mÉtodos de inteligÊncia computacional para detecÇÃo de...
TRANSCRIPT

MÉTODOS DE INTELIGÊNCIA COMPUTACIONAL PARA DETECÇÃO DE FRAUDES DE ENERGIA
ELÉTRICA
Breno Serrano de Araujo
Projeto de Graduação apresentado ao Curso de Engenharia Eletrônica e de Computação da Escola Politécnica, Universidade Federal do Rio de Janeiro, como parte dos requisitos necessários à obtenção do título de Engenheiro. Orientadores: Heraldo Luís Silveira de Almeida Flávio Luis de Mello
Rio de Janeiro
Fevereiro de 2017



iv
UNIVERSIDADE FEDERAL DO RIO DE JANEIRO
Escola Politécnica – Departamento de Eletrônica e de Computação
Centro de Tecnologia, bloco H, sala H-217, Cidade Universitária
Rio de Janeiro – RJ CEP 21949-900
Este exemplar é de propriedade da Universidade Federal do Rio de Janeiro, que
poderá incluí-lo em base de dados, armazenar em computador, microfilmar ou adotar
qualquer forma de arquivamento.
É permitida a menção, reprodução parcial ou integral e a transmissão entre
bibliotecas deste trabalho, sem modificação de seu texto, em qualquer meio que esteja
ou venha a ser fixado, para pesquisa acadêmica, comentários e citações, desde que sem
finalidade comercial e que seja feita a referência bibliográfica completa.
Os conceitos expressos neste trabalho são de responsabilidade do(s) autor(es).

v
DEDICATÓRIA
À minha família.

vi
AGRADECIMENTO
Dedico este trabalho à minha família que sempre me apoiou e incentivou os
meus estudos, mesmo nos momentos difíceis.
Gostaria de agradecer a todos os meus professores da UFRJ que contribuíram de
forma significativa à minha formação acadêmica e pessoal. Aos meus amigos e colegas
de faculdade, que tornaram essa jornada mais agradável e prazerosa.
Agradeço à UFRJ, em conjunto com DAAD e CAPES, pela experiência de
intercâmbio acadêmico na Universidade Técnica de Munique, uma das experiências
mais enriquecedoras que tive a oportunidade de viver.
Ao professor Ricardo Merched, pelo trabalho desenvolvido durante a Iniciação
Científica no Laboratório de Processamento de Sinais (LPS).
Aos meus professores do Colégio Santo Inácio, gostaria de agradecer pelos
valores ensinados durante a minha formação escolar, que vão muito além do conteúdo
acadêmico e que levarei comigo para o resto da vida.
Aos meus amigos e colegas de estágio, agradeço pelo apoio e confiança em mim
e por todas as dicas valiosas, que me permitiram avançar com mais facilidade na
produção deste projeto.
À sociedade brasileira, que de forma indireta contribuiu para a minha formação
nesta Universidade. Este projeto é uma pequena forma de retribuir o investimento e
confiança em mim depositados.

vii
RESUMO
As perdas de energia elétrica por irregularidades, fraudes e furtos configuram
uma perda de receita de bilhões de reais para as distribuidoras brasileiras todo ano.
Diversas abordagens têm sido utilizadas para o combate às perdas não-técnicas pelas
concessionárias, como campanhas de prevenção e conscientização da população e
incentivos às denúncias de fraude. Uma estratégia que vem ganhando força é realização
de inspeções técnicas direcionadas a consumidores que apresentem indícios, baseados
nos dados do cliente, padrões de consumo, apontamentos do leiturista, etc. Este projeto
propõe a aplicação de modelos de redes neurais simples e redes neurais em ensemble
para a seleção de um conjunto de Unidades Consumidoras onde exista alta
probabilidade de serem encontradas fraudes ou irregularidades. Inicialmente são
descritos os principais conceitos relacionados à área de perdas não-técnicas e
apresentados os tipos de dados dos consumidores aos quais as empresas comumente têm
acesso. São selecionadas as características utilizadas para o treinamento dos modelos,
como localização geográfica, classe de consumo, mediana de consumo de energia em
diferentes períodos, etc. Os modelos resultantes são comparados com relação à precisão,
acurácia e tempo de duração do treinamento.
Palavras-Chave: perdas comerciais, perdas não-técnicas, redes neurais, classificação,
aprendizado de máquina.

viii
ABSTRACT
The electric energy loss due to irregularities, fraud and theft represents a loss of
revenue of billions of reais for Brazilian distributors every year. Several approaches
have been used to combat non-technical losses by energy utilities, such as campaigns
for prevention, raising awareness of the population and encouraging the delation of
fraudsters. A strategy that is gaining strength is conducting technical inspections aimed
at consumers who present evidence, based on customer data, consumption patterns,
reader's notes, etc. This project proposes the application of simple neural network
models and neural networks in ensemble for the selection of a set of consuming units for
which a high probability of frauds and irregularities is expected. First, the main
concepts related to the area of non-technical losses are described and the types of
consumer data to which the companies commonly have access are presented. The
features used to train the models are selected, such as geographic location, consumption
class, median energy consumption in different periods, etc. The resulting models are
compared in relation to precision, accuracy and duration of training.
Key-words: commercial losses, non-technical losses, neural networks, classification,
machine learning.

ix
SIGLAS
UC – Unidade Consumidora
PNT – Perdas Não-Técnicas
ANEEL – Agência Nacional de Energia Elétrica
TOI – Termo de Ocorrência de Irregularidade
FC – Fluxo de carga
PCA – Principle Component Analysis
AT – Alta tensão
BT – Baixa tensão
NA – Nada Apurado
NI – Não Inspecionado
VP – Verdadeiro Positivo
FP – Falso Positivo
FN – Falso Negativo
VN – Verdadeiro Negativo
MANN – Model Averaged Neural Network
SVM – Support Vector Machine

x
Sumário
1. Introdução ............................................................................................................... 1
1.1 – Tema ................................................................................................................ 1
1.2 – Delimitação ...................................................................................................... 1
1.3 – Justificativa ...................................................................................................... 1
1.4 – Objetivos .......................................................................................................... 2
1.5 – Metodologia ..................................................................................................... 2
1.6 – Descrição .......................................................................................................... 3
2. Conceitos em Perdas de Energia na Distribuição de Energia Elétrica ....................... 5
2.1 – Introdução ........................................................................................................ 5
2.2 – Leitura de Energia e Notas de Leitura ............................................................... 5
2.3 – Perdas de Energia ............................................................................................. 7
2.4 – Perdas Não-Técnicas (PNT) de Energia Elétrica ............................................... 8
2.5 – Combate às perdas de energia ......................................................................... 10
2.6 – Inspeções Técnicas ......................................................................................... 11
2.7 – Determinações da Agência Nacional de Energia Elétrica ................................ 12
2.8 – Recuperação de Receita .................................................................................. 12
2.9 – Energia Recuperada ........................................................................................ 13
2.10 – Energia Incrementada ................................................................................... 13
2.11 – Indicadores de Desempenho de Inspeções de campo ..................................... 14
3. Aprendizado de Máquina ...................................................................................... 15
3.1 – Redes Neurais (Supervisionadas) .................................................................... 15
3.2 – Separação entre conjunto de treinamento e conjunto de teste ........................... 18
3.3 – Validação cruzada ........................................................................................... 18
3.4 – Variantes da validação cruzada ....................................................................... 19
3.5 – Métricas de desempenho ................................................................................. 20
4. Proposta de Solução .............................................................................................. 24

xi
4.1 – Procedimentos Metodológicos ........................................................................ 24
4.2 – Dados disponíveis à concessionária de energia ................................................ 24
4.3 – Dados do consumidor ..................................................................................... 25
4.4 – Dados da instalação elétrica ............................................................................ 25
4.5 – Dados mensais de consumo ............................................................................ 27
4.6 – Extração de características .............................................................................. 27
4.7 – Análise Descritiva dos Dados ......................................................................... 30
4.8 – Ferramentas utilizadas .................................................................................... 33
4.9 – Experimentos .................................................................................................. 34
4.10 – Considerações Finais .................................................................................... 40
5. Conclusões ............................................................................................................ 42
6. Bibliografia ........................................................................................................... 43

xii
Lista de Figuras Figura 1: Percentual de Perdas do Sistema Global 2016 (ref. 2015) [1] ......................... 9
Figura 2: Neurônio [9]. ............................................................................................... 16
Figura 3: Função sigmóide: utilizada como função de ativação. [10] ........................... 17
Figura 4: Rede neural feedforward com duas camadas escondidas [11]. ...................... 17
Figura 5: Ilustração do ponto de parada do treinamento. [8] ........................................ 19
Figura 6: Método K-fold de validação cruzada. [12] .................................................... 20
Figura 8: Procedimento prático para aplicações de Aprendizado de Máquina .............. 24
Figura 8: Resultados das inspeções realizadas ............................................................. 31
Figura 9: Distribuição das UCs por fase de ligação ..................................................... 31
Figura 10: Distribuição das UCs por classe de consumo .............................................. 32
Figura 11: Os dez municípios com maior número de inspeções com resultado,
identificados pelo código do município ....................................................................... 32
Figura 12: Os quinze municípios com maior número de inspeções com resultado
irregular ...................................................................................................................... 33

xiii
Lista de Tabelas
Tabela 1: Matriz de Confusão ..................................................................................... 21
Tabela 2:Matriz de confusão resultante da aplicação do modelo de redes neurais (nnet)
................................................................................................................................... 36
Tabela 3: Matriz de confusão resultante da aplicação do modelo de emsemble redes
neurais (avNNet) ......................................................................................................... 37
Tabela 4: Matriz de confusão resultante da aplicação do modelo de emsemble redes
neurais (avNNet), com a utilização de notas de leiturista no vetor de características. ... 39
Tabela 5: Resumo dos resultados obtidos por todos os modelos .................................. 39

1
Capítulo 1
Introdução
1.1 – Tema
O presente trabalho é um estudo da aplicação de algoritmos de inteligência
artificial para a detecção de fraudes e irregularidades em energia elétrica, por parte dos
consumidores. Serão usados como base diversos dados de consumidores, aos quais as
distribuidoras de energia comumente têm acesso, como cidade, bairro, fase elétrica,
classe de consumo, histórico de consumo, etc. A partir daí serão escolhidos, com base
no conhecimento do aluno na área, adquirido em sua experiência de estágio,
subconjuntos de dados que têm maior relevância e correlação com ocorrências de fraude
ou irregularidade. Esse subconjunto será usado como base de conhecimento e servirá de
treinamento para os modelos preditivos que serão estudados. Por fim o desempenho dos
modelos será avaliado e comparado.
1.2 – Delimitação
Esse estudo é realizado a partir de dados de consumidores de energia elétrica.
Serão apresentadas aqui as metodologias do estudo, os algoritmos utilizados e os
resultados encontrados. Contudo, dados que identifiquem os consumidores em si não
serão publicados, por questões legais de privacidade e segurança.
Este trabalho foi desenvolvido no âmbito do Laboratório de Inteligência de
Máquina e Modelos de Computação (IM2C) da Escola Politécnica (Poli) da
Universidade Federal do Rio de Janeiro (UFRJ).
1.3 – Justificativa
A quantidade de energia elétrica perdida por motivos de irregularidades, furtos e
fraudes no Brasil vem crescendo nos últimos anos. Segundo a ABRADEE [1], o

