple or o Android da Google.
Por outro lado vemos que no continente africano masior parte dos dispositivos que acedem a Web
possuem o sistema operativo Java ME o que indica o baixo nível tecnológico dos dispositivos
utilizados naquele continente. Existem ainda dois factos curiosos a registar. O primeiro é a exis-
tencia de um sistema operativo de uma consola como terceiro sistema operativo mais usado na
América do Sul, neste caso a consola PlayStation Portable. O segundo facto curioso é a baixa
taxa de dispositivos com Windows Mobile. Apesar do número de sistemas operativos detectados
serem elevados existe evidencia estatística que torna desnecessário uma análise aprofundada de

3.1 Plataformas Móveis 13
Figura 3.1: Cotas de utilização de Sistemas Operativos para os diferentes continentes
todos eles. Assim, serão apenas analisados os seguintes sistemas operativos:
• Android - O Android é uma plataforma desenvolvida pelo gigante Google, bastante flexivel
no que diz respeito ao número de diferentes marcas que o conseguem integrar, seguindo a
política da Google de disponibilizar os seus produtos ao maior número de gente cobrando o
mínimo possível. Nesse sentido também não existe restrições quanto ao tipo de aplicações
que pode executar cabendo apenas ao utilizador essa decisão.
• iPhoneOS - O iPhone tem como imagem de marca a inovação. Isto de facto traduz-se numa
das melhores plataformas que existem no mercado. Ao contrário do Android esta plataforma
é muito fechada e qualquer tipo de aplicação necessita de uma aprovação prévia por parte
da Apple antes de ser difundida.
• Java ME - O Java ME ou Java Micro Edition, é uma plataforma desenvolvida pela Sun
de forma a possibilitar que programadores pudessem desenvolver aplicações em Java para
dispositivos móveis. O Java ME é composto por duas funcionalidades. A primeira funciona-
lidade consiste em construir um profile do tipo de dispositivo móvel e a segunda consiste na
utilização de uma máquina virtual, KVM, que permite a execução do sistema operativo no
dispositivo móvel. A Sun decidiu não incluir o suporte às versões superiores à JRE 1.3 pelo
Java ME se encontra algo desactualizado. Este sistema operativo é geralmente observado
em dispositivos móveis mais antigos onde é largamente utilizado.
• BlackBerry OS - O BlackBerry OS é um sistema operativo desenvolvido pela RIM, Rese-
arch in Motion, e tem como principal público-alvoempresários. Como tal está totalmente
desenhado para facilitar o acesso Wi-Fi, actualizar rapidamente e-mails e listas de notas da
Web e suportar multi-tasking. Em contrapartida as aplicações menos necessárias para este
tipo de mercado foram retiradas e funcionalidades como câmara fotográfica foram menos-
prezadas.

14 Browsers de Plataformas Móveis
• Symbian - Desenvolvido pela Symbian, actualmente Symbian Foundation, este sistema ope-
rativo possibilita o multitasking e permite baixos consumos energéticos pela gestão das me-
mórias que possui. Para esse efeito a plataforma executa todas as aplicações a partir da
ROM libertando a RAM de acessos realmente necessários para a execução da aplicação. O
Symbian encontra-se actualmente aberto para que possa ser utilizado por programadores no
desenvolvimento de aplicações.
• Windows Mobile – O Windows Mobile apesar de cada vez perder mais cota de mercado a
nível mundial merece uma breve descrição devido à importância que já possuiu no mercado
de sistemas operativos para dispositivos móveis. Esta plataforma tem um aspecto visual
muito semelhante a sua versão para computador e talvez devido a isso conseguiu-se impor
neste mercado. O que se verificou posteriormente foi que este sistema operativo não estava
preparado para receber as rápidas inovações tecnológicas que iriam surgir no mercado. Um
exemplo disso é possibilidade de efectuar multi-touching em ecrãs, onde a Microsoft só
muito recentemente actualizou o sistema operativo de forma a suportar essa funcionalidade.
No início deste ano a Microsoft anunciou que irá lançar um novo sistema operativo para
SmartPhones, o Windows Phone 7.
Na tabela 3.1 podemos ver alguns aspectos compartivos entre os vários sistemas operativos
aqui descritos.
Tabela 3.1: Comparação entre Sistemas Operativos Móveis
Sistema Versão Kernel Linguagem de Arquitectura deOperativo Actual Implementação CPU suportadoAndroid 2.2 Monolithic C, C++, Java ARM, x86, MIPS,
Power ArchitectureiOS 4.0 Hybrid C, C++, ARM
Objective-CBlackBerry OS 5.0.0.1013 Java C++ ARM
Symbian 9.5 Microkernel C++ ARM, x86Windows Mobile 6.5.3 Windows CE C++ ARM
3.2 Browsers Moveis
Antes de abordar directamente
Os Browsers móveis, também conhecidos como micro-browser são uma peça muito impor-
tante na disponibilização de conteúdo Web num SmartPhone. Devido às restrições que os SmartPho-
nes possuem, nomeadamente restrições energéticas, de processamento, no débito de dados e ainda
no tamanho limitado dos ecrãs, os micro-browsers possuem características que os distinguem
notoriamente dos browsers utilizados em computadores pessoais. Assim, este tipo de browsers fo-
ram desenvolvidos de forma a reduzir a utilização de energia e a utilização de recursos como por
3.2 Browsers Moveis 15
exemplo a memória tornando-se mais eficientes e menos dependentes dos recursos dos dispositi-
vos. Este facto acarreta que muitas das funcionalidades que normalmente estão disponíveis num
browser convencional não possam ser executadas num Micro-Browser. Isto é facilmente observá-
vel em qualquer Micro-Browser onde podemos constatar limitações na execução de conteúdo em
Flash ou JavaScript. Outro problema que estes Micro-Browsers têm que ultrapassar é a limitação
do tamanho do ecrã onde a página Web vai ser exibida. Não seria viável para um browser expor a
página Web como se se tratasse de um browser convencional. Desta forma os micro-browsers têm
que fazer uma renderização da página Web de uma forma diferente possibilitando ao utilizador
ferramentas de zooming de forma a facilitar a consulta de uma página Web.
Actualmente, devido ao grande desenvolvimento dos SmartPhones, os micro-browsers estão a
diminuir a distância que os separa dos browsers convencionais apresentando cada vez mais integra-
ção com diferentes plataformas e funcionalidades que anteriormente estavam restritas. Segundo
um estudo da QuantCast o número de acessos que um sítio Web sofre a partir de um dispositivo
móvel tem crescido exponencialmente com um crescimento anual acima dos 100%, encontrando-
se neste momento com 1,26% de todos os acessos registados nos Estados Unidos da América. No
mesmo estudo podemos ainda verificar a cota de utilização de cada micro-browser no acesso à
Internet em cada continente (Quantcast, 2010).
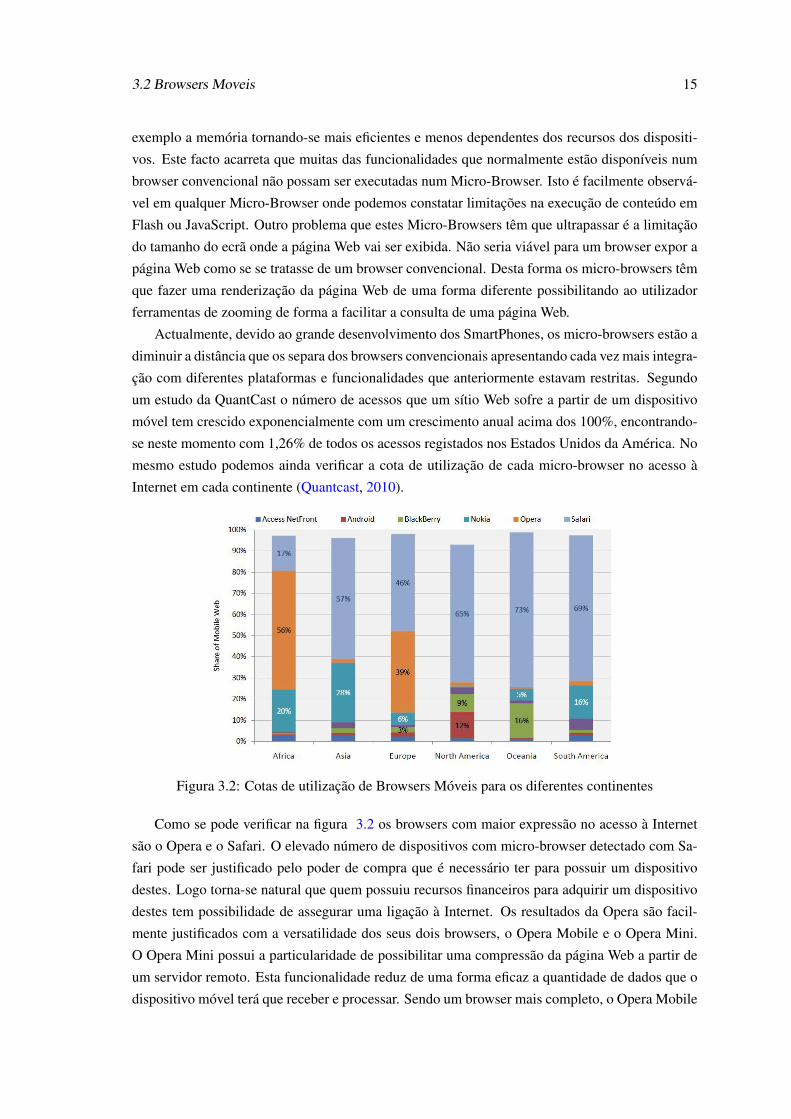
Figura 3.2: Cotas de utilização de Browsers Móveis para os diferentes continentes
Como se pode verificar na figura 3.2 os browsers com maior expressão no acesso à Internet
são o Opera e o Safari. O elevado número de dispositivos com micro-browser detectado com Sa-
fari pode ser justificado pelo poder de compra que é necessário ter para possuir um dispositivo
destes. Logo torna-se natural que quem possuiu recursos financeiros para adquirir um dispositivo
destes tem possibilidade de assegurar uma ligação à Internet. Os resultados da Opera são facil-
mente justificados com a versatilidade dos seus dois browsers, o Opera Mobile e o Opera Mini.
O Opera Mini possui a particularidade de possibilitar uma compressão da página Web a partir de
um servidor remoto. Esta funcionalidade reduz de uma forma eficaz a quantidade de dados que o
dispositivo móvel terá que receber e processar. Sendo um browser mais completo, o Opera Mobile