2
percentual de perdas comerciais em relação à energia injetada no sistema global passou
de 3,99% em 2000 para 5,91% em 2012. Isso se reflete não só em uma perda de receita
para as empresas distribuidoras, como também em um aumento no faturamento dos
consumidores não-fraudadores. O combate a esse tipo de perdas tem se tornado um foco
estratégico para a garantia de receita dessas empresas e para criação de normas e
regulamentos por parte de órgãos reguladores. Para identificar se um consumidor está
de fato furtando ou fraudando energia ainda é preciso que um especialista seja enviado a
campo, no local de consumo, para que seja feita uma inspeção técnica. Com o intuito de
melhorar o resultado estatístico das inspeções, as distribuidoras têm voltado sua atenção
para os dados dos consumidores, utilizando técnicas de Mineração de Dados e análise
de dados na tentativa de identificar previamente possíveis fraudadores, para melhor
direcionar e otimizar inspeções em campo.
1.4 – Objetivos
O objetivo é a apresentação do contexto geral do problema de perdas elétricas
não-técnicas e o estudo e desenvolvimento de algoritmos de inteligência computacional,
que serão utilizados para a identificação de consumidores com perfil suspeito
(candidatos a inspeção). Na apresentação do contexto geral serão explicadas diversas
definições importantes na área de perdas e os principais processos envolvidos serão
detalhadamente descritos, para que o leitor desenvolva um bom conhecimento básico. O
estudo comparativo dos algoritmos será melhor detalhado ao longo do texto.
1.5 – Metodologia
Este trabalho apresentará um comparativo de diferentes algoritmos de
inteligência computacional aplicados à detecção de consumidores suspeitos de
furto/fraude de energia. Serão considerados para este estudo um conjunto de
consumidores que já recebeu, em algum momento, uma visita de um inspetor para
verificação de fraude. Esta visita e, principalmente, o resultado da inspeção (fraude ou
não-fraude) são essenciais para o treinamento e validação dos modelos.

3
Com base no histórico de consumo e outros dados relevantes (localidade, classe
de consumo, etc), os algoritmos têm como objetivo classificar o consumidor como
suspeito ou não. Para tal, o conjunto de consumidores será dividido em subconjuntos
exclusivos de treinamento, validação e teste.
Na fase de treinamento, os dados dos consumidores serão fornecidos ao modelo
e os seus parâmetros serão ajustados, comparando a saída do modelo (classificação
suspeito/não-suspeito) com o resultado da inspeção (fraude/não-fraude).
O subconjunto de validação será usado para evitar um sobreajuste (overfitting).
Para tal, será definido um critério de parada para o aprendizado. No momento em que a
acurácia do modelo sobre o conjunto de treinamento estiver aumentando, mas sua
acurácia sobre o conjunto de validação começar a diminuir, o modelo será considerado
como ajustado. Caso o treinamento não seja abortado, esta situação resultaria em um
modelo enviesado para o conjunto de treinamento. Neste sentido pretende-se evitar isto,
para que o modelo tenha um bom desempenho para qualquer conjunto de consumidores.
Finalizado o treinamento do modelo, seu desempenho será avaliado, sobre o
conjunto de teste. Este procedimento será repetido para todos os algoritmos que forem
utilizados e, enfim, será comparada a efetividade de todos eles a partir de indicadores
como taxa de acerto e outros a serem definidos.
1.6 – Descrição
No capítulo 2 serão abordados os principais conceitos da área de perdas na
distribuição de energia elétrica. O entendimento desses conceitos e definições é de vital
importância para a compreensão geral do problema. Serão definidos termos como
Perdas Técnicas e Perdas Não-Técnicas, será explicado o que são notas de leitura (ou
notas de irregularidade) e por que elas são importantes, além de serem expostos os
conceitos chaves relacionados à recuperação de receita, como energia recuperada e
energia incrementada e listados os principais indicadores de desempenho de inspeções
de campo.
O capítulo 3 apresenta um breve resumo dos conceitos relacionados a
Aprendizado de Máquina (Machine Learning), destacando os pontos importantes para a
aplicação em questão. Será apresentada uma visão geral de modelos de redes neurais,
exibindo os procedimentos que serão adotados. Serão abordados conceitos como a

4
diferença entre conjunto de treinamento e conjunto de teste, validação convencional,
validação cruzada e validação cruzada com repetição. Serão expostas as diversas
métricas de desempenho normalmente utilizadas em problemas de regressão e
classificação e será definida a métrica a ser utilizada no experimento deste projeto.
O capítulo 4 detalha o procedimento experimental utilizado, apresentando a
proposta de solução do problema. Inicialmente serão expostos os dados aos quais as
concessionárias comumente têm acesso, para a partir daí serem escolhidos os dados que
irão definir o vetor de características. O vetor de características servirá de insumo para o
modelo de redes neurais, para classificação das unidades consumidoras como
potencialmente irregulares.
O capítulo 5 mostra a conclusão do projeto, mostrando os principais resultados e
apontando os pontos fortes e fracos do modelo. Por fim, serão sugeridos trabalhos
futuros, como continuação deste projeto.

5
Capítulo 2
Conceitos em Perdas de Energia na
Distribuição de Energia Elétrica
2.1 – Introdução
Este capítulo explicita os principais conceitos relacionados às perdas de energia
na transmissão e distribuição de energia elétrica. Dentre os conceitos a serem
apresentados estão a definição de Perdas Globais de Energia Elétrica, que será dividida
entre Perdas Técnicas e Perdas Não-Técnicas, a descrição das principais causas de
Perdas Não-Técnicas, a descrição do processo de leitura de energia em unidades
consumidoras, incluindo a diferença entre energia consumida, energia calculada e
energia faturada, a definição e a descrição dos tipos mais importantes de Notas de
Leitura, que compõem um importante indicativo de fraude e irregularidade, etc. Este
capítulo tem o objetivo geral de deixar o leitor mais familiarizado com os conceitos e
jargões utilizados na área de combate às perdas de energia.
2.2 – Leitura de Energia e Notas de Leitura
A medição da energia consumida em Unidade Consumidora (UC) é realizada
por um profissional, denominado Leiturista. Ele é treinado para ler e interpretar os
diversos tipos de medidor de energia existentes, utilizando os equipamentos e
ferramentas necessários para tal, e informar a medição à concessionária e aos
consumidores. Existem três tipos principais de medidores de energia: os medidores
analógicos ou de ponteiros, os medidores ciclométricos e os medidores eletrônicos ou
digitais.
Segundo a LIGHT, em [2], os medidores analógicos (ou de ponteiros) são
compostos por quatro relógios, representando os valores de consumo acumulado, onde
cada um indica uma unidade de grandeza. Eles podem ser utilizados em qualquer tipo
de ligação (monofásica, bifásica ou trifásica) e este é o modelo mais antigo adotado
pelas empresas.

6
O medidor ciclométrico é similar a um odômetro analógico em um painel de
carro. É um modelo de medidor de fácil leitura, pois apresenta diretamente em seu
mostrador os números do consumo acumulado registrados. [2]
Os medidores eletrônicos (ou digitais) apresentam, assim como os medidores
ciclométricos, os números do consumo acumulado diretamente no painel. A diferença
percebida pelo leiturista é que este tipo de medidor mostra os valores em um painel
digital. [2]
Vale salientar que, como a leitura nesses equipamentos é cumulativa, o valor
mensal de energia consumida, que é informado aos clientes na conta de energia, é
calculado através da diferença entre a leitura registrada no mês em questão e o valor
obtido no mês anterior.
Além dessa função principal de leitura de energia, espera-se dos leituristas que
eles informem às companhias de energia caso haja alguma irregularidade no conjunto de
fiação de rede e do medidor. Quando isso acontece, o leiturista gera o que é chamado de
“Nota de Leitura” (também conhecida como “Nota de Leiturista” ou “Nota de
Irregularidade”). Na Nota de Leitura o leiturista informa qual tipo de irregularidade que
foi observada. Os tipos de irregularidades estão normalmente tabelados pelas
companhias e cada irregularidade tem um código interno.
As Notas de Leitura com mais relevância incluem as seguintes descrições:
“Suspeita de fraude”;
“Medidor com defeito – display apagado”;
“Local de consumo com ligação direta”;
“Medidor com registrador parado – Local de consumo habitado”;
“Medidor sem Selo”;
“Constante do medidor incorreta”;
“Medidor queimado/danificado, sem leitura”;
entre outras. O número de diferentes descrições e possíveis irregularidades descritas em
uma Nota de Leitura variam de companhia para companhia. As distribuidoras podem ter
entre 70 e 150 possíveis descrições, das quais o leiturista deve escolher a que melhor se
aplica à irregularidade por ele observada.
A escolha das Notas de Leitura mais relevantes para a detecção de
fraudes/irregularidades será abordada no capítulo 4, no momento da escolha das
variáveis para compor o vetor de características.

7
Como o leiturista não tem as ferramentas nem o treinamento adequado para
fazer uma análise técnica do medidor ou da instalação, e ainda, verificar se de fato trata-
se de uma fraude ou de uma irregularidade, é necessário que seja feita uma perícia
técnica por um “Técnico de Inspeção”. Perícias técnicas e outros tópicos relacionados a
irregularidades serão abordados novamente e com mais detalhes ao longo do texto.
2.3 – Perdas de Energia
Segundo Carlos Alexandre Penin [3], “As Perdas Globais de energia podem ser
definidas como a diferença entre a energia entregue a uma determinada rede elétrica e a
energia entregue [aos consumidores finais] regularmente nessa mesma rede. Em uma
companhia distribuidora de energia elétrica, nessa parcela de energia entregue
regularmente encontram-se: a energia fornecida às unidades consumidoras regulares; a
energia fornecida a outras distribuidoras; e a energia fornecida a outros níveis de
tensão. ” As Perdas Globais de energia podem ser divididas em Perdas Técnicas e
Perdas Não-Técnicas.
Perdas Técnicas podem ter várias causas e correspondem à parcela de energia
perdida devido a fenômenos físicos internos aos materiais utilizados nos sistemas
elétricos, durante o processo de transmissão de energia. Este tipo de perda é natural e
inerente a qualquer processo de distribuição. Com o avanço da engenharia elétrica e de
materiais é possível diminuir cada vez mais esses efeitos, porém uma rede de transporte
sem perdas técnicas, isto é, com 100% de eficiência, é algo inalcançável na prática. Para
exemplificar pode-se citar a perda de energia por efeito Joule, que é o tipo mais comum
de perda nos condutores. Ela corresponde à dissipação de potência devido à resistência
elétrica do condutor e pode ser calculada de forma simplificada como a resistência
multiplicada pelo quadrado da corrente passante. Além da chamada Perda Joule em
condutores, as perdas por dissipação de energia podem ocorrer, em maior ou menor
grau, em qualquer componente empregado nos sistemas elétricos, como
transformadores, capacitores, medidores e outros equipamentos.
Existem modelos matemáticos e técnicas para a estimação das perdas técnicas.
As técnicas mais difundidas envolvem cálculos de fluxo de potência, ou fluxo de carga
(FC) nos componentes. “Segundo a metodologia mais difundida atualmente no Brasil,
os cálculos de perdas técnicas são efetuados em cada segmento do sistema, de forma a
permitir modelagem adequada e maior precisão nos resultados. Os segmentos de

8
interesse para concessionárias de distribuição são: rede de alta tensão (69 a 138kV)
incluindo os ramais de subtransmissão, transformação AT/MT, rede primária (MT),
transformador de distribuição (MT/BT), rede secundária, ramal de ligação e medidores
de energia. ” [3]
Outras perdas importantes são: “[...] perdas nas conexões, efeito corona, fugas
nos isolamentos dos equipamentos e nas linhas de transmissão e distribuição, perdas nos
bancos de capacitores e reguladores de tensão, etc.” [3]. O cálculo dessas perdas é mais
difícil de ser realizado e, por este motivo, elas normalmente são estimadas
genericamente como um percentual, usualmente entre 5% e 10%, das perdas técnicas
totais calculadas.
A segunda parcela das Perdas Globais de energia corresponde às Perdas Não-
Técnicas ou, como muitas vezes são denominadas, Perdas Comerciais. Este tipo de
perda ocorre essencialmente quando parte da energia distribuída não é faturada pela
concessionária. As razões para essa falta de faturamento podem ser atribuídas a diversos
fatores e esta será a motivação para o próximo item deste capítulo. Vale ressaltar que
não é possível calcular diretamente essas perdas através de métodos matemáticos e
científicos, porém uma estimativa geral pode ser feita, subtraindo as perdas técnicas das
perdas globais de energia.
2.4 – Perdas Não-Técnicas (PNT) de Energia Elétrica
Como foi visto no item anterior, as perdas não-técnicas são justamente a parcela
das Perdas Globais de energia que não se enquadram como perdas técnicas. Pode-se
estimá-las através da diferença entre as Perdas Globais e as Perdas Técnicas. Além
disso, foi mencionado que essas perdas de energia correspondem à parcela de perdas
decorrente de problemas relacionados ao faturamento, ou mais especificamente, à falta
de faturamento da energia fornecida. Os motivos para isso podem ser os mais diversos e
a seguir serão expostas as causas mais comuns. Para começar, pode-se dividir as perdas
não-técnicas em duas classes principais:
(a) Perdas por irregularidades;
(b) Perdas por fraude ou furto de energia elétrica.
Esta divisão é muito utilizada pelas concessionárias de energia e inclusive a
ANEEL estipula regras específicas para cada uma dessas duas classes para o cálculo da

9
energia a ser recuperada. Serão abordados mais a fundo os conceitos de energia a
recuperar e energia a incrementar, e as respectivas normas da ANEEL, no item
“Recuperação de Receita”.
De modo geral pode-se dizer que irregularidades são perdas causadas por falhas
nos medidores, erros de leitura ou de imprecisões no faturamento, ou outras falhas no
fornecimento ou medição da energia, onde não houve uma adulteração intencional do
medidor ou do fornecimento de energia por parte do cliente consumidor.
Já o termo fraude ou furto de energia descreve justamente os casos em que as
perdas são atribuídas à uma ação do consumidor, que intencionalmente frauda o
fornecimento ou o medidor, ou furta energia diretamente da rede, com o objetivo de
reduzir sua conta mensal de energia. São denominados de fraude os casos em que o
medidor é conscientemente adulterado ou quando se faz um desvio no ramal de entrada,
antes do medidor. Além disso, é considerado furto de energia quando o consumidor faz
uma ligação clandestina direta na rede de distribuição. Essas ligações clandestinas são
popularmente chamadas de “gato”.
O índice de perdas no Brasil varia muito dentre as concessionárias. Para ilustrar
este fato é apresentado na Figura 1 a seguir um gráfico indicando o percentual de perdas
para as distribuidoras brasileiras com os maiores índices.
Figura 1: Percentual de Perdas do Sistema Global 2016 (ref. 2015) [1]

10
2.5 – Combate às perdas de energia
As perdas de energia representam uma grande perda de receita para as
concessionárias no Brasil e, portanto, diversas estratégias têm sido desenvolvidas para
combatê-las. No caso das perdas técnicas a principal estratégia para reduzi-las se baseia
no monitoramento e na manutenção dos componentes utilizados na geração, transmissão
e distribuição de energia, troca de componentes deteriorados, manutenção preventiva e
pesquisa sobre novas técnicas de prevenção da degradação dos equipamentos. Uma das
pesquisas neste âmbito é a desenvolvida pelo CEPEL (Centro de Pesquisa em Energia
Elétrica), onde o autor teve a oportunidade de participar de um estágio durante seis
meses. A pesquisa se baseia na detecção e localização de Descargas Parciais em
transformadores, capacitores e outros componentes utilizados em subestações de
energia, para possibilitar prever quando um equipamento está entrando ou entrará em
estado de deterioração e tomar uma ação devida, seja ela a manutenção ou a troca do
mesmo. Este é apenas um exemplo das diversas frentes de pesquisa nesta área realizadas
no Brasil e no mundo. Como se pode perceber, o combate às perdas técnicas envolve,
em sua maior parte, a aplicação e pesquisa sobre técnicas cada vez mais eficientes de
engenharia.
O combate às perdas não-técnicas de energia, por outro lado, pode envolver
questões mais amplas, como aspectos socioeconômicos e culturais. Um estudo realizado
anualmente pela “Northeast Group, llc”, empresa norte-americana de inteligência de
mercado com experiência em setores de infraestruturas inteligentes e Smart Grid,
aponta que as perdas de energia por fraudes ou furtos, no Brasil, correspondem a uma
perda de receita de mais de 10 bilhões de dólares por ano para as distribuidoras. [4]
Dentre os países emergentes o Brasil é o segundo país que mais perde energia devido a
fraudes e furtos, atrás apenas da Índia, cuja perda de faturamento chega a 16,2 bilhões
de dólares anualmente. Neste sentido muitas distribuidoras apostam em campanhas para
prevenção e conscientização da população quanto ao caráter criminoso da realização de
fraudes ou furtos. Essas campanhas de marketing alertam para o fato de que quem paga
por essa energia são os outros consumidores regulares na rede e mostram as punições
cabíveis para quem for flagrado cometendo este tipo de ato. Algumas campanhas de
prevenção podem ser consideradas bastante agressivas, principalmente no exterior,
como já foi observado em países como Chile, Inglaterra e Estados Unidos, aponta Penin

11
[3]. Ademais, algumas empresas de energia investem em programas sociais e educativos
em comunidades localizadas em áreas sujeitas a elevados índices de perdas comerciais.
[3]
Além das técnicas de prevenção citadas acima, existem também estratégias de
combate a perdas comerciais que se baseiam em inspeções de perícia técnica a
consumidores selecionados, com o objetivo de encontrar irregularidades ou fraudes em
flagrante. Este tipo de estratégia é muito utilizado no Brasil e é nele que será focado este
estudo.
2.6 – Inspeções Técnicas É denominada inspeção técnica (ou visita/perícia técnica) qualquer visita a uma
Unidade Consumidora, realizada por um técnico profissional treinado, com o objetivo
de examinar se existe alguma irregularidade ou fraude. Segundo a ANEEL, define-se
perícia técnica como: “atividade desenvolvida pelo órgão metrológico ou entidade por
ele delegada ou terceiro legalmente habilitado com vistas a examinar e certificar as
condições físicas em que se encontra um determinado sistema ou equipamento de
medição”. [5]
Uma inspeção técnica tem sempre um resultado e um laudo técnico, descrevendo
e mostrando evidências que suportem o resultado. Os resultados podem ser agrupados
em quatro categorias:
(a) Irregularidade
(b) Fraude (ou furto)
(c) NA (Nada apurado) – indica que não houve nenhuma constatação de fraude
ou irregularidade na Unidade Consumidora.
(d) NI (Não Inspecionado) – indica que a inspeção foi agendada, mas por algum
motivo ela não foi realizada, por algum impedimento externo fora do
comum.
Grande parte das concessionárias brasileiras estabelecem metas para a
quantidade de inspeções a serem realizadas por mês, além de metas para a receita total a
ser recuperada por essas inspeções, em termos de energia recuperada e energia
incrementada. Esses dois conceitos são abordados com mais detalhe nos seus
respectivos itens. É importante citar que os procedimentos adotados nas inspeções e os

12
procedimentos subsequentes à constatação de uma irregularidade ou fraude são todos
detalhados e regulados pela ANEEL, como será visto a seguir.
2.7 – Determinações da Agência Nacional de Energia Elétrica
A Agência Nacional de Energia Elétrica (ANEEL) é uma autarquia sob regime
especial (Agência Reguladora), vinculada ao ministério de Minas e Energia, e tem por
finalidade regular e fiscalizar a produção, transmissão, distribuição e comercialização de
energia elétrica, de acordo com a legislação e em conformidade com as diretrizes e as
políticas do governo federal. [6]
Dentre as competências da ANEEL destacam-se a definição dos procedimentos
a serem seguidos ao se constatar uma irregularidade e as devidas compensações de
faturamento para as concessionárias de energia.
A resolução nº 456/00 da ANEEL [7], artigo 72, determina que a concessionária,
ao constatar a ocorrência de qualquer procedimento irregular cuja responsabilidade não
lhe seja atribuível e que tenha provocado faturamento inferior ao correto, deverá adotar
as seguintes providências:
“I - emitir o “Termo de Ocorrência de Irregularidade”, em formulário próprio,
contemplando as informações necessárias ao registro da irregularidade, [...]
II - promover a perícia técnica, [...];
III - implementar outros procedimentos necessários à fiel caracterização da
irregularidade;
IV - proceder a revisão do faturamento com base nas diferenças entre os valores
efetivamente faturados e os apurados por meio de um dos critérios descritos [...]”
A ANEEL descreve, ademais, critérios para o cálculo da compensação de
faturamento. Esses critérios estão fora do escopo deste texto, porém o leitor interessado
pode referir a [7]. Serão apresentados a seguir apenas conceitos básicos envolvidos
nesta compensação.
2.8 – Recuperação de Receita
As perdas não-técnicas de energia no Brasil correspondem a uma perda de
receita de bilhões de reais por ano para as distribuidoras. A maioria delas estabelece
metas para a recuperação de receita, normalmente em termos de energia (em kWh ou

13
MWh) e em termos de faturamento (em reais). Para esclarecer essa recuperação de
receita, serão introduzidos os conceitos de energia recuperada e energia incrementada.
2.9 – Energia Recuperada
Corresponde a toda a energia que foi consumida, porém não foi faturada, durante
o período em que existiu uma irregularidade ou fraude. Quando uma irregularidade ou
fraude é descoberta, a concessionária adota o seguinte procedimento, segundo a
orientação da ANEEL: primeiramente estima-se a data de início do período irregular,
normalmente procurando por uma queda de consumo; a partir daí, observando a energia
consumida anteriormente a esta data, faz-se uma estimativa do nível de consumo normal
(regular) da Unidade Consumidora; e subtrai-se a energia faturada no período irregular
do nível de consumo normal estimado, para obter a quantidade de energia que foi
consumida e não foi faturada.
2.10 – Energia Incrementada
Quando um consumidor irregular é regularizado é de se esperar que seu nível de
energia faturada mensal aumente, de forma que corresponda ao nível de energia
consumida. Este incremento de energia faturada, observado após a regularização de uma
Unidade Consumidora, é denominado de energia incrementada. Normalmente observa-
se o incremento da energia durante um período de 12 meses.
Pode-se pensar na energia incrementada como uma forma de recuperação de
receita, visto que, caso o consumo continuasse irregular, a empresa iria perder a
quantidade de energia aproximadamente igual à energia incrementada. Embora não seja
uma energia que a distribuidora efetivamente deixou de faturar, como é o caso da
energia recuperada, ela serve como um indicador pois representa o faturamento que a
concessionária continuaria perdendo caso a UC não se regularizasse, mas que ela passa
a faturar a partir do momento da regularização. É um indicador utilizado pelas
concessionárias brasileiras.