16 Browsers de Plataformas Móveis
possibilita ao utilizador usar esta funcionalidade. Outro facto interessante deste estudo é o facto de
a taxa de utilização do Internet Explorer Mobile, do gigante Windows, na navegação pela Internet
ser extremamente reduzida. Isto poderá dever-se ao sistema operativo pouco competitivo que esta
empresa apresenta e ao browser pouco apelativo.
Verificando a tabela 3.2 podemos ver uma tabela comparativa das diferentes tecnologias e
protocolos que cada browser suporta. Podemos assim verificar a versatilidade dos browsers Opera
sendo suportados por mais que um sistema operativo diferente. Podemos concluir também que
na maioria dos Micro-Browsers analisados o motor utilizado é o WebKit. Actualmente empresas
como a Reasearch in Motion, empresa que desenvolveu o BlackBerry, ou a Samsung estão a
lançar novos browsers em que utilizam o WebKit como motor de browser. Desta forma este
homogeneização do motor utilizado vai trazer maiores dificuldades na identificação dos browsers
visto que a forma como os browsers constroem as páginas depende directamente do motor de
browser utilizado. Isto pode ser provado fazendo uma análise à arquitectura de um browser. Assim,
analisando os vários elementos representados na figura 3.3 obtemos (Alan Grosskurth, 2006):
Figura 3.3: Arquitectura de um Browser
• User Interface – O subsistema User Interface é a ponte que liga o utilizador ao browser. É
aqui que são disponibilizados recursos como barras de ferramentas, opções de configuração,
visualização do progresso de carregamento da página assim como a integração com outras
possíveis aplicações.
• Browser Engine – O subsistema Browser Engine tem a função de fornecer uma interface
de alto nível para o subsistema Rendering Engine carregando os URIs inseridos no browser
assim como executando funções básicas de um browser como o recarregamento da página
ou o retrocesso à página anterior. Aqui é registada informação relativa a construção da
página como por exemplo, a percentagem da página carregada ou os alertas do JavaScript.
• Rendering Engine – O subsistema Rendering Engine produz a representação visual da pá-
gina Web a carregar. É este subsistema que interpreta o HTML, XML, imagens ou o CSS
de forma a conseguir construir a página Web no browser.

3.2 Browsers Moveis 17
• Networking – O subsistema Networking implementa os protocolos que irão permitir receber
as páginas Web fazendo a tradução entre diferentes grupos de caracteres. Destes protocolos
fazem parte o HTTP ou o FTP. É também possível implementar uma cache neste subsistema
de forma manter recursos recolhidos recentemente.
• JavaScript Interpreter – O subsistema JavaScript Interpreter, tal como o nome indica, é res-
ponsável pela interpretação do código JavaScript que uma página Web possa conter.
• XML Parser – O subsistema XML Parser tem como função a analisar o documento XML
para que com isso consiga construir a árvore de objectos DOM.
• Display Backend – o subsistema Display Backend recolhe informações do sistema operativo
como por exemplo, fontes de letra, definições das janelas, ferramentas, entre outros.
• Data Persistence – O subsistema Data Persistence é o responsável por armazenar informação
relativa à utilização do browser. Essa informação pode ser definições pessoais, marcadores,
cookies, certificados de segurança, cache entre outros.
Neste documento quando é referido motor de browser isso corresponde à união dos subsis-
temas Browser Engine e Rendering Engine. Assim é fácil concluir que para diferentes browsers
que possuam o mesmo motor de browser a forma com estes irão interpretar as páginas Web serão
muito semelhantes.

18B
rowsers
dePlataform
asM
óveis
Tabela 3.2: Comparação entre Browsers Móveis
Browser Versão Motor CSS 1.0 CSS 2.1 CSS 3.0 Java JavaScript Flash Compressão Sistemas OperativosServer-Side compatíveis
Android WebKit 2.1 WebKit Total Total Parcial Sim Sim Parcial Não AndroidBlackBerry 4.2 Mango Total Parcial Parcial Sim Parcial Parcial Não BlackBerry OSNetFront 4.1 NetFront Total Parcial Parcial Sim Sim Parcial Não Windows Mobile
SymbianOpera Mobile 10 Presto Total Total Parcial Sim Sim Parcial Possível Windows Mobile
SymbianOpera Mini 5 Presto Total Parcial Parcial Sim Parcial Não Sim Windows Mobile
SymbianBlackBerry OS
AndroidJava ME
Safari iPhone 3.0 WebKit Total Total Parcial Sim Sim Não Não iOSSymbian WebKit 3.0 WebKit Total Parcial Parcial Sim Parcial Parcial Não Symbian
IE Mobile 6.5 Trident Total Parcial Parcial Sim Parcial Parcial Não Windows Mobile

3.3 Conclusão 19
3.3 Conclusão
Os micro-browsers são um tipo de browser que irá sofrer uma forte evolução ao longo do
tempo. Acompanhando a evolução que estes têm sofrido ao longo dos anos torna-se evidente que
num futuro próximo não haverá distinção entre estes browsers e os browsers convencionais.
Relativamente à analise efectuada neste capítulo podemos verificar que a maior parte dos
browsers analisados têm como motor de browser o WebKit. De facto este motor está-se a tornar
uma plataforma bastante importante no mercado dos browsers móveis. Notícias recentes sugerem
que a RIM irá adoptar um browser com motor WebKit e a Samsung lançou também recentemente
o seu browser WebKit. Estes dois browsers podem ter algum impacto no mercado pelo que devem
ser seguidos num futuro próximo.

20 Browsers de Plataformas Móveis

Capítulo 4
Reconhecimento de Browsers
A concorrência no mercado de browsers originou que existam actualmente na Internet um nú-
mero enorme de browsers com características e funcionalidades diferentes. Tal como foi discutido
anteriormente no capítulo 2, a Click Fraud é um grande problema para a indústria de publicidade
online pelo que se torna necessário encontrar ferramentas que permitam classificar os cliques de
forma a determinar a sua validade. Uma dessas técnicas é a detecção do browser do cliente efec-
tua o clique, pois permite verificar se o browser que originou o pedido é real e se corresponde
com a mais básica informação que é possível retirar dos browsers. Para ser feito o reconheci-
mento do browser existem actualmente algumas técnicas que tiram partido das particularidades de
cada browser de forma a poder encontrar uma possível identificação do browser que originou o
clique. Neste capítulo serão abordadas as técnicas que existem para o reconhecimento de brow-
sers assim como uma descrição do serviço de Auditoria da AuditMark tal como descrito por Rui
Polónia. (Polónia, 2010)
4.1 Técnicas de Reconhecimento de Browers
O reconhecimento do browser é uma peça muito importante na detecção de ClickFraud pelo
que é importante o seu desenvolvimento. A forma mais fácil obter algum tipo de informação sobre
o browser utilizado por um utilizador é a leitura do campo user-agent, que é enviado na execução
do método GET, no protocolo HTTP onde se encontra descrito sobre forma de texto qual é o Brow-
ser usado pelo utilizador. Este método seria suficiente para a sua identificação não fosse simples, a
um utilizador com intenções de mascarar a sua navegação pela Web, adulterar o seu resultado, pois
actualmente existem inúmeros Add-ons ou métodos para browser poderem alterar a informação
contida no campo user-agent. Como tal, este tipo de informação não deverá ser considerada para
uma correcta identificação do Browser mas antes como uma ferramenta para testar a veracidade da
informação que os browsers disponibilizam. Como é possível de verificar ao aceder à Web, exis-
tem no mercado diversos browsers com especificidades diferentes de forma a cativar o utilizador
21