14
2.11 – Indicadores de Desempenho de Inspeções de campo
As concessionárias de energia costumam avaliar o desempenho das inspeções de
campo, de forma agregada, através dos seguintes indicadores:
(a) Procedência (Taxa de acerto): quantidade de inspeções com resultado de
fraude ou irregularidade dividida pela quantidade de inspeções totais
realizadas em um determinado período de tempo.
(b) Energia Recuperada Total ou Energia Incrementada Total: soma da energia
recuperada ou incrementada total de todas as inspeções realizadas.
(c) Produtividade: Energia Recuperada Total dividida pela quantidade total de
inspeções realizadas.
(d) Ticket Médio: Energia Recuperada Total dividida pela quantidade de
inspeções que tiveram resultado de fraude ou de irregularidade.
Este estudo irá focar no indicador de Procedência (Taxa de acerto). Serão
utilizados modelos de Aprendizado de Máquina para classificação, para tentar melhorar
o desempenho das inspeções.

15
Capítulo 3
Aprendizado de Máquina
3.1 – Redes Neurais (Supervisionadas)
Redes Neurais, ou Redes Neurais Artificiais (RNA), é o termo atribuído a um
conjunto de modelos computacionais inspirados nas conexões de neurônios no cérebro
dos animais. É uma tecnologia bem consolidada e extensivamente estudada, que tem
raízes em diversas áreas do conhecimento, como neurociência, matemática, estatística,
física, ciência da computação e engenharia. Suas áreas de aplicação são muito
abrangentes, incluindo campos como processamento de sinais, reconhecimento de
padrões, robótica, sensoriamento remoto, entre outras. A principal característica de
redes neurais é sua habilidade de aprender padrões e estruturas, a partir de dados de
entrada (ou dados de treinamento), e a capacidade de generalizar para dados novos. [8]
De modo geral pode-se dizer redes neurais são empregadas em aplicações que se
resumem a solucionar dois tipos de problema: Classificação e Regressão. No caso deste
projeto tem-se interesse em resolver um problema de Classificação, especificamente:
dada uma Unidade Consumidora de energia e o conhecimento de suas características
(histórico de consumo, localização, ramo de atividade, etc), deseja-se poder classificá-la
como potencialmente irregular/fraudulenta (com recomendação de inspeção técnica) ou
não. Será feito um experimento sobre dados concedidos por uma concessionária de
energia, onde será desenvolvido um modelo de classificação que utiliza internamente
Redes Neurais.
Como já foi mencionado, Redes Neurais é um assunto solidamente estudado e
possui, portanto, uma vasta literatura. Por conta disso, a teoria das RNAs não será
extensivamente abordada com todos os detalhes e o devido rigor matemático neste
tópico, deixando a cargo do leitor a consulta à literatura. Como sugestão, pode-se citar
S. Haykin [8]. Este projeto focará mais na aplicação de RNAs em um contexto
específico, do que em sua teoria. Serão apresentados a seguir, de forma resumida,
apenas os principais conceitos básicos de RNAs.
As RNAs podem ter diversas arquiteturas, dependendo de sua implementação,
mas consistem tipicamente em vários nós (representando os neurônios) interligados e
que se comunicam. A Figura 2 ilustra o modelo de um neurônio com uma função de

16
ativação não-linear. Segundo a definição de S. Haykin [8], cada neurônio pode ser
modelado como uma unidade de processamento de informação, que possui três
elementos fundamentais:
1. Um conjunto de sinapses ou ligações, cada um contendo um peso w.
2. Um somador para somar os sinais de entrada, pesados pelos respectivos
pesos de suas ligações.
3. Uma função de ativação que limita a amplitude do sinal de saída do
neurônio. Tipicamente, intervalo de amplitude de saída de um neurônio é
normalizado para o intervalo [0,1].
Figura 2: Neurônio [9].
Em termos matemáticos pode-se descrever os neurônios pelas equações:
���� = � ��� ��
�
���
�� = �(���� + ��)
onde ��, ��, … , �� são os sinais de entrada; ���, ���, … , ��� são os respectivos pesos
do neurônio j; �� é o viés; �(. ) é a função de ativação; e �� é o sinal de saída do
neurônio. [13]
Existem vários tipos de função de ativação. Uma das mais simples é a função de
corte (ou degrau).
�(�) = �1 �� � > �0 �� � ≤ �
onde C é um corte (threshold).

17
Uma função mais utilizada na prática como função de ativação é a função
sigmóide.
�(�) =1
1 + ����
Figura 3: Função sigmóide: utilizada como função de ativação. [10]
Foram abordados até agora os conceitos relacionados a um neurônio unitário.
Para formar uma rede neural, os neurônios dever estar ligados entre si. A rede é
comumente estruturada em camadas, possuindo uma camada de entrada, uma de saída e
possivelmente uma ou mais camadas internas (ou “escondidas”). A Figura 4 ilustra essa
arquitetura.
Figura 4: Rede neural feedforward com duas camadas escondidas [11].
Os pesos de cada sinapse podem ser inicializados aleatoriamente e eles são
ajustados ao longo de diversas iterações através do algoritmo de Backpropagation. A
cada iteração, o sinal de saída resultante da rede neural é comparado ao resultado real
esperado (redes supervisionadas) e obtém-se uma estimativa do erro. Este erro é

18
utilizado para definir os pesos da próxima iteração. Calcula-se a partir dele o gradiente
local e assim o novo peso é definido pela fórmula: [8]
�
�����çã� �� ����Δ���(�)
� = ����� ��
������������
� × �
����������������(�)
� × �
����� �� ��� ��
����� ���(�)
�
3.2 – Separação entre conjunto de treinamento e conjunto de teste
Uma parte importante para a avaliação de modelos de Aprendizado de Máquina
é a separação do conjunto de dados em um conjunto de treinamento e um conjunto de
teste. O modelo deve ser capaz de aprender a partir dos dados de treinamento, para em
seguida ser aplicado em dados reais (representados pelo conjunto de teste). É desejável
que o modelo seja capaz de generalizar a habilidade de classificação aprendida durante
o treinamento para conjuntos novos, que o modelo nunca tenha antes visto. Este poder
de generalização é, na verdade, o objetivo principal de qualquer modelo de Aprendizado
de Máquina. Essa é uma habilidade atribuída ao processo de aprendizado do ser
humano, que inspira tais modelos computacionais. Portanto, utiliza-se o conjunto de
treinamento para treinar o modelo, mas a avaliação final dos resultados deve ser feita
sobre o conjunto de teste. É importante frisar que após a aplicação do modelo já
treinado sobre o conjunto de teste não se deve mais ajustar nenhum parâmetro nem
realizar nenhum novo treinamento, pois isso enviesará o modelo e invalidará os
resultados.
3.3 – Validação cruzada
Para evitar que o modelo se especialize demais no conjunto de treinamento
(overfitting), é necessário realizar um procedimento de validação durante o treinamento.
O modo convencional de se fazer isto é dividir o conjunto de treinamento em um
subconjunto de estimação, que será fornecido ao modelo, e um subconjunto de
validação. Os sinais de entrada apresentados ao modelo devem vir do subconjunto de
estimação, porém agora o modelo será avaliado também através do erro de validação,
calculado sobre o subconjunto validação. Nas primeiras iterações do treinamento, o erro
calculado em ambos subconjuntos tende a diminuir, porém quando o algoritmo começa

19
a se especializar demais, observa-se que o erro de estimação continua diminuindo
enquanto que o erro de validação começa a aumentar. Neste ponto, é preciso parar o
treinamento. Este método é chamado de método de interrupção precoce de treinamento
e é amplamente utilizado na prática. [8] A Figura 5 ilustra graficamente o método
descrito, que também é chamado na literatura de método de holdout.
Figura 5: Ilustração do ponto de parada do treinamento. [8]
3.4 – Variantes da validação cruzada
Existem variantes para o método de validação cruzada descrito acima. Quando
se tem um conjunto dados pequeno, por exemplo, pode-se utilizar o método K-fold
(multifold cross-validation). Divide-se o conjunto de N amostras em K partições
(subconjuntos disjuntos), onde K > 1, assumindo que N é divisível por K. O modelo é
treinado em todas as partições, exceto uma, e o erro de validação é calculado testando o
modelo no subconjunto que foi deixado de fora. Este procedimento é repetido um total
de K vezes, cada vez utilizando um subconjunto diferente para validação, como
ilustrado na Figura 6, para K = 3. O desempenho do modelo é então avaliado através da
média entre os erros calculados em cada repetição. A desvantagem do método K-fold é
que ele pode requerer um grande volume de processamento computacional, já que o
modelo tem que ser testado K vezes. [8]
Quando a quantidade de dados no conjunto disponível é extremamente limitada,
pode-se usar um caso extremo do método K-fold de validação cruzada, conhecido como
leave-one-out-method. Neste caso N – 1 amostras são fornecidas para o treinamento do

20
modelo e o modelo é validado na amostra deixada de fora. O desempenho do modelo é
então avaliado pela média dos erros das N repetições. [8]
Figura 6: Método K-fold de validação cruzada. [12]
Além dos métodos citados, outros bastante conhecidos são o leave-p-out cross-
validation (caso especial do método K-fold onde K = N - P) e o 2-fold cross-validation
(caso especial do método K-fold onde K = 2) [13] e a validação por Monte Carlo. [14]
3.5 – Métricas de desempenho Para avaliar o desempenho de um modelo, é necessário definir uma métrica, que
nada mais é que uma função que recebe como parâmetro de entrada, o resultado de cada
predição do modelo e seu valor de referência correspondente e retorna um valor de
saída, que corresponde a uma medida de erro de predição. Tem-se a opção de escolher
dentre diversas métricas e essa escolha dependerá da aplicação e de ser um problema de
Regressão ou Classificação.
Para regressão as métricas mais comuns utilizadas são a raiz do erro médio
quadrado (RMSE) e o coeficiente de determinação, também chamado de R².
Para problemas de classificação binária, a avaliação do modelo pode ser feita
através da matriz de confusão. A matriz de confusão é uma tabela 2x2 que contém os

21
quatro possíveis resultados da aplicação de um classificador binário. Na tabela abaixo
A, B, C e D são a quantidade de elementos que se enquadram em cada uma das quatro
situações representadas pelas células da tabela, respectivamente:
A. Verdadeiro Positivo (VP) – quantidade de predições corretas para a classe
“Positivo”;
B. Falso Positivo (FP) – quantidade de predições incorretas para a classe
“Positivo”;
C. Falso Negativo (FN) – quantidade de predições incorretas para a classe
“Negativo”;
D. Verdadeiro Negativo (VN) – quantidade de predições corretas para a classe
“Negativo”
Referência
Positivo Negativo
Pre
diç
ão
Positivo A B
Negativo C D
Tabela 1: Matriz de Confusão
A partir da matriz de confusão podem ser derivadas diversas métricas básicas de
desempenho, como precisão, acurácia, especificidade e sensitividade. Abaixo
encontram-se a definição de algumas das métricas mais utilizadas em diversas
aplicações:
������������� =�
� + �
�������������� =�
� + �
������ã� =�
� + �

22
������ =� + �
� + � + � + �
���� �� ���� =� + �
� + � + � + �
Estas são as métricas mais básicas derivadas da matriz de confusão e as mais
comumente utilizadas em problemas de classificação binária. Além destas, outras
métricas mais avançadas podem ser derivadas, como o coeficiente Kappa de Cohen [15]
e a Característica de Operação do Receptor (ROC). [16] Dependendo do objetivo e da
aplicação do modelo, pode-se também definir métricas “customizadas”. Isto é, baseado
no conhecimento específico da área de conhecimento da aplicação, o projetista do
modelo ou do classificador pode definir métricas específicas que se adequam melhor ao
caso em questão, podendo elas ser derivadas das métricas acima ou não. Pode-se pensar
na métrica de desempenho como simplesmente uma função. Ela toma como parâmetro
de entrada os resultados do modelo e retorna um valor em uma escala numérica, sendo
possível ordenar e comparar diferentes modelos por seu desempenho. Pode-se querer,
por exemplo, projetar um modelo que maximiza ao mesmo tempo a precisão e a
sensibilidade. Para expressar isso matematicamente pode-se definir uma métrica que
seja igual a soma da precisão e da sensibilidade.
No caso desta aplicação, deseja-se avaliar o desempenho das inspeções de
campo de forma agregada. Como foi visto no capítulo 2, uma inspeção de campo pode
ter um dentre 4 possíveis resultados: fraude, irregularidade, NA ou NI. Para as análises
feitas neste projeto serão descartadas do conjunto de dados inspeções com resultado NI,
pois este resultado não acrescenta nenhuma informação útil ao aprendizado do modelo,
da forma como ele será desenvolvido. Além disso, para simplificar o problema e para
trabalhar com classificadores binários, os resultados fraude e irregularidade serão
combinados em uma classe única. A partir deste ponto, não será feita mais distinção
entre esses dois resultados. Referir-se-á à fraude ou à irregularidade simplesmente como
irregularidade. UCs que tiveram uma inspeção com resultado de irregularidade serão
denominadas UCs irregulares e UCs cuja inspeção retornou um resultado NA serão
denominadas regulares. Para a avaliação do modelo será definido, arbitrariamente, que a
classe “Positivo” corresponde a UCs irregulares e a classe “Negativo” às UCs regulares.

23
A concessionária que cedeu os dados para este estudo tem um processo semanal
de levantamento de UCs suspeitas (com potencial de estarem irregulares), as quais serão
selecionadas para receber inspeção técnica. Essas UCs selecionadas para seleção são
comumente chamadas, nesse contexto, de alvos. A empresa normalmente tem um
número N pré-estipulado de alvos que devem ser selecionados para receber inspeção.
Este valor N é determinado levando-se em consideração o custo de realização das
inspeções e a projeção de recuperação total de receita, de forma que as inspeções
técnicas sejam lucrativas para a empresa. Em resumo, deseja-se selecionar N alvos para
inspeção dentre um número total de UCs atendidas pela distribuidora. Faz-se necessário
um modelo que classifique as UCs como potencialmente irregulares ou regulares.
Neste cenário, é interessante a criação de um modelo que selecione os N alvos
com maior potencial de irregularidade e, para avaliar tal modelo, será calculada a
precisão, (ou taxa de acerto) das inspeções, com a restrição de que o número de
inspeções seja igual a N. Isto equivale a dizer que a quantidade de elementos
classificados como “Positivo” é fixa, igual a N (VP + FP = N) e deseja-se que VP seja o
mais próximo possível de N.

24
Capítulo 4
Proposta de Solução 4.1 – Procedimentos Metodológicos Aplicações de análise de dados e de Aprendizado de Máquina tipicamente
seguem uma sequência de passos bem definidos. A Figura 7 a seguir ilustra os
principais passo.
Primeiramente serão apresentados os dados aos quais a concessionária tem
acesso, com uma breve explicação. Depois serão selecionados aqueles que irão compor
o vetor de características que será fornecido ao modelo. Em seguida será realizada uma
breve análise exploratória dos dados, com o intuito de apresentar uma caracterização
descritiva do conjunto utilizado. Depois disso os dados serão fornecidos ao modelo, que
gerará um resultado. Por fim, os resultados serão expostos e avaliados.
4.2 – Dados disponíveis à concessionária de energia
A concessionária de energia elétrica considerada neste estudo tem acesso a uma
diversidade de dados dos consumidores. Pode-se dividi-los nos seguintes subgrupos
principais: dados do consumidor, dados da instalação elétrica e dados mensais de
consumo de energia (incluindo notas de leitura). Nos próximos tópicos cada um destes
Coleta de Dados
Extração de Característica
s
Análise exploratória (descritiva)
Aplicação do Modelo
Avaliação dos Resultados
Figura 7: Procedimento prático para aplicações de Aprendizado de Máquina

25
subgrupos de dados será descrito com mais detalhes, mostrando quais são os principais
dados e por que eles são importantes para a concessionária.
4.3 – Dados do consumidor
Os dados do consumidor são informações que identificam e caracterizam o
consumidor e localizam geograficamente a Unidade Consumidora. São informações
básicas que podem ser obtidas através de um formulário de cadastramento, por exemplo.
Estas informações são obviamente importantes para se estabelecer uma via de
comunicação entre a empresa e seus consumidores, principalmente para o processo
tarifação de energia. Tipicamente tem-se:
(a) Nome da pessoa física ou jurídica;
(b) Localização geográfica: endereço (logradouro) da UC, bairro, localidade,
município, Região ou Base administrativa à qual a UC pertence;
(c) Classe de consumo, podendo ser principalmente residencial, comercial,
industrial, iluminação pública, poder público, entre outros;
(d) Ramo de atividade. Identifica qual é a principal atividade exercida pela UC,
por exemplo: “Residencial (casa)”, “Cultivo de milho”, “Cultivo de feijão”,
“Lanchonetes, casas de chá, de sucos e similares”, “Educação infantil - pré-
escola”, etc.
4.4 – Dados da instalação elétrica
Os dados da instalação elétrica são dados técnicos, importantes para o projeto e
dimensionamento da rede ou para a tarifação da energia. Dentre os mais relevantes
pode-se citar:
(a) Fase da ligação, podendo ser monofásica, bifásica ou trifásica. Ligações
monofásicas correspondem normalmente a consumidores com menor nível
de consumo, enquanto consumidores com ligação trifásica apresentam um
nível de consumo mensal mais elevado. Ligações bifásicas são mais raras do
que os outros tipos de ligação. Na região de análise, por exemplo, tem-se
que, da base de inspeções, 76,00% dos consumidores são monofásicos,

26
23,97% são trifásicos, enquanto que apenas 0,02% dos consumidores têm
ligação bifásica.
(b) Tipo de medidor. Informações gerais sobre o medidor utilizado na UC,
indicando ele se é eletrônico ou eletromecânico, se seu mostrador é de 4, 5
ou 6 dígitos, etc;
(c) Grupo tarifário. Segundo o Manual de Tarifação da Energia Elétrica do
PROCEL [17], as unidades consumidoras são classificadas em dois grupos
tarifários: Grupo A, que tem tarifa binômia e Grupo B, que tem tarifa
monômia. O agrupamento é definido, principalmente, em função do nível de
tensão em que são atendidos e também, como consequência, em função da
demanda (kW);
Este projeto ater-se-á somente a consumidores no grupo B (baixa
tensão), que representa os consumidores mais comuns. A grande maioria dos
consumidores de energia se encaixam nesse grupo.
(d) Subgrupo. Os grupos tarifários são subdivididos em subgrupos.
“O Grupo B é dividido em subgrupos, de acordo com a atividade do
consumidor, conforme apresentados a seguir:
• Subgrupo B1 – residencial e residencial baixa renda;
• Subgrupo B2 – rural e cooperativa de eletrificação rural;
• Subgrupo B3 – demais classes;
• Subgrupo B4 – iluminação pública.
Os consumidores atendidos em alta tensão, acima de 2300 volts, como
indústrias, shopping centers e alguns edifícios comerciais, são classificados
no Grupo A.
Esse grupo é subdividido de acordo com a tensão de atendimento, como
mostrado a seguir.
• Subgrupo A1 para o nível de tensão de 230 kV ou mais;
• Subgrupo A2 para o nível de tensão de 88 a 138 kV;
• Subgrupo A3 para o nível de tensão de 69 kV;
• Subgrupo A3a para o nível de tensão de 30 a 44 kV; Subgrupo A4 para
o nível de tensão de 2,3 a 25 kV;
• Subgrupo AS para sistema subterrâneo.
Os poucos prédios públicos classificados no Grupo A, em geral estão no
Sub-GrupoA4.” [17]

27
4.5 – Dados mensais de consumo Os dados mensais de consumo são importantes para a tarifação feita pelas
empresas e são de extrema importância nesta aplicação, como será visto no próximo
tópico sobre a escolha do vetor de características para o modelo de Aprendizado de
Máquina. Deve-se citar:
(a) Data da leitura ou data de referência. Aqui faz-se uma distinção entre data de
leitura e data de referência, porque pode acontecer que o leiturista não
consiga, em um dado mês, realizar a leitura do medidor de uma dada UC,
devido, por exemplo, a um alagamento na região, impossibilitando o acesso
ao medidor, devido ao mostrador (display) estar apagado ou embaçado no
momento da leitura ou devido a qualquer outro fator que possa impossibilitar
o leiturista de realizar a medição. Nesses casos o consumidor pode ser
faturado pelo consumo mínimo ou pode simplesmente não ser faturado.
(b) Consumo medido e consumo faturado. O consumo medido é a energia, em
kWh, consumida no mês de referência. Corresponde à diferença entre o valor
lido pelo leiturista no mês de referência menos o valor lido no mês anterior.
Consumo faturado é o consumo de energia efetivamente cobrado pela
concessionária. Esses dois valores de consumo podem ser diferentes se, por
exemplo, o consumo medido for menor do que o consumo faturado mínimo
estipulado pela ANEEL para cada tipo de ligação. Para consumidores do
Grupo B, a energia faturada mínima é de 30kWh para consumidores
monofásicos, 50 kWh para bifásicos e 100 kWh para consumidores
trifásicos. Se um consumidor tiver, em um dado menos, um valor de
consumo medido menor do que o valor de energia faturada mínima, para o
seu tipo de ligação, ele será faturado pelo consumo faturado mínimo e, neste
caso, o valor de consumo medido será menor que o de consumo faturado.
4.6 – Extração de características
Será definido agora o vetor de características que será utilizado no treinamento e
teste do modelo. Dentre os dados disponíveis descritos acima, tentar-se-á selecionar
aqueles que têm maior correlação com o resultado das inspeções. Esta é uma tarefa de
suma importância, pois determinará quais informações serão fornecidas ao modelo, e