22 Reconhecimento de Browsers
à sua utilização. Serão essas especificidades que irão tornar possível uma distinção entre os vários
browsers que existem no mercado. A primeira grande diferença que se verifica entre eles deriva
dos diferentes motores que os browsers utilizam, pois são estes que determinam como a página
Web irá ser processada e como é feita a comunicação com o servidor. A segunda diferença vem
do suporte que cada browser oferece às diferentes linguagens de programação ou plataformas que
existem para a execução de conteúdos Web. Esta diferença é talvez a mais importante, pois além
de permitir fazer uma distinção entre browsers de empresas diferentes, permitirá também detectar
diferentes versões de um mesmo browser. Será então a junção destas duas grandes diferenças que
nos permitirá identificar qual o browser utilizado na execução do clique.
4.1.1 Análise dos Cabeçalhos HTTP
Com o desenvolvimento da Web foi necessário criar protocolos que permitam a comunicação
entre clientes e servidores. Como tal, surge em 1990 a primeira versão do protocolo HTTP com
a versão 0.9 desenvolvida pelo britânico Tim Berners-Lee, actual director da World Wide Web
Consortium (W3C) que pela primeira vez introduz o uso de URIs para a identificação de páginas
Web e de hiper-ligações de forma a facilitar a navegabilidade entre páginas. Assim em 1996
surge assim o RFC (Request for Comments) 1945 que descreve a versão 1.0 do protocolo HTTP.
Com o aumento da popularidade do protocolo em 1999, uma parceria entre o W3C e o IETF
lançam a actual versão do protocolo HTTP, versão 1.1 descrita no RFC 2616, que vem colmatar as
deficiências da anterior versão em relação aos requisitos que a Web necessitava, tais como suporte
a outros protocolos (SMTP, FTP, NNTP, entre outros), a possibilidade de uso de Web proxies e
principalmente a possibilidade de troca de mensagens sem ser no formato texto, as mensagens tipo
MIME (Multipurpose Internet Mail Extension). O protocolo HTTP é constituído por 9 métodos,
descritos na tabela que se destinam a assegurar a comunicação entre o cliente, browser, e o servidor
Web.(R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach e T. Berners-Lee, 1999)
De todos estes métodos os mais usais de serem visualizados na comunicação Web Browser
com um Servidor Web são o comando GET e PUT.
4.1.1.1 Análise do método GET
O trabalho desenvolvido por David Carvalho (Carvalho, 2008; Shah, 2005), relativamente à
identificação de browsers pelo comportamento do protocolo HTTP, sugere que os browsers têm
comportamentos diferentes na forma com constroem as mensagens a serem enviadas para o ser-
vidor Web, através do método GET. Este método possui um conjunto alargado de campos mas
geralmente só são declarados um número reduzido dos mesmos. Os campos mais vulgarmente
declarados pelos browsers Web são os seguintes:
Numa análise a diferentes browsers foi então possível constatar dois tipos de diferenças aquando
do uso do método GET. Foram assim detectadas diferenças na forma e no conteúdo das mensagens
transmitidas, que podem ser visualizadas na Figura 4.1.

4.1 Técnicas de Reconhecimento de Browers 23
Tabela 4.1: Métodos HTTP
Método DescriçãoCONNECT Usado para estabelecer uma ligação a um túnel TCP/IP. Este método é usado
geralmente no uso do SSL nas ligações HTTPS.DELETE Este método é usado quando o cliente pretende que o servidor apague, ou mova
para uma localização inacessível, um recurso identificado através do URI.GET O método GET é usado pelo cliente para recolher a informação disponível no
URI indicado.HEAD Este método é usado para recolher apenas o cabeçalho HTTP.
OPTIONS Retorna quais os métodos HTTP que o servidor suporta.PATCH Este método é usado para actualizar recursos.POST O método POST é usado quando se pretende enviar informação para ser proces-
sada para o outro interveniente da ligação.PUT Este método é utilizado para o envio de informação para o outro interveniente
da ligação.TRACE Utilizado pelo cliente para determinar o que os servidores intermédios alteram
no seu pedido.
Diferenças na forma – Esta diferença surge essencialmente devido aos diferentes motores
usados pelos browsers. Como foi verificado no trabalho desenvolvido pelo autor, os browsers não
constroem o método GET exactamente da mesma forma. Entre os vários browsers existem assim
discrepâncias no tipo de campos utilizados, onde é possível identificar campos únicos a browsers
específicos, e na ordem que os campos assumem no pedido.
Diferenças no conteúdo – Foram detectadas também diferenças no conteúdo de alguns cam-
pos do método GET. Estas diferenças são compostas essencialmente por diferenças de capitulação
e diferenças na quantidade de informação transmitida ao servidor. Estas diferenças são geralmente
detectadas no campo Accept-Language.
O aliar destas duas diferenças permitiu assim ao autor elevar a sua certeza aquando da iden-
tificação do browser usado pelo utilizador. Esta técnica por si só é bastante poderosa possuindo
apenas um problema para uma utilização mais generalizada. Para ser possivel efectuar este tipo
de análise é necessário que o servidor guarde para um ficheiro sempre que este receba mensagens
com a indicação do método GET para novas ligações. Desta forma, para um servidor com um
número diário de acessos razoavel, este ficheiro pode atingir valores incomportaveis mesmo que
recolhido diariamente.
4.1.1.2 Análise do método POST
Pela mesma razão já invocada anteriormente aquando da análise do método GET, o método
POST irá também ter uma construção semântica do seu conteúdo e a ordem dos seus campos em
conformidade com o browser utilizado na comunicação. (Shah, 2005) Apesar do método POST
normalmente não ser utilizado pelos browsers, visto estes só recolherem informações do servidor,