28
existem várias técnicas de Mineração de Dados e Aprendizado de Máquina para
resolvê-la. Técnicas matemáticas e estatísticas que envolvem a redução da dimensão dos
dados, como o PCA, são bastante utilizadas. [18]
Diversas análises e estudos aprofundados poderiam ser realizados com o
objetivo de escolher os atributos mais relevantes para esta aplicação. Contudo, esse tipo
de pesquisa vai além do escopo deste projeto, que se aterá a um método mais simples.
Neste experimento as características serão escolhidas de forma mais heurística,
baseadas no conhecimento do autor na área, adquirido através de experiência de estágio.
Serão descritas a seguir as variáveis utilizadas e o motivo pelo qual elas foram
selecionadas.
Neste experimento serão analisadas apenas UCs do Grupo B (unidades
consumidoras de baixa tensão), pois elas representam o consumidor comum.
Normalmente as concessionárias traçam estratégias especiais para UCs do Grupo A. Por
se tratarem de consumidores de alta energia, a receita recuperada tende a ser maior, e
por isso eles recebem uma atenção especial da área de perdas das distribuidoras. É
importante citar também que, por se tratar de uma aplicação de redes neurais
supervisionadas, serão analisadas apenas UCs que tiveram alguma inspeção, com um
resultado válido. Isto pode introduzir um certo viés, pois uma UC que recebe uma
inspeção provavelmente a recebeu porque apresentava algum tipo de comportamento
suspeito. Infelizmente esta é uma limitação prática que não pode ser contornada, no
caso de algoritmos supervisionados.
O primeiro princípio adotado é que o volume de perdas comerciais, em relação
ao total de energia fornecida ao sistema, varia com a localização geográfica. Isto é
verdade tanto para um nível estadual, ou de área de concessão, quanto para um nível
municipal e até mesmo para bairros. Para ilustrar este fato será apresentada no item “4.7
– Análise Descritiva dos Dados” a quantidade de ocorrências de fraudes e
irregularidades nos municípios incluidos no conjunto de dados estudado. Nos
experimentos a serem realizados será analisada apenas uma região da concessionária
que compreende cerca de 400 mil UCs, de onde será usado um banco de inspeções de
aproximadamente 21.400 visitas com resultado. Foram selecionadas as variáveis de
localização geográfica: região administrativa, município e bairro, sendo cada uma
representada por um código.
Serão selecionadas a fase de ligação e a classe da UC, por serem variáveis que
caracterizam indiretamente o consumo. UCs trifásicas comerciais tendem a ter um

29
consumo de energia mais elevado do que UCs bifásicas ou monofásicas residenciais.
Indústrias deveriam ter um consumo mais elevado do que residências comuns. Se isso
não acontece, pode ser que haja alguma irregularidade na indústria. É claro que podem
haver outras explicações, como ela ter fechado ou estar desocupada por um período de
tempo, mas de qualquer forma seria interessante investigar. Este tipo de comparação é
feita naturalmente pelo algoritmo.
Uma estratégia muito utilizada para detecção de irregularidades é a observação
da curva histórica de consumo faturado das UCs e a procura por quedas de consumo. A
lógica é simples: se uma UC regular passa a ter um consumo irregular, parte da energia
consumida não será mais faturada. Considerando que o nível de energia consumida se
mantenha aproximadamente constante, haverá uma queda no faturamento. Para poder
detectar variações incomuns de consumo, foram selecionadas as seguintes estatísticas
dos valores históricos de energia faturada:
MEDIANA_CONS_6M: Mediana de consumo, de 6 meses antes da
inspeção até o último consumo faturado anterior à inspeção – mediana de
6 pontos;
INTERQUARTIL_6M: Amplitude interquartil de consumo, de 6 meses
antes da inspeção até o último consumo faturado anterior à inspeção;
MEDIANA_CONS_18M: Mediana de consumo, de 18 meses antes da
inspeção até 6 meses antes da inspeção – mediana de 12 pontos (período
de um ano);
INTERQUARTIL_18M: Amplitude interquartil de consumo, de 18
meses antes da inspeção até 6 meses antes da inspeção – interquartil de
12 pontos (período de um ano);
MEDIANA_CONS_30M: Mediana de consumo, de 30 meses antes da
inspeção até 18 meses antes da inspeção – mediana de 12 pontos
(período de um ano);
INTERQUARTIL_30M: Amplitude interquartil de consumo, de 30
meses antes da inspeção até 18 meses antes da inspeção – interquartil de
12 pontos (período de um ano).
A mediana e a amplitude interquartil foram utilizadas, em detrimento da média e
desvio padrão, por representarem melhor o conjunto de dados, especialmente quando se

30
trata de conjuntos com poucas observações, como é o caso (6 e 12 pontos). A partir
destas estatísticas básicas pode-se observar, por exemplo, se a UC teve uma variação
muito grande na mediana de consumo, entre um período e outro, o que poderia indicar
uma queda. Outros tipos de observações podem ser feitas, mas isto ficará a cargo do
algoritmo de aprendizado, que de certa forma fará isso internamente durante o processo
de treinamento.
Além das variáveis descritas acima, é necessário obviamente o resultado da
inspeção para o algoritmo supervisionado. Como foi discutido no item “3.5 – Métricas
de Desempenho”, não será feita uma distinção entre irregularidade e fraude. Os dois
possíveis resultados de uma inspeção são, portanto: Regular (N.A.) e Irregular.
Finalmente, a lista completa de variáveis para o treinamento é apresentada a
seguir.
CLASSE
FASE
MUNICÍPIO
BAIRRO
MEDIANA_CONS_6M
MEDIANA_CONS_18M
MEDIANA_CONS_30M
INTERQUARTIL_6M
INTERQUARTIL_18M
INTERQUARTIL_30M
4.7 – Análise Descritiva dos Dados
O experimento será realizado sobre uma base de 21421 inspeções, com
resultados (irregular ou N.A.). A Figura 8 mostra a quantidade de inspeções com cada
resultado. Das 21421 inspeções realizadas, 7062 tiveram resultado “Irregular”, enquanto
que 14359 tiveram resultado “Nada Apurado”. Em termos percentuais, 32,97% das
inspeções tem resultado “Irregular”.

31
Figura 8: Resultados das inspeções realizadas
Esta base de dados corresponde a um banco de inspeções realizadas em
consumidores do grupo B (baixa tensão), em uma região atendida pela concessionária.
Como se pode observar pela Figura 9, a região analisada é composta
majoritariamente por UCs monofásicas, contabilizando 76,01% do total de UCs da base
de dados, enquanto que as UCs trifásicas compõem 23,97% do total. O número de UCs
bifásicas é praticamente desprezível, correspondendo a 0,018% da base.
Figura 9: Distribuição das UCs por fase de ligação
Além disso, a Figura 10 nos mostra a predominância de residências na região.
Elas compõem 58,55% do total de UCs. Nota-se também uma quantidade expressiva de
UCs rurais e comerciais, com 20,25% e 12,28% do total, respectivamente. Outras
classes de consumo representadas na base são: serviço público, poder público,
iluminação pública, industrial e consumo próprio.
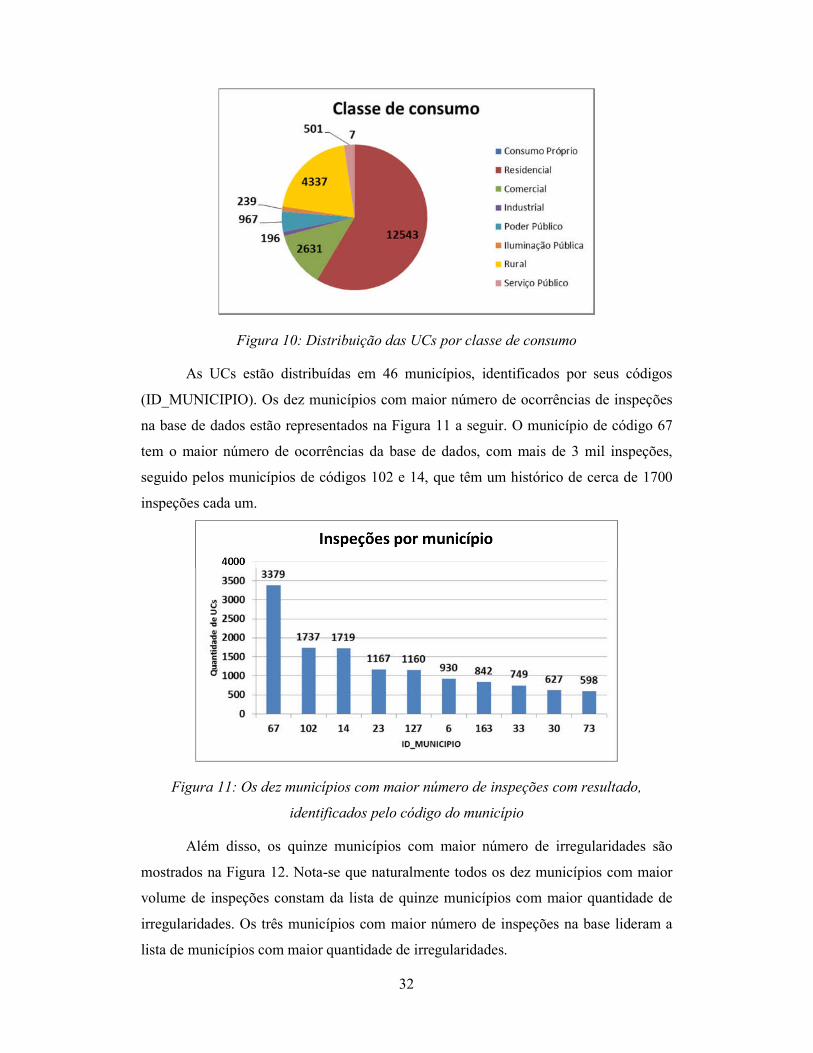
32
Figura 10: Distribuição das UCs por classe de consumo
As UCs estão distribuídas em 46 municípios, identificados por seus códigos
(ID_MUNICIPIO). Os dez municípios com maior número de ocorrências de inspeções
na base de dados estão representados na Figura 11 a seguir. O município de código 67
tem o maior número de ocorrências da base de dados, com mais de 3 mil inspeções,
seguido pelos municípios de códigos 102 e 14, que têm um histórico de cerca de 1700
inspeções cada um.
Figura 11: Os dez municípios com maior número de inspeções com resultado,
identificados pelo código do município
Além disso, os quinze municípios com maior número de irregularidades são
mostrados na Figura 12. Nota-se que naturalmente todos os dez municípios com maior
volume de inspeções constam da lista de quinze municípios com maior quantidade de
irregularidades. Os três municípios com maior número de inspeções na base lideram a
lista de municípios com maior quantidade de irregularidades.

33
Figura 12: Os quinze municípios com maior número de inspeções com resultado
irregular
4.8 – Ferramentas utilizadas
Para o treinamento e a aplicação do modelo foi utilizada a linguagem de
programação R, em conjunto com o pacote “caret”.
R é uma linguagem de programação de código aberto (open-source) e ambiente
de desenvolvimento integrado para computação estatística e gráfica, amplamente
utilizada para o desenvolvimento de software estatísticos e de análise de dados. Foi
criada por Ross Ihaka e Robert Gentleman na Universidade de Auckland, Nova
Zelândia. [19]
O pacote caret (abreviação de “Classification And REgression Training”) é
um conjunto de funções que tentam agilizar o processo de criação de modelos
preditivos. O pacote contém ferramentas para diversas funcionalidades [20], tais como:
Divisão de dados
Pré-processamento
Seleção de características
Ajuste de modelos usando resampling
Estimativa de importância de variáveis
Foi utilizado primeiramente o modelo de redes neurais (nnet) e Model
Averaged Neural Networks (avNNet) através do pacote caret. O primeiro é um
modelo de redes neurais simples e o segundo modelo constrói um ensemble de redes
neurais e o resultado global é calculado a partir da média das saídas de cada rede neural.