24 Reconhecimento de Browsers
Tabela 4.2: Campos mais vulgares do método GET
Campo DescriçãoAccept Especifica quais os tipos de mensagens que o cliente aceita por parte do
servidor.Accept-Charset Especifica qual o conjunto de caracteres que o browser aceita por parte do
servidor.Accept-Encoding Especifica quais os tipos de compactação que o browser aceita por parte
do servidor.Accept-Language Especifica quais a linguagens preferidas pelo browser.
Connection Especifica quais as opções desejadas da ligação.Host Especifica qual o Host ao qual é feito o pedido.
Referer Especifica qual o host de onde surgiu o pedido HTTP.User-Agent Contem informação relativa ao browser utilizado.
não impossibilita que não possam ser geradas mensagens com este método. É assim possível atra-
vés da utilização do JavaScript obrigar o browser a construir uma mensagem invocando o método
POST para enviar ao servidor e de forma a ser possível posteriormente analisar as diferenças e
conseguir uma correcta identificação do browser. Como se pode verificar na Figura 4.2 mais uma
vez é possível detectar diferenças quer na forma e no conteúdo sendo então proveitosa a derivação
da técnica acima descrita para uma correcta identificação do browser.
O aliar destas duas técnicas permite assim elevar a certeza de uma correcta identificação do
browser usado pelo utilizador. Estas técnicas por si só são bastante poderosas possuindo apenas
um problema para uma utilização mais generalizada. Para ser possível efectuar este tipo de análise
é necessário que o servidor guarde para um ficheiro toda a informação relativa ao à utilização dos
métodos GET e POST para novas ligações. Desta forma, para um servidor com um razoável
número de acessos diário, este ficheiro pode atingir valores incomportáveis mesmo que recolhido
diariamente.
4.1.2 Document Object Model
O Document Object Model (DOM) é uma plataforma, desenvolvida pela W3C, como um con-
junto de objectos que define a estrutura dos documentos XML ou HTML e a forma como estes
podem ser acedidos e alterados. (Philippe Le Hégaret, Ray Whitmer e Lauren Wood, 2005) Este
tipo de estrutura das páginas Web possibilitou o aparecimento de um novo conceito, o DHTML,
ou seja, o conceito de páginas Web dinâmicas. Para esse efeito é geralmente usada uma lingua-
gem de programação, como o JavaScript ou o VBScript, para poder aceder aos vários métodos
e propriedades que os vários objectos disponibilizam. Particularmente, o JavaScript é uma lin-
guagem de programação que pode ser executada totalmente do lado do cliente, browser Web, que
possui a particularidade de não ser necessário uma compilação do código, sendo este antes execu-
tado directamente pelo motor do browser aquando do processamento do documento. Desta forma
é possivel através do uso de JavaScript recolher todo o tipo de informação sobre o documento
ou executar conteúdos com a ocorrência de eventos diversos como um clique rato ou o passar

4.1 Técnicas de Reconhecimento de Browers 25
Figura 4.1: Diferenças no uso do método GET entre Internet Explorer e Mozilla Firefox
por cima de alguma parte do documento. A importância do DOM na identificação de browsers
prende-se no facto este possuir um conjunto objectos que caracterizam especificamente propri-
edades e métodos que podem ser recolhidos ou aplicados no browser que está a ser usado pelo
utilizador. O DOM, relativamente à parte da informação do browser, é constituído pelos seguintes
objectos: (W3Schools)
• History – Contém informação sobre o histórico de navegação do browser.
• Location – Contém informação sobre a página.
• Navigator – Contém informação sobre o browser.
• Screen – Contém informação sobre o monitor do utilizador.
• Window – Contém informação sobre a janela no browser.
Da mesma forma como foi descrito na análise dos cabeçalhos HTTP existe uma propriedade
que recolhe o conteúdo do user-agent (Navigator.userAgent) declarado pelo browser. Pelas mes-
mas razões que foram evidenciadas no ponto anterior esta propriedade não deverá ser considerada
para uma correcta identificação do browser, mas antes como método de validação do que o brow-
ser assume ser. Devido aos diferentes motores que os browsers utilizam, estes originam diferen-
tes comportamentos relativamente à forma de como implementam e interagem com os objectos.
Como tal torna-se pertinente a comparação das propriedades e métodos de todos os objectos DOM,
e não apenas dos objectos que possuem informação relativa ao browser, de forma a conseguir uma
diferenciação dos browsers de uma forma mais exacta. Para além das diferenças na interpretação
dos objectos, algumas empresas decidiram implementar objectos que só podem ser interpretados
pelos seus browsers. Um exemplo disso é a propriedade Window.Opera. Esta propriedade diz
apenas respeito ao browser Opera e como tal só é implementado quando este browser é usado.

26 Reconhecimento de Browsers
Figura 4.2: Diferenças no uso do método POST entre Internet Explorer e Mozilla Firefox
4.1.3 HTTP Persistent Connections
Com a necessidade de assegurar uma conexão TCP de forma inenterrupta, foi desenvolvida a
ideia do HTTP Persistent Connections.(Z. Wang, 1998) Este tipo de conexões foram criadas de
forma evitar a abertura de uma nova ligação TCP sempre que fosse necessário o estabelecimento
de uma comunicação entre o par cliente-servidor. Desta forma, este tipo de conexões vieram asse-
gurar que a comunicação poderia ficar activa mesmo sem haver comunicação e posteriormente ser
reutilizadas pelas mesmas partes sem a haver a necessidade de estabelecer novamente uma nova li-
gação. Este tipo de ligações vieram ajudar na redução do tráfego, especialmente nas comunicações
SSL/TLS onde havia até então um exagerado número de pacotes que eram usados só para estabe-
lecer constantemente novas ligações degradando desta forma o desempenho do protocolo HTTP
com largura de banda ocupada desnecessariamente. Relativamente às conexões persistentes po-
demos encontrar diferenças, entre browsers, de duas formas distintas. A primeira das diferenças
deve-se ao facto de os browsers não declararem todos o mesmo número máximo de conexões
persistentes. No caso do Internet Explorer, até à versão 8.0 ele só suportava, no máximo, duas
conexões persistentes. A segunda diferença surge através da diferença no tempo máximo que um
cliente pode estar sem comunicar até a ligação ser destruía. O aliar destas duas diferenças conjuga
mais um método para conseguir ajudar na detecção do browser utilizado.

4.2 Funcionamento do AuditService da AuditMark 27
4.2 Funcionamento do AuditService da AuditMark
O AuditService é o serviço que a AuditMark disponibiliza que tem como objectivo a análise
e classificação qualitativa do tráfego Web. Devido aos poucos conhecimentos pessoais da arqui-
tectura e funcionamento deste serviço, este capítulo será desenvolvido tendo como base o trabalho
de Rui Polónia (Polónia, 2010) relativamente à parte do AuditService. Como tal, será feita uma
exposição do serviço de forma proporcionar um correcto entendimento das várias partes do pro-
cesso de auditoria e de como estas se conjugam. Devido às grandes quantidades de tráfego que
é necessário auditar, o AuditService foi projectado como um sistema modular e distribuído. Este
modelo de funcionamento torna possível distribuir as componentes do serviço de auditoria por
várias máquinas e executar várias instâncias de cada componente simultaneamente o que se traduz
num sistema eficiente e flexível.
Como é possível verificar na Figura 4.3 o serviço AuditService este encontra-se dividido
em três módulos distintos. O módulo de recolha de dados, o módulo Audit-PI e o módulo de
processamento de dados.
Figura 4.3: Arquitectura do AuditService
4.2.1 Módulo de recolha de dados
Este módulo é constituído por todos os componentes destinados à recolha de dados. Fazem
parte deste módulo o JavaScript Interaction Code, o Server Data-Collector e o Data Packager.
• JavaScript Interaction Code (JIC) – O JIC é o componente responsável pela recolha dos da-
dos Web que irão ser auditados pela AudtMark. Esta componente é constituída por vários
ficheiros JavaScript que serão utilizados consecutivamente de forma a recolher a informação
pretendida do utilizador. Para a sua execução é colocado um Web Bug [nota] no servidor
Web que está a ser auditado, de forma a que qualquer utilizador que visite esse servidor seja
redireccionado para o servidor da Auditmark, que contém o primeiro ficheiro JavaScript,
iniciando-se assim a primeira ronda de recolha de dados. Este primeiro ficheiro é responsá-
vel pela recolha da primeira parte dos dados do utilizador e da execução do próximo ficheiro
JavaScript. Este processo é repetido até todos os ficheiros JavaScript terem sido executados

28 Reconhecimento de Browsers
e os dados recolhidos. Como o JavaScript é executado na máquina do cliente, a AuditMark
teve necessidade de utilizar uma ferramenta de ofuscação de código JavaScript de forma a
esconder o processo de recolha de informação do utilizador.
• Server Data-Collector (SDC) – O SDC tem a funcionalidade de recolher os dados obtidos
pelo JIC e transforma-los num ficheiro binário. É este ficheiro binário, o log SDC, que será
posteriormente utilizado para a análise do tráfego ao servidor a auditar.
• Data Packager (DP) – Este componente, implementada em JAVA, tem a função de encapsu-
lar os logs SDC e transmiti-los através de uma ligação JAVA RMI para o próximo módulo
do AuditService, o módulo Audit-PI.
4.2.2 Módulo Audit-PI
O Audit-PI é o módulo onde se encontram as funções de acesso às bases de dados distribuí-
das do AuditService, orquestração de processos, sistemas de filas, escalonador de eventos, entre
outros. É também este módulo o responsável pela gestão do processamento de dados e pela ges-
tão do fluxo de dados entre componentes do serviço. Desta forma podemos considerar o módulo
Audit-PI como o módulo central do AuditService. O Audit-PI é constituído por vários componen-
tes mas aqui só serão retratados os componentes mais importantes para perceber o funcionamento
do Audit-PI e a sua interacção com os restantes módulos.
• Data-Collection Interface (DCI) – A função deste componente é receber os dados que o
componente Data Packager, do módulo Recolha de Dados, transmite, inseri-los no sistema
de base de dados distribuídas e notificar os restantes componentes do serviço AuditService
da existência de dados novos. Para a inserção de dados no sistema de base de dados distri-
buídas são utilizadas stored procedures da componente Data-Acess API.
• Data Processing Orchestrator (DPO) – Esta é o componente responsável pela orquestração
dos processos de processamento de dados. Sempre que o DCI notifica a existência de novos
dados o DPO desencadeia o processamento dos dados a auditar, tendo como base ficheiros
XML que indicam qual o tipo de tarefas, e ordem, que são realizadas.
• Distributed Database Abstraction Interface (DDBA) – O DDBA tem como função isolar os
vários componentes do serviço, do modelo de arquitectura do AuditService. Como tal é
criado um PL/Proxy para as ligações ao sistema de base de dados distribuídas PostGreSQL.
São também implementadas stored procedures para simplificar e unificar os acessos ao sis-
tema de base de dados.
• Data Access API – Este componente é constituído pelas stored procedures. Como foi ex-
presso anteriormente as stored procedures têm como função simplificar o acesso ao sistema
de base de dados. Esta simplificação deve-se à abstracção que as aplicações têm do sistema
de base de dados distribuídas, pois assim, a aplicação deixa de saber qual a localização física
dos dados a serem lidos ou escritos.