34
Segundo a sua descrição em [21], a implementação é baseada fortemente no pacote
“nnet”, desenvolvido por Brian Ripley [22].
Seguindo Ripley (1996) [22], “o mesmo modelo de rede neural é ajustado
usando diferentes sementes de números aleatórios. Todos os modelos resultantes são
usados para previsão. [...] Para a classificação, calcula-se primeiramente a média das
saídas analógicas de cada rede, e depois este valor é traduzido para as classes
previstas. ”
4.9 – Experimentos
Os dados descritos nos itens anteriores foram carregados em uma variável do
tipo data.frame, denominada dataset, e os resultados das inspeções foram
guardados na variável outcomes. A função str do R lista os objetos de um
data.frame, passado como parâmetro, e a estrutura dos mesmos, indicando o tipo de
dado e exibindo as primeiras observações de cada variável. A chamada a essa função
com o parâmetro dataset mostra que há 21421 observações de 10 variáveis (como
mencionado anteriormente).
> str(dataset) 'data.frame': 21421 obs. of 10 variables: $ ID_CLASSE : Factor w/ 8 levels "A","B","C","D",..: 2 2 2 7 2
7 7 2 2 2 ... $ ID_FASE : Factor w/ 3 levels "1","2","3": 1 1 1 1 1 1 1 1
1 1 ... $ ID_MUNICIPIO : Factor w/ 46 levels "102","106","11",..: 32 32
32 32 32 32 32 35 35 42 ... $ ID_BAIRRO : num 8748 17092 1929 15460 15001 ... $ MEDIAN_CONS6 : num 200 30 30 158 30 ... $ MEDIAN_CONS18 : num 193 30 90.5 141.5 30 ... $ MEDIAN_CONS30 : num 138 30 78 192 30 ... $ INTERQUARTIL6 : num 14.5 0 0 31.2 0 ... $ INTERQUARTIL18: num 42 0 29 134 0 ... $ INTERQUARTIL30: num 9 0 65 36.5 0 ...
Este conjunto de dados foi então dividido em um conjunto de treinamento e um
conjunto de teste, contendo 70% e 30% dos dados, respectivamente. Isto corresponde a
14996 observações no conjunto de treinamento e 6425 observações no conjunto de
teste. O conjunto de treinamento foi guardado na variável training e o conjunto de
teste na variável testing. Isto foi feito com auxílio da função
createDataPartition, através do seguinte código.

35
> inTraining <- createDataPartition(outcomes, p=0.7, list=FALSE) > training <- dataset[inTraining,] > training_outcomes <- outcomes[inTraining] > testing <- dataset[-inTraining,] > testing_outcomes <- outcomes[-inTraining]
O treinamento do modelo é realizado através da função train, do pacote
caret. Ela toma como parâmetros o conjunto de treinamento, o resultado das
inspeções para este conjunto, o método (neste caso utilizou-se o modelo de redes
neurais, nnet, e Model Averaged Neural Network, avNNet), a métrica de validação e
os parâmetros de treinamento e validação, definidos através da função
trainControl. Como se pode ver, utilizou-se inicialmente validação cruzada
(repeatedcv) 5-fold, com 10 repetições.
> fitControl <- trainControl( ## 5-fold CV method = "repeatedcv", number = 5, ## repeated ten times repeats = 10, classProbs = TRUE, summaryFunction = twoClassGroup, allowParallel = TRUE)
Com a validação 5-fold, o conjunto de treinamento será dividido em 5 partições
de aproximadamente 3000 observações, que pode ser considerado um número
razoavelmente grande de observações para esta aplicação. O fato de serem apenas 5
partições fará com que o tempo de duração do treinamento não seja tão longo na prática.
A escolha de um número maior de partições para o conjunto de treinamento implica em
um tempo de duração mais longo para o processo de treinamento do modelo. Como será
visto, com estas escolhas de parâmetros o treinamento dos modelos tem duração da
ordem de algumas poucas horas.
Foram utilizados dois modelos para o treinamento: redes neurais (nnet) e
“Model Averaged Neural Network” (avNNet).
> model_nnet <- train(x=training, y=training_outcomes, method ="nnet", metric="mapk", trControl=fitControl) > model_avNNet <- train(x=training, y=training_outcomes, method ="avNNet", metric="mapk", trControl=fitControl)

36
O tempo de duração para o treinamento do primeiro modelo (nnet) foi de 40
minutos, como descrito abaixo em segundos (“elapsed”).
> model_nnet$times $everything user system elapsed 2293.20 7.64 2400.55
O segundo modelo (avNNet) teve um tempo de treinamento notadamente mais
devagar, de 9.268,47 segundos, ou 2 horas e 34 minutos.
> model_avNNet$times $everything user system elapsed 8900.59 72.02 9268.47
Este modelo foi em seguida empregado para a classificação dos elementos no
conjunto de teste, através da função predict.
> predictions_nnet <- predict(model_nnet, newdata=testing) > predictions_avNNet <- predict(model_avNNet, newdata=testing)
Com a chamada à função confusionMatrix, pode-se ver alguns resultados
importantes da avaliação do modelo. A seguir é apresentada a Tabela 2, que mostra a
matriz de confusão resultante da aplicação do primeiro modelo, de redes neurais
(nnet).
Referência
N.A. Irregular
Pre
diç
ão
N.A. 3624 1202
Irregular 683 916
Tabela 2:Matriz de confusão resultante da aplicação do modelo de redes neurais
(nnet)
Como se vê, o modelo apresentou uma precisão de 57,29% e uma acurácia de
70,66%. Para se ter comparativo, destaca-se que a região de análise atende um total de
370387 UCs e, no período de janeiro de 2015 a dezembro de 2016, foram realizadas
8367 inspeções direcionadas, com uma a taxa de acerto acumulada de 30,91%
(equivalente à medida de precisão). Inspeções direcionadas são inspeções a UCs
selecionadas, que apresentem algum indício de irregularidade ou fraude, baseado

37
somente na observação das dados da UC e em notas de leiturista, assim como é feito
neste projeto. Em oposição às inspeções direcionadas, existem também as inspeções
avulsas. São inspeções a UCs que não foram pré-selecionadas, mas que, por exemplo,
chamam a atenção do técnico de inspeção por algum aspecto suspeito, no momento em
que ele passa pela rua. Normalmente são inspeções feitas por técnicos com muito
conhecimento pessoal sobre as regiões com altos índices de irregularidade ou fraude.
A Tabela 3 a seguir mostra a matriz de confusão do segundo modelo utilizado:
“Model Averaged Neural Network” (avNNet).
Referência
N.A. Irregular
Pre
diç
ão
N.A. 4096 1752
Irregular 211 366
Tabela 3: Matriz de confusão resultante da aplicação do modelo de emsemble redes
neurais (avNNet)
Como pode-se ver, o modelo apresenta uma precisão de 63,43%,
aproximadamente 6,41 pontos percentuais maior que o modelo anterior, e uma acurácia
de 69,45%. Este modelo, em comparação com o primeiro, apresenta uma melhor
precisão, porém a acurácia é menor, em 1,21 pontos percentuais.
Para o próximo experimento utilizou-se as características descritas a seguir.
Acrescentou-se às características utilizadas anteriormente, cinco características
relacionadas a notas de irregularidade dadas por leituristas. Essas notas, como foi
detalhado no capítulo 3, representam um forte indício de irregularidade/fraude, porém
não expressam uma certeza de que o consumidor está irregular, dado que o leiturista
carece muitas vezes da habilidade técnica, além de não ser sua função realizar perícias
na instalação. As características adicionadas foram:
QTD_SUSPEITA_FR: quantidade de apontamentos de suspeita de
fraude nos últimos 6 meses, anteriores à inspeção;
QTD_MEDIDOR_DEFEITO: quantidade de apontamentos de medidor
com defeito nos últimos 6 meses, anteriores à inspeção;

38
QTD_3M_PARADO_HABITADO: quantidade de apontamentos de
medidor parado, com o local de consumo habitado, nos últimos 3 meses,
anteriores à inspeção;
QTD_DANIFICADO: quantidade de apontamentos de medidor
danificado, nos últimos 12 meses, anteriores à inspeção;
QTD_DISPLAY_APAGADO: quantidade de apontamentos de medidor
com display apagado, nos últimos 3 meses, anteriores à inspeção;
QTD_EM_QUEIMADO: quantidade de apontamentos de medidor
queimado, nos últimos 3 meses, anteriores à inspeção.
A matriz com todas as observações foi denominada de dataset e foi impressa
abaixo. Ela possui 21421 observações e 16 variáveis (características).
> str(dataset) 'data.frame': 21421 obs. of 16 variables: $ ID_CLASSE : Factor w/ 8 levels "A","B","C","D",..: 2 2 2 7 2 7 7 2 2 2 ... $ ID_FASE : Factor w/ 3 levels "1","2","3": 1 1 1 1 1 1 1 1 1 1 ... $ ID_MUNICIPIO : Factor w/ 46 levels "102","106","11",..: 32 32 32 32 32 32 32 35 35 42 ... $ ID_BAIRRO : num 8748 17092 1929 15460 15001 ... $ MEDIAN_CONS6 : num 200 30 30 158 30 ... $ MEDIAN_CONS18 : num 193 30 90.5 141.5 30 ... $ MEDIAN_CONS30 : num 138 30 78 192 30 ... $ INTERQUARTIL6 : num 14.5 0 0 31.2 0 ... $ INTERQUARTIL18 : num 42 0 29 134 0 ... $ INTERQUARTIL30 : num 9 0 65 36.5 0 ... $ QTD_SUSPEITA_FR : num 0 0 0 2 0 0 0 0 0 0 ... $ QTD_MEDIDOR_DEFEITO : num 0 0 3 0 1 0 0 0 0 0 ... $ QTD_3M_PARADO_HABITADO: num 0 0 2 0 1 0 0 0 0 0 ... $ QTD_DANIFICADO_M200 : num 0 0 0 0 0 0 0 0 0 0 ... $ QTD_DISPLAY_APAGADO : num 0 0 0 0 0 0 0 0 0 0 ... $ QTD_EM_QUEIMADO : num 0 0 0 0 0 0 0 0 0 0 ...
Estas características foram utilizadas para treinar o modelo “Model Averaged
Neural Network” (avNNet). Como nos experimentos realizados anteriormente, o
modelo foi treinado utilizando-se validação cruzada (repeatedcv) 5-fold, com 10
repetições. O tempo de duração do treinamento foi de aproximadamente 3 horas e 6
minutos.
> model_avNNet_NL$times $everything user system elapsed 10637.49 46.44 11157.00

39
Após o treinamento foram feitas predições sobre o conjunto de teste e resultado
é mostrado na Tabela 4 a seguir.
Referência
N.A. Irregular
Pre
diç
ão
N.A. 3985 1179
Irregular 322 939
Tabela 4: Matriz de confusão resultante da aplicação do modelo de emsemble redes
neurais (avNNet), com a utilização de notas de leiturista no vetor de características.
Observa-se que o modelo apresenta uma precisão de 74,46%, o que representa
um aumento de 17,4% com relação ao experimento anterior. A acurácia também
apresenta um valor mais alto, de 76,64%. Era de se esperar que esse experimento tivesse
resultados expressivamente melhores, devido à utilização de notas de leiturista.
A Tabela 5 a seguir resume os principais resultados obtidos nos experimentos
realizados. Nota-se que o modelo treinado com a utilização de notas de leiturista
apresenta o melhor desempenho em termos de precisão e acurácia. No entanto, o último
experimento foi o que apresentou a maior duração para o tempo de treinamento, devido
à maior quantidade de variáveis (características).
Precisão Acurácia Duração do
treinamento
Experimento 1
(nnet) 57,29% 70,66% 40 min
Experimento 2
(avNNet) 63,43% 69,45% 2h 34min
Experimento 3
(avNNet + N.L.) 74,46% 76,64% 3h 6min
Tabela 5: Resumo dos resultados obtidos por todos os modelos