4.3 Conclusão 29
4.2.3 Módulo de processamento de dados
• Data Processing Plugins (DPPs) – Um DPP é uma tarefa, ou método, de processamento
dos dados a ser auditados. Tal como foi escrito anteriormente, o DPO lê as tarefas, para o
processamento dos dados a auditar, num ficheiro XML. Dessa forma, cada DPP é uma tarefa
a ser realizada, sendo este o responsável pelo acesso aos dados a auditar, pelo processamento
e também pelo posterior armazenamento dos resultados obtidos da tarefa.
4.3 Conclusão
Algumas das técnicas de identificação de browsers descritas neste documento são técnicas bas-
tante eficientes para conseguir uma resposta correcta quanto à identificação do browser utilizado.
Tomando como exemplo a técnica da identificação do browser através da leitura da sua árvore de
objectos DOM é possível garantir que o diferente comportamento dos browsers é a melhor forma
de os identificar. Existem objectos DOM para quase todas as tecnologias que o browser utiliza.
Desta forma é sempre possível descobrir diferenças e refinar cada vez mais o grau de exactidão na
identificação do browser. Ainda assim, apesar da eficiência na identificação será impossível ga-
rantir que todos os cliques analisados são 100% validos pois existirá sempre forma de enganar ou
dificultar o trabalho de quem audita o tráfego. Um exemplo disso é a possibilidade de desactiva-
ção do JavaScript, que impossibilita a análise dos objectos DOM, ou de qualquer outra aplicação
ou linguagem que possibilite a identificação do browser ou das suas características. De forma a
concluir este capítulo será apresentada na tabela 4.3 as vantagens e desvantagens de cada técnica
aqui descrita.
Tabela 4.3: Comparação das técnicas de identificação de Browsers
Técnica Vantagens Desvantagens
Método GET Grande fiablilidade nos resulta-dos obtidos
É necessário recolher outro tipode informação que o AuditSer-vice não está preparado para re-colher.
Método POST Grande fiablilidade nos resulta-dos obtidos
É necessário recolher outro tipode informação que o AuditSer-vice não está preparado para re-colher. Se o JavaScript esti-ver desactivado este método nãopode ser usado.
DOM Rápido e eficiente na formacomo recolhe e processa a infor-mação. Fiabilidade nos resulta-dos obtidos.
Se o JavaScript estiver desacti-vado este método não pode serusado.
Persistent Connections Fácil verificação Pouco preciso. É possivel con-figurar o número máximo de co-nexões.

30 Reconhecimento de Browsers

Capítulo 5
Conclusão
5.1 Proposta de Solução
Analisando os métodos que foram apresentados no capítulo 4 é agora necessário proceder a
escolha de uma proposta de solução para o problema proposto. De todos os métodos analisados
o que oferece mais garantias é a análise dos cabeçalhos HTTP. O facto de este método não ser
dependente de outras plataformas ou protocolos traduz-se numa grande vantagem na recolha de
informação acerca do browser. Para além disso este método oferece algumas garantias no que diz
respeito à falsificação dos pacotes que são recolhidos. Por outro lado temos um método com uma
facilidade de implementação maior que é a análise da árvore de objectos DOM. Este método é
bastante simples e produz resultados mais rápidos mas tem o inconveniente de ser dependente do
JavaScript. Tendo em conta que este projecto é levado tem como objectivo a detecção de brow-
sers móveis a taxa de browsers que não suportam o JavaScript ou que só suportam parcialmente
é bastante elevada. Este método torna-se assim mais limitado do que o anteriormente analisado.
Relativamente ao método da análise ao máximo de conexões persistentes que cada browser auto-
riza este método é também de fácil implementação mas não se traduz numa maior eficiência. O
número máximo de conexões pode ser redefinido e o número de browsers com o mesmo número
máximo de conexões é demasiado grande para se poder retirar alguma conclusão.
Tendo em mente esta análise a proposta de solução resume-se então, numa primeira fase, à
análise dos campos HTTP. Serão criados então perfis de para cada browser e serão executados
testes que irão indicar com um grau de probabilidade qual o browser que foi utilizado na pesquisa.
De modo complementar irá também ser implementado o método da análise dos objectos da árvore
DOM. De igual forma ao que irá ser realizado na primeira análise serão criados novos perfis de
browser para poder proceder à identificação do browser. Os perfis quando forem criados terão
como base de decisão pontos da identificação de cada browser. Cada um desses pontos terá uma
pontuação definida em conformidade com a importância do ponto em questão para a identificação
do browser.
31