40
Na prática deve-se combinar essas estratégias de classificação de consumidores
com uma avaliação da sua estimativa de energia a recuperar. A concessionária visa não
só uma alta taxa de acerto nas inspeções, como também um alto retorno em termos de
energia. Uma estratégia utilizada na prática, por exemplo, é focar as inspeções em
clientes comerciais ou industriais, com alto padrão de consumo, mesmo que não
apresentem muitos indícios de irregularidade. Pode ser que essa estratégia tenha uma
taxa de acerto mais baixa, porém os poucos consumidores irregulares deflagrados serão
obrigados a retornar uma quantia relativamente mais alta de energia recuperada à
companhia. No capítulo final será sugerido um trabalho futuro no âmbito de prever a
energia recuperada por consumidores potencialmente irregulares.
4.10 – Considerações Finais
Como foi mencionado no item anterior, a região analisada apresentou uma taxa
de acerto acumulada de 30,91%, para os anos de 2015 e 2016. No entanto, é importante
salientar que uma comparação dos resultados obtidos nos experimentos com essa taxa
histórica não é totalmente justa, devido a alguns fatores.
O desenvolvimento deste projeto foi baseado em modelos supervisionados de
Aprendizado de Máquina, o que pressupõe necessariamente a utilização de dados para
os quais se tem o resultado da classificação (valores de referência). Neste caso, isso
significa dizer que somente foram utilizados dados de UCs que tiveram, em algum
momento dentro do registro histórico da concessionária, uma ou mais inspeções
técnicas para verificação de fraudes e irregularidades. Isto pode introduzir um viés no
conjunto de dados, visto que essas UCs podem ter recebido inspeções devido a algum
critério, que pode ter filtrado o conjunto de dados de forma não aleatória ou não
representativa. Por exemplo, algumas das UCs do conjunto de dados podem ter
apresentado algum indício de irregularidade, o que justificaria a inspeção. Outras podem
ter sido inspecionadas por serem UCs que consomem uma grande quantidade de energia
(inspeções visando a energia recuperada ou a prevenção de perdas em clientes de alto
consumo). Há ainda inspeções que são realizadas por ações especiais, como varreduras
a consumidores sazonais (hotéis, pousadas, restaurantes em cidades de praia, etc) ou
varreduras em locais com alta repercussão midíatica (como uma estratégia para alertar a
população quanto à presença da concessionária no combate às perdas). Infelizmente este

41
viés é inerente à análise e propõe-se como trabalho futuro o estudo de formas de reduzi-
lo e a determinação de uma medida quantitativa para o mesmo.
Outra consideração que vale ressaltar é que, na prática, talvez faça mais sentido
que as UCs sejam entregues à concessionária na forma de uma lista ordenada por
prioridade, onde as UCs com maior potencial de irregularidade estejam no topo. Isto
pode ser feito da seguinte maneira: ao invés de atribuir-se a cada UC uma classe (N.A.
ou irregular), utiliza-se os valores analógicos de saída do modelo. As UCs são então
ordenadas por esses valores. Como a quantidade de UCs a serem selecionadas para
receber inspeções técnicas pode variar dependendo do orçamento, nível de perdas
comerciais totais, entre outros fatores, uma lista dessa forma deixaria a cargo da
concessionária definir o valor de corte que determina quais UCs pertencem a cada
classe prevista. A avaliação dos modelos considerando-se diferentes valores de corte
pode ser feita através da análise da curva de ROC ou da curva de precisão-revocação.
[23] Esse tipo de análise é proposto como uma extensão do projeto, ou futuro trabalho.

42
Capítulo 5
Conclusões
Este projeto propõe o uso de técnicas de Inteligência Artificial e modelos de
Redes Neurais Artificiais para auxiliar na identificação de consumidores de energia com
indícios de irregularidade/fraude. Foram utilizados dados reais de uma concessionária
de energia elétrica para o treinamento e teste dos modelos. Dentre os dados dos quais a
concessionária dispõe, foi selecionado um subconjunto para compor os vetores de
características que foram utilizados na aplicação dos modelos. Foram realizados
experimentos com e sem a utilização de notas de irregularidade de leiturista no vetor de
características e foram utilizados os algoritmos de Aprendizado de Máquina de redes
neurais simples e em ensemble (Model Averaged Neural Network), totalizando três
experimentos. O experimento que apresentou melhores resultados foi o modelo de
MANN, com notas de leiturista, tendo uma precisão de 74,46% na classificação de
irregularidades, tendo uma acurácia de 76,64%. Era de fato esperado que o modelo
treinado com notas de leiturista apresentasse resultados superiores, dado que esses
apontamentos são um grande indicador de fraudes e irregularidades (apesar de nem
sempre serem assertivos). O mesmo modelo de MANN, sem notas de leiturista,
apresentou uma precisão mais baixa, de 63,43%, e uma acurácia de 69,45%. O modelo
de redes neurais simples, treinado sem notas de leiturista, apresentou uma precisão mais
baixa, de 57,29%, e uma acurácia de 70,66%.
Como projeto futuro, planeja-se implementar esses algoritmos em tempo real
para a otimização de inspeções técnicas de irregularidade. Além disso, propõe-se o
estudo e a aplicação de outros algoritmos, como SVM, na busca de classificadores com
melhores desempenhos, e a avaliação dos modelos através da análise da curva de ROC e
da curva de precisão-revocação. Sugere-se a realização de estudos exploratórios para
identificar outras características que possam ter correlação com a existência de
irregularidades. Por fim, propõe-se como futuro trabalho estudar o enviesamento
apresentado pelo conjunto de dados, procurando formas de reduzi-lo, e a determinação
de uma medida quantitativa para o mesmo.

43
Bibliografia
[1] “ABRADEE,” Associação Brasileira de Distribuidores de Energia Elétrica, [Online]. Available: http://www.abradee.com.br/. [Acesso em 16 Janeiro 2017].
[2] LIGHT, [Online]. Available: http://www.light.com.br/para-residencias/Simuladores/leitura.aspx. [Acesso em 26 Novembro 2016].
[3] C. A. d. S. Penin, Combate, Prevenção e Otimização das Perdas Comerciais de Energia Elétrica, São Paulo: Escola Politécnica da Universidade de São Paulo, 2008.
[4] “Emerging Markets Smart Grid: Outlook 2015,” northeast group, llc, [Online]. Available: http://www.northeast-group.com/reports/Brochure-Emerging%20Markets%20Smart%20Grid-Outlook%202015-Northeast%20Group.pdf. [Acesso em 28 Novembro 2016].
[5] ANEEL, “Resolução Normativa Nº 414,” 9 Setembro 2010. [Online]. Available: http://www.aneel.gov.br/documents/656877/14486448/bren2010414.pdf/3bd33297-26f9-4ddf-94c3-f01d76d6f14a?version=1.0. [Acesso em 29 Dezembro 2016].
[6] P. d. R. Casa Civil, “Decreto Nº2335,” 29 Outubro 1997. [Online]. Available: http://www.planalto.gov.br/ccivil_03/decreto/d2335.HTM. [Acesso em 25 Janeiro 2017].
[7] ANEEL, “Resolução Nº456,” 29 Novembro 2000. [Online]. Available: http://www2.aneel.gov.br/cedoc/bres2000456.pdf. [Acesso em 25 Janeiro 2017].
[8] S. S. Haykin, Neural Networks: A Comprehensive Foundation, Prentice Hall, 1994.
[9] “Perceptron,” Wikipedia, [Online]. Available: https://nl.wikipedia.org/wiki/Perceptron. [Acesso em 24 Janeiro 2017].
[10] “Função sigmóide,” Wikipedia, [Online]. Available: https://pt.wikipedia.org/wiki/Fun%C3%A7%C3%A3o_sigm%C3%B3ide. [Acesso em 16 Janeiro 2017].
[11] “Convolutional Neural Networks for Visual Recognition,” [Online]. Available: http://cs231n.github.io/neural-networks-1/. [Acesso em 24 Janeiro 2017].
[12] “Validação Cruzada,” Wikipedia, [Online]. Available: https://pt.wikipedia.org/wiki/Valida%C3%A7%C3%A3o_cruzada. [Acesso em 5 Janeiro 2017].
[13] “Cross Validation (statistics),” Wikipedia, 20 Janeiro 2017. [Online]. Available: https://en.wikipedia.org/wiki/Cross-validation_(statistics). [Acesso em 25 Janeiro 2017].
[14] W. Dubitzky, M. Granzow e D. Berrar, Fundamentals of data mining in genomics and proteomics, Springer Science & Business Media, 2007.
[15] “Cohen's Kappa,” Wikipedia, 7 Fevereiro 2017. [Online]. Available: https://en.wikipedia.org/wiki/Cohen's_kappa. [Acesso em 9 Fevereiro 2017].
[16] “Introduction to the ROC (Receiver Operating Characteristics) plot,” [Online]. Available: https://classeval.wordpress.com/introduction/introduction-to-the-roc-receiver-operating-characteristics-plot/. [Acesso em 2 Janeiro 2017].
[17] “Manual de Tarifação da Energia Elétrica,” PROCEL - Programa Nacional de

44
Conservação de Energia Elétrica, [Online]. Available: http://www.mme.gov.br/documents/10584/1985241/Manual%20de%20Tarif%20En%20El%20-%20Procel_EPP%20-%20Agosto-2011.pdf. [Acesso em 2016 Novembro 26].
[18] J. Shlens, “A Tutorial on Principal Component Analysis,” 4 Abril 2014. [Online]. Available: https://arxiv.org/pdf/1404.1100.pdf. [Acesso em 2 Janeiro 2017].
[19] “R (Linguagem de Programação),” Wikipedia, [Online]. Available: https://pt.wikipedia.org/wiki/R_(linguagem_de_programa%C3%A7%C3%A3o) . [Acesso em 16 Janeiro 2017].
[20] “The caret Package,” Max Kuhn, 29 Novembro 2016. [Online]. Available: http://topepo.github.io/caret/index.html. [Acesso em 16 Janeiro 2017].
[21] “Neural Networks Using Model Averaging,” [Online]. Available: https://rdrr.io/rforge/caret/man/avNNet.html . [Acesso em 17 Janeiro 2017].
[22] B. D. Ripley, Pattern Recognition and Neural Networks, Cambridge University Press, 1996.
[23] “Introduction to the precision-recall plot,” [Online]. Available: https://classeval.wordpress.com/introduction/introduction-to-the-precision-recall-plot/. [Acesso em 9 Fevereiro 2017].
[24] C. C. O. Ramos, Caracterização de Perdas Comerciais em Sistemas de Energia Através de Técnicas Inteligentes, São Paulo: Escola Politécnica da Universidade de São Paulo, 2014.
[25] ANEEL, [Online]. Available: http://www.aneel.gov.br/. [Acesso em 26 Novembro 2016].