32 Conclusão
5.2 Planificação do Trabalho a Desenvolver
De forma a descrever o fluxo de trabalho para o projecto durante a dissertação, foi delineado
um diagrama de Gantt (Figura 5.1). Visto ainda não haver datas definidas sobre a disciplina
Dissertação foi tomado como ponto de partida o dia 13 de Setembro de 2010 e para a entrega do
relatório da Dissertação foi escolhida a data de 31 de Janeiro de 2011. Tendo por base estas datas
foram então definidas as várias tarefas que irão levar ao desenvolvimento do projecto. De notar
que estas tarefas e os prazos definidos não têm carácter definitivo podendo sofrer alterações que
se justifiquem.
Figura 5.1: Diagrama de Gantt do Projecto
Tabela 5.1: Lista das Tarefas
Ordem Tarefa Duração Início Fim Precedências1 Integração na AuditMark 5 dias 13/09/10 17/09/102 Desenvolvimento de uma 30 dias 20/09/10 29/10/10 1
solução para a Identificaçãode Browsers Móveis
3 Identificação e Definição 10 dias 01/11/10 12/11/10 2de Perfis de Browser
4 Testes funcionais, de 20 dias 15/11/10 10/12/10 3validação e de desempenho
5 Optimização da Solução 10 dias 13/12/10 24/12/10 46 Elaboração do Relatório 30 dias 29/11/10 07/01/11
da Dissertação7 Revisão, Impressão 10 dias 17/01/11 28/01/11 6
e Encadernação8 Preparação da Apresentação 10 dias 31/01/11 11/02/11 79 Escrita do Artigo Científico 10 dias 31/01/11 11/02/11 7

5.3 Conclusão 33
5.3 Conclusão
Este documento foi desenvolvido com o objectivo de aprofundar os conhecimentos na área
que engloba o projecto, funcionando como base preparatória para a dissertação que irá ser desen-
volvida no semestre seguinte.
De forma a dar a conhecer a problemática do tema foi desenvolvido um capítulo sobre pu-
blicidade online onde foram analisados os diferentes tipo de publicidade na Internet. Devido ao
peso que a publicidade na Web possui foram analisados ainda os modelos de negócio existentes
onde se englobou os vários modelos de receitas e o volume de negócio que esta forma de publi-
cidade atinge. Feita esta análise é assim possível compreender como os fenómenos de fraude na
Web, como o ClickFraud, surgem. Assim foi apresentada um descrição desta problemática e assim
como das técnicas mais usadas para o praticar.
Feita esta contextualização do problema percebe-se então qual a importância das técnicas de
detecção de browsers para a detecção do Click Fraud. Dessa forma foram analisados as carac-
terísticas dos Browsers Móveis assim como assimiladas as suas limitações. Desta forma foram
analisadas as características das plataformas mais vulgares no acesso à internet por meio móvel,
sendo possível perceber a distribuição da cota de utilização de cada plataforma móvel para per-
ceber a importância de cada uma. Feita esta análise foram analisados em maior pormenor os
Browsers-Moveis também recolhendo as suas características de forma a perceber que técnicas é
que são possíveis de usar para os detectar e se existiam características únicas que os distinguiam.
Depois desta análise concluída, procedeu-se à investigação das técnicas de detecção de brow-
sers que já foram desenvolvidas. Consequentemente, forma descritas três técnicas que permitem
identificar diferenças entre pedidos que um servidor Web recebe e dessa forma criar perfis para a
identificação do browser utilizado. Complementarmente foi descrito duma forma simples a arqui-
tectura do serviço de auditoria da AuditMark de forma delinear uma estratégia para a proposta de
resolução.
Concluindo, a elaboração deste documento serviu para aumentar a base de conhecimento que
servirá como catapulta para o projecto que irá ser desenvolvido durante o processo da dissertação.

34 Conclusão

Referências
Michael Godfrey Alan Grosskurth. Architecture and evolution of the modern web browser, Ju-nho 2006. David R. Cheriton School of Computer Science, University of Waterloo, Waterloo,Canadá.
Attributor. Google ad-server share now at 57%, 2008.Disponível em http://www.attributor.com/blog/google-ad-server-share-now-at-57-microhoo-less-than-15-market-share/,acedido pela última vez a 29 de Abril de 2010.
David T. Carvalho. Utilização de reconhecimento de web browsers para detecção de cliques frau-dulentos, Julho 2008. Relatório do Projecto de Conclusão do Curso, Faculdade de Engenhariada Universidade do Porto.
ClickForensics. Q4 2009 click fraud rate is down. or up. depends., Janeiro 2010. Disponível emhttp://blog.clickforensics.com, acedido pela última vez a 29 de Abril de 2010.
Bruno Ferreira. A survey of click fraud techniques, Julho 2008. Instituto Superior de Engenhariado Porto.
N. Kshetri. The economics of click fraud. Institute of Electrical and Electronics Engineers - IEEE.Security & Privacy, pages 45 – 53, Maio - Junho 2010.
Philippe Le Hégaret, Ray Whitmer e Lauren Wood. Document object model, 2005. Disponívelem http://www.w3.org/DOM/, acedido pela última vez a 18 de Junho de 2010.
Rui Polónia. User tracking through web sessions, Janeiro 2010. Dissertação realizada no âm-bito do Mestrado Integrado em Engenharia Electrotécnica e de Computadores, Faculdade deEngenharia da Universidade do Porto.
PricewaterhouseCoopers. IAB - internet advertising revenue report, Abril 2010. 2009 Full-YearResults.
Quantcast. Quantcast mobile web trends, Janeiro 2010.
R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach e T. Berners-Lee. HTTP - RFC2616, Junho 1999. Disponível em http://www.w3.org/Protocols/, acedido pela últimavez a 18 de Junho de 2010.
Brad Aronson Robbin Zeff. Advertising on the Internet. John Wiley and Sons, Second edition,1999. ISBN 0-471-34404-4.
Shreeraj Shah. Browser identification for web applications, 2005.
35

36 REFERÊNCIAS
Allen Stern. What forms of online advertising are acceptable today?, Julho 2008.
Alexander Tuzhilin. The lane’s gifts v. google report, 2007.
W3Schools. Javascript and HTML DOM reference. Disponível em http://www.w3schools.com/jsref/default.asp, acedido pela última vez a 18 de Junho de 2010.
P. Cao Z. Wang. Persistent connection behavior of popular browsers, 1998. Department of Com-puter Sciences, University of Wisconsin.